C++
This article introduces the C++ programming language.
Overview
C++, high-level computer programming language. Developed by Bjarne Stroustrup of Bell Laboratories in the early 1980s, it is based on the traditional C language but with added object-oriented programming and other capabilities. C++, along with Java, has become popular for developing commercial software packages that incorporate multiple interrelated applications. C++ is considered one of the fastest languages and is very close to low-level languages, thus allowing complete control over memory allocation and management. This very feature and its many other capabilities also make it one of the most difficult languages to learn and handle on a large scale.
C++ is a direct descendant of C95 (C90 plus an Amendment) that retains almost all of C95 as a subset. C++ is not a descendant of C99.
C++ Standards
C++ is standardized by the ISO/IEC C++ Standards Committee (JTC1/SC22/WG21), that’s ISO/IEC JTC1 (Joint Technical Committee 1) / SC22 (Subcommittee 22) / WG21 (Working Group 21). Besides, the C++ standards committee publishes experimental C++ language and library extensions for future standardization.
Also refer to the following links:
- ISO/IEC C++ Standards Committee (JTC1/SC22/WG21)
- News, Status & Discussion about Standard C++
- Current Status of C++ Standard
- C++ Working Pager on GitHub
- C++ Super-FAQ
Timeline of JTC1/SC22/WG21:
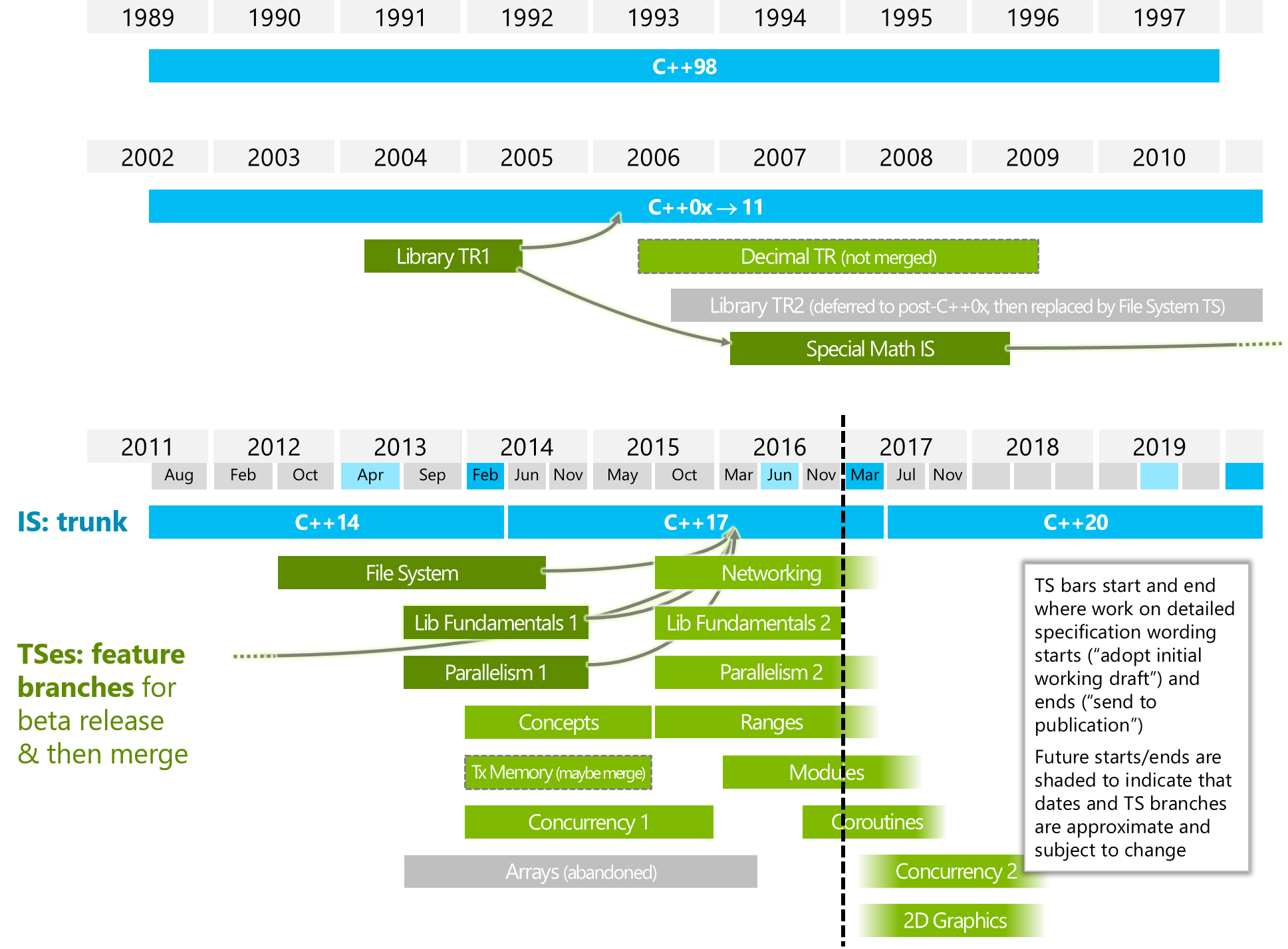
Traditional C++ & Modern C++:

ISO/IEC 14882:1998 (C++98)
In 1998, the ISO working group standardized C++ for the first time as ISO/IEC 14882:1998, which is informally known as C++98.
Final C++98 Working Drafts
The ISO/IEC 14882:1998 was withdrawn and was revised by ISO/IEC 14882:2003. It’s no longer available from ISO.
Compilers implement C++98/03
GCC has full support for the C++98 standard as modified by the 2003 technical corrigendum and some later defect reports, excluding the export feature which was later removed from the language.
This mode is the default in GCC versions prior to 6.1; it can be explicitly selected with the -std=c++98 command-line flag, or -std=gnu++98 to enable GNU extensions as well. Refer to C++ Standards Support in GCC for more details.
ISO/IEC 14882:2003 (C++03)
In 2003, the ISO working group published a new version of the C++ standard called ISO/IEC 14882:2003, which is informally known as C++03. This version of the C++ standard fixed problems identified in C++98.
Final C++03 Working Drafts
The ISO/IEC 14882:2003 was withdrawn and was revised by ISO/IEC 14882:2011. It’s no longer available from ISO.
What is the difference between C++98 and C++03?
From a programmer’s view there is none. The C++03 revision of the standard was a bug fix release for implementers to ensure greater consistency and portability. In particular, tutorial and reference material describing C++98 and C++03 can be used interchangeably by all except compiler writers and standards gurus.
Compilers implement C++98/03
GCC has full support for the C++98 standard as modified by the 2003 technical corrigendum and some later defect reports, excluding the export feature which was later removed from the language.
This mode is the default in GCC versions prior to 6.1; it can be explicitly selected with the -std=c++98 command-line flag, or -std=gnu++98 to enable GNU extensions as well. Refer to C++ Standards Support in GCC for more details.
ISO/IEC 14882:2011 (C++11)
In 2011, the ISO working group published a major revision of the C++ standard called ISO/IEC 14882:2011, which is informally known as C++0x or C++11. It included most of the library enhancements of C++07/TR1, as well as many additions to the core language.
Final C++11 Working Drafts
The ISO/IEC 14882:2011 was withdrawn and was revised by ISO/IEC 14882:2014. It’s no longer available from ISO. A free C++11 working draft is available and the differences between the working draft and the C++11 standard are minor:
What is the difference between C++98/03 and C++11?
See what’s new in C++11. C++11 is a major upgrade over C++98/03, with performance and convenience features that make it feel like a new language. Note that the C++ language will remain stable because compatibility is always a major concern. The committee tries hard not to break your (standard conforming) code. Except for some corner cases you’re unlikely to notice, all valid C++98/03 code is valid C++11 and C++14 code.
New features of C++11
- what’s new in C++11
- C++11 Language Extensions: General Features / Classes / Other Types / Templates / Concurrency / Miscellaneous Language Features
- C++11 Library Extensions: General Libraries / Containers and Algorithms / Concurrency
Compilers implement C++11
The first fully conforming C++11 language implementation was GCC 4.8.1 (May 31, 2013) but it still did not have a conforming standard library. This mode can be selected with the -std=c++11 command-line flag, or -std=gnu++11 to enable GNU extensions as well. Refer to C++ Standards Support in GCC for more details.
The first complete C++11 implementation, including both the language and the standard library, was Clang 3.3 (June 5, 2013).
C++11 Materials
- B. Stroustrup: What is C++11?
- B. Stroustrup: Evolving a language in and for the real world: C++ 1991-2006
- B. Stroustrup: A History of C++: 1979-1991
- B. Stroustrup: C and C++: Siblings
ISO/IEC 14882:2014 (C++14)
In 2014, the ISO working group published a minor but important upgrade over C++11 called ISO/IEC 14882:2014, which is informally known as C++14. The C++14 largely completes C++11.
Final C++14 Working Drafts
The ISO/IEC 14882:2014 was withdrawn and was revised by ISO/IEC 14882:2017. It’s no longer available from ISO. A free C++11 working draft is available and here is the differences between N4140 and the standard (N4141):
What is the difference between C++11 and C++14?
See what’s new in C++14. Note that the C++ language will remain stable because compatibility is always a major concern. The committee tries hard not to break your (standard conforming) code. Except for some corner cases you’re unlikely to notice, all valid C++98/03 and C++11 code is valid C++14 code.
New features of C++14
Compilers implement C++14
The first fully conforming C++14 language implementation is shipped by the January 2014 release of LLVM/Clang 3.4.
GCC has full support for the C++14 standard. This mode is the default in GCC 6.1 and above; it can be explicitly selected with the -std=c++14 command-line flag, or -std=gnu++14 to enable GNU extensions as well. Refer to C++ Standards Support in GCC for more details.
C++14 Materials
- B. Stroustrup: The C++ Programming Language (Fourth Edition)
- B. Stroustrup: A Tour of C++
- Committee papers archive
ISO/IEC 14882:2017 (C++17)
In 2017, the ISO working group published a new revision of the C++ standard called ISO/IEC 14882:2017, which is informally known as C++1z or C++17.
Final C++17 Working Drafts
The ISO/IEC 14882:2017 is available from ISO. A free C++17 working draft is available:
What is the difference between C++14 and C++17?
- Changes between C++14 and C++17 DIS [local pdf]
- Cheatsheet of Modern C++ Language and Library Features
New features of C++17
- C++17 Features
- C++17 Details
- Summary of C++17 features
- C++17 Summary
- C++17 Features that will simplify your code
Compilers implement C++17
GCC has experimental support for C++17. C++17 features are available as part of mainline GCC in the trunk of GCC’s repository and in GCC 5 and later. To enable C++17 support, add the command-line parameter -std=c++17 to your g++ command line. Or, to enable GNU extensions in addition to C++17 features, add -std=gnu++17. Refer to C++ Standards Support in GCC for more details. 2020-06-28: This mode is the default in GCC 11.
NOTE: Because the final ISO C++17 standard is still new, GCC’s support is experimental. No attempt will be made to maintain backward compatibility with implementations of C++17 features that do not reflect the final standard.
C++17 Materials
- Trip report: Summer ISO C++ standards meeting (Oulu)
- New core language papers adopted for C++17
- C++17 Content on InfoQ
ISO/IEC 14882:2020 (C++20)
The most up-to-date version can be found, in source form at https://github.com/cplusplus/draft and in browseable form at http://eel.is/c++draft.
C++20, the most impactful revision of C++ in a decade, is done!
Technical Reports (TRs)
-
ISO/IEC TR 18015:2006 - Technical Report on C++ Performance
The aim of ISO/IEC TR 18015 is to:
- give the reader a model of time and space overheads implied by use of various C++ language and library features;
- debunk widespread myths about performance problems in C++;
- present techniques for use of C++ in applications where performance matters; and
- present techniques for implementing C++ standard language and library facilities to yield efficient code.
The special needs of embedded systems programming are presented, including ROMability and predictability. A separate chapter presents general C and C++ interfaces to the basic hardware facilities of embedded systems.
-
ISO/IEC TR 19768:2007 (C++TR1) - Technical Report on C++ Library Extensions
In 2007, a technical report ISO/IEC TR 19768:2007 - C++ Library Extensions was released, which is informally known as C++07/TR1. While not an official part of the standard, it proposed a number of extensions to the standard library.
-
ISO/IEC TR 29124:2010 - Extensions to the C++ Library to support mathematical special functions
In 2010, a technical report ISO/IEC TR 29124:2010 - C++ Special Math Functions is released. The draft can be found here.
-
ISO/IEC TR 24733:2011 - Extensions for the programming language C++ to support decimal floating-point arithmetic
In 2011, a technical report ISO/IEC TR 24733:2011 - C++ decimal floating point arithmetic extensions is released. Refer to working draft N2849.
-
ISO/IEC TS 18822:2015 - File System Technical Specification
ISO/IEC TS 18822:2015 specifies requirements for implementations of an interface that computer programs written in the C++ programming language may use to perform operations on file systems and their components, such as paths, regular files, and directories. This Technical Specification is applicable to information technology systems that can access hierarchical file systems, such as those with operating systems that conform to the POSIX (3) interface. This Technical Specification is applicable only to vendors who wish to provide the interface it describes.
-
ISO/IEC TS 19570:2015 - Technical Specification for C++ Extensions for Parallelism
C++ Language
Translation Phases
Refer to Phases of translation on CppReference, the C++ source file is processed by the compiler as if the following phases take place, in this exact order:
Phase 1
The individual bytes of the source code file are mapped (in implementation-defined manner) to the characters of the basic source character set. In particular, OS-dependent end-of-line indicators are replaced by newline characters. The basic source character set consists of 96 characters:
- 5 whitespace characters: space (
), horizontal tab (\t), vertical tab (\v), form feed (\f), new-line (\n) - 10 digit characters:
0to9 - 52 letters:
atoz,AtoZ - 29 punctuation characters:
_ { } [ ] # ( ) < > % : ; . ? * + - / ^ & | ~ ! = , \ " '
Any source file character that cannot be mapped to a character in the basic source character set is replaced by its universal character name (escaped with \u or \U) or by some implementation-defined form that is handled equivalently.
Until C++17, trigraph sequences are replaced by corresponding single-character representations:
| Trigraph | Single-character | Description |
|---|---|---|
??< |
{ |
left brace |
??> |
} |
right brace |
??( |
[ |
left bracket |
??) |
] |
right bracket |
??= |
# |
pound sign |
??/ |
\ |
backslash |
??' |
^ |
caret |
??! |
| |
vertical bar |
??- |
~ |
tilde |
Phase 2
Whenever backslash appears at the end of a line (immediately followed by the newline character), both backslash and newline are deleted, combining two physical source lines into one logical source line. This is a single-pass operation; a line ending in two backslashes followed by an empty line does not combine three lines into one. If a universal character name \uXXX is formed in this phase, the behavior is undefined.
If a non-empty source file does not end with a newline character after this step (whether it had no newline originally, or it ended with a backslash), (the behavior is undefined, until C++11) (a terminating newline character is added, since C++11).
Phase 3
The source file is decomposed into comments, sequences of whitespace characters (space, horizontal tab, new-line, vertical tab, and form-feed), and preprocessing tokens, which are the following:
- header names:
<iostream>ormyfile.h - identifiers
- preprocessing numbers
- character and string literals , (including user-defined, since C++11)
- operators and punctuators (including alternative tokens), such as
+,<<=,new,<%,## - individual non-whitespace characters that do not fit in any other category
Since C++11, any transformations performed during phases 1 and 2 between the initial and the final double quote of any raw string literal are reverted.
Each comment is replaced by one space character.
Note: Newlines are kept, and it’s unspecified whether non-newline whitespace sequences may be collapsed into single space characters.
Phase 4
The preprocessor is executed.
Each file introduced with the #include directive goes through phases 1 through 4, recursively.
