C
This article introduces the C programming language.
Overview
The C programming language was developed in 1972 by Dennis Ritchie and Brian Kernighan at the AT&T Corporation for programming computer operating systems. Its capacity to structure data and programs through the composition of smaller units is comparable to that of ALGOL (Algorithmic Language). It uses a compact notation and provides the programmer with the ability to operate with the addresses of data as well as with their values. This ability is important in systems programming, and C shares with assembly language the power to exploit all the features of a computer’s internal architecture.
C Standards
Refer to C Standard Committee (ISO/IEC JTC1/SC22/WG14) and The Development of the C Language:

K&R C
First edition of The C Programming Language published by Brian Kernighan and Dennis Ritchie in 1978. This book, known to C programmers as K&R, served for many years as an informal specification of the language. The version of C that it describes is commonly referred to as K&R C.
ANSI X3.159-1989 (ANSI C, C89)
In 1983, the American National Standards Institute (ANSI) formed a committee, X3J11, to establish a standard specification of C. X3J11 based the C standard on the Unix implementation; however, the non-portable portion of the Unix C library was handed off to the IEEE working group 1003 to become the basis for the 1988 POSIX standard. In 1989, the C standard was ratified as ANSI X3.159-1989 Programming Language C. This version of the language is often referred to as ANSI C, Standard C, or C89.
ISO/IEC 9899:1990 (C90)
In 1990, the ANSI C standard (with formatting changes) was adopted by the International Organization for Standardization (ISO) C Standard Committee (ISO/IEC JTC1/SC22/WG14) as ISO/IEC 9899:1990, which is sometimes called C90. Therefore, the terms C89 and C90 refer to the same programming language.
It has since been amended three times by Technical Corrigenda (COR) or Amendment (AMD):
- ISO/IEC 9899:1990/AM1:1995 (known as C90 AMD1 or C95)
- ISO/IEC 9899:1990/COR1:1995
- ISO/IEC 9899:1990/COR2:1996
The C90 standard was withdrawn and is no longer available from official sources, although it may be found with some document retailers, such as SAI-Global. The final draft (X3J11/90-013 (ANSI numbering) or N119 (WG14 numbering)) is not publicly available, but the final public review draft X3J11/88-090 (1988-05-13) is available and differs minimally from the final C89 standard.
The C90 amendment AMD1, which transforms C90 to C95 is no longer available from official sources, although it may be found with some document retailers, such as Global Engineering Documents.
ISO/IEC 9899:1999 (C99)
The C standard was further revised in the late 1990s, leading to the publication of ISO/IEC 9899:1999 in 1999, which is commonly referred to as C99.
It has since been amended three times by Technical Corrigenda (COR):
- ISO/IEC 9899:1999/COR1:2001
- ISO/IEC 9899:1999/COR2:2004
- ISO/IEC 9899:1999/COR3:2007
The C99 standard was withdrawn and is no longer available from ISO, although it may still be purchased from ANSI. The final C99:TC3 working draft N1256 (2007-09-07) is freely available and differs only minimally from the final C99 standard including all three Technical Corrigenda.
ISO/IEC 9899:2011 (C11)
In 2007, work began on another revision of the C standard, informally called C1X until its official publication on 2011-12-08. The C standards committee adopted guidelines to limit the adoption of new features that had not been tested by existing implementations. The C11 standard adds numerous new features to C and the library, including type generic macros, anonymous structures, improved Unicode support, atomic operations, multi-threading, and bounds-checked functions. It also makes some portions of the existing C99 library optional, and improves compatibility with C++.
It has since been amended by Technical Corrigenda:
- ISO/IEC 9899:2011/COR1:2012
The official C11 Standard can be purchased from the ISO or (at a discount) from ANSI or other member organizations. The latest C11 working draft N1570 (2011-04-12) is available for free and differs only minimally from the final C11 Standard.
ISO/IEC 9899:2018 (C17)
ISO/IEC 9899:2018 (C18) addressed defects in C11 without introducing new language features.
The __STDC_VERSION__ macro is increased to the value 201710L.
The similar draft version is N2310.
List of compilers supporting C18:
- GCC 8.1.0
- LLVM Clang 7.0.0
- IAR EWARM v8.40.1
Technical Reports (TRs)
-
TR 18037: Embedded C
Historically, embedded C programming requires nonstandard extensions to the C language in order to support exotic features. In 2008, the C Standards Committee published a technical report TR 18037: Embedded C extending the C language to address these issues by providing a common standard for all implementations to adhere to. It includes a number of features not available in normal C, such as fixed-point arithmetic, named address spaces, and basic I/O hardware addressing.
C Language
Translation Phases
The C source file is processed by the compiler as if the following phases take place, in this exact order. Actual implementation may combine these actions or process them differently as long as the behavior is the same. Refer to translation phases on CppReference.
Phase 1
The individual bytes of the source code file (which is generally a text file in some multibyte encoding such as UTF-8) are mapped, in implementation defined manner, to the characters of the source character set. In particular, OS-dependent end-of-line indicators are replaced by newline characters. The source character set is a multibyte character set which includes the basic source character set as a single-byte subset, consisting of the following 96 characters:
- 5 whitespace characters: space (
), horizontal tab (\t), vertical tab (\v), form feed (\f), new-line (\n) - 10 digit characters:
0to9 - 52 letters:
atoz,AtoZ - 29 punctuation characters:
_ { } [ ] # ( ) < > % : ; . ? * + - / ^ & | ~ ! = , \ " ’
Trigraph sequences are replaced by corresponding single-character representations. Reason of using trigraph sequences: some characters from the C and C++ character set are not available in all environments. In that cases, use these trigraph sequences in a C or C++ source program instead.
| Trigraph | Single-character | Description |
|---|---|---|
??< |
{ |
left brace |
??> |
} |
right brace |
??( |
[ |
left bracket |
??) |
] |
right bracket |
??= |
# |
pound sign |
??/ |
\ |
backslash |
??' |
^ |
caret |
??! |
| |
vertical bar |
??- |
~ |
tilde |
Phase 2
Whenever backslash \ appears at the end of a line (immediately followed by the newline character), both backslash and newline are deleted, combining two physical source lines into one logical source line. This is a single-pass operation: a line ending in two backslashes followed by an empty line does not combine three lines into one.
If a non-empty source file does not end with a newline character after this step (whether it had no newline originally, or it ended with a backslash), the behavior is undefined.
Phase 3
The source file is decomposed into comments, sequences of whitespace characters (space, horizontal tab, vertical tab, form-feed, new-line), and preprocessing tokens, which are the following
- header names:
<stdio.h>or"myfile.h" - identifiers
- numbers
- character constants and string literals
- operators and punctuators (including alternative tokens), such as
+,<<=,<%,##, orand - individual non-whitespace characters that do not fit in any other category
Each comment is replaced by one space character.
Newlines are kept, and it’s implementation-defined whether non-newline whitespace sequences may be collapsed into single space characters.
Phase 4
Preprocessor is executed.
Each file introduced with the #include directive goes through phases 1 through 4, recursively.
At the end of this phase, all preprocessor directives are removed from the source.
Phase 5
All characters and escape sequences in character constants and string literals are converted from source character set to execution character set (which may be a multibyte character set such as UTF-8, as long as all 96 characters from the basic source character set listed in phase 1 have single-byte representations). If the character specified by an escape sequence isn’t a member of the execution character set, the result is implementation-defined, but is guaranteed to not be a null (wide) character.
Note: the conversion performed at this stage can be controlled by command line options in some implementations: gcc and clang use -finput-charset to specify the encoding of the source character set, -fexec-charset and -fwide-exec-charset to specify the encodings of the execution character set in the string and character literals that don’t have an encoding prefix (since C11).
Phase 6
Adjacent string literals are concatenated.
Phase 7
Compilation takes place: the tokens are syntactically and semantically analyzed and translated as a translation unit.
Phase 8
Linking takes place: Translation units and library components needed to satisfy external references are collected into a program image which contains information needed for execution in its execution environment (the OS).
Keywords
This is a list of reserved keywords in C. Since they are used by the language, these keywords are not available for re-definition.
| Keywords | Standard | Note |
|---|---|---|
| auto | since C89 | |
| break | since C89 | |
| case | since C89 | |
| char | since C89 | |
| const | since C89 | |
| continue | since C89 | |
| default | since C89 | |
| do | since C89 | |
| double | since C89 | |
| else | since C89 | |
| enum | since C89 | |
| extern | since C89 | |
| float | since C89 | |
| for | since C89 | |
| goto | since C89 | |
| if | since C89 | |
| inline | since C99 | |
| int | since C89 | |
| long | since C89 | |
| register | since C89 | |
| restrict | since C99 | |
| return | since C89 | |
| short | since C89 | |
| signed | since C89 | |
| sizeof | since C89 | |
| static | since C89 | |
| struct | since C89 | |
| switch | since C89 | |
| typedef | since C89 | |
| union | since C89 | |
| unsigned | since C89 | |
| void | since C89 | |
| volatile | since C89 | |
| while | since C89 | |
| _Alignas | since C11 | see macro alignas in <stdalign.h> |
| _Alignof | since C11 | see macro alignof in <stdalign.h> |
| _Atomic | since C11 | see macro atomic_bool, atomic_int, … in <stdatomic.h> |
| _Bool | since C99 | see macro bool in <stdbool.h> |
| _Complex | since C99 | see macro complex in <complex.h> |
| _Generic | since C11 | no corresponding macro |
| _Imaginary | since C99 | see macro imaginary in <complex.h> |
| _Noreturn | since C11 | see macro noreturn in <stdnoreturn.h> |
| _Static_assert | since C11 | see macro static_assert in <assert.h> |
| _Thread_local | since C11 | see macro thread_local in threads.h |
Most of the recently reserved words begin with an underscore followed by a capital letter, because identifiers of that form were previously reserved by the C standard for use only by implementations. Since existing program source code should not have been using these identifiers, it would not be affected when C implementations started supporting these extensions to the programming language. Some standard headers do define more convenient synonyms for underscored identifiers. The language previously included a reserved word called entry, but this was seldom implemented, and has now been removed as a reserved word.
sizeof
Whether you use parentheses () depends on whether you want the size of a type or the size of a particular quantity. Parentheses are required for types but are optional for particular quantities. That is, you would use sizeof(char) or sizeof(float) but can use sizeof name or sizeof 6.28. However, it is all right to use parentheses in these cases, too, as in sizeof (6.28).
C says that sizeof returns a value of type size_t. This is an unsigned integer type.
Identifiers
Identifiers Constitution
An identifier is an arbitrarily long sequence of digits, underscores, lowercase and uppercase Latin letters, (and Unicode characters specified using \u and \U escape notation, since C99). A valid identifier must begin with a non-digit character (Latin letter, underscore, or Unicode non-digit character, since C99). Identifiers are case-sensitive.
Reserved Identifiers
Refer to Identifier on CppReference:
The following identifiers are reserved and may not be declared in a program (doing so invokes undefined behavior):
-
The identifiers that are keywords cannot be used for other purposes. In particular,
#defineor#undefof an identifier that is identical to a keyword is not allowed. -
All external identifiers that begin with an underscore.
-
All identifiers that begin with an underscore followed by a capital letter or by another underscore (these reserved identifiers allow the library to use numerous behind-the-scenes non-external macros and functions).
-
All external identifiers defined by the standard library (in hosted environment). This means that no user-supplied external names are allowed to match any library names, not even if declaring a function that is identical to a library function.
-
Identifiers declared as reserved for future use by the standard library, namely:
-
function names
- cerf, cerfc, cexp2, cexpm1, clog10, clog1p, clog2, clgamma, ctgamma and their -f and -l suffixed variants, in
<complex.h> - beginning with is or to followed by a lowercase letter, in
<ctype.h>and<wctype.h> - beginning with str followed by a lowercase letter, in
<stdlib.h> - beginning with str, mem or wcs followed by a lowercase letter, in
<string.h> - beginning with wcs followed by a lowercase letter, in
<wchar.h> - beginning with atomic_ followed by a lowercase letter, in
<stdatomic.h> - beginning with cnd_, mtx_, thrd_ or tss_ followed by a lowercase letter, in
<threads.h>
- cerf, cerfc, cexp2, cexpm1, clog10, clog1p, clog2, clgamma, ctgamma and their -f and -l suffixed variants, in
-
typedef names
- beginning with int or uint and ending with _t, in
<stdint.h> - beginning with atomic_ or memory_ followed by a lowercase letter, in
<stdatomic.h> - beginning with cnd_, mtx_, thrd_ or tss_ followed by a lowercase letter, in
<threads.h>
- beginning with int or uint and ending with _t, in
-
macro names
- beginning with E followed by a digit or an uppercase letter, in
<errno.h> - beginning with FE_ followed by an uppercase letter, in
<fenv.h> - beginning with INT or UINT and ending with _MAX, _MIN, or _C, in
<stdint.h> - beginning with PRI or SCN followed by lowercase letter or the letter X, in
<stdint.h> - beginning with LC_ followed by an uppercase letter, in
<locale.h> - beginning with SIG or SIG_ followed by an uppercase letter, in
<signal.h> - beginning with TIME_ followed by an uppercase letter, in
<time.h> - beginning with ATOMIC_ followed by an uppercase letter, in
<stdatomic.h>
- beginning with E followed by a digit or an uppercase letter, in
-
enumeration constants
- beginning with memory_order_ followed by a lowercase letter, in
<stdatomic.h> - beginning with cnd_, mtx_, thrd_ or tss_ followed by a lowercase letter, in
<threads.h>
- beginning with memory_order_ followed by a lowercase letter, in
-
All other identifiers are available, with no fear of unexpected collisions when moving programs from one compiler and library to another.
