[Kernel] Linux Kernel Reading
This article records my reading of Linux kernel based on Linux v3.2.
1 Linux Kernel Brief Introduction
1.1 Linux Cross Reference
- Linux Cross Reference (LXR)
- Linux Kernel & Device Driver Programming
- Linux Syscall Reference
- FreeBSD and Linux Kernel Cross-Reference
1.2 Linux Kernel Git Repository
Git repositories hosted at kernel.org.
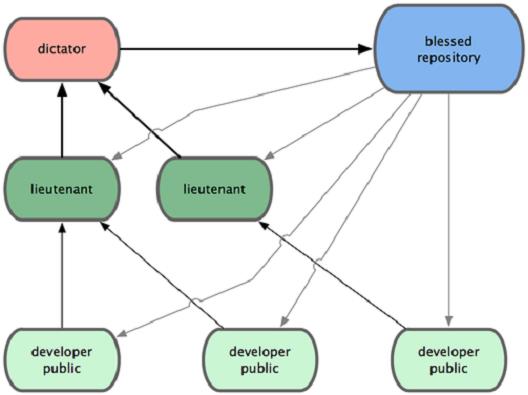
Refer to chapter 6.1.3 of Pro Git for the Git workflow of Linux kernel:
- 1) Regular developers work on their topic branch and rebase their work on top of master. The master branch is that of the dictator.
- 2) Lieutenants merge the developers’ topic branches into their master branch.
- 3) The dictator merges the lieutenants’ master branches into the dictator’s master branch.
- 4) The dictator pushes their master to the reference repository so the other developers can rebase on it.
NOTE: For Linux kernel developers, maybe it’s better for them to rebase their work on top of linux-next branch, refer to 1.2.2 linux-next tree.
Git workflow:
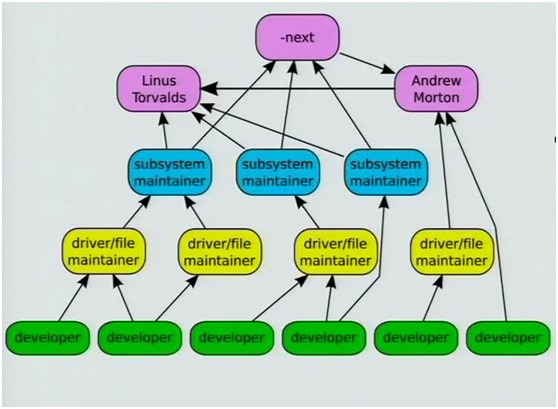
Linux kernel code flow:
1.2.1 Git client repository
Git client:
Git client repository:
- https://github.com/git/git
- https://git.kernel.org/cgit/git/git.git
- git://git.kernel.org/pub/scm/git/git.git
- https://git.kernel.org/pub/scm/git/git.git
- https://kernel.googlesource.com/pub/scm/git/git.git
After Git is installed, you can also get Git via Git itself for updates:
chenwx@chenwx:~ $ git clone https://github.com/git/git
chenwx@chenwx:~ $ cd git/
chenwx@chenwx:~/git $ git checkout master
chenwx@chenwx:~/git $ git pull
chenwx@chenwx:~/git $ git tag -l --sort="v:refname" | tail
v2.3.3
v2.3.4
v2.3.5
v2.4.0-rc0
chenwx@chenwx:~/git $ git checkout v2.3.5
chenwx@chenwx:~/git $ sudo make prefix=/usr all doc info
chenwx@chenwx:~/git $ sudo make prefix=/usr install install-doc install-html install-info
chenwx@chenwx:~/git $ git --version
chenwx@chenwx:~/git $ make distclean
chenwx@chenwx:~/git $ git checkout master
1.2.2 linux-next tree
linux-next tree:
- git://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git
- https://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git
- https://kernel.googlesource.com/pub/scm/linux/kernel/git/next/linux-next.git
Materials related to linux-next tree:
- http://lwn.net/Articles/268881/
- http://lwn.net/Articles/269120/
- http://lwn.net/Articles/289013/
- http://lwn.net/Articles/289245/
The linux-next tree, to be maintained by Stephen Rothwell, is intended to be a gathering point for the patches which are planned to be merged in the next development cycle.
NOTE 1: As a kernel developer, you should send patches against linux-next tree, not the mainline tree.
NOTE 2: You can see which trees have been included by looking in the linux/Next/Trees file in the source. There are also quilt-import.log and merge.log files in the linux/Next directory:
chenwx@chenwx ~/linux/Next $ ll
-rw-r--r-- 1 chenwx chenwx 11K Feb 24 12:47 SHA1s
-rw-r--r-- 1 chenwx chenwx 17K Feb 24 12:47 Trees
-rw-r--r-- 1 chenwx chenwx 92K Feb 24 12:47 merge.log
-rw-r--r-- 1 chenwx chenwx 81 Feb 24 12:47 quilt-import.log
The linux-next tree has following branches:
- stable branch, trackes the master branch of linux mainline tree.
- akpm and akpm-base branches, track http://www.ozlabs.org/~akpm/mmotm/.
- master branch, the tags such as next-20150324 are on this branch.
chenwx@chenwx ~/linux $ git br -r | grep linux-next
linux-next/akpm
linux-next/akpm-base
linux-next/master
linux-next/stable
1.2.2.1 How to track linux-next tree
Tracking linux-next tree is a little bit different from usual trees. In particular, since Stephen Rothwell rebases it quite frequently, you shouldn’t do a git pull on linux-next tree.
Note that linux-next tree isn’t an evolving tree like mainline tree, it’s best to see it as being a list of individual kernels released as tags, i.e. you shouldn’t be merging one into another.
Use the following commands to track linux-next tree:
# (1) Change directory to ~/linux
chenwx@chenwx ~ $ cd linux
# (2) Fetch linux-next plus tags.
# Note that all tags be fetched from the remote in addition to
# whatever else is being fetched by command "git fetch --tags".
chenwx@chenwx ~/linux $ git fetch
chenwx@chenwx ~/linux $ git fetch --tags
# (3) Update linux-next tree
chenwx@chenwx ~/linux $ git checkout master
chenwx@chenwx ~/linux $ git remote update
Fetching origin
# (4) List recent linux-next tags
chenwx@chenwx ~/linux $ git tag -l "next-*" | tail
...
next-20141015
next-20141016
next-20141017
# (5) Choose the linux-next version that you will work from, and
# create a local branch ec-task10-v1 based on that version
chenwx@chenwx ~/linux $ git checkout next-20141017 -b ec-task10-v1
Switched to a new branch 'ec-task10'
1.2.2.2 Subsystem trees
NOTE: Refer to the file linux/Next/Trees in linux-next tree for subsystem trees.
1.2.2.2.1 linux-staging tree
linux-staging tree:
- git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/staging.git
- https://git.kernel.org/pub/scm/linux/kernel/git/gregkh/staging.git
- https://kernel.googlesource.com/pub/scm/linux/kernel/git/gregkh/staging.git
Materials related to linux-staging tree:
The linux-staging tree was created to hold drivers and filesystems and other semi-major additions to the Linux kernel that are not ready to be merged at this point in time. It is here for companies and authors to get a wider range of testing, and to allow for other members of the community to help with the development of these features for the eventual inclusion into the main kernel tree.
1.2.2.2.2 linux-security tree
linux-security tree:
- https://git.kernel.org/cgit/linux/kernel/git/jmorris/linux-security.git
- git://git.kernel.org/pub/scm/linux/kernel/git/jmorris/linux-security.git
- https://git.kernel.org/pub/scm/linux/kernel/git/jmorris/linux-security.git
- https://kernel.googlesource.com/pub/scm/linux/kernel/git/jmorris/linux-security.git
1.2.3 mainline tree
Linux mainline tree:
- git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
- https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
- https://kernel.googlesource.com/pub/scm/linux/kernel/git/torvalds/linux.git
This is Linux Torvalds’ git tree. There is only one branch, that’s master branch, on the mainline tree.
NOTE 1: As a kernel developer, you should send patches against linux-staging or linux-next tree, not the mainline tree.
NOTE 2: Linux Torvalds负责维护mainline tree,在每个开发周期的merge window,新功能补丁会被合入mainline tree.
1.2.4 linux-stable tree
Linux kernel stable tree:
- https://git.kernel.org/cgit/linux/kernel/git/stable/linux-stable.git
- git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
- http://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
- https://kernel.googlesource.com/pub/scm/linux/kernel/git/stable/linux-stable.git
Linux kernel stable patch queue:
- https://git.kernel.org/cgit/linux/kernel/git/stable/stable-queue.git
- git://git.kernel.org/pub/scm/linux/kernel/git/stable/stable-queue.git
- https://git.kernel.org/pub/scm/linux/kernel/git/stable/stable-queue.git
- https://kernel.googlesource.com/pub/scm/linux/kernel/git/stable/stable-queue.git
Each stable release has a corresponding branch on stable tree, such as linux-3.2.y. And its latest commits/maintainers can be found at here.
Check the longterm branches on https://www.kernel.org and use following commands to track those branches:
chenwx@chenwx ~/linux $ git co linux-2.6.32.y
Checking out files: 100% (32771/32771), done.
Branch linux-2.6.32.y set up to track remote branch linux-2.6.32.y from origin.
Switched to a new branch 'linux-2.6.32.y'
chenwx@chenwx ~/linux $ git co linux-3.2.y
Checking out files: 100% (16874/16874), done.
Branch linux-3.2.y set up to track remote branch linux-3.2.y from origin.
Switched to a new branch 'linux-3.2.y'
chenwx@chenwx ~/linux $ git co linux-3.4.y
Checking out files: 100% (32682/32682), done.
Branch linux-3.4.y set up to track remote branch linux-3.4.y from origin.
Switched to a new branch 'linux-3.4.y'
chenwx@chenwx ~/linux $ git co linux-3.10.y
Checking out files: 100% (22201/22201), done.
Branch linux-3.10.y set up to track remote branch linux-3.10.y from origin.
Switched to a new branch 'linux-3.10.y'
chenwx@chenwx ~/linux $ git co linux-3.12.y
Checking out files: 100% (31307/31307), done.
Branch linux-3.12.y set up to track remote branch linux-3.12.y from origin.
Switched to a new branch 'linux-3.12.y'
chenwx@chenwx ~/linux $ git co linux-3.14.y
Checking out files: 100% (15876/15876), done.
Branch linux-3.14.y set up to track remote branch linux-3.14.y from origin.
Switched to a new branch 'linux-3.14.y'
chenwx@chenwx ~/linux $ git br
linux-2.6.32.y
linux-3.10.y
linux-3.12.y
* linux-3.14.y
linux-3.2.y
linux-3.4.y
master
NOTE: linux-stable tree是对已发布的正式版本的后续维护,只包括一些bugfix或安全补丁,但不包括功能补丁。
1.2.5 Setup Linux Kernel Workarea
Run the following commands to clone all Linux kernel repositories into the same directory:
#
# (1) Clone mainline tree linux.git to ~/linux
# git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
# https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
#
chenwx@chenwx ~ $ git clone https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
Cloning into 'linux'...
remote: Counting objects: 3841355, done.
remote: Compressing objects: 100% (75674/75674), done.
remote: Total 3841355 (delta 56478), reused 0 (delta 0)
Receiving objects: 100% (3841355/3841355), 892.40 MiB | 2.47 MiB/s, done.
Resolving deltas: 100% (3147072/3147072), done.
Checking connectivity... done.
Checking out files: 100% (47936/47936), done.
#
# (2) Add next tree linux-next.git to ~/linux
# git://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git
# https://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git
#
chenwx@chenwx ~/linux $ git remote add linux-next https://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git
#
# (2.1) Download source code from linux-next tree
#
chenwx@chenwx ~/linux $ git fetch linux-next
chenwx@chenwx ~/linux $ git fetch --tags linux-next
#
# (2.2) Create local branch to track master branch of linux-next tree
#
chenwx@chenwx ~/linux $ git branch --track next-master linux-next/master
#
# (3) Add stable tree linux-stable.git to ~/linux
# git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
# https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
#
chenwx@chenwx ~/linux $ git remote add linux-stable https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
#
# (3.1) Download source code from linux-stable tree
#
chenwx@chenwx ~/linux $ git fetch linux-stable
chenwx@chenwx ~/linux $ git fetch --tags linux-stable
#
# (3.2) Create local branches to track longterm stable branches
# Check the stable branches on website https://www.kernel.org/
#
chenwx@chenwx ~/linux $ git co linux-3.2.y
chenwx@chenwx ~/linux $ git co linux-3.4.y
chenwx@chenwx ~/linux $ git co linux-3.10.y
chenwx@chenwx ~/linux $ git co linux-3.12.y
chenwx@chenwx ~/linux $ git co linux-3.14.y
chenwx@chenwx ~/linux $ git co linux-3.16.y
chenwx@chenwx ~/linux $ git co linux-3.18.y
chenwx@chenwx ~/linux $ git co linux-4.1.y
chenwx@chenwx ~/linux $ git co linux-4.4.y
chenwx@chenwx ~/linux $ git co linux-4.5.y
chenwx@chenwx ~/linux $ git co linux-4.6.y
#
# (4) Show local branches
#
chenwx@chenwx ~/linux $ git br
linux-3.10.y
linux-3.12.y
linux-3.14.y
linux-3.16.y
linux-3.18.y
linux-3.2.y
linux-3.4.y
linux-4.1.y
linux-4.4.y
linux-4.5.y
linux-4.6.y
* master
next-master
#
# (5) Use the following commands to fetch objects from all remotes
#
chenwx@chenwx ~/linux $ git remote -v
linux-next https://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git (fetch)
linux-next https://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git (push)
linux-stable https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git (fetch)
linux-stable https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git (push)
origin https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git (fetch)
origin https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git (push)
chenwx@chenwx ~/linux $ git remote update
Fetching origin
Fetching linux-stable
Fetching linux-next
chenwx@chenwx ~/linux $ git fetch --all
Fetching origin
Fetching linux-stable
Fetching linux-next
1.2.6 Create new volume with case-sensitive APFS on MacOS
After clone linux repo on MacOS, the workspace is not clean:
chenwx@MacbookAir linux % gst
On branch master
Your branch is up to date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: include/uapi/linux/netfilter/xt_RATEEST.h
modified: include/uapi/linux/netfilter/xt_connmark.h
modified: include/uapi/linux/netfilter/xt_dscp.h
modified: include/uapi/linux/netfilter/xt_mark.h
modified: include/uapi/linux/netfilter/xt_tcpmss.h
modified: include/uapi/linux/netfilter_ipv4/ipt_ecn.h
modified: include/uapi/linux/netfilter_ipv4/ipt_ttl.h
modified: include/uapi/linux/netfilter_ipv6/ip6t_HL.h
modified: net/netfilter/xt_DSCP.c
modified: net/netfilter/xt_HL.c
modified: net/netfilter/xt_RATEEST.c
modified: net/netfilter/xt_tcpmss.c
modified: tools/memory-model/litmus-tests/Z6.0+pooncelock+pooncelock+pombonce.litmus
That’s because the volume on MacOS is case-insensitive APFS by default.
In order to fix the issue, need to create a new volume on MacOS with case-sensitive APFS to contain the repos:
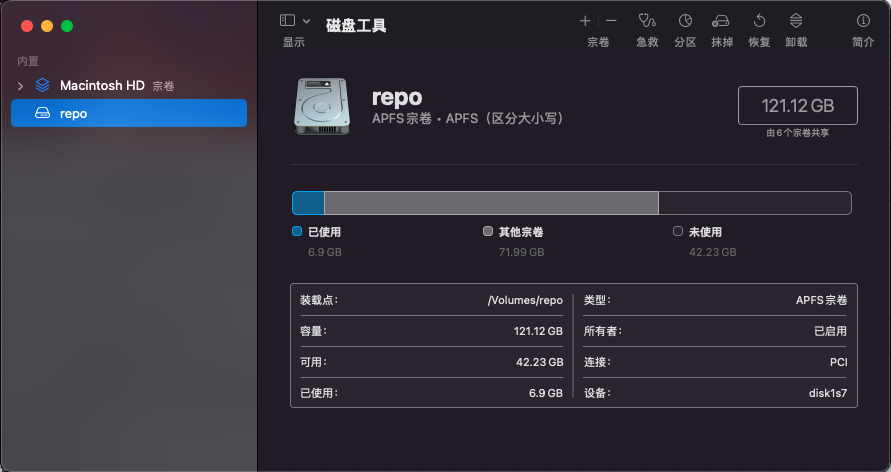
Then, clone repos in the new volume /Volumes/repo/:
chenwx@MacbookAir blog % ll /Volumes/repo
total 0
drwxr-xr-x 19 chenwx staff 608B 2023-02-28 23:30:30 blog
drwxr-xr-x 42 chenwx staff 1.3K 2023-03-14 22:39:38 linux
drwxr-xr-x@ 33 chenwx staff 1.0K 2022-10-24 22:51:52 scripts
drwxr-xr-x 5 chenwx staff 160B 2023-03-13 21:49:21 tMap
1.3 Linux Kernel Mailing lists
订阅和取消订阅邮件列表
1.3.1 lkml.org
lkml.org
在下列页面中列出了每年的邮件统计数字:
可通过下列方式查看某天的邮件:
- https://lkml.org/lkml/<Year>/<Month>/<Day>
- 例如:https://lkml.org/lkml/2014/3/31
最新的100封邮件:
NOTE: 可以通过左侧的”Get diff 1“来提取邮件中的Patch。
1.3.2 lkml.iu.edu
The Linux-Kernel Archive:
1.3.3 marc.info
marc.info
NOTE: 采用Courier New字体,视觉效果好。
1.4 Linux Kernel Releases
通过下列命令查看某 Linux kernel release 的信息,以v3.2为例:
chenwx@chenwx ~/linux $ git tag -l v3.2
v3.2
chenwx@chenwx ~/linux $ git lc v3.2
commit 805a6af8dba5dfdd35ec35dc52ec0122400b2610 (HEAD, tag: v3.2)
Author: Linus Torvalds <torvalds@linux-foundation.org>
AuthorDate: Wed Jan 4 15:55:44 2012 -0800
Commit: Linus Torvalds <torvalds@linux-foundation.org>
CommitDate: Wed Jan 4 15:55:44 2012 -0800
Linux 3.2
Makefile | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
1.4.1 Linux Versions
参见 Understanding the Linux Kernel, 3rd Edition 第 1. Introduction章 第Linux Versions 节:
Up to kernel version 2.5, Linux identified kernels through a simple numbering scheme. Each version was characterized by three numbers, separated by periods. The first two numbers were used to identify the version; the third number identified the release. The second version number identified the type of kernel: if it was even, it denoted a stable version; otherwise, it denoted a development version.
During development of Linux kernel version 2.6, however, a significant change in the version numbering scheme has taken place. Basically, the second number no longer identifies stable or development versions; thus, nowadays kernel developers introduce large and significant changes in the current kernel version 2.6. A new kernel 2.7 branch will be created only when kernel developers will have to test a really disruptive change; this 2.7 branch will lead to a new current kernel version, or it will be backported to the 2.6 version, or finally it will simply be dropped as a dead end.
On 29 May 2011, Linus Torvalds announced that the kernel version would be bumped to 3.0 for the release following 2.6.39, due to the minor version number getting too large and to commemorate the 20th anniversary of Linux. It continued the time-based release practice introduced with 2.6.0, but using the second number - e.g. 3.1 would follow 3.0 after a few months. An additional number (now the third number) would be added on when necessary to designate security and bug fixes, as for example with 3.0.18. The major version number might be raised to 4 at some future date. Refer to https://lkml.org/lkml/2011/5/29/204.
1.4.2 Relationship of Tags
Linux kernel releases are marked by tags, such as v4.16. Run the following command to show the tags:
chenwx@chenwx ~/linux $ git tag -l v[0-9]* --sort=v:refname
v2.6.11
v2.6.11-tree
v2.6.12
v2.6.12-rc2
v2.6.12-rc3
v2.6.12-rc4
v2.6.12-rc5
v2.6.12-rc6
v2.6.12.1
v2.6.12.2
v2.6.12.3
v2.6.12.4
v2.6.12.5
v2.6.12.6
...
v4.16
v4.16-rc1
v4.16-rc2
v4.16-rc3
v4.16-rc4
v4.16-rc5
v4.16-rc6
v4.16-rc7
v4.16.1
v4.16.2
v4.16.3
v4.16.4
v4.16.5
v4.16.6
v4.16.7
v4.16.8
v4.17-rc1
v4.17-rc2
v4.17-rc3
v4.17-rc4
v4.17-rc5
If you want to know the relationship of Linux kernel tags, the Python script linux_kernel_releases.py can be used to draw a figure about it. For instance:
chenwx@chenwx ~/linux $ ~/scripts/linux_kernel_releases.py -l "v3.2 v3.16 v3.18 v4.1 v4.4 v4.9 v4.14" -s "v4.15 v4.16" -o ~/Downloads/
Begin tag : v2.6.12
End tag : v4.16.8
Longterm branch : v3.2 v3.16 v3.18 v4.1 v4.4 v4.9 v4.14
Stable branch : v4.15 v4.16
Output directory : /home/chenwx/Downloads
The output is below figure:

1.4.3 Linux Kernel Release Note
The Linux kernel release notes are collected on website Linux Kernel Newbies:
- Linux v4.0
- Linux v4.1
- Linux v4.2
- Linux v4.3
- Linux v4.4
- Linux v4.5
- Linux v4.6
- Linux v4.7
- Linux v4.8
- Linux v4.9
- Linux v4.10
- Linux v4.11
- Linux v4.12
- Linux v4.13
- Linux v4.14
- Linux v4.15
- Linux v4.16
- Linux v4.17
- Linux v4.18
- Linux v4.19
- Linux v4.20
- Linux v5.0
- Linux v5.1
- Linux v5.2
1.5 Linux Kernel Bug Reporting
Linux内核开发者用于追踪内核Bug的网站
1.6 Linux Kernel Development Process
参见下列文档:
- Kernel development process in Documentation/process/
- How to Participate in the Linux Community from Linux Foundation
Linux kernel development cycle:
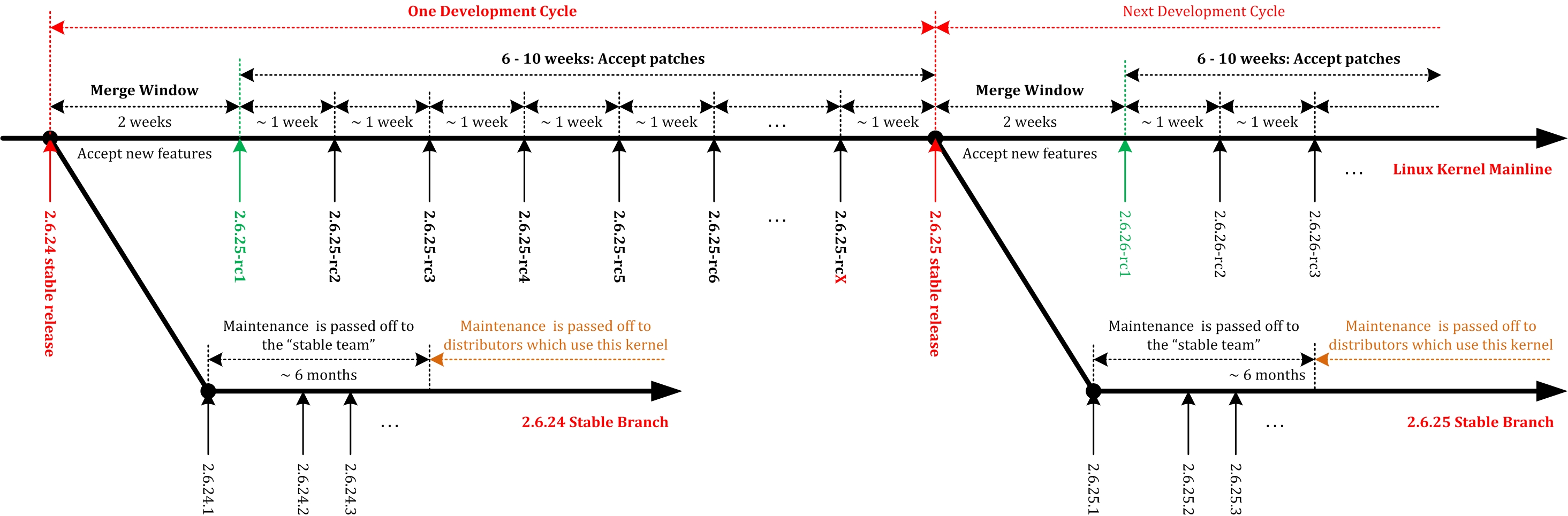
Linux kernel code flow:
1.7 Linux Kernel Related Books
- Linux Kernel Development, 3rd Edition. Robert Love Done on 2014-01-12
- Understanding the Linux Kernel, 3rd Edition. Daniel P. Bovet & Marco Cesati Done on 2014-03-13
- Understanding the Linux Virtual Memory Manager, July 9 2007, Mel Gorman Done on 2014-03-17
- Linux Device Drivers, 3rd Edition. Jonathan Corbet, Alessandro Rubini, Greg Kroah-Hartman
- Understanding Linux Network Internals. Christian Benvenuti
- Linux Memory Management
- LINUX 就该这么学
1.8 Linux Distributions
1.8.1 Git trees for linux distributions
Git trees for linux distributions:
1.8.2 How to check version of linux distributions
1.8.2.1 lsb_release -a
chenwx@chenwx:~ $ lsb_release -a
No LSB modules are available.
Distributor ID: LinuxMint
Description: Linux Mint 19 Tara
Release: 19
Codename: tara
1.8.2.2 /etc/*-release
chenwx@chenwx:~ $ cat /etc/issue
Linux Mint 19 Tara \n \l
chenwx@chenwx:~ $ cat /etc/issue.net
Linux Mint 19 Tara
chenwx@chenwx:~ $ cat /etc/lsb-release
DISTRIB_ID=LinuxMint
DISTRIB_RELEASE=19
DISTRIB_CODENAME=tara
DISTRIB_DESCRIPTION="Linux Mint 19 Tara"
chenwx@chenwx:~ $ cat /etc/os-release
NAME="Linux Mint"
VERSION="19 (Tara)"
ID=linuxmint
ID_LIKE=ubuntu
PRETTY_NAME="Linux Mint 19"
VERSION_ID="19"
HOME_URL="https://www.linuxmint.com/"
SUPPORT_URL="https://forums.ubuntu.com/"
BUG_REPORT_URL="http://linuxmint-troubleshooting-guide.readthedocs.io/en/latest/"
PRIVACY_POLICY_URL="https://www.linuxmint.com/"
VERSION_CODENAME=tara
UBUNTU_CODENAME=bionic
chenwx@chenwx:~ $ cat /etc/debian_version
buster/sid
1.8.2.3 uname -a
chenwx@chenwx:~ $ uname -a
Linux chenwx 4.15.0-39-generic #42-Ubuntu SMP Tue Oct 23 15:48:01 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
1.8.2.4 /proc/version
chenwx@chenwx:~ $ cat /proc/version
Linux version 4.15.0-39-generic (buildd@lgw01-amd64-054) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #42-Ubuntu SMP Tue Oct 23 15:48:01 UTC 2018
1.8.2.5 dmesg
chenwx@chenwx:~ $ dmesg | grep "Linux"
[ 0.000000] Linux version 4.15.0-39-generic (buildd@lgw01-amd64-054) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #42-Ubuntu SMP Tue Oct 23 15:48:01 UTC 2018 (Ubuntu 4.15.0-39.42-generic 4.15.18)
[ 0.044097] ACPI: Added _OSI(Linux-Dell-Video)
[ 0.044098] ACPI: Added _OSI(Linux-Lenovo-NV-HDMI-Audio)
[ 0.050972] ACPI: [Firmware Bug]: BIOS _OSI(Linux) query ignored
[ 1.099636] Linux agpgart interface v0.103
[ 2.044123] usb usb1: Manufacturer: Linux 4.15.0-39-generic ehci_hcd
[ 2.064119] usb usb2: Manufacturer: Linux 4.15.0-39-generic ehci_hcd
[ 2.064730] usb usb3: Manufacturer: Linux 4.15.0-39-generic uhci_hcd
[ 2.065177] usb usb4: Manufacturer: Linux 4.15.0-39-generic uhci_hcd
[ 2.065640] usb usb5: Manufacturer: Linux 4.15.0-39-generic uhci_hcd
[ 2.066097] usb usb6: Manufacturer: Linux 4.15.0-39-generic uhci_hcd
[ 2.066567] usb usb7: Manufacturer: Linux 4.15.0-39-generic uhci_hcd
[ 2.455143] pps_core: LinuxPPS API ver. 1 registered
[ 18.436173] VBoxPciLinuxInit
1.8.2.6 yum / dnf
$ yum info nano
Loaded plugins: fastestmirror, ovl
Loading mirror speeds from cached hostfile
* base: centos.zswap.net
* extras: mirror2.evolution-host.com
* updates: centos.zswap.net
Available Packages
Name : nano
Arch : x86_64
Version : 2.3.1
Release : 10.el7
Size : 440 k
Repo : base/7/x86_64
Summary : A small text editor
URL : http://www.nano-editor.org
License : GPLv3+
Description : GNU nano is a small and friendly text editor.
$ yum repolist
Loaded plugins: fastestmirror, ovl
Loading mirror speeds from cached hostfile
* base: centos.zswap.net
* extras: mirror2.evolution-host.com
* updates: centos.zswap.net
repo id repo name status
base/7/x86_64 CentOS-7 - Base 9591
extras/7/x86_64 CentOS-7 - Extras 388
updates/7/x86_64 CentOS-7 - Updates 1929
repolist: 11908
$ dnf info nano
Last metadata expiration check: 0:01:25 ago on Thu Feb 15 01:59:31 2018.
Installed Packages
Name : nano
Version : 2.8.7
Release : 1.fc27
Arch : x86_64
Size : 2.1 M
Source : nano-2.8.7-1.fc27.src.rpm
Repo : <a href="http://www.jobbole.com/members/system">@System</a>
From repo : fedora
Summary : A small text editor
URL : https://www.nano-editor.org
License : GPLv3+
Description : GNU nano is a small and friendly text editor.
1.8.2.7 rpm
$ rpm -q nano
nano-2.8.7-1.fc27.x86_64
1.8.2.8 apt-get
chenwx@chenwx:~ $ apt-cache policy nano
nano:
Installed: (none)
Candidate: 2.9.3-2
Version table:
2.9.3-2 500
500 http://mirrors.aliyun.com/ubuntu bionic/main amd64 Packages
2 Linux Kernel源代码结构
本文中的目录和文件均相对于目录~/linux/,参见1.2.5 Setup Linux Kernel Workarea节。
2.1 说明文件
linux/目录下的文件:
| Files | Description |
|---|---|
| README | Linux内核说明文档,简要介绍了Linux内核的背景,描述了配置和build内核需要什么。 |
| COPYING | 版权声明 |
| CREDITS | Linux内核贡献人员列表 |
| MAINTAINERS | Linux维护人员信息 |
| REPORTING-BUGS | 报告Bug的流程及模板。 The document is moved to Documentation/admin-guide/reporting-bugs.rst in v4.9, see the following commit: docs-rst: create an user’s manual book commit: 9d85025b0418163fae079c9ba8f8445212de8568 |
Documentation/目录下的文件:
| Documentation/ | Description |
|---|---|
| 00-INDEX | Documentation/下各目录的内容。 The document is removed in v4.19, see the following commit: Drop all 00-INDEX files from Documentation/ commit: a7ddcea58ae22d85d94eabfdd3de75c3742e376b |
| email-clients.txt | 使用邮件发送patch时, 需要对邮件客户端进行特殊配置。 |
| Changes | 列出了成功编译和运行内核所需的各种软件包的最小集合。 |
| CodingStyle | 描述了Linux内核编码风格, 和一些隐藏在背后的基本原理。 所有的想加入内核的新代码应当遵循这篇文档的指导。 绝大数的内核代码维护者只愿意接受那些符合这篇文档描述的风格的补丁, 许多内核开发者也只愿意审查那些符合Linux内核编码风格的代码。 |
| development-process | Linux kernel development process. |
| SubmittingPatches SubmittingDrivers SubmitChecklist |
描述了如何成功的创建和向社区递交一个补丁, 包括:邮件内容、邮件格式、发送者和接收者。 遵循文档里提倡的规则并不一定保证你提交补丁成功 (因为所有的补丁遭受详细而严格的内容和风格的审查), 但是不遵循它们, 提交补丁肯定不成功。 |
| stable_api_nonsense.txt | 这篇文档描述了有意决定在内核里没有固定内核API的基本原因, 这对于理解Linux的开发哲学非常关键, 也对于从其他操作系统转移到Linux上的开发人员非常重要。 |
| SecurityBugs | 如果你确知在Linux Kernel里发现了security problem, 请遵循这篇文档描述的步骤, 帮助通知内核的开发者们并解决这类问题。 |
| ManagementStyle | 这篇文档描述了Linux内核开发者们如何进行管理运作, 以及运作方法背后的分享精神(shared ethos)。 这篇文档对于那些内核开发新手们(或者那些好奇者)值得一读, 因为它解决或解释了很多对于内核维护者独特行为的误解。 |
| stable_kernel_rules.txt | 这篇文档描述了一个稳定的内核版本如何发布的规则, 以及需要做些什么如果你想把一个修改加入到其中的一个版本。 |
| kernel-docs.txt | 关于内核开发的外部文档列表。 |
| applying-patches.txt | 描述了什么是补丁(patch), 以及如何将它应用到内核的不同开发分支(branch)上。 |
| kbuild/kconfig.txt | Information on using the Linux kernel config tools. |
| DocBook/ | 内核里有大量的由内核源码自动生成的文档。 其中包括了内核内部API的全面描述, 和如何处理好锁的规则。 文档格式包括 PDF, Postscritpt, HTML 和 man pages, 可在内核源码主目录下运行下列命令自动生成, 见下文。 |
检查内核代码风格:
// step 1) 运行脚本scripts/Lindent使源代码符合Linux Kernel的代码风格:
$ scripts/Lindent <file>
// 或者,运行下列命令来格式化源代码:
$ indent -kr -i8 -ts8 -sob -l80 -ss -bs -psl <file>
// step 2) 运行下列脚本来检查代码格式的合法性:
$ scripts/checkpatch.pl --terse --file <file>
NOTE 1: The style checker scripts/chechpatch.pl should be viewed as a guide not as the final word. If your code looks better with a violation then its probably best left alone.
NOTE 2: The pre-condition of running scripts/Lindent and indent is that the source files use unix format, use below command to transfer source file format:
# dos2unix <file>
# unix2dos <file>
在内核源码根目录下执行下列命令会在DocBook/目录下生成不同格式的文档,也可以查看在线文档The Linux Kernel documentation。
/*
* (1) 顶层Makefile中有关内核文档的目标
*/
chenwx@chenwx ~/linux $ ll Documentation/DocBook/
total 1.1M
-rw-r--r-- 1 chenwx chenwx 21K Aug 11 09:12 80211.tmpl
-rw-r--r-- 1 chenwx chenwx 7.1K Aug 11 09:12 Makefile
-rw-r--r-- 1 chenwx chenwx 4.0K Aug 11 09:12 alsa-driver-api.tmpl
-rw-r--r-- 1 chenwx chenwx 69K Aug 12 08:25 crypto-API.tmpl
-rw-r--r-- 1 chenwx chenwx 16K Aug 11 09:10 debugobjects.tmpl
-rw-r--r-- 1 chenwx chenwx 15K Aug 11 09:12 device-drivers.tmpl
-rw-r--r-- 1 chenwx chenwx 12K Aug 11 09:10 deviceiobook.tmpl
-rw-r--r-- 1 chenwx chenwx 174K Aug 12 08:25 drm.tmpl
...
chenwx@chenwx ~/linux $ make help
...
Documentation targets:
Linux kernel internal documentation in different formats:
htmldocs - HTML
pdfdocs - PDF
psdocs - Postscript
xmldocs - XML DocBook
mandocs - man pages
installmandocs - install man pages generated by mandocs
cleandocs - clean all generated DocBook files
...
/*
* (2) 编译HTML格式的内核文档
*/
chenwx@chenwx ~/linux $ make O=../linux-build/ htmldocs
...
HTML Documentation/DocBook/z8530book.html
rm -rf Documentation/DocBook/index.html; echo '<h1>Linux Kernel HTML Documentation</h1>' >> Documentation/DocBook/index.html && echo '<h2>Kernel Version: 4.1.6</h2>' >> Documentation/DocBook/index.html && cat Documentation/DocBook/80211.html Documentation/DocBook/alsa-driver-api.html Documentation/DocBook/crypto-API.html Documentation/DocBook/debugobjects.html Documentation/DocBook/device-drivers.html Documentation/DocBook/deviceiobook.html Documentation/DocBook/drm.html Documentation/DocBook/filesystems.html Documentation/DocBook/gadget.html Documentation/DocBook/genericirq.html Documentation/DocBook/kernel-api.html Documentation/DocBook/kernel-hacking.html Documentation/DocBook/kernel-locking.html Documentation/DocBook/kgdb.html Documentation/DocBook/libata.html Documentation/DocBook/librs.html Documentation/DocBook/lsm.html Documentation/DocBook/media_api.html Documentation/DocBook/mtdnand.html Documentation/DocBook/networking.html Documentation/DocBook/rapidio.html Documentation/DocBook/regulator.html Documentation/DocBook/s390-drivers.html Documentation/DocBook/scsi.html Documentation/DocBook/sh.html Documentation/DocBook/tracepoint.html Documentation/DocBook/uio-howto.html Documentation/DocBook/usb.html Documentation/DocBook/w1.html Documentation/DocBook/writing-an-alsa-driver.html Documentation/DocBook/writing_musb_glue_layer.html Documentation/DocBook/writing_usb_driver.html Documentation/DocBook/z8530book.html >> Documentation/DocBook/index.html
/*
* (3) 查看编译后的HTML格式的内核文档
*/
chenwx@chenwx ~/linux $ firefox ../linux-build/Documentation/DocBook/index.html &
2.2 配置文件
| Files | Description |
|---|---|
| Kconfig, */Kconfig | 内核配置选项文件Kconfig |
| Kbuild, */Kbuild | 内核编译系统Kbuild的Makefile文件 |
| Makefile | 顶层Makefile文件 |
2.3 代码文件
| Directory | Description |
|---|---|
| arch/ | 包含所有与特定硬件结构相关的内核代码。arch目录下处理器体系架构介绍,参见Appendix E: arch目录下处理器体系架构介绍节。 |
| block/ | block层的实现。最初block层的代码一部分位于drivers/目录,一部分位于fs/目录,从2.6.15开始,block 层的核心代码被提取出来放在了顶层的block/目录。 |
| certs/ | Since Linux kernel version 3.7 onwards, support has been added for signed kernel modules. When enabled, the Linux kernel will only load kernel modules that are digitally signed with the proper key. This allows further hardening of the system by disallowing unsigned kernel modules, or kernel modules signed with the wrong key, to be loaded. Malicious kernel modules are a common method for loading rootkits on a Linux system. Refer to Signed Kernel Module Support. |
| crypto/ | 内核本身所用的加密API,实现了常用的加密和散列算法,还有一些压缩和CRC校验算法。 |
| drivers/ | 包含内核中所有的设备驱动程序,每种驱动程序占用一个子目录,如块设备,scsi设备驱动程序等。 |
| firmware/ | 使用某些驱动程序而需要的设备固件。 The folder is moved to drivers/base/firmware_loader/builtin/ in v5.0, see the following commit: firmware_loader: move firmware/ to drivers/base/firmware_loader/builtin/ commit: f96182e959a41e35df0adae9ae09a49ff8a618a8 |
| fs/ | 包含所有文件系统的代码,每种文件系统占用一个子目录,如ext2、ext3、ext4等。 |
| include/ | 包含编译内核代码时所需的大部分头文件。与体系架构无关的头文件包含在include/linux目录下。 |
| init/ | 包含内核的初始化代码,这是内核开始工作的起点。 |
| ipc/ | 包含进程间通信的代码。 |
| kernel/ | 包含主要的核心代码。与体系架构有关的核心代码包含在arch/$(ARCH)/kernel/目录下。 |
| lib/ | 核心的库代码。与arch/$(ARCH)/lib下的代码不同,这里的库代码都是用C编写的,在内核新的移植版本中可以直接使用。 |
| mm/ | 包含所有与体系架构无关的内存管理代码。与体系架构有关的内存管理代码包含在arch/$(ARCH)/mm/目录下。 |
| net/ | 包含内核的网络代码。 |
| samples/ | Linux内核的示范代码。 |
| scripts/ | 包含编译内核所用的脚本等文件。 |
| security/ | 包括了不同的Linux安全模型的代码,例如: NSA Security-Enhanced Linux. |
| sound/ | 声卡驱动以及其他声音相关的代码。 |
| tools/ | Tools helpful for developing Linux. 目录 tools/perf/ 中包含由内核维护人员Ingo Molnar等人开发的Linux内核综合性能概要分析工具。 |
| usr/ | Early user-space code (called initramfs). |
| virt/ | Virtualization infrastructure. |
脚本scripts/get_maintainer.pl用于检测指定内核子系统的维护者,例如:
chenwx@chenwx ~/linux $ scripts/get_maintainer.pl -f fs
Alexander Viro <viro@zeniv.linux.org.uk> (maintainer:FILESYSTEMS (VFS...)
linux-fsdevel@vger.kernel.org (open list:FILESYSTEMS (VFS...)
linux-kernel@vger.kernel.org (open list)
3 Linux Kernel配置、编译与升级
Linux kernel的编译流程:
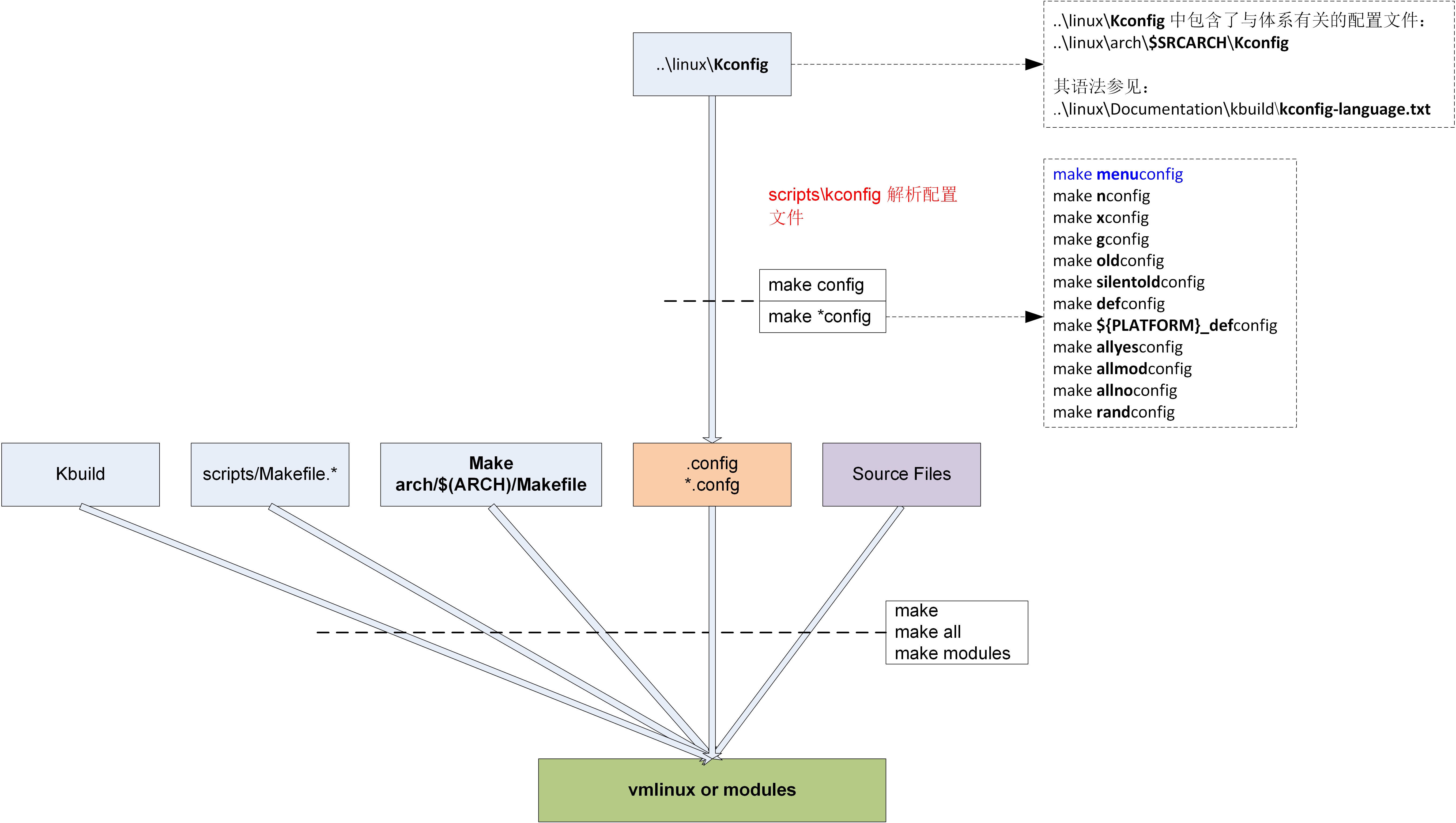
3.1 概述
参见目录Documentation/kbuild/中的下列文档:
| 00-INDEX | info on the kernel build process |
| kbuild.txt | developer information on kbuild |
| kconfig.txt | usage help for make *config |
| kconfig-language.txt | specification of Config Language, the language in Kconfig files |
| makefiles.txt | developer information for linux kernel makefiles |
| modules.txt | how to build modules and to install them |
NOTE: 编译系统前,需要先检查系统中相关工具的版本是否满足文件Documentation/Changes所列出的最小要求,参见3.1A Prerequisite of Building Kernel节。
3.1A Prerequisite of Building Kernel
First, check out the specific version of Linux kernel:
chenwx@chenwx ~/linux $ git co v4.6.4
Checking out files: 100% (9725/9725), done.
Note: checking out 'v4.6.4'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 310ca59d1f1c... Linux 4.6.4
chenwx@chenwx ~/linux $ git st
HEAD detached at v4.6.4
nothing to commit, working tree clean
Then, check the minimal requirements of tools in ~/Documentation/Changes, or you can check the latest version of Documentation/Changes on mainline.
chenwx@chenwx ~/linux $ more Documentation/Changes
...
Current Minimal Requirements
============================
Upgrade to at *least* these software revisions before thinking you've
encountered a bug! If you're unsure what version you're currently
running, the suggested command should tell you.
Again, keep in mind that this list assumes you are already functionally
running a Linux kernel. Also, not all tools are necessary on all
systems; obviously, if you don't have any ISDN hardware, for example,
you probably needn't concern yourself with isdn4k-utils.
o GNU C 3.2 # gcc --version
o GNU make 3.80 # make --version
o binutils 2.12 # ld -v
o util-linux 2.10o # fdformat --version
o module-init-tools 0.9.10 # depmod -V
o e2fsprogs 1.41.4 # e2fsck -V
o jfsutils 1.1.3 # fsck.jfs -V
o reiserfsprogs 3.6.3 # reiserfsck -V
o xfsprogs 2.6.0 # xfs_db -V
o squashfs-tools 4.0 # mksquashfs -version
o btrfs-progs 0.18 # btrfsck
o pcmciautils 004 # pccardctl -V
o quota-tools 3.09 # quota -V
o PPP 2.4.0 # pppd --version
o isdn4k-utils 3.1pre1 # isdnctrl 2>&1|grep version
o nfs-utils 1.0.5 # showmount --version
o procps 3.2.0 # ps --version
o oprofile 0.9 # oprofiled --version
o udev 081 # udevd --version
o grub 0.93 # grub --version || grub-install --version
o mcelog 0.6 # mcelog --version
o iptables 1.4.2 # iptables -V
o openssl & libcrypto 1.0.0 # openssl version
o bc 1.06.95 # bc --version
Actually, the softwares used to build linux kernel is quiet stable. We can get it from the commit history of Documentation/Changes:
chenwx@chenwx ~/linux $ git lhg Documentation/Changes
* 5ebe0ee802c5 2015-11-05 Linus Torvalds Merge tag 'docs-for-linus' of git://git.lwn.net/linux
|\
| * 1c3a54e257f7 2015-09-29 Jonathan Corbet Documentation/Changes: Add bc in "Current Minimal Requirements" section
* | 283e8ba2dfde 2015-09-25 David Howells MODSIGN: Change from CMS to PKCS#7 signing if the openssl is too old
|/
* 3f1d44ae6401 2015-08-27 James Morris Documentation/Changes: Now need OpenSSL devel packages for module signing
* bf5777bcdc54 2014-12-22 Jonathan Corbet Documentation: GNU is frequently spelled Gnu
* 5d330cddb907 2014-12-03 David S. Miller Update old iproute2 and Xen Remus links
* 00703e0b7990 2014-09-06 Jiri Kosina Documentation: remove obsolete pcmcia-cs from Changes
* 03ebb7d03f94 2014-09-06 Jiri Kosina Documentation: update links in Changes
* c8c3f7d621c1 2014-07-12 Linus Torvalds Documentation/Changes: clean up mcelog paragraph
* 221069bed0c7 2014-05-19 Jiri Kosina doc: Note need of bc in the kernel build from 3.10 onwards
* dad337501d49 2013-11-27 Linus Torvalds remove obsolete references to powertweak
* 5adaf851d207 2011-07-11 Linus Torvalds Documentation/Changes: remove some really obsolete text
* e06c37440014 2011-03-22 Linus Torvalds Documentation/Changes: minor corrections
* a65577375844 2010-07-03 Jiri Kosina Documentation update broken web addresses
* d879e19e18eb 2010-03-22 Jan Engelhardt netfilter: xtables: remove xt_string revision 0
* 7a9226370543 2009-12-14 Patrick McHardy netfilter: xtables: document minimal required version
* 082196242e24 2009-06-17 Linus Torvalds Documentation/Changes: perl is needed to build the kernel
* 45e3e1935e28 2009-06-14 Linus Torvalds Merge branch 'master' of git://git.kernel.org/pub/scm/linux/kernel/git/sam/kbuild-next
|\
| * 2185a5ecd98d 2009-06-14 Sam Ravnborg documentation: make version fix
* | 172d899db4bf 2009-04-28 H. Peter Anvin x86, mce: document new 32bit mcelog requirement in Documentation/Changes
|/
* 242f45da5b7b 2009-01-29 Linus Torvalds Documentation/Changes: add required versions for new filesystems
* c3887cd72532 2007-08-02 H. Peter Anvin [x86 setup] Document grub < 0.93 as broken
* 03a67a46af86 2006-11-30 Adrian Bunk Fix typos in doc and comments
* e41217129c66 2006-09-11 Sam Ravnborg Documentaion: update Documentation/Changes with minimum versions
* 890fbae2818a 2005-06-20 Greg Kroah-Hartman [PATCH] devfs: Last little devfs cleanups throughout the kernel tree.
* 44fc355db7c2 2006-03-20 Adrian Bunk Documentation/Changes: remove outdated translation references
* a1365647022e 2006-01-08 Linus Torvalds [PATCH] remove gcc-2 checks
* 62a07e6e9e93 2005-11-07 Linus Torvalds [PATCH] ksymoops related docs update
* ad7e14a55ed7 2005-10-27 Greg Kroah-Hartman [PATCH] update required version of udev
* 909021ea7a8f 2005-09-27 Linus Torvalds [PATCH] fuse: add required version info
* ec0344a2c93c 2005-07-27 Linus Torvalds [PATCH] Documentation/Changes: document the required udev version
* eb05bfe4fbf0 2005-06-30 Linus Torvalds [PATCH] pcmcia: update Documentation
* 5085cb26503a 2005-06-27 Linus Torvalds [PATCH] pcmcia: add some Documentation
* 0c0a400d1deb 2005-06-23 Linus Torvalds [PATCH] oprofile: report anonymous region samples
* 8b0c2d989cc6 2005-05-01 Linus Torvalds [PATCH] DocBook: Use xmlto to process the DocBook files.
* 1da177e4c3f4 2005-04-16 Linus Torvalds (tag: v2.6.12-rc2) Linux-2.6.12-rc2
3.2 Kbuild编译系统
参见下列说明文档:
3.2.0 Kbuild和Makefile的关系
由Documentation/kbuild/makefiles.txt中的描述:
The preferred name for the kbuild files are ‘Makefile’ but ‘Kbuild’ can be used and if both a ‘Makefile’ and a ‘Kbuild’ file exists, then the ‘Kbuild’ file will be used.
可知,Kbuild编译系统的配置文件名为Makefile或Kbuild,若在同一个目录中同时存在Makefile和Kbuild,则优先采用Kbuild,参见scripts/Makefile.build:
# The filename Kbuild has precedence over Makefile
kbuild-dir := $(if $(filter /%,$(src)),$(src),$(srctree)/$(src))
kbuild-file := $(if $(wildcard $(kbuild-dir)/Kbuild),$(kbuild-dir)/Kbuild,$(kbuild-dir)/Makefile)
include $(kbuild-file)
运行下列命令查找同时包含Kbuild和Makefile的目录:
chenwx@chenwx ~/linux $ find . -name Makefile | xargs dirname | sort > dir_Makefile.txt
chenwx@chenwx ~/linux $ find . -name Kbuild | xargs dirname | sort > dir_Kbuild.txt
chenwx@chenwx ~/linux $ comm -12 dir_Makefile.txt dir_Kbuild.txt
.
./arch/arc
./arch/mips
./arch/s390
./arch/sparc
./arch/tile
./arch/x86
./tools/testing/nvdimm
由此可知,同时包含Makefile和Kbuild的目录仅有:
~/linux/
~/linux/arch/arc/
~/linux/arch/mips/
~/linux/arch/s390/
~/linux/arch/sparc/
~/linux/arch/tile/
~/linux/arch/x86/
其中,顶层Makefile是make直接调用的,其他的linux/$(SRCARCH)/Makefile则是通过顶层Makefile引入的:
linux/Makefile
+- include scripts/Kbuild.include
| +- build := -f $(srctree)/scripts/Makefile.build obj
+- include arch/$(SRCARCH)/Makefile
此外,还可以通过下列命令统计内核中Makefile和Kbuild文件数目(v4.9-rc1):
chenwx@chenwx ~/linux $ find . -name Makefile | wc -l
2260
chenwx@chenwx ~/linux $ find . -name Kbuild | wc -l
173
3.2.1 采用Kbuild编译系统的Linux Kernel版本
从Linux Kernel v2.6起,Linux内核的编译采用Kbuild系统。和过去的编译系统有很大的不同,尤其对于Linux内核模块的编译。在新的系统下,Linux编译系统会两次扫描Linux的Makefile:
- 首先,编译系统会读取Linux内核顶层的Makefile (通过在linux的顶层目录执行make命令来读取Makefiles);
- 然后,根据读到的内容第二次读取Kbuild的Makefile来编译Linux内核 (参见3.2.0 Kbuild和Makefile的关系节)。
3.2.1A Components of Kbuild System
The documents related to kbuild system of Linux kernel are located in directory ~/Documentation/kbuild/:
chenwx@chenwx ~/linux $ ll Documentation/kbuild/
-rw-rw-r-- 1 chenwx chenwx 427 Jul 22 20:39 00-INDEX
-rw-rw-r-- 1 chenwx chenwx 2.3K Aug 2 22:12 Kconfig.recursion-issue-01
-rw-rw-r-- 1 chenwx chenwx 2.8K Aug 2 22:12 Kconfig.recursion-issue-02
-rw-rw-r-- 1 chenwx chenwx 1.1K Aug 2 22:12 Kconfig.select-break
-rw-rw-r-- 1 chenwx chenwx 2.4K Aug 2 22:12 headers_install.txt
-rw-rw-r-- 1 chenwx chenwx 8.3K Aug 2 22:12 kbuild.txt
-rw-rw-r-- 1 chenwx chenwx 22K Aug 2 22:12 kconfig-language.txt
-rw-rw-r-- 1 chenwx chenwx 8.7K Jul 22 20:39 kconfig.txt
-rw-rw-r-- 1 chenwx chenwx 47K Aug 2 22:12 makefiles.txt
-rw-rw-r-- 1 chenwx chenwx 17K Jul 22 20:39 modules.txt
The kbuild system of Linux kernel includes the following items:
3.2.1A.1 Top Makefile
The top Makefile is included in the root directory of Linux kernel repository:
chenwx@chenwx ~/linux $ ll Makefile
-rw-rw-r-- 1 chenwx chenwx 57K Jul 22 20:40 Makefile
We alway input make commands in the root directory of Linux kernel repository, that’s the top Makefile is the main entry point of kbuild system.
Refer to section Appendix A: Makefile Tree.
3.2.1A.2 Sub-Makefile
There is one Makefile in each sub-directory of ~/linux. Currently, the number is 2211 in kernel v4.7.2:
chenwx@chenwx ~/linux $ find . -name Makefile | wc -l
2211
And there maybe one Kbuild file in some sub-directories:
chenwx@chenwx ~/linux $ find . -name Kbuild | wc -l
173
3.2.1A.3 Makefile Scripts
Some support scripts of kbuild system are located in directory scripts/:
chenwx@chenwx ~/linux $ ll scripts/Kbuild.include
-rw-rw-r-- 1 chenwx chenwx 15K Aug 14 09:20 scripts/Kbuild.include
chenwx@chenwx ~/linux $ ll scripts/Makefile*
-rw-rw-r-- 1 chenwx chenwx 1.8K Jul 22 20:39 scripts/Makefile
-rw-rw-r-- 1 chenwx chenwx 683 Jul 22 20:39 scripts/Makefile.asm-generic
-rw-rw-r-- 1 chenwx chenwx 15K Jul 22 20:40 scripts/Makefile.build
-rw-rw-r-- 1 chenwx chenwx 2.9K Jul 22 20:39 scripts/Makefile.clean
-rw-rw-r-- 1 chenwx chenwx 1.3K Jul 22 20:39 scripts/Makefile.dtbinst
-rw-rw-r-- 1 chenwx chenwx 2.6K Jul 22 20:39 scripts/Makefile.extrawarn
-rw-rw-r-- 1 chenwx chenwx 2.1K Jul 22 20:39 scripts/Makefile.fwinst
-rw-rw-r-- 1 chenwx chenwx 4.7K Jul 22 20:39 scripts/Makefile.headersinst
-rwxrwxrwx 1 chenwx chenwx 68 Jul 22 04:32 scripts/Makefile.help
-rw-rw-r-- 1 chenwx chenwx 4.6K Jul 22 20:39 scripts/Makefile.host
-rw-rw-r-- 1 chenwx chenwx 934 Jul 22 20:39 scripts/Makefile.kasan
-rw-rw-r-- 1 chenwx chenwx 15K Jul 22 20:40 scripts/Makefile.lib
-rwxrwxrwx 1 chenwx chenwx 1.8K Jul 22 04:32 scripts/Makefile.modbuiltin
-rw-rw-r-- 1 chenwx chenwx 1.3K Jul 22 20:39 scripts/Makefile.modinst
-rw-rw-r-- 1 chenwx chenwx 5.3K Jul 22 20:39 scripts/Makefile.modpost
-rw-rw-r-- 1 chenwx chenwx 1005 Jul 22 20:39 scripts/Makefile.modsign
-rw-rw-r-- 1 chenwx chenwx 1.1K Jul 22 20:39 scripts/Makefile.ubsan
Those Makefile scripts are included in the top Makefile, and come into being a tree with Makefile, refer to Appendix A: Makefile Tree.
3.2.2 Kbuild编译系统概述
3.2.2.1 编译进内核/$(obj-y)
Kbuild Makefile规定所有编译进内核的目标文件都保存在$(obj-y)列表中,而该列表依赖于内核的配置。Kbuild编译$(obj-y)列表中的所有文件。然后,调用”$(LD) -r”将它们连接到*/build-in.o,该类文件会被顶层Makefile链接进vmlinux中。
NOTE: 在Documentation/kbuild/makefiles.txt中,包含下列描述:
The order of files in $(obj-y) is significant. Duplicates in the lists are allowed: the first instance will be linked into built-in.o and succeeding instances will be ignored.
由此可知,$(obj-y)中文件的顺序是重要的!
如何确定$(obj-y)中文件的顺序?
可以根据下列几个方面来确定$(obj-y)中文件的顺序:
1) 确定目录及其子目录的编译顺序,参见3.2.2.4 递归访问下级目录节和Appendix B: make -f scripts/Makefile.build obj=列表节;
2) 根据该目录中的Makefile及配置文件.config来确定该目录下文件的编译顺序。例如linux/fs/ext2/Makefile,根据宏CONFIG_EXT2_*的取值就可以确定文件的编译顺序了:
obj-$(CONFIG_EXT2_FS) += ext2.o
ext2-y := balloc.o dir.o file.o ialloc.o inode.o \
ioctl.o namei.o super.o symlink.o
ext2-$(CONFIG_EXT2_FS_XATTR) += xattr.o xattr_user.o xattr_trusted.o
ext2-$(CONFIG_EXT2_FS_POSIX_ACL) += acl.o
ext2-$(CONFIG_EXT2_FS_SECURITY) += xattr_security.o
3.2.2.2 编译成模块/$(obj-m)
模块可以通过insmod命令加载。$(obj-m)列举出了哪些文件要编译成可加载模块。一个模块可以由一个或多个文件编译而成。如果是一个源文件,Kbuild Makefile只需简单的将其加到$(obj-m)中去就可以了。如果内核模块是由多个源文件编译而成,那就要采用下列方法声明所要编译的模块:
#drivers/isdn/i4l/Makefile
obj-$(CONFIG_FOO) += isdn.o
isdn-objs := isdn_net_lib.o isdn_v110.o isdn_common.o
Kbuild需要知道所编译的模块是基于哪些源文件,所以需要通过变量$(<module_name>-objs)来告诉它。在本例中,isdn是模块名,Kbuild将编译在$(isdn-objs)中列出的所有文件,然后使用”$(LD) -r”生成isdn.o。
NOTE: 上述语法同样适用于将源文件编译进内核。
3.2.2.3 编译成库文件/$(lib-y)/$(lib-m)
在$(lib-y)中列出的文件用来编译成该目录下的一个库文件lib.a,例如lib/lib.a和arch/x86/lib/lib.a。通常,$(lib-y)用于lib/和arch/*/lib目录。
在$(obj-y)与$(lib-y)中同时列出的文件,因为该文件在内核和库文件中都是可以访问的,所以该文件是不会被包含在库文件中的。在$(lib-m)中的文件就要包含在lib.a库文件中。参见scripts/Makefile.lib:
# Figure out what we need to build from the various variables
# ===========================================================================
# When an object is listed to be built compiled-in and modular,
# only build the compiled-in version
obj-m := $(filter-out $(obj-y),$(obj-m))
# Libraries are always collected in one lib file.
# Filter out objects already built-in
lib-y := $(filter-out $(obj-y), $(sort $(lib-y) $(lib-m)))
NOTE: Kbuild Makefile可以同时列出要编译进内核的文件和要编译成库的文件。所以,在一个目录里可以同时存在built-in.o和lib.a两个文件,例如由checksum.o和delay.o两个文件创建一个库文件lib.a:
#arch/x86/lib/Makefile
lib-y := chechsum.o delay.o
为了让Kbuild真正认识到这里要有一个库文件lib.a要创建,其所在的目录要加到$(libs-y)列表中,参见顶层Makefile:
libs-y := lib/
libs-y1 := $(patsubst %/, %/lib.a, $(libs-y))
libs-y2 := $(patsubst %/, %/built-in.o, $(libs-y))
libs-y := $(libs-y1) $(libs-y2)
vmlinux-main := $(core-y) $(libs-y) $(drivers-y) $(net-y)
此外,可以使用下列命令查看lib.a中包含的目标文件:
chenwx@chenwx ~/linux $ objdump -a lib/lib.a
In archive lib/lib.a:
argv_split.o: file format elf32-i386
rw-r--r-- 0/0 1708 Jan 1 02:00 1970 argv_split.o
bug.o: file format elf32-i386
rw-r--r-- 0/0 2256 Jan 1 02:00 1970 bug.o
cmdline.o: file format elf32-i386
rw-r--r-- 0/0 1936 Jan 1 02:00 1970 cmdline.o
...
chenwx@chenwx ~/linux $ readelf -A lib/lib.a
File: lib/lib.a(argv_split.o)
File: lib/lib.a(bug.o)
File: lib/lib.a(cmdline.o)
...
3.2.2.4 递归访问下级目录
一个Kbuild Makefile只对编译所在目录的对象负责。在子目录中文件的编译要由其所在子目录中的Makefile来管理。只要让Kbuild知道它应该递归操作,那么该系统就会在其子目录中自动的调用make递归操作,这就是$(obj-y)和$(obj-m)的作用。例如,ext2被放的一个单独的目录下,在fs目录下的Makefile会告诉Kbuild使用下面的赋值进行向下递归操作:
# fs/Makefile
obj-$(CONFIG_EXT2_FS) += ext2/
如果CONFIG_EXT2_FS被设置为’y’(编译进内核)或是’m’(编译成模块),相应的obj-变量就会被设置,故Kbuild就会递归向下访问ext2目录。Kbuild只是用这些信息来决定是否需要访问该目录,而具体怎么编译由该目录中的Makefile来决定,参见3.4.2.1.3.1.1.1.2 编译$(obj)下的子目录节。
NOTE: 将CONFIG_变量设置成目录名是一个好的编程习惯,这让Kbuild在完全忽略那些相应的CONFIG_值不是’y’和’m’的目录。
3.2.2.5 编译标志
Kbuild编译系统中用到的编译标志包括:
EXTRA_CFLAGS // 用$(CC)编译C源文件时的选项
EXTRA_AFLAGS // 针对每个目录的选项,只不过它是用来编译汇编源代码的
EXTRA_LDFLAGS
EXTRA_ARFLAGS
CFLAGS_$@ // 是$(CC)针对每个文件的选项,而不是目录。$@ 表明了具体操作的文件
AFLAGS_$@
这些EXTRA_开头的大写字母变量都是编译标志,所有的EXTRA_变量只在所定义的Kbuild Makefile中起作用。EXTRA_变量可以在Kbuild Makefile中所有命令中使用。
参见Documentation/kbuild/makefiles.txt 第3.7 Compilation flags节:
--- 3.7 Compilation flags
ccflags-y, asflags-y and ldflags-y
These three flags apply only to the kbuild makefile in which they
are assigned. They are used for all the normal cc, as and ld
invocations happening during a recursive build.
Note: Flags with the same behaviour were previously named:
EXTRA_CFLAGS, EXTRA_AFLAGS and EXTRA_LDFLAGS.
They are still supported but their usage is deprecated.
ccflags-y specifies options for compiling with $(CC).
Example:
# drivers/acpi/acpica/Makefile
ccflags-y := -Os -D_LINUX -DBUILDING_ACPICA
ccflags-$(CONFIG_ACPI_DEBUG) += -DACPI_DEBUG_OUTPUT
This variable is necessary because the top Makefile owns the
variable $(KBUILD_CFLAGS) and uses it for compilation flags for the
entire tree.
asflags-y specifies options for assembling with $(AS).
Example:
#arch/sparc/kernel/Makefile
asflags-y := -ansi
ldflags-y specifies options for linking with $(LD).
Example:
#arch/cris/boot/compressed/Makefile
ldflags-y += -T $(srctree)/$(src)/decompress_$(arch-y).lds
subdir-ccflags-y, subdir-asflags-y
The two flags listed above are similar to ccflags-y and asflags-y.
The difference is that the subdir- variants have effect for the kbuild
file where they are present and all subdirectories.
Options specified using subdir-* are added to the commandline before
the options specified using the non-subdir variants.
Example:
subdir-ccflags-y := -Werror
CFLAGS_$@, AFLAGS_$@
CFLAGS_$@ and AFLAGS_$@ only apply to commands in current
kbuild makefile.
$(CFLAGS_$@) specifies per-file options for $(CC). The $@
part has a literal value which specifies the file that it is for.
Example:
# drivers/scsi/Makefile
CFLAGS_aha152x.o = -DAHA152X_STAT -DAUTOCONF
CFLAGS_gdth.o = # -DDEBUG_GDTH=2 -D__SERIAL__ -D__COM2__ \
-DGDTH_STATISTICS
These two lines specify compilation flags for aha152x.o and gdth.o.
$(AFLAGS_$@) is a similar feature for source files in assembly
languages.
Example:
# arch/arm/kernel/Makefile
AFLAGS_head.o := -DTEXT_OFFSET=$(TEXT_OFFSET)
AFLAGS_crunch-bits.o := -Wa,-mcpu=ep9312
AFLAGS_iwmmxt.o := -Wa,-mcpu=iwmmxt
3.2.3 Make命令
make命令:
# make help // 帮助信息,参见下表
# make V=1 // 输出详细命令,默认V=0
# make -n // 仅打印出要执行的命令,并不进行实际编译
# make -j4 // 可加快编译速度
对于kernel v3.18而言,make help打印下列帮助信息:
chenwx@chenwx ~/linux $ make help
Cleaning targets:
clean - Remove most generated files but keep the config and
enough build support to build external modules
mrproper - Remove all generated files + config + various backup files
distclean - mrproper + remove editor backup and patch files
Configuration targets:
config - Update current config utilising a line-oriented program
nconfig - Update current config utilising a ncurses menu based program
menuconfig - Update current config utilising a menu based program
xconfig - Update current config utilising a QT based front-end
gconfig - Update current config utilising a GTK based front-end
oldconfig - Update current config utilising a provided .config as base
localmodconfig - Update current config disabling modules not loaded
localyesconfig - Update current config converting local mods to core
silentoldconfig - Same as oldconfig, but quietly, additionally update deps
defconfig - New config with default from ARCH supplied defconfig
savedefconfig - Save current config as ./defconfig (minimal config)
allnoconfig - New config where all options are answered with no
allyesconfig - New config where all options are accepted with yes
allmodconfig - New config selecting modules when possible
alldefconfig - New config with all symbols set to default
randconfig - New config with random answer to all options
listnewconfig - List new options
olddefconfig - Same as silentoldconfig but sets new symbols to their default value
kvmconfig - Enable additional options for guest kernel support
tinyconfig - Configure the tiniest possible kernel
Other generic targets:
all - Build all targets marked with [*]
* vmlinux - Build the bare kernel
* modules - Build all modules
modules_install - Install all modules to INSTALL_MOD_PATH (default: /)
firmware_install - Install all firmware to INSTALL_FW_PATH
(default: $(INSTALL_MOD_PATH)/lib/firmware)
dir/ - Build all files in dir and below
dir/file.[oisS] - Build specified target only
dir/file.lst - Build specified mixed source/assembly target only
(requires a recent binutils and recent build (System.map))
dir/file.ko - Build module including final link
modules_prepare - Set up for building external modules
tags/TAGS - Generate tags file for editors
cscope - Generate cscope index
gtags - Generate GNU GLOBAL index
kernelrelease - Output the release version string (use with make -s)
kernelversion - Output the version stored in Makefile (use with make -s)
image_name - Output the image name (use with make -s)
headers_install - Install sanitised kernel headers to INSTALL_HDR_PATH
(default: ./usr)
Static analysers
checkstack - Generate a list of stack hogs
namespacecheck - Name space analysis on compiled kernel
versioncheck - Sanity check on version.h usage
includecheck - Check for duplicate included header files
export_report - List the usages of all exported symbols
headers_check - Sanity check on exported headers
headerdep - Detect inclusion cycles in headers
coccicheck - Check with Coccinelle.
Kernel selftest
kselftest - Build and run kernel selftest (run as root)
Build, install, and boot kernel before
running kselftest on it
Kernel packaging:
rpm-pkg - Build both source and binary RPM kernel packages
binrpm-pkg - Build only the binary kernel package
deb-pkg - Build the kernel as a deb package
tar-pkg - Build the kernel as an uncompressed tarball
targz-pkg - Build the kernel as a gzip compressed tarball
tarbz2-pkg - Build the kernel as a bzip2 compressed tarball
tarxz-pkg - Build the kernel as a xz compressed tarball
perf-tar-src-pkg - Build perf-3.18.0.tar source tarball
perf-targz-src-pkg - Build perf-3.18.0.tar.gz source tarball
perf-tarbz2-src-pkg - Build perf-3.18.0.tar.bz2 source tarball
perf-tarxz-src-pkg - Build perf-3.18.0.tar.xz source tarball
Documentation targets:
Linux kernel internal documentation in different formats:
htmldocs - HTML
pdfdocs - PDF
psdocs - Postscript
xmldocs - XML DocBook
mandocs - man pages
installmandocs - install man pages generated by mandocs
cleandocs - clean all generated DocBook files
Architecture specific targets (x86):
* bzImage - Compressed kernel image (arch/x86/boot/bzImage)
install - Install kernel using
(your) ~/bin/installkernel or
(distribution) /sbin/installkernel or
install to $(INSTALL_PATH) and run lilo
fdimage - Create 1.4MB boot floppy image (arch/x86/boot/fdimage)
fdimage144 - Create 1.4MB boot floppy image (arch/x86/boot/fdimage)
fdimage288 - Create 2.8MB boot floppy image (arch/x86/boot/fdimage)
isoimage - Create a boot CD-ROM image (arch/x86/boot/image.iso)
bzdisk/fdimage*/isoimage also accept:
FDARGS="..." arguments for the booted kernel
FDINITRD=file initrd for the booted kernel
i386_defconfig - Build for i386
x86_64_defconfig - Build for x86_64
make V=0|1 [targets] 0 => quiet build (default), 1 => verbose build
make V=2 [targets] 2 => give reason for rebuild of target
make O=dir [targets] Locate all output files in "dir", including .config
make C=1 [targets] Check all c source with $CHECK (sparse by default)
make C=2 [targets] Force check of all c source with $CHECK
make RECORDMCOUNT_WARN=1 [targets] Warn about ignored mcount sections
make W=n [targets] Enable extra gcc checks, n=1,2,3 where
1: warnings which may be relevant and do not occur too often
2: warnings which occur quite often but may still be relevant
3: more obscure warnings, can most likely be ignored
Multiple levels can be combined with W=12 or W=123
Execute "make" or "make all" to build all targets marked with [*]
For further info see the ./README file
3.3 内核配置
内核版本号由顶层Makefile中的下列变量决定的:
VERSION = 3
PATCHLEVEL = 2
SUBLEVEL = 0
EXTRAVERSION =
# Read KERNELRELEASE from include/config/kernel.release (if it exists)
KERNELRELEASE = $(shell cat include/config/kernel.release 2> /dev/null)
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
可以更改EXTRAVERSION的取值来定义自己的版本号。例如,EXTRAVERSION = -chenwx,则新内核的版本号为3.2.0-chenwx,可通过下列命令查看:
chenwx@chenwx ~/linux $ make kernelrelease
scripts/kconfig/conf --silentoldconfig Kconfig
3.2.1-chenwx
3.3.0 Create Output Directory
It’s better to build Linux kernel on a directory outside of local kernel repository, such as ~/linux-build. In order to use another directory to build Linux kernel, the repository should be clean up:
chenwx@chenwx ~/linux $ make distclean
chenwx@chenwx ~/linux $ mkdir ../linux-build
And then, use parameter O=../linux-build/ in each make command later, such as configure Linux kernel:
chenwx@chenwx ~/linux $ make O=../linux-build/ menuconfig
3.3.1 make config
执行make config的流程:
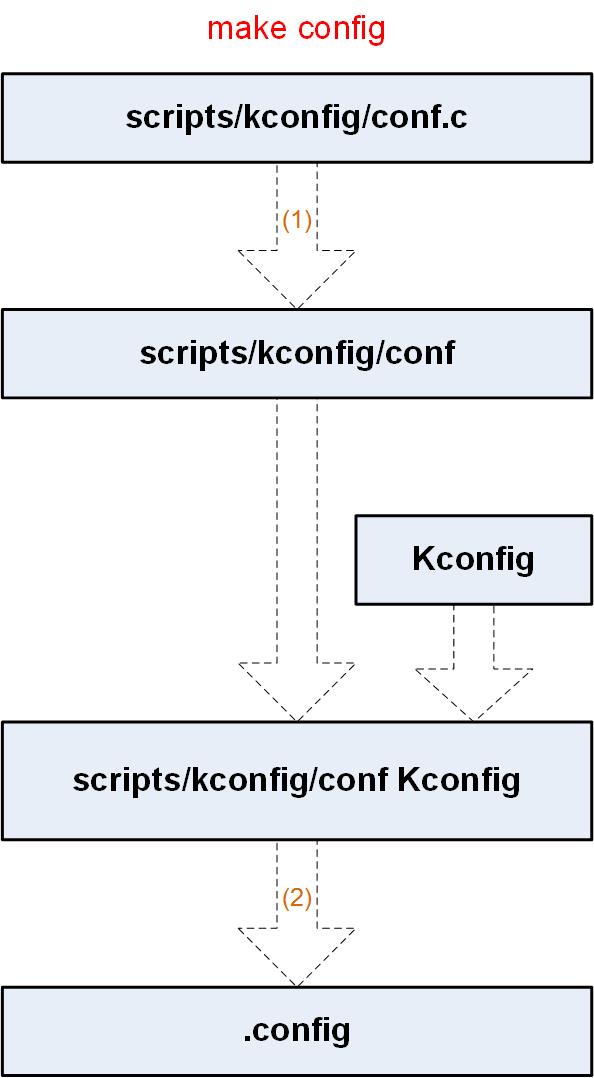
执行make config命令,会调用顶层Makefile中的config目标:
// 定义$(build)变量
include $(srctree)/scripts/Kbuild.include
// 目标config参见[3.3.1.3 config]节
config: scripts_basic outputmakefile FORCE
// 创建目录
$(Q)mkdir -p include/linux include/config
/*
* $(build)定义于scripts/Kbuild.include
* 扩展为 $(MAKE) -f scripts/Makefile.build obj=scripts/kconfig config
*/
$(Q)$(MAKE) $(build)=scripts/kconfig $@
// 编译script/basic/fixdep,参见[3.3.1.1 scripts_basic]节
scripts_basic:
// 扩展为 $(MAKE) -f scripts/Makefile.build obj=scripts/basic
$(Q)$(MAKE) $(build)=scripts/basic
$(Q)rm -f .tmp_quiet_recordmcount
// 参见[3.3.1.2 outputmakefile]节
outputmakefile:
ifneq ($(KBUILD_SRC),)
$(Q)ln -fsn $(srctree) source
// 执行脚本scripts/mkmakefile,用于在$(objtree)指定的目录中生成Makefile
$(Q)$(CONFIG_SHELL) $(srctree)/scripts/mkmakefile \
$(srctree) $(objtree) $(VERSION) $(PATCHLEVEL)
endif
// 因为本规则没有依赖,目标FORCE总会被认为是最新的,所以规则中定义的命令总会被执行
FORCE:
3.3.1.1 scripts_basic
在顶层Makefile中,包含下列规则:
// 定义$(build)变量
include $(srctree)/scripts/Kbuild.include
// 编译scripts/basic/fixdep
scripts_basic:
$(Q)$(MAKE) $(build)=scripts/basic
$(Q)rm -f .tmp_quiet_recordmcount // 参见scripts/recordmcount.pl
$(build)定义于scripts/Kbuild.include:
build := -f $(if $(KBUILD_SRC),$(srctree)/)scripts/Makefile.build obj
因此,$(Q)$(MAKE) $(build)=scripts/basic被扩展为:
$(Q)$(MAKE) -f scripts/Makefile.build obj=scripts/basic
该命令用于编译scripts/basic目录。由于未指定编译目标,故编译scripts/Makefile.build中的默认目标__build:
PHONY := __build
__build:
...
__build: $(if $(KBUILD_BUILTIN),$(builtin-target) $(lib-target) $(extra-y)) \
$(if $(KBUILD_MODULES),$(obj-m) $(modorder-target)) \
$(subdir-ym) $(always)
@:
而其中的$(always)则是由scripts/basic/Makefile引入的。
首先,scripts/Makefile.build中的下列语句将scripts/basic/Makefile包含进来:
// 扩展为kbuild-dir := script/basic
kbuild-dir := $(if $(filter /%,$(src)),$(src),$(srctree)/$(src))
// 扩展为kbuild-file := script/basic/Makefile
kbuild-file := $(if $(wildcard $(kbuild-dir)/Kbuild),$(kbuild-dir)/Kbuild,$(kbuild-dir)/Makefile)
// 此处将script/basic/Makefile包含进来
include $(kbuild-file)
其次,根据scripts/basic/Makefile中的规则:
hostprogs-y := fixdep
always := $(hostprogs-y)
# fixdep is needed to compile other host programs
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
可知,$(always)的取值为fixdep。
那么,fixdep是如何被编译出来的呢?
1) scripts/Makefile.build中的下列语句将scripts/Makefile.host包含进来:
# Do not include host rules unless needed
// 由scripts/basic/Makefile可知,$(hostprogs-y)=fixdep
ifneq ($(hostprogs-y)$(hostprogs-m),)
include scripts/Makefile.host
endif
2) 在scripts/Makefile.host中,包含下列编译fixdep的规则:
// 扩展为__hostprogs := fixdep
__hostprogs := $(sort $(hostprogs-y) $(hostprogs-m))
# C code
# Executables compiled from a single .c file
// 扩展为host-csingle := fixdep
host-csingle := $(foreach m,$(__hostprogs),$(if $($(m)-objs),,$(m)))
// 扩展为host-csingle := scripts/basic/fixdep
host-csingle := $(addprefix $(obj)/,$(host-csingle))
# Create executable from a single .c file
# host-csingle -> Executable
quiet_cmd_host-csingle = HOSTCC $@
cmd_host-csingle = $(HOSTCC) $(hostc_flags) -o $@ $< \
$(HOST_LOADLIBES) $(HOSTLOADLIBES_$(@F))
// 此处的%为fixdep,故fixdep由fixdep.c编译而来的
$(host-csingle): $(obj)/%: $(src)/%.c FORCE
// 调用cmd_host-csingle来实际编译fixdep
$(call if_changed_dep,host-csingle)
NOTE: 在linux-2.6.18中,script/basic目录中包含两个程序:fixdep, docproc。
3.3.1.2 outputmakefile
在顶层Makefile中,包含下列规则:
outputmakefile:
// 由命令行中传入该参数,如make -f ../linux/Makefile KBUILD_SRC=../linux/ config
ifneq ($(KBUILD_SRC),)
$(Q)ln -fsn $(srctree) source // source链接到KBUILD_SRC所代表的目录
$(Q)$(CONFIG_SHELL) $(srctree)/scripts/mkmakefile \
$(srctree) $(objtree) $(VERSION) $(PATCHLEVEL) // $(objtree)为执行make命令时的当前目录
endif
该规则执行脚本scripts/mkmakefile,在输出目录$(objtree)中生成Makefile文件,以便于在目录$(objtree)中直接执行make命令即可编译内核。
举例,假设目录结构如下:
~/
+- linux/ // 包含linux 3.2版本的内核源代码
+- linux-build/ // 输出目录
在~/linux/目录执行下列命令:
chenwx@chenwx ~/linux $ mkdir ../linux-build
chenwx@chenwx ~/linux $ make O=../linux-build/ outputmakefile
HOSTCC scripts/basic/fixdep
GEN /home/chenwx/linux-build/Makefile
HOSTCC scripts/kconfig/conf.o
SHIPPED scripts/kconfig/zconf.tab.c
SHIPPED scripts/kconfig/zconf.lex.c
SHIPPED scripts/kconfig/zconf.hash.c
HOSTCC scripts/kconfig/zconf.tab.o
HOSTLD scripts/kconfig/conf
scripts/kconfig/conf --silentoldconfig Kconfig
***
*** Configuration file ".config" not found!
***
*** Please run some configurator (e.g. "make oldconfig" or
*** "make menuconfig" or "make xconfig").
***
/home/chenwx/linux/scripts/kconfig/Makefile:33: recipe for target 'silentoldconfig' failed
make[3]: *** [silentoldconfig] Error 1
/home/chenwx/linux/Makefile:492: recipe for target 'silentoldconfig' failed
make[2]: *** [silentoldconfig] Error 2
GEN /home/chenwx/linux-build/Makefile
则会在~/linux-build/目录中生成Makefile文件,以后直接在~/linux-build/目录执行make命令就可编译内核了。生成的Makefile如下:
# Automatically generated by /home/chenwx/linux/scripts/mkmakefile: don't edit
VERSION = 3
PATCHLEVEL = 2
lastword = $(word $(words $(1)),$(1))
makedir := $(dir $(call lastword,$(MAKEFILE_LIST)))
ifeq ("$(origin V)", "command line")
VERBOSE := $(V)
endif
ifneq ($(VERBOSE),1)
Q := @
endif
MAKEARGS := -C /home/chenwx/linux
MAKEARGS += O=$(if $(patsubst /%,,$(makedir)),$(CURDIR)/)$(patsubst %/,%,$(makedir))
MAKEFLAGS += --no-print-directory
.PHONY: all $(MAKECMDGOALS)
all := $(filter-out all Makefile,$(MAKECMDGOALS))
all:
$(Q)$(MAKE) $(MAKEARGS) $(all)
Makefile:;
$(all): all
@:
%/: all
@:
那么,在~/linux-build/目录执行make config命令时,其执行过程是怎样的呢?
1) 根据~/linux-build/Makefile中的规则,执行make config命令时,实际执行下列规则:
all:
$(Q)$(MAKE) $(MAKEARGS) $(all)
该规则被扩展为:
make -C /home/chenwx/linux O=/home/chenwx/linux-build/ config
2) 根据顶层Makefile中的下列规则,继而执行其中的sub-make规则:
ifneq ($(KBUILD_OUTPUT),)
# Invoke a second make in the output directory, passing relevant variables
# check that the output directory actually exists
saved-output := $(KBUILD_OUTPUT)
KBUILD_OUTPUT := $(shell cd $(KBUILD_OUTPUT) && /bin/pwd)
$(if $(KBUILD_OUTPUT),, \
$(error output directory "$(saved-output)" does not exist))
PHONY += $(MAKECMDGOALS) sub-make
$(filter-out _all sub-make $(CURDIR)/Makefile, $(MAKECMDGOALS)) _all: sub-make
$(Q)@:
sub-make: FORCE
$(if $(KBUILD_VERBOSE:1=),@)$(MAKE) -C $(KBUILD_OUTPUT) \
KBUILD_SRC=$(CURDIR) \
KBUILD_EXTMOD="$(KBUILD_EXTMOD)" -f $(CURDIR)/Makefile \
$(filter-out _all sub-make,$(MAKECMDGOALS))
# Leave processing to above invocation of make
skip-makefile := 1
endif # ifneq ($(KBUILD_OUTPUT),)
该规则被扩展为:
make -C /home/chenwx/linux-build/ \
KBUILD_SRC=/home/chenwx/linux \
KBUILD_EXTMOD="" -f /home/chenwx/linux-build/Makefile \
config
此后,make config的编译过程与3.3.1 make config节完全相同。
3.3.1.3 config
在顶层Makefile中,包含下列有关config的规则:
config: scripts_basic outputmakefile FORCE
$(Q)mkdir -p include/linux include/config
$(Q)$(MAKE) $(build)=scripts/kconfig $@
首先,创建两个目录:include/linux和include/config。
其次,根据scripts/Kbuild.include中对$(build)的定义:
build := -f $(if $(KBUILD_SRC),$(srctree)/)scripts/Makefile.build obj
$(Q)$(MAKE) $(build)=scripts/kconfig $@ 被扩展为:
$(Q)$(MAKE) -f scripts/Makefile.build obj=scripts/kconfig config
而scripts/Makefile.build中的下列语句将scripts/kconfig/Makefile包含进来:
// 扩展为kbuild-dir := script/kconfig
kbuild-dir := $(if $(filter /%,$(src)),$(src),$(srctree)/$(src))
// 扩展为kbuild-file := script/kconfig/Makefile
kbuild-file := $(if $(wildcard $(kbuild-dir)/Kbuild),$(kbuild-dir)/Kbuild,$(kbuild-dir)/Makefile)
// 此处将script/kconfig/Makefile包含进来
include $(kbuild-file)
因而,make config的最终目标为scripts/kconfig/Makefile中的config:
ifdef KBUILD_KCONFIG // 此处,变量KBUILD_KCONFIG未定义
Kconfig := $(KBUILD_KCONFIG)
else
Kconfig := Kconfig // 故进入本分支
endif
...
config: $(obj)/conf
$< --oldaskconfig $(Kconfig)
...
conf-objs := conf.o zconf.tab.o // conf-objs用于scripts/Makefile.host中的host-cobjs变量
...
hostprogs-y := conf
...
$(obj)/zconf.tab.o: $(obj)/zconf.lex.c $(obj)/zconf.hash.c
而config又依赖于$(obj)/conf,因此需要先编译$(obj)/conf。
那么,$(obj)/conf是如何编译链接的呢?
1) 由scripts/Makefile.host中的下列规则:
__hostprogs := $(sort $(hostprogs-y) $(hostprogs-m)) // __hostprogs := conf
...
# Object (.o) files compiled from .c files
host-cobjs := $(sort $(foreach m,$(__hostprogs),$($(m)-objs))) // host-cobjs := conf-objs
...
# Create .o file from a single .c file
# host-cobjs -> .o
quiet_cmd_host-cobjs = HOSTCC $@
cmd_host-cobjs = $(HOSTCC) $(hostc_flags) -c -o $@ $<
$(host-cobjs): $(obj)/%.o: $(src)/%.c FORCE
$(call if_changed_dep,host-cobjs) // 调用cmd_host-cobjs编译
可知,conf.o由conf.c编译而来,zconf.tab.o由zconf.lex.c和zconf.hash.c编译而来。
2) 然后再根据scripts/Makefile.host中的下列规则:
# C executables linked based on several .o files
host-cmulti := $(foreach m,$(__hostprogs),\ // host-cmulti := conf
$(if $($(m)-cxxobjs),,$(if $($(m)-objs),$(m))))
...
host-cmulti := $(addprefix $(obj)/,$(host-cmulti)) // host-cmulti := scripts/Kconfig/conf
...
# Link an executable based on list of .o files, all plain c
# host-cmulti -> executable
quiet_cmd_host-cmulti = HOSTLD $@
cmd_host-cmulti = $(HOSTCC) $(HOSTLDFLAGS) -o $@ \
$(addprefix $(obj)/,$($(@F)-objs)) \
$(HOST_LOADLIBES) $(HOSTLOADLIBES_$(@F))
$(host-cmulti): $(obj)/%: $(host-cobjs) $(host-cshlib) FORCE
$(call if_changed,host-cmulti) // 调用cmd_host-cmulti链接各.o文件生成conf
将conf.o和zconf.tab.o链接生成conf可执行文件。
在scripts/kconfig/Makefile中,目标config下的规则 $< –oldaskconfig $(Kconfig) 被扩展为: scripts/kconfig/conf –oldaskconfig Kconfig
即调用conf程序解析顶层内核配置文件Kconfig(NOTE: 顶层配置文件中又引入与体系结构有关的配置文件,参见下文),并将用户的配置结果输出到.config文件中(通过scripts\kconfig\confdata.c中的函数conf_write())。
config SRCARCH
string
option env="SRCARCH"
source "arch/$SRCARCH/Kconfig"
3.3.2 make *config
执行make *config的流程:
参见linux/README中的下列命令:
make menuconfig // Text based color menus, radiolists & dialogs
make nconfig // Enhanced text based color menus
make xconfig // X windows (Qt) based configuration tool
make gconfig // X windows (Gtk) based configuration tool
make oldconfig // Default all questions based on the contents of
// your existing ./.config file and asking about new config symbols
make localmodconfig // Update current config disabling modules not loaded
make localyesconfig // Update current config converting local mods to core
make silentoldconfig // Like “make oldconfig”, but avoids cluttering the screen
// with questions already answered. Additionally updates dependencies
make oldnoconfig // Same as silentoldconfig but sets new symbols to their default value
make defconfig // Create file .config by using the default symbol values from either
// arch/$ARCH/defconfig or arch/$ARCH/configs/${PLATFORM}_defconfig,
// depending on the architecture
Make savedefconfig // Save current config as ./defconfig (minimal config)
make ${PLATFORM}_defconfig
// Create a ./.config file by using the default symbol values from
// arch/$ARCH/configs/${PLATFORM}_defconfig. Use "make help" to get
// a list of all available platforms of your architecture
make allyesconfig // Create a ./.config file by setting symbol values to 'y' as much as possible
make allnoconfig // Create a ./.config file by setting symbol values to 'n' as much as possible
make allmodconfig // Create a ./.config file by setting symbol values to 'm' as much as possible
make alldefconfig // New config with all symbols set to default
make randconfig // Create a ./.config file by setting symbol values to random values
make listnewconfig // List new options
NOTE: 可通过执行命令make help,查看系统支持的Configuration Targets.
执行make *config命令,会调用顶层Makefile中的目标:
// 定义$(build)变量
include $(srctree)/scripts/Kbuild.include
// 下列两行与config相同,参见[3.3.1.3 config]节
%config: scripts_basic outputmakefile FORCE
$(Q)mkdir -p include/linux include/config
/*
* $(build)定义参见scripts/Kbuild.include
* $(MAKE) -f scripts/Makefile.build obj=scripts/kconfig *config
*/
$(Q)$(MAKE) $(build)=scripts/kconfig $@
// To build script/basic/fixdep,参见[3.3.1.1 scripts_basic]节
scripts_basic:
// $(Q)$(MAKE) -f scripts/Makefile.build obj=scripts/basic
$(Q)$(MAKE) $(build)=scripts/basic
$(Q)rm -f .tmp_quiet_recordmcount
// 参见[3.3.1.2 outputmakefile]节
outputmakefile:
ifneq ($(KBUILD_SRC),)
$(Q)ln -fsn $(srctree) source
// 执行scripts/mkmakefile,该脚本在$(objtree)指定的目录中生成Makefile
$(Q)$(CONFIG_SHELL) $(srctree)/scripts/mkmakefile \
$(srctree) $(objtree) $(VERSION) $(PATCHLEVEL)
endif
// 因为本规则没有依赖,目标FORCE总会被认为是最新的,所以规则中定义的命令总会被执行
FORCE:
%config: scripts_basic outputmakefile FORCE的下列语句:
$(Q)$(MAKE) $(build)=scripts/kconfig $@ // $(build)定义于scripts/Kbuild.include
被扩展后,变为:
$(Q)$(MAKE) -f scripts/Makefile.build obj=scripts/kconfig *config
而scripts/Makefile.build中的下列语句将scripts/kconfig/Makefile包含进来:
// 扩展为kbuild-dir := script/kconfig
kbuild-dir := $(if $(filter /%,$(src)),$(src),$(srctree)/$(src))
// 扩展为kbuild-file := script/kconfig/Makefile
kbuild-file := $(if $(wildcard $(kbuild-dir)/Kbuild),$(kbuild-dir)/Kbuild,$(kbuild-dir)/Makefile)
// 此处将script/kconfig/Makefile包含进来
include $(kbuild-file)
因而,make config的最终目标为scripts/kconfig/Makefile中的*config:
xconfig: $(obj)/qconf
$< $(Kconfig) // 扩展为scripts/kconfig/qconf Kconfig
gconfig: $(obj)/gconf
$< $(Kconfig) // 扩展为scripts/kconfig/gconf Kconfig
menuconfig: $(obj)/mconf
$< $(Kconfig) // 扩展为scripts/kconfig/mconf Kconfig
nconfig: $(obj)/nconf
$< $(Kconfig) // 扩展为scripts/kconfig/nconf Kconfig
oldconfig: $(obj)/conf
$< --$@ $(Kconfig) // 扩展为scripts/kconfig/conf --oldconfig Kconfig
silentoldconfig: $(obj)/conf
$(Q)mkdir -p include/generated
$< --$@ $(Kconfig) // 扩展为scripts/kconfig/conf --silentoldconfig Kconfig
allnoconfig allyesconfig allmodconfig alldefconfig randconfig: $(obj)/conf
$< --$@ $(Kconfig) // 扩展为scripts/kconfig/conf --$@ Kconfig
defconfig: $(obj)/conf
ifeq ($(KBUILD_DEFCONFIG),)
$< --defconfig $(Kconfig) // 扩展为scripts/kconfig/conf –defconfig Kconfig
else
@echo "*** Default configuration is based on '$(KBUILD_DEFCONFIG)'"
// 扩展为scripts/kconfig/conf --defconfig=arch/$(SRCARCH)/config/$(KBUILD_DEFCONFIG) Kconfig
$(Q)$< --defconfig=arch/$(SRCARCH)/configs/$(KBUILD_DEFCONFIG) $(Kconfig)
endif
%_defconfig: $(obj)/conf
// 扩展为scripts/kconfig/conf --defconfig=arch/$(SRCARCH)/configs/$@ Kconfig
$(Q)$< --defconfig=arch/$(SRCARCH)/configs/$@ $(Kconfig)
make *config的具体编译链接过程与3.3.1 make config节类似。
NOTE 1: It’s entirely possible that that existing .config you used as the basis for your configuration isn’t quite up to date; that is, it may have no entries representing extremely new features that have been added to the kernel. If that’s the case, the “make oldconfig” will stop at each one of those choices and ask you what to do. And if you’re new to building a kernel, you may not know the right answer. One solution is to just keep hitting ENTER and take the default, but that can get tedious. A faster solution is:
// two single quotes, no space between
chenwx@chenwx ~/linux $ yes '' | make oldconfig
NOTE 2: Perhaps the most useful target for beginners is defconfig (short for “default config”) which simply sets your .config to an established set of defaults for your system and architecture. And how can you see these defaults? Simple – from the top of the kernel source tree, just run following command, and you’ll see dozens of default config files for all of the kernel’s supported architectures.
chenwx@chenwx ~/linux $ find arch -name "*defconfig"
3.3.2.1 Use Old Existed Configure
In order to build Linux kernel, build it based on the old existed configure /boot/config-4.4.0-15-generic:
chenwx@chenwx ~/linux $ cp /boot/config-4.4.0-15-generic ../linux-build/.config
chenwx@chenwx ~/linux $ make O=../linux-build/ olddefconfig
make[1]: Entering directory '/home/chenwx/linux-build'
HOSTCC scripts/basic/fixdep
GEN ./Makefile
HOSTCC scripts/kconfig/conf.o
SHIPPED scripts/kconfig/zconf.tab.c
SHIPPED scripts/kconfig/zconf.lex.c
SHIPPED scripts/kconfig/zconf.hash.c
HOSTCC scripts/kconfig/zconf.tab.o
HOSTLD scripts/kconfig/conf
scripts/kconfig/conf --olddefconfig Kconfig
.config:1631:warning: symbol value 'm' invalid for RXKAD
.config:3586:warning: symbol value 'm' invalid for SERIAL_8250_FINTEK
#
# configuration written to .config
#
make[1]: Leaving directory '/home/chenwx/linux-build'
I like to use the command make menuconfig to configure linux kernel because it much more easier to use it.
3.3.3 Kconfig/内核配置选项文件
内核配置文件包括:
Kconfig
arch/$(SRCARCH)/Kconfig
...
其说明参见:
Linux Kernel中的所有Kconfig文件形成了一棵树,参见Appendix C: Kconfig tree。
3.3.4 .config/内核配置结果文件
3.3.4.1 .config的格式
在3.3.1 make config节和3.3.2 make *config节中生成的conf等配置程序读取内核配置选项文件Kconfig中的内核配置信息,并根据用户的选择,生成内核配置结果文件.config,以供后续编译内核时使用(顶层Makefile会读取该文件,参见3.3.4.2 .config如何被顶层Makefile调用节)。内核配置结果文件.config中包含下列内容:
# CONFIG_64BIT is not set
CONFIG_X86_32=y
# CONFIG_X86_64 is not set
CONFIG_X86=y
CONFIG_INSTRUCTION_DECODER=y
CONFIG_OUTPUT_FORMAT="elf32-i386"
CONFIG_ARCH_DEFCONFIG="arch/x86/configs/i386_defconfig"
CONFIG_LOCKDEP_SUPPORT=y
CONFIG_STACKTRACE_SUPPORT=y
...
3.3.4.2 .config如何被顶层Makefile调用
由3.4.2 编译bzImage/$(obj-y)节和3.4.3 编译modules/$(obj-m)节可知,在编译内核和模块时,其目标都要依赖于$(vmlinux-dirs)。而由3.4.2.1.3 $(vmlinux-dirs)节和3.4.2.1.1 prepare节可知,存在下列依赖关系:
$(vmlinux-dirs) <= prepare <= prepare0 <= archprepare <= prepare1 <= include/config/auto.conf
而由3.4.2.1.1.1 include/config/auto.conf节可知,include/config/auto.conf是由.config生成的。需要理解下列两点:
1) 执行make *config命令,将会生成配置文件.config,参见3.3.1 make config节和3.3.2 make *config节;
2) 执行make silentoldconfig命令(执行本命令的前提条件是,系统中必须已存在配置文件.config),将会同时生成下列三个文件:
include/config/auto.conf
与.config文件中的配置完全相同 (NOTE: 这两个文件中行的顺序可能不同,可通过执行下列命令来比较这两个文件的差异):
chenwx@chenwx ~/linux $ cd ../linux-build
chenwx@chenwx ~/linux-build $ sort .config > config.sort
chenwx@chenwx ~/linux-build $ sort .config > .config.sort
chenwx@chenwx ~/linux-build $ sed '/#/d' .config.sort > .config.sort.sed
chenwx@chenwx ~/linux-build $ sort include/config/auto.conf > auto.conf.sort
chenwx@chenwx ~/linux-build $ sed '/#/d' auto.conf.sort > auto.conf.sort.sed
chenwx@chenwx ~/linux-build $ diff -B .config.sort.sed auto.conf.sort.sed
chenwx@chenwx ~/linux-build $
include/config/auto.conf.cmd
本文件包含了生成配置文件include/config/auto.conf时所用到的Kconfig文件。
include/config/tristate.conf
本文件包含了include/config/auto.conf中的部分配置信息,且全为大写字母。
由于include/config/auto.conf与.config完全相同,因此顶层Makefile通过下列语句将.config包含进编译系统中(NOTE: 当include/config/auto.conf生成后,make会重新读取Makefile文件,因而可以通过该语句读取最新的include/config/auto.conf):
# Read in config
-include include/config/auto.conf;
当满足下列条件之一时:
- 不存在include/config/auto.conf时,
- .config比include/config/auto.conf要新时,
- include/config/auto.conf.cmd中包含的任意Kconfig文件比include/config/auto.conf要新时,
将调用顶层Makefile中的下列规则,创建或更新include/config/auto.conf和include/config/auto.conf.cmd文件,此时更新后的include/config/auto.conf与系统中已存在的.config文件完全相同,因而可以自动包含最新的配置:
# If .config is newer than include/config/auto.conf, someone tinkered
# with it and forgot to run make oldconfig.
# if auto.conf.cmd is missing then we are probably in a cleaned tree so
# we execute the config step to be sure to catch updated Kconfig files
include/config/%.conf: $(KCONFIG_CONFIG) include/config/auto.conf.cmd
// 扩展为make scripts/kconfig/conf --silentoldconfig
$(Q)$(MAKE) -f $(srctree)/Makefile silentoldconfig
3.4 内核编译
Linux内核的Makefile分为下列5个部分:
Makefile - 顶层Makefile
.config - 内核配置结果文件,参见[3.3.4 .config/内核配置结果文件]节
arch/$(ARCH)/Makefile - 具体架构的Makefile
scripts/Makefile.* - 通用的规则等,面向所有的Kbuild Makefiles
Kbuild Makefiles - 内核源代码中大约有500个这样的文件(文件名为Kbuild)
Makefile
The top Makefile reads the .config file, which comes from the kernel configuration process. The top Makefile is responsible for building two major products: vmlinux (the resident kernel image) and modules (any module files). It builds these goals by recursively descending into the subdirectories of the kernel source tree.
*/Kbuild
每一个子目录都有一个Kbuild Makefile文件,用来执行从其上层目录传递下来的命令。Kbuild Makefile从.config文件中提取信息,生成Kbuild完成内核编译所需的文件列表。
scripts/Makefile.*
包含了所有的定义、规则等信息。这些文件被用来编译基于Kbuild Makefile的内核。这些文件包括:
Makefile.asm-generic
Makefile.build
Makefile.clean
Makefile.fwinst
Makefile.headersinst
Makefile.help
Makefile.host
Makefile.lib
Makefile.modbuiltin
Makefile.modinst
Makefile.modpost
各Makefile之间存在调用关系,这形成了一棵树,参见Appendix A: Makefile Tree节。
3.4.1 Makefile的Default Target
根据《GNU make v3.8.2》第4.10节可知:
One file can be the target of several rules. All the prerequisites mentioned in all the rules are merged into one list of prerequisites for the target. If the target is older than any prerequisite from any rule, the recipe is executed.
There can only be one recipe to be executed for a file. If more than one rule gives a recipe for the same file, make uses the last one given and prints an error message. (As a special case, if the file’s name begins with a dot, no error message is printed. This odd behavior is only for compatibility with other implementations of make - you should avoid using it). Occasionally it is useful to have the same target invoke multiple recipes which are defined in different parts of your makefile; you can use double-colon rules for this.
顶层Makefile及其包含的Makefile,包含如下规则:
1) 来自顶层Makefile
# That's our default target when none is given on the command line
PHONY := _all
_all:
# If building an external module we do not care about the all: rule
# but instead _all depend on modules
PHONY += all
/*
* 若仅执行make命令,则$(KBUILD_EXTMOD)为空
* 若执行make M=dir或make ... SUBDIRS=$PWD命令,则$(KBUILD_EXTMOD)不为空
*/
ifeq ($(KBUILD_EXTMOD),)
_all: all // 若仅执行make命令,则进入本分支
else
_all: modules // 若执行make M=dir或make ... SUBDIRS=$PWD命令,则进入本分支
endif
// 以x86体系为例,此处为include arch/x86/Makefile,其中包含all: bzImage,如下
include $(srctree)/arch/$(SRCARCH)/Makefile
2) 来自arch/x86/Makfile
# Default kernel to build
all: bzImage
3) 来自顶层Makefile
// 该目标被arch/x86/Makefile中的目标all: bzImage覆盖
all: vmlinux
ifdef CONFIG_MODULES
# By default, build modules as well
all: modules
else # CONFIG_MODULES
...
endif # CONFIG_MODULES
由上述规则可知:
- 执行make命令时,调用顶层Makefile中的目标_all,目标_all依赖于目标all,而目标all又依次依赖于目标bzImage、vmlinux和modules。即执行make命令时,将依次执行目标bzImage、vmlinux和modules,因而生成下列文件:
vmlinux
System.map
arch/x86/boot/bzImage
arch/i386/boot/bzImage // link to ./arch/x86/boot/bzImage
<oneDir>/<twoDir>/*.ko // modules
arch/x86/lib/lib.a // library
lib/lib.a // library
- 执行make vmlinux命令,编译顶层Makefile中的目标vmlinux,参见3.4.2 编译bzImage/$(obj-y)节。生成下列文件:
vmlinux
- 执行make modules命令,编译顶层Makefile中的目标modules,参见3.4.3 编译modules/$(obj-m)节。生成下列文件:
<oneDir>/<twoDir>/*.ko // modules
- 执行下列命令之一来编译外部模块,参见3.4.4 编译external modules节:
# make -C <kernel_src_dir> M=<ext_module_dir> modules
# make -C <kernel_src_dir> SUBDIRS=$PWD modules
NOTE: KBUILD_EXTMOD称为Kbuild扩展模式,若执行命令make M=dir,则变量KBUILD_EXTMOD被置为dir,继而执行下列规则:
# That's our default target when none is given on the command line
PHONY := _all
_all:
# If building an external module we do not care about the all: rule
# but instead _all depend on modules
PHONY += all
ifeq ($(KBUILD_EXTMOD),) // 此时,$(KBUILD_EXTMOD)=dir
_all: all
else
_all: modules // 进入此分支
endif
执行依赖于modules的代码,就相当于执行make modules。这个make方法也是用来提高驱动开发效率,如果只想编译某个具体的驱动,只要指定对应的子目录,就可以只编译这个驱动而不去编译其他的内核代码了。
执行make命令时,各目标的依赖关系:
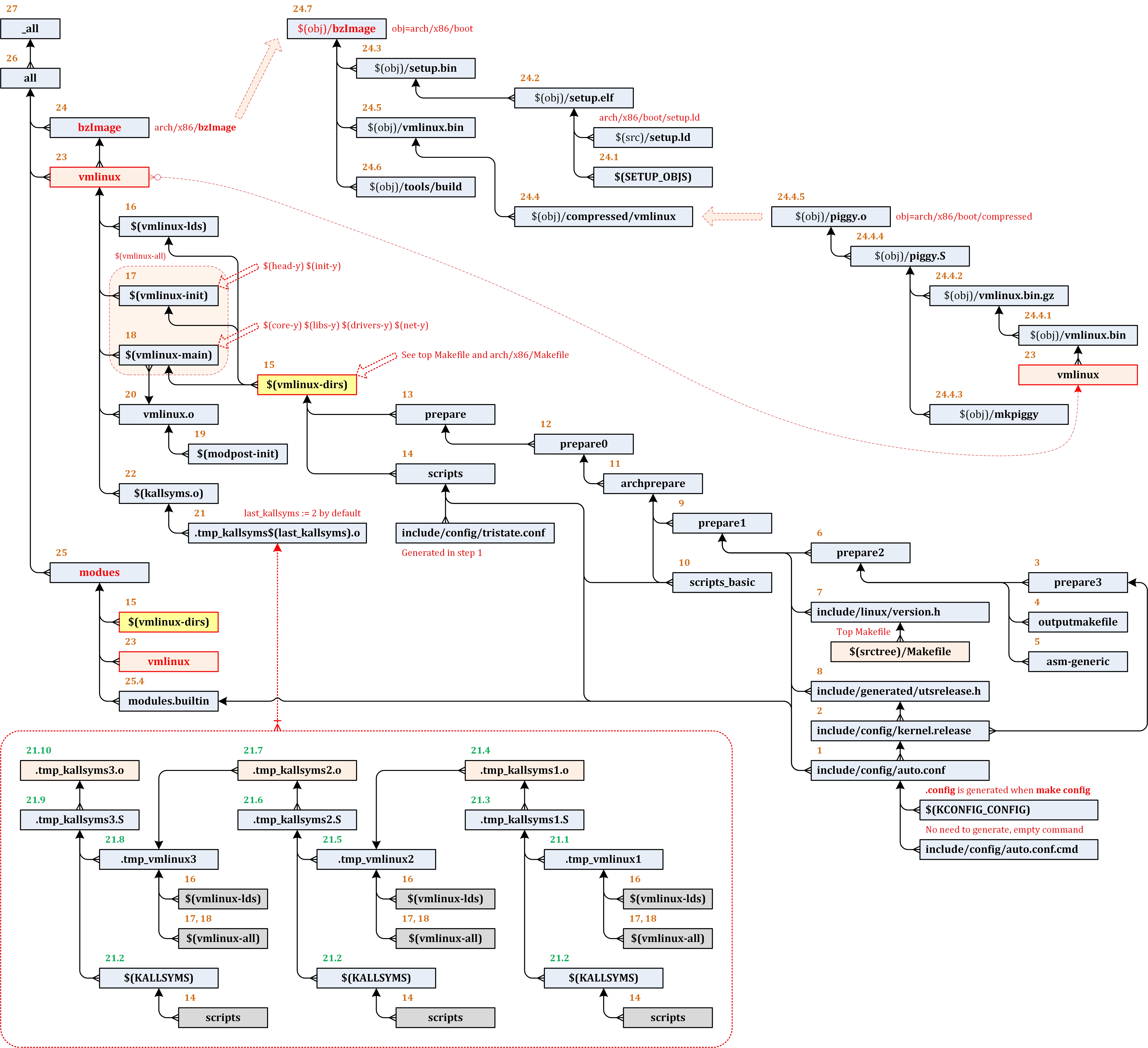
上图中的数字表示对应目标的生成顺序。
3.4.2 编译bzImage/$(obj-y)
在arch/x86/Makefile中,包含下列规则:
boot := arch/x86/boot
# Default kernel to build
all: bzImage
# KBUILD_IMAGE specify target image being built
KBUILD_IMAGE := $(boot)/bzImage
bzImage: vmlinux
ifeq ($(CONFIG_X86_DECODER_SELFTEST),y)
$(Q)$(MAKE) $(build)=arch/x86/tools posttest
endif
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
在顶层Makefile中,包含下列规则:
vmlinux: $(vmlinux-lds) $(vmlinux-init) $(vmlinux-main) vmlinux.o $(kallsyms.o) FORCE
ifdef CONFIG_HEADERS_CHECK
$(Q)$(MAKE) -f $(srctree)/Makefile headers_check
endif
ifdef CONFIG_SAMPLES
$(Q)$(MAKE) $(build)=samples
endif
ifdef CONFIG_BUILD_DOCSRC
$(Q)$(MAKE) $(build)=Documentation
endif
$(call vmlinux-modpost)
$(call if_changed_rule,vmlinux__)
$(Q)rm -f .old_version
...
vmlinux-lds := arch/$(SRCARCH)/kernel/vmlinux.lds
vmlinux-init := $(head-y) $(init-y)
vmlinux-main := $(core-y) $(libs-y) $(drivers-y) $(net-y)
vmlinux-all := $(vmlinux-init) $(vmlinux-main)
...
vmlinux.o : $(modpost-init) $(vmlinux-main) FORCE
modpost-init := $(filter-out init/built-in.o, $(vmlinux-init))
...
kallsyms.o := .tmp_kallsyms$(last_kallsyms).o // last_kallsyms := 2 or 3
...
# The actual objects are generated when descending,
# make sure no implicit rule kicks in
$(sort $(vmlinux-init) $(vmlinux-main)) $(vmlinux-lds): $(vmlinux-dirs) ;
...
PHONY += $(vmlinux-dirs)
$(vmlinux-dirs): prepare scripts
$(Q)$(MAKE) $(build)=$@
3.4.2.1 $(vmlinux-dirs)
在顶层Makefile中,包含下列规则:
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
$(net-y) $(net-m) $(libs-y) $(libs-m)))
# The actual objects are generated when descending,
# make sure no implicit rule kicks in
$(sort $(vmlinux-init) $(vmlinux-main)) $(vmlinux-lds): $(vmlinux-dirs) ;
PHONY += $(vmlinux-dirs)
$(vmlinux-dirs): prepare scripts
$(Q)$(MAKE) $(build)=$@
由此可知,编译vmlinux时,vmlinux所依赖的目标$(vmlinux-init)、$(vmlinux-main)和$(vmlinux-lds)均依赖于$(vmlinux-dirs)。而$(vmlinux-dirs)又依赖于目标prepare和scripts。
3.4.2.1.1 prepare
在顶层Makefile中,包含下列规则:
scripts_basic:
$(Q)$(MAKE) $(build)=scripts/basic
$(Q)rm -f .tmp_quiet_recordmcount
# prepare3 is used to check if we are building in a separate output directory,
# and if so do:
# 1) Check that make has not been executed in the kernel src $(srctree)
prepare3: include/config/kernel.release
ifneq ($(KBUILD_SRC),) // 当不在linux源代码目录编译(参见[3.4.2.1.1.3 outputmakefile]节)时,执行下列命令
@$(kecho) ' Using $(srctree) as source for kernel'
$(Q)if [ -f $(srctree)/.config -o -d $(srctree)/include/config ]; then \
echo " $(srctree) is not clean, please run 'make mrproper'"; \
echo " in the '$(srctree)' directory."; \
/bin/false; \
fi;
endif
# prepare2 creates a makefile if using a separate output directory
prepare2: prepare3 outputmakefile asm-generic
prepare1: prepare2 include/linux/version.h include/generated/utsrelease.h \
include/config/auto.conf
$(cmd_crmodverdir)
archprepare: prepare1 scripts_basic
prepare0: archprepare FORCE
// 扩展为make -f scripts/Makefile.build obj=.
$(Q)$(MAKE) $(build)=.
# All the preparing..
prepare: prepare0
3.4.2.1.1.1 include/config/auto.conf
在Documentation/kbuild/kconfig.txt中,包含下列描述:
KCONFIG_AUTOCONFIG
--------------------------------------------------
This environment variable can be set to specify the path & name of the
"auto.conf" file. Its default value is "include/config/auto.conf".
在顶层Makefile中,包含下列规则:
KCONFIG_CONFIG ?= .config
...
no-dot-config-targets := clean mrproper distclean \
cscope gtags TAGS tags help %docs check% coccicheck \
include/linux/version.h headers_% \
kernelversion %src-pkg
config-targets := 0
mixed-targets := 0
dot-config := 1
// 执行make命令,$(MAKECMDGOALS)为空,不进入本分支
ifneq ($(filter $(no-dot-config-targets), $(MAKECMDGOALS)),)
ifeq ($(filter-out $(no-dot-config-targets), $(MAKECMDGOALS)),)
dot-config := 0
endif
endif
ifeq ($(KBUILD_EXTMOD),)
ifneq ($(filter config %config,$(MAKECMDGOALS)),)
config-targets := 1
ifneq ($(filter-out config %config,$(MAKECMDGOALS)),)
mixed-targets := 1
endif
endif
endif
...
// 由上述规则可知,dot-config取值为1
ifeq ($(dot-config),1)
# Read in config
/*
* 2) 由下文1)处的规则生成include/config/auto.conf后,
* make会重新读取Makefile文件,在此处读取该文件的内容
*/
-include include/config/auto.conf
// 执行make命令时,$(KBUILD_EXTMOD)为空,进入本分支
ifeq ($(KBUILD_EXTMOD),)
# Read in dependencies to all Kconfig* files, make sure to run
# oldconfig if changes are detected.
-include include/config/auto.conf.cmd
# To avoid any implicit rule to kick in, define an empty command
$(KCONFIG_CONFIG) include/config/auto.conf.cmd: ;
# If .config is newer than include/config/auto.conf, someone tinkered
# with it and forgot to run make oldconfig.
# if auto.conf.cmd is missing then we are probably in a cleaned tree so
# we execute the config step to be sure to catch updated Kconfig files
/*
* 1) 执行下列规则,由.config生成include/config/*.conf文件,
* 此后在上文2)处读取该文件的内容
*/
include/config/%.conf: $(KCONFIG_CONFIG) include/config/auto.conf.cmd
$(Q)$(MAKE) -f $(srctree)/Makefile silentoldconfig
else # KBUILD_EXTMOD
# external modules needs include/generated/autoconf.h and include/config/auto.conf
# but do not care if they are up-to-date. Use auto.conf to trigger the test
PHONY += include/config/auto.conf
include/config/auto.conf:
$(Q)test -e include/generated/autoconf.h -a -e $@ || ( \
echo; \
echo " ERROR: Kernel configuration is invalid."; \
echo " include/generated/autoconf.h or $@ are missing."; \
echo " Run 'make oldconfig && make prepare' on kernel src to fix it."; \
echo; \
/bin/false)
endif # KBUILD_EXTMOD
else
# Dummy target needed, because used as prerequisite
include/config/auto.conf: ;
endif # $(dot-config)
由上述规则可知,若.config比include/config/auto.conf要新,则执行下列命令更新include/config/auto.conf文件,将最新的配置包含进来,参见3.3.4.1 .config的格式节和3.3.4.2 .config如何被顶层Makefile调用节:
$(Q)$(MAKE) -f $(srctree)/Makefile silentoldconfig
3.4.2.1.1.2 include/config/kernel.release
在顶层Makefile中,包含下列规则:
# Store (new) KERNELRELASE string in include/config/kernel.release
include/config/kernel.release: include/config/auto.conf FORCE
$(Q)rm -f $@
$(Q)echo "$(KERNELVERSION)$$($(CONFIG_SHELL) $(srctree)/scripts/setlocalversion $(srctree))" > $@
生成的include/config/kernel.release包含下列内容:
3.2.0-chenwx
3.4.2.1.1.3 outputmakefile
3.4.2.1.1.4 asm-generic
在顶层Makefile中,包含下列规则:
# Support for using generic headers in asm-generic
PHONY += asm-generic
asm-generic:
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.asm-generic \
obj=arch/$(SRCARCH)/include/generated/asm
该命令被扩展为(以x86体系为例):
make -f scripts/Makefile.asm-generic obj=arch/x86/include/generated/asm
在scripts/Makefile.asm-generic中,包含下列规则:
// 扩展为arch/x86/include/asm/Kbuild
kbuild-file := $(srctree)/arch/$(SRCARCH)/include/asm/Kbuild
-include $(kbuild-file)
include scripts/Kbuild.include
// 创建目录arch/x86/include/generated/asm
# Create output directory if not already present
_dummy := $(shell [ -d $(obj) ] || mkdir -p $(obj))
quiet_cmd_wrap = WRAP $@
cmd_wrap = echo "\#include <asm-generic/$*.h>" >$@
/*
* 在x86体系中,$(generic-y)为空,故本目标不产生任何文件
* 在其他体系中,该目标用于生成指定的头文件,例如:
* arch/blackfin/include/asm/Kbuild
*/
all: $(patsubst %, $(obj)/%, $(generic-y))
@:
$(obj)/%.h:
$(call cmd,wrap) // 调用cmd_wrap命令
3.4.2.1.1.5 include/linux/version.h
在顶层Makefile中,包含下列规则:
define filechk_version.h
(echo \#define LINUX_VERSION_CODE $(shell \
expr $(VERSION) \* 65536 + 0$(PATCHLEVEL) \* 256 + 0$(SUBLEVEL)); \
echo '#define KERNEL_VERSION(a,b,c) (((a) << 16) + ((b) << 8) + (c))';)
endef
...
include/linux/version.h: $(srctree)/Makefile FORCE
/*
* 参见scripts/Kbuild.include,调用filechk_version.h
* 生成include/linux/version.h
*/
$(call filechk,version.h)
生成的include/linux/version.h包含下列内容:
#define LINUX_VERSION_CODE 197120
#define KERNEL_VERSION(a,b,c) (((a) << 16) + ((b) << 8) + (c))
3.4.2.1.1.6 include/generated/utsrelease.h
在顶层Makefile中,包含下列规则:
uts_len := 64
define filechk_utsrelease.h
if [ `echo -n "$(KERNELRELEASE)" | wc -c ` -gt $(uts_len) ]; then \
echo '"$(KERNELRELEASE)" exceeds $(uts_len) characters' >&2; \
exit 1; \
fi; \
(echo \#define UTS_RELEASE \"$(KERNELRELEASE)\";)
endef
// 依赖于kernel.release,参见[3.4.2.1.1.2 include/config/kernel.release]节
include/generated/utsrelease.h: include/config/kernel.release FORCE
/*
* 参见scripts/Kbuild.include,调用filechk_utsrelease.h
* 生成include/linux/utsrelease.h
*/
$(call filechk,utsrelease.h)
生成的include/generated/utsrelease.h包含下列内容:
#define UTS_RELEASE "3.2.0-chenwx"
3.4.2.1.1.7 prepare1
在顶层Makefile中,包含下列规则:
# When compiling out-of-tree modules, put MODVERDIR in the module
# tree rather than in the kernel tree. The kernel tree might
# even be read-only.
// 扩展为.tmp_versions
export MODVERDIR := $(if $(KBUILD_EXTMOD),$(firstword $(KBUILD_EXTMOD))/).tmp_versions
ifeq ($(KBUILD_EXTMOD),)
prepare1: prepare2 include/linux/version.h include/generated/utsrelease.h \
include/config/auto.conf
// 执行命令cmd_crmodverdir,生成空目录.tmp_versions/
$(cmd_crmodverdir)
...
else # KBUILD_EXTMOD
...
endif # KBUILD_EXTMOD
...
# Create temporary dir for module support files
# clean it up only when building all modules
// 扩展mkdir -p .tmp_versions ; rm -f .tmp_versions/*
cmd_crmodverdir = $(Q)mkdir -p $(MODVERDIR) \
$(if $(KBUILD_MODULES),; rm -f $(MODVERDIR)/*)
3.4.2.1.1.8 scripts_basic
3.4.2.1.1.9 prepare0
在顶层Makefile中,包含下列规则:
prepare0: archprepare FORCE
$(Q)$(MAKE) $(build)=.
其中,命令 $(Q)$(MAKE) $(build)=. 被扩展为:
make -f scripts/Makefile.build obj=.
该命令将编译scripts/Makefile.build中的默认规则__build:
PHONY := __build
__build:
# The filename Kbuild has precedence over Makefile
kbuild-dir := $(if $(filter /%,$(src)),$(src),$(srctree)/$(src))
kbuild-file := $(if $(wildcard $(kbuild-dir)/Kbuild),$(kbuild-dir)/Kbuild,$(kbuild-dir)/Makefile)
include $(kbuild-file) // 将linux/Kbuild包含进来
__build: $(if $(KBUILD_BUILTIN),$(builtin-target) $(lib-target) $(extra-y)) \
$(if $(KBUILD_MODULES),$(obj-m) $(modorder-target)) \
$(subdir-ym) $(always) // 变量$(always)由linux/Kbuild引入
@:
由$(always)可知,该目标会生成下列文件:
include/generated/bounds.h
include/generated/asm-offsets.h
3.4.2.1.2 scripts
在顶层Makefile中,包含下列规则:
ifeq ($(KBUILD_EXTMOD),)
# Additional helpers built in scripts/
# Carefully list dependencies so we do not try to build scripts twice
# in parallel
PHONY += scripts
scripts: scripts_basic include/config/auto.conf include/config/tristate.conf
$(Q)$(MAKE) $(build)=$(@)
...
endif # KBUILD_EXTMOD
3.4.2.1.2.1 scripts_basic
3.4.2.1.2.2 include/config/auto.conf
参见3.4.2.1.1.1 include/config/auto.conf节。
3.4.2.1.2.3 include/config/tristate.conf
参见Documentation/kbuild/kconfig.txt:
KCONFIG_TRISTATE
--------------------------------------------------
This environment variable can be set to specify the path & name of the
"tristate.conf" file. Its default value is "include/config/tristate.conf".
在顶层Makefile中,包含下列规则:
include/config/%.conf: $(KCONFIG_CONFIG) include/config/auto.conf.cmd
$(Q)$(MAKE) -f $(srctree)/Makefile silentoldconfig
由此可知,include/config/tristate.conf是由下列命令生成的:
$(Q)$(MAKE) -f $(srctree)/Makefile silentoldconfig
该命令与生成include/config/auto.conf所用命令是相同的,这两个文件也是同时生成的,参见3.3.4.2 .config如何被顶层Makefile调用节。
在scripts/Makefile.modbuiltin中,通过下列规则将include/config/tristate.conf引入,参见3.4.3.3.1 make -f scripts/Makefile.modbuiltin obj=$*节:
# tristate.conf sets tristate variables to uppercase 'Y' or 'M'
# That way, we get the list of built-in modules in obj-Y
-include include/config/tristate.conf
3.4.2.1.2.4 scripts
在顶层Makefile中,包含下列规则:
ifeq ($(KBUILD_EXTMOD),)
# Additional helpers built in scripts/
# Carefully list dependencies so we do not try to build scripts twice
# in parallel
PHONY += scripts
scripts: scripts_basic include/config/auto.conf include/config/tristate.conf
$(Q)$(MAKE) $(build)=$(@)
endif # KBUILD_EXTMOD
当3.3.1.1 scripts_basic节至3.4.2.1.2.3 include/config/tristate.conf节中的目标完成后,执行下列命令编译scripts目录及其子目录:
make -f scripts/Makefile.build obj=scripts
该编译过程与3.4.2.1.1.8 scripts_basic节类似,只不过变量$(always)是由scripts/Makefile引入的,如下:
hostprogs-$(CONFIG_KALLSYMS) += kallsyms
hostprogs-$(CONFIG_LOGO) += pnmtologo
hostprogs-$(CONFIG_VT) += conmakehash
hostprogs-$(CONFIG_IKCONFIG) += bin2c
hostprogs-$(BUILD_C_RECORDMCOUNT) += recordmcount
always := $(hostprogs-y) $(hostprogs-m)
subdir-y += mod
该目标生成下列可执行文件:
scripts/kallsyms
scripts/pnmtologo
scripts/conmakehash
scripts/bin2c
scripts/recordmcount
scripts/mod/modpost
scripts/mod/mk_elfconfig
3.4.2.1.3 $(vmlinux-dirs)
在顶层Makefile中,包含下列规则:
init-y := init/
drivers-y := drivers/ sound/ firmware/
net-y := net/
libs-y := lib/
core-y := usr/
// 此处以x86体系为例,将arch/x86/Makefile引入
include $(srctree)/arch/$(SRCARCH)/Makefile
core-y += kernel/ mm/ fs/ ipc/ security/ crypto/ block/
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
$(net-y) $(net-m) $(libs-y) $(libs-m)))
PHONY += $(vmlinux-dirs)
$(vmlinux-dirs): prepare scripts
$(Q)$(MAKE) $(build)=$@
在arch/x86/Makefile中,包含下列规则:
libs-y += arch/x86/lib/
# See arch/x86/Kbuild for content of core part of the kernel
core-y += arch/x86/
# drivers-y are linked after core-y
drivers-$(CONFIG_MATH_EMULATION) += arch/x86/math-emu/
drivers-$(CONFIG_PCI) += arch/x86/pci/
# must be linked after kernel/
drivers-$(CONFIG_OPROFILE) += arch/x86/oprofile/
# suspend and hibernation support
drivers-$(CONFIG_PM) += arch/x86/power/
drivers-$(CONFIG_FB) += arch/x86/video/
由此可知,vmlinux-dirs被扩展为:
vmlinux-dirs := \
init \ // $(init-y)
usr arch/x86 kernel mm fs ipc security crypto block \ // $(core-y)
drivers sound firmware \ // $(drivers-y)
arch/x86/math-emu \ // 与CONFIG_MATH_EMULATION有关
arch/x86/pci \ // 与CONFIG_PCI有关
arch/x86/oprofile \ // 与CONFIG_OPROFILE有关
arch/x86/power \ // 与CONFIG_PM有关
arch/x86/video \ // 与CONFIG_FB有关
net \ // $(net-y)
lib arch/x86/lib // $(libs-y)
当$(vmlinux-dirs)所依赖的目标prepare和scripts完成后,将会执行下列命令编译$(vmlinux-dirs):
$(Q)$(MAKE) $(build)=$@
根据scripts/Makefile.build中对build的定义,该命令依次被扩展为:
make -f scripts/Makefile.build obj=init
make -f scripts/Makefile.build obj=usr
make -f scripts/Makefile.build obj=arch/x86 // 此处以x86体系为例,由arch/x86/Makefile中的core-y引入
make -f scripts/Makefile.build obj=kernel
make -f scripts/Makefile.build obj=mm
make -f scripts/Makefile.build obj=fs
make -f scripts/Makefile.build obj=ipc
make -f scripts/Makefile.build obj=security
make -f scripts/Makefile.build obj=crypto
make -f scripts/Makefile.build obj=block
make -f scripts/Makefile.build obj=drivers
make -f scripts/Makefile.build obj=sound
make -f scripts/Makefile.build obj=firmware
make -f scripts/Makefile.build obj=arch/x86/math-emu // 与CONFIG_MATH_EMULATION有关
make -f scripts/Makefile.build obj=arch/x86/pci // 与CONFIG_PCI有关
make -f scripts/Makefile.build obj=arch/x86/oprofile // 与CONFIG_OPROFILE有关
make -f scripts/Makefile.build obj=arch/x86/power // 与CONFIG_PM有关
make -f scripts/Makefile.build obj=arch/x86/video // 与CONFIG_FB有关
make -f scripts/Makefile.build obj=net
make -f scripts/Makefile.build obj=lib
make -f scripts/Makefile.build obj=arch/x86/lib/ // 以x86体系为例,由arch/x86/Makefile中的libs-y引入
当执行这些命令时,如果这些目录下存在子目录,则make会递归调用其子目录下的Kbuild或Makefile(若不存在Kbuild文件),详细的命令调用列表参见Appendix B: make -f scripts/Makefile.build obj=列表节。
3.4.2.1.3.1 make -f scripts/Makefile.build obj=XXX命令的执行过程
因为命令make -f scripts/Makefile.build obj=XXX中没有指定目标,故编译scripts/Makefile.build中的默认目标__build:
src := $(obj)
PHONY := __build
__build:
// kbuild-dir被扩展为obj指定的目录
kbuild-dir := $(if $(filter /%,$(src)),$(src),$(srctree)/$(src))
// kbuild-file被扩展为obj指定目录下的Kbuild或Makefile,其中Kbuild的优先级高于Makefile
kbuild-file := $(if $(wildcard $(kbuild-dir)/Kbuild),$(kbuild-dir)/Kbuild,$(kbuild-dir)/Makefile)
// 此处将obj指定目录下的Kbuild或Makefile包含进来
include $(kbuild-file)
__build: $(if $(KBUILD_BUILTIN),$(builtin-target) $(lib-target) $(extra-y)) \
$(if $(KBUILD_MODULES),$(obj-m) $(modorder-target)) \
$(subdir-ym) $(always)
@:
根据顶层Makefile中对$(KBUILD_BUILTIN)和$(KBUILD_MODULES)的定义可知,上述规则被扩展为:
__build: $(builtin-target) $(lib-target) $(extra-y) $(obj-m) $(modorder-target) $(subdir-ym) $(always)
@:
__build所依赖的各目标参见下列几节:
3.4.2.1.3.1.1 $(builtin-target)
在scripts/Makefile.build中,包含下列规则:
ifneq ($(strip $(obj-y) $(obj-m) $(obj-n) $(obj-) $(subdir-m) $(lib-target)),)
builtin-target := $(obj)/built-in.o
endif
#
# Rule to compile a set of .o files into one .o file
#
ifdef builtin-target
quiet_cmd_link_o_target = LD $@
# If the list of objects to link is empty, just create an empty built-in.o
cmd_link_o_target = $(if $(strip $(obj-y)), \
$(LD) $(ld_flags) -r -o $@ $(filter $(obj-y), $^) \
$(cmd_secanalysis), \
rm -f $@; $(AR) rcs$(KBUILD_ARFLAGS) $@)
$(builtin-target): $(obj-y) FORCE // $(obj-y)参见[3.4.2.1.3.1.1.1 $(obj-y)]节
$(call if_changed,link_o_target) // 调用cmd_link_o_target,参见[3.4.2.1.3.1.1.2 cmd_link_o_target]节
targets += $(builtin-target)
endif # builtin-target
3.4.2.1.3.1.1.1 $(obj-y)
$(obj)指定目录下的Makefile为$(obj-y)赋值。以fs/Makefile为例,其中包含如下规则:
/*
* 此处使用":="为obj-y重新赋值,冲掉obj-y之前的取值。
* 其他Makefile也使用类似方法为obj-y赋值
*/
obj-y := open.o read_write.o file_table.o super.o \
char_dev.o stat.o exec.o pipe.o namei.o fcntl.o \
ioctl.o readdir.o select.o fifo.o dcache.o inode.o \
attr.o bad_inode.o file.o filesystems.o namespace.o \
seq_file.o xattr.o libfs.o fs-writeback.o \
pnode.o drop_caches.o splice.o sync.o utimes.o \
stack.o fs_struct.o statfs.o
ifeq ($(CONFIG_BLOCK),y)
obj-y += buffer.o bio.o block_dev.o direct-io.o mpage.o ioprio.o
else
obj-y += no-block.o
endif
obj-$(CONFIG_BLK_DEV_INTEGRITY) += bio-integrity.o
obj-y += notify/
obj-$(CONFIG_EPOLL) += eventpoll.o
obj-$(CONFIG_ANON_INODES) += anon_inodes.o
obj-$(CONFIG_SIGNALFD) += signalfd.o
...
由此可知,$(obj-y)的取值与某些配置项的取值有关。$(obj)包含两类取值:
- $(obj)目录下需要编译的目标文件,如open.o。其编译过程参见3.4.2.1.3.1.1.1.1 编译$(obj)目录下的目标文件节;
- $(obj)下的子目录,如notify/,其编译为notify/built-in.o,参见3.4.2.1.3.1.1.1.2 编译$(obj)下的子目录节。
3.4.2.1.3.1.1.1.1 编译$(obj)目录下的目标文件
在scripts/Makefile.build中,包含下列规则:
// $(CHECK), $(CHECKFLAGS)定义于顶层Makefile
# Linus' kernel sanity checking tool
ifneq ($(KBUILD_CHECKSRC),0)
ifeq ($(KBUILD_CHECKSRC),2)
quiet_cmd_force_checksrc = CHECK $<
cmd_force_checksrc = $(CHECK) $(CHECKFLAGS) $(c_flags) $< ;
else
quiet_cmd_checksrc = CHECK $<
cmd_checksrc = $(CHECK) $(CHECKFLAGS) $(c_flags) $< ;
endif
endif
ifndef CONFIG_MODVERSIONS
// $(c_flags)定义于scripts/Makefile.lib。cmd_cc_o_c的扩展结果见下文
cmd_cc_o_c = $(CC) $(c_flags) -c -o $@ $<
else
# When module versioning is enabled the following steps are executed:
# o compile a .tmp_<file>.o from <file>.c
# o if .tmp_<file>.o doesn't contain a __ksymtab version, i.e. does
# not export symbols, we just rename .tmp_<file>.o to <file>.o and
# are done.
# o otherwise, we calculate symbol versions using the good old
# genksyms on the preprocessed source and postprocess them in a way
# that they are usable as a linker script
# o generate <file>.o from .tmp_<file>.o using the linker to
# replace the unresolved symbols __crc_exported_symbol with
# the actual value of the checksum generated by genksyms
cmd_cc_o_c = $(CC) $(c_flags) -c -o $(@D)/.tmp_$(@F) $<
cmd_modversions = \
/*
* $(OBJDUMP)定义于顶层Makefile,取值为objdump
* 该语句用于在目标文件中查找是否存在名为__ksymtab的段,
* 参见include/linux/export.h
*/
if $(OBJDUMP) -h $(@D)/.tmp_$(@F) | grep -q __ksymtab; then \
$(call cmd_gensymtypes,$(KBUILD_SYMTYPES),$(@:.o=.symtypes)) \
> $(@D)/.tmp_$(@F:.o=.ver); \
\
$(LD) $(LDFLAGS) -r -o $@ $(@D)/.tmp_$(@F) \
-T $(@D)/.tmp_$(@F:.o=.ver); \
rm -f $(@D)/.tmp_$(@F) $(@D)/.tmp_$(@F:.o=.ver); \
else \
mv -f $(@D)/.tmp_$(@F) $@; \
fi;
endif
ifdef CONFIG_FTRACE_MCOUNT_RECORD
ifdef BUILD_C_RECORDMCOUNT
sub_cmd_record_mcount = \
if [ $(@) != "scripts/mod/empty.o" ]; then \
$(objtree)/scripts/recordmcount $(RECORDMCOUNT_FLAGS) "$(@)"; \
fi;
recordmcount_source := $(srctree)/scripts/recordmcount.c \
$(srctree)/scripts/recordmcount.h
else
sub_cmd_record_mcount = set -e ; perl $(srctree)/scripts/recordmcount.pl "$(ARCH)" \
"$(if $(CONFIG_CPU_BIG_ENDIAN),big,little)" \
"$(if $(CONFIG_64BIT),64,32)" \
"$(OBJDUMP)" "$(OBJCOPY)" "$(CC) $(KBUILD_CFLAGS)" \
"$(LD)" "$(NM)" "$(RM)" "$(MV)" \
"$(if $(part-of-module),1,0)" "$(@)";
recordmcount_source := $(srctree)/scripts/recordmcount.pl
endif
cmd_record_mcount = \
if [ "$(findstring -pg,$(_c_flags))" = "-pg" ]; then \
$(sub_cmd_record_mcount) \
fi;
endif
// 将源文件*.c编译成目标文件*.o,并生成命令文件.*.o.cmd
define rule_cc_o_c
/*
* echo-cmd定义于scripts/Kbuild.include,
* 此处用于显示命令cmd_checksrc,下同
*/
$(call echo-cmd,checksrc) $(cmd_checksrc) \
// 调用cmd_cc_o_c将源文件*.c编译成目标文件*.o
$(call echo-cmd,cc_o_c) $(cmd_cc_o_c); \
// 若定义了CONFIG_MODVERSIONS,则命令cmd_modversions有效
$(cmd_modversions) \
$(call echo-cmd,record_mcount) \
$(cmd_record_mcount) \
scripts/basic/fixdep $(depfile) $@ '$(call make-cmd,cc_o_c)' > \
$(dot-target).tmp; \
// 删除依赖文件,如fs/.open.o.d,该文件是在命令cmd_cc_o_c中生成的
rm -f $(depfile); \
// 生成命令文件,如fs/.open.o.cmd
mv -f $(dot-target).tmp $(dot-target).cmd
endef
# Built-in and composite module parts
$(obj)/%.o: $(src)/%.c $(recordmcount_source) FORCE
$(call cmd,force_checksrc) // 调用cmd_force_checksrc
$(call if_changed_rule,cc_o_c) // 调用rule_cc_o_c
/*
* 后面还有由源代码.S编译成目标文件.o的规则,与.c编译成.o的规则类似
*/
如果未定义CONFIG_MODVERSIONS,则命令cmd_cc_o_c扩展后的结果如下(以fs/open.o为例):
gcc -Wp,-MD,fs/.open.o.d -nostdinc -isystem /usr/lib/gcc/i686-linux-gnu/4.7/include -I/usr/src/linux-3.2/arch/x86/include -Iarch/x86/include/generated -Iinclude -include /usr/src/linux-3.2/include/linux/kconfig.h -D__KERNEL__ -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs -fno-strict-aliasing -fno-common -Werror-implicit-function-declaration -Wno-format-security -fno-delete-null-pointer-checks -O2 -m32 -msoft-float -mregparm=3 -freg-struct-return -mpreferred-stack-boundary=2 -march=i686 -Wa,-mtune=generic32 -ffreestanding -DCONFIG_AS_CFI=1 -DCONFIG_AS_CFI_SIGNAL_FRAME=1 -DCONFIG_AS_CFI_SECTIONS=1 -pipe -Wno-sign-compare -fno-asynchronous-unwind-tables -mno-sse -mno-mmx -mno-sse2 -mno-3dnow -Wframe-larger-than=1024 -fno-stack-protector -Wno-unused-but-set-variable -fomit-frame-pointer -Wdeclaration-after-statement -Wno-pointer-sign -fno-strict-overflow -fconserve-stack -DCC_HAVE_ASM_GOTO -D"KBUILD_STR(s)=#s" -D"KBUILD_BASENAME=KBUILD_STR(open)" -D"KBUILD_MODNAME=KBUILD_STR(open)" -c -o fs/open.o fs/open.c
假设内核中多个目录下存在同名头文件xxx.h,那么某.c文件包含的是哪个目录下的头文件xxx.h呢?
命令cmd_cc_o_c中的变量c_flags定义于scripts/Makefile.lib:
C_flags = -Wp,-MD,$(depfile) $(NOSTDINC_FLAGS) $(LINUXINCLUDE) \
$(__c_flags) $(modkern_cflags) \
-D"KBUILD_STR(s)=\#s" $(basename_flags) $(modname_flags)
其中,变量LINUXINCLUDE定义于顶层Makefile中:
LINUXINCLUDE := -I$(srctree)/arch/$(hdr-arch)/include \
-Iarch/$(hdr-arch)/include/generated –Iinclude \
$(if $(KBUILD_SRC), -I$(srctree)/include) \
-include $(srctree)/include/linux/kconfig.h
由此可知,编译.c文件时查找头文件的目录顺序。以fs/open.o为例,LINUXINCLUDE被扩展为:
-I/usr/src/linux-3.2/arch/x86/include -Iarch/x86/include/generated -Iinclude -include /usr/src/linux-3.2/include/linux/kconfig.h
即查找头文件的目录顺序依次为:
arch/x86/include/ // 与体系架构有关
arch/x86/include/generated/ // 与体系架构有关
include/
include/linux/kconfig.h
3.4.2.1.3.1.1.1.2 编译$(obj)下的子目录
在scripts/Makefile.build中,包含下列规则:
// 引入$(obj)指定目录下的Makefile,从中得到$(obj-y)的取值
# The filename Kbuild has precedence over Makefile
kbuild-dir := $(if $(filter /%,$(src)),$(src),$(srctree)/$(src))
kbuild-file := $(if $(wildcard $(kbuild-dir)/Kbuild),$(kbuild-dir)/Kbuild,$(kbuild-dir)/Makefile)
include $(kbuild-file)
// 定义变量$(subdir-obj-y)和$(subdir-ym),见下文
include scripts/Makefile.lib
# To build objects in subdirs, we need to descend into the directories
$(sort $(subdir-obj-y)): $(subdir-ym) ;
$(subdir-ym):
/*
* 编译$(obj-y)和$(obj-m)中的子目录,
* 参见[3.4.2.1.3.1 make -f scripts/Makefile.build obj=XXX命令的执行过程]节;
* 以fs/notify为例,该命令扩展为: make -f scripts/Makefile.build obj=fs/notify
*/
$(Q)$(MAKE) $(build)=$@
$(subdir-ym)
$(obj-y)定义于scripts/Makefile.lib:
// 获取$(obj-y)和$(obj-m)中的子目录列表
__subdir-y := $(patsubst %/,%,$(filter %/, $(obj-y)))
subdir-y += $(__subdir-y)
__subdir-m := $(patsubst %/,%,$(filter %/, $(obj-m)))
subdir-m += $(__subdir-m)
/*
* $(subdir-ym)为$(obj)的子目录名:
* 以$(obj)=fs为例,则$(subdir-ym)取值为notify等
*/
# Subdirectories we need to descend into
subdir-ym := $(sort $(subdir-y) $(subdir-m))
// Add subdir path
subdir-ym := $(addprefix $(obj)/,$(subdir-ym))
$(subdir-obj-y)
$(subdir-obj-y)定义于scripts/Makefile.lib:
// 若$(obj-y)中包含子目录,则将子目录下的文件编译为built-in.o,如notify/built-in.o
obj-y := $(patsubst %/, %/built-in.o, $(obj-y))
# $(subdir-obj-y) is the list of objects in $(obj-y) which uses dir/ to
# tell kbuild to descend
subdir-obj-y := $(filter %/built-in.o, $(obj-y))
/*
* $(subdir-obj-y)的取值,如 fs/notify/built-in.o fs/proc/built-in.o ...
* 而这些目标文件的编译参见[3.4.2.1.3.1.1 $(builtin-target)]节
*/
subdir-obj-y := $(addprefix $(obj)/,$(subdir-obj-y))
如果$(obj-y)中包含子目录,则将子目录下的源文件编译成一个目标文件built-in.o。
3.4.2.1.3.1.1.2 cmd_link_o_target
在scripts/Makefile.build中,包含下列规则:
#
# Rule to compile a set of .o files into one .o file
#
ifdef builtin-target
quiet_cmd_link_o_target = LD $@
# If the list of objects to link is empty, just create an empty built-in.o
cmd_link_o_target = $(if $(strip $(obj-y)), \
$(LD) $(ld_flags) -r -o $@ $(filter $(obj-y), $^) \
$(cmd_secanalysis), \
rm -f $@; $(AR) rcs$(KBUILD_ARFLAGS) $@)
endif # builtin-target
命令cmd_link_o_target将$(obj)指定目录及其子目录下的目标文件连接成built-in.o。以obj=fs为例,该命令扩展为:
ld -m elf_i386 -r -o fs/built-in.o fs/open.o fs/read_write.o fs/file_table.o fs/super.o fs/char_dev.o fs/stat.o fs/exec.o fs/pipe.o fs/namei.o fs/fcntl.o fs/ioctl.o fs/readdir.o fs/select.o fs/fifo.o fs/dcache.o fs/inode.o fs/attr.o fs/bad_inode.o fs/file.o fs/filesystems.o fs/namespace.o fs/seq_file.o fs/xattr.o fs/libfs.o fs/fs-writeback.o fs/pnode.o fs/drop_caches.o fs/splice.o fs/sync.o fs/utimes.o fs/stack.o fs/fs_struct.o fs/statfs.o fs/buffer.o fs/bio.o fs/block_dev.o fs/direct-io.o fs/mpage.o fs/ioprio.o fs/notify/built-in.o fs/eventpoll.o fs/anon_inodes.o fs/signalfd.o fs/timerfd.o fs/eventfd.o fs/aio.o fs/locks.o fs/binfmt_script.o fs/quota/built-in.o fs/proc/built-in.o fs/partitions/built-in.o fs/sysfs/built-in.o fs/devpts/built-in.o fs/ramfs/built-in.o fs/nls/built-in.o fs/exofs/built-in.o
3.4.2.1.3.1.2 $(lib-target)
在scripts/Makefile.build中,包含下列规则:
// 将$(obj)指定目录下的库文件编译成$(obj)/lib.a
ifneq ($(strip $(lib-y) $(lib-m) $(lib-n) $(lib-)),)
lib-target := $(obj)/lib.a
endif
ifneq ($(strip $(obj-y) $(obj-m) $(obj-n) $(obj-) $(subdir-m) $(lib-target)),)
builtin-target := $(obj)/built-in.o
endif
#
# Rule to compile a set of .o files into one .a file
#
ifdef lib-target
quiet_cmd_link_l_target = AR $@
cmd_link_l_target = rm -f $@; $(AR) rcs$(KBUILD_ARFLAGS) $@ $(lib-y)
/*
* $(lib-y)定义于$(obj)指定目录下的Kbuild或Makefile,
* 并经过scripts/Makefile.lib的进一步处理,参见[3.4.2.1.3.1.2.1 $(lib-y)]节
*/
$(lib-target): $(lib-y) FORCE
// 调用cmd_link_l_target编译$(lib-target)
$(call if_changed,link_l_target)
targets += $(lib-target)
endif
3.4.2.1.3.1.2.1 $(lib-y)
$(lib-y)或$(lib-m)定义于$(obj)指定目录下的Kbuild或Makefile,以lib/Makefile为例,其中包含下列规则:
lib-y := ctype.o string.o vsprintf.o cmdline.o \
rbtree.o radix-tree.o dump_stack.o timerqueue.o \
idr.o int_sqrt.o extable.o prio_tree.o \
sha1.o md5.o irq_regs.o reciprocal_div.o argv_split.o \
proportions.o prio_heap.o ratelimit.o show_mem.o \
is_single_threaded.o plist.o decompress.o
lib-$(CONFIG_MMU) += ioremap.o
lib-$(CONFIG_SMP) += cpumask.o
lib-y += kobject.o kref.o klist.o
...
在scripts/Makefile.lib中,对$(lib-y)或$(lib-m)进一步处理,如下所示:
# Libraries are always collected in one lib file.
# Filter out objects already built-in
lib-y := $(filter-out $(obj-y), $(sort $(lib-y) $(lib-m)))
/*
* 此时,$(lib-y)中包含了要编译进库文件中的目标文件列表,如lib/ctype.o lib/string.o ...
* 编译$(lib-y)时,符合规则"$(obj)/%.o: $(src)/%.c $(recordmcount_source) FORCE"
*/ 参见[3.4.2.1.3.1.1.1.1 编译$(obj)目录下的目标文件]节
lib-y := $(addprefix $(obj)/,$(lib-y))
3.4.2.1.3.1.3 $(extra-y)
$(extra-y)的取值参见$(obj)指定目录下的Kbuild或Makefile。在scripts/Makefile.lib中,对其做进一步处理:
/*
* 此时,$(extra-y)为目标文件列表
* 编译$(lib-y)时,符合规则"$(obj)/%.o: $(src)/%.c $(recordmcount_source) FORCE"
* 参见[3.4.2.1.3.1.1.1.1 编译$(obj)目录下的目标文件]节
*/
extra-y := $(addprefix $(obj)/,$(extra-y))
3.4.2.1.3.1.4 $(obj-m)
$(obj-m)的取值参见$(obj)指定目录下的Kbuild或Makefile。在scripts/Makefile.lib中,对其做进一步处理:
# When an object is listed to be built compiled-in and modular,
# only build the compiled-in version
obj-m := $(filter-out $(obj-y),$(obj-m))
__subdir-m := $(patsubst %/,%,$(filter %/, $(obj-m)))
/*
* $(subdir-m)中包含$(obj-m)中的子目录名,
* 其将在$(builtin-target)中编译,参见[3.4.2.1.3.1.1.1.2 编译$(obj)下的子目录]节
*/
subdir-m += $(__subdir-m)
obj-m := $(filter-out %/, $(obj-m))
/*
* 此时,$(obj-m)中仅包含$(obj)指定目录下的目标文件列表,不包含子目录
* 编译$(obj-m)时,符合规则"$(obj)/%.o: $(src)/%.c $(recordmcount_source) FORCE",
* 参见[3.4.2.1.3.1.1.1.1 编译$(obj)目录下的目标文件]节
*/
obj-m := $(addprefix $(obj)/,$(obj-m))
3.4.2.1.3.1.5 $(modorder-target)
在scripts/Makefile.build中,包含下列规则:
modorder-target := $(obj)/modules.order
#
# Rule to create modules.order file
#
# Create commands to either record .ko file or cat modules.order from
# a subdirectory
modorder-cmds = \
// $(modorder)定义于scripts/Makefile.lib,见下文
$(foreach m, $(modorder), \
$(if $(filter %/modules.order, $m), \
cat $m;, echo kernel/$m;))
// $(subdir-ym)的编译参见[3.4.2.1.3.1.1.1.2 编译$(obj)下的子目录编译$(obj)下的子目录]节
$(modorder-target): $(subdir-ym) FORCE
/*
* 调用modorder-cmds生成$(obj)/modules.order文件,
* 以fs/notify为例,该语句展开为:
* (cat /dev/null; cat fs/notify/dnotify/modules.order;
* cat fs/notify/inotify/modules.order;
* cat fs/notify/fanotify/modules.order;) > fs/notify/modules.order
*/
$(Q)(cat /dev/null; $(modorder-cmds)) > $@
$(modorder)定义于scripts/Makefile.lib:
# Determine modorder.
# Unfortunately, we don't have information about ordering between -y
# and -m subdirs. Just put -y's first.
modorder := $(patsubst %/,%/modules.order, $(filter %/, $(obj-y)) $(obj-m:.o=.ko))
...
modorder := $(addprefix $(obj)/,$(modorder))
3.4.2.1.3.1.6 $(always)
$(always)的取值参见$(obj)指定目录下的Kbuild或Makefile。在scripts/Makefile.lib中,对其做进一步处理:
/*
* 此时,$(always)中仅包含$(obj)指定目录下的目标文件列表
* 编译$(always)时,符合规则"$(obj)/%.o: $(src)/%.c $(recordmcount_source) FORCE",
* 参见[3.4.2.1.3.1.1.1.1 编译$(obj)目录下的目标文件]节
*/
always := $(addprefix $(obj)/,$(always))
3.4.2.2 $(vmlinux-lds)
3.4.2.2.1 vmlinux.lds的作用
编译内核的过程分两步:一是”编译”,二是”链接”。vmlinux.lds就是告诉编译器如何链接编译好的各个.o文件,即如何组织内核的每个函数存放在内核镜像文件的位置,参见Appendix F: vmlinux.lds.S。

3.4.2.2.2 vmlinux.lds如何生成
在顶层Makefile中,包含下列规则:
vmlinux-lds := arch/$(SRCARCH)/kernel/vmlinux.lds
...
# The actual objects are generated when descending,
# make sure no implicit rule kicks in
$(sort $(vmlinux-init) $(vmlinux-main)) $(vmlinux-lds): $(vmlinux-dirs) ;
由3.4.2.1.3 $(vmlinux-dirs)节可知,当编译arch/x86目录时,将执行下列命令:
// 此处以x86体系为例,由arch/x86/Makefile中的core-y引入
make -f scripts/Makefile.build obj=arch/x86
其中,arch/x86/Kbuild包含下列规则:
obj-y += kernel/
即编译子目录arch/x86/kernel,并调用arch/x86/kernel/Makefile,其包含下列规则:
extra-y := head_$(BITS).o head$(BITS).o head.o init_task.o vmlinux.lds
根据3.4.2.1.3.1.3 $(extra-y)节的规则编译$(extra-y),即根据scripts/Makefile.build中的下列规则来生成vmlinux.lds:
# Linker scripts preprocessor (.lds.S -> .lds)
# ---------------------------------------------------------------------------
quiet_cmd_cpp_lds_S = LDS $@
cmd_cpp_lds_S = $(CPP) $(cpp_flags) -P -C -U$(ARCH) \
-D__ASSEMBLY__ -DLINKER_SCRIPT -o $@ $<
$(obj)/%.lds: $(src)/%.lds.S FORCE // vmlinux.lds是由vmlinux.lds.S预编译得来的
$(call if_changed_dep,cpp_lds_S) // 调用cmd_cpp_lds_S生成vmlinux.lds
由此可知,vmlinux.lds是由arch/x86/kernel/vmlinux.lds.S预处理而来,所用命令为cmd_cpp_lds_S。该命令被扩展为(参见编译后产生的命令文件arch/x86/kernel/.vmlinux.lds.cmd):
gcc -E -Wp,-MD,arch/x86/kernel/.vmlinux.lds.d -nostdinc -isystem /usr/lib/gcc/i686-linux-gnu/4.7/include -I/usr/src/linux-3.2/arch/x86/include -Iarch/x86/include/generated -Iinclude -include /usr/src/linux-3.2/include/linux/kconfig.h -D__KERNEL__ -Ui386 -P -C -Ui386 -D__ASSEMBLY__ -DLINKER_SCRIPT -o arch/x86/kernel/vmlinux.lds arch/x86/kernel/vmlinux.lds.S
预处理后的vmlinux.lds是链接器GNU ld的link script文件,它是由Linker Command Language写成的,用于链接.o文件,参见3.4.2.6.1.2 cmd_vmlinux__节。关于link script语法,参见Using ld。
3.4.2.3 $(vmlinux-init)
在顶层Makefile中,包含下列规则:
vmlinux-init := $(head-y) $(init-y)
3.4.2.3.1 $(head-y)
$(head-y)与体系结构有关,其定义于arch/$(ARCH)/Makefile。以x86为例,参见arch/x86/Makefile:
head-y := arch/x86/kernel/head_$(BITS).o // $(BITS) = 32 or 64, 由head_32.S或head_64.S编译而来
head-y += arch/x86/kernel/head$(BITS).o // $(BITS) = 32 or 64, 由head32.S或head64.S编译而来
head-y += arch/x86/kernel/head.o // 由head.c编译而来
head-y += arch/x86/kernel/init_task.o // 由init_task.c编译而来
根据$(vmlinux-dirs)节,在执行命令:
make -f scripts/Makefile.build obj=arch/x86/kernel
编译arch/x86/kernel/目录时,调用arch/x86/kernel/Makefile,其中包含:
extra-y := head_$(BITS).o head$(BITS).o head.o init_task.o vmlinux.lds
因此,$(head-y)中定义的目标文件是在编译$(extra-y)时编译的,参见3.4.2.1.3.1.3 $(extra-y)节。
3.4.2.3.2 $(init-y)
在顶层Makefile中,包含下列规则:
init-y := init/
init-y := $(patsubst %/, %/built-in.o, $(init-y))
根据3.4.2.1.3 $(vmlinux-dirs)节,在执行命令:
make -f scripts/Makefile.build obj=init
编译init/目录时,由于没有指定目标,故编译scripts/Makefile.build中的默认目标__build:
// 扩展为kbuild-dir := init
kbuild-dir := $(if $(filter /%,$(src)),$(src),$(srctree)/$(src))
// 扩展为kbuild-file := init/Makefile
kbuild-file := $(if $(wildcard $(kbuild-dir)/Kbuild),$(kbuild-dir)/Kbuild,$(kbuild-dir)/Makefile)
// 此处将init/Makefile包含进来,其中包括$(obj-y)变量
include $(kbuild-file)
...
__build: $(if $(KBUILD_BUILTIN),$(builtin-target) $(lib-target) $(extra-y)) \
$(if $(KBUILD_MODULES),$(obj-m) $(modorder-target)) \
$(subdir-ym) $(always)
@:
__build依赖于$(builtin-target),在scripts/Makefile.build中,包含如下规则:
// 由init/Makefile可知,$(obj-y)不为空,故此条件成立
ifneq ($(strip $(obj-y) $(obj-m) $(obj-n) $(obj-) $(subdir-m) $(lib-target)),)
builtin-target := $(obj)/built-in.o // init/built-in.o
endif
...
ifdef builtin-target
...
/*
* 扩展为init/built-in.o: $(obj-y) FORCE,
* 其中$(obj-y)定义于init/Makefile
*/
$(builtin-target): $(obj-y) FORCE
/*
* if_changed定义于scripts/Kbuild.include,
* 若为真,则调用cmd_link_o_target
*/
$(call if_changed,link_o_target)
...
endif # builtin-target
由上述规则可知,先编译init/Makefile中$(obj-y)定义的目标文件,然后调用cmd_link_o_target函数链接$(obj-y)中的.o文件生成init/built-in.o。
$(obj-y)定义于init/Makefile中,且与.config中的配置有关:
obj-y := main.o version.o mounts.o
ifneq ($(CONFIG_BLK_DEV_INITRD),y)
obj-y += noinitramfs.o
else
obj-$(CONFIG_BLK_DEV_INITRD) += initramfs.o
endif
obj-$(CONFIG_GENERIC_CALIBRATE_DELAY) += calibrate.o
$(obj-y)中main.o和version.o的编译
main.o和version.o分别由main.c和version.c编译而来,其编译过程满足scripts/ Makefile.build中的规则”$(obj)/%.o: $(src)/%.c $(recordmcount_source) FORCE”,参见3.4.2.1.3.1.1.1.1 编译$(obj)目录下的目标文件节。
$(obj-y)中mounts.o的编译、链接
mounts.o的编译有些复杂。首先,mounts.o不是由mounts.c编译而来,它由多个.c文件编译而来。由init/Makefile中的规则:
mounts-y := do_mounts.o
mounts-$(CONFIG_BLK_DEV_RAM) += do_mounts_rd.o
mounts-$(CONFIG_BLK_DEV_INITRD) += do_mounts_initrd.o
mounts-$(CONFIG_BLK_DEV_MD) += do_mounts_md.o
如果配置项取值如下:
CONFIG_BLK_DEV_RAM = y
CONFIG_BLK_DEV_INITRD = y
CONFIG_BLK_DEV_MD = y
则,mounts-y = do_mounts.o do_mounts_rd.o do_mounts_initrd.o do_mounts_md.o
由scripts/Makefile.lib中的如下规则:
// 扩展为multi-used-y := mounts.o
multi-used-y := $(sort $(foreach m,$(obj-y), $(if $(strip $($(m:.o=-objs)) $($(m:.o=-y))), $(m))))
...
/*
* 扩展为multi-objs-y := $(mounts-y),即:
* multi-objs-y := do_mounts.o do_mounts_rd.o do_mounts_initrd.o do_mounts_md.o
*/
multi-objs-y := $(foreach m, $(multi-used-y), $($(m:.o=-objs)) $($(m:.o=-y)))
再根据scritps/Makefile.build中的如下规则:
$(multi-used-y) : %.o: $(multi-objs-y) FORCE
$(call if_changed,link_multi-y)
...
# Built-in and composite module parts
$(obj)/%.o: $(src)/%.c $(recordmcount_source) FORCE
$(call cmd,force_checksrc)
$(call if_changed_rule,cc_o_c)
可知,首先执行rule_cc_o_c命令,分别将do_mounts.c、do_mounts_rd.c、do_mounts_initrd.c、do_mounts_md.c编译成do_mounts.o、do_mounts_rd.o、do_mounts_initrd.o、do_mounts_md.o;然后执行cmd_multi-y命令,将这些.o文件链接成mounts.o文件。
3.4.2.4 $(vmlinux-main)
在顶层Makefile中,包含如下规则:
vmlinux-main := $(core-y) $(libs-y) $(drivers-y) $(net-y)
...
# The actual objects are generated when descending,
# make sure no implicit rule kicks in
$(sort $(vmlinux-init) $(vmlinux-main)) $(vmlinux-lds): $(vmlinux-dirs) ;
$(vmlinux-main)依赖于$(vmlinux-dirs),其编译过程参见3.4.2.1 $(vmlinux-dirs)节,即通过下列命令编译:
// 编译$(core-y)
make -f scripts/Makefile.build obj=usr
make -f scripts/Makefile.build obj=arch/x86 // 此处以x86体系为例,由arch/x86/Makefile中的core-y引入
make -f scripts/Makefile.build obj=kernel
make -f scripts/Makefile.build obj=mm
make -f scripts/Makefile.build obj=fs
make -f scripts/Makefile.build obj=ipc
make -f scripts/Makefile.build obj=security
make -f scripts/Makefile.build obj=crypto
make -f scripts/Makefile.build obj=block
// 编译$(drivers-y)
make -f scripts/Makefile.build obj=drivers
make -f scripts/Makefile.build obj=sound
make -f scripts/Makefile.build obj=firmware
make -f scripts/Makefile.build obj=arch/x86/math-emu // 与CONFIG_MATH_EMULATION有关
make -f scripts/Makefile.build obj=arch/x86/pci // 与CONFIG_PCI有关
make -f scripts/Makefile.build obj=arch/x86/oprofile // 与CONFIG_OPROFILE有关
make -f scripts/Makefile.build obj=arch/x86/power // 与CONFIG_PM有关
make -f scripts/Makefile.build obj=arch/x86/video // 与CONFIG_FB有关
// 编译$(net-y)
make -f scripts/Makefile.build obj=net
// 编译$(libs-y)
make -f scripts/Makefile.build obj=lib
make -f scripts/Makefile.build obj=arch/x86/lib/ // 以x86为例,由arch/x86/Makefile中的lib-y引入
3.4.2.5 vmlinux.o
在顶层Makefile中,包含如下规则:
/*
* 由[3.4.2.3 $(vmlinux-init)]节可知,modpost-init被扩展
* 为$(head-y),而$(head-y)的编译参见[3.4.2.3.1 $(head-y)]节
*/
modpost-init := $(filter-out init/built-in.o, $(vmlinux-init))
// $(vmlinux-main)的编译参见[3.4.2.4 $(vmlinux-main)]节
vmlinux.o: $(modpost-init) $(vmlinux-main) FORCE
// 调用rule_vmlinux-modpost生成vmlinux.o
$(call if_changed_rule,vmlinux-modpost)
...
// 参见[3.4.2.5.1 cmd_vmlinux-modpost]节
quiet_cmd_vmlinux-modpost = LD $@
cmd_vmlinux-modpost = $(LD) $(LDFLAGS) -r -o $@ \
$(vmlinux-init) --start-group $(vmlinux-main) --end-group \
$(filter-out $(vmlinux-init) $(vmlinux-main) FORCE ,$^)
// 参见[3.4.2.5.2 rule_vmlinux-modpost]节
define rule_vmlinux-modpost
:
// 调用cmd_vmlinux-modpost编译vmlinux.o
+$(call cmd,vmlinux-modpost)
// 根据vmlinux.o生成Module.symvers
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.modpost $@
// 生成命令文件.vmlinux.o.cmd
$(Q)echo 'cmd_$@ := $(cmd_vmlinux-modpost)' > $(dot-target).cmd
endef
3.4.2.5.1 cmd_vmlinux-modpost
调用下列命令链接vmlinux.o:
cmd_vmlinux-modpost = $(LD) $(LDFLAGS) -r -o $@ \
$(vmlinux-init) --start-group $(vmlinux-main) --end-group \
$(filter-out $(vmlinux-init) $(vmlinux-main) FORCE ,$^)
其中,$^ is a list of all the prerequisites of the rule,此处取值为$(modpost-init) $(vmlinux-main)。
该命令被扩展为:
ld -m elf_i386 -r -o vmlinux.o arch/x86/kernel/head_32.o arch/x86/kernel/head32.o arch/x86/kernel/head.o arch/x86/kernel/init_task.o init/built-in.o --start-group usr/built-in.o arch/x86/built-in.o kernel/built-in.o mm/built-in.o fs/built-in.o ipc/built-in.o security/built-in.o crypto/built-in.o block/built-in.o lib/lib.a arch/x86/lib/lib.a lib/built-in.o arch/x86/lib/built-in.o drivers/built-in.o sound/built-in.o firmware/built-in.o arch/x86/math-emu/built-in.o arch/x86/power/built-in.o net/built-in.o –end-group
3.4.2.5.2 rule_vmlinux-modpost
调用cmd_vmlinux-modpost链接vmlinux.o完成后,将执行下列命令:
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.modpost $@
该命令被扩展为:
make -f scripts/Makefile.modpost vmlinux.o
即执行scripts/Makefile.modpost中的vmlinux.o目标:
modpost = scripts/mod/modpost \
$(if $(CONFIG_MODVERSIONS),-m) \
$(if $(CONFIG_MODULE_SRCVERSION_ALL),-a,) \
// kernelsymfile := $(objtree)/Module.symvers
$(if $(KBUILD_EXTMOD),-i,-o) $(kernelsymfile) \
$(if $(KBUILD_EXTMOD),-I $(modulesymfile)) \
$(if $(KBUILD_EXTRA_SYMBOLS), $(patsubst %, -e %,$(KBUILD_EXTRA_SYMBOLS))) \
$(if $(KBUILD_EXTMOD),-o $(modulesymfile)) \
$(if $(CONFIG_DEBUG_SECTION_MISMATCH),,-S) \
$(if $(KBUILD_EXTMOD)$(KBUILD_MODPOST_WARN),-w) \
$(if $(cross_build),-c)
...
quiet_cmd_kernel-mod = MODPOST $@
cmd_kernel-mod = $(modpost) $@
vmlinux.o: FORCE
// 调用cmd_kernel-mod
$(call cmd,kernel-mod)
调用cmd_kernel-mod执行下列命令:
scripts/mod/modpost -m -o /usr/src/linux-3.2/Module.symvers vmlinux.o
输出Module.symvers文件,其中包含基本内核导出的、供模块使用的符号以及CRC校验和。
上述命令执行完成后,继续执行下列命令:
$(Q)echo 'cmd_$@ := $(cmd_vmlinux-modpost)' > $(dot-target).cmd
根据scripts/Kbuild.include中对dot-target的定义:
# Name of target with a '.' as filename prefix. foo/bar.o => foo/.bar.o
dot-target = $(dir $@).$(notdir $@)
可知,该命令被扩展为:
echo 'cmd_vmlinux.o := ld -m elf_i386 -r -o vmlinux.o arch/x86/kernel/head_32.o arch/x86/kernel/head32.o arch/x86/kernel/head.o arch/x86/kernel/init_task.o init/built-in.o --start-group usr/built-in.o arch/x86/built-in.o kernel/built-in.o mm/built-in.o fs/built-in.o ipc/built-in.o security/built-in.o crypto/built-in.o block/built-in.o lib/lib.a arch/x86/lib/lib.a lib/built-in.o arch/x86/lib/built-in.o drivers/built-in.o sound/built-in.o firmware/built-in.o arch/x86/math-emu/built-in.o arch/x86/power/built-in.o net/built-in.o --end-group ' > ./.vmlinux.o.cmd
其输出为./.vmlinux.o.cmd,该文件包含编译vmlinux.o时所用的命令。
3.4.2.6 $(kallsyms.o)
在顶层Makefile中,包含如下规则:
// kallsyms.o的取值与.config中的配置项CONFIG_KALLSYMS有关
ifdef CONFIG_KALLSYMS
last_kallsyms := 2
ifdef KALLSYMS_EXTRA_PASS
ifneq ($(KALLSYMS_EXTRA_PASS),0)
last_kallsyms := 3
endif
endif
// kallsymb.o := .tmp_kallsyms2.o或.tmp_kallsyms3.o
kallsyms.o := .tmp_kallsyms$(last_kallsyms).o
...
endif
.tmp_kallsyms1.o .tmp_kallsyms2.o .tmp_kallsyms3.o: %.o: %.S scripts FORCE
// 调用cmd_as_o_S生成.tmp_kallsym%.o
$(call if_changed_dep,as_o_S)
// KALLSYMS = scripts/kallsyms
.tmp_kallsyms%.S: .tmp_vmlinux% $(KALLSYMS)
// 调用cmd_kallsyms生成.tmp_kallsym%.S
$(call cmd,kallsyms)
# .tmp_vmlinux1 must be complete except kallsyms, so update vmlinux version
.tmp_vmlinux1: $(vmlinux-lds) $(vmlinux-all) FORCE
// 调用rule_ksym_ld链接生成.tmp_vmlinux1
$(call if_changed_rule,ksym_ld)
.tmp_vmlinux2: $(vmlinux-lds) $(vmlinux-all) .tmp_kallsyms1.o FORCE
// 调用cmd_vmlinux__链接生成.tmp_vmlinux2
$(call if_changed,vmlinux__)
.tmp_vmlinux3: $(vmlinux-lds) $(vmlinux-all) .tmp_kallsyms2.o FORCE
// 调用cmd_vmlinux__链接生成.tmp_vmlinux3
$(call if_changed,vmlinux__)
编译链接$(kallsyms.o)的流程:
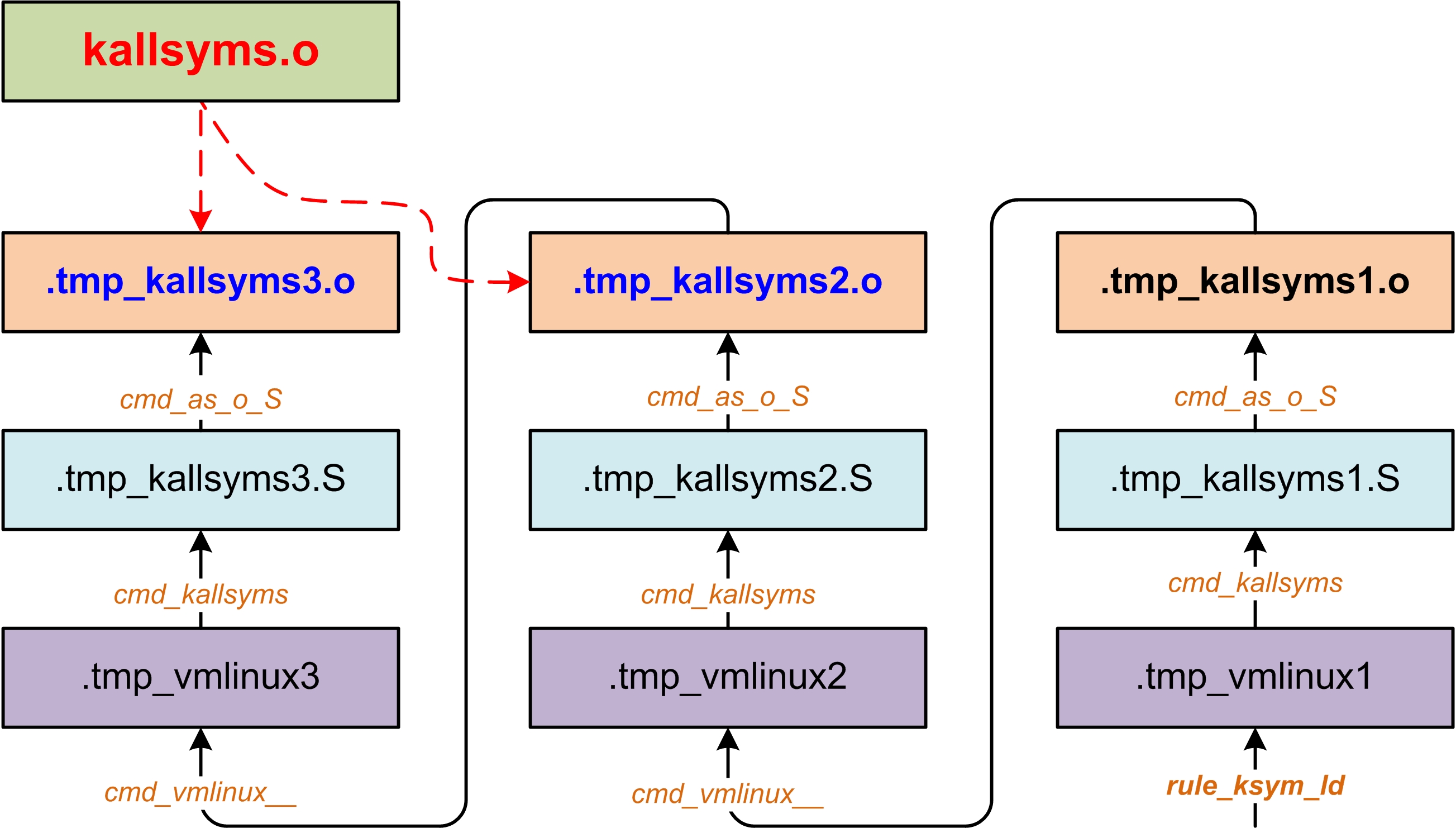
3.4.2.6.1 rule_ksym_ld
在顶层Makefile中,包含如下规则:
# Rule to link vmlinux - also used during CONFIG_KALLSYMS
# May be overridden by arch/$(ARCH)/Makefile
quiet_cmd_vmlinux__ ?= LD $@
cmd_vmlinux__ ?= $(LD) $(LDFLAGS) $(LDFLAGS_vmlinux) -o $@ \
-T $(vmlinux-lds) $(vmlinux-init) \
--start-group $(vmlinux-main) --end-group \
$(filter-out $(vmlinux-lds) $(vmlinux-init) $(vmlinux-main) vmlinux.o FORCE ,$^)
# Generate new vmlinux version
quiet_cmd_vmlinux_version = GEN .version
cmd_vmlinux_version = set -e; \
if [ ! -r .version ]; then \
rm -f .version; \
echo 1 >.version; \
else \
mv .version .old_version; \
expr 0$$(cat .old_version) + 1 >.version; \
fi; \
$(MAKE) $(build)=init
...
define rule_ksym_ld
:
// 调用cmd_vmlinux_version
+$(call cmd,vmlinux_version)
// 调用cmd_vmlinux__
$(call cmd,vmlinux__)
// 生成命令文件..tmp_vmlinux1.cmd
$(Q)echo 'cmd_$@ := $(cmd_vmlinux__)' > $(@D)/.$(@F).cmd
endef
3.4.2.6.1.1 cmd_vmlinux_version
该命令的输出.version文件。
3.4.2.6.1.2 cmd_vmlinux__
链接.tmp_vmlinux1时,该命令被扩展为:
cmd_.tmp_vmlinux1 := ld -m elf_i386 --build-id -o .tmp_vmlinux1 -T arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_32.o arch/x86/kernel/head32.o arch/x86/kernel/head.o arch/x86/kernel/init_task.o init/built-in.o --start-group usr/built-in.o arch/x86/built-in.o kernel/built-in.o mm/built-in.o fs/built-in.o ipc/built-in.o security/built-in.o crypto/built-in.o block/built-in.o lib/lib.a arch/x86/lib/lib.a lib/built-in.o arch/x86/lib/built-in.o drivers/built-in.o sound/built-in.o firmware/built-in.o arch/x86/math-emu/built-in.o arch/x86/power/built-in.o net/built-in.o --end-group
链接.tmp_vmlinux2时,该命令被扩展为:
cmd_.tmp_vmlinux2 := ld -m elf_i386 --build-id -o .tmp_vmlinux2 -T arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_32.o arch/x86/kernel/head32.o arch/x86/kernel/head.o arch/x86/kernel/init_task.o init/built-in.o --start-group usr/built-in.o arch/x86/built-in.o kernel/built-in.o mm/built-in.o fs/built-in.o ipc/built-in.o security/built-in.o crypto/built-in.o block/built-in.o lib/lib.a arch/x86/lib/lib.a lib/built-in.o arch/x86/lib/built-in.o drivers/built-in.o sound/built-in.o firmware/built-in.o arch/x86/math-emu/built-in.o arch/x86/power/built-in.o net/built-in.o --end-group .tmp_kallsyms1.o
链接.tmp_vmlinux3时,该命令被扩展为:
cmd_.tmp_vmlinux3 := ld -m elf_i386 --build-id -o .tmp_vmlinux3 -T arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_32.o arch/x86/kernel/head32.o arch/x86/kernel/head.o arch/x86/kernel/init_task.o init/built-in.o --start-group usr/built-in.o arch/x86/built-in.o kernel/built-in.o mm/built-in.o fs/built-in.o ipc/built-in.o security/built-in.o crypto/built-in.o block/built-in.o lib/lib.a arch/x86/lib/lib.a lib/built-in.o arch/x86/lib/built-in.o drivers/built-in.o sound/built-in.o firmware/built-in.o arch/x86/math-emu/built-in.o arch/x86/power/built-in.o net/built-in.o --end-group .tmp_kallsyms2.o
该命令的输出为.tmp_vmlinux1, .tmp_vmlinux2, 或.tmp_vmlinux3。
链接vmlinux时(参见3.4.2.7.4 rule_vmlinux__节),该命令被扩展为:
cmd_vmlinux := ld -m elf_i386 --build-id -o vmlinux -T arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_32.o arch/x86/kernel/head32.o arch/x86/kernel/head.o arch/x86/kernel/init_task.o init/built-in.o --start-group usr/built-in.o arch/x86/built-in.o kernel/built-in.o mm/built-in.o fs/built-in.o ipc/built-in.o security/built-in.o crypto/built-in.o block/built-in.o lib/lib.a arch/x86/lib/lib.a lib/built-in.o arch/x86/lib/built-in.o drivers/built-in.o sound/built-in.o firmware/built-in.o arch/x86/math-emu/built-in.o arch/x86/power/built-in.o net/built-in.o --end-group .tmp_kallsyms2.o
NOTE: 本命令中最后一个参数为.tmp_kallsyms2.o,也可能为.tmp_kallsyms3.o,具体取值与配置有关,参见3.4.2.6 $(kallsyms.o)节。
3.4.2.6.2 cmd_kallsyms
在顶层Makefile中,包含如下规则:
# Generate .S file with all kernel symbols
quiet_cmd_kallsyms = KSYM $@
cmd_kallsyms = $(NM) -n $< | $(KALLSYMS) \
$(if $(CONFIG_KALLSYMS_ALL),--all-symbols) > $@
在编译.tmp_kallsyms1.S时,该命令被扩展为:
nm -n .tmp_vmlinux1 | scripts/kallsyms --all-symbols > .tmp_kallsyms1.S
在编译.tmp_kallsyms2.S时,该命令被扩展为:
nm -n .tmp_vmlinux2 | scripts/kallsyms --all-symbols > .tmp_kallsyms2.S
在编译.tmp_kallsyms3.S时,该命令被扩展为:
nm -n .tmp_vmlinux3 | scripts/kallsyms --all-symbols > .tmp_kallsyms3.S
3.4.2.6.3 cmd_as_o_S
在顶层Makefile中,包含如下规则:
quiet_cmd_as_o_S = AS $@
cmd_as_o_S = $(CC) $(a_flags) -c -o $@ $<
在编译.tmp_kallsyms1.o时,该命令被扩展为:
cmd_.tmp_kallsyms1.o := gcc -Wp,-MD,./..tmp_kallsyms1.o.d -D__ASSEMBLY__ -m32 -DCONFIG_AS_CFI=1 -DCONFIG_AS_CFI_SIGNAL_FRAME=1 -DCONFIG_AS_CFI_SECTIONS=1 -gdwarf-2 -nostdinc -isystem /usr/lib/gcc/i686-linux-gnu/4.7/include -I/usr/src/linux-3.2/arch/x86/include -Iarch/x86/include/generated -Iinclude -include /usr/src/linux-3.2/include/linux/kconfig.h -D__KERNEL__ -c -o .tmp_kallsyms1.o .tmp_kallsyms1.S
在编译.tmp_kallsyms2.o时,该命令被扩展为:
cmd_.tmp_kallsyms2.o := gcc -Wp,-MD,./..tmp_kallsyms1.o.d -D__ASSEMBLY__ -m32 -DCONFIG_AS_CFI=1 -DCONFIG_AS_CFI_SIGNAL_FRAME=1 -DCONFIG_AS_CFI_SECTIONS=1 -gdwarf-2 -nostdinc -isystem /usr/lib/gcc/i686-linux-gnu/4.7/include -I/usr/src/linux-3.2/arch/x86/include -Iarch/x86/include/generated -Iinclude -include /usr/src/linux-3.2/include/linux/kconfig.h -D__KERNEL__ -c -o .tmp_kallsyms2.o .tmp_kallsyms2.S
在编译.tmp_kallsyms3.o时,该命令被扩展为:
cmd_.tmp_kallsyms3.o := gcc -Wp,-MD,./..tmp_kallsyms1.o.d -D__ASSEMBLY__ -m32 -DCONFIG_AS_CFI=1 -DCONFIG_AS_CFI_SIGNAL_FRAME=1 -DCONFIG_AS_CFI_SECTIONS=1 -gdwarf-2 -nostdinc -isystem /usr/lib/gcc/i686-linux-gnu/4.7/include -I/usr/src/linux-3.2/arch/x86/include -Iarch/x86/include/generated -Iinclude -include /usr/src/linux-3.2/include/linux/kconfig.h -D__KERNEL__ -c -o .tmp_kallsyms3.o .tmp_kallsyms3.S
3.4.2.7 vmlinux
在顶层Makefile中,包含如下规则:
vmlinux: $(vmlinux-lds) $(vmlinux-init) $(vmlinux-main) vmlinux.o $(kallsyms.o) FORCE
/* 参见make -f Makefile headers_check节 */
ifdef CONFIG_HEADERS_CHECK
$(Q)$(MAKE) -f $(srctree)/Makefile headers_check
endif
/*
* 参见make -f scripts/Makefile.build obj=samples节,
* 编译samples目录,内核编程示例
*/
ifdef CONFIG_SAMPLES
$(Q)$(MAKE) $(build)=samples
endif
/*
* 参见make -f scripts/Makefile.build obj=Documentation节,
* 编译Documentation目录
*/
ifdef CONFIG_BUILD_DOCSRC
$(Q)$(MAKE) $(build)=Documentation
endif
// 未定义函数vmlinux-modpost,忽略
$(call vmlinux-modpost)
/*
* 调用rule_vmlinux__链接vmlinux,并
* 生成System.map,参见[3.4.2.7.4 rule_vmlinux__]节
*/
$(call if_changed_rule,vmlinux__)
$(Q)rm -f .old_version
3.4.2.7.1 make -f Makefile headers_check
在顶层Makefile中,包含如下规则:
# Where to locate arch specific headers
hdr-arch := $(SRCARCH) // 此处以x86体系为例
hdr-inst := -rR -f $(srctree)/scripts/Makefile.headersinst obj
# If we do an all arch process set dst to asm-$(hdr-arch)
hdr-dst = $(if $(KBUILD_HEADERS), dst=include/asm-$(hdr-arch), dst=include/asm)
PHONY += __headers
// 参见include/linux/version.h,[3.4.2.1.1.8 scripts_basic]节和[3.4.2.1.1.4 asm-generic]节
__headers: include/linux/version.h scripts_basic asm-generic FORCE
// 编译scripts/unifdef
$(Q)$(MAKE) $(build)=scripts build_unifdef
PHONY += headers_install
headers_install: __headers
$(if $(wildcard $(srctree)/arch/$(hdr-arch)/include/asm/Kbuild),, \
$(error Headers not exportable for the $(SRCARCH) architecture))
// 扩展为make -rR -f $(srctree)/scripts/Makefile.headersinst obj=include
$(Q)$(MAKE) $(hdr-inst)=include
// 扩展为make -rR -f $(srctree)/scripts/Makefile.headersinst obj=arch/x86/include/asm $(hdr-dst)
$(Q)$(MAKE) $(hdr-inst)=arch/$(hdr-arch)/include/asm $(hdr-dst)
PHONY += headers_check
headers_check: headers_install
// 扩展为make -rR -f $(srctree)/scripts/Makefile.headersinst obj=include HDRCHECK=1
$(Q)$(MAKE) $(hdr-inst)=include HDRCHECK=1
// 扩展为make -rR -f $(srctree)/scripts/Makefile.headersinst obj=arch/x86/include/asm $(hdr-dst) HDRCHECK=1
$(Q)$(MAKE) $(hdr-inst)=arch/$(hdr-arch)/include/asm $(hdr-dst) HDRCHECK=1
3.4.2.7.2 make -f scripts/Makefile.build obj=samples
参见3.4.2.1.3.1 make -f scripts/Makefile.build obj=XXX命令的执行过程节。samples目录包含内核编程的示例。
3.4.2.7.3 make -f scripts/Makefile.build obj=Documentation
参见3.4.2.1.3.1 make -f scripts/Makefile.build obj=XXX命令的执行过程节。
3.4.2.7.4 rule_vmlinux__
在顶层Makefile中,包含如下规则:
# Generate System.map
quiet_cmd_sysmap = SYSMAP
cmd_sysmap = $(CONFIG_SHELL) $(srctree)/scripts/mksysmap
# Link of vmlinux
# If CONFIG_KALLSYMS is set .version is already updated
# Generate System.map and verify that the content is consistent
# Use + in front of the vmlinux_version rule to silent warning with make -j2
# First command is ':' to allow us to use + in front of the rule
define rule_vmlinux__
:
// 调用cmd_vmlinux_version,参见[3.4.2.6.1.1 cmd_vmlinux_version]节
$(if $(CONFIG_KALLSYMS),,+$(call cmd,vmlinux_version))
// 调用cmd_vmlinux__链接vmlinux,参见[3.4.2.6.1.2 cmd_vmlinux__]节
$(call cmd,vmlinux__)
// 生成命令文件./.vmlinux.cmd
$(Q)echo 'cmd_$@ := $(cmd_vmlinux__)' > $(@D)/.$(@F).cmd
$(Q)$(if $($(quiet)cmd_sysmap), \
echo ' $($(quiet)cmd_sysmap) System.map' &&) \
// 用于提取vmlinux中的符号,并保存于System.map
$(cmd_sysmap) $@ System.map; \
if [ $$? -ne 0 ]; then \
rm -f $@; \
/bin/false; \
fi;
$(verify_kallsyms)
endef
...
define verify_kallsyms
$(Q)$(if $($(quiet)cmd_sysmap), \
echo ' $($(quiet)cmd_sysmap) .tmp_System.map' &&) \
/*
* 提取.tmp_vmlinux2或.tmp_vmlinux3中的符号
* (参见[3.4.2.6 $(kallsyms.o)]节和[3.4.2.6.1.2 cmd_vmlinux__]节),
* 并保存于.tmp_System.map
*/
$(cmd_sysmap) .tmp_vmlinux$(last_kallsyms) .tmp_System.map
/*
* 比较System.map和.tmp_System.map,
* 应该相同;若不同,则打印错误信息
*/
$(Q)cmp -s System.map .tmp_System.map || \
(echo Inconsistent kallsyms data; \
echo This is a bug - please report about it; \
echo Try "make KALLSYMS_EXTRA_PASS=1" as a workaround; \
rm .tmp_kallsyms* ; /bin/false )
endef
本命令的输出为vmlinux和System.map,其中:
- vmlinux用来生成bzImage,参见3.4.2.8.5.1 $(obj)/piggy.o节;
- System.map被安装到/boot/System.map-3.2.0(通过执行命令make install),参见3.5.4 编译内核节。
查看vmlinux的文件属性:
chenwx@chenwx /usr/src/linux $ file vmlinux
vmlinux: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), statically linked, BuildID[sha1]=0xb14c81a12cca7144a29770565166fe7f8b1748d7, not stripped
3.4.2.8 bzImage
在arch/x86/Makefile中,包含如下规则:
boot := arch/x86/boot
# Default kernel to build
all: bzImage
# KBUILD_IMAGE specify target image being built
KBUILD_IMAGE := $(boot)/bzImage
bzImage: vmlinux
ifeq ($(CONFIG_X86_DECODER_SELFTEST),y)
// 扩展为make -f scripts/Makefile.build obj=arch/x86/tools posttest
$(Q)$(MAKE) $(build)=arch/x86/tools posttest
endif
// 扩展为make -f scripts/Makefile.build obj=arch/x86/boot arch/x86/boot/bzImage
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
// 扩展为mkdir -p /usr/src/linux-3.2/arch/i386/boot
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
/*
* 扩展为ln -fsn ../../x86/boot/bzImage /usr/src/linux-3.2/arch/i386/boot/bzImage
* 即arch/i386/boot/目录中的bzImage为符号链接,指向arch/x86/boot/bzImage
*/
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
编译bzImage的命令为:
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
该命令被扩展为:
make -f scripts/Makefile.build obj=arch/x86/boot arch/x86/boot/bzImage
该命令调用arch/x86/boot/Makefile,并编译目标arch/x86/boot/bzImage。在arch/x86/boot/Makefile中,包含如下规则:
/*
* (1) 参见[3.4.2.8.1 $(src)/setup.ld]节,
* [3.4.2.8.2 $(SETUP_OBJS)]节,[3.4.2.8.3 $(obj)/setup.elf]节
*/
LDFLAGS_setup.elf := -T
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
$(call if_changed,ld)
// (2) 参见[3.4.2.8.4 $(obj)/setup.bin]节
OBJCOPYFLAGS_setup.bin := -O binary
$(obj)/setup.bin: $(obj)/setup.elf FORCE
$(call if_changed,objcopy)
// (3) 参见[3.4.2.8.5 $(obj)/compressed/vmlinux]节
$(obj)/compressed/vmlinux: FORCE
$(Q)$(MAKE) $(build)=$(obj)/compressed $@
// (4) 参见[3.4.2.8.6 $(obj)/vmlinux.bin]节
OBJCOPYFLAGS_vmlinux.bin := -O binary -R .note -R .comment -S
$(obj)/vmlinux.bin: $(obj)/compressed/vmlinux FORCE
$(call if_changed,objcopy)
// (5) 参见[3.4.2.8.8 arch/x86/boot/bzImage]节
$(obj)/bzImage: $(obj)/setup.bin $(obj)/vmlinux.bin $(obj)/tools/build FORCE
$(call if_changed,image)
@echo 'Kernel: $@ is ready' ' (#'`cat .version`')'
各目标之间的依赖关系,参见Appendix I: Targets Tree。
bzImage的生成过程:
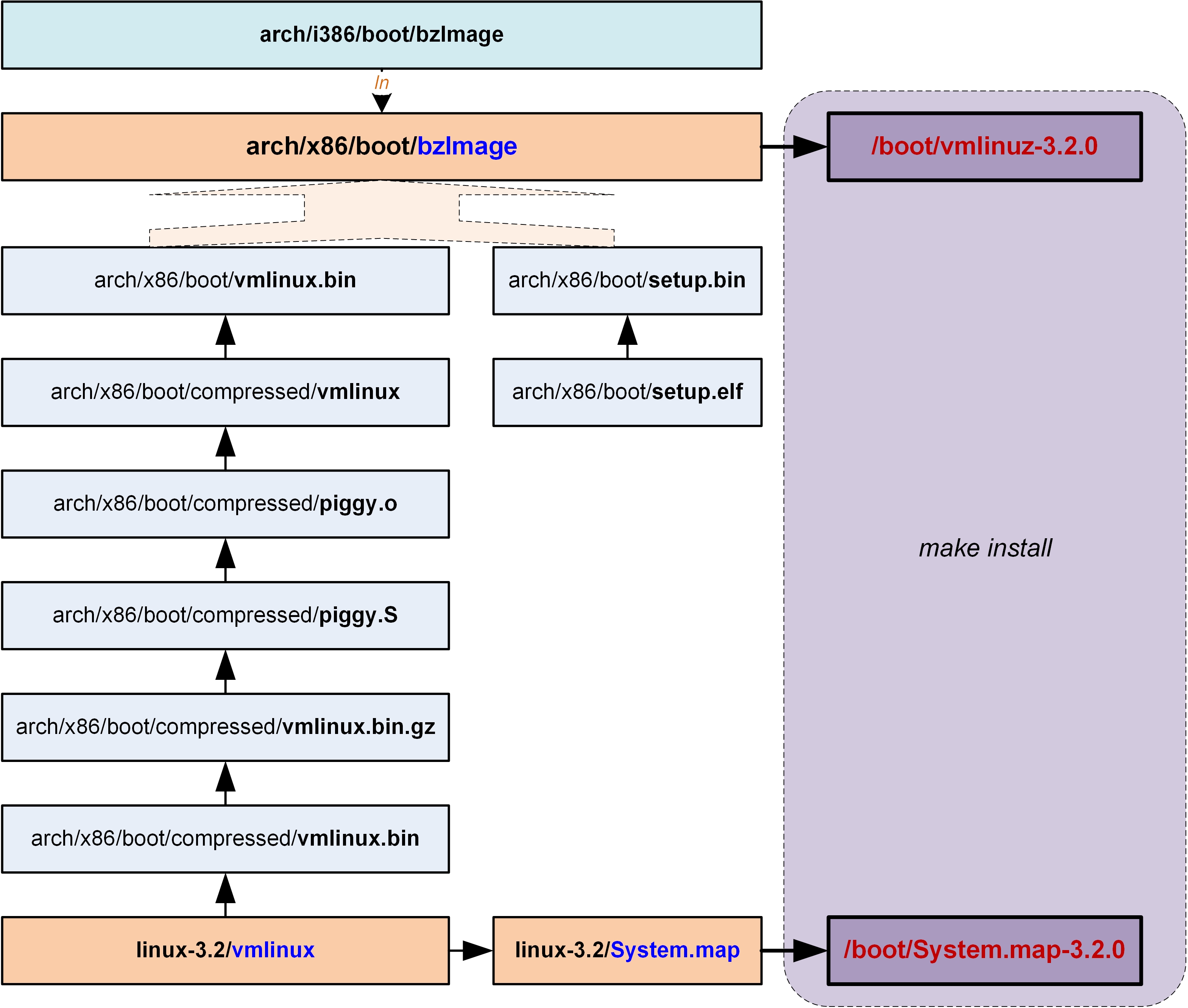
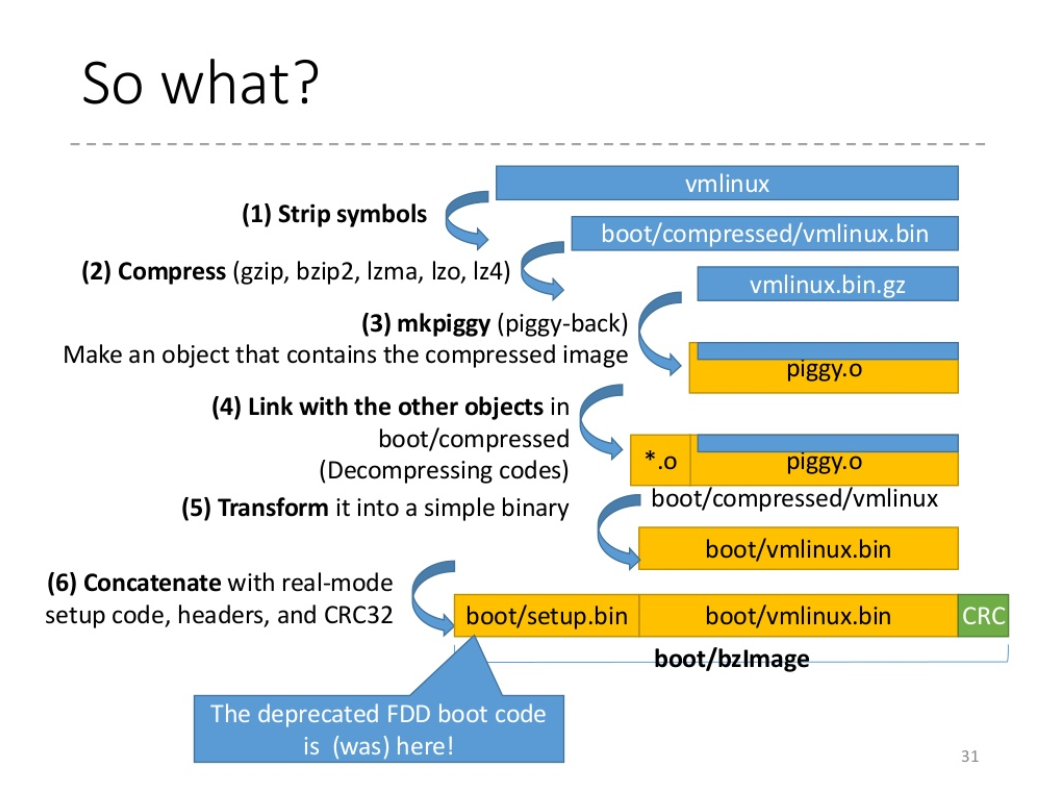
3.4.2.8.1 $(src)/setup.ld
arch/x86/boot/setup.ld是GNU ld的Linker script文件,与$(vmlinux.lds)类似,参见3.4.2.2 $(vmlinux-lds)节。
3.4.2.8.2 $(SETUP_OBJS)
该变量定义于arch/x86/boot/Makefile:
setup-y += a20.o bioscall.o cmdline.o copy.o cpu.o cpucheck.o
setup-y += early_serial_console.o edd.o header.o main.o mca.o memory.o
setup-y += pm.o pmjump.o printf.o regs.o string.o tty.o video.o
setup-y += video-mode.o version.o
setup-$(CONFIG_X86_APM_BOOT) += apm.o
# The link order of the video-*.o modules can matter. In particular,
# video-vga.o *must* be listed first, followed by video-vesa.o.
# Hardware-specific drivers should follow in the order they should be
# probed, and video-bios.o should typically be last.
setup-y += video-vga.o
setup-y += video-vesa.o
setup-y += video-bios.o
...
SETUP_OBJS = $(addprefix $(obj)/,$(setup-y))
3.4.2.8.3 $(obj)/setup.elf
在arch/x86/boot/Makefile中,包含如下规则:
LDFLAGS_setup.elf := -T
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
$(call if_changed,ld)
调用命令cmd_ld将$(SETUP_OBJS)中的文件连接生成arch/x86/boot/setup.elf。命令cmd_ld定义于scripts/Makefile.lib,被扩展为:
ld -m elf_i386 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/apm.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
3.4.2.8.4 $(obj)/setup.bin
在arch/x86/boot/Makefile中,包含如下规则:
OBJCOPYFLAGS_setup.bin := -O binary
$(obj)/setup.bin: $(obj)/setup.elf FORCE
$(call if_changed,objcopy)
调用命令cmd_objcopy由arch/x86/boot/setup.elf生成arch/x86/boot/setup.bin。命令cmd_objcopy定义于scripts/Makefile.lib,被扩展为:
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
That’s write the output file setup.bin from input file setup.elf using the object format binary.
3.4.2.8.5 $(obj)/compressed/vmlinux
在arch/x86/boot/Makefile中,包含如下规则:
$(obj)/compressed/vmlinux: FORCE
$(Q)$(MAKE) $(build)=$(obj)/compressed $@
执行下列命令编译arch/x86/boot/compressed目录:
$(Q)$(MAKE) $(build)=$(obj)/compressed $@
该命令被扩展为:
make -f scripts/Makefile.build obj=arch/x86/boot/compressed arch/x86/boot/compressed/vmlinux
该命令调用arch/x86/boot/compressed/Makefile,其中包含如下规则:
$(obj)/vmlinux: $(obj)/vmlinux.lds $(obj)/head_$(BITS).o $(obj)/misc.o $(obj)/string.o $(obj)/cmdline.o $(obj)/early_serial_console.o $(obj)/piggy.o FORCE
$(call if_changed,ld)
@:
调用命令cmd_ld生成arch/x86/boot/compressed/vmlinux。命令cmd_ld定义于scripts/Makefile.lib,被扩展为:
ld -m elf_i386 -T arch/x86/boot/compressed/vmlinux.lds arch/x86/boot/compressed/head_32.o arch/x86/boot/compressed/misc.o arch/x86/boot/compressed/string.o arch/x86/boot/compressed/cmdline.o arch/x86/boot/compressed/early_serial_console.o arch/x86/boot/compressed/piggy.o -o arch/x86/boot/compressed/vmlinux
输出为arch/x86/boot/compressed/vmlinux,该压缩内核文件大小约为1.6M,要比/usr/src/linux-3.2/vmlinux (参见3.4.2.7.4 rule_vmlinux__节,其大小约46M) 小很多。
查看arch/x86/boot/compressed/vmlinux的文件属性:
chenwx@chenwx /usr/src/linux $ file arch/x86/boot/compressed/vmlinux
arch/x86/boot/compressed/vmlinux: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), statically linked, not stripped
arch/x86/boot/compressed/vmlinux所依赖的各目标文件分别由如下文件生成:
arch/x86/boot/compressed/vmlinux.lds <= arch/x86/boot/compressed/vmlinux.lds.S
arch/x86/boot/compressed/head_32.o <= arch/x86/boot/compressed/head_32.S
arch/x86/boot/compressed/head_64.o <= arch/x86/boot/compressed/head_64.S
arch/x86/boot/compressed/misc.o <= arch/x86/boot/compressed/misc.c, misc.h
arch/x86/boot/compressed/string.o <= arch/x86/boot/compressed/string.c
arch/x86/boot/compressed/cmdline.o <= arch/x86/boot/compressed/cmdline.c
arch/x86/boot/compressed/early_serial_console.o <= arch/x86/boot/compressed/early_serial_console.c
arch/x86/boot/compressed/piggy.o <= arch/x86/boot/compressed/piggy.S,参见[3.4.2.8.5.1 $(obj)/piggy.o]节
3.4.2.8.5.1 $(obj)/piggy.o
在arch/x86/boot/compressed/Makefile中,包含如下规则:
// (1) 参见[3.4.2.8.5.1.1 $(obj)/vmlinux.bin]节
OBJCOPYFLAGS_vmlinux.bin := -R .comment -S
$(obj)/vmlinux.bin: vmlinux FORCE
$(call if_changed,objcopy)
// (2) 参见[3.4.2.8.5.1.2 $(obj)/vmlinux.bin.gz]节
vmlinux.bin.all-y := $(obj)/vmlinux.bin
$(obj)/vmlinux.bin.gz: $(vmlinux.bin.all-y) FORCE
$(call if_changed,gzip)
/*
* (3) 参见[3.4.2.8.5.1.3 $(obj)/mkpiggy]节,
* [3.4.2.8.5.1.4 $(obj)/piggy.S]节,
* [3.4.2.8.5.1.5 $(obj)/piggy.o]节
*/
suffix-$(CONFIG_KERNEL_GZIP) := gz
quiet_cmd_mkpiggy = MKPIGGY $@
cmd_mkpiggy = $(obj)/mkpiggy $< > $@ || ( rm -f $@ ; false )
$(obj)/piggy.S: $(obj)/vmlinux.bin.$(suffix-y) $(obj)/mkpiggy FORCE
$(call if_changed,mkpiggy)
arch/x86/boot/compressed/piggy.o是由arch/x86/boot/compressed/piggy.S编译而来的,各目标之间的依赖关系参见Appendix I: Targets Tree。
3.4.2.8.5.1.1 $(obj)/vmlinux.bin
在arch/x86/boot/compressed/Makefile中,包含如下规则:
OBJCOPYFLAGS_vmlinux.bin := -R .comment -S
$(obj)/vmlinux.bin: vmlinux FORCE
$(call if_changed,objcopy)
调用命令cmd_objcopy生成arch/x86/boot/compressed/vmlinux.bin。命令cmd_objcopy定义于scripts/Makefile.lib,被扩展为:
objcopy -R .comment -S vmlinux arch/x86/boot/compressed/vmlinux.bin
其中,参数的含义如下:
-R sectionname: Remove any section named sectionname from the output file.
-S/--strip-all: Do not copy relocation and symbol information from the source file.
vmlinux为linux-3.2/vmlinux,参见3.4.2.7 vmlinux节。
3.4.2.8.5.1.2 $(obj)/vmlinux.bin.gz
在arch/x86/boot/compressed/Makefile中,包含如下规则:
// 扩展为arch/x86/boot/compressed/vmlinux.bin
vmlinux.bin.all-y := $(obj)/vmlinux.bin
$(obj)/vmlinux.bin.gz: $(vmlinux.bin.all-y) FORCE
$(call if_changed,gzip)
调用命令cmd_gzip将arch/x86/boot/compressed/vmlinux.bin压缩成arch/x86/boot/compressed/vmlinux.bin.gz。命令cmd_gzip定义于scripts/Makefile.lib,被扩展为:
(cat arch/x86/boot/compressed/vmlinux.bin | gzip -n -f -9 > arch/x86/boot/compressed/vmlinux.bin.gz) || (rm -f arch/x86/boot/compressed/vmlinux.bin.gz ; false)
3.4.2.8.5.1.3 $(obj)/mkpiggy
arch/x86/boot/compressed/mkpiggy <= arch/x86/boot/compressed/mkpiggy.c
where, the executable mkpiggy is used when creating arch/x86/boot/compressed/piggy.S, see 3.4.2.8.5.1.4 $(obj)/piggy.S.
3.4.2.8.5.1.4 $(obj)/piggy.S
在arch/x86/boot/compressed/Makefile中,包含如下规则:
suffix-$(CONFIG_KERNEL_GZIP) := gz
...
quiet_cmd_mkpiggy = MKPIGGY $@
cmd_mkpiggy = $(obj)/mkpiggy $< > $@ || ( rm -f $@ ; false )
$(obj)/piggy.S: $(obj)/vmlinux.bin.$(suffix-y) $(obj)/mkpiggy FORCE
$(call if_changed,mkpiggy)
调用命令cmd_mkpiggy生成arch/x86/boot/compressed/piggy.S,该命令被扩展为:
arch/x86/boot/compressed/mkpiggy arch/x86/boot/compressed/vmlinux.bin.gz > arch/x86/boot/compressed/piggy.S || ( rm -f arch/x86/boot/compressed/piggy.S ; false )
由arch/x86/boot/compressed/mkpiggy.c可知,上述命令将arch/x86/boot/compressed/vmlinux.bin.gz添加到 arch/x86/boot/compressed/piggy.S中:
/*
* 此代码被放到.rodata..compressed段中,对该段的连接参见:
* [3.4.2.8.5.2 arch/x86/boot/compressed/vmlinux.lds]节
* 下列变量用于解压二进制文件vmlinux.bin.gz:
* z_input_len, z_extract_offset, input_data
* 参见[4.3.4.1.3 arch/x86/boot/compressed/head_32.S]节
*/
.section .rodata..compressed,"a",@progbits
.globl z_input_len
z_input_len = <ilen>
.globl z_output_len
z_output_len = <olen>
.globl z_extract_offset
z_extract_offset = <offs>
/* z_extract_offset_negative allows simplification of head_32.S */
.globl z_extract_offset_negative
z_extract_offset_negative = <offs>
.globl z_run_size
z_run_size = <run_size>
.globl input_data, input_data_end
input_data:
// 将二进制文件vmlinux.bin.gz包含到这里
.incbin arch/x86/boot/compressed/vmlinux.bin.gz
input_data_end:
**NOTE**: How to embed a binary in your executable?
**Method #1**: Covert the binary to the "hex" text, and #include
(binary_file.hex)
0xeb, 0xfe, 0x90, 0x90, ...
(C file)
unsigned char binary[] = {
#include "binary_file.hex"
};
**Method #2**: Use ".incbin" mnemonic in the assembler
.section .rodata
.global input_data, input_data_end
input_data:
.incbin "binary_file.bin"
input_data_end:
Obviously, mkpiggy uses the Method #2 to generate arch/x86/boot/compressed/piggy.S
3.4.2.8.5.1.5 $(obj)/piggy.o
在scripts/Makefile.build中,包含如下规则:
quiet_cmd_as_o_S = AS $(quiet_modtag) $@
cmd_as_o_S = $(CC) $(a_flags) -c -o $@ $<
$(obj)/%.o: $(src)/%.S FORCE
$(call if_changed_dep,as_o_S)
调用命令cmd_as_o_S将arch/x86/boot/compressed/piggy.S编译成arch/x86/boot/compressed/piggy.o。命令cmd_as_o_S被扩展为:
gcc -Wp,-MD,arch/x86/boot/compressed/.piggy.o.d -nostdinc -isystem /usr/lib/gcc/i686-linux-gnu/4.7/include -I/usr/src/linux-3.2/arch/x86/include -Iarch/x86/include/generated -Iinclude -include /usr/src/linux-3.2/include/linux/kconfig.h -D__KERNEL__ -m32 -D__KERNEL__ -O2 -fno-strict-aliasing -fPIC -DDISABLE_BRANCH_PROFILING -march=i386 -ffreestanding -fno-stack-protector -D__ASSEMBLY__ -c -o arch/x86/boot/compressed/piggy.o arch/x86/boot/compressed/piggy.S
That’s, make an object (arch/x86/boot/compressed/piggy.o) that contains the compressed image (arch/x86/boot/compressed/vmlinux.bin.gz ), see 3.4.2.8.5.1.4 $(obj)/piggy.S.
3.4.2.8.5.2 arch/x86/boot/compressed/vmlinux.lds
该文件包含如下内容:
#include <asm-generic/vmlinux.lds.h>
OUTPUT_FORMAT(CONFIG_OUTPUT_FORMAT, CONFIG_OUTPUT_FORMAT, CONFIG_OUTPUT_FORMAT)
#undef i386
#include <asm/cache.h>
#include <asm/page_types.h>
#ifdef CONFIG_X86_64
OUTPUT_ARCH(i386:x86-64)
ENTRY(startup_64)
#else
OUTPUT_ARCH(i386)
ENTRY(startup_32)
#endif
SECTIONS
{
/* Be careful parts of head_64.S assume startup_32 is at
* address 0.
*/
. = 0;
.head.text : {
_head = . ;
// 包含arch/x86/boot/compressed/head_32.S中的代码
HEAD_TEXT
_ehead = . ;
}
.rodata..compressed : {
/*
* 包含arch/x86/boot/compressed/piggy.S中的代码,
* 参见[3.4.2.8.5.1.4 $(obj)/piggy.S]节
*/
*(.rodata..compressed)
}
.text : {
_text = .; /* Text */
*(.text)
*(.text.*)
_etext = . ;
}
.rodata : {
_rodata = . ;
*(.rodata) /* read-only data */
*(.rodata.*)
_erodata = . ;
}
.got : {
_got = .;
KEEP(*(.got.plt))
KEEP(*(.got))
_egot = .;
}
.data : {
_data = . ;
*(.data)
*(.data.*)
_edata = . ;
}
. = ALIGN(L1_CACHE_BYTES);
.bss : {
_bss = . ;
*(.bss)
*(.bss.*)
*(COMMON)
. = ALIGN(8); /* For convenience during zeroing */
_ebss = .;
}
#ifdef CONFIG_X86_64
. = ALIGN(PAGE_SIZE);
.pgtable : {
_pgtable = . ;
*(.pgtable)
_epgtable = . ;
}
#endif
_end = .;
}
3.4.2.8.6 $(obj)/vmlinux.bin
在arch/x86/boot/Makefile中,包含如下规则:
OBJCOPYFLAGS_vmlinux.bin := -O binary -R .note -R .comment -S
$(obj)/vmlinux.bin: $(obj)/compressed/vmlinux FORCE
$(call if_changed,objcopy)
调用命令cmd_objcopy由arch/x86/boot/compressed/vmlinux 生成arch/x86/boot/vmlinux.bin。命令cmd_objcopy定义于scripts/Makefile.lib,被扩展为:
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
其中,参数的含义如下:
-R sectionname: Remove any section named sectionname from the output file.
-S/--strip-all: Do not copy relocation and symbol information from the source file.
3.4.2.8.7 $(obj)/tools/build
arch/x86/boot/tools/build <= arch/x86/boot/tools/build.c
arch/x86/boot/tools/build的用法参见3.4.2.8.8 arch/x86/boot/bzImage节。
3.4.2.8.8 arch/x86/boot/bzImage
在arch/x86/boot/Makefile中,包含如下规则:
$(obj)/bzImage: $(obj)/setup.bin $(obj)/vmlinux.bin $(obj)/tools/build FORCE
/*
* 调用cmd_image,由arch/x86/boot/setup.bin和
* arch/x86/boot/vmlinux.bin生成arch/x86/boot/bzImage
*/
$(call if_changed,image)
// 打印 Kernel: arch/x86/boot/bzImage is ready (#1)
@echo 'Kernel: $@ is ready' ' (#'`cat .version`')'
...
quiet_cmd_image = BUILD $@
cmd_image = $(obj)/tools/build $(obj)/setup.bin $(obj)/vmlinux.bin > $@
调用命令cmd_image由arch/x86/boot/setup.bin和arch/x86/boot/vmlinux.bin生成arch/x86/boot/bzImage,该命令被扩展为:
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin > arch/x86/boot/bzImage
查看arch/x86/boot/bzImage的文件属性:
chenwx@chenwx /usr/src/linux $ file arch/x86/boot/bzImage
arch/x86/boot/bzImage: Linux kernel x86 boot executable bzImage, version 3.2.0 (chenwx@chenwx) #1 SMP Tue Feb 19 23:35:53 EET 2013, RO-rootFS, swap_dev 0x2, Normal VGA
3.4.3 编译modules/$(obj-m)
运行make modules命令(或者make命令),执行顶层Makefile中的modules目标:
KBUILD_AFLAGS_MODULE := -DMODULE
KBUILD_CFLAGS_MODULE := -DMODULE
KBUILD_LDFLAGS_MODULE := -T $(srctree)/scripts/module-common.lds
...
export KBUILD_AFLAGS_MODULE KBUILD_CFLAGS_MODULE KBUILD_LDFLAGS_MODULE
...
/*
* 由此可知,必须满足CONFIG_MODULES=y才能编译modules;
* 而CONFIG_MODULES根据init/Kconfig中的如下配置项生成:
* menuconfig MODULES
* bool "Enable loadable module support"
*/
ifdef CONFIG_MODULES
all: modules
PHONY += modules
modules: $(vmlinux-dirs) $(if $(KBUILD_BUILTIN),vmlinux) modules.builtin
$(Q)$(AWK) '!x[$$0]++' $(vmlinux-dirs:%=$(objtree)/%/modules.order) > $(objtree)/modules.order
@$(kecho) ' Building modules, stage 2.';
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.modpost
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.fwinst obj=firmware __fw_modbuild
modules.builtin: $(vmlinux-dirs:%=%/modules.builtin)
$(Q)$(AWK) '!x[$$0]++' $^ > $(objtree)/modules.builtin
%/modules.builtin: include/config/auto.conf
$(Q)$(MAKE) $(modbuiltin)=$*
...
else # CONFIG_MODULES
# Modules not configured
# ---------------------------------------------------------------------------
modules modules_install: FORCE
@echo
@echo "The present kernel configuration has modules disabled."
@echo "Type 'make config' and enable loadable module support."
@echo "Then build a kernel with module support enabled."
@echo
@exit 1
endif # CONFIG_MODULES
3.4.3.1 $(vmlinux-dirs)
3.4.3.2 vmlinux
在顶层Makefile中,包含如下规则:
KBUILD_BUILTIN := 1
# If we have only "make modules", don't compile built-in objects.
# When we're building modules with modversions, we need to consider
# the built-in objects during the descend as well, in order to
# make sure the checksums are up to date before we record them.
// 执行make modules时,满足条件,进入本分支;仅执行make时,不进入本分支
ifeq ($(MAKECMDGOALS),modules)
// 参见linux-3.2/Documentation/kbuild/modules.txt第6节
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
endif
若配置了CONFIG_MODVERSIONS,则modules依赖于vmlinux,其执行过程参见3.4.2.7 vmlinux节;否则,modules不依赖于vmlinux。
3.4.3.3 modules.builtin
modules.builtin的含义:
This file lists all modules that are built into the kernel. This is used by modprobe to not fail when trying to load something builtin.
在顶层Makefile中,包含如下规则:
ifdef CONFIG_MODULES
...
modules.builtin: $(vmlinux-dirs:%=%/modules.builtin)
$(Q)$(AWK) '!x[$$0]++' $^ > $(objtree)/modules.builtin
%/modules.builtin: include/config/auto.conf
$(Q)$(MAKE) $(modbuiltin)=$*
...
else # CONFIG_MODULES
...
endif # CONFIG_MODULES
由3.4.3.1 $(vmlinux-dirs)节可知,$(vmlinux-dirs:%=%/modules.builtin)被扩展为:
init/modules.builtin usr/modules.builtin arch/x86/modules.builtin kernel/modules.builtin mm/modules.builtin fs/modules.builtin ipc/modules.builtin security/modules.builtin crypto/modules.builtin block/modules.builtin drivers/modules.builtin sound/modules.builtin firmware/modules.builtin net/modules.builtin lib/modules.builtin arch/x86/lib/modules.builtin
该列表匹配规则:
// include/config/auto.conf参见[3.3.4.2 .config如何被顶层Makefile调用]节和[3.4.2.1.1.1 include/config/auto.conf]节
%/modules.builtin: include/config/auto.conf
$(Q)$(MAKE) $(modbuiltin)=$*
因而执行下列命令:
$(Q)$(MAKE) $(modbuiltin)=$*
其中,$(modbuiltin)定义于scripts/Kbuild.include:
modbuiltin := -f $(if $(KBUILD_SRC),$(srctree)/)scripts/Makefile.modbuiltin obj
故该命令分别被扩展为:
make -f scripts/Makefile.modbuiltin obj=$*
其执行过程参见3.4.3.3.1 make -f scripts/Makefile.modbuiltin obj=$*节。
3.4.3.3.1 make -f scripts/Makefile.modbuiltin obj=$*
由3.4.3.3 modules.builtin节可知,make -f scripts/Makefile.modbuiltin obj=$* 被扩展为:
make -f scripts/Makefile.modbuiltin obj=init
make -f scripts/Makefile.modbuiltin obj=usr
make -f scripts/Makefile.modbuiltin obj=arch/x86
make -f scripts/Makefile.modbuiltin obj=kernel
make -f scripts/Makefile.modbuiltin obj=mm
make -f scripts/Makefile.modbuiltin obj=fs
make -f scripts/Makefile.modbuiltin obj=ipc
make -f scripts/Makefile.modbuiltin obj=security
make -f scripts/Makefile.modbuiltin obj=crypto
make -f scripts/Makefile.modbuiltin obj=block
make -f scripts/Makefile.modbuiltin obj=drivers
make -f scripts/Makefile.modbuiltin obj=sound
make -f scripts/Makefile.modbuiltin obj=firmware
make -f scripts/Makefile.modbuiltin obj=net
make -f scripts/Makefile.modbuiltin obj=lib
make -f scripts/Makefile.modbuiltin obj=arch/x86/lib/
当执行这些命令时,如果这些目录下存在子目录,则make会递归调用其子目录下的Kbuild或Makefile(若不存在Kbuild文件),详细的命令调用列表参见Appendix D: make -f scripts/Makefile.modbuiltin obj=列表节。
由于这些命令未指明编译目标,故编译scripts/Makefile.modbuiltin的默认目标__modbuiltin:
src := $(obj)
PHONY := __modbuiltin
__modbuiltin:
modbuiltin-target := $(obj)/modules.builtin
__modbuiltin: $(modbuiltin-target) $(subdir-ym)
@:
$(modbuiltin-target): $(subdir-ym) FORCE
$(Q)(for m in $(modbuiltin-mods); do echo kernel/$$m; done; \
cat /dev/null $(modbuiltin-subdirs)) > $@
...
$(subdir-ym):
$(Q)$(MAKE) $(modbuiltin)=$@
3.4.3.3.1.1 $(subdir-ym)
在scripts/Makefile.modbuiltin中,包含如下规则:
// auto.conf中的所有配置项格式为CONFIG_xxx=y或m,均为小写,故可得到obj-y和obj-m列表
-include include/config/auto.conf
# tristate.conf sets tristate variables to uppercase 'Y' or 'M'
# That way, we get the list of built-in modules in obj-Y
// tristate.conf中的所有配置项格式为CONFIG_xxx=Y或M,均为大写,故可得到obj-Y或obj-M列表
-include include/config/tristate.conf
...
include scripts/Makefile.lib
__subdir-Y := $(patsubst %/,%,$(filter %/, $(obj-Y)))
subdir-Y += $(__subdir-Y)
subdir-ym := $(sort $(subdir-y) $(subdir-Y) $(subdir-m))
subdir-ym := $(addprefix $(obj)/,$(subdir-ym))
...
$(subdir-ym):
$(Q)$(MAKE) $(modbuiltin)=$@
$(subdir-ym)的取值与如下三部分有关:
- $(subdir-y),参见scripts/Makefile.lib
- $(subdir-m),参见scripts/Makefile.lib
- $(subdir-Y),与配置文件include/config/tristate.conf有关
调用命令 $(Q)$(MAKE) $(modbuiltin)=$@ 递归编译$(obj)指定目录的子目录,该命令被扩展为:
make -f scripts/Makefile.modbuiltin obj=$@
详细命令列表参见Appendix D: make -f scripts/Makefile.modbuiltin obj=列表节。
3.4.3.3.1.2 $(modbuiltin-target)
在scripts/Makefile.modbuiltin中,包含如下规则:
modbuiltin-subdirs := $(patsubst %,%/modules.builtin, $(subdir-ym))
modbuiltin-mods := $(filter %.ko, $(obj-Y:.o=.ko))
modbuiltin-target := $(obj)/modules.builtin
...
$(modbuiltin-target): $(subdir-ym) FORCE
$(Q)(for m in $(modbuiltin-mods); do echo kernel/$$m; done; \
cat /dev/null $(modbuiltin-subdirs)) > $@
该目标执行下列命令:
$(Q)(for m in $(modbuiltin-mods); do echo kernel/$$m; done; \
cat /dev/null $(modbuiltin-subdirs)) > $@
以drivers/input/目录为例,该命令被扩展为:
(for m in drivers/input/input-core.ko drivers/input/mousedev.ko; do echo kernel/$m; done; \
cat /dev/null drivers/input/joystick/modules.builtin drivers/input/keyboard/modules.builtin drivers/input/misc/modules.builtin) > drivers/input/modules.builtin
该命令输出文件modules.builtin,用于保存对应目录及其子目录下的*.ko文件列表。
3.4.3.3.2 modules.builtin
在顶层Makefile中,包含如下规则:
ifdef CONFIG_MODULES
...
modules.builtin: $(vmlinux-dirs:%=%/modules.builtin)
$(Q)$(AWK) '!x[$$0]++' $^ > $(objtree)/modules.builtin
...
else # CONFIG_MODULES
...
endif # CONFIG_MODULES
命令:
$(Q)$(AWK) '!x[$$0]++' $^ > $(objtree)/modules.builtin
被扩展为:
awk '!x[$0]++' init/modules.builtin usr/modules.builtin arch/x86/modules.builtin kernel/modules.builtin mm/modules.builtin fs/modules.builtin ipc/modules.builtin security/modules.builtin crypto/modules.builtin block/modules.builtin drivers/modules.builtin sound/modules.builtin firmware/modules.builtin arch/x86/pci/modules.builtin arch/x86/power/modules.builtin arch/x86/video/modules.builtin net/modules.builtin lib/modules.builtin arch/x86/lib/modules.builtin > /usr/src/linux-3.2/modules.builtin
该命令将所有子目录下的modules.builtin文件(参见3.4.3.3.1.2 $(modbuiltin-target)节)内容输出到文件linux-3.2/modules.builtin中。该文件包含make modules命令生成的所有*.ko文件列表。执行make modules_install时,将linux-3.2/modules.builtin拷贝到/lib/modules/3.2.0/modules.builtin,参见3.5.5 安装内核节。
3.4.3.4 modules
在顶层Makefile中,包含如下规则:
ifdef CONFIG_MODULES
...
modules: $(vmlinux-dirs) $(if $(KBUILD_BUILTIN),vmlinux) modules.builtin
// 生成linux-3.2/modules.order,参见[3.4.3.4.1 modules.order]节
$(Q)$(AWK) '!x[$$0]++' $(vmlinux-dirs:%=$(objtree)/%/modules.order) > $(objtree)/modules.order
@$(kecho) ' Building modules, stage 2.';
// 参见[3.4.3.4.2 make -f scripts/Makefile.modpost]节
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.modpost
// 参见[3.4.3.4.3 make -f scripts/Makefile.fwinst obj=firmware __fw_modbuild]节
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.fwinst obj=firmware __fw_modbuild
...
else # CONFIG_MODULES
...
endif # CONFIG_MODULES
3.4.3.4.1 modules.order
命令 $(Q)$(AWK) ‘!x[$$0]++’ $(vmlinux-dirs:%=$(objtree)/%/modules.order) > $(objtree)/modules.order 被扩展为:
awk '!x[$0]++' /usr/src/linux-3.2/init/modules.order /usr/src/linux-3.2/usr/modules.order /usr/src/linux-3.2/arch/x86/modules.order /usr/src/linux-3.2/kernel/modules.order /usr/src/linux-3.2/mm/modules.order /usr/src/linux-3.2/fs/modules.order /usr/src/linux-3.2/ipc/modules.order /usr/src/linux-3.2/security/modules.order /usr/src/linux-3.2/crypto/modules.order /usr/src/linux-3.2/block/modules.order /usr/src/linux-3.2/drivers/modules.order /usr/src/linux-3.2/sound/modules.order /usr/src/linux-3.2/firmware/modules.order /usr/src/linux-3.2/arch/x86/video/modules.order /usr/src/linux-3.2/net/modules.order /usr/src/linux-3.2/lib/modules.order /usr/src/linux-3.2/arch/x86/lib/modules.order > /usr/src/linux-3.2/modules.order
该命令将所有子目录下的modules.order文件(参见3.4.2.1.3.1.5 $(modorder-target)节)内容输出到文件linux-3.2/modules.order中,该文件列出了构建系统内部模块的次序。执行make modules_install时,将linux-3.2/modules.order拷贝到/lib/modules/3.2.0/modules.order,参见3.5.5 安装内核节。
3.4.3.4.2 make -f scripts/Makefile.modpost
命令 $(Q)$(MAKE) -f $(srctree)/scripts/Makefile.modpost 被扩展为:
make -f /usr/src/linux-3.2/scripts/Makefile.modpost
因为该命令未指定编译目标,故编译scripts/Makefile.modpost中的默认目标_modpost:
PHONY := _modpost
_modpost: __modpost
/*
* 在顶层Makefile中,MODVERDIR := $(if $(KBUILD_EXTMOD),$(firstword $(KBUILD_EXTMOD))/).tmp_versions
* .tmp_versions目录是在目标prepare1中创建的,参见[3.4.2.1.1.7 prepare1]节
* __modules用于保存.tmp_versions/*.mod文件中以dir/subdir/*.ko结尾的所有行,并按字母顺序进行排序
*/
__modules := $(sort $(shell grep -h '\.ko' /dev/null $(wildcard $(MODVERDIR)/*.mod)))
// modules的取值与__modules相同,均为dir/subdir/*.ko列表
modules := $(patsubst %.o,%.ko, $(wildcard $(__modules:.ko=.o)))
...
_modpost: $(if $(KBUILD_MODPOST_NOFINAL), $(modules:.ko:.o),$(modules))
__modpost: $(modules:.ko=.o) FORCE
$(call cmd,modpost) $(wildcard vmlinux) $(filter-out FORCE,$^)
$(modules): %.ko :%.o %.mod.o FORCE
$(call if_changed,ld_ko_o)
$(modules:.ko=.mod.o): %.mod.o: %.mod.c FORCE
$(call if_changed_dep,cc_o_c)
$(modules:.ko=.mod.c): __modpost ;
各目标之间的依赖关系如下:
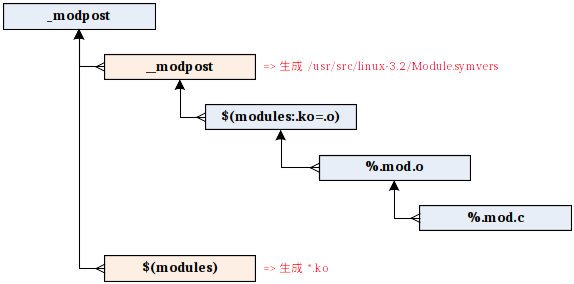
3.4.3.4.2.1 __modpost
在scripts/Makefile.modpost中,包含如下规则:
modpost = scripts/mod/modpost \
$(if $(CONFIG_MODVERSIONS),-m) \
$(if $(CONFIG_MODULE_SRCVERSION_ALL),-a,) \
$(if $(KBUILD_EXTMOD),-i,-o) $(kernelsymfile) \
$(if $(KBUILD_EXTMOD),-I $(modulesymfile)) \
$(if $(KBUILD_EXTRA_SYMBOLS), $(patsubst %, -e %,$(KBUILD_EXTRA_SYMBOLS))) \
$(if $(KBUILD_EXTMOD),-o $(modulesymfile)) \
$(if $(CONFIG_DEBUG_SECTION_MISMATCH),,-S) \
$(if $(KBUILD_EXTMOD)$(KBUILD_MODPOST_WARN),-w) \
$(if $(cross_build),-c)
quiet_cmd_modpost = MODPOST $(words $(filter-out vmlinux FORCE, $^)) modules
cmd_modpost = $(modpost) -s
__modpost: $(modules:.ko=.o) FORCE
$(call cmd,modpost) $(wildcard vmlinux) $(filter-out FORCE,$^)
$(modules:.ko=.o)是在目标$(vmlinux-dirs)中编译完成的,参见3.4.3.1 $(vmlinux-dirs)节。
之后,目标__modpost调用命令:
$(call cmd,modpost) $(wildcard vmlinux) $(filter-out FORCE,$^)
该命令被扩展为:
$(modpost) –s $(wildcard vmlinux) $(filter-out FORCE,$^)
继而被扩展为:
scripts/mod/modpost -a -o /usr/src/linux-3.2/Module.symvers -s $(modules:.ko=.o)
该命令会生成如下文件:
1) /usr/src/linux-3.2/Module.symvers
See Documentation/kbuild/modules.txt:
Module.symvers contains a list of all exported symbols from a kernel build.
2) *.mod.c
以hello.c为例,生成的hello.mod.c文件如下,另参见13.5.1.4 mod->init/mod->exit与init_module()/cleanup_module()的关联节:
#include <linux/module.h>
#include <linux/vermagic.h>
#include <linux/compiler.h>
MODULE_INFO(vermagic, VERMAGIC_STRING);
struct module __this_module
__attribute__((section(".gnu.linkonce.this_module"))) = {
.name = KBUILD_MODNAME,
.init = init_module,
#ifdef CONFIG_MODULE_UNLOAD
.exit = cleanup_module,
#endif
.arch = MODULE_ARCH_INIT,
};
static const struct modversion_info ____versions[]
__used
__attribute__((section("__versions"))) = {
{ 0x35ec255d, "module_layout" },
{ 0x50eedeb8, "printk" },
{ 0xb4390f9a, "mcount" },
};
static const char __module_depends[]
__used
__attribute__((section(".modinfo"))) =
"depends=";
MODULE_INFO(srcversion, "C8EB943C79F42BA9921FE81");
以drivers/net/ethernet/intel/e1000e/e1000e.c为例,编译过程中生成的e1000e.mod.c文件如下:
#include <linux/module.h>
#include <linux/vermagic.h>
#include <linux/compiler.h>
MODULE_INFO(vermagic, VERMAGIC_STRING);
__visible struct module __this_module
__attribute__((section(".gnu.linkonce.this_module"))) = {
.name = KBUILD_MODNAME,
.init = init_module,
#ifdef CONFIG_MODULE_UNLOAD
.exit = cleanup_module,
#endif
.arch = MODULE_ARCH_INIT,
};
MODULE_INFO(intree, "Y");
static const struct modversion_info ____versions[]
__used
__attribute__((section("__versions"))) = {
{ 0x420178e0, __VMLINUX_SYMBOL_STR(module_layout) },
{ 0x6860880e, __VMLINUX_SYMBOL_STR(alloc_pages_current) },
{ 0x3ce4ca6f, __VMLINUX_SYMBOL_STR(disable_irq) },
{ 0x2d3385d3, __VMLINUX_SYMBOL_STR(system_wq) },
{ 0xf744ad48, __VMLINUX_SYMBOL_STR(netdev_info) },
{ 0x8728198a, __VMLINUX_SYMBOL_STR(kmalloc_caches) },
{ 0xd2b09ce5, __VMLINUX_SYMBOL_STR(__kmalloc) },
{ 0x20fcaa16, __VMLINUX_SYMBOL_STR(ethtool_op_get_ts_info) },
{ 0xe4689576, __VMLINUX_SYMBOL_STR(ktime_get_with_offset) },
{ 0xf9a482f9, __VMLINUX_SYMBOL_STR(msleep) },
{ 0x99840d00, __VMLINUX_SYMBOL_STR(timecounter_init) },
{ 0xeec2d, __VMLINUX_SYMBOL_STR(__pm_runtime_idle) },
{ 0xd6ee688f, __VMLINUX_SYMBOL_STR(vmalloc) },
{ 0x65b5fe49, __VMLINUX_SYMBOL_STR(param_ops_int) },
{ 0x91eb9b4, __VMLINUX_SYMBOL_STR(round_jiffies) },
{ 0xaf34e5b8, __VMLINUX_SYMBOL_STR(napi_disable) },
{ 0x754d539c, __VMLINUX_SYMBOL_STR(strlen) },
{ 0xdd2baf66, __VMLINUX_SYMBOL_STR(skb_pad) },
{ 0xee2f9e23, __VMLINUX_SYMBOL_STR(dma_set_mask) },
{ 0x30ad4c2e, __VMLINUX_SYMBOL_STR(pci_disable_device) },
{ 0xf33ff0e, __VMLINUX_SYMBOL_STR(pci_disable_msix) },
{ 0x4ea25709, __VMLINUX_SYMBOL_STR(dql_reset) },
{ 0xb0d99f0c, __VMLINUX_SYMBOL_STR(netif_carrier_on) },
{ 0xea41f64, __VMLINUX_SYMBOL_STR(pm_qos_add_request) },
{ 0x7f13d491, __VMLINUX_SYMBOL_STR(pm_qos_remove_request) },
{ 0xc0a3d105, __VMLINUX_SYMBOL_STR(find_next_bit) },
{ 0x6b06fdce, __VMLINUX_SYMBOL_STR(delayed_work_timer_fn) },
{ 0xab51580, __VMLINUX_SYMBOL_STR(netif_carrier_off) },
{ 0x88bfa7e, __VMLINUX_SYMBOL_STR(cancel_work_sync) },
{ 0xbd8afbb8, __VMLINUX_SYMBOL_STR(__dev_kfree_skb_any) },
{ 0xeae3dfd6, __VMLINUX_SYMBOL_STR(__const_udelay) },
{ 0x9580deb, __VMLINUX_SYMBOL_STR(init_timer_key) },
{ 0xd3000832, __VMLINUX_SYMBOL_STR(pcie_capability_clear_and_set_word) },
{ 0xa57863e, __VMLINUX_SYMBOL_STR(cancel_delayed_work_sync) },
{ 0xe6048175, __VMLINUX_SYMBOL_STR(mutex_unlock) },
{ 0xed21bd02, __VMLINUX_SYMBOL_STR(__pm_runtime_resume) },
{ 0x999e8297, __VMLINUX_SYMBOL_STR(vfree) },
{ 0x83472897, __VMLINUX_SYMBOL_STR(dma_free_attrs) },
{ 0xbfe2cb70, __VMLINUX_SYMBOL_STR(pci_bus_write_config_word) },
{ 0x893a01a6, __VMLINUX_SYMBOL_STR(pci_disable_link_state_locked) },
{ 0xf4c91ed, __VMLINUX_SYMBOL_STR(ns_to_timespec) },
{ 0xc499ae1e, __VMLINUX_SYMBOL_STR(kstrdup) },
{ 0x7d11c268, __VMLINUX_SYMBOL_STR(jiffies) },
{ 0x91ba0d02, __VMLINUX_SYMBOL_STR(__dynamic_netdev_dbg) },
{ 0x3ce3bc30, __VMLINUX_SYMBOL_STR(skb_trim) },
{ 0x1b3b6da3, __VMLINUX_SYMBOL_STR(__netdev_alloc_skb) },
{ 0x27c33efe, __VMLINUX_SYMBOL_STR(csum_ipv6_magic) },
{ 0xcaaacf2e, __VMLINUX_SYMBOL_STR(__pskb_pull_tail) },
{ 0xb0e16c7, __VMLINUX_SYMBOL_STR(ptp_clock_unregister) },
{ 0x4f8b5ddb, __VMLINUX_SYMBOL_STR(_copy_to_user) },
{ 0x76f5966a, __VMLINUX_SYMBOL_STR(pci_set_master) },
{ 0xee7cdf54, __VMLINUX_SYMBOL_STR(netif_schedule_queue) },
{ 0x706d051c, __VMLINUX_SYMBOL_STR(del_timer_sync) },
{ 0xfb578fc5, __VMLINUX_SYMBOL_STR(memset) },
{ 0xf0df2a5f, __VMLINUX_SYMBOL_STR(pci_enable_pcie_error_reporting) },
{ 0xe0e4f728, __VMLINUX_SYMBOL_STR(netif_tx_wake_queue) },
{ 0x36c1f2ce, __VMLINUX_SYMBOL_STR(pci_restore_state) },
{ 0x9c9c66a4, __VMLINUX_SYMBOL_STR(dev_err) },
{ 0x1916e38c, __VMLINUX_SYMBOL_STR(_raw_spin_unlock_irqrestore) },
{ 0x85467e31, __VMLINUX_SYMBOL_STR(current_task) },
{ 0xeb784c5f, __VMLINUX_SYMBOL_STR(ethtool_op_get_link) },
{ 0x27e1a049, __VMLINUX_SYMBOL_STR(printk) },
{ 0xa00aca2a, __VMLINUX_SYMBOL_STR(dql_completed) },
{ 0x4c9d28b0, __VMLINUX_SYMBOL_STR(phys_base) },
{ 0xc39a30e2, __VMLINUX_SYMBOL_STR(free_netdev) },
{ 0xa1c76e0a, __VMLINUX_SYMBOL_STR(_cond_resched) },
{ 0xc7c5ae39, __VMLINUX_SYMBOL_STR(register_netdev) },
{ 0x5792f848, __VMLINUX_SYMBOL_STR(strlcpy) },
{ 0xe6a1061c, __VMLINUX_SYMBOL_STR(dma_alloc_attrs) },
{ 0x16305289, __VMLINUX_SYMBOL_STR(warn_slowpath_null) },
{ 0xfbd63449, __VMLINUX_SYMBOL_STR(__pci_enable_wake) },
{ 0xa5bba893, __VMLINUX_SYMBOL_STR(mutex_lock) },
{ 0x393d4de9, __VMLINUX_SYMBOL_STR(crc32_le) },
{ 0x6d8b0e69, __VMLINUX_SYMBOL_STR(dev_close) },
{ 0x20e7f58, __VMLINUX_SYMBOL_STR(__dev_kfree_skb_irq) },
{ 0x16e5c2a, __VMLINUX_SYMBOL_STR(mod_timer) },
{ 0x660735f6, __VMLINUX_SYMBOL_STR(netif_napi_add) },
{ 0x71b0e23f, __VMLINUX_SYMBOL_STR(ptp_clock_register) },
{ 0x2072ee9b, __VMLINUX_SYMBOL_STR(request_threaded_irq) },
{ 0x3b803f6d, __VMLINUX_SYMBOL_STR(device_wakeup_enable) },
{ 0xf6fd855f, __VMLINUX_SYMBOL_STR(pci_clear_master) },
{ 0x1be08d7c, __VMLINUX_SYMBOL_STR(dev_open) },
{ 0xe523ad75, __VMLINUX_SYMBOL_STR(synchronize_irq) },
{ 0xc542933a, __VMLINUX_SYMBOL_STR(timecounter_read) },
{ 0x69653fc1, __VMLINUX_SYMBOL_STR(dev_notice) },
{ 0x167c5967, __VMLINUX_SYMBOL_STR(print_hex_dump) },
{ 0xfef0a6f1, __VMLINUX_SYMBOL_STR(pci_select_bars) },
{ 0xa8b76a68, __VMLINUX_SYMBOL_STR(timecounter_cyc2time) },
{ 0xa916ca8d, __VMLINUX_SYMBOL_STR(netif_device_attach) },
{ 0xe3c8a6d7, __VMLINUX_SYMBOL_STR(napi_gro_receive) },
{ 0x50e8877f, __VMLINUX_SYMBOL_STR(_dev_info) },
{ 0x40a9b349, __VMLINUX_SYMBOL_STR(vzalloc) },
{ 0xeeb1eb27, __VMLINUX_SYMBOL_STR(pci_disable_link_state) },
{ 0xee2754a8, __VMLINUX_SYMBOL_STR(netif_device_detach) },
{ 0x6839ed62, __VMLINUX_SYMBOL_STR(__alloc_skb) },
{ 0x42c8de35, __VMLINUX_SYMBOL_STR(ioremap_nocache) },
{ 0x12a38747, __VMLINUX_SYMBOL_STR(usleep_range) },
{ 0x7e03c231, __VMLINUX_SYMBOL_STR(pci_enable_msix_range) },
{ 0x927a02a0, __VMLINUX_SYMBOL_STR(pci_bus_read_config_word) },
{ 0x6c4d5fb, __VMLINUX_SYMBOL_STR(__napi_schedule) },
{ 0x70cd1f, __VMLINUX_SYMBOL_STR(queue_delayed_work_on) },
{ 0xb81c3712, __VMLINUX_SYMBOL_STR(pci_cleanup_aer_uncorrect_error_status) },
{ 0x46258b48, __VMLINUX_SYMBOL_STR(pm_schedule_suspend) },
{ 0xa89987e1, __VMLINUX_SYMBOL_STR(napi_complete_done) },
{ 0x7478f512, __VMLINUX_SYMBOL_STR(eth_type_trans) },
{ 0x14496b8c, __VMLINUX_SYMBOL_STR(pskb_expand_head) },
{ 0xbdfb6dbb, __VMLINUX_SYMBOL_STR(__fentry__) },
{ 0x5bbb85a1, __VMLINUX_SYMBOL_STR(netdev_err) },
{ 0x467df16d, __VMLINUX_SYMBOL_STR(netdev_rss_key_fill) },
{ 0x855db502, __VMLINUX_SYMBOL_STR(pci_enable_msi_range) },
{ 0x7f243c4d, __VMLINUX_SYMBOL_STR(pci_unregister_driver) },
{ 0xcc5005fe, __VMLINUX_SYMBOL_STR(msleep_interruptible) },
{ 0x9b5c5d69, __VMLINUX_SYMBOL_STR(kmem_cache_alloc_trace) },
{ 0xe259ae9e, __VMLINUX_SYMBOL_STR(_raw_spin_lock) },
{ 0x680ec266, __VMLINUX_SYMBOL_STR(_raw_spin_lock_irqsave) },
{ 0xf6ebc03b, __VMLINUX_SYMBOL_STR(net_ratelimit) },
{ 0x7bf58702, __VMLINUX_SYMBOL_STR(netdev_warn) },
{ 0xf7de5d93, __VMLINUX_SYMBOL_STR(eth_validate_addr) },
{ 0xabab7c3a, __VMLINUX_SYMBOL_STR(pci_disable_pcie_error_reporting) },
{ 0xfcec0987, __VMLINUX_SYMBOL_STR(enable_irq) },
{ 0x37a0cba, __VMLINUX_SYMBOL_STR(kfree) },
{ 0x69acdf38, __VMLINUX_SYMBOL_STR(memcpy) },
{ 0x93f11a07, __VMLINUX_SYMBOL_STR(___pskb_trim) },
{ 0x75e1fdc7, __VMLINUX_SYMBOL_STR(param_array_ops) },
{ 0x55f9b4c, __VMLINUX_SYMBOL_STR(ptp_clock_index) },
{ 0x53c47218, __VMLINUX_SYMBOL_STR(pci_disable_msi) },
{ 0xf2f2267b, __VMLINUX_SYMBOL_STR(dma_supported) },
{ 0xedc03953, __VMLINUX_SYMBOL_STR(iounmap) },
{ 0x38db821d, __VMLINUX_SYMBOL_STR(pci_prepare_to_sleep) },
{ 0x78dd04c6, __VMLINUX_SYMBOL_STR(pci_dev_run_wake) },
{ 0x880670bd, __VMLINUX_SYMBOL_STR(__pci_register_driver) },
{ 0xc357923c, __VMLINUX_SYMBOL_STR(pm_qos_update_request) },
{ 0x58a2b881, __VMLINUX_SYMBOL_STR(put_page) },
{ 0xb352177e, __VMLINUX_SYMBOL_STR(find_first_bit) },
{ 0xf2c69a59, __VMLINUX_SYMBOL_STR(dev_warn) },
{ 0x3590fefe, __VMLINUX_SYMBOL_STR(unregister_netdev) },
{ 0x2e0d2f7f, __VMLINUX_SYMBOL_STR(queue_work_on) },
{ 0x28318305, __VMLINUX_SYMBOL_STR(snprintf) },
{ 0xbdcf9640, __VMLINUX_SYMBOL_STR(consume_skb) },
{ 0x32b060f5, __VMLINUX_SYMBOL_STR(pci_enable_device_mem) },
{ 0xb99003f0, __VMLINUX_SYMBOL_STR(__napi_alloc_skb) },
{ 0xb651ecb0, __VMLINUX_SYMBOL_STR(skb_tstamp_tx) },
{ 0xfd33aebd, __VMLINUX_SYMBOL_STR(skb_put) },
{ 0xcce7db0, __VMLINUX_SYMBOL_STR(pci_release_selected_regions) },
{ 0x4f6b400b, __VMLINUX_SYMBOL_STR(_copy_from_user) },
{ 0x11a87f43, __VMLINUX_SYMBOL_STR(param_ops_uint) },
{ 0xdf59da8e, __VMLINUX_SYMBOL_STR(pcie_capability_write_word) },
{ 0x9e7d6bd0, __VMLINUX_SYMBOL_STR(__udelay) },
{ 0x68ce7ed9, __VMLINUX_SYMBOL_STR(dma_ops) },
{ 0xd619a163, __VMLINUX_SYMBOL_STR(pci_request_selected_regions_exclusive) },
{ 0xd9f6c399, __VMLINUX_SYMBOL_STR(device_set_wakeup_enable) },
{ 0x7a29ada4, __VMLINUX_SYMBOL_STR(pcie_capability_read_word) },
{ 0xf20dabd8, __VMLINUX_SYMBOL_STR(free_irq) },
{ 0xd8d8f7a7, __VMLINUX_SYMBOL_STR(pci_save_state) },
{ 0xd831efc6, __VMLINUX_SYMBOL_STR(alloc_etherdev_mqs) },
};
static const char __module_depends[]
__used
__attribute__((section(".modinfo"))) =
"depends=ptp";
/*
* 宏MODULE_ALIAS参见[13.1.2.1 MODULE_INFO()/__MODULE_INFO()]节;
* 通过下列命令查看编译后的e1000e.ko中的alias:
* # objdump -s --section=.modinfo ./drivers/net/ethernet/intel/e1000e/e1000e.ko
*/
MODULE_ALIAS("pci:v00008086d0000105Esv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000105Fsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010A4sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010BCsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010A5sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001060sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010D9sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010DAsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010D5sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010B9sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000107Dsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000107Esv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000107Fsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000108Bsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000108Csv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000109Asv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010D3sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010F6sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000150Csv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001096sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010BAsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001098sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010BBsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000104Csv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010C5sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010C4sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000104Asv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000104Bsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000104Dsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001049sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001501sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010C0sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010C2sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010C3sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010BDsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000294Csv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010E5sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010BFsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010F5sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010CBsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010CCsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010CDsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010CEsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010DEsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010DFsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001525sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010EAsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010EBsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010EFsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000010F0sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001502sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001503sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000153Asv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000153Bsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000155Asv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001559sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000015A0sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000015A1sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000015A2sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000015A3sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d0000156Fsv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d00001570sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000015B7sv*sd*bc*sc*i*");
MODULE_ALIAS("pci:v00008086d000015B8sv*sd*bc*sc*i*");
MODULE_INFO(srcversion, "224852E6236A925EFB3CC8C");
3.4.3.4.2.2 %.mod.c=>%.mod.o
*.mod.c是在目标$(builtin-target)执行命令cmd_link_o_target时生成的,参见3.4.2.1.3.1.1.2 cmd_link_o_target节。
在scripts/Makefile.modpost中,包含如下规则:
quiet_cmd_cc_o_c = CC $@
cmd_cc_o_c = $(CC) $(c_flags) $(KBUILD_CFLAGS_MODULE) $(CFLAGS_MODULE) \
-c -o $@ $<
$(modules:.ko=.mod.o): %.mod.o: %.mod.c FORCE
$(call if_changed_dep,cc_o_c)
调用命令cmd_cc_o_c将*.mod.c编译成*.mod.o。以arch/x86/crypto/aes-i586.mod.c为例,该命令被扩展为:
gcc -Wp,-MD,arch/x86/crypto/.aes-i586.mod.o.d -nostdinc -isystem /usr/lib/gcc/i686-linux-gnu/4.7/include -I/usr/src/linux-3.2/arch/x86/include -Iarch/x86/include/generated -Iinclude -include /usr/src/linux-3.2/include/linux/kconfig.h -D__KERNEL__ -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs -fno-strict-aliasing -fno-common -Werror-implicit-function-declaration -Wno-format-security -fno-delete-null-pointer-checks -Os -m32 -msoft-float -mregparm=3 -freg-struct-return -mpreferred-stack-boundary=2 -march=i686 -maccumulate-outgoing-args -Wa,-mtune=generic32 -ffreestanding -fstack-protector -DCONFIG_AS_CFI=1 -DCONFIG_AS_CFI_SIGNAL_FRAME=1 -DCONFIG_AS_CFI_SECTIONS=1 -pipe -Wno-sign-compare -fno-asynchronous-unwind-tables -mno-sse -mno-mmx -mno-sse2 -mno-3dnow -Wframe-larger-than=1024 -Wno-unused-but-set-variable -fno-omit-frame-pointer -fno-optimize-sibling-calls -fno-inline-functions-called-once -Wdeclaration-after-statement -Wno-pointer-sign -fno-strict-overflow -fconserve-stack -DCC_HAVE_ASM_GOTO -D"KBUILD_STR(s)=#s" -D"KBUILD_BASENAME=KBUILD_STR(aes_i586.mod)" -D"KBUILD_MODNAME=KBUILD_STR(aes_i586)" -DMODULE -c -o arch/x86/crypto/aes-i586.mod.o arch/x86/crypto/aes-i586.mod.c
3.4.3.4.2.3 $(modules)
在scripts/Makefile.modpost中,包含如下规则:
quiet_cmd_ld_ko_o = LD [M] $@
cmd_ld_ko_o = $(LD) -r $(LDFLAGS) \
$(KBUILD_LDFLAGS_MODULE) $(LDFLAGS_MODULE) \
-o $@ $(filter-out FORCE,$^)
$(modules): %.ko : %.o %.mod.o FORCE
$(call if_changed,ld_ko_o)
调用命令cmd_ld_ko_o将.mod.o和.o连接成*.ko。以arch/x86/crypto/aes-i586.mod.c为例,该命令被扩展为:
ld -r -m elf_i386 -T /usr/src/linux-3.2/scripts/module-common.lds --build-id -o arch/x86/crypto/aes-i586.ko arch/x86/crypto/aes-i586.o arch/x86/crypto/aes-i586.mod.o
NOTE 1: 执行make modules_install命令时,这些*.ko文件会被安装到/lib/modules/3.2.0/kernel/目录,参见3.5.5 安装内核节。
NOTE 2: script/module-common.lds是生成*.ko文件的链接脚本文件,参见Appendix H: scripts/module-common.lds节。
3.4.3.4.3 make -f scripts/Makefile.fwinst obj=firmware __fw_modbuild
在scripts/Makefile.fwinst中,包含如下规则:
/*
* 引入firmware/Makefile,其中包含$(fw-shipped-m)和$(fw-shipped-y)
* $(fw-shipped-m)和$(fw-shipped-y)中包含*.fw, *.bin, *.dsp列表
*/
include $(srctree)/$(obj)/Makefile
...
mod-fw := $(fw-shipped-m)
# If CONFIG_FIRMWARE_IN_KERNEL isn't set, then install the
# firmware for in-kernel drivers too.
ifndef CONFIG_FIRMWARE_IN_KERNEL
mod-fw += $(fw-shipped-y)
endif
...
__fw_modbuild: $(addprefix $(obj)/,$(mod-fw))
@:
3.4.3.4.3.1 $(mod-fw)
在firmware/Makefile中,包含如下规则:
...
// $(fw-shipped-m)和$(fw-shipped-y)中包含*.fw, *.bin, *.dsp列表
fw-shipped-$(CONFIG_3C359) += 3com/3C359.bin
fw-shipped-$(CONFIG_ACENIC) += $(acenic-objs)
fw-shipped-$(CONFIG_ADAPTEC_STARFIRE) += adaptec/starfire_rx.bin \
adaptec/starfire_tx.bin
fw-shipped-$(CONFIG_ATARI_DSP56K) += dsp56k/bootstrap.bin
fw-shipped-$(CONFIG_ATM_AMBASSADOR) += atmsar11.fw
fw-shipped-$(CONFIG_BNX2X) += bnx2x/bnx2x-e1-6.2.9.0.fw \
bnx2x/bnx2x-e1h-6.2.9.0.fw \
bnx2x/bnx2x-e2-6.2.9.0.fw
fw-shipped-$(CONFIG_BNX2) += bnx2/bnx2-mips-09-6.2.1a.fw \
bnx2/bnx2-rv2p-09-6.0.17.fw \
bnx2/bnx2-rv2p-09ax-6.0.17.fw \
bnx2/bnx2-mips-06-6.2.1.fw \
bnx2/bnx2-rv2p-06-6.0.15.fw
fw-shipped-$(CONFIG_CASSINI) += sun/cassini.bin
fw-shipped-$(CONFIG_COMPUTONE) += intelliport2.bin
...
quiet_cmd_ihex = IHEX $@
cmd_ihex = $(OBJCOPY) -Iihex -Obinary $< $@
...
// firmware/目录中已存在*.ihex文件
$(obj)/%: $(obj)/%.ihex | $(objtree)/$(obj)/$$(dir %)
$(call cmd,ihex)
调用cmd_ihex命令,以firmware/bnx2/bnx2-mips-09-6.2.1a.fw为例,该命令被扩展为:
objcopy -Iihex -Obinary firmware/bnx2/bnx2-mips-09-6.2.1a.fw.ihex firmware/bnx2/bnx2-mips-09-6.2.1a.fw
该命令输出如下文件:
firmware/oneSubdir/twoSubdir/.../*.fw
firmware/oneSubdir/twoSubdir/.../*.bin
firmware/oneSubdir/twoSubdir/.../*.dsp
3.4.4 编译external modules
执行下列命令之一来编译外部模块:
# make -C <kernel_src_dir> M=<ext_module_dir> modules
# make -C <kernel_src_dir> SUBDIRS=$PWD modules
在顶层Makefile中,包含如下规则:
# Use make M=dir to specify directory of external module to build
# Old syntax make ... SUBDIRS=$PWD is still supported
# Setting the environment variable KBUILD_EXTMOD take precedence
ifdef SUBDIRS
KBUILD_EXTMOD ?= $(SUBDIRS)
endif
ifeq ("$(origin M)", "command line")
KBUILD_EXTMOD := $(M)
endif
...
# That's our default target when none is given on the command line
PHONY := _all
_all:
# If building an external module we do not care about the all: rule
# but instead _all depend on modules
PHONY += all
ifeq ($(KBUILD_EXTMOD),)
_all: all
else
_all: modules // 此时定义了KBUILD_EXTMOD,故进入本分支
endif
# When compiling out-of-tree modules, put MODVERDIR in the module
# tree rather than in the kernel tree. The kernel tree might
# even be read-only.
// 在命令cmd_crmodverdir中使用
export MODVERDIR := $(if $(KBUILD_EXTMOD),$(firstword $(KBUILD_EXTMOD))/).tmp_versions
ifeq ($(KBUILD_EXTMOD),)
...
else # KBUILD_EXTMOD
###
# External module support.
# When building external modules the kernel used as basis is considered
# read-only, and no consistency checks are made and the make
# system is not used on the basis kernel. If updates are required
# in the basis kernel ordinary make commands (without M=...) must
# be used.
#
# The following are the only valid targets when building external
# modules.
# make M=dir clean Delete all automatically generated files
# make M=dir modules Make all modules in specified dir
# make M=dir Same as 'make M=dir modules'
# make M=dir modules_install
# Install the modules built in the module directory
# Assumes install directory is already created
# We are always building modules
KBUILD_MODULES := 1
PHONY += crmodverdir
/*
* (1) 该目标执行命令cmd_crmodverdir,用于在外部模块源代码
* 目录中创建临时目录.tmp_versions/,用于保存*.mod文件
*/
crmodverdir:
$(cmd_crmodverdir)
/*
* (2) 检查$(objtree)/Module.symvers是否存在
*/
PHONY += $(objtree)/Module.symvers
$(objtree)/Module.symvers:
@test -e $(objtree)/Module.symvers || ( \
echo; \
echo " WARNING: Symbol version dump $(objtree)/Module.symvers"; \
echo " is missing; modules will have no dependencies and modversions."; \
echo )
/*
* (3) 编译外部模块源代码目录
* 示例:若外部模块源代码所在目录为/ext/module/src,
* 则module-dirs被扩展为_module_/ext/module/src
*/
module-dirs := $(addprefix _module_,$(KBUILD_EXTMOD))
PHONY += $(module-dirs) modules
$(module-dirs): crmodverdir $(objtree)/Module.symvers
/*
* 示例:扩展为make –f scripts/Makefile.build obj=/ext/module/src
* 编译外部模块源代码目录,参见[3.4.2.1.3.1 make -f scripts/Makefile.build obj=XXX命令的执行过程]节,
* 其中,$(obj-m)由外部模块源代码目录中的Makefile配置
*/
$(Q)$(MAKE) $(build)=$(patsubst _module_%,%,$@)
/*
* (4) Stage 2 of building external modules
*/
modules: $(module-dirs)
@$(kecho) ' Building modules, stage 2.';
/*
* 扩展为make –f scripts/Makefile.modpost,
* 其执行过程参见[3.4.3.4.2 make -f scripts/Makefile.modpost]节
*/
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.modpost
endif # KBUILD_EXTMOD
...
# Create temporary dir for module support files
# clean it up only when building all modules
cmd_crmodverdir = $(Q)mkdir -p $(MODVERDIR) \
$(if $(KBUILD_MODULES),; rm -f $(MODVERDIR)/*)
各目标之间的依赖关系如下:
3.4.4A 只编译内核中的某个驱动程序
以驱动程序drivers/net/ethernet/intel/e1000e为例,按照如下步骤编译该驱动程序:
# 切换到和当前内核版本匹配的内核版本
chenwx@chenwx ~/linux $ uname -r
4.2.2-alex
chenwx@chenwx ~/linux $ git co v4.2.2
Previous HEAD position was 64291f7db5bd... Linux 4.2
HEAD is now at 7659db320e01... Linux 4.2.2
# 为编译内核做准备
chenwx@chenwx ~/linux $ make O=../linux-build/ modules_prepare
make[1]: Entering directory `/home/chenwx/linux-build'
SYSTBL arch/x86/entry/syscalls/../../include/generated/asm/syscalls_32.h
SYSHDR arch/x86/entry/syscalls/../../include/generated/asm/unistd_32_ia32.h
SYSHDR arch/x86/entry/syscalls/../../include/generated/asm/unistd_64_x32.h
SYSTBL arch/x86/entry/syscalls/../../include/generated/asm/syscalls_64.h
SYSHDR arch/x86/entry/syscalls/../../include/generated/uapi/asm/unistd_32.h
SYSHDR arch/x86/entry/syscalls/../../include/generated/uapi/asm/unistd_64.h
SYSHDR arch/x86/entry/syscalls/../../include/generated/uapi/asm/unistd_x32.h
HOSTCC scripts/basic/bin2c
HOSTCC arch/x86/tools/relocs_32.o
HOSTCC arch/x86/tools/relocs_64.o
HOSTCC arch/x86/tools/relocs_common.o
HOSTLD arch/x86/tools/relocs
CHK include/config/kernel.release
UPD include/config/kernel.release
Using /home/chenwx/linux as source for kernel
GEN ./Makefile
WRAP arch/x86/include/generated/asm/clkdev.h
WRAP arch/x86/include/generated/asm/cputime.h
WRAP arch/x86/include/generated/asm/dma-contiguous.h
WRAP arch/x86/include/generated/asm/early_ioremap.h
WRAP arch/x86/include/generated/asm/mcs_spinlock.h
WRAP arch/x86/include/generated/asm/mm-arch-hooks.h
CHK include/generated/uapi/linux/version.h
UPD include/generated/uapi/linux/version.h
CHK include/generated/utsrelease.h
UPD include/generated/utsrelease.h
CC kernel/bounds.s
CHK include/generated/bounds.h
UPD include/generated/bounds.h
CHK include/generated/timeconst.h
UPD include/generated/timeconst.h
CC arch/x86/kernel/asm-offsets.s
CHK include/generated/asm-offsets.h
UPD include/generated/asm-offsets.h
CALL /home/chenwx/linux/scripts/checksyscalls.sh
HOSTCC scripts/genksyms/genksyms.o
SHIPPED scripts/genksyms/parse.tab.c
HOSTCC scripts/genksyms/parse.tab.o
SHIPPED scripts/genksyms/lex.lex.c
SHIPPED scripts/genksyms/keywords.hash.c
SHIPPED scripts/genksyms/parse.tab.h
HOSTCC scripts/genksyms/lex.lex.o
HOSTLD scripts/genksyms/genksyms
CC scripts/mod/empty.o
HOSTCC scripts/mod/mk_elfconfig
MKELF scripts/mod/elfconfig.h
HOSTCC scripts/mod/modpost.o
CC scripts/mod/devicetable-offsets.s
GEN scripts/mod/devicetable-offsets.h
HOSTCC scripts/mod/file2alias.o
HOSTCC scripts/mod/sumversion.o
HOSTLD scripts/mod/modpost
HOSTCC scripts/selinux/genheaders/genheaders
HOSTCC scripts/selinux/mdp/mdp
HOSTCC scripts/kallsyms
HOSTCC scripts/conmakehash
HOSTCC scripts/recordmcount
HOSTCC scripts/sortextable
make[1]: Leaving directory `/home/chenwx/linux-build'
# 编译驱动程序drivers/net/ethernet/intel/e1000e
chenwx@chenwx ~/linux $ make O=../linux-build/ M=drivers/net/ethernet/intel/e1000e
make[1]: Entering directory `/home/chenwx/linux-build'
WARNING: Symbol version dump ./Module.symvers
is missing; modules will have no dependencies and modversions.
CC [M] drivers/net/ethernet/intel/e1000e/82571.o
CC [M] drivers/net/ethernet/intel/e1000e/ich8lan.o
CC [M] drivers/net/ethernet/intel/e1000e/80003es2lan.o
CC [M] drivers/net/ethernet/intel/e1000e/mac.o
CC [M] drivers/net/ethernet/intel/e1000e/manage.o
CC [M] drivers/net/ethernet/intel/e1000e/nvm.o
CC [M] drivers/net/ethernet/intel/e1000e/phy.o
CC [M] drivers/net/ethernet/intel/e1000e/param.o
CC [M] drivers/net/ethernet/intel/e1000e/ethtool.o
CC [M] drivers/net/ethernet/intel/e1000e/netdev.o
CC [M] drivers/net/ethernet/intel/e1000e/ptp.o
LD [M] drivers/net/ethernet/intel/e1000e/e1000e.o
Building modules, stage 2.
MODPOST 1 modules
CC drivers/net/ethernet/intel/e1000e/e1000e.mod.o
LD [M] drivers/net/ethernet/intel/e1000e/e1000e.ko
make[1]: Leaving directory `/home/chenwx/linux-build'
# 查看编译后的驱动程序drivers/net/ethernet/intel/e1000e
chenwx@chenwx ~/linux $ ll ../linux-build/drivers/net/ethernet/intel/e1000e
total 13M
-rw-r--r-- 1 chenwx chenwx 314K Oct 7 21:39 80003es2lan.o
-rw-r--r-- 1 chenwx chenwx 334K Oct 7 21:39 82571.o
-rw-r--r-- 1 chenwx chenwx 0 Oct 7 21:39 Module.symvers
-rw-r--r-- 1 chenwx chenwx 8 Oct 7 21:39 built-in.o
-rw-r--r-- 1 chenwx chenwx 4.2M Oct 7 21:39 e1000e.ko
-rw-r--r-- 1 chenwx chenwx 13K Oct 7 21:39 e1000e.mod.c
-rw-r--r-- 1 chenwx chenwx 70K Oct 7 21:39 e1000e.mod.o
-rw-r--r-- 1 chenwx chenwx 4.1M Oct 7 21:39 e1000e.o
-rw-r--r-- 1 chenwx chenwx 410K Oct 7 21:39 ethtool.o
-rw-r--r-- 1 chenwx chenwx 476K Oct 7 21:39 ich8lan.o
-rw-r--r-- 1 chenwx chenwx 337K Oct 7 21:39 mac.o
-rw-r--r-- 1 chenwx chenwx 263K Oct 7 21:39 manage.o
-rw-r--r-- 1 chenwx chenwx 51 Oct 7 21:39 modules.order
-rw-r--r-- 1 chenwx chenwx 855K Oct 7 21:39 netdev.o
-rw-r--r-- 1 chenwx chenwx 284K Oct 7 21:39 nvm.o
-rw-r--r-- 1 chenwx chenwx 287K Oct 7 21:39 param.o
-rw-r--r-- 1 chenwx chenwx 386K Oct 7 21:39 phy.o
-rw-r--r-- 1 chenwx chenwx 266K Oct 7 21:39 ptp.o
chenwx@chenwx ~/linux $ modinfo ../linux-build/drivers/net/ethernet/intel/e1000e/e1000e.ko
filename: /home/chenwx/linux/../linux-build/drivers/net/ethernet/intel/e1000e/e1000e.ko
version: 3.2.5-k
license: GPL
description: Intel(R) PRO/1000 Network Driver
author: Intel Corporation, <linux.nics@intel.com>
srcversion: 224852E6236A925EFB3CC8C
alias: pci:v00008086d000015B8sv*sd*bc*sc*i*
alias: pci:v00008086d000015B7sv*sd*bc*sc*i*
alias: pci:v00008086d00001570sv*sd*bc*sc*i*
alias: pci:v00008086d0000156Fsv*sd*bc*sc*i*
alias: pci:v00008086d000015A3sv*sd*bc*sc*i*
alias: pci:v00008086d000015A2sv*sd*bc*sc*i*
alias: pci:v00008086d000015A1sv*sd*bc*sc*i*
alias: pci:v00008086d000015A0sv*sd*bc*sc*i*
alias: pci:v00008086d00001559sv*sd*bc*sc*i*
alias: pci:v00008086d0000155Asv*sd*bc*sc*i*
alias: pci:v00008086d0000153Bsv*sd*bc*sc*i*
alias: pci:v00008086d0000153Asv*sd*bc*sc*i*
alias: pci:v00008086d00001503sv*sd*bc*sc*i*
alias: pci:v00008086d00001502sv*sd*bc*sc*i*
alias: pci:v00008086d000010F0sv*sd*bc*sc*i*
alias: pci:v00008086d000010EFsv*sd*bc*sc*i*
alias: pci:v00008086d000010EBsv*sd*bc*sc*i*
alias: pci:v00008086d000010EAsv*sd*bc*sc*i*
alias: pci:v00008086d00001525sv*sd*bc*sc*i*
alias: pci:v00008086d000010DFsv*sd*bc*sc*i*
alias: pci:v00008086d000010DEsv*sd*bc*sc*i*
alias: pci:v00008086d000010CEsv*sd*bc*sc*i*
alias: pci:v00008086d000010CDsv*sd*bc*sc*i*
alias: pci:v00008086d000010CCsv*sd*bc*sc*i*
alias: pci:v00008086d000010CBsv*sd*bc*sc*i*
alias: pci:v00008086d000010F5sv*sd*bc*sc*i*
alias: pci:v00008086d000010BFsv*sd*bc*sc*i*
alias: pci:v00008086d000010E5sv*sd*bc*sc*i*
alias: pci:v00008086d0000294Csv*sd*bc*sc*i*
alias: pci:v00008086d000010BDsv*sd*bc*sc*i*
alias: pci:v00008086d000010C3sv*sd*bc*sc*i*
alias: pci:v00008086d000010C2sv*sd*bc*sc*i*
alias: pci:v00008086d000010C0sv*sd*bc*sc*i*
alias: pci:v00008086d00001501sv*sd*bc*sc*i*
alias: pci:v00008086d00001049sv*sd*bc*sc*i*
alias: pci:v00008086d0000104Dsv*sd*bc*sc*i*
alias: pci:v00008086d0000104Bsv*sd*bc*sc*i*
alias: pci:v00008086d0000104Asv*sd*bc*sc*i*
alias: pci:v00008086d000010C4sv*sd*bc*sc*i*
alias: pci:v00008086d000010C5sv*sd*bc*sc*i*
alias: pci:v00008086d0000104Csv*sd*bc*sc*i*
alias: pci:v00008086d000010BBsv*sd*bc*sc*i*
alias: pci:v00008086d00001098sv*sd*bc*sc*i*
alias: pci:v00008086d000010BAsv*sd*bc*sc*i*
alias: pci:v00008086d00001096sv*sd*bc*sc*i*
alias: pci:v00008086d0000150Csv*sd*bc*sc*i*
alias: pci:v00008086d000010F6sv*sd*bc*sc*i*
alias: pci:v00008086d000010D3sv*sd*bc*sc*i*
alias: pci:v00008086d0000109Asv*sd*bc*sc*i*
alias: pci:v00008086d0000108Csv*sd*bc*sc*i*
alias: pci:v00008086d0000108Bsv*sd*bc*sc*i*
alias: pci:v00008086d0000107Fsv*sd*bc*sc*i*
alias: pci:v00008086d0000107Esv*sd*bc*sc*i*
alias: pci:v00008086d0000107Dsv*sd*bc*sc*i*
alias: pci:v00008086d000010B9sv*sd*bc*sc*i*
alias: pci:v00008086d000010D5sv*sd*bc*sc*i*
alias: pci:v00008086d000010DAsv*sd*bc*sc*i*
alias: pci:v00008086d000010D9sv*sd*bc*sc*i*
alias: pci:v00008086d00001060sv*sd*bc*sc*i*
alias: pci:v00008086d000010A5sv*sd*bc*sc*i*
alias: pci:v00008086d000010BCsv*sd*bc*sc*i*
alias: pci:v00008086d000010A4sv*sd*bc*sc*i*
alias: pci:v00008086d0000105Fsv*sd*bc*sc*i*
alias: pci:v00008086d0000105Esv*sd*bc*sc*i*
depends:
vermagic: 4.2.2 SMP mod_unload modversions
parm: debug:Debug level (0=none,...,16=all) (int)
parm: copybreak:Maximum size of packet that is copied to a new buffer on receive (uint)
parm: TxIntDelay:Transmit Interrupt Delay (array of int)
parm: TxAbsIntDelay:Transmit Absolute Interrupt Delay (array of int)
parm: RxIntDelay:Receive Interrupt Delay (array of int)
parm: RxAbsIntDelay:Receive Absolute Interrupt Delay (array of int)
parm: InterruptThrottleRate:Interrupt Throttling Rate (array of int)
parm: IntMode:Interrupt Mode (array of int)
parm: SmartPowerDownEnable:Enable PHY smart power down (array of int)
parm: KumeranLockLoss:Enable Kumeran lock loss workaround (array of int)
parm: WriteProtectNVM:Write-protect NVM [WARNING: disabling this can lead to corrupted NVM] (array of int)
parm: CrcStripping:Enable CRC Stripping, disable if your BMC needs the CRC (array of int)
3.4.5 交叉编译ARM
交叉编译内核需要安装交叉编译器,参见Cross compiling Linux kernel on x86_64。
根据顶层Makefile中的如下定义可知,3.4.1 Makefile的Default Target节至3.4.4 编译external modules节的编译与当前环境的体系架构有关:
# SUBARCH tells the usermode build what the underlying arch is. That is set
# first, and if a usermode build is happening, the "ARCH=um" on the command
# line overrides the setting of ARCH below. If a native build is happening,
# then ARCH is assigned, getting whatever value it gets normally, and
# SUBARCH is subsequently ignored.
SUBARCH := $(shell uname -m | sed -e s/i.86/i386/ -e s/sun4u/sparc64/ \
-e s/arm.*/arm/ -e s/sa110/arm/ \
-e s/s390x/s390/ -e s/parisc64/parisc/ \
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
-e s/sh[234].*/sh/ )
# Cross compiling and selecting different set of gcc/bin-utils
# ---------------------------------------------------------------------------
#
# When performing cross compilation for other architectures ARCH shall be set
# to the target architecture. (See arch/* for the possibilities).
# ARCH can be set during invocation of make:
# make ARCH=ia64
# Another way is to have ARCH set in the environment.
# The default ARCH is the host where make is executed.
# CROSS_COMPILE specify the prefix used for all executables used
# during compilation. Only gcc and related bin-utils executables
# are prefixed with $(CROSS_COMPILE).
# CROSS_COMPILE can be set on the command line
# make CROSS_COMPILE=ia64-linux-
# Alternatively CROSS_COMPILE can be set in the environment.
# A third alternative is to store a setting in .config so that plain
# "make" in the configured kernel build directory always uses that.
# Default value for CROSS_COMPILE is not to prefix executables
# Note: Some architectures assign CROSS_COMPILE in their arch/*/Makefile
export KBUILD_BUILDHOST := $(SUBARCH)
ARCH ?= $(SUBARCH)
CROSS_COMPILE ?= $(CONFIG_CROSS_COMPILE:"%"=%)
# Architecture as present in compile.h
UTS_MACHINE := $(ARCH)
SRCARCH := $(ARCH)
...
如果为其他体系架构编译内核,则需要进行交叉编译。下面以ARM为例,讲解Linux Kernel的交叉编译。
3.4.5.1 安装交叉编译器
以ARM为例,运行下列命令安装交叉编译器:
chenwx@chenwx ~/linux $ sudo apt-get install gcc-arm-linux-gnueabi
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following extra packages will be installed:
binutils-arm-linux-gnueabi cpp-4.7-arm-linux-gnueabi cpp-arm-linux-gnueabi gcc-4.7-arm-linux-gnueabi gcc-4.7-arm-linux-gnueabi-base libc6-armel-cross
libc6-dev-armel-cross libgcc1-armel-cross libgomp1-armel-cross linux-libc-dev-armel-cross
Suggested packages:
binutils-doc gcc-4.7-locales cpp-doc gcc-4.7-multilib-arm-linux-gnueabi libmudflap0-4.7-dev-armel-cross gcc-4.7-doc libgcc1-dbg-armel-cross
libgomp1-dbg-armel-cross libitm1-dbg-armel-cross libquadmath-dbg-armel-cross libmudflap0-dbg-armel-cross binutils-gold automake1.9 flex bison
gdb-arm-linux-gnueabi gcc-doc
The following NEW packages will be installed:
binutils-arm-linux-gnueabi cpp-4.7-arm-linux-gnueabi cpp-arm-linux-gnueabi gcc-4.7-arm-linux-gnueabi gcc-4.7-arm-linux-gnueabi-base gcc-arm-linux-gnueabi
libc6-armel-cross libc6-dev-armel-cross libgcc1-armel-cross libgomp1-armel-cross linux-libc-dev-armel-cross
0 upgraded, 11 newly installed, 0 to remove and 417 not upgraded.
Need to get 20.6 MB of archives.
After this operation, 41.0 MB of additional disk space will be used.
...
chenwx@chenwx ~/linux $ ll /usr/bin | grep arm
-rwxr-xr-x 1 root root 9648 Jul 9 2012 arm2hpdl
-rwxr-xr-x 1 root root 26524 Sep 21 2012 arm-linux-gnueabi-addr2line
-rwxr-xr-x 2 root root 55228 Sep 21 2012 arm-linux-gnueabi-ar
-rwxr-xr-x 2 root root 569784 Sep 21 2012 arm-linux-gnueabi-as
-rwxr-xr-x 1 root root 22164 Sep 21 2012 arm-linux-gnueabi-c++filt
lrwxrwxrwx 1 root root 25 Oct 6 2012 arm-linux-gnueabi-cpp -> arm-linux-gnueabi-cpp-4.7
-rwxr-xr-x 1 root root 515328 Sep 21 2012 arm-linux-gnueabi-cpp-4.7
-rwxr-xr-x 1 root root 26384 Sep 21 2012 arm-linux-gnueabi-elfedit
lrwxrwxrwx 1 root root 25 Oct 6 2012 arm-linux-gnueabi-gcc -> arm-linux-gnueabi-gcc-4.7
-rwxr-xr-x 1 root root 515328 Sep 21 2012 arm-linux-gnueabi-gcc-4.7
-rwxr-xr-x 1 root root 22088 Sep 21 2012 arm-linux-gnueabi-gcc-ar-4.7
-rwxr-xr-x 1 root root 22088 Sep 21 2012 arm-linux-gnueabi-gcc-nm-4.7
-rwxr-xr-x 1 root root 22092 Sep 21 2012 arm-linux-gnueabi-gcc-ranlib-4.7
lrwxrwxrwx 1 root root 26 Oct 6 2012 arm-linux-gnueabi-gcov -> arm-linux-gnueabi-gcov-4.7
-rwxr-xr-x 1 root root 210704 Sep 21 2012 arm-linux-gnueabi-gcov-4.7
-rwxr-xr-x 1 root root 92728 Sep 21 2012 arm-linux-gnueabi-gprof
-rwxr-xr-x 4 root root 494592 Sep 21 2012 arm-linux-gnueabi-ld
-rwxr-xr-x 4 root root 494592 Sep 21 2012 arm-linux-gnueabi-ld.bfd
-rwxr-xr-x 2 root root 2886436 Sep 21 2012 arm-linux-gnueabi-ld.gold
-rwxr-xr-x 2 root root 35092 Sep 21 2012 arm-linux-gnueabi-nm
-rwxr-xr-x 2 root root 204668 Sep 21 2012 arm-linux-gnueabi-objcopy
-rwxr-xr-x 2 root root 307456 Sep 21 2012 arm-linux-gnueabi-objdump
-rwxr-xr-x 2 root root 55240 Sep 21 2012 arm-linux-gnueabi-ranlib
-rwxr-xr-x 1 root root 369540 Sep 21 2012 arm-linux-gnueabi-readelf
-rwxr-xr-x 1 root root 26488 Sep 21 2012 arm-linux-gnueabi-size
-rwxr-xr-x 1 root root 26476 Sep 21 2012 arm-linux-gnueabi-strings
-rwxr-xr-x 2 root root 204668 Sep 21 2012 arm-linux-gnueabi-strip
lrwxrwxrwx 1 root root 9 Jan 22 2013 charmap -> gucharmap
lrwxrwxrwx 1 root root 9 Jan 22 2013 gnome-character-map -> gucharmap
-rwxr-xr-x 1 root root 68276 Sep 28 2012 gucharmap
lrwxrwxrwx 1 root root 26 Jan 22 2013 testparm -> /etc/alternatives/testparm
-rwxr-xr-x 1 root root 1427132 Oct 5 2012 testparm.samba3
chenwx@chenwx ~/linux $ arm-linux-gnueabi-gcc --version
arm-linux-gnueabi-gcc (Ubuntu/Linaro 4.7.2-1ubuntu1) 4.7.2
Copyright (C) 2012 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
3.4.5.2 配置内核ARM
可采用如下两种方式之一配置内核:
1) 运行下列命令配置内核,配置结果保存在~/linux-build/.config中
# make O=../linux-build/ ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- menuconfig
2) 运行下列命令使用arch/arm/configs/目录中的默认配置文件,以acs5k_defconfig为例(参见3.3.2 make *config节)
# make O=../linux-build/ ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- acs5k_defconfig
chenwx@chenwx ~/linux $ ll arch/arm/configs/
-rw-r--r-- 1 chenwx chenwx 1998 Jul 8 20:53 acs5k_defconfig
-rw-r--r-- 1 chenwx chenwx 2011 Jul 8 20:53 acs5k_tiny_defconfig
-rw-r--r-- 1 chenwx chenwx 2617 Jul 8 20:53 am200epdkit_defconfig
-rw-r--r-- 1 chenwx chenwx 2289 Jul 8 20:53 ape6evm_defconfig
-rw-r--r-- 1 chenwx chenwx 4068 Jul 8 20:53 armadillo800eva_defconfig
-rw-r--r-- 1 chenwx chenwx 1315 Jul 8 20:53 assabet_defconfig
-rw-r--r-- 1 chenwx chenwx 5249 Jul 8 20:53 at91_dt_defconfig
...
chenwx@chenwx ~/linux $ make O=../linux-build/ ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- help
...
Architecture specific targets (arm):
* zImage - Compressed kernel image (arch/arm/boot/zImage)
Image - Uncompressed kernel image (arch/arm/boot/Image)
* xipImage - XIP kernel image, if configured (arch/arm/boot/xipImage)
uImage - U-Boot wrapped zImage
bootpImage - Combined zImage and initial RAM disk
(supply initrd image via make variable INITRD=<path>)
* dtbs - Build device tree blobs for enabled boards
dtbs_install - Install dtbs to /boot/dtbs/3.15.0
install - Install uncompressed kernel
zinstall - Install compressed kernel
uinstall - Install U-Boot wrapped compressed kernel
Install using (your) ~/bin/installkernel or
(distribution) /sbin/installkernel or
install to $(INSTALL_PATH) and run lilo
acs5k_defconfig - Build for acs5k
acs5k_tiny_defconfig - Build for acs5k_tiny
am200epdkit_defconfig - Build for am200epdkit
ape6evm_defconfig - Build for ape6evm
armadillo800eva_defconfig - Build for armadillo800eva
assabet_defconfig - Build for assabet
at91_dt_defconfig - Build for at91_dt
at91rm9200_defconfig - Build for at91rm9200
at91sam9260_9g20_defconfig - Build for at91sam9260_9g20
at91sam9261_9g10_defconfig - Build for at91sam9261_9g10
at91sam9263_defconfig - Build for at91sam9263
at91sam9g45_defconfig - Build for at91sam9g45
at91sam9rl_defconfig - Build for at91sam9rl
...
chenwx@chenwx ~/linux $ make O=../linux-build/ ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- acs5k_defconfig
#
# configuration written to .config
#
3.4.5.3 内核的交叉编译
运行下列命令为ARM架构交叉编译内核:
chenwx@chenwx ~/linux $ make O=../linux-build/ ARCH=arm CROSS_COMPILE=arm-linux-gnueabi-
...
LD vmlinux
SORTEX vmlinux
SYSMAP System.map
OBJCOPY arch/arm/boot/Image
Kernel: arch/arm/boot/Image is ready
AS arch/arm/boot/compressed/head.o
GZIP arch/arm/boot/compressed/piggy.gzip
AS arch/arm/boot/compressed/piggy.gzip.o
CC arch/arm/boot/compressed/misc.o
CC arch/arm/boot/compressed/decompress.o
CC arch/arm/boot/compressed/string.o
SHIPPED arch/arm/boot/compressed/hyp-stub.S
AS arch/arm/boot/compressed/hyp-stub.o
SHIPPED arch/arm/boot/compressed/lib1funcs.S
AS arch/arm/boot/compressed/lib1funcs.o
SHIPPED arch/arm/boot/compressed/ashldi3.S
AS arch/arm/boot/compressed/ashldi3.o
LD arch/arm/boot/compressed/vmlinux
OBJCOPY arch/arm/boot/zImage
Kernel: arch/arm/boot/zImage is ready
MODPOST 42 modules
CC arch/arm/crypto/aes-arm.mod.o
LD [M] arch/arm/crypto/aes-arm.ko
CC arch/arm/crypto/sha1-arm.mod.o
LD [M] arch/arm/crypto/sha1-arm.ko
CC crypto/ansi_cprng.mod.o
LD [M] crypto/ansi_cprng.ko
...
chenwx@chenwx ~/linux-build $ ll vmlinux System.map arch/arm/boot/compressed/vmlinux arch/arm/boot/zImage
-rwxr-xr-x 1 chenwx chenwx 985956 Dec 9 11:56 arch/arm/boot/compressed/vmlinux
-rwxr-xr-x 1 chenwx chenwx 947208 Dec 9 11:56 arch/arm/boot/zImage
-rw-r--r-- 1 chenwx chenwx 316549 Dec 9 11:56 System.map
-rwxr-xr-x 1 chenwx chenwx 2435755 Dec 9 11:56 vmlinux
chenwx@chenwx ~/linux-build $ file vmlinux
vmlinux: ELF 32-bit LSB executable, ARM, version 1, statically linked, BuildID[sha1]=0xf2e0153fb842be3137df94af05c48f27dfd510b9, not stripped
chenwx@chenwx ~/linux-build $ file arch/arm/boot/compressed/vmlinux
arch/arm/boot/compressed/vmlinux: ELF 32-bit LSB executable, ARM, version 1, statically linked, not stripped
chenwx@chenwx ~/linux-build $ file arch/arm/boot/zImage
arch/arm/boot/zImage: Linux kernel ARM boot executable zImage (little-endian)
3.4.5.4 安装编译的内核模块
运行下列命令安装编译的内核模块:
# make O=../linux-build/ ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- INSTALL_MOD_PATH=/path/install/modules/ modules_install
chenwx@chenwx ~/linux $ make O=../linux-build/ ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- INSTALL_MOD_PATH=~/arm_mod modules_install
INSTALL arch/arm/crypto/aes-arm.ko
INSTALL arch/arm/crypto/sha1-arm.ko
INSTALL crypto/ansi_cprng.ko
INSTALL crypto/anubis.ko
INSTALL crypto/arc4.ko
INSTALL crypto/blowfish_common.ko
INSTALL crypto/blowfish_generic.ko
INSTALL crypto/camellia_generic.ko
INSTALL crypto/cast5_generic.ko
INSTALL crypto/cast6_generic.ko
INSTALL crypto/cast_common.ko
INSTALL crypto/ccm.ko
INSTALL crypto/cmac.ko
INSTALL crypto/crc32.ko
INSTALL crypto/crc32c.ko
INSTALL crypto/crct10dif_common.ko
INSTALL crypto/crct10dif_generic.ko
INSTALL crypto/ctr.ko
INSTALL crypto/cts.ko
INSTALL crypto/des_generic.ko
INSTALL crypto/fcrypt.ko
INSTALL crypto/gcm.ko
INSTALL crypto/ghash-generic.ko
INSTALL crypto/lrw.ko
INSTALL crypto/md4.ko
INSTALL crypto/michael_mic.ko
INSTALL crypto/pcbc.ko
INSTALL crypto/rmd128.ko
INSTALL crypto/rmd160.ko
INSTALL crypto/rmd256.ko
INSTALL crypto/rmd320.ko
INSTALL crypto/seqiv.ko
INSTALL crypto/sha512_generic.ko
INSTALL crypto/tcrypt.ko
INSTALL crypto/tgr192.ko
INSTALL crypto/vmac.ko
INSTALL crypto/wp512.ko
INSTALL crypto/xcbc.ko
INSTALL crypto/xts.ko
INSTALL fs/ext3/ext3.ko
INSTALL fs/jbd/jbd.ko
INSTALL fs/mbcache.ko
DEPMOD 3.13.0-rc1-00001-g83836a9
chenwx@chenwx ~/linux $ ll ~/arm_mod/
total 12
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:52 .
drwxr-xr-x 36 chenwx chenwx 4096 Dec 9 12:30 ..
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:52 lib
chenwx@chenwx ~/linux $ ll ~/arm_mod/lib/
total 12
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:52 .
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:52 ..
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:52 modules
chenwx@chenwx ~/linux $ ll ~/arm_mod/lib/modules/
total 12
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:52 .
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:52 ..
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:53 3.13.0-rc1-00001-g83836a9
chenwx@chenwx ~/linux $ ll ~/arm_mod/lib/modules/3.13.0-rc1-00001-g83836a9/
total 88
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:53 .
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:52 ..
lrwxrwxrwx 1 chenwx chenwx 33 Dec 10 03:52 build -> /usr/src/linuxkernel/linux-stable
drwxr-xr-x 5 chenwx chenwx 4096 Dec 10 03:53 kernel
-rw-r--r-- 1 chenwx chenwx 615 Dec 10 03:53 modules.alias
-rw-r--r-- 1 chenwx chenwx 946 Dec 10 03:53 modules.alias.bin
-rw-r--r-- 1 chenwx chenwx 1929 Dec 10 03:52 modules.builtin
-rw-r--r-- 1 chenwx chenwx 2526 Dec 10 03:53 modules.builtin.bin
-rw-r--r-- 1 chenwx chenwx 69 Dec 10 03:53 modules.ccwmap
-rw-r--r-- 1 chenwx chenwx 1295 Dec 10 03:53 modules.dep
-rw-r--r-- 1 chenwx chenwx 2892 Dec 10 03:53 modules.dep.bin
-rw-r--r-- 1 chenwx chenwx 52 Dec 10 03:53 modules.devname
-rw-r--r-- 1 chenwx chenwx 73 Dec 10 03:53 modules.ieee1394map
-rw-r--r-- 1 chenwx chenwx 141 Dec 10 03:53 modules.inputmap
-rw-r--r-- 1 chenwx chenwx 81 Dec 10 03:53 modules.isapnpmap
-rw-r--r-- 1 chenwx chenwx 74 Dec 10 03:53 modules.ofmap
-rw-r--r-- 1 chenwx chenwx 1086 Dec 10 03:52 modules.order
-rw-r--r-- 1 chenwx chenwx 99 Dec 10 03:53 modules.pcimap
-rw-r--r-- 1 chenwx chenwx 43 Dec 10 03:53 modules.seriomap
-rw-r--r-- 1 chenwx chenwx 131 Dec 10 03:53 modules.softdep
-rw-r--r-- 1 chenwx chenwx 2755 Dec 10 03:53 modules.symbols
-rw-r--r-- 1 chenwx chenwx 3571 Dec 10 03:53 modules.symbols.bin
-rw-r--r-- 1 chenwx chenwx 189 Dec 10 03:53 modules.usbmap
lrwxrwxrwx 1 chenwx chenwx 33 Dec 10 03:52 source -> /usr/src/linuxkernel/linux-stable
chenwx@chenwx ~/linux $ ll ~/arm_mod/lib/modules/3.13.0-rc1-00001-g83836a9/kernel/
total 20
drwxr-xr-x 5 chenwx chenwx 4096 Dec 10 03:53 .
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:53 ..
drwxr-xr-x 3 chenwx chenwx 4096 Dec 10 03:52 arch
drwxr-xr-x 2 chenwx chenwx 4096 Dec 10 03:53 crypto
drwxr-xr-x 4 chenwx chenwx 4096 Dec 10 03:53 fs
3.4.6 Export Header Files
Refer to following documentations:
If you want to do kernel programming, there is a package corresponding to each running kernel that you can install that provides the kernel space header files against which you can compile your loadable modules so that you don’t even need a full kernel source tree.
There are times when you’re programming for user space but you need header files that define kernel space structures since you’re going to be defining a structure that you want to pass into kernel space, almost certainly via a system call, and you need to get a declaration for that structure somewhere, which leads us to introduce a third type of header file – the kind that are relevant for both kernel and user space.
Such header files are carefully selected from the header files in the kernel source tree, they’re “cleaned” (using a process that will be explained shortly), and they’re bundled into yet another package that you’ll see in a minute. So … where do these header files come from? At the top of your kernel source tree, simply run:
chenwx@chenwx ~/linux $ make distclean [optional]
chenwx@chenwx ~/linux $ make headers_install
at which point a carefully selected subset of the kernel header files scattered around the tree are collected, sanitized and placed carefully under the kernel source tree directory usr/include/, where you can examine them with:
chenwx@chenwx ~/linux $ find usr/include/ | more
usr/include/
usr/include/asm
usr/include/asm/ptrace-abi.h
usr/include/asm/types.h
usr/include/asm/auxvec.h
usr/include/asm/siginfo.h
usr/include/asm/bootparam.h
usr/include/asm/unistd_64.h
usr/include/asm/mman.h
usr/include/asm/hyperv.h
usr/include/asm/perf_regs.h
usr/include/asm/svm.h
usr/include/asm/shmbuf.h
usr/include/asm/fcntl.h
usr/include/asm/unistd.h
usr/include/asm/swab.h
usr/include/asm/stat.h
...
What you’re looking at in the output above is the collection of kernel header files that are also deemed to be appropriate for user space programmers who want to, perhaps, define structures that they will be passing to kernel code. More to the point, these header files have already been packaged for you and are almost certainly already on your system. In the case of Ubuntu 10.04, this would be the linux-libc-dev package:
chenwx@chenwx ~/linux $ dpkg -L linux-libc-dev | more
/.
/usr
/usr/include
/usr/include/asm
/usr/include/asm/ptrace-abi.h
/usr/include/asm/types.h
/usr/include/asm/auxvec.h
/usr/include/asm/siginfo.h
/usr/include/asm/bootparam.h
/usr/include/asm/unistd_64.h
/usr/include/asm/mman.h
/usr/include/asm/hyperv.h
/usr/include/asm/perf_regs.h
/usr/include/asm/svm.h
/usr/include/asm/shmbuf.h
/usr/include/asm/fcntl.h
/usr/include/asm/unistd.h
/usr/include/asm/swab.h
...
3.4.6.1 Who decides which kernel header files are exported?
When you run “make headers_install” from the top of your kernel source tree, who or what decides precisely which kernel header files will get bundled up and stashed under the kernel source directory usr/include/ for later “exporting” to user space? That’s easy.
The header files to be exported are defined by the Kbuild files scattered throughout the kernel source tree. The one at the very top level is the engine, while elsewhere throughout the tree, you’ll find Kbuild files like, say, this one:
chenwx@chenwx ~/linux $ cat include/uapi/Kbuild
# UAPI Header export list
# Top-level Makefile calls into asm-$(ARCH)
# List only non-arch directories below
header-y += asm-generic/
header-y += linux/
header-y += sound/
header-y += mtd/
header-y += rdma/
header-y += video/
header-y += drm/
header-y += xen/
header-y += scsi/
header-y += misc/
That file simply defines that the export process should recursively continue into those subdirectories and keep checking for more Kbuild files. If we check further, we’ll start to see Kbuild files like:
chenwx@chenwx ~/linux $ cat include/uapi/linux/Kbuild
# UAPI Header export list
header-y += android/
header-y += byteorder/
header-y += can/
header-y += caif/
header-y += dvb/
header-y += hdlc/
header-y += hsi/
header-y += iio/
header-y += isdn/
...
header-y += acct.h
header-y += adb.h
header-y += adfs_fs.h
header-y += affs_hardblocks.h
header-y += agpgart.h
header-y += aio_abi.h
header-y += am437x-vpfe.h
header-y += apm_bios.h
header-y += arcfb.h
header-y += atalk.h
header-y += atmapi.h
...
which clearly represents a combination of more recursive directories, plus immediate header files. Quite simply, all kernel Kbuild files have that general structure and, collectively (throughout the entire kernel source tree), they define all of the kernel header files to be exported to user space.
3.4.6.2 What does it mean to “sanitize” one of those header files?
In many cases, the header files to be exported contain some content that is meaningful only in kernel space, and it’s only a subset of the header file that needs to be exported. Kernel-only code is normally surrounded by a preprocessor conditional that checks the value of the __KERNEL__ macro, and part of the the job of the export process (when you run make headers_install) is to examine each file that is being exported, identify the code that is relevant only in kernel space, and remove it. Quite simple, really.
That’s why (for example) the kernel version of the header file include/video/edid.h looks like this:
#ifndef __linux_video_edid_h__
#define __linux_video_edid_h__
#if !defined(__KERNEL__) || defined(CONFIG_X86)
struct edid_info {
unsigned char dummy[128];
};
#ifdef __KERNEL__
extern struct edid_info edid_info;
#endif /* __KERNEL__ */
#endif
#endif /* __linux_video_edid_h__ */
but by the time it ends up in user space and is placed at /usr/include/video/edid.h, it looks like this:
#ifndef __linux_video_edid_h__
#define __linux_video_edid_h__
struct edid_info {
unsigned char dummy[128];
};
#endif /* __linux_video_edid_h__ */
Technically, there’s no actual harm in leaving in that kernel-only content since, when you’re compiling in user space, you’re guaranteed that the preprocessor macro __KERNEL__ will never be set, but it’s cleaner to just strip out that irrelevant content during the export process.
NOTE: If you look carefully, you’ll notice that many of the Kbuild files contain both the variables header-y and unifdef-y to identify the header files to be sanitized and exported. The latter is now deprecated and Kbuild files should now contain only the first form, but the older form is still supported.
3.4.6.3 Installation of Linux API Headers in LFS
参见Linux-4.18.5 API Headers (online)和Linux-4.18.5 API Headers (local pdf)。
The following steps show the installation of Linux API headers in Linux From Scratch (LFS):
chenwx@chenwx ~/linux $ mkdir ../linux-header
chenwx@chenwx ~/linux $ make INSTALL_HDR_PATH=../linux-header/ headers_install
CHK include/generated/uapi/linux/version.h
INSTALL include/asm-generic (35 files)
INSTALL include/drm (21 files)
INSTALL include/linux/android (1 file)
INSTALL include/linux/byteorder (2 files)
INSTALL include/linux/caif (2 files)
INSTALL include/linux/can (5 files)
INSTALL include/linux/dvb (8 files)
INSTALL include/linux/hdlc (1 file)
INSTALL include/linux/hsi (2 files)
INSTALL include/linux/iio (2 files)
INSTALL include/linux/isdn (1 file)
INSTALL include/linux/mmc (1 file)
INSTALL include/linux/netfilter/ipset (4 files)
INSTALL include/linux/netfilter (86 files)
INSTALL include/linux/netfilter_arp (2 files)
INSTALL include/linux/netfilter_bridge (17 files)
INSTALL include/linux/netfilter_ipv4 (9 files)
INSTALL include/linux/netfilter_ipv6 (12 files)
INSTALL include/linux/nfsd (5 files)
INSTALL include/linux/raid (2 files)
INSTALL include/linux/spi (1 file)
INSTALL include/linux/sunrpc (1 file)
INSTALL include/linux/tc_act (12 files)
INSTALL include/linux/tc_ematch (4 files)
INSTALL include/linux/usb (11 files)
INSTALL include/linux/wimax (1 file)
INSTALL include/linux (436 files)
INSTALL include/misc (1 file)
INSTALL include/mtd (5 files)
INSTALL include/rdma/hfi (1 file)
INSTALL include/rdma (14 files)
INSTALL include/scsi/fc (4 files)
INSTALL include/scsi (4 files)
INSTALL include/sound (15 files)
INSTALL include/video (3 files)
INSTALL include/xen (4 files)
INSTALL include/uapi (0 file)
INSTALL include/asm (65 files)
// Remove .install and ..install.cmd files
chenwx@chenwx ~/linux $ find ../linux-header/include \( -name .install -o -name ..install.cmd \) -delete
// Install the linux headers to /usr/include directory
chenwx@chenwx ~/linux $ cp -rv ../linux-header/include/* /usr/include
// Check the generated linux headers
chenwx@chenwx ~/linux $ ll ../linux-header/
drwxrwxr-x 14 chenwx chenwx 4.0K Oct 23 17:23 include
chenwx@chenwx ~/linux $ ll ../linux-header/include/
drwxrwxr-x 2 chenwx chenwx 4.0K Oct 23 17:24 asm
drwxrwxr-x 2 chenwx chenwx 4.0K Oct 23 17:24 asm-generic
drwxrwxr-x 2 chenwx chenwx 4.0K Oct 23 17:24 drm
drwxrwxr-x 25 chenwx chenwx 20K Oct 23 17:24 linux
drwxrwxr-x 2 chenwx chenwx 4.0K Oct 23 17:24 misc
drwxrwxr-x 2 chenwx chenwx 4.0K Oct 23 17:24 mtd
drwxrwxr-x 3 chenwx chenwx 4.0K Oct 23 17:24 rdma
drwxrwxr-x 3 chenwx chenwx 4.0K Oct 23 17:24 scsi
drwxrwxr-x 2 chenwx chenwx 4.0K Oct 23 17:24 sound
drwxrwxr-x 2 chenwx chenwx 4.0K Oct 23 17:24 uapi
drwxrwxr-x 2 chenwx chenwx 4.0K Oct 23 17:24 video
drwxrwxr-x 2 chenwx chenwx 4.0K Oct 23 17:24 xen
chenwx@chenwx ~/linux $ find ../linux-header/include/ -type f | wc -l
797
3.5 内核升级
3.5.1 内核升级准备
3.5.1.1 查看当前系统内核版本
It is easy to tell if you are running a distribution kernel. Unless you downloaded, compiled and installed your own version of kernel from kernel.org, you are running a distribution kernel. To find out the version of your kernel, run uname -r:
chenwx ~ $ uname -r
3.5.0-17-generic
NOTE: If you see anything at all after the dash, you are running a distribution kernel. Please use the support channels offered by your distribution vendor to obtain kernel support.
也可通过下列命令查看内核版本:
chenwx ~ $ cat /proc/version
Linux version 3.15.0-eudyptula-00054-g783e9e8-dirty (chenwx@chenwx) (gcc version 4.8.1 (Ubuntu/Linaro 4.8.1-10ubuntu8) ) #3 SMP Fri May 9 07:56:01 CST 2014
3.5.2 获取新版本内核源代码
3.5.2.1 通过Git Repository下载源代码
1) Download source code from linux.git to directory ~/linux
$ cd ~
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
2) Checkout source code of specific git tree
$ git branch -a
$ git checkout master
$ git tag -l next-*
$ git checkout next-20150224
参见1.2.5 Setup Linux Kernel Workarea节。
3.5.2.2 通过源代码压缩包和补丁下载源代码
1) Download source code from http://www.kernel.org/pub/linux/kernel:
linux-3.2.tar.bz2 05-Jan-2012 00:40 75M
linux-3.2.tar.gz 05-Jan-2012 00:40 94M
linux-3.2.tar.sign 05-Jan-2012 00:40 490
linux-3.2.tar.xz 05-Jan-2012 00:40 62M
2) Unzip source code to directory ~/linux:
$ cd ~
$ rm -rf linux-3.2 // 删除源代码目录
$ rm -rf linux // 删除链接目录
$ gzip -cd linux-3.2.tar.gz | tar xvf - // 生成linux-3.2目录
or,
$ bzip2 -dc linux-3.2.tar.bz2 | tar xvf – // 生成linux-3.2目录
$ ln -s linux-3.2 linux // 重新生成linux链接目录
Refer to linux/README:
Do NOT use the /usr/src/linux area! This area has a (usually incomplete) set of kernel headers that are used by the library header files. They should match the library, and not get messed up by whatever the kernel-du-jour happens to be.
3) Apply patches
参见3.6 内核补丁/Patch节。
3.5.3 配置内核
执行如下命令配置内核:
$ cd ~/linux
// 该命令可确保源代码目录下没有不正确的.o文件
$ make mrproper
$ make clean
$ make distclean
// 参见[3.3.1 make config]节和[3.3.2 make *config]节,产生配置输出文件~/linux-build/.config
$ make config O=../linux-build
$ make *config O=../linux-build
or,
$ cp /boot/config-3.15.9-generic ../linux-build/.config
$ make olddefconfig O=../linux-build
$ make menuconfig O=../linux-build
$ make kernelrelease O=../linux-build
3.2.0-chenwx
NOTE: It’s more convenient to preserve the kernel source untouched and have all the configuration output and compilation results generated in a remote directory.
1) it leaves the source unpolluted by all of those output files, which makes it easier if you want to search the tree using something like grep.
2) it allows you to work with a directory of kernel source for which you have no write access. Perhaps it’s a system directory, or in some other user’s home directory. As long as you can cd to the top of the source tree and have read access to all of the source, you can generate all of the output elsewhere.
3) it lets you work with multiple configurations and builds simultaneously, since you can simply switch from one output directory to another on the fly, using the same kernel source directory as the basis for all of those builds.
There is only one caution, though. Once you initially select an output directory, you must specify that output directory on every subsequent make invocation, but that should simply be obvious. In fact, the last time I checked, you can’t use the remote directory feature if your kernel source tree already shows signs of internal configuration. In short, this feature is meant to be used with a pristine kernel source tree.
在本文中,内核源代码位于~/linux目录下,而编译的输出目录位于~/linux-build目录下。
3.5.4 编译内核
执行如下命令编译内核:
# cd ~/linux
# make menuconfig O=../linux-build
// 建立编译时所需的从属文件。
// NOTE: 在linux-3.2中,已经不需要执行该命令了,执行make dep的输出为:
// *** Warning: make dep is unnecessary now.
# make dep
# make O=../linux-build
# make O=../linux-build –j4
编译内核,具体过程参见3.4.1 Makefile的Default Target节:
- linux-2.6之前版本使用make bzImage命令;
- linux-2.6之后版本可仅使用make命令,相当于之前的make bzImage和make modules命令。
本命令的产生如下输出文件:
~/linux-build/vmlinux
~/linux-build/System.map
~/linux-build/arch/x86/boot/bzImage
~/linux-build/arch/i386/boot/bzImage (linked to ~/linux-build/arch/x86/boot/bzImage)
~/linux-build/oneSubDir/twoSubDir/*.ko (modules)
3.5.5 安装内核
执行如下命令安装内核模块:
# sudo make modules_install O=../linux-build
可加载模块被安装到/lib/modules/3.2.0/目录下:
/lib/modules/3.2.0/source ==链接==> ~/linux-build
/lib/modules/3.2.0/build ==链接==> ~/linux-build
~/linux-build/modules.order ==安装==> /lib/modules/3.2.0/modules.order
~/linux-build/modules.builtin ==安装==> /lib/modules/3.2.0/modules.builtin
[3.4.3.4.2.3 $(modules)]节的输出文件(*.ko) ==安装==> /lib/modules/3.2.0/kernel/目录
[3.4.3.4.3.1 $(mod-fw)]节的输出文件(*.fw/*.bin/*.dsp) ==安装==> /lib/firmware/目录
执行如下命令安装新内核:
# sudo make install O=../linux-build
规则install参见arch/x86/Makefile,其实际执行下列命令:
make -f scripts/Makefile.build obj=arch/x86/boot install
sh /home/linux-3.2/arch/x86/boot/install.sh 3.2.0 arch/x86/boot/bzImage System.map "/boot"
其中,/home/linux-3.2/arch/x86/boot/install.sh调用下列命令安装内核:
/sbin/installkernel 3.2.0 arch/x86/boot/bzImage System.map "/boot"
本命令进行如下操作:
~/linux-build/arch/x86/boot/bzImage (参见[3.4.2.8 bzImage]节) ==安装==> /boot/vmlinuz-3.2.0-chenwx
~/linux-build/System.map (参见[3.4.2.7.4 rule_vmlinux__]节) ==安装==> /boot/System.map-3.2.0-chenwx
~/linux-build/.config (参见[3.3.4 .config/内核配置结果文件]节) ==安装==> /boot/config-3.2.0-chenwx
生成文件:
/boot/initrd.img-3.11.0-12-generic
3.5.5.1 modules_install
运行make modules_install命令,执行顶层Makefile中的modules_install目标:
#
# INSTALL_PATH specifies where to place the updated kernel and system map
# images. Default is /boot, but you can set it to other values
export INSTALL_PATH ?= /boot
#
# INSTALL_DTBS_PATH specifies a prefix for relocations required by build roots.
# Like INSTALL_MOD_PATH, it isn't defined in the Makefile, but can be passed as
# an argument if needed. Otherwise it defaults to the kernel install path
#
export INSTALL_DTBS_PATH ?= $(INSTALL_PATH)/dtbs/$(KERNELRELEASE)
#
# INSTALL_MOD_PATH specifies a prefix to MODLIB for module directory
# relocations required by build roots. This is not defined in the
# makefile but the argument can be passed to make if needed.
#
MODLIB = $(INSTALL_MOD_PATH)/lib/modules/$(KERNELRELEASE)
export MODLIB
ifdef CONFIG_MODULES
# Target to install modules
PHONY += modules_install
modules_install: _modinst_ _modinst_post
PHONY += _modinst_
_modinst_:
@rm -rf $(MODLIB)/kernel
@rm -f $(MODLIB)/source
@mkdir -p $(MODLIB)/kernel
// 创建链接文件/lib/modules/3.2.0/source至~/linux-build
@ln -s `cd $(srctree) && /bin/pwd` $(MODLIB)/source
// 创建链接文件/lib/modules/3.2.0/build至~/linux-build
@if [ ! $(objtree) -ef $(MODLIB)/build ]; then \
rm -f $(MODLIB)/build ; \
ln -s $(CURDIR) $(MODLIB)/build ; \
fi
// 安装文件~/linux-build/modules.order至/lib/modules/3.2.0/modules.order
@cp -f $(objtree)/modules.order $(MODLIB)/
// 安装文件~/linux-build/modules.builtin至/lib/modules/3.2.0/modules.builtin
@cp -f $(objtree)/modules.builtin $(MODLIB)/
// 执行scripts/Makefile.modinst中的目标__modinst以安装编译好的modules
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.modinst
# This depmod is only for convenience to give the initial
# boot a modules.dep even before / is mounted read-write. However the
# boot script depmod is the master version.
PHONY += _modinst_post
_modinst_post: _modinst_
// 执行scripts/Makefile.fwinst中的目标__fw_modinst
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.fwinst obj=firmware __fw_modinst
// 参见[3.5.5.1.1 cmd_depmod]节
$(call cmd,depmod)
else # CONFIG_MODULES
# Modules not configured
# ---------------------------------------------------------------------------
modules modules_install: FORCE
@echo >&2
@echo >&2 "The present kernel configuration has modules disabled."
@echo >&2 "Type 'make config' and enable loadable module support."
@echo >&2 "Then build a kernel with module support enabled."
@echo >&2
@exit 1
endif # CONFIG_MODULES
3.5.5.1.1 cmd_depmod
在顶层Makefile中,包含如下规则:
# SHELL used by kbuild
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
else if [ -x /bin/bash ]; then echo /bin/bash; \
else echo sh; fi ; fi)
// 该命令来自module-init-tools或kmod,参见[13.3.1 加载/卸载模块的命令]节
DEPMOD = /sbin/depmod
// 获取当前编译的内核版本号,例如: 4.2.0-alex
KERNELRELEASE = $(shell cat include/config/kernel.release 2> /dev/null)
# Run depmod only if we have System.map and depmod is executable
quiet_cmd_depmod = DEPMOD $(KERNELRELEASE)
cmd_depmod = $(CONFIG_SHELL) $(srctree)/scripts/depmod.sh $(DEPMOD) \
$(KERNELRELEASE) "$(patsubst y,_,$(CONFIG_HAVE_UNDERSCORE_SYMBOL_PREFIX))"
命令cmd_depmod被扩展为:
/bin/bash /home/chenwx/linux/scripts/depmod.sh /sbin/depmod 4.2.0-alex
其中,命令/sbin/depmod需要首先存在下列目录和文件:
/lib/modules/4.2.0-alex/
/lib/modules/4.2.0-alex/modules.builtin
/lib/modules/4.2.0-alex/modules.order
然后,命令/sbin/depmod生成下列文件:
/lib/modules/4.2.0-alex/modules.alias
/lib/modules/4.2.0-alex/modules.alias.bin
/lib/modules/4.2.0-alex/modules.builtin.bin
/lib/modules/4.2.0-alex/modules.dep
/lib/modules/4.2.0-alex/modules.dep.bin
/lib/modules/4.2.0-alex/modules.devname
/lib/modules/4.2.0-alex/modules.softdep
/lib/modules/4.2.0-alex/modules.symbols
/lib/modules/4.2.0-alex/modules.symbols.bin
3.5.6 配置引导加载程序GRUB(或LILO)
3.5.6.0 LILO与GRUB的比较
所有引导加载程序都以类似的方式工作,满足共同的目的。不过,LILO和GRUB之间有很多不同之处:
- LILO没有交互式命令界面,而GRUB拥有;
- LILO不支持网络引导,而GRUB支持;
- LILO将关于可以引导的操作系统位置的信息物理上存储在MBR中。如果修改了LILO配置文件,必须将LILO第一阶段引导加载程序重写到MBR。相对于GRUB,这是一个更为危险的选择,因为错误配置的MBR可能会让系统无法引导。使用GRUB,如果配置文件配置错误,则只是默认转到GRUB命令行界面。
3.5.6.1 LILO
编辑LILO的引导配置文件/etc/lilo.conf,添加新内核的启动选项,例如:
#
# 主要小节
#
boot=/dev/hda # 告诉LILO在哪里安装引导加载程序
map=/boot/map # 指向引导期间LILO内部使用的映射文件
install=/boot/boot.b # 是LILO在引导过程中内部使用的文件之一
message=/boot/message
# 默认启动新内核
default="Linux-3.2"
# 显示启动菜单...
prompt # 告诉LILO使用用户界面
# ... 并等候5秒
timeout=50 # 是引导提示在自动引导默认OS之前的等待时间(以十分之一秒为单位)
#
# 新内核:默认映像
#
image=/boot/vmlinuz-3.2
label="Linux-3.2"
root=/dev/hda1
read-only
append="devfs=mount resume=/dev/hda5"
#
# 旧内核
# 最好保留旧内核的配置选项,这样不会因升级失败而导致机器无法启动,至少还可用旧内核引导计算机启动
#
image=/boot/vmlinuz
label="linux"
root=/dev/hda1
read-only
append="devfs=mount resume=/dev/hda5"
#
# 软盘启动
#
other=/dev/floppy
label="floppy"
unsafe
保存后退出,然后运行命令:
# lilo
来更新系统引导映象,这样对lilo.conf的修改才会生效。重启操作系统后,在LILO的提示符下按Tab键,可以看到加入的新内核选项。
3.5.6.2 GRUB Legacy
GRUB引导加载程序:
GRUB的配置文件保存在/boot/grub中,其目录结构如下:
/boot/grub
|-- device.map
|-- menu.lst -> ./grub.conf
|-- grub.conf
|-- grub.conf.201108031656
|-- grub.conf.201210281219
|-- grub.conf.201210281220
|-- grub.conf.ORG_SC
|-- splash.xpm.gz
|-- stage1
|-- e2fs_stage1_5
|-- fat_stage1_5
|-- ffs_stage1_5
|-- iso9660_stage1_5
|-- jfs_stage1_5
|-- minix_stage1_5
|-- reiserfs_stage1_5
|-- ufs2_stage1_5
|-- vstafs_stage1_5
|-- xfs_stage1_5
`-- stage2
GRUB有几个重要的文件:stage1、stage1.5、stage2。引导顺序为stage1 -> stage1.5 -> stage2,其中:
- stage1:大小只有512字节,通常放在MBR中,它的作用很简单,就是在系统启动时用于装载stage2并将控制权交给它。
- stage2:GRUB的核心,所有的功能都是由它实现的。
-
stage1.5:介于stage1和stage2之间,起桥梁作用,因为stage2较大,通常是放在一个文件系统中的,但是stage1并不能识别文件系统格式,所以需要stage1.5来引导位于某个文件系统中的stage2。根据文件系统格式的不同,stage1.5也需要相应的文件,它们存放于1-63的柱面之间,如:
- e2fs_stage1_5用于识别ext文件系统格式
- fat_stage1_5用于识别fat文件系统格式
- …
GRUB的引导配置文件为/boot/grub/menu.lst,其链接到./grub.conf,如下所示:
# grub.conf generated by anaconda
#
# Note that you do not have to rerun grub after making changes to this file
# NOTICE: You do not have a /boot partition. This means that
# all kernel and initrd paths are relative to /, eg.
# root (hd0,0)
# kernel /boot/vmlinuz-version ro root=/dev/cciss/c0d0p1
# initrd /boot/initrd-version.img
#boot=/dev/cciss/c0d0
default=0
timeout=5
#console.${METH_SUFFIX}#splashimage=(hd0,0)/boot/grub/splash.xpm.gz
hiddenmenu
password --md5 $1$uQ/fD0$DZpAM1mla6Vauzr2l4rfa0
title Red Hat Enterprise Linux Server (2.6.18-274.18.1.el5)
root (hd0,0)
kernel /boot/vmlinuz-2.6.18-274.18.1.el5 ro root=LABEL=/ rhgb quiet apm=off nomce
initrd /boot/initrd-2.6.18-274.18.1.el5.img
title Red Hat Enterprise Linux Server (2.6.18-194.26.1.el5)
password --md5 $1$uQ/fD0$DZpAM1mla6Vauzr2l4rfa0
root (hd0,0)
kernel /boot/vmlinuz-2.6.18-194.26.1.el5 ro root=LABEL=/ rhgb quiet apm=off nomce
initrd /boot/initrd-2.6.18-194.26.1.el5.img
title Infineon Gold Image (2.6.18-164.el5)
password --md5 $1$uQ/fD0$DZpAM1mla6Vauzr2l4rfa0
root (hd0,0)
kernel /boot/vmlinuz-2.6.18-164.el5 ro root=LABEL=/ rhgb quiet apm=off nomce
initrd /boot/initrd-2.6.18-164.el5.img
# s+c Service Images start
title Red Hat Enterprise Linux Server (2.6.18-274.18.1.el5) Single User
password --md5 $1$uQ/fD0$DZpAM1mla6Vauzr2l4rfa0
root (hd0,0)
kernel /boot/vmlinuz-2.6.18-274.18.1.el5 single ro root=LABEL=/ rhgb quiet apm=off nomce
initrd /boot/initrd-2.6.18-274.18.1.el5.img
title Red Hat E5.0 Rescue System (Network Boot)
password --md5 $1$uQ/fD0$DZpAM1mla6Vauzr2l4rfa0
root (hd0,0)
kernel /boot/vmlinuz.rhEL5 initrd=/boot/initrd.img rescue root=/dev/nfs ks=nfs:10.216.60.23:/kickstart/rules/netboot.redhatel5 ksdevice=eth0 devfs=nomount ramdisk_size=8192 vga=788 nomce
initrd /boot/initrd.rhEL5
title Red Hat E5.0 Installer
password --md5 $1$uQ/fD0$DZpAM1mla6Vauzr2l4rfa0
root (hd0,0)
kernel /boot/vmlinuz.rhEL5 initrd=/boot/initrd.img ks root=/dev/nfs ks=nfs:10.216.60.23:/kickstart/rules/kickstart.redhatel5-x86_64 ksdevice=eth0 devfs=nomount ramdisk_size=8192 vga=788 nomce
initrd /boot/initrd.rhEL5
# s+c Service Images end
其中,
- title表示引导一个操作系统的配置项,可以使多个title项。
- root (hd0,0)用来设置kernel与initrd两项内容的根地址。root指示所需文件存在于哪个磁盘哪个分区上,(hd0,0)表示第一个硬盘,第一个分区,参考/boot/grub/device.map。
- kernel表示内核文件的名字,并且包含一些加载内核时的参数,or代表以只读方式加载。
- initrd是用在内核启动时能够访问的硬盘文件系统,包含一些附加的驱动程序。
编辑/boot/grub/menu.lst并重新启动计算机,就可以看到新添加的内核条目了。
3.5.6.3 GNU GRUB 2
GNU GRUB引导加载程序:
- http://www.gnu.org/software/grub/grub.html
- ftp://ftp.gnu.org/gnu/grub/
- ftp://alpha.gnu.org/gnu/grub/
GNU GRUB is a Multiboot boot loader. It was derived from GRUB, the GRand Unified Bootloader, which was originally designed and implemented by Erich Stefan Boleyn.
GRUB 2 has replaced what was formerly known as GRUB (i.e. version 0.9x), which has, in turn, become GRUB Legacy. Enhancements to GRUB are still being made, but the current released versions are quite usable for normal operation.
GRUB Legacy is no longer being developed.
系统中存在如下有关GRUB 2的命令:
chenwx ~ # ll /usr/bin/grub-* /usr/sbin/grub-*
-rwxr-xr-x 1 root root 63456 10月 11 2013 /usr/bin/grub-editenv
-rwxr-xr-x 1 root root 695084 10月 11 2013 /usr/bin/grub-fstest
-rwxr-xr-x 1 root root 1737 10月 11 2013 /usr/bin/grub-kbdcomp
-rwxr-xr-x 1 root root 43216 10月 11 2013 /usr/bin/grub-menulst2cfg
-rwxr-xr-x 1 root root 83552 10月 11 2013 /usr/bin/grub-mkfont
-rwxr-xr-x 1 root root 131380 10月 11 2013 /usr/bin/grub-mkimage
-rwxr-xr-x 1 root root 63488 10月 11 2013 /usr/bin/grub-mklayout
-rwxr-xr-x 1 root root 71844 10月 11 2013 /usr/bin/grub-mkpasswd-pbkdf2
-rwxr-xr-x 1 root root 207120 10月 11 2013 /usr/bin/grub-mkrelpath
-rwxr-xr-x 1 root root 13510 10月 11 2013 /usr/bin/grub-mkrescue
-rwxr-xr-x 1 root root 6387 10月 11 2013 /usr/bin/grub-mkstandalone
-rwxr-xr-x 1 root root 515820 10月 11 2013 /usr/bin/grub-mount
lrwxrwxrwx 1 root root 34 4月 28 20:14 /usr/bin/grub-ntldr-img -> ../lib/grub/i386-pc/grub-ntldr-img
-rwxr-xr-x 1 root root 83744 10月 11 2013 /usr/bin/grub-script-check
lrwxrwxrwx 1 root root 35 4月 28 20:20 /usr/sbin/grub-bios-setup -> ../lib/grub/i386-pc/grub-bios-setup
-rwxr-xr-x 1 root root 1248 5月 14 2013 /usr/sbin/grub-install
-rwxr-xr-x 1 root root 35079 10月 11 2013 /usr/sbin/grub-install.real
-rwxr-xr-x 1 root root 7689 10月 11 2013 /usr/sbin/grub-mkconfig
-rwxr-xr-x 1 root root 38612 10月 11 2013 /usr/sbin/grub-mkdevicemap
-rwxr-xr-x 1 root root 7530 10月 11 2013 /usr/sbin/grub-mknetdir
-rwxr-xr-x 1 root root 780684 10月 11 2013 /usr/sbin/grub-probe
-rwxr-xr-x 1 root root 3933 10月 11 2013 /usr/sbin/grub-reboot
-rwxr-xr-x 1 root root 3442 10月 11 2013 /usr/sbin/grub-set-default
chenwx ~ # ll /usr/bin/update-grub* /usr/sbin/update-grub*
-rwxr-xr-x 1 root root 64 10月 5 2012 /usr/sbin/update-grub
lrwxrwxrwx 1 root root 11 4月 28 20:20 /usr/sbin/update-grub2 -> update-grub
-rwxr-xr-x 1 root root 241 8月 16 2011 /usr/sbin/update-grub-gfxpayload
修改配置文件/etc/default/grub:
- 设置内核启动选项earlyprink=vga,把系统早期启动的信息打印到显示屏上
- 注释掉GRUB_HIDDEN_TIMEOUT和GRUB_HIDDEN_TIMEOUT_QUIET
- 设置启动菜单超时时间为10:GRUB_TIMEOUT=10,或者,设置为等待用户选择:GRUB_TIMEOUT=-1
#GRUB_HIDDEN_TIMEOUT=0
#GRUB_HIDDEN_TIMEOUT_QUIET=true
GRUB_TIMEOUT=10
GRUB_CMDLINE_LINUX="earlyprink=vga"
执行下列命令更新配置文件/boot/grub/grub.cfg:
# method (1) to upldate /boot/grub/grub.cfg
chenwx@chenwx /boot $ sudo update-grub
[sudo] password for chenwx:
Generating grub.cfg ...
Found linux image: /boot/vmlinuz-3.11.0-12-generic
Found initrd image: /boot/initrd.img-3.11.0-12-generic
Found memtest86+ image: /boot/memtest86+.bin
No volume groups found
done
# method (2) to upldate /boot/grub/grub.cfg
chenwx@chenwx /boot $ su
Password:
chenwx boot # grub-mkconfig > /boot/grub/grub.cfg
Generating grub.cfg ...
Found linux image: /boot/vmlinuz-3.15.9-031509-generic
Found initrd image: /boot/initrd.img-3.15.9-031509-generic
Found linux image: /boot/vmlinuz-3.11.0-12-generic
Found initrd image: /boot/initrd.img-3.11.0-12-generic
Found linux image: /boot/vmlinuz-3.2.0
Found initrd image: /boot/initrd.img-3.2.0
Found memtest86+ image: /boot/memtest86+.bin
No volume groups found
done
3.5.7 重新启动系统前的准备工作
运行脚本dmesg_msg_diff.sh来保存编译内核产生的日志,用于比较和查找错误:
$ dmesg -t -l emerg > `uname -r`.dmesg_current_emerg
$ dmesg -t -l alert > `uname -r`.dmesg_current_alert
$ dmesg -t -l crit > `uname -r`.dmesg_current_alert
$ dmesg -t -l err > `uname -r`.dmesg_current_err
$ dmesg -t -l warn > `uname -r`.dmesg_current_warn
$ dmesg -t -k > `uname -r`.dmesg_kernel
$ dmesg -t > `uname -r`.dmesg_current
运行脚本dmesg_msg_save.sh输出日志文件:
#!/bin/bash
#
# Copyright(c) Chen Weixiang <weixiang.chen@gmail.com>
#
# License: GPLv2
release=`uname -r`
echo "dmesg -t -l emerg > $release.dmesg_emerg"
dmesg -t -l emerg > $release.dmesg_emerg
echo "dmesg -t -l crit > $release.dmesg_crit"
dmesg -t -l crit > $release.dmesg_crit
echo "dmesg -t -l alert > $release.dmesg_alert"
dmesg -t -l alert > $release.dmesg_alert
echo "dmesg -t -l err > $release.dmesg_err"
dmesg -t -l err > $release.dmesg_err
echo "dmesg -t -l warn > $release.dmesg_warn"
dmesg -t -l warn > $release.dmesg_warn
echo "dmesg -t -k > $release.dmesg_kern"
dmesg -t -k > $release.dmesg_kern
echo "dmesg -t > $release.dmesg"
dmesg -t > $release.dmesg
3.5.8 重启系统,并验证新内核
重新启动内核后,首先查看新内核的版本信息:
/*
* (1) 查看内核版本信息
*/
chenwx@chenwx ~/linux $ uname -a
Linux chenwx 4.1.5-alex #2 SMP Wed Aug 12 22:53:34 CST 2015 x86_64 x86_64 x86_64 GNU/Linux
chenwx@chenwx ~/linux $ cat /proc/version
Linux version 4.1.5-alex (chenwx@chenwx) (gcc version 4.8.4 (Ubuntu 4.8.4-2ubuntu1~14.04) ) #2 SMP Wed Aug 12 22:53:34 CST 2015
/*
* (2) 查看头文件信息
*/
chenwx@chenwx ~/linux $ dpkg -L linux-headers-4.1.5-alex
/.
/usr
/usr/src
/usr/src/linux-headers-4.1.5-alex
/usr/src/linux-headers-4.1.5-alex/.config
/usr/src/linux-headers-4.1.5-alex/Module.symvers
/usr/src/linux-headers-4.1.5-alex/init
/usr/src/linux-headers-4.1.5-alex/init/Makefile
/usr/src/linux-headers-4.1.5-alex/init/Kconfig
/usr/src/linux-headers-4.1.5-alex/samples
/usr/src/linux-headers-4.1.5-alex/samples/kdb
/usr/src/linux-headers-4.1.5-alex/samples/kdb/Makefile
/usr/src/linux-headers-4.1.5-alex/samples/hw_breakpoint
...
/usr/src/linux-headers-4.1.5-alex/Kconfig
/usr/share
/usr/share/doc
/usr/share/doc/linux-headers-4.1.5-alex
/usr/share/doc/linux-headers-4.1.5-alex/changelog.Debian.gz
/usr/share/doc/linux-headers-4.1.5-alex/copyright
/lib
/lib/modules
/lib/modules/4.1.5-alex
/lib/modules/4.1.5-alex/build
然后,比较新老内核的dmesg信息,看看新的内核有没有编译错误。
使用dmesg查看隐藏的问题,对于定位新代码带来的bug是一个好方法。一般来说,dmesg不会输出新的crit, alert, emerg级别的错误信息,也不应该出现新的err级别的信息。要注意的是那些warn级别的日志信息。NOTE: warn级别的信息并不是坏消息,新代码带来新的警告信息,不会给内核带去严重的影响。
运行脚本dmesg_msg_save.sh输出日志文件:
#!/bin/bash
#
# Copyright(c) Chen Weixiang <weixiang.chen@gmail.com>
#
# License: GPLv2
if [ "$1" == "" ]; then
echo "$0 <old uname -r>"
exit -1
fi
release=`uname -r`
echo "Start dmesg regression check for $release" > dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
dmesg -t -l emerg > $release.dmesg_emerg
echo "dmesg emergency regressions"
echo "--------------------------" >> dmesg_checks_results
diff $1.dmesg_emerg $release.dmesg_emerg >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
dmesg -t -l crit > $release.dmesg_crit
echo "dmesg critical regressions"
echo "--------------------------" >> dmesg_checks_results
diff $1.dmesg_crit $release.dmesg_crit >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
dmesg -t -l alert > $release.dmesg_alert
echo "dmesg alert regressions" >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
diff $1.dmesg_alert $release.dmesg_alert >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
dmesg -t -l err > $release.dmesg_err
echo "dmesg err regressions" >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
diff $1.dmesg_err $release.dmesg_err >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
dmesg -t -l warn > $release.dmesg_warn
echo "dmesg warn regressions" >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
diff $1.dmesg_warn $release.dmesg_warn >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
dmesg -t -k > $release.dmesg_kern
echo "dmesg_kern regressions" >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
diff $1.dmesg_kern $release.dmesg_kern >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
dmesg -t > $release.dmesg
echo "dmesg regressions" >> dmesg_checks_results
echo "dmesg regressions" >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
diff $1.dmesg $release.dmesg >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
echo "--------------------------" >> dmesg_checks_results
echo "End dmesg regression check for $release" >> dmesg_checks_results
运行脚本dmesg_msg_diff.sh来对比两者的差别:
dmesg -t -l emerg > `uname -r`.dmesg_current_emerg
dmesg -t -l alert > `uname -r`.dmesg_current_alert
dmesg -t -l crit > `uname -r`.dmesg_current_alert
dmesg -t -l err > `uname -r`.dmesg_current_err
dmesg -t -l warn > `uname -r`.dmesg_current_warn
dmesg -t -k > `uname -r`.dmesg_kernel
dmesg -t > `uname -r`.dmesg_current
3.5A 采用make deb-pkg为Debian系统升级内核
NOTE: Thinkpad R61i采用LinuxMint系统,故使用此方法升级内核更方便,简单!
除了采用3.5 内核升级节所述的方法升级内核外,也可以采用make deb-pkg命令编译内核并为Debian系统升级内核:
# 安装必要工具包(仅需执行一次)
chenwx@chenwx ~/linux $ sudo apt-get install kernel-package
# 选择内核版本
chenwx@chenwx ~/linux $ git checkout v4.0.1
# 清空内核目录
chenwx@chenwx ~/linux $ make mrproper
chenwx@chenwx ~/linux $ make mrproper O=../linux-build
chenwx@chenwx ~/linux $ make-kpkg clean
chenwx@chenwx ~/linux $ make-kpkg clean O=../linux-build
# 配置内核
chenwx@chenwx ~/linux $ cp /boot/config-3.13.0-24-generic ../linux-build/.config
chenwx@chenwx ~/linux $ make olddefconfig O=../linux-build
# 清空内核目录,并将内核编译成deb包,其中:
# LOCALVERSION: 等价于顶层Makefile中的EXTRAVERSION
# KDEB_PKGVERSION: 用于命名软件包;若未设置该变量,则采用../linux-build/.version中的取值(该值会递增)
chenwx@chenwx ~/linux $ make deb-pkg O=../linux-build LOCALVERSION=-alex KDEB_PKGVERSION=1
CHK include/config/kernel.release
UPD include/config/kernel.release
make KBUILD_SRC=
HOSTCC scripts/basic/fixdep
HOSTCC arch/x86/tools/relocs_32.o
HOSTCC arch/x86/tools/relocs_64.o
HOSTCC arch/x86/tools/relocs_common.o
HOSTLD arch/x86/tools/relocs
...
# 编译后的deb包位与上级目录,其命名格式为:
# linux-<PACKAGETYPE>-<VERSION.PATCHLEVEL.SUBLEVEL><LOCALVERSION>_<KDEB_PKGVERSION>_<CPUTYPE>.deb
chenwx@chenwx ~/linux $ ll ../linux-*
-rw-r--r-- 1 chenwx chenwx 945K Jun 11 21:03 linux-firmware-image-4.0.1-alex_1_amd64.deb
-rw-r--r-- 1 chenwx chenwx 6.7M Jun 11 21:04 linux-headers-4.0.1-alex_1_amd64.deb
-rw-r--r-- 1 chenwx chenwx 355M Jun 11 21:43 linux-image-4.0.1-alex-dbg_1_amd64.deb
-rw-r--r-- 1 chenwx chenwx 38M Jun 11 21:06 linux-image-4.0.1-alex_1_amd64.deb
-rw-r--r-- 1 chenwx chenwx 781K Jun 11 21:04 linux-libc-dev_1_amd64.deb
# 安装新内核
chenwx@chenwx ~/linux $ sudo dpkg -i ../*.deb
# 重启系统,并验证新内核
chenwx@chenwx ~/linux $ uname -a
Linux chenwx 4.0.1-alex #5 SMP Tue May 5 07:01:44 CST 2015 x86_64 x86_64 x86_64 GNU/Linux
3.5B 采用make-kpkg编译并升级内核
NAME
make-kpkg - build Debian kernel packages from Linux kernel sources
SYNOPSIS
make-kpkg [options] [target [target ...]]
DESCRIPTION
This manual page explains the Debian make-kpkg utility, which is used to create the kernel
related Debian packages. This utility needs to be run from a top level Linux kernel source
directory, which has been previously configured (unless you are using the configure target).
Normally, if kernel-package does not find a .config file in the current directory, it tries
very hard to get an appropriate one (usually a config file already tailored for Debian
kernels for that architecture), and then calls make oldconfig to let the user answer any new
questions. However, this might still result in an inappropriate configuration, you are
encouraged to configure the kernel by the usual means before invoking make-kpkg.
Typically, make-kpkg should be run under fakeroot,
make-kpkg --rootcmd fakeroot kernel_image
but instead you run this command as root (this is not recommended), or under fakeroot, or
tell make-kpkg how to become root (not recommended either, fakeroot is perhaps the safest
option), like so:
make-kpkg --rootcmd sudo kernel_image
The Debian package file is created in the parent directory of the kernel source directory
where this command is run.
Refer to the following commands:
chenwx@chenwx ~/linux $ sudo apt-get install kernel-package
chenwx@chenwx ~/linux $ which make-kpkg
/usr/bin/make-kpkg
chenwx@chenwx ~/linux $ make-kpkg --help
This program should be run in a linux kernel source top level directory.
/usr/share/doc/kernel-package/Problems.gz contains a list of known problems.
usage: make-kpkg [options] target [target ...]
where options are:
--help This message.
--revision number The debian revision number. ([a-zA-Z.~+0-9]) (Must
have digit)
--append-to-version foo
--append_to_version foo an additional kernel sub-version. ([-a-z.+0-9])
Does not require editing the kernel Makefile
over rides env var APPEND_TO_VERSION.
requires a make-kpkg clean
--added-modules foo
--added_modules foo Comma/space separated list of add on modules
affected by the modules_<blah> targets
--arch foo architecture
--cross-compile
--cross_compile target string
--subarch bar Set the subarch for the image being compiled
(have to be on a compatible machine).
--arch-in-name
--arch_in_name Embed the subarch in the image package name
--stem foo Call the packages foo-* instead of kernel-*
--initrd Create a image package suitable for initrd.
-j jobs Sec CONCURRENCY_LEVEL to -I<jobs> for this action.
--jobs jobs Set CONCURRENCY_LEVEL to -I<jobs> for this action.
--pgpsign name An ID used to sign the changes file using pgp.
--config target Change the type of configure done from the default
oldconfig.
--targets Lists the known targets.
--noexec Pass a -n option to the make process
--overlay dir An overlay directory to (re))place file in ./debian
--verbose Pass a V=1 option to the make process
--zimage Create a kernel using zImage rather than bzImage
--bzimage Create a kernel using bzImage (in case the site
wide default is zimage, as set in
/etc/kernel-pkg.conf)
--rootcmd method A command that provides a means of gaining
superuser access (for example, `sudo' or
`fakeroot') as needed by dpkg-buildpackages'
-r option. Does not work for targets binary,
binary-indep, and binary-arch.
--us This option is passed to dpkg-buildpackage, and
directs that package not to sign the
source. This is only relevant for the
buildpackage target.
--uc This option is passed to dpkg-buildpackage, and
directs that package not to sign the
changelog. This is only relevant for the
buildpackage target.
Use one of --zimage or --bzimage, or none, but not both.
Option Format: The options may be shortened to the smallest unique
string, and may be entered with either a - or a -- prefix, and you may
use a space between an option string and a value. Please refer to man
Getopt::Long for details on how the options may be entered.
Version: 12.036+nmu3
Manoj Srivastava <srivasta@debian.org>
chenwx@chenwx ~/linux $ make-kpkg --targets
Known Targets are:
===============================================================================
| Targets | Automatically builds |
===============================================================================
| clean | |
| buildpackage | Builds the whole package |
|* binary | Builds kernel_{source,headers,image,doc} |
|* binary-indep | |
| kernel_source | |
| kernel_doc | |
| kernel_manual | |
|* binary-arch | |
| kernel_headers | |
| kernel_debug | |
| kernel_image | Builds build |
| build | |
| modules | |
| modules_image | |
| modules_config | |
| modules_clean | |
| configure | If you wish to edit files |
| debian | generated by make config |
| debian | Creates ./debian dir |
===============================================================================
*: make-kpkg needs to be run as root (or fakeroot), --rootcmd will not work
See /usr/share/kernel-package/rules for details.
chenwx@chenwx ~/linux $ fakeroot make-kpkg --initrd --append-to-version -alex kernel_image kernel_headers
3.6 内核补丁/Patch
参见Documentation/applying-patches.txt关于内核补丁的描述:
A patch is a small text document containing a delta of changes between two different versions of a source tree. Patches are created with the ‘diff’ program.
To correctly apply a patch you need to know what base it was generated from and what new version the patch will change the source tree into. These should both be present in the patch file metadata or be possible to deduce from the filename.
3.6.1 内核补丁的下载地址
The patches are available at:
Most recent patches are linked from the front page, but they also have specific homes:
The v2.6 and v3.x patches live at
The v2.6 and v3.x -rc patches live at
- ftp://ftp.kernel.org/pub/linux/kernel/v2.6/testing/
- ftp://ftp.kernel.org/pub/linux/kernel/v3.x/testing/
The v2.6 and v3.x -git patches live at
- ftp://ftp.kernel.org/pub/linux/kernel/v2.6/snapshots/
- ftp://ftp.kernel.org/pub/linux/kernel/v3.x/incr/
The v2.6 and v3.x -mm kernels live at
3.6.2 如何应用内核补丁
NOTE: 安装内核补丁前,需要先进入老版本的内核源代码目录,以linux-3.2为例:
# cd ~/linux-3.2
Uncompress and apply the patch:
# zcat path/to/patch-x.y.z.gz | patch -p1
# bzcat path/to/patch-x.y.z.bz2 | patch -p1
# xzcat path/to/patch-x.y.z.xz | patch -p1
Uncompress the patch:
# gunzip patch-x.y.z.gz // 解压后的patch为patch-x.y.z
# bunzip2 patch-x.y.z.bz2 // 解压后的patch为patch-x.y.z
# unxz patch-x.y.z.xz // 解压后的patch为patch-x.y.z
Apply a uncompressed patch:
# patch -p1 < path/to/patch-x.y.z
Revert (undo) a patch:
# patch -p1 -R < path/to/patch-x.y.z
Patch can get the name of the file to use via the -i argument:
# patch -p1 -i path/to/patch-x.y.z
Just print a listing of what would happen, but doesn’t actually make any changes:
# patch -p1 --dry-run path/to/patch-x.y.z
Make patch to be silent except for errors:
# patch -p1 -s path/to/patch-x.y.z
Print more information about the work being done:
# patch -p1 --verbose path/to/patch-x.y.z
3.6.2.1 The 2.6.x.y kernels
Kernels with 4-digit versions are -stable kernels.
These patches are not incremental, meaning that, for example the 2.6.12.3 patch does not apply on top of the 2.6.12.2 kernel source, but rather on top of the base 2.6.12 kernel source. So, in order to apply the 2.6.12.3 patch to your existing 2.6.12.2 kernel source, you have to first back out the 2.6.12.2 patch (so you are left with a base 2.6.12 kernel source) and then apply the new 2.6.12.3 patch. For example:
$ cd ~/linux-2.6.12.2 # change into the kernel source dir
$ patch -p1 -R < ../patch-2.6.12.2 # revert the 2.6.12.2 patch
$ patch -p1 < ../patch-2.6.12.3 # apply the new 2.6.12.3 patch
$ cd ..
$ mv linux-2.6.12.2 linux-2.6.12.3 # rename the kernel source dir
3.6.2.2 The -rc kernels
These are release-candidate kernels (not stable). The -rc patches are not incremental, they apply to a base 2.6.x kernel, just like the 2.6.x.y patches described above (See section The 2.6.x.y kernels).
The kernel version before the –rcN suffix denotes the version of the kernel that this -rc kernel will eventually turn into. So, 2.6.13-rc5 means that this is the fifth release candidate for the 2.6.13 kernel and the patch should be applied on top of the 2.6.12 kernel source.
Here are 3 examples of how to apply these patches:
# First an example of moving from 2.6.12 to 2.6.13-rc3
$ cd ~/linux-2.6.12 # change into the 2.6.12 source dir
$ patch -p1 < ../patch-2.6.13-rc3 # apply the 2.6.13-rc3 patch
$ cd ..
$ mv linux-2.6.12 linux-2.6.13-rc3 # rename the source dir
# Now let's move from 2.6.13-rc3 to 2.6.13-rc5
$ cd ~/linux-2.6.13-rc3 # change into the 2.6.13-rc3 dir
$ patch -p1 -R < ../patch-2.6.13-rc3 # revert the 2.6.13-rc3 patch
$ patch -p1 < ../patch-2.6.13-rc5 # apply the new 2.6.13-rc5 patch
$ cd ..
$ mv linux-2.6.13-rc3 linux-2.6.13-rc5 # rename the source dir
# Finally let's try and move from 2.6.12.3 to 2.6.13-rc5
$ cd ~/linux-2.6.12.3 # change to the kernel source dir
$ patch -p1 -R < ../patch-2.6.12.3 # revert the 2.6.12.3 patch
$ patch -p1 < ../patch-2.6.13-rc5 # apply new 2.6.13-rc5 patch
$ cd ..
$ mv linux-2.6.12.3 linux-2.6.13-rc5 # rename the kernel source dir
3.6.2.3 The -git kernels
These are daily snapshots of Linus’ kernel tree. These patches are usually released daily and represent the current state of Linus’s tree. They are more experimental than -rc kernels since they are generated automatically without even a cursory glance to see if they are sane.
-git patches are not incremental and apply either to a base 2.6.x kernel or a base 2.6.x-rc kernel – you can see which from their name. A patch named 2.6.12-git1 applies to the 2.6.12 kernel source and a patch named 2.6.13-rc3-git2 applies to the source of the 2.6.13-rc3 kernel.
Here are some examples of how to apply these patches:
# moving from 2.6.12 to 2.6.12-git1
$ cd ~/linux-2.6.12 # change to the kernel source dir
$ patch -p1 < ../patch-2.6.12-git1 # apply the 2.6.12-git1 patch
$ cd ..
$ mv linux-2.6.12 linux-2.6.12-git1 # rename the kernel source dir
// moving from 2.6.12-git1 to 2.6.13-rc2-git3
$ cd ~/linux-2.6.12-git1 # change to the kernel source dir
// revert the 2.6.12-git1 patch. we now have a 2.6.12 kernel
$ patch -p1 -R < ../patch-2.6.12-git1
// apply the 2.6.13-rc2 patch. the kernel is now 2.6.13-rc2
$ patch -p1 < ../patch-2.6.13-rc2
// apply the 2.6.13-rc2-git3 patch. the kernel is now 2.6.13-rc2-git3
$ patch -p1 < ../patch-2.6.13-rc2-git3
$ cd ..
$ mv linux-2.6.12-git1 linux-2.6.13-rc2-git3 # rename source dir
3.6.2.4 The -mm kernels
These are experimental kernels released by Andrew Morton.
Here are some examples of applying the -mm patches:
# moving from 2.6.12 to 2.6.12-mm1
$ cd ~/linux-2.6.12 # change to the 2.6.12 source dir
$ patch -p1 < ../2.6.12-mm1 # apply the 2.6.12-mm1 patch
$ cd ..
$ mv linux-2.6.12 linux-2.6.12-mm1 # rename the source appropriately
# moving from 2.6.12-mm1 to 2.6.13-rc3-mm3
$ cd ~/linux-2.6.12-mm1
$ patch -p1 -R < ../2.6.12-mm1 # revert the 2.6.12-mm1 patch. we now have a 2.6.12 source
$ patch -p1 < ../patch-2.6.13-rc3 # apply the 2.6.13-rc3 patch. we now have a 2.6.13-rc3 source
$ patch -p1 < ../2.6.13-rc3-mm3 # apply the 2.6.13-rc3-mm3 patch
$ cd ..
$ mv linux-2.6.12-mm1 linux-2.6.13-rc3-mm3 # rename the source dir
3.6.3 如何生成内核补丁
3.6.3.1 通过diff生成内核补丁
The simplest way to generate a patch is to have two source trees, one that is the vanilla stock kernel (such as linux-3.2-vanilla) and another that is the stock tree with your modifications (such as linux-3.2). To generate a patch of the two trees, issue the following command from one directory above the standard kernel source tree:
# cd /home/
# tar xvf linux-3.2.tar.bz2 // unzip source code to /home/linux-3.2
# mv linux-3.2 linux-3.2-vanilla // source tree without change
# tar xvf linux-3.2.tar.bz2 // unzip source code to /home/linux-3.2
# vi linux-3.2/some/files // make your changes
# diff -uprN -X linux-3.2-vanilla/Documentation/dontdiff linux-3.2-vanilla/ linux-3.2/ > my-patch
Alternatively, if you need to diff only a single file, you can do
# cp linux-3.2/mm/memory.c linux-3.2/mm/memory.c.orig
# vi linux-3.2/mm/memory.c // make your change
# diff -up linux-3.2/mm/memory.c{.orig,} > my-patch
A useful utility is diffstat, which generates a histogram of a patch’s changes (line additions and removals). To generate the output on one of your patches, do
# diffstat -p 1 -w 70 my-patch
NOTE 1: Patches generated with diff should always be unified diff, include the C function that the change affects and be generated from one directory above the kernel source root. A unified diff include more information that just the differences between two lines. It begins with a two line header with the names and creation date of the two files that diff is comparing.
NOTE 2: “dontdiff” is a list of files which are generated by the kernel during the build process, and should be ignored in any diff(1)-generated patch. The “dontdiff” file is included in the kernel tree in 2.6.12 and later. For earlier kernel versions, you can get it from http://www.xenotime.net/linux/doc/dontdiff.
3.6.3.2 通过git生成内核补丁
When you have a commit (or two) in your tree, you can generate a patch for each commit, which you can treat as you do the patches described in the previous section:
# git format-patch -s origin
This generates patches for all commits in your repository and not in the original tree. Git creates the patches in the root of your kernel source tree. To generate patches for only the last N commits, you can execute the following:
# git format-patch -s -N
Use below command to generate the diffstat:
# git diff -M --stat –summary <commit-1> <commit-2>
where, the -M enables rename detection, and the --summary enables a summary of new/deleted or renamed files.
4 Linux系统的启动过程
阅读下列文档:
- linux-3.2/Documentation/x86/boot.txt
- 计算机是如何启动的
- Linux的启动流程
4.1 内核映像的内存布局
在linux-3.2/Documentation/x86/boot.txt中,包含有关内核映像(参见3.4.2.8 bzImage节和3.5.5 安装内核节)的内存布局的描述。根据内核版本的不同,内核映像的内存布局也存在差异,分别参见4.1.1 Image/zImage for Old Kernel节和4.1.2 bzImage for Modern Kernel节,以及下图:

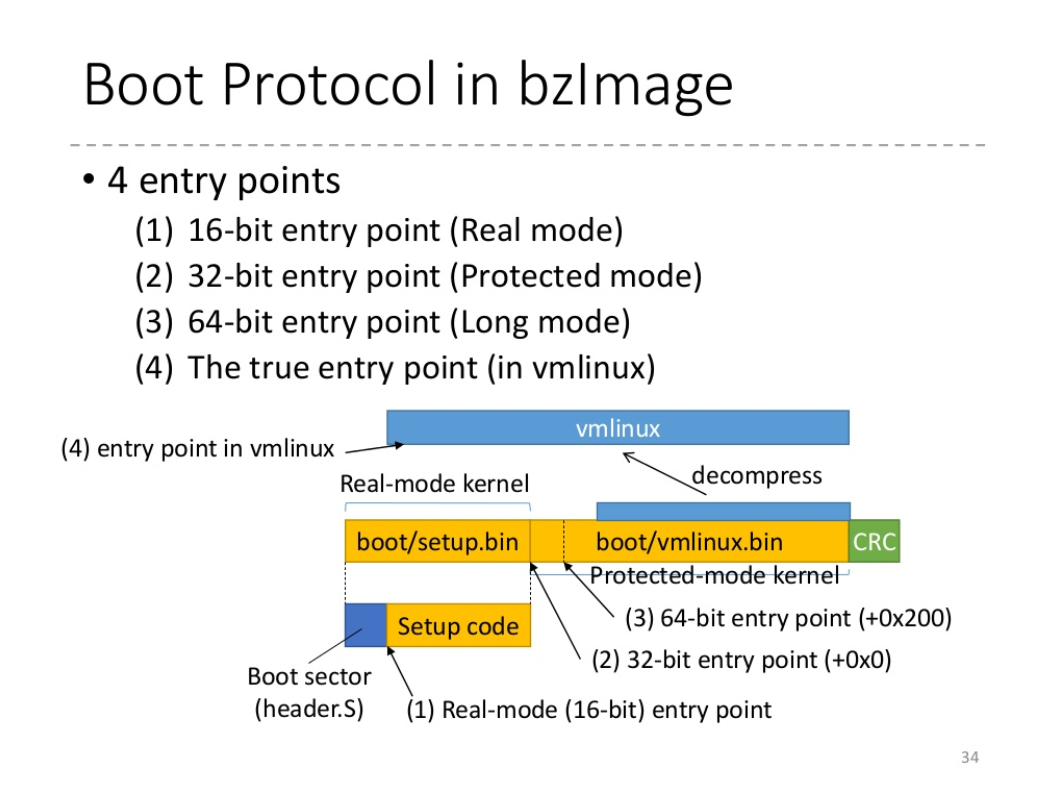

内核映像的内存布局包含如下几个重要部分:
| 内核组成部分 | 模式 | 源代码出处 |
|---|---|---|
| Kernel boot sector | 实模式 | v2.6.23及其之前版本的内核: arch/i386/boot/bootsect.S arch/x86_64/boot/bootsect.S v2.6.24及其之后版本的内核: arch/i386/boot/header.S arch/i386/boot/main.c |
| Kernel setup | 实模式 | v2.6.23及其之前版本的内核: arch/i386/boot/setup.S arch/x86_64/boot/setup.S v2.6.24及其之后版本的内核: arch/i386/boot/header.S arch/i386/boot/main.c |
| Protected-mode kernel | 保护模式 |
实模式
实模式是指寻址采用和8086相同的16位段和偏移量,最大寻址空间1MB,最大分段64KB。

保护模式
保护模式是指寻址采用32位段和偏移量,最大寻址空间4GB,最大分段4GB(Pentium Pre及以后为64GB)。在保护模式下,CPU可以进入虚拟8086方式,这是在保护模式下的实模式程序运行环境。
由4.1.1 Image/zImage for Old Kernel节和4.1.2 bzImage for Modern Kernel节可知:
- real-mode code: boot sector and setup code
- real-mode code can total up to 32KB, although the boot loader may choose to load only the first two sectors (1K)
4.1.1 Image/zImage for Old Kernel
The traditional memory map for the kernel loader, used for Image or zImage kernels, typically looks like:
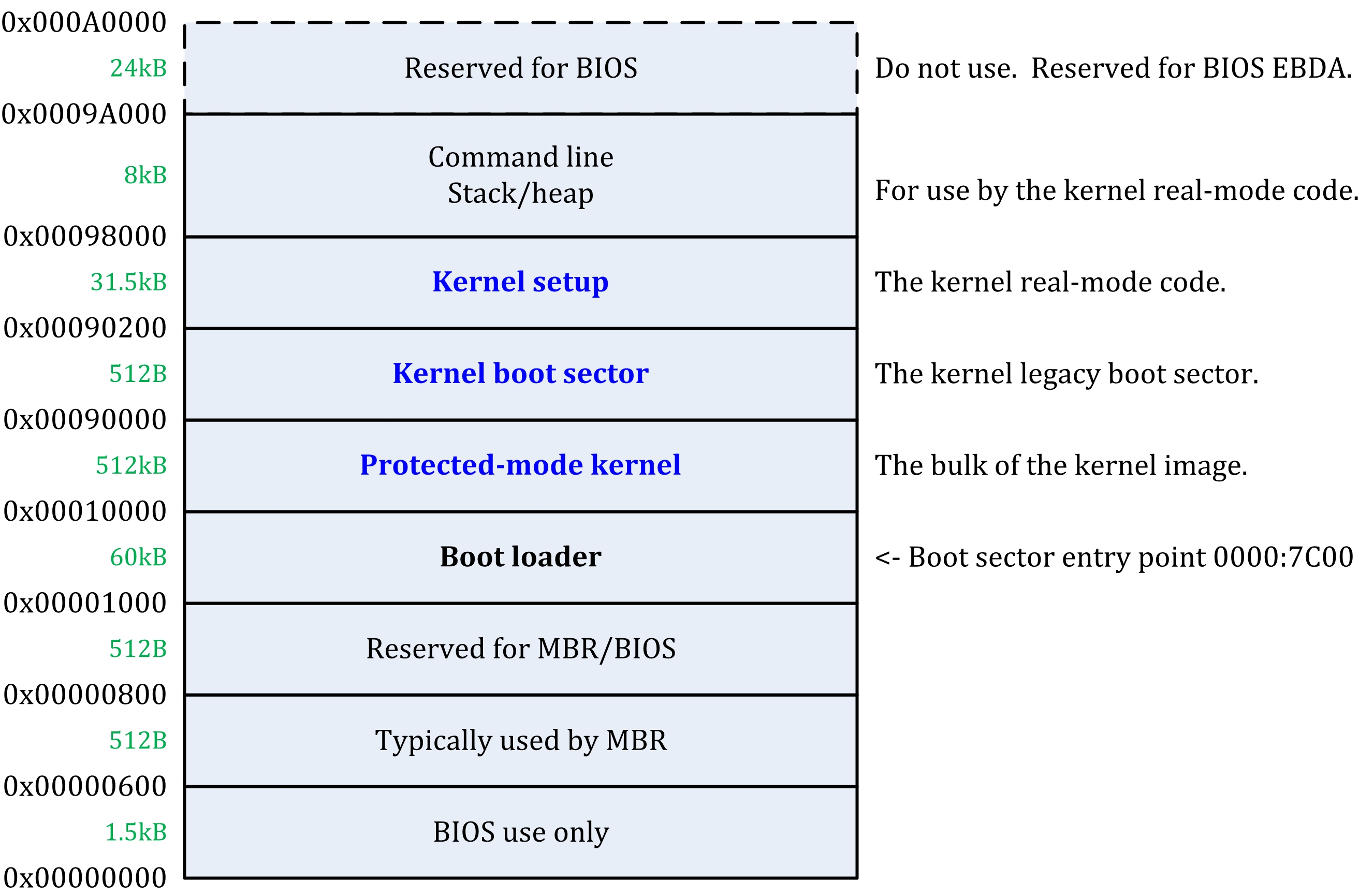
4.1.2 bzImage for Modern Kernel
For a modern bzImage kernel with boot protocol version >= 2.02, a memory layout is suggested like:
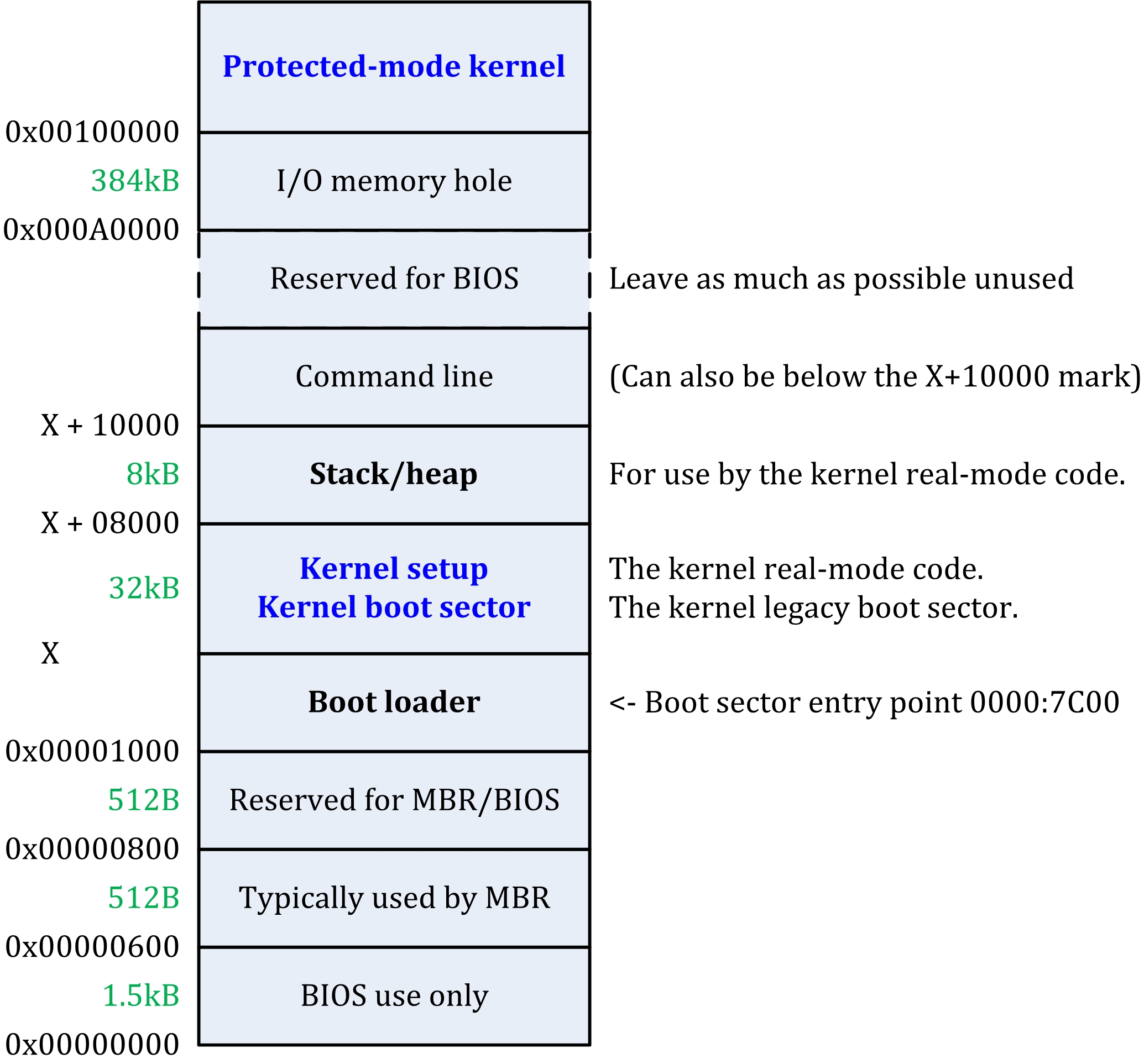
where, the address X is as low as the design of the boot loader permits.
4.2 主引导记录MBR(Master Boot Record)
4.2.1 硬盘结构
硬盘有很多盘片组成,每个盘片的每个面都有一个读写磁头。如果有N个盘片,就有2N个面,对应着2N个磁头(Heads),从0、1、2…开始编号。每个盘片的半径为固定值R的同心圆在逻辑上形成了一个以电机主轴为轴的柱面(Cylinders),由外至里编号为0、1、2…。每个盘片上的每个磁道又被划分为几十个扇区(Sector),通常每个扇区的容量是512字节,并按照一定规则编号1、2、3…,形成Cylinders × Heads × Sector个扇区。
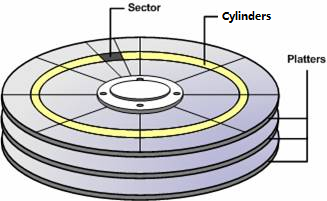
对于硬盘而言,一个扇区可能的字节数为128 x 2^n (n=0,1,2,3)。大多情况下,取n=2,即一个扇区(sector)大小为512字节。
4.2.2 主引导扇区
主引导扇区位于整个硬盘的0柱面0磁头1扇区{(柱面,磁头,扇区)|(0,0,1)},BIOS在执行完自己固有的程序以后就会jump到MBR中的第一条指令,将系统的控制权交由MBR来执行。主引导扇区主要由三部分组成:
- 主引导记录 MBR (Master Boot Record)
- 硬盘分区表 DPT (Disk Partition Table)
- 结束标志字
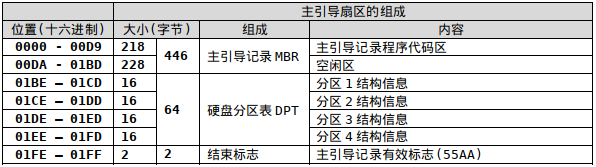
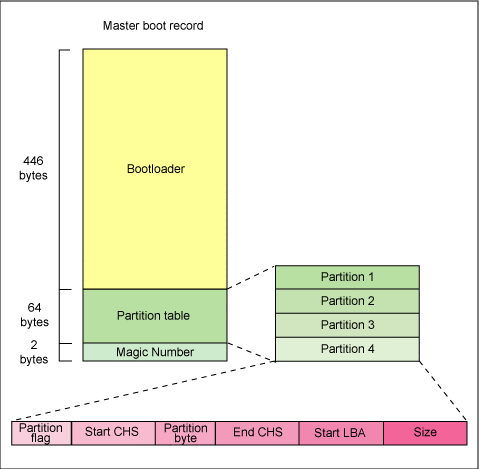
4.2.2.1 主引导记录MBR
主引导记录中包含了硬盘的一系列参数和一段引导程序。其中,硬盘引导程序的主要作用是检查硬盘分区表是否正确并且在系统硬件完成自检后将控制权交给硬盘上的引导程序(如GNU GRUB)。MBR是由分区程序(如Fdisk)所产生的,它是低级格式化的产物,和操作系统没有任何关系,即它不依赖任何操作系统;而且硬盘引导程序也是可以改变的,从而能够实现多系统引导。
4.2.2.2 硬盘分区表DPT
硬盘分区表占据主引导扇区的64个字节(01BE-01FD),可以对四个分区信息进行描述,其中每个分区信息占16个字节。具体每个字节的定义可以参见硬盘分区结构信息。
| 偏移(十六进制) | 长度(字节) | 含义 |
|---|---|---|
| 00 | 1 | 分区状态: 00->非活动分区 80->活动分区,表示系统可引导 其他数值无意义 |
| 01 | 1 | 分区起始磁头号(Head),使用全部8位 |
| 02 | 2 | 分区起始扇区号(Sector),占据02字节的Bit #0-#5; 分区起始柱面号(Cylinder),占据02字节的Bit #6-#7和03字节的全部8位 |
| 04 | 1 | 文件系统标志位: 0B表示分区的文件系统是FAT32 04表示分区的文件系统是FAT16 07表示分区的文件系统是NTFS |
| 05 | 1 | 分区结束磁头号(Head),使用全部8位 |
| 06 | 2 | 分区结束扇区号(Sector),占据06字节的Bit #0-#5; 分区结束柱面号(Cylinder),占据06字节的Bit #6-#7和07字节的全部8位 |
| 08 | 4 | 分区起始相对扇区 |
| 0C | 4 | 分区总的扇区数 |
4.2.2.3 结束标志字
结束标志字55AA(偏移1FE-1FF)是主引导扇区的最后两个字节,用于检验主引导记录是否有效的标志。
4.3 Linux引导过程
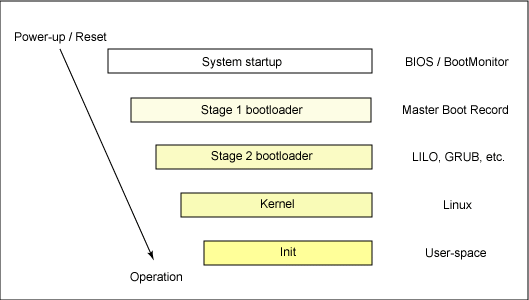
当系统首次引导或系统被重置时,处理器会执行一个位于已知位置处的代码。在PC中,这个位置在基本输入/输出系统(BIOS)中,它保存在主板上的闪存中。嵌入式系统中的中央处理单元(CPU)会调用这个重置向量来启动一个位于闪存/ROM中的已知地址处的程序。在这两种情况下,结果都是相同的。因为PC提供了很多灵活性,BIOS必须确定要使用哪个设备来引导系统。
当找到一个引导设备之后,第一阶段的引导加载程序就被装入RAM并执行。这个引导加载程序的大小小于512字节(一个扇区),其作用是加载第二阶段引导加载程序。
当第二阶段引导加载程序被装入RAM并执行时,通常会显示一个动画界面,并将Linux和一个可选的初始RAM磁盘(临时根文件系统)加载到内存中。在加载内核映像时,第二阶段引导加载程序会将控制权交给内核映像,然后内核就可以进行解压和初始化了。在这个阶段中,第二阶段引导加载程序会检测系统硬件、枚举系统连接的硬件设备、安装根设备,然后加载必要的内核模块。完成这些操作之后启动第一个用户空间程序(init,参见4.3.5 init节),并执行高级系统初始化工作。
这就是 Linux 引导的整个过程。
4.3.1 系统启动 (System startup)
系统启动阶段依赖于引导Linux系统上的硬件。
在嵌入式平台中,当系统加电或重置时,会使用一个启动环境。这方面的例子包括U-Boot、RedBoot和Lucent的MicroMonitor。嵌入式平台通常都是与引导监视器搭配销售的。这些程序位于目标硬件上的闪存中的某一段特殊区域,它们提供了将Linux内核映像下载到闪存并继续执行的方法。除了可以存储并引导Linux映像之外,这些引导监视器还执行一定级别的系统测试和硬件初始化过程。在嵌入式平台中,这些引导监视器通常会涉及第一阶段和第二阶段的引导加载程序。
在PC中,引导Linux系统是从BIOS中的地址0xFFFF0处(即接近于1M内存处)开始的。BIOS的第一个步骤是加电自检(POST, Power On Self Test)。POST的工作是对硬件进行检测。BIOS的第二个步骤是进行本地设备的枚举和初始化。给定BIOS功能的不同用法之后,BIOS由两部分组成:POST代码和运行时服务。当POST完成之后,它被从内存中清理了出来,但是BIOS运行时服务依然保留在内存中,目标操作系统可以使用这些服务。要引导一个操作系统,BIOS运行时会按照CMOS的设置中定义的顺序来搜索处于活动状态且可以引导的设备。引导设备可以是软盘、CD-ROM、硬盘上的某个分区、网络上的某个设备,甚至是USB闪存。通常Linux是从硬盘引导的,其中主引导记录(MBR)中包含主引导加载程序(即第一阶段引导加载程序)。MBR是一个512字节大小的扇区,位于磁盘的第一个扇区中(0柱面0磁头1扇区,参见4.2.2 主引导扇区节)。当MBR被加载到RAM中后,BIOS就会将控制权交给MBR。
提取MBR的信息
要查看MBR的内容,使用下面的命令:
# dd if=/dev/hda of=mbr.bin bs=512 count=1
# od -xa mbr.bin
这个dd命令要以root用户的身份运行,它从/dev/hda(第一个IDE盘)上读取前512个字节的内容,并将其写入mbr.bin文件中。od命令会以十六进制和ASCII码格式打印这个二进制文件的内容。
4.3.2 第一阶段引导加载程序/Stage 1 Bootloader
MBR中的主引导加载程序(第一阶段引导加载程序)是一个512字节大小的映像,其中包含程序代码和硬盘分区表(参见4.2.2 主引导扇区节)。前446字节是主引导加载程序,其中包含可执行代码和错误消息文本。接下来的64字节是硬盘分区表,其中包含4个分区的记录(每个记录的大小是16字节)。MBR以两个特殊字节(0x55AA)结束,该数字会用来检查MBR的有效性。
主引导加载程序用于查找并加载次引导加载程序(第二阶段引导加载程序)。它是通过在硬盘分区表中查找一个活动分区来实现这种功能的。当找到一个活动分区时,它会扫描分区表中的其他分区,以确保它们都不是活动的。当这个过程验证完成之后,就将该活动分区的引导记录从这个设备中读入RAM中并执行它。
4.3.3 第二阶段引导加载程序/Stage 2 Bootloader
次引导加载程序(第二阶段引导加载程序)被形象地称为内核加载程序。这个阶段的任务是加载Linux内核和可选的初始RAM磁盘。
在x86 PC环境中,第一阶段引导加载程序和第二阶段引导加载程序一起被称为GRand Unified Bootloader (GRUB,参见3.5.6.2 GRUB Legacy节和3.5.6.3 GNU GRUB 2节)或者Linux Loader (LILO,参见3.5.6.1 LILO节)。由于LILO有一些缺点,而GRUB克服了这些缺点(参见3.5.6.0 LILO与GRUB的比较节),因此下面重点关注GRUB。
GRUB包含了有关Linux文件系统的知识。GRUB不像LILO一样使用裸扇区,而是可以从ext2或ext3文件系统中加载Linux内核。它是通过将两阶段的引导加载程序转换成三阶段的引导加载程序来实现这项功能的。阶段1 (MBR)引导阶段1.5的引导加载程序,它可以理解包含Linux内核映像的特殊文件系统。这方面的例子包括reiserfs_stage1_5 (要从Reiser日志文件系统上进行加载)或者e2fs_stage1_5 (要从ext2或ext3文件系统上进行加载)。当阶段1.5的引导加载程序被加载并运行时,阶段2的引导加载程序就可以被加载了。
当阶段2加载之后,GRUB就可以在请求时显示可用内核列表(在/etc/grub.conf中定义,同时还有几个软符号链接/etc/grub/menu.lst和/etc/grub.conf)。我们可以选择内核甚至修改附加内核参数。另外,还可以使用一个命令行的shell对引导过程进行高级手工控制。
将第二阶段引导加载程序加载到内存中之后,就可以对文件系统进行查询了,并将默认的内核映像和initrd映像加载到内存中。当这些映像文件准备好之后,阶段2的引导加载程序就可以调用内核映像了。
GRUB 阶段引导加载程序
/boot/grub目录中包含了stage1、stage1.5和stage2引导加载程序,以及很多其他加载程序(例如,CR-ROM使用的是iso9660_stage_1_5)。
4.3.4 Kernel v3.2.0
当内核映像被加载到内存中,且第二阶段引导加载程序释放控制权之后,内核阶段就开始了。内核映像并不是一个可执行的内核,而是一个压缩过的内核映像。通常它是一个zImage (压缩映像,小于512KB)或一个bzImage (较大的压缩映像,大于512KB),它是用gzip压缩的(参见3.4.2.8.5.1 $(obj)/piggy.o节)。在这个内核映像之前是一个例程,它实现少量硬件设置,并对内核映像中包含的内核进行解压,然后将其放入高端内存中,如果有初始RAM磁盘映像,就会将它移动到内存中,并标明以后使用。然后该例程会调用内核,并开始启动内核引导的过程。
4.3.4.1 内核启动过程中的函数调用关系
由arch/x86/boot/setup.ld中的如下代码:
ENTRY(_start)
可知,setup.bin (参见3.4.2.8 bzImage节)的入口点是_start。GRUB会执行jmp_far(0x20, 0)跳过/boot/vmlinuz-3.2.0-chenwx的前0x200个字节,即跳到vmlinuz实模式代码_start处执行,即arch/x86/boot/header.S中的_start,参见4.3.4.1.1 arch/x86/boot/header.S节。
4.3.4.1.1 arch/x86/boot/header.S
NOTE: 几乎header.S中所有的代码都是在准备实模式下的C语言环境。
/*
* header.S从开始到此处(# offset 512, entry point)代码实现的功能和
* 以前内核中arch/i386/boot/bootsect.S的功能是一样的。
* header.S中(# offset 512, entry point)之后代码所实现的功能和以前
* 内核中arch/i386/boot/setup.S的一部分类似,包括:
* - 设置setup header参数;
* - 设置堆栈;
* - 检查setup中的标签;
* - 清除BSS段;
* - 调用入口函数main()
*/
# offset 512, entry point
.globl _start
_start:
# Explicitly enter this as bytes, or the assembler
# tries to generate a 3-byte jump here, which causes
# everything else to push off to the wrong offset.
.byte 0xeb # short (2-byte) jump // #0200处的第一个字节代表短跳转指令,其中0xeb是该指令代码
.byte start_of_setup-1f // #0201处的一个字节表示跳转距离,从标号1到start_of_setup
/*
* CAN_USE_HEAP表示本体系架构是否支持堆,其定义于arch/x86/include/asm/bootparam.h:
* #define CAN_USE_HEAP (1<<7)
*/
CAN_USE_HEAP = 0x80 # If set, the loader also has set
/*
* STACK_SIZE定义于arch/x86/boot/boot.h中,取值为512,故堆的大小为512字节
* _end来自arch/x86/boot/setup.ld,表示整个setup.bin的结尾,
* 参见[4.1.1 Image/zImage for Old Kernel]节(0x00098000处)和[4.1.2 bzImage for Modern Kernel]节(X+08000)
*/
heap_end_ptr: .word _end+STACK_SIZE-512
...
.section ".entrytext", "ax"
start_of_setup:
#ifdef SAFE_RESET_DISK_CONTROLLER
# Reset the disk controller.
movw $0x0000, %ax # Reset disk controller
movb $0x80, %dl # All disks
int $0x13 // 用13号中断重设系统盘的磁盘控制器ax=0x0,dl=0x80
#endif
# Force %es = %ds // 先强制让附加数据段es的内容等于数据段ds的内容
movw %ds, %ax
movw %ax, %es
cld
# Apparently some ancient versions of LILO invoked the kernel with %ss != %ds,
# which happened to work by accident for the old code. Recalculate the stack
# pointer if %ss is invalid. Otherwise leave it alone, LOADLIN sets up the
# stack behind its own code, so we can't blindly put it directly past the heap.
movw %ss, %dx
cmpw %ax, %dx # %ds == %ss?
movw %sp, %dx
je 2f # -> assume %sp is reasonably set
# Invalid %ss, make up a new stack // 设置实模式下的堆栈,参见[4.1.2 bzImage for Modern Kernel]节
movw $_end, %dx // _end来自arch/x86/boot/setup.ld,表示整个setup.bin的结尾
testb $CAN_USE_HEAP, loadflags
jz 1f
movw heap_end_ptr, %dx
1: addw $STACK_SIZE, %dx
jnc 2f
xorw %dx, %dx # Prevent wraparound
// 标号2处的代码将dx中的栈顶地址按双字对齐,即将最低两位清零
2: # Now %dx should point to the end of our stack space
andw $~3, %dx # dword align (might as well...)
jnz 3f
movw $0xfffc, %dx # Make sure we're not zero
3: movw %ax, %ss
movzwl %dx, %esp # Clear upper half of %esp
sti # Now we should have a working stack
# We will have entered with %cs = %ds+0x20, normalize %cs so
# it is on par with the other segments.
pushw %ds
pushw $6f
lretw
6:
# Check signature at end of setup
cmpl $0x5a5aaa55, setup_sig
jne setup_bad
/*
* 清空setup的bss段(非初始化数据段),注意bss段和数据段(data段)的区别:
* bss段存放未初始化的全局变量和静态变量,data段存放初始化后的全局变量和静态变量
*/
# Zero the bss
movw $__bss_start, %di
movw $_end+3, %cx
xorl %eax, %eax
subw %di, %cx
shrw $2, %cx
rep; stosl
# Jump to C code (should not return)
calll main // 跳转到arch/x86/boot/main.c中的main(),参见[4.3.4.1.2 arch/x86/boot/main.c]节
4.3.4.1.2 arch/x86/boot/main.c
arch/x86/boot/header.S最终调用arch/x86/boot/main.c中的main()函数。在执行main()函数时,系统还处于实模式下,其主要功能是为进入保护模式做准备,涉及初始化计算机中的硬件设备,并为内核程序的执行建立环境。虽然之前BIOS已经初始化了大部分硬件设备,但是Linux并不依赖于BIOS,而是以自己的方式重新初始化硬件设备以增强可移植性和健壮性。
void main(void)
{
/* First, copy the boot header into the "zeropage" */
copy_boot_params(); // 参见[4.3.4.1.2.1 copy_boot_params()]节
/* Initialize the early-boot console */
console_init(); // 解析内核参数earlyprintk
if (cmdline_find_option_bool("debug"))
puts("early console in setup code\n");
/* End of heap check */
init_heap(); // 参见[4.3.4.1.2.2 init_heap()]节
/* Make sure we have all the proper CPU support */
if (validate_cpu()) { // 参见[4.3.4.1.2.3 validate_cpu()]节
puts("Unable to boot - please use a kernel appropriate for your CPU.\n");
die();
}
/* Tell the BIOS what CPU mode we intend to run in. */
set_bios_mode(); // 参见[4.3.4.1.2.4 set_bios_mode()]节
/* Detect memory layout */
// 参见[4.3.4.1.2.5 detect_memory()]节和[6.3.1 检测内存段及其大小/boot_params.e820_map]节
detect_memory();
/* Set keyboard repeat rate (why?) */
keyboard_set_repeat(); // 参见[4.3.4.1.2.6 keyboard_set_repeat()]节
/* Query MCA information */
query_mca(); // 参见[4.3.4.1.2.7 query_mca()]节
/* Query Intel SpeedStep (IST) information */
query_ist(); // 参见[4.3.4.1.2.8 query_ist()]节
/* Query APM information */
#if defined(CONFIG_APM) || defined(CONFIG_APM_MODULE)
// 填充boot_params.apm_bios_info,其执行过程与query_ist()类似,参见[4.3.4.1.2.8 query_ist()]节
query_apm_bios();
#endif
/* Query EDD information */
#if defined(CONFIG_EDD) || defined(CONFIG_EDD_MODULE)
/*
* 填充boot_params.eddbuf_entries, boot_params.edd_mbr_sig_buf_entries,
* boot_params.eddbuf,其执行过程与query_ist()类似,参见[4.3.4.1.2.9 query_edd()]节
*/
query_edd();
#endif
/* Set the video mode */
set_video(); // 参见[4.3.4.1.2.10 set_video()]节
/* Do the last things and invoke protected mode */
go_to_protected_mode(); // 参见[4.3.4.1.2.11 go_to_protected_mode()]节
}
4.3.4.1.2.1 copy_boot_params()
该函数定义于arch/x86/boot/main.c:
/*
* struct boot_params定义于arch/x86/include/asm/bootparam.h
* 变量boot_params是main.c的全局变量,且未被初始化,故位于bss段。
* GRUB把vmlinuz加载到内存后,boot_params就位于_bss_start的开始位置。
* 此后,当启动保护模式的分页功能后,第一个页面就是从它开始的(NOTE: 不是从0x0开始)。
* 故内核注释它为zeropage,即所谓的0号页面,足见变量boot_params的重要性。
*/
struct boot_params boot_params __attribute__((aligned(16)));
static void copy_boot_params(void)
{
struct old_cmdline {
u16 cl_magic;
u16 cl_offset;
};
// arch/x86/include/asm/setup.h中OLD_CL_ADDRESS取值为0x020
const struct old_cmdline * const oldcmd = (const struct old_cmdline *)OLD_CL_ADDRESS;
// 变量boot_params的大小刚好是一个页面的大小,即4KB
BUILD_BUG_ON(sizeof boot_params != 4096);
/*
* 将hdr的内容拷贝到全局变量boot_params.hdr中。其中,
* hdr是arch/x86/boot/header.S中定义的数据段中的内容
* 而boot_params.hdr的类型为struct setup_header
* (参见arch/x86/include/asm/bootparam.h),其定义与
* arch/x86/boot/header.S中hdr段的定义相同,故可以使用memcpy()拷贝
*/
memcpy(&boot_params.hdr, &hdr, sizeof hdr);
// arch/x86/include/asm/setup.h中OLD_CL_MAGIC取值为0xA33F
if (!boot_params.hdr.cmd_line_ptr && oldcmd->cl_magic == OLD_CL_MAGIC) {
/* Old-style command line protocol. */
u16 cmdline_seg;
/* Figure out if the command line falls in the region
of memory that an old kernel would have copied up
to 0x90000... */
if (oldcmd->cl_offset < boot_params.hdr.setup_move_size)
cmdline_seg = ds();
else
cmdline_seg = 0x9000;
// 针对旧内核,调整boot_params.hdr.cmd_line_ptr字段的取值
boot_params.hdr.cmd_line_ptr = (cmdline_seg << 4) + oldcmd->cl_offset;
}
}
4.3.4.1.2.2 init_heap()
该函数用来检查内核初始化阶段使用的堆,其定义于arch/x86/boot/main.c:
static void init_heap(void)
{
char *stack_end;
if (boot_params.hdr.loadflags & CAN_USE_HEAP) {
asm("leal %P1(%%esp),%0" : "=r" (stack_end) : "i" (-STACK_SIZE));
// heap_end_ptr参见[4.3.4.1.1 arch/x86/boot/header.S]节,堆栈大小为512字节
heap_end = (char *) ((size_t)boot_params.hdr.heap_end_ptr + 0x200);
// 检查堆的大小,不能溢出,否则就调整到stack_end
if (heap_end > stack_end)
heap_end = stack_end;
} else {
/* Boot protocol 2.00 only, no heap available */
puts("WARNING: Ancient bootloader, some functionality may be limited!\n");
}
}
4.3.4.1.2.3 validate_cpu()
该函数定义于arch/x86/boot/cpu.c:
int validate_cpu(void)
{
u32 *err_flags;
int cpu_level, req_level;
const unsigned char *msg_strs;
/*
* 通过调用arch/x86/boot/cpucheck.c中的check_cpu()函数读取CPU信息,
* 并将其存放在如下变量中:
* cpu_level - 表示系统实际的CPU版本
* req_level - 表示运行本内核所需要的CPU最低版本
* 若cpu_level < req_level,则报错
*/
check_cpu(&cpu_level, &req_level, &err_flags);
if (cpu_level < req_level) {
printf("This kernel requires an %s CPU, ", cpu_name(req_level));
printf("but only detected an %s CPU.\n", cpu_name(cpu_level));
return -1;
}
if (err_flags) {
int i, j;
puts("This kernel requires the following features not present on the CPU:\n");
msg_strs = (const unsigned char *)x86_cap_strs;
for (i = 0; i < NCAPINTS; i++) {
u32 e = err_flags[i];
for (j = 0; j < 32; j++) {
if (msg_strs[0] < i || (msg_strs[0] == i && msg_strs[1] < j)) {
/* Skip to the next string */
msg_strs += 2;
while (*msg_strs++)
;
}
if (e & 1) {
if (msg_strs[0] == i && msg_strs[1] == j && msg_strs[2])
printf("%s ", msg_strs+2);
else
printf("%d:%d ", i, j);
}
e >>= 1;
}
}
putchar('\n');
return -1;
} else {
return 0;
}
}
4.3.4.1.2.4 set_bios_mode()
该函数定义于arch/x86/boot/main.c:
/*
* Tell the BIOS what CPU mode we intend to run in.
*/
static void set_bios_mode(void)
{
#ifdef CONFIG_X86_64
struct biosregs ireg;
initregs(&ireg);
ireg.ax = 0xec00;
ireg.bx = 2;
/*
* intcall是初始化阶段的中断处理函数,此处调用0x15中断,并将BIOS的寄存器设置成ireg变量的值。
* NOTE: 初始化阶段至此,仍处于实模式阶段,Linux内核的中断系统还没有被初始化,该函数是内核编译后临时
* 生成的一个BIOS服务程序,跟arch/x86/boot/header.S中的那些int指令的效果是一样的
*/
intcall(0x15, &ireg, NULL);
#endif
}
4.3.4.1.2.5 detect_memory()
该函数根据物理内存的类型探测内存布局,其定义于arch/x86/boot/memory.c:
int detect_memory(void)
{
int err = -1;
// 填充boot_params.e820_entries和boot_params.e820_map,参见[4.3.4.1.2.5.1 detect_memory_e820()]节
if (detect_memory_e820() > 0)
err = 0;
// 填充boot_params.alt_mem_k
if (!detect_memory_e801())
err = 0;
// 填充boot_params.screen_info.ext_mem_k
if (!detect_memory_88())
err = 0;
return err;
}
4.3.4.1.2.5.1 detect_memory_e820()
该函数定义于arch/x86/boot/memory.c,另参见6.3.1 检测内存段及其大小/boot_params.e820_map节:
static int detect_memory_e820(void)
{
int count = 0;
struct biosregs ireg, oreg;
// 此时,boot_params.e820_map是一个空数组,本函数用于初始化该数组
struct e820entry *desc = boot_params.e820_map;
static struct e820entry buf; /* static so it is zeroed */
initregs(&ireg);
ireg.ax = 0xe820;
ireg.cx = sizeof buf;
ireg.edx = SMAP;
ireg.di = (size_t)&buf;
do {
/*
* int 0x15中断查询物理内存时,每次返回一个内存段的信息,
* 因此要想返回系统中所有的物理内存信息,必须以循环的方式查询
*/
intcall(0x15, &ireg, &oreg);
ireg.ebx = oreg.ebx; /* for next iteration... */
/* BIOSes which terminate the chain with CF = 1 as opposed
to %ebx = 0 don't always report the SMAP signature on
the final, failing, probe. */
if (oreg.eflags & X86_EFLAGS_CF)
break;
/* Some BIOSes stop returning SMAP in the middle of
the search loop. We don't know exactly how the BIOS
screwed up the map at that point, we might have a
partial map, the full map, or complete garbage, so
just return failure. */
if (oreg.eax != SMAP) {
count = 0;
break;
}
*desc++ = buf;
count++;
/*
* boot_params.e820_map数组的最大下标为E820MAX,取值为128,
* 参见arch/x86/include/asm/e820.h
*/
} while (ireg.ebx && count < ARRAY_SIZE(boot_params.e820_map));
// 返回检测到的物理内存段的个数
return boot_params.e820_entries = count;
}
4.3.4.1.2.6 keyboard_set_repeat()
该函数定义于arch/x86/boot/main.c:
/*
* Set the keyboard repeat rate to maximum. Unclear why this
* is done here; this might be possible to kill off as stale code.
*/
static void keyboard_set_repeat(void)
{
struct biosregs ireg;
initregs(&ireg);
ireg.ax = 0x0305;
// 调用int 0x16中断,设置键盘的重复延时和速率
intcall(0x16, &ireg, NULL);
}
4.3.4.1.2.7 query_mca()
该函数定义于arch/x86/boot/mca.c:
int query_mca(void)
{
struct biosregs ireg, oreg;
u16 len;
initregs(&ireg);
ireg.ah = 0xc0;
// 调用BIOS的int 0x15中断,读取系统环境配置表信息
intcall(0x15, &ireg, &oreg);
if (oreg.eflags & X86_EFLAGS_CF)
return -1; /* No MCA present */
set_fs(oreg.es);
len = rdfs16(oreg.bx);
if (len > sizeof(boot_params.sys_desc_table))
len = sizeof(boot_params.sys_desc_table);
// 将系统环境配置表信息保存到boot_params.sys_desc_table中
copy_from_fs(&boot_params.sys_desc_table, oreg.bx, len);
return 0;
}
4.3.4.1.2.8 query_ist()
该函数定义于arch/x86/boot/main.c:
/*
* Get Intel SpeedStep (IST) information.
*/
static void query_ist(void)
{
struct biosregs ireg, oreg;
/* Some older BIOSes apparently crash on this call, so filter
it from machines too old to have SpeedStep at all. */
if (cpu.level < 6)
return;
initregs(&ireg);
ireg.ax = 0xe980; /* IST Support */
ireg.edx = 0x47534943; /* Request value */
// 调用BIOS的int 0x15中断,查询IST信息,并将其保存到boot_params.ist_info中
intcall(0x15, &ireg, &oreg);
boot_params.ist_info.signature = oreg.eax;
boot_params.ist_info.command = oreg.ebx;
boot_params.ist_info.event = oreg.ecx;
boot_params.ist_info.perf_level = oreg.edx;
}
4.3.4.1.2.9 query_edd()
该函数定义于arch/x86/boot/edd.c:
void query_edd(void)
{
char eddarg[8];
int do_mbr = 1;
#ifdef CONFIG_EDD_OFF
int do_edd = 0;
#else
int do_edd = 1;
#endif
int be_quiet;
int devno;
struct edd_info ei, *edp;
u32 *mbrptr;
if (cmdline_find_option("edd", eddarg, sizeof eddarg) > 0) {
if (!strcmp(eddarg, "skipmbr") || !strcmp(eddarg, "skip")) {
do_edd = 1;
do_mbr = 0;
}
else if (!strcmp(eddarg, "off"))
do_edd = 0;
else if (!strcmp(eddarg, "on"))
do_edd = 1;
}
be_quiet = cmdline_find_option_bool("quiet");
edp = boot_params.eddbuf;
mbrptr = boot_params.edd_mbr_sig_buffer;
if (!do_edd)
return;
/* Bugs in OnBoard or AddOnCards Bios may hang the EDD probe,
* so give a hint if this happens.
*/
if (!be_quiet)
printf("Probing EDD (edd=off to disable)... ");
for (devno = 0x80; devno < 0x80+EDD_MBR_SIG_MAX; devno++) {
/*
* Scan the BIOS-supported hard disks and query EDD
* information...
*/
if (!get_edd_info(devno, &ei) && boot_params.eddbuf_entries < EDDMAXNR) {
memcpy(edp, &ei, sizeof ei);
edp++;
boot_params.eddbuf_entries++;
}
if (do_mbr && !read_mbr_sig(devno, &ei, mbrptr++))
boot_params.edd_mbr_sig_buf_entries = devno-0x80+1;
}
if (!be_quiet)
printf("ok\n");
}
4.3.4.1.2.10 set_video()
该函数定义于arch/x86/boot/video.c:
void set_video(void)
{
// vid_mode定义于arch/x86/boot/header.S,其取值为SVGA_MODE
u16 mode = boot_params.hdr.vid_mode;
// 重新设置堆的位置,把它设定到_end处,参见[4.3.4.1.1 arch/x86/boot/header.S]节
RESET_HEAP();
store_mode_params(); // 利用BIOS的显示服务程序对视频显示进行设置,保存到boot_params.screen_info
save_screen(); // 将当前屏幕的内容存储到指定的内存空间中
probe_cards(0); // 扫描显卡
for (;;) {
if (mode == ASK_VGA)
mode = mode_menu();
if (!set_mode(mode))
break;
printf("Undefined video mode number: %x\n", mode);
mode = ASK_VGA;
}
boot_params.hdr.vid_mode = mode;
vesa_store_edid();
/*
* 设置EDID。EDID是一种VESA标准数据格式,其中包含有关监视器及其性能的参数,
* 包括供应商信息、最大图像大小、颜色设置、厂商预设置、频率范围的限制以及显示器
* 名和序列号的字符串
*/
store_mode_params();
/*
* 根据是否进入mode_menu()设置了do_restore来恢复刚刚被保存的screen_info信息,
* 它与save_screen()正好相反
*/
if (do_restore)
restore_screen();
}
4.3.4.1.2.11 go_to_protected_mode()
当main()函数执行到go_to_protected_mode()时,系统就即将告别实模式环境,进入保护模式了。保护模式(Protected Mode,或简写为pmode)是一种80286系列及之后的x86兼容CPU操作模式。保护模式有一些新的特色,设计用来增强多功能和系统稳定度,像是内存保护,分页系统,以及硬件支持的虚拟内存。现今大部分的x86操作系统都在保护模式下运行,包含Linux、FreeBSD、微软Windows 2.0及之后版本。
NOTE: 在执行go_to_protected_mode()时,系统还处于实模式下,只不过是进入与保护模式相关的代码。
该函数定义于arch/x86/boot/pm.c:
/*
* Actual invocation sequence
*/
void go_to_protected_mode(void)
{
/* Hook before leaving real mode, also disables interrupts.
* 若boot_params.hdr.realmode_swtch被设置,则执行该函数,否则,关中断(NMI)
* 由arch/x86/boot/header.S可知,该字段未被设置:
* realmode_swtch: .word 0, 0
*/
realmode_switch_hook();
/* Enable the A20 gate */
if (enable_a20()) { // 参见[4.3.4.1.2.11.1 enable_a20()]节
puts("A20 gate not responding, unable to boot...\n");
die();
}
/* Reset coprocessor (IGNNE#) */
reset_coprocessor();
/* Mask all interrupts in the PIC */
mask_all_interrupts();
/* Actual transition to protected mode... */
setup_idt();
setup_gdt();
/*
* 函数protected_mode_jump()参见[4.3.4.1.2.11.2 protected_mode_jump()]节,该函数需要两个入参:
* 1) 第一个入参:boot_params.hdr.code32_start,定义于arch/x86/boot/header.S,
* 取值为0x100000,由[4.1.2 bzImage for Modern Kernel]节的图可知,该参数表示进入保护模式后
* 执行的第一条内核代码(Protected-mode kernel);
* 2) 第二个入参:&boot_params+(ds()<<4)是传递给内核的参数,为0号页面的地址,
* 即变量boot_params,参见[4.3.4.1.2.1 copy_boot_params()]节
*/
protected_mode_jump(boot_params.hdr.code32_start, (u32)&boot_params + (ds() << 4));
}
4.3.4.1.2.11.1 enable_a20()
PC及其兼容机的第21根地址线(A20)较特殊,PC中安排了一个“门”来控制该地址线是否有效。到了80286,系统的地址总线有原来的20根发展到24根,这样能够访问的内存可以达到224=16MB。Intel在设计80286时提出的目标是向下兼容,所以在实模式下,系统所表现的行为应该和8086/8088所表现的行为完全一样,也就是说,在实模式下,80286及其后续系列,应该和8086/8088完全兼容。但80286芯片却存在一个BUG:因为80286有了A20线,如果程序员访问100000H-10FFEFH之间的内存,系统将实际访问这块内存,而不是像8086/8088那样从0开始。如下图所示:
为了解决上述兼容性问题,IBM使用键盘控制器上剩余的一些输出线来管理第21根地址线(从0开始数是第20根)的有效性,被称为A20 Gate:
1) 如果A20 Gate被打开,则当程序员给出100000H-10FFEFH之间的地址时,系统将真正访问这块内存区域;
2) 如果A20 Gate被关闭,则当程序员给出100000H-10FFEFH之间的地址时,系统仍然使用8086/8088的方式,即取模方式(8086仿真)。绝大多数IBM PC兼容机默认A20 Gate是被关闭的。现在许多新型PC上存在直接通过BIOS功能调用来控制A20 Gate的功能。
上述的内存访问模式都是实模式,在80286以及更高系列的PC中,即使A20 Gate被打开,在实模式下所能够访问的内存最大也只能为10FFEFH,尽管它们的地址总线所能够访问的能力都大大超过这个限制。为了能够访问10FFEFH以上的内存,则必须进入保护模式。
enable_a20()就是用来打开A20 Gate的,参见arch/x86/boot/a20.c。
4.3.4.1.2.11.2 protected_mode_jump()
该函数定义于arch/x86/boot/pmjump.S:
.text
.code16
/*
* void protected_mode_jump(u32 entrypoint, u32 bootparams);
*/
GLOBAL(protected_mode_jump)
movl %edx, %esi # Pointer to boot_params table
xorl %ebx, %ebx
movw %cs, %bx
shll $4, %ebx
addl %ebx, 2f
jmp 1f # Short jump to serialize on 386/486
1:
movw $__BOOT_DS, %cx
movw $__BOOT_TSS, %di
movl %cr0, %edx
// 执行完本行代码后,内核从此告别实模式,开始了内核的保护模式
orb $X86_CR0_PE, %dl # Protected mode
movl %edx, %cr0
# Transition to 32-bit mode
.byte 0x66, 0xea # ljmpl opcode
2: .long in_pm32 # offset // 开始执行in_pm32函数
.word __BOOT_CS # segment
ENDPROC(protected_mode_jump)
.code32
.section ".text32","ax"
GLOBAL(in_pm32)
# Set up data segments for flat 32-bit mode
movl %ecx, %ds
movl %ecx, %es
movl %ecx, %fs
movl %ecx, %gs
movl %ecx, %ss
# The 32-bit code sets up its own stack, but this way we do have
# a valid stack if some debugging hack wants to use it.
addl %ebx, %esp
# Set up TR to make Intel VT happy
ltr %di
# Clear registers to allow for future extensions to the
# 32-bit boot protocol
xorl %ecx, %ecx
xorl %edx, %edx
xorl %ebx, %ebx
xorl %ebp, %ebp
xorl %edi, %edi
# Set up LDTR to make Intel VT happy
lldt %cx
/*
* 开始执行由入参传来的boot_params.hdr.code32_start,
* 即0x100000处的代码(Protected-mode Kernel),
* 参见[4.1.2 bzImage for Modern Kernel]节;
* 在解压vmlinuz之前,这段代码为arch/x86/boot/compressed/head_32.S
* 中的函数startup_32,参见[4.3.4.1.3 arch/x86/boot/compressed/head_32.S]节
*/
jmpl *%eax # Jump to the 32-bit entrypoint
ENDPROC(in_pm32)
NOTE: 从系统启动到函数protected_mode_jump(),并不是第一次进入保护模式,在bootloader阶段,GRUB已经执行过一次保护模式的命令了,即把vmlinuz第三部分的代码拷贝到内存0x100000之后。参见4.3.3 第二阶段引导加载程序/Stage 2 Bootloader节。
4.3.4.1.3 arch/x86/boot/compressed/head_32.S
由4.3.4.1.2.11.2 protected_mode_jump()节可知,进入保护模式后执行的第一个函数为arch/x86/boot/compressed/head_32.S中的函数startup_32:
__HEAD
ENTRY(startup_32)
cld
/*
* Test KEEP_SEGMENTS flag to see if the bootloader is asking
* us to not reload segments
*/
/*
* 参见arch/x86/kernel/asm-offsets.c,BP_loadflags是字段hdr.loadflags相对于
* 结构体boot_params首地址的偏移量,因而,BP_loadflags+%esi就是hdr.loadflags的地址
*/
testb $(1<<6), BP_loadflags(%esi)
jnz 1f
cli
// 参见arch/x86/include/asm/segment.h,__BOOT_DS的取值为24
movl $__BOOT_DS, %eax
movl %eax, %ds
movl %eax, %es
movl %eax, %fs
movl %eax, %gs
movl %eax, %ss
1:
/*
* Calculate the delta between where we were compiled to run
* at and where we were actually loaded at. This can only be done
* with a short local call on x86. Nothing else will tell us what
* address we are running at. The reserved chunk of the real-mode
* data at 0x1e4 (defined as a scratch field) are used as the stack
* for this calculation. Only 4 bytes are needed.
*/
/*
* BP_scratch是字段scratch相对于结构体boot_params首地址的偏移量,
* 即让栈顶指向(BP_scratch+4)(%esi)地址lea指令得到boot_params.scratch
* 的32位物理地址,并将其存放到esp寄存器中
*/
leal (BP_scratch+4)(%esi), %esp
call 1f
1: popl %ebp
subl $1b, %ebp
/*
* %ebp contains the address we are loaded at by the boot loader and %ebx
* contains the address where we should move the kernel image temporarily
* for safe in-place decompression.
*/
#ifdef CONFIG_RELOCATABLE
movl %ebp, %ebx
/*
* BP_kernel_alignment是字段hdr.kernel_alignment相对于结构体boot_params首地址的偏移量
* 在arch/x86/boot/header.S中,kernel_alignment: .long CONFIG_PHYSICAL_ALIGN
* 又在.config中,CONFIG_PHYSICAL_ALIGN=0x1000000
*/
movl BP_kernel_alignment(%esi), %eax
decl %eax
addl %eax, %ebx
notl %eax
andl %eax, %ebx
#else
// 根据arch/x86/include/asm/boot.h和.config中配置可知,LOAD_PHYSICAL_ADDR取值为0x1000000
movl $LOAD_PHYSICAL_ADDR, %ebx
#endif
/* Target address to relocate to for decompression */
addl $z_extract_offset, %ebx
/* Set up the stack */
leal boot_stack_end(%ebx), %esp
/* Zero EFLAGS */
pushl $0
popfl
/*
* Copy the compressed kernel to the end of our buffer
* where decompression in place becomes safe.
*/
pushl %esi
leal (_bss-4)(%ebp), %esi
leal (_bss-4)(%ebx), %edi
// _bss是解压缩程序的BSS段
/*
* _bss – startup_32涵盖了vmlinuz从startup_32以后的代码长度,
* 包括整个待解压内核,然后再右移2位,即除以4
*/
movl $(_bss - startup_32), %ecx
shrl $2, %ecx
// 设置方向标志置位,下一行中的rep是由高地址向低地址进行,
// 即_bss到当前正在执行的startup_32
std
// 把内核映像拷贝到0x1000000以后的内存单元中
rep movsl
cld
popl %esi
/*
* Jump to the relocated address.
*/
leal relocated(%ebx), %eax
/*
* 本行之前的代码将原GRUB加载的内核映像(位于0x100000处)拷贝到0x1000000
* 之后新的内存单元中。本行代码跳转到拷贝后的内核映像(位于0x1000000之后)中
* 的relocated处执行,即离开原GRUB加载的内核映像(位于0x100000处)
*/
jmp *%eax
ENDPROC(startup_32)
.text
relocated:
/*
* Clear BSS (stack is currently empty)
*/
xorl %eax, %eax
leal _bss(%ebx), %edi
leal _ebss(%ebx), %ecx
subl %edi, %ecx
shrl $2, %ecx
rep stosl
/*
* Adjust our own GOT
*/
leal _got(%ebx), %edx
leal _egot(%ebx), %ecx
1:
cmpl %ecx, %edx
jae 2f
addl %ebx, (%edx)
addl $4, %edx
jmp 1b
2:
/*
* Do the decompression, and jump to the new kernel..
*/
/*
* 此段中的下列变量均来自于arch/x86/boot/compressed/mkpiggy.c:
* z_extract_offset_negative, z_input_len, input_data
* 参见[3.4.2.8.5.1.4 $(obj)/piggy.S]节
*/
leal z_extract_offset_negative(%ebx), %ebp
/* push arguments for decompress_kernel: */
pushl %ebp /* output address */ // 解压缩的缓存首地址
pushl $z_input_len /* input_len */ // 待解压缩内核的大小
leal input_data(%ebx), %eax
pushl %eax /* input_data */ // 待解压缩内核的开始地址
leal boot_heap(%ebx), %eax
pushl %eax /* heap area */ // 解压缩内核所用的堆
pushl %esi /* real mode pointer */ // 表示拷贝内核映像之前的内核映像地址
/*
* 调用arch/x86/boot/compressed/misc.c中的decompress_kernel()解压内核,
* 参见[4.3.4.1.3.1 decompress_kernel()]节
*/
call decompress_kernel
addl $20, %esp
#if CONFIG_RELOCATABLE
/*
* Find the address of the relocations.
*/
leal z_output_len(%ebp), %edi
/*
* Calculate the delta between where vmlinux was compiled to run
* and where it was actually loaded.
*/
movl %ebp, %ebx
subl $LOAD_PHYSICAL_ADDR, %ebx
jz 2f /* Nothing to be done if loaded at compiled addr. */
/*
* Process relocations.
*/
1: subl $4, %edi
movl (%edi), %ecx
testl %ecx, %ecx
jz 2f
addl %ebx, -__PAGE_OFFSET(%ebx, %ecx)
jmp 1b
2:
#endif
/*
* Jump to the decompressed kernel.
*/
xorl %ebx, %ebx
/*
* 开始执行解压后的内核,即第二个startup_32()函数,
* 该函数定义于arch/x86/kernel/head_32.S,
* 参见[4.3.4.1.4 arch/x86/kernel/head_32.S]节
*/
jmp *%ebp
4.3.4.1.3.1 decompress_kernel()
该函数定义于arch/x86/boot/compressed/misc.c:
asmlinkage void decompress_kernel(void *rmode, memptr heap, unsigned char *input_data,
unsigned long input_len, unsigned char *output)
{
real_mode = rmode;
if (cmdline_find_option_bool("quiet"))
quiet = 1;
if (cmdline_find_option_bool("debug"))
debug = 1;
if (real_mode->screen_info.orig_video_mode == 7) {
vidmem = (char *) 0xb0000;
vidport = 0x3b4;
} else {
vidmem = (char *) 0xb8000;
vidport = 0x3d4;
}
lines = real_mode->screen_info.orig_video_lines;
cols = real_mode->screen_info.orig_video_cols;
console_init();
if (debug)
putstr("early console in decompress_kernel\n");
free_mem_ptr = heap; /* Heap */
free_mem_end_ptr = heap + BOOT_HEAP_SIZE;
if ((unsigned long)output & (MIN_KERNEL_ALIGN - 1))
error("Destination address inappropriately aligned");
#ifdef CONFIG_X86_64
if (heap > 0x3fffffffffffUL)
error("Destination address too large");
#else
if (heap > ((-__PAGE_OFFSET-(128<<20)-1) & 0x7fffffff))
error("Destination address too large");
#endif
#ifndef CONFIG_RELOCATABLE
if ((unsigned long)output != LOAD_PHYSICAL_ADDR)
error("Wrong destination address");
#endif
if (!quiet)
putstr("\nDecompressing Linux... ");
// 调用lib/decompress_xxx.c中的同名函数
decompress(input_data, input_len, NULL, NULL, output, NULL, error);
parse_elf(output);
if (!quiet)
putstr("done.\nBooting the kernel.\n");
return;
}
4.3.4.1.4 arch/x86/kernel/head_32.S
由4.3.4.1.3 arch/x86/boot/compressed/head_32.S节可知,解压内核后,执行的第一个函数是arch/x86/kernel/head_32.S中的startup_32()函数。该函数主要是为第一个Linux进程(进程0)建立执行环境,主要执行以下操作:
- 把段寄存器初始化为最终值
- 把内核的bss段填充为0
- 初始化包含在swapper_pg_dir的临时内核页表,并初始化pg0,以使线性地址一致地映射同一物理地址
- 把页全局目录的地址存放在cr3寄存器中,并通过设置cr0寄存器的PG位启用分页
- 把从BIOS中获得的系统参数和传递给操作系统的参数boot_params放入第一个页框中
- 为进程0建立内核态堆栈
- 该函数再一次清零eflags寄存器的所有位
- 调用setup_idt用空的中断处理程序填充中断描述符表IDT
- 识别处理器的型号
- 用编译好的GDT和IDT表的地址来填充gdtr和idtr寄存器
- 初始化虚拟机监视器xen
- 调用start_kernel()函数
函数startup_32()定义于arch/x86/kernel/head_32.S:
...
__HEAD
ENTRY(startup_32)
movl pa(stack_start),%ecx
...
movl $(__KERNEL_STACK_CANARY),%eax
movl %eax,%gs
xorl %eax,%eax # Clear LDT
lldt %ax
cld # gcc2 wants the direction flag cleared at all times
pushl $0 # fake return address for unwinder
movb $1, ready
jmp *(initial_code)
...
__REFDATA
.align 4
ENTRY(initial_code)
.long i386_start_kernel // 参见[4.3.4.1.4.2 i386_start_kernel()]节
...
.data
.balign 4
ENTRY(stack_start)
.long init_thread_union+THREAD_SIZE // 为进程0建立内核态堆栈,参见[4.3.4.1.4.1 init_thread_union]节
4.3.4.1.4.1 init_thread_union
该变量定义于include/linux/sched.h:
union thread_union {
struct thread_info thread_info; // 0号进程的thread_info
unsigned long stack[THREAD_SIZE/sizeof(long)]; // THREAD_SIZE的取值为8kB
};
extern union thread_union init_thread_union;
init_thread_union实际定义于arch/x86/kernel/init_task.c中:
union thread_union init_thread_union __init_task_data =
{ INIT_THREAD_INFO(init_task) }; // 参见arch/x86/include/asm/thread_info.h
struct task_struct init_task = INIT_TASK(init_task); // 0号进程的task_struct
其中的__init_task_data定义于include/linux/init_task.h中:
/* Attach to the init_task data structure for proper alignment */
#define __init_task_data __attribute__((__section__(".data..init_task")))
4.3.4.1.4.2 i386_start_kernel()
该函数定义于arch/x86/kernel/head32.c:
void __init i386_start_kernel(void)
{
memblock_init();
memblock_x86_reserve_range(__pa_symbol(&_text), __pa_symbol(&__bss_stop), "TEXT DATA BSS");
#ifdef CONFIG_BLK_DEV_INITRD
/* Reserve INITRD */
if (boot_params.hdr.type_of_loader && boot_params.hdr.ramdisk_image) {
/* Assume only end is not page aligned */
u64 ramdisk_image = boot_params.hdr.ramdisk_image;
u64 ramdisk_size = boot_params.hdr.ramdisk_size;
u64 ramdisk_end = PAGE_ALIGN(ramdisk_image + ramdisk_size);
memblock_x86_reserve_range(ramdisk_image, ramdisk_end, "RAMDISK");
}
#endif
/* Call the subarch specific early setup function */
switch (boot_params.hdr.hardware_subarch) {
case X86_SUBARCH_MRST:
x86_mrst_early_setup();
break;
case X86_SUBARCH_CE4100:
x86_ce4100_early_setup();
break;
default:
i386_default_early_setup();
break;
}
/*
* At this point everything still needed from the boot loader
* or BIOS or kernel text should be early reserved or marked not
* RAM in e820. All other memory is free game.
*/
start_kernel(); // 参见[4.3.4.1.4.3 start_kernel()]节
}
4.3.4.1.4.3 start_kernel()
As specified in chapter 16 of Linux Device Drivers, 2nd Edition:
The architecture-independent starting point is start_kernel() in init/main.c. This function is invoked from architecture-specific code, to which it never returns.
由4.3.4.1.4.2 i386_start_kernel()节可知,i386_start_kernel()将调用start_kernel(),其定义于init/main.c:
asmlinkage void __init start_kernel(void)
{
char * command_line;
/*
* 在arch/x86/kernel/vmlinux.lds中包含该变量的定义;
* 与__initcall_start[], __initcall_end[], __early_initcall_end[]类似,
* 参见[13.5.1.1.1.1 __initcall_start[]/__early_initcall_end[]/__initcall_end[]]节
*/
extern const struct kernel_param __start___param[], __stop___param[];
smp_setup_processor_id();
/*
* Need to run as early as possible, to initialize the
* lockdep hash:
*/
lockdep_init(); // 参见[4.3.4.1.4.3.1 lockdep_init()]节
debug_objects_early_init(); // 参见[4.3.4.1.4.3.2 debug_objects_early_init()]节
/*
* Set up the the initial canary ASAP:
*/
boot_init_stack_canary();
cgroup_init_early();
local_irq_disable(); // 关闭可屏蔽中断,与下文中的local_irq_enable()对应
early_boot_irqs_disabled = true; // 在下文调用local_irq_enable()前将该变量置为false
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them
*/
// 参见[7.6.4.2.1.1 Architecture-dependent routine / tick_handle_periodic()]节
tick_init();
boot_cpu_init();
page_address_init();
printk(KERN_NOTICE "%s", linux_banner);
/*
* 该函数与体系架构有关。内核启动命令行参见[4.3.4.1.4.3.3.1 内核启动命令行]节,
* 内存初始化参见[6.3.2.1 boot_params.e820_map[]=>e820 / e820_saved]节
*/
setup_arch(&command_line);
mm_init_owner(&init_mm, &init_task); // 与配置项CONFIG_MM_OWNER的取值有关
mm_init_cpumask(&init_mm); // 与配置项CONFIG_CPUMASK_OFFSTACK的取值有关
setup_command_line(command_line); // 保存命令行参数,以备后续使用,参见[4.3.4.1.4.3.3.1 内核启动命令行]节
setup_nr_cpu_ids();
setup_per_cpu_areas(); // 参见[16.1.2 Per-CPU Variables的初始化]节
smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */
build_all_zonelists(NULL);
page_alloc_init();
// 解析boot_command_line中的内核选项,参见[4.3.4.1.4.3.3 parse_early_param()/parse_args()]节
printk(KERN_NOTICE "Kernel command line: %s\n", boot_command_line);
parse_early_param();
parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param, &unknown_bootoption);
jump_label_init();
/*
* These use large bootmem allocations and must precede
* kmem_cache_init(). 参见[19.2.1.1.1 默认分配的log_buf]节
*/
setup_log_buf(0);
// 初始化PID哈希链表头,参见[7.1.1.21 PID散列表和链表]节
pidhash_init();
/*
* 初始化VFS的两个重要数据结构dcache和inode的缓存,
* 参见[4.3.4.1.4.3.4 vfs_caches_init_early()]节
*/
vfs_caches_init_early();
/*
* sort_main_extable()用于把编译期间kbuild设置的异常表
* __start___ex_table和__stop___ex_table中的所有元素排序
* 参见include/asm-generic/vmlinux.lds.h和
* arch/x86/kernel/vmlinux.lds.S中的宏EXCEPTION_TABLE,
* 以及arch/x86/kernel/entry_32.S中的__ex_table
*/
sort_main_extable();
// 初始化中断描述符表idt_table[NR_VECTORS],参见[4.3.4.1.4.3.5 trap_init()]节
trap_init();
// 初始化内存管理,参见[4.3.4.1.4.3.6 mm_init()]节
mm_init();
/*
* Set up the scheduler prior starting any interrupts (such as the
* timer interrupt). Full topology setup happens at smp_init()
* time - but meanwhile we still have a functioning scheduler.
*/
sched_init(); // 初始化调度程序,参见[4.3.4.1.4.3.7 sched_init()]节
/*
* Disable preemption - early bootup scheduling is extremely
* fragile until we cpu_idle() for the first time.
*/
preempt_disable(); // 与配置项CONFIG_PREEMPT_COUNT的取值有关,参见[16.10.2 preempt_disable()]节
if (!irqs_disabled()) {
printk(KERN_WARNING "start_kernel(): bug: interrupts were "
"enabled *very* early, fixing it\n");
local_irq_disable();
}
idr_init_cache(); // 参见[15.5.6 idr_init_cache()]节
perf_event_init(); // 与配置项CONFIG_PERF_EVENTS的取值有关
rcu_init(); // 参见[16.12.3 RCU的初始化]节
radix_tree_init();
/* init some links before init_ISA_irqs() */
early_irq_init(); // 参见[4.3.4.1.4.3.8 early_irq_init()]节
init_IRQ(); // 参见[4.3.4.1.4.3.9 init_IRQ()]节
prio_tree_init();
init_timers(); // 参见[7.7.3 定时器模块的编译及初始化]节
hrtimers_init(); // 参见[7.8.4 hrtimer的编译及初始化]节
softirq_init(); // 初始化软中断的TASKLET_SOFTIRQ和HI_SOFTIRQ,参见[4.3.4.1.4.3.10 softirq_init()]节
timekeeping_init();
// 初始化系统日期和时间,参见[7.6.4.2.1.1 Architecture-dependent routine / tick_handle_periodic()]节
time_init();
profile_init(); // 与配置项CONFIG_PROFILING的取值有关
call_function_init();
if (!irqs_disabled())
printk(KERN_CRIT "start_kernel(): bug: interrupts were "
"enabled early\n");
early_boot_irqs_disabled = false;
local_irq_enable(); // 打开可屏蔽中断,与上文中的local_irq_disable()对应
/* Interrupts are enabled now so all GFP allocations are safe. */
gfp_allowed_mask = __GFP_BITS_MASK;
kmem_cache_init_late();
/*
* HACK ALERT! This is early. We're enabling the console before
* we've done PCI setups etc, and console_init() must be aware of
* this. But we do want output early, in case something goes wrong.
*/
/*
* 初始化系统控制台结构,该函数执行后可调用printk()函数
* 将log_buf中符合打印级别要求的系统信息打印到控制台上
*/
console_init();
if (panic_later)
/*
* 当系统出现无法继续运行下去的故障时才调用函数panic(),
* 该函数会导致系统中止,然后显示系统错误号
*/
panic(panic_later, panic_param);
lockdep_info();
/*
* Need to run this when irqs are enabled, because it wants
* to self-test [hard/soft]-irqs on/off lock inversion bugs
* too:
*/
locking_selftest();
#ifdef CONFIG_BLK_DEV_INITRD
if (initrd_start && !initrd_below_start_ok &&
page_to_pfn(virt_to_page((void *)initrd_start)) < min_low_pfn) {
printk(KERN_CRIT "initrd overwritten (0x%08lx < 0x%08lx) - disabling it.\n",
page_to_pfn(virt_to_page((void *)initrd_start)), min_low_pfn);
initrd_start = 0;
}
#endif
page_cgroup_init();
enable_debug_pagealloc();
debug_objects_mem_init(); // 与配置项CONFIG_DEBUG_OBJECTS的取值有关
kmemleak_init();
setup_per_cpu_pageset();
numa_policy_init();
if (late_time_init) // 参见[7.6.4.2.1.1 Architecture-dependent routine / tick_handle_periodic()]节
late_time_init();
sched_clock_init();
calibrate_delay(); // 确定CPU时钟的速度
pidmap_init(); // 初始化pid_namespace结构的全局变量init_pid_ns
anon_vma_init();
#ifdef CONFIG_X86
if (efi_enabled)
efi_enter_virtual_mode();
#endif
thread_info_cache_init();
cred_init();
fork_init(totalram_pages);
proc_caches_init();
buffer_init(); // 初始化页高速缓存
key_init();
security_init(); // 初始化LSM,参见[14.4 LSM的初始化]节
dbg_late_init();
// 用于初始化VFS数据结构的slab缓存,参见[4.3.4.1.4.3.11 vfs_caches_init()]节
vfs_caches_init(totalram_pages);
signals_init(); // 建立数据结构sigqueue的slab缓存,参见[8.3.5 信号的初始化]节
/* rootfs populating might need page-writeback */
page_writeback_init();
#ifdef CONFIG_PROC_FS
proc_root_init(); // 初始化proc文件系统,参见[4.3.4.1.4.3.12 proc_root_init()]节
#endif
cgroup_init();
cpuset_init();
taskstats_init_early();
delayacct_init();
check_bugs();
// 初始化高级配置和电源管理接口ACPI(Advanced Configuration and Power Interface)
acpi_early_init(); /* before LAPIC and SMP init */
sfi_init_late();
ftrace_init(); // 与配置项CONFIG_FTRACE_MCOUNT_RECORD的取值有关
/* Do the rest non-__init'ed, we're now alive */
rest_init(); // 参见[4.3.4.1.4.3.13 rest_init()]节
}
4.3.4.1.4.3.1 lockdep_init()
该函数定义于kernel/lockdep.c:
void lockdep_init(void)
{
int i;
/*
* Some architectures have their own start_kernel()
* code which calls lockdep_init(), while we also
* call lockdep_init() from the start_kernel() itself,
* and we want to initialize the hashes only once:
*/
if (lockdep_initialized)
return;
for (i = 0; i < CLASSHASH_SIZE; i++) // CLASSHASH_SIZE取值为4096
INIT_LIST_HEAD(classhash_table + i); // 初始化散列表classhash_table[CLASSHASH_SIZE]
for (i = 0; i < CHAINHASH_SIZE; i++) // CHAINHASH_SIZE取值为16384
INIT_LIST_HEAD(chainhash_table + i); // 初始化散列表chainhash_table[CHAINHASH_SIZE]
lockdep_initialized = 1;
}
4.3.4.1.4.3.2 debug_objects_early_init()
由lib/Makefile中的如下规则:
obj-$(CONFIG_DEBUG_OBJECTS) += debugobjects.o
可知,debugobjects.c的编译与.config中的配置项CONFIG_DEBUG_OBJECTS有关。
如果CONFIG_DEBUG_OBJECTS=y,则在lib/debugobjects.c中,包含如下有关debug_object_early_init()的代码:
void __init debug_objects_early_init(void)
{
int i;
for (i = 0; i < ODEBUG_HASH_SIZE; i++) // ODEBUG_HASH_SIZE的取值为16384
raw_spin_lock_init(&obj_hash[i].lock);
for (i = 0; i < ODEBUG_POOL_SIZE; i++) // ODEBUG_POOL_SIZE的取值为512
hlist_add_head(&obj_static_pool[i].node, &obj_pool);
}
如果CONFIG_DEBUG_OBJECTS=n,则在include/linux/debugobjects.h中,debug_object_early_init()被定义为空函数:
static inline void debug_objects_early_init(void) { }
4.3.4.1.4.3.3 parse_early_param()/parse_args()
4.3.4.1.4.3.3.1 内核启动命令行
在启动内核时,可以传递一个命令行字符串(即内核参数及其取值),来控制内核启动的过程,例如:
BOOT_IMAGE=/boot/vmlinuz-3.5.0-17-generic root=UUID=61b86fe4-41d9-4de3-a204-f64bf26eb02d ro quiet splash vt.handoff=7
可通过下列命令查看内核启动命令行:
chenwx proc # cat /proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-3.15.0-eudyptula-00054-g783e9e8-dirty root=UUID=fe67c2d0-9b0f-4fd6-8e97-463ce95a7e0c ro quiet splash
在内核启动过程中,涉及到如下几个命令行字符串变量:
- builtin_cmdline
- boot_command_line
- saved_command_line
- command_line
- static_command_line
最初,在引导内核启动时,boot_command_line是由boot_loader传递给内核的,参见arch/x86/kernel/head_32.S中的函数ENTRY(startup_32)。此后,在如下函数调用中:
start_kernel()
-> setup_arch(&command_line) // 参见init/main.c
-> setup_command_line(command_line) // 参见init/main.c
根据编译条件的不同,boot_command_line的取值可能会发生变化,并将boot_command_line赋值给其他变量,参见:
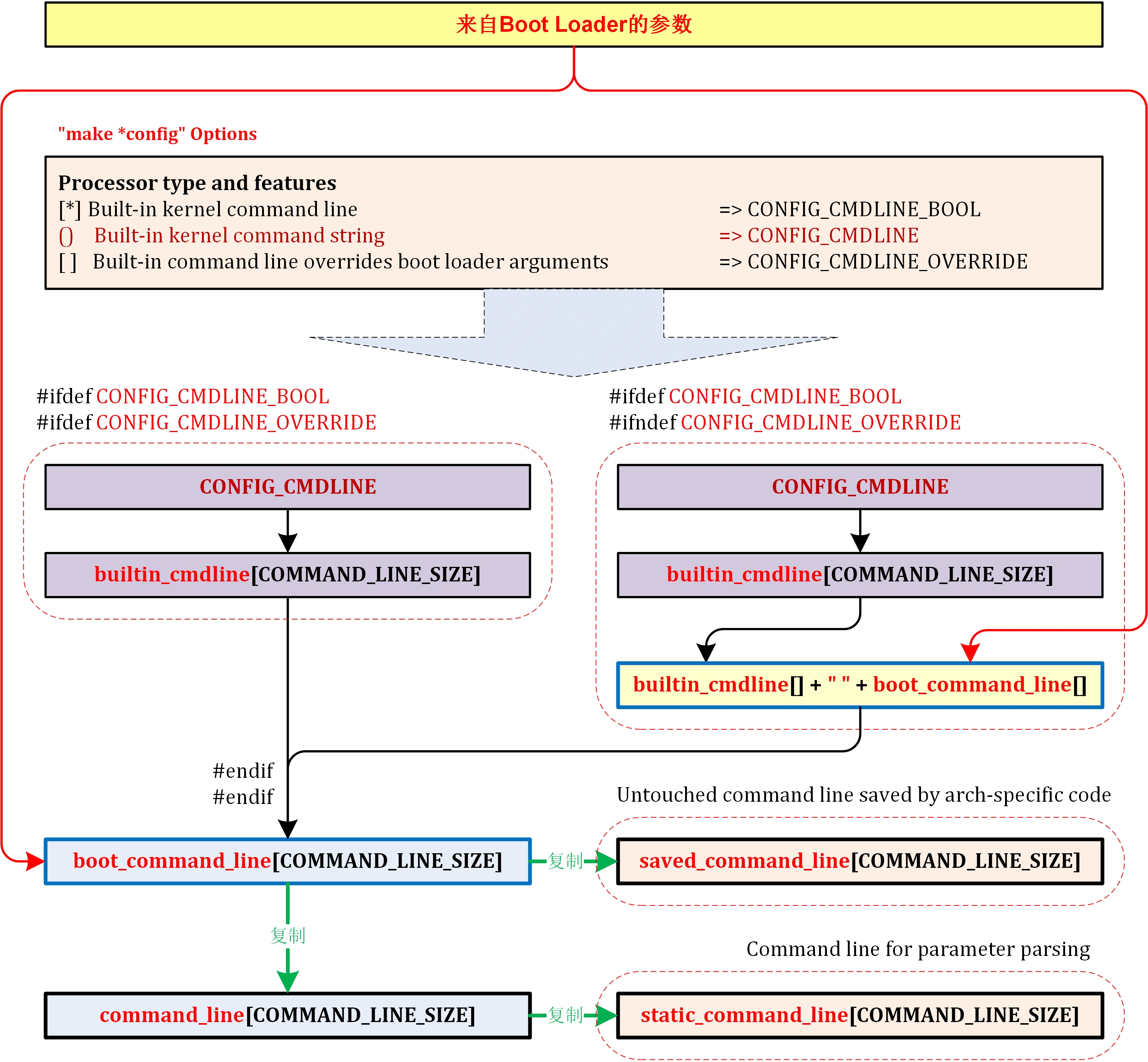
4.3.4.1.4.3.3.1.1 boot_command_line的配置方式
上文中的变量boot_command_line可以由如下两种方式配置:
1) 通过LILO或GRUB等引导加载程序进行配置,参见3.5.6 配置引导加载程序GRUB(或LILO)节。例如/boot/grub/grub.cfg中包含如下内容:
...
menuentry 'Linux Mint 14 MATE 32-bit, 3.5.0-17-generic (/dev/sda1)' --class linuxmint --class gnu-linux --class gnu --class os {
recordfail
gfxmode $linux_gfx_mode
insmod gzio
insmod part_msdos
insmod ext2
set root='hd0,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd0,msdos1 --hint-efi=hd0,msdos1 --hint-baremetal=ahci0,msdos1 61b86fe4-41d9-4de3-a204-f64bf26eb02d
else
search --no-floppy --fs-uuid --set=root 61b86fe4-41d9-4de3-a204-f64bf26eb02d
fi
linux /boot/vmlinuz-3.5.0-17-generic root=UUID=61b86fe4-41d9-4de3-a204-f64bf26eb02d ro quiet splash $vt_handoff
initrd /boot/initrd.img-3.5.0-17-generic
}
menuentry 'Linux Mint 14 MATE 32-bit, 3.5.0-17-generic (/dev/sda1) -- recovery mode' --class linuxmint --class gnu-linux --class gnu --class os {
recordfail
insmod gzio
insmod part_msdos
insmod ext2
set root='hd0,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd0,msdos1 --hint-efi=hd0,msdos1 --hint-baremetal=ahci0,msdos1 61b86fe4-41d9-4de3-a204-f64bf26eb02d
else
search --no-floppy --fs-uuid --set=root 61b86fe4-41d9-4de3-a204-f64bf26eb02d
fi
echo 'Loading Linux 3.5.0-17-generic ...'
linux /boot/vmlinuz-3.5.0-17-generic root=UUID=61b86fe4-41d9-4de3-a204-f64bf26eb02d ro recovery nomodeset
echo 'Loading initial ramdisk ...'
initrd /boot/initrd.img-3.5.0-17-generic
}
...
2) 在配置内核(make *config)时,通过如下选项配置内核参数。这些内核参数被静态的编译进内核,此后通过变量builtin_cmdline访问,参见arch/x86/kernel/setup.c中的setup_arch()函数:
Processor type and features
[*] Built-in kernel command line => CONFIG_CMDLINE_BOOL
() Built-in kernel command string => CONFIG_CMDLINE
[ ] Built-in command line overrides boot loader arguments => CONFIG_CMDLINE_OVERRIDE
4.3.4.1.4.3.3.2 注册内核参数的处理函数
内核参数的处理函数被放置到.init.setup段或__param段,分别由宏early_param(), __setup()和__module_param_call()来完成。参见如下文档:
- Documentation/kernel-parameters.txt
- Documentation/sysctl/kernel.txt
4.3.4.1.4.3.3.2.1 early_param()/__setup()
宏early_param()和__setup()用于注册内核参数的处理函数,这些处理函数被放置到.init.setup段,参见include/linux/init.h:
struct obs_kernel_param {
const char *str; // 内核参数名
int (*setup_func)(char *); // 内核参数的处理函数
int early; // 是否为宏early_param注册的
};
#define __setup(str, fn) \
__setup_param(str, fn, fn, 0)
#define early_param(str, fn) \
__setup_param(str, fn, fn, 1)
#define __setup_param(str, unique_id, fn, early) \
static const char __setup_str_##unique_id[] __initconst \
__aligned(1) = str; \
static struct obs_kernel_param __setup_##unique_id \
__used __section(.init.setup) \
__attribute__((aligned((sizeof(long))))) \
= { __setup_str_##unique_id, fn, early }
这两个宏定义并初始化了类型为struct obs_kernel_param的对象,它被编译到.init.setup段。根据3.4.2.2.2 vmlinux.lds如何生成节,arch/x86/kernel/vmlinux.lds.S被扩展为vmliux.lds(参见Appendix G: vmlinux.lds),其中,.init.setup段包含如下内容:
.init.data : AT(ADDR(.init.data) - 0xC0000000) { *(.init.data) *(.cpuinit.data) *(.meminit.data) . = ALIGN(8); __ctors_start = .; *(.ctors) __ctors_end = .; *(.init.rodata) . = ALIGN(8); __start_ftrace_events = .; *(_ftrace_events) __stop_ftrace_events = .; *(.cpuinit.rodata) *(.meminit.rodata) . = ALIGN(32); __dtb_start = .; *(.dtb.init.rodata) __dtb_end = .; . = ALIGN(16); __setup_start = .; *(.init.setup) __setup_end = .; __initcall_start = .; *(.initcallearly.init) __early_initcall_end = .; *(.initcall0.init) *(.initcall0s.init) *(.initcall1.init) *(.initcall1s.init) *(.initcall2.init) *(.initcall2s.init) *(.initcall3.init) *(.initcall3s.init) *(.initcall4.init) *(.initcall4s.init) *(.initcall5.init) *(.initcall5s.init) *(.initcallrootfs.init) *(.initcall6.init) *(.initcall6s.init) *(.initcall7.init) *(.initcall7s.init) __initcall_end = .; __con_initcall_start = .; *(.con_initcall.init) __con_initcall_end = .; __security_initcall_start = .; *(.security_initcall.init) __security_initcall_end = .; }
因而,可通过__setup_start和__setup_end查询内核参数并调用其处理函数。
NOTE: early_param()与__setup()的不同之处在于,early_param()注册的内核参数必须在其他内核参数之前被处理。以参数foo及处理函数foo_func()为例,这两个宏的扩展结果如下:
- early_param(“foo”, foo_func)
static const char __setup_str_foo_func[] __initconst __aligned(1) = "foo";
static struct obs_kernel_param __setup_foo_func
__used __section(.init.setup) __attribute__((aligned((sizeof(long)))))
= { __setup_str_foo_func, foo_func, 1 }
- __setup(“foo”, foo_func)
static const char __setup_str_foo_func[] __initconst __aligned(1) = "foo";
static struct obs_kernel_param __setup_foo_func
__used __section(.init.setup) __attribute__((aligned((sizeof(long)))))
= { __setup_str_foo_func, foo_func, 0 }
在init/main.c中,包含如下定义:
early_param("debug", debug_kernel);
early_param("quiet", quiet_kernel);
early_param("loglevel", loglevel);
__setup("reset_devices", set_reset_devices);
__setup("init=", init_setup);
__setup("rdinit=", rdinit_setup);
4.3.4.1.4.3.3.2.2 __module_param_call()
宏__module_param_call()用于注册内核参数的处理函数,这些处理函数被放置到__param段,其定义于include/linux/moduleparam.h:
struct kernel_param {
const char *name;
const struct kernel_param_ops *ops;
u16 perm;
u16 flags;
union {
void *arg;
const struct kparam_string *str;
const struct kparam_array *arr;
};
};
/* This is the fundamental function for registering boot/module parameters. */
#define __module_param_call(prefix, name, ops, arg, isbool, perm) \
/* Default value instead of permissions? */ \
static int __param_perm_check_##name __attribute__((unused)) = \
BUILD_BUG_ON_ZERO((perm) < 0 || (perm) > 0777 || ((perm) & 2)) \
+ BUILD_BUG_ON_ZERO(sizeof(""prefix) > MAX_PARAM_PREFIX_LEN); \
static const char __param_str_##name[] = prefix #name; \
static struct kernel_param __moduleparam_const __param_##name \
__used \
__attribute__ ((unused,__section__ ("__param"),aligned(sizeof(void *)))) \
= { __param_str_##name, ops, perm, isbool ? KPARAM_ISBOOL : 0, { arg } }
该宏定义并初始化了类型为struct kernel_param的对象,它被编译到__param段。根据3.4.2.2.2 vmlinux.lds如何生成节,arch/x86/kernel/vmlinux.lds.S被扩展为vmliux.lds(参见Appendix G: vmlinux.lds),其中包含如下内容:
__param : AT(ADDR(__param) - 0xC0000000) { __start___param = .; *(__param) __stop___param = .; }
因而可以通过__start__param和__stop__param查询内核参数并调用其处理函数。
使用__module_param_call()的宏,参见13.1.3.1 与模块参数有关的宏节。
4.3.4.1.4.3.3.3 内核参数处理函数的调用过程
函数start_kernel()调用parse_early_param()和parse_args()来分别处理early_param()和__setup()注册的内核参数处理函数:
asmlinkage void __init start_kernel(void)
{
...
printk(KERN_NOTICE "Kernel command line: %s\n", boot_command_line);
/*
* 解析命令行boot_command_line中的内核参数,并在.init.setup段
* 查找其处理函数,参见[4.3.4.1.4.3.3.3.1 parse_early_param()]节
*/
parse_early_param();
/*
* 解析命令行static_command_line中的内核参数,并在__param段或
* .init.setup段查找其处理函数,参见[4.3.4.1.4.3.3.3.2 parse_args()]节
*/
parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param, &unknown_bootoption);
...
}
4.3.4.1.4.3.3.3.1 parse_early_param()
该函数定义于init/main.c:
/* Arch code calls this early on, or if not, just before other parsing. */
void __init parse_early_param(void)
{
static __initdata int done = 0;
static __initdata char tmp_cmdline[COMMAND_LINE_SIZE];
if (done)
return;
// 解析命令行boot_command_line中的内核参数
/* All fall through to do_early_param. */
strlcpy(tmp_cmdline, boot_command_line, COMMAND_LINE_SIZE);
parse_early_options(tmp_cmdline);
done = 1;
}
void __init parse_early_options(char *cmdline)
{
// 函数do_early_param()参见下文
parse_args("early options", cmdline, NULL, 0, do_early_param);
}
其中,函数parse_args()定义于kernel/params.c:
/* Args looks like "foo=bar,bar2 baz=fuz wiz". */
int parse_args(const char *name, char *args,
const struct kernel_param *params, unsigned num,
int (*unknown)(char *param, char *val))
{
char *param, *val;
DEBUGP("Parsing ARGS: %s\n", args);
/* Chew leading spaces */
args = skip_spaces(args);
while (*args) {
int ret;
int irq_was_disabled;
args = next_arg(args, ¶m, &val); // 获取下一个参数param及其取值val
irq_was_disabled = irqs_disabled();
ret = parse_one(param, val, params, num, unknown); // 解析这个参数
if (irq_was_disabled && !irqs_disabled()) {
printk(KERN_WARNING "parse_args(): option '%s' enabled irq's!\n", param);
}
switch (ret) {
case -ENOENT:
printk(KERN_ERR "%s: Unknown parameter `%s'\n", name, param);
return ret;
case -ENOSPC:
printk(KERN_ERR "%s: `%s' too large for parameter `%s'\n", name, val ?: "", param);
return ret;
case 0:
break;
default:
printk(KERN_ERR "%s: `%s' invalid for parameter `%s'\n", name, val ?: "", param);
return ret;
}
}
/* All parsed OK. */
return 0;
}
其中,函数parse_one()定义于kernel/params.c:
static int parse_one(char *param, char *val,
const struct kernel_param *params, unsigned num_params,
int (*handle_unknown)(char *param, char *val))
{
unsigned int i;
int err;
/*
* 在params中查找同名参数param,若存在,则调用其处理函数;
* start_kernel() -> parse_early_param() -> parse_early_options() -> parse_args(...) 不进入此循环;而
* start_kernel() -> parse_args("Booting kernel", ..., &unknown_bootoption) 要进入此循环,
* 其中,params为__start___param,num_params为__stop___param - __start___param,即__param段的内容,
* 参见[4.3.4.1.4.3.3.2.2 __module_param_call()]节
*/
/* Find parameter */
for (i = 0; i < num_params; i++) {
if (parameq(param, params[i].name)) {
/* No one handled NULL, so do it here. */
if (!val && params[i].ops->set != param_set_bool)
return -EINVAL;
DEBUGP("They are equal! Calling %p\n", params[i].ops->set);
mutex_lock(¶m_lock);
err = params[i].ops->set(val, ¶ms[i]);
mutex_unlock(¶m_lock);
return err;
}
}
/*
* start_kernel() -> parse_early_param() -> parse_early_options() -> parse_args() 要进入此分支,
* 此时,handle_unknown取值为do_early_param,即调用do_early_param(),参见下文;
* start_kernel() -> parse_args("Booting kernel", ..., &unknown_bootoption) 可能会进入此分支,
* 此时,handle_unknown取值为unknown_bootoption,即调用unknown_bootoption(),参见[4.3.4.1.4.3.3.3.2 parse_args()]节
*/
if (handle_unknown) {
DEBUGP("Unknown argument: calling %p\n", handle_unknown);
return handle_unknown(param, val);
}
DEBUGP("Unknown argument `%s'\n", param);
return -ENOENT;
}
函数do_early_param()定义于init/main.c:
/* Check for early params. */
static int __init do_early_param(char *param, char *val)
{
const struct obs_kernel_param *p;
/*
* 查找指定内核参数的处理函数,并调用之;
* 变量__setup_start和__setup_end参见[4.3.4.1.4.3.3.2.1 early_param()/__setup()]节
*/
for (p = __setup_start; p < __setup_end; p++) {
if ((p->early && parameq(param, p->str)) ||
(strcmp(param, "console") == 0 && strcmp(p->str, "earlycon") == 0) ) {
if (p->setup_func(val) != 0)
printk(KERN_WARNING "Malformed early option '%s'\n", param);
}
}
/* We accept everything at this stage. */
return 0;
}
4.3.4.1.4.3.3.3.2 parse_args()
当start_kernel()调用完parse_early_param()后,将调用如下函数解析命令行static_command_line中的内核参数:
parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param, &unknown_bootoption);
其执行过程与4.3.4.1.4.3.3.3.1 parse_early_param()节类似,不同之处在于,函数parse_one()调用handle_unknown()时,实际调用的是函数unknown_bootoption()而不是do_early_param()。
函数unknown_bootoption()定义于init/main.c:
/*
* Unknown boot options get handed to init, unless they look like
* unused parameters (modprobe will find them in /proc/cmdline).
*/
static int __init unknown_bootoption(char *param, char *val)
{
/* Change NUL term back to "=", to make "param" the whole string. */
if (val) {
/* param=val or param="val"? */
if (val == param+strlen(param)+1)
val[-1] = '=';
else if (val == param+strlen(param)+2) {
val[-2] = '=';
memmove(val-1, val, strlen(val)+1);
val--;
} else
BUG();
}
/* Handle obsolete-style parameters */
// 若parse_one()在__param段找不到对应参数的处理函数,则在.init.setup段重新查找
if (obsolete_checksetup(param))
return 0;
/* Unused module parameter. */
if (strchr(param, '.') && (!val || strchr(param, '.') < val))
return 0;
if (panic_later)
return 0;
if (val) {
/* Environment option */
unsigned int i;
for (i = 0; envp_init[i]; i++) {
if (i == MAX_INIT_ENVS) {
panic_later = "Too many boot env vars at `%s'";
panic_param = param;
}
if (!strncmp(param, envp_init[i], val - param))
break;
}
envp_init[i] = param;
} else {
/* Command line option */
unsigned int i;
for (i = 0; argv_init[i]; i++) {
if (i == MAX_INIT_ARGS) {
panic_later = "Too many boot init vars at `%s'";
panic_param = param;
}
}
argv_init[i] = param;
}
return 0;
}
static int __init obsolete_checksetup(char *line)
{
const struct obs_kernel_param *p;
int had_early_param = 0;
/*
* 查找指定内核参数的处理函数,并调用之;
* 其处理过程与函数do_early_param()类似,参见[4.3.4.1.4.3.3.3.1 parse_early_param()]节
*/
p = __setup_start;
do {
int n = strlen(p->str);
if (parameqn(line, p->str, n)) {
if (p->early) {
/* Already done in parse_early_param?
* (Needs exact match on param part).
* Keep iterating, as we can have early
* params and __setups of same names 8( */
if (line[n] == '\0' || line[n] == '=')
had_early_param = 1;
} else if (!p->setup_func) {
printk(KERN_WARNING "Parameter %s is obsolete," ignored\n", p->str);
return 1;
} else if (p->setup_func(line + n)) // 调用内核参数的处理函数
return 1;
}
p++;
} while (p < __setup_end);
return had_early_param;
}
4.3.4.1.4.3.4 vfs_caches_init_early()
该函数用于初始化目录项哈希表(dentry_hashtable)和索引节点哈希表(inode_hashtable),其定义于fs/dcache.c:
void __init vfs_caches_init_early(void)
{
dcache_init_early(); // 参见[4.3.4.1.4.3.4.1 dcache_init_early()]节
inode_init_early(); // 参见[4.3.4.1.4.3.4.2 inode_init_early()]节
}
4.3.4.1.4.3.4.1 dcache_init_early()
该函数定义于fs/dcache.c:
static unsigned int d_hash_mask __read_mostly;
static unsigned int d_hash_shift __read_mostly;
static struct hlist_bl_head *dentry_hashtable __read_mostly;
static __initdata unsigned long dhash_entries;
static void __init dcache_init_early(void)
{
int loop;
// 如果本函数没有创建目录项哈希表,则在dcache_init()中创建,参见[4.3.4.1.4.3.11.1 dcache_init()]节
/* If hashes are distributed across NUMA nodes, defer
* hash allocation until vmalloc space is available.
*/
if (hashdist)
return;
dentry_hashtable = alloc_large_system_hash("Dentry cache",
sizeof(struct hlist_bl_head),
dhash_entries,
13,
HASH_EARLY,
&d_hash_shift,
&d_hash_mask,
0);
for (loop = 0; loop < (1 << d_hash_shift); loop++)
INIT_HLIST_BL_HEAD(dentry_hashtable + loop);
}
其中,变量hashdist定义于mm/page_alloc.c:
int hashdist = HASHDIST_DEFAULT;
而HASHDIST_DEFAULT与配置项CONFIG_NUMA和CONFIG_64BIT有关,其定义于include/linux/bootmem.h:
/* Only NUMA needs hash distribution. 64bit NUMA architectures have
* sufficient vmalloc space.
*/
#if defined(CONFIG_NUMA) && defined(CONFIG_64BIT)
#define HASHDIST_DEFAULT 1
#else
#define HASHDIST_DEFAULT 0
#endif
4.3.4.1.4.3.4.2 inode_init_early()
该函数定义于fs/inode.c:
static unsigned int i_hash_mask __read_mostly;
static unsigned int i_hash_shift __read_mostly;
static struct hlist_head *inode_hashtable __read_mostly;
static __initdata unsigned long ihash_entries;
/*
* Initialize the waitqueues and inode hash table.
*/
void __init inode_init_early(void)
{
int loop;
/* If hashes are distributed across NUMA nodes, defer
* hash allocation until vmalloc space is available.
*/
if (hashdist)
return;
inode_hashtable = alloc_large_system_hash("Inode-cache",
sizeof(struct hlist_head),
ihash_entries,
14,
HASH_EARLY,
&i_hash_shift,
&i_hash_mask,
0);
for (loop = 0; loop < (1 << i_hash_shift); loop++)
INIT_HLIST_HEAD(&inode_hashtable[loop]);
}
4.3.4.1.4.3.5 trap_init()
该函数用于设置中断描述符表中前19个陷阱门所对应的处理程序(这些中断向量都是CPU保留用于异常处理的,参见9.1 中断处理简介节),其定义于arch/x86/kernel/trap.c:
void __init trap_init(void)
{
int i;
#ifdef CONFIG_EISA
void __iomem *p = early_ioremap(0x0FFFD9, 4);
if (readl(p) == 'E' + ('I'<<8) + ('S'<<16) + ('A'<<24))
EISA_bus = 1;
early_iounmap(p, 4);
#endif
/*
* 数组idt_table[]定义于arch/x86/kernel/traps.c,其中,NR_VECTORS=256
* gate_desc idt_table[NR_VECTORS];
*/
set_intr_gate(0, ÷_error); // 填充idt_table[0]
set_intr_gate_ist(2, &nmi, NMI_STACK); // 填充idt_table[2]
/* int4 can be called from all */
set_system_intr_gate(4, &overflow); // 填充idt_table[4]
set_intr_gate(5, &bounds); // 填充idt_table[5]
set_intr_gate(6, &invalid_op); // 填充idt_table[6]
set_intr_gate(7, &device_not_available); // 填充idt_table[7]
#ifdef CONFIG_X86_32
set_task_gate(8, GDT_ENTRY_DOUBLEFAULT_TSS); // 填充idt_table[8]
#else
set_intr_gate_ist(8, &double_fault, DOUBLEFAULT_STACK);
#endif
set_intr_gate(9, &coprocessor_segment_overrun); // 填充idt_table[9]
set_intr_gate(10, &invalid_TSS); // 填充idt_table[10]
set_intr_gate(11, &segment_not_present); // 填充idt_table[11]
set_intr_gate_ist(12, &stack_segment, STACKFAULT_STACK); // 填充idt_table[12]
set_intr_gate(13, &general_protection); // 填充idt_table[13]
set_intr_gate(15, &spurious_interrupt_bug); // 填充idt_table[15]
set_intr_gate(16, &coprocessor_error); // 填充idt_table[16]
set_intr_gate(17, &alignment_check); // 填充idt_table[17]
#ifdef CONFIG_X86_MCE
set_intr_gate_ist(18, &machine_check, MCE_STACK); // 填充idt_table[18]
#endif
set_intr_gate(19, &simd_coprocessor_error); // 填充idt_table[19]
/*
* FIRST_EXTERNAL_VECTOR定义于arch/x86/include/asm/irq_vectors.h,取值为0x20
* 即设置位图used_vectors的前32比特为1,表示中断向量表idt_table的占用情况
*/
/* Reserve all the builtin and the syscall vector: */
for (i = 0; i < FIRST_EXTERNAL_VECTOR; i++)
set_bit(i, used_vectors);
// CONFIG_IA32_EMULATION是否和下面的CONFIG_X86_32冲突?
#ifdef CONFIG_IA32_EMULATION
set_system_intr_gate(IA32_SYSCALL_VECTOR, ia32_syscall); // 填充idt_table[128]
// IA32_SYSCALL_VECTOR定义于arch/x86/include/asm/irq_vectors.h,取值为0x80
set_bit(IA32_SYSCALL_VECTOR, used_vectors);
#endif
#ifdef CONFIG_X86_32
/*
* SYSCALL_VECTOR定义于arch/x86/include/asm/irq_vectors.h,其取值为0x80
* system_call为系统调用总控程序,定义于arch/x86/kernel/entry_32.S,参见[5.5 系统调用]节
* 系统调用使用int 0x80中断,system_call根据系统调用号(保存于eax)查询sys_call_table,
* 找到对应的处理程序并执行
*/
set_system_trap_gate(SYSCALL_VECTOR, &system_call); // 填充idt_table[128]
/*
* SYSCALL_VECTOR定义于arch/x86/include/asm/irq_vectors.h,其取值为0x80
* 在arch/x86/kernel/traps.c中,used_vectors通过宏DECLARE_BITMAP定义:
* DECLARE_BITMAP(used_vectors, NR_VECTORS);
* 扩展后:unsigned long used_vectors[256];
*/
set_bit(SYSCALL_VECTOR, used_vectors);
#endif
/*
* Should be a barrier for any external CPU state:
*/
cpu_init(); // 该函数定义于arch/x86/kernel/cpu/common.c
x86_init.irqs.trap_init(); // x86_init定义于arch/x86/kernel/x86_init.c
}
idt_table[]示意图:
4.3.4.1.4.3.5.1 设置idt_table表项
函数trap_init()调用如下函数设置idt_table表项,其定义于arch/x86/include/asm/desc.h:
static inline void set_intr_gate(unsigned int n, void *addr)
{
BUG_ON((unsigned)n > 0xFF);
_set_gate(n, GATE_INTERRUPT, addr, 0, 0, __KERNEL_CS);
}
static inline void set_intr_gate_ist(int n, void *addr, unsigned ist)
{
BUG_ON((unsigned)n > 0xFF);
_set_gate(n, GATE_INTERRUPT, addr, 0, ist, __KERNEL_CS);
}
static inline void set_system_intr_gate(unsigned int n, void *addr)
{
BUG_ON((unsigned)n > 0xFF);
_set_gate(n, GATE_INTERRUPT, addr, 0x3, 0, __KERNEL_CS);
}
static inline void set_intr_gate(unsigned int n, void *addr)
{
BUG_ON((unsigned)n > 0xFF);
_set_gate(n, GATE_INTERRUPT, addr, 0, 0, __KERNEL_CS);
}
static inline void set_system_trap_gate(unsigned int n, void *addr)
{
BUG_ON((unsigned)n > 0xFF);
_set_gate(n, GATE_TRAP, addr, 0x3, 0, __KERNEL_CS);
}
上述函数均通过调用_set_gate()来实现,其定义于arch/x86/include/asm/desc.h:
static inline void _set_gate(int gate, unsigned type, void *addr, unsigned dpl,
unsigned ist, unsigned seg)
{
gate_desc s;
// 参见[4.3.4.1.4.3.5.1.1 pack_gate()]节
pack_gate(&s, type, (unsigned long)addr, dpl, ist, seg);
/*
* does not need to be atomic because it is only done once at
* setup time
*/
// 将描述符s拷贝到idt_table[gate]项中,参见[4.3.4.1.4.3.5.1.2 write_idt_entry()]节
write_idt_entry(idt_table, gate, &s);
}
4.3.4.1.4.3.5.1.1 pack_gate()
函数pack_gate()定义于arch/x86/include/asm/desc.h:
#ifdef CONFIG_X86_64
static inline void pack_gate(gate_desc *gate, unsigned type, unsigned long func,
unsigned dpl, unsigned ist, unsigned seg)
{
gate->offset_low = PTR_LOW(func);
gate->segment = __KERNEL_CS;
gate->ist = ist;
gate->p = 1;
gate->dpl = dpl;
gate->zero0 = 0;
gate->zero1 = 0;
gate->type = type;
gate->offset_middle = PTR_MIDDLE(func);
gate->offset_high = PTR_HIGH(func);
}
#else
/*
* 给指定的描述符赋值,参见[6.1.1.1 段描述符/Segment Descriptor]节
* NOTE: 没有定义宏CONFIG_X86_64的情况下,入参flags是无效的
*/
static inline void pack_gate(gate_desc *gate, unsigned char type, unsigned long base,
unsigned dpl, unsigned flags, unsigned short seg)
{
gate->a = (seg << 16) | (base & 0xffff);
gate->b = (base & 0xffff0000) | (((0x80 | type | (dpl << 5)) & 0xff) << 8);
}
#endif
4.3.4.1.4.3.5.1.2 write_idt_entry()
该函数定义于arch/x86/include/asm/desc.h:
#ifdef CONFIG_PARAVIRT
#include <asm/paravirt.h>
#else
#define write_idt_entry(dt, entry, g) native_write_idt_entry(dt, entry, g)
#endif /* CONFIG_PARAVIRT */
static inline void native_write_idt_entry(gate_desc *idt, int entry, const gate_desc *gate)
{
memcpy(&idt[entry], gate, sizeof(*gate));
}
4.3.4.1.4.3.6 mm_init()
该函数定义于init/main.c:
static void __init mm_init(void)
{
/*
* page_cgroup requires countinous pages as memmap
* and it's bigger than MAX_ORDER unless SPARSEMEM.
*/
page_cgroup_init_flatmem();
mem_init(); // 参见[4.3.4.1.4.3.6.1 mem_init()]节
kmem_cache_init(); // 参见[6.5.1.1.1 Initialize General Cache/kmem_cache_init()]节
percpu_init_late();
pgtable_cache_init();
vmalloc_init();
}
4.3.4.1.4.3.6.1 mem_init()
该函数定义于arch/x86/mm/init_32.c:
void __init mem_init(void)
{
int codesize, reservedpages, datasize, initsize;
int tmp;
pci_iommu_alloc();
#ifdef CONFIG_FLATMEM
BUG_ON(!mem_map);
#endif
/* this will put all low memory onto the freelists */
// 参见[4.3.4.1.4.3.6.1.1 free_all_bootmem()/free_all_bootmem_core()]节
totalram_pages += free_all_bootmem();
reservedpages = 0;
/*
* max_low_pfn的含义参见[6.3.3 Physical Memory Layout]中的表,其取值被如下函数更新:
* start_kernel() -> setup_arch() -> find_low_pfn_range()
*/
for (tmp = 0; tmp < max_low_pfn; tmp++)
/*
* Only count reserved RAM pages:
*/
if (page_is_ram(tmp) && PageReserved(pfn_to_page(tmp)))
reservedpages++;
// 将高端内存转入Buddy Allocator System中管理,参见[4.3.4.1.4.3.6.1.2 set_highmem_pages_init()]节
set_highmem_pages_init();
// 各变量的含义参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]中的"NOTE 14"
codesize = (unsigned long) &_etext - (unsigned long) &_text;
datasize = (unsigned long) &_edata - (unsigned long) &_etext;
initsize = (unsigned long) &__init_end - (unsigned long) &__init_begin;
// 打印输出参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节NOTE 13
printk(KERN_INFO "Memory: %luk/%luk available "
"(%dk kernel code, %dk reserved, %dk data, %dk init, %ldk highmem)\n",
nr_free_pages() << (PAGE_SHIFT-10), num_physpages << (PAGE_SHIFT-10),
codesize >> 10, reservedpages << (PAGE_SHIFT-10),
datasize >> 10, initsize >> 10, totalhigh_pages << (PAGE_SHIFT-10));
// 打印输出参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节NOTE 13
printk(KERN_INFO "virtual kernel memory layout:\n"
" fixmap : 0x%08lx - 0x%08lx (%4ld kB)\n"
#ifdef CONFIG_HIGHMEM
" pkmap : 0x%08lx - 0x%08lx (%4ld kB)\n"
#endif
" vmalloc : 0x%08lx - 0x%08lx (%4ld MB)\n"
" lowmem : 0x%08lx - 0x%08lx (%4ld MB)\n"
" .init : 0x%08lx - 0x%08lx (%4ld kB)\n"
" .data : 0x%08lx - 0x%08lx (%4ld kB)\n"
" .text : 0x%08lx - 0x%08lx (%4ld kB)\n",
FIXADDR_START, FIXADDR_TOP,
(FIXADDR_TOP - FIXADDR_START) >> 10,
#ifdef CONFIG_HIGHMEM
PKMAP_BASE, PKMAP_BASE+LAST_PKMAP*PAGE_SIZE,
(LAST_PKMAP*PAGE_SIZE) >> 10,
#endif
VMALLOC_START, VMALLOC_END,
(VMALLOC_END - VMALLOC_START) >> 20,
(unsigned long)__va(0), (unsigned long)high_memory,
((unsigned long)high_memory - (unsigned long)__va(0)) >> 20,
(unsigned long)&__init_begin, (unsigned long)&__init_end,
((unsigned long)&__init_end - (unsigned long)&__init_begin) >> 10,
(unsigned long)&_etext, (unsigned long)&_edata,
((unsigned long)&_edata - (unsigned long)&_etext) >> 10,
(unsigned long)&_text, (unsigned long)&_etext,
((unsigned long)&_etext - (unsigned long)&_text) >> 10);
/*
* Check boundaries twice: Some fundamental inconsistencies can
* be detected at build time already.
*/
#define __FIXADDR_TOP (-PAGE_SIZE)
#ifdef CONFIG_HIGHMEM
BUILD_BUG_ON(PKMAP_BASE + LAST_PKMAP*PAGE_SIZE > FIXADDR_START);
BUILD_BUG_ON(VMALLOC_END > PKMAP_BASE);
#endif
#define high_memory (-128UL << 20)
BUILD_BUG_ON(VMALLOC_START >= VMALLOC_END);
#undef high_memory
#undef __FIXADDR_TOP
#ifdef CONFIG_HIGHMEM
BUG_ON(PKMAP_BASE + LAST_PKMAP*PAGE_SIZE > FIXADDR_START);
BUG_ON(VMALLOC_END > PKMAP_BASE);
#endif
BUG_ON(VMALLOC_START >= VMALLOC_END);
BUG_ON((unsigned long)high_memory > VMALLOC_START);
if (boot_cpu_data.wp_works_ok < 0)
test_wp_bit();
}
4.3.4.1.4.3.6.1.1 free_all_bootmem()/free_all_bootmem_core()
Once free_all_bootmem() returns, all the pages in ZONE_NORMAL have been given to the buddy allocator. See section 6.3.2.4 early_node_map[]=>node_data[]->node_zones[].
函数free_all_bootmem()定义于mm/bootmem.c:
static struct list_head bdata_list __initdata = LIST_HEAD_INIT(bdata_list);
/**
* free_all_bootmem - release free pages to the buddy allocator
* Returns the number of pages actually released.
*/
unsigned long __init free_all_bootmem(void)
{
unsigned long total_pages = 0;
bootmem_data_t *bdata;
/*
* 类型bootmem_data_t参见[6.2.9 Boot Memory Allocator/bootmem_data_t]节,
* 变量bdata_list参见[6.2.9.1 变量bdata_list],函数free_all_bootmem_core()参见下文
*/
list_for_each_entry(bdata, &bdata_list, list)
total_pages += free_all_bootmem_core(bdata);
return total_pages;
}
其中,函数free_all_bootmem_core()定义于mm/bootmem.c:
static unsigned long __init free_all_bootmem_core(bootmem_data_t *bdata)
{
int aligned;
struct page *page;
unsigned long start, end, pages, count = 0;
if (!bdata->node_bootmem_map)
return 0;
start = bdata->node_min_pfn;
end = bdata->node_low_pfn;
/*
* If the start is aligned to the machines wordsize, we might
* be able to free pages in bulks of that order.
*/
aligned = !(start & (BITS_PER_LONG - 1));
bdebug("nid=%td start=%lx end=%lx aligned=%d\n", bdata - bootmem_node_data, start, end, aligned);
while (start < end) {
unsigned long *map, idx, vec;
map = bdata->node_bootmem_map;
idx = start - bdata->node_min_pfn;
vec = ~map[idx / BITS_PER_LONG];
/*
* 根据起始页框号是否对齐、空闲页面的多少等因素释放页面到Buddy Allocator Sytem:
* 或者一次释放32个页面,或者一次释放一个页面
*/
if (aligned && vec == ~0UL && start + BITS_PER_LONG < end) {
int order = ilog2(BITS_PER_LONG);
__free_pages_bootmem(pfn_to_page(start), order); // 每次释放32个页面,参见下文
count += BITS_PER_LONG;
} else {
unsigned long off = 0;
while (vec && off < BITS_PER_LONG) {
if (vec & 1) {
page = pfn_to_page(start + off);
__free_pages_bootmem(page, 0); // 每次释放1个页面,参见下文
count++;
}
vec >>= 1;
off++;
}
}
start += BITS_PER_LONG;
}
/*
* 释放位图(bdata->node_bootmem_map)所占用的内存空间:
* 位图用来指示一个页面是否空闲,现在所有内存都归Buddy Allocator System管理,
* 该位图就没有存在的必要了
*/
page = virt_to_page(bdata->node_bootmem_map);
pages = bdata->node_low_pfn - bdata->node_min_pfn;
pages = bootmem_bootmap_pages(pages);
count += pages;
while (pages--)
__free_pages_bootmem(page++, 0); // 参见下文
bdebug("nid=%td released=%lx\n", bdata - bootmem_node_data, count);
return count;
}
其中,函数__free_pages_bootmem()定义于mm/page_alloc.c:
void __meminit __free_pages_bootmem(struct page *page, unsigned int order)
{
if (order == 0) { // 释放单个页面
__ClearPageReserved(page); // 复位page->flags中的标志位PG_reserved
set_page_count(page, 0); // page->_count = 0
set_page_refcounted(page); // page->_count = 1
__free_page(page); // 参见[6.4.2.4 __free_page()/free_page()]节
} else { // 释放2order个页面
int loop;
prefetchw(page);
for (loop = 0; loop < BITS_PER_LONG; loop++) {
struct page *p = &page[loop];
if (loop + 1 < BITS_PER_LONG)
prefetchw(p + 1);
__ClearPageReserved(p); // 复位page->flags中的标志位PG_reserved
set_page_count(p, 0); // page->_count = 0
}
set_page_refcounted(page); // page->_count = 1
__free_pages(page, order); // 参见[6.4.2.4 __free_page()/free_page()]节
}
}
4.3.4.1.4.3.6.1.2 set_highmem_pages_init()
函数set_highmem_pages_init()定义于arch/x86/mm/init_32.c:
void __init set_highmem_pages_init(void)
{
struct zone *zone;
int nid;
for_each_zone(zone) {
unsigned long zone_start_pfn, zone_end_pfn;
if (!is_highmem(zone))
continue;
zone_start_pfn = zone->zone_start_pfn;
zone_end_pfn = zone_start_pfn + zone->spanned_pages;
nid = zone_to_nid(zone);
printk(KERN_INFO "Initializing %s for node %d (%08lx:%08lx)\n",
zone->name, nid, zone_start_pfn, zone_end_pfn);
add_highpages_with_active_regions(nid, zone_start_pfn, zone_end_pfn);
}
totalram_pages += totalhigh_pages;
}
函数add_highpages_with_active_regions()定义于arch/x86/mm/init_32.c:
void __init add_highpages_with_active_regions(int nid, unsigned long start_pfn, unsigned long end_pfn)
{
struct range *range;
int nr_range;
int i;
// 获取页框数
nr_range = __get_free_all_memory_range(&range, nid, start_pfn, end_pfn);
for (i = 0; i < nr_range; i++) {
struct page *page;
int node_pfn;
for (node_pfn = range[i].start; node_pfn < range[i].end; node_pfn++) {
if (!pfn_valid(node_pfn))
continue;
page = pfn_to_page(node_pfn);
/*
* 调用__free_page()将该页加入到Buddy Allocator System中
* 参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节
* 和[6.4.2.4 __free_page()/free_page()]节
*/
add_one_highpage_init(page);
}
}
}
4.3.4.1.4.3.7 sched_init()
该函数定义参见kernel/sched.c:
void __init sched_init(void)
{
...
/*
* Make us the idle thread. Technically, schedule() should not be
* called from this thread, however somewhere below it might be,
* but because we are the idle thread, we just pick up running again
* when this runqueue becomes "idle".
*/
/*
* 将当前进程作为idle进程,放置到当然CPU运行队列的rq->idle域,
* 参见[7.4.2.1 运行队列结构/struct rq]节
*/
init_idle(current, smp_processor_id());
calc_load_update = jiffies + LOAD_FREQ;
/*
* During early bootup we pretend to be a normal task:
*/
// 各调度类组成的链表参见[7.4.5.2.2 pick_next_task()]节和[7.4.4.2 完全公平调度类/fair_sched_class]节
current->sched_class = &fair_sched_class;
...
}
4.3.4.1.4.3.8 early_irq_init()
该函数用于初始化数组irq_desc[],参见9.2.1 struct irq_desc / irq_desc[]节,其定义于kernel/irq/irqdesc.c:
#ifdef CONFIG_SPARSE_IRQ
...
#else /* !CONFIG_SPARSE_IRQ */
int __init early_irq_init(void)
{
int count, i, node = first_online_node;
struct irq_desc *desc;
init_irq_default_affinity();
printk(KERN_INFO "NR_IRQS:%d\n", NR_IRQS);
desc = irq_desc;
count = ARRAY_SIZE(irq_desc);
// 依次为数组irq_desc[]元素赋予默认值
for (i = 0; i < count; i++) {
desc[i].kstat_irqs = alloc_percpu(unsigned int);
alloc_masks(&desc[i], GFP_KERNEL, node);
raw_spin_lock_init(&desc[i].lock);
lockdep_set_class(&desc[i].lock, &irq_desc_lock_class);
desc_set_defaults(i, &desc[i], node, NULL);
}
return arch_early_irq_init();
}
#endif
static void desc_set_defaults(unsigned int irq, struct irq_desc *desc,
int node, struct module *owner)
{
int cpu;
desc->irq_data.irq = irq;
desc->irq_data.chip = &no_irq_chip;
desc->irq_data.chip_data = NULL;
desc->irq_data.handler_data = NULL;
desc->irq_data.msi_desc = NULL;
irq_settings_clr_and_set(desc, ~0, _IRQ_DEFAULT_INIT_FLAGS);
irqd_set(&desc->irq_data, IRQD_IRQ_DISABLED);
desc->handle_irq = handle_bad_irq;
desc->depth = 1;
desc->irq_count = 0;
desc->irqs_unhandled = 0;
desc->name = NULL;
desc->owner = owner;
for_each_possible_cpu(cpu)
*per_cpu_ptr(desc->kstat_irqs, cpu) = 0;
desc_smp_init(desc, node);
}
4.3.4.1.4.3.9 init_IRQ()
该函数用于设置可屏蔽中断,其定义于arch/x86/kernel/irqinit.c:
void __init init_IRQ(void)
{
int i;
/*
* We probably need a better place for this, but it works for
* now ...
*/
x86_add_irq_domains();
/*
* On cpu 0, Assign IRQ0_VECTOR..IRQ15_VECTOR's to IRQ 0..15.
* If these IRQ's are handled by legacy interrupt-controllers like PIC,
* then this configuration will likely be static after the boot. If
* these IRQ's are handled by more mordern controllers like IO-APIC,
* then this vector space can be freed and re-used dynamically as the
* irq's migrate etc.
*/
/*
* legacy_pic参见[4.3.4.1.4.3.9.1 legacy_pic/x86_init]节,其中legacy_pic->nr_legacy_irqs
* 取值为NR_IRQS_LEGACY,即16。因而,此处设置IRQ 0x30..0x3F,参见[9.3.1.1 vector_irq[]]节
* IRQ0_VECTOR定义于arch/x86/include/asm/irq_vectors.h,取值为48,参见[9.1 中断处理简介]节
*/
for (i = 0; i < legacy_pic->nr_legacy_irqs; i++)
per_cpu(vector_irq, 0)[IRQ0_VECTOR + i] = i;
/*
* x86_init参见[4.3.4.1.4.3.9.1 legacy_pic/x86_init]节,其中x86_init.irqs.intr_init
* 取值为native_init_IRQ。因而,如下语句调用函数native_init_IRQ(),
* 参见[4.3.4.1.4.3.9.2 native_init_IRQ()]节
*/
x86_init.irqs.intr_init();
}
4.3.4.1.4.3.9.1 legacy_pic/x86_init
变量legacy_pic定义于arch/x86/kernel/i8259.c:
struct irq_chip i8259A_chip = {
.name = "XT-PIC",
.irq_mask = disable_8259A_irq,
.irq_disable = disable_8259A_irq,
.irq_unmask = enable_8259A_irq,
.irq_mask_ack = mask_and_ack_8259A,
};
struct legacy_pic default_legacy_pic = {
// 取值为16,定义于arch/x86/include/asm/irq_vectors.h
.nr_legacy_irqs = NR_IRQS_LEGACY,
.chip = &i8259A_chip,
.mask = mask_8259A_irq,
.unmask = unmask_8259A_irq,
.mask_all = mask_8259A,
.restore_mask = unmask_8259A,
.init = init_8259A,
.irq_pending = i8259A_irq_pending,
.make_irq = make_8259A_irq,
};
struct legacy_pic *legacy_pic = &default_legacy_pic;
变量x86_init定义于arch/x86/kernel/x86_init.c:
/*
* The platform setup functions are preset with the default functions
* for standard PC hardware.
*/
struct x86_init_ops x86_init __initdata = {
.resources = {
.probe_roms = probe_roms,
.reserve_resources = reserve_standard_io_resources,
.memory_setup = default_machine_specific_memory_setup,
},
.mpparse = {
.mpc_record = x86_init_uint_noop,
.setup_ioapic_ids = x86_init_noop,
.mpc_apic_id = default_mpc_apic_id,
.smp_read_mpc_oem = default_smp_read_mpc_oem,
.mpc_oem_bus_info = default_mpc_oem_bus_info,
.find_smp_config = default_find_smp_config,
.get_smp_config = default_get_smp_config,
},
.irqs = {
.pre_vector_init = init_ISA_irqs,
.intr_init = native_init_IRQ,
.trap_init = x86_init_noop,
},
.oem = {
.arch_setup = x86_init_noop,
.banner = default_banner,
},
.mapping = {
.pagetable_reserve = native_pagetable_reserve,
},
.paging = {
.pagetable_setup_start = native_pagetable_setup_start,
.pagetable_setup_done = native_pagetable_setup_done,
},
.timers = {
.setup_percpu_clockev = setup_boot_APIC_clock,
.tsc_pre_init = x86_init_noop,
.timer_init = hpet_time_init,
.wallclock_init = x86_init_noop,
},
.iommu = {
.iommu_init = iommu_init_noop,
},
.pci = {
.init = x86_default_pci_init,
.init_irq = x86_default_pci_init_irq,
.fixup_irqs = x86_default_pci_fixup_irqs,
},
};
4.3.4.1.4.3.9.2 native_init_IRQ()
该函数定义于arch/x86/kernel/irqinit.c:
void __init native_init_IRQ(void)
{
int i;
/*
* x86_init参见[4.3.4.1.4.3.9.1 legacy_pic/x86_init]节,其中x86_init.irqs.pre_vector_init
* 取值为init_ISA_irqs,因而如下语句调用函数init_ISA_irqs(),参见[4.3.4.1.4.3.9.2.1 init_ISA_irqs()]节
*/
/* Execute any quirks before the call gates are initialised: */
x86_init.irqs.pre_vector_init();
// 参见[4.3.4.1.4.3.9.2.2 apic_intr_init()]节
apic_intr_init();
/*
* Cover the whole vector space, no vector can escape
* us. (some of these will be overridden and become
* 'special' SMP interrupts)
*/
for (i = FIRST_EXTERNAL_VECTOR; i < NR_VECTORS; i++) {
/*
* IA32_SYSCALL_VECTOR could be used in trap_init already.
* used_vectors定义于arch/x86/kernel/traps.c
* used_vectors is BITMAP for irq which is not managed by percpu vector_irq
* used_vectors中的前32个比特位在trap_init()中被赋值,参见[4.3.4.1.4.3.5 trap_init()](#4-3-4-1-4-3-5-trap-init-)节
*/
if (!test_bit(i, used_vectors))
// 数组interrupt[]参见[4.3.4.1.4.3.9.2.3 interrupt[]](#4-3-4-1-4-3-9-2-3-interrupt-)节
set_intr_gate(i, interrupt[i-FIRST_EXTERNAL_VECTOR]);
}
// IRQ2 is cascade interrupt to second interrupt controller
if (!acpi_ioapic && !of_ioapic)
setup_irq(2, &irq2);
#ifdef CONFIG_X86_32
/*
* External FPU? Set up irq13 if so, for
* original braindamaged IBM FERR coupling.
*/
if (boot_cpu_data.hard_math && !cpu_has_fpu)
setup_irq(FPU_IRQ, &fpu_irq); // FPU_IRQ取值为13
irq_ctx_init(smp_processor_id());
#endif
}
4.3.4.1.4.3.9.2.1 init_ISA_irqs()
该函数用于设置ISA中断(IRQ 0x30-0x3F,参见9.1 中断处理简介节)所对应的中断处理程序,其定义于arch/x86/kernel/irqinit.c:
void __init init_ISA_irqs(void)
{
// 外部可屏蔽中断采用8259A中断控制器,参见[4.3.4.1.4.3.9.1 legacy_pic/x86_init]节和节
struct irq_chip *chip = legacy_pic->chip;
const char *name = chip->name;
int i;
#if defined(CONFIG_X86_64) || defined(CONFIG_X86_LOCAL_APIC)
init_bsp_APIC();
#endif
// 调用init_8259A()初始化8259A中断控制器,参见[4.3.4.1.4.3.9.1 legacy_pic/x86_init]节
legacy_pic->init(0);
// 依次设置8259A控制的16个中断向量对应的中断处理函数,即handle_level_irq()
for (i = 0; i < legacy_pic->nr_legacy_irqs; i++)
irq_set_chip_and_handler_name(i, chip, handle_level_irq, name);
}
其中,irq_set_chip_and_handler_name()设置中断控制器芯片及中断处理函数,其定义于kernel/irq/chip.c:
void irq_set_chip_and_handler_name(unsigned int irq, struct irq_chip *chip,
irq_flow_handler_t handle, const char *name)
{
irq_set_chip(irq, chip);
__irq_set_handler(irq, handle, 0, name);
}
/**
* irq_set_chip - set the irq chip for an irq
* @irq: irq number
* @chip: pointer to irq chip description structure
*/
int irq_set_chip(unsigned int irq, struct irq_chip *chip)
{
unsigned long flags;
struct irq_desc *desc = irq_get_desc_lock(irq, &flags, 0);
if (!desc)
return -EINVAL;
if (!chip)
chip = &no_irq_chip;
desc->irq_data.chip = chip;
irq_put_desc_unlock(desc, flags);
/*
* For !CONFIG_SPARSE_IRQ make the irq show up in
* allocated_irqs. For the CONFIG_SPARSE_IRQ case, it is
* already marked, and this call is harmless.
*/
irq_reserve_irq(irq);
return 0;
}
void __irq_set_handler(unsigned int irq, irq_flow_handler_t handle, int is_chained, const char *name)
{
unsigned long flags;
struct irq_desc *desc = irq_get_desc_buslock(irq, &flags, 0);
if (!desc)
return;
if (!handle) {
handle = handle_bad_irq;
} else {
if (WARN_ON(desc->irq_data.chip == &no_irq_chip))
goto out;
}
/* Uninstall? */
if (handle == handle_bad_irq) {
if (desc->irq_data.chip != &no_irq_chip)
mask_ack_irq(desc);
irq_state_set_disabled(desc);
desc->depth = 1;
}
// 设置中断处理函数为handle_level_irq(),参见[9.3.1.2.1 desc->handle_irq()/handle_level_irq()]节
desc->handle_irq = handle;
desc->name = name;
if (handle != handle_bad_irq && is_chained) {
irq_settings_set_noprobe(desc);
irq_settings_set_norequest(desc);
irq_settings_set_nothread(desc);
irq_startup(desc);
}
out:
irq_put_desc_busunlock(desc, flags);
}
4.3.4.1.4.3.9.2.2 apic_intr_init()
该函数设置APIC可屏蔽中断所对应的中断处理程序,其定义于arch/x86/kernel/irqinit.c:
static void __init apic_intr_init(void)
{
smp_intr_init();
#ifdef CONFIG_X86_THERMAL_VECTOR
alloc_intr_gate(THERMAL_APIC_VECTOR, thermal_interrupt); // IRQ 0xFA
#endif
#ifdef CONFIG_X86_MCE_THRESHOLD
alloc_intr_gate(THRESHOLD_APIC_VECTOR, threshold_interrupt); // IRQ 0xF9
#endif
#if defined(CONFIG_X86_64) || defined(CONFIG_X86_LOCAL_APIC)
/* self generated IPI for local APIC timer */
alloc_intr_gate(LOCAL_TIMER_VECTOR, apic_timer_interrupt); // IRQ 0xEF
/* IPI for X86 platform specific use */
alloc_intr_gate(X86_PLATFORM_IPI_VECTOR, x86_platform_ipi); // IRQ 0xF7
/* IPI vectors for APIC spurious and error interrupts */
alloc_intr_gate(SPURIOUS_APIC_VECTOR, spurious_interrupt); // IRQ 0xFF
alloc_intr_gate(ERROR_APIC_VECTOR, error_interrupt); // IRQ 0xFE
/* IRQ work interrupts: */
# ifdef CONFIG_IRQ_WORK
alloc_intr_gate(IRQ_WORK_VECTOR, irq_work_interrupt); // IRQ 0xF6
# endif
#endif
}
4.3.4.1.4.3.9.2.3 interrupt[]
数组interrupt[]定义于arch/x86/kernel/entry_32.S:
/*
* Build the entry stubs and pointer table with some assembler magic.
* We pack 7 stubs into a single 32-byte chunk, which will fit in a
* single cache line on all modern x86 implementations.
*/
.section .init.rodata,"a"
ENTRY(interrupt)
.section .entry.text, "ax"
.p2align 5
.p2align CONFIG_X86_L1_CACHE_SHIFT
ENTRY(irq_entries_start)
RING0_INT_FRAME
vector=FIRST_EXTERNAL_VECTOR // FIRST_EXTERNAL_VECTOR取值为0x20
.rept (NR_VECTORS-FIRST_EXTERNAL_VECTOR+6)/7 // 外层循环,共32次
.balign 32 // 32字节对齐
.rept 7 // 内层循环,共7次
.if vector < NR_VECTORS
.if vector <> FIRST_EXTERNAL_VECTOR
CFI_ADJUST_CFA_OFFSET -4 // 按照CFA规则修改前一个offset,以达到4字节对齐
.endif
1: pushl_cfi $(~vector+0x80) /* Note: always in signed byte range */ // 占2字节
.if ((vector-FIRST_EXTERNAL_VECTOR)%7) <> 6
jmp 2f // 跳转到2处,即long jmp,占5字节
.endif
.previous
.long 1b // 跳转到1处,即short jmp,占2字节
.section .entry.text, "ax"
vector=vector+1
.endif
.endr
2: jmp common_interrupt // 跳转到common_interrupt执行
.endr
END(irq_entries_start)
.previous
END(interrupt)
.previous
/*
* the CPU automatically disables interrupts when executing an IRQ vector,
* so IRQ-flags tracing has to follow that:
*/
.p2align CONFIG_X86_L1_CACHE_SHIFT
common_interrupt:
addl $-0x80,(%esp) /* Adjust vector into the [-256,-1] range */
SAVE_ALL // 保存中断处理程序可能用到的寄存器
TRACE_IRQS_OFF
movl %esp,%eax // 把栈顶指针传给eax寄存器,该寄存器的内容将作为do_IRQ()函数的入参
call do_IRQ // 调用do_IRQ()处理中断,参见[9.3.1 do_IRQ()]节
jmp ret_from_intr // 参见[9.3.2 ret_from_intr]节
ENDPROC(common_interrupt)
CFI_ENDPROC
ENTRY(interrupt)通过伪指令.rept和.endr,在代码段产生(NR_VECTORS - FIRST_EXTERNAL_VECTOR)个跳转到common_interrupt的汇编代码片段,起始地址为irq_entries_start;在数据段产生一个中断数组的符号interrupt,用于记录产生代码段中每个中断向量处理的汇编代码片段地址,在C语言中将interrupt符号作为中断数组变量导入(参见arch/x86/include/asm/hw_irq.h):
extern void (*__initconst interrupt[NR_VECTORS-FIRST_EXTERNAL_VECTOR])(void);
ENTRY(interrupt)编译之后,所生成的代码段和数据段内存布局如下:
ENTRIY(interrupt)汇编代码段主要由两个.rept构成,外层.rept循环(NR_VECTORS-FIRST_EXTERNAL_VECTOR+6)/7次,而其中每次内层.rept循环7次,内层循环所产生的代码以32字节对齐,内层.rept循环产生的代码如上图irq_entries_start中的粗黑方框所示。
以两层.rept循环生成jmp common_interrupt的目的在于:在内循环中,前6次循环产生的代码指令为push和short jmp,而第7次产生的代码指令为push和long jmp。push占2字节,short jmp占2字节,long jmp占5字节,故采取这种方式内层.rept循环7次产生的代码大小为:6 * (2 + 2) + 2 + 5 = 31 字节,而外层循环以32字节对齐。老版本每次都为push和long jmp,相对而言,这种新方法利用short jmp节省了内存开销。
每个中断门描述符将$(~vector+0x80)压栈后都会跳转到common_interrupt处执行。common_interrupt在保存中断现场之后,跳转到do_IRQ()进行中断处理,最后调用iret_from_intr进行中断返回、恢复中断上下文。
common_interrupt在调用do_IRQ()前,中断栈内存布局如下:
4.3.4.1.4.3.10 softirq_init()
该函数用于初始化软中断相关数据结构,其定义于kernel/softirq.c:
void __init softirq_init(void)
{
int cpu;
for_each_possible_cpu(cpu) {
int i;
// 参见[9.2.5 struct tasklet_struct / tasklet_vec[] / tasklet_hi_vec[]]节
per_cpu(tasklet_vec, cpu).tail = &per_cpu(tasklet_vec, cpu).head;
// 参见[9.2.5 struct tasklet_struct / tasklet_vec[] / tasklet_hi_vec[]]节
per_cpu(tasklet_hi_vec, cpu).tail = &per_cpu(tasklet_hi_vec, cpu).head;
for (i = 0; i < NR_SOFTIRQS; i++)
INIT_LIST_HEAD(&per_cpu(softirq_work_list[i], cpu)); // 参见softirq_work_list[]节
}
register_hotcpu_notifier(&remote_softirq_cpu_notifier);
/*
* 设置软中断TASKLET_SOFTIRQ的服务程序为tasklet_action(),
* 参见[9.2.2 struct softirq_action / softirq_vec[]]节和[4.3.4.1.4.3.10.1 tasklet_action()]节
*/
open_softirq(TASKLET_SOFTIRQ, tasklet_action);
/*
* 设置软中断HI_SOFTIRQ的服务程序为tasklet_hi_action(),
* 参见[9.2.2 struct softirq_action / softirq_vec[]]节和[4.3.4.1.4.3.10.2 tasklet_hi_action()]节
*/
open_softirq(HI_SOFTIRQ, tasklet_hi_action);
}
static struct notifier_block __cpuinitdata remote_softirq_cpu_notifier = {
.notifier_call = remote_softirq_cpu_notify,
};
4.3.4.1.4.3.10.1 tasklet_action()
该函数定义于kernel/softirq.c:
static void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
// 从tasklet_vec中获取列表,参见[9.2.5 struct tasklet_struct / tasklet_vec[] / tasklet_hi_vec[]]节
local_irq_disable();
list = __this_cpu_read(tasklet_vec.head);
__this_cpu_write(tasklet_vec.head, NULL);
__this_cpu_write(tasklet_vec.tail, &__get_cpu_var(tasklet_vec).head);
local_irq_enable();
while (list) {
struct tasklet_struct *t = list;
list = list->next;
if (tasklet_trylock(t)) {
if (!atomic_read(&t->count)) {
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
t->func(t->data); // 调用该tasklet的处理函数
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
local_irq_disable();
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
// 将当前CPU对应的irq_stat变量中的域__softirq_pending中的标志位TASKLET_SOFTIRQ置位
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
}
4.3.4.1.4.3.10.2 tasklet_hi_action()
该函数定义于kernel/softirq.c:
static void tasklet_hi_action(struct softirq_action *a)
{
struct tasklet_struct *list;
local_irq_disable();
list = __this_cpu_read(tasklet_hi_vec.head);
__this_cpu_write(tasklet_hi_vec.head, NULL);
__this_cpu_write(tasklet_hi_vec.tail, &__get_cpu_var(tasklet_hi_vec).head);
local_irq_enable();
while (list) {
struct tasklet_struct *t = list;
list = list->next;
if (tasklet_trylock(t)) {
if (!atomic_read(&t->count)) {
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
t->func(t->data); // 调用该tasklet的处理函数
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
local_irq_disable();
t->next = NULL;
*__this_cpu_read(tasklet_hi_vec.tail) = t;
__this_cpu_write(tasklet_hi_vec.tail, &(t->next));
__raise_softirq_irqoff(HI_SOFTIRQ);
local_irq_enable();
}
}
4.3.4.1.4.3.11 vfs_caches_init()
该函数定义于fs/dcache.c:
struct kmem_cache *names_cachep __read_mostly;
void __init vfs_caches_init(unsigned long mempages)
{
unsigned long reserve;
/* Base hash sizes on available memory, with a reserve equal to
150% of current kernel size */
reserve = min((mempages - nr_free_pages()) * 3/2, mempages - 1);
mempages -= reserve;
// 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
names_cachep = kmem_cache_create("names_cache", PATH_MAX, 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL);
dcache_init(); // 参见[4.3.4.1.4.3.11.1 dcache_init()]节
inode_init(); // 参见[4.3.4.1.4.3.11.2 inode_init()]节
files_init(mempages); // 参见[4.3.4.1.4.3.11.3 files_init()]节
mnt_init(); // 参见[4.3.4.1.4.3.11.4 mnt_init()]节
bdev_cache_init(); // 参见[4.3.4.1.4.3.11.5 bdev_cache_init()]节
chrdev_init(); // 参见[4.3.4.1.4.3.11.6 chrdev_init()]节
}
4.3.4.1.4.3.11.1 dcache_init()
该函数与dcache_init_early()类似,如果在dache_init_early()已经创建了目录项哈希表,则dcache_init()不再创建;否则,创建目录项哈希表。因此,调用了本函数后,目录项哈希表(dentry_hashtable)一定存在了。其定义于fs/dcache.c:
static unsigned int d_hash_mask __read_mostly;
static unsigned int d_hash_shift __read_mostly;
static struct hlist_bl_head *dentry_hashtable __read_mostly;
static __initdata unsigned long dhash_entries;
static void __init dcache_init(void)
{
int loop;
/*
* A constructor could be added for stable state like the lists,
* but it is probably not worth it because of the cache nature
* of the dcache.
*/
dentry_cache = KMEM_CACHE(dentry, SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|SLAB_MEM_SPREAD);
// 参见[4.3.4.1.4.3.4.1 dcache_init_early()]节
/* Hash may have been set up in dcache_init_early */
if (!hashdist)
return;
dentry_hashtable = alloc_large_system_hash("Dentry cache",
sizeof(struct hlist_bl_head),
dhash_entries,
13,
0,
&d_hash_shift,
&d_hash_mask,
0);
for (loop = 0; loop < (1 << d_hash_shift); loop++)
INIT_HLIST_BL_HEAD(dentry_hashtable + loop);
}
4.3.4.1.4.3.11.2 inode_init()
该函数与inode_init_early()类似,如果在inode_init_early()已经创建了索引节点哈希表,则inode_init()不再创建;否则,创建索引节点哈希表。因此,调用了本函数后,索引节点哈希表(inode_hashtable)一定存在了。其定义于fs/inode.c:
static unsigned int i_hash_mask __read_mostly;
static unsigned int i_hash_shift __read_mostly;
static struct hlist_head *inode_hashtable __read_mostly;
static __initdata unsigned long ihash_entries;
void __init inode_init(void)
{
int loop;
/* inode slab cache */
// 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
inode_cachep = kmem_cache_create("inode_cache",
sizeof(struct inode),
0,
(SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|
SLAB_MEM_SPREAD),
init_once);
// 参见[4.3.4.1.4.3.4.2 inode_init_early()]节
/* Hash may have been set up in inode_init_early */
if (!hashdist)
return;
inode_hashtable = alloc_large_system_hash("Inode-cache",
sizeof(struct hlist_head),
ihash_entries,
14,
0,
&i_hash_shift,
&i_hash_mask,
0);
for (loop = 0; loop < (1 << i_hash_shift); loop++)
INIT_HLIST_HEAD(&inode_hashtable[loop]);
}
4.3.4.1.4.3.11.3 files_init()
该函数定义于fs/fs_table.c:
/* sysctl tunables... */
struct files_stat_struct files_stat = {
.max_files = NR_FILE
};
DECLARE_LGLOCK(files_lglock);
DEFINE_LGLOCK(files_lglock);
static struct percpu_counter nr_files __cacheline_aligned_in_smp;
void __init files_init(unsigned long mempages)
{
unsigned long n;
// 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
filp_cachep = kmem_cache_create("filp", sizeof(struct file), 0,
SLAB_HWCACHE_ALIGN | SLAB_PANIC, NULL);
/*
* One file with associated inode and dcache is very roughly 1K.
* Per default don't use more than 10% of our memory for files.
*/
n = (mempages * (PAGE_SIZE / 1024)) / 10;
/*
* NR_FILE定义于include/linux/fs.h,取值为8192
* max_t()取n和NR_FILE中的最大值
*/
files_stat.max_files = max_t(unsigned long, n, NR_FILE);
files_defer_init(); // 参见[4.3.4.1.4.3.11.3.1 files_defer_init()]节
lg_lock_init(files_lglock); // 实际调用函数files_lglock_lock_init()
percpu_counter_init(&nr_files, 0); // 将nr_files.count设置为0
}
4.3.4.1.4.3.11.3.1 files_defer_init()
该函数定义于fs/file.c:
int sysctl_nr_open_max = 1024 * 1024; /* raised later */
void __init files_defer_init(void)
{
int i;
for_each_possible_cpu(i)
fdtable_defer_list_init(i);
sysctl_nr_open_max = min((size_t)INT_MAX, ~(size_t)0/sizeof(void *)) & -BITS_PER_LONG;
}
其中,fdtable_defer_list_init()用于初始化指定CPU的变量fdtable_defer_list,参见fs/file.c:
/*
* We use this list to defer free fdtables that have vmalloced
* sets/arrays. By keeping a per-cpu list, we avoid having to embed
* the work_struct in fdtable itself which avoids a 64 byte (i386) increase in
* this per-task structure.
*/
static DEFINE_PER_CPU(struct fdtable_defer, fdtable_defer_list);
static void __devinit fdtable_defer_list_init(int cpu)
{
struct fdtable_defer *fddef = &per_cpu(fdtable_defer_list, cpu);
spin_lock_init(&fddef->lock);
// 将fddef->wq.func赋值为free_fdtable_work,用于释放该wq
INIT_WORK(&fddef->wq, free_fdtable_work);
fddef->next = NULL; // 初始化fdtable链表
}
变量fdtable_defer_list的结构:
4.3.4.1.4.3.11.4 mnt_init()
该函数定义于fs/namespace.c:
static struct list_head *mount_hashtable __read_mostly;
static struct kmem_cache *mnt_cache __read_mostly;
static struct rw_semaphore namespace_sem;
/* /sys/fs */
struct kobject *fs_kobj;
DEFINE_BRLOCK(vfsmount_lock);
void __init mnt_init(void)
{
unsigned u;
int err;
init_rwsem(&namespace_sem);
// 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
mnt_cache = kmem_cache_create("mnt_cache", sizeof(struct vfsmount),
0, SLAB_HWCACHE_ALIGN | SLAB_PANIC, NULL);
mount_hashtable = (struct list_head *)__get_free_page(GFP_ATOMIC);
if (!mount_hashtable)
panic("Failed to allocate mount hash table\n");
printk(KERN_INFO "Mount-cache hash table entries: %lu\n", HASH_SIZE);
for (u = 0; u < HASH_SIZE; u++)
INIT_LIST_HEAD(&mount_hashtable[u]);
br_lock_init(vfsmount_lock);
/*
* 注册并安装sysfs文件系统,参见[4.3.4.1.4.3.11.4.1 sysfs_init()]节:
* - 注册sysfs文件系统后,file_systems链表中添加了一个新元素sysfs_fs_type;
* - 安装sysfs文件系统后,生成了sysfs_mnt。通常,sysfs文件系统被安装在/sys下,
* 可通过 # mount 命令查看
*/
err = sysfs_init();
if (err)
printk(KERN_WARNING "%s: sysfs_init error: %d\n", __func__, err);
// 创建目录/sys/fs,参见[15.7.1.2 kobject_create_and_add()]节
fs_kobj = kobject_create_and_add("fs", NULL);
if (!fs_kobj)
printk(KERN_WARNING "%s: kobj create error\n", __func__);
// 注册rootfs文件系统,参见[4.3.4.1.4.3.11.4.2 init_rootfs()]节
init_rootfs();
// 安装rootfs文件系统,生成系统根目录/,参见[4.3.4.1.4.3.11.4.3 init_mount_tree()]节和[NOTE]
init_mount_tree();
}
为什么不直接把真实的文件系统设置为根文件系统?
答案很简单,因为内核中没有根文件系统的设备驱动,如USB等存放根文件系统的设备驱动,而且即便将根文件系统的设备驱动编译到内核中,此时这些设备驱动还尚未加载,其实所有的设备驱动都是由后面的kernel_init线程加载的,所以需要CPIO initrd, initrd和RAMDisk initrd。另外,root设备都是以设备文件的方式指定的,如果没有根文件系统,设备文件怎么可能存在呢?
start_kernel()
-> vfs_caches_init()
-> mnt_init()
-> init_mount_tree() // 设置根文件系统
-> rest_init()
-> kernel_init()
-> do_pre_smp_initcalls() // 加载设备驱动
-> do_basic_setup() // 加载设备驱动
4.3.4.1.4.3.11.4.1 sysfs_init()
该函数定义于fs/sysfs/mount.c:
static struct vfsmount *sysfs_mnt;
struct kmem_cache *sysfs_dir_cachep;
int __init sysfs_init(void)
{
int err = -ENOMEM;
// 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
sysfs_dir_cachep = kmem_cache_create("sysfs_dir_cache", sizeof(struct sysfs_dirent), 0, 0, NULL);
if (!sysfs_dir_cachep)
goto out;
// 调用bdi_init(&sysfs_backing_dev_info)初始化变量sysfs_backing_dev_info,其定义于fs/sysfs/inode.c
err = sysfs_inode_init();
if (err)
goto out_err;
// 将sysfs文件系统注册到file_systems中,参见[11.2.2.1 注册/注销文件系统]节和[11.3.5.2 Sysfs的编译及初始化]节
err = register_filesystem(&sysfs_fs_type);
if (!err) {
// 安装sysfs文件系统,参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
sysfs_mnt = kern_mount(&sysfs_fs_type);
if (IS_ERR(sysfs_mnt)) {
printk(KERN_ERR "sysfs: could not mount!\n");
err = PTR_ERR(sysfs_mnt);
sysfs_mnt = NULL;
// 若出错,则从file_systems中注销文件系统sysfs_fs_type,参见[11.2.2.1 注册/注销文件系统]节
unregister_filesystem(&sysfs_fs_type);
goto out_err;
}
} else
goto out_err;
out:
return err;
out_err:
kmem_cache_destroy(sysfs_dir_cachep);
sysfs_dir_cachep = NULL;
goto out;
}
4.3.4.1.4.3.11.4.2 init_rootfs()
关于rootfs的介绍,参见Documentation/filesystems/ramfs-rootfs-initramfs.txt:
What is rootfs?
Rootfs is a special instance of ramfs (or tmpfs, if that’s enabled), which is always present in 2.6 systems. You can’t unmount rootfs for approximately the same reason you can’t kill the init process; rather than having special code to check for and handle an empty list, it’s smaller and simpler for the kernel to just make sure certain lists can’t become empty.
Most systems just mount another filesystem over rootfs and ignore it. The amount of space an empty instance of ramfs takes up is tiny.
一般文件系统的注册都是通过宏module_init以及函数do_initcalls()来完成的,但是rootfs的注册却是通过函数init_rootfs()来完成的,这意味着rootfs的注册过程是Linux内核初始化阶段不可分割的一部分!
函数init_rootfs()定义于fs/ramfs/inode.c:
int __init init_rootfs(void)
{
int err;
// 初始化变量ramfs_backing_dev_info
err = bdi_init(&ramfs_backing_dev_info);
if (err)
return err;
/*
* 将rootfs文件系统注册到file_systems中,
* 参见[11.2.2.1 注册/注销文件系统]节和[11.3.2.2 Rootfs编译与初始化及安装过程]节
*/
err = register_filesystem(&rootfs_fs_type);
if (err)
bdi_destroy(&ramfs_backing_dev_info);
return err;
}
4.3.4.1.4.3.11.4.3 init_mount_tree()
该函数定义于fs/namespace.c:
static void __init init_mount_tree(void)
{
struct vfsmount *mnt;
struct mnt_namespace *ns;
struct path root;
/*
* 文件系统rootfs的注册,参见[11.2.2.4.1.2.1 do_kern_mount()]节;
* 此过程中调用了rootfs_mount(),参见[11.2.2.2.1.2.2 rootfs_mount()]节
*/
mnt = do_kern_mount("rootfs", 0, "rootfs", NULL);
if (IS_ERR(mnt))
panic("Can't create rootfs");
// 创建新的namespace,并与mnt链接起来,参见Filesystem_20.jpg中红色框
ns = create_mnt_ns(mnt);
if (IS_ERR(ns))
panic("Can't allocate initial namespace");
init_task.nsproxy->mnt_ns = ns; // 设置INIT进程的根目录
get_mnt_ns(ns); // 增加ns->count计数
root.mnt = ns->root;
root.dentry = ns->root->mnt_root;
// 设置当前进程的current->fs->pwd
set_fs_pwd(current->fs, &root);
// 设置当前进程的current->fs->root, 即将当前的文件系统设置为根文件系统
set_fs_root(current->fs, &root);
}
函数init_mount_tree()执行后的数据结构:
此后,由init_task进程fork出来的子进程也继承了init_task->nsproxy->mnt_ns信息,参见7.2.2.2 copy_process()节中的:
retval = copy_fs(clone_flags, p);
综上,函数init_mount_tree()为VFS建立了根目录”/”,而一旦有了根目录,那么这棵树就可以发展壮大,例如: 可以通过系统调用sys_mkdir在这棵树上建立新的叶子节点等。
NOTE: Filesystem_20.jpg
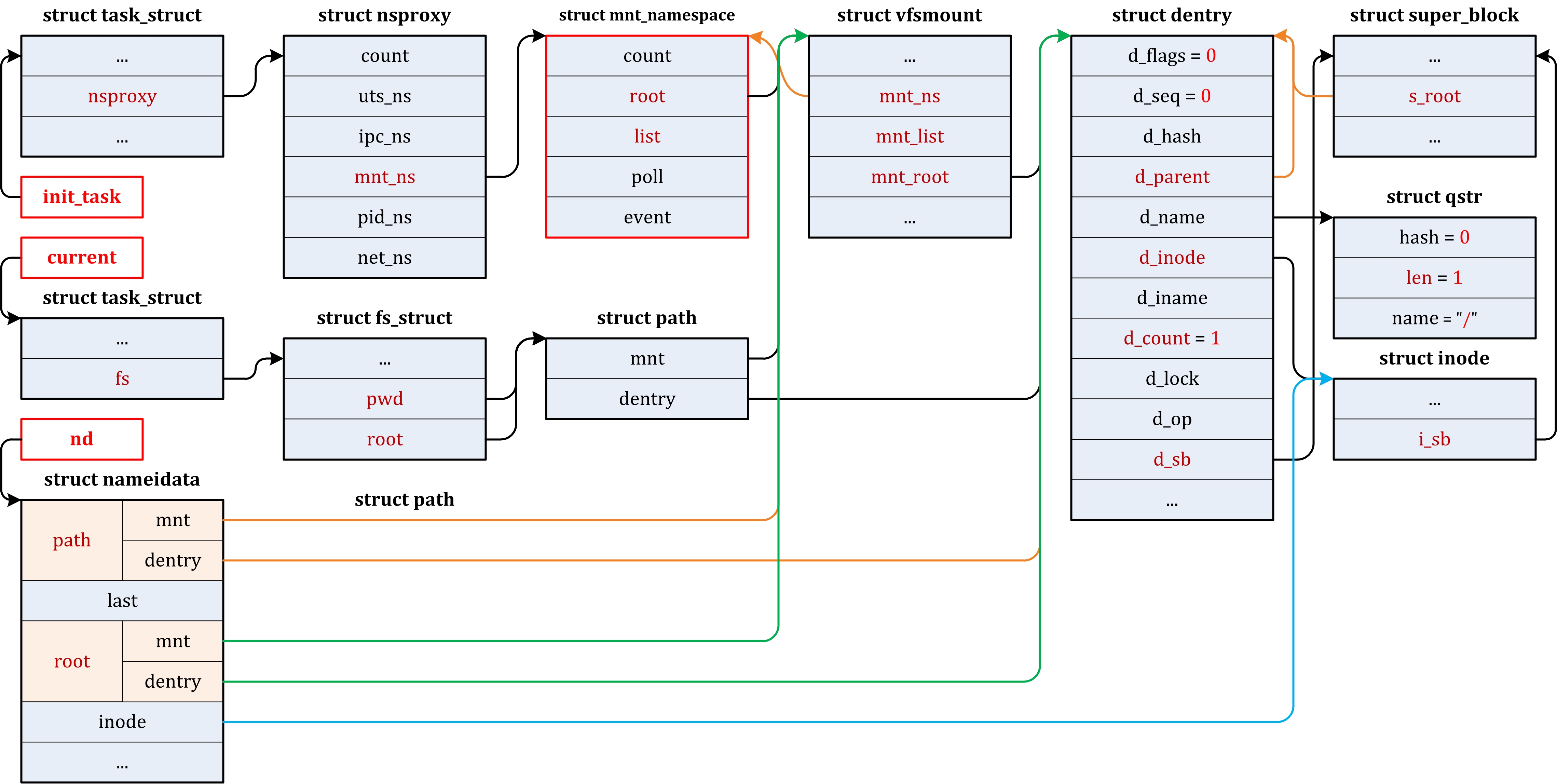
4.3.4.1.4.3.11.5 bdev_cache_init()
- 字符设备初始化函数之一:bdev_cache_init(),参见本节
- 字符设备初始化函数之二:genhd_device_init(),参见10.4.2 块设备的初始化/genhd_device_init()节
该函数定义于fs/block_dev.c:
static __cacheline_aligned_in_smp DEFINE_SPINLOCK(bdev_lock);
static struct kmem_cache * bdev_cachep __read_mostly;
static struct file_system_type bd_type = {
.name = "bdev",
/*
* bd_mount()通过如下函数被调用:
* bdev_cache_init()->kern_mount()->kern_mount_data()
* ->vfs_kern_mount()->mount_fs()中的type->mount()
*/
.mount = bd_mount,
.kill_sb = kill_anon_super,
};
struct super_block *blockdev_superblock __read_mostly;
void __init bdev_cache_init(void)
{
int err;
struct vfsmount *bd_mnt;
// 创建块设备缓存,参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
bdev_cachep = kmem_cache_create("bdev_cache", sizeof(struct bdev_inode), 0,
(SLAB_HWCACHE_ALIGN|SLAB_RECLAIM_ACCOUNT|SLAB_MEM_SPREAD|SLAB_PANIC), init_once);
// 注册bdev文件系统到file_systems,参见[11.2.2.1 注册/注销文件系统]节
err = register_filesystem(&bd_type);
if (err)
panic("Cannot register bdev pseudo-fs");
// 安装bdev文件系统,参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
bd_mnt = kern_mount(&bd_type);
if (IS_ERR(bd_mnt))
panic("Cannot create bdev pseudo-fs");
/*
* This vfsmount structure is only used to obtain the
* blockdev_superblock, so tell kmemleak not to report it.
*/
kmemleak_not_leak(bd_mnt);
blockdev_superblock = bd_mnt->mnt_sb; /* For writeback */
}
4.3.4.1.4.3.11.6 chrdev_init()
- 字符设备初始化函数之一:
chrdev_init(),参见4.3.4.1.4.3.11.6 chrdev_init()节 - 字符设备初始化函数之二:
chr_dev_init(),参见10.3.2 字符设备的初始化/chr_dev_init()节
该函数定义于fs/char_dev.c:
struct backing_dev_info directly_mappable_cdev_bdi = {
.name = "char",
.capabilities = (
#ifdef CONFIG_MMU
/* permit private copies of the data to be taken */
BDI_CAP_MAP_COPY |
#endif
/* permit direct mmap, for read, write or exec */
BDI_CAP_MAP_DIRECT |
BDI_CAP_READ_MAP | BDI_CAP_WRITE_MAP | BDI_CAP_EXEC_MAP |
/* no writeback happens */
BDI_CAP_NO_ACCT_AND_WRITEBACK),
};
static struct kobj_map *cdev_map;
static DEFINE_MUTEX(chrdevs_lock);
void __init chrdev_init(void)
{
/*
* 变量cdev_map在如下函数中被访问:
* - cdev_map(), 参见[10.3.3.3.3.1 cdev_add()]节
* - kobj_lookup(), 参见[10.3.3.3.4.1 kobj_lookup()]节
*/
cdev_map = kobj_map_init(base_probe, &chrdevs_lock);
bdi_init(&directly_mappable_cdev_bdi);
}
初始化完成后的数据结构:
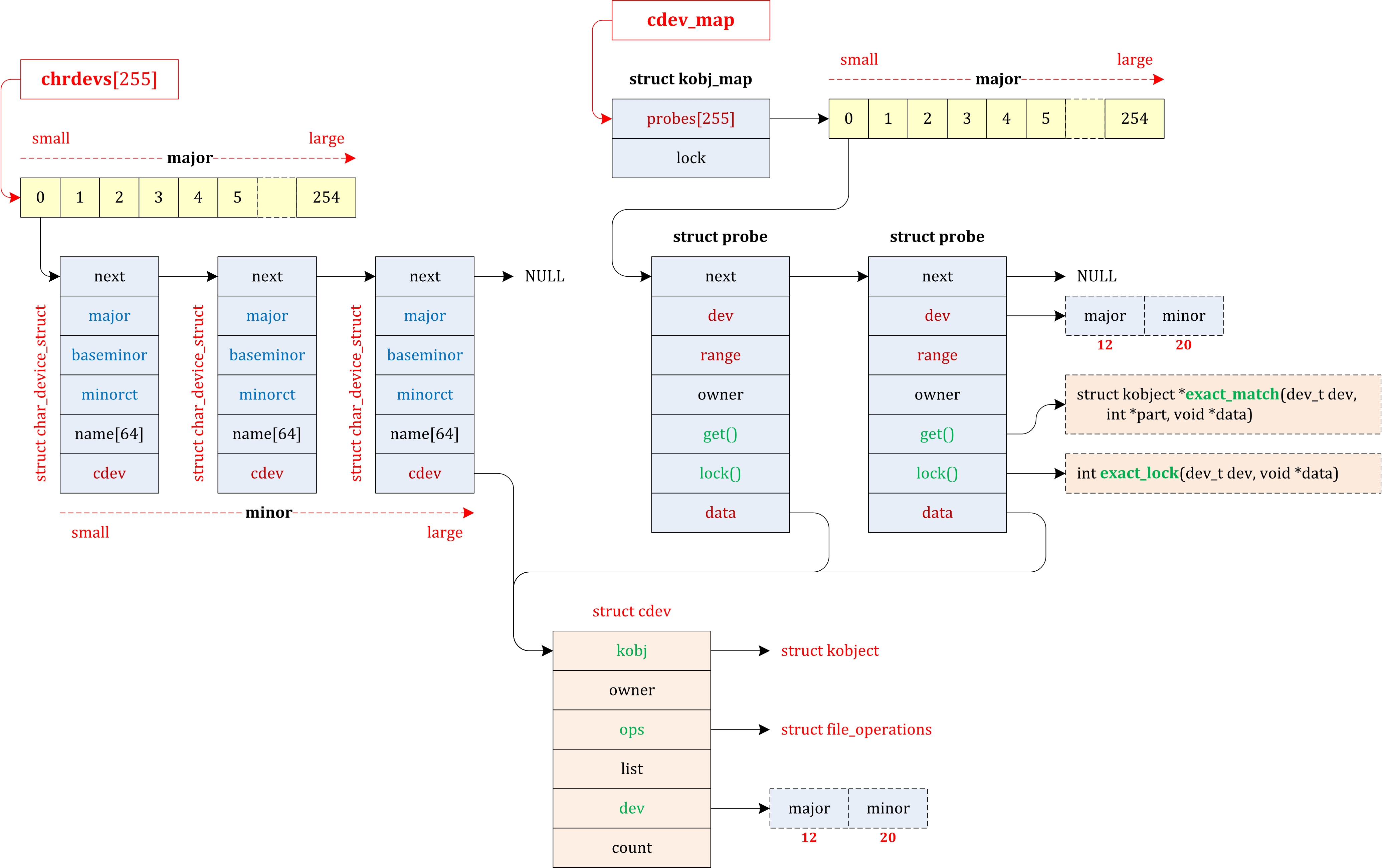
图中struct probe的域data指向struct cdev类型的对象,由函数cdev_add()设置,参见10.3.3.3.3.1 cdev_add()节。
4.3.4.1.4.3.12 proc_root_init()
该函数定义于fs/proc/root.c:
static struct file_system_type proc_fs_type = {
.name = "proc",
.mount = proc_mount, // 参见[11.2.2.2.1.2.4 proc_mount()]节
.kill_sb = proc_kill_sb,
};
struct pid_namespace init_pid_ns = {
.kref = {
.refcount = ATOMIC_INIT(2),
},
.pidmap = {
[ 0 ... PIDMAP_ENTRIES-1] = { ATOMIC_INIT(BITS_PER_PAGE), NULL }
},
.last_pid = 0,
.level = 0,
// 初始化进程描述符,参见[7.2.4.1 进程0/swapper, swapper/0, swapper/1, ...]节
.child_reaper = &init_task,
};
void __init proc_root_init(void)
{
int err;
// 分配缓存空间proc_inode_cachep
proc_init_inodecache();
// 注册proc文件系统,参见[11.2.2.1 注册/注销文件系统]节
err = register_filesystem(&proc_fs_type);
if (err)
return;
/*
* 通过调用kern_mount_data()来安装proc文件系统,
* 参见[11.2.2.2 安装文件系统(1)/kern_mount()]节和[11.2.2.2.1.2.4 proc_mount()]节
*/
err = pid_ns_prepare_proc(&init_pid_ns);
if (err) {
unregister_filesystem(&proc_fs_type);
return;
}
/*
* 创建/proc/mounts到/proc/self/mounts的链接,即/proc/mounts -> /proc/self/mounts
* 通过命令 # cat /proc/mounts,可以查看当前系统中安装的文件系统,参见[11.3 具体的文件系统]节
*/
proc_symlink("mounts", NULL, "self/mounts");
// 创建/proc/net到/proc/self/net的链接,即/proc/net -> /proc/self/net
proc_net_init();
#ifdef CONFIG_SYSVIPC
proc_mkdir("sysvipc", NULL); // 创建/proc/sysvipc目录
#endif
proc_mkdir("fs", NULL); // 创建/proc/fs目录
proc_mkdir("driver", NULL); // 创建/proc/drivers目录
// 创建/proc/fs/nfsd目录
proc_mkdir("fs/nfsd", NULL); /* somewhere for the nfsd filesystem to be mounted */
#if defined(CONFIG_SUN_OPENPROMFS) || defined(CONFIG_SUN_OPENPROMFS_MODULE)
/* just give it a mountpoint */
proc_mkdir("openprom", NULL); // 创建/proc/openprom目录
#endif
/*
* 创建目录: /proc/tty, /proc/tty/ldisc, /proc/tty/driver,
* /proc/tty/ldiscs, /proc/tty/drivers
*/
proc_tty_init();
#ifdef CONFIG_PROC_DEVICETREE
proc_device_tree_init(); // 创建/proc/device-tree目录
#endif
proc_mkdir("bus", NULL); // 创建/proc/bus目录
proc_sys_init(); // 创建/proc/sys目录
}
4.3.4.1.4.3.13 rest_init()
在函数start_kernel()的最后,调用函数rest_init()进行后续的初始化。在init/main.c中,包含如下有关rest_init()的代码:
// 定义并初始化变量kthreadd_done
static __initdata DECLARE_COMPLETION(kthreadd_done);
...
static noinline void __init_refok rest_init(void)
{
int pid;
rcu_scheduler_starting();
/*
* We need to spawn init first so that it obtains pid 1, however
* the init task will end up wanting to create kthreads, which, if
* we schedule it before we create kthreadd, will OOPS.
*/
/*
* 调用kernel_thread()创建pid=1的内核线程,即init线程,参见[7.2.1.4 kernel_thread()]节。
* 该线程将执行kernel_init()函数,参见[4.3.4.1.4.3.13.1 kernel_init()]节
*/
kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
numa_default_policy();
/*
* 调用kernel_thread()创建pid=2的内核线程,即kthreadd线程,参见[7.2.1.4 kernel_thread()]节。
* 该线程执行kthreadd()函数,参见[4.3.4.1.4.3.13.2 kthreadd()]节。
* 对于全局链表kthread_create_list中的每一项,执行函数kthread()
*/
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
rcu_read_lock();
// kthreadd_task的定义参见kernel/kthread.c: struct task_struct *kthreadd_task;
kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns);
rcu_read_unlock();
// 通知kernel_init进程,kthreadd已经完成,参见[4.3.4.1.4.3.13.1 kernel_init()]节
complete(&kthreadd_done);
/*
* The boot idle thread must execute schedule()
* at least once to get things moving:
*/
init_idle_bootup_task(current);
preempt_enable_no_resched(); // 与配置CONFIG_PREEMPT_COUNT有关,参见include/linux/preempt.h
schedule(); // 如果存在一个准备好的进程,则运行它;否则,调用下面的cpu_init()函数
/* Call into cpu_idle with preempt disabled */
preempt_disable(); // 与配置CONFIG_PREEMPT_COUNT有关,参见[16.10.2 preempt_disable()]节
cpu_idle(); // 参见[4.3.4.1.4.3.13.3 cpu_idle()]节
}
4.3.4.1.4.3.13.1 kernel_init()
该函数定义于init/main.c:
static int __init kernel_init(void * unused)
{
/*
* Wait until kthreadd is all set-up.
*/
// 等待kthreadd完成,参见[4.3.4.1.4.3.13 rest_init()]节中的语句rest_init() -> complete(&kthreadd_done)
wait_for_completion(&kthreadd_done);
/*
* init can allocate pages on any node
*/
set_mems_allowed(node_states[N_HIGH_MEMORY]);
/*
* init can run on any cpu.
*/
set_cpus_allowed_ptr(current, cpu_all_mask);
cad_pid = task_pid(current);
smp_prepare_cpus(setup_max_cpus);
do_pre_smp_initcalls(); // 参见[4.3.4.1.4.3.13.1.1 do_pre_smp_initcalls()]节
lockup_detector_init();
smp_init();
sched_init_smp();
do_basic_setup(); // 参见[4.3.4.1.4.3.13.1.2 do_basic_setup()]节
/* Open the /dev/console on the rootfs, this should never fail */
if (sys_open((const char __user *) "/dev/console", O_RDWR, 0) < 0)
printk(KERN_WARNING "Warning: unable to open an initial console.\n");
(void) sys_dup(0);
(void) sys_dup(0);
/*
* check if there is an early userspace init. If yes, let it do all
* the work
*/
/*
* 内核参数"rdinit="用于设置ramdisk_execute_command,
* 参见init/main.c:rdinit_setup();
* 若无内核参数"rdinit=",则设置ramdisk_execute_command="/init",
* 即initrd.img中的init,参见[4.3.4.1.4.3.13.1.4 init_post()]节
*/
if (!ramdisk_execute_command)
ramdisk_execute_command = "/init";
/*
* 若ramdisk_execute_command指定的初始化程序不存在,
* 则复位ramdisk_execute_command = NULL;
* 以避免init_post()执行该初始化程序,参见[4.3.4.1.4.3.13.1.4 init_post()]节
*/
if (sys_access((const char __user *) ramdisk_execute_command, 0) != 0) {
ramdisk_execute_command = NULL;
prepare_namespace(); // 参见[4.3.4.1.4.3.13.1.3 prepare_namespace()]节
}
/*
* Ok, we have completed the initial bootup, and
* we're essentially up and running. Get rid of the
* initmem segments and start the user-mode stuff..
*/
init_post(); // 参见[4.3.4.1.4.3.13.1.4 init_post()]节
return 0;
}
4.3.4.1.4.3.13.1.1 do_pre_smp_initcalls()
该函数定义于init/main.c:
extern initcall_t __initcall_start[], __initcall_end[], __early_initcall_end[];
static void __init do_pre_smp_initcalls(void)
{
initcall_t *fn;
for (fn = __initcall_start; fn < __early_initcall_end; fn++)
do_one_initcall(*fn); // 参见[13.5.1.1.1.2 do_one_initcall()]节
}
4.3.4.1.4.3.13.1.2 do_basic_setup()
该函数定义于init/main.c:
static void __init do_basic_setup(void)
{
cpuset_init_smp();
usermodehelper_init(); // 参见[13.3.2.2.1 khelper_wq]节
shmem_init();
driver_init(); // 参见[10.2.1 设备驱动程序的初始化/driver_init()]节
init_irq_proc();
do_ctors();
usermodehelper_enable();
do_initcalls(); // 参见[13.5.1.1 module被编译进内核时的初始化过程]节
}
4.3.4.1.4.3.13.1.3 prepare_namespace()
该函数定义于init/do_mounts.c:
/*
* Prepare the namespace - decide what/where to mount, load ramdisks, etc.
*/
void __init prepare_namespace(void)
{
int is_floppy;
/*
* 对于将根文件系统存放到USB或者SCSI设备上的情况,Kernel需要
* 等待这些耗时比较久的设备驱动加载完毕,故此处存在一个root_delay
*
* 内核参数"rootdelay="设置root_delay,
* 参见init/do_mounts.c中的root_delay_setup()
*/
if (root_delay) {
printk(KERN_INFO "Waiting %dsec before mounting root device...\n", root_delay);
ssleep(root_delay);
}
/*
* wait for the known devices to complete their probing
*
* Note: this is a potential source of long boot delays.
* For example, it is not atypical to wait 5 seconds here
* for the touchpad of a laptop to initialize.
*/
wait_for_device_probe();
md_run_setup();
/*
* 根据内核参数"root="来设置saved_root_name[],
* 参见init/do_mounts.c中的root_dev_setup().
*
* Set the root_device_name variable with the device
* filename obtained from the "root" boot parameter.
* Also, sets the ROOT_DEV variable with the major
* and minor numbers of the same device file.
*
* 内核参数"root="可通过下列命令查看:
* chenwx@chenwx ~ $ cat /proc/cmdline
* BOOT_IMAGE=/boot/vmlinuz-3.11.0-12-generic \
* root=UUID=fe67c2d0-9b0f-4fd6-8e97-463ce95a7e0c \
* ro quiet splash vt.handoff=7
*/
if (saved_root_name[0]) {
root_device_name = saved_root_name;
/*
* Try #1: 若内核参数"root="代表的字符串以"mtd"或"ubi"开头,
* 则调用mount_block_root()解析该内核参数
*/
if (!strncmp(root_device_name, "mtd", 3) || !strncmp(root_device_name, "ubi", 3)) {
mount_block_root(root_device_name, root_mountflags);
goto out;
}
/*
* Try #2: 若内核参数"root="代表的字符串以"/dev/"或"PARTUUID="开头,
* 则将/dev/<disk_name>转换为Device Number.
* 参见源代码中对函数name_to_dev_t()的注释。
*/
ROOT_DEV = name_to_dev_t(root_device_name);
if (strncmp(root_device_name, "/dev/", 5) == 0)
root_device_name += 5;
}
/*
* Try #3: 若内核参数"root="代表的字符串以"UUID=<uuid>"开头,
* 则需要加载initrd.image,并由其中的init程序(参见[4.3.4.1.4.3.13.1 kernel_init()]节)
* 负责解析"root="字符串"UUID=<uuid>",并挂在相应的设备。
*
* 函数initrd_load()用于加载映像/boot/initrd.img-3.11.0-12-generic,
* 参见[11.3.3.2.2 CONFIG_BLK_DEV_INITRD=y]节
*
* 可通过下列命令解压initrd.img映像:
* $ mv initrd.img-3.11.0-12-generic initrd.img.gz
* $ gunzip initrd.img.gz
* $ cpio -i -d < initrd.img
* $ rm -rf initrd.img
* $ ls
* bin conf etc init lib run sbin scripts usr var
*/
if (initrd_load())
goto out;
/*
* 内核参数"rootwait"设置root_wait,
* 参见init/do_mounts.c中的rootwait_setup()
*/
/* wait for any asynchronous scanning to complete */
if ((ROOT_DEV == 0) && root_wait) {
printk(KERN_INFO "Waiting for root device %s...\n", saved_root_name);
while (driver_probe_done() != 0 || (ROOT_DEV = name_to_dev_t(saved_root_name)) == 0)
msleep(100);
async_synchronize_full();
}
is_floppy = MAJOR(ROOT_DEV) == FLOPPY_MAJOR;
if (is_floppy && rd_doload && rd_load_disk(0))
ROOT_DEV = Root_RAM0;
// 根据ROOT_DEV挂载根文件系统,参见下文;
mount_root();
out:
// 挂载devtmpfs文件系统,参见[11.3.10.3 Devtmpfs的安装]节
devtmpfs_mount("dev");
/*
* Moves the mount point of the mounted filesystem on the root
* directory of the rootfs filesystem.
* Notice that the rootfs special filesystem cannot be unmounted,
* it's only hidden under the disk-based root filesystem.
* 系统调用sys_mount()参见[11.2.2.4 安装文件系统(2)/sys_mount()]节,
* 文件系统rootfs参见[11.2.3 虚拟文件系统(VFS)的初始化]节
*/
sys_mount(".", "/", NULL, MS_MOVE, NULL);
sys_chroot((const char __user __force *)".");
}
其中,函数mount_root()定义于init/do_mounts.c:
void __init mount_root(void)
{
#ifdef CONFIG_ROOT_NFS
if (MAJOR(ROOT_DEV) == UNNAMED_MAJOR) {
if (mount_nfs_root())
return;
printk(KERN_ERR "VFS: Unable to mount root fs via NFS, trying floppy.\n");
ROOT_DEV = Root_FD0;
}
#endif
#ifdef CONFIG_BLK_DEV_FD
if (MAJOR(ROOT_DEV) == FLOPPY_MAJOR) {
/* rd_doload is 2 for a dual initrd/ramload setup */
if (rd_doload==2) {
if (rd_load_disk(1)) {
ROOT_DEV = Root_RAM1;
root_device_name = NULL;
}
} else
change_floppy("root floppy");
}
#endif
#ifdef CONFIG_BLOCK
create_dev("/dev/root", ROOT_DEV);
mount_block_root("/dev/root", root_mountflags);
#endif
}
4.3.4.1.4.3.13.1.4 init_post()
该函数定义于init/main.c:
/* This is a non __init function. Force it to be noinline otherwise gcc
* makes it inline to init() and it becomes part of init.text section
*/
static noinline int init_post(void)
{
/* need to finish all async __init code before freeing the memory */
async_synchronize_full();
free_initmem(); // 参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节
mark_rodata_ro();
system_state = SYSTEM_RUNNING;
numa_default_policy();
current->signal->flags |= SIGNAL_UNKILLABLE;
/*
* Try #1: 启动ramdisk_execute_command指定的初始化程序,
* 其取值参见[4.3.4.1.4.3.13.1 kernel_init()]节的kernel_init():
* a) 由内核参数"rdinit="指定,或者
* b) /init(此初始化程序由initrd.img加载而来,
* 参见[4.3.4.1.4.3.13.1.3 prepare_namespace()]节的Try #3)
* 若该进程成功,则转到用户空间;否则,继续尝试
*/
if (ramdisk_execute_command) {
run_init_process(ramdisk_execute_command);
printk(KERN_WARNING "Failed to execute %s\n", ramdisk_execute_command);
}
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
// Try #2: 启动execute_command指定的初始化程序:
// 由内核参数"init="指定,参见init/main.c中的函数init_setup()
if (execute_command) {
run_init_process(execute_command);
printk(KERN_WARNING "Failed to execute %s. Attempting defaults...\n", execute_command);
}
/*
* 依次尝试启动如下初始化程序。若其中之一启动成功,
* 则转到用户空间;否则,继续尝试。参见[4.3.5 init]节
*/
run_init_process("/sbin/init"); // Try #3: /sbin/init
run_init_process("/etc/init"); // Try #4: /etc/init
run_init_process("/bin/init"); // Try #5: /bin/init
/*
* 若上述init均不存在或无法启动,则启动shell,即/bin/sh;
* 若成功,则转到用户空间;否则,终止启动内核
*/
run_init_process("/bin/sh"); // Try #6: /bin/sh
panic("No init found. Try passing init= option to kernel. "
"See Linux Documentation/init.txt for guidance.");
}
4.3.4.1.4.3.13.2 kthreadd()
在kernel/kthread.c中,包含如下有关kthreadd()的代码(另参见7.2.4.3 kthreadd进程节):
static LIST_HEAD(kthread_create_list);
int kthreadd(void *unused)
{
struct task_struct *tsk = current;
/* Setup a clean context for our children to inherit. */
set_task_comm(tsk, "kthreadd"); // 设置程序名称为kthreadd,参见[7.1.1.25 程序名称]节
ignore_signals(tsk); // 忽略所有信号
set_cpus_allowed_ptr(tsk, cpu_all_mask);
set_mems_allowed(node_states[N_HIGH_MEMORY]);
current->flags |= PF_NOFREEZE | PF_FREEZER_NOSIG;
for (;;) {
set_current_state(TASK_INTERRUPTIBLE); // 设置当前进程为可中断睡眠状态
// 如果链表kthread_create_list为空,则当前进程进入睡眠状态
if (list_empty(&kthread_create_list))
schedule();
// 如果链表kthread_create_list不为空,则设置当前进程为运行状态
__set_current_state(TASK_RUNNING);
spin_lock(&kthread_create_lock);
while (!list_empty(&kthread_create_list)) {
struct kthread_create_info *create;
// 获取链表kthread_create_list中的一项,用于创建指定的内核线程
create = list_entry(kthread_create_list.next, struct kthread_create_info, list);
list_del_init(&create->list);
spin_unlock(&kthread_create_lock);
// 创建指定的内核线程,该线程执行函数kthread(),参见[7.2.4.4.1 kthread_run()]节
create_kthread(create);
spin_lock(&kthread_create_lock);
}
spin_unlock(&kthread_create_lock);
}
return 0;
}
4.3.4.1.4.3.13.3 cpu_idle()
在arch/x86/kernel/process_32.c中,包含如下有关cpu_idle()的代码:
/*
* The idle thread. There's no useful work to be
* done, so just try to conserve power and have a
* low exit latency (ie sit in a loop waiting for
* somebody to say that they'd like to reschedule)
*/
void cpu_idle(void)
{
int cpu = smp_processor_id();
/*
* If we're the non-boot CPU, nothing set the stack canary up
* for us. CPU0 already has it initialized but no harm in
* doing it again. This is a good place for updating it, as
* we wont ever return from this function (so the invalid
* canaries already on the stack wont ever trigger).
*/
boot_init_stack_canary();
current_thread_info()->status |= TS_POLLING;
/* endless idle loop with no priority at all */
while (1) {
tick_nohz_stop_sched_tick(1);
while (!need_resched()) {
check_pgt_cache();
rmb();
if (cpu_is_offline(cpu))
play_dead();
local_touch_nmi();
local_irq_disable();
/* Don't trace irqs off for idle */
stop_critical_timings();
if (cpuidle_idle_call())
pm_idle();
start_critical_timings();
}
tick_nohz_restart_sched_tick();
// 与rest_init()中调用schedule()函数的方式类似,参见[4.3.4.1.4.3.13 rest_init()]节
preempt_enable_no_resched();
// 如果存在一个准备好的进程,则运行它
schedule();
// 与rest_init()中调用schedule()函数的方式类似,参见[4.3.4.1.4.3.13 rest_init()]节
preempt_disable();
}
}
4.3.5 init
当内核被引导并进行初始化之后,内核就可以启动第一个用户级进程:init进程,其进程号为1。这是系统第一个调用的、使用标准C库编译的程序。此前,还没有执行任何标准的C应用程序。
init进程的启动过程参见4.3.4.1.4.3.13.1.4 init_post()节。若无法启动init进程,则打印错误信息:No init found. 参见Documentation/init.txt。
调用函数run_init_process()来启动init进程,其定义于init/main.c:
static const char * argv_init[MAX_INIT_ARGS+2] = { "init", NULL, };
const char * envp_init[MAX_INIT_ENVS+2] = { "HOME=/", "TERM=linux", NULL, };
// 由[4.3.4.1.4.3.13.1.4 init_post()]节可知,入参init_filename依次为"/sbin/init", "/etc/init", "/bin/init"
static void run_init_process(const char *init_filename)
{
argv_init[0] = init_filename;
kernel_execve(init_filename, argv_init, envp_init);
}
其中,函数kernel_execve()定义于arch/x86/kernel/sys_i386_32.c:
/*
* Do a system call from kernel instead of calling sys_execve so we
* end up with proper pt_regs.
*/
int kernel_execve(const char *filename,
const char *const argv[],
const char *const envp[])
{
long __res;
asm volatile ("int $0x80"
: "=a" (__res)
: "0" (__NR_execve), "b" (filename), "c" (argv), "d" (envp) : "memory");
return __res;
}
函数kernel_execve()调用系统调用sys_execve(),参见7.2.1.5 sys_execve()/exec()节;另参见«Linux Device Drivers, 2nd Edition»第16章:
The final call to execve finalizes the transition to user space. There is no magic involved in this transition. As with any execve call in Unix, this one replaces the memory maps of the current process with new memory maps defined by the binary file being executed. It doesn’t matter that, in this case, the calling process is running in kernel space. That’s transparent to the implementation of execve, which just finds that there are no previous memory maps to release before activating the new ones.
Whatever the system setup or command line, the init process is now executing in user space and any further kernel operation takes place in response to system calls coming from init itself or from the processes it forks out.
4.3.5.1 init的种类
The design of init has diverged in Unix systems, such as System III and System V, from the functionality provided by the init in Research Unix and its BSD derivatives. The usage on most Linux distributions is somewhat compatible with System V, but some distributions, such as Slackware, use a BSD-style and others, such as Gentoo, have their own customized version.
Several replacement init implementations have been written with attempt to address design limitations in the standard versions. These include systemd and Upstart, the latter being used by Ubuntu and some other Linux distributions.
Refer to article init system other points, and conclusion in:
4.3.5.1.1 SysV-style init
System V init examines the /etc/inittab file for an :initdefault: entry, which defines any default runlevel. If there is no default runlevel, then init dumps the user to a system console for manual entry of a runlevel.
/etc/inittab用于设定runlevel,例如:
#
# inittab This file describes how the INIT process should set up
# the system in a certain run-level.
#
# Author: Miquel van Smoorenburg, <miquels@drinkel.nl.mugnet.org>
# Modified for RHS Linux by Marc Ewing and Donnie Barnes
#
# Default runlevel. The runlevels used by RHS are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:3:initdefault:
# System initialization.
si::sysinit:/etc/rc.d/rc.sysinit
l0:0:wait:/etc/rc.d/rc 0
l1:1:wait:/etc/rc.d/rc 1
l2:2:wait:/etc/rc.d/rc 2
l3:3:wait:/etc/rc.d/rc 3
l4:4:wait:/etc/rc.d/rc 4
l5:5:wait:/etc/rc.d/rc 5
l6:6:wait:/etc/rc.d/rc 6
# Trap CTRL-ALT-DELETE
#ca::ctrlaltdel:/sbin/shutdown -t3 -r now
# s+c disable_abort_keys_tdsc start
ca::ctrlaltdel:/usr/local/etc/acknowledge_ctrlaltdel
# s+c disable_abort_keys_tdsc end
# When our UPS tells us power has failed, assume we have a few minutes
# of power left. Schedule a shutdown for 2 minutes from now.
# This does, of course, assume you have powerd installed and your
# UPS connected and working correctly.
pf::powerfail:/sbin/shutdown -f -h +2 "Power Failure; System Shutting Down"
# If power was restored before the shutdown kicked in, cancel it.
pr:12345:powerokwait:/sbin/shutdown -c "Power Restored; Shutdown Cancelled"
# Run gettys in standard runlevels
1:2345:respawn:/sbin/mingetty tty1
2:2345:respawn:/sbin/mingetty tty2
3:2345:respawn:/sbin/mingetty tty3
4:2345:respawn:/sbin/mingetty tty4
5:2345:respawn:/sbin/mingetty tty5
6:2345:respawn:/sbin/mingetty tty6
# Run xdm in runlevel 5
x:5:respawn:/etc/X11/prefdm -nodaemon
4.3.5.1.1.1 runlevel
Linux的runlevel取值如下:
| runlevel | Note |
|---|---|
| 0 | 关机 |
| 1 | 单用户模式 |
| 2 | 无网络支持的多用户模式 |
| 3 | 有网络支持的多用户模式 |
| 4 | 保留 |
| 5 | 有网络支持的X-Window支持的多用户模式 |
| 6 | 重新引导系统,即重启 |
Default runlevels for different Linux distributions:
| Operating System | Default runlevel |
|---|---|
| AIX | 2 |
| CentOS | 3 (console/server), or 5 (graphical/desktop) |
| Debian | 2 |
| Gentoo Linux | 3 |
| HP-UX | 3 (console/server/multiuser), or 4 (graphical) |
| Mac OS X | 3 |
| Mandriva Linux | 3 (console/server), or 5 (graphical/desktop) |
| Red Hat Enterprise Linux / Fedora | 3 (console/server), or 5 (graphical/desktop) |
| Slackware Linux | 3 |
| Solaris | 3 |
| SUSE Linux Enterprise/openSUSE Linux | 3 (console/server), or 5 (graphical/desktop) |
| Ubuntu (Server and Desktop) | 2 |
On most systems users can check the current runlevel with either of the following commands:
chenwx@chenwx ~ $ runlevel
N 2
chenwx@chenwx ~ $ who -r
run-level 2 2014-04-14 21:26
4.3.5.1.2 BSD-style init
BSD init runs the initialization shell script located in /etc/rc, then launches getty on text-based terminals or a windowing system such as X on graphical terminals under the control of /etc/ttys. There are no runlevels; the /etc/rc file determines what programs are run by init. The advantage of this system is that it is simple and easy to edit manually. However, new software added to the system may require changes to existing files that risk producing an unbootable system. To mitigate this, BSD variants have long supported a site-specific /etc/rc.local file that is run in a sub-shell near the end of the boot sequence.
A fully modular system was introduced with NetBSD 1.5 and ported to FreeBSD 5.0 and successors. This system executes scripts in the /etc/rc.d directory. Unlike System V’s script ordering, which is derived from the filename of each script, this system uses explicit dependency tags placed within each script. The order in which scripts are executed is determined by the rcorder script based on the requirements stated in these tags.
init进程是非内核进程中第一个被启动运行的,因此它的进程号pid总是1。init读取配置文件/etc/inittab,决定需要启动的运行级别。从根本上说,运行级别规定了整个系统的行为,每个级别满足特定的目的。如果定义了initdefault级别,则直接使用该值,否则需要由用户输入一个代表运行级别的数值。
输入代表运行级别的数字之后,init根据/etc/inittab中的定义执行一个命令脚本程序。缺省的运行级别取决于安装阶段对登录程序的选择:是使用基于文本的,还是使用基于X-Window的登录程序。
当运行级别发生改变时,将根据/etc/inittab中的定义运行一个命令脚本程序。这些命令脚本程序负责启动或者停止该运行级别特定的各种服务。由于需要管理的服务数量很多,因此需要使用rc命令脚本程序。其中,最主要的一个是/etc/rc.d/rc,它负责为每一个运行级别按照正确的顺序调用相应的命令脚本程序。可以想象,这样一个命令脚本程序很容易变得难以控制!为了防止这类事件的发生,需要使用精心设计的方案。
/etc/rc.d
|-- rc.sysinit
|-- rc
|-- init.d
|-- nohup.out
|-- rc.local
|-- rc0.d
|-- rc1.d
|-- rc2.d
|-- rc3.d
|-- rc4.d
|-- rc5.d
`-- rc6.d
对每一个运行级别来说,在/etc/rc.d子目录中都有一个对应的下级目录。这些运行级别的下级子目录的命名方法是rcX.d,其中X代表运行级别。例如:运行级别3的全部命令脚本程序都保存在/etc/rc.d/rc3.d子目录中。在各个运行级别的子目录中,都建立有到/etc/rc.d/init.d子目录中命令脚本程序的符号链接,但是,这些符号链接并不使用命令脚本程序在/etc/rc.d/init.d子目录中原来的名字。如果命令脚本程序是用来启动一个服务的,其符号链接的名字就以字母S打头;如果命令脚本程序是用来关闭一个服务的,其符号链接的名字就以字母K打头。
许多情况下,这些命令脚本程序的执行顺序都很重要。如果没有先配置网络接口,就没有办法使用DNS服务解析主机名!为了安排它们的执行顺序,在字母S或者K的后面紧跟着两位数字,数值小的在数值大的前面执行。如:/etc/rc.d/rc3.d/S50inet就会在/etc/rc.d/rc3.d/S55named之前执行(S50inet配置网络设置,55named启动DNS服务器)。存放在/etc/rc.d/init.d子目录中的、被符号链接上的命令脚本程序是真正的实干家,是它们完成了启动或者停止各种服务的操作过程。当/etc/rc.d/rc运行通过每个特定的运行级别子目录的时候,它会根据数字的顺序依次调用各个命令脚本程序执行。它先运行以字母K打头的命令脚本程序,然后再运行以字母S打头的命令脚本程序。对以字母K打头的命令脚本程序来说,会传递stop参数;类似地对以字母S打头的命令脚本程序来说,会传递start参数。编写自己的rc命令脚本在维护Linux系统运转时,肯定会遇到需要系统管理员对开机或者关机命令脚本进行修改的情况。
4.3.5.1.3 Replacements for init
Rational
The traditional init process was originally only responsible for bringing the computer into a normal running state after power-on, or gracefully shutting down services prior to shutdown. As a result, the design is strictly synchronous, blocking future tasks until the current one has completed. Its tasks must also be defined in advance, as they are limited to this prep or cleanup function. This leaves it unable to handle various non-startup-tasks on a modern desktop computer elegantly, including:
- The addition or removal of USB pen drives and other portable storage / network devices while the machine is running;
- The discovery and scanning of new storage devices, without locking the system, especially when a disk may not even power on until it is scanned;
- The loading of firmware for a device, which may need to occur after it is detected but before it is usable.
Description of replacements for init
Traditionally, one of the major drawbacks of init is that it starts tasks serially, waiting for each to finish loading before moving on to the next. When startup processes end up I/O blocked, this can result in long delays during boot.
Various efforts have been made to replace the traditional init daemons to address this and other design problems, including:
| Replacements for init | Notes |
|---|---|
| BootScripts | used in GoboLinux |
| busybox-init | suited embedded operating systems, employed by OpenWrt before it was replaced with procd |
| DEMONS | a modification of the init start process by KahelOS, where daemons are started only when the DE (desktop environment) started |
| eINIT | a full replacement of init designed to start processes asynchronously, but with the potential of doing it without shell scripts |
| Initng | a full replacement of init designed to start processes asynchronously |
| launchd | a replacement for init introduced in Mac OS X v10.4 (it launches SystemStarter to run old-style ‘rc.local’ and SystemStarter processes) |
| Mudur | an init replacement written in Python and designed to start process asynchronously in use by the Pardus Linux distribution |
| runit | a cross-platform full replacement for init with parallel starting of services |
| s6 | another cross-platform full replacement for init, similar to runit |
| Service Management Facility | a complete full replacement/redesign of init from the ground up in Solaris starting with Solaris 10 |
| systemd | a full replacement for init with parallel starting of services and other features, used by many distributions |
| SystemStarter | a process spawner started by the BSD-style init in Mac OS X prior to Mac OS X v10.4 |
| Upstart | a full replacement of init designed to start processes asynchronously initiated by Ubuntu |
4.3.5.1.3.1 upstart
upstart is an event-based replacement for the /sbin/init daemon which handles starting of tasks and services during boot, stopping them during shutdown and supervising them while the system is running. That means upstart operates asynchronously.
It was originally developed for the Ubuntu distribution, but is intended to be suitable for deployment in all Linux distributions as a replacement for the venerable System-V init.
Easy transition and perfect backwards compatibility with sysvinit were the explicit design goals; accordingly, Upstart can run unmodified sysvinit scripts. In this way it differs from most other init replacements (beside systemd and OpenRC), which usually assume and require complete transition to run properly, and do not support a mixed environment of traditional and new startup methods.
Upstart allows for extensions to its event model through the use of initctl to input custom, single events, or event bridges to integrate many or more-complicated events. By default, Upstart includes bridges for socket, dbus, udev, file, and dconf events; additionally, more bridges (for example, a Mach ports bridge, or a devd (found on FreeBSD systems) bridge) are possible.
UpStart提供了一系列命令来完成管理系统服务的工作,其中的核心命令是initctl,这是一个带子命令风格的命令行工具:
chenwx@chenwx ~ $ initctl version
init (upstart 1.12.1)
chenwx@chenwx ~ $ initctl list
avahi-cups-reload stop/waiting
avahi-daemon start/running, process 532
mountall-net stop/waiting
mountnfs-bootclean.sh start/running
nmbd start/running, process 1637
passwd stop/waiting
rc stop/waiting
rsyslog start/running
...
4.3.5.1.3.2 systemd
systemd is a suite of basic building blocks for a Linux system. It provides a system and service manager that runs as PID 1 and starts the rest of the system. systemd provides aggressive parallelization capabilities, uses socket and D-Bus activation for starting services, offers on-demand starting of daemons, keeps track of processes using Linux control groups, supports snapshotting and restoring of the system state, maintains mount and automount points and implements an elaborate transactional dependency-based service control logic. systemd supports SysV and LSB init scripts and works as a replacement for sysvinit. Other parts include a logging daemon, utilities to control basic system configuration like the hostname, date, locale, maintain a list of logged-in users and running containers and virtual machines, system accounts, runtime directories and settings, and daemons to manage simple network configuration, network time synchronization, log forwarding, and name resolution.
Because it’s a system daemon, and under Unix/Linux those are in lower case, and get suffixed with a lower case d. And since systemd manages the system, it’s called systemd.
systemd software architecture:
Git repository
- git://anongit.freedesktop.org/systemd/systemd
- ssh://git.freedesktop.org/git/systemd/systemd
4.3.5.1.3.2.1 systemd的配置文件
systemd的配置文件放置在下面的目录中:
/usr/lib/systemd/system/: 每个服务最主要的启动脚本设置,类似于以前的/etc/init.d下的文件。
/run/systemd/system/: 系统执行过程中所产生的服务脚本,这些脚本的执行优先级要比/usr/lib/systemd/system/目录下的高。
/etc/systemd/system/: 系统管理员根据系统的需求所创建的执行脚本,类似于以前的/etc/rd.d/rc5.d/Sxx之类的功能。这些脚本的执行优先级要比/run/systemd/system/目录下的高。
故,系统开机时会不会执行某些服务其实是看/etc/systemd/system/下面的设置,所以该目录下是一些链接文件,而实际执行的配置文件都放置在/usr/lib/systemd/system/目录下面。
4.3.5.2 查看当前系统使用的init
执行下列命令查看当前子系统中的init进程:
chenwx@chenwx ~ $ init --version
init (upstart 1.12.1)
Copyright (C) 2006-2014 Canonical Ltd., 2011 Scott James Remnant
This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
或者,init进程更改为systemd:
chenwx@chenwx ~ $ lsb_release -a
No LSB modules are available.
Distributor ID: LinuxMint
Description: Linux Mint 18 Sarah
Release: 18
Codename: sarah
chenwx@chenwx ~ $ ll /sbin/init
lrwxrwxrwx 1 root root 20 Jul 13 00:28 /sbin/init -> /lib/systemd/systemd
chenwx@chenwx ~ $ systemd --version
systemd 229
+PAM +AUDIT +SELINUX +IMA +APPARMOR +SMACK +SYSVINIT +UTMP +LIBCRYPTSETUP +GCRYPT +GNUTLS +ACL +XZ -LZ4 +SECCOMP +BLKID +ELFUTILS +KMOD -IDN
5 系统调用接口/System Call Interface
系统调用帮助:
$ man 2 <system_call_name>
$ man 2 syscalls
系统调用在内核源代码中的声明:
include/linux/syscalls.h // 与体系架构无关
include/asm-generic/syscalls.h // 与体系架构无关
arch/x86/include/asm/syscalls.h // 与体系架构有关
include/asm-generic/unistd.h // 与体系架构无关
include/linux/unistd.h // 与体系架构有关
-> arch/x86/include/asm/unistd.h
arch/x86/include/asm/unistd_32.h // 定义系统调用号__NR_xxxx
5.1 系统调用简介
Linux内核中设置了一组用于实现各种系统功能的子程序,称为系统调用。用户可以在应用程序中调用系统调用。从某种角度来看,系统调用和普通函数非常相似,区别仅在于:系统调用由操作系统内核提供,运行于核心态;而普通函数由函数库或者用户提供,运行于用户态。
随Linux核心还提供了一些C语言函数库,这些库对系统调用进行了包装和扩展。因为这些库函数与系统调用的关系非常紧密,所以习惯上也把这些函数称为系统调用。
The POSIX standard refers to APIs and not to system calls. A system can be certified as POSIX-compliant if it offers the proper set of APIs to the application programs, no matter how the corresponding functions are implemented. As a matter of fact, several non-Unix systems have been certified as POSIX-compliant, because they offer all traditional Unix services in User Mode libraries.
Linux system architecture:
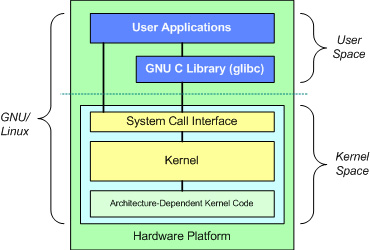
5.2 系统调用的执行过程
系统调用的执行过程:
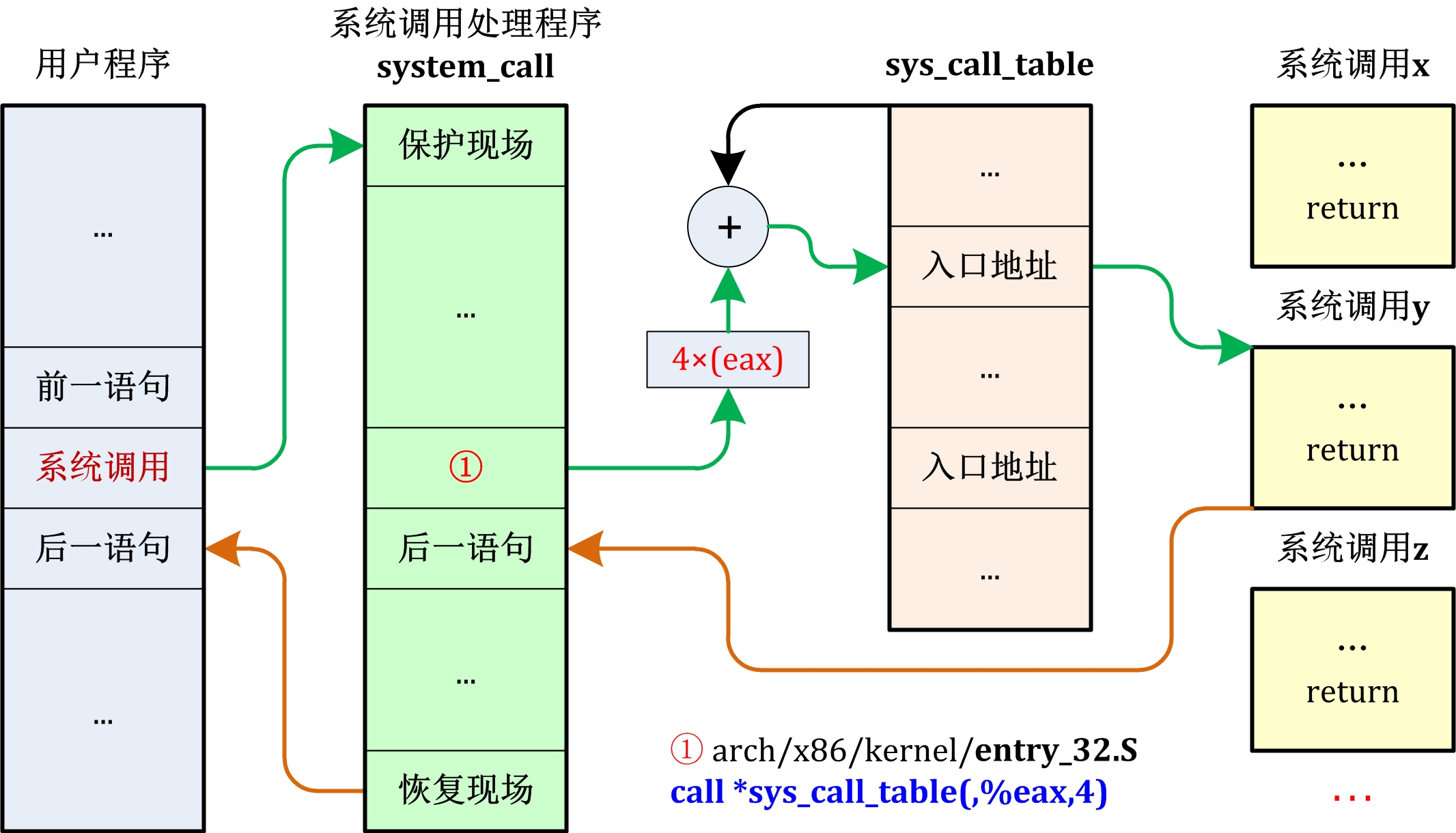
其中,系统调用处理程序为arch/x86/kernel/entry_32.S中的system_call,参见5.4 系统调用的处理程序/system_call节。sys_call_table为arch/x86/kernel/syscall_table_32.S中的sys_call_table,参见5.5.3 系统调用表/sys_call_table节。
5.3 系统调用的初始化
对系统调用的初始化,也就是对INT 0x80软中断的初始化。在系统启动时,下列函数将0x80软中断的处理程序设置为system_call:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> trap_init() // 参见[4.3.4.1.4.3.5 trap_init()]节
-> set_system_trap_gate(SYSCALL_VECTOR, &system_call) // 设置0x80软中断的处理程序为system_call
因而,system_call就是所有系统调用的入口点,参见5.4 系统调用的处理程序/system_call节。
5.4 系统调用的处理程序/system_call
系统调用的处理程序为system_call,其定义于arch/x86/kernel/entry_32.S:
// 该宏表示sys_call_table中系统调用的个数
#define nr_syscalls ((syscall_table_size)/4)
/*
* syscall stub including irq exit should be protected against kprobes
*/
.pushsection .kprobes.text, "ax"
# system call handler stub
// 系统调用处理程序,由trap_init()设置,参见[5.3 系统调用的初始化]节
ENTRY(system_call)
RING0_INT_FRAME # can't unwind into user space anyway
pushl_cfi %eax # save orig_eax
SAVE_ALL
GET_THREAD_INFO(%ebp) # system call tracing in operation / emulation
testl $_TIF_WORK_SYSCALL_ENTRY,TI_flags(%ebp)
jnz syscall_trace_entry
cmpl $(nr_syscalls), %eax
jae syscall_badsys
syscall_call:
/*
* 根据eax寄存器中的系统调用号(参见[5.5.2 系统调用号/__NR_xxx]节),
* 调用sys_call_table中对应的系统调用,其等价于: call near [eax*4+sys_call_table]
* 参见[5.2 系统调用的执行过程]节图中的①
*/
call *sys_call_table(,%eax,4)
movl %eax,PT_EAX(%esp) # store the return value
syscall_exit:
LOCKDEP_SYS_EXIT
DISABLE_INTERRUPTS(CLBR_ANY) # make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
TRACE_IRQS_OFF
movl TI_flags(%ebp), %ecx
testl $_TIF_ALLWORK_MASK, %ecx # current->work
jne syscall_exit_work // 从系统调用返回
...
ENDPROC(system_call)
...
# perform syscall exit tracing
ALIGN
syscall_exit_work:
testl $_TIF_WORK_SYSCALL_EXIT, %ecx
jz work_pending
TRACE_IRQS_ON
ENABLE_INTERRUPTS(CLBR_ANY) # could let syscall_trace_leave() call schedule() instead
movl %esp, %eax
call syscall_trace_leave
jmp resume_userspace // 从内核空间返回到用户空间
END(syscall_exit_work)
...
.section .rodata,"a"
/*
* arch/x86/kernel/syscall_table_32.S定义了sys_call_table,
* 其中包含系统调用号与系统调用函数的对应关系;
* 而系统调用函数的声明包含在include/linux/syscalls.h,
* 参见[5.5.1 系统调用的声明与定义]节
*/
#include "syscall_table_32.S"
// 获得sys_call_table的大小,即字节数
syscall_table_size=(.-sys_call_table)
NOTE: In the following commit, the arch/x86/kernel/entry_32.S is moved to arch/x86/entry/entry_32.S:
chenwx@chenwx:~/linux $ git lc 905a36a28518
commit 905a36a2851838bca5a424fb758e201990234e6e
Author: Ingo Molnar <mingo@kernel.org>
AuthorDate: Wed Jun 3 13:37:36 2015 +0200
Commit: Ingo Molnar <mingo@kernel.org>
CommitDate: Wed Jun 3 18:51:28 2015 +0200
x86/asm/entry: Move entry_64.S and entry_32.S to arch/x86/entry/
Create a new directory hierarchy for the low level x86 entry code:
arch/x86/entry/*
This will host all the low level glue that is currently scattered
all across arch/x86/.
Start with entry_64.S and entry_32.S.
Cc: Borislav Petkov <bp@alien8.de>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Andy Lutomirski <luto@amacapital.net>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
arch/x86/Kbuild | 3 +++
arch/x86/entry/Makefile | 4 ++++
arch/x86/{kernel => entry}/entry_32.S | 0
arch/x86/{kernel => entry}/entry_64.S | 0
arch/x86/kernel/Makefile | 2 +-
5 files changed, 8 insertions(+), 1 deletion(-)
chenwx@chenwx:~/linux $ ll arch/x86/entry/*.S
-rw-r--r-- 1 chenwx chenwx 37K Jun 2 00:30 arch/x86/entry/entry_32.S
-rw-r--r-- 1 chenwx chenwx 48K Jun 2 00:30 arch/x86/entry/entry_64.S
-rw-r--r-- 1 chenwx chenwx 14K Jun 1 21:53 arch/x86/entry/entry_64_compat.S
-rw-r--r-- 1 chenwx chenwx 996 Jun 1 21:53 arch/x86/entry/thunk_32.S
-rw-r--r-- 1 chenwx chenwx 1.6K Jun 1 21:53 arch/x86/entry/thunk_64.S
5.5 系统调用
5.5.1 系统调用的声明与定义
系统调用的格式为:asmlinkage long sys_XXX(…),由如下宏来定义系统调用:
SYSCALL_DEFINE0(name) // 没有入参
SYSCALL_DEFINE1(name, ...) // 1个入参
SYSCALL_DEFINE2(name, ...) // 2个入参
SYSCALL_DEFINE3(name, ...) // 3个入参
SYSCALL_DEFINE4(name, ...) // 4个入参
SYSCALL_DEFINE5(name, ...) // 5个入参
SYSCALL_DEFINE6(name, ...) // 6个入参
该宏定义于include/linux/syscalls.h:
/*
* 1) 定义系统调用的宏
*/
#define __SC_DECL1(t1, a1) t1 a1
#define __SC_DECL2(t2, a2, ...) t2 a2, __SC_DECL1(__VA_ARGS__)
#define __SC_DECL3(t3, a3, ...) t3 a3, __SC_DECL2(__VA_ARGS__)
#define __SC_DECL4(t4, a4, ...) t4 a4, __SC_DECL3(__VA_ARGS__)
#define __SC_DECL5(t5, a5, ...) t5 a5, __SC_DECL4(__VA_ARGS__)
#define __SC_DECL6(t6, a6, ...) t6 a6, __SC_DECL5(__VA_ARGS__)
#ifdef CONFIG_FTRACE_SYSCALLS
#define SYSCALL_DEFINE0(sname) \
SYSCALL_TRACE_ENTER_EVENT(_##sname); \
SYSCALL_TRACE_EXIT_EVENT(_##sname); \
static struct syscall_metadata __used \
__syscall_meta__##sname = { \
.name = "sys_"#sname, \
.syscall_nr = -1, /* Filled in at boot */ \
.nb_args = 0, \
.enter_event = &event_enter__##sname, \
.exit_event = &event_exit__##sname, \
.enter_fields = LIST_HEAD_INIT(__syscall_meta__##sname.enter_fields), \
}; \
static struct syscall_metadata __used \
__attribute__((section("__syscalls_metadata"))) \
*__p_syscall_meta_##sname = &__syscall_meta__##sname; \
asmlinkage long sys_##sname(void)
#else
#define SYSCALL_DEFINE0(name) asmlinkage long sys_##name(void)
#endif
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#ifdef CONFIG_FTRACE_SYSCALLS
#define SYSCALL_DEFINEx(x, sname, ...) \
static const char *types_##sname[] = { \
__SC_STR_TDECL##x(__VA_ARGS__) \
}; \
static const char *args_##sname[] = { \
__SC_STR_ADECL##x(__VA_ARGS__) \
}; \
SYSCALL_METADATA(sname, x); \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#else
#define SYSCALL_DEFINEx(x, sname, ...) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#endif
#ifdef CONFIG_HAVE_SYSCALL_WRAPPERS
#define SYSCALL_DEFINE(name) static inline long SYSC_##name
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__SC_DECL##x(__VA_ARGS__)); \
static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__)); \
asmlinkage long SyS##name(__SC_LONG##x(__VA_ARGS__)) \
{ \
__SC_TEST##x(__VA_ARGS__); \
return (long) SYSC##name(__SC_CAST##x(__VA_ARGS__)); \
} \
SYSCALL_ALIAS(sys##name, SyS##name); \
static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__))
#else /* CONFIG_HAVE_SYSCALL_WRAPPERS */
#define SYSCALL_DEFINE(name) asmlinkage long sys_##name
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__SC_DECL##x(__VA_ARGS__))
#endif /* CONFIG_HAVE_SYSCALL_WRAPPERS */
/*
* 2) 所有系统调用的声明
*/
asmlinkage long sys_restart_syscall(void);
...
asmlinkage long sys_exit(int error_code);
...
系统调用的定义分布于内核源代码多个源文件中:
chenwx@chenwx:~/linux $ find . -type f -name "*.c" | xargs grep SYSCALL_DEFINE | wc -l
445
chenwx@chenwx:~/linux $ find . -type f -name "*.c" | xargs grep SYSCALL_DEFINE
./net/socket.c:SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
./net/socket.c:SYSCALL_DEFINE4(socketpair, int, family, int, type, int, protocol,
./net/socket.c:SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
./net/socket.c:SYSCALL_DEFINE2(listen, int, fd, int, backlog)
./net/socket.c:SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
./net/socket.c:SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
./net/socket.c:SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
./net/socket.c:SYSCALL_DEFINE3(getsockname, int, fd, struct sockaddr __user *, usockaddr,
./net/socket.c:SYSCALL_DEFINE3(getpeername, int, fd, struct sockaddr __user *, usockaddr,
./net/socket.c:SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len,
./net/socket.c:SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len,
./net/socket.c:SYSCALL_DEFINE6(recvfrom, int, fd, void __user *, ubuf, size_t, size,
./net/socket.c:SYSCALL_DEFINE5(setsockopt, int, fd, int, level, int, optname,
./net/socket.c:SYSCALL_DEFINE5(getsockopt, int, fd, int, level, int, optname,
./net/socket.c:SYSCALL_DEFINE2(shutdown, int, fd, int, how)
./net/socket.c:SYSCALL_DEFINE3(sendmsg, int, fd, struct msghdr __user *, msg, unsigned, flags)
./net/socket.c:SYSCALL_DEFINE4(sendmmsg, int, fd, struct mmsghdr __user *, mmsg,
./net/socket.c:SYSCALL_DEFINE3(recvmsg, int, fd, struct msghdr __user *, msg,
./net/socket.c:SYSCALL_DEFINE5(recvmmsg, int, fd, struct mmsghdr __user *, mmsg,
./net/socket.c:SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
./kernel/sysctl_binary.c:SYSCALL_DEFINE1(sysctl, struct __sysctl_args __user *, args)
./kernel/uid16.c:SYSCALL_DEFINE3(chown16, const char __user *, filename, old_uid_t, user, old_gid_t, group)
./kernel/uid16.c:SYSCALL_DEFINE3(lchown16, const char __user *, filename, old_uid_t, user, old_gid_t, group)
./kernel/uid16.c:SYSCALL_DEFINE3(fchown16, unsigned int, fd, old_uid_t, user, old_gid_t, group)
./kernel/uid16.c:SYSCALL_DEFINE2(setregid16, old_gid_t, rgid, old_gid_t, egid)
./kernel/uid16.c:SYSCALL_DEFINE1(setgid16, old_gid_t, gid)
./kernel/uid16.c:SYSCALL_DEFINE2(setreuid16, old_uid_t, ruid, old_uid_t, euid)
./kernel/uid16.c:SYSCALL_DEFINE1(setuid16, old_uid_t, uid)
./kernel/uid16.c:SYSCALL_DEFINE3(setresuid16, old_uid_t, ruid, old_uid_t, euid, old_uid_t, suid)
./kernel/uid16.c:SYSCALL_DEFINE3(getresuid16, old_uid_t __user *, ruid, old_uid_t __user *, euid, old_uid_t __user *, suid)
./kernel/uid16.c:SYSCALL_DEFINE3(setresgid16, old_gid_t, rgid, old_gid_t, egid, old_gid_t, sgid)
./kernel/uid16.c:SYSCALL_DEFINE3(getresgid16, old_gid_t __user *, rgid, old_gid_t __user *, egid, old_gid_t __user *, sgid)
./kernel/uid16.c:SYSCALL_DEFINE1(setfsuid16, old_uid_t, uid)
./kernel/uid16.c:SYSCALL_DEFINE1(setfsgid16, old_gid_t, gid)
./kernel/uid16.c:SYSCALL_DEFINE2(getgroups16, int, gidsetsize, old_gid_t __user *, grouplist)
./kernel/uid16.c:SYSCALL_DEFINE2(setgroups16, int, gidsetsize, old_gid_t __user *, grouplist)
./kernel/uid16.c:SYSCALL_DEFINE0(getuid16)
./kernel/uid16.c:SYSCALL_DEFINE0(geteuid16)
./kernel/uid16.c:SYSCALL_DEFINE0(getgid16)
./kernel/uid16.c:SYSCALL_DEFINE0(getegid16)
./kernel/kexec.c:SYSCALL_DEFINE4(kexec_load, unsigned long, entry, unsigned long, nr_segments,
./kernel/hrtimer.c:SYSCALL_DEFINE2(nanosleep, struct timespec __user *, rqtp,
./kernel/itimer.c:SYSCALL_DEFINE2(getitimer, int, which, struct itimerval __user *, value)
./kernel/itimer.c:SYSCALL_DEFINE3(setitimer, int, which, struct itimerval __user *, value,
./kernel/capability.c:SYSCALL_DEFINE2(capget, cap_user_header_t, header, cap_user_data_t, dataptr)
./kernel/capability.c:SYSCALL_DEFINE2(capset, cap_user_header_t, header, const cap_user_data_t, data)
./kernel/ptrace.c:SYSCALL_DEFINE4(ptrace, long, request, long, pid, unsigned long, addr,
./kernel/posix-timers.c:SYSCALL_DEFINE3(timer_create, const clockid_t, which_clock,
./kernel/posix-timers.c:SYSCALL_DEFINE2(timer_gettime, timer_t, timer_id,
./kernel/posix-timers.c:SYSCALL_DEFINE1(timer_getoverrun, timer_t, timer_id)
./kernel/posix-timers.c:SYSCALL_DEFINE4(timer_settime, timer_t, timer_id, int, flags,
./kernel/posix-timers.c:SYSCALL_DEFINE1(timer_delete, timer_t, timer_id)
./kernel/posix-timers.c:SYSCALL_DEFINE2(clock_settime, const clockid_t, which_clock,
./kernel/posix-timers.c:SYSCALL_DEFINE2(clock_gettime, const clockid_t, which_clock,
./kernel/posix-timers.c:SYSCALL_DEFINE2(clock_adjtime, const clockid_t, which_clock,
./kernel/posix-timers.c:SYSCALL_DEFINE2(clock_getres, const clockid_t, which_clock,
./kernel/posix-timers.c:SYSCALL_DEFINE4(clock_nanosleep, const clockid_t, which_clock, int, flags,
./kernel/nsproxy.c:SYSCALL_DEFINE2(setns, int, fd, int, nstype)
./kernel/exit.c:SYSCALL_DEFINE1(exit, int, error_code)
./kernel/exit.c:SYSCALL_DEFINE1(exit_group, int, error_code)
./kernel/exit.c:SYSCALL_DEFINE5(waitid, int, which, pid_t, upid, struct siginfo __user *,
./kernel/exit.c:SYSCALL_DEFINE4(wait4, pid_t, upid, int __user *, stat_addr,
./kernel/exit.c:SYSCALL_DEFINE3(waitpid, pid_t, pid, int __user *, stat_addr, int, options)
./kernel/events/core.c:SYSCALL_DEFINE5(perf_event_open,
./kernel/timer.c:SYSCALL_DEFINE1(alarm, unsigned int, seconds)
./kernel/timer.c:SYSCALL_DEFINE0(getpid)
./kernel/timer.c:SYSCALL_DEFINE0(getppid)
./kernel/timer.c:SYSCALL_DEFINE0(getuid)
./kernel/timer.c:SYSCALL_DEFINE0(geteuid)
./kernel/timer.c:SYSCALL_DEFINE0(getgid)
./kernel/timer.c:SYSCALL_DEFINE0(getegid)
./kernel/timer.c:SYSCALL_DEFINE0(gettid)
./kernel/timer.c:SYSCALL_DEFINE1(sysinfo, struct sysinfo __user *, info)
./kernel/printk.c:SYSCALL_DEFINE3(syslog, int, type, char __user *, buf, int, len)
./kernel/groups.c:SYSCALL_DEFINE2(getgroups, int, gidsetsize, gid_t __user *, grouplist)
./kernel/groups.c:SYSCALL_DEFINE2(setgroups, int, gidsetsize, gid_t __user *, grouplist)
./kernel/module.c:SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
./kernel/module.c:SYSCALL_DEFINE3(init_module, void __user *, umod,
./kernel/time.c:SYSCALL_DEFINE1(time, time_t __user *, tloc)
./kernel/time.c:SYSCALL_DEFINE1(stime, time_t __user *, tptr)
./kernel/time.c:SYSCALL_DEFINE2(gettimeofday, struct timeval __user *, tv,
./kernel/time.c:SYSCALL_DEFINE2(settimeofday, struct timeval __user *, tv,
./kernel/time.c:SYSCALL_DEFINE1(adjtimex, struct timex __user *, txc_p)
./kernel/futex.c:SYSCALL_DEFINE2(set_robust_list, struct robust_list_head __user *, head,
./kernel/futex.c:SYSCALL_DEFINE3(get_robust_list, int, pid,
./kernel/futex.c:SYSCALL_DEFINE6(futex, u32 __user *, uaddr, int, op, u32, val,
./kernel/fork.c:SYSCALL_DEFINE1(set_tid_address, int __user *, tidptr)
./kernel/fork.c:SYSCALL_DEFINE1(unshare, unsigned long, unshare_flags)
./kernel/sched.c:SYSCALL_DEFINE1(nice, int, increment)
./kernel/sched.c:SYSCALL_DEFINE3(sched_setscheduler, pid_t, pid, int, policy,
./kernel/sched.c:SYSCALL_DEFINE2(sched_setparam, pid_t, pid, struct sched_param __user *, param)
./kernel/sched.c:SYSCALL_DEFINE1(sched_getscheduler, pid_t, pid)
./kernel/sched.c:SYSCALL_DEFINE2(sched_getparam, pid_t, pid, struct sched_param __user *, param)
./kernel/sched.c:SYSCALL_DEFINE3(sched_setaffinity, pid_t, pid, unsigned int, len,
./kernel/sched.c:SYSCALL_DEFINE3(sched_getaffinity, pid_t, pid, unsigned int, len,
./kernel/sched.c:SYSCALL_DEFINE0(sched_yield)
./kernel/sched.c:SYSCALL_DEFINE1(sched_get_priority_max, int, policy)
./kernel/sched.c:SYSCALL_DEFINE1(sched_get_priority_min, int, policy)
./kernel/sched.c:SYSCALL_DEFINE2(sched_rr_get_interval, pid_t, pid,
./kernel/sys.c:SYSCALL_DEFINE3(setpriority, int, which, int, who, int, niceval)
./kernel/sys.c:SYSCALL_DEFINE2(getpriority, int, which, int, who)
./kernel/sys.c:SYSCALL_DEFINE4(reboot, int, magic1, int, magic2, unsigned int, cmd,
./kernel/sys.c:SYSCALL_DEFINE2(setregid, gid_t, rgid, gid_t, egid)
./kernel/sys.c:SYSCALL_DEFINE1(setgid, gid_t, gid)
./kernel/sys.c:SYSCALL_DEFINE2(setreuid, uid_t, ruid, uid_t, euid)
./kernel/sys.c:SYSCALL_DEFINE1(setuid, uid_t, uid)
./kernel/sys.c:SYSCALL_DEFINE3(setresuid, uid_t, ruid, uid_t, euid, uid_t, suid)
./kernel/sys.c:SYSCALL_DEFINE3(getresuid, uid_t __user *, ruid, uid_t __user *, euid, uid_t __user *, suid)
./kernel/sys.c:SYSCALL_DEFINE3(setresgid, gid_t, rgid, gid_t, egid, gid_t, sgid)
./kernel/sys.c:SYSCALL_DEFINE3(getresgid, gid_t __user *, rgid, gid_t __user *, egid, gid_t __user *, sgid)
./kernel/sys.c:SYSCALL_DEFINE1(setfsuid, uid_t, uid)
./kernel/sys.c:SYSCALL_DEFINE1(setfsgid, gid_t, gid)
./kernel/sys.c:SYSCALL_DEFINE1(times, struct tms __user *, tbuf)
./kernel/sys.c:SYSCALL_DEFINE2(setpgid, pid_t, pid, pid_t, pgid)
./kernel/sys.c:SYSCALL_DEFINE1(getpgid, pid_t, pid)
./kernel/sys.c:SYSCALL_DEFINE0(getpgrp)
./kernel/sys.c:SYSCALL_DEFINE1(getsid, pid_t, pid)
./kernel/sys.c:SYSCALL_DEFINE0(setsid)
./kernel/sys.c:SYSCALL_DEFINE1(newuname, struct new_utsname __user *, name)
./kernel/sys.c:SYSCALL_DEFINE1(uname, struct old_utsname __user *, name)
./kernel/sys.c:SYSCALL_DEFINE1(olduname, struct oldold_utsname __user *, name)
./kernel/sys.c:SYSCALL_DEFINE2(sethostname, char __user *, name, int, len)
./kernel/sys.c:SYSCALL_DEFINE2(gethostname, char __user *, name, int, len)
./kernel/sys.c:SYSCALL_DEFINE2(setdomainname, char __user *, name, int, len)
./kernel/sys.c:SYSCALL_DEFINE2(getrlimit, unsigned int, resource, struct rlimit __user *, rlim)
./kernel/sys.c:SYSCALL_DEFINE2(old_getrlimit, unsigned int, resource,
./kernel/sys.c:SYSCALL_DEFINE4(prlimit64, pid_t, pid, unsigned int, resource,
./kernel/sys.c:SYSCALL_DEFINE2(setrlimit, unsigned int, resource, struct rlimit __user *, rlim)
./kernel/sys.c:SYSCALL_DEFINE2(getrusage, int, who, struct rusage __user *, ru)
./kernel/sys.c:SYSCALL_DEFINE1(umask, int, mask)
./kernel/sys.c:SYSCALL_DEFINE5(prctl, int, option, unsigned long, arg2, unsigned long, arg3,
./kernel/sys.c:SYSCALL_DEFINE3(getcpu, unsigned __user *, cpup, unsigned __user *, nodep,
./kernel/exec_domain.c:SYSCALL_DEFINE1(personality, unsigned int, personality)
./kernel/signal.c:SYSCALL_DEFINE0(restart_syscall)
./kernel/signal.c:SYSCALL_DEFINE4(rt_sigprocmask, int, how, sigset_t __user *, nset,
./kernel/signal.c:SYSCALL_DEFINE2(rt_sigpending, sigset_t __user *, set, size_t, sigsetsize)
./kernel/signal.c:SYSCALL_DEFINE4(rt_sigtimedwait, const sigset_t __user *, uthese,
./kernel/signal.c:SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
./kernel/signal.c:SYSCALL_DEFINE3(tgkill, pid_t, tgid, pid_t, pid, int, sig)
./kernel/signal.c:SYSCALL_DEFINE2(tkill, pid_t, pid, int, sig)
./kernel/signal.c:SYSCALL_DEFINE3(rt_sigqueueinfo, pid_t, pid, int, sig,
./kernel/signal.c:SYSCALL_DEFINE4(rt_tgsigqueueinfo, pid_t, tgid, pid_t, pid, int, sig,
./kernel/signal.c:SYSCALL_DEFINE1(sigpending, old_sigset_t __user *, set)
./kernel/signal.c:SYSCALL_DEFINE3(sigprocmask, int, how, old_sigset_t __user *, nset,
./kernel/signal.c:SYSCALL_DEFINE4(rt_sigaction, int, sig,
./kernel/signal.c:SYSCALL_DEFINE0(sgetmask)
./kernel/signal.c:SYSCALL_DEFINE1(ssetmask, int, newmask)
./kernel/signal.c:SYSCALL_DEFINE2(signal, int, sig, __sighandler_t, handler)
./kernel/signal.c:SYSCALL_DEFINE0(pause)
./kernel/signal.c:SYSCALL_DEFINE2(rt_sigsuspend, sigset_t __user *, unewset, size_t, sigsetsize)
./kernel/acct.c:SYSCALL_DEFINE1(acct, const char __user *, name)
./arch/tile/kernel/sys.c:SYSCALL_DEFINE0(flush_cache)
./arch/tile/kernel/sys.c:SYSCALL_DEFINE6(mmap2, unsigned long, addr, unsigned long, len,
./arch/tile/kernel/sys.c:SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
./arch/tile/kernel/process.c:SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
./arch/tile/kernel/process.c:SYSCALL_DEFINE4(execve, const char __user *, path,
./arch/tile/kernel/signal.c:SYSCALL_DEFINE3(sigaltstack, const stack_t __user *, uss,
./arch/tile/kernel/signal.c:SYSCALL_DEFINE1(rt_sigreturn, struct pt_regs *, regs)
./arch/tile/mm/fault.c:SYSCALL_DEFINE2(cmpxchg_badaddr, unsigned long, address,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE1(osf_brk, unsigned long, brk)
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE4(osf_set_program_attributes, unsigned long, text_start,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE4(osf_getdirentries, unsigned int, fd,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE6(osf_mmap, unsigned long, addr, unsigned long, len,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE3(osf_statfs, const char __user *, pathname,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE3(osf_fstatfs, unsigned long, fd,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE4(osf_mount, unsigned long, typenr, const char __user *, path,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE1(osf_utsname, char __user *, name)
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE0(getpagesize)
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE0(getdtablesize)
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE2(osf_getdomainname, char __user *, name, int, namelen)
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE2(osf_proplist_syscall, enum pl_code, code,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE2(osf_sigstack, struct sigstack __user *, uss,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE3(osf_sysinfo, int, command, char __user *, buf, long, count)
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE5(osf_getsysinfo, unsigned long, op, void __user *, buffer,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE5(osf_setsysinfo, unsigned long, op, void __user *, buffer,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE2(osf_gettimeofday, struct timeval32 __user *, tv,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE2(osf_settimeofday, struct timeval32 __user *, tv,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE2(osf_getitimer, int, which, struct itimerval32 __user *, it)
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE3(osf_setitimer, int, which, struct itimerval32 __user *, in,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE2(osf_utimes, const char __user *, filename,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE5(osf_select, int, n, fd_set __user *, inp, fd_set __user *, outp,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE2(osf_getrusage, int, who, struct rusage32 __user *, ru)
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE4(osf_wait4, pid_t, pid, int __user *, ustatus, int, options,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE2(osf_usleep_thread, struct timeval32 __user *, sleep,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE1(old_adjtimex, struct timex32 __user *, txc_p)
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE3(osf_readv, unsigned long, fd,
./arch/alpha/kernel/osf_sys.c:SYSCALL_DEFINE3(osf_writev, unsigned long, fd,
./arch/alpha/kernel/signal.c:SYSCALL_DEFINE2(osf_sigprocmask, int, how, unsigned long, newmask)
./arch/alpha/kernel/signal.c:SYSCALL_DEFINE3(osf_sigaction, int, sig,
./arch/alpha/kernel/signal.c:SYSCALL_DEFINE5(rt_sigaction, int, sig, const struct sigaction __user *, act,
./arch/alpha/kernel/signal.c:SYSCALL_DEFINE1(sigsuspend, old_sigset_t, mask)
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE6(32_mmap2, unsigned long, addr, unsigned long, len,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE4(32_truncate64, const char __user *, path,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE4(32_ftruncate64, unsigned long, fd, unsigned long, __dummy,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE5(32_llseek, unsigned int, fd, unsigned int, offset_high,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE6(32_pread, unsigned long, fd, char __user *, buf, size_t, count,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE6(32_pwrite, unsigned int, fd, const char __user *, buf,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE2(32_sched_rr_get_interval, compat_pid_t, pid,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE6(32_ipc, u32, call, long, first, long, second, long, third,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE6(32_ipc, u32, call, int, first, int, second, int, third,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE4(n32_semctl, int, semid, int, semnum, int, cmd, u32, arg)
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE4(n32_msgsnd, int, msqid, u32, msgp, unsigned int, msgsz,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE5(n32_msgrcv, int, msqid, u32, msgp, size_t, msgsz,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE1(32_personality, unsigned long, personality)
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE4(32_sendfile, long, out_fd, long, in_fd,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE6(32_fanotify_mark, int, fanotify_fd, unsigned int, flags,
./arch/mips/kernel/linux32.c:SYSCALL_DEFINE6(32_futex, u32 __user *, uaddr, int, op, u32, val,
./arch/mips/kernel/signal32.c:SYSCALL_DEFINE3(32_sigaction, long, sig, const struct sigaction32 __user *, act,
./arch/mips/kernel/signal32.c:SYSCALL_DEFINE4(32_rt_sigaction, int, sig,
./arch/mips/kernel/signal32.c:SYSCALL_DEFINE4(32_rt_sigprocmask, int, how, compat_sigset_t __user *, set,
./arch/mips/kernel/signal32.c:SYSCALL_DEFINE2(32_rt_sigpending, compat_sigset_t __user *, uset,
./arch/mips/kernel/signal32.c:SYSCALL_DEFINE3(32_rt_sigqueueinfo, int, pid, int, sig,
./arch/mips/kernel/signal32.c:SYSCALL_DEFINE5(32_waitid, int, which, compat_pid_t, pid,
./arch/mips/kernel/syscall.c:SYSCALL_DEFINE6(mips_mmap, unsigned long, addr, unsigned long, len,
./arch/mips/kernel/syscall.c:SYSCALL_DEFINE6(mips_mmap2, unsigned long, addr, unsigned long, len,
./arch/mips/kernel/syscall.c:SYSCALL_DEFINE1(set_thread_area, unsigned long, addr)
./arch/mips/kernel/syscall.c:SYSCALL_DEFINE3(cachectl, char *, addr, int, nbytes, int, op)
./arch/mips/kernel/signal.c:SYSCALL_DEFINE3(sigaction, int, sig, const struct sigaction __user *, act,
./arch/mips/mm/cache.c:SYSCALL_DEFINE3(cacheflush, unsigned long, addr, unsigned long, bytes,
./arch/unicore32/kernel/sys.c:SYSCALL_DEFINE6(mmap2, unsigned long, addr, unsigned long, len,
./arch/s390/kernel/sys_s390.c:SYSCALL_DEFINE1(mmap2, struct s390_mmap_arg_struct __user *, arg)
./arch/s390/kernel/sys_s390.c:SYSCALL_DEFINE5(s390_ipc, uint, call, int, first, unsigned long, second,
./arch/s390/kernel/sys_s390.c:SYSCALL_DEFINE1(s390_personality, unsigned int, personality)
./arch/s390/kernel/sys_s390.c:SYSCALL_DEFINE5(s390_fadvise64, int, fd, u32, offset_high, u32, offset_low,
./arch/s390/kernel/sys_s390.c:SYSCALL_DEFINE1(s390_fadvise64_64, struct fadvise64_64_args __user *, args)
./arch/s390/kernel/sys_s390.c:SYSCALL_DEFINE(s390_fallocate)(int fd, int mode, loff_t offset,
./arch/s390/kernel/process.c:SYSCALL_DEFINE0(fork)
./arch/s390/kernel/process.c:SYSCALL_DEFINE4(clone, unsigned long, newsp, unsigned long, clone_flags,
./arch/s390/kernel/process.c:SYSCALL_DEFINE0(vfork)
./arch/s390/kernel/process.c:SYSCALL_DEFINE3(execve, const char __user *, name,
./arch/s390/kernel/signal.c:SYSCALL_DEFINE3(sigsuspend, int, history0, int, history1, old_sigset_t, mask)
./arch/s390/kernel/signal.c:SYSCALL_DEFINE3(sigaction, int, sig, const struct old_sigaction __user *, act,
./arch/s390/kernel/signal.c:SYSCALL_DEFINE2(sigaltstack, const stack_t __user *, uss,
./arch/s390/kernel/signal.c:SYSCALL_DEFINE0(sigreturn)
./arch/s390/kernel/signal.c:SYSCALL_DEFINE0(rt_sigreturn)
./arch/x86/kernel/sys_x86_64.c:SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
./arch/blackfin/kernel/sys_bfin.c:SYSCALL_DEFINE3(cacheflush, unsigned long, addr, unsigned long, len, int, op)
./arch/sparc/kernel/sys_sparc_64.c:SYSCALL_DEFINE1(sparc_pipe_real, struct pt_regs *, regs)
./arch/sparc/kernel/sys_sparc_64.c:SYSCALL_DEFINE6(sparc_ipc, unsigned int, call, int, first, unsigned long, second,
./arch/sparc/kernel/sys_sparc_64.c:SYSCALL_DEFINE1(sparc64_personality, unsigned long, personality)
./arch/sparc/kernel/sys_sparc_64.c:SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
./arch/sparc/kernel/sys_sparc_64.c:SYSCALL_DEFINE2(64_munmap, unsigned long, addr, size_t, len)
./arch/sparc/kernel/sys_sparc_64.c:SYSCALL_DEFINE5(64_mremap, unsigned long, addr, unsigned long, old_len,
./arch/sparc/kernel/sys_sparc_64.c:SYSCALL_DEFINE2(getdomainname, char __user *, name, int, len)
./arch/sparc/kernel/sys_sparc_64.c:SYSCALL_DEFINE5(utrap_install, utrap_entry_t, type,
./arch/sparc/kernel/sys_sparc_64.c:SYSCALL_DEFINE5(rt_sigaction, int, sig, const struct sigaction __user *, act,
./drivers/pci/syscall.c:SYSCALL_DEFINE5(pciconfig_read, unsigned long, bus, unsigned long, dfn,
./drivers/pci/syscall.c:SYSCALL_DEFINE5(pciconfig_write, unsigned long, bus, unsigned long, dfn,
./ipc/msg.c:SYSCALL_DEFINE2(msgget, key_t, key, int, msgflg)
./ipc/msg.c:SYSCALL_DEFINE3(msgctl, int, msqid, int, cmd, struct msqid_ds __user *, buf)
./ipc/msg.c:SYSCALL_DEFINE4(msgsnd, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz,
./ipc/msg.c:SYSCALL_DEFINE5(msgrcv, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz,
./ipc/syscall.c:SYSCALL_DEFINE6(ipc, unsigned int, call, int, first, unsigned long, second,
./ipc/sem.c:SYSCALL_DEFINE3(semget, key_t, key, int, nsems, int, semflg)
./ipc/sem.c:SYSCALL_DEFINE(semctl)(int semid, int semnum, int cmd, union semun arg)
./ipc/sem.c:SYSCALL_DEFINE4(semtimedop, int, semid, struct sembuf __user *, tsops,
./ipc/sem.c:SYSCALL_DEFINE3(semop, int, semid, struct sembuf __user *, tsops,
./ipc/shm.c:SYSCALL_DEFINE3(shmget, key_t, key, size_t, size, int, shmflg)
./ipc/shm.c:SYSCALL_DEFINE3(shmctl, int, shmid, int, cmd, struct shmid_ds __user *, buf)
./ipc/shm.c:SYSCALL_DEFINE3(shmat, int, shmid, char __user *, shmaddr, int, shmflg)
./ipc/shm.c:SYSCALL_DEFINE1(shmdt, char __user *, shmaddr)
./ipc/mqueue.c:SYSCALL_DEFINE4(mq_open, const char __user *, u_name, int, oflag, mode_t, mode,
./ipc/mqueue.c:SYSCALL_DEFINE1(mq_unlink, const char __user *, u_name)
./ipc/mqueue.c:SYSCALL_DEFINE5(mq_timedsend, mqd_t, mqdes, const char __user *, u_msg_ptr,
./ipc/mqueue.c:SYSCALL_DEFINE5(mq_timedreceive, mqd_t, mqdes, char __user *, u_msg_ptr,
./ipc/mqueue.c:SYSCALL_DEFINE2(mq_notify, mqd_t, mqdes,
./ipc/mqueue.c:SYSCALL_DEFINE3(mq_getsetattr, mqd_t, mqdes,
./fs/ioctl.c:SYSCALL_DEFINE3(ioctl, unsigned int, fd, unsigned int, cmd, unsigned long, arg)
./fs/select.c:SYSCALL_DEFINE5(select, int, n, fd_set __user *, inp, fd_set __user *, outp,
./fs/select.c:SYSCALL_DEFINE6(pselect6, int, n, fd_set __user *, inp, fd_set __user *, outp,
./fs/select.c:SYSCALL_DEFINE1(old_select, struct sel_arg_struct __user *, arg)
./fs/select.c:SYSCALL_DEFINE3(poll, struct pollfd __user *, ufds, unsigned int, nfds,
./fs/select.c:SYSCALL_DEFINE5(ppoll, struct pollfd __user *, ufds, unsigned int, nfds,
./fs/signalfd.c:SYSCALL_DEFINE4(signalfd4, int, ufd, sigset_t __user *, user_mask,
./fs/signalfd.c:SYSCALL_DEFINE3(signalfd, int, ufd, sigset_t __user *, user_mask,
./fs/locks.c:SYSCALL_DEFINE2(flock, unsigned int, fd, unsigned int, cmd)
./fs/exec.c:SYSCALL_DEFINE1(uselib, const char __user *, library)
./fs/open.c:SYSCALL_DEFINE2(truncate, const char __user *, path, long, length)
./fs/open.c:SYSCALL_DEFINE2(ftruncate, unsigned int, fd, unsigned long, length)
./fs/open.c:SYSCALL_DEFINE(truncate64)(const char __user * path, loff_t length)
./fs/open.c:SYSCALL_DEFINE(ftruncate64)(unsigned int fd, loff_t length)
./fs/open.c:SYSCALL_DEFINE(fallocate)(int fd, int mode, loff_t offset, loff_t len)
./fs/open.c:SYSCALL_DEFINE3(faccessat, int, dfd, const char __user *, filename, int, mode)
./fs/open.c:SYSCALL_DEFINE2(access, const char __user *, filename, int, mode)
./fs/open.c:SYSCALL_DEFINE1(chdir, const char __user *, filename)
./fs/open.c:SYSCALL_DEFINE1(fchdir, unsigned int, fd)
./fs/open.c:SYSCALL_DEFINE1(chroot, const char __user *, filename)
./fs/open.c:SYSCALL_DEFINE2(fchmod, unsigned int, fd, mode_t, mode)
./fs/open.c:SYSCALL_DEFINE3(fchmodat, int, dfd, const char __user *, filename, mode_t, mode)
./fs/open.c:SYSCALL_DEFINE2(chmod, const char __user *, filename, mode_t, mode)
./fs/open.c:SYSCALL_DEFINE3(chown, const char __user *, filename, uid_t, user, gid_t, group)
./fs/open.c:SYSCALL_DEFINE5(fchownat, int, dfd, const char __user *, filename, uid_t, user,
./fs/open.c:SYSCALL_DEFINE3(lchown, const char __user *, filename, uid_t, user, gid_t, group)
./fs/open.c:SYSCALL_DEFINE3(fchown, unsigned int, fd, uid_t, user, gid_t, group)
./fs/open.c:SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, int, mode)
./fs/open.c:SYSCALL_DEFINE4(openat, int, dfd, const char __user *, filename, int, flags,
./fs/open.c:SYSCALL_DEFINE2(creat, const char __user *, pathname, int, mode)
./fs/open.c:SYSCALL_DEFINE1(close, unsigned int, fd)
./fs/open.c:SYSCALL_DEFINE0(vhangup)
./fs/stat.c:SYSCALL_DEFINE2(stat, const char __user *, filename,
./fs/stat.c:SYSCALL_DEFINE2(lstat, const char __user *, filename,
./fs/stat.c:SYSCALL_DEFINE2(fstat, unsigned int, fd, struct __old_kernel_stat __user *, statbuf)
./fs/stat.c:SYSCALL_DEFINE2(newstat, const char __user *, filename,
./fs/stat.c:SYSCALL_DEFINE2(newlstat, const char __user *, filename,
./fs/stat.c:SYSCALL_DEFINE4(newfstatat, int, dfd, const char __user *, filename,
./fs/stat.c:SYSCALL_DEFINE2(newfstat, unsigned int, fd, struct stat __user *, statbuf)
./fs/stat.c:SYSCALL_DEFINE4(readlinkat, int, dfd, const char __user *, pathname,
./fs/stat.c:SYSCALL_DEFINE3(readlink, const char __user *, path, char __user *, buf,
./fs/stat.c:SYSCALL_DEFINE2(stat64, const char __user *, filename,
./fs/stat.c:SYSCALL_DEFINE2(lstat64, const char __user *, filename,
./fs/stat.c:SYSCALL_DEFINE2(fstat64, unsigned long, fd, struct stat64 __user *, statbuf)
./fs/stat.c:SYSCALL_DEFINE4(fstatat64, int, dfd, const char __user *, filename,
./fs/notify/inotify/inotify_user.c:SYSCALL_DEFINE1(inotify_init1, int, flags)
./fs/notify/inotify/inotify_user.c:SYSCALL_DEFINE0(inotify_init)
./fs/notify/inotify/inotify_user.c:SYSCALL_DEFINE3(inotify_add_watch, int, fd, const char __user *, pathname,
./fs/notify/inotify/inotify_user.c:SYSCALL_DEFINE2(inotify_rm_watch, int, fd, __s32, wd)
./fs/notify/fanotify/fanotify_user.c:SYSCALL_DEFINE2(fanotify_init, unsigned int, flags, unsigned int, event_f_flags)
./fs/notify/fanotify/fanotify_user.c:SYSCALL_DEFINE(fanotify_mark)(int fanotify_fd, unsigned int flags,
./fs/filesystems.c:SYSCALL_DEFINE3(sysfs, int, option, unsigned long, arg1, unsigned long, arg2)
./fs/fhandle.c:SYSCALL_DEFINE5(name_to_handle_at, int, dfd, const char __user *, name,
./fs/fhandle.c:SYSCALL_DEFINE3(open_by_handle_at, int, mountdirfd,
./fs/timerfd.c:SYSCALL_DEFINE2(timerfd_create, int, clockid, int, flags)
./fs/timerfd.c:SYSCALL_DEFINE4(timerfd_settime, int, ufd, int, flags,
./fs/timerfd.c:SYSCALL_DEFINE2(timerfd_gettime, int, ufd, struct itimerspec __user *, otmr)
./fs/ioprio.c:SYSCALL_DEFINE3(ioprio_set, int, which, int, who, int, ioprio)
./fs/ioprio.c:SYSCALL_DEFINE2(ioprio_get, int, which, int, who)
./fs/namespace.c:SYSCALL_DEFINE2(umount, char __user *, name, int, flags)
./fs/namespace.c:SYSCALL_DEFINE1(oldumount, char __user *, name)
./fs/namespace.c:SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name,
./fs/namespace.c:SYSCALL_DEFINE2(pivot_root, const char __user *, new_root,
./fs/xattr.c:SYSCALL_DEFINE5(setxattr, const char __user *, pathname,
./fs/xattr.c:SYSCALL_DEFINE5(lsetxattr, const char __user *, pathname,
./fs/xattr.c:SYSCALL_DEFINE5(fsetxattr, int, fd, const char __user *, name,
./fs/xattr.c:SYSCALL_DEFINE4(getxattr, const char __user *, pathname,
./fs/xattr.c:SYSCALL_DEFINE4(lgetxattr, const char __user *, pathname,
./fs/xattr.c:SYSCALL_DEFINE4(fgetxattr, int, fd, const char __user *, name,
./fs/xattr.c:SYSCALL_DEFINE3(listxattr, const char __user *, pathname, char __user *, list,
./fs/xattr.c:SYSCALL_DEFINE3(llistxattr, const char __user *, pathname, char __user *, list,
./fs/xattr.c:SYSCALL_DEFINE3(flistxattr, int, fd, char __user *, list, size_t, size)
./fs/xattr.c:SYSCALL_DEFINE2(removexattr, const char __user *, pathname,
./fs/xattr.c:SYSCALL_DEFINE2(lremovexattr, const char __user *, pathname,
./fs/xattr.c:SYSCALL_DEFINE2(fremovexattr, int, fd, const char __user *, name)
./fs/dcache.c:SYSCALL_DEFINE2(getcwd, char __user *, buf, unsigned long, size)
./fs/utimes.c:SYSCALL_DEFINE2(utime, char __user *, filename, struct utimbuf __user *, times)
./fs/utimes.c:SYSCALL_DEFINE4(utimensat, int, dfd, const char __user *, filename,
./fs/utimes.c:SYSCALL_DEFINE3(futimesat, int, dfd, const char __user *, filename,
./fs/utimes.c:SYSCALL_DEFINE2(utimes, char __user *, filename,
./fs/aio.c:SYSCALL_DEFINE2(io_setup, unsigned, nr_events, aio_context_t __user *, ctxp)
./fs/aio.c:SYSCALL_DEFINE1(io_destroy, aio_context_t, ctx)
./fs/aio.c:SYSCALL_DEFINE3(io_submit, aio_context_t, ctx_id, long, nr,
./fs/aio.c:SYSCALL_DEFINE3(io_cancel, aio_context_t, ctx_id, struct iocb __user *, iocb,
./fs/aio.c:SYSCALL_DEFINE5(io_getevents, aio_context_t, ctx_id,
./fs/eventfd.c:SYSCALL_DEFINE2(eventfd2, unsigned int, count, int, flags)
./fs/eventfd.c:SYSCALL_DEFINE1(eventfd, unsigned int, count)
./fs/statfs.c:SYSCALL_DEFINE2(statfs, const char __user *, pathname, struct statfs __user *, buf)
./fs/statfs.c:SYSCALL_DEFINE3(statfs64, const char __user *, pathname, size_t, sz, struct statfs64 __user *, buf)
./fs/statfs.c:SYSCALL_DEFINE2(fstatfs, unsigned int, fd, struct statfs __user *, buf)
./fs/statfs.c:SYSCALL_DEFINE3(fstatfs64, unsigned int, fd, size_t, sz, struct statfs64 __user *, buf)
./fs/statfs.c:SYSCALL_DEFINE2(ustat, unsigned, dev, struct ustat __user *, ubuf)
./fs/read_write.c:SYSCALL_DEFINE3(lseek, unsigned int, fd, off_t, offset, unsigned int, origin)
./fs/read_write.c:SYSCALL_DEFINE5(llseek, unsigned int, fd, unsigned long, offset_high,
./fs/read_write.c:SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
./fs/read_write.c:SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
./fs/read_write.c:SYSCALL_DEFINE(pread64)(unsigned int fd, char __user *buf,
./fs/read_write.c:SYSCALL_DEFINE(pwrite64)(unsigned int fd, const char __user *buf,
./fs/read_write.c:SYSCALL_DEFINE3(readv, unsigned long, fd, const struct iovec __user *, vec,
./fs/read_write.c:SYSCALL_DEFINE3(writev, unsigned long, fd, const struct iovec __user *, vec,
./fs/read_write.c:SYSCALL_DEFINE5(preadv, unsigned long, fd, const struct iovec __user *, vec,
./fs/read_write.c:SYSCALL_DEFINE5(pwritev, unsigned long, fd, const struct iovec __user *, vec,
./fs/read_write.c:SYSCALL_DEFINE4(sendfile, int, out_fd, int, in_fd, off_t __user *, offset, size_t, count)
./fs/read_write.c:SYSCALL_DEFINE4(sendfile64, int, out_fd, int, in_fd, loff_t __user *, offset, size_t, count)
./fs/sync.c:SYSCALL_DEFINE0(sync)
./fs/sync.c:SYSCALL_DEFINE1(syncfs, int, fd)
./fs/sync.c:SYSCALL_DEFINE1(fsync, unsigned int, fd)
./fs/sync.c:SYSCALL_DEFINE1(fdatasync, unsigned int, fd)
./fs/sync.c:SYSCALL_DEFINE(sync_file_range)(int fd, loff_t offset, loff_t nbytes,
./fs/sync.c:SYSCALL_DEFINE(sync_file_range2)(int fd, unsigned int flags,
./fs/fcntl.c:SYSCALL_DEFINE3(dup3, unsigned int, oldfd, unsigned int, newfd, int, flags)
./fs/fcntl.c:SYSCALL_DEFINE2(dup2, unsigned int, oldfd, unsigned int, newfd)
./fs/fcntl.c:SYSCALL_DEFINE1(dup, unsigned int, fildes)
./fs/fcntl.c:SYSCALL_DEFINE3(fcntl, unsigned int, fd, unsigned int, cmd, unsigned long, arg)
./fs/fcntl.c:SYSCALL_DEFINE3(fcntl64, unsigned int, fd, unsigned int, cmd,
./fs/pipe.c:SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
./fs/pipe.c:SYSCALL_DEFINE1(pipe, int __user *, fildes)
./fs/namei.c:SYSCALL_DEFINE4(mknodat, int, dfd, const char __user *, filename, int, mode,
./fs/namei.c:SYSCALL_DEFINE3(mknod, const char __user *, filename, int, mode, unsigned, dev)
./fs/namei.c:SYSCALL_DEFINE3(mkdirat, int, dfd, const char __user *, pathname, int, mode)
./fs/namei.c:SYSCALL_DEFINE2(mkdir, const char __user *, pathname, int, mode)
./fs/namei.c:SYSCALL_DEFINE1(rmdir, const char __user *, pathname)
./fs/namei.c:SYSCALL_DEFINE3(unlinkat, int, dfd, const char __user *, pathname, int, flag)
./fs/namei.c:SYSCALL_DEFINE1(unlink, const char __user *, pathname)
./fs/namei.c:SYSCALL_DEFINE3(symlinkat, const char __user *, oldname,
./fs/namei.c:SYSCALL_DEFINE2(symlink, const char __user *, oldname, const char __user *, newname)
./fs/namei.c:SYSCALL_DEFINE5(linkat, int, olddfd, const char __user *, oldname,
./fs/namei.c:SYSCALL_DEFINE2(link, const char __user *, oldname, const char __user *, newname)
./fs/namei.c:SYSCALL_DEFINE4(renameat, int, olddfd, const char __user *, oldname,
./fs/namei.c:SYSCALL_DEFINE2(rename, const char __user *, oldname, const char __user *, newname)
./fs/readdir.c:SYSCALL_DEFINE3(old_readdir, unsigned int, fd,
./fs/readdir.c:SYSCALL_DEFINE3(getdents, unsigned int, fd,
./fs/readdir.c:SYSCALL_DEFINE3(getdents64, unsigned int, fd,
./fs/buffer.c:SYSCALL_DEFINE2(bdflush, int, func, long, data)
./fs/eventpoll.c:SYSCALL_DEFINE1(epoll_create1, int, flags)
./fs/eventpoll.c:SYSCALL_DEFINE1(epoll_create, int, size)
./fs/eventpoll.c:SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
./fs/eventpoll.c:SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
./fs/eventpoll.c:SYSCALL_DEFINE6(epoll_pwait, int, epfd, struct epoll_event __user *, events,
./fs/quota/quota.c:SYSCALL_DEFINE4(quotactl, unsigned int, cmd, const char __user *, special,
./fs/splice.c:SYSCALL_DEFINE4(vmsplice, int, fd, const struct iovec __user *, iov,
./fs/splice.c:SYSCALL_DEFINE6(splice, int, fd_in, loff_t __user *, off_in,
./fs/splice.c:SYSCALL_DEFINE4(tee, int, fdin, int, fdout, size_t, len, unsigned int, flags)
./fs/dcookies.c:SYSCALL_DEFINE(lookup_dcookie)(u64 cookie64, char __user * buf, size_t len)
./security/keys/keyctl.c:SYSCALL_DEFINE5(add_key, const char __user *, _type,
./security/keys/keyctl.c:SYSCALL_DEFINE4(request_key, const char __user *, _type,
./security/keys/keyctl.c:SYSCALL_DEFINE5(keyctl, int, option, unsigned long, arg2, unsigned long, arg3,
./mm/process_vm_access.c:SYSCALL_DEFINE6(process_vm_readv, pid_t, pid, const struct iovec __user *, lvec,
./mm/process_vm_access.c:SYSCALL_DEFINE6(process_vm_writev, pid_t, pid,
./mm/mempolicy.c:SYSCALL_DEFINE6(mbind, unsigned long, start, unsigned long, len,
./mm/mempolicy.c:SYSCALL_DEFINE3(set_mempolicy, int, mode, unsigned long __user *, nmask,
./mm/mempolicy.c:SYSCALL_DEFINE4(migrate_pages, pid_t, pid, unsigned long, maxnode,
./mm/mempolicy.c:SYSCALL_DEFINE5(get_mempolicy, int __user *, policy,
./mm/fadvise.c:SYSCALL_DEFINE(fadvise64_64)(int fd, loff_t offset, loff_t len, int advice)
./mm/fadvise.c:SYSCALL_DEFINE(fadvise64)(int fd, loff_t offset, size_t len, int advice)
./mm/mlock.c:SYSCALL_DEFINE2(mlock, unsigned long, start, size_t, len)
./mm/mlock.c:SYSCALL_DEFINE2(munlock, unsigned long, start, size_t, len)
./mm/mlock.c:SYSCALL_DEFINE1(mlockall, int, flags)
./mm/mlock.c:SYSCALL_DEFINE0(munlockall)
./mm/mincore.c:SYSCALL_DEFINE3(mincore, unsigned long, start, size_t, len,
./mm/migrate.c:SYSCALL_DEFINE6(move_pages, pid_t, pid, unsigned long, nr_pages,
./mm/mmap.c:SYSCALL_DEFINE1(brk, unsigned long, brk)
./mm/mmap.c:SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
./mm/mmap.c:SYSCALL_DEFINE1(old_mmap, struct mmap_arg_struct __user *, arg)
./mm/mmap.c:SYSCALL_DEFINE2(munmap, unsigned long, addr, size_t, len)
./mm/nommu.c:SYSCALL_DEFINE1(brk, unsigned long, brk)
./mm/nommu.c:SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
./mm/nommu.c:SYSCALL_DEFINE1(old_mmap, struct mmap_arg_struct __user *, arg)
./mm/nommu.c:SYSCALL_DEFINE2(munmap, unsigned long, addr, size_t, len)
./mm/nommu.c:SYSCALL_DEFINE5(mremap, unsigned long, addr, unsigned long, old_len,
./mm/fremap.c:SYSCALL_DEFINE5(remap_file_pages, unsigned long, start, unsigned long, size,
./mm/filemap.c:SYSCALL_DEFINE(readahead)(int fd, loff_t offset, size_t count)
./mm/mremap.c:SYSCALL_DEFINE5(mremap, unsigned long, addr, unsigned long, old_len,
./mm/msync.c:SYSCALL_DEFINE3(msync, unsigned long, start, size_t, len, int, flags)
./mm/mprotect.c:SYSCALL_DEFINE3(mprotect, unsigned long, start, size_t, len,
./mm/madvise.c:SYSCALL_DEFINE3(madvise, unsigned long, start, size_t, len_in, int, behavior)
./mm/swapfile.c:SYSCALL_DEFINE1(swapoff, const char __user *, specialfile)
./mm/swapfile.c:SYSCALL_DEFINE2(swapon, const char __user *, specialfile, int, swap_flags)
关键字asmlinkage的意义
This is a directive to tell the compiler to look only on the stack for this function’s arguments. This is a required modifier for all system calls.
为什么返回值为long
For compatibility between 32- and 64-bit systems, system calls defined to return an int in user-space return a long in the kernel.
5.5.2 系统调用号/__NR_xxx
在5.5.1 系统调用的声明与定义节中的每个系统调用xxx都对应着一个系统调用号__NR_xxx。当应用程序调用某系统调用时,寄存器eax中保存该系统调用对应的系统调用号。系统调用号定义于如下头文件中:
include/linux/unistd.h // Moved to include/uapi/linux/unistd.h in commit 607ca46e97a1b6594b29647d98a32d545c24bdff
+- arch/x86/include/asm/unistd.h
+- arch/x86/include/asm/unistd_32.h
| +- ...
| +- #define __NR_process_vm_writev 348
| +- #define NR_syscalls 349
+- arch/x86/include/asm/unistd_64.h
+- ...
+- #define __NR_process_vm_writev 311
+- __SYSCALL(__NR_process_vm_writev, sys_process_vm_writev)
在应用程序中仅需包含如下头文件即可:
#include <unistd.h>
include/linux/unistd.h:
#ifndef _LINUX_UNISTD_H_
#define _LINUX_UNISTD_H_
/*
* Include machine specific syscall numbers
*/
#include <asm/unistd.h>
#endif /* _LINUX_UNISTD_H_ */
对于x86而言,asm/unistd.h即为arch/x86/include/asm/unistd.h:
#ifdef __KERNEL__
# ifdef CONFIG_X86_32
# include "unistd_32.h"
# else
# include "unistd_64.h"
# endif
#else
# ifdef __i386__
# include "unistd_32.h"
# else
# include "unistd_64.h"
# endif
#endif
对于x86 32-bit而言,unistd_32.h即为arch/x86/include/asm/unistd_32.h:
#define __NR_restart_syscall 0
#define __NR_exit 1
#define __NR_fork 2
#define __NR_read 3
#define __NR_write 4
#define __NR_open 5
#define __NR_close 6
...
#define __NR_process_vm_readv 347
#define __NR_process_vm_writev 348
#ifdef __KERNEL__
#define NR_syscalls 349
#endif
对于x86 64-bit而言,unistd_64.h即为arch/x86/include/asm/unistd_64.h:
#define __NR_read 0
__SYSCALL(__NR_read, sys_read)
#define __NR_write 1
__SYSCALL(__NR_write, sys_write)
#define __NR_open 2
__SYSCALL(__NR_open, sys_open)
#define __NR_close 3
__SYSCALL(__NR_close, sys_close)
...
#define __NR_process_vm_readv 310
__SYSCALL(__NR_process_vm_readv, sys_process_vm_readv)
#define __NR_process_vm_writev 311
__SYSCALL(__NR_process_vm_writev, sys_process_vm_writev)
#ifdef __KERNEL__
#ifndef COMPILE_OFFSETS
#include <asm/asm-offsets.h>
#define NR_syscalls (__NR_syscall_max + 1)
#endif
#endif
5.5.3 系统调用表/sys_call_table
通过5.5.2 系统调用号/__NR_xxx节的系统调用号,在系统调用表sys_call_table中查找所对应的处理函数。
对于x86 32-bit而言,系统调用表sys_call_table定义于arch/x86/kernel/syscall_table_32.S:
ENTRY(sys_call_table)
.long sys_restart_syscall /* 0 - old "setup()" system call, used for restarting */
.long sys_exit
.long ptregs_fork
.long sys_read
.long sys_write
.long sys_open /* 5 */
.long sys_close
...
.long sys_sendmmsg /* 345 */
.long sys_setns
.long sys_process_vm_readv
.long sys_process_vm_writev
对于x86 64-bit而言,系统调用表sys_call_table定义于arch/x86/kernel/syscall_64.c:
typedef void (*sys_call_ptr_t)(void);
extern void sys_ni_syscall(void);
const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
/*
* Smells like a like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
// 参见[5.5.2 系统调用号/__NR_xxx]节
#include <asm/unistd_64.h>
};
5.5.4 系统调用的参数传递
5.5.4.1 系统调用的入参
参见《Linux Kernel Development.[3rd Edition].[Robert Love]》第5. System Calls章第System Call Handler节:
Simply entering kernel-space alone is not sufficient because multiple system calls exist, all of which enter the kernel in the same manner. Thus, the system call number must be passed into the kernel. On x86, the syscall number is fed to the kernel via the eax register.
In addition to the system call number, most syscalls require that one or more parameters be passed to them. Somehow, user-space must relay the parameters to the kernel during the trap. The easiest way to do this is via the same means that the syscall number is passed: The parameters are stored in registers. On x86-32, the registers ebx, ecx, edx, esi, and edi contain, in order, the first five arguments. In the unlikely case of six or more arguments, a single register is used to hold a pointer to user-space where all the parameters are stored.
5.5.4.2 系统调用的返回值
参见《Linux Kernel Development.[3rd Edition].[Robert Love]》第5. System Calls章第System Call Handler节:
The return value is sent to user-space also via register. On x86, it is written into the eax register.
如果系统调用执行失败,系统调用并不直接返回错误码,而是将错误码保存到全局变量errno中,因而可根据errno的值来确定错误类型。错误码定义于如下头文件中:
include/linux/errno.h // 错误码512-530
-> arch/x86/include/asm/errno.h // 仅包含asm-generic/errno.h,未新增错误码
-> include/asm-generic/errno.h // 错误码35-133
-> include/asm-generic/errno-base.h // 错误码1-34
也可以执行下列命令获得errno的帮助:
chenwx@chenwx: ~/linux $ man errno
ERRNO(3) Linux Programmer's Manual ERRNO(3)
NAME
errno - number of last error
SYNOPSIS
#include <errno.h>
DESCRIPTION
The <errno.h> header file defines the integer variable errno, which is set by system calls and some library
functions in the event of an error to indicate what went wrong.
errno
The value in errno is significant only when the return value of the call indicated an error (i.e., -1 from
most system calls; -1 or NULL from most library functions); a function that succeeds is allowed to change
errno. The value of errno is never set to zero by any system call or library function.
For some system calls and library functions (e.g., getpriority(2)), -1 is a valid return on success. In such
cases, a successful return can be distinguished from an error return by setting errno to zero before the call,
and then, if the call returns a status that indicates that an error may have occurred, checking to see if
errno has a nonzero value.
errno is defined by the ISO C standard to be a modifiable lvalue of type int, and must not be explicitly
declared; errno may be a macro. errno is thread-local; setting it in one thread does not affect its value in
any other thread.
Error numbers and names
Valid error numbers are all positive numbers. The <errno.h> header file defines symbolic names for each of
the possible error numbers that may appear in errno.
All the error names specified by POSIX.1 must have distinct values, with the exception of EAGAIN and EWOULD-
BLOCK, which may be the same.
The error numbers that correspond to each symbolic name vary across UNIX systems, and even across different
architectures on Linux. Therefore, numeric values are not included as part of the list of error names below.
The perror(3) and strerror(3) functions can be used to convert these names to corresponding textual error mes-
sages.
On any particular Linux system, one can obtain a list of all symbolic error names and the corresponding error
numbers using the errno(1) command:
$ errno -l
EPERM 1 Operation not permitted
ENOENT 2 No such file or directory
ESRCH 3 No such process
EINTR 4 Interrupted system call
EIO 5 Input/output error
...
The errno(1) command can also be used to look up individual error numbers and names, and to search for errors
using strings from the error description, as in the following examples:
$ errno 2
ENOENT 2 No such file or directory
$ errno ESRCH
ESRCH 3 No such process
$ errno -s permission
EACCES 13 Permission denied
List of error names
In the list of the symbolic error names below, various names are marked as follows:
* POSIX.1-2001: The name is defined by POSIX.1-2001, and is defined in later POSIX.1 versions, unless other-
wise indicated.
* POSIX.1-2008: The name is defined in POSIX.1-2008, but was not present in earlier POSIX.1 standards.
* C99: The name is defined by C99. Below is a list of the symbolic error names that are defined on Linux:
E2BIG Argument list too long (POSIX.1-2001).
EACCES Permission denied (POSIX.1-2001).
EADDRINUSE Address already in use (POSIX.1-2001).
EADDRNOTAVAIL Address not available (POSIX.1-2001).
EAFNOSUPPORT Address family not supported (POSIX.1-2001).
EAGAIN Resource temporarily unavailable (may be the same value as EWOULDBLOCK) (POSIX.1-2001).
EALREADY Connection already in progress (POSIX.1-2001).
EBADE Invalid exchange.
EBADF Bad file descriptor (POSIX.1-2001).
EBADFD File descriptor in bad state.
EBADMSG Bad message (POSIX.1-2001).
EBADR Invalid request descriptor.
EBADRQC Invalid request code.
EBADSLT Invalid slot.
EBUSY Device or resource busy (POSIX.1-2001).
ECANCELED Operation canceled (POSIX.1-2001).
ECHILD No child processes (POSIX.1-2001).
ECHRNG Channel number out of range.
ECOMM Communication error on send.
ECONNABORTED Connection aborted (POSIX.1-2001).
ECONNREFUSED Connection refused (POSIX.1-2001).
ECONNRESET Connection reset (POSIX.1-2001).
EDEADLK Resource deadlock avoided (POSIX.1-2001).
EDEADLOCK Synonym for EDEADLK.
EDESTADDRREQ Destination address required (POSIX.1-2001).
EDOM Mathematics argument out of domain of function (POSIX.1, C99).
EDQUOT Disk quota exceeded (POSIX.1-2001).
EEXIST File exists (POSIX.1-2001).
EFAULT Bad address (POSIX.1-2001).
EFBIG File too large (POSIX.1-2001).
EHOSTDOWN Host is down.
EHOSTUNREACH Host is unreachable (POSIX.1-2001).
EHWPOISON Memory page has hardware error.
EIDRM Identifier removed (POSIX.1-2001).
EILSEQ Invalid or incomplete multibyte or wide character (POSIX.1, C99).
The text shown here is the glibc error description; in POSIX.1, this error is described as
"Illegal byte sequence".
EINPROGRESS Operation in progress (POSIX.1-2001).
EINTR Interrupted function call (POSIX.1-2001); see signal(7).
EINVAL Invalid argument (POSIX.1-2001).
EIO Input/output error (POSIX.1-2001).
EISCONN Socket is connected (POSIX.1-2001).
EISDIR Is a directory (POSIX.1-2001).
EISNAM Is a named type file.
EKEYEXPIRED Key has expired.
EKEYREJECTED Key was rejected by service.
EKEYREVOKED Key has been revoked.
EL2HLT Level 2 halted.
EL2NSYNC Level 2 not synchronized.
EL3HLT Level 3 halted.
EL3RST Level 3 reset.
ELIBACC Cannot access a needed shared library.
ELIBBAD Accessing a corrupted shared library.
ELIBMAX Attempting to link in too many shared libraries.
ELIBSCN .lib section in a.out corrupted
ELIBEXEC Cannot exec a shared library directly.
ELNRANGE Link number out of range.
ELOOP Too many levels of symbolic links (POSIX.1-2001).
EMEDIUMTYPE Wrong medium type.
EMFILE Too many open files (POSIX.1-2001). Commonly caused by exceeding the RLIMIT_NOFILE resource
limit described in getrlimit(2).
EMLINK Too many links (POSIX.1-2001).
EMSGSIZE Message too long (POSIX.1-2001).
EMULTIHOP Multihop attempted (POSIX.1-2001).
ENAMETOOLONG Filename too long (POSIX.1-2001).
ENETDOWN Network is down (POSIX.1-2001).
ENETRESET Connection aborted by network (POSIX.1-2001).
ENETUNREACH Network unreachable (POSIX.1-2001).
ENFILE Too many open files in system (POSIX.1-2001). On Linux, this is probably a result of encoun-
tering the /proc/sys/fs/file-max limit (see proc(5)).
ENOANO No anode.
ENOBUFS No buffer space available (POSIX.1 (XSI STREAMS option)).
ENODATA No message is available on the STREAM head read queue (POSIX.1-2001).
ENODEV No such device (POSIX.1-2001).
ENOENT No such file or directory (POSIX.1-2001).
Typically, this error results when a specified pathname does not exist, or one of the compo-
nents in the directory prefix of a pathname does not exist, or the specified pathname is a
dangling symbolic link.
ENOEXEC Exec format error (POSIX.1-2001).
ENOKEY Required key not available.
ENOLCK No locks available (POSIX.1-2001).
ENOLINK Link has been severed (POSIX.1-2001).
ENOMEDIUM No medium found.
ENOMEM Not enough space/cannot allocate memory (POSIX.1-2001).
ENOMSG No message of the desired type (POSIX.1-2001).
ENONET Machine is not on the network.
ENOPKG Package not installed.
ENOPROTOOPT Protocol not available (POSIX.1-2001).
ENOSPC No space left on device (POSIX.1-2001).
ENOSR No STREAM resources (POSIX.1 (XSI STREAMS option)).
ENOSTR Not a STREAM (POSIX.1 (XSI STREAMS option)).
ENOSYS Function not implemented (POSIX.1-2001).
ENOTBLK Block device required.
ENOTCONN The socket is not connected (POSIX.1-2001).
ENOTDIR Not a directory (POSIX.1-2001).
ENOTEMPTY Directory not empty (POSIX.1-2001).
ENOTRECOVERABLE State not recoverable (POSIX.1-2008).
ENOTSOCK Not a socket (POSIX.1-2001).
ENOTSUP Operation not supported (POSIX.1-2001).
ENOTTY Inappropriate I/O control operation (POSIX.1-2001).
ENOTUNIQ Name not unique on network.
ENXIO No such device or address (POSIX.1-2001).
EOPNOTSUPP Operation not supported on socket (POSIX.1-2001).
(ENOTSUP and EOPNOTSUPP have the same value on Linux, but according to POSIX.1 these error
values should be distinct.)
EOVERFLOW Value too large to be stored in data type (POSIX.1-2001).
EOWNERDEAD Owner died (POSIX.1-2008).
EPERM Operation not permitted (POSIX.1-2001).
EPFNOSUPPORT Protocol family not supported.
EPIPE Broken pipe (POSIX.1-2001).
EPROTO Protocol error (POSIX.1-2001).
EPROTONOSUPPORT Protocol not supported (POSIX.1-2001).
EPROTOTYPE Protocol wrong type for socket (POSIX.1-2001).
ERANGE Result too large (POSIX.1, C99).
EREMCHG Remote address changed.
EREMOTE Object is remote.
EREMOTEIO Remote I/O error.
ERESTART Interrupted system call should be restarted.
ERFKILL Operation not possible due to RF-kill.
EROFS Read-only filesystem (POSIX.1-2001).
ESHUTDOWN Cannot send after transport endpoint shutdown.
ESPIPE Invalid seek (POSIX.1-2001).
ESOCKTNOSUPPORT Socket type not supported.
ESRCH No such process (POSIX.1-2001).
ESTALE Stale file handle (POSIX.1-2001).
This error can occur for NFS and for other filesystems.
ESTRPIPE Streams pipe error.
ETIME Timer expired (POSIX.1 (XSI STREAMS option)).
(POSIX.1 says "STREAM ioctl(2) timeout".)
ETIMEDOUT Connection timed out (POSIX.1-2001).
ETOOMANYREFS Too many references: cannot splice.
ETXTBSY Text file busy (POSIX.1-2001).
EUCLEAN Structure needs cleaning.
EUNATCH Protocol driver not attached.
EUSERS Too many users.
EWOULDBLOCK Operation would block (may be same value as EAGAIN) (POSIX.1-2001).
EXDEV Improper link (POSIX.1-2001).
EXFULL Exchange full.
NOTES
A common mistake is to do
if (somecall() == -1) {
printf("somecall() failed\n");
if (errno == ...) { ... }
}
where errno no longer needs to have the value it had upon return from somecall() (i.e., it may have been
changed by the printf(3)). If the value of errno should be preserved across a library call, it must be saved:
if (somecall() == -1) {
int errsv = errno;
printf("somecall() failed\n");
if (errsv == ...) { ... }
}
On some ancient systems, <errno.h> was not present or did not declare errno, so that it was necessary to
declare errno manually (i.e., extern int errno). Do not do this. It long ago ceased to be necessary, and it
will cause problems with modern versions of the C library.
SEE ALSO
errno(1), err(3), error(3), perror(3), strerror(3)
COLOPHON
This page is part of release 4.15 of the Linux man-pages project. A description of the project, information
about reporting bugs, and the latest version of this page, can be found at
https://www.kernel.org/doc/man-pages/.
2018-02-02 ERRNO(3)
NOTE: 只有当系统调用执行失败时才会设置全局变量errno;如果系统调用执行成功,则errno的值无定义,并不会被置为0。
5.5.4.3 用户空间和内核空间之间的参数传递
参见《Linux Kernel Development.[3rd Edition].[Robert Love]》第5. System Calls章第System Call Implementation节:
For writing into user-space, the method copy_to_user() is provided. It takes three parameters. The first is the destination memory address in the process’s address space. The second is the source pointer in kernel-space. Finally, the third argument is the size in bytes of the data to copy.
For reading from user-space, the method copy_from_user() is analogous to copy_to_user(). The function reads from the second parameter into the first parameter the number of bytes specified in the third parameter.
Both of these functions return the number of bytes they failed to copy on error. On success, they return zero. It is standard for the syscall to return -EFAULT in the case of such an error. The EFAULT is defined in include/asm-generic/errno-base.h. 参见5.5.4.2 系统调用的返回值节:
#define EFAULT 14 /* Bad address */
5.5.4.3.1 copy_from_user()
要使用函数copy_from_user(),需要包含头文件uaccess.h。内核目录中存在如下两个头文件,其访问顺序参见3.4.2.1.3.1.1.1.1 编译$(obj)目录下的目标文件节。
- arch/x86/include/asm/uaccess.h
- include/asm-generic/uaccess.h
1) 在arch/x86/include/asm/uaccess.h中,存在如下包含关系:
...
#ifdef CONFIG_X86_32
# include "uaccess_32.h"
#else
# include "uaccess_64.h"
#endif
arch/x86/include/asm/uaccess_32.h:
static inline unsigned long __must_check copy_from_user(void *to, const void __user *from, unsigned long n)
{
// 获取to指向内存区的大小,参见[5.5.4.3.1.1 __compiletime_object_size()]节
int sz = __compiletime_object_size(to);
if (likely(sz == -1 || sz >= n))
n = _copy_from_user(to, from, n); // 验证from指向内存区的可读性,并进行拷贝
else
copy_from_user_overflow(); // 打印错误信息:Buffer overflow detected!
return n;
}
arch/x86/include/asm/uaccess_64.h:
static inline unsigned long __must_check copy_from_user(void *to, const void __user *from, unsigned long n)
{
int sz = __compiletime_object_size(to);
might_fault(); // 调用might_sleep()
if (likely(sz == -1 || sz >= n))
n = _copy_from_user(to, from, n); // 验证from指向内存区的可读性,并进行拷贝
#ifdef CONFIG_DEBUG_VM
else
WARN(1, "Buffer overflow detected!\n");
#endif
return n;
}
2) include/asm-generic/uaccess.h:
static inline long copy_from_user(void *to, const void __user * from, unsigned long n)
{
might_sleep();
if (access_ok(VERIFY_READ, from, n))
return __copy_from_user(to, from, n);
else
return n;
}
5.5.4.3.1.1 __compiletime_object_size()
该宏定义于include/linux/compiler-gcc4.h:
#if __GNUC_MINOR__ > 0
#define __compiletime_object_size(obj) __builtin_object_size(obj, 0)
#endif
其中,__builtin_object_size()为GCC的内置函数,参见《Using the GNU Compiler Collection (GCC) v4.1.2》第5 Extensions to the C Language Family章第5.45 Object Size Checking Builtins节:
size_t __builtin_object_size(void * ptr, int type)
is a built-in construct that returns a constant number of bytes from ptr to the end of the object ptr pointer points to (if known at compile time). __builtin_object_size never evaluates its arguments for side-effects.
5.5.4.3.2 copy_to_user()
要使用函数copy_to_user(),需要包含头文件uaccess.h。内核目录中存在如下两个头文件,其访问顺序参见3.4.2.1.3.1.1.1.1 编译$(obj)目录下的目标文件节。
- arch/x86/include/asm/uaccess.h
- include/asm-generic/uaccess.h
在arch/x86/include/asm/uaccess.h中,存在如下包含关系:
1) arch/x86/include/asm/uaccess_32.h:
// 此处为声明,其定义于arch/x86/lib/usercopy_32.c
unsigned long __must_check copy_to_user(void __user *to, const void *from, unsigned long n);
arch/x86/lib/usercopy_32.c:
/**
* copy_to_user: - Copy a block of data into user space.
* @to: Destination address, in user space.
* @from: Source address, in kernel space.
* @n: Number of bytes to copy.
*
* Context: User context only. This function may sleep.
*
* Copy data from kernel space to user space.
*
* Returns number of bytes that could not be copied.
* On success, this will be zero.
*/
unsigned long copy_to_user(void __user *to, const void *from, unsigned long n)
{
if (access_ok(VERIFY_WRITE, to, n))
n = __copy_to_user(to, from, n);
return n;
}
arch/x86/include/asm/uaccess_64.h:
static __always_inline __must_check int copy_to_user(void __user *dst, const void *src, unsigned size)
{
might_fault();
return _copy_to_user(dst, src, size);
}
2) include/asm-generic/uaccess.h:
static inline long copy_to_user(void __user *to, const void *from, unsigned long n)
{
// 若to指向的区域(或磁盘区)为调入内存,则进程休眠,并调度其他进程运行
might_sleep();
// 验证to指向内存区的可写性,并进行拷贝
if (access_ok(VERIFY_WRITE, to, n))
return __copy_to_user(to, from, n);
else
return n;
}
5.5.4.3.3 simple_write_to_buffer()
该函数声明于include/linux/fs.h:
extern ssize_t simple_write_to_buffer(void *to, size_t available, loff_t *ppos,
const void __user *from, size_t count);
该函数定义于fs/libfs.c:
/**
* simple_write_to_buffer - copy data from user space to the buffer
* @to: the buffer to write to
* @available: the size of the buffer
* @ppos: the current position in the buffer
* @from: the user space buffer to read from
* @count: the maximum number of bytes to read
*
* The simple_write_to_buffer() function reads up to @count bytes from the user
* space address starting at @from into the buffer @to at offset @ppos.
*
* On success, the number of bytes written is returned and the offset @ppos is
* advanced by this number, or negative value is returned on error.
**/
ssize_t simple_write_to_buffer(void *to, size_t available, loff_t *ppos,
const void __user *from, size_t count)
{
loff_t pos = *ppos;
size_t res;
if (pos < 0)
return -EINVAL;
if (pos >= available || !count)
return 0;
if (count > available - pos)
count = available – pos;
// 参见[5.5.4.3.2 copy_from_user()]节,该函数返回未成功拷贝的字节数
res = copy_from_user(to + pos, from, count);
if (res == count)
return -EFAULT;
count -= res;
*ppos = pos + count;
return count;
}
5.5.4.3.4 simple_read_from_buffer()
该函数声明于include/linux/fs.h:
extern ssize_t simple_read_from_buffer(void __user *to, size_t count,
loff_t *ppos, const void *from,
size_t available);
该函数定义于fs/libfs.c:
/**
* simple_read_from_buffer - copy data from the buffer to user space
* @to: the user space buffer to read to
* @count: the maximum number of bytes to read
* @ppos: the current position in the buffer
* @from: the buffer to read from
* @available: the size of the buffer
*
* The simple_read_from_buffer() function reads up to @count bytes from the
* buffer @from at offset @ppos into the user space address starting at @to.
*
* On success, the number of bytes read is returned and the offset @ppos is
* advanced by this number, or negative value is returned on error.
**/
ssize_t simple_read_from_buffer(void __user *to, size_t count, loff_t *ppos,
const void *from, size_t available)
{
loff_t pos = *ppos;
size_t ret;
if (pos < 0)
return -EINVAL;
if (pos >= available || !count)
return 0;
if (count > available - pos)
count = available – pos;
// 参见[5.5.4.3.2 copy_to_user()]节,该函数返回未成功拷贝的字节数
ret = copy_to_user(to, from + pos, count);
if (ret == count)
return -EFAULT;
count -= ret;
*ppos = pos + count;
return count;
}
5.6 如何新增系统调用
可以通过如下两种方法为Linux Kernel新增系统调用:
- 通过修改内核源代码新增系统调用;
- 通过内核模块新增系统调用。
相比而言,采用内核模块新增系统调用的方法较好,因为它不需要重新编译内核。
下面以新增系统调用long sys_testsyscall()为例,分别介绍这两种方法。
5.6.1 通过修改内核源代码新增系统调用
1) 确定新增的系统调用号
修改下列文件来确定新增系统调用的系统调用号,并将其加入系统调用表中:
- 修改arch/x86/include/asm/unistd_32.h,为新增的系统调用定义的系统调用号:
#define _NR_testsyscall 350
- 修改arch/x86/kernel/syscall_table_32.S,将新增的系统调用加入到系统调用表,即数组sys_call_table中:
long sys_testsyscall /* 350 */
2) 编写新增的系统调用
编写一个系统调用意味着要给内核增加一个函数,将该函数写入文件kernel/sys.c中,代码如下:
SYSCALL_DEFINE0(testsyscall)
{
console_print("hello world\n");
return 0;
}
3) 使用新增的系统调用
因为C库中没有新增的系统调用的程序段,必须自己建立其代码,如下:
#inculde <syscalls.h>
SYSCALL_DEFINE0(testsyscall)
void main()
{
tsetsyscall();
}
5.6.2 通过内核模块新增系统调用
模块是内核的一部分,但是并没有被编译到内核中。它们被分别编译并连接成一组目标文件,这些文件能被插入到正在运行的内核,或者从正在运行的内核中移走。内核模块至少必须有2个函数:int_module和cleanup_module。第一个函数是在把模块插入内核时调用的; 第二个函数则在删除该模块时调用。
由于内核模块是内核的一部分,所以能访问所有内核资源。根据对linux系统调用机制的分析,如果要新增系统调用,可以编写自己的函数来实现,然后在sys_call_table表中增加一项,使该项中的指针指向自己编写的函数,就可以实现系统调用。
1) 编写系统调用内核模块
#inculde <linux/kernel.h>
#inculde <linux/module.h>
#inculde <linux/modversions.h>
#inculde <linux/sched.h>
#inculde <asm/uaccess.h>
#define _NR_testsyscall 350
extern void *sys_call_table[];
asmlinkage long testsyscall()
{
printf("hello world\n");
return 0;
}
int init_module()
{
sys_call_table[_NR_tsetsyscall] = testsyscall;
printf("system call testsyscall() loaded success\n");
return 0;
}
void cleanup_module()
{
}
2) 使用新增的系统调用
#define <linux/unistd.h>
#define _NR_testsyscall 350
SYSCALL_DEFINE0(testsyscall)
main()
{
testsyscall();
}
3) 编译内核模块并插入内核
编译内核的命令为:
$ gcc -Wall -02 -DMODULE -D_KERNEL_-C syscall.c
参数-Wall通知编译程序显示警告信息;参数-O2是关于代码优化的设置,内核模块必须优化;参数-DMODULE通知头文件向内核模块提供正确的定义;参数-D_KERNEL_通知头文件这个程序代码将在内核模式下运行。编译成功后将生成syscall.o文件。最后使用命令:
$ sudo insmod syscall.o
命令将模块插入内核后,即可使用新增的系统调用。
5.7 如何使用系统调用
程序员使用系统调用的方式:
- 直接调用系统调用
- 通过库函数(如glibc)间接调用系统调用
系统管理员使用系统调用的方式:
- 通过系统命令调用系统调用
5.7.1 程序员使用系统调用
程序员可以直接调用系统调用,也可以通过库函数间接地调用系统调用,参见:
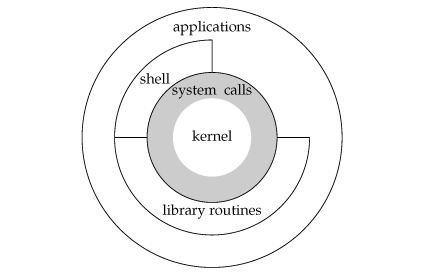
5.7.1.1 直接调用系统调用
直接调用系统调用示例如下:
#include <sys/syscall.h> // 定义系统调用号SYS_xxx,此处为:#define SYS_getpid __NR_getpid
#include <unistd.h> // 定义系统调用号__NR_xxx,此处__NR_getpid取值为20
#include <sys/types.h> // 定义基本类型,此处用pid_t
int main(int argc, char *argv[])
{
// syscall()参见帮助:
// $ man 2 syscall
// 此处实际调用sys_getpid()
pid_t pid = syscall(SYS_getpid);
return 0;
}
在命令行中执行下列命令查看帮助:
$ man 2 syscall
SYSCALL(2) BSD System Calls Manual SYSCALL(2)
NAME
syscall - indirect system call
SYNOPSIS
#include <sys/syscall.h>
#include <unistd.h>
int syscall(int number, ...);
DESCRIPTION
Syscall() performs the system call whose assembly language interface has the specified
number with the specified arguments. Symbolic constants for system calls can be found
in the header file <sys/syscall.h>.
RETURN VALUES
The return value is defined by the system call being invoked. In general, a 0 return value
indicates success. A -1 return value indicates an error, and an error code is stored in errno.
HISTORY
The syscall() function call appeared in 4.0BSD.
4BSD June 16, 1993 4BSD
5.7.1.2 通过库函数间接调用系统调用
可以通过库函数(例如GNU C Library (glibc))间接调用系统调用,示例如下:
#include <sys/types.h> // 定义基本类型,此处用pid_t
int main(int argc, char *argv[])
{
// 调用库函数getpid(),参见《The GNU C Library Reference Manual》
// 第26.3 Process Identification节
pid_t pid = getpid();
return 0;
}
5.7.2 系统管理员使用系统调用
系统命令相对编程接口(API)更高一层,它是内部引用API的可执行程序,如系统命令ls、hostname等。Linux的系统命令格式遵循System V的传统,多数放在/bin和/sbin目录下。
Linux kernel提供了一种非常有用的方法来跟踪某个进程所调用的系统调用,以及该进程所接收到的信号:strace,它可以在命令行中执行,参数为希望跟踪的应用程序。
例如:执行strace hostname以查看hostname使用的系统调用,由此可知hostname使用了诸如open、brk、fstat等系统调用:
chenwx@chenwx ~/alex $ strace hostname
execve("/bin/hostname", ["hostname"], [/* 36 vars */]) = 0
brk(0) = 0x995c000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb76ee000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=83840, ...}) = 0
mmap2(NULL, 83840, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb76d9000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/i386-linux-gnu/libnsl.so.1", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\1\1\1\0\0\0\0\0\0\0\0\0\3\0\3\0\1\0\0\0`1\0\0004\0\0\0"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0644, st_size=92028, ...}) = 0
mmap2(NULL, 104424, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb76bf000
mmap2(0xb76d5000, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x15) = 0xb76d5000
mmap2(0xb76d7000, 6120, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0xb76d7000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/i386-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\1\1\1\0\0\0\0\0\0\0\0\0\3\0\3\0\1\0\0\0000\226\1\0004\0\0\0"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0755, st_size=1730024, ...}) = 0
mmap2(NULL, 1743580, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb7515000
mprotect(0xb76b8000, 4096, PROT_NONE) = 0
mmap2(0xb76b9000, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1a3) = 0xb76b9000
mmap2(0xb76bc000, 10972, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0xb76bc000
close(3) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7514000
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7513000
set_thread_area({entry_number:-1 -> 6, base_addr:0xb75136c0, limit:1048575, seg_32bit:1, contents:0, read_exec_only:0, limit_in_pages:1, seg_not_present:0, useable:1}) = 0
mprotect(0xb76b9000, 8192, PROT_READ) = 0
mprotect(0xb76d5000, 4096, PROT_READ) = 0
mprotect(0x804b000, 4096, PROT_READ) = 0
mprotect(0xb7711000, 4096, PROT_READ) = 0
munmap(0xb76d9000, 83840) = 0
brk(0) = 0x995c000
brk(0x997d000) = 0x997d000
uname({sys="Linux", node="chenwx", ...}) = 0
fstat64(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 0), ...}) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb76ed000
write(1, "chenwx\n", 7chenwx
) = 7
exit_group(0) = ?
5.8 系统命令、用户编程接口API、系统调用、内核函数之间的关系
不要把内核函数想像的过于复杂,其实它和普通函数很像,只不过在内核实现,因此要满足一些内核编程的要求。系统调用是一层用户进入内核的接口,它本身并非内核函数,进入内核后,不同的系统调用会找到对应到各自的内核函数:系统调用服务例程。实际上针对请求提供服务的是内核函数而非调用接口。
Linux系统中存在许多内核函数,有些是内核文件中自己使用的,有些则是可以export出来供内核其他部分共同使用的。内核公开的(export出来的)内核函数可执行下列命令查看:
$ cat /proc/kallsyms
从用户角度向内核看,依次是系统命令、编程接口、系统调用和内核函数。
5.9 特殊的系统调用
5.9.1 sys_ni_syscall()
参见《Linux Kernel Development.[3rd Edition].[Robert Love]》第5. System Calls章第System Call Numbers节:
Linux provides a “not implemented” system call, sys_ni_syscall(), which does nothing except return -ENOSYS, the error corresponding to an invalid system call. This function is used to “plug the hole” in the rare event that a syscall is removed or otherwise made unavailable.
5.10 应用程序调用系统调用的过程
对于不同的内核版本,应用程序调用系统调用的过程也不同:
- 对于Linux kernel 2.5及之前版本的内核,x86处理器使用int 0x80中断方式;
- 对于Linux kernel 2.6及之后版本的内核,IA-32处理器使用sysenter和sysexit指令方式。
5.10.1 x86处理器/int 0x80中断方式
Linux used to implement system calls on all x86 platforms using software interrupts. To execute a system call, user process will copy desired system call number to register eax and will execute int 0x80. This will generate interrupt 0x80 and an interrupt service routine will be called (which results in execution of the system_call function).
系统调用的入口点参见5.5 系统调用节。
5.10.2 IA-32处理器/sysenter和sysexit指令方式
Userland processes (or C library on their behalf) call __kernel_vsyscall to execute system calls. Address of __kernel_vsyscall is not fixed. Kernel passes this address to userland processes using AT_SYSINFO elf parameter. AT_ elf parameters, a.k.a. elf auxiliary vectors, are loaded on the process stack at the time of startup, alongwith the process arguments and the environment variables.
arch/x86/include/asm/elf.h:
#define AT_SYSINFO 32
arch/x86/vdso/vdso32/vdso32.lds.S:
#define VDSO_PRELINK 0
#include "../vdso-layout.lds.S"
/* The ELF entry point can be used to set the AT_SYSINFO value. */
ENTRY(__kernel_vsyscall); // 定义于arch/x86/vdso/vdso32/sysenter.S
/*
* This controls what userland symbols we export from the vDSO.
*/
VERSION
{
LINUX_2.5 {
global:
__kernel_vsyscall; // 定义于arch/x86/vdso/vdso32/syscall.S
__kernel_sigreturn; // 定义于arch/x86/vdso/vdso32/sigreturn.S
__kernel_rt_sigreturn; // 定义于arch/x86/vdso/vdso32/sigreturn.S
local: *;
};
}
/*
* Symbols we define here called VDSO* get their values into vdso32-syms.h.
*/
VDSO32_PRELINK = VDSO_PRELINK;
VDSO32_vsyscall = __kernel_vsyscall;
VDSO32_sigreturn = __kernel_sigreturn;
VDSO32_rt_sigreturn = __kernel_rt_sigreturn;
5.10.2.1 vsyscall page
内核中有一个永久固定映射页面(位于0xFFFFE000-0xFFFFEFFF),名为vsyscall page。这个区域存放了系统调用入口__kernel_vsyscall的代码,以及信号处理程序的返回代码__kernel_sigreturn。当系统初始化时,调用sysenter_setup()函数分配一个空页面,根据系统是否支持syscall、sysenter指令,将vdso32_sysenter_start/ vdso32_sysenter_end,vdso32_sysenter_start/vdso32_sysenter_end,或者vdso32_int80_start/ vdso32_int80_end的代码拷贝过去。页的权限是用户级、只读、可执行,所以用户进程可以直接访问该页代码。
5.10.2.1.1 vsyscall page的创建
在arch/x86/vdso/vdso32-setup.c中,包含如下有关sysenter_setup()的代码:
/*
* X86_FEATURE_SYSENTER32定义于arch/x86/include/asm/cpufeature.h:
* #define X86_FEATURE_SYSENTER32 (3*32+15) /* "" sysenter in ia32 userspace */
* boot_cpu_has()定义于lib/raid6/x86.h
*/
#define vdso32_sysenter() (boot_cpu_has(X86_FEATURE_SYSENTER32))
/*
* X86_FEATURE_SYSCALL32定义于arch/x86/include/asm/cpufeature.h:
* #define X86_FEATURE_SYSCALL32 (3*32+14) /* "" syscall in ia32 userspace */
* boot_cpu_has()定义于lib/raid6/x86.h
*/
#define vdso32_syscall() (boot_cpu_has(X86_FEATURE_SYSCALL32))
...
int __init sysenter_setup(void)
{
/*
* GFP_ATOMIC定义于include/linux/gfp.h,其最终取值为0x20u
* get_zeroed_page()定义于mm/page_alloc.c,该函数返回一个单个的、零填充的页面
*/
void *syscall_page = (void *)get_zeroed_page(GFP_ATOMIC);
const void *vsyscall;
size_t vsyscall_len;
/*
* The virt_to_page(addr) macro yields the address of the page descriptor
* associated with the linear address addr. 其定义于arch/x86/include/asm/page.h:
* #define virt_to_page(kaddr) pfn_to_page(__pa(kaddr) >> PAGE_SHIFT)
* 其中,PAGE_SHIFT定义于arch/x86/include/asm/page_types.h : #define PAGE_SHIFT 12
*/
vdso32_pages[0] = virt_to_page(syscall_page);
#ifdef CONFIG_X86_32
gate_vma_init();
#endif
if (vdso32_syscall()) {
vsyscall = &vdso32_syscall_start;
vsyscall_len = &vdso32_syscall_end - &vdso32_syscall_start;
} else if (vdso32_sysenter()){
vsyscall = &vdso32_sysenter_start;
vsyscall_len = &vdso32_sysenter_end - &vdso32_sysenter_start;
} else {
vsyscall = &vdso32_int80_start;
vsyscall_len = &vdso32_int80_end - &vdso32_int80_start;
}
memcpy(syscall_page, vsyscall, vsyscall_len);
relocate_vdso(syscall_page);
return 0;
}
在arch/x86/vdso/vdso32.S中,包含与下列变量:
- vdso32_syscall_start / vdso32_syscall_end
- vdso32_sysenter_start / vdso32_sysenter_end
- vdso32_int80_start / vdso32_int80_end
有关的代码:
#include <linux/init.h>
__INITDATA
.globl vdso32_int80_start, vdso32_int80_end
vdso32_int80_start:
.incbin "arch/x86/vdso/vdso32-int80.so" // 编译过程参见arch/x86/vdso/Makefile
vdso32_int80_end:
.globl vdso32_syscall_start, vdso32_syscall_end
vdso32_syscall_start:
#ifdef CONFIG_COMPAT
.incbin "arch/x86/vdso/vdso32-syscall.so" // 编译过程参见arch/x86/vdso/Makefile
#endif
vdso32_syscall_end:
.globl vdso32_sysenter_start, vdso32_sysenter_end
vdso32_sysenter_start:
.incbin "arch/x86/vdso/vdso32-sysenter.so" // 编译过程参见arch/x86/vdso/Makefile
vdso32_sysenter_end:
__FINIT
5.10.2.2 用户进程执行系统调用
用户进程调用do_execve()时,该函数把vsyscall页动态链接到进程空间。这样用户程序需要执行系统调用时,可以直接调用vsyscall页里的代码kernel_vsyscall(),根据编译连接情况调用int 80或者sysenter指令实现,从而实现user-kernel的跨越。
采用vsyscall页的内核(V2.5.53以后),把用户信号处理程序中用到的返回代码__kernel_sigreturn也放在了永久固定映射页,这样就不用再放到堆栈里了。
6 内存管理/Memory Management
内存管理的代码主要在mm/目录,特定结构的代码在arch/$(ARCH)/mm/目录。
6.1 段机制和分页机制
- 参见《Linux 操作系统内核分析_陈莉君.pdf》第四章
- 学习Linux必备的硬件基础一网打尽
虚拟地址与物理地址的转换:
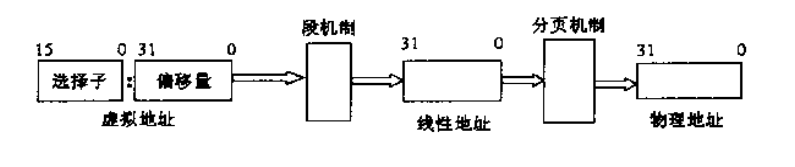
段机制参见6.1.1 段机制节,分页机制参见6.1.2 分页机制节。
6.1.1 段机制
6.1.1.1 段描述符/Segment Descriptor
描述符desc_struct, gate_desc, ldt_desc, tss_desc定义于arch/x86/include/asm/desc_defs.h:
#ifdef CONFIG_X86_64
typedef struct gate_struct64 gate_desc;
typedef struct ldttss_desc64 ldt_desc;
typedef struct ldttss_desc64 tss_desc;
#define gate_offset(g) ((g).offset_low | ((unsigned long)(g).offset_middle << 16) | ((unsigned long)(g).offset_high << 32))
#define gate_segment(g) ((g).segment)
#else
typedef struct desc_struct gate_desc;
typedef struct desc_struct ldt_desc;
typedef struct desc_struct tss_desc;
#define gate_offset(g) (((g).b & 0xffff0000) | ((g).a & 0x0000ffff))
#define gate_segment(g) ((g).a >> 16)
#endif
struct desc_struct {
union {
struct {
unsigned int a;
unsigned int b;
};
struct {
u16 limit0;
u16 base0;
unsigned base1: 8, type: 4, s: 1, dpl: 2, p: 1;
unsigned limit: 4, avl: 1, l: 1, d: 1, g: 1, base2: 8;
};
};
} __attribute__((packed));
/* 16byte gate */
struct gate_struct64 {
u16 offset_low;
u16 segment;
unsigned ist : 3, zero0 : 5, type : 5, dpl : 2, p : 1;
u16 offset_middle;
u32 offset_high;
u32 zero1;
} __attribute__((packed));
/* LDT or TSS descriptor in the GDT. 16 bytes. */
struct ldttss_desc64 {
u16 limit0;
u16 base0;
unsigned base1 : 8, type : 5, dpl : 2, p : 1;
unsigned limit1 : 4, zero0 : 3, g : 1, base2 : 8;
u32 base3;
u32 zero1;
} __attribute__((packed));
// 用于初始化struct desc_struct类型的变量,参见[6.1.1.2.1 全局描述符表GDT]节
#define GDT_ENTRY_INIT(flags, base, limit) { { { \
.a = ((limit) & 0xffff) | (((base) & 0xffff) << 16), \
.b = (((base) & 0xff0000) >> 16) | (((flags) & 0xf0ff) << 8) | \
((limit) & 0xf0000) | ((base) & 0xff000000), \
} } }
// 用于表示desc_struct中的type字段取值,参见下表
enum {
DESC_TSS = 0x9,
DESC_LDT = 0x2,
DESCTYPE_S = 0x10, /* !system */
};
// 用于表示desc_struct中的type字段取值,参见下表
enum {
GATE_INTERRUPT = 0xE, // 中断门
GATE_TRAP = 0xF, // 陷阱门
GATE_CALL = 0xC,
GATE_TASK = 0x5, // 系统门
};
在32位体系结构下,其结构参见:
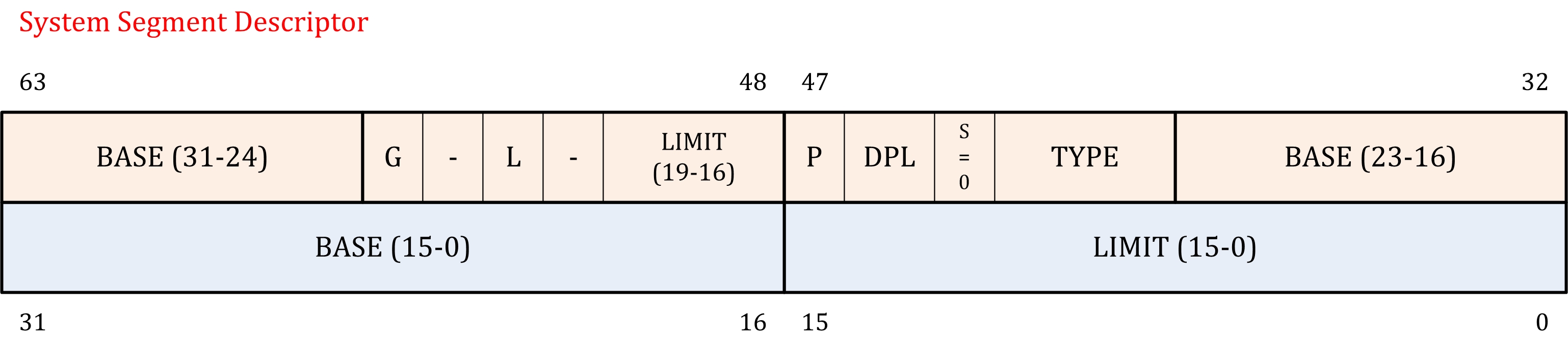
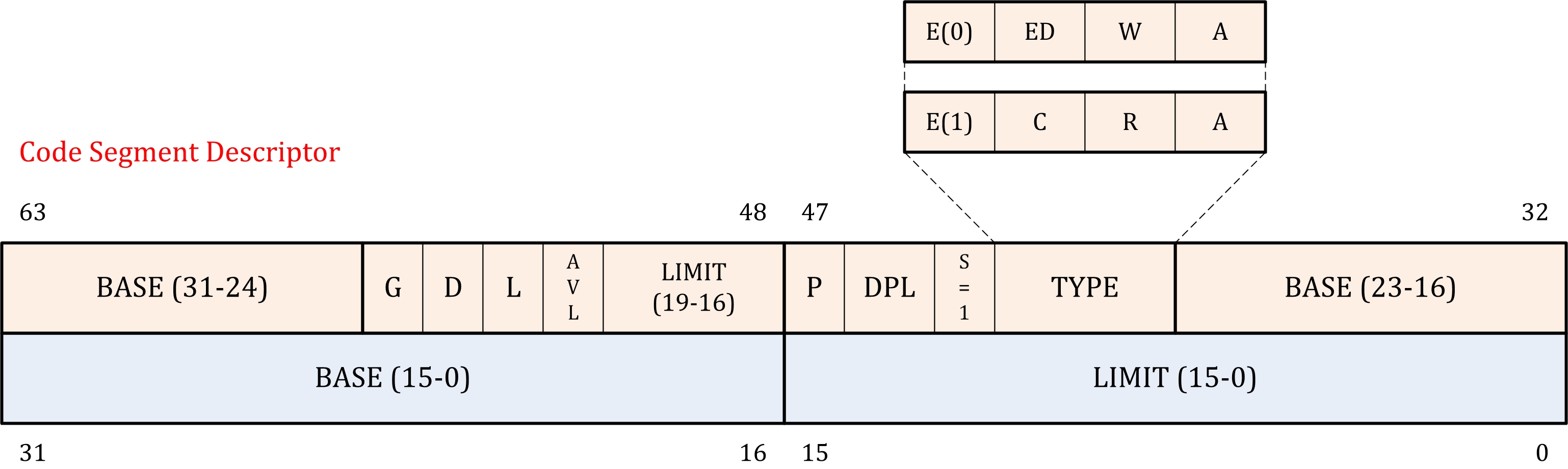
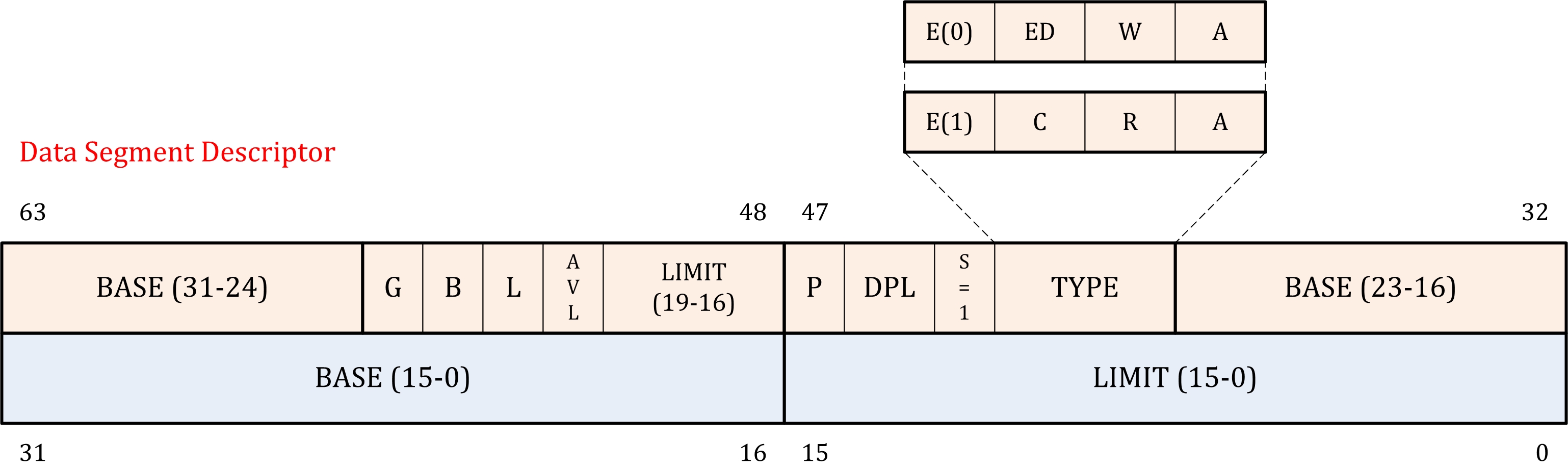
各字段的含义如下表所示:

6.1.1.2 全局段描述符表GDT/全局描述符表寄存器GDTR
6.1.1.2.1 全局描述符表GDT
除了任务门描述符、中断门描述符和陷阱门描述符(这些描述符保存于中断描述符表,参见6.1.1.3 中断描述符表IDT/中断描述符表寄存器IDTR节)外,全局描述符表GDT包含系统中所有任务都可用的那些描述符。
全局描述符表结构struct pdt_page定义于arch/x86/include/asm/desc.h:
struct gdt_page {
/*
* struct desc_struct参见[6.1.1.1 段描述符/Segment Descriptor]节;
* 常量GDT_ENTRIES定义于arch/x86/include/asm/segment.h,取值为32或16
*/
struct desc_struct gdt[GDT_ENTRIES];
} __attribute__((aligned(PAGE_SIZE))); // 页对齐
全局描述符表gdt_page的声明及获取函数参见arch/x86/include/asm/desc.h:
// 声明全局描述符表gdt_page,该宏定义于include/linux/percpu-defs.h
DECLARE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page);
// 获取指定CPU的全局描述符表
static inline struct desc_struct *get_cpu_gdt_table(unsigned int cpu)
{
return per_cpu(gdt_page, cpu).gdt;
}
NOTE: In uniprocessor systems there is only one GDT, while in multiprocessor systems there is one GDT for every CPU in the system.
全局描述符表gdt_page定义于arch/x86/kernel/cpu/common.c:
/*
* The first entry of the GDT is always set to 0. This ensures that logical addresses with
* a null Segment Selector will be considered invalid, thus causing a processor exception.
*/
DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = {
.gdt = {
#ifdef CONFIG_X86_64
/*
* We need valid kernel segments for data and code in long mode too
* IRET will check the segment types kkeil 2000/10/28
* Also sysret mandates a special GDT layout
*
* TLS descriptors are currently at a different place compared to i386.
* Hopefully nobody expects them at a fixed place (Wine?)
*/
[GDT_ENTRY_KERNEL32_CS] = GDT_ENTRY_INIT(0xc09b, 0, 0xfffff), // 1
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff), // 2
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff), // 3
[GDT_ENTRY_DEFAULT_USER32_CS] = GDT_ENTRY_INIT(0xc0fb, 0, 0xfffff), // 4
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff), // 5
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff), // 6
#else
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff), // 12
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff), // 13
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff), // 14
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff), // 15
/*
* Segments used for calling PnP BIOS have byte granularity.
* They code segments and data segments have fixed 64k limits,
* the transfer segment sizes are set at run time.
*/
/* 32-bit code */
[GDT_ENTRY_PNPBIOS_CS32] = GDT_ENTRY_INIT(0x409a, 0, 0xffff), // 18
/* 16-bit code */
[GDT_ENTRY_PNPBIOS_CS16] = GDT_ENTRY_INIT(0x009a, 0, 0xffff), // 19
/* 16-bit data */
[GDT_ENTRY_PNPBIOS_DS] = GDT_ENTRY_INIT(0x0092, 0, 0xffff), // 20
/* 16-bit data */
[GDT_ENTRY_PNPBIOS_TS1] = GDT_ENTRY_INIT(0x0092, 0, 0), // 21
/* 16-bit data */
[GDT_ENTRY_PNPBIOS_TS2] = GDT_ENTRY_INIT(0x0092, 0, 0), // 22
/*
* The APM segments have byte granularity and their bases
* are set at run time. All have 64k limits.
*/
/* 32-bit code */
[GDT_ENTRY_APMBIOS_BASE] = GDT_ENTRY_INIT(0x409a, 0, 0xffff), // 23
/* 16-bit code */
[GDT_ENTRY_APMBIOS_BASE+1] = GDT_ENTRY_INIT(0x009a, 0, 0xffff), // 24
/* data */
[GDT_ENTRY_APMBIOS_BASE+2] = GDT_ENTRY_INIT(0x4092, 0, 0xffff), // 25
[GDT_ENTRY_ESPFIX_SS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff), // 26
[GDT_ENTRY_PERCPU] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff), // 27
GDT_STACK_CANARY_INIT // 28
#endif
}
};
其中,宏DEFINE_PER_CPU_PAGE_ALIGNED()定义于include/linux/percpu-defs.h,其他宏定义于arch/x86/include/asm/segment.h。
由6.1.1.1 段描述符/Segment Descriptor节中GDT_ENTRY_INIT的定义可知,全局描述符表中各表项的基地址(BASE)为0,界限(LIMIT)为0xfffff,故段长为4GB空间(G位为1,故颗粒度为4K字节)。根据段机制,基地址+偏移量=线性地址,可知,0+偏移量=线性地址,即虚拟地址直接映射到了线性地址,也就是说虚拟地址和线性地址是相同的。
由于IA32段机制规定:
- 必须为代码段和数据段创建不同的段;
- Linux内核运行在特权级0,而用户程序运行在特权级别3。根据IA32的段保护机制规定,特权级3的程序无法访问特权级为0的段,所以Linux必须为内核和用户程序分别创建其代码段和数据段。
故,Linux必须创建4个段描述符:
- 特权级0的代码段和数据段:GDT_ENTRY_KERNEL_CS, GDT_ENTRY_KERNEL_DS
- 特权级3的代码段和数据段:GDT_ENTRY_DEFAULT_USER_CS, GDT_ENTRY_DEFAULT_USER_DS
这四个段定义于arch/x86/include/asm/segment.h:
#ifdef CONFIG_X86_32
#define GDT_ENTRY_KERNEL_BASE (12)
#define GDT_ENTRY_KERNEL_CS (GDT_ENTRY_KERNEL_BASE+0)
#define GDT_ENTRY_KERNEL_DS (GDT_ENTRY_KERNEL_BASE+1)
#define GDT_ENTRY_DEFAULT_USER_CS 14
#define GDT_ENTRY_DEFAULT_USER_DS 15
#else
#define GDT_ENTRY_KERNEL_CS 2
#define GDT_ENTRY_KERNEL_DS 3
#define GDT_ENTRY_DEFAULT_USER_DS 5
#define GDT_ENTRY_DEFAULT_USER_CS 6
#endif
这四个段对应的Segment Selector定义于arch/x86/include/asm/segment.h:
#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS*8) // 96, or 16
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS*8) // 104, or 24
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS*8+3) // 115, or 51
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS*8+3) // 123, or 43
综上,各段的字段取值:
| Segment | Base | G | Limit | S | Type | DPL | D/B | P |
|---|---|---|---|---|---|---|---|---|
| user code / __USER_CS | 0x00000000 | 1 | 0xFFFFF | 1 | 10 | 3 | 1 | 1 |
| user data / __USER_DS | 0x00000000 | 1 | 0xFFFFF | 1 | 2 | 3 | 1 | 1 |
| kernel code / __KERNEL_CS | 0x00000000 | 1 | 0xFFFFF | 1 | 10 | 0 | 1 | 1 |
| kernel data / __KERNEL_DS | 0x00000000 | 1 | 0xFFFFF | 1 | 2 | 0 | 1 | 1 |
6.1.1.2.2 全局描述符表寄存器GDTR
全局描述符表寄存器(GDTR)是一个48位的寄存器:低16位保存全局描述符表(GDT)的大小,最大取值为64KB;高32位保存GDT的段基址,取值范围为[0, 4G)地址空间。其结构如下图所示:

6.1.1.3 中断描述符表IDT/中断描述符表寄存器IDTR
6.1.1.3.1 中断描述符表IDT
中断描述符结构gate_desc定义于arch/x86/include/asm/desc_defs.h,参见6.1.1.1 段描述符/Segment Descriptor节。
中断描述符表idt_table定义于arch/x86/kernel/traps.c中,如下:
gate_desc idt_table[NR_VECTORS] __page_aligned_data = { { { { 0, 0 } } }, };
其中,NR_VECTORS取值为256,即中断描述符表可包含256个描述符,参见9.1 中断处理简介节。
中断描述符表只能包含任务门描述符、中断门描述符和陷阱门描述符:
| Task Gate Descriptor | Includes the TSS selector of the process that must replace the current one when an interrupt signal occurs. |
| Interrupt Gate Descriptor | Includes the Segment Selector and the offset inside the segment of an interrupt or exception handler. While transferring control to the proper segment, the processor clears the IF flag, thus disabling further maskable interrupts. |
| Trap Gate Descriptor | Similar to an interrupt gate, except that while transferring control to the proper segment, the processor does not modify the IF flag. |
参见下图,bit 40-43代表中断描述符类型,分别用常量GATE_TASK,GATE_INTERRUPT,GATE_TRAP表示,参见6.1.1.1 段描述符/Segment Descriptor节:
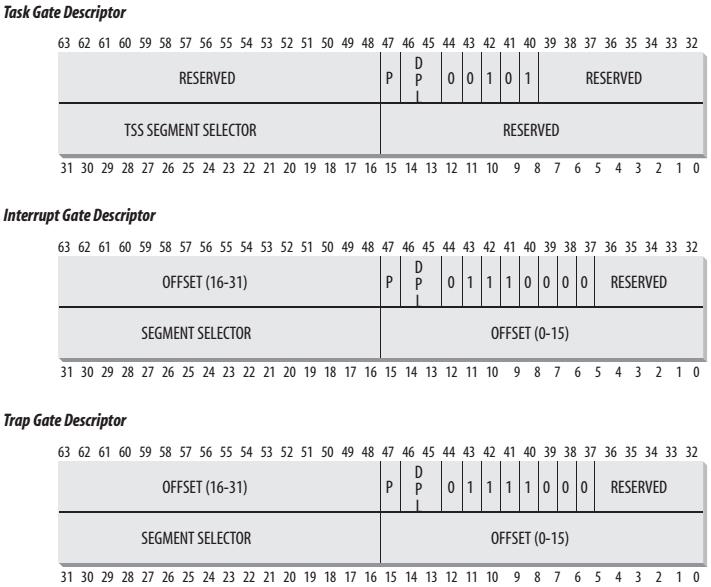
6.1.1.3.1.1 中断描述符表的初步初始化
1) 声明256个门描述符的IDT表空间,参见arch/x86/kernel/head_32.S:
idt_descr:
.word IDT_ENTRIES*8-1 # idt contains 256 entries
.long idt_table
2) 设置指向IDT表地址的寄存器IDTR,参见arch/x86/kernel/head_32.S:
lgdt early_gdt_descr
lidt idt_descr
ljmp $(__KERNEL_CS),$1f
1: movl $(__KERNEL_DS),%eax # reload all the segment registers
ENTRY(early_gdt_descr)
.word GDT_ENTRIES*8-1
.long gdt_page /* Overwritten for secondary CPUs */
3) 初始化256个门描述符。对于每个门描述符,段选择子都指向内核段,段偏移都指向函数igore_int(),该函数只打印信息:
Unknown interrupt or fault at: %p %p %p\n
/*
* setup_idt
*
* sets up a idt with 256 entries pointing to
* ignore_int, interrupt gates. It doesn't actually load
* idt - that can be done only after paging has been enabled
* and the kernel moved to PAGE_OFFSET. Interrupts
* are enabled elsewhere, when we can be relatively
* sure everything is ok.
*
* Warning: %esi is live across this function.
*/
setup_idt:
lea ignore_int,%edx
movl $(__KERNEL_CS << 16),%eax
movw %dx,%ax /* selector = 0x0010 = cs */
movw $0x8E00,%dx /* interrupt gate - dpl=0, present */
lea idt_table,%edi
mov $256,%ecx
rp_sidt:
movl %eax,(%edi)
movl %edx,4(%edi)
addl $8,%edi
dec %ecx
jne rp_sidt
/* This is the default interrupt "handler" :-) */
ALIGN
ignore_int:
cld
#ifdef CONFIG_PRINTK
pushl %eax
pushl %ecx
pushl %edx
pushl %es
pushl %ds
movl $(__KERNEL_DS),%eax
movl %eax,%ds
movl %eax,%es
cmpl $2,early_recursion_flag
je hlt_loop
incl early_recursion_flag
pushl 16(%esp)
pushl 24(%esp)
pushl 32(%esp)
pushl 40(%esp)
pushl $int_msg
call printk
call dump_stack
addl $(5*4),%esp
popl %ds
popl %es
popl %edx
popl %ecx
popl %eax
#endif
iret
int_msg:
.asciz "Unknown interrupt or fault at: %p %p %p\n"
NOTE: The ignore_int() handler should never be executed. The occurrence of “Unknown interrupt” messages on the console or in the log files denotes either a hardware problem (an I/O device is issuing unforeseen interrupts) or a kernel problem (an interrupt or exception is not being handled properly).
6.1.1.3.1.2 中断描述符表的最终初始化
中断描述符表的最终初始化分为两部分:
- 异常:由函数trap_init()实现,被系统初始化入口函数start_kernel()调用,参见4.3.4.1.4.3.5 trap_init()节;
- 中断:由函数init_IRQ()实现,被系统初始化入口函数start_kernel()调用,参见4.3.4.1.4.3.9 init_IRQ()节。
6.1.1.3.2 中断描述符表寄存器IDTR
中断描述符表寄存器(IDTR)与全局描述符表寄存器(GDTR)类似,参见6.1.1.2.2 全局描述符表寄存器GDTR节。
6.1.1.4 局部描述符表LDT/局部描述符表寄存器LDTR
6.1.1.4.1 局部描述符表LDT
局部描述符表包含与特定任务有关的描述符,每个任务都有一个各自的局部描述符表LDT。每个任务的局部描述符表也用一个描述符来表示,称为LDT描述符,它包含了局部描述符表的信息,在全局描述符表GDT中(参见6.1.1.1 段描述符/Segment Descriptor节中的表,当S=0, TYPE=2时,该项即为LDT描述符)。
局部描述符结构ldt_desc定义于arch/x86/include/asm/desc_defs.h,参见6.1.1.1 段描述符/Segment Descriptor节。
6.1.1.4.2 局部描述符表寄存器LDTR
局部描述符表寄存器(LDTR)包括如下两部分:
- 可见部分: 16-bit Index,用来选择全局描述符表GDT中的局部描述符表LDT中的描述符;
- 不可见部分: 48-bit BASE/LIMIT,用来保存局部描述符表的基地址和界限。
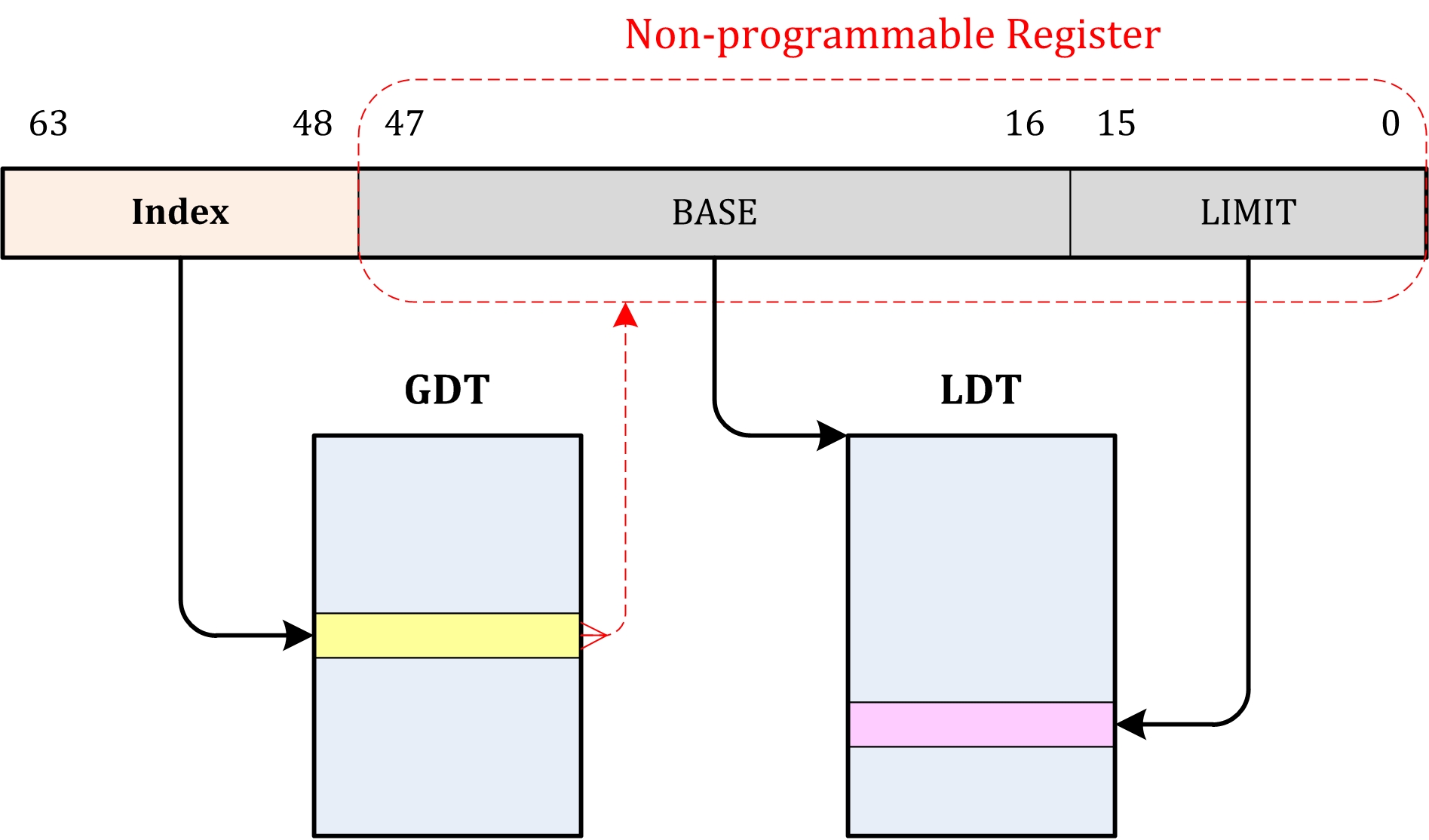
6.1.1.5 段选择器(Segment Selector)与描述符表寄存器
6.1.1.5.1 段选择器(Segment Selector)
在实模式下,段寄存器存储的是真实的段地址;在保护模式下,16位的段寄存器无法存储32位的段地址,故它被称为段选择器,即段寄存器的作用是用来选择段描述符,这样就把段描述符中的32位段地址(参见6.1.1.1 段描述符/Segment Descriptor节表格中的BASE域)作为实际的段地址。
段选择器结构及各字段含义如下:

| Field | Description |
|---|---|
| Index | Identifies the Segment Descriptor entry contained in the GDT or in the LDT. 占13 bit,取值范围[0, 8191] |
| TI | Table Indicator: specifies whether the Segment Descriptor is included in the GDT (TI = 0) or in the LDT (TI = 1). |
| RPL | Requestor Privilege Level: specifies the Current Privilege Level of the CPU (see section 6.1.1.1 段描述符/Segment Descriptor) when the corresponding Segment Selector is loaded into the cs register; it also may be used to selectively weaken the processor privilege level when accessing data segments (see Intel documentation for details). |
在arch/x86/include/asm/kvm.h中,包含如下类型:
struct kvm_segment {
__u64 base;
__u32 limit;
__u16 selector; // 段选择器
__u8 type;
__u8 present, dpl, db, s, l, g, avl;
__u8 unusable;
__u8 padding;
};
在arch/x86/include/linux/kvm_host.h中,包含如下宏,分别用于获取段选择器中的TI和RPL字段:
#define SELECTOR_TI_MASK (1 << 2)
#define SELECTOR_RPL_MASK 0x03
6.1.1.5.2 Logical Address转换到Linear Address
参见«Understanding the Linux Kernel, 3rd Edition»第2. Memory Addressing章第Segmentation Unit节:
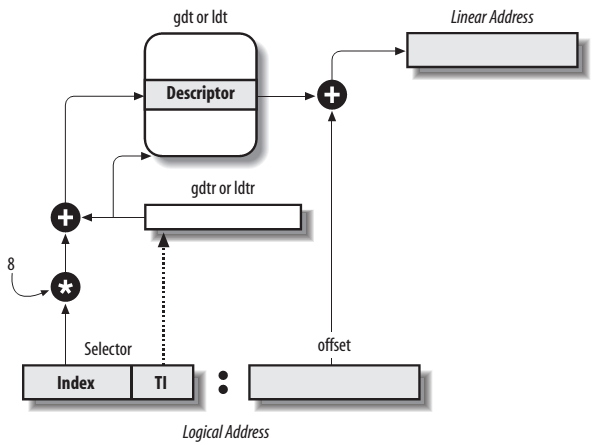
The segmentation unit performs the following operations:
-
Examines the TI field of the Segment Selector to determine which Descriptor Table stores the Segment Descriptor. This field indicates that the Descriptor is either in the GDT (in which case the segmentation unit gets the base linear address of the GDT from the gdtr register) or in the active LDT (in which case the segmentation unit gets the base linear address of that LDT from the ldtr register).
-
Computes the address of the Segment Descriptor from the index field of the Segment Selector. The index field is multiplied by 8 (the size of a Segment Descriptor), and the result is added to the content of the gdtr or ldtr register.
-
Adds the offset of the logical address to the BASE field of the Segment Descriptor, thus obtaining the linear address.
6.1.2 分页机制
寄存器参见下图:
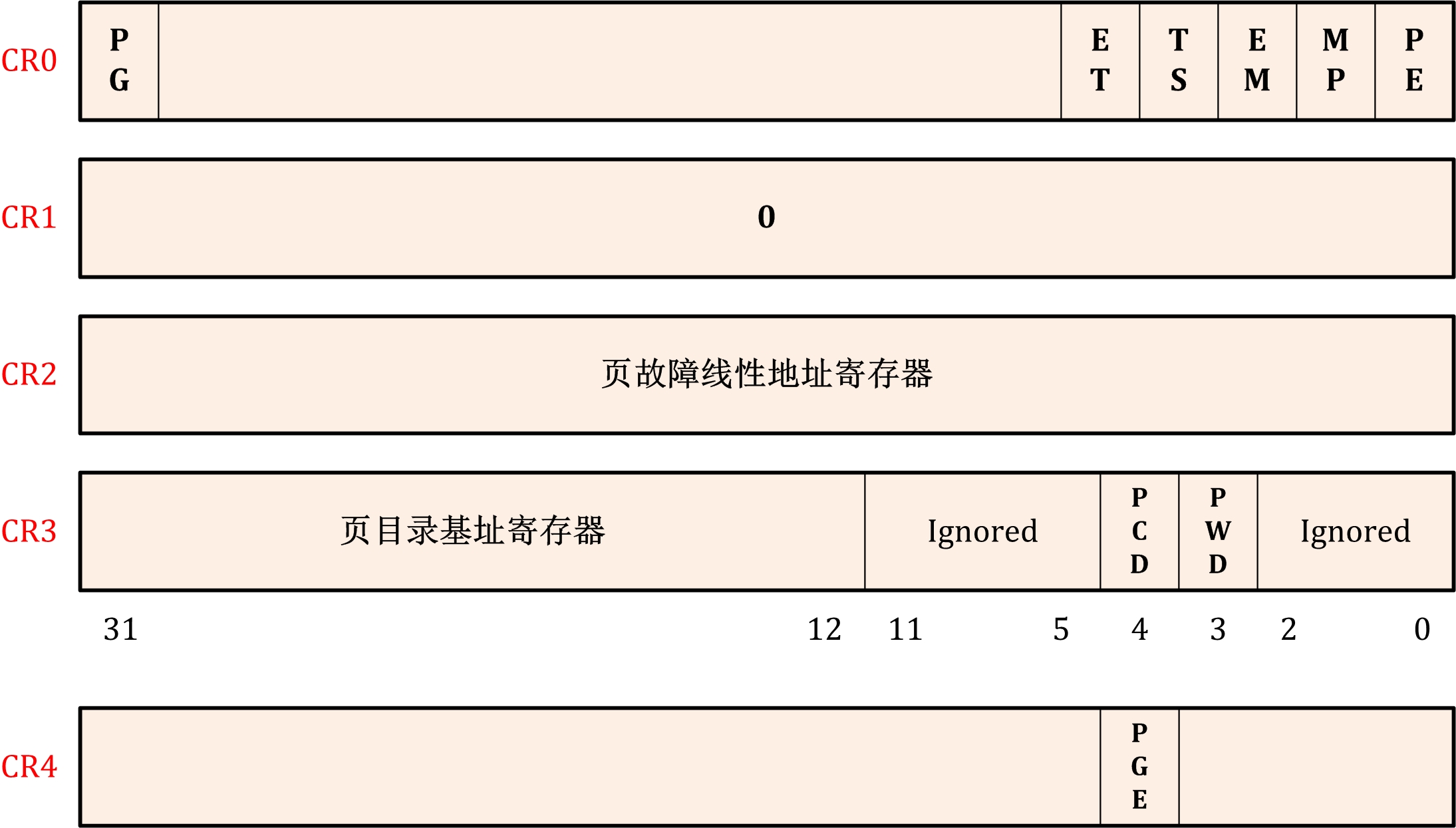
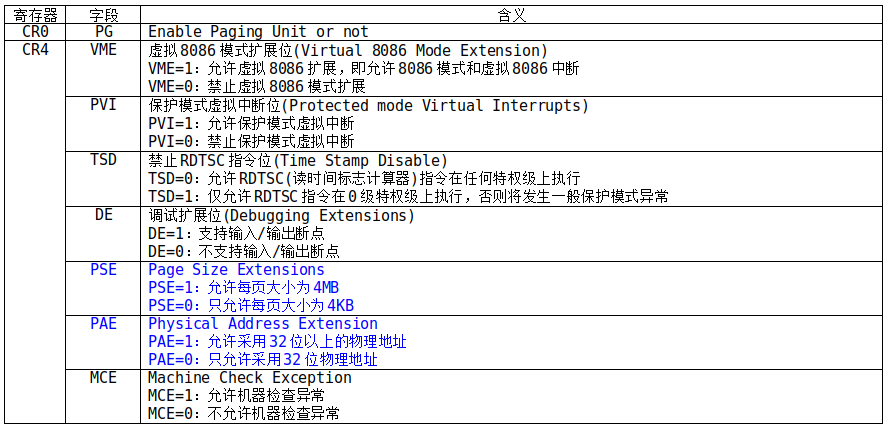
Starting with the 80386, all 80×86 processors support paging; it is enabled by setting the PG flag of a control register named CR0. When PG = 0, linear addresses are interpreted as physical addresses.
80386使用4K字节大小的页。每一页都有4K字节长,并在4K字节的边界上对齐,即每一页的起始地址都能被4K整除。因此,80386把4G字节的线性地址空间划分为1M个页面。因为每页的整个4K字节作为一个单位进行映射,并且每页都对齐4K字节的边界,故线性地址的低12位经过分页机制后直接作为物理地址的低12位使用。重定位函数也因此可看成是把线性地址的高20位转换为对应物理地址的高20位的转换函数。
6.1.2.1 两级页表结构
两级页表结构的第一级为页目录,存储在一个4KB的页中(该页的基地址保存在CR3中,参见6.1.2 分页机制节中的寄存器图)。页目录表中共有1024个表项,每个表项大小为4字节并指向一个第二级表。线性地址的最高10位(即31-22位)用来产生第一级的索引,由索引得到的表项指定并选择了1K个二级表中的一个表。
两级页表结构的第二级为页表,也刚好存储在一个4KB的页中。页表中共有1024个表项,每个表项大小为4字节并包含一个页的物理基地址。线性地址的中间10位(即21-12位)用来产生第二级的索引,以获得包含页物理地址的页表项。这个物理地址的高20位与线性地址的低12位形成最后的物理地址,也就是页转化过程输出的物理地址。
NOTE 1: The aim of this two-level scheme is to reduce the amount of RAM required for per-process Page Tables.
NOTE 2: Each active process must have a Page Directory assigned to it. However, there is no need to allocate RAM for all Page Tables of a process at once; it is more efficient to allocate RAM for a Page Table only when the process effectively needs it.
6.1.2.1.1 页目录项/Page Directory Entry
Refer to «Intel 64 and IA-32 Architectures Software Developer’s Manual_201309» Figure 4-4. Formats of CR3 and Paging-Structure Entries with 32-Bit Paging:
| Field | Description |
|---|---|
| P | If it is set, the referred-to page (or Page Table) is contained in main memory; if the flag is 0, the page is not contained in main memory and the remaining entry bits may be used by the operating system for its own purposes. If the entry of a Page Table or Page Directory needed to perform an address translation has the Presentflag cleared, the paging unit stores the linear address in a control register named cr2 and generates exception 14: the Page Fault exception. |
| R/W | Contains the access right (Read/Write or Read) of the page or of the Page Table. If the flag of a Page Directory or Page Table entry is equal to 0, the corresponding Page Table or page can only be read; otherwise it can be read and written. |
| U/S | Contains the privilege level required to access the page or Page Table. When this flag is 0, the page can be addressed only when theCPLis less than 3 (this means, for Linux, when the processor is in Kernel Mode). When the flag is 1, the page can always be addressed. |
| A | Set each time the paging unit addresses the corresponding page frame. This flag may be used by the operating system when selecting pages to be swapped out. The paging unit never resets this flag; this must be done by the operating system. |
| 20位页表地址 | Because each page frame has a 4-KB capacity, its physical address must be a multiple of 4096, so the 12 least significant bits of the physical address are always equal to 0. If the field refers to a Page Directory, the page frame contains a Page Table; if it refers to a Page Table, the page frame contains a page of data. |
| PS | Page Size flag. Applies only to Page Directory entries. If it is set, the entry refers to a 2 MB– or 4 MB–long page frame. See section Extended Paging and Physical Address Extension (PAE). |
由U/S和R/W为页目录项提供保护属性:
| U/S | R/W | 允许级别3 | 允许级别0、1、2 |
| 0 | 0 | 无 | 读/写 |
| 0 | 1 | 无 | 读/写 |
| 1 | 0 | 只读 | 读/写 |
| 1 | 1 | 读/写 | 读/写 |
6.1.2.1.2 页表项/Page Table Entry
Page table entry:

| Field | Description |
|---|---|
| P | If it is set, the referred-to page (or Page Table) is contained in main memory; if the flag is 0, the page is not contained in main memory and the remaining entry bits may be used by the operating system for its own purposes. If the entry of a Page Table or Page Directory needed to perform an address translation has the Presentflag cleared, the paging unit stores the linear address in a control register named cr2 and generates exception 14: the Page Fault exception. |
| R/W | Contains the access right (Read/Write or Read) of the page or of the Page Table. If the flag of a Page Directory or Page Table entry is equal to 0, the corresponding Page Table or page can only be read; otherwise it can be read and written. |
| U/S | Contains the privilege level required to access the page or Page Table. When this flag is 0, the page can be addressed only when theCPLis less than 3 (this means, for Linux, when the processor is in Kernel Mode). When the flag is 1, the page can always be addressed. |
| A | Set each time the paging unit addresses the corresponding page frame. This flag may be used by the operating system when selecting pages to be swapped out. The paging unit never resets this flag; this must be done by the operating system. |
| D | Applies only to the Page Table entries. It is set each time a write operation is performed on the page frame. As with the Accessed flag, Dirty may be used by the operating system when selecting pages to be swapped out. The paging unit never resets this flag; this must be done by the operating system. |
| 20位页表地址 | Because each page frame has a 4-KB capacity, its physical address must be a multiple of 4096, so the 12 least significant bits of the physical address are always equal to 0. If the field refers to a Page Directory, the page frame contains a Page Table; if it refers to a Page Table, the page frame contains a page of data. |
| G | Applies only to Page Table entries. This flag was introduced in the Pentium Pro to prevent frequently used pages from being flushed from the TLB cache. It works only if the Page Global Enable (PGE) flag of registercr4is set. |
6.1.2.2 Linear Address转换到Physical Address
线性地址到物理地址的转换步骤如下:
1) CR3包含页目录的起始地址,用32位线性地址的最高10位A31-A22作为页目录的页目录项的索引,将它乘以4,与CR3中的页目录的起始地址相加,形成相应页表的地址。
2) 从指定的地址中取出32位页目录项,在页目录项中取出高20位页表地址,并与低12位0,形成32位的页表起始地址。用32位线性地址中的A21-A12位作为页表的页面的索引,将它乘以4,与页表的起始地址相加,形成32位页面地址。
3) 将A11-A0作为相对于页面地址的偏移量,与32位页面地址相加,形成32位物理地址。
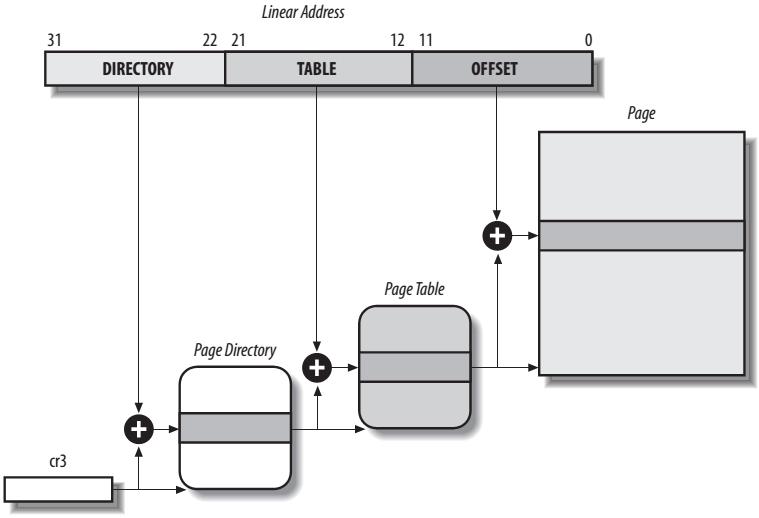
6.1.2.2.1 Extended Paging
Starting with the Pentium model, 80×86 microprocessors introduce extended paging, which allows page frames to be 4 MB instead of 4 KB in size (see below figure). Extended paging is used to translate large contiguous linear address ranges into corresponding physical ones; in these cases, the kernel can do without intermediate Page Tables and thus save memory and preserve TLB entries.
Extended paging is enabled by setting the Page Size (PS) flag of a Page Directory entry, see section 页目录项/Page Directory Entry.
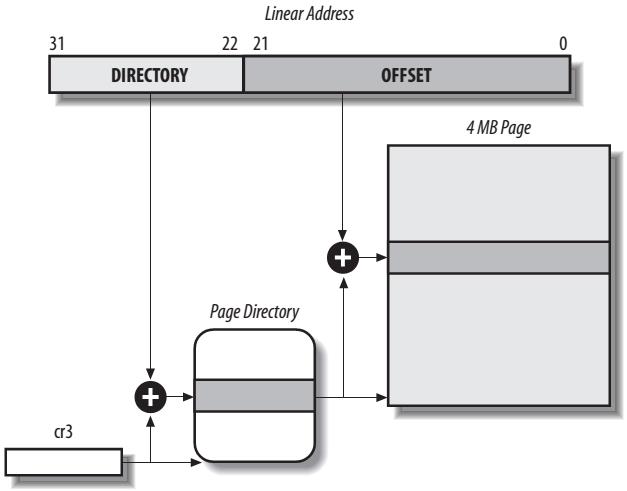
NOTE: Only the 10 most significant bits of the 20-bit physical address field are significant. This is because each physical address is aligned on a 4-MB boundary, so the 22 least significant bits of the address are 0.
6.1.2.3 Physical Address Extension (PAE)
参见 «Understanding the Linux Kernel, 3rd Edition»第2. Memory Addressing章第The Physical Address Extension (PAE) Paging Mechanism节:
The amount of RAM supported by a processor is limited by the number of address pins connected to the address bus. Older Intel processors from the 80386 to the Pentium used 32-bit physical addresses. In theory, up to 4 GB of RAM could be installed on such systems.
However, big servers that need to run hundreds or thousands of processes at the same time require more than 4 GB of RAM, and in recent years this created a pressure on Intel to expand the amount of RAM supported on the 32-bit 80×86 architecture.
Intel has satisfied these requests by increasing the number of address pins on its processors from 32 to 36. Starting with the Pentium Pro, all Intel processors are now able to address up to 236 = 64 GB of RAM. However, the increased range of physical addresses can be exploited only by introducing a new paging mechanism that translates 32-bit linear addresses into 36-bit physical ones.
With the Pentium Pro processor, Intel introduced a mechanism called Physical Address Extension (PAE). Another mechanism, Page Size Extension (PSE-36), was introduced in the Pentium III processor, but Linux does not use it.
PAE is activated by setting the Physical Address Extension (PAE) flag in the cr4 control register. The Page Size (PS) flag in the page directory entry enables large page sizes (2 MB when PAE is enabled).
6.1.2.3.1 Paging Mechanism of PAE
Intel has changed the paging mechanism in order to support PAE.
-
The 64 GB of RAM are split into 224 distinct page frames, and the physical address field of Page Table entries has been expanded from 20 to 24 bits. Because a PAE Page Table entry must include the 12 flag bits and the 24 physical address bits, for a grand total of 36, the Page Table entry size has been doubled from 32 bits to 64 bits. As a result, a 4-KB PAE Page Table includes 512 entries instead of 1,024.
-
A new level of Page Table called the Page Directory Pointer Table (PDPT) consisting of four 64-bit entries has been introduced.
-
The cr3 control register contains a 27-bit Page Directory Pointer Table (PDPT) base address field. Because PDPTs are stored in the first 4 GB of RAM and aligned to a multiple of 32 bytes (25), 27 bits are sufficient to represent the base address of such tables.
-
When mapping linear addresses to 4 KB pages (PS flag cleared in Page Directory entry), the 32 bits of a linear address are interpreted in the following way. Refer to below figure:
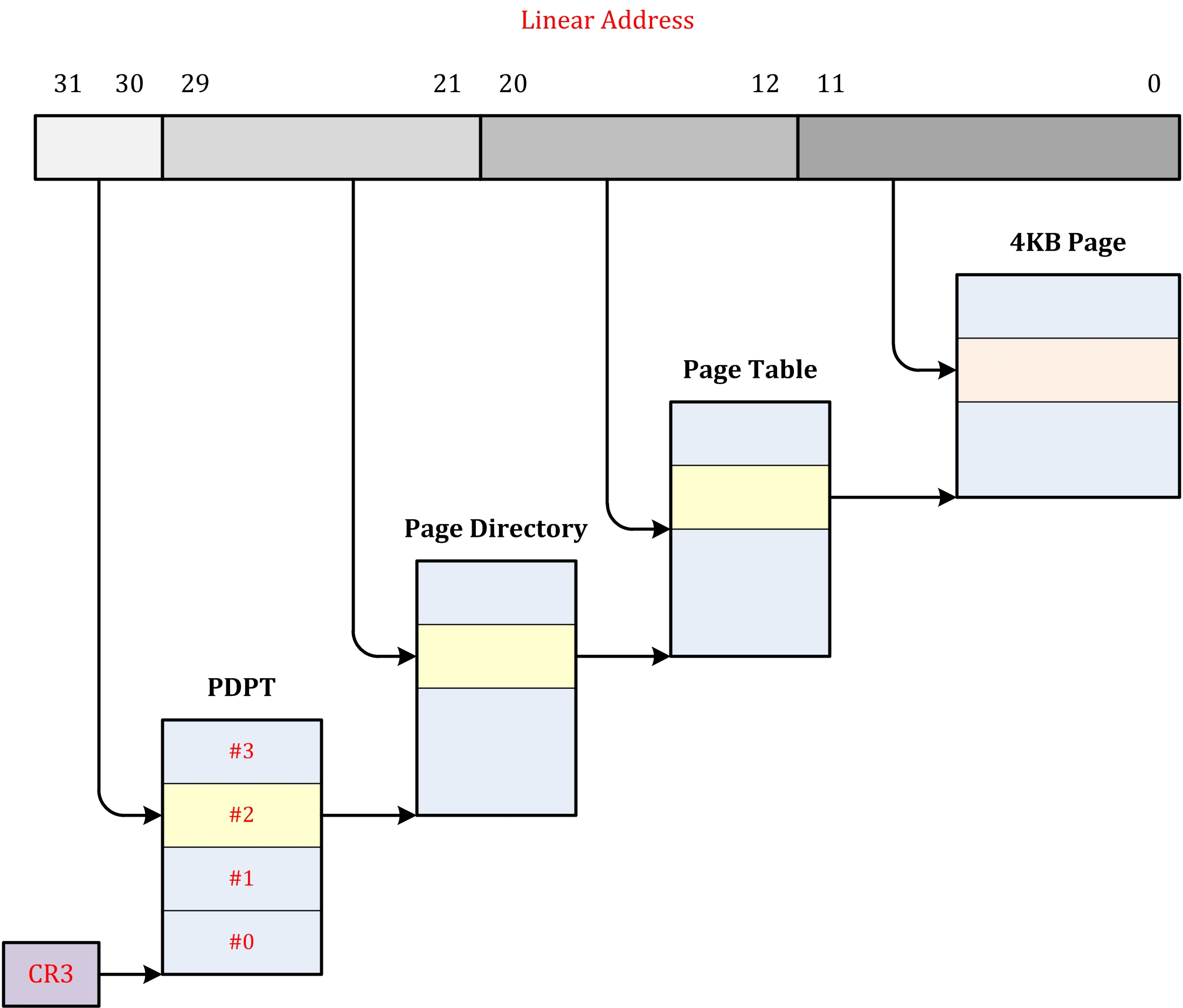
- When mapping linear addresses to 2-MB pages (PS flag set in Page Directory entry), the 32 bits of a linear address are interpreted in the following way. Refer to below figure:
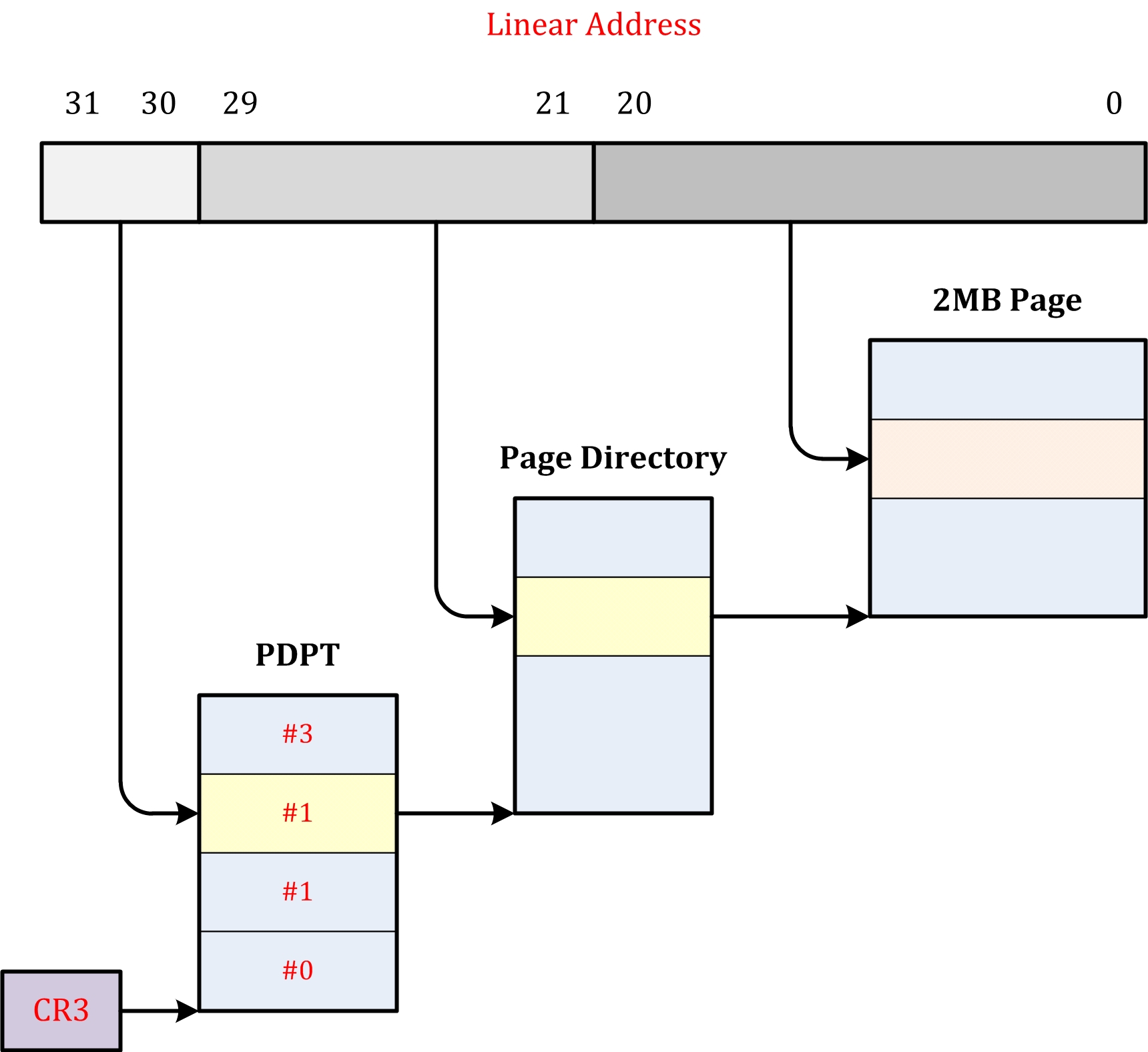
To summarize, once cr3 is set, it is possible to address up to 4 GB of RAM. If we want to address more RAM, we’ll have to put a new value in cr3 or change the content of the PDPT. However, the main problem with PAE is that linear addresses are still 32 bits long. This forces kernel programmers to reuse the same linear addresses to map different areas of RAM. Clearly, PAE does not enlarge the linear address space of a process, because it deals only with physical addresses. Furthermore, only the kernel can modify the page tables of the processes, thus a process running in User Mode cannot use a physical address space larger than 4 GB. On the other hand, PAE allows the kernel to exploit up to 64 GB of RAM, and thus to increase significantly the number of processes in the system.
6.1.2.4 Paging for 64-bit Architectures
As we have seen in the previous sections, two-level paging is commonly used by 32-bit microprocessors. Two-level paging, however, is not suitable for computers that adopt a 64-bit architecture. Let’s use a thought experiment to explain why:
Start by assuming a standard page size of 4 KB. Because 1 KB covers a range of 210 addresses, 4 KB covers 212 addresses, so the Offset field is 12 bits. This leaves up to 52 bits of the linear address to be distributed between the Table and the Directory fields. If we now decide to use only 48 of the 64 bits for addressing (this restriction leaves us with a comfortable 256 TB address space!), the remaining 48-12 = 36 bits will have to be split among Table and the Directory fields. If we now decide to reserve 18 bits for each of these two fields, both the Page Directory and the Page Tables of each process should include 218 entries—that is, more than 256,000 entries.
For that reason, all hardware paging systems for 64-bit processors make use of additional paging levels. The number of levels used depends on the type of processor. Below table summarizes the main characteristics of the hardware paging systems used by some 64-bit platforms supported by Linux.
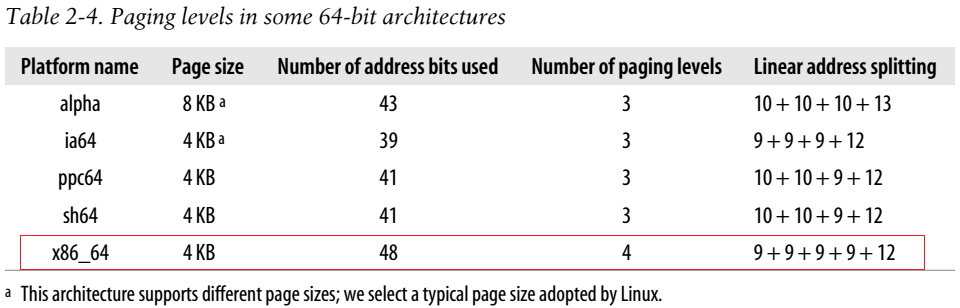
NOTE: 在x86-64架构下,不存在高端内存(ZONE_HIGHMEM)区域。
6.1.2.5 页面高速缓冲寄存器
在启用分页机制的情况下,每次存储器访问都要存取两级页表,这就大大降低了访问速度。所以,为了提高速度,在386中设置了一个最近存取页面的高速缓冲寄存器,它自动保存32项处理器最近使用的页面地址,因此可以覆盖128K字节的存储器地址。当进行存储器访问时,先检查要访问的页面是否在高速缓冲器中,如果在,就不必经过两级访问了;如果不在,再进行两级访问。平均而言,页面高速缓冲寄存器大约有98%的命中率,也就是说每次访问存储器时,只有2%的情况必须访问两级分页机构。其示意图如下:
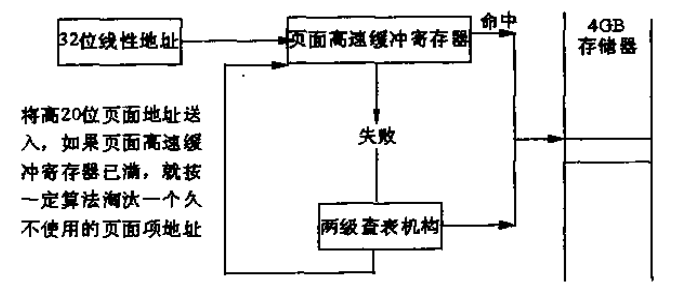
6.1.2.6 Paging in Linux Kernel
参见«Understanding the Linux Kernel, 3rd Edition»第2. Memory Addressing章第Paging in Linux节:
Two paging levels are sufficient for 32-bit architectures, while 64-bit architectures require a higher number of paging levels. Up to version 2.6.10, the Linux paging model consisted of three paging levels. Starting with version 2.6.11, a four-level paging model has been adopted. The four types of page tables illustrated in below figure are called:
- Page Global Directory
- Page Upper Directory
- Page Middle Directory
- Page Table
Linux paging model:
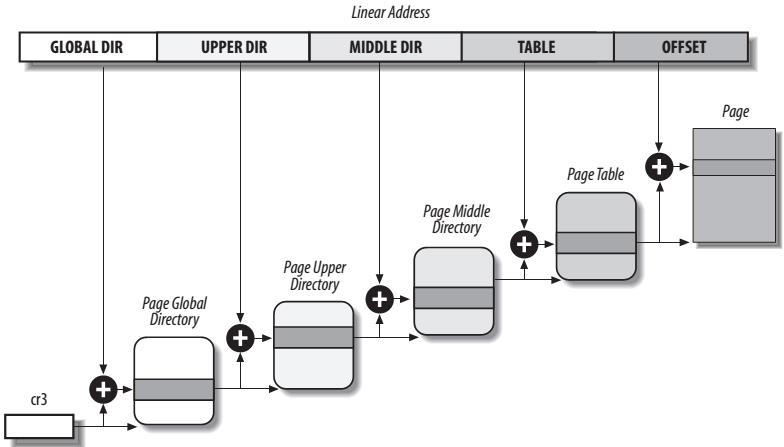
The Page Global Directory includes the addresses of several Page Upper Directories, which in turn include the addresses of several Page Middle Directories, which in turn include the addresses of several Page Tables. Each Page Table entry points to a page frame. Thus the linear address can be split into up to five parts. 6.1.2 分页机制节中的寄存器图 does not show the bit numbers, because the size of each part depends on the computer architecture.
For 32-bit architectures with no Physical Address Extension, two paging levels are sufficient. Linux essentially eliminates the Page Upper Directory and the Page Middle Directory fields by saying that they contain zero bits. However, the positions of the Page Upper Directory and the Page Middle Directory in the sequence of pointers are kept so that the same code can work on 32-bit and 64-bit architectures. The kernel keeps a position for the Page Upper Directory and the Page Middle Directory by setting the number of entries in them to 1 and mapping these two entries into the proper entry of the Page Global Directory.
For 32-bit architectures with the Physical Address Extension enabled, three paging levels are used. The Linux’s Page Global Directory corresponds to the 80×86’s Page Directory Pointer Table (PDPT), the Page Upper Directory is eliminated, the Page Middle Directory corresponds to the 80×86’s Page Directory, and the Linux’s Page Table corresponds to the 80×86’s Page Table.
Finally, for 64-bit architectures three or four levels of paging are used depending on the linear address bit splitting performed by the hardware, see section 6.1.2.4 Paging for 64-bit Architectures Table 2-4. For x86-64, four levels of paging are used.
Each process has its own Page Global Directory (mm_struct->pgd) and its own set of Page Tables. When a process switch occurs (see section 7.4.5.2.3 context_switch()), Linux saves the cr3 control register in the descriptor of the process previously in execution and then loads cr3 with the value stored in the descriptor of the process to be executed next. Thus, when the new process resumes its execution on the CPU, the paging unit refers to the correct set of Page Tables.
6.1.2.6.1 页表结构层级
PAGETABLE_LEVELS表示页表层级,取值为2,3,或4,其分别定义于:
arch/x86/include/asm/pgtable-2level_types.h
#define PAGETABLE_LEVELS 2
arch/x86/include/asm/pgtable-3level_types.h
#define PAGETABLE_LEVELS 3
arch/x86/include/asm/pgtable-64_types.h
#define PAGETABLE_LEVELS 4
各头文件的引用关系如下:
arch/x86/include/asm/pgtable.h
+- arch/x86/include/asm/pgtable_types.h
| +- #ifdef CONFIG_X86_32
| | #include "pgtable_32_types.h"
| | +- #ifdef CONFIG_X86_PAE
| | | #include <asm/pgtable-3level_types.h> // PAGETABLE_LEVELS = 3
| | | +- typedef u64 pteval_t;
| | | +- typedef u64 pmdval_t;
| | | +- typedef u64 pudval_t;
| | | +- typedef u64 pgdval_t;
| | | +- typedef union {
| | | struct { unsigned long pte_low, pte_high; };
| | | pteval_t pte;
| | | } pte_t;
| | | +- #ifdef CONFIG_PARAVIRT
| | | #define SHARED_KERNEL_PMD (pv_info.shared_kernel_pmd)
| | | #else
| | | #define SHARED_KERNEL_PMD 1
| | | #endif
| | | +- #define PAGETABLE_LEVELS 3
| | | +- #define PGDIR_SHIFT 30
| | | +- #define PTRS_PER_PGD 4
| | | +- #define PMD_SHIFT 21
| | | +- #define PTRS_PER_PMD 512
| | | +- #define PTRS_PER_PTE 512
| | +- #else
| | | #include <asm/pgtable-2level_types.h> // PAGETABLE_LEVELS = 2
| | | +- typedef unsigned long pteval_t;
| | | +- typedef unsigned long pmdval_t;
| | | +- typedef unsigned long pudval_t;
| | | +- typedef unsigned long pgdval_t;
| | | +- typedef union {
| | | pteval_t pte;
| | | pteval_t pte_low;
| | | } pte_t;
| | | +- #define SHARED_KERNEL_PMD 0
| | | +- #define PAGETABLE_LEVELS 2
| | | +- #define PGDIR_SHIFT 22
| | | +- #define PTRS_PER_PGD 1024
| | | +- #define PTRS_PER_PTE 1024
| | +- #endif
| +- #else
| | #include "pgtable_64_types.h" // PAGETABLE_LEVELS = 4
| | +- typedef unsigned long pteval_t;
| | +- typedef unsigned long pmdval_t;
| | +- typedef unsigned long pudval_t;
| | +- typedef unsigned long pgdval_t;
| | +- typedef struct { pteval_t pte; } pte_t;
| | +- #define SHARED_KERNEL_PMD 0
| | +- #define PAGETABLE_LEVELS 4
| | +- #define PGDIR_SHIFT 39
| | +- #define PTRS_PER_PGD 512
| | +- #define PUD_SHIFT 30
| | +- #define PTRS_PER_PUD 512
| | +- #define PMD_SHIFT 21
| | +- #define PTRS_PER_PMD 512
| | +- #define PTRS_PER_PTE 512
| +- #endif
| |
| |
| +- typedef struct { pgdval_t pgd; } pgd_t;
| |
| |
| +- #if PAGETABLE_LEVELS > 3
| | typedef struct { pudval_t pud; } pud_t;
| +- #else
| | #include <asm-generic/pgtable-nopud.h>
| | +- typedef struct { pgd_t pgd; } pud_t;
| | +- #define PUD_SHIFT PGDIR_SHIFT
| | +- #define PTRS_PER_PUD 1
| +- #endif
| |
| +- #if PAGETABLE_LEVELS > 2
| | typedef struct { pmdval_t pmd; } pmd_t;
| +- #else
| | #include <asm-generic/pgtable-nopmd.h>
| | +- typedef struct { pud_t pud; } pmd_t;
| | +- #define PMD_SHIFT PUD_SHIFT
| | +- #define PTRS_PER_PMD 1
| +- #endif
|
|
+- #ifdef CONFIG_X86_32
| +- #include "pgtable_32.h"
+- #else
| +- #include "pgtable_64.h"
+- #endif
页表结构:
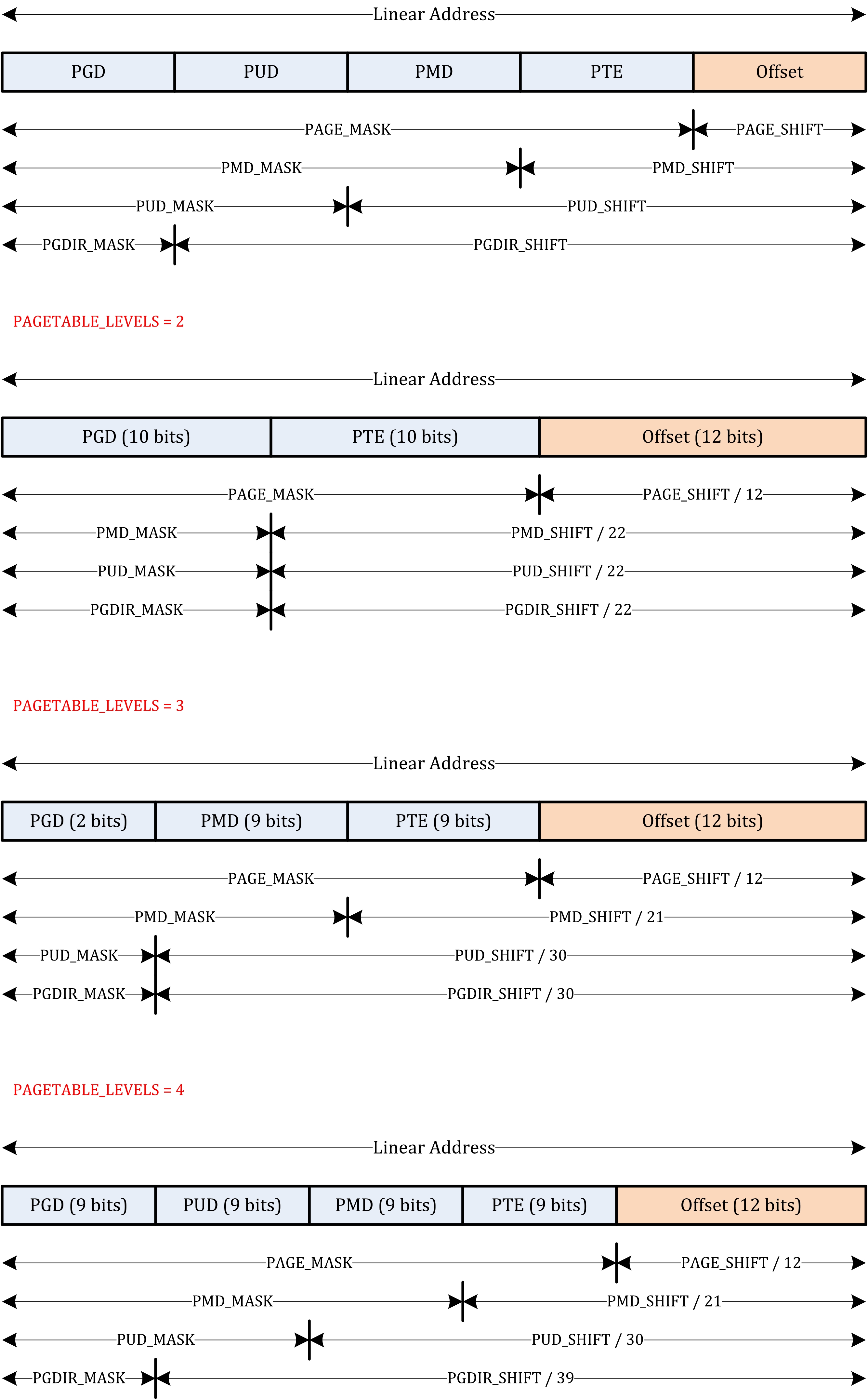
6.1.2.6.1.1 与页目录表项/页表项有关的操作函数
除了6.1.2.6.2 页目录结构/pgd_t节至6.1.2.6.5 页面结构/pte_t节中的函数,如下函数用于操作页目录表项/页表项:
pgd_none()
pud_none()
pmd_none()
pte_none()
Yield the value 1 if the corresponding entry has the value 0; otherwise, they yield the value 0.
pgd_clear()
pud_clear()
pmd_clear()
pte_clear()
Clear an entry of the corresponding page table, thus forbidding a process to use the linear addresses mapped by the page table entry. The ptep_get_and_clear() function clears a Page Table entry and returns the previous value.
set_pgd()
set_pud()
set_pmd()
set_pte()
Write a given value into a page table entry; set_pte_atomicis() identical to set_pte(), but when PAE is enabled it also ensures that the 64-bit value is written atomically.
pte_same(a,b)
Returns 1 if two Page Table entries a and b refer to the same page and specify the same access privileges, 0 otherwise.
pmd_large(e)
Returns 1 if the Page Middle Directory entryerefers to a large page (2 MB or 4 MB), 0 otherwise.
pgd_bad()
pud_bad()
pmd_bad()
The pud_bad() and pgd_bad() macros always yield 0.
The pmd_bad() macro is used by functions to check Page Middle Directory entries passed as input parameters. It yields the value 1 if the entry points to a bad Page Table — that is, if at least one of the following conditions applies:
- The page is not in main memory (Present flag cleared).
- The page allows only Read access (Read/Writeflag cleared).
- Either Accessed or Dirtyis cleared (Linux always forces these flags to be set for every existing Page Table).
No pte_bad() macro is defined, because it is legal for a Page Table entry to refer to a page that is not present in main memory, not writable, or not accessible at all.
pgd_present()
pud_present()
pmd_present()
pte_present()
The pud_present() and pgd_present() macros always yield the value 1.
The pmd_present() macro yields the value 1 if the Present flag of the corresponding entry is equal to 1 — that is, if the corresponding page or Page Table is loaded in main memory.
The pte_present() macro yields the value 1 if either the Present flag or the Page Size flag of a Page Table entry is equal to 1, the value 0 otherwise. Recall that the Page Size flag in Page Table entries has no meaning for the paging unit of the microprocessor; the kernel, however, marks Present equal to 0 and Page Size equal to 1 for the pages present in main memory but without read, write, or execute privileges. In this way, any access to such pages triggers a Page Fault exception because Present is cleared, and the kernel can detect that the fault is not due to a missing page by checking the value of Page Size.
6.1.2.6.2 页目录结构/pgd_t
6.1.2.6.2.1 pgd_t结构
页目录项结构为pgd_t,如6.1.2.1.1 页目录项/Page Directory Entry节的图所示,其定义于arch/x86/include/asm/pgtable_types.h:
typedef struct { pgdval_t pgd; } pgd_t;
按照体系架构的不同,pgdval_t定义于如下头文件:
1) arch/x86/include/asm/pgtable-2level_types.h
typedef unsigned long pgdval_t;
/*
* traditional i386 two-level paging structure:
*/
// 线性地址的最高10位用来产生页目录项索引,
// 参见[6.1.2.2 Linear Address转换到Physical Address]节
#define PGDIR_SHIFT 22
#define PTRS_PER_PGD 1024 // 页目录中包含1024个页目录项
2) arch/x86/include/asm/pgtable-3level_types.h
typedef u64 pgdval_t;
/*
* PGDIR_SHIFT determines what a top-level page table entry can map
*/
// 线性地址的最高2位用来产生PDPT,参见[6.1.2.3.1 Paging Mechanism of PAE]节
#define PGDIR_SHIFT 30
#define PTRS_PER_PGD 4 // PDPT中包含4个项
3) arch/x86/include/asm/pgtable_64_types.h
typedef unsigned long pgdval_t;
/*
* PGDIR_SHIFT determines what a top-level page table entry can map
*/
// 线性地址中的9位(A47-A39)用来产生页目录项,
// 参见[6.1.2.4 Paging for 64-bit Architectures]节
#define PGDIR_SHIFT 39
// 页目录中包含512个页目录项
#define PTRS_PER_PGD 512
6.1.2.6.2.2 pgd_offset()/pgd_offset_k()
操作页目录表的函数定义于arch/x86/include/asm/pgtable.h:
/*
* the pgd page can be thought of an array like this: pgd_t[PTRS_PER_PGD]
*
* this macro returns the index of the entry in the pgd page which would
* control the given virtual address
*/
#define pgd_index(address) (((address) >> PGDIR_SHIFT) & (PTRS_PER_PGD - 1))
/*
* pgd_offset() returns a (pgd_t *)
* pgd_index() is used get the offset into the pgd page's array of pgd_t's;
*/
// 用于获取进程虚拟地址address的一级页目录项指针,其中mm为mm_struct类型,参见[6.2.6 struct mm_struct]节
#define pgd_offset(mm, address) ((mm)->pgd + pgd_index((address)))
/*
* a shortcut which implies the use of the kernel's pgd, instead of a process's
*/
// 用于获取内核地址address的一级页目录字指针,其中init_mm定义于mm/init-mm.c,
// init_mm->pgd = swapper_pg_dir
#define pgd_offset_k(address) pgd_offset(&init_mm, (address))
6.1.2.6.2.3 pgd_val()/native_pgd_val()/native_make_pgd()
宏pgd_val()用于获取页目录表项的值,其定义于arch/x86/include/asm/pgtable.h:
#define pgd_val(x) native_pgd_val(x)
static inline pgdval_t native_pgd_val(pgd_t pgd)
{
return pgd.pgd;
}
static inline pgd_t native_make_pgd(pgdval_t val)
{
return (pgd_t) { val };
}
6.1.2.6.2.4 pgd_flags()
该函数定义于arch/x86/include/asm/pgtable_types.h:
/* PTE_PFN_MASK extracts the PFN from a (pte|pmd|pud|pgd)val_t */
#define PTE_PFN_MASK ((pteval_t)PHYSICAL_PAGE_MASK) // A31-A12置1,其他位置0
/* PTE_FLAGS_MASK extracts the flags from a (pte|pmd|pud|pgd)val_t */
#define PTE_FLAGS_MASK (~PTE_PFN_MASK) // A11-A0置1,其他位置0
static inline pgdval_t pgd_flags(pgd_t pgd)
{
// 函数native_pgd_val()参见[6.1.2.6.2.3 pgd_val()/native_pgd_val()/native_make_pgd()]节
return native_pgd_val(pgd) & PTE_FLAGS_MASK;
}
其中,PHYSICAL_PAGE_MASK定义于arch/x86/include/asm/page_types.h:
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1)) // A11-A0置0,其他位置1
#define __PHYSICAL_MASK ((phys_addr_t)((1ULL << __PHYSICAL_MASK_SHIFT) - 1)) // A31-A0置1,高位置0
/* Cast PAGE_MASK to a signed type so that it is sign-extended if
virtual addresses are 32-bits but physical addresses are larger
(ie, 32-bit PAE). */
#define PHYSICAL_PAGE_MASK (((signed long)PAGE_MASK) & __PHYSICAL_MASK) // A31-A12置1,其他位置0
6.1.2.6.2.4.1 PDG Flags
页目录项中各标志位定义于arch/x86/include/asm/pgtable_types.h:
#define _PAGE_BIT_PRESENT 0 /* is present */
#define _PAGE_BIT_RW 1 /* writeable */
#define _PAGE_BIT_USER 2 /* userspace addressable */
#define _PAGE_BIT_PWT 3 /* page write through */
#define _PAGE_BIT_PCD 4 /* page cache disabled */
#define _PAGE_BIT_ACCESSED 5 /* was accessed (raised by CPU) */
#define _PAGE_BIT_DIRTY 6 /* was written to (raised by CPU) */
#define _PAGE_BIT_PSE 7 /* 4 MB (or 2MB) page */
#define _PAGE_BIT_PAT 7 /* on 4KB pages */
#define _PAGE_BIT_GLOBAL 8 /* Global TLB entry PPro+ */
#define _PAGE_BIT_UNUSED1 9 /* available for programmer */
#define _PAGE_BIT_IOMAP 10 /* flag used to indicate IO mapping */
#define _PAGE_BIT_HIDDEN 11 /* hidden by kmemcheck */
#define _PAGE_BIT_PAT_LARGE 12 /* On 2MB or 1GB pages */
#define _PAGE_BIT_SPECIAL _PAGE_BIT_UNUSED1
#define _PAGE_BIT_CPA_TEST _PAGE_BIT_UNUSED1
#define _PAGE_BIT_SPLITTING _PAGE_BIT_UNUSED1 /* only valid on a PSE pmd */
#define _PAGE_BIT_NX 63 /* No execute: only valid after cpuid check */
#define _PAGE_PRESENT (_AT(pteval_t, 1) << _PAGE_BIT_PRESENT)
#define _PAGE_RW (_AT(pteval_t, 1) << _PAGE_BIT_RW)
#define _PAGE_USER (_AT(pteval_t, 1) << _PAGE_BIT_USER)
#define _PAGE_PWT (_AT(pteval_t, 1) << _PAGE_BIT_PWT)
#define _PAGE_PCD (_AT(pteval_t, 1) << _PAGE_BIT_PCD)
#define _PAGE_ACCESSED (_AT(pteval_t, 1) << _PAGE_BIT_ACCESSED)
#define _PAGE_DIRTY (_AT(pteval_t, 1) << _PAGE_BIT_DIRTY)
#define _PAGE_PSE (_AT(pteval_t, 1) << _PAGE_BIT_PSE)
#define _PAGE_GLOBAL (_AT(pteval_t, 1) << _PAGE_BIT_GLOBAL)
#define _PAGE_UNUSED1 (_AT(pteval_t, 1) << _PAGE_BIT_UNUSED1)
#define _PAGE_IOMAP (_AT(pteval_t, 1) << _PAGE_BIT_IOMAP)
#define _PAGE_PAT (_AT(pteval_t, 1) << _PAGE_BIT_PAT)
#define _PAGE_PAT_LARGE (_AT(pteval_t, 1) << _PAGE_BIT_PAT_LARGE)
#define _PAGE_SPECIAL (_AT(pteval_t, 1) << _PAGE_BIT_SPECIAL)
#define _PAGE_CPA_TEST (_AT(pteval_t, 1) << _PAGE_BIT_CPA_TEST)
#define _PAGE_SPLITTING (_AT(pteval_t, 1) << _PAGE_BIT_SPLITTING)
#ifdef CONFIG_KMEMCHECK
#define _PAGE_HIDDEN (_AT(pteval_t, 1) << _PAGE_BIT_HIDDEN)
#else
#define _PAGE_HIDDEN (_AT(pteval_t, 0))
#endif
#if defined(CONFIG_X86_64) || defined(CONFIG_X86_PAE)
#define _PAGE_NX (_AT(pteval_t, 1) << _PAGE_BIT_NX)
#else
#define _PAGE_NX (_AT(pteval_t, 0))
#endif
6.1.2.6.2.5 pgd_page_vaddr()
该函数用于获取PGD所在页面的虚拟地址,其定义于arch/x86/include/asm/pgtable.h:
static inline unsigned long pgd_page_vaddr(pgd_t pgd)
{
// PTE_PFN_MASK定义于[6.1.2.6.2.4 pgd_flags()]节
return (unsigned long)__va((unsigned long)pgd_val(pgd) & PTE_PFN_MASK);
}
其中,__va(x)定义于arch/x86/include/asm/page.h:
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
其中,PAGE_OFFSET参见6.3.2.4 early_node_map[]=>node_data[]->node_zones[]中的”NOTE 14”。
6.1.2.6.2.6 pgd_alloc()/pgd_free()
pgd_alloc(mm)
Allocates a new Page Global Directory; if PAE is enabled, it also allocates the three children Page Middle Directories that map the User Mode linear addresses. The argument mm (the address of a memory descriptor) is ignored on the 80x86 architecture.
pgd_free(pgd)
Releases the Page Global Directory at address pgd; if PAE is enabled, it also releases the three Page Middle Directories that map the User Mode linear addresses.
该函数定义于arch/x86/mm/pgtable.c:
pgd_t *pgd_alloc(struct mm_struct *mm)
{
pgd_t *pgd;
pmd_t *pmds[PREALLOCATED_PMDS];
pgd = (pgd_t *)__get_free_page(PGALLOC_GFP);
if (pgd == NULL)
goto out;
// 创建进程的页目录表
mm->pgd = pgd;
// 分配pmd_t结构
if (preallocate_pmds(pmds) != 0)
goto out_free_pgd;
if (paravirt_pgd_alloc(mm) != 0)
goto out_free_pmds;
/*
* Make sure that pre-populating the pmds is atomic with
* respect to anything walking the pgd_list, so that they
* never see a partially populated pgd.
*/
spin_lock(&pgd_lock);
pgd_ctor(mm, pgd); // 初始化pgd
pgd_prepopulate_pmd(mm, pgd, pmds); // 初始化pmds
spin_unlock(&pgd_lock);
return pgd;
out_free_pmds:
free_pmds(pmds);
out_free_pgd:
free_page((unsigned long)pgd);
out:
return NULL;
}
void pgd_free(struct mm_struct *mm, pgd_t *pgd)
{
pgd_mop_up_pmds(mm, pgd);
pgd_dtor(pgd);
paravirt_pgd_free(mm, pgd);
free_page((unsigned long)pgd);
}
6.1.2.6.3 页目录结构/pud_t
6.1.2.6.3.1 pud_t结构
该结构的定义参见6.1.2.1 两级页表结构节。
6.1.2.6.3.2 pud_offset()
该函数定义于arch/x86/include/asm/pgtable.h:
static inline unsigned long pud_index(unsigned long address)
{
return (address >> PUD_SHIFT) & (PTRS_PER_PUD - 1);
}
static inline pud_t *pud_offset(pgd_t *pgd, unsigned long address)
{
// 函数pgd_page_vaddr()参见[6.1.2.6.2.5 pgd_page_vaddr()]节
return (pud_t *)pgd_page_vaddr(*pgd) + pud_index(address);
}
6.1.2.6.3.3 pud_val()/native_pud_val()
该宏定义于arch/x86/include/asm/pgtable.h:
#define pud_val(x) native_pud_val(x)
其中,native_pud_val()定义于arch/x86/include/asm/pgtable_types.h:
#if PAGETABLE_LEVELS > 3
typedef struct { pudval_t pud; } pud_t;
static inline pud_t native_make_pud(pmdval_t val)
{
return (pud_t) { val };
}
static inline pudval_t native_pud_val(pud_t pud)
{
return pud.pud;
}
#else
#include <asm-generic/pgtable-nopud.h>
static inline pudval_t native_pud_val(pud_t pud)
{
// 参见[6.1.2.6.2.3 pgd_val()/native_pgd_val()/native_make_pgd()]节
return native_pgd_val(pud.pgd);
}
#endif
6.1.2.6.3.4 pud_flags()
该函数定义于arch/x86/include/asm/pgtable_types.h:
static inline pudval_t pud_flags(pud_t pud)
{
// PTE_FLAGS_MASK参见[6.1.2.6.4.4 pmd_flags()]节
return native_pud_val(pud) & PTE_FLAGS_MASK;
}
6.1.2.6.3.5 pud_page_vaddr()
该函数定义于arch/x86/include/asm/pgtable.h:
static inline unsigned long pud_page_vaddr(pud_t pud)
{
return (unsigned long)__va((unsigned long)pud_val(pud) & PTE_PFN_MASK);
}
6.1.2.6.3.6 pud_alloc()/pud_free()
pud_alloc(mm, pgd, addr)
In a two- or three-level paging system, this function does nothing: it simply returns the linear address of the Page Global Directory entry pgd.
pud_free(x)
In a two- or three-level paging system, this macro does nothing.
6.1.2.6.4 页目录结构/pmd_t
6.1.2.6.4.1 pmd_t结构
该结构的定义参见6.1.2.1 两级页表结构节。
6.1.2.6.4.2 pmd_offset()
该函数定义于arch/x86/include/asm/pgtable.h:
static inline unsigned long pmd_index(unsigned long address)
{
return (address >> PMD_SHIFT) & (PTRS_PER_PMD - 1);
}
static inline pmd_t *pmd_offset(pud_t *pud, unsigned long address)
{
return (pmd_t *)pud_page_vaddr(*pud) + pmd_index(address);
}
6.1.2.6.4.3 pmd_val()/native_pmd_val()
该宏定义于arch/x86/include/asm/pgtable.h:
#define pmd_val(x) native_pmd_val(x)
其中,native_pmd_val()定义于arch/x86/include/asm/pgtable_types.h:
#if PAGETABLE_LEVELS > 2
typedef struct { pmdval_t pmd; } pmd_t;
static inline pmd_t native_make_pmd(pmdval_t val)
{
return (pmd_t) { val };
}
static inline pmdval_t native_pmd_val(pmd_t pmd)
{
return pmd.pmd;
}
#else
#include <asm-generic/pgtable-nopmd.h>
static inline pmdval_t native_pmd_val(pmd_t pmd)
{
// 参见[6.1.2.6.2.3 pgd_val()/native_pgd_val()/native_make_pgd()]节
return native_pgd_val(pmd.pud.pgd);
}
#endif
6.1.2.6.4.4 pmd_flags()
该函数定义于arch/x86/include/asm/pgtable_types.h:
static inline pmdval_t pmd_flags(pmd_t pmd)
{
// PTE_FLAGS_MASK参见[6.1.2.6.4.4 pmd_flags()]节
return native_pmd_val(pmd) & PTE_FLAGS_MASK;
}
6.1.2.6.4.5 pmd_page_vaddr()/pmd_pfn()
该函数定义于arch/x86/include/asm/pgtable.h:
static inline unsigned long pmd_page_vaddr(pmd_t pmd)
{
return (unsigned long)__va(pmd_val(pmd) & PTE_PFN_MASK);
}
static inline unsigned long pmd_pfn(pmd_t pmd)
{
return (pmd_val(pmd) & PTE_PFN_MASK) >> PAGE_SHIFT;
}
6.1.2.6.4.6 pmd_alloc()/pmd_free()
pmd_alloc(mm, pud, addr)
Defined so generic three-level paging systems can allocate a new Page Middle Directory for the linear address addr. If PAE is not enabled, the function simply returns the input parameter pud — that is, the address of the entry in the Page Global Directory. If PAE is enabled, the function returns the linear address of the Page Middle Directory entry that maps the linear address addr. The argument cw is ignored.
pmd_free(x)
Does nothing, because Page Middle Directories are allocated and deallocated together with their parent Page Global Directory.
6.1.2.6.5 页面结构/pte_t
6.1.2.6.5.1 pte_t结构
该结构的定义参见6.1.2.1 两级页表结构节。
6.1.2.6.5.2 pte_offset_kernel()
该函数定义于arch/x86/include/asm/pgtable.h:
static inline pte_t *pte_offset_kernel(pmd_t *pmd, unsigned long address)
{
return (pte_t *)pmd_page_vaddr(*pmd) + pte_index(address);
}
6.1.2.6.5.3 pte_val()/native_pte_val()
该宏用于获取页表项的值,其定义于arch/x86/include/asm/pgtable.h:
#define pte_val(x) native_pte_val(x)
其中,native_pte_val()定义于arch/x86/include/asm/pgtable_types.h:
static inline pteval_t native_pte_val(pte_t pte)
{
return pte.pte;
}
static inline pte_t native_make_pte(pteval_t val)
{
return (pte_t) { .pte = val };
}
6.1.2.6.5.4 pte_flags()
该函数定义于arch/x86/include/asm/pgtable_types.h:
static inline pteval_t pte_flags(pte_t pte)
{
return native_pte_val(pte) & PTE_FLAGS_MASK;
}
6.1.2.6.5.4.1 PTE的标志位函数
PTE的标志位函数定义于arch/x86/include/asm/pgtable.h:
static inline int pte_dirty(pte_t pte)
{
return pte_flags(pte) & _PAGE_DIRTY;
}
static inline int pte_young(pte_t pte)
{
return pte_flags(pte) & _PAGE_ACCESSED;
}
static inline int pte_write(pte_t pte)
{
return pte_flags(pte) & _PAGE_RW;
}
static inline int pte_file(pte_t pte)
{
return pte_flags(pte) & _PAGE_FILE;
}
static inline int pte_huge(pte_t pte)
{
return pte_flags(pte) & _PAGE_PSE;
}
static inline int pte_global(pte_t pte)
{
return pte_flags(pte) & _PAGE_GLOBAL;
}
static inline int pte_exec(pte_t pte)
{
return !(pte_flags(pte) & _PAGE_NX);
}
static inline int pte_special(pte_t pte)
{
return pte_flags(pte) & _PAGE_SPECIAL;
}
6.1.2.6.5.5 pte_page()/pte_pfn()
该函数定义于arch/x86/include/asm/pgtable.h:
static inline unsigned long pte_pfn(pte_t pte)
{
return (pte_val(pte) & PTE_PFN_MASK) >> PAGE_SHIFT;
}
#define pte_page(pte) pfn_to_page(pte_pfn(pte))
The pfn_to_page(pfn) yields the address of the page descriptor associated with the page frame having number pfn. 其定义于include/asm-generic/memory_model.h:
#if defined(CONFIG_FLATMEM)
// 变量mem_map参见[6.2.2.1 mem_map]节
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + ARCH_PFN_OFFSET)
#elif defined(CONFIG_DISCONTIGMEM)
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid); \
})
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \
(unsigned long)(__pg - __pgdat->node_mem_map) + __pgdat->node_start_pfn; \
})
#elif defined(CONFIG_SPARSEMEM_VMEMMAP)
/* memmap is virtually contiguous. */
#define __pfn_to_page(pfn) (vmemmap + (pfn))
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
#elif defined(CONFIG_SPARSEMEM)
/*
* Note: section's mem_map is encorded to reflect its start_pfn.
* section[i].section_mem_map == mem_map's address - start_pfn;
*/
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
int __sec = page_to_section(__pg); \
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
})
#endif /* CONFIG_FLATMEM/DISCONTIGMEM/SPARSEMEM */
#define pfn_to_page __pfn_to_page
#define page_to_pfn __page_to_pfn
6.1.2.6.5.6 pte_alloc_map()/pte_free()/pte_alloc_kernel()/pte_free_kernel()/clear_page_range()
pte_alloc_map(mm, pmd, addr)
Receives as parameters the addressof a Page Middle Directory entry pmd and a linear address addr, and returns the address of the Page Table entry corresponding to addr. If the Page Middle Directory entry is null, the function allocatesa new Page Table by invoking pte_alloc_one(). If a new Page Table is allocated, the entry corresponding toaddris initialized and the User/Supervisor flag is set. If the Page Table is kept in high memory, the kernel establishes a temporary kernel mapping, to be released by pte_unmap.
pte_free(pte)
Releases the Page Table associated with theptepage descriptor pointer.
pte_alloc_kernel(mm, pmd, addr)
If the Page Middle Directory entry pmd associated with the address addr is null, the function allocates a new Page Table. It then returns the linear address of the Page Table entry associated withaddr. Used only for master kernel page tables.
pte_free_kernel(pte)
Equivalent to pte_free(), but used for master kernel page tables.
clear_page_range(mmu, start, end)
Clears the contents of the page tables of a process from linear address start to end by iteratively releasing its Page Tables and clearing the Page Middle Directory entries.
6.2 与内存管理有关的数据结构
6.2.1 PAGE_SIZE
PAGE_SIZE表示页面的大小,取值为4096,即页面大小为4KB,其定义于include/asm-generic/page.h:
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#ifdef __ASSEMBLY__
#define PAGE_SIZE (1 << PAGE_SHIFT)
#else
#define PAGE_SIZE (1UL << PAGE_SHIFT)
#endif
#define PAGE_MASK (~(PAGE_SIZE-1))
6.2.2 struct page
该结构定义于include/linux/mm_types.h:
struct page {
/* First double word block */
// Array of flags (see below).
// Also encodes the zone number to which the page frame belongs.
unsigned long flags;
// Used when the page is inserted into the page cache, or
// when it belongs to an anonymous region.
struct address_space *mapping;
/* Second double word */
struct {
union {
// Used by several kernel components with different meanings.
// For instance, it identifies the position of the data stored
// in the page frame within the page’s disk image or within an
// anonymous region, or it stores a swapped-out page identifier.
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* slub first free object */
};
union {
/* Used for cmpxchg_double in slub */
unsigned long counters;
struct {
union {
// Number of Page Table entries that refer to the page frame (-1 if none).
atomic_t _mapcount;
struct {
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
// Page frame’s reference counter. The page_count() returns
// the value of the _count field.
// If _count == -1, the corresponding page frame is free and
// can be assigned to any process or to the kernel itself.
// If _count >= 0, the page frame is assigned to one or more
// processes or is used to store some kernel data structures.
atomic_t _count;
};
};
};
/* Third double word block */
union {
// Contains pointers to the least recently used doubly linked list of pages.
struct list_head lru;
struct {
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages;
short int pobjects;
#endif
};
};
/* Remainder is not double word aligned */
union {
// Available to the kernel component that is using the page.
// For instance, it’s a buffer head pointer in case of buffer page.
// If the page is free, this field is used by the buddy allocator system:
// 用于保存其order值,参见[6.4.1.1.2.1.1.1.1 __rmqueue_smallest()]节:
// * 在__rmqueue_smallest()->rmv_page_order()复位为0;
// * 在__rmqueue_smallest()->expand()置为特定的order值。
unsigned long private;
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* SLUB: Pointer to slab */
// 通过buffered_rmqueue()->prep_new_page()
// ->prep_compound_page()设置,参见[6.4.1.1.2.1.2 prep_new_page()]节
struct page *first_page; /* Compound tail pages */
};
#if defined(WANT_PAGE_VIRTUAL)
Void *virtual;
#endif
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags;
#endif
#ifdef CONFIG_KMEMCHECK
Void *shadow;
#endif
};
struct page的结构图:
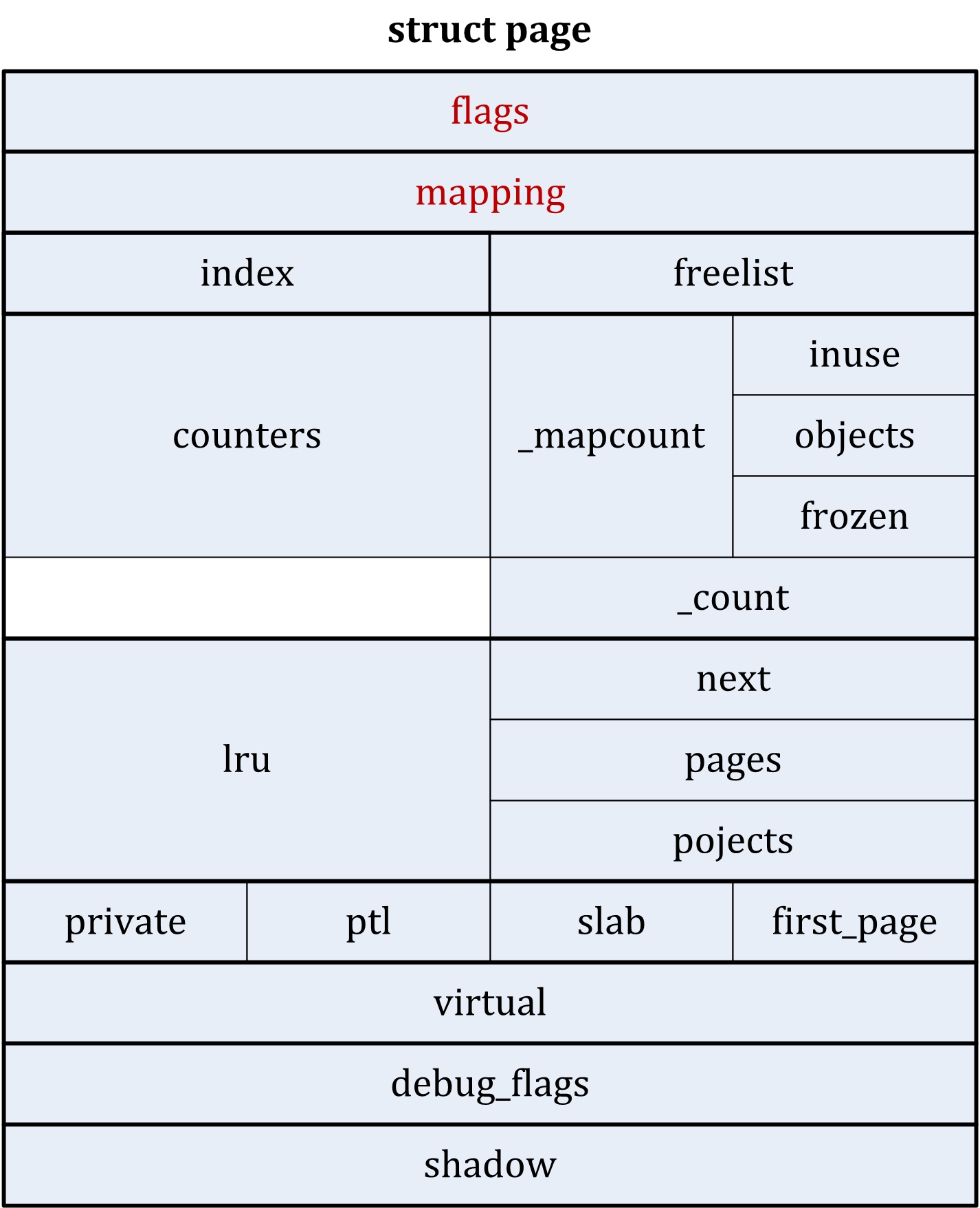
struct page中flags域的取值如下,参见include/linux/page-flags.h:
enum pageflags {
// for instance, it’s involved in a disk I/O operation.
PG_locked, /* Page is locked. Don't touch. */
PG_error, // An I/O error occurred while transferring the page.
PG_referenced, // The page has been recently accessed.
PG_uptodate, // It’s set after completing a read operation, unless a disk I/O error happened.
PG_dirty, // The page has been modified.
PG_lru, // The page is in the active or inactive page list.
PG_active, // The page is in the active page list.
PG_slab, // The page frame is included in a slab.
PG_owner_priv_1, /* Owner use. If pagecache, fs may use*/
PG_arch_1, // Not used on the 80x86 architecture.
PG_reserved, // The page frame is reserved for kernel code or is unusable.
// The private field of the page descriptor stores meaningful data.
PG_private, /* If pagecache, has fs-private data */
PG_private_2, /* If pagecache, has fs aux data */
// The page is being written to disk by means of the writepage() method.
PG_writeback, /* Page is under writeback */
#ifdef CONFIG_PAGEFLAGS_EXTENDED
PG_head, /* A head page */
PG_tail, /* A tail page */
#else
// The page frame is handled through the extended paging mechanism.
PG_compound, /* A compound page */
#endif
// The page belongs to the swap cache.
PG_swapcache, /* Swap page: swp_entry_t in private */
// All data in the page frame corresponds to blocks allocated on disk.
PG_mappedtodisk, /* Has blocks allocated on-disk */
// The page has been marked to be written to disk in order to reclaim memory.
PG_reclaim, /* To be reclaimed asap */
PG_swapbacked, /* Page is backed by RAM/swap */
PG_unevictable, /* Page is "unevictable" */
#ifdef CONFIG_MMU
PG_mlocked, /* Page is vma mlocked */
#endif
#ifdef CONFIG_ARCH_USES_PG_UNCACHED
PG_uncached, /* Page has been mapped as uncached */
#endif
#ifdef CONFIG_MEMORY_FAILURE
PG_hwpoison, /* hardware poisoned page. Don't touch */
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
PG_compound_lock,
#endif
__NR_PAGEFLAGS,
/* Filesystems */
// Used by some filesystems such as Ext2 and Ext3.
PG_checked = PG_owner_priv_1,
/* Two page bits are conscripted by FS-Cache to maintain local caching
* state. These bits are set on pages belonging to the netfs's inodes
* when those inodes are being locally cached.
*/
PG_fscache = PG_private_2, /* page backed by cache */
/* XEN */
PG_pinned = PG_owner_priv_1,
PG_savepinned = PG_dirty,
/* SLOB */
PG_slob_free = PG_private,
};
6.2.2.1 mem_map
All page descriptors are stored in the mem_map array. 其定义于mm/memory.c:
#ifndef CONFIG_NEED_MULTIPLE_NODES
/* use the per-pgdat data instead for discontigmem - mbligh */
unsigned long max_mapnr;
struct page *mem_map;
#endif
变量mem_map初始化过程如下:
start_kernel()
-> setup_arch()
-> paging_init()
-> zone_sizes_init()
-> free_area_init_nodes()
-> free_area_init_node()
-> alloc_node_mem_map()
函数alloc_node_mem_map()定义于mm/page_alloc.c:
static void __init_refok alloc_node_mem_map(struct pglist_data *pgdat)
{
/* Skip empty nodes */
if (!pgdat->node_spanned_pages)
return;
#ifdef CONFIG_FLAT_NODE_MEM_MAP
/* ia64 gets its own node_mem_map, before this, without bootmem */
if (!pgdat->node_mem_map) {
unsigned long size, start, end;
struct page *map;
/*
* The zone's endpoints aren't required to be MAX_ORDER
* aligned but the node_mem_map endpoints must be in order
* for the buddy allocator to function correctly.
*/
// MAX_ORDER_NR_PAGES = 1024
start = pgdat->node_start_pfn & ~(MAX_ORDER_NR_PAGES - 1);
end = pgdat->node_start_pfn + pgdat->node_spanned_pages;
end = ALIGN(end, MAX_ORDER_NR_PAGES);
size = (end - start) * sizeof(struct page);
map = alloc_remap(pgdat->node_id, size);
if (!map)
map = alloc_bootmem_node_nopanic(pgdat, size);
pgdat->node_mem_map = map + (pgdat->node_start_pfn - start);
}
#ifndef CONFIG_NEED_MULTIPLE_NODES
/*
* With no DISCONTIG, the global mem_map is just set as node 0's
*/
if (pgdat == NODE_DATA(0)) {
mem_map = NODE_DATA(0)->node_mem_map;
#ifdef CONFIG_ARCH_POPULATES_NODE_MAP
if (page_to_pfn(mem_map) != pgdat->node_start_pfn)
mem_map -= (pgdat->node_start_pfn - ARCH_PFN_OFFSET);
#endif /* CONFIG_ARCH_POPULATES_NODE_MAP */
}
#endif
#endif /* CONFIG_FLAT_NODE_MEM_MAP */
}
Page descriptor与其所描述的Page之间的关系:
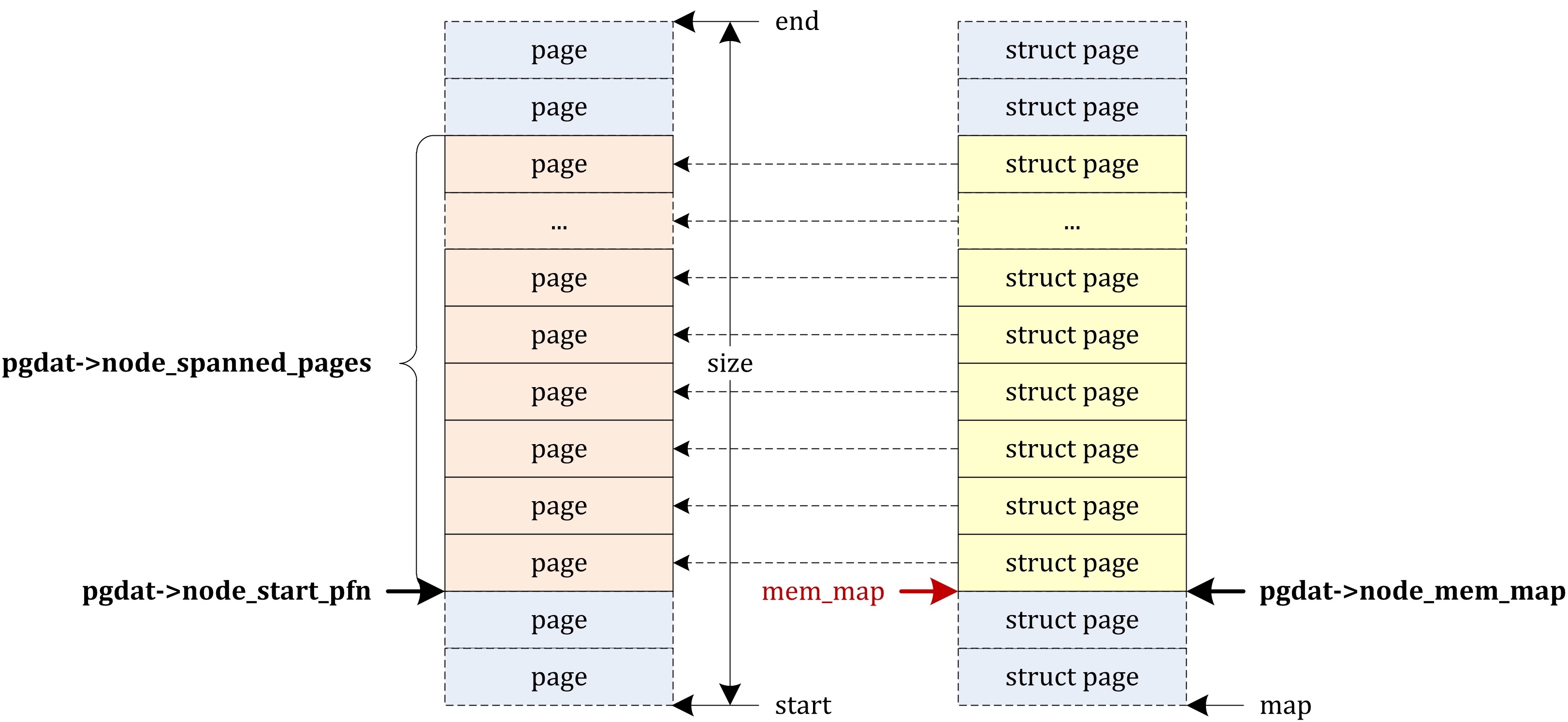
变量mem_map用于计算page descriptor与物理页面之间的映射关系,即宏__pfn_to_page(pfn)和__page_to_pfn(page),参见6.1.2.6.5.5 pte_page()/pte_pfn()节。
6.2.3 struct zone
该结构定义于include/linux/mmzone.h:
struct zone {
// 参见enum zone_watermarks
unsigned long watermark[NR_WMARK];
unsigned long percpu_drift_mark;
unsigned long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
// 取值与struct zone->zone_pgdat->node_nid相同
int node;
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif
// The Per-CPU Page Frame Cache
struct per_cpu_pageset __percpu *pageset;
spinlock_t lock;
int all_unreclaimable;
#ifdef CONFIG_MEMORY_HOTPLUG
seqlock_t span_seqlock;
#endif
/*
* Identifies the blocks of free page frames in the zone.
*
* Buddy Allocator System Algorithm. All free page frames are grouped into 11 lists
* of blocks that contain groups of 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, and 1024
* contiguous page frames, respectively. that’s, free_area[k] has 2k contiguous page
* frames.
*
* NOTE #1: The physical address of the first page frame of a block is a multiple of
* the group size. for example, the initial address of a 16-page-frame block is a
* multiple of 16×212
*
* NOTE #2: The free_list field of free_area[k] is the head of a doubly linked circular
* list that collects the page descriptors associated with the free blocks of 2k pages.
* More precisely, this list includes the page descriptors of the starting page frame
* of every block of 2k free page frames; the pointers to the adjacent elements in the
* list are stored in the lru field of the page descriptor.
*/
struct free_area free_area[MAX_ORDER];
#ifndef CONFIG_SPARSEMEM
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
#ifdef CONFIG_COMPACTION
unsigned int compact_considered;
unsigned int compact_defer_shift;
#endif
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
struct zone_lru {
struct list_head list;
} lru[NR_LRU_LISTS];
struct zone_reclaim_stat reclaim_stat;
// Counter used when doing page frame reclaiming in the zone
unsigned long pages_scanned;
unsigned long flags;
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
unsigned int inactive_ratio;
ZONE_PADDING(_pad2_)
// Hash table of wait queues of processes waiting for one of the pages of the zone.
wait_queue_head_t *wait_table;
unsigned long wait_table_hash_nr_entries;
// Power-of-2 order of the size of the wait queue hash table array.
unsigned long wait_table_bits;
// struct pglist_data->node_zones[*]指向本结构体,而本域指向struct pglist_data
struct pglist_data *zone_pgdat;
// 本zone包含的物理页的起始帧号,即页地址中12-31位的取值
unsigned long zone_start_pfn;
unsigned long spanned_pages; /* total size of the zone in pages, including holes */
unsigned long present_pages; /* amount of memory (excluding holes) */
// 本zone的名字,取值参见数组zone_names[]
const char *name;
} ____cacheline_internodealigned_in_smp;
其结构参见6.3.2.4 early_node_map[]=>node_data[]->node_zones[]节中的”NOTE 14”中的”变量node_data的结构”图。
6.2.4 pg_data_t
该类型定义于include/linux/mmzone.h:
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; // Array of zone descriptors of the node
struct zonelist node_zonelists[MAX_ZONELISTS]; // Used by the page allocator
int nr_zones; // Number of zones in the node
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
// The first page of the struct page array representing each physical frame in the node.
// It will be placed somewhere within the global mem_map array.
struct page *node_mem_map; // Array of page descriptors of the node
#ifdef CONFIG_CGROUP_MEM_RES_CTLR
struct page_cgroup *node_page_cgroup;
#endif
#endif
#ifndef CONFIG_NO_BOOTMEM
// Pointer to Boot Memory Allocatoer, which is used in the kernel initialization phase.
// 参见[4.3.4.1.4.3.6.1.1 free_all_bootmem()/free_all_bootmem_core()]节和[6.2.9.2 Initialise the Boot Memory Allocator]节
struct bootmem_data *bdata;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* Nests above zone->lock and zone->size_seqlock.
*/
spinlock_t node_size_lock;
#endif
// Index of the first page frame in the node
unsigned long node_start_pfn;
// Size of the memory node, excluding holes (in page frames)
unsigned long node_present_pages; /* total number of physical pages */
// Size of the node, including holes (in page frames)
unsigned long node_spanned_pages; /* total size of physical page range, including holes */
// Identifier of the node, starts at 0
int node_id;
// Wait queue for the kswapd pageout daemon
wait_queue_head_t kswapd_wait;
// Pointer to the process descriptor of the kswapd kernel thread. 参见[6.4.1.1.3.1.1 kswapd]节
struct task_struct *kswapd;
// Logarithmic size of free blocks to be created by kswapd
int kswapd_max_order;
enum zone_type classzone_idx;
} pg_data_t;
其结构参见6.3.2.4 early_node_map[]=>node_data[]->node_zones[]节中的”NOTE 14”中的”变量node_data的结构”图。。
在mm/bootmem.c中定义了一个该类型的全局变量contig_page_data:
#ifndef CONFIG_NEED_MULTIPLE_NODES
struct pglist_data __refdata contig_page_data = {
.bdata = &bootmem_node_data[0]
};
#endif
该变量可通过include/linux/mmzone.h中的如下宏访问:
#ifndef CONFIG_NEED_MULTIPLE_NODES
extern struct pglist_data contig_page_data;
#define NODE_DATA(nid) (&contig_page_data)
#define NODE_MEM_MAP(nid) mem_map
#else /* CONFIG_NEED_MULTIPLE_NODES */
#include <asm/mmzone.h>
#endif /* !CONFIG_NEED_MULTIPLE_NODES */
6.2.5 gfp_t
该类型定义于include/linux/gfp.h:
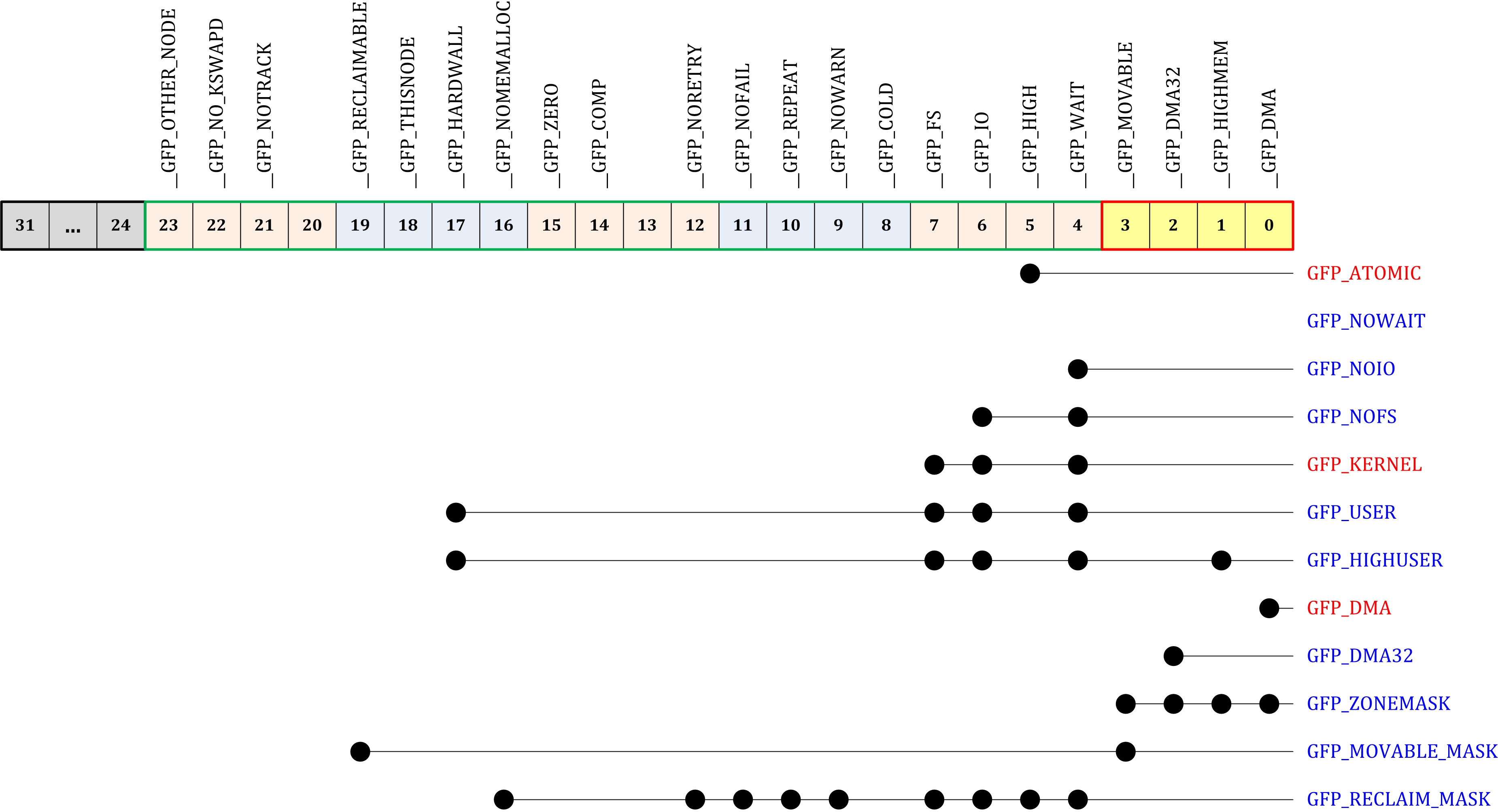
6.2.6 struct mm_struct
The kernel represents a process’s address space with a data structure called the memory descriptor. This structure contains all the information related to the process address space. The memory descriptor is represented by struct mm_struct and defined in include/linux/mm_types.h:
struct mm_struct {
// Pointer to the head of the list of memory region objects. 参见[6.2.7 struct vm_area_struct]节
struct vm_area_struct *mmap; /* list of VMAs */
// Pointer to the root of the red-black tree of memory region objects
struct rb_root mm_rb;
// Pointer to the last referenced memory region object
struct vm_area_struct *mmap_cache; /* last find_vma result */
#ifdef CONFIG_MMU
// Method that searches an available linear address interval in the process address space
unsigned long (*get_unmapped_area) (struct file *filp, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
// Method invoked when releasing a linear address interval
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
#endif
// Identifies the linear address of the first allocated anonymousmemory region or file memory mapping
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
/*
* Address from which the kernel will look for a free interval of linear addresses
* in the process address space
*/
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
/*
* Pointer to the Page Global Directory, which is a physical page frame.
* 参见[6.1.2.2 Linear Address转换到Physical Address]节
* On the x86, the process page table is loaded by copying mm_struct->pgd
* into the cr3 register which has the side effect of flushing the TLB.
* In fact this is how the function __flush_tlb() is implemented in the
* architecture dependent code.
*/
pgd_t *pgd;
/*
* mm_count is main usage counter; all users in mm_users count as one unit in mm_count.
* Every time the mm_count is decreased, the kernel checks whether it becomes zero;
* if so, the memory descriptor is deallocated because it is no longer in use.
*/
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
/*
* map_count field contains the number of memory regions owned by the process.
* By default, a process may own up to 65,536 different memory regions;
* however, the system administrator may change this limit by writing in
* /proc/sys/vm/max_map_count,参见[6.8.2.1.1 do_mmap_pgoff()]节,do_mmap_pgoff():
* if (mm->map_count > sysctl_max_map_count)
*/
int map_count; /* number of VMAs */
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct rw_semaphore mmap_sem; // Memory regions’read/write semaphore
/*
* List of maybe swapped mm's.
* These are globally strung together off init_mm.mmlist,
* and are protected by mmlist_lock.
*/
/*
* The first element of list mmlist is init_mm.mmlist,
* which is used by process 0 in the initialization
*/
struct list_head mmlist;
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long shared_vm; /* Shared pages (files) */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE */
unsigned long stack_vm; /* VM_GROWSUP/DOWN */
unsigned long reserved_vm; /* VM_RESERVED|VM_IO pages */
unsigned long def_flags;
unsigned long nr_ptes; /* Page table pages */
/*
* start_code / end_code: Initial / Final address of executable code
* start_data / end_data: Initial / Final address of initialized data
*/
unsigned long start_code, end_code, start_data, end_data;
/*
* start_brk / brk: Initial / Current final address of the heap
* start_stack: Initial address of User Mode stack
*/
unsigned long start_brk, brk, start_stack;
/*
* arg_start / arg_end: Initial / Final address of command-line arguments
* env_start / end_start: Initial / Final address of environment variables
*/
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_var_t cpu_vm_mask_var;
/* Architecture-specific MM context */
mm_context_t context;
/* Swap token stuff */
/*
* Last value of global fault stamp as seen by this process.
* In other words, this value gives an indication of how long
* it has been since this task got the token.
* Look at mm/thrash.c
*/
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct hlist_head ioctx_list;
#endif
#ifdef CONFIG_MM_OWNER
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
/* store ref to file /proc/<pid>/exe symlink points to */
struct file *exe_file;
unsigned long num_exe_file_vmas;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_CPUMASK_OFFSTACK
struct cpumask cpumask_allocation;
#endif
};
链表mm_struct:
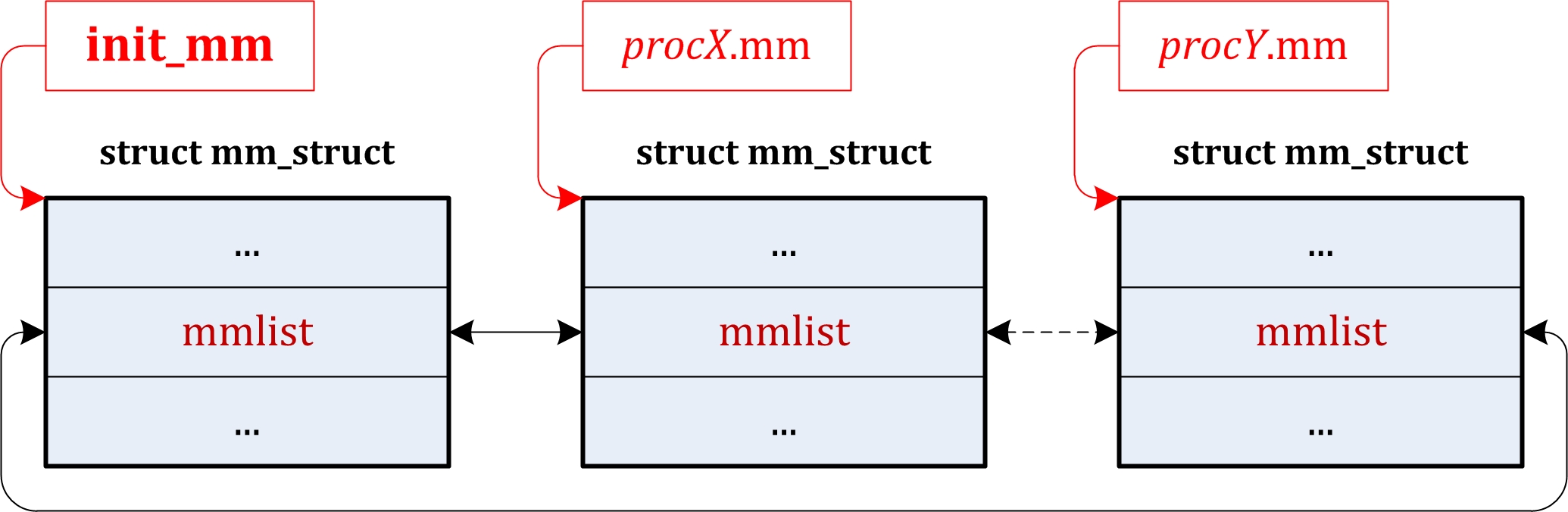
若存在进程号为1234的进程,则可通过如下两种方式查看其虚拟内存空间:
$ cat /proc/1234/maps
$ cat /proc/1234/smaps
$ pmap 1234
6.2.7 struct vm_area_struct
Linux implements a memory region by means of an object of type vm_area_struct.
Each memory region descriptor identifies a linear address interval. The vm_start field contains the first linear address of the interval, while the vm_end field contains the first linear address outside of the interval; vm_end – vm_start thus denotes the length of the memory region.
Memory regions owned by a process never overlap, and the kernel tries to merge regions when a new one is allocated right next to an existing one. Two adjacent regions can be merged if their access rights match.
该结构定义于include/linux/mm_types.h:
struct vm_area_struct {
// 参见[6.2.6 struct mm_struct]节
struct mm_struct *vm_mm; /* The address space we belong to. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
struct rb_node vm_rb;
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
union {
struct {
struct list_head list;
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem & page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
// 参见[6.2.7.1 struct vm_operations_struct]节
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
/* Offset (within vm_file) in PAGE_SIZE units, *not* PAGE_CACHE_SIZE */
unsigned long vm_pgoff;
// Pointer to the file being mapped, see below figure "Address space of a process backing a file"
struct file *vm_file; /* File we map to (can be NULL). */
void *vm_private_data; /* was vm_pte (shared mem) */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
All the regions owned by a process are linked in a simple list. Regions appear in the list in ascending order by memory address; however, successive regions can be separated by an area of unused memory addresses.
A full list of mapped regions a process has may be viewed via the proc interface at /proc/
Descriptors related to the address space of a process:
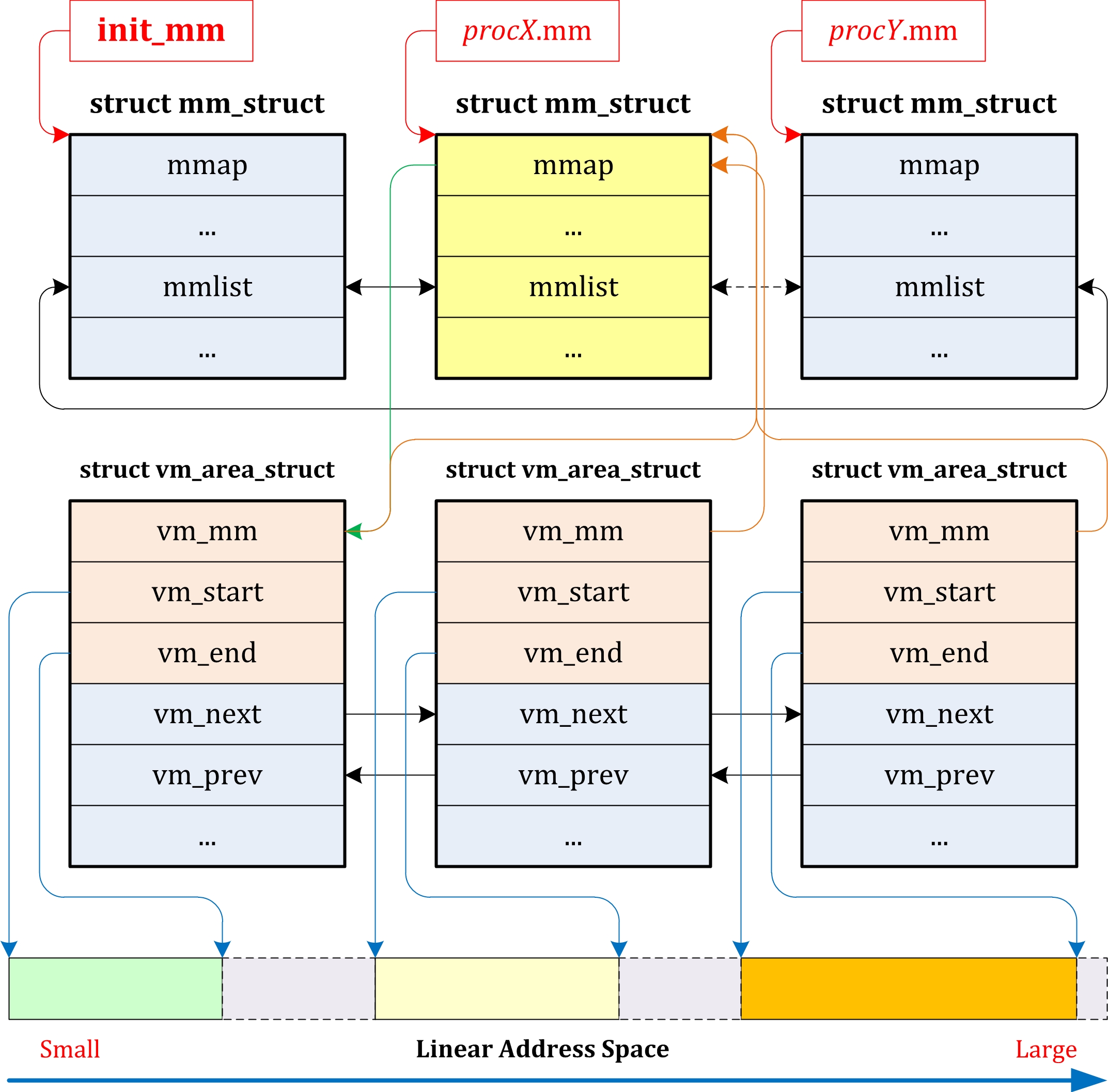
Address space of a process backing a file:
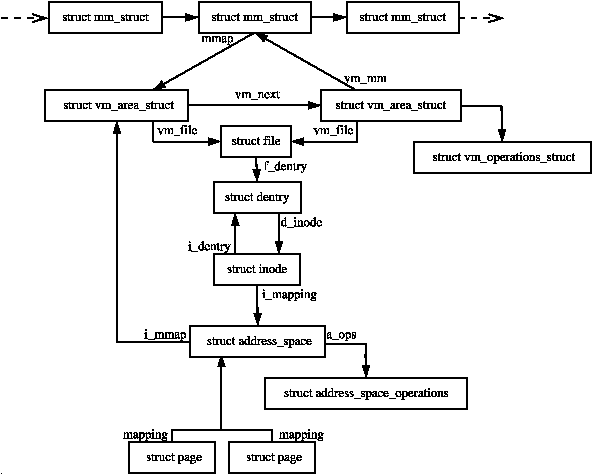
6.2.7.1 struct vm_operations_struct
该结构定义于include/linux/mm_types.h:
struct vm_operations_struct {
// Invoked when the memory region is added to the set of regions owned by a process.
void (*open)(struct vm_area_struct * area);
// Invoked when the memory region is removed from the set of regions owned by a process.
void (*close)(struct vm_area_struct * area);
/*
* The callback is responsible for locating the page in the page cache or
* allocating a page and populating it with the required data before returning it.
* See section fault()/filemap_fault()
*/
int (*fault)(struct vm_area_struct *vma, struct vm_fault *vmf);
/* notification that a previously read-only page is about to become
* writable, if an error is returned it will cause a SIGBUS */
int (*page_mkwrite)(struct vm_area_struct *vma, struct vm_fault *vmf);
/* called by access_process_vm when get_user_pages() fails, typically
* for use by special VMAs that can switch between memory and hardware
*/
int (*access)(struct vm_area_struct *vma, unsigned long addr, void *buf, int len, int write);
#ifdef CONFIG_NUMA
/*
* set_policy() op must add a reference to any non-NULL @new mempolicy
* to hold the policy upon return. Caller should pass NULL @new to
* remove a policy and fall back to surrounding context--i.e. do not
* install a MPOL_DEFAULT policy, nor the task or system default
* mempolicy.
*/
int (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new);
/*
* get_policy() op must add reference [mpol_get()] to any policy at
* (vma,addr) marked as MPOL_SHARED. The shared policy infrastructure
* in mm/mempolicy.c will do this automatically.
* get_policy() must NOT add a ref if the policy at (vma,addr) is not
* marked as MPOL_SHARED. vma policies are protected by the mmap_sem.
* If no [shared/vma] mempolicy exists at the addr, get_policy() op
* must return NULL--i.e., do not "fallback" to task or system default
* policy.
*/
struct mempolicy *(*get_policy)(struct vm_area_struct *vma, unsigned long addr);
int (*migrate)(struct vm_area_struct *vma, const nodemask_t *from,
const nodemask_t *to, unsigned long flags);
#endif
};
6.2.7.1.1 fault()/filemap_fault()
struct vm_operations_struct->fault可被注册为filemap_fault(),其定义于mm/filemap.c:
const struct vm_operations_struct generic_file_vm_ops = {
.fault = filemap_fault,
};
/**
* filemap_fault - read in file data for page fault handling
* @vma: vma in which the fault was taken
* @vmf: struct vm_fault containing details of the fault
*
* filemap_fault() is invoked via the vma operations vector for a
* mapped memory region to read in file data during a page fault.
*
* The goto's are kind of ugly, but this streamlines the normal case of having
* it in the page cache, and handles the special cases reasonably without
* having a lot of duplicated code.
*/
int filemap_fault(struct vm_area_struct *vma, struct vm_fault *vmf)
{
int error;
struct file *file = vma->vm_file;
struct address_space *mapping = file->f_mapping;
struct file_ra_state *ra = &file->f_ra;
struct inode *inode = mapping->host;
pgoff_t offset = vmf->pgoff;
struct page *page;
pgoff_t size;
int ret = 0;
size = (i_size_read(inode) + PAGE_CACHE_SIZE - 1) >> PAGE_CACHE_SHIFT;
if (offset >= size)
return VM_FAULT_SIGBUS;
/*
* Do we have something in the page cache already?
*/
page = find_get_page(mapping, offset);
if (likely(page)) {
/*
* We found the page, so try async readahead before
* waiting for the lock.
*/
do_async_mmap_readahead(vma, ra, file, page, offset);
} else {
/* No page in the page cache at all */
do_sync_mmap_readahead(vma, ra, file, offset);
count_vm_event(PGMAJFAULT);
mem_cgroup_count_vm_event(vma->vm_mm, PGMAJFAULT);
ret = VM_FAULT_MAJOR;
retry_find:
page = find_get_page(mapping, offset);
if (!page)
goto no_cached_page;
}
if (!lock_page_or_retry(page, vma->vm_mm, vmf->flags)) {
page_cache_release(page);
return ret | VM_FAULT_RETRY;
}
/* Did it get truncated? */
if (unlikely(page->mapping != mapping)) {
unlock_page(page);
put_page(page);
goto retry_find;
}
VM_BUG_ON(page->index != offset);
/*
* We have a locked page in the page cache, now we need to check
* that it's up-to-date. If not, it is going to be due to an error.
*/
if (unlikely(!PageUptodate(page)))
goto page_not_uptodate;
/*
* Found the page and have a reference on it.
* We must recheck i_size under page lock.
*/
size = (i_size_read(inode) + PAGE_CACHE_SIZE - 1) >> PAGE_CACHE_SHIFT;
if (unlikely(offset >= size)) {
unlock_page(page);
page_cache_release(page);
return VM_FAULT_SIGBUS;
}
vmf->page = page;
return ret | VM_FAULT_LOCKED;
no_cached_page:
/*
* We're only likely to ever get here if MADV_RANDOM is in
* effect.
*/
error = page_cache_read(file, offset);
/*
* The page we want has now been added to the page cache.
* In the unlikely event that someone removed it in the
* meantime, we'll just come back here and read it again.
*/
if (error >= 0)
goto retry_find;
/*
* An error return from page_cache_read can result if the
* system is low on memory, or a problem occurs while trying
* to schedule I/O.
*/
if (error == -ENOMEM)
return VM_FAULT_OOM;
return VM_FAULT_SIGBUS;
page_not_uptodate:
/*
* Umm, take care of errors if the page isn't up-to-date.
* Try to re-read it _once_. We do this synchronously,
* because there really aren't any performance issues here
* and we need to check for errors.
*/
ClearPageError(page);
error = mapping->a_ops->readpage(file, page);
if (!error) {
wait_on_page_locked(page);
if (!PageUptodate(page))
error = -EIO;
}
page_cache_release(page);
if (!error || error == AOP_TRUNCATED_PAGE)
goto retry_find;
/* Things didn't work out. Return zero to tell the mm layer so. */
shrink_readahead_size_eio(file, ra);
return VM_FAULT_SIGBUS;
}
6.2.8 struct address_space
该结构定义于include/linux/fs.h:
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and lock protecting it */
unsigned int i_mmap_writable; /* count VM_SHARED mappings */
struct prio_tree_root i_mmap; /* tree of private and shared mappings */
struct list_head i_mmap_nonlinear; /*list VM_NONLINEAR mappings */
struct mutex i_mmap_mutex; /* protect tree, count, list */
/* Protected by tree_lock together with the radix tree */
unsigned long nrpages; /* number of total pages */
pgoff_t writeback_index; /* writeback starts here */
// 参见[6.2.8.1 struct address_space_operations]节
const struct address_space_operations *a_ops; /* methods */
unsigned long flags; /* error bits/gfp mask */
struct backing_dev_info *backing_dev_info; /* device readahead, etc */
spinlock_t private_lock; /* for use by the address_space */
struct list_head private_list; /* ditto */
struct address_space *assoc_mapping; /* ditto */
} __attribute__((aligned(sizeof(long))));
6.2.8.1 struct address_space_operations
该结构定义于include/linux/fs.h:
struct address_space_operations {
/*
* Write a page to disk. The offset within the file
* to write to is stored within the struct page.
*/
int (*writepage)(struct page *page, struct writeback_control *wbc);
// Read a page from disk
int (*readpage)(struct file *, struct page *);
/* Write back some dirty pages from this mapping. */
int (*writepages)(struct address_space *, struct writeback_control *);
/* Set a page dirty. Return true if this dirtied it */
int (*set_page_dirty)(struct page *page);
int (*readpages)(struct file *filp, struct address_space *mapping,
struct list_head *pages, unsigned nr_pages);
int (*write_begin)(struct file *, struct address_space *mapping, loff_t pos,
unsigned len, unsigned flags, struct page **pagep, void **fsdata);
int (*write_end)(struct file *, struct address_space *mapping, loff_t pos, unsigned len,
unsigned copied, struct page *page, void *fsdata);
/* Unfortunately this kludge is needed for FIBMAP. Don't use it */
sector_t (*bmap)(struct address_space *, sector_t);
void (*invalidatepage)(struct page *, unsigned long);
int (*releasepage)(struct page *, gfp_t);
void (*freepage)(struct page *);
ssize_t (*direct_IO)(int, struct kiocb *, const struct iovec *iov,
loff_t offset, unsigned long nr_segs);
int (*get_xip_mem)(struct address_space *, pgoff_t, int, void **, unsigned long *);
/* migrate the contents of a page to the specified target */
int (*migratepage)(struct address_space *, struct page *, struct page *);
int (*launder_page)(struct page *);
int (*is_partially_uptodate)(struct page *, read_descriptor_t *, unsigned long);
int (*error_remove_page)(struct address_space *, struct page *);
};
6.2.9 Boot Memory Allocator/bootmem_data_t
In order to allocate memory to initialise itself, a specialised allocator called the Boot Memory Allocator is used. It is based on the most basic of allocators, a First Fit allocator which uses a bitmap to represent memory instead of linked lists of free blocks. If a bit is 1, the page is allocated and 0 if unallocated. To satisfy allocations of sizes smaller than a page, the allocator records the Page Frame Number (PFN) of the last allocation and the offset the allocation ended at. Subsequent small allocations are “merged” together and stored on the same page.
bootmem_data_t定义于include/linux/bootmem.h:
#ifndef CONFIG_NO_BOOTMEM
/*
* node_bootmem_map is a map pointer - the bits represent all physical
* memory pages (including holes) on the node.
*/
typedef struct bootmem_data {
// Starting physical address of the represented block
unsigned long node_min_pfn;
// End physical address, in other words, the end of the ZONE_NORMAL this node represents
unsigned long node_low_pfn;
// The location of the bitmap representing allocated or free pages with each bit
void *node_bootmem_map;
// The offset within the the page of the end of the last allocation. If 0, the page used is full.
unsigned long last_end_off;
/*
* The PFN of the page used with the last allocation.
* Using this with the last_end_off field, a test can
* be made to see if allocations can be merged with the
* page used for the last allocation rather than using
* up a full new page.
*/
unsigned long hint_idx;
struct list_head list;
} bootmem_data_t;
#endif
6.2.9.1 变量bdata_list
所有类型为bootmem_data_t的变量链接到双向循环链表bdata_list中,其赋值过程参见6.2.9.2 Initialise the Boot Memory Allocator节。该变量定义于mm/bootmem.c:
static struct list_head bdata_list __initdata = LIST_HEAD_INIT(bdata_list);
链表bdata_list:
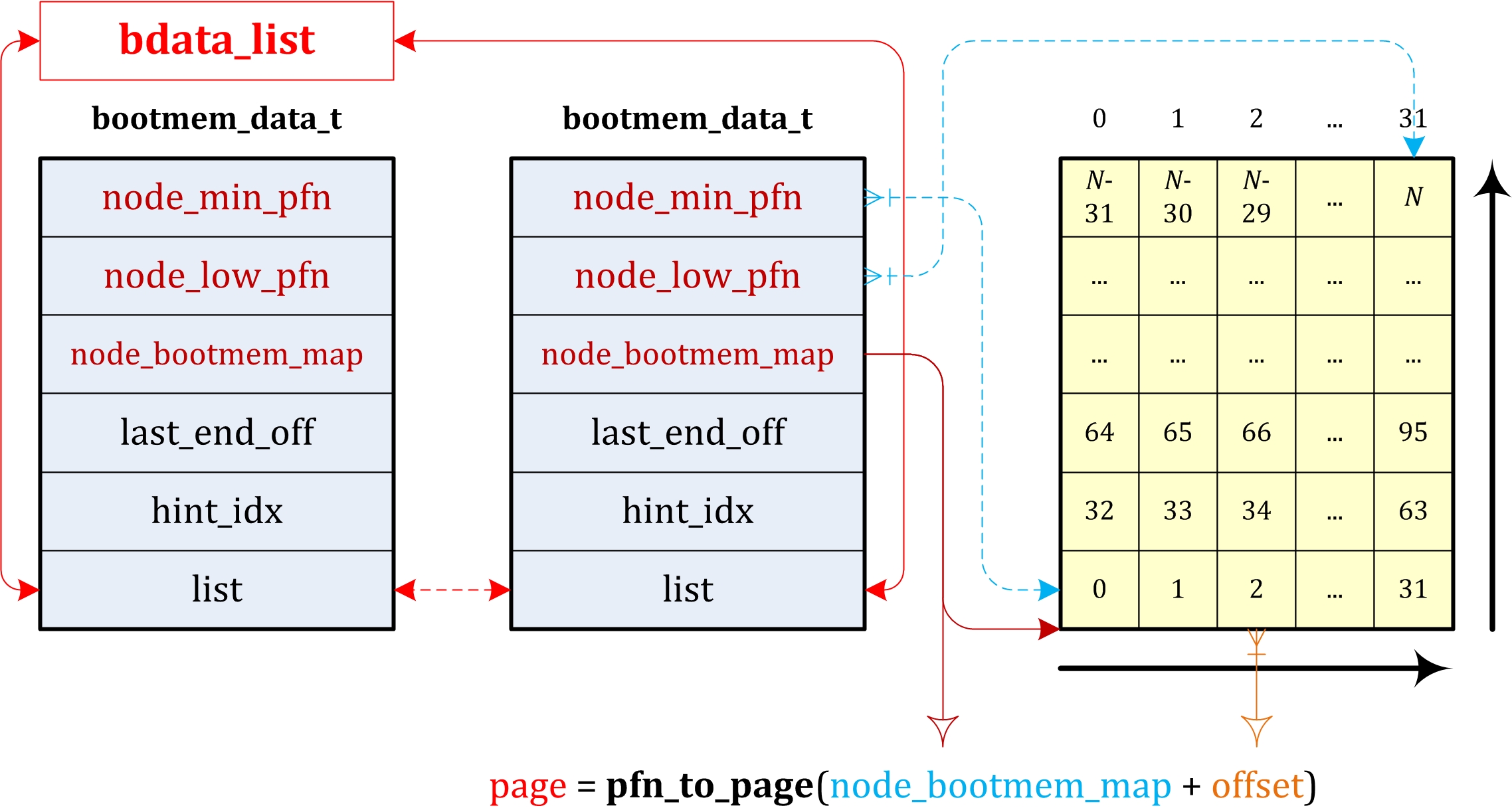
6.2.9.2 Initialise the Boot Memory Allocator
Each architecture is required to supply a setup_arch() function which, among other tasks, is responsible for acquiring the necessary parameters to initialise the boot memory allocator.
Each architecture has its own function to get the necessary parameters. On the x86, it is called setup_arch(). Regardless of the architecture, the tasks are essentially the same. See section 6.3.2.2 e820=>memblock.memory. The parameters it calculates are:
| Variable Name | Description |
|---|---|
| min_low_pfn | Page frame number of the first usable page frame after the kernel image in RAM |
| max_low_pfn | Page frame number of the last page frame directly mapped by the kernel (low memory) |
| highstart_pfn | Page frame number of the first page frame not directly mapped by the kernel |
| highend_pfn | Page frame number of the last page frame not directly mapped by the kernel |
| max_pfn | Page frame number of the last usable page frame |
函数init_bootmem()定义于mm/bootmem.c:
/**
* init_bootmem_node - register a node as boot memory
* @pgdat: node to register
* @freepfn: pfn where the bitmap for this node is to be placed
* @startpfn: first pfn on the node
* @endpfn: first pfn after the node
*
* Returns the number of bytes needed to hold the bitmap for this node.
*/
unsigned long __init init_bootmem_node(pg_data_t *pgdat, unsigned long freepfn,
unsigned long startpfn, unsigned long endpfn)
{
return init_bootmem_core(pgdat->bdata, freepfn, startpfn, endpfn);
}
其中,函数init_bootmem_core()定义于include/linux/mmzone.h:
/*
* Called once to set up the allocator itself.
*/
static unsigned long __init init_bootmem_core(bootmem_data_t *bdata, unsigned long mapstart,
unsigned long start, unsigned long end)
{
unsigned long mapsize;
mminit_validate_memmodel_limits(&start, &end);
bdata->node_bootmem_map = phys_to_virt(PFN_PHYS(mapstart));
bdata->node_min_pfn = start;
bdata->node_low_pfn = end;
link_bootmem(bdata); // 将bdata插入到链表bdata_list的适当位置
/*
* Initially all pages are reserved - setup_arch() has to
* register free RAM areas explicitly.
*/
mapsize = bootmap_bytes(end - start);
memset(bdata->node_bootmem_map, 0xff, mapsize);
bdebug("nid=%td start=%lx map=%lx end=%lx mapsize=%lx\n",
bdata - bootmem_node_data, start, mapstart, end, mapsize);
return mapsize;
}
其中,函数link_bootmem()定义于include/linux/mmzone.h:
static void __init link_bootmem(bootmem_data_t *bdata)
{
struct list_head *iter;
// 变量bdata_list参见[6.2.9.1 变量bdata_list]节
list_for_each(iter, &bdata_list) {
bootmem_data_t *ent;
ent = list_entry(iter, bootmem_data_t, list);
if (bdata->node_min_pfn < ent->node_min_pfn)
break;
}
list_add_tail(&bdata->list, iter);
}
6.2.9.3 Boot Memory Allocator APIs
6.2.9.3.1 Boot Memory Allocator API for UMA Architectures
unsigned long init_bootmem(unsigned long start, unsigned long page)
This initialises the memory between 0 and the PFN page. The beginning of usable memory is at the PFN start.
void reserve_bootmem(unsigned long addr, unsigned long size)
Mark the pages between the address addr and addr+size reserved. Requests to partially reserve a page will result in the full page being reserved.
void free_bootmem(unsigned long addr, unsigned long size)
Mark the pages between the address addr and addr+size free.
void *alloc_bootmem(unsigned long size)
Allocate size number of bytes from ZONE_NORMAL. The allocation will be aligned to the L1 hardware cache to get the maximum benefit from the hardware cache.
void *alloc_bootmem_low(unsigned long size)
Allocate size number of bytes from ZONE_DMA. The allocation will be aligned to the L1 hardware cache.
void *alloc_bootmem_pages(unsigned long size)
Allocate size number of bytes from ZONE_NORMAL aligned on a page size so that full pages will be returned to the caller.
void *alloc_bootmem_low_pages(unsigned long size)
Allocate size number of bytes from ZONE_NORMAL aligned on a page size so that full pages will be returned to the caller.
unsigned long bootmem_bootmap_pages(unsigned long pages)
Calculate the number of pages required to store a bitmap representing the allocation state of pages number of pages.
unsigned long free_all_bootmem()
Used at the boot allocator end of life. It cycles through all pages in the bitmap. For each one that is free, the flags are cleared and the page is freed to the physical page allocator (See next chapter) so the runtime allocator can set up its free lists.
6.2.9.3.2 Boot Memory Allocator API for NUMA Architectures
unsigned long init_bootmem_node(pg_data_t *pgdat, unsigned long freepfn, unsigned long startpfn, unsigned long endpfn)
For use with NUMA architectures. It initialise the memory between PFNs startpfn and endpfn with the first usable PFN at freepfn. Once initialised, the pgdat node is inserted into the pgdat_list.
void reserve_bootmem_node(pg_data_t *pgdat, unsigned long physaddr, unsigned long size)
Mark the pages between the address addr and addr+size on the specified node pgdat reserved. Requests to partially reserve a page will result in the full page being reserved.
void free_bootmem_node(pg_data_t *pgdat, unsigned long physaddr, unsigned long size)
Mark the pages between the address addr and addr+size on the specified node pgdat free.
void *alloc_bootmem_node(pg_data_t *pgdat, unsigned long size)
Allocate size number of bytes from ZONE_NORMAL on the specified node pgdat. The allocation will be aligned to the L1 hardware cache to get the maximum benefit from the hardware cache.
void *alloc_bootmem_pages_node(pg_data_t *pgdat, unsigned long size)
Allocate size number of bytes from ZONE_NORMAL on the specified node pgdat aligned on a page size so that full pages will be returned to the caller.
void *alloc_bootmem_low_pages_node(pg_data_t *pgdat, unsigned long size)
Allocate size number of bytes from ZONE_NORMAL on the specified node pgdat aligned on a page size so that full pages will be returned to the caller.
unsigned long free_all_bootmem_node(pg_data_t *pgdat)
Used at the boot allocator end of life. It cycles through all pages in the bitmap for the specified node. For each one that is free, the page flags are cleared and the page is freed to the physical page allocator (See next chapter) so the runtime allocator can set up its free lists.
6.2.10 struct vm_struct
该结构定义于include/linux/vmalloc.h:
struct vm_struct {
/*
* vm_struct list ordered by address and the
* list is protected by the vmlist_lock lock
*/
struct vm_struct *next;
// The starting address of the memory block.
void *addr;
// the size in bytes
unsigned long size;
/*
* Set either to VM_ALLOC, in the case of use
* with vmalloc() or VM_IOREMAP when ioremap is
* used to map high memory into the kernel virtual
* address space.
*/
unsigned long flags;
struct page **pages;
unsigned int nr_pages;
phys_addr_t phys_addr;
void *caller;
};
该结构参见6.6.2.1.1 __vmalloc_node_range()节中的图。
6.3 内存管理的初始化
内存管理的初始化分为如下步骤:
- 检测内存段及其大小,参见6.3.1 检测内存段及其大小/boot_params.e820_map节;
- 映射内存页面映射至分区,参见6.3.2 映射内存页面页至分区/node_data[]->node_zones[]节。
内存管理的初始化参见[4.3.4.1.4.3.6 mm_init()]节。
6.3.1 检测内存段及其大小/boot_params.e820_map
系统启动时,将调用arch/x86/boot/main.c中的main(),参见4.3.4.1.2 arch/x86/boot/main.c节,其调用关系如下:
main() // arch/x86/boot/main.c
-> detect_memory()
-> detect_memory_e820() // Fill boot_params.e820_map by calling BIOS interrupt
函数detect_memory_e820()通过调用BIOS中断来检测当前系统中的内存段及其大小,并将结果保存到boot_params.e820_map中,其结构如下图所示。每个连续的内存空间构成boot_params.e820_map[]中的一个元素,其首地址为addr,大小为size,类型为type。
boot_params.e820_map:
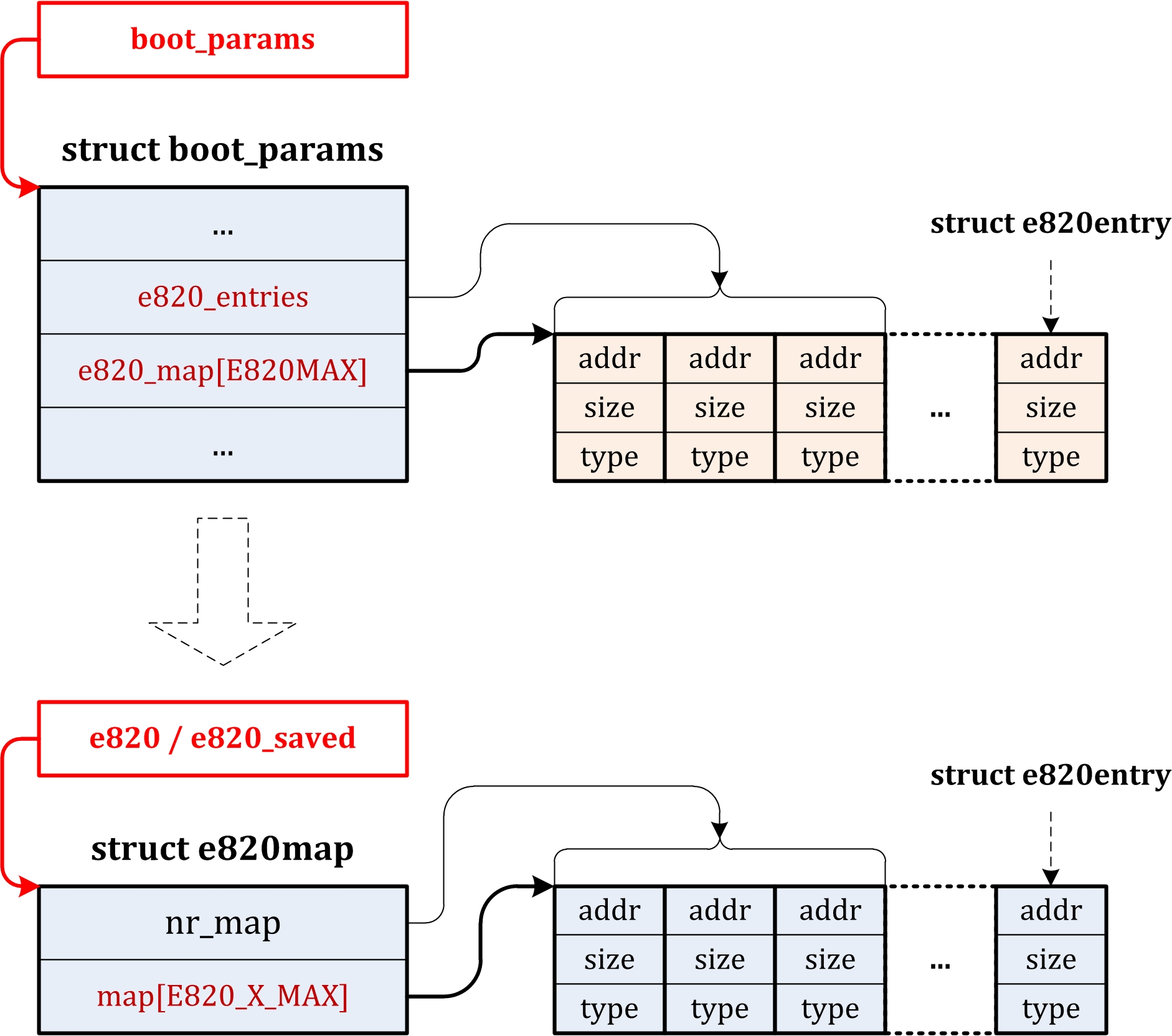
6.3.2 映射内存页面页至分区/node_data[]->node_zones[]
由6.3.1 检测内存段及其大小/boot_params.e820_map节可知,系统中的内存状态信息保存到数组boot_params.e820_map[]中。此后,在系统启动过程中,该数组将进行如下转换:
boot_params.e820_map[]
-> e820 / e820_saved // 参见[6.3.2.1 boot_params.e820_map[]=>e820 / e820_saved]节
-> memblock.memory // 参见[6.3.2.2 e820=>memblock.memory]节
-> early_node_map[] // 参见[6.3.2.3 memblock.memory=>early_node_map[]]节
-> node_data[]->node_zones[] // 参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节
6.3.2.1 boot_params.e820_map[]=>e820 / e820_saved
内存状态信息从boot_params.e820_map[]到e820 / e820_saved的转换是在如下函数调用中发生的:
start_kernel()
-> setup_arch(&command_line)
-> setup_memory_map()
-> x86_init.resources.memory_setup() // Call e820.c: default_machine_specific_memory_setup()
-> sanitize_e820_map() // Remove overlaps from boot_params.e820_map
-> append_e820_map()
-> __append_e820_map() // boot_params.e820_map => e820
-> e820_add_region()
-> __e820_add_region(&e820)
-> memcpy(&e820_saved, &e820, ...) // e820 => e820_saved
-> printk(KERN_INFO "BIOS-provided physical RAM map:\n");
-> e820_print_map() // 打印e820,示例参见NOTE 1
-> e820_reserve_setup_data() // Set reserved setup data in e820
-> e820_update_range() // e820 => boot_params.hdr.setup_data, 示例参见NOTE 2
-> sanitize_e820_map(e820.map, ...) // Remove overlaps from e820
-> memcpy(&e820_saved, &e820, ...) // e820 => e820_saved
-> printk(KERN_INFO "extended physical RAM map:\n");
-> e820_print_map() // Not comes here!
-> finish_e820_parsing() // Printing memory info of e820 if userdef is True
NOTE 1:
e820: BIOS-provided physical RAM map:
BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved
BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
BIOS-e820: [mem 0x0000000000100000-0x000000001ffeffff] usable
BIOS-e820: [mem 0x000000001fff0000-0x000000001fffffff] ACPI data
BIOS-e820: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved
NOTE 2:
e820: update [mem 0x00000000-0x0000ffff] usable ==> reserved
e820: remove [mem 0x000a0000-0x000fffff] usable
6.3.2.2 e820=>memblock.memory
内存状态信息从e820到memblock.memory的转换是在如下函数调用中发生的:
start_kernel()
-> setup_arch(&command_line)
-> Functions in section [6.3.2.1 boot_params.e820_map[]=>e820 / e820_saved]
-> max_pfn = e820_end_of_ram_pfn() // max_pfn = last_pfn
-> e820_end_pfn(MAX_ARCH_PFN, E820_RAM) // 查找e820.map[]中类型为E820_RAM的最大页框号
-> printk(KERN_INFO "last_pfn = %#lx // 示例参见NOTE 3
max_arch_pfn = %#lx\n", last_pfn, max_arch_pfn);
-> find_low_pfn_range() // 为max_low_pfn赋值
-> if (max_pfn <= MAXMEM_PFN)
lowmem_pfn_init()
-> max_low_pfn = max_pfn;
else
highmem_pfn_init()
-> max_low_pfn = MAXMEM_PFN;
-> printk(KERN_DEBUG "initial memory mapped : 0 - %08lx\n", max_pfn_mapped<<PAGE_SHIFT);
-> setup_trampolines() // 示例参见NOTE 4
-> max_low_pfn_mapped = init_memory_mapping(0, max_low_pfn<<PAGE_SHIFT); // 示例参见NOTE 4
-> find_early_table_space(...) // 示例参见NOTE 4
-> max_pfn_mapped = max_low_pfn_mapped;
-> memblock_x86_fill() // e820 => memblock.memory
-> memblock_add()
-> memblock_add_region(&memblock.memory, ...)
-> memblock_analyze() // Update memblock.memory_size
memblock.memory的结构:
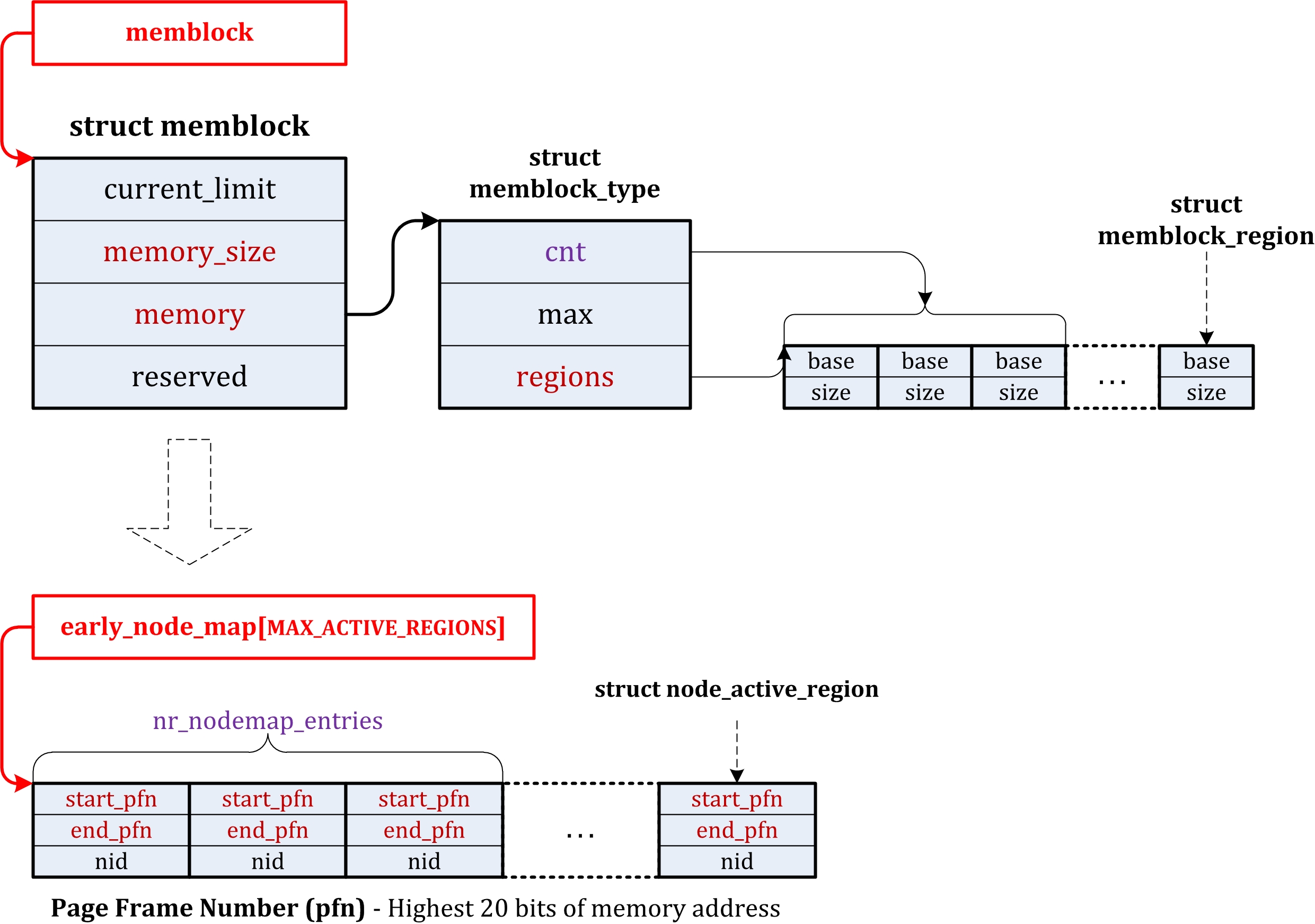
NOTE 3:
e820: last_pfn = 0x1fff0 max_arch_pfn = 0x1000000
=> last_pfn表示e820.map[]中类型为E820_RAM的最大页框号
=> max_arch_pfn为最大页框号,与地址空间有关(NOTE: 此时PAE开启),其取值参见arch/x86/kernel/e820.c:
#ifdef CONFIG_X86_32
# ifdef CONFIG_X86_PAE
# define MAX_ARCH_PFN (1ULL<<(36-PAGE_SHIFT)) // 0x0100,0000
# else
# define MAX_ARCH_PFN (1ULL<<(32-PAGE_SHIFT)) // 0x0010,0000
# endif
#else /* CONFIG_X86_32 */
# define MAX_ARCH_PFN MAXMEM>>PAGE_SHIFT
#endif
NOTE 4:
initial memory mapped: [mem 0x00000000-0x01ffffff]
Base memory trampoline at [c009b000] 9b000 size 16384
init_memory_mapping: [mem 0x00000000-0x1ffeffff]
[mem 0x00000000-0x001fffff] page 4k // 2MB空间,每页面占4KB,共计512个页面
[mem 0x00200000-0x1fdfffff] page 2M // 508MB空间,每页面占2MB,共计254个页面
[mem 0x1fe00000-0x1ffeffff] page 4k // ~2MB空间,每页面占4KB,共计496个页面
kernel direct mapping tables up to 0x1ffeffff @ [mem 0x01ffa000-0x01ffffff]
=> 由此可知,当前映射的内存空间约为512MB,其对应的页面描述符占用0x01ffa000-0x01ffffff的内存空间
6.3.2.3 memblock.memory=>early_node_map[]
内存状态信息从memblock.memory到early_node_map[]的转换是在如下函数调用中发生的:
start_kernel()
-> setup_arch(&command_line)
-> Functions in section [6.3.2.2 e820=>memblock.memory]
-> initmem_init() // arch/x86/mm/init_32.c
-> memblock_x86_register_active_regions()
// Get active region (Physical Frame Number, pfn)
-> memblock_x86_find_active_region()
-> add_active_range() // memblock.memory => early_node_map[], mm/page_alloc.c
-> printk(KERN_NOTICE "%ldMB HIGHMEM available.\n", // 示例参见NOTE 5
pages_to_mb(highend_pfn - highstart_pfn));
-> printk(KERN_NOTICE "%ldMB LOWMEM available.\n", // 示例参见NOTE 6
pages_to_mb(max_low_pfn));
-> setup_bootmem_allocator() // 示例参见NOTE 7
// 安装bootmem分配器,此分配器在伙伴系统起来之前用来承担内存的分配等任务
-> after_bootmem = 1;
数组early_node_map[]的结构:
其中start_pfn和end_pfn域表示Physical Frame Number,取值为内存地址的高20 bits (12-31 bit)。因为内存页大小为4KB,内存页是4KB对齐的,故内存页地址的低12 bits取值为0。因此只需要内存地址的高20 bits就可以表示内存也的地址了。
NOTE 5:
0MB HIGHMEM available.
NOTE 6:
511MB LOWMEM available.
NOTE 7:
mapped low ram: 0 - 1fff0000
low ram: 0 – 1fff0000
6.3.2.4 early_node_map[]=>node_data[]->node_zones[]
内存状态信息从early_node_map[]到node_data[]->node_zones[]的转换是在如下函数调用中发生的:
start_kernel()
-> setup_arch(&command_line)
-> Functions in section [6.3.2.3 memblock.memory=>early_node_map[]]
-> x86_init.paging.pagetable_setup_start(swapper_pg_dir) // native_pagetable_setup_start()
-> paging_init()
-> pagetable_init()
// Initialise the page tables necessary to reference all physical memory in
// ZONE_DMA and ZONE_NORMAL. High memory in ZONE_HIGHMEM cannot be directly
// referenced and mappings are set up for it.
-> permanent_kmaps_init(swapper_pg_dir) // 参见[6.7.1.1 pkmap_page_table的初始化]节
-> __flush_tlb_all() // Refresh CR3 register
-> kmap_init() // 参见[6.7.2 Temporary Kernel Mapping]节
-> sparse_init() // mm/sparse.c
-> zone_sizes_init()
-> free_area_init_nodes() // early_node_map[] => node_data[]
-> sort_node_map() // Sort early_node_map[] by ->start_pfn
-> printk("Zone PFN ranges:\n"); // 示例参见NOTE 8
...
// Set node_data[nid], see [6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节中的"NOTE 14"中的图"变量node_data的结构"
-> for_each_online_node(nid) {
-> free_area_init_node(nid, NULL, find_min_pfn_for_node(nid), NULL)
// find_min_pfn_for_node(nid)从early_node_map[i].start_pfn中查找最小值
-> calculate_node_totalpages()
-> pgdat->node_spanned_pages = totalpages;
// Fill node_data[]->node_spanned_pages
-> pgdat->node_present_pages = realtotalpages;
// Fill node_data[]->node_present_pages
-> printk(KERN_DEBUG "On node %d totalpages: %lu\n",
pgdat->node_id, realtotalpages);
// 示例参见NOTE 9
-> alloc_node_mem_map(pgdat)
// Set mem_map and pgdat->node_mem_map,参见[6.2.2.1 mem_map]节,示例参见NOTE 10
-> printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx,
node_mem_map %08lx\n", nid, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
// 示例参见NOTE 10
// Set node_data[nid]->node_zones[j]
-> free_area_init_core()
-> for (j = 0; j < MAX_NR_ZONES; j++) {
-> printk(KERN_DEBUG ...) // 示例参见NOTE 11
-> zone_pcp_init() // 示例参见NOTE 11
-> printk(KERN_DEBUG " %s zone: %lu pages, LIFO batch:%u\n",
zone->name, zone→present_pages, zone_batchsize(zone));
-> init_currently_empty_zone()
// 初始化node_data[nid]->node_zones[j]->free_area[*], 此时页面不可用
-> zone_init_free_lists()
-> memmap_init()
-> memmap_init_zone() // mm/page_alloc.c
-> for (pfn = start_pfn; pfn < end_pfn; pfn++) {
// Set each page in the range. Get Page Descriptor:
// page = mem_map + pfn;
-> page = pfn_to_page(pfn)
// 设置page->flags中有关zone、node和section的标志位
-> set_page_links(page, ...)
// No user: page->_count = 1
-> init_page_count(page)
// 清除Buddy标志: page->_mapcount=-1
-> reset_page_mapcount(page)
// 置位page->flags中的标志位PG_reserved
-> SetPageReserved(page)
-> set_pageblock_migratetype(page, MIGRATE_MOVABLE)
-> set_pageblock_flags_group()
// 初始化page->lru
-> INIT_LIST_HEAD(&page->lru)
// Set page->virtual
-> set_page_address()
}
}
-> node_set_state(nid, N_HIGH_MEMORY)
-> check_for_regular_memory(pgdat)
}
// native_pagetable_setup_done()
-> x86_init.paging.pagetable_setup_done(swapper_pg_dir)
-> build_all_zonelists() // 示例参见NOTE 12
-> mm_init() // 参见[4.3.4.1.4.3.6 mm_init()]节
-> mem_init() // 参见[4.3.4.1.4.3.6.1 mem_init()]节,示例参见NOTE 13
/*
* 将低端内存转入Buddy Allocator System中管理,
* 参见[4.3.4.1.4.3.6.1.1 free_all_bootmem()/free_all_bootmem_core()]节
*/
-> free_all_bootmem()
// 参见[4.3.4.1.4.3.6.1.1 free_all_bootmem()/free_all_bootmem_core()]节
-> free_all_bootmem_core()
-> __free_pages_bootmem()
-> __free_page() // 参见[6.4.2.4 __free_page()/free_page()]节
// 将高端内存转入Buddy Allocator System中管理,参见[4.3.4.1.4.3.6.1.2 set_highmem_pages_init()]节
-> set_highmem_pages_init()
-> add_highpages_with_active_regions()
-> __get_free_all_memory_range()
-> add_one_highpage_init()
-> __free_page() // 参见[6.4.2.4 __free_page()/free_page()]节
-> rest_init()
-> kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
-> kernel_init()
-> init_post()
-> free_initmem()
/* All initilisation function that are required only during system
* start-up are marked __init and put in region __init_begin to
* __init_end. The function free_initmem() frees all pages from
* __init_begin to __init_end to the Buddy Allocator System.
* The region __init_begin to __init_end is defined in vmlinux.lds.
* 示例参见NOTE 14
*/
-> printk(KERN_INFO "Freeing %s: %luk freed\n", ...);
NOTE 8:
Zone ranges:
DMA [mem 0x00010000-0x00ffffff] // 16320 KB, 4080 pages
Normal [mem 0x01000000-0x1ffeffff] // 507840 KB, 126960 pages
HighMem empty
Movable zone start for each node // Print PFNs ZONE_MOVABLE begins at in each node
Early memory node ranges // Print early_node_map[], include DMA and Normal.
node 0: [mem 0x00010000-0x0009efff] // early_node_map[0].start_pfn - early_node_map[0].end_pfn
node 0: [mem 0x00100000-0x1ffeffff] // early_node_map[1].start_pfn - early_node_map[1].end_pfn
NOTE 9;
On node 0 totalpages: 130943
=> ((0x0009efff - 0x00010000 + 1) + (0x1ffeffff - 0x00100000 + 1)) / (4 * 1024) = 130943 pages
=> Total memory: 511 MB, include DMA and Normal.
NOTE 10:
free_area_init_node: node 0, pgdat c18a0840, node_mem_map dfbef200
NOTE 11:
DMA zone: 32 pages used for memmap
DMA zone: 0 pages reserved
DMA zone: 3951 pages, LIFO batch:0
Normal zone: 992 pages used for memmap
Normal zone: 125968 pages, LIFO batch:31
=> 32 + 3951 + 992 + 125968 = 130943 pages
NOTE 12:
Built 1 zonelists in Zone order, mobility grouping on. Total pages: 129919
NOTE 13:
Initializing HighMem for node 0 (00000000:00000000)
Memory: 492840k/524224k available (5956k kernel code, 30932k reserved, 2928k data, 756k init, 0k highmem)
virtual kernel memory layout:
fixmap : 0xfff15000 - 0xfffff000 ( 936 kB)
pkmap : 0xffc00000 - 0xffe00000 (2048 kB)
vmalloc : 0xe07f0000 - 0xffbfe000 ( 500 MB)
lowmem : 0xc0000000 - 0xdfff0000 ( 511 MB) // [__va(0), high_memory]
.init : 0xc18ae000 - 0xc196b000 ( 756 kB) // [__init_begin, __init_end]
.data : 0xc15d1358 - 0xc18ad6c0 (2928 kB) // [_etext, _edata]
.text : 0xc1000000 - 0xc15d1358 (5956 kB) // [_text, _etext]
=> 各变量定义于vmlinux.lds
=> Virtual Kernel Memory Layout参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节中的"NOTE 14"的图和[6.3.3 Physical Memory Layout]节。
NOTE 14:
Freeing unused kernel memory: 756k freed
Memory layout on 32-bit kernel:
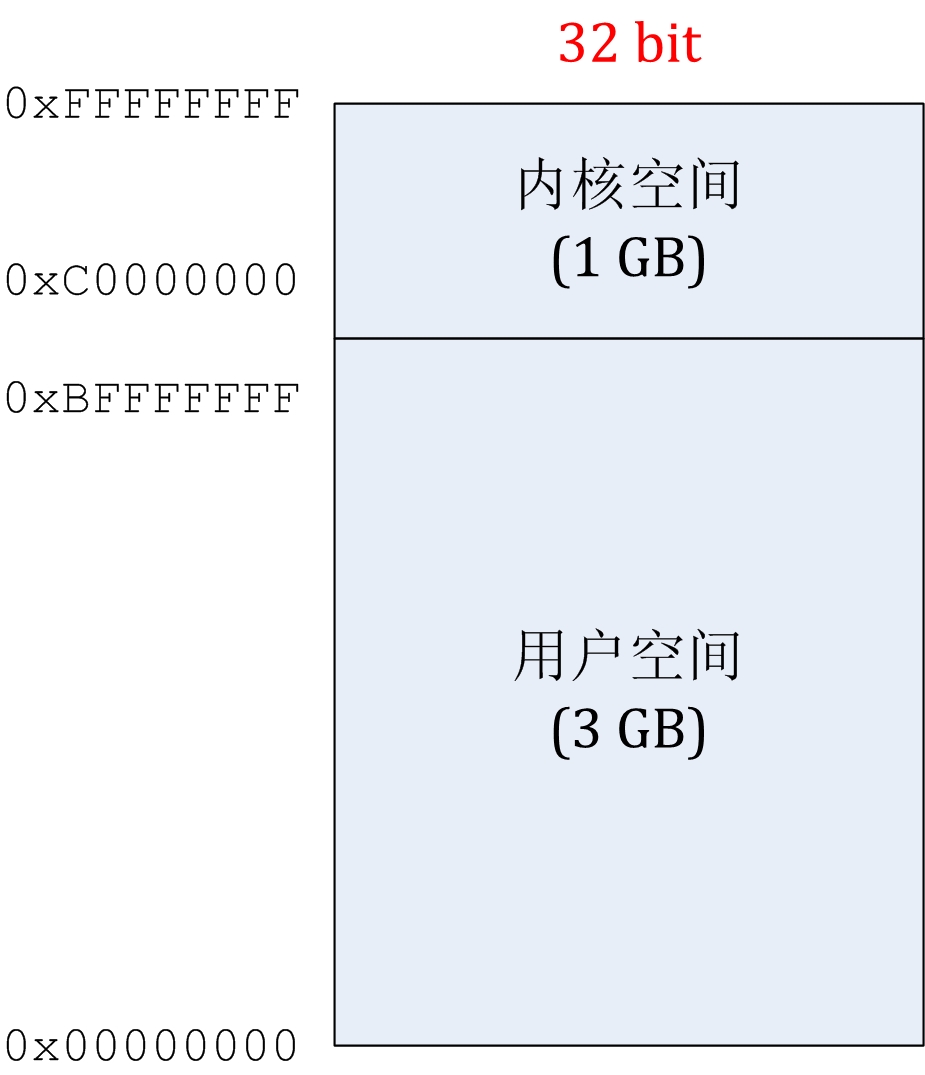
Memory layout on 64-bit kernel:
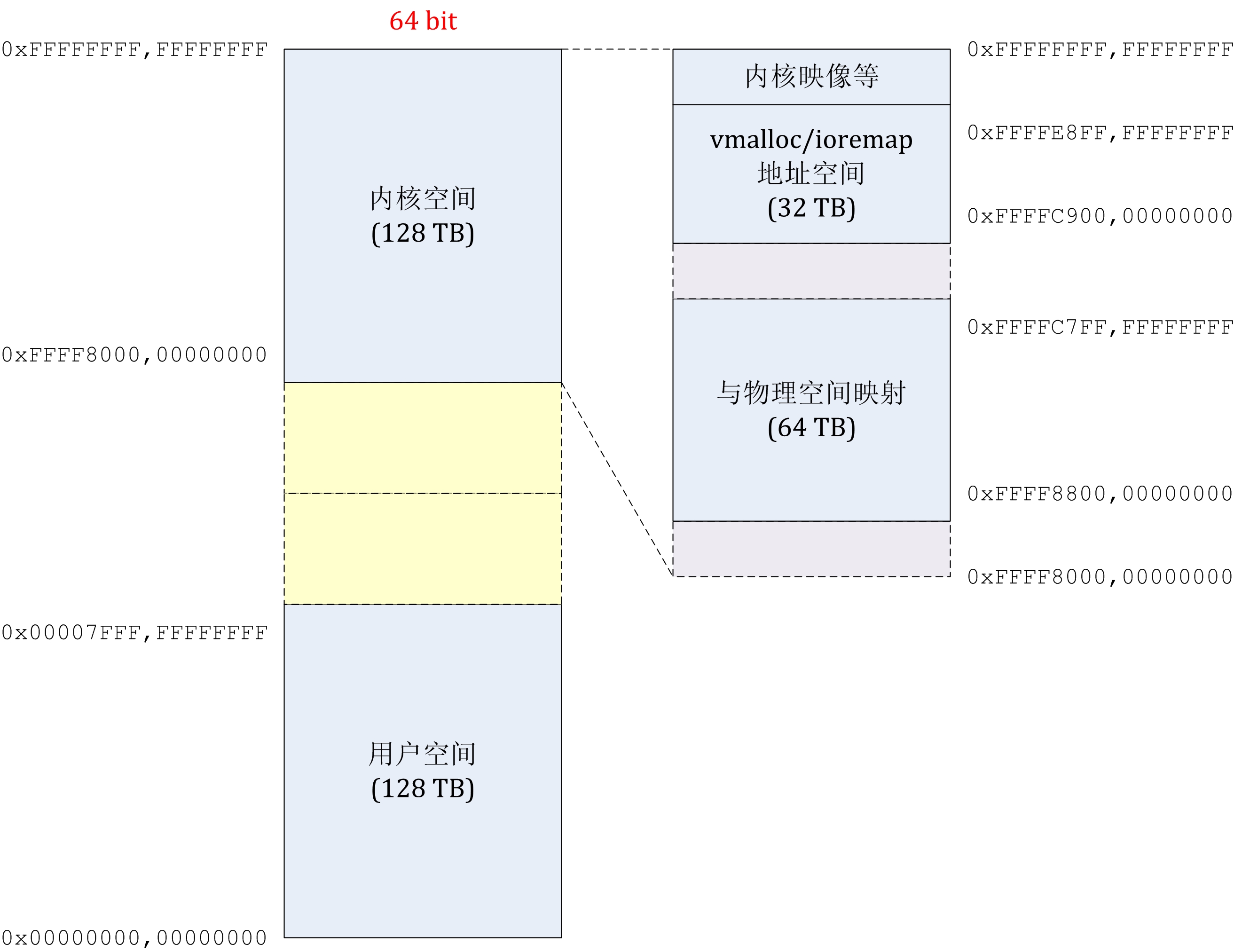
Virtual kernel memory layout on 32-bit kernel:
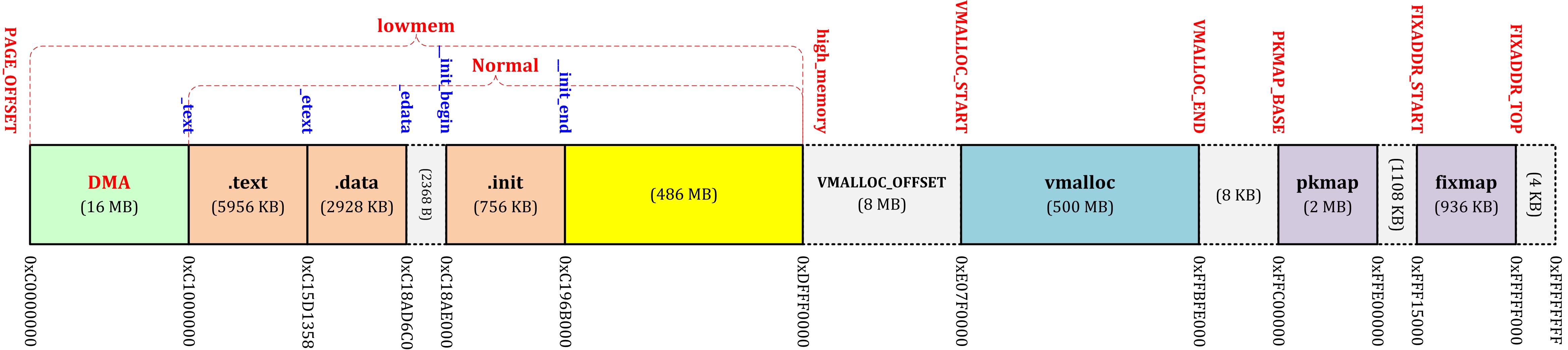
变量node_data的结构:
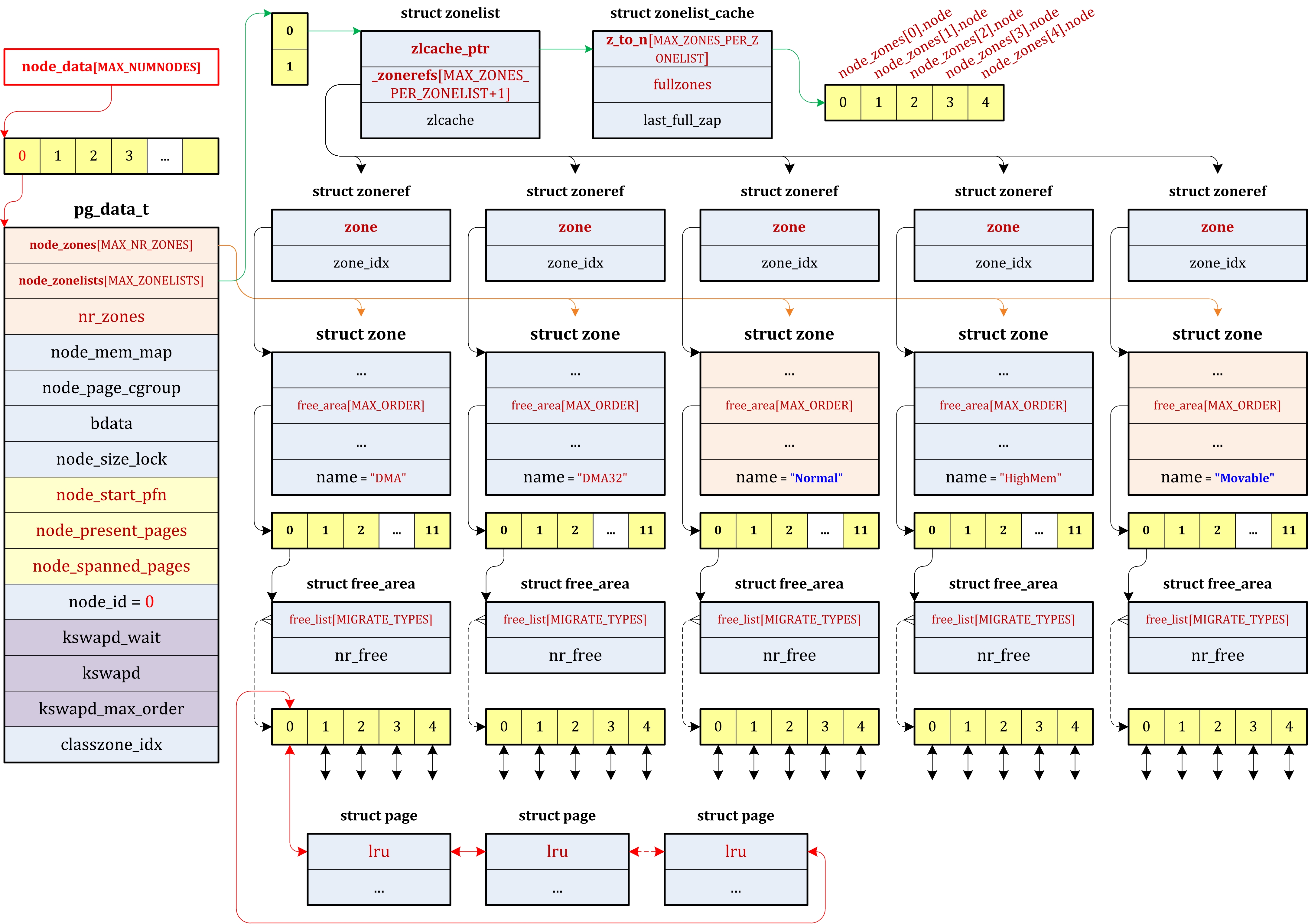
各段内存的用途如下:
[PAGE_OFFSET, VMALLOC_START - VMALLOC_OFFSET]
The region is the physical memory map and the size of the region depends on the amount of available RAM. Between the physical memory map and the vmalloc address space, there is a gap of space VMALLOC_OFFSET in size, which on the x86 is 8MB, to guard against out of bounds errors.
[VMALLOC_START, VMALLOC_END]
In low memory systems, the remaining amount of the virtual address space, minus a 2 page gap, is used by vmalloc() for representing non-contiguous memory allocations in a contiguous virtual address space. In high-memory systems, the vmalloc area extends as far as PKMAP_BASE minus the two page gap and two extra regions are introduced.
[PKMAP_BASE, PKMAP_BASE + LAST_PKMAP * PAGE_SIZE]
This is an area reserved for the mapping of high memory pages into low memory with kmap(), see section kmap(). Refer to arch/x86/include/asm/pgtable_32_types.h:
#ifdef CONFIG_X86_PAE
#define LAST_PKMAP 512 // PKMAP区占2MB空间
#else
#define LAST_PKMAP 1024 // PKMAP区占4MB空间
#endif
[FIXADDR_START, FIXADDR_TOP]
The regain is for fixed virtual address mappings. Fixed virtual addresses are needed for subsystems that need to know the virtual address at compile time such as the Advanced Programmable Interrupt Controller (APIC). FIXADDR_TOP is statically defined to be 0xFFFFE000 on the x86 which is one page before the end of the virtual address space. The size of the fixed mapping region is calculated at compile time in __FIXADDR_SIZE and used to index back from FIXADDR_TOP to give the start of the region FIXADDR_START. See section kmap_atomic().
可通过下列命令查看当前系统的内存布局,其含义参见Documentation/filesystems/proc.txt:
chenwx proc # cat /proc/iomem
00000000-00000fff : reserved
00001000-0009fbff : System RAM
0009fc00-0009ffff : reserved
000a0000-000bffff : Video RAM area
000c0000-000c7fff : Video ROM
000e2000-000eebff : Adapter ROM
000f0000-000fffff : reserved
000f0000-000fffff : System ROM
00100000-5ffeffff : System RAM
01000000-01831996 : Kernel code
01831997-01c1c9bf : Kernel data
01d12000-01dfbfff : Kernel bss
5fff0000-5fffffff : ACPI Tables
e0000000-e3ffffff : 0000:00:02.0
f0000000-f001ffff : 0000:00:03.0
f0000000-f001ffff : e1000
f0400000-f07fffff : 0000:00:04.0
f0400000-f07fffff : vboxguest
f0800000-f0803fff : 0000:00:04.0
f0804000-f0804fff : 0000:00:06.0
f0804000-f0804fff : ohci_hcd
f0806000-f0807fff : 0000:00:0d.0
f0806000-f0807fff : ahci
fee00000-fee00fff : Local APIC
fffc0000-ffffffff : reserved
可通过如何命令查看系统当前的内存信息,其含义参见Documentation/filesystems/proc.txt:
chenwx proc # cat /proc/buddyinfo
Node 0, zone DMA 9 5 2 1 8 4 3 2 0 2 0
Node 0, zone Normal 98 106 84 63 56 42 12 5 2 4 44
Node 0, zone HighMem 280 233 119 122 73 33 6 8 3 1 43
chenwx proc # cat /proc/pagetypeinfo
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 4 2 1 1 1 1 1 1 0 0 0
Node 0, zone DMA, type Reclaimable 0 1 0 0 0 1 1 1 0 1 0
Node 0, zone DMA, type Movable 3 0 0 0 6 2 1 0 0 0 0
Node 0, zone DMA, type Reserve 0 0 0 0 0 0 0 0 0 1 0
Node 0, zone DMA, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 1 1 0 3 0 0 0 0 0 2 0
Node 0, zone Normal, type Reclaimable 8 12 4 2 0 1 1 0 0 1 0
Node 0, zone Normal, type Movable 0 142 65 33 30 39 10 4 1 2 43
Node 0, zone Normal, type Reserve 0 0 0 0 0 0 0 0 0 0 1
Node 0, zone Normal, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone HighMem, type Unmovable 1 0 0 4 8 11 4 5 3 0 1
Node 0, zone HighMem, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone HighMem, type Movable 115 75 73 81 63 22 2 3 0 1 41
Node 0, zone HighMem, type Reserve 0 0 0 0 0 0 0 0 0 0 1
Node 0, zone HighMem, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone HighMem, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Reclaimable Movable Reserve CMA Isolate
Node 0, zone DMA 1 2 4 1 0 0
Node 0, zone Normal 24 46 366 2 0 0
Node 0, zone HighMem 9 0 312 1 0 0
6.3.3 Physical Memory Layout
参见«Understanding the Linux Kernel, 3rd Edition»第2. Memory Addressing章第Physical Memory Layout节:
The kernel considers the following page frames asreserved:
- Those falling in the unavailable physical address ranges.
- Those containing the kernel’s code and initialized data structures. A page contained in a reserved page frame can never be dynamically assigned or swapped to disk.
As a general rule, the Linux kernel is installed in RAM starting from the physical address 0x00100000 — i.e., from the second megabyte.
Variables describing the kernel’s physical memory layout
| Variable Name | Description |
|---|---|
| num_physpages | Page frame number of the highest usable page frame |
| totalram_pages | Total number of usable page frames |
| min_low_pfn | Page frame number of the first usable page frame after the kernel image in RAM |
| max_pfn | Page frame number of the last usable page frame |
| max_low_pfn | Page frame number of the last page frame directly mapped by the kernel (low memory) |
| totalhigh_pages | Total number of page frames not directly mapped by the kernel (high memory) |
| highstart_pfn | Page frame number of the first page frame not directly mapped by the kernel |
| highend_pfn | Page frame number of the last page frame not directly mapped by the kernel |
The symbol _text, which corresponds to physical address 0x00100000, denotes the address of the first byte of kernel code. The end of the kernel code is similarly identified by the symbol _etext. Kernel data is divided into two groups: initialized and uninitialized. The initialized data starts right after _etext and ends at _edata. The uninitialized data follows and ends up at _end. 这些变量的定义参见内核编译时生成的vmlinux.lds.
6.3.3.1 Process Page Tables
The linear address space of a process is divided into two parts:
1) Linear addresses from 0x00000000 to 0xBFFFFFFF can be addressed when the process runs in either User or Kernel Mode.
2) Linear addresses from 0xC0000000 to 0xFFFFFFFF can be addressed only when the process runs in Kernel Mode.
When a process runs in User Mode, it issues linear addresses smaller than 0xC0000000; when it runs in Kernel Mode, it is executing kernel code and the linear addresses issued are greater than or equal to 0xC0000000. In some cases, however, the kernel must access the User Mode linear address space to retrieve or store data.
6.3.3.2 Kernel Page Tables
6.4 分配/释放内存页
The buddy allocator system algorithm adopts the page frame as the basic memory area.
6.4.1 分配/释放多个内存页
6.4.1.1 alloc_pages()/alloc_pages_node()
The function allocates 2order (that is, 1 « order) contiguous physical pages and returns a pointer to the first page’s page structure; on error it returns NULL.
该函数定义于include/linux/gfp.h:
/*
* IBM-compatible PCs use the Uniform Memory Access model (UMA),
* thus the NUMA support is not really required.
*/
#ifdef CONFIG_NUMA
extern struct page *alloc_pages_current(gfp_t gfp_mask, unsigned order); // 定义于mm/mempolicy.c
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
#else
// gfp_mask参见[6.2.5 gfp_t]节
#define alloc_pages(gfp_mask, order) alloc_pages_node(numa_node_id(), gfp_mask, order)
#endif
函数alloc_pages_node()定义于include/linux/gfp.h:
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
{
/* Unknown node is current node */
if (nid < 0)
nid = numa_node_id();
// node_zonelist()返回node_data[]->node_zonelists[],
// 参见[6.4.1.1.2.1 buffered_rmqueue()]节中的图"Per-CPU page frame cache"
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}
其中,函数__alloc_pages()定义于include/linux/gfp.h:
static inline struct page *__alloc_pages(gfp_t gfp_mask, unsigned int order, struct zonelist *zonelist)
{
return __alloc_pages_nodemask(gfp_mask, order, zonelist, NULL);
}
其中,函数__alloc_pages_nodemask()定义于mm/page_alloc.c:
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
enum zone_type high_zoneidx = gfp_zone(gfp_mask);
struct zone *preferred_zone;
struct page *page;
int migratetype = allocflags_to_migratetype(gfp_mask);
gfp_mask &= gfp_allowed_mask;
lockdep_trace_alloc(gfp_mask);
// If __GFP_WAIT is set, then here can wait and reschedule.
might_sleep_if(gfp_mask & __GFP_WAIT);
// 通过fail_page_alloc和标志位快速判断是否会分配失败
if (should_fail_alloc_page(gfp_mask, order))
return NULL;
/*
* Check the zones suitable for the gfp_mask contain at least one
* valid zone. It's possible to have an empty zonelist as a result
* of GFP_THISNODE and a memoryless node
*/
if (unlikely(!zonelist->_zonerefs->zone))
return NULL;
get_mems_allowed();
/* The preferred zone is used for statistics later */ // 参见[6.4.1.1.1 first_zones_zonelist()]节
first_zones_zonelist(zonelist, high_zoneidx,
nodemask ? : &cpuset_current_mems_allowed, &preferred_zone);
if (!preferred_zone) {
put_mems_allowed();
return NULL;
}
/* First allocation attempt */ // 参见[6.4.1.1.2 get_page_from_freelist()]节
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, nodemask, order, zonelist,
high_zoneidx, ALLOC_WMARK_LOW|ALLOC_CPUSET, preferred_zone, migratetype);
if (unlikely(!page)) // 参见[6.4.1.1.3 __alloc_pages_slowpath()]节
page = __alloc_pages_slowpath(gfp_mask, order, zonelist,
high_zoneidx, nodemask, preferred_zone, migratetype);
put_mems_allowed();
trace_mm_page_alloc(page, order, gfp_mask, migratetype);
return page;
}
6.4.1.1.1 first_zones_zonelist()
该函数定义于include/linux/mmzone.h:
/**
* first_zones_zonelist - Returns the first zone at or below highest_zoneidx
* within the allowed nodemask in a zonelist
* @zonelist - The zonelist to search for a suitable zone
* @highest_zoneidx - The zone index of the highest zone to return
* @nodes - An optional nodemask to filter the zonelist with
* @zone - The first suitable zone found is returned via this parameter
*
* This function returns the first zone at or below a given zone index that is
* within the allowed nodemask. The zoneref returned is a cursor that can be
* used to iterate the zonelist with next_zones_zonelist by advancing it by
* one before calling.
*/
static inline struct zoneref *first_zones_zonelist(struct zonelist *zonelist,
enum zone_type highest_zoneidx, nodemask_t *nodes, struct zone **zone)
{
return next_zones_zonelist(zonelist->_zonerefs, highest_zoneidx, nodes, zone);
}
其中,函数next_zones_zonelist()定义于mm/mmzone.c:
/* Returns the next zone at or below highest_zoneidx in a zonelist */
struct zoneref *next_zones_zonelist(struct zoneref *z, enum zone_type highest_zoneidx,
nodemask_t *nodes, struct zone **zone)
{
/*
* Find the next suitable zone to use for the allocation.
* Only filter based on nodemask if it's set
*/
if (likely(nodes == NULL))
while (zonelist_zone_idx(z) > highest_zoneidx) // z->zone_idx > highest_zoneidx
z++;
else
while (zonelist_zone_idx(z) > highest_zoneidx || // z->zone_idx > highest_zoneidx
(z->zone && !zref_in_nodemask(z, nodes)))
z++;
*zone = zonelist_zone(z); // *zone = z->zone
return z;
}
6.4.1.1.2 get_page_from_freelist()
该函数定义于mm/page_alloc.c:
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *get_page_from_freelist(gfp_t gfp_mask, nodemask_t *nodemask,
unsigned int order, struct zonelist *zonelist, int high_zoneidx,
int alloc_flags, struct zone *preferred_zone, int migratetype)
{
struct zoneref *z;
struct page *page = NULL;
int classzone_idx;
struct zone *zone;
nodemask_t *allowednodes = NULL; /* zonelist_cache approximation */
int zlc_active = 0; /* set if using zonelist_cache */
int did_zlc_setup = 0; /* just call zlc_setup() one time */
classzone_idx = zone_idx(preferred_zone);
zonelist_scan:
/*
* Scan zonelist, looking for a zone with enough free.
* See also cpuset_zone_allowed() comment in kernel/cpuset.c.
*/
for_each_zone_zonelist_nodemask(zone, z, zonelist, high_zoneidx, nodemask) {
if (NUMA_BUILD && zlc_active && !zlc_zone_worth_trying(zonelist, z, allowednodes))
continue;
if ((alloc_flags & ALLOC_CPUSET) && !cpuset_zone_allowed_softwall(zone, gfp_mask))
continue;
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (!(alloc_flags & ALLOC_NO_WATERMARKS)) {
unsigned long mark;
int ret;
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
if (zone_watermark_ok(zone, order, mark, classzone_idx, alloc_flags))
goto try_this_zone;
if (NUMA_BUILD && !did_zlc_setup && nr_online_nodes > 1) {
/*
* we do zlc_setup if there are multiple nodes
* and before considering the first zone allowed
* by the cpuset.
*/
allowednodes = zlc_setup(zonelist, alloc_flags);
zlc_active = 1;
did_zlc_setup = 1;
}
if (zone_reclaim_mode == 0)
goto this_zone_full;
/*
* As we may have just activated ZLC, check if the first
* eligible zone has failed zone_reclaim recently.
*/
if (NUMA_BUILD && zlc_active && !zlc_zone_worth_trying(zonelist, z, allowednodes))
continue;
ret = zone_reclaim(zone, gfp_mask, order);
switch (ret) {
case ZONE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case ZONE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (!zone_watermark_ok(zone, order, mark, classzone_idx, alloc_flags))
goto this_zone_full;
}
}
try_this_zone:
// 参见[6.4.1.1.2.1 buffered_rmqueue()]节
page = buffered_rmqueue(preferred_zone, zone, order, gfp_mask, migratetype);
if (page)
break;
this_zone_full:
if (NUMA_BUILD)
zlc_mark_zone_full(zonelist, z);
}
if (unlikely(NUMA_BUILD && page == NULL && zlc_active)) {
/* Disable zlc cache for second zonelist scan */
zlc_active = 0;
goto zonelist_scan;
}
return page;
}
6.4.1.1.2.1 buffered_rmqueue()
Function buffered_rmqueue() returns the page descriptor of the first allocated page frame, or NULL if the memory zone does not include a group of contiguous page frames of the requested size.
该函数定义于mm/page_alloc.c:
/*
* Really, prep_compound_page() should be called from __rmqueue_bulk(). But
* we cheat by calling it from here, in the order > 0 path. Saves a branch
* or two.
*/
static inline struct page *buffered_rmqueue(struct zone *preferred_zone,
struct zone *zone, int order, gfp_t gfp_flags, int migratetype)
{
unsigned long flags;
struct page *page;
/*
* 冷页表示该空闲页已经不再高速缓存中了(一般是指L2 Cache);热页表示该空闲页仍然在高速缓存中。
* 冷热页是针对于每CPU的,在每个zone中,都会针对所有的CPU初始化一个包含冷热页的per-cpu-pageset
*/
int cold = !!(gfp_flags & __GFP_COLD);
again:
if (likely(order == 0)) { // 分配单个页面(从缓存中分配)
struct per_cpu_pages *pcp;
struct list_head *list;
local_irq_save(flags);
// Per-CPU Page Frame Cache,参见[6.4.1.1.2.1 buffered_rmqueue()]节中的图"Per-CPU page frame cache"
pcp = &this_cpu_ptr(zone->pageset)->pcp;
list = &pcp->lists[migratetype];
if (list_empty(list)) {
// 若缓存为空,则分配pcp->batch的页来填充缓存。参见[6.4.1.1.2.1.1 rmqueue_bulk()]节
pcp->count += rmqueue_bulk(zone, 0, pcp->batch, list, migratetype, cold);
if (unlikely(list_empty(list)))
goto failed;
}
/*
* 冷热页是保存在一条链表上的:热页通过list->next访问,冷页通过list->prev访问。
* 另参见[6.4.1.5.1 free_hot_cold_page()]节
*/
if (cold)
page = list_entry(list->prev, struct page, lru);
else
page = list_entry(list->next, struct page, lru);
list_del(&page->lru);
pcp->count--;
} else { // 分配2order个连续页面(从Buddy Allocator System中分配)
if (unlikely(gfp_flags & __GFP_NOFAIL)) {
/*
* __GFP_NOFAIL is not to be used in new code.
*
* All __GFP_NOFAIL callers should be fixed so that they
* properly detect and handle allocation failures.
*
* We most definitely don't want callers attempting to
* allocate greater than order-1 page units with
* __GFP_NOFAIL.
*/
WARN_ON_ONCE(order > 1);
}
spin_lock_irqsave(&zone->lock, flags);
page = __rmqueue(zone, order, migratetype); // 参见[6.4.1.1.2.1.1.1 __rmqueue()]节
spin_unlock(&zone->lock);
if (!page)
goto failed;
// 更新zone->vm_stat[NR_FREE_PAGES]和vm_stat[NR_FREE_PAGES]
__mod_zone_page_state(zone, NR_FREE_PAGES, -(1 << order));
}
__count_zone_vm_events(PGALLOC, zone, 1 << order);
zone_statistics(preferred_zone, zone, gfp_flags);
local_irq_restore(flags);
VM_BUG_ON(bad_range(zone, page));
if (prep_new_page(page, order, gfp_flags)) // 参见[6.4.1.1.2.1.2 prep_new_page()]节
goto again;
return page;
failed:
local_irq_restore(flags);
return NULL;
}
Per-CPU page frame cache:
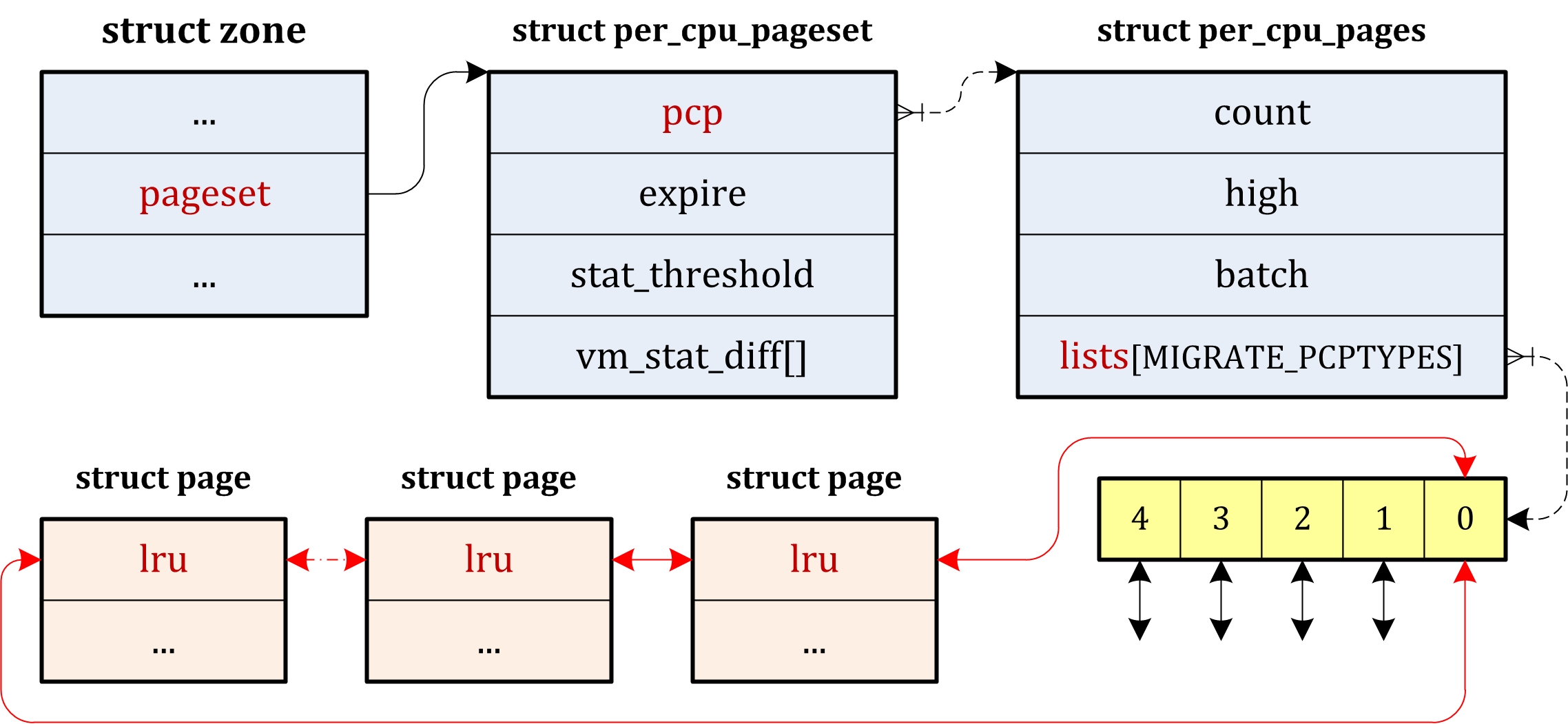
6.4.1.1.2.1.1 rmqueue_bulk()
该函数定义于mm/page_alloc.c:
/*
* Obtain a specified number of elements from the buddy allocator, all under
* a single hold of the lock, for efficiency. Add them to the supplied list.
* Returns the number of new pages which were placed at *list.
*/
// 由[6.4.1.1.2.1 buffered_rmqueue()]节可知,rmqueue_bulk(zone, 0, pcp->batch, list, migratetype, cold);
static int rmqueue_bulk(struct zone *zone, unsigned int order, unsigned long count,
struct list_head *list, int migratetype, int cold)
{
int i;
spin_lock(&zone->lock);
for (i = 0; i < count; ++i) {
struct page *page = __rmqueue(zone, order, migratetype); // 参见[6.4.1.1.2.1.1.1 __rmqueue()]节
if (unlikely(page == NULL))
break;
/*
* Split buddy pages returned by expand() are received here
* in physical page order. The page is added to the callers and
* list and the list head then moves forward. From the callers
* perspective, the linked list is ordered by page number in
* some conditions. This is useful for IO devices that can
* merge IO requests if the physical pages are ordered
* properly.
*/
if (likely(cold == 0))
list_add(&page->lru, list);
else
list_add_tail(&page->lru, list);
// page->private = migratetype
set_page_private(page, migratetype);
list = &page->lru;
}
__mod_zone_page_state(zone, NR_FREE_PAGES, -(i << order));
spin_unlock(&zone->lock);
return i;
}
6.4.1.1.2.1.1.1 __rmqueue()
该函数定义于mm/page_alloc.c:
/*
* Do the hard work of removing an element from the buddy allocator.
* Call me with the zone->lock already held.
*/
static struct page *__rmqueue(struct zone *zone, unsigned int order, int migratetype)
{
struct page *page;
retry_reserve:
page = __rmqueue_smallest(zone, order, migratetype); // 参见[6.4.1.1.2.1.1.1.1 __rmqueue_smallest()]节
if (unlikely(!page) && migratetype != MIGRATE_RESERVE) {
page = __rmqueue_fallback(zone, order, migratetype); // 参见[6.4.1.1.2.1.1.1.2 __rmqueue_fallback()]节
/*
* Use MIGRATE_RESERVE rather than fail an allocation. goto
* is used because __rmqueue_smallest is an inline function
* and we want just one call site
*/
if (!page) {
migratetype = MIGRATE_RESERVE;
goto retry_reserve;
}
}
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}
6.4.1.1.2.1.1.1.1 __rmqueue_smallest()
该函数定义于mm/page_alloc.c:
/*
* Go through the free lists for the given migratetype and remove
* the smallest available page from the freelists
*/
static inline struct page *__rmqueue_smallest(struct zone *zone, unsigned int order, int migratetype)
{
unsigned int current_order;
struct free_area * area;
struct page *page;
/*
* 与__rmqueue_fallback()不同,参见[6.4.1.1.2.1.1.1.2 __rmqueue_fallback()]节:
* 此处按order由小到大的顺序分配,且只查找指定的migratetype类型
*/
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
// 若该大小为2order的free_area为空,则从2order+1的free_area里面找
if (list_empty(&area->free_list[migratetype]))
continue;
// 获取第一个页面,参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节中的"NOTE 14"中的图"变量node_data的结构"
page = list_entry(area->free_list[migratetype].next, struct page, lru);
// 将该页面及其后连续的共2order个页面从列表中移出
list_del(&page->lru);
// 1) 清除Buddy Allocator标志,即page->_mapcount = -1;
// 2) 设置page->private = 0. NOTE: 页描述符中的private保存其对应的order值.
rmv_page_order(page);
area->nr_free--;
/*
* When it becomes necessary to use a block of 2k page frames to
* satisfy a request for 2h page frames (k > h), the program
* allocates the first 2h page frames and iteratively reassigns
* the last 2k–2h page frames to the free_area lists that have
* indexes between h and k.
* 此处,current_order >= order,示例参见下图"从order=4的free_area中分配1个页面"。
* 另参见[6.2.3 struct zone]节中free_area[]的注释
*/
expand(zone, page, order, current_order, area, migratetype);
return page;
}
return NULL;
}
其中,函数expand()定义于mm/slab_alloc.c:
static inline void expand(struct zone *zone, struct page *page, int low,
int high, struct free_area *area, int migratetype)
{
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
size >>= 1;
VM_BUG_ON(bad_range(zone, &page[size]));
// 将2high个页面添加到链表area->free_list[]的头部
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
/*
* 设置&page[size]->private = high. NOTE: 页描述符中的private保存其对应的order值;
* 设置Buddy Allocator标志,即&page[size]->_mapcount = PAGE_BUDDY_MAPCOUNT_VALUE
*/
set_page_order(&page[size], high);
}
}
当high=4,low=3时,函数expand()的执行结果:
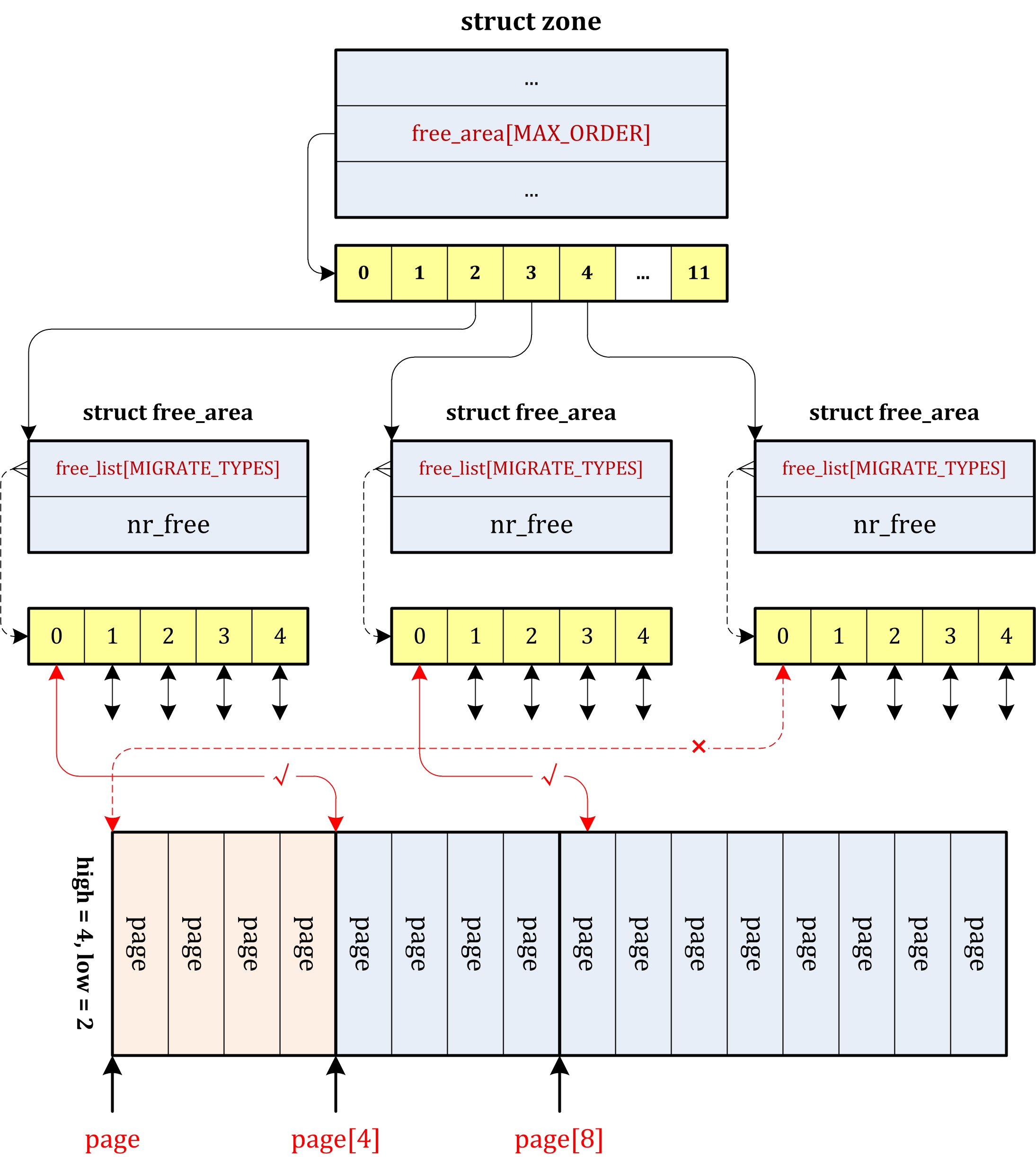
从order=4的free_area中分配1个页面:
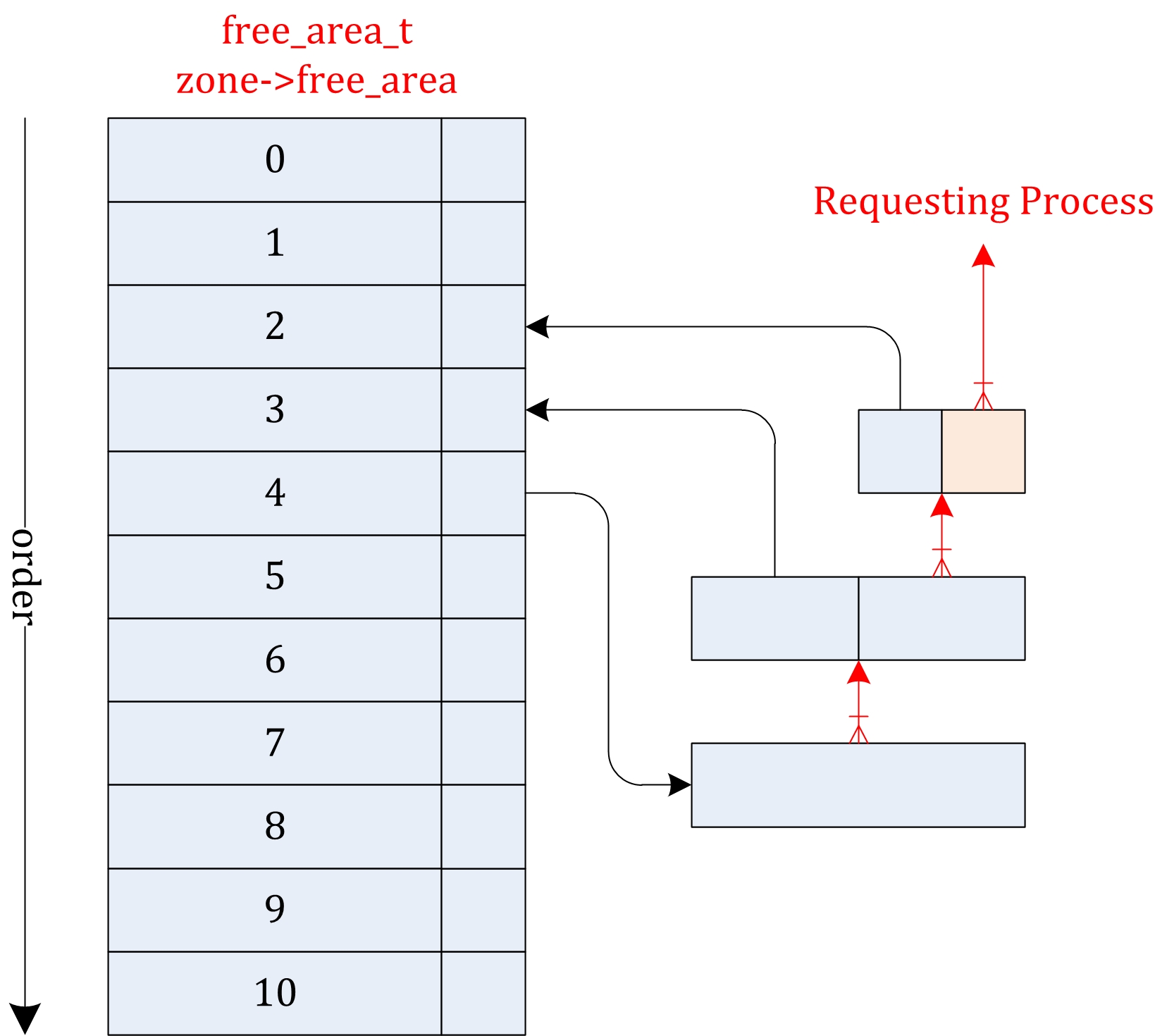
6.4.1.1.2.1.1.1.2 __rmqueue_fallback()
该函数定义于mm/page_alloc.c:
/*
* This array describes the order lists are fallen back to when
* the free lists for the desirable migrate type are depleted
*/
static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
[MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE, MIGRATE_RESERVE }, /* Never used */
};
/* Remove an element from the buddy allocator from the fallback list */
static inline struct page *__rmqueue_fallback(struct zone *zone, int order, int start_migratetype)
{
struct free_area * area;
int current_order;
struct page *page;
int migratetype, i;
/*
* 与__rmqueue_smallest()不同(参见[6.4.1.1.2.1.1.1.1 __rmqueue_smallest()]节):
* 此处按order由大到小的顺序分配,且查找所有的migratetype类型
*/
/* Find the largest possible block of pages in the other list */
for (current_order = MAX_ORDER-1; current_order >= order; --current_order) {
for (i = 0; i < MIGRATE_TYPES - 1; i++) {
migratetype = fallbacks[start_migratetype][i];
/* MIGRATE_RESERVE handled later if necessary */
if (migratetype == MIGRATE_RESERVE)
continue;
area = &(zone->free_area[current_order]);
if (list_empty(&area->free_list[migratetype]))
continue;
page = list_entry(area->free_list[migratetype].next, struct page, lru);
area->nr_free--;
/*
* If breaking a large block of pages, move all free
* pages to the preferred allocation list. If falling
* back for a reclaimable kernel allocation, be more
* aggressive about taking ownership of free pages
*/
if (unlikely(current_order >= (pageblock_order >> 1))
|| start_migratetype == MIGRATE_RECLAIMABLE
|| page_group_by_mobility_disabled) {
unsigned long pages;
pages = move_freepages_block(zone, page, start_migratetype);
/* Claim the whole block if over half of it is free */
if (pages >= (1 << (pageblock_order-1)) || page_group_by_mobility_disabled)
set_pageblock_migratetype(page, start_migratetype);
migratetype = start_migratetype;
}
/* Remove the page from the freelists */
list_del(&page->lru);
rmv_page_order(page);
/* Take ownership for orders >= pageblock_order */
if (current_order >= pageblock_order)
change_pageblock_range(page, current_order, start_migratetype);
// 参见[6.4.1.1.2.1.1.1.1 __rmqueue_smallest()]节
expand(zone, page, order, current_order, area, migratetype);
trace_mm_page_alloc_extfrag(page, order, current_order, start_migratetype, migratetype);
return page;
}
}
return NULL;
}
6.4.1.1.2.1.2 prep_new_page()
该函数定义于mm/page_alloc.c:
static int prep_new_page(struct page *page, int order, gfp_t gfp_flags)
{
int i;
for (i = 0; i < (1 << order); i++) {
struct page *p = page + i;
if (unlikely(check_new_page(p))) // 判断页面合法性,参见[6.4.1.1.2.1.2 prep_new_page()]节
return 1;
}
set_page_private(page, 0); // page->private = 0
set_page_refcounted(page); // page->_count = 1
arch_alloc_page(page, order);
kernel_map_pages(page, 1 << order, 1);
if (gfp_flags & __GFP_ZERO)
prep_zero_page(page, order, gfp_flags); // Fill the allocated memory area with zeros.
if (order && (gfp_flags & __GFP_COMP))
prep_compound_page(page, order); // 参见[6.4.1.1.2.1.2.2 prep_compound_page()]节
return 0;
}
6.4.1.1.2.1.2.1 check_new_page()
该函数定义于mm/page_alloc.c:
static inline int check_new_page(struct page *page)
{
if (unlikely(page_mapcount(page) // &(page)->_mapcount) + 1
| (page->mapping != NULL)
| (atomic_read(&page->_count) != 0)
| (page->flags & PAGE_FLAGS_CHECK_AT_PREP)
| (mem_cgroup_bad_page_check(page)))) {
bad_page(page);
return 1;
}
return 0;
}
6.4.1.1.2.1.2.2 prep_compound_page()
该函数定义于mm/page_alloc.c:
void prep_compound_page(struct page *page, unsigned long order)
{
int i;
int nr_pages = 1 << order;
// page[1].lru.next = (void *)free_compound_page;
set_compound_page_dtor(page, free_compound_page);
// page[1].lru.prev = (void *)order;
set_compound_order(page, order);
// 设置page->flags中的PG_head标志位,参见include/linux/page-flags.h
__SetPageHead(page);
for (i = 1; i < nr_pages; i++) {
struct page *p = page + i;
__SetPageTail(p); // page->flags |= PG_head_tail_mask;
set_page_count(p, 0); // page->_count = 0
p->first_page = page; // 链接页面
}
}
6.4.1.1.3 __alloc_pages_slowpath()
该函数定义于mm/page_alloc.c:
static inline struct page *__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, enum zone_type high_zoneidx,
nodemask_t *nodemask, struct zone *preferred_zone, int migratetype)
{
const gfp_t wait = gfp_mask & __GFP_WAIT;
struct page *page = NULL;
int alloc_flags;
unsigned long pages_reclaimed = 0;
unsigned long did_some_progress;
bool sync_migration = false;
/*
* In the slowpath, we sanity check order to avoid ever trying to
* reclaim >= MAX_ORDER areas which will never succeed. Callers may
* be using allocators in order of preference for an area that is
* too large.
*/
if (order >= MAX_ORDER) {
WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN));
return NULL;
}
/*
* GFP_THISNODE (meaning __GFP_THISNODE, __GFP_NORETRY and
* __GFP_NOWARN set) should not cause reclaim since the subsystem
* (f.e. slab) using GFP_THISNODE may choose to trigger reclaim
* using a larger set of nodes after it has established that the
* allowed per node queues are empty and that nodes are
* over allocated.
*/
if (NUMA_BUILD && (gfp_mask & GFP_THISNODE) == GFP_THISNODE)
goto nopage;
restart:
// 参见[6.4.1.1.3.1 wake_all_kswapd()]节
if (!(gfp_mask & __GFP_NO_KSWAPD))
wake_all_kswapd(order, zonelist, high_zoneidx, zone_idx(preferred_zone));
/*
* OK, we're below the kswapd watermark and have kicked background
* reclaim. Now things get more complex, so set up alloc_flags according
* to how we want to proceed.
*/
alloc_flags = gfp_to_alloc_flags(gfp_mask);
/*
* Find the true preferred zone if the allocation is unconstrained by
* cpusets.
*/
if (!(alloc_flags & ALLOC_CPUSET) && !nodemask)
first_zones_zonelist(zonelist, high_zoneidx, NULL, &preferred_zone);
rebalance:
/* This is the last chance, in general, before the goto nopage. */
// 参见[6.4.1.1.2 get_page_from_freelist()]节
page = get_page_from_freelist(gfp_mask, nodemask, order, zonelist, high_zoneidx,
alloc_flags & ~ALLOC_NO_WATERMARKS, preferred_zone, migratetype);
if (page)
goto got_pg;
/* Allocate without watermarks if the context allows */
if (alloc_flags & ALLOC_NO_WATERMARKS) {
page = __alloc_pages_high_priority(gfp_mask, order, zonelist,
high_zoneidx, nodemask, preferred_zone, migratetype);
if (page)
goto got_pg;
}
/* Atomic allocations - we can't balance anything */
if (!wait)
goto nopage;
/* Avoid recursion of direct reclaim */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* Avoid allocations with no watermarks from looping endlessly */
if (test_thread_flag(TIF_MEMDIE) && !(gfp_mask & __GFP_NOFAIL))
goto nopage;
/*
* Try direct compaction. The first pass is asynchronous. Subsequent
* attempts after direct reclaim are synchronous
*/
page = __alloc_pages_direct_compact(gfp_mask, order, zonelist, high_zoneidx, nodemask,
alloc_flags, preferred_zone, migratetype, &did_some_progress, sync_migration);
if (page)
goto got_pg;
sync_migration = true;
/* Try direct reclaim and then allocating */
page = __alloc_pages_direct_reclaim(gfp_mask, order, zonelist, high_zoneidx,
nodemask, alloc_flags, preferred_zone, migratetype, &did_some_progress);
if (page)
goto got_pg;
/*
* If we failed to make any progress reclaiming, then we are
* running out of options and have to consider going OOM
*/
if (!did_some_progress) {
if ((gfp_mask & __GFP_FS) && !(gfp_mask & __GFP_NORETRY)) {
if (oom_killer_disabled)
goto nopage;
page = __alloc_pages_may_oom(gfp_mask, order, zonelist,
high_zoneidx, nodemask, preferred_zone, migratetype);
if (page)
goto got_pg;
if (!(gfp_mask & __GFP_NOFAIL)) {
/*
* The oom killer is not called for high-order
* allocations that may fail, so if no progress
* is being made, there are no other options and
* retrying is unlikely to help.
*/
if (order > PAGE_ALLOC_COSTLY_ORDER)
goto nopage;
/*
* The oom killer is not called for lowmem
* allocations to prevent needlessly killing
* innocent tasks.
*/
if (high_zoneidx < ZONE_NORMAL)
goto nopage;
}
goto restart;
}
}
/* Check if we should retry the allocation */
pages_reclaimed += did_some_progress;
if (should_alloc_retry(gfp_mask, order, pages_reclaimed)) {
/* Wait for some write requests to complete then retry */
wait_iff_congested(preferred_zone, BLK_RW_ASYNC, HZ/50);
goto rebalance;
} else {
/*
* High-order allocations do not necessarily loop after
* direct reclaim and reclaim/compaction depends on compaction
* being called after reclaim so call directly if necessary
*/
page = __alloc_pages_direct_compact(gfp_mask, order, zonelist, high_zoneidx, nodemask,
alloc_flags, preferred_zone, migratetype, &did_some_progress, sync_migration);
if (page)
goto got_pg;
}
nopage:
warn_alloc_failed(gfp_mask, order, NULL);
return page;
got_pg:
if (kmemcheck_enabled)
kmemcheck_pagealloc_alloc(page, order, gfp_mask);
return page;
}
6.4.1.1.3.1 wake_all_kswapd()
该函数定义于mm/page_alloc.c:
static inline void wake_all_kswapd(unsigned int order, struct zonelist *zonelist,
enum zone_type high_zoneidx, enum zone_type classzone_idx)
{
struct zoneref *z;
struct zone *zone;
for_each_zone_zonelist(zone, z, zonelist, high_zoneidx)
wakeup_kswapd(zone, order, classzone_idx); // 参见[6.4.1.1.3.1.1.2 wakeup_kswapd()]节
}
6.4.1.1.3.1.1 kswapd
6.4.1.1.3.1.1.1 kswapd线程的初始化
结构pg_date_t中的变量kswapd是通过函数kswapd_init()设置的,其定义于mm/vmscan.c:
static int __init kswapd_init(void)
{
int nid;
swap_setup();
for_each_node_state(nid, N_HIGH_MEMORY)
kswapd_run(nid);
hotcpu_notifier(cpu_callback, 0);
return 0;
}
/*
* 由mm/Makefile可知,vmscan.c被直接编译进内核,因此kswapd_init()在系统启动时执行,参见[13.5.1.1.1.1.1 .initcall*.init]节
* kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
* ^
* +-- 其中的.initcall6.init
*/
module_init(kswapd_init)
其中,函数kswapd_run()定义于mm/vmscan.c:
int kswapd_run(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
int ret = 0;
if (pgdat->kswapd)
return 0;
// 创建kswapd内核线程,参见[7.2.4.4.1 kthread_run()]节,该线程执行函数kswapd().
pgdat->kswapd = kthread_run(kswapd, pgdat, "kswapd%d", nid);
if (IS_ERR(pgdat->kswapd)) {
/* failure at boot is fatal */
BUG_ON(system_state == SYSTEM_BOOTING);
printk("Failed to start kswapd on node %d\n",nid);
ret = -1;
}
return ret;
}
其中,函数kswapd()定义于mm/vmscan.c:
static int kswapd(void *p)
{
unsigned long order, new_order;
unsigned balanced_order;
int classzone_idx, new_classzone_idx;
int balanced_classzone_idx;
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
struct reclaim_state reclaim_state = {
.reclaimed_slab = 0,
};
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);
lockdep_set_current_reclaim_state(GFP_KERNEL);
if (!cpumask_empty(cpumask))
set_cpus_allowed_ptr(tsk, cpumask);
current->reclaim_state = &reclaim_state;
/*
* Tell the memory management that we're a "memory allocator",
* and that if we need more memory we should get access to it
* regardless (see "__alloc_pages()"). "kswapd" should
* never get caught in the normal page freeing logic.
*
* (Kswapd normally doesn't need memory anyway, but sometimes
* you need a small amount of memory in order to be able to
* page out something else, and this flag essentially protects
* us from recursively trying to free more memory as we're
* trying to free the first piece of memory in the first place).
*/
tsk->flags |= PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD;
set_freezable();
order = new_order = 0;
balanced_order = 0;
classzone_idx = new_classzone_idx = pgdat->nr_zones - 1;
balanced_classzone_idx = classzone_idx;
for ( ; ; ) {
int ret;
/*
* If the last balance_pgdat was unsuccessful it's unlikely a
* new request of a similar or harder type will succeed soon
* so consider going to sleep on the basis we reclaimed at
*/
if (balanced_classzone_idx >= new_classzone_idx && balanced_order == new_order) {
new_order = pgdat->kswapd_max_order;
new_classzone_idx = pgdat->classzone_idx;
pgdat->kswapd_max_order = 0;
pgdat->classzone_idx = pgdat->nr_zones - 1;
}
if (order < new_order || classzone_idx > new_classzone_idx) {
/*
* Don't sleep if someone wants a larger 'order'
* allocation or has tigher zone constraints
*/
order = new_order;
classzone_idx = new_classzone_idx;
} else {
kswapd_try_to_sleep(pgdat, balanced_order, balanced_classzone_idx);
order = pgdat->kswapd_max_order;
classzone_idx = pgdat->classzone_idx;
new_order = order;
new_classzone_idx = classzone_idx;
pgdat->kswapd_max_order = 0;
pgdat->classzone_idx = pgdat->nr_zones - 1;
}
ret = try_to_freeze();
if (kthread_should_stop())
break;
/*
* We can speed up thawing tasks if we don't call balance_pgdat
* after returning from the refrigerator
*/
if (!ret) {
trace_mm_vmscan_kswapd_wake(pgdat->node_id, order);
balanced_classzone_idx = classzone_idx;
balanced_order = balance_pgdat(pgdat, order, &balanced_classzone_idx);
}
}
return 0;
}
6.4.1.1.3.1.1.2 wakeup_kswapd()
该函数定义于mm/vmscan.c:
void wakeup_kswapd(struct zone *zone, int order, enum zone_type classzone_idx)
{
pg_data_t *pgdat;
if (!populated_zone(zone))
return;
if (!cpuset_zone_allowed_hardwall(zone, GFP_KERNEL))
return;
pgdat = zone->zone_pgdat;
if (pgdat->kswapd_max_order < order) {
pgdat->kswapd_max_order = order;
pgdat->classzone_idx = min(pgdat->classzone_idx, classzone_idx);
}
if (!waitqueue_active(&pgdat->kswapd_wait))
return;
if (zone_watermark_ok_safe(zone, order, low_wmark_pages(zone), 0, 0))
return;
trace_mm_vmscan_wakeup_kswapd(pgdat->node_id, zone_idx(zone), order);
// 唤醒pgdat->kswapd_wait进程,参见[7.4.10.1 wake_up_XXX()]节
wake_up_interruptible(&pgdat->kswapd_wait);
}
6.4.1.2 page_address()
The page_address() function returns the linear address associated with the page frame, or NULL if the page frame is in high memory and is not mapped.
根据编译选项的不同,其定义也不同,如下表所示:
| Macros Definitions WANT_PAGE_VIRTUAL |
Macros Definitions CONFIG_HIGHMEM |
page_address() |
|---|---|---|
| Defined | - | #define page_address(page) ((page)->virtual) |
| Not Defined | Not Defined | #define page_address(page) lowmem_page_address(page),参见6.4.1.2.1 lowmem_page_address()节 |
| Not Defined | Defined | 定义于mm/highmem.c,参见6.4.1.2.2 page_address() in mm/highmem.c节 |
参见include/linux/mm.h:
#if defined(CONFIG_HIGHMEM) && !defined(WANT_PAGE_VIRTUAL)
#define HASHED_PAGE_VIRTUAL
#endif
#if defined(WANT_PAGE_VIRTUAL)
#define page_address(page) ((page)->virtual)
#define set_page_address(page, address) \
do { \
(page)->virtual = (address); \
} while(0)
#define page_address_init() do { } while(0)
#endif
#if defined(HASHED_PAGE_VIRTUAL)
void *page_address(const struct page *page); // mm/highmem.c
void set_page_address(struct page *page, void *virtual);
void page_address_init(void);
#endif
#if !defined(HASHED_PAGE_VIRTUAL) && !defined(WANT_PAGE_VIRTUAL)
#define page_address(page) lowmem_page_address(page)
#define set_page_address(page, address) do { } while(0)
#define page_address_init() do { } while(0)
#endif
6.4.1.2.1 lowmem_page_address()
该函数定义于include/linux/mm.h:
static __always_inline void *lowmem_page_address(const struct page *page)
{
// page_to_pfn()参见[6.1.2.6.5.5 pte_page()/pte_pfn()]节,__va()参见[6.1.2.6.2.5 pgd_page_vaddr()]节
return __va(PFN_PHYS(page_to_pfn(page)));
}
其中,宏PFN_PHYS()定义于include/linux/pfn.h:
#define PFN_PHYS(x) ((phys_addr_t)(x) << PAGE_SHIFT)
6.4.1.2.2 page_address() in mm/highmem.c
该函数定义于mm/highmem.c:
/**
* page_address - get the mapped virtual address of a page
* @page: &struct page to get the virtual address of
*
* Returns the page's virtual address.
*/
void *page_address(const struct page *page)
{
unsigned long flags;
void *ret;
struct page_address_slot *pas;
// 若不是高端内存,参见[6.4.1.2.1 lowmem_page_address()]节
if (!PageHighMem(page))
return lowmem_page_address(page);
/*
* 获取page_address_htable中page所在的表项,
* 参见下图"变量page_address_htable"
*/
pas = page_slot(page);
ret = NULL;
spin_lock_irqsave(&pas->lock, flags);
if (!list_empty(&pas->lh)) {
struct page_address_map *pam;
list_for_each_entry(pam, &pas->lh, list) {
if (pam->page == page) {
ret = pam->virtual;
goto done;
}
}
}
done:
spin_unlock_irqrestore(&pas->lock, flags);
return ret;
}
变量page_address_htable:
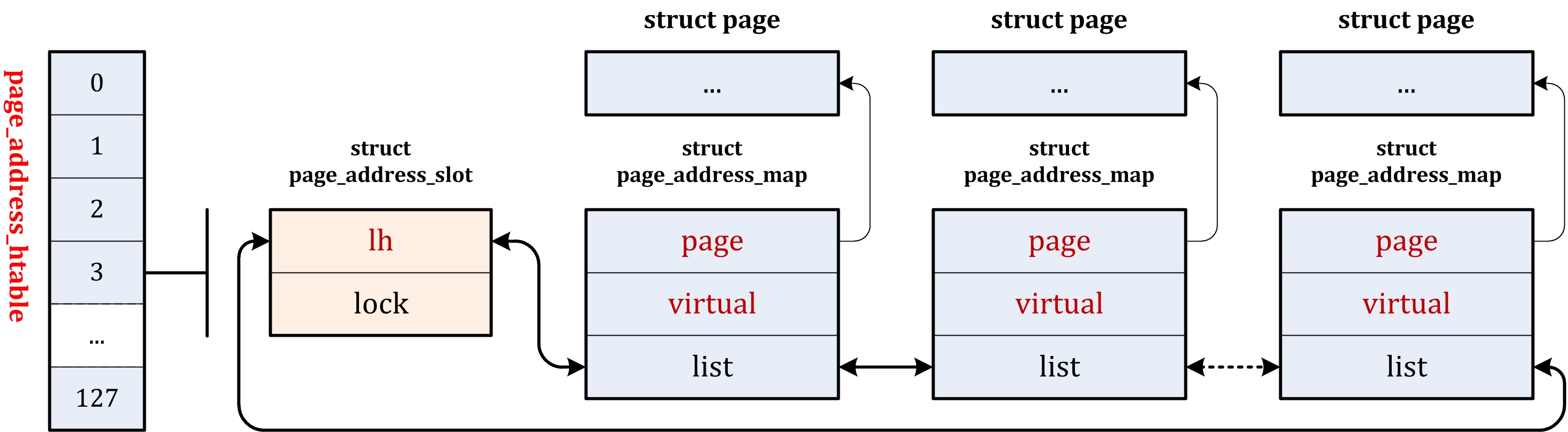
6.4.1.3 __get_free_pages()
Function that is similar to alloc_pages(), but it returns the linear address of the first allocated page.
该函数定义于mm/page_alloc.c:
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
/*
* __get_free_pages() returns a 32-bit address, which cannot represent
* a highmem page
*/
VM_BUG_ON((gfp_mask & __GFP_HIGHMEM) != 0);
page = alloc_pages(gfp_mask, order); // 参见[6.4.1.1 alloc_pages()/alloc_pages_node()]节
if (!page)
return 0;
return (unsigned long) page_address(page); // 参见[6.4.1.2 page_address()]节
}
6.4.1.4 __get_dma_pages()
Macro used to get page frames suitable for DMA; see include/linux/gfp.h:
// 参见[6.4.1.3 __get_free_pages()]节
#define __get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA, (order))
6.4.1.5 free_pages()/__free_pages()
void __free_pages(struct page *page, unsigned int order);
The function __free_pages() checks the page descriptor pointed to by page; if the page frame is not reserved (i.e., if the PG_reserved flag is equal to 0), it decreases the count field of the descriptor. If count becomes 0, it assumes that 2order contiguous page frames starting from the one corresponding to page are no longer used. In this case, the function releases the page frames.
void free_pages(unsigned long addr, unsigned int order);
The function free_pages() is similar to __free_pages(), but it receives as an argument the linear address addr of the first page frame to be released.
函数free_pages()定义于mm/page_alloc.c:
void free_pages(unsigned long addr, unsigned int order)
{
if (addr != 0) {
VM_BUG_ON(!virt_addr_valid((void *)addr));
__free_pages(virt_to_page((void *)addr), order);
}
}
函数__free_pages()定义于mm/page_alloc.c:
void __free_pages(struct page *page, unsigned int order)
{
// if page->_count-- is 0, then the page has no users, release it!
if (put_page_testzero(page)) {
if (order == 0)
free_hot_cold_page(page, 0); // 参见[6.4.1.5.1 free_hot_cold_page()]节
else
__free_pages_ok(page, order); // 参见[6.4.1.5.2 __free_pages_ok()]节
}
}
6.4.1.5.1 free_hot_cold_page()
该函数定义于mm/page_alloc.c:
/*
* Free a 0-order page
* cold == 1 ? free a cold page : free a hot page
*/
void free_hot_cold_page(struct page *page, int cold)
{
struct zone *zone = page_zone(page);
struct per_cpu_pages *pcp;
unsigned long flags;
int migratetype;
// 判断并清除page->flags中的PG_mlocked标志位
int wasMlocked = __TestClearPageMlocked(page);
// 参见[6.4.1.5.1.1 free_pages_prepare()]节
if (!free_pages_prepare(page, 0))
return;
migratetype = get_pageblock_migratetype(page);
// page->private = migratetype
set_page_private(page, migratetype);
local_irq_save(flags);
if (unlikely(wasMlocked))
// 更新page->vm_stat[NR_MLOCK]和vm_stat[NR_MLOCK]
free_page_mlock(page);
// 更新vm_event_states.event[PGFREE]
__count_vm_event(PGFREE);
/*
* We only track unmovable, reclaimable and movable on pcp lists.
* Free ISOLATE pages back to the allocator because they are being
* offlined but treat RESERVE as movable pages so we can get those
* areas back if necessary. Otherwise, we may have to free
* excessively into the page allocator
*/
if (migratetype >= MIGRATE_PCPTYPES) {
if (unlikely(migratetype == MIGRATE_ISOLATE)) {
// 参见[6.4.1.5.1.2 free_one_page()]节
free_one_page(zone, page, 0, migratetype);
goto out;
}
migratetype = MIGRATE_MOVABLE;
}
/*
* 将该页面插入Per-CPU Page Frame Cache,
* 参见[6.4.1.1.2.1 buffered_rmqueue()]节中的图"Per-CPU page frame cache"
*/
pcp = &this_cpu_ptr(zone->pageset)->pcp;
if (cold)
list_add_tail(&page->lru, &pcp->lists[migratetype]);
else
list_add(&page->lru, &pcp->lists[migratetype]);
pcp->count++;
/*
* 若超过阀值,则释放batch个页面到Buddy Allocator System
* 与buffered_rmqueue()->rmqueue_bulk()对应,
* 参见[6.4.1.1.2.1 buffered_rmqueue()]节
*/
if (pcp->count >= pcp->high) {
free_pcppages_bulk(zone, pcp->batch, pcp);
pcp->count -= pcp->batch;
}
out:
local_irq_restore(flags);
}
6.4.1.5.1.1 free_pages_prepare()
该函数定义于mm/page_alloc.c:
static bool free_pages_prepare(struct page *page, unsigned int order)
{
int i;
int bad = 0;
trace_mm_page_free_direct(page, order);
kmemcheck_free_shadow(page, order);
// page->mapping & PAGE_MAPPING_ANON) != 0
if (PageAnon(page))
page->mapping = NULL;
for (i = 0; i < (1 << order); i++)
// 与check_new_page()对应,参见[6.4.1.1.2.1.2 prep_new_page()]节
bad += free_pages_check(page + i);
if (bad)
return false;
// 判断是否为高端内存
if (!PageHighMem(page)) {
debug_check_no_locks_freed(page_address(page),PAGE_SIZE << order);
debug_check_no_obj_freed(page_address(page), PAGE_SIZE << order);
}
arch_free_page(page, order);
kernel_map_pages(page, 1 << order, 0);
return true;
}
6.4.1.5.1.2 free_one_page()
该函数定义于mm/page_alloc.c:
static void free_one_page(struct zone *zone, struct page *page, int order, int migratetype)
{
spin_lock(&zone->lock);
zone->all_unreclaimable = 0;
zone->pages_scanned = 0;
// 参见[6.4.1.5.1.2.1 __free_one_page()]节
__free_one_page(page, zone, order, migratetype);
__mod_zone_page_state(zone, NR_FREE_PAGES, 1 << order);
spin_unlock(&zone->lock);
}
6.4.1.5.1.2.1 __free_one_page()
该函数定义于mm/page_alloc.c:
static inline void __free_one_page(struct page *page,
struct zone *zone, unsigned int order, int migratetype)
{
unsigned long page_idx;
unsigned long combined_idx;
unsigned long uninitialized_var(buddy_idx);
struct page *buddy;
// 判断是否为复合页:page->flags & ((1L << PG_head) | (1L << PG_tail)
if (unlikely(PageCompound(page)))
if (unlikely(destroy_compound_page(page, order)))
return;
VM_BUG_ON(migratetype == -1);
// page_idx取页框号的低11比特位,参见[6.2.3 struct zone]节中free_area[]的注释
page_idx = page_to_pfn(page) & ((1 << MAX_ORDER) - 1);
VM_BUG_ON(page_idx & ((1 << order) - 1));
VM_BUG_ON(bad_range(zone, page));
// 按order从小到大的顺序,查找该页面对应的最大伙伴页面
while (order < MAX_ORDER-1) {
// 获得该页对应的伙伴页的索引,其中page[8]对应的伙伴页为page
buddy_idx = __find_buddy_index(page_idx, order);
// 找到该页对应的伙伴页,并判断其合法性
buddy = page + (buddy_idx - page_idx);
if (!page_is_buddy(page, buddy, order))
break;
/* Our buddy is free, merge with it and move up one order. */
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
// 1) 清除Buddy Allocator标志,即page->_mapcount = -1;
// 2) 设置page->private = 0. NOTE: 页描述符中的private保存其对应的order值.
rmv_page_order(buddy);
combined_idx = buddy_idx & page_idx;
page = page + (combined_idx - page_idx);
page_idx = combined_idx;
order++;
}
/*
* 找到最大的伙伴页面后,设置标志:
* 设置page->private = order. NOTE: 页描述符中的private保存其对应的order值;
* 设置Buddy Allocator标志,即page->_mapcount = PAGE_BUDDY_MAPCOUNT_VALUE
*/
set_page_order(page, order);
/*
* If this is not the largest possible page, check if the buddy
* of the next-highest order is free. If it is, it's possible
* that pages are being freed that will coalesce soon. In case,
* that is happening, add the free page to the tail of the list
* so it's less likely to be used soon and more likely to be merged
* as a higher order page
*/
if ((order < MAX_ORDER-2) && pfn_valid_within(page_to_pfn(buddy))) {
struct page *higher_page, *higher_buddy;
combined_idx = buddy_idx & page_idx;
higher_page = page + (combined_idx - page_idx);
buddy_idx = __find_buddy_index(combined_idx, order + 1);
higher_buddy = page + (buddy_idx - combined_idx);
if (page_is_buddy(higher_page, higher_buddy, order + 1)) {
list_add_tail(&page->lru, &zone->free_area[order].free_list[migratetype]);
goto out;
}
}
// 将最大的伙伴页面链接到对应order的空闲链表中,并更新计数
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
out:
zone->free_area[order].nr_free++;
}
6.4.1.5.1.3 free_pcppages_bulk()
该函数定义于mm/page_alloc.c:
/*
* Frees a number of pages from the PCP lists
* Assumes all pages on list are in same zone, and of same order.
* count is the number of pages to free.
*
* If the zone was previously in an "all pages pinned" state then look to
* see if this freeing clears that state.
*
* And clear the zone's pages_scanned counter, to hold off the "all pages are
* pinned" detection logic.
*/
static void free_pcppages_bulk(struct zone *zone, int count, struct per_cpu_pages *pcp)
{
int migratetype = 0;
int batch_free = 0;
int to_free = count;
spin_lock(&zone->lock);
zone->all_unreclaimable = 0;
zone->pages_scanned = 0;
while (to_free) {
struct page *page;
struct list_head *list;
/*
* Remove pages from lists in a round-robin fashion. A
* batch_free count is maintained that is incremented when an
* empty list is encountered. This is so more pages are freed
* off fuller lists instead of spinning excessively around empty
* lists
*/
do {
batch_free++;
if (++migratetype == MIGRATE_PCPTYPES)
migratetype = 0;
list = &pcp->lists[migratetype];
} while (list_empty(list));
/* This is the only non-empty list. Free them all. */
if (batch_free == MIGRATE_PCPTYPES)
batch_free = to_free;
do {
page = list_entry(list->prev, struct page, lru);
/* must delete as __free_one_page list manipulates */
list_del(&page->lru);
/* MIGRATE_MOVABLE list may include MIGRATE_RESERVEs */
// 参见[6.4.1.5.1.2.1 __free_one_page()]节
__free_one_page(page, zone, 0, page_private(page));
trace_mm_page_pcpu_drain(page, 0, page_private(page));
} while (--to_free && --batch_free && !list_empty(list));
}
__mod_zone_page_state(zone, NR_FREE_PAGES, count);
spin_unlock(&zone->lock);
}
6.4.1.5.2 __free_pages_ok()
该函数定义于mm/page_alloc.c:
static void __free_pages_ok(struct page *page, unsigned int order)
{
unsigned long flags;
// 判断并清除page->flags中的PG_mlocked标志位
int wasMlocked = __TestClearPageMlocked(page);
// 参见[6.4.1.5.1.1 free_pages_prepare()]节
if (!free_pages_prepare(page, order))
return;
local_irq_save(flags);
if (unlikely(wasMlocked))
free_page_mlock(page);
__count_vm_events(PGFREE, 1 << order);
// 参见[6.4.1.5.1.2 free_one_page()]节
free_one_page(page_zone(page), page, order, get_pageblock_migratetype(page));
local_irq_restore(flags);
}
6.4.2 分配/释放单个内存页
6.4.2.1 alloc_page()
The macro alloc_page() used to get a single page frame; see include/linux/gfp.h:
// 参见[6.4.1.1 alloc_pages()/alloc_pages_node()]节
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
It returns the address of the descriptor of the allocated page frame or returns NULL if the allocation failed.
6.4.2.2 get_zeroed_page()
Function get_zeroed_page() used to obtain a page frame filled with zeros; see mm/page_alloc.c:
unsigned long get_zeroed_page(gfp_t gfp_mask)
{
// 参见[6.4.1.3 __get_free_pages()]节
return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}
It returns the linear address of the obtained page frame.
6.4.2.3 __get_free_page()
The macro __get_free_page() used to get a single page frame; see include/linux/gfp.h:
// 参见[6.4.1.3 __get_free_pages()]节
#define __get_free_page(gfp_mask) __get_free_pages((gfp_mask), 0)
6.4.2.4 __free_page()/free_page()
Macro __free_page() releases the page frame having the descriptor pointed to by page; Macro free_page() releases the page frame having the linear address addr. See include/linux/gfp.h:
// 参见[6.4.1.5 free_pages()/__free_pages()]节
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr), 0)
6.5 Slab Allocator
Running a memory area allocation algorithm on top of the buddy algorithm (参见6.4 分配/释放内存页节) is not particularly efficient. A better algorithm is derived from the slab allocator schema that was adopted for the first time in the Sun Microsystems Solaris 2.4 operating system.
The slab allocator groups objects into caches. Each cache is a “store” of objects of the same type.
The area of main memory that contains a cache is divided into slabs; each slab consists of one or more contiguous page frames that contain both allocated and free objects.
Run following command to get a full list of caches available on a running system (参见6.5.1.1.2.1 查看slab的分配信息):
# cat /proc/slabinfo
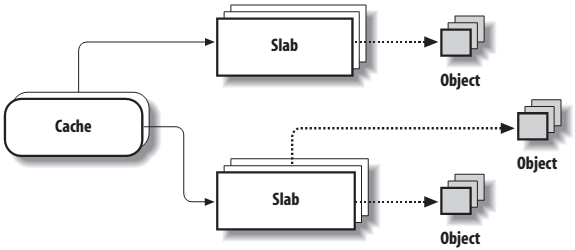
6.5.0 SLAB/SLUB/SLOB Allocator配置选项
通过如下选项配置SLAB/SLUB/SLOB Allocator:
General setup --->
Choose SLAB allocator (SLAB) --->
(X) SLAB
( ) SLUB (Unqueued Allocator)
( ) SLOB (Simple Allocator)
由此可知,这三个配置选项是互斥的,因而只能选择其中之一!
NOTE: SLAB/SLUB/SLOB allocator的区别:
- SLAB是基础,是最早从Sun OS那引进的;
- SLUB是在Slab上进行的改进,在大型机上表现出色,据说还被IA-64作为默认;
- SLOB是针对小型系统设计的,主要是嵌入式。
6.5.1 Cache Descriptor/struct kmem_cache
Each cache is described by a structure of type struct kmem_cache. 该结构定义于include/linux/slab_def.h:
struct kmem_cache {
/* 1) Cache tunables. Protected by cache_chain_mutex */
// Number of objects to be transferred in bulk to or from the local caches.
unsigned int batchcount;
// Maximum number of free objects in the local caches.
unsigned int limit;
unsigned int shared;
unsigned int buffer_size;
u32 reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
// See SLAB_xxx in include/linux/slab.h
unsigned int flags; /* constant flags */
// Number of objects packed into a single slab.
// All slabs of the cache have the same size.
unsigned int num; /* # of objs per slab */
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
// Logarithm of the number of contiguous page frames included in a single slab.
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
// Set of flags passed to the buddy allocator system function when allocating page frames.
gfp_t gfpflags;
// Number of colors for the slabs
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
/*
* Pointer to the general slab cache containing the slab descriptors.
* NULL if internal slab descriptors are used;
*/
struct kmem_cache *slabp_cache;
// The size of a single slab.
unsigned int slab_size;
// Set of flags that describe dynamic properties of the cache.
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *obj);
/* 4) cache creation/removal */
// Character array storing the name of the cache.
const char *name;
/*
* Pointers for the doubly linked list of cache descriptors.
* 参见Subjects/Chapter06_Memory_Management/Figures/Memery_Layout_15.jpg
*/
struct list_head next;
/* 5) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. buffer_size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
int obj_size;
#endif /* CONFIG_DEBUG_SLAB */
/* 6) per-cpu/per-node data, touched during every alloc/free */
/*
* We put array[] at the end of kmem_cache, because we want to size
* this array to nr_cpu_ids slots instead of NR_CPUS (see kmem_cache_init()).
* We still use [NR_CPUS] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of cpus.
*/
struct kmem_list3 **nodelists;
// Per-CPU array of pointers to local caches of free objects.
struct array_cache *array[NR_CPUS];
/*
* Do not add fields after array[]
*/
};
struct kmem_list3定义于mm/slab.c:
struct kmem_list3 {
// Doubly linked circular list of slab descriptors with both free and nonfree object.
struct list_head slabs_partial; /* partial list first, better asm code */
// Doubly linked circular list of slab descriptors with no free objects.
struct list_head slabs_full;
// Doubly linked circular list of slab descriptors with free objects only.
struct list_head slabs_free;
// Number of free objects in the cache.
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
spinlock_t list_lock;
// Pointer to a local cache shared by all CPUs.
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
// Below two variable are used by the slab allocator’s page reclaiming algorithm.
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
};
Relationship between cache and slab descriptors:
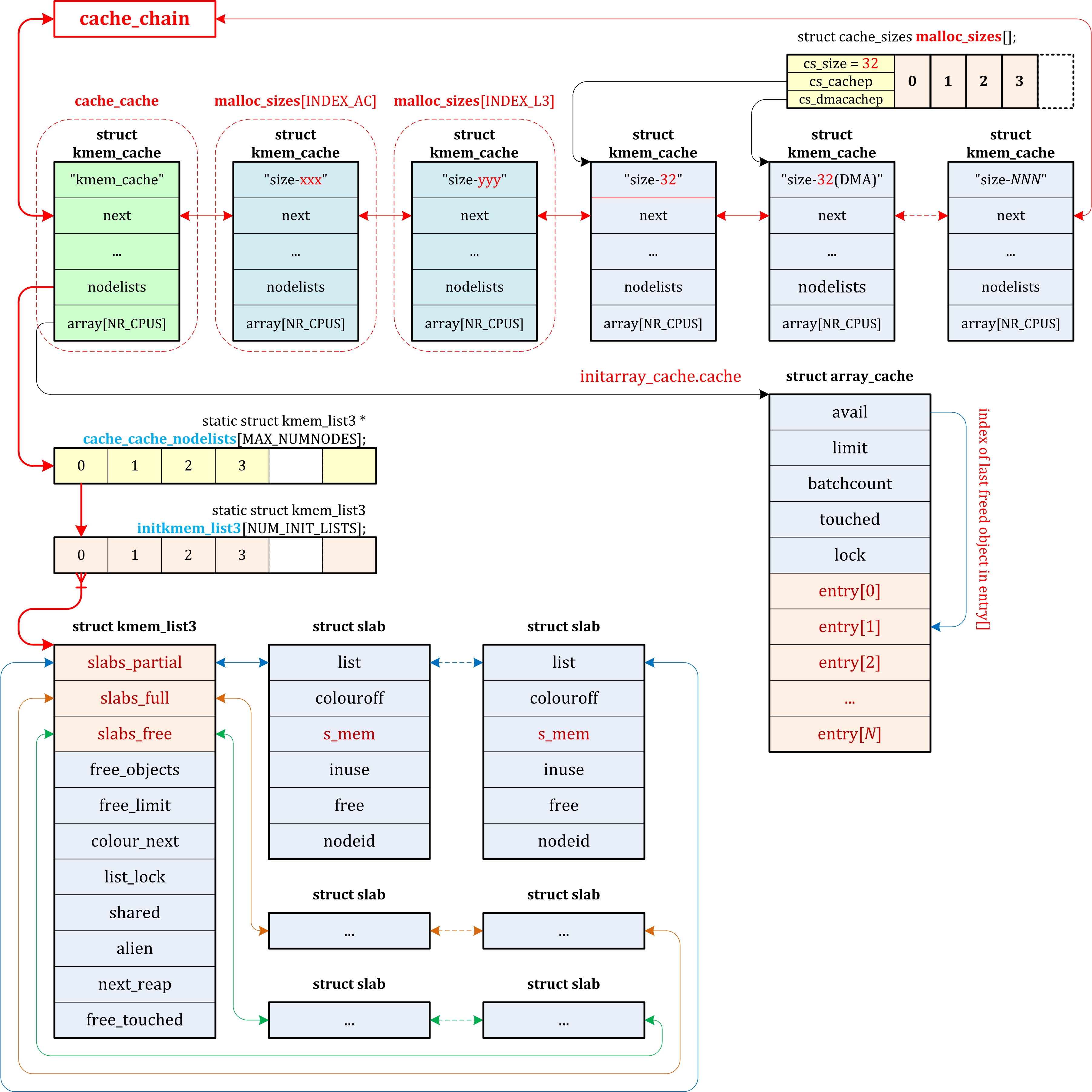
NOTE: Memery_Layout_15.jpg
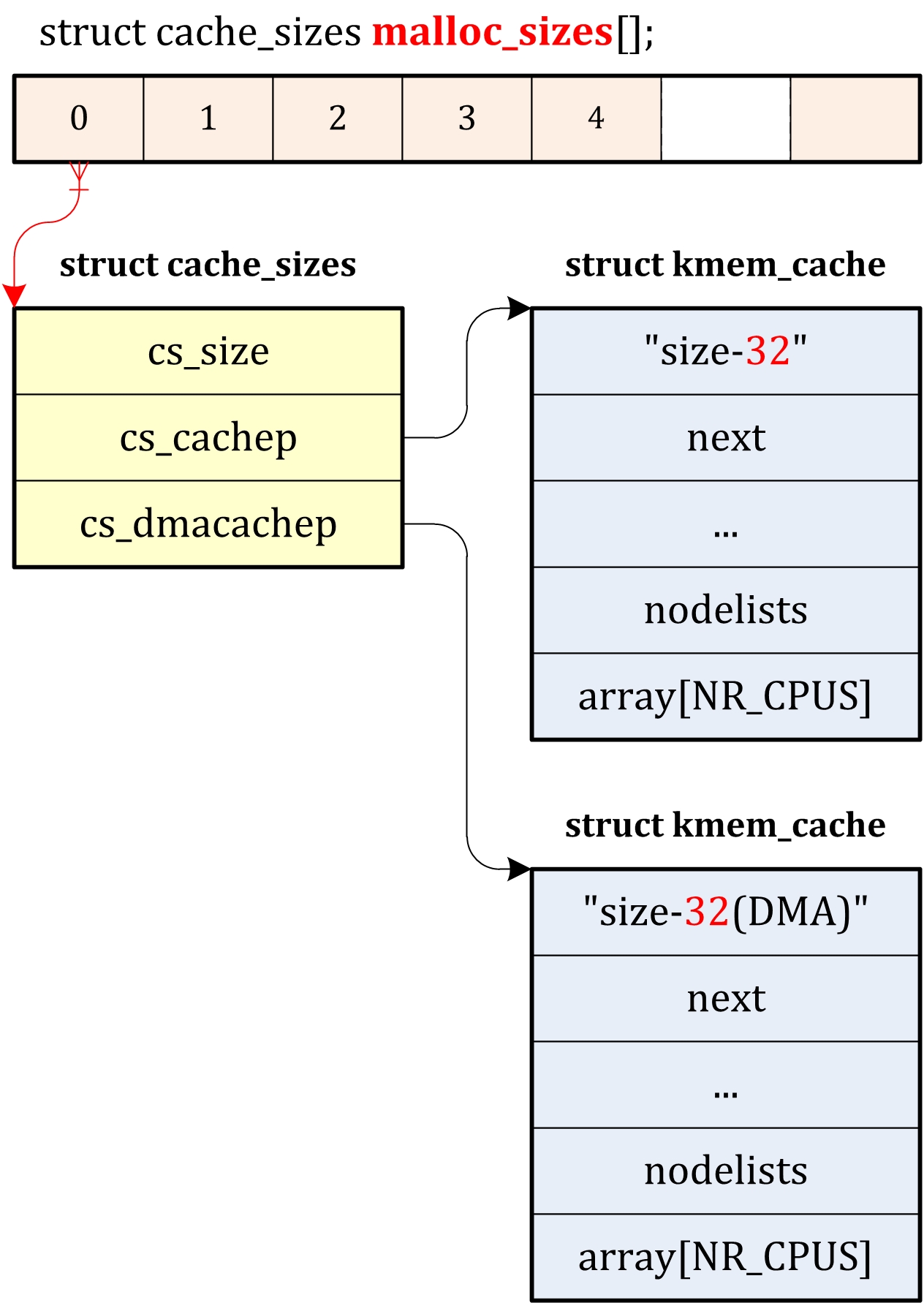
6.5.1.1 General Cache/Specific Cache
Caches are divided into two types: general and specific.
- General caches are used only by the slab allocator for its own purposes;
- Specific caches are used by the remaining parts of the kernel.
The names of all general and specific caches can be obtained at runtime by reading /proc/slabinfo; this file also specifies the number of free objects and the number of allocated objects in each cache.
The general caches are:
1) A first cache called kmem_cache whose objects are the cache descriptors of the remaining caches used by the kernel. The cache_cache variable contains the descriptor of this special cache. See mm/slab.c:
/* internal cache of cache description objs */
static struct kmem_list3 *cache_cache_nodelists[MAX_NUMNODES];
static struct kmem_cache cache_cache = {
.nodelists = cache_cache_nodelists,
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES, // 1
.shared = 1,
.buffer_size = sizeof(struct kmem_cache),
.name = "kmem_cache",
};
2) Several additional caches contain general purpose memory areas. The range of the memory area sizes typically includes 13 geometrically distributed sizes. A table called malloc_sizes (whose elements are of type cache_sizes) points to 26 cache descriptors associated with memory areas of size 32, 64, 128, 256, 512, 1,024, 2,048, 4,096, 8,192, 16,384, 32,768, 65,536, and 131,072 bytes. For each size, there are two caches: one suitable for ISA DMA allocations and the other for normal allocations. See mm/slab.c:
struct cache_sizes malloc_sizes[] = {
#define CACHE(x) { .cs_size = (x) },
#include <linux/kmalloc_sizes.h>
CACHE(ULONG_MAX)
#undef CACHE
};
static struct cache_names __initdata cache_names[] = {
#define CACHE(x) { .name = "size-" #x, .name_dma = "size-" #x "(DMA)" },
#include <linux/kmalloc_sizes.h>
{NULL,}
#undef CACHE
};
数组malloc_sizes[]的结构示意图:
其中,数组malloc_sizes[]和cache_names[]被扩展为:
struct cache_sizes malloc_sizes[] = {
#if (PAGE_SIZE == 4096)
{ .cs_size = 32 },
#endif
{ .cs_size = 64 },
#if L1_CACHE_BYTES < 64
{ .cs_size = 96 },
#endif
{ .cs_size = 128 },
#if L1_CACHE_BYTES < 128
{ .cs_size = 192 },
#endif
{ .cs_size = 256 },
{ .cs_size = 512 },
{ .cs_size = 1024 },
{ .cs_size = 2048 },
{ .cs_size = 4096 },
{ .cs_size = 8192 },
{ .cs_size = 16384 },
{ .cs_size = 32768 },
{ .cs_size = 65536 },
{ .cs_size = 131072 },
#if KMALLOC_MAX_SIZE >= 262144
{ .cs_size = 262144 },
#endif
#if KMALLOC_MAX_SIZE >= 524288
{ .cs_size = 524288 },
#endif
#if KMALLOC_MAX_SIZE >= 1048576
{ .cs_size = 1048576 },
#endif
#if KMALLOC_MAX_SIZE >= 2097152
{ .cs_size = 2097152 },
#endif
#if KMALLOC_MAX_SIZE >= 4194304
{ .cs_size = 4194304 },
#endif
#if KMALLOC_MAX_SIZE >= 8388608
{ .cs_size = 8388608 },
#endif
#if KMALLOC_MAX_SIZE >= 16777216
{ .cs_size = 16777216 },
#endif
#if KMALLOC_MAX_SIZE >= 33554432
{ .cs_size = 33554432 },
#endif
{ .cs_size = ULONG_MAX }
};
static struct cache_names __initdata cache_names[] = {
#if (PAGE_SIZE == 4096)
{ .name = "size-32", .name_dma = "size-32(MDA)" },
#endif
{ .name = "size-64", .name_dma = "size-64(MDA)" },
#if L1_CACHE_BYTES < 64
{ .name = "size-96", .name_dma = "size-96(MDA)" },
#endif
{ .name = "size-128", .name_dma = "size-128(MDA)" },
#if L1_CACHE_BYTES < 128
{ .name = "size-192", .name_dma = "size-192(MDA)" },
#endif
{ .name = "size-256", .name_dma = "size-256(MDA)" },
{ .name = "size-512", .name_dma = "size-512(MDA)" },
{ .name = "size-1024", .name_dma = "size-1024(MDA)" },
{ .name = "size-2048", .name_dma = "size-2048(MDA)" },
{ .name = "size-4096", .name_dma = "size-4096(MDA)" },
{ .name = "size-8192", .name_dma = "size-8192(MDA)" },
{ .name = "size-16384", .name_dma = "size-16384(MDA)" },
{ .name = "size-32768", .name_dma = "size-32768(MDA)" },
{ .name = "size-65536", .name_dma = "size-65536(MDA)" },
{ .name = "size-131072", .name_dma = "size-131072(MDA)" },
#if KMALLOC_MAX_SIZE >= 262144
{ .name = "size-262144", .name_dma = "size-262144(MDA)" },
#endif
#if KMALLOC_MAX_SIZE >= 524288
{ .name = "size-524288", .name_dma = "size-524288(MDA)" },
#endif
#if KMALLOC_MAX_SIZE >= 1048576
{ .name = "size-1048576", .name_dma = "size-1048576(MDA)" },
#endif
#if KMALLOC_MAX_SIZE >= 2097152
{ .name = "size-2097152", .name_dma = "size-2097152(MDA)" },
#endif
#if KMALLOC_MAX_SIZE >= 4194304
{ .name = "size-4194304", .name_dma = "size-4194304(MDA)" },
#endif
#if KMALLOC_MAX_SIZE >= 8388608
{ .name = "size-8388608", .name_dma = "size-8388608(MDA)" },
#endif
#if KMALLOC_MAX_SIZE >= 16777216
{ .name = "size-16777216", .name_dma = "size-16777216(MDA)" },
#endif
#if KMALLOC_MAX_SIZE >= 33554432
{ .name = "size-33554432", .name_dma = "size-33554432(MDA)" },
#endif
{ NULL, }
};
6.5.1.1.1 Initialize General Cache/kmem_cache_init()
The kmem_cache_init() function is invoked during system initialization to set up the general caches.
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> mm_init() // 参见[4.3.4.1.4.3.6 mm_init()]节
-> kmem_cache_init()
该函数定义于mm/slab.c:
#define NUM_INIT_LISTS (3 * MAX_NUMNODES)
static struct kmem_list3 __initdata initkmem_list3[NUM_INIT_LISTS];
static struct list_head cache_chain;
/*
* Initialisation. Called after the page allocator have been initialised and
* before smp_init().
*/
void __init kmem_cache_init(void)
{
size_t left_over;
struct cache_sizes *sizes;
struct cache_names *names;
int i;
int order;
int node;
if (num_possible_nodes() == 1)
use_alien_caches = 0;
for (i = 0; i < NUM_INIT_LISTS; i++) {
kmem_list3_init(&initkmem_list3[i]);
if (i < MAX_NUMNODES)
cache_cache.nodelists[i] = NULL;
}
// cache_cache->nodelists[i] = &initkmem_list3[i]
set_up_list3s(&cache_cache, CACHE_CACHE);
/*
* Fragmentation resistance on low memory - only use bigger
* page orders on machines with more than 32MB of memory.
*/
if (totalram_pages > (32 << 20) >> PAGE_SHIFT)
slab_break_gfp_order = BREAK_GFP_ORDER_HI;
/* Bootstrap is tricky, because several objects are allocated
* from caches that do not exist yet:
* 1) initialize the cache_cache cache: it contains the struct
* kmem_cache structures of all caches, except cache_cache itself:
* cache_cache is statically allocated.
* Initially an __init data area is used for the head array and the
* kmem_list3 structures, it's replaced with a kmalloc allocated
* array at the end of the bootstrap.
* 2) Create the first kmalloc cache.
* The struct kmem_cache for the new cache is allocated normally.
* An __init data area is used for the head array.
* 3) Create the remaining kmalloc caches, with minimally sized
* head arrays.
* 4) Replace the __init data head arrays for cache_cache and the first
* kmalloc cache with kmalloc allocated arrays.
* 5) Replace the __init data for kmem_list3 for cache_cache and
* the other cache's with kmalloc allocated memory.
* 6) Resize the head arrays of the kmalloc caches to their final sizes.
*/
node = numa_mem_id();
/* 1) create the cache_cache. 并将cache_cache链接到链表cache_chain中 */
INIT_LIST_HEAD(&cache_chain);
list_add(&cache_cache.next, &cache_chain);
cache_cache.colour_off = cache_line_size();
cache_cache.array[smp_processor_id()] = &initarray_cache.cache;
cache_cache.nodelists[node] = &initkmem_list3[CACHE_CACHE + node];
/*
* struct kmem_cache size depends on nr_node_ids & nr_cpu_ids
*/
cache_cache.buffer_size = offsetof(struct kmem_cache, array[nr_cpu_ids]) +
nr_node_ids * sizeof(struct kmem_list3 *);
#if DEBUG
cache_cache.obj_size = cache_cache.buffer_size;
#endif
cache_cache.buffer_size = ALIGN(cache_cache.buffer_size, cache_line_size());
cache_cache.reciprocal_buffer_size = reciprocal_value(cache_cache.buffer_size);
for (order = 0; order < MAX_ORDER; order++) {
cache_estimate(order, cache_cache.buffer_size, cache_line_size(), 0,
&left_over, &cache_cache.num);
if (cache_cache.num)
break;
}
BUG_ON(!cache_cache.num);
cache_cache.gfporder = order;
cache_cache.colour = left_over / cache_cache.colour_off;
cache_cache.slab_size = ALIGN(cache_cache.num * sizeof(kmem_bufctl_t) + sizeof(struct slab),
cache_line_size());
/* 2+3) create the kmalloc caches */
sizes = malloc_sizes; // 变量malloc_sizes参见[6.5.1.1 General Cache/Specific Cache]节
names = cache_names; // 变量cache_names参见[6.5.1.1 General Cache/Specific Cache]节
/*
* Initialize the caches that provide memory for the array cache and the
* kmem_list3 structures first. Without this, further allocations will bug.
*/
/*
* 创建一个cache并链接到链表cache_chain中,
* 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
*/
sizes[INDEX_AC].cs_cachep = kmem_cache_create(names[INDEX_AC].name, sizes[INDEX_AC].cs_size,
ARCH_KMALLOC_MINALIGN, ARCH_KMALLOC_FLAGS|SLAB_PANIC, NULL);
if (INDEX_AC != INDEX_L3) {
/*
* 创建一个cache并链接到链表cache_chain中,
* 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
*/
sizes[INDEX_L3].cs_cachep = kmem_cache_create(names[INDEX_L3].name, sizes[INDEX_L3].cs_size,
ARCH_KMALLOC_MINALIGN, ARCH_KMALLOC_FLAGS|SLAB_PANIC, NULL);
}
slab_early_init = 0;
while (sizes->cs_size != ULONG_MAX) {
/*
* For performance, all the general caches are L1 aligned.
* This should be particularly beneficial on SMP boxes, as it
* eliminates "false sharing".
* Note for systems short on memory removing the alignment will
* allow tighter packing of the smaller caches.
*/
if (!sizes->cs_cachep) {
/*
* 创建一个cache并链接到链表cache_chain中,
* 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
*/
sizes->cs_cachep = kmem_cache_create(names->name, sizes->cs_size,
ARCH_KMALLOC_MINALIGN, ARCH_KMALLOC_FLAGS|SLAB_PANIC, NULL);
}
#ifdef CONFIG_ZONE_DMA
/*
* 创建一个cache并链接到链表cache_chain中,
* 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
*/
sizes->cs_dmacachep = kmem_cache_create(names->name_dma, sizes->cs_size,
ARCH_KMALLOC_MINALIGN, ARCH_KMALLOC_FLAGS|SLAB_CACHE_DMA|SLAB_PANIC, NULL);
#endif
sizes++;
names++;
}
/* 4) Replace the bootstrap head arrays */
{
struct array_cache *ptr;
ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);
BUG_ON(cpu_cache_get(&cache_cache) != &initarray_cache.cache);
memcpy(ptr, cpu_cache_get(&cache_cache), sizeof(struct arraycache_init));
/*
* Do not assume that spinlocks can be initialized via memcpy:
*/
spin_lock_init(&ptr->lock);
cache_cache.array[smp_processor_id()] = ptr;
ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);
BUG_ON(cpu_cache_get(malloc_sizes[INDEX_AC].cs_cachep) != &initarray_generic.cache);
memcpy(ptr, cpu_cache_get(malloc_sizes[INDEX_AC].cs_cachep), sizeof(struct arraycache_init));
/*
* Do not assume that spinlocks can be initialized via memcpy:
*/
spin_lock_init(&ptr->lock);
malloc_sizes[INDEX_AC].cs_cachep->array[smp_processor_id()] = ptr;
}
/* 5) Replace the bootstrap kmem_list3's */
{
int nid;
for_each_online_node(nid) {
init_list(&cache_cache, &initkmem_list3[CACHE_CACHE + nid], nid);
init_list(malloc_sizes[INDEX_AC].cs_cachep, &initkmem_list3[SIZE_AC + nid], nid);
if (INDEX_AC != INDEX_L3) {
init_list(malloc_sizes[INDEX_L3].cs_cachep, &initkmem_list3[SIZE_L3 + nid], nid);
}
}
}
g_cpucache_up = EARLY;
}
6.5.1.1.2 Create a Specific Cache/kmem_cache_create()
宏KMEM_CACHE()用于创建cache,其定义于include/linux/slab.h:
/*
* Please use this macro to create slab caches. Simply specify the
* name of the structure and maybe some flags that are listed above.
*
* The alignment of the struct determines object alignment. If you
* f.e. add ____cacheline_aligned_in_smp to the struct declaration
* then the objects will be properly aligned in SMP configurations.
*/
#define KMEM_CACHE(__struct, __flags) kmem_cache_create(#__struct, \
sizeof(struct __struct), __alignof__(struct __struct), \
(__flags), NULL)
或者直接调用函数kmem_cache_create()来创建cache,其定义于mm/slab.c:
/**
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo to identify this cache.
* @size: The size of objects to be created in this cache.
* @align: The required alignment for the objects.
* @flags: SLAB flags
* @ctor: A constructor for the objects.
*
* Returns a ptr to the cache on success, NULL on failure.
* Cannot be called within a int, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache.
*
* @name must be valid until the cache is destroyed. This implies that
* the module calling this has to destroy the cache before getting unloaded.
*
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*/
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *))
{
size_t left_over, slab_size, ralign;
struct kmem_cache *cachep = NULL, *pc;
gfp_t gfp;
/*
* Sanity checks... these are all serious usage bugs.
*/
if (!name || in_interrupt() || (size < BYTES_PER_WORD) || size > KMALLOC_MAX_SIZE) {
printk(KERN_ERR "%s: Early error in slab %s\n", __func__, name);
BUG();
}
/*
* We use cache_chain_mutex to ensure a consistent view of
* cpu_online_mask as well. Please see cpuup_callback
*/
if (slab_is_available()) {
get_online_cpus();
mutex_lock(&cache_chain_mutex);
}
// 检查链表cache_chain中是否已存在该cache
list_for_each_entry(pc, &cache_chain, next) {
char tmp;
int res;
/*
* This happens when the module gets unloaded and doesn't
* destroy its slab cache and no-one else reuses the vmalloc
* area of the module. Print a warning.
*/
res = probe_kernel_address(pc->name, tmp);
if (res) {
printk(KERN_ERR "SLAB: cache with size %d has lost its name\n", pc->buffer_size);
continue;
}
if (!strcmp(pc->name, name)) {
printk(KERN_ERR "kmem_cache_create: duplicate cache %s\n", name);
dump_stack();
goto oops;
}
}
#if DEBUG
WARN_ON(strchr(name, ' ')); /* It confuses parsers */
#if FORCED_DEBUG
/*
* Enable redzoning and last user accounting, except for caches with
* large objects, if the increased size would increase the object size
* above the next power of two: caches with object sizes just above a
* power of two have a significant amount of internal fragmentation.
*/
if (size < 4096 || fls(size - 1) == fls(size-1 + REDZONE_ALIGN + 2 * sizeof(unsigned long long)))
flags |= SLAB_RED_ZONE | SLAB_STORE_USER;
if (!(flags & SLAB_DESTROY_BY_RCU))
flags |= SLAB_POISON;
#endif
if (flags & SLAB_DESTROY_BY_RCU)
BUG_ON(flags & SLAB_POISON);
#endif
/*
* Always checks flags, a caller might be expecting debug support which
* isn't available.
*/
/* To prevent callers using the wrong flags, a CREATE_MASK is defined
* consisting of all the allowable flags. When a cache is being created,
* the requested flags are compared against the CREATE_MASK and reported
* as a bug if invalid flags are used.
*/
BUG_ON(flags & ~CREATE_MASK);
/*
* Check that size is in terms of words. This is needed to avoid
* unaligned accesses for some archs when redzoning is used, and makes
* sure any on-slab bufctl's are also correctly aligned.
*/
if (size & (BYTES_PER_WORD - 1)) {
size += (BYTES_PER_WORD - 1);
size &= ~(BYTES_PER_WORD - 1);
}
/* calculate the final buffer alignment: */
/*
* The objects managed by the slab allocator are aligned in memory
* - that is, they are stored in memory cells whose initial physical
* addresses are multiples of a given constant, which is usually a
* power of 2. This constant is called the alignment factor.
* The largest alignment factor allowed by the slab allocator
* is 4,096 — the page frame size.
*/
/* 1) arch recommendation: can be overridden for debug */
if (flags & SLAB_HWCACHE_ALIGN) {
/*
* Default alignment: as specified by the arch code. Except if
* an object is really small, then squeeze multiple objects into
* one cacheline.
*/
ralign = cache_line_size();
while (size <= ralign / 2)
ralign /= 2;
} else {
/*
* Usually, microcomputers access memory cells more quickly
* if their physical addresses are aligned with respect to
* the word size (that's, to the width of the internal memory
* bus of the computer).
*/
ralign = BYTES_PER_WORD;
}
/*
* Redzoning and user store require word alignment or possibly larger.
* Note this will be overridden by architecture or caller mandated
* alignment if either is greater than BYTES_PER_WORD.
*/
if (flags & SLAB_STORE_USER)
ralign = BYTES_PER_WORD;
if (flags & SLAB_RED_ZONE) {
ralign = REDZONE_ALIGN;
/* If redzoning, ensure that the second redzone is suitably
* aligned, by adjusting the object size accordingly. */
size += REDZONE_ALIGN - 1;
size &= ~(REDZONE_ALIGN - 1);
}
/* 2) arch mandated alignment */
if (ralign < ARCH_SLAB_MINALIGN) {
ralign = ARCH_SLAB_MINALIGN;
}
/* 3) caller mandated alignment */
if (ralign < align) {
ralign = align;
}
/* disable debug if necessary */
if (ralign > __alignof__(unsigned long long))
flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
/*
* 4) Store it.
*/
align = ralign;
if (slab_is_available())
gfp = GFP_KERNEL;
else
gfp = GFP_NOWAIT;
/* Get cache's description obj. 参见[6.5.1.1.3.1 kmem_cache_zalloc()]节 */
cachep = kmem_cache_zalloc(&cache_cache, gfp);
if (!cachep)
goto oops;
cachep->nodelists = (struct kmem_list3 **)&cachep->array[nr_cpu_ids];
#if DEBUG
cachep->obj_size = size;
/*
* Both debugging options require word-alignment which is calculated
* into align above.
*/
if (flags & SLAB_RED_ZONE) {
/* add space for red zone words */
cachep->obj_offset += sizeof(unsigned long long);
size += 2 * sizeof(unsigned long long);
}
if (flags & SLAB_STORE_USER) {
/* user store requires one word storage behind the end of
* the real object. But if the second red zone needs to be
* aligned to 64 bits, we must allow that much space.
*/
if (flags & SLAB_RED_ZONE)
size += REDZONE_ALIGN;
else
size += BYTES_PER_WORD;
}
#if FORCED_DEBUG && defined(CONFIG_DEBUG_PAGEALLOC)
if (size >= malloc_sizes[INDEX_L3 + 1].cs_size &&
cachep->obj_size > cache_line_size() &&
ALIGN(size, align) < PAGE_SIZE) {
cachep->obj_offset += PAGE_SIZE - ALIGN(size, align);
size = PAGE_SIZE;
}
#endif
#endif
/*
* Determine if the slab management is 'on' or 'off' slab.
* (bootstrapping cannot cope with offslab caches so don't do
* it too early on. Always use on-slab management when
* SLAB_NOLEAKTRACE to avoid recursive calls into kmemleak)
*/
if ((size >= (PAGE_SIZE >> 3)) && !slab_early_init && !(flags & SLAB_NOLEAKTRACE))
/*
* Size is large, assume best to place the slab management obj
* off-slab (should allow better packing of objs).
*/
flags |= CFLGS_OFF_SLAB;
size = ALIGN(size, align);
left_over = calculate_slab_order(cachep, size, align, flags);
if (!cachep->num) {
printk(KERN_ERR "kmem_cache_create: couldn't create cache %s.\n", name);
kmem_cache_free(&cache_cache, cachep);
cachep = NULL;
goto oops;
}
slab_size = ALIGN(cachep->num * sizeof(kmem_bufctl_t) + sizeof(struct slab), align);
/*
* If the slab has been placed off-slab, and we have enough space then
* move it on-slab. This is at the expense of any extra colouring.
*/
if (flags & CFLGS_OFF_SLAB && left_over >= slab_size) {
flags &= ~CFLGS_OFF_SLAB;
left_over -= slab_size;
}
if (flags & CFLGS_OFF_SLAB) {
/* really off slab. No need for manual alignment */
slab_size = cachep->num * sizeof(kmem_bufctl_t) + sizeof(struct slab);
#ifdef CONFIG_PAGE_POISONING
/* If we're going to use the generic kernel_map_pages()
* poisoning, then it's going to smash the contents of
* the redzone and userword anyhow, so switch them off.
*/
if (size % PAGE_SIZE == 0 && flags & SLAB_POISON)
flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
#endif
}
cachep->colour_off = cache_line_size();
/* Offset must be a multiple of the alignment. */
if (cachep->colour_off < align)
cachep->colour_off = align;
cachep->colour = left_over / cachep->colour_off;
cachep->slab_size = slab_size;
cachep->flags = flags;
cachep->gfpflags = 0;
if (CONFIG_ZONE_DMA_FLAG && (flags & SLAB_CACHE_DMA))
cachep->gfpflags |= GFP_DMA;
cachep->buffer_size = size;
cachep->reciprocal_buffer_size = reciprocal_value(size);
if (flags & CFLGS_OFF_SLAB) {
cachep->slabp_cache = kmem_find_general_cachep(slab_size, 0u);
/*
* This is a possibility for one of the malloc_sizes caches.
* But since we go off slab only for object size greater than
* PAGE_SIZE/8, and malloc_sizes gets created in ascending order,
* this should not happen at all.
* But leave a BUG_ON for some lucky dude.
*/
BUG_ON(ZERO_OR_NULL_PTR(cachep->slabp_cache));
}
cachep->ctor = ctor;
cachep->name = name;
// 设置cachep->array[*]
if (setup_cpu_cache(cachep, gfp)) {
__kmem_cache_destroy(cachep);
cachep = NULL;
goto oops;
}
if (flags & SLAB_DEBUG_OBJECTS) {
/*
* Would deadlock through slab_destroy()->call_rcu()->
* debug_object_activate()->kmem_cache_alloc().
*/
WARN_ON_ONCE(flags & SLAB_DESTROY_BY_RCU);
slab_set_debugobj_lock_classes(cachep);
}
/* cache setup completed, link it into the list */
list_add(&cachep->next, &cache_chain);
oops:
if (!cachep && (flags & SLAB_PANIC))
panic("kmem_cache_create(): failed to create slab `%s'\n", name);
if (slab_is_available()) {
mutex_unlock(&cache_chain_mutex);
put_online_cpus();
}
return cachep;
}
6.5.1.1.2.1 查看slab的分配信息
调用宏KMEM_CACHE()或者函数kmem_cache_create()来创建specific cache时,若满足如下条件之一,则可以在/proc/slabinfo中显示slab的分配信息:
- 入参flags中包含SLAB_POISON, SLAB_RED_ZONE等标志,仅包含SLAB_HWCACHE_ALIGN,则不可以;
- 入参ctor不为NULL;即定义了构造函数,即使该构造函数为空函数。
使用下列命令查看slab的分配信息:
chenwx@chenwx ~ $ sudo cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
UDPLITEv6 0 0 1088 15 4 : tunables 0 0 0 : slabdata 0 0 0
UDPv6 17 30 1088 15 4 : tunables 0 0 0 : slabdata 2 2 0
tw_sock_TCPv6 0 0 256 16 1 : tunables 0 0 0 : slabdata 0 0 0
...
kmalloc-64 22167 22336 64 64 1 : tunables 0 0 0 : slabdata 349 349 0
kmalloc-32 10328 10752 32 128 1 : tunables 0 0 0 : slabdata 84 84 0
kmalloc-16 5888 5888 16 256 1 : tunables 0 0 0 : slabdata 23 23 0
kmalloc-8 5118 5120 8 512 1 : tunables 0 0 0 : slabdata 10 10 0
kmem_cache_node 192 192 64 64 1 : tunables 0 0 0 : slabdata 3 3 0
kmem_cache 112 112 256 16 1 : tunables 0 0 0 : slabdata 7 7 0
chenwx@chenwx ~ $ sudo slabtop
Active / Total Objects (% used) : 654908 / 679233 (96.4%)
Active / Total Slabs (% used) : 26620 / 26620 (100.0%)
Active / Total Caches (% used) : 65 / 95 (68.4%)
Active / Total Size (% used) : 191054.42K / 194205.16K (98.4%)
Minimum / Average / Maximum Object : 0.01K / 0.29K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
179556 173481 96% 0.10K 4604 39 18416K buffer_head
174594 174490 99% 0.19K 8314 21 33256K dentry
94736 94736 100% 0.96K 5921 16 94736K ext4_inode_cache
41514 30931 74% 0.04K 407 102 1628K ext4_extent_status
31794 31187 98% 0.55K 2271 14 18168K radix_tree_node
24570 23241 94% 0.19K 1170 21 4680K kmalloc-192
23364 23051 98% 0.11K 649 36 2596K sysfs_dir_cache
22656 21742 95% 0.06K 354 64 1416K kmalloc-64
11102 11065 99% 0.57K 793 14 6344K inode_cache
10752 10016 93% 0.03K 84 128 336K kmalloc-32
8576 7744 90% 0.06K 134 64 536K anon_vma
8304 7635 91% 0.25K 519 16 2076K kmalloc-256
7225 7225 100% 0.05K 85 85 340K shared_policy_node
5888 5888 100% 0.02K 23 256 92K kmalloc-16
5120 5118 99% 0.01K 10 512 40K kmalloc-8
...
chenwx@chenwx ~/linux-next $ ll /sys/kernel/slab/
total 0
drwxr-xr-x 2 root root 0 Jan 19 21:43 :at-0000016
drwxr-xr-x 2 root root 0 Jan 19 21:43 :at-0000032
...
lrwxrwxrwx 1 root root 0 Jan 19 21:43 Acpi-Namespace -> :t-0000040
lrwxrwxrwx 1 root root 0 Jan 19 21:43 Acpi-Operand -> :t-0000072
lrwxrwxrwx 1 root root 0 Jan 19 21:43 Acpi-Parse -> :t-0000048
lrwxrwxrwx 1 root root 0 Jan 19 21:43 Acpi-ParseExt -> :t-0000072
lrwxrwxrwx 1 root root 0 Jan 19 21:43 Acpi-State -> :t-0000080
lrwxrwxrwx 1 root root 0 Jan 19 21:43 PING -> :t-0000896
lrwxrwxrwx 1 root root 0 Jan 19 21:43 PINGv6 -> :t-0001088
lrwxrwxrwx 1 root root 0 Jan 19 21:43 RAW -> :t-0000896
lrwxrwxrwx 1 root root 0 Jan 19 21:43 RAWv6 -> :t-0001088
...
若系统配置了SLUB,则可用下列命令查看系统中的slab信息:
chenwx@chenwx ~/linux-next/tools/vm $ grep "CONFIG_SLUB" /boot/config-3.13.0-24-generic
CONFIG_SLUB_DEBUG=y
CONFIG_SLUB=y
CONFIG_SLUB_CPU_PARTIAL=y
# CONFIG_SLUB_DEBUG_ON is not set
# CONFIG_SLUB_STATS is not set
chenwx@chenwx ~/linux-next/tools/vm $ ./slabinfo -a
:at-0000104 <- ext4_prealloc_space buffer_head
:at-0000136 <- ext4_allocation_context ext4_groupinfo_4k
:at-0000256 <- jbd2_transaction_s dquot
:t-0000016 <- dm_mpath_io kmalloc-16 ecryptfs_file_cache
:t-0000024 <- numa_policy fsnotify_event_holder scsi_data_buffer
:t-0000032 <- ecryptfs_dentry_info_cache kmalloc-32 sd_ext_cdb inotify_event_private_data fanotify_response_event dnotify_struct
:t-0000040 <- Acpi-Namespace dm_io khugepaged_mm_slot ext4_system_zone
:t-0000048 <- shared_policy_node ksm_mm_slot ksm_stable_node fasync_cache Acpi-Parse jbd2_inode nsproxy identity ftrace_event_field ip_fib_alias
:t-0000056 <- ip_fib_trie uhci_urb_priv
:t-0000064 <- ecryptfs_key_sig_cache fib6_nodes id_kmem_cache secpath_cache dmaengine-unmap-2 kmalloc-64 tcp_bind_bucket anon_vma_chain io ksm_rmap_item fs_cache ecryptfs_global_auth_tok_cache
:t-0000072 <- ftrace_event_file Acpi-ParseExt Acpi-Operand eventpoll_pwq
:t-0000104 <- flow_cache blkdev_ioc
:t-0000112 <- sysfs_dir_cache task_delay_info fsnotify_mark blkdev_integrity
:t-0000120 <- fsnotify_event dnotify_mark inotify_inode_mark cfq_io_cq
:t-0000128 <- ecryptfs_key_tfm_cache eventpoll_epi ip6_mrt_cache kmalloc-128 scsi_sense_cache btree_node pid ip_mrt_cache uid_cache kiocb
:t-0000192 <- kmalloc-192 dmaengine-unmap-16 key_jar cred_jar inet_peer_cache vm_area_struct bio_integrity_payload ip_dst_cache file_lock_cache bio-0
:t-0000256 <- filp sgpool-8 scsi_cmd_cache skbuff_head_cache biovec-16 kmalloc-256 request_sock_TCP request_sock_TCPv6 pool_workqueue
:t-0000384 <- ip6_dst_cache blkdev_requests i915_gem_object
:t-0000512 <- skbuff_fclone_cache kmalloc-512 sgpool-16 task_xstate
:t-0000640 <- dio kioctx files_cache
:t-0000896 <- PING UNIX mm_struct ecryptfs_sb_cache RAW
:t-0001024 <- sgpool-32 kmalloc-1024 biovec-64
:t-0001088 <- signal_cache dmaengine-unmap-128 PINGv6 RAWv6
:t-0002048 <- biovec-128 sgpool-64 kmalloc-2048
:t-0002112 <- idr_layer_cache dmaengine-unmap-256
:t-0004096 <- names_cache biovec-256 ecryptfs_headers net_namespace kmalloc-4096 ecryptfs_xattr_cache sgpool-128
6.5.1.1.2.2 如何创建和读取文件/proc/slabinfo
1) Create file /proc/slabinfo
slab_proc_init()
-> proc_create("slabinfo", S_IWUSR|S_IRUSR, NULL, &proc_slabinfo_operations);
static const struct file_operations proc_slabinfo_operations = {
.open = slabinfo_open,
.read = seq_read,
.write = slabinfo_write,
.llseek = seq_lseek,
.release = seq_release,
};
2) Read from /proc/slabinfo
proc_slabinfo_operations->open()
-> slabinfo_open()
-> seq_open(file, &slabinfo_op);
-> p = file->private_data;
-> p->op = op; // file->private_data->op = &slabinfo_op;
static const struct seq_operations slabinfo_op = {
.start = s_start,
.next = s_next,
.stop = s_stop,
.show = s_show,
};
proc_slabinfo_operations->read()
-> seq_read()
-> m = file->private_data;
-> m->op->start(m, &pos); // slabinfo_op->start => s_start()
-> m->op->show(m, p); // slabinfo_op->show => s_show()
-> m->op->next(m, p, &pos); // slabinfo_op->next => s_next()
-> m->op->stop(m, p); // slabinfo_op->stop => s_stop()
-> ... loop again ...
proc_slabinfo_operations->close()
-> seq_release()
-> m = file->private_data;
-> kfree(m->buf);
-> kfree(m);
6.5.1.1.3 Allocate an object from Specific Cache
6.5.1.1.3.1 kmem_cache_zalloc()
该函数的调用关系如下:
kmem_cache_zalloc(&cache_cache, gfp)
-> kmem_cache_alloc(k, flags | __GFP_ZERO) // 参见[6.5.1.1.3.2 kmem_cache_alloc()]节
-> __cache_alloc(cachep, flags, ..)
-> __do_cache_alloc()
-> ____cache_alloc()
-> cache_alloc_refill()
-> cache_grow()
-> kmem_getpages()
-> alloc_pages_exact_node()
-> __alloc_pages() // 参见[6.4.1.1 alloc_pages()/alloc_pages_node()]节
该函数定义于include/linux/slab.h:
static inline void *kmem_cache_zalloc(struct kmem_cache *k, gfp_t flags)
{
// 参见[6.5.1.1.3.2 kmem_cache_alloc()]节
return kmem_cache_alloc(k, flags | __GFP_ZERO);
}
6.5.1.1.3.2 kmem_cache_alloc()
该函数定义于mm/slab.c:
/**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache. The flags are only relevant
* if the cache has no available objects.
*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *ret = __cache_alloc(cachep, flags, __builtin_return_address(0));
trace_kmem_cache_alloc(_RET_IP_, ret, obj_size(cachep), cachep->buffer_size, flags);
return ret;
}
其中,函数__cache_alloc()定义于mm/slab.c:
static __always_inline void *__cache_alloc(struct kmem_cache *cachep, gfp_t flags, void *caller)
{
unsigned long save_flags;
void *objp;
flags &= gfp_allowed_mask;
lockdep_trace_alloc(flags);
if (slab_should_failslab(cachep, flags))
return NULL;
cache_alloc_debugcheck_before(cachep, flags);
local_irq_save(save_flags);
objp = __do_cache_alloc(cachep, flags);
local_irq_restore(save_flags);
objp = cache_alloc_debugcheck_after(cachep, flags, objp, caller);
kmemleak_alloc_recursive(objp, obj_size(cachep), 1, cachep->flags, flags);
prefetchw(objp);
if (likely(objp))
kmemcheck_slab_alloc(cachep, flags, objp, obj_size(cachep));
if (unlikely((flags & __GFP_ZERO) && objp))
memset(objp, 0, obj_size(cachep));
return objp;
}
其中,函数__do_cache_alloc()定义于mm/slab.c:
#ifdef CONFIG_NUMA
static __always_inline void *__do_cache_alloc(struct kmem_cache *cache, gfp_t flags)
{
void *objp;
if (unlikely(current->flags & (PF_SPREAD_SLAB | PF_MEMPOLICY))) {
objp = alternate_node_alloc(cache, flags);
if (objp)
goto out;
}
objp = ____cache_alloc(cache, flags);
/*
* We may just have run out of memory on the local node.
* ____cache_alloc_node() knows how to locate memory on other nodes
*/
if (!objp)
objp = ____cache_alloc_node(cache, flags, numa_mem_id());
out:
return objp;
}
#else
static __always_inline void *__do_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
return ____cache_alloc(cachep, flags);
}
#endif /* CONFIG_NUMA */
其中,函数____cache_alloc()定义于mm/slab.c:
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *objp;
struct array_cache *ac;
check_irq_off();
// ac = cachep->array[smp_processor_id()];
ac = cpu_cache_get(cachep);
if (likely(ac->avail)) {
STATS_INC_ALLOCHIT(cachep);
ac->touched = 1;
/*
* The avail field contains the index in the local cache
* of the entry that points to the last freed object.
*/
objp = ac->entry[--ac->avail];
} else {
STATS_INC_ALLOCMISS(cachep);
// 参见[6.5.1.1.3.2.1 cache_alloc_refill()]节
objp = cache_alloc_refill(cachep, flags);
/*
* the 'ac' may be updated by cache_alloc_refill(),
* and kmemleak_erase() requires its correct value.
*/
// ac = cachep->array[smp_processor_id()];
ac = cpu_cache_get(cachep);
}
/*
* To avoid a false negative, if an object that is in one of the
* per-CPU caches is leaked, we need to make sure kmemleak doesn't
* treat the array pointers as a reference to the object.
*/
if (objp)
kmemleak_erase(&ac->entry[ac->avail]);
return objp;
}
6.5.1.1.3.2.1 cache_alloc_refill()
该函数定义于mm/slab.c:
static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags)
{
int batchcount;
struct kmem_list3 *l3;
struct array_cache *ac;
int node;
retry:
check_irq_off();
node = numa_mem_id();
ac = cpu_cache_get(cachep);
batchcount = ac->batchcount;
if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {
/*
* If there was little recent activity on this cache, then
* perform only a partial refill. Otherwise we could generate
* refill bouncing.
*/
batchcount = BATCHREFILL_LIMIT;
}
l3 = cachep->nodelists[node];
BUG_ON(ac->avail > 0 || !l3);
spin_lock(&l3->list_lock);
/* See if we can refill from the shared array */
if (l3->shared && transfer_objects(ac, l3->shared, batchcount)) {
l3->shared->touched = 1;
goto alloc_done;
}
while (batchcount > 0) {
struct list_head *entry;
struct slab *slabp;
/* Get slab alloc is to come from. */
// 1) Get slab alloc from ->slabs_parial by default;
entry = l3->slabs_partial.next;
// 2) Get slab alloc from ->slabs_free is ->slabs_parial is empty;
if (entry == &l3->slabs_partial) {
l3->free_touched = 1;
entry = l3->slabs_free.next;
// 3) Alloc new slab even if ->slabs_free is empty.
if (entry == &l3->slabs_free)
goto must_grow;
}
slabp = list_entry(entry, struct slab, list);
check_slabp(cachep, slabp);
check_spinlock_acquired(cachep);
/*
* The slab was either on partial or free list so
* there must be at least one object available for
* allocation.
*/
BUG_ON(slabp->inuse >= cachep->num);
while (slabp->inuse < cachep->num && batchcount--) {
STATS_INC_ALLOCED(cachep);
STATS_INC_ACTIVE(cachep);
STATS_SET_HIGH(cachep);
// 参见[6.5.1.1.3.2.1.1 slab_get_obj()]节
ac->entry[ac->avail++] = slab_get_obj(cachep, slabp, node);
}
check_slabp(cachep, slabp);
/* move slabp to correct slabp list: */
list_del(&slabp->list);
if (slabp->free == BUFCTL_END)
list_add(&slabp->list, &l3->slabs_full);
else
list_add(&slabp->list, &l3->slabs_partial);
}
must_grow:
l3->free_objects -= ac->avail;
alloc_done:
spin_unlock(&l3->list_lock);
if (unlikely(!ac->avail)) {
int x;
// 参见[6.5.1.1.3.2.2 cache_grow()]节
x = cache_grow(cachep, flags | GFP_THISNODE, node, NULL);
/* cache_grow can reenable interrupts, then ac could change. */
ac = cpu_cache_get(cachep);
if (!x && ac->avail == 0) /* no objects in sight? abort */
return NULL;
if (!ac->avail) /* objects refilled by interrupt? */
goto retry;
}
ac->touched = 1;
return ac->entry[--ac->avail];
}
6.5.1.1.3.2.1.1 slab_get_obj()
该函数定义于mm/slab.c:
static void *slab_get_obj(struct kmem_cache *cachep, struct slab *slabp, int nodeid)
{
// objp = slabp->s_mem + cachep->buffer_size * slabp->free;
void *objp = index_to_obj(cachep, slabp, slabp->free);
kmem_bufctl_t next;
slabp->inuse++;
// next = (kmem_bufctl_t *)(slabp + 1)[slabp->free];
next = slab_bufctl(slabp)[slabp->free];
#if DEBUG
slab_bufctl(slabp)[slabp->free] = BUFCTL_FREE;
WARN_ON(slabp->nodeid != nodeid);
#endif
slabp->free = next;
return objp;
}
6.5.1.1.3.2.2 cache_grow()
该函数定义于mm/slab.c:
/*
* Grow (by 1) the number of slabs within a cache. This is called by
* kmem_cache_alloc() when there are no active objs left in a cache.
*/
static int cache_grow(struct kmem_cache *cachep, gfp_t flags, int nodeid, void *objp)
{
struct slab *slabp;
size_t offset;
gfp_t local_flags;
struct kmem_list3 *l3;
/*
* Be lazy and only check for valid flags here, keeping it out of the
* critical path in kmem_cache_alloc().
*/
BUG_ON(flags & GFP_SLAB_BUG_MASK);
local_flags = flags & (GFP_CONSTRAINT_MASK|GFP_RECLAIM_MASK);
/* Take the l3 list lock to change the colour_next on this node */
check_irq_off();
l3 = cachep->nodelists[nodeid];
spin_lock(&l3->list_lock);
/* Get colour for the slab, and cal the next value. */
offset = l3->colour_next;
l3->colour_next++;
if (l3->colour_next >= cachep->colour)
l3->colour_next = 0;
spin_unlock(&l3->list_lock);
offset *= cachep->colour_off;
if (local_flags & __GFP_WAIT)
local_irq_enable();
/*
* The test for missing atomic flag is performed here, rather than
* the more obvious place, simply to reduce the critical path length
* in kmem_cache_alloc(). If a caller is seriously mis-behaving they
* will eventually be caught here (where it matters).
*/
kmem_flagcheck(cachep, flags);
/*
* Get mem for the objs. Attempt to allocate a physical page from 'nodeid'.
*/
if (!objp)
objp = kmem_getpages(cachep, local_flags, nodeid); // 参见[6.5.1.1.3.2.2.1 kmem_getpages()]节
if (!objp)
goto failed;
/* Get slab management. */
slabp = alloc_slabmgmt(cachep, objp, offset, local_flags & ~GFP_CONSTRAINT_MASK, nodeid);
if (!slabp)
goto opps1;
slab_map_pages(cachep, slabp, objp);
// Applies the constructor method (if defined)
// to all the objects contained in the new slab.
cache_init_objs(cachep, slabp);
if (local_flags & __GFP_WAIT)
local_irq_disable();
check_irq_off();
spin_lock(&l3->list_lock);
/* Make slab active. */
// Add the newly obtained slab descriptor at the end
// of the fully free slab list of the cache descriptor.
list_add_tail(&slabp->list, &(l3->slabs_free));
STATS_INC_GROWN(cachep);
l3->free_objects += cachep->num;
spin_unlock(&l3->list_lock);
return 1;
opps1:
kmem_freepages(cachep, objp);
failed:
if (local_flags & __GFP_WAIT)
local_irq_disable();
return 0;
}
6.5.1.1.3.2.2.1 kmem_getpages()
The method obtains from the zoned page frame allocator the group of page frames needed to store a single slab.
该函数定义于mm/slab.c:
/*
* Interface to system's page allocator. No need to hold the cache-lock.
*
* If we requested dmaable memory, we will get it. Even if we
* did not request dmaable memory, we might get it, but that
* would be relatively rare and ignorable.
*/
static void *kmem_getpages(struct kmem_cache *cachep, gfp_t flags, int nodeid)
{
struct page *page;
int nr_pages;
int i;
#ifndef CONFIG_MMU
/*
* Nommu uses slab's for process anonymous memory allocations, and thus
* requires __GFP_COMP to properly refcount higher order allocations
*/
flags |= __GFP_COMP;
#endif
flags |= cachep->gfpflags;
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
flags |= __GFP_RECLAIMABLE;
// 通过调用__alloc_pages()分配2cachep->gfporder个连续物理页面,参见[6.4.1.1 alloc_pages()/alloc_pages_node()]节
page = alloc_pages_exact_node(nodeid, flags | __GFP_NOTRACK, cachep->gfporder);
if (!page)
return NULL;
nr_pages = (1 << cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
add_zone_page_state(page_zone(page), NR_SLAB_RECLAIMABLE, nr_pages);
else
add_zone_page_state(page_zone(page), NR_SLAB_UNRECLAIMABLE, nr_pages);
for (i = 0; i < nr_pages; i++)
__SetPageSlab(page + i); // 设置page->flags中的标志位PG_slab
if (kmemcheck_enabled && !(cachep->flags & SLAB_NOTRACK)) {
kmemcheck_alloc_shadow(page, cachep->gfporder, flags, nodeid);
if (cachep->ctor)
kmemcheck_mark_uninitialized_pages(page, nr_pages);
else
kmemcheck_mark_unallocated_pages(page, nr_pages);
}
return page_address(page);
}
6.5.1.1.3.2.2.2 alloc_slabmgmt()
该函数定义于mm/slab.c:
/*
* Get the memory for a slab management obj.
* For a slab cache when the slab descriptor is off-slab, slab descriptors
* always come from malloc_sizes caches. The slab descriptor cannot
* come from the same cache which is getting created because,
* when we are searching for an appropriate cache for these
* descriptors in kmem_cache_create, we search through the malloc_sizes array.
* If we are creating a malloc_sizes cache here it would not be visible to
* kmem_find_general_cachep till the initialization is complete.
* Hence we cannot have slabp_cache same as the original cache.
*/
static struct slab *alloc_slabmgmt(struct kmem_cache *cachep, void *objp,
int colour_off, gfp_t local_flags, int nodeid)
{
struct slab *slabp;
/*
* 检测cachep->flags中的标志位CFLGS_OFF_SLAB:
* If the CFLGS_OFF_SLAB flag of the cache descriptor is set,
* the slab descriptor is allocated from the general cache
* pointed to by the slabp_cache field of the cache descriptor;
* Otherwise, the slab descriptor is allocated in the first
* page frame of the slab.
*/
if (OFF_SLAB(cachep)) {
/* Slab management obj is off-slab. */
/*
* 通过调用kmem_cache_alloc(cachep, flags)来分配object,
* 参见[6.5.1.1.3.1 kmem_cache_zalloc()]节
*/
slabp = kmem_cache_alloc_node(cachep->slabp_cache, local_flags, nodeid);
/*
* If the first object in the slab is leaked (it's allocated
* but no one has a reference to it), we want to make sure
* kmemleak does not treat the ->s_mem pointer as a reference
* to the object. Otherwise we will not report the leak.
*/
kmemleak_scan_area(&slabp->list, sizeof(struct list_head), local_flags);
if (!slabp)
return NULL;
} else {
slabp = objp + colour_off;
colour_off += cachep->slab_size;
}
slabp->inuse = 0;
slabp->colouroff = colour_off;
slabp->s_mem = objp + colour_off;
slabp->nodeid = nodeid;
slabp->free = 0;
return slabp;
}
6.5.1.1.3.2.2.3 slab_map_pages()
The kernel must be able to determine, given a page frame, whether it is used by the slab allocator and, if so, to derive quickly the addresses of the corresponding cache and slab descriptors. Therefore, slab_map_pages() scans all page descriptors of the page frames assigned to the new slab, and loads the next and prev subfields of the lru fields in the page descriptors with the addresses of, respectively, the cache descriptor and the slab descriptor. This works correctly because the lru field is used by functions of the buddy system only when the page frame is free, while page frames handled by the slab allocator functions have the PG_slab flag set and are not free as far as the buddy allocator system is concerned.
该函数定义于mm/slab.c:
/*
* Map pages beginning at addr to the given cache and slab. This is required
* for the slab allocator to be able to lookup the cache and slab of a
* virtual address for kfree, ksize, and slab debugging.
*/
static void slab_map_pages(struct kmem_cache *cache, struct slab *slab, void *addr)
{
int nr_pages;
struct page *page;
page = virt_to_page(addr);
nr_pages = 1;
if (likely(!PageCompound(page)))
nr_pages <<= cache->gfporder;
do {
// page->lru.next = (struct list_head *)cache;
page_set_cache(page, cache);
// page->lru.prev = (struct list_head *)slab;
page_set_slab(page, slab);
page++;
} while (--nr_pages);
}
6.5.1.1.4 Deallocate an object to Specific Cache/kmem_cache_free()
该函数定义于mm/slab.c:
/**
* kmem_cache_free - Deallocate an object
* @cachep: The cache the allocation was from.
* @objp: The previously allocated object.
*
* Free an object which was previously allocated from this
* cache.
*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
{
unsigned long flags;
local_irq_save(flags);
debug_check_no_locks_freed(objp, obj_size(cachep));
if (!(cachep->flags & SLAB_DEBUG_OBJECTS))
debug_check_no_obj_freed(objp, obj_size(cachep));
__cache_free(cachep, objp, __builtin_return_address(0));
local_irq_restore(flags);
trace_kmem_cache_free(_RET_IP_, objp);
}
6.5.1.1.5 Destroy a Specific Cache/kmem_cache_destroy()
该函数定义于mm/slab.c:
/**
* kmem_cache_destroy - delete a cache
* @cachep: the cache to destroy
*
* Remove a &struct kmem_cache object from the slab cache.
*
* It is expected this function will be called by a module when it is
* unloaded. This will remove the cache completely, and avoid a duplicate
* cache being allocated each time a module is loaded and unloaded, if the
* module doesn't have persistent in-kernel storage across loads and unloads.
*
* The cache must be empty before calling this function.
*
* The caller must guarantee that no one will allocate memory from the cache
* during the kmem_cache_destroy().
*/
void kmem_cache_destroy(struct kmem_cache *cachep)
{
BUG_ON(!cachep || in_interrupt());
/* Find the cache in the chain of caches. */
get_online_cpus();
mutex_lock(&cache_chain_mutex);
/*
* the chain is never empty, cache_cache is never destroyed
*/
list_del(&cachep->next);
// 参见[6.5.1.1.5.1 __cache_shrink()]节
if (__cache_shrink(cachep)) {
slab_error(cachep, "Can't free all objects");
list_add(&cachep->next, &cache_chain);
mutex_unlock(&cache_chain_mutex);
put_online_cpus();
return;
}
if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU))
rcu_barrier();
// 参见[6.5.1.1.5.2 __kmem_cache_destroy()]节
__kmem_cache_destroy(cachep);
mutex_unlock(&cache_chain_mutex);
put_online_cpus();
}
6.5.1.1.5.1 __cache_shrink()
该函数定义于mm/slab.c:
/* Called with cache_chain_mutex held to protect against cpu hotplug */
static int __cache_shrink(struct kmem_cache *cachep)
{
int ret = 0, i = 0;
struct kmem_list3 *l3;
drain_cpu_caches(cachep);
check_irq_on();
for_each_online_node(i) {
l3 = cachep->nodelists[i];
if (!l3)
continue;
drain_freelist(cachep, l3, l3->free_objects);
ret += !list_empty(&l3->slabs_full) || !list_empty(&l3->slabs_partial);
}
return (ret ? 1 : 0); // cachep中是否还存在空闲slabs
}
6.5.1.1.5.2 __kmem_cache_destroy()
该函数定义于mm/slab.c:
static void __kmem_cache_destroy(struct kmem_cache *cachep)
{
int i;
struct kmem_list3 *l3;
for_each_online_cpu(i)
kfree(cachep->array[i]);
/* NUMA: free the list3 structures */
for_each_online_node(i) {
l3 = cachep->nodelists[i];
if (l3) {
kfree(l3->shared);
free_alien_cache(l3->alien);
kfree(l3);
}
}
kmem_cache_free(&cache_cache, cachep);
}
6.5.2 Slab Descriptor/struct slab
该结构定义于mm/slab.c:
struct slab {
union {
struct {
/*
* Pointers for one of the three doubly linked list of slab
* descriptors (either the slabs_full, slabs_partial, or slabs_free
* list in the kmem_list3 structure of the cache descriptor)
*/
struct list_head list;
// Offset of the first object in the slab.
// The address of the first object is s_mem + colouroff.
unsigned long colouroff;
// Address of first object (either allocated or free) in the slab.
void *s_mem; /* including colour offset */
// Number of objects in the slab that are currently used (not free).
unsigned int inuse; /* num of objs active in slab */
// Index of next free object in the slab, or BUFCTL_END
// if there are no free objects left.
kmem_bufctl_t free;
unsigned short nodeid;
};
struct slab_rcu __slab_cover_slab_rcu;
};
};
Slab descriptors can be stored in two possible places:
1) External slab descriptor: Stored outside the slab, in one of the general caches not suitable for ISA DMA pointed to by cache_sizes.
2) Internal slab descriptor: Stored inside the slab, at the beginning of the first page frame assigned to the slab.
The slab allocator chooses the second solution when the size of the objects is smaller than 512MB or when internal fragmentation leaves enough space for the slab descriptor and the object descriptor inside the slab. The CFLGS_OFF_SLAB flag in the flags field of the cache descriptor is set to one if the slab descriptor is stored outside the slab; it is set to zero otherwise. 参见6.5.1.1.3.2.2.2 alloc_slabmgmt()节中的alloc_slabmgmt().
6.5.3 Object Descriptor/kmem_bufctl_t
该结构定义于mm/slab.c:
typedef unsigned int kmem_bufctl_t;
#define BUFCTL_END (((kmem_bufctl_t)(~0U))-0) // 0xFFFF
#define BUFCTL_FREE (((kmem_bufctl_t)(~0U))-1) // 0xFFFE
#define BUFCTL_ACTIVE (((kmem_bufctl_t)(~0U))-2) // 0xFFFD
#define SLAB_LIMIT (((kmem_bufctl_t)(~0U))-3) // 0xFFFC
Each object has a short descriptor of type kmem_bufctl_t. Object descriptors are stored in an array placed right after the corresponding slab descriptor. Thus, like the slab descriptors themselves, the object descriptors of a slab can be stored in two possible ways:
1) External object descriptors
Stored outside the slab, in the general cache pointed to by the slabp_cache field of the cache descriptor. The size of the memory area, and thus the particular general cache used to store object descriptors, depends on the number of objects stored in the slab (num field of the cache descriptor).
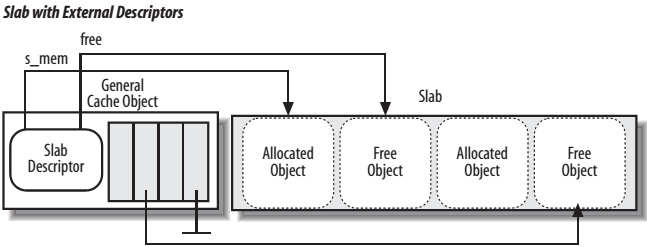
2) Internal object descriptors
Stored inside the slab, right before the objects they describe.
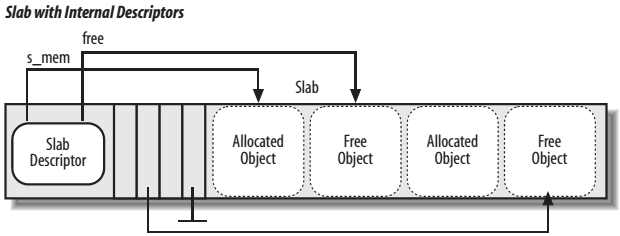
6.6 分配/释放内存区域(memory area)
6.6.1 Allocate Physically Contiguous Memory
6.6.1.1 kzalloc()/kmalloc()
该函数定义于include/linux/slab.h:
/**
* kzalloc - allocate memory. The memory is set to zero.
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate (see kmalloc).
*/
static inline void *kzalloc(size_t size, gfp_t flags)
{
return kmalloc(size, flags | __GFP_ZERO);
}
函数kmalloc()定义于include/linux/slab_def.h:
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
struct kmem_cache *cachep;
void *ret;
/*
* GCC buitin function __builtin_constant_p():
* returns the integer 1 if the argument is known
* to be a compiletime constant and 0 if it is not
* known to be a compile-time constant.
*/
if (__builtin_constant_p(size)) {
int i = 0;
if (!size)
return ZERO_SIZE_PTR;
/*
* Use the malloc_sizes table to locate the
* nearest power-of-2 size to the requested size.
*/
#define CACHE(x) \
if (size <= x) \
goto found; \
else \
i++;
#include <linux/kmalloc_sizes.h>
#undef CACHE
return NULL;
found:
#ifdef CONFIG_ZONE_DMA
if (flags & GFP_DMA)
cachep = malloc_sizes[i].cs_dmacachep;
else
#endif
cachep = malloc_sizes[i].cs_cachep;
// 参见[6.6.1.1.1 kmem_cache_alloc_trace()]节
ret = kmem_cache_alloc_trace(size, cachep, flags);
return ret;
}
// 参见[6.6.1.1.2 __kmalloc()]节
return __kmalloc(size, flags);
}
6.6.1.1.1 kmem_cache_alloc_trace()
该函数定义于include/linux/slab_def.h:
#ifdef CONFIG_TRACING
extern void *kmem_cache_alloc_trace(size_t size, struct kmem_cache *cachep, gfp_t flags);
#else
static __always_inline void *kmem_cache_alloc_trace(size_t size, struct kmem_cache *cachep, gfp_t flags)
{
// 参见[6.5.1.1.3.1 kmem_cache_zalloc()]节
return kmem_cache_alloc(cachep, flags);
}
#endif
6.6.1.1.2 __kmalloc()
该函数定义于mm/slab.c:
#if defined(CONFIG_DEBUG_SLAB) || defined(CONFIG_TRACING)
void *__kmalloc(size_t size, gfp_t flags)
{
return __do_kmalloc(size, flags, __builtin_return_address(0));
}
#else
void *__kmalloc(size_t size, gfp_t flags)
{
return __do_kmalloc(size, flags, NULL);
}
#endif
6.6.1.2 kcalloc()
该函数定义于include/linux/slab.h:
/**
* kcalloc - allocate memory for an array. The memory is set to zero.
* @n: number of elements.
* @size: element size.
* @flags: the type of memory to allocate.
*/
static inline void *kcalloc(size_t n, size_t size, gfp_t flags)
{
if (size != 0 && n > ULONG_MAX / size)
return NULL;
// 参见[6.6.1.1.2 __kmalloc()]节
return __kmalloc(n * size, flags | __GFP_ZERO);
}
6.6.1.3 kfree()
该函数定义于mm/slab.c:
/**
* kfree - free previously allocated memory
* @objp: pointer returned by kmalloc.
*
* If @objp is NULL, no operation is performed.
*
* Don't free memory not originally allocated by kmalloc()
* or you will run into trouble.
*/
void kfree(const void *objp)
{
struct kmem_cache *c;
unsigned long flags;
trace_kfree(_RET_IP_, objp);
if (unlikely(ZERO_OR_NULL_PTR(objp)))
return;
local_irq_save(flags);
kfree_debugcheck(objp);
// 参见[6.6.1.3.1 virt_to_cache()]节
c = virt_to_cache(objp);
debug_check_no_locks_freed(objp, obj_size(c));
debug_check_no_obj_freed(objp, obj_size(c));
__cache_free(c, (void *)objp, __builtin_return_address(0));
local_irq_restore(flags);
}
6.6.1.3.1 virt_to_cache()
该函数定义于mm/slab.c:
static inline struct kmem_cache *virt_to_cache(const void *obj)
{
// page = virt_to_page(obj)->first_page
struct page *page = virt_to_head_page(obj);
// (struct slab *)page->lru.prev; 参见[6.5.1.1.3.2.2.3 slab_map_pages()]节
return page_get_cache(page);
}
6.6.2 Allocate Virtually Contiguous Memory
6.6.2.1 vzalloc()/vmalloc()
函数vzalloc()定义于mm/vmalloc.c:
/**
* vzalloc - allocate virtually contiguous memory with zero fill
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
* The memory allocated is set to zero.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
void *vzalloc(unsigned long size)
{
return __vmalloc_node_flags(size, -1, GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
}
函数vmalloc()定义于mm/vmalloc.c:
/**
* vmalloc - allocate virtually contiguous memory
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, -1, GFP_KERNEL | __GFP_HIGHMEM);
}
其中,函数__vmalloc_node_flags()定义于mm/vmalloc.c:
static inline void *__vmalloc_node_flags(unsigned long size, int node, gfp_t flags)
{
return __vmalloc_node(size, 1, flags, PAGE_KERNEL, node, __builtin_return_address(0));
}
其中,函数__vmalloc_node()定义于mm/vmalloc.c:
/**
* __vmalloc_node - allocate virtually contiguous memory
* @size: allocation size
* @align: desired alignment
* @gfp_mask: flags for the page level allocator
* @prot: protection mask for the allocated pages
* @node: node to use for allocation or -1
* @caller: caller's return address
*
* Allocate enough pages to cover @size from the page level
* allocator with @gfp_mask flags. Map them into contiguous
* kernel virtual space, using a pagetable protection of @prot.
*/
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot, int node, void *caller)
{
/*
* 函数vmalloc()从区间[VMALLOC_START, VMALLOC_END]中分配内存空间,
* 参见[6.6.2.1.1 __vmalloc_node_range()]节
*/
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, node, caller);
}
6.6.2.1.1 __vmalloc_node_range()
该函数定义于mm/vmalloc.c:
/**
* __vmalloc_node_range - allocate virtually contiguous memory
* @size: allocation size
* @align: desired alignment
* @start: vm area range start
* @end: vm area range end
* @gfp_mask: flags for the page level allocator
* @prot: protection mask for the allocated pages
* @node: node to use for allocation or -1
* @caller: caller's return address
*
* Allocate enough pages to cover @size from the page level
* allocator with @gfp_mask flags. Map them into contiguous
* kernel virtual space, using a pagetable protection of @prot.
*/
void *__vmalloc_node_range(unsigned long size, unsigned long align,
unsigned long start, unsigned long end, gfp_t gfp_mask,
pgprot_t prot, int node, void *caller)
{
struct vm_struct *area;
void *addr;
unsigned long real_size = size;
/*
* Round up the value of the size to a multiple of 4,096
* (the page frame size); The main advantage of this schema
* is to avoid external fragmentation, while the disadvantage
* is that it is necessary to fiddle with the kernel Page
* Tables. Clearly, the size of a noncontiguous memory area
* must be a multiple of 4,096.
*/
size = PAGE_ALIGN(size);
if (!size || (size >> PAGE_SHIFT) > totalram_pages)
goto fail;
// 参见[6.6.2.1.1.1 __get_vm_area_node()]节
area = __get_vm_area_node(size, align, VM_ALLOC | VM_UNLIST,
start, end, node, gfp_mask, caller);
if (!area)
goto fail;
// 参见[6.6.2.1.1.2 __vmalloc_area_node()]节
addr = __vmalloc_area_node(area, gfp_mask, prot, node, caller);
if (!addr)
return NULL;
/*
* In this function, newly allocated vm_struct is not added
* to vmlist at __get_vm_area_node(). so, it is added here.
*/
// 参见[6.6.2.1.1.3 insert_vmalloc_vmlist()]节
insert_vmalloc_vmlist(area);
/*
* A ref_count = 3 is needed because the vm_struct and vmap_area
* structures allocated in the __get_vm_area_node() function contain
* references to the virtual address of the vmalloc'ed block.
*/
kmemleak_alloc(addr, real_size, 3, gfp_mask);
return addr;
fail:
warn_alloc_failed(gfp_mask, 0, "vmalloc: allocation failure: %lu bytes\n", real_size);
return NULL;
}
函数vmalloc()的返回结果addr:
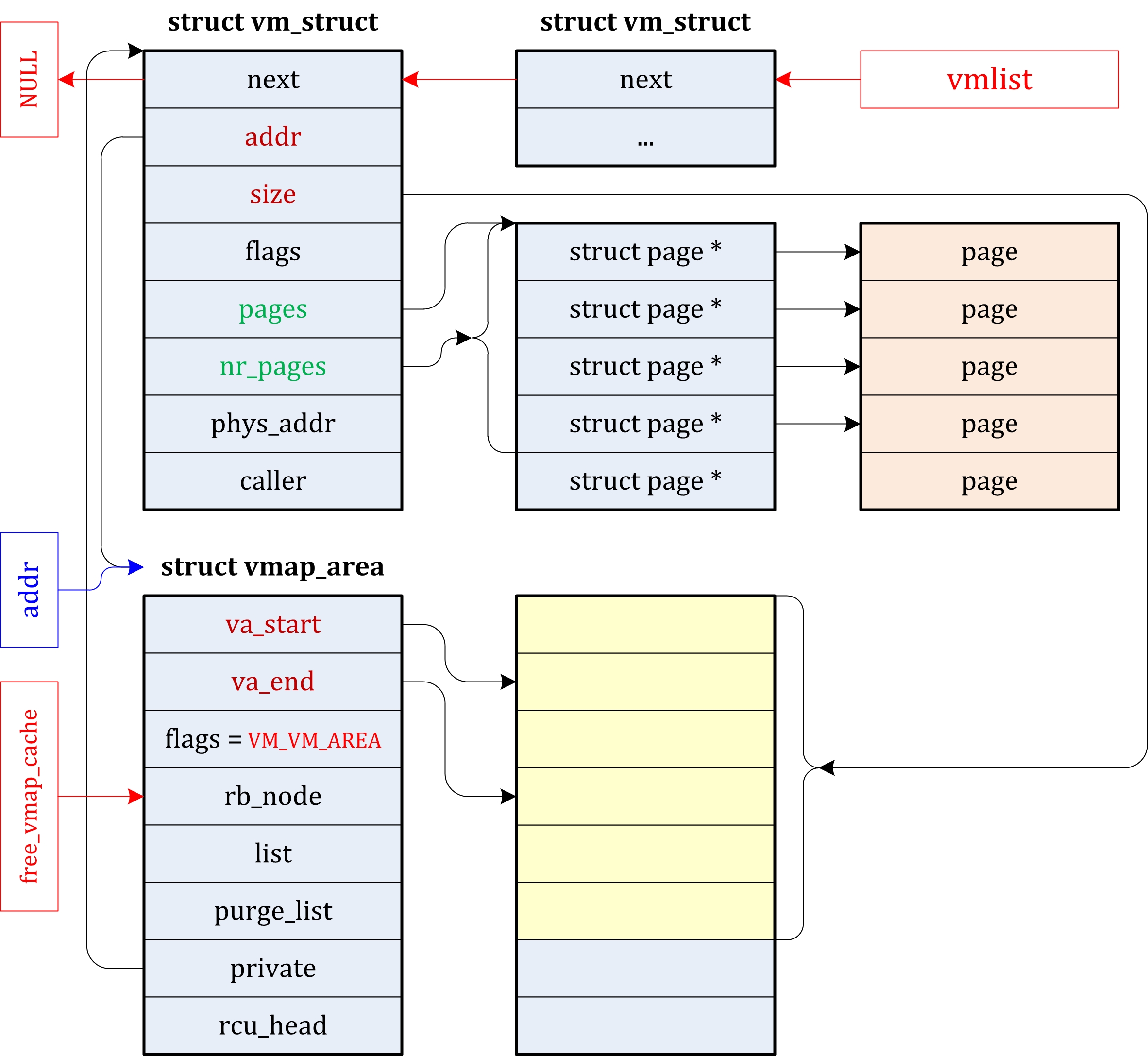
6.6.2.1.1.1 __get_vm_area_node()
该函数定义于mm/vmalloc.c:
static struct vm_struct *__get_vm_area_node(unsigned long size,
unsigned long align, unsigned long flags, unsigned long start,
unsigned long end, int node, gfp_t gfp_mask, void *caller)
{
struct vmap_area *va;
struct vm_struct *area;
BUG_ON(in_interrupt());
if (flags & VM_IOREMAP) {
int bit = fls(size);
if (bit > IOREMAP_MAX_ORDER)
bit = IOREMAP_MAX_ORDER;
else if (bit < PAGE_SHIFT)
bit = PAGE_SHIFT;
align = 1ul << bit;
}
size = PAGE_ALIGN(size);
if (unlikely(!size))
return NULL;
// 参见[6.6.2.1.1.1.1 kzalloc_node()]节
area = kzalloc_node(sizeof(*area), gfp_mask & GFP_RECLAIM_MASK, node);
if (unlikely(!area))
return NULL;
/*
* We always allocate a guard page.
*/
size += PAGE_SIZE;
// 参见[6.6.2.1.1.1.2 alloc_vmap_area()]节
va = alloc_vmap_area(size, align, start, end, node, gfp_mask);
if (IS_ERR(va)) {
kfree(area);
return NULL;
}
/*
* When this function is called from __vmalloc_node_range,
* we do not add vm_struct to vmlist here to avoid
* accessing uninitialized members of vm_struct such as
* pages and nr_pages fields. They will be set later.
* To distinguish it from others, we use a VM_UNLIST flag.
*/
if (flags & VM_UNLIST)
setup_vmalloc_vm(area, va, flags, caller); // 参见[6.6.2.1.1.1.3 setup_vmalloc_vm()]节
else
insert_vmalloc_vm(area, va, flags, caller);
return area;
}
6.6.2.1.1.1.1 kzalloc_node()
该函数定义于mm/vmalloc.c:
/**
* kzalloc_node - allocate zeroed memory from a particular memory node.
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate (see kmalloc).
* @node: memory node from which to allocate
*/
static inline void *kzalloc_node(size_t size, gfp_t flags, int node)
{
/*
* Invoke kmalloc() to request a group of contiguous
* page frames large enough to contain an array of page
* descriptor pointers. 参见[6.6.1.1 kzalloc()/kmalloc()]节
*/
return kmalloc_node(size, flags | __GFP_ZERO, node);
}
6.6.2.1.1.1.2 alloc_vmap_area()
该函数定义于mm/vmalloc.c:
/*
* Allocate a region of KVA of the specified size and alignment, within the
* vstart and vend.
*/
static struct vmap_area *alloc_vmap_area(unsigned long size, unsigned long align,
unsigned long vstart, unsigned long vend, int node, gfp_t gfp_mask)
{
struct vmap_area *va;
struct rb_node *n;
unsigned long addr;
int purged = 0;
struct vmap_area *first;
BUG_ON(!size);
BUG_ON(size & ~PAGE_MASK);
BUG_ON(!is_power_of_2(align));
/*
* Invoke kmalloc() to request a group of contiguous
* page frames large enough to contain an array of
* page descriptor pointers. 参见[6.6.1.1 kzalloc()/kmalloc()]节
*/
va = kmalloc_node(sizeof(struct vmap_area), gfp_mask & GFP_RECLAIM_MASK, node);
if (unlikely(!va))
return ERR_PTR(-ENOMEM);
retry:
spin_lock(&vmap_area_lock);
/*
* Invalidate cache if we have more permissive parameters.
* cached_hole_size notes the largest hole noticed _below_
* the vmap_area cached in free_vmap_cache: if size fits
* into that hole, we want to scan from vstart to reuse
* the hole instead of allocating above free_vmap_cache.
* Note that __free_vmap_area may update free_vmap_cache
* without updating cached_hole_size or cached_align.
*/
if (!free_vmap_cache
|| size < cached_hole_size
|| vstart < cached_vstart
|| align < cached_align) {
nocache:
cached_hole_size = 0;
free_vmap_cache = NULL;
}
/* record if we encounter less permissive parameters */
cached_vstart = vstart;
cached_align = align;
/* find starting point for our search */
if (free_vmap_cache) {
first = rb_entry(free_vmap_cache, struct vmap_area, rb_node);
addr = ALIGN(first->va_end, align);
if (addr < vstart)
goto nocache;
if (addr + size - 1 < addr)
goto overflow;
} else {
addr = ALIGN(vstart, align);
if (addr + size - 1 < addr)
goto overflow;
n = vmap_area_root.rb_node;
first = NULL;
while (n) {
struct vmap_area *tmp;
tmp = rb_entry(n, struct vmap_area, rb_node);
if (tmp->va_end >= addr) {
first = tmp;
if (tmp->va_start <= addr)
break;
n = n->rb_left;
} else
n = n->rb_right;
}
if (!first)
goto found;
}
/* from the starting point, walk areas until a suitable hole is found */
while (addr + size > first->va_start && addr + size <= vend) {
if (addr + cached_hole_size < first->va_start)
cached_hole_size = first->va_start - addr;
addr = ALIGN(first->va_end, align);
if (addr + size - 1 < addr)
goto overflow;
n = rb_next(&first->rb_node);
if (n)
first = rb_entry(n, struct vmap_area, rb_node);
else
goto found;
}
found:
if (addr + size > vend)
goto overflow;
va->va_start = addr;
va->va_end = addr + size;
va->flags = 0;
// 将新分配的va插入到红黑树vmap_area_root中
__insert_vmap_area(va);
free_vmap_cache = &va->rb_node;
spin_unlock(&vmap_area_lock);
BUG_ON(va->va_start & (align-1));
BUG_ON(va->va_start < vstart);
BUG_ON(va->va_end > vend);
return va;
overflow:
spin_unlock(&vmap_area_lock);
if (!purged) {
purge_vmap_area_lazy();
purged = 1;
goto retry;
}
if (printk_ratelimit())
printk(KERN_WARNING "vmap allocation for size %lu failed: "
"use vmalloc=<size> to increase size.\n", size);
kfree(va);
return ERR_PTR(-EBUSY);
}
6.6.2.1.1.1.3 setup_vmalloc_vm()
该函数定义于mm/vmalloc.c:
static void setup_vmalloc_vm(struct vm_struct *vm, struct vmap_area *va,
unsigned long flags, void *caller)
{
vm->flags = flags;
vm->addr = (void *)va->va_start;
vm->size = va->va_end - va->va_start;
vm->caller = caller;
va->private = vm;
va->flags |= VM_VM_AREA;
}
6.6.2.1.1.2 __vmalloc_area_node()
该函数定义于mm/vmalloc.c:
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node, void *caller)
{
const int order = 0;
struct page **pages;
unsigned int nr_pages, array_size, i;
gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO;
nr_pages = (area->size - PAGE_SIZE) >> PAGE_SHIFT;
array_size = (nr_pages * sizeof(struct page *));
area->nr_pages = nr_pages;
/* Please note that the recursion is strictly bounded. */
if (array_size > PAGE_SIZE) {
// 参见[6.6.2.1 vzalloc()/vmalloc()]节
pages = __vmalloc_node(array_size, 1, nested_gfp|__GFP_HIGHMEM, PAGE_KERNEL, node, caller);
area->flags |= VM_VPAGES;
} else {
/*
* Invoke kmalloc() to request a group of contiguous
* page frames large enough to contain an array of
* page descriptor pointers. 参见[6.6.1.1 kzalloc()/kmalloc()]节
*/
pages = kmalloc_node(array_size, nested_gfp, node);
}
area->pages = pages;
area->caller = caller;
if (!area->pages) {
remove_vm_area(area->addr);
kfree(area);
return NULL;
}
for (i = 0; i < area->nr_pages; i++) {
struct page *page;
gfp_t tmp_mask = gfp_mask | __GFP_NOWARN;
if (node < 0)
page = alloc_page(tmp_mask); // 参见[6.4.2.1 alloc_page()]节
else
page = alloc_pages_node(node, tmp_mask, order); // 参见[6.4.1.1 alloc_pages()/alloc_pages_node()]节
if (unlikely(!page)) {
/* Successfully allocated i pages, free them in __vunmap() */
area->nr_pages = i;
goto fail;
}
area->pages[i] = page;
}
if (map_vm_area(area, prot, &pages))
goto fail;
return area->addr;
fail:
warn_alloc_failed(gfp_mask, order,
"vmalloc: allocation failure, allocated %ld of %ld bytes\n",
(area->nr_pages*PAGE_SIZE), area->size);
vfree(area->addr);
return NULL;
}
6.6.2.1.1.3 insert_vmalloc_vmlist()
该函数定义于mm/vmalloc.c:
static void insert_vmalloc_vmlist(struct vm_struct *vm)
{
struct vm_struct *tmp, **p;
vm->flags &= ~VM_UNLIST;
write_lock(&vmlist_lock);
for (p = &vmlist; (tmp = *p) != NULL; p = &tmp->next) {
if (tmp->addr >= vm->addr)
break;
}
vm->next = *p;
*p = vm;
write_unlock(&vmlist_lock);
}
6.6.2.2 vmalloc_32()
该函数定义于mm/vmalloc.c:
/**
* vmalloc_32 - allocate virtually contiguous memory (32bit addressable)
* @size: allocation size
*
* Allocate enough 32bit PA addressable pages to cover @size from the
* page level allocator and map them into contiguous kernel virtual space.
*/
void *vmalloc_32(unsigned long size)
{
// 参见[6.6.2.1 vzalloc()/vmalloc()]节
return __vmalloc_node(size, 1, GFP_VMALLOC32, PAGE_KERNEL, -1, __builtin_return_address(0));
}
6.6.2.3 vfree()
The vfree() function releases noncontiguous memory areas created by vmalloc() or vmalloc_32(), while the vunmap() function releases memory areas created by vmap().
该函数定义于mm/vmalloc.c:
/**
* vfree - release memory allocated by vmalloc()
* @addr: memory base address
*
* Free the virtually continuous memory area starting at @addr, as
* obtained from vmalloc(), vmalloc_32() or __vmalloc(). If @addr is
* NULL, no operation is performed.
*
* Must not be called in interrupt context.
*/
void vfree(const void *addr)
{
BUG_ON(in_interrupt());
kmemleak_free(addr);
// 参见[6.6.2.3.1 __vunmap()]节
__vunmap(addr, 1);
}
6.6.2.3.1 __vunmap()
该函数定义于mm/vmalloc.c:
static void __vunmap(const void *addr, int deallocate_pages)
{
struct vm_struct *area;
if (!addr)
return;
if ((PAGE_SIZE-1) & (unsigned long)addr) {
WARN(1, KERN_ERR "Trying to vfree() bad address (%p)\n", addr);
return;
}
area = remove_vm_area(addr); // 参见[6.6.2.3.1.1 remove_vm_area()]节
if (unlikely(!area)) {
WARN(1, KERN_ERR "Trying to vfree() nonexistent vm area (%p)\n", addr);
return;
}
debug_check_no_locks_freed(addr, area->size);
debug_check_no_obj_freed(addr, area->size);
if (deallocate_pages) {
int i;
for (i = 0; i < area->nr_pages; i++) {
struct page *page = area->pages[i];
BUG_ON(!page);
__free_page(page); // 参见[6.4.2.4 __free_page()/free_page()]节
}
if (area->flags & VM_VPAGES)
vfree(area->pages); // 参见[6.6.2.3 vfree()]节
else
kfree(area->pages); // 参见[6.6.2.3 vfree()]节
}
kfree(area); // 参见[6.6.2.3 vfree()]节
return;
}
6.6.2.3.1.1 remove_vm_area()
该函数定义于mm/vmalloc.c:
/**
* remove_vm_area - find and remove a continuous kernel virtual area
* @addr: base address
*
* Search for the kernel VM area starting at @addr, and remove it.
* This function returns the found VM area, but using it is NOT safe
* on SMP machines, except for its size or flags.
*/
struct vm_struct *remove_vm_area(const void *addr)
{
struct vmap_area *va;
va = find_vmap_area((unsigned long)addr);
if (va && va->flags & VM_VM_AREA) {
// 将va移出链表vmlist,参见[6.6.2.1.1 __vmalloc_node_range()]节中的图"函数vmalloc()的返回结果addr"
struct vm_struct *vm = va->private;
if (!(vm->flags & VM_UNLIST)) {
struct vm_struct *tmp, **p;
/*
* remove from list and disallow access to
* this vm_struct before unmap. (address range
* confliction is maintained by vmap.)
*/
write_lock(&vmlist_lock);
for (p = &vmlist; (tmp = *p) != vm; p = &tmp->next)
;
*p = tmp->next;
write_unlock(&vmlist_lock);
}
vmap_debug_free_range(va->va_start, va->va_end);
free_unmap_vmap_area(va);
vm->size -= PAGE_SIZE;
return vm;
}
return NULL;
}
6.7 Kernel Mappings of High-Memory Page Frames
The linear address that corresponds to the end of the directly mapped physical memory, and thus to the beginning of the high memory, is stored in the high_memory variable, which is set to 896 MB. Page frames above the 896 MB boundary are not generally mapped in the fourth gigabyte of the kernel linear address spaces, so the kernel is unable to directly access them. This implies that each page allocator function that returns the linear address of the assigned page frame doesn’t work for high memory page frames, that is, for page frames in the ZONE_HIGHME Mmemory zone.
变量high_memory定义于mm/memory.c:
/*
* A number of key systems in x86 including ioremap() rely on the assumption
* that high_memory defines the upper bound on direct map memory, then end
* of ZONE_NORMAL. Under CONFIG_DISCONTIG this means that max_low_pfn and
* highstart_pfn must be the same; there must be no gap between ZONE_NORMAL
* and ZONE_HIGHMEM.
*/
void * high_memory;
变量high_memory的初始化过程如下:
start_kernel()
-> setup_arch()
-> initmem_init() // arch/x86/mm/init_32.c
The allocation of high-memory page frames is done only through the alloc_pages() function and its alloc_page() shortcut.
Page frames in high memory that do not have a linear address cannot be accessed by the kernel. Therefore, part of the last 128 MB of the kernel linear address space is dedicated to mapping high-memory page frames.
The kernel uses three different mechanisms to map page frames in high memory; they are called:
- Permanent Kernel Mapping, see section Permanent Kernel Mapping
- Temporary Kernel Mapping, see section emporary Kernel Mapping
- Noncontiguous Memory Allocation, see section Allocate Virtually Contiguous Memory
6.7.1 Permanent Kernel Mapping
Permanent kernel mappings allow the kernel to establish long-lasting mappings of high-memory page frames into the kernel address space. They use a dedicated Page Table in the master kernel page tables. The pkmap_page_table variable (see section 6.7.1.1 pkmap_page_table的初始化) stores the address of this Page Table, while the LAST_PKMAP macro yields the number of entries. As usual, the Page Table includes either 512 or 1,024 entries, according to whether PAE is enabled or disabled; thus, the kernel can access at most 2 or 4 MB of high memory at once. The Page Table maps the linear addresses starting from PKMAP_BASE.
The current state of the page table entries is managed by a simple array called pkmap_count which has LAST_PKMAP entries in it. Each element is not exactly a reference count but it is very close. If the entry is 0, the page is free and has not been used since the last TLB flush. If it is 1, the slot is unused but a page is still mapped there waiting for a TLB flush. Flushes are delayed until every slot has been used at least once as a global flush is required for all CPUs when the global page tables are modified and is extremely expensive. Any higher value is a reference count of n-1 users of the page.
Establishing a permanent kernel mapping may block the current process; this happens when no free Page Table entries exist that can be used as “windows” on the page frames in high memory. Thus, a permanent kernel mapping cannot be established in interrupt handlers and deferrable functions.
参见mm/highmem.c:
static int pkmap_count[LAST_PKMAP];
static unsigned int last_pkmap_nr;
static __cacheline_aligned_in_smp DEFINE_SPINLOCK(kmap_lock);
pte_t *pkmap_page_table;
static DECLARE_WAIT_QUEUE_HEAD(pkmap_map_wait);
其中,LAST_PKMAP和PKMAP_BASE定义于arch/x86/include/asm/pgtable_32_types.h:
#ifdef CONFIG_X86_PAE
#define LAST_PKMAP 512
#else
#define LAST_PKMAP 1024
#endif
#define PKMAP_BASE ((FIXADDR_BOOT_START - PAGE_SIZE * (LAST_PKMAP + 1)) & PMD_MASK)
变量pkmap_page_table的结果:
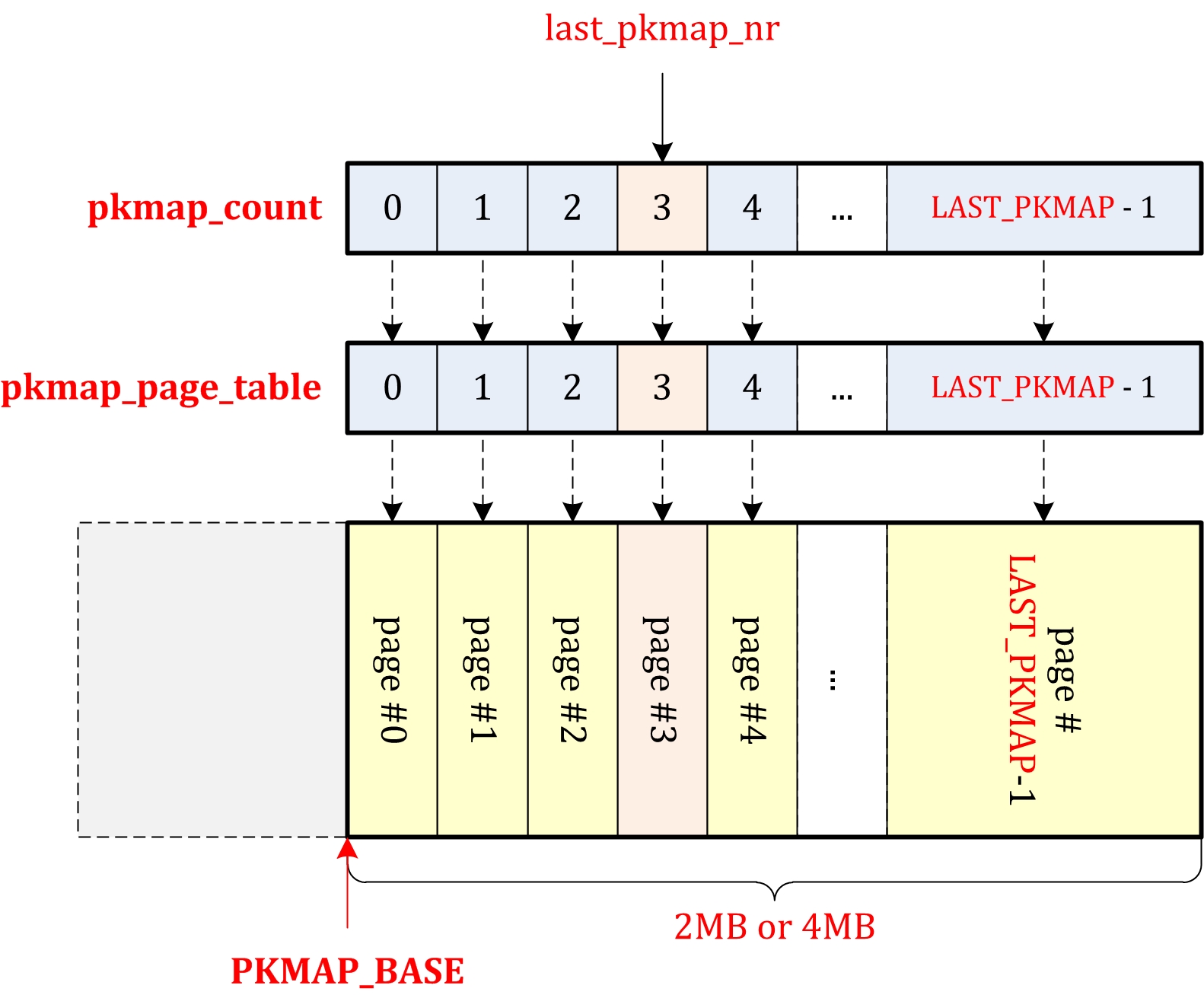
6.7.1.1 pkmap_page_table的初始化
start_kernel()
-> setup_arch()
-> paging_init()
-> pagetable_init() // 参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节
-> permanent_kmaps_init(swapper_pg_dir)
函数permanent_kmaps_init()定义于arch/x86/mm/init_32.c:
#ifdef CONFIG_HIGHMEM
static void __init permanent_kmaps_init(pgd_t *pgd_base)
{
unsigned long vaddr;
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
vaddr = PKMAP_BASE;
// 即调用:page_table_range_init(PKMAP_BASE, PKMAP_BASE + PAGE_SIZE*LAST_PKMAP, swapper_pg_dir);
page_table_range_init(vaddr, vaddr + PAGE_SIZE*LAST_PKMAP, pgd_base);
pgd = swapper_pg_dir + pgd_index(vaddr);
pud = pud_offset(pgd, vaddr);
pmd = pmd_offset(pud, vaddr);
pte = pte_offset_kernel(pmd, vaddr);
/*
* The page table entry for use with kmap() is called
* pkmap_page_table which is located at PKMAP_BASE.
*/
pkmap_page_table = pte;
}
#endif
其中,函数page_table_range_init()定义于arch/x86/mm/init_32.c:
// 即调用:page_table_range_init(PKMAP_BASE, PKMAP_BASE + PAGE_SIZE*LAST_PKMAP, swapper_pg_dir);
static void __init page_table_range_init(unsigned long start, unsigned long end, pgd_t *pgd_base)
{
int pgd_idx, pmd_idx;
unsigned long vaddr;
pgd_t *pgd;
pmd_t *pmd;
pte_t *pte = NULL;
vaddr = start;
pgd_idx = pgd_index(vaddr);
pmd_idx = pmd_index(vaddr);
pgd = pgd_base + pgd_idx;
for ( ; (pgd_idx < PTRS_PER_PGD) && (vaddr != end); pgd++, pgd_idx++) {
pmd = one_md_table_init(pgd);
pmd = pmd + pmd_index(vaddr);
for (; (pmd_idx < PTRS_PER_PMD) && (vaddr != end); pmd++, pmd_idx++) {
pte = page_table_kmap_check(one_page_table_init(pmd), pmd, vaddr, pte);
vaddr += PMD_SIZE;
}
pmd_idx = 0;
}
}
6.7.1.2 kmap()
The kmap() function establishes a permanent kernel mapping.
NOTE: The kmap pool is quite small so it is important that users of kmap() call kunmap() as quickly as possible because the pressure on this small window grows incrementally worse as the size of high memory grows in comparison to low memory.
该函数定义于arch/x86/mm/highmem_32.c:
void *kmap(struct page *page)
{
might_sleep();
/*
* If the page is already in low memory and simply
* returns the address if it is.
*/
if (!PageHighMem(page))
return page_address(page); // 参见[6.4.1.2 page_address()]节
/* If it is a high page to be mapped, kmap_high() is
* called to map a highmem page into memory.
*/
return kmap_high(page); // 参见[6.7.1.2.1 kmap_high()]节
}
6.7.1.2.1 kmap_high()
该函数定义于mm/highmem.c:
/**
* kmap_high - map a highmem page into memory
* @page: &struct page to map
*
* Returns the page's virtual memory address.
*
* We cannot call this from interrupts, as it may block.
*/
void *kmap_high(struct page *page)
{
unsigned long vaddr;
/*
* For highmem pages, we can't trust "virtual" until
* after we have the lock.
*/
lock_kmap();
/*
* If the page isn’t mapped yet (vaddr = NULL), call
* map_new_virtual() to provide a mapping for the page.
*/
vaddr = (unsigned long)page_address(page); // 参见[6.4.1.2.2 page_address() in mm/highmem.c]节
if (!vaddr)
vaddr = map_new_virtual(page); // 参见[6.7.1.2.1.1 map_new_virtual()]节
/*
* Once a mapping has been created, the corresponding
* entry in the pkmap_count array is incremented and
* the virtual address in low memory returned.
*/
pkmap_count[PKMAP_NR(vaddr)]++;
BUG_ON(pkmap_count[PKMAP_NR(vaddr)] < 2);
unlock_kmap();
return (void*) vaddr;
}
6.7.1.2.1.1 map_new_virtual()
该函数定义于mm/highmem.c:
static inline unsigned long map_new_virtual(struct page *page)
{
unsigned long vaddr;
int count;
start:
count = LAST_PKMAP;
/* Find an empty entry */
/*
* linearly scan pkmap_count to find an empty entry
* starting at last_pkmap_nr instead of 0
*/
for (;;) {
last_pkmap_nr = (last_pkmap_nr + 1) & LAST_PKMAP_MASK;
if (!last_pkmap_nr) {
/*
* flush_all_zero_pkmaps() starts scan of the counters
* that have the value 1. Each counter that has a value
* of 1 denotes an entry in pkmap_page_table that is free
* but cannot be used because the corresponding TLB entry
* has not yet been flushed. flush_all_zero_pkmaps() resets
* their counters to zero, deletes the corresponding elements
* from page_address_htable hash table, and issues TLB flushes
* on all entries of pkmap_page_table.
*/
flush_all_zero_pkmaps();
count = LAST_PKMAP;
}
if (!pkmap_count[last_pkmap_nr])
break; /* Found a usable entry */
if (--count)
continue;
/*
* If cannot find a null counter in pkmap_count, then blocks the
* current process until some other process releases an entry of
* the pkmap_page_table Page Table. That’s, the process sleeps on
* the pkmap_map_wait wait queue until it’s woken up after next
* kunmap(). 参见[6.7.1.3 kunmap()]节
*/
/*
* Sleep for somebody else to unmap their entries
*/
{
// 参见[7.4.2.4.2 定义/初始化等待队列/wait_queue_t]节
DECLARE_WAITQUEUE(wait, current);
__set_current_state(TASK_UNINTERRUPTIBLE);
add_wait_queue(&pkmap_map_wait, &wait);
unlock_kmap();
schedule();
remove_wait_queue(&pkmap_map_wait, &wait);
lock_kmap();
/* Somebody else might have mapped it while we slept */
// 参见[6.4.1.2.2 page_address() in mm/highmem.c]节
if (page_address(page))
return (unsigned long)page_address(page);
/* Re-start */
goto start;
}
}
vaddr = PKMAP_ADDR(last_pkmap_nr);
set_pte_at(&init_mm, vaddr, &(pkmap_page_table[last_pkmap_nr]), mk_pte(page, kmap_prot));
// 设置引用计数,并将该page链接到page_address_htable中的适当位置
pkmap_count[last_pkmap_nr] = 1;
set_page_address(page, (void *)vaddr);
return vaddr;
}
6.7.1.3 kunmap()
The kunmap() function destroys a permanent kernel mapping established previously by kmap().
该函数定义于mm/highmem_32.c:
void kunmap(struct page *page)
{
if (in_interrupt())
BUG();
/*
* If the page already exists in low memory and
* needs no further handling.
*/
if (!PageHighMem(page))
return;
kunmap_high(page); // 参见[6.7.1.3.1 kunmap_high()]节
}
6.7.1.3.1 kunmap_high()
该函数定义于mm/highmem.c:
/**
* kunmap_high - unmap a highmem page into memory
* @page: &struct page to unmap
*
* If ARCH_NEEDS_KMAP_HIGH_GET is not defined then this may be called
* only from user context.
*/
void kunmap_high(struct page *page)
{
unsigned long vaddr;
unsigned long nr;
unsigned long flags;
int need_wakeup;
lock_kmap_any(flags);
vaddr = (unsigned long)page_address(page);
BUG_ON(!vaddr);
nr = PKMAP_NR(vaddr); // pkmap_count[]和pkmap_page_table[]下标
/*
* A count must never go down to zero without a TLB flush!
*/
need_wakeup = 0;
/*
* Decrement the corresponding element for this page in
* pkmap_count. If it reaches 1, which means no more users
* but a TLB flush is required), any process waiting on
* the pkmap_map_wait is woken up as a slot is now available.
*/
switch (--pkmap_count[nr]) {
case 0:
BUG();
case 1:
/*
* Avoid an unnecessary wake_up() function call.
* The common case is pkmap_count[] == 1, but
* no waiters.
* The tasks queued in the wait-queue are guarded
* by both the lock in the wait-queue-head and by
* the kmap_lock. As the kmap_lock is held here,
* no need for the wait-queue-head's lock. Simply
* test if the queue is empty.
*/
// pkmap_map_wait中的等待进程是由kmap()->kmap_high()->map_new_virtual()设置的
need_wakeup = waitqueue_active(&pkmap_map_wait);
}
unlock_kmap_any(flags);
/* do wake-up, if needed, race-free outside of the spin lock */
if (need_wakeup)
wake_up(&pkmap_map_wait);
}
6.7.2 Temporary Kernel Mapping
Temporary kernel mappings are simpler to implement than permanent kernel mappings; moreover, they can be used inside interrupt handlers and deferrable functions, because requesting a temporary kernel mapping never blocks the current process.
Every page frame in high memory can be mapped through a window in the kernel address space — namely, a Page Table entry that is reserved for this purpose. The number of windows reserved for temporary kernel mappings is quite small. Each CPU has its own set of windows, represented by the enum km_type data structure. Each symbol defined in this data structure identifies the linear address of a window. See include/asm-generic/kmap_types.h.
The kernel must ensure that the same window is never used by two kernel control paths at the same time. Thus, each symbol in the km_type structure is dedicated to one kernel component and is named after the component.
Each symbol in km_type, except the last one, is an index of a fix-mapped linear address. The enum fixed_addresses data structure includes the symbols FIX_KMAP_BEGIN and FIX_KMAP_END; the latter is assigned to the index FIX_KMAP_BEGIN + (KM_TYPE_NR * NR_CPUS) - 1. In this manner, there are KM_TYPE_NR fix-mapped linear addresses for each CPU in the system. Furthermore, the kernel initializes the kmap_pte variable with the address of the Page Table entry corresponding to the fix_to_virt(FIX_KMAP_BEGIN) linear address:
start_kernel()
-> setup_arch()
-> paging_init()
-> kmap_init() // 参见[6.3.2.4 early_node_map[]=>node_data[]->node_zones[]]节
6.7.2.1 kmap_atomic()
To establish a temporary kernel mapping, the kernel invokes the kmap_atomic() function.
该宏定义于include/linux/highmem.h:
#define kmap_atomic(page, args...) __kmap_atomic(page)
其中,函数__kmap_atomic()定义于arch/x86/mm/highmem_32.c:
void *__kmap_atomic(struct page *page)
{
return kmap_atomic_prot(page, kmap_prot);
}
/*
* kmap_atomic/kunmap_atomic is significantly faster than kmap/kunmap because
* no global lock is needed and because the kmap code must perform a global TLB
* invalidation when the kmap pool wraps.
*
* However when holding an atomic kmap it is not legal to sleep, so atomic
* kmaps are appropriate for short, tight code paths only.
*/
void *kmap_atomic_prot(struct page *page, pgprot_t prot)
{
unsigned long vaddr;
int idx, type;
/* even !CONFIG_PREEMPT needs this, for in_atomic in do_page_fault */
pagefault_disable();
if (!PageHighMem(page))
return page_address(page);
type = kmap_atomic_idx_push();
idx = type + KM_TYPE_NR*smp_processor_id();
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
BUG_ON(!pte_none(*(kmap_pte-idx)));
set_pte(kmap_pte-idx, mk_pte(page, prot));
arch_flush_lazy_mmu_mode();
return (void *)vaddr;
}
6.7.2.2 kunmap_atomic()
To destroy a temporary kernel mapping, the kernel uses the kunmap_atomic() function.
该宏定义于include/linux/highmem.h:
#define kunmap_atomic(addr, args...) \
do { \
BUILD_BUG_ON(__same_type((addr), struct page *)); \
__kunmap_atomic(addr); \
} while (0)
其中,函数__kunmap_atomic()定义于arch/x86/mm/highmem_32.c:
void __kunmap_atomic(void *kvaddr)
{
unsigned long vaddr = (unsigned long) kvaddr & PAGE_MASK;
if (vaddr >= __fix_to_virt(FIX_KMAP_END) &&
vaddr <= __fix_to_virt(FIX_KMAP_BEGIN)) {
int idx, type;
type = kmap_atomic_idx();
idx = type + KM_TYPE_NR * smp_processor_id();
#ifdef CONFIG_DEBUG_HIGHMEM
WARN_ON_ONCE(vaddr != __fix_to_virt(FIX_KMAP_BEGIN + idx));
#endif
/*
* Force other mappings to Oops if they'll try to access this
* pte without first remap it. Keeping stale mappings around
* is a bad idea also, in case the page changes cacheability
* attributes or becomes a protected page in a hypervisor.
*/
kpte_clear_flush(kmap_pte-idx, vaddr);
kmap_atomic_idx_pop();
arch_flush_lazy_mmu_mode();
}
#ifdef CONFIG_DEBUG_HIGHMEM
else {
BUG_ON(vaddr < PAGE_OFFSET);
BUG_ON(vaddr >= (unsigned long)high_memory);
}
#endif
pagefault_enable();
}
6.8 虚拟内存空间/Virtual Memory Area
与Virtual Memory Area有关的数据结构参见6.2.7 struct vm_area_struct节,其结构参见6.2.7 struct vm_area_struct节中的图”Descriptors related to the address space of a process”。
6.8.1 Find a Memory Regin
find_vma_intersection()
Find the first memory region that overlaps a given linear address interval.
find_vma_prepare()
Locate the position of the new leaf in the red-black tree that corresponds to a given linear address and returns the addresses of the preceding memory region and of the parent node of the leaf to be inserted.
get_unmapped_area()
Searche the process address space to find an available linear address interval.
6.8.1.1 find_vma()
Function find_vma() is used to find the closest region to a given address.
该函数定义于mm/mmap.c:
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
{
struct vm_area_struct *vma = NULL;
if (mm) {
/* Check the cache first. */
/* (Cache hit rate is typically around 35%.) */
vma = mm->mmap_cache;
if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) {
struct rb_node * rb_node;
rb_node = mm->mm_rb.rb_node;
vma = NULL;
while (rb_node) {
struct vm_area_struct * vma_tmp;
vma_tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if (vma_tmp->vm_end > addr) {
vma = vma_tmp;
if (vma_tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
mm->mmap_cache = vma;
}
}
return vma;
}
6.8.1.2 find_vma_prev()
The find_vma_prev() function is similar to find_vma(), except that it writes in an additional pprev parameter a pointer to the descriptor of the memory region that precedes the one selected by the function.
该函数定义于mm/mmap.c:
/* Same as find_vma, but also return a pointer to the previous VMA in *pprev. */
struct vm_area_struct *find_vma_prev(struct mm_struct *mm, unsigned long addr,
struct vm_area_struct **pprev)
{
struct vm_area_struct *vma = NULL, *prev = NULL;
struct rb_node *rb_node;
if (!mm)
goto out;
/* Guard against addr being lower than the first VMA */
vma = mm->mmap;
/* Go through the RB tree quickly. */
rb_node = mm->mm_rb.rb_node;
while (rb_node) {
struct vm_area_struct *vma_tmp;
vma_tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if (addr < vma_tmp->vm_end) {
rb_node = rb_node->rb_left;
} else {
prev = vma_tmp;
if (!prev->vm_next || (addr < prev->vm_next->vm_end))
break;
rb_node = rb_node->rb_right;
}
}
out:
*pprev = prev;
return prev ? prev->vm_next : vma;
}
6.8.2 Allocate a Linear Address Interval
6.8.2.1 do_mmap()
该函数定义于include/linux/mm.h:
static inline unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long offset)
{
unsigned long ret = -EINVAL;
if ((offset + PAGE_ALIGN(len)) < offset)
goto out;
if (!(offset & ~PAGE_MASK))
ret = do_mmap_pgoff(file, addr, len, prot, flag, offset >> PAGE_SHIFT);
out:
return ret;
}
6.8.2.1.1 do_mmap_pgoff()
该函数定义于mm/mmap.c:
unsigned long do_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff)
{
struct mm_struct * mm = current->mm;
struct inode *inode;
vm_flags_t vm_flags;
int error;
unsigned long reqprot = prot;
/*
* Does the application expect PROT_READ to imply PROT_EXEC?
*
* (the exception is when the underlying filesystem is noexec
* mounted, in which case we dont add PROT_EXEC.)
*/
if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
if (!(file && (file->f_path.mnt->mnt_flags & MNT_NOEXEC)))
prot |= PROT_EXEC;
if (!len)
return -EINVAL;
if (!(flags & MAP_FIXED))
addr = round_hint_to_min(addr);
/* Careful about overflows.. */
len = PAGE_ALIGN(len);
if (!len)
return -ENOMEM;
/* offset overflow? */
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EOVERFLOW;
/* Too many mappings? */
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
// 参见[6.8.1 Find a Memory Regin]节
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (addr & ~PAGE_MASK)
return addr;
/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
vm_flags = calc_vm_prot_bits(prot) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
if (flags & MAP_LOCKED)
if (!can_do_mlock())
return -EPERM;
/* mlock MCL_FUTURE? */
if (vm_flags & VM_LOCKED) {
unsigned long locked, lock_limit;
locked = len >> PAGE_SHIFT;
locked += mm->locked_vm;
lock_limit = rlimit(RLIMIT_MEMLOCK);
lock_limit >>= PAGE_SHIFT;
if (locked > lock_limit && !capable(CAP_IPC_LOCK))
return -EAGAIN;
}
inode = file ? file->f_path.dentry->d_inode : NULL;
if (file) {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if ((prot & PROT_WRITE) && !(file->f_mode & FMODE_WRITE))
return -EACCES;
/*
* Make sure we don't allow writing to an append-only
* file..
*/
if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
/*
* Make sure there are no mandatory locks on the file.
*/
if (locks_verify_locked(inode))
return -EAGAIN;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
/* fall through */
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
if (file->f_path.mnt->mnt_flags & MNT_NOEXEC) {
if (vm_flags & VM_EXEC)
return -EPERM;
vm_flags &= ~VM_MAYEXEC;
}
if (!file->f_op || !file->f_op->mmap)
return -ENODEV;
break;
default:
return -EINVAL;
}
} else {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
/*
* Ignore pgoff.
*/
pgoff = 0;
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
/*
* Set pgoff according to addr for anon_vma.
*/
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
error = security_file_mmap(file, reqprot, prot, flags, addr, 0);
if (error)
return error;
// 参见[6.8.2.1.1.1 mmap_region()]节
return mmap_region(file, addr, len, flags, vm_flags, pgoff);
}
6.8.2.1.1.1 mmap_region()
该函数定义于mm/mmap.c:
unsigned long mmap_region(struct file *file, unsigned long addr, unsigned long len,
unsigned long flags, vm_flags_t vm_flags, unsigned long pgoff)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
int correct_wcount = 0;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;
struct inode *inode = file ? file->f_path.dentry->d_inode : NULL;
/* Clear old maps */
error = -ENOMEM;
munmap_back:
// 参见[6.8.1 Find a Memory Regin]节
vma = find_vma_prepare(mm, addr, &prev, &rb_link, &rb_parent);
if (vma && vma->vm_start < addr + len) {
if (do_munmap(mm, addr, len)) // 参见[6.8.5.1 do_munmap()]节
return -ENOMEM;
goto munmap_back;
}
/* Check against address space limit. */
if (!may_expand_vm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
/*
* Set 'VM_NORESERVE' if we should not account for the
* memory use of this mapping.
*/
if ((flags & MAP_NORESERVE)) {
/* We honor MAP_NORESERVE if allowed to overcommit */
if (sysctl_overcommit_memory != OVERCOMMIT_NEVER)
vm_flags |= VM_NORESERVE;
/* hugetlb applies strict overcommit unless MAP_NORESERVE */
if (file && is_file_hugepages(file))
vm_flags |= VM_NORESERVE;
}
/*
* Private writable mapping: check memory availability
*/
if (accountable_mapping(file, vm_flags)) {
charged = len >> PAGE_SHIFT;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
if (security_vm_enough_memory(charged))
return -ENOMEM;
vm_flags |= VM_ACCOUNT;
}
/*
* Can we just expand an old mapping?
*/
/*
* Check whether the preceding memory region can be expanded
* in such a way to include the new interval.
* The preceding memory region must have exactly the same flags
* as those memory regions stored in vm_flags.
* 参见[6.8.2.1.1.1.1 Merge Contiguous Region/vma_merge()]节
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags, NULL, file, pgoff, NULL);
if (vma)
goto out;
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL); // 参见[6.5.1.1.3.1 kmem_cache_zalloc()]节
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
if (file) {
error = -EINVAL;
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
goto free_vma;
if (vm_flags & VM_DENYWRITE) {
error = deny_write_access(file);
if (error)
goto free_vma;
correct_wcount = 1;
}
vma->vm_file = file;
get_file(file);
error = file->f_op->mmap(file, vma);
if (error)
goto unmap_and_free_vma;
if (vm_flags & VM_EXECUTABLE)
added_exe_file_vma(mm);
/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
*/
addr = vma->vm_start;
pgoff = vma->vm_pgoff;
vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) {
/*
* If MAP_SHARED is set and the new memory region
* doesn’t map a file on disk, it’s a shared anonymous
* region. Shared anonymous regions are mainly used
* for interprocess communications.
*/
error = shmem_zero_setup(vma);
if (error)
goto free_vma;
}
if (vma_wants_writenotify(vma)) {
pgprot_t pprot = vma->vm_page_prot;
/* Can vma->vm_page_prot have changed??
*
* Answer: Yes, drivers may have changed it in their
* f_op->mmap method.
*
* Ensures that vmas marked as uncached stay that way.
*/
vma->vm_page_prot = vm_get_page_prot(vm_flags & ~VM_SHARED);
if (pgprot_val(pprot) == pgprot_val(pgprot_noncached(pprot)))
vma->vm_page_prot = pgprot_noncached(vma->vm_page_prot);
}
// Insert the new region in the memory region list and red-black tree.
vma_link(mm, vma, prev, rb_link, rb_parent);
file = vma->vm_file;
/* Once vma denies write, undo our temporary denial count */
if (correct_wcount)
atomic_inc(&inode->i_writecount);
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
vm_stat_account(mm, vm_flags, file, len >> PAGE_SHIFT);
/*
* Invoke make_pages_present() to allocate all pages
* of memory region in succession & lock them in RAM
*/
if (vm_flags & VM_LOCKED) {
if (!mlock_vma_pages_range(vma, addr, addr + len))
mm->locked_vm += (len >> PAGE_SHIFT);
} else if ((flags & MAP_POPULATE) && !(flags & MAP_NONBLOCK))
make_pages_present(addr, addr + len);
// Return the linear address of the new memory region
return addr;
unmap_and_free_vma:
if (correct_wcount)
atomic_inc(&inode->i_writecount);
vma->vm_file = NULL;
fput(file);
/* Undo any partial mapping done by a device driver. */
unmap_region(mm, vma, prev, vma->vm_start, vma->vm_end);
charged = 0;
free_vma:
kmem_cache_free(vm_area_cachep, vma);
unacct_error:
if (charged)
vm_unacct_memory(charged);
return error;
}
6.8.2.1.1.1.1 Merge Contiguous Region/vma_merge()
该函数定义于mm/mmap.c:
struct vm_area_struct *vma_merge(struct mm_struct *mm, struct vm_area_struct *prev,
unsigned long addr, unsigned long end, unsigned long vm_flags, struct anon_vma *anon_vma,
struct file *file, pgoff_t pgoff, struct mempolicy *policy)
{
pgoff_t pglen = (end - addr) >> PAGE_SHIFT;
struct vm_area_struct *area, *next;
int err;
/*
* We later require that vma->vm_flags == vm_flags,
* so this tests vma->vm_flags & VM_SPECIAL, too.
*/
if (vm_flags & VM_SPECIAL)
return NULL;
if (prev)
next = prev->vm_next;
else
next = mm->mmap;
area = next;
if (next && next->vm_end == end) /* cases 6, 7, 8 */
next = next->vm_next;
/*
* Can it merge with the predecessor?
*/
if (prev && prev->vm_end == addr &&
mpol_equal(vma_policy(prev), policy) &&
can_vma_merge_after(prev, vm_flags, anon_vma, file, pgoff)) {
/*
* OK, it can. Can we now merge in the successor as well?
*/
if (next && end == next->vm_start &&
mpol_equal(policy, vma_policy(next)) &&
can_vma_merge_before(next, vm_flags, anon_vma, file, pgoff+pglen) &&
is_mergeable_anon_vma(prev->anon_vma, next->anon_vma, NULL)) { /* cases 1, 6 */
err = vma_adjust(prev, prev->vm_start, next->vm_end, prev->vm_pgoff, NULL);
} else /* cases 2, 5, 7 */
err = vma_adjust(prev, prev->vm_start, end, prev->vm_pgoff, NULL);
if (err)
return NULL;
khugepaged_enter_vma_merge(prev);
return prev;
}
/*
* Can this new request be merged in front of next?
*/
if (next && end == next->vm_start &&
mpol_equal(policy, vma_policy(next)) &&
can_vma_merge_before(next, vm_flags, anon_vma, file, pgoff+pglen)) {
if (prev && addr < prev->vm_end) /* case 4 */
err = vma_adjust(prev, prev->vm_start, addr, prev->vm_pgoff, NULL);
else /* cases 3, 8 */
err = vma_adjust(area, addr, next->vm_end, next->vm_pgoff - pglen, NULL);
if (err)
return NULL;
khugepaged_enter_vma_merge(area);
return area;
}
return NULL;
}
6.8.3 Insert a Memory Region
6.8.3.1 insert_vm_struct()
该函数定义于mm/mmap.c:
/* Insert vm structure into process list sorted by address
* and into the inode's i_mmap tree. If vm_file is non-NULL
* then i_mmap_mutex is taken here.
*/
int insert_vm_struct(struct mm_struct * mm, struct vm_area_struct * vma)
{
struct vm_area_struct * __vma, * prev;
struct rb_node ** rb_link, * rb_parent;
/*
* The vm_pgoff of a purely anonymous vma should be irrelevant
* until its first write fault, when page's anon_vma and index
* are set. But now set the vm_pgoff it will almost certainly
* end up with (unless mremap moves it elsewhere before that
* first wfault), so /proc/pid/maps tells a consistent story.
*
* By setting it to reflect the virtual start address of the
* vma, merges and splits can happen in a seamless way, just
* using the existing file pgoff checks and manipulations.
* Similarly in do_mmap_pgoff and in do_brk.
*/
if (!vma->vm_file) {
BUG_ON(vma->anon_vma);
vma->vm_pgoff = vma->vm_start >> PAGE_SHIFT;
}
// 参见[6.8.1 Find a Memory Regin]节
__vma = find_vma_prepare(mm,vma->vm_start,&prev,&rb_link,&rb_parent);
if (__vma && __vma->vm_start < vma->vm_end)
return -ENOMEM;
if ((vma->vm_flags & VM_ACCOUNT) && security_vm_enough_memory_mm(mm, vma_pages(vma)))
return -ENOMEM;
vma_link(mm, vma, prev, rb_link, rb_parent);
return 0;
}
6.8.4 Remap and Move a Memory Region
6.8.4.1 sys_mremap()
该函数定义于mm/mremap.c:
SYSCALL_DEFINE5(mremap, unsigned long, addr, unsigned long, old_len,
unsigned long, new_len, unsigned long, flags, unsigned long, new_addr)
{
unsigned long ret;
down_write(¤t->mm->mmap_sem);
ret = do_mremap(addr, old_len, new_len, flags, new_addr); // 参见[6.8.4.1.1 do_mremap()]节
up_write(¤t->mm->mmap_sem);
return ret;
}
6.8.4.1.1 do_mremap()
该函数定义于mm/mremap.c:
/*
* Expand (or shrink) an existing mapping, potentially moving it at the
* same time (controlled by the MREMAP_MAYMOVE flag and available VM space)
*
* MREMAP_FIXED option added 5-Dec-1999 by Benjamin LaHaise
* This option implies MREMAP_MAYMOVE.
*/
unsigned long do_mremap(unsigned long addr, unsigned long old_len,
unsigned long new_len, unsigned long flags, unsigned long new_addr)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
unsigned long ret = -EINVAL;
unsigned long charged = 0;
if (flags & ~(MREMAP_FIXED | MREMAP_MAYMOVE))
goto out;
if (addr & ~PAGE_MASK)
goto out;
old_len = PAGE_ALIGN(old_len);
new_len = PAGE_ALIGN(new_len);
/*
* We allow a zero old-len as a special case
* for DOS-emu "duplicate shm area" thing. But
* a zero new-len is nonsensical.
*/
if (!new_len)
goto out;
if (flags & MREMAP_FIXED) {
if (flags & MREMAP_MAYMOVE)
ret = mremap_to(addr, old_len, new_addr, new_len);
goto out;
}
/*
* Always allow a shrinking remap: that just unmaps
* the unnecessary pages..
* do_munmap does all the needed commit accounting
*/
if (old_len >= new_len) {
ret = do_munmap(mm, addr+new_len, old_len - new_len); // 参见[6.8.5.1 do_munmap()]节
if (ret && old_len != new_len)
goto out;
ret = addr;
goto out;
}
/*
* Ok, we need to grow..
*/
vma = vma_to_resize(addr, old_len, new_len, &charged);
if (IS_ERR(vma)) {
ret = PTR_ERR(vma);
goto out;
}
/* old_len exactly to the end of the area..
*/
if (old_len == vma->vm_end - addr) {
/* can we just expand the current mapping? */
if (vma_expandable(vma, new_len - old_len)) {
int pages = (new_len - old_len) >> PAGE_SHIFT;
if (vma_adjust(vma, vma->vm_start, addr + new_len, vma->vm_pgoff, NULL)) {
ret = -ENOMEM;
goto out;
}
mm->total_vm += pages;
vm_stat_account(mm, vma->vm_flags, vma->vm_file, pages);
if (vma->vm_flags & VM_LOCKED) {
mm->locked_vm += pages;
mlock_vma_pages_range(vma, addr + old_len, addr + new_len);
}
ret = addr;
goto out;
}
}
/*
* We weren't able to just expand or shrink the area,
* we need to create a new one and move it..
*/
ret = -ENOMEM;
if (flags & MREMAP_MAYMOVE) {
unsigned long map_flags = 0;
if (vma->vm_flags & VM_MAYSHARE)
map_flags |= MAP_SHARED;
new_addr = get_unmapped_area(vma->vm_file, 0, new_len,
vma->vm_pgoff + ((addr - vma->vm_start) >> PAGE_SHIFT), map_flags);
if (new_addr & ~PAGE_MASK) {
ret = new_addr;
goto out;
}
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
ret = security_file_mmap(NULL, 0, 0, 0, new_addr, 1);
if (ret)
goto out;
ret = move_vma(vma, addr, old_len, new_len, new_addr);
}
out:
if (ret & ~PAGE_MASK)
vm_unacct_memory(charged);
return ret;
}
6.8.5 Release/Delete a Linear Address Interval
6.8.5.1 do_munmap()
该函数定义于mm/mmap.c:
/* Munmap is split into 2 main parts -- this part which finds
* what needs doing, and the areas themselves, which do the
* work. This now handles partial unmappings.
* Jeremy Fitzhardinge <jeremy@goop.org>
*/
int do_munmap(struct mm_struct *mm, unsigned long start, size_t len)
{
unsigned long end;
struct vm_area_struct *vma, *prev, *last;
if ((start & ~PAGE_MASK) || start > TASK_SIZE || len > TASK_SIZE-start)
return -EINVAL;
if ((len = PAGE_ALIGN(len)) == 0)
return -EINVAL;
/* Find the first overlapping VMA */
vma = find_vma(mm, start); // 参见[6.8.1.1 find_vma()]节
if (!vma)
return 0;
prev = vma->vm_prev;
/* we have start < vma->vm_end */
/* if it doesn't overlap, we have nothing.. */
end = start + len;
if (vma->vm_start >= end)
return 0;
/*
* If we need to split any vma, do it now to save pain later.
*
* Note: mremap's move_vma VM_ACCOUNT handling assumes a partially
* unmapped vm_area_struct will remain in use: so lower split_vma
* places tmp vma above, and higher split_vma places tmp vma below.
*/
if (start > vma->vm_start) {
int error;
/*
* Make sure that map_count on return from munmap() will
* not exceed its limit; but let map_count go just above
* its limit temporarily, to help free resources as expected.
*/
if (end < vma->vm_end && mm->map_count >= sysctl_max_map_count)
return -ENOMEM;
error = __split_vma(mm, vma, start, 0); // 参见[6.8.5.1.1 __split_vma()]节
if (error)
return error;
prev = vma;
}
/* Does it split the last one? */
last = find_vma(mm, end); // 参见[6.8.1.1 find_vma()]节
if (last && end > last->vm_start) {
int error = __split_vma(mm, last, end, 1); // 参见[6.8.5.1.1 __split_vma()]节
if (error)
return error;
}
vma = prev? prev->vm_next : mm->mmap;
/*
* unlock any mlock()ed ranges before detaching vmas
*/
if (mm->locked_vm) {
struct vm_area_struct *tmp = vma;
while (tmp && tmp->vm_start < end) {
if (tmp->vm_flags & VM_LOCKED) {
mm->locked_vm -= vma_pages(tmp);
munlock_vma_pages_all(tmp);
}
tmp = tmp->vm_next;
}
}
/*
* Remove the vma's, and unmap the actual pages
*/
detach_vmas_to_be_unmapped(mm, vma, prev, end);
unmap_region(mm, vma, prev, start, end); // 参见[6.8.5.1.2 unmap_region()]节
/* Fix up all other VM information */
remove_vma_list(mm, vma);
return 0;
}
6.8.5.1.1 __split_vma()
The purpose of the split_vma() function is to split a memory region that intersects a linear address interval into two smaller regions, one outside of the interval and the other inside. The input parameter new_below specifies whether the intersection occurs at the beginning or at the end of the interval.
该函数定义于mm/mmap.c:
static int __split_vma(struct mm_struct * mm, struct vm_area_struct * vma,
unsigned long addr, int new_below)
{
struct mempolicy *pol;
struct vm_area_struct *new;
int err = -ENOMEM;
if (is_vm_hugetlb_page(vma) && (addr & ~(huge_page_mask(hstate_vma(vma)))))
return -EINVAL;
// 参见[6.5.1.1.3.1 kmem_cache_zalloc()]节
new = kmem_cache_alloc(vm_area_cachep, GFP_KERNEL);
if (!new)
goto out_err;
/* most fields are the same, copy all, and then fixup */
*new = *vma;
INIT_LIST_HEAD(&new->anon_vma_chain);
if (new_below)
new->vm_end = addr;
else {
new->vm_start = addr;
new->vm_pgoff += ((addr - vma->vm_start) >> PAGE_SHIFT);
}
pol = mpol_dup(vma_policy(vma));
if (IS_ERR(pol)) {
err = PTR_ERR(pol);
goto out_free_vma;
}
vma_set_policy(new, pol);
if (anon_vma_clone(new, vma))
goto out_free_mpol;
if (new->vm_file) {
get_file(new->vm_file);
if (vma->vm_flags & VM_EXECUTABLE)
added_exe_file_vma(mm);
}
if (new->vm_ops && new->vm_ops->open)
new->vm_ops->open(new);
if (new_below)
err = vma_adjust(vma, addr, vma->vm_end, vma->vm_pgoff +
((addr - new->vm_start) >> PAGE_SHIFT), new);
else
err = vma_adjust(vma, vma->vm_start, addr, vma->vm_pgoff, new);
/* Success. */
if (!err)
return 0;
/* Clean everything up if vma_adjust failed. */
if (new->vm_ops && new->vm_ops->close)
new->vm_ops->close(new);
if (new->vm_file) {
if (vma->vm_flags & VM_EXECUTABLE)
removed_exe_file_vma(mm);
fput(new->vm_file);
}
unlink_anon_vmas(new);
out_free_mpol:
mpol_put(pol);
out_free_vma:
kmem_cache_free(vm_area_cachep, new);
out_err:
return err;
}
6.8.5.1.2 unmap_region()
The unmap_region() function walks through a list of memory regions and releases the page frames belonging to them.
该函数定义于mm/mmap.c:
static void unmap_region(struct mm_struct *mm, struct vm_area_struct *vma,
struct vm_area_struct *prev, unsigned long start, unsigned long end)
{
struct vm_area_struct *next = prev? prev->vm_next: mm->mmap;
struct mmu_gather tlb;
unsigned long nr_accounted = 0;
lru_add_drain();
/*
* Initialize a per-CPU variable named mmu_gathers:
* The contents of mmu_gathers are architecture-dependent:
* generally speaking, the variable should store all
* information required for a successful updating of
* the page table entries of a process.
*/
tlb_gather_mmu(&tlb, mm, 0);
update_hiwater_rss(mm);
/*
* Scan all Page Table entries belonging to the linear
* address interval: if only one CPU is available, the
* function invokes free_swap_and_cache() repeatedly to
* release the corresponding page; otherwise, the function
* saves the pointers of the corresponding page descriptors
* in the mmu_gathers local variable.
*/
unmap_vmas(&tlb, vma, start, end, &nr_accounted, NULL);
vm_unacct_memory(nr_accounted);
/*
* Try to reclaim the Page Tables of the process that have
* been emptied in the previous step.
*/
free_pgtables(&tlb, vma, prev ? prev->vm_end : FIRST_USER_ADDRESS,
next ? next->vm_start : 0);
/*
* Invokes flush_tlb_mm() to flush the TLB;
* In multiprocessor system, invokes free_pages_and_swap_cache()
* to release the page frames whose pointers have been collected
* in the mmu_gather data structure.
*/
tlb_finish_mmu(&tlb, start, end);
}
6.8.5.2 exit_mmap()
该函数定义于mm/mmap.c:
/* Release all mmaps. */
void exit_mmap(struct mm_struct *mm)
{
struct mmu_gather tlb;
struct vm_area_struct *vma;
unsigned long nr_accounted = 0;
unsigned long end;
/* mm's last user has gone, and its about to be pulled down */
mmu_notifier_release(mm);
if (mm->locked_vm) {
vma = mm->mmap;
while (vma) {
if (vma->vm_flags & VM_LOCKED)
munlock_vma_pages_all(vma);
vma = vma->vm_next;
}
}
arch_exit_mmap(mm);
vma = mm->mmap;
if (!vma) /* Can happen if dup_mmap() received an OOM */
return;
lru_add_drain();
flush_cache_mm(mm);
tlb_gather_mmu(&tlb, mm, 1);
/* update_hiwater_rss(mm) here? but nobody should be looking */
/* Use -1 here to ensure all VMAs in the mm are unmapped */
end = unmap_vmas(&tlb, vma, 0, -1, &nr_accounted, NULL);
vm_unacct_memory(nr_accounted);
free_pgtables(&tlb, vma, FIRST_USER_ADDRESS, 0);
tlb_finish_mmu(&tlb, 0, end);
/*
* Walk the list again, actually closing and freeing it,
* with preemption enabled, without holding any MM locks.
*/
while (vma)
vma = remove_vma(vma);
BUG_ON(mm->nr_ptes > (FIRST_USER_ADDRESS+PMD_SIZE-1)>>PMD_SHIFT);
}
6.9 Page Fault/do_page_fault()
Each architecture registers an architecture-specific function for the handling of page faults.
Pages in the process linear address space are not necessarily resident in memory. For example, allocations made on behalf of a process are not satisfied immediately as the space is just reserved within the vm_area_struct. Other examples of non-resident pages include the page having been swapped out to backing storage or writing a read-only page.
Linux, like most operating systems, has a Demand Fetch policy as its fetch policy for dealing with pages that are not resident. This states that the page is only fetched from backing storage when the hardware raises a page fault exception (see Vec=0xEC in 9.1 中断处理简介节中的表”中断向量(vector)取值”) which the operating system traps and allocates a page.
There are two types of page fault, major and minor faults. Major page faults occur when data has to be read from disk which is an expensive operation, else the fault is referred to as a minor, or soft page fault. Linux maintains statistics on the number of these types of page faults with the task_struct->maj_flt and task_struct->min_flt fields respectively (see section 7.1 进程描述符/struct task_struct).
The page fault handler in Linux is expected to recognise and act on a number of different types of page faults listed in the following table.
Reasons For Page Faulting:
| Exception | Type | Action |
|---|---|---|
| Region valid but page not allocated | Minor | Allocate a page frame from the physical page allocator |
| Region not valid but is beside an expandable region like the stack | Minor | Expand the region and allocate a page |
| Page swapped out but present in swap cache | Minor | Re-establish the page in the process page tables and drop a reference to the swap cache |
| Page swapped out to backing storage | Major | Find where the page with information stored in the PTE and read it from disk |
| Page write when marked read-only | Minor | If the page is a COW page, make a copy of it, mark it writable and assign it to the process. If it is in fact a bad write, send a SIGSEGV signal |
| Region is invalid or process has no permissions to access | Error | Send a SEGSEGV signal to the process |
| Fault occurred in the kernel portion address space | Minor | If the fault occurred in the vmalloc area of the address space, the current process page tables are updated against the master page table held by init_mm. This is the only valid kernel page fault that may occur |
| Fault occurred in the userspace region while in kernel mode | Error | If a fault occurs, it means a kernel system did not copy from userspace properly and caused a page fault. This is a kernel bug which is treated quite severely. |
函数do_page_fault()定义于arch/x86/mm/fault.c:
/*
* This routine handles page faults. It determines the address, and the problem,
* and then passes it off to one of the appropriate routines.
*/
dotraplinkage void __kprobes do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
unsigned long address;
struct mm_struct *mm;
int fault;
int write = error_code & PF_WRITE;
unsigned int flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE |
(write ? FAULT_FLAG_WRITE : 0);
tsk = current;
mm = tsk->mm;
/* Get the faulting address: */
address = read_cr2(); // 参见[6.1.2 分页机制]节中的图"寄存器"
/*
* Detect and handle instructions that would cause a page fault for
* both a tracked kernel page and a userspace page.
*/
if (kmemcheck_active(regs))
kmemcheck_hide(regs);
prefetchw(&mm->mmap_sem);
if (unlikely(kmmio_fault(regs, address)))
return;
/*
* We fault-in kernel-space virtual memory on-demand. The
* 'reference' page table is init_mm.pgd.
*
* NOTE! We MUST NOT take any locks for this case. We may
* be in an interrupt or a critical region, and should
* only copy the information from the master page table,
* nothing more.
*
* This verifies that the fault happens in kernel space
* (error_code & 4) == 0, and that the fault was not a
* protection error (error_code & 9) == 0.
*/
if (unlikely(fault_in_kernel_space(address))) { // address >= TASK_SIZE_MAX
if (!(error_code & (PF_RSVD | PF_USER | PF_PROT))) {
// Handle a fault on the vmalloc area
if (vmalloc_fault(address) >= 0)
return;
if (kmemcheck_fault(regs, address, error_code))
return;
}
/* Can handle a stale RO->RW TLB: */
// Handle a spurious fault caused by a stale TLB entry
if (spurious_fault(error_code, address))
return;
/* kprobes don't want to hook the spurious faults: */
if (notify_page_fault(regs))
return;
/*
* Don't take the mm semaphore here. If we fixup a prefetch
* fault we could otherwise deadlock:
*/
bad_area_nosemaphore(regs, error_code, address);
return;
}
/* kprobes don't want to hook the spurious faults: */
if (unlikely(notify_page_fault(regs)))
return;
/*
* It's safe to allow irq's after cr2 has been saved and the
* vmalloc fault has been handled.
*
* User-mode registers count as a user access even for any
* potential system fault or CPU buglet:
*/
if (user_mode_vm(regs)) {
local_irq_enable();
error_code |= PF_USER;
} else {
if (regs->flags & X86_EFLAGS_IF)
local_irq_enable();
}
if (unlikely(error_code & PF_RSVD))
pgtable_bad(regs, error_code, address);
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, address);
/*
* If we're in an interrupt, have no user context or are running
* in an atomic region then we must not take the fault:
*/
if (unlikely(in_atomic() || !mm)) {
bad_area_nosemaphore(regs, error_code, address);
return;
}
/*
* When running in the kernel we expect faults to occur only to
* addresses in user space. All other faults represent errors in
* the kernel and should generate an OOPS. Unfortunately, in the
* case of an erroneous fault occurring in a code path which already
* holds mmap_sem we will deadlock attempting to validate the fault
* against the address space. Luckily the kernel only validly
* references user space from well defined areas of code, which are
* listed in the exceptions table.
*
* As the vast majority of faults will be valid we will only perform
* the source reference check when there is a possibility of a
* deadlock. Attempt to lock the address space, if we cannot we then
* validate the source. If this is invalid we can skip the address
* space check, thus avoiding the deadlock:
*/
if (unlikely(!down_read_trylock(&mm->mmap_sem))) {
if ((error_code & PF_USER) == 0 && !search_exception_tables(regs->ip)) {
bad_area_nosemaphore(regs, error_code, address);
return;
}
retry:
down_read(&mm->mmap_sem);
} else {
/*
* The above down_read_trylock() might have succeeded in
* which case we'll have missed the might_sleep() from
* down_read():
*/
might_sleep();
}
vma = find_vma(mm, address); // 参见[6.8.1.1 find_vma()]节
if (unlikely(!vma)) {
bad_area(regs, error_code, address);
return;
}
if (likely(vma->vm_start <= address))
goto good_area;
if (unlikely(!(vma->vm_flags & VM_GROWSDOWN))) {
bad_area(regs, error_code, address);
return;
}
if (error_code & PF_USER) {
/*
* Accessing the stack below %sp is always a bug.
* The large cushion allows instructions like enter
* and pusha to work. ("enter $65535, $31" pushes
* 32 pointers and then decrements %sp by 65535.)
*/
if (unlikely(address + 65536 + 32 * sizeof(unsigned long) < regs->sp)) {
bad_area(regs, error_code, address);
return;
}
}
if (unlikely(expand_stack(vma, address))) {
bad_area(regs, error_code, address);
return;
}
/*
* Ok, we have a good vm_area for this memory access, so
* we can handle it..
*/
good_area:
if (unlikely(access_error(error_code, vma))) {
bad_area_access_error(regs, error_code, address);
return;
}
/*
* If for any reason at all we couldn't handle the fault,
* make sure we exit gracefully rather than endlessly redo
* the fault:
*/
/*
* If handle_mm_fault() returns 1, it’s a minor fault,
* 2 is a major fault, 0 sends a SIGBUS error and any
* other value invokes the out of memory handler.
* 参见[6.9.1 handle_mm_fault()]节
*/
fault = handle_mm_fault(mm, vma, address, flags);
if (unlikely(fault & (VM_FAULT_RETRY|VM_FAULT_ERROR))) {
if (mm_fault_error(regs, error_code, address, fault))
return;
}
/*
* Major/minor page fault accounting is only done on the
* initial attempt. If we go through a retry, it is extremely
* likely that the page will be found in page cache at that point.
*/
if (flags & FAULT_FLAG_ALLOW_RETRY) {
if (fault & VM_FAULT_MAJOR) {
tsk->maj_flt++;
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MAJ, 1, regs, address);
} else {
tsk->min_flt++;
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MIN, 1, regs, address);
}
if (fault & VM_FAULT_RETRY) {
/* Clear FAULT_FLAG_ALLOW_RETRY to avoid any risk
* of starvation. */
flags &= ~FAULT_FLAG_ALLOW_RETRY;
goto retry;
}
}
check_v8086_mode(regs, address, tsk);
up_read(&mm->mmap_sem);
}
6.9.1 handle_mm_fault()
该函数定义于mm/memory.c:
int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
__set_current_state(TASK_RUNNING);
count_vm_event(PGFAULT);
mem_cgroup_count_vm_event(mm, PGFAULT);
/* do counter updates before entering really critical section. */
check_sync_rss_stat(current);
if (unlikely(is_vm_hugetlb_page(vma)))
return hugetlb_fault(mm, vma, address, flags);
pgd = pgd_offset(mm, address);
pud = pud_alloc(mm, pgd, address);
if (!pud)
return VM_FAULT_OOM;
pmd = pmd_alloc(mm, pud, address);
if (!pmd)
return VM_FAULT_OOM;
if (pmd_none(*pmd) && transparent_hugepage_enabled(vma)) {
if (!vma->vm_ops)
return do_huge_pmd_anonymous_page(mm, vma, address, pmd, flags);
} else {
pmd_t orig_pmd = *pmd;
barrier();
if (pmd_trans_huge(orig_pmd)) {
if (flags & FAULT_FLAG_WRITE &&
!pmd_write(orig_pmd) &&
!pmd_trans_splitting(orig_pmd))
return do_huge_pmd_wp_page(mm, vma, address, pmd, orig_pmd);
return 0;
}
}
/*
* Use __pte_alloc instead of pte_alloc_map, because we can't
* run pte_offset_map on the pmd, if an huge pmd could
* materialize from under us from a different thread.
*/
if (unlikely(pmd_none(*pmd)) && __pte_alloc(mm, vma, pmd, address))
return VM_FAULT_OOM;
/* if an huge pmd materialized from under us just retry later */
if (unlikely(pmd_trans_huge(*pmd)))
return 0;
/*
* A regular pmd is established and it can't morph into a huge pmd
* from under us anymore at this point because we hold the mmap_sem
* read mode and khugepaged takes it in write mode. So now it's
* safe to run pte_offset_map().
*/
pte = pte_offset_map(pmd, address);
// 参见[6.9.1.1 handle_pte_fault()]节
return handle_pte_fault(mm, vma, address, pte, pmd, flags);
}
6.9.1.1 handle_pte_fault()
该函数定义于mm/memory.c:
int handle_pte_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *pte, pmd_t *pmd, unsigned int flags)
{
pte_t entry;
spinlock_t *ptl;
entry = *pte;
if (!pte_present(entry)) {
/*
* If no PTE has been allocated, do_anonymous_page()
* is called which handles Demand Allocation.
*/
if (pte_none(entry)) {
if (vma->vm_ops) {
if (likely(vma->vm_ops->fault))
return do_linear_fault(mm, vma, address, pte, pmd, flags, entry);
}
return do_anonymous_page(mm, vma, address, pte, pmd, flags);
}
if (pte_file(entry))
return do_nonlinear_fault(mm, vma, address, pte, pmd, flags, entry);
/*
* Otherwise it is a page that has been swapped out
* to disk and do_swap_page() performs Demand Paging.
*/
return do_swap_page(mm, vma, address, pte, pmd, flags, entry);
}
ptl = pte_lockptr(mm, pmd);
spin_lock(ptl);
if (unlikely(!pte_same(*pte, entry)))
goto unlock;
if (flags & FAULT_FLAG_WRITE) {
/*
* If the PTE is write protected, then do_wp_page() is
* called as the page is a Copy-On-Write (COW) page.
* A COW page is one which is shared between multiple
* processes (usually a parent and child) until a write
* occurs after which a private copy is made for the
* writing process.
*/
if (!pte_write(entry))
return do_wp_page(mm, vma, address, pte, pmd, ptl, entry);
/*
* If it is not a COW page, the page is simply marked
* dirty as it has been written to.
*/
entry = pte_mkdirty(entry);
}
/*
* If the page has been read and is present but a fault still
* occurred. This can occur with some architectures that do
* not have a three level page table. In this case, the PTE
* is simply established and marked young.
*/
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vma, address, pte, entry, flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vma, address, pte);
} else {
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vma, address);
}
unlock:
pte_unmap_unlock(pte, ptl);
return 0;
}
6.9.2 Out Of Memory (OOM) Management
Out Of Memory (OOM) manager has one simple task: check if there is enough available memory to satisfy, verify that the system is truely out of memory and if so, select a process to kill.
6.9.2.1 mm_fault_error()
该函数定义于arch/x86/mm/fault.c:
static noinline int mm_fault_error(struct pt_regs *regs, unsigned long error_code,
unsigned long address, unsigned int fault)
{
/*
* Pagefault was interrupted by SIGKILL. We have no reason to
* continue pagefault.
*/
if (fatal_signal_pending(current)) {
if (!(fault & VM_FAULT_RETRY))
up_read(¤t->mm->mmap_sem);
if (!(error_code & PF_USER))
no_context(regs, error_code, address);
return 1;
}
if (!(fault & VM_FAULT_ERROR))
return 0;
if (fault & VM_FAULT_OOM) {
/* Kernel mode? Handle exceptions or die: */
if (!(error_code & PF_USER)) {
up_read(¤t->mm->mmap_sem);
no_context(regs, error_code, address);
return 1;
}
out_of_memory(regs, error_code, address);
} else {
if (fault & (VM_FAULT_SIGBUS|VM_FAULT_HWPOISON|VM_FAULT_HWPOISON_LARGE))
do_sigbus(regs, error_code, address, fault);
else
BUG();
}
return 1;
}
其中,函数out_of_memory()定义于arch/x86/mm/fault.c:
static void out_of_memory(struct pt_regs *regs, unsigned long error_code, unsigned long address)
{
/*
* We ran out of memory, call the OOM killer, and return the userspace
* (which will retry the fault, or kill us if we got oom-killed):
*/
up_read(¤t->mm->mmap_sem);
pagefault_out_of_memory();
}
其中,函数pagefault_out_of_memory()定义于mm/oom_kill.c:
/*
* The pagefault handler calls here because it is out of memory, so kill a
* memory-hogging task. If a populated zone has ZONE_OOM_LOCKED set, a parallel
* oom killing is already in progress so do nothing. If a task is found with
* TIF_MEMDIE set, it has been killed so do nothing and allow it to exit.
*/
void pagefault_out_of_memory(void)
{
if (try_set_system_oom()) {
out_of_memory(NULL, 0, 0, NULL); // 参见[6.9.2.1.1 out_of_memory()]节
clear_system_oom();
}
if (!test_thread_flag(TIF_MEMDIE))
schedule_timeout_uninterruptible(1);
}
6.9.2.1.1 out_of_memory()
该函数定义于mm/oom_kill.c:
/**
* out_of_memory - kill the "best" process when we run out of memory
* @zonelist: zonelist pointer
* @gfp_mask: memory allocation flags
* @order: amount of memory being requested as a power of 2
* @nodemask: nodemask passed to page allocator
*
* If we run out of memory, we have the choice between either
* killing a random task (bad), letting the system crash (worse)
* OR try to be smart about which process to kill. Note that we
* don't have to be perfect here, we just have to be good.
*/
void out_of_memory(struct zonelist *zonelist, gfp_t gfp_mask, int order, nodemask_t *nodemask)
{
const nodemask_t *mpol_mask;
struct task_struct *p;
unsigned long totalpages;
unsigned long freed = 0;
unsigned int points;
enum oom_constraint constraint = CONSTRAINT_NONE;
int killed = 0;
blocking_notifier_call_chain(&oom_notify_list, 0, &freed);
if (freed > 0)
/* Got some memory back in the last second. */
return;
/*
* If current has a pending SIGKILL, then automatically select it. The
* goal is to allow it to allocate so that it may quickly exit and free
* its memory.
*/
if (fatal_signal_pending(current)) {
set_thread_flag(TIF_MEMDIE);
return;
}
/*
* Check if there were limitations on the allocation (only relevant for
* NUMA) that may require different handling.
*/
constraint = constrained_alloc(zonelist, gfp_mask, nodemask, &totalpages);
mpol_mask = (constraint == CONSTRAINT_MEMORY_POLICY) ? nodemask : NULL;
check_panic_on_oom(constraint, gfp_mask, order, mpol_mask);
read_lock(&tasklist_lock);
if (sysctl_oom_kill_allocating_task &&
!oom_unkillable_task(current, NULL, nodemask) &&
current->mm) {
/*
* oom_kill_process() needs tasklist_lock held. If it returns
* non-zero, current could not be killed so we must fallback to
* the tasklist scan.
*/
if (!oom_kill_process(current, gfp_mask, order, 0, totalpages, NULL, nodemask,
"Out of memory (oom_kill_allocating_task)"))
goto out;
}
retry:
/*
* It's responsible for choosing a process to kill.
* It decides by stepping through each running task
* and calculating how suitable it is for killing
* with the function oom_badness().
*/
p = select_bad_process(&points, totalpages, NULL, mpol_mask);
if (PTR_ERR(p) == -1UL)
goto out;
/* Found nothing?!?! Either we hang forever, or we panic. */
if (!p) {
dump_header(NULL, gfp_mask, order, NULL, mpol_mask);
read_unlock(&tasklist_lock);
panic("Out of memory and no killable processes...\n");
}
/*
* Once a task is selected, the list is walked again and
* each process that shares the same mm_struct as the
* selected process (i.e. they are threads) is sent a signal.
* If the process has CAP_SYS_RAWIO capabilities, a SIGTERM
* is sent to give the process a chance of exiting cleanly,
* otherwise a SIGKILL is sent.
*/
if (oom_kill_process(p, gfp_mask, order, points, totalpages, NULL, nodemask, "Out of memory"))
goto retry;
killed = 1;
out:
read_unlock(&tasklist_lock);
/*
* Give "p" a good chance of killing itself before we
* retry to allocate memory unless "p" is current
*/
if (killed && !test_thread_flag(TIF_MEMDIE))
schedule_timeout_uninterruptible(1);
}
6.10 Reserved Page Frame Pool
参见«Understanding the Linux Kernel, 3rd Edition» 第8. Memory Management章第The Pool of Reserved Page Frames节:
Memory allocation requests can be satisfied in two different ways. If enough free memory is available, the request can be satisfied immediately. Otherwise, some memory reclaiming must take place, and the kernel control path that made the request is blocked until additional memory has been freed.
However, some kernel control paths cannot be blocked while requesting memory — this happens, for instance, when handling an interrupt or when executing code inside a critical region. In these cases, a kernel control path should issue atomic memory allocation requests (using the GFP_ATOMIC flag). An atomic request never blocks: if there are not enough free pages, the allocation simply fails.
Although there is no way to ensure that an atomic memory allocation request never fails, the kernel tries hard to minimize the likelihood of this unfortunate event. In order to do this, the kernel reserves a pool of page frames for atomic memory allocation requests to be used only on low-on-memory conditions.
The amount of the reserved memory (in kilobytes) is stored in the min_free_kbytes variable. Its initial value is set during kernel initialization and depends on the amount of physical memory that is directly mapped in the kernel’s fourth gigabyte of linear addresses — that is, it depends on the number of page frames included in the ZONE_DMA and ZONE_NORMAL memory zones:
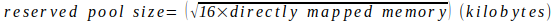
However, initially min_free_kbytes cannot be lower than 128 and greater than 65,536.
全局变量min_free_kbytes定义于mm/page_alloc.c:
int min_free_kbytes = 1024;
int __meminit init_per_zone_wmark_min(void)
{
unsigned long lowmem_kbytes;
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
if (min_free_kbytes < 128)
min_free_kbytes = 128;
if (min_free_kbytes > 65536)
min_free_kbytes = 65536;
setup_per_zone_wmarks();
refresh_zone_stat_thresholds();
setup_per_zone_lowmem_reserve();
setup_per_zone_inactive_ratio();
return 0;
}
/*
* 由mm/Makefile可知,mm/page_alloc.c被直接编译进内核,
* 故在系统启动时如下初始化函数被调用,
* 参见[13.5.1.1 module被编译进内核时的初始化过程](#13-5-1-1-module-)节
*/
module_init(init_per_zone_wmark_min)
The ZONE_DMA and ZONE_NORMAL memory zones contribute to the reserved memory with a number of page frames proportional to their relative sizes.
The pages_min field of the zone descriptor stores the number of reserved page frames inside the zone. That field plays also a role for the page frame reclaiming algorithm, together with the pages_low and pages_high fields. The pages_low field is always set to 5/4 of the value of pages_min, and pages_high is always set to 3/2 of the value of pages_min.
7 内核/Kernel
7.1 进程描述符/struct task_struct
Linux系统中每个进程都有一个进程描述符结构struct task_struct,即操作系统课程中的进程控制块PCB,它是理解任务调度的关键。struct task_struct是一个巨大的结构体,其定义于include/linux/sched.h:
struct task_struct {
// 其取值参见[7.1.1.1 进程状态]节
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack; // 参见[7.1.1.3 进程内核栈]节
atomic_t usage; // 参见[7.1.1.14 进程描述符使用计数]节
unsigned int flags; /* per process flags, defined below */ // 参见[7.1.1.4 标志]节
unsigned int ptrace; // 参见[7.1.1.6 ptrace系统调用]节
#ifdef CONFIG_SMP
struct llist_node wake_entry;
int on_cpu;
#endif
int on_rq;
// 进程调度有关的变量,参见[7.4 进程调度]节
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* list of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
/*
* fpu_counter contains the number of consecutive context switches
* that the FPU is used. If this is over a threshold, the lazy fpu
* saving becomes unlazy to save the trap. This is an unsigned char
* so that after 256 times the counter wraps and the behavior turns
* lazy again; this to deal with bursty apps that only use FPU for
* a short time
*/
unsigned char fpu_counter; // 参见[7.1.1.15 FPU使用计数]节
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq; // 参见[7.1.1.16 块设备I/O层的跟踪工具]节
#endif
unsigned int policy; // 参见[7.4 进程调度]节
cpumask_t cpus_allowed; // 参见[7.4 进程调度]节
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting; // 参见[7.1.1.17 RCU同步原语]节
char rcu_read_unlock_special; // 参见[7.1.1.17 RCU同步原语]节
struct list_head rcu_node_entry; // 参见[7.1.1.17 RCU同步原语]节
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TREE_PREEMPT_RCU
struct rcu_node *rcu_blocked_node; // 参见[7.1.1.17 RCU同步原语]节
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#ifdef CONFIG_RCU_BOOST
struct rt_mutex *rcu_boost_mutex; // 参见[7.1.1.17 RCU同步原语]节
#endif /* #ifdef CONFIG_RCU_BOOST */
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info; // 参见[7.1.1.18 用于调度器统计进程的运行信息]节
#endif
struct list_head tasks; // 参见[7.1.1.19 进程链表]节
#ifdef CONFIG_SMP
struct plist_node pushable_tasks; // 参见[7.1.1.19 进程链表]节
#endif
// mm field points to the memory descriptor owned by the process;
// active_mm field points to the memory descriptor used by the process when it is in execution.
// For regular processes, the two fields store the same pointer.
// Kernel threads don’t own any memory descriptor, thus their mm field is always NULL.
// When a kernel thread is selected for execution, its active_mm field is initialized
// to the value of the active_mm of the previously running process.
struct mm_struct *mm, *active_mm; // 参见[7.1.1.9 进程地址空间]节和[6.2.6 struct mm_struct]节
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1; // 参见[7.1.1.9 进程地址空间]节
#endif
#if defined(SPLIT_RSS_COUNTING)
struct task_rss_stat rss_stat; // 参见[7.1.1.9 进程地址空间]节
#endif
/* task state */
int exit_state; // 其取值参见[7.1.1.1 进程状态]节
int exit_code, exit_signal; // 参见[7.1.1.10 判断标志]节
int pdeath_signal; /* The signal sent when the parent dies */ // 参见[7.1.1.10 判断标志]节
unsigned int jobctl; /* JOBCTL_*, siglock protected */ // 参见[7.1.1.10 判断标志]节
unsigned int personality; // 参见[7.1.1.10 判断标志]节
unsigned did_exec:1; // 参见[7.1.1.10 判断标志]节
unsigned in_execve:1; /* Tell the LSMs that the process is doing an execve */ // 参见[7.1.1.10 判断标志]节
unsigned in_iowait:1; // 参见[7.1.1.10 判断标志]节
/* Revert to default priority/policy when forking */
unsigned sched_reset_on_fork:1; // 参见[7.1.1.10 判断标志]节
unsigned sched_contributes_to_load:1;
pid_t pid; // 参见[7.1.1.2 进程标识符]节
pid_t tgid; // 参见[7.1.1.2 进程标识符]节
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary; // 参见[7.1.1.20 防止内核堆栈溢出]节
#endif
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct *real_parent; /* real parent process */ // 参见[7.1.1.5 进程的亲属关系]节
struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */ // 参见[7.1.1.5 进程的亲属关系]节
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */ // 参见[7.1.1.5 进程的亲属关系]节
struct list_head sibling; /* linkage in my parent's children list */ // 参见[7.1.1.5 进程的亲属关系]节
struct task_struct *group_leader; /* threadgroup leader */ // 参见[7.1.1.5 进程的亲属关系]节
/*
* ptraced is the list of tasks this task is using ptrace on.
* This includes both natural children and PTRACE_ATTACH targets.
* p->ptrace_entry is p's link on the p->parent->ptraced list.
*/
struct list_head ptraced; // 参见[7.1.1.6 ptrace系统调用]节
struct list_head ptrace_entry; // 参见[7.1.1.6 ptrace系统调用]节
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX]; // 参见[7.1.1.21 PID散列表和链表]节
struct list_head thread_group; // 参见[7.1.1.21 PID散列表和链表]节
struct completion *vfork_done; /* for vfork() */ // 参见[7.1.1.22 do_fork函数]节
int __user *set_child_tid; /* CLONE_CHILD_SETTID */ // 参见[7.1.1.22 do_fork函数]节
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */ // 参见[7.1.1.22 do_fork函数]节
cputime_t utime, stime, utimescaled, stimescaled; // 参见[7.1.1.11 时间]节
cputime_t gtime; // 参见[7.1.1.11 时间]节
#ifndef CONFIG_VIRT_CPU_ACCOUNTING
cputime_t prev_utime, prev_stime; // 参见[7.1.1.11 时间]节
#endif
unsigned long nvcsw, nivcsw; /* context switch counts */ // 参见[7.1.1.11 时间]节
struct timespec start_time; /* monotonic time */ // 参见[7.1.1.11 时间]节
struct timespec real_start_time; /* boot based time */ // 参见[7.1.1.11 时间]节
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt; // 参见[7.1.1.23 缺页统计]节和[6.9 Page Fault/do_page_fault()]节
struct task_cputime cputime_expires; // 参见[7.1.1.11 时间]节
struct list_head cpu_timers[3]; // 参见[7.1.1.11 时间]节
/* process credentials */ // 参见[7.1.1.24 进程权能]节
const struct cred __rcu *real_cred; /* objective and real subjective task credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task credentials (COW) */
struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */
// 参见[7.1.1.25 程序名称]节
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock it with task_lock())
- initialized normally by setup_new_exec */
/* file system info */
int link_count, total_link_count; // 参见[7.1.1.26 文件系统]节
#ifdef CONFIG_SYSVIPC
/* ipc stuff */
struct sysv_sem sysvsem; // 参见[7.1.1.27 进程通信/SYSVIPC]节
#endif
#ifdef CONFIG_DETECT_HUNG_TASK
/* hung task detection */
unsigned long last_switch_count; // 参见[7.1.1.11 时间]节
#endif
/* CPU-specific state of this task */
struct thread_struct thread; // 参加[7.1.1.28 处理器特有数据]节
/* filesystem information */
struct fs_struct *fs; // 参见[7.1.1.26 文件系统]节和[11.2.1.7.2 struct fs_struct]节
/* open file information */
struct files_struct *files; // 参见[7.1.1.26 文件系统]节和[11.2.1.7.1 struct files_struct]节
/* namespaces */
struct nsproxy *nsproxy; // 参见[7.1.1.29 命名空间]节
/* signal handlers */
struct signal_struct *signal; // 参见[7.1.1.12 信号处理]节
struct sighand_struct *sighand; // 参见[7.1.1.12 信号处理]节
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending; // 参见[7.1.1.12 信号处理]节
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
struct audit_context *audit_context; // 参见[7.1.1.30 进程审计]节
#ifdef CONFIG_AUDITSYSCALL
uid_t loginuid; // 参见[7.1.1.30 进程审计]节
unsigned int sessionid; // 参见[7.1.1.30 进程审计]节
#endif
seccomp_t seccomp; // 参见[7.1.1.31 安全计算]节
/* Thread group tracking */
u32 parent_exec_id; // 参见[7.1.1.32 用于copy_process函数使用CLONE_PARENT标记时]节
u32 self_exec_id; // 参见[7.1.1.32 用于copy_process函数使用CLONE_PARENT标记时]节
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, mempolicy */
spinlock_t alloc_lock; // 参见[7.1.1.13 保护资源分配或释放的自旋锁]节
#ifdef CONFIG_GENERIC_HARDIRQS
/* IRQ handler threads */
struct irqaction *irqaction; // 参见[7.1.1.33 中断]节
#endif
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock; // 参见[7.1.1.34 task_rq_lock函数所使用的锁]节
#ifdef CONFIG_RT_MUTEXES // 参见[7.1.1.35 基于PI协议的等待互斥锁]节
/* PI waiters blocked on a rt_mutex held by this task */
struct plist_head pi_waiters;
/* Deadlock detection and priority inheritance handling */
struct rt_mutex_waiter *pi_blocked_on;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
/* mutex deadlock detection */
struct mutex_waiter *blocked_on; // 参见[7.1.1.36 死锁检测]节
#endif
#ifdef CONFIG_TRACE_IRQFLAGS // 参见[7.1.1.33 中断]节
unsigned int irq_events;
unsigned long hardirq_enable_ip;
unsigned long hardirq_disable_ip;
unsigned int hardirq_enable_event;
unsigned int hardirq_disable_event;
int hardirqs_enabled;
int hardirq_context;
unsigned long softirq_disable_ip;
unsigned long softirq_enable_ip;
unsigned int softirq_disable_event;
unsigned int softirq_enable_event;
int softirqs_enabled;
int softirq_context;
#endif
#ifdef CONFIG_LOCKDEP // 参见[7.1.1.37 lockdep]节
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
int lockdep_depth;
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
gfp_t lockdep_reclaim_gfp;
#endif
/* journalling filesystem info */
void *journal_info; // 参见[7.1.1.39 JFS文件系统]节
/* stacked block device info */
struct bio_list *bio_list; // 参见[7.1.1.40 块设备链表]节
#ifdef CONFIG_BLOCK
/* stack plugging */
struct blk_plug *plug;
#endif
/* VM state */
struct reclaim_state *reclaim_state; // 参见[7.1.1.41 内存回收]节
struct backing_dev_info *backing_dev_info; // 参见[7.1.1.42 存放块设备I/O数据流量信息]节
struct io_context *io_context; // 参见[7.1.1.43 I/O调度器所使用的信息]节
unsigned long ptrace_message; // 参见[7.1.1.6 ptrace系统调用]节
siginfo_t *last_siginfo; /* For ptrace use. */ // 参见[7.1.1.6 ptrace系统调用]节
struct task_io_accounting ioac; // 参见[7.1.1.44 记录进程的I/O计数]节
#if defined(CONFIG_TASK_XACCT) // 参见[7.1.1.44 记录进程的I/O计数]节
u64 acct_rss_mem1; /* accumulated rss usage */
u64 acct_vm_mem1; /* accumulated virtual memory usage */
cputime_t acct_timexpd; /* stime + utime since last update */
#endif
#ifdef CONFIG_CPUSETS // 参见[7.1.1.45 CPUSET功能]节
nodemask_t mems_allowed; /* Protected by alloc_lock */
int mems_allowed_change_disable;
int cpuset_mem_spread_rotor;
int cpuset_slab_spread_rotor;
#endif
#ifdef CONFIG_CGROUPS // 参见[7.1.1.46 Control Groups]节
/* Control Group info protected by css_set_lock */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock */
struct list_head cg_list;
#endif
#ifdef CONFIG_FUTEX // 参见[7.1.1.47 Futex同步机制]节
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
#endif
#ifdef CONFIG_PERF_EVENTS // 参见[7.1.1.7 Performance Event]节
struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts];
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
#ifdef CONFIG_NUMA // 参见[7.1.1.48 非一致内存访问(NUMA)]节
struct mempolicy *mempolicy; /* Protected by alloc_lock */
short il_next;
short pref_node_fork;
#endif
struct rcu_head rcu; // 参见[7.1.1.49 RCU链表]节
/*
* cache last used pipe for splice
*/
struct pipe_inode_info *splice_pipe;
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays; // 参见[7.1.1.51 延迟计数]节
#endif
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail; // 参见[7.1.1.52 Fault Injection]节
#endif
/*
* when (nr_dirtied >= nr_dirtied_pause), it's time to call
* balance_dirty_pages() for some dirty throttling pause
*/
int nr_dirtied;
int nr_dirtied_pause;
// 参见[7.1.1.53 Infrastructure for displaying latency]节
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
/*
* time slack values; these are used to round up poll() and
* select() etc timeout values. These are in nanoseconds.
*/
unsigned long timer_slack_ns; // 参见[7.1.1.54 Time slack values]节
unsigned long default_timer_slack_ns; // 参见[7.1.1.54 Time slack values]节
struct list_head *scm_work_list; // 参见[7.1.1.55 socket控制消息]节
#ifdef CONFIG_FUNCTION_GRAPH_TRACER // 参见[7.1.1.56 ftrace跟踪器]节
/* Index of current stored address in ret_stack */
int curr_ret_stack;
/* Stack of return addresses for return function tracing */
struct ftrace_ret_stack *ret_stack;
/* time stamp for last schedule */
unsigned long long ftrace_timestamp;
/*
* Number of functions that haven't been traced
* because of depth overrun.
*/
atomic_t trace_overrun;
/* Pause for the tracing */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING // 参见[7.1.1.56 ftrace跟踪器]节
/* state flags for use by tracers */
unsigned long trace;
/* bitmask and counter of trace recursion */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
// 参见[7.1.1.46 Control Groups]节
#ifdef CONFIG_CGROUP_MEM_RES_CTLR /* memcg uses this to do batch job */
struct memcg_batch_info {
int do_batch; /* incremented when batch uncharge started */
struct mem_cgroup *memcg; /* target memcg of uncharge */
unsigned long nr_pages; /* uncharged usage */
unsigned long memsw_nr_pages; /* uncharged mem+swap usage */
} memcg_batch;
#endif
#ifdef CONFIG_HAVE_HW_BREAKPOINT
atomic_t ptrace_bp_refcnt; // 参见[7.1.1.6 ptrace系统调用]节
#endif
};
可通过下列命令查看进程1684的有关信息:
chenwx proc # cat 1684/status
Name: cinnamon
State: R (running)
Tgid: 1684
Ngid: 0
Pid: 1684
PPid: 1655
TracerPid: 0
Uid: 1000 1000 1000 1000
Gid: 1000 1000 1000 1000
FDSize: 32
Groups: 4 24 27 30 46 112 118 1000
VmPeak: 576760 kB
VmSize: 537716 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 171856 kB
VmRSS: 157588 kB
VmData: 198996 kB
VmStk: 136 kB
VmExe: 8 kB
VmLib: 70360 kB
VmPTE: 548 kB
VmSwap: 0 kB
Threads: 6
SigQ: 0/11942
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000021001000
SigCgt: 0000000180014002
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
CapBnd: 0000001fffffffff
Seccomp: 0
Cpus_allowed: 1
Cpus_allowed_list: 0
Mems_allowed: 1
Mems_allowed_list: 0
voluntary_ctxt_switches: 163421
nonvoluntary_ctxt_switches: 240193
7.1.1 进程描述符成员简介
7.1.1.1 进程状态
struct task_struct中与进程状态有关的域包括:
volatile long state;
int exit_state;
这些域的取值定义于include/linux/sched.h:
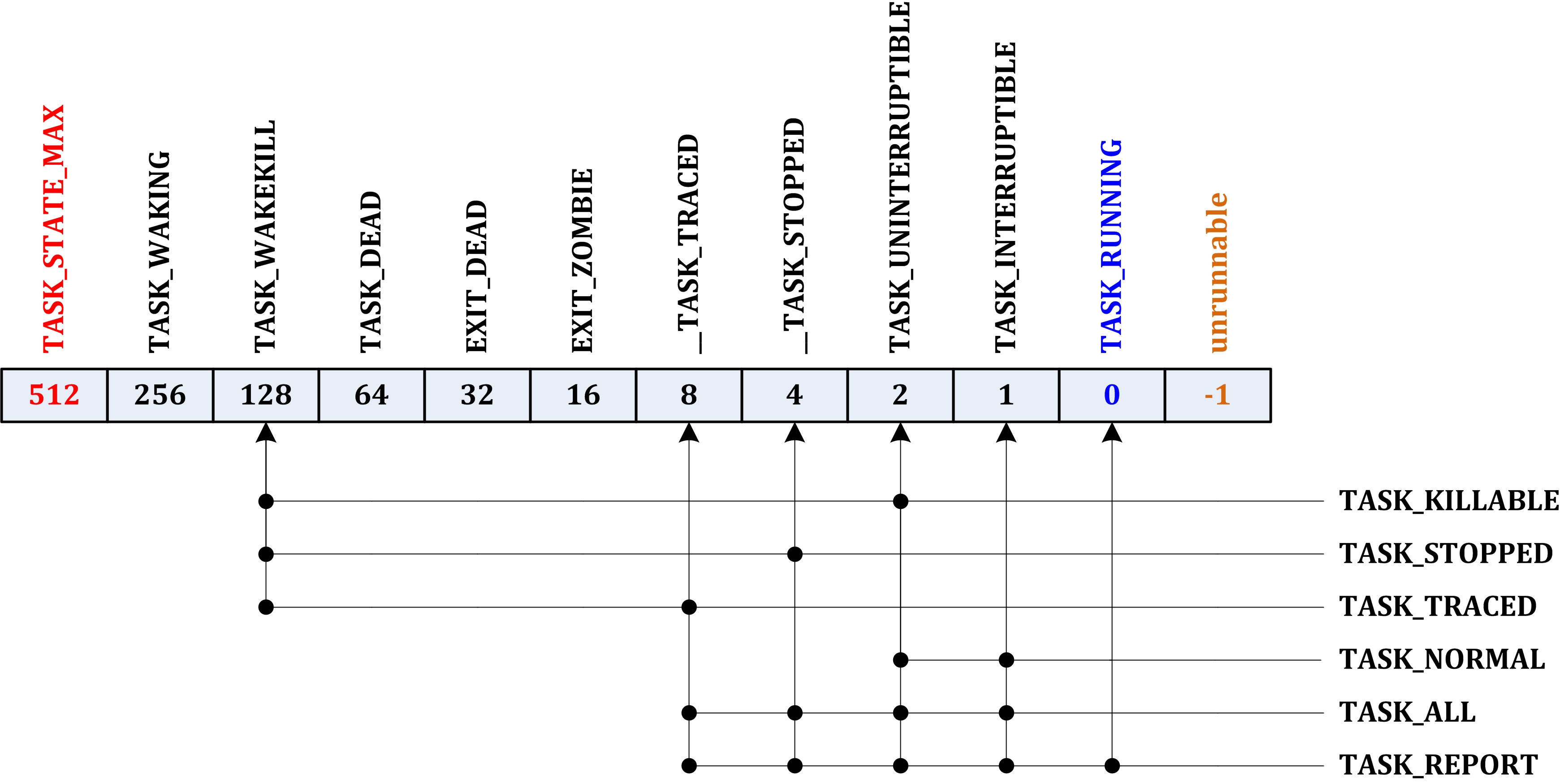
进程状态转换图:
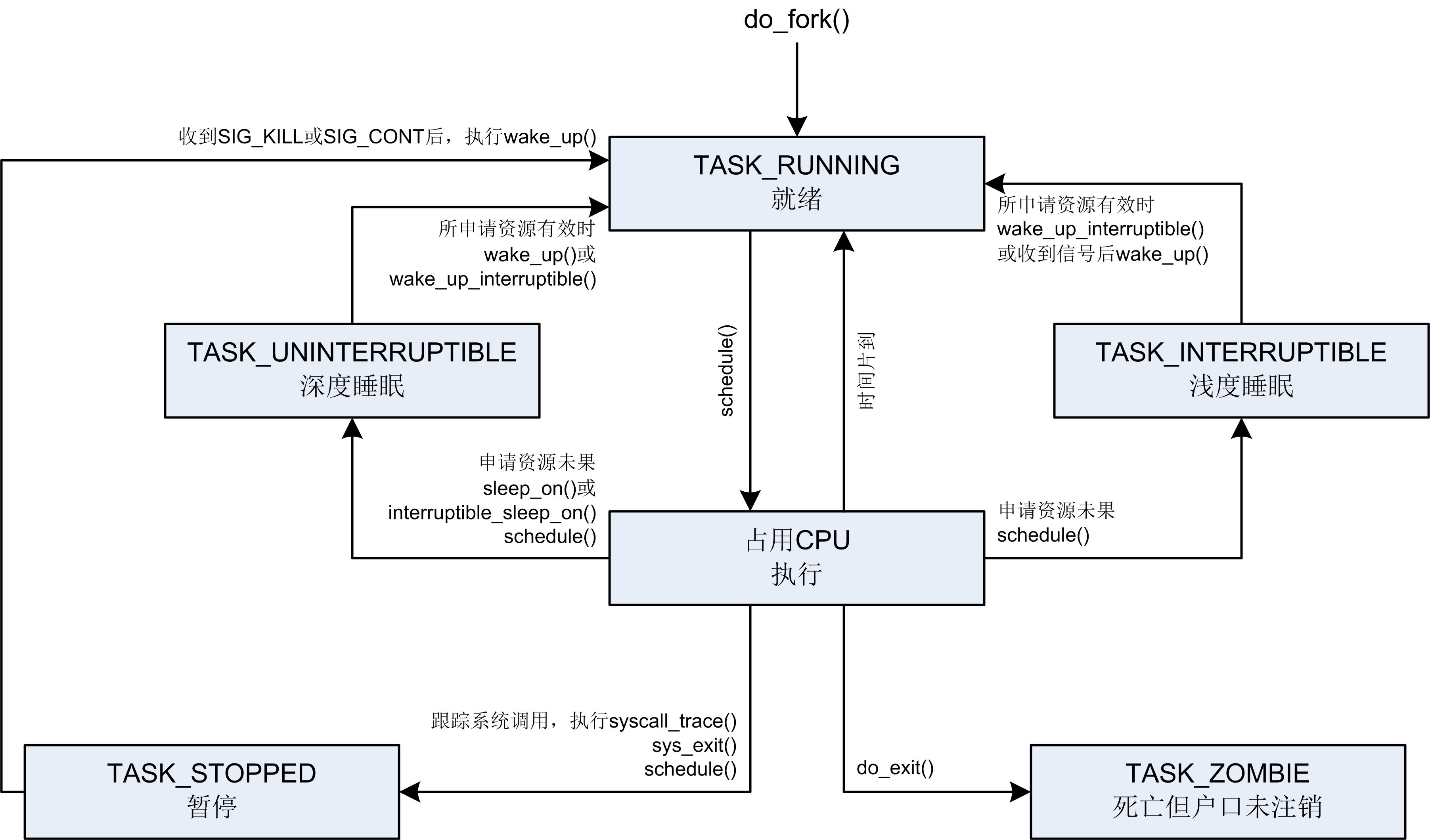
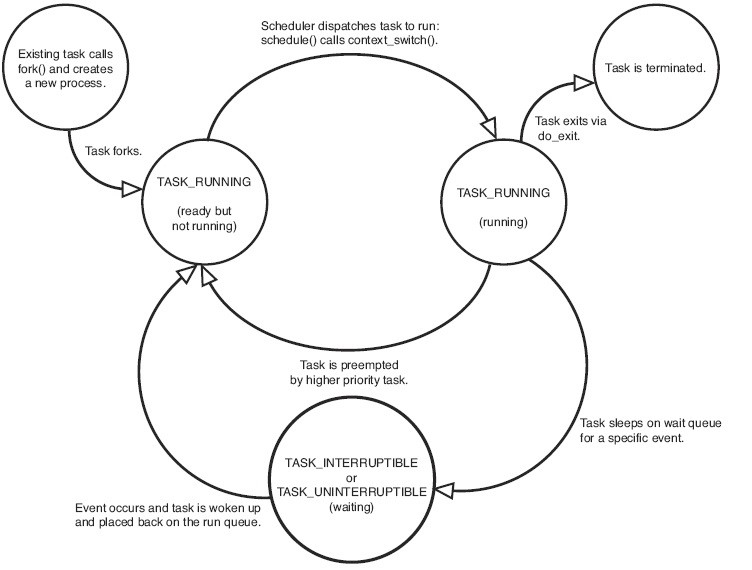
| 进程状态 | 备注 |
|---|---|
| TASK_RUNNING | 无论进程是否正在占用CPU,只要具备运行条件,都处于该状态。Linux把所有TASK_RUNNING状态的task_struct组成一个可运行队列run queue,调度程序从这个队列中选择进程运行。参见7.4 进程调度节。 |
| TASK_INTERRUPTIBLE | Linux将阻塞状态划分成TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE, TASK_STOPPED三种状态。处于TASK_INTERRUPTIBLE状态的进程在资源有效时被唤醒,也可以通过信号或定时中断唤醒。 |
| TASK_UNINTERRUPTIBLE | 处于该状态的进程只有当资源有效时被唤醒,不能通过信号或定时中断唤醒。 |
| TASK_STOPPED | Process execution has been stopped; the process enters this state after receiving a SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU signal. 处于该状态的进程只能通过其他进程的信号才能唤醒。 |
| TASK_TRACED | Process execution has been stopped by a debugger. When a process is being monitored by another (such as when a debugger executes a ptrace system call to monitor a test program), each signal may put the process in the TASK_TRACED state. |
| TASK_ZOMBIE | Process execution is terminated, but the parent process has not yet issued a wait4()or waitpid() system call to return information about the dead process. Before the wait( )-like call is issued, the kernel cannot discard the data contained in the dead process descriptor because the parent might need it. |
| EXIT_DEAD | The final state: the process is being removed by the system because the parent process has just issued await4() or waitpid() system call for it. Changing its state from EXIT_ZOMBIE to EXIT_DEAD avoids race conditions due to other threads of execution that execute wait()-like calls on the same process. |
状态TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE之间的区别,参见《Linux Kernel Development.[3rd Edition].[Robert Love]》第4. Process Scheduling章第Sleeping and Waking Up节:
Two states are associated with sleeping, TASK_INTERRUPTIBLE and TASK_UNINTERRUPTIBLE. They differ only in that tasks in the TASK_UNINTERRUPTIBLE state ignore signals, whereas tasks in the TASK_INTERRUPTIBLE state wake up prematurely and respond to a signal if one is issued. Both types of sleeping tasks sit on a wait queue, waiting for an event to occur, and are not runnable.
7.1.1.1.1 设置进程状态
Calling following function to set process state, see include/linux/sched.h:
/*
* set_current_state() includes a barrier so that the write of current->state
* is correctly serialised wrt the caller's subsequent test of whether to
* actually sleep:
*
* set_current_state(TASK_UNINTERRUPTIBLE);
* if (do_i_need_to_sleep())
* schedule();
*
* If the caller does not need such serialisation then use __set_current_state()
*/
#define __set_current_state(state_value) \
do { current->state = (state_value); } while (0)
#define set_current_state(state_value) \
set_mb(current->state, (state_value))
In older code, you often see something like this instead:
current->state = TASK_INTERRUPTIBLE;
But changing current directly in that manner is discouraged; such code breaks easily when data structures change.
7.1.1.2 进程标识符
task_struct结构中与进程标识符有关的域包括:
pid_t pid;
pid_t tgid;
pid_t定义于include/linux/types.h:
typedef __kernel_pid_t pid_t;
而,__kernel_pid_t定义于linux/posix_types.h:
typedef int __kernel_pid_t;
因此,进程标识符的取值范围定义于include/linux/threads.h:
#ifndef _LINUX_THREADS_H
#define _LINUX_THREADS_H
/*
* The default limit for the nr of threads is now in
* /proc/sys/kernel/threads-max.
*/
/*
* Maximum supported processors. Setting this smaller saves quite a
* bit of memory. Use nr_cpu_ids instead of this except for static bitmaps.
*/
#ifndef CONFIG_NR_CPUS
/* FIXME: This should be fixed in the arch's Kconfig */
#define CONFIG_NR_CPUS 1
#endif
/* Places which use this should consider cpumask_var_t. */
#define NR_CPUS CONFIG_NR_CPUS
#define MIN_THREADS_LEFT_FOR_ROOT 4
/*
* This controls the default maximum pid allocated to a process
*/
#define PID_MAX_DEFAULT (CONFIG_BASE_SMALL ? 0x1000 : 0x8000)
/*
* A maximum of 4 million PIDs should be enough for a while.
* [NOTE: PID/TIDs are limited to 2^29 ~= 500+ million, see futex.h.]
*/
#define PID_MAX_LIMIT (CONFIG_BASE_SMALL ? PAGE_SIZE * 8 : \
(sizeof(long) > 4 ? 4 * 1024 * 1024 : PID_MAX_DEFAULT))
/*
* Define a minimum number of pids per cpu. Heuristically based
* on original pid max of 32k for 32 cpus. Also, increase the
* minimum settable value for pid_max on the running system based
* on similar defaults. See kernel/pid.c:pidmap_init() for details.
*/
#define PIDS_PER_CPU_DEFAULT 1024
#define PIDS_PER_CPU_MIN 8
#endif
In fact, the POSIX 1003.1c standard states that all threads of a multithreaded application must have the same PID. To comply with this standard, Linux makes use of thread groups. The identifier shared by the threads is the PID of the thread group leader, that is, the PID of the first lightweight process in the group; it is stored in the tgid field of the process descriptors. The getpid() system call returns the value of tgid relative to the current process instead of the value of pid, so all the threads of a multithreaded application share the same identifier. Most processes belong to a thread group consisting of a single member; as thread group leaders, they have the tgid field equal to the pid field, thus the getpid() system call works as usual for this kind of process.
NOTE: If the system is willing to break compatibility with old applications, the administrator may increase the maximum value via /proc/sys/kernel/pid_max.
7.1.1.3 进程内核栈
struct task_struct中与进程内核栈有关的域为:
void *stack;
其类型为union thread_union。
7.1.1.3.1 进程内核栈的结构/union thread_union
Linux Kernel通过union thread_union来表示进程的内核栈,参见include/linux/sched.h:
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
其中,THREAD_SIZE定义于arch/x86/include/asm/page_32_types.h,其值为8192:
#define THREAD_ORDER 1
#define THREAD_SIZE (PAGE_SIZE << THREAD_ORDER) // PAGE_SIZE取值为4096
struct thread_info定义于arch/x86/include/asm/thread_info.h:
struct thread_info {
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
// 其取值为TIF_xxx,参见arch/x86/include/asm/thread_info.h
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
// 本进程所在的CPU ID
__u32 cpu; /* current CPU */
// 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
int preempt_count; /* 0 => preemptable, <0 => BUG */
mm_segment_t addr_limit;
struct restart_block restart_block;
void __user *sysenter_return;
#ifdef CONFIG_X86_32
/* ESP of the previous stack in case of nested (IRQ) stacks */
unsigned long previous_esp;
__u8 supervisor_stack[0];
#endif
int uaccess_err;
};
7.1.1.3.1.1 struct thread_info->preempt_count
struct thread_info中preempt_count域的取值:
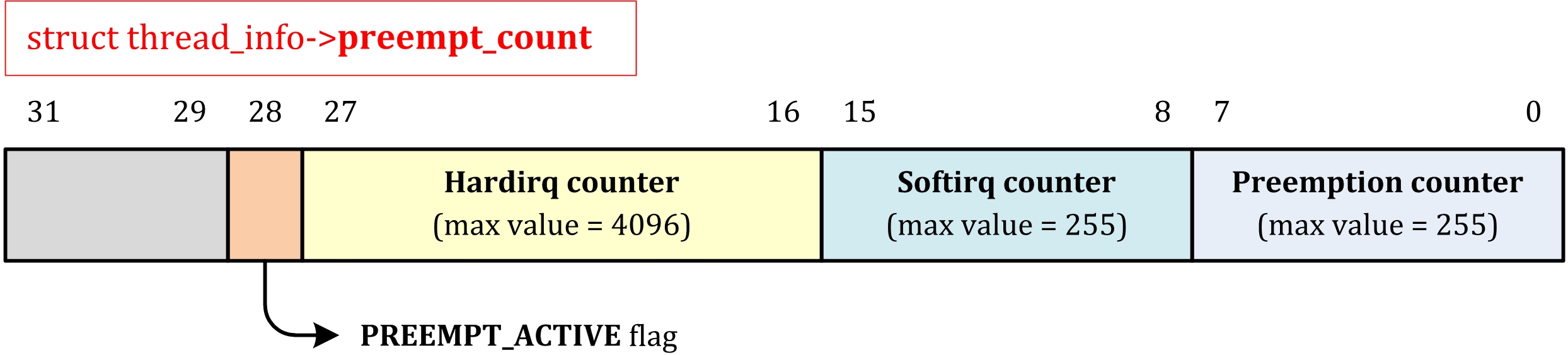
Preemption counter
Keeps track of how many times kernel preemption has been explicitly disabled on the local CPU; the value zero means that kernel preemption has not been explicitly disabled at all.
Softirq counter
Specifies how many levels deep the disabling of deferrable functions is (level 0 means that deferrable functions are enabled).
Hardirq counter
Specifies the number of nested interrupt handlers on the local CPU (the value is increased by irq_enter() and decreased by irq_exit().
各标志位定义于include/linux/hardirq.h:
#define PREEMPT_BITS 8
#define SOFTIRQ_BITS 8
#define NMI_BITS 1
#define MAX_HARDIRQ_BITS 10
#ifndef HARDIRQ_BITS
# define HARDIRQ_BITS MAX_HARDIRQ_BITS
#endif
#if HARDIRQ_BITS > MAX_HARDIRQ_BITS
#error HARDIRQ_BITS too high!
#endif
#define PREEMPT_SHIFT 0 // 0
#define SOFTIRQ_SHIFT (PREEMPT_SHIFT + PREEMPT_BITS) // 8
#define HARDIRQ_SHIFT (SOFTIRQ_SHIFT + SOFTIRQ_BITS) // 16
#define NMI_SHIFT (HARDIRQ_SHIFT + HARDIRQ_BITS) // 26
#define __IRQ_MASK(x) ((1UL << (x))-1)
#define PREEMPT_MASK (__IRQ_MASK(PREEMPT_BITS) << PREEMPT_SHIFT) // 0x000000FF
#define SOFTIRQ_MASK (__IRQ_MASK(SOFTIRQ_BITS) << SOFTIRQ_SHIFT) // 0x0000FF00
#define HARDIRQ_MASK (__IRQ_MASK(HARDIRQ_BITS) << HARDIRQ_SHIFT) // 0x03FF0000
#define NMI_MASK (__IRQ_MASK(NMI_BITS) << NMI_SHIFT) // 0x04000000
#define PREEMPT_OFFSET (1UL << PREEMPT_SHIFT) // 0x00000001
#define SOFTIRQ_OFFSET (1UL << SOFTIRQ_SHIFT) // 0x00000100
#define HARDIRQ_OFFSET (1UL << HARDIRQ_SHIFT) // 0x00010000
#define NMI_OFFSET (1UL << NMI_SHIFT) // 0x04000000
#define SOFTIRQ_DISABLE_OFFSET (2 * SOFTIRQ_OFFSET) // 0x00000200
#ifndef PREEMPT_ACTIVE
#define PREEMPT_ACTIVE_BITS 1
#define PREEMPT_ACTIVE_SHIFT (NMI_SHIFT + NMI_BITS) // 27
#define PREEMPT_ACTIVE (__IRQ_MASK(PREEMPT_ACTIVE_BITS) << PREEMPT_ACTIVE_SHIFT) // 0x08000000
#endif
#if PREEMPT_ACTIVE < (1 << (NMI_SHIFT + NMI_BITS))
#error PREEMPT_ACTIVE is too low!
#endif
#define hardirq_count() (preempt_count() & HARDIRQ_MASK)
#define softirq_count() (preempt_count() & SOFTIRQ_MASK)
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK | NMI_MASK))
#define in_irq() (hardirq_count())
#define in_softirq() (softirq_count())
#define in_interrupt() (irq_count())
#define in_serving_softirq() (softirq_count() & SOFTIRQ_OFFSET)
#define in_nmi() (preempt_count() & NMI_MASK)
7.1.1.3.1.2 内核栈与进程描述符的关系
进程内核栈(union thread_union)与进程描述符(struct task_struct)的关系:
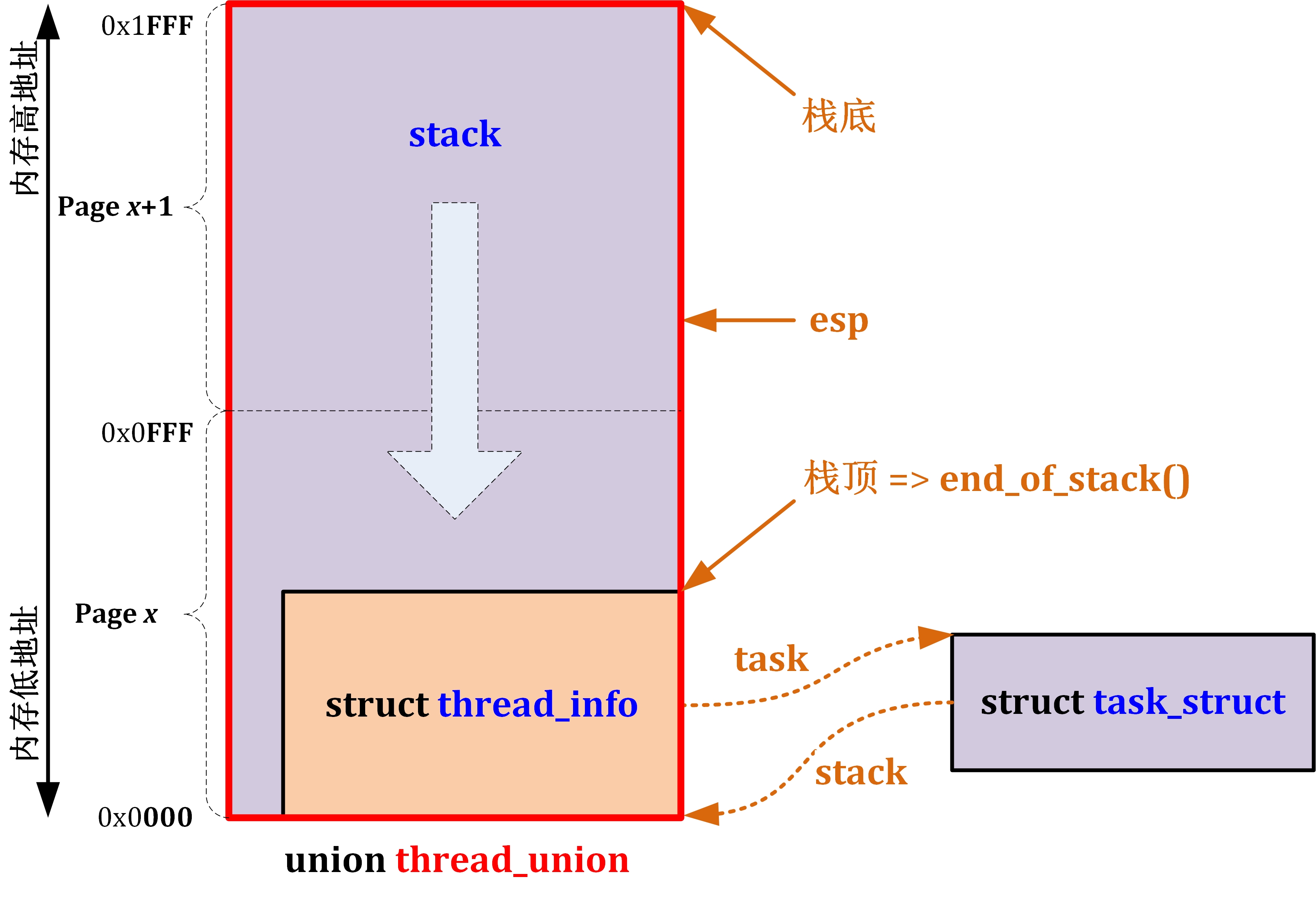
NOTE: do_fork() -> copy_process() -> dup_task_struct()在end_of_stack()处填充了一个魔数STACK_END_MAGIC,其取值为0x57AC6E9D,参见7.2.2.2.1 dup_task_struct()节。
7.1.1.3.1.3 alloc_thread_info_node()/free_thread_info()
The kernel uses the alloc_thread_info_node() and free_thread_info() macros to allocate and release the memory area storing a thread_info structure and a kernel stack.
7.1.1.3.1.4 current_thread_info()
该函数用于获取指向当前进程内核栈的指针,其定义于arch/x86/include/asm/thread_info.h:
/*
* ESP专门用作堆栈指针,也被称为栈顶指针,堆栈的顶部是地址小的区域,
* 压入堆栈的数据越多,ESP也就越来越小。在32位平台上,ESP每次减少4字节。
*/
/* how to get the current stack pointer from C */
register unsigned long current_stack_pointer asm("esp") __used;
// 获取当前进程的thread_info结构的首地址
/* how to get the thread information struct from C */
static inline struct thread_info *current_thread_info(void)
{
/*
* current_stack_pointer即下图中的esp所指的位置
* ~(THREAD_SIZE - 1)的二进制取值为0 0000 0000 0000,
* 即取当前进程内核栈的低地址,也就是thread_info所在位置
*/
return (struct thread_info *) (current_stack_pointer & ~(THREAD_SIZE - 1));
}
7.1.1.3.1.5 current
宏current用来获取当前进程的进程描述符,其定义于arch/x86/include/asm/current.h:
DECLARE_PER_CPU(struct task_struct *, current_task);
static __always_inline struct task_struct *get_current(void)
{
return percpu_read_stable(current_task);
}
#define current get_current()
7.1.1.3.2 进程内核栈的分配与释放
通过alloc_thread_info_node()分配内核栈,通过free_thread_info()释放所分配的内核栈。参见kernel/fork.c:
#ifndef __HAVE_ARCH_THREAD_INFO_ALLOCATOR
static struct thread_info *alloc_thread_info_node(struct task_struct *tsk, int node)
{
#ifdef CONFIG_DEBUG_STACK_USAGE
gfp_t mask = GFP_KERNEL | __GFP_ZERO;
#else
gfp_t mask = GFP_KERNEL;
#endif
// THREAD_SIZE_ORDER定义于arch/arm/include/asm/thread_info.h,取值为1
struct page *page = alloc_pages_node(node, mask, THREAD_SIZE_ORDER);
return page ? page_address(page) : NULL;
}
static inline void free_thread_info(struct thread_info *ti)
{
free_pages((unsigned long)ti, THREAD_SIZE_ORDER);
}
#endif
函数alloc_thread_info()通过调用__get_free_pages()分配2个页的内存,它的首地址是8192字节对齐的。
7.1.1.4 标志
task_struct结构中的标志flags为:
unsigned int flags;
该域可以取如下值,定义于include/linux/sched.h:
/*
* Per process flags
*/
#define PF_STARTING 0x00000002 /* being created */
#define PF_EXITING 0x00000004 /* getting shut down */
#define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */
#define PF_VCPU 0x00000010 /* I'm a virtual CPU */
#define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */
#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
#define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */
#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
#define PF_DUMPCORE 0x00000200 /* dumped core */
#define PF_SIGNALED 0x00000400 /* killed by a signal */
#define PF_MEMALLOC 0x00000800 /* Allocating memory */
#define PF_NPROC_EXCEEDED 0x00001000 /* set_user noticed that RLIMIT_NPROC was exceeded */
#define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */
#define PF_FREEZING 0x00004000 /* freeze in progress. do not account to load */
#define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */
#define PF_FROZEN 0x00010000 /* frozen for system suspend */
#define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */
#define PF_KSWAPD 0x00040000 /* I am kswapd */
#define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */
#define PF_KTHREAD 0x00200000 /* I am a kernel thread */
#define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */
#define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */
#define PF_SPREAD_PAGE 0x01000000 /* Spread page cache over cpuset */
#define PF_SPREAD_SLAB 0x02000000 /* Spread some slab caches over cpuset */
#define PF_THREAD_BOUND 0x04000000 /* Thread bound to specific cpu */
#define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */
#define PF_MEMPOLICY 0x10000000 /* Non-default NUMA mempolicy */
#define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */
#define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */
#define PF_FREEZER_NOSIG 0x80000000 /* Freezer won't send signals to it */
7.1.1.5 进程的亲属关系
Processes created by a program have a parent/child relationship. When a process creates multiple children, these children have sibling relationships. Several fields must be introduced in a process descriptor to represent these relationships; they are listed in below list respect to a given process P.
struct task_struct *real_parent;
Points to the process descriptor of the process that created P or to the descriptor of process 1 (init) if the parent process no longer exists. (Therefore, when a user starts a background process and exits the shell, the background process becomes the child of init.)
struct task_struct *parent;
Pointsto the current parent of P (this is the process that must be signaled when the child process terminates); its value usually coincides with that of real_parent. It may occasionally differ, such as when another process issues a ptrace() system call requesting that it be allowed to monitor P.
struct list_head children;
The head of the list containing all children created by P.
struct list_head sibling;
The pointers to the next and previous elements in the list of the sibling processes, those that have the same parent as P.
struct task_struct *group_leader;
Process descriptor pointer of the group leader of P.
可以通过7.1.2.1 双向循环链表节的宏查询其他进程描述符的信息。
7.1.1.6 ptrace系统调用
task_struct结构中包含与ptrace有关的成员:
unsigned int ptrace;
struct list_head ptraced;
struct list_head ptrace_entry;
unsigned long ptrace_message;
siginfo_t *last_siginfo; /* For ptrace use. */
#ifdef CONFIG_HAVE_HW_BREAKPOINT
atomic_t ptrace_bp_refcnt;
#endif
ptrace设置为0时表示不需要被跟踪,其可能的取值定义于:
#define PTRACE_EVENT_FORK 1
#define PTRACE_EVENT_VFORK 2
#define PTRACE_EVENT_CLONE 3
#define PTRACE_EVENT_EXEC 4
#define PTRACE_EVENT_VFORK_DONE 5
#define PTRACE_EVENT_EXIT 6
#define PTRACE_EVENT_STOP 7
#define PT_PTRACED 0x00000001
#define PT_DTRACE 0x00000002 /* delayed trace (used on m68k, i386) */
#define PT_TRACESYSGOOD 0x00000004
#define PT_PTRACE_CAP 0x00000008 /* ptracer can follow suid-exec */
/* PT_TRACE_* event enable flags */
#define PT_EVENT_FLAG_SHIFT 4
#define PT_EVENT_FLAG(event) (1 << (PT_EVENT_FLAG_SHIFT + (event) - 1))
#define PT_TRACE_FORK PT_EVENT_FLAG(PTRACE_EVENT_FORK)
#define PT_TRACE_VFORK PT_EVENT_FLAG(PTRACE_EVENT_VFORK)
#define PT_TRACE_CLONE PT_EVENT_FLAG(PTRACE_EVENT_CLONE)
#define PT_TRACE_EXEC PT_EVENT_FLAG(PTRACE_EVENT_EXEC)
#define PT_TRACE_VFORK_DONE PT_EVENT_FLAG(PTRACE_EVENT_VFORK_DONE)
#define PT_TRACE_EXIT PT_EVENT_FLAG(PTRACE_EVENT_EXIT)
#define PT_TRACE_MASK 0x000003f4
7.1.1.7 Performance Event
task_struct结构中包含如下与performance event有关的成员:
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts];
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
Performance Event是一款随Linux内核代码一同发布和维护的性能诊断工具。这些成员用于帮助PerformanceEvent分析进程的性能问题。参见如下两篇文章:
7.1.1.8 进程调度
task_struct结构中包含如下与进程调度有关的成员:
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class; // 参见[7.4.4 进程的调度类/struct sched_class]节
struct sched_entity se;
struct sched_rt_entity rt;
unsigned int policy; // 参见[7.4.3 进程的调度策略/policy]节
cpumask_t cpus_allowed; // 用于控制进程可以在哪个CPU上运行
7.1.1.8.1 进程优先级
- prio:动态优先级
- static_prio:静态优先级,可以通过nice系统调用来进行修改
- normal_prio:其值取决于静态优先级和调度策略
- rt_priority:实时优先级
进程优先级的取值参见include/linux/sched.h:
/*
* Priority of a process goes from 0..MAX_PRIO-1, valid RT
* priority is 0..MAX_RT_PRIO-1, and SCHED_NORMAL/SCHED_BATCH
* tasks are in the range MAX_RT_PRIO..MAX_PRIO-1. Priority
* values are inverted: lower p->prio value means higher priority.
*
* The MAX_USER_RT_PRIO value allows the actual maximum
* RT priority to be separate from the value exported to
* user-space. This allows kernel threads to set their
* priority to a value higher than any user task. Note:
* MAX_RT_PRIO must not be smaller than MAX_USER_RT_PRIO.
*/
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
/*
* 优先级取值范围为[0..140),其中[0..99]为实时进程优先级,
* [100..139]为普通进程优先级。且取值越小,优先级越高
*/
#define MAX_PRIO (MAX_RT_PRIO + 40)
#define DEFAULT_PRIO (MAX_RT_PRIO + 20) // 默认优先级为120
nice与priority取值之间的映射关系,参见kernel/sched.c:
/*
* Convert user-nice values [ -20 ... 0 ... 19 ]
* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],
* and back.
*/
// nice的取值范围为[-20..19],一一对应于prioriy的取值范围[100..139]
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
#define PRIO_TO_NICE(prio) ((prio) - MAX_RT_PRIO - 20)
#define TASK_NICE(p) PRIO_TO_NICE((p)->static_prio)
/*
* 'User priority' is the nice value converted to something we
* can work with better when scaling various scheduler parameters,
* it's a [ 0 ... 39 ] range.
*/
#define USER_PRIO(p) ((p)-MAX_RT_PRIO) // [0..39]
#define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio) // [0..39]
#define MAX_USER_PRIO (USER_PRIO(MAX_PRIO)) // 40
7.1.1.8.2 调度实体/struct sched_entity/struct sched_rt_entity
se是普通进程的调度实体;rt是实时进程的调度实体。
struct sched_entity和struct sched_rt_entity表示一个可调度实体(进程,进程组等)。它包含了完整的调度信息,用于实现对单个任务或任务组的调度。调度实体可能与进程没有关联。
7.1.1.9 进程地址空间
struct mm_struct *mm, *active_mm;
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif
#if defined(SPLIT_RSS_COUNTING)
struct task_rss_stat rss_stat;
#endif
mm指向当前进程所拥有的内存描述符。active_mm指向进程运行时所使用的内存描述符。对于普通进程而言,这两个指针变量的值相同。但是,内核线程不拥有任何内存描述符,所以它们的mm总是为NULL。当内核线程得以运行时,它的active_mm成员被初始化为前一个运行进程的active_mm(为改进上下文切换时间的一种优化)。
brk_randomized用来确定对随机堆内存的探测。
rss_stat用来记录缓冲信息。
7.1.1.10 判断标志
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
unsigned int jobctl; /* JOBCTL_*, siglock protected */
unsigned int personality;
unsigned did_exec:1;
unsigned in_execve:1; /* Tell the LSMs that the process is doing an execve */
unsigned in_iowait:1;
/* Revert to default priority/policy when forking */
unsigned sched_reset_on_fork:1;
exit_code用于设置进程的终止代号,这个值要么是_exit()或exit_group()系统调用参数(正常终止),要么是由内核提供的一个错误代号(异常终止)。
exit_signal被置为-1时表示本进程是某个线程组的一员。只有当该线程组的最后一个成员终止时,才会产生一个信号,以通知线程组的领头进程的父进程。
pdeath_signal用于判断父进程终止时发送信号。
personality用于处理不同的ABI,其可能取值如下,参见include/linux/personality.h:
enum {
PER_LINUX = 0x0000,
PER_LINUX_32BIT = 0x0000 | ADDR_LIMIT_32BIT,
PER_LINUX_FDPIC = 0x0000 | FDPIC_FUNCPTRS,
PER_SVR4 = 0x0001 | STICKY_TIMEOUTS | MMAP_PAGE_ZERO,
PER_SVR3 = 0x0002 | STICKY_TIMEOUTS | SHORT_INODE,
PER_SCOSVR3 = 0x0003 | STICKY_TIMEOUTS | WHOLE_SECONDS | SHORT_INODE,
PER_OSR5 = 0x0003 | STICKY_TIMEOUTS | WHOLE_SECONDS,
PER_WYSEV386 = 0x0004 | STICKY_TIMEOUTS | SHORT_INODE,
PER_ISCR4 = 0x0005 | STICKY_TIMEOUTS,
PER_BSD = 0x0006,
PER_SUNOS = 0x0006 | STICKY_TIMEOUTS,
PER_XENIX = 0x0007 | STICKY_TIMEOUTS | SHORT_INODE,
PER_LINUX32 = 0x0008,
PER_LINUX32_3GB = 0x0008 | ADDR_LIMIT_3GB,
PER_IRIX32 = 0x0009 | STICKY_TIMEOUTS, /* IRIX5 32-bit */
PER_IRIXN32 = 0x000a | STICKY_TIMEOUTS, /* IRIX6 new 32-bit */
PER_IRIX64 = 0x000b | STICKY_TIMEOUTS, /* IRIX6 64-bit */
PER_RISCOS = 0x000c,
PER_SOLARIS = 0x000d | STICKY_TIMEOUTS,
PER_UW7 = 0x000e | STICKY_TIMEOUTS | MMAP_PAGE_ZERO,
PER_OSF4 = 0x000f, /* OSF/1 v4 */
PER_HPUX = 0x0010,
PER_MASK = 0x00ff,
};
- did_exec用于记录进程代码是否被execve()函数所执行。
- in_execve用于通知LSM是否被do_execve()函数所调用。
- in_iowait用于判断是否进行iowait计数。
- sched_reset_on_fork用于判断是否恢复默认的优先级或调度策略。
7.1.1.11 时间
task_struct结构中包含如下与时间有关的成员变量:
cputime_t utime, stime, utimescaled, stimescaled;
cputime_t gtime;
#ifndef CONFIG_VIRT_CPU_ACCOUNTING
cputime_t prev_utime, prev_stime;
#endif
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time; /* monotonic time */
struct timespec real_start_time; /* boot based time */
struct task_cputime cputime_expires;
struct list_head cpu_timers[3];
#ifdef CONFIG_DETECT_HUNG_TASK
/* hung task detection */
unsigned long last_switch_count;
#endif
- utime/stime用于记录进程在用户态/内核态下所经过的节拍数(定时器)。prev_utime/prev_stime是先前的运行时间。
- utimescaled/stimescaled也是用于记录进程在用户态/内核态的运行时间,但它们以处理器的频率为刻度。
- gtime是以节拍计数的虚拟机运行时间(guest time)。
- nvcsw/nivcsw是自愿(voluntary)/非自愿(involuntary)上下文切换计数。last_switch_count是nvcsw和nivcsw的总和。
- start_time和real_start_time都是进程创建时间,real_start_time还包含了进程睡眠时间,常用于/proc/pid/stat。
- cputime_expires用来统计进程或进程组被跟踪的处理器时间,其中的三个成员对应着cpu_timers[3]的三个链表。
7.1.1.12 信号处理
/* signal handlers */
// Pointer to the process's signal descriptor,线程组共用的信号
struct signal_struct *signal;
// Pointer to the process's signal handler descriptor,线程组共用
struct sighand_struct *sighand;
/*
* blocked: Mask of blocked signals
* real_blocked: Temporary mask of blocked signals
* (used by the rt_sigtimedwait()system call)
*/
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
// Data structure storing the private pending signals
struct sigpending pending;
// Address of alternative signal handler stack. 可不提供
unsigned long sas_ss_sp;
// Size of alternative signal handler stack. 可不提供
size_t sas_ss_size;
/*
* Pointer to a function used by a device driver to
* block some signals of the process
*/
int (*notifier)(void *priv);
/*
* Pointer to data that might be used by the notifier
* function (previous field of table)
*/
void *notifier_data;
/*
* Bit mask of signals blocked by a device driver
* through a notifier function
*/
sigset_t *notifier_mask;
设备驱动程序常用notifier指向的函数来阻塞进程的某些信号(notifier_mask是这些信号的位掩码),notifier_data指的是notifier所指向的函数可能使用的数据。
参见8.3 信号/Signal节。
7.1.1.13 保护资源分配或释放的自旋锁
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, mempolicy */
spinlock_t alloc_lock;
7.1.1.14 进程描述符使用计数
atomic_t usage;
当usage被置为2时,表示进程描述符正在被使用而且其相应的进程处于活动状态。
7.1.1.15 FPU使用计数
/*
* fpu_counter contains the number of consecutive context switches
* that the FPU is used. If this is over a threshold, the lazy fpu
* saving becomes unlazy to save the trap. This is an unsigned char
* so that after 256 times the counter wraps and the behavior turns
* lazy again; this to deal with bursty apps that only use FPU for
* a short time
*/
unsigned char fpu_counter;
7.1.1.16 块设备I/O层的跟踪工具
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
blktrace是一个针对Linux内核中块设备I/O层的跟踪工具。
7.1.1.17 RCU同步原语
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
char rcu_read_unlock_special;
struct list_head rcu_node_entry;
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TREE_PREEMPT_RCU
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#ifdef CONFIG_RCU_BOOST
struct rt_mutex *rcu_boost_mutex;
#endif /* #ifdef CONFIG_RCU_BOOST */
7.1.1.18 用于调度器统计进程的运行信息
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
7.1.1.19 进程链表
struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
#endif
7.1.1.20 防止内核堆栈溢出
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary;
#endif
在GCC编译内核时,需要加上-fstack-protector选项。
7.1.1.21 PID散列表和链表
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
其中,PIDTYPE_MAX定义于include/linux/pid.h:
enum pid_type
{
PIDTYPE_PID, // PID of the process
PIDTYPE_PGID, // PID of the group leader process
PIDTYPE_SID, // PID of the session leader process
PIDTYPE_MAX
};
struct pid_link定义于:
struct pid_link
{
struct hlist_node node;
struct pid *pid;
};
pids[i]组成的哈希链表结构参见15.2 哈希链表/struct hlist_head/struct hlist_node节。
哈希链表头保存在数组pid_hash中,其定义于kernel/pid.c:
static struct hlist_head *pid_hash;
pid_hash在函数pidhash_init()中初始化,其定义于kernel/pid.c:
/*
* The pid hash table is scaled according to the amount of memory in the
* machine. From a minimum of 16 slots up to 4096 slots at one gigabyte or
* more.
*/
void __init pidhash_init(void)
{
int i, pidhash_size;
// pid_hash分配一个页面
pid_hash = alloc_large_system_hash("PID", sizeof(*pid_hash), 0, 18,
HASH_EARLY | HASH_SMALL, &pidhash_shift, NULL, 4096);
pidhash_size = 1 << pidhash_shift;
for (i = 0; i < pidhash_size; i++)
INIT_HLIST_HEAD(&pid_hash[i]);
}
其调用关系如下:
start_kernel()
-> pidhash_init()
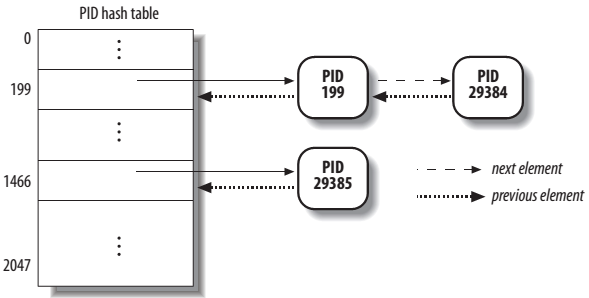
7.1.1.22 do_fork函数
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
在执行do_fork()时,如果给定特别标志,则vfork_done会指向一个特殊地址。
如果copy_process函数的clone_flags参数的值被置为CLONE_CHILD_SETTID或CLONE_CHILD_CLEARTID,则会把child_tidptr参数的值分别复制到set_child_tid和clear_child_tid成员。这些标志说明必须改变子进程用户态地址空间的child_tidptr所指向的变量的值。
7.1.1.23 缺页统计
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
7.1.1.24 进程权能
/* process credentials */
const struct cred __rcu *real_cred; /* objective and real subjective task credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task credentials (COW) */
struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */
7.1.1.25 程序名称
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock it with task_lock())
- initialized normally by setup_new_exec */
7.1.1.26 文件系统
/* file system info */
int link_count, total_link_count;
/* filesystem information */
struct fs_struct *fs; // 参见[11.2.1.7.2 struct fs_struct]节
/* open file information */
struct files_struct *files; // 参见[11.2.1.7.1 struct files_struct]节
- fs用来表示进程与文件系统的联系,包括当前目录和根目录。
- files表示进程当前打开的文件。
7.1.1.27 进程通信/SYSVIPC
#ifdef CONFIG_SYSVIPC
/* ipc stuff */
struct sysv_sem sysvsem;
#endif
7.1.1.28 处理器特有数据
/* CPU-specific state of this task */
struct thread_struct thread;
7.1.1.29 命名空间
/* namespaces */
struct nsproxy *nsproxy;
7.1.1.30 进程审计
struct audit_context *audit_context;
#ifdef CONFIG_AUDITSYSCALL
uid_t loginuid;
unsigned int sessionid;
#endif
7.1.1.31 安全计算
seccomp_t seccomp;
7.1.1.32 用于copy_process函数使用CLONE_PARENT标记时
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
7.1.1.33 中断
#ifdef CONFIG_GENERIC_HARDIRQS
/* IRQ handler threads */
struct irqaction *irqaction;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
unsigned int irq_events;
unsigned long hardirq_enable_ip;
unsigned long hardirq_disable_ip;
unsigned int hardirq_enable_event;
unsigned int hardirq_disable_event;
int hardirqs_enabled;
int hardirq_context;
unsigned long softirq_disable_ip;
unsigned long softirq_enable_ip;
unsigned int softirq_disable_event;
unsigned int softirq_enable_event;
int softirqs_enabled;
int softirq_context;
#endif
7.1.1.34 task_rq_lock函数所使用的锁
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
7.1.1.35 基于PI协议的等待互斥锁
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task */
struct plist_head pi_waiters;
/* Deadlock detection and priority inheritance handling */
struct rt_mutex_waiter *pi_blocked_on;
#endif
- PI指的是priority inheritance(优先级继承)。
7.1.1.36 死锁检测
#ifdef CONFIG_DEBUG_MUTEXES
/* mutex deadlock detection */
struct mutex_waiter *blocked_on;
#endif
7.1.1.37 lockdep
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
int lockdep_depth;
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
gfp_t lockdep_reclaim_gfp;
#endif
参见内核说明文档Documentation/lockdep-design.txt
7.1.1.39 JFS文件系统
/* journalling filesystem info */
void *journal_info;
7.1.1.40 块设备链表
/* stacked block device info */
struct bio_list *bio_list;
7.1.1.41 内存回收
struct reclaim_state *reclaim_state;
7.1.1.42 存放块设备I/O数据流量信息
struct backing_dev_info *backing_dev_info;
7.1.1.43 I/O调度器所使用的信息
struct io_context *io_context;
7.1.1.44 记录进程的I/O计数
struct task_io_accounting ioac;
#if defined(CONFIG_TASK_XACCT)
u64 acct_rss_mem1; /* accumulated rss usage */
u64 acct_vm_mem1; /* accumulated virtual memory usage */
cputime_t acct_timexpd; /* stime + utime since last update */
#endif
在Ubuntu 11.04上,执行cat获得进程1的I/O计数如下:
$ sudo cat /proc/1/io
rchar: 164258906
wchar: 455212837
syscr: 388847
syscw: 92563
read_bytes: 439251968
write_bytes: 14143488
cancelled_write_bytes: 2134016
输出的数据项刚好是task_io_accounting结构体的所有成员。
7.1.1.45 CPUSET功能
#ifdef CONFIG_CPUSETS
nodemask_t mems_allowed; /* Protected by alloc_lock */
int mems_allowed_change_disable;
int cpuset_mem_spread_rotor;
int cpuset_slab_spread_rotor;
#endif
7.1.1.46 Control Groups
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock */
struct list_head cg_list;
#endif
#ifdef CONFIG_CGROUP_MEM_RES_CTLR /* memcg uses this to do batch job */
struct memcg_batch_info {
int do_batch; /* incremented when batch uncharge started */
struct mem_cgroup *memcg; /* target memcg of uncharge */
unsigned long nr_pages; /* uncharged usage */
unsigned long memsw_nr_pages; /* uncharged mem+swap usage */
} memcg_batch;
#endif
7.1.1.47 Futex同步机制
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
#endif
7.1.1.48 非一致内存访问(NUMA)
NUMA: Non-Uniform Memory Access,非一致内存访问
#ifdef CONFIG_NUMA
struct mempolicy *mempolicy; /* Protected by alloc_lock */
short il_next;
short pref_node_fork;
#endif
7.1.1.49 RCU链表
struct rcu_head rcu;
7.1.1.50 管道
/*
* cache last used pipe for splice
*/
struct pipe_inode_info *splice_pipe;
7.1.1.51 延迟计数
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
7.1.1.52 Fault Injection
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
#endif
参考内核说明文件Documentation/fault-injection/fault-injection.txt
7.1.1.53 Infrastructure for displaying latency
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
7.1.1.54 Time slack values
/*
* time slack values; these are used to round up poll() and
* select() etc timeout values. These are in nanoseconds.
*/
unsigned long timer_slack_ns;
unsigned long default_timer_slack_ns;
7.1.1.55 socket控制消息
struct list_head *scm_work_list;
7.1.1.56 ftrace跟踪器
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack */
int curr_ret_stack;
/* Stack of return addresses for return function tracing */
struct ftrace_ret_stack *ret_stack;
/* time stamp for last schedule */
unsigned long long ftrace_timestamp;
/*
* Number of functions that haven't been traced
* because of depth overrun.
*/
atomic_t trace_overrun;
/* Pause for the tracing */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING
/* state flags for use by tracers */
unsigned long trace;
/* bitmask and counter of trace recursion */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
7.1.2 进程描述符链表
7.1.2.1 双向循环链表
内核中所有分配的进程描述符组成了一个双向循环链表。由于init_task总是存在的,因此可以将其作为链表头,进而可以查询其他进程。在include/linux/sched.h中有如下宏定义用于进程链表操作:
#define next_task(p) \
list_entry_rcu((p)->tasks.next, struct task_struct, tasks)
#define for_each_process(p) \
for (p = &init_task ; (p = next_task(p)) != &init_task ; )
其中,变量init_task定义于arch/x86/kernel/init_task.c:
/*
* Initial task structure.
*
* All other task structs will be allocated on slabs in fork.c
*/
struct task_struct init_task = INIT_TASK(init_task);
举例:查询系统中所有的进程描述符
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/sched.h>
int init_module(void)
{
struct task_struct *tsk;
for_each_process(tsk) {
printk(KERN_INFO "=== %s [%d] parent %s\n", tsk->comm, tsk->pid, tsk->parent->comm);
}
printk(KERN_INFO "Current task is %s [%d]\n", current->comm, current->pid);
return 0;
}
void cleanup_module(void)
{
return;
}
其对应的Makefile:
obj-m += procsview.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KDIR) SUBDIRS=$(PWD) modules
执行下列命令编译/加载此模块:
# make
# insmod procsview.ko
执行下列命令查看结果:
# dmesg
...
[92483.950958] === swapper/0 [0] parent swapper/0
[92483.950971] === init [1] parent swapper/0
[92483.950979] === kthreadd [2] parent swapper/0
[92483.950986] === ksoftirqd/0 [3] parent kthreadd
[92483.950993] === kworker/u:0 [5] parent kthreadd
[92483.951001] === migration/0 [6] parent kthreadd
[92483.951008] === watchdog/0 [7] parent kthreadd
[92483.951016] === cpuset [8] parent kthreadd
[92483.951023] === khelper [9] parent kthreadd
...
7.1.2.2 哈希表
7.1.3 进程与线程
根据《Linux Kernel Development, 3rd Edition》第3 Process Management章的The Linux Implementation of Threads节可知:
Linux has a unique implementation of threads. To the Linux kernel, there is no concept of a thread. Linux implements all threads as standard processes. The Linux kernel does not provide any special scheduling semantics or data structures to represent threads.
Instead, a thread is merely a process that shares certain resources with other processes. Each thread has a unique task_struct and appears to the kernel as a normal process — threads just happen to share resources, such as an address space, with other processes.
7.2 进程创建
7.2.1 与进程创建有关的系统调用/用户接口
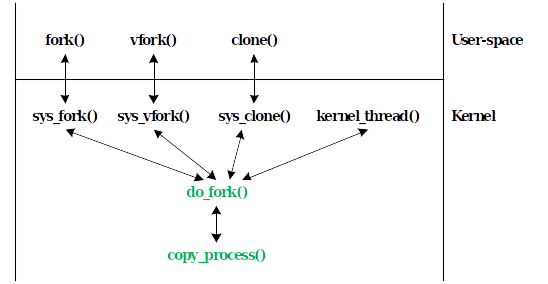
7.2.1.1 sys_fork()/fork()
一个现有进程(父进程)调用sys_fork() / sys_vfork()函数是Linux内核创建一个新进程(子进程)的唯一方法。NOTE: 这种方法并不适用于交换进程、init进程和页守护进程,因为这些进程是由内核作为自举过程的一部分而以特殊方式创建的。
使用sys_fork() / fork()时,子进程复制父进程的全部资源。由于要复制父进程的进程描述符task_struct给子进程,而进程描述符的结构体很大(参见7.1 进程描述符/struct task_struct节),因此这一过程的开销很大。Linux采用了“写时复制技术”(copy-on-write,COW),使子进程先共享父进程的物理页,只有当子进程进行写操作时,再复制对应的物理页,避免了无用的复制开销,从而提高了系统性能。
系统调用sys_fork()的定义参见arch/x86/kernel/process.c:
int sys_fork(struct pt_regs *regs)
{
// do_fork()参见[7.2.2 do_fork()]节,SIGCHLD参见[7.2.2.1 Cloning Flags]节
return do_fork(SIGCHLD, regs->sp, regs, 0, NULL, NULL);
}
用户接口fork()的声明如下:
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
fork()函数的返回值:在子进程中为0,在父进程中为子进程的PID,出错时为-1。
由fork()创建的新进程被称为子进程(child process)。该函数被调用一次,但返回两次。两次返回值的区别是子进程的返回值是0,而父进程的返回值则是新子进程的进程PID。将子进程PID返回给父进程的理由是:因为一个进程的子进程可以多于一个,但是没有一个函数使一个进程获得其所有子进程的PID。Fork()使子进程得到返回值0的理由是:一个进程只会有一个父进程,所以子进程总是可以调用getppid()以获得其父进程的PID(进程ID 0总是由交换进程使用,所以一个子进程的进程ID不可能为0)。
子进程和父进程继续执行fork()之后的指令。子进程是父进程的复制品,即子进程获得父进程数据空间、堆和栈的复制品。NOTE: 这是子进程所拥有的拷贝,父、子进程并不共享这些存储空间部分。如果正文段是只读的,则父、子进程共享正文段。
fork()的经典例子:
// 例子1:打印两个hello
#include <stdio.h>
int main()
{
fork();
printf("hello!\n");
exit(0);
}
Output:
hello
hello
// 例子2:打印四个hello
#include <stdio.h>
int main()
{
fork();
fork();
printf("hello!\n");
exit(0);
}
Output:
hello
hello
hello
hello
// 例子3:打印八个hello
#include <stdio.h>
int main()
{
fork();
fork();
fork();
printf("hello!\n");
exit(0);
}
Output:
hello
hello
hello
hello
hello
hello
hello
hello
例子:根据fork()的返回值区分父子进程
#include <stdio.h> /* printf, stderr, fprintf */
#include <sys/types.h> /* pid_t */
#include <unistd.h> /* _exit, fork */
#include <stdlib.h> /* exit */
#include <errno.h> /* errno */
int main(void)
{
pid_t pid;
/* Output from both the child and the parent process will be written
* to the standard output, as they both run at the same time.
*/
pid = fork();
if (pid == -1)
{
/* Error: When fork() returns -1, an error happened
* (for example, number of processes reached the limit).
*/
fprintf(stderr, "can't fork, error %d\n", errno);
exit(EXIT_FAILURE);
}
else if (pid == 0)
{
/* Child process: When fork() returns 0, we are in the child process. */
int j;
for (j = 0; j < 10; j++)
{
printf("child: %d\n", j);
sleep(1);
}
_exit(0); /* Note that we do not use exit() */
}
else
{
/* When fork() returns a positive number, we are in the parent process
* (the fork return value is the PID of the newly created child process)
* Again we count up to ten.
*/
int i;
for (i = 0; i < 10; i++)
{
printf("parent: %d\n", i);
sleep(1);
}
exit(0);
}
return 0;
}
7.2.1.2 sys_vfork()/vfork()
该系统调用创建的子进程完全运行在父进程的地址空间上,子进程对地址空间任何数据的修改同样为父进程所见。且该系统调用执行时父进程被堵塞,直到子进程运行结束。
系统调用sys_vfork()定义于arch/x86/kernel/process.c:
/*
* This is trivial, and on the face of it looks like it
* could equally well be done in user mode.
*
* Not so, for quite unobvious reasons - register pressure.
* In user mode vfork() cannot have a stack frame, and if
* done by calling the "clone()" system call directly, you
* do not have enough call-clobbered registers to hold all
* the information you need.
*/
int sys_vfork(struct pt_regs *regs)
{
// do_fork()参见[7.2.2 do_fork()]节,CLONE_VFORK, CLONE_VM, SIGCHLD参见[7.2.2.1 Cloning Flags]节
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs->sp, regs, 0, NULL, NULL);
}
用户接口vfork()的声明如下:
#include <sys/types.h>
#include <unistd.h>
pid_t vfork(void);
根据《Linux Kernel Development.[3rd Edition].[Robert Love]》 第3 Process Management章的vfork()节可知:
Today, with copy-on-write and child-runs first semantics, the only benefit to vfork() is not copying the parent page tables entries.
7.2.1.3 sys_clone()/clone()
该系统调用是Linux系统所特有的,其NPTL (Native POSIX Thread Library)的实现依赖此函数。与sys_fork()和sys_vfork()相比,sys_clone()对进程创建有更好的控制能力,能控制子进程和父进程共享何种资源。
系统调用sys_clone()定义于arch/x86/kernel/process.c:
long sys_clone(unsigned long clone_flags, unsigned long newsp,
void __user *parent_tid, void __user *child_tid, struct pt_regs *regs)
{
if (!newsp)
newsp = regs->sp;
// do_fork()参见[7.2.2 do_fork()]节,clone_flags参见[7.2.2.1 Cloning Flags]节
return do_fork(clone_flags, newsp, regs, 0, parent_tid, child_tid);
}
sys_clone() is a system call in the Linux kernel that creates a child process that may share parts of its execution context with the parent. It is often used to implement multithreading. In practice, sys_clone() is not often called directly, but instead using a threading library (such as pthreads) that uses clone() when starting a thread (such as during a call to pthread_create()).
用户接口clone()的声明如下:
#include <sched.h>
int clone(int (*fn) (void *), void *child_stack, int flags, void *arg);
clone() creates a new thread that starts with the function pointed to by the fn argument (as opposed to fork() which continues with the next command after fork()). The child_stack argument is a pointer to a memory space to be used as the stack for the new thread (which must be malloc’ed before that; on most architectures stack grows down, so the pointer should point at the end of the space), flags specify what gets inherited from the parent process (see section 7.2.2.1 Cloning Flags), and arg is the argument passed to the function. It returns the process ID of the child process or -1 on failure.
7.2.1.4 kernel_thread()
由于内核对进程和线程不做区分,所以内核线程(kernel thread)又称为内核进程(kernel process)。NOTE: 不能把普通进程中的线程理解为进程。
内核线程和普通进程的区别:
- 内核线程只运行在内核态,普通进程可以运行在内核态和用户态。
- 内核线程只能调用内核函数,普通进程可以通过系统调用调用内核函数。
- 内核线程只能运行在大于PAGE_OFFSET的地址空间,而普通进程可以使用4G的地址空间(除了访问用户空间的3G,通过系统调用可以访问内核空间的1G空间)。
由于内核线程不受用户态上下文的拖累,常被内核用于执行一些重要的任务,如刷新磁盘高速缓存,交换不同的页面。在Linux系统中使用命令:
$ ps -ef
查看结果中用方括号([])括起来的进程就是内核线程。
内核线程除了各自的栈和硬件上下文外,共享所有资源。内核利用内核线程来完成一些后台工作,如kswapd,ksoftirqd。内核线程由kernel_thread()在内核态创建。
其定义参见arch/x86/kernel/process.c:
/*
* Create a kernel thread
*/
int kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
struct pt_regs regs;
memset(®s, 0, sizeof(regs));
regs.si = (unsigned long) fn; // 新创建的内核线程要执行的函数
regs.di = (unsigned long) arg; // 函数fn的入参
#ifdef CONFIG_X86_32
regs.ds = __USER_DS; // 参见[6.1.1.2.1 全局描述符表GDT]节
regs.es = __USER_DS; // 参见[6.1.1.2.1 全局描述符表GDT]节
regs.fs = __KERNEL_PERCPU; // 参见[6.1.1.2.1 全局描述符表GDT]节
regs.gs = __KERNEL_STACK_CANARY; // 参见[6.1.1.2.1 全局描述符表GDT]节
#else
regs.ss = __KERNEL_DS; // 参见[6.1.1.2.1 全局描述符表GDT]节
#endif
regs.orig_ax = -1;
regs.ip = (unsigned long) kernel_thread_helper;
regs.cs = __KERNEL_CS | get_kernel_rpl();
regs.flags = X86_EFLAGS_IF | 0x2;
/* Ok, create the new process.. */
/*
* do_fork()参见[7.2.2 do_fork()]节,flags参见[7.2.2.1 Cloning Flags]节;
* The CLONE_VM flag avoids the duplication of the page
* tables of the calling process: this duplication would
* be a waste of time and memory, because the new kernel
* thread will not access the User Mode address space
* anyway. The CLONE_UNTRACED flag ensures that no process
* will be able to trace the new kernel thread, even if
* the calling process is being traced.
*/
return do_fork(flags | CLONE_VM | CLONE_UNTRACED, 0, ®s, 0, NULL, NULL);
}
函数kernel_thread()会被rest_init()调用,在系统启动时创建相关内核线程,参见4.3.4.1.4.3.13 rest_init()节。此外,kernel_thread()还会被如下函数调用:
static void create_kthread(struct kthread_create_info *create);
static void __init handle_initrd(void);
static int wait_for_helper(void *data);
static void __call_usermodehelper(struct work_struct *work);
7.2.1.5 sys_execve()/exec()
系统调用sys_execve()定义于arch/x86/kernel/process.c:
/*
* sys_execve() executes a new program.
*/
long sys_execve(const char __user *name,
const char __user *const __user *argv,
const char __user *const __user *envp, struct pt_regs *regs)
{
long error;
char *filename;
filename = getname(name);
error = PTR_ERR(filename);
if (IS_ERR(filename))
return error;
error = do_execve(filename, argv, envp, regs); // 参见[7.2.3 do_execve()]节
#ifdef CONFIG_X86_32
if (error == 0) {
/* Make sure we don't return using sysenter.. */
set_thread_flag(TIF_IRET);
}
#endif
putname(filename);
return error;
}
In computing, exec is a functionality of an operating system that runs an executable file in the context of an already existing process, replacing the previous executable. This act is also referred to as an overlay. It is especially important in Unix-like systems, although exists elsewhere. As a new process is not created, the process identifier (PID) does not change, but the machine code, data, heap, and stack of the process are replaced by those of the new program.
The exec is available for many programming languages including compilable languages and some scripting languages. In OS command interpreters exec built-in command replaces the shell process with the specified program. Though, in some languages the call named exec means passing the command line to a command interpreter, a different function.
Interfaces to exec and its implementations vary. Depending on programming language it may be accessible via one or more functions, and depending on operating system it may be represented with one or more actual system calls. For this reason exec is sometimes described as a collection of functions.
Standard names of such functions in C are execl, execle, execlp, execv, execve, and execvp (see below), but not “exec” itself. Linux kernel has one corresponding system call named “execve”, whereas all aforementioned functions are user-space wrappers around it.
Higher-level languages usually provide one call named exec.
exec用户接口的声明如下:
#include <unistd.h>
/* Replace the current process, executing PATH with arguments ARGV and
environment ENVP. ARGV and ENVP are terminated by NULL pointers. */
int execve(const char *path, char *const argv[], char *const envp[]);
/* Execute PATH with arguments ARGV and environment from `environ'. */
int execv (const char *path, char *const argv[]);
/* Execute FILE, searching in the `PATH' environment variable if it contains
no slashes, with arguments ARGV and environment from `environ'. */
int execvp(const char *file, char *const argv[]);
/* Execute PATH with all arguments after PATH until
a NULL pointer and environment from `environ'. */
int execl (const char *path, const char*arg, ...);
/* Execute FILE, searching in the `PATH' environment variable if
it contains no slashes, with all arguments after FILE until a
NULL pointer and environment from `environ'. */
int execlp(const char *file, const char*arg, ...);
/* Execute PATH with all arguments after PATH until a NULL pointer,
and the argument after that for environment. */
int execle(const char *path, const char*arg, ..., char * const envp[]);
The base of each is exec (execute), followed by one or more letters:
| e | An array of pointers to environment variables is explicitly passed to the new process image. |
| l | Command-line arguments are passed individually to the function. |
| p | Uses the PATH environment variable to find the file named in the path argument to be executed. |
| v | Command-line arguments are passed to the function as an array of pointers. |
path
The argument specifies the path name of the file to execute as the new process image. Arguments beginning at arg are pointers to arguments to be passed to the new process image. The argv value is an array of pointers to arguments.
arg
The first argument arg0 should be the name of the executable file. Usually it is the same value as the path argument. Some programs may incorrectly rely on this argument providing the location of the executable, but there is no guarantee of this nor is it standardized across platforms.
envp
Argument envp is an array of pointers to environment settings. The exec calls named ending with an e alter the environment for the new process image by passing a list of environment settings through the envp argument. This argument is an array of character pointers; each element (except for the final element) points to a null-terminated string defining an environment variable. Each null-terminated string has the form name=value where name is the environment variable name, and value is the value of that that variable. The final element of the envp array must be null.
In the execl, execlp, execv, and execvp calls, the new process image inherits the current environment variables.
A file descriptor open when an exec call is made remain open in the new process image, unless was fcntled with FD_CLOEXEC. This aspect is used to specify the standard streams (stdin, stdout and stderr) of the new program.
A successful overlay destroys the previous memory address space of the process, and all its memory areas, that were not shared, are reclaimed by the operating system. Consequently, all its data that were not passed to the new program, or otherwise saved, become lost.
Return value
A successful exec replaces the current process image, so it cannot return anything to the program that made the call. Processes do have an exit status, but that value is collected by the parent process.
If an exec function does return to the calling program, an error occurs, the return value is −1, and errno is set to one of the following values:
| Name | Notes |
|---|---|
| E2BIG | The argument list exceeds the system limit. |
| EACCES | The specified file has a locking or sharing violation. |
| ENOENT | The file or path name not found. |
| ENOMEM | Not enough memory is available to execute the new process image. |
各函数之间的关系如下:
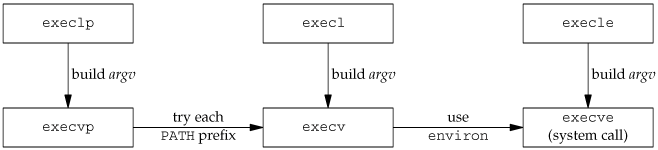
Also see man page:
$ man exec
7.2.1.6 system()
system()的声明如下:
#include <stdlib.h>
int system(const char *command);
system() executes a command specified in command by calling /bin/sh -c command, and returns after the command has been completed. During execution of the command, SIGCHLD will be blocked, and SIGINT and SIGQUIT will be ignored.
该函数的执行过程分为三个步骤:
- 1) fork一个子进程,参见7.2.1.1 sys_fork()/fork()节;
- 2) 在子进程中调用exec函数去执行command命令,参见7.2.1.5 sys_execve()/exec()节;
- 3) 在父进程中调用wait去等待子进程结束。NOTE: system() does not affect the wait status of any other children.
Return Value
The value returned is -1 on error, and the return status of the command otherwise. This latter return status is in the format specified in wait. Thus, the exit code of the command will be WEXITSTATUS(status). In case /bin/sh could not be executed, the exit status will be that of a command that does exit(127).
If the value of command is NULL, system() returns nonzero if the shell is available, and zero if not.
7.2.2 do_fork()
创建进程是通过调用函数do_fork()完成的。
函数do_fork()会被下列系统调用调用:
int sys_fork(struct pt_regs *regs); // 参见[7.2.1.1 sys_fork()/fork()]节
int sys_vfork(struct pt_regs *regs); // 参见[7.2.1.2 sys_vfork()/vfork()]节
long sys_clone(unsigned long clone_flags,
unsigned long newsp,
void __user *parent_tid,
void __user *child_tid,
struct pt_regs *regs); // 参见[7.2.1.3 sys_clone()/clone()]节
函数do_fork()也会被下列函数调用:
int kernel_thread(int (*fn)(void *), void *arg, unsigned long flags);
函数do_fork()定义于kernel/fork.c:
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
/* clone_flags: See section [7.2.2.1 Cloning Flags]
* stack_start: specifies the User Mode stack pointer to be assigned to
* the esp register of the child process.
* regs: Pointer to the values of the general purpose registers saved into
* the Kernel Mode stack when switching from User Mode to Kernel Mode.
* stack_size: Unused (always set to 0)
* parent_tidptr: Specifies the address of a User Mode variable of the parent
* process that will hold the PID of the new lightweight process.
* Meaningful only if the CLONE_PARENT_SETTID flag is set.
* child_tidptr: Specifies the address of a User Mode variable of the new
* lightweight process that will hold the PID of such process.
* Meaningful only if the CLONE_CHILD_SETTIDflag is set.
*/
long do_fork(unsigned long clone_flags, unsigned long stack_start,
struct pt_regs *regs, unsigned long stack_size,
int __user *parent_tidptr, int __user *child_tidptr)
{
struct task_struct *p; // 子进程的进程描述符
int trace = 0;
long nr; // 子进程号
/*
* Do some preliminary argument and permissions checking before we
* actually start allocating stuff
*/
/*
* 一些必要的检查工作,在sys_fork(), sys_vfork(),
* kernel_thread()中都没有传递CLONE_NEWUSER,
* 由此可知,此段代码没有执行,这个检查主要是为sys_clone()使用的
*/
if (clone_flags & CLONE_NEWUSER) {
if (clone_flags & CLONE_THREAD)
return -EINVAL;
/* hopefully this check will go away when userns support is complete */
if (!capable(CAP_SYS_ADMIN) || !capable(CAP_SETUID) || !capable(CAP_SETGID))
return -EPERM;
}
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (likely(user_mode(regs)) && !(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
/*
* 调用copy_process()创建进程。在系统资源允许的情况下,
* 拷贝进程描述符,当然进程号是不同的, 参见[7.2.2.2 copy_process()]节
*/
p = copy_process(clone_flags, stack_start, regs, stack_size, child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
trace_sched_process_fork(current, p);
// 子进程号,取自p->pids[PIDTYPE_PID].pid
nr = task_pid_vnr(p);
/*
* 在sys_fork(), sys_vfork(), kernel_thread()中没有设置
* CLONE_PARENT_SETTID,且parent_tidptr=NULL,故此段代码
* 是为sys_clone()使用的
*/
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
/*
* 检查标志位CLONE_VFORK,用于sys_vfork()或sys_clone();
* 如果设置了CLONE_VFORK,则父进程会被阻塞,直至子进程调用了
* exec()或exit()退出;此处初始化完成量vfork,完成量的作用:
* 直到任务A发出信号通知任务B发生了某个特定事件时,任务B才会
* 开始执行,否则任务B一直等待
*/
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
}
audit_finish_fork(p);
/*
* We set PF_STARTING at creation in case tracing wants to
* use this to distinguish a fully live task from one that
* hasn't finished SIGSTOP raising yet. Now we clear it
* and set the child going.
*/
p->flags &= ~PF_STARTING;
// 将进程加入到运行队列中,参见[7.2.2.3 wake_up_new_task()]节
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event(trace, nr);
if (clone_flags & CLONE_VFORK) {
freezer_do_not_count();
/*
* 如果设置了CLONE_VFORK,则父进程会被阻塞,直至
* 子进程调用了exec()或exit()。即调用系统调用
* vfork()时,子进程先执行。当子进程调用exec()或
* 退出时向父进程发出信号,此时父进程才会被唤醒执行
*/
wait_for_completion(&vfork);
freezer_count();
ptrace_event(PTRACE_EVENT_VFORK_DONE, nr);
}
} else {
// 如果copy_process()错误,则先释放已分配的pid
nr = PTR_ERR(p);
}
return nr;
}
7.2.2.1 Cloning Flags
函数do_fork()的入参clone_flags提供了很多标志来表明进程的创建方式,其定义于include/linux/sched.h:
/*
* cloning flags:
*/
#define CSIGNAL 0x000000ff /* signal mask to be sent at exit */
#define CLONE_VM 0x00000100 /* set if VM shared between processes */
#define CLONE_FS 0x00000200 /* set if fs info shared between processes */
#define CLONE_FILES 0x00000400 /* set if open files shared between processes */
#define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */
#define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */
#define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release */
#define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */
#define CLONE_THREAD 0x00010000 /* Same thread group? */
#define CLONE_NEWNS 0x00020000 /* New namespace group? */
#define CLONE_SYSVSEM 0x00040000 /* share system V SEM_UNDO semantics */
#define CLONE_SETTLS 0x00080000 /* create a new TLS for the child */
#define CLONE_PARENT_SETTID 0x00100000 /* set the TID in the parent */
#define CLONE_CHILD_CLEARTID 0x00200000 /* clear the TID in the child */
#define CLONE_DETACHED 0x00400000 /* Unused, ignored */
#define CLONE_UNTRACED 0x00800000 /* set if the tracing process can't force CLONE_PTRACE on this clone */
#define CLONE_CHILD_SETTID 0x01000000 /* set the TID in the child */
/* 0x02000000 was previously the unused CLONE_STOPPED (Start in stopped state)
and is now available for re-use. */
#define CLONE_NEWUTS 0x04000000 /* New utsname group? */
#define CLONE_NEWIPC 0x08000000 /* New ipcs */
#define CLONE_NEWUSER 0x10000000 /* New user namespace */
#define CLONE_NEWPID 0x20000000 /* New pid namespace */
#define CLONE_NEWNET 0x40000000 /* New network namespace */
#define CLONE_IO 0x80000000 /* Clone io context */
上述宏定义均占用独立的比特位,可用或(|)组合使用。其低八比特位没有使用,是为了和信号量组合使用,低八位用于指定子进程退出时子进程向父进程发出的信号。
7.2.2.2 copy_process()
该函数定义于kernel/fork.c:
/*
* This creates a new process as a copy of the old one,
* but does not actually start it yet.
*
* It copies the registers, and all the appropriate
* parts of the process environment (as per the clone
* flags). The actual kick-off is left to the caller.
*/
static struct task_struct *copy_process(unsigned long clone_flags, unsigned long stack_start,
struct pt_regs *regs, unsigned long stack_size,
int __user *child_tidptr, struct pid *pid, int trace)
{
int retval;
struct task_struct *p; // 子进程的进程描述符
int cgroup_callbacks_done = 0;
/*
* CLONE_NEWNS表示子进程需要自己的命名空间,而CLONE_FS则
* 代表子进程共享父进程的根目录和当前工作目录,两者不可兼容
*/
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* Thread groups must share signals as well, and detached threads
* can only be started up within the thread group.
*/
/*
* 若子进程和父进程属于同一个线程组(CLONE_THREAD被设置),
* 则子进程必须共享父进程的信号(CLONE_SIGHAND被设置)
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way of the above,
* thread groups also imply shared VM. Blocking this case allows
* for various simplifications in other code.
*/
/*
* 若子进程共享父进程的信号,则必须同时共享父进程的内存描述符
* 和所有的页表(CLONE_VM被设置)
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/*
* Siblings of global init remain as zombies on exit since they are
* not reaped by their parent (swapper). To solve this and to avoid
* multi-rooted process trees, prevent global and container-inits
* from creating siblings.
*/
if ((clone_flags & CLONE_PARENT) && current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
/*
* 调用系统安全框架创建进程,在配置内核时没有选择CONFIG_SECURITY,
* 则系统安全框架函数为空函数,返回值为0;调用变量security_ops中的
* 对应函数,参见[14.4.2 security_xxx()]节
*/
retval = security_task_create(clone_flags);
if (retval)
goto fork_out;
retval = -ENOMEM;
/*
* 该函数为子进程创建一个新的内核栈,并分配一个新的进程描述符和thread_info
* 结构,然后把父进程的进程描述符和thread_info拷贝进去。此处是完全拷贝,即
* 子进程和父进程的进程描述符/thread_info完全相同。参见[7.2.2.2.1 dup_task_struct()]节
*/
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
#ifdef CONFIG_PROVE_LOCKING
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
// 判断是否超出了设置权限
if (atomic_read(&p->real_cred->user->processes) >= task_rlimit(p, RLIMIT_NPROC)) {
if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) && p->real_cred->user != INIT_USER)
goto bad_fork_free;
}
current->flags &= ~PF_NPROC_EXCEEDED;
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
/*
* If multiple threads are within copy_process(), then this check
* triggers too late. This doesn't hurt, the check is only there
* to stop root fork bombs.
*/
/*
* 判断线程数量是否超出了系统允许的范围,否则释放已经申请到的资源
* max_threads在kernel/fork中的fork_init()中定义,系统允许
* 的最大进程数和系统的内存大小有关,其具体取值参见:
* start_kernel() -> fork_init()
* 可通过cat /proc/sys/kernel/threads-max从用户空间查看此值
* 可通过echo NewValue > /proc/sys/kernel/threads-max从用
* 户空间更改此值
*/
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
/*
* 下列代码主要是初始化子进程的进程描述符和复制父进程的资源给子进程;
* 此前,父子进程的进程描述符是完全相同的;
* 此后,子进程的进程描述符的某些域被初始化,故父子进程的进程描述符不再完全相同
*/
// 模块引用计数操作
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
/*
* execve系统调用计数初始化为0: it counts the number of
* execve() system calls issued by the process.
*/
p->did_exec = 0;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
copy_flags(clone_flags, p); // 设置状态标记,因为目前状态表示是从父进程拷贝过来的
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = cputime_zero;
p->stime = cputime_zero;
p->gtime = cputime_zero;
p->utimescaled = cputime_zero;
p->stimescaled = cputime_zero;
#ifndef CONFIG_VIRT_CPU_ACCOUNTING
p->prev_utime = cputime_zero;
p->prev_stime = cputime_zero;
#endif
#if defined(SPLIT_RSS_COUNTING)
memset(&p->rss_stat, 0, sizeof(p->rss_stat));
#endif
p->default_timer_slack_ns = current->timer_slack_ns;
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cpu_timers_init(p);
do_posix_clock_monotonic_gettime(&p->start_time);
p->real_start_time = p->start_time;
monotonic_to_bootbased(&p->real_start_time);
p->io_context = NULL;
p->audit_context = NULL;
if (clone_flags & CLONE_THREAD)
threadgroup_fork_read_lock(current);
cgroup_fork(p);
#ifdef CONFIG_NUMA
p->mempolicy = mpol_dup(p->mempolicy);
if (IS_ERR(p->mempolicy)) {
retval = PTR_ERR(p->mempolicy);
p->mempolicy = NULL;
goto bad_fork_cleanup_cgroup;
}
mpol_fix_fork_child_flag(p);
#endif
#ifdef CONFIG_CPUSETS
p->cpuset_mem_spread_rotor = NUMA_NO_NODE;
p->cpuset_slab_spread_rotor = NUMA_NO_NODE;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
p->irq_events = 0;
#ifdef __ARCH_WANT_INTERRUPTS_ON_CTXSW
p->hardirqs_enabled = 1;
#else
p->hardirqs_enabled = 0;
#endif
p->hardirq_enable_ip = 0;
p->hardirq_enable_event = 0;
p->hardirq_disable_ip = _THIS_IP_;
p->hardirq_disable_event = 0;
p->softirqs_enabled = 1;
p->softirq_enable_ip = _THIS_IP_;
p->softirq_enable_event = 0;
p->softirq_disable_ip = 0;
p->softirq_disable_event = 0;
p->hardirq_context = 0;
p->softirq_context = 0;
#endif
#ifdef CONFIG_LOCKDEP
p->lockdep_depth = 0; /* no locks held yet */
p->curr_chain_key = 0;
p->lockdep_recursion = 0;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
p->blocked_on = NULL; /* not blocked yet */
#endif
#ifdef CONFIG_CGROUP_MEM_RES_CTLR
p->memcg_batch.do_batch = 0;
p->memcg_batch.memcg = NULL;
#endif
/* Perform scheduler related setup. Assign this task to a CPU. */
sched_fork(p); // 参见[7.2.2.2.2 sched_fork()]节
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
retval = audit_alloc(p);
if (retval)
goto bad_fork_cleanup_policy;
/* copy all the process information */
retval = copy_semundo(clone_flags, p);
if (retval)
goto bad_fork_cleanup_audit;
retval = copy_files(clone_flags, p);
if (retval)
goto bad_fork_cleanup_semundo;
// 复制文件系统信息,参见[4.3.4.1.4.3.11.4.3 init_mount_tree()]节
retval = copy_fs(clone_flags, p);
if (retval)
goto bad_fork_cleanup_files;
retval = copy_sighand(clone_flags, p);
if (retval)
goto bad_fork_cleanup_fs;
retval = copy_signal(clone_flags, p);
if (retval)
goto bad_fork_cleanup_sighand;
// 参见[7.2.2.2.3 copy_mm()]节
retval = copy_mm(clone_flags, p);
if (retval)
goto bad_fork_cleanup_signal;
retval = copy_namespaces(clone_flags, p);
if (retval)
goto bad_fork_cleanup_mm;
retval = copy_io(clone_flags, p);
if (retval)
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
}
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
/*
* Clear TID on mm_release()?
*/
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr : NULL;
#ifdef CONFIG_BLOCK
p->plug = NULL;
#endif
#ifdef CONFIG_FUTEX
p->robust_list = NULL;
#ifdef CONFIG_COMPAT
p->compat_robust_list = NULL;
#endif
INIT_LIST_HEAD(&p->pi_state_list);
p->pi_state_cache = NULL;
#endif
/*
* sigaltstack should be cleared when sharing the same VM
*/
if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM)
p->sas_ss_sp = p->sas_ss_size = 0;
/*
* Syscall tracing and stepping should be turned off in the
* child regardless of CLONE_PTRACE.
*/
user_disable_single_step(p);
/*
* so the ret_from_fork() function will not notify the
* debugging process about the system call termination.
*/
clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE);
#ifdef TIF_SYSCALL_EMU
clear_tsk_thread_flag(p, TIF_SYSCALL_EMU);
#endif
clear_all_latency_tracing(p);
/* ok, now we should be set up.. */
p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL);
p->pdeath_signal = 0;
p->exit_state = 0;
p->nr_dirtied = 0;
p->nr_dirtied_pause = 128 >> (PAGE_SHIFT - 10);
/*
* Ok, make it visible to the rest of the system.
* We dont wake it up yet.
*/
p->group_leader = p;
INIT_LIST_HEAD(&p->thread_group);
/* Now that the task is set up, run cgroup callbacks if
* necessary. We need to run them before the task is visible
* on the tasklist. */
cgroup_fork_callbacks(p);
cgroup_callbacks_done = 1;
/* Need tasklist lock for parent etc handling! */
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(¤t->sighand->siglock);
/*
* Process group and session signals need to be delivered to just the
* parent before the fork or both the parent and the child after the
* fork. Restart if a signal comes in before we add the new process to
* it's process group.
* A fatal signal pending means that current will exit, so the new
* thread can't slip out of an OOM kill (or normal SIGKILL).
*/
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
if (clone_flags & CLONE_THREAD) {
current->signal->nr_threads++;
atomic_inc(¤t->signal->live);
atomic_inc(¤t->signal->sigcnt);
p->group_leader = current->group_leader;
list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group);
}
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
if (thread_group_leader(p)) {
if (is_child_reaper(pid))
p->nsproxy->pid_ns->child_reaper = p;
p->signal->leader_pid = pid;
p->signal->tty = tty_kref_get(current->signal->tty);
attach_pid(p, PIDTYPE_PGID, task_pgrp(current));
attach_pid(p, PIDTYPE_SID, task_session(current));
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
__this_cpu_inc(process_counts);
}
attach_pid(p, PIDTYPE_PID, pid);
nr_threads++;
}
total_forks++;
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
if (clone_flags & CLONE_THREAD)
threadgroup_fork_read_unlock(current);
perf_event_fork(p);
return p; // 返回指向子进程的进程描述符的指针
bad_fork_free_pid:
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_io:
if (p->io_context)
exit_io_context(p);
bad_fork_cleanup_namespaces:
exit_task_namespaces(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
if (!(clone_flags & CLONE_THREAD))
free_signal_struct(p->signal);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup_semundo:
exit_sem(p);
bad_fork_cleanup_audit:
audit_free(p);
bad_fork_cleanup_policy:
perf_event_free_task(p);
#ifdef CONFIG_NUMA
mpol_put(p->mempolicy);
bad_fork_cleanup_cgroup:
#endif
if (clone_flags & CLONE_THREAD)
threadgroup_fork_read_unlock(current);
cgroup_exit(p, cgroup_callbacks_done);
delayacct_tsk_free(p);
module_put(task_thread_info(p)->exec_domain->module);
bad_fork_cleanup_count:
atomic_dec(&p->cred->user->processes);
exit_creds(p);
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
}
copy_process()创建进程之后并未执行,而是返回到do_fork()中,将新创建的进程加入到运行队列中等待被执行。
7.2.2.2.1 dup_task_struct()
该函数根据父进程创建子进程内核栈和进程描述符,其被copy_process()调用,定义于kernel/fork.c:
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int node = tsk_fork_get_node(orig);
int err;
prepare_to_copy(orig);
// 创建进程描述符
tsk = alloc_task_struct_node(node);
if (!tsk)
return NULL;
// 创建进程内核栈thread_info,参见[7.1.1.3.2 进程内核栈的分配与释放]节
ti = alloc_thread_info_node(tsk, node);
if (!ti) {
free_task_struct(tsk);
return NULL;
}
// 复制父进程的进程描述符到子进程,使子进程的进程描述符和父进程的完全相同
err = arch_dup_task_struct(tsk, orig);
if (err)
goto out;
/*
* 使子进程的进程描述符中的stack域指向子进程的内核栈
* thread_info,参见[7.1.1.3 进程内核栈]节
*/
tsk->stack = ti;
/*
* 复制父进程的内核栈thread_info到子进程,但其task
* 域指向子进程的进程描述符tsk,参见[7.1.1.3 进程内核栈]节
*/
setup_thread_stack(tsk, orig);
clear_user_return_notifier(tsk);
clear_tsk_need_resched(tsk);
stackend = end_of_stack(tsk); // 堆栈尾部
// 参见include/linux/magic.h,其取值为0x57AC6E9D
*stackend = STACK_END_MAGIC; /* for overflow detection */
#ifdef CONFIG_CC_STACKPROTECTOR
tsk->stack_canary = get_random_int();
#endif
/*
* One for us, one for whoever does the "release_task()" (usually parent)
*/
atomic_set(&tsk->usage, 2);
#ifdef CONFIG_BLK_DEV_IO_TRACE
tsk->btrace_seq = 0;
#endif
tsk->splice_pipe = NULL;
account_kernel_stack(ti, 1);
return tsk;
out:
// 释放分配的进程内核栈,参见[7.1.1.3.2 进程内核栈的分配与释放]节
free_thread_info(ti);
free_task_struct(tsk);
return NULL;
}
7.2.2.2.2 sched_fork()
该函数定义于kernel/sched.c:
void sched_fork(struct task_struct *p)
{
unsigned long flags;
int cpu = get_cpu();
__sched_fork(p);
/*
* We mark the process as running here. This guarantees that
* nobody will actually run it, and a signal or other external
* event cannot wake it up and insert it on the runqueue either.
*/
p->state = TASK_RUNNING;
/*
* Make sure we do not leak PI boosting priority to the child.
*/
p->prio = current->normal_prio;
/*
* Revert to default priority/policy on fork if requested.
*/
if (unlikely(p->sched_reset_on_fork)) {
if (task_has_rt_policy(p)) {
p->policy = SCHED_NORMAL;
p->static_prio = NICE_TO_PRIO(0);
p->rt_priority = 0;
} else if (PRIO_TO_NICE(p->static_prio) < 0)
p->static_prio = NICE_TO_PRIO(0);
p->prio = p->normal_prio = __normal_prio(p);
set_load_weight(p);
/*
* We don't need the reset flag anymore after the fork. It has
* fulfilled its duty:
*/
p->sched_reset_on_fork = 0;
}
if (!rt_prio(p->prio))
p->sched_class = &fair_sched_class;
if (p->sched_class->task_fork)
p->sched_class->task_fork(p);
/*
* The child is not yet in the pid-hash so no cgroup attach races,
* and the cgroup is pinned to this child due to cgroup_fork()
* is ran before sched_fork().
*
* Silence PROVE_RCU.
*/
raw_spin_lock_irqsave(&p->pi_lock, flags);
set_task_cpu(p, cpu);
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
if (likely(sched_info_on()))
memset(&p->sched_info, 0, sizeof(p->sched_info));
#endif
#if defined(CONFIG_SMP)
p->on_cpu = 0;
#endif
#ifdef CONFIG_PREEMPT_COUNT
/* Want to start with kernel preemption disabled. */
// 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
task_thread_info(p)->preempt_count = 1;
#endif
#ifdef CONFIG_SMP
plist_node_init(&p->pushable_tasks, MAX_PRIO);
#endif
put_cpu();
}
7.2.2.2.3 copy_mm()
该函数定义于kernel/fork.c:
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
int retval;
tsk->min_flt = tsk->maj_flt = 0;
tsk->nvcsw = tsk->nivcsw = 0;
#ifdef CONFIG_DETECT_HUNG_TASK
tsk->last_switch_count = tsk->nvcsw + tsk->nivcsw;
#endif
tsk->mm = NULL;
tsk->active_mm = NULL;
/*
* Are we cloning a kernel thread?
*
* We need to steal a active VM for that..
*/
oldmm = current->mm;
if (!oldmm)
return 0;
// 若设置了CLONE_VM标志,则只需增加父进程内存的使用计数,而无需复制内存页
if (clone_flags & CLONE_VM) {
atomic_inc(&oldmm->mm_users);
mm = oldmm;
goto good_mm;
}
// 若未设置CLONE_VM标志,则需要复制父进程(current)的内存页给子进程(tsk)
retval = -ENOMEM;
mm = dup_mm(tsk);
if (!mm)
goto fail_nomem;
good_mm:
/* Initializing for Swap token stuff */
mm->token_priority = 0;
mm->last_interval = 0;
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
fail_nomem:
return retval;
}
7.2.2.3 wake_up_new_task()
该函数用于唤醒一个新创建的进程,其定义于kernel/sched.c:
/*
* wake_up_new_task - wake up a newly created task for the first time.
*
* This function will do some initial scheduler statistics housekeeping
* that must be done for every newly created context, then puts the task
* on the runqueue and wakes it.
*/
void wake_up_new_task(struct task_struct *p)
{
unsigned long flags;
struct rq *rq;
raw_spin_lock_irqsave(&p->pi_lock, flags);
#ifdef CONFIG_SMP
/*
* Fork balancing, do it here and not earlier because:
* - cpus_allowed can change in the fork path
* - any previously selected cpu might disappear through hotplug
*/
set_task_cpu(p, select_task_rq(p, SD_BALANCE_FORK, 0));
#endif
rq = __task_rq_lock(p);
// 调用对应调度类的sched_class->enqueue_task()将进程描述符p加入运行队列rq
activate_task(rq, p, 0);
p->on_rq = 1;
trace_sched_wakeup_new(p, true);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken)
p->sched_class->task_woken(rq, p);
#endif
task_rq_unlock(rq, p, &flags);
}
7.2.2.3.1 activate_task()
该函数定义于kernel/sched.c:
/*
* activate_task - move a task to the runqueue.
*/
static void activate_task(struct rq *rq, struct task_struct *p, int flags)
{
if (task_contributes_to_load(p))
rq->nr_uninterruptible--;
enqueue_task(rq, p, flags);
}
其中,函数enqueue_task()定义于kernel/sched.c:
static void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{
update_rq_clock(rq);
sched_info_queued(p);
// 调用对应调度类的sched_class->enqueue_task()
p->sched_class->enqueue_task(rq, p, flags);
}
7.2.3 do_execve()
该函数定义于fs/exec.c:
int do_execve(const char *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp,
struct pt_regs *regs)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execve_common(filename, argv, envp, regs);
}
其中,函数do_execve_common()定义于fs/exec.c:
static int do_execve_common(const char *filename, struct user_arg_ptr argv,
struct user_arg_ptr envp, struct pt_regs *regs)
{
struct linux_binprm *bprm; // 保存要执行的文件相关的数据
struct file *file;
struct files_struct *displaced;
bool clear_in_exec;
int retval;
const struct cred *cred = current_cred();
/*
* We move the actual failure in case of RLIMIT_NPROC excess from
* set*uid() to execve() because too many poorly written programs
* don't check setuid() return code. Here we additionally recheck
* whether NPROC limit is still exceeded.
*/
if ((current->flags & PF_NPROC_EXCEEDED) &&
atomic_read(&cred->user->processes) > rlimit(RLIMIT_NPROC)) {
retval = -EAGAIN;
goto out_ret;
}
/* We're below the limit (still or again), so we don't want to make
* further execve() calls fail. */
current->flags &= ~PF_NPROC_EXCEEDED;
retval = unshare_files(&displaced);
if (retval)
goto out_ret;
retval = -ENOMEM;
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
if (!bprm)
goto out_files;
retval = prepare_bprm_creds(bprm);
if (retval)
goto out_free;
retval = check_unsafe_exec(bprm);
if (retval < 0)
goto out_free;
clear_in_exec = retval;
current->in_execve = 1;
// 打开要执行的文件,并检查其有效性(此处的检查并不完备)
file = open_exec(filename);
retval = PTR_ERR(file);
if (IS_ERR(file))
goto out_unmark;
// 在多处理器系统中才有效,用以分配负载最低的CPU来执行新程序
sched_exec();
// 下面开始填充linux_binprm结构
bprm->file = file;
bprm->filename = filename;
bprm->interp = filename;
retval = bprm_mm_init(bprm);
if (retval)
goto out_file;
bprm->argc = count(argv, MAX_ARG_STRINGS);
if ((retval = bprm->argc) < 0)
goto out;
bprm->envc = count(envp, MAX_ARG_STRINGS);
if ((retval = bprm->envc) < 0)
goto out;
/*
* Check permissions, then read the first 128 (BINPRM_BUF_SIZE)
* bytes to bprm->buf. ELF文件的头52字节(32位系统,参见结构Elf32_Ehdr)
* 或64字节(64位系统,参见结构Elf64_Ehdr)为ELF Header.
* 下面search_binary_handler()将根据该结构查找对应格式的处理函数,并进行处理
*/
retval = prepare_binprm(bprm);
if (retval < 0)
goto out;
// 将文件名、环境变量和命令行参数拷贝到新分配的页面中
retval = copy_strings_kernel(1, &bprm->filename, bprm);
if (retval < 0)
goto out;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < 0)
goto out;
/*
* 查找能够处理该可执行文件格式的处理函数,并调用相应的load_library()
* 函数进行处理。以ELF格式文件为例,其对应的load_library()函数参见
* fs/binfmt_elf.c:
* static int load_elf_binary(struct linux_binprm *bprm,
* struct pt_regs *regs);
* 其中包含如下语句:
* /* Get the exec-header */
* loc->elf_ex = *((struct elfhdr *)bprm->buf);
* 参见[7.2.3.1 search_binary_handler()]节
*/
retval = search_binary_handler(bprm, regs);
if (retval < 0)
goto out;
/* execve succeeded */
current->fs->in_exec = 0;
current->in_execve = 0;
acct_update_integrals(current);
free_bprm(bprm);
if (displaced)
put_files_struct(displaced);
return retval;
out:
if (bprm->mm) {
acct_arg_size(bprm, 0);
mmput(bprm->mm);
}
out_file:
if (bprm->file) {
allow_write_access(bprm->file);
fput(bprm->file);
}
out_unmark:
if (clear_in_exec)
current->fs->in_exec = 0;
current->in_execve = 0;
out_free:
free_bprm(bprm);
out_files:
if (displaced)
reset_files_struct(displaced);
out_ret:
return retval;
}
7.2.3.1 search_binary_handler()
该函数根据可执行程序的格式查找其对应的处理函数。其定义于fs/exec.c:
/*
* cycle the list of binary formats handler, until one recognizes the image
*/
int search_binary_handler(struct linux_binprm *bprm, struct pt_regs *regs)
{
unsigned int depth = bprm->recursion_depth;
int try, retval;
struct linux_binfmt *fmt;
pid_t old_pid;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
retval = security_bprm_check(bprm);
if (retval)
return retval;
retval = audit_bprm(bprm);
if (retval)
return retval;
/* Need to fetch pid before load_binary changes it */
rcu_read_lock();
old_pid = task_pid_nr_ns(current, task_active_pid_ns(current->parent));
rcu_read_unlock();
retval = -ENOENT;
for (try=0; try<2; try++) {
read_lock(&binfmt_lock);
/*
* 变量formats是保存注册到系统中的可执行文件格式信息的链表,
* 参见[7.2.3.2 Binary Handler的注册和取消]节
*/
list_for_each_entry(fmt, &formats, lh) {
/*
* 获取该可执行文件所对应的处理程序。不同可执行文件对应不同的处理程序:
* 由register_binfmt(), insert_binfmt(), unregister_binfmt()
* 注册和取消,参见[7.2.3.2 Binary Handler的注册和取消]节
*/
int (*fn)(struct linux_binprm *, struct pt_regs *) = fmt->load_binary;
if (!fn)
continue;
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
retval = fn(bprm, regs); // 执行该可执行文件所对应的处理程序
/*
* Restore the depth counter to its starting value
* in this call, so we don't have to rely on every
* load_binary function to restore it on return.
*/
bprm->recursion_depth = depth;
if (retval >= 0) {
if (depth == 0)
ptrace_event(PTRACE_EVENT_EXEC, old_pid);
put_binfmt(fmt);
allow_write_access(bprm->file);
if (bprm->file)
fput(bprm->file);
bprm->file = NULL;
current->did_exec = 1;
proc_exec_connector(current);
return retval;
}
read_lock(&binfmt_lock);
put_binfmt(fmt);
if (retval != -ENOEXEC || bprm->mm == NULL)
break;
if (!bprm->file) {
read_unlock(&binfmt_lock);
return retval;
}
}
read_unlock(&binfmt_lock);
#ifdef CONFIG_MODULES
if (retval != -ENOEXEC || bprm->mm == NULL) {
break;
} else {
#define printable(c) (((c)=='\t') || ((c)=='\n') || (0x20<=(c) && (c)<=0x7e))
if (printable(bprm->buf[0]) &&
printable(bprm->buf[1]) &&
printable(bprm->buf[2]) &&
printable(bprm->buf[3]))
break; /* -ENOEXEC */
if (try)
break; /* -ENOEXEC */
request_module("binfmt-%04x", *(unsigned short *)(&bprm->buf[2]));
}
#else
break;
#endif
}
return retval;
}
7.2.3.2 Binary Handler的注册和取消
不同格式的可执行文件需要使用不同的处理程序,且这些处理程序需要注册到系统中:
- register_binfmt() / insert_binfmt() 用于注册指定的处理函数;
- unregister_binfmt() 用于取消注册指定的处理函数。
函数register_binfmt()和insert_binfmt()定义于include/linux/binfmts.h:
/*
* This structure defines the functions that are used
* to load the binary formats that linux accepts.
*/
struct linux_binfmt {
struct list_head lh;
struct module *module;
int (*load_binary)(struct linux_binprm *, struct pt_regs * regs);
int (*load_shlib)(struct file *);
int (*core_dump)(struct coredump_params *cprm);
unsigned long min_coredump; /* minimal dump size */
};
/* Registration of default binfmt handlers */
static inline int register_binfmt(struct linux_binfmt *fmt)
{
return __register_binfmt(fmt, 0);
}
/* Same as above, but adds a new binfmt at the top of the list */
static inline int insert_binfmt(struct linux_binfmt *fmt)
{
return __register_binfmt(fmt, 1);
}
其中,函数定义于fs/exec.c:
/*
* formats保存了注册到系统中的可执行文件格式信息的链表。
* search_binary_handler()查询该链表以得到对应的处理
* 程序,参见[7.2.3.1 search_binary_handler()]节
*/
static LIST_HEAD(formats);
static DEFINE_RWLOCK(binfmt_lock);
int __register_binfmt(struct linux_binfmt * fmt, int insert)
{
if (!fmt)
return -EINVAL;
write_lock(&binfmt_lock);
insert ? list_add(&fmt->lh, &formats) : list_add_tail(&fmt->lh, &formats);
write_unlock(&binfmt_lock);
return 0;
}
函数unregister_binfmt()定义于fs/exec.c:
oid unregister_binfmt(struct linux_binfmt * fmt)
{
write_lock(&binfmt_lock);
list_del(&fmt->lh);
write_unlock(&binfmt_lock);
}
7.2.3.3 ELF Format Binary Handler
ELF格式可执行程序所对应的处理函数为load_elf_binary(),参见fs/binfmt_elf.c:
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary, // ELF格式可执行文件对应的处理函数
.load_shlib = load_elf_library, // ELF格式可执行文件对应的处理函数
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};
static int __init init_elf_binfmt(void)
{
return register_binfmt(&elf_format); // 参见[7.2.3.2 Binary Handler的注册和取消]节
}
static void __exit exit_elf_binfmt(void)
{
/* Remove the COFF and ELF loaders. */
unregister_binfmt(&elf_format); // 参见[7.2.3.2 Binary Handler的注册和取消]节
}
/*
* 若module被编译进内核,其初始化函数在系统启动时被调用,
* 其清理函数将不会被调用,参见[13.5.1.1 module被编译进内核时的初始化过程]节;
* 若module被编译成独立模块,其初始化函数在执行insmod时调用,
* 参见[13.5.1.2 insmod调用sys_init_module()]节;其清理函数在执行rmmod时
* 调用,参见[13.5.1.3 rmmod调用sys_delete_module()]节
*/
core_initcall(init_elf_binfmt);
module_exit(exit_elf_binfmt);
函数load_elf_binary()和load_elf_library()定义于fs/binfmt_elf.c。这两个函数与ELF可执行文件的格式有密切关系,32位和64位ELF可执行文件的格式分别参见《TIS ELF Specification Version 1.2》和《ELF-64 Object File Format Version 1.5》。
7.2.4 特殊进程的创建
7.2.4.1 进程0/swapper, swapper/0, swapper/1, …
Linux系统中,只有进程0(idle process, or swapper process)是静态分配的。进程0的进程描述符定义于arch/x86/kernel/init_task.c:
/*
* Initial task structure.
*
* All other task structs will be allocated on slabs in fork.c
*/
struct task_struct init_task = INIT_TASK(init_task);
通过宏INIT_TASK填充init_task中的各个域,其定义于include/linux/init_task.h。在系统启动时,start_kernel()会初始化或填充init_task的域,参见4.3.4.1.4.3 start_kernel()节。
每个CPU存在一个进程0(idle进程)。若只有一个CPU,则该CPU对应的进程0的名字(struct task_struct中的comm域)为swapper;若存在多个CPU,则对应与CPU n的进程0的名字为swapper/n。参见4.3.4.1.4.3.7 sched_init()节,其调用关系为:
start_kernel() -> sched_init() -> init_idle():
#if defined(CONFIG_SMP)
sprintf(idle->comm, "%s/%d", INIT_TASK_COMM, cpu);
#endif
进程0所属的调度类为idle_sched_class,其处于调度类链表中的最后一个位置,参见7.4.5.2.2 pick_next_task()节。
NOTE: 参见«Understanding the Linux Kernel, 3rd Edition»第3. Process章第Process 0节:
In multiprocessor systems there is a process 0 for each CPU. Right after the power on, the BIOS of the computer starts a single CPU while disabling the others. The swapper process running on CPU 0 initializes the kernel data structures, then enables the other CPUs and creates the additional swapper processes by means of the copy_process() function passing to it the value 0 as the new PID. Moreover, the kernel sets the cpu field of the thread_info descriptor of each forked process to the proper CPU index.
7.2.4.1.1 在SMP系统上如何为每个CPU创建一个idle进程/进程0
如果在配置系统时,配置了CONFIG_SMP,则编译后的系统为SMP系统。同时,可以通过CONFIG_NR_CPUS指定CPU的个数,NR_CPUS是根据CONFIG_NR_CPUS设置的。
每个CPU存在一个自己的运行队列runqueues(参见7.4.2.1 运行队列结构/struct rq节),其idle域即指向属于该CPU的idle进程(进程0)的进程描述符,参见kernel/sched.c中的init_idle():
void __cpuinit init_idle(struct task_struct *idle, int cpu)
{
struct rq *rq = cpu_rq(cpu);
...
rq->curr = rq->idle = idle;
#if defined(CONFIG_SMP)
idle->on_cpu = 1;
#endif
...
}
因而可以通过idle_task()获得指定CPU上idle进程(进程0)的进程描述符,参见kernel/sched.c:
/**
* idle_task - return the idle task for a given cpu.
* @cpu: the processor in question.
*/
struct task_struct *idle_task(int cpu)
{
/*
* 通过指定CPU上的运行队列获取idle进程描述符。该值是通过如下函数调用设置的:
* kernel_init() -> smp_init() -> cpu_up(cpu) -> _cpu_up(cpu, 0)
* -> __cpu_up(cpu) -> smp_ops.cpu_up(cpu) -> do_boot_cpu(apicid, cpu)
* -> init_idle(c_idle.idle, cpu)
*/
return cpu_rq(cpu)->idle;
}
7.2.4.2 进程1/init
内核通过start_kernel() -> rest_init()中的如下语句创建进程1,参见4.3.4.1.4.3.13 rest_init()节和4.3.4.1.4.3.13.1 kernel_init()节。
kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
虽然每个CPU对应一个进程0,但是系统中只存在一个进程1。
7.2.4.3 kthreadd进程
内核通过start_kernel() -> rest_init()中的如下语句创建kthreadd进程,参见4.3.4.1.4.3.13 rest_init()节和4.3.4.1.4.3.13.2 kthreadd()节。
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
...
kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns);
kthreadd进程用于创建链表kthread_create_list中指定的内核线程。
Q: 链表kthread_create_list中的线程信息是如何添加进去的?
A: 通过宏kthread_run()向链表kthread_create_list中添加想要创建的进程,参见7.2.4.4 通过链表kthread_create_list创建内核线程节和7.2.4.4.1 kthread_run()节。
7.2.4.4 通过链表kthread_create_list创建内核线程
7.2.4.4.1 kthread_run()
宏kthread_run()用于创建内核线程,其定义参见include/linux/kthread.h:
/*
* 宏kthread_create()创建的新内核线程不会自动进入运行状态,
* 除非调用wake_up_process()唤醒该线程;而宏kthread_run()
* 创建新的内核线程,并运行该线程,参见下文
*/
#define kthread_create(threadfn, data, namefmt, arg...) \
kthread_create_on_node(threadfn, data, -1, namefmt, ##arg)
/**
* kthread_run - create and wake a thread.
* @threadfn: the function to run until signal_pending(current).
* @data: data ptr for @threadfn.
* @namefmt: printf-style name for the thread.
*
* Description: Convenient wrapper for kthread_create() followed by
* wake_up_process(). Returns the kthread or ERR_PTR(-ENOMEM).
*/
/*
* NOTE: 其实并不是kthread_run()创建了内核线程,它只是将创建内核线程所需的信息
* 添加到了链表kthread_create_list中,然后等待kthreadd进程创建所需要的线程
*/
#define kthread_run(threadfn, data, namefmt, ...) \
({ \
struct task_struct *__k \
= kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); \ // 创建指定的内核线程
if (!IS_ERR(__k)) \
wake_up_process(__k); \ // 唤醒创建的内核线程
__k; \
})
其中,kthread_create_on_node()的定义参见kernel/kthread.c:
/**
* kthread_create_on_node - create a kthread.
* @threadfn: the function to run until signal_pending(current).
* @data: data ptr for @threadfn.
* @node: memory node number.
* @namefmt: printf-style name for the thread.
*
* Description: This helper function creates and names a kernel
* thread. The thread will be stopped: use wake_up_process() to start
* it. See also kthread_run().
*
* If thread is going to be bound on a particular cpu, give its node
* in @node, to get NUMA affinity for kthread stack, or else give -1.
* When woken, the thread will run @threadfn() with @data as its
* argument. @threadfn() can either call do_exit() directly if it is a
* standalone thread for which no one will call kthread_stop(), or
* return when 'kthread_should_stop()' is true (which means
* kthread_stop() has been called). The return value should be zero
* or a negative error number; it will be passed to kthread_stop().
*
* Returns a task_struct or ERR_PTR(-ENOMEM).
*/
struct task_struct *kthread_create_on_node(int (*threadfn)(void *data),
void *data, int node, const char namefmt[], ...)
{
struct kthread_create_info create;
create.threadfn = threadfn;
create.data = data;
create.node = node;
init_completion(&create.done);
/*
* 将需要创建的内核线程信息保存到链表kthread_create_list中,
* 由kthreadd进程创建该线程,参见[7.2.4.3 kthreadd进程]节
*/
spin_lock(&kthread_create_lock);
list_add_tail(&create.list, &kthread_create_list);
spin_unlock(&kthread_create_lock);
/*
* 唤醒kthreadd_task进程,使其创建指定的线程,
* 参见[7.2.4.3 kthreadd进程]节,并等待该线程创建完成
*/
wake_up_process(kthreadd_task);
wait_for_completion(&create.done);
if (!IS_ERR(create.result)) {
static const struct sched_param param = { .sched_priority = 0 };
va_list args;
va_start(args, namefmt);
vsnprintf(create.result->comm, sizeof(create.result->comm), namefmt, args);
va_end(args);
/*
* root may have changed our (kthreadd's) priority or CPU mask.
* The kernel thread should not inherit these properties.
*/
sched_setscheduler_nocheck(create.result, SCHED_NORMAL, ¶m);
set_cpus_allowed_ptr(create.result, cpu_all_mask);
}
return create.result;
}
7.2.4.4.2 kthread_stop()
该函数用于结束kthread_create()所创建的线程,其定义参见kernel/kthread.c:
/**
* kthread_stop - stop a thread created by kthread_create().
* @k: thread created by kthread_create().
*
* Sets kthread_should_stop() for @k to return true, wakes it, and
* waits for it to exit. This can also be called after kthread_create()
* instead of calling wake_up_process(): the thread will exit without
* calling threadfn().
*
* If threadfn() may call do_exit() itself, the caller must ensure
* task_struct can't go away.
*
* Returns the result of threadfn(), or %-EINTR if wake_up_process()
* was never called.
*/
int kthread_stop(struct task_struct *k)
{
struct kthread *kthread;
int ret;
trace_sched_kthread_stop(k);
get_task_struct(k);
kthread = to_kthread(k);
// 如果该线程在调用kthread_stop()之前就结束了,则crash!
barrier(); /* it might have exited */
if (k->vfork_done != NULL) {
// 设置should_stop标志,唤醒该线程,并等待线程结束
kthread->should_stop = 1;
wake_up_process(k);
wait_for_completion(&kthread->exited);
}
ret = k->exit_code;
put_task_struct(k);
trace_sched_kthread_stop_ret(ret);
return ret;
}
7.2.4.4.3 kthread_should_stop()
该函数返回当前线程should_stop标志的取值,用于创建的线程检查结束标志,并决定是否退出。NOTE: 线程完全可以在完成自己的工作后主动结束,不需等待should_stop标志。其定义于kernel/kthread.c:
/**
* kthread_should_stop - should this kthread return now?
*
* When someone calls kthread_stop() on your kthread, it will be woken
* and this will return true. You should then return, and your return
* value will be passed through to kthread_stop().
*/
int kthread_should_stop(void)
{
return to_kthread(current)->should_stop;
}
7.3 进程终结
进程终结可以通过几个事件驱动、通过正常的进程结束(当一个C程序从main()函数返回时startup routine调用exit())、通过信号或着通过显式地调用exit()函数。
7.3.1 与进程终结有关的系统调用/用户接口
进程终结时内核释放其所占有的资源,并通知父进程更新父子关系。进程的终结一般是显示或隐式地调用了eixt(),或者接收到某种信号。不管是什么原因导致进程终结,最终都会调用do_exit()来处理。
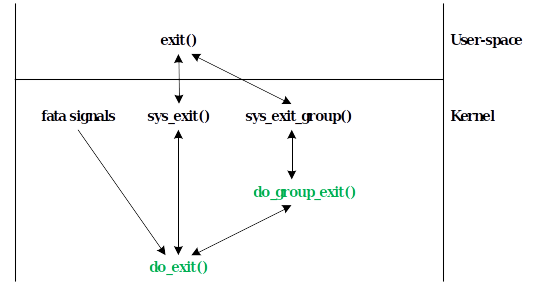
7.3.1.1 sys_exit_group()/sys_exit()/exit()
系统调用sys_exit_group()和sys_exit()定义于kernel/exit.c:
/*
* this kills every thread in the thread group. Note that any externally
* wait4()-ing process will get the correct exit code - even if this
* thread is not the thread group leader.
*/
SYSCALL_DEFINE1(exit_group, int, error_code)
{
do_group_exit((error_code & 0xff) << 8); // 参见[7.3.2 do_group_exit()]节
/* NOTREACHED */
return 0;
}
SYSCALL_DEFINE1(exit, int, error_code)
{
do_exit((error_code & 0xff) << 8); // 参见[7.3.3 do_exit()]节
}
函数sys_exit_group()终止整个线程组中的进程,而函数sys_exit()只终止某个进程。
用户接口exit()的声明如下:
#include <stdlib.h>
void exit(int status);
void _Exit(int status);
#include <unistd.h>
void _exit(int status);
函数exit():在执行该函数时,进程会检查文件打开情况,清理I/O缓存。如果缓存中有数据,就会将它们写入相应的文件。这样就防止了文件数据的丢失,然后终止进程。
函数_exit():在执行该函数时,并不清理标准输入输出缓存,而是直接清除内存空间,当然也就把文件缓存中尚未写入文件的数据给销毁了。
由此可见,使用exit()更安全。
7.3.2 do_group_exit()
该函数定义于kernel/exit.c:
/*
* Take down every thread in the group. This is called by fatal signals
* as well as by sys_exit_group (below).
*/
NORET_TYPE void do_group_exit(int exit_code)
{
struct signal_struct *sig = current->signal;
BUG_ON(exit_code & 0x80); /* core dumps don't get here */
/*
* signal_group_exit(): Checks whether the SIGNAL_GROUP_EXIT flag
* of the exiting process is not zero, which means that the kernel
* already started an exit procedure for this thread group.
if (signal_group_exit(sig))
exit_code = sig->group_exit_code;
else if (!thread_group_empty(current)) {
struct sighand_struct *const sighand = current->sighand;
spin_lock_irq(&sighand->siglock);
if (signal_group_exit(sig))
/* Another thread got here before we took the lock. */
exit_code = sig->group_exit_code;
else {
sig->group_exit_code = exit_code;
sig->flags = SIGNAL_GROUP_EXIT;
/*
* Kill the other processes in the thread group of current,
* if any. In order to do this, the function scans the per
* PID list in the PIDTYPE_TGID hash table corresponding to
* current->tgid; for each process in the list different from
* current, it sends a SIGKILL signal to it. As a result, all
* such processes will eventually execute the do_exit()
* function, and thus they will be killed.
*/
zap_other_threads(current);
}
spin_unlock_irq(&sighand->siglock);
}
do_exit(exit_code); // 参见[7.3.3 do_exit()]节
/* NOTREACHED */
}
7.3.3 do_exit()
该函数定义于kernel/exit.c:
NORET_TYPE void do_exit(long code)
{
struct task_struct *tsk = current; // 获取当前运行进程
int group_dead;
profile_task_exit(tsk);
WARN_ON(blk_needs_flush_plug(tsk));
if (unlikely(in_interrupt()))
panic("Aiee, killing interrupt handler!");
if (unlikely(!tsk->pid))
panic("Attempted to kill the idle task!");
/*
* If do_exit is called because this processes oopsed, it's possible
* that get_fs() was left as KERNEL_DS, so reset it to USER_DS before
* continuing. Amongst other possible reasons, this is to prevent
* mm_release()->clear_child_tid() from writing to a user-controlled
* kernel address.
*/
set_fs(USER_DS);
ptrace_event(PTRACE_EVENT_EXIT, code);
validate_creds_for_do_exit(tsk);
/*
* We're taking recursive faults here in do_exit. Safest is to just
* leave this task alone and wait for reboot.
*/
// 标志PF_EXITING表示进程正在终止,参见下文中的 exit_signals(tsk);
if (unlikely(tsk->flags & PF_EXITING)) {
printk(KERN_ALERT "Fixing recursive fault but reboot is needed!\n");
/*
* We can do this unlocked here. The futex code uses
* this flag just to verify whether the pi state
* cleanup has been done or not. In the worst case it
* loops once more. We pretend that the cleanup was
* done as there is no way to return. Either the
* OWNER_DIED bit is set by now or we push the blocked
* task into the wait for ever nirwana as well.
*/
tsk->flags |= PF_EXITPIDONE;
set_current_state(TASK_UNINTERRUPTIBLE);
schedule(); // 调度其他进程运行,参见[7.4.5 schedule()]节
}
exit_irq_thread();
/*
* 设置PF_EXITING标志来表明进程正在退出,并清除所有信号处理函数。
* 内核的其他部分会利用PF_EXITING标志来防止在进程被删除时还试图
* 处理此进程,参见上述的语句块:
* if (unlikely(tsk->flags & PF_EXITING)) {
*/
exit_signals(tsk); /* sets PF_EXITING */
/*
* tsk->flags are checked in the futex code to protect against
* an exiting task cleaning up the robust pi futexes.
*/
smp_mb();
raw_spin_unlock_wait(&tsk->pi_lock);
if (unlikely(in_atomic()))
printk(KERN_INFO "note: %s[%d] exited with preempt_count %d\n",
current->comm, task_pid_nr(current), preempt_count());
acct_update_integrals(tsk);
/* sync mm's RSS info before statistics gathering */
if (tsk->mm)
sync_mm_rss(tsk, tsk->mm);
group_dead = atomic_dec_and_test(&tsk->signal->live);
if (group_dead) {
/*
* 取消tsk->signal->real_timer定时器,
* 参见[7.8.3.3 取消定时器/hrtimer_cancel()]节
*/
hrtimer_cancel(&tsk->signal->real_timer);
exit_itimers(tsk->signal);
if (tsk->mm)
setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm);
}
acct_collect(code, group_dead);
if (group_dead)
tty_audit_exit();
if (unlikely(tsk->audit_context))
audit_free(tsk);
tsk->exit_code = code;
taskstats_exit(tsk, group_dead);
/*
* 下面分别调用exit_mm(),exit_sem(),exit_files()、exit_fs()
* 和exit_thread()函数,以便从进程描述符中分离出与分页、信号量、文
* 件系统、打开文件描述符以及I/O权限位图相关的数据结构。如果没有其它
* 进程共享这些数据结构,那么这些函数还会删除这些数据结构。
* /
// 释放进程描述符task_struct中的mm_struct内存
exit_mm(tsk);
if (group_dead)
acct_process();
trace_sched_process_exit(tsk);
exit_sem(tsk); // 退出接收IPC semaphore的队列
exit_shm(tsk); // 退出进程名字空间
exit_files(tsk); // Decrement the usage count of objects related to file descriptors
exit_fs(tsk); // Decrement the usage count of objects related to filesystem data
check_stack_usage(); // 检查栈的使用情况
exit_thread(); // 资源释放
/*
* Flush inherited counters to the parent - before the parent
* gets woken up by child-exit notifications.
*
* because of cgroup mode, must be called before cgroup_exit()
*/
perf_event_exit_task(tsk);
cgroup_exit(tsk, 1);
if (group_dead)
disassociate_ctty(1);
module_put(task_thread_info(tsk)->exec_domain->module);
proc_exit_connector(tsk);
/*
* FIXME: do that only when needed, using sched_exit tracepoint
*/
ptrace_put_breakpoints(tsk);
/*
* Send signals to the task’s parent, reparents any of the
* task’s children to another thread in their thread group
* or the init process, and sets the task’s exit state,
* stored in exit_state in the task_struct structure, to
* EXIT_ZOMBIE. 参见[7.3.3.1 exit_notify()]节
*/
exit_notify(tsk, group_dead);
#ifdef CONFIG_NUMA
task_lock(tsk);
mpol_put(tsk->mempolicy);
tsk->mempolicy = NULL;
task_unlock(tsk);
#endif
#ifdef CONFIG_FUTEX
if (unlikely(current->pi_state_cache))
kfree(current->pi_state_cache);
#endif
/*
* Make sure we are holding no locks:
*/
debug_check_no_locks_held(tsk);
/*
* We can do this unlocked here. The futex code uses this flag
* just to verify whether the pi state cleanup has been done
* or not. In the worst case it loops once more.
*/
tsk->flags |= PF_EXITPIDONE;
if (tsk->io_context)
exit_io_context(tsk);
if (tsk->splice_pipe)
__free_pipe_info(tsk->splice_pipe);
validate_creds_for_do_exit(tsk);
preempt_disable(); // 参见[16.10.2 preempt_disable()]节
exit_rcu();
/* causes final put_task_struct in finish_task_switch(). */
tsk->state = TASK_DEAD;
/*
* 调度其他进程运行,参见[7.4.5 schedule()]节;
* Because the process is now not schedulable, this is
* the last code the task will ever execute. The only
* memory it occupies is its kernel stack, the structure
* thread_info, and the task_struct structure. do_exit()
* never returns.
*/
schedule();
BUG();
/* Avoid "noreturn function does return". */
for (;;)
cpu_relax(); /* For when BUG is null */
}
僵死进程是一个进程已经退出,它的内存和资源已经释放掉了,但是为了使系统在它退出后能够获得它的退出状态等信息,它的进程描述符仍然保留。
一个进程退出时,它的父进程会接收到一个SIGCHLD信号,一般情况下这个信号的处理函数会执行wait()系列函数等待子进程的结束。从子进程退出到父进程调用wait()函数(子进程结束)的这段时间,子进程被称为僵死进程。执行命令ps -ef,在结果中以z结尾的进程就是僵死进程。
僵死进程很特殊,因为它没有任何可执行代码,不会被调度,只有一个进程描述符用来记录退出等状态,除此之外不再占用其他任何资源。
如果僵死进程的父进程没有调用wait(),则该进程会一直处于僵死状态。如果父进程结束,内核会在当前线程组里为其找一个父进程,如果没找到,则把init进程作为其父进程,此时新的父进程将负责清除其进程。如果父进程一直不结束,该进程会一直僵死。在root下使用kill -9命令也不能将其杀死。
7.3.3.1 exit_notify()
该函数定义于kernel/exit.c:
/*
* Send signals to all our closest relatives so that they know
* to properly mourn us.
*/
static void exit_notify(struct task_struct *tsk, int group_dead)
{
bool autoreap;
/*
* This does two things:
*
* A. Make init inherit all the child processes
* B. Check to see if any process groups have become orphaned
* as a result of our exiting, and if they have any stopped
* jobs, send them a SIGHUP and then a SIGCONT. (POSIX 3.2.2.2)
*/
forget_original_parent(tsk); // 参见[7.3.3.1.1 forget_original_parent()]节
exit_task_namespaces(tsk);
write_lock_irq(&tasklist_lock);
if (group_dead)
kill_orphaned_pgrp(tsk->group_leader, NULL);
/*
* Let father know we died.
*
* Thread signals are configurable, but you aren't going to use
* that to send signals to arbitrary processes.
* That stops right now.
*
* If the parent exec id doesn't match the exec id we saved
* when we started then we know the parent has changed security
* domain.
*
* If our self_exec id doesn't match our parent_exec_id then
* we have changed execution domain as these two values started
* the same after a fork.
*/
if (thread_group_leader(tsk) && tsk->exit_signal != SIGCHLD &&
(tsk->parent_exec_id != tsk->real_parent->self_exec_id ||
tsk->self_exec_id != tsk->parent_exec_id))
tsk->exit_signal = SIGCHLD;
if (unlikely(tsk->ptrace)) {
int sig = thread_group_leader(tsk) && thread_group_empty(tsk) &&
!ptrace_reparented(tsk) ? tsk->exit_signal : SIGCHLD;
autoreap = do_notify_parent(tsk, sig);
} else if (thread_group_leader(tsk)) {
autoreap = thread_group_empty(tsk) && do_notify_parent(tsk, tsk->exit_signal);
} else {
autoreap = true;
}
/*
* 子进程在结束前不一定都需要经过一个EXIT_ZOMBIE过程。
* 若父进程调用了waitpid()等待子进程:
* 则父进程会显式处理它发来的SIGCHILD信号,子进程结束
* 时会自我清理(在下文中自己调用release_task()清理);
* 若父进程未调用waitpid()等待子进程:
* 则父进程不会处理SIGCHLD信号,子进程不会马上被清理,
* 而是变成EXIT_ZOMBIE状态,成为僵尸进程。
* 若子进程退出时父进程恰好正在睡眠(sleep):
* 父进程没有及时处理SIGCHLD信号,子进程也会成为僵尸进程。
* 只要父进程在醒来后能调用waitpid(),也能清理僵尸子进程,
* 因为系统调用wait()内部有清理僵尸子进程的代码。
* 综上,如果父进程一直没有调用waitpid(),那么僵尸子进程就只
* 能等到父进程退出时被init接管了。init进程会负责清理这些僵
* 尸进程。
*/
tsk->exit_state = autoreap ? EXIT_DEAD : EXIT_ZOMBIE;
/* mt-exec, de_thread() is waiting for group leader */
if (unlikely(tsk->signal->notify_count < 0))
wake_up_process(tsk->signal->group_exit_task);
write_unlock_irq(&tasklist_lock);
/* If the process is dead, release it - nobody will wait for it */
if (autoreap)
release_task(tsk); // 参见[7.3.3.1.2 release_task()]节
}
7.3.3.1.1 forget_original_parent()
该函数将当前进程的所有子进程的父进程ID设置为1 (init),让init接管所有这些子进程,以避免成为孤儿进程。如果当前进程是某个进程组的组长,其销毁导致进程组变为“无领导状态“,则向每个组内进程发送挂起信号SIGHUP,然后发送SIGCONT。
该函数定义于kernel/exit.c:
static void forget_original_parent(struct task_struct *father)
{
struct task_struct *p, *n, *reaper;
LIST_HEAD(dead_children);
write_lock_irq(&tasklist_lock);
/*
* Note that exit_ptrace() and find_new_reaper() might
* drop tasklist_lock and reacquire it.
*/
exit_ptrace(father);
/*
* Find and return another task in the process’s thread
* group. If another task is not in the thread group,
* it finds and returns the init process.
*/
reaper = find_new_reaper(father);
/*
* Now that a suitable new parent for the children is found,
* each child needs to be located and reparented to reaper.
*/
list_for_each_entry_safe(p, n, &father->children, sibling) {
struct task_struct *t = p;
do {
t->real_parent = reaper;
if (t->parent == father) {
BUG_ON(t->ptrace);
t->parent = t->real_parent;
}
if (t->pdeath_signal)
group_send_sig_info(t->pdeath_signal, SEND_SIG_NOINFO, t);
} while_each_thread(p, t);
reparent_leader(father, p, &dead_children);
}
write_unlock_irq(&tasklist_lock);
BUG_ON(!list_empty(&father->children));
list_for_each_entry_safe(p, n, &dead_children, sibling) {
list_del_init(&p->sibling);
release_task(p); // 参见[7.3.3.1.2 release_task()]节
}
}
7.3.3.1.2 release_task()
该函数定义于kernel/exit.c:
void release_task(struct task_struct * p)
{
struct task_struct *leader;
int zap_leader;
repeat:
/* don't need to get the RCU readlock here - the process is dead and
* can't be modifying its own credentials. But shut RCU-lockdep up */
rcu_read_lock();
atomic_dec(&__task_cred(p)->user->processes);
rcu_read_unlock();
proc_flush_task(p);
write_lock_irq(&tasklist_lock);
ptrace_release_task(p);
/*
* Cancel any pending signal and to release the signal_struct
* descriptor of the process. Remove the process from the
* pidhash and remove the process from the task list; Releases
* any remaining resources used by the now dead process and
* finalizes statistics and bookkeeping.
*/
__exit_signal(p);
/*
* If we are the last non-leader member of the thread
* group, and the leader is zombie, then notify the
* group leader's parent process. (if it wants notification.)
*/
zap_leader = 0;
leader = p->group_leader;
if (leader != p && thread_group_empty(leader) && leader->exit_state == EXIT_ZOMBIE) {
/*
* If we were the last child thread and the leader has
* exited already, and the leader's parent ignores SIGCHLD,
* then we are the one who should release the leader.
*/
zap_leader = do_notify_parent(leader, leader->exit_signal);
if (zap_leader)
leader->exit_state = EXIT_DEAD;
}
write_unlock_irq(&tasklist_lock);
release_thread(p);
/*
* Call put_task_struct() to free the pages containing
* the process’s kernel stack and thread_info structure
* and deallocate the slab cache containing the task_struct.
* At this point, the process descriptor and all resources
* belonging solely to the process have been freed.
*/
call_rcu(&p->rcu, delayed_put_task_struct);
p = leader;
if (unlikely(zap_leader))
goto repeat;
}
7.4 进程调度
7.4.1 进程调度的初始化
系统启动时的进程调度初始化,参见4.3.4.1.4.3.7 sched_init()节。
7.4.2 与进程调度有关的数据结构
7.4.2.1 运行队列结构/struct rq
该结构定义于kernel/sched.c:
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
// Number of runnable processes in the runqueue lists
unsigned long nr_running;
/*
* CPU load factor based on the average number of processes
* in the runqueue.
* 在每次触发scheduler_tick()时(参见[7.4.6 scheduler_tick()]节),会调用函数
* update_cpu_load()更新cpu_load数组; 在系统初始化时,sched_init()
* 把rq的cpu_load数组初始化为0;可以通过函数update_cpu_load()更新
* cpu_load数组,公式如下:
* cpu_load[0]直接等于rq中load.weight的值
* cpu_load[1]=(cpu_load[1]*(2-1)+cpu_load[0])/2
* cpu_load[2]=(cpu_load[2]*(4-1)+cpu_load[0])/4
* cpu_load[3]=(cpu_load[3]*(8-1)+cpu_load[0])/8
* cpu_load[4]=(cpu_load[4]*(16-1)+cpu_load[0]/16
* this_cpu_load()的返回值是cpu_load[0]。
* 在进行cpu blance或migration时,调用source_load()、target_load()
* 取得对该处理器cpu_load数组的index值,来进行计算。
*/
#define CPU_LOAD_IDX_MAX 5
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
unsigned long last_load_update_tick;
#ifdef CONFIG_NO_HZ
u64 nohz_stamp;
unsigned char nohz_balance_kick;
#endif
int skip_clock_update;
/* capture load from *all* tasks on this cpu: */
struct load_weight load;
/*
* scheduler_tick()每次调用update_cpu_load()时,
* 该值加1,用来反映当前cpu_load的更新次数
*/
unsigned long nr_load_updates;
/*
* Number of process switches performed by the CPU.
* 在调用schedule()时累加。可通过nr_context_switches()
* 统计目前所有处理器总共的context switch次数,或着通过查
* 看文件/proc/stat中的ctxt位得知目前整个系统触发context
* switch的次数
*/
u64 nr_switches;
/*
* 完全公平调度CFS运行队列。其初始化过程参见start_kernel()
* -> sched_init() -> init_cfs_rq()
* 参见[7.4.2.1.1 完全公平调度(CFS)运行队列结构/struct cfs_rq]节
*/
struct cfs_rq cfs;
/*
* 实时任务运行队列。其初始化过程参见start_kernel()
* -> sched_init() -> init_rt_rq()
* 参见[7.4.2.1.2 实时调度运行队列结构/struct rt_rq]节
*/
struct rt_rq rt;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* list of leaf cfs_rq on this cpu: */
struct list_head leaf_cfs_rq_list;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct list_head leaf_rt_rq_list;
#endif
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
/*
* Number of processes that were previously in the runqueue
* lists and are now sleeping in TASK_UNINTERRUPTIBLE state
* (only the sum of these fields across all runqueues is
* meaningful)
*/
unsigned long nr_uninterruptible;
/*
* curr:指向本CPU上的当前运行进程的进程描述符,即current。schedule()
* -> __schedule() –> rq->curr = next;
* idle:指向本CPU上的idle进程;start_kernel() -> sched_init()
* -> init_idle(),参见[4.3.4.1.4.3.7 sched_init()]节
* stop:指向本CPU上的stop进程;cpu_stop_init() -> cpu_stop_cpu_callback()
* -> sched_set_stop_task()
*/
struct task_struct *curr, *idle, *stop;
// 基于处理器的jiffies值,用以记录下次进行cpu balancing的时间点
unsigned long next_balance;
/*
* Used during a process switch to store the address of the
* memory descriptor of the process being replaced
*/
struct mm_struct *prev_mm;
u64 clock; // 当前CPU的时钟值
u64 clock_task;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct root_domain *rd;
struct sched_domain *sd;
unsigned long cpu_power;
unsigned char idle_balance;
/* For active balancing */
int post_schedule;
int active_balance;
int push_cpu;
struct cpu_stop_work active_balance_work;
/* cpu of this runqueue: */
int cpu;
int online;
u64 rt_avg;
u64 age_stamp;
u64 idle_stamp;
u64 avg_idle;
#endif
#ifdef CONFIG_IRQ_TIME_ACCOUNTING
u64 prev_irq_time;
#endif
#ifdef CONFIG_PARAVIRT
u64 prev_steal_time;
#endif
#ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING
u64 prev_steal_time_rq;
#endif
/* calc_load related fields */
unsigned long calc_load_update;
long calc_load_active;
#ifdef CONFIG_SCHED_HRTICK
#ifdef CONFIG_SMP
int hrtick_csd_pending;
struct call_single_data hrtick_csd;
#endif
struct hrtimer hrtick_timer;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
unsigned long long rq_cpu_time;
/* could above be rq->cfs_rq.exec_clock + rq->rt_rq.rt_runtime ? */
/* sys_sched_yield() stats */
unsigned int yld_count;
/* schedule() stats */
unsigned int sched_switch;
unsigned int sched_count;
unsigned int sched_goidle;
/* try_to_wake_up() stats */
unsigned int ttwu_count;
unsigned int ttwu_local;
#endif
#ifdef CONFIG_SMP
struct llist_head wake_list;
#endif
};
7.4.2.1.1 完全公平调度(CFS)运行队列结构/struct cfs_rq
该结构定义于kernel/sched.c:
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load; // 运行负载
unsigned long nr_running, h_nr_running;
u64 exec_clock;
u64 min_vruntime; // 最小运行时间
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
// CFS运行队列红黑树的根节点
struct rb_root tasks_timeline;
/*
* 保存红黑树最左侧的节点,该节点是最小运行时间的节点。
* 当选择下一个进程来运行时,就可以直接选择该节点
*/
struct rb_node *rb_leftmost;
struct list_head tasks;
struct list_head *balance_iterator;
/*
* 'curr' points to currently running entity on this cfs_rq.
* It is set to NULL otherwise (i.e when none are currently running).
*/
struct sched_entity *curr, *next, *last, *skip;
#ifdef CONFIG_SCHED_DEBUG
unsigned int nr_spread_over;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /* cpu runqueue to which this cfs_rq is attached */
/*
* leaf cfs_rqs are those that hold tasks (lowest schedulable entity in
* a hierarchy). Non-leaf lrqs hold other higher schedulable entities
* (like users, containers etc.)
*
* leaf_cfs_rq_list ties together list of leaf cfs_rq's in a cpu. This
* list is used during load balance.
*/
int on_list;
struct list_head leaf_cfs_rq_list;
struct task_group *tg; /* group that "owns" this runqueue */
#ifdef CONFIG_SMP
/*
* the part of load.weight contributed by tasks
*/
unsigned long task_weight;
/*
* h_load = weight * f(tg)
*
* Where f(tg) is the recursive weight fraction assigned to
* this group.
*/
unsigned long h_load;
/*
* Maintaining per-cpu shares distribution for group scheduling
*
* load_stamp is the last time we updated the load average
* load_last is the last time we updated the load average and saw load
* load_unacc_exec_time is currently unaccounted execution time
*/
u64 load_avg;
u64 load_period;
u64 load_stamp, load_last, load_unacc_exec_time;
unsigned long load_contribution;
#endif
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_timestamp;
int throttled, throttle_count;
struct list_head throttled_list;
#endif
#endif
};
CFS运行队列的红黑树结构如下:
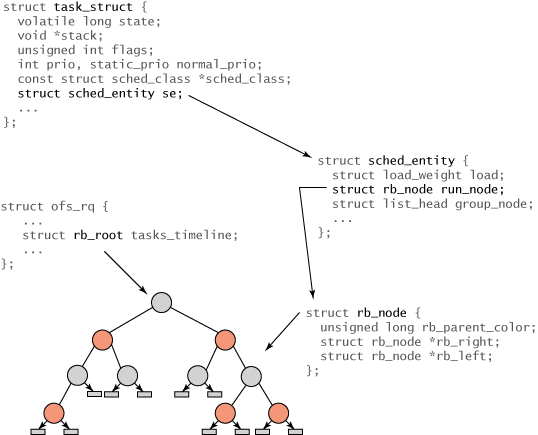
7.4.2.1.2 实时调度运行队列结构/struct rt_rq
7.4.2.2 运行队列变量/runqueues
每个CPU有且只有一个运行队列runqueues,该变量定义与kernel/sched.c:
static DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
若未定义CONFIG_SMP,则该定义被扩展为:
__typeof__(struct rq) runqueues;
若定义了CONFIG_SMP,则该定义被扩展为:
__percpu __attribute__((section(".data..percpu" "..shared_aligned"))) __typeof__(struct rq) runqueues __attribute__((__aligned__(32)));
如下宏用来操纵runqueues变量:
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu))) // 获取指定CPU上的运行队列
#define this_rq() (&__get_cpu_var(runqueues)) // 获取本CPU上的运行队列,与raw_rq()相同
#define task_rq(p) cpu_rq(task_cpu(p)) // 获取指定进程描述符p所在的运行队列
#define cpu_curr(cpu) (cpu_rq(cpu)->curr) // 获取指定CPU上正在运行进程的进程描述符
#define raw_rq() (&__raw_get_cpu_var(runqueues)) // 获取本CPU上的运行队列,与this_rq()相同
7.4.2.3 增加/删除运行队列中的进程描述符
在执行fork()时,将新创建的进程描述符增加到运行队列中,参见[7.2.2.3.1 activate_task()]节。
在执行schedule()时,将指定的进程描述符从运行队列中删除,参见[7.4.5.2.1 deactivate_task()]节。
7.4.2.4 等待队列/wait_queue_head_t/wait_queue_t
wait_queue_head_t为等待队列头,其定义于include/linux/wait.h:
struct __wait_queue_head {
spinlock_t lock; // 等待队列的自旋锁锁
struct list_head task_list; // 将等待队列连接成双向循环链表
};
typedef struct __wait_queue_head wait_queue_head_t;
wait_queue_t为等待队列,其定义于include/linux/wait.h:
typedef struct __wait_queue wait_queue_t;
struct __wait_queue {
/*
* A process waiting for a resource that can be granted to
* just one process at a time is a typical exclusive process.
* Processes waiting for an event that may concern any of
* them are nonexclusive process. 而flags表示进程是否为互斥进程,
* 取值为1 (WQ_FLAG_EXCLUSIVE)或0:
* 1: exclusive processes, are selectively woken up by the kernel;
* 0: nonexclusive processes, are always woken up by the kernel
* when an event occurs.
*/
unsigned int flags;
#define WQ_FLAG_EXCLUSIVE 0x01
void *private; // 指向struct task_struct对象的指针
wait_queue_func_t func; // 该进程的唤醒函数
struct list_head task_list; // 用于将该进程链接成双向循环链表
};
等待队列:
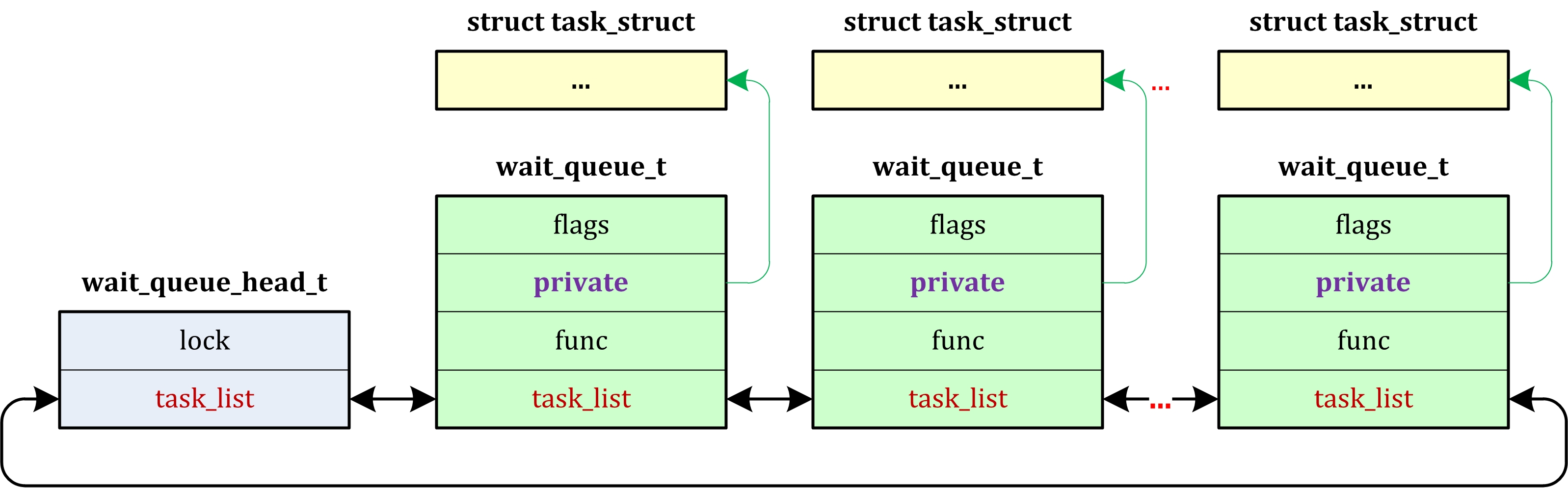
7.4.2.4.1 定义/初始化等待队列头/wait_queue_head_t
通过如下宏或函数定义初始化等待队列头,参见include/linux/wait.h:
#define DECLARE_WAIT_QUEUE_HEAD(name) \
wait_queue_head_t name = __WAIT_QUEUE_HEAD_INITIALIZER(name)
#define __WAIT_QUEUE_HEAD_INITIALIZER(name) { \
.lock = __SPIN_LOCK_UNLOCKED(name.lock), \
.task_list = { &(name).task_list, &(name).task_list } }
#define init_waitqueue_head(q) \
do { \
static struct lock_class_key __key; \
__init_waitqueue_head((q), &__key); \
} while (0)
#ifdef CONFIG_LOCKDEP
# define __WAIT_QUEUE_HEAD_INIT_ONSTACK(name) \
({ init_waitqueue_head(&name); name; })
# define DECLARE_WAIT_QUEUE_HEAD_ONSTACK(name) \
wait_queue_head_t name = __WAIT_QUEUE_HEAD_INIT_ONSTACK(name)
#else
# define DECLARE_WAIT_QUEUE_HEAD_ONSTACK(name) DECLARE_WAIT_QUEUE_HEAD(name)
#endif
// 判断等待队列是否为空
static inline int waitqueue_active(wait_queue_head_t *q)
{
return !list_empty(&q->task_list);
}
A wait queue head can be defined and initialized statically with:
DECLARE_WAIT_QUEUE_HEAD(name);
or dynamically as follows:
wait_queue_head_t my_queue;
init_waitqueue_head(&my_queue);
7.4.2.4.2 定义/初始化等待队列/wait_queue_t
通过如下宏或函数定义初始化等待队列,参见include/linux/wait.h:
#define DECLARE_WAITQUEUE(name, tsk) \
wait_queue_t name = __WAITQUEUE_INITIALIZER(name, tsk)
#define __WAITQUEUE_INITIALIZER(name, tsk) { \
.private = tsk, \
.func = default_wake_function, \ // 参见[7.4.10.2.2 default_wake_function()]节
.task_list = { NULL, NULL } }
#define DEFINE_WAIT(name) \
DEFINE_WAIT_FUNC(name, autoremove_wake_function) // 参见[7.4.10.2.1 autoremove_wake_function()]节
#define DEFINE_WAIT_FUNC(name, function) \
wait_queue_t name = { \
.private = current, \
.func = function, \
.task_list = LIST_HEAD_INIT((name).task_list), \
}
#define init_wait(wait) \
do { \
(wait)->private = current; \
(wait)->func = autoremove_wake_function; \ // 参见[7.4.10.2.1 autoremove_wake_function()]节
INIT_LIST_HEAD(&(wait)->task_list); \
(wait)->flags = 0; \
} while (0)
static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p)
{
q->flags = 0;
q->private = p;
q->func = default_wake_function; // 参见[7.4.10.2.2 default_wake_function()]节
}
static inline void init_waitqueue_func_entry(wait_queue_t *q, wait_queue_func_t func)
{
q->flags = 0;
q->private = NULL;
q->func = func;
}
7.4.3 进程的调度策略/policy
struct task_struct中的policy域表示进程的调度策略。include/linux/sched.h中定义了如下五种调度策略:
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
/* Can be ORed in to make sure the process is reverted back to SCHED_NORMAL on fork */
#define SCHED_RESET_ON_FORK 0x40000000
7.4.3.1 实时进程的调度
对于实时进程,Linux采用了如下两种调度策略:
SCHED_FIFO
A First-In, First-Out real-time process. When the scheduler assigns the CPU to the process, it leaves the process descriptor in its current position in the runqueue list. If no other higher-priority real-time process is runnable, the process continues to use the CPU as long as it wishes, even if other real-time processes that have the same priority are runnable.
SCHED_RR
A Round Robin real-time process. When the scheduler assigns the CPU to the process, it puts the process descriptor at the end of the runqueue list. This policy ensures a fair assignment of CPU time to all SCHED_RR real-time processes that have the same priority.
struct task_struct中与实时进程的调度有关的域包括:
unsigned int rt_priority;
其取值范围为[0, MAX_RT_PRIO),即[0, 100),参见7.1.1.8.1 进程优先级节。
The scheduler always favors a higher priority runnable process over a lower priority one; in other words, a real-time process inhibits the execution of every lower-priority process while it remains runnable.
7.4.3.2 普通进程的调度
对于普通进程,Linux采用了如下三种调度策略:
SCHED_NORMAL
A conventional, time-shared process. 通过CFS调度器(Completely Fair Scheduler,完全公平调度)实现,这是默认的调度策略。
SCHED_BATCH
除了不能抢占外与常规任务一样,允许任务运行更长时间,更好地使用高速缓存,适合于非交互的批处理任务。
SCHED_IDLE
在系统负载很低时使用。
struct task_struct中与实时进程的调度有关的域包括:
int prio, static_prio, normal_prio;
其中,prio为动态优先级,static_prio为静态优先级。这二者的取值范围均为[MAX_RT_PRIO, MAX_RT_PRIO),即[100, 140),参见7.1.1.8.1 进程优先级节。
参见«Understanding the Linux Kernel, 3rd Edition»第7. Process Scheduling章第Scheduling of Conventional Processes节。
7.4.3.3 更改进程调度策略的命令
可以使用命令chrt来更改进程的调度策略:
chenwx@chenwx ~/linux $ chrt --help
Show or change the real-time scheduling attributes of a process.
Set policy:
chrt [options] <priority> <command> [<arg>...]
chrt [options] -p <priority> <pid>
Get policy:
chrt [options] -p <pid>
Policy options:
-b, --batch set policy to SCHED_BATCH
-f, --fifo set policy to SCHED_FIFO
-i, --idle set policy to SCHED_IDLE
-o, --other set policy to SCHED_OTHER
-r, --rr set policy to SCHED_RR (default)
Scheduling flag:
-R, --reset-on-fork set SCHED_RESET_ON_FORK for FIFO or RR
Other options:
-a, --all-tasks operate on all the tasks (threads) for a given pid
-m, --max show min and max valid priorities
-p, --pid operate on existing given pid
-v, --verbose display status information
-h, --help display this help and exit
-V, --version output version information and exit
For more details see chrt(1).
chenwx@chenwx ~/linux $ chrt -m
SCHED_OTHER min/max priority : 0/0
SCHED_FIFO min/max priority : 1/99
SCHED_RR min/max priority : 1/99
SCHED_BATCH min/max priority : 0/0
SCHED_IDLE min/max priority : 0/0
chenwx@chenwx ~/linux $ gedit &
[2] 6152
[1] Done gedit
chenwx@chenwx ~/linux $ chrt -p 6152
pid 6152's current scheduling policy: SCHED_OTHER
pid 6152's current scheduling priority: 0
chenwx@chenwx ~/linux $ sudo chrt -p -r 99 6152
chenwx@chenwx ~/linux $ chrt -p 6152
pid 6152's current scheduling policy: SCHED_RR
pid 6152's current scheduling priority: 99
7.4.3.4 RT Throttling
参见文档:
- «Linux内核精髓:精通Linux内核必会的75个绝技 / LINUX KERNEL HACKS»
- HACK #9: RT Group Scheduling与RT Throttling
- HACK #10: Fair Group Scheduling
- Documentation/scheduler/sched-rt-group.txt
RT Throttling是对分配给实时进程的CPU时间进行限制的功能。使用实时调度策略的进程由于bug等出现不可控错误时,完全不调度其他进程,系统就会无响应。通过限制分配给实时进程的每个单位时间的CPU时间,就可以防止因使用实时调度策略的进程出现bug而系统无相应。Linux kernel 2.6.25后的版本可以使用该功能。
分配给实时进程的CPU时间可使用sysctl来获取、设置:
// 默认设置:单位时间为1秒
chenwx@chenwx ~/linux $ sysctl -n kernel.sched_rt_period_us
1000000
chenwx@chenwx ~/linux $ cat /proc/sys/kernel/sched_rt_period_us
1000000
/*
* 默认设置:单位时间内,为实时进程分配的CPU时间为0.95秒,
* 为非实时进程分配的CPU时间为0.05秒
*/
chenwx@chenwx ~/linux $ sysctl -n kernel.sched_rt_runtime_us
950000
chenwx@chenwx ~/linux $ cat /proc/sys/kernel/sched_rt_runtime_us
950000
/*
* 更改设置:单位时间内,为实时进程分配的CPU时间改为0.9秒,
* 为非实时进程分配的CPU时间为0.1秒
*/
chenwx@chenwx ~/linux $ sudo sysctl -w kernel.sched_rt_runtime_us=900000
[sudo] password for chenwx:
kernel.sched_rt_runtime_us = 900000
chenwx@chenwx ~/linux $ sysctl -n kernel.sched_rt_runtime_us
900000
chenwx@chenwx ~/linux $ cat /proc/sys/kernel/sched_rt_runtime_us
900000
/*
* 如果将为实时进程分配的CPU时间设置为-1,则会取消对实时进程分配CPU时间的限制.
* => 这种情况下,若某实时进程进入死循环,则系统将会无响应!
*/
chenwx@chenwx ~/linux $ sysctl -w kernel.sched_rt_runtime_us=-1
kernel.sched_rt_runtime_us = -1
chenwx@chenwx ~/linux $ sysctl -n kernel.sched_rt_runtime_us
-1
chenwx@chenwx ~/linux $ cat /proc/sys/kernel/sched_rt_runtime_us
-1
7.4.4 进程的调度类/struct sched_class
该结构体表示调度类,是对调度器操作的面向对象抽象,协助内核调度程序的各种工作。调度类是调度器的核心,每种调度算法模块需要实现该结构体建议的一组函数。其定义于include/linux/sched.h:
struct sched_class {
// 指向下一个调度类。各调度类的链接关系参见[7.4.5.2.2 pick_next_task()]节
const struct sched_class *next;
/*
* 将进程描述符p加入运行队列,p已就绪。会被static void enqueue_task(...)
* 调用,参见kernel/sched.c
*/
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
/*
* 将进程描述符p移出运行队列,p被阻塞或睡眠。会被static void dequeue_task(...)
* 调用,参见kernel/sched.c
*/
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
/*
* 任务放弃CPU。对于rt任务,会重新入队列触发调度,cfs任务会把任务放到rb tree
* 的最右端,然后挑选最左边的任务运行。会被系统调用sys_sched_yield()调用
*/
void (*yield_task) (struct rq *rq);
/*
* Yield the current processor to another thread in your thread group, or
* accelerate that thread toward the processor it's on. 会被yield_to()调用
*/
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
// 检查p是否可抢占当前运行任务。会被static void check_preempt_curr()调用
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
/*
* 挑选下一个可运行任务。会被调用
* static inline struct task_struct *pick_next_task(struct rq *rq)
*/
struct task_struct * (*pick_next_task) (struct rq *rq);
// 处理上一次运行的任务p
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP
// 选择任务的运行队列,实际就是挑选合适的CPU运行任务
int (*select_task_rq)(struct task_struct *p, int sd_flag, int flags);
/*
* 调度前的处理,rt实现:如果本队列之前运行的任务为最高优先级,
* 说明本队列没有高优先级任务抢占当前运行任务,则其他队列有可能存在
* 比本队列的任务高的rt任务,尝试pull过来
*/
void (*pre_schedule) (struct rq *this_rq, struct task_struct *task);
// 调度完成后的处理。rt实现,把就绪任务放入push队列
void (*post_schedule) (struct rq *this_rq);
// 正在唤醒,准备唤醒任务时的处理。cfs实现,修改任务的vruntime
void (*task_waking) (struct task_struct *task);
// 唤醒任务后的处理。rt实现,如果没有置调度标志且任务可push,则尝试push到其他CPU上
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
/*
* 设置任务的CPU亲和性在本调度类下特殊实现。
* 用户接口、迁移时使用,rt实现,由set_cpus_allowed_ptr调用,
* dequeue/enqueue可push队列
*/
void (*set_cpus_allowed)(struct task_struct *p, const struct cpumask *newmask);
// 任务队列状态active
void (*rq_online)(struct rq *rq);
// 任务队列状态inactive
void (*rq_offline)(struct rq *rq);
#endif
// 设置当前的运行任务,当任务被调度运行时
void (*set_curr_task) (struct rq *rq);
// 时间中断处理,更新任务运行时间,检查时间片是否已到。由scheduler_tick()调用
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
// 任务p被创建时的处理,CFS有实现,把p放入队列的合适位置
void (*task_fork) (struct task_struct *p);
/*
* 任务切换出当前调度算法,当前调度算法需要做的动作。例如:rt任务切换成非实时任务,
* 则rt class需要判断当前队列是否还有实时任务,若没有需要从其他队列pull任务过来
*/
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
// 任务切换到当前调度算法
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
// 任务更改优先级的处理
void (*prio_changed) (struct rq *this_rq, struct task_struct *task, int oldprio);
// 获取任务时间片
unsigned int (*get_rr_interval) (struct rq *rq, struct task_struct *task);
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_move_group) (struct task_struct *p, int on_rq);
#endif
};
目前内核中实现了以下四种调度类:
/*
* kernel/sched_stoptask.c
* 属于这个调度类的任务具有最高调度优先级,可以抢占其他任何任务,
* 目前只有迁移任务属于这个调度类
*/
static const struct sched_class stop_sched_class = {
...
};
// kernel/sched_rt.c
static const struct sched_class rt_sched_class = {
...
};
// kernel/sched_fair.c
static const struct sched_class fair_sched_class = {
...
};
// kernel/sched_idletask.c
static const struct sched_class idle_sched_class = {
...
};
7.4.4.1 实时调度类/rt_sched_class
7.4.4.2 完全公平调度类/fair_sched_class
对于CFS调度类,它的运行队列是cfs_rq,其内部使用红黑树组织调度实体。对于RT调度类,它的运行队列是rt_rq,其内部使用优先级bitmap+双向链表组织调度实体。与调度类相关的几个数据结构的关系:
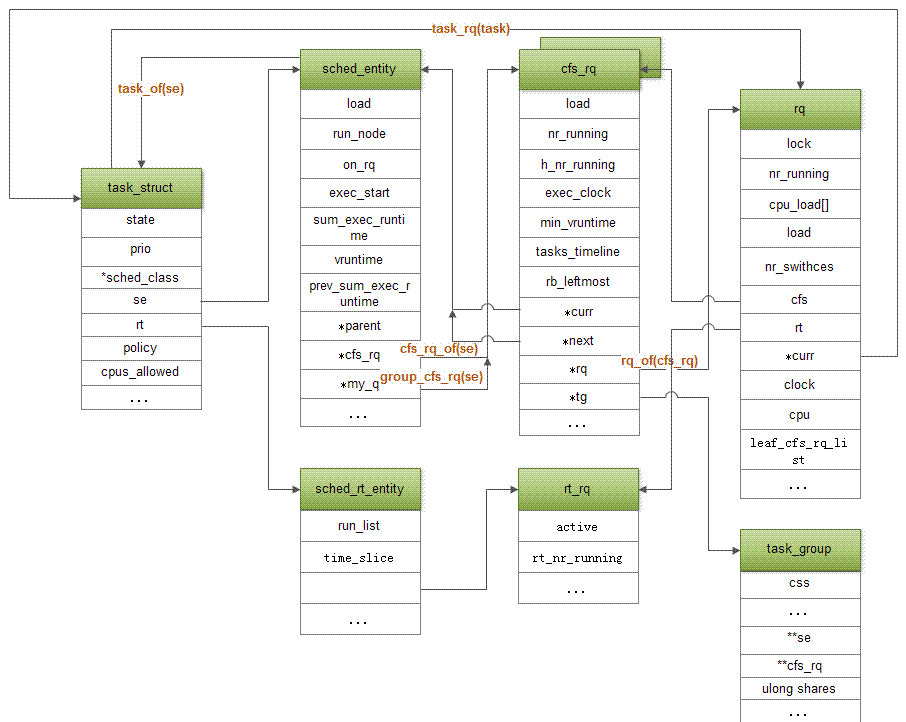
7.4.5 schedule()
该函数定义于kernel/sched.c:
asmlinkage void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk); // 参见[7.4.5.1 sched_submit_work()]节
__schedule(); // 参见[7.4.5.2 __schedule()]节
}
7.4.5.1 sched_submit_work()
该函数定义于kernel/sched.c:
static inline void sched_submit_work(struct task_struct *tsk)
{
// tsk->state: -1 unrunnable, 0 runnable, >0 stopped
if (!tsk->state)
return;
/*
* If we are going to sleep and we have plugged IO queued,
* make sure to submit it to avoid deadlocks.
*/
if (blk_needs_flush_plug(tsk))
blk_schedule_flush_plug(tsk);
}
7.4.5.2 __schedule()
该函数定义于kernel/sched.c:
/*
* __schedule() is the main scheduler function.
*/
/*
* __sched定义于include/linux/sched.h:
* #define __sched __attribute__((__section__(".sched.text")))
*/
static void __sched __schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
need_resched:
preempt_disable(); // 参见[16.10.2 preempt_disable()]节
cpu = smp_processor_id(); // 获得当前CPU的标示符
rq = cpu_rq(cpu); // 获得当前CPU的变量runqueues,参见[7.4.2.2 运行队列变量/runqueues]节
rcu_note_context_switch(cpu);
prev = rq->curr; // prev用于保存当前进程的进程描述符
schedule_debug(prev);
/*
* 被扩展为sysctl_sched_features & (1UL << __SCHED_FEAT_HRTICK)
* 用于判断变量sysctl_sched_features中的标志位__SCHED_FEAT_HRTICK
* 是否置位,参见kernel/sched_features.h
* 若置位,则调用hrtick_clear()->hrtimer_cancel()取消rq->hrtick_timer
* 定时器,参见[7.8.3.3 取消定时器/hrtimer_cancel()]节
*/
if (sched_feat(HRTICK))
hrtick_clear(rq);
raw_spin_lock_irq(&rq->lock);
// 非自愿的上下文切换计数,参见[7.1.1.11 时间]节
switch_count = &prev->nivcsw;
/*
* 若当前进程不在运行状态,内核态没有被抢占,且内核抢占有效,
* 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
*/
// state: -1 unrunnable, 0 runnable, >0 stopped
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
/*
* 若当前进程状态为TASK_INTERRUPTIBLE / TASK_WAKEKILL,
* 或存在信号SIGKILL,则将当前进程状态设为TASK_RUNNING;
*/
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
/*
* 否则,将当前进程从runqueues中删除:
* 通过调用属于自己调度类的dequeue_task()方法,
* 参见[7.4.5.2.1 deactivate_task()]节
*/
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0; // 标识当前进程不在runqueues中
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw; // 自愿的上下文切换计数
}
// 调用对应调度类的pre_schedule()函数
pre_schedule(rq, prev);
// 若runqueues上进程数为0,则从其他CPU上调度进程,进行负载均衡
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
/*
* 通过调用当前进程所属调度类的put_prev_task(),将当前进程放入运行
* 队列的合适位置。对于CFS而言,将当前进程插入到cfs_rq红黑树的合适位置;
*/
put_prev_task(rq, prev);
// 从runqueues中选择最适合的进程,并保存到next中。参见[7.4.5.2.2 pick_next_task()]节
next = pick_next_task(rq);
clear_tsk_need_resched(prev); // 清除当前进程的重调度标识
rq->skip_clock_update = 0;
// 检查当前进程(prev)与所选进程(next)是否是同一进程,不属于同一进程才需要切换
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next; // 用所选进程代替当前进程
++*switch_count; // 增加非自愿上下文切换计数,或者自愿上下文却换计数
// 切换进程上下文,参见[7.4.5.2.3 context_switch()]节
context_switch(rq, prev, next); /* unlocks the rq */
/*
* The context switch have flipped the stack from under us
* and restored the local variables which were saved when
* this task called schedule() in the past. prev == current
* is still correct, but it can be moved to another cpu/rq.
*/
cpu = smp_processor_id(); // 获取新CPU的标识符
rq = cpu_rq(cpu); // 获取新CPU的runqueues变量
} else
raw_spin_unlock_irq(&rq->lock); // 若不需要切换进程,则只需要解锁
// 调用对应调度类的post_schedule()
post_schedule(rq);
// 参见[16.10.3 preempt_enable()/preempt_enable_no_resched()]节
preempt_enable_no_resched();
/*
* 测试current->stack->flags中的标志位TIF_NEED_RESCHED
* 是否被置位,若被置位,则重新调度其他进程运行;
* The flag is a message to the kernel that the scheduler
* should be invoked as soon as possible because another
* process deserves to run.
*/
if (need_resched())
goto need_resched;
}
1) 内核抢占概念
当进程位于内核空间,有更高优先级的任务出现时,如果该内核支持抢占的话,则挂起当前任务,执行更高优先级的任务。
2) 用户抢占的概念
内核即将返回用户空间时,如果need_resched标志被设置,会导致schedule()被调用,此时就会发生用户抢占。内核无论是在从中断处理程序还是在系统调用后返回,都会检查need_resched标志。如果它被设置了,那么内核会选择一个其他(更合适的)进程投入运行。
3) 内核抢占好处
这是实时系统所要求的。如果硬件中断开启了一个实时进程,如果内核不支持抢占的话,被开启的实时进程就要等到当前进程执行完毕才能被调度,这就带来了延时,实时性不好。如果内核支持抢占的话,就可以将当前进程挂起,来执行实时进程,这样实时性好。
4) 什么情况下不能抢占内核
- 内核正进行中断处理;
- 内核正在进行中断上下文的Bottom Half(中断的底半部)处理;
- 内核的代码段正持有spinlock自旋锁、writelock/readlock读写锁等锁,处于这些锁的保护状态中;
- 内核正在执行调度程序scheduler,这种情况正对应schedule()函数;
- 内核正在对每个CPU“私有”的数据结构操作。
7.4.5.2.1 deactivate_task()
该函数定义于kernel/sched.c:
/*
* deactivate_task - remove a task from the runqueue.
*/
static void deactivate_task(struct rq *rq, struct task_struct *p, int flags)
{
if (task_contributes_to_load(p))
rq->nr_uninterruptible++;
dequeue_task(rq, p, flags);
}
static void dequeue_task(struct rq *rq, struct task_struct *p, int flags)
{
update_rq_clock(rq);
sched_info_dequeued(p);
p->sched_class->dequeue_task(rq, p, flags);
}
7.4.5.2.2 pick_next_task()
该函数定义于kernel/sched.c:
#define sched_class_highest (&stop_sched_class)
#define for_each_class(class) \
for (class = sched_class_highest; class; class = class->next)
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *pick_next_task(struct rq *rq)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
/*
* 若该运行队列中的进程数与公平调度队列中的进程数相同,则表示
* 没有实时进程,故可以在公平调度队列中选择下一个可运行进程。
*/
if (likely(rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
/*
* 否则,依次调用如下调度类的pick_next_task(),直到选择出下
* 一个可运行进程。stop_sched_class -> rt_sched_class
* -> fair_sched_class -> idle_sched_class。在调度过程中,
* p永远不会返回NULL,因为至少存在idle进程的进程描述符;
* idle进程的进程描述符是由idle_sched_class返回,idle进程的
* 进程描述符的初始化参见[4.3.4.1.4.3.7 sched_init()]节
*/
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
BUG(); /* the idle class will always have a runnable task */
}
7.4.5.2.3 context_switch()
该函数定义于kernel/sched.c:
/*
* context_switch - switch to the new MM and the new
* thread's register state.
*/
static inline void context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
/*
* Switch the virtual memory mapping from the previous
* process’s to that of the new process. 参见[7.4.5.2.3.1 switch_mm()]节
*/
switch_mm(oldmm, mm, next);
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
#ifndef __ARCH_WANT_UNLOCKED_CTXSW
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
#endif
/* Here we just switch the register state and the stack. */
/*
* Switch the processor state from the previous process’s
* to the current’s. This involves saving and restoring
* stack information and the processor registers and any
* other architecture-specific state that must be managed
* and restored on a per-process basis. 参见[7.4.5.2.3.2 switch_to()]节
*/
switch_to(prev, next, prev);
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the 'rq' on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
}
7.4.5.2.3.1 switch_mm()
该函数定义于arch/x86/include/asm/mm_context.h:
static inline void switch_mm(struct mm_struct *prev, struct mm_struct *next, struct task_struct *tsk)
{
unsigned cpu = smp_processor_id();
if (likely(prev != next)) {
#ifdef CONFIG_SMP
percpu_write(cpu_tlbstate.state, TLBSTATE_OK);
percpu_write(cpu_tlbstate.active_mm, next);
#endif
cpumask_set_cpu(cpu, mm_cpumask(next));
/* Re-load page tables */
/*
* 重新加载页表,即修改CR3寄存器的值。参见[6.1.2 分页机制]节
* 切换地址空间发生在切换堆栈(参见[7.4.5.2.3.2 switch_to()]节)之前,
* 不会影响后续代码执行,因为进程的切换发生在内核态,内核
* 态地址空间是共用的。没有修改堆栈指针及其他寄存器的值,
* 即堆栈没有变,栈内值未发生改变。
*/
load_cr3(next->pgd);
/* stop flush ipis for the previous mm */
cpumask_clear_cpu(cpu, mm_cpumask(prev));
/*
* load the LDT, if the LDT is different:
*/
if (unlikely(prev->context.ldt != next->context.ldt))
load_LDT_nolock(&next->context);
}
#ifdef CONFIG_SMP
else {
percpu_write(cpu_tlbstate.state, TLBSTATE_OK);
BUG_ON(percpu_read(cpu_tlbstate.active_mm) != next);
if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next))) {
/* We were in lazy tlb mode and leave_mm disabled
* tlb flush IPI delivery. We must reload CR3
* to make sure to use no freed page tables.
*/
load_cr3(next->pgd);
load_LDT_nolock(&next->context);
}
}
#endif
}
7.4.5.2.3.2 switch_to()
该宏定义于arch/x86/include/asm/system.h:
/*
* Saving eflags is important. It switches not only IOPL between tasks,
* it also protects other tasks from NT leaking through sysenter etc.
*/
/*
* prev and next are input parameters that specify the memory locations
* containing the descriptor address of the process being replaced and
* the descriptor address of the new process, respectively.
* last is an output parameter that specifies a memory location in which
* the macro writes the descriptor address of process C (of course, this
* is done after A resumes its execution).
*/
#define switch_to(prev, next, last) \
do { \
/* \
* Context-switching clobbers all registers, so we clobber \
* them explicitly, via unused output variables. \
* (EAX and EBP is not listed because EBP is saved/restored \
* explicitly for wchan access and EAX is the return value of \
* __switch_to()) \
*/ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \ // NOTE 1
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \ // NOTE 2
"pushl %[next_ip]\n\t" /* restore EIP */ \
__switch_canary \
"jmp __switch_to\n" /* regparm call */ \ // NOTE 3
"1:\t" \ // NOTE 4
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0)
NOTE 1:
movel %[next_sp],%%esp为修改堆栈指针,使其指向next进程的堆栈。因为在内核态中,栈顶指针减去8K偏移(两页)便可得到thread_info位置,从而在切换后current_thread_info内容为切换后的新进程的thread_info内容。
Loads next->thread.esp in esp. From now on, the kernel operates on the Kernel Mode stack of next, so this instruction performs the actual process switch from prev to next.
NOTE 2:
Saves the address labeled 1 (shown later in NOTE 3) in prev->thread.eip. When the process being replaced resumes its execution, the process executes the instruction labeled as 1.
NOTE 3:
调用arch/x86/kernel/process_32.c或arch/x86/kernel/process_64.c中的函数__switch_to(),参见7.4.5.2.3.2.1 __switch_to()节。
7.4.5.2.3.2.1 __switch_to()
该函数定义于arch/x86/kernel/process_32.c:
__notrace_funcgraph
struct task_struct *__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread,
*next = &next_p->thread;
// get the index of the local CPU, namely the CPU that executes the code.
int cpu = smp_processor_id();
struct tss_struct *tss = &per_cpu(init_tss, cpu);
bool preload_fpu;
/* never put a printk in __switch_to... printk() calls wake_up*() indirectly */
/*
* If the task has used fpu the last 5 timeslices, just do a full
* restore of the math state immediately to avoid the trap; the
* chances of needing FPU soon are obviously high now
*/
preload_fpu = tsk_used_math(next_p) && next_p->fpu_counter > 5;
// optionally save the contents of the FPU, MMX, and XMM registers of the prev_p process.
__unlazy_fpu(prev_p);
/* we're going to use this soon, after a few expensive things */
if (preload_fpu)
prefetch(next->fpu.state);
/*
* Reload esp0.
*/
load_sp0(tss, next);
/*
* Save away %gs. No need to save %fs, as it was saved on the
* stack on entry. No need to save %es and %ds, as those are
* always kernel segments while inside the kernel. Doing this
* before setting the new TLS descriptors avoids the situation
* where we temporarily have non-reloadable segments in %fs
* and %gs. This could be an issue if the NMI handler ever
* used %fs or %gs (it does not today), or if the kernel is
* running inside of a hypervisor layer.
*/
lazy_save_gs(prev->gs);
/*
* Load the per-thread Thread-Local Storage descriptor.
*/
load_TLS(next, cpu);
/*
* Restore IOPL if needed. In normal use, the flags restore
* in the switch assembly will handle this. But if the kernel
* is running virtualized at a non-zero CPL, the popf will
* not restore flags, so it must be done in a separate step.
*/
if (get_kernel_rpl() && unlikely(prev->iopl != next->iopl))
set_iopl_mask(next->iopl);
/*
* Now maybe handle debug registers and/or IO bitmaps
*/
if (unlikely(task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV ||
task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT))
__switch_to_xtra(prev_p, next_p, tss);
/* If we're going to preload the fpu context, make sure clts
is run while we're batching the cpu state updates. */
if (preload_fpu)
clts();
/*
* Leave lazy mode, flushing any hypercalls made here.
* This must be done before restoring TLS segments so
* the GDT and LDT are properly updated, and must be
* done before math_state_restore, so the TS bit is up
* to date.
*/
arch_end_context_switch(next_p);
if (preload_fpu)
__math_state_restore();
/*
* Restore %gs if needed (which is common)
*/
if (prev->gs | next->gs)
lazy_load_gs(next->gs);
percpu_write(current_task, next_p);
return prev_p;
}
7.4.6 scheduler_tick()
该函数定义于kernel/sched.c:
/*
* This function gets called by the timer code, with HZ frequency.
* We call it with interrupts disabled.
*/
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
sched_clock_tick();
raw_spin_lock(&rq->lock);
update_rq_clock(rq);
update_cpu_load_active(rq);
curr->sched_class->task_tick(rq, curr, 0);
raw_spin_unlock(&rq->lock);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq, cpu);
#endif
}
该函数的调用关系如下:
tick_handle_periodic() // 参见[7.6.4.2.1.1 Architecture-dependent routine / tick_handle_periodic()]节
-> tick_periodic()
-> update_process_times()
-> scheduler_tick()
run_timer_softirq() // 参见[7.7.4 定时器的超时处理/run_timer_softirq()]节
-> hrtimer_run_pending()
-> hrtimer_switch_to_hres()
-> tick_setup_sched_timer() // 设置hrtimer定时器,参见[7.8.5.2.1.2 tick_setup_sched_timer()]节
-> tick_sched_timer() // hrtimer定时器超时后调用该函数,参见[7.8.5.2.1.2.1 tick_sched_timer()]节
-> update_process_times()
-> scheduler_tick()
7.4.7 schedule_timeout()
A more optimal method of delaying execution is to use schedule_timeout(). This call puts your task to sleep until at least the specified time has elapsed. There is no guarantee that the sleep duration will be exactly the specified time - only that the duration is at least as long as specified. When the specified time has elapsed, the kernel wakes the task up and places it back on the runqueue.
The schedule_timeout() requires that the caller first set the current process state, so a typical call looks like:
set_current_state(TASK_INTERRUPTIBLE); // set task’s state to interruptible sleep
schedule_timeout(s * HZ); // take a nap and wake up in “s” seconds
or,
set_current_state(TASK_UNINTERRUPTIBLE); // set task’s state to un-interruptible sleep
schedule_timeout(s * HZ); // take a nap and wake up in “s” seconds
NOTE: The task must be in one of these two states before schedule_timeout() is called or else the task will not go to sleep.
该函数定义于kernel/timer.c:
/**
* schedule_timeout - sleep until timeout
* @timeout: timeout value in jiffies
*
* Make the current task sleep until @timeout jiffies have
* elapsed. The routine will return immediately unless
* the current task state has been set (see set_current_state()).
*
* You can set the task state as follows -
*
* %TASK_UNINTERRUPTIBLE - at least @timeout jiffies are guaranteed to
* pass before the routine returns. The routine will return 0
*
* %TASK_INTERRUPTIBLE - the routine may return early if a signal is
* delivered to the current task. In this case the remaining time
* in jiffies will be returned, or 0 if the timer expired in time
*
* The current task state is guaranteed to be TASK_RUNNING when this
* routine returns.
*
* Specifying a @timeout value of %MAX_SCHEDULE_TIMEOUT will schedule
* the CPU away without a bound on the timeout. In this case the return
* value will be %MAX_SCHEDULE_TIMEOUT.
*
* In all cases the return value is guaranteed to be non-negative.
*/
signed long __sched schedule_timeout(signed long timeout)
{
struct timer_list timer;
unsigned long expire;
switch (timeout)
{
case MAX_SCHEDULE_TIMEOUT:
/*
* These two special cases are useful to be comfortable
* in the caller. Nothing more. We could take
* MAX_SCHEDULE_TIMEOUT from one of the negative value
* but I'd like to return a valid offset (>=0) to allow
* the caller to do everything it want with the retval.
*/
schedule(); // 参见[7.4.5 schedule()]节
goto out;
default:
/*
* Another bit of PARANOID. Note that the retval will be
* 0 since no piece of kernel is supposed to do a check
* for a negative retval of schedule_timeout() (since it
* should never happens anyway). You just have the printk()
* that will tell you if something is gone wrong and where.
*/
if (timeout < 0) {
printk(KERN_ERR "schedule_timeout: wrong timeout value %lx\n", timeout);
dump_stack();
current->state = TASK_RUNNING;
goto out;
}
}
expire = timeout + jiffies;
/*
* 设置定时器timer,超时处理函数为process_timeout(),其入参
* 为当前进程的进程描述符current,参见[7.4.7.1 process_timeout()]节
*/
setup_timer_on_stack(&timer, process_timeout, (unsigned long)current);
/* 将定时器参见[7.7.2.1.1.2.2 __mod_timer()]节 */
__mod_timer(&timer, expire, false, TIMER_NOT_PINNED);
/*
* 调度其他进程运行,参见[7.4.5 schedule()]节;调用本函数前,当前进程
* 状态被设置为TASK_INTERRUPTIBLE/TASK_UNINTERRUPTIBLE,
* 故当前进程进入休眠状态,并等待定时器超时;
*/
schedule();
/* 定时器超时后,删除该定时器 */
del_singleshot_timer_sync(&timer);
/* Remove the timer from the object tracker */
destroy_timer_on_stack(&timer);
timeout = expire - jiffies;
out:
/*
* The function either returns 0, if the timeout is expired,
* or the number of ticks left to the time-out expiration if
* the process was awakened for some other reason.
*/
return timeout < 0 ? 0 : timeout;
}
7.4.7.1 process_timeout()
该函数定义于kernel/timer.c:
static void process_timeout(unsigned long __data)
{
// 入参__data为进程描述符,唤醒该进程,参见[7.4.10.2.3 wake_up_process()]节
wake_up_process((struct task_struct *)__data);
}
7.4.7A schedule_timeout_XXX()
该函数定义于kernel/time/timer.c:
/*
* We can use __set_current_state() here because schedule_timeout() calls
* schedule() unconditionally.
*/
signed long __sched schedule_timeout_interruptible(signed long timeout)
{
__set_current_state(TASK_INTERRUPTIBLE);
return schedule_timeout(timeout);
}
signed long __sched schedule_timeout_killable(signed long timeout)
{
__set_current_state(TASK_KILLABLE);
return schedule_timeout(timeout);
}
signed long __sched schedule_timeout_uninterruptible(signed long timeout)
{
__set_current_state(TASK_UNINTERRUPTIBLE);
return schedule_timeout(timeout);
}
7.4.8 cond_resched()
The call to cond_resched() schedules a new process, but only if need_resched is set. In other words, this solution conditionally invokes the scheduler only if there is some more important task to run. Note that because this approach invokes the scheduler, you cannot make use of it from an interrupt handler — only from process context.
该宏定义于include/linux/sched.h:
#define cond_resched() ({ \
__might_sleep(__FILE__, __LINE__, 0); \
_cond_resched(); \
})
7.4.8.1 _cond_resched()
该函数定义于kernel/sched.c:
int __sched _cond_resched(void)
{
if (should_resched()) {
__cond_resched();
return 1;
}
return 0;
}
7.4.8.1.1 should_resched()
该函数定义于kernel/sched.c:
static inline int should_resched(void)
{
/*
* 若需要重新调度进程且允许进程抢占,则返回True;否则,返回False
* preempt_count()参见[16.10.1 preempt_count()]节和
* [7.1.1.3.1.1 struct thread_info->preempt_count]节
*/
return need_resched() && !(preempt_count() & PREEMPT_ACTIVE);
}
7.4.8.1.1.1 need_resched()
该函数定义于include/linux/sched.h:
static inline int need_resched(void)
{
/*
* 通过检查current->stack->flags中的标志位TIF_NEED_RESCHED,
* 来判断是否需要重新调度其他进程运行;该标志位可通过函数
* set_tsk_need_resched()、宏set_need_resched()来设置
*/
return unlikely(test_thread_flag(TIF_NEED_RESCHED));
}
7.4.8.1.2 __cond_resched()
该函数定义于kernel/sched.c:
static void __cond_resched(void)
{
/*
* 不允许进程抢占,即preempt_count() += val,
* 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
*/
add_preempt_count(PREEMPT_ACTIVE);
// 调度其他进程运行,参见[7.4.5.2 __schedule()]节
__schedule();
/*
* 允许进程抢占,即preempt_count() -= val,
* 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
*/
sub_preempt_count(PREEMPT_ACTIVE);
}
7.4.9 进程休眠
7.4.9.1 加入等待队列
当进程进入休眠状态时,进程被加入到等待队列(参见7.4.2.4 等待队列/wait_queue_head_t/wait_queue_t节)中,通过如下几节中的函数添加等待队列:
7.4.9.1.1 add_wait_queue()/__add_wait_queue_exclusive()
该函数定义于kernel/wait.c:
void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait)
{
unsigned long flags;
// 复位互斥进程标志
wait->flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
// 将等待队列wait添加到链表q的头部
__add_wait_queue(q, wait);
spin_unlock_irqrestore(&q->lock, flags);
}
// 与add_wait_queue()的区别在于:没有加锁,且将进程互斥标志置位
static inline void __add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t *wait)
{
wait->flags |= WQ_FLAG_EXCLUSIVE;
__add_wait_queue(q, wait);
}
static inline void __add_wait_queue(wait_queue_head_t *head, wait_queue_t *new)
{
list_add(&new->task_list, &head->task_list);
}
7.4.9.1.2 add_wait_queue_exclusive()/__add_wait_queue_tail_exclusive()
该函数定义于kernel/wait.c:
void add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t *wait)
{
unsigned long flags;
// 置位互斥进程标志
wait->flags |= WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
// 将等待队列wait添加到链表q的头尾部
__add_wait_queue_tail(q, wait);
spin_unlock_irqrestore(&q->lock, flags);
}
// 与add_wait_queue_exclusive()的区别在于:没有加锁
static inline void __add_wait_queue_tail_exclusive(wait_queue_head_t *q, wait_queue_t *wait)
{
wait->flags |= WQ_FLAG_EXCLUSIVE;
__add_wait_queue_tail(q, wait);
}
static inline void __add_wait_queue_tail(wait_queue_head_t *head, wait_queue_t *new)
{
list_add_tail(&new->task_list, &head->task_list);
}
7.4.9.2 休眠函数
函数sleep_on(), sleep_on_timeout(), interruptible_sleep_on(), interruptible_sleep_on_timeout()用于进程休眠,其定义于kernel/sched.c:
void __sched sleep_on(wait_queue_head_t *q)
{
sleep_on_common(q, TASK_UNINTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
long __sched sleep_on_timeout(wait_queue_head_t *q, long timeout)
{
return sleep_on_common(q, TASK_UNINTERRUPTIBLE, timeout);
}
/*
* set state to TASK_UNINTERRUPTIBLE, so that the process
* also can be woken up by receiving a signal.
*/
void __sched interruptible_sleep_on(wait_queue_head_t *q)
{
sleep_on_common(q, TASK_INTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
long __sched interruptible_sleep_on_timeout(wait_queue_head_t *q, long timeout)
{
return sleep_on_common(q, TASK_INTERRUPTIBLE, timeout);
}
这些函数均通过调用sleep_on_common()实现其功能,仅入参不同而已,参见7.4.9.2.1 sleep_on_common()节。
As you might expect, these functions unconditionally put the current process to sleep on the given queue. These functions are strongly deprecated, however, and you should never use them. The problem is obvious if you think about it: sleep_on offers no way to protect against race conditions. There is always a window between when your code decides it must sleep and when sleep_on actually effects that sleep. A wakeup that arrives during that window is missed. For this reason, code that calls sleep_on is never entirely safe.
NOTE: Those macros are removed from kernel after v3.15. Refer to commit b8780c363d808a726a34793caa900923d32b6b80:
chenwx@chenwx ~/linux $ git lc b8780c363d808a726a34793caa900923d32b6b80
commit b8780c363d808a726a34793caa900923d32b6b80
Author: Arnd Bergmann <arnd@arndb.de>
AuthorDate: Mon Apr 7 17:33:06 2014 +0200
Commit: Linus Torvalds <torvalds@linux-foundation.org>
CommitDate: Mon Apr 7 11:24:06 2014 -0700
sched: remove sleep_on() and friends
This is the final piece in the puzzle, as all patches to remove the
last users of \(interruptible_\|\)sleep_on\(_timeout\|\) have made it
into the 3.15 merge window. The work was long overdue, and this
interface in particular should not have survived the BKL removal
that was done a couple of years ago.
Citing Jon Corbet from http://lwn.net/2001/0201/kernel.php3":
"[...] it was suggested that the janitors look for and fix all code
that calls sleep_on() [...] since (1) almost all such code is
incorrect, and (2) Linus has agreed that those functions should
be removed in the 2.5 development series".
We haven't quite made it for 2.5, but maybe we can merge this for 3.15.
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Ingo Molnar <mingo@kernel.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Documentation/DocBook/kernel-hacking.tmpl | 10 ----------
include/linux/wait.h | 11 -----------
kernel/sched/core.c | 46 ----------------------------------------------
3 files changed, 67 deletions(-)
7.4.9.2.1 sleep_on_common()
该函数定义于kernel/sched.c:
static long __sched sleep_on_common(wait_queue_head_t *q, int state, long timeout)
{
unsigned long flags;
wait_queue_t wait;
/*
* 参见[7.4.2.4.2 定义/初始化等待队列/wait_queue_t]节,为当前进程创建等待队列,
* 其唤醒函数为default_wake_function(),参见[7.4.10.2.2 default_wake_function()]节
*/
init_waitqueue_entry(&wait, current);
// 设置当前进程为TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE
__set_current_state(state);
spin_lock_irqsave(&q->lock, flags);
/*
* 将等待队列wait添加到链表q中,
* 参见[7.4.9.1.1 add_wait_queue()/__add_wait_queue_exclusive()]节
*/
__add_wait_queue(q, &wait);
spin_unlock(&q->lock);
/*
* 调度其他进程运行,当前进程转入休眠状态,并指定的休眠时间,
* 参见[7.4.7 schedule_timeout()]节
*/
timeout = schedule_timeout(timeout);
spin_lock_irq(&q->lock);
/*
* 当前进程被唤醒后,将等待队列wait从链表q中移出,
* 参见[7.4.9.5.1 remove_wait_queue()]节
*/
__remove_wait_queue(q, &wait);
spin_unlock_irqrestore(&q->lock, flags);
return timeout;
}
7.4.9.3 prepare_to_wait()/prepare_to_wait_exclusive()/finish_wait()
Those methods offer yet another way to put the current process to sleep in a wait queue. Typically, they are used as follows:
DEFINE_WAIT(wait); // 参见[7.4.2.4.2 定义/初始化等待队列/wait_queue_t]节
prepare_to_wait_exclusive(&wq, &wait, TASK_INTERRUPTIBLE); /* wq is the head of the wait queue */
/* ... */
if (!condition)
schedule();
finish_wait(&wq, &wait);
该函数定义于kernel/wait.c:
/*
* Note: we use "set_current_state()" _after_ the wait-queue add,
* because we need a memory barrier there on SMP, so that any
* wake-function that tests for the wait-queue being active
* will be guaranteed to see waitqueue addition _or_ subsequent
* tests in this thread will see the wakeup having taken place.
*
* The spin_unlock() itself is semi-permeable and only protects
* one way (it only protects stuff inside the critical region and
* stops them from bleeding out - it would still allow subsequent
* loads to move into the critical region).
*/
void prepare_to_wait(wait_queue_head_t *q, wait_queue_t *wait, int state)
{
unsigned long flags;
wait->flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
if (list_empty(&wait->task_list))
__add_wait_queue(q, wait); // 添加到等待队列头部
set_current_state(state);
spin_unlock_irqrestore(&q->lock, flags);
}
/*
* An exclusive wait acts very much like a normal sleep, with two important differences:
* - When a wait queue entry has the WQ_FLAG_EXCLUSIVE flag set, it is added to the end
* of the wait queue. Entries without that flag are, instead, added to the beginning.
* - When wake_up is called on a wait queue, it stops after waking the first process that
* has the WQ_FLAG_EXCLUSIVE flag set.
*
* The end result is that processes performing exclusive waits are awakened one at a time,
* in an orderly manner, and do not create thundering herds. The kernel still wakes up all
* nonexclusive waiters every time, however.
*
* Employing exclusive waits within a driver is worth considering if two conditions are met:
* - you expect significant contention for a resource, and
* - waking a single process is sufficient to completely consume the resource when it becomes
* available.
*/
void prepare_to_wait_exclusive(wait_queue_head_t *q, wait_queue_t *wait, int state)
{
unsigned long flags;
wait->flags |= WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
if (list_empty(&wait->task_list))
__add_wait_queue_tail(q, wait); // 添加到等待队列尾部
set_current_state(state);
spin_unlock_irqrestore(&q->lock, flags);
}
/**
* finish_wait - clean up after waiting in a queue
* @q: waitqueue waited on
* @wait: wait descriptor
*
* Sets current thread back to running state and removes
* the wait descriptor from the given waitqueue if still
* queued.
*/
void finish_wait(wait_queue_head_t *q, wait_queue_t *wait)
{
unsigned long flags;
__set_current_state(TASK_RUNNING);
/*
* We can check for list emptiness outside the lock
* IFF:
* - we use the "careful" check that verifies both
* the next and prev pointers, so that there cannot
* be any half-pending updates in progress on other
* CPU's that we haven't seen yet (and that might
* still change the stack area.
* and
* - all other users take the lock (ie we can only
* have _one_ other CPU that looks at or modifies
* the list).
*/
if (!list_empty_careful(&wait->task_list)) {
spin_lock_irqsave(&q->lock, flags);
list_del_init(&wait->task_list);
spin_unlock_irqrestore(&q->lock, flags);
}
}
7.4.9.4 wait_event_XXX()
The simplest way of sleeping in the Linux kernel is a macro called wait_event (with a few variants). Those macros put the calling process to sleep on a wait queue until a given condition is verified. Refer to include/linux/wait.h.
wait_event(queue, condition)
wait_event_interruptible(queue, condition)
wait_event_timeout(queue, condition, timeout)
wait_event_interruptible_timeout(queue, condition, timeout)
Note that the timeout value represents the number of jiffies to wait, not an absolute time value. The value is represented by a signed number, because it sometimes is the result of a subtraction, although the functions complain through a printk statement if the provided timeout is negative. If the timeout expires, the functions return 0; if the process is awakened by another event, it returns the remaining delay expressed in jiffies. The return value is never negative, even if the delay is greater than expected because of system load.
7.4.9.4.1 wait_event()
/**
* wait_event - sleep until a condition gets true
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
*
* The process is put to sleep (TASK_UNINTERRUPTIBLE) until the
* @condition evaluates to true. The @condition is checked each time
* the waitqueue @wq is woken up.
*
* wake_up() has to be called after changing any variable that could
* change the result of the wait condition.
*/
#define wait_event(wq, condition) \
do { \
if (condition) \
break; \
__wait_event(wq, condition); \
} while (0)
#define __wait_event(wq, condition) \
do { \
DEFINE_WAIT(__wait); \
\
for (;;) { \
prepare_to_wait(&wq, &__wait, TASK_UNINTERRUPTIBLE); \
if (condition) \
break; \
schedule(); \ // 参见[7.4.5 schedule()]节
} \
finish_wait(&wq, &__wait); \
} while (0)
7.4.9.4.2 wait_event_interruptible()
/**
* wait_event_interruptible - sleep until a condition gets true
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
*
* The process is put to sleep (TASK_INTERRUPTIBLE) until the
* @condition evaluates to true or a signal is received.
* The @condition is checked each time the waitqueue @wq is woken up.
*
* wake_up() has to be called after changing any variable that could
* change the result of the wait condition.
*
* The function will return -ERESTARTSYS if it was interrupted by a
* signal and 0 if @condition evaluated to true.
*/
#define wait_event_interruptible(wq, condition) \
({ \
int __ret = 0; \
if (!(condition)) \
__wait_event_interruptible(wq, condition, __ret); \
__ret; \
})
#define __wait_event_interruptible(wq, condition, ret) \
do { \
DEFINE_WAIT(__wait); \
\
for (;;) { \
prepare_to_wait(&wq, &__wait, TASK_INTERRUPTIBLE); \
if (condition) \
break; \
if (!signal_pending(current)) { \
schedule(); \ // 参见[7.4.5 schedule()]节
continue; \
} \
ret = -ERESTARTSYS; \
break; \
} \
finish_wait(&wq, &__wait); \
} while (0)
7.4.9.4.3 wait_event_timeout()
/**
* wait_event_timeout - sleep until a condition gets true or a timeout elapses
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
* @timeout: timeout, in jiffies
*
* The process is put to sleep (TASK_UNINTERRUPTIBLE) until the
* @condition evaluates to true. The @condition is checked each time
* the waitqueue @wq is woken up.
*
* wake_up() has to be called after changing any variable that could
* change the result of the wait condition.
*
* The function returns 0 if the @timeout elapsed, and the remaining
* jiffies if the condition evaluated to true before the timeout elapsed.
*/
#define wait_event_timeout(wq, condition, timeout) \
({ \
long __ret = timeout; \
if (!(condition)) \
__wait_event_timeout(wq, condition, __ret); \
__ret; \
})
#define __wait_event_timeout(wq, condition, ret) \
do { \
DEFINE_WAIT(__wait); \
\
for (;;) { \
prepare_to_wait(&wq, &__wait, TASK_UNINTERRUPTIBLE); \
if (condition) \
break; \
ret = schedule_timeout(ret); \ // 参见[7.4.7 schedule_timeout()]节
if (!ret) \
break; \
} \
finish_wait(&wq, &__wait); \
} while (0)
7.4.9.4.4 wait_event_interruptible_timeout()
/**
* wait_event_interruptible_timeout - sleep until a condition gets true or a timeout elapses
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
* @timeout: timeout, in jiffies
*
* The process is put to sleep (TASK_INTERRUPTIBLE) until the
* @condition evaluates to true or a signal is received.
* The @condition is checked each time the waitqueue @wq is woken up.
*
* wake_up() has to be called after changing any variable that could
* change the result of the wait condition.
*
* The function returns 0 if the @timeout elapsed, -ERESTARTSYS if it
* was interrupted by a signal, and the remaining jiffies otherwise
* if the condition evaluated to true before the timeout elapsed.
*/
#define wait_event_interruptible_timeout(wq, condition, timeout) \
({ \
long __ret = timeout; \
if (!(condition)) \
__wait_event_interruptible_timeout(wq, condition, __ret); \
__ret; \
})
#define __wait_event_interruptible_timeout(wq, condition, ret) \
do { \
DEFINE_WAIT(__wait); \
\
for (;;) { \
prepare_to_wait(&wq, &__wait, TASK_INTERRUPTIBLE); \
if (condition) \
break; \
if (!signal_pending(current)) { \
ret = schedule_timeout(ret); \ // 参见[7.4.7 schedule_timeout()]节
if (!ret) \
break; \
continue; \
} \
ret = -ERESTARTSYS; \
break; \
} \
finish_wait(&wq, &__wait); \
} while (0)
7.4.9.5 移出等待队列
当进程被唤醒时,进程被移出等待队列(参见7.4.2.4 等待队列/wait_queue_head_t/wait_queue_t节)中,通过如下几节中的函数移出等待队列:
7.4.9.5.1 remove_wait_queue()
该函数定义于kernel/wait.c:
void remove_wait_queue(wait_queue_head_t *q, wait_queue_t *wait)
{
unsigned long flags;
spin_lock_irqsave(&q->lock, flags);
// 将wait从链表q中移出
__remove_wait_queue(q, wait);
spin_unlock_irqrestore(&q->lock, flags);
}
static inline void __remove_wait_queue(wait_queue_head_t *head, wait_queue_t *old)
{
list_del(&old->task_list);
}
7.4.10 唤醒进程
7.4.10.1 wake_up_XXX()
wake_up wakes up all processes waiting on the given queue (though the situation is a little more complicated than that). The other form (wake_up_interruptible) restricts itself to processes performing an interruptible sleep. In general, the two are indistinguishable (if you are using interruptible sleeps); in practice, the convention is to use wake_up if you are using wait_event and wake_up_interruptble if you use wait_event_interruptible.
wake_up(wait_queue_head_t *queue);
wake_up_interruptible(wait_queue_head_t *queue);
wake_up awakens every process on the queue that is not in an exclusive wait, and exactly one exclusive waiter, if it exists. wake_up_interruptible does the same, with the exception that it skips over processes in an uninterruptible sleep. These functions can, before returning, cause one or more of the processes awakened to be scheduled (although this does not happen if they are called from an atomic context).
wake_up_nr(wait_queue_head_t *queue, int nr);
wake_up_interruptible_nr(wait_queue_head_t *queue, int nr);
These functions perform similarly to wake_up, except they can awaken up to nr exclusive waiters, instead of just one. Note that passing 0 is interpreted as asking for all of the exclusive waiters to be awakened, rather than none of them.
wake_up_all(wait_queue_head_t *queue);
wake_up_interruptible_all(wait_queue_head_t *queue);
This form of wake_up awakens all processes whether they are performing an exclusive wait or not (though the interruptible form still skips processes doing uninterruptible waits).
wake_up_interruptible_sync(wait_queue_head_t *queue);
Normally, a process that is awakened may preempt the current process and be scheduled into the processor before wake_up returns. In other words, a call to wake_up may not be atomic. If the process calling wake_up is running in an atomic context (it holds a spinlock, for example, or is an interrupt handler), this rescheduling does not happen. Normally, that protection is adequate. If, however, you need to explicitly ask to not be scheduled out of the processor at this time, you can use the “sync” variant of wake_up_interruptible. This function is most often used when the caller is about to reschedule anyway, and it is more efficient to simply finish what little work remains first.
Refer to include/linux/wait.h:
#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
#define wake_up_nr(x, nr) __wake_up(x, TASK_NORMAL, nr, NULL)
#define wake_up_all(x) __wake_up(x, TASK_NORMAL, 0, NULL)
/*
* It’s similar to wake_up(), except that it’s called
* when the spin lock in wait_queue_head_t is already held.
*/
#define wake_up_locked(x) __wake_up_locked((x), TASK_NORMAL)
#define wake_up_interruptible(x) __wake_up(x, TASK_INTERRUPTIBLE, 1, NULL)
#define wake_up_interruptible_nr(x, nr) __wake_up(x, TASK_INTERRUPTIBLE, nr, NULL)
#define wake_up_interruptible_all(x) __wake_up(x, TASK_INTERRUPTIBLE, 0, NULL)
#define wake_up_interruptible_sync(x) __wake_up_sync((x), TASK_INTERRUPTIBLE, 1)
/*
* Wakeup macros to be used to report events to the targets.
*/
#define wake_up_poll(x, m) __wake_up(x, TASK_NORMAL, 1, (void *) (m))
#define wake_up_locked_poll(x, m) __wake_up_locked_key((x), TASK_NORMAL, (void *) (m))
#define wake_up_interruptible_poll(x, m) __wake_up(x, TASK_INTERRUPTIBLE, 1, (void *) (m))
#define wake_up_interruptible_sync_poll(x, m) __wake_up_sync_key((x), TASK_INTERRUPTIBLE, 1, (void *) (m))
其中,函数__wake_up()定义于kernel/sched.c:
/**
* __wake_up - wake up threads blocked on a waitqueue.
* @q: the waitqueue
* @mode: which threads
* @nr_exclusive: how many wake-one or wake-many threads to wake up
* @key: is directly passed to the wakeup function
*
* It may be assumed that this function implies a write memory barrier before
* changing the task state if and only if any tasks are woken up.
*/
void __wake_up(wait_queue_head_t *q, unsigned int mode, int nr_exclusive, void *key)
{
unsigned long flags;
spin_lock_irqsave(&q->lock, flags);
__wake_up_common(q, mode, nr_exclusive, 0, key);
spin_unlock_irqrestore(&q->lock, flags);
}
7.4.10.1.1 __wake_up_common()
该函数定义于kernel/sched.c:
/*
* The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just
* wake everything up. If it's an exclusive wakeup (nr_exclusive == small +ve
* number) then we wake all the non-exclusive tasks and one exclusive task.
*
* There are circumstances in which we can try to wake a task which has already
* started to run but is not in state TASK_RUNNING. try_to_wake_up() returns
* zero in this (rare) case, and we handle it by continuing to scan the queue.
*/
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
// 循环链表q中的所有等待队列curr,并调用其唤醒函数curr->func()
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
/*
* 由[7.4.2.4.2 定义/初始化等待队列/wait_queue_t]节可知,等待队列curr的唤醒函数
* 包含如下几个,参见[7.4.10.2 唤醒函数]节
* autoremove_wake_function(), default_wake_function(), ...
*/
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
7.4.10.2 唤醒函数
7.4.10.2.1 autoremove_wake_function()
该函数定义于kernel/wait.c:
int autoremove_wake_function(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
// 唤醒等待队列wait中的进程,参见[7.4.10.2.2 default_wake_function()]节
int ret = default_wake_function(wait, mode, sync, key);
if (ret)
list_del_init(&wait->task_list); // 将等待队列wait移出等待队列链表
return ret;
}
7.4.10.2.2 default_wake_function()
该函数定义于kernel/sched.c:
int default_wake_function(wait_queue_t *curr, unsigned mode, int wake_flags, void *key)
{
// 唤醒等待队列中的进程curr->private,参见[7.4.10.2.2.1 try_to_wake_up()]节
return try_to_wake_up(curr->private, mode, wake_flags);
}
7.4.10.2.2.1 try_to_wake_up()
该函数定义于kernel/sched.c:
static int try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
smp_wmb();
raw_spin_lock_irqsave(&p->pi_lock, flags);
if (!(p->state & state)) // 只有指定状态的进程才能被唤醒
goto out;
success = 1; /* we're going to change ->state */
// 获取进程p所在的CPU,即p->stack->cpu
cpu = task_cpu(p);
// 参见[7.4.10.2.2.1.1 ttwu_remote()]节
if (p->on_rq && ttwu_remote(p, wake_flags))
goto stat;
#ifdef CONFIG_SMP
/*
* If the owning (remote) cpu is still in the middle of schedule() with
* this task as prev, wait until its done referencing the task.
*/
while (p->on_cpu) {
#ifdef __ARCH_WANT_INTERRUPTS_ON_CTXSW
/*
* In case the architecture enables interrupts in
* context_switch(), we cannot busy wait, since that
* would lead to deadlocks when an interrupt hits and
* tries to wake up @prev. So bail and do a complete
* remote wakeup.
*/
if (ttwu_activate_remote(p, wake_flags))
goto stat;
#else
cpu_relax();
#endif
}
/*
* Pairs with the smp_wmb() in finish_lock_switch().
*/
smp_rmb();
p->sched_contributes_to_load = !!task_contributes_to_load(p);
p->state = TASK_WAKING;
/*
* 调用对应调度类的task_waking(),
* 参见[7.4.4 进程的调度类/struct sched_class]节
*/
if (p->sched_class->task_waking)
p->sched_class->task_waking(p);
// 参见[7.4.10.2.2.1.2 select_task_rq()]节
cpu = select_task_rq(p, SD_BALANCE_WAKE, wake_flags);
if (task_cpu(p) != cpu) {
wake_flags |= WF_MIGRATED;
set_task_cpu(p, cpu);
}
#endif /* CONFIG_SMP */
// 将进程状态设置为TASK_RUNNING,并将其插入运行队列
ttwu_queue(p, cpu);
stat:
ttwu_stat(p, cpu, wake_flags);
out:
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
return success;
}
7.4.10.2.2.1.1 ttwu_remote()
该函数定义于kernel/sched.c:
static int ttwu_remote(struct task_struct *p, int wake_flags)
{
struct rq *rq;
int ret = 0;
rq = __task_rq_lock(p);
if (p->on_rq) {
ttwu_do_wakeup(rq, p, wake_flags);
ret = 1;
}
__task_rq_unlock(rq);
return ret;
}
7.4.10.2.2.1.1.1 ttwu_do_wakeup()
该函数定义于kernel/sched.c:
/*
* Mark the task runnable and perform wakeup-preemption.
*/
static void ttwu_do_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
trace_sched_wakeup(p, true);
check_preempt_curr(rq, p, wake_flags);
p->state = TASK_RUNNING;
#ifdef CONFIG_SMP
/*
* 调用对应调度类的task_woken(),
* 参见[7.4.4 进程的调度类/struct sched_class]节
*/
if (p->sched_class->task_woken)
p->sched_class->task_woken(rq, p);
if (rq->idle_stamp) {
u64 delta = rq->clock - rq->idle_stamp;
u64 max = 2*sysctl_sched_migration_cost;
if (delta > max)
rq->avg_idle = max;
else
update_avg(&rq->avg_idle, delta);
rq->idle_stamp = 0;
}
#endif
}
7.4.10.2.2.1.2 select_task_rq()
该函数定义于kernel/sched.c:
/*
* The caller (fork, wakeup) owns p->pi_lock, ->cpus_allowed is stable.
*/
static inline int select_task_rq(struct task_struct *p, int sd_flags, int wake_flags)
{
/*
* 调用对应调度类的select_task_rq(),
* 参见[7.4.4 进程的调度类/struct sched_class]节
*/
int cpu = p->sched_class->select_task_rq(p, sd_flags, wake_flags);
/*
* In order not to call set_task_cpu() on a blocking task we need
* to rely on ttwu() to place the task on a valid ->cpus_allowed
* cpu.
*
* Since this is common to all placement strategies, this lives here.
*
* [ this allows ->select_task() to simply return task_cpu(p) and
* not worry about this generic constraint ]
*/
if (unlikely(!cpumask_test_cpu(cpu, tsk_cpus_allowed(p)) || !cpu_online(cpu)))
cpu = select_fallback_rq(task_cpu(p), p);
return cpu;
}
7.4.10.2.3 wake_up_process()
该函数定义于kernel/sched.c:
int wake_up_process(struct task_struct *p)
{
/*
* 参见[7.4.10.2.2.1 try_to_wake_up()]节,唤醒满足状态TASK_ALL的进程p,其中TASK_ALL为:
* TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE | __TASK_STOPPED | __TASK_TRACED
*/
return try_to_wake_up(p, TASK_ALL, 0);
}
7.4.11 与进程调度有关的系统调用
与进程调度有关的系统调用如下:
SYSCALL_DEFINE1(sched_getscheduler, pid_t, pid)
SYSCALL_DEFINE3(sched_setscheduler, pid_t, pid, int, policy, struct sched_param __user *, param)
Refer to kernel/sched.c. Get/set the policy (scheduling class) of a thread.
SYSCALL_DEFINE1(nice, int, increment)
Refer to kernel/sched.c. Change the priority of the current process。参数increment的取值范围为[-40..40]。 The nice() system call is maintained for backward compatibility only; it has been replaced by the setpriority() system call.
SYSCALL_DEFINE2(getpriority, int, which, int, who)
SYSCALL_DEFINE3(setpriority, int, which, int, who, int, niceval)
Refer to kernel/sys.c. Not return the normal nice-value, but a negated value that has been offset by 20 (i.e. it returns [40..1] instead of [-20..19]) to stay compatible.
SYSCALL_DEFINE3(sched_getaffinity, pid_t, pid, unsigned int, len, unsigned long __user *, user_mask_ptr)
SYSCALL_DEFINE3(sched_setaffinity, pid_t, pid, unsigned int, len, unsigned long __user *, user_mask_ptr)
Refer to kernel/sched.c. The sched_getaffinity() and sched_setaffinity() system calls respectively return and set up the CPU affinity mask of a process — the bit mask of the CPUs that are allowed to execute the process. This mask is stored in the cpus_allowed field of the process descriptor.
SYSCALL_DEFINE0(sched_yield)
The system call allows a process to relinquish the CPU voluntarily without being suspended. The call is used mainly by SCHED_FIFO realtime processes.
SYSCALL_DEFINE1(sched_get_priority_min, int, policy)
SYSCALL_DEFINE1(sched_get_priority_max, int, policy)
Refer to kernel/sched.c. Returns the minimum/maximum rt_priority that can be used by a given scheduling class.
SYSCALL_DEFINE2(sched_getparam, pid_t, pid, struct sched_param __user *, param)
SYSCALL_DEFINE2(sched_setparam, pid_t, pid, struct sched_param __user *, param)
Refer to kernel/sched.c. The system calls retrieve/set the scheduling parameters for the process identified by pid.
SYSCALL_DEFINE2(sched_rr_get_interval, pid_t, pid, struct timespec __user *, interval)
Refer to kernel/sched.c. Writes the default timeslice value of a given process into the user-space timespec buffer. A value of ‘0’ means infinity. 通过调用对应调度类的sched_class->get_rr_interval()函数实现。
7.5 工作队列/workqueue
参见文档:Documentation/workqueue.txt
工作队列和定时器函数处理有些类似,都是执行回调函数,但和定时器处理函数不同的是:定时器回调函数只执行一次,且执行定时器回调函数时是在时钟中断中,限制比较多,因此回调程序不能太复杂;而工作队列是通过内核线程实现,一直有效,可重复执行,由于执行时降低了线程的优先级,执行时可能休眠,因此工作队列用于处理那些不是很紧急的任务,如垃圾回收等,通常在系统空闲时执行。在xfrm库中就广泛使用了workqueue。使用时,只需要定义work_struct结构,然后调用函数schedule_work()/schedule_delayed_work()即可。
此外,workqueue是中断处理中Bottom Half的一种实现方式,参见9.3.1.3 irq_exit()节。
7.5.1 与workqueue有关的数据结构
7.5.1.1 struct work_struct
该结构定义于include/linux/workqueue.h:
/*
* A worker thread executes this function (see [7.5.5.1.1.1.1 process_one_work()]),
* and thus, the function runs in process context. By default,
* interrupts are enabled and no locks are held. If needed, the
* function can sleep.
*/
typedef void (*work_func_t)(struct work_struct *work);
...
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
data域包含了一些标志位,可通过宏work_data_bits(work)获得指定work的data域,参见include/linux/workqueue.h:
/*
* The first word is the work queue pointer and the flags rolled into one
*/
#define work_data_bits(work) ((unsigned long *)(&(work)->data))
enum {
WORK_STRUCT_PENDING_BIT = 0, /* work item is pending execution */
WORK_STRUCT_DELAYED_BIT = 1, /* work item is delayed */
WORK_STRUCT_CWQ_BIT = 2, /* data points to cwq */
WORK_STRUCT_LINKED_BIT = 3, /* next work is linked to this one */
#ifdef CONFIG_DEBUG_OBJECTS_WORK
WORK_STRUCT_STATIC_BIT = 4, /* static initializer (debugobjects) */
WORK_STRUCT_COLOR_SHIFT = 5, /* color for workqueue flushing */
#else
WORK_STRUCT_COLOR_SHIFT = 4, /* color for workqueue flushing */
#endif
WORK_STRUCT_COLOR_BITS = 4,
WORK_STRUCT_PENDING = 1 << WORK_STRUCT_PENDING_BIT, // 1
WORK_STRUCT_DELAYED = 1 << WORK_STRUCT_DELAYED_BIT, // 2
WORK_STRUCT_CWQ = 1 << WORK_STRUCT_CWQ_BIT, // 4
WORK_STRUCT_LINKED = 1 << WORK_STRUCT_LINKED_BIT, // 8
#ifdef CONFIG_DEBUG_OBJECTS_WORK
WORK_STRUCT_STATIC = 1 << WORK_STRUCT_STATIC_BIT, // 16
#else
WORK_STRUCT_STATIC = 0,
#endif
/*
* The last color is no color used for works which don't
* participate in workqueue flushing.
*/
WORK_NR_COLORS = (1 << WORK_STRUCT_COLOR_BITS) - 1, // 15
WORK_NO_COLOR = WORK_NR_COLORS, // 15
/* special cpu IDs */
WORK_CPU_UNBOUND = NR_CPUS,
WORK_CPU_NONE = NR_CPUS + 1,
WORK_CPU_LAST = WORK_CPU_NONE,
/*
* Reserve 7 bits off of cwq pointer w/ debugobjects turned
* off. This makes cwqs aligned to 256 bytes and allows 15
* workqueue flush colors.
*/
WORK_STRUCT_FLAG_BITS = WORK_STRUCT_COLOR_SHIFT + WORK_STRUCT_COLOR_BITS, // 9 or 8
WORK_STRUCT_FLAG_MASK = (1UL << WORK_STRUCT_FLAG_BITS) - 1,
WORK_STRUCT_WQ_DATA_MASK = ~WORK_STRUCT_FLAG_MASK,
WORK_STRUCT_NO_CPU = WORK_CPU_NONE << WORK_STRUCT_FLAG_BITS,
/* bit mask for work_busy() return values */
WORK_BUSY_PENDING = 1 << 0,
WORK_BUSY_RUNNING = 1 << 1,
};
data域的结构如下图所示:
#ifdef CONFIG_DEBUG_OBJECTS_WORK
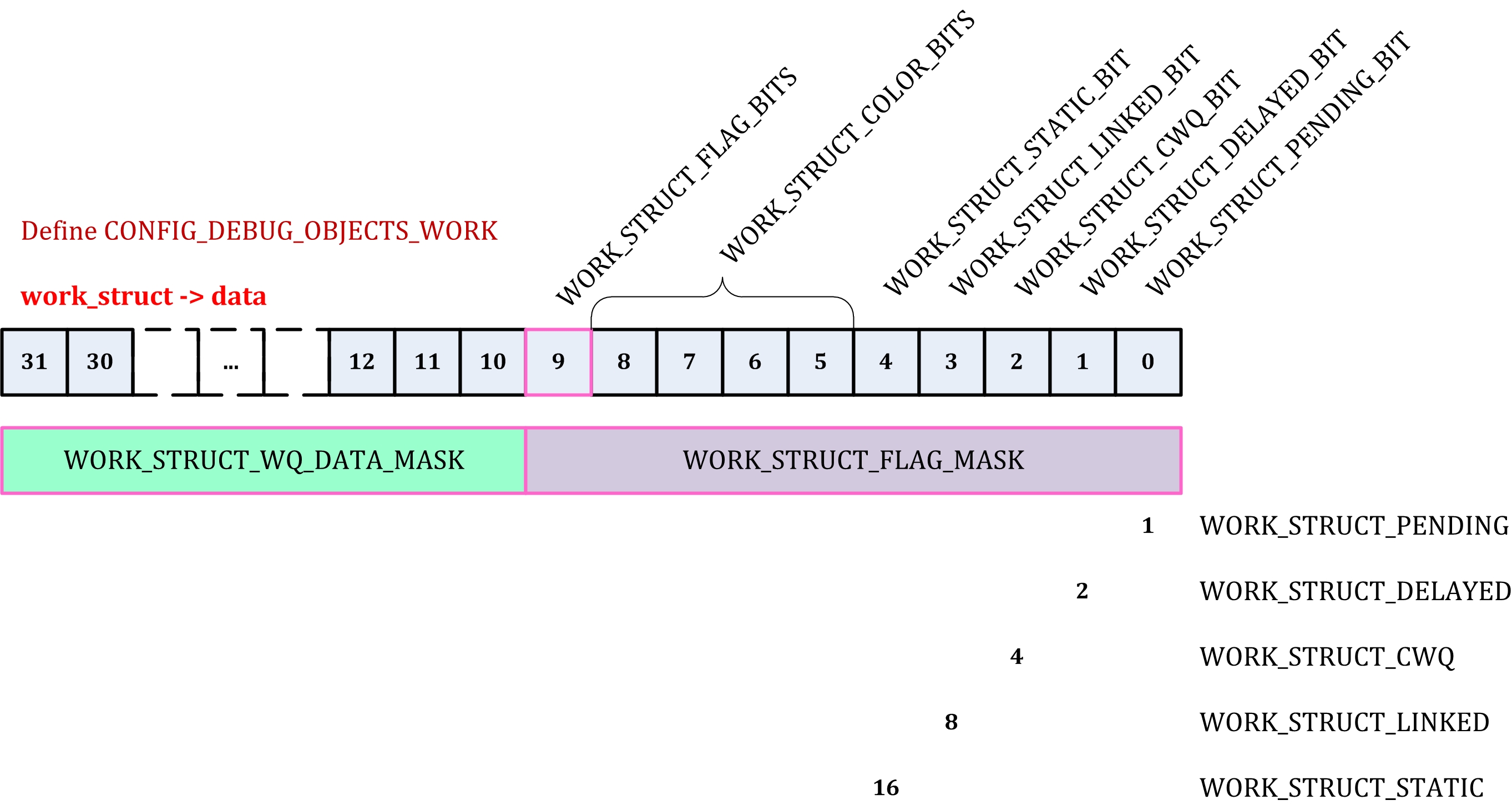
#else
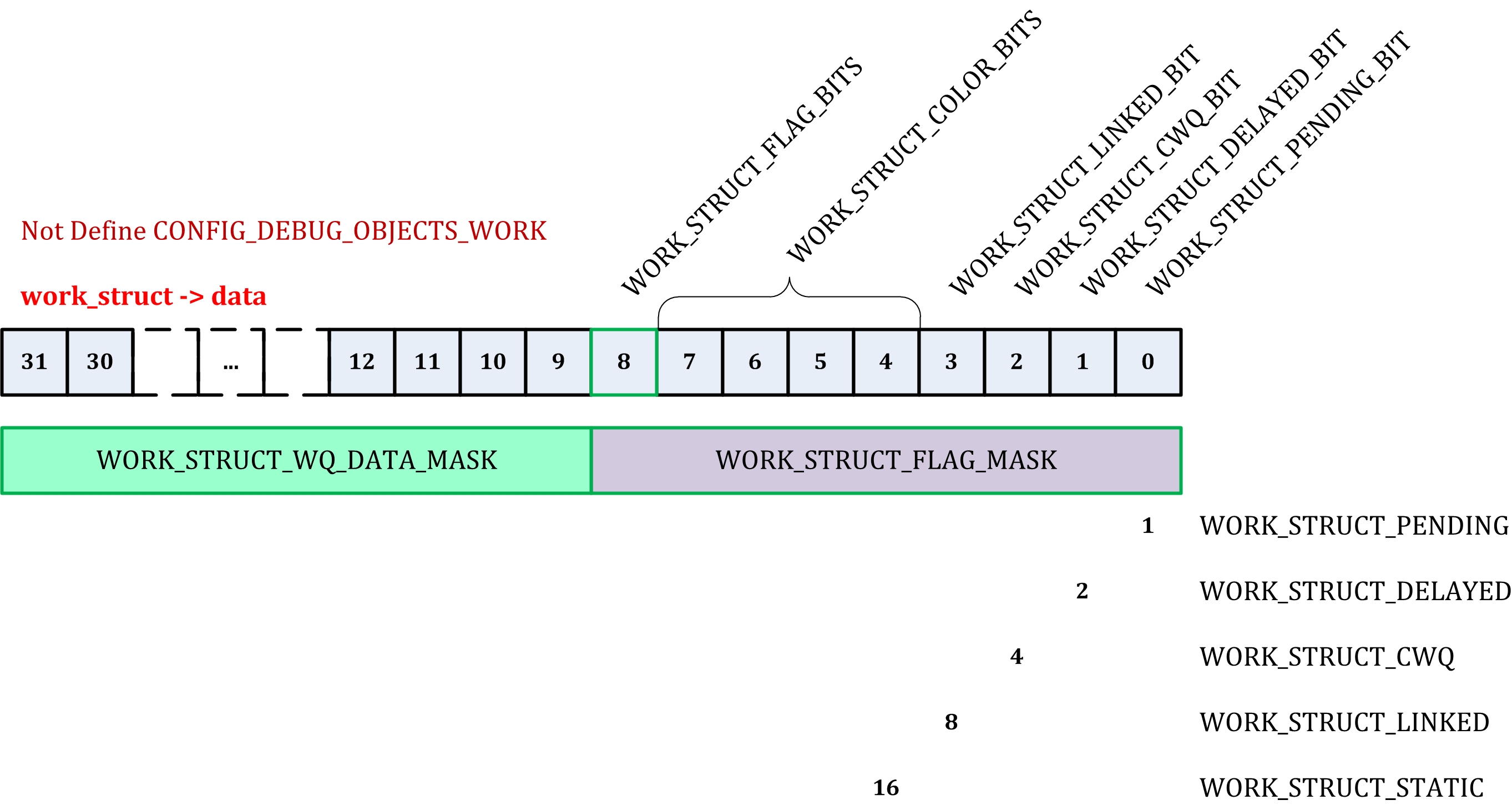
#endif
可以通过如下宏定义并初始化struct work_struct类型的对象,参见include/linux/workqueue.h:
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
#define PREPARE_WORK(_work, _func) \
do { \
(_work)->func = (_func); \
} while (0)
#de```fine INIT_WORK(_work, _func) \
do { \
__INIT_WORK((_work), (_func), 0); \
} while (0)
#define INIT_WORK_ONSTACK(_work, _func) \
do { \
__INIT_WORK((_work), (_func), 1); \
} while (0)
可以通过如下宏操纵struct work_struct类型的对象,参见include/linux/workqueue.h:
/**
* work_pending - Find out whether a work item is currently pending
* @work: The work item in question
*/
#define work_pending(work) \
test_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))
/**
* work_clear_pending - for internal use only, mark a work item as not pending
* @work: The work item in question
*/
#define work_clear_pending(work) \
clear_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))
7.5.1.2 struct delayed_work
在include/linux/workqueue.h中,包含如下代码:
struct delayed_work {
struct work_struct work; // 参见[7.5.1.1 struct work_struct]节
struct timer_list timer; // 定时器
};
可以通过如下宏定义并初始化struct work_struct类型的对象,参见include/linux/workqueue.h:
#define DECLARE_DELAYED_WORK(n, f) \
struct delayed_work n = __DELAYED_WORK_INITIALIZER(n, f)
#define DECLARE_DEFERRED_WORK(n, f) \
struct delayed_work n = __DEFERRED_WORK_INITIALIZER(n, f)
#define PREPARE_DELAYED_WORK(_work, _func) \
PREPARE_WORK(&(_work)->work, (_func))
#define INIT_DELAYED_WORK(_work, _func) \
do { \
INIT_WORK(&(_work)->work, (_func)); \
init_timer(&(_work)->timer); \
} while (0)
#define INIT_DELAYED_WORK_ONSTACK(_work, _func) \
do { \
INIT_WORK_ONSTACK(&(_work)->work, (_func)); \
init_timer_on_stack(&(_work)->timer); \
} while (0)
#define INIT_DELAYED_WORK_DEFERRABLE(_work, _func) \
do { \
INIT_WORK(&(_work)->work, (_func)); \
init_timer_deferrable(&(_work)->timer); \
} while (0)
可以通过如下宏操纵struct work_struct类型的对象,参见include/linux/workqueue.h:
/**
* work_pending - Find out whether a work item is currently pending
* @work: The work item in question
*/
#define work_pending(work) \
test_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))
/**
* work_clear_pending - for internal use only, mark a work item as not pending
* @work: The work item in question
*/
#define work_clear_pending(work) \
clear_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))
通过函数to_delayed_work()可将指向struct work_struct类型的指针转换成指向struct delayed_work类型的指针,参见include/linux/workqueue.h:
static inline struct delayed_work *to_delayed_work(struct work_struct *work)
{
return container_of(work, struct delayed_work, work);
}
7.5.1.3 struct workqueue_struct
该结构定义于kernel/workqueue.c:
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*/
struct workqueue_struct {
// 参见include/linux/workqueue.h
unsigned int flags; /* W: WQ_* flags */
union {
struct cpu_workqueue_struct __percpu *pcpu;
struct cpu_workqueue_struct *single;
unsigned long v;
} cpu_wq; /* I: cwq's */
struct list_head list; /* W: list of all workqueues */
struct mutex flush_mutex; /* protects wq flushing */
int work_color; /* F: current work color */
int flush_color; /* F: current flush color */
atomic_t nr_cwqs_to_flush; /* flush in progress */
struct wq_flusher *first_flusher; /* F: first flusher */
struct list_head flusher_queue; /* F: flush waiters */
struct list_head flusher_overflow; /* F: flush overflow list */
mayday_mask_t mayday_mask; /* cpus requesting rescue */
struct worker *rescuer; /* I: rescue worker */
int nr_drainers; /* W: drain in progress */
int saved_max_active; /* W: saved cwq max_active */
const char *name; /* I: workqueue name */
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
在kernel/workqueue.c中定义了一个全局的工作队列链表workqueues:
/* Serializes the accesses to the list of workqueues. */
static DEFINE_SPINLOCK(workqueue_lock);
static LIST_HEAD(workqueues);
新创建的工作队列(通过wq->list域)会被链接到workqueues的头部,参见7.5.2.1 alloc_workqueue()节。
struct workqueue_struct, struct cpu_workqueue_struct, struct global_cwq, struct work_struct各结构之间的关系:
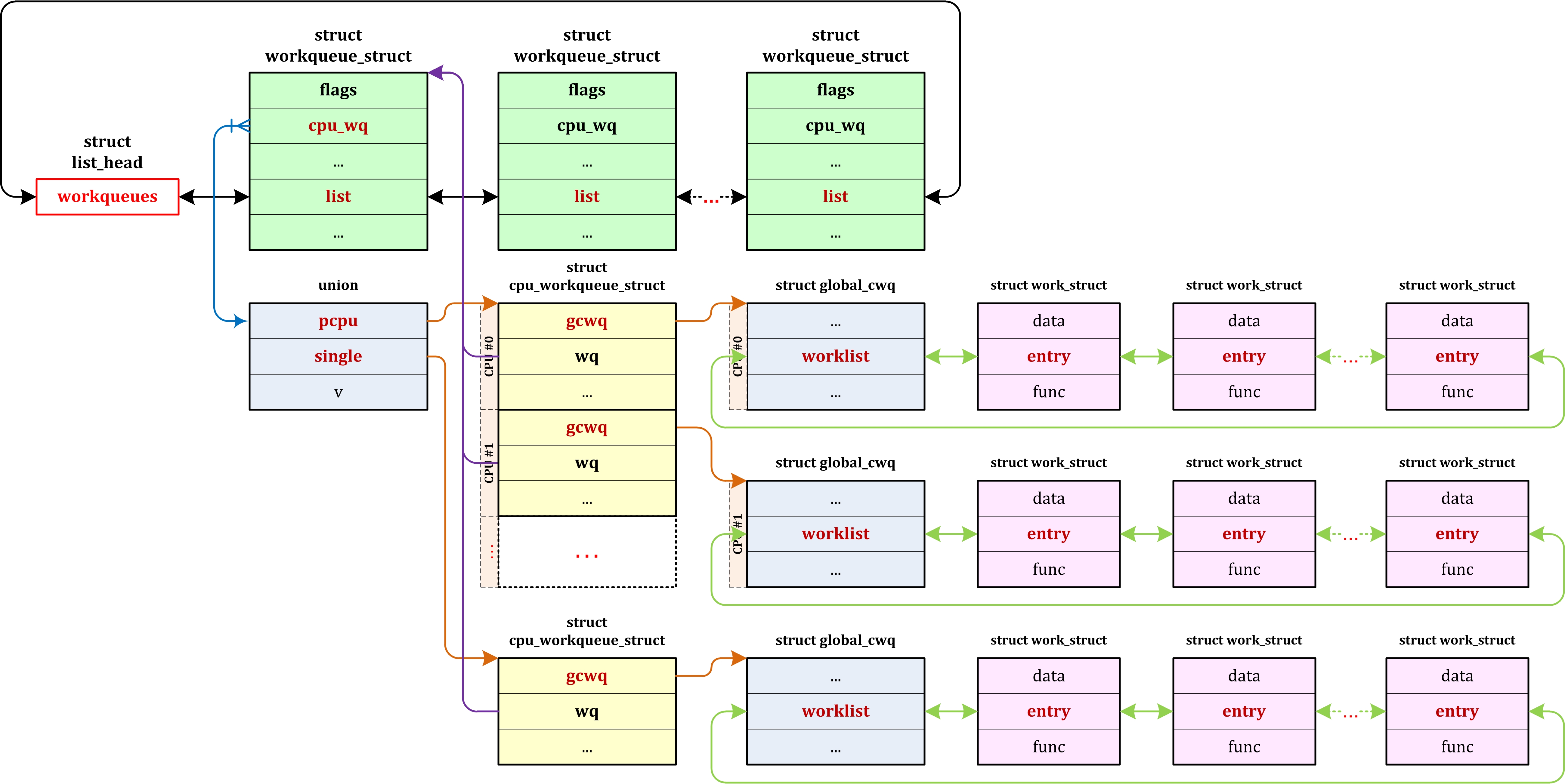
7.5.1.4 struct cpu_workqueue_struct
该结构定义于kernel/workqueue.c:
/*
* The per-CPU workqueue. The lower WORK_STRUCT_FLAG_BITS of
* work_struct->data are used for flags and thus cwqs need to be
* aligned at two's power of the number of flag bits.
*/
struct cpu_workqueue_struct {
struct global_cwq *gcwq; /* I: the associated gcwq */
struct workqueue_struct *wq; /* I: the owning workqueue */
int work_color; /* L: current color */
int flush_color; /* L: flushing color */
int nr_in_flight[WORK_NR_COLORS]; /* L: nr of in_flight works */
int nr_active; /* L: nr of active works */
int max_active; /* L: max active works */
struct list_head delayed_works; /* L: delayed works */
};
7.5.1.5 struct global_cwq
该结构定义于kernel/workqueue.c:
/*
* Global per-cpu workqueue. There's one and only one for each cpu
* and all works are queued and processed here regardless of their
* target workqueues.
*/
struct global_cwq {
spinlock_t lock; /* the gcwq lock */
/*
* 将struct work_struct中的entry域链接起来,
* 参见[7.5.1.3 struct workqueue_struct]节中的图
*/
struct list_head worklist; /* L: list of pending works */
unsigned int cpu; /* I: the associated cpu */
unsigned int flags; /* L: GCWQ_* flags */
int nr_workers; /* L: total number of workers */
int nr_idle; /* L: currently idle ones */
/* workers are chained either in the idle_list or busy_hash */
struct list_head idle_list; /* X: list of idle workers */
struct hlist_head busy_hash[BUSY_WORKER_HASH_SIZE]; /* L: hash of busy workers */
struct timer_list idle_timer; /* L: worker idle timeout */
struct timer_list mayday_timer; /* L: SOS timer for dworkers */
struct ida worker_ida; /* L: for worker IDs */
struct task_struct *trustee; /* L: for gcwq shutdown */
unsigned int trustee_state; /* L: trustee state */
wait_queue_head_t trustee_wait; /* trustee wait */
struct worker *first_idle; /* L: first idle worker */
} ____cacheline_aligned_in_smp;
7.5.1.6 struct worker
该结构定义于kernel/workqueue.c:
/*
* The poor guys doing the actual heavy lifting. All on-duty workers
* are either serving the manager role, on idle list or on busy hash.
*/
struct worker {
/* on idle list while idle, on busy hash table while busy */
union {
struct list_head entry; /* L: while idle */
struct hlist_node hentry; /* L: while busy */
};
struct work_struct *current_work; /* L: work being processed */
struct cpu_workqueue_struct *current_cwq; /* L: current_work's cwq */
struct list_head scheduled; /* L: scheduled works */
// 该内核线程由函数alloc_worker()创建,参见[7.5.2.1 alloc_workqueue()]节
struct task_struct *task; /* I: worker task */
// 参见[7.5.1.3 struct workqueue_struct]节中的图
struct global_cwq *gcwq; /* I: the associated gcwq */
/* 64 bytes boundary on 64bit, 32 on 32bit */
unsigned long last_active; /* L: last active timestamp */
unsigned int flags; /* X: flags */
int id; /* I: worker id */
/*
* 函数alloc_worker()为之赋值:
* rebind_work.func = worker_rebind_fn,
* 参见[7.5.2.1 alloc_workqueue()]节
*/
struct work_struct rebind_work; /* L: rebind worker to cpu */
};
函数alloc_worker()用于分配并初始化worker,其定义于kernel/workqueue.c:
static struct worker *alloc_worker(void)
{
struct worker *worker;
worker = kzalloc(sizeof(*worker), GFP_KERNEL);
if (worker) {
INIT_LIST_HEAD(&worker->entry);
INIT_LIST_HEAD(&worker->scheduled);
INIT_WORK(&worker->rebind_work, worker_rebind_fn);
/* on creation a worker is in !idle && prep state */
worker->flags = WORKER_PREP;
}
return worker;
}
7.5.2 创建workqueue
在include/linux/workqueue.h中定义了如下宏用于创建workqueue:
#define create_workqueue(name) \
alloc_workqueue((name), WQ_MEM_RECLAIM, 1)
#define create_freezable_workqueue(name) \
alloc_workqueue((name), WQ_FREEZABLE | WQ_UNBOUND | WQ_MEM_RECLAIM, 1)
#define create_singlethread_workqueue(name) \
alloc_workqueue((name), WQ_UNBOUND | WQ_MEM_RECLAIM, 1)
The parameter name is used to name the kernel threads (参见7.5.5 workqueue的初始化/init_workqueues()节的init_workqueues()). For example, the default events queue is created via
struct workqueue_struct *keventd_wq;
keventd_wq = create_workqueue(“events”);
7.5.2.1 alloc_workqueue()
通过宏alloc_workqueue()创建工作队列,其定义于include/linux/workqueue.h:
/*
* name: 工作队列的名字
* flags: 取值为include/linux/workqueue.h中WQ_*值,
* 参见Documentation/workqueue.txt中对各标志的介绍
* max_active: determines the maximum number of execution
* contexts per CPU which can be assigned to the work
* items of a wq.
*/
#ifdef CONFIG_LOCKDEP
#define alloc_workqueue(name, flags, max_active) \
({ \
static struct lock_class_key __key; \
const char *__lock_name; \
\
if (__builtin_constant_p(name)) \
__lock_name = (name); \
else \
__lock_name = #name; \
\
__alloc_workqueue_key((name), (flags), (max_active), \
&__key, __lock_name); \
})
#else
#define alloc_workqueue(name, flags, max_active) \
__alloc_workqueue_key((name), (flags), (max_active), NULL, NULL)
#endif
函数__alloc_workqueue_key()定义于kernel/workqueue.c:
static DEFINE_PER_CPU(struct global_cwq, global_cwq); // 每个CPU对应一个变量
static struct global_cwq unbound_global_cwq; // 全局变量
...
struct workqueue_struct *__alloc_workqueue_key(const char *name, unsigned int flags,
int max_active, struct lock_class_key *key,
const char *lock_name)
{
struct workqueue_struct *wq;
unsigned int cpu;
/*
* Workqueues which may be used during memory reclaim should
* have a rescuer to guarantee forward progress.
*/
if (flags & WQ_MEM_RECLAIM)
flags |= WQ_RESCUER;
/*
* Unbound workqueues aren't concurrency managed and should be
* dispatched to workers immediately.
*/
if (flags & WQ_UNBOUND)
flags |= WQ_HIGHPRI;
max_active = max_active ?: WQ_DFL_ACTIVE;
max_active = wq_clamp_max_active(max_active, flags, name);
// 为工作队列wq分配空间,并初始化
wq = kzalloc(sizeof(*wq), GFP_KERNEL);
if (!wq)
goto err;
wq->flags = flags;
wq->saved_max_active = max_active;
mutex_init(&wq->flush_mutex);
atomic_set(&wq->nr_cwqs_to_flush, 0);
INIT_LIST_HEAD(&wq->flusher_queue);
INIT_LIST_HEAD(&wq->flusher_overflow);
wq->name = name;
lockdep_init_map(&wq->lockdep_map, lock_name, key, 0);
INIT_LIST_HEAD(&wq->list);
// 为工作队列的成员wq->cpu_wq.pcpu或者wq->cpu_wq.single分配空间,并初始化
if (alloc_cwqs(wq) < 0)
goto err;
for_each_cwq_cpu(cpu, wq) {
// 返回wq->cpu_wq.single,或者对应CPU的变量wq->cpu_wq.pcpu
struct cpu_workqueue_struct *cwq = get_cwq(cpu, wq);
// 返回变量unbound_global_cwq的地址,或者对应CPU的变量global_cwq的地址
struct global_cwq *gcwq = get_gcwq(cpu);
BUG_ON((unsigned long)cwq & WORK_STRUCT_FLAG_MASK);
cwq->gcwq = gcwq;
cwq->wq = wq;
cwq->flush_color = -1;
cwq->max_active = max_active;
INIT_LIST_HEAD(&cwq->delayed_works);
}
if (flags & WQ_RESCUER) {
struct worker *rescuer;
/*
* 为wq->mayday_mask赋值,该值在rescuer_thread()使用,
* 参见[7.5.2.1.1 rescuer_thread()]节
*/
if (!alloc_mayday_mask(&wq->mayday_mask, GFP_KERNEL))
goto err;
// 为该工作队列分配worker
wq->rescuer = rescuer = alloc_worker();
if (!rescuer)
goto err;
/*
* 调用kthread_create()为该工作队列创建内核线程,
* 参见[7.2.4.4.1 kthread_run()]节;该线程将执行函数rescuer_thread(),
* 参见[7.5.2.1.1 rescuer_thread()]节,其入参为新创建的工作队列wq
*/
rescuer->task = kthread_create(rescuer_thread, wq, "%s", name);
if (IS_ERR(rescuer->task))
goto err;
rescuer->task->flags |= PF_THREAD_BOUND;
// 唤醒该内核线程,使之进入运行状态
wake_up_process(rescuer->task);
}
/*
* workqueue_lock protects global freeze state and workqueues
* list. Grab it, set max_active accordingly and add the new
* workqueue to workqueues list.
*/
spin_lock(&workqueue_lock);
if (workqueue_freezing && wq->flags & WQ_FREEZABLE)
for_each_cwq_cpu(cpu, wq)
get_cwq(cpu, wq)->max_active = 0;
/*
* 将新创建的工作队列wq添加到链表workqueues头部,
* 参见[7.5.1.3 struct workqueue_struct]节
*/
list_add(&wq->list, &workqueues);
spin_unlock(&workqueue_lock);
return wq;
err:
if (wq) {
free_cwqs(wq);
free_mayday_mask(wq->mayday_mask);
kfree(wq->rescuer);
kfree(wq);
}
return NULL;
}
7.5.2.1.1 rescuer_thread()
该函数定义于kernel/workqueue.c:
// __wq为struct workqueue_struct类型的对象
static int rescuer_thread(void *__wq)
{
struct workqueue_struct *wq = __wq;
struct worker *rescuer = wq->rescuer;
struct list_head *scheduled = &rescuer->scheduled;
bool is_unbound = wq->flags & WQ_UNBOUND;
unsigned int cpu;
set_user_nice(current, RESCUER_NICE_LEVEL);
repeat:
// 设置当前内核线程的状态为可中断状态
set_current_state(TASK_INTERRUPTIBLE);
if (kthread_should_stop())
return 0;
/*
* See whether any cpu is asking for help. Unbounded
* workqueues use cpu 0 in mayday_mask for CPU_UNBOUND.
*/
/*
* 在函数alloc_workqueue() -> alloc_mayday_mask()中
* 为变量wq->mayday_mask赋值,参见[7.5.2.1 alloc_workqueue()]节
*/
for_each_mayday_cpu(cpu, wq->mayday_mask) {
unsigned int tcpu = is_unbound ? WORK_CPU_UNBOUND : cpu;
// 返回wq->cpu_wq.single,或者对应CPU的变量wq->cpu_wq.pcpu
struct cpu_workqueue_struct *cwq = get_cwq(tcpu, wq);
struct global_cwq *gcwq = cwq->gcwq;
struct work_struct *work, *n;
__set_current_state(TASK_RUNNING);
mayday_clear_cpu(cpu, wq->mayday_mask);
/* migrate to the target cpu if possible */
rescuer->gcwq = gcwq;
worker_maybe_bind_and_lock(rescuer);
/*
* Slurp in all works issued via this workqueue and
* process'em.
*/
BUG_ON(!list_empty(&rescuer->scheduled));
// 循环&gcwq->worklist链表中的每个work元素
list_for_each_entry_safe(work, n, &gcwq->worklist, entry)
if (get_work_cwq(work) == cwq)
/*
* 将符合条件的work链接到scheduled链表(即rescuer->scheduled)中;
* 该链表在函数process_scheduled_works()中处理
*/
move_linked_works(work, scheduled, &n);
/*
* 处理链表rescuer->scheduled中的各work元素,
* 参见[7.5.5.1.1.1 process_scheduled_works()]节
*/
process_scheduled_works(rescuer);
/*
* Leave this gcwq. If keep_working() is %true, notify a
* regular worker; otherwise, we end up with 0 concurrency
* and stalling the execution.
*/
if (keep_working(gcwq))
wake_up_worker(gcwq); // 参见[7.5.2.1.1.2 wake_up_worker()]节
spin_unlock_irq(&gcwq->lock);
}
// 调度进程运行,参见[7.4.5 schedule()]节
schedule();
goto repeat;
}
7.5.2.1.1.1 process_scheduled_works()/process_one_work()
函数process_scheduled_works()定义于kernel/workqueue.c:
/**
* process_scheduled_works - process scheduled works
* @worker: self
*
* Process all scheduled works. Please note that the scheduled list
* may change while processing a work, so this function repeatedly
* fetches a work from the top and executes it.
*
* CONTEXT:
* spin_lock_irq(gcwq->lock) which may be released and regrabbed
* multiple times.
*/
static void process_scheduled_works(struct worker *worker)
{
while (!list_empty(&worker->scheduled)) {
struct work_struct *work = list_first_entry(&worker->scheduled,
struct work_struct, entry);
process_one_work(worker, work);
}
}
函数process_one_work()定义于kernel/workqueue.c:
/**
* process_one_work - process single work
* @worker: self
* @work: work to process
*
* Process @work. This function contains all the logics necessary to
* process a single work including synchronization against and
* interaction with other workers on the same cpu, queueing and
* flushing. As long as context requirement is met, any worker can
* call this function to process a work.
*
* CONTEXT:
* spin_lock_irq(gcwq->lock) which is released and regrabbed.
*/
static void process_one_work(struct worker *worker, struct work_struct *work)
__releases(&gcwq->lock)
__acquires(&gcwq->lock)
{
struct cpu_workqueue_struct *cwq = get_work_cwq(work);
struct global_cwq *gcwq = cwq->gcwq;
struct hlist_head *bwh = busy_worker_head(gcwq, work);
bool cpu_intensive = cwq->wq->flags & WQ_CPU_INTENSIVE;
work_func_t f = work->func;
int work_color;
struct worker *collision;
#ifdef CONFIG_LOCKDEP
/*
* It is permissible to free the struct work_struct from
* inside the function that is called from it, this we need to
* take into account for lockdep too. To avoid bogus "held
* lock freed" warnings as well as problems when looking into
* work->lockdep_map, make a copy and use that here.
*/
struct lockdep_map lockdep_map = work->lockdep_map;
#endif
/*
* A single work shouldn't be executed concurrently by
* multiple workers on a single cpu. Check whether anyone is
* already processing the work. If so, defer the work to the
* currently executing one.
*/
collision = __find_worker_executing_work(gcwq, bwh, work);
if (unlikely(collision)) {
// 如果已经有worker执行本work,则将该work移出列表
move_linked_works(work, &collision->scheduled, NULL);
return;
}
/* claim and process */
debug_work_deactivate(work);
hlist_add_head(&worker->hentry, bwh);
worker->current_work = work;
worker->current_cwq = cwq;
work_color = get_work_color(work);
/* record the current cpu number in the work data and dequeue */
set_work_cpu(work, gcwq->cpu);
list_del_init(&work->entry);
/*
* If HIGHPRI_PENDING, check the next work, and, if HIGHPRI,
* wake up another worker; otherwise, clear HIGHPRI_PENDING.
*/
if (unlikely(gcwq->flags & GCWQ_HIGHPRI_PENDING)) {
struct work_struct *nwork = list_first_entry(&gcwq->worklist, struct work_struct, entry);
if (!list_empty(&gcwq->worklist) && get_work_cwq(nwork)->wq->flags & WQ_HIGHPRI)
wake_up_worker(gcwq);
else
gcwq->flags &= ~GCWQ_HIGHPRI_PENDING;
}
/*
* CPU intensive works don't participate in concurrency
* management. They're the scheduler's responsibility.
*/
if (unlikely(cpu_intensive))
worker_set_flags(worker, WORKER_CPU_INTENSIVE, true);
spin_unlock_irq(&gcwq->lock);
// 复位work->data的标志位WORK_STRUCT_PENDING_BIT
work_clear_pending(work);
lock_map_acquire_read(&cwq->wq->lockdep_map);
lock_map_acquire(&lockdep_map);
trace_workqueue_execute_start(work);
f(work); // 执行work的处理函数work->func()
/*
* While we must be careful to not use "work" after this, the trace
* point will only record its address.
*/
trace_workqueue_execute_end(work);
lock_map_release(&lockdep_map);
lock_map_release(&cwq->wq->lockdep_map);
if (unlikely(in_atomic() || lockdep_depth(current) > 0)) {
printk(KERN_ERR "BUG: workqueue leaked lock or atomic: "
"%s/0x%08x/%d\n",
current->comm, preempt_count(), task_pid_nr(current));
printk(KERN_ERR " last function: ");
print_symbol("%s\n", (unsigned long)f);
debug_show_held_locks(current);
dump_stack();
}
spin_lock_irq(&gcwq->lock);
/* clear cpu intensive status */
if (unlikely(cpu_intensive))
worker_clr_flags(worker, WORKER_CPU_INTENSIVE);
/* we're done with it, release */
hlist_del_init(&worker->hentry);
worker->current_work = NULL;
worker->current_cwq = NULL;
cwq_dec_nr_in_flight(cwq, work_color, false);
}
7.5.2.1.1.2 wake_up_worker()
该函数定义于kernel/workqueue.c:
static void wake_up_worker(struct global_cwq *gcwq)
{
// 返回gcwq空闲链表中的第一个worker
struct worker *worker = first_worker(gcwq);
/*
* 唤醒worker所在的内核线程,该线程执行函数worker_thread(),
* 参见[7.5.5.1.1 worker_thread()]节
*/
if (likely(worker))
wake_up_process(worker->task);
}
static struct worker *first_worker(struct global_cwq *gcwq)
{
if (unlikely(list_empty(&gcwq->idle_list)))
return NULL;
return list_first_entry(&gcwq->idle_list, struct worker, entry);
}
7.5.3 释放workqueue
7.5.3.1 destroy_workqueue()
该函数定义于kernel/workqueue.c:
/**
* destroy_workqueue - safely terminate a workqueue
* @wq: target workqueue
*
* Safely destroy a workqueue. All work currently pending will be done first.
*/
void destroy_workqueue(struct workqueue_struct *wq)
{
unsigned int cpu;
/* drain it before proceeding with destruction */
drain_workqueue(wq);
/*
* wq list is used to freeze wq, remove from list after
* flushing is complete in case freeze races us.
*/
spin_lock(&workqueue_lock);
list_del(&wq->list);
spin_unlock(&workqueue_lock);
/* sanity check */
for_each_cwq_cpu(cpu, wq) {
struct cpu_workqueue_struct *cwq = get_cwq(cpu, wq);
int i;
for (i = 0; i < WORK_NR_COLORS; i++)
BUG_ON(cwq->nr_in_flight[i]);
BUG_ON(cwq->nr_active);
BUG_ON(!list_empty(&cwq->delayed_works));
}
if (wq->flags & WQ_RESCUER) {
kthread_stop(wq->rescuer->task);
free_mayday_mask(wq->mayday_mask);
kfree(wq->rescuer);
}
free_cwqs(wq);
kfree(wq);
}
7.5.4 调度work
7.5.4.1 schedule_work()
该函数定义于kernel/workqueue.c:
/*
* system_wq由初始化函数init_workqueues()创建,
* 参见[7.5.5 workqueue的初始化/init_workqueues()]节
*/
struct workqueue_struct *system_wq __read_mostly;
/**
* schedule_work - put work task in global workqueue
* @work: job to be done
*
* Returns zero if @work was already on the kernel-global workqueue and
* non-zero otherwise.
*
* This puts a job in the kernel-global workqueue if it was not already
* queued and leaves it in the same position on the kernel-global
* workqueue otherwise.
*/
int schedule_work(struct work_struct *work)
{
return queue_work(system_wq, work);
}
7.5.4.1.1 queue_work()
该函数定义于kernel/workqueue.c:
/**
* queue_work - queue work on a workqueue
* @wq: workqueue to use
* @work: work to queue
*
* Returns 0 if @work was already on a queue, non-zero otherwise.
*
* We queue the work to the CPU on which it was submitted, but if the CPU dies
* it can be processed by another CPU.
*/
int queue_work(struct workqueue_struct *wq, struct work_struct *work)
{
int ret;
ret = queue_work_on(get_cpu(), wq, work);
put_cpu();
return ret;
}
/**
* queue_work_on - queue work on specific cpu
* @cpu: CPU number to execute work on
* @wq: workqueue to use
* @work: work to queue
*
* Returns 0 if @work was already on a queue, non-zero otherwise.
*
* We queue the work to a specific CPU, the caller must ensure it
* can't go away.
*/
int queue_work_on(int cpu, struct workqueue_struct *wq, struct work_struct *work)
{
int ret = 0;
/*
* 若标志位WORK_STRUCT_PENDING_BIT未置位,表明该work还未链接到workqueue中,
* 则设置该标志位,并链接到workqueue中
*/
if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) {
// 参见[7.5.4.1.1.1 __queue_work()]节
__queue_work(cpu, wq, work);
ret = 1;
}
return ret;
}
7.5.4.1.1.1 __queue_work()
该函数将指定的work链接到workqueue中,其定义于kernel/workqueue.c:
static void __queue_work(unsigned int cpu, struct workqueue_struct *wq, struct work_struct *work)
{
struct global_cwq *gcwq;
struct cpu_workqueue_struct *cwq;
struct list_head *worklist;
unsigned int work_flags;
unsigned long flags;
debug_work_activate(work);
/* if dying, only works from the same workqueue are allowed */
// 标识位WQ_DRAINING在函数destroy_workqueue()->drain_workqueue()中被置位
if (unlikely(wq->flags & WQ_DRAINING) && WARN_ON_ONCE(!is_chained_work(wq)))
return;
/* determine gcwq to use */
if (!(wq->flags & WQ_UNBOUND)) {
struct global_cwq *last_gcwq;
if (unlikely(cpu == WORK_CPU_UNBOUND))
cpu = raw_smp_processor_id();
/*
* It's multi cpu. If @wq is non-reentrant and @work
* was previously on a different cpu, it might still
* be running there, in which case the work needs to
* be queued on that cpu to guarantee non-reentrance.
*/
/*
* 获取指定CPU的、类型为struct global_cwq的变量,
* 参见[7.5.1.3 struct workqueue_struct]节中的图
*/
gcwq = get_gcwq(cpu);
if (wq->flags & WQ_NON_REENTRANT &&
(last_gcwq = get_work_gcwq(work)) && last_gcwq != gcwq) {
struct worker *worker;
spin_lock_irqsave(&last_gcwq->lock, flags);
worker = find_worker_executing_work(last_gcwq, work);
if (worker && worker->current_cwq->wq == wq)
gcwq = last_gcwq;
else {
/* meh... not running there, queue here */
spin_unlock_irqrestore(&last_gcwq->lock, flags);
spin_lock_irqsave(&gcwq->lock, flags);
}
} else
spin_lock_irqsave(&gcwq->lock, flags);
} else {
/*
* 若wq->flags设置了标志位WQ_UNBOUND,
* 则gcwq = unbound_global_cwq
*/
gcwq = get_gcwq(WORK_CPU_UNBOUND);
spin_lock_irqsave(&gcwq->lock, flags);
}
/* gcwq determined, get cwq and queue */
cwq = get_cwq(gcwq->cpu, wq);
trace_workqueue_queue_work(cpu, cwq, work);
BUG_ON(!list_empty(&work->entry));
cwq->nr_in_flight[cwq->work_color]++;
work_flags = work_color_to_flags(cwq->work_color);
// worklist的取值与如下因素有关:1) 当前激活的work数目
if (likely(cwq->nr_active < cwq->max_active)) {
trace_workqueue_activate_work(work);
cwq->nr_active++;
// 2) cwq->flags中的优先级标志位
worklist = gcwq_determine_ins_pos(gcwq, cwq);
} else {
work_flags |= WORK_STRUCT_DELAYED;
worklist = &cwq->delayed_works;
}
// 将该work插入到链表worklist的尾部,参见[7.5.4.1.1.1.1 insert_work()]节
insert_work(cwq, work, worklist, work_flags);
spin_unlock_irqrestore(&gcwq->lock, flags);
}
7.5.4.1.1.1.1 insert_work()
该函数定义于kernel/workqueue.c:
/**
* insert_work - insert a work into gcwq
* @cwq: cwq @work belongs to
* @work: work to insert
* @head: insertion point
* @extra_flags: extra WORK_STRUCT_* flags to set
*
* Insert @work which belongs to @cwq into @gcwq after @head.
* @extra_flags is or'd to work_struct flags.
*
* CONTEXT:
* spin_lock_irq(gcwq->lock).
*/
static void insert_work(struct cpu_workqueue_struct *cwq,
struct work_struct *work, struct list_head *head,
unsigned int extra_flags)
{
struct global_cwq *gcwq = cwq->gcwq;
/* we own @work, set data and link */
// 设置work->data域;需要注意的是,data中包含了cwq地址的一部分
set_work_cwq(work, cwq, extra_flags);
/*
* Ensure that we get the right work->data if we see the
* result of list_add() below, see try_to_grab_pending().
*/
smp_wmb();
// 将work链接到链表末尾
list_add_tail(&work->entry, head);
/*
* Ensure either worker_sched_deactivated() sees the above
* list_add_tail() or we see zero nr_running to avoid workers
* lying around lazily while there are works to be processed.
*/
smp_mb();
// 若需要,唤醒第一个空闲的worker进程
if (__need_more_worker(gcwq))
wake_up_worker(gcwq);
}
7.5.4.2 schedule_delayed_work()
该函数定义于kernel/workqueue.c:
/*
* system_wq由初始化函数init_workqueues()创建,
* 参见[7.5.5 workqueue的初始化/init_workqueues()]节
*/
struct workqueue_struct *system_wq __read_mostly;
/**
* schedule_delayed_work - put work task in global workqueue after delay
* @dwork: job to be done
* @delay: number of jiffies to wait or 0 for immediate execution
*
* After waiting for a given time this puts a job in the kernel-global
* workqueue.
*/
int schedule_delayed_work(struct delayed_work *dwork, unsigned long delay)
{
return queue_delayed_work(system_wq, dwork, delay);
}
/**
* queue_delayed_work - queue work on a workqueue after delay
* @wq: workqueue to use
* @dwork: delayable work to queue
* @delay: number of jiffies to wait before queueing
*
* Returns 0 if @work was already on a queue, non-zero otherwise.
*/
int queue_delayed_work(struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay)
{
if (delay == 0)
return queue_work(wq, &dwork->work); // 参见[7.5.4.1.1 queue_work()]节
return queue_delayed_work_on(-1, wq, dwork, delay); // 参见[7.5.4.2.1 queue_delayed_work_on()]节
}
7.5.4.2.1 queue_delayed_work_on()
该函数定义于kernel/workqueue.c:
/**
* queue_delayed_work_on - queue work on specific CPU after delay
* @cpu: CPU number to execute work on
* @wq: workqueue to use
* @dwork: work to queue
* @delay: number of jiffies to wait before queueing
*
* Returns 0 if @work was already on a queue, non-zero otherwise.
*/
int queue_delayed_work_on(int cpu, struct workqueue_struct *wq,
struct delayed_work *dwork, unsigned long delay)
{
int ret = 0;
struct timer_list *timer = &dwork->timer;
struct work_struct *work = &dwork->work;
/*
* 若标志位WORK_STRUCT_PENDING_BIT未置位,表明该work还未链接到workqueue中,
* 则设置该标志位,并等待链接到特定链表中
*/
if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) {
unsigned int lcpu;
BUG_ON(timer_pending(timer));
BUG_ON(!list_empty(&work->entry));
timer_stats_timer_set_start_info(&dwork->timer);
/*
* This stores cwq for the moment, for the timer_fn.
* Note that the work's gcwq is preserved to allow
* reentrance detection for delayed works.
*/
if (!(wq->flags & WQ_UNBOUND)) {
struct global_cwq *gcwq = get_work_gcwq(work);
if (gcwq && gcwq->cpu != WORK_CPU_UNBOUND)
lcpu = gcwq->cpu;
else
lcpu = raw_smp_processor_id();
} else
lcpu = WORK_CPU_UNBOUND;
// 设置work->data域
set_work_cwq(work, get_cwq(lcpu, wq), 0);
/*
* 设置定时器,当定时器到时后,调用函数delayed_work_timer_fn(),
* 该函数将指定的work加入到链表中
*/
timer->expires = jiffies + delay;
// 函数delayed_work_timer_fn()的入参
timer->data = (unsigned long)dwork;
// 定时器处理函数,参见[7.5.4.2.1.1 delayed_work_timer_fn()]节
timer->function = delayed_work_timer_fn;
if (unlikely(cpu >= 0))
add_timer_on(timer, cpu); // 参见[7.7.2.1.2 add_timer_on()]节
else
add_timer(timer); // 参见[7.7.2.1.1 add_timer()]节
ret = 1;
}
return ret;
}
7.5.4.2.1.1 delayed_work_timer_fn()
该函数定义于kernel/workqueue.c:
static void delayed_work_timer_fn(unsigned long __data)
{
struct delayed_work *dwork = (struct delayed_work *)__data;
struct cpu_workqueue_struct *cwq = get_work_cwq(&dwork->work);
// 参见[7.5.4.1.1.1 __queue_work()]节
__queue_work(smp_processor_id(), cwq->wq, &dwork->work);
}
7.5.4.3 flush_schedule_work()
This function waits until all entries in the queue are executed before returning. While waiting for any pending work to execute, the function sleeps.Therefore, you can call it only from process context.
Note that this function does not cancel any delayed work.That is, any work that was scheduled via schedule_delayed_work(), and whose delay is not yet up, is not flushed via flush_scheduled_work(). To cancel delayed work, call:
int cancel_delayed_work(struct work_struct *work);
该函数定义于kernel/workqueue.c:
void flush_scheduled_work(void)
{
flush_workqueue(system_wq);
}
7.5.5 workqueue的初始化/init_workqueues()
在kernel/workqueue.c中,包含如下初始化函数:
struct workqueue_struct *system_wq __read_mostly;
struct workqueue_struct *system_long_wq __read_mostly;
struct workqueue_struct *system_nrt_wq __read_mostly;
struct workqueue_struct *system_unbound_wq __read_mostly;
struct workqueue_struct *system_freezable_wq __read_mostly;
...
static DEFINE_PER_CPU(struct global_cwq, global_cwq);
...
static int __init init_workqueues(void)
{
unsigned int cpu;
int i;
cpu_notifier(workqueue_cpu_callback, CPU_PRI_WORKQUEUE);
/* initialize gcwqs */
/*
* 依次获取每个CPU对应的变量global_cwq,并初始化之。
* 参见[7.5.1.3 struct workqueue_struct]节中的图
*/
for_each_gcwq_cpu(cpu) {
struct global_cwq *gcwq = get_gcwq(cpu);
spin_lock_init(&gcwq->lock);
INIT_LIST_HEAD(&gcwq->worklist);
gcwq->cpu = cpu;
gcwq->flags |= GCWQ_DISASSOCIATED;
INIT_LIST_HEAD(&gcwq->idle_list);
for (i = 0; i < BUSY_WORKER_HASH_SIZE; i++)
INIT_HLIST_HEAD(&gcwq->busy_hash[i]);
init_timer_deferrable(&gcwq->idle_timer);
gcwq->idle_timer.function = idle_worker_timeout;
gcwq->idle_timer.data = (unsigned long)gcwq;
setup_timer(&gcwq->mayday_timer, gcwq_mayday_timeout, (unsigned long)gcwq);
// 初始化数据结构,参见[15.5.1.2 struct ida]节
ida_init(&gcwq->worker_ida);
gcwq->trustee_state = TRUSTEE_DONE;
init_waitqueue_head(&gcwq->trustee_wait);
}
/* create the initial worker */
// 为每个CPU创建处理workqueue的内核线程worker,并启动该内核线程
for_each_online_gcwq_cpu(cpu) {
struct global_cwq *gcwq = get_gcwq(cpu);
struct worker *worker;
if (cpu != WORK_CPU_UNBOUND)
gcwq->flags &= ~GCWQ_DISASSOCIATED;
// 为每个CPU创建一个内核线程worker,参见[7.5.5.1 create_worker()]节
worker = create_worker(gcwq, true);
BUG_ON(!worker);
spin_lock_irq(&gcwq->lock);
start_worker(worker); // 启动worker对应的内核线程
spin_unlock_irq(&gcwq->lock);
}
// 调用alloc_workqueue()创建多个工作队列,参见[7.5.2.1 alloc_workqueue()]节
system_wq = alloc_workqueue("events", 0, 0);
system_long_wq = alloc_workqueue("events_long", 0, 0);
system_nrt_wq = alloc_workqueue("events_nrt", WQ_NON_REENTRANT, 0);
system_unbound_wq = alloc_workqueue("events_unbound", WQ_UNBOUND, WQ_UNBOUND_MAX_ACTIVE);
system_freezable_wq = alloc_workqueue("events_freezable", WQ_FREEZABLE, 0);
BUG_ON(!system_wq || !system_long_wq || !system_nrt_wq || !system_unbound_wq || !system_freezable_wq);
return 0;
}
early_initcall(init_workqueues);
在kernel/Makefile中,包含如下定义:
obj-y = sched.o fork.o exec_domain.o panic.o printk.o \
cpu.o exit.o itimer.o time.o softirq.o resource.o \
sysctl.o sysctl_binary.o capability.o ptrace.o timer.o user.o \
signal.o sys.o kmod.o workqueue.o pid.o \
rcupdate.o extable.o params.o posix-timers.o \
kthread.o wait.o kfifo.o sys_ni.o posix-cpu-timers.o mutex.o \
hrtimer.o rwsem.o nsproxy.o srcu.o semaphore.o \
notifier.o ksysfs.o sched_clock.o cred.o \
async.o range.o
由此可知,workqueue是被编译进内核的。由如下代码:
early_initcall(init_workqueues);
以及13.5.1.1 module被编译进内核时的初始化过程节可知,系统启动时,workqueue的初始化过程如下:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcallearly.init
7.5.5.1 create_worker()
该函数定义于kernel/workqueue.c:
/**
* create_worker - create a new workqueue worker
* @gcwq: gcwq the new worker will belong to
* @bind: whether to set affinity to @cpu or not
*
* Create a new worker which is bound to @gcwq. The returned worker
* can be started by calling start_worker() or destroyed using
* destroy_worker().
*
* CONTEXT:
* Might sleep. Does GFP_KERNEL allocations.
*
* RETURNS:
* Pointer to the newly created worker.
*/
static struct worker *create_worker(struct global_cwq *gcwq, bool bind)
{
bool on_unbound_cpu = gcwq->cpu == WORK_CPU_UNBOUND;
struct worker *worker = NULL;
int id = -1;
spin_lock_irq(&gcwq->lock);
// 调用ida_get_new()分配新的worker ID,参见[15.5.1.2 struct ida]节
while (ida_get_new(&gcwq->worker_ida, &id)) {
spin_unlock_irq(&gcwq->lock);
if (!ida_pre_get(&gcwq->worker_ida, GFP_KERNEL))
goto fail;
spin_lock_irq(&gcwq->lock);
}
spin_unlock_irq(&gcwq->lock);
// 分配并初始化worker,参见[7.5.1.6 struct worker]节
worker = alloc_worker();
if (!worker)
goto fail;
worker->gcwq = gcwq;
worker->id = id;
/*
* 创建worker内核线程(参见[7.2.4.4.1 kthread_run()]节),该线程
* 执行函数worker_thread(),参见[7.5.5.1.1 worker_thread()]节
*/
if (!on_unbound_cpu)
worker->task = kthread_create_on_node(worker_thread, worker, cpu_to_node(gcwq->cpu),
"kworker/%u:%d", gcwq->cpu, id);
else
worker->task = kthread_create(worker_thread, worker, "kworker/u:%d", id);
if (IS_ERR(worker->task))
goto fail;
/*
* A rogue worker will become a regular one if CPU comes
* online later on. Make sure every worker has
* PF_THREAD_BOUND set.
*/
if (bind && !on_unbound_cpu)
kthread_bind(worker->task, gcwq->cpu);
else {
worker->task->flags |= PF_THREAD_BOUND;
if (on_unbound_cpu)
worker->flags |= WORKER_UNBOUND;
}
return worker;
fail:
if (id >= 0) {
spin_lock_irq(&gcwq->lock);
ida_remove(&gcwq->worker_ida, id);
spin_unlock_irq(&gcwq->lock);
}
kfree(worker);
return NULL;
}
7.5.5.1.1 worker_thread()
线程worker被函数wake_up_worker()唤醒(参见7.5.2.1.1.2 wake_up_worker()节),并执行函数worker_thread(),其定义于kernel/workqueue.c:
/**
* worker_thread - the worker thread function
* @__worker: self
*
* The gcwq worker thread function. There's a single dynamic pool of
* these per each cpu. These workers process all works regardless of
* their specific target workqueue. The only exception is works which
* belong to workqueues with a rescuer which will be explained in
* rescuer_thread().
*/
static int worker_thread(void *__worker)
{
struct worker *worker = __worker;
struct global_cwq *gcwq = worker->gcwq;
/* tell the scheduler that this is a workqueue worker */
worker->task->flags |= PF_WQ_WORKER;
woke_up:
spin_lock_irq(&gcwq->lock);
/* DIE can be set only while we're idle, checking here is enough */
if (worker->flags & WORKER_DIE) {
spin_unlock_irq(&gcwq->lock);
worker->task->flags &= ~PF_WQ_WORKER;
return 0;
}
worker_leave_idle(worker);
recheck:
/* no more worker necessary? */
if (!need_more_worker(gcwq))
goto sleep;
/* do we need to manage? */
if (unlikely(!may_start_working(gcwq)) && manage_workers(worker))
goto recheck;
/*
* ->scheduled list can only be filled while a worker is
* preparing to process a work or actually processing it.
* Make sure nobody diddled with it while I was sleeping.
*/
BUG_ON(!list_empty(&worker->scheduled));
/*
* When control reaches this point, we're guaranteed to have
* at least one idle worker or that someone else has already
* assumed the manager role.
*/
worker_clr_flags(worker, WORKER_PREP);
do {
// 取得work结构,参见[7.5.1.3 struct workqueue_struct]节中的图
struct work_struct *work = list_first_entry(&gcwq->worklist, struct work_struct, entry);
if (likely(!(*work_data_bits(work) & WORK_STRUCT_LINKED))) {
/* optimization path, not strictly necessary */
process_one_work(worker, work); // 参见[7.5.5.1.1.1.1 process_one_work()]节
if (unlikely(!list_empty(&worker->scheduled)))
process_scheduled_works(worker); // 参见[7.5.5.1.1.1 process_scheduled_works()]节
} else {
move_linked_works(work, &worker->scheduled, NULL);
process_scheduled_works(worker); // 参见[7.5.5.1.1.1 process_scheduled_works()]节
}
} while (keep_working(gcwq));
worker_set_flags(worker, WORKER_PREP, false);
sleep:
if (unlikely(need_to_manage_workers(gcwq)) && manage_workers(worker))
goto recheck;
/*
* gcwq->lock is held and there's no work to process and no
* need to manage, sleep. Workers are woken up only while
* holding gcwq->lock or from local cpu, so setting the
* current state before releasing gcwq->lock is enough to
* prevent losing any event.
*/
worker_enter_idle(worker);
__set_current_state(TASK_INTERRUPTIBLE);
spin_unlock_irq(&gcwq->lock);
schedule();
goto woke_up;
}
7.5.5.1.1.1 process_scheduled_works()
该函数处理worker->scheduled链表上的work,其定义于kernel/workqueue.c:
/**
* process_scheduled_works - process scheduled works
* @worker: self
*
* Process all scheduled works. Please note that the scheduled list
* may change while processing a work, so this function repeatedly
* fetches a work from the top and executes it.
*
* CONTEXT:
* spin_lock_irq(gcwq->lock) which may be released and regrabbed
* multiple times.
*/
static void process_scheduled_works(struct worker *worker)
{
while (!list_empty(&worker->scheduled)) {
struct work_struct *work = list_first_entry(&worker->scheduled, struct work_struct, entry);
process_one_work(worker, work); // 参见[7.5.5.1.1.1.1 process_one_work()]节
}
}
7.5.5.1.1.1.1 process_one_work()
该函数用于处理指定的work,其定义于kernel/workqueue.c:
/**
* process_one_work - process single work
* @worker: self
* @work: work to process
*
* Process @work. This function contains all the logics necessary to
* process a single work including synchronization against and
* interaction with other workers on the same cpu, queueing and
* flushing. As long as context requirement is met, any worker can
* call this function to process a work.
*
* CONTEXT:
* spin_lock_irq(gcwq->lock) which is released and regrabbed.
*/
static void process_one_work(struct worker *worker, struct work_struct *work)
__releases(&gcwq->lock)
__acquires(&gcwq->lock)
{
struct cpu_workqueue_struct *cwq = get_work_cwq(work);
struct global_cwq *gcwq = cwq->gcwq;
struct hlist_head *bwh = busy_worker_head(gcwq, work);
bool cpu_intensive = cwq->wq->flags & WQ_CPU_INTENSIVE;
work_func_t f = work->func;
int work_color;
struct worker *collision;
#ifdef CONFIG_LOCKDEP
/*
* It is permissible to free the struct work_struct from
* inside the function that is called from it, this we need to
* take into account for lockdep too. To avoid bogus "held
* lock freed" warnings as well as problems when looking into
* work->lockdep_map, make a copy and use that here.
*/
struct lockdep_map lockdep_map = work->lockdep_map;
#endif
/*
* A single work shouldn't be executed concurrently by
* multiple workers on a single cpu. Check whether anyone is
* already processing the work. If so, defer the work to the
* currently executing one.
*/
collision = __find_worker_executing_work(gcwq, bwh, work);
if (unlikely(collision)) {
move_linked_works(work, &collision->scheduled, NULL);
return;
}
/* claim and process */
debug_work_deactivate(work);
hlist_add_head(&worker->hentry, bwh);
worker->current_work = work;
worker->current_cwq = cwq;
work_color = get_work_color(work);
/* record the current cpu number in the work data and dequeue */
set_work_cpu(work, gcwq->cpu);
list_del_init(&work->entry);
/*
* If HIGHPRI_PENDING, check the next work, and, if HIGHPRI,
* wake up another worker; otherwise, clear HIGHPRI_PENDING.
*/
if (unlikely(gcwq->flags & GCWQ_HIGHPRI_PENDING)) {
struct work_struct *nwork = list_first_entry(&gcwq->worklist, struct work_struct, entry);
if (!list_empty(&gcwq->worklist) && get_work_cwq(nwork)->wq->flags & WQ_HIGHPRI)
wake_up_worker(gcwq);
else
gcwq->flags &= ~GCWQ_HIGHPRI_PENDING;
}
/*
* CPU intensive works don't participate in concurrency
* management. They're the scheduler's responsibility.
*/
if (unlikely(cpu_intensive))
worker_set_flags(worker, WORKER_CPU_INTENSIVE, true);
spin_unlock_irq(&gcwq->lock);
work_clear_pending(work);
lock_map_acquire_read(&cwq->wq->lockdep_map);
lock_map_acquire(&lockdep_map);
trace_workqueue_execute_start(work);
f(work); // 执行处理函数
/*
* While we must be careful to not use "work" after this, the trace
* point will only record its address.
*/
trace_workqueue_execute_end(work);
lock_map_release(&lockdep_map);
lock_map_release(&cwq->wq->lockdep_map);
if (unlikely(in_atomic() || lockdep_depth(current) > 0)) {
printk(KERN_ERR "BUG: workqueue leaked lock or atomic: %s/0x%08x/%d\n",
current->comm, preempt_count(), task_pid_nr(current));
printk(KERN_ERR " last function: ");
print_symbol("%s\n", (unsigned long)f);
debug_show_held_locks(current);
dump_stack();
}
spin_lock_irq(&gcwq->lock);
/* clear cpu intensive status */
if (unlikely(cpu_intensive))
worker_clr_flags(worker, WORKER_CPU_INTENSIVE);
/* we're done with it, release */
hlist_del_init(&worker->hentry);
worker->current_work = NULL;
worker->current_cwq = NULL;
cwq_dec_nr_in_flight(cwq, work_color, false);
}
7.5.6 创建work示例
源代码wqueue.c如下:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/workqueue.h>
MODULE_LICENSE("GPL");
void *wq_process(struct work_struct *work)
{
printk("start workqueue process\n");
printk("work->data: %d\n", work->data);
printk("work->func: %p\n", work->func);
printk("Add of wq_process(): %p\n", wq_process);
return 0;
}
DECLARE_WORK(my_work, wq_process);
static int __init wq_init(void)
{
printk("workqueue module init\n");
schedule_work(&my_work);
return 0;
}
static void __exit wq_exit(void)
{
printk("workqueue module exit\n");
}
module_init(wq_init);
module_exit(wq_exit);
编译wqueue.c所用的Makefile如下:
obj-m := wqueue.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
make -C $(KDIR) M=$(PWD) modules
clean:
rm *.o *.ko *.mod.c Modules.symvers modules.order -f
执行命令的过程如下:
chenwx@chenwx ~/alex/module/workqueue $ sudo insmod wqueue.ko
chenwx@chenwx ~/alex/module/workqueue $ lsmod
Module Size Used by
wqueue 12441 0
vboxsf 42503 0
...
chenwx@chenwx ~/alex/module/workqueue $ dmesg | tail
...
[45988.104743] work->data: 0
[45988.104752] work->func: e19c4000
[45988.104758] Add of wq_process(): e19c4000
chenwx@chenwx ~/alex/module/workqueue $ sudo rmmod wqueue
chenwx@chenwx ~/alex/module/workqueue $ dmesg | tail
...
[45988.104743] work->data: 0
[45988.104752] work->func: e19c4000
[45988.104758] Add of wq_process(): e19c4000
[46161.764209] workqueue module exit
7.6 Time Management
7.6.1 The Tick Rate: HZ
The frequency of the system timer (the tick rate) is programmed on system boot based on a static preprocessor define, HZ. The value of HZ differs for each supported architecture. On some supported architectures, it even differs between machine types.
The tick rate has a frequency of HZ hertz and a period of 1/HZ seconds.
在arch/x86/include/asm/param.h中,包含如下内容:
#include <asm-generic/param.h>
而在include/asm-generic/param.h中,包含HZ的定义:
#ifdef __KERNEL__
# define HZ CONFIG_HZ /* Internal kernel timer frequency */
# define USER_HZ 100 /* some user interfaces are */
# define CLOCKS_PER_SEC (USER_HZ) /* in "ticks" like times() */
#endif
#ifndef HZ
#define HZ 100
#endif
CONFIG_HZ的配置文件为kernel/Kconfig.hz,其对应的配置选项为:
Processor type and features --->
Timer frequency (250 HZ) ---> // CONFIG_HZ
( ) 100 HZ // CONFIG_HZ_100
(X) 250 HZ // CONFIG_HZ_250
( ) 300 HZ // CONFIG_HZ_300
( ) 1000 HZ // CONFIG_HZ_1000
若CONFIG_HZ=250,则tick rate为250Hz,即每个tick时长为:1/250 = 4 ms
7.6.2 Jiffies
The global variable jiffies holds the number of ticks that have occurred since the system booted. On boot, the kernel initializes the variable to zero, and it is incremented by one during each timer interrupt. Thus, because there are HZ timer interrupts in a second, there are HZ jiffies in a second. The system uptime (see /proc/uptime) is therefore jiffies/HZ seconds.
在函数do_timer()中更新jiffies,参见7.6.4.2.1.2.1 do_timer()节。
在include/linux/jiffies.h中,包含如下变量声明:
/*
* some arch's have a small-data section that can be accessed register-relative
* but that can only take up to, say, 4-byte variables. jiffies being part of
* an 8-byte variable may not be correctly accessed unless we force the issue
*/
#define __jiffy_data __attribute__((section(".data")))
/*
* The 64-bit value is not atomic - you MUST NOT read it
* without sampling the sequence number in xtime_lock.
* get_jiffies_64() will do this for you as appropriate.
*/
extern u64 __jiffy_data jiffies_64;
extern unsigned long volatile __jiffy_data jiffies;
在arch/x86/kernel/vmlinux.lds.S中,包含如下内容:
#ifdef CONFIG_X86_32
OUTPUT_ARCH(i386)
ENTRY(phys_startup_32)
jiffies = jiffies_64;
#else
OUTPUT_ARCH(i386:x86-64)
ENTRY(phys_startup_64)
jiffies_64 = jiffies;
#endif
The ld scripts vmlinux.lds.S overlays the jiffies variable over the start of the jiffies_64 variable: jiffies = jiffies_64;
Thus, jiffies is the lower 32 bits of the full 64-bit jiffies_64 variable. The layout of jiffies and jiffies_64:
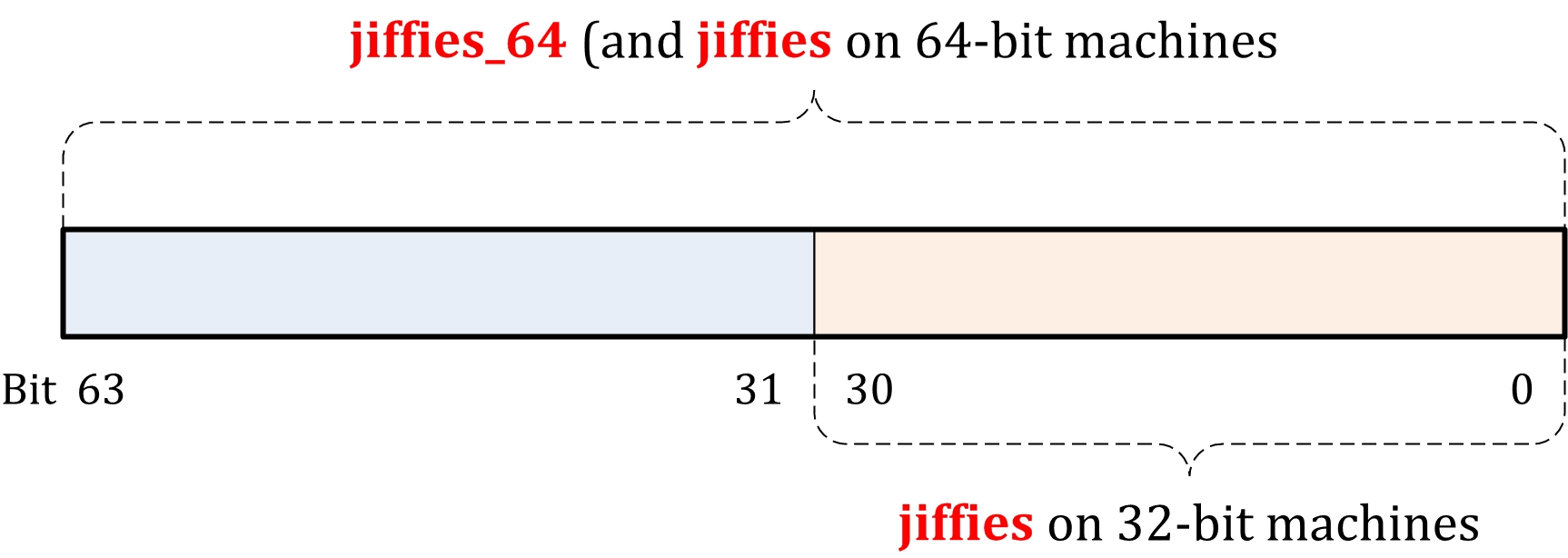
在kernel/timer.c中,包含jiffies_64的定义:
u64 jiffies_64 __cacheline_aligned_in_smp = INITIAL_JIFFIES;
其中,INITIAL_JIFFIES定义于include/linux/jiffies.h:
/*
* Have the 32 bit jiffies value wrap 5 minutes after boot
* so jiffies wrap bugs show up earlier.
*/
#define INITIAL_JIFFIES ((unsigned long)(unsigned int) (-300*HZ))
The kernel initializes jiffies to a special initial value INITIAL_JIFFIES, causing the variable to overflow more often, catching bugs. When the actual value of jiffies is sought, this “offset” is first subtracted. See method sched_clock() in kernel/sched_clock.c:
/*
* Scheduler clock - returns current time in nanosec units.
* This is default implementation.
* Architectures and sub-architectures can override this.
*/
unsigned long long __attribute__((weak)) sched_clock(void)
{
return (unsigned long long)(jiffies - INITIAL_JIFFIES) * (NSEC_PER_SEC / HZ);
}
NOTE 1: You might wonder why jiffies has not been directly declared as a 64-bit unsigned long long integer on the 80×86 architecture. The answer is that accesses to 64-bit variables in 32-bit architectures cannot be done atomically. Therefore, every read operation on the whole 64 bits requires some synchronization technique to ensure that the counter is not updated while the two 32-bit half-counters are read; as a consequence, every 64-bit read operation is significantly slower than a 32-bit read operation.
NOTE 2: Needless to say, both jiffies and jiffies_64 must be considered read-only.
7.6.2.1 获得Jiffies的取值
On 32-bit architectures, code that accesses jiffies simply reads the lower 32 bits of jiffies_64. The function get_jiffies_64() can be used to read the full 64-bit value.
On 64-bit architectures, jiffies_64 and jiffies refer to the same thing. Code can either read jiffies or call get_jiffies_64() as both actions have the same effect.
函数get_jiffies_64()声明/定义于include/linux/jiffies.h:
#if (BITS_PER_LONG < 64)
u64 get_jiffies_64(void);
#else
static inline u64 get_jiffies_64(void)
{
return (u64)jiffies;
}
#endif
和kernel/time/jiffies.c:
#if (BITS_PER_LONG < 64)
u64 get_jiffies_64(void)
{
unsigned long seq;
u64 ret;
do {
seq = read_seqbegin(&xtime_lock); // 参见[16.5.3.1 read_seqbegin()]节
ret = jiffies_64;
} while (read_seqretry(&xtime_lock, seq)); // 参见[16.5.3.2 read_seqretry()]节
return ret;
}
#endif
7.6.2.2 比较Jiffies的大小
在include/linux/jiffies.h中,包含如下用于比较jiffies大小的宏:
/*
* These inlines deal with timer wrapping correctly. You are
* strongly encouraged to use them
* 1. Because people otherwise forget
* 2. Because if the timer wrap changes in future you won't have to
* alter your driver code.
*
* time_after(a,b) returns true if the time a is after time b.
*
* Do this with "<0" and ">=0" to only test the sign of the result. A
* good compiler would generate better code (and a really good compiler
* wouldn't care). Gcc is currently neither.
*/
#define time_after(a,b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)(b) - (long)(a) < 0))
#define time_before(a,b) time_after(b,a)
#define time_after_eq(a,b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)(a) - (long)(b) >= 0))
#define time_before_eq(a,b) time_after_eq(b,a)
/*
* These four macros compare jiffies and 'a' for convenience.
*/
/* time_is_before_jiffies(a) return true if a is before jiffies */
#define time_is_before_jiffies(a) time_after(jiffies, a)
/* time_is_after_jiffies(a) return true if a is after jiffies */
#define time_is_after_jiffies(a) time_before(jiffies, a)
/* time_is_before_eq_jiffies(a) return true if a is before or equal to jiffies*/
#define time_is_before_eq_jiffies(a) time_after_eq(jiffies, a)
/* time_is_after_eq_jiffies(a) return true if a is after or equal to jiffies*/
#define time_is_after_eq_jiffies(a) time_before_eq(jiffies, a)
7.6.2.2.1 Jiffies的溢出
以time_after(a,b)为例,入参为unsigned long类型,在比较大小时先将其转变为long类型:
#define time_after(a,b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)(b) - (long)(a) < 0))
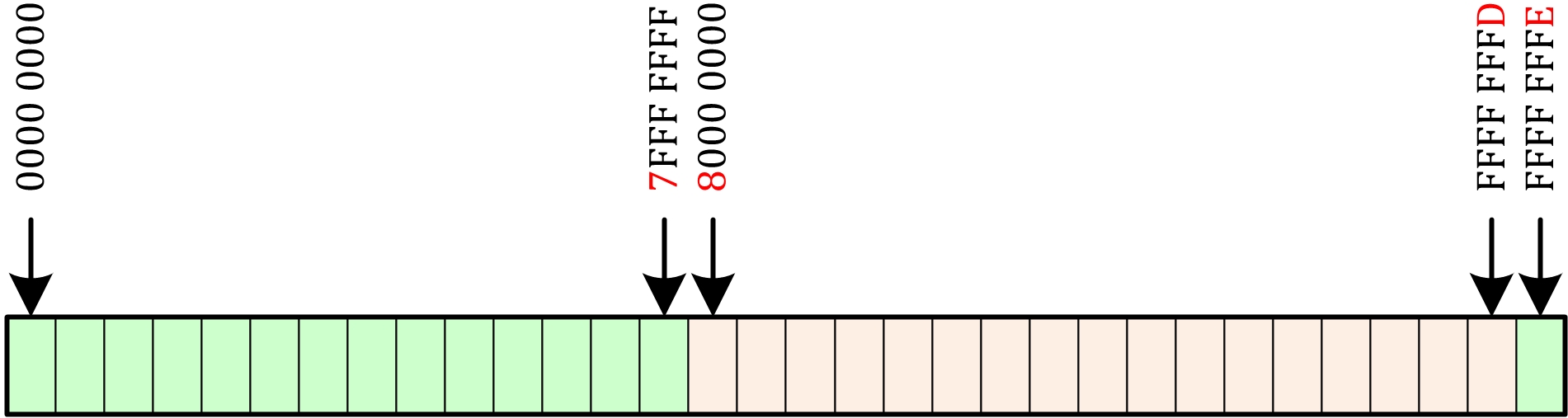
上图中,每个方格表示一个unsigned long类型的数值。当b = 0xFFFF
- 若a取浅绿色方格内的数值,则time_after(a, b)返回的结果为True,正确
- 若a取浅红色方格内的数值,则time_after(a, b)返回的结果为False,错误
因此,只有当a与b之差的绝对值小于0x8000 0000时,这些宏才能返回正确结果,否则结果是错误的。若HZ = 250,则0x8000 0000表示0x8000 0000 / HZ = 0x0083 126E秒(即99天),而内核代码中,用这些宏比较的两个值之差不会超过99天,因此可以安全使用。
7.6.2.3 Jiffies与时间的转换
在include/linux/jiffies.h中,包含如下时间与Jiffies之间的转换函数:
/*
* jiffies <=> microseconds (毫秒: 1/1000s)
*/
extern unsigned int jiffies_to_msecs(const unsigned long j);
extern unsigned long msecs_to_jiffies(const unsigned int m);
/*
* jiffies <=> useconds (微秒: 1/1000000s)
*/
extern unsigned int jiffies_to_usecs(const unsigned long j);
extern unsigned long usecs_to_jiffies(const unsigned int u);
/*
* jiffies <=> nanoseconds (纳秒: 1/1000000000s)
*/
extern u64 nsec_to_clock_t(u64 x);
extern u64 nsecs_to_jiffies64(u64 n);
extern unsigned long nsecs_to_jiffies(u64 n);
/*
* jiffies <=> struct timeval (seconds and microseconds)
*/
extern void jiffies_to_timeval(const unsigned long jiffies, struct timeval *value);
extern unsigned long timeval_to_jiffies(const struct timeval *value);
/*
* jiffies <=> struct timespec (seconds and nanoseconds)
*/
extern void jiffies_to_timespec(const unsigned long jiffies, struct timespec *value);
extern unsigned long timespec_to_jiffies(const struct timespec *value);
/*
* jiffies <=> clock_t
*/
extern clock_t jiffies_to_clock_t(unsigned long x);
extern unsigned long clock_t_to_jiffies(unsigned long x);
extern u64 jiffies_64_to_clock_t(u64 x);
7.6.3 xtime
The xtime variable stores the current time and date. 其定义于kernel/time/timekeeping.c:
__cacheline_aligned_in_smp DEFINE_SEQLOCK(xtime_lock);
static struct timespec xtime __attribute__ ((aligned (16)));
变量xtime由函数update_wall_time()更新,参见7.6.4.2.1.2.1 do_timer()节。
The current time is also available (though with jiffy granularity) from the xtime variable, a struct timespec value. Direct use of this variable is discouraged because it is difficult to atomically access both the fields. Therefore, the kernel offers the utility function:
#include <linux/time.h>
struct timespec current_kernel_time(void);
7.6.3.1 struct timespec / struct timespec64
struct timespec定义于include/linux/time.h:
#ifndef _STRUCT_TIMESPEC
#define _STRUCT_TIMESPEC
struct timespec {
/*
* Stores the number of seconds that have
* elapsed since midnight of January 1, 1970 (UTC)
*/
__kernel_time_t tv_sec; /* seconds */
/*
* Stores the number of nanoseconds that have
* elapsed within the last second; its value
* ranges between 0 and 999,999,999
*/
long tv_nsec; /* nanoseconds */
};
#endif
struct timespec64定义于include/linux/time64.h:
typedef __s64 time64_t;
/*
* This wants to go into uapi/linux/time.h once we agreed about the
* userspace interfaces.
*/
#if __BITS_PER_LONG == 64
# define timespec64 timespec
#else
struct timespec64 {
time64_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
#endif
7.6.3.2 struct timeval
struct timeval定义于include/linux/time.h:
struct timeval {
__kernel_time_t tv_sec; /* seconds */
__kernel_suseconds_t tv_usec; /* microseconds */
};
7.6.4 Hardware Clocks and Timers
7.6.4.1 Real-Time Clock (RTC)
The real-time clock (RTC) provides a nonvolatile device for storing the system time. The RTC continues to keep track of time even when the system is off by way of a small battery typically included on the system board.
On boot, the kernel reads the RTC and uses it to initialize the wall time, which is stored in the xtime variable. Nonetheless, the real time clock’s primary importance is only during boot, when the xtime variable is initialized.
7.6.4.2 System Timer
The system timer serves a much more important (and frequent) role in the kernel’s timekeeping. The idea behind the system timer, regardless of architecture, is the same - to provide a mechanism for driving an interrupt at a periodic rate.
On x86, the primary system timer is the programmable interrupt timer (PIT). The PIT exists on all PC machines and has been driving interrupts since the days of DOS. The kernel programs the PIT on boot to drive the system timer interrupt (interrupt zero) at HZ frequency. It is a simple device with limited functionality, but it gets the job done. Other x86 time sources include the local APIC timer and the processor’s time stamp counter (TSC).
7.6.4.2.1 Timer Interrupt Handler
The timer interrupt is broken into two pieces: an architecture-dependent and an architecture-independent routine.
7.6.4.2.1.1 Architecture-dependent routine / tick_handle_periodic()
PIT: Programmable Interrupt Timer
在x86体系架构下,通过7.6.4.2.1.1.1 tick_init()节至7.6.4.2.1.1.3 late_time_init()节将PIT的处理函数设置为tick_handle_periodic()。通过7.6.4.2.1.1.4 timer_interrupt()节执行该函数。
在系统启动时,函数start_kernel()通过调用如下函数设置PIT的处理函数:
asmlinkage void __init start_kernel(void)
{
...
tick_init(); // 参见[7.6.4.2.1.1.1 tick_init()]节
...
time_init(); // 参见[7.6.4.2.1.1.2 time_init()]节
...
if (late_time_init)
late_time_init(); // 参见[7.6.4.2.1.1.3 late_time_init()]节
...
}
7.6.4.2.1.1.1 tick_init()
函数tick_init()用于将tick_notifier注册到链表clockevents_chain中,其调用关系如下:
tick_init() // 参见kernel/time/tick-common.c
-> clockevents_register_notifier(&tick_notifier)
-> raw_notifier_chain_register(&clockevents_chain, nb) // nb = &tick_notifier
-> notifier_chain_register(&nh->head, n) // nh = &clockevents_chain
// n = &tick_notifier
变量tick_notifier定义于kernel/time/tick-common.c:
static struct notifier_block tick_notifier = {
.notifier_call = tick_notify,
};
链表clockevents_chain的结构:
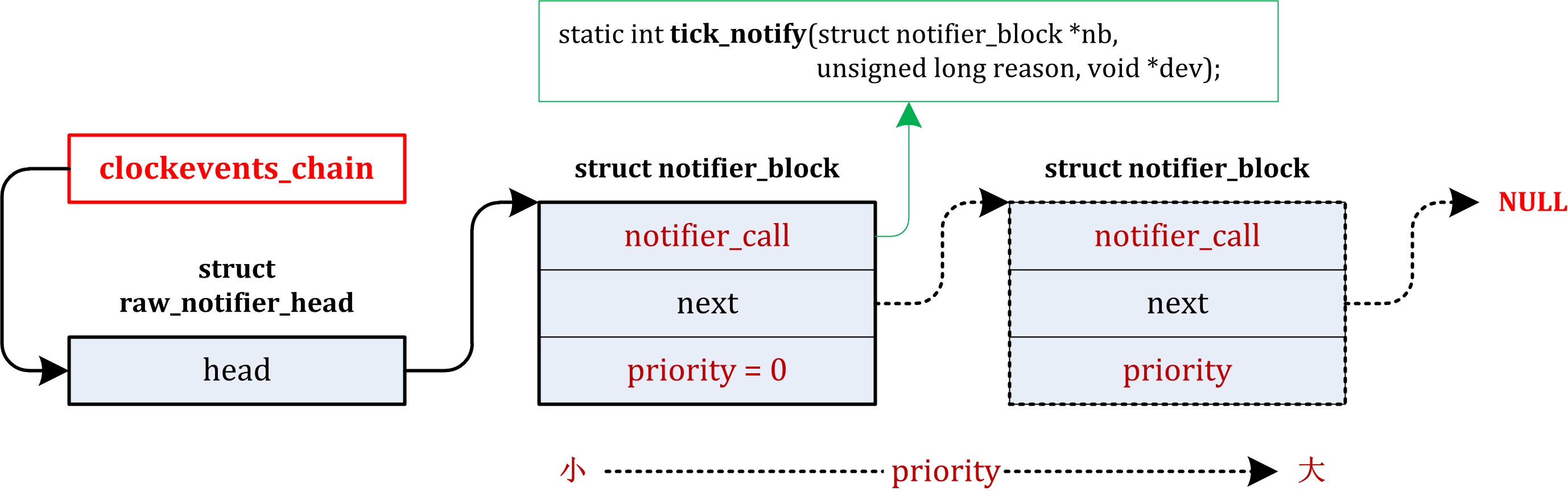
7.6.4.2.1.1.2 time_init()
该函数定义于arch/x86/kernel/time.c:
/* Default late time init is NULL. archs can override this later. */
void (*__initdata late_time_init)(void);
void __init time_init(void)
{
// 在[7.6.4.2.1.1.3 late_time_init()]节调用late_time_init(),即调用x86_late_time_init()
late_time_init = x86_late_time_init;
}
7.6.4.2.1.1.3 late_time_init()
由7.6.4.2.1.1.2 time_init()节可知,late_time_init被设置为x86_late_time_init(),而该函数定义于arch/x86/kernel/time.c:
static __init void x86_late_time_init(void)
{
x86_init.timers.timer_init();
tsc_init();
}
其中,变量x86_init定义于arch/x86/kernel/x86_init.c:
struct x86_init_ops x86_init __initdata = {
...
.timers = {
.setup_percpu_clockev = setup_boot_APIC_clock,
.tsc_pre_init = x86_init_noop,
.timer_init = hpet_time_init,
.wallclock_init = x86_init_noop,
},
...
};
因而调用x86_init.timers.timer_init()就是调用函数hpet_time_init(),其定义于arch/x86/kernel/time.c:
void __init hpet_time_init(void)
{
if (!hpet_enable()) // 此处,假设没有启用High Precision Event Timer (HPET)
setup_pit_timer(); // 参见[7.6.4.2.1.1.3.1 setup_pit_timer()]节
setup_default_timer_irq(); // 参见[7.6.4.2.1.1.3.2 setup_default_timer_irq()]节
}
7.6.4.2.1.1.3.1 setup_pit_timer()
该函数定义于arch/x86/kernel/i8253.c:
struct clock_event_device *global_clock_event;
void __init setup_pit_timer(void)
{
/*
* 将i8253_clockevent.event_handler设置为tick_handle_periodic,
* 参见[7.6.4.2.1.1.3.1.1 clockevent_i8253_init()]节
*/
clockevent_i8253_init(true);
/*
* 在timer_interrupt()中,通过变量global_clock_event调用函数
* tick_handle_periodic(),参见[7.6.4.2.1.1.4 timer_interrupt()]节
*/
global_clock_event = &i8253_clockevent;
}
7.6.4.2.1.1.3.1.1 clockevent_i8253_init()
该函数定义于drivers/clocksource/i8253.c,其调用关系如下:
clockevent_i8253_init(true)
-> i8253_clockevent.features |= CLOCK_EVT_FEAT_ONESHOT;
-> clockevents_config_and_register(&i8253_clockevent, PIT_TICK_RATE, 0xF, 0x7FFF)
-> clockevents_register_device(dev) // dev = &i8253_clockevent
// 将i8253_clockevent添加到链表clockevent_devices
-> list_add(&dev->list, &clockevent_devices);
-> clockevents_do_notify(CLOCK_EVT_NOTIFY_ADD, dev); // dev = &i8253_clockevent
函数clockevents_do_notify()将指定设备的event_handler设置为tick_handle_periodic(),此处即:
i8253_clockevent.event_handler = tick_handle_periodic;
其调用关系如下:
clockevents_do_notify(CLOCK_EVT_NOTIFY_ADD, dev); // dev = &i8253_clockevent
-> raw_notifier_call_chain(&clockevents_chain, reason, dev) // reason = CLOCK_EVT_NOTIFY_ADD
-> __raw_notifier_call_chain(nh, val, v, -1, NULL) // nh = &clockevents_chain
-> notifier_call_chain(&nh->head, val, v, nr_to_call, nr_calls)
-> nb->notifier_call(nb, val, v)
由于7.6.4.2.1.1.1 tick_init()节可知,链表clockevents_chain中的第一个元素为tick_notifier,且:
tick_notifier->notifier_call = tick_notify;
故,调用nb->notifier_call(nb, val, v)就是调用:
tick_notifier->notifier_call(&tick_notifier, CLOCK_EVT_NOTIFY_ADD, &i8253_clockevent);
即调用:
tick_notify(&tick_notifier, CLOCK_EVT_NOTIFY_ADD, &i8253_clockevent);
此后,其调用关系如下:
tick_notify(&tick_notifier, CLOCK_EVT_NOTIFY_ADD, &i8253_clockevent)
-> tick_check_new_device(dev) // dev = &i8253_clockevent
-> tick_setup_device(td, newdev, cpu, cpumask_of(cpu)) // td = &tick_cpu_device
-> tick_setup_periodic(newdev, 0); // newdev = &i8253_clockevent
// dev = &i8253_clockevent, broadcast=0
-> tick_set_periodic_handler(dev, broadcast)
-> dev->event_handler = tick_handle_periodic;
故:
i8253_clock.event_handler = tick_handle_periodic;
7.6.4.2.1.1.3.2 setup_default_timer_irq()
该函数定义于arch/x86/kernel/time.c:
static struct irqaction irq0 = {
.handler = timer_interrupt,
.flags = IRQF_DISABLED | IRQF_NOBALANCING | IRQF_IRQPOLL | IRQF_TIMER,
.name = "timer"
};
void __init setup_default_timer_irq(void)
{
/*
* 将IRQ0 (参见[9.1 中断处理简介](#9-1-)节表格中的0x30,即Timer)的中断处理函数设
* 置为timer_interrupt(),参见[9.4.1.2 setup_irq()/__setup_irq()]节;
* 当接收到Timer中断时,系统将调用其处理函数timer_interrupt(),
* 参见[7.6.4.2.1.1.4 timer_interrupt()]节
*/
setup_irq(0, &irq0);
}
7.6.4.2.1.1.4 timer_interrupt()
该函数定义于arch/x86/kernel/time.c:
/*
* Default timer interrupt handler for PIT/HPET
*/
static irqreturn_t timer_interrupt(int irq, void *dev_id)
{
/* Keep nmi watchdog up to date */
// 增加irq_stat.irq0_irqs的计数,参见[9.2.3 irq_stat[]]节。NMI watchdog参见下文
inc_irq_stat(irq0_irqs);
/*
* 由[7.6.4.2.1.1.3.1 setup_pit_timer()]节可知,global_clock_event = &i8253_clockevent;
* 由[7.6.4.2.1.1.3.1.1 clockevent_i8253_init()]节可知,i8253_clockevent.event_handler = tick_handle_periodic;
* 故此处调用函数tick_handle_periodic(),参见[7.6.4.2.1.1.4.1 tick_handle_periodic()]节
*/
global_clock_event->event_handler(global_clock_event);
/* MCA bus quirk: Acknowledge irq0 by setting bit 7 in port 0x61 */
if (MCA_bus)
outb_p(inb_p(0x61)| 0x80, 0x61);
return IRQ_HANDLED;
}
NOTE: NMI Watchdog
In multiprocessor systems, Linux offers yet another feature to kernel developers: a watchdog system, which might be quite useful to detect kernel bugs that cause a system freeze. To activate such a watchdog, the kernel must be booted with the nmi_watchdog parameter.
The watchdog is based on a clever hardware feature of local and I/O APICs: they can generate periodic NMI interrupts on every CPU. Because NMI interrupts are not masked by thecliassembly language instruction, the watchdog can detect deadlocks even when interrupts are disabled.
As a consequence, once every tick, all CPUs, regardless of what they are doing, start executing the NMI interrupt handler; in turn, the handler invokes do_nmi(). This function gets the logical number n of the CPU, and then checks the apic_timer_irqs field of the nth entry of irq_stat(see section 9.2.3 irq_stat[]). If the CPU is working properly, the value must be different from the value read at the previous NMI interrupt. When the CPU is running properly, the nth entry of the apic_timer_irqs field is increased by the local timer interrupt handler; if the counter is not increased, the local timer interrupt handler has not been executed in a whole tick. Not a good thing, you know.
When the NMI interrupt handler detects a CPU freeze, it rings all the bells: it logs scary messages in the system logfiles, dumps the contents of the CPU registers and of the kernel stack (kernel oops), and finally kills the current process. This gives kernel developers a chance to discover what’s gone wrong.
7.6.4.2.1.1.4.1 tick_handle_periodic()
该函数定义于kernel/time/tick-common.c:
/*
* Event handler for periodic ticks
*/
void tick_handle_periodic(struct clock_event_device *dev)
{
int cpu = smp_processor_id();
ktime_t next;
/*
* 调用与体系架构无关的处理函数,
* 参见[7.6.4.2.1.2 Architecture-independent routine / tick_periodic()]节
*/
tick_periodic(cpu);
if (dev->mode != CLOCK_EVT_MODE_ONESHOT)
return;
/*
* Setup the next period for devices, which do not have
* periodic mode:
*/
next = ktime_add(dev->next_event, tick_period);
for (;;) {
if (!clockevents_program_event(dev, next, false))
return;
/*
* Have to be careful here. If we're in oneshot mode,
* before we call tick_periodic() in a loop, we need
* to be sure we're using a real hardware clocksource.
* Otherwise we could get trapped in an infinite
* loop, as the tick_periodic() increments jiffies,
* when then will increment time, posibly causing
* the loop to trigger again and again.
*/
/*
* 调用与体系架构无关的处理函数,
* 参见[7.6.4.2.1.2 Architecture-independent routine / tick_periodic()]节
*/
if (timekeeping_valid_for_hres())
tick_periodic(cpu);
next = ktime_add(next, tick_period);
}
}
7.6.4.2.1.2 Architecture-independent routine / tick_periodic()
由7.6.4.2.1.1.4.1 tick_handle_periodic()节可知,函数tick_handle_periodic()调用与体系架构无关的函数tick_periodic()。该函数定义于kernel/time/tick-common.c:
static void tick_periodic(int cpu)
{
if (tick_do_timer_cpu == cpu) {
write_seqlock(&xtime_lock);
/* Keep track of the next tick event */
tick_next_period = ktime_add(tick_next_period, tick_period);
// 参见[7.6.4.2.1.2.1 do_timer()]节
do_timer(1);
write_sequnlock(&xtime_lock);
}
// 参见[7.6.4.2.1.2.2 update_process_times()]节
update_process_times(user_mode(get_irq_regs()));
profile_tick(CPU_PROFILING);
}
7.6.4.2.1.2.1 do_timer()
该函数定义于kernel/time/timekeeping.c:
/*
* The 64-bit jiffies value is not atomic - you MUST NOT read it
* without sampling the sequence number in xtime_lock.
* jiffies is defined in the linker script...
*/
void do_timer(unsigned long ticks)
{
// 更新jiffies
jiffies_64 += ticks;
/*
* Updates the wall time (xtime) in accordance
* with the elapsed ticks. 参见[7.6.3 xtime]节
*/
update_wall_time();
// updates the system’s load average statistics
calc_global_load(ticks);
}
7.6.4.2.1.2.2 update_process_times()
该函数定义于kernel/timer.c:
/*
* Called from the timer interrupt handler to charge one tick to the current
* process. user_tick is 1 if the tick is user time, 0 for system.
*/
void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id();
/* Note: this timer irq context must be accounted for as well. */
// does the actual updating of the process’s times
account_process_tick(p, user_tick);
run_local_timers(); // 参见[7.6.4.2.1.2.2.1 run_local_timers()]节
rcu_check_callbacks(cpu, user_tick);
printk_tick();
#ifdef CONFIG_IRQ_WORK
if (in_irq())
irq_work_run();
#endif
/*
* Decrements the currently running process’s timeslice
* and sets need_resched if needed. On SMP machines, it
* also balances the perprocessor runqueues as needed.
* 参见[7.4.6 scheduler_tick()]节
*/
scheduler_tick();
run_posix_cpu_timers(p);
}
7.6.4.2.1.2.2.1 run_local_timers()
The run_local_timers() function marks a softirq to handle the execution of any expired timers. 该函数定义于kernel/timer.c:
/*
* Called by the local, per-CPU timer interrupt on SMP.
*/
void run_local_timers(void)
{
hrtimer_run_queues(); // 参见[7.8.5.1 低精度模式/hrtimer_run_queues()]节
raise_softirq(TIMER_SOFTIRQ); // 参见[7.7.4 定时器的超时处理/run_timer_softirq()]节
}
7.6.5 mktime()/mktime_64()
There is a kernel function that turns a wallclock time into a jiffies value in include/linux/time.h:
/**
* Deprecated. Use mktime64().
*/
static inline unsigned long mktime(const unsigned int year, const unsigned int mon,
const unsigned int day, const unsigned int hour,
const unsigned int min, const unsigned int sec)
{
return mktime64(year, mon, day, hour, min, sec);
}
其中,mktime64()定义于kernel/time/time.c:
/*
* mktime64 - Converts date to seconds.
* Converts Gregorian date to seconds since 1970-01-01 00:00:00.
* Assumes input in normal date format, i.e. 1980-12-31 23:59:59
* => year=1980, mon=12, day=31, hour=23, min=59, sec=59.
*
* [For the Julian calendar (which was used in Russia before 1917,
* Britain & colonies before 1752, anywhere else before 1582,
* and is still in use by some communities) leave out the
* -year/100+year/400 terms, and add 10.]
*
* This algorithm was first published by Gauss (I think).
*/
time64_t mktime64(const unsigned int year0, const unsigned int mon0,
const unsigned int day, const unsigned int hour,
const unsigned int min, const unsigned int sec)
{
unsigned int mon = mon0, year = year0;
/* 1..12 -> 11,12,1..10 */
if (0 >= (int) (mon -= 2)) {
mon += 12; /* Puts Feb last since it has leap day */
year -= 1;
}
return ((((time64_t)
(year/4 - year/100 + year/400 + 367*mon/12 + day) +
year*365 - 719499
)*24 + hour /* now have hours */
)*60 + min /* now have minutes */
)*60 + sec; /* finally seconds */
}
7.7 定时器/timer
不同于第高分辨率定时器/hrtimer章,本章介绍的定时器为低分辨率定时器。
The implementation of the timers has been designed to meet the following requirements and assumptions:
- Timer management must be as lightweight as possible.
- The design should scale well as the number of active timers increases.
- Most timers expire within a few seconds or minutes at most, while timers with long delays are pretty rare.
- A timer should run on the same CPU that registered it. See add_timer()->internal_add_timer().
7.7.1 与定时器有关的数据结构
7.7.1.1 struct timer_list
该结构定义于include/linux/timer.h:
struct timer_list {
/*
* All fields that change during normal runtime grouped to the same cacheline.
*/
struct list_head entry;
/*
* It specifies when the timer expires; the time is expressed as
* the number of ticks that have elapsed since the system started up.
* All timers that have an expires value smaller than or equal to
* the value of jiffies are considered to be expired or decayed.
*/
unsigned long expires;
/* 指向包含本定时器的变量 */
struct tvec_base *base;
/*
* 本定时器的超时处理函数为function(),其入参为data:
* The data parameter enables you to register multiple timers with
* the same handler, and differentiate between them via the argument.
* It could store the device ID or other meaningful data that could
* be used by the function to differentiate the device.
*/
void (*function)(unsigned long);
unsigned long data;
/*
* 对到期时间精度不太敏感的定时器,允许适当地延迟定时器到期时刻,slack用于
* 计算每次延迟的HZ数;可通过函数set_timer_slack()设置或修改slack域
*/
int slack;
#ifdef CONFIG_TIMER_STATS
int start_pid;
void *start_site;
char start_comm[16];
#endif
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
在include/linux/timer.h中,包含如下宏用于定义或者初始化定时器:
#define DEFINE_TIMER(_name, _function, _expires, _data) \
struct timer_list _name = \
TIMER_INITIALIZER(_function, _expires, _data)
#define init_timer(timer) \
init_timer_key((timer), NULL, NULL)
#define setup_timer(timer, fn, data) \
setup_timer_key((timer), NULL, NULL, (fn), (data))
7.7.1.2 struct tvec_root / struct tvec
这两个结构体均定义于kernel/timer.c,用于struct tvec_base:
/*
* per-CPU timer vector definitions:
*/
#define TVN_BITS (CONFIG_BASE_SMALL ? 4 : 6)
#define TVR_BITS (CONFIG_BASE_SMALL ? 6 : 8)
#define TVN_SIZE (1 << TVN_BITS) // 64 (或16)
#define TVR_SIZE (1 << TVR_BITS) // 256 (或64)
#define TVN_MASK (TVN_SIZE - 1)
#define TVR_MASK (TVR_SIZE - 1)
struct tvec {
// vec[i]为定时器双向循环链表的表头,其中下标i为定时器超时jeffies距离当前jeffies的差值
struct list_head vec[TVN_SIZE];
};
struct tvec_root {
// vec[i]为定时器双向循环链表的表头,其中下标i为定时器超时jeffies距离当前jeffies的差值
struct list_head vec[TVR_SIZE];
};
7.7.1.3 struct tvec_base
该结构定义于kernel/timer.c:
struct tvec_base {
spinlock_t lock;
// 指向当前正在运行的定时器,在__run_timers()中设置,参见[7.7.4.1 __run_timers()]节
struct timer_list *running_timer;
/*
* Represents the earliest expiration time of the dynamic timers
* yet to be checked:
* - if it coincides with the value of jiffies, no backlog of
* deferrable functions has accumulated;
* - if it's smaller than jiffies, lists of dynamic timers that
* refer to previous ticks must be dealt with.
* The field is set to jiffies at system startup and is increased
* only by the run_timer_softirq().
*/
unsigned long timer_jiffies;
// 下一次定时器超时的jiffies值,与struct timer_list中的expires类似
unsigned long next_timer;
struct tvec_root tv1; // 256 (或64)个定时器链表
struct tvec tv2; // 64 (或16)个定时器链表
struct tvec tv3; // 64 (或16)个定时器链表
struct tvec tv4; // 64 (或16)个定时器链表
struct tvec tv5; // 64 (或16)个定时器链表
} ____cacheline_aligned;
在kernel/timer.c中,内核定义了一个全局变量boot_tvec_bases,并且为每个CPU定义了一个指向该全局变量的指针tvec_bases:
struct tvec_base boot_tvec_bases;
static DEFINE_PER_CPU(struct tvec_base *, tvec_bases) = &boot_tvec_bases;
定时器各结构之间的关系:
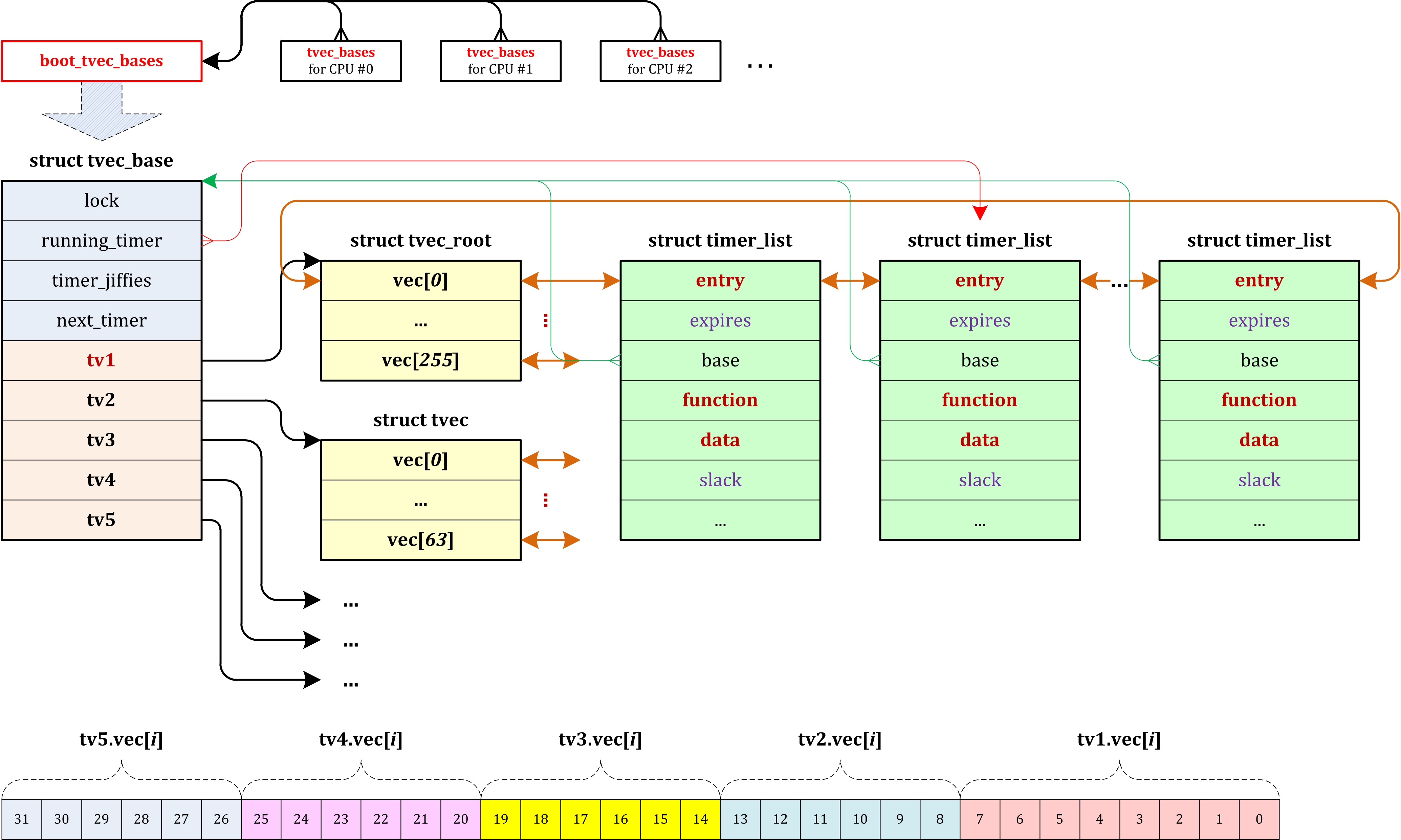
新增一个定时器t时,t被链接到tv1.vec[x]至tv5.vec[x]中的哪个链表是根据idx = (t.expires – base.timer_jiffies)的取值来确定的,其中base.timer_jiffies代表定时器系统的当前时刻,参见7.7.2.1.1.2.2.1 internal_add_timer()节。
确定定时器t所在的链表,参见上图。
确定定时器t所在的链表
| idx (t.expires - base.timer_jiffies) |
tv*.vec[i] |
|---|---|
| [0x00000000, 0x000000FF] | tv1.vec[idx] |
| [0x00000100, 0x00003FFF] | tv2.vec[idx & 0x00003F00] |
| [0x00004000, 0x000FFFFF] | tv3.vec[idx & 0x000FC000] |
| [0x00100000, 0x03FFFFFF] | tv4.vec[idx & 0x03F00000] |
| [0x04000000, 0xFFFFFFFF] | tv5.vec[idx & 0xFC000000] |
7.7.2 定时器操作
7.7.2.1 新增定时器/add_timer()/add_timer_on()
7.7.2.1.1 add_timer()
该函数定义于kernel/timer.c:
/**
* add_timer - start a timer
* @timer: the timer to be added
*
* The kernel will do a ->function(->data) callback from the
* timer interrupt at the ->expires point in the future. The
* current time is 'jiffies'.
*
* The timer's ->expires, ->function (and if the handler uses it, ->data)
* fields must be set prior calling this function.
*
* Timers with an ->expires field in the past will be executed in the next
* timer tick.
*/
void add_timer(struct timer_list *timer)
{
BUG_ON(timer_pending(timer)); // 参见[7.7.2.1.1.1 timer_pending()]节
mod_timer(timer, timer->expires); // 参见[7.7.2.1.1.2 mod_timer()]节
}
7.7.2.1.1.1 timer_pending()
该函数用于判断定时器timer是否已插入到链表中,其定义于kernel/timer.c:
static inline int timer_pending(const struct timer_list * timer)
{
return timer->entry.next != NULL;
}
7.7.2.1.1.2 mod_timer()
该函数定义于kernel/timer.c:
int mod_timer(struct timer_list *timer, unsigned long expires)
{
expires = apply_slack(timer, expires); // 参见[7.7.2.1.1.2.1 apply_slack()]节
/*
* This is a common optimization triggered by the
* networking code - if the timer is re-modified
* to be the same thing then just return:
*/
if (timer_pending(timer) && timer->expires == expires) // 参见[7.7.2.1.1.1 timer_pending()]节
return 1;
return __mod_timer(timer, expires, false, TIMER_NOT_PINNED); // 参见[7.7.2.1.1.2.2 __mod_timer()]节
}
7.7.2.1.1.2.1 apply_slack()
该函数定义于kernel/timer.c:
/*
* Decide where to put the timer while taking the slack into account
*
* Algorithm:
* 1) calculate the maximum (absolute) time
* 2) calculate the highest bit where the expires and new max are different
* 3) use this bit to make a mask
* 4) use the bitmask to round down the maximum time, so that all last
* bits are zeros
*/
static inline unsigned long apply_slack(struct timer_list *timer, unsigned long expires)
{
unsigned long expires_limit, mask;
int bit;
if (timer->slack >= 0) {
expires_limit = expires + timer->slack;
} else {
long delta = expires - jiffies;
if (delta < 256)
return expires;
expires_limit = expires + delta / 256;
}
mask = expires ^ expires_limit;
if (mask == 0)
return expires;
bit = find_last_bit(&mask, BITS_PER_LONG);
mask = (1 << bit) - 1;
expires_limit = expires_limit & ~(mask);
return expires_limit;
}
7.7.2.1.1.2.2 __mod_timer()
该函数定义于kernel/timer.c:
static inline int __mod_timer(struct timer_list *timer, unsigned long expires,
bool pending_only, int pinned)
{
struct tvec_base *base, *new_base;
unsigned long flags;
int ret = 0 , cpu;
timer_stats_timer_set_start_info(timer);
BUG_ON(!timer->function);
base = lock_timer_base(timer, &flags);
if (timer_pending(timer)) { // 若定时器已经在链表中了
detach_timer(timer, 0); // 则从链表中删除该定时器
if (timer->expires == base->next_timer &&
!tbase_get_deferrable(timer->base))
base->next_timer = base->timer_jiffies;
ret = 1;
} else {
if (pending_only)
goto out_unlock;
}
debug_activate(timer, expires);
cpu = smp_processor_id();
#if defined(CONFIG_NO_HZ) && defined(CONFIG_SMP)
if (!pinned && get_sysctl_timer_migration() && idle_cpu(cpu))
cpu = get_nohz_timer_target();
#endif
new_base = per_cpu(tvec_bases, cpu);
if (base != new_base) {
/*
* We are trying to schedule the timer on the local CPU.
* However we can't change timer's base while it is running,
* otherwise del_timer_sync() can't detect that the timer's
* handler yet has not finished. This also guarantees that
* the timer is serialized wrt itself.
*/
if (likely(base->running_timer != timer)) {
/* See the comment in lock_timer_base() */
timer_set_base(timer, NULL);
spin_unlock(&base->lock);
base = new_base;
spin_lock(&base->lock);
timer_set_base(timer, base);
}
}
timer->expires = expires;
// time_before()参见[7.6.2.2 比较Jiffies的大小]节
if (time_before(timer->expires, base->next_timer) && !tbase_get_deferrable(timer->base))
base->next_timer = timer->expires;
/*
* 将定时器timer插入到定时器链表(参见[7.7.1.3 struct tvec_base]节)中,
* 参见[7.7.2.1.1.2.2.1 internal_add_timer()]节; internal_add_timer() adds
* the new timer to a double-linked list of timers within
* a "cascading table" associated to the current CPU.
*/
internal_add_timer(base, timer);
out_unlock:
spin_unlock_irqrestore(&base->lock, flags);
return ret;
}
7.7.2.1.1.2.2.1 internal_add_timer()
该函数定义于kernel/timer.c:
static void internal_add_timer(struct tvec_base *base, struct timer_list *timer)
{
unsigned long expires = timer->expires;
/*
* 获取定时器超时时刻(expires)距离当前时刻(base->timer_jiffies)
* 的时间差,用于确定该定时器所在的数组
*/
unsigned long idx = expires - base->timer_jiffies;
struct list_head *vec;
// 定时器timer插入到定时器链表中,参见[7.7.1.3 struct tvec_base]节,[7.7.1.3 struct tvec_base]节中的图和表
if (idx < TVR_SIZE) {
int i = expires & TVR_MASK;
vec = base->tv1.vec + i;
} else if (idx < 1 << (TVR_BITS + TVN_BITS)) {
int i = (expires >> TVR_BITS) & TVN_MASK;
vec = base->tv2.vec + i;
} else if (idx < 1 << (TVR_BITS + 2 * TVN_BITS)) {
int i = (expires >> (TVR_BITS + TVN_BITS)) & TVN_MASK;
vec = base->tv3.vec + i;
} else if (idx < 1 << (TVR_BITS + 3 * TVN_BITS)) {
int i = (expires >> (TVR_BITS + 2 * TVN_BITS)) & TVN_MASK;
vec = base->tv4.vec + i;
} else if ((signed long) idx < 0) {
/*
* Can happen if you add a timer with expires == jiffies,
* or you set a timer to go off in the past
*/
vec = base->tv1.vec + (base->timer_jiffies & TVR_MASK);
} else {
int i;
/* If the timeout is larger than 0xffffffff on 64-bit
* architectures then we use the maximum timeout:
*/
if (idx > 0xffffffffUL) {
idx = 0xffffffffUL;
expires = idx + base->timer_jiffies;
}
i = (expires >> (TVR_BITS + 3 * TVN_BITS)) & TVN_MASK;
vec = base->tv5.vec + i;
}
/*
* Timers are FIFO:
*/
list_add_tail(&timer->entry, vec);
}
7.7.2.1.2 add_timer_on()
该函数定义于kernel/timer.c:
/**
* add_timer_on - start a timer on a particular CPU
* @timer: the timer to be added
* @cpu: the CPU to start it on
*
* This is not very scalable on SMP. Double adds are not possible.
*/
void add_timer_on(struct timer_list *timer, int cpu)
{
struct tvec_base *base = per_cpu(tvec_bases, cpu);
unsigned long flags;
timer_stats_timer_set_start_info(timer);
BUG_ON(timer_pending(timer) || !timer->function);
spin_lock_irqsave(&base->lock, flags);
timer_set_base(timer, base);
debug_activate(timer, timer->expires);
if (time_before(timer->expires, base->next_timer) &&
!tbase_get_deferrable(timer->base))
base->next_timer = timer->expires;
// 参见[7.7.2.1.1.2.2.1 internal_add_timer()]节
internal_add_timer(base, timer);
/*
* Check whether the other CPU is idle and needs to be
* triggered to reevaluate the timer wheel when nohz is
* active. We are protected against the other CPU fiddling
* with the timer by holding the timer base lock. This also
* makes sure that a CPU on the way to idle can not evaluate
* the timer wheel.
*/
wake_up_idle_cpu(cpu);
spin_unlock_irqrestore(&base->lock, flags);
}
7.7.2.2 修改定时器/mod_timer()/mod_timer_pending()
7.7.2.2.1 mod_timer()
7.7.2.2.2 mod_timer_pending()
该函数定义于kernel/timer.c:
/**
* mod_timer_pending - modify a pending timer's timeout
* @timer: the pending timer to be modified
* @expires: new timeout in jiffies
*
* mod_timer_pending() is the same for pending timers as mod_timer(),
* but will not re-activate and modify already deleted timers.
*
* It is useful for unserialized use of timers.
*/
int mod_timer_pending(struct timer_list *timer, unsigned long expires)
{
// 参见[7.7.2.1.1.2.2 __mod_timer()]节
return __mod_timer(timer, expires, true, TIMER_NOT_PINNED);
}
7.7.2.3 删除定时器/del_timer()/del_timer_sync()
7.7.2.3.1 del_timer()
该函数定义于kernel/timer.c:
/**
* del_timer - deactive a timer.
* @timer: the timer to be deactivated
*
* del_timer() deactivates a timer - this works on both active and inactive
* timers.
*
* The function returns whether it has deactivated a pending timer or not.
* (ie. del_timer() of an inactive timer returns 0, del_timer() of an
* active timer returns 1.)
*/
int del_timer(struct timer_list *timer)
{
struct tvec_base *base;
unsigned long flags;
int ret = 0;
timer_stats_timer_clear_start_info(timer);
if (timer_pending(timer)) {
base = lock_timer_base(timer, &flags);
if (timer_pending(timer)) {
detach_timer(timer, 1); // 将定时器timer从链表中删除
if (timer->expires == base->next_timer && !tbase_get_deferrable(timer->base))
base->next_timer = base->timer_jiffies;
ret = 1;
}
spin_unlock_irqrestore(&base->lock, flags);
}
return ret;
}
7.7.2.3.2 del_timer_sync()
On a multiprocessing machine, the timer handler might already be executing on another processor. To deactivate the timer and wait until a potentially executing handler for the timer exits, use del_timer_sync(). In almost all cases, you should use del_timer_sync() over del_timer().
Unlike del_timer(), del_timer_sync() cannot be used from interrupt context.
在include/linux/timer.h中,包含如下代码:
#ifdef CONFIG_SMP
extern int del_timer_sync(struct timer_list *timer);
#else
# define del_timer_sync(t) del_timer(t)
#endif
若定义了CONFIG_SMP,则函数del_timer_sync()定义于kernel/timer.c:
#ifdef CONFIG_SMP
int del_timer_sync(struct timer_list *timer)
{
#ifdef CONFIG_LOCKDEP
unsigned long flags;
/*
* If lockdep gives a backtrace here, please reference
* the synchronization rules above.
*/
local_irq_save(flags);
lock_map_acquire(&timer->lockdep_map);
lock_map_release(&timer->lockdep_map);
local_irq_restore(flags);
#endif
/*
* don't use it in hardirq context, because it
* could lead to deadlock.
*/
WARN_ON(in_irq());
for (;;) {
// 参见[7.7.2.3.2.1 try_to_del_timer_sync(timer)]节
int ret = try_to_del_timer_sync(timer);
if (ret >= 0)
return ret;
cpu_relax();
}
}
#endif
7.7.2.3.2.1 try_to_del_timer_sync(timer)
该函数定义于kernel/timer.c:
/**
* try_to_del_timer_sync - Try to deactivate a timer
* @timer: timer do del
*
* This function tries to deactivate a timer. Upon successful (ret >= 0)
* exit the timer is not queued and the handler is not running on any CPU.
*/
int try_to_del_timer_sync(struct timer_list *timer)
{
struct tvec_base *base;
unsigned long flags;
int ret = -1;
base = lock_timer_base(timer, &flags);
if (base->running_timer == timer)
goto out;
timer_stats_timer_clear_start_info(timer);
ret = 0;
if (timer_pending(timer)) {
detach_timer(timer, 1); // 将定时器timer从链表中删除
if (timer->expires == base->next_timer && !tbase_get_deferrable(timer->base))
base->next_timer = base->timer_jiffies;
ret = 1;
}
out:
spin_unlock_irqrestore(&base->lock, flags);
return ret;
}
7.7.2.3.3 del_singleshot_timer_sync()
该宏定义于include/linux/timer.h:
#define del_singleshot_timer_sync(t) del_timer_sync(t) // 参见[7.7.2.3.2 del_timer_sync()]节
7.7.3 定时器模块的编译及初始化
由kernel/Makefile中的如下变量可知,timer不是被编译成模块,而是直接被编译进内核:
obj-y = sched.o fork.o exec_domain.o panic.o printk.o \
cpu.o exit.o itimer.o time.o softirq.o resource.o \
sysctl.o sysctl_binary.o capability.o ptrace.o timer.o user.o \
signal.o sys.o kmod.o workqueue.o pid.o \
rcupdate.o extable.o params.o posix-timers.o \
kthread.o wait.o kfifo.o sys_ni.o posix-cpu-timers.o mutex.o \
hrtimer.o rwsem.o nsproxy.o srcu.o semaphore.o \
notifier.o ksysfs.o sched_clock.o cred.o \
async.o range.o
在系统启动时调用定时器初始化函数init_timers():
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> init_timers()
该函数定义于kernel/timer.c:
void __init init_timers(void)
{
// 参见[7.7.3.1 timer_cpu_notify()]节
int err = timer_cpu_notify(&timers_nb, (unsigned long)CPU_UP_PREPARE, (void *)(long)smp_processor_id());
init_timer_stats();
BUG_ON(err != NOTIFY_OK);
register_cpu_notifier(&timers_nb);
/*
* 设置软中断TIMER_SOFTIRQ的处理程序为run_timer_softirq(),参见[9.2.2 struct softirq_action / softirq_vec[]]节;
* 该处理程序在函数__do_softirq()中被调用,参见[9.3.1.3.1.1.1 __do_softirq()]节;由此可知,定时器超时
* 处理函数是在软中断上下文中执行的;
* 处理程序run_timer_softirq()参见[7.7.4 定时器的超时处理/run_timer_softirq()]节
*/
open_softirq(TIMER_SOFTIRQ, run_timer_softirq);
}
7.7.3.1 timer_cpu_notify()
该函数定义于kernel/timer.c:
static int __cpuinit timer_cpu_notify(struct notifier_block *self,
unsigned long action, void *hcpu)
{
long cpu = (long)hcpu;
int err;
switch(action) {
case CPU_UP_PREPARE:
case CPU_UP_PREPARE_FROZEN:
err = init_timers_cpu(cpu); // 参见[7.7.3.1.1 init_timers_cpu()]节
if (err < 0)
return notifier_from_errno(err);
break;
#ifdef CONFIG_HOTPLUG_CPU
case CPU_DEAD:
case CPU_DEAD_FROZEN:
migrate_timers(cpu);
break;
#endif
default:
break;
}
return NOTIFY_OK;
}
7.7.3.1.1 init_timers_cpu()
该函数定义于kernel/timer.c:
static int __cpuinit init_timers_cpu(int cpu)
{
int j;
struct tvec_base *base;
static char __cpuinitdata tvec_base_done[NR_CPUS];
if (!tvec_base_done[cpu]) {
static char boot_done;
if (boot_done) {
/*
* The APs use this path later in boot
*/
base = kmalloc_node(sizeof(*base), GFP_KERNEL | __GFP_ZERO, cpu_to_node(cpu));
if (!base)
return -ENOMEM;
/* Make sure that tvec_base is 2 byte aligned */
if (tbase_get_deferrable(base)) {
WARN_ON(1);
kfree(base);
return -ENOMEM;
}
per_cpu(tvec_bases, cpu) = base;
} else {
/*
* This is for the boot CPU - we use compile-time
* static initialisation because per-cpu memory isn't
* ready yet and because the memory allocators are not
* initialised either.
*/
boot_done = 1;
base = &boot_tvec_bases;
}
tvec_base_done[cpu] = 1;
} else {
base = per_cpu(tvec_bases, cpu);
}
spin_lock_init(&base->lock);
for (j = 0; j < TVN_SIZE; j++) {
INIT_LIST_HEAD(base->tv5.vec + j);
INIT_LIST_HEAD(base->tv4.vec + j);
INIT_LIST_HEAD(base->tv3.vec + j);
INIT_LIST_HEAD(base->tv2.vec + j);
}
for (j = 0; j < TVR_SIZE; j++)
INIT_LIST_HEAD(base->tv1.vec + j);
base->timer_jiffies = jiffies;
base->next_timer = base->timer_jiffies;
return 0;
}
7.7.4 定时器的超时处理/run_timer_softirq()
该函数被软中断处理函数__do_softirq()调用,参见9.3.1.3.1.1.1 __do_softirq()节和[9.2.2.1 注册软中断处理函数/open_softirq()]节中的表,其定义于kernel/timer.c:
/*
* This function runs timers and the timer-tq in bottom half context.
*/
static void run_timer_softirq(struct softirq_action *h)
{
struct tvec_base *base = __this_cpu_read(tvec_bases);
hrtimer_run_pending(); // 参见[7.8.5.2.1 切换到高精度模式]节
if (time_after_eq(jiffies, base->timer_jiffies)) // 参见[7.6.2.2 比较Jiffies的大小]节
__run_timers(base); // 参见[7.7.4.1 __run_timers()]节
}
7.7.4.1 __run_timers()
该函数定义于kernel/timer.c:
#define INDEX(N) ((base->timer_jiffies >> (TVR_BITS + (N) * TVN_BITS)) & TVN_MASK)
/**
* __run_timers - run all expired timers (if any) on this CPU.
* @base: the timer vector to be processed.
*
* This function cascades all vectors and executes all expired timer
* vectors.
*/
static inline void __run_timers(struct tvec_base *base)
{
struct timer_list *timer;
spin_lock_irq(&base->lock);
// 只要定时器的当前时刻早于系统的当前时刻,就可能存在已超时的定时器,因而需要继续处理
while (time_after_eq(jiffies, base->timer_jiffies)) {
struct list_head work_list;
struct list_head *head = &work_list;
/*
* 根据base->timer_jiffies的低8位(或低6位)来确定定时器所在的链表,
* 参见[7.7.1.3 struct tvec_base]节中的图
* NOTE: 此处不是按照tv1.vec[0], tv1.vec[1], ... 的顺序来处理定时器
*/
int index = base->timer_jiffies & TVR_MASK;
/*
* Cascade timers:
*/
/*
* 由[7.7.1.3 struct tvec_base]节中的图可知:
* 若index为0,表示base->timer_jiffies的低8位有进位,
* 此时要根据其8-13位的取值,将定时器从某个tv2链表(如tv2.vec[x])
* 迁移到tv1.vec[*];
* 同理,若8-13位为0,则要根据其14-19位的取值,将定时器从某个tv3链表
* (如tv3.vec[x])迁移到tv2或tv1中;
* 以此类推,可得tv4, tv5中定时器的迁移
*/
if (!index &&
(!cascade(base, &base->tv2, INDEX(0))) &&
(!cascade(base, &base->tv3, INDEX(1))) &&
!cascade(base, &base->tv4, INDEX(2)))
cascade(base, &base->tv5, INDEX(3)); // 参见[7.7.4.1.1 cascade()]节
// 调整时钟滴答计数
++base->timer_jiffies;
// 将链表base->tv1.vec[index]中的元素转移到链表work_list中,并循环处理
list_replace_init(base->tv1.vec + index, &work_list);
while (!list_empty(head)) {
void (*fn)(unsigned long);
unsigned long data;
// 从前至后依次处理链表中的所有定时器
timer = list_first_entry(head, struct timer_list,entry);
fn = timer->function;
data = timer->data;
timer_stats_account_timer(timer);
base->running_timer = timer; // 设置当前正在处理的定时器
detach_timer(timer, 1); // 将定时器timer从链表中移除
spin_unlock_irq(&base->lock);
call_timer_fn(timer, fn, data); // 调用定时器处理函数fn(data)
spin_lock_irq(&base->lock);
}
}
base->running_timer = NULL; // 清除当前正在处理的定时器
spin_unlock_irq(&base->lock);
}
7.7.4.1.1 cascade()
该函数定义于kernel/timer.c:
static int cascade(struct tvec_base *base, struct tvec *tv, int index)
{
/* cascade all the timers from tv up one level */
struct timer_list *timer, *tmp;
struct list_head tv_list;
// 变量tv_list中保存需要迁移的链表
list_replace_init(tv->vec + index, &tv_list);
/*
* We are removing _all_ timers from the list, so we
* don't have to detach them individually.
*/
list_for_each_entry_safe(timer, tmp, &tv_list, entry) {
BUG_ON(tbase_get_base(timer->base) != base);
/*
* 将定时器timer重新加入定时器链表中,实际上会迁移到下一级
* 的tv数组中,参见[7.7.2.1.1.2.2.1 internal_add_timer()]节
*/
internal_add_timer(base, timer);
}
return index;
}
综上可知,内核中低分辨率定时器的实现非常精妙,它既实现了大量定时器的管理,又实现了快速的O(1)查找超时定时器的能力。利用巧妙的数组结构,使得只需在间隔256个tick时间才处理一次迁移操作。5个数组(tv1 – tv5)就像5个齿轮,它们随着base->timer_jifffies的增长而不停地转动,每次只需处理第一个齿轮的某一个齿节,低一级的齿轮转动一圈,高一级的齿轮转动一个齿,同时自动把即将超时的定时器迁移到下一级齿轮中,所以低分辨率定时器通常又被叫做时间轮(time wheel)。事实上,该实现方法是一个很好的空间换时间的软件算法。
7.7.5 定时器编程示例
源文件test_timer.c如下:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/timer.h>
MODULE_LICENSE("GPL");
struct timer_list t;
void timer_func(unsigned long data)
{
printk("*** Time out, data: %ld\n", data);
}
static int __init timer_init(void)
{
printk("*** Timer init ***\n");
setup_timer(&t, timer_func, 1010);
add_timer(&t);
return 0;
}
static void __exit timer_exit(void)
{
printk("*** Timer exit ***\n");
}
module_init(timer_init);
module_exit(timer_exit);
编译test_timer.c所用的Makefile如下:
obj-m := test_timer.o
# ‘uname –r’ print kernel release
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
make -C $(KDIR) M=$(PWD) modules
clean:
rm *.o *.ko *.mod.c Modules.symvers modules.order -f
执行命令的过程如下:
chenwx@chenwx ~/alex/timer $ make
make -C /lib/modules/3.5.0-17-generic/build M=/home/chenwx/alex/timer modules
make[1]: Entering directory `/usr/src/linux-headers-3.5.0-17-generic'
CC [M] /home/chenwx/alex/timer/test_timer.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/chenwx/alex/timer/test_timer.mod.o
LD [M] /home/chenwx/alex/timer/test_timer.ko
make[1]: Leaving directory `/usr/src/linux-headers-3.5.0-17-generic'
chenwx@chenwx ~/alex/timer $ ll
total 100
drwxr-xr-x 3 chenwx chenwx 4096 Dec 7 09:37 .
drwxr-xr-x 8 chenwx chenwx 4096 Dec 7 08:35 ..
-rw-r--r-- 1 chenwx chenwx 231 Dec 7 08:58 Makefile
-rw-r--r-- 1 chenwx chenwx 45 Dec 7 09:37 modules.order
-rw-r--r-- 1 chenwx chenwx 0 Dec 7 09:00 Module.symvers
-rw-r--r-- 1 chenwx chenwx 474 Dec 7 09:34 test_timer.c
-rw-r--r-- 1 chenwx chenwx 3182 Dec 7 09:37 test_timer.ko
-rw-r--r-- 1 chenwx chenwx 263 Dec 7 09:37 .test_timer.ko.cmd
-rw-r--r-- 1 chenwx chenwx 754 Dec 7 09:37 test_timer.mod.c
-rw-r--r-- 1 chenwx chenwx 1956 Dec 7 09:37 test_timer.mod.o
-rw-r--r-- 1 chenwx chenwx 26095 Dec 7 09:37 .test_timer.mod.o.cmd
-rw-r--r-- 1 chenwx chenwx 2540 Dec 7 09:37 test_timer.o
-rw-r--r-- 1 chenwx chenwx 25992 Dec 7 09:37 .test_timer.o.cmd
drwxr-xr-x 2 chenwx chenwx 4096 Dec 7 09:37 .tmp_versions
chenwx@chenwx ~/alex/timer $ sudo insmod test_timer.ko
[sudo] password for chenwx:
chenwx@chenwx ~/alex/timer $ dmesg | tail
...
[ 1019.255595] *** Timer init ***
[ 1019.256197] *** Time out, data: 1010
chenwx@chenwx ~/alex/timer $ sudo rmmod test_timer
chenwx@chenwx ~/alex/timer $ dmesg | tail
...
[ 1019.255595] *** Timer init ***
[ 1019.256197] *** Time out, data: 1010
[ 1053.784719] *** Timer exit ***
7.8 高分辨率定时器/hrtimer
7.8.1 hrtimer简介
阅读如下文档:
- Documentation/timers
内核使用红黑树rbtree(参见15.6 Red-Black Tree (rbtree)节)来组织hrtimer。
7.8.2 与hrtimer有关的数据结构
7.8.2.1 struct hrtimer
该结构定义于include/linux/hrtimer.h:
struct hrtimer {
/*
* 链接红黑树的节点,其中node.expires取值域_softexpires相同,
* 参见函数hrtimer_set_expires_range_ns()
*/
struct timerqueue_node node;
// 本定时器的超时时间,与node.expires取值相同
ktime_t _softexpires;
/*
* 定时器超时处理函数,入参为指向本定时器的指针;返回值为枚举类型,
* 用于确定该hrtimer是否需要被重新激活
*/
enum hrtimer_restart (*function)(struct hrtimer *);
// 指向时间基准的指针
struct hrtimer_clock_base *base;
/*
* 表示hrtimer当前的状态,取值为include/linux/hrtimer.h中
* 以HRTIMER_STATE_打头的宏
*/
unsigned long state;
#ifdef CONFIG_TIMER_STATS
int start_pid;
void *start_site;
char start_comm[16];
#endif
};
7.8.2.2 struct hrtimer_clock_base
该结构定义于include/linux/hrtimer.h:
struct hrtimer_clock_base {
struct hrtimer_cpu_base *cpu_base;
// 取值参见类型enum hrtimer_base_type
int index;
/*
* clockid到index的转换参见kernel/hrtimer.c中的数组
* hrtimer_clock_to_base_table[MAX_CLOCKS]
*/
clockid_t lockid;
// 红黑树根节点,该树包含了所有使用该时间基准系统的hrtimer
struct timerqueue_head active;
// 时间基准系统的精度
ktime_t resolution;
// 获取该基准系统时间的函数
ktime_t (*get_time)(void);
// 当前jiffies
ktime_t softirq_time;
ktime_t offset;
};
7.8.2.3 struct hrtimer_cpu_base
该结构定义于include/linux/hrtimer.h:
struct hrtimer_cpu_base {
raw_spinlock_t lock;
/*
* 本域为bitmap,由1左移struct hrtimer_clock_base -> index位构成,
* 用于表示clock_base[]数组中哪些处于激活状态,参见函数enqueue_hrtimer()
*/
unsigned long active_bases;
#ifdef CONFIG_HIGH_RES_TIMERS
ktime_t expires_next;
int hres_active;
int hang_detected;
unsigned long nr_events;
unsigned long nr_retries;
unsigned long nr_hangs;
ktime_t max_hang_time;
#endif
struct hrtimer_clock_base clock_base[HRTIMER_MAX_CLOCK_BASES];
};
在kernel/hrtimer.c中,内核为每个CPU定义了一个该类型的变量hrtimer_bases:
DEFINE_PER_CPU(struct hrtimer_cpu_base, hrtimer_bases) =
{
.clock_base =
{
{
.index = HRTIMER_BASE_MONOTONIC,
.clockid = CLOCK_MONOTONIC,
.get_time = &ktime_get,
.resolution = KTIME_LOW_RES,
},
{
.index = HRTIMER_BASE_REALTIME,
.clockid = CLOCK_REALTIME,
.get_time = &ktime_get_real,
.resolution = KTIME_LOW_RES,
},
{
.index = HRTIMER_BASE_BOOTTIME,
.clockid = CLOCK_BOOTTIME,
.get_time = &ktime_get_boottime,
.resolution = KTIME_LOW_RES,
},
}
};
各结构之间的关系:
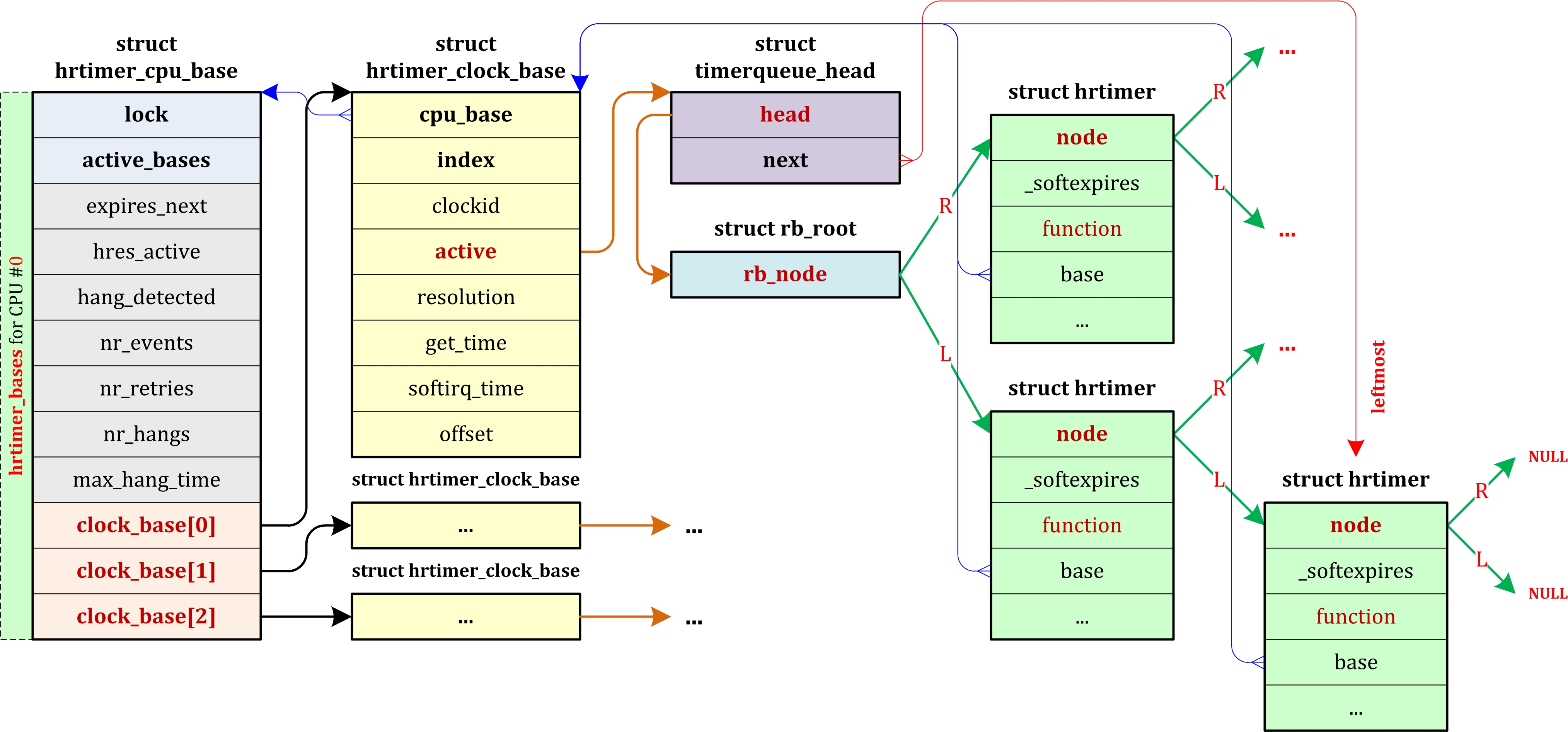
7.8.3 hrtimer定时器操作
7.8.3.1 初始化定时器/hrtimer_init()/hrtimer_init_on_stack()
7.8.3.1.1 hrtimer_init()
该函数定义于kernel/hrtimer.c:
/**
* hrtimer_init - initialize a timer to the given clock
* @timer: the timer to be initialized
* @clock_id: the clock to be used
* @mode: timer mode abs/rel
*/
void hrtimer_init(struct hrtimer *timer, clockid_t clock_id,
enum hrtimer_mode mode)
{
debug_init(timer, clock_id, mode);
__hrtimer_init(timer, clock_id, mode);
}
7.8.3.1.1.1 __hrtimer_init()
该函数定义于kernel/hrtimer.c:
static void __hrtimer_init(struct hrtimer *timer, clockid_t clock_id,
enum hrtimer_mode mode)
{
struct hrtimer_cpu_base *cpu_base;
int base;
memset(timer, 0, sizeof(struct hrtimer));
// 获得当前CPU对应的全局变量hrtimer_bases
cpu_base = &__raw_get_cpu_var(hrtimer_bases);
if (clock_id == CLOCK_REALTIME && mode != HRTIMER_MODE_ABS)
clock_id = CLOCK_MONOTONIC;
// 翻译CLOCK_XXX => HRTIMER_BASE_XXX
base = hrtimer_clockid_to_base(clock_id);
timer->base = &cpu_base->clock_base[base];
timerqueue_init(&timer->node); // 初始化定时器的红黑树
#ifdef CONFIG_TIMER_STATS
timer->start_site = NULL;
timer->start_pid = -1;
memset(timer->start_comm, 0, TASK_COMM_LEN);
#endif
}
7.8.3.1.2 hrtimer_init_on_stack()
在include/linux/hrtimer.h中,包含如下定义:
#ifdef CONFIG_DEBUG_OBJECTS_TIMERS
extern void hrtimer_init_on_stack(struct hrtimer *timer, clockid_t which_clock,
enum hrtimer_mode mode);
#else
static inline void hrtimer_init_on_stack(struct hrtimer *timer,
clockid_t which_clock,
enum hrtimer_mode mode)
{
hrtimer_init(timer, which_clock, mode);
}
#endif
在kernel/hrtimer.c中,包含如下定义:
#ifdef CONFIG_DEBUG_OBJECTS_TIMERS
void hrtimer_init_on_stack(struct hrtimer *timer, clockid_t clock_id,
enum hrtimer_mode mode)
{
debug_object_init_on_stack(timer, &hrtimer_debug_descr);
__hrtimer_init(timer, clock_id, mode);
}
#endif
7.8.3.2 启动定时器/hrtimer_start()/hrtimer_start_expires()
7.8.3.2.1 hrtimer_start()
该函数定义于kernel/hrtimer.c:
/**
* hrtimer_start - (re)start an hrtimer on the current CPU
* @timer: the timer to be added
* @tim: expiry time
* @mode: expiry mode: absolute (HRTIMER_ABS) or relative (HRTIMER_REL)
*
* Returns:
* 0 on success
* 1 when the timer was active
*/
int hrtimer_start(struct hrtimer *timer, ktime_t tim, const enum hrtimer_mode mode)
{
return __hrtimer_start_range_ns(timer, tim, 0, mode, 1);
}
7.8.3.2.1.1 __hrtimer_start_range_ns()
该函数定义于kernel/hrtimer.c:
int __hrtimer_start_range_ns(struct hrtimer *timer, ktime_t tim,
unsigned long delta_ns, const enum hrtimer_mode mode, int wakeup)
{
struct hrtimer_clock_base *base, *new_base;
unsigned long flags;
int ret, leftmost;
base = lock_hrtimer_base(timer, &flags);
/* Remove an active timer from the queue: */
ret = remove_hrtimer(timer, base);
/* Switch the timer base, if necessary: */
new_base = switch_hrtimer_base(timer, base, mode & HRTIMER_MODE_PINNED);
// 如果mode使用相对时间,则需要加上当前时间,因为hrtimer内部使用绝对时间
if (mode & HRTIMER_MODE_REL) {
tim = ktime_add_safe(tim, new_base->get_time());
/*
* CONFIG_TIME_LOW_RES is a temporary way for architectures
* to signal that they simply return xtime in
* do_gettimeoffset(). In this case we want to round up by
* resolution when starting a relative timer, to avoid short
* timeouts. This will go away with the GTOD framework.
*/
#ifdef CONFIG_TIME_LOW_RES
tim = ktime_add_safe(tim, base->resolution);
#endif
}
// 设置超时时间,即timer->_softexpires, timer->node.expires
hrtimer_set_expires_range_ns(timer, tim, delta_ns);
// 设置timer->start_site, timer->start_pid, timer->start_comm
timer_stats_hrtimer_set_start_info(timer);
// 将timer插入到红黑树的适当位置,其中红黑树的最左边的叶子节点是最早超时的定时器
leftmost = enqueue_hrtimer(timer, new_base);
/*
* Only allow reprogramming if the new base is on this CPU.
* (it might still be on another CPU if the timer was pending)
*
* XXX send_remote_softirq() ?
*/
if (leftmost && new_base->cpu_base == &__get_cpu_var(hrtimer_bases))
hrtimer_enqueue_reprogram(timer, new_base, wakeup);
unlock_hrtimer_base(timer, &flags);
return ret;
}
7.8.3.2.2 hrtimer_start_expires()
该函数定义于include/linux/hrtimer.h:
static inline int hrtimer_start_expires(struct hrtimer *timer, enum hrtimer_mode mode)
{
unsigned long delta;
ktime_t soft, hard;
soft = hrtimer_get_softexpires(timer);
hard = hrtimer_get_expires(timer);
delta = ktime_to_ns(ktime_sub(hard, soft));
return hrtimer_start_range_ns(timer, soft, delta, mode);
}
7.8.3.3 取消定时器/hrtimer_cancel()
该函数定义于kernel/hrtimer.c:
/**
* hrtimer_cancel - cancel a timer and wait for the handler to finish.
* @timer: the timer to be cancelled
*
* Returns:
* 0 when the timer was not active
* 1 when the timer was active
*/
int hrtimer_cancel(struct hrtimer *timer)
{
for (;;) {
int ret = hrtimer_try_to_cancel(timer);
if (ret >= 0)
return ret;
cpu_relax();
}
}
7.8.3.3.1 hrtimer_try_to_cancel()
该函数定义于kernel/hrtimer.c:
/**
* hrtimer_try_to_cancel - try to deactivate a timer
* @timer: hrtimer to stop
*
* Returns:
* 0 when the timer was not active
* 1 when the timer was active
* -1 when the timer is currently excuting the callback function and
* cannot be stopped
*/
int hrtimer_try_to_cancel(struct hrtimer *timer)
{
struct hrtimer_clock_base *base;
unsigned long flags;
int ret = -1;
base = lock_hrtimer_base(timer, &flags);
if (!hrtimer_callback_running(timer))
ret = remove_hrtimer(timer, base);
unlock_hrtimer_base(timer, &flags);
return ret;
}
7.8.3.4 推迟定时器/hrtimer_forward()
该函数定义于kernel/hrtimer.c:
/**
* hrtimer_forward - forward the timer expiry
* @timer: hrtimer to forward
* @now: forward past this time
* @interval: the interval to forward
*
* Forward the timer expiry so it will expire in the future.
* Returns the number of overruns.
*/
u64 hrtimer_forward(struct hrtimer *timer, ktime_t now, ktime_t interval)
{
u64 orun = 1;
ktime_t delta;
delta = ktime_sub(now, hrtimer_get_expires(timer));
if (delta.tv64 < 0)
return 0;
if (interval.tv64 < timer->base->resolution.tv64)
interval.tv64 = timer->base->resolution.tv64;
if (unlikely(delta.tv64 >= interval.tv64)) {
s64 incr = ktime_to_ns(interval);
orun = ktime_divns(delta, incr);
hrtimer_add_expires_ns(timer, incr * orun);
if (hrtimer_get_expires_tv64(timer) > now.tv64)
return orun;
/*
* This (and the ktime_add() below) is the
* correction for exact:
*/
orun++;
}
hrtimer_add_expires(timer, interval);
return orun;
}
7.8.4 hrtimer的编译及初始化
由kernel/Makefile中的如下变量可知,hrtimer不是被编译成模块,而是直接被编译进内核:
obj-y = sched.o fork.o exec_domain.o panic.o printk.o \
cpu.o exit.o itimer.o time.o softirq.o resource.o \
sysctl.o sysctl_binary.o capability.o ptrace.o timer.o user.o \
signal.o sys.o kmod.o workqueue.o pid.o \
rcupdate.o extable.o params.o posix-timers.o \
kthread.o wait.o kfifo.o sys_ni.o posix-cpu-timers.o mutex.o \
hrtimer.o rwsem.o nsproxy.o srcu.o semaphore.o \
notifier.o ksysfs.o sched_clock.o cred.o \
async.o range.o
在kernel/hrtimer.c中,包含初始化函数hrtimers_init():
static struct notifier_block __cpuinitdata hrtimers_nb = {
.notifier_call = hrtimer_cpu_notify,
};
...
void __init hrtimers_init(void)
{
// 参见[7.8.4.1 hrtimer_cpu_notify()]节
hrtimer_cpu_notify(&hrtimers_nb, (unsigned long)CPU_UP_PREPARE,
(void *)(long)smp_processor_id());
register_cpu_notifier(&hrtimers_nb);
#ifdef CONFIG_HIGH_RES_TIMERS
/*
* 设置软中断HRTIMER_SOFTIRQ的处理程序为run_hrtimer_softirq(),
* 参见[9.2.2 struct softirq_action / softirq_vec[]]节;该处理程序在函数__do_softirq()中被调用,
* 参见[9.3.1.3.1.1.1 __do_softirq()]节;由此可知,定时器超时处理函数是在软中断上下文
* 中执行的;处理程序run_hrtimer_softirq()
* 参见[7.8.5.3 HRTIMER_SOFTIRQ软中断/run_hrtimer_softirq()]节
*/
open_softirq(HRTIMER_SOFTIRQ, run_hrtimer_softirq);
#endif
}
hrtimers_init()的调用关系如下:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> hrtimers_init()
7.8.4.1 hrtimer_cpu_notify()
该函数定义于kernel/hrtimer.c:
static int __cpuinit hrtimer_cpu_notify(struct notifier_block *self,
unsigned long action, void *hcpu)
{
int scpu = (long)hcpu;
switch (action) {
case CPU_UP_PREPARE:
case CPU_UP_PREPARE_FROZEN:
init_hrtimers_cpu(scpu);
break;
#ifdef CONFIG_HOTPLUG_CPU
case CPU_DYING:
case CPU_DYING_FROZEN:
clockevents_notify(CLOCK_EVT_NOTIFY_CPU_DYING, &scpu);
break;
case CPU_DEAD:
case CPU_DEAD_FROZEN:
{
clockevents_notify(CLOCK_EVT_NOTIFY_CPU_DEAD, &scpu);
migrate_hrtimers(scpu);
break;
}
#endif
default:
break;
}
return NOTIFY_OK;
}
7.8.4.1.1 init_hrtimers_cpu()
该函数定义于kernel/hrtimer.c:
static void __cpuinit init_hrtimers_cpu(int cpu)
{
struct hrtimer_cpu_base *cpu_base = &per_cpu(hrtimer_bases, cpu);
int i;
raw_spin_lock_init(&cpu_base->lock);
for (i = 0; i < HRTIMER_MAX_CLOCK_BASES; i++) {
cpu_base->clock_base[i].cpu_base = cpu_base;
timerqueue_init_head(&cpu_base->clock_base[i].active);
}
hrtimer_init_hres(cpu_base);
}
7.8.5 hrtimer的超时处理
内核中有如下3个入口对hrtimer系统的超时定时器进行处理:
- 未切换到高精度模式时,在每个jiffie的tick事件中断中进行查询和处理;
- 在HRTIMER_SOFTIRQ软中断中进行查询和处理;
- 切换到高精度模式后,在每个clock_event_device的到期事件中断中进行查询和处理;
7.8.5.1 低精度模式/hrtimer_run_queues()
系统并不是一开始就会支持高精度模式,而是在系统启动后的某个阶段,等所有的条件都满足后,才会切换到高精度模式。当系统还没有切换到高精度模式时,所有的高精度定时器运行在低精度模式下,在每个jiffie的tick事件中断中进行超时定时器的查询和处理,显然此时的精度和低分辨率定时器是一样的(HZ级别)。
低精度模式下,每个tick事件中断中,函数hrtimer_run_queues()会被调用,由它完成定时器的超时处理,参见7.6.4.2.1.2.2.1 run_local_timers()节。该函数定义于kernel/hrtimer.c:
void hrtimer_run_queues(void)
{
struct timerqueue_node *node;
struct hrtimer_cpu_base *cpu_base = &__get_cpu_var(hrtimer_bases);
struct hrtimer_clock_base *base;
int index, gettime = 1;
// 若当前处于高精度模式,则直接返回
if (hrtimer_hres_active())
return;
// 若当前处于低精度模式,则遍历每种时间基准系统
for (index = 0; index < HRTIMER_MAX_CLOCK_BASES; index++) {
base = &cpu_base->clock_base[index];
// 该时间基准系统是否存在红黑树
if (!timerqueue_getnext(&base->active))
continue;
if (gettime) {
// 设置每种时间基准系统的base->clock_base[*].softirq_time
hrtimer_get_softirq_time(cpu_base);
gettime = 0;
}
raw_spin_lock(&cpu_base->lock);
/*
* 函数timerqueue_getnext()返回base->active->next,
* 即红黑树中的左下节点(最早超时的定时器);之所以能在
* while循环中使用该函数,是因为__run_hrtimer()会在移除
* 旧的左下节点时,新的左下节点会被更新到base->active->next
* 域中,使得循环可以继续执行,直到没有新的超时定时器为止
*/
while ((node = timerqueue_getnext(&base->active))) {
struct hrtimer *timer;
timer = container_of(node, struct hrtimer, node);
// 若最早超时的定时器还未超时,则无需处理,直接返回;
if (base->softirq_time.tv64 <= hrtimer_get_expires_tv64(timer))
break;
// 否则,调用该超时定时器的处理函数,参见[7.8.5.1.1 __run_hrtimer()]节
__run_hrtimer(timer, &base->softirq_time);
}
raw_spin_unlock(&cpu_base->lock);
}
}
此时,函数hrtimer_run_queues()的调用关系如下:
consider_steal_time(unsigned long new_itm)
-> run_local_timers()
-> hrtimer_run_queues()
update_process_times(int user_tick)
-> run_local_timers()
-> hrtimer_run_queues()
7.8.5.1.1 __run_hrtimer()
该函数定义于kernel/hrtimer.c:
static void __run_hrtimer(struct hrtimer *timer, ktime_t *now)
{
struct hrtimer_clock_base *base = timer->base;
struct hrtimer_cpu_base *cpu_base = base->cpu_base;
enum hrtimer_restart (*fn)(struct hrtimer *);
int restart;
WARN_ON(!irqs_disabled());
debug_deactivate(timer);
// 将该定时器从红黑树中移出,并更新base->active->next域
__remove_hrtimer(timer, base, HRTIMER_STATE_CALLBACK, 0);
timer_stats_account_hrtimer(timer);
fn = timer->function;
/*
* Because we run timers from hardirq context, there is no chance
* they get migrated to another cpu, therefore its safe to unlock
* the timer base.
*/
raw_spin_unlock(&cpu_base->lock);
trace_hrtimer_expire_entry(timer, now);
restart = fn(timer); // 调用定时器的超时处理函数
trace_hrtimer_expire_exit(timer);
raw_spin_lock(&cpu_base->lock);
/*
* Note: We clear the CALLBACK bit after enqueue_hrtimer and
* we do not reprogramm the event hardware. Happens either in
* hrtimer_start_range_ns() or in hrtimer_interrupt()
*/
if (restart != HRTIMER_NORESTART) {
BUG_ON(timer->state != HRTIMER_STATE_CALLBACK);
// 将该定时器重新插入红黑树,并更新base->active->next域
enqueue_hrtimer(timer, base);
}
WARN_ON_ONCE(!(timer->state & HRTIMER_STATE_CALLBACK));
timer->state &= ~HRTIMER_STATE_CALLBACK;
}
7.8.5.2 高精度模式/hrtimer_interrupt()
切换到高精度模式后,原来给CPU提供tick事件的tick_device(clock_event_device)会被高精度定时器系统接管,它的中断事件回调函数被设置为hrtimer_interrupt(),红黑树中最左下节点的定时器的超时时间被编程到该clock_event_device中,这样每次clock_event_device的中断意味着至少有一个高精度定时器超时。另外,当timekeeper系统中的时间需要修正,或者clock_event_device的到期事件时间被重新编程时,系统会发出HRTIMER_SOFTIRQ软中断,软中断的处理函数run_hrtimer_softirq()最终也会调用函数hrtimer_interrupt()对超时定时器进行处理,所以在这里只要讨论函数hrtimer_interrupt()的实现即可。
该函数定义于kernel/hrtimer.c:
void hrtimer_interrupt(struct clock_event_device *dev)
{
struct hrtimer_cpu_base *cpu_base = &__get_cpu_var(hrtimer_bases);
ktime_t expires_next, now, entry_time, delta;
int i, retries = 0;
BUG_ON(!cpu_base->hres_active);
cpu_base->nr_events++;
dev->next_event.tv64 = KTIME_MAX;
entry_time = now = ktime_get();
retry:
expires_next.tv64 = KTIME_MAX;
raw_spin_lock(&cpu_base->lock);
/*
* We set expires_next to KTIME_MAX here with cpu_base->lock
* held to prevent that a timer is enqueued in our queue via
* the migration code. This does not affect enqueueing of
* timers which run their callback and need to be requeued on
* this CPU.
*/
cpu_base->expires_next.tv64 = KTIME_MAX;
// 与函数hrtimer_run_queues()类似
for (i = 0; i < HRTIMER_MAX_CLOCK_BASES; i++) {
struct hrtimer_clock_base *base;
struct timerqueue_node *node;
ktime_t basenow;
if (!(cpu_base->active_bases & (1 << i)))
continue;
base = cpu_base->clock_base + i;
basenow = ktime_add(now, base->offset);
while ((node = timerqueue_getnext(&base->active))) {
struct hrtimer *timer;
timer = container_of(node, struct hrtimer, node);
/*
* The immediate goal for using the softexpires is
* minimizing wakeups, not running timers at the
* earliest interrupt after their soft expiration.
* This allows us to avoid using a Priority Search
* Tree, which can answer a stabbing querry for
* overlapping intervals and instead use the simple
* BST we already have.
* We don't add extra wakeups by delaying timers that
* are right-of a not yet expired timer, because that
* timer will have to trigger a wakeup anyway.
*/
if (basenow.tv64 < hrtimer_get_softexpires_tv64(timer)) {
ktime_t expires;
expires = ktime_sub(hrtimer_get_expires(timer), base->offset);
if (expires.tv64 < expires_next.tv64)
expires_next = expires;
break;
}
__run_hrtimer(timer, &basenow);
}
}
/*
* Store the new expiry value so the migration code can verify
* against it.
*/
cpu_base->expires_next = expires_next;
raw_spin_unlock(&cpu_base->lock);
/* Reprogramming necessary ? */
if (expires_next.tv64 == KTIME_MAX || !tick_program_event(expires_next, 0)) {
cpu_base->hang_detected = 0;
return;
}
/*
* The next timer was already expired due to:
* - tracing
* - long lasting callbacks
* - being scheduled away when running in a VM
*
* We need to prevent that we loop forever in the hrtimer
* interrupt routine. We give it 3 attempts to avoid
* overreacting on some spurious event.
*/
now = ktime_get();
cpu_base->nr_retries++;
if (++retries < 3)
goto retry;
/*
* Give the system a chance to do something else than looping
* here. We stored the entry time, so we know exactly how long
* we spent here. We schedule the next event this amount of
* time away.
*/
cpu_base->nr_hangs++;
cpu_base->hang_detected = 1;
delta = ktime_sub(now, entry_time);
if (delta.tv64 > cpu_base->max_hang_time.tv64)
cpu_base->max_hang_time = delta;
/*
* Limit it to a sensible value as we enforce a longer
* delay. Give the CPU at least 100ms to catch up.
*/
if (delta.tv64 > 100 * NSEC_PER_MSEC)
expires_next = ktime_add_ns(now, 100 * NSEC_PER_MSEC);
else
expires_next = ktime_add(now, delta);
tick_program_event(expires_next, 1);
printk_once(KERN_WARNING "hrtimer: interrupt took %llu ns\n",
ktime_to_ns(delta));
}
7.8.5.2.1 切换到高精度模式
函数hrtimer_run_pending()定义于kernel/hrtimer.c:
/*
* 该函数被run_timer_softirq()调用,
* 参见[7.7.4 定时器的超时处理/run_timer_softirq()]节
*/
void hrtimer_run_pending(void)
{
// 若当前已处于高精度模式,则直接返回
if (hrtimer_hres_active())
return;
/*
* This _is_ ugly: We have to check in the softirq context,
* whether we can switch to highres and / or nohz mode. The
* clocksource switch happens in the timer interrupt with
* xtime_lock held. Notification from there only sets the
* check bit in the tick_oneshot code, otherwise we might
* deadlock vs. xtime_lock.
*/
// 否则,切换到高精度模式(判断hrtimer_hres_enabled)
if (tick_check_oneshot_change(!hrtimer_is_hres_enabled()))
hrtimer_switch_to_hres();
}
函数hrtimer_switch_to_hres()定义于kernel/hrtimer.c:
/*
* Switch to high resolution mode
*/
static int hrtimer_switch_to_hres(void)
{
int i, cpu = smp_processor_id();
struct hrtimer_cpu_base *base = &per_cpu(hrtimer_bases, cpu);
unsigned long flags;
if (base->hres_active)
return 1;
local_irq_save(flags);
/*
* 设置tick_cpu_device->evtdev->event_handler = hrtimer_interrupt,
* 参见[7.8.5.2.1.1 tick_init_highres()]节。在高精度模式下,调用hrtimer_interrupt()
* 进行处理
*/
if (tick_init_highres()) {
local_irq_restore(flags);
printk(KERN_WARNING "Could not switch to high resolution "
"mode on CPU %d\n", cpu);
return 0;
}
base->hres_active = 1;
for (i = 0; i < HRTIMER_MAX_CLOCK_BASES; i++)
base->clock_base[i].resolution = KTIME_HIGH_RES;
// 创建模拟tick事件的定时器,参见[7.8.5.2.1.2 tick_setup_sched_timer()]节
tick_setup_sched_timer();
/* "Retrigger" the interrupt to get things going */
retrigger_next_event(NULL);
local_irq_restore(flags);
return 1;
}
7.8.5.2.1.1 tick_init_highres()
该函数定义于kernel/time/tick-oneshot.c:
#ifdef CONFIG_HIGH_RES_TIMERS
/**
* tick_init_highres - switch to high resolution mode
*
* Called with interrupts disabled.
*/
int tick_init_highres(void)
{
return tick_switch_to_oneshot(hrtimer_interrupt);
}
#endif
...
int tick_switch_to_oneshot(void (*handler)(struct clock_event_device *))
{
struct tick_device *td = &__get_cpu_var(tick_cpu_device);
struct clock_event_device *dev = td->evtdev;
if (!dev || !(dev->features & CLOCK_EVT_FEAT_ONESHOT) || !tick_device_is_functional(dev)) {
printk(KERN_INFO "Clockevents: could not switch to one-shot mode:");
if (!dev) {
printk(" no tick device\n");
} else {
if (!tick_device_is_functional(dev))
printk(" %s is not functional.\n", dev->name);
else
printk(" %s does not support one-shot mode.\n", dev->name);
}
return -EINVAL;
}
td->mode = TICKDEV_MODE_ONESHOT;
dev->event_handler = handler;
clockevents_set_mode(dev, CLOCK_EVT_MODE_ONESHOT);
tick_broadcast_switch_to_oneshot();
return 0;
}
7.8.5.2.1.2 tick_setup_sched_timer()
当系统切换到高精度模式后,tick_device被高精度定时器系统接管,不再定期地产生tick事件。到kernel v3.4为止,内核还没有彻底废除jiffies机制,系统还要依赖定期到来的tick事件,供进程调度系统和时间更新等操作,大量存在的低精度定时器也仍然依赖于jiffies的计数,所以尽管tick_device被接管,高精度定时器系统还是要想办法继续提供定期的tick事件。为了达到这一目的,内核使用了一个取巧的办法:既然高精度模式已经启用,可以定义一个hrtimer,把它的到期时间设定为一个jiffy的时间,当这个hrtimer到期时,在这个hrtimer的超时处理函数中,进行和原来的tick_device同样的操作,然后把该hrtimer的到期时间顺延一个jiffy周期,如此反复循环,完美地模拟了原有tick_device的功能。
该函数定义于kernel/time/tick-sched.c:
static DEFINE_PER_CPU(struct tick_sched, tick_cpu_sched);
#ifdef CONFIG_HIGH_RES_TIMERS
void tick_setup_sched_timer(void)
{
struct tick_sched *ts = &__get_cpu_var(tick_cpu_sched);
ktime_t now = ktime_get();
/*
* Emulate tick processing via per-CPU hrtimers:
*/
hrtimer_init(&ts->sched_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS);
/*
* 定时器超时处理函数设为tick_sched_timer(),
* 入参为ts->sched_timer,参见[7.8.5.2.1.2.1 tick_sched_timer()]节
*/
ts->sched_timer.function = tick_sched_timer;
/* Get the next period (per cpu) */
hrtimer_set_expires(&ts->sched_timer, tick_init_jiffy_update());
for (;;) {
// 定时器超时时刻设为下一个jiffy时刻
hrtimer_forward(&ts->sched_timer, now, tick_period);
hrtimer_start_expires(&ts->sched_timer, HRTIMER_MODE_ABS_PINNED);
/* Check, if the timer was already in the past */
if (hrtimer_active(&ts->sched_timer))
break;
now = ktime_get();
}
#ifdef CONFIG_NO_HZ
if (tick_nohz_enabled)
ts->nohz_mode = NOHZ_MODE_HIGHRES;
#endif
}
#endif /* HIGH_RES_TIMERS */
7.8.5.2.1.2.1 tick_sched_timer()
该函数定义于kernel/time/tick-sched.c:
static enum hrtimer_restart tick_sched_timer(struct hrtimer *timer)
{
struct tick_sched *ts = container_of(timer, struct tick_sched, sched_timer);
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
int cpu = smp_processor_id();
#ifdef CONFIG_NO_HZ
/*
* Check if the do_timer duty was dropped. We don't care about
* concurrency: This happens only when the cpu in charge went
* into a long sleep. If two cpus happen to assign themself to
* this duty, then the jiffies update is still serialized by
* xtime_lock.
*/
if (unlikely(tick_do_timer_cpu == TICK_DO_TIMER_NONE))
tick_do_timer_cpu = cpu;
#endif
/* Check, if the jiffies need an update */
if (tick_do_timer_cpu == cpu)
tick_do_update_jiffies64(now);
/*
* Do not call, when we are not in irq context and have
* no valid regs pointer
*/
if (regs) {
/*
* When we are idle and the tick is stopped, we have to touch
* the watchdog as we might not schedule for a really long
* time. This happens on complete idle SMP systems while
* waiting on the login prompt. We also increment the "start of
* idle" jiffy stamp so the idle accounting adjustment we do
* when we go busy again does not account too much ticks.
*/
if (ts->tick_stopped) {
touch_softlockup_watchdog();
ts->idle_jiffies++;
}
update_process_times(user_mode(regs));
profile_tick(CPU_PROFILING);
}
// 把本定时器的超时时刻推迟一个tick周期
hrtimer_forward(timer, now, tick_period);
// 该hrtimer定时器需要再次启动,以便产生下一个tick事件
return HRTIMER_RESTART;
}
7.8.5.3 HRTIMER_SOFTIRQ软中断/run_hrtimer_softirq()
该函数定义于kernel/hrtimer.c:
static void run_hrtimer_softirq(struct softirq_action *h)
{
hrtimer_peek_ahead_timers();
}
...
void hrtimer_peek_ahead_timers(void)
{
unsigned long flags;
local_irq_save(flags);
__hrtimer_peek_ahead_timers();
local_irq_restore(flags);
}
...
static void __hrtimer_peek_ahead_timers(void)
{
struct tick_device *td;
/*
* 若当前未处于高精度模式,则直接返回;在低精度模式下,
* 调用hrtimer_run_queues()进行处理,
* 参见[7.8.5.1 低精度模式/hrtimer_run_queues()]节
*/
if (!hrtimer_hres_active())
return;
/*
* 若处于高精度模式,则调用hrtimer_interrupt()进行处理,
* 参见[7.8.5.2 高精度模式/hrtimer_interrupt()]节
*/
td = &__get_cpu_var(tick_cpu_device);
// 参见[7.8.5.2.1 切换到高精度模式]节
if (td && td->evtdev)
hrtimer_interrupt(td->evtdev);
}
7.8.6 与hrtimer有关的系统调用
7.8.6.1 sys_nanosleep()
该系统调用定义于kernel/hrtimer.c:
SYSCALL_DEFINE2(nanosleep, struct timespec __user *, rqtp, struct timespec __user *, rmtp)
{
struct timespec tu;
if (copy_from_user(&tu, rqtp, sizeof(tu)))
return -EFAULT;
if (!timespec_valid(&tu))
return -EINVAL;
return hrtimer_nanosleep(&tu, rmtp, HRTIMER_MODE_REL, CLOCK_MONOTONIC);
}
7.8.6.1.1 hrtimer_nanosleep()
该函数定义于kernel/hrtimer.c:
long hrtimer_nanosleep(struct timespec *rqtp, struct timespec __user *rmtp,
const enum hrtimer_mode mode, const clockid_t clockid)
{
struct restart_block *restart;
struct hrtimer_sleeper t;
int ret = 0;
unsigned long slack;
slack = current->timer_slack_ns;
if (rt_task(current))
slack = 0;
// 参见[7.8.3.1.2 hrtimer_init_on_stack()]节
hrtimer_init_on_stack(&t.timer, clockid, mode);
hrtimer_set_expires_range_ns(&t.timer, timespec_to_ktime(*rqtp), slack);
/*
* 将当前进程休眠指定时间,参见[7.8.6.1.1.1 do_nanosleep()]节
* 若休眠时长等于指定时间,则直接退出;否则,需要设置
* current->stack->restart_block
*/
if (do_nanosleep(&t, mode))
goto out;
/* Absolute timers do not update the rmtp value and restart: */
if (mode == HRTIMER_MODE_ABS) {
ret = -ERESTARTNOHAND;
goto out;
}
if (rmtp) {
// 因为定时器未超时而退出,需要将其剩余时长保存到rmtp
ret = update_rmtp(&t.timer, rmtp);
if (ret <= 0)
goto out;
}
restart = ¤t_thread_info()->restart_block;
/*
* 该函数在sys_restart_syscall()中被调用,
* 参见[7.8.6.1.1.2 hrtimer_nanosleep_restart()]节和[8.3.4.1.3 sys_restart_syscall()]节
*/
restart->fn = hrtimer_nanosleep_restart;
restart->nanosleep.clockid = t.timer.base->clockid;
restart->nanosleep.rmtp = rmtp;
restart->nanosleep.expires = hrtimer_get_expires_tv64(&t.timer);
/*
* 返回该错误码,表示要重新执行该系统调用,参见[8.3.4.1 do_signal()]节
* 参见<<Understanding the Linux Kernel, 3rd Edition>>
* Chaper 11: Reexecution of System Calls
*/
ret = -ERESTART_RESTARTBLOCK;
out:
destroy_hrtimer_on_stack(&t.timer);
return ret;
}
7.8.6.1.1.1 do_nanosleep()
该函数定义于kernel/hrtimer.c:
static int __sched do_nanosleep(struct hrtimer_sleeper *t, enum hrtimer_mode mode)
{
/*
* 设置定时器的超时处理函数为hrtimer_wakeup();函数hrtimer_wakeup()
* 用于唤醒当前进程,并将t->task = NULL,用于退出下面的do-while循环
*/
hrtimer_init_sleeper(t, current);
do {
// 设置当前进程为可中断状态
set_current_state(TASK_INTERRUPTIBLE);
// 启动定时器,此时t->timer->state取值为HRTIMER_STATE_ENQUEUED
hrtimer_start_expires(&t->timer, mode);
// 检查定时器是否启动。若定时器未启动,则不挂起当前进程;
if (!hrtimer_active(&t->timer))
t->task = NULL;
// 若定时器已启动,则调度其他进程运行,当前进程被挂起,并等待唤醒
if (likely(t->task))
schedule();
hrtimer_cancel(&t->timer);
mode = HRTIMER_MODE_ABS;
/*
* 退出while循环的两个条件:
* 1) 定时器超时,此时t->task = NULL,参见定时器超时处理函数hrtimer_wakeup();
* 2) 其他事件唤醒当前进程,此时current->stack->flags中的标志位TIF_SIGPENDING被置位
*/
} while (t->task && !signal_pending(current));
__set_current_state(TASK_RUNNING);
/*
* 若因为定时器超时而退出,则返回true,表示休眠了指定的时间长度;
* 否则,返回false,表示被其他进程唤醒,休眠时长小于指定的时间长度
*/
return t->task == NULL;
}
7.8.6.1.1.2 hrtimer_nanosleep_restart()
该函数定义于kernel/hrtimer.c:
long __sched hrtimer_nanosleep_restart(struct restart_block *restart)
{
struct hrtimer_sleeper t;
struct timespec __user *rmtp;
int ret = 0;
hrtimer_init_on_stack(&t.timer, restart->nanosleep.clockid, HRTIMER_MODE_ABS);
hrtimer_set_expires_tv64(&t.timer, restart->nanosleep.expires);
// 此处与hrtimer_nanosleep()的调用类似,参见[7.8.6.1.1 hrtimer_nanosleep()]节
if (do_nanosleep(&t, HRTIMER_MODE_ABS))
goto out;
rmtp = restart->nanosleep.rmtp;
if (rmtp) {
ret = update_rmtp(&t.timer, rmtp);
if (ret <= 0)
goto out;
}
/* The other values in restart are already filled in */
ret = -ERESTART_RESTARTBLOCK;
out:
destroy_hrtimer_on_stack(&t.timer);
return ret;
}
7.8.7 hrtimer编程示例
源文件test_hrtimer.c如下:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/hrtimer.h>
MODULE_LICENSE("GPL");
struct hrtimer hrt;
enum hrtimer_restart hrtimer_func(struct hrtimer *hrt)
{
printk("*** Hrtimer time out, function: %p\n", hrt->function);
return HRTIMER_NORESTART;
}
static int __init timer_init(void)
{
ktime_t now;
printk("*** Hrtimer init ***\n");
printk("*** hrtimer_func() add: %p\n", hrtimer_func);
now = ktime_get();
hrtimer_init(&hrt, CLOCK_MONOTONIC, HRTIMER_MODE_ABS);
hrt.function = hrtimer_func;
hrtimer_set_expires(&hrt, now);
hrtimer_forward(&hrt, now, ktime_set(2, 100));
hrtimer_start_expires(&hrt, HRTIMER_MODE_ABS);
if (hrtimer_active(&hrt))
printk("*** Hrtimer started succeed.\n");
else
printk("*** Hrtimer started failed.\n");
return 0;
}
static void __exit timer_exit(void)
{
printk("*** Hrtimer exit ***\n");
}
module_init(timer_init);
module_exit(timer_exit);
编译test_hrtimer.c所用的Makefile如下:
obj-m := test_hrtimer.o
# 'uname -r' print kernel release
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
make -C $(KDIR) M=$(PWD) modules
clean:
rm *.o *.ko *.mod.c Modules.symvers modules.order -f
执行命令的过程如下:
chenwx@chenwx ~/alex/hrtimer $ make
make -C /lib/modules/3.5.0-17-generic/build M=/home/chenwx/alex/hrtimer modules
make[1]: Entering directory `/usr/src/linux-headers-3.5.0-17-generic'
CC [M] /home/chenwx/alex/hrtimer/test_hrtimer.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/chenwx/alex/hrtimer/test_hrtimer.mod.o
LD [M] /home/chenwx/alex/hrtimer/test_hrtimer.ko
make[1]: Leaving directory `/usr/src/linux-headers-3.5.0-17-generic'
chenwx@chenwx ~/alex/hrtimer $ ll
total 100
drwxr-xr-x 3 chenwx chenwx 4096 Dec 8 11:36 .
drwxr-xr-x 9 chenwx chenwx 4096 Dec 8 11:09 ..
-rw-r--r-- 1 chenwx chenwx 233 Dec 8 11:10 Makefile
-rw-r--r-- 1 chenwx chenwx 49 Dec 8 11:36 modules.order
-rw-r--r-- 1 chenwx chenwx 0 Dec 8 11:36 Module.symvers
-rw-r--r-- 1 chenwx chenwx 921 Dec 8 11:33 test_hrtimer.c
-rw-r--r-- 1 chenwx chenwx 3851 Dec 8 11:36 test_hrtimer.ko
-rw-r--r-- 1 chenwx chenwx 279 Dec 8 11:36 .test_hrtimer.ko.cmd
-rw-r--r-- 1 chenwx chenwx 832 Dec 8 11:36 test_hrtimer.mod.c
-rw-r--r-- 1 chenwx chenwx 2088 Dec 8 11:36 test_hrtimer.mod.o
-rw-r--r-- 1 chenwx chenwx 26139 Dec 8 11:36 .test_hrtimer.mod.o.cmd
-rw-r--r-- 1 chenwx chenwx 3160 Dec 8 11:36 test_hrtimer.o
-rw-r--r-- 1 chenwx chenwx 26189 Dec 8 11:36 .test_hrtimer.o.cmd
drwxr-xr-x 2 chenwx chenwx 4096 Dec 8 11:36 .tmp_versions
chenwx@chenwx ~/alex/hrtimer $ sudo insmod test_hrtimer.ko
chenwx@chenwx ~/alex/hrtimer $ lsmod | grep test_hrtimer
test_hrtimer 12413 0
chenwx@chenwx ~/alex/hrtimer $ dmesg | tail
...
[ 3447.649338] *** Hrtimer init ***
[ 3447.649352] *** hrtimer_func() add: e0e05000
[ 3447.649363] *** Hrtimer started succeed.
[ 3449.650737] *** Hrtimer time out, function: e0e05000
chenwx@chenwx ~/alex/hrtimer $ sudo rmmod test_hrtimer
chenwx@chenwx ~/alex/hrtimer $ dmesg | tail
...
[ 3447.649338] *** Hrtimer init ***
[ 3447.649352] *** hrtimer_func() add: e0e05000
[ 3447.649363] *** Hrtimer started succeed.
[ 3449.650737] *** Hrtimer time out, function: e0e05000
[ 3476.841762] *** Hrtimer exit ***
8 进程间通信/IPC
所有System V IPC对象权限都包含在数据结构ipc_perm中,参见include/linux/ipc.h。System V消息是在ipc/msg.c中实现,共享内存在ipc/shm.c中,信号量在ipc/sem.c中,管道在fs/pipe.c中实现。
8.1 Linux进程间通信简介
Linux的进程间通信机制基本上是从Unix平台的进程间通信机制继承而来的。而对Unix发展做出重大贡献的两大主力:AT&T的贝尔实验室和BSD(加州大学伯克利分校的伯克利软件发布中心)在进程间通信方面的侧重点有所不同。前者对Unix早期的进程间通信机制进行了系统地改进和扩充,形成了system V IPC,通信进程被局限在单个计算机内;而后者则跳过了这个限制,形成了基于套接字socket的进程间通信机制。Linux则把两者继承了下来,参见:
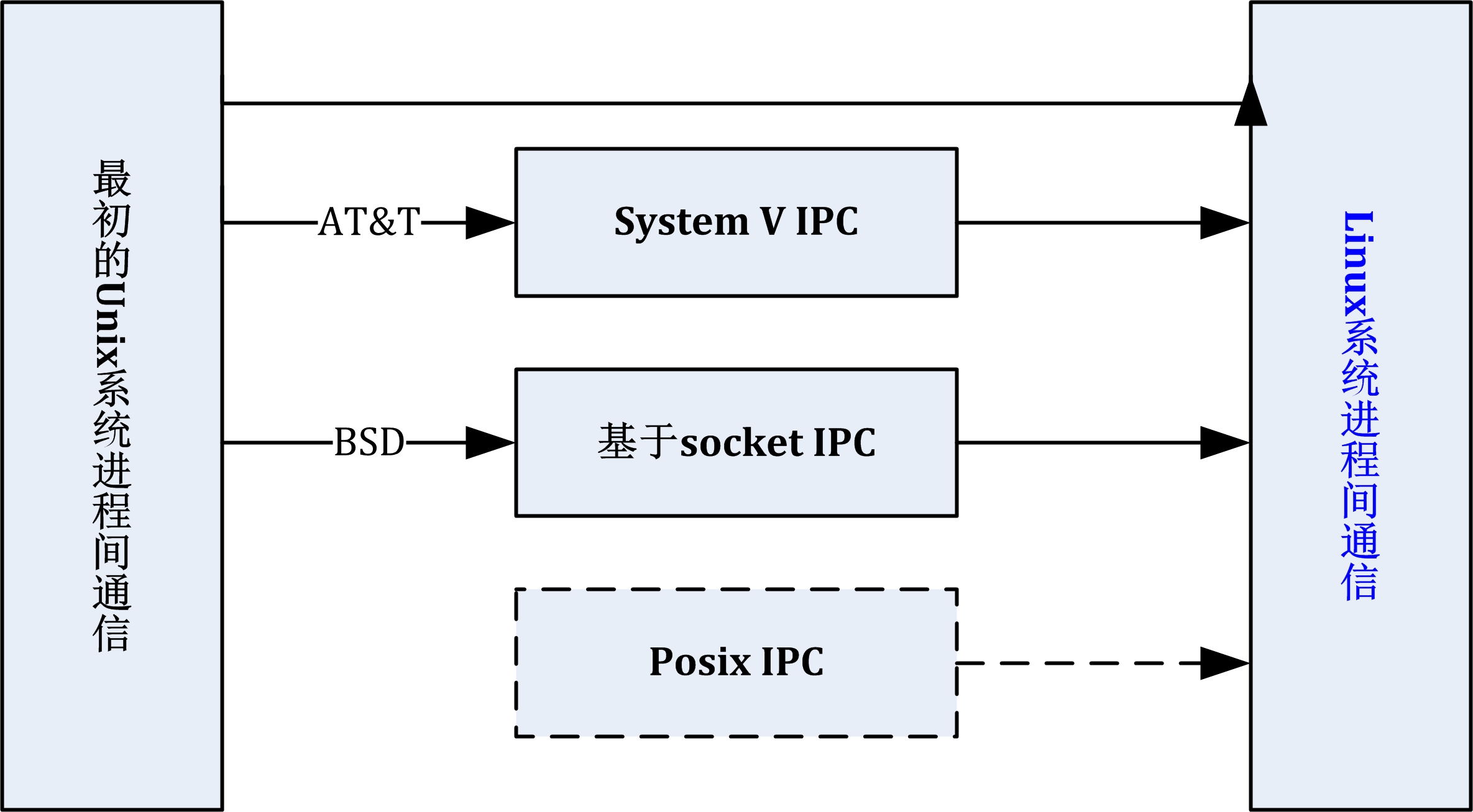
- 最初的Unix IPC包括:管道、FIFO、信号;
- System V IPC包括:System V消息队列、System V信号灯、System V共享内存区;
- Posix IPC包括:Posix消息队列、Posix信号灯、Posix共享内存区。
由于Unix版本的多样性,电子电气工程协会(IEEE)开发了一个独立的Unix标准,这个新的ANSI Unix标准被称为计算机环境的可移植性操作系统界面(PSOIX)。现有大部分Unix和流行版本都是遵循POSIX标准的,而Linux从一开始就遵循POSIX标准。
Linux系统的进程间通信主要包括如下几种:
-
管道(pipe)、命名管道(named pipe)
管道可用于具有亲属关系进程间的通信,命名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲属关系进程间的通信。
-
信号(signal)
信号用于通知接收进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;Linux除了支持Unix早期信号函数sigal()外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction()函数重新实现了signal()函数)。
-
消息队列(message)
消息队列是消息的链表,包括Posix消息队列、system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
-
共享内存(share memory)
共享内存使多个进程可以访问同一块内存空间,它是最快的可用IPC形式。它是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量,结合使用,来达到进程间的同步及互斥。
-
信号量(semaphore)
信号量主要作为进程间以及同一进程不同线程之间的同步手段。
-
套接字(socket)
套接字是更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
使用下列命令查看系统中进程间通信情况:
$ ipcs
8.2 管道(pipe)/命名管道(named pipe)
8.2.1 管道(pipe)
管道(pipe)具有以下特点:
- 管道是半双工的,只支持数据的单向流动。两进程间通信时需要建立起两个管道;
- 管道使用pipe()函数创建,只能用于父子进程或者兄弟进程之间的通信;
- 管道对于两端的进程而言,实质上是一种独立的文件,只存在于内存中;
- 数据的读写操作:一个进程向管道中写数据,所写的数据添加到管道缓冲区的尾部;另一个进程在管道中缓冲区的头部读数据。
与管道有关的系统调用为sys_pipe(),参见fs/pipe.c:
/*
* sys_pipe() is the normal C calling standard for creating
* a pipe. It's not the way Unix traditionally does this, though.
*/
SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
{
int fd[2];
int error;
error = do_pipe_flags(fd, flags);
if (!error) {
if (copy_to_user(fildes, fd, sizeof(fd))) {
sys_close(fd[0]);
sys_close(fd[1]);
error = -EFAULT;
}
}
return error;
}
/*
* filedes为包含两个元素的数组,其中filedes[0]
* 为管道的读取端,filedes[1]为管道的写入端
*/
SYSCALL_DEFINE1(pipe, int __user *, fildes)
{
return sys_pipe2(fildes, 0);
}
其中,主函数do_pipe_flags()定义如下,参见fs/pipe.c:
int do_pipe_flags(int *fd, int flags)
{
struct file *fw, *fr;
int error;
int fdw, fdr;
if (flags & ~(O_CLOEXEC | O_NONBLOCK))
return -EINVAL;
fw = create_write_pipe(flags);
if (IS_ERR(fw))
return PTR_ERR(fw);
fr = create_read_pipe(fw, flags);
error = PTR_ERR(fr);
if (IS_ERR(fr))
goto err_write_pipe;
error = get_unused_fd_flags(flags);
if (error < 0)
goto err_read_pipe;
fdr = error;
error = get_unused_fd_flags(flags);
if (error < 0)
goto err_fdr;
fdw = error;
audit_fd_pair(fdr, fdw);
fd_install(fdr, fr);
fd_install(fdw, fw);
fd[0] = fdr;
fd[1] = fdw;
return 0;
err_fdr:
put_unused_fd(fdr);
err_read_pipe:
path_put(&fr->f_path);
put_filp(fr);
err_write_pipe:
free_write_pipe(fw);
return error;
}
8.2.2 命名管道(named pipe)
命名管道也是半双工的,不过它允许没有亲属关系的进程间进行通信。也就是说,命名管道提供了一个路径名与之关联,以FIFO(先进先出)的形式存在于文件系统中。这样即使是不相干的进程也可以通过FIFO相互通信,只要它们能访问所提供的路径即可。
值得注意的是,只有在管道有读端时,向管道中写数据才有意义。否则,向管道中写数据的进程会收到内核发出来的SIGPIPE信号,应用程序可以自定义该信号处理函数,或者直接忽略该信号。
创建命名管道:
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
int main(void)
{
char buf[80];
int fd;
unlink("zieckey_fifo");
mkfifo("zieckey_fifo", 0777);
}
写命名管道:
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
int main(void)
{
int fd;
char s[] = "Hello!\n";
fd = open("zieckey_fifo", O_WRONLY);
while(1)
{
write(fd, s, sizeof(s));
sleep(1);
}
return 0;
}
读命名管道:
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
int main(void)
{
int fd;
char buf[80];
fd = open("zieckey_fifo", O_RDONLY);
while(1)
{
read(fd, buf, sizeof(buf));
printf("%s\n", buf);
sleep(1);
}
return 0;
}
8.2.3 管道模块被编译进内核时的初始化过程
在fs/pipe.c中包含如下代码:
static int __init init_pipe_fs(void)
{
int err = register_filesystem(&pipe_fs_type);
if (!err) {
pipe_mnt = kern_mount(&pipe_fs_type);
if (IS_ERR(pipe_mnt)) {
err = PTR_ERR(pipe_mnt);
unregister_filesystem(&pipe_fs_type);
}
}
return err;
}
static void __exit exit_pipe_fs(void)
{
// 参见[11.2.2.3 卸载文件系统(1)/kern_unmount()]节
kern_unmount(pipe_mnt);
unregister_filesystem(&pipe_fs_type);
}
fs_initcall(init_pipe_fs);
module_exit(exit_pipe_fs);
其中,fs_initcall()和module_exit()参见13.5.1.1 module被编译进内核时的初始化过程节。可知,当module被编译进内核时,其初始化函数需要在系统启动时被调用。其调用过程为:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall5.init
8.3 信号/Signal
8.3.1 信号简介
信号机制是进程间相互传递消息的一种方法,信号又被称为软中断信号,或软中断。从其命名可知,它的实质和使用很象中断。所以,信号可以说是进程控制的一部分。
软中断信号(signal)用来通知进程发生了异步事件。进程间可以互相通过系统调用kill发送软中断信号。内核也可以因为内部事件而给进程发送信号,通知进程发生了某个事件。NOTE: 信号只是用来通知某进程发生了什么事件,并不给该进程传递任何数据(信号是一个整数,不包含额外的参数)。
收到信号的进程对各种信号有不同的处理方法,基本可以分为三类:
- 第一种方法:类似中断的处理程序,对于需要处理的信号,进程可以指定处理函数,由该函数来处理。
- 第二种方法:忽略某个信号,对该信号不做任何处理,就象未发生过一样。
- 第三种方法:对该信号的处理保留系统的默认值,这是缺省操作。NOTE: SIGKILL和SIGSTOP信号不能被忽略,不能被阻塞,也不能使用用户自定义的函数处理,所以总是执行它们的默认行为。
在进程表的表项中有一个软中断信号域(struct sigpending pending –> signal,参见[7.1.1.12 信号处理]节),该域中每一位对应一个信号,当有信号发送给该进程时,对应位被置位。由此可知,进程对不同的信号可以同时保留,但对于同一个信号,进程并不知道在处理之前来过多少个。
有两个特殊情况需要注意:
- 1) 任何进程都不能给进程0(即swapper进程)发送信号;
- 2) 发给进程1的信号都会被丢弃,除非它们被捕获。所以进程0不会死亡,进程1仅在int程序结束时死亡。
8.3.2 与信号有关的数据结构
struct task_struct包含与信号有关的域参见[7.1.1.12 信号处理]节:
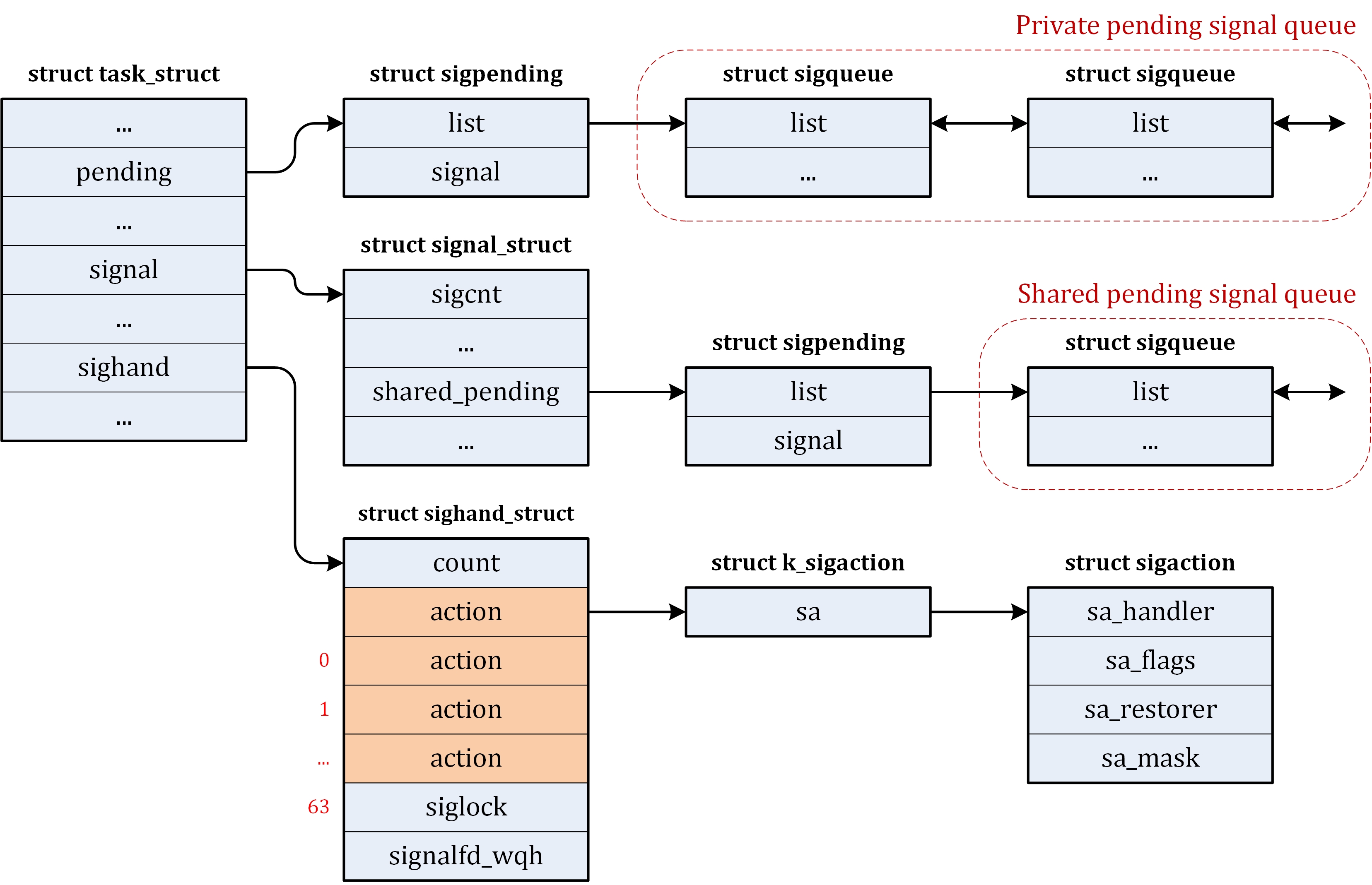
8.3.2.1 信号的种类及取值
信号分为两类:
- 非实时信号:信号取值范围为[1, 31]
- 实时信号:信号取值范围为[32, 64]
NOTE: 0不是有效的信号值,只用于检查是当前进程否有发送信号的权限,并不真正发送,参见8.3.3.7 group_send_sig_info()节。
POSIX定义的信号,参见«IEEE Std 1003.1-2008 POSIX.Base Specifications, Issue 7» 第Vol. 2: System Interfaces卷第Chapter 3: System Interfaces章第signal节。
8.3.2.1.1 非实时信号/Regular Signal
Linux系统包含如下非实时信号,定义于arch/x86/include/asm/signal.h:
#define SIGHUP 1
#define SIGINT 2
#define SIGQUIT 3
#define SIGILL 4
#define SIGTRAP 5
#define SIGABRT 6
#define SIGIOT 6
#define SIGBUS 7
#define SIGFPE 8
#define SIGKILL 9
#define SIGUSR1 10
#define SIGSEGV 11
#define SIGUSR2 12
#define SIGPIPE 13
#define SIGALRM 14
#define SIGTERM 15
#define SIGSTKFLT 16
#define SIGCHLD 17
#define SIGCONT 18
#define SIGSTOP 19
#define SIGTSTP 20
#define SIGTTIN 21
#define SIGTTOU 22
#define SIGURG 23
#define SIGXCPU 24
#define SIGXFSZ 25
#define SIGVTALRM 26
#define SIGPROF 27
#define SIGWINCH 28
#define SIGIO 29
#define SIGPOLL SIGIO
/*
#define SIGLOST 29
*/
#define SIGPWR 30
#define SIGSYS 31
#define SIGUNUSED 31
/* These should not be considered constants from userland. */
#define SIGRTMIN 32
#define SIGRTMAX _NSIG
信号的默认处理方法及注释如下表所示:
The first 31 signals in Linux/i386
| # | Signal Name | Default Action | Comment | POSIX |
|---|---|---|---|---|
| 1 | SIGHUP | Terminate | Hang up controlling terminal or process | Yes |
| 2 | SIGINT | Terminate | Interrupt from keyboard | Yes |
| 3 | SIGQUIT | Dump | Quit from keyboard | Yes |
| 4 | SIGILL | Dump | Illegal instruction | Yes |
| 5 | SIGTRAP | Dump | Breakpoint for debugging | No |
| 6 | SIGABRT | Dump | Abnormal termination | Yes |
| 6 | SIGIOT | Dump | Equivalent to SIGABRT | No |
| 7 | SIGBUS | Dump | Bus error | No |
| 8 | SIGFPE | Dump | Floating-point exception | Yes |
| 9 | SIGKILL | Terminate | Forced-process termination | Yes |
| 10 | SIGUSR1 | Terminate | Available to processes | Yes |
| 11 | SIGSEGV | Dump | Invalid memory reference | Yes |
| 12 | SIGUSR2 | Terminate | Available to processes | Yes |
| 13 | SIGPIPE | Terminate | Write to pipe with no readers | Yes |
| 14 | SIGALRM | Terminate | Real-timerclock | Yes |
| 15 | SIGTERM | Terminate | Process termination | Yes |
| 16 | SIGSTKFLT | Terminate | Coprocessor stack error | No |
| 17 | SIGCHLD | Ignore | Child process stopped or terminated, or got signal if traced | Yes |
| 18 | SIGCONT | Continue | Resume execution, if stopped | Yes |
| 19 | SIGSTOP | Stop | Stop process execution | Yes |
| 20 | SIGTSTP | Stop | Stop process issued from tty | Yes |
| 21 | SIGTTIN | Stop | Background process requires input | Yes |
| 22 | SIGTTOU | Stop | Background process requires output | Yes |
| 23 | SIGURG | Ignore | Urgent condition on socket | No |
| 24 | SIGXCPU | Dump | CPU time limit exceeded | No |
| 25 | SIGXFSZ | Dump | File size limit exceeded | No |
| 26 | SIGVTALRM | Terminate | Virtual timer clock | No |
| 27 | SIGPROF | Terminate | Profile timer clock | No |
| 28 | SIGWINCH | Ignore | Window resizing | No |
| 29 | SIGIO | Terminate | I/O now possible | No |
| 29 | SIGPOLL | Terminate | Equivalent to SIGIO | No |
| 30 | SIGPWR | Terminate | Power supply failure | No |
| 31 | SIGSYS | Dump | Bad system call | No |
| 31 | SIGUNUSED | Dump | Equivalent to SIGSYS | No |
可以在终端中执行下列命令获得信号列表:
chenwx@chenwx /usr/src/linux $ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
8.3.2.1.2 实时信号/Real-time Signal
Besides the regular signals described in previous section, the POSIX standard has introduced a new class of signals denoted as real-time signals; their signal numbers range from 32 to 64 on Linux. They mainly differ from regular signals because they are always queued so that multiple signals sent will be received. On the other hand, regular signals of the same kind are not queued: if a regular signal is sent many times in a row, just one of them is delivered to the receiving process. Although the Linux kernel does not use real-time signals, it fully supports the POSIX standard by means of several specific system calls.
Linux内核通过如下系统调用支持实时信号,参见kernel/signal.c:
SYSCALL_DEFINE4(rt_sigaction, int, sig, const struct sigaction __user *, act,
struct sigaction __user *, oact, size_t, sigsetsize)
SYSCALL_DEFINE2(rt_sigpending, sigset_t __user *, set, size_t, sigsetsize)
SYSCALL_DEFINE4(rt_sigprocmask, int, how, sigset_t __user *, nset,
sigset_t __user *, oset, size_t, sigsetsize)
SYSCALL_DEFINE3(rt_sigqueueinfo, pid_t, pid, int, sig, siginfo_t __user *, uinfo)
SYSCALL_DEFINE2(rt_sigsuspend, sigset_t __user *, unewset, size_t, sigsetsize)
SYSCALL_DEFINE4(rt_sigtimedwait, const sigset_t __user *, uthese, siginfo_t __user *, uinfo,
const struct timespec __user *, uts, size_t, sigsetsize)
8.3.2.2 sigset_t
sigset_t占64 bits,被当作Bit Array来使用,每一比特对应一种信号。其定义于arch/x86/include/asm/signal.h:
#ifndef __ASSEMBLY__
#include <linux/types.h>
#include <linux/time.h>
#include <linux/compiler.h>
/* Avoid too many header ordering problems. */
struct siginfo;
#ifdef __KERNEL__
#include <linux/linkage.h>
/* Most things should be clean enough to redefine this
at will, if care is taken to make libc match. */
#define _NSIG 64
#ifdef __i386__
# define _NSIG_BPW 32
#else
# define _NSIG_BPW 64
#endif
#define _NSIG_WORDS (_NSIG / _NSIG_BPW)
typedef unsigned long old_sigset_t; /* at least 32 bits */
typedef struct {
unsigned long sig[_NSIG_WORDS];
} sigset_t;
#else
/* Here we must cater to libcs that poke about in kernel headers. */
#define NSIG 32
typedef unsigned long sigset_t;
#endif /* __KERNEL__ */
#endif /* __ASSEMBLY__ */
8.3.2.3 sigpending
该结构定义于include/linux/signal.h:
struct sigpending {
struct list_head list;
sigset_t signal; // 参见[8.3.2.2 sigset_t]节
};
8.3.2.4 siginfo_t
siginfo_t结构定义于include/asm-generic/siginfo.h:
typedef struct siginfo {
int si_signo; // signal ID,参见[8.3.2.1 信号的种类及取值]节
int si_errno; // 导致该信号被发出的错误码,0:不是因为错误才发出该信号
int si_code; // 标识谁发出了该信号,其取值参见下文
union {
int _pad[SI_PAD_SIZE];
/* kill() */
struct {
__kernel_pid_t _pid; /* sender's pid */
__ARCH_SI_UID_T _uid; /* sender's uid */
} _kill;
/* POSIX.1b timers */
struct {
__kernel_timer_t _tid; /* timer id */
int _overrun; /* overrun count */
char _pad[sizeof( __ARCH_SI_UID_T) - sizeof(int)];
sigval_t _sigval; /* same as below */
int _sys_private; /* not to be passed to user */
} _timer;
/* POSIX.1b signals */
struct {
__kernel_pid_t _pid; /* sender's pid */
__ARCH_SI_UID_T _uid; /* sender's uid */
sigval_t _sigval;
} _rt;
/* SIGCHLD */
struct {
__kernel_pid_t _pid; /* which child */
__ARCH_SI_UID_T _uid; /* sender's uid */
int _status; /* exit code */
__kernel_clock_t _utime;
__kernel_clock_t _stime;
} _sigchld;
/* SIGILL, SIGFPE, SIGSEGV, SIGBUS */
struct {
void __user *_addr; /* faulting insn/memory ref. */
#ifdef __ARCH_SI_TRAPNO
int _trapno; /* TRAP # which caused the signal */
#endif
short _addr_lsb; /* LSB of the reported address */
} _sigfault;
/* SIGPOLL */
struct {
__ARCH_SI_BAND_T _band; /* POLL_IN, POLL_OUT, POLL_MSG */
int _fd;
} _sigpoll;
} _sifields; // union字段,其中哪个成员有效取决于信号
} siginfo_t;
si_code的可能取值参见include/asm-generic/siginfo.h:
/*
* si_code values
* Digital reserves positive values for kernel-generated signals.
*/
#define SI_USER 0 /* sent by kill, sigsend, raise */
#define SI_KERNEL 0x80 /* sent by the kernel from somewhere */
#define SI_QUEUE -1 /* sent by sigqueue */
#define SI_TIMER __SI_CODE(__SI_TIMER,-2) /* sent by timer expiration */
#define SI_MESGQ __SI_CODE(__SI_MESGQ,-3) /* sent by real time mesq state change */
#define SI_ASYNCIO -4 /* sent by AIO completion */
#define SI_SIGIO -5 /* sent by queued SIGIO */
#define SI_TKILL -6 /* sent by tkill, tgkill system call */
#define SI_DETHREAD -7 /* sent by execve() killing subsidiary threads */
#define SI_FROMUSER(siptr) ((siptr)->si_code <= 0)
#define SI_FROMKERNEL(siptr) ((siptr)->si_code > 0)
8.3.2.5 sigqueue
该结构定义于include/linux/signal.h:
/*
* Real Time signals may be queued.
*/
struct sigqueue {
struct list_head list; // 信号链表
int flags;
siginfo_t info; // 参见[8.3.2.2 sigset_t]节
struct user_struct *user;
};
8.3.2.6 signal_struct
该结构定义于include/linux/sched.h:
struct signal_struct {
atomic_t sigcnt; // Usage counter of the signal descriptor
atomic_t live; // Number of live processes in the thread group
int nr_threads;
wait_queue_head_t wait_chldexit; /* for wait4() */
/* current thread group signal load-balancing target: */
struct task_struct *curr_target;
/* shared signal handling: */
struct sigpending shared_pending;
/* thread group exit support */
int group_exit_code;
/* overloaded:
* - notify group_exit_task when ->count is equal to notify_count
* - everyone except group_exit_task is stopped during signal delivery
* of fatal signals, group_exit_task processes the signal.
*/
int notify_count;
struct task_struct *group_exit_task;
/* thread group stop support, overloads group_exit_code too */
int group_stop_count;
unsigned int flags; /* see SIGNAL_* flags below */
...
};
8.3.2.7 sighand_struct/k_sigaction/sigaction
sighand_struct结构定义于include/linux/sched.h:
struct sighand_struct {
atomic_t count; // Usage counter of the signal handler descriptor
struct k_sigaction action[_NSIG]; // 描述每一种信号对应的处理函数
spinlock_t siglock;
wait_queue_head_t signalfd_wqh;
};
k_sigaction结构定义于arch/x86/include/asm/signal.h:
struct k_sigaction {
struct sigaction sa;
};
sigaction结构定义于arch/x86/include/asm/signal.h:
struct sigaction {
// 指向信号处理函数,其类型为void __signalfn_t(int);
__sighandler_t sa_handler;
unsigned long sa_flags;
// 其类型为void __restorefn_t(void);
__sigrestore_t sa_restorer;
// 当该信号对应的处理函数被执行时,sa_mask中指定的信号必须屏蔽
sigset_t sa_mask; /* mask last for extensibility */
};
sa_handler指向信号处理函数,其取值还可以为:
#define SIG_DFL ((__force __sighandler_t)0) /* default signal handling */
#define SIG_IGN ((__force __sighandler_t)1) /* ignore signal */
#define SIG_ERR ((__force __sighandler_t)-1) /* error return from signal */
sa_flags取值参见arch/x86/include/asm/signal.h:
#define SA_NOCLDSTOP 0x00000001u
#define SA_NOCLDWAIT 0x00000002u
#define SA_SIGINFO 0x00000004u
#define SA_ONSTACK 0x08000000u
#define SA_RESTART 0x10000000u
#define SA_NODEFER 0x40000000u
#define SA_RESETHAND 0x80000000u
#define SA_NOMASK SA_NODEFER
#define SA_ONESHOT SA_RESETHAND
#define SA_RESTORER 0x04000000
8.3.3 信号的发送
无论信号从内核还是从另外一个进程被发送给另一个线程(目标进程),内核会调用下列函数之一来发送信号,参见[8.3.3.1 sys_tkill()/sys_tgkill()]节至[8.3.3.3 force_sig()/force_sig_info()]节。
Kernel functions that generate a signal for a process
| Name | Description |
|---|---|
| send_sig() | Sends a signal to a single process |
| send_sig_info() | Like send_sig(), with extended information in a siginfo_t structure |
| force_sig() | Sends a signal that cannot be explicitly ignored or blocked by the process |
| force_sig_info() | Like force_sig(), with extended information in a siginfo_t structure |
| sys_tkill() | System call handler of tkill() |
| sys_tgkill() | System call handler of tgkill() |
无论信号从内核还是从另外一个进程被发送给另一个线程组(目标进程),内核会调用下列函数之一来发送信号,参见[8.3.3.4 sys_kill()]节至8.3.3.7 group_send_sig_info()节。
Kernel functions that generate a signal for a thread group
| Name | Description |
|---|---|
| kill_pid() | Sends a signal to all thread groups in a process group |
| kill_pid_info() | Like kill_pid(), with extended information in a siginfo_t structure |
| kill_proc_info() | Sends a signal to a single thread group identified by the PID of one of its members, with extended information in a siginfo_t structure |
| sys_kill() | System call handler of kill() |
| sys_rt_sigqueueinfo() | System call handler of rt_sigqueueinfo() |
| group_send _sig_info() | Sends a signal to a single thread group identified by the process descriptor of one of its members |
8.3.3.1 sys_tkill()/sys_tgkill()
函数调用关系如下:
sys_tkill() / sys_tgkill()
-> do_tkill()
-> do_send_specific()
-> do_send_sig_info() // 参见[8.3.3.1.1 do_send_specific()/do_send_sig_info()]节
-> send_signal() // 参见[8.3.3.8 send_signal()]节
该函数定义于kernel/signal.c:
/**
* sys_tgkill - send signal to one specific thread
* @tgid: the thread group ID of the thread
* @pid: the PID of the thread
* @sig: signal to be sent
*
* This syscall also checks the @tgid and returns -ESRCH even if the PID
* exists but it's not belonging to the target process anymore. This
* method solves the problem of threads exiting and PIDs getting reused.
*/
SYSCALL_DEFINE3(tgkill, pid_t, tgid, pid_t, pid, int, sig)
{
/* This is only valid for single tasks */
if (pid <= 0 || tgid <= 0)
return -EINVAL;
return do_tkill(tgid, pid, sig);
}
/**
* sys_tkill - send signal to one specific task
* @pid: the PID of the task
* @sig: signal to be sent
*
* Send a signal to only one task, even if it's a CLONE_THREAD task.
*/
SYSCALL_DEFINE2(tkill, pid_t, pid, int, sig)
{
/* This is only valid for single tasks */
if (pid <= 0)
return -EINVAL;
return do_tkill(0, pid, sig);
}
其中,函数do_tkill()定义于kernel/signal.c:
static int do_tkill(pid_t tgid, pid_t pid, int sig)
{
struct siginfo info;
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_TKILL;
info.si_pid = task_tgid_vnr(current);
info.si_uid = current_uid();
// 参见[8.3.3.1.1 do_send_specific()/do_send_sig_info()]节
return do_send_specific(tgid, pid, sig, &info);
}
8.3.3.1.1 do_send_specific()/do_send_sig_info()
该函数定义于kernel/signal.c:
static int do_send_specific(pid_t tgid, pid_t pid, int sig, struct siginfo *info)
{
struct task_struct *p;
int error = -ESRCH;
rcu_read_lock();
p = find_task_by_vpid(pid);
if (p && (tgid <= 0 || task_tgid_vnr(p) == tgid)) {
error = check_kill_permission(sig, info, p);
/*
* The null signal is a permissions and process existence
* probe. No signal is actually delivered.
*/
if (!error && sig) {
error = do_send_sig_info(sig, info, p, false);
/*
* If lock_task_sighand() failed we pretend the task
* dies after receiving the signal. The window is tiny,
* and the signal is private anyway.
*/
if (unlikely(error == -ESRCH))
error = 0;
}
}
rcu_read_unlock();
return error;
}
其中,函数do_send_sig_info()定义于kernel/signal.c:
int do_send_sig_info(int sig, struct siginfo *info, struct task_struct *p, bool group)
{
unsigned long flags;
int ret = -ESRCH;
if (lock_task_sighand(p, &flags)) {
ret = send_signal(sig, info, p, group); // 参见[8.3.3.8 send_signal()]节
unlock_task_sighand(p, &flags);
}
return ret;
}
8.3.3.2 send_sig()/send_sig_info()
函数调用关系如下:
send_sig()
-> send_sig_info()
-> do_send_sig_info() // 参见[8.3.3.1.1 do_send_specific()/do_send_sig_info()]节
-> send_signal() // 参见[8.3.3.8 send_signal()]节
该函数定义于kernel/signal.c:
int send_sig(int sig, struct task_struct *p, int priv)
{
return send_sig_info(sig, __si_special(priv), p);
}
int send_sig_info(int sig, struct siginfo *info, struct task_struct *p)
{
/*
* Make sure legacy kernel users don't send in bad values
* (normal paths check this in check_kill_permission).
*/
if (!valid_signal(sig))
return -EINVAL;
// 参见[8.3.3.1.1 do_send_specific()/do_send_sig_info()]节
return do_send_sig_info(sig, info, p, false);
}
8.3.3.3 force_sig()/force_sig_info()
相对于send_sig()/send_sig_info()而言,force_sig()/force_sig_info()函数发送的信号不能被目标进程忽略或阻塞。
函数调用关系如下:
force_sig()
-> force_sig_info()
-> specific_send_sig_info()
-> send_signal() // 参见[8.3.3.8 send_signal()]节
该函数定义于kernel/signal.c:
void force_sig(int sig, struct task_struct *p)
{
force_sig_info(sig, SEND_SIG_PRIV, p);
}
/*
* Force a signal that the process can't ignore: if necessary
* we unblock the signal and change any SIG_IGN to SIG_DFL.
*
* Note: If we unblock the signal, we always reset it to SIG_DFL,
* since we do not want to have a signal handler that was blocked
* be invoked when user space had explicitly blocked it.
*
* We don't want to have recursive SIGSEGV's etc, for example,
* that is why we also clear SIGNAL_UNKILLABLE.
*/
int force_sig_info(int sig, struct siginfo *info, struct task_struct *t)
{
unsigned long int flags;
int ret, blocked, ignored;
struct k_sigaction *action;
spin_lock_irqsave(&t->sighand->siglock, flags);
action = &t->sighand->action[sig-1]; // 该信号对应的处理函数
ignored = action->sa.sa_handler == SIG_IGN; // 该信号是否被目标进程忽略
blocked = sigismember(&t->blocked, sig); // 该信号是否被目标进程阻塞
if (blocked || ignored) {
action->sa.sa_handler = SIG_DFL; // 若该信号被忽略或阻塞,则使用该信号的默认处理函数
if (blocked) {
sigdelset(&t->blocked, sig); // 若该信号被阻塞,则取消对该信号的阻塞
recalc_sigpending_and_wake(t);
}
}
if (action->sa.sa_handler == SIG_DFL)
t->signal->flags &= ~SIGNAL_UNKILLABLE;
ret = specific_send_sig_info(sig, info, t); // 向目标进程t发送信号sig
spin_unlock_irqrestore(&t->sighand->siglock, flags);
return ret;
}
其中,函数specific_send_sig_info()定义于kernel/signal.c:
static int specific_send_sig_info(int sig, struct siginfo *info, struct task_struct *t)
{
return send_signal(sig, info, t, 0); // 参见[8.3.3.8 send_signal()]节
}
8.3.3.4 sys_kill()
函数调用关系如下:
sys_kill()
-> kill_something_info()
-> group_send_sig_info()
-> do_send_sig_info() // 参见[8.3.3.1.1 do_send_specific()/do_send_sig_info()]节
-> send_signal() // 参见[8.3.3.8 send_signal()]节
该函数定义于kernel/signal.c:
/**
* sys_kill - send a signal to a process
* @pid: the PID of the process
* @sig: signal to be sent
*/
SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
{
struct siginfo info;
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_USER;
info.si_pid = task_tgid_vnr(current);
info.si_uid = current_uid();
return kill_something_info(sig, &info, pid);
}
/*
* kill_something_info() interprets pid in interesting ways just like kill(2).
*
* POSIX specifies that kill(-1,sig) is unspecified, but what we have
* is probably wrong. Should make it like BSD or SYSV.
*/
static int kill_something_info(int sig, struct siginfo *info, pid_t pid)
{
int ret;
// for pid == n (n > 0), The process with pid n will be signaled
if (pid > 0) {
rcu_read_lock();
ret = kill_pid_info(sig, info, find_vpid(pid));
rcu_read_unlock();
return ret;
}
read_lock(&tasklist_lock);
/*
* for pid == 0, All processes in the current process group are signaled
* for pid == -n (n > 1), All processes in the process group n are signaled
*/
if (pid != -1) {
ret = __kill_pgrp_info(sig, info, pid ? find_vpid(-pid) : task_pgrp(current));
} else { // for pid == -1, All processes with pid larger than 1 will be signaled
int retval = 0, count = 0;
struct task_struct * p;
for_each_process(p) {
if (task_pid_vnr(p) > 1 && !same_thread_group(p, current)) {
// 参见[8.3.3.7 group_send_sig_info()]节
int err = group_send_sig_info(sig, info, p);
++count;
if (err != -EPERM)
retval = err;
}
}
ret = count ? retval : -ESRCH;
}
read_unlock(&tasklist_lock);
return ret;
}
8.3.3.5 sys_rt_sigqueueinfo()
函数调用关系如下:
sys_rt_sigqueueinfo()
-> kill_proc_info() // 参见[8.3.3.6 kill_pid()/kill_proc_info()/kill_pid_info()]节
-> kill_pid_info() // 参见[8.3.3.6 kill_pid()/kill_proc_info()/kill_pid_info()]节
-> group_send_sig_info() // 参见[8.3.3.7 group_send_sig_info()]节
-> do_send_sig_info() // 参见[8.3.3.1.1 do_send_specific()/do_send_sig_info()]节
-> send_signal() // 参见[8.3.3.8 send_signal()]节
该函数定义于kernel/signal.c:
/**
* sys_rt_sigqueueinfo - send signal information to a signal
* @pid: the PID of the thread
* @sig: signal to be sent
* @uinfo: signal info to be sent
*/
SYSCALL_DEFINE3(rt_sigqueueinfo, pid_t, pid, int, sig, siginfo_t __user *, uinfo)
{
siginfo_t info;
if (copy_from_user(&info, uinfo, sizeof(siginfo_t)))
return -EFAULT;
/* Not even root can pretend to send signals from the kernel.
* Nor can they impersonate a kill()/tgkill(), which adds source info.
*/
if (info.si_code >= 0 || info.si_code == SI_TKILL) {
/* We used to allow any < 0 si_code */
WARN_ON_ONCE(info.si_code < 0);
return -EPERM;
}
info.si_signo = sig;
/* POSIX.1b doesn't mention process groups. */
// 参见[8.3.3.6 kill_pid()/kill_proc_info()/kill_pid_info()]节
return kill_proc_info(sig, &info, pid);
}
8.3.3.6 kill_pid()/kill_proc_info()/kill_pid_info()
函数调用关系如下:
kill_pid() / kill_proc_info()
-> kill_pid_info()
-> group_send_sig_info() // 参见[8.3.3.7 group_send_sig_info()]节
-> do_send_sig_info() // 参见[8.3.3.1.1 do_send_specific()/do_send_sig_info()]节
-> send_signal() // 参见[8.3.3.8 send_signal()]节
该函数定义于kernel/signal.c:
int kill_pid(struct pid *pid, int sig, int priv)
{
return kill_pid_info(sig, __si_special(priv), pid);
}
int kill_proc_info(int sig, struct siginfo *info, pid_t pid)
{
int error;
rcu_read_lock();
error = kill_pid_info(sig, info, find_vpid(pid));
rcu_read_unlock();
return error;
}
int kill_pid_info(int sig, struct siginfo *info, struct pid *pid)
{
int error = -ESRCH;
struct task_struct *p;
rcu_read_lock();
retry:
p = pid_task(pid, PIDTYPE_PID);
if (p) {
// 参见[8.3.3.7 group_send_sig_info()]节
error = group_send_sig_info(sig, info, p);
if (unlikely(error == -ESRCH))
/*
* The task was unhashed in between, try again.
* If it is dead, pid_task() will return NULL,
* if we race with de_thread() it will find the
* new leader.
*/
goto retry;
}
rcu_read_unlock();
return error;
}
8.3.3.7 group_send_sig_info()
函数调用关系如下:
group_send_sig_info()
-> check_kill_permission()
-> do_send_sig_info() // 参见[8.3.3.1.1 do_send_specific()/do_send_sig_info()]节
-> send_signal() // 参见[8.3.3.8 send_signal()]节
该函数定义于kernel/signal.c:
/*
* send signal info to all the members of a group
*/
int group_send_sig_info(int sig, struct siginfo *info, struct task_struct *p)
{
int ret;
rcu_read_lock();
ret = check_kill_permission(sig, info, p);
rcu_read_unlock();
// 0不是有效的信号取值,不会发送
if (!ret && sig)
// 参见[8.3.3.1.1 do_send_specific()/do_send_sig_info()]节
ret = do_send_sig_info(sig, info, p, true);
return ret;
}
8.3.3.8 send_signal()
上述几节中的函数/系统调用最终都通过调用send_signal()向指定的进程/进程组发送信号,其定义于kernel/signal.c:
static int send_signal(int sig, struct siginfo *info, struct task_struct *t, int group)
{
int from_ancestor_ns = 0;
#ifdef CONFIG_PID_NS
from_ancestor_ns = si_fromuser(info) && !task_pid_nr_ns(current, task_active_pid_ns(t));
#endif
return __send_signal(sig, info, t, group, from_ancestor_ns);
}
其中,函数__send_signal()定义于kernel/signal.c:
static int __send_signal(int sig, struct siginfo *info, struct task_struct *t,
int group, int from_ancestor_ns)
{
struct sigpending *pending;
struct sigqueue *q;
int override_rlimit;
trace_signal_generate(sig, info, t);
assert_spin_locked(&t->sighand->siglock);
// Special process for signal SIGCONT, SIGSTOP
if (!prepare_signal(sig, t, from_ancestor_ns))
return 0;
// 根据入参group来选择pending signal queue,参见[8.3.2 与信号有关的数据结构]节中的图
pending = group ? &t->signal->shared_pending : &t->pending;
/*
* Short-circuit ignored signals and support queuing
* exactly one non-rt signal, so that we can get more
* detailed information about the cause of the signal.
*/
// 非实时信号在pending signal queue队列中最多存在一个
if (legacy_queue(pending, sig))
return 0;
/*
* fast-pathed signals for kernel-internal things like SIGSTOP or SIGKILL.
*/
if (info == SEND_SIG_FORCED)
goto out_set;
/*
* Real-time signals must be queued if sent by sigqueue, or
* some other real-time mechanism. It is implementation
* defined whether kill() does so. We attempt to do so, on
* the principle of least surprise, but since kill is not
* allowed to fail with EAGAIN when low on memory we just
* make sure at least one signal gets delivered and don't
* pass on the info struct.
*/
if (sig < SIGRTMIN)
override_rlimit = (is_si_special(info) || info->si_code >= 0);
else
override_rlimit = 0;
// Allocate a new signal queue record, 参见[8.3.5 信号的初始化]节
q = __sigqueue_alloc(sig, t, GFP_ATOMIC | __GFP_NOTRACK_FALSE_POSITIVE, override_rlimit);
if (q) {
// 将分配的sigqueue结构链接到选中的pending signal queue队列尾部
list_add_tail(&q->list, &pending->list);
switch ((unsigned long) info) {
case (unsigned long) SEND_SIG_NOINFO:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_USER;
q->info.si_pid = task_tgid_nr_ns(current, task_active_pid_ns(t));
q->info.si_uid = current_uid();
break;
case (unsigned long) SEND_SIG_PRIV:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_KERNEL;
q->info.si_pid = 0;
q->info.si_uid = 0;
break;
default:
copy_siginfo(&q->info, info);
if (from_ancestor_ns)
q->info.si_pid = 0;
break;
}
} else if (!is_si_special(info)) {
if (sig >= SIGRTMIN && info->si_code != SI_USER) {
/*
* Queue overflow, abort. We may abort if the
* signal was rt and sent by user using something
* other than kill().
*/
trace_signal_overflow_fail(sig, group, info);
return -EAGAIN;
} else {
/*
* This is a silent loss of information. We still
* send the signal, but the *info bits are lost.
*/
trace_signal_lose_info(sig, group, info);
}
}
out_set:
signalfd_notify(t, sig);
// Sets the bit corresponding to the signal in the bit mask of the queue
sigaddset(&pending->signal, sig);
complete_signal(sig, t, group); // 参见[8.3.3.8.1 通知目标进程接收信号/complete_signal()]节
return 0;
}
8.3.3.8.1 通知目标进程接收信号/complete_signal()
该函数将设置目标进程的状态,以告知目标进程有新的信号到达。其定义于kernel/signal.c:
static void complete_signal(int sig, struct task_struct *p, int group)
{
struct signal_struct *signal = p->signal;
struct task_struct *t;
/*
* Now find a thread we can wake up to take the signal off the queue.
*
* If the main thread wants the signal, it gets first crack.
* Probably the least surprising to the average bear.
*/
if (wants_signal(sig, p))
t = p;
else if (!group || thread_group_empty(p))
/*
* There is just one thread and it does not need to be woken.
* It will dequeue unblocked signals before it runs again.
*/
return;
else {
/*
* Otherwise try to find a suitable thread.
*/
t = signal->curr_target;
while (!wants_signal(sig, t)) {
t = next_thread(t);
if (t == signal->curr_target)
/*
* No thread needs to be woken.
* Any eligible threads will see
* the signal in the queue soon.
*/
return;
}
signal->curr_target = t;
}
/*
* Found a killable thread. If the signal will be fatal,
* then start taking the whole group down immediately.
*/
if (sig_fatal(p, sig) &&
!(signal->flags & (SIGNAL_UNKILLABLE | SIGNAL_GROUP_EXIT)) &&
!sigismember(&t->real_blocked, sig) &&
(sig == SIGKILL || !t->ptrace)) {
/*
* This signal will be fatal to the whole group.
*/
if (!sig_kernel_coredump(sig)) {
/*
* Start a group exit and wake everybody up.
* This way we don't have other threads
* running and doing things after a slower
* thread has the fatal signal pending.
*/
signal->flags = SIGNAL_GROUP_EXIT;
signal->group_exit_code = sig;
signal->group_stop_count = 0;
t = p;
do {
task_clear_jobctl_pending(t, JOBCTL_PENDING_MASK);
sigaddset(&t->pending.signal, SIGKILL);
signal_wake_up(t, 1);
} while_each_thread(p, t);
return;
}
}
/*
* The signal is already in the shared-pending queue.
* Tell the chosen thread to wake up and dequeue it.
*/
signal_wake_up(t, sig == SIGKILL);
return;
}
其中,函数signal_wake_up()定义于kernel/signal.c:
/*
* Tell a process that it has a new active signal..
*
* NOTE! we rely on the previous spin_lock to
* lock interrupts for us! We can only be called with
* "siglock" held, and the local interrupt must
* have been disabled when that got acquired!
*
* No need to set need_resched since signal event passing
* goes through ->blocked
*/
void signal_wake_up(struct task_struct *t, int resume)
{
unsigned int mask;
// 设置目标进程的t->stack->flags为TIF_SIGPENDING
set_tsk_thread_flag(t, TIF_SIGPENDING);
/*
* For SIGKILL, we want to wake it up in the stopped/traced/killable
* case. We don't check t->state here because there is a race with it
* executing another processor and just now entering stopped state.
* By using wake_up_state, we ensure the process will wake up and
* handle its death signal.
*/
mask = TASK_INTERRUPTIBLE;
if (resume)
mask |= TASK_WAKEKILL;
if (!wake_up_state(t, mask))
kick_process(t); // 仅在CONFIG_SMP定义时才有意义
}
其中,函数wake_up_state()定义于kernel/sched.c:
int wake_up_state(struct task_struct *p, unsigned int state)
{
return try_to_wake_up(p, state, 0); // 参见[7.4.10.2.2.1 try_to_wake_up()]节
}
8.3.4 信号的接收与处理
The kernel checks the value of the TIF_SIGPENDING flag of the process before allowing the process to resume its execution in User Mode. Thus, the kernel checks for the existence of pending signals every time it finishes handling an interrupt or an exception. If it has pending signals, then calling handler do_notify_resume()->do_signal(), refer to section 9.3.2 ret_from_intr.
函数do_notify_resume()定义于arch/x86/kernel/signal.c:
/*
* notification of userspace execution resumption
* - triggered by the TIF_WORK_MASK flags
*/
/*
* regs: The address of the stack area where the User Mode
* register contents of the current process are saved.
*/
void do_notify_resume(struct pt_regs *regs, void *unused, __u32 thread_info_flags)
{
#ifdef CONFIG_X86_MCE
/* notify userspace of pending MCEs */
if (thread_info_flags & _TIF_MCE_NOTIFY)
mce_notify_process();
#endif /* CONFIG_X86_64 && CONFIG_X86_MCE */
/* deal with pending signal delivery */
if (thread_info_flags & _TIF_SIGPENDING) // 该标志为的设置参见[8.3.3.8.1 通知目标进程接收信号/complete_signal()]节
do_signal(regs); // 参见[8.3.4.1 do_signal()]节
if (thread_info_flags & _TIF_NOTIFY_RESUME) {
clear_thread_flag(TIF_NOTIFY_RESUME);
tracehook_notify_resume(regs);
if (current->replacement_session_keyring)
key_replace_session_keyring();
}
if (thread_info_flags & _TIF_USER_RETURN_NOTIFY)
fire_user_return_notifiers();
#ifdef CONFIG_X86_32
clear_thread_flag(TIF_IRET);
#endif /* CONFIG_X86_32 */
}
8.3.4.1 do_signal()
该函数定义于arch/x86/kernel/signal.c:
/*
* Note that 'init' is a special process: it doesn't get signals it doesn't
* want to handle. Thus you cannot kill init even with a SIGKILL even by
* mistake.
*/
static void do_signal(struct pt_regs *regs)
{
struct k_sigaction ka;
siginfo_t info;
int signr;
/*
* We want the common case to go fast, which is why we may in certain
* cases get here from kernel mode. Just return without doing anything
* if so.
* X86_32: vm86 regs switched out by assembly code before reaching
* here, so testing against kernel CS suffices.
*/
if (!user_mode(regs))
return;
/*
* 参见[8.3.4.1.1 get_signal_to_deliver()]节,信号处理方式1(忽略)
* 和信号处理方式3(使用默认处理函数)在该函数中实现
*/
signr = get_signal_to_deliver(&info, &ka, regs, NULL);
if (signr > 0) {
/* Whee! Actually deliver the signal. */
/*
* 参见[8.3.4.1.2 handle_signal()]节,信号处理方式2(使用用户
* 指定的信号处理函数)在该函数中实现
*/
handle_signal(signr, &info, &ka, regs);
return;
}
/* Did we come from a system call? */
if (syscall_get_nr(current, regs) >= 0) {
/* Restart the system call - no handlers present */
switch (syscall_get_error(current, regs)) {
case -ERESTARTNOHAND:
case -ERESTARTSYS:
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
/*
* 若系统调用返回错误码为ERESTART_RESTARTBLOCK,则需要
* 重新执行该系统调用。例子参见[7.8.6.1.1 hrtimer_nanosleep()]节;
* 另参见<<Understanding Linux Kernel, 3rd Edition>>
* Chaper 11: Reexecution of System Calls
*/
case -ERESTART_RESTARTBLOCK:
/*
* 执行系统调用sys_restart_syscall(),
* 参见[8.3.4.1.3 sys_restart_syscall()]节
*/
regs->ax = NR_restart_syscall;
regs->ip -= 2;
break;
}
}
/*
* If there's no signal to deliver, we just put the saved sigmask back.
*/
if (current_thread_info()->status & TS_RESTORE_SIGMASK) {
current_thread_info()->status &= ~TS_RESTORE_SIGMASK;
set_current_blocked(¤t->saved_sigmask);
}
}
8.3.4.1.1 get_signal_to_deliver()
该函数用来获取pending signal queue中的信号,其定义参见kernel/signal.c:
int get_signal_to_deliver(siginfo_t *info, struct k_sigaction *return_ka, struct pt_regs *regs, void *cookie)
{
struct sighand_struct *sighand = current->sighand;
struct signal_struct *signal = current->signal;
int signr;
relock:
/*
* We'll jump back here after any time we were stopped in TASK_STOPPED.
* While in TASK_STOPPED, we were considered "frozen enough".
* Now that we woke up, it's crucial if we're supposed to be
* frozen that we freeze now before running anything substantial.
*/
try_to_freeze();
spin_lock_irq(&sighand->siglock);
/*
* Every stopped thread goes here after wakeup. Check to see if
* we should notify the parent, prepare_signal(SIGCONT) encodes
* the CLD_ si_code into SIGNAL_CLD_MASK bits.
*/
if (unlikely(signal->flags & SIGNAL_CLD_MASK)) {
int why;
if (signal->flags & SIGNAL_CLD_CONTINUED)
why = CLD_CONTINUED;
else
why = CLD_STOPPED;
signal->flags &= ~SIGNAL_CLD_MASK;
spin_unlock_irq(&sighand->siglock);
/*
* Notify the parent that we're continuing. This event is
* always per-process and doesn't make whole lot of sense
* for ptracers, who shouldn't consume the state via
* wait(2) either, but, for backward compatibility, notify
* the ptracer of the group leader too unless it's gonna be
* a duplicate.
*/
read_lock(&tasklist_lock);
do_notify_parent_cldstop(current, false, why);
if (ptrace_reparented(current->group_leader))
do_notify_parent_cldstop(current->group_leader, true, why);
read_unlock(&tasklist_lock);
goto relock;
}
for (;;) {
struct k_sigaction *ka;
if (unlikely(current->jobctl & JOBCTL_STOP_PENDING) &&
do_signal_stop(0))
goto relock;
if (unlikely(current->jobctl & JOBCTL_TRAP_MASK)) {
do_jobctl_trap();
spin_unlock_irq(&sighand->siglock);
goto relock;
}
/*
* 从Private pending signal queue或Shared pending
* signal queue中取出一个信号,参见[8.3.4.1.1.1 dequeue_signal()]节
*/
signr = dequeue_signal(current, ¤t->blocked, info);
if (!signr)
break; /* will return 0 */
if (unlikely(current->ptrace) && signr != SIGKILL) {
signr = ptrace_signal(signr, info, regs, cookie);
if (!signr)
continue;
}
// 获取指定信号的处理函数
ka = &sighand->action[signr-1];
/* Trace actually delivered signals. */
trace_signal_deliver(signr, info, ka);
// 信号处理方式1:忽略该信号
if (ka->sa.sa_handler == SIG_IGN) /* Do nothing. */
continue;
// 信号处理方式2:使用用户指定的信号处理函数
if (ka->sa.sa_handler != SIG_DFL) {
/* Run the handler. */
*return_ka = *ka;
/*
* 若设置表示位SA_ONESHOT,则该信号第一次处理使用
* 用户指定的处理函数,此后使用默认处理函数
*/
if (ka->sa.sa_flags & SA_ONESHOT)
ka->sa.sa_handler = SIG_DFL;
break; /* will return non-zero "signr" value */
}
// 信号处理方式3:使用信号的默认处理函数
/*
* Now we are doing the default action for this signal.
*/
// - for signals: SIGCONT, SIGCHLD, SIGWINCH, SIGURG
if (sig_kernel_ignore(signr)) /* Default is nothing. */
continue;
/*
* Global init gets no signals it doesn't want.
* Container-init gets no signals it doesn't want from same
* container.
*
* Note that if global/container-init sees a sig_kernel_only()
* signal here, the signal must have been generated internally
* or must have come from an ancestor namespace. In either
* case, the signal cannot be dropped.
*/
/*
* - for signals: SIGKILL, SIGSTOP
* The SIGKILL and SIGSTOP signals cannot be ignored, caught,
* or blocked, and their default actions must always be executed.
* Therefore, SIGKILL and SIGSTOP allow a user with appropriate
* privileges to terminate and to stop, respectively, every process,
* regardless of the defenses taken by the program it is executing.
*/
if (unlikely(signal->flags & SIGNAL_UNKILLABLE) && !sig_kernel_only(signr))
continue;
// - for signals: SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU
if (sig_kernel_stop(signr)) {
/*
* The default action is to stop all threads in
* the thread group. The job control signals
* do nothing in an orphaned pgrp, but SIGSTOP
* always works. Note that siglock needs to be
* dropped during the call to is_orphaned_pgrp()
* because of lock ordering with tasklist_lock.
* This allows an intervening SIGCONT to be posted.
* We need to check for that and bail out if necessary.
*/
if (signr != SIGSTOP) {
spin_unlock_irq(&sighand->siglock);
/* signals can be posted during this window */
if (is_current_pgrp_orphaned())
goto relock;
spin_lock_irq(&sighand->siglock);
}
/*
* do_signal_stop() handles group stop for SIGSTOP and
* other stop signals. 检查当前进程是否是线程组中的第一个正在
* 被停止的进程,如果是,它就激活一个组停(group stop)。本质上,
* 它会把信号描述符的group_stop_count字段设置为正值,并且唤醒
* 线程组中的每一个进程。每一个进程都会查看该字段,从而认识到正在
* 停止整个线程组,并把自己的状态改为 TASK_STOPPED,然后调用
* schedule()
*/
if (likely(do_signal_stop(info->si_signo))) {
/* It released the siglock. */
goto relock;
}
/*
* We didn't actually stop, due to a race
* with SIGCONT or something like that.
*/
continue;
}
spin_unlock_irq(&sighand->siglock);
/*
* Anything else is fatal, maybe with a core dump.
*/
current->flags |= PF_SIGNALED;
/*
* - for signals: SIGQUIT, SIGILL, SIGTRAP, SIGABRT,
* SIGFPE, SIGSEGV, SIGBUS, SIGSYS, SIGXCPU,
* SIGXFSZ, SIGEMT
*/
if (sig_kernel_coredump(signr)) {
if (print_fatal_signals)
print_fatal_signal(regs, info->si_signo);
/*
* If it was able to dump core, this kills all
* other threads in the group and synchronizes with
* their demise. If we lost the race with another
* thread getting here, it set group_exit_code
* first and our do_group_exit call below will use
* that value and ignore the one we pass it.
*/
do_coredump(info->si_signo, info->si_signo, regs);
}
/*
* Death signals, no core dump.
*/
do_group_exit(info->si_signo);
/* NOTREACHED */
}
spin_unlock_irq(&sighand->siglock);
return signr;
}
8.3.4.1.1.1 dequeue_signal()
该函数定义于kernel/signal.c:
/*
* Dequeue a signal and return the element to the caller, which is expected to free it.
*
* All callers have to hold the siglock.
*/
int dequeue_signal(struct task_struct *tsk, sigset_t *mask, siginfo_t *info)
{
int signr;
/*
* We only dequeue private signals from ourselves, we don't let signalfd steal them
*/
// 从Private pending signal queue中获取信号
signr = __dequeue_signal(&tsk->pending, mask, info);
if (!signr) {
// 从Shared pending signal queue中获取信号
signr = __dequeue_signal(&tsk->signal->shared_pending, mask, info);
/*
* itimer signal ?
*
* itimers are process shared and we restart periodic
* itimers in the signal delivery path to prevent DoS
* attacks in the high resolution timer case. This is
* compliant with the old way of self-restarting
* itimers, as the SIGALRM is a legacy signal and only
* queued once. Changing the restart behaviour to
* restart the timer in the signal dequeue path is
* reducing the timer noise on heavy loaded !highres
* systems too.
*/
if (unlikely(signr == SIGALRM)) {
struct hrtimer *tmr = &tsk->signal->real_timer;
if (!hrtimer_is_queued(tmr) && tsk->signal->it_real_incr.tv64 != 0) {
hrtimer_forward(tmr, tmr->base->get_time(), tsk->signal->it_real_incr);
hrtimer_restart(tmr);
}
}
}
// 重置TIF_SIGPENDING标志
recalc_sigpending();
if (!signr)
return 0;
if (unlikely(sig_kernel_stop(signr))) {
/*
* Set a marker that we have dequeued a stop signal. Our
* caller might release the siglock and then the pending
* stop signal it is about to process is no longer in the
* pending bitmasks, but must still be cleared by a SIGCONT
* (and overruled by a SIGKILL). So those cases clear this
* shared flag after we've set it. Note that this flag may
* remain set after the signal we return is ignored or
* handled. That doesn't matter because its only purpose
* is to alert stop-signal processing code when another
* processor has come along and cleared the flag.
*/
current->jobctl |= JOBCTL_STOP_DEQUEUED;
}
if ((info->si_code & __SI_MASK) == __SI_TIMER && info->si_sys_private) {
/*
* Release the siglock to ensure proper locking order
* of timer locks outside of siglocks. Note, we leave
* irqs disabled here, since the posix-timers code is
* about to disable them again anyway.
*/
spin_unlock(&tsk->sighand->siglock);
do_schedule_next_timer(info);
spin_lock(&tsk->sighand->siglock);
}
return signr;
}
8.3.4.1.2 handle_signal()
下图描述了信号处理函数的执行流程。假设一个非阻塞的信号发给目标进程。当一个中断或异常发生后,目标进程从用户态(U1)进入核心态,在它切换回用户态(U1)之前,内核调用do_signal()逐一处理悬挂的非阻塞信号(参见8.3.4.1 do_signal()节)。而如果目标进程设置了对信号的处理函数,那么它会调用handle_signal()来调用自定义的信号处理函数(使用setup_rt_frame()来为信号处理函数设置栈),此时当切换到用户态时,目标进程执行的是信号处理函数而不是U1。当信号处理函数结束后,位于setup_rt_frame()栈上的返回代码(return code)被执行,该返回代码会执行rt_sigreturn,从而把U1的上下文从setup_rt_frame栈中拷贝到核心栈。此后,内核可以切换回U1。
NOTE: 在信号的三种处理方式中,只有使用自定义的信号处理函数才需要这样麻烦。
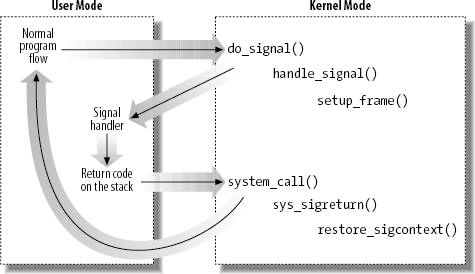
该函数定义于arch/x86/kernel/signal.c:
static int handle_signal(unsigned long sig, siginfo_t *info, struct k_sigaction *ka, struct pt_regs *regs)
{
sigset_t blocked;
int ret;
/* Are we from a system call? */
if (syscall_get_nr(current, regs) >= 0) {
/* If so, check system call restarting.. */
switch (syscall_get_error(current, regs)) {
case -ERESTART_RESTARTBLOCK:
case -ERESTARTNOHAND:
regs->ax = -EINTR;
break;
case -ERESTARTSYS:
if (!(ka->sa.sa_flags & SA_RESTART)) {
regs->ax = -EINTR;
break;
}
/* fallthrough */
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
}
}
/*
* If TF is set due to a debugger (TIF_FORCED_TF), clear the TF
* flag so that register information in the sigcontext is correct.
*/
if (unlikely(regs->flags & X86_EFLAGS_TF) && likely(test_and_clear_thread_flag(TIF_FORCED_TF)))
regs->flags &= ~X86_EFLAGS_TF;
ret = setup_rt_frame(sig, ka, info, regs); // 参见[8.3.4.1.2.1 setup_rt_frame()]节
if (ret)
return ret;
/*
* Clear the direction flag as per the ABI for function entry.
*/
regs->flags &= ~X86_EFLAGS_DF;
/*
* Clear TF when entering the signal handler, but
* notify any tracer that was single-stepping it.
* The tracer may want to single-step inside the
* handler too.
*/
regs->flags &= ~X86_EFLAGS_TF;
sigorsets(&blocked, ¤t->blocked, &ka->sa.sa_mask);
/*
* 若未设置SA_NODEFER,那么在执行信号处理函数时,就要阻塞
* sigaction.sa_mask中指定的所有信号以及sig本身
*/
if (!(ka->sa.sa_flags & SA_NODEFER))
sigaddset(&blocked, sig);
set_current_blocked(&blocked);
tracehook_signal_handler(sig, info, ka, regs, test_thread_flag(TIF_SINGLESTEP));
return 0;
}
8.3.4.1.2.1 setup_rt_frame()
该函数定义于arch/x86/kernel/signal.c:
static int setup_rt_frame(int sig, struct k_sigaction *ka, siginfo_t *info, struct pt_regs *regs)
{
int usig = signr_convert(sig);
sigset_t *set = ¤t->blocked;
int ret;
if (current_thread_info()->status & TS_RESTORE_SIGMASK)
set = ¤t->saved_sigmask;
/* Set up the stack frame */
if (is_ia32) {
if (ka->sa.sa_flags & SA_SIGINFO)
ret = ia32_setup_rt_frame(usig, ka, info, set, regs);
else
ret = ia32_setup_frame(usig, ka, set, regs);
} else
ret = __setup_rt_frame(sig, ka, info, set, regs);
if (ret) {
force_sigsegv(sig, current);
return -EFAULT;
}
current_thread_info()->status &= ~TS_RESTORE_SIGMASK;
return ret;
}
static int __setup_rt_frame(int sig, struct k_sigaction *ka, siginfo_t *info,
sigset_t *set, struct pt_regs *regs)
{
struct rt_sigframe __user *frame;
void __user *restorer;
int err = 0;
void __user *fpstate = NULL;
frame = get_sigframe(ka, regs, sizeof(*frame), &fpstate);
if (!access_ok(VERIFY_WRITE, frame, sizeof(*frame)))
return -EFAULT;
put_user_try {
put_user_ex(sig, &frame->sig);
put_user_ex(&frame->info, &frame->pinfo);
put_user_ex(&frame->uc, &frame->puc);
err |= copy_siginfo_to_user(&frame->info, info);
/* Create the ucontext. */
if (cpu_has_xsave)
put_user_ex(UC_FP_XSTATE, &frame->uc.uc_flags);
else
put_user_ex(0, &frame->uc.uc_flags);
put_user_ex(0, &frame->uc.uc_link);
put_user_ex(current->sas_ss_sp, &frame->uc.uc_stack.ss_sp);
put_user_ex(sas_ss_flags(regs->sp), &frame->uc.uc_stack.ss_flags);
put_user_ex(current->sas_ss_size, &frame->uc.uc_stack.ss_size);
err |= setup_sigcontext(&frame->uc.uc_mcontext, fpstate, regs, set->sig[0]);
err |= __copy_to_user(&frame->uc.uc_sigmask, set, sizeof(*set));
/*
* 当用户自定的信号处理函数在用户态执行结束后,会执行系统调用
* sys_rt_sigreturn,因而会从用户态再次转换到内核态
*/
/* Set up to return from userspace. */
restorer = VDSO32_SYMBOL(current->mm->context.vdso, rt_sigreturn);
if (ka->sa.sa_flags & SA_RESTORER)
restorer = ka->sa.sa_restorer;
put_user_ex(restorer, &frame->pretcode);
/*
* This is movl $__NR_rt_sigreturn, %ax ; int $0x80
*
* WE DO NOT USE IT ANY MORE! It's only left here for historical
* reasons and because gdb uses it as a signature to notice
* signal handler stack frames.
*/
put_user_ex(*((u64 *)&rt_retcode), (u64 *)frame->retcode);
} put_user_catch(err);
if (err)
return -EFAULT;
/* Set up registers for signal handler */
regs->sp = (unsigned long)frame;
/*
* 当本函数返回到do_signal()且do_signal()执行结束后,
* 进程由核心态切换到用户态,并开始执行此信号处理函数
*/
regs->ip = (unsigned long)ka->sa.sa_handler;
regs->ax = (unsigned long)sig;
regs->dx = (unsigned long)&frame->info;
regs->cx = (unsigned long)&frame->uc;
regs->ds = __USER_DS;
regs->es = __USER_DS;
regs->ss = __USER_DS;
regs->cs = __USER_CS;
return 0;
}
其中,函数__setup_rt_frame()定义于arch/x86/kernel/signal.c:
static int __setup_rt_frame(int sig, struct k_sigaction *ka, siginfo_t *info,
sigset_t *set, struct pt_regs *regs)
{
struct rt_sigframe __user *frame;
void __user *restorer;
int err = 0;
void __user *fpstate = NULL;
frame = get_sigframe(ka, regs, sizeof(*frame), &fpstate);
if (!access_ok(VERIFY_WRITE, frame, sizeof(*frame)))
return -EFAULT;
put_user_try {
put_user_ex(sig, &frame->sig);
put_user_ex(&frame->info, &frame->pinfo);
put_user_ex(&frame->uc, &frame->puc);
err |= copy_siginfo_to_user(&frame->info, info);
/* Create the ucontext. */
if (cpu_has_xsave)
put_user_ex(UC_FP_XSTATE, &frame->uc.uc_flags);
else
put_user_ex(0, &frame->uc.uc_flags);
put_user_ex(0, &frame->uc.uc_link);
put_user_ex(current->sas_ss_sp, &frame->uc.uc_stack.ss_sp);
put_user_ex(sas_ss_flags(regs->sp), &frame->uc.uc_stack.ss_flags);
put_user_ex(current->sas_ss_size, &frame->uc.uc_stack.ss_size);
err |= setup_sigcontext(&frame->uc.uc_mcontext, fpstate, regs, set->sig[0]);
err |= __copy_to_user(&frame->uc.uc_sigmask, set, sizeof(*set));
/*
* 当用户自定的信号处理函数在用户态执行结束后,会执行系统调用
* sys_rt_sigreturn,因而会从用户态再次转换到内核态
*/
/* Set up to return from userspace. */
restorer = VDSO32_SYMBOL(current->mm->context.vdso, rt_sigreturn);
if (ka->sa.sa_flags & SA_RESTORER)
restorer = ka->sa.sa_restorer;
put_user_ex(restorer, &frame->pretcode);
/*
* This is movl $__NR_rt_sigreturn, %ax ; int $0x80
*
* WE DO NOT USE IT ANY MORE! It's only left here for historical
* reasons and because gdb uses it as a signature to notice
* signal handler stack frames.
*/
put_user_ex(*((u64 *)&rt_retcode), (u64 *)frame->retcode);
} put_user_catch(err);
if (err)
return -EFAULT;
/* Set up registers for signal handler */
regs->sp = (unsigned long)frame;
/*
* 当本函数返回到do_signal()且do_signal()执行结束后,
* 进程由核心态切换到用户态,并开始执行此信号处理函数
*/
regs->ip = (unsigned long)ka->sa.sa_handler;
regs->ax = (unsigned long)sig;
regs->dx = (unsigned long)&frame->info;
regs->cx = (unsigned long)&frame->uc;
regs->ds = __USER_DS;
regs->es = __USER_DS;
regs->ss = __USER_DS;
regs->cs = __USER_CS;
return 0;
}
8.3.4.1.3 sys_restart_syscall()
该系统调用定义于kernel/signal.c:
SYSCALL_DEFINE0(restart_syscall)
{
struct restart_block *restart = ¤t_thread_info()->restart_block;
return restart->fn(restart);
}
8.3.4.2 设置信号处理函数/sys_sigaction()/sys_rt_sigaction()
函数sys_sigaction()定义于arch/x86/kernel/signal.c:
asmlinkage int sys_sigaction(int sig, const struct old_sigaction __user *act,
struct old_sigaction __user *oact)
{
struct k_sigaction new_ka, old_ka;
int ret = 0;
if (act) {
old_sigset_t mask;
if (!access_ok(VERIFY_READ, act, sizeof(*act)))
return -EFAULT;
get_user_try {
get_user_ex(new_ka.sa.sa_handler, &act->sa_handler);
get_user_ex(new_ka.sa.sa_flags, &act->sa_flags);
get_user_ex(mask, &act->sa_mask);
get_user_ex(new_ka.sa.sa_restorer, &act->sa_restorer);
} get_user_catch(ret);
if (ret)
return -EFAULT;
siginitset(&new_ka.sa.sa_mask, mask);
}
// 参见[8.3.4.2.1 do_sigaction()]节
ret = do_sigaction(sig, act ? &new_ka : NULL, oact ? &old_ka : NULL);
// oact用来保存该信号原来的信号处理函数,后续可能需要恢复原来的信号处理函数
if (!ret && oact) {
if (!access_ok(VERIFY_WRITE, oact, sizeof(*oact)))
return -EFAULT;
put_user_try {
put_user_ex(old_ka.sa.sa_handler, &oact->sa_handler);
put_user_ex(old_ka.sa.sa_flags, &oact->sa_flags);
put_user_ex(old_ka.sa.sa_mask.sig[0], &oact->sa_mask);
put_user_ex(old_ka.sa.sa_restorer, &oact->sa_restorer);
} put_user_catch(ret);
if (ret)
return -EFAULT;
}
return ret;
}
函数sys_rt_sigaction()定义参见kernel/signal.c:
/**
* sys_rt_sigaction - alter an action taken by a process
* @sig: signal to be sent
* @act: new sigaction
* @oact: used to save the previous sigaction
* @sigsetsize: size of sigset_t type
*/
SYSCALL_DEFINE4(rt_sigaction, int, sig, const struct sigaction __user *, act,
struct sigaction __user *, oact, size_t, sigsetsize)
{
struct k_sigaction new_sa, old_sa;
int ret = -EINVAL;
/* XXX: Don't preclude handling different sized sigset_t's. */
if (sigsetsize != sizeof(sigset_t))
goto out;
if (act) {
if (copy_from_user(&new_sa.sa, act, sizeof(new_sa.sa)))
return -EFAULT;
}
// 参见[8.3.4.2.1 do_sigaction()]节
ret = do_sigaction(sig, act ? &new_sa : NULL, oact ? &old_sa : NULL);
if (!ret && oact) {
if (copy_to_user(oact, &old_sa.sa, sizeof(old_sa.sa)))
return -EFAULT;
}
out:
return ret;
}
此外,因为兼容问题,系统调用sys_signal()还是存在的,但其功能已被sys_sigaction()替代,参见kernel/signal.c:
/*
* For backwards compatibility. Functionality superseded by sigaction.
*/
SYSCALL_DEFINE2(signal, int, sig, __sighandler_t, handler)
{
struct k_sigaction new_sa, old_sa;
int ret;
new_sa.sa.sa_handler = handler;
new_sa.sa.sa_flags = SA_ONESHOT | SA_NOMASK;
sigemptyset(&new_sa.sa.sa_mask);
// 参见[8.3.4.2.1 do_sigaction()]节
ret = do_sigaction(sig, &new_sa, &old_sa);
return ret ? ret : (unsigned long)old_sa.sa.sa_handler;
}
8.3.4.2.1 do_sigaction()
该函数定义于kernel/signal.c:
int do_sigaction(int sig, struct k_sigaction *act, struct k_sigaction *oact)
{
struct task_struct *t = current;
struct k_sigaction *k;
sigset_t mask;
if (!valid_signal(sig) || sig < 1 || (act && sig_kernel_only(sig)))
return -EINVAL;
k = &t->sighand->action[sig-1];
spin_lock_irq(¤t->sighand->siglock);
if (oact)
*oact = *k;
if (act) {
// SIGKILL和SIGSTOP信号不会被屏蔽掉
sigdelsetmask(&act->sa.sa_mask, sigmask(SIGKILL) | sigmask(SIGSTOP));
*k = *act;
/*
* POSIX 3.3.1.3:
* "Setting a signal action to SIG_IGN for a signal that is
* pending shall cause the pending signal to be discarded,
* whether or not it is blocked."
*
* "Setting a signal action to SIG_DFL for a signal that is
* pending and whose default action is to ignore the signal
* (for example, SIGCHLD), shall cause the pending signal to
* be discarded, whether or not it is blocked"
*/
if (sig_handler_ignored(sig_handler(t, sig), sig)) {
sigemptyset(&mask);
sigaddset(&mask, sig);
// Shared pending signal queue
rm_from_queue_full(&mask, &t->signal->shared_pending);
do {
// Private pending signal queue
rm_from_queue_full(&mask, &t->pending);
t = next_thread(t);
} while (t != current);
}
}
spin_unlock_irq(¤t->sighand->siglock);
return 0;
}
8.3.4.3 获取被阻塞的悬挂信号/sys_sigpending()/sys_rt_sigpending()
该函数定义于kernel/signal.c:
/**
* sys_sigpending - examine pending signals
* @set: where mask of pending signal is returned
*/
SYSCALL_DEFINE1(sigpending, old_sigset_t __user *, set)
{
return do_sigpending(set, sizeof(*set));
}
/**
* sys_rt_sigpending - examine a pending signal that has been raised while blocked
* @set: stores pending signals
* @sigsetsize: size of sigset_t type or larger
*/
SYSCALL_DEFINE2(rt_sigpending, sigset_t __user *, set, size_t, sigsetsize)
{
return do_sigpending(set, sigsetsize);
}
其中,函数do_sigpending()定义于kernel/signal.c:
long do_sigpending(void __user *set, unsigned long sigsetsize)
{
long error = -EINVAL;
sigset_t pending;
if (sigsetsize > sizeof(sigset_t))
goto out;
spin_lock_irq(¤t->sighand->siglock);
sigorsets(&pending, ¤t->pending.signal, ¤t->signal->shared_pending.signal);
spin_unlock_irq(¤t->sighand->siglock);
/* Outside the lock because only this thread touches it. */
sigandsets(&pending, ¤t->blocked, &pending);
error = -EFAULT;
if (!copy_to_user(set, &pending, sigsetsize))
error = 0;
out:
return error;
}
8.3.4.4 修改被阻塞信号的集合/sys_sigprocmask()/sys_rt_sigprocmask()/sigprocmask()
其定义参见kernel/signal.c:
/**
* sys_sigprocmask - examine and change blocked signals
* @how: whether to add, remove, or set signals
* @nset: signals to add or remove (if non-null)
* @oset: previous value of signal mask if non-null
*
* Some platforms have their own version with special arguments;
* others support only sys_rt_sigprocmask.
*/
SYSCALL_DEFINE3(sigprocmask, int, how, old_sigset_t __user *, nset, old_sigset_t __user *, oset)
{
old_sigset_t old_set, new_set;
sigset_t new_blocked;
old_set = current->blocked.sig[0];
if (nset) {
if (copy_from_user(&new_set, nset, sizeof(*nset)))
return -EFAULT;
new_set &= ~(sigmask(SIGKILL) | sigmask(SIGSTOP));
new_blocked = current->blocked;
switch (how) {
case SIG_BLOCK:
sigaddsetmask(&new_blocked, new_set);
break;
case SIG_UNBLOCK:
sigdelsetmask(&new_blocked, new_set);
break;
case SIG_SETMASK:
new_blocked.sig[0] = new_set;
break;
default:
return -EINVAL;
}
set_current_blocked(&new_blocked);
}
if (oset) {
if (copy_to_user(oset, &old_set, sizeof(*oset)))
return -EFAULT;
}
return 0;
}
/**
* sys_rt_sigprocmask - change the list of currently blocked signals
* @how: whether to add, remove, or set signals
* @nset: stores pending signals
* @oset: previous value of signal mask if non-null
* @sigsetsize: size of sigset_t type
*/
SYSCALL_DEFINE4(rt_sigprocmask, int, how, sigset_t __user *, nset,
sigset_t __user *, oset, size_t, sigsetsize)
{
sigset_t old_set, new_set;
int error;
/* XXX: Don't preclude handling different sized sigset_t's. */
if (sigsetsize != sizeof(sigset_t))
return -EINVAL;
old_set = current->blocked;
if (nset) {
if (copy_from_user(&new_set, nset, sizeof(sigset_t)))
return -EFAULT;
sigdelsetmask(&new_set, sigmask(SIGKILL)|sigmask(SIGSTOP));
error = sigprocmask(how, &new_set, NULL);
if (error)
return error;
}
if (oset) {
if (copy_to_user(oset, &old_set, sizeof(sigset_t)))
return -EFAULT;
}
return 0;
}
/*
* This is also useful for kernel threads that want to temporarily
* (or permanently) block certain signals.
*
* NOTE! Unlike the user-mode sys_sigprocmask(), the kernel
* interface happily blocks "unblockable" signals like SIGKILL
* and friends.
*/
int sigprocmask(int how, sigset_t *set, sigset_t *oldset)
{
struct task_struct *tsk = current;
sigset_t newset;
/* Lockless, only current can change ->blocked, never from irq */
if (oldset)
*oldset = tsk->blocked;
switch (how) {
case SIG_BLOCK:
sigorsets(&newset, &tsk->blocked, set);
break;
case SIG_UNBLOCK:
sigandnsets(&newset, &tsk->blocked, set);
break;
case SIG_SETMASK:
newset = *set;
break;
default:
return -EINVAL;
}
set_current_blocked(&newset);
return 0;
}
8.3.4.5 暂停进程/sys_sigsuspend()/sys_rt_sigsuspend()
系统调用sys_sigsuspend()定义于arch/x86/kernel/signal.c:
/*
* Atomically swap in the new signal mask, and wait for a signal.
*/
asmlinkage int sys_sigsuspend(int history0, int history1, old_sigset_t mask)
{
sigset_t blocked;
current->saved_sigmask = current->blocked;
// 复位信号SIGKILL和SIGSTOP的掩码
mask &= _BLOCKABLE;
siginitset(&blocked, mask);
set_current_blocked(&blocked);
// 调度其他进程来运行,参见[7.4.5 schedule()]节
current->state = TASK_INTERRUPTIBLE;
schedule();
set_restore_sigmask();
return -ERESTARTNOHAND;
}
系统调用sys_rt_sigsuspend()定义于kernel/signal.c:
/**
* sys_rt_sigsuspend - replace the signal mask for a value with the
* @unewset value until a signal is received
* @unewset: new signal mask value
* @sigsetsize: size of sigset_t type
*/
SYSCALL_DEFINE2(rt_sigsuspend, sigset_t __user *, unewset, size_t, sigsetsize)
{
sigset_t newset;
/* XXX: Don't preclude handling different sized sigset_t's. */
if (sigsetsize != sizeof(sigset_t))
return -EINVAL;
if (copy_from_user(&newset, unewset, sizeof(newset)))
return -EFAULT;
sigdelsetmask(&newset, sigmask(SIGKILL)|sigmask(SIGSTOP));
current->saved_sigmask = current->blocked;
set_current_blocked(&newset);
// 调度其他进程来运行,参见[7.4.5 schedule()]节
current->state = TASK_INTERRUPTIBLE;
schedule();
set_restore_sigmask();
return -ERESTARTNOHAND;
}
8.3.5 信号的初始化
在系统启动时,start_kernel()调用signals_init()对信号进行初始化,参见4.3.4.1.4.3 start_kernel()节。
函数signals_init()定义于kernel/signal.c:
/*
* SLAB caches for signal bits.
*/
static struct kmem_cache *sigqueue_cachep;
void __init signals_init(void)
{
/*
* 宏KMEM_CACHE()替换后的代码如下,参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节:
* kmem_cache_create("sigqueue", sizeof(struct sigqueue),
* __alignof__(struct sigqueue), SLAB_PANIC, NULL)
*/
sigqueue_cachep = KMEM_CACHE(sigqueue, SLAB_PANIC);
}
如下函数用于操作变量sigqueue_cachep,参见kernel/signal.c:
/*
* allocate a new signal queue record
* - this may be called without locks if and only if t == current, otherwise an
* appropriate lock must be held to stop the target task from exiting
*/
/*
* 函数调用关系:send_signal() -> __send_signal() -> __sigqueue_alloc(),
* 参见[8.3.3.8 send_signal()]节
*/
static struct sigqueue *__sigqueue_alloc(int sig, struct task_struct *t, gfp_t flags, int override_rlimit)
{
struct sigqueue *q = NULL;
struct user_struct *user;
/*
* Protect access to @t credentials. This can go away when all
* callers hold rcu read lock.
*/
rcu_read_lock();
user = get_uid(__task_cred(t)->user);
atomic_inc(&user->sigpending);
rcu_read_unlock();
if (override_rlimit ||
atomic_read(&user->sigpending) <= task_rlimit(t, RLIMIT_SIGPENDING)) {
// 参见[6.5.1.1.3.1 kmem_cache_zalloc()]节
q = kmem_cache_alloc(sigqueue_cachep, flags);
} else {
print_dropped_signal(sig);
}
if (unlikely(q == NULL)) {
atomic_dec(&user->sigpending);
free_uid(user);
} else {
INIT_LIST_HEAD(&q->list);
q->flags = 0;
q->user = user;
}
return q;
}
/*
* 函数调用关系之一:
* release_task() -> __exit_signal() -> flush_sigqueue() -> __sigqueue_free()
*/
static void __sigqueue_free(struct sigqueue *q)
{
if (q->flags & SIGQUEUE_PREALLOC)
return;
atomic_dec(&q->user->sigpending);
free_uid(q->user);
kmem_cache_free(sigqueue_cachep, q);
}
8.4 消息队列/Message Queue
8.4.1 消息队列简介
消息队列的最佳定义是:内核地址空间中的内部链表。消息可以顺序地发送到消息队列中,并以几种不同的方式从消息队列中获取。当然,每个消息队列都是由IPC标识符所唯一标识的。
8.4.2 与消息队列有关的数据结构
8.4.2.1 struct idr
struct idr可通过进程描述符引用到,参见:
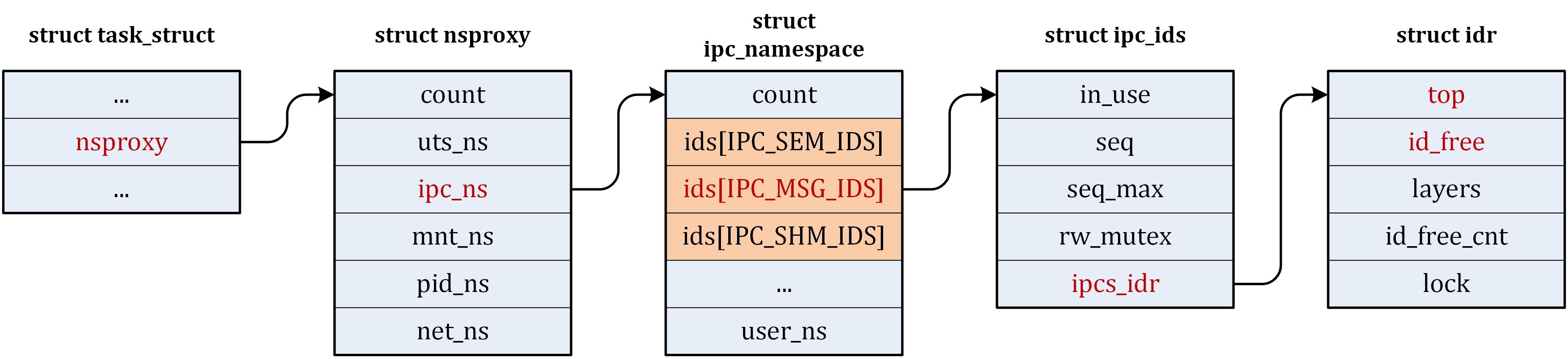
idr结构中的id_free链表由idr_pre_get()创建的,参见15.5.3.1 分配节点空间/idr_pre_get()节。
idr结构中的top域是指向一个32叉树的树根,其结构参见:
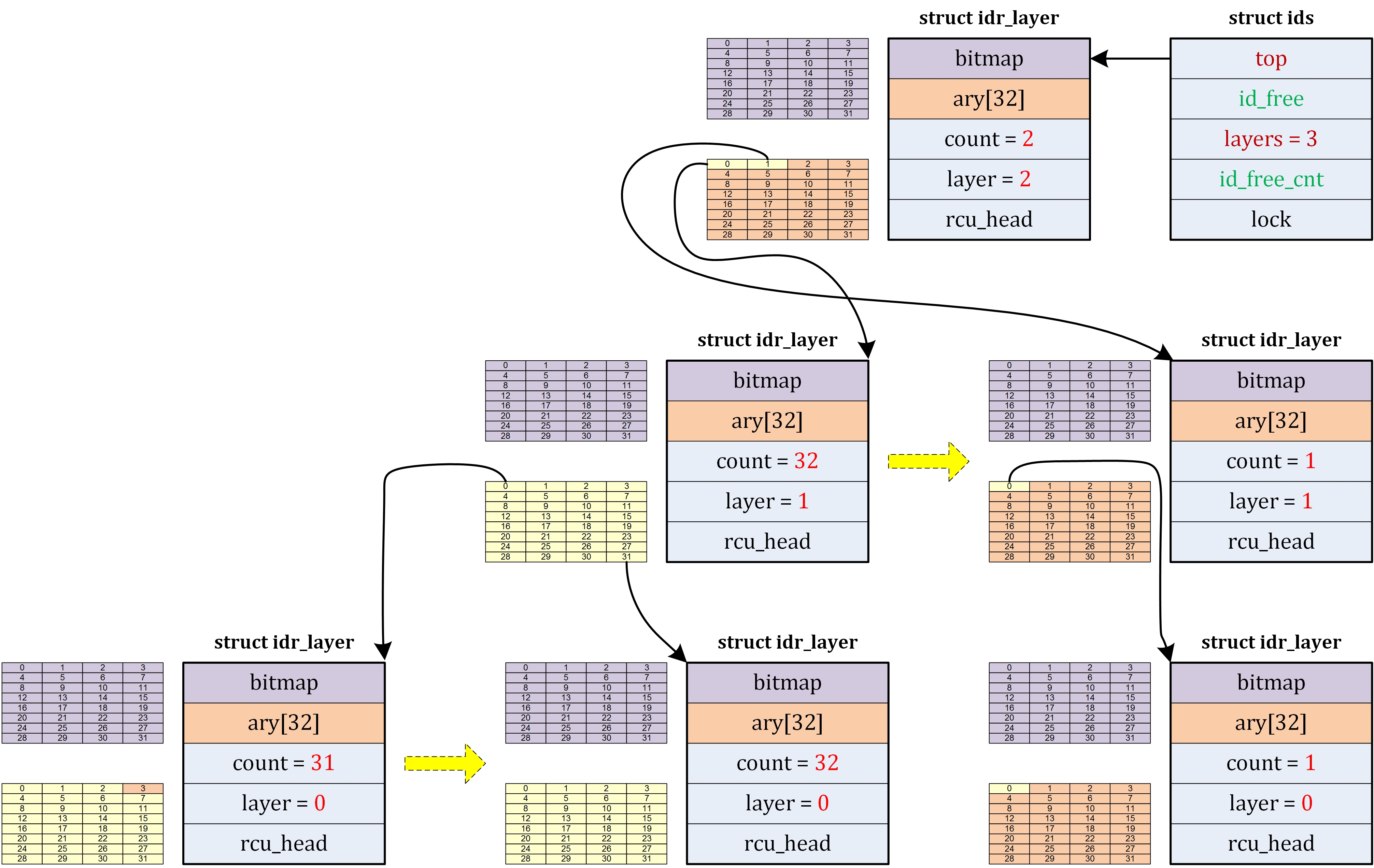
另参见idr机制(32叉树)。其中,pa[*]->ary[id & IDR_MASK]域指向了消息队列中的q_perm域,即msq.q_perm(参见8.4.2.1 struct msg_queue / struct msg_msg节),其调用函数关系如下(参见8.4.3.1.1.2 newque()节):
newque() -> ipc_addid() -> idr_get_new() -> idr_get_new_above_int() -> rcu_assign_pointer()
8.4.2.1 struct msg_queue / struct msg_msg
struct msg_queue和struct msg_msg定义于include/linux/msg.h,其结构参见:
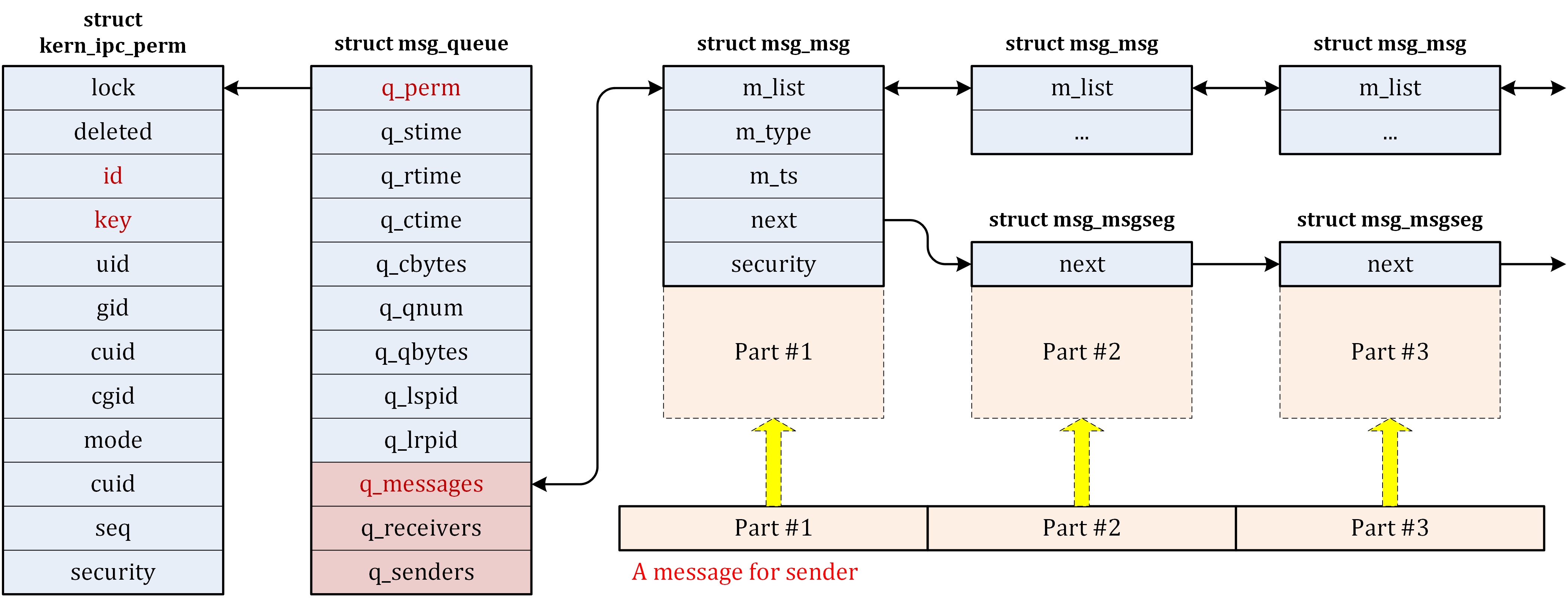
struct msg_queue类型的对象即为消息队列,假设为msq,则msq.q_perm域指明了该消息队列的属性,其中msq.q_perm.key和msq.q_perm.id建立了对应关系,参见8.4.3.1.1.2 newque()节。
8.4.2.2 struct msgbuf
struct msgbuf的定义参见include/linux/msg.h:
/* message buffer for msgsnd and msgrcv calls */
struct msgbuf {
long mtype; /* type of message */
/*
* 消息的开始,其长度由另外的参数指定;
* 消息的结构由发送进程和接收进程协商确定
*/
char mtext[1]; /* message text */
};
8.4.3 创建/打开消息队列
8.4.3.1 sys_msgget()
系统调用sys_msgget()用于创建一个新的消息队列,或者打开一个已存在的消息队列,其定义参见ipc/msg.c:
// 参数key由ftok()产生,参见ftok手册:
/*
* #include <sys/types.h>
* #include <sys/ipc.h>
* key_t ftok(const char *pathname, int proj_id);
*
* The ftok() function uses the identity of the file named
* by the given pathname (which must refer to an existing,
* accessible file) and the least significant 8 bits of
* proj_id (which must be nonzero) to generate a key_t type
* System V IPC key.
* /
SYSCALL_DEFINE2(msgget, key_t, key, int, msgflg)
{
struct ipc_namespace *ns;
struct ipc_ops msg_ops;
struct ipc_params msg_params;
ns = current->nsproxy->ipc_ns;
/*
* 设置newque()函数指针,该函数在ipcget_new()或ipcget_public()
* 中被调用,参见[8.4.3.1.1.1 ipcget_new()/ipcget_public()]节
*/
msg_ops.getnew = newque;
msg_ops.associate = msg_security;
msg_ops.more_checks = NULL;
msg_params.key = key;
msg_params.flg = msgflg;
return ipcget(ns, &msg_ids(ns), &msg_ops, &msg_params);
}
8.4.3.1.1 ipcget()
函数ipcget()定义于ipc/util.c:
/**
* ipcget - Common sys_*get() code
* @ns : namsepace
* @ids : IPC identifier set
* @ops : operations to be called on ipc object creation, permission checks
* and further checks
* @params : the parameters needed by the previous operations.
*
* Common routine called by sys_msgget(), sys_semget() and sys_shmget().
*/
int ipcget(struct ipc_namespace *ns, struct ipc_ids *ids, struct ipc_ops *ops, struct ipc_params *params)
{
// 创建消息队列的两种方法之一:key == IPC_PRIVATE
if (params->key == IPC_PRIVATE)
return ipcget_new(ns, ids, ops, params);
/*
* 创建消息队列的两种方法之二:key未与特定类型的IPC结构相结合,
* 且params.flg中指定了IPC_CREAT标志
*/
else
return ipcget_public(ns, ids, ops, params);
}
8.4.3.1.1.1 ipcget_new()/ipcget_public()
函数ipcget_new()和ipcget_public()定义于ipc/util.c:
/**
* ipcget_new - create a new ipc object
* @ns: namespace
* @ids: IPC identifer set
* @ops: the actual creation routine to call
* @params: its parameters
*
* This routine is called by sys_msgget, sys_semget() and sys_shmget()
* when the key is IPC_PRIVATE.
*/
static int ipcget_new(struct ipc_namespace *ns, struct ipc_ids *ids,
struct ipc_ops *ops, struct ipc_params *params)
{
int err;
retry:
err = idr_pre_get(&ids->ipcs_idr, GFP_KERNEL);
if (!err)
return -ENOMEM;
down_write(&ids->rw_mutex);
/*
* 调用函数newque()创建新的消息队列,参见[8.4.3.1.1.2 newque()]节;
* 或者,调用函数newseg()创建新的共享内存段,参见[8.5.3.1.1 newseg()]节;
* 或者,调用函数newary()创建新的信号量,参见[8.6.3.1.1 newary()]节
*/
err = ops->getnew(ns, params);
up_write(&ids->rw_mutex);
if (err == -EAGAIN)
goto retry;
return err;
}
/**
* ipcget_public - get an ipc object or create a new one
* @ns: namespace
* @ids: IPC identifer set
* @ops: the actual creation routine to call
* @params: its parameters
*
* This routine is called by sys_msgget, sys_semget() and sys_shmget()
* when the key is not IPC_PRIVATE.
* It adds a new entry if the key is not found and does some permission
* / security checkings if the key is found.
*
* On success, the ipc id is returned.
*/
static int ipcget_public(struct ipc_namespace *ns, struct ipc_ids *ids,
struct ipc_ops *ops, struct ipc_params *params)
{
struct kern_ipc_perm *ipcp;
int flg = params->flg;
int err;
retry:
err = idr_pre_get(&ids->ipcs_idr, GFP_KERNEL);
/*
* Take the lock as a writer since we are potentially going to add
* a new entry + read locks are not "upgradable"
*/
down_write(&ids->rw_mutex);
ipcp = ipc_findkey(ids, params->key);
if (ipcp == NULL) {
/* key not used */
if (!(flg & IPC_CREAT))
err = -ENOENT;
else if (!err)
err = -ENOMEM;
else
/*
* 调用函数newque()创建新的消息队列,参见[8.4.3.1.1.2 newque()]节;
* 或者调用函数newseg()创建新的共享内存段,参见[8.5.3.1.1 newseg()]节
*/
err = ops->getnew(ns, params);
} else {
/* ipc object has been locked by ipc_findkey() */
if (flg & IPC_CREAT && flg & IPC_EXCL)
err = -EEXIST;
else {
err = 0;
if (ops->more_checks)
err = ops->more_checks(ipcp, params);
if (!err)
/*
* ipc_check_perms returns the IPC id on
* success
*/
err = ipc_check_perms(ns, ipcp, ops, params);
}
ipc_unlock(ipcp);
}
up_write(&ids->rw_mutex);
if (err == -EAGAIN)
goto retry;
return err;
}
8.4.3.1.1.2 newque()
函数newque()用于创建新的消息队列,其定义于ipc/msg.c:
/**
* newque - Create a new msg queue
* @ns: namespace
* @params: ptr to the structure that contains the key and msgflg
*
* Called with msg_ids.rw_mutex held (writer)
*/
static int newque(struct ipc_namespace *ns, struct ipc_params *params)
{
struct msg_queue *msq;
int id, retval;
key_t key = params->key;
int msgflg = params->flg;
// 分配消息队列空间
msq = ipc_rcu_alloc(sizeof(*msq));
if (!msq)
return -ENOMEM;
msq->q_perm.mode = msgflg & S_IRWXUGO;
// 为q_perm.key赋值,后续为q_perm.id赋值,因而key与id建立了映射关系
msq->q_perm.key = key;
msq->q_perm.security = NULL;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
retval = security_msg_queue_alloc(msq);
if (retval) {
ipc_rcu_putref(msq);
return retval;
}
/*
* ipc_addid() locks msq
*/
/*
* ipc_addid()为q_perm.id赋值,先前已为q_perm.key赋值,因而key
* 与id建立了映射关系;另外,通过ipc_addid() -> idr_get_new()
* -> idr_get_new_above_int() -> rcu_assign_pointer()将
* pa[0]->ary[id & IDR_MASK]指向msq->q_perm,参见[8.4.2.1 struct idr]节
*/
id = ipc_addid(&msg_ids(ns), &msq->q_perm, ns->msg_ctlmni);
if (id < 0) {
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
security_msg_queue_free(msq);
ipc_rcu_putref(msq);
return id;
}
msq->q_stime = msq->q_rtime = 0;
msq->q_ctime = get_seconds();
msq->q_cbytes = msq->q_qnum = 0;
msq->q_qbytes = ns->msg_ctlmnb;
msq->q_lspid = msq->q_lrpid = 0;
INIT_LIST_HEAD(&msq->q_messages);
INIT_LIST_HEAD(&msq->q_receivers);
INIT_LIST_HEAD(&msq->q_senders);
msg_unlock(msq);
return msq->q_perm.id;
}
8.4.4 发送消息
8.4.4.1 sys_msgsnd()
系统调用sys_msgsnd()用于发送消息,其定义于ipc/msg.c:
SYSCALL_DEFINE4(msgsnd, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz, int, msgflg)
{
long mtype;
if (get_user(mtype, &msgp->mtype))
return -EFAULT;
return do_msgsnd(msqid, mtype, msgp->mtext, msgsz, msgflg);
}
long do_msgsnd(int msqid, long mtype, void __user *mtext, size_t msgsz, int msgflg)
{
struct msg_queue *msq;
struct msg_msg *msg;
int err;
struct ipc_namespace *ns;
ns = current->nsproxy->ipc_ns;
if (msgsz > ns->msg_ctlmax || (long) msgsz < 0 || msqid < 0)
return -EINVAL;
if (mtype < 1)
return -EINVAL;
/*
* 重新组装消息体,参见[8.4.2.1 struct msg_queue / struct msg_msg]节;
* 与store_msg()对应,参见[8.4.5.1 sys_msgrcv()]节
*/
msg = load_msg(mtext, msgsz);
if (IS_ERR(msg))
return PTR_ERR(msg);
msg->m_type = mtype;
msg->m_ts = msgsz;
msq = msg_lock_check(ns, msqid);
if (IS_ERR(msq)) {
err = PTR_ERR(msq);
goto out_free;
}
for (;;) {
struct msg_sender s;
err = -EACCES;
// 检查权限,消息发送者应该在消息队列上有写的权限
if (ipcperms(ns, &msq->q_perm, S_IWUGO))
goto out_unlock_free;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_msg_queue_msgsnd(msq, msg, msgflg);
if (err)
goto out_unlock_free;
/*
* 若消息队列可以容纳该消息,则跳出for(;;)循环,并发送该消息;
* 否则,根据是否设置了IPC_NOWAIT标志进行处理
*/
if (msgsz + msq->q_cbytes <= msq->q_qbytes &&
1 + msq->q_qnum <= msq->q_qbytes) {
break;
}
/*
* 若设置了IPC_NOWAIT标志,且消息队列无法容纳该消息,则发送
* 进程不会阻塞,而是立即返回
*/
/* queue full, wait: */
if (msgflg & IPC_NOWAIT) {
err = -EAGAIN;
goto out_unlock_free;
}
/*
* 若未设置IPC_NOWAIT标志,则发送进程阻塞,并等待消息队列唤醒
* 本进程重新发送该消息。将本进程放入消息队列的等待发送队列,等
* 消息队列有空间时再唤醒发送进程
*/
ss_add(msq, &s);
ipc_rcu_getref(msq);
msg_unlock(msq);
schedule(); // 当前进程阻塞,调度其他进程运行
ipc_lock_by_ptr(&msq->q_perm);
ipc_rcu_putref(msq);
if (msq->q_perm.deleted) {
err = -EIDRM;
goto out_unlock_free;
}
// 将本进程移出消息队列的等待发送队列,并尝试重新发送该消息
ss_del(&s);
if (signal_pending(current)) {
err = -ERESTARTNOHAND;
goto out_unlock_free;
}
}
msq->q_lspid = task_tgid_vnr(current);
msq->q_stime = get_seconds();
/*
* pipelined_send()依次检查消息队列的接收进程列表。如果找到
* 了接收该消息的进程,则直接发送消息给该进程,并尝试唤醒该进程;
*/
if (!pipelined_send(msq, msg)) {
/* no one is waiting for this message, enqueue it */
/*
* 否则,将消息添加到消息队列末尾,
* 参见[8.4.2.1 struct msg_queue / struct msg_msg]节
*/
list_add_tail(&msg->m_list, &msq->q_messages);
msq->q_cbytes += msgsz;
msq->q_qnum++;
atomic_add(msgsz, &ns->msg_bytes);
atomic_inc(&ns->msg_hdrs);
}
err = 0;
msg = NULL;
out_unlock_free:
msg_unlock(msq);
out_free:
if (msg != NULL)
free_msg(msg);
return err;
}
8.4.5 接收消息
8.4.5.1 sys_msgrcv()
系统调用sys_msgrcv()用于接收消息,其定义于ipc/msg.c:
SYSCALL_DEFINE5(msgrcv, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz, long, msgtyp, int, msgflg)
{
long err, mtype;
err = do_msgrcv(msqid, &mtype, msgp->mtext, msgsz, msgtyp, msgflg);
if (err < 0)
goto out;
if (put_user(mtype, &msgp->mtype))
err = -EFAULT;
out:
return err;
}
long do_msgrcv(int msqid, long *pmtype, void __user *mtext,
size_t msgsz, long msgtyp, int msgflg)
{
struct msg_queue *msq;
struct msg_msg *msg;
int mode;
struct ipc_namespace *ns;
if (msqid < 0 || (long) msgsz < 0)
return -EINVAL;
mode = convert_mode(&msgtyp, msgflg);
ns = current->nsproxy->ipc_ns;
msq = msg_lock_check(ns, msqid);
if (IS_ERR(msq))
return PTR_ERR(msq);
for (;;) {
struct msg_receiver msr_d;
struct list_head *tmp;
msg = ERR_PTR(-EACCES);
// 消息接收进程应该有读消息队列的权限
if (ipcperms(ns, &msq->q_perm, S_IRUGO))
goto out_unlock;
msg = ERR_PTR(-EAGAIN);
tmp = msq->q_messages.next;
// 依次检查消息队列中的各消息
while (tmp != &msq->q_messages) {
struct msg_msg *walk_msg;
walk_msg = list_entry(tmp, struct msg_msg, m_list);
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
if (testmsg(walk_msg, msgtyp, mode) &&
!security_msg_queue_msgrcv(msq, walk_msg, current, msgtyp, mode)) {
msg = walk_msg;
if (mode == SEARCH_LESSEQUAL && walk_msg->m_type != 1) {
msg = walk_msg;
msgtyp = walk_msg->m_type - 1;
} else {
msg = walk_msg;
break;
}
}
tmp = tmp->next;
}
/*
* 如果找到了指定的消息,则跳出for(;;)循环,并接收该消息;
* 否则,根据是否设置了IPC_NOWAIT标志进行处理
*/
if (!IS_ERR(msg)) {
/*
* Found a suitable message.
* Unlink it from the queue.
*/
if ((msgsz < msg->m_ts) && !(msgflg & MSG_NOERROR)) {
msg = ERR_PTR(-E2BIG);
goto out_unlock;
}
list_del(&msg->m_list); // 从消息队列中取出该消息
msq->q_qnum--;
msq->q_rtime = get_seconds();
msq->q_lrpid = task_tgid_vnr(current);
msq->q_cbytes -= msg->m_ts;
atomic_sub(msg->m_ts, &ns->msg_bytes);
atomic_dec(&ns->msg_hdrs);
ss_wakeup(&msq->q_senders, 0); // 唤醒该消息的发送进程
msg_unlock(msq);
break;
}
/*
* 若设置了IPC_NOWAIT标志,且消息队列中没有找到指定的消息,
* 则接收进程不会阻塞,而是立即返回
*/
/* No message waiting. Wait for a message */
if (msgflg & IPC_NOWAIT) {
msg = ERR_PTR(-ENOMSG);
goto out_unlock;
}
/*
* 若未设置IPC_NOWAIT标志,则接收进程阻塞,并等待消息队列唤醒本进程
* 重新接收该消息。将当前进程放入消息队列的接收进程列表,等待接该消息
*/
list_add_tail(&msr_d.r_list, &msq->q_receivers);
msr_d.r_tsk = current;
msr_d.r_msgtype = msgtyp;
msr_d.r_mode = mode;
if (msgflg & MSG_NOERROR)
msr_d.r_maxsize = INT_MAX;
else
msr_d.r_maxsize = msgsz;
msr_d.r_msg = ERR_PTR(-EAGAIN);
current->state = TASK_INTERRUPTIBLE;
msg_unlock(msq);
schedule(); // 当前进程阻塞,调度其他进程运行
/* Lockless receive, part 1:
* Disable preemption. We don't hold a reference to the queue
* and getting a reference would defeat the idea of a lockless
* operation, thus the code relies on rcu to guarantee the
* existence of msq:
* Prior to destruction, expunge_all(-EIRDM) changes r_msg.
* Thus if r_msg is -EAGAIN, then the queue not yet destroyed.
* rcu_read_lock() prevents preemption between reading r_msg
* and the spin_lock() inside ipc_lock_by_ptr().
*/
rcu_read_lock();
/* Lockless receive, part 2:
* Wait until pipelined_send or expunge_all are outside of
* wake_up_process(). There is a race with exit(), see
* ipc/mqueue.c for the details.
*/
msg = (struct msg_msg*)msr_d.r_msg;
while (msg == NULL) {
cpu_relax();
msg = (struct msg_msg *)msr_d.r_msg;
}
/* Lockless receive, part 3:
* If there is a message or an error then accept it without
* locking.
*/
if (msg != ERR_PTR(-EAGAIN)) {
rcu_read_unlock();
break;
}
/* Lockless receive, part 3:
* Acquire the queue spinlock.
*/
ipc_lock_by_ptr(&msq->q_perm);
rcu_read_unlock();
/* Lockless receive, part 4:
* Repeat test after acquiring the spinlock.
*/
msg = (struct msg_msg*)msr_d.r_msg;
if (msg != ERR_PTR(-EAGAIN))
goto out_unlock;
// 接收到指定消息,将当前进程移出消息队列的接收进程列表
list_del(&msr_d.r_list);
if (signal_pending(current)) {
msg = ERR_PTR(-ERESTARTNOHAND);
out_unlock:
msg_unlock(msq);
break;
}
}
if (IS_ERR(msg))
return PTR_ERR(msg);
msgsz = (msgsz > msg->m_ts) ? msg->m_ts : msgsz;
*pmtype = msg->m_type;
/*
* 重新组装该消息体,参见[8.4.2.1 struct msg_queue / struct msg_msg]节;
* 与load_msg()对应,参见[8.4.4.1 sys_msgsnd()]节
*/
if (store_msg(mtext, msg, msgsz))
msgsz = -EFAULT;
free_msg(msg);
return msgsz;
}
8.4.6 操纵消息队列
8.4.6.1 sys_msgctl()
系统调用sys_msgctl()用于操纵消息队列,包含如下四种操作:
- IPC_RMID
- IPC_SET
- IPC_STAT
- IPC_INFO
该系统调用的定义于ipc/msg.c:
SYSCALL_DEFINE3(msgctl, int, msqid, int, cmd, struct msqid_ds __user *, buf)
{
struct msg_queue *msq;
int err, version;
struct ipc_namespace *ns;
if (msqid < 0 || cmd < 0)
return -EINVAL;
version = ipc_parse_version(&cmd);
ns = current->nsproxy->ipc_ns;
switch (cmd) {
case IPC_INFO:
case MSG_INFO:
{
struct msginfo msginfo;
int max_id;
if (!buf)
return -EFAULT;
/*
* We must not return kernel stack data.
* due to padding, it's not enough
* to set all member fields.
*/
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_msg_queue_msgctl(NULL, cmd);
if (err)
return err;
memset(&msginfo, 0, sizeof(msginfo));
msginfo.msgmni = ns->msg_ctlmni;
msginfo.msgmax = ns->msg_ctlmax;
msginfo.msgmnb = ns->msg_ctlmnb;
msginfo.msgssz = MSGSSZ;
msginfo.msgseg = MSGSEG;
down_read(&msg_ids(ns).rw_mutex);
if (cmd == MSG_INFO) {
msginfo.msgpool = msg_ids(ns).in_use;
msginfo.msgmap = atomic_read(&ns->msg_hdrs);
msginfo.msgtql = atomic_read(&ns->msg_bytes);
} else {
msginfo.msgmap = MSGMAP;
msginfo.msgpool = MSGPOOL;
msginfo.msgtql = MSGTQL;
}
max_id = ipc_get_maxid(&msg_ids(ns));
up_read(&msg_ids(ns).rw_mutex);
if (copy_to_user(buf, &msginfo, sizeof(struct msginfo)))
return -EFAULT;
return (max_id < 0) ? 0 : max_id;
}
case MSG_STAT: /* msqid is an index rather than a msg queue id */
case IPC_STAT:
{
struct msqid64_ds tbuf;
int success_return;
if (!buf)
return -EFAULT;
if (cmd == MSG_STAT) {
msq = msg_lock(ns, msqid);
if (IS_ERR(msq))
return PTR_ERR(msq);
success_return = msq->q_perm.id;
} else {
msq = msg_lock_check(ns, msqid);
if (IS_ERR(msq))
return PTR_ERR(msq);
success_return = 0;
}
err = -EACCES;
if (ipcperms(ns, &msq->q_perm, S_IRUGO))
goto out_unlock;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_msg_queue_msgctl(msq, cmd);
if (err)
goto out_unlock;
memset(&tbuf, 0, sizeof(tbuf));
kernel_to_ipc64_perm(&msq->q_perm, &tbuf.msg_perm);
tbuf.msg_stime = msq->q_stime;
tbuf.msg_rtime = msq->q_rtime;
tbuf.msg_ctime = msq->q_ctime;
tbuf.msg_cbytes = msq->q_cbytes;
tbuf.msg_qnum = msq->q_qnum;
tbuf.msg_qbytes = msq->q_qbytes;
tbuf.msg_lspid = msq->q_lspid;
tbuf.msg_lrpid = msq->q_lrpid;
msg_unlock(msq);
if (copy_msqid_to_user(buf, &tbuf, version))
return -EFAULT;
return success_return;
}
case IPC_SET:
case IPC_RMID:
err = msgctl_down(ns, msqid, cmd, buf, version);
return err;
default:
return -EINVAL;
}
out_unlock:
msg_unlock(msq);
return err;
}
8.4.7 消息队列的初始化
当消息队列模块编译进内核时,在系统初始化时,会调用消息队列的初始化函数msg_init(),其调用关系如下:
ipc_init()
-> msg_init()
-> msg_init_ns(&init_ipc_ns)
-> ipc_init_ids(&ns->ids[IPC_MSG_IDS]);
在ipc/util.c中包含如下代码:
static int __init ipc_init(void)
{
sem_init();
msg_init();
shm_init();
hotplug_memory_notifier(ipc_memory_callback, IPC_CALLBACK_PRI);
register_ipcns_notifier(&init_ipc_ns);
return 0;
}
__initcall(ipc_init);
其中,__initcall()的定义参见include/linux/init.h:
#define __initcall(fn) device_initcall(fn)
而device_initcall()的定义参见13.5.1.1 module被编译进内核时的初始化过程节。可知,当module被编译进内核时,其初始化函数需要在系统启动时被调用。其调用过程为:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
8.4.8 消息队列示例
创建源文件test_thread.c:
#include <pthread.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/stat.h>
#include <errno.h>
int qid = 0;
int sndCnt = 10;
int rcvCnt = 10;
volatile int flag = 0;
typedef struct msg {
long mtype;
int test;
} MyMsg;
void* msgRev(void * args)
{
MyMsg rcmsg;
while(--rcvCnt)
{
int msgsz = msgrcv(qid, &rcmsg, sizeof(MyMsg)-4, 0, 0);
printf("** Msg recv, type: %ld, test: %d\n", rcmsg.mtype, rcmsg.test);
}
pthread_exit(NULL);
}
void* msgSnd(void * args)
{
while (--sndCnt)
{
MyMsg mymsg;
mymsg.mtype = sndCnt;
mymsg.test = sndCnt + 100;
int ret = msgsnd(qid, &mymsg, sizeof(MyMsg)-4, 0);
if (ret != 0)
printf("*** ERROR, ret = %d, errno = %d\n", ret, errno);
else
printf("*** Msg send, type: %ld, test: %d\n", mymsg.mtype, mymsg.test);
}
pthread_exit(NULL);
}
int main(void)
{
pthread_t pid, mainpid;
qid = msgget(IPC_PRIVATE, IPC_CREAT | S_IRUSR | S_IWUSR);
printf("*** Msg queue id: %d created.\n", qid);
int result = pthread_create(&pid, NULL, msgSnd, NULL);
if (result != 0)
{
printf("Create msgSnd thread failed!\n");
}
result = pthread_create(&mainpid, NULL, msgRev, NULL);
if (result != 0)
{
printf("Create msgRev thread failed!\n");
}
sleep(5);
return 0;
}
执行下列命令编译、执行该文件:
chenwx@chenwx ~/alex $ ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
chenwx@chenwx ~/alex $ gcc -pthread -o test_thread test_thread.c
chenwx@chenwx ~/alex $ ./test_thread
*** Msg queue id: 360449 created.
*** Msg send, type: 9, test: 109
*** Msg send, type: 8, test: 108
*** Msg send, type: 7, test: 107
*** Msg send, type: 6, test: 106
*** Msg send, type: 5, test: 105
*** Msg send, type: 4, test: 104
*** Msg send, type: 3, test: 103
*** Msg send, type: 2, test: 102
*** Msg send, type: 1, test: 101
*** Msg recv, type: 9, test: 109
*** Msg recv, type: 8, test: 108
*** Msg recv, type: 7, test: 107
*** Msg recv, type: 6, test: 106
*** Msg recv, type: 5, test: 105
*** Msg recv, type: 4, test: 104
*** Msg recv, type: 3, test: 103
*** Msg recv, type: 2, test: 102
*** Msg recv, type: 1, test: 101
chenwx@chenwx ~/alex $ ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x00000000 360449 chenwx 600 0 0
8.5 共享内存/Share Memory
8.5.1 共享内存简介
共享内存允许两个或多个进程共享同一块内存(这块内存会映射到各进程自己独立的地址空间),从而使这些进程可以相互通信。在GNU/Linux中,所有进程都有唯一的虚拟地址空间,而共享内存允许一个进程使用公共内存段。但是对内存的共享访问其复杂度也相应增加。
共享内存的优点是简易性。使用消息队列时,一个进程要向消息队列中写入消息,这会引起从用户地址空间向内核地址空间的一次复制,同样一个进程读取消息时也要进行一次复制。而共享内存完全省去了这些操作。共享内存会映射到进程的虚拟地址空间,进程对其可以直接访问,避免了数据的复制过程。因此,共享内存是GNU/Linux现在可用的最快速的IPC机制。
8.5.2 与共享内存有关的数据结构
8.5.2.1 struct idr
与消息队列类似,struct idr可通过进程描述符引用到,参见8.4.2.1 struct idr节。
8.5.2.2 struct shmid_kernel
其定义于include/linux/shm.h,参见:
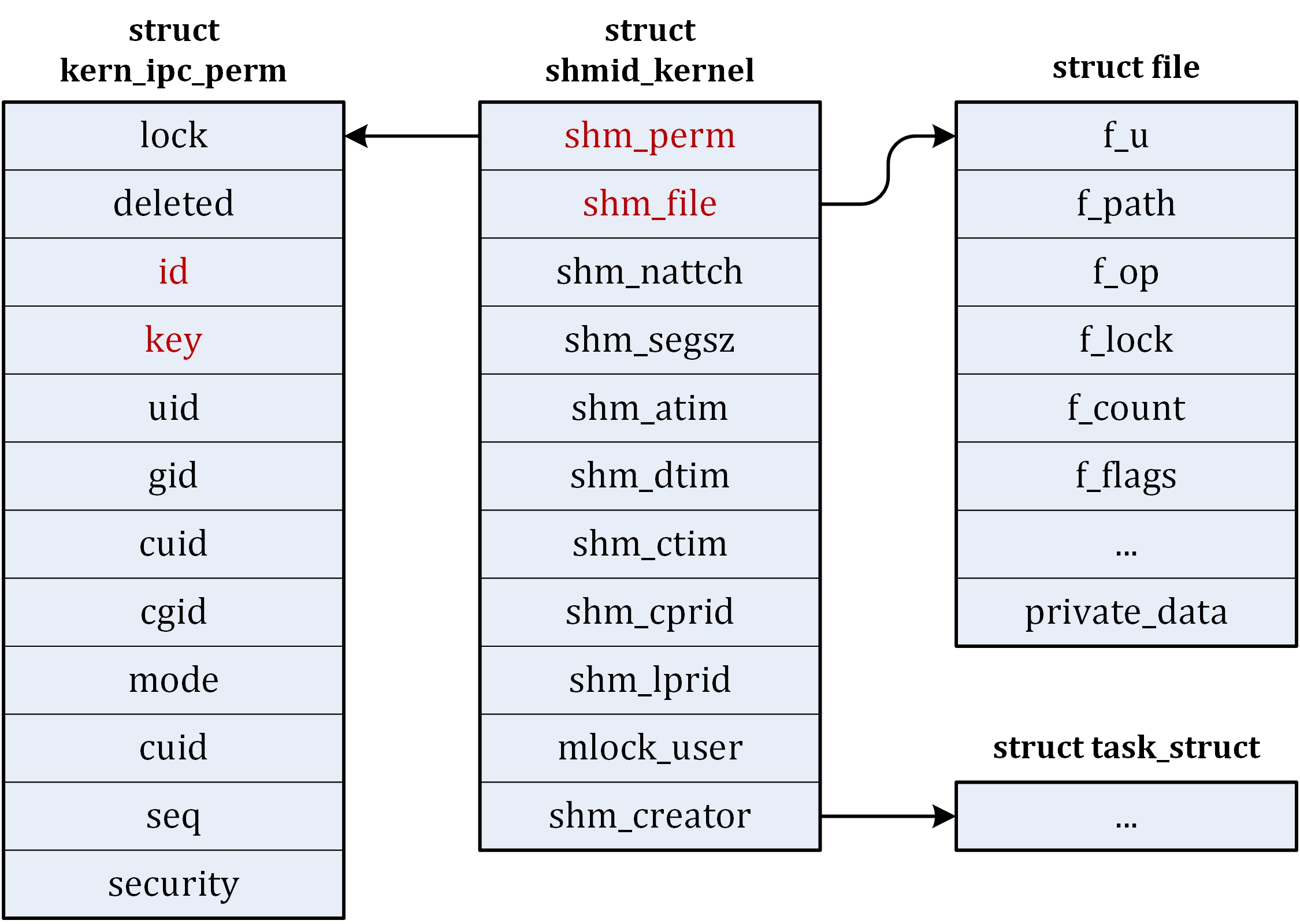
8.5.3 创建/打开共享内存
8.5.3.1 sys_shmget()
系统调用sys_shmget()用于创建新的共享内存段,或打开已存在的共享内存段,其定义于ipc/shm.c:
SYSCALL_DEFINE3(shmget, key_t, key, size_t, size, int, shmflg)
{
struct ipc_namespace *ns;
struct ipc_ops shm_ops;
struct ipc_params shm_params;
ns = current->nsproxy->ipc_ns;
/*
* 设置newseg()函数指针,该函数在ipcget_new()或ipcget_public()
* 中被调用,参见[8.4.3.1.1.1 ipcget_new()/ipcget_public()]节
*/
shm_ops.getnew = newseg;
shm_ops.associate = shm_security;
shm_ops.more_checks = shm_more_checks;
shm_params.key = key;
shm_params.flg = shmflg;
shm_params.u.size = size;
// 与消息队列类似,参见[8.4.3.1.1 ipcget()]节
return ipcget(ns, &shm_ids(ns), &shm_ops, &shm_params);
}
8.5.3.1.1 newseg()
函数newseg()的定义于ipc/shm.c:
/**
* newseg - Create a new shared memory segment
* @ns: namespace
* @params: ptr to the structure that contains key, size and shmflg
*
* Called with shm_ids.rw_mutex held as a writer.
*/
static int newseg(struct ipc_namespace *ns, struct ipc_params *params)
{
key_t key = params->key;
int shmflg = params->flg;
size_t size = params->u.size;
int error;
struct shmid_kernel *shp;
int numpages = (size + PAGE_SIZE -1) >> PAGE_SHIFT;
struct file * file;
char name[13];
int id;
vm_flags_t acctflag = 0;
if (size < SHMMIN || size > ns->shm_ctlmax)
return -EINVAL;
if (ns->shm_tot + numpages > ns->shm_ctlall)
return -ENOSPC;
shp = ipc_rcu_alloc(sizeof(*shp));
if (!shp)
return -ENOMEM;
// 为shm_perm.key赋值,后续为shm_perm.id赋值,因而key与id建立了映射关系
shp->shm_perm.key = key;
shp->shm_perm.mode = (shmflg & S_IRWXUGO);
shp->mlock_user = NULL;
shp->shm_perm.security = NULL;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
error = security_shm_alloc(shp);
if (error) {
ipc_rcu_putref(shp);
return error;
}
sprintf (name, "SYSV%08x", key);
if (shmflg & SHM_HUGETLB) {
/* hugetlb_file_setup applies strict accounting */
if (shmflg & SHM_NORESERVE)
acctflag = VM_NORESERVE;
file = hugetlb_file_setup(name, size, acctflag, &shp->mlock_user, HUGETLB_SHMFS_INODE);
} else {
/*
* Do not allow no accounting for OVERCOMMIT_NEVER, even
* if it's asked for.
*/
if ((shmflg & SHM_NORESERVE) && sysctl_overcommit_memory != OVERCOMMIT_NEVER)
acctflag = VM_NORESERVE;
file = shmem_file_setup(name, size, acctflag);
}
error = PTR_ERR(file);
if (IS_ERR(file))
goto no_file;
/*
* ipc_addid()为shm_perm.id赋值,先前已为shm_perm.key赋值,因而key
* 与id建立了映射关系;另外,通过ipc_addid() -> idr_get_new() ->
* idr_get_new_above_int() -> rcu_assign_pointer()将
* pa[0]->ary[id & IDR_MASK]指向msq->shm_perm,参见[8.4.2.1 struct idr]节
*/
id = ipc_addid(&shm_ids(ns), &shp->shm_perm, ns->shm_ctlmni);
if (id < 0) {
error = id;
goto no_id;
}
shp->shm_cprid = task_tgid_vnr(current);
shp->shm_lprid = 0;
shp->shm_atim = shp->shm_dtim = 0;
shp->shm_ctim = get_seconds();
shp->shm_segsz = size;
shp->shm_nattch = 0;
shp->shm_file = file;
shp->shm_creator = current;
/*
* shmid gets reported as "inode#" in /proc/pid/maps.
* proc-ps tools use this. Changing this will break them.
*/
file->f_dentry->d_inode->i_ino = shp->shm_perm.id;
ns->shm_tot += numpages;
error = shp->shm_perm.id;
shm_unlock(shp);
return error;
no_id:
if (is_file_hugepages(file) && shp->mlock_user)
user_shm_unlock(size, shp->mlock_user);
fput(file);
no_file:
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
security_shm_free(shp);
ipc_rcu_putref(shp);
return error;
}
8.5.4 操纵共享内存
8.5.4.1 sys_shmctl()
系统调用sys_shmctl()用于操纵共享内存,其定义于ipc/shm.c:
SYSCALL_DEFINE3(shmctl, int, shmid, int, cmd, struct shmid_ds __user *, buf)
{
struct shmid_kernel *shp;
int err, version;
struct ipc_namespace *ns;
if (cmd < 0 || shmid < 0) {
err = -EINVAL;
goto out;
}
version = ipc_parse_version(&cmd);
ns = current->nsproxy->ipc_ns;
switch (cmd) { /* replace with proc interface ? */
case IPC_INFO:
{
struct shminfo64 shminfo;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_shm_shmctl(NULL, cmd);
if (err)
return err;
memset(&shminfo, 0, sizeof(shminfo));
shminfo.shmmni = shminfo.shmseg = ns->shm_ctlmni;
shminfo.shmmax = ns->shm_ctlmax;
shminfo.shmall = ns->shm_ctlall;
shminfo.shmmin = SHMMIN;
if(copy_shminfo_to_user(buf, &shminfo, version))
return -EFAULT;
down_read(&shm_ids(ns).rw_mutex);
err = ipc_get_maxid(&shm_ids(ns));
up_read(&shm_ids(ns).rw_mutex);
if(err<0)
err = 0;
goto out;
}
case SHM_INFO:
{
struct shm_info shm_info;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_shm_shmctl(NULL, cmd);
if (err)
return err;
memset(&shm_info, 0, sizeof(shm_info));
down_read(&shm_ids(ns).rw_mutex);
shm_info.used_ids = shm_ids(ns).in_use;
shm_get_stat(ns, &shm_info.shm_rss, &shm_info.shm_swp);
shm_info.shm_tot = ns->shm_tot;
shm_info.swap_attempts = 0;
shm_info.swap_successes = 0;
err = ipc_get_maxid(&shm_ids(ns));
up_read(&shm_ids(ns).rw_mutex);
if (copy_to_user(buf, &shm_info, sizeof(shm_info))) {
err = -EFAULT;
goto out;
}
err = err < 0 ? 0 : err;
goto out;
}
case SHM_STAT:
case IPC_STAT:
{
struct shmid64_ds tbuf;
int result;
if (cmd == SHM_STAT) {
shp = shm_lock(ns, shmid);
if (IS_ERR(shp)) {
err = PTR_ERR(shp);
goto out;
}
result = shp->shm_perm.id;
} else {
shp = shm_lock_check(ns, shmid);
if (IS_ERR(shp)) {
err = PTR_ERR(shp);
goto out;
}
result = 0;
}
err = -EACCES;
if (ipcperms(ns, &shp->shm_perm, S_IRUGO))
goto out_unlock;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_shm_shmctl(shp, cmd);
if (err)
goto out_unlock;
memset(&tbuf, 0, sizeof(tbuf));
kernel_to_ipc64_perm(&shp->shm_perm, &tbuf.shm_perm);
tbuf.shm_segsz = shp->shm_segsz;
tbuf.shm_atime = shp->shm_atim;
tbuf.shm_dtime = shp->shm_dtim;
tbuf.shm_ctime = shp->shm_ctim;
tbuf.shm_cpid = shp->shm_cprid;
tbuf.shm_lpid = shp->shm_lprid;
tbuf.shm_nattch = shp->shm_nattch;
shm_unlock(shp);
if(copy_shmid_to_user(buf, &tbuf, version))
err = -EFAULT;
else
err = result;
goto out;
}
case SHM_LOCK:
case SHM_UNLOCK:
{
struct file *uninitialized_var(shm_file);
lru_add_drain_all(); /* drain pagevecs to lru lists */
shp = shm_lock_check(ns, shmid);
if (IS_ERR(shp)) {
err = PTR_ERR(shp);
goto out;
}
audit_ipc_obj(&(shp->shm_perm));
if (!ns_capable(ns->user_ns, CAP_IPC_LOCK)) {
uid_t euid = current_euid();
err = -EPERM;
if (euid != shp->shm_perm.uid && euid != shp->shm_perm.cuid)
goto out_unlock;
if (cmd == SHM_LOCK && !rlimit(RLIMIT_MEMLOCK))
goto out_unlock;
}
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_shm_shmctl(shp, cmd);
if (err)
goto out_unlock;
if(cmd==SHM_LOCK) {
struct user_struct *user = current_user();
if (!is_file_hugepages(shp->shm_file)) {
err = shmem_lock(shp->shm_file, 1, user);
if (!err && !(shp->shm_perm.mode & SHM_LOCKED)){
shp->shm_perm.mode |= SHM_LOCKED;
shp->mlock_user = user;
}
}
} else if (!is_file_hugepages(shp->shm_file)) {
shmem_lock(shp->shm_file, 0, shp->mlock_user);
shp->shm_perm.mode &= ~SHM_LOCKED;
shp->mlock_user = NULL;
}
shm_unlock(shp);
goto out;
}
case IPC_RMID:
case IPC_SET:
err = shmctl_down(ns, shmid, cmd, buf, version);
return err;
default:
return -EINVAL;
}
out_unlock:
shm_unlock(shp);
out:
return err;
}
8.5.5 挂接共享内存
8.5.5.1 sys_shmat()
系统调用sys_shmat()用于挂接一个共享内存段,其定义于ipc/shm.c:
SYSCALL_DEFINE3(shmat, int, shmid, char __user *, shmaddr, int, shmflg)
{
unsigned long ret;
long err;
err = do_shmat(shmid, shmaddr, shmflg, &ret);
if (err)
return err;
force_successful_syscall_return();
return (long)ret;
}
/*
* Fix shmaddr, allocate descriptor, map shm, add attach descriptor to lists.
*
* NOTE! Despite the name, this is NOT a direct system call entrypoint. The
* "raddr" thing points to kernel space, and there has to be a wrapper around
* this.
*/
long do_shmat(int shmid, char __user *shmaddr, int shmflg, ulong *raddr)
{
struct shmid_kernel *shp;
unsigned long addr;
unsigned long size;
struct file * file;
int err;
unsigned long flags;
unsigned long prot;
int acc_mode;
unsigned long user_addr;
struct ipc_namespace *ns;
struct shm_file_data *sfd;
struct path path;
fmode_t f_mode;
err = -EINVAL;
if (shmid < 0)
goto out;
else if ((addr = (ulong)shmaddr)) {
if (addr & (SHMLBA-1)) {
if (shmflg & SHM_RND)
addr &= ~(SHMLBA-1); /* round down */
else
#ifndef __ARCH_FORCE_SHMLBA
if (addr & ~PAGE_MASK)
#endif
goto out;
}
flags = MAP_SHARED | MAP_FIXED;
} else {
if ((shmflg & SHM_REMAP))
goto out;
flags = MAP_SHARED;
}
if (shmflg & SHM_RDONLY) {
prot = PROT_READ;
acc_mode = S_IRUGO;
f_mode = FMODE_READ;
} else {
prot = PROT_READ | PROT_WRITE;
acc_mode = S_IRUGO | S_IWUGO;
f_mode = FMODE_READ | FMODE_WRITE;
}
if (shmflg & SHM_EXEC) {
prot |= PROT_EXEC;
acc_mode |= S_IXUGO;
}
/*
* We cannot rely on the fs check since SYSV IPC does have an
* additional creator id...
*/
ns = current->nsproxy->ipc_ns;
shp = shm_lock_check(ns, shmid);
if (IS_ERR(shp)) {
err = PTR_ERR(shp);
goto out;
}
err = -EACCES;
if (ipcperms(ns, &shp->shm_perm, acc_mode))
goto out_unlock;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_shm_shmat(shp, shmaddr, shmflg);
if (err)
goto out_unlock;
path = shp->shm_file->f_path;
path_get(&path);
shp->shm_nattch++;
size = i_size_read(path.dentry->d_inode);
shm_unlock(shp);
err = -ENOMEM;
sfd = kzalloc(sizeof(*sfd), GFP_KERNEL);
if (!sfd)
goto out_put_dentry;
file = alloc_file(&path, f_mode,
is_file_hugepages(shp->shm_file) ? &shm_file_operations_huge : &shm_file_operations);
if (!file)
goto out_free;
file->private_data = sfd;
file->f_mapping = shp->shm_file->f_mapping;
sfd->id = shp->shm_perm.id;
sfd->ns = get_ipc_ns(ns);
sfd->file = shp->shm_file;
sfd->vm_ops = NULL;
down_write(¤t->mm->mmap_sem);
if (addr && !(shmflg & SHM_REMAP)) {
err = -EINVAL;
if (find_vma_intersection(current->mm, addr, addr + size))
goto invalid;
/*
* If shm segment goes below stack, make sure there is some
* space left for the stack to grow (at least 4 pages).
*/
if (addr < current->mm->start_stack &&
addr > current->mm->start_stack - size - PAGE_SIZE * 5)
goto invalid;
}
// 参见[6.8.2 Allocate a Linear Address Interval]节
user_addr = do_mmap(file, addr, size, prot, flags, 0);
*raddr = user_addr;
err = 0;
if (IS_ERR_VALUE(user_addr))
err = (long)user_addr;
invalid:
up_write(¤t->mm->mmap_sem);
fput(file);
out_nattch:
down_write(&shm_ids(ns).rw_mutex);
shp = shm_lock(ns, shmid);
BUG_ON(IS_ERR(shp));
shp->shm_nattch--;
if (shm_may_destroy(ns, shp))
shm_destroy(ns, shp);
else
shm_unlock(shp);
up_write(&shm_ids(ns).rw_mutex);
out:
return err;
out_unlock:
shm_unlock(shp);
goto out;
out_free:
kfree(sfd);
out_put_dentry:
path_put(&path);
goto out_nattch;
}
8.5.6 分离共享内存
进程退出时会自动分离已挂接的共享内存段,但是仍建议当进程不再使用共享段时调用sys_shmdt()来卸载共享内存段。注意,当一个进程fork出父进程和子进程时,父进程先前创建的所有共享内存区段都会被子进程继承。如果该段已经做了删除标记(在前面以IPC_RMID指令调用shmctl),而当前挂接数已经变为0,这个区段就会被移除。
8.5.6.1 sys_shmdt()
该系统调用定义于ipc/shm.c:
/*
* detach and kill segment if marked destroyed.
* The work is done in shm_close.
*/
SYSCALL_DEFINE1(shmdt, char __user *, shmaddr)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
unsigned long addr = (unsigned long)shmaddr;
int retval = -EINVAL;
#ifdef CONFIG_MMU
loff_t size = 0;
struct vm_area_struct *next;
#endif
if (addr & ~PAGE_MASK)
return retval;
down_write(&mm->mmap_sem);
/*
* This function tries to be smart and unmap shm segments that
* were modified by partial mlock or munmap calls:
* - It first determines the size of the shm segment that should be
* unmapped: It searches for a vma that is backed by shm and that
* started at address shmaddr. It records it's size and then unmaps
* it.
* - Then it unmaps all shm vmas that started at shmaddr and that
* are within the initially determined size.
* Errors from do_munmap are ignored: the function only fails if
* it's called with invalid parameters or if it's called to unmap
* a part of a vma. Both calls in this function are for full vmas,
* the parameters are directly copied from the vma itself and always
* valid - therefore do_munmap cannot fail. (famous last words?)
*/
/*
* If it had been mremap()'d, the starting address would not
* match the usual checks anyway. So assume all vma's are
* above the starting address given.
*/
vma = find_vma(mm, addr);
#ifdef CONFIG_MMU
while (vma) {
next = vma->vm_next;
/*
* Check if the starting address would match, i.e. it's
* a fragment created by mprotect() and/or munmap(), or it
* otherwise it starts at this address with no hassles.
*/
if ((vma->vm_ops == &shm_vm_ops) &&
(vma->vm_start - addr)/PAGE_SIZE == vma->vm_pgoff) {
size = vma->vm_file->f_path.dentry->d_inode->i_size;
do_munmap(mm, vma->vm_start, vma->vm_end - vma->vm_start);
/*
* We discovered the size of the shm segment, so
* break out of here and fall through to the next
* loop that uses the size information to stop
* searching for matching vma's.
*/
retval = 0;
vma = next;
break;
}
vma = next;
}
/*
* We need look no further than the maximum address a fragment
* could possibly have landed at. Also cast things to loff_t to
* prevent overflows and make comparisons vs. equal-width types.
*/
size = PAGE_ALIGN(size);
while (vma && (loff_t)(vma->vm_end - addr) <= size) {
next = vma->vm_next;
/* finding a matching vma now does not alter retval */
if ((vma->vm_ops == &shm_vm_ops) &&
(vma->vm_start - addr)/PAGE_SIZE == vma->vm_pgoff)
do_munmap(mm, vma->vm_start, vma->vm_end - vma->vm_start);
vma = next;
}
#else /* CONFIG_MMU */
/* under NOMMU conditions, the exact address to be destroyed must be
* given */
retval = -EINVAL;
if (vma->vm_start == addr && vma->vm_ops == &shm_vm_ops) {
do_munmap(mm, vma->vm_start, vma->vm_end - vma->vm_start);
retval = 0;
}
#endif
up_write(&mm->mmap_sem);
return retval;
}
8.5.7 共享内存的初始化
当共享内存模块编译进内核时,在系统初始化时,会调用共享内存的初始化函数。在ipc/shm.c中,包含如下代码:
static int __init ipc_ns_init(void)
{
shm_init_ns(&init_ipc_ns);
return 0;
}
pure_initcall(ipc_ns_init);
其中,pure_initcall()定义与include/linux/init.h中,参见13.5.1.1 module被编译进内核时的初始化过程节。当module被编译进内核时,其初始化函数需要在系统启动时被调用。其调用过程为:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall0.init
此后,还存在如下初始化调用:
ipc_init() // 参见[8.4.7 消息队列的初始化]节
-> shm_init()
-> ipc_init_proc_interface()
8.6 信号量/sem
8.6.1 信号量简介
1965年,荷兰学者Dijkstra提出了利用信号量机制解决进程同步问题,信号量正式成为有效的进程同步工具。现在信号量机制被广泛的用于单处理机和多处理机系统以及计算机网络中。
信号量S是一个整数,当S大于等于零时代表可供并发进程使用的资源实体数,当S小于零时则表示正在等待使用临界区的进程数。
Dijkstra同时提出了对信号量操作的PV原语。
- P原语操作的动作是:
- 1) S减1;
- 2) 若S减1后仍大于等于零,则进程继续执行;
- 3) 若S减1后小于零,则该进程被阻塞后进入与该信号相对应的队列中,然后转进程调度。
- V原语操作的动作是:
- 1) S加1;
- 2) 若相加结果大于零,则进程继续执行;
- 3) 若相加结果小于或等于零,则从该信号的等待队列中唤醒一等待进程,然后再返回原进程继续执行或转进程调度。
PV操作对于每一个进程来说,都只能进行一次,而且必须成对使用。在PV原语行期间不允许有中断的发生。
信号量机制分为:
- 整型信号量机制
- 记录型信号量机制
- AND型信号量机制
- 信号量集
8.6.2 与信号量有关的数据结构
8.6.2.1 struct idr
该结构示意图:
8.6.2.2 struct sem_array
该结构示意图:
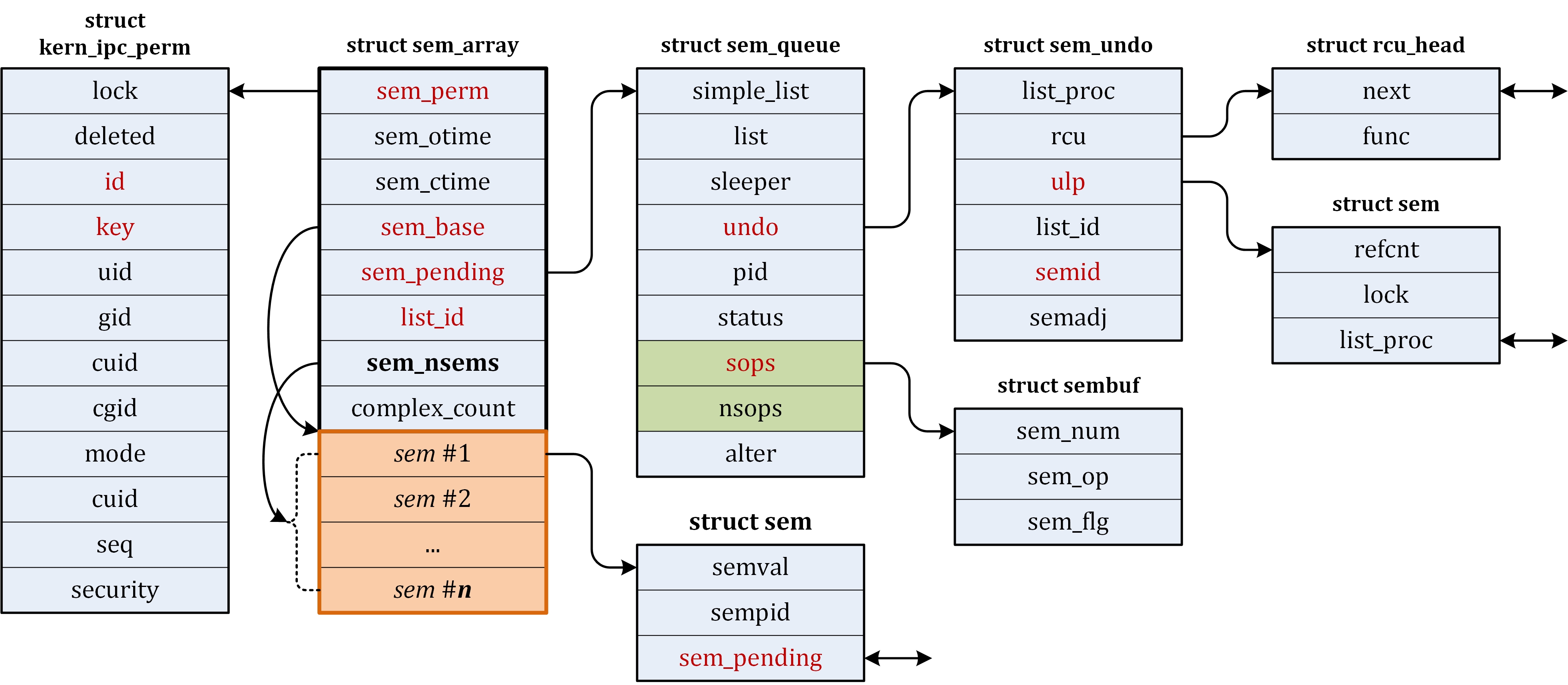
8.6.2.2.1 struct sembuf
在sembuf结构中:
- sem_num是对应信号量集中的某一个资源,其取值范围是从0到对应信号量集的资源总数(semarray.sem_nsems)之间的整数。
- sem_op指明想要进行的操作。其取值为一个整数:
- sem_op > 0:释放相应的资源数,如果有两个信号量,释放信号量1,则其semval+1;
- sem_op = 0:进程阻塞直到信号量的取值为0,当信号量的取值已经为0,则函数立即返回;
- sem_op < 0:请求sem_op的绝对值的资源数;
- sem_flg指明sys_semop()的行为。
该参数可设置为IPC_NOWAIT或SEM_UNDO两种状态。只有将sem_flg指定为SEM_UNDO标志后,semadj(所指定信号量针对调用进程的调整值)才会更新。此外,如果此操作指定SEM_UNDO,系统更新过程中会撤消此信号量的计数(semadj)。此操作可以随时进行(它永远不会强制等待的过程)。调用进程必须有改变信号量集的权限。
8.6.3 创建/打开信号量集
8.6.3.1 sys_semget()
系统调用sys_semget()用于创建新的信号量,或者打开已有的信号量。其定义于ipc/sem.c:
/*
* key – 其值一般是由系统调用sys_ftok()返回的
* nsems – 取值大于等于0,用于指明该信号量集中可用资源数。当打开一个已
* 存在的信号量集时,该参数取值为0
* semflg – IPC_CREAT: 如果信号量集在系统内核中不存在,则创建信号量集;
* IPC_EXCL:与IPC_CREAT一同使用时,如果信号量集已经存在,
* 则调用失败。NOTE: 单独使用IPC_EXCL标志没有意义
*/
SYSCALL_DEFINE3(semget, key_t, key, int, nsems, int, semflg)
{
struct ipc_namespace *ns;
struct ipc_ops sem_ops;
struct ipc_params sem_params;
ns = current->nsproxy->ipc_ns;
if (nsems < 0 || nsems > ns->sc_semmsl)
return -EINVAL;
/*
* 设置newary()函数指针,该函数在ipcget_new()或ipcget_public()
* 中被调用,参见[8.4.3.1.1.1 ipcget_new()/ipcget_public()]节
*/
sem_ops.getnew = newary;
sem_ops.associate = sem_security;
sem_ops.more_checks = sem_more_checks;
sem_params.key = key;
sem_params.flg = semflg;
sem_params.u.nsems = nsems;
/*
* 与消息队列类似,参见[8.4.3.1.1 ipcget()]节,返回值为新创建的信号量集的句柄,
* 参见[8.6.3.1.1 newary()]节
*/
return ipcget(ns, &sem_ids(ns), &sem_ops, &sem_params);
}
8.6.3.1.1 newary()
函数newary()用于创建新的信号量,其定义于ipc/sem.c:
/**
* newary - Create a new semaphore set
* @ns: namespace
* @params: ptr to the structure that contains key, semflg and nsems
*
* Called with sem_ids.rw_mutex held (as a writer)
*/
static int newary(struct ipc_namespace *ns, struct ipc_params *params)
{
int id;
int retval;
struct sem_array *sma;
int size;
key_t key = params->key;
int nsems = params->u.nsems;
int semflg = params->flg;
int i;
if (!nsems)
return -EINVAL;
if (ns->used_sems + nsems > ns->sc_semmns)
return -ENOSPC;
// 由此可知,信号量数组结尾处紧接着数个信号量,参见[8.6.2.2 struct sem_array]节
size = sizeof (*sma) + nsems * sizeof (struct sem);
sma = ipc_rcu_alloc(size);
if (!sma) {
return -ENOMEM;
}
memset(sma, 0, size);
sma->sem_perm.mode = (semflg & S_IRWXUGO);
// 为q_perm.key赋值,后续为q_perm.id赋值,因而key与id建立了映射关系
sma->sem_perm.key = key;
sma->sem_perm.security = NULL;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
retval = security_sem_alloc(sma);
if (retval) {
ipc_rcu_putref(sma);
return retval;
}
/*
* ipc_addid()为sem_perm.id赋值,先前已为sem_perm.key赋值,因而key
* 与id建立了映射关系;另外,通过ipc_addid() -> idr_get_new() ->
* idr_get_new_above_int() -> rcu_assign_pointer()将
* pa[0]->ary[id & IDR_MASK]指向msq->sem_perm,参见[8.4.2.1 struct idr]节
*/
id = ipc_addid(&sem_ids(ns), &sma->sem_perm, ns->sc_semmni);
if (id < 0) {
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
security_sem_free(sma);
ipc_rcu_putref(sma);
return id;
}
ns->used_sems += nsems;
sma->sem_base = (struct sem *) &sma[1];
for (i = 0; i < nsems; i++)
INIT_LIST_HEAD(&sma->sem_base[i].sem_pending);
sma->complex_count = 0;
INIT_LIST_HEAD(&sma->sem_pending);
INIT_LIST_HEAD(&sma->list_id);
sma->sem_nsems = nsems;
sma->sem_ctime = get_seconds();
sem_unlock(sma);
// 返回值为信号量集的句柄,参见[8.6.2.2 struct sem_array]节
return sma->sem_perm.id;
}
8.6.4 操纵信号量集
8.6.4.1 sys_semctl()
系统调用sys_semctl()用于操纵信号量,其定义于ipc/sem.c:
SYSCALL_DEFINE(semctl)(int semid, int semnum, int cmd, union semun arg)
{
int err = -EINVAL;
int version;
struct ipc_namespace *ns;
if (semid < 0)
return -EINVAL;
version = ipc_parse_version(&cmd);
ns = current->nsproxy->ipc_ns;
switch(cmd) {
case IPC_INFO:
case SEM_INFO:
case IPC_STAT:
case SEM_STAT:
err = semctl_nolock(ns, semid, cmd, version, arg);
return err;
case GETALL:
case GETVAL:
case GETPID:
case GETNCNT:
case GETZCNT:
case SETVAL:
case SETALL:
err = semctl_main(ns,semid,semnum,cmd,version,arg);
return err;
case IPC_RMID:
case IPC_SET:
err = semctl_down(ns, semid, cmd, version, arg);
return err;
default:
return -EINVAL;
}
}
#ifdef CONFIG_HAVE_SYSCALL_WRAPPERS
asmlinkage long SyS_semctl(int semid, int semnum, int cmd, union semun arg)
{
return SYSC_semctl((int) semid, (int) semnum, (int) cmd, arg);
}
SYSCALL_ALIAS(sys_semctl, SyS_semctl);
#endif
8.6.4.2 sys_semop()/sys_semtimedop()
系统调用sys_semop()与sys_semctl()的区别与联系:
sys_semop()用于操作一个信号量集,其实质是通过修改sem_op指定对资源要进行的操作;而sys_semctl()则是对信号量本身的值进行操作,可以修改信号量的值或者删除一个信号量。
系统调用sys_semop()用于操作用信号量,其定义于ipc/sem.c:
/*
* semid – 信号量集的句柄,即sys_semget()的返回值,参见[8.6.3.1 sys_semget()]节
* tsops – 用户指定的操作
* nsops – tsops指定的空间中包含sembuf结构的个数
*/
SYSCALL_DEFINE3(semop, int, semid, struct sembuf __user *, tsops, unsigned, nsops)
{
return sys_semtimedop(semid, tsops, nsops, NULL);
}
semtimedop() behaves identically to semop() except that in those cases where the calling thread would sleep, the duration of that sleep is limited by the amount of elapsed time specified by the timespec structure whose address is passed in the timeout argument. (This sleep interval will be rounded up to the system clock granularity, and kernel scheduling delays mean that the interval may overrun by a small amount.) If the specified time limit has been reached, semtimedop() fails with errno set to EAGAIN (and none of the operations in sops is performed). If the timeout argument is NULL, then semtimedop() behaves exactly like semop().
sys_semtimeop()的定义于ipc/sem.c:
SYSCALL_DEFINE4(semtimedop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops, const struct timespec __user *, timeout)
{
int error = -EINVAL;
struct sem_array *sma;
struct sembuf fast_sops[SEMOPM_FAST]; // SEMOPM_FAST取值为64
struct sembuf* sops = fast_sops, *sop;
struct sem_undo *un;
int undos = 0, alter = 0, max;
struct sem_queue queue;
unsigned long jiffies_left = 0;
struct ipc_namespace *ns;
struct list_head tasks;
ns = current->nsproxy->ipc_ns;
if (nsops < 1 || semid < 0)
return -EINVAL;
if (nsops > ns->sc_semopm)
return -E2BIG;
if(nsops > SEMOPM_FAST) {
sops = kmalloc(sizeof(*sops)*nsops,GFP_KERNEL);
if(sops == NULL)
return -ENOMEM;
}
if (copy_from_user(sops, tsops, nsops * sizeof(*tsops))) {
error =- EFAULT;
goto out_free;
}
if (timeout) {
struct timespec _timeout;
if (copy_from_user(&_timeout, timeout, sizeof(*timeout))) {
error = -EFAULT;
goto out_free;
}
if (_timeout.tv_sec < 0 || _timeout.tv_nsec < 0 ||
_timeout.tv_nsec >= 1000000000L) {
error = -EINVAL;
goto out_free;
}
jiffies_left = timespec_to_jiffies(&_timeout);
}
// 循环所有用户指定的操作,以得到如下三个参数:max, undos, alter
max = 0;
for (sop = sops; sop < sops + nsops; sop++) {
if (sop->sem_num >= max)
max = sop->sem_num;
if (sop->sem_flg & SEM_UNDO)
undos = 1;
if (sop->sem_op != 0)
alter = 1;
}
if (undos) {
un = find_alloc_undo(ns, semid);
if (IS_ERR(un)) {
error = PTR_ERR(un);
goto out_free;
}
} else
un = NULL;
INIT_LIST_HEAD(&tasks);
// 获取信号量队列
sma = sem_lock_check(ns, semid);
if (IS_ERR(sma)) {
if (un)
rcu_read_unlock();
error = PTR_ERR(sma);
goto out_free;
}
/*
* semid identifiers are not unique - find_alloc_undo may have
* allocated an undo structure, it was invalidated by an RMID
* and now a new array with received the same id. Check and fail.
* This case can be detected checking un->semid. The existence of
* "un" itself is guaranteed by rcu.
*/
error = -EIDRM;
if (un) {
if (un->semid == -1) {
rcu_read_unlock();
goto out_unlock_free;
} else {
/*
* rcu lock can be released, "un" cannot disappear:
* - sem_lock is acquired, thus IPC_RMID is
* impossible.
* - exit_sem is impossible, it always operates on
* current (or a dead task).
*/
rcu_read_unlock();
}
}
error = -EFBIG;
if (max >= sma->sem_nsems)
goto out_unlock_free;
error = -EACCES;
if (ipcperms(ns, &sma->sem_perm, alter ? S_IWUGO : S_IRUGO))
goto out_unlock_free;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
error = security_sem_semop(sma, sops, nsops, alter);
if (error)
goto out_unlock_free;
// 对信号量集中的进行指定的操作
error = try_atomic_semop(sma, sops, nsops, un, task_tgid_vnr(current));
if (error <= 0) {
if (alter && error == 0)
do_smart_update(sma, sops, nsops, 1, &tasks);
goto out_unlock_free;
}
/* We need to sleep on this operation, so we put the current
* task into the pending queue and go to sleep.
*/
queue.sops = sops;
queue.nsops = nsops;
queue.undo = un;
queue.pid = task_tgid_vnr(current);
queue.alter = alter;
if (alter)
list_add_tail(&queue.list, &sma->sem_pending);
else
list_add(&queue.list, &sma->sem_pending);
if (nsops == 1) {
struct sem *curr;
curr = &sma->sem_base[sops->sem_num];
if (alter)
list_add_tail(&queue.simple_list, &curr->sem_pending);
else
list_add(&queue.simple_list, &curr->sem_pending);
} else {
INIT_LIST_HEAD(&queue.simple_list);
sma->complex_count++;
}
queue.status = -EINTR;
queue.sleeper = current;
sleep_again:
current->state = TASK_INTERRUPTIBLE;
sem_unlock(sma);
if (timeout)
// 参见[7.4.7 schedule_timeout()]节
jiffies_left = schedule_timeout(jiffies_left);
else
schedule();
error = get_queue_result(&queue);
if (error != -EINTR) {
/* fast path: update_queue already obtained all requested
* resources.
* Perform a smp_mb(): User space could assume that semop()
* is a memory barrier: Without the mb(), the cpu could
* speculatively read in user space stale data that was
* overwritten by the previous owner of the semaphore.
*/
smp_mb();
goto out_free;
}
sma = sem_lock(ns, semid);
/*
* Wait until it's guaranteed that no wakeup_sem_queue_do() is ongoing.
*/
error = get_queue_result(&queue);
/*
* Array removed? If yes, leave without sem_unlock().
*/
if (IS_ERR(sma)) {
goto out_free;
}
/*
* If queue.status != -EINTR we are woken up by another process.
* Leave without unlink_queue(), but with sem_unlock().
*/
if (error != -EINTR) {
goto out_unlock_free;
}
/*
* If an interrupt occurred we have to clean up the queue
*/
if (timeout && jiffies_left == 0)
error = -EAGAIN;
/*
* If the wakeup was spurious, just retry
*/
if (error == -EINTR && !signal_pending(current))
goto sleep_again;
unlink_queue(sma, &queue);
out_unlock_free:
sem_unlock(sma);
// 唤醒某些进程
wake_up_sem_queue_do(&tasks);
out_free:
if(sops != fast_sops)
kfree(sops);
return error;
}
8.6.5 信号量的初始化
信号量的初始化过程与消息队列的初始化过程类似,参见8.4.7 消息队列的初始化节。函数调用关系如下:
ipc_init()
-> sem_init()
-> sem_init_ns()
-> ipc_init_proc_interface()
8.7 套接字/Socket
8.7.1 套接字简介
socket起源于Unix,而Unix/Linux基本哲学之一就是”一切皆文件”,都可以用“打开open –> 读写write/read -> 关闭close的模式来操作。socket就是该模式的一个实现,socket是一种特殊的文件,一些socket函数就是对其进行操作(读/写IO、打开、关闭)。
socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在socket接口后面,对用户来说,一组简单的接口就是全部,让socket去组织数据,以符合指定的协议。
NOTE: 其实socket也没有层的概念,它只是一个facade设计模式的应用,让编程变的更简单。
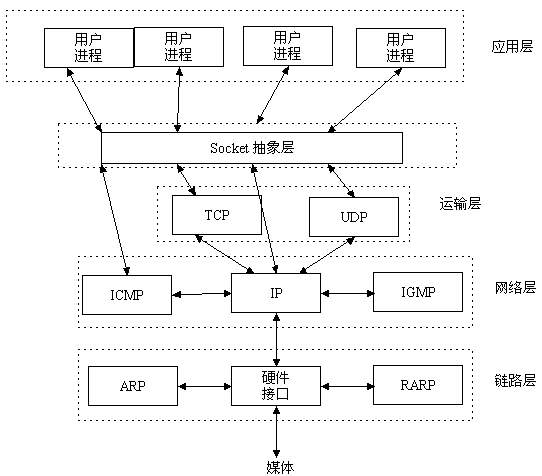
8.7.2 与套接字有关的数据结构
8.7.2.1 struct sockaddr
该结构定义于include/linux/socket.h
8.7.2.2 struct mmsghdr
该结构定义于include/linux/socket.h
8.7.2.3 struct socket
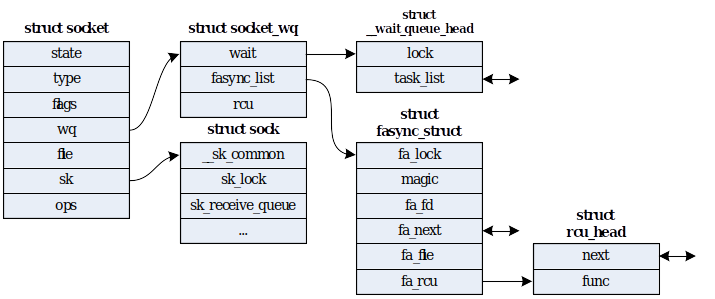
8.7.2.4 struct net_proto_family
数组net_families的定义于net/socket.c:
static DEFINE_SPINLOCK(net_family_lock);
static const struct net_proto_family __rcu *net_families[NPROTO] __read_mostly;
数组net_families,参见:
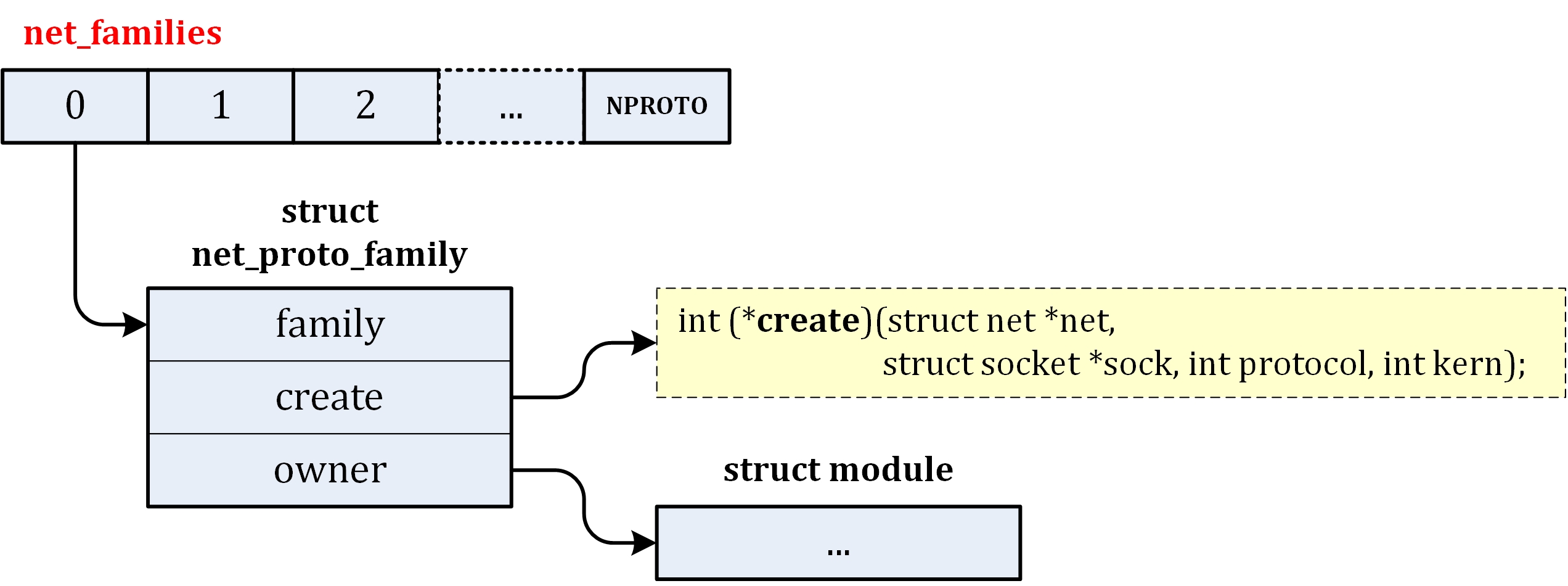
该数组包含了注册到系统中的所有网络协议族的信息,数组元素个数为NPROTO,每个元素对应的协议族参见include/linux/socket.h:
/* Protocol families, same as address families. */
#define PF_UNSPEC AF_UNSPEC
#define PF_UNIX AF_UNIX
#define PF_LOCAL AF_LOCAL
#define PF_INET AF_INET
#define PF_AX25 AF_AX25
#define PF_IPX AF_IPX
#define PF_APPLETALK AF_APPLETALK
#define PF_NETROM AF_NETROM
#define PF_BRIDGE AF_BRIDGE
#define PF_ATMPVC AF_ATMPVC
#define PF_X25 AF_X25
#define PF_INET6 AF_INET6
#define PF_ROSE AF_ROSE
#define PF_DECnet AF_DECnet
#define PF_NETBEUI AF_NETBEUI
#define PF_SECURITY AF_SECURITY
#define PF_KEY AF_KEY
#define PF_NETLINK AF_NETLINK
#define PF_ROUTE AF_ROUTE
#define PF_PACKET AF_PACKET
#define PF_ASH AF_ASH
#define PF_ECONET AF_ECONET
#define PF_ATMSVC AF_ATMSVC
#define PF_RDS AF_RDS
#define PF_SNA AF_SNA
#define PF_IRDA AF_IRDA
#define PF_PPPOX AF_PPPOX
#define PF_WANPIPE AF_WANPIPE
#define PF_LLC AF_LLC
#define PF_CAN AF_CAN
#define PF_TIPC AF_TIPC
#define PF_BLUETOOTH AF_BLUETOOTH
#define PF_IUCV AF_IUCV
#define PF_RXRPC AF_RXRPC
#define PF_ISDN AF_ISDN
#define PF_PHONET AF_PHONET
#define PF_IEEE802154 AF_IEEE802154
#define PF_CAIF AF_CAIF
#define PF_ALG AF_ALG
#define PF_NFC AF_NFC
#define PF_MAX AF_MAX
8.7.2.4.1 网络协议族的注册与取消
net_families数组的各元素是通过sock_register()和sock_unregister()注册和取消的,参见net/socket.c。
/**
* sock_register - add a socket protocol handler
* @ops: description of protocol
*
* This function is called by a protocol handler that wants to
* advertise its address family, and have it linked into the
* socket interface. The value ops->family coresponds to the
* socket system call protocol family.
*/
int sock_register(const struct net_proto_family *ops)
{
int err;
if (ops->family >= NPROTO) {
printk(KERN_CRIT "protocol %d >= NPROTO(%d)\n", ops->family, NPROTO);
return -ENOBUFS;
}
spin_lock(&net_family_lock);
if (rcu_dereference_protected(net_families[ops->family], lockdep_is_held(&net_family_lock)))
err = -EEXIST;
else {
RCU_INIT_POINTER(net_families[ops->family], ops); // 注册指定的协议族
err = 0;
}
spin_unlock(&net_family_lock);
printk(KERN_INFO "NET: Registered protocol family %d\n", ops->family);
return err;
}
/**
* sock_unregister - remove a protocol handler
* @family: protocol family to remove
*
* This function is called by a protocol handler that wants to
* remove its address family, and have it unlinked from the
* new socket creation.
*
* If protocol handler is a module, then it can use module reference
* counts to protect against new references. If protocol handler is not
* a module then it needs to provide its own protection in
* the ops->create routine.
*/
void sock_unregister(int family)
{
BUG_ON(family < 0 || family >= NPROTO);
spin_lock(&net_family_lock);
RCU_INIT_POINTER(net_families[family], NULL); // 取消指定的协议族
spin_unlock(&net_family_lock);
synchronize_rcu();
printk(KERN_INFO "NET: Unregistered protocol family %d\n", family);
}
sock_register()和sock_unregister()会被实现协议族功能的模块调用,用于注册指定的协议族。以IP协议为例,在net/ipv4/af_inet.c中,包含如下代码:
static const struct net_proto_family inet_family_ops = {
// Internet IP Protocol
.family = PF_INET,
/*
* 该函数用于创建对应协议族的socket,被sock_create()/__sock_create()调用,
* 参见[8.7.3.1.1 sock_create()/__sock_create()]节。同时,该函数还会为sock->ops赋值,
* 用于实现struct proto_ops中与本协议族有关的接口,参见[8.7.3.2 sys_bind()]节至
* [8.7.3.8 sys_shutdown()/sys_close()]节
*/
.create = inet_create,
/*
* 指定包含本协议族的模块,被sock_create()/__sock_create()调用,
* 参见[8.7.3.1.1 sock_create()/__sock_create()]节
*/
.owner = THIS_MODULE,
};
static int __init inet_init(void)
{
...
(void)sock_register(&inet_family_ops);
...
}
/*
* 当本模块被编译进内核时,fs_initcall()的定义,参见[13.5.1.1 module被编译进内核时的初始化过程]节,
* 即__define_initcall("5",fn,5)。在系统启动时,该协议族会被注册到系统中;
* 当本模块被编译成module时,在执行insmod xxx时,该协议族被注册到系统中
*/
fs_initcall(inet_init);
8.7.3 套接字接口
基本的socket接口函数如下图所示:
8.7.3.1 sys_socket()
该系统调用定义于net/socket.c:
/*
* family – 协议族,其取值为PF_xxx,参见include/linux/socket.h
* type – 协议类型,其取值为SOCK_xxx,参见include/linux/net.h中的类型enum sock_type
* protocol – 协议,其取值为IPPROTO_xxx,参见include/linux/in.h
* 返回值为文件描述符fd
*/
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
int retval;
struct socket *sock;
int flags;
/* Check the SOCK_* constants for consistency. */
BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);
BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);
flags = type & ~SOCK_TYPE_MASK;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
type &= SOCK_TYPE_MASK;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
// 为sock分配空间并初始化
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
goto out;
// 为sock分配文件描述符
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
if (retval < 0)
goto out_release;
out:
/* It may be already another descriptor 8) Not kernel problem. */
return retval;
out_release:
sock_release(sock);
return retval;
}
8.7.3.1.1 sock_create()/__sock_create()
系统调用sys_socket()调用sock_create()创建socket,其定义于net/socket.c:
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
/*
* Check protocol is in range
*/
if (family < 0 || family >= NPROTO)
return -EAFNOSUPPORT;
if (type < 0 || type >= SOCK_MAX)
return -EINVAL;
/* Compatibility.
This uglymoron is moved from INET layer to here to avoid
deadlock in module load.
*/
if (family == PF_INET && type == SOCK_PACKET) {
static int warned;
if (!warned) {
warned = 1;
printk(KERN_INFO "%s uses obsolete (PF_INET,SOCK_PACKET)\n",
current->comm);
}
family = PF_PACKET;
}
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_socket_create(family, type, protocol, kern);
if (err)
return err;
/*
* Allocate the socket and allow the family to set things up. if
* the protocol is 0, the family is instructed to select an appropriate
* default.
*/
sock = sock_alloc();
if (!sock) {
if (net_ratelimit())
printk(KERN_WARNING "socket: no more sockets\n");
return -ENFILE; /* Not exactly a match, but it’s the closest posix thing */
}
sock->type = type;
#ifdef CONFIG_MODULES
/* Attempt to load a protocol module if the find failed.
*
* 12/09/1996 Marcin: But! this makes REALLY only sense, if the user
* requested real, full-featured networking support upon configuration.
* Otherwise module support will break!
*/
if (rcu_access_pointer(net_families[family]) == NULL)
request_module("net-pf-%d", family);
#endif
rcu_read_lock();
pf = rcu_dereference(net_families[family]);
err = -EAFNOSUPPORT;
if (!pf)
goto out_release;
/*
* We will call the ->create function, that possibly is in a loadable
* module, so we have to bump that loadable module refcnt first.
*/
if (!try_module_get(pf->owner))
goto out_release;
/* Now protected by module ref count */
rcu_read_unlock();
// 调用对应协议族的创建函数,参见[8.7.2.4.1 网络协议族的注册与取消]节
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
/*
* Now to bump the refcnt of the [loadable] module that owns this
* socket at sock_release time we decrement its refcnt.
*/
if (!try_module_get(sock->ops->owner))
goto out_module_busy;
/*
* Now that we're done with the ->create function, the [loadable]
* module can have its refcnt decremented
*/
module_put(pf->owner);
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_socket_post_create(sock, family, type, protocol, kern);
if (err)
goto out_sock_release;
*res = sock;
return 0;
out_module_busy:
err = -EAFNOSUPPORT;
out_module_put:
sock->ops = NULL;
module_put(pf->owner);
out_sock_release:
sock_release(sock);
return err;
out_release:
rcu_read_unlock();
goto out_sock_release;
}
8.7.3.2 sys_bind()
系统调用sys_socket()创建了一个socket,但并未分配一个具体的地址。如果要为它分配一个地址,就必须调用sys_bind()把一个地址族中的特定地址赋给socket;否则,当调用sys_connect()、sys_listen()时系统会自动随机分配一个端口。
系统调用sys_bind()定义于net/socket.c:
/*
* Bind a name to a socket. Nothing much to do here since it's
* the protocol's responsibility to handle the local address.
*
* We move the socket address to kernel space before we call
* the protocol layer (having also checked the address is ok).
*/
/*
* fd - socket描述字,由sys_socket(),唯一标识一个socket。
* sys_bind()就是将给这个描述字绑定一个名字
* umyaddr - 指向要绑定给fd的协议地址
* addrlen - umyaddr对应的地址长度
*/
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
err = move_addr_to_kernel(umyaddr, addrlen, (struct sockaddr *)&address);
if (err >= 0) {
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_socket_bind(sock, (struct sockaddr *)&address, addrlen);
// 参见[8.7.2.4.1 网络协议族的注册与取消]节
if (!err)
err = sock->ops->bind(sock, (struct sockaddr *)&address, addrlen);
}
fput_light(sock->file, fput_needed);
}
return err;
}
Q:为什么服务器端要调用bind(),而客户端不需要呢?
A:通常服务器在启动时都会绑定一个众所周知的地址(如IP地址和端口号),用于提供服务,客户就可以通过它来接连服务器;而客户端就不用指定,由系统自动分配一个端口号和自身的IP地址组合。这就是为什么通常服务器端在listen()之前会调用bind(),而客户端就不会调用,而是在connect()时由系统随机生成一个。
8.7.3.3 sys_listen()
作为服务器,在调用socket()、bind()后会调用listen()来监听这个socket,如果客户端这时调用connect()发出连接请求,服务器端就会接收到这个请求。
系统调用sys_listen()定义于net/socket.c:
/*
* Perform a listen. Basically, we allow the protocol to do anything
* necessary for a listen, and if that works, we mark the socket as
* ready for listening.
*/
/*
* sys_socket()系统调用创建的socket默认是一个主动类型的,sys_listen()
* 将该socket变为被动类型的,等待客户的连接请求
* backlog - 指定socket(即fd)可以排队的最大连接个数
*/
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned)backlog > somaxconn)
backlog = somaxconn;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_socket_listen(sock, backlog);
// 参见[8.7.2.4.1 网络协议族的注册与取消]节
if (!err)
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
8.7.3.4 sys_connect()
该系统调用定义于net/socket.c:
/*
* Attempt to connect to a socket with the server address. The address
* is in user space so we verify it is OK and move it to kernel space.
*
* For 1003.1g we need to add clean support for a bind to AF_UNSPEC to
* break bindings
*
* NOTE: 1003.1g draft 6.3 is broken with respect to AX.25/NetROM and
* other SEQPACKET protocols that take time to connect() as it doesn't
* include the -EINPROGRESS status for such sockets.
*/
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr, int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = move_addr_to_kernel(uservaddr, addrlen, (struct sockaddr *)&address);
if (err < 0)
goto out_put;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_socket_connect(sock, (struct sockaddr *)&address, addrlen);
if (err)
goto out_put;
// 参见[8.7.2.4.1 网络协议族的注册与取消]节
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, sock->file->f_flags);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
8.7.3.5 sys_accept()
服务器段调用accept()来接受客户端的连接。如果accept()成功返回,则服务器与客户已经正确建立连接了,此时服务器通过accept()返回的套接字来完成与客户的通信。
系统调用sys_accept()定义参见net/socket.c:
SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen)
{
return sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0);
}
/*
* For accept, we attempt to create a new socket, set up the link
* with the client, wake up the client, then return the new
* connected fd. We collect the address of the connector in kernel
* space and move it to user at the very end. This is unclean because
* we open the socket then return an error.
*
* 1003.1g adds the ability to recvmsg() to query connection pending
* status to recvmsg. We need to add that support in a way thats
* clean when we restucture accept also.
*/
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
struct file *newfile;
int err, len, newfd, fput_needed;
struct sockaddr_storage address;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = -ENFILE;
newsock = sock_alloc();
if (!newsock)
goto out_put;
newsock->type = sock->type;
newsock->ops = sock->ops;
/*
* We don't need try_module_get here, as the listening socket (sock)
* has the protocol module (sock->ops->owner) held.
*/
__module_get(newsock->ops->owner);
newfd = sock_alloc_file(newsock, &newfile, flags);
if (unlikely(newfd < 0)) {
err = newfd;
sock_release(newsock);
goto out_put;
}
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_socket_accept(sock, newsock);
if (err)
goto out_fd;
// 参见[8.7.2.4.1 网络协议族的注册与取消]节
err = sock->ops->accept(sock, newsock, sock->file->f_flags);
if (err < 0)
goto out_fd;
if (upeer_sockaddr) {
if (newsock->ops->getname(newsock, (struct sockaddr *)&address, &len, 2) < 0) {
err = -ECONNABORTED;
goto out_fd;
}
err = move_addr_to_user((struct sockaddr *)&address, len, upeer_sockaddr, upeer_addrlen);
if (err < 0)
goto out_fd;
}
/* File flags are not inherited via accept() unlike another OSes. */
fd_install(newfd, newfile);
err = newfd;
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
out_fd:
fput(newfile);
put_unused_fd(newfd);
goto out_put;
}
NOTE: accept()默认会阻塞进程,直到有一个客户端连接建立后返回,它返回的是一个新的可用的套接字,这个套接字是连接套接字。此时我们需要区分两种套接字:
-
监听套接字:监听套接字正如accept()的参数sockfd,它是监听套接字。在调用listen()函数后,服务器调用socket()函数生成的套接字,被称为监听socket描述字(监听套接字)
-
连接套接字:一个套接字会从主动连接的套接字变为一个监听套接字;而accept()函数返回的是已连接socket描述字(连接套接字),它代表着一个网络已经存在的点点连接。
一个服务器通常通常仅仅只创建一个监听套接字,它在该服务器的生命周期内一直存在。内核为每个由服务器进程接受的客户连接创建了一个连接套接字,当服务器完成了对某个客户的服务,相应的连接套接字就被关闭。
为什么要有两种套接字?原因很简单,如果只使用一种描述字的话,那么它的功能太多,使用不方便。此外,连接套接字并没有占用新的端口与客户端通信,依然使用与监听套接字相同的端口号。
8.7.3.6 发送与接收消息