At the end of this phase, all preprocessor directives are removed from the source.
Phase 5
All characters in character literals and string literals are converted from the source character set to the execution character set (which may be a multibyte character set such as UTF-8, as long as the 96 characters of the basic source character set listed in phase 1 have single-byte representations).
Escape sequences and universal character names in character literals and non-raw string literals are expanded and converted to the execution character set. If the character specified by a universal character name isn’t a member of the execution character set, the result is implementation-defined, but is guaranteed not to be a null (wide) character.
Note: The conversion performed at this stage can be controlled by command line options in some implementations: gcc and clang use -finput-charset to specify the encoding of the source character set, -fexec-charset and -fwide-exec-charset to specify the encodings of the execution character set in the string and character literals (that don’t have an encoding prefix, since C++11).
Phase 6
Adjacent string literals are concatenated.
Phase 7
Compilation takes place: each preprocessing token is converted to a token. The tokens are syntactically and semantically analyzed and translated as a translation unit.
Phase 8
Each translation unit is examined to produce a list of required template instantiations, including the ones requested by explicit instantiations. The definitions of the templates are located, and the required instantiations are performed to produce instantiation units.
Phase 9
Translation units, instantiation units, and library components needed to satisfy external references are collected into a program image which contains information needed for execution in its execution environment.
Note: Some compilers don’t implement instantiation units (also known as [template repositories(http://docs.oracle.com/cd/E18659_01/html/821-1383/bkagr.html#scrolltoc) or template registries) and simply compile each template instantiation at Phase 7, storing the code in the object file where it is implicitly or explicitly requested, and then the linker collapses these compiled instantiations into one at Phase 9.
Keywords
This is a list of reserved keywords in C++. Since they are used by the language, these keywords are not available for re-definition or overloading. Also refer to C++ Keywords Reference Material.
| Keywords | Standard |
|---|---|
| alignas | since C++11 |
| alignof | since C++11 |
| and | |
| and_eq | |
| asm | |
| atomic_cancel | TM TS |
| atomic_commit | TM TS |
| atomic_noexcept | TM TS |
| auto | (1) |
| bitand | |
| bitor | |
| bool | |
| break | |
| case | |
| catch | |
| char | |
| char16_t | since C++11 |
| char32_t | since C++11 |
| class | (1) |
| compl | |
| concept | concepts TS |
| const | |
| constexpr | since C++11 |
| const_cast | |
| continue | |
| decltype | since C++11 |
| default | (1) |
| delete | (1) |
| do | |
| double | |
| dynamic_cast | |
| else | |
| enum | |
| explicit | |
| export | (1) |
| extern | (1) |
| false | |
| float | |
| for | |
| friend | |
| goto | |
| if | |
| import | modules TS |
| inline | (1) |
| int | |
| long | |
| module | modules TS |
| mutable | (1) |
| namespace | |
| new | |
| noexcept | since C++11 |
| not | |
| not_eq | |
| nullptr | since C++11 |
| operator | |
| or | |
| or_eq | |
| private | |
| protected | |
| public | |
| register | (2) |
| reinterpret_cast | |
| requires | concepts TS |
| return | |
| short | |
| signed | |
| sizeof | (1) |
| static | |
| static_assert | since C++11 |
| static_cast | |
| struct | (1) |
| switch | |
| synchronized | TM TS |
| template | |
| this | |
| thread_local | since C++11 |
| throw | |
| true | |
| try | |
| typedef | |
| typeid | |
| typename | |
| union | |
| unsigned | |
| using | (1) |
| virtual | |
| void | |
| volatile | |
| wchar_t | |
| while | |
| xor | |
| xor_eq |
NOTE:
- (1) - meaning changed or new meaning added in C++11. Note: the keyword export is also used by Modules TS.
- (2) - meaning changed in C++17.
Note that and, bitor, or, xor, compl, bitand, and_eq, or_eq, xor_eq, not, and not_eq (along with the digraphs <%, %>, <:, :>, %:, and %:%:) provide an alternative way to represent standard tokens.
Alternative Tokens
There are alternative spellings for several operators and other tokens that use non-ISO646 characters. In all respects of the language, each alternative token behaves exactly the same as its primary token, except for its spelling (the stringification operator can make the spelling visible). The two-letter alternative tokens are sometimes called digraphs:
| Primary | Alternative |
|---|---|
&& |
and |
&= |
and_eq |
& |
bitand |
| |
bitor |
~ |
compl |
! |
not |
!= |
not_eq |
|| |
or |
|= |
or_eq |
^ |
xor |
^= |
xor_eq |
{ |
<% |
} |
%> |
[ |
<: |
] |
:> |
# |
%: |
## |
%:%: |
Identifiers
Identifiers Constitution
An identifier is an arbitrarily long sequence of digits, underscores, lowercase and uppercase Latin letters, and most Unicode characters. A valid identifier must begin with a non-digit character (Latin letter, underscore, or Unicode non-digit character). Identifiers are case-sensitive, and every character is significant.
Reserved Identifiers
An identifier can be used to name objects, references, functions, enumerators, types, class members, namespaces, templates, template specializations, parameter packs, goto labels, and other entities, with the following exceptions:
- the identifiers that are keywords cannot be used for other purposes;
- the identifiers with a double underscore anywhere are reserved;
- the identifiers that begin with an underscore followed by an uppercase letter are reserved;
- the identifiers that begin with an underscore are reserved in the global namespace.
Reserved here means that the standard library headers #define or declare such identifiers for their internal needs, the compiler may predefine non-standard identifiers of that kind, and that name mangling algorithm may assume that some of these identifiers are not in use. If the programmer uses such identifiers, the behavior is undefined.
In addition, it’s undefined behavior to #define or #undef names identical to keywords. If at least one standard library header is included, it’s undefined behavior to #define or #undef identifiers identical to names declared in any standard library header.
Translation Limits
Operators
Refer to C++ Operators Reference Material.
| Operators | Associativity |
|---|---|
() [] -> . |
left to right |
! ~ ++ -- + - (type) * & sizeof |
right to left |
* / % |
left to right |
+ - |
left to right |
<< >> |
left to right |
< <= > >= |
left to right |
== != |
left to right |
& |
left to right |
^ |
left to right |
| |
left to right |
&& |
left to right |
|| |
left to right |
?: |
right to left |
= += -= *= /= %= <<= >>= &= ^= |= |
right to left |
, |
left to right |
Run the following command to get the operator priority under Linux environment:
chenwx@chenwx ~ $ man operator
NAME
operator - C operator precedence and order of evaluation
DESCRIPTION
This manual page lists C operators and their precedence in evaluation.
Operator Associativity
() [] -> . left to right
! ~ ++ -- + - (type) * & sizeof right to left
* / % left to right
+ - left to right
<< >> left to right
< <= > >= left to right
== != left to right
& left to right
^ left to right
| left to right
&& left to right
|| left to right
?: right to left
= += -= *= /= %= <<= >>= &= ^= |= right to left
, left to right
COLOPHON
This page is part of release 3.54 of the Linux man-pages project. A description of the project, and information about reporting bugs, can befound at http://www.kernel.org/doc/man-pages/.
Comments
C-style comments or multi-line comments, which cannot be nested.
/* comment */
C++-style comments or single-line comments (since C99), which can be nested.
// comment until end of the line
All comments are removed from the program at translation phase 3 by replacing each comment with a single whitespace character.
Because comments are removed before the preprocessor stage, a macro cannot be used to form a comment and an unterminated C-style comment doesn’t spill over from an #include‘d file.
Besides commenting out, other mechanisms used for source code exclusion are:
#if 0
std::cout << "this will not be executed or even compiled\n";
#endif
and
if (false)
{
std::cout << "this will not be executed\n"
}
Types
The C++ type system consists of Fundamental Types and Compound Types, refer to C++ Types on CppReference.
Fundamental Types
std::is_fundamental is defined in header <type_traits>:
template< class T >
struct is_fundamental; (since C++11)
If T is a fundamental type (that is, arithmetic type, void, or nullptr_t), provides the member constant value equal true. For any other type, value is false:
#include <iostream>
#include <type_traits>
class A {};
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_fundamental<A>::value << '\n';
std::cout << std::is_fundamental<int>::value << '\n';
std::cout << std::is_fundamental<int&>::value << '\n';
std::cout << std::is_fundamental<int*>::value << '\n';
std::cout << std::is_fundamental<float>::value << '\n';
std::cout << std::is_fundamental<float&>::value << '\n';
std::cout << std::is_fundamental<float*>::value << '\n';
}
void
The void type with an empty set of values. It is an incomplete type that cannot be completed (consequently, objects of type void are disallowed). There are no arrays of void, nor references to void. However, pointers to void and functions returning type void are permitted.
std::is_void is defined in header <type_traits>:
template< class T >
struct is_void; (since C++11)
Checks whether T is a void type. Provides the member constant value that is equal to true, if T is the type void, const void, volatile void, or const volatile void. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_void<void>::value << '\n';
std::cout << std::is_void<int>::value << '\n';
}
std::nullptr_t
Since C++11, the keyword nullptr denotes the pointer literal. It is a prvalue of type std::nullptr_t. There exist implicit conversions from nullptr to null pointer value of any pointer type and any pointer to member type. Similar conversions exist for any null pointer constant, which includes values of type std::nullptr_t as well as the macro NULL.
std::nullptr_t is the type of the null pointer literal, nullptr. It is a distinct type that is not itself a pointer type or a pointer to member type.
#include <cstddef>
#include <iostream>
void f(int* pi)
{
std::cout << "Pointer to integer overload\n";
}
void f(double* pd)
{
std::cout << "Pointer to double overload\n";
}
void f(std::nullptr_t nullp)
{
std::cout << "null pointer overload\n";
}
int main()
{
int* pi; double* pd;
// call void f(int* pi)
f(pi);
// call void f(double* pd)
f(pd);
// would be ambiguous without void f(nullptr_t)
f(nullptr);
// ambiguous overload: all three functions are candidates
// f(NULL);
}
std::is_null_pointer is defined in header <type_traits>:
template< class T >
struct is_null_pointer; (since C++14)
Checks whether T is the type std::nullptr_t. Provides the member constant value that is equal to true, if T is the type std::nullptr_t, const std::nullptr_t, volatile std::nullptr_t, or const volatile std::nullptr_t. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
int main()
{
std::cout << std::boolalpha
<< std::is_null_pointer< decltype(nullptr) >::value << ' '
<< std::is_null_pointer< int* >::value << '\n'
<< std::is_pointer< decltype(nullptr) >::value << ' '
<< std::is_pointer<int*>::value << '\n';
}
Arithmetic Types
std::is_arithmetic is defined in header <type_traits>:
template< class T >
struct is_arithmetic; (since C++11)
If T is an arithmetic type (that is, an integral type or a floating-point type), provides the member constant value equal true. For any other type, value is false.
#include <iostream>
#include <type_traits>
class A {};
int main()
{
std::cout << std::boolalpha;
std::cout << "A: " << std::is_arithmetic<A>::value << '\n';
std::cout << "bool " << std::is_arithmetic<bool>::value << '\n';
std::cout << "int: " << std::is_arithmetic<int>::value << '\n';
std::cout << "int const: " << std::is_arithmetic<int const>::value << '\n';
std::cout << "int &: " << std::is_arithmetic<int&>::value << '\n';
std::cout << "int *: " << std::is_arithmetic<int*>::value << '\n';
std::cout << "float: " << std::is_arithmetic<float>::value << '\n';
std::cout << "float const: " << std::is_arithmetic<float const>::value << '\n';
std::cout << "float &: " << std::is_arithmetic<float&>::value << '\n';
std::cout << "float *: " << std::is_arithmetic<float*>::value << '\n';
}
bool
The bool type is capable of holding one of the two values: true or false. The value of sizeof(bool) is implementation defined and might differ from 1.
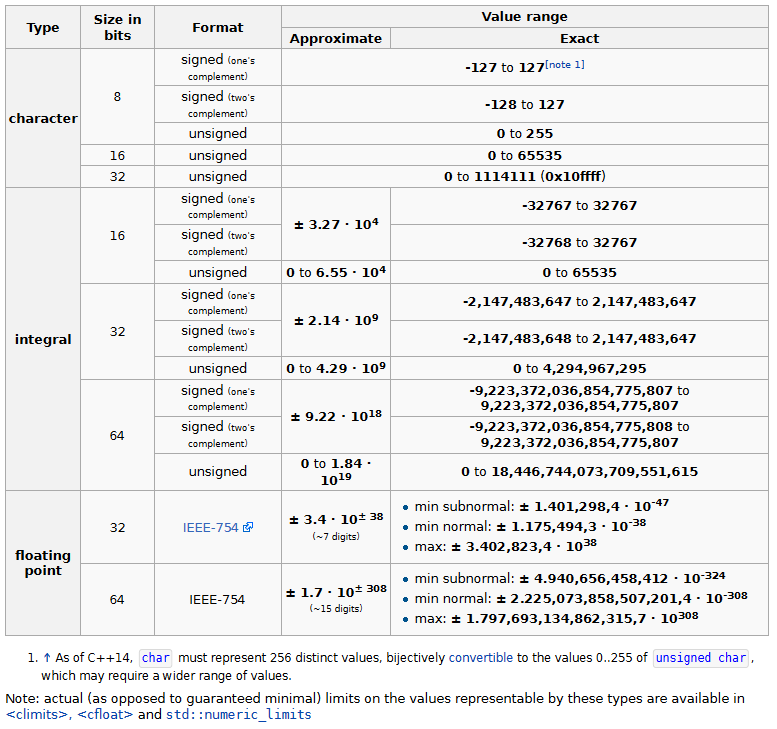
Narrow Character Types
Narrow character types include:
-
char: type for character representation which can be most efficiently processed on the target system (has the same representation and alignment as eithersigned charorunsigned char, but is always a distinct type). -
signed char: type for signed character representation. -
unsigned char: type for unsigned character representation. Also used to inspect object representations (raw memory).
Wide Character Types
Wide character types include:
-
char16_t: (since C++11) type for UTF-16 character representation, required to be large enough to represent any UTF-16 code unit (16 bits). It has the same size, signedness, and alignment asstd::uint_least16_t, but is a distinct type. -
char32_t: (since C++11) type for UTF-32 character representation, required to be large enough to represent any UTF-32 code unit (32 bits). It has the same size, signedness, and alignment asstd::uint_least32_t, but is a distinct type. -
wchar_t: type for wide character representation. Required to be large enough to represent any supported character code point (32 bits on systems that support Unicode. A notable exception is Windows, wherewchar_tis 16 bits and holds UTF-16 code units). It has the same size, signedness, and alignment as one of the integral types, but is a distinct type.
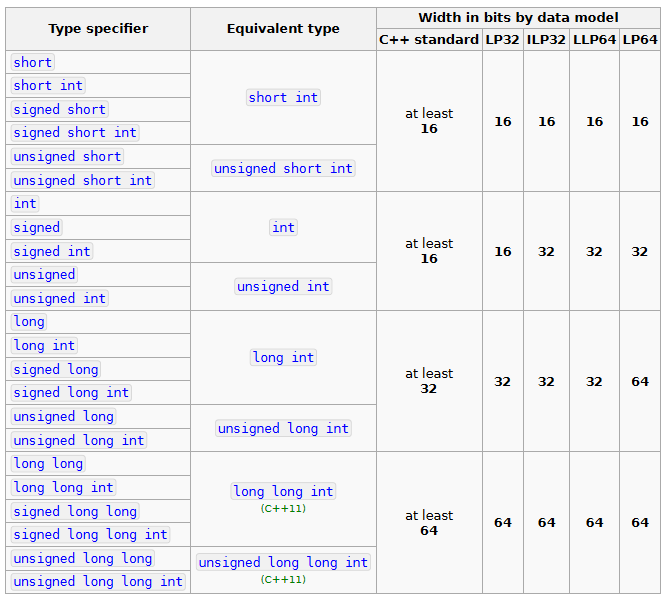
Signed Integer Types
Signed integer types include:
-
int: basic integer type. The keywordintmay be omitted if any of the modifiers listed below are used. If no length modifiers are present, it’s guaranteed to have a width of at least 16 bits. However, on 32/64 bit systems it is almost exclusively guaranteed to have width of at least 32 bits. -
short int: target type will be optimized for space and will have width of at least 16 bits. -
long int: target type will have width of at least 32 bits. -
long long int: (since C++11) target type will have width of at least 64 bits.