Note: In C++, identifiers with a double underscore anywhere are reserved everywhere. In C, only the ones that begin with a double underscore are reserved.
Translation Limits
Even though there is no specific limit on the length of identifiers, early compilers had limits on the number of significant initial characters in identifiers and the linkers imposed stricter limits on the names with external linkage. C requires that at least the following limits are supported by any standard-compliant implementation:
until C99
- 31 significant initial characters in an internal identifier or a macro name
- 6 significant initial characters in an external identifier
- 511 external identifiers in one translation unit
- 127 identifiers with block scope declared in one block
- 1024 macro identifiers simultaneously defined in one preprocessing translation unit
since C99
- 63 significant initial characters in an internal identifier or a macro name
- 31 significant initial characters in an external identifier
- 4095 external identifiers in one translation unit
- 511 identifiers with block scope declared in one block
- 4095 macro identifiers simultaneously defined in one preprocessing translation unit
Scope
Refer to scope on CppReference:
Each identifier that appears in a C program is visible (that is, may be used) only in some possibly discontiguous portion of the source code called its scope.
Within a scope, an identifier may designate more than one entity only if the entities are in different name spaces.
C has four kinds of scopes:
Nested Scopes
If two different entities named by the same identifier are in scope at the same time, and they belong to the same name space, the scopes are nested (no other form of scope overlap is allowed), and the declaration that appears in the inner scope hides the declaration that appears in the outer scope:
// The name space here is ordinary identifiers.
int a; // file scope of name a begins here
void f(void)
{
// the block scope of the name a begins here; hides file-scope a
int a = 1;
{
// the scope of the inner a begins here, outer a is hidden
int a = 2;
printf("%d\n", a); // inner a is in scope, prints 2
} // the block scope of the inner a ends here
printf("%d\n", a); // the outer a is in scope, prints 1
} // the scope of the outer a ends here
void g(int a); // name a has function prototype scope; hides file-scope a
Block Scope
The scope of any identifier declared inside a compound statement, including function bodies, (or in any expression, declaration, or statement appearing in if, switch, for, while, or do-while statement, since C99), or within the parameter list of a function definition begins at the point of declaration and ends at the end of the block or statement in which it was declared.
void f(int n) // scope of the function parameter 'n' begins
{ // the body of the function begins
++n; // 'n' is in scope and refers to the function parameter
// int n = 2; // error: cannot redeclare identifier in the same scope
for (int n = 0; n<10; ++n) { // scope of loop-local 'n' begins
printf("%d\n", n); // prints 0 1 2 3 4 5 6 7 8 9
} // scope of the loop-local 'n' ends
// the function parameter 'n' is back in scope
printf("%d\n", n); // prints the value of the parameter
} // scope of function parameter 'n' ends
int a = n; // Error: name 'n' is not in scope
Block-scope variables have no linkage and automatic storage duration by default. Note that storage duration for non-VLA (Variable Length Arrays) local variables begins when the block is entered, but until the declaration is seen, the variable is not in scope and cannot be accessed.
File Scope
The scope of any identifier declared outside of any block or parameter list begins at the point of declaration and ends at the end of the translation unit.
int i; // scope of i begins
// scope of g begins (note, a has block scope)
static int g(int a)
{
return a;
}
int main(void)
{
i = g(2); // i and g are in scope
}
File-scope identifiers have external linkage and static storage duration by default.
Function Scope
A label (and only a label) declared inside a function is in scope everywhere in that function, in all nested blocks, before and after its own declaration. Note: a label is declared implicitly, by using an otherwise unused identifier before the colon character before any statement.
void f()
{
{
goto label; // label in scope even though declared later
label:;
}
goto label; // label ignores block scope
}
void g()
{
goto label; // error: label not in scope in g()
}
Function Prototype Scope
The scope of a name introduced in the parameter list of a function declaration that is not a definition ends at the end of the function declarator.
int f(int n,
int a[n]); // n is in scope and refers to the first parameter
Note that if there are multiple or nested declarators in the declaration, the scope ends at the end of the nearest enclosing function declarator:
// function name 'f' is at file scope
void f (
// the identifier 'f' is now in scope, file-scope 'f' is hidden
long double f,
// 'f' refers to the first parameter, which is in scope
char (**a)[10 * sizeof f]
);
/*
* this declares a pointer to function returning
* a pointer to an array of 3 int
*/
enum { n = 3 };
int (*(*g)(int n))[n]; // the scope of the function parameter 'n' ends
// at the end of its function declarator in
// the array declarator, global n is in scope
Point of Declaration
The scope of structure, union, and enumeration tags begins immediately after the appearance of the tag in a type specifier that declares the tag.
struct Node {
struct Node* next; // Node is in scope and refers to this struct
};
The scope of enumeration constant begins immediately after the appearance of its defining enumerator in an enumerator list.
enum { x = 12 };
{
enum
{
// new x is not in scope until the comma, x is initialized to 13
x = x + 1,
// the new enumerator x is now in scope, y is initialized to 14
y = x + 1
};
}
The scope of any other identifier begins just after the end of its declarator and before the initializer, if any:
// scope of the first 'x' begins
int x = 2;
{
// scope of the newly declared x begins after the declarator (x[x]).
// Within the declarator, the outer 'x' is still in scope.
// This declares a VLA (Variable Length Arrays) array of 2 int.
int x[x];
}
// scope of the outer 'x' begins
unsigned char x = 32;
{
// scope of the inner 'x' begins before the initializer (= x)
// this does not initialize the inner 'x' with the value 32,
// this initializes the inner 'x' with its own, indeterminate, value
unsigned char x = x;
}
unsigned long factorial(unsigned long n)
// declarator ends, 'factorial' is in scope from this point
{
return n<2 ? 1 : n*factorial(n-1); // recursive call
}
As a special case, the scope of a type name that is not a declaration of an identifier is considered to begin just after the place within the type name where the identifier would appear were it not omitted.
Notes:
Prior to C89, identifiers with external linkage had file scope even when introduced within a block, and because of that, a C89 compiler is not required to diagnose the use of an extern identifier that has gone out of scope (such use is undefined behavior).
Local variables within a loop body can hide variables declared in the init clause of a for loop in C (their scope is nested), but cannot do that in C++.
Unlike C++, C has no struct scope: names declared within a struct/union/enum declaration are in the same scope as the struct declaration (except that data members are in their own member name space):
struct foo {
struct baz {};
enum color {RED, BLUE};
};
struct baz b; // baz is in scope
enum color x = RED; // color and RED are in scope
Lifetime
Every object in C exists, has a constant address, retains its last-stored value (except when the value is indeterminate), (and for VLA (Variable Length Arrays), retains its size, since C99) over a portion of program execution known as this object’s lifetime.
For the objects that are declared with automatic, static, and thread storage duration, lifetime equals their storage duration. Note the difference between non-VLA and VLA (Variable Length Arrays) automatic storage duration.
For the objects with allocated storage duration, the lifetime begins when the allocation function returns (including the return from realloc) and ends when the realloc or deallocation function is called. Note that since allocated objects have no declared type, the type of the lvalue expression first used to access this object becomes its effective type.
Accessing an object outside of its lifetime is undefined behavior.
int* foo(void) {
int a = 17; // a has automatic storage duration
return &a;
} // lifetime of a ends
int main(void) {
// p points to an object past lifetime ("dangling pointer")
int* p = foo();
int n = *p; // undefined behavior
}
A pointer to an object (or one past the object) whose lifetime ended has indeterminate value.
Temporary lifetime
Struct and union objects with array members (either direct or members of nested struct/union members) that are designated by non-lvalue expressions, have temporary lifetime. Temporary lifetime begins when the expression that refers to such object is evaluated and ends (at the next sequence point, until C11) (when the containing full expression or full declarator ends, since C11).
Any attempt to modify an object with temporary lifetime results in undefined behavior.
struct T { double a[4]; };
struct T f(void) { return (struct T){3.15}; }
double g1(double* x) { return *x; }
void g2(double* x) { *x = 1.0; }
int main(void)
{
double d = g1(f().a); // C99: UB access to a[0] in g1 whose lifetime ended
// at the sequence point at the start of g1
// C11: OK, d is 3.15
g2(f().a); // C99: UB modification of a[0] whose lifetime ended at the sequence point
// C11: UB attempt to modify a temporary object
}
Lookup and Name Spaces
When an identifier is encountered in a C program, a lookup is performed to locate the declaration that introduced that identifier and that is currently in scope. C allows more than one declaration for the same identifier to be in scope simultaneously if these identifiers belong to different categories, called name spaces:
- Label name space: all identifiers declared as labels.
- Tag names: all identifiers declared as names of structs, unions and enumerated types. Note that all three kinds of tags share one name space.
- Member names: all identifiers declared as members of any one struct or union. Every struct and union introduces its own name space of this kind.
- All other identifiers, called ordinary identifiers to distinguish from (1-3) (function names, object names, typedef names, enumeration constants).
At the point of lookup, the name space of an identifier is determined by the manner in which it is used:
- identifier appearing as the operand of a goto statement is looked up in the label name space.
- identifier that follows the keyword struct, union, or enum is looked up in the tag name space.
- identifier that follows the member access or member access through pointer operator is looked up in the name space of members of the type determined by the left-hand operand of the member access operator.
- all other identifiers are looked up in the name space of ordinary identifiers.
Notes
The names of macros are not part of any name space because they are replaced by the preprocessor prior to semantic analysis.
It is common practice to inject struct/union/enum names into the name space of the ordinary identifiers using a typedef declaration:
struct A { }; // introduces the name A in tag name space
typedef struct A A; // first, lookup for A after "struct" finds one in tag name space
// then introduces the name A in the ordinary name space
struct A* p; // OK, this A is looked up in the tag name space
A* q; // OK, this A is looked up in the ordinary name space
A well-known example of the same identifier being used across two name spaces is the identifier stat from the POSIX header sys/stat.h. It names a function when used as an ordinary identifier and indicates a struct when used as a tag.
Unlike in C++, enumeration constants are not struct members, and their name space is the name space of ordinary identifiers, and since there is no struct scope in C, their scope is the scope in which the struct declaration appears:
struct tagged_union
{
enum {INT, FLOAT, STRING} type;
int integer;
float floating_point;
char *string;
} tu;
tu.type = INT; // OK in C, error in C++
Operators
| Operators | Associativity | Description |
|---|---|---|
() [] -> . |
left to right | Function call, array access, member access |
! ~ ++ -- + - * (type) sizeof |
right to left | Unary operators, increment operator, decrement operator, sign operators, type cast, sizeof |
* / % |
left to right | Arithmetic operators: multiplication, division, modulo |
+ - |
left to right | Arithmetic operators: addition, subtraction |
<< >> |
left to right | Bitwise operators: left shift, right shift |
< <= > >= |
left to right | Relational operators: less-than, less and equal than, larger than, larger and equal than |
== != |
left to right | Relational operators: equal, not equal |
& |
left to right | Bitwise operators: bitwise AND |
^ |
left to right | Bitwise operators: bitwise exclusive OR (XOR) |
| |
left to right | Bitwise operators: bitwise inclusive OR |
&& |
left to right | Logical operators: AND |
|| |
left to right | Logical operators: OR |
?: |
right to left | Conditional expression (ternary) |
= += -= *= /= %= <<= >>= &= ^= |= |
right to left | Assignment operators |
, |
left to right | Comma operator |
Run the following command to get the operator priority under Linux environment:
chenwx@chenwx ~ $ man operator
NAME
operator - C operator precedence and order of evaluation
DESCRIPTION
This manual page lists C operators and their precedence in evaluation.