Unsigned Integer Types
unsigned short intunsigned intunsigned long intunsigned long long int
Floating-point Types
std::is_floating_point is defined in header <type_traits>:
template< class T >
struct is_floating_point; (since C++11)
Checks whether T is a floating-point type. Provides the member constant value which is equal to true, if T is the type float, double, long double, including any cv-qualified variants. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
class A {};
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_floating_point<A>::value << '\n';
std::cout << std::is_floating_point<float>::value << '\n';
std::cout << std::is_floating_point<int>::value << '\n';
}
-
float: single precision floating point type. Usually IEEE-754 32 bit floating point type -
double: double precision floating point type. Usually IEEE-754 64 bit floating point type -
long double: extended precision floating point type. Does not necessarily map to types mandated by IEEE-754. Usually 80-bit x87 floating point type on x86 and x86-64 architectures.
Floating-point types may support special values:
-
infinity (positive and negative), see INFINITY
-
the negative zero,
-0.0. It compares equal to the positive zero, but is meaningful in some arithmetic operations, e.g.1.0/0.0 == INFINITY, but1.0/-0.0 == -INFINITY), and for some mathematical functions, e.g.sqrt(std::complex) -
not-a-number (NaN), which does not compare equal with anything (including itself). Multiple bit patterns represent NaNs, see std::nan, NAN. Note that C++ takes no special notice of signalling NaNs other than detecting their support by std::numeric_limits::has_signaling_NaN, and treats all NaNs as quiet.
Real floating-point numbers may be used with arithmetic operators + - / * and various mathematical functions from <cmath>. Both built-in operators and library functions may raise floating-point exceptions and set errno as described in math_errhandling.
Floating-point expressions may have greater range and precision than indicated by their types, see FLT_EVAL_METHOD. Floating-point expressions may also be contracted, that is, calculated as if all intermediate values have infinite range and precision, see []#pragma STDC FP_CONTRACT](http://en.cppreference.com/w/cpp/preprocessor/impl#Standard_pragmas).
Some operations on floating-point numbers are affected by and modify the state of the floating-point environment (most notably, the rounding direction).
Implicit conversions are defined between real floating types and integer types.
See Limits of floating point types and std::numeric_limits for additional details, limits, and properties of the floating-point types.
Compound Types
std::is_compound is defined in header <type_traits>:
template< class T >
struct is_compound; (since C++11)
If T is a compound type (that is, array, function, object pointer, function pointer, member object pointer, member function pointer, reference, class, union, or enumeration, including any cv-qualified variants), provides the member constant value equal true. For any other type, value is false.
#include <iostream>
#include <type_traits>
int main() {
class cls {};
std::cout << (std::is_compound<cls>::value
? "T is compound"
: "T is not a compound") << '\n';
std::cout << (std::is_compound<int>::value
? "T is compound"
: "T is not a compound") << '\n';
}
Note: Compound types are the types that are constructed from fundamental types. Any C++ type is either fundamental or compound.
Reference Types
A reference variable declaration is any simple declaration whose declarator has the form
& attr(optional) declarator (1)
&& attr(optional) declarator (2) (since C++11)
Type (1) Lvalue reference declarator: the declaration S& D; declares D as an lvalue reference to the type determined by decl-specifier-seq S.
Type (2) Rvalue reference declarator: the declaration S&& D; declares D as an rvalue reference to the type determined by decl-specifier-seq S.
A reference is required to be initialized to refer to a valid object or function: see reference initialization.
There are no references to void and no references to references.
Reference types cannot be cv-qualified at the top level; there is no syntax for that in declaration, and if a qualification is introduced through a typedef, decltype, or template type argument, it is ignored.
References are not objects; they do not necessarily occupy storage, although the compiler may allocate storage if it is necessary to implement the desired semantics (e.g. a non-static data member of reference type usually increases the size of the class by the amount necessary to store a memory address).
Because references are not objects, there are no arrays of references, no pointers to references, and no references to references:
int& a[3]; // error
int&* p; // error
int& &r; // error
Since C++11, it is permitted to form references to references through type manipulations in templates or typedefs, in which case the reference collapsing rules apply: rvalue reference to rvalue reference collapses to rvalue reference, all other combinations form lvalue reference:
typedef int& lref;
typedef int&& rref;
int n;
lref& r1 = n; // type of r1 is int&
lref&& r2 = n; // type of r2 is int&
rref& r3 = n; // type of r3 is int&
rref&& r4 = 1; // type of r4 is int&&
Lvalue References
Lvalue references can be used to alias an existing object (optionally with different cv-qualification):
#include <iostream>
#include <string>
int main()
{
std::string s = "Ex";
std::string& r1 = s;
const std::string& r2 = s;
r1 += "ample"; // modifies s
// r2 += "!"; // error: cannot modify through reference to const
std::cout << r2 << '\n'; // prints s, which now holds "Example"
}
They can also be used to implement pass-by-reference semantics in function calls:
#include <iostream>
#include <string>
void double_string(std::string& s)
{
s += s; // 's' is the same object as main()'s 'str'
}
int main()
{
std::string str = "Test";
double_string(str);
std::cout << str << '\n';
}
When a function’s return type is lvalue reference, the function call expression becomes an lvalue expression:
#include <iostream>
#include <string>
char& char_number(std::string& s, std::size_t n)
{
return s.at(n); // string::at() returns a reference to char
}
int main()
{
std::string str = "Test";
char_number(str, 1) = 'a'; // the function call is lvalue, can be assigned to
std::cout << str << '\n';
}
Rvalue References
Rvalue references can be used to extend the lifetimes of temporary objects (note, lvalue references to const can extend the lifetimes of temporary objects too, but they are not modifiable through them):
#include <iostream>
#include <string>
int main()
{
std::string s1 = "Test";
// std::string&& r1 = s1; // error: can't bind to lvalue
const std::string& r2 = s1 + s1; // okay: lvalue reference to const extends lifetime
// r2 += "Test"; // error: can't modify through reference to const
std::string&& r3 = s1 + s1; // okay: rvalue reference extends lifetime
r3 += "Test"; // okay: can modify through reference to non-const
std::cout << r3 << '\n';
}
More importantly, when a function has both rvalue reference and lvalue reference overloads, the rvalue reference overload binds to rvalues (including both prvalues and xvalues), while the lvalue reference overload binds to lvalues:
#include <iostream>
#include <utility>
void f(int& x)
{
std::cout << "lvalue reference overload f(" << x << ")\n";
}
void f(const int& x)
{
std::cout << "lvalue reference to const overload f(" << x << ")\n";
}
void f(int&& x)
{
std::cout << "rvalue reference overload f(" << x << ")\n";
}
int main()
{
int i = 1;
const int ci = 2;
f(i); // calls f(int&)
f(ci); // calls f(const int&)
f(3); // calls f(int&&)
// would call f(const int&) if f(int&&) overload wasn't provided
f(std::move(i)); // calls f(int&&)
// rvalue reference variables are lvalues when used in expressions
int&& x = 1;
f(x); // calls f(int& x)
f(std::move(x)); // calls f(int&& x)
}
Dangling References
Although references, once initialized, always refer to valid objects or functions, it is possible to create a program where the lifetime of the referred-to object ends, but the reference remains accessible (dangling). Accessing such a reference is undefined behavior. A common example is a function returning a reference to an automatic variable:
std::string& f()
{
std::string s = "Example";
return s; // exits the scope of s:
// its destructor is called and its storage deallocated
}
std::string& r = f(); // dangling reference
std::cout << r; // undefined behavior: reads from a dangling reference
std::string s = f(); // undefined behavior: copy-initializes from a dangling reference
Note that rvalue references and lvalue references to const extend the lifetimes of temporary objects (see reference_initialization#Lifetime_of_a_temporary for rules and exceptions).
If the referred-to object was destroyed (e.g. by explicit destructor call), but the storage was not deallocated, a reference to the out-of-lifetime object may be used in limited ways, and may become valid if the object is recreated in the same storage (see Access outside of lifetime for details).
Check References Types
std::is_reference is defined in header <type_traits>:
template< class T >
struct is_reference; (since C++11)
If T is a reference type (lvalue reference or rvalue reference), provides the member constant value equal true. For any other type, value is false.
#include <iostream>
#include <type_traits>
class A {};
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_reference<A>::value << '\n';
std::cout << std::is_reference<A&>::value << '\n';
std::cout << std::is_reference<A&&>::value << '\n';
std::cout << std::is_reference<int>::value << '\n';
std::cout << std::is_reference<int&>::value << '\n';
std::cout << std::is_reference<int&&>::value << '\n';
}
std::is_lvalue_reference is defined in header <type_traits>:
template< class T >
struct is_lvalue_reference; (since C++11)
Checks whether T is a lvalue reference type. Provides the member constant value which is equal to true, if T is a lvalue reference type. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
class A {};
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_lvalue_reference<A>::value << '\n';
std::cout << std::is_lvalue_reference<A&>::value << '\n';
std::cout << std::is_lvalue_reference<A&&>::value << '\n';
std::cout << std::is_lvalue_reference<int>::value << '\n';
std::cout << std::is_lvalue_reference<int&>::value << '\n';
std::cout << std::is_lvalue_reference<int&&>::value << '\n';
}
std::is_rvalue_reference is defined in header <type_traits>:
template< class T >
struct is_rvalue_reference; (since C++11)
Checks whether T is a rvalue reference type. Provides the member constant value which is equal to true, if T is a rvalue reference type. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
class A {};
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_rvalue_reference<A>::value << '\n';
std::cout << std::is_rvalue_reference<A&>::value << '\n';
std::cout << std::is_rvalue_reference<A&&>::value << '\n';
std::cout << std::is_rvalue_reference<int>::value << '\n';
std::cout << std::is_rvalue_reference<int&>::value << '\n';
std::cout << std::is_rvalue_reference<int&&>::value << '\n';
}
Pointer Types
There are no pointers to references and there are no pointers to bit fields.
Constness
| Sytax | Description |
|---|---|
const T* |
pointer to constant object |
T const* |
pointer to constant object |
T* const |
constant pointer to object |
const T* const |
constant pointer to constant object |
// pc is a non-const pointer to const int
// cpc is a const pointer to const int
// ppc is a non-const pointer to non-const pointer to const int
const int ci = 10, *pc = &ci, *const cpc = pc, **ppc;
// p is a non-const pointer to non-const int
// cp is a const pointer to non-const int
int i, *p, *const cp = &i;
i = ci; // okay: value of const int copied into non-const int
*cp = ci; // okay: non-const int (pointed-to by const pointer) can be changed
pc++; // okay: non-const pointer (to const int) can be changed
pc = cpc; // okay: non-const pointer (to const int) can be changed
pc = p; // okay: non-const pointer (to const int) can be changed
ppc = &pc; // okay: address of pointer to const int is pointer to pointer to const int
ci = 1; // error: const int cannot be changed
ci++; // error: const int cannot be changed
*pc = 2; // error: pointed-to const int cannot be changed
cp = &ci; // error: const pointer (to non-const int) cannot be changed
cpc++; // error: const pointer (to const int) cannot be changed
p = pc; // error: pointer to non-const int cannot point to const int
ppc = &p; // error: pointer to pointer to const int cannot point to
// pointer to non-const int
Pointers to Objects
A pointer to object can be initialized with the return value of the address-of operator & applied to any expression of object type, including another pointer type:
int n;
int* np = &n; // pointer to int
int* const* npp = &np; // non-const pointer to const pointer to non-const int
int a[2];
int (*ap)[2] = &a; // pointer to array of int
struct S { int n; };
S s = {1};
int* sp = &s.n; // pointer to the int that is a member of s
Pointers may appear as operands to the built-in indirection operator (unary operator *), which returns the lvalue expression identifying the pointed-to object:
int n;
int* p = &n; // pointer to n
int& r = *p; // reference is bound to the lvalue expression that identifies n
r = 7; // stores the int 7 in n
std::cout << *p; // lvalue-to-rvalue implicit conversion reads the value from n
Pointers to class objects may also appear as the left-hand operands of the member access operators operator-> and operator->*.
Because of the array-to-pointer implicit conversion, pointer to the first element of an array can be initialized with an expression of array type:
int a[2];
int* p1 = a; // pointer to the first element a[0] (an int) of the array a
int b[6][3][8];
int (*p2)[3][8] = b; // pointer to the first element b[0] of the array b,
// which is an array of 3 arrays of 8 ints
Because of the derived-to-base implicit conversion for pointers, pointer to a base class can be initialized with the address of a derived class:
struct Base {};
struct Derived : Base {};
Derived d;
Base* p = &d;
If Derived is polymorphic, such pointer may be used to make virtual function calls.
Certain addition, subtraction, increment, and decrement operators are defined for pointers to elements of arrays: such pointers satisfy the RandomAccessIterator requirements and allow the C++ library algorithms to work with raw arrays.
Comparison operators are defined for pointers to objects in some situations: two pointers that represent the same address compare equal, two null pointer values compare equal, pointers to elements of the same array compare the same as the array indexes of those elements, and pointers to non-static data members with the same member access compare in order of declaration of those members.
Many implementations also provide strict total ordering of pointers of random origin, e.g. if they are implemented as addresses within continuous virtual address space. Those implementations that do not (e.g. where not all bits of the pointer are part of a memory address and have to be ignored for comparison, or an additional calculation is required or otherwise pointer and integer is not a 1 to 1 relationship), provide a specialization of std::less for pointers that has that guarantee. This makes it possible to use all pointers of random origin as keys in standard associative containers such as std::set or std::map.
Pointers to Functions
A pointer to function can be initialized with an address of a non-member function or a static member function. Because of the function-to-pointer implicit conversion, the address-of operator & is optional:
void f(int);
void (*p1)(int) = &f;
void (*p2)(int) = f; // same as &f
Unlike functions or references to functions, pointers to functions are objects and thus can be stored in arrays, copied, assigned, etc.
A pointer to function can be used as the left-hand operand of the function call operator, this invokes the pointed-to function:
int f(int n)
{
std::cout << n << '\n';
return n * n;
}
int main()
{
int (*p)(int) = f;
int x = p(7);
}
Dereferencing a function pointer yields the lvalue identifying the pointed-to function:
int f();
int (*p)() = f; // pointer p is pointing to f
int (&r)() = *p; // the lvalue that identifies f is bound to a reference
r(); // function f invoked through lvalue reference
(*p)(); // function f invoked through the function lvalue
p(); // function f invoked directly through the pointer
A pointer to function may be initialized from an overload set which may include functions, function template specializations, and function templates, if only one overload matches the type of the pointer (see address of an overloaded function for more detail):
template<typename T> T f(T n) { return n; }
double f(double n) { return n; }
int main()
{
int (*p)(int) = f; // instantiates and selects f<int>
}
Equality comparison operators are defined for pointers to functions (they compare equal if pointing to the same function).
Pointer to Member Types
Pointer to member types include the following two types:
- Pointers to Data Members
- Pointer to Member Function
Pointers to Data Members
A pointer to non-static member object m which is a member of class C can be initialized with the expression &C::m exactly. Expressions such as &(C::m) or &m inside C’s member function do not form pointers to members.
Such pointer may be used as the right-hand operand of the pointer-to-member access operators operator.* and operator->*:
struct C { int m; };
int main()
{
int C::* p = &C::m; // pointer to data member m of class C
C c = {7};
std::cout << c.*p << '\n'; // prints 7
C* cp = &c;
cp->m = 10;
std::cout << cp->*p << '\n'; // prints 10
}
Pointer to data member of an accessible unambiguous non-virtual base class can be implicitly converted to pointer to the same data member of a derived class:
struct Base { int m; };
struct Derived : Base {};
int main()
{
int Base::* bp = &Base::m;
int Derived::* dp = bp;
Derived d;
d.m = 1;
std::cout << d.*dp << ' ' << d.*bp << '\n'; // prints 1 1
}
Conversion in the opposite direction, from a pointer to data member of a derived class to a pointer to data member of an unambiguous non-virtual base class, is allowed with static_cast and explicit cast, even if the base class does not have that member (but the most-derived class does, when the pointer is used for access):
struct Base {};
struct Derived : Base { int m; };
int main()
{
int Derived::* dp = &Derived::m;
int Base::* bp = static_cast<int Base::*>(dp);
Derived d;
d.m = 7;
std::cout << d.*bp << '\n'; // okay: prints 7
Base b;
std::cout << b.*bp << '\n'; // undefined behavior
}
The pointed-to type of a pointer-to-member may be a pointer-to-member itself: pointers to members can be multilevel, and can be cv-qualifed differently at every level. Mixed multi-level combinations of pointers and pointers-to-members are also allowed:
struct A
{
int m;
// const pointer to non-const member
int A::* const p;
};
int main()
{
// non-const pointer to data member which is a const pointer to non-const member
int A::* const A::* p1 = &A::p;
const A a = {1, &A::m};
std::cout << a.*(a.*p1) << '\n'; // prints 1
// regular non-const pointer to a const pointer-to-member
int A::* const* p2 = &a.p;
std::cout << a.**p2 << '\n'; // prints 1
}
Pointers to Member Functions
A pointer to non-static member function f which is a member of class C can be initialized with the expression &C::f exactly. Expressions such as &(C::f) or &f inside C’s member function do not form pointers to member functions.
Such pointer may be used as the right-hand operand of the pointer-to-member access operators operator.* and operator->*. The resulting expression can be used only as the left-hand operand of a function-call operator:
struct C
{
void f(int n) { std::cout << n << '\n'; }
};
int main()
{
void (C::* p)(int) = &C::f; // pointer to member function f of class C
C c;
(c.*p)(1); // prints 1
C* cp = &c;
(cp->*p)(2); // prints 2
}
Pointer to member function of a base class can be implicitly converted to pointer to the same member function of a derived class:
struct Base
{
void f(int n) { std::cout << n << '\n'; }
};
struct Derived : Base {};
int main()
{
void (Base::* bp)(int) = &Base::f;
void (Derived::* dp)(int) = bp;
Derived d;
(d.*dp)(1);
(d.*bp)(2);
}
Conversion in the opposite direction, from a pointer to member function of a derived class to a pointer to member function of an unambiguous non-virtual base class, is allowed with static_cast and explicit cast, even if the base class does not have that member function (but the most-derived class does, when the pointer is used for access):
struct Base {};
struct Derived : Base
{
void f(int n) { std::cout << n << '\n'; }
};
int main()
{
void (Derived::* dp)(int) = &Derived::f;
void (Base::* bp)(int) = static_cast<void (Base::*)(int)>(dp);
Derived d;
(d.*bp)(1); // okay: prints 1
Base b;
(b.*bp)(2); // undefined behavior
}
Pointers to member functions may be used as callbacks or as function objects, often after applying std::mem_fn or std::bind:
#include <iostream>
#include <string>
#include <algorithm>
#include <functional>
int main()
{
std::vector<std::string> v = {"a", "ab", "abc"};
std::vector<std::size_t> l;
transform(v.begin(), v.end(), std::back_inserter(l),
std::mem_fn(&std::string::size));
for(std::size_t n : l)
std::cout << n << ' ';
}
Pointers to void
Pointer to object of any type can be implicitly converted to pointer to void (optionally cv-qualified). The reverse conversion, which requires static_cast or explicit cast, yields the original pointer value:
int n = 1;
int* p1 = &n;
void* pv = p1;
int* p2 = static_cast<int*>(pv);
std::cout << *p2 << '\n'; // prints 1
If the original pointer is pointing to a base class subobject within an object of some polymorphic type, dynamic_cast may be used to obtain a void* that is pointing at the complete object of the most derived type.
Pointers to void are used to pass objects of unknown type, which is common in C interfaces: std::malloc returns void*, std::qsort expects a user-provided callback that accepts two const void* arguments. pthread_create expects a user-provided callback that accepts and returns void*. In all cases, it is the caller’s responsibility to cast the pointer to the correct type before use.
Null Pointers
Pointers of every type have a special value known as null pointer value of that type. A pointer whose value is null does not point to an object or a function (dereferencing a null pointer is undefined behavior), and compares equal to all pointers of the same type whose value is also null.
To initialize a pointer to null or to assign the null value to an existing pointer, the null pointer literal nullptr, the null pointer constant NULL, or the implicit conversion from the integer value 0 may be used.
Zero- and value-initialization also initialize pointers to their null values.
Null pointers can be used to indicate the absence of an object (e.g. function::target()), or as other error condition indicators (e.g. dynamic_cast). In general, a function that receives a pointer argument almost always needs to check if the value is null and handle that case differently (for example, the delete expression does nothing when a null pointer is passed).
Check Pointer Types
std::is_pointer is defined in header <type_traits>:
template< class T >
struct is_pointer; (since C++11)
Checks whether T is a pointer to object or a pointer to function (but not a pointer to member/member function). Provides the member constant value which is equal to true, if T is a object/function pointer type. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
class A {};
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_pointer<A>::value << '\n';
std::cout << std::is_pointer<A *>::value << '\n';
std::cout << std::is_pointer<A &>::value << '\n';
std::cout << std::is_pointer<int>::value << '\n';
std::cout << std::is_pointer<int *>::value << '\n';
std::cout << std::is_pointer<int **>::value << '\n';
std::cout << std::is_pointer<int[10]>::value << '\n';
std::cout << std::is_pointer<std::nullptr_t>::value << '\n';
}
std::is_member_pointer is defined in header <type_traits>:
template< class T >
struct is_member_pointer; (since C++11)
If T is pointer to non-static member object or a pointer to non-static member function, provides the member constant value equal true. For any other type, value is false.
#include <iostream>
#include <type_traits>
int main() {
class cls {};
std::cout << (std::is_member_pointer<int(cls::*)>::value
? "T is member pointer"
: "T is not a member pointer") << '\n';
std::cout << (std::is_member_pointer<int>::value
? "T is member pointer"
: "T is not a member pointer") << '\n';
}
std::is_member_object_pointer is defined in header <type_traits>:
template< class T >
struct is_member_object_pointer; (since C++11)
Checks whether T is a non-static member object. Provides the member constant value which is equal to true, if T is a non-static member object type. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
int main() {
class cls {};
std::cout << (std::is_member_object_pointer<int(cls::*)>::value
? "T is member object pointer"
: "T is not a member object pointer") << '\n';
std::cout << (std::is_member_object_pointer<int(cls::*)()>::value
? "T is member object pointer"
: "T is not a member object pointer") << '\n';
}
std::is_member_function_pointer is defined in header <type_traits>:
template< class T >
struct is_member_function_pointer; (since C++11)
Checks whether T is a non-static member function pointer. Provides the member constant value which is equal to true, if T is a non-static member function pointer type. Otherwise, value is equal to false.
#include <type_traits>
class A {
public:
void member() { }
};
int main()
{
// fails at compile time if A::member is a data member and not a function
static_assert(std::is_member_function_pointer<decltype(&A::member)>::value,
"A::member is not a member function.");
}
Array Types
Arrays can be constructed from any fundamental type (except void), pointers, pointers to members, classes, enumerations, or from other arrays (in which case the array is said to be multi-dimensional). There are no arrays of references, arrays of functions, or arrays of abstract class types.
Applying cv-qualifiers to an array type (through typedef or template type manipulation) applies the qualifiers to the element type, but any array type whose elements are of cv-qualified type is considered to have the same cv-qualification.
// a and b have the same const-qualified type "array of 5 const char"
typedef const char CC;
CC a[5] = {};
typedef char CA[5];
const CA b = {};
When used with new[]-expression, the size of an array may be zero; such an array has no elements:
int* p = new int[0]; // accessing p[0] or *p is undefined
delete[] p; // cleanup still required
Assignment
Objects of array type cannot be modified as a whole: even though they are lvalues (e.g. an address of array can be taken), they cannot appear on the left hand side of an assignment operator:
int a[3] = {1, 2, 3}, b[3] = {4, 5, 6};
int (*p)[3] = &a; // okay: address of a can be taken
a = b; // error: a is an array
struct { int c[3]; } s1, s2 = {3, 4, 5};
s1 = s2; // okay: implicity-defined copy assignment operator
// can assign data members of array type
Array-to-pointer Decay
There is an implicit conversion from lvalues and rvalues of array type to rvalues of pointer type: it constructs a pointer to the first element of an array. This conversion is used whenever arrays appear in context where arrays are not expected, but pointers are:
#include <iostream>
#include <numeric>
#include <iterator>
void g(int (&a)[3])
{
std::cout << a[0] << '\n';
}
void f(int* p)
{
std::cout << *p << '\n';
}
int main()
{
int a[3] = {1, 2, 3};
int* p = a;
std::cout << sizeof a << '\n' // prints size of array
<< sizeof p << '\n'; // prints size of a pointer
// where arrays are acceptable, but pointers aren't, only arrays may be used
g(a); // okay: function takes an array by reference
// g(p); // error
for(int n: a) // okay: arrays can be used in range-for loops
std::cout << n << ' '; // prints elements of the array
// for(int n: p) // error
// std::cout << n << ' ';
std::iota(std::begin(a), std::end(a), 7); // okay: begin and end take arrays
// std::iota(std::begin(p), std::end(p), 7); // error
// where pointers are acceptable, but arrays aren't, both may be used:
f(a); // okay: function takes a pointer
f(p); // okay: function takes a pointer
std::cout << *a << '\n' // prints the first element
<< *p << '\n' // same
<< *(a + 1) << ' ' << a[1] << '\n' // prints the second element
<< *(p + 1) << ' ' << p[1] << '\n'; // same
}
Multidimensional Arrays
When the element type of an array is another array, it is said that the array is multidimensional:
// array of 2 arrays of 3 int each
int a[2][3] = { {1, 2, 3}, // can be viewed as a 2 × 3 matrix
{4, 5, 6} }; // with row-major layout
Note that when array-to-pointer decay is applied, a multidimensional array is converted to a pointer to its first element (e.g., a pointer to its first row or to its first plane): array-to-pointer decay is applied only once.
int a[2]; // array of 2 int
int* p1 = a; // a decays to a pointer to the first element of a
int b[2][3]; // array of 2 arrays of 3 int
// int** p2 = b; // error: b does not decay to int**
int (*p2)[3] = b; // b decays to a pointer to the first 3-element row of b
int c[2][3][4]; // array of 2 arrays of 3 arrays of 4 int
// int*** p3 = c; // error: c does not decay to int***
int (*p3)[3][4] = c; // c decays to a pointer to the first 3 × 4-element plane of c
Arrays of Unknown Bound
If expr is omitted in the declaration of an array, the type declared is array of unknown bound of T, which is a kind of incomplete type, except when used in a declaration with an aggregate initializer:
extern int x[]; // the type of x is "array of unknown bound of int"
int a[] = {1, 2, 3}; // the type of a is "array of 3 int"
Because array element cannot have incomplete type, multidimensional arrays cannot have unknown bound in a dimension other than the first:
extern int a[][2]; // okay: array of unknown bound of arrays of 2 int
extern int b[2][]; // error: array has incomplete element type
References and pointers to arrays of unknown bound can be formed, but cannot be initialized or assigned from arrays and pointers to arrays of known bound. Note that in the C programming language, pointers to arrays of unknown bound are compatible with pointers to arrays of known bound and are thus convertible and assignable in both directions.
extern int a1[];
int (&r1)[] = a1; // okay
int (*p1)[] = &a1; // okay
int (*q)[2] = &a1; // error (but okay in C)
int a2[] = {1, 2, 3};
int (&r2)[] = a2; // error
int (*p2)[] = &a2; // error (but okay in C)
Pointers to arrays of unknown bound cannot participate in pointer arithmetic and cannot be used on the left of the subscript operator, but can be dereferenced. (Pointers and references to arrays of unknown bound cannot be used in function parameters, until C++14).
Array rvalues
Although arrays cannot be returned from functions by value and cannot be targets of most cast expressions, array prvalues may be formed by using a type alias to construct an array temporary using brace-initialized functional cast.
(Like class prvalues, array prvalues convert to xvalues by temporary materialization when evaluated, since C++17.)
Array xvalues may be formed directly by accessing an array member of a class rvalue or by using std::move or another cast or function call that returns an rvalue reference.
Check Array Types
std::is_array is defined in header <type_traits>:
template< class T >
struct is_array; (since C++11)
Checks whether T is an array type. Provides the member constant value which is equal to true, if T is an array type. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
class A {};
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_array<A>::value << '\n';
std::cout << std::is_array<A[]>::value << '\n';
std::cout << std::is_array<A[3]>::value << '\n';
std::cout << std::is_array<float>::value << '\n';
std::cout << std::is_array<int>::value << '\n';
std::cout << std::is_array<int[]>::value << '\n';
std::cout << std::is_array<int[3]>::value << '\n';
}
Function Types
A function declaration introduces the function name and its type. A function definition associates the function name/type with the function body.
Function declarations may appear in any scope. A function declaration at class scope introduces a class member function (unless the friend specifier is used), see member functions and friend functions for details.
The return type of a function cannot be a function type or an array type (but can be a pointer or reference to those).
Check Function Types
std::is_function is defined in header <type_traits>:
template< class T >
struct is_function; (since C++11)
Checks whether T is a function type. Types like std::function, lambdas, classes with overloaded operator() and pointers to functions don’t count as function types. Provides the member constant value which is equal to true, if T is a function type. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
struct A {};
int f()
{
return 1;
}
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_function<A>::value << '\n';
std::cout << std::is_function<int(int)>::value << '\n';
std::cout << std::is_function<decltype(f)>::value << '\n';
std::cout << std::is_function<int>::value << '\n';
}
Enumeration Types
There are two distinct kinds of enumerations:
- unscoped enumeration, declared with the enum-key
enum - scoped enumeration, declared with the enum-key
enum classorenum struct
Unscoped Enumeration
enum name { enumerator = constexpr , enumerator = constexpr , ... } (1)
enum name : type { enumerator = constexpr , enumerator = constexpr , ... } (2) (since C++11)
enum name : type ; (3) (since C++11)
- Declares an unscoped enumeration type whose underlying type is not fixed (in this case, the underlying type is either
intor, if not all enumerator values can be represented as int, an implementation-defined larger integral type that can represent all enumerator values. If the enumerator-list is empty, the underlying type is as if the enumeration had a single enumerator with value 0). - Declares an unscoped enumeration type whose underlying type is fixed.
- Opaque enum declaration for an unscoped enumeration must specify the underlying type.