Operator Associativity
() [] -> . left to right
! ~ ++ -- + - (type) * & sizeof right to left
* / % left to right
+ - left to right
<< >> left to right
< <= > >= left to right
== != left to right
& left to right
^ left to right
| left to right
&& left to right
|| left to right
?: right to left
= += -= *= /= %= <<= >>= &= ^= |= right to left
, left to right
COLOPHON
This page is part of release 3.54 of the Linux man-pages project. A description of the project, and information about reporting bugs, can befound at http://www.kernel.org/doc/man-pages/.
Comments
C-style comments or multi-line comments, which cannot be nested.
/* comment */
C++-style comments or single-line comments (since C99), which can be nested.
// comment until end of the line
All comments are removed from the program at translation phase 3 by replacing each comment with a single whitespace character.
Because comments are removed before the preprocessor stage, a macro cannot be used to form a comment and an unterminated C-style comment doesn’t spill over from an #include‘d file.
/* An attempt to use a macro to form a comment. */
/* But, a space replaces characters "//". */
#ifndef DEBUG
#define PRINTF //
#else
#define PRINTF printf
#endif
...
PRINTF("Error in file %s at line %i\n", __FILE__, __LINE__);
Besides commenting out, other mechanisms used for source code exclusion are:
#if 0
puts("this will not be compiled");
/* no conflict with C-style comments */
// no conflict with C++-style comments
#endif
and
if (0) {
puts("this will be compiled but not be executed");
/* no conflict with C-style comments */
// no conflict with C++-style comments
}
Preprocessor
The preprocessor is executed at translation phase 4, before the compilation, which is executed at translation phase 7. The result of preprocessing is single file which is then passed to the actual compiler. Refer to Preprocessor on CppReference.
The preprocessor has the source file translation capabilities:
- Conditional compile of parts of source file: controlled by directives
#if,#else,#elif,#ifdef,#ifndefand#endif - Replace text macros while possibly concatenating or quoting identifiers: controlled by directives
#defineand#undef, and operators#and## - Include other files: controlled by directive
#include - Cause an error: controlled by directive
#error
The following aspects of the preprocessor can be controlled:
- Implementation defined behavior: controlled by directive
#pragma(and operator_Pragma, since C99) - File name and line information available to the preprocessor: controlled by directive
#line
NOTE: Those preprocessor directives are defined by the standard. The standard does not define behavior for other directives: they might be ignored, have some useful meaning, or make the program ill-formed. Even if otherwise ignored, they are removed from the source code when the preprocessor is done. A common non-standard extension is the directive #warning which emits a user-defined message during compilation.
The output of preprocessing of source file example.c to file example.l:
gcc -E -o example.l example.c
Conditional Inclusion
The preprocessor supports conditional compilation of parts of a source file. This behavior is controlled by #if, #else, #elif, #ifdef, #ifndef and #endif directives.
It is possible to control preprocessing itself with conditional statements that are evaluated during preprocessing. This provides a way to include code selectively, depending on the value of conditions evaluated during compilation.
#define ABCD 2
#include <stdio.h>
int main(void)
{
#ifdef ABCD
printf("1: yes\n");
#else
printf("1: no\n");
#endif
#ifndef ABCD
printf("2: no1\n");
#elif ABCD == 2
printf("2: yes\n");
#else
printf("2: no2\n");
#endif
#if !defined(DCBA) && (ABCD < 2*4-3)
printf("3: yes\n");
#endif
}
Checks if the identifier was defined using #define directive:
#ifdef identifieris essentially equivalent to#if defined(identifier).#ifndef identifieris essentially equivalent to#if !defined(identifier).
Header Guards
#ifndef FILENAME_H
#define FILENAME_H
/* contents of the header */
#endif /* FILENAME_H */
Replacing Text Macros
The preprocessor supports text macro replacement and function-like text macro replacement.
#define IDNTIFIER replacement-list (1)
#define IDNTIFIER(parameters) replacement-list (2)
#define IDNTIFIER(parameters, ...) replacement-list (3) since C99
#define IDNTIFIER(...) replacement-list (4) since C99
#undef IDNTIFIER (5)
The #define directives define the IDNTIFIER as a macro, that is they instruct the compiler to replace all successive occurrences of identifier with replacement-list, which can be optionally additionally processed. Substitutions are made only for tokens, and do not take place within quoted strings.
The IDNTIFIER in a #define has the same form as a variable name. Capitalizing constants IDNTIFIER is just another technique to make programs more readable. If the IDNTIFIER is already defined as any type of macro, the program is ill-formed unless the definitions are identical.
Normally the replacement-text is the rest of the line, but a long definition may be continued onto several lines by placing a \ at the end of each line to be continued.
There is no semicolon ; at the end of a #define line because this is a substitution mechanism, not a C statement.
The scope of a name defined with #define is from its point of definition to the end of the source file being compiled. A macro definition may use previous macro definitions.
It is also possible to define macros with arguments, so the replacement-text can be different for different calls of the macro. Version (2) of the #define directive defines a simple function-like macro.
Some care also has to be taken with parentheses to make sure the order of evaluation is preserved, such as:
#define square(x) x * x
It’s better to add parentheses for each input parameter, such as:
#define max(A, B) ((A) > (B) ? (A) : (B))
Version (3) of the #define directive defines a function-like macro with variable number of arguments. The additional arguments can be accessed using __VA_ARGS__ identifier, which is then replaced with arguments, supplied with the identifier to be replaced.
Version (4) of the #define directive defines a function-like macro with variable number of arguments, but no regular arguments. The arguments can be accessed only with __VA_ARGS__ identifier, which is then replaced with arguments, supplied with identifier to be replaced.
The #undef directive undefines the IDNTIFIER, that is it cancels the previous definition of the identifier by #define directive. If the IDNTIFIER does not have an associated macro, the directive is ignored. Usually, it’s used to ensure that a routine is really a function, not a macro:
#undef getchar
int getchar(void)
{
...
}
# and ## operators
In function-like macros, a # operator before an identifier in the replacement-list runs the identifier through parameter replacement and encloses the result in quotes, effectively creating a string literal. In addition, the preprocessor adds backslashes to escape the quotes surrounding embedded string literals, if any, and doubles the backslashes within the string as necessary. All leading and trailing whitespace is removed, and any sequence of whitespace in the middle of the text (but not inside embedded string literals) is collapsed to a single space. This operation is called stringification. If the result of stringification is not a valid string literal, the behavior is undefined.
When # appears before __VA_ARGS__, the entire expanded __VA_ARGS__ is enclosed in quotes (since C99):
#define showlist(...) puts(#__VA_ARGS__)
showlist(); // expands to puts("")
showlist(1, "x", int); // expands to puts("1, \"x\", int")
A ## operator between any two successive identifiers in the replacement-list runs parameter replacement on the two identifiers and then concatenates the result. This operation is called concatenation or token pasting. Only tokens that form a valid token together may be pasted: identifiers that form a longer identifier, digits that form a number, or operators + and = that form a +=. A comment cannot be created by pasting / and * because comments are removed from text before macro substitution is considered. If the result of concatenation is not a valid token, the behavior is undefined.
Note: some compilers offer an extension that allows ## to appear after a comma and before __VA_ARGS__, in which case the ## does nothing when __VA_ARGS__ is non-empty, but removes the comma when __VA_ARGS__ is empty: this makes it possible to define macros such as fprintf (stderr, format, ##__VA_ARGS__).
Predefined Macros
The following macro names are predefined in any translation unit:
| Macros | Version | Description |
|---|---|---|
__STDC__ |
expands to the integer constant 1. This macro is intended to indicate a conforming implementation (macro constant) | |
__STDC_VERSION__ |
C95 | expands to an integer constant of type long whose value increases with each version of the C standard (macro constant):199409L for C95199901L for C99201112L for C11 |
__STDC_HOSTED__ |
C99 | expands to the integer constant 1 if the implementation is hosted (runs under an OS), 0 if freestanding (runs without an OS) (macro constant) |
__FILE__ |
expands to the name of the current file, as a character string literal, can be changed by the #line directive (macro constant) | |
__LINE__ |
expands to the source file line number, an integer constant, can be changed by the #line directive (macro constant) | |
__DATE__ |
expands to the date of translation, a character string literal of the form Mmm dd yyyy. The name of the month is as if generated by asctime and the first character of dd is a space if the day of the month is less than 10 (macro constant) | |
__TIME__ |
expands to the time of translation, a character string literal of the form hh:mm:ss, as in the time generated by asctime() (macro constant) |
The following additional macro names may be predefined by an implementation:
| Macros | Version | Description |
|---|---|---|
__STDC_ISO_10646__ |
C99 | expands to an integer constant of the form yyyymmL, if wchar_t uses Unicode, the date indicates the latest revision of Unicode supported (macro constant) |
__STDC_IEC_559__ |
C99 | expands to 1 if IEC 60559 is supported (macro constant) |
__STDC_IEC_559_COMPLEX__ |
C99 | expands to 1 if IEC 60559 complex arithmetic is supported (macro constant) |
__STDC_UTF_16__ |
C11 | expands to 1 if char16_t use UTF-16 encoding (macro constant) |
__STDC_UTF_32__ |
C11 | expands to 1 if char32_t use UTF-32 encoding (macro constant) |
__STDC_MB_MIGHT_NEQ_WC__ |
C99 | expands to 1 if wide character encoding of the basic character set may not equal their narrow encoding, such as on EBCDIC-based systems that use Unicode for wchar_t (macro constant) |
__STDC_ANALYZABLE__ |
C11 | expands to 1 if analyzability is supported (macro constant) |
__STDC_LIB_EXT1__ |
C11 | expands to an integer constant 201112L if bounds-checking interfaces are supported (macro constant) |
__STDC_NO_ATOMICS__ |
C11 | expands to 1 if atomic types and atomic operations library are not supported (macro constant) |
__STDC_NO_COMPLEX__ |
C11 | expands to 1 if complex types and complex math library are not supported (macro constant) |
__STDC_NO_THREADS__ |
C11 | expands to 1 if multithreading is not supported (macro constant) |
__STDC_NO_VLA__ |
C11 | expands to 1 if variable-length arrays are not supported (macro constant) |
The values of these macros (except for __FILE__ and __LINE__) remain constant throughout the translation unit. Attempts to redefine or undefine these macros result in undefined behavior.
Since C99, the predefined variable __func__ is not a preprocessor macro, even though it is sometimes used together with __FILE__ and __LINE__, e.g. by assert.
Substitution of Macros
The C90 added a second way to create symbolic constants – using the const keyword to convert a declaration for a variable into a declaration for a constant. This newer approach is more flexible than using #define:
const int MONTHS = 12;
Actually, C has yet a third way to create symbolic constants, and that is the enum facility.
File Inclusion
Includes source file, identified by filename, into the current source file at the line immediately after the directive.
#include <filename> (1)
#include "filename" (2)
The first version of the directive searches only standard include directories. The standard C++ library, as well as standard C library, is implicitly included in standard include directories. The standard include directories can be controlled by the user through compiler options.
The second version of the directive first searches the directory where the current file resides and, only if the file is not found, searches the standard include directories.
There are often several #include lines at the beginning of a source file, to include common #define statements and extern declarations, or to access the function prototype declarations for library functions from headers like <stdio.h>.
An included file may itself contain #include lines. Naturally, when an included file is changed, all files that depend on it must be recompiled.
error Directive
The #error directive shows the given error message and renders the program ill-formed.
#error error_message
After encountering the #error directive, an implementation displays the diagnostic message error_message and renders the program ill-formed (the compilation stops). The error_message can consist of several words not necessarily in quotes.
pragma Directive
Implementation defined behavior is controlled by #pragma directive. The #pragma directive controls implementation-specific behavior of the compiler, such as disabling compiler warnings or changing alignment requirements. Any #pragma that is not recognized is ignored.
#pragma pragma_params (1)
_Pragma (string-literal) (2) (since C99)
Version (1) behaves in an implementation-defined manner (unless pragma_params is one of the standard pragmas shown below.
Version (2) removes the encoding prefix (if any), the outer quotes, and leading/trailing whitespace from string-literal, replaces each \" with " and each \\ with \, then tokenizes the result (as in translation phase 3), and then uses the result as if the input to #pragma in version (1).
Standard pragmas
The following three pragmas are defined by the language standard:
#pragma STDC FENV_ACCESS arg (1)
#pragma STDC FP_CONTRACT arg (2)
#pragma STDC CX_LIMITED_RANGE arg (3)
where, arg is either ON or OFF or DEFAULT.