Each enumerator becomes a named constant of the enumeration’s type (that is, name), visible in the enclosing scope, and can be used whenever constants are required.
enum Color { red, green, blue };
Color r = red;
switch(r)
{
case red : std::cout << "red\n"; break;
case green: std::cout << "green\n"; break;
case blue : std::cout << "blue\n"; break;
}
Each enumerator is associated with a value of the underlying type. When initializers are provided in the enumerator-list, the values of enumerators are defined by those initializers. If the first enumerator does not have an initializer, the associated value is zero. For any other enumerator whose definition does not have an initializer, the associated value is the value of the previous enumerator plus one.
enum Foo { a, b, c = 10, d, e = 1, f, g = f + c };
//a = 0, b = 1, c = 10, d = 11, e = 1, f = 2, g = 12
Values of unscoped enumeration type are implicitly-convertible to integral types. If the underlying type is not fixed, the value is convertible to the first type from the following list able to hold their entire value range: int, unsigned int, long, unsigned long, long long, or unsigned long long. If the underlying type is fixed, the values can be converted to their promoted underlying type.
enum color { red, yellow, green = 20, blue };
color col = red;
int n = blue; // n == 21
Values of integer, floating-point, and other enumeration types can be converted, such as by static_cast, to any enumeration type. The result is (unspecified, until C++17) (undefined behavior, since C++17) if the value, converted to the enumeration’s underlying type, is out of this enumeration’s range. If the underlying type is fixed, the range is the range of the underlying type. If the underlying type is not fixed, the range is all values possible for the smallest bit field large enough to hold all enumerators of the target enumeration. Note that the value after such conversion may not necessarily equal any of the named enumerators defined for the type.
enum access_t { read = 1, write = 2, exec = 4 }; // enumerators: 1, 2, 4 range: 0..7
access_t rw = static_cast<access_t>(3);
assert(rw & read && rw & write);
The name of an unscoped enumeration may be omitted: such declaration only introduces the enumerators into the enclosing scope:
enum { a, b, c = 0, d = a + 2 }; // defines a = 0, b = 1, c = 0, d = 2
When an unscoped enumeration is a class member, its enumerators may be accessed using class member access operators . and ->:
struct X
{
enum direction { left = 'l', right = 'r' };
};
X x;
X* p = &x;
int a = X::direction::left; // allowed only in C++11 and later
int b = X::left;
int c = x.left;
int d = p->left;
Scoped Enumerations
Since C++11,
enum struct|class name { enumerator = constexpr , enumerator = constexpr , ... } (1)
enum struct|class name : type { enumerator = constexpr , enumerator = constexpr , ... } (2)
enum struct|class name ; (3)
enum struct|class name : type ; (4)
- declares a scoped enumeration type whose underlying type is
int(the keywords class and struct are exactly equivalent) - declares a scoped enumeration type whose underlying type is type
- opaque enum declaration for a scoped enumeration whose underlying type is
int - opaque enum declaration for a scoped enumeration whose underlying type is type
Each enumerator becomes a named constant of the enumeration’s type (that is, name), which is contained within the scope of the enumeration, and can be accessed using scope resolution operator. There are no implicit conversions from the values of a scoped enumerator to integral types, although static_cast may be used to obtain the numeric value of the enumerator.
enum class Color { red, green = 20, blue };
Color r = Color::blue;
switch(r)
{
case Color::red : std::cout << "red\n"; break;
case Color::green: std::cout << "green\n"; break;
case Color::blue : std::cout << "blue\n"; break;
}
// int n = r; // error: no scoped enum to int conversion
int n = static_cast<int>(r); // OK, n = 21
Since C++17, both scoped enumeration types and unscoped enumeration types whose underlying type is fixed can be initialized from an integer without a cast, using list initialization, if all of the following is true:
- the initialization is direct-list-initialization
- the initializer list has only a single element
- the enumeration is either scoped or unscoped with underlying type fixed
- the conversion is non-narrowing
This makes it possible to introduce new integer types (e.g. SafeInt) that enjoy the same existing calling conventions as their underlying integer types, even on ABIs expressly designed to penalize passing/returning structures by value.
enum byte : unsigned char {}; // byte is a new integer type
byte b { 42 }; // OK as of C++17 (direct-list-initialization)
byte c = { 42 }; // error
byte d = byte{ 42 }; // OK as of C++17; same value as b
byte e { -1 }; // error
struct A { byte b; };
A a1 = { { 42 } }; // error
A a2 = { byte{ 42 } }; // OK as of C++17
void f(byte);
f({ 42 }); // error
enum class Handle : std::uint32_t { Invalid = 0 };
Handle h { 42 }; // OK as of C++17
Example:
#include <iostream>
// enum that takes 16 bits
enum smallenum: int16_t
{
a,
b,
c
};
// color may be red (value 0), yellow (value 1), green (value 20), or blue (value 21)
enum color
{
red,
yellow,
green = 20,
blue
};
// altitude may be altitude::high or altitude::low
enum class altitude: char
{
high = 'h',
low = 'l', // C++11 allows the extra comma
};
// the constant d is 0, the constant e is 1, the constant f is 3
enum
{
d,
e,
f = e + 2
};
//enumeration types (both scoped and unscoped) can have overloaded operators
std::ostream& operator<<(std::ostream& os, color c)
{
switch(c)
{
case red : os << "red"; break;
case yellow: os << "yellow"; break;
case green : os << "green"; break;
case blue : os << "blue"; break;
default : os.setstate(std::ios_base::failbit);
}
return os;
}
std::ostream& operator<<(std::ostream& os, altitude al)
{
return os << static_cast<char>(al);
}
int main()
{
color col = red;
altitude a;
a = altitude::low;
std::cout << "col = " << col << '\n'
<< "a = " << a << '\n'
<< "f = " << f << '\n';
}
Union Types
A union is a special class type that can hold only one of its non-static data members at a time.
A union can have member functions (including constructors and destructors), but not virtual functions.
A union cannot have base classes and cannot be used as a base class.
A union cannot have data members of reference types.
Until C++11, unions cannot contain a non-static data member with a non-trivial special member function (copy constructor, copy-assignment operator, or destructor).
Since C++11:
- If a union contains a non-static data member with a non-trivial copy/move constructor, copy/move assignment, or destructor, that function is deleted by default in the union and needs to be defined explicitly by the programmer.
- If a union contains a non-static data member with a non-trivial default constructor, the default constructor of the union is deleted by default unless a variant member of the union has a default member initializer.
- At most one variant member can have a default member initializer.
Just like in struct declaration, the default member access in a union is public.
The union is only as big as necessary to hold its largest data member. The other data members are allocated in the same bytes as part of that largest member. The details of that allocation are implementation-defined, and it’s undefined behavior to read from the member of the union that wasn’t most recently written. Many compilers implement, as a non-standard language extension, the ability to read inactive members of a union.
#include <iostream>
union S
{
std::int32_t n; // occupies 4 bytes
std::uint16_t s[2]; // occupies 4 bytes
std::uint8_t c; // occupies 1 byte
}; // the whole union occupies 4 bytes
int main()
{
// initializes the first member, s.n is now the active member
S s = { 0x12345678 };
// at this point, reading from s.s or s.c is undefined behavior
std::cout << std::hex << "s.n = " << s.n << '\n';
s.s[0] = 0x0011; // s.s is now the active member
// at this point, reading from n or c is UB but most compilers define it
std::cout << "s.c is now " << +s.c << '\n' // 11 or 00, depending on platform
<< "s.n is now " << s.n << '\n'; // 12340011 or 00115678
}
Each member is allocated as if it is the only member of the class.
Since C++11, if members of a union are classes with user-defined constructors and destructors, to switch the active member, explicit destructor and placement new are generally needed:
#include <iostream>
#include <string>
#include <vector>
union S
{
std::string str;
std::vector<int> vec;
~S() {} // needs to know which member is active, only possible in union-like class
}; // the whole union occupies max(sizeof(string), sizeof(vector<int>))
int main()
{
S s = {"Hello, world"};
// at this point, reading from s.vec is undefined behavior
std::cout << "s.str = " << s.str << '\n';
s.str.~basic_string<char>();
new (&s.vec) std::vector<int>;
// now, s.vec is the active member of the union
s.vec.push_back(10);
std::cout << s.vec.size() << '\n';
s.vec.~vector<int>();
}
If two union members are standard-layout types, it’s well-defined to examine their common subsequence on any compiler.
Member Lifetime
The lifetime of a union member begins when the member is made active. If another member was active previously, its lifetime ends.
When active member of a union is switched by an assignment expression of the form E1 = E2 that uses either the built-in assignment operator or a trivial assignment operator, for each union member X that appears in the member access and array subscript subexpressions of E1 that is not a class with non-trivial or deleted default constructors, if modification of X would have undefined behavior under type aliasing rules, an object of the type of X is implicitly created in the nominated storage; no initialization is performed and the beginning of its lifetime is sequenced after the value computation of the left and right operands and before the assignment.
union A { int x; int y[4]; };
struct B { A a; };
union C { B b; int k; };
int f() {
C c; // does not start lifetime of any union member
c.b.a.y[3] = 4; // OK: "c.b.a.y[3]", names union members c.b and c.b.a.y;
// This creates objects to hold union members c.b and c.b.a.y
return c.b.a.y[3]; // OK: c.b.a.y refers to newly created object
}
struct X { const int a; int b; };
union Y { X x; int k; };
void g() {
Y y = { { 1, 2 } }; // OK, y.x is active union member (9.2)
int n = y.x.a;
y.k = 4; // OK: ends lifetime of y.x, y.k is active member of union
y.x.b = n; // undefined behavior: y.x.b modified outside its lifetime,
// "y.x.b" names y.x, but X's default constructor is deleted,
// so union member y.x's lifetime does not implicitly start
}
Anonymous Unions
An anonymous union is an unnamed union definition that does not simultaneously define any variables (including objects of the union type, references, or pointers to the union).
union { member-specification } ;
Anonymous unions have further restrictions: they cannot have member functions, cannot have static data members, and all their data members must be public. The only declarations allowed are non-static data members and static_assert declarations, since C++14.
Members of an anonymous union are injected in the enclosing scope (and must not conflict with other names declared there).
int main()
{
union
{
int a;
const char* p;
};
a = 1;
p = "Jennifer";
}
Namespace-scope anonymous unions must be declared static unless they appear in an unnamed namespace.
Union-like classes
A union-like class is either a (non-union) class that has at least one anonymous union as a member or a union. A union-like class has a set of variant members:
- the non-static data members of its member anonymous unions;
- in addition, if the union-like class is a union, its non-static data members that are not anonymous unions.
Union-like classes can be used to implement tagged unions.
#include <iostream>
// S has one non-static data member (tag),
// three enumerator members (CHAR, INT, DOUBLE),
// and three variant members (c, i, d)
struct S
{
enum { CHAR, INT, DOUBLE } tag;
union
{
char c;
int i;
double d;
};
};
void print_s(const S& s)
{
switch(s.tag)
{
case S::CHAR: std::cout << s.c << '\n'; break;
case S::INT: std::cout << s.i << '\n'; break;
case S::DOUBLE: std::cout << s.d << '\n'; break;
}
}
int main()
{
S s = { S::CHAR, 'a' };
print_s(s);
s.tag = S::INT;
s.i = 123;
print_s(s);
}
Since C++17, the C++ standard library includes std::variant, which can replace many uses of unions and union-like classes. The example above can be re-written as:
#include <variant>
#include <iostream>
int main()
{
std::variant<char, int, double> s = 'a';
std::visit([](auto x){ std::cout << x << '\n';}, s);
s = 123;
std::visit([](auto x){ std::cout << x << '\n';}, s);
}
Check Union Types
std::is_union is defined in header <type_traits>:
template< class T >
struct is_union; (since C++11)
Checks whether T is a union type. Provides the member constant value, which is equal to true if T is a union type . Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
struct A {};
typedef union {
int a;
float b;
} B;
struct C {
B d;
};
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_union<A>::value << '\n';
std::cout << std::is_union<B>::value << '\n';
std::cout << std::is_union<C>::value << '\n';
std::cout << std::is_union<int>::value << '\n';
}
Struct Types
The class keys struct and class are indistinguishable in C++, except that the default access mode and default inheritance mode are public if class declaration uses the struct class-key and private if the class declaration uses the class class-key. Both class and struct can be used in a class definition.
位结构是一种特殊的结构,在需要按位访问一个字节或字的多个比特位时,位结构比按位运算符更加方便。位结构定义的一般形式为:
struct 位结构名
{
数据类型 变量名: 整型常数;
数据类型 变量名: 整型常数;
} 位结构变量;
其中: 数据类型必须是int (unsigned or signed)。整型常数必须是非负的整数,表示二进制位的个数,即表示有多少位。变量名是可选项,可以不命名, 这样规定是为了排列需要。
例如:
struct
{
unsigned incon: 8; /*incon占用低字节的0~7位,共8位*/
unsigned txcolor: 4; /*txcolor占用高字节的0~3位,共4位*/
unsigned bgcolor: 3; /*bgcolor占用高字节的4~6位,共3位*/
unsigned blink: 1; /*blink占用高字节的第7位*/
} ch;
位结构成员的访问与结构成员的访问相同。例如: 访问上例位结构中的bgcolor成员可写成ch.bgcolor。注意:
- 位结构中的成员可以定义为unsigned,也可定义为signed,但当成员长度为1时,会被认为是unsigned类型,因为单个位不可能具有符号。
- 位结构中的成员不能使用数组和指针,但位结构变量可以是数组和指针,如果是指针,其成员访问方式同结构指针。
- 位结构总长度(位数),是各个位成员定义的位数之和,可以超过两个字节。
- 位结构成员可以与其它结构成员一起使用。
- 一个位域必须存储在同一个字节中,不能跨两个字节。若一个字节所剩空间不够存放另一位域时,应从下一单元起存放该位域。也可以有意使某位域从下一单元开始。由于位域不允许跨两个字节,因此位域的长度不能大于一个字节的长度,也就是说不能超过8位二进制位。例如:
struct bs
{
unsigned a:4
unsigned :0 /*空域*/
unsigned b:4 /*从下一单元开始存放*/
unsigned c:4
}
For instance:
struct info
{
char name[8];
int age;
struct addr address;
float pay;
unsigned state: 1;
unsigned pay: 1;
} workers;
上例的结构定义了关于一个工人的信息。其中有两个位结构成员, 每个位结构成员只有一位, 因此只占一个字节但保存了两个信息, 该字节中第一位表示工人的状态, 第二位表示工资是否已发放。由此可见使用位结构可以节省存贮空间。
Class Types
Refer to Class for details.
Class
Classes provide the four features commonly present in Object-Oriented Programming (OOP) languages: abstraction, encapsulation, inheritance, and polymorphism.
Abstraction
Encapsulation
Encapsulation is the hiding of information to ensure that data structures and operators are used as intended and to make the usage model more obvious to the developer. C++ provides the ability to define classes and functions as its primary encapsulation mechanisms. Within a class, members can be declared as either public, protected, or private to explicitly enforce encapsulation.
- A public member of the class is accessible to any function.
- A private member is accessible only to functions that are members of that class and to functions and classes explicitly granted access permission by the class (friends).
- A protected member is accessible to members of classes that inherit from the class in addition to the class itself and any friends.
It is generally considered good practice to make all data private or protected, and to make public only those functions that are part of a minimal interface for users of the class. This can hide the details of data implementation, allowing the designer to later fundamentally change the implementation without changing the interface in any way.
Inheritance
Inheritance allows one data type to acquire properties of other data types.
Inheritance from a base class may be declared as public, protected, or private. This access specifier determines whether unrelated and derived classes can access the inherited public and protected members of the base class. Only public inheritance corresponds to what is usually meant by inheritance. The other two forms are much less frequently used. If the access specifier is omitted, a class inherits privately, while a struct inherits publicly.
Base classes may be declared as virtual; this is called virtual inheritance. Virtual inheritance ensures that only one instance of a base class exists in the inheritance graph, avoiding some of the ambiguity problems of multiple inheritance.
Multiple inheritance is a C++ feature not found in most other languages, allowing a class to be derived from more than one base class; this allows for more elaborate inheritance relationships.
Polymorphism
Polymorphism enables one common interface for many implementations, and for objects to act differently under different circumstances.
C++ supports several kinds of static (resolved at compile-time) and dynamic (resolved at runtime) polymorphisms. Compile-time polymorphism does not allow for certain run-time decisions, while runtime polymorphism typically incurs a performance penalty.
Static Polymorphism
-
Function overloading allows programs to declare multiple functions having the same name but with different arguments. The functions are distinguished by the number or types of their formal parameters. Thus, the same function name can refer to different functions depending on the context in which it is used. The type returned by the function is not used to distinguish overloaded functions and would result in a compile-time error message.
-
Templates in C++ provide a sophisticated mechanism for writing generic, polymorphic code.
Dynamic Polymorphism
-
Inheritance: Variable pointers and references to a base class type in C++ can also refer to objects of any derived classes of that type. This allows arrays and other kinds of containers to hold pointers to objects of differing types. This enables dynamic (run-time) polymorphism, where the referred objects can behave differently depending on their (actual, derived) types.
-
Virtual member functions: When a function in a derived class overrides a function in a base class, the function to call is determined by the type of the object. A given function is overridden when there exists no difference in the number or type of parameters between two or more definitions of that function. Hence, at compile time, it may not be possible to determine the type of the object and therefore the correct function to call, given only a base class pointer; the decision is therefore put off until runtime. This is called dynamic dispatch. Virtual member functions allow the most specific implementation of the function to be called, according to the actual run-time type of the object. In C++ implementations, this is commonly done using virtual function tables. If the object type is known, this may be bypassed by prepending a fully qualified class name before the function call, but in general calls to virtual functions are resolved at run time.
Notes:
- 用virtual关键字声明的函数叫做虚函数,虚函数肯定是类的成员函数。
- 包含虚函数的类都有一个一维的虚函数表叫做虚表。类的对象有一个指向虚表开始的虚指针。虚表是和类对应的,虚表指针是和对象对应的。
- 多态性是一个接口多种实现,是面向对象的核心。分为类的多态性和函数的多态性。
- 多态用虚函数来实现,结合动态绑定。
- 虚函数只能借助于指针或者引用来达到多态的效果。
- 纯虚函数是虚函数再加上=0。
- 抽象类是指包括至少一个纯虚函数的类。
函数重载
- const用在传值参数上,不能做为重载的依据
void fun(int); ×
void fun(const int); ×
- const用在指针上,可以做为重载的依据
void f(int *); √
void f(const int *); √
- const用在引用上,可以做为重载的依据
void f(int &); √
void f(const int &); √
- const用在函数本身,可以做为重载的依据
void f(int); √
void f(int) const; √
Constructors
- 构造函数与类同名,且无返回类型。
- C++语言对于一个类可以声明多少个构造函数没有限制,只要每个构造函数的参数表是惟一的即可。
- 缺省构造函数是指不需要用户指定实参就能够被调用的构造函数,这并不意味着它不能接受实参,只意味着构造函数的每个参数都有一个缺省值与之关联。
- 构造函数的可访问性由其声明所在的访问区来决定。若把构造函数放到非公有访问区内,从而会限制或显式禁止某些形式的对象创建动作。
- 用一个类对象初始化该类的另一个对象被称为缺省按成员初始化。在概念上,一个类对象向该类的另一个对象作拷贝是通过依次拷贝每个非静态数据成员来实现的。类的设计者也可以通过提供特殊的拷贝构造函数来改变缺省的行为。如果定义了拷贝构造函数,则在用一个类对象初始化该类另一个对象时它就会被调用。
构造函数的调用顺序总是如下:
- 基类构造函数。如果有多个基类,则构造函数的调用顺序是某类在类派生表中出现的顺序,而不是它们在成员初始化表中的顺序。
- 成员类对象构造函数。如果有多个成员类对象,则构造函数的调用顺序是对象在类中被声明的顺序,而不是它们出现在成员初始化表中的顺序。
- 派生类构造函数。作为一般规则,派生类构造函数应该不能直接向一个基类数据成员赋值,给适当的基类构造函数。
Destructors
- 析构函数是一个特殊的、由用户定义的成员函数,当该类的对象离开了它的域,或者delete表达式应用到一个该类的对象的指针上时,析构函数会自动被调用。
- 析构函数的名字是在类名前加上波浪线(~),它不返回任何值,也没有任何参数。因为它不能指定任何参数,因而它也不能被重载。
- 尽管我们可以为一个类定义多个构造函数,但是我们只能提供一个析构函数,它将被应用在类的所有对象上。
派生类的析构函数调用顺序与它的构造函数调用顺序相反,因而析构函数的调用顺序如下:
- 派生类析构函数
- 成员类对象析构函数
- 基类析构函数
Static Member Variables
静态成员变量被当作类的全局对象。对于非静态成员变量,每个类对象都有自己的拷贝,而静态成员变量对每个类类型只有一个拷贝。静态成员变量只有一份,由该类类型的所有对象共享访问。
同全局对象相比,使用静态成员变量有两个优势:
- 静态成员变量没有进入程序的全局名字空间,因此不存在与程序中其他全局名字冲突的可能性;
- 可以实现信息隐藏。静态成员变量可以是private成员,而全局对象不能。
在类体中的成员变量声明前面加上关键字static就使该成员变量成为静态的。static成员变量遵从public, private, protected访问规则。
静态成员变量在该类定义之外被初始化,如同一个成员函数被定义在类定义之外一样,在这种定义中的静态成员变量的名字必须被其类名限定修饰,例如:
#include "account.h"
double Account::_interestRate = 0.0589;
与全局对象一样,对于静态成员变量,在程序中也只能提供一个定义。这意味着,静态成员变量的初始化不应该被放在头文件中,而应该放在含有类的非inline函数定义的文件中。静态成员变量可以被声明为任意类型,它们可以是const对象、数组或类对象等。
Basic Concepts
Object
C++ programs create, destroy, refer to, access, and manipulate objects. An object, in C++, is a region of storage that has
- size (can be determined with
sizeof); - alignment requirement (can be determined with
alignof); - storage duration (automatic, static, dynamic, thread-local);
- lifetime (bounded by storage duration or temporary);
- type;
- value (which may be indeterminate, e.g. for default-initialized non-class types);
- optionally, a name.
The following entities are not objects: value, reference, function, enumerator, type, non-static class member, bit-field, template, class or function template specialization, namespace, parameter pack, and this.
A variable is an object or a reference that is not a non-static data member, that is introduced by a declaration.
Objects are created by definitions, new-expressions, throw-expressions, when changing the active member of a union, and where temporary objects are required.
Object Representation and Value Representation
For an object of type T, object representation is the sequence of sizeof(T) objects of type unsigned char (or, equivalently, std::byte) beginning at the same address as the T object.
The value representation of an object is the set of bits that hold the value of its type T.
Subobjects
An object can contain other objects, which are called subobjects. These include
- member objects
- base class subobjects
- array elements
An object that is not a subobject of another object is called complete object.
Complete objects, member objects, and array elements are also known as most derived objects, to distinguish them from base class subobjects. The size of a most derived object that is not a bit field is required to be non-zero (the size of a base class subobject may be zero: see empty base optimization).
Any two objects with overlapping lifetimes (that are not bit fields) are guaranteed to have different addresses unless one of them is a subobject of another or provides storage for another, or if they are subobjects of different type within the same complete object, and one of them is a zero-size base.
static const char c1 = ’x’;
static const char c2 = ’x’;
assert(&c1 != &c2); // same values, different addresses
Polymorphic Objects
Objects of class type that declare or inherit at least one virtual function are polymorphic objects. Within each polymorphic object, the implementation stores additional information (in every existing implementation, it is one pointer unless optimized out), which is used by virtual function calls and by the RTTI features (dynamic_cast and typeid) to determine, at run time, the type with which the object was created, regardless of the expression it is used in.
For non-polymorphic objects, the interpretation of the value is determined from the expression in which the object is used, and is decided at compile time.
#include <iostream>
#include <typeinfo>
struct Base1 {
// polymorphic type: declares a virtual member
virtual ~Base1() {}
};
struct Derived1 : Base1 {
// polymorphic type: inherits a virtual member
};
struct Base2 {
// non-polymorphic type
};
struct Derived2 : Base2 {
// non-polymorphic type
};
int main()
{
Derived1 obj1; // object1 created with type Derived1
Derived2 obj2; // object2 created with type Derived2
Base1& b1 = obj1; // b1 refers to the object obj1
Base2& b2 = obj2; // b2 refers to the object obj2
std::cout << "Expression type of b1: " << typeid(decltype(b1)).name() << '\n'
<< "Expression type of b2: " << typeid(decltype(b2)).name() << '\n'
<< "Object type of b1: " << typeid(b1).name() << '\n'
<< "Object type of b2: " << typeid(b2).name() << '\n'
<< "size of b1: " << sizeof b1 << '\n'
<< "size of b2: " << sizeof b2 << '\n';
}
Strict Aliasing
Accessing an object using an expression of a type other than the type with which it was created is undefined behavior in many cases, see reinterpret_cast for the list of exceptions and examples.
Alignment
Every object type has the property called alignment requirement, which is an integer value (of type std::size_t, always a power of 2) representing the number of bytes between successive addresses at which objects of this type can be allocated. The alignment requirement of a type can be queried with alignof or std::alignment_of. The pointer alignment function std::align can be used to obtain a suitably-aligned pointer within some buffer, and std::aligned_storage can be used to obtain suitably-aligned storage.
Each object type imposes its alignment requirement on every object of that type; stricter alignment (with larger alignment requirement) can be requested using alignas.
In order to satisfy alignment requirements of all non-static members of a class, padding may be inserted after some of its members.
#include <iostream>
// objects of type S can be allocated at any address
// because both S.a and S.b can be allocated at any address
struct S {
char a; // size: 1, alignment: 1
char b; // size: 1, alignment: 1
}; // size: 2, alignment: 1
// objects of type X must be allocated at 4-byte boundaries
// because X.n must be allocated at 4-byte boundaries
// because int's alignment requirement is (usually) 4
struct X {
int n; // size: 4, alignment: 4
char c; // size: 1, alignment: 1
// three bytes padding
}; // size: 8, alignment: 4
int main()
{
std::cout << "sizeof(S) = " << sizeof(S)
<< " alignof(S) = " << alignof(S) << '\n';
std::cout << "sizeof(X) = " << sizeof(X)
<< " alignof(X) = " << alignof(X) << '\n';
}
The weakest alignment (the smallest alignment requirement) is the alignment of char, signed char, and unsigned char, which equals 1; the largest fundamental alignment of any type is the alignment of std::max_align_t. If a type’s alignment is made stricter (larger) than std::max_align_t using alignas, it is known as a type with extended alignment requirement. A type whose alignment is extended or a class type whose non-static data member has extended alignment is an over-aligned type. It is implementation-defined if new-expression, std::allocator::allocate, and std::get_temporary_buffer support over-aligned types. Allocators instantiated with over-aligned types are allowed to fail to instantiate at compile time, to throw std::bad_alloc at runtime, to silently ignore unsupported alignment requirement, or to handle them correctly.
Scope
Each name that appears in a C++ program is only valid in some possibly discontiguous portion of the source code called its scope.
Within a scope, unqualified name lookup can be used to associate the name with its declaration.
Block Scope
The potential scope of a variable introduced by a declaration in a block (compound statement) begins at the point of declaration and ends at the end of the block. Actual scope is the same as potential scope unless there is a nested block with a declaration that introduces identical name (in which case, the entire potential scope of the nested declaration is excluded from the scope of the outer declaration).
int main()
{
int a = 0; // scope of the first 'a' begins
++a; // the name 'a' is in scope and refers to the first 'a'
{
int a = 1; // scope of the second 'a' begins
// scope of the first 'a' is interrupted
a = 42; // 'a' is in scope and refers to the second 'a'
} // block ends, scope of the second 'a' ends
// scope of the first 'a' resumes
} // block ends, scope of the first 'a' ends
int b = a; // Error: name 'a' is not in scope
The potential scope of a function parameter (including parameters of a lambda expression) begins at the point of declaration and ends at the end of the last exception handler of the function-try-block, or at the end of the function body if a function try block was not used.
int f(int n = 2) // scope of 'n' begins
try // function try block
{ // the body of the function begins
++n; // 'n' is in scope and refers to the function parameter
{
int n = 2; // scope of the local variable 'n' begins
// scope of function parameter 'n' interrupted
++n; // 'n' refers to the local variable in this block
} // scope of the local variable 'n' ends
// scope of function parameter 'n' resumes
} catch(...) {
++n; // n is in scope and refers to the function parameter
throw;
} // last exception handler ends, scope of function parameter 'n' ends
int a = n; // Error: name 'n' is not in scope
The potential scope of a name declared in an exception handler begins at the point of declaration and ends when the exception handler ends, and is not in scope in another exception handler or in the enclosing block.
try {
f();
} catch(const std::runtime_error& re) { // scope of re begins
int n = 1; // scope of n begins
std::cout << re.what(); // re is in scope
} // scope of re ends, scope of n ends
catch(std::exception& e) {
std::cout << re.what(); // error: re is not in scope
++n; // error: n is not in scope
}
The potential scope of a name declared in the init-statement of the for loop, in the condition of a for loop, in the range_declaration of a range for loop, in the condition of the if statement, while loop, or switch statement begins at the point of declaration and ends at the end of the controlled statement.
Base* bp = new Derived;
if(Derived* dp = dynamic_cast<Derived*>(bp))
{
dp->f(); // dp is in scope
} // scope of dp ends
for(int n = 0; // scope of n begins
n < 10; // n is in scope
++n) // n is in scope
{
std::cout << n << ' '; // n is in scope
} // scope of n ends
Function Prototype Scope
The scope of a name introduced in the parameter list of a function declaration that is not a definition ends at the end of the function declarator. If there are multiple or nested declarators in the declaration, the scope ends at the end of the nearest enclosing function declarator.
const int n = 3;
int f1(int n, // scope of global 'n' interrupted, scope of parameter 'n' begins
int y = n); // error: default argument references a parameter
int (*(*f2)(int n))[n]; // OK: the scope of the function parameter 'n'
// ends at the end of its function declarator
// in the array declarator, global n is in scope
// (this declares a pointer to function returning a pointer to an array of 3 int)
// by contrast
auto (*f3)(int n)->int (*)[n]; // error: parameter 'n' as array bound
Function Scope
A label (and only a label) declared inside a function is in scope everywhere in that function, in all nested blocks, before and after its own declaration.
void f()
{
{
goto label; // label in scope even though declared later
label:;
}
goto label; // label ignores block scope
}
void g()
{
goto label; // error: label not in scope in g()
}
Namespace Scope
The potential scope of any entity declared in a namespace begins at the declaration and consists of the concatenation of all namespace definitions for the same namespace name that follow, plus, for any using-directive that introduced this name or its entire namespace into another scope, the rest of that scope.
The top-level scope of a translation unit (file scope or global scope) is also a namespace and is properly called global namespace scope. The potential scope of any entity declared in the global namespace scope begins at the declaration and continues to the end of the translation unit.