Version (1): If set to ON, informs the compiler that the program will access or modify floating-point environment, which means that optimizations that could subvert flag tests and mode changes (e.g., global common subexpression elimination, code motion, and constant folding) are prohibited. The default value is implementation-defined, usually OFF.
Version (2): Allows contracting of floating-point expressions, that is optimizations that omit rounding errors and floating-point exceptions that would be observed if the expression was evaluated exactly as written. For example, allows the implementation of (x*y) + z with a single fused multiply-add CPU instruction. The default value is implementation-defined, usually ON.
Version (3): Informs the compiler that multiplication, division, and absolute value of complex numbers may use simplified mathematical formulas (x+iy)×(u+iv) = (xu-yv)+i(yu+xv), (x+iy)/(u+iv) = [(xu+yv)+i(yu-xv)]/(u2+v2), and |x+iy| = √x2+y2, despite the possibility of intermediate overflow. In other words, the programmer guarantees that the range of the values that will be passed to those function is limited. The default value is OFF.
Non-standard pragmas
The #pragma once is a non-standard pragma that is supported by the vast majority of modern compilers. If it appears in a header file, it indicates that it is only to be parsed once, even if it is (directly or indirectly) included multiple times in the same source file.
Standard approach to preventing multiple inclusion of the same header is by using header guards:
#ifndef FILENAME_H
#define FILENAME_H
/* contents of the header */
#endif /* FILENAME_H */
So that all but the first inclusion of the header in any translation unit are excluded from compilation.
With #pragma once, the same header appears as
#pragma once
/* contents of the header */
Unlike header guards, this #pragma makes it impossible to erroneously use the same macro name in more than one file. On the other hand, since with #pragma once files are excluded based on their filesystem-level identity, this can’t protect against including a header twice if it exists in more than one location in a project.
The #pragma packspecifies packing alignment for structure and union members.
line Directive
The #line directive changes the current line number and file name in the preprocessor. This directive is used by some automatic code generation tools which produce C++ source files from a file written in another language. In that case, #line directives may be inserted in the generated C++ file referencing line numbers and the file name of the original (human-editable) source file.
#line lineno (1)
#line lineno "filename" (2)
Version (1): Changes the current preprocessor line number to lineno. Occurrences of the macro __LINE__ beyond this point will expand to lineno plus the number of actual source code lines encountered since.
Version (2): Also changes the current preprocessor file name to filename. Occurrences of the macro __FILE__ beyond this point will produce filename.
Any preprocessing tokens (macro constants or expressions) are permitted as arguments to #line as long as they expand to a valid decimal integer optionally following a valid character string.
#include <assert.h>
#define FNAME "test.c"
int main(void)
{
#line 777 FNAME
assert(2+2 == 5);
}
Escape Sequences
Escape sequences are used to represent certain special characters within string literals and character constants. The following escape sequences are available. ISO C requires a diagnostic if the backslash is followed by any character not listed here:
| Escape sequence | Description | Representation | Means |
|---|---|---|---|
\' |
single quote | byte 0x27 (in ASCII encoding) | character constant ' |
\" |
double quote | byte 0x22 (in ASCII encoding) | character constant " |
\? |
question mark | byte 0x3f (in ASCII encoding) | character constant ? |
\\ |
backslash | byte 0x5c (in ASCII encoding) | character constant \ |
\a |
audible bell | byte 0x07 (in ASCII encoding) | produces an audible or visible alert, which shall not change the active position. |
\b |
backspace | byte 0x08 (in ASCII encoding) | moves the active position back one space on the current line. |
\f |
form feed / new page | byte 0x0c (in ASCII encoding) | moves the active position to the start of the next page. |
\n |
line feed / new line | byte 0x0a (in ASCII encoding) | moves the active position to the beginning of the next line. |
\r |
carriage return | byte 0x0d (in ASCII encoding) | moves the active position to the beginning of the current line. |
\t |
horizontal tab | byte 0x09 (in ASCII encoding) | moves the active position to the next horizontal tab stop. |
\v |
vertical tab | byte 0x0b (in ASCII encoding) | moves the active position to the next vertical tab position. |
\nnn |
arbitrary octal value | byte nnn | |
\xnn\Xnn |
arbitrary hexadecimal value | byte nn | |
\unnnn |
Unicode character that is not in the basic character set. May result in several characters. | code point U+nnnn | |
\Unnnnnnnn |
Unicode character that is not in the basic character set. May result in several characters. | code point U+nnnnnnnn |
- The escape sequence represents only a single character.
- The escape sequences provides a general and extensible mechanism for representing hard-to-type or invisible characters.
Types
Basic Types
The C language provides the four basic arithmetic type specifiers char, int, float and double, and the modifiers signed, unsigned, short and long.
The actual size of integer types varies by implementation. The standard only requires size relations between the data types and minimum sizes for each data type:
long long => long => int => short => char
That’s, the relation requirements are that the long long (at least 64 bits) is not smaller than long (at least 32 bits), which is not smaller than int (at least 16 bits), which is not smaller than short (at least 16 bits). As size of char (at least 8 bits) is always the minimum supported data type, no other data types (except bit-fields) can be smaller.
The actual size and behavior of floating-point types also vary by implementation. The only guarantee is that long double is not smaller than double, which is not smaller than float. Usually, the 32-bit and 64-bit IEEE 754 binary floating-point formats are used, if supported by hardware.
The following sections list the permissible combinations to specify a large set of storage size-specific declarations, refer to C Data Types.
char
| Standard | since C89 |
| Format Specifier | Character output: %cNumerical output: refer to unsigned char or signed char |
| Size | at least 8 bits |
| Explanation | Smallest addressable unit of the machine that can contain basic character set. It is an integer type. Actual type can be either signed or unsigned depending on the implementation. Your compiler manual should tell you which type your char is, or you can check the limits.h header file. Also refer to Escape Sequences |
| Constants | A character constant is an integer, written as one character within single quotes, such as char c = 'A' or char c = 65, char c = \0x41, char c = \0101. |
signed char
| Standard | since C89 |
| Format Specifier | Character output: %cNumerical output: Decimal notation: %hhi, %hhd |
| Size | at least 8 bits |
| Explanation | Of the same size as char, but guaranteed to be signed. Also refer to Escape Sequences |
| Constants | A character constant is an integer, written as one character within single quotes, such as char c = 'A' or char c = 65. |
unsigned char
| Standard | since C89 |
| Format Specifier | Character output: %cNumerical output: Decimal notation: %hhuOctal notation: %hho, %#hhoHexadecimal notation: %hhx, %#hhx, %hhX, %#hhx |
| Size | at least 8 bits |
| Explanation | Of the same size as char, but guaranteed to be unsigned. It is represented in binary notation without padding bits; thus, its range is exactly [0, 2^CHAR_BIT - 1]. Also refer to Escape Sequences |
| Constants | A character constant is an integer, written as one character within single quotes, such as char c = 'A' or char c = 65. |
short / short int / signed short / signed short int
| Standard | since C89 |
| Format Specifier | Decimal notation: %hi, %hdOctal notation: %ho, %#hoHexadecimal notation: %hx, %#hx, %#hX |
| Size | at least 16 bits |
| Explanation | Short signed integer type. |
| Constants |
unsigned short / unsigned short int
| Standard | since C89 |
| Format Specifier | Decimal notation: %huOctal notation: %ho, %#hoHexadecimal notation: %hx, %#hx, %#hX |
| Size | at least 16 bits |
| Explanation | Similar to short, but unsigned. |
| Constants |
int / signed / signed int
The int type is a signed integer. That means it must be an integer and it can be positive, negative, or zero. The range in possible values depends on the computer system.
| Standard | since C89 |
| Format Specifier | Decimal notation: %i, %dOctal notation: %o, %#oHexadecimal notation: %x, %#x, %#X |
| Size | at least 16 bits. Typically, it uses one machine word for storage. |
| Explanation | Basic signed integer type. |
| Constants | A int constant is written without suffix, as 1234, 02322, 0x4D2 |
unsigned / unsigned int
| Standard | since C89 |
| Format Specifier | Decimal notation: %u |
| Size | at least 16 bits |
| Explanation | Similar to int, but unsigned. |
| Constants | An unsigned int constant is written with a terminal u or U (perfer U), as 1234U, 02322U, 0x4D2U |
When do you use the various int types? First, consider unsigned types. It is natural to use them for counting because you don’t need negative numbers, and the unsigned types enable you to reach higher positive numbers than the signed types.
long / long int / signed long / signed long int
| Standard | since C89 |
| Format Specifier | Decimal notation: %li or %ld |
| Size | at least 32 bits |
| Explanation | Long signed integer type. |
| Constants | A long constant is written with a terminal l or L (perfer L), as in 1234L, 02322L, 0x4D2L |
unsigned long / unsigned long int
| Standard | since C89 |
| Format Specifier | Decimal notation: %luOctal notation: %lo, %#loHexadecimal notation: %lx, %#lx, %#lX |
| Size | at least 32 bits |
| Explanation | Similar to long, but unsigned. |
| Constants | A unsigned long constant is written with a terminal ul or UL (perfer UL), as in 1234UL, 02322UL, 0x4D2UL |
long long / long long int / signed long long / signed long long int
| Standard | since C99 |
| Format Specifier | Decimal notation: %lli or %lld |
| Size | at least 64 bits |
| Explanation | Long long signed integer type. |
| Constants | A long long constant is written with a terminal ll or LL (perfer LL), as in 1234LL, 02322LL, 0x4D2LL |
unsigned long long / unsigned long long int
| Standard | since C99 |
| Format Specifier | Decimal notation: %lluOctal notation: %llo, %#lloHexadecimal notation: %llx, %#llx, %#llX |
| Size | at least 64 bits |
| Explanation | Similar to long long, but unsigned. |
| Constants | A unsigned long long constant is written with a terminal ull, llu or ULL, LLU (perfer ULL), as in 1234ULL, 02322ULL, 0x4D2ULL |
float
| Standard | since C89 |
| Format Specifier | Decimal notation: %f, promoted automatically to double for printf() |
| Size | |
| Explanation | Real floating-point type, usually referred to as a single-precision floating-point type. Actual properties unspecified (except minimum limits), however on most systems this is the IEEE 754 single-precision binary floating-point format. This format is required by the optional Annex F: IEC 60559 floating-point arithmetic. Accurate: 6 digits |
| Constants | An float constant is written with a terminal f or F (perfer F), as 123.4F, 1.234e5F, 1.234E-5F |
double
| Standard | since C89 |
| Format Specifier | Decimal notation: %f, %FExponential notation: %e, %EDecimal or exponential notation depending on the value: %g, %GHexadecimal notation (since C99): %a, %AFor scanf(): %lf or %lF |
| Size | |
| Explanation | Real floating-point type, usually referred to as a double-precision floating-point type. Actual properties unspecified (except minimum limits), however on most systems this is the IEEE 754 double-precision binary floating-point format. This format is required by the optional Annex F: IEC 60559 floating-point arithmetic. Accurate: 10 digits |
| Constants | An double constant is written without suffix, as 123.4, 1.234e+5, 1.234E-5 |
long double
| Standard | since C89 |
| Format Specifier | Decimal notation: %Lf or %LFExponential notation: %Le, %LEDecimal or exponential notation depending on the value: %Lg, %LGHexadecimal notation (since C99): %La, %LA |
| Size | |
| Explanation | Real floating-point type, usually mapped to an extended precision floating-point number format. Actual properties unspecified. Unlike types float and double, it can be either 80-bit floating point format, the non-IEEE double-double or IEEE 754 quadruple-precision floating-point format if a higher precision format is provided, otherwise it is the same as double. Accurate: 10 digits |
| Constants | An float constant is written with a terminal l or L (prefer L), as 123.4L |
_Bool
- Boolean values represent
trueandfalse; C uses 1 fortrueand 0 forfalse. - It is an unsigned int and need only be large enough to accommodate the range 0 through 1.
- When the header
<stdbool.h>is included, the Boolean type is also accessible asbool.
Complex Floating Types
Complex floating types model the mathematical complex numbers, that is the numbers that can be written as a sum of a real number and a real number multiplied by the imaginary unit: a + bi.