The scope of an entity declared in an unnamed namespace or in an inline namespace includes the enclosing namespace.
namespace N { // scope of N begins (as a member of global namespace)
int i; // scope of i begins
int g(int a) { return a; } // scope of g begins
int j(); // scope of j begins
void q(); // scope of q begins
namespace {
int x; // scope of x begins
} // scope of x does not end
inline namespace inl { // scope of inl begins
int y; // scope of y begins
} // scope of y does not end
} // scope of i,g,j,q,inl,x,y interrupted
namespace {
int l = 1; // scope of l begins
} // scope of l does not end (it's a member of unnamed namespace)
namespace N { // scope of i,g,j,q,inl,x,y continues
int g(char a) { // overloads N::g(int)
return l+a; // l from unnamed namespace is in scope
}
int i; // error: duplicate definition (i is already in scope)
int j(); // OK: repeat function declaration is allowed
int j() { // OK: definition of the earlier-declared N::j()
return g(i); // calls N::g(int)
}
int q(); // error: q is already in scope with different return type
} // scope of i,g,j,q,inl,x,y interrupted
int main() {
using namespace N; // scope of i,g,j,q,inl,x,y resumes
i = 1; // N::i is in scope
x = 1; // N::(anonymous)::x is in scope
y = 1; // N::inl::y is in scope
inl::y = 2; // N::inl is also in scope
} // scope of i,g,j,q,inl,x,y interrupted
Class Scope
The potential scope of a name declared in a class begins at the point of declaration and includes the rest of the class body and all function bodies (even if defined outside the class definition or before the declaration of the name), default arguments, exception specifications, in-class brace-or-equal initializers, and all these things in nested classes, recursively.
class X {
int f(int a = n) { // X::n is in scope inside default parameter
return a*n; // X::n is in scope inside function body
}
int g();
int i = n*2; // X::n is in scope inside initializer
// int x[n]; // Error: n is not in scope in class body
static const int n = 1;
int x[n]; // OK: n is now in scope in class body
};
int X::g() {
return n; // X::n is in scope in out-of-class member function body
}
If a name is used in a class body before it is declared, and another declaration for that name is in scope, the program is ill-formed, no diagnostic required.
typedef int c; // ::c
enum { i = 1 }; // ::i
class X {
char v[i]; // Error: at this point, i refers to ::i
// but there is also X::i
int f() {
// OK: X::c, not ::c is in scope inside a member function
return sizeof(c);
}
char c; // X::c
enum { i = 2 }; // X::i
};
typedef char* T;
struct Y {
T a; // error: at this point, T refers to ::T, but there is also Y::T
typedef long T;
T b;
};
Names of any class members can only be used in four contexts:
- in its own class scope or in the class scope of a derived class
- after the
.operator applied to an expression of the type of its class or a class derived from it - after the
->operator applied to an expression of the type of pointer to its class or pointers to a class derived from it - after the
::operator applied to the name of its class or the name of a class derived from it
Enumeration Scope
The name of an enumerator introduced in a scoped enumeration begins at the point of declaration and ends at the end of the enum specifier (in contrast, unscoped enumerators are in scope after the end of the enum specifier).
enum e1_t { // unscoped enumeration
A,
B = A*2
}; // scope of A and B does not end
enum class e2_t { // scoped enumeration
SA,
SB = SA*2 // SA is in scope
}; // scope of SA and SB ends
e1_t e1 = B; // OK, B is in scope
// e2_t e2 = SB; // Error: SB is not in scope
e2_t e2 = e2_t::SB; // OK
Template Parameter Scope
The potential scope of a template parameter name begins immediately at the point of declaration and continues to the end of the smallest template declaration in which it was introduced. In particular, a template parameter can be used in the declarations of subsequent template parameters and in the specifications of base classes, but can’t be used in the declarations of the preceding template parameters.
template< typename T, // scope of T begins
T* p, // T can be used for a non-type parameter
class U = T // T can be used for a default type
>
class X : public Array<T> // T can be used in base class name
{
// T can be used inside the body as well
}; // scopes of T and U end, scope of X continues
The potential scope of the name of the parameter of a template template parameter is the smallest template parameter list in which that name appears:
typedef int N;
template< N X, // non-type parameter of type int
typename N, // scope of this N begins, scope of ::N interrupted
template<N Y> class T // N here is the template parameter, not int
> struct A;
Point of Declaration
Scope begins at the point of declaration, which is located as follows:
For variables and other names introduced by simple declarations, the point of declaration is immediately after that name’s declarator and before its initializer, if any:
unsigned char x = 32; // scope of the first 'x' begins
{
unsigned char x = x;
// scope of the second 'x' begins before the initializer (= x)
// this does not initialize the second 'x' with the value 32,
// this initializes the second 'x' with its own, indeterminate, value
}
std::function<int(int)> f = [&](int n){return n>1 ? n*f(n-1) : n;};
// the name of the function 'f' is in scope within the lambda, and can
// be correctly captured by reference, giving a recursive function
const int x = 2; // scope of the first 'x' begins
{
int x[x] = {};
// scope of the second x begins before the initializer (= {})
// but after the declarator (x[x]). Within the declarator, the outer
// 'x' is still in scope. This declares an array of 2 int.
}
The point of declaration of a class or template is immediately after the identifier that names the class (or the template-id that names the template) appears in its class-head, and is already in scope in the list of the base classes:
// the name 'S' is in scope immediately after it appears,
// so it can be used in the list of base classes
struct S: std::enable_shared_from_this<S>
{
};
The point of declaration of an enumeration is immediately after the identifier that names it appears in the enum specifier or opaque enum declaration, whichever is used first:
enum E : int { // E is already in scope
A = sizeof(E)
};
The point of declaration of a type alias or alias template is immediately after the type-id to which the alias refers:
using T = int; // point of declaration of T is at the semicolon
using T = T; // same as T = int
The point of declaration of an enumerator is immediately after its definition (not before the initializer as it is for variables):
const int x = 12;
{
enum {
x = x + 1, // point of declaration is at the comma, x is initialized to 13
y = x + 1 // the enumerator x is now in scope, y is initialized to 14
};
}
The point of declaration for an injected-class-name is immediately following the opening brace of its class (or class template) definition:
template<typename T>
struct Array
// : std::enable_shared_from_this<Array> // Error: the injected class name is not in scope
: std::enable_shared_from_this< Array<T> > // OK: the template-name Array is in scope
{ // the injected class name Array is now in scope as if a public member name
Array* p; // pointer to Array<T>
};
Comparison of C and C++
C++ Libraries
C++ Standard Library
Refer to C++ Standard Library Reference Material, which is abbreviated to contain only the most frequently used items. The information included here is not meant to be complete or definitive in any way, but more of a quick reference or quick reminder of what something looks like if you need to look it up in a hurry, and you’ve left your handy hard-copy reference on the bus. Thus, infrequently used functions (or variations of functions) and other entities may not appear.
Also refer to C++ Standard Library header files.
Utilities Library
| C++_Headers | Standard | Note |
|---|---|---|
| <cstdlib> | General purpose utilities: program control, dynamic memory allocation, random numbers, sort and search | |
| <csignal> | Functions and macro constants for signal management | |
| <csetjmp> | Macro (and function) that saves (and jumps) to an execution context | |
| <cstdarg> | Handling of variable length argument lists | |
| <typeinfo> | Runtime type information utilities | |
| <typeindex> | since C++11 | std::type_index |
| <type_traits> | since C++11 | Compile-time type information |
| <bitset> | std::bitset class template | |
| <functional> | Function objects, designed for use with the standard algorithms | |
| <utility> | Various utility components | |
| <ctime> | C-style time/date utilites | |
| <chrono> | since C++11 | C++ time utilites |
| <cstddef> | typedefs for types such as size_t, NULL and others | |
| <initializer_list> | since C++11 | std::initializer_list class template |
| <tuple> | since C++11 | std::tuple class template |
| <any> | since C++17 | std::any class template |
| <optional> | since C++17 | std::optional class template |
| <variant> | since C++17 | std::variant class template |
Dynamic Memory Management
| C++_Headers | Standard | Note |
|---|---|---|
| <new> | Low-level memory management utilities | |
| <memory> | Higher level memory management utilities | |
| <scoped_allocator> | since C++11 | Nested allocator class |
| <memory_resource> | since C++17 | Polymorphic allocators and memory resources |
Numeric Limits
| C++_Headers | Standard | Note |
|---|---|---|
| <climits> | limits of integral types | |
| <cfloat> | limits of float types | |
| <cstdint> | since C++11 | fixed-size types and limits of other types |
| <cinttypes> | since C++11 | formatting macros, intmax_t and uintmax_t math and conversions |
| <limits> | standardized way to query properties of arithmetic types |
Error Handling
| C++_Headers | Standard | Note |
|---|---|---|
| <exception> | Exception handling utilities | |
| <stdexcept> | Standard exception objects | |
| <cassert> | Conditionally compiled macro that compares its argument to zero | |
| <system_error> | since C++11 | defines std::error_code, a platform-dependent error code |
| <cerrno> | Macro containing the last error number |
Strings Library
| C++_Headers | Standard | Note |
|---|---|---|
| <cctype> | functions to determine the type contained in character data | |
| <cwctype> | functions for determining the type of wide character data | |
| <cstring> | various narrow character string handling functions | |
| <cwchar> | various wide and multibyte string handling functions | |
| <cuchar> | since C++11 | C-style Unicode character conversion functions |
| <string> | std::basic_string class template | |
| <string_view> | since C++17 | std::basic_string_view class template |
Containers Library
| C++_Headers | Standard | Note |
|---|---|---|
| <array> | since C++11 | std::array container |
| <vector> | std::vector container | |
| <deque> | std::deque container | |
| <list> | std::list container | |
| <forward_list> | since C++11 | std::forward_list container |
| <set> | std::set and std::multiset associative containers | |
| <map> | std::map and std::multimap associative containers | |
| <unordered_set> | since C++11 | std::unordered_set and std::unordered_multiset unordered associative containers |
| <unordered_map> | since C++11 | std::unordered_map and std::unordered_multimap unordered associative containers |
| <stack> | std::stack container adaptor | |
| <queue> | std::queue and std::priority_queue container adaptors |
Algorithms Library
| C++_Headers | Standard | Note |
|---|---|---|
| <algorithm> | Algorithms that operate on containers | |
| <execution> | C++17 | Predefined execution policies for parallel versions of the algorithms |
Iterators Library
| C++_Headers | Standard | Note |
|---|---|---|
| <iterator> | Container iterators |
Numerics Library
| C++_Headers | Standard | Note |
|---|---|---|
| <cmath> | Common mathematics functions | |
| <complex> | Complex number type | |
| <valarray> | Class for representing and manipulating arrays of values | |
| <random> | since C++11 | Random number generators and distributions |
| <numeric> | Numeric operations on values in containers | |
| <ratio> | since C++11 | Compile-time rational arithmetic |
| <cfenv> | since C++11 | Floating-point environment access functions |
Input/output Library
| C++_Headers | Standard | Note |
|---|---|---|
| <iosfwd> | forward declarations of all classes in the input/output library | |
| <ios> | std::ios_base class, std::basic_ios class template and several typedefs | |
| <istream> | std::basic_istream class template and several typedefs | |
| <ostream> | std::basic_ostream, std::basic_iostream class templates and several typedefs | |
| <iostream> | several standard stream objects | |
| <fstream> | std::basic_fstream, std::basic_ifstream, std::basic_ofstream class templates and several typedefs | |
| <sstream> | std::basic_stringstream, std::basic_istringstream, std::basic_ostringstream class templates and several typedefs | |
| <strstream> | std::strstream, std::istrstream, std::ostrstream (deprecated) | |
| <iomanip> | Helper functions to control the format or input and output | |
| <streambuf> | std::basic_streambuf class template | |
| <cstdio> | C-style input-output functions |
Localization Library
| C++_Headers | Standard | Note |
|---|---|---|
| <locale> | Localization utilities | |
| <clocale> | C localization utilities | |
| <codecvt> | since C++11 | Unicode conversion facilities |
Regular Expressions Library
| C++_Headers | Standard | Note |
|---|---|---|
| <regex> | since C++11 | Classes, algorithms and iterators to support regular expression processing |
Atomic Operations Library
| C++_Headers | Standard | Note |
|---|---|---|
| <atomic> | since C++11 | Atomic operations library |
Thread support Library
| C++_Headers | Standard | Note |
|---|---|---|
| <thread> | since C++11 | std::thread class and supporting functions |
| <mutex> | since C++11 | mutual exclusion primitives |
| <shared_mutex> | since C++14 | shared mutual exclusion primitives |
| <future> | since C++11 | primitives for asynchronous computations |
| <condition_variable> | since C++11 | thread waiting conditions |
Filesystem Library
| C++_Headers | Standard | Note |
|---|---|---|
| <filesystem> | since C++17 | std::path class and supporting functions |
Standard Template Library (STL)
Standard Template Library (STL) is a sophisticated and powerful library of template classes and template functions that implement many common data structures and algorithms, and forms part of the C++ Standard Library. Refer to STL FAQ: A Few Questions and Answers, C++ Standard Template Library (STL) Reference Material and Standard Template Library on Wikipedia.
The STL components are divided into six broad categories on the basis of functionality: Containers, Iterators, Algorithms, Function Objects, Utilities, and Allocators:
Headers that provide access to STL containers and container adaptors

- vector: Provides linear, contiguous storage, with fast inserts at the back end only. This class is often referred to as a better array that we should all now use in place of arrays. Like a great deal of free advice, this too should be followed with caution.
- deque: Provides linear, non-contiguous storage, with fast inserts at both ends.
-
list: Provides linear, doubly-linked storage, with fast inserts anywhere.
- map: Provides a collection of 1-to-1 mappings, i.e. a collection of key/value pairs (pair objects) in which the first element of such a pair is a key and the second element of the pair is the value corresponding to that key, and the pair objects are maintained in sorted key order. In a map the keys must be unique.
- multimap: Like a map, except that pairs with duplicate keys are permitted.
- set: Provides a set of items which must have keys (or themselves be keys, in the simplest cases), with fast associative lookup. In a set the item keys must be unique, but (somewhat counter intuitively for a set) the item keys are ordered.
-
multiset: Like a set, except that items with duplicate keys are permitted.
- stack: Adapts the deque container to provide strict last-in, first-out (LIFO) behavior.
- queue: Adapts the deque container to provide strict first-in, first-out (FIFO) behavior.
- priority_queue: Adapts the vector container to maintain items in a sorted order.
Header that provides access to STL iterator facilities

Headers that provide access to STL algorithms

Header that provides access to STL functors, binders, negators and function adaptors

Header that provides access to STL utilities

Header that provides access to STL memory facilities
Open Source C++ Libraries
Refer to open source C++ libraries for a list of open source C++ libraries.
SGI Standard Template Library
The SGI Standard Template Library, or STL, is a C++ library of container classes, algorithms, and iterators; it provides many of the basic algorithms and data structures of computer science. The STL is a generic library, meaning that its components are heavily parameterized: almost every component in the STL is a template. You should make sure that you understand how templates work in C++ before you use the STL. Refer to Standard Template Library Programmer’s Guide.
STLport
STLport is a multiplatform C++ Standard Library implementation. It is a free, open-source product, featuring the following:
- Standard (ISO/IEC 14882) compliance;
- Advanced techniques and optimizations for maximum efficiency;
- Exception safety and thread safety;
- Important extensions: hash tables, singly-linked list, rope;
- Power debug mode: run time check of the correctness of iterators and containers usage.
GNU Multiple Precision Arithmetic Library (GMP)
GNU Multiple Precision Arithmetic Library (GMP) is a free library for arbitrary precision arithmetic, operating on signed integers, rational numbers, and floating-point numbers. There is no practical limit to the precision except the ones implied by the available memory in the machine GMP runs on. GMP has a rich set of functions, and the functions have a regular interface.
The main target applications for GMP are cryptography applications and research, Internet security applications, algebra systems, computational algebra research, etc.
GMP is carefully designed to be as fast as possible, both for small operands and for huge operands. The speed is achieved by using fullwords as the basic arithmetic type, by using fast algorithms, with highly optimised assembly code for the most common inner loops for a lot of CPUs, and by a general emphasis on speed.
The first GMP release was made in 1991. It is continually developed and maintained, with a new release about once a year.
Since version 6, GMP is distributed under the dual licenses, GNU LGPL v3 and GNU GPL v2. These licenses make the library free to use, share, and improve, and allow you to pass on the result. The GNU licenses give freedoms, but also set firm restrictions on the use with non-free programs.
GMP is part of the GNU project. For more information about the GNU project, please see the official GNU web site.
GMP’s main target platforms are Unix-type systems, such as GNU/Linux, Solaris, HP-UX, Mac OS X/Darwin, BSD, AIX, etc. It also is known to work on Windows in both 32-bit and 64-bit mode.
GMP is brought to you by a team listed in the manual.
GMP is carefully developed and maintained, both technically and legally. We of course inspect and test contributed code carefully, but equally importantly we make sure we have the legal right to distribute the contributions, meaning users can safely use GMP. To achieve this, we will ask contributors to sign paperwork where they allow us to distribute their work.