The three complex types are:
float _Complex, also available asfloat complexif<complex.h>is includeddouble _Complex, also available asdouble complexif<complex.h>is includedlong double _Complex, also available aslong double complexifis included
#include <complex.h>
#include <stdio.h>
int main(void)
{
double complex z = 1 + 2*I;
z = 1/z;
printf("1/(1.0+2.0i) = %.1f%+.1fi\n", creal(z), cimag(z));
}
Each complex type has the same object representation and alignment requirements as an array of two elements of the corresponding real type (float for float complex, double for double complex, long double for long double complex). The first element of the array holds the real part, and the second element of the array holds the imaginary component.
float a[4] = { 1, 2, 3, 4 };
float complex z1, z2;
memcpy(&z1, a, sizeof z1); // z1 becomes 1.0 + 2.0i
memcpy(&z2, a+2, sizeof z2); // z2 becomes 3.0 + 4.0i
Complex numbers may be used with arithmetic operators + - * /, possibly mixed with imaginary and real numbers. There are many mathematical functions defined for complex numbers in <complex.h>. Both built-in operators and library functions may raise floating-point exceptions and set errno.
Increment and decrement are not defined for complex types.
Imaginary Floating Types
Imaginary floating types model the mathematical imaginary numbers, that is numbers that can be written as a real number multiplied by the imaginary unit: bi.
The three imaginary types are:
float _Imaginary, also available asfloat imaginaryif<complex.h>is includeddouble _Imaginary, also available asdouble imaginaryif<complex.h>is includedlong double _Imaginary, also available aslong double imaginaryif<complex.h>is included
#include <complex.h>
#include <stdio.h>
int main(void)
{
double imaginary z = 3*I;
z = 1/z;
printf("1/(3.0i) = %+.1fi\n", cimag(z));
}
Each of the three imaginary types has the same object representation and alignment requirement as its corresponding real type (float for float imaginary, double for double imaginary, long double for long double imaginary).
Imaginary numbers may be used with arithmetic operators + - * /, possibly mixed with complex and real numbers. There are many mathematical functions defined for imaginary numbers in <complex.h>. Both built-in operators and library functions may raise floating-point exceptions and set errno.
Increment and decrement are not defined for imaginary types.
Properties of Basic Types
Information about the actual properties, such as size, of the basic arithmetic types, is provided via macro constants in two headers:
<limits.h>header (climitsheader in C++) defines macros for integer types<float.h>header (cfloatheader in C++) defines macros for floating-point types
The actual values depend on the implementation.
Properties of Integer Types
| Macros | Description |
|---|---|
| CHAR_BIT | size of the char type in bits, at least 8 bits |
| CHAR_MIN | minimum possible value of char type |
| CHAR_MAX | maximum possible value of char type |
| MB_LEN_MAX | maximum number of bytes in a multibyte character |
| SCHAR_MIN | minimum possible value of signed char type |
| SCHAR_MAX | maximum possible value of signed char type |
| UCHAR_MAX | maximum possible value of unsigned char type |
| SHRT_MIN | minimum possible value of signed short type |
| SHRT_MAX | maximum possible value of signed short type |
| USHRT_MAX | maximum possible value of unsigned short type |
| INT_MIN | minimum possible value of signed int type |
| INT_MAX | maximum possible value of signed int type |
| UINT_MAX | maximum possible value of unsigned int type |
| LONG_MIN | minimum possible value of signed long type |
| LONG_MAX | maximum possible value of signed long type |
| ULONG_MAX | maximum possible value of unsigned long type |
| LLONG_MIN | (since C99) minimum possible value of signed long long type |
| LLONG_MAX | (since C99) maximum possible value of signed long long type |
| ULLONG_MAX | (since C99) maximum possible value of unsigned long long type |
Properties of Floating-point Types
| Macros | Description |
|---|---|
| FLT_MIN | minimum normalized positive value of float type |
| DBL_MIN | minimum normalized positive value of double type |
| LDBL_MIN | minimum normalized positive value of long double type |
| FLT_TRUE_MIN | minimum positive value of float type |
| DBL_TRUE_MIN | minimum positive value of double type |
| LDBL_TRUE_MIN | (since C11) minimum positive value of long double type |
| FLT_MAX | maximum finite value of float type |
| DBL_MAX | maximum finite value of double type |
| LDBL_MAX | maximum finite value of long double type |
| FLT_ROUNDS | rounding mode for floating-point operations |
| FLT_EVAL_METHOD | (since C99) evaluation method of expressions involving different floating-point types |
| FLT_RADIX | radix of the exponent in the floating-point types |
| FLT_DIG | number of decimal digits that can be represented without losing precision by float type |
| DBL_DIG | number of decimal digits that can be represented without losing precision by double type |
| LDBL_DIG | number of decimal digits that can be represented without losing precision by long double type |
| FLT_EPSILON | difference between 1.0 and the next representable value of float type |
| DBL_EPSILON | difference between 1.0 and the next representable value of double type |
| LDBL_EPSILON | difference between 1.0 and the next representable value of long double type |
| FLT_MANT_DIG | number of FLT_RADIX-base digits in the floating-point significand for float type |
| DBL_MANT_DIG | number of FLT_RADIX-base digits in the floating-point significand for double type |
| LDBL_MANT_DIG | number of FLT_RADIX-base digits in the floating-point significand for long double type |
| FLT_MIN_EXP | minimum negative integer such that FLT_RADIX raised to a power one less than that number is a normalized float type |
| DBL_MIN_EXP | minimum negative integer such that FLT_RADIX raised to a power one less than that number is a normalized double type |
| LDBL_MIN_EXP | minimum negative integer such that FLT_RADIX raised to a power one less than that number is a normalized long double type |
| FLT_MIN_10_EXP | minimum negative integer such that 10 raised to that power is a normalized float type |
| DBL_MIN_10_EXP | minimum negative integer such that 10 raised to that power is a normalized double type |
| LDBL_MIN_10_EXP | minimum negative integer such that 10 raised to that power is a normalized long double type |
| FLT_MAX_EXP | maximum positive integer such that FLT_RADIX raised to a power one less than that number is a normalized float type |
| DBL_MAX_EXP | maximum positive integer such that FLT_RADIX raised to a power one less than that number is a normalized double type |
| LDBL_MAX_EXP | maximum positive integer such that FLT_RADIX raised to a power one less than that number is a normalized long double type |
| FLT_MAX_10_EXP | maximum positive integer such that 10 raised to that power is a normalized float type |
| DBL_MAX_10_EXP | maximum positive integer such that 10 raised to that power is a normalized double type |
| LDBL_MAX_10_EXP | maximum positive integer such that 10 raised to that power is a normalized long double type |
| DECIMAL_DIG | (since C99) minimum number of decimal digits such that any number of the widest supported floating-point type can be represented in decimal with a precision of DECIMAL_DIG digits and read back in the original floating-point type without changing its value. DECIMAL_DIG is at least 10. |
Fixed-width Integer Types
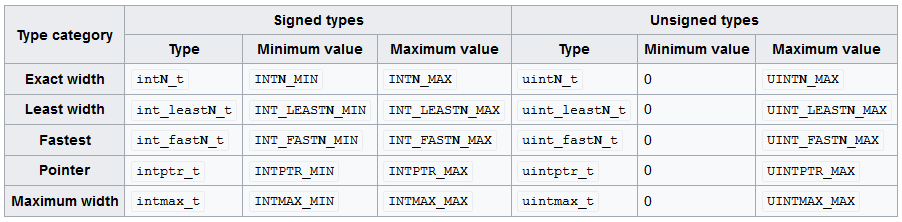
The C99 standard includes definitions of several new integer types to enhance the portability of programs. The already available basic integer types were deemed insufficient, because their actual sizes are implementation defined and may vary across different systems. The new types are especially useful in embedded environments where hardware usually supports only several types and that support varies between different environments. All new types are defined in <inttypes.h> header (cinttypes header in C++) and also are available at <stdint.h> header (cstdint header in C++). The types can be grouped into the following categories:
- Exact-width integer types which are guaranteed to have the same number N of bits across all implementations. Included only if it is available in the implementation.
- Least-width integer types which are guaranteed to be the smallest type available in the implementation, that has at least specified number N of bits. Guaranteed to be specified for at least N = 8, 16, 32, 64.
- Fastest integer types which are guaranteed to be the fastest integer type available in the implementation, that has at least specified number N of bits. Guaranteed to be specified for at least N = 8, 16, 32, 64.
- Pointer integer types which are guaranteed to be able to hold a pointer. Included only if it is available in the implementation.
- Maximum-width integer types which are guaranteed to be the largest integer type in the implementation.
The following table summarizes the types and the interface to acquire the implementation details (N refers to the number of bits):
Type Conversions
The basic rules of type conversion are:
-
When appearing in an expression,
charandshort, bothsignedandunsigned, are automatically converted tointor, if necessary, tounsigned int(Ifshortis the same size asint,unsigned shortis larger thanint; in that case,unsigned shortis converted tounsigned int). Under K&R C, but not under current C,floatis automatically converted todouble. Because they are conversions to larger types, they are called promotions. -
In any operation involving two types, both values are converted to the higher ranking of the two types.
-
The ranking of types, from highest to lowest, is
long double,double,float,unsigned long long,long long,unsigned long,long,unsigned int, andint. One possible exception is whenlongandintare the same size, in which caseunsigned intoutrankslong. Theshortandchartypes don’t appear in this list because they would have been already promoted tointor perhapsunsigned int. -
In an assignment statement, the final result of the calculations is converted to the type of the variable being assigned a value. This process can result in promotion, as described in rule 1, or demotion, in which a value is converted to a lower-ranking type.
-
When passed as function arguments,
charandshortare converted toint, andfloatis converted todouble. This automatic promotion can be overridden by function prototyping.
Promotion is usually a smooth, uneventful process, but demotion can lead to real trouble. The reason is simple: The lower-ranking type may not be big enough to hold the complete number. When floating types are demoted to integer types, they are truncated, or rounded toward zero. That means 23.12 and 23.99 both are truncated to 23 and that -23.5 is truncated to -23.
(type) : As the cast operator, converts the following value to the type specified by the enclosed keyword(s).
Derived Types
Arrays
Refer to Array on CppReference.
An array is a series of values of the same type, such as 10 chars or 15 ints, stored sequentially. The whole array bears a single name, and the individual items, or elements, are accessed by using an integer index.
The numbers used to identify the array elements are called subscripts, indices, or offsets. The subscripts must be integers and the subscripting begins with 0.
C99 allows you to use const values for specifying an array size, but C90 didn’t. #define works with both.
An array may be initialized by following its declaration with a list of initializers enclosed in braces and separated by commas:
int days[12] = { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
When the size of the array is omitted, the compiler will compute the length by counting the initializers:
int days[] = { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
If there are fewer initializers for an array than the specified size, the others will be zero for external, static and automatic variables. It is an error to have too many initializers.
There is no way to specify repetition of an initializer, nor to initialize an element in the middle of an array without supplying all the preceding values as well.
Character arrays are a special case of initialization; a string may be used instead of the braces and commas notation:
char pattern = "ould";
is a shorthand for the longer but equivalent:
char pattern[] = { 'o', 'u', 'l', 'd', '\0' };
Character String
C language uses an array to hold a character string. A character string is a series of one or more characters. C uses null character \0 to mark the end of a string.
char name[40] = "Zing went the strings of my heart!";

Structures
A structure is a collection of one or more variables, possibly of different types, grouped together under a single name for convenient handling. Structures are a way of storing multiple pieces of data in one variable.
struct Point {
int x;
int y;
};
struct Point ptA, ptB;
struct MorePoint {
int x;
int y;
int y;
} ptC, ptD;
A struct declaration defines a type. Structures may contain pointers to structs of its own type, which is common in linked data structures, such as:
struct Node_t {
int value;
struct Node_t *left;
struct Node_t *right;
};
Note that a new struct name may also be introduced just by using a struct tag within another declaration, but if a previously declared struct with the same name exists in the tag name space, the tag would refer to that name:
struct s* p = NULL; // tag naming an unknown struct declares it
struct s { int a; }; // definition for the struct pointed to by p
void g(void)
{
struct s; // forward declaration of a new, local struct s
// this hides global struct s until the end of this block
struct s *p; // pointer to local struct s
// without the forward declaration above,
// this would point at the file-scope s
struct s { char* p; }; // definitions of the local struct s
}
In order to allow structs that refer to each other, the struct need to be forward declaration:
struct y; // forward declaration
struct x { struct y *p; /* ... */ };
struct y { struct x *q; /* ... */ };
Structures can be nested:
struct Employee
{
char ename[20];
int eid;
float salary;
struct Date
{
int year;
int month;
int day;
} entryDate;
}
A C implementation has freedom to design the memory layout of the struct, with few restrictions; one being that the memory address of the first member will be the same as the address of struct itself. That’s, a pointer to a struct can be cast to a pointer to its first member (or, if the member is a bit field, to its allocation unit). Likewise, a pointer to the first member of a struct can be cast to a pointer to the enclosing struct.
A user-written function can directly return a structure, though it will often not be very efficient at run-time.
The only legal operations on a structure are copying it or assigning to it as a unit, taking its address with &, and accessing its members. Copy and assignment include passing arguments to functions and returning values from functions as well.
Number of elements of array keytab:
struct key {
char *word;
int count;
} keytab[100];
#define NKEYS (sizeof keytab / sizeof(struct key))
#define NKEYS (sizeof keytab / sizeof(keytab[0]))
Note: A sizeof can not be used in a #if line, because the preprocessor does not parse type names. But the expression in the #define is not evaluated by the preprocessor, so the code here is legal.
Anonymous Struct
Since C11, similar to union, an unnamed member of a struct whose type is a struct without name is known as anonymous struct. Every member of an anonymous struct is considered to be a member of the enclosing struct or union. This applies recursively if the enclosing struct or union is also anonymous.
struct v {
union { // anonymous union
struct { int i, j; }; // anonymous structure
struct { long k, l; } w;
};
int m;
} v1;
v1.i = 2; // valid
v1.k = 3; // invalid: inner structure is not anonymous
v1.w.k = 5; // valid
Similar to union, the behavior of the program is undefined if struct is defined without any named members (including those obtained via anonymous nested structs or unions).
Bit-fields
Structure with bit-field has format:
struct {
unsigned int is_keyword : 1;
unsigned int is_extern : 1;
unsigned int is_static : 1;
} flags;
- Whether a field may overlap a word boundary is implementation-defined.
- Fields need not be names; unnamed fields (a colon and width only) are used for padding.
- The special width 0 may be used to force alignment at the next word boundary.
- Fields may be declared only as
int; for portability, specifysignedorunsignedexplicitly. - They are not arrays and they do not have addresses, so the
&operator cannot be applied on them.
Flexible Array Member
Since C99, a struct can also end with a flexible array member, which is an array without a given dimension, and it should be the last member of such a struct, as in the following example:
struct double_vector_st {
size_t length;
double array[]; // the flexible array member should be last
};
Initialization, sizeof, and the assignment operator ignore the flexible array member. Structures with flexible array members (or unions whose last member is a structure with flexible array member) cannot appear as array elements or as members of other structures.
struct s { int n; double d[]; }; // s.d is a flexible array member
struct s t1 = { 0 }; // OK, d is as if double d[1], but UB to access
struct s t2 = { 1, { 4.2 } }; // error: initialization ignores flexible array
// if sizeof (double) == 8
struct s *s1 = malloc(sizeof (struct s) + 64); // as if d was double d[8]
struct s *s2 = malloc(sizeof (struct s) + 46); // as if d was double d[5]
s1 = malloc(sizeof (struct s) + 10); // now as if d was double d[1]
s2 = malloc(sizeof (struct s) + 6); // same, but UB to access
double *dp = &(s1->d[0]); // OK
*dp = 42; // OK
dp = &(s2->d[0]); // OK
*dp = 42; // undefined behavior
*s1 = *s2; // only copies s.n, not any element of s.d
// except those caught in sizeof (struct s)
In previous standards of the C language, it was common to declare a zero-sized array member instead of a flexible array member. The GCC compiler explicitly accepts zero-sized arrays for such purposes.
C++ does not have flexible array members.
Struct Initialization
Structs may be initialized or assigned to using compound literals. When initializing a struct, the first initializer in the list initializes the first declared member (unless a designator is specified, since C99), and all subsequent initializers (without designators, since C99) initialize the struct members declared after the one initialized by the previous expression.
struct point { double x, y, z; } p = { 1.2, 1.3 }; // p.x=1.2, p.y=1.3, p.z=0.0
div_t answer = { .quot = 2, .rem = -1 }; // order of elements in div_t may vary
A designator causes the following initializer to initialize the struct member described by the designator. Initialization then continues forward in order of declaration, beginning with the next element declared after the one described by the designator.
struct {
int sec, min, hour, day, mon, year;
} z = {
.day = 31, 12, 2014,
.sec = 30, 15, 17
}; // initializes z to { 30, 15, 17, 31, 12, 2014}
The initializer list may have a trailing comma, which is ignored:
struct {
double x, y;
} p = {
1.0,
2.0, // trailing comma OK
};
In C, the braced list of initializers cannot be empty (note that C++ allows empty lists, and also note that a struct in C cannot be empty):
struct { int n; } s = { 0 }; // OK
struct { int n; } s = {}; // Error: initializer-list cannot be empty
struct {} s = {}; // Error: struct cannot be empty, initializer-list cannot be empty
As with all other initialization, every expression in the initializer list must be a constant expression when initializing arrays of static or thread-local storage duration:
static struct { char* p } s = { malloc(1) }; // error
Note: It’s an error to provide more initializers than members.
Offset of structure memebers
The macro offsetof expands to a constant of type size_t, the value of which is the offset, in bytes, from the beginning of an object of specified type to its specified member, including padding if any. The macro offsetof is defined in header <stddef.h>.
#include <stdio.h>
#include <stddef.h>
struct S {
char c;
double d;
};
int main(void)
{
printf("the first element is at offset %zu\n", offsetof(struct S, c));
printf("the double is at offset %zu\n", offsetof(struct S, d));
}
Unions
A union is a variable that may hold (at different times) objects of different types and sizes, with the compiler keeping track of size and alignment requirements.
Unions provide a way to manipulate different kinds of data in a single area of storage, without embedding any machine-dependent information in the program.
The usage of union is consistent: the type retrieved must be the type most recently stored. It is the programmer’s responsibility to keep track of which type is currently stored in a union; the results are implementation-dependent if something is stored as one type and extracted as another.
In effect, a union is a structure in which all members have offset zero from the base, the structure is big enough to hold the widest member, and the alignment is appropriate for all of the types in the union.
A pointer to a union can be cast to a pointer to each of its members (if a union has bit field members, the pointer to a union can be cast to the pointer to the bit field’s underlying type). Likewise, a pointer to any member of a union can be cast to a pointer to the enclosing union.
Anonymous Union
Since C11, similar to struct, an unnamed member of a union whose type is a union without name is known as anonymous union. Every member of an anonymous union is considered to be a member of the enclosing struct or union. This applies recursively if the enclosing struct or union is also anonymous.
struct v {
union { // anonymous union
struct { int i, j; }; // anonymous structure
struct { long k, l; } w;
};
int m;
} v1;
v1.i = 2; // valid
v1.k = 3; // invalid: inner structure is not anonymous
v1.w.k = 5; // valid
Similar to struct, the behavior of the program is undefined if union is defined without any named members (including those obtained via anonymous nested structs or unions).
Union Initialization
A union may only be initialized with a value of the type of its first member. When initializing a union, the initializer list must have only one member, which initializes the first member of the union (unless a designated initializer is used, since C99).
union {
int x;
char c[4];
} u = { 1 }, // makes u.x active with value 1
u2 = { .c = { '\1' } }; // makes u2.c active with value { '\1','\0','\0','\0' }
Enumerations
Refer to enum on CppReference.
Pointers
Pointer is a type of an object that refers to a function or an object of another type, possibly adding qualifiers. Pointer may also refer to nothing, which is indicated by the special null pointer value.
A pointer is a variable that contains the address of a variable.
int i = 0;
int *p = &i;
float *p, **pp; // p is a pointer to float
// pp is a pointer to a pointer to float
int (*fp)(int); // fp is a pointer to function with type int(int)
The qualifiers that appear between * and the identifier (or other nested declarator) qualify the type of the pointer that is being declared:
int n;
const int *pc = &n; // pc is a non-const pointer to a const int
// *pc = 2; // Error: n cannot be changed through p without a cast
pc = NULL; // OK: pc itself can be changed
int* const cp = &n; // cp is a const pointer to a non-const int
*cp = 2; // OK to change n through cp
// cp = NULL; // Error: cp itself cannot be changed
int* const *pcp = &cp; // non-const pointer to const pointer to non-const int
The & operator only applies to objects in memory: variables and array elements. It cannot be applied to expressions, constants, or register variables.
Note that a pointer is constrained to point to a particular kind of object: every pointer points to a specific data type. Exception: a pointer to void void * is used to hold any type of pointer but cannot be dereferenced itself.
Pointer arguments enable a function to access and change objects in the function that called it, such as:
char *strcpy(char *dest, const char *src);
There is one difference between an array name (for instance, int a[10];) and a pointer (for instance, int *pa;) that must be kept in mind. A pointer is a variable, so pa = a and pa++ are legal. But an array name is not a variable; constructions like a = pa and a++ are illegal.
When an array name is passed to a function, what is passed is the location of the initial element. Within the called function, this argument is a local variable, and so an array name parameter is a pointer, that is, a variable containing an address.
If p is a pointer to some element of an array, then p++ increments p to point to the next element, and p += i increments it to point i elements beyond where it currently does.
The valid pointer operations are assignment of pointers of the same type, adding or subtracting a pointer and an integer, subtracting or comparing two pointers to members of the same array, and assigning or comparing to zero. All other pointer arithmetic is illegal.
Pointer to object of any type can be implicitly converted to pointer to void (optionally const or volatile-qualified), and vice versa:
int n = 1, *p = &n;
void* pv = p; // int* to void*
int* p2 = pv; // void* to int*
printf("%d\n", *p2); // prints 1
Pointers to void are used to pass objects of unknown type, which is common in generic interfaces:
mallocreturnsvoid*.qsortexpects a user-provided callback that accepts two constvoid*arguments.pthread_createexpects a user-provided callback that accepts and returnsvoid*.
In all cases, it is the caller’s responsibility to convert the pointer to the correct type before use.
Note: Although any pointer to object can be cast to pointer to object of a different type, dereferencing a pointer to the type different from the declared type of the object is almost always undefined behavior.
Character Pointers
Pointers to char are often used to represent strings. To represent a valid byte string, a pointer must be pointing at a char that is an element of an array of char, and there must be a char with the value zero at some index greater or equal to the index of the element referenced by the pointer.
char amessage[] = "now is the time"; /* an array */
char *pmessage = "now is the time"; /* a pointer */
In this example, the amessage is an array, just big enough to hold the sequence of characters and '\0' that initializes it. Individual characters within the array may be changed but amessage will always refer to the same storage. On the other hand, the pmessage is a pointer, initialized to point to a string constant; the pointer may subsequently be modified to point elsewhere, but the result is undefined if you try to modify the string contents.
Function Pointers
In C, a function itself is not a variable, but it is possible to define pointers to functions, which can be assigned, placed in arrays, passed to functions, returned by functions, and so on.
/* a function decleration */
int *func(int num);
/* a pointer to function, and assign a function to it */
int *(*pfunc)(int num);
pfunc = func;
/* an array of 10 pointers to function, and assign a function to the first element */
int *(*pfa[10])(int num);
pfa[0] = func;
/* typedef it for */
typedef int *(*fp)(int num);
fp = func;
NULL Pointers
Pointers of every type have a special value known as null pointer value of that type. A pointer whose value is null does not point to an object or a function (dereferencing a null pointer is undefined behavior), and compares equal to all pointers of the same type whose value is also null.
To initialize a pointer to null or to assign the null value to an existing pointer, a null pointer constant (NULL, or any other integer constant with the value zero) may be used. static initialization also initializes pointers to their null values.
Null pointers can indicate the absence of an object or can be used to indicate other types of error conditions. In general, a function that receives a pointer argument almost always needs to check if the value is null and handle that case differently (for example, free does nothing when a null pointer is passed).
Atomic
Atomic syntax:
_Atomic ( type-name ) (1) (since C11)
_Atomic type-name (2) (since C11)
Version (1) Use as a type specifier; this designates a new atomic type.
Version (2) Use as a type qualifier; this designates the atomic version of type-name. In this role, it may be mixed with const, volatile, and restrict, although unlike other qualifiers, the atomic version of type-name may have a different size, alignment, and object representation.
type-name: any type other than array or function. For (1), type-name also cannot be atomic or cvr-qualified.
The header <stdatomic.h> defines 37 convenience macros, from atomic_bool to atomic_uintmax_t, which simplify the use of this keyword with built-in and library types.
_Atomic const int *p1; // p is a pointer to an atomic const int
const atomic_int *p2; // same
const _Atomic(int) *p3; // same
Objects of atomic types are the only objects that are free from data races, that is, they may be modified by two threads concurrently or modified by one and read by another.
Each atomic object has its own associated modification order, which is a total order of modifications made to that object. If, from some thread’s point of view, modification A of some atomic M happens-before modification B of the same atomic M, then in the modification order of M, A occurs before B.
Note that although each atomic object has its own modification order, it is not a total order; different threads may observe modifications to different atomic objects in different orders.