C++ Code Conventions
The main point of a C++ coding standard is to provide a set of rules for using C++ for a particular purpose in a particular environment. It follows that there cannot be one coding standard for all uses and all users. For a given application (or company, application area, etc.), a good coding standard is better than no coding standard. On the other hand, we have seen many examples that demonstrate that a bad coding standard is worse than no coding standard. Please choose your rules with care and with solid knowledge of your application area.
- C++ Super-FAQ: Coding Standards
- C++ Coding Standards: 101 Rules, Guidelines, and Best Practices
- JSF Air Vehicle C++ Coding Standards
- High Integrity C++ Coding Standard
- A Coding Convention for C++ Code
- Programming in C++, Rules and Recommendations
C++ Core Guidelines
MISRA C++
In the beginning C was considered unsuitable for safety critical and safety related systems, however, it was so used …
In 1998, as a response to this situation, MISRA (Motor Industry Software Reliability Association) produced MISRA C, a set of guidelines to aid the development of safety related systems in C in the automotive world. Since then, MISRA C has been adopted by the wider embedded systems community and has become the dominant, international coding guidelines for the use of C in critical systems. The MISRA C guidelines are widely accepted as fulfilling the requirements for a language subset as required by both the 1994 MISRA Development guidelines for vehicle based software and IEC 61508.
Things move on, and now C++ is in the position once held by C; many people believe that it should not be used for critical systems, but its use within the field is growing and that growth is without a common set of guidelines.
MISRA has recently completed work on the production of a set of guidelines for the use of C++ in critical systems, the output of which will be a set of guidelines similar to those that were produced for C.
Refer to MISRA publications for more information.
MISRA C++:2008
The document, known as MISRA C++ Guidelines for the use of the C++ language in critical systems, was published and officially launched on 5 June 2008. Also refer to C++ Programming Style Conventions Reference Material.
SEI CERT Coding Standards
The C++ rules and recommendations in this wiki are a work in progress and reflect the current thinking of the secure coding community. Because this is a development website, many pages are incomplete or contain errors. As rules and recommendations mature, they are published in report or book form as official releases. These releases are issued as dictated by the needs and interests of the secure software development community. Also refer to SEI CERT Coding Standards and CERT website.
GNU Coding Standards
The GNU Coding Standards were written by Richard Stallman and other GNU Project volunteers. Their purpose is to make the GNU system clean, consistent, and easy to install. This document can also be read as a guide to writing portable, robust and reliable programs. It focuses on programs written in C, but many of the rules and principles are useful even if you write in another programming language. The rules often state reasons for writing in a certain way. Refer to GNU Coding Standards.
Google C++ Style Guide
C++ is one of the main development languages used by many of Google’s open-source projects. As every C++ programmer knows, the language has many powerful features, but this power brings with it complexity, which in turn can make code more bug-prone and harder to read and maintain.
The goal of Google C++ Style Guide (local pdf) is to manage this complexity by describing in detail the dos and don’ts of writing C++ code. These rules exist to keep the code base manageable while still allowing coders to use C++ language features productively.
Style, also known as readability, is what we call the conventions that govern our C++ code. The term Style is a bit of a misnomer, since these conventions cover far more than just source file formatting.
Most open-source projects developed by Google conform to the requirements in Google C++ Style Guide.
Common Weakness Enumeration (CWE)
Common Weakness Enumeration (CWE) is a community-developed list of common software security weaknesses. It serves as a common language, a measuring stick for software security tools, and as a baseline for weakness identification, mitigation, and prevention efforts.
- Common Weakness Enumeration (CWE)
- CWE List latest version and version 3.1
- CWE/SANS Top 25 Most Dangerous Software Errors on SANS and SonarSource
SonarCFamily for C/C++
SonarSource delivers what is probably the best static code analyzer you can find on the market for C/C++. Based on our own C/C++ compiler front-end, it uses the most advanced techniques (pattern matching, dataflow analysis) to analyze code and find code smells, bugs and security vulnerabilities. As for any product we develop at SonarSource, it was built on the following principles: depth, accuracy and speed.
SonarCFamily for C/C++ has a great coverage of well-established quality standards. The SonarCFamily for C/C++ capability is available in Eclipse CDT for developers (SonarLint) as well as throughout the development chain for automated code review with self-hosted SonarQube or on-line SonarCloud.
Chromium Coding Style
LLVM Coding Standards
The LLVM Coding Standards attempts to describe a few coding standards that are being used in the LLVM source tree. Although no coding standards should be regarded as absolute requirements to be followed in all instances, coding standards are particularly important for large-scale code bases that follow a library-based design (like LLVM).
Mozilla Style Guide
The Mozilla Style Guide attempts to explain the basic styles and patterns used in the Mozilla codebase. New code should try to conform to these standards, so it is as easy to maintain as existing code. There are exceptions, but it’s still important to know the rules!
This article is particularly for those new to the Mozilla codebase, and in the process of getting their code reviewed. Before requesting a review, please read over this document, making sure that your code conforms to recommendations.
Qt Coding Style
The Qt Coding Style an overview of the low-level coding conventions we use when writing Qt code. See Coding Conventions for the higher-level conventions. The data has been gathered by mining the Qt sources, discussion forums, email threads and through collaboration of the developers.
Kdelibs Coding Style
The Kdelibs Coding Style describes the recommended coding style for kdelibs. Nobody is forced to use this style, but to have consistent formatting of the source code files it is recommended to make use of it.
In short: Kdelibs coding style follows the Qt coding style, with one main difference: using curly braces even when the body of a conditional statement contains only one line.
C++ Code Formatter
GNU Indent
The indent program can be used to make code easier to read. It can also convert from one style of writing C to another. indent understands a substantial amount about the syntax of C, but it also attempts to cope with incomplete and misformed syntax.
Artistic Style
Artistic Style is a source code indenter, formatter, and beautifier for the C, C++, C++/CLI, Objective‑C, C# and Java programming languages. Also refer to Indentation Style and Programming Style.
Clone astyle repo:
chenwx@chenwx ~ $ svn checkout https://svn.code.sf.net/p/astyle/code/trunk astyle-code
A astyle-code/AStyleTest
A astyle-code/AStyleTest/file-py
A astyle-code/AStyleTest/file-py/clang_tidy.py
...
A astyle-code/AStyleDev/src-j/AStyleInterface.java
A astyle-code/AStyleDev/test-data/ASFormatter.cpp
A astyle-code/AStyleDev/scripts/astyle-clean.bat
Checked out revision 655.
chenwx@chenwx ~ $ cd astyle-code/
chenwx@chenwx ~/astyle-code $ ll
total 20K
drwxrwxr-x 6 chenwx chenwx 4.0K Apr 25 21:52 AStyle
drwxrwxr-x 14 chenwx chenwx 4.0K Apr 25 21:53 AStyleDev
drwxrwxr-x 13 chenwx chenwx 4.0K Apr 25 21:51 AStyleTest
drwxrwxr-x 7 chenwx chenwx 4.0K Apr 25 21:53 AStyleWx
drwxrwxr-x 13 chenwx chenwx 4.0K Apr 25 21:52 AStyleWxTest
Build astyle from source code:
chenwx@chenwx ~/astyle-code $ cd AStyle/build/gcc/
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ make
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/astyle_main.cpp -o obj/astyle_main.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASBeautifier.cpp -o obj/ASBeautifier.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASFormatter.cpp -o obj/ASFormatter.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASEnhancer.cpp -o obj/ASEnhancer.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASLocalizer.cpp -o obj/ASLocalizer.o
g++ -DNDEBUG -O3 -Wall -Wextra -fno-rtti -fno-exceptions -std=c++11 -c ../../src/ASResource.cpp -o obj/ASResource.o
g++ -s -o bin/astyle obj/astyle_main.o obj/ASBeautifier.o obj/ASFormatter.o obj/ASEnhancer.o obj/ASLocalizer.o obj/ASResource.o
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ ll
total 16K
-rw-rw-r-- 1 chenwx chenwx 5.3K Apr 25 21:52 Makefile
drwxrwxr-x 2 chenwx chenwx 4.0K Apr 25 22:20 bin
drwxrwxr-x 2 chenwx chenwx 4.0K Apr 25 22:20 obj
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ ll bin/
total 444K
-rwxrwxr-x 1 chenwx chenwx 444K Apr 25 22:20 astyle
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ ./bin/astyle --version
Artistic Style Version 3.2 beta
Install the built astyle:
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ sudo make install
[sudo] password for chenwx:
install -o root -g root -m 755 -d /usr/bin
install -o root -g root -m 755 -d /usr/share/doc/astyle
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ which astyle
/usr/bin/astyle
chenwx@chenwx ~/astyle-code/AStyle/build/gcc $ astyle --version
Artistic Style Version 3.2 beta
Useful options of Artistic Style:
astyle --style=allman --indent=spaces=4 -H -Y -c -j -p -y -xL -xV -xb -xf -xh -xg <filename>
C++ Compilers
GCC (GNU Compiler Collection)
The GNU Compiler Collection includes front ends for C, C++, Objective-C, Fortran, Ada, and Go, as well as libraries for these languages (libstdc++,…). GCC was originally written as the compiler for the GNU operating system. The GNU system was developed to be 100% free software, free in the sense that it respects the user’s freedom.
For information about C++11 support in a specific version of GCC, please see C++11 Support in GCC.
Also refer to:
Clang
The goal of the Clang project is to create a new C based language front-end: C, C++, Objective C/C++, OpenCL C and others for the LLVM compiler.
For information about C++11 support in a specific version of Clang, please see C++ Support in Clang.
Refer to Clang official site and Clang Compiler User’s Manual for more information.
Microsoft Visual C++
- Microsoft Development Tools and Languages
- Visual Studio
- Visual C++ Quick References
- C++11/14 Core Language Features in VS 2013 and the Nov 2013 CTP
EDG eccp
The C++ front end supports the ISO/IEC 14882 standard. The C++14, C++11, and C++98/03 versions of the language are fully supported. (see our description of language features).
Under control of command-line options, the front end also supports ANSI/ISO C (both C89 and C99, and the Embedded C TR), the Microsoft dialects of C and C++ (including C++/CLI), GNU C and C++, Clang C and C++, Sun C++, the cfront 2.1 and 3.0.n dialects of C++, and K&R/pcc C.
Refer to EDG (Edison Design Group) eccp for more information.
Intel C++ Compiler
If you are here, you are looking for ways to make your application run faster. Boost performance by augmenting your development process with the Intel C++ Compiler. The Intel C++ Compiler plugs right into popular development environments like Visual Studio, Eclipse, XCode, and Android Studio; The Intel C++ Compiler is compatible with popular compilers including Visual C++ (Windows) and GCC (Linux, OS X and Android).
Refer to Intel C++ Compiler official site.
IBM XL C++
IBM XL C and C++ compilers offer advanced compiler and optimization technologies and are built on a common code base for easier porting of your applications between platforms. They comply with the latest C/C++ international standards and industry specifications and support a large array of common language features.
Refer to IBM XLC++ official site.
Sun/Oracle C++
The C++ compiler (CC) supports the ISO International Standard for C++, ISO IS 14882:1998, Programming Language–C++. The README file that accompanies the current release describes any departures from requirements in the standard. Refer to Sun/Oracle C++ User Guide.
Embarcadero C++ Builder
Develop for many platforms in fast, modern C++ with an enhanced Clang compiler. Seamlessly compile and deploy across platforms and devices. Design a UI once, then quickly specialize for each platform or device - much like subclassing code. Use robust and powerful frameworks for enterprise-strength databases, REST, cloud, IoT and more - whether you’re a team of a hundreds or a micro-startup. Accelerate your development: spend more time coding, less time on UI design, no time on platform-specific porting.
C++Builder gives you fast, powerful, modern C++; one compiler, one debugger, one IDE, four platforms; amazing frameworks; and lets you speed up your development, focus on your code and bring your app to market faster than any other C++ toolchain.
Refer to Embarcadero C++ Builder official site.
Cray C++ Compiler
The Cray Compiling Environment (CCE) contains both the Cray C and C++ compilers. The Cray C compiler conforms to the International Organization of Standards (ISO) standard ISO/IEC 9899:1999 (C99). The Cray C++ compiler conforms to the ISO/IEC 14882:2003 standard, with some exceptions.
Refer to Cray C and C++ Reference Manual.
Digital Mars C++
Digital Mars D compilers for Win32, Linux and OS X. C and C++ Compilers for Win32, Win16, DOS32 and DOS. Fastest compile/link times, powerful optimization technology, Design by Contract, complete library source, HTML browsable documentation, disassembler, librarian, resource compiler, make, etc., command line and GUI versions, tutorials, sample code, online updates, Standard Template Library, and much more.
Refer to Digital Mars C++.
Online Compilers
Try one of these online compiler pages, which offer a range of compilers including the latest from Clang, GCC, Intel, and Microsoft. Some are compile-only to let you check whether your code is legal, and some let you also run your test programs to see their output. Refer to Get Started: Standard C++:
- gcc.godbolt.org (Clang, GCC, Intel ICC)
- Wandbox (Clang, gcc – includes Boost)
- Online Visual Studio Compiler (VC++)
- Stacked-Crooked (GCC)
- Rextester (Clang, GCC, VC++)
- ideone.com (GCC, Clang)
Tools
include-what-you-use
The include-what-you-use is a tool for use with clang to analyze #include in C and C++ source files. Refer to include-what-you-use repo on GitHub.
SonarQube
Examples
Change character in string
#include <iostream>
#include <string>
#include <algorithm>
int main()
{
uint32_t i = 1;
std::string s { "hello" };
std::cout << i++ << ": " << s << std::endl;
transform(s.begin(), s.begin()+1, s.begin(), toupper);
std::cout << i++ << ": " << s << std::endl;
transform(s.begin(), s.begin()+1, s.begin(), tolower);
std::cout << i++ << ": " << s << std::endl;
s.front() = toupper(s.front());
std::cout << i++ << ": " << s << std::endl;
return 0;
}
1: hello
2: Hello
3: hello
4: Hello
Books
- Programming: Principles and Practice using C++ (Bjarne Stroustrup)
- A Tour of C++ (Bjarne Stroustrup)
- Learning Standard C++ as a New Language (Bjarne Stroustrup)
- Why C++ is not just an Object-Oriented Programming Language
- The C++ Programming Language (4th Edition)
- The Design and Evolution of C++
- C++ Supplementary with Threads Programming Course.pdf
- C++ Primer: 3rd Edition (CN) or 4th Edition (EN)
- C++ Primer Plus (6th Edition)
- The Boost C++ Libraries
- C++ Annotations
- Introduction to Design Patterns in C++ with Qt4
- How to Think Like a Computer Scientist: C++ Version
- C++ GUI Programming with Qt 3
- Open Data Structures in C++
- Cross-Platform GUI Programming with wxWidgets
- The Rook’s Guide to C++
- An Introduction to GCC
References
- Bjarne Stroustrup’s homepage
- Bjarne Stroustrup’s C++ FAQ
- News, Status & Discussion about Standard C++
- Get Started: Standard C++
- Linux: C/C++ Libraries
- ISO/IEC C++ Standards Committee (JTC1/SC22/WG21)
- Papers 2011 of JTC1/SC22/WG21
- C++ Standards Committee Papers
- C++ Super-FAQ
- C++0x FAQ
- C++11 FAQ
- Garbage Collector FAQ
- C++ programming language on Wikipedia
- C/C++ Reference
- cplusplus.com
- C++ Reference Material from Saint Mary’s University
- C++ Reference Material: Strings in C and C++
- C++ Reference Material: Input and Output
- MISRA C++
- Software Engineering Institute (SEI)
- Best Practices Criteria for Free/Libre and Open Source Software (FLOSS)
- Common Weakness Enumeration (CWE)
- CWE List
- CWE/SANS Top 25 Most Dangerous Software Errors
- SonarCFamily for C/C++
- GCC
- C++0x Compiler Support
- Elements of Modern C++ Style
- ACCU (Association of C and C++ Users)
- Code Simplicity