There are four coherences that are guaranteed for all atomic operations:
-
write-write coherence: If an operation A that modifies an atomic object M happens-before an operation B that modifies M, then A appears earlier than B in the modification order of M.
-
read-read coherence: If a value computation A of an atomic object M happens before a value computation B of M, and A takes its value from a side effect X on M, then the value computed by B is either the value stored by X or is the value stored by a side effect Y on M, where Y appears later than X in the modification order of M.
-
read-write coherence: If a value computation A of an atomic object M happens-before an operation B on M, then A takes its value from a side effect X on M, where X appears before B in the modification order of M.
-
write-read coherence: If a side effect X on an atomic object M happens-before a value computation B of M, then the evaluation B takes its value from X or from a side effect Y that appears after X in the modification order of M.
typedef
The typedef declaration provides a way to declare an identifier as a type alias, to be used to replace a possibly complex type name.
The keyword typedef is used in a declaration, in the grammatical position of a storage-class specifier, except that it does not affect storage or linkage:
// declares int_t to be an alias for the type int
typedef int int_t;
// declares char_t to be an alias for char
// char_p to be an alias for char*
// fp to be an alias for char(*)(void)
typedef char char_t, *char_p, (*fp)(void);
If a declaration uses typedef as storage-class specifier, every declarator in it defines an identifier as an alias to the type specified. Since only one storage-class specifier is permitted in a declaration, typedef declaration cannot be static or extern.
typedef declaration does not introduce a distinct type, it only establishes a synonym for an existing type, thus typedef names are compatible with the types they alias. Typedef names share the name space with ordinary identifiers such as enumerators, variables and function.
Since C99, a typedef for a VLA (Variable Length Array) can only appear at block scope. The length of the array is evaluated each time the flow of control passes over the typedef declaration, as opposed to the declaration of the array itself:
void copyt(int n)
{
typedef int B[n]; // B is a VLA, its size is n, evaluated now
n += 1;
B a; // size of a is n from before +=1
int b[n]; // a and b are different sizes
for (int i = 1; i < n; i++)
a[i-1] = b[i];
}
typedef name may be an incomplete type, which may be completed as usual:
typedef int A[]; // A is int[]
A a = {1, 2}, b = {3,4,5}; // type of a is int[2], type of b is int[3]
typedef declarations are often used to inject names from the tag name space into the ordinary name space:
typedef struct tnode tnode; // tnode in ordinary name space
// is an alias to tnode in tag name space
struct tnode {
int count;
tnode *left, *right; // same as struct tnode *left, *right;
}; // now tnode is also a complete type
tnode s, *sp; // same as struct tnode s, *sp;
They can even avoid using the tag name space at all:
typedef struct {
double hi, lo;
} range;
range z, *zp;
typedef names are also commonly used to simplify the syntax of complex declarations:
// array of 5 pointers to functions returning pointers to arrays of 3 ints
int (*(*callbacks[5])(void))[3]
// same with typedefs
typedef int arr_t[3]; // arr_t is array of 3 int
typedef arr_t* (*fp)(void); // pointer to function returning arr_t*
fp callbacks[5];
Libraries often expose system-dependent or configuration-dependent types as typedef names, to present a consistent interface to the users or to other library components:
#if defined(_LP64)
typedef int wchar_t;
#else
typedef long wchar_t;
#endif
Statements
The loop (for, while, do..while) is a powerful programming tool. You should pay particular attention to three aspects when setting up a loop:
- Clearly defining the condition that causes the loop to terminate.
- Making sure the values used in the loop test are initialized before the first use.
- Making sure the loop does something to update the test each cycle.
if..else
The if..else is used where code needs to be executed only if some condition is true.
if (expression1)
{
statements;
}
else if (expression2)
{
statements;
}
else
{
statements;
}
Because the else part of an if-else is optional, there is an ambiguity when an else if omitted from a nested if sequence. This is resolved by associating the else with the closest previous else-less if, such as:
if (n > 0)
if (a > b)
z = a;
else
z = b;
You can use the conditional expression expression1 ? expression2 : expression3 when you have a variable to which you want to assign one of two possible values. A typical example is setting a variable equal to the maximum of two values:
max = (a > b) ? a : b;
switch
The switch statement is a multi-way decision that tests whether an expression matches one of a number of constant integer values, and branches accordingly.
All case expressions must be different.
The case labeled default is executed if none of the other cases are satisfied. A default is optional; if it isn’t there and if none of the cases match, no action at all takes place. Cases and the default clause can occur in any order.
The break statement causes an immediate exit from the switch. Because cases serve just as labels, after the code for one case is done, execution falls through to the next unless you take explicit action to escape. break and return are the most common ways to leave a switch.
As a matter of good form, put a break after the last case (the default here) even though it’s logically unnecessary. Some day when another case gets added at the end, this bit of defensive programming will save you.
switch (expr)
{
case const1:
statements;
break;
case const2:
statements;
break;
default:
statements;
break;
}
for
The for statement is used as a shorter equivalent of while loop.
for (expr1; expr2; expr3)
{
statements;
}
while
The while statement executes a statement repeatedly, until the value of expression becomes equal to zero. The test takes place before each iteration.
while (expr)
{
statements;
}
do..while
The do..while executes a statement repeatedly until the value of condition becomes false. The test takes place after each iteration, that’s the do-while body is always executed at least once.
do
{
statements;
}
while(expr);
break and continue
The break statement provides an early exit from for, while, do-while and switch. A break causes the innermost enclosing loop or switch to be exited immediately.
The continue statement causes the rest of an iteration to be skipped and the next iteration of the enclosing for, while, or do-while loop to be started.
- In the while and do-while, this means that the test part is executed immediately;
- In the for, control passes to the increment step.
The continue statement applies only to loops, not to switch. A continue inside a switch inside a loop causes the next loop iteration.
goto and labels
There are a few situations where goto may find a place. The most common is to abandon processing in some deeply nested structure, such as breaking out of two or more loops at once (a single break gets you out of the innermost loop only).
A label has the same form as a variable name, and is followed by a colon. It can be attached to any statement in the same function as the goto. The scope of a label is the entire function.
goto label;
...
label:
statement
Functions
In C, all variables must be declared before they are used, usually at the beginning of the function before any executable statements.
return-type function-name(argument-declarations)
{
declarations;
statements;
}
Various parts may be absent:
- If the return-type is omitted, int is assumed.
A minimal function is
dummy() {}
which does nothing and returns nothing.
-
If a function declaration does not include arguments, as in
double atof();that is taken to mean that nothing is to be assumed about the arguments of atof; all parameter checking is turned off. This special meaning of the empty argument list is intended to permit older C programs to compile with new compilers. But it’s a bad idea to use it with new C programs. -
If the function takes arguments, declare them; if it takes no arguments, use void.
main()
Every C program coded to run in a hosted execution environment contains the definition (not the prototype) of a function called main, which is the designated start of the program. The name and type of the entry point to any freestanding program (boot loaders, OS kernels, etc) are implementation-defined.
int main(int argc, char *argv[])
{
...
}
Normally you are at liberty to give functions whatever names you like, but main is special: your program begins executing at the beginning of main. This means that every program must have a main somewhere.
Input paramters:
argcis the number of command-line arguments the program was invoked with.argvis a pointer to an array of character strings that contain the arguments, one per string.- By convention,
argv[0]is the name by which the program was invoked, soargcis at least 1.
Return value:
- If the return statement is used, the return value is used as the argument to the implicit call to
exit(). - The values zero and
EXIT_SUCCESSindicate successful termination, the valueEXIT_FAILUREindicates unsuccessful termination.
External Variables
- External variables are defined outside of any function, and are thus potentionally available to many functions.
- Functions themselves are always external, because C does not allow functions to be defined inside other functions.
-
By default, external variables and functions have the property that all references to them by the same name, even from functions compiled separately, are references to the same thing.
- External variables are also useful because of their greater scope and lifetime.
- The scope of an external variable or a function lasts from the point at which it is declared to the end of the file being compiled.
-
If an external variable is to be referred to before it is defined, or if it is defined in a different source file from the one where it is being used, then an extern declaration is mandatory.
- It is important to distinguish between the declaration of an external variable and its definition.
- There must be only one definition of an external variable among all the files that make up the source program; other files may contain extern declarations to access it.
- Array sizes must be specified with the definition, but are optional with an extern declaration.
-
Initialization of an external variable goes only with the definition.
- definition:
double val[MAXVAL]; - declaration:
extern double val[];
- definition:
-
If a large number of variables must be shared among functions, external variables are more convenient and efficient than long argument lists. However, this reasoning should be applied with some caution, for it can have a bad effect on program structure, and lead to programs with too many data connections between functions.
- In the absence of explicit initialization, external and static variables are guaranteed to be initialized to zero; automatic and register variables have undefined initial values.
- For external and static variables, the initializer must be a constant expression. The initialization is done once, conceptionally before the program begins execution.
- For external and static variables, the initializer must be a constant expression.
Static Variables
- The static declaration, applied to an external variable or function, limits the scope of that object to the rest of the source file being compiled.
-
The static declaration can also be applied to internal variables. Internal static variables are local to a particular function just as automatic variables are, but unlike automatics, they remain in existence rather than coming and going each time the function is activated. This means that internal static variables provide private, permanent storage within a single function.
- In the absence of explicit initialization, external and static variables are guaranteed to be initialized to zero; automatic and register variables have undefined initial values.
- For external and static variables, the initializer must be a constant expression.
Automatic Variables
Register Variables
- A register declaration advises the compiler that the variable in question will be heavily used. The idea is that register variables are to be placed in machine registers, which may result in smaller and faster programs. But compilers are free to ignore the advice.
- The register declaration can only be applied to automatic variables and to the formal parameters of a function.
-
In practice, there are restrictions on register variables, reflecting the realities of underlying hardware.
- Only a few variables in each function may be kept in registers, and only certain types are allowed. Excess register declarations are harmless, however, since the word register is ignored for excess or disallowed declarations.
- It is not possible to take the address of a register variable, regardless of whether the variable is actually placed in a register.
- The specific restrictions on number and types of register variables vary from machine to machine.
- In the absence of explicit initialization, external and static variables are guaranteed to be initialized to zero; automatic and register variables have undefined initial values.
- For automatic and register variables, the initializer is not restricted to being a constant: it may be any expression involving previously defined values, even function calls.
void func(unsigned m, register long n)
{
register int i;
...
}
C Libraries
C Standard Library
Refer to Standard C Reference and C++ Standard Library (but no STL) Reference Material.
The C standards committee publishes experimental C language and library extensions for future standardization. Refer to Experimental C Standard Libraries.
The C Standard Library header files are listed in following table:
| C Header | Standard | Note | Links |
|---|---|---|---|
| <assert.h> | for enforcing assertions when functions execute | 1 2 3 | |
| <complex.h> | since C99 | Complex number arithmetic | 1 |
| <ctype.h> | for classifying characters | 1 2 3 | |
| <errno.h> | for testing error codes reported by library functions | 1 2 3 | |
| <fenv.h> | since C99 | for accessing the floating-point environment | 1 2 |
| <float.h> | for testing floating-point type properties | 1 2 3 | |
| <inttypes.h> | since C99 | Format conversion of integer types | 1 2 |
| <iso646.h> | since C95 | for programming in ISO 646 variant character sets | 1 2 3 |
| <limits.h> | for testing integer type properties | 1 2 3 | |
| <locale.h> | for adapting to different cultural conventions | 1 2 3 | |
| <math.h> | for computing common mathematical functions | 1 2 3 | |
| <setjmp.h> | for executing nonlocal goto statements | 1 2 3 | |
| <signal.h> | for controlling various exceptional conditions | 1 2 3 | |
| <stdalign.h> | since C11 | alignas and alignof convenience macros | 1 |
| <stdarg.h> | for accessing a varying number of arguments | 1 2 3 | |
| <stdatomic.h> | since C11 | Atomic types | 1 |
| <stdbool.h> | since C99 | Boolean type | 1 2 |
| <stddef.h> | for defining several useful types and macros | 1 2 3 | |
| <stdint.h> | since C99 | Fixed-width integer types | 1 2 3 |
| <stdio.h> | for performing input and output | 1 2 3 | |
| <stdlib.h> | for general utilities: memory management, program utilities, string conversions, random numbers | 1 2 3 | |
| <stdnoreturn.h> | since C11 | noreturn convenience macros | 1 |
| <string.h> | for manipulating several kinds of strings | 1 2 3 | |
| <tgmath.h> | since C99 | Type-generic math (macros wrapping math.h and complex.h | 1 2 |
| <threads.h> | since C11 | Thread library | 1 |
| <time.h> | for converting between various time and date formats | 1 2 3 | |
| <uchar.h> | since C11 | UTF-16 and UTF-32 character utilities | 1 2 |
| <wchar.h> | since C95 | for manipulating wide streams and several kinds of strings | 1 2 3 |
| <wctype.h> | since C95 | for classifying wide characters | 1 2 3 |
Open Source C Libraries
Refer to list of open source C libraries.
GNU C Library (glibc)
Refer to GNU C Library (glibc).
C Code Conventions
MISRA C
MISRA (Motor Industry Software Reliability Association) was originally established as a collaboration between vehicle manufacturers, component suppliers and engineering consultancies, and seeks to promote best practice in developing safety-related electronic systems in road vehicles and other embedded systems. To this end MISRA publishes documents that provide accessible information for engineers and management, and holds events to permit the exchange of experiences between practitioners.
As part of these activities, MISRA C was first published in 1998. The intention was to provide a restricted subset of a standardized structured language as required in the 1994 MISRA Guidelines for automotive systems being developed to meet the requirements of Safety Integrity Level (SIL) 2 and above.
Since its launch in 1998, the uptake and usage of MISRA C has far exceeded the authors’s original expectations. MISRA C was originally developed to support the language requirements of the 1994 MISRA Guidelines, as noted above. Since that time, however, MISRA C has been adopted and used across a wide variety of industries and applications including the rail, aerospace, military and medical sectors. Furthermore, a significant number of tools are available that support enforcing the MISRA C rules. In Japan, a Japanese translation of MISRA C has been published by JSAE, and the MISRA C Study Group have produced a book (in Japanese) giving detailed explanations of the rules and additional code examples.
Refer to MISRA publications for more information.
MISRA C:1998 (MISRA C1)
MISRA C:1998 (MISRA C1) is the original version of MISRA C. It remains available for legacy projects that need to refer to it, but MISRA C:2012 (see below) should be used for all new projects.
MISRA C:2004 (MISRA C2)
A considerable amount of feedback on the original version of MISRA C was received and it was recognized that a revision was appropriate, in particular to address the following:
- Ensuring that the language used is consistent with the standard language
- Replacing generalized rules for Undefined Behaviour with specific rules targeted at Undefined Behaviour only
- Ensuring one rule, one issue; i.e. complex rules are split into atomic rules for ease of compliance
- Adding to and improving the code examples
- Removing the option for tool-less use
In updating MISRA C, the aim was to avoid new material and to ensure backwards compatibility with the earlier version (MISRA C1 / MISRA C:1998) where possible.
The second version of MISRA C is known as MISRA C:2004 and is titled Guidelines for the use of the C language in critical systems.
In July 2007, an Exemplar Suite was released. This is a set of code examples that demonstrate conforming and non-conforming code for the majority of the MISRA C rules. This Exemplar Suite is of value to users both in understanding the rules and also in evaluating the performance of rule-checking tools, although in this respect it must be understood that the Exemplar Suite is not a conformance testing suite.
In July 2007, a Technical Corrigendum was also issued, giving updates based on some of the most commonly-asked questions and also issues identified during the development of the Exemplar Suite. When MISRA C:2004 was reprinted in June 2008, the opportunity was taken to incorporate the text of the Technical Corrigendum.
Refer to MISRA-C:2004 for details.
MISRA C:2012 (MISRA C3)
MISRA C:2012 was published on 18 March 2013. MISRA C:2012 extends support to the C99 version of the language whilst maintaining guidelines for C90. Other improvements, many of which have been made as a result of user feedback, include: better rationales for every guideline, identified decidability so users can better interpret the output of checking tools, greater granularity of rules to allow more precise control, a number of expanded examples and integration of MISRA AC AGC. A cross reference for ISO 26262 has also been produced.
SEI CERT Coding Standards
The C rules and recommendations in this wiki are a work in progress and reflect the current thinking of the secure coding community. Because this is a development website, many pages are incomplete or contain errors. As rules and recommendations mature, they are published in report or book form as official releases. These releases are issued as dictated by the needs and interests of the secure software development community. Also refer to SEI CERT Coding Standards and CERT website.
GNU Coding Standards
The GNU Coding Standards were written by Richard Stallman and other GNU Project volunteers. Their purpose is to make the GNU system clean, consistent, and easy to install. This document can also be read as a guide to writing portable, robust and reliable programs. It focuses on programs written in C, but many of the rules and principles are useful even if you write in another programming language. The rules often state reasons for writing in a certain way. Refer to GNU Coding Standards.
Common Weakness Enumeration (CWE)
Common Weakness Enumeration (CWE) is a community-developed list of common software security weaknesses. It serves as a common language, a measuring stick for software security tools, and as a baseline for weakness identification, mitigation, and prevention efforts.
- Common Weakness Enumeration (CWE)
- CWE List latest version and version 3.1
- CWE/SANS Top 25 Most Dangerous Software Errors on SANS and SonarSource
SonarCFamily for C/C++
SonarSource delivers what is probably the best static code analyzer you can find on the market for C/C++. Based on our own C/C++ compiler front-end, it uses the most advanced techniques (pattern matching, dataflow analysis) to analyze code and find code smells, bugs and security vulnerabilities. As for any product we develop at SonarSource, it was built on the following principles: depth, accuracy and speed.
SonarCFamily for C/C++ has a great coverage of well-established quality standards. The SonarCFamily for C/C++ capability is available in Eclipse CDT for developers (SonarLint) as well as throughout the development chain for automated code review with self-hosted SonarQube or on-line SonarCloud.
Chromium Coding Style
LLVM Coding Standards
The LLVM Coding Standards attempts to describe a few coding standards that are being used in the LLVM source tree. Although no coding standards should be regarded as absolute requirements to be followed in all instances, coding standards are particularly important for large-scale code bases that follow a library-based design (like LLVM).
Mozilla Style Guide
The Mozilla Style Guide attempts to explain the basic styles and patterns used in the Mozilla codebase. New code should try to conform to these standards, so it is as easy to maintain as existing code. There are exceptions, but it’s still important to know the rules!
This article is particularly for those new to the Mozilla codebase, and in the process of getting their code reviewed. Before requesting a review, please read over this document, making sure that your code conforms to recommendations.
Qt Coding Style
The Qt Coding Style an overview of the low-level coding conventions we use when writing Qt code. See Coding Conventions for the higher-level conventions. The data has been gathered by mining the Qt sources, discussion forums, email threads and through collaboration of the developers.
Kdelibs Coding Style
The Kdelibs Coding Style describes the recommended coding style for kdelibs. Nobody is forced to use this style, but to have consistent formatting of the source code files it is recommended to make use of it.
In short: Kdelibs coding style follows the Qt coding style, with one main difference: using curly braces even when the body of a conditional statement contains only one line.
C Code Formatter
GNU Indent
The indent program can be used to make code easier to read. It can also convert from one style of writing C to another. indent understands a substantial amount about the syntax of C, but it also attempts to cope with incomplete and misformed syntax.
Artistic Style
Artistic Style is a source code indenter, formatter, and beautifier for the C, C++, C++/CLI, Objective‑C, C# and Java programming languages. Also refer to Indentation Style and Programming Style.
Clone astyle repo:
chenwx@chenwx ~ $ svn checkout https://svn.code.sf.net/p/astyle/code/trunk astyle-code
A astyle-code/AStyleTest
A astyle-code/AStyleTest/file-py
A astyle-code/AStyleTest/file-py/clang_tidy.py
...
A astyle-code/AStyleDev/src-j/AStyleInterface.java
A astyle-code/AStyleDev/test-data/ASFormatter.cpp
A astyle-code/AStyleDev/scripts/astyle-clean.bat
Checked out revision 655.
chenwx@chenwx ~ $ cd astyle-code/
chenwx@chenwx ~/astyle-code $ ll
total 20K
drwxrwxr-x 6 chenwx chenwx 4.0K Apr 25 21:52 AStyle
drwxrwxr-x 14 chenwx chenwx 4.0K Apr 25 21:53 AStyleDev
drwxrwxr-x 13 chenwx chenwx 4.0K Apr 25 21:51 AStyleTest
drwxrwxr-x 7 chenwx chenwx 4.0K Apr 25 21:53 AStyleWx
drwxrwxr-x 13 chenwx chenwx 4.0K Apr 25 21:52 AStyleWxTest
Build astyle from source code:
chenwx@chenwx ~/astyle-code $ cd AStyle/build/gcc/
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ make
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/astyle_main.cpp -o obj/astyle_main.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASBeautifier.cpp -o obj/ASBeautifier.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASFormatter.cpp -o obj/ASFormatter.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASEnhancer.cpp -o obj/ASEnhancer.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASLocalizer.cpp -o obj/ASLocalizer.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASResource.cpp -o obj/ASResource.o
g++ -s -o bin/astyle obj/astyle_main.o obj/ASBeautifier.o obj/ASFormatter.o obj/ASEnhancer.o obj/ASLocalizer.o obj/ASResource.o
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ ll
total 16K
-rw-rw-r-- 1 chenwx chenwx 5.3K Apr 25 21:52 Makefile
drwxrwxr-x 2 chenwx chenwx 4.0K Apr 25 22:20 bin
drwxrwxr-x 2 chenwx chenwx 4.0K Apr 25 22:20 obj
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ ll bin/
total 444K
-rwxrwxr-x 1 chenwx chenwx 444K Apr 25 22:20 astyle
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ ./bin/astyle --version
Artistic Style Version 3.2 beta
Install the built astyle:
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ sudo make install
[sudo] password for chenwx:
install -o root -g root -m 755 -d /usr/bin
install -o root -g root -m 755 -d /usr/share/doc/astyle
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ which astyle
/usr/bin/astyle
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ astyle --version
Artistic Style Version 3.2 beta
Useful options of Artistic Style:
astyle --style=allman --indent=spaces=4 -H -Y -c -j -p -y -xL -xV -xb -xf -xh -xg <filename>
C Compilers
GCC (GNU Compiler Collection)
The GNU Compiler Collection (GCC) includes front ends for C, C++, Objective-C, Fortran, Ada, and Go, as well as libraries for these languages (libstdc++, …). GCC was originally written as the compiler for the GNU operating system. The GNU system was developed to be 100% free software, free in the sense that it respects the user’s freedom.
Clang
Clang is a compiler front end for the programming languages C, C++, Objective-C, Objective-C++, OpenMP, OpenCL, and CUDA. It uses LLVM (Low Level Virtual Machine) as its back end and has been part of the LLVM release cycle since LLVM 2.6.
It is designed to be able to replace the full GNU Compiler Collection (GCC). Its contributors include Apple, Microsoft, Google, ARM, Sony, Intel and Advanced Micro Devices (AMD). It is open-source software, with source code released under the University of Illinois/NCSA License, a permissive free software licence.
The Clang project includes the Clang front end and the Clang static analyzer and several code analysis tools.
Background
LLVM was intended originally to use GCC’s front end, but GCC turned out to cause some problems for developers of LLVM and at Apple. The GCC source code is a large and somewhat cumbersome system for developers to work with; as one long-time GCC developer put it, Trying to make the hippo dance is not really a lot of fun.
Apple software makes heavy use of Objective-C, but the Objective-C front-end in GCC is a low priority for GCC developers. Also, GCC does not integrate smoothly into Apple’s IDE. Finally, GCC is licensed under GNU General Public License (GPL) version 3, which requires developers who distribute extensions for, or modified versions of, GCC to make their source code available, whereas LLVM has a BSD-like license which does not force users to release their source code changes when publishing compiled binaries of those changes.
Apple chose to develop a new compiler front end from scratch, supporting C, Objective-C and C++. This clang project was open-sourced in July 2007.
Coliru Online Compiler
C IDE
Tools
include-what-you-use
The include-what-you-use is a tool for use with clang to analyze #include in C and C++ source files. Refer to include-what-you-use repo on GitHub.
SonarQube
Books
- The C Programming Language, 2nd edition
- C Primer Plus, 5th edition
References
- Linux: C/C++ Libraries
- C programming language on Wikipedia
- JTC1/SC22/WG14 - C
- C/C++ Reference
- cplusplus.com
- Standard C
- Standard C Index
- comp.lang.c FAQ
- MISRA C
- Software Engineering Institute (SEI)
- Best Practices Criteria for Free/Libre and Open Source Software (FLOSS)
- Common Weakness Enumeration (CWE)
- CWE List
- CWE/SANS Top 25 Most Dangerous Software Errors
- SonarCFamily for C/C++
- GCC
- Clang
- Clang on wikipedia
- Visual Studio 2015: C/C++ Language and Standard Libraries