其中,sendmsg()/recvmsg()是最通用的I/O函数。
8.7.3.7 操纵套接字
参见net/socket.c:
- sys_getsockname() / sys_getpeername()
- sys_getsockopt() / sys_setsockopt()
8.7.3.8 sys_shutdown()/sys_close()
系统调用sys_shutdown()定义于net/socket.c:
/*
* Shutdown a socket.
*/
SYSCALL_DEFINE2(shutdown, int, fd, int, how)
{
int err, fput_needed;
struct socket *sock;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock != NULL) {
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
err = security_socket_shutdown(sock, how);
// 参见[8.7.2.4.1 网络协议族的注册与取消]节
if (!err)
err = sock->ops->shutdown(sock, how);
fput_light(sock->file, fput_needed);
}
return err;
}
系统调用sys_close()定义于fs/open.c:
/*
* Careful here! We test whether the file pointer is NULL before
* releasing the fd. This ensures that one clone task can't release
* an fd while another clone is opening it.
*/
SYSCALL_DEFINE1(close, unsigned int, fd)
{
struct file * filp;
struct files_struct *files = current->files;
struct fdtable *fdt;
int retval;
spin_lock(&files->file_lock);
fdt = files_fdtable(files);
if (fd >= fdt->max_fds)
goto out_unlock;
filp = fdt->fd[fd];
if (!filp)
goto out_unlock;
rcu_assign_pointer(fdt->fd[fd], NULL);
FD_CLR(fd, fdt->close_on_exec);
__put_unused_fd(files, fd);
spin_unlock(&files->file_lock);
retval = filp_close(filp, files);
/* can't restart close syscall because file table entry was cleared */
if (unlikely(retval == -ERESTARTSYS ||
retval == -ERESTARTNOINTR ||
retval == -ERESTARTNOHAND ||
retval == -ERESTART_RESTARTBLOCK))
retval = -EINTR;
return retval;
out_unlock:
spin_unlock(&files->file_lock);
return -EBADF;
}
8.7.4 套接字的初始化
在net/socket.c中,包含如下定义:
static int __init sock_init(void)
{
// ...
}
core_initcall(sock_init); /* early initcall */
其中,core_initcall()的定义参见13.5.1.1 module被编译进内核时的初始化过程节。可知,当module被编译进内核时,其初始化函数需要在系统启动时被调用。其调用过程为:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall1.init
9 中断处理
内核的中断处理代码是几乎所有的微处理器所特有的。x86体系结构的中断处理代码在arch/x86/kernel/irq.c中。
9.1 中断处理简介
Intel x86系列处理器共支持256种向量中断,为了使处理器较容易地识别每种中断源,将它们从0到255编号,即赋与一个中断类型码n,Intel把这个八位的无符号整数叫做一个向量,因而也称为中断向量。所有256种中断可分为两大类:异常(Exception)和中断(Interrupt)。
- 异常(Exception)又分为故障(Fault)、陷阱(Trap)和终止(Abort),它们的共同点是既不使用中断控制器,又不能被屏蔽;
- 中断(Interrupt)又分为外部可屏蔽中断(INTR,Maskable Interrupt)和外部非屏蔽中断(NMI,Nomaskable Interrupt),所有I/O设备产生的中断请求(IRQ)均引起可屏蔽中断,而紧急的事件(如硬件故障)引起的故障产生非屏蔽中断。
异常(Exception)
| 中断分类 | 原因 | 异/同步 | 返回行为 | 备注 |
|---|---|---|---|---|
| 陷阱(Trap) | 有意的异常 | 同步 | 总是返回到下一条指令 | 既不使用中断控制器,又不能被屏蔽。参见9.1.2 异常(Exception)/非屏蔽中断(NMI)节 |
| 故障(Fault) | 潜在可恢复的错误 | 同步 | 返回到当前指令 | 既不使用中断控制器,又不能被屏蔽。参见9.1.2 异常(Exception)/非屏蔽中断(NMI)节 |
| 终止(Abort) | 不可恢复的错误 | 同步 | 不会返回 |
中断(Interrupt)
| 中断分类 | 原因 | 异/同步 | 返回行为 | 备注 |
|---|---|---|---|---|
| 可屏蔽中断(INTR) | 来自I/O设备的信号 | 异步 | 总是返回到下一条指令 | 所有I/O设备产生的中断请求(IRQ)均引起可屏蔽中断。参见9.1.1 可屏蔽中断/INTR节 |
| 非屏蔽中断(NMI) | 来自I/O设备的信号 | 异步 | 总是返回到下一条指令 | 紧急的事件(如硬件故障)引起非屏蔽中断。参见9.1.2 异常(Exception)/非屏蔽中断(NMI)节 |
9.1.1 可屏蔽中断/INTR
在x86体系架构下,存在两个中断控制器:8159A可编程中断控制器,高级可编程中断控制器(APIC)。在命令行执行下列命令,如果输出结果中列出了IO-APIC,则说明系统正在使用高级可编程中断控制器(APIC);如果是XT-PIC,则意味着系统正在使用8259A可编程中断控制器。
# cat /proc/interrupts
CPU0
0: 257 XT-PIC-XT-PIC timer
1: 24662 XT-PIC-XT-PIC i8042
2: 0 XT-PIC-XT-PIC cascade
5: 105116 XT-PIC-XT-PIC ahci, snd_intel8x0
8: 0 XT-PIC-XT-PIC rtc0
9: 143985 XT-PIC-XT-PIC acpi, vboxguest
10: 50733 XT-PIC-XT-PIC eth0
11: 452 XT-PIC-XT-PIC ohci_hcd:usb1
12: 14983 XT-PIC-XT-PIC i8042
14: 0 XT-PIC-XT-PIC ata_piix
15: 97176 XT-PIC-XT-PIC ata_piix
NMI: 0 Non-maskable interrupts
LOC: 7839086 Local timer interrupts
SPU: 0 Spurious interrupts
PMI: 0 Performance monitoring interrupts
IWI: 0 IRQ work interrupts
RTR: 0 APIC ICR read retries
RES: 0 Rescheduling interrupts
CAL: 0 Function call interrupts
TLB: 0 TLB shootdowns
TRM: 0 Thermal event interrupts
THR: 0 Threshold APIC interrupts
MCE: 0 Machine check exceptions
MCP: 333 Machine check polls
ERR: 0
MIS: 0
# cat /proc/interrupts
CPU0
0: 90504 IO-APIC-edge timer
1: 131 IO-APIC-edge i8042
8: 4 IO-APIC-edge rtc
9: 0 IO-APIC-level acpi
12: 111 IO-APIC-edge i8042
14: 1862 IO-APIC-edge ide0
15: 28 IO-APIC-edge ide1
177: 9 IO-APIC-level eth0
185: 0 IO-APIC-level via82cxxx
...
9.1.1.1 8259A可编程中断控制器/PIC
8259A可编程中断控制器:
Intel x86通过两片中断控制器8259A来响应15个外中断源,每个8259A可管理8个中断源。第一级8259A(称主片)的第二个中断请求输入端,与第二级8259A(称从片)的中断输出端INT相连。与中断控制器相连的每条线叫做中断线。要使用中断线,就要先申请中断线,即IRQ(Interrupt ReQuirement)。
并不是每个设备都可以向中断线上发中断信号的,只有对某一条确定的中断线拥有了控制权,才可以向这条中断线上发送信号。由于计算机的外部设备越来越多,所以15条中断线已经不够用了,中断线是非常宝贵的资源,只有当设备需要中断时才申请占用一个IRQ,或者是在申请IRQ时采用共享中断的方式,这样可以让更多的设备使用中断。
中断控制器8259A执行如下操作:
- 1) 监视中断线,检查产生的中断请求(IRQ)信号;
- 2) 如果中断线上产生了一个中断请求信号:
- a) 把接收到的IRQ信号转换成一个对应的向量;
- b) 把该向量存放到中断控制器的一个I/O端口,从而允许CPU通过数据总线读取此向量;
- c) 把产生的IRQ信号发送到CPU的INTR引脚,即发出一个中断请求;
- d) 等待,直到CPU确认该中断请求,然后把它写进可编程中断控制器的一个I/O端口;此时,清INTR线。
- 3) 返回到第一步。
对于外部I/O请求的屏蔽可分为两种情况:
- 一种是从CPU的角度,也就是清除eflag的中断标志位(IF)。当IF=0时,禁止任何外部I/O的中断请求,即关中断;
- 一种是从中断控制器的角度,因为中断控制器中有一个8位的中断屏蔽寄存器(IMR),每比特位对应8259A中的一条中断线,如果要禁用某条中断线,则把IMR相应位置1,若要启用该中断线,则置0。
可屏蔽中断(INTR)的取值范围为[0x30, 0xFF],参见9.1 中断处理简介节中的表”中断向量(vector)取值”。这些可屏蔽中断对应的处理程序是由init_IRQ()设置的,参见4.3.4.1.4.3.9 init_IRQ()节。
9.1.1.2 高级可编程中断控制器/APIC
8259A可编程中断控制器只适合单CPU的情况,为了充分挖掘SMP体系结构的并行性,能够把中断传递给系统中的每个CPU是至关重要的。基于此,Intel引入了一种名为I/O高级可编程控制器(APIC)的新组件来替代老式的8259A可编程中断控制器。参见9 中断处理节。
9.1.2 异常(Exception)/非屏蔽中断(NMI)
异常是CPU内部出现的中断,也就是说,在CPU执行特定指令时出现的非法情况。非屏蔽中断是计算机内部硬件出错时引起的异常情况。Intel把非屏蔽中断作为异常的一种来处理,因此后面所提到的异常也包括了非屏蔽中断。在CPU执行一个异常处理程序时,就不再为其他异常或可屏蔽中断请求服务,也就是说,当某个异常被响应后,CPU清除eflag的中IF位,禁止任何可屏蔽中断。但如果又有异常产生,则由CPU锁存(CPU具有缓冲异常的能力),待这个异常处理完后,才响应被锁存的异常。此处讨论的异常中断向量取值范围为[0, 31]。
Intel x86处理器发布了大约20种异常(具体数字与处理器模式有关,参见«Intel 64 and IA-32 Architectures Software Developer’s Manual» Table 6-1. Exceptions and Interrupts),其取值范围为[0x0, 0x1F]。Linux内核必须为每种异常提供一个专门的异常处理程序,当系统启动时由trap_init()设置,参见4.3.4.1.4.3.5 trap_init()节。需要特别说明的是,在某些异常处理程序开始执行之前,CPU控制单元会产生一个硬件错误码,内核先把这个错误码压入内核栈中。
9.2 与中断处理有关的数据结构
9.2.1 struct irq_desc / irq_desc[]
该结构体定义于include/linux/irqdesc.h:
struct irq_desc {
struct irq_data irq_data;
struct timer_rand_state *timer_rand_state;
unsigned int __percpu *kstat_irqs;
irq_flow_handler_t handle_irq;
#ifdef CONFIG_IRQ_PREFLOW_FASTEOI
irq_preflow_handler_t preflow_handler;
#endif
struct irqaction *action; /* IRQ action list */
unsigned int status_use_accessors;
unsigned int core_internal_state__do_not_mess_with_it;
unsigned int depth; /* nested irq disables */
unsigned int wake_depth; /* nested wake enables */
unsigned int irq_count; /* For detecting broken IRQs */
unsigned long last_unhandled; /* Aging timer for unhandled count */
unsigned int irqs_unhandled;
raw_spinlock_t lock;
struct cpumask *percpu_enabled;
#ifdef CONFIG_SMP
const struct cpumask *affinity_hint;
struct irq_affinity_notify *affinity_notify;
#ifdef CONFIG_GENERIC_PENDING_IRQ
cpumask_var_t pending_mask;
#endif
#endif
unsigned long threads_oneshot;
atomic_t threads_active;
wait_queue_head_t wait_for_threads;
#ifdef CONFIG_PROC_FS
struct proc_dir_entry *dir;
#endif
struct module *owner;
const char *name;
} ____cacheline_internodealigned_in_smp;
在kernel/irq/irqdesc.c中定义了一个struct irq_desc类型的全局数组irq_desc[]:
#ifdef CONFIG_SPARSE_IRQ
...
else
struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {
[0 ... NR_IRQS-1] = {
.handle_irq = handle_bad_irq,
.depth = 1,
.lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock),
}
};
endif
数组irq_desc[]的结构,参见:
数组irq_desc[]的初始化及赋值:
- 由early_irq_init()初始化,参见4.3.4.1.4.3.8 early_irq_init()节;
- 由init_IRQ()->native_init_IRQ()->init_ISA_irqs()将其中的中断处理函数设置为handle_level_irq(),参见4.3.4.1.4.3.9 init_IRQ()节。
9.2.2 struct softirq_action / softirq_vec[]
该结构定义于include/linux/interrupt.h:
struct softirq_action
{
void (*action)(struct softirq_action *);
};
系统定义了一个全局数组softirq_vec[],参见kernel/softirq.c:
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
char *softirq_to_name[NR_SOFTIRQS] = {
"HI", "TIMER", "NET_TX", "NET_RX", "BLOCK", "BLOCK_IOPOLL",
"TASKLET", "SCHED", "HRTIMER", "RCU"
};
该数组是个全局变量,系统中每个CPU所看到的是同一个数组,不过每个CPU均有自己的“软中断控制/状态”结构,这些数据结构形成一个以CPU编号为下标的数组irq_stat[],参见9.2.3 irq_stat[]节。
NOTE: The index of the softirq_vec[] determines its priority: a lower index means higher priority because softirq functions will be executed starting from index 0. 参见9.3.1.3.1.1.1 __do_softirq()节的函数__do_softirq()。
softirq_vec[]:
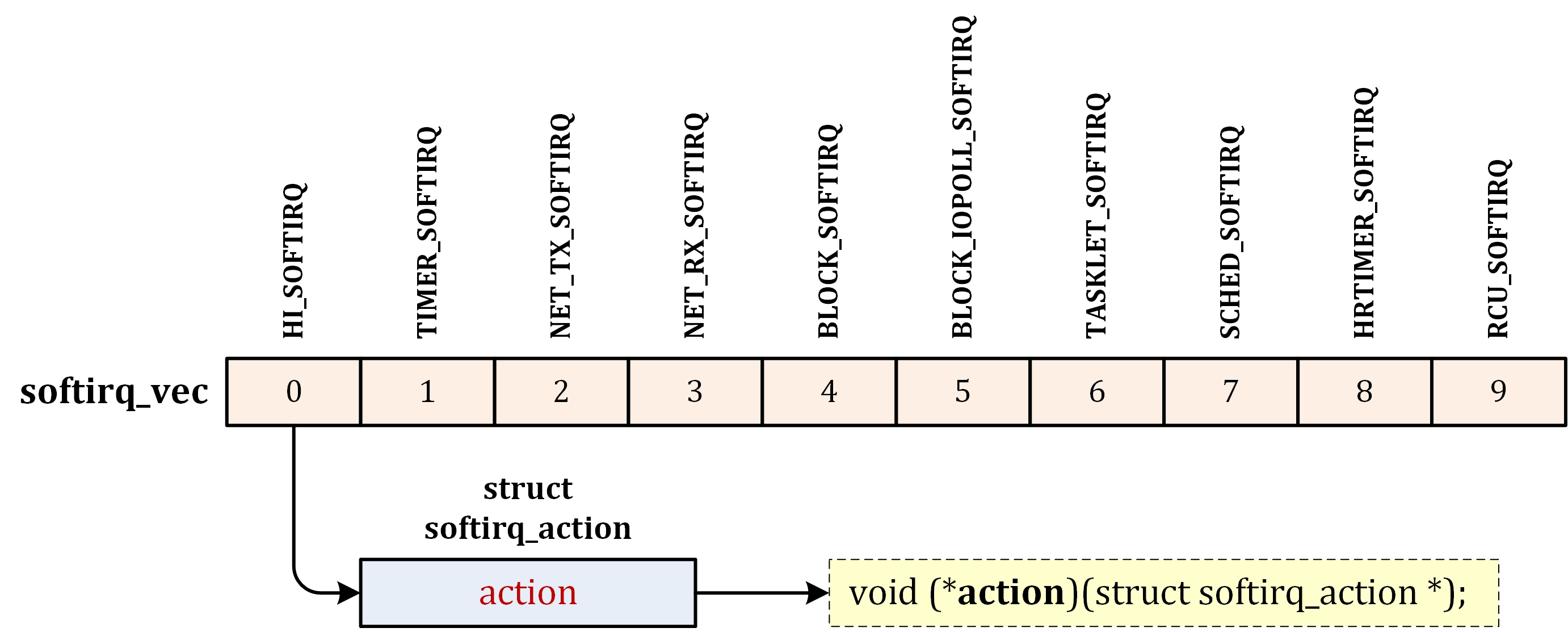
9.2.2.1 注册软中断处理函数/open_softirq()
函数open_softirq()用于注册软中断处理函数,即为数组softirq_vec[]中的action赋值。其定义于kernel/softirq.c:
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
函数softirq_init()(参见4.3.4.1.4.3.10 softirq_init()节)和各相关模块的初始化函数为数组softirq_vec[]赋值,其结果参见下表。这些软中断处理函数在__do_softirq()中被调用,参见9.3.1.3.1.1.1 __do_softirq()节。
软中断处理函数
| i | softirq_vec[i].action | 赋值函数 | 调用关系 |
| HI_SOFTIRQ | tasklet_hi_action(),参见9.2.5.5 Tasklet的处理函数/tasklet_action()/tasklet_hi_action()节 | kernel/softirq.c: softirq_init() | start_kernel() -> softirq_init() |
| TIMER_SOFTIRQ | run_timer_softirq(),参见7.7.4 定时器的超时处理/run_timer_softirq()节和7.6.4.2.1.2.2.1 run_local_timers()节 | kernel/timer.c: init_timers() | start_kernel() -> init_timers() |
| NET_TX_SOFTIRQ | net_tx_action() | net/core/dev.c: net_dev_init() | net模块加载到系统中时 |
| NET_RX_SOFTIRQ | net_rx_action() | net/core/dev.c: net_dev_init() | net模块加载到系统中时 |
| BLOCK_SOFTIRQ | blk_done_softirq() | block/blk-softirq.c: blk_softirq_init() | block模块加载到系统中时 |
| BLOCK_IOPOLL_SOFTIRQ | blk_iopoll_softirq() | block/blk-iopoll.c: blk_iopoll_setup() | block模块加载到系统中时 |
| TASKLET_SOFTIRQ | tasklet_action(),参见9.2.5.5 Tasklet的处理函数/tasklet_action()/tasklet_hi_action()节 | kernel/softirq.c: softirq_init() | start_kernel() -> softirq_init() |
| SCHED_SOFTIRQ | run_rebalance_domains() | kernel/sched.c: sched_init() | start_kernel() -> sched_init() |
| HRTIMER_SOFTIRQ | run_hrtimer_softirq() | kernel/hrtimer.c: hrtimers_init() | start_kernel() -> hrtimers_init() |
| RCU_SOFTIRQ | rcu_process_callbacks(),参见16.12.3 RCU的初始化节 | kernel/rcutiny_plugin.h, kernel/rcutree.c: rcu_init() | start_kernel() -> rcu_init() |
By convention, HI_SOFTIRQ is always the first and RCU_SOFTIRQ is always the last entry.
The softirq handlers run with interrupts enabled and cannot sleep. While a handler runs, softirqs on the current processor are disabled. Another processor, however, can execute other softirqs. If the same softirq is raised again while it is executing, another processor can run it simultaneously.
9.2.3 irq_stat[]
数组irq_stat[]定义于arch/x86/kernel/irq_32.c:
DEFINE_PER_CPU_SHARED_ALIGNED(irq_cpustat_t, irq_stat);
#define __ARCH_IRQ_STAT
或者kernel/softirq.c:
#ifndef __ARCH_IRQ_STAT
irq_cpustat_t irq_stat[NR_CPUS] ____cacheline_aligned;
#endif
数组irq_stat[]是一个全局变量,各CPU可以按其自身的编号访问相应的域。
Q: 数组irq_stat[]是如何初始化和赋值的?
A: irq_stat[cpu]. __softirq_pending表示在cpu上存在待处理的软中断,即若irq_stat[cpu]. __softirq_pending的nr比特位置位,则表示存在类型为softirq_vec[nr]的软中断等待处理,参见9.2.2 struct softirq_action / softirq_vec[]节。
NOTE: In Symmetric Multiprocessing model (SMP), when a hardware device raises an IRQ signal, the multi-APIC system selects one of the CPUs and delivers the signal to the corresponding local APIC, which in turn interrupts its CPU. No other CPUs are notified of the event.
9.2.3.1 激活软中断/raise_softirq()/raise_softirq_irqoff()
通过函数raise_softirq()激活指定的软中断,即将irq_stat[cpu].__softirq_pending中的某位置位,其定义于kernel/softirq.c:
void raise_softirq(unsigned int nr)
{
unsigned long flags;
local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
}
/*
* This function must run with irqs disabled!
*/
inline void raise_softirq_irqoff(unsigned int nr)
{
__raise_softirq_irqoff(nr);
/*
* If we're in an interrupt or softirq, we're done
* (this also catches softirq-disabled code). We will
* actually run the softirq once we return from
* the irq or softirq.
*
* Otherwise we wake up ksoftirqd to make sure we
* schedule the softirq soon.
*/
if (!in_interrupt()) // 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
wakeup_softirqd(); // 参见[9.3.1.3.1.2 ksoftirqd]节
}
其中函数__raise_softirq_irqoff()定义于include/linux/interrupt.h:
// nr表示哪种类型的软中断,参见[9.2.2 struct softirq_action / softirq_vec[]]节中的宏xxx_SOFTIRQ
static inline void __raise_softirq_irqoff(unsigned int nr)
{
trace_softirq_raise(nr);
or_softirq_pending(1UL << nr); // 将指定类型的软中断置位
}
宏or_softirq_pending()定义于arch/x86/include/linux/hardirq.h:
#define or_softirq_pending(x) percpu_or(irq_stat.__softirq_pending, (x))
其中,irq_stat.__softirq_pending的每个比特位表示数组irq_desc[]相应元素的状态,参见9.2.2 struct softirq_action / softirq_vec[]节中的图”softirq_vec[]”。
9.2.3.2 取消软中断/set_softirq_pending()
该宏定义于arch/x86/include/linux/hardirq.h:
#define set_softirq_pending(x) percpu_write(irq_stat.__softirq_pending, (x))
如下语句取消所有软中断:
set_softirq_pending(0);
如下语句取消特定的软中断,例如NET_TX_SOFTIRQ:
__u32 pending;
pending = local_softirq_pending() & ~(1 << NET_TX_SOFTIRQ);
set_softirq_pending(pending);
9.2.3.3 查询软中断状态/local_softirq_pending()
该宏用于查询软中断状态,其定义于arch/x86/include/linux/hardirq.h:
#define local_softirq_pending() percpu_read(irq_stat.__softirq_pending)
9.2.4 softirq_work_list[]
该数组定义于kernel/softirq.c:
DEFINE_PER_CPU(struct list_head [NR_SOFTIRQS], softirq_work_list);
EXPORT_PER_CPU_SYMBOL(softirq_work_list);
该数组在softirq_init()中被初始化,参见4.3.4.1.4.3.10 softirq_init()节。
9.2.5 struct tasklet_struct / tasklet_vec[] / tasklet_hi_vec[]
Tasklets resemble kernel timers in some ways. They are always run at interrupt time, they always run on the same CPU that schedules them, and they receive an unsigned long argument. Unlike kernel timers, however, you can’t ask to execute the function at a specific time. By scheduling a tasklet, you simply ask for it to be executed at a later time chosen by the kernel. This behavior is especially useful with interrupt handlers, where the hardware interrupt must be managed as quickly as possible, but most of the data management can be safely delayed to a later time. Actually, a tasklet, just like a kernel timer, is executed (in atomic mode) in the context of a “soft interrupt”, a kernel mechanism that executes asynchronous tasks with hardware interrupts enabled.
Tasklets offer a number of interesting features:
- A tasklet can be disabled and re-enabled later; it won’t be executed until it is enabled as many times as it has been disabled.
- Just like timers, a tasklet can reregister itself.
- A tasklet can be scheduled to execute at normal priority or high priority. The latter group is always executed first.
- Tasklets may be run immediately if the system is not under heavy load but never later than the next timer tick.
- A tasklets can be concurrent with other tasklets but is strictly serialized with respect to itself - the same tasklet never runs simultaneously on more than one processor. Also, as already noted, a tasklet always runs on the same CPU that schedules it.
该结构定义于include/linux/interrupt.h:
struct tasklet_struct
{
struct tasklet_struct *next; // 将tasklet链接成一个队列
unsigned long state; // 见下文
atomic_t count; // 用来禁用(1)或者启用(0)该tasklet
void (*func)(unsigned long); // Tasklet处理函数
unsigned long data; // 函数void (*func)(unsigned long)的入参
};
// struct tasklet_struct -> state的取值范围
enum
{
TASKLET_STATE_SCHED, /* Tasklet is scheduled for execution */
TASKLET_STATE_RUN /* Tasklet is running (SMP only) */
};
在kernel/softirq.c中定义了两个全局数组tasklet_vec[]和tasklet_hi_vec[]:
/*
* Tasklets
*/
struct tasklet_head
{
struct tasklet_struct *head;
struct tasklet_struct **tail;
};
static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);
该数组结构,参见:
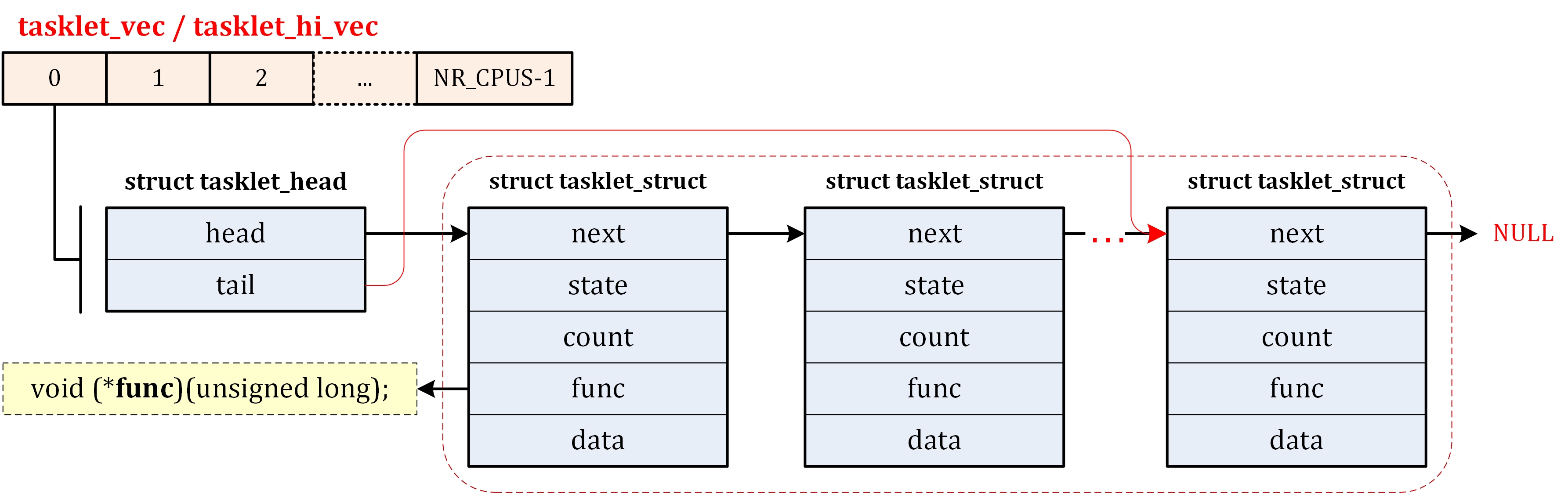
该数组在softirq_init()中初始化,参见4.3.4.1.4.3.10 softirq_init()节。
9.2.5.1 Takslet的定义及初始化
如下宏或函数用于定义或初始化Tasklet:
- DECLARE_TASKLET()
- DECLARE_TASKLET_DISABLED()
- tasklet_init()
宏DECLARE_TASKLET()和DECLARE_TASKLET_DISABLED()用于定义并初始化Tasklet,其定义于include/linux/interrupt.h:
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
The difference between the two macros is the initial reference count. The first macro creates the tasklet with a count of zero, and the tasklet is enabled. The second macro sets count to one, and the tasklet is disabled.
或者,先定义struct tasklet_struct类型的变量,然后再调用函数tasklet_init()初始化,其定义于kernel/softirq.c:
void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long),
unsigned long data)
{
t->next = NULL;
t->state = 0;
atomic_set(&t->count, 0);
t->func = func;
t->data = data;
}
这与宏DECLARE_TASKLET()的效果相同。
9.2.5.2 Tasklet的启用与禁用
函数tasklet_enable()和tasklet_hi_enable()用于启用指定的Tasklet,其定义于include/linux/interrupt.h:
/*
* This function also must be called before a tasklet
* created with DECLARE_TASKLET_DISABLED() is usable.
*/
static inline void tasklet_enable(struct tasklet_struct *t)
{
smp_mb__before_atomic_dec();
atomic_dec(&t->count);
}
static inline void tasklet_hi_enable(struct tasklet_struct *t)
{
smp_mb__before_atomic_dec();
atomic_dec(&t->count);
}
函数tasklet_disable()和tasklet_disable_nosync()用于禁用指定的Tasklet,其定义于include/linux/interrupt.h:
/*
* Disables the given tasklet.
* If the tasklet is currently running, the function will
* not return until it finishes executing.
*/
static inline void tasklet_disable(struct tasklet_struct *t)
{
tasklet_disable_nosync(t);
tasklet_unlock_wait(t);
smp_mb();
}
/*
* Disables the given tasklet but does not wait for the tasklet
* to complete prior to returning. This is usually not safe
* because you cannot assume the tasklet is not still running.
*/
static inline void tasklet_disable_nosync(struct tasklet_struct *t)
{
atomic_inc(&t->count);
smp_mb__after_atomic_inc();
}
9.2.5.3 Tasklet的调度/tasklet_schedule()/tasklet_hi_schedule()
函数tasklet_schedule()和tasklet_hi_schedule()用于将指定的Tasklet分别添加到链表tasklet_vec和tasklet_hi_vec的末尾,其定义于include/linux/interrupt.h:
static inline void tasklet_schedule(struct tasklet_struct *t)
{
/*
* 若标志位TASKLET_STATE_SCHED置位,则表示该Tasklet已经被
* 调度运行,此时直接返回;否则,进行调度
*/
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
static inline void tasklet_hi_schedule(struct tasklet_struct *t)
{
/*
* 若标志位TASKLET_STATE_SCHED置位,则表示该Tasklet已经被
* 调度运行,此时直接返回;否则,进行调度
*/
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_hi_schedule(t);
}
其中,__tasklet_schedule()和__tasklet_hi_schedule()定义于kernel/softirq.c:
void __tasklet_schedule(struct tasklet_struct *t)
{
unsigned long flags;
local_irq_save(flags);
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
// 激活该Tasklet,参见[9.2.3.1 激活软中断/raise_softirq()/raise_softirq_irqoff()]节
raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_restore(flags);
}
void __tasklet_hi_schedule(struct tasklet_struct *t)
{
unsigned long flags;
local_irq_save(flags);
t->next = NULL;
*__this_cpu_read(tasklet_hi_vec.tail) = t;
__this_cpu_write(tasklet_hi_vec.tail, &(t->next));
// 激活该Tasklet,参见[9.2.3.1 激活软中断/raise_softirq()/raise_softirq_irqoff()]节
raise_softirq_irqoff(HI_SOFTIRQ);
local_irq_restore(flags);
}
9.2.5.4 Tasklet的移除/tasklet_kill()/tasklet_kill_immediate()
该函数定义于kernel/softirq.c:
void tasklet_kill(struct tasklet_struct *t)
{
if (in_interrupt())
printk("Attempt to kill tasklet from interrupt\n");
/*
* 标志位TASKLET_STATE_SCHED是通过函数task_schedule()设置的,
* 参见[9.2.5.3 Tasklet的调度/tasklet_schedule()/tasklet_hi_schedule()]节
*/
while (test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) {
do {
yield();
} while (test_bit(TASKLET_STATE_SCHED, &t->state));
}
tasklet_unlock_wait(t);
clear_bit(TASKLET_STATE_SCHED, &t->state);
}
/*
* tasklet_kill_immediate is called to remove a tasklet which can already be
* scheduled for execution on @cpu.
*
* Unlike tasklet_kill, this function removes the tasklet
* _immediately_, even if the tasklet is in TASKLET_STATE_SCHED state.
*
* When this function is called, @cpu must be in the CPU_DEAD state.
*/
void tasklet_kill_immediate(struct tasklet_struct *t, unsigned int cpu)
{
struct tasklet_struct **i;
BUG_ON(cpu_online(cpu));
BUG_ON(test_bit(TASKLET_STATE_RUN, &t->state));
if (!test_bit(TASKLET_STATE_SCHED, &t->state))
return;
/* CPU is dead, so no lock needed. */
for (i = &per_cpu(tasklet_vec, cpu).head; *i; i = &(*i)->next) {
if (*i == t) {
*i = t->next;
/* If this was the tail element, move the tail ptr */
if (*i == NULL)
per_cpu(tasklet_vec, cpu).tail = i;
return;
}
}
BUG();
}
9.2.5.5 Tasklet的处理函数/tasklet_action()/tasklet_hi_action()
链表tasklet_vec和tasklet_hi_vec的处理函数分别为tasklet_action()和tasklet_hi_action()。这两个处理函数是由softirq_init()设置的(参见4.3.4.1.4.3.10 softirq_init()节),由__do_softirq()调用的(参见9.3.1.3.1.1.1 __do_softirq()节)。
函数tasklet_action()和tasklet_hi_action()定义于kernel/softirq.c:
static void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
// Clear the list takslet_vec[] for this processor by setting it equal to NULL
local_irq_disable();
list = __this_cpu_read(tasklet_vec.head);
__this_cpu_write(tasklet_vec.head, NULL);
__this_cpu_write(tasklet_vec.tail, &__get_cpu_var(tasklet_vec).head);
local_irq_enable();
while (list) {
struct tasklet_struct *t = list;
list = list->next;
/*
* If this is a multiprocessing machine, check whether the tasklet
* is running on another processor by checking the TASKLET_STATE_RUN
* flag.
*/
if (tasklet_trylock(t)) {
/*
* Check for a zero t->count value, to ensure that the tasklet
* is not disabled. NOTE: Unless the tasklet function reactivates
* itself, every tasklet activation triggers at most one execution
* of the tasklet function.
*/
if (!atomic_read(&t->count)) {
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
// 调用每个Tasklet的处理函数,参见[9.2.5 struct tasklet_struct / tasklet_vec[] / tasklet_hi_vec[]]节中的图
t->func(t->data);
// Clear TASKLET_STATE_RUN flag in the tasklet’s state field
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
/*
* If the tasklet is currently running on another CPU, don’t
* execute it now and skip to the next pending tasklet. Add
* the taskle to tasklet_vec[] again and tasklet. So, the
* same tasklet will not run concurrently, even on two
* different processors.
*/
local_irq_disable();
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
}
static void tasklet_hi_action(struct softirq_action *a)
{
struct tasklet_struct *list;
/*
* Clear the list tasklet_hi_vec[] for this processor
* by setting it equal to NULL
*/
local_irq_disable();
list = __this_cpu_read(tasklet_hi_vec.head);
__this_cpu_write(tasklet_hi_vec.head, NULL);
__this_cpu_write(tasklet_hi_vec.tail, &__get_cpu_var(tasklet_hi_vec).head);
local_irq_enable();
while (list) {
struct tasklet_struct *t = list;
list = list->next;
/*
* If this is a multiprocessing machine, check whether the
* tasklet is running on another processor by checking the
* TASKLET_STATE_RUN flag. If the tasklet is not currently
* running, ...
*/
if (tasklet_trylock(t)) {
/*
* Check for a zero t->count value, to ensure that the
* tasklet is not disabled. NOTE: Unless the tasklet
* function reactivates itself, every tasklet activation
* triggers at most one execution of the tasklet function.
*/
if (!atomic_read(&t->count)) {
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
// 调用每个Tasklet的处理函数,参见[9.2.5 struct tasklet_struct / tasklet_vec[] / tasklet_hi_vec[]]节中的图
t->func(t->data);
// Clear TASKLET_STATE_RUN flag in the tasklet’s state field
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
/*
* If the tasklet is currently running on another CPU, do not
* execute it now and skip to the next pending tasklet. Add the
* taskle to tasklet_hi_vec[] again and run it later.
*/
local_irq_disable();
t->next = NULL;
*__this_cpu_read(tasklet_hi_vec.tail) = t;
__this_cpu_write(tasklet_hi_vec.tail, &(t->next));
__raise_softirq_irqoff(HI_SOFTIRQ);
local_irq_enable();
}
}
9.3 异常/中断处理流程
当异常/中断发生后,首先根据中断号和IDTR(参见6.1.1.3.2 中断描述符表寄存器IDTR节)在IDT(参见6.1.1.3.1 中断描述符表IDT节)中查找对应项(假设为SS1),并从该项中取出段选择子,由该段选择子和GDTR(参见6.1.1.2.2 全局描述符表寄存器GDTR节)在GDT(参见6.1.1.2.1 全局描述符表GDT节)中查找对应项(假设为SS2)。SS1中的DPL域表示中断处理程序应该在哪个级别下运行(一般是0级,即内核态下运行中断处理程序)。如果当前进程的CS中的低两位比中断处理程序的DPL还小(数值越小,级别越高,kernel的数值为0),那么就直接出现异常,因为不可能会有某个进程的运行级别会被中断还低。经过此步骤的确认后,CS和EIP分别被赋值予SS1中的段选择子和偏移量,这意味着下一个执行的指令是:
- 若中断号在[0, 31]范围内(即异常),则执行trap_init()函数中指定的中断处理函数,参见4.3.4.1.4.3.5 trap_init()节;
- 若中断号在[32, 255]范围内(即中断),则执行init_IRQ()函数中指定的中断处理函数(参见4.3.4.1.4.3.9 init_IRQ()节),即interrupt数组中对应项(参见4.3.4.1.4.3.9.2.3 interrupt[]节),也就是跳转到common_interrupt处,并开始执行do_IRQ()进行中断处理(参见9.3.1 do_IRQ()节),完成后,执行ret_from_intr(参见9.3.2 ret_from_intr节)从中断中返回。
9.3.1 do_IRQ()
该函数被common_interrupt程序段(参见4.3.4.1.4.3.9.2.3 interrupt[]节)调用,其定义于arch/x86/kernel/irq.c:
/*
* do_IRQ handles all normal device IRQ's (the special
* SMP cross-CPU interrupts have their own specific
* handlers).
*/
/*
* Because the C calling convention places function arguments
* at the top of the stack, the pt_regs structure contains the
* initial register values that were previously saved in the
* assembly entry routine. 参见[4.3.4.1.4.3.9.2.3 interrupt[]]节common_interrupt程
* 序中的SAVE_ALL
*/
unsigned int __irq_entry do_IRQ(struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
/*
* 由[4.3.4.1.4.3.9.2.3 interrupt[]]节的common_interrupt程序段可知,regs->orig_ax
* 的取值范围为[-256, -1],故此处vector的取值范围为[1, 256]
*/
/* high bit used in ret_from_ code */
unsigned vector = ~regs->orig_ax;
unsigned irq;
exit_idle();
/*
* Increases a counter representing the number of nested
* interrupt handlers. The counter is stored in the
* preempt_count field of the thread_info structure of the
* current process. 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
*/
irq_enter();
// 数组vector_irq[]参见[9.3.1.1 vector_irq[]]节
irq = __this_cpu_read(vector_irq[vector]);
// 参见[9.3.1.2 handle_irq()]节
if (!handle_irq(irq, regs)) {
ack_APIC_irq();
if (printk_ratelimit())
pr_emerg("%s: %d.%d No irq handler for vector (irq %d)\n",
__func__, smp_processor_id(), vector, irq);
}
/*
* Exit an interrupt context. Process softirqs
* if needed and possible. 参见[9.3.1.3 irq_exit()]节
*/
irq_exit();
set_irq_regs(old_regs);
return 1;
}
9.3.1.1 vector_irq[]
数组vector_irq[]定义于arch/x86/kernel/irqinit.c:
DEFINE_PER_CPU(vector_irq_t, vector_irq) = {
[0 ... NR_VECTORS - 1] = -1,
};
其中,类型vector_irq_t定义于arch/x86/include/asm/hw_irq.h:
typedef int vector_irq_t[NR_VECTORS]; // NR_VECTORS取值为256
因此,vector_irq是包含256个元素的整型数组,每个元素表示中断号。定义时,每个元素被初始化为-1,在init_IRQ()中,IRQ 0x30-0x3F被分别设置为0-15,参见4.3.4.1.4.3.9 init_IRQ()节,如下表所示:
vector_irq:
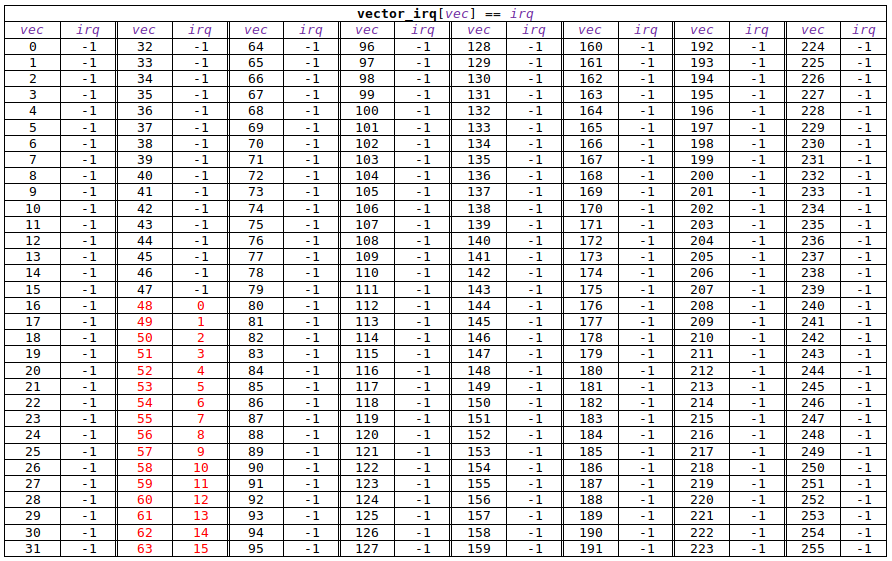
9.3.1.2 handle_irq()
该函数定义于arch/x86/kernel/irq_32.c:
bool handle_irq(unsigned irq, struct pt_regs *regs)
{
struct irq_desc *desc;
int overflow;
overflow = check_stack_overflow();
// 从数组irq_desc[]中查找下标为irq的项,参见[9.2.1 struct irq_desc / irq_desc[]]节
desc = irq_to_desc(irq);
if (unlikely(!desc))
return false;
if (!execute_on_irq_stack(overflow, desc, irq)) {
if (unlikely(overflow))
print_stack_overflow();
desc->handle_irq(irq, desc); // 参见[9.3.1.2.1 desc->handle_irq()/handle_level_irq()]节
}
return true;
}
static inline int execute_on_irq_stack(int overflow, struct irq_desc *desc, int irq)
{
union irq_ctx *curctx, *irqctx;
u32 *isp, arg1, arg2;
curctx = (union irq_ctx *) current_thread_info();
irqctx = __this_cpu_read(hardirq_ctx);
/*
* this is where we switch to the IRQ stack. However, if we are
* already using the IRQ stack (because we interrupted a hardirq
* handler) we can't do that and just have to keep using the
* current stack (which is the irq stack already after all)
*/
if (unlikely(curctx == irqctx))
return 0;
/* build the stack frame on the IRQ stack */
isp = (u32 *) ((char *)irqctx + sizeof(*irqctx));
irqctx->tinfo.task = curctx->tinfo.task;
irqctx->tinfo.previous_esp = current_stack_pointer;
/*
* Copy the softirq bits in preempt_count so that the
* softirq checks work in the hardirq context.
*/
// 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
irqctx->tinfo.preempt_count =
(irqctx->tinfo.preempt_count & ~SOFTIRQ_MASK) |
(curctx->tinfo.preempt_count & SOFTIRQ_MASK);
if (unlikely(overflow))
call_on_stack(print_stack_overflow, isp);
asm volatile("xchgl %%ebx,%%esp \n"
"call *%%edi \n"
"movl %%ebx,%%esp \n"
: "=a" (arg1), "=d" (arg2), "=b" (isp)
: "0" (irq), "1" (desc), "2" (isp),
"D" (desc->handle_irq) // 参见[9.3.1.2.1 desc->handle_irq()/handle_level_irq()]节
: "memory", "cc", "ecx");
return 1;
}
9.3.1.2.1 desc->handle_irq()/handle_level_irq()
在9.3.1.2 handle_irq()节中,handle_irq()最终都会调用desc->handle_irq()来进行中断处理。由9.2.1 struct irq_desc / irq_desc[]节可知,desc->handle_irq被设置为handle_level_irq,因而最终调用的中断处理函数为handle_level_irq()。该函数为8259A中断控制器控制的16个中断向量所对应的中断处理程序,其定义于kernel/irq/chip.c:
/**
* handle_level_irq - Level type irq handler
* @irq: the interrupt number
* @desc: the interrupt description structure for this irq
*
* Level type interrupts are active as long as the hardware line has
* the active level. This may require to mask the interrupt and unmask
* it after the associated handler has acknowledged the device, so the
* interrupt line is back to inactive.
*/
void handle_level_irq(unsigned int irq, struct irq_desc *desc)
{
raw_spin_lock(&desc->lock);
mask_ack_irq(desc);
// IRQD_IRQ_INPROGRESS标志位在handle_irq_event()中设置,见下文
if (unlikely(irqd_irq_inprogress(&desc->irq_data)))
if (!irq_check_poll(desc))
goto out_unlock;
desc->istate &= ~(IRQS_REPLAY | IRQS_WAITING);
kstat_incr_irqs_this_cpu(irq, desc);
/*
* If its disabled or no action available
* keep it masked and get out of here
*/
if (unlikely(!desc->action || irqd_irq_disabled(&desc->irq_data)))
goto out_unlock;
// 进行中断处理,参见[9.3.1.2.1.1 handle_irq_event()]节
handle_irq_event(desc);
if (!irqd_irq_disabled(&desc->irq_data) && !(desc->istate & IRQS_ONESHOT))
unmask_irq(desc);
out_unlock:
raw_spin_unlock(&desc->lock);
}
9.3.1.2.1.1 handle_irq_event()
该函数定义于kernel/irq/handle.c:
irqreturn_t handle_irq_event(struct irq_desc *desc)
{
struct irqaction *action = desc->action;
irqreturn_t ret;
desc->istate &= ~IRQS_PENDING;
irqd_set(&desc->irq_data, IRQD_IRQ_INPROGRESS);
raw_spin_unlock(&desc->lock);
// 参见[9.3.1.2.1.1.1 handle_irq_event_percpu()]节
ret = handle_irq_event_percpu(desc, action);
raw_spin_lock(&desc->lock);
irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS);
return ret;
}
9.3.1.2.1.1.1 handle_irq_event_percpu()
该函数定义于kernel/irq/handle.c:
irqreturn_t handle_irq_event_percpu(struct irq_desc *desc, struct irqaction *action)
{
irqreturn_t retval = IRQ_NONE;
unsigned int random = 0, irq = desc->irq_data.irq;
do {
irqreturn_t res;
trace_irq_handler_entry(irq, action);
/*
* 依次调用用户在desc->action链表中注册的处理函数,
* 参见[9.2.1 struct irq_desc / irq_desc[]]节的该结构体定义于include/linux/irqdesc.h:;
* 该handler是通过__setup_irq()设置的,直接或间接调用__setup_irq()的函数,
* 参见[9.4 中断处理函数的注册/注销]节:
* * native_init_IRQ() -> setup_irq()
* * setup_irq() -> __setup_irq()
* * request_percpu_irq() -> __setup_irq()
* * setup_percpu_irq() -> __setup_irq()
* * request_threaded_irq() -> __setup_irq()
*/
res = action->handler(irq, action->dev_id);
trace_irq_handler_exit(irq, action, res);
if (WARN_ONCE(!irqs_disabled(), "irq %u handler %pF enabled interrupts\n",
irq, action->handler))
local_irq_disable();
switch (res) {
case IRQ_WAKE_THREAD:
/*
* Catch drivers which return WAKE_THREAD but
* did not set up a thread function
*/
if (unlikely(!action->thread_fn)) {
warn_no_thread(irq, action);
break;
}
irq_wake_thread(desc, action);
/* Fall through to add to randomness */
case IRQ_HANDLED:
random |= action->flags;
break;
default:
break;
}
retval |= res;
// 参见[9.2.1 struct irq_desc / irq_desc[]]节的该结构体定义于include/linux/irqdesc.h:
action = action->next;
} while (action);
if (random & IRQF_SAMPLE_RANDOM)
add_interrupt_randomness(irq);
if (!noirqdebug)
note_interrupt(irq, desc, retval);
return retval;
}
9.3.1.3 irq_exit()
Q:为什么中断分为两部分来处理?
A:中断服务程序一般都是在中断请求关闭的条件下执行的,以避免嵌套而使中断控制复杂化。但是,中断是一个随机事件,它随时会到来,如果关中断的时间太长,CPU就不能及时响应其他的中断请求,从而造成中断的丢失。因此,内核的目标就是尽可能快的处理完中断请求,尽其所能把更多的处理向后推迟。例如,假设一个数据块已经达到了网线,当中断控制器接受到这个中断请求信号时,Linux内核只是简单地标志数据到来了,然后让处理器恢复到它以前运行的状态,其余的处理稍后再进行(如把数据移入一个缓冲区,接收数据的进程就可以在缓冲区找到数据)。因此,内核把中断处理分为两部分:前半部分(Top Half)和后半部分(Bottom Half),前半部分内核立即执行,而后半部分留着稍后处理。
首先,一个快速的“前半部分”来处理硬件发出的请求,它必须在一个新的中断产生之前终止。通常地,除了在设备和一些内存缓冲区(如果设备用到了DMA,就不止这些)之间移动或传送数据,确定硬件是否处于健全的状态之外,这一部分做的工作很少。
然后,让一些与中断处理相关的有限个函数作为“后半部分”来运行:
- 允许一个普通的内核函数,而不仅仅是服务于中断的一个函数,能以后半部分的身份来运行;
- 允许几个内核函数合在一起作为一个后半部分来运行。
前半部分运行时是关中断的,而后半部分运行时是允许中断请求的,这是二者之间的主要区别。
Q: Bottom Half的实现机制有哪些?
A: 参见《Linux Kernel Development.[3rd Edition].[Robert Love]》第8. Bottom Halves and Deferring Work章第Bottom Halves节:
Currently, three methods exist for deferring work:
- softirqs (Refer to section 9.2.2 struct softirq_action / softirq_vec[]
- tasklets (Refer to section 9.2.5 struct tasklet_struct / tasklet_vec[] / tasklet_hi_vec[]
- work queues (Refer to section 7.5 工作队列/workqueue) Tasklets are built on softirqs and, therefore, both are similar. The work queue mechanism is an entirely different creature and is built on kernel threads.
Q: Which Bottom Half Should I Use?
A: As a device driver author, the decision whether to use softirqs versus tasklets is simple: You almost always want to use tasklets.
-
Softirqs, by design, provide the least serialization. This requires softirq handlers to go through extra steps to ensure that shared data is safe because two or more softirqs of the same type may run concurrently on different processors.
-
Tasklets make more sense if the code is not finely threaded. They have a simpler interface and, because two tasklets of the same type might not run concurrently, they are easier to implement. Tasklets are effectively softirqs that do not run concurrently. A driver developer should always choose tasklets over softirqs, unless prepared to utilize per-processor variables or similar magic to ensure that the softirq can safely run concurrently on multiple processors.
If your deferred work needs to run in process context, your only choice of the three is work queues. If process context is not a requirement — specifically, if you have no need to sleep — softirqs or tasklets are perhaps better suited. Work queues involve the highest overhead because they involve kernel threads and, therefore, context switching.
Bottom Half Comparison:
| Bottom Half | Context | Inherent Serialization | Reference |
|---|---|---|---|
| Softirq | Interrupt context | None | Section 9.2.2 struct softirq_action / softirq_vec[] |
| Tasklet | Interrupt context | Against the same tasklet | Section 9.2.5 struct tasklet_struct / tasklet_vec[] / tasklet_hi_vec[] |
| Work queues | Process context | None (scheduled as process context) | Section 7.5 工作队列/workqueue |
In short, normal driver writers have two choices. First, do you need a schedulable entity to perform your deferred work — fundamentally, do you need to sleep for any reason? Then work queues are your only option. Otherwise, tasklets are preferred. Only if scalability becomes a concern do you investigate softirqs.
在中断处理函数完成后,irq_exit()处理软中断,其定义于kernel/softirq.c:
/*
* Exit an interrupt context. Process softirqs if needed and possible:
*/
void irq_exit(void)
{
account_system_vtime(current);
trace_hardirq_exit();
/*
* Decreases the interrupt counter. 与do_IRQ()->irq_enter()对应,
* 参见[9.3.1 do_IRQ()]节
*/
sub_preempt_count(IRQ_EXIT_OFFSET);
/*
* in_interrupt():参见[9.5.3 Status of the Interrupt System]节,限制了软中断
* 服务程序既不能在一个硬中断服务程序内部执行,也不能在一个软中断服务程序内部
* 执行(即不能嵌套);
* local_softirq_pending():检查irq_stat[cpu].__softirq_pending,
* 查看是否有软中断请求在等待执行。其中,irq_stat[cpu].__softirq_pending
* 是通过函数__raise_softirq_irqoff()来置位的,参见[9.2.3 irq_stat[]]节
*/
if (!in_interrupt() && local_softirq_pending())
invoke_softirq(); // 参见[9.3.1.3.1 invoke_softirq()]节
rcu_irq_exit();
#ifdef CONFIG_NO_HZ
/* Make sure that timer wheel updates are propagated */
if (idle_cpu(smp_processor_id()) && !in_interrupt() && !need_resched())
tick_nohz_stop_sched_tick(0);
#endif
// 参见[16.10.3 preempt_enable()/preempt_enable_no_resched()]节
preempt_enable_no_resched();
}
9.3.1.3.1 invoke_softirq()
该函数定义于kernel/softirq.c:
#ifdef __ARCH_IRQ_EXIT_IRQS_DISABLED
static inline void invoke_softirq(void)
{
if (!force_irqthreads)
__do_softirq(); // 参见[9.3.1.3.1.1.1 __do_softirq()]节
else {
__local_bh_disable((unsigned long)__builtin_return_address(0), SOFTIRQ_OFFSET);
wakeup_softirqd(); // 唤醒内核线程ksoftirqd,参见[9.3.1.3.1.2 ksoftirqd]节
__local_bh_enable(SOFTIRQ_OFFSET);
}
}
#else // 内核代码中未定义__ARCH_IRQ_EXIT_IRQS_DISABLED,因此进入此分支
static inline void invoke_softirq(void)
{
if (!force_irqthreads)
do_softirq(); // 参见[9.3.1.3.1.1 do_softirq()]节
else {
__local_bh_disable((unsigned long)__builtin_return_address(0), SOFTIRQ_OFFSET);
wakeup_softirqd(); // 唤醒内核线程ksoftirqd,参见[9.3.1.3.1.2 ksoftirqd]节
__local_bh_enable(SOFTIRQ_OFFSET);
}
}
#endif
9.3.1.3.1.1 do_softirq()
该函数定义于kernel/softirq.c:
// __ARCH_HAS_DO_SOFTIRQ定义于arch/x86/include/linux/irq.h
#ifndef __ARCH_HAS_DO_SOFTIRQ
asmlinkage void do_softirq(void)
{
__u32 pending;
unsigned long flags;
// 不在中断上下文中,才处理软中断,参见[9.5.3 Status of the Interrupt System]节
if (in_interrupt())
/*
* This situation indicates either that do_softirq()
* has been invoked in interrupt context or that the
* softirqs are currently disabled.
*/
return;
local_irq_save(flags);
// 查询当前CPU是否存在待处理的软中断,参见[9.2.3 irq_stat[]]节
pending = local_softirq_pending();
// 若存在待处理的软中断,则调用对应的软中断处理函数,参见[9.3.1.3.1.1.1 __do_softirq()]节
if (pending)
__do_softirq();
local_irq_restore(flags);
}
#endif
9.3.1.3.1.1.1 __do_softirq()
该函数定义于kernel/softirq.c:
/*
* We restart softirq processing MAX_SOFTIRQ_RESTART times,
* and we fall back to softirqd after that.
*
* This number has been established via experimentation.
* The two things to balance is latency against fairness -
* we want to handle softirqs as soon as possible, but they
* should not be able to lock up the box.
*/
#define MAX_SOFTIRQ_RESTART 10
asmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
// 获取当前CPU是否存在待处理的软中断(参见[9.2.3 irq_stat[]]节),并保存到变量pending中
pending = local_softirq_pending();
account_system_vtime(current);
// Disable Bottom Half,参见[9.3.1.3.1.1.1.1 Disable Bottom Half]节
__local_bh_disable((unsigned long)__builtin_return_address(0), SOFTIRQ_OFFSET);
// 增加软中断计数,即current->softirq_context++
lockdep_softirq_enter();
cpu = smp_processor_id();
restart:
/* Reset the pending bitmask before enabling irqs */
// 软中断的状态已经保存到变量pending中,因而可将irq_stat.__softirq_pending复位
set_softirq_pending(0);
// Enable local interrupts. 软中断处理过程中要保持开中断,这是Top Half与Bottom Half的关键区别!
local_irq_enable();
h = softirq_vec;
do {
/*
* 依次查询softirq_vec[]中的每种软中断,若置位,
* 则调用对应的处理函数,参见[9.2.2 struct softirq_action / softirq_vec[]]节;
*/
if (pending & 1) {
unsigned int vec_nr = h - softirq_vec;
int prev_count = preempt_count();
kstat_incr_softirqs_this_cpu(vec_nr);
trace_softirq_entry(vec_nr);
// 调用指定软中断的处理程序,参见[9.2.2.1 注册软中断处理函数/open_softirq()]节中的表
h->action(h);
trace_softirq_exit(vec_nr);
if (unlikely(prev_count != preempt_count())) {
printk(KERN_ERR "huh, entered softirq %u %s %p with preempt_count %08x, exited with %08x?\n",
vec_nr, softirq_to_name[vec_nr], h->action, prev_count, preempt_count());
preempt_count() = prev_count;
}
rcu_bh_qs(cpu);
}
h++;
/*
* 右移,故低位对应的软中断具有高优先级,
* 参见[9.2.2 struct softirq_action / softirq_vec[]]节
*/
pending >>= 1;
} while (pending);
// Disable local interrupts
local_irq_disable();
/*
* 重新查询当前CPU是否存在待处理的软中断,若存在且查询次数
* 未超过10次,则再次处理软中断;
*/
pending = local_softirq_pending();
if (pending && --max_restart)
goto restart;
/*
* 若存在且查询次数超过了10次,则唤醒内核线程ksoftirqd,
* 由其来处理软中断,参见[9.3.1.3.1.2 ksoftirqd]节;
*/
if (pending)
wakeup_softirqd();
// 减小软中断计数,即current->softirq_context--
lockdep_softirq_exit();
account_system_vtime(current);
// Enable Bottom Half,参见[9.3.1.3.1.1.1.2 Enable Bottom Half]节
__local_bh_enable(SOFTIRQ_OFFSET);
}
Q: Why repeat MAX_SOFTIRQ_RESTART times in __do_softirq()?
A: While executing a softirq function, new pending softirqs might pop up; in order to ensure a low latency time for the deferrable funtions, __do_softirq() keeps running until all pending softirqs have been executed. This mechanism, however, could force __do_softirq() to run for long periods of time, thus considerably delaying User Mode processes. For that reason, __do_softirq() performs a fixed number of iterations and then returns. The remaining pending softirqs, if any, will be handled in due time by the ksoftirqd kernel thread.
9.3.1.3.1.1.1.1 Disable Bottom Half
函数local_bh_disable()和__local_bh_disable()用于禁用Bottom Half,其定义于kernel/softirq.c:
void local_bh_disable(void)
{
__local_bh_disable((unsigned long)__builtin_return_address(0), SOFTIRQ_DISABLE_OFFSET);
}
#ifdef CONFIG_TRACE_IRQFLAGS
static void __local_bh_disable(unsigned long ip, unsigned int cnt)
{
unsigned long flags;
WARN_ON_ONCE(in_irq());
raw_local_irq_save(flags);
/*
* The preempt tracer hooks into add_preempt_count and will break
* lockdep because it calls back into lockdep after SOFTIRQ_OFFSET
* is set and before current->softirq_enabled is cleared.
* We must manually increment preempt_count here and manually
* call the trace_preempt_off later.
*/
/*
* current_thread_info()->preempt_count += cnt,
* 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
*/
preempt_count() += cnt;
/*
* Were softirqs turned off above:
*/
if (softirq_count() == cnt)
trace_softirqs_off(ip);
raw_local_irq_restore(flags);
if (preempt_count() == cnt)
trace_preempt_off(CALLER_ADDR0, get_parent_ip(CALLER_ADDR1));
}
#else /* !CONFIG_TRACE_IRQFLAGS */
static inline void __local_bh_disable(unsigned long ip, unsigned int cnt)
{
// current_thread_info()->preempt_count += cnt
add_preempt_count(cnt);
barrier();
}
#endif /* CONFIG_TRACE_IRQFLAGS */
9.3.1.3.1.1.1.2 Enable Bottom Half
函数_local_bh_enable() / __local_bh_enable()用于启用Bottom Half,其定义于kernel/softirq.c:
/*
* Special-case - softirqs can safely be enabled in
* cond_resched_softirq(), or by __do_softirq(),
* without processing still-pending softirqs:
*/
void _local_bh_enable(void)
{
__local_bh_enable(SOFTIRQ_DISABLE_OFFSET);
}
static void __local_bh_enable(unsigned int cnt)
{
WARN_ON_ONCE(in_irq());
WARN_ON_ONCE(!irqs_disabled());
if (softirq_count() == cnt)
trace_softirqs_on((unsigned long)__builtin_return_address(0));
// current_thread_info()->preempt_count -= cnt
sub_preempt_count(cnt);
}
函数local_bh_enable()也可用于启用Bottom Half,不同之处在于,它还会检查是否存在待处理的软中断并执行这些软中断处理函数。其定义于kernel/softirq.c:
void local_bh_enable(void)
{
_local_bh_enable_ip((unsigned long)__builtin_return_address(0));
}
static inline void _local_bh_enable_ip(unsigned long ip)
{
WARN_ON_ONCE(in_irq() || irqs_disabled());
#ifdef CONFIG_TRACE_IRQFLAGS
local_irq_disable();
#endif
/*
* Are softirqs going to be turned on now:
*/
if (softirq_count() == SOFTIRQ_DISABLE_OFFSET)
trace_softirqs_on(ip);
/*
* Keep preemption disabled until we are done with
* softirq processing:
*/
sub_preempt_count(SOFTIRQ_DISABLE_OFFSET - 1);
if (unlikely(!in_interrupt() && local_softirq_pending()))
do_softirq(); // 参见[9.3.1.3.1.1 do_softirq()]节
dec_preempt_count();
#ifdef CONFIG_TRACE_IRQFLAGS
local_irq_enable();
#endif
preempt_check_resched();
}
9.3.1.3.1.2 ksoftirqd
ksoftirqd是处理软中断的内核线程,其定义于kernel/softirq.c:
DEFINE_PER_CPU(struct task_struct *, ksoftirqd);
该内核线程在系统启动softirq模块时被创建并唤醒,参见kernel/softirq.c:
// ksoftirqd内核线程执行本函数
static int run_ksoftirqd(void * __bind_cpu)
{
set_current_state(TASK_INTERRUPTIBLE);
while (!kthread_should_stop()) {
preempt_disable();
// 若没有待处理的软中断,则调度其他进程运行
if (!local_softirq_pending()) {
// 参见[16.10.3 preempt_enable()/preempt_enable_no_resched()]节
preempt_enable_no_resched();
schedule();
preempt_disable();
}
__set_current_state(TASK_RUNNING);
// 若存在待处理的软中断,则调用对应的处理函数
while (local_softirq_pending()) {
/* Preempt disable stops cpu going offline.
If already offline, we'll be on wrong CPU:
don't process */
if (cpu_is_offline((long)__bind_cpu))
goto wait_to_die;
local_irq_disable();
if (local_softirq_pending())
__do_softirq(); // 参见[9.3.1.3.1.1.1 __do_softirq()]节
local_irq_enable();
// 参见[16.10.3 preempt_enable()/preempt_enable_no_resched()]节
preempt_enable_no_resched();
cond_resched(); // 参见[7.4.8 cond_resched()]节
preempt_disable();
rcu_note_context_switch((long)__bind_cpu);
}
// 参见[16.10.3 preempt_enable()/preempt_enable_no_resched()]节
preempt_enable();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
wait_to_die:
// 参见[16.10.3 preempt_enable()/preempt_enable_no_resched()]节
preempt_enable();
/* Wait for kthread_stop */
set_current_state(TASK_INTERRUPTIBLE);
while (!kthread_should_stop()) {
schedule();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
}
static int __cpuinit cpu_callback(struct notifier_block *nfb, unsigned long action, void *hcpu)
{
int hotcpu = (unsigned long)hcpu;
struct task_struct *p;
switch (action) {
case CPU_UP_PREPARE:
case CPU_UP_PREPARE_FROZEN:
/*
* There is one thread per processor.
* The threads are each named ksoftirqd/n where n is the
* processor number. Having a thread on each processor
* ensures an idle processor, if available, can always
* service softirqs. 参见[7.2.4.4.1 kthread_run()]节
*/
p = kthread_create_on_node(run_ksoftirqd, hcpu, cpu_to_node(hotcpu),
"ksoftirqd/%d", hotcpu);
if (IS_ERR(p)) {
printk("ksoftirqd for %i failed\n", hotcpu);
return notifier_from_errno(PTR_ERR(p));
}
kthread_bind(p, hotcpu);
// 将ksoftirqd指向新创建的内核线程
per_cpu(ksoftirqd, hotcpu) = p;
break;
case CPU_ONLINE:
case CPU_ONLINE_FROZEN:
// 唤醒内核线程ksoftirqd,参见[7.4.10.2.3 wake_up_process()]节
wake_up_process(per_cpu(ksoftirqd, hotcpu));
break;
#ifdef CONFIG_HOTPLUG_CPU
case CPU_UP_CANCELED:
case CPU_UP_CANCELED_FROZEN:
if (!per_cpu(ksoftirqd, hotcpu))
break;
/* Unbind so it can run. Fall thru. */
kthread_bind(per_cpu(ksoftirqd, hotcpu),
cpumask_any(cpu_online_mask));
case CPU_DEAD:
case CPU_DEAD_FROZEN: {
static const struct sched_param param = {
.sched_priority = MAX_RT_PRIO-1
};
p = per_cpu(ksoftirqd, hotcpu);
per_cpu(ksoftirqd, hotcpu) = NULL;
sched_setscheduler_nocheck(p, SCHED_FIFO, ¶m);
kthread_stop(p);
takeover_tasklets(hotcpu);
break;
}
#endif /* CONFIG_HOTPLUG_CPU */
}
return NOTIFY_OK;
}
static __init int spawn_ksoftirqd(void)
{
void *cpu = (void *)(long)smp_processor_id();
// 创建内核线程ksoftirqd
int err = cpu_callback(&cpu_nfb, CPU_UP_PREPARE, cpu);
BUG_ON(err != NOTIFY_OK);
// 唤醒内核线程ksoftirqd
cpu_callback(&cpu_nfb, CPU_ONLINE, cpu);
register_cpu_notifier(&cpu_nfb);
return 0;
}
/*
* kernel/softirq.c是直接编译进内核的,参见kernel/Makefile中的变量obj-y;
* 因而在系统初始化时调用spawn_ksoftirqd(),参见[13.5.1.1 module被编译进内核时的初始化过程]节
*/
early_initcall(spawn_ksoftirqd);
9.3.2 ret_from_intr
函数do_IRQ()处理所有外设的中断请求,当该函数执行时,内核栈栈顶包含的就是do_IRQ()的返回地址,该地址指向ret_from_intr。实际上,ret_from_intr是一段汇编语言的入口点。虽然这里讨论的是中断的返回,但实际上中断、异常及系统调用的返回是放在一起实现的,故常以函数的形式提到如下这三个入口点:
- ret_from_intr: 终止中断处理程序
- ret_from_sys_call: 终止系统调用,即由0x80引起的异常
- ret_from_exception: 终止除了0x80外的所有异常
ret_from_intr定义于arch/x86/kernel/entry_32.S:
#define nr_syscalls ((syscall_table_size)/4)
#ifdef CONFIG_PREEMPT
#define preempt_stop(clobbers) DISABLE_INTERRUPTS(clobbers); TRACE_IRQS_OFF
#else
#define preempt_stop(clobbers)
#define resume_kernel restore_all
#endif
...
#ifdef CONFIG_VM86
#define resume_userspace_sig check_userspace
#else
#define resume_userspace_sig resume_userspace
#endif
...
ret_from_exception:
preempt_stop(CLBR_ANY)
ret_from_intr:
GET_THREAD_INFO(%ebp)
check_userspace:
/*
* 如下两条mov指令把中断发生前的EFALGS寄存器的高16位与代码段
* CS寄存器的内容拼揍成32位的长整数,其目的是要检验:
* - 中断前CPU是否够运行于VM86模式
* - 中断前CPU是运行在用户空间还是内核空间
*/
movl PT_EFLAGS(%esp), %eax # mix EFLAGS and CS
movb PT_CS(%esp), %al
/*
* VM86模式是为在i386保护模式下模拟运行DOS软件而设置的,EFALGS
* 寄存器高16位中有个标志位表示CPU是否运行在VM86模式:
* - SEGMENT_RPL_MASK定义于arch/x86/include/asm/segment.h,
* 取值为0x3
* - X86_EFLAGS_VM定义于arch/x86/include/asm/processor-flags.h,
* 取值为0x00020000
*/
andl $(X86_EFLAGS_VM | SEGMENT_RPL_MASK), %eax
/*
* CS的最低两位表示中断发生时CPU的运行级别CPL,若这两位为3,则说明
* 中断发生于用户空间。
* USER_RPL定义于arch/x86/include/asm/segment.h,取值为0x3
*/
cmpl $USER_RPL, %eax
/*
* 如果中断发生在内核空间,则控制权直接转移到标号resume_kernel.
* 若未定义CONFIG_PREEMPT,则跳转至restore_all.
*/
jb resume_kernel # not returning to v8086 or userspace
// 否则,恢复到用户空间
ENTRY(resume_userspace)
LOCKDEP_SYS_EXIT
DISABLE_INTERRUPTS(CLBR_ANY) # make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
TRACE_IRQS_OFF
// _TIF_WORK_MASK定义于arch/x86/include/asm/thread_info.h,表示需要重新调度
movl TI_flags(%ebp), %ecx
andl $_TIF_WORK_MASK, %ecx # is there any work to be done on
# int/exception return?
// 若需要重新调度,则跳转至work_pending处执行,继而执行schedule()函数
jne work_pending
// 若无需重新调度,则恢复中断现场,并彻底从中断中返回
jmp restore_all
END(ret_from_exception)
#ifdef CONFIG_PREEMPT
ENTRY(resume_kernel)
DISABLE_INTERRUPTS(CLBR_ANY)
cmpl $0,TI_preempt_count(%ebp) # non-zero preempt_count ?
jnz restore_all
need_resched:
movl TI_flags(%ebp), %ecx # need_resched set ?
testb $_TIF_NEED_RESCHED, %cl
jz restore_all
testl $X86_EFLAGS_IF,PT_EFLAGS(%esp) # interrupts off (exception path) ?
jz restore_all
call preempt_schedule_irq
jmp need_resched
END(resume_kernel)
#endif
CFI_ENDPROC
...
restore_all:
TRACE_IRQS_IRET
restore_all_notrace:
movl PT_EFLAGS(%esp), %eax # mix EFLAGS, SS and CS
# Warning: PT_OLDSS(%esp) contains the wrong/random values if we
# are returning to the kernel.
# See comments in process.c:copy_thread() for details.
movb PT_OLDSS(%esp), %ah
movb PT_CS(%esp), %al
andl $(X86_EFLAGS_VM | (SEGMENT_TI_MASK << 8) | SEGMENT_RPL_MASK), %eax
cmpl $((SEGMENT_LDT << 8) | USER_RPL), %eax
CFI_REMEMBER_STATE
je ldt_ss # returning to user-space with LDT SS
restore_nocheck:
RESTORE_REGS 4 # skip orig_eax/error_code
irq_return:
INTERRUPT_RETURN
...
# perform work that needs to be done immediately before resumption
ALIGN
RING0_PTREGS_FRAME # can't unwind into user space anyway
work_pending:
testb $_TIF_NEED_RESCHED, %cl
jz work_notifysig
work_resched:
call schedule // 执行schedule()函数重新进行进程调度
LOCKDEP_SYS_EXIT
DISABLE_INTERRUPTS(CLBR_ANY) # make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
TRACE_IRQS_OFF
movl TI_flags(%ebp), %ecx
andl $_TIF_WORK_MASK, %ecx # is there any work to be done other
# than syscall tracing?
jz restore_all
// 再次检查是否需要重新调度
testb $_TIF_NEED_RESCHED, %cl
jnz work_resched
work_notifysig: # deal with pending signals and
# notify-resume requests
#ifdef CONFIG_VM86
testl $X86_EFLAGS_VM, PT_EFLAGS(%esp)
movl %esp, %eax
jne work_notifysig_v86 # returning to kernel-space or
# vm86-space
xorl %edx, %edx
call do_notify_resume
jmp resume_userspace_sig
ALIGN
work_notifysig_v86:
pushl_cfi %ecx # save ti_flags for do_notify_resume
call save_v86_state # %eax contains pt_regs pointer
popl_cfi %ecx
movl %eax, %esp
#else
movl %esp, %eax
#endif
xorl %edx, %edx
call do_notify_resume // 参见[8.3.4 信号的接收与处理]节
jmp resume_userspace_sig // 转移至check_userspace或resume_userspace处执行
END(work_pending)
ret_from_intr的流程图如下:
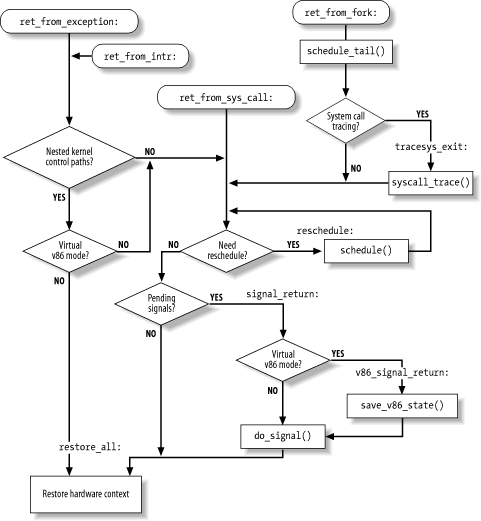
参见«Understanding the Linux Kernel, 3rd Edition»第4. Interrupts and Exceptions章第Returning from Interrupts and Exceptions节:
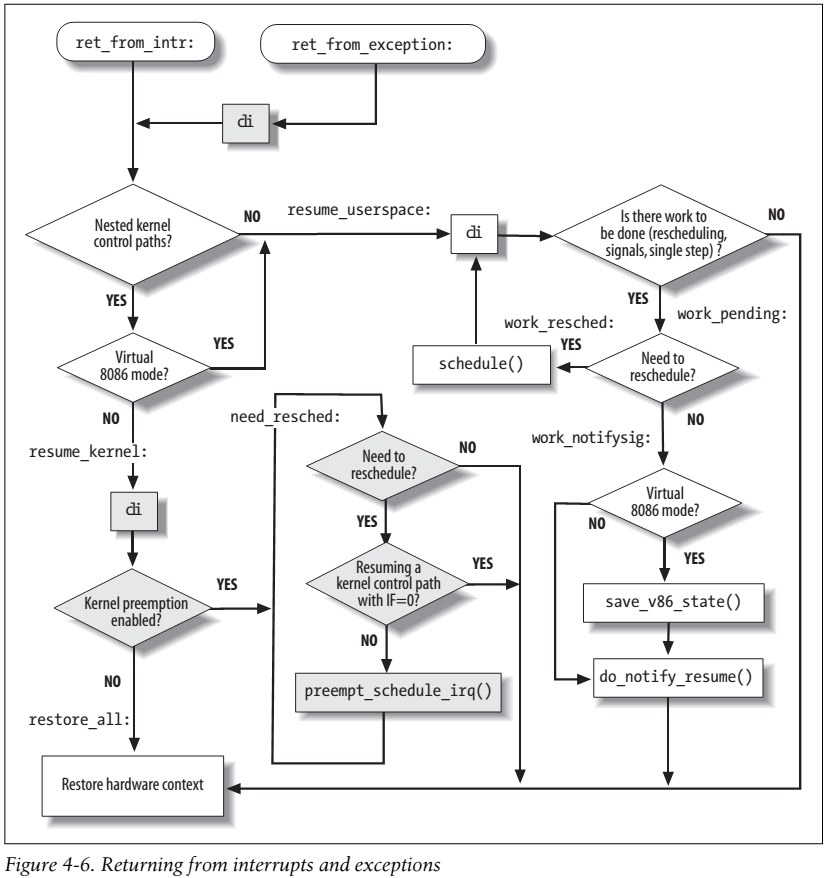
9.4 中断处理函数的注册/注销
中断处理程序是管理硬件的驱动程序的组成部分。每种设备都有相关的驱动程序,如果设备使用中断的方式与CPU通信,那么驱动程序就需要注册中断处理程序。
9.4.1 request_irq()
Before activating a device that is going to use an IRQ line, the corresponding driver invokes request_irq(). 该函数定义于include/linux/interrupt.h:
#ifdef CONFIG_GENERIC_HARDIRQS
// 参见[9.4.1.1 request_threaded_irq()]节
extern int __must_check
request_threaded_irq(unsigned int irq, irq_handler_t handler,
irq_handler_t thread_fn,
unsigned long flags, const char *name, void *dev);
/*
* 如果定义了CONFIG_GENERIC_HARDIRQS,则request_irq()调用
* kernel/irq/manage.c中定义的request_threaded_irq()。
* 并且编译时,kernel/irq目录下的文件会被编译进内核,参见
* kernel/Makefile中的如下语句:
* obj-$(CONFIG_GENERIC_HARDIRQS) += irq/
*/
static inline int __must_check
request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,
const char *name, void *dev)
{
return request_threaded_irq(irq, handler, NULL, flags, name, dev);
}
...
#else
/*
* 如果未定义CONFIG_GENERIC_HARDIRQS,则该体系架构(参见sparc, m68k ...注释)
* 需要提供request_irq()函数的实现。并且编译时,kernel/irq目录下的文件不会被
* 编译进内核,参见kernel/Makefile中的如下语句:
* obj-$(CONFIG_GENERIC_HARDIRQS) += irq/
* 因为内核其他的地方会调用request_threaded_irq()函数,所以在此定义了该函数
*/
extern int __must_check
request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,
const char *name, void *dev);
/*
* Special function to avoid ifdeffery in kernel/irq/devres.c which
* gets magically built by GENERIC_HARDIRQS=n architectures (sparc,
* m68k). I really love these $@%#!* obvious Makefile references:
* ../../../kernel/irq/devres.o
*/
static inline int __must_check
request_threaded_irq(unsigned int irq, irq_handler_t handler,
irq_handler_t thread_fn,
unsigned long flags, const char *name, void *dev)
{
return request_irq(irq, handler, flags, name, dev);
}
...
#endif
函数request_irq()的入参
| request_irq()函数入参 | 含义 |
| unsigned int irq | 要分配的中断号。对于某些设备,如传统PC上的系统时钟或键盘等设备,中断号是提前确定的。而对于其它设备要么事动态探测获取,要么是编程动态确定 |
| irq_handler_t handler | 中断处理函数指针,其定义于 include/linux/interrupt.h: typedef irqreturn_t (*irq_handler_t)(int, void *); 中断处理函数的编写参见9.6 编写中断处理函数节 |
| unsigned long flags | 标志位,参见include/linux/interrupt.h中以IRQF_开头的宏,如下图 |
| const char *name | 设备描述信息 |
| void *dev | 用于识别共享中断线(参见标志位IRQF_SHARED)的众多设备驱动程序的某一个设备 |
Note that request_irq() can sleep and therefore cannot be called from interrupt context or other situations where code cannot block. It is a common mistake to call request_irq() when it is unsafe to sleep.
9.4.1.1 request_threaded_irq()
该函数定义于kernel/irq/manage.c:
int request_threaded_irq(unsigned int irq, irq_handler_t handler,
irq_handler_t thread_fn, unsigned long irqflags,
const char *devname, void *dev_id)
{
struct irqaction *action;
struct irq_desc *desc;
int retval;
/*
* Sanity-check: shared interrupts must pass in a real dev-ID,
* otherwise we'll have trouble later trying to figure out
* which interrupt is which (messes up the interrupt freeing
* logic etc).
*/
if ((irqflags & IRQF_SHARED) && !dev_id)
return -EINVAL;
/*
* 根据中断号,在数组irq_desc[]查找对应的中断描述符,
* 参见[9.2.1 struct irq_desc / irq_desc[]]节
*/
desc = irq_to_desc(irq);
if (!desc)
return -EINVAL;
/*
* 检查desc->status_use_accessors中的标志位
* IRQ_NOREQUEST和IRQ_PER_CPU_DEVID
*/
if (!irq_settings_can_request(desc) || WARN_ON(irq_settings_is_per_cpu_devid(desc)))
return -EINVAL;
if (!handler) {
if (!thread_fn)
return -EINVAL;
// 默认的中断处理函数,见下文
handler = irq_default_primary_handler;
}
action = kzalloc(sizeof(struct irqaction), GFP_KERNEL);
if (!action)
return -ENOMEM;
action->handler = handler;
action->thread_fn = thread_fn;
action->flags = irqflags;
action->name = devname;
action->dev_id = dev_id;
chip_bus_lock(desc);
/*
* 将action结构加入到desc->action链表中,
* 参见[9.2.1 struct irq_desc / irq_desc[]]节和[9.4.1.2 setup_irq()/__setup_irq()]节
*/
retval = __setup_irq(irq, desc, action);
chip_bus_sync_unlock(desc);
if (retval)
kfree(action);
#ifdef CONFIG_DEBUG_SHIRQ_FIXME
if (!retval && (irqflags & IRQF_SHARED)) {
/*
* It's a shared IRQ -- the driver ought to be prepared for it
* to happen immediately, so let's make sure....
* We disable the irq to make sure that a 'real' IRQ doesn't
* run in parallel with our fake.
*/
unsigned long flags;
disable_irq(irq);
local_irq_save(flags);
handler(irq, dev_id);
local_irq_restore(flags);
enable_irq(irq);
}
#endif
return retval;
}
/*
* Default primary interrupt handler for threaded interrupts. Is
* assigned as primary handler when request_threaded_irq is called
* with handler == NULL. Useful for oneshot interrupts.
*/
static irqreturn_t irq_default_primary_handler(int irq, void *dev_id)
{
return IRQ_WAKE_THREAD;
}
9.4.1.2 setup_irq()/__setup_irq()
函数setup_irq()定义于kernel/irq/manage.c:
/**
* setup_irq - setup an interrupt
* @irq: Interrupt line to setup
* @act: irqaction for the interrupt
*
* Used to statically setup interrupts in the early boot process.
*/
int setup_irq(unsigned int irq, struct irqaction *act)
{
int retval;
struct irq_desc *desc = irq_to_desc(irq);
if (WARN_ON(irq_settings_is_per_cpu_devid(desc)))
return -EINVAL;
chip_bus_lock(desc);
retval = __setup_irq(irq, desc, act);
chip_bus_sync_unlock(desc);
return retval;
}
函数__setup_irq()定义于kernel/irq/manage.c:
/*
* Internal function to register an irqaction - typically used to
* allocate special interrupts that are part of the architecture.
*/
static int __setup_irq(unsigned int irq, struct irq_desc *desc, struct irqaction *new)
{
struct irqaction *old, **old_ptr;
const char *old_name = NULL;
unsigned long flags, thread_mask = 0;
int ret, nested, shared = 0;
cpumask_var_t mask;
if (!desc)
return -EINVAL;
if (desc->irq_data.chip == &no_irq_chip)
return -ENOSYS;
if (!try_module_get(desc->owner))
return -ENODEV;
/*
* Some drivers like serial.c use request_irq() heavily,
* so we have to be careful not to interfere with a
* running system.
*/
if (new->flags & IRQF_SAMPLE_RANDOM) {
/*
* This function might sleep, we want to call it first,
* outside of the atomic block.
* Yes, this might clear the entropy pool if the wrong
* driver is attempted to be loaded, without actually
* installing a new handler, but is this really a problem,
* only the sysadmin is able to do this.
*/
rand_initialize_irq(irq);
}
/*
* Check whether the interrupt nests into another interrupt
* thread.
*/
// 检查desc->status_use_accessors中的标志位IRQ_NESTED_THREAD
nested = irq_settings_is_nested_thread(desc);
if (nested) {
if (!new->thread_fn) {
ret = -EINVAL;
goto out_mput;
}
/*
* Replace the primary handler which was provided from
* the driver for non nested interrupt handling by the
* dummy function which warns when called.
*/
new->handler = irq_nested_primary_handler; // 参见下文
} else {
// 检查desc->status_use_accessors中的标志位IRQ_NOTHREAD
if (irq_settings_can_thread(desc))
// 设置new->handler = irq_default_primary_handler
irq_setup_forced_threading(new);
}
/*
* Create a handler thread when a thread function is supplied
* and the interrupt does not nest into another interrupt
* thread.
*/
if (new->thread_fn && !nested) {
struct task_struct *t;
/*
* 创建内核线程,参见[7.2.4.4.1 kthread_run()]节。
* 函数irq_thread()定义于kernel/irq/manage.c
*/
t = kthread_create(irq_thread, new, "irq/%d-%s", irq, new->name);
if (IS_ERR(t)) {
ret = PTR_ERR(t);
goto out_mput;
}
/*
* We keep the reference to the task struct even if
* the thread dies to avoid that the interrupt code
* references an already freed task_struct.
*/
get_task_struct(t); // 增加t->usage值
new->thread = t;
}
if (!alloc_cpumask_var(&mask, GFP_KERNEL)) {
ret = -ENOMEM;
goto out_thread;
}
/*
* The following block of code has to be executed atomically
*/
raw_spin_lock_irqsave(&desc->lock, flags);
old_ptr = &desc->action;
old = *old_ptr;
if (old) {
/*
* Can't share interrupts unless both agree to and are
* the same type (level, edge, polarity). So both flag
* fields must have IRQF_SHARED set and the bits which
* set the trigger type must match. Also all must
* agree on ONESHOT.
*/
if (!((old->flags & new->flags) & IRQF_SHARED) ||
((old->flags ^ new->flags) & IRQF_TRIGGER_MASK) ||
((old->flags ^ new->flags) & IRQF_ONESHOT)) {
old_name = old->name;
goto mismatch;
}
/* All handlers must agree on per-cpuness */
if ((old->flags & IRQF_PERCPU) != (new->flags & IRQF_PERCPU))
goto mismatch;
/* add new interrupt at end of irq queue */
do {
thread_mask |= old->thread_mask;
old_ptr = &old->next;
old = *old_ptr;
} while (old);
shared = 1;
}
/*
* Setup the thread mask for this irqaction. Unlikely to have
* 32 resp 64 irqs sharing one line, but who knows.
*/
if (new->flags & IRQF_ONESHOT && thread_mask == ~0UL) {
ret = -EBUSY;
goto out_mask;
}
// ffz() - find first zero in word
new->thread_mask = 1 << ffz(thread_mask);
if (!shared) {
init_waitqueue_head(&desc->wait_for_threads);
/* Setup the type (level, edge polarity) if configured: */
if (new->flags & IRQF_TRIGGER_MASK) {
ret = __irq_set_trigger(desc, irq, new->flags & IRQF_TRIGGER_MASK);
if (ret)
goto out_mask;
}
desc->istate &= ~(IRQS_AUTODETECT | IRQS_SPURIOUS_DISABLED | IRQS_ONESHOT | IRQS_WAITING);
irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS);
if (new->flags & IRQF_PERCPU) {
irqd_set(&desc->irq_data, IRQD_PER_CPU);
irq_settings_set_per_cpu(desc);
}
if (new->flags & IRQF_ONESHOT)
desc->istate |= IRQS_ONESHOT;
if (irq_settings_can_autoenable(desc))
irq_startup(desc);
else
/* Undo nested disables: */
desc->depth = 1;
/* Exclude IRQ from balancing if requested */
if (new->flags & IRQF_NOBALANCING) {
irq_settings_set_no_balancing(desc);
irqd_set(&desc->irq_data, IRQD_NO_BALANCING);
}
/* Set default affinity mask once everything is setup */
setup_affinity(irq, desc, mask);
} else if (new->flags & IRQF_TRIGGER_MASK) {
unsigned int nmsk = new->flags & IRQF_TRIGGER_MASK;
// 检查desc->status_use_accessors中的标志位IRQ_TYPE_SENSE_MASK
unsigned int omsk = irq_settings_get_trigger_mask(desc);
if (nmsk != omsk)
/* hope the handler works with current trigger mode */
pr_warning("IRQ %d uses trigger mode %u; requested %u\n", irq, nmsk, omsk);
}
/*
* 将新的action结构加入到desc->action链表中。
* 该处理函数在handle_irq_event_percpu()被调用,
* 参见[9.3.1.2.1.1.1 handle_irq_event_percpu()]节
*/
new->irq = irq;
*old_ptr = new;
/* Reset broken irq detection when installing new handler */
desc->irq_count = 0;
desc->irqs_unhandled = 0;
/*
* Check whether we disabled the irq via the spurious handler
* before. Reenable it and give it another chance.
*/
if (shared && (desc->istate & IRQS_SPURIOUS_DISABLED)) {
desc->istate &= ~IRQS_SPURIOUS_DISABLED;
__enable_irq(desc, irq, false); // 参见下文
}
raw_spin_unlock_irqrestore(&desc->lock, flags);
/*
* Strictly no need to wake it up, but hung_task complains
* when no hard interrupt wakes the thread up.
*/
if (new->thread)
wake_up_process(new->thread);
register_irq_proc(irq, desc); // 创建/proc/irq/1234
new->dir = NULL;
register_handler_proc(irq, new); // 创建/proc/irq/1234/handler/
free_cpumask_var(mask);
return 0;
mismatch:
#ifdef CONFIG_DEBUG_SHIRQ
if (!(new->flags & IRQF_PROBE_SHARED)) {
printk(KERN_ERR "IRQ handler type mismatch for IRQ %d\n", irq);
if (old_name)
printk(KERN_ERR "current handler: %s\n", old_name);
dump_stack();
}
#endif
ret = -EBUSY;
out_mask:
raw_spin_unlock_irqrestore(&desc->lock, flags);
free_cpumask_var(mask);
out_thread:
if (new->thread) {
struct task_struct *t = new->thread;
new->thread = NULL;
if (likely(!test_bit(IRQTF_DIED, &new->thread_flags)))
kthread_stop(t);
put_task_struct(t);
}
out_mput:
module_put(desc->owner);
return ret;
}
函数__setup_irq()中用到的两个函数irq_nested_primary_handler()和__enable_irq():
/*
* Primary handler for nested threaded interrupts. Should never be
* called.
*/
static irqreturn_t irq_nested_primary_handler(int irq, void *dev_id)
{
WARN(1, "Primary handler called for nested irq %d\n", irq);
return IRQ_NONE;
}
void __enable_irq(struct irq_desc *desc, unsigned int irq, bool resume)
{
if (resume) {
if (!(desc->istate & IRQS_SUSPENDED)) {
if (!desc->action)
return;
if (!(desc->action->flags & IRQF_FORCE_RESUME))
return;
/* Pretend that it got disabled ! */
desc->depth++;
}
desc->istate &= ~IRQS_SUSPENDED;
}
switch (desc->depth) {
case 0:
err_out:
WARN(1, KERN_WARNING "Unbalanced enable for IRQ %d\n", irq);
break;
case 1: {
if (desc->istate & IRQS_SUSPENDED)
goto err_out;
/* Prevent probing on this irq: */
// 将desc->status_use_accessors中的标志位IRQ_NOPROBE置位
irq_settings_set_noprobe(desc);
irq_enable(desc);
check_irq_resend(desc, irq);
/* fall-through */
}
default:
desc->depth--;
}
}
9.4.2 free_irq()
该函数用于注销由request_irq()注册的中断,其定义于kernel/irq/manage.c:
/**
* free_irq - free an interrupt allocated with request_irq
* @irq: Interrupt line to free
* @dev_id: Device identity to free
*
* Remove an interrupt handler. The handler is removed and if the
* interrupt line is no longer in use by any driver it is disabled.
* On a shared IRQ the caller must ensure the interrupt is disabled
* on the card it drives before calling this function. The function
* does not return until any executing interrupts for this IRQ
* have completed.
*
* This function must not be called from interrupt context.
*/
void free_irq(unsigned int irq, void *dev_id)
{
// 根据中断号,在数组irq_desc[]查找对应的中断描述符,参见[9.2.1 struct irq_desc / irq_desc[]]节
struct irq_desc *desc = irq_to_desc(irq);
// 检查desc->status_use_accessors中的标志位IRQ_PER_CPU_DEVID
if (!desc || WARN_ON(irq_settings_is_per_cpu_devid(desc)))
return;
#ifdef CONFIG_SMP
if (WARN_ON(desc->affinity_notify))
desc->affinity_notify = NULL;
#endif
// 调用desc->irq_data.chip->irq_bus_lock()
chip_bus_lock(desc);
// 释放__free_irq()返回的irqaction结构,参见[9.4.2.1 __free_irq()]节
kfree(__free_irq(irq, dev_id));
// 调用desc->irq_data.chip->irq_bus_sync_unlock()
chip_bus_sync_unlock(desc);
}
9.4.2.1 __free_irq()
该函数定义于kernel/irq/manage.c:
/*
* Internal function to unregister an irqaction - used to free
* regular and special interrupts that are part of the architecture.
*/
static struct irqaction *__free_irq(unsigned int irq, void *dev_id)
{
struct irq_desc *desc = irq_to_desc(irq);
struct irqaction *action, **action_ptr;
unsigned long flags;
WARN(in_interrupt(), "Trying to free IRQ %d from IRQ context!\n", irq);
if (!desc)
return NULL;
raw_spin_lock_irqsave(&desc->lock, flags);
/*
* There can be multiple actions per IRQ descriptor, find the right
* one based on the dev_id:
*/
action_ptr = &desc->action;
for (;;) {
action = *action_ptr;
if (!action) {
WARN(1, "Trying to free already-free IRQ %d\n", irq);
raw_spin_unlock_irqrestore(&desc->lock, flags);
return NULL;
}
if (action->dev_id == dev_id)
break;
// 参见[9.2.1 struct irq_desc / irq_desc[]]节
action_ptr = &action->next;
}
/* Found it - now remove it from the list of entries: */
*action_ptr = action->next;
/* Currently used only by UML, might disappear one day: */
#ifdef CONFIG_IRQ_RELEASE_METHOD
if (desc->irq_data.chip->release)
desc->irq_data.chip->release(irq, dev_id);
#endif
/* If this was the last handler, shut down the IRQ line: */
if (!desc->action)
/*
* 尝试调用如下函数关闭中断线:
* desc->irq_data.chip->irq_shutdown(), or
* desc->irq_data.chip->irq_disable(), or
* desc->irq_data.chip->irq_mask()
*/
irq_shutdown(desc);
#ifdef CONFIG_SMP
/* make sure affinity_hint is cleaned up */
if (WARN_ON_ONCE(desc->affinity_hint))
desc->affinity_hint = NULL;
#endif
raw_spin_unlock_irqrestore(&desc->lock, flags);
unregister_handler_proc(irq, action);
/* Make sure it's not being used on another CPU: */
synchronize_irq(irq);
#ifdef CONFIG_DEBUG_SHIRQ
/*
* It's a shared IRQ -- the driver ought to be prepared for an IRQ
* event to happen even now it's being freed, so let's make sure that
* is so by doing an extra call to the handler ....
*
* ( We do this after actually deregistering it, to make sure that a
* 'real' IRQ doesn't run in * parallel with our fake. )
*/
if (action->flags & IRQF_SHARED) {
local_irq_save(flags);
action->handler(irq, dev_id);
local_irq_restore(flags);
}
#endif
if (action->thread) {
if (!test_bit(IRQTF_DIED, &action->thread_flags))
kthread_stop(action->thread);
put_task_struct(action->thread);
}
module_put(desc->owner);
return action;
}
9.5 控制中断
参见«Understanding the Linux Kernel, 3rd Edition»第5. Kernel Synchronization章第Local Interrupt Disabling节:
Interrupt disabling is one of the key mechanisms used to ensure that a sequence of kernel statements is treated as a critical section. It allows a kernel control path to continue executing even when hardware devices issue IRQ signals, thus providing an effective way to protect data structures that are also accessed by interrupt handlers. By itself, however, local interrupt disabling does not protect against concurrent accesses to data structures by interrupt handlers running on other CPUs, so in multiprocessor systems, local interrupt disabling is often coupled with spin locks.
9.5.1 Disable and Enable Interrupts
To disable interrupts locally for the current processor (and only the current processor) and then later reenable them, do the following:
local_irq_disable();
/* interrupts are disabled on the local CPU .. */
local_irq_enable();
Or, save interrupts state first and then restore interrupts to a previous state:
unsigned long flags;
local_irq_save(flags); /* interrupts are now disabled */
/* interrupts are disabled on the local CPU .. */
local_irq_restore(flags); /* interrupts are restored to their previous state */
These functions are usually implemented as a single assembly operation. (Of course, this depends on the architecture.) Indeed, on x86, local_irq_disable() is a simple cli and local_irq_enable() is a simple sti instruction. cli and sti are the assembly calls to clear and set the allow interrupts flag, respectively. In other words, they disable and enable interrupt delivery on the issuing processor.
Those macros are defined in include/linux/irqflags.h.
9.5.2 Disable and Enable a Specific Interrupt Line
In some cases, it is useful to disable only a specific interrupt line for the entire system. This is called masking out an interrupt line. Linux provides four interfaces for this task, which are defined in kernel/irq/manage.c:
void disable_irq(unsigned int irq);
void disable_irq_nosync(unsigned int irq);
void enable_irq(unsigned int irq);
void synchronize_irq(unsigned int irq);
The first two functions disable a given interrupt line in the interrupt controller. This disables delivery of the given interrupt to all processors in the system. Additionally, the disable_irq()function does not return until any currently executing handler completes. Thus, callers are assured not only that new interrupts will not be delivered on the given line, but also that any already executing handlers have exited. The function disable_irq_nosync() does not wait for current handlers to complete.
The function synchronize_irq() waits for a specific interrupt handler to exit, if it is executing, before returning.
Calls to these functions nest. For each call to disable_irq() or disable_irq_nosync() on a given interrupt line, a corresponding call to enable_irq() is required. Only on the last call to enable_irq() is the interrupt line actually enabled. For example, if disable_irq() is called twice, the interrupt line is not actually reenabled until the second call to enable_irq().
All three of these functions can be called from interrupt or process context and do not sleep. If calling from interrupt context, be careful! You do not want, for example, to enable an interrupt line while you are handling it.
9.5.3 Status of the Interrupt System
It is often useful to know the state of the interrupt system (for example, whether interrupts are enabled or disabled) or whether you are currently executing in interrupt context.
The macro irq_disabled() returns nonzero if the interrupt system on the local processor is disabled. Otherwise, it returns zero. It’s defined in include/linux/irqflags.h:
#ifdef CONFIG_TRACE_IRQFLAGS_SUPPORT
#define irqs_disabled() \
({ \
unsigned long _flags; \
raw_local_save_flags(_flags); \
raw_irqs_disabled_flags(_flags); \
})
#else
#define irqs_disabled() (raw_irqs_disabled())
#endif
Below macros, defined in include/linux/hardirq.h, provide an interface to check the kernel’s current context:
/*
* Are we doing bottom half or hardware interrupt processing?
* Are we in a softirq context? Interrupt context?
* in_softirq - Are we currently processing softirq or have bh disabled?
* in_serving_softirq - Are we currently processing softirq?
*/
#define in_interrupt() (irq_count())
#define in_irq() (hardirq_count())
#define in_softirq() (softirq_count())
#define in_serving_softirq() (softirq_count() & SOFTIRQ_OFFSET)
/*
* Are we in NMI context?
*/
#define in_nmi() (preempt_count() & NMI_MASK)
The most useful is in_interrupt(): It returns nonzero if the kernel is performing any type of interrupt handling. This includes either executing an interrupt handler or a bottom half handler.
More often, you want to check whether you are in process context. That is, you want to ensure you are not in interrupt context. This is often the case because code wants to do something that can only be done from process context, such as sleep. If in_interrupt() returns zero, the kernel is in process context.
The macro in_irq() returns nonzero only if the kernel is specifically executing an interrupt handler.
另参见7.1.1.3.1.1 struct thread_info->preempt_count节。
9.6 编写中断处理函数
9.6.1 中断处理函数原型
中断处理函数的原型参见include/linux/interrupt.h:
typedef irqreturn_t (*irq_handler_t)(int irq, void *dev);
其返回类型为irqreturn_t,参见include/linux/irqreturn.h:
/**
* enum irqreturn
* @IRQ_NONE interrupt was not from this device
* @IRQ_HANDLED interrupt was handled by this device
* @IRQ_WAKE_THREAD handler requests to wake the handler thread
*/
enum irqreturn {
IRQ_NONE = (0 << 0),
IRQ_HANDLED = (1 << 0),
IRQ_WAKE_THREAD = (1 << 1),
};
typedef enum irqreturn irqreturn_t;
/*
* If x is nonzero, this macro returns IRQ_HANDLED.
* Otherwise, the macro returns IRQ_NONE.
*/
#define IRQ_RETVAL(x) ((x) != IRQ_NONE)
The interrupt handler is normally marked static because it is never called directly from another file.
9.6.2 编写中断处理函数的注意事项
The role of the interrupt handler depends entirely on the device and its reasons for issuing the interrupt. At a minimum, most interrupt handlers need to provide acknowledgment to the device that they received the interrupt. Devices that are more complex need to additionally send and receive data and perform extended work in the interrupt handler.
Interrupt handlers in Linux need not be reentrant. When a given interrupt handler is executing, the corresponding interrupt line is masked out on all processors, preventing another interrupt on the same line from being received. Normally all other interrupts are enabled, so other interrupts are serviced, but the current line is always disabled. Consequently, the same interrupt handler is never invoked concurrently to service a nested interrupt. This greatly simplifies writing your interrupt handler.
Interrupt context is time-critical because the interrupt handler interrupts other code. Code should be quick and simple.
The setup of an interrupt handler’s stacks is a configuration option. Historically, interrupt handlers did not receive their own stacks. Instead, they would share the stack of the process that they interrupted. The kernel stack is two pages in size; typically, that is 8KB on 32-bit architectures and 16KB on 64-bit architectures. Because in this setup interrupt handlers share the stack, they must be exceptionally frugal with what data they allocate there.
9.6.3 中断处理函数示例
以drivers/char/rtc.c为例,中断处理函数的写法如下:
static irqreturn_t rtc_interrupt(int irq, void *dev_id)
{
/*
* Can be an alarm interrupt, update complete interrupt,
* or a periodic interrupt. We store the status in the
* low byte and the number of interrupts received since
* the last read in the remainder of rtc_irq_data.
*/
spin_lock(&rtc_lock);
rtc_irq_data += 0x100;
rtc_irq_data &= ~0xff;
if (is_hpet_enabled()) {
/*
* In this case it is HPET RTC interrupt handler
* calling us, with the interrupt information
* passed as arg1, instead of irq.
*/
rtc_irq_data |= (unsigned long)irq & 0xF0;
} else {
rtc_irq_data |= (CMOS_READ(RTC_INTR_FLAGS) & 0xF0);
}
if (rtc_status & RTC_TIMER_ON)
mod_timer(&rtc_irq_timer, jiffies + HZ/rtc_freq + 2*HZ/100);
spin_unlock(&rtc_lock);
/* Now do the rest of the actions */
spin_lock(&rtc_task_lock);
if (rtc_callback)
rtc_callback->func(rtc_callback->private_data);
spin_unlock(&rtc_task_lock);
wake_up_interruptible(&rtc_wait);
kill_fasync(&rtc_async_queue, SIGIO, POLL_IN);
return IRQ_HANDLED;
}
9.7 中断的初始化
在系统启动时,需要初始化中断,参见:
- 6.1.1.3.1.1 中断描述符表的初步初始化节
- 6.1.1.3.1.2 中断描述符表的最终初始化节
- 4.3.4.1.4.3.5 trap_init()节
- 4.3.4.1.4.3.8 early_irq_init()节
- 4.3.4.1.4.3.9 init_IRQ()节
10 设备驱动程序/Device Driver
Reading materials:
参见《Linux Device Drivers, 3rd Edition》第一章第The Role of the Device Driver节:
- The role of a device driver is providing mechanism, not policy.
- The distinction between mechanism and policy is one of the best ideas behind the Unix design. Most programming problems can indeed be split into two parts: what capabilities are to be provided (the mechanism) and how those capabilities can be used (the policy). If the two issues are addressed by different parts of the program, or even by different programs altogether, the software package is much easier to develop and to adapt to particular needs.
10.1 Linux Kernel中的设备驱动程序
10.1.1 Location of Device Drivers
内核中包含了大量的设备驱动程序:
- 10.1.1.1 Device Driver in driver/,内核中的大部分驱动程序位于本目录
- 10.1.1.2 Device Driver in block/
- 10.1.1.3 Device Driver in firmware/
- 10.1.1.4 Device Driver in net/
- 10.1.1.5 Device Driver in sound/
10.1.1.1 Device Driver in driver/
driver/accessibility/braille
This adds a minimalistic braille screen reader support. This is meant to be used by blind people e.g. on boot failures or when / cannot be mounted etc and thus the userland screen readers can not work.
driver/acpi/
高级配置和电源接口(ACPI: Advanced Configuration and Power Interface)驱动程序,用于管理电源的使用。
driver/amba/
高级微控制器总线架构(AMBA: Advanced Microcontroller Bus Architecture)是与片上系统(SoC)的管理和互连的协议。SoC是一块包含许多或所有必要的计算机组件的芯片。这里的AMBA驱动让内核能够运行在这上面。
driver/android/
driver/ata/
该目录包含PATA和SATA设备的驱动程序。串行ATA(SATA)是一种连接主机总线适配器到像硬盘那样的存储器的计算机总线接口。并行ATA(PATA)用于连接存储设备,如硬盘驱动器,软盘驱动器,光盘驱动器的标准,PATA就是我们所说的IDE。
driver/atm/
异步通信模式(ATM: Asynchronous Transfer Mode)是一种通信标准。这里有各种接到PCI桥的驱动(它们连接到PCI总线)和以太网控制器(控制以太网通信的集成电路芯片)。
driver/auxdisplay/
该目录提供了三个驱动: LCD帧缓存(frame buffer)驱动、LCD控制器驱动和一个LCD驱动。这些驱动用于管理液晶显示器 — 液晶显示器会在按压时显示波纹。NOTE: 按压会损害屏幕,所以请不要用力戳LCD显示屏。
driver/base/
这是个重要的目录包含了固件、系统总线、虚拟化能力等基本的驱动程序。
driver/bcma/
这些驱动程序用于使用基于AMBA协议的总线。AMBA协议是由博通公司开发的。
driver/block/
块设备驱动程序。提供对块设备的支持,像软驱、SCSI磁带、TCP网络块设备等。
driver/bluetooth/
蓝牙是一种安全的无线个人区域网络标准(PANs)。蓝牙驱动程序就在该目录中,它允许系统使用各种蓝牙设备。例如,一个蓝牙鼠标不用电缆,并且计算机有一个电子狗(小型USB接收器)。Linux系统必须能够知道进入电子狗的信号,否则蓝牙设备无法工作。
driver/bus/
该目录包含了三个驱动: 第一个是转换ocp接口协议到scp协议,第二个是设备间的互联驱动,第三个是用于处理互联中的错误处理。
driver/cdrom/
This directory hosts the generic CD-ROM interface. Both the IDE and SCSI cdrom drivers rely on drivers/cdrom/cdrom.c for some of their functionality. 该目录包含两个驱动:第一个是cd-rom,包括DVD和CD的读写;第二个是gd-rom(只读GB光盘),GD光盘是1.2GB容量的光盘,这像一个更大的CD或者更小的DVD。GD通常用于世嘉游戏机中。
driver/char/
字符设备驱动程序。字符设备每次传输数据传输一个字符。该目录中的驱动程序包括打印机、PS3闪存驱动、东芝SMM驱动和随机数发生器驱动等。
driver/clk/
这些驱动程序用于系统时钟。
driver/clocksource/
这些驱动用于作为定时器的时钟。
driver/connector/
这些驱动使内核知道当进程fork并使用proc连接器更改UID(用户ID)、GID(组ID)和SID(会话ID)。内核需要知道什么时候进程fork(CPU中运行多个任务)并执行。否则,内核可能会低效管理资源。
driver/cpufreq/
这些驱动改变CPU的电源能耗。
driver/cpuidle/
这些驱动用来管理空闲的CPU。一些系统使用多个CPU,其中一个驱动可以让这些CPU负载相当。
driver/crypto/
这些驱动提供加密功能。
driver/dax/
driver/dca/
直接缓存访问(DCA: Direct Cache Access)驱动允许内核访问CPU缓存。CPU缓存就像CPU内置的RAM。CPU缓存的速度比RAM更快。然而,CPU缓存的容量比RAM小得多。CPU在这个缓存系统上存储了最重要的和执行的代码。
driver/devfreq/
这个驱动程序提供了一个通用的动态电压和频率调整(DVFS: Generic Dynamic Voltage and Frequency Scaling)框架,可以根据需要改变CPU频率来节约能源。这就是所谓的CPU节能。
driver/dio/
数字输入/输出(DIO: Digital Input/Output)总线驱动允许内核可以使用DIO总线。
driver/dma/
直接内存访问(DMA: Direct Memory Access)驱动允许设备无需CPU直接访问内存。这减少了CPU的负载。
driver/dma-buf/
driver/edac/
错误检测和校正(Error Detection And Correction)驱动帮助减少和纠正错误。
driver/eisa/
扩展工业标准结构总线(Extended Industry Standard Architecture)驱动提供内核对EISA总线的支持。
driver/extcon/
外部连接器(EXTernal CONnectors)驱动用于检测设备插入时的变化。例如:extcon会检测用户是否插入了USB驱动器。
driver/firewire/
这些驱动用于控制苹果制造的类似于USB的火线设备。
driver/firmware/
这些驱动用于和像BIOS(计算机的基本输入输出系统固件)之类的设备的固件通信。BIOS用于启动操作系统和控制硬件与设备的固件。一些BIOS允许用户超频CPU。超频是使CPU运行在一个更快的速度。CPU速度以MHz或GHz来衡量。一个3.7 GHz的CPU的速度明显快于一个700Mhz的CPU。
driver/fmc/
driver/fpga/
driver/gpio/
通用输入/输出(GPIO: General Purpose Input/Output)是可由用户控制行为的芯片的管脚。这里的驱动就是控制GPIO。
driver/gpu/
这些驱动控制VGA、GPU和直接渲染管理(DRM: Direct Rendering Manager)。VGA是640*480的模拟计算机显示器或是简化的分辨率标准。GPU是图形处理器。DRM是一个Unix渲染系统。
driver/hid/
这驱动用于对USB人机界面设备的支持。
driver/hsi/
这个驱动用于内核访问像Nokia N900这样的蜂窝式调制解调器。
driver/hv/
这个驱动用于提供Linux中的键值对(KVP: Key Value Pair)功能。
driver/hwmon/
硬件监控驱动用于内核读取硬件传感器上的信息。例如:CPU上有个温度传感器,那么内核就可以追踪温度的变化并相应地调节风扇的速度。
driver/hwspinlock/
硬件自旋锁驱动允许系统同时使用两个或者更多的处理器,或使用一个处理器上的两个或更多的核心。
driver/hwtracing/
driver/i2c/
I2C驱动可以使计算机使用I2C协议处理主板上的低速外设。系统管理总线(SMBus: System Management Bus)驱动管理SMBus,这是一种用于轻量级通信的two-wire总线。
**driver/ide/
这些驱动用来处理像CDROM和硬盘这些PATA/IDE设备。The IDE family of device drivers used to live in drivers/block but has expanded to the point where they were moved into a separate directory.
driver/idle/
这个驱动用来管理Intel处理器的空闲功能。
driver/iio/
工业I/O核心驱动程序用来处理数模转换器或模数转换器。
driver/infiniband/
Infiniband是在企业数据中心和一些超级计算机中使用的一种高性能的端口。该目录中的驱动用来支持Infiniband硬件。
driver/input/
这些驱动用于输入处理,包括游戏杆、鼠标、键盘、游戏端口(旧式的游戏杆接口)、遥控器、触控、耳麦按钮和许多其他的驱动。如今的操纵杆使用USB端口,但是在上世纪80、90年代,操纵杆是插在游戏端口的。Input management is another facility meant to simplify and standardize activities that are common to several drivers, and to offer a unified interface to user space.
driver/iommu/
输入/输出内存管理单元(IOMMU: Input/Output Memory Management Unit)驱动用来管理内存管理单元中的IOMMU。IOMMU连接DMA IO总线到内存上。IOMMU是设备在没有CPU帮助下直接访问内存的桥梁。这有助于减少处理器的负载。
driver/ipack/
Ipack代表的是Industry Pack。这个驱动是一个虚拟总线,允许在载体和夹板之间操作。
driver/irqchip/
这些驱动程序允许硬件的中断请求(IRQ)发送到处理器,暂时挂起一个正在运行的程序而去运行一个特殊的程序(称为一个中断处理程序)。
driver/isdn/
这些驱动用于支持综合业务数字网(ISDN),这是用于同步数字传输语音、视频、数据和其他网络服务使用传统电话网络的电路的通信标准。
driver/leds/
用于LED的驱动。
driver/lguest/
lguest用于管理客户机系统的中断。中断是CPU被重要任务打断的硬件或软件信号。CPU接着给硬件或软件一些处理资源。
driver/lightnvm/
driver/macintosh/
苹果设备的驱动程序。
driver/mailbox/
这个文件夹中的驱动(pl320-pci)用于管理邮箱系统的连接。
driver/mcb/
driver/md/
多设备驱动用于支持磁盘阵列,一种多块硬盘间共享或复制数据的系统。 This directory is concerned with implementing RAID functionality and the Logical Volume Manager abstraction.
driver/media/
媒体驱动提供了对收音机、调谐器、视频捕捉卡、DVB标准的数字电视等等的支持。驱动还提供了对不同通过USB或火线端口插入的多媒体设备的支持。This directory collects other communication media, currently radio and video input devices.
driver/memory/
支持内存的重要驱动。
driver/memstick/
这个驱动用于支持Sony记忆棒。
driver/message/
这些驱动用于运行LSI Fusion MPT(一种消息传递技术)固件的LSI PCI芯片/适配器。LSI大规模集成,这代表每片芯片上集成了几万晶体管。
driver/mfd/
多用途设备(MFD)驱动提供了对可以提供诸如电子邮件、传真、复印机、扫描仪、打印机功能的多用途设备的支持。这里的驱动还给MFD设备提供了一个通用多媒体通信端口(MCP)层。
driver/misc/
该目录包含了不适合放在其他目录的各种驱动,就像光线传感器驱动。
driver/mmc/
MMC卡驱动用于处理用于MMC标准的闪存卡。
driver/mtd/
内存技术设备(MTD: Memory Technology Devices)驱动程序用于Linux和闪存的交互,这就像一层闪存转换层。其他块设备和字符设备的驱动程序不会以闪存设备的操作方式来做映射。尽管USB记忆卡和SD卡是闪存设备,但它们不使用这个驱动,因为他们隐藏在系统的块设备接口后。这个驱动用于新型闪存设备的通用闪存驱动器驱动。
driver/net/
网络驱动提供像AppleTalk、TCP和其他的网络协议。这些驱动也提供对调制解调器、USB 2.0的网络设备、和射频设备的支持。This directory is the home for most interface adapters. Unlike drivers/scsi, this directory doesn’t include the actual communication protocols, which live in the top-level net/ directory tree.
driver/nfc/
这个驱动是德州仪器的共享传输层之间的接口和NCI核心。
driver/ntb/
不透明的桥接驱动提供了在PCIe系统的不透明桥接。PCIe是一种高速扩展总线标准。
driver/nubus/
NuBus是一种32位并行计算总线,用于支持苹果设备。
driver/nvdimm/
driver/nvme/
driver/nvmem/
driver/of/
这个驱动程序提供设备树中创建、访问和解释程序的OF助手。设备树是一种数据结构,用于描述硬件。
driver/oprofile/
这个驱动用于从驱动到用户空间进程(运行在用户态下的应用)评测整个系统。这帮助开发人员找到性能问题。
driver/parisc/
这些驱动用于HP生产的PA-RISC架构设备。PA-RISC是一种特殊指令集的处理器。
driver/parport/
并口驱动提供了Linux下的并口支持。
driver/pci/
这些驱动提供了PCI总线服务。
driver/pcmcia/
这些是笔记本的pc卡驱动。
driver/perf/
driver/phy/
driver/pinctrl/
这些驱动用来处理引脚控制设备。引脚控制器可以禁用或启用I/O设备。
driver/platform/
该目录包含了不同的计算机平台的驱动,像Acer、Dell、Toshiba、IBM、Intel、Chrombooks等。
driver/pnp/
即插即用驱动允许用户在插入一个像USB的设备后可以立即使用而不必手动配置设备。
driver/power/
电源驱动使内核可以测量电池电量,检测充电器和进行电源管理。
driver/powercap/
driver/pps/
Pulse-Per-Second驱动用来控制电流脉冲速率,用于计时。
driver/ps3/
这是Sony的游戏控制台驱动 - PlayStation3.
driver/ptp/
图片传输协议(PTP)驱动支持一种从数码相机中传输图片的协议。
driver/pwm/
脉宽调制(PWM)驱动用于控制设备的电流脉冲,主要用于控制像CPU风扇。
driver/rapidio/
RapidIO驱动用于管理RapidIO架构,它是一种高性能分组交换,用于电路板上交互芯片的交互技术,也用于互相使用底板的电路板。
driver/ras/
driver/regulator/
校准驱动用于校准电流、温度、或其他可能系统存在的校准硬件。
driver/remoteproc/
这些驱动用来管理远程处理器。
driver/reset/
driver/rpmsg/
这个驱动用来控制支持大量驱动的远程处理器通讯总线(rpmsg)。这些总线提供消息传递设施,促进客户端驱动程序编写自己的连接协议消息。
driver/rtc/
实时时钟(RTC)驱动使内核可以读取时钟。
driver/s390/
用于31/32位的大型机架构的驱动。
driver/sbus/
用于管理基于SPARC Sbus总线驱动。
driver/scsi/
允许内核使用SCSI标准外围设备,例如: Linux将在与SCSI硬件传输数据时使用SCSI驱动。 Everything related to the SCSI bus has always been placed in this directory. This includes both controller-independent support for specific devices (such as hard drives and tapes) and drivers for specific SCSI controller boards.
driver/sfi/
简单固件接口(SFI)驱动允许固件发送信息表给操作系统,这些表的数据称为SFI表。
driver/sh/
该驱动用于支持SuperHway总线。
driver/sn/
该驱动用于支持IOC3串口。
driver/soc/
driver/spi/
这些驱动处理串行设备接口总线(SPI),它是一个在在全双工下运行的同步串行数据链路标准。全双工是指两个设备可以同一时间同时发送和接收信息,双工指的是双向通信。设备在主/从模式下通信(取决于设备配置)。
driver/spmi/
driver/ssb/
SSB (Sonics Silicon Backplane)驱动提供对在不同博通芯片和嵌入式设备上使用的迷你总线的支持。
driver/staging/
该目录含有许多子目录。这里所有的驱动还需要在加入主内核前经过更多的开发工作。
driver/target/
SCSI设备驱动程序。
driver/tc/
这些驱动用于Tubro Channel。Tubro Channel是数字设备公司开发的32位开放总线,这主要用于DEC工作站。
driver/thermal/
Thermal驱动使CPU保持较低温度。
driver/thunderbolt/
driver/tty/
tty驱动用于管理物理终端连接。
driver/uio/
该驱动允许用户编译运行在用户空间而不是内核空间的驱动,这使用户驱动不会导致内核崩溃。
driver/usb/
通用串行总线(USB)设备允许内核使用USB端口。闪存驱动和记忆卡已经包含了固件和控制器,所以这些驱动程序允许内核使用USB接口和与USB设备。
driver/uwb/
Ultra-WideBand驱动用来管理短距离,高带宽通信的超低功耗的射频设备。
driver/vfio/
允许设备访问用户空间的VFIO驱动。
driver/vhost/
这是用于宿主内核中的virtio服务器驱动,用于虚拟化中。
driver/video/
这是用来管理显卡和监视器的视频驱动。 The directory is concerned with video output, not video input.
driver/virt/
这些驱动用来虚拟化。
driver/virtio/
这个驱动用来在虚拟PCI设备上使用virtio设备,用于虚拟化中。
driver/vlynq/
这个驱动控制着由德州仪器开发的专有接口。这些都是宽带产品,像WLAN和调制解调器,VOIP处理器,音频和数字媒体信号处理芯片。
driver/vme/
WMEbus最初是为摩托罗拉68000系列处理器开发的总线标准。
driver/w1/
这些驱动用来控制one-wire总线。
driver/watchdog/
该驱动管理看门狗定时器,这是一个可以用来检测和恢复异常的定时器。
driver/xen/
该驱动是Xen管理程序系统。这是个允许用户在一台计算机的软件或硬件运行多个操作系统。这意味着xen的代码将允许用户在同一时间的一台计算机上运行两个或更多的Linux系统。用户也可以在Linux上运行Windows、Solaris、FreeBSD、或其他操作系统。
driver/zorro/
该驱动提供Zorro Amiga总线支持。
10.1.1.2 Device Driver in block/
block/
Block层的实现。最初,block层的代码一部分位于drivers目录,一部分位于fs目录,从2.6.15开始,block层的核心代码被提取出来放在了顶层的block目录。
10.1.1.3 Device Driver in firmware/
firmware/
二进制固件程序。
NOTE: firmware/目录下的文件为二进制固件,用于支持某些硬件设备。该目录下的文件不是开放源代码的,因此存在固件之争(2002年,Richard Stallman曾质疑这些二进制固件使得Linux成为非自由软件,甚至违反了GPL License)。而driver/firmware/目录下的文件则是开放源代码的。
10.1.1.4 Device Driver in net/
net/
网络驱动程序。
10.1.1.5 Device Driver in sound/
sound/
声卡驱动程序。
10.1.2 设备驱动程序在Linux Kernel中的比重
在Linux Kernel v3.2.0中,设备驱动程序大小所占比重约52.68%:
- Total size: 410M
- Directory drivers/ size: 216M, 52.68%
在每个Linux Kernel Release中,改动最大的部分也是设备驱动程序,例如:
Linux Kernel v3.10
chenwx@chenwx ~/linux $ git diff --shortstat v3.9 v3.10 drivers/
5121 files changed, 431416 insertions(+), 265193 deletions(-)
chenwx@chenwx ~/linux $ git diff --shortstat v3.9 v3.10
10471 files changed, 663996 insertions(+), 395390 deletions(-)
64.97% 67.07%
Linux Kernel v3.11
chenwx@chenwx ~/linux $ git diff --shortstat v3.10 v3.11 drivers/
4734 files changed, 590741 insertions(+), 236962 deletions(-)
chenwx@chenwx ~/linux $ git diff --shortstat v3.10 v3.11
9692 files changed, 789124 insertions(+), 341338 deletions(-)
74.86% 69.42%
Linux Kernel v3.12
chenwx@chenwx ~/linux $ git diff --shortstat v3.11 v3.12 drivers/
4409 files changed, 427509 insertions(+), 165182 deletions(-)
chenwx@chenwx ~/linux $ git diff --shortstat v3.11 v3.12
8636 files changed, 587981 insertions(+), 264385 deletions(-)
72.70% 62.48%
Linux Kernel v3.13
chenwx@chenwx ~/linux $ git diff --shortstat v3.12 v3.13 drivers/
4616 files changed, 231474 insertions(+), 108537 deletions(-)
chenwx@chenwx ~/linux $ git diff --shortstat v3.12 v3.13
9850 files changed, 441972 insertions(+), 237926 deletions(-)
52.37% 45.61%
Linux Kernel 3.14
chenwx@chenwx ~/linux $ git diff --shortstat v3.13 v3.14 drivers/
5244 files changed, 409987 insertions(+), 162394 deletions(-)
chenwx@chenwx ~/linux $ git diff --shortstat v3.13 v3.14
10601 files changed, 606195 insertions(+), 265116 deletions(-)
67.63% 61.25%
10.1.3 设备驱动程序的分类
根据«Understanding Modern Device Drivers»第2.1节可知,设备驱动程序分为如下三大类:
- Char Drivers, see 10.3 Char Drivers
- Block Drivers, see 10.4 Block Drivers
- Network Drivers, see 10.5 Network Drivers
Most device drivers represent physical hardware. However, some device drivers are virtual, providing access to kernel functionality. 参见10.3.4.1 内存设备节. Some of the most common Pseudo devices are:
- the kernel random number generator (accessible at
/dev/randomand/dev/urandom), - the null device (accessible at
/dev/null) - the zero device (accessible at
/dev/zero) - the full device (accessible at
/dev/full) - the memory device (accessible at
/dev/mem)
执行下列命令查看系统中的设备信息:
chenwx ~ $ cat /proc/devices
Character devices:
1 mem
4 /dev/vc/0
4 tty
4 ttyS
5 /dev/tty
5 /dev/console
5 /dev/ptmx
5 ttyprintk
6 lp
7 vcs
10 misc
13 input
21 sg
29 fb
99 ppdev
108 ppp
116 alsa
128 ptm
136 pts
180 usb
189 usb_device
216 rfcomm
226 drm
250 bsg
251 watchdog
252 ptp
253 pps
254 rtc
Block devices:
1 ramdisk
259 blkext
7 loop
8 sd
9 md
11 sr
65 sd
66 sd
67 sd
68 sd
69 sd
70 sd
71 sd
128 sd
129 sd
130 sd
131 sd
132 sd
133 sd
134 sd
135 sd
251 device-mapper
252 nullb
253 virtblk
254 mdp
执行下列命令查看主/次设备号:
chenwx ~ $ ls -l /dev
crw-rw---- 1 root video 10, 175 Nov 14 18:43 agpgart
crw------- 1 root root 10, 235 Nov 14 18:43 autofs
drwxr-xr-x 2 root root 660 Nov 15 02:42 block
drwxr-xr-x 2 root root 80 Nov 15 02:42 bsg
crw------- 1 root root 10, 234 Nov 14 18:43 btrfs-control
drwxr-xr-x 3 root root 60 Nov 15 02:42 bus
drwxr-xr-x 2 root root 3760 Nov 14 23:36 char
crw------- 1 root root 5, 1 Nov 14 18:43 console
lrwxrwxrwx 1 root root 11 Nov 15 02:42 core -> /proc/kcore
drwxr-xr-x 2 root root 60 Nov 15 02:42 cpu
...
NOTE: 某些主设备号已被预先静态的指定给了许多常见设备,这些已被分配掉的主设备号都列在Documentation/devices.txt中。
10.2 Linux的设备驱动模型/Device Driver Model
10.2.1 设备驱动程序的初始化/driver_init()
设备驱动程序的初始化函数为driver_init(),其调用关系如下:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> rest_init() // 参见[4.3.4.1.4.3.13 rest_init()]节
-> kernel_init() // 参见[4.3.4.1.4.3.13.1 kernel_init()]节
-> do_basic_setup() // 参见[4.3.4.1.4.3.13.1.2 do_basic_setup()]节
-> driver_init()
函数driver_init()定义于drivers/base/init.c:
/**
* driver_init - initialize driver model.
*
* Call the driver model init functions to initialize their
* subsystems. Called early from init/main.c.
*/
void __init driver_init(void)
{
/* These are the core pieces */
devtmpfs_init(); // 参见[11.3.10.2 Devtmpfs的编译及初始化]节
devices_init(); // 参见[10.2.1.1 devices_init()]节
buses_init(); // 参见[10.2.1.2 buses_init()]节
classes_init(); // 参见[10.2.1.3 classes_init()]节
firmware_init(); // 参见[10.2.1.4 firmware_init()]节
hypervisor_init(); // 参见[10.2.1.5 hypervisor_init()]节
/* These are also core pieces, but must come after the
* core core pieces.
*/
platform_bus_init(); // 参见[10.2.1.6 platform_bus_init()]节
system_bus_init(); // 参见[10.2.1.7 system_bus_init()]节
cpu_dev_init(); // 参见[10.2.1.8 cpu_dev_init()]节
memory_dev_init(); // 参见[10.2.1.9 memory_dev_init()]节
}
10.2.1.1 devices_init()
该函数定义于drivers/base/core.c:
int __init devices_init(void)
{
/*
* 创建目录/sys/devices,参见[15.7.4.1 kset_create_and_add()]节
* 变量device_uevent_ops,参见[15.7.5.1 device_uevent_ops]节
* The variable devices_kset is a kset to create /sys/devices/.
*/
devices_kset = kset_create_and_add("devices", &device_uevent_ops, NULL);
if (!devices_kset)
return -ENOMEM;
// 创建目录/sys/dev,参见[15.7.1.2 kobject_create_and_add()]节
dev_kobj = kobject_create_and_add("dev", NULL);
if (!dev_kobj)
goto dev_kobj_err;
// 创建目录/sys/dev/block,参见[15.7.1.2 kobject_create_and_add()]节
sysfs_dev_block_kobj = kobject_create_and_add("block", dev_kobj);
if (!sysfs_dev_block_kobj)
goto block_kobj_err;
// 创建目录/sys/dev/char,参见[15.7.1.2 kobject_create_and_add()]节
sysfs_dev_char_kobj = kobject_create_and_add("char", dev_kobj);
if (!sysfs_dev_char_kobj)
goto char_kobj_err;
return 0;
char_kobj_err:
kobject_put(sysfs_dev_block_kobj); // 参见[15.7.2.2 kobject_put()]节
block_kobj_err:
kobject_put(dev_kobj); // 参见[15.7.2.2 kobject_put()]节
dev_kobj_err:
kset_unregister(devices_kset);
return -ENOMEM;
}
10.2.1.2 buses_init()
该函数定义于drivers/base/bus.c:
int __init buses_init(void)
{
// 创建目录/sys/bus,参见[15.7.4.1 kset_create_and_add()]节
bus_kset = kset_create_and_add("bus", &bus_uevent_ops, NULL);
if (!bus_kset)
return -ENOMEM;
return 0;
}
10.2.1.3 classes_init()
该函数定义于drivers/base/class.c:
int __init classes_init(void)
{
// 创建目录/sys/class,参见[15.7.4.1 kset_create_and_add()]节
class_kset = kset_create_and_add("class", NULL, NULL);
if (!class_kset)
return -ENOMEM;
return 0;
}
10.2.1.4 firmware_init()
该函数定义于drivers/base/firmware.c:
int __init firmware_init(void)
{
// 创建目录/sys/firmware,参见[15.7.1.2 kobject_create_and_add()]节
firmware_kobj = kobject_create_and_add("firmware", NULL);
if (!firmware_kobj)
return -ENOMEM;
return 0;
}
10.2.1.5 hypervisor_init()
该函数定义于drivers/base/hypervisor.c:
int __init hypervisor_init(void)
{
// 创建目录/sys/hypervisor,参见[15.7.1.2 kobject_create_and_add()]节
hypervisor_kobj = kobject_create_and_add("hypervisor", NULL);
if (!hypervisor_kobj)
return -ENOMEM;
return 0;
}
10.2.1.6 platform_bus_init()
该函数定义于drivers/base/platform.c:
struct device platform_bus = {
.init_name = "platform",
};
struct bus_type platform_bus_type = {
.name = "platform",
.dev_attrs = platform_dev_attrs,
.match = platform_match,
.uevent = platform_uevent,
.pm = &platform_dev_pm_ops,
};
int __init platform_bus_init(void)
{
int error;
// clean up early platform code in driver list: early_platform_device_list
early_platform_cleanup();
/*
* 注册platform_bus设备,参见[10.2.3.3 注册设备/device_register()]节;
* 变量platform_bus用于platform_bus_register(),
* 参见[10.2.5.1 注册平台设备/platform_device_register()]节
*/
error = device_register(&platform_bus);
if (error)
return error;
error = bus_register(&platform_bus_type);
if (error)
device_unregister(&platform_bus);
return error;
}
10.2.1.7 system_bus_init()
该函数定义于drivers/base/sys.c:
int __init system_bus_init(void)
{
/*
* 创建目录/sys/devices/system
* 参见[15.7.4.1 kset_create_and_add()]节和[10.2.1.1 devices_init()]节
*/
system_kset = kset_create_and_add("system", NULL, &devices_kset->kobj);
if (!system_kset)
return -ENOMEM;
return 0;
}
10.2.1.8 cpu_dev_init()
该函数定义于drivers/base/cpu.c:
struct sysdev_class cpu_sysdev_class = {
.name = "cpu",
.attrs = cpu_sysdev_class_attrs,
};
int __init cpu_dev_init(void)
{
int err;
// 参见[10.2.1.8.1 sysdev_class_register()]节
err = sysdev_class_register(&cpu_sysdev_class);
#if defined(CONFIG_SCHED_MC) || defined(CONFIG_SCHED_SMT)
if (!err)
err = sched_create_sysfs_power_savings_entries(&cpu_sysdev_class);
#endif
return err;
}
10.2.1.8.1 sysdev_class_register()
该函数定义于drivers/base/sys.c:
int sysdev_class_register(struct sysdev_class *cls)
{
int retval;
pr_debug("Registering sysdev class '%s'\n", cls->name);
INIT_LIST_HEAD(&cls->drivers);
memset(&cls->kset.kobj, 0x00, sizeof(struct kobject));
// 设置父节点为/sys/devices/system,参见[10.2.1.7 system_bus_init()]节
cls->kset.kobj.parent = &system_kset->kobj;
cls->kset.kobj.ktype = &ktype_sysdev_class;
cls->kset.kobj.kset = system_kset;
// 设置kset.kobj->name = "cpu",对应目录为/sys/devices/system/cpu
retval = kobject_set_name(&cls->kset.kobj, "%s", cls->name);
if (retval)
return retval;
// 创建kset.kobj所对应的目录/sys/devices/system/cpu
retval = kset_register(&cls->kset);
/*
* 在/sys/devices/system/cpu目录下创建cls->attrs包含的文件,
* 参见[11.3.5.6.1 sysfs_create_files()]节
*/
if (!retval && cls->attrs)
retval = sysfs_create_files(&cls->kset.kobj, (const struct attribute **)cls->attrs);
return retval;
}
10.2.1.9 memory_dev_init()
该函数定义于drivers/base/memory.c:
static const struct kset_uevent_ops memory_uevent_ops = {
.name = memory_uevent_name, // "memory"
.uevent = memory_uevent,
};
/*
* Initialize the sysfs support for memory devices...
*/
int __init memory_dev_init(void)
{
unsigned int i;
int ret;
int err;
unsigned long block_sz;
memory_sysdev_class.kset.uevent_ops = &memory_uevent_ops;
// 创建目录/sys/devices/system/memory,参见[10.2.1.8.1 sysdev_class_register()]节
ret = sysdev_class_register(&memory_sysdev_class);
if (ret)
goto out;
block_sz = get_memory_block_size();
sections_per_block = block_sz / MIN_MEMORY_BLOCK_SIZE;
/*
* Create entries for memory sections that were found
* during boot and have been initialized
*/
// 创建目录/sys/devices/system/memory/memoryXXX,及其子目录和子文件
for (i = 0; i < NR_MEM_SECTIONS; i++) {
if (!present_section_nr(i))
continue;
err = add_memory_section(0, __nr_to_section(i), MEM_ONLINE, BOOT);
if (!ret)
ret = err;
}
// 创建文件/sys/devices/system/memory/probe
err = memory_probe_init();
if (!ret)
ret = err;
/*
* 创建如下文件:
* - /sys/devices/system/memory/hard_offline_page
* - /sys/devices/system/memory/soft_offline_page
*/
err = memory_fail_init();
if (!ret)
ret = err;
// 创建文件/sys/devices/system/memory/block_size_bytes
err = block_size_init();
if (!ret)
ret = err;
out:
if (ret)
printk(KERN_ERR "%s() failed: %d\n", __func__, ret);
return ret;
10.2.2 struct bus_type
该结构定义于include/linux/device.h:
struct bus_type {
const char *name; // 总线名称
struct bus_attribute *bus_attrs; // 总线属性
struct device_attribute *dev_attrs; // 该总线上所有设备的默认属性
struct driver_attribute *drv_attrs; // 该总线上所有驱动的默认属性
int (*match)(struct device *dev, struct device_driver *drv);
int (*uevent)(struct device *dev, struct kobj_uevent_env *env);
int (*probe)(struct device *dev);
int (*remove)(struct device *dev);
void (*shutdown)(struct device *dev);
int (*suspend)(struct device *dev, pm_message_t state);
int (*resume)(struct device *dev);
const struct dev_pm_ops *pm; // 设备电源管理
struct iommu_ops *iommu_ops;
struct subsys_private *p; // 私有数据,完全由驱动核心初始化并使用,参见下文
};
其中, struct subsys_private定义于drivers/base/base.h:
struct subsys_private {
struct kset subsys;
struct kset *devices_kset;
struct kset *drivers_kset;
/*
* 该链表用来链接struct device->knode_class元素,参见如下函数调用:
* device_register()->device_add()->klist_add_tail(&dev->knode_class,
* &dev->class->p->klist_devices)
*
* 查询该链表的函数:bus_find_device(), bus_for_each_dev()
*/
struct klist klist_devices;
/*
* 该链表用来链接struct device_driver->p->klist_drivers元素,参见如下函数调用:
* driver_register()->bus_add_driver()->klist_add_tail()
* 查询该链表的函数:bus_for_each_drv()
*/
struct klist klist_drivers;
struct blocking_notifier_head bus_notifier;
unsigned int drivers_autoprobe:1;
// 指向本结构所属的struct bus_type
struct bus_type *bus;
struct list_head class_interfaces;
struct kset glue_dirs;
struct mutex class_mutex;
struct class *class;
};
10.2.2.1 bus_register()
该函数定义于drivers/base/bus.c:
/**
* bus_register - register a bus with the system.
* @bus: bus.
*
* Once we have that, we registered the bus with the kobject
* infrastructure, then register the children subsystems it has:
* the devices and drivers that belong to the bus.
*/
int bus_register(struct bus_type *bus)
{
int retval;
struct subsys_private *priv;
priv = kzalloc(sizeof(struct subsys_private), GFP_KERNEL);
if (!priv)
return -ENOMEM;
priv->bus = bus;
bus->p = priv;
BLOCKING_INIT_NOTIFIER_HEAD(&priv->bus_notifier);
/*
* 设置priv->subsys.kobj->name = bus->name
* 下文中,通过调用kset_register()来创建目录/sys/bus/XXX
* 通过下列命令在内核源代码中搜索关键字"bus_register(&":
* $ git grep -n "bus_register(&"
*/
retval = kobject_set_name(&priv->subsys.kobj, "%s", bus->name);
if (retval)
goto out;
// 设置该bus的父目录为/sys/bus,参见[10.2.1.2 buses_init()]节
priv->subsys.kobj.kset = bus_kset;
priv->subsys.kobj.ktype = &bus_ktype;
/*
* 设置自动匹配驱动程序,如下函数会判断该字段:
* - bus_probe_device(),参见[10.2.3.3.2.3 bus_probe_device()]节
* - bus_add_driver(),参见[10.2.4.1.1 添加设备驱动程序/bus_add_driver()]节
*/
priv->drivers_autoprobe = 1;
/*
* 将该bus注册到目录/sys/bus/XXX
* 其中,XXX为priv->subsys->kobj->name,即上文中的bus->name
*/
retval = kset_register(&priv->subsys);
if (retval)
goto out;
// 创建文件/sys/bus/XXX/uevent
retval = bus_create_file(bus, &bus_attr_uevent);
if (retval)
goto bus_uevent_fail;
/*
* 创建目录/sys/bus/XXX/devices,该目录下的每个子目录对应于一个设备,
* 参见[15.7.4.1 kset_create_and_add()]节
*/
priv->devices_kset = kset_create_and_add("devices", NULL, &priv->subsys.kobj);
if (!priv->devices_kset) {
retval = -ENOMEM;
goto bus_devices_fail;
}
/*
* 创建目录/sys/bus/XXX/drivers,该目录下的每个子目录对应于一个设备驱动程序,
* 参见[15.7.4.1 kset_create_and_add()]节
*/
priv->drivers_kset = kset_create_and_add("drivers", NULL, &priv->subsys.kobj);
if (!priv->drivers_kset) {
retval = -ENOMEM;
goto bus_drivers_fail;
}
// 初始化链表,参见[15.1.13 双向循环链表的封装/struct klist]节
klist_init(&priv->klist_devices, klist_devices_get, klist_devices_put);
klist_init(&priv->klist_drivers, NULL, NULL);
/*
* 创建下列文件:
* - /sys/bus/XXX/drivers_probe
* - /sys/bus/XXX/drivers_autoprobe
*/
retval = add_probe_files(bus);
if (retval)
goto bus_probe_files_fail;
/*
* Add default attributes for this bus.
* 即创建文件:bus->bus_attrs[idx]->attr
*/
retval = bus_add_attrs(bus);
if (retval)
goto bus_attrs_fail;
pr_debug("bus: '%s': registered\n", bus->name);
return 0;
bus_attrs_fail:
remove_probe_files(bus);
bus_probe_files_fail:
kset_unregister(bus->p->drivers_kset);
bus_drivers_fail:
kset_unregister(bus->p->devices_kset);
bus_devices_fail:
bus_remove_file(bus, &bus_attr_uevent);
bus_uevent_fail:
kset_unregister(&bus->p->subsys);
out:
kfree(bus->p);
bus->p = NULL;
return retval;
}
例如:
// 查看系统中注册的bus
chenwx@chenwx ~/linux $ ll /sys/bus/
drwxr-xr-x 4 root root 0 Oct 24 21:30 acpi
drwxr-xr-x 4 root root 0 Oct 24 21:30 clockevents
drwxr-xr-x 4 root root 0 Oct 24 21:30 clocksource
drwxr-xr-x 4 root root 0 Oct 24 21:30 container
drwxr-xr-x 4 root root 0 Oct 24 21:30 cpu
drwxr-xr-x 4 root root 0 Oct 24 21:30 event_source
drwxr-xr-x 4 root root 0 Oct 24 21:30 firewire
drwxr-xr-x 4 root root 0 Oct 24 21:30 hdaudio
drwxr-xr-x 4 root root 0 Oct 24 21:30 hid
drwxr-xr-x 4 root root 0 Oct 24 21:30 i2c
drwxr-xr-x 4 root root 0 Oct 24 21:30 machinecheck
drwxr-xr-x 4 root root 0 Oct 24 21:30 mdio_bus
drwxr-xr-x 4 root root 0 Oct 24 21:30 memory
drwxr-xr-x 4 root root 0 Oct 24 21:30 mipi-dsi
drwxr-xr-x 4 root root 0 Oct 24 21:30 mmc
drwxr-xr-x 4 root root 0 Oct 24 21:30 nd
drwxr-xr-x 4 root root 0 Oct 24 21:30 node
drwxr-xr-x 4 root root 0 Oct 24 21:30 parport
drwxr-xr-x 5 root root 0 Oct 24 21:30 pci
drwxr-xr-x 4 root root 0 Oct 24 21:30 pci_express
drwxr-xr-x 4 root root 0 Oct 24 21:30 pcmcia
drwxr-xr-x 4 root root 0 Oct 24 21:30 platform
drwxr-xr-x 4 root root 0 Oct 24 21:30 pnp
drwxr-xr-x 4 root root 0 Oct 24 21:30 rapidio
drwxr-xr-x 4 root root 0 Oct 24 21:30 scsi
drwxr-xr-x 4 root root 0 Oct 24 21:30 sdio
drwxr-xr-x 4 root root 0 Oct 24 21:30 serio
drwxr-xr-x 4 root root 0 Oct 24 21:30 snd_seq
drwxr-xr-x 4 root root 0 Oct 24 21:30 spi
drwxr-xr-x 4 root root 0 Oct 24 21:30 usb
drwxr-xr-x 4 root root 0 Oct 24 21:30 virtio
drwxr-xr-x 4 root root 0 Oct 24 21:30 vme
drwxr-xr-x 4 root root 0 Oct 24 21:30 workqueue
drwxr-xr-x 4 root root 0 Oct 24 21:30 xen
drwxr-xr-x 4 root root 0 Oct 24 21:30 xen-backend
// 查看某bus的目录结构
chenwx@chenwx ~/linux $ ll /sys/bus/acpi/
drwxr-xr-x 2 root root 0 Oct 24 21:46 devices
drwxr-xr-x 14 root root 0 Oct 24 21:46 drivers
-rw-r--r-- 1 root root 4.0K Oct 24 21:46 drivers_autoprobe
--w------- 1 root root 4.0K Oct 24 21:46 drivers_probe
--w------- 1 root root 4.0K Oct 24 21:46 uevent
// 查找内核源代码中的struct bus_type对象
chenwx@chenwx ~/linux $ git grep -n "bus_register(&"
...
drivers/acpi/bus.c:1156: result = bus_register(&acpi_bus_type);
...
chenwx@chenwx ~/linux $ cat drivers/acpi/bus.c
struct bus_type acpi_bus_type = {
.name = "acpi",
.match = acpi_bus_match,
.probe = acpi_device_probe,
.remove = acpi_device_remove,
.uevent = acpi_device_uevent,
};
10.2.2.2 bus_unregister()
该函数定义于drivers/base/bus.c:
/**
* bus_unregister - remove a bus from the system
* @bus: bus.
*
* Unregister the child subsystems and the bus itself.
* Finally, we call bus_put() to release the refcount
*/
void bus_unregister(struct bus_type *bus)
{
pr_debug("bus: '%s': unregistering\n", bus->name);
bus_remove_attrs(bus);
remove_probe_files(bus);
kset_unregister(bus->p->drivers_kset);
kset_unregister(bus->p->devices_kset);
bus_remove_file(bus, &bus_attr_uevent);
kset_unregister(&bus->p->subsys);
kfree(bus->p);
bus->p = NULL;
}
10.2.3 struct device
该结构定义于include/linux/device.h:
/**
* struct device - The basic device structure
*
* At the lowest level, every device in a Linux system is represented by an
* instance of struct device. The device structure contains the information
* that the device model core needs to model the system. Most subsystems,
* however, track additional information about the devices they host. As a
* result, it is rare for devices to be represented by bare device structures;
* instead, that structure, like kobject structures, is usually embedded within
* a higher-level representation of the device.
*/
struct device {
// 该设备的父设备
struct device *parent;
// 用于保存该设备的私有数据,参见下文
struct device_private *p;
struct kobject kobj;
/* initial name of the device */
const char *init_name;
/* the type of device, device name is kept in type→name */
const struct device_type *type;
/* mutex to synchronize calls to its driver. */
struct mutex mutex;
/* type of bus device is on */
struct bus_type *bus;
/* which driver has allocated this device */
struct device_driver *driver;
/* Platform specific data, device core doesn't touch it */
void *platform_data;
// 电源管理相关信息
struct dev_pm_info power;
struct dev_pm_domain *pm_domain;
#ifdef CONFIG_NUMA
/* NUMA node this device is close to */
int numa_node;
#endif
/* dma mask (if dma'able device) */
u64 *dma_mask;
/*
* Like dma_mask, but for alloc_coherent mappings as not all hardware
* supports 64 bit addresses for consistent allocations such descriptors.
*/
u64 coherent_dma_mask;
struct device_dma_parameters *dma_parms;
/* dma pools (if dma'ble) */
struct list_head dma_pools;
/* internal for coherent mem override */
struct dma_coherent_mem *dma_mem;
/* arch specific additions */
struct dev_archdata archdata;
/* associated device tree node */
struct device_node *of_node;
/* dev_t, creates the sysfs "dev" */
dev_t devt;
spinlock_t devres_lock;
struct list_head devres_head;
/*
* 元素dev->knode_class被链接到以dev->class->p->klist_devices为链表头的链表中,
* 参见函数调用:device_register()->device_add()
*/
struct klist_node knode_class;
struct class *class;
/* optional groups */
const struct attribute_group **groups;
void (*release)(struct device *dev);
};
其中,struct device_private定义于drivers/base/base.h:
struct device_private {
/*
* 该链表用来链接本设备的子设备所对应的struct device->p->knode_parent
* 元素,参见函数调用: device_register()->device_add()
* 查询该链表的函数: device_find_child(), device_for_each_child()
*/
struct klist klist_children;
/*
* 该元素被链接到以struct device->parent->p->klist_children
* 为链表头的链表中,参见如下函数调用:
* device_register()->device_add()
*/
struct klist_node knode_parent;
/*
* 该元素被链接到以struct device_driver->p->klist_devices
* 为链表头的链表中,参见如下函数调用:
* driver_register()->bus_add_driver()->driver_attach()
* ->__driver_attach()->driver_probe_device()->really_probe()
* ->driver_bound()
*/
struct klist_node knode_driver;
/*
* 该元素被链接到以struct bus_type->p->klist_devices
* 为链表头的链表中,参见如下函数调用:
* device_add(dev)->bus_add_device(dev)
* ->klist_add_tail(&dev->p->knode_bus, &bus->p->klist_devices);
*/
struct klist_node knode_bus;
void *driver_data;
// 指向使用本结构体的设备
struct device *device;
};
10.2.3.1 创建设备/device_create()
该函数定义于drivers/base/core.c:
/**
* device_create - creates a device and registers it with sysfs
* @class: pointer to the struct class that this device should be registered to
* @parent: pointer to the parent struct device of this new device, if any
* @devt: the dev_t for the char device to be added
* @drvdata: the data to be added to the device for callbacks
* @fmt: string for the device's name
*
* This function can be used by char device classes. A struct device
* will be created in sysfs, registered to the specified class.
*
* A "dev" file will be created, showing the dev_t for the device, if
* the dev_t is not 0,0.
*
* If a pointer to a parent struct device is passed in, the newly created
* struct device will be a child of that device in sysfs.
*
* The pointer to the struct device will be returned from the call.
* Any further sysfs files that might be required can be created using this
* pointer.
*
* Returns &struct device pointer on success, or ERR_PTR() on error.
*
* Note: the struct class passed to this function must have previously
* been created with a call to class_create().
*/
struct device *device_create(struct class *class, struct device *parent,
dev_t devt, void *drvdata, const char *fmt, ...)
{
va_list vargs;
struct device *dev;
va_start(vargs, fmt);
dev = device_create_vargs(class, parent, devt, drvdata, fmt, vargs);
va_end(vargs);
return dev;
}
其中,函数device_create_vargs()定义于drivers/base/core.c:
struct device *device_create_vargs(struct class *class, struct device *parent,
dev_t devt, void *drvdata, const char *fmt,
va_list args)
{
struct device *dev = NULL;
int retval = -ENODEV;
if (class == NULL || IS_ERR(class))
goto error;
dev = kzalloc(sizeof(*dev), GFP_KERNEL);
if (!dev) {
retval = -ENOMEM;
goto error;
}
dev->devt = devt;
dev->class = class;
/*
* 如下函数调用会使用dev->parent:
* device_register()->device_add()->setup_parent()
* ->get_device_parent()->virtual_device_parent()
*/
dev->parent = parent;
/*
* 释放该设备的处理函数为device_create_release(),该函数被下列函数调用:
* device_unregister(dev)
* -> put_device(dev)
* -> kobject_put(&dev->kobj)
* -> kref_put(&kobj->kref, kobject_release)
* -> kobject_release()
* -> kobject_cleanup(struct kobject *kobj)
* -> struct kobj_type *t = get_ktype(kobj);
* -> t->release(kobj) // NOTE (1)
* -> device_release()
* -> dev->release(dev)
* -> device_create_release()
*
* 其中,NOTE (1)处t->release()是通过下面的函数赋值的:
* device_create() // 参见本节
* -> device_create_vargs()
* -> device_register() // 参见[10.2.3.3 注册设备/device_register()]节
* -> device_initialize(struct device *dev)
* -> kobject_init(&dev->kobj, &device_ktype)
* -> dev->kobj->ktype = device_ktype
*/
dev->release = device_create_release;
// 设置dev->p->driver_data = drvdata;
dev_set_drvdata(dev, drvdata);
// 设置kobj->name
retval = kobject_set_name_vargs(&dev->kobj, fmt, args);
if (retval)
goto error;
// 注册设备,参见[10.2.3.3 注册设备/device_register()]节
retval = device_register(dev);
if (retval)
goto error;
return dev;
error:
put_device(dev);
return ERR_PTR(retval);
}
10.2.3.2 销毁设备/destroy_device()
该函数定义于drivers/base/core.c:
/**
* device_destroy - removes a device that was created with device_create()
* @class: pointer to the struct class that this device was registered with
* @devt: the dev_t of the device that was previously registered
*
* This call unregisters and cleans up a device that was created with a
* call to device_create().
*/
void device_destroy(struct class *class, dev_t devt)
{
struct device *dev;
// device iterator for locating a particular device
dev = class_find_device(class, NULL, &devt, __match_devt);
if (dev) {
put_device(dev);
// 参见[10.2.3.4 注销设备/device_unregister()]节
device_unregister(dev);
}
}
10.2.3.3 注册设备/device_register()
该函数定义于drivers/base/core.c:
/**
* device_register - register a device with the system.
* @dev: pointer to the device structure
*
* This happens in two clean steps - initialize the device
* and add it to the system. The two steps can be called
* separately, but this is the easiest and most common.
* I.e. you should only call the two helpers separately if
* have a clearly defined need to use and refcount the device
* before it is added to the hierarchy.
*
* NOTE: _Never_ directly free @dev after calling this function, even
* if it returned an error! Always use put_device() to give up the
* reference initialized in this function instead.
*/
int device_register(struct device *dev)
{
device_initialize(dev); // 参见[10.2.3.3.1 设备初始化/device_initialize()]节
return device_add(dev); // 参见[10.2.3.3.2 添加设备/device_add()]节
}
10.2.3.3.1 设备初始化/device_initialize()
该函数定义于drivers/base/core.c:
static struct kobj_type device_ktype = {
.release = device_release,
.sysfs_ops = &dev_sysfs_ops,
.namespace = device_namespace,
};
/**
* device_initialize - init device structure.
* @dev: device.
*
* This prepares the device for use by other layers by initializing
* its fields.
* It is the first half of device_register(), if called by
* that function, though it can also be called separately, so one
* may use @dev's fields. In particular, get_device()/put_device()
* may be used for reference counting of @dev after calling this
* function.
*
* NOTE: Use put_device() to give up your reference instead of freeing
* @dev directly once you have called this function.
*/
void device_initialize(struct device *dev)
{
/*
* 设置该device的父目录为/sys/devices,
* 参见[10.2.1.1 devices_init()]节
*/
dev->kobj.kset = devices_kset;
// 设置dev->kobj->ktype = &device_ktype
kobject_init(&dev->kobj, &device_ktype);
INIT_LIST_HEAD(&dev->dma_pools);
mutex_init(&dev->mutex);
lockdep_set_novalidate_class(&dev->mutex);
spin_lock_init(&dev->devres_lock);
INIT_LIST_HEAD(&dev->devres_head);
device_pm_init(dev);
set_dev_node(dev, -1);
}
10.2.3.3.2 添加设备/device_add()
该函数定义于drivers/base/core.c:
static struct device_attribute uevent_attr =
__ATTR(uevent, S_IRUGO | S_IWUSR, show_uevent, store_uevent);
static struct device_attribute devt_attr =
__ATTR(dev, S_IRUGO, show_dev, NULL);
/**
* device_add - add device to device hierarchy.
* @dev: device.
*
* This is part 2 of device_register(), though may be called
* separately _iff_ device_initialize() has been called separately.
*
* This adds @dev to the kobject hierarchy via kobject_add(), adds it
* to the global and sibling lists for the device, then
* adds it to the other relevant subsystems of the driver model.
*
* NOTE: _Never_ directly free @dev after calling this function, even
* if it returned an error! Always use put_device() to give up your
* reference instead.
*/
int device_add(struct device *dev)
{
struct device *parent = NULL;
struct class_interface *class_intf;
int error = -EINVAL;
// 增加设备的索引计数,即dev->kobj->kref->refcount
dev = get_device(dev);
if (!dev)
goto done;
// 初始化设备私有数据dev->p
if (!dev->p) {
error = device_private_init(dev);
if (error)
goto done;
}
/*
* for statically allocated devices, which should all be converted
* some day, we need to initialize the name. We prevent reading back
* the name, and force the use of dev_name()
*/
// 将dev->kobj->name设置为dev->init_name,并复位dev->init_name
if (dev->init_name) {
dev_set_name(dev, "%s", dev->init_name);
dev->init_name = NULL;
}
// 测试dev->kobj->name是否设置成功
if (!dev_name(dev)) {
error = -EINVAL;
goto name_error;
}
pr_debug("device: '%s': %s\n", dev_name(dev), __func__);
/*
* 增加父设备的索引计数,即dev->parent->kobj->kref->refcount
* 并将dev->kobj.parent设置为parent->kobj
* 参见[10.2.3.3.2.1 setup_parent()]节
*/
parent = get_device(dev->parent);
setup_parent(dev, parent);
/* use parent numa_node */
// 将dev->numa_node设置为parent->numa_node
if (parent)
set_dev_node(dev, dev_to_node(parent));
/* first, register with generic layer. */
/* we require the name to be set before, and pass NULL */
// 设置dev->kobj->parent = dev->kobj.parent,并创建目录/sys/devices/XXX
// 其中,XXX为dev->kobj->name,即上文中的dev->init_name
error = kobject_add(&dev->kobj, dev->kobj.parent, NULL);
if (error)
goto Error;
/* notify platform of device entry */
// 由init_acpi_device_notify()设置函数指针 platform_notify
if (platform_notify)
platform_notify(dev);
// 创建文件/sys/devices/XXX/uevent
// 参见[10.2.3.3.2.2.2 创建设备属性/device_create_file()]节
error = device_create_file(dev, &uevent_attr);
if (error)
goto attrError;
if (MAJOR(dev->devt)) {
// 创建文件/sys/devices/XXX/dev
// 参见[10.2.3.3.2.2.2 创建设备属性/device_create_file()]节
error = device_create_file(dev, &devt_attr);
if (error)
goto ueventattrError;
/*
* 创建链接文件/sys/class/YYY/mmm:nnn,
* 其指向/sys/devices/XXX/YYY/mmm:nnn
*/
error = device_create_sys_dev_entry(dev);
if (error)
goto devtattrError;
/*
* 目录/dev被挂载为devtmpfs文件系统,故可通过向线程
* devtmpfsd发送request来创建设备文件/dev/DevName,
* 参见[11.3.10.2.2.1 devtmpfs_create_node()]节;
*
* 文件名/dev/DevName是通过如下函数获得的,
* devtmpfs_create_node()->device_get_devnode()
* 参见[11.3.10.2.2.1.1 device_get_devnode()]节
*/
devtmpfs_create_node(dev);
}
/*
* 创建链接文件/sys/devices/XXX/subsystem,
* 其指向/sys/bus/event_source
*/
error = device_add_class_symlinks(dev);
if (error)
goto SymlinkError;
/*
* 在目录/sys/devices/XXX中创建如下属性文件:
* - dev->class->dev_attrs
* - dev->class->dev_bin_attrs
*/
error = device_add_attrs(dev);
if (error)
goto AttrsError;
/*
* 在目录/sys/devices/XXX中创建属性文件
* dev->bus->dev_attrs[idx]
*/
error = bus_add_device(dev);
if (error)
goto BusError;
error = dpm_sysfs_add(dev);
if (error)
goto DPMError;
// 将元素dev->power.entry添加到链表dpm_list的尾部
device_pm_add(dev);
/* Notify clients of device addition. This call must come
* after dpm_sysf_add() and before kobject_uevent().
*/
if (dev->bus)
blocking_notifier_call_chain(&dev->bus->p->bus_notifier, BUS_NOTIFY_ADD_DEVICE, dev);
// 参见[15.7.5 kobject_uevent()]节
kobject_uevent(&dev->kobj, KOBJ_ADD);
/*
* 为该新设备查找对应的驱动程序(probe drivers for a new device)
* 参见[10.2.3.3.2.3 bus_probe_device()]节
*/
bus_probe_device(dev);
/*
* 将元素dev->p->knode_parent链接到以
* dev->parent->p->klist_children为链表头的链表中
*/
if (parent)
klist_add_tail(&dev->p->knode_parent, &parent->p->klist_children);
if (dev->class) {
mutex_lock(&dev->class->p->class_mutex);
/* tie the class to the device */
klist_add_tail(&dev->knode_class, &dev->class->p->klist_devices);
/* notify any interfaces that the device is here */
list_for_each_entry(class_intf, &dev->class->p->class_interfaces, node)
if (class_intf->add_dev)
class_intf->add_dev(dev, class_intf);
mutex_unlock(&dev->class->p->class_mutex);
}
done:
/*
* 对应于get_device(),用于减小设备的索引计数,
* 即dev->kobj->kref->refcount
*/
put_device(dev);
return error;
DPMError:
bus_remove_device(dev);
BusError:
device_remove_attrs(dev);
AttrsError:
device_remove_class_symlinks(dev);
SymlinkError:
if (MAJOR(dev->devt))
devtmpfs_delete_node(dev);
if (MAJOR(dev->devt))
device_remove_sys_dev_entry(dev);
devtattrError:
if (MAJOR(dev->devt))
device_remove_file(dev, &devt_attr);
ueventattrError:
device_remove_file(dev, &uevent_attr);
attrError:
kobject_uevent(&dev->kobj, KOBJ_REMOVE);
// 参见[15.7.2.2.1.1 kobject_del()]节
kobject_del(&dev->kobj);
Error:
cleanup_device_parent(dev);
if (parent)
put_device(parent);
name_error:
kfree(dev->p);
dev->p = NULL;
goto done;
}
10.2.3.3.2.1 setup_parent()
该函数定义于drivers/base/core.c:
static void setup_parent(struct device *dev, struct device *parent)
{
struct kobject *kobj;
kobj = get_device_parent(dev, parent);
if (kobj)
dev->kobj.parent = kobj;
}
static struct kobject *get_device_parent(struct device *dev, struct device *parent)
{
if (dev->class) {
static DEFINE_MUTEX(gdp_mutex);
struct kobject *kobj = NULL;
struct kobject *parent_kobj;
struct kobject *k;
#ifdef CONFIG_BLOCK
/* block disks show up in /sys/block */
if (sysfs_deprecated && dev->class == &block_class) {
if (parent && parent->class == &block_class)
return &parent->kobj;
return &block_class.p->subsys.kobj;
}
#endif
/*
* If we have no parent, we live in "virtual".
* Class-devices with a non class-device as parent, live
* in a "glue" directory to prevent namespace collisions.
*/
if (parent == NULL)
parent_kobj = virtual_device_parent(dev);
else if (parent->class && !dev->class->ns_type)
return &parent->kobj;
else
parent_kobj = &parent->kobj;
mutex_lock(&gdp_mutex);
/* find our class-directory at the parent and reference it */
spin_lock(&dev->class->p->glue_dirs.list_lock);
list_for_each_entry(k, &dev->class->p->glue_dirs.list, entry)
if (k->parent == parent_kobj) {
kobj = kobject_get(k);
break;
}
spin_unlock(&dev->class->p->glue_dirs.list_lock);
if (kobj) {
mutex_unlock(&gdp_mutex);
return kobj;
}
/* or create a new class-directory at the parent device */
k = class_dir_create_and_add(dev->class, parent_kobj);
/* do not emit an uevent for this simple "glue" directory */
mutex_unlock(&gdp_mutex);
return k;
}
if (parent)
return &parent->kobj;
return NULL;
}
static struct kobject *virtual_device_parent(struct device *dev)
{
static struct kobject *virtual_dir = NULL;
/*
* 创建目录/sys/devices/virtual
* 参见[15.7.1.2 kobject_create_and_add()]节
*/
if (!virtual_dir)
virtual_dir = kobject_create_and_add("virtual", &devices_kset->kobj);
return virtual_dir;
}
10.2.3.3.2.2 创建/删除设备属性
创建/删除设备驱动属性分为如下几个步骤:
- 1) 定义设备属性,即定义struct device_attribute类型的对象,并实现其show()/store()函数;
- 2) 调用device_create_file()创建设备属性;
- 3) 调用device_remove_file()删除设备属性。
10.2.3.3.2.2.1 定义设备属性/struct device_attribute
struct device_attribute表示设备属性,其定义于include/linux/device.h:
struct device_attribute {
struct attribute attr;
ssize_t (*show)(struct device *dev, struct device_attribute *attr, char *buf);
ssize_t (*store)(struct device *dev, struct device_attribute *attr, const char *buf, size_t count);
};
struct dev_ext_attribute {
struct device_attribute attr;
void *var;
};
如下宏用来定义设备属性,其定义于include/linux/device.h:
#define DEVICE_ATTR(_name, _mode, _show, _store) \
struct device_attribute dev_attr_##_name = __ATTR(_name, _mode, _show, _store)
#define DEVICE_ATTR_RO(_name) \
struct device_attribute dev_attr_##_name = __ATTR_RO(_name)
/* kernel v3.10 */
#define DEVICE_ATTR_WO(_name) \
struct device_attribute dev_attr_##_name = __ATTR_WO(_name)
/* kernel v3.10 */
#define DEVICE_ATTR_RW(_name) \
struct device_attribute dev_attr_##_name = __ATTR_RW(_name)
#define DEVICE_ATTR_IGNORE_LOCKDEP(_name, _mode, _show, _store) \
struct device_attribute dev_attr_##_name = \
__ATTR_IGNORE_LOCKDEP(_name, _mode, _show, _store)
#define DEVICE_ULONG_ATTR(_name, _mode, _var) \
struct dev_ext_attribute dev_attr_##_name = \
{ __ATTR(_name, _mode, device_show_ulong, device_store_ulong), &(_var) }
#define DEVICE_INT_ATTR(_name, _mode, _var) \
struct dev_ext_attribute dev_attr_##_name = \
{ __ATTR(_name, _mode, device_show_int, device_store_int), &(_var) }
#define DEVICE_BOOL_ATTR(_name, _mode, _var) \
struct dev_ext_attribute dev_attr_##_name = \
{ __ATTR(_name, _mode, device_show_bool, device_store_bool), &(_var) }
其中,__ATTR之类的宏定义于include/linux/sysfs.h:
#define __ATTR(_name,_mode,_show,_store) { \
.attr = { .name = __stringify(_name), .mode = _mode }, \
.show = _show, \
.store = _store, \
}
#define __ATTR_RO(_name) { \
.attr = { .name = __stringify(_name), .mode = S_IRUGO }, \
.show = _name##_show, \
}
/* kernel v3.10 */
#define __ATTR_WO(_name) { \
.attr = { .name = __stringify(_name), .mode = S_IWUSR }, \
.store = _name##_store, \
}
/* kernel v3.10 */
#define __ATTR_RW(_name) __ATTR(_name, (S_IWUSR | S_IRUGO), \
_name##_show, _name##_store)
【设备属性定义举例】
如下定义:
DEVICE_ATTR_RW(foo);
被扩展为:
struct device_attribute dev_attr_foo = {
.attr = {
.name = "foo",
.mode = (S_IWUSR | S_IRUGO),
},
.show = foo_show,
.store = foo_store,
};
然后实现如下函数:
ssize_t *foo_show(struct device *dev, struct device_attribute *attr, char *buf);
ssize_t *foo_store(struct device *dev, struct device_attribute *attr, const char *buf, size_t count);
10.2.3.3.2.2.2 创建设备属性/device_create_file()
该函数定义于drivers/base/core.c:
/**
* device_create_file - create sysfs attribute file for device.
* @dev: device.
* @attr: device attribute descriptor.
*/
int device_create_file(struct device *dev, const struct device_attribute *attr)
{
int error = 0;
if (dev) {
WARN(((attr->attr.mode & S_IWUGO) && !attr->store),
"Attribute %s: write permission without 'store'\n",
attr->attr.name);
WARN(((attr->attr.mode & S_IRUGO) && !attr->show),
"Attribute %s: read permission without 'show'\n",
attr->attr.name);
// 参见[11.3.5.6.2 sysfs_create_file()]节
error = sysfs_create_file(&dev->kobj, &attr->attr);
}
return error;
}
10.2.3.3.2.2.3 删除设备属性/device_remove_file()
该函数定义于drivers/base/core.c:
/**
* device_remove_file - remove sysfs attribute file.
* @dev: device.
* @attr: device attribute descriptor.
*/
void device_remove_file(struct device *dev, const struct device_attribute *attr)
{
// 参见[11.3.5.6.3 sysfs_remove_file()]节
if (dev)
sysfs_remove_file(&dev->kobj, &attr->attr);
}
10.2.3.3.2.3 bus_probe_device()
该函数定义于drivers/base/bus.c:
/**
* bus_probe_device - probe drivers for a new device
* @dev: device to probe
*
* - Automatically probe for a driver if the bus allows it.
*/
void bus_probe_device(struct device *dev)
{
struct bus_type *bus = dev->bus;
int ret;
/*
* 若支持自动匹配(参见[10.2.2.1 bus_register()]节),
* 则自动匹配注册到同一bus的device和driver (参见下文)
*/
if (bus && bus->p->drivers_autoprobe) {
ret = device_attach(dev);
WARN_ON(ret < 0);
}
}
/**
* device_attach - try to attach device to a driver.
* @dev: device.
*
* Walk the list of drivers that the bus has and call
* driver_probe_device() for each pair. If a compatible
* pair is found, break out and return.
*
* Returns 1 if the device was bound to a driver;
* 0 if no matching driver was found;
* -ENODEV if the device is not registered.
*
* When called for a USB interface, @dev->parent lock must be held.
*/
int device_attach(struct device *dev)
{
int ret = 0;
device_lock(dev);
if (dev->driver) {
/*
* 1) 若该设备已配置了驱动程序:
* 1.1) 若dev->p->knode_driver已指向其对应的驱动程序,说明dev->p->knode_driver已被
* 链接到以struct device_driver->p->klist_devices为链表头的链表中,则直接返回;
* 1.2) 若dev->p->knode_driver未指向其对应的驱动程序,说明dev->p->knode_driver未被
* 链接到以struct device_driver->p->klist_devices为链表头的链表中,则调用
* device_bind_driver->driver_bound();
*/
if (klist_node_attached(&dev->p->knode_driver)) {
ret = 1;
goto out_unlock;
}
ret = device_bind_driver(dev);
if (ret == 0)
ret = 1;
else {
dev->driver = NULL;
ret = 0;
}
} else {
/*
* 2) 若该设备还未配置了驱动程序:
* 则对链表drv->bus->p->klist_devices->k_list中的每个元素,
* 调用函数__driver_attach(device, driver);
* 该函数尝试将匹配的driver和device绑定到一起.
* NOTE: 链表drv->bus->p->klist_devices->k_list中链接的是元素
* struct device->p->knode_bus->n_node
*/
pm_runtime_get_noresume(dev);
ret = bus_for_each_drv(dev->bus, NULL, dev, __device_attach);
pm_runtime_put_sync(dev);
}
out_unlock:
device_unlock(dev);
return ret;
}
其中,函数__device_attach()定义于drivers/base/dd.c:
static int __device_attach(struct device_driver *drv, void *data)
{
struct device *dev = data;
/*
* 调用函数drv->bus->match(dev, drv)来查看某device和该driver是否匹配:
* 若匹配,则返回非0值;否则,返回0
*/
if (!driver_match_device(drv, dev))
return 0;
/*
* 若该device和driver匹配,且该device还未指定匹配的driver,
* 则调用driver_probe_device()->really_probe()来绑定该device和driver
* 参见[10.2.3.3.2.3.1 driver_probe_device()]节
*/
return driver_probe_device(drv, dev);
}
10.2.3.3.2.3.1 driver_probe_device()
该函数定义于drivers/base/dd.c:
/**
* driver_probe_device - attempt to bind device & driver together
* @drv: driver to bind a device to
* @dev: device to try to bind to the driver
*
* This function returns -ENODEV if the device is not registered,
* 1 if the device is bound successfully and 0 otherwise.
*
* This function must be called with @dev lock held. When called for a
* USB interface, @dev->parent lock must be held as well.
*/
int driver_probe_device(struct device_driver *drv, struct device *dev)
{
int ret = 0;
if (!device_is_registered(dev))
return -ENODEV;
pr_debug("bus: '%s': %s: matched device %s with driver %s\n",
drv->bus->name, __func__, dev_name(dev), drv->name);
pm_runtime_get_noresume(dev);
pm_runtime_barrier(dev);
ret = really_probe(dev, drv);
pm_runtime_put_sync(dev);
return ret;
}
static int really_probe(struct device *dev, struct device_driver *drv)
{
int ret = 0;
atomic_inc(&probe_count);
pr_debug("bus: '%s': %s: probing driver %s with device %s\n",
drv->bus->name, __func__, drv->name, dev_name(dev));
WARN_ON(!list_empty(&dev->devres_head));
// 将dev的驱动程序设置为drv,并创建dev->driver->p->kobj和dev->kobj之间的相互链接文件
dev->driver = drv;
if (driver_sysfs_add(dev)) {
printk(KERN_ERR "%s: driver_sysfs_add(%s) failed\n", __func__, dev_name(dev));
goto probe_failed;
}
// 调用函数dev->bus->probe()或者drv->probe()来判断设备dev和驱动程序drv是否匹配
if (dev->bus->probe) {
ret = dev->bus->probe(dev);
if (ret)
goto probe_failed;
} else if (drv->probe) {
ret = drv->probe(dev);
if (ret)
goto probe_failed;
}
/*
* 将元素dev->p->knode_driver添加到链表dev->driver->p->klist_devices
* 的尾部,即链表drv->p->klist_devices尾部
*/
driver_bound(dev);
ret = 1;
pr_debug("bus: '%s': %s: bound device %s to driver %s\n",
drv->bus->name, __func__, dev_name(dev), drv->name);
goto done;
probe_failed:
devres_release_all(dev);
driver_sysfs_remove(dev);
dev->driver = NULL;
if (ret != -ENODEV && ret != -ENXIO) {
/* driver matched but the probe failed */
printk(KERN_WARNING "%s: probe of %s failed with error %d\n",
drv->name, dev_name(dev), ret);
} else {
pr_debug("%s: probe of %s rejects match %d\n",
drv->name, dev_name(dev), ret);
}
/*
* Ignore errors returned by ->probe so that the next driver can try
* its luck.
*/
ret = 0;
done:
atomic_dec(&probe_count);
wake_up(&probe_waitqueue);
return ret;
}
10.2.3.4 注销设备/device_unregister()
该函数定义于drivers/base/core.c:
/**
* device_unregister - unregister device from system.
* @dev: device going away.
*
* We do this in two parts, like we do device_register(). First,
* we remove it from all the subsystems with device_del(), then
* we decrement the reference count via put_device(). If that
* is the final reference count, the device will be cleaned up
* via device_release() above. Otherwise, the structure will
* stick around until the final reference to the device is dropped.
*/
void device_unregister(struct device *dev)
{
pr_debug("device: '%s': %s\n", dev_name(dev), __func__);
/*
* delete device from system.
* 参见[10.2.3.4.1 删除设备/device_del()]节
*/
device_del(dev);
/*
* 对应于get_device(),用于减小设备的索引计数,
* 即dev->kobj->kref->refcount
*/
put_device(dev);
}
10.2.3.4.1 删除设备/device_del()
该函数定义于drivers/base/core.c:
/**
* device_del - delete device from system.
* @dev: device.
*
* This is the first part of the device unregistration
* sequence. This removes the device from the lists we control
* from here, has it removed from the other driver model
* subsystems it was added to in device_add(), and removes it
* from the kobject hierarchy.
*
* NOTE: this should be called manually _iff_ device_add() was
* also called manually.
*/
void device_del(struct device *dev)
{
struct device *parent = dev->parent;
struct class_interface *class_intf;
/*
* Notify clients of device removal. This call must come
* before dpm_sysfs_remove().
*/
if (dev->bus)
blocking_notifier_call_chain(&dev->bus->p->bus_notifier,
BUS_NOTIFY_DEL_DEVICE, dev);
device_pm_remove(dev);
dpm_sysfs_remove(dev);
if (parent)
klist_del(&dev->p->knode_parent);
if (MAJOR(dev->devt)) {
devtmpfs_delete_node(dev);
device_remove_sys_dev_entry(dev);
device_remove_file(dev, &devt_attr);
}
if (dev->class) {
device_remove_class_symlinks(dev);
mutex_lock(&dev->class->p->class_mutex);
/* notify any interfaces that the device is now gone */
list_for_each_entry(class_intf, &dev->class->p->class_interfaces, node)
if (class_intf->remove_dev)
class_intf->remove_dev(dev, class_intf);
/* remove the device from the class list */
klist_del(&dev->knode_class);
mutex_unlock(&dev->class->p->class_mutex);
}
device_remove_file(dev, &uevent_attr);
device_remove_attrs(dev);
bus_remove_device(dev);
/*
* Some platform devices are driven without driver attached
* and managed resources may have been acquired. Make sure
* all resources are released.
*/
devres_release_all(dev);
/*
* Notify the platform of the removal, in case they
* need to do anything...
*/
if (platform_notify_remove)
platform_notify_remove(dev);
kobject_uevent(&dev->kobj, KOBJ_REMOVE);
cleanup_device_parent(dev);
kobject_del(&dev->kobj);
put_device(parent);
}
10.2.4 struct device_driver
该结构定义于include/linux/device.h:
/**
* struct device_driver - The basic device driver structure
*
* The device driver-model tracks all of the drivers known to the system.
* The main reason for this tracking is to enable the driver core to match
* up drivers with new devices. Once drivers are known objects within the
* system, however, a number of other things become possible. Device drivers
* can export information and configuration variables that are independent
* of any specific device.
*/
struct device_driver {
const char *name;
struct bus_type *bus;
struct module *owner;
const char *mod_name; /* used for built-in modules */
bool suppress_bind_attrs; /* disables bind/unbind via sysfs */
const struct of_device_id *of_match_table;
// 参见[13.1.2.2 MODULE_DEVICE_TABLE()]节
int (*probe) (struct device *dev);
int (*remove) (struct device *dev);
void (*shutdown) (struct device *dev);
int (*suspend) (struct device *dev, pm_message_t state);
int (*resume) (struct device *dev);
const struct attribute_group **groups;
const struct dev_pm_ops *pm;
// 指向struct device_driver对象
struct driver_private *p;
};
其中,struct driver_private定义于drivers/base/base.h:
struct driver_private {
struct kobject kobj;
/*
* 该链表将使用本驱动程序的设备链接到一起;
*
* 该链表用来链接struct device->p->knode_driver元素,参见如下函数调用:
* driver_register()->bus_add_driver()->driver_attach()
* ->__driver_attach()->driver_probe_device()->really_probe()
* ->driver_bound()
* 查询该链表的函数:driver_find_device(), driver_for_each_device()
*/
struct klist klist_devices;
/*
* 该元素被链接到以struct device_driver->bus->p->klist_drivers
* 为链表头的链表中,参见如下函数调用:
* driver_register()->bus_add_driver()->klist_add_tail()
*/
struct klist_node knode_bus;
struct module_kobject *mkobj;
// 指向struct device_driver对象
struct device_driver *driver;
};
10.2.4.1 注册驱动程序/driver_register()
该函数定义于drivers/base/driver.c:
/**
* driver_register - register driver with bus
* @drv: driver to register
*
* We pass off most of the work to the bus_add_driver() call,
* since most of the things we have to do deal with the bus
* structures.
*/
int driver_register(struct device_driver *drv)
{
int ret;
struct device_driver *other;
BUG_ON(!drv->bus->p);
if ((drv->bus->probe && drv->probe) ||
(drv->bus->remove && drv->remove) ||
(drv->bus->shutdown && drv->shutdown))
printk(KERN_WARNING "Driver '%s' needs updating - please use bus_type methods\n", drv->name);
/*
* 查找链表drv->bus->p->drivers_kset->list上是否已存在该驱动程序(drv->name)
* 其中,链表drv->bus->p->drivers_kset->list上链接的是struct device_driver->p->kobj->entry元素
* 参见本节中的图Device_Driver_Model.jpg
*/
other = driver_find(drv->name, drv->bus);
if (other) {
put_driver(other);
printk(KERN_ERR "Error: Driver '%s' is already registered, aborting...\n", drv->name);
return -EBUSY;
}
// 添加设备驱动程序到bus,参见[10.2.4.1.1 添加设备驱动程序/bus_add_driver()]节
ret = bus_add_driver(drv);
if (ret)
return ret;
ret = driver_add_groups(drv, drv->groups);
if (ret)
bus_remove_driver(drv);
return ret;
}
NOTE: Device_Driver_Model.jpg
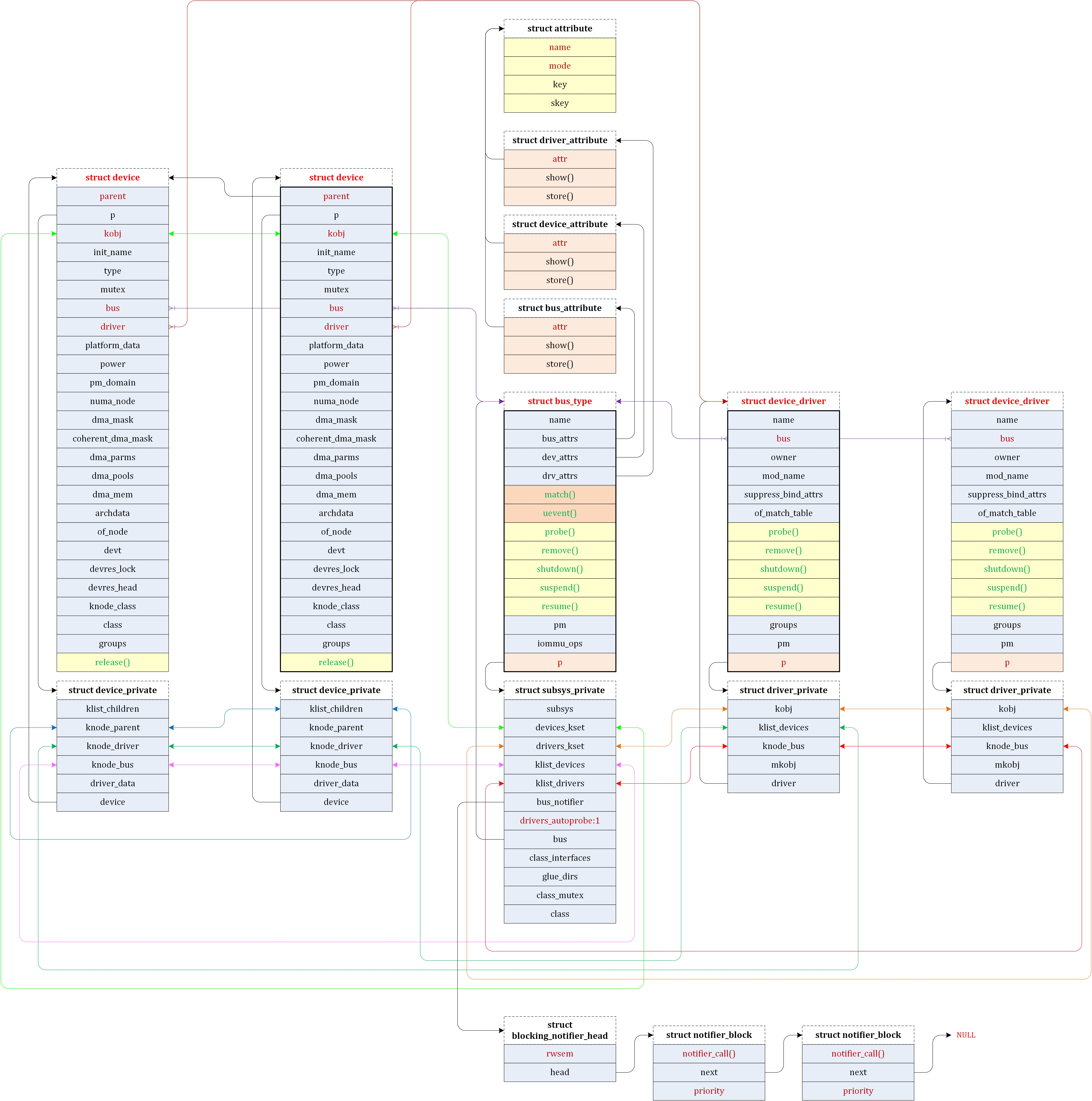
10.2.4.1.1 添加设备驱动程序/bus_add_driver()
该函数定义于drivers/base/driver.c:
static struct kobj_type driver_ktype = {
.sysfs_ops = &driver_sysfs_ops,
.release = driver_release,
};
/**
* bus_add_driver - Add a driver to the bus.
* @drv: driver.
*/
int bus_add_driver(struct device_driver *drv)
{
struct bus_type *bus;
struct driver_private *priv;
int error = 0;
// 1) 增加drv->bus->p->subsys->kobj->kref引用计数
bus = bus_get(drv->bus);
if (!bus)
return -EINVAL;
pr_debug("bus: '%s': add driver %s\n", bus->name, drv->name);
// 2) 分配并初始化struct driver_private类型的对象priv,并将priv和drv相互链接起来
priv = kzalloc(sizeof(*priv), GFP_KERNEL);
if (!priv) {
error = -ENOMEM;
goto out_put_bus;
}
klist_init(&priv->klist_devices, NULL, NULL);
priv->driver = drv;
drv->p = priv;
priv->kobj.kset = bus->p->drivers_kset;
/*
* 2.1) 设置如下参数:
* &priv->kobj->ktype = &driver_ktype
* &priv->kobj->name = drv->name
* &priv->kobj->parent = NULL
*/
error = kobject_init_and_add(&priv->kobj, &driver_ktype, NULL, "%s", drv->name);
if (error)
goto out_unregister;
/*
* 若支持自动匹配(参见[10.2.2.1 bus_register()]节),
* 则自动匹配注册到同一bus的device和driver,
* 参见[10.2.4.1.1.1 driver_attach()]节
*/
if (drv->bus->p->drivers_autoprobe) {
error = driver_attach(drv);
if (error)
goto out_unregister;
}
// 将元素drv->p->knode_bus链接到以drv->bus->p->klist_drivers为链表头的链表中
klist_add_tail(&priv->knode_bus, &bus->p->klist_drivers);
/*
* 创建如下两个链接:
* - 由drv->p->kobj到drv->owner->mkobj->kobj的链接文件
* - 由drv->owner->mkobj->drivers_dir到drv->p->kobj的链接文件
*/
module_add_driver(drv->owner, drv);
// 参见[10.2.4.1.1.2.2 创建设备驱动属性/driver_create_file()]节
error = driver_create_file(drv, &driver_attr_uevent);
if (error) {
printk(KERN_ERR "%s: uevent attr (%s) failed\n", __func__, drv->name);
}
error = driver_add_attrs(bus, drv);
if (error) {
/* How the hell do we get out of this pickle? Give up */
printk(KERN_ERR "%s: driver_add_attrs(%s) failed\n", __func__, drv->name);
}
if (!drv->suppress_bind_attrs) {
error = add_bind_files(drv);
if (error) {
/* Ditto */
printk(KERN_ERR "%s: add_bind_files(%s) failed\n", __func__, drv->name);
}
}
/*
* notify userspace by sending an uevent
* 参见[15.7.5 kobject_uevent()]节
*/
kobject_uevent(&priv->kobj, KOBJ_ADD);
return 0;
out_unregister:
kobject_put(&priv->kobj); // 参见[15.7.2.2 kobject_put()]节
kfree(drv->p);
drv->p = NULL;
out_put_bus:
bus_put(bus);
return error;
}
10.2.4.1.1.1 driver_attach()
该函数定义于drivers/base/dd.c:
/**
* driver_attach - try to bind driver to devices.
* @drv: driver.
*
* Walk the list of devices that the bus has on it and try to
* match the driver with each one. If driver_probe_device()
* returns 0 and the @dev->driver is set, we've found a
* compatible pair.
*/
int driver_attach(struct device_driver *drv)
{
/*
* 对链表drv->bus->p->klist_devices->k_list中的每个元素,
* 调用函数__driver_attach(device, driver); 该函数尝试将
* 匹配的driver和device绑定到一起。
* NOTE: 链表drv->bus->p->klist_devices->k_list中链接的是
* struct device->p->knode_bus->n_node元素
*/
return bus_for_each_dev(drv->bus, NULL, drv, __driver_attach);
}
static int __driver_attach(struct device *dev, void *data)
{
struct device_driver *drv = data;
/*
* Lock device and try to bind to it. We drop the error
* here and always return 0, because we need to keep trying
* to bind to devices and some drivers will return an error
* simply if it didn't support the device.
*
* driver_probe_device() will spit a warning if there
* is an error.
*/
/*
* 调用函数drv->bus->match(dev, drv)来查看某device和该driver是否匹配:
* 若匹配,则返回非0值;否则,返回0
*/
if (!driver_match_device(drv, dev))
return 0;
if (dev->parent) /* Needed for USB */
device_lock(dev->parent);
device_lock(dev);
/*
* 若该device和driver匹配,且该device还未指定匹配的driver,
* 则调用driver_probe_device()->really_probe()来绑定该device
* 和driver。参见[10.2.3.3.2.3.1 driver_probe_device()]节
*/
if (!dev->driver)
driver_probe_device(drv, dev);
device_unlock(dev);
if (dev->parent)
device_unlock(dev->parent);
return 0;
}
10.2.4.1.1.2 创建/删除设备驱动属性
创建/删除设备驱动属性分为如下几个步骤:
- 1) 定义设备属性,即定义struct driver_attribute类型的对象,并实现其show()/store()函数;
- 2) 调用driver_create_file()创建设备属性;
- 3) 调用driver_remove_file()删除设备属性。
10.2.4.1.1.2.1 定义设备驱动属性
结构体struct driver_attribute表示设备属性,其定义于include/linux/device.h:
struct driver_attribute {
struct attribute attr;
ssize_t (*show)(struct device_driver *driver, char *buf);
ssize_t (*store)(struct device_driver *driver, const char *buf, size_t count);
};
如下宏用来定义设备属性,其定义于include/linux/device.h:
#define DRIVER_ATTR(_name, _mode, _show, _store) \
struct driver_attribute driver_attr_##_name = __ATTR(_name, _mode, _show, _store)
#define DRIVER_ATTR_RW(_name) \
struct driver_attribute driver_attr_##_name = __ATTR_RW(_name)
#define DRIVER_ATTR_RO(_name) \
struct driver_attribute driver_attr_##_name = __ATTR_RO(_name)
#define DRIVER_ATTR_WO(_name) \
struct driver_attribute driver_attr_##_name = __ATTR_WO(_name)
【设备属性定义举例】
如下定义:
DRIVER_ATTR_RW(foo);
被扩展为:
struct driver_attribute driver_attr_foo = {
.attr = {
.name = "foo",
// 宏DRIVER_ATTR_XX对应的属性不同
.mode = (S_IWUSR | S_IRUGO),
},
.show = foo_show,
.store = foo_store,
};
然后实现如下函数:
ssize_t *foo_show(struct device_driver *driver, char *buf);
ssize_t *foo_store(struct device_driver *driver, const char *buf, size_t count);
10.2.4.1.1.2.2 创建设备驱动属性/driver_create_file()
该函数定义于drivers/base/driver.c:
/**
* driver_create_file - create sysfs file for driver.
* @drv: driver.
* @attr: driver attribute descriptor.
*/
int driver_create_file(struct device_driver *drv,
const struct driver_attribute *attr)
{
int error;
// 参见[11.3.5.6.2 sysfs_create_file()]节
if (drv)
error = sysfs_create_file(&drv->p->kobj, &attr->attr);
else
error = -EINVAL;
return error;
}
10.2.4.1.1.2.3 删除设备驱动属性/driver_remove_file()
该函数定义于drivers/base/driver.c:
/**
* driver_remove_file - remove sysfs file for driver.
* @drv: driver.
* @attr: driver attribute descriptor.
*/
void driver_remove_file(struct device_driver *drv,
const struct driver_attribute *attr)
{
// 参见[11.3.5.6.3 sysfs_remove_file()]节
if (drv)
sysfs_remove_file(&drv->p->kobj, &attr->attr);
}
10.2.4.2 注销驱动程序/driver_unregister()
该函数定义于drivers/base/driver.c:
/**
* driver_unregister - remove driver from system.
* @drv: driver.
*
* Again, we pass off most of the work to the bus-level call.
*/
void driver_unregister(struct device_driver *drv)
{
if (!drv || !drv->p) {
WARN(1, "Unexpected driver unregister!\n");
return;
}
driver_remove_groups(drv, drv->groups);
bus_remove_driver(drv);
}
/**
* bus_remove_driver - delete driver from bus's knowledge.
* @drv: driver.
*
* Detach the driver from the devices it controls, and remove
* it from its bus's list of drivers. Finally, we drop the reference
* to the bus we took in bus_add_driver().
*/
void bus_remove_driver(struct device_driver *drv)
{
if (!drv->bus)
return;
if (!drv->suppress_bind_attrs)
remove_bind_files(drv);
driver_remove_attrs(drv->bus, drv);
// 参见[10.2.4.1.1.2.3 删除设备驱动属性/driver_remove_file()]节
driver_remove_file(drv, &driver_attr_uevent);
klist_remove(&drv->p->knode_bus);
pr_debug("bus: '%s': remove driver %s\n", drv->bus->name, drv->name);
/*
* detach driver from all devices it controls
* 参见[10.2.4.2.1 driver_detach()]节
*/
driver_detach(drv);
module_remove_driver(drv);
// 参见[15.7.2.2 kobject_put()]节
kobject_put(&drv->p->kobj);
bus_put(drv->bus);
}
10.2.4.2.1 driver_detach()
该函数定义于drivers/base/dd.c:
/**
* driver_detach - detach driver from all devices it controls.
* @drv: driver.
*/
void driver_detach(struct device_driver *drv)
{
struct device_private *dev_prv;
struct device *dev;
for (;;) {
spin_lock(&drv->p->klist_devices.k_lock);
if (list_empty(&drv->p->klist_devices.k_list)) {
spin_unlock(&drv->p->klist_devices.k_lock);
break;
}
// 轮询使用本驱动程序的每个设备,即轮询 链表drv->p->klist_devices
dev_prv = list_entry(drv->p->klist_devices.k_list.prev,
struct device_private, knode_driver.n_node);
dev = dev_prv->device;
get_device(dev);
spin_unlock(&drv->p->klist_devices.k_lock);
if (dev->parent) /* Needed for USB */
device_lock(dev->parent);
device_lock(dev);
// 若该设备使用为本驱动程序,则释放该设备
if (dev->driver == drv)
__device_release_driver(dev);
device_unlock(dev);
if (dev->parent)
device_unlock(dev->parent);
put_device(dev);
}
}
/*
* __device_release_driver() must be called with @dev lock held.
* When called for a USB interface, @dev->parent lock must be held as well.
*/
static void __device_release_driver(struct device *dev)
{
struct device_driver *drv;
drv = dev->driver;
if (drv) {
pm_runtime_get_sync(dev);
driver_sysfs_remove(dev);
if (dev->bus)
blocking_notifier_call_chain(&dev->bus->p->bus_notifier,
BUS_NOTIFY_UNBIND_DRIVER, dev);
pm_runtime_put_sync(dev);
// 通过调用dev->bus->remove()或者drv->remove()来释放该设备
if (dev->bus && dev->bus->remove)
dev->bus->remove(dev);
else if (drv->remove)
drv->remove(dev);
// Release all managed resources
devres_release_all(dev);
dev->driver = NULL;
klist_remove(&dev->p->knode_driver);
if (dev->bus)
blocking_notifier_call_chain(&dev->bus->p->bus_notifier,
BUS_NOTIFY_UNBOUND_DRIVER, dev);
}
}
10.2.4.3 何时调用struct device_driver中的probe()函数
Probe是指在Linux内核中,若存在相同名称的device和device_driver (NOTE: 还存在其它方式,暂时不关注),内核就会执行struct device_driver中的回调函数probe(),而该函数就是所有driver的入口,可以执行诸如硬件设备初始化、字符设备注册、设备文件操作、ops注册等动作。
结构体struct device_driver中函数probe()的调用时机如下:
(1) 将struct device类型的变量注册到内核中时自动触发,如device_register(), device_add(), device_create_vargs(), device_create()等
device_register() // 参见[10.2.3.3 注册设备/device_register()]节
-> device_add()
-> bus_probe_device()
-> device_attach()
-> device_bind_driver()
-> driver_bound()
-> bus_for_each_drv(.., __device_attach)
-> __device_attach()
-> driver_probe_device()
-> really_probe()
-> dev->bus->probe(dev), or drv->probe(dev);
-> driver_bound()
(2) 将struct device_driver类型的变量注册到内核中时自动触发,如driver_register()
driver_register() // 参见[10.2.4.1 注册驱动程序/driver_register()]节
-> bus_add_driver()
-> driver_attach()
-> bus_for_each_dev(.., __driver_attach)
-> __driver_attach()
-> driver_probe_device()
-> really_probe()
-> dev->bus->probe(dev), or drv->probe(dev);
-> driver_bound()
(3) 手动查找同一bus下的所有device_driver,若存在与指定device同名的driver,则执行probe()。例如device_attach(),参见(1)。
(4) 手动查找同一bus下的所有device,若存在与指定driver同名的device,则执行probe()。例如driver_attach(),参见(2)。
(5) 自行调用driver的接口probe(),并在该接口中将该driver绑定到某个device结构中,即设置dev->driver。例如device_bind_driver(),参见(1)。
10.2.5 struct platform_device
该结构定义于include/linux/platform_device.h:
struct platform_device {
const char *name;
int id;
struct device dev;
u32 num_resources;
struct resource *resource;
const struct platform_device_id *id_entry;
/* MFD cell pointer */
struct mfd_cell *mfd_cell;
/* arch specific additions */
struct pdev_archdata archdata;
};
10.2.5.1 注册平台设备/platform_device_register()
该函数定义于drivers/base/platform.c:
/**
* platform_add_devices - add a numbers of platform devices
* @devs: array of platform devices to add
* @num: number of platform devices in array
*/
int platform_add_devices(struct platform_device **devs, int num)
{
int i, ret = 0;
for (i = 0; i < num; i++) {
ret = platform_device_register(devs[i]);
if (ret) {
while (--i >= 0)
platform_device_unregister(devs[i]);
break;
}
}
return ret;
}
/**
* platform_device_register - add a platform-level device
* @pdev: platform device we're adding
*/
int platform_device_register(struct platform_device *pdev)
{
// 参见[10.2.3.3.1 设备初始化/device_initialize()]节
device_initialize(&pdev->dev);
arch_setup_pdev_archdata(pdev);
// 参见下文
return platform_device_add(pdev);
}
/**
* platform_device_add - add a platform device to device hierarchy
* @pdev: platform device we're adding
*
* This is part 2 of platform_device_register(), though may be called
* separately _iff_ pdev was allocated by platform_device_alloc().
*/
int platform_device_add(struct platform_device *pdev)
{
int i, ret = 0;
if (!pdev)
return -EINVAL;
// 设置本设备的父节点,参见[10.2.1.6 platform_bus_init()]节
if (!pdev->dev.parent)
pdev->dev.parent = &platform_bus;
pdev->dev.bus = &platform_bus_type;
if (pdev->id != -1)
dev_set_name(&pdev->dev, "%s.%d", pdev->name, pdev->id);
else
dev_set_name(&pdev->dev, "%s", pdev->name);
for (i = 0; i < pdev->num_resources; i++) {
struct resource *p, *r = &pdev->resource[i];
if (r->name == NULL)
r->name = dev_name(&pdev->dev);
p = r->parent;
if (!p) {
if (resource_type(r) == IORESOURCE_MEM)
p = &iomem_resource;
else if (resource_type(r) == IORESOURCE_IO)
p = &ioport_resource;
}
if (p && insert_resource(p, r)) {
printk(KERN_ERR
"%s: failed to claim resource %d\n",
dev_name(&pdev->dev), i);
ret = -EBUSY;
goto failed;
}
}
pr_debug("Registering platform device '%s'. Parent at %s\n",
dev_name(&pdev->dev), dev_name(pdev->dev.parent));
// 参见[10.2.3.3.2 添加设备/device_add()]节
ret = device_add(&pdev->dev);
if (ret == 0)
return ret;
failed:
while (--i >= 0) {
struct resource *r = &pdev->resource[i];
unsigned long type = resource_type(r);
if (type == IORESOURCE_MEM || type == IORESOURCE_IO)
release_resource(r);
}
return ret;
}
10.2.5.2 注销平台设备/platform_device_unregister()
该函数定义于drivers/base/platform.c:
/**
* platform_device_unregister - unregister a platform-level device
* @pdev: platform device we're unregistering
*
* Unregistration is done in 2 steps. First we release all resources
* and remove it from the subsystem, then we drop reference count by
* calling platform_device_put().
*/
void platform_device_unregister(struct platform_device *pdev)
{
platform_device_del(pdev);
platform_device_put(pdev);
}
/**
* platform_device_del - remove a platform-level device
* @pdev: platform device we're removing
*
* Note that this function will also release all memory- and port-based
* resources owned by the device (@dev->resource). This function must
* _only_ be externally called in error cases. All other usage is a bug.
*/
void platform_device_del(struct platform_device *pdev)
{
int i;
if (pdev) {
device_del(&pdev->dev);
if (pdev->id_auto) {
ida_simple_remove(&platform_devid_ida, pdev->id);
pdev->id = PLATFORM_DEVID_AUTO;
}
for (i = 0; i < pdev->num_resources; i++) {
struct resource *r = &pdev->resource[i];
unsigned long type = resource_type(r);
if (type == IORESOURCE_MEM || type == IORESOURCE_IO)
release_resource(r);
}
}
}
10.2.6 struct platform_driver
该结构定义于include/linux/platform_device.h:
struct platform_driver {
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*resume)(struct platform_device *);
struct device_driver driver;
const struct platform_device_id *id_table;
};
10.2.6.1 注册平台驱动程序/platform_driver_register()
该结构定义于include/linux/platform_device.h:
/**
* platform_driver_register - register a driver for platform-level devices
* @drv: platform driver structure
*/
int platform_driver_register(struct platform_driver *drv)
{
// 参见[10.2.1.6 platform_bus_init()]节
drv->driver.bus = &platform_bus_type;
if (drv->probe)
drv->driver.probe = platform_drv_probe;
if (drv->remove)
drv->driver.remove = platform_drv_remove;
if (drv->shutdown)
drv->driver.shutdown = platform_drv_shutdown;
// 参见[10.2.4.1 注册驱动程序/driver_register()]节
return driver_register(&drv->driver);
}
10.2.6.2 注销平台驱动程序/platform_driver_unregister()
该结构定义于include/linux/platform_device.h:
/**
* platform_driver_unregister - unregister a driver for platform-level devices
* @drv: platform driver structure
*/
void platform_driver_unregister(struct platform_driver *drv)
{
// 参见[10.2.4.2 注销驱动程序/driver_unregister()]节
driver_unregister(&drv->driver);
}
10.2.7 struct class
内核中定义了结构体struct class,顾名思义,一个struct class结构体类型变量对应一个类,内核同时提供了函数 class_create()来创建一个类,这个类存放于sysfs(即/sys/class/)下面,一旦创建好了这个类,再调用函数device_create()在/dev目录下创建相应的设备节点。这样,加载模块时,用户空间中的udev会自动响应device_create()函数,去/sysfs下寻找对应的类从而创建设备节点。
对struct class的初始化,参见10.2.1.3 classes_init()节。
该结构定义于include/linux/device.h:
struct class {
// 类名
const char *name;
// 类所属的模块,比如usb模块、led模块等
struct module *owner;
// 类所添加的属性
struct class_attribute *class_attrs;
// 类所包含的设备所添加的属性
struct device_attribute *dev_attrs;
struct bin_attribute *dev_bin_attrs;
// 用于标识类所包含的设备属于块设备还是字符设备
struct kobject *dev_kobj;
// 用于在设备发出uevent消息时添加环境变量
int (*dev_uevent)(struct device *dev, struct kobj_uevent_env *env);
// 设备节点的相对路径名
char* (*devnode)(struct device *dev, mode_t *mode);
// 类被释放时调用的函数
void (*class_release)(struct class *class);
// 设备被释放时调用的函数
void (*dev_release)(struct device *dev);
// 设备休眠时调用的函数
int (*suspend)(struct device *dev, pm_message_t state);
// 设备被唤醒时调用的函数
int (*resume)(struct device *dev);
const struct kobj_ns_type_operations *ns_type;
const void *(*namespace)(struct device *dev);
// 用于电源管理的函数
const struct dev_pm_ops *pm;
struct subsys_private *p;
};
其中,struct subsys_private定义于drivers/base/base.h:
struct subsys_private {
struct kset subsys;
struct kset *devices_kset;
struct kset *drivers_kset;
struct klist klist_devices;
struct klist klist_drivers;
struct blocking_notifier_head bus_notifier;
unsigned int drivers_autoprobe:1;
struct bus_type *bus;
struct list_head class_interfaces;
struct kset glue_dirs;
struct mutex class_mutex;
// 指向包含本结构的class对象
struct class *class;
};
10.2.7.1 class_create()
该宏定义于include/linux/device.h:
/* This is a #define to keep the compiler from merging different
* instances of the __key variable */
#define class_create(owner, name) \
({ \
static struct lock_class_key __key; \
__class_create(owner, name, &__key); \
})
其中,函数__class_create()定义于drivers/base/class.c:
/**
* class_create - create a struct class structure
* @owner: pointer to the module that is to "own" this struct class
* @name: pointer to a string for the name of this class.
* @key: the lock_class_key for this class; used by mutex lock debugging
*
* This is used to create a struct class pointer that can then be used
* in calls to device_create().
*
* Returns &struct class pointer on success, or ERR_PTR() on error.
*
* Note, the pointer created here is to be destroyed when finished by
* making a call to class_destroy().
*/
struct class *__class_create(struct module *owner, const char *name,
struct lock_class_key *key)
{
struct class *cls;
int retval;
cls = kzalloc(sizeof(*cls), GFP_KERNEL);
if (!cls) {
retval = -ENOMEM;
goto error;
}
cls->name = name;
cls->owner = owner;
cls->class_release = class_create_release;
// 参见[10.2.7.1.1 class_register()/__class_register()]节
retval = __class_register(cls, key);
if (retval)
goto error;
return cls;
error:
kfree(cls);
return ERR_PTR(retval);
}
10.2.7.1.1 class_register()/__class_register()
该宏定义于include/linux/device.h:
/* This is a #define to keep the compiler from merging different
* instances of the __key variable */
#define class_register(class) \
({ \
static struct lock_class_key __key; \
__class_register(class, &__key); \
})
其中,函数__class_register()定义于drivers/base/class.c:
int __class_register(struct class *cls, struct lock_class_key *key)
{
struct subsys_private *cp;
int error;
pr_debug("device class '%s': registering\n", cls->name);
cp = kzalloc(sizeof(*cp), GFP_KERNEL);
if (!cp)
return -ENOMEM;
klist_init(&cp->klist_devices, klist_class_dev_get, klist_class_dev_put);
INIT_LIST_HEAD(&cp->class_interfaces);
kset_init(&cp->glue_dirs);
__mutex_init(&cp->class_mutex, "struct class mutex", key);
error = kobject_set_name(&cp->subsys.kobj, "%s", cls->name);
if (error) {
kfree(cp);
return error;
}
/* set the default /sys/dev directory for devices of this class */
/*
* 变量sysfs_dev_char_kobj参见[10.2.1.1 devices_init()]节;
* 函数调用genhd_device_init()->class_register()时,不进入
* 此条件分支,参见[10.4.2 块设备的初始化/genhd_device_init()]节
*/
if (!cls->dev_kobj)
cls->dev_kobj = sysfs_dev_char_kobj;
/*
* 变量class_kset参见[10.2.1.3 classes_init()]节
*/
#if defined(CONFIG_BLOCK)
/* let the block class directory show up in the root of sysfs */
if (!sysfs_deprecated || cls != &block_class)
cp->subsys.kobj.kset = class_kset;
#else
cp->subsys.kobj.kset = class_kset;
#endif
cp->subsys.kobj.ktype = &class_ktype;
cp->class = cls;
cls->p = cp;
// 参见[15.7.4 kset]节
error = kset_register(&cp->subsys);
if (error) {
kfree(cp);
return error;
}
error = add_class_attrs(class_get(cls));
class_put(cls);
return error;
}
10.2A 与设备驱动程序有关的系统调用
10.2A.1 ioctl()
Most drivers need - in addition to the ability to read and write the device - the ability to perform various types of hardware control via the device driver. Most devices can perform operations beyond simple data transfers; user space must often be able to request, for example, that the device lock its door, eject its media, report error information, change a baud rate, or self destruct. These operations are usually supported via the ioctl method, which implements the system call by the same name.
系统调用sys_ioctl()定义于fs/ioctl.c:
SYSCALL_DEFINE3(ioctl, unsigned int, fd, unsigned int, cmd, unsigned long, arg)
{
struct file *filp;
int error = -EBADF;
int fput_needed;
// 根据入参fd,从当前进程描述符中取出相应的file对象
filp = fget_light(fd, &fput_needed);
if (!filp)
goto out;
// 参见security/security.c
error = security_file_ioctl(filp, cmd, arg);
if (error)
goto out_fput;
// 参见[10.2A.1.1 do_vfs_ioctl()]节
error = do_vfs_ioctl(filp, fd, cmd, arg);
out_fput:
fput_light(filp, fput_needed);
out:
return error;
}
10.2A.1.1 do_vfs_ioctl()
该函数定义于fs/ioctl.c:
/*
* When you add any new common ioctls to the switches above and below
* please update compat_sys_ioctl() too.
*
* do_vfs_ioctl() is not for drivers and not intended to be EXPORT_SYMBOL()'d.
* It's just a simple helper for sys_ioctl and compat_sys_ioctl.
*/
int do_vfs_ioctl(struct file *filp, unsigned int fd, unsigned int cmd, unsigned long arg)
{
int error = 0;
int __user *argp = (int __user *)arg;
struct inode *inode = filp->f_path.dentry->d_inode;
/*
* 1) These predefined commands are recognized by the kernel.
* 参见[10.2A.1.3 Predefined ioctl commands]节;
* 其宏定义于include/asm-generic/ioctls.h
*/
switch (cmd) {
case FIOCLEX:
// 参见fs/fcntl.c中的函数set_close_on_exec()
set_close_on_exec(fd, 1);
break;
case FIONCLEX:
// 参见fs/fcntl.c中的函数set_close_on_exec()
set_close_on_exec(fd, 0);
break;
case FIONBIO:
// 设置filp->f_flags
error = ioctl_fionbio(filp, argp);
break;
case FIOASYNC:
// 该函数调用filp->f_op->fasync()
error = ioctl_fioasync(fd, filp, argp);
break;
case FIOQSIZE:
if (S_ISDIR(inode->i_mode) || S_ISREG(inode->i_mode) ||
S_ISLNK(inode->i_mode)) {
loff_t res = inode_get_bytes(inode);
error = copy_to_user(argp, &res, sizeof(res)) ? -EFAULT : 0;
} else
error = -ENOTTY;
break;
case FIFREEZE:
// 该函数调用filp->f_path.dentry->d_inode->i_sb->s_op->freeze_fs()
error = ioctl_fsfreeze(filp);
break;
case FITHAW:
// 该函数调用filp->f_path.dentry->d_inode->i_sb->s_op->unfreeze_fs()
error = ioctl_fsthaw(filp);
break;
case FS_IOC_FIEMAP:
// 该函数调用filp->f_path.dentry->d_inode->i_op->fiemap()
return ioctl_fiemap(filp, arg);
case FIGETBSZ:
return put_user(inode->i_sb->s_blocksize, argp);
/*
* 2) Specific commands decoded by devices drivers
*/
default:
if (S_ISREG(inode->i_mode))
// 该函数调用vfs_ioctl(),参见[10.2A.1.1.1 vfs_ioctl()]节
error = file_ioctl(filp, cmd, arg);
else
// 参见[10.2A.1.1.1 vfs_ioctl()]节
error = vfs_ioctl(filp, cmd, arg);
break;
}
return error;
}
10.2A.1.1.1 vfs_ioctl()
该函数定义于fs/ioctl.c:
/**
* vfs_ioctl - call filesystem specific ioctl methods
* @filp: open file to invoke ioctl method on
* @cmd: ioctl command to execute
* @arg: command-specific argument for ioctl
*
* Invokes filesystem specific ->unlocked_ioctl, if one exists; otherwise
* returns -ENOTTY.
*
* Returns 0 on success, -errno on error.
*/
static long vfs_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int error = -ENOTTY;
if (!filp->f_op || !filp->f_op->unlocked_ioctl)
goto out;
/*
* 函数unlocked_ioctl()定义于struct file_operations,
* 参见[11.2.1.5.1 文件操作/struct file_operations]节;
* 该函数是由设备驱动程序定义,并由函数register_chrdev()
* 注册到struct cdev->ops->unlocked_ioctl,
* 参见[10.3.3.1 register_chrdev()]节
*/
error = filp->f_op->unlocked_ioctl(filp, cmd, arg);
if (error == -ENOIOCTLCMD)
error = -EINVAL;
out:
return error;
}
10.2A.1.2 ioctl command encoding
参见《Linux Device Drivers, 3rd edition》第Advanced Char Driver Operations章第Choosing the ioctl Commands节:
To choose ioctl numbers for your driver according to the Linux kernel convention, you should first check include/asm/ioctl.h (that’s include/asm-generic/ioctl.h) and Documentation/ioctl-number.txt. The header defines the bitfields you will be using: type (magic number), ordinal number, direction of transfer, and size of argument. The ioctl-number.txt file lists the magic numbers used throughout the kernel, so you’ll be able to choose your own magic number and avoid overlaps. The text file also lists the reasons why the convention should be used. The ioctl command encoding has following struture:
DIR SIZE COMMAND
--------------------------------------
| | | 16 |
| 2 | 14 |-------------------|
| | | 8 | 8 |
--------------------------------------
TYPE NR
其中,各字段的含义如下:
| Field | Description |
|---|---|
| Direction | The direction of data transfer, if the particular command involves a data transfer. The possible values are _IOC_NONE (no data transfer), _IOC_READ, _IOC_WRITE, and _IOC_READ|_IOC_WRITE (data is transferred both ways). Data transfer is seen from the application’s point of view; _IOC_READ means reading from the device, so the driver must write to user space. Note that the field is a bit mask, so _IOC_ READ and _IOC_WRITE can be extracted using a logical AND operation. |
| Size | The size of user data involved. The width of this field is architecture dependent, but is usually 13 or 14 bits. You can find its value for your specific architecture in the macro _IOC_SIZEBITS. It’s not mandatory that you use the size field - the kernel does not check it - but it is a good idea. Proper use of this field can help detect user-space programming errors and enable you to implement backward compatibility if you ever need to change the size of the relevant data item. If you need larger data structures, however, you can just ignore the size field. |
| Type | The magic number. Just choose one number (after consulting ioctl-number.txt) and use it throughout the driver. This field is eight bits wide (_IOC_TYPEBITS). |
| Number | The ordinal (sequential) number. It’s eight bits (_IOC_NRBITS) wide. |
使用如下宏编码ioctl command:
#define _IOC(dir,type,nr,size) \
(((dir) << _IOC_DIRSHIFT) | \
((type) << _IOC_TYPESHIFT) | \
((nr) << _IOC_NRSHIFT) | \
((size) << _IOC_SIZESHIFT))
#define _IO(type,nr) _IOC(_IOC_NONE,(type),(nr),0)
#define _IOR(type,nr,size) _IOC(_IOC_READ,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOW(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOWR(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOR_BAD(type,nr,size) _IOC(_IOC_READ,(type),(nr),sizeof(size))
#define _IOW_BAD(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),sizeof(size))
#define _IOWR_BAD(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),sizeof(size))
使用如下宏解码ioctl command:
/* used to decode ioctl numbers.. */
#define _IOC_DIR(nr) (((nr) >> _IOC_DIRSHIFT) & _IOC_DIRMASK)
#define _IOC_TYPE(nr) (((nr) >> _IOC_TYPESHIFT) & _IOC_TYPEMASK)
#define _IOC_NR(nr) (((nr) >> _IOC_NRSHIFT) & _IOC_NRMASK)
#define _IOC_SIZE(nr) (((nr) >> _IOC_SIZESHIFT) & _IOC_SIZEMASK)
10.2A.1.3 Predefined ioctl commands
Although the ioctl system call is most often used to act on devices, a few commands are recognized by the kernel. Note that these commands, when applied to your device, are decoded before your own file operations are called. Thus, if you choose the same number for one of your ioctl commands, you won‘t ever see any request for that command, and the application gets something unexpected because of the conflict between the ioctl numbers.
The predefined commands are divided into three groups:
- Those that can be issued on any file (regular, device, FIFO, or socket).
- Those that are issued only on regular files.
- Those specific to the filesystem type.
Commands in the last group are executed by the implementation of the hosting filesystem (this is how the chattr command works). Device driver writers are interested only in the first group of commands, whose magic number is T.
See Using ioctl().
10.2A.2 compat_sys_ioctl()
该系统调用定义于fs/impact_ioctl.c:
asmlinkage long compat_sys_ioctl(unsigned int fd, unsigned int cmd, unsigned long arg)
{
struct file *filp;
int error = -EBADF;
int fput_needed;
filp = fget_light(fd, &fput_needed);
if (!filp)
goto out;
/* RED-PEN how should LSM module know it's handling 32bit? */
error = security_file_ioctl(filp, cmd, arg);
if (error)
goto out_fput;
/*
* To allow the compat_ioctl handlers to be self contained
* we need to check the common ioctls here first.
* Just handle them with the standard handlers below.
*/
switch (cmd) {
case FIOCLEX:
case FIONCLEX:
case FIONBIO:
case FIOASYNC:
case FIOQSIZE:
break;
#if defined(CONFIG_IA64) || defined(CONFIG_X86_64)
case FS_IOC_RESVSP_32:
case FS_IOC_RESVSP64_32:
error = compat_ioctl_preallocate(filp, compat_ptr(arg));
goto out_fput;
#else
case FS_IOC_RESVSP:
case FS_IOC_RESVSP64:
error = ioctl_preallocate(filp, compat_ptr(arg));
goto out_fput;
#endif
case FIBMAP:
case FIGETBSZ:
case FIONREAD:
if (S_ISREG(filp->f_path.dentry->d_inode->i_mode))
break;
/*FALL THROUGH*/
default:
if (filp->f_op && filp->f_op->compat_ioctl) {
/*
* 函数compat_ioctl()定义于struct file_operations,
* 参见[11.2.1.5.1 文件操作/struct file_operations]节;
* 该函数是由设备驱动程序定义,并由函数register_chrdev()
* 注册到struct cdev->ops->unlocked_ioctl,
* 参见[10.3.3.1 register_chrdev()]节
*/
error = filp->f_op->compat_ioctl(filp, cmd, arg);
if (error != -ENOIOCTLCMD)
goto out_fput;
}
// 若未设置函数compat_ioctl(),则调用unlocked_ioctl()
if (!filp->f_op || !filp->f_op->unlocked_ioctl)
goto do_ioctl;
break;
}
if (compat_ioctl_check_table(XFORM(cmd)))
goto found_handler;
error = do_ioctl_trans(fd, cmd, arg, filp);
if (error == -ENOIOCTLCMD) {
static int count;
if (++count <= 50)
compat_ioctl_error(filp, fd, cmd, arg);
error = -EINVAL;
}
goto out_fput;
found_handler:
arg = (unsigned long)compat_ptr(arg);
do_ioctl:
// 参见[10.2A.1.1 do_vfs_ioctl()]节
error = do_vfs_ioctl(filp, fd, cmd, arg);
out_fput:
fput_light(filp, fput_needed);
out:
return error;
}
10.2B Linux系统如何自动加载设备驱动程序
Linux通过如下步骤自动加载硬件设备所对应的驱动程序:
10.2B.1 驱动程序声明其支持的硬件设备版本
驱动程序开发人员在驱动程序中通过宏MODULE_DEVICE_TABLE来声明该驱动程序所支持的硬件设备版本,参见13.1.2.2 MODULE_DEVICE_TABLE()节。以drivers/net/ethernet/intel/e1000e/netdev.c为例:
static const struct pci_device_id e1000_pci_tbl[] = {
...
/*
* PCI_VENDOR_ID_INTEL定义于include/linux/pci_ids.h:
* #define PCI_VENDOR_ID_INTEL 0x8086
* E1000_DEV_ID_ICH8_IGP_M_AMT定义于drivers/net/ethernet/intel/e1000e/hw.h:
* #define E1000_DEV_ID_ICH8_IGP_M_AMT 0x1049
*/
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_ICH8_IGP_M_AMT), board_ich8lan },
...
{ 0, 0, 0, 0, 0, 0, 0 } /* terminate list */
};
MODULE_DEVICE_TABLE(pci, e1000_pci_tbl);
由13.1.2.2 MODULE_DEVICE_TABLE()可知,当编译驱动程序时,根据编译方式的不同,对宏MODULE_GENERIC_TABLE(gtype,name)的处理方式也不同,参见include/linux/module.h:
- 当驱动程序编译进内核时,因为内核可以直接访问该数组,故
MODULE_GENERIC_TABLE(gtype,name)被定义为空; - 当驱动程序编译成模块时,宏
MODULE_GENERIC_TABLE(gtype,name)通过*.mod.c->*.mod.o被编译到*.ko文件中的.modinfo段,参见3.4.3.4.2.1 __modpost节。
当安装模块时,各模块中.modinfo段的MODULE_GENERIC_TABLE()被提取到下列文件中, 参见3.5.5.1.1 cmd_depmod节:
/lib/modules/<kernelrelease>/modules.alias
例如:
chenwx@chenwx:~ $ cat /lib/modules/`uname -r`/modules.alias | grep 1049
alias pci:v00008086d00001049sv*sd*bc*sc*i* e1000e
10.2B.2 内核发现硬件设备并发送uevent到用户空间
当内核发现硬件设备时,根据驱动程序编译方式的不同,加载该驱动程序的方式也有所不同:
10.2B.2.1 当驱动程序被编译进内核时的情形
当驱动程序被编译进内核时,通过如下方式绑定该硬件所对应的驱动程序(以PCI网卡设备为例,kernel v4.2.2):
struct x86_init_ops x86_init __initdata = {
...
.pci = {
/*
* x86_default_pci_init is defined to:
* pci_acpi_init() : if CONFIG_PCI and CONFIG_ACPI defined;
* pci_legacy_init(): if only CONFIG_PCI defined.
*/
.init = x86_default_pci_init,
.init_irq = x86_default_pci_init_irq,
.fixup_irqs = x86_default_pci_fixup_irqs,
},
};
kernel_init()
-> do_basic_setup()
-> do_initcalls()
/*
* Part 1: scan devices on PCI bus and register them
*/
-> subsys_initcall(pci_subsys_init)
-> pci_subsys_init()
-> x86_init.pci.init()
-> pci_legacy_init()
-> printk("PCI: Probing PCI hardware\n")
-> pcibios_scan_root(0)
-> sd = kzalloc(sizeof(*sd), GFP_KERNEL);
-> sd->node = x86_pci_root_bus_node(busnum)
-> x86_pci_root_bus_resources(busnum, &resources)
-> bus = pci_scan_root_bus(NULL, 0, &pci_root_ops, sd, &resources)
-> b = pci_create_root_bus(parent, bus, ops, sysdata, resources)
-> pci_scan_child_bus(b)
-> for (devfn = 0; devfn < 0x100; devfn += 8) {
-> pci_scan_slot(bus, devfn)
-> pci_scan_single_device(bus, devfn)
-> dev = pci_get_slot(bus, devfn)
-> dev = pci_scan_device(bus, devfn)
-> pci_bus_read_dev_vendor_id(bus, devfn, &l, 60*1000)
-> dev = pci_alloc_dev(bus)
-> dev->vendor = l & 0xffff;
-> dev->device = (l >> 16) & 0xffff;
-> pci_setup_device(dev)
-> pci_device_add(dev, bus)
-> list_add_tail(&dev->bus_list, &bus->devices)
-> dev->match_driver = false; // [NOTE1]
-> device_add(&dev->dev)
-> kobject_uevent(&dev->kobj, KOBJ_ADD)
-> bus_probe_device(dev)
-> device_initial_probe(dev)
-> __device_attach(dev, true)
-> bus_for_each_drv(dev->bus, NULL, &data, __device_attach_driver)
-> __device_attach_driver()
-> driver_match_device(drv, dev)
-> drv->bus->match()
-> pci_bus_match()
-> return 0; // see [NOTE1]
/*
* list the device dev to bus->p->p->klist_devices
*/
-> bus_add_device(dev)
-> klist_add_tail(&dev->p->knode_bus, &bus->p->klist_devices)
}
-> pci_bus_add_devices(bus)
/* loop each device on list bus->devices */
-> list_for_each_entry(dev, &bus->devices, bus_list) {
-> pci_bus_add_device(dev)
-> dev->match_driver = true; // [NOTE2]
-> device_attach(&dev->dev)
-> __device_attach(dev, false)
-> bus_for_each_drv(dev->bus, NULL, &data, __device_attach_driver)
-> __device_attach_driver()
-> driver_match_device(drv, dev)
-> drv->bus->match()
-> pci_bus_match()
/*
* cannot find match driver yet, because
* the driver is not registered yet.
*/
-> pci_match_device(pci_drv, pci_dev)
-> dev->is_added = 1;
}
/* loop each device on list bus->devices */
-> list_for_each_entry(dev, &bus->devices, bus_list) {
-> child = dev->subordinate;
-> pci_bus_add_devices(child)
}
/*
* Part 2: register drivers and bind it to supported devices
* This is happened when kernel initializes the driver modules.
*/
-> module_init(e1000_init_module)
-> pci_register_driver(&e1000_driver)
-> __pci_register_driver(driver, THIS_MODULE, KBUILD_MODNAME)
-> drv->driver.bus = &pci_bus_type;
-> driver_register(&drv->driver)
-> bus_add_driver(drv)
-> klist_add_tail(&priv->knode_bus, &bus->p->klist_drivers);
-> driver_attach(drv)
/*
* loop each device on list bus->p->klist_devices,
* and call __driver_attach() with each device.
*/
-> bus_for_each_dev(drv->bus, NULL, drv, __driver_attach)
-> __driver_attach()
-> driver_match_device(drv, dev)
-> drv->bus->match(dev, drv)
-> pci_bus_match()
/* find the supported device here */
-> pci_match_device(pci_drv, pci_dev)
-> driver_probe_device(drv, dev)
-> really_probe(dev, drv)
/* bound the dev and its driver drv together */
-> dev->driver = drv;
10.2B.2.2 当驱动程序被编译成模块时的情形
当驱动程序被编译成模块时,通过如下方式加载该硬件所对应的驱动程序(以PCI网卡设备为例):
struct x86_init_ops x86_init __initdata = {
...
.pci = {
/*
* x86_default_pci_init is defined to:
* pci_acpi_init() : if CONFIG_PCI and CONFIG_ACPI defined;
* pci_legacy_init(): if only CONFIG_PCI defined.
*/
.init = x86_default_pci_init,
.init_irq = x86_default_pci_init_irq,
.fixup_irqs = x86_default_pci_fixup_irqs,
},
};
kernel_init()
-> do_basic_setup()
-> do_initcalls()
/*
* Part 1: scan devices on PCI bus and register them
*/
-> subsys_initcall(pci_subsys_init)
-> pci_subsys_init()
-> x86_init.pci.init()
-> pci_legacy_init()
-> printk("PCI: Probing PCI hardware\n")
-> pcibios_scan_root(0)
-> sd = kzalloc(sizeof(*sd), GFP_KERNEL);
-> sd->node = x86_pci_root_bus_node(busnum)
-> x86_pci_root_bus_resources(busnum, &resources)
-> bus = pci_scan_root_bus(NULL, 0, &pci_root_ops, sd, &resources)
-> pci_create_root_bus(parent, bus, ops, sysdata, resources)
-> pci_scan_child_bus()
-> for (devfn = 0; devfn < 0x100; devfn += 8) {
-> pci_scan_slot()
-> pci_scan_single_device(bus, devfn)
-> dev = pci_get_slot(bus, devfn)
-> dev = pci_scan_device(bus, devfn)
-> pci_bus_read_dev_vendor_id(bus, devfn, &l, 60*1000)
-> dev = pci_alloc_dev(bus)
-> dev->vendor = l & 0xffff;
-> dev->device = (l >> 16) & 0xffff;
-> pci_setup_device(dev)
-> pci_device_add(dev, bus)
-> list_add_tail(&dev->bus_list, &bus->devices)
-> dev->match_driver = false; // [NOTE1]
-> device_add(&dev->dev)
/*
* 向用户空间广播netlink uevent,进程udevd负责加载模块,参见:
* [15.7.5 kobject_uevent()]节和
* [10.2B.3.4 守护进程udevd接收uevent并加载对应的驱动程序]节
*/
-> kobject_uevent(&dev->kobj, KOBJ_ADD)
-> kobject_uevent_env(&dev->kobj, KOBJ_ADD, NULL)
-> netlink_broadcast_filtered()
-> sk_for_each_bound(sk, &nl_table[ssk->sk_protocol].mc_list)
-> do_one_broadcast()
-> netlink_broadcast_deliver(sk, p->skb2)
-> __netlink_sendskb(sk, skb)
-> skb_queue_tail(&sk->sk_receive_queue, skb)
-> sk->sk_data_ready(sk)
-> consume_skb(skb)
-> consume_skb(info.skb2)
-> bus_probe_device(dev)
-> device_initial_probe(dev)
-> __device_attach(dev, true)
-> bus_for_each_drv(dev->bus, NULL, &data, __device_attach_driver)
-> __device_attach_driver()
-> driver_match_device(drv, dev)
-> drv->bus->match()
-> pci_bus_match()
-> return 0; // see [NOTE1]
/* list the device dev to bus->p->p->klist_devices */
-> bus_add_device(dev)
-> klist_add_tail(&dev->p->knode_bus, &bus->p->klist_devices)
}
-> pci_bus_add_devices(bus)
/* loop each device on list bus->devices */
-> list_for_each_entry(dev, &bus->devices, bus_list) {
-> pci_bus_add_device(dev)
-> dev->match_driver = true; // [NOTE2]
-> device_attach(&dev->dev)
-> __device_attach(dev, false)
-> bus_for_each_drv(dev->bus, NULL, &data, __device_attach_driver)
-> __device_attach_driver()
-> driver_match_device(drv, dev)
-> drv->bus->match()
-> pci_bus_match()
/*
* cannot find match driver yet, because
* the driver is not registered yet.
*/
-> pci_match_device(pci_drv, pci_dev)
-> dev->is_added = 1;
}
/* loop each device on list bus->devices */
-> list_for_each_entry(dev, &bus->devices, bus_list) {
-> child = dev->subordinate;
-> pci_bus_add_devices(child)
}
/*
* Part 2: Register drivers and bind it to supported devices.
* This is happened when udevd loads the specified driver module.
*/
-> module_init(e1000_init_module)
-> pci_register_driver(&e1000_driver)
-> __pci_register_driver(driver, THIS_MODULE, KBUILD_MODNAME)
-> drv->driver.bus = &pci_bus_type;
-> driver_register(&drv->driver)
-> bus_add_driver(drv)
-> klist_add_tail(&priv->knode_bus, &bus->p->klist_drivers);
-> driver_attach(drv)
/*
* loop each device on list bus->p->klist_devices,
* and call __driver_attach() with each device.
*/
-> bus_for_each_dev(drv->bus, NULL, drv, __driver_attach)
-> __driver_attach()
-> driver_match_device(drv, dev)
-> drv->bus->match(dev, drv)
-> pci_bus_match()
/* find the supported device here */
-> pci_match_device(pci_drv, pci_dev)
-> driver_probe_device(drv, dev)
-> really_probe(dev, drv)
/* bound the dev and its driver drv together */
-> dev->driver = drv;
10.2B.3 守护进程udevd接收uevent并加载对应的驱动程序
10.2B.3.1 udev
systemd中包含了udev程序:
# 下载systemd的源代码
chenwx@chenwx ~ $ git clone git://anongit.freedesktop.org/systemd/systemd
# udev的源代码
chenwx@chenwx ~ $ ll systemd/src/udev/
lrwxrwxrwx 1 chenwx chenwx 11 Oct 28 2014 Makefile -> ../Makefile
drwxr-xr-x 2 chenwx chenwx 4.0K Oct 1 10:30 ata_id
drwxr-xr-x 2 chenwx chenwx 4.0K May 10 19:18 cdrom_id
drwxr-xr-x 2 chenwx chenwx 4.0K Mar 20 2015 collect
drwxr-xr-x 2 chenwx chenwx 4.0K Mar 20 2015 mtd_probe
drwxr-xr-x 2 chenwx chenwx 4.0K Jun 22 22:22 net
drwxr-xr-x 2 chenwx chenwx 4.0K May 10 19:18 scsi_id
-rw-r--r-- 1 chenwx chenwx 12K May 10 19:18 udev-builtin-blkid.c
-rw-r--r-- 1 chenwx chenwx 1.7K Mar 20 2015 udev-builtin-btrfs.c
-rw-r--r-- 1 chenwx chenwx 6.7K Oct 1 10:30 udev-builtin-hwdb.c
-rw-r--r-- 1 chenwx chenwx 14K Jun 22 22:22 udev-builtin-input_id.c
-rw-r--r-- 1 chenwx chenwx 9.3K Jun 22 22:22 udev-builtin-keyboard.c
-rw-r--r-- 1 chenwx chenwx 3.9K Oct 1 18:36 udev-builtin-kmod.c
-rw-r--r-- 1 chenwx chenwx 21K Jun 22 22:22 udev-builtin-net_id.c
-rw-r--r-- 1 chenwx chenwx 3.3K Jan 13 2015 udev-builtin-net_setup_link.c
-rw-r--r-- 1 chenwx chenwx 25K Jun 22 22:22 udev-builtin-path_id.c
-rw-r--r-- 1 chenwx chenwx 2.6K Mar 20 2015 udev-builtin-uaccess.c
-rw-r--r-- 1 chenwx chenwx 18K Jun 22 22:22 udev-builtin-usb_id.c
-rw-r--r-- 1 chenwx chenwx 3.9K Mar 20 2015 udev-builtin.c
-rw-r--r-- 1 chenwx chenwx 14K May 19 23:34 udev-ctrl.c
-rw-r--r-- 1 chenwx chenwx 37K Oct 1 10:30 udev-event.c
-rw-r--r-- 1 chenwx chenwx 15K May 10 19:18 udev-node.c
-rw-r--r-- 1 chenwx chenwx 112K Oct 1 10:30 udev-rules.c
-rw-r--r-- 1 chenwx chenwx 5.1K Mar 20 2015 udev-watch.c
-rw-r--r-- 1 chenwx chenwx 49 Oct 20 2014 udev.conf
-rw-r--r-- 1 chenwx chenwx 8.6K Oct 1 10:30 udev.h
-rw-r--r-- 1 chenwx chenwx 74 Oct 20 2014 udev.pc.in
-rw-r--r-- 1 chenwx chenwx 6.4K Mar 20 2015 udevadm-control.c
-rw-r--r-- 1 chenwx chenwx 24K Mar 20 2015 udevadm-hwdb.c
-rw-r--r-- 1 chenwx chenwx 19K May 10 19:18 udevadm-info.c
-rw-r--r-- 1 chenwx chenwx 12K May 10 19:18 udevadm-monitor.c
-rw-r--r-- 1 chenwx chenwx 5.4K May 10 19:18 udevadm-settle.c
-rw-r--r-- 1 chenwx chenwx 3.4K Mar 20 2015 udevadm-test-builtin.c
-rw-r--r-- 1 chenwx chenwx 5.7K Jun 22 22:22 udevadm-test.c
-rw-r--r-- 1 chenwx chenwx 13K Oct 1 10:30 udevadm-trigger.c
-rw-r--r-- 1 chenwx chenwx 1.7K Feb 17 2015 udevadm-util.c
-rw-r--r-- 1 chenwx chenwx 913 Feb 17 2015 udevadm-util.h
-rw-r--r-- 1 chenwx chenwx 4.2K Mar 20 2015 udevadm.c
-rw-r--r-- 1 chenwx chenwx 63K Oct 1 10:30 udevd.c
drwxr-xr-x 2 chenwx chenwx 4.0K Mar 20 2015 v4l_id
通过下列命令查看udev的man page:
chenwx@chenwx ~ $ man udev
NAME
udev - Linux dynamic device management
DESCRIPTION
udev supplies the system software with device events, manages permissions of device nodes
and may create additional symlinks in the /dev directory, or renames network interfaces.
The kernel usually just assigns unpredictable device names based on the order of discovery.
Meaningful symlinks or network device names provide a way to reliably identify devices based
on their properties or current configuration.
The udev daemon, systemd-udevd.service(8), receives device uevents directly from the kernel
whenever a device is added or removed from the system, or it changes its state. When udev
receives a device event, it matches its configured set of rules against various device
attributes to identify the device. Rules that match may provide additional device information
to be stored in the udev database or to be used to create meaningful symlink names.
All device information udev processes is stored in the udev database and sent out to
possible event subscribers. Access to all stored data and the event sources is provided
by the library libudev.
通过下列命令查看守护进程udevd的man page:
chenwx@chenwx ~ $ man udevd
NAME
systemd-udevd.service, systemd-udevd-control.socket, systemd-udevd-kernel.socket,
systemd-udevd - Device event managing daemon
SYNOPSIS
systemd-udevd.service
systemd-udevd-control.socket
systemd-udevd-kernel.socket
/usr/lib/systemd/systemd-udevd [--daemon] [--debug] [--children-max=] [--exec-delay=]
[--resolve-names=early|late|never] [--version] [--help]
DESCRIPTION
systemd-udevd listens to kernel uevents. For every event, systemd-udevd executes matching
instructions specified in udev rules. See udev(7).
The behavior of the running daemon can be changed with udevadm control.
OPTIONS
--daemon
Detach and run in the background.
--debug
Print debug messages to stderr.
--children-max=
Limit the number of events executed in parallel.
--exec-delay=
Delay the execution of RUN instruction by the given number of seconds. This option
might be useful when debugging system crashes during coldplug caused by loading
non-working kernel modules.
--resolve-names=
Specify when systemd-udevd should resolve names of users and groups. When set to
early (the default) names will be resolved when the rules are parsed. When set to
late names will be resolved for every event. When set to never names will never be
resolved and all devices will be owned by root.
--version
Print version number.
--help
Print help text.
ENVIRONMENT
$UDEV_LOG=
Set the logging priority.
KERNEL COMMAND LINE
Parameters starting with "rd." will be read when systemd-udevd is used in an initrd.
udev.log-priority=, rd.udev.log-priority=
Set the logging priority.
udev.children-max=, rd.udev.children-max=
Limit the number of events executed in parallel.
udev.exec-delay=, rd.udev.exec-delay=
Delay the execution of RUN instruction by the given number of seconds. This option
might be useful when debugging system crashes during coldplug caused by loading
non-working kernel modules.
net.ifnames=
Network interfaces are renamed to give them predictable names when possible. It is
enabled by default, specifying 0 disables it.
CONFIGURATION FILE
udev expects its main configuration file at /etc/udev/udev.conf. It consists of a set of
variables allowing the user to override default udev values. All empty lines or lines
beginning with '#' are ignored. The following variables can be set:
udev_log
The logging priority. Valid values are the numerical syslog priorities or their textual
representations: err, info and debug.
SEE ALSO
udev(7), udevadm(8)
10.2B.3.2 系统启动时如何启动udevd守护进程
系统启动时,init进程执行配置文件/etc/init/udev.conf来启动udevd:
# udev - device node and kernel event manager
#
# The udev daemon receives events from the kernel about changes in the
# /sys filesystem and manages the /dev filesystem.
description "device node and kernel event manager"
start on virtual-filesystems
stop on runlevel [06]
expect fork
respawn
exec /lib/systemd/systemd-udevd --daemon
系统启动后,在dmesg中可查看到如下信息:
chenwx@chenwx ~ $ dmesg | grep udevd
[ 2.363533] systemd-udevd[103]: starting version 204
[ 6.080163] systemd-udevd[379]: starting version 204
10.2B.3.3 编写udev规则
系统管理员编写的udev规则保存在/etc/udev/rules.d/目录,规则文件名要以.rules结尾。各种软件包提供的规则文件位于/lib/udev/rules.d/目录。若这两个目录中存在相同名字的文件,则udev使用/etc中的文件。
如何编写udev规则:
程序udevadm monitor可将驱动程序核心事件和udev事件处理的计时可视化。在输出结果中,UEVENT行显示内核已经通过netlink发送的事件,而UDEV行显示已经完成的udev事件处理程序,计时以微秒为单位显示。UEVENT和UDEV之间的时间是udev用于处理此事件或者udev守护程序延迟执行从而同步此事件与相关以及已运行的事件的时间。例如,硬盘分区的事件总是等待主磁盘设备事件完成,因为分区事件可能依赖于主磁盘事件从硬件查询的数据。
chenwx@chenwx ~ $ udevadm monitor
monitor will print the received events for:
UDEV - the event which udev sends out after rule processing
KERNEL - the kernel uevent
KERNEL[19749.454359] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001/input/input7/mouse0 (input)
KERNEL[19749.459136] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001/input/input7/event5 (input)
UDEV [19749.460452] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001/input/input7/mouse0 (input)
UDEV [19749.460922] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001/input/input7/event5 (input)
KERNEL[19749.463189] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001/input/input7 (input)
KERNEL[19749.463359] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001/hidraw/hidraw0 (hidraw)
KERNEL[19749.463374] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001 (hid)
KERNEL[19749.463386] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0 (usb)
KERNEL[19749.463490] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1 (usb)
UDEV [19749.463938] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001/hidraw/hidraw0 (hidraw)
UDEV [19749.468204] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001/input/input7 (input)
UDEV [19749.468806] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0001 (hid)
UDEV [19749.489601] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0 (usb)
UDEV [19749.491286] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1 (usb)
KERNEL[19752.074349] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1 (usb)
KERNEL[19752.077144] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0 (usb)
KERNEL[19752.094874] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002 (hid)
KERNEL[19752.095059] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002/input/input13 (input)
KERNEL[19752.095224] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002/input/input13/mouse0 (input)
KERNEL[19752.149251] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002/input/input13/event5 (input)
KERNEL[19752.149478] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002/hidraw/hidraw0 (hidraw)
UDEV [19752.389412] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1 (usb)
UDEV [19752.396916] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0 (usb)
UDEV [19752.400218] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002 (hid)
UDEV [19752.401058] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002/hidraw/hidraw0 (hidraw)
UDEV [19752.402641] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002/input/input13 (input)
UDEV [19752.405595] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002/input/input13/event5 (input)
UDEV [19752.407068] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0002/input/input13/mouse0 (input)
通过下列命令来显示完整的事件环境:
chenwx@chenwx ~ $ udevadm monitor --env
monitor will print the received events for:
UDEV - the event which udev sends out after rule processing
KERNEL - the kernel uevent
KERNEL[19950.203666] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0003/input/input14/mouse0 (input)
ACTION=remove
DEVNAME=/dev/input/mouse0
DEVPATH=/devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0003/input/input14/mouse0
MAJOR=13
MINOR=32
SEQNUM=2272
SUBSYSTEM=input
UDEV [19950.205943] remove /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0003/input/input14/mouse0 (input)
ACTION=remove
DEVLINKS=/dev/input/by-id/usb-Logitech_USB-PS_2_Optical_Mouse-mouse /dev/input/by-path/pci-0000:00:1a.1-usb-0:1:1.0-mouse
DEVNAME=/dev/input/mouse0
DEVPATH=/devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/0003:046D:C050.0003/input/input14/mouse0
ID_BUS=usb
ID_INPUT=1
ID_INPUT_MOUSE=1
ID_MODEL=USB-PS_2_Optical_Mouse
ID_MODEL_ENC=USB-PS\x2f2\x20Optical\x20Mouse
ID_MODEL_ID=c050
ID_PATH=pci-0000:00:1a.1-usb-0:1:1.0
ID_PATH_TAG=pci-0000_00_1a_1-usb-0_1_1_0
ID_REVISION=2720
ID_SERIAL=Logitech_USB-PS_2_Optical_Mouse
ID_TYPE=hid
ID_USB_DRIVER=usbhid
ID_USB_INTERFACES=:030102:
ID_USB_INTERFACE_NUM=00
ID_VENDOR=Logitech
ID_VENDOR_ENC=Logitech
ID_VENDOR_ID=046d
MAJOR=13
MINOR=32
SEQNUM=2272
SUBSYSTEM=input
USEC_INITIALIZED=4770015
......
KERNEL[19952.179325] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1 (usb)
ACTION=add
BUSNUM=004
DEVNAME=/dev/bus/usb/004/005
DEVNUM=005
DEVPATH=/devices/pci0000:00/0000:00:1a.1/usb4/4-1
DEVTYPE=usb_device
MAJOR=189
MINOR=388
PRODUCT=46d/c050/2720
SEQNUM=2279
SUBSYSTEM=usb
TYPE=0/0/0
KERNEL[19952.182198] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0 (usb)
ACTION=add
DEVPATH=/devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0
DEVTYPE=usb_interface
INTERFACE=3/1/2
MODALIAS=usb:v046DpC050d2720dc00dsc00dp00ic03isc01ip02in00
PRODUCT=46d/c050/2720
SEQNUM=2280
SUBSYSTEM=usb
TYPE=0/0/0
......
UDEV [19952.250889] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1 (usb)
ACTION=add
BUSNUM=004
DEVNAME=/dev/bus/usb/004/005
DEVNUM=005
DEVPATH=/devices/pci0000:00/0000:00:1a.1/usb4/4-1
DEVTYPE=usb_device
ID_BUS=usb
ID_MODEL=USB-PS_2_Optical_Mouse
ID_MODEL_ENC=USB-PS\x2f2\x20Optical\x20Mouse
ID_MODEL_FROM_DATABASE=RX 250 Optical Mouse
ID_MODEL_ID=c050
ID_REVISION=2720
ID_SERIAL=Logitech_USB-PS_2_Optical_Mouse
ID_USB_INTERFACES=:030102:
ID_VENDOR=Logitech
ID_VENDOR_ENC=Logitech
ID_VENDOR_FROM_DATABASE=Logitech, Inc.
ID_VENDOR_ID=046d
MAJOR=189
MINOR=388
PRODUCT=46d/c050/2720
SEQNUM=2279
SUBSYSTEM=usb
TYPE=0/0/0
UPOWER_VENDOR=Logitech, Inc.
USEC_INITIALIZED=2179402
UDEV [19952.255182] add /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0 (usb)
ACTION=add
DEVPATH=/devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0
DEVTYPE=usb_interface
ID_MODEL_FROM_DATABASE=RX 250 Optical Mouse
ID_VENDOR_FROM_DATABASE=Logitech, Inc.
INTERFACE=3/1/2
MODALIAS=usb:v046DpC050d2720dc00dsc00dp00ic03isc01ip02in00
PRODUCT=46d/c050/2720
SEQNUM=2280
SUBSYSTEM=usb
TYPE=0/0/0
USEC_INITIALIZED=2182309
......
udev也将消息发送给syslog。用于控制将哪些消息发送到系统日志的默认系统日志优先级在udev配置文件/etc/udev/udev.conf中指定,可用命令udevadm control log_priority=level/number来更改正在运行的守护程序的日志优先权。
10.2B.3.4 守护进程udevd接收uevent并加载对应的驱动程序
udevd通过创建netlink socket来接收内核发出的netlink uevent:
/* systemd/src/udev/udevd.c */
main()
-> listen_fds()
/* systemd/src/libudev/libudev-monitor.c */
-> udev_monitor_new_from_netlink(udev, "kernel")
-> udev_monitor_new_from_netlink_fd(udev, name, -1)
-> udev_monitor = udev_monitor_new(udev);
/* receive netlink uevent broadcase from kernel */
-> udev_monitor->sock = socket(PF_NETLINK,
SOCK_RAW|SOCK_CLOEXEC|SOCK_NONBLOCK,
NETLINK_KOBJECT_UEVENT);
-> udev_monitor->snl.nl.nl_family = AF_NETLINK;
-> udev_monitor->snl.nl.nl_groups = group;
/* default destination for sending */
-> udev_monitor->snl_destination.nl.nl_family = AF_NETLINK;
-> udev_monitor->snl_destination.nl.nl_groups = UDEV_MONITOR_UDEV;
当udevd接收到内核广播的netlink uevent后,根据如下信息来加载对应的驱动程序:
- 内核广播的netlink uevent中的参数MODALIAS;
- /lib/modules/`uname -r`/modules.alias, 参见3.5.5.1.1 cmd_depmod节;
- /lib/udev/rules.d/80-drivers.rules.
其中,/lib/udev/rules.d/80-drivers.rules包含下列规则:
# do not edit this file, it will be overwritten on update
ACTION=="remove", GOTO="drivers_end"
# 以驱动程序e1000e为例,MODALIAS=pci:v00008086d00001049sv*sd*bc*sc*i*
# 通过执行kmod load $env{MODALIAS}来加载匹配的驱动程序模块,参见源文件
# systemd/src/udev/udev-builtin-kmod.c中的函数builtin_kmod()
ENV{MODALIAS}=="?*", RUN{builtin}="kmod load $env{MODALIAS}"
SUBSYSTEM=="tifm", ENV{TIFM_CARD_TYPE}=="SD", RUN{builtin}="kmod load tifm_sd"
SUBSYSTEM=="tifm", ENV{TIFM_CARD_TYPE}=="MS", RUN{builtin}="kmod load tifm_ms"
SUBSYSTEM=="memstick", RUN{builtin}="kmod load ms_block mspro_block"
SUBSYSTEM=="i2o", RUN{builtin}="kmod load i2o_block"
SUBSYSTEM=="module", KERNEL=="parport_pc", RUN{builtin}="kmod load ppdev"
SUBSYSTEM=="serio", ENV{MODALIAS}=="?*", RUN{builtin}="kmod load $env{MODALIAS}"
SUBSYSTEM=="graphics", RUN{builtin}="kmod load fbcon"
KERNEL=="mtd*ro", ENV{MTD_FTL}=="smartmedia", RUN{builtin}="kmod load sm_ftl"
LABEL="drivers_end"
10.3 Char Drivers
«Linux Kernel Development, 3rd Edition» Chaper 14. The Block I/O Layer:
Character devices, or char devices, are accessed as a stream of sequential data, one byte after another. Example character devices are serial ports, keyboards, mice, printers and most pseudo-devices. If the hardware device is accessed as a stream of data, it is implemented as a character device. On the other hand, if the device is accessed randomly (nonsequentially), it is a block device.
下列命令输出结果中的第一列为c,则该设备为字符设备,另参见10.3.4.0 字符设备列表节:
chenwx@chenwx ~ $ ll /dev
crw-rw-rw- 1 root root 1, 3 Nov 27 20:51 null
crw-rw-rw- 1 root root 1, 8 Nov 27 20:51 random
crw-rw-rw- 1 root tty 5, 0 Nov 28 08:28 tty
crw--w---- 1 root tty 4, 0 Nov 27 20:51 tty0
crw-rw---- 1 root tty 4, 1 Nov 27 20:51 tty1
crw-rw-rw- 1 root root 1, 5 Nov 27 20:51 zero
...
由drivers/Makefile中的下列配置可知,字符设备位于drivers/char/目录,并且被编译进内核的:
# tty/ comes before char/ so that the VT console is the boot-time
# default.
obj-y += tty/
obj-y += char/
而由drivers/char/Makefile中的下列配置可知,mem.o, random.o和msic.o被直接编译进内核,其他模块根据配置被编译进内核或者编译成模块:
chenwx@chenwx:~/linux $ grep obj-y drivers/char/Makefile
obj-y += mem.o random.o
obj-y += misc.o
10.3.1 描述字符设备的数据结构
数组chrdevs[]定义于fs/char_dev.c:
static struct char_device_struct {
struct char_device_struct *next; // 指向单链表中的下一项
unsigned int major; // 主设备号
unsigned int baseminor; // 起始次设备号
int minorct; // 次设备号的范围
char name[64]; // 处理该设备编号范围内的设备驱动的名称
struct cdev *cdev; // will die. 该字段指向字符设备驱动程序描述符的指针
} *chrdevs[CHRDEV_MAJOR_HASH_SIZE]; // index可通过调用函数major_to_index(major)获得
该数组的大小为:
#define CHRDEV_MAJOR_HASH_SIZE 255
并通过下列函数将major转换为数组下标:
static inline int major_to_index(unsigned major)
{
return major % CHRDEV_MAJOR_HASH_SIZE;
}
而结构体struct cdev用于描述字符设备,其定义于include/linux/cdev.h:
struct cdev {
struct kobject kobj; // 参见[15.7 kobject]节
struct module *owner; // 指向提供驱动程序的模块,参见[13.4.1.1 struct module]节
const struct file_operations *ops; // 一组文件操作,用于实现与硬件通信的具体操作
struct list_head list; // 包含cdev的双向循环链表
dev_t dev; // 主次设备号
unsigned int count; // 表示与该设备关联的次设备的数目
};
其结构参见:
10.3.2 字符设备的初始化/chr_dev_init()
- 字符设备初始化函数之一:
chrdev_init(),参见4.3.4.1.4.3.11.6 chrdev_init()节 - 字符设备初始化函数之二:
chr_dev_init(),参见10.3.2 字符设备的初始化/chr_dev_init()节
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> vfs_caches_init() // 参见[4.3.4.1.4.3.11 vfs_caches_init()]节
-> chrdev_init() // 参见[4.3.4.1.4.3.11.6 chrdev_init()]节
-> rest_init() // 参见[4.3.4.1.4.3.13 rest_init()]节
-> kernel_init() // 参见[4.3.4.1.4.3.13.1 kernel_init()]节
-> do_basic_setup() // 参见[4.3.4.1.4.3.13.1.2 do_basic_setup()]节
-> do_initcalls() // 参见[13.5.1.1.1 do_initcalls()]节
-> do_one_initcall() // 参见[13.5.1.1.1.2 do_one_initcall()]节
-> fs_initcall(chr_dev_init) // 参见[13.5.1.1.1.1.1 .initcall*.init]节中的initcall5.init
-> chr_dev_init() // 参见本节
函数chr_dev_init()用于初始化字符设备,其定义于drivers/char/mem.c:
/*
* 数组devlist[]用于创建下列内存设备,以Minor为数组下表:
* Name Major Minor (=数组devlist[]的下标)
* -----------------------------------------------------------------------------
* /dev/mem 1 1
* /dev/kmem 1 2
* /dev/null 1 3
* /dev/port 1 4
* /dev/zero 1 5
* /dev/full 1 7
* /dev/random 1 8
* /dev/urandom 1 9
* /dev/kmsg 1 11
* /dev/oldmem 1 12 // which is already removed!
*/
static const struct memdev {
const char *name;
mode_t mode;
const struct file_operations *fops;
struct backing_dev_info *dev_info;
} devlist[] = {
[1] = { "mem", 0, &mem_fops, &directly_mappable_cdev_bdi },
#ifdef CONFIG_DEVKMEM
[2] = { "kmem", 0, &kmem_fops, &directly_mappable_cdev_bdi },
#endif
[3] = { "null", 0666, &null_fops, NULL },
#ifdef CONFIG_DEVPORT
[4] = { "port", 0, &port_fops, NULL },
#endif
[5] = { "zero", 0666, &zero_fops, &zero_bdi },
[7] = { "full", 0666, &full_fops, NULL },
[8] = { "random", 0666, &random_fops, NULL },
[9] = { "urandom", 0666, &urandom_fops, NULL },
[11] = { "kmsg", 0, &kmsg_fops, NULL },
#ifdef CONFIG_CRASH_DUMP
[12] = { "oldmem", 0, &oldmem_fops, NULL },
#endif
};
static int __init chr_dev_init(void)
{
int minor;
int err;
// 1) 初始化设备/dev/zero
err = bdi_init(&zero_bdi);
if (err)
return err;
/*
* 2) 注册字符设备/dev/mem,其主设备号为1,共占用256个次设备号;
* 参见[10.3.3.1 register_chrdev()]节
*/
if (register_chrdev(MEM_MAJOR, "mem", &memory_fops))
printk("unable to get major %d for memory devs\n", MEM_MAJOR);
// 3) 创建目录/sys/class/mem/,参见[10.2.7.1 class_create()]节
mem_class = class_create(THIS_MODULE, "mem");
if (IS_ERR(mem_class))
return PTR_ERR(mem_class);
/*
* 函数mem_devnode(dev, ..)用于获取字符设备的属性:
* devlist[MINOR(dev->devt)].mode
*/
mem_class->devnode = mem_devnode;
/*
* 4) 依次创建数组devlist[]中的内存设备 /dev/devlist[idx].name,
* 其函数调用关系为: device_create()->device_create_vargs()
* ->device_register()->device_initialize()->device_add()
* ->devtmpfsd()->handle()->handle_create()->vfs_mknod()
*/
for (minor = 1; minor < ARRAY_SIZE(devlist); minor++) {
if (!devlist[minor].name)
continue;
/*
* 创建字符设备devlist[minor],主设备号为1,次设备号为minor,
* 并生成目录/sys/class/mem/<devlist[minor].name>,
* 参见[10.2.3.1 创建设备/device_create()]节
*/
device_create(mem_class, NULL, MKDEV(MEM_MAJOR, minor),
NULL, devlist[minor].name);
}
/*
* 5) 注册字符设备/dev/tty和/dev/console,参见[10.3.2.1 tty_init()]节
*/
return tty_init();
}
fs_initcall(chr_dev_init);
其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall5.init
10.3.2.1 tty_init()
该函数定义于drivers/tty/tty_io.c:
/*
* Ok, now we can initialize the rest of the tty devices and can count
* on memory allocations, interrupts etc..
*/
int __init tty_init(void)
{
/*
* 1) 创建字符设备/dev/tty
*/
/*
* 1.1) 初始化变量tty_cdev,参见[10.3.3.3.2.2 静态分配和初始化cdev对象/cdev_init()]节
*/
cdev_init(&tty_cdev, &tty_fops);
/*
* 1.2) 添加字符设备/dev/tty,参见[10.3.3.3.3.1 cdev_add()]节
* 和[10.3.3.3.1.2 register_chrdev_region()]节
*/
if (cdev_add(&tty_cdev, MKDEV(TTYAUX_MAJOR, 0), 1) ||
register_chrdev_region(MKDEV(TTYAUX_MAJOR, 0), 1, "/dev/tty") < 0)
panic("Couldn't register /dev/tty driver\n");
/*
* 1.3) 创建字符设备/dev/tty,参见[10.2.3.1 创建设备/device_create()]节
*/
device_create(tty_class, NULL, MKDEV(TTYAUX_MAJOR, 0), NULL, "tty");
/*
* 2) 创建字符设备/dev/console
*/
/*
* 2.1) 初始化变量console_cdev,参见[10.3.3.3.2.2 静态分配和初始化cdev对象/cdev_init()]节
*/
cdev_init(&console_cdev, &console_fops);
/*
* 2.2) 添加字符设备/dev/console,参见[10.3.3.3.3.1 cdev_add()]节
* 和[10.3.3.3.1.2 register_chrdev_region()]节
*/
if (cdev_add(&console_cdev, MKDEV(TTYAUX_MAJOR, 1), 1) ||
register_chrdev_region(MKDEV(TTYAUX_MAJOR, 1), 1, "/dev/console") < 0)
panic("Couldn't register /dev/console driver\n");
/*
* 2.3) 创建字符设备/dev/console,参见[10.2.3.1 创建设备/device_create()]节
*/
consdev = device_create(tty_class, NULL, MKDEV(TTYAUX_MAJOR, 1), NULL, "console");
if (IS_ERR(consdev))
consdev = NULL;
else
WARN_ON(device_create_file(consdev, &dev_attr_active) < 0);
#ifdef CONFIG_VT
vty_init(&console_fops);
#endif
return 0;
}
其中,TTYAUX_MAJOR定义于include/linux/major.h:
#define TTYAUX_MAJOR 5
查看主次设备号:
chenwx@chenwx:~ $ ll /dev/tty /dev/console
crw------- 1 root root 5, 1 Jun 9 14:25 /dev/console
crw-rw-rw- 1 root tty 5, 0 Jun 9 20:48 /dev/tty
10.3.3 注册/注销字符设备
字符设备的注册与注销有如下两种方式:
1) 通过函数register_chrdev()注册字符设备,通过函数unregister_chrdev()注销字符设备,参见10.3.3.1 register_chrdev()节和10.3.3.2 unregister_chrdev()节;
2) 通过下列步骤完成字符设备的注册与注销,这种方式是register_chrdev()和unregister_chrdev()的组成步骤,参见10.3.3.3 注册/注销字符设备的分步骤节。
NOTE: If you dig through much driver code in the 2.6 kernel, you may notice that quite a few char drivers do not use the cdev interface described in section 10.3.3.3 注册/注销字符设备的分步骤节. But new code should not use it; this mechanism will likely go away in a future kernel.
2.1) 申请设备号
register_chrdev_region():静态申请设备号,参见10.3.3.3.1.2 register_chrdev_region()节alloc_chrdev_region():动态申请设备号,参见10.3.3.3.1.1 alloc_chrdev_region()节
2.2) 分配和初始化cdev对象
2.2.1) 静态分配和初始化cdev对象
struct cdev mycdev;
cdev_init(&mycdev, &fops);
mycdev->owner = THIS_MODULE;
其中,函数cdev_init()用于初始化cdev的成员,并建立cdev与file_operations之间的连接(即设置文件操作函数cdev->ops,读取/写入该字符设备时将调用cdev->ops中的对应函数),参见10.3.3.3.2.2 静态分配和初始化cdev对象/cdev_init()节。
2.2.2) 动态分配和初始化cdev对象
struct cdev *mycdev = cdev_alloc();
mycdev->ops = &fops;
mycdev->owner = THIS_MODULE;
其中,函数cdev_alloc()用于动态分配cdev对象,参见10.3.3.3.2.1 动态分配和初始化cdev对象/cdev_alloc()节。
2.3) 添加cdev对象
cdev_add(): Once the cdev structure is set up, the final step is to tell the kernel about it. See section 10.3.3.3.3.1 cdev_add().
NOTE: There are a couple of important things to keep in mind when using cdev_add(). The first is that this call can fail. If it returns a negative error code, your device has not been added to the system. It almost always succeeds, however, and that brings up the other point: as soon as cdev_add() returns, your device is live and its operations can be called by the kernel. You should not call cdev_add() until your driver is completely ready to handle operations on the device.
2.4) 访问字符设备
2.5) 删除cdev对象
cdev_del(): To remove a char device from the system. Clearly, you should not access the cdev structure after passing it to cdev_del(). See section 10.3.3.3.3.2 cdev_del().
2.6) 释放设备号
unregister_chrdev_region(): See section 10.3.3.3.1.4 unregister_chrdev_region().
10.3.3.1 register_chrdev()
该函数定义于include/linux/fs.h:
/*
* A call to register_chrdev registers minor numbers 0–255 for the given major,
* and sets up a default cdev structure for each. Drivers using this interface
* must be prepared to handle open calls on all 256 minor numbers (whether they
* correspond to real devices or not), and they cannot use major or minor numbers
* greater than 255.
*/
static inline int register_chrdev(unsigned int major, const char *name,
const struct file_operations *fops)
{
// 分配主设备号为major,起始次设备号为0,共连续256个次设备号
return __register_chrdev(major, 0, 256, name, fops);
}
其中,__register_chrdev()定义于fs/char_dev.c:
/**
* __register_chrdev() - create and register a cdev occupying a range of minors
* @major: major device number or 0 for dynamic allocation
* @baseminor: first of the requested range of minor numbers
* @count: the number of minor numbers required
* @name: name of this range of devices
* @fops: file operations associated with this devices
*
* If @major == 0 this functions will dynamically allocate a major and return
* its number.
*
* If @major > 0 this function will attempt to reserve a device with the given
* major number and will return zero on success.
*
* Returns a -ve errno on failure.
*
* The name of this device has nothing to do with the name of the device in
* /dev. It only helps to keep track of the different owners of devices. If
* your module name has only one type of devices it's ok to use e.g. the name
* of the module here.
*/
int __register_chrdev(unsigned int major, unsigned int baseminor,
unsigned int count, const char *name,
const struct file_operations *fops)
{
struct char_device_struct *cd;
struct cdev *cdev;
int err = -ENOMEM;
/*
* 分配/初始化struct char_device_struct类型的变量,
* 并将其插入到链表chrdevs[major%255]中的适当位置,
* 参见[10.3.3.3.1.3 __register_chrdev_region()]节
*/
cd = __register_chrdev_region(major, baseminor, count, name);
if (IS_ERR(cd))
return PTR_ERR(cd);
/*
* 动态分配/初始化struct cdev类型的对象,
* 并设置cdev->kobj->ktype = &ktype_cdev_dynamic;
* 参见[10.3.3.3.2.1 动态分配和初始化cdev对象/cdev_alloc()]节
*/
cdev = cdev_alloc();
if (!cdev)
goto out2;
cdev->owner = fops->owner;
cdev->ops = fops;
// 设置cdev->kobj->name = name
kobject_set_name(&cdev->kobj, "%s", name);
/*
* 将cdev链接到cdev_map.probe[major].data中,
* 参见[10.3.3.3.3.1 cdev_add()]节
*/
err = cdev_add(cdev, MKDEV(cd->major, baseminor), count);
if (err)
goto out;
cd->cdev = cdev;
// 若动态分配主设备号,则返回动态分配的主设备号,否则返回0
return major ? 0 : cd->major;
out:
// 参见[15.7.2.2 kobject_put()]节
kobject_put(&cdev->kobj);
out2:
kfree(__unregister_chrdev_region(cd->major, baseminor, count));
return err;
}
10.3.3.2 unregister_chrdev()
If you use register_chrdev(), the proper function to remove your device(s) from the system is unregister_chrdev().
该函数定义于include/linux/fs.h:
static inline void unregister_chrdev(unsigned int major, const char *name)
{
__unregister_chrdev(major, 0, 256, name);
}
其中,__unregister_chrdev()定义于fs/char_dev.c:
/**
* __unregister_chrdev - unregister and destroy a cdev
* @major: major device number
* @baseminor: first of the range of minor numbers
* @count: the number of minor numbers this cdev is occupying
* @name: name of this range of devices
*
* Unregister and destroy the cdev occupying the region described by
* @major, @baseminor and @count. This function undoes what
* __register_chrdev() did.
*/
void __unregister_chrdev(unsigned int major, unsigned int baseminor,
unsigned int count, const char *name)
{
struct char_device_struct *cd;
// 参见[10.3.3.3.1.5 __unregister_chrdev_region()]节
cd = __unregister_chrdev_region(major, baseminor, count);
if (cd && cd->cdev)
cdev_del(cd->cdev); // 参见[10.3.3.3.3.2 cdev_del()]节
kfree(cd);
}
10.3.3.3 注册/注销字符设备的分步骤
10.3.3.3.1 申请/释放设备号
10.3.3.3.1.1 alloc_chrdev_region()
该函数定义于fs/char_dev.c:
/**
* alloc_chrdev_region() - register a range of char device numbers
* @dev: output parameter for first assigned number
* @baseminor: first of the requested range of minor numbers
* @count: the number of minor numbers required
* @name: the name of the associated device or driver
*
* Allocates a range of char device numbers. The major number will be
* chosen dynamically, and returned (along with the first minor number)
* in @dev. Returns zero or a negative error code.
*/
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count,
const char *name)
{
struct char_device_struct *cd;
/*
* 分配/初始化struct char_device_struct类型的对象,
* 并将其插入到链表chrdevs[major%255]中的适当位置,
* 参见[10.3.3.3.1.3 __register_chrdev_region()]节
*/
cd = __register_chrdev_region(0, baseminor, count, name);
if (IS_ERR(cd))
return PTR_ERR(cd);
// 构造主次设备号: 高12 bit为主设备号,低20 bit为次设备号
*dev = MKDEV(cd->major, cd->baseminor);
return 0;
}
10.3.3.3.1.2 register_chrdev_region()
该函数定义于fs/char_dev.c:
/**
* register_chrdev_region() - register a range of device numbers
* @from: the first in the desired range of device numbers; must include
* the major number.
* @count: the number of consecutive device numbers required
* @name: the name of the device or driver.
*
* Return value is zero on success, a negative error code on failure.
*/
int register_chrdev_region(dev_t from, unsigned count, const char *name)
{
struct char_device_struct *cd;
dev_t to = from + count;
dev_t n, next;
for (n = from; n < to; n = next) {
next = MKDEV(MAJOR(n)+1, 0);
if (next > to)
next = to;
/*
* 分配和初始化struct char_device_struct的对象,
* 并将其插入到链表chrdevs[major%255]中的适当位置,
* 参见[10.3.3.3.1.3 __register_chrdev_region()]节
*/
cd = __register_chrdev_region(MAJOR(n), MINOR(n), next - n, name);
if (IS_ERR(cd))
goto fail;
}
return 0;
fail:
to = n;
for (n = from; n < to; n = next) {
next = MKDEV(MAJOR(n)+1, 0);
kfree(__unregister_chrdev_region(MAJOR(n), MINOR(n), next - n));
}
return PTR_ERR(cd);
}
10.3.3.3.1.3 __register_chrdev_region()
该函数定义于fs/char_dev.c:
/*
* Register a single major with a specified minor range.
*
* If major == 0 this functions will dynamically allocate a major and return
* its number.
*
* If major > 0 this function will attempt to reserve the passed range of
* minors and will return zero on success.
*
* Returns a -ve errno on failure.
*/
static struct char_device_struct *
__register_chrdev_region(unsigned int major, unsigned int baseminor,
int minorct, const char *name)
{
struct char_device_struct *cd, **cp;
int ret = 0;
int i;
cd = kzalloc(sizeof(struct char_device_struct), GFP_KERNEL);
if (cd == NULL)
return ERR_PTR(-ENOMEM);
mutex_lock(&chrdevs_lock);
/*
* 若major == 0,则动态分配主设备号:
* 按从后向前的顺序查找数组chrdevs[],若某元素为空,
* 则该元素对应的下标即为新分配的主设备号;由此可知,
* 动态分配主设备号的顺序是由大到小
*/
/* temporary */
if (major == 0) {
for (i = ARRAY_SIZE(chrdevs)-1; i > 0; i--) {
if (chrdevs[i] == NULL)
break;
}
/*
* 若数组chrdevs[]的255个元素全部被用,则直接返回。特例:
* 若数组chrdevs[]全部占用,但某个主设备号chrdevs[major]所
* 对应的辅设备号只占用了1个,这种情况下无法使用动态分配设备号,
* 只能使用静态分配设备号的方式来申请!
*/
if (i == 0) {
ret = -EBUSY;
goto out;
}
major = i;
ret = major;
}
cd->major = major;
cd->baseminor = baseminor;
cd->minorct = minorct;
strlcpy(cd->name, name, sizeof(cd->name));
/*
* 查找新元素cd应插入到链表chrdevs[major%255]中的位置,按如下条件查找:
* - 按链表chrdevs[major%255]中major由小到大的顺序
* - 按链表chrdevs[major%255]中baseminor由小到大的顺序
*/
i = major_to_index(major);
for (cp = &chrdevs[i]; *cp; cp = &(*cp)->next)
if ((*cp)->major > major ||
((*cp)->major == major &&
(((*cp)->baseminor >= baseminor) ||
((*cp)->baseminor + (*cp)->minorct > baseminor))))
break;
/* Check for overlapping minor ranges. */
if (*cp && (*cp)->major == major) {
int old_min = (*cp)->baseminor;
int old_max = (*cp)->baseminor + (*cp)->minorct - 1;
int new_min = baseminor;
int new_max = baseminor + minorct - 1;
/* New driver overlaps from the left. */
if (new_max >= old_min && new_max <= old_max) {
ret = -EBUSY;
goto out;
}
/* New driver overlaps from the right. */
if (new_min <= old_max && new_min >= old_min) {
ret = -EBUSY;
goto out;
}
}
/*
* 将对象cd插入到链表chrdevs[major%255]中,参见本节中的图chrdevs[]_1.jpg
*/
cd->next = *cp;
*cp = cd;
mutex_unlock(&chrdevs_lock);
return cd;
out:
mutex_unlock(&chrdevs_lock);
kfree(cd);
return ERR_PTR(ret);
}
NOTE: chrdevs[]_1.jpg
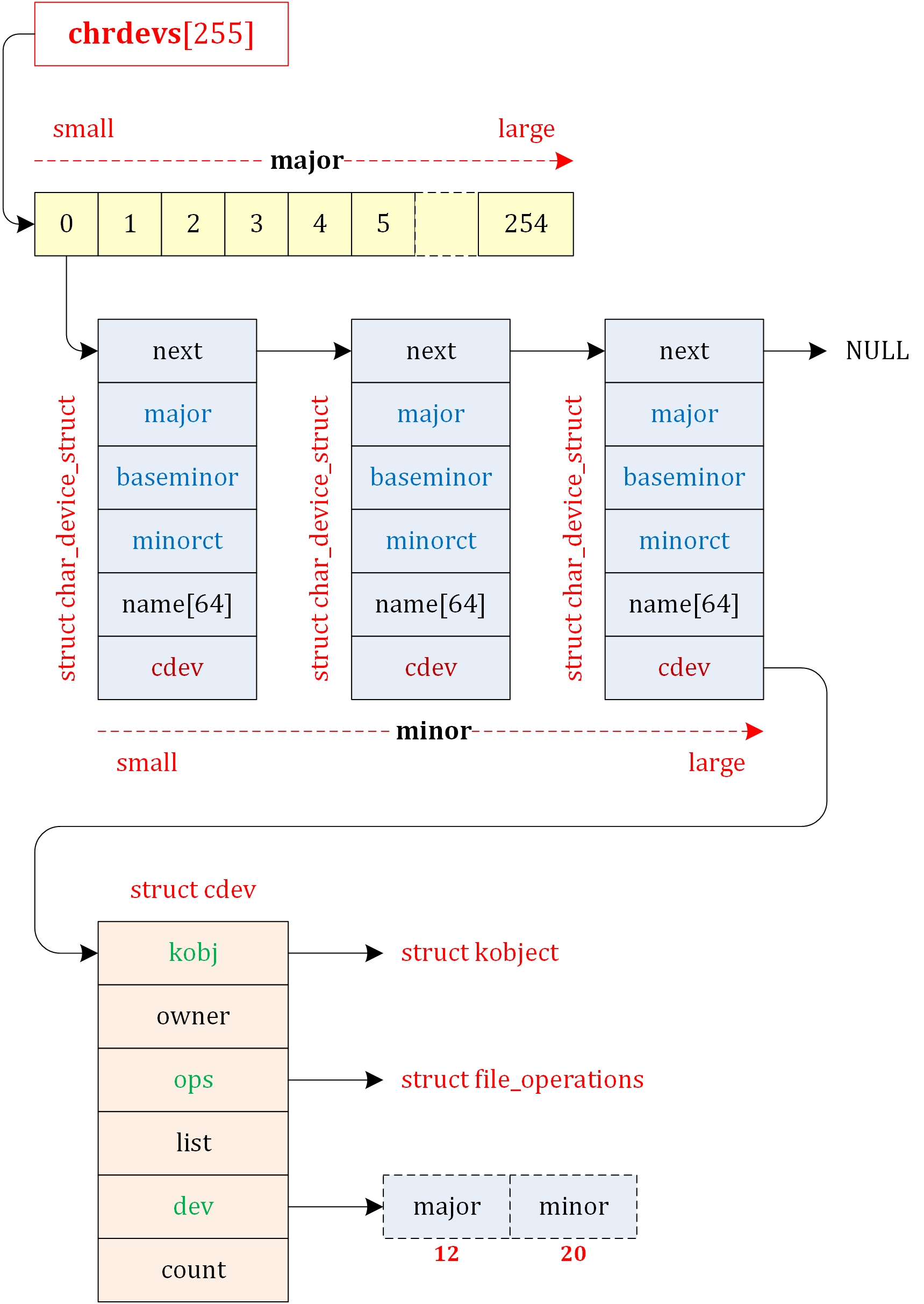
10.3.3.3.1.4 unregister_chrdev_region()
该函数定义于fs/char_dev.c:
/**
* unregister_chrdev_region() - return a range of device numbers
* @from: the first in the range of numbers to unregister
* @count: the number of device numbers to unregister
*
* This function will unregister a range of @count device numbers,
* starting with @from. The caller should normally be the one who
* allocated those numbers in the first place...
*/
void unregister_chrdev_region(dev_t from, unsigned count)
{
dev_t to = from + count;
dev_t n, next;
for (n = from; n < to; n = next) {
next = MKDEV(MAJOR(n)+1, 0);
if (next > to)
next = to;
// 参见[10.3.3.3.1.5 __unregister_chrdev_region()]节
kfree(__unregister_chrdev_region(MAJOR(n), MINOR(n), next - n));
}
}
10.3.3.3.1.5 __unregister_chrdev_region()
该函数定义于fs/char_dev.c:
static struct char_device_struct *
__unregister_chrdev_region(unsigned major, unsigned baseminor, int minorct)
{
struct char_device_struct *cd = NULL, **cp;
int i = major_to_index(major);
mutex_lock(&chrdevs_lock);
for (cp = &chrdevs[i]; *cp; cp = &(*cp)->next)
if ((*cp)->major == major &&
(*cp)->baseminor == baseminor &&
(*cp)->minorct == minorct)
break;
// 将符合条件的元素从链表chrdevs[i]删除
if (*cp) {
cd = *cp;
*cp = cd->next;
}
mutex_unlock(&chrdevs_lock);
return cd;
}
10.3.3.3.2 分配/初始化cdev对象
10.3.3.3.2.1 动态分配和初始化cdev对象/cdev_alloc()
该函数定义于fs/char_dev.c:
/**
* cdev_alloc() - allocate a cdev structure
*
* Allocates and returns a cdev structure, or NULL on failure.
*/
struct cdev *cdev_alloc(void)
{
struct cdev *p = kzalloc(sizeof(struct cdev), GFP_KERNEL);
if (p) {
INIT_LIST_HEAD(&p->list);
/*
* 与cdev_init()相比,其函数指针release不同:
* &p->kobj->ktype = &ktype_cdev_dynamic;
*/
kobject_init(&p->kobj, &ktype_cdev_dynamic);
}
return p;
}
static struct kobj_type ktype_cdev_dynamic = {
.release = cdev_dynamic_release,
};
static void cdev_dynamic_release(struct kobject *kobj)
{
struct cdev *p = container_of(kobj, struct cdev, kobj);
struct kobject *parent = kobj->parent;
cdev_purge(p);
kfree(p);
kobject_put(parent);
}
10.3.3.3.2.2 静态分配和初始化cdev对象/cdev_init()
该函数适用于静态创建类型为struct cdev的对象后,初始化该对象,例如:
struct cdev mycdev;
cdev_init(&mycdev, &fops);
该函数定义于fs/char_dev.c:
/**
* cdev_init() - initialize a cdev structure
* @cdev: the structure to initialize
* @fops: the file_operations for this device
*
* Initializes @cdev, remembering @fops, making it ready to add to the
* system with cdev_add().
*/
void cdev_init(struct cdev *cdev, const struct file_operations *fops)
{
memset(cdev, 0, sizeof *cdev);
INIT_LIST_HEAD(&cdev->list);
/*
* 与cdev_alloc()的不同之处在于,函数release()不同:
* &cdev->kobj->ktype = &ktype_cdev_default;
*/
kobject_init(&cdev->kobj, &ktype_cdev_default);
cdev->ops = fops;
}
static struct kobj_type ktype_cdev_default = {
.release = cdev_default_release,
};
static void cdev_default_release(struct kobject *kobj)
{
struct cdev *p = container_of(kobj, struct cdev, kobj);
struct kobject *parent = kobj->parent;
cdev_purge(p);
kobject_put(parent);
}
10.3.3.3.3 添加/删除cdev对象
10.3.3.3.3.1 cdev_add()
该函数定义于fs/char_dev.c:
/**
* cdev_add() - add a char device to the system
* @p: the cdev structure for the device
* @dev: the first device number for which this device is responsible
* @count: the number of consecutive minor numbers corresponding to this
* device
*
* cdev_add() adds the device represented by @p to the system, making it
* live immediately. A negative error code is returned on failure.
*/
int cdev_add(struct cdev *p, dev_t dev, unsigned count)
{
p->dev = dev;
p->count = count;
/*
* 变量cdev_map是由函数chrdev_init()创建的,
* 参见[4.3.4.1.4.3.11.6 chrdev_init()]节
*/
return kobj_map(cdev_map, dev, count, NULL, exact_match, exact_lock, p);
}
其中,函数kobj_map()定义于drivers/base/map.c:
int kobj_map(struct kobj_map *domain, dev_t dev, unsigned long range,
struct module *module, kobj_probe_t *probe,
int (*lock)(dev_t, void *), void *data)
{
unsigned n = MAJOR(dev + range - 1) - MAJOR(dev) + 1;
unsigned index = MAJOR(dev);
unsigned i;
struct probe *p;
if (n > 255)
n = 255;
p = kmalloc(sizeof(struct probe) * n, GFP_KERNEL);
if (p == NULL)
return -ENOMEM;
// 这n个struct probe类型的对象,其各元素的取值完全相同
for (i = 0; i < n; i++, p++) {
p->owner = module;
/*
* 此函数被kobj_lookup()调用,参见[10.3.3.3.4.1 kobj_lookup()]节;
* 若本函数是通过cdev_add()->kobj_map()调用的,则p->get = exact_match;
*/
p->get = probe;
/*
* 此函数被kobj_lookup()调用,参见[10.3.3.3.4.1 kobj_lookup()]节;
* 若本函数是通过cdev_add()->kobj_map()调用的,则p->lock = exact_lock;
*/
p->lock = lock;
p->dev = dev;
p->range = range;
// 所有的p->data均指向同一struct cdev类型的对象
p->data = data;
}
// 将这n个struct probe类型的对象插入到数组cdev_map[]中
mutex_lock(domain->lock);
for (i = 0, p -= n; i < n; i++, p++, index++) {
struct probe **s = &domain->probes[index % 255];
while (*s && (*s)->range < range)
s = &(*s)->next;
p->next = *s;
*s = p;
}
mutex_unlock(domain->lock);
return 0;
}
10.3.3.3.3.2 cdev_del()
该函数定义于fs/char_dev.c:
/**
* cdev_del() - remove a cdev from the system
* @p: the cdev structure to be removed
*
* cdev_del() removes @p from the system, possibly freeing the structure
* itself.
*/
void cdev_del(struct cdev *p)
{
cdev_unmap(p->dev, p->count);
kobject_put(&p->kobj); // 参见[15.7.2.2 kobject_put()]节
}
static void cdev_unmap(dev_t dev, unsigned count)
{
kobj_unmap(cdev_map, dev, count);
}
其中,函数kobj_unmap()定义于drivers/base/map.c:
void kobj_unmap(struct kobj_map *domain, dev_t dev, unsigned long range)
{
unsigned n = MAJOR(dev + range - 1) - MAJOR(dev) + 1;
unsigned index = MAJOR(dev);
unsigned i;
struct probe *found = NULL;
if (n > 255)
n = 255;
mutex_lock(domain->lock);
for (i = 0; i < n; i++, index++) {
struct probe **s;
for (s = &domain->probes[index % 255]; *s; s = &(*s)->next) {
struct probe *p = *s;
if (p->dev == dev && p->range == range) {
*s = p->next;
if (!found)
found = p;
break;
}
}
}
mutex_unlock(domain->lock);
kfree(found);
}
10.3.3.3.4 访问字符设备
如何将read()和write()等文件操作与cdev->ops中的函数关联起来的呢?
1) 字符设备的驱动程序调用函数init_special_node()来设置inode->i_fop指针,该函数定义于fs/inode.c:
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) { // 字符设备S_IFCHR
inode->i_fop = &def_chr_fops;
inode->i_rdev = rdev;
} else if (S_ISBLK(mode)) { // 块设备S_IFBLK
inode->i_fop = &def_blk_fops;
inode->i_rdev = rdev;
} else if (S_ISFIFO(mode)) // FIFO special file, or a pipe. S_IFIFO
inode->i_fop = &def_fifo_fops;
else if (S_ISSOCK(mode)) // 网络设备S_IFSOCK
inode->i_fop = &bad_sock_fops;
else
printk(KERN_DEBUG "init_special_inode: bogus i_mode (%o) for"
" inode %s:%lu\n", mode, inode->i_sb->s_id,
inode->i_ino);
}
2) 变量def_chr_fops指定字符设备的open()函数,该变量定义于fs/char_dev.c:
/*
* Dummy default file-operations: the only thing this does
* is contain the open that then fills in the correct operations
* depending on the special file...
*/
const struct file_operations def_chr_fops = {
.open = chrdev_open,
.llseek = noop_llseek,
};
3) 通过函数chrdev_open()来获取字符设备的函数指针cdev->ops,该函数定义于fs/char_dev.c:
/*
* Called every time a character special file is opened
*/
static int chrdev_open(struct inode *inode, struct file *filp)
{
struct cdev *p;
struct cdev *new = NULL;
int ret = 0;
spin_lock(&cdev_lock);
p = inode->i_cdev;
if (!p) {
/*
* 1) 若该指针为空,则从cdev_map->probes[]中查找该字符设备
*/
struct kobject *kobj;
int idx;
spin_unlock(&cdev_lock);
/*
* 从链表cdev_map->probes[MAJOR(inode->i_rdev)%255]中
* 查找符合条件的字符设备,参见[10.3.3.3.4.1 kobj_lookup()]节
*/
kobj = kobj_lookup(cdev_map, inode->i_rdev, &idx);
if (!kobj)
return -ENXIO;
new = container_of(kobj, struct cdev, kobj);
spin_lock(&cdev_lock);
/* Check i_cdev again in case somebody beat us to it while
we dropped the lock. */
p = inode->i_cdev;
if (!p) {
inode->i_cdev = p = new;
list_add(&inode->i_devices, &p->list);
new = NULL;
} else if (!cdev_get(p)) // 增加该字符设备的引用计数p->kobj->kref
ret = -ENXIO;
} else if (!cdev_get(p))
/*
* 2) 若该指针不为空,则增加该字符设备的引用计数p->kobj->kref
*/
ret = -ENXIO;
spin_unlock(&cdev_lock);
cdev_put(new);
if (ret)
return ret;
ret = -ENXIO;
// 获取该字符设备的文件操作函数,用于后续的文件操作函数read(), write(), ...
filp->f_op = fops_get(p->ops);
if (!filp->f_op)
goto out_cdev_put;
// 调用该字符设备对应的open()函数
if (filp->f_op->open) {
ret = filp->f_op->open(inode, filp);
if (ret)
goto out_cdev_put;
}
return 0;
out_cdev_put:
cdev_put(p);
return ret;
}
此后,read()和write()等文件操作函数将会调用cdev->ops->read()和cdev->ops->write()等函数,参见如下章节:
10.3.3.3.4.1 kobj_lookup()
该函数定义于drivers/base/map.c:
struct kobject *kobj_lookup(struct kobj_map *domain, dev_t dev, int *index)
{
struct kobject *kobj;
struct probe *p;
unsigned long best = ~0UL;
retry:
mutex_lock(domain->lock);
/*
* 根据主设备号MAJOR(dev),从链表cdev_map→probes[MAJOR(dev)%255]
* 中查找符合条件的字符设备
*/
for (p = domain->probes[MAJOR(dev) % 255]; p; p = p->next) {
struct kobject *(*probe)(dev_t, int *, void *);
struct module *owner;
void *data;
// 查找符合条件的字符设备
if (p->dev > dev || p->dev + p->range - 1 < dev)
continue;
if (p->range - 1 >= best)
break;
// 增加模块的引用计数p->owner->refptr->incs
if (!try_module_get(p->owner))
continue;
owner = p->owner;
data = p->data;
probe = p->get;
best = p->range - 1;
*index = dev – p->dev;
/*
* 调用该字符设备的lock()函数来锁定该字符设备; 其中,函数
* 指针p->lock是由函数cdev_add()->kobj_map()设置的,
* 即exact_lock(),参见[10.3.3.3.3.1 cdev_add()]节
*/
if (p->lock && p->lock(dev, data) < 0) {
module_put(owner);
continue;
}
mutex_unlock(domain->lock);
/*
* 调用该字符设备的get()函数来查看该字符设备是否符合条件;
* 其中,函数指针p->get是由函数cdev_add()->kobj_map()
* 设置的,即exact_match(),参见[10.3.3.3.3.1 cdev_add()]节
*/
kobj = probe(dev, index, data);
/* Currently ->owner protects _only_ ->probe() itself. */
module_put(owner);
if (kobj)
return kobj;
goto retry;
}
mutex_unlock(domain->lock);
return NULL;
}
10.3.4 具体的字符设备
10.3.4.0 字符设备列表
执行下列命令查看系统中的字符设备,另参见10.1.3 设备驱动程序的分类节:
chenwx@chenwx ~/linux $ ls -l /dev
/* (1) MEM_MAJOR = 1 */
// 内存设备,参见[10.3.4.1 内存设备]节
crw-r----- 1 root kmem 1, 1 Dec 30 08:20 mem
crw-rw-rw- 1 root root 1, 3 Dec 30 08:20 null
crw-r----- 1 root kmem 1, 4 Dec 30 08:20 port
crw-rw-rw- 1 root root 1, 5 Dec 30 08:20 zero
crw-rw-rw- 1 root root 1, 7 Dec 30 08:20 full
crw-rw-rw- 1 root root 1, 8 Dec 30 08:20 random
crw-rw-rw- 1 root root 1, 9 Dec 30 08:20 urandom
crw-r--r-- 1 root root 1, 11 Dec 30 08:20 kmsg
/* (2) TTY_MAJOR = 4 */
// 参见vty_init()
crw--w---- 1 root tty 4, 0 Dec 30 08:20 tty0
crw-rw---- 1 root tty 4, 1 Dec 30 08:20 tty1
crw-rw---- 1 root tty 4, 2 Dec 30 08:20 tty2
crw-rw---- 1 root tty 4, 3 Dec 30 08:20 tty3
crw-rw---- 1 root tty 4, 4 Dec 30 08:20 tty4
crw-rw---- 1 root tty 4, 5 Dec 30 08:20 tty5
crw-rw---- 1 root tty 4, 6 Dec 30 08:20 tty6
crw--w---- 1 root tty 4, 7 Dec 30 08:20 tty7
crw--w---- 1 root tty 4, 8 Dec 30 08:20 tty8
crw--w---- 1 root tty 4, 9 Dec 30 08:20 tty9
crw--w---- 1 root tty 4, 10 Dec 30 08:20 tty10
crw--w---- 1 root tty 4, 11 Dec 30 08:20 tty11
crw--w---- 1 root tty 4, 12 Dec 30 08:20 tty12
crw--w---- 1 root tty 4, 13 Dec 30 08:20 tty13
crw--w---- 1 root tty 4, 14 Dec 30 08:20 tty14
crw--w---- 1 root tty 4, 15 Dec 30 08:20 tty15
crw--w---- 1 root tty 4, 16 Dec 30 08:20 tty16
crw--w---- 1 root tty 4, 17 Dec 30 08:20 tty17
crw--w---- 1 root tty 4, 18 Dec 30 08:20 tty18
crw--w---- 1 root tty 4, 19 Dec 30 08:20 tty19
crw--w---- 1 root tty 4, 20 Dec 30 08:20 tty20
crw--w---- 1 root tty 4, 21 Dec 30 08:20 tty21
crw--w---- 1 root tty 4, 22 Dec 30 08:20 tty22
crw--w---- 1 root tty 4, 23 Dec 30 08:20 tty23
crw--w---- 1 root tty 4, 24 Dec 30 08:20 tty24
crw--w---- 1 root tty 4, 25 Dec 30 08:20 tty25
crw--w---- 1 root tty 4, 26 Dec 30 08:20 tty26
crw--w---- 1 root tty 4, 27 Dec 30 08:20 tty27
crw--w---- 1 root tty 4, 28 Dec 30 08:20 tty28
crw--w---- 1 root tty 4, 29 Dec 30 08:20 tty29
crw--w---- 1 root tty 4, 30 Dec 30 08:20 tty30
crw--w---- 1 root tty 4, 31 Dec 30 08:20 tty31
crw--w---- 1 root tty 4, 32 Dec 30 08:20 tty32
crw--w---- 1 root tty 4, 33 Dec 30 08:20 tty33
crw--w---- 1 root tty 4, 34 Dec 30 08:20 tty34
crw--w---- 1 root tty 4, 35 Dec 30 08:20 tty35
crw--w---- 1 root tty 4, 36 Dec 30 08:20 tty36
crw--w---- 1 root tty 4, 37 Dec 30 08:20 tty37
crw--w---- 1 root tty 4, 38 Dec 30 08:20 tty38
crw--w---- 1 root tty 4, 39 Dec 30 08:20 tty39
crw--w---- 1 root tty 4, 40 Dec 30 08:20 tty40
crw--w---- 1 root tty 4, 41 Dec 30 08:20 tty41
crw--w---- 1 root tty 4, 42 Dec 30 08:20 tty42
crw--w---- 1 root tty 4, 43 Dec 30 08:20 tty43
crw--w---- 1 root tty 4, 44 Dec 30 08:20 tty44
crw--w---- 1 root tty 4, 45 Dec 30 08:20 tty45
crw--w---- 1 root tty 4, 46 Dec 30 08:20 tty46
crw--w---- 1 root tty 4, 47 Dec 30 08:20 tty47
crw--w---- 1 root tty 4, 48 Dec 30 08:20 tty48
crw--w---- 1 root tty 4, 49 Dec 30 08:20 tty49
crw--w---- 1 root tty 4, 50 Dec 30 08:20 tty50
crw--w---- 1 root tty 4, 51 Dec 30 08:20 tty51
crw--w---- 1 root tty 4, 52 Dec 30 08:20 tty52
crw--w---- 1 root tty 4, 53 Dec 30 08:20 tty53
crw--w---- 1 root tty 4, 54 Dec 30 08:20 tty54
crw--w---- 1 root tty 4, 55 Dec 30 08:20 tty55
crw--w---- 1 root tty 4, 56 Dec 30 08:20 tty56
crw--w---- 1 root tty 4, 57 Dec 30 08:20 tty57
crw--w---- 1 root tty 4, 58 Dec 30 08:20 tty58
crw--w---- 1 root tty 4, 59 Dec 30 08:20 tty59
crw--w---- 1 root tty 4, 60 Dec 30 08:20 tty60
crw--w---- 1 root tty 4, 61 Dec 30 08:20 tty61
crw--w---- 1 root tty 4, 62 Dec 30 08:20 tty62
crw--w---- 1 root tty 4, 63 Dec 30 08:20 tty63
// 参见vty_init()->tty_register_driver(console_driver)->tty_register_device()
crw-rw---- 1 root dialout 4, 64 Dec 30 08:20 ttyS0
crw-rw---- 1 root dialout 4, 65 Dec 30 08:20 ttyS1
crw-rw---- 1 root dialout 4, 66 Dec 30 08:20 ttyS2
crw-rw---- 1 root dialout 4, 67 Dec 30 08:20 ttyS3
crw-rw---- 1 root dialout 4, 68 Dec 30 08:20 ttyS4
crw-rw---- 1 root dialout 4, 69 Dec 30 08:20 ttyS5
crw-rw---- 1 root dialout 4, 70 Dec 30 08:20 ttyS6
crw-rw---- 1 root dialout 4, 71 Dec 30 08:20 ttyS7
crw-rw---- 1 root dialout 4, 72 Dec 30 08:20 ttyS8
crw-rw---- 1 root dialout 4, 73 Dec 30 08:20 ttyS9
crw-rw---- 1 root dialout 4, 74 Dec 30 08:20 ttyS10
crw-rw---- 1 root dialout 4, 75 Dec 30 08:20 ttyS11
crw-rw---- 1 root dialout 4, 76 Dec 30 08:20 ttyS12
crw-rw---- 1 root dialout 4, 77 Dec 30 08:20 ttyS13
crw-rw---- 1 root dialout 4, 78 Dec 30 08:20 ttyS14
crw-rw---- 1 root dialout 4, 79 Dec 30 08:20 ttyS15
crw-rw---- 1 root dialout 4, 80 Dec 30 08:20 ttyS16
crw-rw---- 1 root dialout 4, 81 Dec 30 08:20 ttyS17
crw-rw---- 1 root dialout 4, 82 Dec 30 08:20 ttyS18
crw-rw---- 1 root dialout 4, 83 Dec 30 08:20 ttyS19
crw-rw---- 1 root dialout 4, 84 Dec 30 08:20 ttyS20
crw-rw---- 1 root dialout 4, 85 Dec 30 08:20 ttyS21
crw-rw---- 1 root dialout 4, 86 Dec 30 08:20 ttyS22
crw-rw---- 1 root dialout 4, 87 Dec 30 08:20 ttyS23
crw-rw---- 1 root dialout 4, 88 Dec 30 08:20 ttyS24
crw-rw---- 1 root dialout 4, 89 Dec 30 08:20 ttyS25
crw-rw---- 1 root dialout 4, 90 Dec 30 08:20 ttyS26
crw-rw---- 1 root dialout 4, 91 Dec 30 08:20 ttyS27
crw-rw---- 1 root dialout 4, 92 Dec 30 08:20 ttyS28
crw-rw---- 1 root dialout 4, 93 Dec 30 08:20 ttyS29
crw-rw---- 1 root dialout 4, 94 Dec 30 08:20 ttyS30
crw-rw---- 1 root dialout 4, 95 Dec 30 08:20 ttyS31
/* (3) TTYAUX_MAJOR = 5 */
// 参见[10.3.2.1 tty_init()]节
crw-rw-rw- 1 root tty 5, 0 Dec 30 08:20 tty
crw------- 1 root root 5, 1 Dec 30 08:20 console
// 参见devpts_mount()->mknod_ptmx()
crw-rw-rw- 1 root tty 5, 2 Dec 31 08:38 ptmx
// 参见ttyprintk_init()
crw------- 1 root root 5, 3 Dec 30 08:20 ttyprintk
/* (4) VCS_MAJOR = 7 */
// 参见vcs_make_sysfs()
crw-rw---- 1 root tty 7, 0 Dec 30 08:20 vcs
crw-rw---- 1 root tty 7, 1 Dec 30 08:20 vcs1
crw-rw---- 1 root tty 7, 2 Dec 30 08:20 vcs2
crw-rw---- 1 root tty 7, 3 Dec 30 08:20 vcs3
crw-rw---- 1 root tty 7, 4 Dec 30 08:20 vcs4
crw-rw---- 1 root tty 7, 5 Dec 30 08:20 vcs5
crw-rw---- 1 root tty 7, 6 Dec 30 08:20 vcs6
crw-rw---- 1 root tty 7, 7 Dec 30 08:20 vcs7
crw-rw---- 1 root tty 7, 8 Dec 30 08:20 vcs8
crw-rw---- 1 root tty 7, 128 Dec 30 08:20 vcsa
crw-rw---- 1 root tty 7, 129 Dec 30 08:20 vcsa1
crw-rw---- 1 root tty 7, 130 Dec 30 08:20 vcsa2
crw-rw---- 1 root tty 7, 131 Dec 30 08:20 vcsa3
crw-rw---- 1 root tty 7, 132 Dec 30 08:20 vcsa4
crw-rw---- 1 root tty 7, 133 Dec 30 08:20 vcsa5
crw-rw---- 1 root tty 7, 134 Dec 30 08:20 vcsa6
crw-rw---- 1 root tty 7, 135 Dec 30 08:20 vcsa7
crw-rw---- 1 root tty 7, 136 Dec 30 08:20 vcsa8
/* (5) MISC_MAJOR = 10 */
// 参见mousedev_init()
crw------- 1 root root 10, 1 Dec 30 08:20 psaux
crw------- 1 root root 10, 58 Dec 30 08:20 network_throughput
crw------- 1 root root 10, 59 Dec 30 08:20 network_latency
crw------- 1 root root 10, 60 Dec 30 08:20 cpu_dma_latency
// 参见ecryptfs_init()->ecryptfs_init_messaging()->ecryptfs_init_ecryptfs_miscdev()
crw------- 1 root root 10, 61 Dec 30 08:20 ecryptfs
crw-rw-r--+ 1 root root 10, 62 Dec 30 08:20 rfkill // 参见rfkill_init()
crw------- 1 root root 10, 63 Dec 30 08:20 vga_arbiter // 参见vga_arb_device_init()
crw------- 1 root root 10, 144 Dec 30 08:20 nvram // 参见nvram_init()
crw-rw---- 1 root video 10, 175 Dec 30 08:20 agpgart // 参见agp_frontend_initialize()
crw------- 1 root root 10, 203 Dec 30 08:20 cuse // 参见cuse_init()
crw------- 1 root root 10, 223 Dec 30 08:20 uinput // 参见uinput_init()
crw------- 1 root root 10, 224 Dec 30 08:20 tpm0 // 参见tpm_register_hardware()
crw------- 1 root root 10, 227 Dec 30 08:20 mcelog // 参见mcheck_init_device()
crw------- 1 root root 10, 228 Dec 30 08:20 hpet // 参见hpet_init()
crw-rw-rw- 1 root root 10, 229 Dec 30 08:20 fuse // 参见fuse_dev_init()
crw------- 1 root root 10, 231 Dec 30 08:20 snapshot // 参见snapshot_device_init()
crw------- 1 root root 10, 234 Dec 30 08:20 btrfs-control // 参见btrfs_interface_init()
crw------- 1 root root 10, 235 Dec 30 08:20 autofs // 参见autofs_dev_ioctl_init()
crw------- 1 root root 10, 237 Dec 30 08:20 loop-control // 参见loop_init()
crw------- 1 root root 10, 238 Dec 30 08:20 vhost-net // 参见vhost_net_init()
crw------- 1 root root 10, 239 Dec 30 08:20 uhid
/* (6) SCSI_GENERIC_MAJOR = 21 */
// 参见sg_add()
crw-rw---- 1 root disk 21, 0 Dec 30 08:20 sg0
crw-rw---- 1 root disk 21, 1 Dec 30 08:20 sg1
/* (7) FB_MAJOR = 29 */
crw-rw---- 1 root video 29, 0 Dec 30 08:20 fb0 // 参见do_register_framebuffer()
/* (8) COMPAQ_CISS_MAJOR4 = 108 */
crw------- 1 root root 108, 0 Dec 30 08:20 ppp // 参见ppp_init()
/* (9) 动态分配的主设备号248 */
crw------- 1 root root 248, 0 Dec 30 08:20 hidraw0 // 参见hidraw_connect()
/* (10) 动态分配的主设备号249 */
// 参见cxacru_heavy_init()->cxacru_find_firmware()->request_firmware()
// ->_request_firmware()->fw_create_instance()
crw------- 1 root root 249, 0 Dec 30 08:20 fw0
/* (11) 动态分配的主设备号254 */
crw------- 1 root root 254, 0 Dec 30 08:20 rtc0
主设备号均定义于include/linux/major.h
10.3.4.1 内存设备
系统中存在下列特殊内存设备,其主设备号均为1,次设备号为数组devlist[]的下标。这些内存设备是由函数chr_dev_init()根据数组devlist[]创建的,参见10.3.2 字符设备的初始化/chr_dev_init()节:
Name Major Minor (=数组devlist[]的下标)
--------------------------------------------------------------------------
/dev/mem 1 1
/dev/kmem 1 2
/dev/null 1 3
/dev/port 1 4
/dev/zero 1 5
/dev/full 1 7
/dev/random 1 8
/dev/urandom 1 9
/dev/kmsg 1 11
10.3.4.1.1 /dev/mem, /dev/kmem, /dev/port
/dev/mem
It is a character device file that is an image of the main memory of the computer. It may be used, for example, to examine (and even patch) the system. Byte addresses in /dev/mem are interpreted as physical memory addresses. References to nonexistent locations cause errors to be returned. Refer to man mem:
MEM(4) Linux Programmer's Manual MEM(4)
NAME
mem, kmem, port - system memory, kernel memory and system ports
DESCRIPTION
/dev/mem is a character device file that is an image of the main memory of the computer. It may be used, for
example, to examine (and even patch) the system.
Byte addresses in /dev/mem are interpreted as physical memory addresses. References to nonexistent locations
cause errors to be returned.
Examining and patching is likely to lead to unexpected results when read-only or write-only bits are present.
Since Linux 2.6.26, and depending on the architecture, the CONFIG_STRICT_DEVMEM kernel configuration option
limits the areas which can be accessed through this file. For example: on x86, RAM access is not allowed but
accessing memory-mapped PCI regions is.
It is typically created by:
mknod -m 660 /dev/mem c 1 1
chown root:kmem /dev/mem
The file /dev/kmem is the same as /dev/mem, except that the kernel virtual memory rather than physical memory
is accessed. Since Linux 2.6.26, this file is available only if the CONFIG_DEVKMEM kernel configuration
option is enabled.
It is typically created by:
mknod -m 640 /dev/kmem c 1 2
chown root:kmem /dev/kmem
/dev/port is similar to /dev/mem, but the I/O ports are accessed.
It is typically created by:
mknod -m 660 /dev/port c 1 4
chown root:kmem /dev/port
FILES
/dev/mem
/dev/kmem
/dev/port
SEE ALSO
chown(1), mknod(1), ioperm(2)
COLOPHON
This page is part of release 4.15 of the Linux man-pages project. A description of the project, information
about reporting bugs, and the latest version of this page, can be found at
https://www.kernel.org/doc/man-pages/.
Linux 2015-01-02 MEM(4)
可以用来访问物理内存,比如X用来访问显卡的物理内存,或嵌入式中访问GPIO。用法一般就是open,然后mmap,接着可以使用map之后的地址来访问物理内存。这其实就是实现用户空间驱动的一种方法。
mmap内存镜像/dev/mem到用户空间:
- 在内核(驱动)中,使用函数
_get_fre_pages(x, y)申请物理页面,返回物理首地址X; - 在用户空间,mmap文件/dem/mem的偏移X处到自己进程空间,对其操作;
- /dev/mem是系统物理内存的全镜像文件,在该文件中偏移X即在内存偏移X;
- 内核(驱动)向设备文件,比如/dev/video1,写一定格式的数据;
- 在用户空间,mmap文件/dev/video1到进程空间,然后进行读写即可。
/dev/kmem
The file /dev/kmem is the same as /dev/mem, except that the kernel virtual memory rather than physical memory is accessed. Refer to man mem.
可以用来访问kernel的变量,参见What’s the difference between /dev/kmem and /dev/mem (local pdf).
/dev/port
/dev/port is similar to /dev/mem, but the I/O ports are accessed. Refer to man mem.
10.3.4.1.2 /dev/null, /dev/zero, /dev/full
/dev/null
In some operating systems, the null device is a device file that discards all data written to it but reports that the write operation succeeded. This device is called /dev/null on Unix or Unix-like systems
chenwx@chenwx ~ $ cat /dev/null
chenwx@chenwx ~ $ echo "discard this piece of data" > /dev/null
/dev/zero
/dev/zero is a special file in Unix-like operating systems that provides as many null characters (ASCII NUL, 0x00) as are read from it. One of the typical uses is to provide a character stream for initializing data storage.
/*
* 创建大小为1MB的文件foobar,并初始化其内容为null
**/
chenwx@chenwx ~ $ dd if=/dev/zero of=foobar count=1024 bs=1024
1024+0 records in
1024+0 records out
1048576 bytes (1.0 MB, 1.0 MiB) copied, 0.00347384 s, 302 MB/s
/*
* 文件foobar大小为1MB,但是用cat命令无法显示其内容,因为cat认为null为文件结束;
* 而通过vim可以显示foobar的内容: @^@^@^@^@^@^@^@ ...
*/
chenwx@chenwx ~ $ ll foobar
-rw-rw-r-- 1 chenwx chenwx 1.0M Aug 5 22:11 foobar
chenwx@chenwx ~ $ cat foobar
chenwx@chenwx ~ $
chenwx@chenwx ~ $ vim foobar
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
/dev/full
In Linux /dev/full or the always full device is a special file that always returns the error code ENOSPC (meaning “No space left on device”) on writing, and provides an infinite number of null characters to any process that reads from it (similar to /dev/zero). This device is usually used when testing the behaviour of a program when it encounters a “disk full” error.
chenwx@chenwx ~ $ echo "Hello world" > /dev/full
bash: echo: write error: No space left on device
10.3.4.1.3 /dev/random, /dev/urandom
/dev/random
特殊的设备文件,可以用作随机数发生器或伪随机数发生器。它允许程序访问来自设备驱动程序或其它来源的背景噪声,Linux是第一个以背景噪声产生真正的随机数的实现。
/dev/urandom
/dev/random的一个副本是/dev/urandom,其中u表示unlocked,即非阻塞的随机数发生器。它会重复使用熵池中的数据以产生伪随机数据。这表示对/dev/urandom的读取操作不会产生阻塞,但其输出的熵可能小于/dev/random的。
/*
* 特殊设备文件/dev/random, /dev/urandom
* 及其配置文件/proc/sys/kernel/random/
*/
chenwx@chenwx ~ $ ll /dev/*random
crw-rw-rw- 1 root root 1, 8 Aug 5 18:57 /dev/random
crw-rw-rw- 1 root root 1, 9 Aug 5 18:57 /dev/urandom
chenwx@chenwx ~ $ ll /proc/sys/kernel/random
-r--r--r-- 1 root root 0 Aug 5 18:57 boot_id
-r--r--r-- 1 root root 0 Aug 5 21:14 entropy_avail
-r--r--r-- 1 root root 0 Aug 5 18:57 poolsize
-rw-r--r-- 1 root root 0 Aug 5 21:14 read_wakeup_threshold
-rw-r--r-- 1 root root 0 Aug 5 21:14 urandom_min_reseed_secs
-r--r--r-- 1 root root 0 Aug 5 21:14 uuid
-rw-r--r-- 1 root root 0 Aug 5 21:14 write_wakeup_threshold
chenwx@chenwx ~ $ cat /proc/sys/kernel/random/boot_id
676341b5-2d07-41f6-bd7d-80b3730aaebd
chenwx@chenwx ~ $ cat /proc/sys/kernel/random/entropy_avail
907
chenwx@chenwx ~ $ cat /proc/sys/kernel/random/poolsize
4096
chenwx@chenwx ~ $ cat /proc/sys/kernel/random/read_wakeup_threshold
64
chenwx@chenwx ~ $ cat /proc/sys/kernel/random/urandom_min_reseed_secs
60
chenwx@chenwx ~ $ cat /proc/sys/kernel/random/uuid
c1f08f01-bc29-4bfb-9ed8-bc0fbc1ca800
chenwx@chenwx ~ $ cat /proc/sys/kernel/random/write_wakeup_threshold
896
/*
* 由于/dev/urandom的数据是非常多,不能直接用cat读取,这里取首行。输出为乱码。
*/
chenwx@chenwx ~ $ head -1 /dev/urandom
j-��F<��
/*
* cksum将读取的文件内容生成唯一的整型数据,只有文件内容不变,生成结果就不会变化;
* cut以" "分割,然后得到分割的第一个字段数据。
*/
chenwx@chenwx ~ $ head -10 /dev/urandom | cksum | cut -f1 -d" "
1880117834
/*
* 获取一个 8 位的随机数,除了 0, 1, o,O, l 之外
*/
chenwx@chenwx ~ $ tr -dc A-NP-Za-kmnp-z2-9 < /dev/urandom | head -c 8
bs2afZRp
chenwx@chenwx ~ $ tr -dc A-NP-Za-kmnp-z2-9 < /dev/urandom | head -c 8
UvPg32sP
此外,还可以通过环境变量RANDOM来获取随机数:
chenwx@chenwx ~ $ echo $RANDOM
15154
chenwx@chenwx ~ $ echo $RANDOM
84
chenwx@chenwx ~ $ echo $RANDOM
6412
10.3.4.1.4 /dev/kmsg
/dev/kmsg
The /dev/kmsg character device node provides userspace access to the kernel’s printk buffer.
/*
* 直接显示/dev/kmsg中的日志信息
*/
chenwx@chenwx ~ $ cat /dev/kmsg
...
4,1062,1506008763,-;ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
4,1063,4266009097,-;ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
4,1064,4758330408,-;perf interrupt took too long (5018 > 5000), lowering kernel.perf_event_max_sample_rate to 25000
4,1065,6666002792,-;ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
/*
* 通过dmesg命令显示kernel's printk buffer.
* 日志内容是相同的,只是输出格式不同而已
*/
chenwx@chenwx ~ $ dmesg | tail
[ 1506.008763] ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
[ 4266.009097] ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
[ 4758.330408] perf interrupt took too long (5018 > 5000), lowering kernel.perf_event_max_sample_rate to 25000
[ 6666.002792] ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
/*
* 向/dev/kmsg写入日志信息
*/
chenwx@chenwx ~ $ sudo -c 'echo write to /dev/kmsg > /dev/kmsg'
chenwx@chenwx ~ $ cat /dev/kmsg
...
4,1061,223934777,-;perf interrupt took too long (2510 > 2500), lowering kernel.perf_event_max_sample_rate to 50000
4,1062,1506008763,-;ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
4,1063,4266009097,-;ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
4,1064,4758330408,-;perf interrupt took too long (5018 > 5000), lowering kernel.perf_event_max_sample_rate to 25000
4,1065,6666002792,-;ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
12,1066,10858919792,-;write to /dev/kmsg
chenwx@chenwx ~ $ dmesg | tail -5
[ 1506.008763] ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
[ 4266.009097] ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
[ 4758.330408] perf interrupt took too long (5018 > 5000), lowering kernel.perf_event_max_sample_rate to 25000
[ 6666.002792] ath5k: ath5k_hw_get_isr: ISR: 0x00000080 IMR: 0x00000000
[10858.919792] write to /dev/kmsg
10.3.4.2 USB drivers
由drivers/Makefile中的下列配置可知,USB drivers实现于drivers/usb/目录,且其核心代码位于drivers/usb/core目录中:
obj-$(CONFIG_USB_OTG_UTILS) += usb/
obj-$(CONFIG_USB) += usb/
obj-$(CONFIG_PCI) += usb/
obj-$(CONFIG_USB_GADGET) += usb/
10.3.4.2.0 查看USB设备信息
可运行下列命令查看USB设备信息:
# list USB devices
chenwx@chenwx ~/linux-next $ lsusb
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 007 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 006 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 005 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 004 Device 003: ID 046d:c050 Logitech, Inc. RX 250 Optical Mouse
Bus 004 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 003 Device 002: ID 0a5c:2110 Broadcom Corp. BCM2045B (BDC-2) [Bluetooth Controller]
Bus 003 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
chenwx@chenwx ~ $ lsusb -t
/: Bus 07.Port 1: Dev 1, Class=root_hub, Driver=uhci_hcd/2p, 12M
/: Bus 06.Port 1: Dev 1, Class=root_hub, Driver=uhci_hcd/2p, 12M
/: Bus 05.Port 1: Dev 1, Class=root_hub, Driver=uhci_hcd/2p, 12M
/: Bus 04.Port 1: Dev 1, Class=root_hub, Driver=uhci_hcd/2p, 12M
|__ Port 1: Dev 3, If 0, Class=Human Interface Device, Driver=usbhid, 1.5M
/: Bus 03.Port 1: Dev 1, Class=root_hub, Driver=uhci_hcd/2p, 12M
|__ Port 1: Dev 2, If 0, Class=Wireless, Driver=btusb, 12M
|__ Port 1: Dev 2, If 1, Class=Wireless, Driver=btusb, 12M
|__ Port 1: Dev 2, If 2, Class=Vendor Specific Class, Driver=, 12M
|__ Port 1: Dev 2, If 3, Class=Application Specific Interface, Driver=, 12M
/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=ehci-pci/6p, 480M
/: Bus 01.Port 1: Dev 1, Class=root_hub, Driver=ehci-pci/4p, 480M
# print USB device details
chenwx@chenwx /proc/bus $ usb-devices
...
T: Bus=04 Lev=01 Prnt=01 Port=00 Cnt=01 Dev#= 3 Spd=1.5 MxCh= 0
D: Ver= 2.00 Cls=00(>ifc ) Sub=00 Prot=00 MxPS= 8 #Cfgs= 1
P: Vendor=046d ProdID=c050 Rev=27.20
S: Manufacturer=Logitech
S: Product=USB-PS/2 Optical Mouse
C: #Ifs= 1 Cfg#= 1 Atr=a0 MxPwr=98mA
I: If#= 0 Alt= 0 #EPs= 1 Cls=03(HID ) Sub=01 Prot=02 Driver=usbhid
...
# 参见[10.3.4.2.2.1 usb_debugfs_init()]节
chenwx@chenwx ~ $ sudo cat /sys/kernel/debug/usb/devices
...
T: Bus=04 Lev=01 Prnt=01 Port=00 Cnt=01 Dev#= 2 Spd=1.5 MxCh= 0
D: Ver= 2.00 Cls=00(>ifc ) Sub=00 Prot=00 MxPS= 8 #Cfgs= 1
P: Vendor=046d ProdID=c050 Rev=27.20
S: Manufacturer=Logitech
S: Product=USB-PS/2 Optical Mouse
C:* #Ifs= 1 Cfg#= 1 Atr=a0 MxPwr= 98mA
I:* If#= 0 Alt= 0 #EPs= 1 Cls=03(HID ) Sub=01 Prot=02 Driver=usbhid
E: Ad=81(I) Atr=03(Int.) MxPS= 5 Ivl=10ms
...
chenwx@chenwx ~ $ udevadm info -p /sys/bus/usb/devices/4-1 -q property
BUSNUM=004
DEVNAME=/dev/bus/usb/004/003
DEVNUM=003
DEVPATH=/devices/pci0000:00/0000:00:1a.1/usb4/4-1
DEVTYPE=usb_device
DRIVER=usb
ID_BUS=usb
ID_MODEL=USB-PS_2_Optical_Mouse
ID_MODEL_ENC=USB-PS\x2f2\x20Optical\x20Mouse
ID_MODEL_FROM_DATABASE=RX 250 Optical Mouse
ID_MODEL_ID=c050
ID_REVISION=2720
ID_SERIAL=Logitech_USB-PS_2_Optical_Mouse
ID_USB_INTERFACES=:030102:
ID_VENDOR=Logitech
ID_VENDOR_ENC=Logitech
ID_VENDOR_FROM_DATABASE=Logitech, Inc.
ID_VENDOR_ID=046d
MAJOR=189
MINOR=386
PRODUCT=46d/c050/2720
SUBSYSTEM=usb
TYPE=0/0/0
UPOWER_VENDOR=Logitech, Inc.
USEC_INITIALIZED=543730949
# 查看该USB鼠标的驱动程序信息
chenwx@chenwx ~ $ modinfo usbhid
filename: /lib/modules/3.13.0-24-generic/kernel/drivers/hid/usbhid/usbhid.ko
license: GPL
description: USB HID core driver
author: Jiri Kosina
author: Vojtech Pavlik
author: Andreas Gal
srcversion: 5723C9E26D102FADB8376D9
alias: usb:v*p*d*dc*dsc*dp*ic03isc*ip*in*
depends: hid
intree: Y
vermagic: 3.13.0-24-generic SMP mod_unload modversions
signer: Magrathea: Glacier signing key
sig_key: 00:A5:A6:57:59:DE:47:4B:C5:C4:31:20:88:0C:1B:94:A5:39:F4:31
sig_hashalgo: sha512
parm: mousepoll:Polling interval of mice (uint)
parm: ignoreled:Autosuspend with active leds (uint)
parm: quirks:Add/modify USB HID quirks by specifying quirks=vendorID:productID:quirks where vendorID, productID, and quirks are all in 0x-prefixed hex (array of charp)
# provide a graphical summary of USB devices connected to the system
chenwx@chenwx ~ $ usbview &
10.3.4.2.1 与USB有关的数据结构
struct usb_device;
sturct usb_device_driver; // 参见[10.3.4.2.3 注册/注销USB设备驱动程序/struct usb_device_driver]节
struct usb_driver; // 参见[10.3.4.2.4 注册/注销USB接口驱动程序/struct usb_driver]节
struct usb_interface;
struct usb_class_driver;
10.3.4.2.2 USB的初始化/usb_init()
该函数定义于drivers/usb/core/usb.c:
static int __init usb_init(void)
{
int retval;
// To disable USB, use kernel command line parameter 'nousb'
if (nousb) {
pr_info("%s: USB support disabled\n", usbcore_name);
return 0;
}
/*
* 创建目录/sys/kernel/debug/usb和文件/sys/kernel/debug/usb/devices
* 参见[10.3.4.2.2.1 usb_debugfs_init()]节
*/
retval = usb_debugfs_init();
if (retval)
goto out;
// 创建目录/sys/bus/usb,参见[10.2.2.1 bus_register()]节
retval = bus_register(&usb_bus_type);
if (retval)
goto bus_register_failed;
// 将元素usb_bus_nb插入到链表usb_bus_type->p->bus_notifier中
retval = bus_register_notifier(&usb_bus_type, &usb_bus_nb);
if (retval)
goto bus_notifier_failed;
/*
* 注册USB主设备号USB_MAJOR = 180,
* 参见[10.3.4.2.2.2 usb_major_init()]节
*/
retval = usb_major_init();
if (retval)
goto major_init_failed;
/*
* 注册USB接口驱动程序usbfs_driver
* 参见[10.3.4.2.4 注册/注销USB接口驱动程序/struct usb_driver]节
*/
retval = usb_register(&usbfs_driver);
if (retval)
goto driver_register_failed;
// 注册字符设备usb_device_cdev
retval = usb_devio_init();
if (retval)
goto usb_devio_init_failed;
/*
* 注册文件系统usbfs,并创建目录/proc/bus/usb
* 参见[10.3.4.2.2.3 usbfs_init()]节
*/
retval = usbfs_init();
if (retval)
goto fs_init_failed;
// 参见[10.3.4.2.2.4 usb_hub_init()]节
retval = usb_hub_init();
if (retval)
goto hub_init_failed;
/*
* 注册USB子系统中唯一的设备驱动程序
* 参见[10.3.4.2.3 注册/注销USB设备驱动程序/struct usb_device_driver]节
*/
retval = usb_register_device_driver(&usb_generic_driver, THIS_MODULE);
if (!retval)
goto out;
usb_hub_cleanup();
hub_init_failed:
usbfs_cleanup();
fs_init_failed:
usb_devio_cleanup();
usb_devio_init_failed:
usb_deregister(&usbfs_driver);
driver_register_failed:
usb_major_cleanup();
major_init_failed:
bus_unregister_notifier(&usb_bus_type, &usb_bus_nb);
bus_notifier_failed:
bus_unregister(&usb_bus_type);
bus_register_failed:
usb_debugfs_cleanup();
out:
return retval;
}
10.3.4.2.2.1 usb_debugfs_init()
该函数定义于drivers/usb/core/usb.c:
static int usb_debugfs_init(void)
{
// 创建目录/sys/kernel/debug/usb
usb_debug_root = debugfs_create_dir("usb", NULL);
if (!usb_debug_root)
return -ENOENT;
// 创建文件/sys/kernel/debug/usb/devices
usb_debug_devices = debugfs_create_file("devices", 0444,
usb_debug_root, NULL, &usbfs_devices_fops);
if (!usb_debug_devices) {
debugfs_remove(usb_debug_root);
usb_debug_root = NULL;
return -ENOENT;
}
return 0;
}
10.3.4.2.2.2 usb_major_init()
该函数定义于drivers/usb/core/file.c:
int usb_major_init(void)
{
int error;
// 参见[10.3.3.1 register_chrdev()]节
error = register_chrdev(USB_MAJOR, "usb", &usb_fops);
if (error)
printk(KERN_ERR "Unable to get major %d for usb devices\n", USB_MAJOR);
return error;
}
10.3.4.2.2.3 usbfs_init()
该函数定义于drivers/usb/core/inode.c:
static struct file_system_type usb_fs_type = {
.owner = THIS_MODULE,
.name = "usbfs",
.mount = usb_mount,
.kill_sb = kill_litter_super,
};
int __init usbfs_init(void)
{
int retval;
// 注册文件系统usbfs,用于将系统中的USB设备信息挂载到目录/proc/bus/usb中
retval = register_filesystem(&usb_fs_type);
if (retval)
return retval;
// 将元素usbfs_nb插入到链表usb_notifier_list中
usb_register_notify(&usbfs_nb);
/* create mount point for usbfs */
// 创建目录/proc/bus/usb
usbdir = proc_mkdir("bus/usb", NULL);
return 0;
}
10.3.4.2.2.4 usb_hub_init()
该函数定义于drivers/usb/core/inode.c:
int usb_hub_init(void)
{
/*
* 注册USB接口驱动程序hub_driver
* 参见[10.3.4.2.4 注册/注销USB接口驱动程序/struct usb_driver]节
*/
if (usb_register(&hub_driver) < 0) {
printk(KERN_ERR "%s: can't register hub driver\n", usbcore_name);
return -1;
}
/*
* 创建内核线程khubd,该内核线程执行函数hub_thread()
* 参见[10.3.4.2.2.4.1 hub_thread()]节
*/
khubd_task = kthread_run(hub_thread, NULL, "khubd");
if (!IS_ERR(khubd_task))
return 0;
/* Fall through if kernel_thread failed */
usb_deregister(&hub_driver);
printk(KERN_ERR "%s: can't start khubd\n", usbcore_name);
return -1;
}
10.3.4.2.2.4.1 hub_thread()
内核线程khubd执行该函数,其定义于drivers/usb/core/inode.c:
/*
* 该链表用于链接struct usb_hub中的域event_list;
* 由函数kick_khubd()向该链表添加元素,参见下文
*/
static LIST_HEAD(hub_event_list); /* List of hubs needing servicing */
static int hub_thread(void *__unused)
{
/* khubd needs to be freezable to avoid intefering with USB-PERSIST
* port handover. Otherwise it might see that a full-speed device
* was gone before the EHCI controller had handed its port over to
* the companion full-speed controller.
*/
set_freezable();
do {
// 依次处理链表hub_event_list中的请求
hub_events();
wait_event_freezable(khubd_wait,
!list_empty(&hub_event_list) || kthread_should_stop());
} while (!kthread_should_stop() || !list_empty(&hub_event_list));
pr_debug("%s: khubd exiting\n", usbcore_name);
return 0;
}
static void kick_khubd(struct usb_hub *hub)
{
unsigned long flags;
spin_lock_irqsave(&hub_event_lock, flags);
if (!hub->disconnected && list_empty(&hub->event_list)) {
// 将hub添加到链表hub_event_list的尾部
list_add_tail(&hub->event_list, &hub_event_list);
/* Suppress autosuspend until khubd runs */
usb_autopm_get_interface_no_resume(to_usb_interface(hub->intfdev));
wake_up(&khubd_wait);
}
spin_unlock_irqrestore(&hub_event_lock, flags);
}
10.3.4.2.2.4.2 插入USB设备后的函数调用
当插入USB鼠标时,日志如下:
[ 502.848215] usb 4-1: USB disconnect, device number 2
[ 504.368161] usb 4-1: new low-speed USB device number 3 using uhci_hcd
[ 504.544973] usb 4-1: New USB device found, idVendor=046d, idProduct=c050
[ 504.544980] usb 4-1: New USB device strings: Mfr=1, Product=2, SerialNumber=0
[ 504.544985] usb 4-1: Product: USB-PS/2 Optical Mouse
[ 504.544990] usb 4-1: Manufacturer: Logitech
函数调用关系如下:
subsys_initcall(usb_init)
-> usb_init() // 参见[10.3.4.2.2 USB的初始化/usb_init()]节
-> usb_hub_init()
-> khubd_task = kthread_run(hub_thread, NULL, "khubd");
hub_thread() // 参见[10.3.4.2.2.4.1 hub_thread()]节
-> hub_events()
-> hub_port_connect_change()
-> usb_new_device()
-> announce_device() // (1) Print above logs
-> device_add(&udev->dev)
-> bus_probe_device()
-> device_attach()
-> bus_for_each_drv(.., __device_attach)
-> __device_attach()
-> driver_match_device(drv, dev)
// (2) Call hid_bus_match() here
-> drv->bus->match(dev, drv)
-> hid_bus_match()
-> hid_match_device()
-> hid_match_one_id()
-> driver_probe_device(drv, dev)
-> really_probe(dev, drv)
// (3) Call hid_device_probe()
-> dev->bus->probe()
-> drv->probe()
-> driver_bound()
[ 504.563215] input: Logitech USB-PS/2 Optical Mouse as /devices/pci0000:00/0000:00:1a.1/usb4/4-1/4-1:1.0/input/input13
[ 504.563524] hid-generic 0003:046D:C050.0002: input,hidraw0: USB HID v1.10 Mouse [Logitech USB-PS/2 Optical Mouse] on usb-0000:00:1a.1-1/input0
hid_device_probe() // (4) called by really_probe()
-> hid_open_report()
-> hid_hw_start()
-> hid_connect()
-> hid_info(hdev, "%s: %s HID v%x.%02x %s [%s] on %s\n",
buf, bus, hdev->version >> 8, hdev->version & 0xff,
type, hdev->name, hdev->phys);
由上述打印可知,函数hid_info()中各域的取值如下:
hid-generic 0003:046D:C050.0002:
-> hdev's driver points to hid_generic
buf = input,hidraw0
bus = USB
hdev->version >> 8 = 1
hdev->version & 0xff = 10
type = Mouse
hdev->name = Logitech USB-PS/2 Optical Mouse
hdev->phys = usb-0000:00:1a.1-1/input0
10.3.4.2.3 注册/注销USB设备驱动程序/struct usb_device_driver
USB子系统中唯一的设备驱动程序是usb_generic_driver,其定义于drivers/usb/core/generic.c:
struct usb_device_driver usb_generic_driver = {
.name = "usb",
/*
* 该函数通过如下函数调用,参见[10.3.4.2.3.1.1.1 generic_probe()]节:
* driver_register()->bus_add_driver()->driver_attach()
* ->__driver_attach()->driver_probe_device()->really_probe()
* ->probe()->usb_probe_device()->probe()
*/
.probe = generic_probe,
/*
* 该函数通过如下函数调用,参见[10.3.4.2.3.2.1.1 generic_disconnect()]节:
* driver_unregister()->bus_remove_driver()->driver_detach()
* ->__device_release_driver()->remove()->usb_unbind_device()
* ->disconnect()
*/
.disconnect = generic_disconnect,
#ifdef CONFIG_PM
.suspend = generic_suspend,
.resume = generic_resume,
#endif
/*
* 函数usb_probe_device()会判断此字段,
* 参见[10.3.4.2.3.1.1 usb_probe_device()]节
*/
.supports_autosuspend = 1,
};
该设备驱动程序是由如下函数注册:
usb_init() // 参见[10.3.4.2.2 USB的初始化/usb_init()]节
-> usb_register_device_driver(&usb_generic_driver, THIS_MODULE);
10.3.4.2.3.1 注册USB设备驱动程序/usb_register_device_driver()
该函数定义于drivers/usb/core/driver.c:
/**
* usb_register_device_driver - register a USB device (not interface) driver
* @new_udriver: USB operations for the device driver
* @owner: module owner of this driver.
*
* Registers a USB device driver with the USB core. The list of
* unattached devices will be rescanned whenever a new driver is
* added, allowing the new driver to attach to any recognized devices.
* Returns a negative error code on failure and 0 on success.
*/
int usb_register_device_driver(struct usb_device_driver *new_udriver,
struct module *owner)
{
int retval = 0;
if (usb_disabled())
return -ENODEV;
new_udriver->drvwrap.for_devices = 1;
new_udriver->drvwrap.driver.name = (char *) new_udriver->name;
new_udriver->drvwrap.driver.bus = &usb_bus_type;
/*
* 函数probe()由如下函数调用,参见[10.3.4.2.3.1.1 usb_probe_device()]节
* driver_register()->bus_add_driver()->driver_attach()->__driver_attach()
* ->driver_probe_device()->really_probe()->probe()->usb_probe_device()
*/
new_udriver->drvwrap.driver.probe = usb_probe_device;
/*
* 函数remove()由如下函数调用,参见[10.3.4.2.3.2.1 usb_unbind_device()]节
* driver_unregister()->bus_remove_driver()->driver_detach()
* ->__device_release_driver()->remove()->usb_unbind_device()
*/
new_udriver->drvwrap.driver.remove = usb_unbind_device;
new_udriver->drvwrap.driver.owner = owner;
// 参见[10.2.4.1 注册驱动程序/driver_register()]节
retval = driver_register(&new_udriver->drvwrap.driver);
if (!retval) {
pr_info("%s: registered new device driver %s\n",
usbcore_name, new_udriver->name);
usbfs_update_special();
} else {
printk(KERN_ERR "%s: error %d registering device "
" driver %s\n", usbcore_name, retval, new_udriver->name);
}
return retval;
}
10.3.4.2.3.1.1 usb_probe_device()
该函数定义于drivers/usb/core/driver.c:
/* called from driver core with dev locked */
static int usb_probe_device(struct device *dev)
{
struct usb_device_driver *udriver = to_usb_device_driver(dev->driver);
struct usb_device *udev = to_usb_device(dev);
int error = 0;
dev_dbg(dev, "%s\n", __func__);
/* TODO: Add real matching code */
/* The device should always appear to be in use
* unless the driver suports autosuspend.
*/
/*
* 由[10.3.4.2.3 注册/注销USB设备驱动程序/struct usb_device_driver]节可知,
* usb_generic_driver.supports_autosuspend = 1,故不进入此分支
*/
if (!udriver->supports_autosuspend)
error = usb_autoresume_device(udev);
/*
* 调用USB设备驱动程序的probe()函数,即函数generic_probe(),
* 参见[10.3.4.2.3.1.1.1 generic_probe()]节
*/
if (!error)
error = udriver->probe(udev);
return error;
}
10.3.4.2.3.1.1.1 generic_probe()
该函数定义于drivers/usb/core/generic.c:
static int generic_probe(struct usb_device *udev)
{
int err, c;
/* Choose and set the configuration. This registers the interfaces
* with the driver core and lets interface drivers bind to them.
*/
if (usb_device_is_owned(udev))
; /* Don't configure if the device is owned */
else if (udev->authorized == 0)
dev_err(&udev->dev, "Device is not authorized for usage\n");
else {
c = usb_choose_configuration(udev);
if (c >= 0) {
err = usb_set_configuration(udev, c);
if (err) {
dev_err(&udev->dev, "can't set config #%d, error %d\n", c, err);
/* This need not be fatal. The user can try to
* set other configurations. */
}
}
}
/* USB device state == configured ... usable */
usb_notify_add_device(udev);
return 0;
}
10.3.4.2.3.2 注销USB设备驱动程序/usb_deregister_device_driver()
该函数定义于drivers/usb/core/driver.c:
/**
* usb_deregister_device_driver - unregister a USB device (not interface) driver
* @udriver: USB operations of the device driver to unregister
* Context: must be able to sleep
*
* Unlinks the specified driver from the internal USB driver list.
*/
void usb_deregister_device_driver(struct usb_device_driver *udriver)
{
pr_info("%s: deregistering device driver %s\n",
usbcore_name, udriver->name);
// 参见[10.2.4.2 注销驱动程序/driver_unregister()]节
driver_unregister(&udriver->drvwrap.driver);
usbfs_update_special();
}
10.3.4.2.3.2.1 usb_unbind_device()
该函数定义于drivers/usb/core/driver.c:
/* called from driver core with dev locked */
static int usb_unbind_device(struct device *dev)
{
struct usb_device *udev = to_usb_device(dev);
struct usb_device_driver *udriver = to_usb_device_driver(dev->driver);
/*
* 调用USB设备驱动程序的disconnect()函数,即函数generic_disconnect(),
* 参见[10.3.4.2.3 注册/注销USB设备驱动程序/struct usb_device_driver]节
*/
udriver->disconnect(udev);
/*
* 由[10.3.4.2.3 注册/注销USB设备驱动程序/struct usb_device_driver]节可知,
* usb_generic_driver.supports_autosuspend = 1,故不进入此分支
*/
if (!udriver->supports_autosuspend)
usb_autosuspend_device(udev);
return 0;
}
10.3.4.2.3.2.1.1 generic_disconnect()
该函数定义于drivers/usb/core/generic.c:
static void generic_disconnect(struct usb_device *udev)
{
usb_notify_remove_device(udev);
/* if this is only an unbind, not a physical disconnect, then
* unconfigure the device */
if (udev->actconfig)
usb_set_configuration(udev, -1);
}
10.3.4.2.4 注册/注销USB接口驱动程序/struct usb_driver
10.3.4.2.4.1 注册USB接口驱动程序/usb_register()
该宏定义于include/linux/usb.h:
/* use a define to avoid include chaining to get THIS_MODULE & friends */
#define usb_register(driver) \
usb_register_driver(driver, THIS_MODULE, KBUILD_MODNAME)
其中,函数usb_register_driver()定义于drivers/usb/core/driver.c:
/**
* usb_register_driver - register a USB interface driver
* @new_driver: USB operations for the interface driver
* @owner: module owner of this driver.
* @mod_name: module name string
*
* Registers a USB interface driver with the USB core. The list of
* unattached interfaces will be rescanned whenever a new driver is
* added, allowing the new driver to attach to any recognized interfaces.
* Returns a negative error code on failure and 0 on success.
*
* NOTE: if you want your driver to use the USB major number, you must call
* usb_register_dev() to enable that functionality. This function no longer
* takes care of that.
*/
int usb_register_driver(struct usb_driver *new_driver, struct module *owner,
const char *mod_name)
{
int retval = 0;
if (usb_disabled())
return -ENODEV;
new_driver->drvwrap.for_devices = 0;
new_driver->drvwrap.driver.name = (char *) new_driver->name;
new_driver->drvwrap.driver.bus = &usb_bus_type;
/*
* 函数probe()由如下函数调用,参见[10.3.4.2.4.1.1 usb_probe_interface()]节
* driver_register()->bus_add_driver()->driver_attach()->__driver_attach()
* ->driver_probe_device()->really_probe()->probe()->usb_probe_interface()
*/
new_driver->drvwrap.driver.probe = usb_probe_interface;
/*
* 函数remove()由如下函数调用,参见[10.3.4.2.4.2.1 usb_unbind_interface()]节
* driver_unregister()->bus_remove_driver()->driver_detach()
* ->__device_release_driver()->remove()->usb_unbind_interface()
*/
new_driver->drvwrap.driver.remove = usb_unbind_interface;
new_driver->drvwrap.driver.owner = owner;
new_driver->drvwrap.driver.mod_name = mod_name;
spin_lock_init(&new_driver->dynids.lock);
INIT_LIST_HEAD(&new_driver->dynids.list);
// 参见[10.2.4.1 注册驱动程序/driver_register()]节
retval = driver_register(&new_driver->drvwrap.driver);
if (retval)
goto out;
usbfs_update_special();
// 创建文件new_id
retval = usb_create_newid_file(new_driver);
if (retval)
goto out_newid;
// 创建文件remove_id
retval = usb_create_removeid_file(new_driver);
if (retval)
goto out_removeid;
pr_info("%s: registered new interface driver %s\n",
usbcore_name, new_driver->name);
out:
return retval;
out_removeid:
usb_remove_newid_file(new_driver);
out_newid:
driver_unregister(&new_driver->drvwrap.driver);
printk(KERN_ERR "%s: error %d registering interface "
" driver %s\n", usbcore_name, retval, new_driver->name);
goto out;
}
10.3.4.2.4.1.1 usb_probe_interface()
该函数定义于drivers/usb/core/driver.c:
/* called from driver core with dev locked */
static int usb_probe_interface(struct device *dev)
{
struct usb_driver *driver = to_usb_driver(dev->driver);
struct usb_interface *intf = to_usb_interface(dev);
struct usb_device *udev = interface_to_usbdev(intf);
const struct usb_device_id *id;
int error = -ENODEV;
dev_dbg(dev, "%s\n", __func__);
intf->needs_binding = 0;
if (usb_device_is_owned(udev))
return error;
if (udev->authorized == 0) {
dev_err(&intf->dev, "Device is not authorized for usage\n");
return error;
}
id = usb_match_id(intf, driver->id_table);
if (!id)
id = usb_match_dynamic_id(intf, driver);
if (!id)
return error;
dev_dbg(dev, "%s - got id\n", __func__);
error = usb_autoresume_device(udev);
if (error)
return error;
intf->condition = USB_INTERFACE_BINDING;
/* Probed interfaces are initially active. They are
* runtime-PM-enabled only if the driver has autosuspend support.
* They are sensitive to their children's power states.
*/
pm_runtime_set_active(dev);
pm_suspend_ignore_children(dev, false);
if (driver->supports_autosuspend)
pm_runtime_enable(dev);
/* Carry out a deferred switch to altsetting 0 */
if (intf->needs_altsetting0) {
error = usb_set_interface(udev, intf->altsetting[0].desc.bInterfaceNumber, 0);
if (error < 0)
goto err;
intf->needs_altsetting0 = 0;
}
error = driver->probe(intf, id);
if (error)
goto err;
intf->condition = USB_INTERFACE_BOUND;
usb_autosuspend_device(udev);
return error;
err:
intf->needs_remote_wakeup = 0;
intf->condition = USB_INTERFACE_UNBOUND;
usb_cancel_queued_reset(intf);
/* Unbound interfaces are always runtime-PM-disabled and -suspended */
if (driver->supports_autosuspend)
pm_runtime_disable(dev);
pm_runtime_set_suspended(dev);
usb_autosuspend_device(udev);
return error;
}
10.3.4.2.4.2 注销USB接口驱动程序/usb_deregister()
该函数定义于drivers/usb/core/driver.c:
/**
* usb_deregister - unregister a USB interface driver
* @driver: USB operations of the interface driver to unregister
* Context: must be able to sleep
*
* Unlinks the specified driver from the internal USB driver list.
*
* NOTE: If you called usb_register_dev(), you still need to call
* usb_deregister_dev() to clean up your driver's allocated minor numbers,
* this * call will no longer do it for you.
*/
void usb_deregister(struct usb_driver *driver)
{
pr_info("%s: deregistering interface driver %s\n",
usbcore_name, driver->name);
usb_remove_removeid_file(driver);
usb_remove_newid_file(driver);
usb_free_dynids(driver);
// 参见[10.2.4.2 注销驱动程序/driver_unregister()]节
driver_unregister(&driver->drvwrap.driver);
usbfs_update_special();
}
10.3.4.2.4.2.1 usb_unbind_interface()
该函数定义于drivers/usb/core/driver.c:
/* called from driver core with dev locked */
static int usb_unbind_interface(struct device *dev)
{
struct usb_driver *driver = to_usb_driver(dev->driver);
struct usb_interface *intf = to_usb_interface(dev);
struct usb_device *udev;
int error, r;
intf->condition = USB_INTERFACE_UNBINDING;
/* Autoresume for set_interface call below */
udev = interface_to_usbdev(intf);
error = usb_autoresume_device(udev);
/* Terminate all URBs for this interface unless the driver
* supports "soft" unbinding.
*/
if (!driver->soft_unbind)
usb_disable_interface(udev, intf, false);
driver->disconnect(intf);
usb_cancel_queued_reset(intf);
/* Reset other interface state.
* We cannot do a Set-Interface if the device is suspended or
* if it is prepared for a system sleep (since installing a new
* altsetting means creating new endpoint device entries).
* When either of these happens, defer the Set-Interface.
*/
if (intf->cur_altsetting->desc.bAlternateSetting == 0) {
/* Already in altsetting 0 so skip Set-Interface.
* Just re-enable it without affecting the endpoint toggles.
*/
usb_enable_interface(udev, intf, false);
} else if (!error && !intf->dev.power.is_prepared) {
r = usb_set_interface(udev, intf->altsetting[0].desc.bInterfaceNumber, 0);
if (r < 0)
intf->needs_altsetting0 = 1;
} else {
intf->needs_altsetting0 = 1;
}
usb_set_intfdata(intf, NULL);
intf->condition = USB_INTERFACE_UNBOUND;
intf->needs_remote_wakeup = 0;
/* Unbound interfaces are always runtime-PM-disabled and -suspended */
if (driver->supports_autosuspend)
pm_runtime_disable(dev);
pm_runtime_set_suspended(dev);
/* Undo any residual pm_autopm_get_interface_* calls */
for (r = atomic_read(&intf->pm_usage_cnt); r > 0; --r)
usb_autopm_put_interface_no_suspend(intf);
atomic_set(&intf->pm_usage_cnt, 0);
if (!error)
usb_autosuspend_device(udev);
return 0;
}
10.3.4.2.5 注册/注销USB设备
10.3.4.2.5.1 注册USB设备/usb_register_dev()
该函数定义于drivers/usb/core/file.c:
/**
* usb_register_dev - register a USB device, and ask for a minor number
* @intf: pointer to the usb_interface that is being registered
* @class_driver: pointer to the usb_class_driver for this device
*
* This should be called by all USB drivers that use the USB major number.
* If CONFIG_USB_DYNAMIC_MINORS is enabled, the minor number will be
* dynamically allocated out of the list of available ones. If it is not
* enabled, the minor number will be based on the next available free minor,
* starting at the class_driver->minor_base.
*
* This function also creates a usb class device in the sysfs tree.
*
* usb_deregister_dev() must be called when the driver is done with
* the minor numbers given out by this function.
*
* Returns -EINVAL if something bad happens with trying to register a
* device, and 0 on success.
*/
int usb_register_dev(struct usb_interface *intf,
struct usb_class_driver *class_driver)
{
int retval;
int minor_base = class_driver->minor_base;
int minor;
char name[20];
char *temp;
#ifdef CONFIG_USB_DYNAMIC_MINORS
/*
* We don't care what the device tries to start at, we want to start
* at zero to pack the devices into the smallest available space with
* no holes in the minor range.
*/
minor_base = 0;
#endif
if (class_driver->fops == NULL)
return -EINVAL;
if (intf->minor >= 0)
return -EADDRINUSE;
// 参见[10.3.4.2.5.1.1 init_usb_class()]节
retval = init_usb_class();
if (retval)
return retval;
dev_dbg(&intf->dev, "looking for a minor, starting at %d", minor_base);
/*
* 分配次设备号:若数组usb_minors[minor] == NULL,
* 则该下标minor所代表的次设备号可用
*/
down_write(&minor_rwsem);
for (minor = minor_base; minor < MAX_USB_MINORS; ++minor) {
if (usb_minors[minor])
continue;
usb_minors[minor] = class_driver->fops;
intf->minor = minor;
break;
}
up_write(&minor_rwsem);
if (intf->minor < 0)
return -EXFULL;
/* create a usb class device for this usb interface */
snprintf(name, sizeof(name), class_driver->name, minor - minor_base);
temp = strrchr(name, '/');
if (temp && (temp[1] != '\0'))
++temp;
else
temp = name;
// 参见[10.2.3.1 创建设备/device_create()]节
intf->usb_dev = device_create(usb_class->class, &intf->dev,
MKDEV(USB_MAJOR, minor), class_driver, "%s", temp);
if (IS_ERR(intf->usb_dev)) {
down_write(&minor_rwsem);
usb_minors[minor] = NULL;
intf->minor = -1;
up_write(&minor_rwsem);
retval = PTR_ERR(intf->usb_dev);
}
return retval;
}
10.3.4.2.5.1.1 init_usb_class()
该函数定义于drivers/usb/core/file.c:
static struct usb_class {
struct kref kref;
struct class *class;
} *usb_class;
static int init_usb_class(void)
{
int result = 0;
// 若已创建该对象,则增加其引用计数
if (usb_class != NULL) {
kref_get(&usb_class->kref);
goto exit;
}
usb_class = kmalloc(sizeof(*usb_class), GFP_KERNEL);
if (!usb_class) {
result = -ENOMEM;
goto exit;
}
kref_init(&usb_class->kref);
// 参见[10.2.7.1 class_create()]节
usb_class->class = class_create(THIS_MODULE, "usb");
if (IS_ERR(usb_class->class)) {
result = IS_ERR(usb_class->class);
printk(KERN_ERR "class_create failed for usb devices\n");
kfree(usb_class);
usb_class = NULL;
goto exit;
}
usb_class->class->devnode = usb_devnode;
exit:
return result;
}
10.3.4.2.5.2 注销USB设备/usb_deregister_dev()
该函数定义于drivers/usb/core/file.c:
/**
* usb_deregister_dev - deregister a USB device's dynamic minor.
* @intf: pointer to the usb_interface that is being deregistered
* @class_driver: pointer to the usb_class_driver for this device
*
* Used in conjunction with usb_register_dev(). This function is called
* when the USB driver is finished with the minor numbers gotten from a
* call to usb_register_dev() (usually when the device is disconnected
* from the system.)
*
* This function also removes the usb class device from the sysfs tree.
*
* This should be called by all drivers that use the USB major number.
*/
void usb_deregister_dev(struct usb_interface *intf,
struct usb_class_driver *class_driver)
{
if (intf->minor == -1)
return;
dbg ("removing %d minor", intf->minor);
down_write(&minor_rwsem);
usb_minors[intf->minor] = NULL;
up_write(&minor_rwsem);
// 参见[10.2.3.2 销毁设备/destroy_device()]节
device_destroy(usb_class->class, MKDEV(USB_MAJOR, intf->minor));
intf->usb_dev = NULL;
intf->minor = -1;
/*
* 减小usb_class->kref的引用计数;若减至0,则调用
* 函数release_usb_class()释放变量usb_class
*/
destroy_usb_class();
}
10.4 Block Drivers
«Linux Kernel Development, 3rd Edition» Chaper 14. The Block I/O Layer:
Block devices are hardware devices distinguished by the random (that is, not necessarily sequential) access of fixed-size chunks of data. The fixed-size chunks of data are called blocks. The most common block device is a hard disk, but many other block devices exist, such as floppy drives, Blu-ray readers, and flash memory.
The smallest addressable unit on a block device is a sector. Sectors come in various powers of two, but 512 bytes is the most common size.
Software has different goals and therefore imposes its own smallest logically addressable unit, which is the block. Because the device’s smallest addressable unit is the sector, the block size can be no smaller than the sector and must be a multiple of a sector. The kernel also requires that a block be no larger than the page size. Common block sizes are 512 bytes, 1 kilobyte, and 4 kilobytes.
下列命令输出结果中的第一列为b,则该设备为块设备:
chenwx@chenwx ~ $ ll /dev
brw-rw---- 1 root disk 7, 0 Nov 27 20:51 loop0
brw-rw---- 1 root disk 7, 1 Nov 27 20:51 loop1
brw-rw---- 1 root disk 7, 2 Nov 27 20:51 loop2
brw-rw---- 1 root disk 7, 3 Nov 27 20:51 loop3
brw-rw---- 1 root disk 1, 0 Nov 27 20:51 ram0
brw-rw---- 1 root disk 1, 1 Nov 27 20:51 ram1
brw-rw---- 1 root disk 1, 2 Nov 27 20:51 ram2
brw-rw---- 1 root disk 1, 3 Nov 27 20:51 ram3
brw-rw---- 1 root disk 8, 0 Nov 27 20:51 sda
brw-rw---- 1 root disk 8, 1 Nov 28 21:03 sda1
brw-rw---- 1 root disk 8, 16 Nov 27 20:51 sdb
brw-rw---- 1 root disk 8, 17 Nov 27 20:51 sdb1
...
The block drivers are located in directory block/.
10.4.0 与块设备有关的命令
10.4.0.1 lsblk
The lsblk stands for List Block Devices, print block devices by their assigned name (but not RAM) on the standard output in a tree-like fashion.
chenwx@chenwx ~/linux $ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 298.1G 0 disk
`-sda1 8:1 0 298.1G 0 part /media/chenwx/Work
sdb 8:16 0 111.8G 0 disk
|-sdb1 8:17 0 100M 0 part
|-sdb2 8:18 0 58.4G 0 part
|-sdb3 8:19 0 484M 0 part
|-sdb4 8:20 0 1K 0 part
`-sdb5 8:21 0 52.8G 0 part /
chenwx@chenwx ~/linux $ lsblk -l
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 298.1G 0 disk
sda1 8:1 0 298.1G 0 part /media/chenwx/Work
sdb 8:16 0 111.8G 0 disk
sdb1 8:17 0 100M 0 part
sdb2 8:18 0 58.4G 0 part
sdb3 8:19 0 484M 0 part
sdb4 8:20 0 1K 0 part
sdb5 8:21 0 52.8G 0 part /
NOTE: lsblk is very useful and easiest way to know the name of New Usb Device you just plugged in, especially when you have to deal with disk/blocks in terminal.
10.4.1 描述块设备的数据结构
10.4.1.1 struct block_device
每个块设备都是由一个block_device结构的描述符来表示struct block_device。所有的块设备描述符被插入一个全局链表中,链表首部是由变量all_bdevs表示的,参见fs/block_dev.c。链表链接所用的指针位于块设备描述符的bd_list字段中。
该结构定义于include/linux/fs.h:
struct block_device {
// 块设备的主设备号/次设备号
dev_t bd_dev; /* not a kdev_t - it's a search key */
// 计数器,统计块设备已经被打开的次数
int bd_openers;
// 指向bdev文件系统中块设备对应的索引节点的指针
struct inode *bd_inode; /* will die */
struct super_block *bd_super;
struct mutex bd_mutex; /* open/close mutex */
// 已打开的块设备文件的索引节点链表的首部
struct list_head bd_inodes;
void *bd_claiming;
// 块设备描述符的当前所有者
void *bd_holder;
// 计数器,统计对bd_holder字段设置的次数
int bd_holders;
bool bd_write_holder;
#ifdef CONFIG_SYSFS
struct list_head bd_holder_disks;
#endif
// 如果块设备是一个分区,则指向整个磁盘的块设备描述符;否则,指向该块设备描述符
struct block_device *bd_contains;
// 块大小
unsigned bd_block_size;
// 指向分区描述符的指针;若该块设备不是一个分区,则为NULL
struct hd_struct *bd_part;
/* number of times partitions within this device have been opened. */
unsigned bd_part_count;
// 当需要读块设备的分区表时设置的标志
int bd_invalidated;
// 指向块设备中基本磁盘的gendisk结构的指针
struct gendisk *bd_disk;
// 用于块设备描述符链表的指针
struct list_head bd_list;
/*
* Private data. You must have bd_claim'ed the block_device
* to use this. NOTE: bd_claim allows an owner to claim
* the same device multiple times, the owner must take special
* care to not mess up bd_private for that case.
*/
unsigned long bd_private;
/* The counter of freeze processes */
int bd_fsfreeze_count;
/* Mutex for freeze */
struct mutex bd_fsfreeze_mutex;
};
10.4.1.2 struct buffer_head
该结构定义于include/linux/blk_types.h:
struct buffer_head {
unsigned long b_state; /* buffer state bitmap (see enum bh_state_bits) */
struct buffer_head *b_this_page; /* circular list of page's buffers */
struct page *b_page; /* the page this bh is mapped to */
sector_t b_blocknr; /* start block number */
size_t b_size; /* size of mapping */
char *b_data; /* pointer to data within the page */
struct block_device *b_bdev;
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated with another mapping */
struct address_space *b_assoc_map; /* mapping this buffer is associated with */
atomic_t b_count; /* users using this buffer_head */
};
该结构参见:
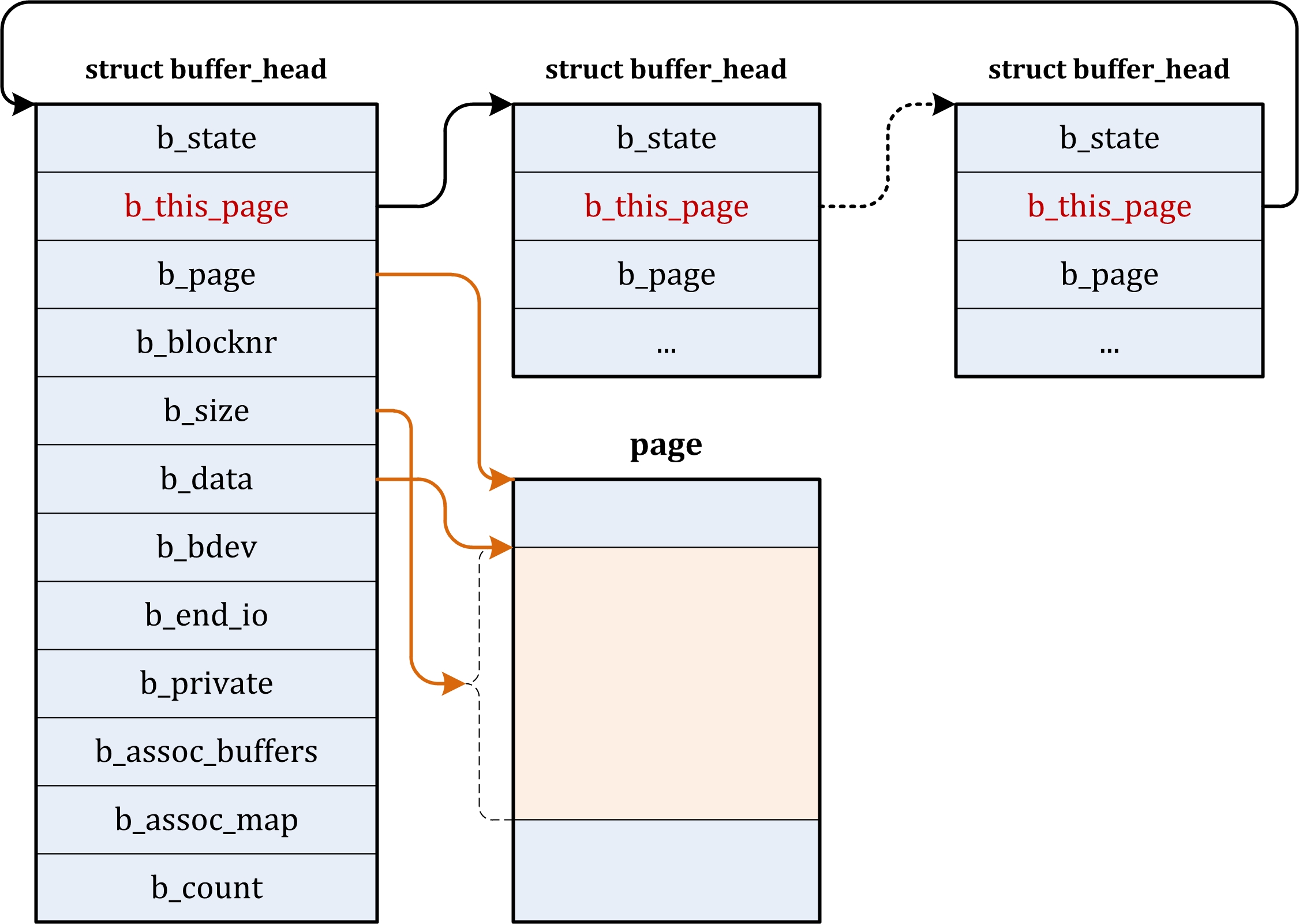
10.4.1.3 struct bio
该结构定义于include/linux/blk_types.h:
struct bio {
sector_t bi_sector; /* device address in 512 byte sectors */
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
unsigned long bi_flags; /* status, command, etc */
unsigned long bi_rw; /* bottom bits READ/WRITE, top bits priority */
unsigned short bi_vcnt; /* how many bio_vec's */
unsigned short bi_idx; /* current index into bvl_vec */
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned int bi_phys_segments;
unsigned int bi_size; /* residual I/O count */
/*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
*/
unsigned int bi_seg_front_size;
unsigned int bi_seg_back_size;
unsigned int bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
bio_end_io_t *bi_end_io;
void *bi_private;
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
bio_destructor_t *bi_destructor; /* destructor */
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[0];
};
该结构参见:
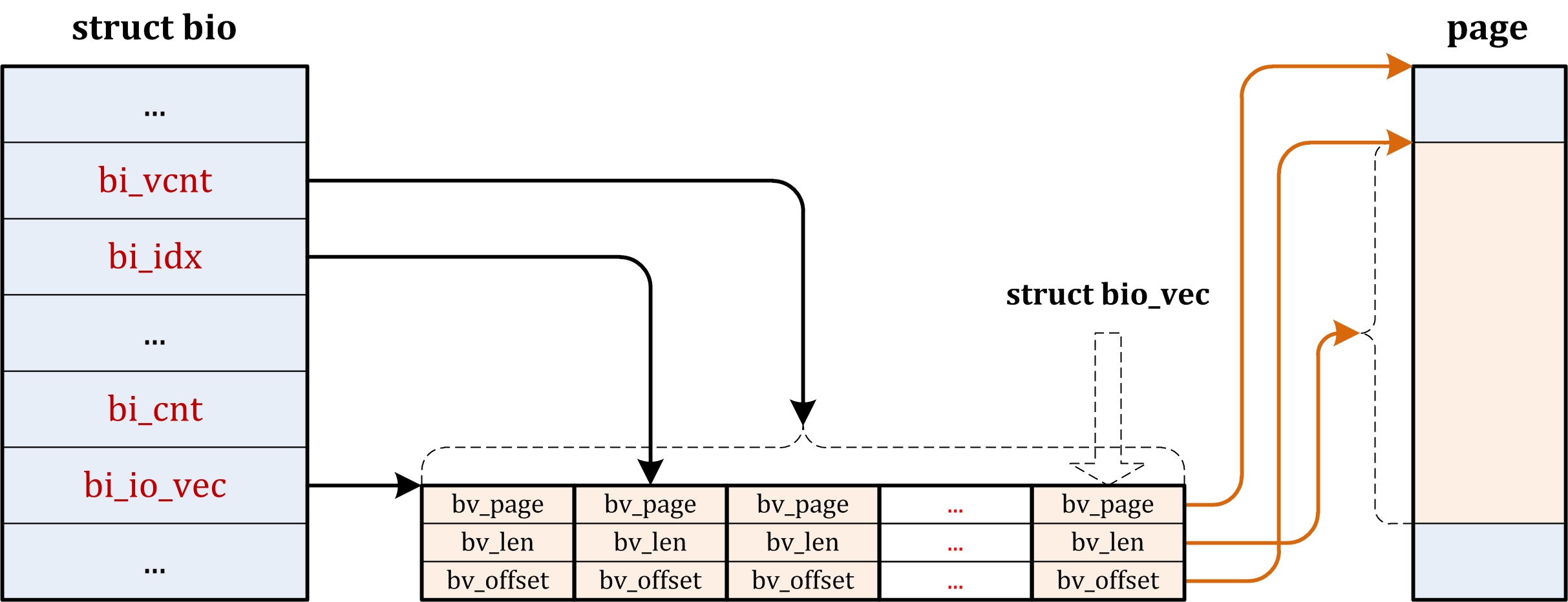
10.4.1.4 struct request_queue
Block devices maintain request queues to store their pending block I/O requests. Requests are added to the queue by higher-level code in the kernel, such as filesystems. As long as the request queue is nonempty, the block device driver associated with the queue grabs the request from the head of the queue and submits it to its associated block device. Each item in the queue’s request list is a single request, of type struct request.
该结构定义于include/linux/blkdev.h:
struct request_queue {
/*
* Together with queue_head for cacheline sharing
*/
struct list_head queue_head;
struct request *last_merge;
struct elevator_queue *elevator;
/*
* the queue request freelist, one for reads and one for writes
*/
struct request_list rq;
request_fn_proc *request_fn;
make_request_fn *make_request_fn;
prep_rq_fn *prep_rq_fn;
unprep_rq_fn *unprep_rq_fn;
merge_bvec_fn *merge_bvec_fn;
softirq_done_fn *softirq_done_fn;
rq_timed_out_fn *rq_timed_out_fn;
dma_drain_needed_fn *dma_drain_needed;
lld_busy_fn *lld_busy_fn;
/*
* Dispatch queue sorting
*/
sector_t end_sector;
struct request *boundary_rq;
/*
* Delayed queue handling
*/
struct delayed_work delay_work;
struct backing_dev_info backing_dev_info;
/*
* The queue owner gets to use this for whatever they like.
* ll_rw_blk doesn't touch it.
*/
void *queuedata;
/*
* various queue flags, see QUEUE_* below
*/
unsigned long queue_flags;
/*
* queue needs bounce pages for pages above this limit
*/
gfp_t bounce_gfp;
/*
* protects queue structures from reentrancy. ->__queue_lock should
* _never_ be used directly, it is queue private. always use
* ->queue_lock.
*/
spinlock_t __queue_lock;
spinlock_t *queue_lock;
/*
* queue kobject
*/
struct kobject kobj;
/*
* queue settings
*/
unsigned long nr_requests; /* Max # of requests */
unsigned int nr_congestion_on;
unsigned int nr_congestion_off;
unsigned int nr_batching;
unsigned int dma_drain_size;
void *dma_drain_buffer;
unsigned int dma_pad_mask;
unsigned int dma_alignment;
struct blk_queue_tag *queue_tags;
struct list_head tag_busy_list;
unsigned int nr_sorted;
unsigned int in_flight[2];
unsigned int rq_timeout;
struct timer_list timeout;
struct list_head timeout_list;
struct queue_limits limits;
/*
* sg stuff
*/
unsigned int sg_timeout;
unsigned int sg_reserved_size;
int node;
#ifdef CONFIG_BLK_DEV_IO_TRACE
struct blk_trace *blk_trace;
#endif
/*
* for flush operations
*/
unsigned int flush_flags;
unsigned int flush_not_queueable:1;
unsigned int flush_queue_delayed:1;
unsigned int flush_pending_idx:1;
unsigned int flush_running_idx:1;
unsigned long flush_pending_since;
struct list_head flush_queue[2];
struct list_head flush_data_in_flight;
struct request flush_rq;
struct mutex sysfs_lock;
#if defined(CONFIG_BLK_DEV_BSG)
bsg_job_fn *bsg_job_fn;
int bsg_job_size;
struct bsg_class_device bsg_dev;
#endif
#ifdef CONFIG_BLK_DEV_THROTTLING
/* Throttle data */
struct throtl_data *td;
#endif
};
10.4.2 块设备的初始化/genhd_device_init()
- 字符设备初始化函数之一:
bdev_cache_init(),参见4.3.4.1.4.3.11.5 bdev_cache_init()节 - 字符设备初始化函数之二:
genhd_device_init(),参见10.4.2 块设备的初始化/genhd_device_init()节
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> vfs_caches_init() // 参见[4.3.4.1.4.3.11 vfs_caches_init()]节
-> bdev_cache_init() // 参见[4.3.4.1.4.3.11.5 bdev_cache_init()]节
-> rest_init() // 参见[4.3.4.1.4.3.13 rest_init()]节
-> kernel_init() // 参见[4.3.4.1.4.3.13.1 kernel_init()]节
-> do_basic_setup() // 参见[4.3.4.1.4.3.13.1.2 do_basic_setup()]节
-> do_initcalls() // 参见[13.5.1.1.1 do_initcalls()]节
-> do_one_initcall() // 参见[13.5.1.1.1.2 do_one_initcall()]节
-> subsys_initcall(genhd_device_init) // 参见[13.5.1.1.1.1.1 .initcall*.init]节中的initcall4.init
-> genhd_device_init() // 参见本节
该函数定义于block/genhd.c:
static int __init genhd_device_init(void)
{
int error;
// 变量sysfs_dev_block_kobj参见[10.2.1.1 devices_init()]节
block_class.dev_kobj = sysfs_dev_block_kobj;
// 参见[10.2.7.1.1 class_register()/__class_register()]节
error = class_register(&block_class);
if (unlikely(error))
return error;
// 初始化变量bdev_map,参见本节中的图major_names[255]_2.jpg
bdev_map = kobj_map_init(base_probe, &block_class_lock);
// 参见[10.4.2.1 blk_dev_init()]节
blk_dev_init();
// 注册块设备blkext,其主设备号为259,参见[10.4.3.1 register_blkdev()]节
register_blkdev(BLOCK_EXT_MAJOR, "blkext");
/* create top-level block dir */
// 创建目录/sys/block,参见[15.7.1.2 kobject_create_and_add()]节
if (!sysfs_deprecated)
block_depr = kobject_create_and_add("block", NULL);
return 0;
}
NOTE: major_names[255]_2.jpg
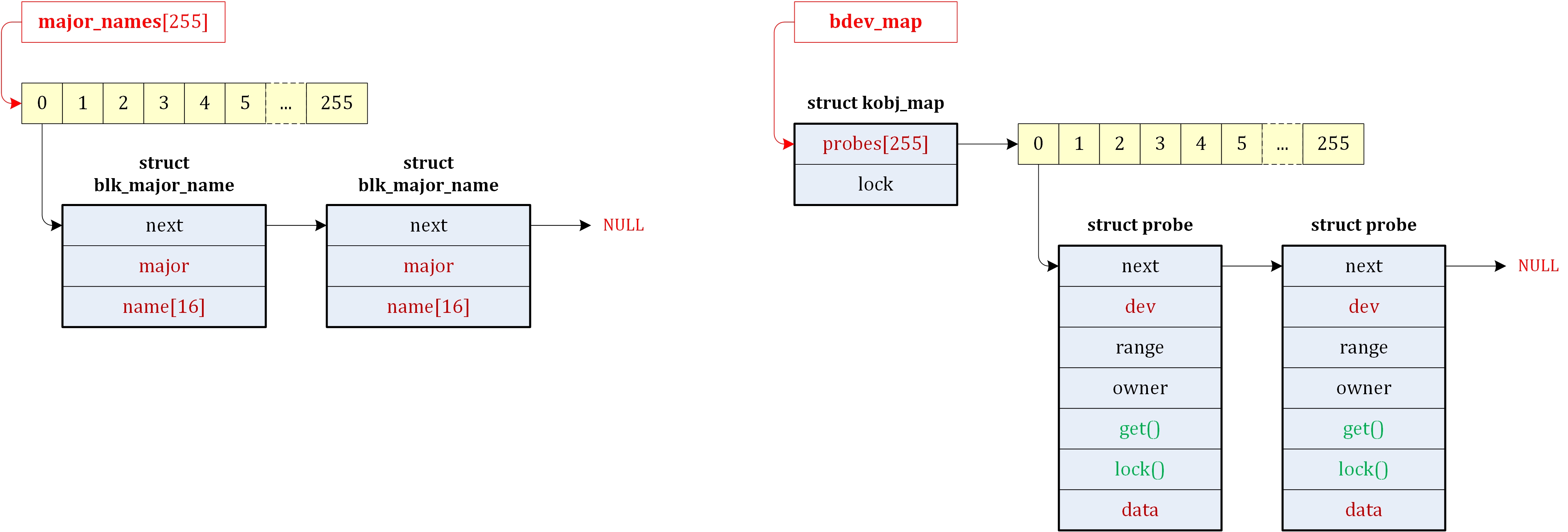
10.4.2.1 blk_dev_init()
该函数定义于block/blk-core.c:
int __init blk_dev_init(void)
{
BUILD_BUG_ON(__REQ_NR_BITS > 8 * sizeof(((struct request *)0)->cmd_flags));
/* used for unplugging and affects IO latency/throughput - HIGHPRI */
// 创建工作队列kblockd,参见[7.5.2.1 alloc_workqueue()]节
kblockd_workqueue = alloc_workqueue("kblockd", WQ_MEM_RECLAIM | WQ_HIGHPRI, 0);
if (!kblockd_workqueue)
panic("Failed to create kblockd\n");
// 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
request_cachep = kmem_cache_create("blkdev_requests",
sizeof(struct request), 0, SLAB_PANIC, NULL);
// 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
blk_requestq_cachep = kmem_cache_create("blkdev_queue",
sizeof(struct request_queue),
0, SLAB_PANIC, NULL);
return 0;
}
10.4.3 注册/注销块设备
10.4.3.1 register_blkdev()
该函数定义于block/genhd.c:
/**
* register_blkdev - register a new block device
*
* @major: the requested major device number [1..255]. If @major=0, try to
* allocate any unused major number.
* @name: the name of the new block device as a zero terminated string
*
* The @name must be unique within the system.
*
* The return value depends on the @major input parameter.
* - if a major device number was requested in range [1..255] then the
* function returns zero on success, or a negative error code
* - if any unused major number was requested with @major=0 parameter
* then the return value is the allocated major number in range
* [1..255] or a negative error code otherwise
*/
/*
* 由如下函数调用可知,入参major的取值范围不止在[1, 255],其中BLOCK_EXT_MAJOR = 259
* genhd_device_init()->register_blkdev(BLOCK_EXT_MAJOR, "blkext");
*/
int register_blkdev(unsigned int major, const char *name)
{
struct blk_major_name **n, *p;
int index, ret = 0;
mutex_lock(&block_class_lock);
/*
* 若major == 0,则动态分配主设备号:
* 按从后向前的顺序查找数组major_names[],若某元素为空,
* 则该元素对应的下标即为新分配的主设备号;由此可知,
* 动态分配主设备号的顺序是由大到小
*/
/* temporary */
if (major == 0) {
for (index = ARRAY_SIZE(major_names)-1; index > 0; index--) {
if (major_names[index] == NULL)
break;
}
// 若数组major_names[]的255个元素全部被用,则直接返回;
if (index == 0) {
printk("register_blkdev: failed to get major for %s\n", name);
ret = -EBUSY;
goto out;
}
major = index;
ret = major;
}
p = kmalloc(sizeof(struct blk_major_name), GFP_KERNEL);
if (p == NULL) {
ret = -ENOMEM;
goto out;
}
p->major = major;
strlcpy(p->name, name, sizeof(p->name));
p->next = NULL;
/*
* 查找新元素p应插入到链表major_names[major%255]中的位置;
* 举例:如下函数调用中,该元素被插入链表major_names[4]中,
* genhd_device_init()->register_blkdev(BLOCK_EXT_MAJOR, "blkext")
*/
index = major_to_index(major);
for (n = &major_names[index]; *n; n = &(*n)->next) {
if ((*n)->major == major)
break;
}
if (!*n)
*n = p;
else
ret = -EBUSY;
if (ret < 0) {
printk("register_blkdev: cannot get major %d for %s\n", major, name);
kfree(p);
}
out:
mutex_unlock(&block_class_lock);
return ret;
}
10.4.3.2 unregister_blkdev()
该函数定义于block/genhd.c:
void unregister_blkdev(unsigned int major, const char *name)
{
struct blk_major_name **n;
struct blk_major_name *p = NULL;
int index = major_to_index(major);
mutex_lock(&block_class_lock);
for (n = &major_names[index]; *n; n = &(*n)->next)
if ((*n)->major == major)
break;
if (!*n || strcmp((*n)->name, name)) {
WARN_ON(1);
} else {
p = *n;
*n = p->next;
}
mutex_unlock(&block_class_lock);
kfree(p);
}
10.4.4 I/O Scheduler
| I/O Scheduler | Source Code | CONFIG_XXX | elevator= |
|---|---|---|---|
| Linus elevator | block/elevator.c | as |
|
| Deadline I/O scheduler | block/deadline-iosched.c | CONFIG_IOSCHED_DEADLINE CONFIG_DEFAULT_DEADLINE |
deadline |
| Complete Fair Queuing (CFQ) | block/cfq-iosched.c | CONFIG_IOSCHED_CFQ CONFIG_DEFAULT_CFQ |
cfq |
| Noop I/O scheduler | block/noop-iosched.c | CONFIG_IOSCHED_NOOP CONFIG_DEFAULT_NOOP |
noop |
默认的I/O Schedule是Complete Fair Queuing (CFQ)。可以使用内核参数elevator=来配置I/O Scheduler。
10.5 Network Drivers
下列命令输出结果中的第一列为s,则该设备为网络设备:
chenwx@chenwx ~ $ ll /dev
srw-rw-rw- 1 root root 0 Nov 27 20:51 log
chenwx@chenwx ~ $ ll /sys/class/net/
lrwxrwxrwx 1 root root 0 Sep 14 18:45 eth0 -> ../../devices/pci0000:00/0000:00:19.0/net/eth0
lrwxrwxrwx 1 root root 0 Sep 14 18:45 lo -> ../../devices/virtual/net/lo
chenwx@chenwx ~ $ ll /sys/devices/virtual/net/lo
-r--r--r-- 1 root root 4.0K Sep 14 20:27 addr_assign_type
-r--r--r-- 1 root root 4.0K Sep 14 20:27 addr_len
-r--r--r-- 1 root root 4.0K Sep 14 20:27 address
-r--r--r-- 1 root root 4.0K Sep 14 20:27 broadcast
-rw-r--r-- 1 root root 4.0K Sep 14 20:27 carrier
-r--r--r-- 1 root root 4.0K Sep 14 20:27 carrier_changes
-r--r--r-- 1 root root 4.0K Sep 14 20:27 dev_id
-r--r--r-- 1 root root 4.0K Sep 14 20:27 dev_port
-r--r--r-- 1 root root 4.0K Sep 14 20:27 dormant
-r--r--r-- 1 root root 4.0K Sep 14 20:27 duplex
-rw-r--r-- 1 root root 4.0K Sep 14 20:27 flags
-rw-r--r-- 1 root root 4.0K Sep 14 20:27 gro_flush_timeout
-rw-r--r-- 1 root root 4.0K Sep 14 20:27 ifalias
-r--r--r-- 1 root root 4.0K Sep 14 15:50 ifindex
-r--r--r-- 1 root root 4.0K Sep 14 20:27 iflink
-r--r--r-- 1 root root 4.0K Sep 14 20:27 link_mode
-rw-r--r-- 1 root root 4.0K Sep 14 20:27 mtu
-r--r--r-- 1 root root 4.0K Sep 14 20:27 name_assign_type
-rw-r--r-- 1 root root 4.0K Sep 14 20:27 netdev_group
-r--r--r-- 1 root root 4.0K Sep 14 20:27 operstate
-r--r--r-- 1 root root 4.0K Sep 14 20:27 phys_port_id
-r--r--r-- 1 root root 4.0K Sep 14 20:27 phys_port_name
-r--r--r-- 1 root root 4.0K Sep 14 20:27 phys_switch_id
drwxr-xr-x 2 root root 0 Sep 14 20:27 power
drwxr-xr-x 4 root root 0 Sep 14 20:27 queues
-r--r--r-- 1 root root 4.0K Sep 14 20:27 speed
drwxr-xr-x 2 root root 0 Sep 14 20:27 statistics
lrwxrwxrwx 1 root root 0 Sep 14 15:50 subsystem -> ../../../../class/net
-rw-r--r-- 1 root root 4.0K Sep 14 20:27 tx_queue_len
-r--r--r-- 1 root root 4.0K Sep 14 15:50 type
-rw-r--r-- 1 root root 4.0K Sep 14 2015 uevent
chenwx@chenwx ~ $ ll /sys/devices/pci0000\:00/0000\:00\:19.0/net/eth0/
-r--r--r-- 1 root root 4.0K Sep 14 15:50 addr_assign_type
-r--r--r-- 1 root root 4.0K Sep 14 20:28 addr_len
-r--r--r-- 1 root root 4.0K Sep 14 15:50 address
-r--r--r-- 1 root root 4.0K Sep 14 20:28 broadcast
-rw-r--r-- 1 root root 4.0K Sep 14 20:28 carrier
-r--r--r-- 1 root root 4.0K Sep 14 20:28 carrier_changes
-r--r--r-- 1 root root 4.0K Sep 14 15:50 dev_id
-r--r--r-- 1 root root 4.0K Sep 14 20:28 dev_port
lrwxrwxrwx 1 root root 0 Sep 14 15:50 device -> ../../../0000:00:19.0
-r--r--r-- 1 root root 4.0K Sep 14 20:28 dormant
-r--r--r-- 1 root root 4.0K Sep 14 20:28 duplex
-rw-r--r-- 1 root root 4.0K Sep 14 20:28 flags
-rw-r--r-- 1 root root 4.0K Sep 14 20:28 gro_flush_timeout
-rw-r--r-- 1 root root 4.0K Sep 14 20:28 ifalias
-r--r--r-- 1 root root 4.0K Sep 14 15:50 ifindex
-r--r--r-- 1 root root 4.0K Sep 14 15:50 iflink
-r--r--r-- 1 root root 4.0K Sep 14 20:28 link_mode
-rw-r--r-- 1 root root 4.0K Sep 14 20:28 mtu
-r--r--r-- 1 root root 4.0K Sep 14 20:28 name_assign_type
-rw-r--r-- 1 root root 4.0K Sep 14 20:28 netdev_group
-r--r--r-- 1 root root 4.0K Sep 14 20:28 operstate
-r--r--r-- 1 root root 4.0K Sep 14 20:28 phys_port_id
-r--r--r-- 1 root root 4.0K Sep 14 20:28 phys_port_name
-r--r--r-- 1 root root 4.0K Sep 14 20:28 phys_switch_id
drwxr-xr-x 2 root root 0 Sep 14 20:28 power
drwxr-xr-x 4 root root 0 Sep 14 2015 queues
-r--r--r-- 1 root root 4.0K Sep 14 20:28 speed
drwxr-xr-x 2 root root 0 Sep 14 20:28 statistics
lrwxrwxrwx 1 root root 0 Sep 14 15:50 subsystem -> ../../../../../class/net
-rw-r--r-- 1 root root 4.0K Sep 14 20:28 tx_queue_len
-r--r--r-- 1 root root 4.0K Sep 14 15:50 type
-rw-r--r-- 1 root root 4.0K Sep 14 2015 uevent
10.5.0 基本知识
10.5.0.1 TCP/IP参考模型
| OSI参考模型 | TCP/IP参考模型 | 具体协议示例 |
|---|---|---|
| L7: 应用层(Application Layer) | L4: 应用层(Application Layer) | HTTP, SMTP, FTP, … |
| L6: 表示层(Presentation Layer) | L4: 应用层(Application Layer) | ASN.1, NCP, … |
| L5: 会话层(Session Layer) | L4: 应用层(Application Layer) | SSH, ASAP, X.225, … |
| L4: 传输层(Transport Layer) | L3: 传输层(Transport Layer) | TCP, UDP, TLS, RTP, SCTP, … |
| L3: 网络层(Network Layer) | L2: 网络互连层(Internet Layer) | IP, ICMP, BGP, … |
| L2: 数据链路层(Data Link Layer) | L1: 网络接口层(Network Access Layer) | 以太网, 令牌环, HDLC, 帧中继, ISDN, … |
| L1: 物理层(Physical Layer) | L1: 网络接口层(Network Access Layer) | 光纤, 无线电, … |
10.5.0.2 与网络设备有关的命令
命令ifconfig用于配置网络接口:
ifconfig - configure a network interface
SYNOPSIS
ifconfig [-v] [-a] [-s] [interface]
ifconfig [-v] interface [aftype] options | address ...
DESCRIPTION
Ifconfig is used to configure the kernel-resident network interfaces. It is used at boot
time to set up interfaces as necessary. After that, it is usually only needed when debugging
or when system tuning is needed.
If no arguments are given, ifconfig displays the status of the currently active interfaces.
If a single interface argument is given, it displays the status of the given interface only;
if a single -a argument is given, it displays the status of all interfaces, even those that
are down. Otherwise, it configures an interface.
例如:
chenwx@chenwx ~ $ ifconfig
eth0 Link encap:Ethernet HWaddr 00:1c:25:76:75:eb
inet addr:192.168.1.109 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::21c:25ff:fe76:75eb/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:49185 errors:0 dropped:0 overruns:0 frame:0
TX packets:235164 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:35297669 (35.2 MB) TX bytes:20815563 (20.8 MB)
Interrupt:20 Memory:fe000000-fe020000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:51853 errors:0 dropped:0 overruns:0 frame:0
TX packets:51853 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:24077890 (24.0 MB) TX bytes:24077890 (24.0 MB)
10.5.1 描述网络设备的数据结构
10.5.1.1 struct net_device
该结构定义于include/linux/netdevice.h:
/* Kernel tag: v4.2 */
struct net_device {
char name[IFNAMSIZ];
/*
* 链接至struct net -> dev_name_head,
* 参见[10.5.1.1.1 分配网络设备/alloc_netdev()]节:
* register_netdevice() -> list_netdevice()
*/
struct hlist_node name_hlist;
char *ifalias;
/*
* I/O specific fields
* FIXME: Merge these and struct ifmap into one
*/
unsigned long mem_end;
unsigned long mem_start;
unsigned long base_addr;
int irq;
atomic_t carrier_changes;
/*
* Some hardware also needs these fields (state,dev_list,
* napi_list,unreg_list,close_list) but they are not
* part of the usual set specified in Space.c.
*/
unsigned long state;
/*
* 链接至struct net -> dev_base_head,
* 参见[10.5.1.1.1 分配网络设备/alloc_netdev()]节:
* register_netdevice() -> list_netdevice()
*/
struct list_head dev_list;
struct list_head napi_list;
struct list_head unreg_list;
struct list_head close_list;
struct list_head ptype_all;
struct list_head ptype_specific;
struct {
struct list_head upper;
struct list_head lower;
} adj_list;
struct {
struct list_head upper;
struct list_head lower;
} all_adj_list;
netdev_features_t features;
netdev_features_t hw_features;
netdev_features_t wanted_features;
netdev_features_t vlan_features;
netdev_features_t hw_enc_features;
netdev_features_t mpls_features;
int ifindex;
int group;
struct net_device_stats stats;
atomic_long_t rx_dropped;
atomic_long_t tx_dropped;
#ifdef CONFIG_WIRELESS_EXT
const struct iw_handler_def *wireless_handlers;
struct iw_public_data *wireless_data;
#endif
// 参见[10.5.1.2 struct net_device_ops]节
const struct net_device_ops *netdev_ops;
const struct ethtool_ops *ethtool_ops;
#ifdef CONFIG_NET_SWITCHDEV
const struct switchdev_ops *switchdev_ops;
#endif
const struct header_ops *header_ops;
unsigned int flags;
unsigned int priv_flags;
unsigned short gflags;
unsigned short padded;
unsigned char operstate;
unsigned char link_mode;
unsigned char if_port;
unsigned char dma;
unsigned int mtu;
unsigned short type;
unsigned short hard_header_len;
unsigned short needed_headroom;
unsigned short needed_tailroom;
/* Interface address info. */
unsigned char perm_addr[MAX_ADDR_LEN];
unsigned char addr_assign_type;
unsigned char addr_len;
unsigned short neigh_priv_len;
unsigned short dev_id;
unsigned short dev_port;
spinlock_t addr_list_lock;
unsigned char name_assign_type;
bool uc_promisc;
struct netdev_hw_addr_list uc;
struct netdev_hw_addr_list mc;
struct netdev_hw_addr_list dev_addrs;
#ifdef CONFIG_SYSFS
struct kset *queues_kset;
#endif
unsigned int promiscuity;
unsigned int allmulti;
/* Protocol specific pointers */
#if IS_ENABLED(CONFIG_VLAN_8021Q)
struct vlan_info __rcu *vlan_info;
#endif
#if IS_ENABLED(CONFIG_NET_DSA)
struct dsa_switch_tree *dsa_ptr;
#endif
#if IS_ENABLED(CONFIG_TIPC)
struct tipc_bearer __rcu *tipc_ptr;
#endif
void *atalk_ptr;
struct in_device __rcu *ip_ptr;
struct dn_dev __rcu *dn_ptr;
struct inet6_dev __rcu *ip6_ptr;
void *ax25_ptr;
struct wireless_dev *ieee80211_ptr;
struct wpan_dev *ieee802154_ptr;
#if IS_ENABLED(CONFIG_MPLS_ROUTING)
struct mpls_dev __rcu *mpls_ptr;
#endif
/*
* Cache lines mostly used on receive path (including eth_type_trans())
*/
unsigned long last_rx;
/* Interface address info used in eth_type_trans() */
unsigned char *dev_addr;
#ifdef CONFIG_SYSFS
struct netdev_rx_queue *_rx;
unsigned int num_rx_queues;
unsigned int real_num_rx_queues;
#endif
unsigned long gro_flush_timeout;
rx_handler_func_t __rcu *rx_handler;
void __rcu *rx_handler_data;
#ifdef CONFIG_NET_CLS_ACT
struct tcf_proto __rcu *ingress_cl_list;
#endif
struct netdev_queue __rcu *ingress_queue;
#ifdef CONFIG_NETFILTER_INGRESS
struct list_head nf_hooks_ingress;
#endif
unsigned char broadcast[MAX_ADDR_LEN];
#ifdef CONFIG_RFS_ACCEL
struct cpu_rmap *rx_cpu_rmap;
#endif
/*
* 链接至struct net -> dev_index_head,
* 参见[10.5.1.1.1 分配网络设备/alloc_netdev()]节:
* register_netdevice() -> list_netdevice()
*/
struct hlist_node index_hlist;
/*
* Cache lines mostly used on transmit path
*/
struct netdev_queue *_tx ____cacheline_aligned_in_smp;
unsigned int num_tx_queues;
unsigned int real_num_tx_queues;
struct Qdisc *qdisc;
unsigned long tx_queue_len;
spinlock_t tx_global_lock;
int watchdog_timeo;
#ifdef CONFIG_XPS
struct xps_dev_maps __rcu *xps_maps;
#endif
/* These may be needed for future network-power-down code. */
/*
* trans_start here is expensive for high speed devices on SMP,
* please use netdev_queue->trans_start instead.
*/
unsigned long trans_start;
struct timer_list watchdog_timer;
int __percpu *pcpu_refcnt;
struct list_head todo_list;
struct list_head link_watch_list;
// 网络设备的注册状态
enum {
// alloc_netdev_mqs()将此域处初始化为0
NETREG_UNINITIALIZED=0,
// register_netdevice()设置
NETREG_REGISTERED, /* completed register_netdevice */
// rollback_registered_many()设置
NETREG_UNREGISTERING, /* called unregister_netdevice */
// netdev_run_todo()设置
NETREG_UNREGISTERED, /* completed unregister todo */
// free_netdev()设置
NETREG_RELEASED, /* called free_netdev */
// init_dummy_netdev()设置
NETREG_DUMMY, /* dummy device for NAPI poll */
} reg_state:8;
bool dismantle;
enum {
RTNL_LINK_INITIALIZED,
RTNL_LINK_INITIALIZING,
} rtnl_link_state:16;
void (*destructor)(struct net_device *dev);
#ifdef CONFIG_NETPOLL
struct netpoll_info __rcu *npinfo;
#endif
possible_net_t nd_net;
/* mid-layer private */
union {
void *ml_priv;
struct pcpu_lstats __percpu *lstats;
struct pcpu_sw_netstats __percpu *tstats;
struct pcpu_dstats __percpu *dstats;
struct pcpu_vstats __percpu *vstats;
};
struct garp_port __rcu *garp_port;
struct mrp_port __rcu *mrp_port;
// 参见[10.2.3 struct device]节
struct device dev;
const struct attribute_group *sysfs_groups[4];
const struct attribute_group *sysfs_rx_queue_group;
const struct rtnl_link_ops *rtnl_link_ops;
/* for setting kernel sock attribute on TCP connection setup */
#define GSO_MAX_SIZE 65536
unsigned int gso_max_size;
#define GSO_MAX_SEGS 65535
u16 gso_max_segs;
u16 gso_min_segs;
#ifdef CONFIG_DCB
const struct dcbnl_rtnl_ops *dcbnl_ops;
#endif
u8 num_tc;
struct netdev_tc_txq tc_to_txq[TC_MAX_QUEUE];
u8 prio_tc_map[TC_BITMASK + 1];
#if IS_ENABLED(CONFIG_FCOE)
unsigned int fcoe_ddp_xid;
#endif
#if IS_ENABLED(CONFIG_CGROUP_NET_PRIO)
struct netprio_map __rcu *priomap;
#endif
struct phy_device *phydev;
struct lock_class_key *qdisc_tx_busylock;
};
10.5.1.1.1 分配网络设备/alloc_netdev()
宏alloc_netdev()定义于include/linux/netdevice.h:
#define alloc_netdev(sizeof_priv, name, name_assign_type, setup) \
alloc_netdev_mqs(sizeof_priv, name, name_assign_type, setup, 1, 1)
其中,函数alloc_netdev_mqs()定义于net/core/dev.c:
/**
* alloc_netdev_mqs - allocate network device
* @sizeof_priv: size of private data to allocate space for
* @name: device name format string
* @name_assign_type: origin of device name
* @setup: callback to initialize device
* @txqs: the number of TX subqueues to allocate
* @rxqs: the number of RX subqueues to allocate
*
* Allocates a struct net_device with private data area for driver use
* and performs basic initialization. Also allocates subqueue structs
* for each queue on the device.
*
* 私有数据块位与struct net_device数据结构的后面,通过函数netdev_priv()获取其开始地址.
*/
struct net_device *alloc_netdev_mqs(int sizeof_priv, const char *name,
unsigned char name_assign_type,
void (*setup)(struct net_device *),
unsigned int txqs, unsigned int rxqs)
{
struct net_device *dev;
size_t alloc_size;
struct net_device *p;
BUG_ON(strlen(name) >= sizeof(dev->name));
if (txqs < 1) {
pr_err("alloc_netdev: Unable to allocate device with zero queues\n");
return NULL;
}
#ifdef CONFIG_SYSFS
if (rxqs < 1) {
pr_err("alloc_netdev: Unable to allocate device with zero RX queues\n");
return NULL;
}
#endif
alloc_size = sizeof(struct net_device);
if (sizeof_priv) {
/* ensure 32-byte alignment of private area */
alloc_size = ALIGN(alloc_size, NETDEV_ALIGN);
alloc_size += sizeof_priv;
}
/* ensure 32-byte alignment of whole construct */
alloc_size += NETDEV_ALIGN - 1;
p = kzalloc(alloc_size, GFP_KERNEL | __GFP_NOWARN | __GFP_REPEAT);
if (!p)
p = vzalloc(alloc_size);
if (!p)
return NULL;
/*
* struct net_device并不是位于分配的内存区域的开始位置,而是
* 有padded字节的偏移量;将该偏移量保存到dev->padded中,用
* 于释放网络设备,参见free_netdev()->netdev_freemem()
*/
dev = PTR_ALIGN(p, NETDEV_ALIGN);
dev->padded = (char *)dev - (char *)p;
dev->pcpu_refcnt = alloc_percpu(int);
if (!dev->pcpu_refcnt)
goto free_dev;
if (dev_addr_init(dev))
goto free_pcpu;
dev_mc_init(dev);
dev_uc_init(dev);
/*
* 设置网络名字空间,即: dev->nd_net->net = init_net;
* 函数net_ns_init()将init_net.list添加到链表net_namespace_list中:
* net_ns_init() -> list_add_tail_rcu(&init_net.list, &net_namespace_list);
*/
dev_net_set(dev, &init_net);
dev->gso_max_size = GSO_MAX_SIZE;
dev->gso_max_segs = GSO_MAX_SEGS;
dev->gso_min_segs = 0;
INIT_LIST_HEAD(&dev->napi_list);
INIT_LIST_HEAD(&dev->unreg_list);
INIT_LIST_HEAD(&dev->close_list);
INIT_LIST_HEAD(&dev->link_watch_list);
INIT_LIST_HEAD(&dev->adj_list.upper);
INIT_LIST_HEAD(&dev->adj_list.lower);
INIT_LIST_HEAD(&dev->all_adj_list.upper);
INIT_LIST_HEAD(&dev->all_adj_list.lower);
INIT_LIST_HEAD(&dev->ptype_all);
INIT_LIST_HEAD(&dev->ptype_specific);
dev->priv_flags = IFF_XMIT_DST_RELEASE | IFF_XMIT_DST_RELEASE_PERM;
setup(dev);
dev->num_tx_queues = txqs;
dev->real_num_tx_queues = txqs;
if (netif_alloc_netdev_queues(dev))
goto free_all;
#ifdef CONFIG_SYSFS
dev->num_rx_queues = rxqs;
dev->real_num_rx_queues = rxqs;
if (netif_alloc_rx_queues(dev))
goto free_all;
#endif
strcpy(dev->name, name);
dev->name_assign_type = name_assign_type;
dev->group = INIT_NETDEV_GROUP;
if (!dev->ethtool_ops)
dev->ethtool_ops = &default_ethtool_ops;
nf_hook_ingress_init(dev);
return dev;
free_all:
free_netdev(dev);
return NULL;
free_pcpu:
free_percpu(dev->pcpu_refcnt);
free_dev:
netdev_freemem(dev);
return NULL;
}
10.5.1.1.2 释放网络设备/free_netdev()
该函数定义于net/core/dev.c:
/**
* free_netdev - free network device
* @dev: device
*
* This function does the last stage of destroying an allocated device
* interface. The reference to the device object is released.
* If this is the last reference then it will be freed.
*/
void free_netdev(struct net_device *dev)
{
struct napi_struct *p, *n;
netif_free_tx_queues(dev);
#ifdef CONFIG_SYSFS
kvfree(dev->_rx);
#endif
kfree(rcu_dereference_protected(dev->ingress_queue, 1));
/* Flush device addresses */
dev_addr_flush(dev);
list_for_each_entry_safe(p, n, &dev->napi_list, dev_list)
netif_napi_del(p);
free_percpu(dev->pcpu_refcnt);
dev->pcpu_refcnt = NULL;
/* Compatibility with error handling in drivers */
if (dev->reg_state == NETREG_UNINITIALIZED) {
netdev_freemem(dev);
return;
}
BUG_ON(dev->reg_state != NETREG_UNREGISTERED);
dev->reg_state = NETREG_RELEASED;
/* will free via device release */
put_device(&dev->dev);
}
10.5.1.1.3 注册网络设备/register_netdev()
该函数定义于net/core/dev.c:
/**
* register_netdev - register a network device
* @dev: device to register
*
* Take a completed network device structure and add it to the kernel
* interfaces. A %NETDEV_REGISTER message is sent to the netdev notifier
* chain. 0 is returned on success. A negative errno code is returned
* on a failure to set up the device, or if the name is a duplicate.
*
* This is a wrapper around register_netdevice that takes the rtnl semaphore
* and expands the device name if you passed a format string to
* alloc_netdev.
*/
int register_netdev(struct net_device *dev)
{
int err;
rtnl_lock();
err = register_netdevice(dev);
rtnl_unlock();
return err;
}
其中,函数register_netdevice()定义于net/core/dev.c:
/**
* register_netdevice - register a network device
* @dev: device to register
*
* Take a completed network device structure and add it to the kernel
* interfaces. A %NETDEV_REGISTER message is sent to the netdev notifier
* chain. 0 is returned on success. A negative errno code is returned
* on a failure to set up the device, or if the name is a duplicate.
*
* Callers must hold the rtnl semaphore. You may want
* register_netdev() instead of this.
*
* BUGS:
* The locking appears insufficient to guarantee two parallel registers
* will not get the same name.
*/
int register_netdevice(struct net_device *dev)
{
int ret;
struct net *net = dev_net(dev);
BUG_ON(dev_boot_phase);
ASSERT_RTNL();
might_sleep();
/* When net_device's are persistent, this will be fatal. */
BUG_ON(dev->reg_state != NETREG_UNINITIALIZED);
BUG_ON(!net);
spin_lock_init(&dev->addr_list_lock);
netdev_set_addr_lockdep_class(dev);
ret = dev_get_valid_name(net, dev, dev->name);
if (ret < 0)
goto out;
/* Init, if this function is available */
if (dev->netdev_ops->ndo_init) {
ret = dev->netdev_ops->ndo_init(dev);
if (ret) {
if (ret > 0)
ret = -EIO;
goto out;
}
}
if (((dev->hw_features | dev->features) & NETIF_F_HW_VLAN_CTAG_FILTER) &&
(!dev->netdev_ops->ndo_vlan_rx_add_vid ||
!dev->netdev_ops->ndo_vlan_rx_kill_vid)) {
netdev_WARN(dev, "Buggy VLAN acceleration in driver!\n");
ret = -EINVAL;
goto err_uninit;
}
/*
* 为该网络设备分配一个可用的索引号
*/
ret = -EBUSY;
if (!dev->ifindex)
dev->ifindex = dev_new_index(net);
else if (__dev_get_by_index(net, dev->ifindex))
goto err_uninit;
/*
* Transfer changeable features to wanted_features and enable
* software offloads (GSO and GRO).
*/
dev->hw_features |= NETIF_F_SOFT_FEATURES;
dev->features |= NETIF_F_SOFT_FEATURES;
dev->wanted_features = dev->features & dev->hw_features;
if (!(dev->flags & IFF_LOOPBACK)) {
dev->hw_features |= NETIF_F_NOCACHE_COPY;
}
/*
* Make NETIF_F_HIGHDMA inheritable to VLAN devices.
*/
dev->vlan_features |= NETIF_F_HIGHDMA;
/*
* Make NETIF_F_SG inheritable to tunnel devices.
*/
dev->hw_enc_features |= NETIF_F_SG;
/*
* Make NETIF_F_SG inheritable to MPLS.
*/
dev->mpls_features |= NETIF_F_SG;
// 参见[10.5.1.3.4 网络设备事件通知函数/call_netdevice_notifiers()]节
ret = call_netdevice_notifiers(NETDEV_POST_INIT, dev);
ret = notifier_to_errno(ret);
if (ret)
goto err_uninit;
/*
* Create sysfs entries for network device.
* 参见[10.5.1.1.3.1 netdev_register_kobject()]节
*/
ret = netdev_register_kobject(dev);
if (ret)
goto err_uninit;
dev->reg_state = NETREG_REGISTERED;
__netdev_update_features(dev);
/*
* Default initial state at registry is that the
* device is present.
*/
set_bit(__LINK_STATE_PRESENT, &dev->state);
linkwatch_init_dev(dev);
dev_init_scheduler(dev);
dev_hold(dev);
/*
* 将dev->dev_list, dev->name_hlist, dev->index_hlist链接至struct net相应的链表中;
* 可通过函数dev_get_by_name()从struct net->dev_name_head中查找指定的网络设备;
* 可通过函数dev_get_by_index()从struct net->dev_index_head中查找指定的网络设备;
*/
list_netdevice(dev);
add_device_randomness(dev->dev_addr, dev->addr_len);
/* If the device has permanent device address, driver should
* set dev_addr and also addr_assign_type should be set to
* NET_ADDR_PERM (default value).
*/
if (dev->addr_assign_type == NET_ADDR_PERM)
memcpy(dev->perm_addr, dev->dev_addr, dev->addr_len);
/* Notify protocols, that a new device appeared. */
// 参见[10.5.1.3.4 网络设备事件通知函数/call_netdevice_notifiers()]节
ret = call_netdevice_notifiers(NETDEV_REGISTER, dev);
ret = notifier_to_errno(ret);
if (ret) {
rollback_registered(dev);
dev->reg_state = NETREG_UNREGISTERED;
}
/*
* Prevent userspace races by waiting until the network
* device is fully setup before sending notifications.
*/
if (!dev->rtnl_link_ops ||
dev->rtnl_link_state == RTNL_LINK_INITIALIZED)
rtmsg_ifinfo(RTM_NEWLINK, dev, ~0U, GFP_KERNEL);
out:
return ret;
err_uninit:
if (dev->netdev_ops->ndo_uninit)
dev->netdev_ops->ndo_uninit(dev);
goto out;
}
10.5.1.1.3.1 netdev_register_kobject()
该函数定义于net/core/net-sysfs.c:
/* Create sysfs entries for network device. */
int netdev_register_kobject(struct net_device *ndev)
{
struct device *dev = &(ndev->dev);
const struct attribute_group **groups = ndev->sysfs_groups;
int error = 0;
// 参见[10.2.3.3.1 设备初始化/device_initialize()]节
device_initialize(dev);
dev->class = &net_class;
dev->platform_data = ndev;
dev->groups = groups;
// 将dev->kobj->name设置为ndev->name
dev_set_name(dev, "%s", ndev->name);
#ifdef CONFIG_SYSFS
/* Allow for a device specific group */
if (*groups)
groups++;
*groups++ = &netstat_group;
#if IS_ENABLED(CONFIG_WIRELESS_EXT) || IS_ENABLED(CONFIG_CFG80211)
if (ndev->ieee80211_ptr)
*groups++ = &wireless_group;
#if IS_ENABLED(CONFIG_WIRELESS_EXT)
else if (ndev->wireless_handlers)
*groups++ = &wireless_group;
#endif
#endif
#endif /* CONFIG_SYSFS */
// 参见[10.2.3.3.2 添加设备/device_add()]节
error = device_add(dev);
if (error)
return error;
error = register_queue_kobjects(ndev);
if (error) {
device_del(dev);
return error;
}
pm_runtime_set_memalloc_noio(dev, true);
return error;
}
10.5.1.1.4 注销网络设备
10.5.1.1.4.1 unregister_netdev()
该函数定义于net/core/dev.c:
/**
* unregister_netdev - remove device from the kernel
* @dev: device
*
* This function shuts down a device interface and removes it
* from the kernel tables.
*
* This is just a wrapper for unregister_netdevice that takes
* the rtnl semaphore. In general you want to use this and not
* unregister_netdevice.
*/
void unregister_netdev(struct net_device *dev)
{
// 获取互斥锁rtnl_mutex; 函数__rtnl_unlock()用于释放该互斥锁
rtnl_lock();
unregister_netdevice(dev);
rtnl_unlock(); // 参见[10.5.1.1.4.2 rtnl_unlock()]节
}
其中,函数unregister_netdevice()定义于include/linux/netdevice.h:
static inline void unregister_netdevice(struct net_device *dev)
{
unregister_netdevice_queue(dev, NULL);
}
/**
* unregister_netdevice_queue - remove device from the kernel
* @dev: device
* @head: list
*
* This function shuts down a device interface and removes it
* from the kernel tables.
* If head not NULL, device is queued to be unregistered later.
*
* Callers must hold the rtnl semaphore. You may want
* unregister_netdev() instead of this.
*/
void unregister_netdevice_queue(struct net_device *dev, struct list_head *head)
{
ASSERT_RTNL();
if (head) {
list_move_tail(&dev->unreg_list, head);
} else {
rollback_registered(dev);
/*
* 将待注销的网络设备链接到net_todo_list中,并通过如下函数释放该设备:
* rtnl_unlock()->netdev_run_todo(),参见[10.5.1.1.4.2 rtnl_unlock()]节
*/
/* Finish processing unregister after unlock */
net_set_todo(dev);
}
}
10.5.1.1.4.2 rtnl_unlock()
该函数定义于net/core/rtnetlink.c:
void rtnl_unlock(void)
{
/* This fellow will unlock it for us. */
netdev_run_todo();
}
其中,函数netdev_run_todo()定义于net/core/dev.c:
/* The sequence is:
*
* rtnl_lock();
* ...
* register_netdevice(x1);
* register_netdevice(x2);
* ...
* unregister_netdevice(y1);
* unregister_netdevice(y2);
* ...
* rtnl_unlock();
* free_netdev(y1);
* free_netdev(y2);
*
* We are invoked by rtnl_unlock().
* This allows us to deal with problems:
* 1) We can delete sysfs objects which invoke hotplug
* without deadlocking with linkwatch via keventd.
* 2) Since we run with the RTNL semaphore not held, we can sleep
* safely in order to wait for the netdev refcnt to drop to zero.
*
* We must not return until all unregister events added during
* the interval the lock was held have been completed.
*/
void netdev_run_todo(void)
{
struct list_head list;
/* Snapshot list, allow later requests */
list_replace_init(&net_todo_list, &list);
__rtnl_unlock();
/* Wait for rcu callbacks to finish before next phase */
if (!list_empty(&list))
rcu_barrier();
while (!list_empty(&list)) {
struct net_device *dev = list_first_entry(&list, struct net_device, todo_list);
list_del(&dev->todo_list);
rtnl_lock();
// 参见[10.5.1.3.4 网络设备事件通知函数/call_netdevice_notifiers()]节
call_netdevice_notifiers(NETDEV_UNREGISTER_FINAL, dev);
__rtnl_unlock();
if (unlikely(dev->reg_state != NETREG_UNREGISTERING)) {
pr_err("network todo '%s' but state %d\n",
dev->name, dev->reg_state);
dump_stack();
continue;
}
dev->reg_state = NETREG_UNREGISTERED;
netdev_wait_allrefs(dev);
/* paranoia */
BUG_ON(netdev_refcnt_read(dev));
BUG_ON(!list_empty(&dev->ptype_all));
BUG_ON(!list_empty(&dev->ptype_specific));
WARN_ON(rcu_access_pointer(dev->ip_ptr));
WARN_ON(rcu_access_pointer(dev->ip6_ptr));
WARN_ON(dev->dn_ptr);
if (dev->destructor)
dev->destructor(dev);
/* Report a network device has been unregistered */
rtnl_lock();
dev_net(dev)->dev_unreg_count--;
__rtnl_unlock();
wake_up(&netdev_unregistering_wq);
/* Free network device */
kobject_put(&dev->dev.kobj); // 参见[15.7.2.2 kobject_put()]节
}
}
10.5.1.1.5 启动网络设备/dev_open()
该函数定义于net/core/dev.c:
/**
* dev_open - prepare an interface for use.
* @dev: device to open
*
* Takes a device from down to up state. The device's private open
* function is invoked and then the multicast lists are loaded. Finally
* the device is moved into the up state and a %NETDEV_UP message is
* sent to the netdev notifier chain.
*
* Calling this function on an active interface is a nop. On a failure
* a negative errno code is returned.
*/
int dev_open(struct net_device *dev)
{
int ret;
if (dev->flags & IFF_UP)
return 0;
ret = __dev_open(dev);
if (ret < 0)
return ret;
rtmsg_ifinfo(RTM_NEWLINK, dev, IFF_UP|IFF_RUNNING, GFP_KERNEL);
// 参见[10.5.1.3.4 网络设备事件通知函数/call_netdevice_notifiers()]节
call_netdevice_notifiers(NETDEV_UP, dev);
return ret;
}
static int __dev_open(struct net_device *dev)
{
const struct net_device_ops *ops = dev->netdev_ops;
int ret;
ASSERT_RTNL();
if (!netif_device_present(dev))
return -ENODEV;
/* Block netpoll from trying to do any rx path servicing.
* If we don't do this there is a chance ndo_poll_controller
* or ndo_poll may be running while we open the device
*/
netpoll_poll_disable(dev);
// 参见[10.5.1.3.4 网络设备事件通知函数/call_netdevice_notifiers()]节
ret = call_netdevice_notifiers(NETDEV_PRE_UP, dev);
ret = notifier_to_errno(ret);
if (ret)
return ret;
set_bit(__LINK_STATE_START, &dev->state);
/*
* 调用设备驱动程序提供的接口来启动网络设备
*/
if (ops->ndo_validate_addr)
ret = ops->ndo_validate_addr(dev);
if (!ret && ops->ndo_open)
ret = ops->ndo_open(dev);
netpoll_poll_enable(dev);
/*
* 启用设备时设置标志位__LINK_STATE_START,表示设备可以传递数据;
* 关闭设备时清除该标志位,参见[10.5.1.1.6 禁用网络设备/dev_close()]节
*/
if (ret)
clear_bit(__LINK_STATE_START, &dev->state);
else {
dev->flags |= IFF_UP;
dev_set_rx_mode(dev);
dev_activate(dev);
add_device_randomness(dev->dev_addr, dev->addr_len);
}
return ret;
}
10.5.1.1.6 禁用网络设备/dev_close()
该函数定义于net/core/dev.c:
/**
* dev_close - shutdown an interface.
* @dev: device to shutdown
*
* This function moves an active device into down state. A
* %NETDEV_GOING_DOWN is sent to the netdev notifier chain. The device
* is then deactivated and finally a %NETDEV_DOWN is sent to the notifier
* chain.
*/
int dev_close(struct net_device *dev)
{
if (dev->flags & IFF_UP) {
LIST_HEAD(single);
list_add(&dev->close_list, &single);
dev_close_many(&single, true);
list_del(&single);
}
return 0;
}
int dev_close_many(struct list_head *head, bool unlink)
{
struct net_device *dev, *tmp;
/* Remove the devices that don't need to be closed */
list_for_each_entry_safe(dev, tmp, head, close_list)
if (!(dev->flags & IFF_UP))
list_del_init(&dev->close_list);
__dev_close_many(head);
list_for_each_entry_safe(dev, tmp, head, close_list) {
rtmsg_ifinfo(RTM_NEWLINK, dev, IFF_UP|IFF_RUNNING, GFP_KERNEL);
// 参见[10.5.1.3.4 网络设备事件通知函数/call_netdevice_notifiers()]节
call_netdevice_notifiers(NETDEV_DOWN, dev);
if (unlink)
list_del_init(&dev->close_list);
}
return 0;
}
static int __dev_close_many(struct list_head *head)
{
struct net_device *dev;
ASSERT_RTNL();
might_sleep();
list_for_each_entry(dev, head, close_list) {
/* Temporarily disable netpoll until the interface is down */
netpoll_poll_disable(dev);
// 参见[10.5.1.3.4 网络设备事件通知函数/call_netdevice_notifiers()]节
call_netdevice_notifiers(NETDEV_GOING_DOWN, dev);
/*
* 关闭设备时清除标志位__LINK_STATE_START,表示设备禁止传递数据;
* 启用设备时设置该标志位,参见[10.5.1.1.5 启动网络设备/dev_open()]节
*/
clear_bit(__LINK_STATE_START, &dev->state);
/* Synchronize to scheduled poll. We cannot touch poll list, it
* can be even on different cpu. So just clear netif_running().
*
* dev->stop() will invoke napi_disable() on all of it's
* napi_struct instances on this device.
*/
smp_mb__after_atomic(); /* Commit netif_running(). */
}
dev_deactivate_many(head);
list_for_each_entry(dev, head, close_list) {
const struct net_device_ops *ops = dev->netdev_ops;
/*
* Call the device specific close. This cannot fail.
* Only if device is UP
*
* We allow it to be called even after a DETACH hot-plug
* event.
*/
if (ops->ndo_stop)
ops->ndo_stop(dev);
dev->flags &= ~IFF_UP;
netpoll_poll_enable(dev);
}
return 0;
}
10.5.1.2 struct net_device_ops
该结构定义于include/linux/netdevice.h:
/* Kernel tag: v4.2 */
struct net_device_ops {
int (*ndo_init)(struct net_device *dev);
void (*ndo_uninit)(struct net_device *dev);
int (*ndo_open)(struct net_device *dev);
int (*ndo_stop)(struct net_device *dev);
netdev_tx_t (*ndo_start_xmit) (struct sk_buff *skb, struct net_device *dev);
u16 (*ndo_select_queue)(struct net_device *dev, struct sk_buff *skb,
void *accel_priv, select_queue_fallback_t fallback);
void (*ndo_change_rx_flags)(struct net_device *dev, int flags);
void (*ndo_set_rx_mode)(struct net_device *dev);
int (*ndo_set_mac_address)(struct net_device *dev, void *addr);
int (*ndo_validate_addr)(struct net_device *dev);
int (*ndo_do_ioctl)(struct net_device *dev, struct ifreq *ifr, int cmd);
int (*ndo_set_config)(struct net_device *dev, struct ifmap *map);
int (*ndo_change_mtu)(struct net_device *dev, int new_mtu);
int (*ndo_neigh_setup)(struct net_device *dev, struct neigh_parms *);
void (*ndo_tx_timeout) (struct net_device *dev);
struct rtnl_link_stats64* (*ndo_get_stats64)(struct net_device *dev,
struct rtnl_link_stats64 *storage);
struct net_device_stats* (*ndo_get_stats)(struct net_device *dev);
int (*ndo_vlan_rx_add_vid)(struct net_device *dev, __be16 proto, u16 vid);
int (*ndo_vlan_rx_kill_vid)(struct net_device *dev, __be16 proto, u16 vid);
#ifdef CONFIG_NET_POLL_CONTROLLER
void (*ndo_poll_controller)(struct net_device *dev);
int (*ndo_netpoll_setup)(struct net_device *dev, struct netpoll_info *info);
void (*ndo_netpoll_cleanup)(struct net_device *dev);
#endif
#ifdef CONFIG_NET_RX_BUSY_POLL
int (*ndo_busy_poll)(struct napi_struct *dev);
#endif
int (*ndo_set_vf_mac)(struct net_device *dev, int queue, u8 *mac);
int (*ndo_set_vf_vlan)(struct net_device *dev, int queue, u16 vlan, u8 qos);
int (*ndo_set_vf_rate)(struct net_device *dev, int vf, int min_tx_rate, int max_tx_rate);
int (*ndo_set_vf_spoofchk)(struct net_device *dev, int vf, bool setting);
int (*ndo_get_vf_config)(struct net_device *dev, int vf, struct ifla_vf_info *ivf);
int (*ndo_set_vf_link_state)(struct net_device *dev, int vf, int link_state);
int (*ndo_get_vf_stats)(struct net_device *dev, int vf, struct ifla_vf_stats *vf_stats);
int (*ndo_set_vf_port)(struct net_device *dev, int vf, struct nlattr *port[]);
int (*ndo_get_vf_port)(struct net_device *dev, int vf, struct sk_buff *skb);
int (*ndo_set_vf_rss_query_en)(struct net_device *dev, int vf, bool setting);
int (*ndo_setup_tc)(struct net_device *dev, u8 tc);
#if IS_ENABLED(CONFIG_FCOE)
int (*ndo_fcoe_enable)(struct net_device *dev);
int (*ndo_fcoe_disable)(struct net_device *dev);
int (*ndo_fcoe_ddp_setup)(struct net_device *dev, u16 xid,
struct scatterlist *sgl, unsigned int sgc);
int (*ndo_fcoe_ddp_done)(struct net_device *dev, u16 xid);
int (*ndo_fcoe_ddp_target)(struct net_device *dev, u16 xid,
struct scatterlist *sgl, unsigned int sgc);
int (*ndo_fcoe_get_hbainfo)(struct net_device *dev, struct netdev_fcoe_hbainfo *hbainfo);
#endif
#if IS_ENABLED(CONFIG_LIBFCOE)
#define NETDEV_FCOE_WWNN 0
#define NETDEV_FCOE_WWPN 1
int (*ndo_fcoe_get_wwn)(struct net_device *dev, u64 *wwn, int type);
#endif
#ifdef CONFIG_RFS_ACCEL
int (*ndo_rx_flow_steer)(struct net_device *dev, const struct sk_buff *skb,
u16 rxq_index, u32 flow_id);
#endif
int (*ndo_add_slave)(struct net_device *dev, struct net_device *slave_dev);
int (*ndo_del_slave)(struct net_device *dev, struct net_device *slave_dev);
netdev_features_t (*ndo_fix_features)(struct net_device *dev, netdev_features_t features);
int (*ndo_set_features)(struct net_device *dev, netdev_features_t features);
int (*ndo_neigh_construct)(struct neighbour *n);
void (*ndo_neigh_destroy)(struct neighbour *n);
int (*ndo_fdb_add)(struct ndmsg *ndm, struct nlattr *tb[], struct net_device *dev,
const unsigned char *addr, u16 vid, u16 flags);
int (*ndo_fdb_del)(struct ndmsg *ndm, struct nlattr *tb[], struct net_device *dev,
const unsigned char *addr, u16 vid);
int (*ndo_fdb_dump)(struct sk_buff *skb, struct netlink_callback *cb,
struct net_device *dev, struct net_device *filter_dev, int idx);
int (*ndo_bridge_setlink)(struct net_device *dev, struct nlmsghdr *nlh, u16 flags);
int (*ndo_bridge_getlink)(struct sk_buff *skb, u32 pid, u32 seq,
struct net_device *dev, u32 filter_mask, int nlflags);
int (*ndo_bridge_dellink)(struct net_device *dev, struct nlmsghdr *nlh, u16 flags);
int (*ndo_change_carrier)(struct net_device *dev, bool new_carrier);
int (*ndo_get_phys_port_id)(struct net_device *dev, struct netdev_phys_item_id *ppid);
int (*ndo_get_phys_port_name)(struct net_device *dev, char *name, size_t len);
void (*ndo_add_vxlan_port)(struct net_device *dev, sa_family_t sa_family, __be16 port);
void (*ndo_del_vxlan_port)(struct net_device *dev, sa_family_t sa_family, __be16 port);
void* (*ndo_dfwd_add_station)(struct net_device *pdev, struct net_device *dev);
void (*ndo_dfwd_del_station)(struct net_device *pdev, void *priv);
netdev_tx_t (*ndo_dfwd_start_xmit) (struct sk_buff *skb, struct net_device *dev, void *priv);
int (*ndo_get_lock_subclass)(struct net_device *dev);
netdev_features_t (*ndo_features_check) (struct sk_buff *skb, struct net_device *dev,
netdev_features_t features);
int (*ndo_set_tx_maxrate)(struct net_device *dev, int queue_index, u32 maxrate);
int (*ndo_get_iflink)(const struct net_device *dev);
};
10.5.1.3 网络设备通知链/netdev_chain
变量netdev_chain定义于net/core/dev.c:
#define RAW_NOTIFIER_INIT(name) { .head = NULL }
#define RAW_NOTIFIER_HEAD(name) \
struct raw_notifier_head name = RAW_NOTIFIER_INIT(name)
static RAW_NOTIFIER_HEAD(netdev_chain);
其中,struct raw_notifier_head和struct notifier_block定义于include/linux/notifier.h:
struct raw_notifier_head {
struct notifier_block __rcu *head;
};
struct notifier_block {
notifier_fn_t notifier_call;
struct notifier_block __rcu *next;
int priority;
};
/*
* 入参action定义于include/linux/netdevice.h,
* 参见[10.5.1.3.1 网络设备通知事件]节
*/
typedef int (*notifier_fn_t)(struct notifier_block *nb, unsigned long action, void *data);
/*
* 函数notifier_call()的返回值类型
*/
#define NOTIFY_DONE 0x0000 /* Don't care */
#define NOTIFY_OK 0x0001 /* Suits me */
#define NOTIFY_STOP_MASK 0x8000 /* Don't call further */
#define NOTIFY_BAD (NOTIFY_STOP_MASK|0x0002) /* Bad/Veto action */
/*
* Clean way to return from the notifier and stop further calls.
*/
#define NOTIFY_STOP (NOTIFY_OK|NOTIFY_STOP_MASK)
10.5.1.3.1 网络设备通知事件
网络设备通知事件定义于include/linux/netdevice.h:
/*
* netdevice notifier chain. Please remember to update the rtnetlink
* notification exclusion list in rtnetlink_event() when adding new
* types.
*/
#define NETDEV_UP 0x0001 /* For now you can't veto a device up/down */
#define NETDEV_DOWN 0x0002
#define NETDEV_REBOOT 0x0003 /* Tell a protocol stack a network interface
detected a hardware crash and restarted
- we can use this eg to kick tcp sessions
once done */
#define NETDEV_CHANGE 0x0004 /* Notify device state change */
#define NETDEV_REGISTER 0x0005
#define NETDEV_UNREGISTER 0x0006
#define NETDEV_CHANGEMTU 0x0007 /* notify after mtu change happened */
#define NETDEV_CHANGEADDR 0x0008
#define NETDEV_GOING_DOWN 0x0009
#define NETDEV_CHANGENAME 0x000A
#define NETDEV_FEAT_CHANGE 0x000B
#define NETDEV_BONDING_FAILOVER 0x000C
#define NETDEV_PRE_UP 0x000D
#define NETDEV_PRE_TYPE_CHANGE 0x000E
#define NETDEV_POST_TYPE_CHANGE 0x000F
#define NETDEV_POST_INIT 0x0010
#define NETDEV_UNREGISTER_FINAL 0x0011
#define NETDEV_RELEASE 0x0012
#define NETDEV_NOTIFY_PEERS 0x0013
#define NETDEV_JOIN 0x0014
#define NETDEV_CHANGEUPPER 0x0015
#define NETDEV_RESEND_IGMP 0x0016
#define NETDEV_PRECHANGEMTU 0x0017 /* notify before mtu change happened */
#define NETDEV_CHANGEINFODATA 0x0018
#define NETDEV_BONDING_INFO 0x0019
10.5.1.3.2 注册网络设备通知块/register_netdevice_notifier()
该函数定义于net/core/dev.c:
/**
* register_netdevice_notifier - register a network notifier block
* @nb: notifier
*
* Register a notifier to be called when network device events occur.
* The notifier passed is linked into the kernel structures and must
* not be reused until it has been unregistered. A negative errno code
* is returned on a failure.
*
* When registered all registration and up events are replayed
* to the new notifier to allow device to have a race free
* view of the network device list.
*/
int register_netdevice_notifier(struct notifier_block *nb)
{
struct net_device *dev;
struct net_device *last;
struct net *net;
int err;
rtnl_lock();
// 将nb链接到全局链表netdev_chain中
err = raw_notifier_chain_register(&netdev_chain, nb);
if (err)
goto unlock;
if (dev_boot_phase)
goto unlock;
/*
* 轮询每个网络设备,并调用call_netdevice_notifier()
* 函数通知事件NETDEV_REGISTER和NETDEV_UP
*/
for_each_net(net) {
for_each_netdev(net, dev) {
err = call_netdevice_notifier(nb, NETDEV_REGISTER, dev);
err = notifier_to_errno(err);
if (err)
goto rollback;
if (!(dev->flags & IFF_UP))
continue;
call_netdevice_notifier(nb, NETDEV_UP, dev);
}
}
unlock:
rtnl_unlock();
return err;
rollback:
last = dev;
for_each_net(net) {
for_each_netdev(net, dev) {
if (dev == last)
goto outroll;
if (dev->flags & IFF_UP) {
call_netdevice_notifier(nb, NETDEV_GOING_DOWN, dev);
call_netdevice_notifier(nb, NETDEV_DOWN, dev);
}
call_netdevice_notifier(nb, NETDEV_UNREGISTER, dev);
}
}
outroll:
raw_notifier_chain_unregister(&netdev_chain, nb);
goto unlock;
}
10.5.1.3.3 注销网络设备通知块/unregister_netdevice_notifier()
该函数定义于net/core/dev.c:
/**
* unregister_netdevice_notifier - unregister a network notifier block
* @nb: notifier
*
* Unregister a notifier previously registered by
* register_netdevice_notifier(). The notifier is unlinked into the
* kernel structures and may then be reused. A negative errno code
* is returned on a failure.
*
* After unregistering unregister and down device events are synthesized
* for all devices on the device list to the removed notifier to remove
* the need for special case cleanup code.
*/
int unregister_netdevice_notifier(struct notifier_block *nb)
{
struct net_device *dev;
struct net *net;
int err;
rtnl_lock();
err = raw_notifier_chain_unregister(&netdev_chain, nb);
if (err)
goto unlock;
for_each_net(net) {
for_each_netdev(net, dev) {
if (dev->flags & IFF_UP) {
call_netdevice_notifier(nb, NETDEV_GOING_DOWN, dev);
call_netdevice_notifier(nb, NETDEV_DOWN, dev);
}
call_netdevice_notifier(nb, NETDEV_UNREGISTER, dev);
}
}
unlock:
rtnl_unlock();
return err;
}
10.5.1.3.4 网络设备事件通知函数/call_netdevice_notifiers()
该函数定义于net/core/dev.c:
/**
* call_netdevice_notifiers - call all network notifier blocks
* @val: value passed unmodified to notifier function
* @dev: net_device pointer passed unmodified to notifier function
*
* Call all network notifier blocks. Parameters and return value
* are as for raw_notifier_call_chain().
*/
int call_netdevice_notifiers(unsigned long val, struct net_device *dev)
{
struct netdev_notifier_info info;
return call_netdevice_notifiers_info(val, dev, &info);
}
/**
* call_netdevice_notifiers_info - call all network notifier blocks
* @val: value passed unmodified to notifier function
* @dev: net_device pointer passed unmodified to notifier function
* @info: notifier information data
*
* Call all network notifier blocks. Parameters and return value
* are as for raw_notifier_call_chain().
*/
static int call_netdevice_notifiers_info(unsigned long val,
struct net_device *dev,
struct netdev_notifier_info *info)
{
ASSERT_RTNL();
netdev_notifier_info_init(info, dev); // info->dev = dev
return raw_notifier_call_chain(&netdev_chain, val, info);
}
int raw_notifier_call_chain(struct raw_notifier_head *nh, unsigned long val, void *v)
{
return __raw_notifier_call_chain(nh, val, v, -1, NULL);
}
/**
* __raw_notifier_call_chain - Call functions in a raw notifier chain
* @nh: Pointer to head of the raw notifier chain
* @val: Value passed unmodified to notifier function
* @v: Pointer passed unmodified to notifier function
* @nr_to_call: See comment for notifier_call_chain.
* @nr_calls: See comment for notifier_call_chain
*
* Calls each function in a notifier chain in turn. The functions
* run in an undefined context.
* All locking must be provided by the caller.
*
* If the return value of the notifier can be and'ed
* with %NOTIFY_STOP_MASK then raw_notifier_call_chain()
* will return immediately, with the return value of
* the notifier function which halted execution.
* Otherwise the return value is the return value
* of the last notifier function called.
*/
int __raw_notifier_call_chain(struct raw_notifier_head *nh,
unsigned long val, void *v,
int nr_to_call, int *nr_calls)
{
return notifier_call_chain(&nh->head, val, v, nr_to_call, nr_calls);
}
/**
* notifier_call_chain - Informs the registered notifiers about an event.
* @nl: Pointer to head of the blocking notifier chain
* @val: Value passed unmodified to notifier function
* @v: Pointer passed unmodified to notifier function
* @nr_to_call: Number of notifier functions to be called. Don't care
* value of this parameter is -1.
* @nr_calls: Records the number of notifications sent. Don't care
* value of this field is NULL.
* @returns: notifier_call_chain returns the value returned by the
* last notifier function called.
*/
static int notifier_call_chain(struct notifier_block **nl,
unsigned long val, void *v,
int nr_to_call, int *nr_calls)
{
int ret = NOTIFY_DONE;
struct notifier_block *nb, *next_nb;
nb = rcu_dereference_raw(*nl);
while (nb && nr_to_call) {
next_nb = rcu_dereference_raw(nb->next);
#ifdef CONFIG_DEBUG_NOTIFIERS
if (unlikely(!func_ptr_is_kernel_text(nb->notifier_call))) {
WARN(1, "Invalid notifier called!");
nb = next_nb;
continue;
}
#endif
ret = nb->notifier_call(nb, val, v);
if (nr_calls)
(*nr_calls)++;
if ((ret & NOTIFY_STOP_MASK) == NOTIFY_STOP_MASK)
break;
nb = next_nb;
nr_to_call--;
}
return ret;
}
10.5.1.4 struct sk_buff / struct skb_shared_info
struct sk_buff是Linux网络系统中的核心结构体,Linux网络中的所有数据包的封装以及解封装都是在这个结构体的基础上进行。该结构定义于include/linux/skbuff.h:
/**
* struct sk_buff - socket buffer
* @next: Next buffer in list
* @prev: Previous buffer in list
* ...
*/
struct sk_buff {
union {
struct {
/*
* 通过next和prev将struct sk_buff链接成双向链表,
* 链表头为struct sk_buff_head. 通过如下函数操作该链表:
* skb_queue_head(), skb_queue_tail(), skb_insert(),
* skb_dequeue(), skb_dequeue_tail(), ...
*/
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
union {
ktime_t tstamp;
struct skb_mstamp skb_mstamp;
};
};
struct rb_node rbnode; /* used in netem & tcp stack */
};
/*
* pointer to a sock data structure of the socket that owns this buffer.
* This pointer is needed when data is either locally generated or being
* received by a local process, because the data and socket-related information
* is used by L4 (TCP or UDP) and by the user application. When a buffer is
* merely being forwarded (that is, neither the source nor the destination is
* on the local machine), this pointer is NULL.
*/
struct sock *sk;
/*
* The role of the device represented by dev depends on whether the packet
* stored in the buffer is about to be transmitted or has just been received.
*
* - When a packet is received, the device driver updates this field with the
* pointer to the data structure representing the receiving interface.
*
* - When a packet is to be transmitted, this parameter represents the device
* through which it will be sent out. The code that sets the value is more
* complicated than the code for receiving a packet.
*/
struct net_device *dev;
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*
* In the code for each layer, access is done through macros
* to make the code more readable.
*/
char cb[48] __aligned(8);
unsigned long _skb_refdst;
/*
* This function pointer can be initialized to a routine that performs
* some activity when the buffer is removed. When the buffer does not
* belong to a socket, the destructor is usually not initialized. When
* the buffer belongs to a socket, it is usually set to sock_rfree or
* sock_wfree (by the skb_set_owner_r and skb_set_owner_w initialization
* functions, respectively). The two sock_xxx routines are used to update
* the amount of memory held by the socket in its queues.
*/
void (*destructor)(struct sk_buff *skb);
#ifdef CONFIG_XFRM
struct sec_path *sp;
#endif
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct nf_conntrack *nfct;
#endif
#if IS_ENABLED(CONFIG_BRIDGE_NETFILTER)
struct nf_bridge_info *nf_bridge;
#endif
/*
* len: The total number of bytes in the packet.
* data_len: SKBs are composed of a linear data buffer,
* and optionally a set of one or more page
* buffers. If there are page buffers, the
* total number of bytes in the page buffer
* area is 'data_len'.
*
* The number of bytes in the linear buffer is 'skb->len – skb->data_len'.
* There is a shorthand function for this in 'skb_headlen()'.
*/
unsigned int len, data_len;
/*
* mac_len: Hold the length of the MAC header.
*/
__u16 mac_len, hdr_len;
/* Following fields are _not_ copied in __copy_skb_header()
* Note that queue_mapping is here mostly to fill a hole.
*/
kmemcheck_bitfield_begin(flags1);
__u16 queue_mapping;
__u8 cloned:1,
nohdr:1,
fclone:2,
peeked:1,
head_frag:1,
xmit_more:1;
/* one bit hole */
kmemcheck_bitfield_end(flags1);
/* fields enclosed in headers_start/headers_end are copied
* using a single memcpy() in __copy_skb_header()
*/
/* private: */
__u32 headers_start[0];
/* public: */
/* if you move pkt_type around you also must adapt those constants */
#ifdef __BIG_ENDIAN_BITFIELD
#define PKT_TYPE_MAX (7 << 5)
#else
#define PKT_TYPE_MAX 7
#endif
#define PKT_TYPE_OFFSET() offsetof(struct sk_buff, __pkt_type_offset)
__u8 __pkt_type_offset[0];
// 其取值参见include/uapi/linux/if_packet.h中的PACKET_XXX
__u8 pkt_type:3;
__u8 pfmemalloc:1;
__u8 ignore_df:1;
__u8 nfctinfo:3;
__u8 nf_trace:1;
__u8 ip_summed:2;
__u8 ooo_okay:1;
__u8 l4_hash:1;
__u8 sw_hash:1;
__u8 wifi_acked_valid:1;
__u8 wifi_acked:1;
__u8 no_fcs:1;
/* Indicates the inner headers are valid in the skbuff. */
__u8 encapsulation:1;
__u8 encap_hdr_csum:1;
__u8 csum_valid:1;
__u8 csum_complete_sw:1;
__u8 csum_level:2;
__u8 csum_bad:1;
#ifdef CONFIG_IPV6_NDISC_NODETYPE
__u8 ndisc_nodetype:2;
#endif
__u8 ipvs_property:1;
__u8 inner_protocol_type:1;
__u8 remcsum_offload:1;
/* 3 or 5 bit hole */
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u16 tc_verd; /* traffic control verdict */
#endif
#endif
union {
__wsum csum;
struct {
__u16 csum_start;
__u16 csum_offset;
};
};
__u32 priority;
int skb_iif;
__u32 hash;
__be16 vlan_proto;
__u16 vlan_tci;
#if defined(CONFIG_NET_RX_BUSY_POLL) || defined(CONFIG_XPS)
union {
unsigned int napi_id;
unsigned int sender_cpu;
};
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
union {
__u32 mark;
__u32 reserved_tailroom;
};
union {
__be16 inner_protocol;
__u8 inner_ipproto;
};
__u16 inner_transport_header;
__u16 inner_network_header;
__u16 inner_mac_header;
__be16 protocol;
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
/* private: */
__u32 headers_end[0];
/* public: */
/* These elements must be at the end, see alloc_skb() for details. */
/*
* head: Head of buffer. head和data之间的空间为headroom;
* data: Data head pointer. data和tail之间的空间为user data;
* tail: Data tail pointer. tail和end之间的空间为user data;
* end: 指向struct skb_shared_info结构,可通过skb_shinfo(SKB)访问
*/
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head, *data;
/*
* represent the total size of the buffer, including
* the sk_buff structure itself. It is initially set
* by the function alloc_skb() to len+sizeof(sk_buff)
* when the buffer is allocated for a requested data
* space of len bytes. The field gets updated whenever
* skb->len is increased.
*/
unsigned int truesize;
/*
* the reference count, or the number of entities using
* this sk_buff buffer. The main use of this parameter
* is to avoid freeing the sk_buff structure when someone
* is still using it. For this reason, each user of the
* buffer should increment and decrement this field when
* necessary. This counter covers only the users of the
* sk_buff data structure; the buffer containing the actual
* data is covered by skb_shinfo(skb)->dataref.
*/
atomic_t users;
};
struct skb_shared_info定义于include/linux/skbuff.h:
/*
* This data is invariant across clones and lives at
* the end of the header data, ie. at skb->end.
*/
struct skb_shared_info {
/*
* nr_frags states how many frags there are
* active in the frags[] array.
*/
unsigned char nr_frags;
__u8 tx_flags;
unsigned short gso_size;
/* Warning: this field is not always filled in (UFO)! */
unsigned short gso_segs;
unsigned short gso_type;
/*
* The frag_list is used to maintain a chain of SKBs
* organized for IP fragmentation purposes, it is
* _not_ used for maintaining paged data.
*
* Check ip_push_pending_frames()->ip_finish_skb() for
* populating the frag_list with skbs which queued in
* sk->sk_write_queue and check ip_fragment() for
* processing the frag_list.
*
* 通过如下函数操作frag_list单向链表:
* skb_frag_list_init(): 初始化链表
* skb_has_frag_list() : 是否存在->frag_list链表
* skb_frag_add_head() : 将skb添加到->frag_list链表头部
*
* 通过skb_walk_frags()轮询frag_list单项链表
*/
struct sk_buff *frag_list;
struct skb_shared_hwtstamps hwtstamps;
u32 tskey;
__be32 ip6_frag_id;
/*
* Warning : all fields before dataref are cleared in __alloc_skb()
*/
atomic_t dataref;
/* Intermediate layers must ensure that destructor_arg
* remains valid until skb destructor */
void *destructor_arg;
/* must be last field, see pskb_expand_head() */
/*
* The frags[] holds the frag descriptors themselves.
* See following for type skb_frag_t. A helper routine
* skb_fill_page_desc() is available to help you fill
* in page descriptors.
*/
skb_frag_t frags[MAX_SKB_FRAGS];
};
typedef struct skb_frag_struct skb_frag_t;
struct skb_frag_struct {
struct {
struct page *p;
} page;
#if (BITS_PER_LONG > 32) || (PAGE_SIZE >= 65536)
__u32 page_offset;
__u32 size;
#else
__u16 page_offset;
__u16 size;
#endif
};
10.5.1.4.1 发送网络数据包的流程
发送网络数据包的流程举例如下:
/* (1) 分配skb,并初始化该结构 */
skb = alloc_skb(1500, GFP_ATOMIC);
skb->dev = dev;
/* 例行填充skb元数据 */
/* (2) 保留skb区域 */
skb_reserve(skb, 2 + sizeof(struct ethhdr) +
sizeof(struct iphdr) +
sizeof(struct iphdr) +
sizeof(app_data));
/* (3) 填充应用数据区 */
p = skb_push(skb, sizeof(app_data));
memcpy(p, &app_data[0], sizeof(app_data));
/* (4) 填充传输层头 */
p = skb_push(skb, sizeof(struct udphdr));
udphdr = (struct udphdr *)p;
/* 在udphdr中填充udphdr字段,略 */
skb_reset_transport_header(skb);
/* (5) 填充IP头 */
p = skb_push(skb, sizeof(struct iphdr));
iphdr = (struct iphdr*)p;
/* 在iphdr中填充iphdr字段,略 */
skb_reset_network_header(skb);
/* (6) 填充以太网头 */
p = skb_push(skb, sizeof(struct ethhdr));
ethhdr = (struct ethhdr*)p;
/* 在ethhdr中填充ethhdr字段,略 */
skb_reset_mac_header(skb);
/* (7) 发射 */
dev_queue_xmit(skb);
10.5.1.4.2 操作skb链表
struct sk_buff通过元素prev/next链接成以struct sk_buff_head为链表头的双向链表中,其结构参见:

下列函数用于操作skb链表struct sk_buff_head:
// Create a split out lock class for each invocation.
static inline void skb_queue_head_init(struct sk_buff_head *list);
static inline void skb_queue_head_init_class(struct sk_buff_head *list, struct lock_class_key *class);
// Check if a queue is empty.
static inline int skb_queue_empty(const struct sk_buff_head *list);
// Get queue length.
static inline __u32 skb_queue_len(const struct sk_buff_head *list_);
// Check if skb is the first entry in the queue.
static inline bool skb_queue_is_first(const struct sk_buff_head *list, const struct sk_buff *skb);
// Check if skb is the last entry in the queue.
static bool skb_queue_is_last(const struct sk_buff_head *list, const struct sk_buff *skb);
// Return the prev packet in the queue.
// It is only valid to call this if skb_queue_is_first() evaluates to false.
static inline struct sk_buff *skb_queue_prev(const struct sk_buff_head *list, const struct sk_buff *skb);
// Return the next packet in the queue.
// It is only valid to call this if skb_queue_is_last() evaluates to false.
static inline struct sk_buff *skb_queue_next(const struct sk_buff_head *list, const struct sk_buff *skb);
// Queue a buffer at the list head.
void skb_queue_head(struct sk_buff_head *list, struct sk_buff *newsk);
// Queue a buffer at the list tail.
void skb_queue_tail(struct sk_buff_head *list, struct sk_buff *newsk);
// Insert a packet before a given packet in a list.
void skb_insert(struct sk_buff *old, struct sk_buff *newsk, struct sk_buff_head *list);
// Append a packet after a given packet in a list.
void skb_append(struct sk_buff *old, struct sk_buff *newsk, struct sk_buff_head *list);
// Remove a buffer from a list.
void skb_unlink(struct sk_buff *skb, struct sk_buff_head *list);
// Remove from the head of the queue.
struct sk_buff *skb_dequeue(struct sk_buff_head *list);
// Remove from the tail of the queue.
struct sk_buff *skb_dequeue_tail(struct sk_buff_head *list);
// Empty a list.
void skb_queue_purge(struct sk_buff_head *list);
10.5.1.4.3 分配skb/__alloc_skb()
该函数定义于net/core/dev.c:
/**
* __alloc_skb - allocate a network buffer
* @size: size to allocate
* @gfp_mask: allocation mask
* @flags: If SKB_ALLOC_FCLONE is set, allocate from fclone cache
* instead of head cache and allocate a cloned (child) skb.
* If SKB_ALLOC_RX is set, __GFP_MEMALLOC will be used for
* allocations in case the data is required for writeback
* @node: numa node to allocate memory on
*
* Allocate a new &sk_buff. The returned buffer has no headroom and a
* tail room of at least size bytes. The object has a reference count
* of one. The return is the buffer. On a failure the return is %NULL.
*
* Buffers may only be allocated from interrupts using a @gfp_mask of
* %GFP_ATOMIC.
*/
struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask, int flags, int node)
{
struct kmem_cache *cache;
struct skb_shared_info *shinfo;
struct sk_buff *skb;
u8 *data;
bool pfmemalloc;
/*
* (1) 从缓冲区skbuff_head_cache或skbuff_fclone_cache中分配skb
*
* 若设置了SKB_ALLOC_FCLONE,则从缓冲区skbuff_head_cache中分配skb,
* 分配的空间是struct sk_buff; 否则,从缓冲区skbuff_fclone_cache中
* 分配skb,分配的空间是struct sk_buff_fclones;
* 缓冲区skbuff_head_cache和skbuff_fclone_cache是由如下函数创建的:
* core_initcall(sock_init) in net/socket.c->sock_init()->skb_init()
* 参见[10.5.2.1 应用层(L4)的初始化/sock_init()]节
*/
cache = (flags & SKB_ALLOC_FCLONE) ? skbuff_fclone_cache : skbuff_head_cache;
if (sk_memalloc_socks() && (flags & SKB_ALLOC_RX))
gfp_mask |= __GFP_MEMALLOC;
/* Get the HEAD */
skb = kmem_cache_alloc_node(cache, gfp_mask & ~__GFP_DMA, node);
if (!skb)
goto out;
prefetchw(skb);
/*
* (2) 分配数据区: 其后紧跟struct skb_shared_info区
*/
/*
* We do our best to align skb_shared_info on a separate cache
* line. It usually works because kmalloc(X > SMP_CACHE_BYTES) gives
* aligned memory blocks, unless SLUB/SLAB debug is enabled.
* Both skb->head and skb_shared_info are cache line aligned.
*/
size = SKB_DATA_ALIGN(size);
size += SKB_DATA_ALIGN(sizeof(struct skb_shared_info));
data = kmalloc_reserve(size, gfp_mask, node, &pfmemalloc);
if (!data)
goto nodata;
/*
* kmalloc(size) might give us more room than requested.
* Put skb_shared_info exactly at the end of allocated zone,
* to allow max possible filling before reallocation.
*/
size = SKB_WITH_OVERHEAD(ksize(data));
prefetchw(data + size);
/*
* Only clear those fields we need to clear, not those that we will
* actually initialise below. Hence, don't put any more fields after
* the tail pointer in struct sk_buff!
*/
memset(skb, 0, offsetof(struct sk_buff, tail));
/* Account for allocated memory : skb + skb->head */
skb->truesize = SKB_TRUESIZE(size);
skb->pfmemalloc = pfmemalloc;
atomic_set(&skb->users, 1);
skb->head = data;
skb->data = data;
// skb->tail = skb->data - skb->head;
skb_reset_tail_pointer(skb);
skb->end = skb->tail + size;
skb->mac_header = (typeof(skb->mac_header))~0U;
skb->transport_header = (typeof(skb->transport_header))~0U;
/* make sure we initialize shinfo sequentially */
shinfo = skb_shinfo(skb);
memset(shinfo, 0, offsetof(struct skb_shared_info, dataref));
atomic_set(&shinfo->dataref, 1);
kmemcheck_annotate_variable(shinfo->destructor_arg);
/*
* 若从缓冲区skbuff_fclone_cache中分配skb,
* 分配的空间是struct sk_buff_fclones,则返回其中的skb1
*/
if (flags & SKB_ALLOC_FCLONE) {
struct sk_buff_fclones *fclones;
fclones = container_of(skb, struct sk_buff_fclones, skb1);
kmemcheck_annotate_bitfield(&fclones->skb2, flags1);
skb->fclone = SKB_FCLONE_ORIG;
atomic_set(&fclones->fclone_ref, 1);
fclones->skb2.fclone = SKB_FCLONE_CLONE;
fclones->skb2.pfmemalloc = pfmemalloc;
}
out:
return skb;
nodata:
kmem_cache_free(cache, skb);
skb = NULL;
goto out;
}
函数__alloc_skb()是最基础的分配skb的函数,内核代码中还有如下包装函数:
alloc_skb() // 从缓冲区skbuff_head_cache中分配skb,分配的空间是struct sk_buff
-> __alloc_skb(size, priority, 0, NUMA_NO_NODE)
alloc_skb_fclone() // 从缓冲区skbuff_fclone_cache中分配skb,分配的空间是struct sk_buff_fclones
-> __alloc_skb(size, priority, SKB_ALLOC_FCLONE, NUMA_NO_NODE)
dev_alloc_skb()
-> netdev_alloc_skb(NULL, length)
-> __netdev_alloc_skb(dev, length, GFP_ATOMIC)
__dev_alloc_skb()
-> __netdev_alloc_skb(NULL, length, gfp_mask)
sock_alloc_send_pskb()
sock_alloc_send_skb()
-> sock_alloc_send_pskb(sk, size, 0, noblock, errcode, 0)
sk_stream_alloc_skb()
sock_wmalloc()
__alloc_rx_skb()
-> __alloc_skb(length, gfp_mask, SKB_ALLOC_RX, NUMA_NO_NODE)
skb_copy()
-> __alloc_skb(size, gfp_mask, skb_alloc_rx_flag(skb), NUMA_NO_NODE)
skb_copy_expand()
-> __alloc_skb(newheadroom + skb->len + newtailroom, gfp_mask, skb_alloc_rx_flag(skb), NUMA_NO_NODE)
__pskb_copy_fclone()
-> __alloc_skb(size, gfp_mask, flags, NUMA_NO_NODE)
skb_segment()
-> __alloc_skb(hsize + doffset + headroom, GFP_ATOMIC, skb_alloc_rx_flag(head_skb), NUMA_NO_NODE)
10.5.1.4.4 注销skb/kfree_skb()
该函数定义于net/core/dev.c:
/**
* kfree_skb - free an sk_buff
* @skb: buffer to free
*
* Drop a reference to the buffer and free it if the usage count has
* hit zero.
*/
void kfree_skb(struct sk_buff *skb)
{
if (unlikely(!skb))
return;
if (likely(atomic_read(&skb->users) == 1))
smp_rmb();
else if (likely(!atomic_dec_and_test(&skb->users)))
return;
trace_kfree_skb(skb, __builtin_return_address(0));
__kfree_skb(skb);
}
/**
* __kfree_skb - private function
* @skb: buffer
*
* Free an sk_buff. Release anything attached to the buffer.
* Clean the state. This is an internal helper function. Users should
* always call kfree_skb
*/
void __kfree_skb(struct sk_buff *skb)
{
skb_release_all(skb);
kfree_skbmem(skb);
}
/* Free everything but the sk_buff shell. */
static void skb_release_all(struct sk_buff *skb)
{
skb_release_head_state(skb);
if (likely(skb->head))
skb_release_data(skb);
}
/*
* Free an skbuff by memory without cleaning the state.
*/
static void kfree_skbmem(struct sk_buff *skb)
{
struct sk_buff_fclones *fclones;
switch (skb->fclone) {
case SKB_FCLONE_UNAVAILABLE:
kmem_cache_free(skbuff_head_cache, skb);
return;
case SKB_FCLONE_ORIG:
fclones = container_of(skb, struct sk_buff_fclones, skb1);
/* We usually free the clone (TX completion) before original skb
* This test would have no chance to be true for the clone,
* while here, branch prediction will be good.
*/
if (atomic_read(&fclones->fclone_ref) == 1)
goto fastpath;
break;
default: /* SKB_FCLONE_CLONE */
fclones = container_of(skb, struct sk_buff_fclones, skb2);
break;
}
if (!atomic_dec_and_test(&fclones->fclone_ref))
return;
fastpath:
kmem_cache_free(skbuff_fclone_cache, fclones);
}
10.5.1.4.5 操作skb
下列函数用于获取skb的某些信息:
// Check if the skb is nonlinear, that's the value of skb->data_len;
static inline bool skb_is_nonlinear(const struct sk_buff *skb);
// Return the number of bytes of free space at the head of an &sk_buff.
static inline unsigned int skb_headroom(const struct sk_buff *skb);
// Return the number of bytes of free space at the tail of an sk_buff.
static inline int skb_tailroom(const struct sk_buff *skb);
// Is the buffer a clone.
// Returns true if the buffer was generated with skb_clone() and
// is one of multiple shared copies of the buffer.
static inline int skb_cloned(const struct sk_buff *skb);
// The number of bytes in the linear buffer of the skb.
static inline unsigned int skb_headlen(const struct sk_buff *skb);
下列函数用于操作skb:
// Increase the headroom of an empty &sk_buff by reducing the tail room.
// This is only allowed for an empty buffer.
static inline void skb_reserve(struct sk_buff *skb, int len);
// Add data to the start of a buffer;
// If this would exceed the total buffer headroom the kernel will panic.
unsigned char *skb_push(struct sk_buff *skb, unsigned int len);
// Remove data from the start of a buffer.
unsigned char *skb_pull(struct sk_buff *skb, unsigned int len);
// Add data to a buffer.
// If this would exceed the total buffer size the kernel will panic.
unsigned char *skb_put(struct sk_buff *skb, unsigned int len);
// Remove end from a buffer.
// Cut the length of a buffer down by removing data from the tail. The skb must be linear.
void skb_trim(struct sk_buff *skb, unsigned int len);
// Create private copy of an sk_buff.
struct sk_buff *skb_copy(const struct sk_buff *skb, gfp_t gfp_mask);
// Duplicate an sk_buff.
// The new one is not owned by a socket. Both copies share the same packet data but not structure.
struct sk_buff *skb_clone(struct sk_buff *skb, gfp_t gfp_mask);
// Convert paged skb to linear one.
static inline int skb_linearize(struct sk_buff *skb);
// Copy data out from a packet (non-paged buffer only) into another buffer.
static inline void * __must_check
skb_header_pointer(const struct sk_buff *skb, int offset, int len, void *buffer);
// copy the specified number of bytes from the source skb (non-paged buffer and/or paged buffer)
// to the destination buffer.
int skb_copy_bits(const struct sk_buff *skb, int offset, void *to, int len);
10.5.2 网络设备的初始化
Linux内核中网络协议栈的初始化包括:
- 应用层(L4)的初始化:
sock_init() - 传输层(L3)的初始化:
proto_init() - 网络互连层(L2)的初始化:
inet_init()for IPv4,inet6_init()for IPv6 - 网络接口层(L1)的初始化:
e100_init_module(),net_dev_init()
10.5.2.1 应用层(L4)的初始化/sock_init()
该函数定义于net/socket.c:
static struct file_system_type sock_fs_type = {
.name = "sockfs",
.mount = sockfs_mount,
.kill_sb = kill_anon_super,
};
static int __init sock_init(void)
{
int err;
/*
* Initialize sock SLAB cache.
*/
sk_init();
/*
* Initialize skbuff SLAB cache
*/
skb_init();
/*
* Initialize the protocols module.
*/
init_inodecache();
// 注册sockfs文件系统,参见[11.2.2.1 注册/注销文件系统]节
err = register_filesystem(&sock_fs_type);
if (err)
goto out_fs;
// 挂载sockfs文件系统,参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
sock_mnt = kern_mount(&sock_fs_type);
if (IS_ERR(sock_mnt)) {
err = PTR_ERR(sock_mnt);
goto out_mount;
}
/*
* The real protocol initialization is performed in later initcalls.
*/
#ifdef CONFIG_NETFILTER
netfilter_init();
#endif
#ifdef CONFIG_NETWORK_PHY_TIMESTAMPING
skb_timestamping_init();
#endif
out:
return err;
out_mount:
unregister_filesystem(&sock_fs_type);
out_fs:
goto out;
}
core_initcall(sock_init);
其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall1.init
10.5.2.2 传输层(L3)的初始化/proto_init()
该函数定义于net/socket.c:
static __net_initdata struct pernet_operations proto_net_ops = {
.init = proto_init_net,
.exit = proto_exit_net,
};
static int __init proto_init(void)
{
return register_pernet_subsys(&proto_net_ops);
}
subsys_initcall(proto_init);
其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall4.init
10.5.2.3 网络互连层(L2)的初始化
10.5.2.3.1 inet_init()
该函数定义于net/ipv4/af_inet.c:
static int __init inet_init(void)
{
struct sk_buff *dummy_skb;
struct inet_protosw *q;
struct list_head *r;
int rc = -EINVAL;
BUILD_BUG_ON(sizeof(struct inet_skb_parm) > sizeof(dummy_skb->cb));
sysctl_local_reserved_ports = kzalloc(65536 / 8, GFP_KERNEL);
if (!sysctl_local_reserved_ports)
goto out;
// 将元素tcp_prot->node添加到链表proto_list中
rc = proto_register(&tcp_prot, 1);
if (rc)
goto out_free_reserved_ports;
// 将元素udp_prot->node添加到链表proto_list中
rc = proto_register(&udp_prot, 1);
if (rc)
goto out_unregister_tcp_proto;
// 将元素raw_prot->node添加到链表proto_list中
rc = proto_register(&raw_prot, 1);
if (rc)
goto out_unregister_udp_proto;
// 将元素ping_prot->node添加到链表proto_list中
rc = proto_register(&ping_prot, 1);
if (rc)
goto out_unregister_raw_proto;
/*
* Tell SOCKET that we are alive...
*/
/*
* 将inet_family_ops注册到数组net_families[]中,即:
* net_families[inet_family_ops->family] = &inet_family_ops;
*/
(void)sock_register(&inet_family_ops);
#ifdef CONFIG_SYSCTL
ip_static_sysctl_init();
#endif
/*
* Add all the base protocols.
*/
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
printk(KERN_CRIT "inet_init: Cannot add ICMP protocol\n");
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
printk(KERN_CRIT "inet_init: Cannot add UDP protocol\n");
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
printk(KERN_CRIT "inet_init: Cannot add TCP protocol\n");
#ifdef CONFIG_IP_MULTICAST
if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0)
printk(KERN_CRIT "inet_init: Cannot add IGMP protocol\n");
#endif
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
/*
* Set the ARP module up
*/
arp_init();
/*
* Set the IP module up
*/
ip_init();
tcp_v4_init();
/* Setup TCP slab cache for open requests. */
tcp_init();
/* Setup UDP memory threshold */
udp_init();
/* Add UDP-Lite (RFC 3828) */
udplite4_register();
ping_init();
/*
* Set the ICMP layer up
*/
if (icmp_init() < 0)
panic("Failed to create the ICMP control socket.\n");
/*
* Initialise the multicast router
*/
#if defined(CONFIG_IP_MROUTE)
if (ip_mr_init())
printk(KERN_CRIT "inet_init: Cannot init ipv4 mroute\n");
#endif
/*
* Initialise per-cpu ipv4 mibs
*/
if (init_ipv4_mibs())
printk(KERN_CRIT "inet_init: Cannot init ipv4 mibs\n");
ipv4_proc_init();
ipfrag_init();
dev_add_pack(&ip_packet_type);
rc = 0;
out:
return rc;
out_unregister_raw_proto:
proto_unregister(&raw_prot);
out_unregister_udp_proto:
proto_unregister(&udp_prot);
out_unregister_tcp_proto:
proto_unregister(&tcp_prot);
out_free_reserved_ports:
kfree(sysctl_local_reserved_ports);
goto out;
}
fs_initcall(inet_init);
其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall5.init
10.5.2.3.2 inet6_init()
该函数定义于net/ipv6/af_inet6.c:
static int __init inet6_init(void)
{
struct sk_buff *dummy_skb;
struct list_head *r;
int err = 0;
BUILD_BUG_ON(sizeof(struct inet6_skb_parm) > sizeof(dummy_skb->cb));
/* Register the socket-side information for inet6_create. */
for(r = &inetsw6[0]; r < &inetsw6[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
if (disable_ipv6_mod) {
printk(KERN_INFO
"IPv6: Loaded, but administratively disabled, "
"reboot required to enable\n");
goto out;
}
err = proto_register(&tcpv6_prot, 1);
if (err)
goto out;
err = proto_register(&udpv6_prot, 1);
if (err)
goto out_unregister_tcp_proto;
err = proto_register(&udplitev6_prot, 1);
if (err)
goto out_unregister_udp_proto;
err = proto_register(&rawv6_prot, 1);
if (err)
goto out_unregister_udplite_proto;
/* We MUST register RAW sockets before we create the ICMP6,
* IGMP6, or NDISC control sockets.
*/
err = rawv6_init();
if (err)
goto out_unregister_raw_proto;
/* Register the family here so that the init calls below will
* be able to create sockets. (?? is this dangerous ??)
*/
err = sock_register(&inet6_family_ops);
if (err)
goto out_sock_register_fail;
#ifdef CONFIG_SYSCTL
err = ipv6_static_sysctl_register();
if (err)
goto static_sysctl_fail;
#endif
/*
* ipngwg API draft makes clear that the correct semantics
* for TCP and UDP is to consider one TCP and UDP instance
* in a host available by both INET and INET6 APIs and
* able to communicate via both network protocols.
*/
err = register_pernet_subsys(&inet6_net_ops);
if (err)
goto register_pernet_fail;
err = icmpv6_init();
if (err)
goto icmp_fail;
err = ip6_mr_init();
if (err)
goto ipmr_fail;
err = ndisc_init();
if (err)
goto ndisc_fail;
err = igmp6_init();
if (err)
goto igmp_fail;
err = ipv6_netfilter_init();
if (err)
goto netfilter_fail;
/* Create /proc/foo6 entries. */
#ifdef CONFIG_PROC_FS
err = -ENOMEM;
if (raw6_proc_init())
goto proc_raw6_fail;
if (udplite6_proc_init())
goto proc_udplite6_fail;
if (ipv6_misc_proc_init())
goto proc_misc6_fail;
if (if6_proc_init())
goto proc_if6_fail;
#endif
err = ip6_route_init();
if (err)
goto ip6_route_fail;
err = ip6_flowlabel_init();
if (err)
goto ip6_flowlabel_fail;
err = addrconf_init();
if (err)
goto addrconf_fail;
/* Init v6 extension headers. */
err = ipv6_exthdrs_init();
if (err)
goto ipv6_exthdrs_fail;
err = ipv6_frag_init();
if (err)
goto ipv6_frag_fail;
/* Init v6 transport protocols. */
err = udpv6_init();
if (err)
goto udpv6_fail;
err = udplitev6_init();
if (err)
goto udplitev6_fail;
err = tcpv6_init();
if (err)
goto tcpv6_fail;
err = ipv6_packet_init();
if (err)
goto ipv6_packet_fail;
#ifdef CONFIG_SYSCTL
err = ipv6_sysctl_register();
if (err)
goto sysctl_fail;
#endif
out:
return err;
#ifdef CONFIG_SYSCTL
sysctl_fail:
ipv6_packet_cleanup();
#endif
ipv6_packet_fail:
tcpv6_exit();
tcpv6_fail:
udplitev6_exit();
udplitev6_fail:
udpv6_exit();
udpv6_fail:
ipv6_frag_exit();
ipv6_frag_fail:
ipv6_exthdrs_exit();
ipv6_exthdrs_fail:
addrconf_cleanup();
addrconf_fail:
ip6_flowlabel_cleanup();
ip6_flowlabel_fail:
ip6_route_cleanup();
ip6_route_fail:
#ifdef CONFIG_PROC_FS
if6_proc_exit();
proc_if6_fail:
ipv6_misc_proc_exit();
proc_misc6_fail:
udplite6_proc_exit();
proc_udplite6_fail:
raw6_proc_exit();
proc_raw6_fail:
#endif
ipv6_netfilter_fini();
netfilter_fail:
igmp6_cleanup();
igmp_fail:
ndisc_cleanup();
ndisc_fail:
ip6_mr_cleanup();
ipmr_fail:
icmpv6_cleanup();
icmp_fail:
unregister_pernet_subsys(&inet6_net_ops);
register_pernet_fail:
#ifdef CONFIG_SYSCTL
ipv6_static_sysctl_unregister();
static_sysctl_fail:
#endif
sock_unregister(PF_INET6);
rtnl_unregister_all(PF_INET6);
out_sock_register_fail:
rawv6_exit();
out_unregister_raw_proto:
proto_unregister(&rawv6_prot);
out_unregister_udplite_proto:
proto_unregister(&udplitev6_prot);
out_unregister_udp_proto:
proto_unregister(&udpv6_prot);
out_unregister_tcp_proto:
proto_unregister(&tcpv6_prot);
goto out;
}
module_init(inet6_init);
其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
10.5.2.4 网络接口层(L1)的初始化/net_dev_init()
该函数定义于net/core/dev.c:
/*
* Initialize the DEV module. At boot time this walks the device list and
* unhooks any devices that fail to initialise (normally hardware not
* present) and leaves us with a valid list of present and active devices.
*/
/*
* This is called single threaded during boot, so no need to take the rtnl semaphore.
*/
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
BUG_ON(!dev_boot_phase);
if (dev_proc_init())
goto out;
if (netdev_kobject_init())
goto out;
INIT_LIST_HEAD(&ptype_all);
for (i = 0; i < PTYPE_HASH_SIZE; i++)
INIT_LIST_HEAD(&ptype_base[i]);
if (register_pernet_subsys(&netdev_net_ops))
goto out;
/*
* Initialise the packet receive queues.
*/
for_each_possible_cpu(i) {
struct softnet_data *sd = &per_cpu(softnet_data, i);
memset(sd, 0, sizeof(*sd));
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
sd->completion_queue = NULL;
INIT_LIST_HEAD(&sd->poll_list);
sd->output_queue = NULL;
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->csd.flags = 0;
sd->cpu = i;
#endif
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
sd->backlog.gro_list = NULL;
sd->backlog.gro_count = 0;
}
dev_boot_phase = 0;
/* The loopback device is special if any other network devices
* is present in a network namespace the loopback device must
* be present. Since we now dynamically allocate and free the
* loopback device ensure this invariant is maintained by
* keeping the loopback device as the first device on the
* list of network devices. Ensuring the loopback devices
* is the first device that appears and the last network device
* that disappears.
*/
if (register_pernet_device(&loopback_net_ops))
goto out;
if (register_pernet_device(&default_device_ops))
goto out;
/*
* 分别设置如下软中断的服务服务程序,参见[9.2.2 struct softirq_action / softirq_vec[]]节:
* - NET_TX_SOFTIRQ的服务程序为net_tx_action()
* - NET_RX_SOFTIRQ的服务程序为net_rx_action()
* 该服务程序被__do_softirq()调用,参见[9.3.1.3.1.1.1 __do_softirq()]节
*/
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
hotcpu_notifier(dev_cpu_callback, 0);
dst_init();
dev_mcast_init();
rc = 0;
out:
return rc;
}
subsys_initcall(net_dev_init);
其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall4.init
10.5.3 发送/接收数据包
10.5.3.1 发送数据包
dev_queue_xmit(skb)
-> dev_queue_xmit_sk(skb->sk, skb)
-> __dev_queue_xmit(skb, NULL)
-> __dev_xmit_skb(skb, q, dev, txq)
-> sch_direct_xmit()
-> dev_hard_start_xmit(skb, dev, txq, &ret)
-> xmit_one(skb, dev, txq, next != NULL)
-> netdev_start_xmit()
-> __netdev_start_xmit(ops, skb, dev, more)
-> dev->netdev_ops->ndo_start_xmit(skb, dev)
-> dev_xmit_complete()
10.5.3.2 接收数据包
网卡驱动
-> netif_receive_skb()
-> netif_receive_skb_sk(skb->sk, skb)
-> netif_receive_skb_internal(skb)
-> __netif_receive_skb(skb)
-> __netif_receive_skb_core(skb, ..)
-> deliver_skb()
-> packet_type.func()
10.6 Peripheral Component Interconnect (PCI)
PCI (Peripheral Component Interconnect)驱动程序实现于drivers/pci/pci.c,声明于include/linux/pci.h。
PCI (Peripheral Component Interconnect)是一种连接电脑主板和外部设备的总线标准。一般PCI设备可分为两种形式:
- 1) 直接布放在主板上的集成电路上,在PCI规范中称作”平面设备”(planar device);
- 2) 安装在插槽上的扩展卡。
PCI Standards:
11 文件系统/Filesystem
11.1 文件系统简介
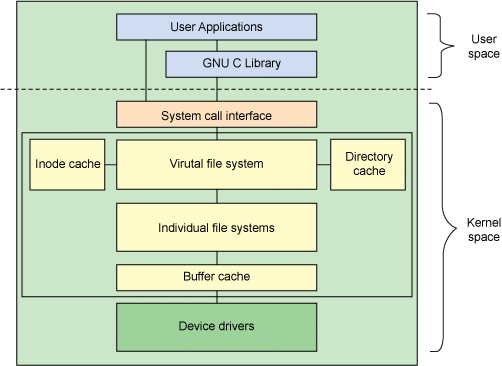
虚拟文件系统又称虚拟文件系统转换(Virual Filesystem Switch, VFS)。说它虚拟,是因为它所有的数据结构都是在系统运行以后才建立,并在卸载时删除,而在磁盘上并没有存储这些数据结构。显然,如果只有VFS系统是无法工作的,因为它的这些数据结构不能凭空而来,只有与实际的文件系统,如Ext2、Minix、MSDOS、VFAT等相结合,才能开始工作,所以VFS并不是一个真正的文件系统。与VFS相对的Ext2、Minix、MSDOS等为具体文件系统(Individual file systems)。
VFS是内核的一个子系统,其它子系统只与VFS打交道,而并不与具体文件系统发生联系。对具体文件系统来说,VFS是一个管理者,而对内核的其它子系统来说,VFS是它们与具体文件系统的一个接口。Its main strength is providing a common interface to several kinds of filesystems.
VFS提供一个统一的接口(即file_operatoin结构,参见11.2.1.5.1 文件操作/struct file_operations节),一个具体文件系统要想被Linux支持,就必须按照这个接口编写自己的操作函数,而将自己的细节对内核其它子系统隐藏起来。因而,对内核其它子系统以及运行在操作系统之上的用户程序而言,所有的文件系统都是一样的。实际上,要支持一个新的文件系统,主要任务就是编写这些接口函数。
概括来说,VFS主要有以下几个作用:
- 对具体文件系统的数据结构进行抽象,以一种统一的数据结构进行管理。
- 接受用户层的系统调用,如open、write、stat、link等。
- 支持多种具体文件系统之间相互访问。
- 接受内核其他子系统的操作请求,特别是内存管理子系统。
11.1.1 Filesystem Hierarchy Standard (FHS)
参见如下网站:
- Filesystem Hierarchy Standard (Specifications Archive)
- Filesystem Hierarchy Standard
- Wikipedia: Filesystem Hierarchy Standard
File System Hierarchy (FHS) releases:
| Version | Release Date | Notes |
| v1.0 | 1994-02-14 | FSSTND (File System STaNDard) |
| v1.1 | 1994-10-09 | FSSTND (File System STaNDard) |
| v1.2 | 1995-03-28 | FSSTND (File System STaNDard) |
| v2.0 | 1997-10-26 | FHS 2.0 is the direct successor for FSSTND 1.2. Name of the standard was changed to Filesystem Hierarchy Standard. |
| v2.1 | 2000-04-12 | FHS (Filesystem Hierarchy Standard) |
| v2.2 | 2001-05-23 | FHS (Filesystem Hierarchy Standard) |
| v2.3 | 2004-01-29 | FHS (Filesystem Hierarchy Standard) |
| v3.0 | 2015-06-03 | FHS (Filesystem Hierarchy Standard) |
Run following commands to check man page of file system hierarchy (FHS):
$ man hier
11.1.2 Materials related to File System
11.2 虚拟文件系统(VFS)
11.2.1 虚拟文件系统(VFS)相关数据结构
VFS数据结构之间的关系,参见:
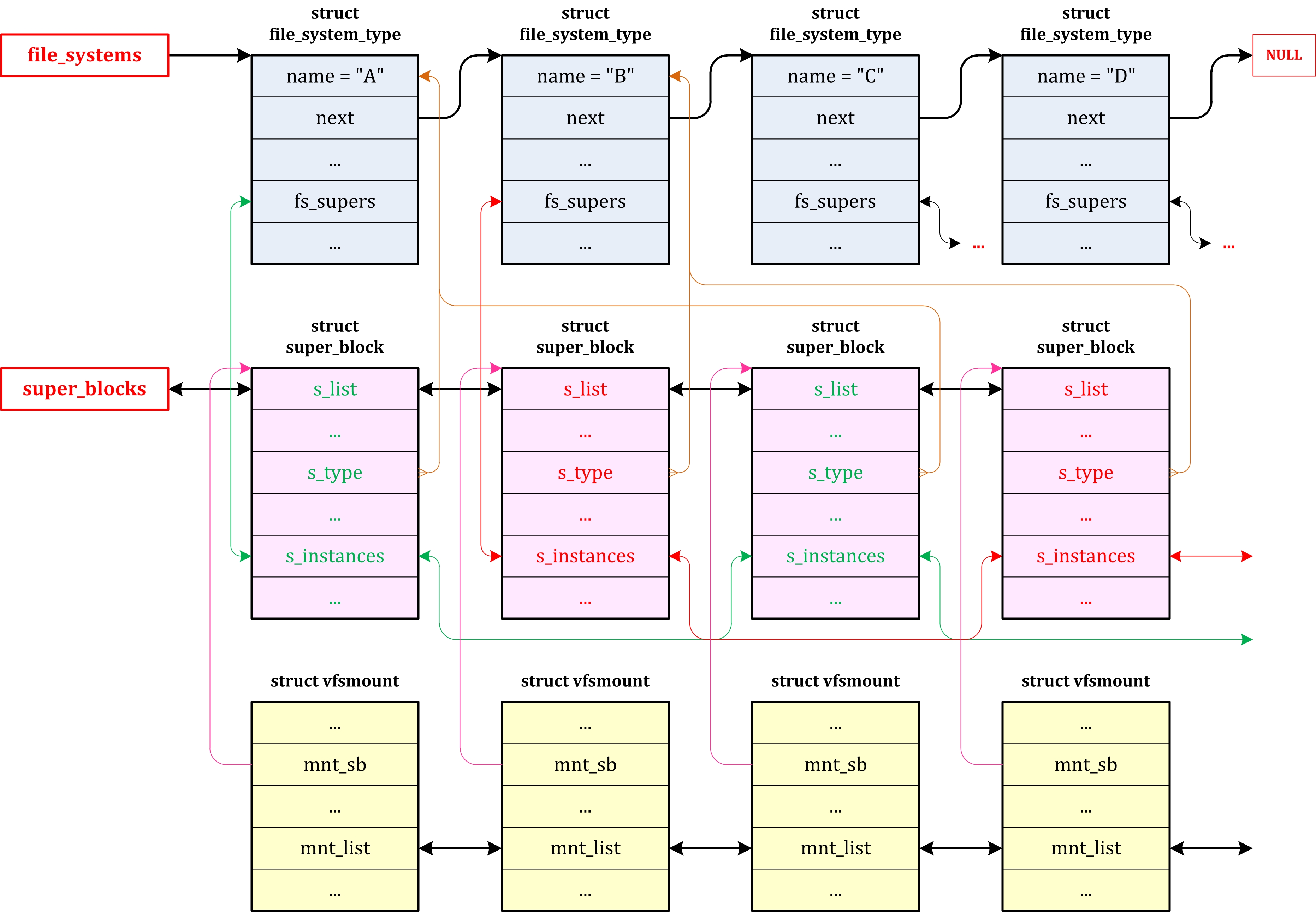
11.2.1.1 文件系统类型/struct file_system_type
该结构定义于include/linux/fs.h:
struct file_system_type {
// 文件系统的名字
const char *name;
// 标志位,参见下文
int fs_flags;
/*
* Read the superblock off the disk. 该函数的调用关系如下:
* do_kern_mount() / kern_mount_data() // 参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
* -> vfs_kern_mount(type, ..) // 参见[11.2.2.2.1 vfs_kern_mount()]节
* -> mount_fs(type, ..) // 参见[11.2.2.2.1.2 mount_fs()]节
* -> type->mount()
*/
struct dentry *(*mount) (struct file_system_type *, int, const char *, void *);
/*
* Terminate access to the superblock. 该函数的调用关系如下:
* sys_umount() // 参见[11.2.2.5 卸载文件系统(2)/sys_oldumount()/sys_umount()]节
* -> mntput_no_expire()
* -> mntfree()
* -> deactivate_super()
* -> deactivate_locked_super()
* -> fs->kill_sb()
*/
void (*kill_sb) (struct super_block *);
/*
* Pointer to the module implementing the filesystem.
* 若该文件系统被编译进内核,则该字段为NULL,参见[13.4.1 与模块有关的结构体]节
*/
struct module *owner;
// 将系统支持的所有文件系统形成一个单链表file_systems
struct file_system_type *next;
/*
* Head of a list of superblock objects having the same filesystem type.
* 该链表是由sget()函数链接起来的,参见[11.2.2.1 注册/注销文件系统]节。
* NOTE: 在kernel v3.3中,变量fs_supers的类型改为struct hlist_head,
* 参见[15.2 哈希链表/struct hlist_head/struct hlist_node]节
*/
struct list_head fs_supers;
/*
* The remaining fields are used for runtime lock validation.
*/
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key s_vfs_rename_key;
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
};
其中,标志位fs_flags的取值如下:
/* public flags for file_system_type */
#define FS_REQUIRES_DEV 1 /* 任何文件系统必须位于物理磁盘设备上 */
#define FS_BINARY_MOUNTDATA 2 /* 文件系统使用二进制安装数据 */
#define FS_HAS_SUBTYPE 4 /* 参见[11.2.2.4.1.2.1.1 get_fs_type()]节 */
#define FS_REVAL_DOT 16384 /* Check the paths ".", ".." for staleness */
#define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */
NOTE: There is only one file_system_type per filesystem, regardless of how many instances of the filesystem are mounted on the system, or whether the filesystem is even mounted at all.
11.2.1.1.1 文件系统链表/file_systems
系统中存在一个struct file_system_type类型的全局变量file_systems,其定义于fs/filesystem.c:
static struct file_system_type *file_systems;
static DEFINE_RWLOCK(file_systems_lock);
file_systems单链表,参见:
11.2.1.1.1.1 如何向file_systems注册文件系统及其先后顺序
通过函数register_filesystem()/unregister_filesystem()向单链表file_systems中注册/注销指定的文件系统,参见11.2.2.1 注册/注销文件系统节。其调用关系如下:
<source-code-of-specific-filesystem>
-> fs_install(<fs-init-func>), or // pipefs等
fs_install_sync(<fs-init-func>), or
rootfs_initcall(<fs-init-func>), or // initramfs等,参见[11.3.3.2 Initramfs编译与初始化]节
module_init(<fs-init-func>), or // ext2, ext3, ext4, efs, fat等
<fs-init-func> is called during system init // sysfs, ramfs等
-> <fs-init-func>
-> register_filesystem(<fs-object-ptr>) // 参见[11.2.2.1 注册/注销文件系统]节
-> <fs-object-ptr> is appended into list file_systems
在单链表file_systems中注册的文件系统参见11.2.1.1.2 查看系统中注册的文件系统节,其先后顺序是如何确定的呢?由13.5.1.1.1.1.1 .initcall*.init节可知,宏fs_install(), fs_install_sync(), rootfs_initcall()和module_init()分别被扩展为__early_initcall_end和__initcall_end之间的*(.initcall5.init) *(.initcall5s.init) *(.initcallrootfs.init) *(.initcall6.init),如下所示(另参见13.5.1.1.1.1 __initcall_start[]/__early_initcall_end[]/__initcall_end[]节):
.init.data : AT(ADDR(.init.data) - 0xC0000000) { *(.init.data) *(.cpuinit.data) *(.meminit.data) . = ALIGN(8); __ctors_start = .; *(.ctors) __ctors_end = .; *(.init.rodata) . = ALIGN(8); __start_ftrace_events = .; *(_ftrace_events) __stop_ftrace_events = .; *(.cpuinit.rodata) *(.meminit.rodata) . = ALIGN(32); __dtb_start = .; *(.dtb.init.rodata) __dtb_end = .; . = ALIGN(16); __setup_start = .; *(.init.setup) __setup_end = .; __initcall_start = .; *(.initcallearly.init) __early_initcall_end = .; *(.initcall0.init) *(.initcall0s.init) *(.initcall1.init) *(.initcall1s.init) *(.initcall2.init) *(.initcall2s.init) *(.initcall3.init) *(.initcall3s.init) *(.initcall4.init) *(.initcall4s.init) *(.initcall5.init) *(.initcall5s.init) *(.initcallrootfs.init) *(.initcall6.init) *(.initcall6s.init) *(.initcall7.init) *(.initcall7s.init) __initcall_end = .; __con_initcall_start = .; *(.con_initcall.init) __con_initcall_end = .; __security_initcall_start = .; *(.security_initcall.init) __security_initcall_end = .; }
因而,可根据如下方法来确定某文件系统在单链表file_systems中的位置:
- 1) 该文件系统的初始化函数是被哪个宏调用的: fs_install(), fs_install_sync(), rootfs_initcall(), or module_init()
- 2) 链接目标文件vmlinux时各.o文件的先后顺序,参见下图:
11.2.1.1.2 查看系统中注册的文件系统
NOTE: 内核中file_systems为单链表,所以通过单链表file_systems来获取文件系统只能按照注册的先后顺序来查找!
11.2.1.1.2.1 通过/proc/filesystems查看
通过下列命令显示在链表file_systems中注册的文件系统,参见11.3.4.4.3 /proc/filesystems节:
/*
* 按照文件系统在单链表file_systems中的顺序排列,
* 即按照文件系统注册的先后顺序来排列
*/
chenwx@chenwx ~ $ cat /proc/filesystems
nodev sysfs
nodev rootfs
nodev ramfs
nodev bdev
nodev proc
nodev cgroup
nodev cpuset
nodev tmpfs
nodev devtmpfs
nodev debugfs
nodev securityfs
nodev sockfs
nodev pipefs
nodev devpts
ext3
ext2
ext4
nodev hugetlbfs
vfat
nodev ecryptfs
fuseblk
nodev fuse
nodev fusectl
nodev pstore
nodev mqueue
nodev binfmt_misc
nodev vboxsf
// check the file system type of your system
chenwx@chenwx ~ $ df -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/sdb5 ext4 54351300 44295312 7271988 86% /
none tmpfs 4 0 4 0% /sys/fs/cgroup
udev devtmpfs 1972792 4 1972788 1% /dev
tmpfs tmpfs 397448 1400 396048 1% /run
none tmpfs 5120 0 5120 0% /run/lock
none tmpfs 1987220 788 1986432 1% /run/shm
none tmpfs 102400 20 102380 1% /run/user
/dev/sda1 fuseblk 312568828 227924832 84643996 73% /media/chenwx/Work
chenwx@chenwx ~ $ df -T -t ext4
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/sdb5 ext4 54351300 44295328 7271972 86% /
chenwx@chenwx ~ $ df -T -x ext4
Filesystem Type 1K-blocks Used Available Use% Mounted on
none tmpfs 4 0 4 0% /sys/fs/cgroup
udev devtmpfs 1972792 4 1972788 1% /dev
tmpfs tmpfs 397448 1400 396048 1% /run
none tmpfs 5120 0 5120 0% /run/lock
none tmpfs 1987220 788 1986432 1% /run/shm
none tmpfs 102400 20 102380 1% /run/user
/dev/sda1 fuseblk 312568828 227924832 84643996 73% /media/chenwx/Work
11.2.1.1.2.2 通过编写内核模块查看
编写模块showfs.c:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/mm_types.h>
#include <linux/gfp.h>
#include <linux/fs.h>
#include <linux/kallsyms.h>
#include <linux/string.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Chen Weixiang");
MODULE_DESCRIPTION("Check Filesystem Module");
static void mod_main(void)
{
struct file_system_type *fs;
char *sym_name = "file_systems";
unsigned long sym_addr;
unsigned long sum = 0;
sym_addr = kallsyms_lookup_name(sym_name);
fs = (struct file_system_type *)(*(unsigned long *)sym_addr);
while (fs != NULL)
{
printk("fs: %s \t\tfs_flags: 0x%08X\n", fs->name, fs->fs_flags);
fs = fs->next;
sum++;
}
printk("=== total %d elements in list file_systems ===\n", sum);
}
static int __init mod_init(void)
{
printk("=== insmod module ===\n");
mod_main();
return 0;
}
static void __exit mod_exit(void)
{
printk("=== rmmod module ===\n\n");
}
module_init(mod_init);
module_exit(mod_exit);
编写Makefile:
#
# Usage: make o=<source-file-name-without-extension>
#
obj-m := $(o).o
# 'uname –r' print kernel release
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
make -C $(KDIR) M=$(PWD) modules
clean:
make -C $(KDIR) M=$(PWD) clean
执行下列命令编译并执行:
chenwx@chenwx ~/test-kernel $ make o=showfs
make -C /lib/modules/3.15.0-eudyptula-00054-g783e9e8-dirty/build M=/home/chenwx/test modules
make[1]: Entering directory `/home/chenwx/linux'
Building modules, stage 2.
MODPOST 1 modules
make[1]: Leaving directory `/home/chenwx/linux'
chenwx@chenwx ~/test-kernel $ sudo insmod showfs.ko
chenwx@chenwx ~/test-kernel $ sudo rmmod showfs
chenwx@chenwx ~/test-kernel $ dmesg
[ 8977.106267] === insmod module ===
[ 8977.116806] fs: sysfs fs_flags: 0x00000028
[ 8977.116810] fs: rootfs fs_flags: 0x00000000
[ 8977.116811] fs: ramfs fs_flags: 0x00000008
[ 8977.116813] fs: bdev fs_flags: 0x00000000
[ 8977.116814] fs: proc fs_flags: 0x00000028
[ 8977.116816] fs: cpuset fs_flags: 0x00000000
[ 8977.116817] fs: cgroup fs_flags: 0x00000008
[ 8977.116819] fs: tmpfs fs_flags: 0x00000008
[ 8977.116820] fs: devtmpfs fs_flags: 0x00000000
[ 8977.116821] fs: debugfs fs_flags: 0x00000000
[ 8977.116823] fs: tracefs fs_flags: 0x00000000
[ 8977.116824] fs: securityfs fs_flags: 0x00000000
[ 8977.116826] fs: sockfs fs_flags: 0x00000000
[ 8977.116827] fs: bpf fs_flags: 0x00000008
[ 8977.116829] fs: pipefs fs_flags: 0x00000000
[ 8977.116830] fs: devpts fs_flags: 0x00000018
[ 8977.116832] fs: ext3 fs_flags: 0x00000009
[ 8977.116833] fs: ext2 fs_flags: 0x00000009
[ 8977.116834] fs: ext4 fs_flags: 0x00000009
[ 8977.116836] fs: hugetlbfs fs_flags: 0x00000000
[ 8977.116837] fs: vfat fs_flags: 0x00000001
[ 8977.116839] fs: ecryptfs fs_flags: 0x00000000
[ 8977.116840] fs: fuseblk fs_flags: 0x0000000D
[ 8977.116842] fs: fuse fs_flags: 0x0000000C
[ 8977.116843] fs: fusectl fs_flags: 0x00000000
[ 8977.116844] fs: pstore fs_flags: 0x00000000
[ 8977.116845] fs: mqueue fs_flags: 0x00000008
[ 8977.116847] fs: btrfs fs_flags: 0x00000003
[ 8977.116848] fs: autofs fs_flags: 0x00000000
[ 8977.116850] fs: binfmt_misc fs_flags: 0x00000000
[ 8977.116851] === total 30 elements in list file_systems ===
[22500.116960] === rmmod module ===
11.2.1.2 超级块结构/struct super_block
The superblock object is implemented by each filesystem and is used to store information describing that specific filesystem. This object usually corresponds to the filesystem superblock or the filesystem control block, which is stored in a special sector on disk (hence the object’s name). Filesystems that are not disk-based (a virtual memory–based filesystem, such as sysfs, for example) generate the superblock on-the-fly and store it in memory.
该结构定义于include/linux/fs.h:
struct super_block {
// list of all superblocks. 将所有超级块链接起来,形成双向链表super_blocks
struct list_head s_list; /* Keep this first */
/*
* 包含该具体文件系统的块设备号,通过MAJOR(s_dev)和MINOR(s_dev)获得主次设备号;
* 另外,可通过命令 "ls -l /dev" 查看系统中各设备的主次设备号
*/
dev_t s_dev; /* search index; _not_ kdev_t */
/*
* Modified (dirty) flag, which specifies whether the superblock
* is dirty, that’s, whether the data on the disk must be updated.
*/
unsigned char s_dirt;
/*
* s_blocksize_bits: block size in bits
* s_blocksize: block size in bytes
* => s_blocksize = 2 ^ s_blocksize_bits
*/
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
/*
* 本超级块所属的文件系统,参见[11.2.1.1 文件系统类型/struct file_system_type]节和
* Subjects/Chapter11_Filesystem/Figures/Filesystem_15.jpg
*/
struct file_system_type *s_type;
/*
* 指向某个特定文件系统的、用于超级块操作的函数集合,参见[11.2.1.2.3 超级块操作/struct super_operations]节。
* 通过[11.2.1.2.3.2 如何为super_blocks[x]->s_op赋值]节的方式为s_op指针赋值
*/
const struct super_operations *s_op;
// 指向某个特定文件系统的、用于限额操作的函数集合
const struct dquot_operations *dq_op;
// Disk quota administration methods
const struct quotactl_ops *s_qcop;
// Export operations used by network filesystems
const struct export_operations *s_export_op;
// mount flags, refer to MS_xxx in include/linux/fs.h
unsigned long s_flags;
/*
* filesystem’s magic number,是区分不同文件系统的标志,
* 参见include/linux/magic.h中的宏xxx_MAGIC
*/
unsigned long s_magic;
/*
* Dentry object of the filesystem’s root directory.
* 参见[11.2.1.3 目录项/struct dentry]节
*/
struct dentry *s_root;
struct rw_semaphore s_umount; // unmount semaphore
struct mutex s_lock; // 锁标志位,若被置位,则其它进程不能对该超级块操作
int s_count; // superblock reference count
atomic_t s_active; // active reference count
#ifdef CONFIG_SECURITY
// security module
void *s_security;
#endif
// extended attribute handlers
const struct xattr_handler **s_xattr;
/*
* struct super_block通过s_inodes域链接到所有的
* inodes (that’s struct inode->i_sb_list).
* struct inode通过i_sb域链接到其所属的super_block.
*/
struct list_head s_inodes; /* all inodes */
struct hlist_bl_head s_anon; /* anonymous dentries for (nfs) exporting */
// list of assigned files,参见[11.2.1.2.2.1.1 alloc_super()]节
#ifdef CONFIG_SMP
struct list_head __percpu *s_files;
#else
struct list_head s_files;
#endif
/*
* s_dentry_lru是由struct dentry->i_lru组成的链表,
* s_nr_dentry_unused表示该链表中元素的个数,参见[11.2.1.3 目录项/struct dentry]节
*/
/* s_dentry_lru, s_nr_dentry_unused protected by dcache.c lru locks */
struct list_head s_dentry_lru; /* unused dentry lru */
int s_nr_dentry_unused; /* # of dentry on lru */
/*
* s_inode_lru是由struct inode->d_lru组成的链表
* s_nr_inodes_unused表示该链表中元素的个数,参见[11.2.1.4 索引节点/struct inode]节
*/
/* s_inode_lru_lock protects s_inode_lru and s_nr_inodes_unused */
spinlock_t s_inode_lru_lock ____cacheline_aligned_in_smp;
struct list_head s_inode_lru; /* unused inode lru */
int s_nr_inodes_unused; /* # of inodes on lru */
struct block_device *s_bdev; // associated block device
struct backing_dev_info *s_bdi; // block device information
struct mtd_info *s_mtd; // memory disk information
/*
* 同一种文件系统可能存在多个超级块,并通过s_instances域链接起来,
* 组成双向链表file_systems->fs_supers,参见[11.2.1.1.1 文件系统链表/file_systems]节;
* s_instances域会被sget()函数引用,参见[11.2.2.1 注册/注销文件系统]节
*/
struct list_head s_instances;
struct quota_info s_dquot; /* Diskquota specific options */
int s_frozen; // frozen status
wait_queue_head_t s_wait_unfrozen; // wait queue on freeze
// 函数sget()将struct file_system_type->name拷贝到s_id[],参见[11.2.1.2.2.1.1 alloc_super()]节
char s_id[32]; /* Informational name */
u8 s_uuid[16]; /* UUID */
void *s_fs_info; /* Filesystem private info */
// mount permissions, refer to FMODE_xxx in include/linux/fs.h
fmode_t s_mode;
/* Granularity of c/m/atime in ns. Cannot be worse than a second */
u32 s_time_gran;
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned. Rename semaphore.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
char *s_subtype;
/*
* Saved mount options for lazy filesystems using generic_show_options()
*/
char __rcu *s_options;
/*
* 其作为默认值赋给struct dentry->d_op,
* 参见[11.2.1.3.2 如何分配dentry并为struct dentry->d_op赋值]节
*/
const struct dentry_operations *s_d_op; /* default d_op for dentries */
/*
* Saved pool identifier for cleancache (-1 means none)
*/
int cleancache_poolid;
struct shrinker s_shrink; /* per-sb shrinker handle */
};
11.2.1.2.1 超级块链表/super_blocks
struct super_block类型的全局变量为super_blocks,其定义于fs/super.c:
LIST_HEAD(super_blocks);
DEFINE_SPINLOCK(sb_lock);
每种具体的文件系统都存在一个或多个超级块,其s_list域被链接到super_blocks链表中,参见fs/super.c:
/*
* 在安装文件系统时,调用sget()函数,参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
* 和[11.2.2.4 安装文件系统(2)/sys_mount()]节
*/
struct super_block *sget(struct file_system_type *type,
int (*test)(struct super_block *,void *),
int (*set)(struct super_block *,void *),
void *data);
super_blocks双向链表,参见:
11.2.1.2.2 分配/注销超级块
11.2.1.2.2.1 分配超级块/sget()
该函数为指定的文件系统分配超级块,其定义于fs/super.c:
/**
* sget - find or create a superblock
* @type: filesystem type superblock should belong to
* @test: comparison callback
* @set: setup callback
* @data: argument to each of them, that’s test() and set()
*/
struct super_block *sget(struct file_system_type *type,
int (*test)(struct super_block *, void *),
int (*set)(struct super_block *, void *),
void *data)
{
struct super_block *s = NULL;
struct super_block *old;
int err;
retry:
spin_lock(&sb_lock);
if (test) {
/*
* 遍历双向链表type->fs_supers,检查该文件系统是否已存在满足条件的超级块,
* 参见[11.2.1.1.1 文件系统链表/file_systems]节中的元素fs_supers
*/
list_for_each_entry(old, &type->fs_supers, s_instances) {
/*
* 检测该文件系统是否已存在满足条件的超级块:
* - 若不存在满足条件的超级块,则继续查找;
*/
if (!test(old, data))
continue;
/*
* - 若已存在满足条件的超级块,则增加该超级块的引用计数,
* 即old->s_active++
*/
if (!grab_super(old))
goto retry;
/*
* 由下文中的b)处跳转至此处时,s指向已创建的超级块,则注销该超级块
*/
if (s) {
up_write(&s->s_umount);
// 注销该超级块,参见[11.2.1.2.2.2.1 destroy_super()]节
destroy_super(s);
s = NULL;
}
down_write(&old->s_umount);
if (unlikely(!(old->s_flags & MS_BORN))) {
deactivate_locked_super(old);
goto retry;
}
// 若该文件系统已存在满足条件的超级块,则直接返回该超级块
return old;
}
}
if (!s) {
spin_unlock(&sb_lock);
/*
* a) 否则,分配一个新的超级块,并进行初始化,
* 参见[11.2.1.2.2.1.1 alloc_super()]节
*/
s = alloc_super(type);
if (!s)
return ERR_PTR(-ENOMEM);
/*
* b) 创建超级块的过程中,链表type->fs_supers
* 中可能出现满足条件的超级块,故再次检查
*/
goto retry;
}
/*
* 若在链表type->fs_supers中未找到满足条件的超级块,
* 则使用a)处新创建的超级块,并设置该超级块的私有信息
*/
err = set(s, data);
if (err) {
spin_unlock(&sb_lock);
up_write(&s->s_umount);
// 注销该超级块,参见[11.2.1.2.2.2.1 destroy_super()]节
destroy_super(s);
return ERR_PTR(err);
}
s->s_type = type; // 将超级块链接到其所属的文件系统
strlcpy(s->s_id, type->name, sizeof(s->s_id)); // s_id[]保存了文件系统的名字
list_add_tail(&s->s_list, &super_blocks); // 将该超级块链接到super_blocks链表中
list_add(&s->s_instances, &type->fs_supers); // 将该超级块链接到该文件系统的fs_supers链表中
spin_unlock(&sb_lock);
get_filesystem(type); // 加载该文件系统所在的模块type->owner
/*
* alloc_super()为s->s_shrink赋值,参见[11.2.1.2.2.1.1 alloc_super()]节;
* register_shrinker()初始化s->s_shrink->nr_in_batch,
* 并将s->s_shrink->list链接到链表shrinker_list的末尾
*/
register_shrinker(&s->s_shrink);
return s;
}
函数sget()的调用关系,参见11.2.1.2.3.2 如何为super_blocks[x]->s_op赋值节。
链表shrinker_list,参见:
11.2.1.2.2.1.1 alloc_super()
该函数用于分配并初始化一个超级块,其定义于fs/super.c:
struct backing_dev_info default_backing_dev_info = {
.name = "default",
.ra_pages = VM_MAX_READAHEAD * 1024 / PAGE_CACHE_SIZE,
.state = 0,
.capabilities = BDI_CAP_MAP_COPY,
};
/**
* alloc_super - create new superblock
* @type: filesystem type superblock should belong to
*
* Allocates and initializes a new &struct super_block. alloc_super()
* returns a pointer new superblock or %NULL if allocation had failed.
*/
static struct super_block *alloc_super(struct file_system_type *type)
{
struct super_block *s = kzalloc(sizeof(struct super_block), GFP_USER);
static const struct super_operations default_op;
if (s) {
if (security_sb_alloc(s)) {
kfree(s);
s = NULL;
goto out;
}
#ifdef CONFIG_SMP
s->s_files = alloc_percpu(struct list_head);
if (!s->s_files) {
security_sb_free(s);
kfree(s);
s = NULL;
goto out;
} else {
int i;
for_each_possible_cpu(i)
INIT_LIST_HEAD(per_cpu_ptr(s->s_files, i));
}
#else
INIT_LIST_HEAD(&s->s_files);
#endif
s->s_bdi = &default_backing_dev_info;
INIT_LIST_HEAD(&s->s_instances);
INIT_HLIST_BL_HEAD(&s->s_anon);
INIT_LIST_HEAD(&s->s_inodes);
INIT_LIST_HEAD(&s->s_dentry_lru);
INIT_LIST_HEAD(&s->s_inode_lru);
spin_lock_init(&s->s_inode_lru_lock);
init_rwsem(&s->s_umount);
mutex_init(&s->s_lock);
lockdep_set_class(&s->s_umount, &type->s_umount_key);
/*
* The locking rules for s_lock are up to the
* filesystem. For example ext3fs has different
* lock ordering than usbfs:
*/
lockdep_set_class(&s->s_lock, &type->s_lock_key);
/*
* sget() can have s_umount recursion.
*
* When it cannot find a suitable sb, it allocates a new
* one (this one), and tries again to find a suitable old
* one.
*
* In case that succeeds, it will acquire the s_umount
* lock of the old one. Since these are clearly distrinct
* locks, and this object isn't exposed yet, there's no
* risk of deadlocks.
*
* Annotate this by putting this lock in a different
* subclass.
*/
down_write_nested(&s->s_umount, SINGLE_DEPTH_NESTING);
s->s_count = 1;
atomic_set(&s->s_active, 1);
mutex_init(&s->s_vfs_rename_mutex);
lockdep_set_class(&s->s_vfs_rename_mutex, &type->s_vfs_rename_key);
mutex_init(&s->s_dquot.dqio_mutex);
mutex_init(&s->s_dquot.dqonoff_mutex);
init_rwsem(&s->s_dquot.dqptr_sem);
init_waitqueue_head(&s->s_wait_unfrozen);
s->s_maxbytes = MAX_NON_LFS;
s->s_op = &default_op;
s->s_time_gran = 1000000000;
s->cleancache_poolid = -1;
// 参见Subjects/Chapter11_Filesystem/Figures/Filesystem_26.jpg
s->s_shrink.seeks = DEFAULT_SEEKS;
s->s_shrink.shrink = prune_super; // 该函数定义于fs/super.c
s->s_shrink.batch = 1024;
}
out:
return s;
}
11.2.1.2.2.2 注销超级块/put_super()
该函数用于注销超级块,其定义于fs/super.c:
/**
* put_super - drop a temporary reference to superblock
* @sb: superblock in question
*
* Drops a temporary reference, frees superblock if there's no
* references left.
*/
void put_super(struct super_block *sb)
{
spin_lock(&sb_lock);
__put_super(sb);
spin_unlock(&sb_lock);
}
/*
* Drop a superblock's refcount. The caller must hold sb_lock.
*/
void __put_super(struct super_block *sb)
{
// 若该超级块不再被引用,则注销之
if (!--sb->s_count) {
/*
* 将该超级块从链表super_blocks中移除并初始化,
* 参见[11.2.1.2.1 超级块链表/super_blocks]节
*/
list_del_init(&sb->s_list);
// 注销该超级块,参见[11.2.1.2.2.2.1 destroy_super()]节
destroy_super(sb);
}
}
11.2.1.2.2.2.1 destroy_super()
该函数用于注销超级块,其定义于fs/super.c:
/**
* destroy_super - frees a superblock
* @s: superblock to free
*
* Frees a superblock.
*/
static inline void destroy_super(struct super_block *s)
{
#ifdef CONFIG_SMP
free_percpu(s->s_files);
#endif
security_sb_free(s);
kfree(s->s_subtype);
kfree(s->s_options);
kfree(s);
}
11.2.1.2.3 超级块操作/struct super_operations
该结构用于struct super_block中的s_op域,其定义于include/linux/fs.h:
struct super_operations {
/*
* Creates and initializes a new inode object under the
* given superblock
*/
struct inode *(*alloc_inode)(struct super_block *sb);
/*
* Deallocates the given inode
*/
void (*destroy_inode)(struct inode *);
/*
* Invoked by the VFS when an inode is dirtied (modified).
* Journaling filesystems (such as ext3) use this function
* to perform journal updates.
*/
void (*dirty_inode) (struct inode *, int flags);
/*
* Writes the given inode to disk.
* The wbc parameter specifies whether the operation should
* be synchronous.
*/
int (*write_inode) (struct inode *, struct writeback_control *wbc);
/*
* Called by the VFS when the last reference to an inode is
* dropped. Normal Unix filesystems do not define this function,
* in which case the VFS simply deletes the inode. The caller
* must hold the inode_lock.
*/
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
/*
* Called by the VFS on unmount to release the given superblock
* object.
*/
void (*put_super) (struct super_block *);
/*
* Updates the on-disk superblock with the specified superblock.
* The VFS uses this function to synchronize a modified in-memory
* superblock with the disk. The caller must hold the s_lock lock.
*/
void (*write_super) (struct super_block *);
/*
* Synchronizes filesystem metadata with the on-disk filesystem.
* The wait parameter specifies whether the operation is synchronous.
*/
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_fs) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
/*
* Called by the VFS to obtain filesystem statistics. The statistics
* related to the given filesystem are placed in kstatfs.
*/
int (*statfs) (struct dentry *, struct kstatfs *);
/*
* Called by the VFS when the filesystem is remounted with new
* mount options.
*/
int (*remount_fs) (struct super_block *, int *, char *);
/*
* Called by the VFS to interrupt a mount operation. It's used
* by network filesystems, such as NFS.
*/
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct vfsmount *);
int (*show_devname)(struct seq_file *, struct vfsmount *);
int (*show_path)(struct seq_file *, struct vfsmount *);
int (*show_stats)(struct seq_file *, struct vfsmount *);
#ifdef CONFIG_QUOTA
ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
#endif
int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t);
int (*nr_cached_objects)(struct super_block *);
void (*free_cached_objects)(struct super_block *, int);
};
Some of these functions are optional; a specific filesystem can then set its value in the superblock operations structure to NULL. If the associated pointer is NULL, the VFS either calls a generic function or does nothing, depending on the operation.
11.2.1.2.3.1 具体文件系统的struct super_operations对象
每种具体的文件系统都定义了自己的struct super_operations对象:
EXT3 in fs/ext3/super.c
static const struct super_operations ext3_sops = {
.alloc_inode = ext3_alloc_inode,
.destroy_inode = ext3_destroy_inode,
.write_inode = ext3_write_inode,
.dirty_inode = ext3_dirty_inode,
.drop_inode = ext3_drop_inode,
.evict_inode = ext3_evict_inode,
.put_super = ext3_put_super,
.sync_fs = ext3_sync_fs,
.freeze_fs = ext3_freeze,
.unfreeze_fs = ext3_unfreeze,
.statfs = ext3_statfs,
.remount_fs = ext3_remount,
.show_options = ext3_show_options,
#ifdef CONFIG_QUOTA
.quota_read = ext3_quota_read,
.quota_write = ext3_quota_write,
#endif
.bdev_try_to_free_page = bdev_try_to_free_page,
};
NFS in fs/nfs/super.c
static const struct super_operations nfs_sops = {
.alloc_inode = nfs_alloc_inode,
.destroy_inode = nfs_destroy_inode,
.write_inode = nfs_write_inode,
.put_super = nfs_put_super,
.statfs = nfs_statfs,
.evict_inode = nfs_evict_inode,
.umount_begin = nfs_umount_begin,
.show_options = nfs_show_options,
.show_devname = nfs_show_devname,
.show_path = nfs_show_path,
.show_stats = nfs_show_stats,
.remount_fs = nfs_remount,
};
11.2.1.2.3.2 如何为super_blocks[x]->s_op赋值
每种具体文件系统的struct super_operations对象是通过如下方式赋值给super_blocks[x]->s_op的:
/* 手动(参见[11.2.2.4 安装文件系统(2)/sys_mount()]节)或自动(参见[11.4 文件系统的自动安装]节)调用如下函数 */
kern_mount() / do_kern_mount() // 参见[11.2.2.4.1.2.1 do_kern_mount()]节
-> vfs_kern_mount() // 参见[11.2.2.2.1 vfs_kern_mount()]节
-> mount_fs() // 参见[11.2.2.2.1.2 mount_fs()]节
-> type->mount() // 其中type为某种具体的文件系统类型,参见[11.2.2.2.1.2 mount_fs()]节
-> 方式1: 该具体文件系统的mount()函数直接或间接地调用sget()以分配超级块sb. 参见[11.2.1.2.2.1 分配超级块/sget()]节
-> 方式2: 该具体文件系统的mount()函数直接或间接地为超级块sb->s_op赋值
以EXT3为例,其调用过程如下:
/* 手动(参见[11.2.2.4 安装文件系统(2)/sys_mount()]节)或自动(参见[11.4 文件系统的自动安装]节)调用如下函数 */
kern_mount(ext3_fs_type, ...) / do_kern_mount(ext3_fs_type, ...)
-> vfs_kern_mount() // 参见[11.2.2.4.1.2.1 do_kern_mount()]节
-> mount_fs() // 参见[11.2.2.2.1.2 mount_fs()]节
-> &ext3_fs_type->mount() // that’s ext3_mount()
-> ext3_mount() // 参见fs/ext3/super.c
-> mount_bdev(..., ext3_fill_super)
-> s = sget(...) // 参见[11.2.1.2.2.1 分配超级块/sget()]节
-> ext3_fill_super(s, ...)
-> s->s_op = &ext3_sops; // 参见[11.2.1.2.3.1 具体文件系统的struct super_operations对象]节
11.2.1.3 目录项/struct dentry
The VFS treats directories as a type of file. In the path /bin/vi, both bin and vi are files — bin being the special directory file and vi being a regular file. An inode object represents each of these components. Despite this useful unification, the VFS often needs to perform directory-specific operations, such as path name lookup. Path name lookup involves translating each component of a path, ensuring it is valid, and following it to the next component.
To facilitate this, the VFS employs the concept of a directory entry (dentry). A dentry is a specific component in a path. Using the previous example, /, bin, and vi are all dentry objects. The first two are directories and the last is a regular file. This is an important point: Dentry objects are all components in a path, including files. Resolving a path and walking its components is a nontrivial exercise, time-consuming and heavy on string operations, which are expensive to execute and cumbersome to code. The dentry object makes the whole process easier.
Dentries might also include mount points. In the path /mnt/cdrom/foo, the components /, mnt, cdrom, and foo are all dentry objects. The VFS constructs dentry objects on-the-fly, as needed, when performing directory operations. Because the dentry object is not physically stored on the disk, no flag in struct dentry specifies whether the object is modified (that is, whether it is dirty and needs to be written back to disk).
该结构定义于include/linux/dcache.h:
struct dentry {
/* RCU lookup touched fields */
// dentry flags, 其取值为include/linux/dcache.h中的宏DCACHE_XXX
unsigned int d_flags; /* protected by d_lock */
seqcount_t d_seq; /* per dentry seqlock */
/*
* 链接成哈希链表dentry_hashtable,参见fs/dcache.c
* 链表类型struct hlist_bl_node,
* 参见[15.3 加锁哈希链表/struct hlist_bl_head/struct hlist_bl_node]节
*/
struct hlist_bl_node d_hash; /* lookup hash list */
// dentry object of parent
struct dentry *d_parent; /* parent directory */
/*
* dentry name, used by d_op->d_compare()
* 参见[11.2.1.3.1 目录项操作/struct dentry_operations]节
*/
struct qstr d_name;
/*
* 一个有效的dentry必定对应一个inode,因为一个dentry
* 要么代表着一个文件,要么代表着一个目录(实际上目录也是文件),
* 故只要dentry有效,则其d_inode域必定指向一个inode;
*
* 反之则不然,一个inode可能对应着不止一个dentry:
* 因为一个文件可能有不止一个文件名或路径名(一个文件可被link到其他文件名),
* 故链表struct inode->i_dentry将同一个文件的所有目录项
* (通过struct dentry->d_alias域)链接到一起,
* 而struct inode->i_nlink表示该链表中元素的个数
*/
struct inode *d_inode; /* Where the name belongs to - NULL is negative */
// short name. d_name.name points to d_iname[]
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
/* Ref lookup also touches following */
unsigned int d_count; /* protected by d_lock */ // usage count
spinlock_t d_lock; /* per dentry lock */
// 目录项操作,参见[11.2.1.3.1 目录项操作/struct dentry_operations]节
const struct dentry_operations *d_op;
// 目录项树的根,即文件的超级块
struct super_block *d_sb; /* The root of the dentry tree */
// 参见[11.2.1.3.1 目录项操作/struct dentry_operations]节
unsigned long d_time; /* used by d_op->d_revalidate(). */
// 特定文件系统的数据,参见[11.3.5.4.1 sysfs_open_file()]节
void *d_fsdata; /* fs-specific data */
/*
* Unused list. 各d_lru链接成链表struct super_block->s_dentry_lru,
* 而struct super_block->s_nr_dentry_unused表示该链表中元素的个数;
* 参见[11.2.1.2 超级块结构/struct super_block]节
*/
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
// list of dentries within the same directory
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu; // RCU locking
} d_u;
// subdirectories of this directory
struct list_head d_subdirs; /* our children */
/*
* list of alias inodes,同一个文件的所有目录项都通过该域链接到
* 链表struct dentry->d_inode->i_dentry中,参见d_inode域的注释
*/
struct list_head d_alias; /* inode alias list */
};
dentry父子关系示意图:
dentry与inode关系示意图:
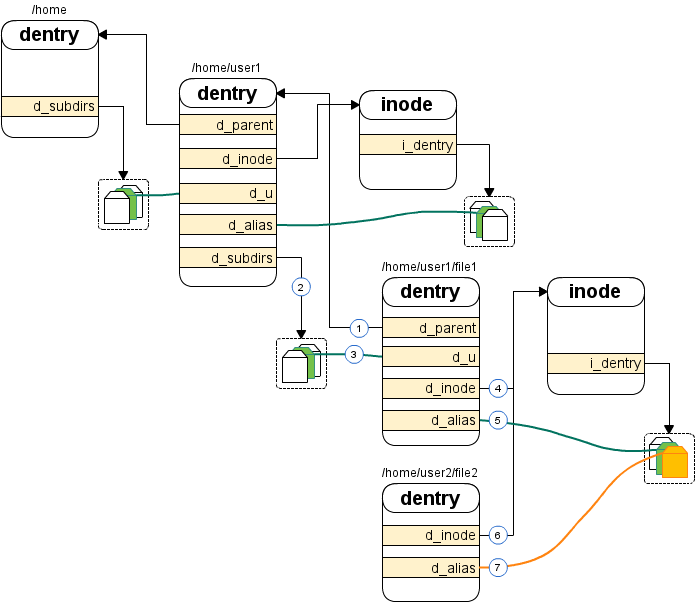
11.2.1.3.1 目录项操作/struct dentry_operations
该结构用于struct dentry中的d_op域,其定义于include/linux/dcache.h:
struct dentry_operations {
/*
* Determines whether the given dentry object is valid.
* The VFS calls this function whenever it is preparing
* to use a dentry from the dcache. Most filesystems set
* this method to NULL because their dentry objects in
* the dcache are always valid.
*/
int (*d_revalidate)(struct dentry *, struct nameidata *);
/*
* Creates a hash value from the given dentry. The VFS
* calls this function whenever it adds a dentry to the
* hash table.
*/
int (*d_hash)(const struct dentry *, const struct inode *, struct qstr *);
/*
* Called by the VFS to compare two filenames, name1 and
* name2. Most filesystems leave this at the VFS default,
* which is a simple string compare. For some filesystems,
* such as FAT, a simple string compare is insufficient.
* The FAT filesystem is not case sensitive and therefore
* needs to implement a comparison function that disregards
* case. This function requires the dcache_lock.
*/
int (*d_compare)(const struct dentry *, const struct inode *, const struct dentry *,
const struct inode *, unsigned int, const char *, const struct qstr *);
/*
* Called by the VFS when the specified dentry object's
* d_count reaches zero. This function requires the
* dcache_lock.
*/
int (*d_delete)(const struct dentry *);
/*
* Called by the VFS when the specified dentry is going
* to be freed. The default function does nothing.
*/
void (*d_release)(struct dentry *);
void (*d_prune)(struct dentry *);
/*
* Called by the VFS when a dentry object loses its associated
* inode: (say, because the entry was deleted from the disk).
* By default, the VFS simply calls the iput() function to
* release the inode. If a filesystem overrides this function,
* it must also call iput() in addition to performing whatever
* filesystem-specific work it requires.
*/
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
struct vfsmount *(*d_automount)(struct path *);
int (*d_manage)(struct dentry *, bool);
} ____cacheline_aligned;
11.2.1.3.2 如何分配dentry并为struct dentry->d_op赋值
函数d_alloc()和d_delete()分别用于分配和注销dentry,其定义于fs/dcache.c:
struct dentry *d_alloc(struct dentry * parent, const struct qstr *name)
{
/*
* 从缓存dentry_cache中分配dentry,并为dentry->d_op赋默认值,
* 参见[11.2.2.2.1.2.1.1.3 __d_alloc()]节: dentry->d_op = parent->d_sb->s_d_op;
* 即: struct dentry->d_op来自于struct super_block->s_d_op
*/
struct dentry *dentry = __d_alloc(parent->d_sb, name);
if (!dentry)
return NULL;
spin_lock(&parent->d_lock);
/*
* don't need child lock because it is not subject
* to concurrency here.
*/
__dget_dlock(parent);
dentry->d_parent = parent;
list_add(&dentry->d_u.d_child, &parent->d_subdirs);
spin_unlock(&parent->d_lock);
return dentry;
}
void d_delete(struct dentry * dentry)
{
struct inode *inode;
int isdir = 0;
/*
* Are we the only user?
*/
again:
spin_lock(&dentry->d_lock);
inode = dentry->d_inode;
isdir = S_ISDIR(inode->i_mode);
if (dentry->d_count == 1) {
if (inode && !spin_trylock(&inode->i_lock)) {
spin_unlock(&dentry->d_lock);
cpu_relax();
goto again;
}
dentry->d_flags &= ~DCACHE_CANT_MOUNT;
dentry_unlink_inode(dentry);
fsnotify_nameremove(dentry, isdir);
return;
}
if (!d_unhashed(dentry))
__d_drop(dentry);
spin_unlock(&dentry->d_lock);
fsnotify_nameremove(dentry, isdir);
}
11.2.1.4 索引节点/struct inode
The inode (index node) object represents all the information needed by the kernel to manipulate a file or directory. For Unix-style filesystems, this information is simply read from the on-disk inode. If a filesystem does not have inodes, however, the filesystem must obtain the information from wherever it is stored on the disk. Filesystems without inodes generally store file-specific information as part of the file; unlike Unix-style filesystems, they do not separate file data from its control information. Some modern filesystems do neither and store file metadata as part of an on-disk database. Whatever the case, the inode object is constructed in memory in whatever manner is applicable to the filesystem.
文件系统处理文件所需要的所有信息都放在称为索引节点的数据结构中。文件名可以随时更改,但是索引节点对文件是唯一的,并且随文件的存在而存在。具体文件系统的索引节点是存储在磁盘上的,是一种静态结构,要使用它,必须调入内存,填写VFS的索引节点,因此也称VFS索引节点是动态节点。
An inode represents each file on a filesystem, but the inode object is constructed in memory only as files are accessed.
该结构定义于include/linux/fs.h:
struct inode {
/*
* 文件的类型与访问权限,可取下列值,其定义于include/linux/stat.h:
* S_IFLNK, S_IFREG, S_IFDIR, S_IFCHR, S_IFBLK, S_IFIFO, S_IFSOCK
*/
umode_t i_mode;
/*
* inode的标志位,可取下列值,其定义于include/linux/fs.h:
* IOP_FASTPERM, IOP_LOOKUP, IOP_NOFOLLOW
*/
unsigned short i_opflags;
uid_t i_uid; // user id of owner
gid_t i_gid; // group id of owner
unsigned int i_flags; // 文件系统的安装标志
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl;
struct posix_acl *i_default_acl;
#endif
/*
* 索引节点操作,参见[11.2.1.4.1 索引节点操作/struct inode_operations]节,
* 其值根据i_mode的取值不同而不同,参见[11.2.1.4.2 如何分配inode并为struct inode->i_op赋值]节
*/
const struct inode_operations *i_op;
/*
* associated superblock.
* struct super_block通过s_inodes域链接到所有的inodes (that’s struct inode->i_sb_list).
* struct inode通过i_sb域链接到其所属的super_block.
*/
struct super_block *i_sb;
/*
* 链接所有可交换的页面,associated mapping.
* 参见[6.2.7 struct vm_area_struct]节和[6.2.8 struct address_space]节
*/
struct address_space *i_mapping;
// security module
#ifdef CONFIG_SECURITY
void *i_security;
#endif
/* Stat data, not accessed from path walking */
unsigned long i_ino; // inode number
/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/
union {
// number of hard links. 表示链表i_dentry中元素的个数
const unsigned int i_nlink;
unsigned int __i_nlink;
};
dev_t i_rdev; // real device node
struct timespec i_atime; // last access time
struct timespec i_mtime; // last modify time
struct timespec i_ctime; // last change time
spinlock_t i_lock; /* i_bytes, i_blocks, maybe i_size */
unsigned short i_bytes; // bytes consumed
blkcnt_t i_blocks; // file size in blocks
loff_t i_size; // file size in bytes
// serializer for i_size
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
/* Misc */
unsigned long i_state; // 索引节点的状态标志
struct mutex i_mutex;
unsigned long dirtied_when; /* jiffies of first dirtying */
struct hlist_node i_hash; // 指向哈希链表的指针
struct list_head i_wb_list; /* backing dev IO list */
/*
* Unused list.
* struct inode->i_lru链接成链表struct super_block->s_inode_lru;
* struct super_block->s_nr_inodes_unused表示该链表中元素的个数,
* 参见[11.2.1.2 超级块结构/struct super_block]节
*/
struct list_head i_lru; /* inode LRU list */
// 链接到struct super_block->s_inodes
struct list_head i_sb_list;
/*
* 参见[11.2.1.3 目录项/struct dentry]节:
* struct inode->i_dentry将属于同一文件的dentry(通过struct dentry->d_alias)链接到一起;
* struct dentry->d_inode指向该目录项所属的inode.
*/
union {
struct list_head i_dentry;
struct rcu_head i_rcu;
};
atomic_t i_count; // reference counter,若为0,表明该节点可丢弃或被重新使用
unsigned int i_blkbits; // block size in bits
u64 i_version; // versioning number
atomic_t i_dio_count;
atomic_t i_writecount; // 写进程的引用计数
// 文件操作,参见[11.2.1.5.1 文件操作/struct file_operations]节
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct file_lock *i_flock; // file lock list
struct address_space i_data; // mapping for device
#ifdef CONFIG_QUOTA
struct dquot *i_dquot[MAXQUOTAS]; // disk quotas for inode
#endif
struct list_head i_devices; // list of block devices
// These three pointers are stored in a union because a given inode can represent only
// one of these (or none of them) at a time.
union {
struct pipe_inode_info *i_pipe; // pipe information
struct block_device *i_bdev; // block device driver
struct cdev *i_cdev; // character device driver
};
__u32 i_generation; // 为以后的开发保留
#ifdef CONFIG_FSNOTIFY
__u32 i_fsnotify_mask; /* all events this inode cares about */
struct hlist_head i_fsnotify_marks;
#endif
#ifdef CONFIG_IMA
atomic_t i_readcount; /* struct files open RO */
#endif
void *i_private; /* fs or device private pointer */
};
struct inode->i_mode域的取值:
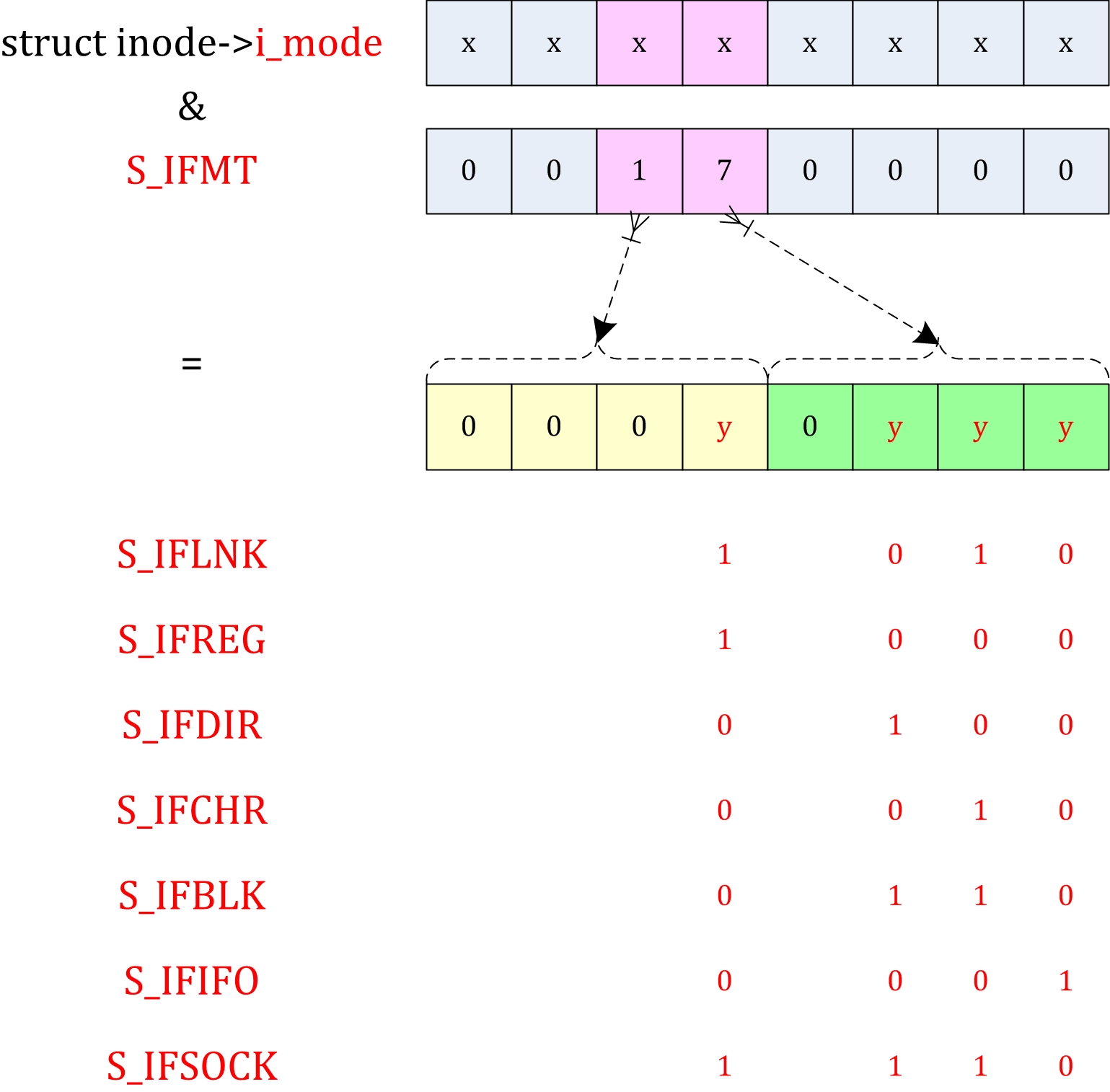
dentry与inode关系示意图:
11.2.1.4.1 索引节点操作/struct inode_operations
该结构定义于include/linux/fs.h:
struct inode_operations {
/*
* Searches a directory for an inode corresponding to
* a filename specified in the given dentry.
*/
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
/*
* Called by the VFS to translate a symbolic link to the
* inode to which it points. The link pointed at by dentry
* is translated and the result is stored in the nameidata
* structure.
*/
void * (*follow_link) (struct dentry *, struct nameidata *);
/*
* Checks whether the specified access mode is allowed for
* the file referenced by inode. This function returns zero
* if the access is allowed and a negative error code otherwise.
* Most filesystems set this field to NULL and use the generic
* VFS method, which simply compares the mode bits in the inode's
* objects to the given mask. More complicated filesystems, such
* as those supporting access control lists (ACLs), have a specific
* permission() method.
*/
int (*permission) (struct inode *, int);
struct posix_acl * (*get_acl)(struct inode *, int);
/*
* Called by the readlink() system call to copy at most buflen
* bytes of the full path associated with the symbolic link
* specified by dentry into the specified buffer.
*/
int (*readlink) (struct dentry *, char __user *, int);
/*
* Called by the VFS to clean up after a call to follow_link().
*/
void (*put_link) (struct dentry *, struct nameidata *, void *);
/*
* VFS calls this function from the creat() and open() system
* calls to create a new inode associated with the given dentry
* object with the specified initial mode.
*/
int (*create) (struct inode *, struct dentry *,int, struct nameidata *);
/*
* Invoked by the link() system call to create a hard link of the
* file old_dentry in the directory dir with the new filename dentry.
*/
int (*link) (struct dentry *, struct inode *, struct dentry *);
/*
* Called from the unlink() system call to remove the inode
* specified by the directory entry dentry from the directory dir.
*/
int (*unlink) (struct inode *, struct dentry *);
/*
* Called from the symlink() system call to create a symbolic link
* named symname to the file represented by dentry in the directory dir.
*/
int (*symlink) (struct inode *, struct dentry *, const char *);
/*
* Called from the mkdir() system call to create a new directory with
* the given initial mode.
*/
int (*mkdir) (struct inode *, struct dentry *, int);
/*
* Called by the rmdir() system call to remove the directory
* referenced by dentry from the directory dir.
*/
int (*rmdir) (struct inode *, struct dentry *);
/*
* Called by the mknod() system call to create a special file
* (device file, named pipe, or socket). The file is referenced
* by the device rdev and the directory entry dentry in the
* directory dir. The initial permissions are given via mode.
*/
int (*mknod) (struct inode *, struct dentry *, int, dev_t);
/*
* Called by the VFS to move the file specified by old_dentry
* from the old_dir directory to the directory new_dir, with
* the filename specified by new_dentry.
*/
int (*rename) (struct inode *, struct dentry *, struct inode *, struct dentry *);
/*
* Called by the VFS to modify the size of the given file.
* Before invocation, the inode's i_size field must be set
* to the desired new size.
*/
void (*truncate) (struct inode *);
/*
* Called from notify_change() to notify a "change event" after
* an inode has been modified.
*/
int (*setattr) (struct dentry *, struct iattr *);
/*
* Invoked by the VFS upon noticing that an inode needs to be
* refreshed from disk.
*/
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
/*
* Used by the VFS to set the extended attribute name to the
* value value on the file referenced by dentry.
*/
int (*setxattr) (struct dentry *, const char *, const void *, size_t, int);
/*
* Used by the VFS to copy into value the value of
* the extended attribute name for the specified file.
*/
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
/*
* Copies the list of all attributes for the specified file
* into the buffer list.
*/
ssize_t (*listxattr) (struct dentry *, char *, size_t);
/*
* Removes the given attribute from the given file.
*/
int (*removexattr) (struct dentry *, const char *);
void (*truncate_range)(struct inode *, loff_t, loff_t);
int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start, u64 len);
} ____cacheline_aligned;
11.2.1.4.2 如何分配inode并为struct inode->i_op赋值
struct super_operations->alloc_inode/destroy_inode分别用于分配和注销inode,并分别通过alloc_inode()和destroy_inode()调用,其定义于fs/inode.c:
static struct inode *alloc_inode(struct super_block *sb)
{
struct inode *inode;
/*
* 若该超级块存在函数alloc_inode(),则调用该函数为inode分配空间;
* 否则,从缓存inode_cachep中为inode分配空间,参见[4.3.4.1.4.3.11.2 inode_init()]节和
* [6.5.1.1.3.1 kmem_cache_zalloc()]节
*/
if (sb->s_op->alloc_inode)
inode = sb->s_op->alloc_inode(sb);
else
inode = kmem_cache_alloc(inode_cachep, GFP_KERNEL);
if (!inode)
return NULL;
/*
* perform inode structure intialisation.
* 若初始化成功,则返回分配的inode节点;
* 否则,注销分配的inode空间,并返回NULL
*/
if (unlikely(inode_init_always(sb, inode))) {
if (inode->i_sb->s_op->destroy_inode)
inode->i_sb->s_op->destroy_inode(inode);
else
kmem_cache_free(inode_cachep, inode);
return NULL;
}
return inode;
}
static void destroy_inode(struct inode *inode)
{
BUG_ON(!list_empty(&inode->i_lru));
__destroy_inode(inode);
/*
* 若该超级块存在函数destroy_inode(),则调用该函数收回inode占用的空间;
* 否则,调用函数i_callback()将inode占用的空间返回到缓存inode_cachep中
*/
if (inode->i_sb->s_op->destroy_inode)
inode->i_sb->s_op->destroy_inode(inode);
else
call_rcu(&inode->i_rcu, i_callback);
}
以EXT3为例,分配inode并为struct inode->i_op赋值的过程如下:
/* 手动(参见[11.2.2.4 安装文件系统(2)/sys_mount()]节)或自动(参见[11.4 文件系统的自动安装]节)调用如下函数 */
kern_mount(ext3_fs_type, ...) / do_kern_mount(ext3_fs_type, ...)
-> vfs_kern_mount() // 参见[11.2.2.4.1.2.1 do_kern_mount()]节
-> mount_fs() // 参见[11.2.2.2.1.2 mount_fs()]节
-> &ext3_fs_type->mount() // that’s ext3_mount()
-> ext3_mount() // 参见fs/ext3/super.c
-> mount_bdev(..., ext3_fill_super)
-> s = sget(...) // 参见[11.2.1.2.2.1 分配超级块/sget()]节和[11.2.1.2.3.2 如何为super_blocks[x]->s_op赋值]节
-> ext3_fill_super(s, ...)
-> s->s_op = &ext3_sops; // 参见[11.2.1.2.3.1 具体文件系统的struct super_operations对象]节
-> root = ext3_iget(sb, EXT3_ROOT_INO);
/* 1) 分配ext3文件系统的inode */
-> inode = iget_locked(sb, ino);
-> inode = alloc_inode(sb);
/* 2) 根据inode->i_mode的取值,为inode->i_op赋值 */
-> if (S_ISREG(inode->i_mode)) {
inode->i_op = &ext3_file_inode_operations;
} else if (S_ISDIR(inode->i_mode)) {
inode->i_op = &ext3_dir_inode_operations;
} else if (S_ISLNK(inode->i_mode)) {
if (ext3_inode_is_fast_symlink(inode)) {
inode->i_op = &ext3_fast_symlink_inode_operations;
} else {
inode->i_op = &ext3_symlink_inode_operations;
} else {
inode->i_op = &ext3_special_inode_operations;
}
11.2.1.4.3 如何查看inode信息
11.2.1.4.3.1 inode的内容
inode包含文件的元信息,具体来说有以下内容:
- 文件的字节数
- 文件拥有者的User ID
- 文件的Group ID
- 文件的读、写、执行权限
- 文件的时间戳,共有三个:
- ctime指inode上一次变动的时间
- mtime指文件内容上一次变动的时间
- atime指文件上一次打开的时间
- 链接数,即有多少文件名指向这个inode
- 文件数据block的位置
即,除了文件名以外的所有文件信息,都保存在inode中。
可使用stat命令查看某文件的inode信息:
chenwx@chenwx ~ $ stat README.Alex
File: 'README.Alex'
Size: 2571 Blocks: 8 IO Block: 4096 regular file
Device: 815h/2069d Inode: 787323 Links: 1
Access: (0600/-rw-------) Uid: ( 1000/ chenwx) Gid: ( 1000/ chenwx)
Access: 2016-10-26 22:25:35.834554345 +0800
Modify: 2015-06-24 21:07:06.384638316 +0800
Change: 2015-06-24 21:07:06.400638396 +0800
Birth: -
11.2.1.4.3.2 inode的大小
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域:
- 数据区,用于存放文件数据
- inode区(inode table),用于存放inode所包含的信息
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在硬盘格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
由于每个文件都必须有一个对应的inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。此时,就无法在该硬盘上创建新文件了。
可以使用df命令查看每个硬盘分区的inode总数和已经使用的数量:
chenwx@chenwx ~ $ df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
udev 491108 552 490556 1% /dev
tmpfs 496451 834 495617 1% /run
/dev/sdb5 3465216 895891 2569325 26% /
tmpfs 496451 11 496440 1% /dev/shm
tmpfs 496451 5 496446 1% /run/lock
tmpfs 496451 18 496433 1% /sys/fs/cgroup
cgmfs 496451 14 496437 1% /run/cgmanager/fs
tmpfs 496451 20 496431 1% /run/user/1000
/dev/sda1 40467436 140535 40326901 1% /media/chenwx/Work
查看每个inode节点的大小,可以用如下命令:
chenwx@chenwx ~ $ mount | grep sdb5
/dev/sdb5 on / type ext4 (rw,relatime,errors=remount-ro,data=ordered)
chenwx@chenwx ~ $ sudo dumpe2fs -h /dev/sdb5 | grep "Inode size"
dumpe2fs 1.42.13 (17-May-2015)
Inode size: 256
11.2.1.4.3.3 inode号码
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
NOTE: Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上,用户通过文件名打开文件。实际上,系统内部这个过程分成三步:
- 1) 首先,系统找到该文件名对应的inode号码;
- 2) 其次,通过inode号码获取inode信息;
- 3) 最后,根据inode信息找到文件数据所在的block,即可读出数据。
通过ls -i命令可以查看文件名对应的inode号码:
chenwx@chenwx ~ $ ls -i README.Alex
787323 README.Alex
chenwx@chenwx ~ $ ls -i linux
1580793 COPYING 1604857 block 2251773 mm
1573039 CREDITS 1604945 crypto 2251883 net
1580797 Documentation 1605093 drivers 2253602 samples
1582342 Kbuild 1605876 firmware 2253723 scripts
1600649 Kconfig 1606062 fs 2254036 security
1574290 MAINTAINERS 1989201 include 2254234 sound
1574304 Makefile 1990451 init 1622467 tools
1582343 README 1990465 ipc 2266507 usr
1582344 REPORTING-BUGS 1990480 kernel 2266513 virt
1600659 arch 2251467 lib
11.2.1.4.3.4 硬链接
一般情况下,文件名和inode号码是”一一对应”的关系,即每个inode号码对应一个文件名。但是,Unix/Linux系统允许多个文件名指向同一个inode号码。这就意味着:
- 可以用不同的文件名访问同样的内容;
- 对文件内容进行修改,会影响到所有文件名;
- 删除一个文件名,不会影响另一个文件名的访问。
这种情况就被称为”硬链接”(hard link),例如:
chenwx@chenwx ~ $ ls -li update_repo.sh*
788014 -rwx--x--x 1 chenwx chenwx 1277 Oct 27 2014 update_repo.sh
chenwx@chenwx ~ $ ln update_repo.sh update_repo.sh.ln1
chenwx@chenwx ~ $ ls -li update_repo.sh*
788014 -rwx--x--x 2 chenwx chenwx 1277 Oct 27 2014 update_repo.sh
788014 -rwx--x--x 2 chenwx chenwx 1277 Oct 27 2014 update_repo.sh.ln1
chenwx@chenwx ~ $ ln update_repo.sh update_repo.sh.ln2
chenwx@chenwx ~ $ ls -li update_repo.sh*
788014 -rwx--x--x 3 chenwx chenwx 1277 Oct 27 2014 update_repo.sh
788014 -rwx--x--x 3 chenwx chenwx 1277 Oct 27 2014 update_repo.sh.ln1
788014 -rwx--x--x 3 chenwx chenwx 1277 Oct 27 2014 update_repo.sh.ln2
chenwx@chenwx ~ $ rm -rf update_repo.sh.ln2
chenwx@chenwx ~ $ ls -li update_repo.sh*
788014 -rwx--x--x 2 chenwx chenwx 1277 Oct 27 2014 update_repo.sh
788014 -rwx--x--x 2 chenwx chenwx 1277 Oct 27 2014 update_repo.sh.ln1
chenwx@chenwx ~ $ rm -rf update_repo.sh.ln1
chenwx@chenwx ~ $ ls -li update_repo.sh*
788014 -rwx--x--x 1 chenwx chenwx 1277 Oct 27 2014 update_repo.sh
创建了硬链接后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做”链接数”,用于记录指向该inode的文件名总数,此时就会增加1。反之,删除一个文件名,就会使得inode节点中的”链接数”减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的”链接数”。创建目录时,默认会生成两个目录项: “.”和”..”。前者的inode号码就是当前目录的inode号码,等同于当前目录的”硬链接”;后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的”硬链接”。所以,任何一个目录的”硬链接”总数,总是等于2加上它的子目录总数(含隐藏目录)。
11.2.1.4.3.4 软链接
文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的”软链接”(soft link)或者”符号链接”(symbolic link)。
这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错: “No such file or directory”。这是软链接与硬链接最大的不同: 文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode”链接数”不会因此发生变化。
chenwx@chenwx ~ $ ls -li update_repo.sh*
788014 -rwx--x--x 1 chenwx chenwx 1277 Oct 27 2014 update_repo.sh
chenwx@chenwx ~ $ ln -s update_repo.sh update_repo.sh.ln1
chenwx@chenwx ~ $ ls -li update_repo.sh*
788014 -rwx--x--x 1 chenwx chenwx 1277 Oct 27 2014 update_repo.sh
787836 lrwxrwxrwx 1 chenwx chenwx 14 Dec 1 20:46 update_repo.sh.ln1 -> update_repo.sh
11.2.1.4.3.5 inode的特殊作用
由于inode号码与文件名的分离,这种机制导致了一些Unix/Linux系统特有的现象:
- 1) 若文件名包含特殊字符,则该文件无法正常删除。此时,直接删除inode节点,就能起到删除文件的作用。
- 2) 移动文件或重命名文件,只是改变文件名,不影响inode号码。
- 3) 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法根据inode号码得知文件名。
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。
11.2.1.5 文件/struct file
The file object is used to represent a file opened by a process. Processes deal directly with files, not superblocks, inodes, or dentries.
The file object is the in-memory representation of an open file. The object (but not the physical file) is created in response to the open() system call and destroyed in response to the close() system call. All these file-related calls are actually methods defined in the file operations table. Because multiple processes can open and manipulate a file at the same time, there can be multiple file objects in existence for the same file. The file object merely represents a process’s view of an open file. The object points back to the dentry (which in turn points back to the inode) that actually represents the open file. The inode and dentry objects, of course, are unique.
Similar to the dentry object, the file object does not actually correspond to any on-disk data. Therefore, no flag in the object represents whether the object is dirty and needs to be written back to disk. The file object does point to its associated dentry object via the f_dentry pointer. The dentry in turn points to the associated inode, which reflects whether the file itself is dirty.
在Linux中,进程是通过文件描述符(file descriptors,fd)而不是文件名来访问文件的,文件描述符实际上是一个整数。Linux中规定每个进程能最多能同时使用NR_OPEN个文件描述符,其定义于include/linux/limits.h:
#define NR_OPEN 1024
每个文件都有一个32位的数字来表示下一个读写的字节位置,该数字叫做文件位置。每次打开一个文件,除非明确要求,文件位置都被置为0,即文件的开始处,此后的读或写操作都将从文件的开始处执行,但可以通过执行系统调用struct file_operations->lseek(随机存储)对这个文件位置进行修改。Linux中专门用struct file来保存打开文件的文件位置,该结构被称为打开的文件描述(open file description)。这个数据结构的设置是煞费苦心的,因为它与进程的联系非常紧密,可以说这是VFS中一个比较难于理解的数据结构。
首先,为什么不把文件位置干脆存放在索引节点中,而要多此一举,设一个新的数据结构呢?Linux中的文件是能够共享的,假如把文件位置存放在索引节点中,则如果有两个或更多个进程同时打开同一个文件时,它们将去访问同一个索引节点,于是一个进程的lseek操作将影响到另一个进程的读操作,这显然是不允许也是不可想象的。
另一个想法是既然进程是通过文件描述符访问文件的,为什么不用一个与文件描述符数组相平行的数组来保存每个打开文件的文件位置?这个想法也是不能实现的,原因就在于在生成一个新进程时,子进程要共享父进程的所有信息,包括文件描述符数组。
一个文件不仅可以被不同的进程分别打开,而且也可以被同一个进程先后多次打开。如果一个进程先后多次打开同一个文件,则每一次打开都要分配一个新的文件描述符,并且指向一个新的file结构,尽管它们都指向同一个索引节点,但是,如果一个子进程不和父进程共享同一个file结构,而是也如上面一样,分配一个新的file结构,会出现什么情况了?来看一个例子:
假设有一个输出重定位到某文件A的shell script,我们知道,shell是作为一个进程运行的,当它生成第一个子进程时,将以0作为A的文件位置开始输出,假设输出了2K的数据,则现在文件位置为2K。然后,shell继续读取脚本,生成另一个子进程,它要共享shell的file结构,也就是共享文件位置,所以第二个进程的文件位置是2K,将接着第一个进程输出内容的后面输出。如果shell不和子进程共享文件位置,则第二个进程就有可能重写第一个进程的输出了,这显然不是希望得到的结果。
至此,已经可以看出设置file结构的原因所在了。
struct file中主要保存了文件位置,此外,还把指向该文件索引节点的指针也放在其中。file结构形成一个双链表,称为系统打开文件表,其最大长度是NR_FILE,其定义于include/linux/fs.h:
#define NR_FILE 8192 /* this can well be larger on a larger system */
struct file定义于include/linux/fs.h:
struct file {
/*
* fu_list becomes invalid after file_free is called and queued via
* fu_rcuhead for RCU freeing
*/
union {
struct list_head fu_list; // list of file objects
struct rcu_head fu_rcuhead; // RCU list after freeing
} f_u;
struct path f_path; // contains the dentry
#define f_dentry f_path.dentry
#define f_vfsmnt f_path.mnt
// 指向文件操作集合的指针,参见[11.2.1.5.1 文件操作/struct file_operations]节
const struct file_operations *f_op;
/*
* Protects f_ep_links, f_flags, f_pos vs i_size in lseek SEEK_CUR.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock; // per-file struct lock
#ifdef CONFIG_SMP
int f_sb_list_cpu;
#endif
atomic_long_t f_count; // file object’s usage count
unsigned int f_flags; // flags specified on open
fmode_t f_mode; // file access mode
loff_t f_pos; // file offset (file pointer)
struct fown_struct f_owner; // owner data for signals
const struct cred *f_cred; // file credentials
struct file_ra_state f_ra; // read-ahead state
u64 f_version; // version number
#ifdef CONFIG_SECURITY
void *f_security; // security module
#endif
/* needed for tty driver, and maybe others */
void *private_data; // tty driver hook
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping; // page cache mapping
#ifdef CONFIG_DEBUG_WRITECOUNT
unsigned long f_mnt_write_state; // debugging state
#endif
};
引用file结构:
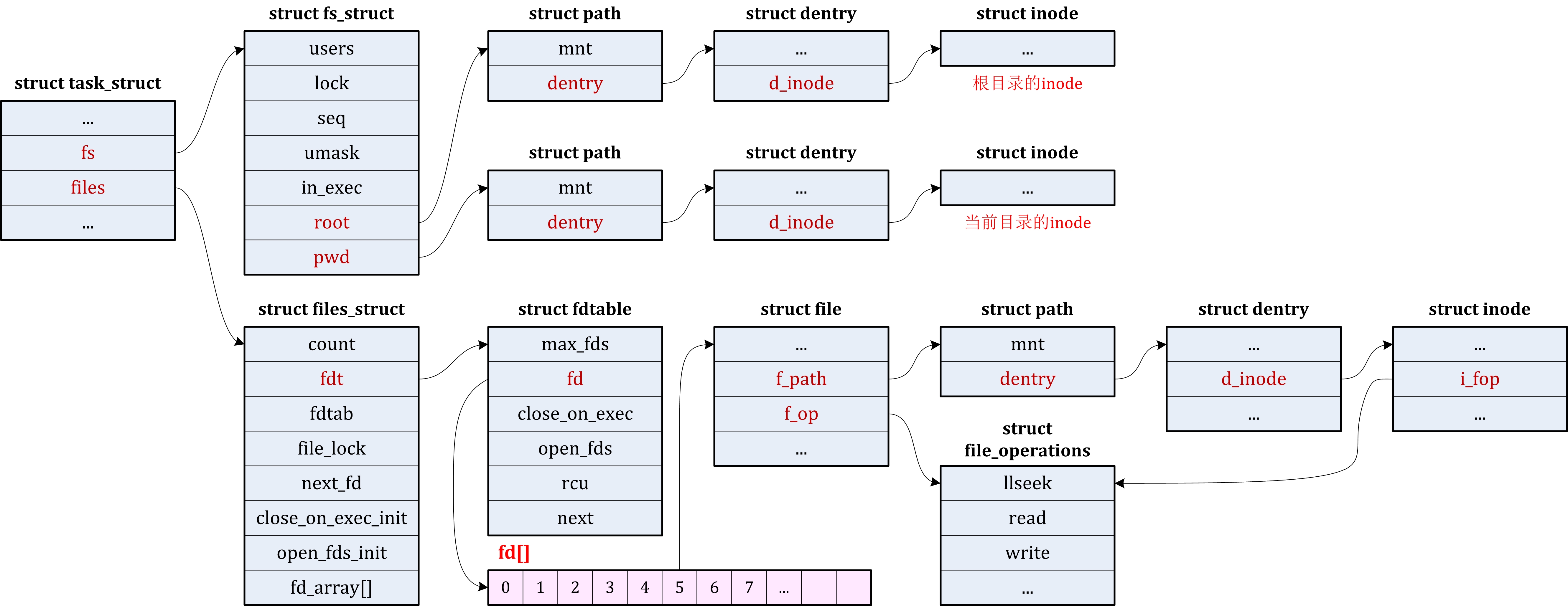
其中,根目录的inode和当前目录的inode,参见4.3.4.1.4.3.11.4.3 init_mount_tree()节。
11.2.1.5.1 文件操作/struct file_operations
该结构定义于include/linux/fs.h:
struct file_operations {
/*
* This field is used to prevent the module from being
* unloaded while its operations are in use. Almost all
* the time, it is simply initialized to THIS_MODULE,
* a macro defined in <linux/module.h>.
* 参见[13.4.2.4 How to access symbols]节
*/
struct module *owner;
/*
* Used to change the current read/write position in a
* file, and the new position is returned as a (positive)
* return value. It is called via the llseek() system call.
*/
loff_t (*llseek) (struct file *, loff_t, int);
/*
* Used to retrieve data from the device. A null pointer
* in this position causes the read system call to fail
* with -EINVAL ("Invalid argument"). A nonnegative return
* value represents the number of bytes successfully read.
* This function is called by the read() system call.
* See read.
*/
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
/*
* Sends data to the device. If NULL, -EINVAL is returned to
* the program calling the write() system call. The return
* value, if nonnegative, represents the number of bytes
* successfully written. This function is called by the
* write() system call. See section write.
*/
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
/*
* Initiates an asynchronous read — a read operation that
* might not complete before the function returns. If this
* method is NULL, all operations will be processed
* (synchronously) by read() instead. This function is called
* by the aio_read() and read() system call. See read.
*/
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
/*
* Initiates an asynchronous write operation on the device.
* This function is called by the aio_write() and write()
* system call. See write.
*/
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
/*
* This field should be NULL for device files; It is used
* for reading directories and is useful only for filesystems.
* This function is called by the readdir() system call.
*/
int (*readdir) (struct file *, void *, filldir_t);
/*
* This method is the back end of three system calls: poll,
* epoll, and select, all of which are used to query whether
* a read or write to one or more file descriptors would block.
* This method should return a bit mask indicating whether
* non-blocking reads or writes are possible, and, possibly,
* provide the kernel with information that can be used to put
* the calling process to sleep until I/O becomes possible.
* If a driver leaves its poll method NULL, the device is
* assumed to be both readable and writable without blocking.
*/
unsigned int (*poll) (struct file *, struct poll_table_struct *);
/*
* Implements the same functionality as ioctl() but without
* needing to hold the BKL. The VFS calls unlocked_ioctl()
* if it exists in lieu of ioctl() when userspace invokes the
* ioctl() system call. Thus filesystems need implement only
* one, preferably unlocked_ioctl().
*/
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
/*
* Implements a portable variant of ioctl() for use on 64-bit
* systems by 32-bit applications. This function is designed
* to be 32-bit safe even on 64-bit architectures, performing
* any necessary size conversions.
* New drivers should design their ioctl commands such that all
* are portable, and thus enable compat_ioctl() and unlocked_ioctl()
* to point to the same function.
* Like unlocked_ioctl(), compat_ioctl() does not hold the BKL.
*/
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
/*
* Used to request a mapping of device memory to a process's
* address space. If this method is NULL, the mmap system call
* returns -ENODEV. It is called by the mmap() system call.
*/
int (*mmap) (struct file *, struct vm_area_struct *);
/*
* Though this is always the first operation performed on the
* device file, the driver is not required to declare a
* corresponding method. If this entry is NULL, opening the
* device always succeeds, but your driver isn't notified.
* It is called by the open() system call.
*/
int (*open) (struct inode *, struct file *);
/*
* Invoked when a process closes its copy of a file descriptor
* for a device; it should execute (and wait for) any outstanding
* operations on the device.
*/
int (*flush) (struct file *, fl_owner_t id);
/*
* Invoked when the file structure is being released.
* Like open(), release() can be NULL.
*/
int (*release) (struct inode *, struct file *);
/*
* This method is the back end of the fsync system call,
* which a user calls to flush any pending data.
* If this pointer is NULL, the system call returns -EINVAL.
*/
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
/*
* Called by the aio_fsync() system call to write all cached
* data for the file associated with iocb to disk.
*/
int (*aio_fsync) (struct kiocb *, int datasync);
/*
* Enables or disables signal notification of asynchronous I/O.
* The field can be NULL if the driver doesn't support
* asynchronous notification.
*/
int (*fasync) (int, struct file *, int);
/*
* Manipulates a file lock on the given file.
* Locking is an indispensable feature for regular files
* but is almost never implemented by device drivers.
*/
int (*lock) (struct file *, int, struct file_lock *);
/*
* It's called by the kernel to send data, one page at a time,
* to the corresponding file. Device drivers do not usually
* implement sendpage.
*/
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
/*
* Find a suitable location in the process's address space
* to map in a memory segment on the underlying device.
*/
unsigned long (*get_unmapped_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
/*
* Allows a module to check the flags passed to an
* fcntl(F_SETFL...) call.
*/
int (*check_flags)(int);
/*
* Used to implement the flock() system call, which provides
* advisory locking.
*/
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **);
long (*fallocate)(struct file *file, int mode, loff_t offset, loff_t len);
};
11.2.1.5.2 如何分配file并为struct file->f_op赋值
函数alloc_file()用于分配并初始化一个struct file类型的对象:
/**
* alloc_file - allocate and initialize a 'struct file'
* @mnt: the vfsmount on which the file will reside
* @dentry: the dentry representing the new file
* @mode: the mode with which the new file will be opened
* @fop: the 'struct file_operations' for the new file
*
* Use this instead of get_empty_filp() to get a new
* 'struct file'. Do so because of the same initialization
* pitfalls reasons listed for init_file(). This is a
* preferred interface to using init_file().
*
* If all the callers of init_file() are eliminated, its
* code should be moved into this function.
*/
struct file *alloc_file(struct path *path, fmode_t mode,
const struct file_operations *fop)
{
struct file *file;
// 分配空的struct file类型的对象
file = get_empty_filp();
if (!file)
return NULL;
// 初始化分配的struct file类型的对象
file->f_path = *path;
file->f_mapping = path->dentry->d_inode->i_mapping;
file->f_mode = mode;
file->f_op = fop;
/*
* These mounts don't really matter in practice
* for r/o bind mounts. They aren't userspace-
* visible. We do this for consistency, and so
* that we can do debugging checks at __fput()
*/
if ((mode & FMODE_WRITE) && !special_file(path->dentry->d_inode->i_mode)) {
file_take_write(file);
WARN_ON(mnt_clone_write(path->mnt));
}
if ((mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_inc(path->dentry->d_inode);
return file;
}
当进程打开文件时,调用alloc_file()为struct file->f_op赋值,参见11.2.4.2.1.2.1.1.1 dentry_open()/__dentry_open()节。
11.2.1.6 虚拟文件系统安装结构/struct vfsmount
该结构定义于include/linux/mount.h(为了显示各字段之间的关系,下表中各字段的先后顺序已被调整):
struct vfsmount {
/*
* Pointers for the hash table list, see global variable
* mount_hashtable in fs/namespace.c
*/
struct list_head mnt_hash;
// 如下两个域组成的链表,参见Subjects/Chapter11_Filesystem/Figures/Filesystem_29.jpg
struct mnt_namespace *mnt_ns; /* containing namespace */
struct list_head mnt_list; // 通过本域将所有的struct vfsmount实例链接起来
// 如下三个域组成的链表参见Subjects/Chapter11_Filesystem/Figures/Filesystem_17.jpg
struct vfsmount *mnt_parent; /* fs we are mounted on */
struct list_head mnt_mounts; /* list of children, anchored here */
struct list_head mnt_child; /* and going through their mnt_child */
// 如下三个域组成的链表参见Subjects/Chapter11_Filesystem/Figures/Filesystem_19.jpg
struct list_head mnt_slave_list; /* list of slave mounts */
struct list_head mnt_slave; /* slave list entry */
struct vfsmount *mnt_master; /* slave is on master->mnt_slave_list */
// 若mnt_flags中标志位MNT_SHARED置位,则各struct vfsmount通过域mnt_share形成双向链表
// 参见Subjects/Chapter11_Filesystem/Figures/Filesystem_31.jpg
struct list_head mnt_share; /* circular list of shared mounts */
struct list_head mnt_expire; /* link in fs-specific expiry list */
// Points to the dentry of the mount point directory where the filesystem is mounted
struct dentry *mnt_mountpoint; /* dentry of mountpoint */
// Points to the dentry of the root directory of this filesystem
struct dentry *mnt_root; /* root of the mounted tree */
// Points to the superblock object of this filesystem
struct super_block *mnt_sb; /* pointer to superblock */
// 标志位,其取值为include/linux/mount.h中的MNT_xxx
int mnt_flags;
#ifdef CONFIG_SMP
struct mnt_pcp __percpu *mnt_pcp;
atomic_t mnt_longterm; /* how many of the refs are longterm */
#else
int mnt_count; // usage counter
int mnt_writers; // writers counter
#endif
/* 4 bytes hole on 64bits arches without fsnotify */
#ifdef CONFIG_FSNOTIFY
__u32 mnt_fsnotify_mask;
struct hlist_head mnt_fsnotify_marks;
#endif
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
int mnt_expiry_mark; /* true if marked for expiry */
int mnt_pinned; // pinned count
int mnt_ghosts; // ghosts count
};
进程通过task_struct访问vfsmount结构:
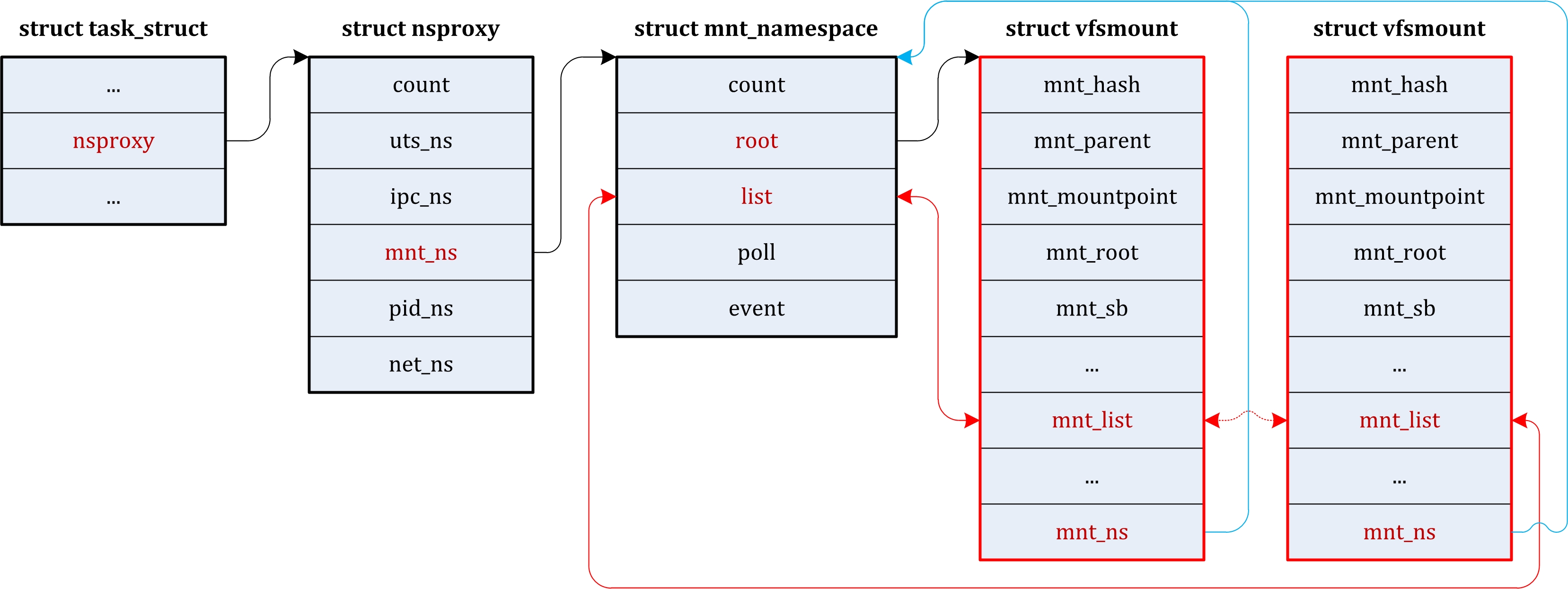
其赋值过程参见4.3.4.1.4.3.11.4.3 init_mount_tree()节。
11.2.1.6.1 虚拟文件系统安装点数组mount_hashtable[idx]及各链表
struct vfsmount类型的全局变量为mount_hashtable,其定义于fs/namespace.c:
static struct list_head *mount_hashtable __read_mostly;
static struct kmem_cache *mnt_cache __read_mostly;
static struct rw_semaphore namespace_sem;
函数mnt_init()为变量mount_hashtable分配空间,参见4.3.4.1.4.3.11.4 mnt_init()节。
mount_hashtable哈希链表结构:
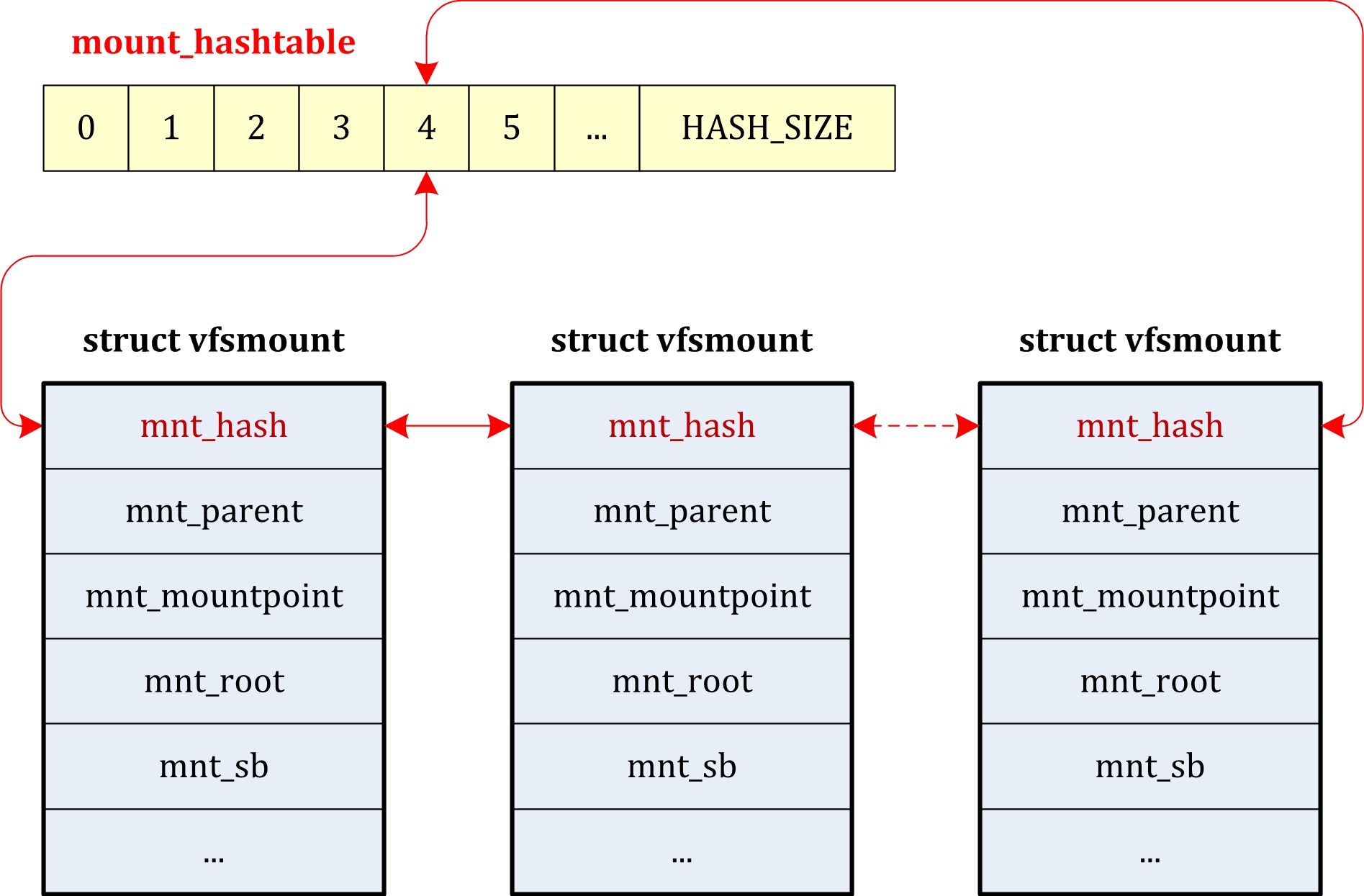
mnt_share链表:

struct vfsmount父子关系:
- mnt_mounts/mnt_child/mnt_parent
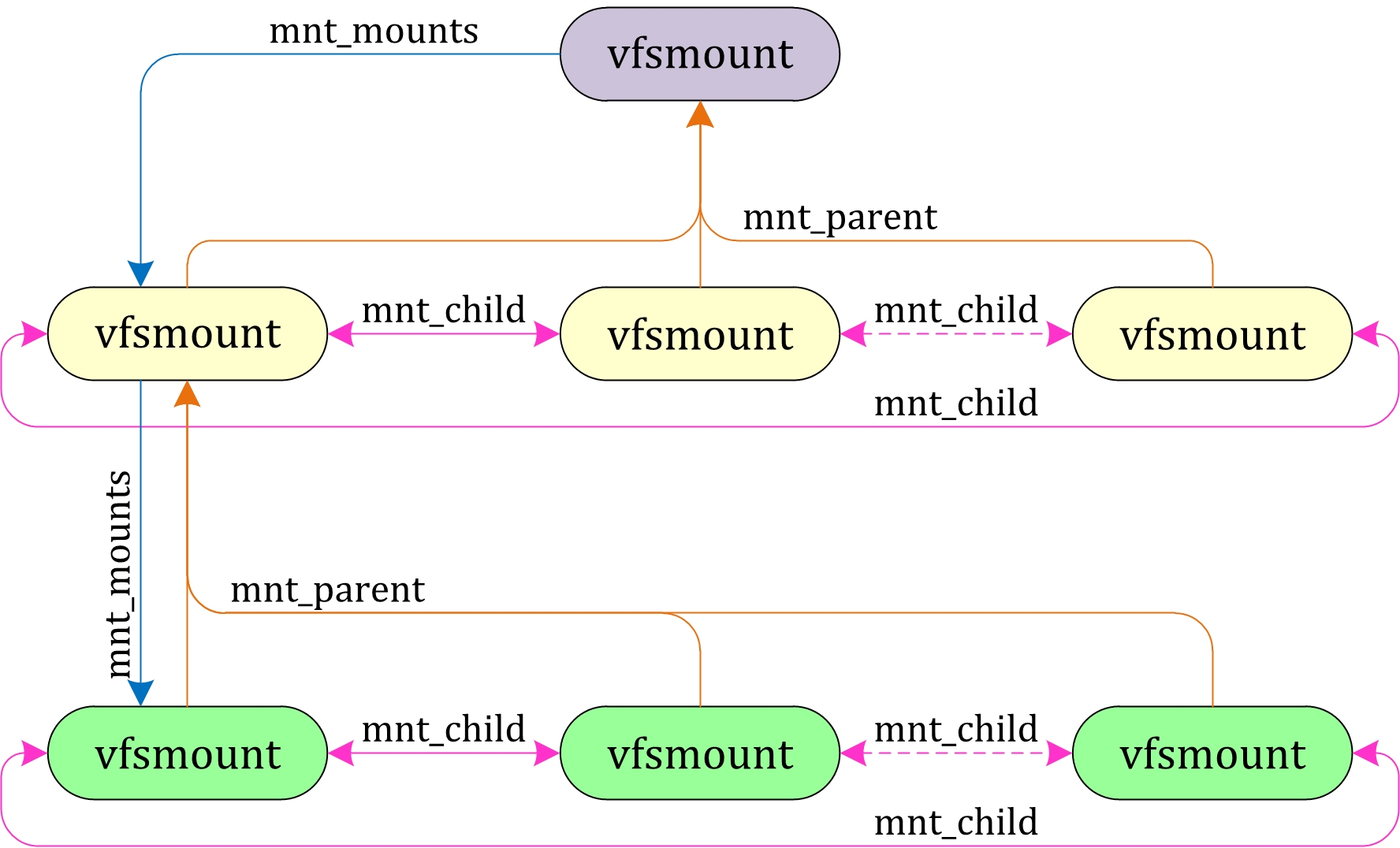
- mnt_slave_list/mnt_slave/mnt_master
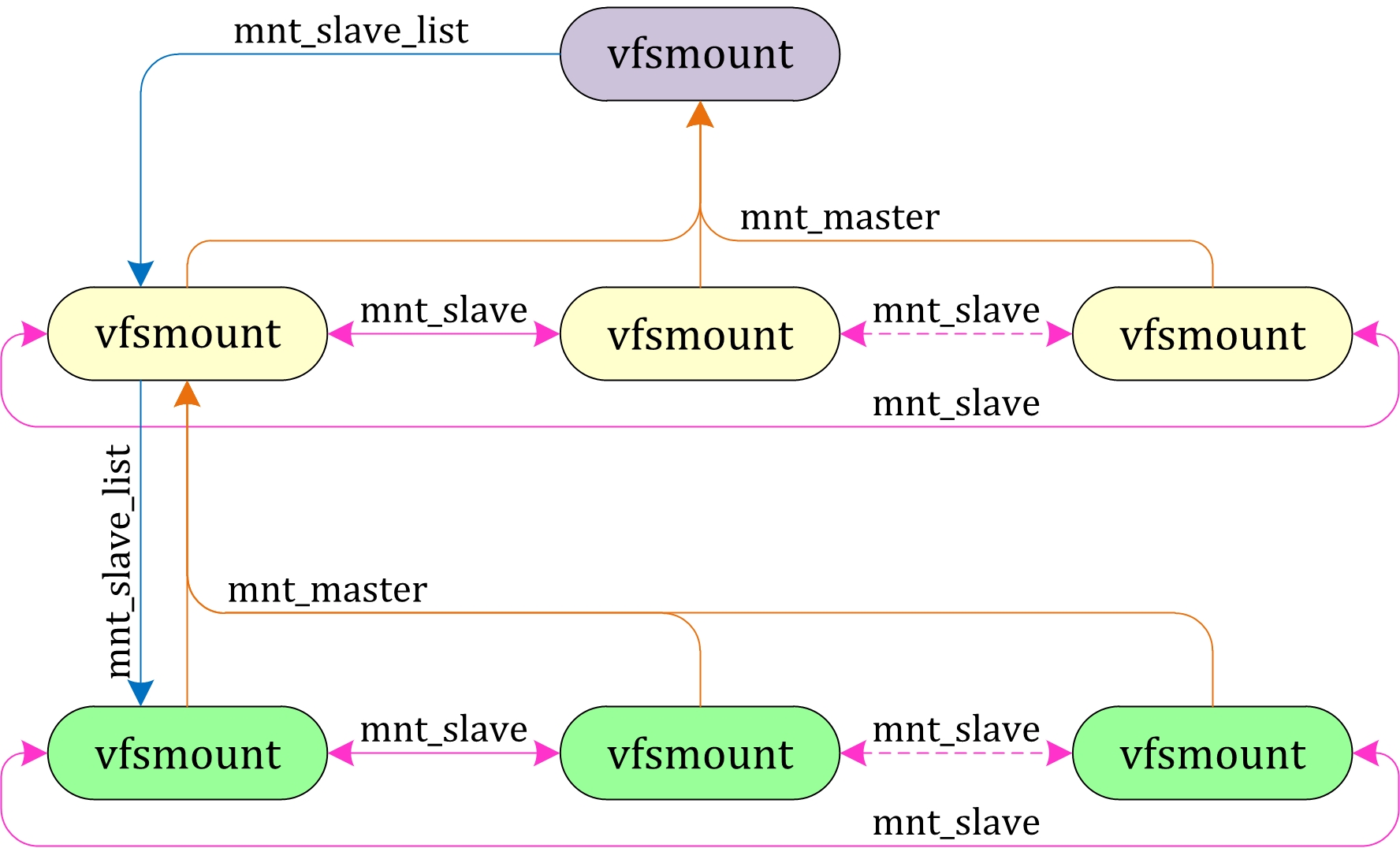
11.2.1.6.2 如何创建struct vfsmount对象
struct vfsmount类型的对象是在安装文件系统时创建的:
kern_mount(type) / kern_mount_data(type, NULL) // 参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
-> mnt = vfs_kern_mount(type, MS_KERNMOUNT, // 参见[11.2.2.2.1 vfs_kern_mount()]节
type->name, data);
-> alloc_vfsmnt(name) // 参见[11.2.2.2.1.1 alloc_vfsmnt()]节
-> mnt = kmem_cache_zalloc(mnt_cache, GFP_KERNEL);
其中,缓冲区mnt_cache是在系统启动时初始化的:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> vfs_caches_init() // 参见[4.3.4.1.4.3.11 vfs_caches_init()]节
-> mnt_init() // 参见[4.3.4.1.4.3.11.4 mnt_init()]节
-> mnt_cache = kmem_cache_create( // 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
"mnt_cache", sizeof(struct vfsmount),
0, SLAB_HWCACHE_ALIGN | SLAB_PANIC, NULL);
11.2.1.7 Data Structures Associated with a Process
11.2.1.7.1 struct files_struct
每个进程用一个struct files_struct类型的对象files(参见11 文件系统/Filesystem节)来记录文件描述符的使用情况,files_struct结构称为用户打开文件表,它是进程的私有数据,参见11.2.4.2.1 open()节以及下图:
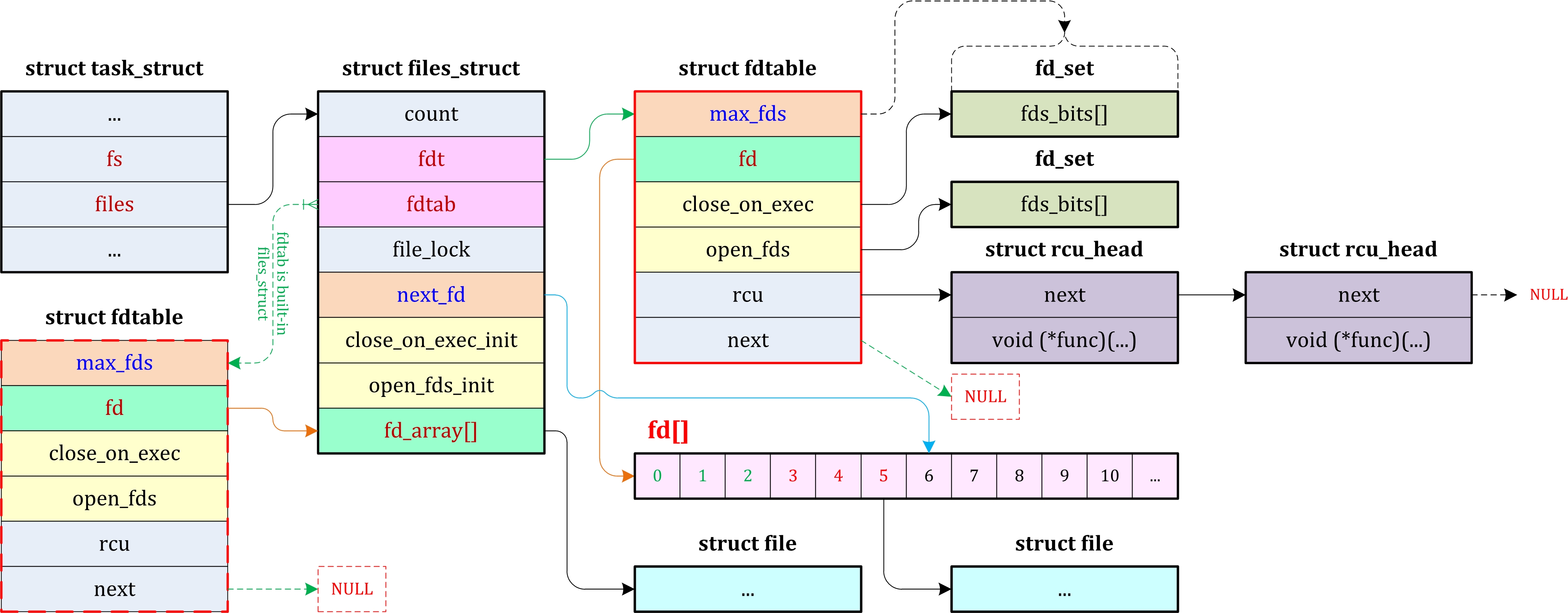
该结构定义于include/linux/fdtable.h:
#define NR_OPEN_DEFAULT BITS_PER_LONG
/*
* Open file table structure
*/
struct files_struct {
/* read mostly part */
/*
* Usage count. Following functions use it:
* get_files_struct(), put_files_struct(), ...
*/
atomic_t count;
struct fdtable __rcu *fdt; // pointer to other fd table
struct fdtable fdtab; // base fd table
/*
* written part on a separate cache line in SMP. per-file lock
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
// cache of next available fd, see alloc_fd() in fs/file.c
int next_fd;
/*
* 分别用于初始化fdt->close_on_exec和fdt->open_fds,
* 参见fs/file.c中的struct files_struct init_files;
*/
struct embedded_fd_set close_on_exec_init;
struct embedded_fd_set open_fds_init;
// base files array, points to the list of open file objects
struct file __rcu *fd_array[NR_OPEN_DEFAULT];
};
struct fdtable {
unsigned int max_fds; // 当前文件对象的最大数
/*
* fd指向文件对象数组的指针,该数组的长度存放在max_fds域中。
* 通常,fd域指向files_struct结构的fd_array域,该域包括32个文件对象指针。
* 若进程打开的文件数目多于32个,则内核就分配一个新的、更大的文件指针数组,并
* 将其地址存放在fd域中;同时更新max_fds域;
* 通常,fd数组的索引就是文件描述符(file descriptor):
* - 数组的第一个元素(索引为0)是进程的标准输入文件
* - 数组的第二个元素(索引为1)是进程的标准输出文件
* - 数组的第三个元素(索引为2)是进程的标准错误文件
* 可通过"ll /proc/<1684>/fd/"查看fd数组的内容。
*/
struct file __rcu **fd; /* current fd array */
fd_set *close_on_exec; // 执行exec()时需要关闭的文件描述符
fd_set *open_fds; // 打开文件描述符的掩码
struct rcu_head rcu;
struct fdtable *next;
};
/*
* The embedded_fd_set is a small fd_set,
* suitable for most tasks (which open <= BITS_PER_LONG files)
*/
struct embedded_fd_set {
unsigned long fds_bits[1];
};
current->files结构:
11.2.1.7.2 struct fs_struct
struct fs_struct contains filesystem information related to a process and is pointed at by the fs field in the process descriptor.
该结构定义于include/linux/fs_struct.h:
struct fs_struct {
int users; // 共享该表的进程个数
spinlock_t lock; // per-structure lock
seqcount_t seq; // 用于表中字段的读/写自旋锁
/*
* 系统调用umask()用于为新创建的文件设置初始文件权限,参见kernel/sys.c;
* 函数current_umask()返回current->fs->umask的取值
*/
int umask;
/*
* currently executing a file, see functions:
* sys_execve()->do_execve()->do_execve_common()
*/
int in_exec;
/*
* root - root directory
* pwd - current working directory
*/
struct path root, pwd;
};
11.2.1.7.3 struct mnt_namespace
该结构定义于include/linux/mnt_namespace.h:
struct mnt_namespace {
atomic_t count; // usage count
struct vfsmount *root; // root directory
struct list_head list; // list of mount points
wait_queue_head_t poll; // polling waitqueue
int event; // event count
};
其结构参见:
11.2.2 虚拟文件系统(VFS)相关操作
VFS是虚拟的,它无法涉及到具体文件系统的细节,所以必然在VFS和具体文件系统之间有一些接口,这就是VFS设计的一些有关操作的数据结构。这些数据结构就好象是一个标准,具体文件系统要想被Linux支持,就必须按这个标准来编写自己操作函数。实际上,也正是这样,各种Linux支持的具体文件系统都有一套自己的操作函数,在安装时,这些结构体的成员指针将被初始化,指向对应的函数。如果说VFS体现了Linux的优越性的话,那么这些数据结构的设计就体现了VFS的优越性所在。VFS和具体文件系统的关系,如下图所示:
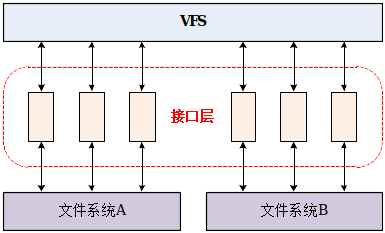
11.2.2.1 注册/注销文件系统
函数register_filesystem()用于注册指定的文件系统,其定义于fs/filesystem.c:
/**
* register_filesystem - register a new filesystem
* @fs: the file system structure
*
* Adds the file system passed to the list of file systems the kernel
* is aware of for mount and other syscalls. Returns 0 on success,
* or a negative errno code on an error.
*
* The &struct file_system_type that is passed is linked into the kernel
* structures and must not be freed until the file system has been
* unregistered.
*/
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
// 文件系统的名字不能包含".",参见[11.2.2.4.1.2.1.2 fs_set_subtype()]节
BUG_ON(strchr(fs->name, '.'));
// 一次只能注册一个文件系统,即fs->next = NULL;
if (fs->next)
return -EBUSY;
/*
* 初始化该文件系统的超级块链表,
* 参见[11.2.1.1.1 文件系统链表/file_systems]节
*/
INIT_LIST_HEAD(&fs->fs_supers);
write_lock(&file_systems_lock);
/*
* 根据文件系统的名字,检查链表file_systems中是否已
* 存在该文件系统,参见[11.2.1.1.1 文件系统链表/file_systems]节。
* 若链表file_systems中已存在该文件系统,则注册失败;
* 否则,将该文件系统添加至链表file_systems的末尾
*/
p = find_filesystem(fs->name, strlen(fs->name));
if (*p)
res = -EBUSY;
else
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
函数unregister_filesystem()用于注销指定的文件系统,其定义于fs/filesystem.c:
/**
* unregister_filesystem - unregister a file system
* @fs: filesystem to unregister
*
* Remove a file system that was previously successfully registered
* with the kernel. An error is returned if the file system is not found.
* Zero is returned on a success.
*
* Once this function has returned the &struct file_system_type structure
* may be freed or reused.
*/
int unregister_filesystem(struct file_system_type * fs)
{
struct file_system_type ** tmp;
write_lock(&file_systems_lock);
/*
* 从链表file_systems中查找指定的文件系统并注销
* 该文件系统,参见[11.2.1.1.1 文件系统链表/file_systems]节
*/
tmp = &file_systems;
while (*tmp) {
if (fs == *tmp) {
*tmp = fs->next;
fs->next = NULL;
write_unlock(&file_systems_lock);
synchronize_rcu();
return 0;
}
tmp = &(*tmp)->next;
}
write_unlock(&file_systems_lock);
return -EINVAL;
}
11.2.2.2 安装文件系统(1)/kern_mount()
When a filesystem is mounted on a directory, the contents of the directory in the parent filesystem are no longer accessible, because every pathname, including the mount point, will refer to the mounted filesystem. However, the original directory’s content shows up again when the filesystem is unmounted. This somewhat surprising feature of Unix filesystems is used by system administrators to hide files; they simply mount a filesystem on the directory containing the files to be hidden.
宏kern_mount()用来安装文件系统,其定义于include/linux/fs.h:
/*
* 参数type为struct file_system_type类型,
* 参见[11.2.1.1 文件系统类型/struct file_system_type]节
*/
#define kern_mount(type) kern_mount_data(type, NULL)
其中,函数```kern_mount_data()```定义于fs/namespace.c:
struct vfsmount *kern_mount_data(struct file_system_type *type, void *data)
{
struct vfsmount *mnt;
// 安装type类型的文件系统,并返回该文件系统的挂载点,参见[11.2.2.2.1 vfs_kern_mount()]节
mnt = vfs_kern_mount(type, MS_KERNMOUNT, type->name, data);
if (!IS_ERR(mnt)) {
/*
* it is a longterm mount, don't release mnt until
* we unmount before file sys is unregistered
*/
/*
* increment atomic variable: mnt->mnt_longterm
* 与kern_unmount()->mnt_make_shortterm()相对应,
* 参见[11.2.2.3 卸载文件系统(1)/kern_unmount()]节
*/
mnt_make_longterm(mnt);
}
return mnt;
}
函数kern_mount()的调用关系如下:
fs_initcall(anon_inode_init)
-> anon_inode_init()
-> register_filesystem(&anon_inode_fs_type);
-> anon_inode_mnt = kern_mount(&anon_inode_fs_type);
vfs_caches_init()
-> bdev_cache_init()
-> register_filesystem(&bd_type);
-> bd_mnt = kern_mount(&bd_type);
module_init(init_devpts_fs)
-> init_devpts_fs()
-> register_filesystem(&devpts_fs_type);
-> devpts_mnt = kern_mount(&devpts_fs_type);
module_init(init_hugetlbfs_fs)
-> init_hugetlbfs_fs()
-> register_filesystem(&hugetlbfs_fs_type);
-> vfsmount = kern_mount(&hugetlbfs_fs_type);
mnt_init()
-> sysfs_init()
-> register_filesystem(&sysfs_fs_type);
-> sysfs_mnt = kern_mount(&sysfs_fs_type);
module_init(init_mtdchar)
-> init_mtdchar()
-> register_filesystem(&mtd_inodefs_type);
-> mtd_inode_mnt = kern_mount(&mtd_inodefs_type);
__initcall(pfm_init)
-> pfm_init()
-> init_pfm_fs()
-> register_filesystem(&pfm_fs_type);
-> pfmfs_mnt = kern_mount(&pfm_fs_type);
fs_initcall(init_pipe_fs)
-> init_pipe_fs()
-> register_filesystem(&pipe_fs_type);
-> pipe_mnt = kern_mount(&pipe_fs_type);
__initcall(init_sel_fs)
-> init_sel_fs()
-> register_filesystem(&sel_fs_type);
-> selinuxfs_mount = kern_mount(&sel_fs_type);
do_basic_setup()
-> shmem_init()
-> register_filesystem(&shmem_fs_type);
-> shm_mnt = kern_mount(&shmem_fs_type);
__initcall(init_smk_fs)
-> init_smk_fs()
-> register_filesystem(&smk_fs_type);
-> smackfs_mount = kern_mount(&smk_fs_type);
core_initcall(sock_init)
-> sock_init()
-> register_filesystem(&sock_fs_type);
-> sock_mnt = kern_mount(&sock_fs_type);
11.2.2.2.1 vfs_kern_mount()
该函数定义于fs/namespace.c:
struct vfsmount *vfs_kern_mount(struct file_system_type *type, int flags,
const char *name, void *data)
{
struct vfsmount *mnt;
struct dentry *root;
if (!type)
return ERR_PTR(-ENODEV);
/*
* Allocate a new mounted filesystem descriptor and
* stores its address in the mnt local variable.
* 从缓存mnt_cache(由mnt_init()分配,参见[4.3.4.1.4.3.11.4 mnt_init()]节)
* 中分配并初始化类型为struct vfsmount的内存,
* 参见[11.2.2.2.1.1 alloc_vfsmnt()]节
*/
mnt = alloc_vfsmnt(name);
if (!mnt)
return ERR_PTR(-ENOMEM);
/*
* 通过kern_mount()调用本函数时,设置MS_KERNMOUNT标志,
* 参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
*/
if (flags & MS_KERNMOUNT)
mnt->mnt_flags = MNT_INTERNAL;
/*
* 挂载指定类型的文件系统,并返回挂载后根目录的目录项dentry,
* 参见[11.2.2.2.1.2 mount_fs()]节
*/
root = mount_fs(type, flags, name, data);
if (IS_ERR(root)) {
free_vfsmnt(mnt);
return ERR_CAST(root);
}
mnt->mnt_root = root;
mnt->mnt_sb = root->d_sb;
// 该文件系统挂载后根目录的目录项
mnt->mnt_mountpoint = mnt->mnt_root;
/*
* 此处先将mnt_parent指向自己,当调用do_add_mount()时
* 再将其指向父目录的挂载点,参见[11.2.2.4.1.2.2 do_add_mount()]节
*/
mnt->mnt_parent = mnt;
return mnt;
}
函数vfs_kern_mount()执行后的示意图:
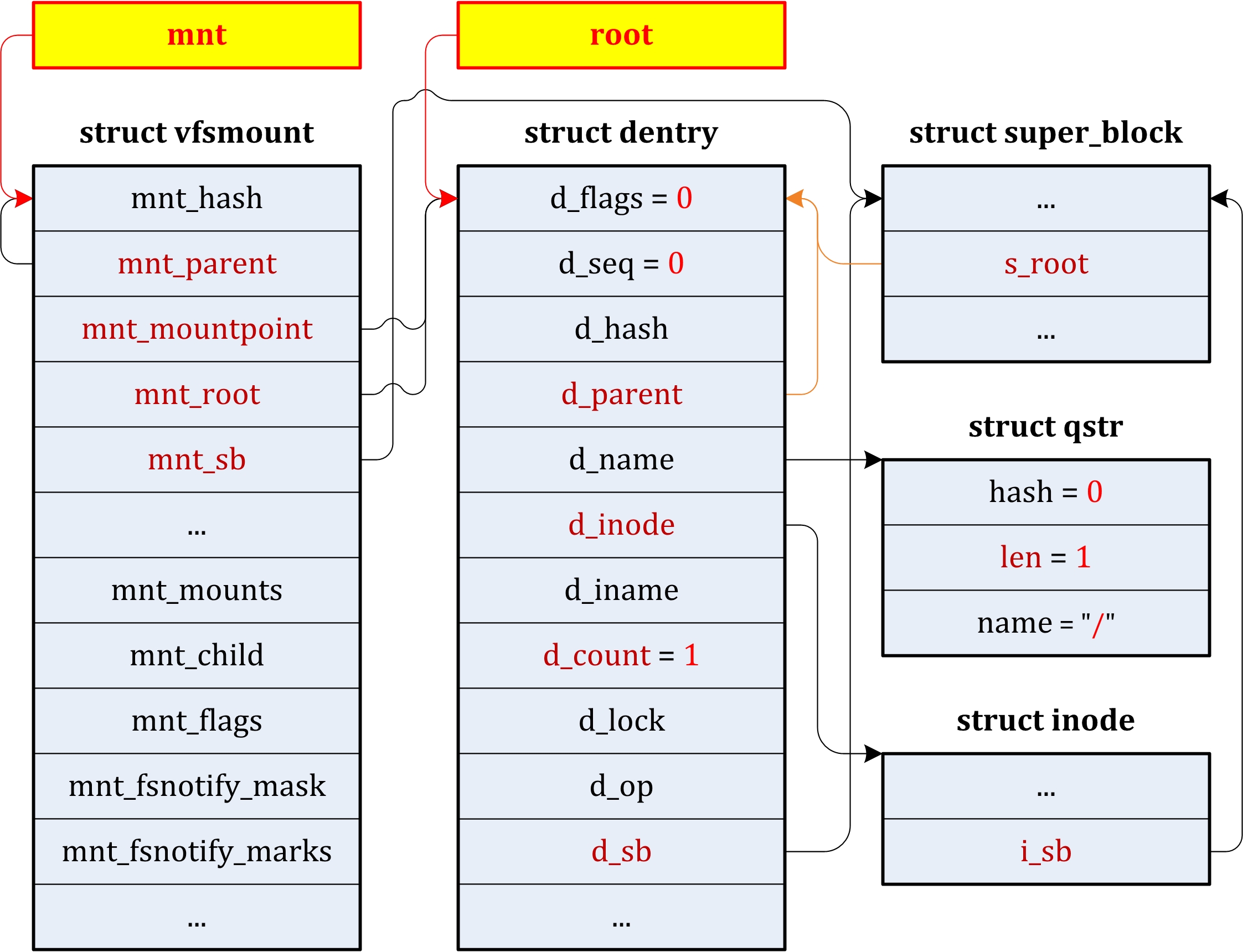
11.2.2.2.1.1 alloc_vfsmnt()
该函数用于分配类型为struct vfsmount的对象,其定义于fs/namespace.c:
static struct vfsmount *alloc_vfsmnt(const char *name)
{
// 从缓存mnt_cache中为mnt分配空间,参见[4.3.4.1.4.3.11.4 mnt_init()]节和[6.5.1.1.3.1 kmem_cache_zalloc()]节
struct vfsmount *mnt = kmem_cache_zalloc(mnt_cache, GFP_KERNEL);
if (mnt) {
int err;
// 分配mnt->mnt_id
err = mnt_alloc_id(mnt);
if (err)
goto out_free_cache;
// 根据文件系统名或者设备名为mnt->mnt_devname赋值
if (name) {
mnt->mnt_devname = kstrdup(name, GFP_KERNEL);
if (!mnt->mnt_devname)
goto out_free_id;
}
#ifdef CONFIG_SMP
mnt->mnt_pcp = alloc_percpu(struct mnt_pcp);
if (!mnt->mnt_pcp)
goto out_free_devname;
this_cpu_add(mnt->mnt_pcp->mnt_count, 1);
#else
mnt->mnt_count = 1;
mnt->mnt_writers = 0;
#endif
// 初始化各链表头
INIT_LIST_HEAD(&mnt->mnt_hash);
INIT_LIST_HEAD(&mnt->mnt_child);
INIT_LIST_HEAD(&mnt->mnt_mounts);
INIT_LIST_HEAD(&mnt->mnt_list);
INIT_LIST_HEAD(&mnt->mnt_expire);
INIT_LIST_HEAD(&mnt->mnt_share);
INIT_LIST_HEAD(&mnt->mnt_slave_list);
INIT_LIST_HEAD(&mnt->mnt_slave);
#ifdef CONFIG_FSNOTIFY
INIT_HLIST_HEAD(&mnt->mnt_fsnotify_marks);
#endif
}
return mnt;
#ifdef CONFIG_SMP
out_free_devname:
kfree(mnt->mnt_devname);
#endif
out_free_id:
mnt_free_id(mnt);
out_free_cache:
kmem_cache_free(mnt_cache, mnt);
return NULL;
}
11.2.2.2.1.2 mount_fs()
该函数安装指定类型的文件系统,其定义于fs/super.c:
struct dentry *mount_fs(struct file_system_type *type, int flags,
const char *name, void *data)
{
struct dentry *root;
struct super_block *sb;
char *secdata = NULL;
int error = -ENOMEM;
/*
* 通过kern_mount()->vfs_kern_mount()->mount_fs()调用时,
* data = NULL; 参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
*/
if (data && !(type->fs_flags & FS_BINARY_MOUNTDATA)) {
secdata = alloc_secdata();
if (!secdata)
goto out;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
error = security_sb_copy_data(data, secdata);
if (error)
goto out_free_secdata;
}
/*
* 调用指定文件系统的安装函数(参见[11.2.1.1 文件系统类型/struct file_system_type]节)
* 来挂载文件系统,并返回挂载后根目录的目录项。
*
* 根据文件系统类型的不同,其安装函数也不同:
* - 若文件系统为sysfs_fs_type,则调用sysfs_mount(),参见[4.3.4.1.4.3.11.4.1 sysfs_init()]节和[11.2.2.2.1.2.1 sysfs_mount()]节;
* - 若文件系统为rootfs_fs_type,则调用rootfs_mount(),参见[4.3.4.1.4.3.11.4.2 init_rootfs()]节和[11.2.2.2.1.2.2 rootfs_mount()]节;
* - 若文件系统为bd_type,则调用bd_mount(),参见[4.3.4.1.4.3.11.5 bdev_cache_init()]节和[11.2.2.2.1.2.3 bd_mount()]节;
* - 若文件系统为proc,则调用proc_mount(),参见[4.3.4.1.4.3.12 proc_root_init()]节和[11.2.2.2.1.2.4 proc_mount()]节;
* - 若文件系统为debugfs,则调用debug_mount(),参见[11.3.7.2 Debugfs的编译及初始化]节和[11.2.2.2.1.2.5 debug_mount()]节;
* - ...
* 其共同点为: 1) 分配该文件系统的超级块; 2) 分配挂载点dentry结构
*/
root = type->mount(type, flags, name, data);
if (IS_ERR(root)) {
error = PTR_ERR(root);
goto out_free_secdata;
}
sb = root->d_sb;
BUG_ON(!sb);
WARN_ON(!sb->s_bdi);
WARN_ON(sb->s_bdi == &default_backing_dev_info);
sb->s_flags |= MS_BORN;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
error = security_sb_kern_mount(sb, flags, secdata);
if (error)
goto out_sb;
/*
* filesystems should never set s_maxbytes larger than MAX_LFS_FILESIZE
* but s_maxbytes was an unsigned long long for many releases. Throw
* this warning for a little while to try and catch filesystems that
* violate this rule.
*/
WARN((sb->s_maxbytes < 0), "%s set sb->s_maxbytes to "
"negative value (%lld)\n", type->name, sb->s_maxbytes);
up_write(&sb->s_umount);
free_secdata(secdata);
return root;
out_sb:
dput(root);
deactivate_locked_super(sb);
out_free_secdata:
free_secdata(secdata);
out:
return ERR_PTR(error);
}
11.2.2.2.1.2.1 sysfs_mount()
该函数用于安装sysfs文件系统(参见4.3.4.1.4.3.11.4.1 sysfs_init()节),其定义于fs/sysfs/mount.c:
static struct dentry *sysfs_mount(struct file_system_type *fs_type, int flags,
const char *dev_name, void *data)
{
struct sysfs_super_info *info;
enum kobj_ns_type type;
struct super_block *sb;
int error;
// info保存了sysfs文件系统的超级块的私有信息
info = kzalloc(sizeof(*info), GFP_KERNEL);
if (!info)
return ERR_PTR(-ENOMEM);
/*
* 函数kobj_ns_grab_current()通过kobj_ns_ops_tbl[type]->grab_current_ns()
* 返回current->nsproxy->net_ns;
* kobj_ns_ops_tbl[]通过如下函数调用注册sysfs的命名空间:
* subsys_initcall(net_dev_init)
* -> netdev_kobject_init()
* -> kobj_ns_type_register(&net_ns_type_operations)
*/
for (type = KOBJ_NS_TYPE_NONE; type < KOBJ_NS_TYPES; type++)
info->ns[type] = kobj_ns_grab_current(type);
/*
* 创建超级块,并将其链接到super_blocks链表
* (参见[11.2.1.2.1 超级块链表/super_blocks]节)中,参见[11.2.1.2.2.1 分配超级块/sget()]节
*/
sb = sget(fs_type, sysfs_test_super, sysfs_set_super, info);
if (IS_ERR(sb) || sb->s_fs_info != info)
free_sysfs_super_info(info);
if (IS_ERR(sb))
return ERR_CAST(sb);
if (!sb->s_root) {
sb->s_flags = flags;
// 分配根节点sb->s_root,参见[11.2.2.2.1.2.1.1 sysfs_fill_super()]节
error = sysfs_fill_super(sb, data, flags & MS_SILENT ? 1 : 0);
if (error) {
deactivate_locked_super(sb);
return ERR_PTR(error);
}
sb->s_flags |= MS_ACTIVE;
}
// 增加根目录的目录项的使用计数,并返回该目录项,参见[11.2.2.2.1.2.1.2 dget()]节
return dget(sb->s_root);
}
11.2.2.2.1.2.1.1 sysfs_fill_super()
该函数定义于fs/sysfs/mount.c:
static int sysfs_fill_super(struct super_block *sb, void *data, int silent)
{
struct inode *inode;
struct dentry *root;
sb->s_blocksize = PAGE_CACHE_SIZE;
sb->s_blocksize_bits = PAGE_CACHE_SHIFT;
sb->s_magic = SYSFS_MAGIC;
sb->s_op = &sysfs_ops;
sb->s_time_gran = 1;
/* get root inode, initialize and unlock it */
mutex_lock(&sysfs_mutex);
inode = sysfs_get_inode(sb, &sysfs_root); // 参见[11.2.2.2.1.2.1.1.1 sysfs_get_inode()]节
mutex_unlock(&sysfs_mutex);
if (!inode) {
pr_debug("sysfs: could not get root inode\n");
return -ENOMEM;
}
/* instantiate and link root dentry */
root = d_alloc_root(inode); // 参见[11.2.2.2.1.2.1.1.2 d_alloc_root()]节
if (!root) {
pr_debug("%s: could not get root dentry!\n",__func__);
iput(inode);
return -ENOMEM;
}
root->d_fsdata = &sysfs_root;
sb->s_root = root; // 该超级块所在的根目录
return 0;
}
11.2.2.2.1.2.1.1.1 sysfs_get_inode()
该函数定义于fs/sysfs/inode.c:
struct inode *sysfs_get_inode(struct super_block *sb, struct sysfs_dirent *sd)
{
struct inode *inode;
inode = iget_locked(sb, sd->s_ino);
if (inode && (inode->i_state & I_NEW))
sysfs_init_inode(sd, inode);
return inode;
}
其中,函数sysfs_init_inode()定义于fs/sysfs/inode.c:
static void sysfs_init_inode(struct sysfs_dirent *sd, struct inode *inode)
{
struct bin_attribute *bin_attr;
inode->i_private = sysfs_get(sd);
inode->i_mapping->a_ops = &sysfs_aops;
inode->i_mapping->backing_dev_info = &sysfs_backing_dev_info;
inode->i_op = &sysfs_inode_operations;
set_default_inode_attr(inode, sd->s_mode);
sysfs_refresh_inode(sd, inode);
/* initialize inode according to type */
switch (sysfs_type(sd)) {
// 1) 设置目录操作函数,参见fs/sysfs/dir.c
case SYSFS_DIR:
inode->i_op = &sysfs_dir_inode_operations;
inode->i_fop = &sysfs_dir_operations;
break;
// 2) 设置文件操作函数,参见fs/sysfs/file.c和[11.3.5.4 sysfs文件操作/sysfs_file_operations]节
case SYSFS_KOBJ_ATTR:
inode->i_size = PAGE_SIZE;
inode->i_fop = &sysfs_file_operations;
break;
// 3) 设置二进制文件操作函数,参见fs/sysfs/bin.c
case SYSFS_KOBJ_BIN_ATTR:
bin_attr = sd->s_bin_attr.bin_attr;
inode->i_size = bin_attr->size;
inode->i_fop = &bin_fops;
break;
// 4) 设置链接操作函数,参见fs/sysfs/symlink.c
case SYSFS_KOBJ_LINK:
inode->i_op = &sysfs_symlink_inode_operations;
break;
default:
BUG();
}
unlock_new_inode(inode);
}
11.2.2.2.1.2.1.1.2 d_alloc_root()
该函数定义于fs/dcache.c:
/**
* d_alloc_root - allocate root dentry
* @root_inode: inode to allocate the root for
*
* Allocate a root ("/") dentry for the inode given. The inode is
* instantiated and returned. %NULL is returned if there is insufficient
* memory or the inode passed is %NULL.
*/
struct dentry * d_alloc_root(struct inode * root_inode)
{
struct dentry *res = NULL;
if (root_inode) {
// 根目录名和长度
static const struct qstr name = { .name = "/", .len = 1 };
/*
* 从缓存dentry_cache中(参见[4.3.4.1.4.3.11.1 dcache_init()]节)分配根目录项,
* 并赋值,参见[11.2.2.2.1.2.1.1.3 __d_alloc()]节
*/
res = __d_alloc(root_inode->i_sb, &name);
// 填写根目录项对应的inode信息,参见[11.2.2.2.1.2.1.1.4 d_instantiate()]节
if (res)
d_instantiate(res, root_inode);
}
return res;
}
函数d_alloc_root()执行后的目录项结构:
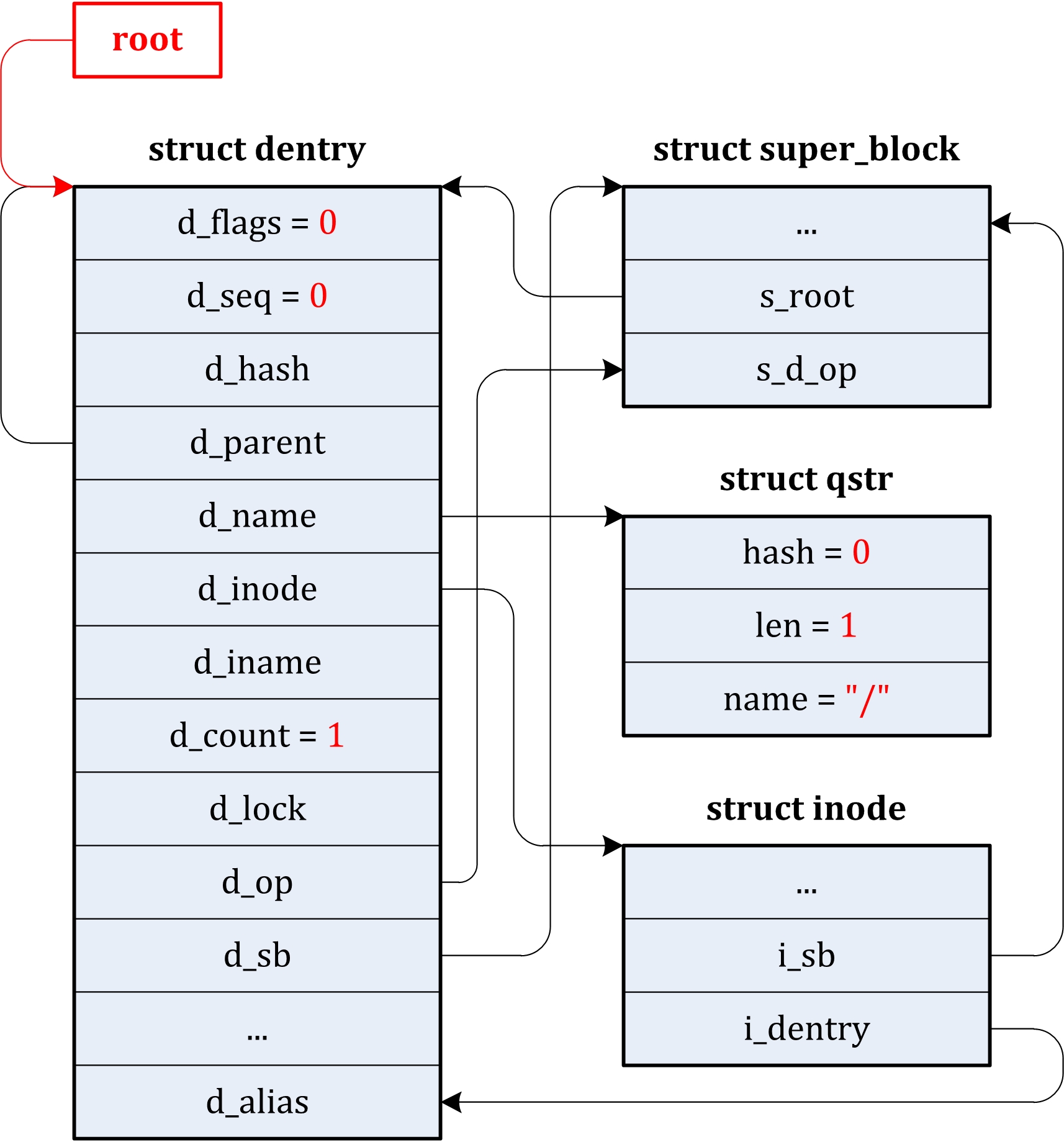
11.2.2.2.1.2.1.1.3 __d_alloc()
该函数定义于fs/dcache.c:
/**
* __d_alloc - allocate a dcache entry
* @sb: filesystem it will belong to
* @name: qstr of the name
*
* Allocates a dentry. It returns %NULL if there is insufficient memory
* available. On a success the dentry is returned. The name passed in is
* copied and the copy passed in may be reused after this call.
*/
struct dentry *__d_alloc(struct super_block *sb, const struct qstr *name)
{
struct dentry *dentry;
char *dname;
/*
* 从缓存dentry_cache中获取目录项,参见[4.3.4.1.4.3.11.1 dcache_init()]节
* 和[6.5.1.1.3.1 kmem_cache_zalloc()]节
*/
dentry = kmem_cache_alloc(dentry_cache, GFP_KERNEL);
if (!dentry)
return NULL;
// 初始化该目录项
if (name->len > DNAME_INLINE_LEN-1) {
dname = kmalloc(name->len + 1, GFP_KERNEL);
if (!dname) {
kmem_cache_free(dentry_cache, dentry);
return NULL;
}
} else {
dname = dentry->d_iname;
}
dentry->d_name.name = dname;
dentry->d_name.len = name->len;
dentry->d_name.hash = name->hash;
memcpy(dname, name->name, name->len);
dname[name->len] = 0;
dentry->d_count = 1;
dentry->d_flags = 0;
spin_lock_init(&dentry->d_lock);
seqcount_init(&dentry->d_seq);
dentry->d_inode = NULL;
dentry->d_parent = dentry;
dentry->d_sb = sb;
dentry->d_op = NULL;
dentry->d_fsdata = NULL;
INIT_HLIST_BL_NODE(&dentry->d_hash);
INIT_LIST_HEAD(&dentry->d_lru);
INIT_LIST_HEAD(&dentry->d_subdirs);
INIT_LIST_HEAD(&dentry->d_alias);
INIT_LIST_HEAD(&dentry->d_u.d_child);
/*
* 为下列变量赋值:
* - dentry->d_op = dentry->d_sb->s_d_op;
* - dentry→d_flags = ...
*/
d_set_d_op(dentry, dentry->d_sb->s_d_op);
this_cpu_inc(nr_dentry);
return dentry;
}
11.2.2.2.1.2.1.1.4 d_instantiate()
该函数定义于fs/dcache.c:
/**
* d_instantiate - fill in inode information for a dentry
* @entry: dentry to complete
* @inode: inode to attach to this dentry
*
* Fill in inode information in the entry.
*
* This turns negative dentries into productive full members
* of society.
*
* NOTE! This assumes that the inode count has been incremented
* (or otherwise set) by the caller to indicate that it is now
* in use by the dcache.
*/
void d_instantiate(struct dentry *entry, struct inode * inode)
{
BUG_ON(!list_empty(&entry->d_alias));
if (inode)
spin_lock(&inode->i_lock);
__d_instantiate(entry, inode);
if (inode)
spin_unlock(&inode->i_lock);
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
security_d_instantiate(entry, inode);
}
static void __d_instantiate(struct dentry *dentry, struct inode *inode)
{
spin_lock(&dentry->d_lock);
if (inode) {
if (unlikely(IS_AUTOMOUNT(inode)))
dentry->d_flags |= DCACHE_NEED_AUTOMOUNT;
list_add(&dentry->d_alias, &inode->i_dentry);
}
dentry->d_inode = inode;
dentry_rcuwalk_barrier(dentry);
spin_unlock(&dentry->d_lock);
// 更新dentry->d_flags
fsnotify_d_instantiate(dentry, inode);
}
11.2.2.2.1.2.1.2 dget()
该函数定义于include/linux/dcache.h:
static inline struct dentry *dget(struct dentry *dentry)
{
if (dentry) {
spin_lock(&dentry->d_lock);
dget_dlock(dentry);
spin_unlock(&dentry->d_lock);
}
return dentry;
}
/**
* dget, dget_dlock - get a reference to a dentry
* @dentry: dentry to get a reference to
*
* Given a dentry or %NULL pointer increment the reference count
* if appropriate and return the dentry. A dentry will not be
* destroyed when it has references.
*/
static inline struct dentry *dget_dlock(struct dentry *dentry)
{
if (dentry)
dentry->d_count++;
return dentry;
}
11.2.2.2.1.2.2 rootfs_mount()
该函数定义于fs/ramfs/inode.c:
static struct dentry *rootfs_mount(struct file_system_type *fs_type, int flags, const char *dev_name, void *data)
{
return mount_nodev(fs_type, flags|MS_NOUSER, data, ramfs_fill_super);
}
其中,函数mount_nodev(fs_type, flags|MS_NOUSER, data, ramfs_fill_super)被扩展为:
mount_nodev(rootfs_fs_type, 0|MS_NOUSER, NULL, ramfs_fill_super)
函数mount_nodev()定义于fs/super.c:
struct dentry *mount_nodev(struct file_system_type *fs_type, int flags, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
int error;
/*
* 创建超级块,并将其链接到super_blocks链表
* (参见[11.2.1.2.1 超级块链表/super_blocks]节)中,参见[11.2.1.2.2.1 分配超级块/sget()]节
*/
struct super_block *s = sget(fs_type, NULL, set_anon_super, NULL);
if (IS_ERR(s))
return ERR_CAST(s);
s->s_flags = flags;
// 根据入参,此处实际调用了函数ramfs_fill_super(s, NULL, 0),参见下文
error = fill_super(s, data, flags & MS_SILENT ? 1 : 0);
if (error) {
deactivate_locked_super(s);
return ERR_PTR(error);
}
s->s_flags |= MS_ACTIVE;
return dget(s->s_root);
}
函数ramfs_fill_super()定义于fs/ramfs/inode.c:
static const struct super_operations ramfs_ops = {
.statfs = simple_statfs,
.drop_inode = generic_delete_inode,
.show_options = generic_show_options,
};
int ramfs_fill_super(struct super_block *sb, void *data, int silent)
{
struct ramfs_fs_info *fsi;
struct inode *inode = NULL;
struct dentry *root;
int err;
// 为sb->s_options赋值
save_mount_options(sb, data);
fsi = kzalloc(sizeof(struct ramfs_fs_info), GFP_KERNEL);
sb->s_fs_info = fsi;
if (!fsi) {
err = -ENOMEM;
goto fail;
}
err = ramfs_parse_options(data, &fsi->mount_opts);
if (err)
goto fail;
sb->s_maxbytes = MAX_LFS_FILESIZE;
sb->s_blocksize = PAGE_CACHE_SIZE;
sb->s_blocksize_bits = PAGE_CACHE_SHIFT;
sb->s_magic = RAMFS_MAGIC;
sb->s_op = &ramfs_ops;
sb->s_time_gran = 1;
// 创建索引节点,并初始化
inode = ramfs_get_inode(sb, NULL, S_IFDIR | fsi->mount_opts.mode, 0);
if (!inode) {
err = -ENOMEM;
goto fail;
}
// 创建根目录项,参见[11.2.2.2.1.2.1.1.2 d_alloc_root()]节
root = d_alloc_root(inode);
sb->s_root = root;
if (!root) {
err = -ENOMEM;
goto fail;
}
return 0;
fail:
kfree(fsi);
sb->s_fs_info = NULL;
iput(inode);
return err;
}
11.2.2.2.1.2.3 bd_mount()
该函数用来安装bdev文件系统,其定义于fs/block_dev.c:
static const struct super_operations bdev_sops = {
.statfs = simple_statfs,
.alloc_inode = bdev_alloc_inode,
.destroy_inode = bdev_destroy_inode,
.drop_inode = generic_delete_inode,
.evict_inode = bdev_evict_inode,
};
static struct dentry *bd_mount(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
return mount_pseudo(fs_type, "bdev:", &bdev_sops, NULL, 0x62646576);
}
其中,函数mount_pseudo()定义于fs/libfs.c:
/*
* Common helper for pseudo-filesystems (sockfs, pipefs, bdev - stuff that
* will never be mountable)
*/
struct dentry *mount_pseudo(struct file_system_type *fs_type, char *name,
const struct super_operations *ops,
const struct dentry_operations *dops, unsigned long magic)
{
/*
* 创建超级块,并将其链接到super_blocks链表
* (参见[11.2.1.2.1 超级块链表/super_blocks]节)中,参见[11.2.1.2.2.1 分配超级块/sget()]节
*/
struct super_block *s = sget(fs_type, NULL, set_anon_super, NULL);
struct dentry *dentry;
struct inode *root;
struct qstr d_name = {.name = name, .len = strlen(name)};
if (IS_ERR(s))
return ERR_CAST(s);
s->s_flags = MS_NOUSER;
s->s_maxbytes = MAX_LFS_FILESIZE;
s->s_blocksize = PAGE_SIZE;
s->s_blocksize_bits = PAGE_SHIFT;
s->s_magic = magic;
s->s_op = ops ? ops : &simple_super_operations;
s->s_time_gran = 1;
root = new_inode(s);
if (!root)
goto Enomem;
/*
* since this is the first inode, make it number 1. New inodes created
* after this must take care not to collide with it (by passing
* max_reserved of 1 to iunique).
*/
root->i_ino = 1;
root->i_mode = S_IFDIR | S_IRUSR | S_IWUSR;
root->i_atime = root->i_mtime = root->i_ctime = CURRENT_TIME;
// 创建目录项,参见[11.2.2.2.1.2.1.1.3 __d_alloc()]节
dentry = __d_alloc(s, &d_name);
if (!dentry) {
iput(root);
goto Enomem;
}
// 填写根目录项对应的inode信息,参见[11.2.2.2.1.2.1.1.4 d_instantiate()]节
d_instantiate(dentry, root);
s->s_root = dentry;
s->s_d_op = dops;
s->s_flags |= MS_ACTIVE;
return dget(s->s_root);
Enomem:
deactivate_locked_super(s);
return ERR_PTR(-ENOMEM);
}
11.2.2.2.1.2.4 proc_mount()
该函数安装proc文件系统,其调用关系如下:
proc_root_init() // 参见[4.3.4.1.4.3.12 proc_root_init()]节
-> register_filesystem(&proc_fs_type)
-> pid_ns_prepare_proc(&init_pid_ns) // 参见[4.3.4.1.4.3.12 proc_root_init()]节
-> kern_mount_data(&proc_fs_type, &init_pid_ns); // 参见[11.2.2.2.1 vfs_kern_mount()]节
-> vfs_kern_mount(type, MS_KERNMOUNT, type->name, data); // 参见[11.2.2.2.1 vfs_kern_mount()]节
-> mount_fs(type, flags, name, data); // 参见[11.2.2.2.1.2 mount_fs()]节
-> type->mount() // 即proc_fs_type->proc_mount()
函数proc_mount()定义于fs/proc/root.c:
static struct dentry *proc_mount(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
int err;
struct super_block *sb;
struct pid_namespace *ns;
struct proc_inode *ei;
/*
* 由如下函数调用可知,flags包含标志位MS_KERNMOUNT:
* kern_mount_data()->vfs_kern_mount(type, MS_KERNMOUNT, ...)
*/
if (flags & MS_KERNMOUNT)
ns = (struct pid_namespace *)data; // data = &init_pid_ns; see kernel/pid.c
else
ns = current->nsproxy->pid_ns;
/*
* 创建超级块,并将其链接到super_blocks链表
* (参见[11.2.1.2.1 超级块链表/super_blocks]节)中,参见[11.2.1.2.2.1 分配超级块/sget()]节
*/
sb = sget(fs_type, proc_test_super, proc_set_super, ns);
if (IS_ERR(sb))
return ERR_CAST(sb);
if (!sb->s_root) {
sb->s_flags = flags;
err = proc_fill_super(sb); // 参见[11.2.2.2.1.2.4.1 proc_fill_super()]节
if (err) {
deactivate_locked_super(sb);
return ERR_PTR(err);
}
sb->s_flags |= MS_ACTIVE;
}
ei = PROC_I(sb->s_root->d_inode);
if (!ei->pid) {
rcu_read_lock();
ei->pid = get_pid(find_pid_ns(1, ns));
rcu_read_unlock();
}
return dget(sb->s_root);
}
11.2.2.2.1.2.4.1 proc_fill_super()
该函数定义于fs/proc/inode.c:
static const struct super_operations proc_sops = {
.alloc_inode = proc_alloc_inode,
.destroy_inode = proc_destroy_inode,
.drop_inode = generic_delete_inode,
.evict_inode = proc_evict_inode,
.statfs = simple_statfs,
};
int proc_fill_super(struct super_block *s)
{
struct inode * root_inode;
s->s_flags |= MS_NODIRATIME | MS_NOSUID | MS_NOEXEC;
s->s_blocksize = 1024;
s->s_blocksize_bits = 10;
s->s_magic = PROC_SUPER_MAGIC; // PROC_SUPER_MAGIC = 0x9fa0
s->s_op = &proc_sops;
s->s_time_gran = 1;
// proc_root->count++; proc_root参见下文
pde_get(&proc_root);
root_inode = proc_get_inode(s, &proc_root); // 获取inode
if (!root_inode)
goto out_no_root;
root_inode->i_uid = 0;
root_inode->i_gid = 0;
s->s_root = d_alloc_root(root_inode); // 参见[11.2.2.2.1.2.1.1.2 d_alloc_root()]节
if (!s->s_root)
goto out_no_root;
return 0;
out_no_root:
printk("proc_read_super: get root inode failed\n");
iput(root_inode);
pde_put(&proc_root);
return -ENOMEM;
}
其中,变量proc_root定义于fs/proc/root.c:
/*
* This is the root "inode" in the /proc tree..
*/
struct proc_dir_entry proc_root = {
.low_ino = PROC_ROOT_INO, // PROC_ROOT_INO = 1
.namelen = 5,
.mode = S_IFDIR | S_IRUGO | S_IXUGO,
.nlink = 2,
.count = ATOMIC_INIT(1),
.proc_iops = &proc_root_inode_operations,
.proc_fops = &proc_root_operations,
.parent = &proc_root,
.name = "/proc",
};
/*
* proc root can do almost nothing..
*/
static const struct inode_operations proc_root_inode_operations = {
.lookup = proc_root_lookup,
.getattr = proc_root_getattr,
};
/*
* The root /proc directory is special, as it has the
* <pid> directories. Thus we don't use the generic
* directory handling functions for that..
*/
static const struct file_operations proc_root_operations = {
.read = generic_read_dir,
.readdir = proc_root_readdir,
.llseek = default_llseek,
};
11.2.2.2.1.2.5 debug_mount()
该函数定义于fs/debugfs/inode.c:
static struct dentry *debug_mount(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
return mount_single(fs_type, flags, data, debug_fill_super);
}
其中,函数mount_single()定义于fs/super.c:
struct dentry *mount_single(struct file_system_type *fs_type, int flags, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
struct super_block *s;
int error;
// 分配超级块,参见[11.2.1.2.2.1 分配超级块/sget()]节
s = sget(fs_type, compare_single, set_anon_super, NULL);
if (IS_ERR(s))
return ERR_CAST(s);
if (!s->s_root) {
s->s_flags = flags;
/*
* 由函数debug_mount()可知,此处调用debug_fill_super()
* 填充超级块,其定义于fs/debugfs/inode.c
*/
error = fill_super(s, data, flags & MS_SILENT ? 1 : 0);
if (error) {
deactivate_locked_super(s);
return ERR_PTR(error);
}
s->s_flags |= MS_ACTIVE;
} else {
// asks filesystem to change mount options
do_remount_sb(s, flags, data, 0);
}
// 返回debugfs的挂载点目录项,参见[11.2.2.2.1.2.1.2 dget()]节
return dget(s->s_root);
}
11.2.2.3 卸载文件系统(1)/kern_unmount()
该函数定义于fs/namespace.c:
/*
* 本函数的入参struct vfsmount *mnt是函数kern_mount()的返回值,
* 参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
*/
void kern_unmount(struct vfsmount *mnt)
{
/* release long term mount so mount point can be released */
if (!IS_ERR_OR_NULL(mnt)) {
/*
* decrement atomic variable: mnt->mnt_longterm
* 与kern_mount()->mnt_make_longterm()相对应,
* 参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
*/
mnt_make_shortterm(mnt);
mntput(mnt); // 参见[11.2.2.3.2 mntput()]节
}
}
函数kern_unmount()的调用关系如下:
module_exit(exit_hugetlbfs_fs)
-> exit_hugetlbfs_fs()
-> kern_unmount(hugetlbfs_vfsmount);
put_ipc_ns()
-> mq_put_mnt()
-> kern_unmount(ns->mq_mnt);
module_exit(cleanup_mtdchar)
-> cleanup_mtdchar()
-> kern_unmount(mtd_inode_mnt);
module_exit(exit_pipe_fs)
-> exit_pipe_fs()
-> kern_unmount(pipe_mnt);
-> unregister_filesystem(&pipe_fs_type);
release_task()
-> proc_flush_task()
-> pid_ns_release_proc()
-> kern_unmount(ns->proc_mnt);
selinux_disable()
-> exit_sel_fs()
-> kern_unmount(selinuxfs_mount);
-> unregister_filesystem(&sel_fs_type);
11.2.2.3.1 mnt_make_shortterm()
该函数定义于fs/namespace.c:
void mnt_make_shortterm(struct vfsmount *mnt)
{
#ifdef CONFIG_SMP
// 若mnt->mnt_longterm - 1 != 1,则返回;
if (atomic_add_unless(&mnt->mnt_longterm, -1, 1))
return;
/*
* 否则,若mnt->mnt_longterm - 1 == 1,
* 则可以卸载该文件系统,继续将mnt->mnt_longterm减1
*/
br_write_lock(vfsmount_lock);
atomic_dec(&mnt->mnt_longterm);
br_write_unlock(vfsmount_lock);
#endif
}
11.2.2.3.2 mntput()
该函数定义于fs/namespace.c:
void mntput(struct vfsmount *mnt)
{
if (mnt) {
/* avoid cacheline pingpong, hope gcc doesn't get "smart" */
if (unlikely(mnt->mnt_expiry_mark))
mnt->mnt_expiry_mark = 0;
mntput_no_expire(mnt);
}
}
其中,函数mntput_no_expire()定义于fs/namespace.c:
static void mntput_no_expire(struct vfsmount *mnt)
{
put_again:
#ifdef CONFIG_SMP
br_read_lock(vfsmount_lock);
if (likely(atomic_read(&mnt->mnt_longterm))) {
mnt_dec_count(mnt); // mnt->mnt_pcp->mnt_count--
br_read_unlock(vfsmount_lock);
return;
}
br_read_unlock(vfsmount_lock);
br_write_lock(vfsmount_lock);
mnt_dec_count(mnt); // mnt->mnt_pcp->mnt_count--
if (mnt_get_count(mnt)) {
br_write_unlock(vfsmount_lock);
return;
}
#else
mnt_dec_count(mnt); // mnt->mnt_count--
if (likely(mnt_get_count(mnt)))
return;
br_write_lock(vfsmount_lock);
#endif
if (unlikely(mnt->mnt_pinned)) {
mnt_add_count(mnt, mnt->mnt_pinned + 1);
mnt->mnt_pinned = 0;
br_write_unlock(vfsmount_lock);
acct_auto_close_mnt(mnt); // 轮询链表acct_list,参见kernel/acct.c
goto put_again;
}
br_write_unlock(vfsmount_lock);
mntfree(mnt);
}
其中,函数mntfree()用于释放mnt结构,其定义于fs/namespace.c:
static inline void mntfree(struct vfsmount *mnt)
{
struct super_block *sb = mnt->mnt_sb;
/*
* This probably indicates that somebody messed
* up a mnt_want/drop_write() pair. If this
* happens, the filesystem was probably unable
* to make r/w->r/o transitions.
*/
/*
* The locking used to deal with mnt_count decrement provides barriers,
* so mnt_get_writers() below is safe.
*/
WARN_ON(mnt_get_writers(mnt));
fsnotify_vfsmount_delete(mnt); // loop variable: mnt->mnt_fsnotify_marks
dput(mnt->mnt_root); // release dentry: mnt->mnt_root
free_vfsmnt(mnt); // free memory of variable: mnt
deactivate_super(sb); // drop an active reference to superblock: mnt->mnt_sb
}
11.2.2.4 安装文件系统(2)/sys_mount()
该系统调用定义于fs/namespace.c:
/*
* 使用命令 "strace mount –t sysfs sysfs_name /MySysFs" 安装sysfs文件系统时,
* strace结果包含如下系统调用:
* mount("sysfs_name", "/MySysFs", "sysfs", MS_MGC_VAL, NULL) = 0
*/
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name,
char __user *, type, unsigned long, flags, void __user *, data)
{
int ret;
char *kernel_type;
char *kernel_dir;
char *kernel_dev;
unsigned long data_page;
// 获取文件系统类型
ret = copy_mount_string(type, &kernel_type);
if (ret < 0)
goto out_type;
// 获取文件系统安装点
kernel_dir = getname(dir_name);
if (IS_ERR(kernel_dir)) {
ret = PTR_ERR(kernel_dir);
goto out_dir;
}
// 获取设备类型
ret = copy_mount_string(dev_name, &kernel_dev);
if (ret < 0)
goto out_dev;
// 获取安装选项
ret = copy_mount_options(data, &data_page);
if (ret < 0)
goto out_data;
/*
* 安装文件系统的主函数,参见[11.2.2.4.1 do_mount()]节。示例:
* do_mount("sysfs_name", "/MySysFs", "sysfs", MS_MGC_VAL, NULL)
*/
ret = do_mount(kernel_dev, kernel_dir, kernel_type, flags, (void *) data_page);
free_page(data_page);
out_data:
kfree(kernel_dev);
out_dev:
putname(kernel_dir);
out_dir:
kfree(kernel_type);
out_type:
return ret;
}
命令mount和umount的配置文件是/etc/mtab,其简介如下:
The file /etc/mtab is special - it is used by mount and umount to remember which filesystems were mounted, with which options, and by whom - in other words, the mount table plus some extra information. This can be useful. However, the important thing to realise about /etc/mtab is that it is only maintained by the mount and umount programs themselves - it is not a way of accessing the kernel’s internal mount table (to do that on Linux systems, look at /proc/mounts, which is the same format as /etc/mtab but lacks some of the extra information, as it is not remembered by the kernel). This means that if, for some reason, I wrote my own program which mounted a filesystem with the mount() system call, it would not show up in /etc/mtab, because didn’t use the normal mount command. This wouldn’t really hurt anything, except for the fact that some of the features which rely on /etc/mtab’s extra information (such as non-superuser umounts) wouldn’t work.
chenwx@chenwx ~/ $ mount
/dev/sda1 on / type ext4 (rw,errors=remount-ro)
proc on /proc type proc (rw,noexec,nosuid,nodev)
sysfs on /sys type sysfs (rw,noexec,nosuid,nodev)
none on /sys/fs/cgroup type tmpfs (rw)
none on /sys/fs/fuse/connections type fusectl (rw)
none on /sys/kernel/debug type debugfs (rw)
none on /sys/kernel/security type securityfs (rw)
udev on /dev type devtmpfs (rw,mode=0755)
devpts on /dev/pts type devpts (rw,noexec,nosuid,gid=5,mode=0620)
tmpfs on /run type tmpfs (rw,noexec,nosuid,size=10%,mode=0755)
none on /run/lock type tmpfs (rw,noexec,nosuid,nodev,size=5242880)
none on /run/shm type tmpfs (rw,nosuid,nodev)
none on /run/user type tmpfs (rw,noexec,nosuid,nodev,size=104857600,mode=0755)
none on /sys/fs/pstore type pstore (rw)
binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,noexec,nosuid,nodev)
systemd on /sys/fs/cgroup/systemd type cgroup (rw,noexec,nosuid,nodev,none,name=systemd)
vboxshare on /media/sf_vboxshare type vboxsf (gid=108,rw)
gvfsd-fuse on /run/user/1000/gvfs type fuse.gvfsd-fuse (rw,nosuid,nodev,user=chenwx)
chenwx@chenwx ~/ $ cat /etc/mtab
/dev/sda1 / ext4 rw,errors=remount-ro 0 0
proc /proc proc rw,noexec,nosuid,nodev 0 0
sysfs /sys sysfs rw,noexec,nosuid,nodev 0 0
none /sys/fs/cgroup tmpfs rw 0 0
none /sys/fs/fuse/connections fusectl rw 0 0
none /sys/kernel/debug debugfs rw 0 0
none /sys/kernel/security securityfs rw 0 0
udev /dev devtmpfs rw,mode=0755 0 0
devpts /dev/pts devpts rw,noexec,nosuid,gid=5,mode=0620 0 0
tmpfs /run tmpfs rw,noexec,nosuid,size=10%,mode=0755 0 0
none /run/lock tmpfs rw,noexec,nosuid,nodev,size=5242880 0 0
none /run/shm tmpfs rw,nosuid,nodev 0 0
none /run/user tmpfs rw,noexec,nosuid,nodev,size=104857600,mode=0755 0 0
none /sys/fs/pstore pstore rw 0 0
binfmt_misc /proc/sys/fs/binfmt_misc binfmt_misc rw,noexec,nosuid,nodev 0 0
systemd /sys/fs/cgroup/systemd cgroup rw,noexec,nosuid,nodev,none,name=systemd 0 0
vboxshare /media/sf_vboxshare vboxsf gid=108,rw 0 0
gvfsd-fuse /run/user/1000/gvfs fuse.gvfsd-fuse rw,nosuid,nodev,user=chenwx 0 0
chenwx@chenwx ~/ $ cat /proc/mounts
rootfs / rootfs rw 0 0
sysfs /sys sysfs rw,nosuid,nodev,noexec,relatime 0 0
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0
udev /dev devtmpfs rw,relatime,size=764332k,nr_inodes=191083,mode=755 0 0
devpts /dev/pts devpts rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000 0 0
tmpfs /run tmpfs rw,nosuid,noexec,relatime,size=154268k,mode=755 0 0
/dev/disk/by-uuid/fe67c2d0-9b0f-4fd6-8e97-463ce95a7e0c / ext4 rw,relatime,errors=remount-ro,data=ordered 0 0
none /sys/fs/cgroup tmpfs rw,relatime,size=4k,mode=755 0 0
none /sys/fs/fuse/connections fusectl rw,relatime 0 0
none /sys/kernel/debug debugfs rw,relatime 0 0
none /sys/kernel/security securityfs rw,relatime 0 0
none /run/lock tmpfs rw,nosuid,nodev,noexec,relatime,size=5120k 0 0
none /run/shm tmpfs rw,nosuid,nodev,relatime 0 0
none /run/user tmpfs rw,nosuid,nodev,noexec,relatime,size=102400k,mode=755 0 0
none /sys/fs/pstore pstore rw,relatime 0 0
binfmt_misc /proc/sys/fs/binfmt_misc binfmt_misc rw,nosuid,nodev,noexec,relatime 0 0
systemd /sys/fs/cgroup/systemd cgroup rw,nosuid,nodev,noexec,relatime,name=systemd 0 0
none /media/sf_vboxshare vboxsf rw,nodev,relatime 0 0
gvfsd-fuse /run/user/1000/gvfs fuse.gvfsd-fuse rw,nosuid,nodev,relatime,user_id=1000,group_id=1000 0 0
11.2.2.4.1 do_mount()
该函数定义于fs/namespace.c:
/*
* Flags is a 32-bit value that allows up to 31 non-fs dependent flags to
* be given to the mount() call (ie: read-only, no-dev, no-suid etc).
*
* data is a (void *) that can point to any structure up to
* PAGE_SIZE-1 bytes, which can contain arbitrary fs-dependent
* information (or be NULL).
*
* Pre-0.97 versions of mount() didn't have a flags word.
* When the flags word was introduced its top half was required
* to have the magic value 0xC0ED, and this remained so until 2.4.0-test9.
* Therefore, if this magic number is present, it carries no information
* and must be discarded.
*/
// 示例:do_mount("sysfs_name", "/MySysFs", "sysfs", MS_MGC_VAL, NULL)
long do_mount(char *dev_name, char *dir_name, char *type_page,
unsigned long flags, void *data_page)
{
struct path path;
int retval = 0;
int mnt_flags = 0;
/* Discard magic */
if ((flags & MS_MGC_MSK) == MS_MGC_VAL)
flags &= ~MS_MGC_MSK;
/* Basic sanity checks */
if (!dir_name || !*dir_name || !memchr(dir_name, 0, PAGE_SIZE))
return -EINVAL;
if (data_page)
((char *)data_page)[PAGE_SIZE - 1] = 0;
/*
* ... and get the mountpoint
* 获取安装目录dir_name所对应的安装点(path.mnt)和目录项(path.dentry),
* 参见[11.2.2.4.1.1 kern_path()/do_path_lookup()]节和Subjects/Chapter11_Filesystem/Figures/Filesystem_21.jpg
* 示例:kern_path("/MySysFs", LOOKUP_FOLLOW, &path)
*/
retval = kern_path(dir_name, LOOKUP_FOLLOW, &path);
if (retval)
return retval;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
retval = security_sb_mount(dev_name, &path, type_page, flags, data_page);
if (retval)
goto dput_out;
/* Default to relatime unless overriden */
if (!(flags & MS_NOATIME))
mnt_flags |= MNT_RELATIME;
/* Separate the per-mountpoint flags */
if (flags & MS_NOSUID)
mnt_flags |= MNT_NOSUID;
if (flags & MS_NODEV)
mnt_flags |= MNT_NODEV;
if (flags & MS_NOEXEC)
mnt_flags |= MNT_NOEXEC;
if (flags & MS_NOATIME)
mnt_flags |= MNT_NOATIME;
if (flags & MS_NODIRATIME)
mnt_flags |= MNT_NODIRATIME;
if (flags & MS_STRICTATIME)
mnt_flags &= ~(MNT_RELATIME | MNT_NOATIME);
if (flags & MS_RDONLY)
mnt_flags |= MNT_READONLY;
flags &= ~(MS_NOSUID | MS_NOEXEC | MS_NODEV | MS_ACTIVE | MS_BORN | MS_NOATIME |
MS_NODIRATIME | MS_RELATIME| MS_KERNMOUNT | MS_STRICTATIME);
/*
* 1) The purpose of MS_REMOUNT is usually to change the
* mount flags in s_flags field of superblock object and
* mounted filesystem flags in the mnt_flags field of the
* mounted filesystem object.
*/
if (flags & MS_REMOUNT)
retval = do_remount(&path, flags & ~MS_REMOUNT, mnt_flags, data_page);
/*
* 2) User is asking to make visible a file or directory
* on another point of the system directory tree.
*/
else if (flags & MS_BIND)
retval = do_loopback(&path, dev_name, flags & MS_REC);
/*
* 3) Recursively change the type of the mountpoint.
*/
else if (flags & (MS_SHARED | MS_PRIVATE | MS_SLAVE | MS_UNBINDABLE))
retval = do_change_type(&path, flags);
/*
* 4) User is asking to change the mount point of an
* already mounted filesystem.
*/
else if (flags & MS_MOVE)
retval = do_move_mount(&path, dev_name);
/*
* 5) User asks to mount either a special filesystem or
* a regular filesystem stored in a disk partition.
* 参见[11.2.2.4.1.2 do_new_mount()]节。示例:
* do_new_mount(&path, "sysfs", 0, MNT_RELATIME, "sysfs_name", NULL)
*/
else
retval = do_new_mount(&path, type_page, flags, mnt_flags, dev_name, data_page);
dput_out:
path_put(&path);
return retval;
}
11.2.2.4.1.1 kern_path()/do_path_lookup()
函数kern_path()定义于fs/namei.c:
int kern_path(const char *name, unsigned int flags, struct path *path)
{
struct nameidata nd;
// 示例:do_path_lookup(AT_FDCWD, "/MySysFs", LOOKUP_FOLLOW, &nd)
int res = do_path_lookup(AT_FDCWD, name, flags, &nd);
// 参见Subjects/Chapter11_Filesystem/Figures/Filesystem_21.jpg中的nd.path
if (!res)
*path = nd.path;
return res;
}
其中,函数do_path_lookup()定义于fs/namei.c:
static int do_path_lookup(int dfd, const char *name, unsigned int flags,
struct nameidata *nd)
{
// 示例:path_lookupat(AT_FDCWD, "/MySysFs", LOOKUP_FOLLOW | LOOKUP_RCU, &nd)
int retval = path_lookupat(dfd, name, flags | LOOKUP_RCU, nd);
if (unlikely(retval == -ECHILD)) // No child processes
retval = path_lookupat(dfd, name, flags, nd);
if (unlikely(retval == -ESTALE)) // Stale NFS file handle
retval = path_lookupat(dfd, name, flags | LOOKUP_REVAL, nd);
if (likely(!retval)) {
if (unlikely(!audit_dummy_context())) {
if (nd->path.dentry && nd->inode)
audit_inode(name, nd->path.dentry);
}
}
return retval;
}
11.2.2.4.1.1.1 path_lookupat()
该函数定义于fs/namei.c:
/* Returns 0 and nd will be valid on success; Retuns error, otherwise. */
static int path_lookupat(int dfd, const char *name,
unsigned int flags, struct nameidata *nd)
{
struct file *base = NULL;
struct path path;
int err;
/*
* Path walking is largely split up into 2 different synchronisation
* schemes, rcu-walk and ref-walk (explained in
* Documentation/filesystems/path-lookup.txt). These share much of the
* path walk code, but some things particularly setup, cleanup, and
* following mounts are sufficiently divergent that functions are
* duplicated. Typically there is a function foo(), and its RCU
* analogue, foo_rcu().
*
* -ECHILD is the error number of choice (just to avoid clashes) that
* is returned if some aspect of an rcu-walk fails. Such an error must
* be handled by restarting a traditional ref-walk (which will always
* be able to complete).
*/
/*
* 初始化nd,并获取变量: nd->path, nd->inode;参见[11.2.2.4.1.1.1.1 path_init()]节
* 示例:path_init(AT_FDCWD, "/MySysFs", LOOKUP_FOLLOW | LOOKUP_RCU | LOOKUP_PARENT, nd, &base)
*/
err = path_init(dfd, name, flags | LOOKUP_PARENT, nd, &base);
if (unlikely(err))
return err;
/*
* total_link_count用来记录符号链接的深度,每穿
* 越一次符号链接该值就加一,最大允许40层符号链接,
* 参见函数follow_link()
*/
current->total_link_count = 0;
/*
* 示例:link_path_walk("/MySysFs", nd),
* 参见[11.2.2.4.1.1.1.2 link_path_walk()]节
*/
err = link_path_walk(name, nd);
if (!err && !(flags & LOOKUP_PARENT)) {
err = lookup_last(nd, &path);
while (err > 0) {
void *cookie;
struct path link = path;
nd->flags |= LOOKUP_PARENT;
err = follow_link(&link, nd, &cookie);
if (!err)
err = lookup_last(nd, &path);
put_link(nd, &link, cookie);
}
}
if (!err)
err = complete_walk(nd); // 参见[11.2.2.4.1.1.1.3 complete_walk()]节
if (!err && nd->flags & LOOKUP_DIRECTORY) {
if (!nd->inode->i_op->lookup) {
path_put(&nd->path);
err = -ENOTDIR;
}
}
if (base)
fput(base);
if (nd->root.mnt && !(nd->flags & LOOKUP_ROOT)) {
path_put(&nd->root);
nd->root.mnt = NULL;
}
return err;
}
11.2.2.4.1.1.1.1 path_init()
函数path_init()用于初始化nd中的如下成员变量:
nd->last_type
nd->flags
nd->depth
nd->root
nd->path
nd->inode
struct nameidata定义于include/linux/namei.h:
enum { MAX_NESTED_LINKS = 8 };
struct nameidata {
struct path path; // 保存当前搜索到的路径
struct qstr last; // 保存当前子路径名及其散列值
struct path root; // 保存根目录的信息
/*
* path.dentry.d_inode
* 指向当前找到的目录项的inode结构
*/
struct inode *inode;
unsigned int flags; // 和查找相关的标志位
unsigned seq; // 相关目录项的顺序锁序号
/*
* 表示当前子路径的类型,其取值为:
* LAST_NORM - 普通的路径名
* LAST_ROOT - "/"
* LAST_DOT - "."
* LAST_DOTDOT - ".."
* LAST_BIND - 符号链接
*/
int last_type;
// 记录在解析符号链接过程中的递归深度
unsigned depth;
// 记录相应递归深度的符号链接的路径
char *saved_names[MAX_NESTED_LINKS + 1];
/* Intent data */
union {
struct open_intent open;
} intent;
};
该函数定义于fs/namei.c:
// 示例:path_init(AT_FDCWD, "/MySysFs", LOOKUP_FOLLOW | LOOKUP_RCU | LOOKUP_PARENT, nd, &base)
static int path_init(int dfd, const char *name, unsigned int flags,
struct nameidata *nd, struct file **fp)
{
int retval = 0;
int fput_needed;
struct file *file;
/*
* if there are only slashes...
* 即在路径名中只有"/"
*/
nd->last_type = LAST_ROOT;
nd->flags = flags | LOOKUP_JUMPED;
nd->depth = 0;
/*
* 若从根目录开始查找文件,则设置nd->path = nd->root;
* 使用LOOKUP_ROOT标志位的函数包括:
* do_file_open_root(), vfs_path_lookup()
* 这些函数在调用path_init()之前已经为下列变量赋值:
* nd.root.dentry, nd.root.mnt
*/
if (flags & LOOKUP_ROOT) {
struct inode *inode = nd->root.dentry->d_inode;
if (*name) {
if (!inode->i_op->lookup)
return -ENOTDIR;
retval = inode_permission(inode, MAY_EXEC);
if (retval)
return retval;
}
nd->path = nd->root;
nd->inode = inode;
if (flags & LOOKUP_RCU) {
br_read_lock(vfsmount_lock);
rcu_read_lock();
nd->seq = __read_seqcount_begin(&nd->path.dentry->d_seq);
} else {
path_get(&nd->path);
}
return 0;
}
nd->root.mnt = NULL;
if (*name=='/') {
/*
* 1) If the first character of the pathname is "/",
* the pathname is absolute, and the search starts
* from the directory identified by current->fs->root
* (the process root directory).
*/
if (flags & LOOKUP_RCU) {
br_read_lock(vfsmount_lock);
rcu_read_lock();
/*
* 设置nd->root = current->fs->root;
* nd->seq = nd->root.dentry->d_seq.sequence
*/
set_root_rcu(nd);
} else {
// 设置nd->root = current->fs->root
set_root(nd);
path_get(&nd->root);
}
nd->path = nd->root;
} else if (dfd == AT_FDCWD) {
/*
* 2) If dfd == AT_FDCWD (-100), then the pathname is
* relative, and the search starts from the directory
* identified by current->fs->pwd (the process current
* directory).
*/
if (flags & LOOKUP_RCU) {
struct fs_struct *fs = current->fs;
unsigned seq;
br_read_lock(vfsmount_lock);
rcu_read_lock();
do {
seq = read_seqcount_begin(&fs->seq);
nd->path = fs->pwd;
nd->seq = __read_seqcount_begin(&nd->path.dentry->d_seq);
} while (read_seqcount_retry(&fs->seq, seq));
} else {
// 设置nd->path = current->fs->pwd
get_fs_pwd(current->fs, &nd->path);
}
} else {
/*
* 3) Otherwise, the pathname is relative to the file specified
* by file descriptor dfd, then the search starts from the
* directory identified by current->files->fdt->fd[dfd]->f_path.
*/
struct dentry *dentry;
file = fget_raw_light(dfd, &fput_needed);
retval = -EBADF;
if (!file)
goto out_fail;
dentry = file->f_path.dentry;
if (*name) {
retval = -ENOTDIR;
if (!S_ISDIR(dentry->d_inode->i_mode))
goto fput_fail;
retval = inode_permission(dentry->d_inode, MAY_EXEC);
if (retval)
goto fput_fail;
}
nd->path = file->f_path;
if (flags & LOOKUP_RCU) {
if (fput_needed)
*fp = file;
nd->seq = __read_seqcount_begin(&nd->path.dentry->d_seq);
br_read_lock(vfsmount_lock);
rcu_read_lock();
} else {
path_get(&file->f_path);
fput_light(file, fput_needed);
}
}
nd->inode = nd->path.dentry->d_inode;
return 0;
fput_fail:
fput_light(file, fput_needed);
out_fail:
return retval;
}
该函数完成后,变量nd的结构如下:
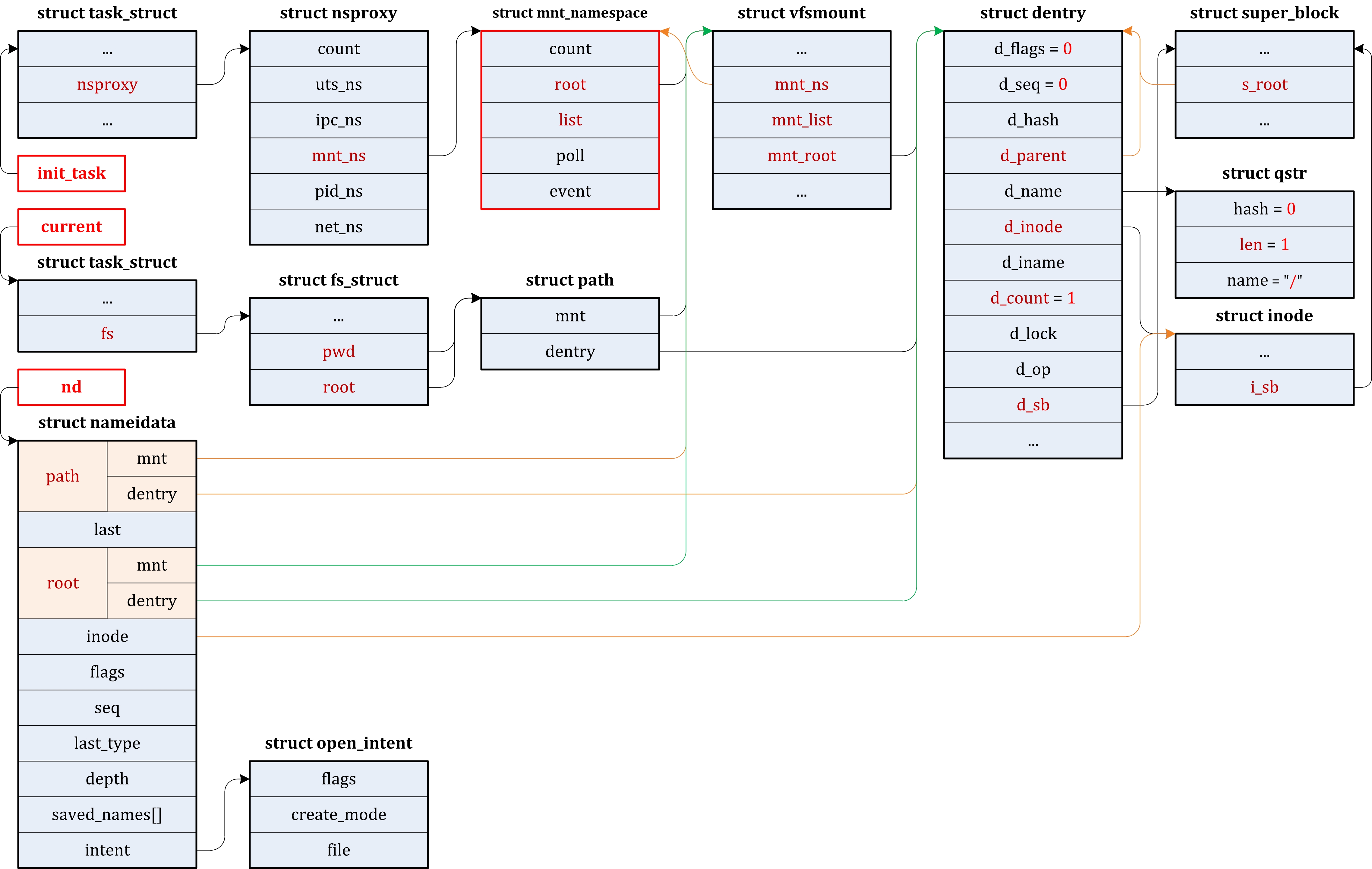
11.2.2.4.1.1.1.2 link_path_walk()
该函数定义于fs/namei.c:
/*
* Name resolution.
* This is the basic name resolution function, turning a pathname into
* the final dentry. We expect 'base' to be positive and a directory.
*
* Returns 0 and nd will have valid dentry and mnt on success.
* Returns error and drops reference to input namei data on failure.
*/
static int link_path_walk(const char *name, struct nameidata *nd)
{
struct path next;
int err;
/*
* 跳过路径名name前部的、(连续的)路径分隔符'/',例如:
* $ ls -l /dev
* $ ls -l ///dev/
*/
while (*name=='/')
name++;
/*
* 若路径名name解析已完成,则说明整个路径只包含一个'/',直接返回;
* 此时,变量nd->last_type的取值为LAST_ROOT,参见[11.2.2.4.1.1.1.1 path_init()]节
*/
if (!*name)
return 0;
/* At this point we know we have a real path component. */
for(;;) {
unsigned long hash;
struct qstr this;
unsigned int c;
int type;
/*
* 1) 检查nd->inode的访问权限nd->inode是由
* 函数path_init()设置的,参见[11.2.2.4.1.1.1.1 path_init()]节
*/
err = may_lookup(nd);
if (err)
break;
/*
* 2) 将路径名name中某节点的信息保存到this中,例如:
* 将路径名"/home/chenwx/tmp"中节点chenwx的信息保存到this中
*/
this.name = name;
/*
* 2.1) 计算路径名中某节点的哈希值,计算公式如下,其中c为路径中的每个字符:
* hash = (hash + (c << 4) + (c >> 4)) * 11;
*
* do-while循环终止的条件:
* a) 不存在子目录或文件: name以'\0'结束,或者以路径分隔符'/'结束;
* b) 存在子目录或文件: name以路径分隔符'/',且其后存在其他字符。
*/
c = *(const unsigned char *)name;
hash = init_name_hash();
do {
name++;
hash = partial_name_hash(c, hash);
c = *(const unsigned char *)name;
} while (c && (c != '/'));
this.len = name - (const char *) this.name;
this.hash = end_name_hash(hash);
/*
* 3) 检查本节点(this)的组成,即本级目录的可能情况:
*/
type = LAST_NORM;
/*
* 3.1) 该节点为特殊目录".."或".",例如:
* /home/../chenwx2/tmp, /home/./chenwx/tmp
*/
if (this.name[0] == '.') switch (this.len) {
case 2:
if (this.name[1] == '.') {
type = LAST_DOTDOT;
nd->flags |= LOOKUP_JUMPED;
}
break;
case 1:
type = LAST_DOT;
}
/*
* 3.2) 该节点为普通目录,例如:
* /home/chenwx/tmp
*/
if (likely(type == LAST_NORM)) {
struct dentry *parent = nd->path.dentry;
nd->flags &= ~LOOKUP_JUMPED;
// 若标志位DCACHE_OP_HASH置位,则需要重新计算hash值
if (unlikely(parent->d_flags & DCACHE_OP_HASH)) {
err = parent->d_op->d_hash(parent, nd->inode, &this);
if (err < 0)
break;
}
}
/*
* 4) 继续检查路径名name中的后续节点
*/
/*
* 4.1) 若到达路径名name中的最后一个节点,则
* 跳转到last_component标志处,并返回
*/
/* remove trailing slashes? */
if (!c)
goto last_component;
while (*++name == '/');
if (!*name)
goto last_component;
/*
* 4.2)
* 若路径名name中存在后续节点,即存在子目录或文件,则继续
* 查找,参见[11.2.2.4.1.1.1.2.1 walk_component()]节。通过walk_component()
* 查找本节点(this)对应的inode,并将nd->inode设置为最
* 新的inode,准备继续解析后续节点。因为目录项所管理的inode
* 在系统中通过hash表进行维护,因此通过hash值可以很容易
* 的找到inode。若内存中还不存在inode对象,对于ext3文
* 件系统则会通过函数ext3_lookup()从磁盘上获取inode的
* 元数据信息,并构造目录项中所有的inode对象。
*
* 当walk_component()返回时,如果当前子路径是一个真正的
* 目录的话,那么nd已经"站在"当前节点上并等着下一次循环再
* 往前"站"一步。而如果当前子路径只是一个符号链接的话,nd
* 会在原地不动,也就是说:如果不是真正的目录nd绝不会站上
* 去。对于next来说,不管当前子路径是不是真正的目录它都会
* 先站上去再说。接着next会和nest_symlink联手帮助nd在
* 下一个真正的目录"上位"。
*/
err = walk_component(nd, &next, &this, type, LOOKUP_FOLLOW);
if (err < 0)
return err;
if (err) {
err = nested_symlink(&next, nd);
if (err)
return err;
}
/*
* 4.3) 若变量nd->inode->i_opflags中已设置标志位IOP_LOOKUP,
* 或者nd->inode->i_op->lookup != NULL,则继续查询下级
* 目录;否则,终止
*/
if (can_lookup(nd->inode))
continue;
err = -ENOTDIR; /* Not a directory */
break;
/* here ends the main loop */
last_component:
/*
* 路径名name中最后一个节点不需要解析处理,
* 此处结束解析,正确返回
*/
nd->last = this;
nd->last_type = type;
return 0;
}
terminate_walk(nd);
return err;
}
函数link_path_walk(name, nd)执行完成后,变量nd中的path和inode指向路径name中最后一部分所对应的dentry结构和inode结构,参见:
而函数kern_path()只需要变量nd.path所包含的信息。
11.2.2.4.1.1.1.2.1 walk_component()
该函数定义于fs/namei.c:
static inline int walk_component(struct nameidata *nd, struct path *path,
struct qstr *name, int type, int follow)
{
struct inode *inode;
int err;
/*
* 1) 若当前子路径是"."或"..",则调用handle_dots()来处理
*
* "." and ".." are special - ".." especially so because it
* has to be able to know about the current root directory
* and parent relationships.
*/
if (unlikely(type != LAST_NORM))
return handle_dots(nd, type);
/*
* 2) 若当前子路径为普通目录
* 查找最后一次挂载到目录name上的文件系统所对应的挂载点(path->mnt)、
* 目录项(path->dentry)及索引节点(inode),参见[11.2.2.4.1.1.1.2.2 do_lookup()]节
*/
err = do_lookup(nd, name, path, &inode);
if (unlikely(err)) {
terminate_walk(nd);
return err;
}
if (!inode) {
path_to_nameidata(path, nd);
terminate_walk(nd);
return -ENOENT;
}
if (should_follow_link(inode, follow)) {
if (nd->flags & LOOKUP_RCU) {
if (unlikely(unlazy_walk(nd, path->dentry))) {
terminate_walk(nd);
return -ECHILD;
}
}
BUG_ON(inode != path->dentry->d_inode);
return 1;
}
/*
* 查找成功结束,则为变量nd中的元素赋值:
* nd->path.mnt = path->mnt;
* nd->path.dentry = path->dentry;
* nd->inode = inode;
*/
path_to_nameidata(path, nd);
nd->inode = inode;
return 0;
}
11.2.2.4.1.1.1.2.2 do_lookup()
该函数定义于fs/namei.c:
static int do_lookup(struct nameidata *nd, struct qstr *name,
struct path *path, struct inode **inode)
{
struct vfsmount *mnt = nd->path.mnt;
struct dentry *dentry, *parent = nd->path.dentry;
int need_reval = 1;
int status = 1;
int err;
/*
* Rename seqlock is not required here because in the off chance
* of a false negative due to a concurrent rename, we're going to
* do the non-racy lookup, below.
*/
if (nd->flags & LOOKUP_RCU) {
unsigned seq;
*inode = nd->inode;
dentry = __d_lookup_rcu(parent, name, &seq, inode);
if (!dentry)
goto unlazy;
/* Memory barrier in read_seqcount_begin of child is enough */
if (__read_seqcount_retry(&parent->d_seq, nd->seq))
return -ECHILD;
nd->seq = seq;
if (unlikely(dentry->d_flags & DCACHE_OP_REVALIDATE)) {
status = d_revalidate(dentry, nd);
if (unlikely(status <= 0)) {
if (status != -ECHILD)
need_reval = 0;
goto unlazy;
}
}
if (unlikely(d_need_lookup(dentry)))
goto unlazy;
path->mnt = mnt;
path->dentry = dentry;
// 参见[11.2.2.4.1.1.1.2.3 __follow_mount_rcu()]节
if (unlikely(!__follow_mount_rcu(nd, path, inode)))
goto unlazy;
if (unlikely(path->dentry->d_flags & DCACHE_NEED_AUTOMOUNT))
goto unlazy;
return 0;
unlazy:
if (unlazy_walk(nd, dentry))
return -ECHILD;
} else {
dentry = __d_lookup(parent, name);
}
if (dentry && unlikely(d_need_lookup(dentry))) {
dput(dentry);
dentry = NULL;
}
retry:
if (unlikely(!dentry)) {
struct inode *dir = parent->d_inode;
BUG_ON(nd->inode != dir);
mutex_lock(&dir->i_mutex);
dentry = d_lookup(parent, name);
if (likely(!dentry)) {
dentry = d_alloc_and_lookup(parent, name, nd);
if (IS_ERR(dentry)) {
mutex_unlock(&dir->i_mutex);
return PTR_ERR(dentry);
}
/* known good */
need_reval = 0;
status = 1;
} else if (unlikely(d_need_lookup(dentry))) {
dentry = d_inode_lookup(parent, dentry, nd);
if (IS_ERR(dentry)) {
mutex_unlock(&dir->i_mutex);
return PTR_ERR(dentry);
}
/* known good */
need_reval = 0;
status = 1;
}
mutex_unlock(&dir->i_mutex);
}
if (unlikely(dentry->d_flags & DCACHE_OP_REVALIDATE) && need_reval)
status = d_revalidate(dentry, nd);
if (unlikely(status <= 0)) {
if (status < 0) {
dput(dentry);
return status;
}
if (!d_invalidate(dentry)) {
dput(dentry);
dentry = NULL;
need_reval = 1;
goto retry;
}
}
path->mnt = mnt;
path->dentry = dentry;
err = follow_managed(path, nd->flags);
if (unlikely(err < 0)) {
path_put_conditional(path, nd);
return err;
}
if (err)
nd->flags |= LOOKUP_JUMPED;
*inode = path->dentry->d_inode;
return 0;
}
11.2.2.4.1.1.1.2.3 __follow_mount_rcu()
该函数定义于fs/namei.c:
/*
* Try to skip to top of mountpoint pile in rcuwalk mode. Fail if
* we meet a managed dentry that would need blocking.
*/
static bool __follow_mount_rcu(struct nameidata *nd, struct path *path,
struct inode **inode)
{
for (;;) {
struct vfsmount *mounted;
/*
* Don't forget we might have a non-mountpoint managed dentry
* that wants to block transit.
*/
if (unlikely(managed_dentry_might_block(path->dentry)))
return false;
/*
* 1) 若path->dentry->d_flags中置位DCACHE_MOUNTED,
* 则表示有文件系统挂载到该目录项path->dentry上
*/
if (!d_mountpoint(path->dentry))
break;
// 2) 查找挂载到目录项path->dentry上的挂载点(mounted)
mounted = __lookup_mnt(path->mnt, path->dentry, 1);
/*
* 2.1) 若未查找到挂载到目录项path->dentry上的挂载点,
* 则跳出循环,返回true
*/
if (!mounted)
break;
/*
* 2.2) 若查找到挂载到目录项path->dentry上的挂载点,
* 则将其更新到path->mnt, path->dentry中,并继续检
* 查是否有其他文件系统挂载到新的path->dentry中,直到
* 找到最后一次挂载到目录项path->dentry上的文件系统所
* 对应的挂载点,参见[11.5 在同一目录挂载多种文件系统]节
*/
path->mnt = mounted;
path->dentry = mounted->mnt_root;
nd->flags |= LOOKUP_JUMPED;
nd->seq = read_seqcount_begin(&path->dentry->d_seq);
/*
* Update the inode too. We don't need to re-check the
* dentry sequence number here after this d_inode read,
* because a mount-point is always pinned.
*/
*inode = path->dentry->d_inode;
}
return true;
}
示例: ext3的tmp目录先后挂载了两个文件系统minix和nfs
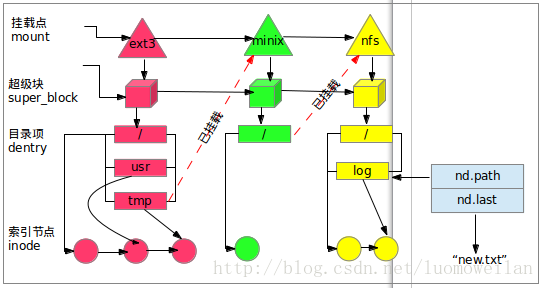
11.2.2.4.1.1.1.2.4 __lookup_mnt()
该函数定义于fs/namespace.c:
/*
* find the first or last mount at @dentry on vfsmount @mnt depending on
* @dir. If @dir is set return the first mount else return the last mount.
* vfsmount_lock must be held for read or write.
*/
struct vfsmount *__lookup_mnt(struct vfsmount *mnt, struct dentry *dentry, int dir)
{
/*
* 从哈希链表mount_hashtable中查找(mnt, dentry)
* 所在的链表头mount_hashtable[idx]
*/
struct list_head *head = mount_hashtable + hash(mnt, dentry);
struct list_head *tmp = head;
struct vfsmount *p, *found = NULL;
/*
* 在链表mount_hashtable[idx]中查找挂载到目录项
* dentry上的文件系统的挂载点
*/
for (;;) {
tmp = dir ? tmp->next : tmp->prev;
p = NULL;
/*
* 若轮询链表mount_hashtable[idx]中的所有
* 元素均为找到符合条件的挂载点,则返回NULL
*/
if (tmp == head)
break;
p = list_entry(tmp, struct vfsmount, mnt_hash);
// 若找到符合条件的挂载点,则返回;否则,继续查找
if (p->mnt_parent == mnt && p->mnt_mountpoint == dentry) {
found = p;
break;
}
}
return found;
}
11.2.2.4.1.1.1.3 complete_walk()
该函数定义于fs/namei.c:
/**
* complete_walk - successful completion of path walk
* @nd: pointer nameidata
*
* If we had been in RCU mode, drop out of it and legitimize nd->path.
* Revalidate the final result, unless we'd already done that during
* the path walk or the filesystem doesn't ask for it. Return 0 on
* success, -error on failure. In case of failure caller does not
* need to drop nd->path.
*/
static int complete_walk(struct nameidata *nd)
{
struct dentry *dentry = nd->path.dentry;
int status;
if (nd->flags & LOOKUP_RCU) {
nd->flags &= ~LOOKUP_RCU;
if (!(nd->flags & LOOKUP_ROOT))
nd->root.mnt = NULL;
spin_lock(&dentry->d_lock);
if (unlikely(!__d_rcu_to_refcount(dentry, nd->seq))) {
spin_unlock(&dentry->d_lock);
rcu_read_unlock();
br_read_unlock(vfsmount_lock);
return -ECHILD;
}
BUG_ON(nd->inode != dentry->d_inode);
spin_unlock(&dentry->d_lock);
mntget(nd->path.mnt);
rcu_read_unlock();
br_read_unlock(vfsmount_lock);
}
if (likely(!(nd->flags & LOOKUP_JUMPED)))
return 0;
if (likely(!(dentry->d_flags & DCACHE_OP_REVALIDATE)))
return 0;
if (likely(!(dentry->d_sb->s_type->fs_flags & FS_REVAL_DOT)))
return 0;
/* Note: we do not d_invalidate() */
status = d_revalidate(dentry, nd);
if (status > 0)
return 0;
if (!status)
status = -ESTALE;
path_put(&nd->path);
return status;
}
11.2.2.4.1.2 do_new_mount()
该函数定义于fs/namespace.c:
/*
* create a new mount for userspace and request it to be added into the namespace's tree
*/
/*
* 入参path中包含了安装目录所对应的安装点(path.mnt)和目录项(path.dentry)
* 示例:do_new_mount(&path, "sysfs", 0, MNT_RELATIME, "sysfs_name", NULL)
*/
static int do_new_mount(struct path *path, char *type, int flags,
int mnt_flags, char *name, void *data)
{
struct vfsmount *mnt;
int err;
if (!type)
return -EINVAL;
/* we need capabilities... */
if (!capable(CAP_SYS_ADMIN))
return -EPERM;
/*
* 挂载指定的文件系统,并返回生成的挂载点结构mnt,参见[11.2.2.4.1.2.1 do_kern_mount()]节
* 示例:do_kern_mount("sysfs", 0, "sysfs_name", NULL)
*/
mnt = do_kern_mount(type, flags, name, data);
if (IS_ERR(mnt))
return PTR_ERR(mnt);
/*
* 将指定文件系统的挂载点mnt链接到安装目录所对应的安装点(path.mnt)
* 和目录项(path.dentry),参见[11.2.2.4.1.2.2 do_add_mount()]节. 示例:
* do_add_mount(mnt, path, MNT_RELATIME)
*/
err = do_add_mount(mnt, path, mnt_flags);
if (err)
mntput(mnt);
return err;
}
11.2.2.4.1.2.1 do_kern_mount()
该函数用来安装文件系统,其定义于fs/namespace.c:
/*
* 参数fstype用于查找文件系统,即struct file_system_type->name
* 示例:do_kern_mount("sysfs", 0, "sysfs_name", NULL)
*/
struct vfsmount *do_kern_mount(const char *fstype, int flags, const char *name, void *data)
{
/*
* 从链表file_systems中查找指定的文件系统类型,
* 参见[11.2.1.1 文件系统类型/struct file_system_type]节和[11.2.2.4.1.2.1.1 get_fs_type()]节
*/
struct file_system_type *type = get_fs_type(fstype);
struct vfsmount *mnt;
if (!type)
return ERR_PTR(-ENODEV);
// 安装type类型的文件系统,并返回挂载点mnt,参见[11.2.2.2.1 vfs_kern_mount()]节
mnt = vfs_kern_mount(type, flags, name, data);
/*
* 设置文件系统子类型,参见[11.2.2.4.1.2.1.1 get_fs_type()]节和[11.2.2.4.1.2.1.2 fs_set_subtype()]节
* 设置该标志位的文件系统包括: fuse_fs_type, fuseblk_fs_type
*/
if (!IS_ERR(mnt) && (type->fs_flags & FS_HAS_SUBTYPE) && !mnt->mnt_sb->s_subtype)
mnt = fs_set_subtype(mnt, fstype);
/*
* 增加计数: type->owner->refptr->decs
* 唤醒等待进程: type->owner->waiter
*/
put_filesystem(type);
return mnt;
}
11.2.2.4.1.2.1.1 get_fs_type()
该函数定义于fs/filesystem.c:
struct file_system_type *get_fs_type(const char *name)
{
struct file_system_type *fs;
const char *dot = strchr(name, '.');
int len = dot ? dot - name : strlen(name);
/*
* 从链表file_systems中查找该文件系统;
* 若该文件系统被编译为模块,则增加该模块的引用计数:
* fs->owner->refptr->incs
*/
fs = __get_fs_type(name, len);
/*
* 若存在下列情况之一,则调用request_module()加载包含该文件系统的模块,
* 参见[13.3.2.1 kerneld]节和[13.3.1.2 kmod]节:
* 1) 链表file_systems中未包含该文件系统,即该文件系统未被注册到系统中;
* 2) 该文件系统被编译为模块,但该模块未被加载到系统中;
*/
if (!fs && (request_module("%.*s", len, name) == 0))
fs = __get_fs_type(name, len);
/*
* Refer to http://lwn.net/Articles/221779/
* A possibly better scheme would be to encode the
* real type in the type field as "type.subtype".
*/
if (dot && fs && !(fs->fs_flags & FS_HAS_SUBTYPE)) {
put_filesystem(fs);
fs = NULL;
}
return fs;
}
其中,函数__get_fs_type()定义于fs/filesystem.c:
static struct file_system_type *__get_fs_type(const char *name, int len)
{
struct file_system_type *fs;
read_lock(&file_systems_lock);
// 从链表file_systems中查找指定的文件系统,即检查该文件系统是否注册到系统中
fs = *(find_filesystem(name, len));
/*
* 若该文件系统已注册到系统中,(当该文件系统被编译为模块时)则
* 增加该模块的引用计数: fs->owner->refptr->incs
*/
if (fs && !try_module_get(fs->owner))
fs = NULL;
read_unlock(&file_systems_lock);
return fs;
}
11.2.2.4.1.2.1.2 fs_set_subtype()
该函数定义于fs/filesystem.c:
static struct vfsmount *fs_set_subtype(struct vfsmount *mnt, const char *fstype)
{
int err;
// 文件系统子类型的命名方式: type.subtype
const char *subtype = strchr(fstype, '.');
if (subtype) {
subtype++;
err = -EINVAL;
if (!subtype[0])
goto err;
} else
subtype = "";
mnt->mnt_sb->s_subtype = kstrdup(subtype, GFP_KERNEL);
err = -ENOMEM;
if (!mnt->mnt_sb->s_subtype)
goto err;
return mnt;
err:
mntput(mnt); // 参见[11.2.2.3.2 mntput()]节
return ERR_PTR(err);
}
11.2.2.4.1.2.2 do_add_mount()
该函数定义于fs/namespace.c:
/*
* add a mount into a namespace's mount tree
*/
static int do_add_mount(struct vfsmount *newmnt, struct path *path, int mnt_flags)
{
int err;
mnt_flags &= ~(MNT_SHARED | MNT_WRITE_HOLD | MNT_INTERNAL);
err = lock_mount(path);
if (err)
return err;
err = -EINVAL;
if (!(mnt_flags & MNT_SHRINKABLE) && !check_mnt(path->mnt))
goto unlock;
/* Refuse the same filesystem on the same mount point */
err = -EBUSY;
if (path->mnt->mnt_sb == newmnt->mnt_sb &&
path->mnt->mnt_root == path->dentry)
goto unlock;
// 该安装点是一个符号链接
err = -EINVAL;
if (S_ISLNK(newmnt->mnt_root->d_inode->i_mode))
goto unlock;
newmnt->mnt_flags = mnt_flags;
/*
* Insert the new mounted filesystem object in the
* namespace list, in the hash table, and in the
* children list of the parent-mounted filesystem.
* 参见[11.2.2.4.1.2.2.1 graft_tree()]节
*/
err = graft_tree(newmnt, path);
unlock:
unlock_mount(path);
return err;
}
11.2.2.4.1.2.2.1 graft_tree()
该函数定义于fs/namespace.c:
static int graft_tree(struct vfsmount *mnt, struct path *path)
{
/*
* The FS_NOMOUNT flag says that the filesystem must
* never be mounted from userland, but is used only
* kernel-internally. This flag was introduced in
* 2.3.99-pre7 and disappeared in Linux 2.5.22. This
* was used, for example, for pipefs, the implementation
* of Unix pipes using a kernel-internal filesystem (see
* fs/pipe.c). Even though the flag has disappeared, the
* concept remains, and is now represented by the MS_NOUSER
* flag.
*/
if (mnt->mnt_sb->s_flags & MS_NOUSER)
return -EINVAL;
// 对比挂载点和安装目录所对应的索引节点模式,均应取值为S_IFDIR
if (S_ISDIR(path->dentry->d_inode->i_mode) !=
S_ISDIR(mnt->mnt_root->d_inode->i_mode))
return -ENOTDIR;
// check path->dentry: (1) is unhashed; and (2) is not root directory
if (d_unlinked(path->dentry))
return -ENOENT;
// mnt is attached to path
return attach_recursive_mnt(mnt, path, NULL);
}
其中,函数attach_recursive_mnt()定义于fs/namespace.c:
/*
* @source_mnt : mount tree to be attached
* @path : place the mount tree @source_mnt is attached
* @parent_path : if non-null, detach the source_mnt from its parent and
* store the parent mount and mountpoint dentry.
* (done when source_mnt is moved)
*
* NOTE: in the table below explains the semantics when a source mount
* of a given type is attached to a destination mount of a given type.
* ---------------------------------------------------------------------------
* | BIND MOUNT OPERATION |
* |**************************************************************************
* | source--> | shared | private | slave | unbindable |
* | dest | | | | |
* | | | | | |
* | v | | | | |
* |**************************************************************************
* | shared | shared(++) | shared(+) | shared(+++) | invalid |
* | | | | | |
* | non-shared | shared(+) | private | slave(*) | invalid |
* ***************************************************************************
* A bind operation clones the source mount and mounts the clone on the
* destination mount.
*
* (++) the cloned mount is propagated to all the mounts in the propagation
* tree of the destination mount and the cloned mount is added to
* the peer group of the source mount.
* (+) the cloned mount is created under the destination mount and is marked
* as shared. The cloned mount is added to the peer group of the source
* mount.
* (+++) the mount is propagated to all the mounts in the propagation tree
* of the destination mount and the cloned mount is made slave
* of the same master as that of the source mount. The cloned mount
* is marked as 'shared and slave'.
* (*) the cloned mount is made a slave of the same master as that of the
* source mount.
*
* ---------------------------------------------------------------------------
* | MOVE MOUNT OPERATION |
* |**************************************************************************
* | source--> | shared | private | slave | unbindable |
* | dest | | | | |
* | | | | | |
* | v | | | | |
* |**************************************************************************
* | shared | shared(+) | shared(+) | shared(+++) | invalid |
* | | | | | |
* | non-shared | shared(+*) | private | slave(*) | unbindable |
* ***************************************************************************
*
* (+) the mount is moved to the destination. And is then propagated to
* all the mounts in the propagation tree of the destination mount.
* (+*) the mount is moved to the destination.
* (+++) the mount is moved to the destination and is then propagated to
* all the mounts belonging to the destination mount's propagation tree.
* the mount is marked as 'shared and slave'.
* (*) the mount continues to be a slave at the new location.
*
* if the source mount is a tree, the operations explained above is
* applied to each mount in the tree.
*
* Must be called without spinlocks held, since this function can sleep
* in allocations.
*/
static int attach_recursive_mnt(struct vfsmount *source_mnt,
struct path *path, struct path *parent_path)
{
LIST_HEAD(tree_list);
struct vfsmount *dest_mnt = path->mnt;
struct dentry *dest_dentry = path->dentry;
struct vfsmount *child, *p;
int err;
// dest_mnt->mnt_flags & MNT_SHARED
if (IS_MNT_SHARED(dest_mnt)) {
/*
* 轮询source_mnt->mnt_mounts/->mnt_child链表,并为域mnt_group_id赋值
* - source_mnt->mnt_group_id
* - 链表source_mnt->mnt_mounts中各元素的域mnt_group_id,
* - 链表source_mnt->mnt_mounts中各元素的子链表中各元素的域mnt_group_id
* - ...
*/
err = invent_group_ids(source_mnt, true);
if (err)
goto out;
}
/*
* mount 'source_mnt' under the destination 'dest_mnt'
* at dentry 'dest_dentry'. And propagate that mount to
* all the peer and slave mounts of 'dest_mnt'.
* 参见[11.2.2.4.1.2.2.1.1 propagate_mnt()]节
*/
err = propagate_mnt(dest_mnt, dest_dentry, source_mnt, &tree_list);
if (err)
goto out_cleanup_ids;
br_write_lock(vfsmount_lock);
/*
* 若dest_mnt->mnt_flags & MNT_SHARED,
* 则置位source_mnt->mnt_flags |= MNT_SHARED
*/
if (IS_MNT_SHARED(dest_mnt)) {
for (p = source_mnt; p; p = next_mnt(p, source_mnt))
set_mnt_shared(p);
}
if (parent_path) {
detach_mnt(source_mnt, parent_path);
attach_mnt(source_mnt, path);
touch_mnt_namespace(parent_path->mnt->mnt_ns);
} else {
mnt_set_mountpoint(dest_mnt, dest_dentry, source_mnt);
commit_tree(source_mnt); // 参见[11.2.2.4.1.2.2.1.2 commit_tree()]节
}
list_for_each_entry_safe(child, p, &tree_list, mnt_hash) {
list_del_init(&child->mnt_hash);
commit_tree(child); // 参见[11.2.2.4.1.2.2.1.2 commit_tree()]节
}
br_write_unlock(vfsmount_lock);
return 0;
out_cleanup_ids:
if (IS_MNT_SHARED(dest_mnt))
cleanup_group_ids(source_mnt, NULL);
out:
return err;
}
11.2.2.4.1.2.2.1.1 propagate_mnt()
该函数定义于fs/pnode.c:
/*
* mount 'source_mnt' under the destination 'dest_mnt' at
* dentry 'dest_dentry'. And propagate that mount to
* all the peer and slave mounts of 'dest_mnt'.
* Link all the new mounts into a propagation tree headed at
* source_mnt. Also link all the new mounts using ->mnt_list
* headed at source_mnt's ->mnt_list
*
* @dest_mnt: destination mount.
* @dest_dentry: destination dentry.
* @source_mnt: source mount.
* @tree_list : list of heads of trees to be attached.
*/
int propagate_mnt(struct vfsmount *dest_mnt, struct dentry *dest_dentry,
struct vfsmount *source_mnt, struct list_head *tree_list)
{
struct vfsmount *m, *child;
int ret = 0;
struct vfsmount *prev_dest_mnt = dest_mnt;
struct vfsmount *prev_src_mnt = source_mnt;
LIST_HEAD(tmp_list);
LIST_HEAD(umount_list);
/*
* 轮询如下两个链表:
* - dest_mnt->mnt_slave_list/->mnt_slave
* - dest_mnt->mnt_share
*/
for (m = propagation_next(dest_mnt, dest_mnt); m;
m = propagation_next(m, dest_mnt)) {
int type;
struct vfsmount *source;
if (IS_MNT_NEW(m))
continue;
source = get_source(m, prev_dest_mnt, prev_src_mnt, &type);
if (!(child = copy_tree(source, source->mnt_root, type))) {
ret = -ENOMEM;
list_splice(tree_list, tmp_list.prev);
goto out;
}
if (is_subdir(dest_dentry, m->mnt_root)) {
mnt_set_mountpoint(m, dest_dentry, child);
list_add_tail(&child->mnt_hash, tree_list);
} else {
/*
* This can happen if the parent mount was bind mounted
* on some subdirectory of a shared/slave mount.
*/
list_add_tail(&child->mnt_hash, &tmp_list);
}
prev_dest_mnt = m;
prev_src_mnt = child;
}
out:
br_write_lock(vfsmount_lock);
while (!list_empty(&tmp_list)) {
child = list_first_entry(&tmp_list, struct vfsmount, mnt_hash);
umount_tree(child, 0, &umount_list); // 参见[11.2.2.5.2.1 umount_tree()]节
}
br_write_unlock(vfsmount_lock);
release_mounts(&umount_list); // 参见[11.2.2.5.2.2 release_mounts()]节
return ret;
}
11.2.2.4.1.2.2.1.2 commit_tree()
该函数定义于fs/namespace.c:
static void commit_tree(struct vfsmount *mnt)
{
struct vfsmount *parent = mnt->mnt_parent;
struct vfsmount *m;
LIST_HEAD(head);
struct mnt_namespace *n = parent->mnt_ns;
BUG_ON(parent == mnt);
// 将mnt->mnt_list添加到链表parent->mnt_ns->list尾部
list_add_tail(&head, &mnt->mnt_list);
list_for_each_entry(m, &head, mnt_list) {
m->mnt_ns = n;
__mnt_make_longterm(m); // mnt->mnt_longterm++
}
list_splice(&head, n->list.prev);
/*
* 将mnt->mnt_hash添加到链表mount_hashtable[idx]尾部
* 其中,下标idx由hash()计算得来
*/
list_add_tail(&mnt->mnt_hash, mount_hashtable + hash(parent, mnt->mnt_mountpoint));
// 将mnt->mnt_child添加到链表parent->mnt_mounts尾部
list_add_tail(&mnt->mnt_child, &parent->mnt_mounts);
// 为n->event赋值,并唤醒链表n->poll中的等待进程
touch_mnt_namespace(n);
}
其中,函数hash()用于计算数组mount_hashtable[idx]的下标idx,其定义于fs/namespace.c:
static inline unsigned long hash(struct vfsmount *mnt, struct dentry *dentry)
{
unsigned long tmp = ((unsigned long)mnt / L1_CACHE_BYTES);
tmp += ((unsigned long)dentry / L1_CACHE_BYTES);
tmp = tmp + (tmp >> HASH_SHIFT);
return tmp & (HASH_SIZE - 1);
}
11.2.2.5 卸载文件系统(2)/sys_oldumount()/sys_umount()
该系统调用定义于fs/namespace.c:
#ifdef __ARCH_WANT_SYS_OLDUMOUNT
/*
* The 2.0 compatible umount. No flags.
*/
/*
* umount <fs-mount-point>
* 示例:使用命令 "strace umount sysfs_name" 手动卸载sysfs
* 文件系统时,strace结果包含如下系统调用:
* oldumount("/MySysFs") = 0
*/
SYSCALL_DEFINE1(oldumount, char __user *, name)
{
return sys_umount(name, 0);
}
#endif
/*
* Now umount can handle mount points as well as block devices.
* This is important for filesystems which use unnamed block devices.
*
* We now support a flag for forced unmount like the other 'big iron'
* unixes. Our API is identical to OSF/1 to avoid making a mess of AMD
*/
SYSCALL_DEFINE2(umount, char __user *, name, int, flags)
{
struct path path;
int retval;
int lookup_flags = 0;
/*
* 入参flags只能取如下标志中的一个或几个:
* MNT_FORCE、MNT_DETACH、MNT_EXPIRE、UMOUNT_NOFOLLOW
*/
if (flags & ~(MNT_FORCE | MNT_DETACH | MNT_EXPIRE | UMOUNT_NOFOLLOW))
return -EINVAL;
if (!(flags & UMOUNT_NOFOLLOW))
lookup_flags |= LOOKUP_FOLLOW;
/*
* 获取路径名name所对应的安装点(path.mnt)及其目录项(path.dentry),
* 参见[11.2.2.5.1 user_path_at()]节
*/
retval = user_path_at(AT_FDCWD, name, lookup_flags, &path);
if (retval)
goto out;
retval = -EINVAL;
// 若找到的最终目录不是文件系统的挂载点,则退出
if (path.dentry != path.mnt->mnt_root)
goto dput_and_out;
// 若要卸载的文件系统还没有安装到命名空间中,则退出
if (!check_mnt(path.mnt))
goto dput_and_out;
// 检查当前进程是否有管理员权限
retval = -EPERM;
if (!capable(CAP_SYS_ADMIN))
goto dput_and_out;
// 卸载文件系统的主函数,参见[11.2.2.5.2 do_umount()]节
retval = do_umount(path.mnt, flags);
dput_and_out:
/* we mustn't call path_put() as that would clear mnt_expiry_mark */
dput(path.dentry);
/*
* 通过下列函数调用来调用指定文件系统的kill_sb()函数:
* mntput_no_expire()
* -> mntfree()
* -> deactivate_super()
* -> deactivate_locked_super()
* -> fs->kill_sb()
*/
mntput_no_expire(path.mnt);
out:
return retval;
}
11.2.2.5.1 user_path_at()
该函数定义于fs/namei.c:
int user_path_at(int dfd, const char __user *name, unsigned flags, struct path *path)
{
return user_path_at_empty(dfd, name, flags, path, 0);
}
int user_path_at_empty(int dfd, const char __user *name, unsigned flags,
struct path *path, int *empty)
{
struct nameidata nd;
// 将路径名name从用户空间拷贝到内核空间tmp
char *tmp = getname_flags(name, flags, empty);
int err = PTR_ERR(tmp);
if (!IS_ERR(tmp)) {
BUG_ON(flags & LOOKUP_PARENT);
/*
* 查找路径名tmp所对应的安装点(nd.path.mnt)及其
* 目录项(nd.path.dentry),参见[11.2.2.4.1.1 kern_path()/do_path_lookup()]节
*/
err = do_path_lookup(dfd, tmp, flags, &nd);
putname(tmp);
if (!err)
*path = nd.path;
}
return err;
}
11.2.2.5.2 do_umount()
该函数定义于fs/namespace.c:
static int event;
static int do_umount(struct vfsmount *mnt, int flags)
{
// 获取挂载点mnt所对应的超级块对象
struct super_block *sb = mnt->mnt_sb;
int retval;
LIST_HEAD(umount_list);
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
retval = security_sb_umount(mnt, flags);
if (retval)
return retval;
/*
* Allow userspace to request a mountpoint be expired rather than
* unmounting unconditionally. Unmount only happens if:
* (1) the mark is already set (the mark is cleared by mntput())
* (2) the usage count == 1 [parent vfsmount] + 1 [sys_umount]
*/
// 若设置了MNT_EXPIRE标志,则标记挂载点"到期"
if (flags & MNT_EXPIRE) {
/*
* 若要卸载的文件系统是根文件系统或者同时设置了
* MNT_FORCE或MNT_DETACH,则返回-EINVAL
*/
if (mnt == current->fs->root.mnt || flags & (MNT_FORCE | MNT_DETACH))
return -EINVAL;
/*
* probably don't strictly need the lock here if we examined
* all race cases, but it's a slowpath.
*/
/*
* 检查mnt的引用计数,若不为2,则返回-EBUSY;
* 在卸载文件系统时,该文件系统不能有引用者:
* 这个2代表mnt->mnt_parent和sys_umount()对本vfsmount的引用
*/
br_write_lock(vfsmount_lock);
if (mnt_get_count(mnt) != 2) {
br_write_unlock(vfsmount_lock);
return -EBUSY;
}
br_write_unlock(vfsmount_lock);
if (!xchg(&mnt->mnt_expiry_mark, 1))
return -EAGAIN;
}
/*
* If we may have to abort operations to get out of this
* mount, and they will themselves hold resources we must
* allow the fs to do things. In the Unix tradition of
* 'Gee thats tricky lets do it in userspace' the umount_begin
* might fail to complete on the first run through as other tasks
* must return, and the like. Thats for the mount program to worry
* about for the moment.
*/
if (flags & MNT_FORCE && sb->s_op->umount_begin) {
// 调用指定文件系统的卸载函数,参见[11.2.1.2.3 超级块操作/struct super_operations]节
sb->s_op->umount_begin(sb);
}
/*
* No sense to grab the lock for this test, but test itself looks
* somewhat bogus. Suggestions for better replacement?
* Ho-hum... In principle, we might treat that as umount + switch
* to rootfs. GC would eventually take care of the old vfsmount.
* Actually it makes sense, especially if rootfs would contain a
* /reboot - static binary that would close all descriptors and
* call reboot(9). Then init(8) could umount root and exec /reboot.
*/
/*
* 1) 若要卸载的文件系统是根文件系统,且未设置MNT_DETACH标志,
* 则调用do_remount_sb()重新安装根文件系统为只读;
* 其中,标志MNT_DETACH用于标记该挂载点为不能再访问,
* 直到该挂载点不busy时才卸载
*/
if (mnt == current->fs->root.mnt && !(flags & MNT_DETACH)) {
/*
* Special case for "unmounting" root ...
* we just try to remount it readonly.
*/
down_write(&sb->s_umount);
if (!(sb->s_flags & MS_RDONLY))
retval = do_remount_sb(sb, MS_RDONLY, NULL, 0);
up_write(&sb->s_umount);
return retval;
}
/*
* 2) 若要卸载的文件系统不是根文件系统,或者设置了MNT_DETACH标志:
*/
down_write(&namespace_sem);
br_write_lock(vfsmount_lock);
event++;
/*
* 2.1) 若未设置MNT_DETACH标志,则调用shrink_submounts()卸载挂载点mnt及其所有子挂载点
*/
if (!(flags & MNT_DETACH))
shrink_submounts(mnt, &umount_list);
/*
* 2.2) 若(a)设置了MNT_DETACH标志,或者(b)未设置MNT_DETACH标志且能够成功卸载挂载点mnt,
* 则调用umount_tree()卸载该文件系统及其所有子文件系统
*/
retval = -EBUSY;
if (flags & MNT_DETACH || !propagate_mount_busy(mnt, 2)) {
/*
* 将mnt->mnt_list中的元素移至umount_list链表,并初始化,参见[11.2.2.5.2.1 umount_tree()]节
*/
if (!list_empty(&mnt->mnt_list))
umount_tree(mnt, 1, &umount_list);
retval = 0;
}
br_write_unlock(vfsmount_lock);
up_write(&namespace_sem);
// 释放链表umount_list中的struct vfsmount结构,参见[11.2.2.5.2.2 release_mounts()]节
release_mounts(&umount_list);
return retval;
}
11.2.2.5.2.1 umount_tree()
该函数定义于fs/namespace.c:
void umount_tree(struct vfsmount *mnt, int propagate, struct list_head *kill)
{
LIST_HEAD(tmp_list);
struct vfsmount *p;
for (p = mnt; p; p = next_mnt(p, mnt))
list_move(&p->mnt_hash, &tmp_list);
if (propagate)
propagate_umount(&tmp_list);
list_for_each_entry(p, &tmp_list, mnt_hash) {
list_del_init(&p->mnt_expire);
list_del_init(&p->mnt_list);
__touch_mnt_namespace(p->mnt_ns);
p->mnt_ns = NULL;
__mnt_make_shortterm(p);
list_del_init(&p->mnt_child);
if (p->mnt_parent != p) {
p->mnt_parent->mnt_ghosts++;
dentry_reset_mounted(p->mnt_parent, p->mnt_mountpoint);
}
change_mnt_propagation(p, MS_PRIVATE);
}
list_splice(&tmp_list, kill);
}
11.2.2.5.2.2 release_mounts()
该函数定义于fs/namespace.c:
void release_mounts(struct list_head *head)
{
struct vfsmount *mnt;
while (!list_empty(head)) {
mnt = list_first_entry(head, struct vfsmount, mnt_hash);
list_del_init(&mnt->mnt_hash);
if (mnt->mnt_parent != mnt) {
struct dentry *dentry;
struct vfsmount *m;
br_write_lock(vfsmount_lock);
dentry = mnt->mnt_mountpoint;
m = mnt->mnt_parent;
mnt->mnt_mountpoint = mnt->mnt_root;
mnt->mnt_parent = mnt;
m->mnt_ghosts--;
br_write_unlock(vfsmount_lock);
// 这两个函数减小dentry和m的引用计数,减到0时释放
dput(dentry);
mntput(m);
}
// struct vfsmount类型的对象所占用的内存空间最终在mntput()中释放
mntput(mnt);
}
}
11.2.3 虚拟文件系统(VFS)的初始化
Mounting the root filesystem is a two-stage procedure, shown in the following list:
- 1) The kernel mounts the special rootfs filesystem, which simply provides an empty directory that serves as initial mount point.
- 2) The kernel mounts the real root filesystem over the empty directory.
Why does the kernel bother to mount the rootfs filesystem before the real one? Well, the rootfs filesystem allows the kernel to easily change the real root filesystem. In fact, in some cases, the kernel mounts and unmounts several root filesystems, one after the other. For instance, the initial bootstrap CD of a distribution might load in RAM a kernel with a minimal set of drivers, which mounts as root a minimal filesystem stored in a ramdisk. Next, the programs in this initial root filesystem probe the hardware of the system (for instance, they determine whether the hard disk is EIDE, SCSI, or whatever), load all needed kernel modules, and remount the root filesystem from a physical block device.
虚拟文件系统的初始化流程如下:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> vfs_caches_init_early() // 参见[4.3.4.1.4.3.4 vfs_caches_init_early()]节
-> dcache_init_early() // 分配并初始化dentry_hashtable
-> inode_init_early() // 分配并初始化inode_hashtable
-> vfs_caches_init(totalram_pages) // 参见[4.3.4.1.4.3.11 vfs_caches_init()]节
-> names_cachep = ... // 分配并初始化names_cachep
-> dcache_init() // 分配并初始化dentry_cache, dentry_hashtable
-> inode_init() // 分配并初始化inode_cachep, inode_hashtable
-> files_init() // 分配并初始化filp_cachep, 设置sysctl_nr_open_max
-> files_stat.max_files = ... // 设置打开文件的最大数目
-> fdtable_defer_list_init() // fs/file.c, 初始化全局变量fdtable_defer_list->wq
-> percpu_counter_init(&nr_files, 0) // 初始化全局变量nr_files为0
-> mnt_init() // 参见[4.3.4.1.4.3.11.4 mnt_init()]节
-> mnt_cache = ... // 分配并初始化mnt_cache
-> mount_hashtable = ... // 分配并初始化mount_hashtable
-> sysfs_init()
-> fs_kobj = ... // 创建内核对象fs_kobj
/* Phase 1: Mounting the rootfs filesystem */
-> init_rootfs() // 加载rootfs文件系统,参见[4.3.4.1.4.3.11.4.2 init_rootfs()]节
-> init_mount_tree() // 创建根目录树,参见[4.3.4.1.4.3.11.4.3 init_mount_tree()]节
/* 分配并初始化bdev_cachep, blockdev_superblock,参见[4.3.4.1.4.3.11.5 bdev_cache_init()]节 */
-> bdev_cache_init()
-> chrdev_init() // 分配并初始化cdev_map,参见[4.3.4.1.4.3.11.6 chrdev_init()]节
-> rest_init() // 参见[4.3.4.1.4.3.13 rest_init()]节
-> kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
-> kernel_init() // 参见[4.3.4.1.4.3.13.1 kernel_init()]节
-> if (!ramdisk_execute_command)
ramdisk_execute_command = "/init";
if (sys_access((const char __user *) ramdisk_execute_command, 0) != 0) {
ramdisk_execute_command = NULL;
/* Phase 2: Mounting the real root filesystem */
prepare_namespace(); // 参见[4.3.4.1.4.3.13.1.3 prepare_namespace()]节
}
11.2.4 文件系统相关系统调用
11.2.4.1 文件系统操作相关系统调用
| 文件系统操作 | 备注 | 所在的源文件 | 备注 |
|---|---|---|---|
| mkdir | 创建目录 | fs/namei.c | |
| makedirat | 创建目录 | fs/namei.c | |
| rmdir | 删除目录 | fs/namei.c | |
| chdir | 改变当前工作目录 | fs/open.c | |
| fchdir | 改变当前工作目录 | fs/open.c | |
| chroot | 改变根目录 | fs/open.c | |
| readdir | 读取目录项 | fs/readdir.c | |
| getdents | 读取目录项 | fs/readdir.c | |
| rename | 文件改名 | fs/namei.c | |
| renameat | 文件改名 | fs/namei.c | |
| chmod | 改变文件属性 | fs/open.c | |
| fchmod | 改变文件属性 | fs/open.c | |
| fchmodat | 改变文件属性 | fs/open.c | |
| chown | 改变文件的属主或用户组 | fs/open.c | |
| lchown | 改变文件的属主或用户组 | fs/open.c | |
| fchown | 改变文件的属主或用户组 | fs/open.c | |
| fchownat | 改变文件的属主或用户组 | fs/open.c | |
| stat | 取文件状态信息 | fs/stat.c | |
| lstat | 取文件状态信息 | fs/stat.c | |
| fstat | 取文件状态信息 | fs/stat.c | |
| newstat | 取文件状态信息 | fs/stat.c | |
| newlstat | 取文件状态信息 | fs/stat.c | |
| newfstat | 取文件状态信息 | fs/stat.c | |
| stat64 | 取文件状态信息 | fs/stat.c | |
| lstat64 | 取文件状态信息 | fs/stat.c | |
| fstat64 | 取文件状态信息 | fs/stat.c | |
| fstatat64 | 取文件状态信息 | fs/stat.c | |
| statfs | 取文件系统信息 | fs/statfs.c | |
| fstatfs | 取文件状态信息 | fs/statfs.c | |
| ustat | 取文件系统信息 | fs/statfs.c | |
| link | 创建链接 | fs/namei.c | |
| linkat | 创建链接 | fs/namei.c | |
| symlink | 创建符号链接 | fs/namei.c | |
| symlinkat | 创建符号链接 | fs/namei.c | |
| unlink | 删除链接 | fs/namei.c | |
| unlinkat | 删除链接 | fs/namei.c | |
| readlink | 读符号链接的值 | fs/stat.c | |
| readlinkat | 读符号链接的值 | fs/stat.c | |
| mknod | 创建索引节点 | fs/namei.c | 参见11.2.4.1.1 mknod()/mknodat()节 |
| mknodat | 创建索引节点 | fs/namei.c | 参见11.2.4.1.1 mknod()/mknodat()节 |
| mount | 安装文件系统 | fs/namespace.h | |
| umount | 卸载文件系统 | fs/namespace.h | |
| oldumount | 卸载文件系统 | fs/namespace.c | |
| utime | 改变文件的访问修改时间 | fs/utimes.c | |
| utimes | 改变文件的访问修改时间 | fs/utimes.c | |
| access | 确定文件的可存取性 | fs/open.c | |
| quotactl | 控制磁盘配额 | fs/quota/quota.c |
11.2.4.1.1 mknod()/mknodat()
系统调用sys_mknod()定义于fs/namei.c:
SYSCALL_DEFINE3(mknod, const char __user *, filename, int, mode, unsigned, dev)
{
return sys_mknodat(AT_FDCWD, filename, mode, dev);
}
系统调用sys_mknodat()定义于fs/namei.c:
SYSCALL_DEFINE4(mknodat, int, dfd, const char __user *, filename, int, mode, unsigned, dev)
{
struct dentry *dentry;
struct path path;
int error;
if (S_ISDIR(mode))
return -EPERM;
dentry = user_path_create(dfd, filename, &path, 0);
if (IS_ERR(dentry))
return PTR_ERR(dentry);
if (!IS_POSIXACL(path.dentry->d_inode))
mode &= ~current_umask();
// 检查mode取值是否合法
error = may_mknod(mode);
if (error)
goto out_dput;
// get write access to a mount
error = mnt_want_write(path.mnt);
if (error)
goto out_dput;
// 参见[14.4.2 security_xxx()]节
error = security_path_mknod(&path, dentry, mode, dev);
if (error)
goto out_drop_write;
switch (mode & S_IFMT) {
case 0:
case S_IFREG:
// 创建普通文件,参见[11.2.4.1.1.1 vfs_create()]节
error = vfs_create(path.dentry->d_inode, dentry, mode, NULL);
break;
case S_IFCHR:
case S_IFBLK:
// 创建字符设备/块设备文件,参见[11.2.4.1.1.2 vfs_mknod()]节
error = vfs_mknod(path.dentry->d_inode, dentry, mode, new_decode_dev(dev));
break;
case S_IFIFO:
case S_IFSOCK:
// 创建网络设备文件,参见[11.2.4.1.1.2 vfs_mknod()]节
error = vfs_mknod(path.dentry->d_inode, dentry, mode, 0);
break;
}
out_drop_write:
mnt_drop_write(path.mnt);
out_dput:
dput(dentry);
mutex_unlock(&path.dentry->d_inode->i_mutex);
path_put(&path);
return error;
}
11.2.4.1.1.1 vfs_create()
该函数定义于fs/namei.c:
int vfs_create(struct inode *dir, struct dentry *dentry, int mode, struct nameidata *nd)
{
int error = may_create(dir, dentry);
if (error)
return error;
if (!dir->i_op->create)
return -EACCES; /* shouldn't it be ENOSYS? */
mode &= S_IALLUGO;
mode |= S_IFREG;
error = security_inode_create(dir, dentry, mode);
if (error)
return error;
/*
* 调用父目录的create()函数,
* 参见[11.2.4.2.0 如何查找某文件所对应的文件操作函数]节
*/
error = dir->i_op->create(dir, dentry, mode, nd);
if (!error)
fsnotify_create(dir, dentry);
return error;
}
11.2.4.1.1.2 vfs_mknod()
该函数定义于fs/namei.c:
int vfs_mknod(struct inode *dir, struct dentry *dentry, int mode, dev_t dev)
{
int error = may_create(dir, dentry);
if (error)
return error;
if ((S_ISCHR(mode) || S_ISBLK(mode)) &&
!ns_capable(inode_userns(dir), CAP_MKNOD))
return -EPERM;
if (!dir->i_op->mknod)
return -EPERM;
error = devcgroup_inode_mknod(mode, dev);
if (error)
return error;
error = security_inode_mknod(dir, dentry, mode, dev);
if (error)
return error;
/*
* 调用父目录的mknod()函数,
* 参见[11.2.4.2.0 如何查找某文件所对应的文件操作函数]节
*/
error = dir->i_op->mknod(dir, dentry, mode, dev);
if (!error)
fsnotify_create(dir, dentry);
return error;
}
11.2.4.2 文件读写操作相关系统调用
文件读写操作对应的数据结构为struct file_operations,参见11.2.1.5.1 文件操作/struct file_operations节。
| 文件读写操作 | 备注 | 所在的源文件 | 备注 |
|---|---|---|---|
| creat | 创建新文件 | fs/open.c | |
| open | 打开文件 | fs/open.c | 参见11.2.4.2.1 open()节 |
| close | 关闭文件描述符 | fs/open.c | 参见11.2.4.2.4 close()节 |
| read | 读文件 | fs/read_write.c | 参见11.2.4.2.1 open()节 |
| readv | 从文件读入数据到缓冲数组中 | fs/read_write.c | |
| pread64 | 对文件随机读 | fs/read_write.c | |
| preadv | 对文件随机读 | fs/read_write.c | |
| write | 写文件 | fs/read_write.c | 参见11.2.4.2.3 write()节 |
| writev | 将缓冲数组里的数据写入文件 | fs/read_write.c | |
| pwrite64 | 对文件随机写 | fs/read_write.c | |
| pwritev | 对文件随机写 | fs/read_write.c | |
| truncate | 截断文件 | fs/open.c | |
| ftruncate | 截断文件 | fs/open.c | |
| fsync | 把文件在内存中的部分写回磁盘 | fs/sync.c | |
| lseek | 移动文件指针 | fs/read_write.c | |
| llseek | 在64位地址空间里移动文件指针 | fs/read_write.c | |
| dup | 复制已打开的文件描述符 | fs/fcntl.c | |
| dup2 | 按指定条件复制文件描述符 | fs/fcntl.c | |
| dup3 | 按指定条件复制文件描述符 | fs/fcntl.c | |
| flock | 文件加/解锁 | fs/locks.c | |
| umask | 设置文件权限掩码 | kernel/sys.c | |
| poll | I/O多路转换 | fs/select.c | |
| fcntl | 文件控制 | fs/fcntl.c |
11.2.4.2.0 如何查找某文件所对应的文件操作函数
1) Find file system of the specific file.
1.1) Use command mount to list all mounted file systems:
chenwx@chenwx ~ $ mount
/dev/sdb5 on / type ext4 (rw,errors=remount-ro)
proc on /proc type proc (rw,noexec,nosuid,nodev)
sysfs on /sys type sysfs (rw,noexec,nosuid,nodev)
none on /sys/fs/cgroup type tmpfs (rw)
none on /sys/fs/fuse/connections type fusectl (rw)
none on /sys/kernel/debug type debugfs (rw)
none on /sys/kernel/security type securityfs (rw)
udev on /dev type devtmpfs (rw,mode=0755)
devpts on /dev/pts type devpts (rw,noexec,nosuid,gid=5,mode=0620)
tmpfs on /run type tmpfs (rw,noexec,nosuid,size=10%,mode=0755)
none on /run/lock type tmpfs (rw,noexec,nosuid,nodev,size=5242880)
none on /run/shm type tmpfs (rw,nosuid,nodev)
none on /run/user type tmpfs (rw,noexec,nosuid,nodev,size=104857600,mode=0755)
none on /sys/fs/pstore type pstore (rw)
binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,noexec,nosuid,nodev)
systemd on /sys/fs/cgroup/systemd type cgroup (rw,noexec,nosuid,nodev,none,name=systemd)
gvfsd-fuse on /run/user/1000/gvfs type fuse.gvfsd-fuse (rw,nosuid,nodev,user=chenwx)
/dev/sda1 on /media/chenwx/Work type fuseblk (rw,nosuid,nodev,allow_other,default_permissions,blksize=4096)
1.2) Find corresponding variable of struct file_system_type for the specific file system. Take devtmpfs for instance:
chenwx@chenwx ~/linux $ git grep -n \"devtmpfs\"
drivers/base/devtmpfs.c:65: .name = "devtmpfs",
drivers/base/devtmpfs.c:371: err = sys_mount("devtmpfs", (char *)mntdir, "devtmpfs", MS_SILENT, NULL);
drivers/base/devtmpfs.c:396: *err = sys_mount("devtmpfs", "/", "devtmpfs", MS_SILENT, options);
The instance of struct file_system_type for Devtmpfs is defined in file drivers/base/devtmpfs.c:
static struct file_system_type dev_fs_type = {
.name = "devtmpfs",
.mount = dev_mount,
.kill_sb = kill_litter_super,
};
2) Check method mount() of the specific file system (that’s, the member mount of struct file_system_type). Here it’s dev_mount():
static struct dentry *dev_mount(struct file_system_type *fs_type, int flags,
const char *dev_name, void *data)
{
#ifdef CONFIG_TMPFS
return mount_single(fs_type, flags, data, shmem_fill_super);
#else
return mount_single(fs_type, flags, data, ramfs_fill_super);
#endif
}
3) A type of method fill_super() is called by method mount() of the specific file system:
int (*fill_super)(struct super_block *sb, void *data, int silent);
Here, it’s ramfs_fill_super():
int ramfs_fill_super(struct super_block *sb, void *data, int silent)
{
...
struct inode *inode = NULL;
...
inode = ramfs_get_inode(sb, NULL, S_IFDIR | fsi->mount_opts.mode, 0);
...
root = d_alloc_root(inode);
...
sb->s_root = root;
...
}
In method ramfs_fill_super(), a variable of type struct inode is allocated and initalized. In the method that creates a variable of type struct inode, here is ramfs_get_inode(), the element i_fop of type struct inode is assigned to file operations:
struct inode *ramfs_get_inode(struct super_block *sb,
const struct inode *dir, int mode, dev_t dev)
{
struct inode * inode = new_inode(sb);
if (inode) {
inode->i_ino = get_next_ino();
inode_init_owner(inode, dir, mode);
inode->i_mapping->a_ops = &ramfs_aops;
inode->i_mapping->backing_dev_info = &ramfs_backing_dev_info;
mapping_set_gfp_mask(inode->i_mapping, GFP_HIGHUSER);
mapping_set_unevictable(inode->i_mapping);
inode->i_atime = inode->i_mtime = inode->i_ctime = CURRENT_TIME;
switch (mode & S_IFMT) {
default:
init_special_inode(inode, mode, dev);
break;
case S_IFREG:
inode->i_op = &ramfs_file_inode_operations;
inode->i_fop = &ramfs_file_operations;
break;
case S_IFDIR:
inode->i_op = &ramfs_dir_inode_operations;
inode->i_fop = &simple_dir_operations;
/* directory inodes start off with i_nlink == 2 (for "." entry) */
inc_nlink(inode);
break;
case S_IFLNK:
inode->i_op = &page_symlink_inode_operations;
break;
}
}
return inode;
}
Check the variables assigned to inode->i_fop with different mode, you will get file operation methods.
NOTE: Refer to 11.2.4.2.1.2.1.1.1 dentry_open()/__dentry_open(). Also check following statements in methods sys_open()->do_sys_open()->do_filp_open()->path_openat()->do_last()->nameidata_to_filp()->__dentry_open():
static struct file *__dentry_open(struct dentry *dentry, struct vfsmount *mnt,
struct file *f,
int (*open)(struct inode *, struct file *),
const struct cred *cred)
{
...
inode = dentry->d_inode;
f->f_op = fops_get(inode->i_fop);
...
}
11.2.4.2.1 open()
该系统调用定义于fs/open.c:
/*
* 参见[5.5.1 系统调用的声明与定义]节,该系统调用扩展被扩展为:
* asmlinkage long sys_open(const char __user *filename, int flags, umode_t mode);
*
* Given a filename for a file, open() returns a file descriptor, a small, nonnegative
* integer for use in subsequent system calls (read, write, lseek, etc.). The file
* descriptor returned by a successful call will be the lowest-numbered file descriptor
* not currently open for the process.
*
* filename: the file name (with path) will be opened.
*
* flags: it must include one of the following access modes: O_RDONLY, O_WRONLY, or
* O_RDWR, corresponding to read-only, write-only, or read/write, respectively.
*
* zero or more file creation flags and file status flags can be bitwise-or'd
* in flags.
*
* The file creation flags are:
* O_CLOEXEC, O_CREAT, O_DIRECTORY, O_EXCL, O_NOCTTY, O_NOFOLLOW, O_TMPFILE,
* O_TRUNC
*
* The file status flags are:
* O_APPEND, O_ASYNC, O_DIRECT, O_DSYNC, O_LARGEFILE, O_NOATIME, O_NONBLOCK,
* O_NDELAY, O_PATH, O_SYNC
*
* The distinction between these two groups of flags is that the file status
* flags can be retrieved and (in some cases) modified.
*
* mode: it specifies the file mode bits be applied when a new file is created. This
* argument must be supplied when O_CREAT or O_TMPFILE is specified in flags;
* if neither O_CREAT nor O_TMPFILE is specified, then mode is ignored.
*
* The values of mode are:
* S_IRWXU (00700), S_IRUSR (00400), S_IWUSR (00200), S_IXUSR (00100),
* S_IRWXG (00070), S_IRGRP (00040), S_IWGRP (00020), S_IXGRP (00010),
* S_IRWXO (00007), S_IROTH (00004), S_IWOTH (00002), S_IXOTH (00001),
* S_ISUID (0004000), S_ISGID (0002000), S_ISVTX (0001000)
*
* Refer to http://man7.org/linux/man-pages/man2/open.2.html
*
* For instance:
* open("/home/chenwx/abc.txt", O_WRONLY|O_CREAT|O_NOCTTY|O_NONBLOCK, 0666) = 3
*/
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, int, mode)
{
long ret;
/*
* 判断: BITS_PER_LONG != 32
* 对于64位的kernel,添加标志位O_LARGEFILE到flags
*/
if (force_o_largefile())
flags |= O_LARGEFILE;
/*
* 该函数返回文件描述符fd,参见[11.2.4.2.1.1 do_sys_open()]节
* AT_FDCWD: special value used to indicate openat()
* should use the current working directory
* if the filename starts with relative path.
*/
ret = do_sys_open(AT_FDCWD, filename, flags, mode);
/* avoid REGPARM breakage on x86: */
asmlinkage_protect(3, ret, filename, flags, mode);
return ret;
}
系统调用open()执行后的示意图:
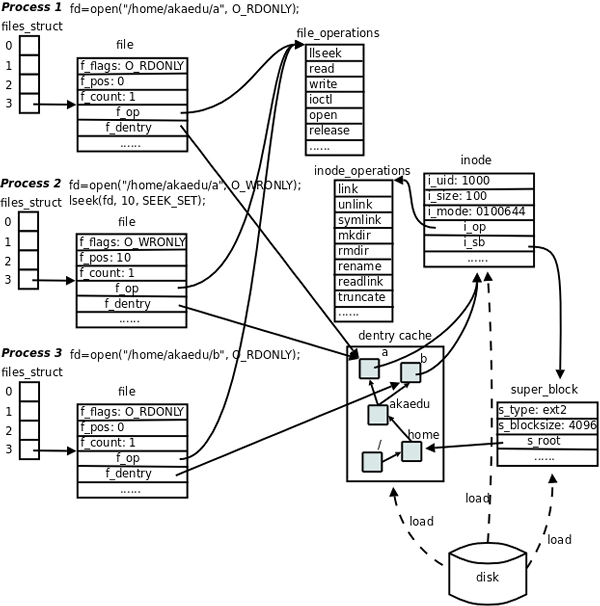
11.2.4.2.1.1 do_sys_open()
该函数定义于fs/open.c:
long do_sys_open(int dfd, const char __user *filename, int flags, int mode)
{
struct open_flags op;
/*
* 根据入参flags和mode来构造op和lookup;
* 其中,lookup的取值可包含LOOKUP_DIRECTORY, LOOKUP_FOLLOW;
* 并检查flags的合法性,(如有必要)修改flags中的标志位
*/
int lookup = build_open_flags(flags, mode, &op);
/*
* The getname() copies the filename from user space to kernel space:
* getname()->getname_flags()->do_getname()->strncpy_from_user()
*/
char *tmp = getname(filename);
int fd = PTR_ERR(tmp);
if (!IS_ERR(tmp)) {
// It returns the first unused file descriptor fd.
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
/*
* 调用do_filp_open()来搜索tmp中指定的路径,
* 并打开对应的文件,参见[11.2.4.2.1.2 do_filp_open()]节
*/
struct file *f = do_filp_open(dfd, tmp, &op, lookup);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
// 通过fsnotify机制来唤醒文件系统中的监控进程
fsnotify_open(f);
/*
* Install a file pointer in the fd array:
* current->files->fdt->fd[fd] = f;
*/
fd_install(fd, f);
}
}
/*
* Free the kernel space which contains filename
* copied from user space by getname().
*/
putname(tmp);
}
/*
* 返回文件描述符fd,可用于如下系统调用的入参:
* - sys_read(fd, ..),参见[11.2.4.2.2 read()]节
* - sys_write(fd, ..),参见[11.2.4.2.3 write()]节
* ...
*/
return fd;
}
11.2.4.2.1.2 do_filp_open()
该函数定义于fs/namei.c:
struct file *do_filp_open(int dfd, const char *pathname,
const struct open_flags *op, int flags)
{
struct nameidata nd;
struct file *filp;
// 1) 先试图在尽量不加锁的情况下完成路径查找(LOOKUP_RCU)
filp = path_openat(dfd, pathname, &nd, op, flags | LOOKUP_RCU);
// 2) 若不能找到,则试图在对路径上各节点加锁的情况下完成查找
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(dfd, pathname, &nd, op, flags);
// 3) 若在查找过程中出现路径上某些节点失效的情况,则进行LOOKUP_REVAL查找
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(dfd, pathname, &nd, op, flags | LOOKUP_REVAL);
return filp;
}
其中,函数path_openat()定义于fs/namei.c:
/*
* dfd: 路径查找的起点,可以是根目录,可以是当前工作目录(AT_FDCWD),也可以传入一个fd作为起点;
* pathname: 要打开的路径;
*/
static struct file *path_openat(int dfd, const char *pathname, struct nameidata *nd,
const struct open_flags *op, int flags)
{
struct file *base = NULL;
struct file *filp;
struct path path;
int error;
/*
* Find an unused file structure and return a pointer to it.
* The file structure is allocated from cache filp_cachep,
* see method files_init() in section [4.3.4.1.4.3.11.3 files_init()].
*/
filp = get_empty_filp();
if (!filp)
return ERR_PTR(-ENFILE);
filp->f_flags = op->open_flag;
nd->intent.open.file = filp;
nd->intent.open.flags = open_to_namei_flags(op->open_flag);
nd->intent.open.create_mode = op->mode;
/*
* path_init()是对真正遍历路径环境的初始化,即设置变量nd:
* nd->path, nd->inode,参见[11.2.2.4.1.1.1.1 path_init()]节;nd用于存储
* 遍历路径的中间结果
*/
error = path_init(dfd, pathname, flags | LOOKUP_PARENT, nd, &base);
if (unlikely(error))
goto out_filp;
/*
* link_path_walk(): turn a pathname into the final dentry.
* 更新变量: nd->path, nd->inode, nd->last, nd->last_type,
* 参见[11.2.2.4.1.1.1.2 link_path_walk()]节
*/
current->total_link_count = 0;
error = link_path_walk(pathname, nd);
if (unlikely(error))
goto out_filp;
// 调用函数do_last()来处理最后一个子路径,参见[11.2.4.2.1.2.1 do_last()]节
filp = do_last(nd, &path, op, pathname);
while (unlikely(!filp)) { /* trailing symlink */
struct path link = path;
void *cookie;
if (!(nd->flags & LOOKUP_FOLLOW)) {
path_put_conditional(&path, nd);
path_put(&nd->path);
filp = ERR_PTR(-ELOOP);
break;
}
nd->flags |= LOOKUP_PARENT;
nd->flags &= ~(LOOKUP_OPEN | LOOKUP_CREATE | LOOKUP_EXCL);
error = follow_link(&link, nd, &cookie);
if (unlikely(error))
filp = ERR_PTR(error);
else
filp = do_last(nd, &path, op, pathname);
put_link(nd, &link, cookie);
}
out:
if (nd->root.mnt && !(nd->flags & LOOKUP_ROOT))
path_put(&nd->root);
if (base)
fput(base);
release_open_intent(nd);
return filp;
out_filp:
filp = ERR_PTR(error);
goto out;
}
11.2.4.2.1.2.1 do_last()
该函数定义于fs/namei.c:
/*
* Handle the last step of open()
*/
static struct file *do_last(struct nameidata *nd, struct path *path,
const struct open_flags *op, const char *pathname)
{
struct dentry *dir = nd->path.dentry;
struct dentry *dentry;
int open_flag = op->open_flag;
int will_truncate = open_flag & O_TRUNC;
int want_write = 0;
int acc_mode = op->acc_mode;
struct file *filp;
int error;
/*
* LOOKUP_PARENT是在patn_init()中设置的,因为当时的目标是
* 找到最终文件的父目录,参见[11.2.2.4.1.1.1.1 path_init()]节。
* 而本函数do_last()要找的是最终文件,所以需要将该标志位清除
*/
nd->flags &= ~LOOKUP_PARENT;
nd->flags |= op->intent;
/*
* 根据nd->last_type的取值进行处理
*/
/*
* 1) 若nd->last_type取值为
* LAST_DOTDOT, LAST_DOT, LAST_ROOT, LAST_BIND
*/
switch (nd->last_type) {
case LAST_DOTDOT:
case LAST_DOT:
error = handle_dots(nd, nd->last_type);
if (error)
return ERR_PTR(error);
/* fallthrough */
case LAST_ROOT:
error = complete_walk(nd);
if (error)
return ERR_PTR(error);
audit_inode(pathname, nd->path.dentry);
if (open_flag & O_CREAT) {
error = -EISDIR;
goto exit;
}
goto ok;
case LAST_BIND:
error = complete_walk(nd);
if (error)
return ERR_PTR(error);
audit_inode(pathname, dir);
goto ok;
}
/*
* 2) 若nd->last_type的取值为LAST_NORM,即普通文件
*/
/*
* 2.1) 如果不是创建新文件
*/
if (!(open_flag & O_CREAT)) {
int symlink_ok = 0;
if (nd->last.name[nd->last.len])
nd->flags |= LOOKUP_FOLLOW | LOOKUP_DIRECTORY;
if (open_flag & O_PATH && !(nd->flags & LOOKUP_FOLLOW))
symlink_ok = 1;
/* we _can_ be in RCU mode here */
error = walk_component(nd, path, &nd->last, LAST_NORM, !symlink_ok);
if (error < 0)
return ERR_PTR(error);
if (error) /* symlink */
return NULL;
/* sayonara */
error = complete_walk(nd);
if (error)
return ERR_PTR(-ECHILD);
error = -ENOTDIR;
if (nd->flags & LOOKUP_DIRECTORY) {
if (!nd->inode->i_op->lookup)
goto exit;
}
audit_inode(pathname, nd->path.dentry);
goto ok;
}
/* create side of things */
/*
* This will *only* deal with leaving RCU mode - LOOKUP_JUMPED has been
* cleared when we got to the last component we are about to look up
*/
error = complete_walk(nd);
if (error)
return ERR_PTR(error);
audit_inode(pathname, dir);
error = -EISDIR;
/* trailing slashes? */
if (nd->last.name[nd->last.len])
goto exit;
mutex_lock(&dir->d_inode->i_mutex);
dentry = lookup_hash(nd);
error = PTR_ERR(dentry);
if (IS_ERR(dentry)) {
mutex_unlock(&dir->d_inode->i_mutex);
goto exit;
}
path->dentry = dentry;
path->mnt = nd->path.mnt;
/* Negative dentry, just create the file */
if (!dentry->d_inode) {
int mode = op->mode;
if (!IS_POSIXACL(dir->d_inode))
mode &= ~current_umask();
/*
* This write is needed to ensure that a
* rw->ro transition does not occur between
* the time when the file is created and when
* a permanent write count is taken through
* the 'struct file' in nameidata_to_filp().
*/
error = mnt_want_write(nd->path.mnt);
if (error)
goto exit_mutex_unlock;
want_write = 1;
/* Don't check for write permission, don't truncate */
open_flag &= ~O_TRUNC;
will_truncate = 0;
acc_mode = MAY_OPEN;
error = security_path_mknod(&nd->path, dentry, mode, 0);
if (error)
goto exit_mutex_unlock;
error = vfs_create(dir->d_inode, dentry, mode, nd);
if (error)
goto exit_mutex_unlock;
mutex_unlock(&dir->d_inode->i_mutex);
dput(nd->path.dentry);
nd->path.dentry = dentry;
goto common;
}
/*
* It already exists.
*/
mutex_unlock(&dir->d_inode->i_mutex);
audit_inode(pathname, path->dentry);
error = -EEXIST;
if (open_flag & O_EXCL)
goto exit_dput;
error = follow_managed(path, nd->flags);
if (error < 0)
goto exit_dput;
if (error)
nd->flags |= LOOKUP_JUMPED;
error = -ENOENT;
if (!path->dentry->d_inode)
goto exit_dput;
if (path->dentry->d_inode->i_op->follow_link)
return NULL;
/*
* nd->path.mnt = path->mnt;
* nd->path.dentry = path->dentry;
*/
path_to_nameidata(path, nd);
nd->inode = path->dentry->d_inode;
/* Why this, you ask? _Now_ we might have grown LOOKUP_JUMPED... */
error = complete_walk(nd);
if (error)
goto exit;
error = -EISDIR;
if (S_ISDIR(nd->inode->i_mode))
goto exit;
ok:
if (!S_ISREG(nd->inode->i_mode))
will_truncate = 0;
if (will_truncate) {
error = mnt_want_write(nd->path.mnt);
if (error)
goto exit;
want_write = 1;
}
common:
/*
* Check for access rights to a given inode:
* nd->path->dentry->d_inode
*/
error = may_open(&nd->path, acc_mode, open_flag);
if (error)
goto exit;
/*
* Get file descriptor: filp = nd->intent.open.file;
* 参见[11.2.4.2.1.2.1.1 nameidata_to_filp()]节
*/
filp = nameidata_to_filp(nd);
if (!IS_ERR(filp)) {
error = ima_file_check(filp, op->acc_mode);
if (error) {
fput(filp);
filp = ERR_PTR(error);
}
}
if (!IS_ERR(filp)) {
if (will_truncate) {
error = handle_truncate(filp);
if (error) {
fput(filp);
filp = ERR_PTR(error);
}
}
}
out:
if (want_write)
mnt_drop_write(nd->path.mnt);
path_put(&nd->path);
return filp;
exit_mutex_unlock:
mutex_unlock(&dir->d_inode->i_mutex);
exit_dput:
path_put_conditional(path, nd);
exit:
filp = ERR_PTR(error);
goto out;
}
11.2.4.2.1.2.1.1 nameidata_to_filp()
该函数定义于fs/open.c:
/**
* nameidata_to_filp - convert a nameidata to an open filp.
* @nd: pointer to nameidata
* @flags: open flags
*
* Note that this function destroys the original nameidata
*/
struct file *nameidata_to_filp(struct nameidata *nd)
{
const struct cred *cred = current_cred();
struct file *filp;
/* Pick up the filp from the open intent */
filp = nd->intent.open.file;
nd->intent.open.file = NULL;
/* Has the filesystem initialised the file for us? */
if (filp->f_path.dentry == NULL) {
path_get(&nd->path);
// 参见[11.2.4.2.1.2.1.1.1 dentry_open()/__dentry_open()]节
filp = __dentry_open(nd->path.dentry, nd->path.mnt, filp, NULL, cred);
}
return filp;
}
11.2.4.2.1.2.1.1.1 dentry_open()/__dentry_open()
该函数定义于fs/open.c:
/*
* dentry_open() will have done dput(dentry) and mntput(mnt) if it returns an
* error.
*/
struct file *dentry_open(struct dentry *dentry, struct vfsmount *mnt, int flags,
const struct cred *cred)
{
int error;
struct file *f;
validate_creds(cred);
/* We must always pass in a valid mount pointer. */
BUG_ON(!mnt);
error = -ENFILE;
f = get_empty_filp();
if (f == NULL) {
dput(dentry);
mntput(mnt);
return ERR_PTR(error);
}
f->f_flags = flags;
return __dentry_open(dentry, mnt, f, NULL, cred);
}
static struct file *__dentry_open(struct dentry *dentry, struct vfsmount *mnt,
struct file *f,
int (*open)(struct inode *, struct file *),
const struct cred *cred)
{
static const struct file_operations empty_fops = {};
struct inode *inode;
int error;
f->f_mode = OPEN_FMODE(f->f_flags) | FMODE_LSEEK | FMODE_PREAD | FMODE_PWRITE;
if (unlikely(f->f_flags & O_PATH))
f->f_mode = FMODE_PATH;
inode = dentry->d_inode;
if (f->f_mode & FMODE_WRITE) {
error = __get_file_write_access(inode, mnt);
if (error)
goto cleanup_file;
if (!special_file(inode->i_mode))
file_take_write(f);
}
f->f_mapping = inode->i_mapping;
f->f_path.dentry = dentry;
f->f_path.mnt = mnt;
f->f_pos = 0;
file_sb_list_add(f, inode->i_sb);
if (unlikely(f->f_mode & FMODE_PATH)) {
f->f_op = &empty_fops;
return f;
}
/*
* 此处为文件操作函数指针赋值,与具体的文件系统相关;后续的文件操作将调用这些函数:
* - sys_read系统调用将会调用file->f_op->read(),参见[11.2.4.2.2 read()]节
* - sys_write系统调用将会调用file->f_op->write(),参见[11.2.4.2.3 write()]节
* ...
*/
f->f_op = fops_get(inode->i_fop);
error = security_dentry_open(f, cred);
if (error)
goto cleanup_all;
error = break_lease(inode, f->f_flags);
if (error)
goto cleanup_all;
if (!open && f->f_op)
open = f->f_op->open;
if (open) {
error = open(inode, f);
if (error)
goto cleanup_all;
}
if ((f->f_mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_inc(inode);
f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC);
file_ra_state_init(&f->f_ra, f->f_mapping->host->i_mapping);
/* NB: we're sure to have correct a_ops only after f_op->open */
if (f->f_flags & O_DIRECT) {
if (!f->f_mapping->a_ops ||
((!f->f_mapping->a_ops->direct_IO) &&
(!f->f_mapping->a_ops->get_xip_mem))) {
fput(f);
f = ERR_PTR(-EINVAL);
}
}
return f;
cleanup_all:
fops_put(f->f_op);
if (f->f_mode & FMODE_WRITE) {
put_write_access(inode);
if (!special_file(inode->i_mode)) {
/*
* We don't consider this a real
* mnt_want/drop_write() pair
* because it all happenend right
* here, so just reset the state.
*/
file_reset_write(f);
mnt_drop_write(mnt);
}
}
file_sb_list_del(f);
f->f_path.dentry = NULL;
f->f_path.mnt = NULL;
cleanup_file:
put_filp(f);
dput(dentry);
mntput(mnt);
return ERR_PTR(error);
}
11.2.4.2.2 read()
该系统调用定义于fs/read_write.c:
/*
* 参见[5.5.1 系统调用的声明与定义]节,该系统调用扩展被扩展为:
* asmlinkage long sys_read(unsigned int fd, char __user * buf, size_t count);
*
* read() attempts to read up to count bytes from file descriptor
* fd into the buffer starting at buf.
*
* fd: 系统调用sys_open()返回的文件描述符,参见[11.2.4.2.1 open()]节
*
* buf: read buffer in user space.
*
* count: If count is zero, read() may detect the errors. In the
* absence of any errors, or if read() does not check for
* errors, a read() with a count of 0 returns zero and has
* no other effects.
*
* If the count is greater than SSIZE_MAX, the result is
* unspecified.
*
* Refer to http://man7.org/linux/man-pages/man2/read.2.html
*/
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
// 参见[11.2.1.5 文件/struct file]节
struct file *file;
ssize_t ret = -EBADF;
int fput_needed;
// 根据入参fd,从当前进程描述符中取出对应的file对象
file = fget_light(fd, &fput_needed);
if (file) {
// 取出此次读写前的当前位置pos = file->f_pos
loff_t pos = file_pos_read(file);
/*
* 从file中读出count字节到buf中,并移动pos,
* 参见[11.2.4.2.2.1 vfs_read()]节
*/
ret = vfs_read(file, buf, count, &pos);
// 保存此次读写后的当前位置file->f_pos = pos
file_pos_write(file, pos);
// 更新文件的引用计数file->f_count
fput_light(file, fput_needed);
}
// 返回读取的字节数
return ret;
}
11.2.4.2.2.1 vfs_read()
该函数定义于fs/read_write.c:
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
// 若该文件无可读属性,则直接返回
if (!(file->f_mode & FMODE_READ))
return -EBADF;
// 若该文件系统未定义读函数,则直接返回
if (!file->f_op || (!file->f_op->read && !file->f_op->aio_read))
return -EINVAL;
// checks if a user space pointer buf is valid
if (unlikely(!access_ok(VERIFY_WRITE, buf, count)))
return -EFAULT;
// 对要读取的文件进行合法性检查
ret = rw_verify_area(READ, file, pos, count);
if (ret >= 0) {
count = ret;
/*
* 调用函数file->f_op->read或file->f_op->aio_read
* 来读取该文件,该函数由具体的文件系统来定义,
* 参见[11.2.4.2.0 如何查找某文件所对应的文件操作函数]节
*/
if (file->f_op->read)
/*
* 调用file->f_op->read(),参见[11.2.1.5.1 文件操作/struct file_operations]节
*
* 其中,函数指针file->f_op->read是由如下函数调用赋值的:
* sys_open()->do_sys_open()->do_filp_open()->path_openat()
* ->do_last()->nameidata_to_filp()->__dentry_open():
* ...
* inode = dentry->d_inode;
* f->f_op = fops_get(inode->i_fop);
* ...
* 参见[11.2.4.2.1.2.1.1.1 dentry_open()/__dentry_open()]节
*/
ret = file->f_op->read(file, buf, count, pos);
else
/*
* 调用file->f_op->aio_read(..),
* 参见[11.2.1.5.1 文件操作/struct file_operations]节
*/
ret = do_sync_read(file, buf, count, pos);
if (ret > 0) {
fsnotify_access(file);
add_rchar(current, ret);
}
inc_syscr(current);
}
return ret;
}
11.2.4.2.3 write()
该系统调用定义于fs/read_write.c:
/*
* 参见[5.5.1 系统调用的声明与定义]节,该系统调用扩展被扩展为:
* asmlinkage long sys_write(unsigned int fd, char __user * buf, size_t count);
*
* write() writes up to count bytes from the buffer pointed buf
* to the file referred to by the file descriptor fd.
* fd into the buffer starting at buf.
*
* fd: 系统调用sys_open()返回的文件描述符,参见[11.2.4.2.1 open()]节
*
* buf: write buffer in user space.
*
* count: The number of bytes written may be less than count if,
* e.g., there is insufficient space on the underlying
* physical medium, or the RLIMIT_FSIZE resource limit is
* encountered, or the call was interrupted by a signal
* handler after having written less than count bytes.
*
* Refer to http://man7.org/linux/man-pages/man2/write.2.html
*/
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf, size_t, count)
{
struct file *file;
ssize_t ret = -EBADF;
int fput_needed;
// 根据入参fd,从当前进程描述符中取出相应的file对象
file = fget_light(fd, &fput_needed);
if (file) {
// 取出此次读写前的当前位置pos = file->f_pos;
loff_t pos = file_pos_read(file);
/*
* 将buf中的count字节写入file并移动pos,
* 参见[11.2.4.2.3.1 vfs_write()]节
*/
ret = vfs_write(file, buf, count, &pos);
// 保存此次读写后的当前位置file->f_pos = pos;
file_pos_write(file, pos);
// 更新文件的引用计数file->f_count
fput_light(file, fput_needed);
}
// 返回写入的字节数
return ret;
}
11.2.4.2.3.1 vfs_write()
该函数定义于fs/read_write.c:
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
// 若该文件无可写属性,则直接返回
if (!(file->f_mode & FMODE_WRITE))
return -EBADF;
// 若该文件系统未定义写函数,则直接返回
if (!file->f_op || (!file->f_op->write && !file->f_op->aio_write))
return -EINVAL;
// checks if a user space pointer buf is valid
if (unlikely(!access_ok(VERIFY_READ, buf, count)))
return -EFAULT;
// 对要写入的文件进行合法性检查
ret = rw_verify_area(WRITE, file, pos, count);
if (ret >= 0) {
count = ret;
/*
* 调用函数file->f_op->write或file->f_op->aio_write
* 来写入该文件,该函数由具体的文件系统来定义,
* 参见[11.2.4.2.0 如何查找某文件所对应的文件操作函数]节
*/
if (file->f_op->write)
/*
* 调用file->f_op->write(..),参见[11.2.1.5.1 文件操作/struct file_operations]节
*
* 其中,函数指针file->f_op->read是由如下函数调用赋值的:
* sys_open()->do_sys_open()->do_filp_open()->path_openat()
* ->do_last()->nameidata_to_filp()->__dentry_open():
* ...
* inode = dentry->d_inode;
* f->f_op = fops_get(inode->i_fop);
* ...
* 参见[11.2.4.2.1.2.1.1.1 dentry_open()/__dentry_open()]节
*/
ret = file->f_op->write(file, buf, count, pos);
else
/*
* 调用file->f_op->aio_write(..),
* 参见[11.2.1.5.1 文件操作/struct file_operations]节
*/
ret = do_sync_write(file, buf, count, pos);
if (ret > 0) {
fsnotify_modify(file);
add_wchar(current, ret);
}
inc_syscw(current);
}
return ret;
}
11.2.4.2.4 close()
该系统调用定义于fs/open.c:
/*
* Careful here! We test whether the file pointer is NULL before
* releasing the fd. This ensures that one clone task can't release
* an fd while another clone is opening it.
*
* 参见[5.5.1 系统调用的声明与定义]节,该系统调用扩展被扩展为:
* asmlinkage long sys_close(unsigned int fd);
*
* close() closes a file descriptor, so that it no longer refers
* to any file and may be reused. Any record locks held on the file
* it was associated with, and owned by the process, are removed
* (regardless of the file descriptor that was used to obtain the lock).
*
* fd: 系统调用sys_open()返回的文件描述符,参见[11.2.4.2.1 open()]节
*
* Refer to http://man7.org/linux/man-pages/man2/close.2.html
*/
SYSCALL_DEFINE1(close, unsigned int, fd)
{
struct file * filp;
struct files_struct *files = current->files;
struct fdtable *fdt;
int retval;
spin_lock(&files->file_lock);
fdt = files_fdtable(files);
if (fd >= fdt->max_fds)
goto out_unlock;
// 获取文件描述符fd对应的file
filp = fdt->fd[fd];
if (!filp)
goto out_unlock;
rcu_assign_pointer(fdt->fd[fd], NULL);
/*
* 清除标志位close_on_exec,表示进程
* 结束时不应该关闭对应位的文件描述对象
*/
FD_CLR(fd, fdt->close_on_exec);
// 清除该文件描述符fd对应的分配位图
__put_unused_fd(files, fd);
spin_unlock(&files->file_lock);
retval = filp_close(filp, files); // 参见下文
/* can't restart close syscall because file table entry was cleared */
if (unlikely(retval == -ERESTARTSYS ||
retval == -ERESTARTNOINTR ||
retval == -ERESTARTNOHAND ||
retval == -ERESTART_RESTARTBLOCK))
retval = -EINTR;
return retval;
out_unlock:
spin_unlock(&files->file_lock);
return -EBADF;
}
/*
* "id" is the POSIX thread ID. We use the
* files pointer for this..
*/
int filp_close(struct file *filp, fl_owner_t id)
{
int retval = 0;
// filp的引用计数为零,无效,直接返回
if (!file_count(filp)) {
printk(KERN_ERR "VFS: Close: file count is 0\n");
return 0;
}
/*
* 调用filp->f_op->flush(),参见[11.2.1.5.1 文件操作/struct file_operations]节
*
* 其中,函数指针file->f_op->flush是由如下函数调用赋值的:
* sys_open()->do_sys_open()->do_filp_open()->path_openat()
* ->do_last()->nameidata_to_filp()->__dentry_open():
* ...
* inode = dentry->d_inode;
* f->f_op = fops_get(inode->i_fop);
* ...
* 参见[11.2.4.2.1.2.1.1.1 dentry_open()/__dentry_open()]节
*
* 该函数由具体的文件系统定义,
* 参见[11.2.4.2.0 如何查找某文件所对应的文件操作函数]节
*/
if (filp->f_op && filp->f_op->flush)
retval = filp->f_op->flush(filp, id);
if (likely(!(filp->f_mode & FMODE_PATH))) {
dnotify_flush(filp, id);
// 文件要关闭了,将进程拥有的该文件的强制锁清除掉
locks_remove_posix(filp, id);
}
// 更新文件引用计数file->f_count,若减至0,则释放该文件
fput(filp);
return retval;
}
11.3 具体的文件系统
可通过下列命令查看注册到当前系统中的文件系统,参见11.2.1.1.2 查看系统中注册的文件系统节:
# cat /proc/filesystems
可通过下列命令查看挂载到当前系统中的文件系统,参见11.2.2.4 安装文件系统(2)/sys_mount()节:
# cat /proc/mounts
或通过下列命令查看挂载到当前系统中的文件系统:
# mount
通过下列命令查看文件系统的帮助信息:
# man fs
Linux支持的普通文件系统
| 文件系统 | 描述 |
|---|---|
| Minix | Linux最早支持的文件系统。主要缺点是最大64M的磁盘分区和最长14个字符的文件名的限制 |
| Ext | 第一个Linux专用的文件系统,支持2G磁盘分区,255字符的文件名。但性能有问题 |
| Xiafs | 在Minix基础上发展起来,克服了Minix的主要缺点。但很快被更完善的文件系统取代 |
| Ext2 | 当前实际上的Linux标准文件系统。性能强大,易扩充,可移植 |
| Ext3 | 日志文件系统。Ext3文件系统是对稳定的Ext2文件系统的改进 |
| System V | Unix早期支持的文件系统,也有与Minix相同的限制 |
| NFS | 网络文件系统。使用户可以像访问本地文件一样访问远程主机上的文件 |
| ISO 9660 | 光盘使用的文件系统 |
| Msdos | Dos文件系统,系统力图使它表现的像Unix |
| UMSDOS | 该文件系统允许MSDOS文件系统可以当作Linux固有的文件系统一样使用 |
| Vfat | fat文件系统的扩展,支持长文件名 |
| Ntfs | windows NT的文件系统 |
| Hpfs | OS/2的文件系统 |
Linux支持的特殊文件系统
| Name | Mount Point | Description |
|---|---|---|
| Bdev | None | Block devices |
| binfmt_misc | Any | Miscellaneous executable formats |
| devpts | /dev/pts | Pseudoterminal support (Open Group’s Unix98 standard) |
| eventpollfs | None | Used by the efficient event polling mechanism |
| futexfs | None | Used by the futex (Fast Userspace Locking) mechanism |
| pipefs | None | Pipes |
| proc | /proc | General access point to kernel data structures |
| rootfs | None | Provides an empty root directory for the bootstrap phase |
| Shm | None | IPC-shared memory regions |
| Mqueue | Any | Used to implement POSIX message queues |
| sockfs | None | Sockets |
| sysfs | /sysfs | General access point to system data |
| Tmpfs | Any | Temporary files (kept in RAM unless swapped) |
| usbfs | /proc/bus/usb | USB devices |
11.3.1 Ramfs
11.3.1.1 Ramfs简介
See Documentation/filesystems/ramfs-rootfs-initramfs.txt
Ramfs is a very simple filesystem that exports Linux’s disk caching mechanisms (the page cache and dentry cache) as a dynamically resizable RAM-based filesystem.
Normally all files are cached in memory by Linux. Pages of data read from backing store (usually the block device the filesystem is mounted on) are kept around in case it’s needed again, but marked as clean (freeable) in case the Virtual Memory system needs the memory for something else. Similarly, data written to files is marked clean as soon as it has been written to backing store, but kept around for caching purposes until the VM reallocates the memory. A similar mechanism (the dentry cache) greatly speeds up access to directories.
With ramfs, there is no backing store. Files written into ramfs allocate dentries and page cache as usual, but there’s nowhere to write them to. This means the pages are never marked clean, so they can’t be freed by the VM when it’s looking to recycle memory.
The amount of code required to implement ramfs is tiny, because all the work is done by the existing Linux caching infrastructure. Basically, you’re mounting the disk cache as a filesystem. Because of this, ramfs is not an optional component removable via menuconfig, since there would be negligible space savings.
11.3.1.2 Ramfs的编译及初始化
Ramfs定义于fs/ramfs/inode.c:
static struct file_system_type ramfs_fs_type = {
.name = "ramfs",
/*
* 函数ramfs_mount()是通过下列函数调用的:
* sys_mount()
* -> do_mount()
* -> do_new_mount()
* -> do_kern_mount()
* -> vfs_kern_mount()
* -> mount_fs(type, flags, name, data)
* -> type->mount(type, flags, name, data)
*/
.mount = ramfs_mount,
/*
* 函数ramfs_kill_sb()是通过下列函数调用的:
* sys_unmount()
* -> mntput_no_expire()
* -> mntfree()
* -> deactivate_super()
* -> deactivate_locked_super()
* -> fs->kill_sb()
* 参见[11.2.2.5 卸载文件系统(2)/sys_oldumount()/sys_umount()]节
*/
.kill_sb = ramfs_kill_sb,
};
static int __init init_ramfs_fs(void)
{
// 注册ramfs文件系统,参见[11.2.2.1 注册/注销文件系统]节
return register_filesystem(&ramfs_fs_type);
}
// 由于Ramfs不会被注销,因而此处没有调用module_exit()
module_init(init_ramfs_fs)
由fs/Makefile的如下代码:
obj-y += ramfs/
可知,没有选项配置可以将Ramfs编译成模块,因而Ramfs是被编译进内核的,其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
由此初始化过程以及11.4 文件系统的自动安装节可知,ramfs只被注册到系统中,但并未被挂载到系统中!
11.3.1.3 Ramfs的节点操作函数与文件操作函数
由下列函数调用:
ramfs_mount()
-> mount_nodev(fs_type, flags, data, ramfs_fill_super)
-> fill_super(s, data, flags & MS_SILENT ? 1 : 0)
-> ramfs_fill_super()
-> sb->s_maxbytes = MAX_LFS_FILESIZE; // 该文件系统最大能使用的内存大小
-> sb->s_blocksize = PAGE_CACHE_SIZE;
-> sb->s_blocksize_bits = PAGE_CACHE_SHIFT;
-> inode = ramfs_get_inode(sb, NULL, S_IFDIR | fsi->mount_opts.mode, 0)
-> struct inode *inode = new_inode(sb);
-> if (inode) {
inode->i_ino = get_next_ino();
inode_init_owner(inode, dir, mode);
inode->i_mapping->a_ops = &ramfs_aops;
inode->i_mapping->backing_dev_info = &ramfs_backing_dev_info;
mapping_set_gfp_mask(inode->i_mapping, GFP_HIGHUSER);
mapping_set_unevictable(inode->i_mapping);
inode->i_atime = inode->i_mtime = inode->i_ctime = CURRENT_TIME;
switch (mode & S_IFMT) {
default:
init_special_inode(inode, mode, dev);
break;
case S_IFREG:
inode->i_op = &ramfs_file_inode_operations;
inode->i_fop = &ramfs_file_operations;
break;
case S_IFDIR:
inode->i_op = &ramfs_dir_inode_operations;
inode->i_fop = &simple_dir_operations;
/* directory inodes start off with i_nlink == 2 (for "." entry) */
inc_nlink(inode);
break;
case S_IFLNK:
inode->i_op = &page_symlink_inode_operations;
break;
}
}
inode操作函数ramfs_dir_inode_operations和文件操作函数simple_dir_operations定义如下,其中只有名为ramfs_xxx的函数为ramfs所定义的函数,其他函数均来自于libfs.c:
static const struct inode_operations ramfs_dir_inode_operations = {
.create = ramfs_create,
.lookup = simple_lookup,
.link = simple_link,
.unlink = simple_unlink,
.symlink = ramfs_symlink,
.mkdir = ramfs_mkdir,
.rmdir = simple_rmdir,
.mknod = ramfs_mknod,
.rename = simple_rename,
};
const struct file_operations simple_dir_operations = {
.open = dcache_dir_open,
.release = dcache_dir_close,
.llseek = dcache_dir_lseek,
.read = generic_read_dir,
.readdir = dcache_readdir,
.fsync = noop_fsync,
};
11.3.1.4 Ramfs的使用方法
通过下列命令来挂载Ramfs文件系统:
chenwx chenwx # mkdir -p ~/fs-mount-point
chenwx chenwx # mount -t ramfs none ~/fs-mount-pint
chenwx chenwx # mount | grep ramfs
none on /home/chenwx/fs-mount-point type ramfs (rw,relatime)
11.3.2 Rootfs
11.3.2.1 Rootfs简介
See Documentation/filesystems/ramfs-rootfs-initramfs.txt
Rootfs is a special instance of ramfs (or tmpfs, if that’s enabled), which is always present in 2.6 systems. You can’t unmount rootfs for approximately the same reason you can’t kill the init process; rather than having special code to check for and handle an empty list, it’s smaller and simpler for the kernel to just make sure certain lists can’t become empty.
Most systems just mount another filesystem over rootfs and ignore it. The amount of space an empty instance of ramfs takes up is tiny.
If CONFIG_TMPFS is enabled, rootfs will use tmpfs instead of ramfs by default. To force ramfs, add “rootfstype=ramfs” to the kernel command line.
11.3.2.2 Rootfs编译与初始化及安装过程
与Ramfs类似,Rootfs也定义于fs/ramfs/inode.c,也是直接编译进内核的:
static struct file_system_type rootfs_fs_type = {
.name = "rootfs",
/*
* rootfs_mount()通过被如下函数调用,
* 参见[4.3.4.1.4.3.11.4.3 init_mount_tree()]节和[11.2.2.2.1.2.2 rootfs_mount()]节:
* init_mount_tree()->do_kern_mount()->
* vfs_kern_mount()->mount_fs()中的type->mount()
*/
.mount = rootfs_mount,
.kill_sb = kill_litter_super,
};
Rootfs的初始化及安装过程,参见下列章节:
NOTE: 由内核参数”root=”指定根文件系统的位置,参见4.3.4.1.4.3.13.1.3 prepare_namespace()节。
11.3.3 Initramfs
11.3.3.1 Initramfs简介
See Documentation/filesystems/ramfs-rootfs-initramfs.txt:
Today (kernel 2.6.16), initramfs is always compiled in, but not always used.
11.3.3.2 Initramfs编译与初始化
由init/Makefile的如下代码:
ifneq ($(CONFIG_BLK_DEV_INITRD),y)
obj-y += noinitramfs.o
else
obj-$(CONFIG_BLK_DEV_INITRD) += initramfs.o
endif
mounts-$(CONFIG_BLK_DEV_INITRD) += do_mounts_initrd.o
可知,Initramfs的编译与配置选项CONFIG_BLK_DEV_INITRD的取值有关,参见11.3.3.2.1 CONFIG_BLK_DEV_INITRD=n节和11.3.3.2.2 CONFIG_BLK_DEV_INITRD=y节。
11.3.3.2.1 CONFIG_BLK_DEV_INITRD=n
当执行make alldefconfig时,输出的配置文件.config包含如下内容:
# CONFIG_BLK_DEV_INITRD is not set
故默认情况下,编译noinitramfs.o,参见init/noinitramfs.c:
/*
* Create a simple rootfs that is similar to the default initramfs
*/
static int __init default_rootfs(void)
{
int err;
err = sys_mkdir((const char __user __force *) "/dev", 0755);
if (err < 0)
goto out;
err = sys_mknod((const char __user __force *) "/dev/console",
S_IFCHR | S_IRUSR | S_IWUSR, new_encode_dev(MKDEV(5, 1)));
if (err < 0)
goto out;
err = sys_mkdir((const char __user __force *) "/root", 0700);
if (err < 0)
goto out;
return 0;
out:
printk(KERN_WARNING "Failed to create a rootfs\n");
return err;
}
rootfs_initcall(default_rootfs);
其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcallrootfs.init
11.3.3.2.2 CONFIG_BLK_DEV_INITRD=y
这种情况下,编译initramfs.o,参见init/initramfs.c:
static int __init populate_rootfs(void)
{
/*
* 函数unpack_to_rootfs()用于解压包到rootfs,其实initramfs是压缩过的CPIO文件。
* __initramfs_start定义于arch/x86/kernel/vmlinux.lds,即.init.ramfs段
*/
char *err = unpack_to_rootfs(__initramfs_start, __initramfs_size);
if (err)
panic(err); /* Failed to decompress INTERNAL initramfs */
/*
* 判断是否加载了initrd,无论对于哪种格式的initrd,即无论是CPIO-initrd还是Image-initrd,
* bootloader都会将其拷贝到initrd_start;如果是initramfs,则该值为空
*/
if (initrd_start) {
#ifdef CONFIG_BLK_DEV_RAM // 若要支持Image-initrd,必须要配置CONFIG_BLK_DEV_RAM
int fd;
printk(KERN_INFO "Trying to unpack rootfs image as initramfs...\n");
/*
* 变量initrd_start和initrd_end的取值参见reserve_initrd()和relocate_initrd(),
* 这两个函数定义于arch/x86/kernel/setup.c,其调用关系如下:
* setup_arch() -> reserve_initrd() -> relocate_initrd()
* 命令dmesg | grep RAMDISK的输出如下:
* [ 0.000000] RAMDISK: [mem 0x34f4c000-0x3679dfff]
*
* 区域[initrd_start, initrd_end]表示/initrd.image,示例如下:
* /initrd.img -> boot/initrd.img-3.11.0-12-generic
* 映像/initrd.img是通过如下函数调用加载而来的,参见[4.3.4.1.4.3.13.1.3 prepare_namespace()]节:
* kernel_init() -> prepare_namespace() -> initrd_load()
*/
err = unpack_to_rootfs((char *)initrd_start, initrd_end - initrd_start);
if (!err) {
free_initrd(); // 释放initrd所占用的内存空间
return 0;
} else {
clean_rootfs();
unpack_to_rootfs(__initramfs_start, __initramfs_size);
}
printk(KERN_INFO "rootfs image is not initramfs (%s); looks like an initrd\n", err);
// 将内存中的initrd保存到initrd.image中,以释放内存空间
fd = sys_open((const char __user __force *) "/initrd.image", O_WRONLY|O_CREAT, 0700);
if (fd >= 0) {
sys_write(fd, (char *)initrd_start, initrd_end - initrd_start);
sys_close(fd);
free_initrd(); // 释放initrd所占用的内存空间
}
#else
printk(KERN_INFO "Unpacking initramfs...\n");
err = unpack_to_rootfs((char *)initrd_start, initrd_end - initrd_start);
if (err)
printk(KERN_EMERG "Initramfs unpacking failed: %s\n", err);
free_initrd();
#endif
}
return 0;
}
rootfs_initcall(populate_rootfs);
其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcallrootfs.init
11.3.4 Proc
通常,Proc文件系统被挂载到/proc目录。
11.3.4.1 Proc简介
See Documentation/filesystems/proc.txt
11.3.4.2 Proc的编译及初始化
由fs/Makefile可知,Proc的编译与配置项CONFIG_PROC_FS有关:
obj-$(CONFIG_PROC_FS) += proc/
Proc的初始化过程参见[4.3.4.1.4.3.12 proc_root_init()](#4-3-4-1-4-3-12-proc-root-init-)节。
变量proc_fs_type定义于fs/proc/root.c:
static struct file_system_type proc_fs_type = {
.name = "proc",
.mount = proc_mount, // 参见[11.2.2.2.1.2.4 proc_mount()]节
.kill_sb = proc_kill_sb,
};
11.3.4.3 Proc的安装
文件系统proc的安装过程参见11.2.2.2.1.2.4 proc_mount()节和[11.4 文件系统的自动安装]节。
11.3.4.4 /proc目录结构
/proc/目录下的文件及文件夹
| /proc/ | Description |
|---|---|
| <1234> | Each of the numbered directories corresponds to an actual process ID. |
| apm | Advanced power management info. |
| bus | Directory containing bus specific information. |
| cmdline | Kernel command line. |
| cpuinfo | Information about the processor, such as its type, make, model, and performance. |
| devices | List of device drivers configured into the currently running kernel (block and character). |
| dma | Shows which DMA channels are being used at the moment. |
| driver | Various drivers grouped here, currently rtc. |
| execdomains | Execdomains, related to security. |
| fb | Frame Buffer devices. |
| filesystems | Filesystems configured/supported into/by the kernel. |
| mounts | Mounted filesystems. |
| fs | File system parameters. |
| ide | This subdirectory contains information about all IDE devices of which the kernel is aware. There is one subdirectory for each IDE controller, the file drivers and a link for each IDE device, pointing to the device directory in the controller-specific subtree. |
| interrupts | Shows which interrupts are in use, and how many of each there have been. |
| iomem | Memory map. |
| meminfo | Information about memory usage, both physical and swap. Concatenating this file produces similar results to using ‘free’ or the first few lines of ‘top’. |
| ioports | Which I/O ports are in use at the moment. |
| irq | Masks for irq to cpu affinity. |
| softirqs | Soft irq. |
| isapnp | ISA PnP (Plug&Play) Info. |
| kcore | An image of the physical memory of the system (can be ELF or A.OUT (deprecated in 2.4)). This is exactly the same size as your physical memory, but does not really take up that much memory; it is generated on the fly as programs access it. (Remember: unless you copy it elsewhere, nothing under /proc takes up any disk space at all.) |
| kmsg | Messages output by the kernel. These are also routed to syslog. |
| ksyms | Kernel symbol table. |
| loadavg | The ‘load average’ of the system; three indicators of how much work the system has done during the last 1, 5 & 15 minutes. |
| locks | Kernel locks. |
| misc | Miscellaneous pieces of information. This is for information that has no real place within the rest of the proc filesystem. |
| modules | Kernel modules currently loaded. Typically its output is the same as that given by the ‘lsmod’ command. |
| mtrr | Information regarding mtrrs. |
| net | Status information about network protocols. |
| parport | The directory /proc/parport contains information about the parallel ports of your system. It has one subdirectory for each port, named after the port number (0, 1, 2, …). |
| partitions | Table of partitions known to the system. |
| pci, bus/pci | Depreciated info of PCI bus. |
| rtc | Real time clock. |
| scsi | If you have a SCSI host adapter in your system, you’ll find a subdirectory named after the driver for this adapter in /proc/scsi. |
| self | A symbolic link to the process directory of the program that is looking at /proc. When two processes look at /proc, they get different links. This is mainly a convenience to make it easier for programs to get at their process directory. |
| slabinfo | The slabinfo file gives information about memory usage at the slab level. |
| stat | Overall/various statistics about the system, such as the number of page faults since the system was booted. |
| swaps | Swap space utilization. |
| sys | This is not only a source of information, it also allows you to change parameters within the kernel without the need for recompilation or even a system reboot. Refer to section 11.3.4.4.2 /proc/sys. |
| sysvipc | Info of SysVIPC Resources (msg, sem, shm). |
| tty | Information about the available and actually used tty’s can be found in the directory /proc/tty. You’ll find entries for drivers and line disciplines in this directory. |
| uptime | The time the system has been up. |
| version | The kernel version. |
| video | BTTV info of video resources. |
11.3.4.4.1 /proc/kmsg
/proc/kmsg是通过proc_kmsg_init()创建的,其定义于fs/proc/kmsg.c:
/*
* 变量proc_kmsg_operations中的函数均调用do_syslog(),
* 参见[19.2.1.5.1 do_syslog()]节
*/
static const struct file_operations proc_kmsg_operations = {
.read = kmsg_read,
.poll = kmsg_poll,
.open = kmsg_open,
.release = kmsg_release,
.llseek = generic_file_llseek,
};
static int __init proc_kmsg_init(void)
{
proc_create("kmsg", S_IRUSR, NULL, &proc_kmsg_operations);
return 0;
}
module_init(proc_kmsg_init);
11.3.4.4.2 /proc/sys
目录/proc/sys是由函数proc_sys_init()创建的,其调用关系如下:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> proc_root_init() // 参见[4.3.4.1.4.3.12 proc_root_init()]节
-> register_filesystem(&proc_fs_type)
-> pid_ns_prepare_proc(&init_pid_ns)
-> kern_mount_data(&proc_fs_type, ns)
-> vfs_kern_mount()
-> mount_fs()
-> type->mount() // proc_fs_type->mount = proc_mount;
-> proc_mount() // 参见[11.2.2.2.1.2.4 proc_mount()]节
-> proc_fill_super()
-> proc_get_inode()
-> proc_sys_init() // 创建/proc/sys 目录
该函数定义于fs/proc/proc_sysctl.c:
int __init proc_sys_init(void)
{
struct proc_dir_entry *proc_sys_root;
proc_sys_root = proc_mkdir("sys", NULL);
proc_sys_root->proc_iops = &proc_sys_dir_operations;
proc_sys_root->proc_fops = &proc_sys_dir_file_operations;
proc_sys_root->nlink = 0;
return 0;
}
// 目录/proc/sys的inode处理函数
static const struct inode_operations proc_sys_dir_operations = {
.lookup = proc_sys_lookup,
.permission = proc_sys_permission,
.setattr = proc_sys_setattr,
.getattr = proc_sys_getattr,
};
// 目录/proc/sys的文件处理函数
static const struct file_operations proc_sys_dir_file_operations = {
.read = generic_read_dir,
.readdir = proc_sys_readdir,
.llseek = generic_file_llseek,
};
static const struct file_operations proc_sys_file_operations = {
.open = proc_sys_open,
.poll = proc_sys_poll,
.read = proc_sys_read,
.write = proc_sys_write,
.llseek = default_llseek,
};
11.3.4.4.2.0 与/proc/sys目录有关的数据结构
有关/proc/sys目录的数据结构包含在kernel/sysctl.c中,其中包括:
static struct ctl_table_header root_table_header = {
{
{
.count = 1,
.ctl_table = root_table,
.ctl_entry = LIST_HEAD_INIT(sysctl_table_root.default_set.list),
}
},
.root = &sysctl_table_root,
.set = &sysctl_table_root.default_set,
};
static struct ctl_table_root sysctl_table_root = {
.root_list = LIST_HEAD_INIT(sysctl_table_root.root_list),
.default_set.list = LIST_HEAD_INIT(root_table_header.ctl_entry),
};
/*
* /proc/sys/目录除了包含下列子目录外,还包括子目录net和abi,其中:
* - net子目录是由???注册的
* - abi子目录是由arch/x86/vdso/vdso32-setup.c中的如下函数注册的:
* ia32_binfmt_init()->register_sysctl_table(abi_root_table2)
*/
static struct ctl_table root_table[] = {
{
.procname = "kernel",
.mode = 0555,
.child = kern_table,
},
{
.procname = "vm",
.mode = 0555,
.child = vm_table,
},
{
.procname = "fs",
.mode = 0555,
.child = fs_table,
},
{
.procname = "debug",
.mode = 0555,
.child = debug_table,
},
{
.procname = "dev",
.mode = 0555,
.child = dev_table,
},
{ }
};
11.3.4.4.2.1 Configure kernel parameters
11.3.4.4.2.1.1 echo “value” > /proc/sys/xxx
使用ls -l来查看/proc/sys目录下的文件:
- 若某文件可写,则说明可通过修改该文件来配置系统参数;
- 若某文件不可写,则说明不能通过修改该文件来配置系统参数,而仅仅是列出一些系统信息而已。
若文件可写,则可通过下列命令修改系统配置参数:
chenwx@chenwx ~/linux $ ll /proc/sys/kernel/hostname
-rw-r--r-- 1 root root 0 Jul 22 09:13 /proc/sys/kernel/hostname
chenwx@chenwx ~/linux $ su
chenwx linux # echo "chenwx-pc" > /proc/sys/kernel/hostname
chenwx linux # cat /proc/sys/kernel/hostname
chenwx-pc
chenwx linux # sysctl -q kernel.hostname
kernel.hostname = chenwx-pc
chenwx linux # hostname
chenwx-pc
NOTE: 通过这种方式将某内核参数修改为新值后,在系统重启后,新值将无法保存;如果需要新值在重启后也可以保留,需要直接修改配置文件/etc/sysctl.conf,参见11.3.4.4.2.1.3 通过配置文件/etc/sysctl.conf配置内核参数节。
11.3.4.4.2.1.2 通过命令/sbin/sysctl配置内核参数
可通过sysctl命令修改/proc/sys目录下的内核参数:
NAME
sysctl - configure kernel parameters at runtime
SYNOPSIS
sysctl [options] [variable[=value]] [...]
sysctl -p [file or regexp] [...]
DESCRIPTION
sysctl is used to modify kernel parameters at runtime. The parameters available are those
listed under /proc/sys/. Procfs is required for sysctl support in Linux. You can use sysctl
to both read and write sysctl data.
PARAMETERS
variable
The name of a key to read from. An example is kernel.ostype. The '/' separator is
also accepted in place of a '.'.
variable=value
To set a key, use the form variable=value where variable is the key and value is the
value to set it to. If the value contains quotes or characters which are parsed by
the shell, you may need to enclose the value in double quotes. This requires the -w
parameter to use.
-n, --values
Use this option to disable printing of the key name when printing values.
-e, --ignore
Use this option to ignore errors about unknown keys.
-N, --names
Use this option to only print the names. It may be useful with shells that have
programmable completion.
-q, --quiet
Use this option to not display the values set to stdout.
-w, --write
Use this option when you want to change a sysctl setting.
-p[FILE], --load[=FILE]
Load in sysctl settings from the file specified or /etc/sysctl.conf if none given.
Specifying - as filename means reading data from standard input. Using this option
will mean arguments to sysctl are files, which are read in order they are specified.
The file argument can may be specified as reqular expression.
-a, --all
Display all values currently available.
--deprecated
Include deprecated parameters to --all values listing.
-b, --binary
Print value without new line.
--system
Load settings from all system configuration files.
/run/sysctl.d/*.conf
/etc/sysctl.d/*.conf
/usr/local/lib/sysctl.d/*.conf
/usr/lib/sysctl.d/*.conf
/lib/sysctl.d/*.conf
/etc/sysctl.conf
-r, --pattern pattern
Only apply settings that match pattern. The pattern uses extended regular
expression syntax.
-A Alias of -a
-d Alias of -h
-f Alias of -p
-X Alias of -a
-o Does nothing in favour of BSD compatibility.
-x Does nothing in favour of BSD compatibility.
-h, --help
Display help text and exit.
-V, --version
Display version information and exit.
EXAMPLES
/sbin/sysctl -a
/sbin/sysctl -n kernel.hostname
/sbin/sysctl -w kernel.domainname="example.com"
/sbin/sysctl -p/etc/sysctl.conf
/sbin/sysctl -a --pattern forward
/sbin/sysctl -a --pattern forward$
/sbin/sysctl -a --pattern 'net.ipv4.conf.(eth|wlan)0.arp'
/sbin/sysctl --system --pattern '^net.ipv6'
DEPRECATED PARAMETERS
The base_reachable_time and retrans_time are deprecated. The sysctl command does not allow
changing values of there parameters. Users who insist to use deprecated kernel interfaces
should values to /proc file system by other means. For example:
echo 256 > /proc/sys/net/ipv6/neigh/eth0/base_reachable_time
FILES
/proc/sys
/etc/sysctl.conf
SEE ALSO
sysctl.conf(5) regex(7)
AUTHOR
George Staikos <staikos@0wned.org>
REPORTING BUGS
Please send bug reports to <procps@freelists.org>
可通过下列命令临时修改系统配置参数:
chenwx linux # sysctl -q kernel.hostname
kernel.hostname = chenwx-pc
chenwx linux # sysctl -w kernel.hostname="chenwx "
kernel.hostname = chenwx
NOTE: 通过这种方式将某内核参数修改为新值后,在系统重启后,新值将无法保存;如果需要新值在重启后也可以保留,需要直接修改配置文件/etc/sysctl.conf,参见11.3.4.4.2.1.3 通过配置文件/etc/sysctl.conf配置内核参数节。
11.3.4.4.2.1.3 通过配置文件/etc/sysctl.conf配置内核参数
通过修改配置文件/etc/sysctl.conf来配置内核参数:
NAME
sysctl.conf - sysctl preload/configuration file
DESCRIPTION
sysctl.conf is a simple file containing sysctl values to be read in and set by sysctl.
The syntax is simply as follows:
# comment
; comment
token = value
Note that blank lines are ignored, and whitespace before and after a token or value is
ignored, although a value can contain whitespace within. Lines which begin with a # or ;
are considered comments and ignored.
EXAMPLE
# sysctl.conf sample
#
kernel.domainname = example.com
; this one has a space which will be written to the sysctl!
kernel.modprobe = /sbin/mod probe
FILES
/run/sysctl.d/*.conf
/etc/sysctl.d/*.conf
/usr/local/lib/sysctl.d/*.conf
/usr/lib/sysctl.d/*.conf
/lib/sysctl.d/*.conf
/etc/sysctl.conf
The paths where sysctl preload files usually exit. See also sysctl option --system.
SEE ALSO
sysctl(8)
AUTHOR
George Staikos <staikos@0wned.org>
REPORTING BUGS
Please send bug reports to <procps@freelists.org>
修改完/etc/sysctl.conf后,新配置的参数并不会立即生效,需要执行下列命令使新配置的参数立即生效:
// 查看内核参数kernel.hostname的当前值
chenwx ~ # cat /proc/sys/kernel/hostname
chenwx
chenwx ~ # hostname
chenwx
// 修改配置选项"kernel.hostname=chenwx-pc-2"
chenwx ~ # vim /etc/sysctl.conf
// 使配置参数立即生效
chenwx ~ # sysctl -p
kernel.hostname = chenwx-pc-2
chenwx ~ # cat /proc/sys/kernel/hostname
chenwx-pc-2
chenwx ~ # sysctl -q kernel.hostname
kernel.hostname = chenwx-pc-2
chenwx ~ # hostname
chenwx-pc-2
11.3.4.4.2.2 系统启动时如何加载/etc/sysctl.conf
在系统启动时,进程init将执行配置文件/etc/init/*.conf,参见4.3.5.1.3.1 upstart节。当调用脚本/etc/init/procps.conf时,将执行/etc/sysctl.conf中配置的内核参数:
chenwx@chenwx ~ $ ll /etc/init/procps.conf
-rw-r--r-- 1 root root 363 Jan 6 2014 /etc/init/procps.conf
chenwx@chenwx ~ $ cat /etc/init/procps.conf
# procps - set sysctls from /etc/sysctl.conf
#
# This task sets kernel sysctl variables from /etc/sysctl.conf and
# /etc/sysctl.d
description "set sysctls from /etc/sysctl.conf"
instance $UPSTART_EVENTS
env UPSTART_EVENTS=
start on virtual-filesystems or static-network-up
task
script
cat /etc/sysctl.d/*.conf /etc/sysctl.conf | sysctl -e -p -
end script
11.3.4.4.3 /proc/filesystems
/proc/filesystems是通过proc_filesystems_init()创建的,其定义于fs/filesystems.c:
#ifdef CONFIG_PROC_FS
static int filesystems_proc_show(struct seq_file *m, void *v)
{
struct file_system_type * tmp;
read_lock(&file_systems_lock);
tmp = file_systems;
while (tmp) {
seq_printf(m, "%s\t%s\n",
(tmp->fs_flags & FS_REQUIRES_DEV) ? "" : "nodev",
tmp->name);
tmp = tmp->next;
}
read_unlock(&file_systems_lock);
return 0;
}
static int __init proc_filesystems_init(void)
{
proc_create_single("filesystems", 0, NULL, filesystems_proc_show);
return 0;
}
// 参见[13.5.1 module_init()/module_exit()]节
module_init(proc_filesystems_init);
#endif
11.3.4.5 与proc文件系统有关的数据结构
11.3.4.5.1 struct proc_dir_entry
该结构定义于include/linux/proc_fs.h:
/*
* This is not completely implemented yet. The idea is to
* create an in-memory tree (like the actual /proc filesystem
* tree) of these proc_dir_entries, so that we can dynamically
* add new files to /proc.
*
* The "next" pointer creates a linked list of one /proc directory,
* while parent/subdir create the directory structure (every
* /proc file has a parent, but "subdir" is NULL for all
* non-directory entries).
*/
typedef int (read_proc_t)(char *page, char **start, off_t off, int count, int *eof, void *data);
typedef int (write_proc_t)(struct file *file, const char __user *buffer, unsigned long count, void *data);
struct proc_dir_entry {
unsigned int low_ino;
mode_t mode;
nlink_t nlink;
uid_t uid;
gid_t gid;
loff_t size;
const struct inode_operations *proc_iops;
/*
* NULL ->proc_fops means "PDE is going away RSN" or
* "PDE is just created". In either case, e.g. ->read_proc won't be
* called because it's too late or too early, respectively.
*
* If you're allocating ->proc_fops dynamically, save a pointer
* somewhere.
*/
const struct file_operations *proc_fops;
struct proc_dir_entry *next, *parent, *subdir;
void *data;
read_proc_t *read_proc;
write_proc_t *write_proc;
atomic_t count; /* use count */
int pde_users; /* number of callers into module in progress */
struct completion *pde_unload_completion;
struct list_head pde_openers; /* who did ->open, but not ->release */
spinlock_t pde_unload_lock; /* proc_fops checks and pde_users bumps */
u8 namelen;
char name[];
};
11.3.4.6 创建/删除目录
- 函数proc_mkdir()用于创建目录;
- 函数remove_proc_entry()用于删除目录或文件,参见11.3.4.7.3 remove_proc_entry()节。
11.3.4.6.1 proc_mkdir()
该函数定义于fs/proc/generic.c:
struct proc_dir_entry *proc_mkdir(const char *name, struct proc_dir_entry *parent)
{
return proc_mkdir_mode(name, S_IRUGO | S_IXUGO, parent);
}
struct proc_dir_entry *proc_mkdir_mode(const char *name, mode_t mode,
struct proc_dir_entry *parent)
{
struct proc_dir_entry *ent;
// 参见[11.3.4.6.1.1 __proc_create()]节
ent = __proc_create(&parent, name, S_IFDIR | mode, 2);
if (ent) {
// 参见[11.3.4.6.1.2 proc_register()]节
if (proc_register(parent, ent) < 0) {
kfree(ent);
ent = NULL;
}
}
return ent;
}
11.3.4.6.1.1 __proc_create()
该函数定义于fs/proc/generic.c:
static struct proc_dir_entry *__proc_create(struct proc_dir_entry **parent,
const char *name, mode_t mode, nlink_t nlink)
{
struct proc_dir_entry *ent = NULL;
const char *fn = name;
unsigned int len;
/* make sure name is valid */
if (!name || !strlen(name)) goto out;
if (xlate_proc_name(name, parent, &fn) != 0)
goto out;
/* At this point there must not be any '/' characters beyond *fn */
if (strchr(fn, '/'))
goto out;
len = strlen(fn);
ent = kmalloc(sizeof(struct proc_dir_entry) + len + 1, GFP_KERNEL);
if (!ent) goto out;
memset(ent, 0, sizeof(struct proc_dir_entry));
memcpy(ent->name, fn, len + 1);
ent->namelen = len;
ent->mode = mode;
ent->nlink = nlink;
atomic_set(&ent->count, 1);
ent->pde_users = 0;
spin_lock_init(&ent->pde_unload_lock);
ent->pde_unload_completion = NULL;
INIT_LIST_HEAD(&ent->pde_openers);
out:
return ent;
}
11.3.4.6.1.2 proc_register()
该函数定义于fs/proc/generic.c:
static int proc_register(struct proc_dir_entry * dir, struct proc_dir_entry * dp)
{
unsigned int i;
struct proc_dir_entry *tmp;
i = get_inode_number();
if (i == 0)
return -EAGAIN;
dp->low_ino = i;
if (S_ISDIR(dp->mode)) {
if (dp->proc_iops == NULL) {
dp->proc_fops = &proc_dir_operations;
dp->proc_iops = &proc_dir_inode_operations;
}
dir->nlink++;
} else if (S_ISLNK(dp->mode)) {
if (dp->proc_iops == NULL)
dp->proc_iops = &proc_link_inode_operations;
} else if (S_ISREG(dp->mode)) {
if (dp->proc_fops == NULL)
dp->proc_fops = &proc_file_operations;
if (dp->proc_iops == NULL)
dp->proc_iops = &proc_file_inode_operations;
}
spin_lock(&proc_subdir_lock);
for (tmp = dir->subdir; tmp; tmp = tmp->next)
if (strcmp(tmp->name, dp->name) == 0) {
WARN(1, KERN_WARNING "proc_dir_entry '%s/%s' already registered\n", dir->name, dp->name);
break;
}
dp->next = dir->subdir;
dp->parent = dir;
dir->subdir = dp;
spin_unlock(&proc_subdir_lock);
return 0;
}
11.3.4.7 创建/删除文件
11.3.4.7.1 proc_create()
该函数定义于include/linux/proc_fs.h:
static inline struct proc_dir_entry *proc_create(const char *name, mode_t mode,
struct proc_dir_entry *parent,
const struct file_operations *proc_fops)
{
return proc_create_data(name, mode, parent, proc_fops, NULL);
}
其中,函数proc_create_data()定义于fs/proc/generic.c:
struct proc_dir_entry *proc_create_data(const char *name, mode_t mode,
struct proc_dir_entry *parent,
const struct file_operations *proc_fops, void *data)
{
struct proc_dir_entry *pde;
nlink_t nlink;
if (S_ISDIR(mode)) {
if ((mode & S_IALLUGO) == 0)
mode |= S_IRUGO | S_IXUGO;
nlink = 2;
} else {
if ((mode & S_IFMT) == 0)
mode |= S_IFREG;
if ((mode & S_IALLUGO) == 0)
mode |= S_IRUGO;
nlink = 1;
}
// 参见[11.3.4.6.1.1 __proc_create()]节
pde = __proc_create(&parent, name, mode, nlink);
if (!pde)
goto out;
/*
* 函数create_proc_entry()未为这两个域的赋值,
* 参见[11.3.4.7.2 create_proc_read_entry()]节
*/
pde->proc_fops = proc_fops;
pde->data = data;
// 参见[11.3.4.6.1.2 proc_register()]节
if (proc_register(parent, pde) < 0)
goto out_free;
return pde;
out_free:
kfree(pde);
out:
return NULL;
}
11.3.4.7.2 create_proc_read_entry()
函数create_proc_read_entry()定义于include/linux/proc_fs.h:
static inline struct proc_dir_entry *create_proc_read_entry(const char *name,
mode_t mode, struct proc_dir_entry *base,
read_proc_t *read_proc, void * data)
{
struct proc_dir_entry *res = create_proc_entry(name, mode, base);
if (res) {
// 读取该文件时调用指定的read_proc()函数
res->read_proc = read_proc;
res->data = data;
}
return res;
}
其中,函数create_proc_entry()用于创建类型为struct proc_dir_entry的对象,其定义于include/linux/proc_fs.h:
struct proc_dir_entry *create_proc_entry(const char *name, mode_t mode,
struct proc_dir_entry *parent)
{
struct proc_dir_entry *ent;
nlink_t nlink;
if (S_ISDIR(mode)) {
if ((mode & S_IALLUGO) == 0)
mode |= S_IRUGO | S_IXUGO;
nlink = 2;
} else {
if ((mode & S_IFMT) == 0)
mode |= S_IFREG;
if ((mode & S_IALLUGO) == 0)
mode |= S_IRUGO;
nlink = 1;
}
// 参见[11.3.4.6.1.1 __proc_create()]节
ent = __proc_create(&parent, name, mode, nlink);
if (ent) {
// 参见[11.3.4.6.1.2 proc_register()]节
if (proc_register(parent, ent) < 0) {
kfree(ent);
ent = NULL;
}
}
return ent;
}
11.3.4.7.3 remove_proc_entry()
该函数定义于fs/proc/generic.c:
/*
* Remove a /proc entry and free it if it's not currently in use.
*/
void remove_proc_entry(const char *name, struct proc_dir_entry *parent)
{
struct proc_dir_entry **p;
struct proc_dir_entry *de = NULL;
const char *fn = name;
unsigned int len;
spin_lock(&proc_subdir_lock);
if (__xlate_proc_name(name, &parent, &fn) != 0) {
spin_unlock(&proc_subdir_lock);
return;
}
len = strlen(fn);
for (p = &parent->subdir; *p; p=&(*p)->next ) {
if (proc_match(len, fn, *p)) {
de = *p;
*p = de->next;
de->next = NULL;
break;
}
}
spin_unlock(&proc_subdir_lock);
if (!de) {
WARN(1, "name '%s'\n", name);
return;
}
spin_lock(&de->pde_unload_lock);
/*
* Stop accepting new callers into module. If you're
* dynamically allocating ->proc_fops, save a pointer somewhere.
*/
de->proc_fops = NULL;
/* Wait until all existing callers into module are done. */
if (de->pde_users > 0) {
DECLARE_COMPLETION_ONSTACK(c);
if (!de->pde_unload_completion)
de->pde_unload_completion = &c;
spin_unlock(&de->pde_unload_lock);
wait_for_completion(de->pde_unload_completion);
spin_lock(&de->pde_unload_lock);
}
while (!list_empty(&de->pde_openers)) {
struct pde_opener *pdeo;
pdeo = list_first_entry(&de->pde_openers, struct pde_opener, lh);
list_del(&pdeo->lh);
spin_unlock(&de->pde_unload_lock);
pdeo->release(pdeo->inode, pdeo->file);
kfree(pdeo);
spin_lock(&de->pde_unload_lock);
}
spin_unlock(&de->pde_unload_lock);
if (S_ISDIR(de->mode))
parent->nlink--;
de->nlink = 0;
WARN(de->subdir, KERN_WARNING "%s: removing non-empty directory "
"'%s/%s', leaking at least '%s'\n", __func__,
de->parent->name, de->name, de->subdir->name);
pde_put(de);
}
11.3.4.8 创建/删除符号链接
11.3.4.8.1 proc_symlink()
该函数定义于fs/proc/generic.c:
struct proc_dir_entry *proc_symlink(const char *name,
struct proc_dir_entry *parent, const char *dest)
{
struct proc_dir_entry *ent;
// 参见[11.3.4.6.1.1 __proc_create()]节
ent = __proc_create(&parent, name,
(S_IFLNK | S_IRUGO | S_IWUGO | S_IXUGO),1);
if (ent) {
ent->data = kmalloc((ent->size=strlen(dest))+1, GFP_KERNEL);
if (ent->data) {
strcpy((char*)ent->data,dest);
// 参见[11.3.4.6.1.2 proc_register()]节
if (proc_register(parent, ent) < 0) {
kfree(ent->data);
kfree(ent);
ent = NULL;
}
} else {
kfree(ent);
ent = NULL;
}
}
return ent;
}
11.3.5 Sysfs
通常,Sysfs文件系统被挂载到/sys目录。
11.3.5.1 Sysfs简介
参见如下文档:
- Documentation/filesystems/sysfs.txt
- Documentation/filesystems/sysfs-pci.txt
- Documentation/filesystems/sysfs-tagging.txt
- Documentation/sysfs-rules.txt
- Documentation/kobject.txt
参见«Linux Kernel Development, 3rd Edition»第17. Devices and Modules章第sysfs节:
The sysfs filesystem is an in-memory virtual filesystem that provides a view of the kobject hierarchy. It enables users to view the device topology of their system as a simple filesystem.
Most systems mount it at /sys by doing:
$ mount -t sysfs sysfs /sys
The magic behind sysfs is simply tying kobjects to directory entries via the dentry member inside each kobject. The dentry structure represents directory entries. By linking kobjects to dentries, kobjects trivially map to directories. Exporting the kobjects as a filesystem is now as easy as building a tree of the dentries in memory.
参见«Understanding the Linux Kernel, 3rd Edition»第13. I/O Architecture and Device Drivers章第The sysfs Filesystem节:
The sysfs filesystem is a special filesystem similar to /proc that is usually mounted on the /sys directory. The /proc filesystem was the first special filesystem designed to allow User Mode applications to access kernel internal data structures. The /sysfs filesystem has essentially the same objective, but it provides additional information on kernel data structures; furthermore, /sysfs is organized in a more structured way than /proc. Likely, both /proc and /sysfs will continue to coexist in the near future.
11.3.5.1.1 Sysfs文件系统的内部结构及外部表现
Sysfs文件系统的内部结构与外部表现:
| sysfs在内核中的组成要素 | 在用户空间的显示 |
|---|---|
| 内核对象(kobject) | 目录(struct sysfs_direct),参见11.3.5.5 创建/删除目录节 |
| 对象属性(attribute) | 文件(struct attribute),参见11.3.5.6 创建/删除文件节 |
| 对象关系(relationship) | 链接(Symbolic Link),参见11.3.5.7 创建/删除符号链接节 |
11.3.5.1.2 /sys目录结构
/sys/block/
该目录创建于10.4.2 块设备的初始化/genhd_device_init()。
该目录包含系统中当前所有的块设备,按照功能来说放置在/sys/class之下会更合适,但只是由于历史遗留因素而一直存在于/sys/block, 但从2.6.22开始就已标记为过时,只有配置了CONFIG_SYSFS_DEPRECATED后编译的内核才会存在这个目录,并且在2.6.26内核中已正式移到/sys/class/block,旧的接口/sys/block为了向后兼容保留存在,但其中的内容已经变为指向它们在/sys/devices/中真实设备的符号链接文件:
chenwx@chenwx:~ $ uname -a
Linux chenwx 5.0.0-16-generic #17~18.04.1-Ubuntu SMP Mon May 20 14:00:27 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
chenwx@chenwx:~ $ ll /sys/block/
lrwxrwxrwx 1 root root 0 Jun 9 16:34 loop0 -> ../devices/virtual/block/loop0
lrwxrwxrwx 1 root root 0 Jun 9 16:34 loop1 -> ../devices/virtual/block/loop1
lrwxrwxrwx 1 root root 0 Jun 9 16:34 loop2 -> ../devices/virtual/block/loop2
lrwxrwxrwx 1 root root 0 Jun 9 16:34 loop3 -> ../devices/virtual/block/loop3
lrwxrwxrwx 1 root root 0 Jun 9 16:34 loop4 -> ../devices/virtual/block/loop4
lrwxrwxrwx 1 root root 0 Jun 9 16:34 loop5 -> ../devices/virtual/block/loop5
lrwxrwxrwx 1 root root 0 Jun 9 16:34 loop6 -> ../devices/virtual/block/loop6
lrwxrwxrwx 1 root root 0 Jun 9 16:34 loop7 -> ../devices/virtual/block/loop7
lrwxrwxrwx 1 root root 0 Jun 9 16:34 sda -> ../devices/pci0000:00/0000:00:0d.0/ata3/host2/target2:0:0/2:0:0:0/block/sda
lrwxrwxrwx 1 root root 0 Jun 9 16:34 sr0 -> ../devices/pci0000:00/0000:00:01.1/ata2/host1/target1:0:0/1:0:0:0/block/sr0
/sys/bus/
该目录创建于10.2.1.2 buses_init()。
这是内核设备按总线类型分层放置的目录结构,/sys/devices中的所有设备都是连接于某种总线之下,在这里的每一种具体总线之下可以找到每一个具体设备的符号链接,它也是构成Linux统一设备模型的一部分。
/sys/class/
该目录创建于10.2.1.3 classes_init()。
这是按照设备功能分类的设备模型,如系统所有输入设备都会出现在/sys/class/input之下,而不论它们是以何种总线连接到系统,它也是构成Linux统一设备模型的一部分。
/sys/dev/
该目录创建于10.2.1.1 devices_init()。
该目录下维护一个按字符设备和块设备的主次号码(major:minor)链接到真实的设备(/sys/devices下)的符号链接文件,它是在内核 2.6.26首次引入的。
/sys/devices/
该目录创建于10.2.1.1 devices_init()。
这是内核对系统中所有设备的分层次表达模型,也是/sys文件系统管理设备的最重要的目录结构。
/sys/firmware/
该目录创建于10.2.1.4 firmware_init()。
这里是系统加载固件机制的对用户空间的接口,关于固件有专用于固件加载的一套API,在LDD3一书中有关于内核支持固件加载机制的更详细的介绍。
/sys/fs/
该目录创建于4.3.4.1.4.3.11.4 mnt_init()。
这里按照设计是用于描述系统中所有文件系统,包括文件系统本身和按文件系统分类存放的已挂载点,但目前只有fuse,gfs2等少数文件系统支持sysfs接口,一些传统的虚拟文件系统(VFS)层次控制参数仍然在sysctl (/proc/sys/fs)接口中。
/sys/hypervisor/
该目录创建于10.2.1.5 hypervisor_init()。
/sys/kernel/
该目录创建于函数ksysfs_init(),参见kernel/ksysfs.c和13.5.1.1 module被编译进内核时的初始化过程。
这里是内核所有可调整参数的位置,目前只有uevent_helper,kexec_loaded,mm,和新式的 slab分配器等几项较新的设计在使用它,其它内核可调整参数仍然位于 sysctl (/proc/sys/kernel)接口中。
/sys/module/
该目录创建于param_sysfs_init(),参见13.1.3.2 系统启动过程时对.init.setup段模块参数的处理。
这里有系统中所有模块的信息,不论这些模块是以内联(inlined)方式编译到内核映像文件(vmlinuz)中还是编译为外部模块(ko文件),都可能会出现在/sys/module中:
- 编译为外部模块(ko文件)在加载后会出现对应的
/sys/module/<module_name>/,并且在这个目录下会出现一些属性文件和属性目录来表示此外部模块的一些信息,如版本号、加载状态、所提供的驱动程序等; - 编译为内联方式的模块则只在当它有非0属性的模块参数时会出现对应的
/sys/module/<module_name>,这些模块的可用参数会出现在/sys/modules/<modname>/parameters/<param_name>中,如/sys/module/printk/parameters/time这个可读写参数控制着内联模块printk在打印内核消息时是否加上时间前缀。所有内联模块的参数也可以由<module_name>.<param_name>=<value>的形式写在内核启动参数上,如启动内核时加上参数printk.time=1与向/sys/module/printk/parameters/time写入1的效果相同。没有非0属性参数的内联模块不会出现于此目录下。
/sys/power/
该目录创建于函数pm_init(),参见kernel/power/main.c和13.5.1.1 module被编译进内核时的初始化过程。
这里是系统中电源选项,这个目录下有几个属性文件可以用于控制整个机器的电源状态,如可以向其中写入控制命令让机器关机、重启等。
/sys/slab/
该目录存在于2.6.23及其以前的内核中,在2.6.24以后移至/sys/kernel/slab。从2.6.23开始可以选择SLAB内存分配器的实现,并且新的SLUB (Unqueued Slab Allocator)被设置为缺省值;如果编译了此选项,在/sys下就会出现/sys/slab,里面有每一个kmem_cache结构体的可调整参数。对应于旧的SLAB内存分配器下的/proc/slabinfo动态调整接口,新式的/sys/kernel/slab/<slab_name>接口中的各项信息和可调整项显得更为清晰。
11.3.5.2 Sysfs的编译及初始化
由fs/Makefile可知,Sysfs的编译与配置项CONFIG_SYSFS有关:
obj-$(CONFIG_SYSFS) += sysfs/
Sysfs的初始化过程参见4.3.4.1.4.3.11.4.1 sysfs_init()节。
变量sysfs_fs_type定义于fs/sysfs/mount.c:
static struct file_system_type sysfs_fs_type = {
.name = "sysfs",
/*
* sysfs_mount()通过如下函数被调用,参见[11.2.2.2.1.2.1 sysfs_mount()]节:
* sysfs_init()->kern_mount()->kern_mount_data()
* ->vfs_kern_mount()->mount_fs()中的type->mount()
*/
.mount = sysfs_mount,
.kill_sb = sysfs_kill_sb,
};
11.3.5.3 Sysfs的安装
文件系统sysfs的安装过程参见11.4 文件系统的自动安装节。
11.3.5.4 sysfs文件操作/sysfs_file_operations
该变量定义于fs/sysfs/file.c:
const struct file_operations sysfs_file_operations = {
.read = sysfs_read_file,
.write = sysfs_write_file,
.llseek = generic_file_llseek,
.open = sysfs_open_file,
.release = sysfs_release,
.poll = sysfs_poll,
};
该变量的引用关系如下:
sysfs_mount() // 参见[11.2.2.2.1.2.1 sysfs_mount()]节
-> sysfs_fill_super() // 参见[11.2.2.2.1.2.1.1 sysfs_fill_super()]节
-> sysfs_get_inode() // 参见[11.2.2.2.1.2.1.1.1 sysfs_get_inode()]节
-> sysfs_init_inode() // 参见[11.2.2.2.1.2.1.1.1 sysfs_get_inode()]节
struct sysfs_direct树形结构:
11.3.5.4.1 sysfs_open_file()
该函数定义于fs/sysfs/file.c:
static int sysfs_open_file(struct inode *inode, struct file *file)
{
/*
* file->f_path.dentry->d_fsdata指向sysfs文件系统中的某个节点,
* 参见Subjects/Chapter11_Filesystem/Figures/sysfs_02.jpg
*/
struct sysfs_dirent *attr_sd = file->f_path.dentry->d_fsdata;
struct kobject *kobj = attr_sd->s_parent->s_dir.kobj;
struct sysfs_buffer *buffer;
const struct sysfs_ops *ops;
int error = -EACCES;
/* need attr_sd for attr and ops, its parent for kobj */
if (!sysfs_get_active(attr_sd))
return -ENODEV;
/* every kobject with an attribute needs a ktype assigned */
if (kobj->ktype && kobj->ktype->sysfs_ops)
ops = kobj->ktype->sysfs_ops;
else {
WARN(1, KERN_ERR "missing sysfs attribute operations for "
"kobject: %s\n", kobject_name(kobj));
goto err_out;
}
/* File needs write support.
* The inode's perms must say it's ok,
* and we must have a store method.
*/
if (file->f_mode & FMODE_WRITE) {
if (!(inode->i_mode & S_IWUGO) || !ops->store)
goto err_out;
}
/* File needs read support.
* The inode's perms must say it's ok, and we there
* must be a show method for it.
*/
if (file->f_mode & FMODE_READ) {
if (!(inode->i_mode & S_IRUGO) || !ops->show)
goto err_out;
}
/*
* 1) 分配buffer,并填充各域
*/
/* No error? Great, allocate a buffer for the file, and store it
* it in file->private_data for easy access.
*/
error = -ENOMEM;
buffer = kzalloc(sizeof(struct sysfs_buffer), GFP_KERNEL);
if (!buffer)
goto err_out;
mutex_init(&buffer->mutex);
buffer->needs_read_fill = 1;
/*
* buffer->ops在如下函数中被引用:
* - sysfs_read_file()->fill_read_buffer(),参见[11.3.5.4.2 sysfs_read_file()]节和[11.3.5.4.2.1 fill_read_buffer()]节
* - sysfs_write_file()->flush_write_buffer(),参见[11.3.5.4.3.2 flush_write_buffer()]节
*/
buffer->ops = ops;
/*
* file->private_date在如下函数中被引用:
* - sysfs_read_file(),参见[11.3.5.4.2 sysfs_read_file()]节
* - sysfs_write_file(),参见[11.3.5.4.3 sysfs_write_file()]节
*/
file->private_data = buffer;
/*
* 2) 将buffer链接到attr_sd->s_attr.open->buffers链表中
*/
/* make sure we have open dirent struct, 参见[11.3.5.4.1.1 sysfs_get_open_dirent()]节 */
error = sysfs_get_open_dirent(attr_sd, buffer);
if (error)
goto err_free;
/* open succeeded, put active references */
sysfs_put_active(attr_sd);
return 0;
err_free:
kfree(buffer);
err_out:
sysfs_put_active(attr_sd);
return error;
}
11.3.5.4.1.1 sysfs_get_open_dirent()
该函数定义于fs/sysfs/file.c:
static int sysfs_get_open_dirent(struct sysfs_dirent *sd, struct sysfs_buffer *buffer)
{
struct sysfs_open_dirent *od, *new_od = NULL;
retry:
/*
* 2) 将新分配的new_od链接到sd->s_attr.open->buffers链表中
*/
spin_lock_irq(&sysfs_open_dirent_lock);
if (!sd->s_attr.open && new_od) {
sd->s_attr.open = new_od;
new_od = NULL;
}
od = sd->s_attr.open;
if (od) {
atomic_inc(&od->refcnt);
list_add_tail(&buffer->list, &od->buffers);
}
spin_unlock_irq(&sysfs_open_dirent_lock);
if (od) {
kfree(new_od);
return 0;
}
/*
* 1) 分配类型为struct sysfs_open_dirent的变量new_od,并初始化
*/
/* not there, initialize a new one and retry */
new_od = kmalloc(sizeof(*new_od), GFP_KERNEL);
if (!new_od)
return -ENOMEM;
atomic_set(&new_od->refcnt, 0);
atomic_set(&new_od->event, 1);
init_waitqueue_head(&new_od->poll);
INIT_LIST_HEAD(&new_od->buffers);
goto retry;
}
struct sysfs_open_direct结构:
11.3.5.4.2 sysfs_read_file()
该函数定义于fs/sysfs/file.c:
static ssize_t sysfs_read_file(struct file *file, char __user *buf,
size_t count, loff_t *ppos)
{
/*
* file->private_data在sysfs_open_file()中赋值,
* 参见[11.3.5.4.1 sysfs_open_file()]节
*/
struct sysfs_buffer *buffer = file->private_data;
ssize_t retval = 0;
mutex_lock(&buffer->mutex);
if (buffer->needs_read_fill || *ppos == 0) {
/*
* 1) 调用ops->show()将内核空间中的某数据(由用户定义)拷贝到
* 内核空间(buffer->page)中,参见[11.3.5.4.2.1 fill_read_buffer()]节
*/
retval = fill_read_buffer(file->f_path.dentry, buffer);
if (retval)
goto out;
}
pr_debug("%s: count = %zd, ppos = %lld, buf = %s\n",
__func__, count, *ppos, buffer->page);
/*
* 2) 将数据从内核空间(buffer->page)拷贝到用户空间(buf),
* 参见[5.5.4.3.4 simple_read_from_buffer()]节
*/
retval = simple_read_from_buffer(buf, count, ppos, buffer->page, buffer->count);
out:
mutex_unlock(&buffer->mutex);
return retval;
}
11.3.5.4.2.1 fill_read_buffer()
该函数定义于fs/sysfs/file.c:
static int fill_read_buffer(struct dentry *dentry, struct sysfs_buffer *buffer)
{
// attr_sd对应于需要读取的sysfs中某节点的struct sysfs_dirent
struct sysfs_dirent *attr_sd = dentry->d_fsdata;
struct kobject *kobj = attr_sd->s_parent->s_dir.kobj;
// buffer->ops在sysfs_open_file()中赋值,参见[11.3.5.4.1 sysfs_open_file()]节
const struct sysfs_ops *ops = buffer->ops;
int ret = 0;
ssize_t count;
if (!buffer->page)
buffer->page = (char *)get_zeroed_page(GFP_KERNEL);
if (!buffer->page)
return -ENOMEM;
/* need attr_sd for attr and ops, its parent for kobj */
if (!sysfs_get_active(attr_sd))
return -ENODEV;
buffer->event = atomic_read(&attr_sd->s_attr.open->event);
/*
* 调用ops->show()来将内核空间中的数据拷贝到buffer->page中;
* 该函数由用户实现,并通过如下函数设置:
* - kobject_init_and_add(.., &xxx_ktype, .., ..);
* 其中,xxx_ktype.sysfs_ops = &xxx_sysfs_ops;
*/
count = ops->show(kobj, attr_sd->s_attr.attr, buffer->page);
sysfs_put_active(attr_sd);
/*
* The code works fine with PAGE_SIZE return but it's likely to
* indicate truncated result or overflow in normal use cases.
*/
if (count >= (ssize_t)PAGE_SIZE) {
print_symbol("fill_read_buffer: %s returned bad count\n", (unsigned long)ops->show);
/* Try to struggle along */
count = PAGE_SIZE - 1;
}
if (count >= 0) {
buffer->needs_read_fill = 0;
buffer->count = count;
} else {
ret = count;
}
return ret;
}
11.3.5.4.3 sysfs_write_file()
该函数定义于fs/sysfs/file.c:
static ssize_t sysfs_write_file(struct file *file, const char __user *buf,
size_t count, loff_t *ppos)
{
/*
* file->private_date在sysfs_open_file()中赋值,
* 参见[11.3.5.4.1 sysfs_open_file()]节
*/
struct sysfs_buffer *buffer = file->private_data;
ssize_t len;
mutex_lock(&buffer->mutex);
/*
* 1) 将数据从用户空间(buf)拷贝到内核空间(buffer->page)中,
* 参见[11.3.5.4.3.1 fill_write_buffer()]节
*/
len = fill_write_buffer(buffer, buf, count);
/*
* 2) 调用ops->store()将内核空间(buffer->page)中的数据拷贝到
* 内核空间中的某处(由用户定义),参见[11.3.5.4.3.2 flush_write_buffer()]节
*/
if (len > 0)
len = flush_write_buffer(file->f_path.dentry, buffer, len);
if (len > 0)
*ppos += len;
mutex_unlock(&buffer->mutex);
return len;
}
11.3.5.4.3.1 fill_write_buffer()
该函数定义于fs/sysfs/file.c:
static int fill_write_buffer(struct sysfs_buffer *buffer, const char __user *buf, size_t count)
{
int error;
if (!buffer->page)
buffer->page = (char *)get_zeroed_page(GFP_KERNEL);
if (!buffer->page)
return -ENOMEM;
if (count >= PAGE_SIZE)
count = PAGE_SIZE - 1;
error = copy_from_user(buffer->page, buf, count);
buffer->needs_read_fill = 1;
/* if buf is assumed to contain a string, terminate it by \0,
so e.g. sscanf() can scan the string easily */
buffer->page[count] = 0;
return error ? -EFAULT : count;
}
11.3.5.4.3.2 flush_write_buffer()
该函数定义于fs/sysfs/file.c:
static int flush_write_buffer(struct dentry * dentry, struct sysfs_buffer * buffer, size_t count)
{
struct sysfs_dirent *attr_sd = dentry->d_fsdata;
struct kobject *kobj = attr_sd->s_parent->s_dir.kobj;
// buffer->ops在sysfs_open_file()中赋值,参见[11.3.5.4.1 sysfs_open_file()]节
const struct sysfs_ops *ops = buffer->ops;
int rc;
/* need attr_sd for attr and ops, its parent for kobj */
if (!sysfs_get_active(attr_sd))
return -ENODEV;
/*
* 调用ops->store()将内核空间(buffer->page)中的数据拷贝到
* 内核空间中的某处(由用户定义);该函数由用户实现
*/
rc = ops->store(kobj, attr_sd->s_attr.attr, buffer->page, count);
sysfs_put_active(attr_sd);
return rc;
}
11.3.5.5 创建/删除目录
11.3.5.5.1 sysfs_create_dir()
函数sysfs_create_dir()的调用关系如下:
kobject_add(struct kobject *kobj,
struct kobject *parent,
const char *fmt, ...) // 参见15.7.1.2.2 kobject_add()节
-> kobject_add_varg(kobj, parent, fmt, args) // 参见15.7.1.2.2.1 kobject_add_varg()节
-> kobject_add_internal(kobj) // 参见15.7.1.2.2.2 kobject_add_internal()节
-> create_dir(kobj) // 参见15.7.1.2.2.2.1 create_dir()/populate_dir()节
-> sysfs_create_dir(kobj) // 参见本节
kset_register(struct kset *k)
-> kobject_add_internal(&k->kobj) // 参见15.7.1.2.2.2 kobject_add_internal()节
-> create_dir(kobj) // 参见15.7.1.2.2.2.1 create_dir()/populate_dir()节
-> sysfs_create_dir(kobj) // 参见本节
函数sysfs_create_dir()定义于fs/sysfs/dir.c:
/**
* sysfs_create_dir - create a directory for an object.
* @kobj: object we're creating directory for.
*/
int sysfs_create_dir(struct kobject * kobj)
{
enum kobj_ns_type type;
struct sysfs_dirent *parent_sd, *sd;
const void *ns = NULL;
int error = 0;
BUG_ON(!kobj);
/*
* 若kobj的父节点kobj->parent不为空,则将新目录创建于kobj->parent->sd目录之下;
* 否则,将新目录创建于sysfs顶级目录之下,即sysfs_root,参见[4.3.4.1.4.3.11.4.1 sysfs_init()]节
*/
if (kobj->parent)
parent_sd = kobj->parent->sd;
else
parent_sd = &sysfs_root;
/*
* 获取父节点parent_sd的命名空间类型,若为KOBJ_NS_TYPE_NET,则调用函数
* kobj->ktype->namespace()来获取命名空间类型,该函数是由kobject_init_and_add()设置的,
* 参见[15.7.1.1 kobject_init_and_add()]节
*/
if (sysfs_ns_type(parent_sd))
ns = kobj->ktype->namespace(kobj);
// 获取kobj对应的kobj_ns_type
type = sysfs_read_ns_type(kobj);
/*
* 为kobj创建对应的目录,并链接到kobj->sd.
* 其中,kobject_name(kobj)用于获取kobj->name,
* 而该内核对象名是由函数kobject_set_name()设置的
*/
error = create_dir(kobj, parent_sd, type, ns, kobject_name(kobj), &sd);
if (!error)
kobj->sd = sd;
return error;
}
static int create_dir(struct kobject *kobj, struct sysfs_dirent *parent_sd,
enum kobj_ns_type type, const void *ns, const char *name,
struct sysfs_dirent **p_sd)
{
umode_t mode = S_IFDIR| S_IRWXU | S_IRUGO | S_IXUGO;
struct sysfs_addrm_cxt acxt;
struct sysfs_dirent *sd;
int rc;
/*
* 从缓存sysfs_dir_cachep(参见[4.3.4.1.4.3.11.4.1 sysfs_init()]节)中
* 分配类型为struct sysfs_dirent的对象并初始化,该对象被链接到kobj->sd
*/
sd = sysfs_new_dirent(name, mode, SYSFS_DIR);
if (!sd)
return -ENOMEM;
sd->s_flags |= (type << SYSFS_NS_TYPE_SHIFT);
sd->s_ns = ns;
sd->s_dir.kobj = kobj;
/*
* link sd to its parent parent_sd (that’s sd->s_parent = parent_sd),
* and its sibling list. 参见[11.3.5.5.1.1 sysfs_add_one()/__sysfs_add_one()]节
*/
sysfs_addrm_start(&acxt, parent_sd);
rc = sysfs_add_one(&acxt, sd);
sysfs_addrm_finish(&acxt);
// 若成功,则返回刚刚创建的sd; 否则,释放该sd并返回错误码
if (rc == 0)
*p_sd = sd;
else
sysfs_put(sd);
return rc;
}
11.3.5.5.1.1 sysfs_add_one()/__sysfs_add_one()
该函数定义于fs/sysfs/dir.c:
/**
* sysfs_add_one - add sysfs_dirent to parent
* @acxt: addrm context to use
* @sd: sysfs_dirent to be added
*
* Get @acxt->parent_sd and set sd->s_parent to it and increment
* nlink of parent inode if @sd is a directory and link into the
* children list of the parent.
*
* This function should be called between calls to
* sysfs_addrm_start() and sysfs_addrm_finish() and should be
* passed the same @acxt as passed to sysfs_addrm_start().
*
* LOCKING:
* Determined by sysfs_addrm_start().
*
* RETURNS:
* 0 on success, -EEXIST if entry with the given name already
* exists.
*/
int sysfs_add_one(struct sysfs_addrm_cxt *acxt, struct sysfs_dirent *sd)
{
int ret;
ret = __sysfs_add_one(acxt, sd);
if (ret == -EEXIST) {
char *path = kzalloc(PATH_MAX, GFP_KERNEL);
WARN(1, KERN_WARNING
"sysfs: cannot create duplicate filename '%s'\n",
(path == NULL) ? sd->s_name :
strcat(strcat(sysfs_pathname(acxt->parent_sd, path), "/"),
sd->s_name));
kfree(path);
}
return ret;
}
int __sysfs_add_one(struct sysfs_addrm_cxt *acxt, struct sysfs_dirent *sd)
{
struct sysfs_inode_attrs *ps_iattr;
if (!!sysfs_ns_type(acxt->parent_sd) != !!sd->s_ns) {
WARN(1, KERN_WARNING "sysfs: ns %s in '%s' for '%s'\n",
sysfs_ns_type(acxt->parent_sd)? "required": "invalid",
acxt->parent_sd->s_name, sd->s_name);
return -EINVAL;
}
/*
* 从红黑树acxt->parent_sd->s_dir.name_tree.rb_node中查找
* 名为sd->s_name的元素,若已存在同名元素,则返回错误码-EEXIST.
* NOTE: 红黑树struct sysfs_dirent->s_dir.name_tree.rb_node中
* 链接的是struct sysfs_dirent->name_node元素
*/
if (sysfs_find_dirent(acxt->parent_sd, sd->s_ns, sd->s_name))
return -EEXIST;
// 设置父目录
sd->s_parent = sysfs_get(acxt->parent_sd);
/*
* 将sd->inode_node链接到父目录的红黑树struct sysfs_dirent->s_dir.inode_tree.rb_node中,
* 将sd->name_node链接到父目录的红黑树struct sysfs_dirent->s_dir.name_tree.rb_node中
*/
sysfs_link_sibling(sd);
/* Update timestamps on the parent */
ps_iattr = acxt->parent_sd->s_iattr;
if (ps_iattr) {
struct iattr *ps_iattrs = &ps_iattr->ia_iattr;
ps_iattrs->ia_ctime = ps_iattrs->ia_mtime = CURRENT_TIME;
}
return 0;
}
/**
* sysfs_link_sibling - link sysfs_dirent into sibling list
* @sd: sysfs_dirent of interest
*
* Link @sd into its sibling list which starts from
* sd->s_parent->s_dir.children.
*
* Locking:
* mutex_lock(sysfs_mutex)
*/
static void sysfs_link_sibling(struct sysfs_dirent *sd)
{
struct sysfs_dirent *parent_sd = sd->s_parent;
struct rb_node **p;
struct rb_node *parent;
/*
* 此前create_dir()->sysfs_new_dirent(name, mode, SYSFS_DIR)
* 将sd->s_flags设置为SYSFS_DIR. 故此处增加父目录中的子目录计数
*/
if (sysfs_type(sd) == SYSFS_DIR)
parent_sd->s_dir.subdirs++;
// 1) 将sd->inode_node链接到父目录的红黑树struct sysfs_dirent->s_dir.inode_tree.rb_node中
p = &parent_sd->s_dir.inode_tree.rb_node;
parent = NULL;
while (*p) {
parent = *p;
#define node rb_entry(parent, struct sysfs_dirent, inode_node)
if (sd->s_ino < node->s_ino) {
p = &node->inode_node.rb_left;
} else if (sd->s_ino > node->s_ino) {
p = &node->inode_node.rb_right;
} else {
printk(KERN_CRIT "sysfs: inserting duplicate inode '%lx'\n", (unsigned long) sd->s_ino);
BUG();
}
#undef node
}
// 参见[15.6.5.1 rb_link_node()]节
rb_link_node(&sd->inode_node, parent, p);
// 参见[15.6.5.2 rb_insert_color()]节
rb_insert_color(&sd->inode_node, &parent_sd->s_dir.inode_tree);
// 2) 将sd->name_node链接到父目录的红黑树struct sysfs_dirent->s_dir.name_tree.rb_node中
p = &parent_sd->s_dir.name_tree.rb_node;
parent = NULL;
while (*p) {
int c;
parent = *p;
#define node rb_entry(parent, struct sysfs_dirent, name_node)
c = strcmp(sd->s_name, node->s_name);
if (c < 0) {
p = &node->name_node.rb_left;
} else {
p = &node->name_node.rb_right;
}
#undef node
}
// 参见[15.6.5.1 rb_link_node()]节
rb_link_node(&sd->name_node, parent, p);
// 参见[15.6.5.2 rb_insert_color()]节
rb_insert_color(&sd->name_node, &parent_sd->s_dir.name_tree);
}
11.3.5.5.2 sysfs_remove_dir()
该函数定义于fs/sysfs/dir.c:
/**
* sysfs_remove_dir - remove an object's directory.
* @kobj: object.
*
* The only thing special about this is that we remove any files in
* the directory before we remove the directory, and we've inlined
* what used to be sysfs_rmdir() below, instead of calling separately.
*/
void sysfs_remove_dir(struct kobject * kobj)
{
struct sysfs_dirent *sd = kobj->sd;
spin_lock(&sysfs_assoc_lock);
kobj->sd = NULL;
spin_unlock(&sysfs_assoc_lock);
__sysfs_remove_dir(sd);
}
static void __sysfs_remove_dir(struct sysfs_dirent *dir_sd)
{
struct sysfs_addrm_cxt acxt;
struct rb_node *pos;
if (!dir_sd)
return;
pr_debug("sysfs %s: removing dir\n", dir_sd->s_name);
sysfs_addrm_start(&acxt, dir_sd);
pos = rb_first(&dir_sd->s_dir.inode_tree);
while (pos) {
struct sysfs_dirent *sd = rb_entry(pos, struct sysfs_dirent, inode_node);
pos = rb_next(pos);
if (sysfs_type(sd) != SYSFS_DIR)
sysfs_remove_one(&acxt, sd);
}
sysfs_addrm_finish(&acxt);
remove_dir(dir_sd);
}
static void remove_dir(struct sysfs_dirent *sd)
{
struct sysfs_addrm_cxt acxt;
sysfs_addrm_start(&acxt, sd->s_parent);
sysfs_remove_one(&acxt, sd);
sysfs_addrm_finish(&acxt);
}
void sysfs_remove_one(struct sysfs_addrm_cxt *acxt, struct sysfs_dirent *sd)
{
struct sysfs_inode_attrs *ps_iattr;
BUG_ON(sd->s_flags & SYSFS_FLAG_REMOVED);
/*
* 将sd->inode_node从父目录的红黑树struct sysfs_dirent->s_dir.inode_tree.rb_node中删除,
* 将sd->name_node从父目录的红黑树struct sysfs_dirent->s_dir.name_tree.rb_node中删除
*/
sysfs_unlink_sibling(sd);
/* Update timestamps on the parent */
ps_iattr = acxt->parent_sd->s_iattr;
if (ps_iattr) {
struct iattr *ps_iattrs = &ps_iattr->ia_iattr;
ps_iattrs->ia_ctime = ps_iattrs->ia_mtime = CURRENT_TIME;
}
/*
* 将sd添加到acxt->removed中,该元素将在下列函数调用中进行下一步处理:
* __sysfs_remove_dir()->sysfs_addrm_finish(&acxt)
*/
sd->s_flags |= SYSFS_FLAG_REMOVED;
sd->u.removed_list = acxt->removed;
acxt->removed = sd;
}
11.3.5.6 创建/删除文件
11.3.5.6.1 sysfs_create_files()
该函数定义于fs/sysfs/file.c:
int sysfs_create_files(struct kobject *kobj, const struct attribute **ptr)
{
int err = 0;
int i;
for (i = 0; ptr[i] && !err; i++)
err = sysfs_create_file(kobj, ptr[i]); // 参见[11.3.5.6.2 sysfs_create_file()]节
if (err)
while (--i >= 0)
sysfs_remove_file(kobj, ptr[i]); // 参见[11.3.5.6.3 sysfs_remove_file()]节
return err;
}
11.3.5.6.2 sysfs_create_file()
该函数定义于fs/sysfs/file.c:
/**
* sysfs_create_file - create an attribute file for an object.
* @kobj: object we're creating for.
* @attr: attribute descriptor.
*/
int sysfs_create_file(struct kobject * kobj, const struct attribute * attr)
{
BUG_ON(!kobj || !kobj->sd || !attr);
// 参见[11.3.5.6.2.1 sysfs_add_file()]节
return sysfs_add_file(kobj->sd, attr, SYSFS_KOBJ_ATTR);
}
11.3.5.6.2.1 sysfs_add_file()
该函数定义于fs/sysfs/file.c:
int sysfs_add_file(struct sysfs_dirent *dir_sd, const struct attribute *attr, int type)
{
return sysfs_add_file_mode(dir_sd, attr, type, attr->mode);
}
int sysfs_add_file_mode(struct sysfs_dirent *dir_sd,
const struct attribute *attr, int type, mode_t amode)
{
umode_t mode = (amode & S_IALLUGO) | S_IFREG;
struct sysfs_addrm_cxt acxt;
struct sysfs_dirent *sd;
const void *ns;
int rc;
rc = sysfs_attr_ns(dir_sd->s_dir.kobj, attr, &ns);
if (rc)
return rc;
sd = sysfs_new_dirent(attr->name, mode, type);
if (!sd)
return -ENOMEM;
sd->s_ns = ns;
/*
* 为什么如下调用中也设置sd->s_attr.attr,
* 而不是设置sd->s_bin_attr.attr?
* sysfs_create_bin_file()
* ->sysfs_add_file(.., SYSFS_KOBJ_BIN_ATTR)
* ->sysfs_add_file_mode()
*/
sd->s_attr.attr = (void *)attr;
sysfs_dirent_init_lockdep(sd);
sysfs_addrm_start(&acxt, dir_sd);
// 参见[11.3.5.5.1.1 sysfs_add_one()/__sysfs_add_one()]节
rc = sysfs_add_one(&acxt, sd);
sysfs_addrm_finish(&acxt);
if (rc)
sysfs_put(sd);
return rc;
}
11.3.5.6.3 sysfs_remove_file()
该函数定义于fs/sysfs/file.c:
/**
* sysfs_remove_file - remove an object attribute.
* @kobj: object we're acting for.
* @attr: attribute descriptor.
*
* Hash the attribute name and kill the victim.
*/
/*
* After the call, the attribute will no longer appear
* in the kobject's sysfs entry. Do be aware, however,
* that a user-space process could have an open file
* descriptor for that attribute, and that show() and
* store() calls are still possible after the attribute
* has been removed.
*/
void sysfs_remove_file(struct kobject * kobj, const struct attribute * attr)
{
const void *ns;
if (sysfs_attr_ns(kobj, attr, &ns))
return;
sysfs_hash_and_remove(kobj->sd, ns, attr->name);
}
int sysfs_hash_and_remove(struct sysfs_dirent *dir_sd, const void *ns, const char *name)
{
struct sysfs_addrm_cxt acxt;
struct sysfs_dirent *sd;
if (!dir_sd)
return -ENOENT;
sysfs_addrm_start(&acxt, dir_sd);
/*
* 从红黑树dir_sd->parent_sd->s_dir.name_tree.rb_node中
* 查找名为name的元素
* NOTE: 红黑树struct sysfs_dirent->s_dir.name_tree.rb_node中
* 链接的是struct sysfs_dirent->name_node元素
*/
sd = sysfs_find_dirent(dir_sd, ns, name);
if (sd)
sysfs_remove_one(&acxt, sd);
sysfs_addrm_finish(&acxt);
if (sd)
return 0;
else
return -ENOENT;
}
11.3.5.6.4 sysfs_create_bin_file()
Binary attributes
The sysfs conventions call for all attributes to contain a single value in a human-readable text format. That said, there is an occasional, rare need for the creation of attributes which can handle larger chunks of binary data. In the 2.6.0-test kernel, the only use of binary attributes is in the firmware subsystem. When a device requiring firmware is encountered in the system, a user-space program can be started (via the hotplug mechanism); that program then passes the firmware code to the kernel via binary sysfs attribute. If you are contemplating any other use of binary attributes, you should think carefully and be sure there is no other way to accomplish your objective.
该函数定义于fs/sysfs/bin.c:
/**
* sysfs_create_bin_file - create binary file for object.
* @kobj: object.
* @attr: attribute descriptor.
*/
int sysfs_create_bin_file(struct kobject *kobj, const struct bin_attribute *attr)
{
BUG_ON(!kobj || !kobj->sd || !attr);
// 参见[11.3.5.6.2.1 sysfs_add_file()]节
return sysfs_add_file(kobj->sd, &attr->attr, SYSFS_KOBJ_BIN_ATTR);
}
对sysfs文件系统中二进制文件的读写是由fs/sysfs/bin.c中的bin_fops定义的:
const struct file_operations bin_fops = {
.read = read,
.write = write,
.mmap = mmap,
.llseek = generic_file_llseek,
.open = open,
.release = release,
};
而不是由struct sysfs_dirent->s_bin_attr->bin_attr中的函数指针指定的函数完成的。
11.3.5.6.5 sysfs_remove_bin_file()
该函数定义于fs/sysfs/bin.c:
/**
* sysfs_remove_bin_file - remove binary file for object.
* @kobj: object.
* @attr: attribute descriptor.
*/
void sysfs_remove_bin_file(struct kobject *kobj, const struct bin_attribute *attr)
{
// 参见[11.3.5.6.3 sysfs_remove_file()]节
sysfs_hash_and_remove(kobj->sd, NULL, attr->attr.name);
}
11.3.5.7 创建/删除符号链接
11.3.5.7.1 sysfs_create_link()
该函数定义于fs/sysfs/symlink.c:
/**
* sysfs_create_link - create symlink between two objects.
* @kobj: object whose directory we're creating the link in.
* @target: object we're pointing to.
* @name: name of the symlink.
*/
/*
* The function will create a link (called name) pointing to
* target's sysfs entry as an attribute of kobj. It will be
* a relative link, so it works regardless of where sysfs is
* mounted on any particular system.
*
* NOTE: The link will persist even if target is removed from
* the system.
*/
int sysfs_create_link(struct kobject *kobj, struct kobject *target, const char *name)
{
return sysfs_do_create_link(kobj, target, name, 1);
}
static int sysfs_do_create_link(struct kobject *kobj, struct kobject *target, const char *name, int warn)
{
struct sysfs_dirent *parent_sd = NULL;
struct sysfs_dirent *target_sd = NULL;
struct sysfs_dirent *sd = NULL;
struct sysfs_addrm_cxt acxt;
enum kobj_ns_type ns_type;
int error;
BUG_ON(!name);
/*
* 若kobj->parent不为空,则新目录创建于kobj->parent->sd
* 目录之下;否则,新目录创建于sysfs顶级目录
*/
if (!kobj)
parent_sd = &sysfs_root;
else
parent_sd = kobj->sd;
error = -EFAULT;
if (!parent_sd)
goto out_put;
/* target->sd can go away beneath us but is protected with
* sysfs_assoc_lock. Fetch target_sd from it.
*/
spin_lock(&sysfs_assoc_lock);
if (target->sd)
target_sd = sysfs_get(target->sd);
spin_unlock(&sysfs_assoc_lock);
error = -ENOENT;
if (!target_sd)
goto out_put;
error = -ENOMEM;
sd = sysfs_new_dirent(name, S_IFLNK|S_IRWXUGO, SYSFS_KOBJ_LINK);
if (!sd)
goto out_put;
ns_type = sysfs_ns_type(parent_sd);
if (ns_type)
sd->s_ns = target->ktype->namespace(target);
sd->s_symlink.target_sd = target_sd;
target_sd = NULL; /* reference is now owned by the symlink */
sysfs_addrm_start(&acxt, parent_sd);
// 参见[11.3.5.5.1.1 sysfs_add_one()/__sysfs_add_one()]节
/* Symlinks must be between directories with the same ns_type */
if (!ns_type ||
(ns_type == sysfs_ns_type(sd->s_symlink.target_sd->s_parent))) {
if (warn)
error = sysfs_add_one(&acxt, sd);
else
error = __sysfs_add_one(&acxt, sd);
} else {
error = -EINVAL;
WARN(1, KERN_WARNING
"sysfs: symlink across ns_types %s/%s -> %s/%s\n",
parent_sd->s_name,
sd->s_name,
sd->s_symlink.target_sd->s_parent->s_name,
sd->s_symlink.target_sd->s_name);
}
sysfs_addrm_finish(&acxt);
if (error)
goto out_put;
return 0;
out_put:
sysfs_put(target_sd);
sysfs_put(sd);
return error;
}
11.3.5.7.2 sysfs_remove_link()
该函数定义于fs/sysfs/symlink.c:
/**
* sysfs_remove_link - remove symlink in object's directory.
* @kobj: object we're acting for.
* @name: name of the symlink to remove.
*/
void sysfs_remove_link(struct kobject * kobj, const char * name)
{
struct sysfs_dirent *parent_sd = NULL;
if (!kobj)
parent_sd = &sysfs_root;
else
parent_sd = kobj->sd;
// 参见[11.3.5.6.3 sysfs_remove_file()]节
sysfs_hash_and_remove(parent_sd, NULL, name);
}
11.3.6 FUSE
Fuse文件系统包括Fuseblk,Fusefs,Fusectl这几部分。
11.3.6.1 FUSE简介
参见如下文档:
- Documentation/filesystems/fuse.txt
- http://fuse.sourceforge.net/
How does it work?
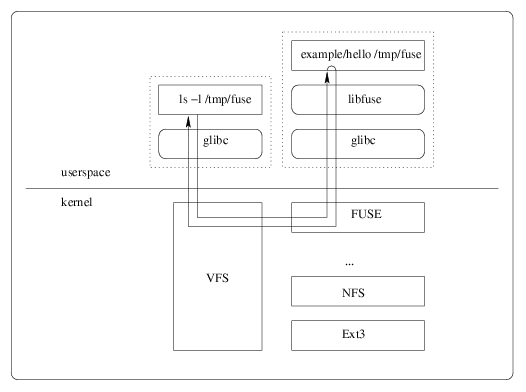
11.3.6.2 FUSE的编译及初始化
由fs/Makefile可知,FUSE的编译与配置项CONFIG_FUSE_FS有关:
obj-$(CONFIG_FUSE_FS) += fuse/
FUSE的初始化代码参见fs/fuse/inode.c:
struct list_head fuse_conn_list;
static int __init fuse_init(void)
{
int res;
printk(KERN_INFO "fuse init (API version %i.%i)\n",
FUSE_KERNEL_VERSION, FUSE_KERNEL_MINOR_VERSION);
INIT_LIST_HEAD(&fuse_conn_list);
// 注册fuseblk和fuse文件系统,参见[11.3.6.2.1 fuse_fs_init()]节
res = fuse_fs_init();
if (res)
goto err;
// 参见[11.3.6.2.2 fuse_dev_init()]节
res = fuse_dev_init();
if (res)
goto err_fs_cleanup;
/*
* 创建/sys/fs/fuse和/sys/fs/fuse/connections目录,
* 参见[11.3.6.2.3 fuse_sysfs_init()]节
*/
res = fuse_sysfs_init();
if (res)
goto err_dev_cleanup;
// 注册fusectl文件系统,参见[11.3.6.2.4 fuse_ctl_init()]节
res = fuse_ctl_init();
if (res)
goto err_sysfs_cleanup;
// 调整max_user_bgreq和max_user_congthresh的取值
sanitize_global_limit(&max_user_bgreq);
sanitize_global_limit(&max_user_congthresh);
return 0;
err_sysfs_cleanup:
fuse_sysfs_cleanup();
err_dev_cleanup:
fuse_dev_cleanup();
err_fs_cleanup:
fuse_fs_cleanup();
err:
return res;
}
static void __exit fuse_exit(void)
{
printk(KERN_DEBUG "fuse exit\n");
fuse_ctl_cleanup();
fuse_sysfs_cleanup();
fuse_fs_cleanup();
fuse_dev_cleanup();
}
module_init(fuse_init);
module_exit(fuse_exit);
当FUSE编译进内核时,其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
11.3.6.2.1 fuse_fs_init()
该函数定义于fs/fuse/inode.c:
static struct kmem_cache *fuse_inode_cachep;
static struct file_system_type fuse_fs_type = {
.owner = THIS_MODULE,
.name = "fuse",
.fs_flags = FS_HAS_SUBTYPE, // 参见[11.2.2.4.1.2.1.1 get_fs_type()]节
.mount = fuse_mount,
.kill_sb = fuse_kill_sb_anon,
};
#ifdef CONFIG_BLOCK
static struct file_system_type fuseblk_fs_type = {
.owner = THIS_MODULE,
.name = "fuseblk",
.mount = fuse_mount_blk,
.kill_sb = fuse_kill_sb_blk,
.fs_flags = FS_REQUIRES_DEV | FS_HAS_SUBTYPE, // 参见[11.2.2.4.1.2.1.1 get_fs_type()]节
};
static inline int register_fuseblk(void)
{
return register_filesystem(&fuseblk_fs_type);
}
static inline void unregister_fuseblk(void)
{
unregister_filesystem(&fuseblk_fs_type);
}
#else
...
#endif
static int __init fuse_fs_init(void)
{
int err;
// 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
fuse_inode_cachep = kmem_cache_create("fuse_inode", sizeof(struct fuse_inode),
0, SLAB_HWCACHE_ALIGN, fuse_inode_init_once);
err = -ENOMEM;
if (!fuse_inode_cachep)
goto out;
// 注册fuseblk文件系统
err = register_fuseblk();
if (err)
goto out2;
// 注册fuse文件系统
err = register_filesystem(&fuse_fs_type);
if (err)
goto out3;
return 0;
out3:
unregister_fuseblk();
out2:
kmem_cache_destroy(fuse_inode_cachep);
out:
return err;
}
11.3.6.2.2 fuse_dev_init()
该函数定义于fs/fuse/dev.c:
static struct kmem_cache *fuse_req_cachep;
static struct miscdevice fuse_miscdevice = {
.minor = FUSE_MINOR,
.name = "fuse",
.fops = &fuse_dev_operations,
};
int __init fuse_dev_init(void)
{
int err = -ENOMEM;
// 参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
fuse_req_cachep = kmem_cache_create("fuse_request", sizeof(struct fuse_req), 0, 0, NULL);
if (!fuse_req_cachep)
goto out;
err = misc_register(&fuse_miscdevice);
if (err)
goto out_cache_clean;
return 0;
out_cache_clean:
kmem_cache_destroy(fuse_req_cachep);
out:
return err;
}
11.3.6.2.3 fuse_sysfs_init()
该函数定义于fs/fuse/inode.c:
static struct kobject *fuse_kobj;
static struct kobject *connections_kobj;
static int fuse_sysfs_init(void)
{
int err;
/*
* 在fs_kobj指定的目录(即/sys/fs/,参见[4.3.4.1.4.3.11.4 mnt_init()]节)
* 下创建fuse目录,参见[15.7.1.2 kobject_create_and_add()]节
*/
fuse_kobj = kobject_create_and_add("fuse", fs_kobj);
if (!fuse_kobj) {
err = -ENOMEM;
goto out_err;
}
/*
* 在fuse_kobj指定的目录(即/sys/fs/fuse)下创建
* connections目录,参见[15.7.1.2 kobject_create_and_add()]节
*/
connections_kobj = kobject_create_and_add("connections", fuse_kobj);
if (!connections_kobj) {
err = -ENOMEM;
goto out_fuse_unregister;
}
return 0;
out_fuse_unregister:
// 参见[15.7.2.2 kobject_put()]节
kobject_put(fuse_kobj);
out_err:
return err;
}
11.3.6.2.4 fuse_ctl_init()
该函数注册Fusectl文件系统,其定义于fs/fuse/control.c。通常,该文件系统被安装到/sys/fs/fuse/connections目录。
static struct file_system_type fuse_ctl_fs_type = {
.owner = THIS_MODULE,
.name = "fusectl",
.mount = fuse_ctl_mount,
.kill_sb = fuse_ctl_kill_sb,
};
int __init fuse_ctl_init(void)
{
// 注册fusectl文件系统,参见[11.2.2.1 注册/注销文件系统]节
return register_filesystem(&fuse_ctl_fs_type);
}
void fuse_ctl_cleanup(void)
{
// 注销fusectl文件系统,参见[11.2.2.1 注册/注销文件系统]节
unregister_filesystem(&fuse_ctl_fs_type);
}
11.3.6.3 FUSE的安装
文件系统fusectl的安装过程参见11.4 文件系统的自动安装节。
11.3.7 Debugfs
通常,Debugfs文件系统被挂载到/sys/kernel/debug目录。
11.3.7.1 Debugfs简介
See below documentations:
- Documentation/filesystems/debugfs.txt
- http://lwn.net/Articles/334546/
- http://lwn.net/Articles/115405/
Debugfs is a special filesystem (technically referred as a kernel space-user-space interface) available in Linux kernel since version 2.6.10-rc3. It was written by Greg Kroah-Hartman.
It is a simple to use RAM-based file system specially designed for debugging purposes. debugfs exists as a simple way for kernel developers to make information available to user space.
Unlike /proc, which is only meant for information about a process, or sysfs, which has strict one-value-per-file rules, debugfs has no rules at all. Developers can put any information they want there.
It is typically mounted in /sys/kernel/debug with a command like:
# mount -t debugfs none /sys/kernel/debug
It can be manipulated using several calls from the C header file linux/debugfs.h. These include:
- debugfs_create_file — for creating a file in the debug filesystem
- debugfs_create_dir — for creating a directory inside the debug filesystem
- debugfs_remove — for removing a debugfs entry from the debug filesytem
Also see section dev_dbg().
11.3.7.2 Debugfs的编译及初始化
由fs/Makefile可知,Debugfs的编译与配置项CONFIG_DEBUG_FS有关:
obj-$(CONFIG_DEBUG_FS) += debugfs/
Debugfs的初始化代码定义于fs/debugfs/inode.c:
static bool debugfs_registered;
static struct file_system_type debug_fs_type = {
.owner = THIS_MODULE,
.name = "debugfs",
/*
* 函数debug_mount()参见[11.2.2.2.1.2.5 debug_mount()]节,其调用过程如下:
* mount -t debugfs none /sys/kernel/debug
* => sys_mount()->do_mount()->do_new_mount()->
* do_kern_mount()->vfs_kern_mount()->mount_fs()
* => type->mount()
*/
.mount = debug_mount,
.kill_sb = kill_litter_super,
};
static struct kobject *debug_kobj;
static int __init debugfs_init(void)
{
int retval;
/*
* 在kernel_kobj指定的目录(即/sys/kernel/目录)下创建debug目录,
* 即/sys/kernel/debug/,参见[15.7.1.2 kobject_create_and_add()]节
*/
debug_kobj = kobject_create_and_add("debug", kernel_kobj);
if (!debug_kobj)
return -EINVAL;
// 注册debugfs文件系统,参见[11.2.2.1 注册/注销文件系统]节
retval = register_filesystem(&debug_fs_type);
if (retval)
kobject_put(debug_kobj); // 参见[15.7.2.2 kobject_put()]节
else
debugfs_registered = true;
return retval;
}
core_initcall(debugfs_init);
当Debugfs编译进内核时,其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall1.init
11.3.7.3 Debugfs的安装
文件系统debugfs的安装过程参见11.4 文件系统的自动安装节。
此后,当进程init执行配置文件/etc/init/mounted-debugfs.conf时,将目录/sys/kernel/debug的执行权限被修改为0700:
chenwx@chenwx ~ $ cd /etc/init
chenwx@chenwx /etc/init $ ll mounted-debugfs.conf
-rw-r--r-- 1 root root 405 Oct 9 2013 mounted-debugfs.conf
chenwx@chenwx /etc/init $ cat mounted-debugfs.conf
# mounted-debugfs - Fix perms on /sys/kernel/debug filesystem
#
# Since /sys/kernel/debug should not be used on production systems,
# this makes sure that the tree is kept accessible only by root.
description "Fix-up /sys/kernel/debug filesystem"
start on mounted MOUNTPOINT=/sys/kernel/debug TYPE=debugfs
env MOUNTPOINT=/sys/kernel/debug
task
script
chmod 0700 "${MOUNTPOINT}" || true
end script
11.3.8 Securityfs
通常,Securityfs文件系统被挂载到/sys/kernel/security目录。
11.3.8.1 Securityfs简介
SecurityFS is a virtual filesystem in memory for security kernel modules. Kernel security modules place their policies and other data here. The user-space sees SecurityFS as a part of SysFS. SecurityFS is mounted on /sys/kernel/security/. Some of the security modules read and write files here that are used for configuring the security modules. The Linux Security Modules (LSM) will manually mount SecurityFS because the LSMs read/write data on this pseudo-filesystem, unless the filesystem is already mounted.
The LSMs make a folder on the root of SecurityFS with their name on it. For example, AppArmor would make a directory titled “apparmor” at /sys/kernel/security/.
11.3.8.2 Securityfs的编译及初始化
由security/Makefile可知,Securityfs的编译与配置项CONFIG_SECURITYFS有关:
obj-$(CONFIG_SECURITYFS) += inode.o
Securityfs的初始化代码参见security/inode.c:
static struct file_system_type fs_type = {
.owner = THIS_MODULE,
.name = "securityfs",
.mount = get_sb,
.kill_sb = kill_litter_super,
};
static struct kobject *security_kobj;
static int __init securityfs_init(void)
{
int retval;
/*
* 在kernel_kobj指定的目录(即/sys/kernel/目录)下创建security目录,
* 即/sys/kernel/security/,参见[15.7.1.2 kobject_create_and_add()]节
*/
security_kobj = kobject_create_and_add("security", kernel_kobj);
if (!security_kobj)
return -EINVAL;
// 注册securityfs文件系统,参见[11.2.2.1 注册/注销文件系统]节
retval = register_filesystem(&fs_type);
if (retval)
kobject_put(security_kobj); // 参见[15.7.2.2 kobject_put()]节
return retval;
}
core_initcall(securityfs_init);
当Securityfs编译进内核时,其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall1.init
11.3.8.3 Securityfs的安装
文件系统securityfs的安装过程参见11.4 文件系统的自动安装节。
11.3.9 Tmpfs
通常,Tmpfs文件系统被挂载到/tmp目录。
11.3.9.1 Tmpfs简介
See Documentation/filesystems/tmpfs.txt
tmpfs is a common name for a temporary file storage facility on many Unix-like operating systems. It is intended to appear as a mounted file system, but stored in volatile memory instead of a persistent storage device. A similar construction is a RAM disk, which appears as a virtual disk drive and hosts a disk file system.
Everything stored in tmpfs is temporary in the sense that no files will be created on the hard drive; however, swap space is used as backing store in case of low memory situations. On reboot, everything in tmpfs will be lost.
The memory used by tmpfs grows and shrinks to accommodate the files it contains and can be swapped out to swap space.
Many Unix distributions enable and use tmpfs by default for the /tmp branch of the file system or for shared memory. This can be observed with df as in this example:
Filesystem Size Used Avail Use% Mounted on
tmpfs 256M 688K 256M 1% /tmp
On some Linux distributions (e.g. Debian, Ubuntu), /tmp is a normal directory, but /dev/shm uses tmpfs.
tmpfs is supported by the Linux kernel from version 2.4 and up. tmpfs (previously known as shmfs) is based on the ramfs code used during bootup and also uses the page cache, but unlike ramfs it supports swapping out less-used pages to swap space as well as filesystem size and inode limits to prevent out of memory situations (defaulting to half of physical RAM and half the number of RAM pages, respectively). These options are set at mount time and may be modified by remounting the filesystem.
11.3.9.2 Tmpfs的编译及初始化
Tmpfs实现于mm/shmem.c:
#ifdef CONFIG_SHMEM
static struct file_system_type shmem_fs_type = {
.owner = THIS_MODULE,
.name = "tmpfs",
.mount = shmem_mount, // 定义于mm/shmem.c
.kill_sb = kill_litter_super,
};
int __init shmem_init(void)
{
int error;
error = bdi_init(&shmem_backing_dev_info);
if (error)
goto out4;
error = shmem_init_inodecache();
if (error)
goto out3;
// 注册tmpfs文件系统,参见[11.2.2.1 注册/注销文件系统]节
error = register_filesystem(&shmem_fs_type);
if (error) {
printk(KERN_ERR "Could not register tmpfs\n");
goto out2;
}
// 安装tmpfs文件系统,参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
shm_mnt = vfs_kern_mount(&shmem_fs_type, MS_NOUSER, shmem_fs_type.name, NULL);
if (IS_ERR(shm_mnt)) {
error = PTR_ERR(shm_mnt);
printk(KERN_ERR "Could not kern_mount tmpfs\n");
goto out1;
}
return 0;
out1:
unregister_filesystem(&shmem_fs_type);
out2:
shmem_destroy_inodecache();
out3:
bdi_destroy(&shmem_backing_dev_info);
out4:
shm_mnt = ERR_PTR(error);
return error;
}
#else /* !CONFIG_SHMEM */
static struct file_system_type shmem_fs_type = {
.name = "tmpfs",
.mount = ramfs_mount, // 参见[11.3.1.2 Ramfs的编译及初始化]节
.kill_sb = kill_litter_super,
};
int __init shmem_init(void)
{
// 注册tmpfs文件系统,参见[11.2.2.1 注册/注销文件系统]节
BUG_ON(register_filesystem(&shmem_fs_type) != 0);
// 安装tmpfs文件系统,参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
shm_mnt = kern_mount(&shmem_fs_type);
BUG_ON(IS_ERR(shm_mnt));
return 0;
}
#endif /* CONFIG_SHMEM */
在系统初始化时,shmem_init()的调用过程如下:
start_kernel()
-> rest_init()
-> kernel_init() // 参见[4.3.4.1.4.3.13.1 kernel_init()]节
-> do_basic_setup() // 参见[4.3.4.1.4.3.13.1.2 do_basic_setup()]节
-> shmem_init()
11.3.9.3 Tmpfs的安装
文件系统tmpfs的安装过程有如下两种方式:
- 在初始化的过程中调用shmem_init()来安装tmpfs,参见11.3.9.2 Tmpfs的编译及初始化节;
- 系统启动后,在配置文件中设置tmpfs的安装路径并启动安装,参见11.4 文件系统的自动安装节。
11.3.10 Devtmpfs
通常,Devtmpfs文件系统被挂载到/dev目录。
11.3.10.0 History
Refer to «Linux_From_Scratch_v7.10-systemd.pdf» S7.3.1:
In February 2000, a new filesystem called devfs was merged into the 2.3.46 kernel and was made available during the 2.4 series of stable kernels. Although it was present in the kernel source itself, this method of creating devices dynamically never received overwhelming support from the core kernel developers.
The main problem with the approach adopted by devfs was the way it handled device detection, creation, and naming. The latter issue, that of device node naming, was perhaps the most critical. It is generally accepted that if device names are allowed to be configurable, then the device naming policy should be up to a system administrator, not imposed on them by any particular developer(s). The devfs file system also suffered from race conditions that were inherent in its design and could not be fixed without a substantial revision to the kernel. It was marked as deprecated for a long period – due to a lack of maintenance – and was finally removed from the kernel in June, 2006.
With the development of the unstable 2.5 kernel tree, later released as the 2.6 series of stable kernels, a new virtual filesystem called sysfs came to be. The job of sysfs is to export a view of the system’s hardware configuration to userspace processes. With this userspace-visible representation, the possibility of developing a userspace replacement for devfs became much more realistic.
One may wonder how sysfs knows about the devices present on a system and what device numbers should be used for them. Drivers that have been compiled into the kernel directly register their objects with a sysfs (devtmpfs internally) as they are detected by the kernel. For drivers compiled as modules, this registration will happen when the module is loaded. Once the sysfs filesystem is mounted (on /sys), data which the drivers register with sysfs are available to userspace processes and to udevd for processing (including modifications to device nodes).
Device files are created by the kernel by the devtmpfs filesystem. Any driver that wishes to register a device node will go through the devtmpfs (via the driver core) to do it. When a devtmpfs instance is mounted on /dev, the device node will initially be created with a fixed name, permissions, and owner. A short time later, the kernel will send a uevent to udevd. Based on the rules specified in the files within the /etc/udev/rules.d, /lib/udev/rules.d, and /run/udev/rules.d directories, udevd will create additional symlinks to the device node, or change its permissions, owner, or group, or modify the internal udevd database entry (name) for that object. The rules in these three directories are numbered and all three directories are merged together. If udevd can’t find a rule for the device it is creating, it will leave the permissions and ownership at whatever devtmpfs used initially.
11.3.10.1 Devtmpfs简介
11.3.10.2 Devtmpfs的编译及初始化
由drivers/base/Makefile可知,Devtmpfs的编译与配置项CONFIG_DEVTMPFS有关:
obj-$(CONFIG_DEVTMPFS) += devtmpfs.o
Devtmpfs的初始化代码参见drivers/base/devtmpfs.c:
static struct file_system_type dev_fs_type = {
.name = "devtmpfs",
.mount = dev_mount,
.kill_sb = kill_litter_super,
};
static struct task_struct *thread;
static DECLARE_COMPLETION(setup_done);
/*
* Create devtmpfs instance, driver-core devices will add their device
* nodes here.
*/
int __init devtmpfs_init(void)
{
// 注册devtmpfs文件系统,参见[11.2.2.1 注册/注销文件系统]节
int err = register_filesystem(&dev_fs_type);
if (err) {
printk(KERN_ERR "devtmpfs: unable to register devtmpfs type %i\n", err);
return err;
}
/*
* 调用kthread_run()创建内核线程kdevtmpfs(参见[7.2.4.4.1 kthread_run()]节),
* 该内核线程将执行函数devtmpfsd(),参见[11.3.10.2.1 devtmpfsd()]节
*/
thread = kthread_run(devtmpfsd, &err, "kdevtmpfs");
if (!IS_ERR(thread)) {
// 等待内核线程kdevtmpfs完成安装工作,参见[11.3.10.2.1 devtmpfsd()]节
wait_for_completion(&setup_done);
} else {
err = PTR_ERR(thread);
thread = NULL;
}
if (err) {
printk(KERN_ERR "devtmpfs: unable to create devtmpfs %i\n", err);
unregister_filesystem(&dev_fs_type);
return err;
}
printk(KERN_INFO "devtmpfs: initialized\n");
return 0;
}
函数devtmpfs_init()的调用关系如下:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> rest_init() // 参见[4.3.4.1.4.3.13 rest_init()]节
-> kernel_init() // 参见[4.3.4.1.4.3.13.1 kernel_init()]节
-> do_basic_setup() // 参见[4.3.4.1.4.3.13.1 kernel_init()]节
-> driver_init() // 参见[10.2.1 设备驱动程序的初始化/driver_init()]节
-> devtmpfs_init() // 参见[11.3.10.2 Devtmpfs的编译及初始化]节
-> devtmpfsd() // 参见[11.3.10.2.1 devtmpfsd()]节
-> sys_mount("devtmpfs", "/", "devtmpfs", ..); // 将devtmpfs挂载到/devtmpfs目录
-> handle() // 参见[11.3.10.2.1.1 handle()]节
-> handle_create()
-> kern_path_create()
-> vfs_mknod() // 创建设备节点/dev/XXX,且必须是字符设备或块设备
-> handle_remove()
-> prepare_namespace()
-> devtmpfs_mount("dev"); // 参见[11.3.10.3.1 devtmpfs_mount()]节
-> sys_mount("devtmpfs", (char *)mntdir, "devtmpfs", ..); // 将devtmpfs挂载到/dev目录
11.3.10.2.1 devtmpfsd()
该函数定义于drivers/base/devtmpfs.c:
static struct req {
struct req *next;
struct completion done;
int err;
const char *name;
mode_t mode; /* 0 => delete */
struct device *dev;
} *requests;
static int devtmpfsd(void *p)
{
char options[] = "mode=0755";
int *err = p;
*err = sys_unshare(CLONE_NEWNS);
if (*err)
goto out;
// 安装devtmpfs文件系统到目录/,参见[11.2.2.4 安装文件系统(2)/sys_mount()]节
*err = sys_mount("devtmpfs", "/", "devtmpfs", MS_SILENT, options);
if (*err)
goto out;
/*
* 将进程的当前工作目录(pwd)设定为devtmpfs文件系统的根目录,即/dev目录;
* 因而,调用handle()->handle_create()->vfs_mknod()时,在/dev目录创建设备文件
*/
sys_chdir("/.."); /* will traverse into overmounted root */
sys_chroot(".");
// 通知父进程当前线程的状态
complete(&setup_done);
/*
* 扫描requests链表,并处理其中的每个请求;
* 创建设备节点时,通过device_add()->devtmpfs_create_node()向requests链表中添加请求,
* 参见[10.2.3.3.2 添加设备/device_add()]节和[11.3.10.2.2.1 devtmpfs_create_node()]节
*/
while (1) {
spin_lock(&req_lock);
while (requests) {
struct req *req = requests;
requests = NULL;
spin_unlock(&req_lock);
while (req) {
struct req *next = req->next;
// 对requests链表中的每个元素调用handle()函数
req->err = handle(req->name, req->mode, req->dev);
complete(&req->done);
req = next;
}
spin_lock(&req_lock);
}
set_current_state(TASK_INTERRUPTIBLE);
spin_unlock(&req_lock);
schedule();
__set_current_state(TASK_RUNNING);
}
return 0;
out:
complete(&setup_done);
return *err;
}
11.3.10.2.1.1 handle()
该函数定义于drivers/base/devtmpfs.c:
static int handle(const char *name, mode_t mode, struct device *dev)
{
if (mode)
return handle_create(name, mode, dev); // 参见[11.3.10.2.1.1.1 handle_create()]节
else
return handle_remove(name, dev); // 参见[11.3.10.2.1.1.2 handle_remove()]节
}
11.3.10.2.1.1.1 handle_create()
该函数定义于drivers/base/devtmpfs.c:
static int handle_create(const char *nodename, mode_t mode, struct device *dev)
{
struct dentry *dentry;
struct path path;
int err;
/*
* 查看新节点nodename的父目录是否存在,其返回值dentry为
* 新节点nodename的父目录对应的目录项
*/
dentry = kern_path_create(AT_FDCWD, nodename, &path, 0);
if (dentry == ERR_PTR(-ENOENT)) {
// 若父目录不存在,则创建该目录
create_path(nodename);
// 重新查找新创建的目录所对应的目录项dentry
dentry = kern_path_create(AT_FDCWD, nodename, &path, 0);
}
if (IS_ERR(dentry))
return PTR_ERR(dentry);
// 创建指定的设备文件/dev/DevName,参见[11.2.4.1.1 mknod()/mknodat()]节
err = vfs_mknod(path.dentry->d_inode, dentry, mode, dev->devt);
if (!err) {
struct iattr newattrs;
/* fixup possibly umasked mode */
newattrs.ia_mode = mode;
newattrs.ia_valid = ATTR_MODE;
mutex_lock(&dentry->d_inode->i_mutex);
notify_change(dentry, &newattrs);
mutex_unlock(&dentry->d_inode->i_mutex);
/* mark as kernel-created inode */
dentry->d_inode->i_private = &thread;
}
dput(dentry);
mutex_unlock(&path.dentry->d_inode->i_mutex);
path_put(&path);
return err;
}
11.3.10.2.1.1.2 handle_remove()
该函数定义于drivers/base/devtmpfs.c:
static int handle_remove(const char *nodename, struct device *dev)
{
struct nameidata nd;
struct dentry *dentry;
struct kstat stat;
int deleted = 1;
int err;
err = kern_path_parent(nodename, &nd);
if (err)
return err;
mutex_lock_nested(&nd.path.dentry->d_inode->i_mutex, I_MUTEX_PARENT);
dentry = lookup_one_len(nd.last.name, nd.path.dentry, nd.last.len);
if (!IS_ERR(dentry)) {
if (dentry->d_inode) {
err = vfs_getattr(nd.path.mnt, dentry, &stat);
if (!err && dev_mynode(dev, dentry->d_inode, &stat)) {
struct iattr newattrs;
/*
* before unlinking this node, reset permissions
* of possible references like hardlinks
*/
newattrs.ia_uid = 0;
newattrs.ia_gid = 0;
newattrs.ia_mode = stat.mode & ~0777;
newattrs.ia_valid = ATTR_UID | ATTR_GID | ATTR_MODE;
mutex_lock(&dentry->d_inode->i_mutex);
notify_change(dentry, &newattrs);
mutex_unlock(&dentry->d_inode->i_mutex);
err = vfs_unlink(nd.path.dentry->d_inode, dentry);
if (!err || err == -ENOENT)
deleted = 1;
}
} else {
err = -ENOENT;
}
dput(dentry);
} else {
err = PTR_ERR(dentry);
}
mutex_unlock(&nd.path.dentry->d_inode->i_mutex);
path_put(&nd.path);
if (deleted && strchr(nodename, '/'))
delete_path(nodename);
return err;
}
11.3.10.2.2 创建/删除devtmpfs节点
11.3.10.2.2.1 devtmpfs_create_node()
该函数定义于drivers/base/devtmpfs.c:
int devtmpfs_create_node(struct device *dev)
{
const char *tmp = NULL;
struct req req;
/*
* 判断内核线程kdevtmpfs是否存在,该内核线程由devtmpfs_init()创建,
* 参见[11.3.10.2 Devtmpfs的编译及初始化]节
*/
if (!thread)
return 0;
req.mode = 0;
/*
* 获取文件名,用于创建文件/dev/DevName,
* 参见[11.3.10.2.2.1.1 device_get_devnode()]节
*/
req.name = device_get_devnode(dev, &req.mode, &tmp);
if (!req.name)
return -ENOMEM;
/*
* 将req.mode设置为非0,表示创建该req,
* 参见[11.3.10.2.1.1 handle()]节
*/
if (req.mode == 0)
req.mode = 0600;
// 该请求只能是块设备,或字符设备
if (is_blockdev(dev))
req.mode |= S_IFBLK;
else
req.mode |= S_IFCHR;
req.dev = dev;
init_completion(&req.done);
// 将该请求req添加到链表requests头部
spin_lock(&req_lock);
req.next = requests;
requests = &req;
spin_unlock(&req_lock);
/*
* 唤醒内核线程kdevtmpfs来处理链表requests中的请求,
* 参见[11.3.10.2.1 devtmpfsd()]节
*/
wake_up_process(thread);
wait_for_completion(&req.done);
kfree(tmp);
return req.err;
}
11.3.10.2.2.1.1 device_get_devnode()
该函数定义于drivers/base/core.c:
/**
* device_get_devnode - path of device node file
* @dev: device
* @mode: returned file access mode
* @tmp: possibly allocated string
*
* Return the relative path of a possible device node.
* Non-default names may need to allocate a memory to compose
* a name. This memory is returned in tmp and needs to be
* freed by the caller.
*/
const char *device_get_devnode(struct device *dev, mode_t *mode, const char **tmp)
{
char *s;
*tmp = NULL;
/* the device type may provide a specific name */
if (dev->type && dev->type->devnode)
*tmp = dev->type->devnode(dev, mode);
if (*tmp)
return *tmp;
/* the class may provide a specific name */
if (dev->class && dev->class->devnode)
*tmp = dev->class->devnode(dev, mode);
if (*tmp)
return *tmp;
/* return name without allocation, tmp == NULL */
if (strchr(dev_name(dev), '!') == NULL)
return dev_name(dev);
/* replace '!' in the name with '/' */
*tmp = kstrdup(dev_name(dev), GFP_KERNEL);
if (!*tmp)
return NULL;
while ((s = strchr(*tmp, '!')))
s[0] = '/';
return *tmp;
}
通过如下函数调用获取设备名称,用于创建文件/dev/DevName:
device_create(class, parent, devt, drvdata, fmt, "DevNameString")
-> device_create_vargs(class, parent, devt, drvdata, fmt, "DevNameString")
-> dev = kzalloc(sizeof(*dev), GFP_KERNEL);
-> dev->dev->class = class;
// 1) dev->kobj->name = "DevNameString"
-> kobject_set_name_vargs(&dev->kobj, fmt, "DevNameString");
-> device_register(dev)
-> device_initialize(dev)
-> device_add(dev)
// 2) dev->kobj->name = dev->init_name;
// so, dev->init_name has higher priority than "DevNameString"!
-> dev_set_name(dev, "%s", dev->init_name);
-> dev->init_name = NULL; // 3) set dev->init_name = NULL
-> devtmpfs_create_node(dev)
-> device_get_devnode(dev)
-> 1) dev->type->devnode(dev, ..); // 4) try #1: dev->type->devnode()
2) dev->class->devnode(dev, ..); // 5) try #2: dev->class->devnode()
3) dev_name(dev)
-> dev->init_name // 6) try #3: dev->init_name; it's NULL now
/*
* 7) try #4: dev->kobj->name;
* that's, dev->init_name, or "DevNameString"
*/
-> kobject_name(&dev->kobj);
11.3.10.2.2.2 devtmpfs_delete_node()
该函数定义于drivers/base/devtmpfs.c:
int devtmpfs_delete_node(struct device *dev)
{
const char *tmp = NULL;
struct req req;
/*
* 判断内核线程kdevtmpfs是否存在,该内核线程由devtmpfs_init()
* 创建,参见[11.3.10.2 Devtmpfs的编译及初始化]节
*/
if (!thread)
return 0;
req.name = device_get_devnode(dev, NULL, &tmp);
if (!req.name)
return -ENOMEM;
/*
* 将req.mode设置为0,表示删除该req,
* 参见[11.3.10.2.1.1 handle()]节
*/
req.mode = 0;
req.dev = dev;
init_completion(&req.done);
spin_lock(&req_lock);
req.next = requests;
requests = &req;
spin_unlock(&req_lock);
wake_up_process(thread);
wait_for_completion(&req.done);
kfree(tmp);
return req.err;
}
11.3.10.3 Devtmpfs的安装
文件系统devtmpfs的安装过程包含如下三种方式:
- 在系统初始化的过程中调用devtmpfs_init()->devtmpfs_init()来安装devtmpfs,参见11.3.10.2.1 devtmpfsd()节;
- 在系统初始化过程中调用devtmpfs_mount()来安装devtmpfs,参见11.3.10.3.1 devtmpfs_mount()节;
- 系统启动后,在配置文件中设置devtmpfs的安装路径并启动安装,参见11.4 文件系统的自动安装节。
11.3.10.3.1 devtmpfs_mount()
函数devtmpfs_mount()的调用过程如下:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> rest_init() // 参见[4.3.4.1.4.3.13 rest_init()]节
-> kernel_init() // 参见[4.3.4.1.4.3.13.1 kernel_init()]节
-> prepare_namespace() // 参见[4.3.4.1.4.3.13.1.3 prepare_namespace()]节
-> devtmpfs_mount("dev"); // 将devtmpfs文件系统挂载到/dev目录
该函数定义于drivers/base/devtmpfs.c:
/*
* If configured, or requested by the commandline, devtmpfs will be
* auto-mounted after the kernel mounted the root filesystem.
*/
int devtmpfs_mount(const char *mntdir)
{
int err;
if (!mount_dev)
return 0;
/*
* 内核线程thread是由函数devtmpfs_init()创建的,
* 参见[11.3.10.2 Devtmpfs的编译及初始化]节
*/
if (!thread)
return 0;
// 参见[11.2.2.4 安装文件系统(2)/sys_mount()]节
err = sys_mount("devtmpfs", (char *)mntdir, "devtmpfs", MS_SILENT, NULL);
if (err)
printk(KERN_INFO "devtmpfs: error mounting %i\n", err);
else
printk(KERN_INFO "devtmpfs: mounted\n");
return err;
}
11.3.11 Devpts
通常,Devpts文件系统被挂载到/dev/pts目录。
11.3.11.1 Devpts简介
See Documentation/filesystems/devpts.txt
11.3.11.2 Devpts的编译及初始化
由fs/devpts/Makefile可知,Devpts的编译与配置项CONFIG_UNIX98_PTYS有关:
obj-$(CONFIG_UNIX98_PTYS) += devpts.o
devpts-$(CONFIG_UNIX98_PTYS) := inode.o
Devpts的初始化代码定义于fs/devpts/inode.c:
static struct vfsmount *devpts_mnt;
static struct file_system_type devpts_fs_type = {
.name = "devpts",
.mount = devpts_mount,
.kill_sb = devpts_kill_sb,
};
static int __init init_devpts_fs(void)
{
// 注册devpts文件系统,参见[11.2.2.1 注册/注销文件系统]节
int err = register_filesystem(&devpts_fs_type);
if (!err) {
// 安装devpts文件系统,参见[11.2.2.2 安装文件系统(1)/kern_mount()]节
devpts_mnt = kern_mount(&devpts_fs_type);
if (IS_ERR(devpts_mnt)) {
err = PTR_ERR(devpts_mnt);
unregister_filesystem(&devpts_fs_type);
}
}
return err;
}
module_init(init_devpts_fs)
当Devpts编译进内核时,其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
11.3.11.3 Devpts的安装
文件系统devpts的安装过程参见11.3.11.2 Devpts的编译及初始化节和11.4 文件系统的自动安装节。
11.3.12 VFAT
11.3.12.1 VFAT简介
See Documentation/filesystems/vfat.txt
11.3.12.2 VFAT的编译及初始化
VFAT的编译与如下配置项有关:
- fs/Makefile:
obj-$(CONFIG_FAT_FS) += fat/
- fs/fat/Makefile:
obj-$(CONFIG_VFAT_FS) += vfat.o
VFAT的初始化代码定义于fs/fat/namei_vfat.c:
static struct file_system_type vfat_fs_type = {
.owner = THIS_MODULE,
.name = "vfat",
.mount = vfat_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
static int __init init_vfat_fs(void)
{
return register_filesystem(&vfat_fs_type);
}
static void __exit exit_vfat_fs(void)
{
unregister_filesystem(&vfat_fs_type);
}
module_init(init_vfat_fs)
module_exit(exit_vfat_fs)
当VFAT编译进内核时,其初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
11.3.12.3 VFAT的安装
文件系统devpts的安装过程参见11.4 文件系统的自动安装节。
11.3.13 Ext2
11.3.13.1 Ext2简介
See Documentation/filesystems/ext2.txt
11.3.13.2 Ext2的编译及初始化
由fs/Makefile可知,Ext2的编译与配置项CONFIG_EXT2_FS有关:
obj-$(CONFIG_EXT3_FS) += ext3/ # Before ext2 so root fs can be ext3
obj-$(CONFIG_EXT2_FS) += ext2/
# We place ext4 after ext2 so plain ext2 root fs's are mounted using ext2
# unless explicitly requested by rootfstype
obj-$(CONFIG_EXT4_FS) += ext4/
Ext2的初始化代码定义于fs/ext2/super.c:
static struct file_system_type ext2_fs_type = {
.owner = THIS_MODULE,
.name = "ext2",
.mount = ext2_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
static int __init init_ext2_fs(void)
{
int err = init_ext2_xattr();
if (err)
return err;
err = init_inodecache();
if (err)
goto out1;
err = register_filesystem(&ext2_fs_type);
if (err)
goto out;
return 0;
out:
destroy_inodecache();
out1:
exit_ext2_xattr();
return err;
}
static void __exit exit_ext2_fs(void)
{
unregister_filesystem(&ext2_fs_type);
destroy_inodecache();
exit_ext2_xattr();
}
module_init(init_ext2_fs)
module_exit(exit_ext2_fs)
若将CONFIG_EXT2_FS配置为y,即将Ext2编译进内核时,Ext2的初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
11.3.13.3 Ext2的安装
文件系统Ext2的安装过程参见11.4 文件系统的自动安装节。
11.3.14 Ext3
通常,Ext3文件系统被挂载到/dev/sda1目录。
11.3.14.1 Ext3简介
See Documentation/filesystems/ext3.txt
Ext3(Third Extended File System,第三扩展文件系统),是一种日志文件系统,是很多Linux发行版的默认文件系统。Stephen Tweedie在1999年2月的内核邮件列表中,最早显示了他使用扩展的ext2,该文件系统从2.4.15版本的内核开始,合并到内核主线中。
11.3.14.2 Ext3的编译及初始化
由fs/Makefile可知,Ext3的编译与配置项CONFIG_EXT3_FS有关:
obj-$(CONFIG_EXT3_FS) += ext3/ # Before ext2 so root fs can be ext3
obj-$(CONFIG_EXT2_FS) += ext2/
# We place ext4 after ext2 so plain ext2 root fs's are mounted using ext2
# unless explicitly requested by rootfstype
obj-$(CONFIG_EXT4_FS) += ext4/
由fs/ext3/Makefile可知,编译Ext3需要如下文件:
#
# Makefile for the linux ext3-filesystem routines.
#
obj-$(CONFIG_EXT3_FS) += ext3.o
ext3-y := balloc.o bitmap.o dir.o file.o fsync.o ialloc.o inode.o \
ioctl.o namei.o super.o symlink.o hash.o resize.o ext3_jbd.o
ext3-$(CONFIG_EXT3_FS_XATTR) += xattr.o xattr_user.o xattr_trusted.o
ext3-$(CONFIG_EXT3_FS_POSIX_ACL) += acl.o
ext3-$(CONFIG_EXT3_FS_SECURITY) += xattr_security.o
Ext3的初始化代码定义于fs/ext3/super.c:
static struct file_system_type ext3_fs_type = {
// 参见[13.4.2.4 How to access symbols]节
.owner = THIS_MODULE,
.name = "ext3",
/*
* ext3_mount()通过如下函数被调用,参见[11.2.2.4 安装文件系统(2)/sys_mount()]节:
* sys_mount()->do_mount()->do_new_mount()->do_kern_mount()
* ->vfs_kern_mount()->mount_fs()中的type->mount()
*/
.mount = ext3_mount,
/*
* kill_block_super()通过如下函数被调用:
* sys_umount()->mntput_no_expire()->mntfree()->
* deactivate_super()->deactivate_locked_super()->
* fs->kill_sb()
*/
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
static int __init init_ext3_fs(void)
{
int err = init_ext3_xattr();
if (err)
return err;
err = init_inodecache();
if (err)
goto out1;
err = register_filesystem(&ext3_fs_type);
if (err)
goto out;
return 0;
out:
destroy_inodecache();
out1:
exit_ext3_xattr();
return err;
}
static void __exit exit_ext3_fs(void)
{
unregister_filesystem(&ext3_fs_type);
destroy_inodecache();
exit_ext3_xattr();
}
MODULE_AUTHOR("Remy Card, Stephen Tweedie, Andrew Morton, Andreas Dilger, Theodore Ts'o and others");
MODULE_DESCRIPTION("Second Extended Filesystem with journaling extensions");
MODULE_LICENSE("GPL");
module_init(init_ext3_fs)
module_exit(exit_ext3_fs)
若将CONFIG_EXT3_FS配置为y,即将Ext3编译进内核时,Ext3的初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
11.3.14.3 Ext3的安装
文件系统Ext3的安装过程参见11.4 文件系统的自动安装节。
11.3.15 Ext4
11.3.15.1 Ext4简介
See Documentation/filesystems/ext4.txt
11.3.15.2 Ext4的编译及初始化
由fs/Makefile可知,Ext4的编译与配置项CONFIG_EXT4_FS有关:
obj-$(CONFIG_EXT3_FS) += ext3/ # Before ext2 so root fs can be ext3
obj-$(CONFIG_EXT2_FS) += ext2/
# We place ext4 after ext2 so plain ext2 root fs's are mounted using ext2
# unless explicitly requested by rootfstype
obj-$(CONFIG_EXT4_FS) += ext4/
Ext4的初始化代码定义于fs/ext4/super.c:
static struct file_system_type ext4_fs_type = {
.owner = THIS_MODULE,
.name = "ext4",
.mount = ext4_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
static int __init ext4_init_fs(void)
{
int i, err;
ext4_check_flag_values();
for (i = 0; i < EXT4_WQ_HASH_SZ; i++) {
mutex_init(&ext4__aio_mutex[i]);
init_waitqueue_head(&ext4__ioend_wq[i]);
}
err = ext4_init_pageio();
if (err)
return err;
err = ext4_init_system_zone();
if (err)
goto out6;
ext4_kset = kset_create_and_add("ext4", NULL, fs_kobj);
if (!ext4_kset)
goto out5;
ext4_proc_root = proc_mkdir("fs/ext4", NULL);
err = ext4_init_feat_adverts();
if (err)
goto out4;
err = ext4_init_mballoc();
if (err)
goto out3;
err = ext4_init_xattr();
if (err)
goto out2;
err = init_inodecache();
if (err)
goto out1;
register_as_ext3(); // 注册文件系统ext3_fs_type
register_as_ext2(); // 注册文件系统ext2_fs_type
err = register_filesystem(&ext4_fs_type); // 注册文件系统ext4_fs_type
if (err)
goto out;
ext4_li_info = NULL;
mutex_init(&ext4_li_mtx);
return 0;
out:
unregister_as_ext2();
unregister_as_ext3();
destroy_inodecache();
out1:
ext4_exit_xattr();
out2:
ext4_exit_mballoc();
out3:
ext4_exit_feat_adverts();
out4:
if (ext4_proc_root)
remove_proc_entry("fs/ext4", NULL);
kset_unregister(ext4_kset);
out5:
ext4_exit_system_zone();
out6:
ext4_exit_pageio();
return err;
}
static void __exit ext4_exit_fs(void)
{
ext4_destroy_lazyinit_thread();
unregister_as_ext2();
unregister_as_ext3();
unregister_filesystem(&ext4_fs_type);
destroy_inodecache();
ext4_exit_xattr();
ext4_exit_mballoc();
ext4_exit_feat_adverts();
remove_proc_entry("fs/ext4", NULL);
kset_unregister(ext4_kset);
ext4_exit_system_zone();
ext4_exit_pageio();
}
module_init(ext4_init_fs)
module_exit(ext4_exit_fs)
若将CONFIG_EXT4_FS配置为y,即将Ext4编译进内核时,Ext4的初始化过程参见13.5.1.1 module被编译进内核时的初始化过程节,即:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
11.3.15.3 Ext4的安装
文件系统ext4的安装过程参见11.4 文件系统的自动安装节。
11.3.15.4 创建ext2/ext3/ext4文件系统的命令
NAME
mke2fs - create an ext2/ext3/ext4 filesystem
SYNOPSIS
mke2fs [ -c | -l filename ] [ -b block-size ] [ -D ] [ -f fragment-size ]
[ -g blocks-per-group ] [ -G number-of-groups ] [ -i bytes-per-inode ]
[ -I inode-size ] [ -j ] [ -J journal-options ] [ -N number-of-inodes ]
[ -n ] [ -m reserved-blocks-percentage ] [ -o creator-os ]
[ -O [^]feature[,...] ] [ -q ] [ -r fs-revision-level ] [ -E extended-options ]
[ -v ] [ -F ] [ -L volume-label ] [ -M last-mounted-directory ] [ -S ]
[ -t fs-type ] [ -T usage-type ] [ -U UUID ] [ -V ] device [ fs-size ]
mke2fs -O journal_dev [ -b block-size ] [ -L volume-label ] [ -n ] [ -q ]
[ -v ] external-journal [ fs-size ]
...
11.3.16 Btrfs
11.4 文件系统的自动安装
在系统启动时,进程init将执行配置文件/etc/init/*.conf,参见4.3.5.1.3.1 upstart节。
配置文件/etc/init/mountall.conf包含如下内容:
chenwx@chenwx /etc/init $ ll mountall.conf
-rw-r--r-- 1 root root 1232 Oct 9 2013 mountall.conf
chenwx@chenwx /etc/init $ cat mountall.conf
# mountall - Mount filesystems on boot
#
# This helper mounts filesystems in the correct order as the devices
# and mountpoints become available.
description "Mount filesystems on boot"
start on startup
stop on starting rcS
expect daemon
task
emits virtual-filesystems
emits local-filesystems
emits remote-filesystems
emits all-swaps
emits filesystem
emits mounting
emits mounted
script
. /etc/default/rcS || true
[ -f /forcefsck ] && force_fsck="--force-fsck"
[ "$FSCKFIX" = "yes" ] && fsck_fix="--fsck-fix"
# Doesn't work so well if mountall is responsible for mounting /proc, heh.
if [ -e /proc/cmdline ]; then
read line < /proc/cmdline
for arg in $line; do
case $arg in
-q|--quiet|-v|--verbose|--debug)
debug_arg=$arg
;;
esac
done < /proc/cmdline
fi
# set $LANG so that messages appearing in plymouth are translated
if [ -r /etc/default/locale ]; then
. /etc/default/locale || true
export LANG LANGUAGE LC_MESSAGES LC_ALL
fi
exec mountall --daemon $force_fsck $fsck_fix $debug_arg
end script
post-stop script
rm -f /forcefsck 2>dev/null || true
end script
其中,命令mountall将安装文件/lib/init/fstab和/etc/fstab中配置的文件系统:
1) /lib/init/fstab
chenwx@chenwx /etc/init $ cat /lib/init/fstab
# /lib/init/fstab: static file system information.
#
# These are the filesystems that are always mounted on boot, you can
# override any of these by copying the appropriate line from this file into
# /etc/fstab and tweaking it as you see fit. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
/dev/root / rootfs defaults 0 1
none /proc proc nodev,noexec,nosuid 0 0
none /proc/sys/fs/binfmt_misc binfmt_misc nodev,noexec,nosuid,optional 0 0
none /sys sysfs nodev,noexec,nosuid 0 0
none /sys/fs/cgroup tmpfs optional,uid=0,gid=0,mode=0755,size=1024 0 0
none /sys/fs/fuse/connections fusectl optional 0 0
none /sys/kernel/debug debugfs optional 0 0
none /sys/kernel/security securityfs optional 0 0
none /sys/firmware/efi/efivars efivarfs optional 0 0
none /spu spufs gid=spu,optional 0 0
none /dev devtmpfs,tmpfs mode=0755 0 0
none /dev/pts devpts noexec,nosuid,gid=tty,mode=0620 0 0
none /tmp none defaults 0 0
none /run tmpfs noexec,nosuid,size=10%,mode=0755 0 0
none /run/lock tmpfs nodev,noexec,nosuid,size=5242880 0 0
none /run/shm tmpfs nosuid,nodev 0 0
none /run/user tmpfs nodev,noexec,nosuid,size=104857600,mode=0755 0 0
none /sys/fs/pstore pstore optional 0 0
例如:文件系统debugfs被安装到/sys/kernel/debug目录。
2) /etc/fstab
chenwx@chenwx /etc/init $ cat /etc/fstab
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/sda1 during installation
UUID=fe67c2d0-9b0f-4fd6-8e97-463ce95a7e0c / ext4 errors=remount-ro 0 1
# swap was on /dev/sda5 during installation
UUID=4d735370-825b-411f-9167-090146a8dd09 none swap sw 0 0
11.4.1 UUID
A UUID (Universally Unique IDentifier) is used to uniquely identify objects. This 128bit standard allows anyone to create a unique uuid.
Linux now prefers to use UUID, LABEL, or symlinks to identify media storage devices on a system. Directly using /dev/hd# or /dev/sd# is no longer preferred since these device assignments can change between system boots:
- all filesystems should be specified by UUID=
or LABEL= for each partition. - all physical devices should be specified by a symlink, like /dev/cdrom for a cd drive and /dev/disk/by-id/… for each physical hard drive.
运行命令blkid查看UUID:
chenwx@chenwx ~ $ blkid
/dev/sda1: UUID="61b86fe4-41d9-4de3-a204-f64bf26eb02d" TYPE="ext4"
/dev/sda5: UUID="bfba9918-f4ef-41ed-a733-733cc066e32e" TYPE="swap"
chenwx@chenwx ~ $ blkid -V
blkid from util-linux 2.27.1 (libblkid 2.27.0, 02-Nov-2015)
chenwx@chenwx ~ $ blkid
/dev/sda1: LABEL="Work" UUID="60742AE4742ABCA2" TYPE="ntfs"
/dev/sdb1: LABEL="系统保留" UUID="CE96646496644F51" TYPE="ntfs" PARTUUID="000beffd-01"
/dev/sdb2: LABEL="Windows" UUID="A6386E3E386E0E1D" TYPE="ntfs" PARTUUID="000beffd-02"
/dev/sdb3: UUID="A81EC4DF1EC4A820" TYPE="ntfs" PARTUUID="000beffd-03"
/dev/sdb5: UUID="51ce0b57-1d7f-4da3-b46f-d6a0ea64c81d" TYPE="ext4" PARTUUID="000beffd-05"
也可以通过下列命令查看UUID:
chenwx@chenwx ~/linux $ ll /dev/disk/
drwxr-xr-x 2 root root 360 Aug 17 22:30 by-id
drwxr-xr-x 2 root root 100 Aug 17 22:30 by-label
drwxr-xr-x 2 root root 200 Aug 17 22:30 by-path
drwxr-xr-x 2 root root 140 Aug 17 22:30 by-uuid
chenwx@chenwx ~/linux $ ll /dev/disk/by-id/
lrwxrwxrwx 1 root root 9 Aug 10 08:41 ata-CSD_CAZ320S -> ../../sda
lrwxrwxrwx 1 root root 10 Aug 10 08:41 ata-CSD_CAZ320S-part1 -> ../../sda1
lrwxrwxrwx 1 root root 9 Aug 10 08:41 ata-Samsung_SSD_840_EVO_120GB_S1D5NSDF307270Y -> ../../sdb
lrwxrwxrwx 1 root root 10 Aug 10 08:41 ata-Samsung_SSD_840_EVO_120GB_S1D5NSDF307270Y-part1 -> ../../sdb1
lrwxrwxrwx 1 root root 10 Aug 10 08:41 ata-Samsung_SSD_840_EVO_120GB_S1D5NSDF307270Y-part2 -> ../../sdb2
lrwxrwxrwx 1 root root 10 Aug 10 08:41 ata-Samsung_SSD_840_EVO_120GB_S1D5NSDF307270Y-part3 -> ../../sdb3
lrwxrwxrwx 1 root root 10 Aug 10 08:41 ata-Samsung_SSD_840_EVO_120GB_S1D5NSDF307270Y-part4 -> ../../sdb4
lrwxrwxrwx 1 root root 10 Aug 10 08:41 ata-Samsung_SSD_840_EVO_120GB_S1D5NSDF307270Y-part5 -> ../../sdb5
lrwxrwxrwx 1 root root 9 Aug 10 08:41 wwn-0x500000e041e9d01a -> ../../sda
lrwxrwxrwx 1 root root 10 Aug 10 08:41 wwn-0x500000e041e9d01a-part1 -> ../../sda1
lrwxrwxrwx 1 root root 9 Aug 10 08:41 wwn-0x50025388a0331a8d -> ../../sdb
lrwxrwxrwx 1 root root 10 Aug 10 08:41 wwn-0x50025388a0331a8d-part1 -> ../../sdb1
lrwxrwxrwx 1 root root 10 Aug 10 08:41 wwn-0x50025388a0331a8d-part2 -> ../../sdb2
lrwxrwxrwx 1 root root 10 Aug 10 08:41 wwn-0x50025388a0331a8d-part3 -> ../../sdb3
lrwxrwxrwx 1 root root 10 Aug 10 08:41 wwn-0x50025388a0331a8d-part4 -> ../../sdb4
lrwxrwxrwx 1 root root 10 Aug 10 08:41 wwn-0x50025388a0331a8d-part5 -> ../../sdb5
chenwx@chenwx ~/linux $ ll /dev/disk/by-uuid/
lrwxrwxrwx 1 root root 10 Aug 10 08:41 51ce0b57-1d7f-4da3-b46f-d6a0ea64c81d -> ../../sdb5
lrwxrwxrwx 1 root root 10 Aug 10 08:41 60742AE4742ABCA2 -> ../../sda1
lrwxrwxrwx 1 root root 10 Aug 10 08:41 A6386E3E386E0E1D -> ../../sdb2
lrwxrwxrwx 1 root root 10 Aug 10 08:41 A81EC4DF1EC4A820 -> ../../sdb3
lrwxrwxrwx 1 root root 10 Aug 10 08:41 CE96646496644F51 -> ../../sdb1
chenwx@chenwx ~/linux $ ll /dev/disk/by-label/
lrwxrwxrwx 1 root root 10 Aug 10 08:41 Windows -> ../../sdb2
lrwxrwxrwx 1 root root 10 Aug 10 08:41 Work -> ../../sda1
lrwxrwxrwx 1 root root 10 Aug 10 08:41 系统保留 -> ../../sdb1
chenwx@chenwx ~/linux $ ll /dev/disk/by-path/
lrwxrwxrwx 1 root root 9 Aug 10 08:41 pci-0000:00:1f.1-ata-1 -> ../../sda
lrwxrwxrwx 1 root root 10 Aug 10 08:41 pci-0000:00:1f.1-ata-1-part1 -> ../../sda1
lrwxrwxrwx 1 root root 9 Aug 10 08:41 pci-0000:00:1f.2-ata-1 -> ../../sdb
lrwxrwxrwx 1 root root 10 Aug 10 08:41 pci-0000:00:1f.2-ata-1-part1 -> ../../sdb1
lrwxrwxrwx 1 root root 10 Aug 10 08:41 pci-0000:00:1f.2-ata-1-part2 -> ../../sdb2
lrwxrwxrwx 1 root root 10 Aug 10 08:41 pci-0000:00:1f.2-ata-1-part3 -> ../../sdb3
lrwxrwxrwx 1 root root 10 Aug 10 08:41 pci-0000:00:1f.2-ata-1-part4 -> ../../sdb4
lrwxrwxrwx 1 root root 10 Aug 10 08:41 pci-0000:00:1f.2-ata-1-part5 -> ../../sdb5
运行命令lsblk查看硬盘分区情况:
chenwx@chenwx ~ $ lsblk -f
NAME FSTYPE LABEL MOUNTPOINT
Sda
+-sda1 ext4 /
+-sda2
+-sda5 swap [SWAP]
sr0
chenwx@chenwx ~ $ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 25G 0 disk
├─sda1 8:1 0 24G 0 part /
├─sda2 8:2 0 1K 0 part
└─sda5 8:5 0 1G 0 part [SWAP]
sr0 11:0 1 1024M 0 rom
11.5 在同一目录挂载多种文件系统
在同一目录挂载多种文件系统,后挂载的文件系统会隐藏之前挂载的文件系统,如下所示:
# 创建目录~/tmp,用于挂载文件系统tmpfs和debugfs
chenwx@chenwx ~ $ mkdir ~/tmp
# 在~/tmp目录挂载文件系统tmpfs
chenwx@chenwx ~ $ sudo mount -t tmpfs none tmp
chenwx@chenwx ~ $ mount | grep ~/tmp
none on /home/chenwx/tmp type tmpfs (rw)
# 创建文件~/tmp/name,并写入字符串"tmpfs"
chenwx@chenwx ~ $ echo "tmpfs" > ~/tmp/name
chenwx@chenwx ~ $ ll ~/tmp
-rw-r--r-- 1 chenwx chenwx 8 Sep 20 21:14 name
chenwx@chenwx ~ $ cat ~/tmp/name
tmpfs
# 在~/tmp目录挂载文件系统debugfs
chenwx@chenwx ~ $ sudo mount -t debugfs none tmp
chenwx@chenwx ~ $ mount | grep ~/tmp
none on /home/chenwx/tmp type tmpfs (rw)
none on /home/chenwx/tmp type debugfs (rw)
# 查看~/tmp目录下的文件
chenwx@chenwx ~ $ sudo ls -l ~/tmp/name
ls: cannot access /home/chenwx/tmp/name: No such file or directory
chenwx@chenwx ~ $ sudo ls -l ~/tmp
drwxr-xr-x 2 root root 0 Sep 19 19:07 acpi
drwxr-xr-x 31 root root 0 Sep 19 19:07 bdi
drwxr-xr-x 2 root root 0 Sep 19 19:07 bluetooth
drwxr-xr-x 2 root root 0 Sep 19 19:07 btrfs
drwxr-xr-x 2 root root 0 Sep 19 19:07 cleancache
drwxr-xr-x 3 root root 0 Sep 19 19:07 clk
drwxr-xr-x 2 root root 0 Sep 19 19:07 dma_buf
drwxr-xr-x 3 root root 0 Sep 19 19:08 dri
drwxr-xr-x 2 root root 0 Sep 19 19:07 dynamic_debug
drwxr-xr-x 2 root root 0 Sep 19 19:07 extfrag
-rw-r--r-- 1 root root 0 Sep 19 19:07 fault_around_order
drwxr-xr-x 2 root root 0 Sep 19 19:07 frontswap
-r--r--r-- 1 root root 0 Sep 19 19:07 gpio
drwxr-xr-x 2 root root 0 Sep 19 19:07 kprobes
drwxr-xr-x 3 root root 0 Sep 19 19:07 kvm-guest
drwxr-xr-x 2 root root 0 Sep 19 19:07 mce
drwxr-xr-x 2 root root 0 Sep 19 19:07 pinctrl
-r--r--r-- 1 root root 0 Sep 19 19:07 pwm
drwxr-xr-x 2 root root 0 Sep 19 19:07 regmap
drwxr-xr-x 3 root root 0 Sep 19 19:07 regulator
-rw-r--r-- 1 root root 0 Sep 19 19:07 sched_features
-r--r--r-- 1 root root 0 Sep 19 19:07 sleep_time
-r--r--r-- 1 root root 0 Sep 19 19:07 suspend_stats
drwxr-xr-x 7 root root 0 Sep 19 19:07 tracing
drwxr-xr-x 5 root root 0 Sep 19 19:07 usb
drwxr-xr-x 2 root root 0 Sep 19 19:07 virtio-ports
-r--r--r-- 1 root root 0 Sep 19 19:07 wakeup_sources
drwxr-xr-x 2 root root 0 Sep 19 19:07 x86
# 从~/tmp卸载文件系统debugfs
chenwx@chenwx ~ $ sudo umount ~/tmp
chenwx@chenwx ~ $ mount | grep ~/tmp
none on /home/chenwx/tmp type tmpfs (rw)
# 文件~/tmp/name重新显示出来
chenwx@chenwx ~ $ ll ~/tmp
-rw-r--r-- 1 chenwx chenwx 8 Sep 20 21:00 name
chenwx@chenwx ~ $ cat ~/tmp/name
tmpfs
# 从~/tmp卸载文件系统tmpfs
chenwx@chenwx ~ $ sudo umount ~/tmp
chenwx@chenwx ~ $ mount | grep ~/tmp
chenwx@chenwx ~ $ ll ~/tmp
total 0
其原理参见如下函数调用:
kern_path() // 参见[11.2.2.4.1.1 kern_path()/do_path_lookup()]节
-> do_path_lookup() // 参见[11.2.2.4.1.1 kern_path()/do_path_lookup()]节
-> path_lookupat() // 参见[11.2.2.4.1.1.1 path_lookupat()]节
-> link_path_walk() // 参见[11.2.2.4.1.1.1.2 link_path_walk()]节
-> walk_component() // 参见[11.2.2.4.1.1.1.2.1 walk_component()]节
-> do_lookup() // 参见[11.2.2.4.1.1.1.2.2 do_lookup()]节
-> __follow_mount_rcu() // 参见[11.2.2.4.1.1.1.2.3 __follow_mount_rcu()]节
-> __lookup_mnt() // 参见[11.2.2.4.1.1.1.2.4 __lookup_mnt()]节
12 网络/Net
网络代码保存在net/目录中,大部分的include文件在include/net下,BSD套接字代码在net/socket.c中,IP第4版本的套节口代码在net/ipv4/af_inet.c。一般的协议支持代码(包括sk_buff处理例程)在net/core下,TCP/IP网络代码在net/ipv4下,网络设备驱动程序在drivers/net下。
socket可以用于进程间通信,参见8.7 套接字/Socket节。
13 可加载内核模块/Loadable Kernel Module
Loadable kernel modules (LKM) in Linux are loaded (and unloaded) by the modprobe command. They are located in /lib/modules and have had the extension .ko (“kernel object”) since version 2.6 (previous versions used the .o extension). The lsmod command lists the loaded kernel modules. In emergency cases, when the system fails to boot due to e.g. broken modules, specific modules can be enabled or disabled by modifying the kernel boot parameters list (for example, if using GRUB, by pressing ‘e’ in the GRUB start menu, then editing the kernel parameter line).
module被动态加载到kernel里成为kernel的一部分,加载到kernel中的module具有跟kernel一样的权力,可访问kernel中的任何数据结构。kdebug是用来debug kernel的,其工作原理如下:先将它本身的一个module加载到kernel中,而在user space的gdb就可以跟这个module沟通,获得kernel里数据结构的取值;此外,还可以经由加载到kernel的module来更改kernel里数据结构的取值。
参见如下文档:
- Documentation/kbuild/modules.txt
13.0 Why Modules?
The benefit of kernel modules:
- To update the kernel features while running;
- To reduce memory consumption (and CPU overhead) by loading only necessary modules;
- Avoiding GPL (Not required to compliant with GPL; proprietary drivers).
There are six main things LKMs are used for:
Device drivers. A device driver is designed for a specific piece of hardware. The kernel uses it to communicate with that piece of hardware without having to know any details of how the hardware works. For example, there is a device driver for ATA disk drives. There is one for NE2000 compatible Ethernet cards. To use any device, the kernel must contain a device driver for it.
Filesystem drivers. A filesystem driver interprets the contents of a filesystem (which is typically the contents of a disk drive) as files and directories and such. There are lots of different ways of storing files and directories and such on disk drives, on network servers, and in other ways. For each way, you need a filesystem driver. For example, there’s a filesystem driver for the ext2 filesystem type used almost universally on Linux disk drives. There is one for the MS-DOS filesystem too, and one for NFS.
System calls. User space programs use system calls to get services from the kernel. For example, there are system calls to read a file, to create a new process, and to shut down the system. Most system calls are integral to the system and very standard, so are always built into the base kernel (no LKM option). But you can invent a system call of your own and install it as an LKM. Or you can decide you don’t like the way Linux does something and override an existing system call with an LKM of your own.
Network drivers. A network driver interprets a network protocol. It feeds and consumes data streams at various layers of the kernel’s networking function. For example, if you want an IPX link in your network, you would use the IPX driver.
TTY line disciplines. These are essentially augmentations of device drivers for terminal devices.
Executable interpreters. An executable interpreter loads and runs an executable. Linux is designed to be able to run executables in various formats, and each must have its own executable interpreter.
13.1 模块的编写
13.1.1 模块源文件示例
模块源文件hello.c:
#include <linux/module.h>
#include <linux/init.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Chen Weixiang");
MODULE_DESCRIPTION("A Hello Module");
int isSayHello = 0;
static int sayHello()
{
isSayHello = 1;
printk("Hello World\n");
return 0;
}
EXPORT_SYMBOL(sayHello);
static int __init hello_init(void)
{
printk("Hello module init\n");
return 0;
}
static void __exit hello_exit(void)
{
printk("Hello module exit\n");
}
module_init(hello_init);
module_exit(hello_exit);
NOTE 1: Because module init/exit functions (here is hello_init, hello_exit) are typically not directly invoked by external code, you don’t need to export the function beyond file-level scope, and they can be marked as static.
NOTE 2: In actual modules, init functions register resources, initialize hardware, allocate data structures, and so on.
13.1.2 与模块有关的宏
13.1.2.1 MODULE_INFO()/__MODULE_INFO()
宏__MODULE_INFO()定义于include/linux/moduleparam.h:
#define ___module_cat(a,b) __mod_ ## a ## b
#define __module_cat(a,b) ___module_cat(a,b)
#ifdef MODULE
/*
* 该宏在.modinfo段中添加字符串"tag=info"
*/
#define __MODULE_INFO(tag, name, info) \
static const char __module_cat(name,__LINE__)[] \
__used __attribute__((section(".modinfo"), unused, aligned(1))) \
= __stringify(tag) "=" info
#else /* !MODULE */
/* This struct is here for syntactic coherency, it is not used */
#define __MODULE_INFO(tag, name, info) \
struct __module_cat(name,__LINE__) {}
#endif
宏MODULE_INFO()定义于include/linux/module.h:
/*
* Generic info of form tag = "info"
* 该宏在.modinfo段中添加字符串"tag=info"
*/
#define MODULE_INFO(tag, info) __MODULE_INFO(tag, tag, info)
下列宏是通过MODULE_INFO()和__MODULE_INFO()来定义的:
/* 该宏在.modinfo段中添加字符串"author=_author" */
#define MODULE_AUTHOR(_author) MODULE_INFO(author, _author)
/* 该宏在.modinfo段中添加字符串"license=_license" */
#define MODULE_LICENSE(_license) MODULE_INFO(license, _license)
/* 该宏在.modinfo段中添加字符串"version=_version" */
#if defined(MODULE) || !defined(CONFIG_SYSFS)
#define MODULE_VERSION(_version) MODULE_INFO(version, _version)
#else
#define MODULE_VERSION(_version) \
static struct module_version_attribute ___modver_attr = { \
.mattr = { \
.attr = { \
.name = "version", \
.mode = S_IRUGO, \
}, \
.show = __modver_version_show, \
}, \
.module_name = KBUILD_MODNAME, \
.version = _version, \
}; \
static const struct module_version_attribute \
__used __attribute__ ((__section__ ("__modver"))) \
* __moduleparam_const __modver_attr = &___modver_attr
#endif
NOTE 1: The specific licenses recognized by the kernel are:
- “GPL” (for any version of the GNU General Public License),
- “GPL v2” (for GPL version two only),
- “GPL and additional rights”,
- “Dual BSD/GPL”,
- “Dual MPL/GPL”, and
- “Proprietary”.
NOTE 2: Unless your module is explicitly marked as being under a free license recognized by the kernel, it is assumed to be proprietary, and the kernel is “tainted” when the module is loaded.
/* 该宏在.modinfo段中添加字符串"description=_description" */
#define MODULE_DESCRIPTION(_description) MODULE_INFO(description, _description)
/* 该宏在.modinfo段中添加字符串"parm=_parm:desc" */
#define MODULE_PARM_DESC(_parm, desc) __MODULE_INFO(parm, _parm, #_parm ":" desc)
/* 该宏在.modinfo段中添加字符串"alias=_alias" */
#define MODULE_ALIAS(_alias) MODULE_INFO(alias, _alias)
/* 该宏在.modinfo段中添加字符串"firmware=_firmware" */
#define MODULE_FIRMWARE(_firmware) MODULE_INFO(firmware, _firmware)
/* Not Yet Implemented */
#define MODULE_SUPPORTED_DEVICE(name)
NOTE 3: The various MODULE_ declarations can appear anywhere within your source file out-side of a function. A relatively recent convention in kernel code, however, is to put these declarations at the end of the file.
通过下列命令查看.modinfo段的内容:
chenwx@chenwx ~/Downloads/helloworld $ objdump -s --section=.modinfo helloworld.ko
helloworld.ko: file format elf64-x86-64
Contents of section .modinfo:
0000 64657363 72697074 696f6e3d 41204865 description=A He
0010 6c6c6f20 4d6f6475 6c650061 7574686f llo Module.autho
0020 723d4368 656e2057 65697869 616e6700 r=Chen Weixiang.
0030 6c696365 6e73653d 47504c00 73726376 license=GPL.srcv
0040 65727369 6f6e3d45 35454538 38324232 ersion=E5EE882B2
0050 37364339 35353035 37334533 31420064 76C9550573E31B.d
0060 6570656e 64733d00 7665726d 61676963 epends=.vermagic
0070 3d342e31 2e302d61 6c657820 534d5020 =4.1.0-alex SMP
0080 6d6f645f 756e6c6f 6164206d 6f647665 mod_unload modve
0090 7273696f 6e732000 rsions .
chenwx@chenwx ~/Downloads/helloworld $ modinfo helloworld.ko
filename: /home/chenwx/Downloads/helloworld/helloworld.ko
description: A Hello Module
author: Chen Weixiang
license: GPL
srcversion: 4D296D6B8A330EA0D60086F
depends:
vermagic: 4.1.0-alex SMP mod_unload modversions
parm: isSayHello:set 0 to disable printing hello world. set 1 to enable it (int)
13.1.2.2 MODULE_DEVICE_TABLE()
This Macro is used by all USB and PCI drivers. This macro describes which devices each specific driver can support. At compilation time, the build process extracts this information out of the driver and builds a table. The table is called modules.pcimap and modules.usbmap for all PCI and USB devices, respectively, and exists in the directory /lib/modules/<kernel_version>/.
该宏定义于include/linux/module.h:
/*
* 声明类型为struct type##_device_id的变量,并为之创建别名name
* 其中,type的取值为pci, usb, ieee1394, pcmcia, ...
* 该宏在驱动程序中的用法参见[10.2B.1 驱动程序声明其支持的硬件设备版本]节
*/
#define MODULE_DEVICE_TABLE(type,name) MODULE_GENERIC_TABLE(type##_device,name)
#ifdef MODULE
/*
* 编译成模块后,由MODULE_DEVICE_TABLE()定义的device table被提取
* 到*.mod.c文件中,参见[3.4.3.4.2.1 __modpost]节中的示例e1000e.mod.c
*/
#define MODULE_GENERIC_TABLE(gtype,name) \
extern const struct gtype##_id __mod_##gtype##_table \
__attribute__ ((unused, alias(__stringify(name))))
#else /* !MODULE */
/*
* 编译进内核后,由MODULE_DEVICE_TABLE()定义的device table
* 可直接被访问到,无需提取出来
*/
#define MODULE_GENERIC_TABLE(gtype,name)
#endif
宏MODULE_DEVICE_TABLE()一般用于热插拔设备的驱动程序中,参见Documentation/usb/hotplug.txt:
A short example, for a driver that supports several specific USB devices and their quirks, might have a MODULE_DEVICE_TABLE like this:
static const struct usb_device_id mydriver_id_table = {
{ USB_DEVICE (0x9999, 0xaaaa), driver_info: QUIRK_X },
{ USB_DEVICE (0xbbbb, 0x8888), driver_info: QUIRK_Y|QUIRK_Z },
...
{ } /* end with an all-zeroes entry */
}
MODULE_DEVICE_TABLE(usb, mydriver_id_table);
Most USB device drivers should pass these tables to the USB subsystem as well as to the module management subsystem. Not all, though: some driver frameworks connect using interfaces layered over USB, and so they won’t need such a “struct usb_driver”.
Drivers that connect directly to the USB subsystem should be declared something like this:
static struct usb_driver mydriver = {
.name = "mydriver",
.id_table = mydriver_id_table,
.probe = my_probe,
.disconnect = my_disconnect,
/* if using the usb chardev framework: */
.minor = MY_USB_MINOR_START,
.fops = my_file_ops,
/* if exposing any operations through usbdevfs: */
.ioctl = my_ioctl,
}
When the USB subsystem knows about a driver’s device ID table, it’s used when choosing drivers to probe(). The thread doing new device processing checks drivers’ device ID entries from the MODULE_DEVICE_TABLE against interface and device descriptors for the device. It will only call probe() if there is a match, and the third argument to probe() will be the entry that matched.
If you don’t provide an id_table for your driver, then your driver may get probed for each new device; the third parameter to probe() will be null.
其中,函数probe()参见10.2.4 struct device_driver节中struct device_driver的成员函数probe()。
13.1.2.3 EXPORT_SYMBOL()
下列宏用于导出符号:
- EXPORT_SYMBOL()
- EXPORT_SYMBOL_GPL()
- EXPORT_SYMBOL_GPL_FUTURE()
其定义于include/linux/export.h:
#ifdef CONFIG_MODULES
/* 若配置支持编译模块,则才可以export symbols */
/* For every exported symbol, place a struct in the __ksymtab section */
#define __EXPORT_SYMBOL(sym, sec) \
extern typeof(sym) sym; \
__CRC_SYMBOL(sym, sec) \
static const char __kstrtab_##sym[] \
__attribute__((section("__ksymtab_strings"), aligned(1))) \
= MODULE_SYMBOL_PREFIX #sym; \
static const struct kernel_symbol __ksymtab_##sym \
__used \
__attribute__((section("___ksymtab" sec "+" #sym), unused)) \
= { (unsigned long)&sym, __kstrtab_##sym }
#define EXPORT_SYMBOL(sym) __EXPORT_SYMBOL(sym, "")
#define EXPORT_SYMBOL_GPL(sym) __EXPORT_SYMBOL(sym, "_gpl")
#define EXPORT_SYMBOL_GPL_FUTURE(sym) __EXPORT_SYMBOL(sym, "_gpl_future")
#ifdef CONFIG_UNUSED_SYMBOLS
#define EXPORT_UNUSED_SYMBOL(sym) __EXPORT_SYMBOL(sym, "_unused")
#define EXPORT_UNUSED_SYMBOL_GPL(sym) __EXPORT_SYMBOL(sym, "_unused_gpl")
#else /* !CONFIG_UNUSED_SYMBOLS */
#define EXPORT_UNUSED_SYMBOL(sym)
#define EXPORT_UNUSED_SYMBOL_GPL(sym)
#endif
#else /* !CONFIG_MODULES... */
/* 若配置不支持编译模块,则下列宏被定义成空,即不可以export symbols */
#define EXPORT_SYMBOL(sym)
#define EXPORT_SYMBOL_GPL(sym)
#define EXPORT_SYMBOL_GPL_FUTURE(sym)
#define EXPORT_UNUSED_SYMBOL(sym)
#define EXPORT_UNUSED_SYMBOL_GPL(sym)
#endif /* CONFIG_MODULES */
宏EXPORT_SYMBOL(sym)扩展后的代码如下:
extern typeof(sym) sym;
/*
* Part 1: Mark the CRC weak since genksyms apparently decides
* not to generate a checksums for some symbols
*/
extern void *__crc_##sym __attribute__((weak));
static const unsigned long __kcrctab_##sym
__used __attribute__((section("___kcrctab" "+" #sym), unused))
= (unsigned long) &__crc_##sym;
/*
* Part 2: For every exported symbol, place a struct in the
* __ksymtab+sym section
*/
static const char __kstrtab_##sym[]
__attribute__((section("__ksymtab_strings"), aligned(1)))
= MODULE_SYMBOL_PREFIX #sym;
static const struct kernel_symbol __ksymtab_##sym
__used __attribute__((section("___ksymtab" "+" #sym), unused))
= { (unsigned long)&sym, __kstrtab_##sym }
宏EXPORT_SYMBOL_GPL(sym)扩展后的代码如下:
extern typeof(sym) sym;
/*
* Part 1: Mark the CRC weak since genksyms apparently decides
* not to generate a checksums for some symbols
*/
extern void *__crc_##sym __attribute__((weak));
static const unsigned long __kcrctab_##sym
__used __attribute__((section("___kcrctab" "_gpl" "+" #sym), unused))
= (unsigned long) &__crc_##sym;
/*
* Part 2: For every exported symbol, place a struct in the
* __ksymtab_gpl+sym section
*/
static const char __kstrtab_##sym[]
__attribute__((section("__ksymtab_strings"), aligned(1)))
= MODULE_SYMBOL_PREFIX #sym;
static const struct kernel_symbol __ksymtab_##sym
__used __attribute__((section("___ksymtab" "_gpl" "+" #sym), unused))
= { (unsigned long)&sym, __kstrtab_##sym }
宏EXPORT_SYMBOL_GPL_FUTURE(sym)扩展后的代码如下:
extern typeof(sym) sym;
/*
* Part 1: Mark the CRC weak since genksyms apparently decides
* not to generate a checksums for some symbols
*/
extern void *__crc_##sym __attribute__((weak));
static const unsigned long __kcrctab_##sym
__used __attribute__((section("___kcrctab" "_gpl_future" "+" #sym), unused))
= (unsigned long) &__crc_##sym;
/*
* Part 2: For every exported symbol, place a struct in the
* __ksymtab_gpl_future+sym section
*/
static const char __kstrtab_##sym[]
__attribute__((section("__ksymtab_strings"), aligned(1)))
= MODULE_SYMBOL_PREFIX #sym;
static const struct kernel_symbol __ksymtab_##sym
__used __attribute__((section("___ksymtab" "_gpl_future" "+" #sym), unused))
= { (unsigned long)&sym, __kstrtab_##sym }
宏EXPORT_UNUSED_SYMBOL(sym)扩展后的代码如下:
extern typeof(sym) sym;
/*
* Part 1: Mark the CRC weak since genksyms apparently decides
* not to generate a checksums for some symbols
*/
extern void *__crc_##sym __attribute__((weak));
static const unsigned long __kcrctab_##sym
__used __attribute__((section("___kcrctab" "_unused" "+" #sym), unused))
= (unsigned long) &__crc_##sym;
/*
* Part 2: For every exported symbol, place a struct in the
* __ksymtab_unused+sym section
*/
static const char __kstrtab_##sym[]
__attribute__((section("__ksymtab_strings"), aligned(1)))
= MODULE_SYMBOL_PREFIX #sym;
static const struct kernel_symbol __ksymtab_##sym
__used __attribute__((section("___ksymtab" "_unused" "+" #sym), unused))
= { (unsigned long)&sym, __kstrtab_##sym }
宏EXPORT_UNUSED_SYMBOL_GPL(sym)扩展后的代码如下:
extern typeof(sym) sym;
/*
* Part 1: Mark the CRC weak since genksyms apparently decides
* not to generate a checksums for some symbols
*/
extern void *__crc_##sym __attribute__((weak));
static const unsigned long __kcrctab_##sym
__used __attribute__((section("___kcrctab" "_unused_gpl" "+" #sym), unused))
= (unsigned long) &__crc_##sym;
/*
* Part 2: For every exported symbol, place a struct in the
* __ksymtab_unused_gpl+sym section
*/
static const char __kstrtab_##sym[]
__attribute__((section("__ksymtab_strings"), aligned(1)))
= MODULE_SYMBOL_PREFIX #sym;
static const struct kernel_symbol __ksymtab_##sym
__used __attribute__((section("___ksymtab" "_unused_gpl" "+" #sym), unused))
= { (unsigned long)&sym, __kstrtab_##sym }
由此可知,这些宏export出来的符号分别被放置到下列section中:
| Macros | Sections after compiling | Sections after linking (参见13.1.2.3.1 如何将符号从__ksymtab+sym段移到__ksymtab段节) |
|---|---|---|
| EXPORT_SYMBOL(sym) | ___ksymtab+sym___kcrctab+sym__ksymtab_strings |
__ksymtab__kcrctab__ksymtab_strings |
| EXPORT_SYMBOL_GPL(sym) | ___ksymtab_gpl+sym___kcrctab_gpl+sym__ksymtab_strings |
__ksymtab_gpl__kcrctab_gpl__ksymtab_strings |
| EXPORT_SYMBOL_GPL_FUTURE(sym) | ___ksymtab_gpl_future+sym___kcrctab_gpl_future+sym__ksymtab_strings |
__ksymtab_gpl_future__kcrctab_gpl_future__ksymtab_strings |
| EXPORT_UNUSED_SYMBOL(sym) | ___ksymtab_unused+sym___kcrctab_unused+sym__ksymtab_strings |
__ksymtab_unused__kcrctab_unused__ksymtab_strings |
| EXPORT_UNUSED_SYMBOL_GPL(sym) | ___ksymtab_unused_gpl+sym___kcrctab_unused_gpl+sym__ksymtab_strings |
__ksymtab_unused_gpl__kcrctab_unused_gpl__ksymtab_strings |
NOTE: Either of the above macros makes the given symbol available outside the module. The _GPL version makes the symbol available to GPL-licensed modules only.
使用下列命令查看该宏导出的符号:
chenwx@chenwx ~ $ objdump -t -j __ksymtab helloworld.ko
helloworld.ko: file format elf64-x86-64
SYMBOL TABLE:
0000000000000000 l d __ksymtab 0000000000000000 __ksymtab
0000000000000000 g O __ksymtab 0000000000000010 __ksymtab_sayHello
13.1.2.3.1 如何将符号从__ksymtab+sym段移到__ksymtab段
1) 将模块编译进内核的情况
在include/asm-generic/vmlinux.lds.h中,包含如下内容:
/* Kernel symbol table: Normal symbols */ \
__ksymtab : AT(ADDR(__ksymtab) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___ksymtab) = .; \
*(SORT(___ksymtab+*)) \
VMLINUX_SYMBOL(__stop___ksymtab) = .; \
} \
\
/* Kernel symbol table: GPL-only symbols */ \
__ksymtab_gpl : AT(ADDR(__ksymtab_gpl) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___ksymtab_gpl) = .; \
*(SORT(___ksymtab_gpl+*)) \
VMLINUX_SYMBOL(__stop___ksymtab_gpl) = .; \
} \
\
/* Kernel symbol table: Normal unused symbols */ \
__ksymtab_unused : AT(ADDR(__ksymtab_unused) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___ksymtab_unused) = .; \
*(SORT(___ksymtab_unused+*)) \
VMLINUX_SYMBOL(__stop___ksymtab_unused) = .; \
} \
\
/* Kernel symbol table: GPL-only unused symbols */ \
__ksymtab_unused_gpl : AT(ADDR(__ksymtab_unused_gpl) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___ksymtab_unused_gpl) = .; \
*(SORT(___ksymtab_unused_gpl+*)) \
VMLINUX_SYMBOL(__stop___ksymtab_unused_gpl) = .; \
} \
\
/* Kernel symbol table: GPL-future-only symbols */ \
__ksymtab_gpl_future : AT(ADDR(__ksymtab_gpl_future) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___ksymtab_gpl_future) = .; \
*(SORT(___ksymtab_gpl_future+*)) \
VMLINUX_SYMBOL(__stop___ksymtab_gpl_future) = .; \
} \
\
/* Kernel symbol table: Normal symbols */ \
__kcrctab : AT(ADDR(__kcrctab) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___kcrctab) = .; \
*(SORT(___kcrctab+*)) \
VMLINUX_SYMBOL(__stop___kcrctab) = .; \
} \
\
/* Kernel symbol table: GPL-only symbols */ \
__kcrctab_gpl : AT(ADDR(__kcrctab_gpl) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___kcrctab_gpl) = .; \
*(SORT(___kcrctab_gpl+*)) \
VMLINUX_SYMBOL(__stop___kcrctab_gpl) = .; \
} \
\
/* Kernel symbol table: Normal unused symbols */ \
__kcrctab_unused : AT(ADDR(__kcrctab_unused) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___kcrctab_unused) = .; \
*(SORT(___kcrctab_unused+*)) \
VMLINUX_SYMBOL(__stop___kcrctab_unused) = .; \
} \
\
/* Kernel symbol table: GPL-only unused symbols */ \
__kcrctab_unused_gpl : AT(ADDR(__kcrctab_unused_gpl) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___kcrctab_unused_gpl) = .; \
*(SORT(___kcrctab_unused_gpl+*)) \
VMLINUX_SYMBOL(__stop___kcrctab_unused_gpl) = .; \
} \
\
/* Kernel symbol table: GPL-future-only symbols */ \
__kcrctab_gpl_future : AT(ADDR(__kcrctab_gpl_future) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__start___kcrctab_gpl_future) = .; \
*(SORT(___kcrctab_gpl_future+*)) \
VMLINUX_SYMBOL(__stop___kcrctab_gpl_future) = .; \
} \
\
/* Kernel symbol table: strings */ \
__ksymtab_strings : AT(ADDR(__ksymtab_strings) - LOAD_OFFSET) { \
*(__ksymtab_strings) \
}
由此生成的vmlinux.lds包含如下内容,参见Appendix G: vmlinux.lds节:
__ksymtab : AT(ADDR(__ksymtab) - 0xC0000000) { __start___ksymtab = .; *(SORT(___ksymtab+*)) __stop___ksymtab = .; }
__ksymtab_gpl : AT(ADDR(__ksymtab_gpl) - 0xC0000000) { __start___ksymtab_gpl = .; *(SORT(___ksymtab_gpl+*)) __stop___ksymtab_gpl = .; }
__ksymtab_unused : AT(ADDR(__ksymtab_unused) - 0xC0000000) { __start___ksymtab_unused = .; *(SORT(___ksymtab_unused+*)) __stop___ksymtab_unused = .; }
__ksymtab_unused_gpl : AT(ADDR(__ksymtab_unused_gpl) - 0xC0000000) { __start___ksymtab_unused_gpl = .; *(SORT(___ksymtab_unused_gpl+*)) __stop___ksymtab_unused_gpl = .; }
__ksymtab_gpl_future : AT(ADDR(__ksymtab_gpl_future) - 0xC0000000) { __start___ksymtab_gpl_future = .; *(SORT(___ksymtab_gpl_future+*)) __stop___ksymtab_gpl_future = .; }
__kcrctab : AT(ADDR(__kcrctab) - 0xC0000000) { __start___kcrctab = .; *(SORT(___kcrctab+*)) __stop___kcrctab = .; }
__kcrctab_gpl : AT(ADDR(__kcrctab_gpl) - 0xC0000000) { __start___kcrctab_gpl = .; *(SORT(___kcrctab_gpl+*)) __stop___kcrctab_gpl = .; }
__kcrctab_unused : AT(ADDR(__kcrctab_unused) - 0xC0000000) { __start___kcrctab_unused = .; *(SORT(___kcrctab_unused+*)) __stop___kcrctab_unused = .; }
__kcrctab_unused_gpl : AT(ADDR(__kcrctab_unused_gpl) - 0xC0000000) { __start___kcrctab_unused_gpl = .; *(SORT(___kcrctab_unused_gpl+*)) __stop___kcrctab_unused_gpl = .; }
__kcrctab_gpl_future : AT(ADDR(__kcrctab_gpl_future) - 0xC0000000) { __start___kcrctab_gpl_future = .; *(SORT(___kcrctab_gpl_future+*)) __stop___kcrctab_gpl_future = .; }
__ksymtab_strings : AT(ADDR(__ksymtab_strings) - 0xC0000000) { *(__ksymtab_strings) }
因而,在链接vmlinux时,使用的链接脚本文件为arch/x86/kernel/vmlinux.lds,故:
段___ksymtab+sym中的符号被移到段__ksymtab中,
段___ksymtab_gpl+sym中的符号被移到段__ksymtab_gpl中,
段___ksymtab_gpl_future+sym中的符号被移到段__ksymtab_gpl_future中,
段___ksymtab_unused+sym中的符号被移到段__ksymtab_unused中,
段___ksymtab_unused_gpl+sym中的符号被移到段__ksymtab_unused_gpl中
段___kcrctab+sym中的符号被移到段__kcrctab中,
段___kcrctab_gpl+sym中的符号被移到段__kcrctab_gpl中,
段___kcrctab_gpl_future+sym中的符号被移到段__kcrctab_gpl_future中,
段___kcrctab_unused+sym中的符号被移到段__kcrctab_unused中,
段___kcrctab_unused_gpl+sym中的符号被移到段__kcrctab_unused_gpl中
段___ksymtab_strings中的符号被移到段__ksymtab_strings中
2) 将模块编译成独立模块的情况
在链接*.ko时,使用的链接脚本文件为scripts/module-common.lds,参见3.4.3.4.2.3 $(modules)节和Appendix H: scripts/module-common.lds节。故:
段___ksymtab+sym中的符号被移到段__ksymtab中,
段___ksymtab_gpl+sym中的符号被移到段__ksymtab_gpl中,
段___ksymtab_gpl_future+sym中的符号被移到段__ksymtab_gpl_future中,
段___ksymtab_unused+sym中的符号被移到段__ksymtab_unused中,
段___ksymtab_unused_gpl+sym中的符号被移到段__ksymtab_unused_gpl中
段___kcrctab+sym中的符号被移到段__kcrctab中。同理,
段___kcrctab_gpl+sym中的符号被移到段__kcrctab_gpl中,
段___kcrctab_gpl_future+sym中的符号被移到段__kcrctab_gpl_future中,
段___kcrctab_unused+sym中的符号被移到段__kcrctab_unused中,
段___kcrctab_unused_gpl+sym中的符号被移到段__kcrctab_unused_gpl中
段___ksymtab_strings中的符号被移到段__ksymtab_strings中
此后,这些段中的符号被如下函数使用:
load_module() // 参见[13.5.1.2.1 load_module()]节
-> find_module_sections() // 参见[13.5.1.2.1.1 find_module_sections()]节
Exported symbols的作用范围,参见13.4.2.0 Scope of Kernel symbols节。
13.1.2.4 __init/__initdata/__exit/__exitdata
The __init macro causes the init function to be discarded and its memory freed once the init function finishes for built−in drivers, but not loadable modules. If you think about when the init function is invoked, this makes perfect sense. There is also an __initdata which works similarly to __init but for init variables rather than functions.
The __exit macro causes the omission of the function when the module is built into the kernel, and like __init, has no effect for loadable modules. Again, if you consider when the cleanup function runs, this makes complete sense; built−in drivers don’t need a cleanup function, while loadable modules do.
Those macros are defined in include/linux/init.h:
/*
* 对如下段的链接,参见[Appendix G: vmlinux.lds]节:
* .init.text, init.data, .exit.text, .exit.data
*/
#define __init __section(.init.text) __cold notrace
#define __initdata __section(.init.data)
#define __exit __section(.exit.text) __exitused __cold notrace
#define __exitdata __section(.exit.data)
NOTE 1: If your module does not define a cleanup function, the kernel does not allow it to be unloaded.
NOTE 2: Does my module even need an exit routine?
What if there’s absolutely no cleanup required when your module is unloaded? Can you just not define an exit routine at all? Well, sort of. The problem is that, once you load that module, you can’t unload it anymore.
The reasoning behind this is (apparently) that if you don’t define an exit routine for your module, the kernel simply can’t trust your module to simply exit and not leave a mess behind. So if you don’t define an exit routine, you’re not allowed to leave. It’s as simple as that.
If you load module which without exit routine, you have only two options to get rid of that module. You can either reboot the system, or you can use rmmod -f (for “force”), but only if your kernel has been configured to allow forced module unloading.
NOTE 3: Technically speaking, the __init and __exit are not essential, they exist simply for the sake of efficiency.
The __init qualifier is the simpler of the two; it identifies any routine that can be discarded once the module has loaded, which makes perfect sense since, once a module’s initialization code has executed, it has no further value and it can be thrown away, and that’s why you should see that qualifier on every module entry routine you ever run across – so that entry code doesn’t just hang around in kernel memory, wasting space. And as for the __exit qualifier? Well, that one’s a bit trickier.
Clearly, it can’t also possibly represent code that can be discarded after loading; after all, it’s the exit code so it needs to stick around until unloading. But there are two situations where the exit code can be discarded, and both of those situations represent cases where you know for a fact that that exit code will never, ever, ever be called.
The first case is when you’ve simply configured a kernel that doesn’t support module unloading. Unusual, yes, but if you pop back into the kernel configuration menu, you do have the right to build a kernel that allows module loading but doesn’t allow module unloading. Admittedly, that’s a strange situation but, technically, it can be done and, if that’s the case, then there’s no possibility of that module ever being unloaded and, therefore, the exit code is superfluous.
The second case is if you eventually add your module code into the kernel source tree and add configuration information for it. If you then choose to add that feature to your kernel as a loadable module, then the exit code has to stay. On the other hand, if you choose to build that feature directly into the kernel, then it’s not a loadable module anymore and the exit code will again never have a chance of executing.
And one more point. It’s possible to have more than one routine in a source file tagged with either __init or __exit, if either your entry or exit routines call other routines for modularity. There’s no reason for all your entry or exit code to exist in a single routine – you’re certainly welcome to break all that functionality over multiple functions if it makes your code more readable.
13.1.3 模块参数
The Linux kernel provides a simple framework, enabling drivers to declare parameters that the user can specify on either boot or module load and then have these parameters exposed in your driver as global variables.
NOTE 1: All new module parameters should be documented with MODULE_PARM_DESC(), see 13.1.2.1 MODULE_INFO()/__MODULE_INFO():
MODULE_PARM_DESC(mod_parm_name, "description string of specific module parameter");
NOTE 2: All module parameters should be given a default value; insmod changes the value only if explicitly told to by the user.
13.1.3.1 与模块参数有关的宏
13.1.3.1.0 MODULE_PARAM_PREFIX
该宏定义于include/linux/moduleparam.h:
/*
* You can override this manually, but generally this should match
* the module name.
*/
#ifdef MODULE
#define MODULE_PARAM_PREFIX /* empty */
#else
/* KBUILD_MODNAME的定义参见scripts/Makefile.lib */
#define MODULE_PARAM_PREFIX KBUILD_MODNAME "."
#endif
可按如下方式定义自己所需的MODULE_PARAM_PREFIX,参见block/genhd.c:
#undef MODULE_PARAM_PREFIX
#define MODULE_PARAM_PREFIX "block."
以helloworld.ko为例,若将MODULE_PARAM_PREFIX设置为”helloworld.”,则参数名变为:
chenwx@chenwx ~ $ ll /sys/module/helloworld/parameters/
-r--r--r-- 1 root root 4.0K Jul 26 22:17 helloworld.isSayHello
chenwx@chenwx ~ $ cat /sys/module/helloworld/parameters/helloworld.isSayHello
0
13.1.3.1.1 module_param_cb()/__module_param_call()
该宏定义于include/linux/moduleparam.h:
/* Obsolete - use module_param_cb() */
#define module_param_call(name, set, get, arg, perm) \
static struct kernel_param_ops __param_ops_##name = { (void *)set, (void *)get }; \
__module_param_call(MODULE_PARAM_PREFIX, name, &__param_ops_##name, arg, \
__same_type(arg, bool *), (perm) + sizeof(__check_old_set_param(set))*0)
/**
* module_param_cb - general callback for a module/cmdline parameter
* @name: a valid C identifier which is the parameter name.
* @ops: the set & get operations for this parameter.
* @perm: visibility in sysfs.
*
* The ops can have NULL set or get functions.
*/
#define module_param_cb(name, ops, arg, perm) \
__module_param_call(MODULE_PARAM_PREFIX, name, ops, arg, \
__same_type((arg), bool *), perm)
/*
* This is the fundamental function for registering boot/module parameters.
* 在__param段中添加类型为struct kernel_param的元素,且这些元素可通过数组
* [__start___param, __stop___param]来访问,参见函数param_sysfs_builtin();
* 当加载内核模块时,该段中的元素被函数load_module()->find_module_sections()访问,
* 参见[13.1.3.3.1 模块加载时对模块参数的处理]节
*/
#define __module_param_call(prefix, name, ops, arg, isbool, perm) \
/* Default value instead of permissions? */ \
static int __param_perm_check_##name __attribute__((unused)) = \
BUILD_BUG_ON_ZERO((perm) < 0 || (perm) > 0777 || ((perm) & 2)) \
+ BUILD_BUG_ON_ZERO(sizeof(""prefix) > MAX_PARAM_PREFIX_LEN); \
\
static const char __param_str_##name[] = prefix #name; \
\
static struct kernel_param __moduleparam_const __param_##name \
__used __attribute__((unused,__section__ ("__param"),aligned(sizeof(void *)))) \
= { __param_str_##name, ops, perm, isbool ? KPARAM_ISBOOL : 0, { arg } }
参见下图:
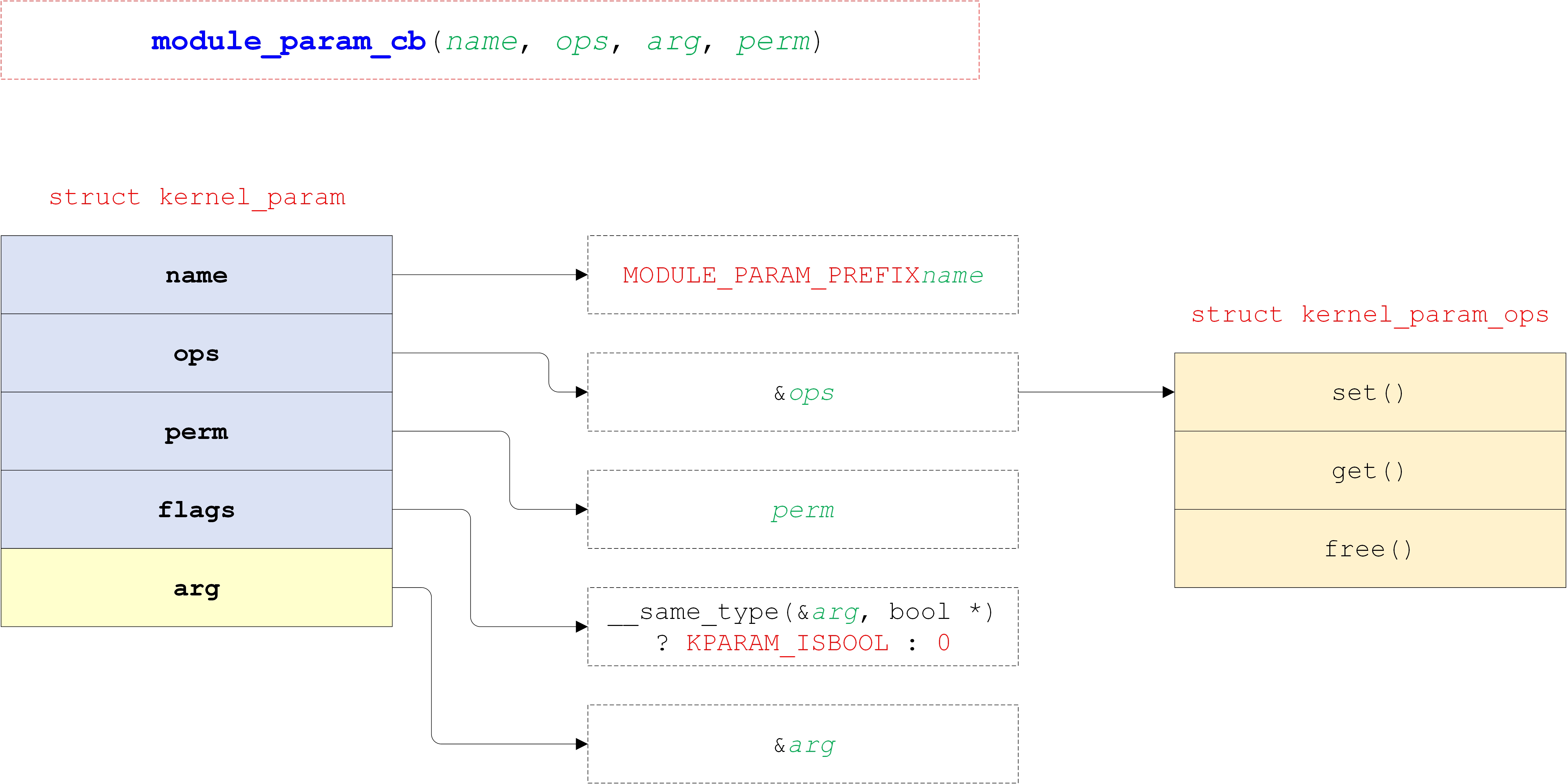
13.1.3.1.2 __MODULE_PARM_TYPE()
该宏定义于include/linux/moduleparam.h:
/*
* 在.modinfo段中添加字符串"parmtype=name:_type",其中,
* 宏__MODULE_INFO()参见[13.1.2.1 MODULE_INFO()/__MODULE_INFO()]节
*/
#define __MODULE_PARM_TYPE(name, _type) \
__MODULE_INFO(parmtype, name##type, #name ":" _type)
13.1.3.1.3 module_param()/module_param_named()
该宏定义于include/linux/moduleparam.h:
/**
* module_param - typesafe helper for a module/cmdline parameter
* @name: the variable to alter, and exposed parameter name.
* @type: the type of the parameter
* @perm: visibility in sysfs.
*
* @name becomes the module parameter, or (prefixed by KBUILD_MODNAME and a
* ".") the kernel commandline parameter. Note that - is changed to _, so
* the user can use "foo-bar=1" even for variable "foo_bar".
*
* @perm is 0 if the the variable is not to appear in sysfs, or 0444
* for world-readable, 0644 for root-writable, etc. Note that if it
* is writable, you may need to use kparam_block_sysfs_write() around
* accesses (esp. charp, which can be kfreed when it changes).
* See 13.1.3.3.1 模块加载时对模块参数的处理.
*
* The @type is simply pasted to refer to a param_ops_##type and a
* param_check_##type: for convenience many standard types are provided but
* you can create your own by defining those variables.
*
* Standard types are:
* byte, short, ushort, int, uint, long, ulong
* charp: a character pointer
* bool: a bool, values 0/1, y/n, Y/N.
* invbool: the above, only sense-reversed (N = true).
*/
#define module_param(name, type, perm) \
module_param_named(name, name, type, perm)
/**
* module_param_named - typesafe helper for a renamed module/cmdline parameter
* @name: a valid C identifier which is the parameter name.
* @value: the actual lvalue to alter.
* @type: the type of the parameter
* @perm: visibility in sysfs.
*
* Usually it's a good idea to have variable names and user-exposed names the
* same, but that's harder if the variable must be non-static or is inside a
* structure. This allows exposure under a different name.
*/
#define module_param_named(name, value, type, perm) \
param_check_##type(name, &(value)); \
module_param_cb(name, ¶m_ops_##type, &value, perm); \
__MODULE_PARM_TYPE(name, #type)
分别参见如下示意图:
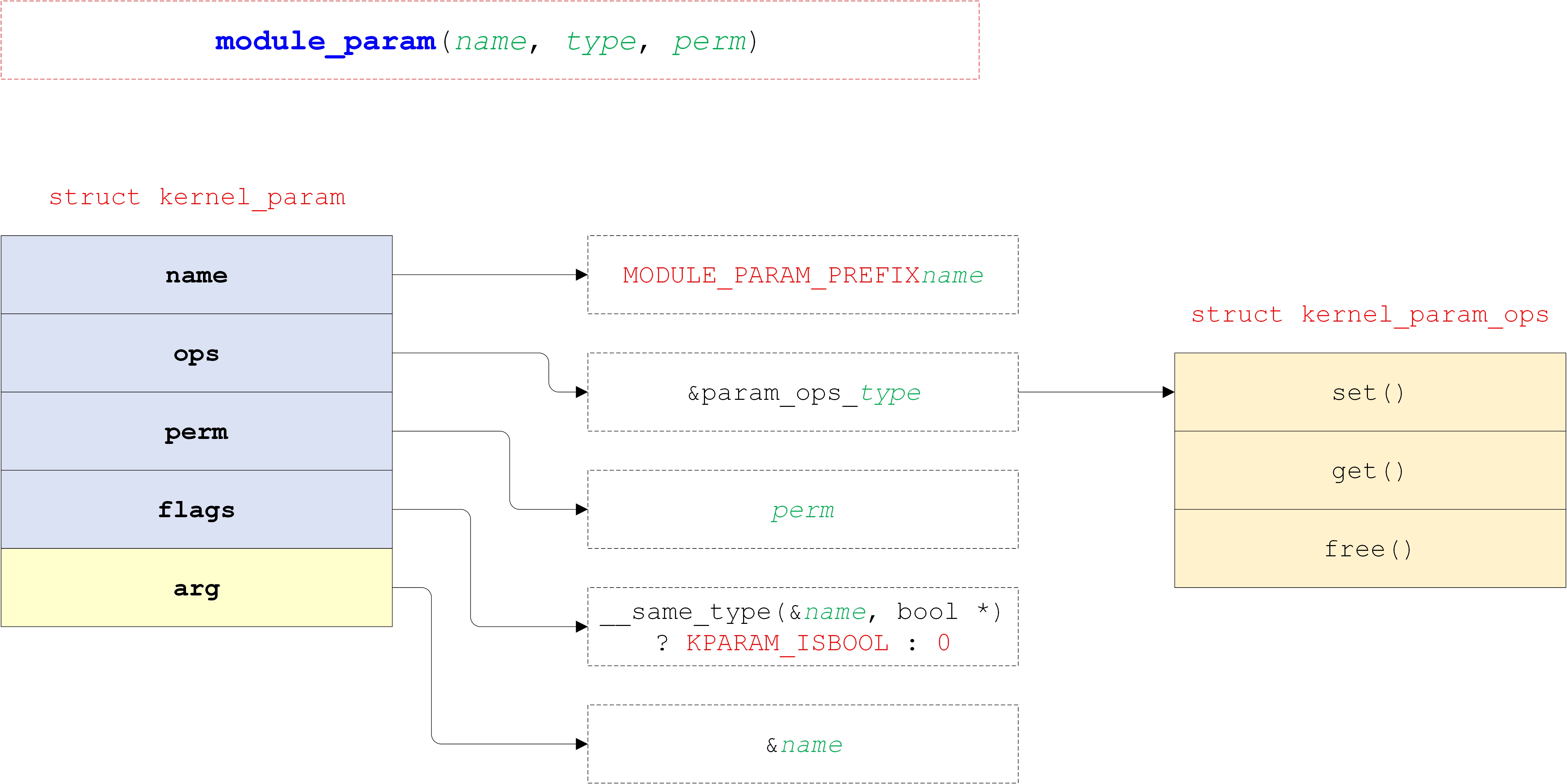
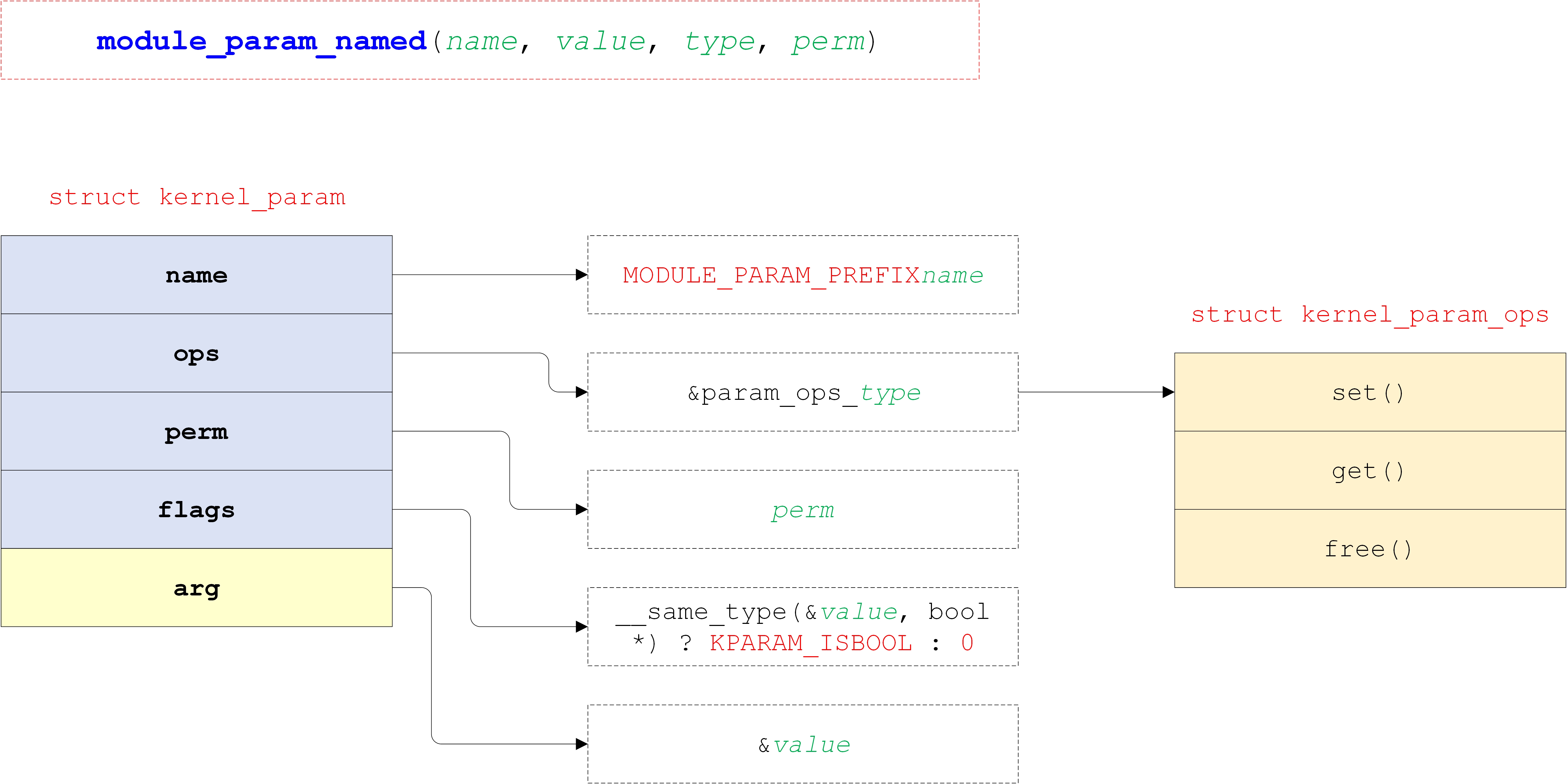
宏module_param(name, type, perm)中入参type所对应的ops如下:
| type | ops | Reference |
|---|---|---|
| byte | param_ops_byte | 13.1.3.1.3.1 STANDARD_PARAM_DEF(name, ..)定义的param_ops_name |
| short | param_ops_short | 13.1.3.1.3.1 STANDARD_PARAM_DEF(name, ..)定义的param_ops_name |
| ushort | param_ops_ushort | 13.1.3.1.3.1 STANDARD_PARAM_DEF(name, ..)定义的param_ops_name |
| int | param_ops_int | 13.1.3.1.3.1 STANDARD_PARAM_DEF(name, ..)定义的param_ops_name |
| uint | param_ops_uint | 13.1.3.1.3.1 STANDARD_PARAM_DEF(name, ..)定义的param_ops_name |
| long | param_ops_long | 13.1.3.1.3.1 STANDARD_PARAM_DEF(name, ..)定义的param_ops_name |
| ulong | param_ops_ulong | 13.1.3.1.3.1 STANDARD_PARAM_DEF(name, ..)定义的param_ops_name |
| charp | param_ops_charp | 13.1.3.1.3.2 param_ops_charp |
| bool | param_ops_bool | 13.1.3.1.3.3 param_ops_bool |
| invbool | param_ops_invbool | 13.1.3.1.3.4 param_ops_invbool |
13.1.3.1.3.1 STANDARD_PARAM_DEF(name, ..)定义的param_ops_name
类型byte, short, ushort, int, uint, long, ulong所对应的ops是由宏STANDARD_PARAM_DEF()定义的,参见kernel/params.c:
#define STANDARD_PARAM_DEF(name, type, format, tmptype, strtolfn) \
int param_set_##name(const char *val, const struct kernel_param *kp) \
{ \
tmptype l; \
int ret; \
\
ret = strtolfn(val, 0, &l); \
if (ret < 0 || ((type)l != l)) \
return ret < 0 ? ret : -EINVAL; \
*((type *)kp->arg) = l; \
return 0; \
} \
int param_get_##name(char *buffer, const struct kernel_param *kp) \
{ \
return sprintf(buffer, format, *((type *)kp->arg)); \
} \
struct kernel_param_ops param_ops_##name = { \
.set = param_set_##name, \
.get = param_get_##name, \
}; \
EXPORT_SYMBOL(param_set_##name); \
EXPORT_SYMBOL(param_get_##name); \
EXPORT_SYMBOL(param_ops_##name)
STANDARD_PARAM_DEF(byte, unsigned char, "%c", unsigned long, strict_strtoul);
STANDARD_PARAM_DEF(short, short, "%hi", long, strict_strtol);
STANDARD_PARAM_DEF(ushort, unsigned short, "%hu", unsigned long, strict_strtoul);
STANDARD_PARAM_DEF(int, int, "%i", long, strict_strtol);
STANDARD_PARAM_DEF(uint, unsigned int, "%u", unsigned long, strict_strtoul);
STANDARD_PARAM_DEF(long, long, "%li", long, strict_strtol);
STANDARD_PARAM_DEF(ulong, unsigned long, "%lu", unsigned long, strict_strtoul);
13.1.3.1.3.2 param_ops_charp
类型charp所对应的ops定义于kernel/params.c:
int param_set_charp(const char *val, const struct kernel_param *kp)
{
if (strlen(val) > 1024) {
printk(KERN_ERR "%s: string parameter too long\n",
kp->name);
return -ENOSPC;
}
maybe_kfree_parameter(*(char **)kp->arg);
/* This is a hack. We can't kmalloc in early boot, and we
* don't need to; this mangled commandline is preserved. */
if (slab_is_available()) {
*(char **)kp->arg = kmalloc_parameter(strlen(val)+1);
if (!*(char **)kp->arg)
return -ENOMEM;
strcpy(*(char **)kp->arg, val);
} else
*(const char **)kp->arg = val;
return 0;
}
EXPORT_SYMBOL(param_set_charp);
int param_get_charp(char *buffer, const struct kernel_param *kp)
{
return sprintf(buffer, "%s", *((char **)kp->arg));
}
EXPORT_SYMBOL(param_get_charp);
static void param_free_charp(void *arg)
{
maybe_kfree_parameter(*((char **)arg));
}
struct kernel_param_ops param_ops_charp = {
.set = param_set_charp,
.get = param_get_charp,
.free = param_free_charp,
};
EXPORT_SYMBOL(param_ops_charp);
13.1.3.1.3.3 param_ops_bool
类型bool所对应的ops定义于kernel/params.c:
/* Actually could be a bool or an int, for historical reasons. */
int param_set_bool(const char *val, const struct kernel_param *kp)
{
bool v;
int ret;
/* No equals means "set"... */
if (!val) val = "1";
/* One of =[yYnN01] */
ret = strtobool(val, &v);
if (ret)
return ret;
if (kp->flags & KPARAM_ISBOOL)
*(bool *)kp->arg = v;
else
*(int *)kp->arg = v;
return 0;
}
EXPORT_SYMBOL(param_set_bool);
int param_get_bool(char *buffer, const struct kernel_param *kp)
{
bool val;
if (kp->flags & KPARAM_ISBOOL)
val = *(bool *)kp->arg;
else
val = *(int *)kp->arg;
/* Y and N chosen as being relatively non-coder friendly */
return sprintf(buffer, "%c", val ? 'Y' : 'N');
}
EXPORT_SYMBOL(param_get_bool);
struct kernel_param_ops param_ops_bool = {
.set = param_set_bool,
.get = param_get_bool,
};
EXPORT_SYMBOL(param_ops_bool);
13.1.3.1.3.4 param_ops_invbool
类型invbool所对应的ops定义于kernel/params.c:
/* This one must be bool. */
int param_set_invbool(const char *val, const struct kernel_param *kp)
{
int ret;
bool boolval;
struct kernel_param dummy;
dummy.arg = &boolval;
dummy.flags = KPARAM_ISBOOL;
ret = param_set_bool(val, &dummy);
if (ret == 0)
*(bool *)kp->arg = !boolval;
return ret;
}
EXPORT_SYMBOL(param_set_invbool);
int param_get_invbool(char *buffer, const struct kernel_param *kp)
{
return sprintf(buffer, "%c", (*(bool *)kp->arg) ? 'N' : 'Y');
}
EXPORT_SYMBOL(param_get_invbool);
struct kernel_param_ops param_ops_invbool = {
.set = param_set_invbool,
.get = param_get_invbool,
};
EXPORT_SYMBOL(param_ops_invbool);
13.1.3.1.4 module_param_string()
该宏定义于include/linux/moduleparam.h:
/**
* module_param_string - a char array parameter
* @name: the name of the parameter
* @string: the string variable
* @len: the maximum length of the string, incl. terminator
* @perm: visibility in sysfs.
*
* This actually copies the string when it's set (unlike type charp).
* @len is usually just sizeof(string).
*/
#define module_param_string(name, string, len, perm) \
static const struct kparam_string __param_string_##name = { len, string }; \
__module_param_call(MODULE_PARAM_PREFIX, name, ¶m_ops_string, \
.str = &__param_string_##name, 0, perm); \
__MODULE_PARM_TYPE(name, "string")
参见下图:
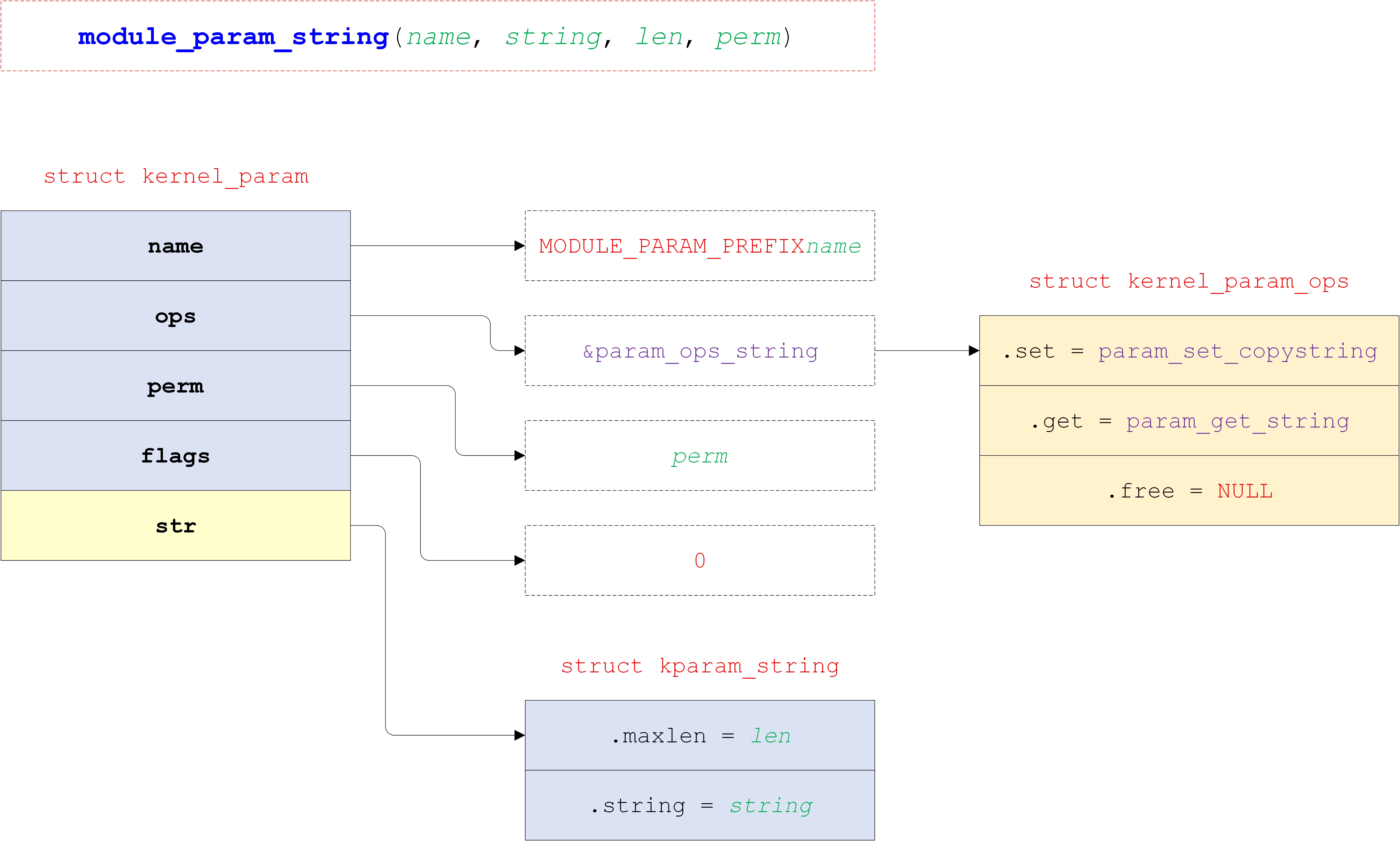
13.1.3.1.4.1 param_ops_string
类型string所对应的ops定义于kernel/params.c:
int param_set_copystring(const char *val, const struct kernel_param *kp)
{
const struct kparam_string *kps = kp->str;
if (strlen(val)+1 > kps->maxlen) {
printk(KERN_ERR "%s: string doesn't fit in %u chars.\n",
kp->name, kps->maxlen-1);
return -ENOSPC;
}
strcpy(kps->string, val);
return 0;
}
EXPORT_SYMBOL(param_set_copystring);
int param_get_string(char *buffer, const struct kernel_param *kp)
{
const struct kparam_string *kps = kp->str;
return strlcpy(buffer, kps->string, kps->maxlen);
}
EXPORT_SYMBOL(param_get_string);
struct kernel_param_ops param_ops_string = {
.set = param_set_copystring,
.get = param_get_string,
};
EXPORT_SYMBOL(param_ops_string);
13.1.3.1.5 module_param_array()/module_param_array_named()
该宏定义于include/linux/moduleparam.h:
/**
* module_param_array - a parameter which is an array of some type
* @name: the name of the array variable
* @type: the type, as per module_param()
* @nump: optional pointer filled in with the number written
* @perm: visibility in sysfs
*
* Input and output are as comma-separated values. Commas inside values
* don't work properly (eg. an array of charp).
*
* ARRAY_SIZE(@name) is used to determine the number of elements in the
* array, so the definition must be visible.
*/
#define module_param_array(name, type, nump, perm) \
module_param_array_named(name, name, type, nump, perm)
/**
* module_param_array_named - renamed parameter which is an array of some type
* @name: a valid C identifier which is the parameter name
* @array: the name of the array variable
* @type: the type, as per module_param()
* @nump: optional pointer filled in with the number written
* @perm: visibility in sysfs
*
* This exposes a different name than the actual variable name. See
* module_param_named() for why this might be necessary.
*/
#define module_param_array_named(name, array, type, nump, perm) \
static const struct kparam_array __param_arr_##name = { \
.max = ARRAY_SIZE(array), \
.num = nump, \
.ops = ¶m_ops_##type, \
.elemsize = sizeof(array[0]), \
.elem = array \
}; \
__module_param_call(MODULE_PARAM_PREFIX, name, \
¶m_array_ops, .arr = &__param_arr_##name, \
__same_type(array[0], bool), perm); \
__MODULE_PARM_TYPE(name, "array of " #type)
参见下图:
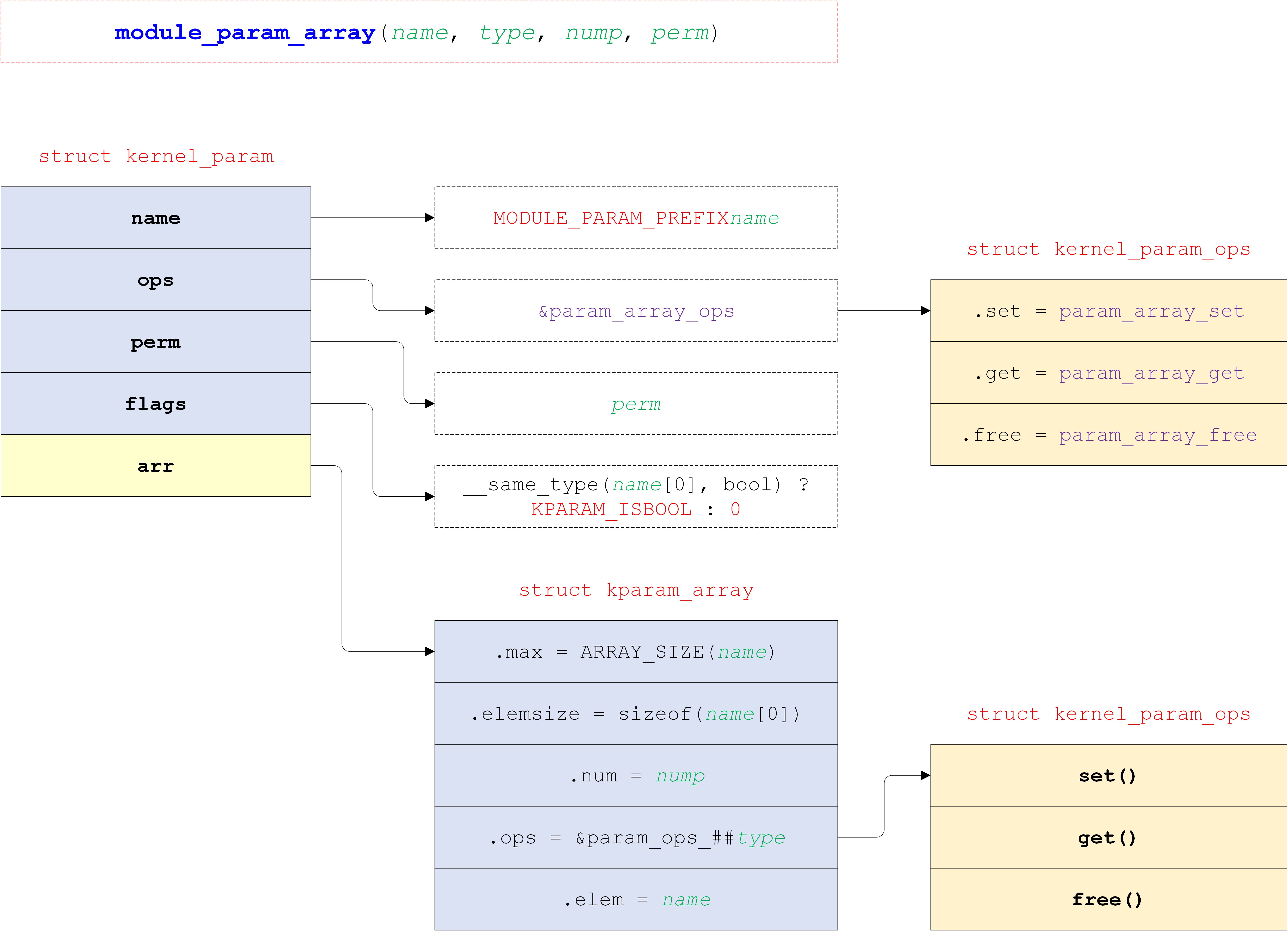
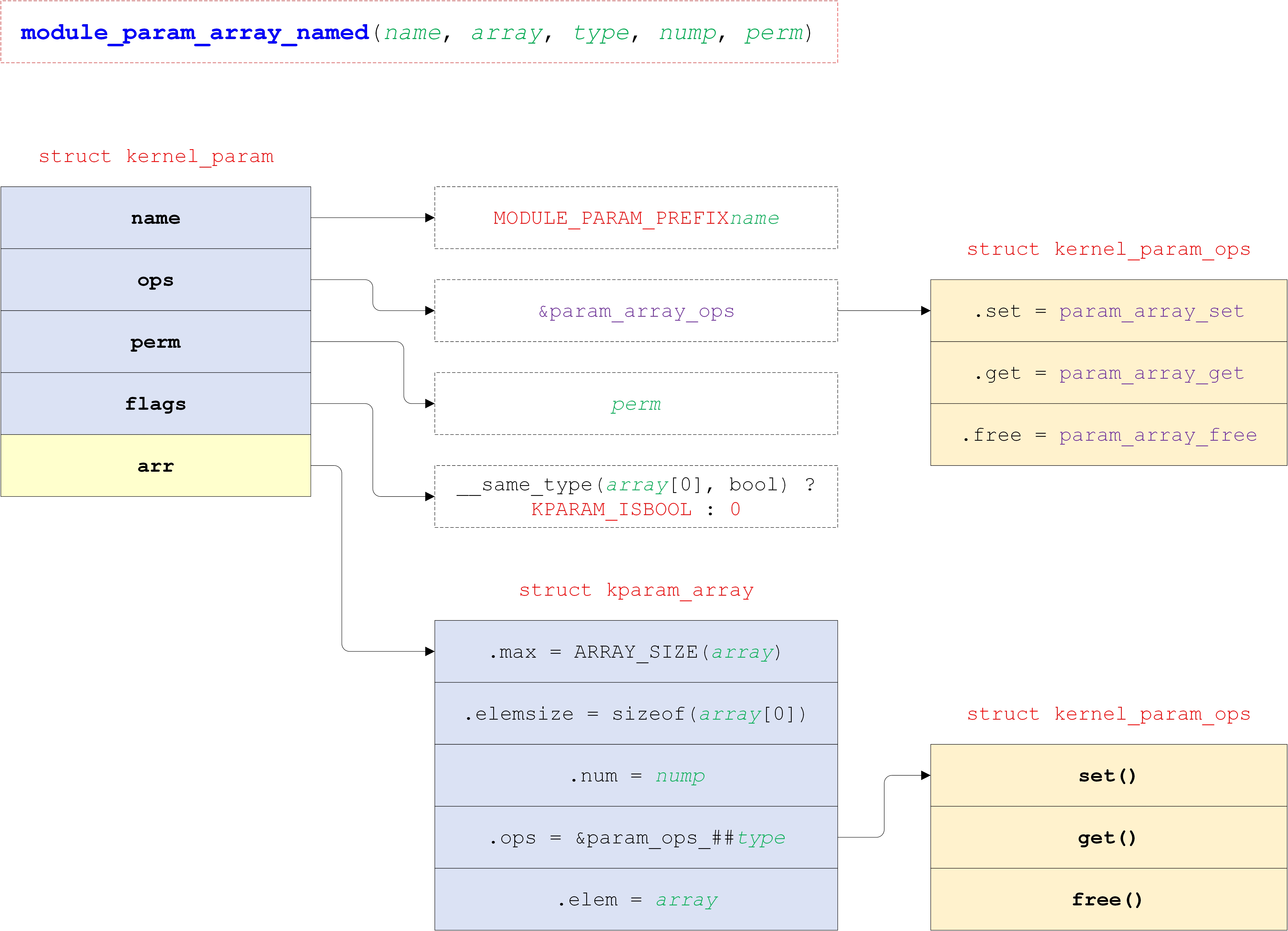
13.1.3.1.5.1 param_array_ops
类型array所对应的ops定义于kernel/params.c:
/* We break the rule and mangle the string. */
static int param_array(const char *name, const char *val, unsigned int min,
unsigned int max, void *elem, int elemsize,
int (*set)(const char *, const struct kernel_param *kp),
u16 flags, unsigned int *num)
{
int ret;
struct kernel_param kp;
char save;
/* Get the name right for errors. */
kp.name = name;
kp.arg = elem;
kp.flags = flags;
*num = 0;
/* We expect a comma-separated list of values. */
do {
int len;
if (*num == max) {
printk(KERN_ERR "%s: can only take %i arguments\n",
name, max);
return -EINVAL;
}
len = strcspn(val, ",");
/* nul-terminate and parse */
save = val[len];
((char *)val)[len] = '\0';
BUG_ON(!mutex_is_locked(¶m_lock));
ret = set(val, &kp);
if (ret != 0)
return ret;
kp.arg += elemsize;
val += len+1;
(*num)++;
} while (save == ',');
if (*num < min) {
printk(KERN_ERR "%s: needs at least %i arguments\n",
name, min);
return -EINVAL;
}
return 0;
}
static int param_array_set(const char *val, const struct kernel_param *kp)
{
const struct kparam_array *arr = kp->arr;
unsigned int temp_num;
return param_array(kp->name, val, 1, arr->max, arr->elem,
arr->elemsize, arr->ops->set, kp->flags,
arr->num ?: &temp_num);
}
static int param_array_get(char *buffer, const struct kernel_param *kp)
{
int i, off, ret;
const struct kparam_array *arr = kp->arr;
struct kernel_param p;
p = *kp;
for (i = off = 0; i < (arr->num ? *arr->num : arr->max); i++) {
if (i)
buffer[off++] = ',';
p.arg = arr->elem + arr->elemsize * i;
BUG_ON(!mutex_is_locked(¶m_lock));
ret = arr->ops->get(buffer + off, &p);
if (ret < 0)
return ret;
off += ret;
}
buffer[off] = '\0';
return off;
}
static void param_array_free(void *arg)
{
unsigned int i;
const struct kparam_array *arr = arg;
if (arr->ops->free)
for (i = 0; i < (arr->num ? *arr->num : arr->max); i++)
arr->ops->free(arr->elem + arr->elemsize * i);
}
struct kernel_param_ops param_array_ops = {
.set = param_array_set,
.get = param_array_get,
.free = param_array_free,
};
EXPORT_SYMBOL(param_array_ops);
13.1.3.1.6 core_param()
该宏定义于include/linux/moduleparam.h:
/**
* core_param - define a historical core kernel parameter.
* @name: the name of the cmdline and sysfs parameter (often the same as var)
* @var: the variable
* @type: the type of the parameter
* @perm: visibility in sysfs
*
* core_param is just like module_param(), but cannot be modular and
* doesn't add a prefix (such as "printk."). This is for compatibility
* with __setup(), and it makes sense as truly core parameters aren't
* tied to the particular file they're in.
*/
#define core_param(name, var, type, perm) \
param_check_##type(name, &(var)); \
__module_param_call("", name, ¶m_ops_##type, \
&var, __same_type(var, bool), perm)
NOTE: The parameter appears in /sys/module/kernel/parameters/, not /sys/module/<module-name>/parameters/.
13.1.3.1.7 Define specific type for module parameter
If you really need a type that does not appear in the list of above sections, there are hooks in the module code that allow you to define them; see moduleparam.h for details on how to do that.
首先,定义如下宏,新类型为myType:
#define module_param_myType(name, myType, perm) \
module_param_named_myType(name, name, myType, perm)
#define module_param_named_myType(name, value, myType, perm) \
param_check_##myType(name, &(value)); \
module_param_cb(name, ¶m_ops_##myType, &value, perm); \
__MODULE_PARM_TYPE(name, #myType)
然后,定义如下宏或者函数:
param_check_myType(name, p),可参考param_check_byte(name, p)的定义;- 函数指针param_ops_myType中的
set(),get(),free()等函数,参见13.1.3.1.1 module_param_cb()/__module_param_call()节。
13.1.3.2 系统启动过程时对.init.setup段模块参数的处理
在系统启动过程中,处理由early_param()和__setup()定义在.init.setup段中的模块参数,参见4.3.4.1.4.3.3.2 注册内核参数的处理函数节,其函数调用关系如下:
start_kernel()
-> parse_early_param() // 参见[4.3.4.1.4.3.3.3.1 parse_early_param()]节
-> parse_early_options()
-> parse_args(.., do_early_param) // 参见[4.3.4.1.4.3.3.3.2 parse_args()]节
-> do_early_param()
-> p->setup_func(val) // (1) 处理由宏early_param()定义的模块参数
-> parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param, &unknown_bootoption)
-> unknown_bootoption()
-> obsolete_checksetup()
-> if (p->early) {
...
} else if (!p->setup_func) {
...
} else if (p->setup_func(line + n)) // (2) 处理由宏__setup()定义的模块参数
...
-> rest_init()
-> kernel_init()
-> do_pre_smp_initcalls()
-> do_one_initcall() // init functions in [__initcall_start, __early_initcall_end)
-> fn()
-> do_basic_setup()
-> do_initcalls()
-> do_one_initcall() // init functions in [__early_initcall_end, __initcall_end)
-> fn() // (3) method param_sysfs_init() is called here!
/*
* The method param_sysfs_init() is in section .initcall4.init,
* which is located in [__early_initcall_end, __initcall_end).
*/
param_sysfs_init()
-> module_kset = kset_create_and_add("module", &module_uevent_ops, NULL)
-> module_sysfs_initialized = 1;
-> version_sysfs_builtin()
-> param_sysfs_builtin()
参见下图:

13.1.3.3 编译成模块时对模块参数的处理
13.1.3.3.1 模块加载时对模块参数的处理
使用下列命令获取指定模块的模块参数:
# modinfo <module-name> | grep parm:
在加载模块时,使用下列命令为模块参数赋值:
# insmod <module-name> <param-name>=<param-value>
在加载模块时,由下列函数调用处理模块参数:
load_module() // 参见[13.5.1.2.1 load_module()]节
-> find_module_sections(mod, &info)
/*
* 获取该模块中定义的所有模块参数,参见[13.1.3.1.1 module_param_cb()/__module_param_call()]节
*/
-> mod->kp = section_objs(info, "__param", sizeof(*mod->kp), &mod->num_kp);
-> mod->args = strndup_user(uargs, ~0UL >> 1) // 获取加载模块时传入的模块参数
-> parse_args(mod->name, mod->args, mod->kp, mod->num_kp, NULL)
-> while (*args) {
next_arg(args, ¶m, &val)
parse_one(param, val, params, num, NULL)
-> params[i].ops->set(val, ¶ms[i]) // 调用该模块参数对应的set()函数
}
-> mod_sysfs_setup(mod, &info, mod->kp, mod->num_kp)
-> mod_sysfs_init(mod)
/*
* 变量module_kset是/sys/module对应的kset,由函数param_sysfs_init()为之赋值,
* 参见[13.1.3.2 系统启动过程时对.init.setup段模块参数的处理]节
*/
-> kset_find_obj(module_kset, mod->name)
/*
* 创建目录/sys/module/<module-name>,参见[15.7.1.1 kobject_init_and_add()]节
*/
-> kobject_init_and_add(&mod->mkobj.kobj, &module_ktype, NULL, "%s", mod->name)
/*
* 创建目录/sys/module/<module-name>/holders
*/
-> kobject_create_and_add("holders", &mod->mkobj.kobj)
-> module_param_sysfs_setup(mod, kparam, num_params)
-> for (i = 0; i < num_params; i++) {
/*
* 设置参数的处理函数,参见[13.1.3.3.2 模块加载后对模块参数的处理]节
*/
add_sysfs_param(&mod->mkobj, &kparam[i], kparam[i].name)
-> sysfs_attr_init(&new->attrs[num].mattr.attr);
-> new->attrs[num].param = kp;
-> new->attrs[num].mattr.show = param_attr_show;
-> new->attrs[num].mattr.store = param_attr_store;
-> new->attrs[num].mattr.attr.name = (char *)name;
-> new->attrs[num].mattr.attr.mode = kp->perm;
-> new->num = num+1;
}
-> sysfs_create_group()
-> module_add_modinfo_attrs(mod)
-> mod->modinfo_attrs = kzalloc((sizeof(struct module_attribute) *
(ARRAY_SIZE(modinfo_attrs) + 1)), GFP_KERNEL);
-> sysfs_attr_init(&temp_attr->attr);
-> sysfs_create_file(&mod->mkobj.kobj,&temp_attr->attr);
-> add_usage_links(mod)
-> sysfs_create_link(use->target->holders_dir, &mod->mkobj.kobj, mod->name);
-> add_sect_attrs(mod, info)
-> sysfs_create_group(&mod->mkobj.kobj, §_attrs->grp)
-> add_notes_attrs(mod, info)
-> kobject_create_and_add("notes", &mod->mkobj.kobj)
-> sysfs_create_bin_file(notes_attrs->dir, ¬es_attrs->attrs[i])
-> kobject_uevent(&mod->mkobj.kobj, KOBJ_ADD)
13.1.3.3.2 模块加载后对模块参数的处理
对于已加载到内核的模块,其模块参数会列举在/sys/module/<module-name>/parameters/目录下,若拥有相应权限,则可使用下列命令显示/修改指定的模块参数:
# ls -l /sys/module/<module-name>/parameters/<parm-name>
# cat /sys/module/<module-name>/parameters/<parm-name>
# echo -n <new-module-value> > /sys/module/<module-name>/parameters/<parm-name>
sysfs文件系统最终调用如下函数显示/修改模块参数,参见13.1.3.3.1 模块加载时对模块参数的处理节:
param_attr_show()
-> attribute->param->ops->get(buf, attribute->param)
param_attr_store()
-> attribute->param->ops->set(buf, attribute->param)
13.1.3.3.3 模块卸载时对模块参数的处理
在卸载模块时,调用模块参数对应的free函数来释放模块参数:
delete_module() // 参见[13.5.1.3 rmmod调用sys_delete_module()]节
-> free_module(mod)
-> mod_sysfs_teardown(mod)
-> destroy_params(mod->kp, mod->num_kp)
-> for (i = 0; i < num; i++)
if (params[i].ops->free)
params[i].ops->free(params[i].arg);
由13.1.3.1.3 module_param()/module_param_named()节至13.1.3.1.5 module_param_array()/module_param_array_named()节可知,宏module_param(.., charp, ..)和module_param_array()定义的模块参数有param[i].ops->free()函数。
13.2 模块的编译
13.2.1 编译外部模块的前提条件
13.2.1.1 内核配置选项
+- include/linux/elf.h
+- include/linux/module.h
+- arch/x86/include/asm/module.h
| +- include/asm-generic/module.h
+- kernel/module.c
由kernel/Makefile可知,module.c的编译与配置选项CONFIG_MODULES有关:
obj-$(CONFIG_MODULES) += module.o
只有配置了内核选项CONFIG_MODULES,内核才支持module操作:
[*] Enable loadable module support ---> // CONFIG_MODULES [boolean]
[ ] Forced module loading // CONFIG_MODULE_FORCE_LOAD [boolean]
[*] Module unloading // CONFIG_MODULE_UNLOAD [boolean]
[*] Forced module unloading // CONFIG_MODULE_FORCE_UNLOAD [boolean]
[ ] Module versioning support // CONFIG_MODVERSIONS [boolean]
[ ] Source checksum for all modules // CONFIG_MODULE_SRCVERSION_ALL [boolean]
其中,各配置选项的含义如下:
| Configure | Description |
|---|---|
| CONFIG_MODULE_FORCE_LOAD | Allow loading of modules without version information (ie. modprobe --force). Forced module loading sets the ‘F’ (forced) taint flag and is usually a really bad idea. |
| CONFIG_MODULE_UNLOAD | Without this option you will not be able to unload any modules (note that some modules may not be unloadable anyway), which makes your kernel smaller, faster and simpler. If unsure, say Y. |
| CONFIG_MODULE_FORCE_UNLOAD | This option allows you to force a module to unload, even if the kernel believes it is unsafe: the kernel will remove the module without waiting for anyone to stop using it (using the -f option to rmmod). This is mainly for kernel developers and desperate users. If unsure, say N. |
| CONFIG_MODVERSIONS | Usually, you have to use modules compiled with your kernel. Saying Y here makes it sometimes possible to use modules compiled for different kernels, by adding enough information to the modules to (hopefully) spot any changes which would make them incompatible with the kernel you are running. If unsure, say N. |
| CONFIG_MODULE_SRCVERSION_ALL | Modules which contain a MODULE_VERSION get an extra “srcversion” field inserted into their modinfo section, which contains a sum of the source files which made it. This helps maintainers see exactly which source was used to build a module (since others sometimes change the module source without updating the version). With this option, such a “srcversion” field will be created for all modules. If unsure, say N. |
13.2.1.2 Prebuilt kernel with configuration and headers
Refer to Documentation/kbuild/modules.txt:
=== 2. How to Build External Modules
To build external modules, you must have a prebuilt kernel available that contains the configuration and header files used in the build. Also, the kernel must have been built with modules enabled. If you are using a distribution kernel, there will be a package for the kernel you are running provided by your distribution.
An alternative is to use the “make” target “modules_prepare.” This will make sure the kernel contains the information required. The target exists solely as a simple way to prepare a kernel source tree for building external modules.
NOTE: “modules_prepare” will not build Module.symvers even if CONFIG_MODVERSIONS is set; therefore, a full kernel build needs to be executed to make module versioning work.
13.2.2 Makefile
13.2.2.0 Standard Makefile
Standard Makefile for kernels <= 2.4
TARGET := module_name
INCLUDE := -I/lib/modules/`uname -r`/build/include
CFLAGS := -O2 -Wall -DMODULE -D__KERNEL__ -DLINUX
CC := gcc
${TARGET}.o: ${TARGET}.c
$(CC) $(CFLAGS) ${INCLUDE} -c ${TARGET}.c
Standard Makefile for kernels > 2.4
obj-m := <name-of-module>.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
13.2.2.1 Makefile v1
用于编译hello模块的Makefile:
obj-m := hello.o
# 'uname -r' print kernel release
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
# targets, refer to 编译external modules
all:
make -C $(KDIR) M=$(PWD) modules
clean:
make -C $(KDIR) M=$(PWD) clean
在hello.c所在的目录执行make命令,编译hello模块:
chenwx@chenwx ~/alex/module $ ll
-rw-r--r-- 1 chenwx chenwx 295 Aug 7 05:02 hello.c
-rw-r--r-- 1 chenwx chenwx 187 Aug 7 05:05 Makefile
chenwx@chenwx ~/alex/module $ make
make -C /lib/modules/3.5.0-17-generic/build M=/home/chenwx/alex/module modules
make[1]: Entering directory `/usr/src/linux-headers-3.5.0-17-generic'
CC [M] /home/chenwx/alex/module/hello.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/chenwx/alex/module/hello.mod.o
LD [M] /home/chenwx/alex/module/hello.ko
make[1]: Leaving directory `/usr/src/linux-headers-3.5.0-17-generic'
chenwx@chenwx ~/alex/module $ ll
-rw-r--r-- 1 chenwx chenwx 295 Aug 7 05:02 hello.c
-rw-r--r-- 1 chenwx chenwx 187 Aug 7 05:05 Makefile
-rw-r--r-- 1 chenwx chenwx 2471 Aug 7 05:18 hello.ko
-rw-r--r-- 1 chenwx chenwx 247 Aug 7 05:18 .hello.ko.cmd
-rw-r--r-- 1 chenwx chenwx 663 Aug 7 05:18 hello.mod.c
-rw-r--r-- 1 chenwx chenwx 1760 Aug 7 05:18 hello.mod.o
-rw-r--r-- 1 chenwx chenwx 26045 Aug 7 05:18 .hello.mod.o.cmd
-rw-r--r-- 1 chenwx chenwx 1284 Aug 7 05:18 hello.o
-rw-r--r-- 1 chenwx chenwx 25942 Aug 7 05:18 .hello.o.cmd
-rw-r--r-- 1 chenwx chenwx 41 Aug 7 05:18 modules.order
-rw-r--r-- 1 chenwx chenwx 0 Aug 7 05:18 Module.symvers
drwxr-xr-x 2 chenwx chenwx 4096 Aug 7 05:18 .tmp_versions
13.2.2.2 Makefile v2
Makefile v1只能编译名为hello.c的源文件,为了使该Makefile可编译其他源文件,可将源文件名作为make命令行参数,使Makefile更通用。Makefile更新如下:
#
# Usage: make o=<source-file-name-without-extension>
#
obj-m := $(o).o
# 'uname -r' print kernel release
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
# enable macor DEBUG in order to use pr_debug()
ccflags-y += -DDEBUG
# targets, refer to 编译external modules
all:
make -C $(KDIR) M=$(PWD) modules
clean:
make -C $(KDIR) M=$(PWD) clean
在源文件所在的目录执行make命令,编译指定模块:
chenwx@chenwx ~/alex/module $ ll
-rw-r--r-- 1 chenwx chenwx 295 Aug 7 05:02 hello.c
-rw-r--r-- 1 chenwx chenwx 295 Aug 7 05:02 fs.c
-rw-r--r-- 1 chenwx chenwx 187 Aug 7 05:05 Makefile
chenwx@chenwx ~/alex/module $ make o=hello
make -C /lib/modules/3.5.0-17-generic/build M=/home/chenwx/alex/module modules
make[1]: Entering directory `/usr/src/linux-headers-3.5.0-17-generic'
CC [M] /home/chenwx/alex/module/hello.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/chenwx/alex/module/hello.mod.o
LD [M] /home/chenwx/alex/module/hello.ko
make[1]: Leaving directory `/usr/src/linux-headers-3.5.0-17-generic'
chenwx@chenwx ~/alex/module $ make o=fs
make -C /lib/modules/3.5.0-17-generic/build M=/home/chenwx/alex/module modules
make[1]: Entering directory `/usr/src/linux-headers-3.5.0-17-generic'
CC [M] /home/chenwx/alex/module/fs.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/chenwx/alex/module/fs.mod.o
LD [M] /home/chenwx/alex/module/fs.ko
make[1]: Leaving directory `/usr/src/linux-headers-3.5.0-17-generic'
chenwx@chenwx ~/alex/module $ ll
-rw-r--r-- 1 chenwx chenwx 187 Aug 7 05:05 Makefile
-rw-r--r-- 1 chenwx chenwx 295 Aug 7 05:02 hello.c
-rw-r--r-- 1 chenwx chenwx 2471 Aug 7 05:18 hello.ko
-rw-r--r-- 1 chenwx chenwx 247 Aug 7 05:18 .hello.ko.cmd
-rw-r--r-- 1 chenwx chenwx 663 Aug 7 05:18 hello.mod.c
-rw-r--r-- 1 chenwx chenwx 1760 Aug 7 05:18 hello.mod.o
-rw-r--r-- 1 chenwx chenwx 26045 Aug 7 05:18 .hello.mod.o.cmd
-rw-r--r-- 1 chenwx chenwx 1284 Aug 7 05:18 hello.o
-rw-r--r-- 1 chenwx chenwx 25942 Aug 7 05:18 .hello.o.cmd
-rw-r--r-- 1 chenwx chenwx 295 Aug 7 05:02 fs.c
-rw-r--r-- 1 chenwx chenwx 2471 Aug 7 05:18 fs.ko
-rw-r--r-- 1 chenwx chenwx 247 Aug 7 05:18 .fs.ko.cmd
-rw-r--r-- 1 chenwx chenwx 663 Aug 7 05:18 fs.mod.c
-rw-r--r-- 1 chenwx chenwx 1760 Aug 7 05:18 fs.mod.o
-rw-r--r-- 1 chenwx chenwx 26045 Aug 7 05:18 .fs.mod.o.cmd
-rw-r--r-- 1 chenwx chenwx 1284 Aug 7 05:18 fs.o
-rw-r--r-- 1 chenwx chenwx 25942 Aug 7 05:18 .fs.o.cmd
-rw-r--r-- 1 chenwx chenwx 41 Aug 7 05:18 modules.order
-rw-r--r-- 1 chenwx chenwx 0 Aug 7 05:18 Module.symvers
drwxr-xr-x 2 chenwx chenwx 4096 Aug 7 05:18 .tmp_versions
13.2.2.3 Makefile v3
Makefile v2每次只能编译一个源文件,为了使该Makefile每次可编译多个源文件,可将多个源文件名作为make命令行参数。Makefile更新如下:
#
# Usage:
# make o=<one source file name with or without extension>
# make o="<multiple source file names with or without extension>"
#
objects := $(addsuffix .o,$(basename $(strip $(o))))
ifneq ($(filter-out clean, $(MAKECMDGOALS)),)
ifeq ($(objects),)
$(error No object to be compiled)
else
$(warning Compiling $(objects))
endif
endif
obj-m := $(objects)
# 'uname -r' print kernel release
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
# enable macor DEBUG in order to use pr_debug()
ccflags-y += -DDEBUG
# targets, refer to 编译external modules
all:
make -C $(KDIR) M=$(PWD) modules
clean:
make -C $(KDIR) M=$(PWD) clean
在源文件所在目录执行make命令,编译指定模块:
chenwx@chenwx ~/test $ ll
-rw-r--r-- 1 chenwx chenwx 646 May 27 05:07 convert_dev.c
-rw-r--r-- 1 chenwx chenwx 799 May 27 05:10 fs.c
-rw-r--r-- 1 chenwx chenwx 624 May 27 04:59 hello.c
-rw-r--r-- 1 chenwx chenwx 654 May 27 06:12 Makefile
chenwx@chenwx ~/test $ make o="hello fs.c convert_dev.c"
make -C /lib/modules/3.11.0-12-generic/build M=/home/chenwx/test modules
make[1]: Entering directory `/usr/src/linux-headers-3.11.0-12-generic'
CC [M] /home/chenwx/test/hello.o
CC [M] /home/chenwx/test/fs.o
CC [M] /home/chenwx/test/convert_dev.o
Building modules, stage 2.
MODPOST 3 modules
CC /home/chenwx/test/convert_dev.mod.o
LD [M] /home/chenwx/test/convert_dev.ko
CC /home/chenwx/test/fs.mod.o
LD [M] /home/chenwx/test/fs.ko
CC /home/chenwx/test/hello.mod.o
LD [M] /home/chenwx/test/hello.ko
make[1]: Leaving directory `/usr/src/linux-headers-3.11.0-12-generic'
chenwx@chenwx ~/test $ ll
-rw-r--r-- 1 chenwx chenwx 654 May 27 06:12 Makefile
-rw-r--r-- 1 chenwx chenwx 646 May 27 05:07 convert_dev.c
-rw-r--r-- 1 chenwx chenwx 3390 May 27 06:17 convert_dev.ko
-rw-r--r-- 1 chenwx chenwx 771 May 27 06:17 convert_dev.mod.c
-rw-r--r-- 1 chenwx chenwx 1844 May 27 06:17 convert_dev.mod.o
-rw-r--r-- 1 chenwx chenwx 2088 May 27 06:17 convert_dev.o
-rw-r--r-- 1 chenwx chenwx 799 May 27 05:10 fs.c
-rw-r--r-- 1 chenwx chenwx 649 May 27 05:16 fs_init.c
-rw-r--r-- 1 chenwx chenwx 126 May 27 05:16 fs_init.h
-rw-r--r-- 1 chenwx chenwx 3537 May 27 06:17 fs.ko
-rw-r--r-- 1 chenwx chenwx 776 May 27 06:17 fs.mod.c
-rw-r--r-- 1 chenwx chenwx 1836 May 27 06:17 fs.mod.o
-rw-r--r-- 1 chenwx chenwx 2252 May 27 06:17 fs.o
-rw-r--r-- 1 chenwx chenwx 624 May 27 04:59 hello.c
-rw-r--r-- 1 chenwx chenwx 3366 May 27 06:17 hello.ko
-rw-r--r-- 1 chenwx chenwx 715 May 27 06:17 hello.mod.c
-rw-r--r-- 1 chenwx chenwx 1776 May 27 06:17 hello.mod.o
-rw-r--r-- 1 chenwx chenwx 2148 May 27 06:17 hello.o
-rw-r--r-- 1 chenwx chenwx 105 May 27 06:17 modules.order
-rw-r--r-- 1 chenwx chenwx 0 May 27 05:24 Module.symvers
13.2.3 模块的编译过程
- 内核模块的编译,参见3.4.3 编译modules/$(obj-m)节;
- 外部模块的编译,参见3.4.4 编译external modules节。
13.2.3.1 编译基于特定内核版本的模块
若编译基于特定内核版本的模块,则按如下步骤操作:
/*
* (1) 编写待编译模块的源文件和Makefile,
* 其中Makefile参见[13.2.2.3 Makefile v3]节
*/
chenwx@chenwx ~/helloworld $ ll
total 8.0K
-rw-r--r-- 1 chenwx chenwx 638 May 3 16:59 Makefile
-rw-r--r-- 1 chenwx chenwx 703 Jul 26 22:26 helloworld.c
/*
* (2) 清空内核源代码目录,并checkout指定版本的内核源代码
*/
chenwx@chenwx ~/helloworld $ cd ~/linux
chenwx@chenwx ~/linux $ make distclean
CLEAN .
CLEAN arch/x86/tools
CLEAN .tmp_versions
CLEAN scripts/basic
CLEAN scripts/genksyms
CLEAN scripts/kconfig
CLEAN scripts/mod
CLEAN scripts/selinux/genheaders
CLEAN scripts/selinux/mdp
CLEAN scripts
CLEAN include/config include/generated arch/x86/include/generated
CLEAN .config .config.old
chenwx@chenwx ~/linux $ git co v4.1.6
Previous HEAD position was 352cb8677f83... Linux 4.1.5
HEAD is now at 4ff62ca06c0c... Linux 4.1.6
chenwx@chenwx ~/linux $ git st
HEAD detached at v4.1.6
nothing to commit, working directory clean
/*
* (2.1) 若直接编译模块,则不成功,其原因
* 参见[13.2.1.2 Prebuilt kernel with configuration and headers]节
* 和[NOTE1]
*/
chenwx@chenwx ~/linux $ cd ~/helloworld/
chenwx@chenwx ~/helloworld $ make KDIR=~/linux o=helloworld.c
make -C /home/chenwx/linux M=/home/chenwx/helloworld modules
make[1]: Entering directory `/home/chenwx/linux'
ERROR: Kernel configuration is invalid.
include/generated/autoconf.h or include/config/auto.conf are missing.
Run 'make oldconfig && make prepare' on kernel src to fix it.
WARNING: Symbol version dump ./Module.symvers
is missing; modules will have no dependencies and modversions.
CC [M] /home/chenwx/helloworld/helloworld.o
In file included from <command-line>:0:0:
././include/linux/kconfig.h:4:32: fatal error: generated/autoconf.h: No such file or directory
#include <generated/autoconf.h>
^
compilation terminated.
make[2]: *** [/home/chenwx/helloworld/helloworld.o] Error 1
make[1]: *** [_module_/home/chenwx/helloworld] Error 2
make[1]: Leaving directory `/home/chenwx/linux'
make: *** [all] Error 2
/*
* (3) 配置内核源代码,并为编译模块做准备
*/
chenwx@chenwx ~/helloworld $ cd ~/linux
chenwx@chenwx ~/linux $ cp /boot/config-4.1.5-alex .config
chenwx@chenwx ~/linux $ make olddefconfig
HOSTCC scripts/basic/fixdep
HOSTCC scripts/kconfig/conf.o
SHIPPED scripts/kconfig/zconf.tab.c
SHIPPED scripts/kconfig/zconf.lex.c
SHIPPED scripts/kconfig/zconf.hash.c
HOSTCC scripts/kconfig/zconf.tab.o
HOSTLD scripts/kconfig/conf
scripts/kconfig/conf --olddefconfig Kconfig
#
# configuration written to .config
#
chenwx@chenwx ~/linux $ make modules_prepare
scripts/kconfig/conf --silentoldconfig Kconfig
SYSTBL arch/x86/syscalls/../include/generated/asm/syscalls_32.h
SYSHDR arch/x86/syscalls/../include/generated/asm/unistd_32_ia32.h
SYSHDR arch/x86/syscalls/../include/generated/asm/unistd_64_x32.h
SYSTBL arch/x86/syscalls/../include/generated/asm/syscalls_64.h
SYSHDR arch/x86/syscalls/../include/generated/uapi/asm/unistd_32.h
SYSHDR arch/x86/syscalls/../include/generated/uapi/asm/unistd_64.h
SYSHDR arch/x86/syscalls/../include/generated/uapi/asm/unistd_x32.h
HOSTCC scripts/basic/bin2c
HOSTCC arch/x86/tools/relocs_32.o
HOSTCC arch/x86/tools/relocs_64.o
HOSTCC arch/x86/tools/relocs_common.o
HOSTLD arch/x86/tools/relocs
CHK include/config/kernel.release
UPD include/config/kernel.release
WRAP arch/x86/include/generated/asm/clkdev.h
WRAP arch/x86/include/generated/asm/cputime.h
WRAP arch/x86/include/generated/asm/dma-contiguous.h
WRAP arch/x86/include/generated/asm/early_ioremap.h
WRAP arch/x86/include/generated/asm/mcs_spinlock.h
WRAP arch/x86/include/generated/asm/scatterlist.h
CHK include/generated/uapi/linux/version.h
UPD include/generated/uapi/linux/version.h
CHK include/generated/utsrelease.h
UPD include/generated/utsrelease.h
CC kernel/bounds.s
CHK include/generated/bounds.h
UPD include/generated/bounds.h
CC arch/x86/kernel/asm-offsets.s
CHK include/generated/asm-offsets.h
UPD include/generated/asm-offsets.h
CALL scripts/checksyscalls.sh
HOSTCC scripts/genksyms/genksyms.o
SHIPPED scripts/genksyms/parse.tab.c
HOSTCC scripts/genksyms/parse.tab.o
SHIPPED scripts/genksyms/lex.lex.c
SHIPPED scripts/genksyms/keywords.hash.c
SHIPPED scripts/genksyms/parse.tab.h
HOSTCC scripts/genksyms/lex.lex.o
HOSTLD scripts/genksyms/genksyms
CC scripts/mod/empty.o
HOSTCC scripts/mod/mk_elfconfig
MKELF scripts/mod/elfconfig.h
HOSTCC scripts/mod/modpost.o
CC scripts/mod/devicetable-offsets.s
GEN scripts/mod/devicetable-offsets.h
HOSTCC scripts/mod/file2alias.o
HOSTCC scripts/mod/sumversion.o
HOSTLD scripts/mod/modpost
HOSTCC scripts/selinux/genheaders/genheaders
HOSTCC scripts/selinux/mdp/mdp
HOSTCC scripts/kallsyms
HOSTCC scripts/conmakehash
HOSTCC scripts/recordmcount
HOSTCC scripts/sortextable
/*
* (4) 编译基于特定内核版本的模块
*/
chenwx@chenwx ~/linux $ cd ~/helloworld/
chenwx@chenwx ~/helloworld $ make KDIR=~/linux o=helloworld.c
make -C /home/chenwx/linux M=/home/chenwx/helloworld modules
make[1]: Entering directory `/home/chenwx/linux'
WARNING: Symbol version dump ./Module.symvers
is missing; modules will have no dependencies and modversions.
CC [M] /home/chenwx/helloworld/helloworld.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/chenwx/helloworld/helloworld.mod.o
LD [M] /home/chenwx/helloworld/helloworld.ko
make[1]: Leaving directory `/home/chenwx/linux'
chenwx@chenwx ~/helloworld $ ll
total 200K
-rw-r--r-- 1 chenwx chenwx 638 May 3 16:59 Makefile
-rw-r--r-- 1 chenwx chenwx 69 Aug 31 22:12 Module.symvers
-rw-r--r-- 1 chenwx chenwx 703 Jul 26 22:26 helloworld.c
-rw-r--r-- 1 chenwx chenwx 85K Aug 31 22:12 helloworld.ko
-rw-r--r-- 1 chenwx chenwx 612 Aug 31 22:12 helloworld.mod.c
-rw-r--r-- 1 chenwx chenwx 50K Aug 31 22:12 helloworld.mod.o
-rw-r--r-- 1 chenwx chenwx 39K Aug 31 22:12 helloworld.o
-rw-r--r-- 1 chenwx chenwx 45 Aug 31 22:12 modules.order
chenwx@chenwx ~/helloworld $ modinfo helloworld.ko
filename: /home/chenwx/helloworld/helloworld.ko
description: A Hello Module
author: Chen Weixiang
license: GPL
srcversion: 4D296D6B8A330EA0D60086F
depends:
vermagic: 4.1.6 SMP mod_unload modversions
parm: isSayHello:set 0 to disable printing hello world. set 1 to enable it (int)
NOTE: You can’t build a module against an absolutely sterile, pristine, make distcleaned kernel tree. At the very least, the kernel tree being used must be configured because there are some versioning files that are created by the configuration process that are essential to the module build process. But that’s not enough.
You also need to perform at least the first part of the kernel build process since that will generate a few more files that the module build process needs. However, unlike what some documentation tells you, you don’t need to perform an entire build. All that’s required is, in the kernel source tree, to run the subsequent command:
# make modules_prepare
Without getting into massive detail, that make invocation will run just enough of the kernel build process that the tree is now ready to let modules build against it. And once you do that in your kernel source tree, your module build should now work.
13.2.4 测试模块
下面编译并测试13.1.1 模块源文件示例节的hello.c模块:
chenwx@chenwx ~/alex/module $ modinfo hello.ko
filename: hello.ko
license: GPL
srcversion: 80A7CFE31FFFDD3F54DDB04
depends:
vermagic: 3.5.0-17-generic SMP mod_unload modversions 686
chenwx@chenwx ~/alex/module $ sudo insmod hello.ko
chenwx@chenwx ~/alex/module $ lsmod
Module Size Used by
hello 12393 0
hid 82142 2 hid_generic,usbhid
// 或者查看日志文件/var/log/kern.log
chenwx@chenwx ~/alex/module $ dmesg | tail
[ 1346.914114] usb 1-1: >Manufacturer: VirtualBox
[ 1346.932248] input: VirtualBox USB Tablet as /devices/pci0000:00/0000:00:06.0/usb1/1-1/1-1:1.0/input/input6
[ 1346.933869] hid-generic 0003:80EE:0021.0002: >input,hidraw0: USB HID v1.10 Mouse [VirtualBox USB Tablet] on usb-0000:00:06.0-1/input0
[ 1347.096468] e1000: eth0 NIC Link is Down
[ 1351.105984] e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: RX
[ 5007.862201] Hello module init
chenwx@chenwx ~/alex/module $ cat /proc/kallsyms | grep sayHello
00000000 T sayHello [hello]
00000000 r __ksymtab_sayHello [hello]
00000000 r __kstrtab_sayHello [hello]
00000000 r __kcrctab_sayHello [hello]
chenwx@chenwx ~/alex/module $ cat /proc/kallsyms | grep hello
00000000 T sayHello [hello]
00000000 t hello_exit [hello]
00000000 r __ksymtab_sayHello [hello]
00000000 r __kstrtab_sayHello [hello]
00000000 r __kcrctab_sayHello [hello]
00000000 d __this_module [hello]
00000000 t cleanup_module [hello]
chenwx@chenwx ~/alex/module $ sudo rmmod hello
chenwx@chenwx ~/alex/module $ lsmod
Module Size Used by
hid 82142 2 hid_generic,usbhid
chenwx@chenwx ~/alex/module $ dmesg | tail
[ 1346.932248] input: VirtualBox USB Tablet as /devices/pci0000:00/0000:00:06.0/usb1/1-1/1-1:1.0/input/input6
[ 1346.933869] hid-generic 0003:80EE:0021.0002: >input,hidraw0: USB HID v1.10 Mouse [VirtualBox USB Tablet] on usb-0000:00:06.0-1/input0
[ 1347.096468] e1000: eth0 NIC Link is Down
[ 1351.105984] e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: RX
[ 5007.862201] Hello module init
[ 5042.121131] Hello module exit
chenwx@chenwx ~/alex/module $ cat /proc/kallsyms | grep hello
chenwx@chenwx ~/alex/module $
13.2.5 Sections of Compiled Module
The compiled modules may have following sections, you can run command “readelf -e
| Section Name | Description |
|---|---|
.gnu.linkonce.this_module |
Module structue, that’s struct module. See 13.4.2.4 How to access symbols |
.modinfo |
String-style module information (Licence, etc). See 13.1.2.1 MODULE_INFO()/__MODULE_INFO() |
__versions |
Expected (compile-time) versions (CRC) of the symbols that this module depends on. |
__ksymtab* |
Table of symbols which this module exports. See 13.1.2.3 EXPORT_SYMBOL(), 13.5.1.2.1.1 find_module_sections(), and Appendix H: scripts/module-common.lds |
__kcrctab* |
Table of versions of symbols which this module exports. See 13.1.2.3 EXPORT_SYMBOL(), 13.5.1.2.1.1 find_module_sections() and Appendix H: scripts/module-common.lds |
*.init |
Sections used while initialization (__init). See 13.1.2.4 __init/__initdata/__exit/__exitdata and 13.5.1.1.1.1 __initcall_start[]/__early_initcall_end[]/__initcall_end[] |
.text, .data, etc. |
The code and data. |
where, * is one of (none), _gpl, _gpl_future, _unused, unused_gpl.
13.3 模块的加载/卸载
13.3.1 加载/卸载模块的命令
加载/卸载模块的命令与系统调用的关系:
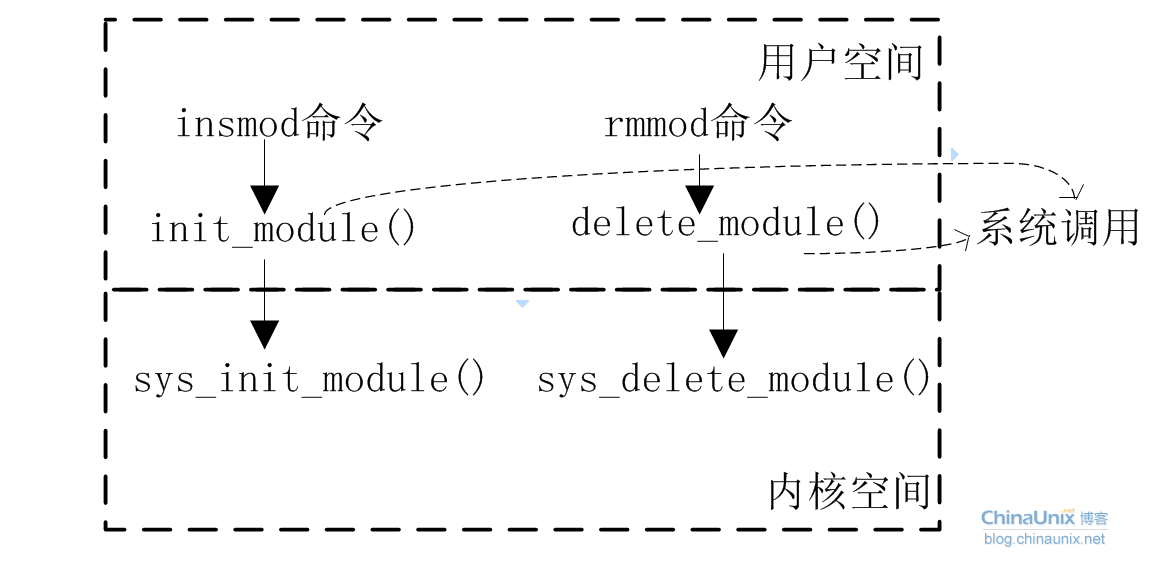
13.3.1.1 module-init-tools
module-init-tools提供了如下实用程序,用于加载、管理内核模块:
modprobe
新版本的Linux常用这个命令来加载和卸载系统内核模块
lsmod
查看当前系统加载的内核模块(含各种驱动等),信息来源于文件/proc/modules.
insmod
加载一个系统内核模块到内核中,常用modprobe命令代替(推荐使用modprobe命令)。
insmod.static
insmod的静态编译版本。
rmmod
从内核卸载一个已经加载的模块,常用modprobe -r代替(推荐使用modprobe命令)。
depmod
生成module dependency file,该文件保存在/lib/modules/<当前内核版本>/modules.dep,用于insmod等命令安装模块时使用。
modinfo
查看指定module的信息。
ksyms
Display exported kernel symbols. The format is address, name, and defining module. If no command ksyms, you can use below command to get exported kernel symbols:
# cat /proc/kallsyms
nm
List symbols from object files.
在网站http://www.kernel.org/pub/linux/utils/kernel/module-init-tools/下载module-init-tools,例如module-init-tools-3.15:
module-init-tools-3.15.tar.bz2 02-Jun-2011 17:43 224K
module-init-tools-3.15.tar.bz2.sign 02-Jun-2011 17:43 249
module-init-tools-3.15.tar.gz 02-Jun-2011 17:43 340K
module-init-tools-3.15.tar.gz.sign 02-Jun-2011 17:43 190
module-init-tools-3.15.tar.xz 02-Jun-2011 17:43 187K
module-init-tools-3.15.tar.xz.sign 02-Jun-2011 17:43 249
# cp jvxf module-init-tools-3.15.tar.xz ~
# cd ~
# tar vxf module-init-tools-3.15.tar.xz
# cd module-init-tools-3.15
# ./configure --prefix=/
# make // 编译module-init-tools,编译结果在build/目录下
# make install // 将编译的工具安装到系统中
# depmod // update /lib/modules/<kernel version> for the latest release
13.3.1.2 kmod
kmod replaces module-init-tools, which is end-of-life. Most of its tools are rewritten on top of libkmod, so it can be used as a drop in replacements. Somethings however were changed. Reasons vary from “the feature was already long deprecated on module-init-tools” to “it would be too much trouble to support it”.
# 下载kmod源代码至~/kmod目录
chenwx@chenwx ~ $ git clone http://git.kernel.org/pub/scm/utils/kernel/kmod/kmod.git
# 选择最新版本的kmod代码
chenwx@chenwx ~ $ cd mod
chenwx@chenwx ~/kmod $ git tag -l
...
v20
chenwx@chenwx ~/kmod $ git co v20
Note: checking out 'v20'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b new_branch_name
HEAD is now at d9c71758595c... kmod 20
# 编译该版本的kmod
chenwx@chenwx ~/kmod $ aclocal
chenwx@chenwx ~/kmod $ libtoolize --force
libtoolize: putting auxiliary files in AC_CONFIG_AUX_DIR, `build-aux'.
libtoolize: linking file `build-aux/ltmain.sh'
libtoolize: putting macros in AC_CONFIG_MACRO_DIR, `m4'.
libtoolize: linking file `m4/libtool.m4'
libtoolize: linking file `m4/ltoptions.m4'
libtoolize: linking file `m4/ltsugar.m4'
libtoolize: linking file `m4/ltversion.m4'
libtoolize: linking file `m4/lt~obsolete.m4'
chenwx@chenwx ~/kmod $ autoconf
chenwx@chenwx ~/kmod $ autoheader
chenwx@chenwx ~/kmod $ automake --add-missing
chenwx@chenwx ~/kmod $ ./configure CFLAGS="-g -O2" --prefix=/usr --sysconfdir=/etc --libdir=/usr/lib
...
config.status: creating libkmod/docs/version.xml
config.status: creating config.h
config.status: config.h is unchanged
config.status: executing depfiles commands
config.status: executing libtool commands
kmod 20
=======
prefix: /usr
sysconfdir: /etc
libdir: /usr/lib
rootlibdir: /usr/lib
includedir: ${prefix}/include
bindir: ${exec_prefix}/bin
Bash completions dir: /usr/share/bash-completion/completions
compiler: gcc -std=gnu99
cflags: -pipe -DANOTHER_BRICK_IN_THE -Wall -W -Wextra -Wno-inline -Wvla -Wundef -Wformat=2 -Wlogical-op -Wsign-compare -Wformat-security -Wmissing-include-dirs -Wformat-nonliteral -Wold-style-definition -Wpointer-arith -Winit-self -Wdeclaration-after-statement -Wfloat-equal -Wmissing-prototypes -Wstrict-prototypes -Wredundant-decls -Wmissing-declarations -Wmissing-noreturn -Wshadow -Wendif-labels -Wstrict-aliasing=3 -Wwrite-strings -Wno-long-long -Wno-overlength-strings -Wno-unused-parameter -Wno-missing-field-initializers -Wno-unused-result -Wnested-externs -Wchar-subscripts -Wtype-limits -Wuninitialized -fno-common -fdiagnostics-show-option -fvisibility=hidden -ffunction-sections -fdata-sections -g -O2
ldflags: -Wl,--as-needed -Wl,--no-undefined -Wl,--gc-sections
tools: yes
python bindings: no
logging: yes
compression: xz=no zlib=no
debug: no
coverage: no
doc:
man: yes
chenwx@chenwx ~/kmod $ make
...
CC tools/static-nodes.o
CCLD tools/kmod
GEN libkmod/libkmod.pc
Making all in libkmod/docs
make[2]: Nothing to be done for `all'.
Making all in man
make[2]: Nothing to be done for `all'.
chenwx@chenwx ~/kmod $ sudo make install
...
/bin/mkdir -p '/usr/lib/pkgconfig'
/usr/bin/install -c -m 644 libkmod/libkmod.pc '/usr/lib/pkgconfig'
Making install in libkmod/docs
make[2]: Nothing to be done for `install-exec-am'.
make[2]: Nothing to be done for `install-data-am'.
Making install in man
make[2]: Nothing to be done for `install-exec-am'.
/bin/mkdir -p '/usr/share/man/man5'
/usr/bin/install -c -m 644 depmod.d.5 modprobe.d.5 modules.dep.5 modules.dep.bin.5 '/usr/share/man/man5'
/bin/mkdir -p '/usr/share/man/man8'
/usr/bin/install -c -m 644 kmod.8 depmod.8 insmod.8 lsmod.8 rmmod.8 modprobe.8 modinfo.8 '/usr/share/man/man8'
chenwx@chenwx ~/kmod $ kmod -V
kmod version 20
# kmod的用法
chenwx@chenwx ~/kmod $ kmod -h
kmod - Manage kernel modules: list, load, unload, etc
Usage:
kmod [options] command [command_options]
Options:
-V, --version show version
-h, --help show this help
Commands:
help Show help message
list list currently loaded modules
static-nodes outputs the static-node information installed with the currently running kernel
kmod also handles gracefully if called from following symlinks:
lsmod compat lsmod command
rmmod compat rmmod command
insmod compat insmod command
modinfo compat modinfo command
modprobe compat modprobe command
depmod compat depmod command
chenwx@chenwx ~/kmod $ ll `which lsmod`
lrwxrwxrwx 1 root root 9 Oct 24 20:48 /sbin/lsmod -> /bin/kmod
chenwx@chenwx ~/kmod $ ll `which rmmod`
lrwxrwxrwx 1 root root 9 Oct 24 20:48 /sbin/rmmod -> /bin/kmod
chenwx@chenwx ~/kmod $ ll `which insmod`
lrwxrwxrwx 1 root root 9 Oct 24 20:48 /sbin/insmod -> /bin/kmod
chenwx@chenwx ~/kmod $ ll `which modinfo`
lrwxrwxrwx 1 root root 9 Oct 24 20:48 /sbin/modinfo -> /bin/kmod
chenwx@chenwx ~/kmod $ ll `which modprobe`
lrwxrwxrwx 1 root root 9 Oct 24 20:48 /sbin/modprobe -> /bin/kmod
chenwx@chenwx ~/kmod $ ll `which depmod`
lrwxrwxrwx 1 root root 9 Oct 24 20:48 /sbin/depmod -> /bin/kmod
13.3.2 模块的守护进程
虽然不同的内核版本使用不同的模块守护进程(kerneld或kmod),但均使用宏或函数request_module()来加载指定模块。
13.3.2.1 kerneld
在Linux Kernel v2.0.x中,由User Mode的守护进程kerneld处理要求载入module的工作,并通过执行modprobe命令载入所需的模块。
kerneld涉及到的文件包括:
- include/linux/kerneld.h
- ipc/msg.c
在include/linux/kerneld.h中,包含如下代码:
#ifdef __KERNEL__
extern int kerneld_send(int msgtype, int ret_size, int msgsz,
const char *text, const char *ret_val);
/*
* Request that a module should be loaded.
* Wait for the exit status from insmod/modprobe.
* If it fails, it fails... at least we tried...
*/
static inline int request_module(const char *name)
{
return kerneld_send(KERNELD_REQUEST_MODULE,
0 | KERNELD_WAIT,
strlen(name), name, NULL);
}
/*
* Request the removal of a module, maybe don't wait for it.
* It doesn't matter if the removal fails, now does it?
*/
static inline int release_module(const char *name, int waitflag)
{
return kerneld_send(KERNELD_RELEASE_MODULE,
0 | (waitflag?KERNELD_WAIT:KERNELD_NOWAIT),
strlen(name), name, NULL);
}
/*
* Request a delayed removal of a module, but don't wait for it.
* The delay is done by kerneld (default: 60 seconds)
*/
static inline int delayed_release_module(const char *name)
{
return kerneld_send(KERNELD_DELAYED_RELEASE_MODULE,
0 | KERNELD_NOWAIT,
strlen(name), name, NULL);
}
/*
* Attempt to cancel a previous request for removal of a module,
* but don't wait for it.
* This call can be made if the kernel wants to prevent a delayed
* unloading of a module.
*/
static inline int cancel_release_module(const char *name)
{
return kerneld_send(KERNELD_CANCEL_RELEASE_MODULE,
0 | KERNELD_NOWAIT,
strlen(name), name, NULL);
}
/*
* Perform an "inverted" system call, maybe return the exit status
*/
static inline int ksystem(const char *cmd, int waitflag)
{
return kerneld_send(KERNELD_SYSTEM,
0 | (waitflag?KERNELD_WAIT:KERNELD_NOWAIT),
strlen(cmd), cmd, NULL);
}
/*
* Try to create a route, possibly by opening a ppp-connection
*/
static inline int kerneld_route(const char *ip_route)
{
return kerneld_send(KERNELD_REQUEST_ROUTE,
0 | KERNELD_WAIT,
strlen(ip_route), ip_route, NULL);
}
/*
* Handle an external screen blanker
*/
static inline int kerneld_blanker(int on_off) /* 0 => "off", else "on" */
{
return kerneld_send(KERNELD_BLANKER,
0 | (on_off ? KERNELD_NOWAIT : KERNELD_WAIT),
strlen(on_off ? "on" : "off"), on_off ? "on" : "off", NULL);
#endif /* __KERNEL__ */
在Kernel Mode下,调用request_module()函数加载指定模块时,该函数调用kerneld_send()传送对应的消息给守护进程kerneld,以完成载入模块的动作。函数kerneld_send()定义于ipc/msg.c:
int kerneld_send(int msgtype, int ret_size, int msgsz,
const char *text, const char *ret_val)
{
int status = -ENOSYS;
#ifdef CONFIG_KERNELD
static int id = KERNELD_MINSEQ;
struct kerneld_msg kmsp = { msgtype, NULL_KDHDR, (char *)text };
int msgflg = S_IRUSR | S_IWUSR | IPC_KERNELD | MSG_NOERROR;
unsigned long flags;
if (kerneld_msqid == -1)
return -ENODEV;
/* Do not wait for an answer at interrupt-time! */
if (intr_count)
ret_size &= ~KERNELD_WAIT;
#ifdef NEW_KERNELD_PROTOCOL
else
kmsp.pid = current->pid;
#endif
msgsz += KDHDR;
if (ret_size & KERNELD_WAIT) {
save_flags(flags);
cli();
if (++id <= 0) /* overflow */
id = KERNELD_MINSEQ;
kmsp.id = id;
restore_flags(flags);
}
status = real_msgsnd(kerneld_msqid, (struct msgbuf *)&kmsp, msgsz, msgflg);
if ((status >= 0) && (ret_size & KERNELD_WAIT)) {
ret_size &= ~KERNELD_WAIT;
kmsp.text = (char *)ret_val;
status = real_msgrcv(kerneld_msqid, (struct msgbuf *)&kmsp,
KDHDR + ((ret_val)?ret_size:0), kmsp.id, msgflg);
if (status > 0) /* a valid answer contains at least a long */
status = kmsp.id;
}
#endif /* CONFIG_KERNELD */
return status;
}
函数kerneld_send()调用函数real_msgsnd(),把Kernel Mode中所要求的消息传给在User Mode下的守护进程kerneld,而User Mode下的守护进程kerneld则通过函数msgrcv()取得kernel发送来的消息,并载入或移除指定的模块。
13.3.2.2 kmod
在Linux Kernel v2.1.x以后的版本中,通过调用宏request_module()来加载指定模块。
宏request_module()的调用关系如下:
request_module()
-> __request_module()
-> call_usermodehelper_fns()
-> call_usermodehelper_setup()
-> call_usermodehelper_setfns()
-> call_usermodehelper_exec()
-> queue_work()
宏request_module()定义于include/linux/kmod.h:
#ifdef CONFIG_MODULES
extern char modprobe_path[]; /* for sysctl */
extern __printf(2, 3) int __request_module(bool wait, const char *name, ...);
#define request_module(mod...) __request_module(true, mod)
#define request_module_nowait(mod...) __request_module(false, mod)
#define try_then_request_module(x, mod...) ((x) ?: (__request_module(true, mod), (x)))
#else
static inline int request_module(const char *name, ...) { return -ENOSYS; }
static inline int request_module_nowait(const char *name, ...) { return -ENOSYS; }
#define try_then_request_module(x, mod...) (x)
#endif
其中,函数__request_module()定义于kernel/mod.c:
#ifdef CONFIG_MODULES
/*
* modprobe_path is set via /proc/sys.
*/
char modprobe_path[KMOD_PATH_LEN] = "/sbin/modprobe";
int __request_module(bool wait, const char *fmt, ...)
{
va_list args;
char module_name[MODULE_NAME_LEN];
unsigned int max_modprobes;
int ret;
char *argv[] = { modprobe_path, "-q", "--", module_name, NULL };
static char *envp[] = { "HOME=/",
"TERM=linux",
"PATH=/sbin:/usr/sbin:/bin:/usr/bin",
NULL };
static atomic_t kmod_concurrent = ATOMIC_INIT(0);
#define MAX_KMOD_CONCURRENT 50 /* Completely arbitrary value - KAO */
static int kmod_loop_msg;
// 获取模块名module_name
va_start(args, fmt);
ret = vsnprintf(module_name, MODULE_NAME_LEN, fmt, args);
va_end(args);
if (ret >= MODULE_NAME_LEN)
return -ENAMETOOLONG;
// 调用变量security_ops中的对应函数,参见[14.4.2 security_xxx()]节
ret = security_kernel_module_request(module_name);
if (ret)
return ret;
max_modprobes = min(max_threads/2, MAX_KMOD_CONCURRENT);
atomic_inc(&kmod_concurrent);
if (atomic_read(&kmod_concurrent) > max_modprobes) {
/* We may be blaming an innocent here, but unlikely */
if (kmod_loop_msg < 5) {
printk(KERN_ERR "request_module: runaway loop modprobe %s\n", module_name);
kmod_loop_msg++;
}
atomic_dec(&kmod_concurrent);
return -ENOMEM;
}
trace_module_request(module_name, wait, _RET_IP_);
// 调用call_usermodehelper_fns()加载指定模块
ret = call_usermodehelper_fns(modprobe_path, argv, envp,
wait ? UMH_WAIT_PROC : UMH_WAIT_EXEC,
NULL, NULL, NULL);
atomic_dec(&kmod_concurrent);
return ret;
}
#endif /* CONFIG_MODULES */
其中,函数call_usermodehelper_fns()定义于include/linux/kmod.h:
static inline int call_usermodehelper_fns(char *path, char **argv, char **envp, enum umh_wait wait,
int (*init)(struct subprocess_info *info, struct cred *new),
void (*cleanup)(struct subprocess_info *), void *data)
{
struct subprocess_info *info;
gfp_t gfp_mask = (wait == UMH_NO_WAIT) ? GFP_ATOMIC : GFP_KERNEL;
// 分配并初始化struct subprocess_info类型的对象info
info = call_usermodehelper_setup(path, argv, envp, gfp_mask);
if (info == NULL)
return -ENOMEM;
// 为对象info中的域init, cleanup, data赋值,此处均为NULL
call_usermodehelper_setfns(info, init, cleanup, data);
// 调用call_usermodehelper_exec()加载指定模块
return call_usermodehelper_exec(info, wait);
}
其中,函数call_usermodehelper_setup(), call_usermodehelper_setfns()和call_usermodehelper_exec()均定义于kernel/kmod.c:
static struct workqueue_struct *khelper_wq;
struct subprocess_info *call_usermodehelper_setup(char *path, char **argv,
char **envp, gfp_t gfp_mask)
{
struct subprocess_info *sub_info;
sub_info = kzalloc(sizeof(struct subprocess_info), gfp_mask);
if (!sub_info)
goto out;
/*
* 将&sub_info->work->func域赋值为函数指针__call_usermodehelper,
* 参见[13.3.2.2.2 __call_usermodehelper()]节
*/
INIT_WORK(&sub_info->work, __call_usermodehelper);
sub_info->path = path;
sub_info->argv = argv;
sub_info->envp = envp;
out:
return sub_info;
}
void call_usermodehelper_setfns(struct subprocess_info *info,
int (*init)(struct subprocess_info *info, struct cred *new),
void (*cleanup)(struct subprocess_info *info), void *data)
{
info->cleanup = cleanup;
info->init = init;
info->data = data;
}
int call_usermodehelper_exec(struct subprocess_info *sub_info, enum umh_wait wait)
{
DECLARE_COMPLETION_ONSTACK(done);
int retval = 0;
helper_lock();
if (sub_info->path[0] == '\0')
goto out;
/*
* 工作队列khelper_wq参见[13.3.2.2.1 khelper_wq]节;
* 标志位usermodehelper_disabled由函数usermodehelper_enable()
* 和usermodehelper_disable()控制
*/
if (!khelper_wq || usermodehelper_disabled) {
retval = -EBUSY;
goto out;
}
sub_info->complete = &done;
sub_info->wait = wait;
/*
* 将工作&sub_info->work添加到工作队列khelper_wq中,并等待其完成;
* 当执行&sub_info->work时,将调用函数__call_usermodehelper(),
* 参见[13.3.2.2.2 __call_usermodehelper()]节;
* 当完成&sub_info->work后,函数__call_usermodehelper()会通过
* done域通知本进程工作已完成
*/
queue_work(khelper_wq, &sub_info->work);
if (wait == UMH_NO_WAIT) /* task has freed sub_info */
goto unlock;
wait_for_completion(&done);
retval = sub_info->retval;
out:
call_usermodehelper_freeinfo(sub_info);
unlock:
helper_unlock();
return retval;
}
13.3.2.2.1 khelper_wq
工作队列khelper_wq由usermodehelper_init()创建,其定义于kernel/kmod.c:
static struct workqueue_struct *khelper_wq;
void __init usermodehelper_init(void)
{
/*
* 创建内核线程khelper,运行命令 "ps -ef | grep khelper" 来查看该线程:
* root 20 2 0 Dec17 ? 00:00:00 [khelper]
*/
khelper_wq = create_singlethread_workqueue("khelper");
BUG_ON(!khelper_wq);
}
函数usermodehelper_init()的调用关系如下:
do_basic_setup() // 参见[4.3.4.1.4.3.13.1.2 do_basic_setup()]节
-> usermodehelper_init() // 创建工作队列khelper_wq
-> usermodehelper_enable() // 设置标志位usermodehelper_disabled = 0
工作队列有关的内容,参见7.5 工作队列/workqueue节。
13.3.2.2.2 __call_usermodehelper()
该函数定义于kernel/kmod.c:
static void __call_usermodehelper(struct work_struct *work)
{
/*
* 由对象work获取对象sub_info的地址,sub_info是由函数
* call_usermodehelper_fns()分配并初始化的,参见[13.3.1.2 kmod]节
*/
struct subprocess_info *sub_info = container_of(work, struct subprocess_info, work);
enum umh_wait wait = sub_info->wait;
pid_t pid;
/* CLONE_VFORK: wait until the usermode helper has execve'd
* successfully We need the data structures to stay around
* until that is done. */
/*
* 调用kernel_thread()创建内核线程,参见[7.2.1.4 kernel_thread()]节;
* 并执行函数wait_for_helper()或____call_usermodehelper(),
* 入参为sub_info,参见[13.3.2.2.2.1 wait_for_helper()]节
* 和[13.3.2.2.2.2 ____call_usermodehelper()]节
*/
if (wait == UMH_WAIT_PROC)
pid = kernel_thread(wait_for_helper, sub_info, CLONE_FS | CLONE_FILES | SIGCHLD);
else
pid = kernel_thread(____call_usermodehelper, sub_info, CLONE_VFORK | SIGCHLD);
switch (wait) {
case UMH_NO_WAIT:
call_usermodehelper_freeinfo(sub_info);
break;
case UMH_WAIT_PROC:
if (pid > 0)
break;
/* FALLTHROUGH */
case UMH_WAIT_EXEC:
if (pid < 0)
sub_info->retval = pid;
/*
* 通知函数call_usermodehelper_exec()所在的进程当前工作已完成,
* 参见[13.3.1.2 kmod]节中的函数call_usermodehelper_exec()
*/
complete(sub_info->complete);
}
}
13.3.2.2.2.1 wait_for_helper()
该函数定义于kernel/kmod.c:
static int wait_for_helper(void *data)
{
struct subprocess_info *sub_info = data;
pid_t pid;
/* If SIGCLD is ignored sys_wait4 won't populate the status. */
spin_lock_irq(¤t->sighand->siglock);
current->sighand->action[SIGCHLD-1].sa.sa_handler = SIG_DFL;
spin_unlock_irq(¤t->sighand->siglock);
/*
* 调用kernel_thread()创建内核线程,参见[7.2.1.4 kernel_thread()]节;
* 并执行函数____call_usermodehelper(),入参为sub_info,
* 参见[13.3.2.2.2.2 ____call_usermodehelper()]节
*/
pid = kernel_thread(____call_usermodehelper, sub_info, SIGCHLD);
if (pid < 0) {
sub_info->retval = pid;
} else {
int ret = -ECHILD;
/*
* Normally it is bogus to call wait4() from in-kernel because
* wait4() wants to write the exit code to a userspace address.
* But wait_for_helper() always runs as keventd, and put_user()
* to a kernel address works OK for kernel threads, due to their
* having an mm_segment_t which spans the entire address space.
*
* Thus the __user pointer cast is valid here.
*/
sys_wait4(pid, (int __user *)&ret, 0, NULL);
/*
* If ret is 0, either ____call_usermodehelper failed and the
* real error code is already in sub_info->retval or
* sub_info->retval is 0 anyway, so don't mess with it then.
*/
if (ret)
sub_info->retval = ret;
}
complete(sub_info->complete);
return 0;
}
13.3.2.2.2.2 ____call_usermodehelper()
该函数定义于kernel/kmod.c:
static kernel_cap_t usermodehelper_bset = CAP_FULL_SET;
static kernel_cap_t usermodehelper_inheritable = CAP_FULL_SET;
/*
* This is the task which runs the usermode application
*/
static int ____call_usermodehelper(void *data)
{
struct subprocess_info *sub_info = data;
struct cred *new;
int retval;
spin_lock_irq(¤t->sighand->siglock);
flush_signal_handlers(current, 1);
spin_unlock_irq(¤t->sighand->siglock);
/* We can run anywhere, unlike our parent keventd(). */
set_cpus_allowed_ptr(current, cpu_all_mask);
/*
* Our parent is keventd, which runs with elevated scheduling priority.
* Avoid propagating that into the userspace child.
*/
set_user_nice(current, 0);
retval = -ENOMEM;
new = prepare_kernel_cred(current);
if (!new)
goto fail;
spin_lock(&umh_sysctl_lock);
new->cap_bset = cap_intersect(usermodehelper_bset, new->cap_bset);
new->cap_inheritable = cap_intersect(usermodehelper_inheritable, new->cap_inheritable);
spin_unlock(&umh_sysctl_lock);
if (sub_info->init) {
retval = sub_info->init(sub_info, new);
if (retval) {
abort_creds(new);
goto fail;
}
}
commit_creds(new);
/*
* 通过调用系统调用sys_execve()来执行/sbin/modprobe,以加载指定模块;
* sub_info各域由__request_module()赋值,参见[13.3.1.2 kmod]节
*/
retval = kernel_execve(sub_info->path,
(const char *const *)sub_info->argv,
(const char *const *)sub_info->envp);
/* Exec failed? */
fail:
sub_info->retval = retval;
do_exit(0); // 参见[7.3.3 do_exit()]节
}
13.3.3 系统启动时自动加载模块
根据init程序的不同,系统启动式自动加载模块的方式也不同。init程序参见4.3.5 init节,其对应的自动加载模块的方法参见如下几节:
13.3.3.1 SysV-style init
当采用SysV-style init时,系统启动时会调用/etc/rc.d/rc.sysinit进行系统初始化,参见4.3.5.1.1 SysV-style init节。在rc.sysinit中包含如下代码:
# Load other user-defined modules
for file in /etc/sysconfig/modules/*.modules ; do
[ -x $file ] && $file
done
# Load modules (for backward compatibility with VARs)
if [ -f /etc/rc.modules ]; then
/etc/rc.modules
fi
...
# Initialize ACPI bits
if [ -d /proc/acpi ]; then
for module in /lib/modules/$unamer/kernel/drivers/acpi/* ; do
module=${module##*/}
module=${module%.ko}
modprobe $module >/dev/null 2>&1
done
fi
此处有两种方式自动加载模块:
1) 在目录/etc/sysconfig/modules/中添加文件*.modules,并在该文件中添加加载模块的命令。以udev-stw.modules为例,其中包含如下代码:
#!/bin/sh
MODULES="nvram floppy parport lp snd-powermac"
[ -f /etc/sysconfig/udev-stw ] && . /etc/sysconfig/udev-stw
for i in $MODULES ; do
modprobe $i >/dev/null 2>&1
done
2) 在文件/etc/rc.modules中添加加载模块的命令,并执行该文件。
13.3.3.2 upstart
当采用upstart作为init程序时,系统启动时自动加载模块的方法如下:
chenwx@chenwx ~ $ ll /etc/modules
-rw-r--r-- 1 root root 255 Oct 24 20:50 /etc/modules
chenwx@chenwx ~ $ cat /etc/modules
# /etc/modules: kernel modules to load at boot time.
#
# This file contains the names of kernel modules that should be loaded
# at boot time, one per line. Lines beginning with "#" are ignored.
# Parameters can be specified after the module name.
lp
rtc
Q: upstart如何执行读取文件/etc/modules,并加载指定的模块呢?
A: upstart会执行/etc/init/kmod.conf文件,而该文件用于加载/etc/modules中指定的模块:
chenwx@chenwx ~ $ ll /etc/init/kmod.conf
-rw-r--r-- 1 root root 689 Apr 10 2014 /etc/init/kmod.conf
chenwx@chenwx ~ $ cat /etc/init/kmod.conf
# kmod - load modules from /etc/modules
#
# This task loads the kernel modules specified in the /etc/modules file
description "load modules from /etc/modules"
start on (startup
and started udev)
task
script
[ -f /etc/modules ] && files="/etc/modules" || files=""
hash="#"
dirs="/etc/modules-load.d /run/modules-load.d /lib/modules-load.d"
for dir in $dirs; do
files="$files $(run-parts --list --regex='\.conf$' $dir 2> /dev/null || true)"
done
for file in $files; do
while read module args; do
[ -n "$module" ] && [ "${module#${hash}}" = "${module}" ] || continue
modprobe $module $args || :
done < $file
done
end script
13.3.3.3 systemd
/etc/systemd/system.conf文件包含了大量的systemd控制命令。假如未作任何的更改,文件中的所有行应该都是注释掉的,这代表了systemd正使用默认的运行方式。这个文件中可以设置日志级别,可以修改日志的基本设置。所有设置项都可以在man手册的systemd-system.conf(5)中查看。
有一些命令可以帮助分析systemd的启动进程,例如:
systemctl list-units -t service [--all]
systemctl list-units -t target [--all]
systemctl show -p Wants multi-user.target
systemctl status sshd.service
chenwx@chenwx ~ $ systemctl list-units -t service
UNIT LOAD ACTIVE SUB DESCRIPTION
accounts-daemon.service loaded active running Accounts Service
acpid.service loaded active running ACPI event daemon
atd.service loaded active running Deferred execution scheduler
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
binfmt-support.service loaded active exited Enable support for additional executable binary formats
bitlbee.service loaded active running LSB: Start and stop BitlBee IRC to other chat networks gateway
bluetooth.service loaded active running Bluetooth service
busybox-klogd.service loaded active exited LSB: Starts klogd
busybox-syslogd.service loaded active running LSB: Starts syslogd
cgmanager.service loaded active running Cgroup management daemon
clamav-freshclam.service loaded active running ClamAV virus database updater
colord.service loaded active running Manage, Install and Generate Color Profiles
console-kit-log-system-start.service loaded active exited Console System Startup Logging
console-setup.service loaded active exited Set console font and keymap
cpufrequtils.service loaded active exited LSB: set CPUFreq kernel parameters
cron.service loaded active running Regular background program processing daemon
cups-browsed.service loaded active running Make remote CUPS printers available locally
dbus.service loaded active running D-Bus System Message Bus
fetchmail.service loaded active exited LSB: init-Script for system wide fetchmail daemon
getty@tty1.service loaded active running Getty on tty1
grub-common.service loaded active exited LSB: Record successful boot for GRUB
hddtemp.service loaded active exited LSB: disk temperature monitoring daemon
irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
keyboard-setup.service loaded active exited Set console keymap
kmod-static-nodes.service loaded active exited Create list of required static device nodes for the current kern
lightdm.service loaded active running Light Display Manager
lm-sensors.service loaded active exited Initialize hardware monitoring sensors
loadcpufreq.service loaded active exited LSB: Load kernel modules needed to enable cpufreq scaling
lvm2-lvmetad.service loaded active running LVM2 metadata daemon
lvm2-monitor.service loaded active exited Monitoring of LVM2 mirrors, snapshots etc. using dmeventd or pro
mcelog.service loaded active running LSB: Machine Check Exceptions (MCE) collector & decoder
* mldonkey-server.service loaded failed failed LSB: Server for the mldonkey peer-to-peer downloader.
ModemManager.service loaded active running Modem Manager
networking.service loaded active exited Raise network interfaces
NetworkManager-wait-online.service loaded active exited Network Manager Wait Online
NetworkManager.service loaded active running Network Manager
nmbd.service loaded active running LSB: start Samba NetBIOS nameserver (nmbd)
* ntp.service loaded failed failed LSB: Start NTP daemon
ondemand.service loaded active exited LSB: Set the CPU Frequency Scaling governor to "ondemand"
openvpn.service loaded active exited OpenVPN service
polkitd.service loaded active running Authenticate and Authorize Users to Run Privileged Tasks
quota.service loaded active exited Initial Check File System Quotas
rc-local.service loaded active exited /etc/rc.local Compatibility
resolvconf.service loaded active exited Nameserver information manager
rtkit-daemon.service loaded active running RealtimeKit Scheduling Policy Service
samba-ad-dc.service loaded active exited LSB: start Samba daemons for the AD DC
setvtrgb.service loaded active exited Set console scheme
smbd.service loaded active running LSB: start Samba SMB/CIFS daemon (smbd)
speech-dispatcher.service loaded active exited LSB: Speech Dispatcher
systemd-backlight@backlight:acpi_video0.service loaded active exited Load/Save Screen Backlight Brightness of backlight:acpi_video0
systemd-backlight@backlight:intel_backlight.service loaded active exited Load/Save Screen Backlight Brightness of backlight:intel_backlig
systemd-journal-flush.service loaded active exited Flush Journal to Persistent Storage
systemd-journald.service loaded active running Journal Service
systemd-logind.service loaded active running Login Service
systemd-modules-load.service loaded active exited Load Kernel Modules
systemd-random-seed.service loaded active exited Load/Save Random Seed
systemd-remount-fs.service loaded active exited Remount Root and Kernel File Systems
systemd-sysctl.service loaded active exited Apply Kernel Variables
systemd-tmpfiles-setup-dev.service loaded active exited Create Static Device Nodes in /dev
systemd-tmpfiles-setup.service loaded active exited Create Volatile Files and Directories
systemd-udev-trigger.service loaded active exited udev Coldplug all Devices
systemd-udevd.service loaded active running udev Kernel Device Manager
systemd-update-utmp.service loaded active exited Update UTMP about System Boot/Shutdown
systemd-user-sessions.service loaded active exited Permit User Sessions
udisks2.service loaded active running Disk Manager
upower.service loaded active running Daemon for power management
user@1000.service loaded active running User Manager for UID 1000
virtualbox-guest-utils.service loaded active exited LSB: VirtualBox Linux Additions
winbind.service loaded active running LSB: start Winbind daemon
wpa_supplicant.service loaded active running WPA supplicant
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
70 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
chenwx@chenwx ~ $ systemctl list-units -t target
UNIT LOAD ACTIVE SUB DESCRIPTION
basic.target loaded active active Basic System
bluetooth.target loaded active active Bluetooth
cryptsetup.target loaded active active Encrypted Volumes
getty.target loaded active active Login Prompts
graphical.target loaded active active Graphical Interface
local-fs-pre.target loaded active active Local File Systems (Pre)
local-fs.target loaded active active Local File Systems
multi-user.target loaded active active Multi-User System
network-online.target loaded active active Network is Online
network.target loaded active active Network
nss-user-lookup.target loaded active active User and Group Name Lookups
paths.target loaded active active Paths
remote-fs-pre.target loaded active active Remote File Systems (Pre)
remote-fs.target loaded active active Remote File Systems
slices.target loaded active active Slices
sockets.target loaded active active Sockets
sound.target loaded active active Sound Card
swap.target loaded active active Swap
sysinit.target loaded active active System Initialization
time-sync.target loaded active active System Time Synchronized
timers.target loaded active active Timers
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
21 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
chenwx@chenwx /etc/systemd $ systemctl show -p Wants multi-user.target
Wants=cgproxy.service cgmanager.service plymouth-quit.service dbus.service ondemand.service cups.path winbind.service smbd.service systemd-l
chenwx@chenwx /etc/systemd $ systemctl status sshd.service
* sshd.service
Loaded: not-found (Reason: No such file or directory)
Active: inactive (dead)
13.4 模块在内核中的表示
13.4.1 与模块有关的结构体
13.4.1.1 struct module
该结构定义于include/linux/module.h:
struct module_use {
struct list_head source_list;
struct list_head target_list;
struct module *source, *target;
};
enum module_state
{
MODULE_STATE_LIVE, // the module is active
MODULE_STATE_COMING, // the module is being initialized
MODULE_STATE_GOING, // the module is being removed
};
struct module
{
// The internal state of the module
enum module_state state;
/* Member of list of modules */
// Pointers for the list of modules,参见下文
struct list_head list;
/* Unique handle for this module */
/*
* Module name,与宏THIS_MODULE有关,参见[13.4.2.4 How to access symbols]节
* 和[13.5.1.4 mod->init/mod->exit与init_module()/cleanup_module()的关联]节
*/
char name[MODULE_NAME_LEN];
/* Sysfs stuff. */
// Includes a kobject data structure and a pointer to this module object
struct module_kobject mkobj;
struct module_attribute *modinfo_attrs;
const char *version;
const char *srcversion;
struct kobject *holders_dir;
/* Exported symbols,参见[13.4.2.4 How to access symbols]节 */
// Pointer to an array of exported symbols
const struct kernel_symbol *syms;
// Pointer to an array of CRC values for the exported symbols
const unsigned long *crcs;
// Number of exported symbols
unsigned int num_syms;
/* Kernel parameters. */
struct kernel_param *kp;
unsigned int num_kp;
/* GPL-only exported symbols. */
// Number of GPL-exported symbols
unsigned int num_gpl_syms;
// Pointer to an array of GPL-exported symbols
const struct kernel_symbol *gpl_syms;
// Pointer to an array of CRC values for the GPL-exported symbols
const unsigned long *gpl_crcs;
#ifdef CONFIG_UNUSED_SYMBOLS
/* unused exported symbols. */
const struct kernel_symbol *unused_syms;
const unsigned long *unused_crcs;
unsigned int num_unused_syms;
/* GPL-only, unused exported symbols. */
unsigned int num_unused_gpl_syms;
const struct kernel_symbol *unused_gpl_syms;
const unsigned long *unused_gpl_crcs;
#endif
/* symbols that will be GPL-only in the near future. */
const struct kernel_symbol *gpl_future_syms;
const unsigned long *gpl_future_crcs;
unsigned int num_gpl_future_syms;
/* Exception table */
// Number of entries in the module’s exception table
unsigned int num_exentries;
// Pointer to the module’s exception table
struct exception_table_entry *extable;
/* Startup function. */
// The initialization method of the module
int (*init)(void);
/* If this is non-NULL, vfree after init() returns */
/*
* Pointer to the dynamic memory area allocated
* for module’s initialization: "init" sections
*/
void *module_init;
/* Here is the actual code + data, vfree'd on unload. */
/*
* Pointer to the dynamic memory area allocated
* for module’s core functions and data structures
*/
void *module_core;
/* Here are the sizes of the init and core sections */
/*
* init_size: Size of the dynamic memory area
* required for module’s initialization
* Core_size: Size of the dynamic memory area
* required for module’s core functions
* and data structures
*/
unsigned int init_size, core_size;
/* The size of the executable code in each section. */
/*
* init_text_size: Size of the executable code
* used for module’s initialization;
* core_text_size: Size of the core executable
* code of the module.
* Those to variables are used only when linking
* the module.
*/
unsigned int init_text_size, core_text_size;
/* Size of RO sections of the module (text+rodata) */
unsigned int init_ro_size, core_ro_size;
/* Arch-specific module values */
// Architecture-dependent fields (none in the 80×86 architecture)
struct mod_arch_specific arch;
unsigned int taints; /* same bits as kernel:tainted */
#ifdef CONFIG_GENERIC_BUG
/* Support for BUG */
Unsigned num_bugs;
struct list_head bug_list;
struct bug_entry *bug_table;
#endif
#ifdef CONFIG_KALLSYMS
/*
* We keep the symbol and string tables for kallsyms.
* The core_* fields below are temporary, loader-only (they
* could really be discarded after module init).
*/
/*
* symtab: Pointer to an array of module’s ELF
* symbols for the /proc/kallsyms file
*/
Elf_Sym *symtab, *core_symtab;
/*
* num_symtab: Number of module’s ELF symbols
* shown in /proc/kallsyms
*/
unsigned int num_symtab, core_num_syms;
/*
* strtab: The string table for the module’s ELF
* symbols shown in /proc/kallsyms
*/
char *strtab, *core_strtab;
/* Section attributes */
/*
* Pointer to an array of module’s section attribute
* descriptors (displayed in the sysfs filesystem)
*/
struct module_sect_attrs *sect_attrs;
/* Notes attributes */
struct module_notes_attrs *notes_attrs;
#endif
/* The command line arguments (may be mangled). People like
keeping pointers to this stuff */
// Command line arguments used when linking the module
char *args;
#ifdef CONFIG_SMP
/* Per-cpu data. */
// Pointer to CPU-specific memory areas
void __percpu *percpu;
unsigned int percpu_size;
#endif
#ifdef CONFIG_TRACEPOINTS
unsigned int num_tracepoints;
struct tracepoint *const *tracepoints_ptrs;
#endif
#ifdef HAVE_JUMP_LABEL
struct jump_entry *jump_entries;
unsigned int num_jump_entries;
#endif
#ifdef CONFIG_TRACING
unsigned int num_trace_bprintk_fmt;
const char **trace_bprintk_fmt_start;
#endif
#ifdef CONFIG_EVENT_TRACING
struct ftrace_event_call **trace_events;
unsigned int num_trace_events;
#endif
#ifdef CONFIG_FTRACE_MCOUNT_RECORD
unsigned int num_ftrace_callsites;
unsigned long *ftrace_callsites;
#endif
#ifdef CONFIG_MODULE_UNLOAD
/* What modules depend on me? */
struct list_head source_list; // 依赖于本模块的模块列表
/* What modules do I depend on? */
struct list_head target_list; // 本模块所依赖模块的列表
/* Who is waiting for us to be unloaded */
// The process that is trying to unload the module
struct task_struct *waiter;
/* Destruction function. */
// Exit method of the module
void (*exit)(void);
struct module_ref {
unsigned int incs;
unsigned int decs;
} __percpu *refptr;
#endif
#ifdef CONFIG_CONSTRUCTORS
/* Constructor functions. */
ctor_fn_t *ctors;
unsigned int num_ctors;
#endif
};
13.3.2.1.1 modules链表
链表modules包含了系统中已加载的模块,该链表的元素是由函数load_module()添加进来的,参见13.5.1.2.1 load_module()节。该链表定义于kernel/module.c:
DEFINE_MUTEX(module_mutex);
static LIST_HEAD(modules);
#ifdef CONFIG_KGDB_KDB
struct list_head *kdb_modules = &modules; /* kdb needs the list of modules */
#endif /* CONFIG_KGDB_KDB */
链表modules的结构:

#else
#define THIS_MODULE ((struct module *)0)
#endif
每个模块加载到系统中后,都会生成一个对应的struct module类型的对象,而宏THIS_MODULE就指向该对象,参见13.4.2.4 How to access symbols节。
13.4.1.2 struct load_info
该结构定义于kernel/module.c:
struct load_info {
Elf_Ehdr *hdr;
unsigned long len;
Elf_Shdr *sechdrs;
char *secstrings, *strtab;
unsigned long *strmap;
unsigned long symoffs, stroffs;
struct _ddebug *debug;
unsigned int num_debug;
struct {
unsigned int sym, str, mod, vers, info, pcpu;
} index;
};
该类型的变量是由函数load_module()分配的,参见13.5.1.2.1 load_module()节。
13.4.2 Kernel Symbol Table
A good post related to kernel symbol table (kallsyms) in http://onebitbug.me/2011/03/04/introducing-linux-kernel-symbols/, which is also pasted in here.
13.4.2.0 Scope of Kernel symbols
You can think of kernel symbols (either functions or data objects) as being visible at three different levels in the kernel source code:
| Type | Scope | Definition |
|---|---|---|
| static | visible only within their own source file (just like standard user space programming) | static int var; static void set_flag(bool flag); |
| external | potentially visible to any other code built into the kernel itself | In kernel/sched/proc.c: unsigned long calc_load_update; In kernel/sched/sched.h: extern unsigned long calc_load_update; |
| exported | visible and available to any loadable module | EXPORT_SYMBOL() which exports a given symbol to all loadable modules;EXPORT_SYMBOL_GPL() which exports a given symbol to only those modules that have a GPL-compatible license. 参见13.1.2.3 EXPORT_SYMBOL()节 |
Functions that are exported are available for use by modules. Functions that are not exported cannot be invoked by modules. The linking and invoking rules are much more stringent for modules than code in the core kernel image. Core code can call any non-static interface in the kernel because all core source files are linked into a single base image. Exported symbols, of course, must be non-static, too.
The set of kernel symbols that are exported are known as the exported kernel interfaces or even (gasp) the kernel API.
Make sure you appreciate the significance of this sentence: “Core code can call any non-static interface in the kernel because all core source files are linked into a single base image.”. That means that normal non-static, unexported symbols in kernel space are available to other routines that are built into the kernel, but are not available to loadable modules. In short, your modules are working with a more restricted kernel symbol table than other routines that are part of the kernel itself.
13.4.2.1 Introducing Linux Kernel Symbols
In kernel developing, sometimes we have to examine some kernel status, or we want to reuse some kernel facilities, we need to access (read, write, execute) kernel symbols. In this article, we will see how the kernel maintains the symbol table, and how we can use the kernel symbols.
This article is more of a guide to reading kernel source code and kernel development. So we will work a lot with source code.
13.4.2.2 What are kernel symbols
Let’s begin with some basic knowledge. In programming language, a symbol is either a variable or a function. Or more generally, we can say, a symbol is a name representing an space in the memory, which stores data (variable, for reading and writing) or instructions (function, for executing). To make life easier for cooperation among various kernel function unit, there are thousands of global symbols in Linux kernel. A global variable is defined outside of any function body. A global function is declared without inline and static. All global symbols are listed in /proc/kallsyms. It looks like this:
$ tail /proc/kallsyms
ffffffff81da9000 b .brk.dmi_alloc
ffffffff81db9000 B __brk_limit
ffffffffff600000 T vgettimeofday
ffffffffff600140 t vread_tsc
ffffffffff600170 t vread_hpet
ffffffffff600180 D __vsyscall_gtod_data
ffffffffff600400 T vtime
ffffffffff600800 T vgetcpu
ffffffffff600880 D __vgetcpu_mode
ffffffffff6008c0 D __jiffies
It’s in nm’s output format. The first column is the symbol’s address, the second column is the symbol type. You can see the detailed instruction in nm’s manpage. See below table:
1st column
The symbol address, in the radix selected by options (see below), or hexadecimal by default.
2nd column
The symbol type. At least the following types are used; others are, as well, depending on the object file format.
- If lowercase, the symbol is local;
- If uppercase, the symbol is global (external).
| A | The symbol’s value is absolute, and will not be changed by further linking. |
| B | The symbol is in the uninitialized data section (known as BSS). |
| C | The symbol is common. Common symbols are uninitialized data. When linking, multiple common symbols may appear with the same name. If the symbol is defined anywhere, the common symbols are treated as undefined references. |
| D | The symbol is in the initialized data section. |
| G | The symbol is in an initialized data section for small objects. Some object file formats permit more efficient access to small data objects, such as a global int variable as opposed to a large global array. |
| I | The symbol is an indirect reference to another symbol. This is a GNU extension to the a.out object file format which is rarely used. |
| N | The symbol is a debugging symbol. |
| R | The symbol is in a read only data section. |
| S | The symbol is in an uninitialized data section for small objects. |
| T | The symbol is in the text (code) section. |
| U | The symbol is undefined. |
| V | The symbol is a weak object. When a weak defined symbol is linked with a normal defined symbol, the normal defined symbol is used with no error. When a weak undefined symbol is linked and the symbol is not defined, the value of the weak symbol becomes zero with no error. |
| W | The symbol is a weak symbol that has not been specifically tagged as a weak object symbol. When a weak defined symbol is linked with a normal defined symbol, the normal defined symbol is used with no error. When a weak undefined symbol is linked and the symbol is not defined, the value of the symbol is determined in a system-specific manner without error. Uppercase indicates that a default value has been specified. |
| - | The symbol is a stabs symbol in an a.out object file. In this case, the next values printed are the stabs other field, the stabs desc field, and the stab type. Stabs symbols are used to hold debugging information. |
| ? | The symbol type is unknown, or object file format specific. |
3rd column
The symbol name.
In general, one will tell you this is the output of nm vmlinux. However, some entries in this symbol table are from loadable kernel modules, how can they be listed here? Let’s see how this table is generated.
13.4.2.3 How is /proc/kallsyms generated
As we have seen in the last two sections, contents of procfs files are generated on reading, so don’t try to find this file anywhere on your disk. But we can directly go to the kernel source for the answer. First, let’s find the code that creates this file in kernel/kallsyms.c.
static const struct file_operations kallsyms_operations = {
.open = kallsyms_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release_private,
};
static int __init kallsyms_init(void)
{
proc_create("kallsyms", 0444, NULL, &kallsyms_operations);
return 0;
}
device_initcall(kallsyms_init);
On creating the file, the kernel associates the open() operation with kallsyms_open(), read()->seq_read(), llseek()->seq_lseek() and release()->seq_release_private(). Here we see that this file is a sequence file.
The detail about sequence file is out of scope of this article. There is a comprehensive description located in kernel documentation, please go through Documentation/filesystems/seq_file.txt if you don’t know what is sequence file. In a short way, due to the page limitation in proc_read_t, the kernel introduced sequence file for kernel to provide large amount of information to the user.
Ok, back to the source. In kallsyms_open(), it does nothing more than create and reset the iterator for seq_read operation, and of course set the seq_operations, see kernel/kallsyms.c:
static const struct seq_operations kallsyms_op = {
.start = s_start,
.next = s_next,
.stop = s_stop,
.show = s_show
};
static int kallsyms_open(struct inode *inode, struct file *file)
{
/*
* We keep iterator in m->private, since normal case is to
* s_start from where we left off, so we avoid doing
* using get_symbol_offset for every symbol.
*/
struct kallsym_iter *iter;
int ret;
iter = kmalloc(sizeof(*iter), GFP_KERNEL);
if (!iter)
return -ENOMEM;
reset_iter(iter, 0);
ret = seq_open(file, &kallsyms_op);
if (ret == 0)
((struct seq_file *)file->private_data)->private = iter;
else
kfree(iter);
return ret;
}
So, for our goals, we care about s_start() and s_next(). They both invoke update_iter(), and the core of update_iter() is get_ksymbol_mod(), and followed by get_ksymbol_core(). At last, we reached module_get_kallsym() in kernel/module.c:
static void *s_start(struct seq_file *m, loff_t *pos)
{
if (!update_iter(m->private, *pos))
return NULL;
return m->private;
}
static void *s_next(struct seq_file *m, void *p, loff_t *pos)
{
(*pos)++;
if (!update_iter(m->private, *pos))
return NULL;
return p;
}
/* Returns false if pos at or past end of file. */
static int update_iter(struct kallsym_iter *iter, loff_t pos)
{
/* Module symbols can be accessed randomly. */
if (pos >= kallsyms_num_syms) {
iter->pos = pos;
return get_ksymbol_mod(iter);
}
/* If we're not on the desired position, reset to new position. */
if (pos != iter->pos)
reset_iter(iter, pos);
iter->nameoff += get_ksymbol_core(iter);
iter->pos++;
return 1;
}
static int get_ksymbol_mod(struct kallsym_iter *iter)
{
if (module_get_kallsym(iter->pos - kallsyms_num_syms, &iter->value,
&iter->type, iter->name, iter->module_name,
&iter->exported) < 0)
return 0;
return 1;
}
int module_get_kallsym(unsigned int symnum, unsigned long *value, char *type,
char *name, char *module_name, int *exported)
{
struct module *mod;
preempt_disable();
// 链表modules中包含系统内所有注册的模块,参见[13.4.1.1 struct module]节
list_for_each_entry_rcu(mod, &modules, list) {
if (symnum < mod->num_symtab) {
*value = mod->symtab[symnum].st_value;
*type = mod->symtab[symnum].st_info;
strlcpy(name, mod->strtab + mod->symtab[symnum].st_name, KSYM_NAME_LEN);
strlcpy(module_name, mod->name, MODULE_NAME_LEN);
*exported = is_exported(name, *value, mod);
preempt_enable();
return 0;
}
symnum -= mod->num_symtab;
}
preempt_enable();
return -ERANGE;
}
In module_get_kallsym(), it iterates all modules and symbols. Five properties are assigned values. value is the symbol’s address, type is the symbol’s type, name is the symbol’s name, module_name is the module name if the module is not compiled in core, otherwise empty. exported indicates whether the symbol is exported. Have you ever wondered why there are some many “local” (the type char is in lower case) symbols in the symbol table? Let’s have a lookat s_show():
static int s_show(struct seq_file *m, void *p)
{
struct kallsym_iter *iter = m->private;
/* Some debugging symbols have no name. Ignore them. */
if (!iter->name[0])
return 0;
if (iter->module_name[0]) {
char type;
/*
* Label it "global" if it is exported, "local" if not exported.
*/
type = iter->exported ? toupper(iter->type) : tolower(iter->type);
seq_printf(m, "%pK %c %s\t[%s]\n", (void *)iter->value, type, iter->name, iter->module_name);
} else
seq_printf(m, "%pK %c %s\n", (void *)iter->value, iter->type, iter->name);
return 0;
}
Ok, clear about it? All these symbols are global in C language aspect, but only exported symbols are labeled as “global”.
After the iteration finished, we see the contents of /proc/kallsyms.
13.4.2.4 How to access symbols
Here, access can be read, write and execute. Let’s have a look at this simplest module:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/jiffies.h>
MODULE_AUTHOR("Stephen Zhang");
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("Use exported symbols");
static int __init lkm_init(void)
{
printk(KERN_INFO "[%s] module loaded.\n", __this_module.name);
printk("[%s] current jiffies: %lu.\n", __this_module.name, jiffies);
return 0;
}
static void __exit lkm_exit(void)
{
printk(KERN_INFO "[%s] module unloaded.\n", __this_module.name);
}
module_init(lkm_init);
module_exit(lkm_exit);
In this module, we used printk() and jiffies, which are both symbols from kernel space. Why are these symbols available in our code? Because they are “exported”.
You can think of kernel symbols as visible at three different levels in the kernel source code:
- “static”, and therefore visible only within their own source file
- “external”, and therefore potentially visible to any other code built into the kernel itself, and
- “exported”, and therefore visible and available to any loadable module.
The kernel use two macros to export symbols:
- EXPORT_SYMBOL exports the symbol to any loadable module
- EXPORT_SYMBOL_GPL exports the symbol only to GPL-licensed modules
We find the two symbols exported in the kernel source code:
kernel/printk.c: EXPORT_SYMBOL(printk);
kernel/time.c: EXPORT_SYMBOL(jiffies);
Except for examine the kernel code to find whether a symbol is exported, is there anyway to identify it more easily? The answer is sure! All exported entry have another symbol prefixed with __ksymtab_. e.g.
$ cat /proc/kallsyms
...
ffffffff81a4ef00 r __ksymtab_printk
ffffffff81a4eff0 r __ksymtab_jiffies
...
Let’s just have another look at the definition of EXPORT_SYMBOL in include/linux/export.h:
/* For every exported symbol, place a struct in the __ksymtab section */
#define __EXPORT_SYMBOL(sym, sec) \
extern typeof(sym) sym; \
__CRC_SYMBOL(sym, sec) \
static const char __kstrtab_##sym[] \
__attribute__((section("__ksymtab_strings"), aligned(1))) \
= MODULE_SYMBOL_PREFIX #sym; \
static const struct kernel_symbol __ksymtab_##sym \
__used \
__attribute__((section("__ksymtab" sec), unused)) \
= { (unsigned long)&sym, __kstrtab_##sym }
// 扩展后的EXPORT_SYMBOL(sym)参见[13.1.2.3 EXPORT_SYMBOL()]节
#define EXPORT_SYMBOL(sym) \
__EXPORT_SYMBOL(sym, "")
The highlighted line places a struct kernel_symbol __ksymtab_##sym into the symbol table.
There is one more thing that worth noting, __this_module is not an exported symbol, nor is it defined anywhere in the kernel source. In the kernel, all we can find about __this_module are nothing more than the following two lines in include/linux/export.h:
extern struct module __this_module;
#define THIS_MODULE (&__this_module)
How?! It’s not defined in the kernel, what to link against while insmod then? Don’t panic. Have you noticed the temporary file hello.mod.c while compiling the module (see [3.4.3.4.2 make -f scripts/Makefile.modpost])? Here is the definition for __this_module:
// 变量__this_module被链接到.gnu.linkonce.this_module段
struct module __this_module
__attribute__((section(".gnu.linkonce.this_module"))) = {
/*
* KBUILD_MODNAME定义于scripts/Makefile.lib:
* modname_flags = $(if $(filter 1,$(words $(modname))), \
* -DKBUILD_MODNAME=$(call name-fix,$(modname)))
*/
.name = KBUILD_MODNAME,
/*
* 函数init_module和cleanup_module参见下列章节:
* [13.5.0 init_module()/cleanup_module()]节和
* [13.5.1 module_init()/module_exit()]节
*/
.init = init_module,
#ifdef CONFIG_MODULE_UNLOAD
.exit = cleanup_module,
#endif
/*
* MODULE_ARCH_INIT的定义参见下列文件:
* - arch/m68k/include/asm/module.h
* - include/linux/module.h
*/
.arch = MODULE_ARCH_INIT,
};
So far, as we see, we can use any exported symbols directly in our module; the only thing we have to do is to include the corresponding header file, or just to have the right declaration. Then, what if we want to access the other symbols in the kernel? Though it’s not a good idea to do such a thing, any symbol that is not exported, usually don’t expect anyone else to visit them, avoiding potential disasters; someday, just to fulfill one’s curiosity, or one knows exactly what he is doing, we have to access the non-exported symbols. Let’s go further.
13.4.2.5 How to access non-exported symbol
For each symbol in the kernel, we have an entry in /proc/kallsyms, and we have addresses for all of them. Since we are in the kernel, we can see any bit we want to see! Just read from that address. Let’s take resume_file as an example. Source code comes first:
#include <linux/module.h>
#include <linux/kallsyms.h>
#include <linux/string.h>
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("Access non-exported symbols");
MODULE_AUTHOR("Stephen Zhang");
static int __init lkm_init(void)
{
char *sym_name = "resume_file";
unsigned long sym_addr = kallsyms_lookup_name(sym_name);
char filename[256];
strncpy(filename, (char *)sym_addr, 255);
printk(KERN_INFO "[%s] %s (0x%lx): %s\n", __this_module.name, sym_name, sym_addr, filename);
return 0;
}
static void __exit lkm_exit(void)
{
}
module_init(lkm_init);
module_exit(lkm_exit);
Here, instead of parsing /proc/kallsyms to find the a symbol’s address, we use kallsyms_lookup_name() to do it. Then, we just treat the address as char *, which is the type of resume_file, and read it using strncpy().
Let’s see what happens when we run:
$ sudo insmod lkm_hello.ko
$ dmesg | tail -n 1
[lkm_hello] resume_file (0xffffffff81c17140): /dev/sda6
$ grep resume_file /proc/kallsyms
ffffffff81c17140 d resume_file
Yeap! We did it! And we see the symbol address returned by kallsyms_lookup_name() is exactly the same as in /proc/kallsyms. Just like read, you can also write to a symbol’s address, but be careful, some addresses are in rodata section or text section, which cannot be written. If you try to write to a readonly address, you will probably get a kernel oops. However, this does not mean NO. You can turn off the protection. Follow instructions in this page. The basic idea is changing the page attribute:
int set_page_rw(long unsigned int _addr)
{
struct page *pg;
pgprot_t prot;
pg = virt_to_page(_addr);
prot.pgprot = VM_READ | VM_WRITE;
return change_page_attr(pg, 1, prot);
}
int set_page_ro(long unsigned int _addr)
{
struct page *pg;
pgprot_t prot;
pg = virt_to_page(_addr);
prot.pgprot = VM_READ;
return change_page_attr(pg, 1, prot);
}
13.4.2.6 Conclusion
Well, that’s too much for this post. In this article, we first dig into the Linux kernel source code, to find out how the kernel symbol table is generated. Then we learned how to use exported kernel symbols in our modules. Finally, we saw the tricky way to access all kernel symbols within a module.
13.5 模块的初始化与清理
13.5.0 init_module()/cleanup_module()
Kernel modules must have at least two functions: a “start” (initialization) function called init_module() which is called when the module is insmoded into the kernel, and an “end” (cleanup) function called cleanup_module() which is called just before it is rmmoded. Actually, things have changed starting with kernel 2.3.13. You can now use whatever name you like for the start and end functions of a module, refer macros module_init() and module_exit() in section 13.5.1 module_init()/module_exit(). In fact, the new method is the preferred method. However, many people still use init_module() and cleanup_module() for their start and end functions.
/*
* helloworld.c − The simplest kernel module.
*/
#include <linux/module.h> /* Needed by all modules */
#include <linux/kernel.h> /* Needed for KERN_INFO */
int init_module(void)
{
printk(KERN_INFO "Hello world 1.\n");
/* A non 0 return means init_module failed; module can't be loaded. */
return 0;
}
void cleanup_module(void)
{
printk(KERN_INFO "Goodbye world 1.\n");
}
13.5.1 module_init()/module_exit()
每个module都需要调用函数module_init()和module_exit(),该函数定义于include/linux/init.h:
typedef int (*initcall_t)(void);
typedef void (*exitcall_t)(void);
/*
* 当编译module时,Makefile会定义MODULE宏,参见[3.4.3 编译modules/$(obj-m)]节;
* 如果未定义MODULE,则表明本module被直接编译进了内核,此时module的初始化
* 函数需要在系统启动时调用,无需执行insmod命令
*/
#ifndef MODULE
/**
* module_init() - driver initialization entry point
* @x: function to be run at kernel boot time or module insertion
*
* module_init() will either be called during do_initcalls() (if
* builtin) or at module insertion time (if a module). There can only
* be one per module.
*/
#define module_init(x) __initcall(x);
#define __initcall(fn) device_initcall(fn)
// module_init()被扩展到.initcall6.init段,参见[13.5.1.1.1.1.1 .initcall*.init]节
#define device_initcall(fn) __define_initcall("6",fn,6)
/**
* module_exit() - driver exit entry point
* @x: function to be run when driver is removed
*
* module_exit() will wrap the driver clean-up code
* with cleanup_module() when used with rmmod when
* the driver is a module. If the driver is statically
* compiled into the kernel, module_exit() has no effect.
* There can only be one per module.
*/
#define module_exit(x) __exitcall(x);
#define __exitcall(fn) \
static exitcall_t __exitcall_##fn __exit_call = fn
#else
/*
* 若定义了MODULE,则表明本module被编译成了独立的模块,
* 此时module的初始化函数在insmod时被调用
*/
/*
* 在宏module_init()中将init_module()声明为函数initfn的别名,
* 故调用init_module()就是调用initfn(),
* 参见[13.5.1.4 mod->init/mod->exit与init_module()/cleanup_module()的关联]节;
* 其中,函数alias()参见<<Using the GNU Compiler Collection (GCC)>>
* 第5.24 Declaring Attributes of Functions章
*/
/* Each module must use one module_init(). */
#define module_init(initfn) \
static inline initcall_t __inittest(void) \
{ return initfn; } \
int init_module(void) __attribute__((alias(#initfn)));
/*
* 在宏module_exit()中将cleanup_module声明为函数exitfn的别名,
* 故调用cleanup_module()就是调用exitfn(),
* 参见[13.5.1.4 mod->init/mod->exit与init_module()/cleanup_module()的关联]节;
* 其中,函数alias()参见<<Using the GNU Compiler Collection (GCC)>>
* 第5.24 Declaring Attributes of Functions章
*/
/* This is only required if you want to be unloadable. */
#define module_exit(exitfn) \
static inline exitcall_t __exittest(void) \
{ return exitfn; } \
void cleanup_module(void) __attribute__((alias(#exitfn)));
#endif
宏module_init()所传递的参数是模块初始化函数,该函数被do_one_initcall()调用,而调用函数do_one_initcall()分为两种情况:
- 当module被编译进内核时,其初始化函数需要在系统启动时被调用,参见13.5.1.1 module被编译进内核时的初始化过程节;
- 当module被编译成单独的模块时,其初始化函数在insmod时被调用,参见13.5.1.2 insmod调用sys_init_module()节。
宏module_exit()所传递的参数是模块卸载函数,该函数在delete_modules()中,或者在rmmod时调用,参见13.5.1.3 rmmod调用sys_delete_module()节。
NOTE: If a module is compiled into the static kernel image, the exit function would not be included, and it would never be invoked because if it were not a module, the code could never be removed from memory.
13.5.1.1 module被编译进内核时的初始化过程
系统启动时,通过下列两种方法执行某些初始化函数:
1) 调用__initcall_start和__early_initcall_end之间的初始化函数
kernel_init() -> do_pre_smp_initcalls() -> do_one_initcall()
2) 调用__early_initcall_end和__initcall_end之间的初始化函数
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
函数do_pre_smp_initcalls()定义于init/main.c,参见4.3.4.1.4.3.13.1.1 do_pre_smp_initcalls()节。
函数do_basic_setup()定义于init/main.c,参见4.3.4.1.4.3.13.1.2 do_basic_setup()节。
13.5.1.1.1 do_initcalls()
该函数定义于init/main.c:
/*
* 所有初始化函数被存放到一个数组空间中,如下三个变量表示特定的数组下标,
* 参见[13.5.1.1.1.1 __initcall_start[]/__early_initcall_end[]/__initcall_end[]]节
*/
extern initcall_t __initcall_start[], __initcall_end[], __early_initcall_end[];
static void __init do_initcalls(void)
{
initcall_t *fn;
/*
* 依次执行__early_initcall_end与__initcall_end之间的初始化函数,
* 参见[13.5.1.1.1.1 __initcall_start[]/__early_initcall_end[]/__initcall_end[]]节;
* 其中,函数do_one_initcall()用于执行函数fn(),参见[13.5.1.1.1.2 do_one_initcall()]节
*/
for (fn = __early_initcall_end; fn < __initcall_end; fn++)
do_one_initcall(*fn);
}
13.5.1.1.1.1 __initcall_start[]/__early_initcall_end[]/__initcall_end[]
在arch/x86/kernel/vmlinux.lds.S中,包含如下代码:
#include <asm-generic/vmlinux.lds.h>
SECTIONS
{
...
INIT_DATA_SECTION(16)
...
}
其中,宏INIT_DATA_SECTION定义于include/asm-generic/vmlinux.lds.h:
#ifndef SYMBOL_PREFIX
#define VMLINUX_SYMBOL(sym) sym
#else
#define PASTE2(x,y) x##y
#define PASTE(x,y) PASTE2(x,y)
#define VMLINUX_SYMBOL(sym) PASTE(SYMBOL_PREFIX, sym)
#endif
#define INIT_DATA_SECTION(initsetup_align) \
.init.data : AT(ADDR(.init.data) - LOAD_OFFSET) { \
INIT_DATA \
INIT_SETUP(initsetup_align) \
INIT_CALLS \
CON_INITCALL \
SECURITY_INITCALL \
INIT_RAM_FS \
}
#define INIT_CALLS \
VMLINUX_SYMBOL(__initcall_start) = .; \
INITCALLS \
VMLINUX_SYMBOL(__initcall_end) = .;
#define INITCALLS \
*(.initcallearly.init) \
VMLINUX_SYMBOL(__early_initcall_end) = .; \
*(.initcall0.init) \
*(.initcall0s.init) \
*(.initcall1.init) \
*(.initcall1s.init) \
*(.initcall2.init) \
*(.initcall2s.init) \
*(.initcall3.init) \
*(.initcall3s.init) \
*(.initcall4.init) \
*(.initcall4s.init) \
*(.initcall5.init) \
*(.initcall5s.init) \
*(.initcallrootfs.init) \
*(.initcall6.init) \
*(.initcall6s.init) \
*(.initcall7.init) \
*(.initcall7s.init)
由arch/x86/kernel/vmlinux.lds.S扩展而来(参见3.4.2.2.2 vmlinux.lds如何生成节)的vmliux.lds(详见Appendix G: vmlinux.lds节)包含了.init.data段,其中的初始化函数如下:
.init.data : AT(ADDR(.init.data) - 0xC0000000) { *(.init.data) *(.cpuinit.data) *(.meminit.data) . = ALIGN(8); __ctors_start = .; *(.ctors) __ctors_end = .; *(.init.rodata) . = ALIGN(8); __start_ftrace_events = .; *(_ftrace_events) __stop_ftrace_events = .; *(.cpuinit.rodata) *(.meminit.rodata) . = ALIGN(32); __dtb_start = .; *(.dtb.init.rodata) __dtb_end = .; . = ALIGN(16); __setup_start = .; *(.init.setup) __setup_end = .; __initcall_start = .; *(.initcallearly.init) __early_initcall_end = .; *(.initcall0.init) *(.initcall0s.init) *(.initcall1.init) *(.initcall1s.init) *(.initcall2.init) *(.initcall2s.init) *(.initcall3.init) *(.initcall3s.init) *(.initcall4.init) *(.initcall4s.init) *(.initcall5.init) *(.initcall5s.init) *(.initcallrootfs.init) *(.initcall6.init) *(.initcall6s.init) *(.initcall7.init) *(.initcall7s.init) __initcall_end = .; __con_initcall_start = .; *(.con_initcall.init) __con_initcall_end = .; __security_initcall_start = .; *(.security_initcall.init) __security_initcall_end = .; }
NOTE: 在Linux Kernel源代码中有些找不到来源的变量是在vmlinux.lds中定义的。
13.5.1.1.1.1.1 .initcall*.init
段.initcall*.init是由如下宏扩展而来的,参见include/linux/init.h:
#ifndef MODULE
#ifndef __ASSEMBLY__
#define __define_initcall(level,fn,id) \
static initcall_t __initcall_##fn##id __used \
__attribute__((__section__(".initcall" level ".init"))) = fn
/*
* Early initcalls run before initializing SMP.
* Only for built-in code, not modules.
*/
#define early_initcall(fn) __define_initcall("early",fn,early)
/*
* A "pure" initcall has no dependencies on anything else, and purely
* initializes variables that couldn't be statically initialized.
* This only exists for built-in code, not for modules.
*/
#define pure_initcall(fn) __define_initcall("0",fn,0)
#define core_initcall(fn) __define_initcall("1",fn,1)
#define core_initcall_sync(fn) __define_initcall("1s",fn,1s)
#define postcore_initcall(fn) __define_initcall("2",fn,2)
#define postcore_initcall_sync(fn) __define_initcall("2s",fn,2s)
#define arch_initcall(fn) __define_initcall("3",fn,3)
#define arch_initcall_sync(fn) __define_initcall("3s",fn,3s)
#define subsys_initcall(fn) __define_initcall("4",fn,4)
#define subsys_initcall_sync(fn) __define_initcall("4s",fn,4s)
#define fs_initcall(fn) __define_initcall("5",fn,5)
#define fs_initcall_sync(fn) __define_initcall("5s",fn,5s)
#define rootfs_initcall(fn) __define_initcall("rootfs",fn,rootfs)
#define device_initcall(fn) __define_initcall("6",fn,6)
#define device_initcall_sync(fn) __define_initcall("6s",fn,6s)
#define late_initcall(fn) __define_initcall("7",fn,7)
#define late_initcall_sync(fn) __define_initcall("7s",fn,7s)
#define __initcall(fn) device_initcall(fn)
#define __exitcall(fn) \
static exitcall_t __exitcall_##fn __exit_call = fn
#endif /* __ASSEMBLY__ */
#define module_init(x) __initcall(x);
#define module_exit(x) __exitcall(x);
#else /* MODULE */
...
#endif
综上可知,当module被编译进内核时,其初始化函数需要在系统启动时被调用。其调用过程为:
kernel_init() -> do_basic_setup() -> do_initcalls() -> do_one_initcall()
^
+-- 其中的.initcall6.init
此外,由如下注释可知,当module被编译进内核时,其清理函数cleanup_module()不会被调用:
#ifndef MODULE
/**
* module_exit() - driver exit entry point
* @x: function to be run when driver is removed
*
* module_exit() will wrap the driver clean-up code
* with cleanup_module() when used with rmmod when
* the driver is a module. If the driver is statically
* compiled into the kernel, module_exit() has no effect.
* There can only be one per module.
*/
#define module_exit(x) __exitcall(x);
#define __exitcall(fn) \
static exitcall_t __exitcall_##fn __exit_call = fn
#else
...
#endif
13.5.1.1.1.2 do_one_initcall()
该函数用于调用指定module的初始化函数,其定义于init/main.c:
int __init_or_module do_one_initcall(initcall_t fn)
{
int count = preempt_count();
int ret;
/*
* 内核参数initcall_debug参见Documentation/kernel-parameters.txt:
* initcall_debug [KNL] Trace initcalls as they are executed.
* Useful for working out where the kernel
* is dying during startup.
*/
if (initcall_debug)
ret = do_one_initcall_debug(fn);
else
ret = fn();
msgbuf[0] = 0;
if (ret && ret != -ENODEV && initcall_debug)
sprintf(msgbuf, "error code %d ", ret);
if (preempt_count() != count) {
strlcat(msgbuf, "preemption imbalance ", sizeof(msgbuf));
preempt_count() = count;
}
if (irqs_disabled()) {
strlcat(msgbuf, "disabled interrupts ", sizeof(msgbuf));
local_irq_enable();
}
if (msgbuf[0]) {
printk("initcall %pF returned with %s\n", fn, msgbuf);
}
return ret;
}
static int __init_or_module do_one_initcall_debug(initcall_t fn)
{
ktime_t calltime, delta, rettime;
unsigned long long duration;
int ret;
printk(KERN_DEBUG "calling %pF @ %i\n", fn, task_pid_nr(current));
calltime = ktime_get();
ret = fn();
rettime = ktime_get();
delta = ktime_sub(rettime, calltime);
duration = (unsigned long long) ktime_to_ns(delta) >> 10;
printk(KERN_DEBUG "initcall %pF returned %d after %lld usecs\n", fn, ret, duration);
return ret;
}
13.5.1.2 insmod调用sys_init_module()
当module被编译为独立的模块时,通过执行insmod命令将其加载到系统中,参见13.3 模块的加载/卸载节。
系统调用sys_init_module()定义于kernel/module.c:
/*
* umod points to a buffer containing the binary image to be loaded;
* len specifies the size of that buffer.
*
* The module image should be a valid ELF image, built for the running kernel.
*
* uargs is a string containing space-delimited specifications of the values for module parameters
* (defined inside the module using module_param() and module_param_array()). The kernel parses
* this string and initializes the specified parameters. Each of the parameter specifications
* has the form: name[=value[,value...]]
*/
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
struct module *mod;
int ret = 0;
/* Must have permission */
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
/* Do all the hard work. 参见[13.5.1.2.1 load_module()]节 */
mod = load_module(umod, len, uargs);
if (IS_ERR(mod))
return PTR_ERR(mod);
blocking_notifier_call_chain(&module_notify_list, MODULE_STATE_COMING, mod);
/* Set RO and NX regions for core */
set_section_ro_nx(mod->module_core, mod->core_text_size,
mod->core_ro_size, mod->core_size);
/* Set RO and NX regions for init */
set_section_ro_nx(mod->module_init, mod->init_text_size,
mod->init_ro_size, mod->init_size);
// 调用模块构造函数mod->ctors[idx]()
do_mod_ctors(mod);
/*
* Start the module. 调用init_module()函数,参见[13.5.1.1.1.2 do_one_initcall()]节和
* [13.5.1.4 mod->init/mod->exit与init_module()/cleanup_module()的关联]节
*/
if (mod->init != NULL)
ret = do_one_initcall(mod->init);
if (ret < 0) {
/* Init routine failed: abort. Try to protect us from buggy refcounters. */
mod->state = MODULE_STATE_GOING;
synchronize_sched();
module_put(mod);
blocking_notifier_call_chain(&module_notify_list, MODULE_STATE_GOING, mod);
free_module(mod);
wake_up(&module_wq);
return ret;
}
if (ret > 0) {
printk(KERN_WARNING
"%s: '%s'->init suspiciously returned %d, it should follow 0/-E convention\n"
"%s: loading module anyway...\n", __func__, mod->name, ret, __func__);
dump_stack();
}
/*
* 只有当模块的初始化函数执行成功(ret >= 0),才会执行此后的代码
*/
/* Now it's a first class citizen! Wake up anyone waiting for it. */
mod->state = MODULE_STATE_LIVE;
wake_up(&module_wq);
blocking_notifier_call_chain(&module_notify_list, MODULE_STATE_LIVE, mod);
/* We need to finish all async code before the module init sequence is done */
async_synchronize_full();
mutex_lock(&module_mutex);
/* Drop initial reference. */
module_put(mod);
trim_init_extable(mod);
#ifdef CONFIG_KALLSYMS
mod->num_symtab = mod->core_num_syms;
mod->symtab = mod->core_symtab;
mod->strtab = mod->core_strtab;
#endif
unset_module_init_ro_nx(mod);
module_free(mod, mod->module_init);
mod->module_init = NULL;
mod->init_size = 0;
mod->init_ro_size = 0;
mod->init_text_size = 0;
mutex_unlock(&module_mutex);
return 0;
}
13.5.1.2.1 load_module()
该函数定义于kernel/module.c:
/* Allocate and load the module: note that size of section 0 is always
zero, and we rely on this for optional sections. */
static struct module *load_module(void __user *umod, unsigned long len,
const char __user *uargs)
{
struct load_info info = { NULL, };
struct module *mod;
long err;
DEBUGP("load_module: umod=%p, len=%lu, uargs=%p\n", umod, len, uargs);
/* Copy in the blobs from userspace, check they are vaguely sane. */
err = copy_and_check(&info, umod, len, uargs);
if (err)
return ERR_PTR(err);
/* Figure out module layout, and allocate all the memory. */
mod = layout_and_allocate(&info);
if (IS_ERR(mod)) {
err = PTR_ERR(mod);
goto free_copy;
}
/* Now module is in final location, initialize linked lists, etc. */
err = module_unload_init(mod);
if (err)
goto free_module;
/*
* Now we've got everything in the final locations, we can find
* optional sections. 参见[13.5.1.2.1.1 find_module_sections()]节
*/
find_module_sections(mod, &info);
err = check_module_license_and_versions(mod);
if (err)
goto free_unload;
/* Set up MODINFO_ATTR fields */
setup_modinfo(mod, &info);
/* Fix up syms, so that st_value is a pointer to location. */
err = simplify_symbols(mod, &info);
if (err < 0)
goto free_modinfo;
// Fix up the addresses in the module
err = apply_relocations(mod, &info);
if (err < 0)
goto free_modinfo;
// Extable and per-cpu initialization
err = post_relocation(mod, &info);
if (err < 0)
goto free_modinfo;
// Flush I-cache for the module area
flush_module_icache(mod);
/* Now copy in args */
mod->args = strndup_user(uargs, ~0UL >> 1);
if (IS_ERR(mod->args)) {
err = PTR_ERR(mod->args);
goto free_arch_cleanup;
}
/* Mark state as coming so strong_try_module_get() ignores us. */
mod->state = MODULE_STATE_COMING;
/* Now sew it into the lists so we can get lockdep and oops
* info during argument parsing. No one should access us, since
* strong_try_module_get() will fail.
* lockdep/oops can run asynchronous, so use the RCU list insertion
* function to insert in a way safe to concurrent readers.
* The mutex protects against concurrent writers.
*/
mutex_lock(&module_mutex);
if (find_module(mod->name)) {
err = -EEXIST;
goto unlock;
}
/* This has to be done once we're sure module name is unique. */
dynamic_debug_setup(info.debug, info.num_debug);
/* Find duplicate symbols */
err = verify_export_symbols(mod);
if (err < 0)
goto ddebug;
module_bug_finalize(info.hdr, info.sechdrs, mod);
// 将该模块添加到链表modules中,参见[13.3.2.1.1 modules链表]节
list_add_rcu(&mod->list, &modules);
mutex_unlock(&module_mutex);
/* Module is ready to execute: parsing args may do that. */
err = parse_args(mod->name, mod->args, mod->kp, mod->num_kp, NULL);
if (err < 0)
goto unlink;
/* Link in to syfs. */
err = mod_sysfs_setup(mod, &info, mod->kp, mod->num_kp);
if (err < 0)
goto unlink;
/* Get rid of temporary copy and strmap. */
kfree(info.strmap);
free_copy(&info);
/* Done! */
trace_module_load(mod);
return mod;
unlink:
mutex_lock(&module_mutex);
/* Unlink carefully: kallsyms could be walking list. */
list_del_rcu(&mod->list);
module_bug_cleanup(mod);
ddebug:
dynamic_debug_remove(info.debug);
unlock:
mutex_unlock(&module_mutex);
synchronize_sched();
kfree(mod->args);
free_arch_cleanup:
module_arch_cleanup(mod);
free_modinfo:
free_modinfo(mod);
free_unload:
module_unload_free(mod);
free_module:
module_deallocate(mod, &info);
free_copy:
free_copy(&info);
return ERR_PTR(err);
}
13.5.1.2.1.1 find_module_sections()
该函数定义于kernel/module.c:
static void find_module_sections(struct module *mod, struct load_info *info)
{
mod->kp = section_objs(info, "__param", sizeof(*mod->kp), &mod->num_kp);
/*
* 获取宏EXPORT_SYMBOL(sym)导出到段__ksymtab和__kcrctab中的符号,
* 参见[13.1.2.3 EXPORT_SYMBOL()]节
*/
mod->syms = section_objs(info, "__ksymtab", sizeof(*mod->syms), &mod->num_syms);
mod->crcs = section_addr(info, "__kcrctab");
/*
* 获取宏EXPORT_SYMBOL_GPL(sym)导出到段__ksymtab_gpl和__kcrctab_gpl中的符号,
* 参见[13.1.2.3 EXPORT_SYMBOL()]节
*/
mod->gpl_syms = section_objs(info, "__ksymtab_gpl", sizeof(*mod->gpl_syms), &mod->num_gpl_syms);
mod->gpl_crcs = section_addr(info, "__kcrctab_gpl");
/*
* 获取宏EXPORT_SYMBOL_GPL_FUTURE(sym)导出到段__ksymtab_gpl_future
* 和__kcrctab_gpl_future中的符号,参见[13.1.2.3 EXPORT_SYMBOL()]节
*/
mod->gpl_future_syms = section_objs(info, "__ksymtab_gpl_future",
sizeof(*mod->gpl_future_syms), &mod->num_gpl_future_syms);
mod->gpl_future_crcs = section_addr(info, "__kcrctab_gpl_future");
#ifdef CONFIG_UNUSED_SYMBOLS
/*
* 获取宏EXPORT_UNUSED_SYMBOL(sym)导出到段__ksymtab_unused
* 和__kcrctab_unused中的符号,参见[13.1.2.3 EXPORT_SYMBOL()]节
*/
mod->unused_syms = section_objs(info, "__ksymtab_unused",
sizeof(*mod->unused_syms), &mod->num_unused_syms);
mod->unused_crcs = section_addr(info, "__kcrctab_unused");
/*
* 获取宏EXPORT_UNUSED_SYMBOL_GPL(sym)导出到段__ksymtab_unused_gpl
* 和__kcrctab_unused_gpl中的符号,参见[13.1.2.3 EXPORT_SYMBOL()]节
*/
mod->unused_gpl_syms = section_objs(info, "__ksymtab_unused_gpl",
sizeof(*mod->unused_gpl_syms), &mod->num_unused_gpl_syms);
mod->unused_gpl_crcs = section_addr(info, "__kcrctab_unused_gpl");
#endif
#ifdef CONFIG_CONSTRUCTORS
mod->ctors = section_objs(info, ".ctors", sizeof(*mod->ctors), &mod->num_ctors);
#endif
#ifdef CONFIG_TRACEPOINTS
mod->tracepoints_ptrs = section_objs(info, "__tracepoints_ptrs",
sizeof(*mod->tracepoints_ptrs), &mod->num_tracepoints);
#endif
#ifdef HAVE_JUMP_LABEL
mod->jump_entries = section_objs(info, "__jump_table",
sizeof(*mod->jump_entries), &mod->num_jump_entries);
#endif
#ifdef CONFIG_EVENT_TRACING
mod->trace_events = section_objs(info, "_ftrace_events",
sizeof(*mod->trace_events), &mod->num_trace_events);
/*
* This section contains pointers to allocated objects in the trace
* code and not scanning it leads to false positives.
*/
kmemleak_scan_area(mod->trace_events, sizeof(*mod->trace_events) * mod->num_trace_events, GFP_KERNEL);
#endif
#ifdef CONFIG_TRACING
mod->trace_bprintk_fmt_start = section_objs(info, "__trace_printk_fmt",
sizeof(*mod->trace_bprintk_fmt_start), &mod->num_trace_bprintk_fmt);
/*
* This section contains pointers to allocated objects in the trace
* code and not scanning it leads to false positives.
*/
kmemleak_scan_area(mod->trace_bprintk_fmt_start,
sizeof(*mod->trace_bprintk_fmt_start) * mod->num_trace_bprintk_fmt, GFP_KERNEL);
#endif
#ifdef CONFIG_FTRACE_MCOUNT_RECORD
/* sechdrs[0].sh_size is always zero */
mod->ftrace_callsites = section_objs(info, "__mcount_loc",
sizeof(*mod->ftrace_callsites), &mod->num_ftrace_callsites);
#endif
mod->extable = section_objs(info, "__ex_table", sizeof(*mod->extable), &mod->num_exentries);
if (section_addr(info, "__obsparm"))
printk(KERN_WARNING "%s: Ignoring obsolete parameters\n", mod->name);
info->debug = section_objs(info, "__verbose", sizeof(*info->debug), &info->num_debug);
}
13.5.1.3 rmmod调用sys_delete_module()
当module被编译为独立的模块时,可以执行rmmod命令从系统中卸载该模块,参见13.3 模块的加载/卸载节。
rmmod最终调用系统调用sys_delete_module(),其定义于kernel/module.c:
SYSCALL_DEFINE2(delete_module, const char __user *, name_user, unsigned int, flags)
{
struct module *mod;
char name[MODULE_NAME_LEN];
int ret, forced = 0;
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
/*
* 1) 获取模块名
*/
if (strncpy_from_user(name, name_user, MODULE_NAME_LEN-1) < 0)
return -EFAULT;
name[MODULE_NAME_LEN-1] = '\0';
if (mutex_lock_interruptible(&module_mutex) != 0)
return -EINTR;
/*
* 2) 从链表modules中查找名为name的模块
*/
mod = find_module(name);
if (!mod) {
ret = -ENOENT;
goto out;
}
/*
* 3) 检查该模块是否可被移除
*/
if (!list_empty(&mod->source_list)) {
/* Other modules depend on us: get rid of them first. */
ret = -EWOULDBLOCK;
goto out;
}
/* Doing init or already dying? */
if (mod->state != MODULE_STATE_LIVE) {
/* FIXME: if (force), slam module count and wake up waiter --RR */
DEBUGP("%s already dying\n", mod->name);
ret = -EBUSY;
goto out;
}
/*
* If it has an init func, it must have an exit func to unload.
* 检查初始化函数和清理函数,即mod->init和mod->exit,
* 参见[13.5.1.4 mod->init/mod->exit与init_module()/cleanup_module()的关联]节
*/
if (mod->init && !mod->exit) {
// 与配置选项CONFIG_MODULE_FORCE_UNLOAD有关
forced = try_force_unload(flags);
if (!forced) {
/* This module can't be removed */
ret = -EBUSY;
goto out;
}
}
/* Set this up before setting mod->state */
mod->waiter = current;
/* Stop the machine so refcounts can't move and disable module. */
ret = try_stop_module(mod, flags, &forced);
if (ret != 0)
goto out;
/* Never wait if forced. */
if (!forced && module_refcount(mod) != 0)
wait_for_zero_refcount(mod);
mutex_unlock(&module_mutex);
/*
* Final destruction now no one is using it. 调用清理函数cleanup_module(),
* 参见[13.5.1.4 mod->init/mod->exit与init_module()/cleanup_module()的关联]节
*/
if (mod->exit != NULL)
mod->exit();
blocking_notifier_call_chain(&module_notify_list, MODULE_STATE_GOING, mod);
async_synchronize_full();
/* Store the name of the last unloaded module for diagnostic purposes */
strlcpy(last_unloaded_module, mod->name, sizeof(last_unloaded_module));
free_module(mod);
return 0;
out:
mutex_unlock(&module_mutex);
return ret;
}
13.5.1.4 mod->init/mod->exit与init_module()/cleanup_module()的关联
函数add_header()定义于scripts/mod/modpost.c:
/**
* Header for the generated file
**/
static void add_header(struct buffer *b, struct module *mod)
{
buf_printf(b, "#include <linux/module.h>\n");
buf_printf(b, "#include <linux/vermagic.h>\n");
buf_printf(b, "#include <linux/compiler.h>\n");
buf_printf(b, "\n");
buf_printf(b, "MODULE_INFO(vermagic, VERMAGIC_STRING);\n");
buf_printf(b, "\n");
buf_printf(b, "struct module __this_module\n");
buf_printf(b, "__attribute__((section(\".gnu.linkonce.this_module\"))) = {\n");
buf_printf(b, " .name = KBUILD_MODNAME,\n");
if (mod->has_init)
buf_printf(b, " .init = init_module,\n");
if (mod->has_cleanup)
buf_printf(b, "#ifdef CONFIG_MODULE_UNLOAD\n"
" .exit = cleanup_module,\n"
"#endif\n");
buf_printf(b, " .arch = MODULE_ARCH_INIT,\n");
buf_printf(b, "};\n");
}
参见3.4.3.4.2.1 __modpost节,在执行scripts/mod/modpost时生成*.mod.c文件,该文件中包含了struct module类型的对象__this_module:
#include <linux/module.h> // 定义struct module
#include <linux/vermagic.h> // 定义VERMAGIC_STRING
#include <linux/compiler.h>
MODULE_INFO(vermagic, VERMAGIC_STRING);
/*
* struct module定义于include/linux/module.h,
* 此处仅为其中的四个成员变量赋值
*/
struct module __this_module
__attribute__((section(\".gnu.linkonce.this_module\"))) = {
/*
* KBUILD_MODNAME定义于scripts/Makefile.lib:
* modname_flags = $(if $(filter 1,$(words $(modname))),\
* -DKBUILD_MODNAME=$(call name-fix,$(modname)))
*/
.name = KBUILD_MODNAME,
/*
* 函数init_module和cleanup_module参见下列章节:
* [13.5.0 init_module()/cleanup_module()]节和
* [13.5.1 module_init()/module_exit()]节
*/
.init = init_module,
#ifdef CONFIG_MODULE_UNLOAD
.exit = cleanup_module,
#endif
/*
* MODULE_ARCH_INIT的定义参见下列文件:
* - arch/m68k/include/asm/module.h
* - include/linux/module.h
*/
.arch = MODULE_ARCH_INIT,
};
当*.mod.c被编译成*.mod.o后,变量__this_module被包含在*.mod.o的.gnu.linkonce.this_module段内,参见3.4.3.4.2.2 %.mod.c=>%.mod.o节,例如:
chenwx@chenwx ~/alex/module $ objdump -h hello.mod.o
hello.mod.o: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000000 00000000 00000000 00000034 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000000 00000000 00000000 00000034 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 00000000 00000000 00000034 2**2
ALLOC
3 .modinfo 00000066 00000000 00000000 00000034 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 __versions 000000c0 00000000 00000000 000000a0 2**5
CONTENTS, ALLOC, LOAD, READONLY, DATA
5 .gnu.linkonce.this_module 0000017c 00000000 00000000 00000160 2**5
CONTENTS, ALLOC, LOAD, RELOC, DATA, LINK_ONCE_DISCARD
6 .comment 0000002b 00000000 00000000 000002dc 2**0
CONTENTS, READONLY
7 .note.GNU-stack 00000000 00000000 00000000 00000307 2**0
CONTENTS, READONLY
在加载module时,段.gnu.linkonce.this_module会被如下函数读取:
load_module() // 参见[13.5.1.2.1 load_module()]节
-> layout_and_allocate()
-> setup_load_info()
static struct module *setup_load_info(struct load_info *info)
{
struct module *mod;
...
info->index.mod = find_sec(info, ".gnu.linkonce.this_module");
if (!info->index.mod) {
printk(KERN_WARNING "No module found in object\n");
return ERR_PTR(-ENOEXEC);
}
/* This is temporary: point mod into copy of data. */
mod = (void *)info->sechdrs[info->index.mod].sh_addr;
...
return mod;
}
故,此后可通过调用mod->init()和mod->exit()来调用初始化函数和清理函数了,参见13.5.1.3 rmmod调用sys_delete_module()节。
14 Linux Security Module/LSM
14.1 Linux Security Module简介
参见文档:Documentation/security/
Projects within Linux Security Module:
| Category | Projects | Note | Location | Accepted by Mainline at |
|---|---|---|---|---|
| Access Control | Linux Security Modules (LSM) | the API for access control frameworks | security/security.c security/capability.c |
Linux 2.6 (2003-12) |
| Access Control | Security Enhanced Linux (SELinux) | a flexible and fine-grained MAC framework | security/selinux/ | Linux 2.6 (2003-12) |
| Access Control | Smack | the Simplified Mandatory Access Control Kernel for Linux | security/smack/ | Linux 2.6.25 (2008-04) |
| Access Control | TOMOYO | a pathname-based access control system (LiveCD available) | security/tomoyo/ | Linux 2.6.30 (2009-06) |
| Access Control | AppArmor | a pathname-based access control system | security/apparmor/ | Linux 2.6.36 (2010-10) |
| Access Control | Yama | collects a number of system-wide DAC security protections | security/yama/ | Linux 3.4 (2012-05) |
14.2 与LSM有关的配置选项
Linux 3.2中包含如下与LSM有关的配置选项:
Security options --->
-*- Enable access key retention support
< > TRUSTED KEYS (NEW)
< > ENCRYPTED KEYS (NEW)
[ ] Enable the /proc/keys file by which keys may be viewed
[ ] Restrict unprivileged access to the kernel syslog (NEW)
[*] Enable different security models
-*- Enable the securityfs filesystem
-*- Socket and Networking Security Hooks
[ ] XFRM (IPSec) Networking Security Hooks
-*- Security hooks for pathname based access control
(0) Low address space for LSM to protect from user allocation
[*] NSA SELinux Support
[*] NSA SELinux boot parameter
(0) NSA SELinux boot parameter default value
[*] NSA SELinux runtime disable
[*] NSA SELinux Development Support
[*] NSA SELinux AVC Statistics
(1) NSA SELinux checkreqprot default value
[ ] NSA SELinux maximum supported policy format version
[*] Simplified Mandatory Access Control Kernel Support
[*] TOMOYO Linux Support
(2048) Default maximal count for learning mode (NEW)
(1024) Default maximal count for audit log (NEW)
[ ] Activate without calling userspace policy loader. (NEW)
(/sbin/tomoyo-init) Location of userspace policy loader (NEW)
(/sbin/init) Trigger for calling userspace policy loader (NEW)
[*] AppArmor support
(1) AppArmor boot parameter default value
[ ] Integrity Measurement Architecture(IMA)
[ ] EVM support (NEW)
Default security module (AppArmor) --->
( ) SELinux
( ) Simplified Mandatory Access Control
( ) TOMOYO
(X) AppArmor
( ) Unix Discretionary Access Controls
14.3 与LSM有关的数据结构
14.3.1 struct security_operations
该结构定义于include/linux/security.h:
struct security_operations {
char name[SECURITY_NAME_MAX + 1];
int (*ptrace_access_check) (struct task_struct *child, unsigned int mode);
int (*ptrace_traceme) (struct task_struct *parent);
int (*capget) (struct task_struct *target, kernel_cap_t *effective,
kernel_cap_t *inheritable, kernel_cap_t *permitted);
int (*capset) (struct cred *new, const struct cred *old, const kernel_cap_t *effective,
const kernel_cap_t *inheritable, const kernel_cap_t *permitted);
int (*capable) (struct task_struct *tsk, const struct cred *cred,
struct user_namespace *ns, int cap, int audit);
int (*quotactl) (int cmds, int type, int id, struct super_block *sb);
int (*quota_on) (struct dentry *dentry);
int (*syslog) (int type);
int (*settime) (const struct timespec *ts, const struct timezone *tz);
int (*vm_enough_memory) (struct mm_struct *mm, long pages);
int (*bprm_set_creds) (struct linux_binprm *bprm);
int (*bprm_check_security) (struct linux_binprm *bprm);
int (*bprm_secureexec) (struct linux_binprm *bprm);
void (*bprm_committing_creds) (struct linux_binprm *bprm);
void (*bprm_committed_creds) (struct linux_binprm *bprm);
int (*sb_alloc_security) (struct super_block *sb);
void (*sb_free_security) (struct super_block *sb);
int (*sb_copy_data) (char *orig, char *copy);
int (*sb_remount) (struct super_block *sb, void *data);
int (*sb_kern_mount) (struct super_block *sb, int flags, void *data);
int (*sb_show_options) (struct seq_file *m, struct super_block *sb);
int (*sb_statfs) (struct dentry *dentry);
int (*sb_mount) (char *dev_name, struct path *path, char *type, unsigned long flags, void *data);
int (*sb_umount) (struct vfsmount *mnt, int flags);
int (*sb_pivotroot) (struct path *old_path, struct path *new_path);
int (*sb_set_mnt_opts) (struct super_block *sb, struct security_mnt_opts *opts);
void (*sb_clone_mnt_opts) (const struct super_block *oldsb, struct super_block *newsb);
int (*sb_parse_opts_str) (char *options, struct security_mnt_opts *opts);
#ifdef CONFIG_SECURITY_PATH
int (*path_unlink) (struct path *dir, struct dentry *dentry);
int (*path_mkdir) (struct path *dir, struct dentry *dentry, int mode);
int (*path_rmdir) (struct path *dir, struct dentry *dentry);
int (*path_mknod) (struct path *dir, struct dentry *dentry, int mode, unsigned int dev);
int (*path_truncate) (struct path *path);
int (*path_symlink) (struct path *dir, struct dentry *dentry, const char *old_name);
int (*path_link) (struct dentry *old_dentry, struct path *new_dir, struct dentry *new_dentry);
int (*path_rename) (struct path *old_dir, struct dentry *old_dentry,
struct path *new_dir, struct dentry *new_dentry);
int (*path_chmod) (struct dentry *dentry, struct vfsmount *mnt, mode_t mode);
int (*path_chown) (struct path *path, uid_t uid, gid_t gid);
int (*path_chroot) (struct path *path);
#endif
int (*inode_alloc_security) (struct inode *inode);
void (*inode_free_security) (struct inode *inode);
int (*inode_init_security) (struct inode *inode, struct inode *dir,
const struct qstr *qstr, char **name, void **value, size_t *len);
int (*inode_create) (struct inode *dir, struct dentry *dentry, int mode);
int (*inode_link) (struct dentry *old_dentry, struct inode *dir, struct dentry *new_dentry);
int (*inode_unlink) (struct inode *dir, struct dentry *dentry);
int (*inode_symlink) (struct inode *dir, struct dentry *dentry, const char *old_name);
int (*inode_mkdir) (struct inode *dir, struct dentry *dentry, int mode);
int (*inode_rmdir) (struct inode *dir, struct dentry *dentry);
int (*inode_mknod) (struct inode *dir, struct dentry *dentry, int mode, dev_t dev);
int (*inode_rename) (struct inode *old_dir, struct dentry *old_dentry,
struct inode *new_dir, struct dentry *new_dentry);
int (*inode_readlink) (struct dentry *dentry);
int (*inode_follow_link) (struct dentry *dentry, struct nameidata *nd);
int (*inode_permission) (struct inode *inode, int mask);
int (*inode_setattr) (struct dentry *dentry, struct iattr *attr);
int (*inode_getattr) (struct vfsmount *mnt, struct dentry *dentry);
int (*inode_setxattr) (struct dentry *dentry, const char *name,
const void *value, size_t size, int flags);
void (*inode_post_setxattr) (struct dentry *dentry, const char *name,
const void *value, size_t size, int flags);
int (*inode_getxattr) (struct dentry *dentry, const char *name);
int (*inode_listxattr) (struct dentry *dentry);
int (*inode_removexattr) (struct dentry *dentry, const char *name);
int (*inode_need_killpriv) (struct dentry *dentry);
int (*inode_killpriv) (struct dentry *dentry);
int (*inode_getsecurity) (const struct inode *inode, const char *name, void **buffer, bool alloc);
int (*inode_setsecurity) (struct inode *inode, const char *name, const void *value, size_t size, int flags);
int (*inode_listsecurity) (struct inode *inode, char *buffer, size_t buffer_size);
void (*inode_getsecid) (const struct inode *inode, u32 *secid);
int (*file_permission) (struct file *file, int mask);
int (*file_alloc_security) (struct file *file);
void (*file_free_security) (struct file *file);
int (*file_ioctl) (struct file *file, unsigned int cmd, unsigned long arg);
int (*file_mmap) (struct file *file, unsigned long reqprot, unsigned long prot,
unsigned long flags, unsigned long addr, unsigned long addr_only);
int (*file_mprotect) (struct vm_area_struct *vma, unsigned long reqprot, unsigned long prot);
int (*file_lock) (struct file *file, unsigned int cmd);
int (*file_fcntl) (struct file *file, unsigned int cmd, unsigned long arg);
int (*file_set_fowner) (struct file *file);
int (*file_send_sigiotask) (struct task_struct *tsk, struct fown_struct *fown, int sig);
int (*file_receive) (struct file *file);
int (*dentry_open) (struct file *file, const struct cred *cred);
int (*task_create) (unsigned long clone_flags);
int (*cred_alloc_blank) (struct cred *cred, gfp_t gfp);
void (*cred_free) (struct cred *cred);
int (*cred_prepare)(struct cred *new, const struct cred *old, gfp_t gfp);
void (*cred_transfer)(struct cred *new, const struct cred *old);
int (*kernel_act_as)(struct cred *new, u32 secid);
int (*kernel_create_files_as)(struct cred *new, struct inode *inode);
int (*kernel_module_request)(char *kmod_name);
int (*task_fix_setuid) (struct cred *new, const struct cred *old, int flags);
int (*task_setpgid) (struct task_struct *p, pid_t pgid);
int (*task_getpgid) (struct task_struct *p);
int (*task_getsid) (struct task_struct *p);
void (*task_getsecid) (struct task_struct *p, u32 *secid);
int (*task_setnice) (struct task_struct *p, int nice);
int (*task_setioprio) (struct task_struct *p, int ioprio);
int (*task_getioprio) (struct task_struct *p);
int (*task_setrlimit) (struct task_struct *p, unsigned int resource, struct rlimit *new_rlim);
int (*task_setscheduler) (struct task_struct *p);
int (*task_getscheduler) (struct task_struct *p);
int (*task_movememory) (struct task_struct *p);
int (*task_kill) (struct task_struct *p, struct siginfo *info, int sig, u32 secid);
int (*task_wait) (struct task_struct *p);
int (*task_prctl) (int option, unsigned long arg2, unsigned long arg3,
unsigned long arg4, unsigned long arg5);
void (*task_to_inode) (struct task_struct *p, struct inode *inode);
int (*ipc_permission) (struct kern_ipc_perm *ipcp, short flag);
void (*ipc_getsecid) (struct kern_ipc_perm *ipcp, u32 *secid);
int (*msg_msg_alloc_security) (struct msg_msg *msg);
void (*msg_msg_free_security) (struct msg_msg *msg);
int (*msg_queue_alloc_security) (struct msg_queue *msq);
void (*msg_queue_free_security) (struct msg_queue *msq);
int (*msg_queue_associate) (struct msg_queue *msq, int msqflg);
int (*msg_queue_msgctl) (struct msg_queue *msq, int cmd);
int (*msg_queue_msgsnd) (struct msg_queue *msq, struct msg_msg *msg, int msqflg);
int (*msg_queue_msgrcv) (struct msg_queue *msq, struct msg_msg *msg,
struct task_struct *target, long type, int mode);
int (*shm_alloc_security) (struct shmid_kernel *shp);
void (*shm_free_security) (struct shmid_kernel *shp);
int (*shm_associate) (struct shmid_kernel *shp, int shmflg);
int (*shm_shmctl) (struct shmid_kernel *shp, int cmd);
int (*shm_shmat) (struct shmid_kernel *shp, char __user *shmaddr, int shmflg);
int (*sem_alloc_security) (struct sem_array *sma);
void (*sem_free_security) (struct sem_array *sma);
int (*sem_associate) (struct sem_array *sma, int semflg);
int (*sem_semctl) (struct sem_array *sma, int cmd);
int (*sem_semop) (struct sem_array *sma, struct sembuf *sops, unsigned nsops, int alter);
int (*netlink_send) (struct sock *sk, struct sk_buff *skb);
int (*netlink_recv) (struct sk_buff *skb, int cap);
void (*d_instantiate) (struct dentry *dentry, struct inode *inode);
int (*getprocattr) (struct task_struct *p, char *name, char **value);
int (*setprocattr) (struct task_struct *p, char *name, void *value, size_t size);
int (*secid_to_secctx) (u32 secid, char **secdata, u32 *seclen);
int (*secctx_to_secid) (const char *secdata, u32 seclen, u32 *secid);
void (*release_secctx) (char *secdata, u32 seclen);
int (*inode_notifysecctx)(struct inode *inode, void *ctx, u32 ctxlen);
int (*inode_setsecctx)(struct dentry *dentry, void *ctx, u32 ctxlen);
int (*inode_getsecctx)(struct inode *inode, void **ctx, u32 *ctxlen);
#ifdef CONFIG_SECURITY_NETWORK
int (*unix_stream_connect) (struct sock *sock, struct sock *other, struct sock *newsk);
int (*unix_may_send) (struct socket *sock, struct socket *other);
int (*socket_create) (int family, int type, int protocol, int kern);
int (*socket_post_create) (struct socket *sock, int family, int type, int protocol, int kern);
int (*socket_bind) (struct socket *sock, struct sockaddr *address, int addrlen);
int (*socket_connect) (struct socket *sock, struct sockaddr *address, int addrlen);
int (*socket_listen) (struct socket *sock, int backlog);
int (*socket_accept) (struct socket *sock, struct socket *newsock);
int (*socket_sendmsg) (struct socket *sock, struct msghdr *msg, int size);
int (*socket_recvmsg) (struct socket *sock, struct msghdr *msg, int size, int flags);
int (*socket_getsockname) (struct socket *sock);
int (*socket_getpeername) (struct socket *sock);
int (*socket_getsockopt) (struct socket *sock, int level, int optname);
int (*socket_setsockopt) (struct socket *sock, int level, int optname);
int (*socket_shutdown) (struct socket *sock, int how);
int (*socket_sock_rcv_skb) (struct sock *sk, struct sk_buff *skb);
int (*socket_getpeersec_stream) (struct socket *sock, char __user *optval, int __user *optlen, unsigned len);
int (*socket_getpeersec_dgram) (struct socket *sock, struct sk_buff *skb, u32 *secid);
int (*sk_alloc_security) (struct sock *sk, int family, gfp_t priority);
void (*sk_free_security) (struct sock *sk);
void (*sk_clone_security) (const struct sock *sk, struct sock *newsk);
void (*sk_getsecid) (struct sock *sk, u32 *secid);
void (*sock_graft) (struct sock *sk, struct socket *parent);
int (*inet_conn_request) (struct sock *sk, struct sk_buff *skb, struct request_sock *req);
void (*inet_csk_clone) (struct sock *newsk, const struct request_sock *req);
void (*inet_conn_established) (struct sock *sk, struct sk_buff *skb);
int (*secmark_relabel_packet) (u32 secid);
void (*secmark_refcount_inc) (void);
void (*secmark_refcount_dec) (void);
void (*req_classify_flow) (const struct request_sock *req, struct flowi *fl);
int (*tun_dev_create)(void);
void (*tun_dev_post_create)(struct sock *sk);
int (*tun_dev_attach)(struct sock *sk);
#endif /* CONFIG_SECURITY_NETWORK */
#ifdef CONFIG_SECURITY_NETWORK_XFRM
int (*xfrm_policy_alloc_security) (struct xfrm_sec_ctx **ctxp, struct xfrm_user_sec_ctx *sec_ctx);
int (*xfrm_policy_clone_security) (struct xfrm_sec_ctx *old_ctx, struct xfrm_sec_ctx **new_ctx);
void (*xfrm_policy_free_security) (struct xfrm_sec_ctx *ctx);
int (*xfrm_policy_delete_security) (struct xfrm_sec_ctx *ctx);
int (*xfrm_state_alloc_security) (struct xfrm_state *x, struct xfrm_user_sec_ctx *sec_ctx, u32 secid);
void (*xfrm_state_free_security) (struct xfrm_state *x);
int (*xfrm_state_delete_security) (struct xfrm_state *x);
int (*xfrm_policy_lookup) (struct xfrm_sec_ctx *ctx, u32 fl_secid, u8 dir);
int (*xfrm_state_pol_flow_match) (struct xfrm_state *x, struct xfrm_policy *xp, const struct flowi *fl);
int (*xfrm_decode_session) (struct sk_buff *skb, u32 *secid, int ckall);
#endif /* CONFIG_SECURITY_NETWORK_XFRM */
/* key management security hooks */
#ifdef CONFIG_KEYS
int (*key_alloc) (struct key *key, const struct cred *cred, unsigned long flags);
void (*key_free) (struct key *key);
int (*key_permission) (key_ref_t key_ref, const struct cred *cred, key_perm_t perm);
int (*key_getsecurity)(struct key *key, char **_buffer);
#endif /* CONFIG_KEYS */
#ifdef CONFIG_AUDIT
int (*audit_rule_init) (u32 field, u32 op, char *rulestr, void **lsmrule);
int (*audit_rule_known) (struct audit_krule *krule);
int (*audit_rule_match) (u32 secid, u32 field, u32 op, void *lsmrule, struct audit_context *actx);
void (*audit_rule_free) (void *lsmrule);
#endif /* CONFIG_AUDIT */
};
14.4 LSM的初始化
系统启动时,start_kernel()调用security_init()来初始化LSM。函数security_init()的定义与配置选项CONFIG_SECURITY有关,参见include/linux/security.h:
/*
* CONFIG_SECURITY是配置Linux Security Module的总开关
*/
#ifdef CONFIG_SECURITY
extern int security_init(void); // 定义于security/security.c
#else
static inline int security_init(void)
{
return 0;
}
#endif
函数security_init()定义于security/security.c:
static struct security_operations *security_ops;
static struct security_operations default_security_ops = {
.name = "default",
};
int __init security_init(void)
{
printk(KERN_INFO "Security Framework initialized\n");
/*
* 1) 设置默认的Security Module:
* 若default_security_ops中的某函数指针为空,
* 则设置为默认值,参见[14.4.1 security_fixup_ops()]节
*/
security_fixup_ops(&default_security_ops);
security_ops = &default_security_ops;
/*
* 2) 注册其他类型的Security Module:
* 调用__security_initcall_start和__security_initcall_end
* 之间的初始化函数,这些函数由宏security_initcall()设置,
* 参见[14.5.1 register_security()]节
*/
do_security_initcalls();
return 0;
}
14.4.1 security_fixup_ops()
该函数定义于security/capability.c:
#define set_to_cap_if_null(ops, function) \
do { \
if (!ops->function) { \
ops->function = cap_##function; \
pr_debug("Had to override the " #function \
" security operation with the default.\n"); \
} \
} while (0)
void __init security_fixup_ops(struct security_operations *ops)
{
/*
* 设置ops->ptrace_access_check = cap_ptrace_access_check;
* 而函数cap_ptrace_access_check()定义于security/capability.c
*/
set_to_cap_if_null(ops, ptrace_access_check);
set_to_cap_if_null(ops, ptrace_traceme);
set_to_cap_if_null(ops, capget);
...
}
14.4.2 security_xxx()
执行完上述初始化函数后,内核就可以调用名为security_xxx()的函数了,这类函数将调用函数security_ops->xxx()。
以security_syslog()为例,其定义于security/security.c:
int security_syslog(int type)
{
/*
* 根据不同的Linux Security Module配置,调用不同函数:
* 1) 若使用默认配置default_security_ops,则调用cap_syslog(),
* 该函数直接返回0,参见security/capability.c;
* 2) 若采用Smack,则调用smack_syslog(),
* 参见security/smack/smack_lsm.c中的变量smack_ops;
* 3) ...
*/
return security_ops->syslog(type);
}
14.5 Security Framework的注册/恢复
14.5.1 register_security()
函数register_security()用于注册security framework,其定义于security/security.c:
/**
* register_security - registers a security framework with the kernel
* @ops: a pointer to the struct security_options that is to be registered
*
* This function allows a security module to register itself with the
* kernel security subsystem. Some rudimentary checking is done on the @ops
* value passed to this function. You'll need to check first if your LSM
* is allowed to register its @ops by calling security_module_enable(@ops).
*
* If there is already a security module registered with the kernel,
* an error will be returned. Otherwise %0 is returned on success.
*/
int __init register_security(struct security_operations *ops)
{
/*
* 调用security_fixup_ops()为ops中未赋值的函数指针设置默认值,
* 参见[14.4.1 security_fixup_ops()]节
*/
if (verify(ops)) {
printk(KERN_DEBUG "%s could not verify "
"security_operations structure.\n", __func__);
return -EINVAL;
}
if (security_ops != &default_security_ops) // 参见[14.4 LSM的初始化]节
return -EAGAIN;
security_ops = ops;
return 0;
}
该函数被如下函数调用:
1) security/selinux/hooks.c: selinux_init() SECURITY_SELINUX
2) security/tomoyo/tomoyo.c: tomoyo_init() SECURITY_TOMOYO
3) security/apparmor/lsm.c: apparmor_init() SECURITY_APPARMOR
4) security/smack/smack_lsm.c: smack_init() SECURITY_SMACK
调用函数register_security()之前,必须先调用函数security_module_enable()来判断指定的安全模块是否已经被启用。其定义于security/security.c:
/* Boot-time LSM user choice */
static __initdata char chosen_lsm[SECURITY_NAME_MAX + 1] = CONFIG_DEFAULT_SECURITY;
/**
* security_module_enable - Load given security module on boot ?
* @ops: a pointer to the struct security_operations that is to be checked.
*
* Each LSM must pass this method before registering its own operations
* to avoid security registration races. This method may also be used
* to check if your LSM is currently loaded during kernel initialization.
*
* Return true if:
* - The passed LSM is the one chosen by user at boot time,
* - or the passed LSM is configured as the default and the user did not
* choose an alternate LSM at boot time.
* Otherwise, return false.
*/
int __init security_module_enable(struct security_operations *ops)
{
return !strcmp(ops->name, chosen_lsm);
}
其中,变量chosen_lsm根据配置选项确定,参见security/Kconfig:
config DEFAULT_SECURITY
string
default "selinux" if DEFAULT_SECURITY_SELINUX
default "smack" if DEFAULT_SECURITY_SMACK
default "tomoyo" if DEFAULT_SECURITY_TOMOYO
default "apparmor" if DEFAULT_SECURITY_APPARMOR
default "" if DEFAULT_SECURITY_DAC
14.5.2 reset_security_ops()
函数reset_security_ops()用于恢复默认的security framework,其定义于security/security.c:
void reset_security_ops(void)
{
security_ops = &default_security_ops;
}
15 内核数据结构
15.1 双向循环链表/struct list_head
该结构定义于include/linux/types.h:
struct list_head {
struct list_head *next, *prev;
};
15.1.1 链表的定义与初始化
空双向循环链表的结构如下:
1) 可通过如下函数初始化空双向循环链表,其定义于include/linux/list.h:
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
2) 可通过如下宏定义并初始化双向循环链表,其定义于include/linux/list.h:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
15.1.2 向链表中添加元素
包含有效元素的双向循环链表的结构如下:
函数list_add()和list_add_tail()用于向双向循环链表中添加元素,其定义于include/linux/list.h:
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
#ifndef CONFIG_DEBUG_LIST
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
#else
// 参见lib/list_debug.c
extern void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next);
#endif
函数list_add_rcu()和list_add_tail_rcu()用于向双向循环链表中添加元素,其定义于include/linux/rculist.h:
/**
* list_add_rcu - add a new entry to rcu-protected list
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*
* The caller must take whatever precautions are necessary
* (such as holding appropriate locks) to avoid racing
* with another list-mutation primitive, such as list_add_rcu()
* or list_del_rcu(), running on this same list.
* However, it is perfectly legal to run concurrently with
* the _rcu list-traversal primitives, such as
* list_for_each_entry_rcu().
*/
static inline void list_add_rcu(struct list_head *new, struct list_head *head)
{
__list_add_rcu(new, head, head->next);
}
/**
* list_add_tail_rcu - add a new entry to rcu-protected list
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*
* The caller must take whatever precautions are necessary
* (such as holding appropriate locks) to avoid racing
* with another list-mutation primitive, such as list_add_tail_rcu()
* or list_del_rcu(), running on this same list.
* However, it is perfectly legal to run concurrently with
* the _rcu list-traversal primitives, such as
* list_for_each_entry_rcu().
*/
static inline void list_add_tail_rcu(struct list_head *new, struct list_head *head)
{
__list_add_rcu(new, head->prev, head);
}
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add_rcu(struct list_head *new,
struct list_head *prev, struct list_head *next)
{
new->next = next;
new->prev = prev;
rcu_assign_pointer(list_next_rcu(prev), new);
next->prev = new;
}
/*
* return the ->next pointer of a list_head in an rcu safe
* way, we must not access it directly
*/
#define list_next_rcu(list) (*((struct list_head __rcu **)(&(list)->next)))
15.1.3 从链表中删除元素
函数list_del()和list_del_init()用于从双向循环链表删除元素,其定义于include/linux/list.h:
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
#ifndef CONFIG_DEBUG_LIST
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
#else
extern void __list_del_entry(struct list_head *entry); // 参见lib/list_debug.c
extern void list_del(struct list_head *entry); // 参见lib/list_debug.c
#endif
/**
* list_del_init - deletes entry from list and reinitialize it.
* @entry: the element to delete from the list.
*/
static inline void list_del_init(struct list_head *entry)
{
__list_del_entry(entry);
INIT_LIST_HEAD(entry);
}
函数list_del_rcu()用于从双向循环链表删除元素,其定义于include/linux/rculist.h:
/**
* list_del_rcu - deletes entry from list without re-initialization
* @entry: the element to delete from the list.
*
* Note: list_empty() on entry does not return true after this,
* the entry is in an undefined state. It is useful for RCU based
* lockfree traversal.
*
* In particular, it means that we can not poison the forward
* pointers that may still be used for walking the list.
*
* The caller must take whatever precautions are necessary
* (such as holding appropriate locks) to avoid racing
* with another list-mutation primitive, such as list_del_rcu()
* or list_add_rcu(), running on this same list.
* However, it is perfectly legal to run concurrently with
* the _rcu list-traversal primitives, such as
* list_for_each_entry_rcu().
*
* Note that the caller is not permitted to immediately free
* the newly deleted entry. Instead, either synchronize_rcu()
* or call_rcu() must be used to defer freeing until an RCU
* grace period has elapsed.
*/
static inline void list_del_rcu(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->prev = LIST_POISON2;
}
Note that it does not free any memory belonging to entry or the data structure in which it is embedded; this function merely removes the element from the list.
15.1.4 替换链表中的元素
函数list_replace()和list_replace_init()用于替换双向循环链表中的某元素,其定义于include/linux/list.h:
/**
* list_replace - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace(struct list_head *old, struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
static inline void list_replace_init(struct list_head *old, struct list_head *new)
{
list_replace(old, new);
INIT_LIST_HEAD(old);
}
函数list_replace_rcu()用于替换双向循环链表中的某元素,其定义于include/linux/rculist.h:
/**
* list_replace_rcu - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* The @old entry will be replaced with the @new entry atomically.
* Note: @old should not be empty.
*/
static inline void list_replace_rcu(struct list_head *old, struct list_head *new)
{
new->next = old->next;
new->prev = old->prev;
rcu_assign_pointer(list_next_rcu(new->prev), new);
new->next->prev = new;
old->prev = LIST_POISON2;
}
15.1.5 移动链表中的元素
函数list_move()和list_move_tail()将元素从一个双向循环链表移动到另外一个双向循环链表中,其定义于include/linux/list.h:
/**
* list_move - delete from one list and add as another's head
* @list: the entry to move
* @head: the head that will precede our entry
*/
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del_entry(list);
list_add(list, head);
}
/**
* list_move_tail - delete from one list and add as another's tail
* @list: the entry to move
* @head: the head that will follow our entry
*/
static inline void list_move_tail(struct list_head *list, struct list_head *head)
{
__list_del_entry(list);
list_add_tail(list, head);
}
15.1.6 判断链表是否为空或仅有一个元素
函数list_empty()和list_empty_careful()用于判断双向循环链表是否为空,函数list_is_singular()用于判断双向循环链表是否仅有一个元素,其定义于include/linux/list.h:
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
/**
* list_empty_careful - tests whether a list is empty and not being modified
* @head: the list to test
*
* Description:
* tests whether a list is empty _and_ checks that no other CPU might be
* in the process of modifying either member (next or prev)
*
* NOTE: using list_empty_careful() without synchronization
* can only be safe if the only activity that can happen
* to the list entry is list_del_init(). Eg. it cannot be used
* if another CPU could re-list_add() it.
*/
static inline int list_empty_careful(const struct list_head *head)
{
struct list_head *next = head->next;
return (next == head) && (next == head->prev);
}
/**
* list_is_singular - tests whether a list has just one entry.
* @head: the list to test.
*/
static inline int list_is_singular(const struct list_head *head)
{
return !list_empty(head) && (head->next == head->prev);
}
15.1.7 判断某元素是否为链表中的最后一个元素
函数list_is_last()用于判断某元素是否位于双向循环链表的末尾,其定义于include/linux/list.h:
/**
* list_is_last - tests whether @list is the last entry in list @head
* @list: the entry to test
* @head: the head of the list
*/
static inline int list_is_last(const struct list_head *list, const struct list_head *head)
{
return list->next == head;
}
15.1.8 轮转链表/移动链表头
轮转链表即将链表头向后移动一个位置。函数list_rotate_left()用于轮转链表,其定义于include/linux/list.h:
/**
* list_rotate_left - rotate the list to the left
* @head: the head of the list
*/
static inline void list_rotate_left(struct list_head *head)
{
struct list_head *first;
if (!list_empty(head)) {
first = head->next;
list_move_tail(first, head);
}
}
其结果如下:
15.1.9 切分链表
函数list_cut_position()用于切分链表,其定义于include/linux/list.h:
/**
* list_cut_position - cut a list into two
* @list: a new list to add all removed entries
* @head: a list with entries
* @entry: an entry within head, could be the head itself
* and if so we won't cut the list
*
* This helper moves the initial part of @head, up to and
* including @entry, from @head to @list. You should
* pass on @entry an element you know is on @head. @list
* should be an empty list or a list you do not care about
* losing its data.
*
*/
static inline void list_cut_position(struct list_head *list,
struct list_head *head, struct list_head *entry)
{
if (list_empty(head))
return;
if (list_is_singular(head) && (head->next != entry && head != entry))
return;
if (entry == head)
INIT_LIST_HEAD(list);
else
__list_cut_position(list, head, entry);
}
static inline void __list_cut_position(struct list_head *list,
struct list_head *head, struct list_head *entry)
{
struct list_head *new_first = entry->next;
list->next = head->next;
list->next->prev = list;
list->prev = entry;
entry->next = list;
head->next = new_first;
new_first->prev = head;
}
函数list_cut_position(list, head, elem2)的执行结果如下:
15.1.10 拼接链表
函数list_splice(),list_splice_init(),list_splice_tail()和list_splice_tail_init()用于拼接两个链表,其定义于include/linux/list.h:
/**
* list_splice - join two lists, this is designed for stacks
* @list: the new list to add.
* @head: the place to add it in the first list.
*/
static inline void list_splice(const struct list_head *list, struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head, head->next);
}
/**
* list_splice_tail - join two lists, each list being a queue
* @list: the new list to add.
* @head: the place to add it in the first list.
*/
static inline void list_splice_tail(struct list_head *list, struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head->prev, head);
}
/**
* list_splice_init - join two lists and reinitialise the emptied list.
* @list: the new list to add.
* @head: the place to add it in the first list.
*
* The list at @list is reinitialised
*/
static inline void list_splice_init(struct list_head *list, struct list_head *head)
{
if (!list_empty(list)) {
__list_splice(list, head, head->next);
INIT_LIST_HEAD(list);
}
}
/**
* list_splice_tail_init - join two lists and reinitialise the emptied list
* @list: the new list to add.
* @head: the place to add it in the first list.
*
* Each of the lists is a queue.
* The list at @list is reinitialised
*/
static inline void list_splice_tail_init(struct list_head *list, struct list_head *head)
{
if (!list_empty(list)) {
__list_splice(list, head->prev, head);
INIT_LIST_HEAD(list);
}
}
static inline void __list_splice(const struct list_head *list,
struct list_head *prev, struct list_head *next)
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
first->prev = prev;
prev->next = first;
last->next = next;
next->prev = last;
}
函数list_splice_rcn()用于拼接两个链表,其定义于include/linux/rculist.h:
/**
* list_splice_init_rcu - splice an RCU-protected list into an existing list.
* @list: the RCU-protected list to splice
* @head: the place in the list to splice the first list into
* @sync: function to sync: synchronize_rcu(), synchronize_sched(), ...
*
* @head can be RCU-read traversed concurrently with this function.
*
* Note that this function blocks.
*
* Important note: the caller must take whatever action is necessary to
* prevent any other updates to @head. In principle, it is possible
* to modify the list as soon as sync() begins execution.
* If this sort of thing becomes necessary, an alternative version
* based on call_rcu() could be created. But only if -really-
* needed -- there is no shortage of RCU API members.
*/
static inline void list_splice_init_rcu(struct list_head *list,
struct list_head *head, void (*sync)(void))
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
struct list_head *at = head->next;
if (list_empty(list))
return;
/* "first" and "last" tracking list, so initialize it. */
INIT_LIST_HEAD(list);
/*
* At this point, the list body still points to the source list.
* Wait for any readers to finish using the list before splicing
* the list body into the new list. Any new readers will see
* an empty list.
*/
sync();
/*
* Readers are finished with the source list, so perform splice.
* The order is important if the new list is global and accessible
* to concurrent RCU readers. Note that RCU readers are not
* permitted to traverse the prev pointers without excluding
* this function.
*/
last->next = at;
rcu_assign_pointer(list_next_rcu(head), first);
first->prev = head;
at->prev = last;
}
函数list_splice_init(list, head)的执行结果如下:
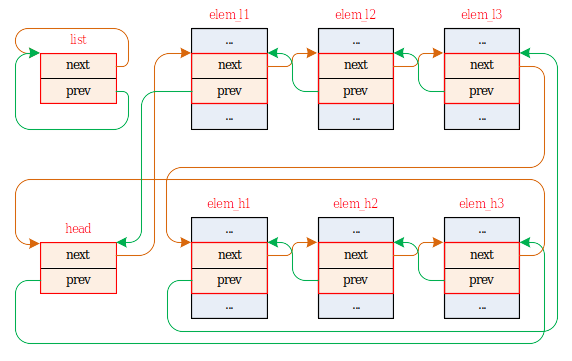
15.1.11 获取包含链表元素的对象的地址
宏list_entry()和list_first_entry()可用于获取包含链表元素的对象的地址,其定义于include/linux/list.h:
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
/**
* list_first_entry - get the first element from a list
* @ptr: the list head to take the element from.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*
* Note, that list is expected to be not empty.
*/
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
宏list_entry_rcu()可用于获取包含链表元素的对象的地址,其定义于include/linux/rculist.h:
/**
* list_entry_rcu - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*
* This primitive may safely run concurrently with the _rcu list-mutation
* primitives such as list_add_rcu() as long as it's guarded by rcu_read_lock().
*/
#define list_entry_rcu(ptr, type, member) \
({typeof (*ptr) __rcu *__ptr = (typeof (*ptr) __rcu __force *)ptr; \
container_of((typeof(ptr))rcu_dereference_raw(__ptr), type, member); \
})
/**
* list_first_entry_rcu - get the first element from a list
* @ptr: the list head to take the element from.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*
* Note, that list is expected to be not empty.
*
* This primitive may safely run concurrently with the _rcu list-mutation
* primitives such as list_add_rcu() as long as it's guarded by rcu_read_lock().
*/
#define list_first_entry_rcu(ptr, type, member) \
list_entry_rcu((ptr)->next, type, member)
/**
* list_first_or_null_rcu - get the first element from a list
* @ptr: the list head to take the element from.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*
* Note that if the list is empty, it returns NULL.
*
* This primitive may safely run concurrently with the _rcu list-mutation
* primitives such as list_add_rcu() as long as it's guarded by rcu_read_lock().
*/
#define list_first_or_null_rcu(ptr, type, member) \
({struct list_head *__ptr = (ptr); \
struct list_head *__next = ACCESS_ONCE(__ptr->next); \
likely(__ptr != __next) ? list_entry_rcu(__next, type, member) : NULL; \
})
其中,宏container_of()定义于include/linux/kernel.h:
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) ); })
函数retPtr = list_entry(ptr, type, member)的执行结果如下:
15.1.12 遍历链表元素
下列宏可用于遍历链表元素:
15.1.12.1 list_for_each()/list_for_each_safe()
下列宏用于向后遍历双向循环链表,其中pos指向struct list_head类型的对象,其定义于include/linux/list.h:
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
/**
* __list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*
* This variant doesn't differ from list_for_each() any more.
* We don't do prefetching in either case.
*/
#define __list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; \
pos != (head); \
pos = n, n = pos->next)
15.1.12.2 list_for_each_prev()/list_for_each_prev_safe()
下列宏用于向前遍历双向循环链表,其中pos指向struct list_head类型的对象,其定义于include/linux/list.h:
/**
* list_for_each_prev - iterate over a list backwards
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; pos != (head); pos = pos->prev)
/**
* list_for_each_prev_safe - iterate over a list backwards safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_prev_safe(pos, n, head) \
for (pos = (head)->prev, n = pos->prev; \
pos != (head); \
pos = n, n = pos->prev)
15.1.12.3 list_for_each_entry()/list_for_each_entry_safe()/list_for_each_entry_rcu()
下列宏用于向后遍历双向循环链表,其中pos指向包含struct list_head类型元素的对象,其定义于include/linux/list.h:
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/**
* list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
下列宏用于向后遍历双向循环链表,其中pos指向包含struct list_head类型元素的对象,其定义于include/linux/rculist.h:
/**
* list_for_each_entry_rcu - iterate over rcu list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* This list-traversal primitive may safely run concurrently with
* the _rcu list-mutation primitives such as list_add_rcu()
* as long as the traversal is guarded by rcu_read_lock().
*/
#define list_for_each_entry_rcu(pos, head, member) \
for (pos = list_entry_rcu((head)->next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry_rcu(pos->member.next, typeof(*pos), member))
15.1.12.4 list_for_each_entry_reverse()/list_for_each_entry_safe_reverse()
下列宏用于向前遍历双向循环链表,其中pos指向包含struct list_head类型元素的对象,其定义于include/linux/list.h:
/**
* list_for_each_entry_reverse - iterate backwards over list of given type.
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_reverse(pos, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.prev, typeof(*pos), member))
/**
* list_for_each_entry_safe_reverse - iterate backwards over list safe against removal
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate backwards over list of given type, safe against removal
* of list entry.
*/
#define list_for_each_entry_safe_reverse(pos, n, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member), \
n = list_entry(pos->member.prev, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.prev, typeof(*n), member))
15.1.12.5 list_prepare_entry()
其定义于include/linux/list.h:
/**
* list_prepare_entry - prepare a pos entry for use in list_for_each_entry_continue()
* @pos: the type * to use as a start point
* @head: the head of the list
* @member: the name of the list_struct within the struct.
*
* Prepares a pos entry for use as a start point in list_for_each_entry_continue().
*/
#define list_prepare_entry(pos, head, member) \
((pos) ? : list_entry(head, typeof(*pos), member))
该用于获取遍历链表的起始位置。如果pos不为空,则pos的值不变;否则,返回head指向的后一个元素。例如:
struct BB *pos = NULL;
struct head_struct *head = objectA.memberA.next;
pos = list_prepare_entry(pos, head, memberB);
返回pos的位置如下图所示:
15.1.12.6 list_for_each_continue_rcu()
下列宏定义于include/linux/rculist.h:
/**
* list_for_each_continue_rcu
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*
* Iterate over an rcu-protected list, continuing after current point.
*
* This list-traversal primitive may safely run concurrently with
* the _rcu list-mutation primitives such as list_add_rcu()
* as long as the traversal is guarded by rcu_read_lock().
*/
#define list_for_each_continue_rcu(pos, head) \
for ((pos) = rcu_dereference_raw(list_next_rcu(pos)); \
(pos) != (head); \
(pos) = rcu_dereference_raw(list_next_rcu(pos)))
15.1.12.7 list_for_each_entry_continue()/list_for_each_entry_safe_continue()/list_for_each_entry_continue_rcu()
下列宏定义于include/linux/list.h:
/**
* list_for_each_entry_continue - continue iteration over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Continue to iterate over list of given type, continuing after
* the current position.
*/
#define list_for_each_entry_continue(pos, head, member) \
for (pos = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/**
* list_for_each_entry_safe_continue - continue list iteration safe against removal
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate over list of given type, continuing after current point,
* safe against removal of list entry.
*/
#define list_for_each_entry_safe_continue(pos, n, head, member) \
for (pos = list_entry(pos->member.next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
函数list_for_each_entry_continue(pos, head, member)和list_for_each_entry_continue_reverse(pos, head, member)分别用于从pos开始向前和向后遍历链表,如下图所示:
下列宏定义于include/linux/rculist.h:
/**
* list_for_each_entry_continue_rcu - continue iteration over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Continue to iterate over list of given type, continuing after
* the current position.
*/
#define list_for_each_entry_continue_rcu(pos, head, member) \
for (pos = list_entry_rcu(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry_rcu(pos->member.next, typeof(*pos), member))
15.1.12.8 list_for_each_entry_continue_reverse()
/**
* list_for_each_entry_continue_reverse - iterate backwards from the given point
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Start to iterate over list of given type backwards, continuing after (注意:不包含当前的pos)
* the current position.
*/
#define list_for_each_entry_continue_reverse(pos, head, member) \
for (pos = list_entry(pos->member.prev, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.prev, typeof(*pos), member))
15.1.12.9 list_for_each_entry_from()/list_for_each_entry_safe_from()
/**
* list_for_each_entry_from - iterate over list of given type from the current point
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate over list of given type, continuing from current position. (NOTE: 包含当前的pos)
*/
#define list_for_each_entry_from(pos, head, member) \
for (; &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/**
* list_for_each_entry_safe_from - iterate over list from current point safe against removal
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate over list of given type from current point, safe against
* removal of list entry.
*/
#define list_for_each_entry_safe_from(pos, n, head, member) \
for (n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
15.1.12.10 list_safe_reset_next()
/**
* list_safe_reset_next - reset a stale list_for_each_entry_safe loop
* @pos: the loop cursor used in the list_for_each_entry_safe loop
* @n: temporary storage used in list_for_each_entry_safe
* @member: the name of the list_struct within the struct.
*
* list_safe_reset_next is not safe to use in general if the list may be
* modified concurrently (eg. the lock is dropped in the loop body). An
* exception to this is if the cursor element (pos) is pinned in the list,
* and list_safe_reset_next is called after re-taking the lock and before
* completing the current iteration of the loop body.
*/
#define list_safe_reset_next(pos, n, member) \
n = list_entry(pos->member.next, typeof(*pos), member)
15.1.13 双向循环链表的封装/struct klist
该结构定义于include/linux/klist.h:
struct klist {
spinlock_t k_lock;
struct list_head k_list;
void (*get)(struct klist_node *);
void (*put)(struct klist_node *);
} __attribute__ ((aligned (sizeof(void *))));
struct klist_node {
void *n_klist; /* never access directly */
struct list_head n_node;
struct kref n_ref;
};
双向循环链表是由一个struct klist类型的对象和多个struct klist_node类型的对象链接而成(通过struct klist->k_list和struct klist_node->n_node),链表头为struct klist->k_list,链表元素为struct klist_node->n_node
- struct klist中的函数
get()用于向链表中添加元素时调用; - struct klist中的函数
put()用于从链表中删除元素时调用; - struct klist_node中的域n_ref用于指示包含该元素的对象的引用计数,这是该链表的主要作用;
- struct klist_node中的域n_klist指向链表头struct klist。
与struct klist有关的接口函数如下:
- 初始化struct klist类型的对象:宏
KLIST_INIT(),函数klist_init() - 定义并初始化struct klist类型的对象:宏
DEFINE_KLIST() - 将某元素添加到某双向循环链表的头或尾:函数
klist_add_head(),函数klist_add_tail() - 将某元素添加到某双向循环链表中某元素之前或之后:函数
klist_add_before(),函数klist_add_after() - 从双向循环链表中删除某元素:函数
klist_del(),函数klist_remove() - 判断某元素是否链接到某双向循环链表中:函数
klist_node_attached() - 轮询双向循环链表:函数
klist_iter_init(),函数klist_iter_init_node(),函数klist_next(),函数klist_iter_exit()
15.2 哈希链表/struct hlist_head/struct hlist_node
该结构定义于include/linux/types.h:
/*
* 由此可知,struct hlist_head比struct list_head节省一个指针的存储空间
*/
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
15.2.1 哈希链表的定义与初始化
空哈希链表的结构如下:

可以通过如下函数或宏初始化哈希链表,参见include/linux/list.h:
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}
15.2.2 向链表中添加元素
包含有效元素的哈希链表的结构如下:
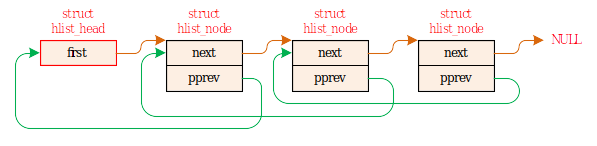
下列函数用于向哈希链表中添加元素,其定义于include/linux/list.h:
// 将元素n链接到链表头h之后、第一个元素之前
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
}
// 本函数将元素n插入到元素next之前。其中,入参n为新插入的元素,入参next为原链表中的元素
/* next must be != NULL */
static inline void hlist_add_before(struct hlist_node *n, struct hlist_node *next)
{
n->pprev = next->pprev;
n->next = next;
next->pprev = &n->next;
*(n->pprev) = n;
}
// 本函数将元素next插入到元素n之后。其中,入参n为原链表中的元素,入参next为新插入的元素
static inline void hlist_add_after(struct hlist_node *n, struct hlist_node *next)
{
next->next = n->next;
n->next = next;
next->pprev = &n->next;
if(next->next)
next->next->pprev = &next->next;
}
/* after that we'll appear to be on some hlist and hlist_del will work */
static inline void hlist_add_fake(struct hlist_node *n)
{
n->pprev = &n->next;
}
下列函数用于向哈希链表中添加元素,其定义于include/linux/rculist.h:
/**
* hlist_add_head_rcu
* @n: the element to add to the hash list.
* @h: the list to add to.
*
* Description:
* Adds the specified element to the specified hlist,
* while permitting racing traversals.
*
* The caller must take whatever precautions are necessary
* (such as holding appropriate locks) to avoid racing
* with another list-mutation primitive, such as hlist_add_head_rcu()
* or hlist_del_rcu(), running on this same list.
* However, it is perfectly legal to run concurrently with
* the _rcu list-traversal primitives, such as
* hlist_for_each_entry_rcu(), used to prevent memory-consistency
* problems on Alpha CPUs. Regardless of the type of CPU, the
* list-traversal primitive must be guarded by rcu_read_lock().
*/
static inline void hlist_add_head_rcu(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
n->pprev = &h->first;
rcu_assign_pointer(hlist_first_rcu(h), n);
if (first)
first->pprev = &n->next;
}
/**
* hlist_add_before_rcu
* @n: the new element to add to the hash list.
* @next: the existing element to add the new element before.
*
* Description:
* Adds the specified element to the specified hlist
* before the specified node while permitting racing traversals.
*
* The caller must take whatever precautions are necessary
* (such as holding appropriate locks) to avoid racing
* with another list-mutation primitive, such as hlist_add_head_rcu()
* or hlist_del_rcu(), running on this same list.
* However, it is perfectly legal to run concurrently with
* the _rcu list-traversal primitives, such as
* hlist_for_each_entry_rcu(), used to prevent memory-consistency
* problems on Alpha CPUs.
*/
static inline void hlist_add_before_rcu(struct hlist_node *n, struct hlist_node *next)
{
n->pprev = next->pprev;
n->next = next;
rcu_assign_pointer(hlist_pprev_rcu(n), n);
next->pprev = &n->next;
}
/**
* hlist_add_after_rcu
* @prev: the existing element to add the new element after.
* @n: the new element to add to the hash list.
*
* Description:
* Adds the specified element to the specified hlist
* after the specified node while permitting racing traversals.
*
* The caller must take whatever precautions are necessary
* (such as holding appropriate locks) to avoid racing
* with another list-mutation primitive, such as hlist_add_head_rcu()
* or hlist_del_rcu(), running on this same list.
* However, it is perfectly legal to run concurrently with
* the _rcu list-traversal primitives, such as
* hlist_for_each_entry_rcu(), used to prevent memory-consistency
* problems on Alpha CPUs.
*/
static inline void hlist_add_after_rcu(struct hlist_node *prev, struct hlist_node *n)
{
n->next = prev->next;
n->pprev = &prev->next;
rcu_assign_pointer(hlist_next_rcu(prev), n);
if (n->next)
n->next->pprev = &n->next;
}
/*
* return the first or the next element in an RCU protected hlist
*/
#define hlist_first_rcu(head) (*((struct hlist_node __rcu **)(&(head)->first)))
#define hlist_next_rcu(node) (*((struct hlist_node __rcu **)(&(node)->next)))
#define hlist_pprev_rcu(node) (*((struct hlist_node __rcu **)((node)->pprev)))
15.2.3 判断链表是否为空
static inline int hlist_empty(const struct hlist_head *h)
{
return !h->first;
}
15.2.4 判断元素是否被链接到哈希表
static inline int hlist_unhashed(const struct hlist_node *h)
{
return !h->pprev;
}
15.2.5 从链表中删除元素
下列函数用于从哈希链表删除元素,其定义于include/linux/list.h:
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
*pprev = next;
if (next)
next->pprev = pprev;
}
static inline void hlist_del(struct hlist_node *n)
{
__hlist_del(n);
n->next = LIST_POISON1;
n->pprev = LIST_POISON2;
}
static inline void hlist_del_init(struct hlist_node *n)
{
if (!hlist_unhashed(n)) {
__hlist_del(n);
INIT_HLIST_NODE(n);
}
}
下列函数用于从哈希链表删除元素,其定义于include/linux/rculist.h:
/**
* hlist_del_rcu - deletes entry from hash list without re-initialization
* @n: the element to delete from the hash list.
*
* Note: list_unhashed() on entry does not return true after this,
* the entry is in an undefined state. It is useful for RCU based
* lockfree traversal.
*
* In particular, it means that we can not poison the forward
* pointers that may still be used for walking the hash list.
*
* The caller must take whatever precautions are necessary
* (such as holding appropriate locks) to avoid racing
* with another list-mutation primitive, such as hlist_add_head_rcu()
* or hlist_del_rcu(), running on this same list.
* However, it is perfectly legal to run concurrently with
* the _rcu list-traversal primitives, such as
* hlist_for_each_entry().
*/
static inline void hlist_del_rcu(struct hlist_node *n)
{
__hlist_del(n);
n->pprev = LIST_POISON2;
}
/**
* hlist_del_init_rcu - deletes entry from hash list with re-initialization
* @n: the element to delete from the hash list.
*
* Note: list_unhashed() on the node return true after this. It is
* useful for RCU based read lockfree traversal if the writer side
* must know if the list entry is still hashed or already unhashed.
*
* In particular, it means that we can not poison the forward pointers
* that may still be used for walking the hash list and we can only
* zero the pprev pointer so list_unhashed() will return true after
* this.
*
* The caller must take whatever precautions are necessary (such as
* holding appropriate locks) to avoid racing with another
* list-mutation primitive, such as hlist_add_head_rcu() or
* hlist_del_rcu(), running on this same list. However, it is
* perfectly legal to run concurrently with the _rcu list-traversal
* primitives, such as hlist_for_each_entry_rcu().
*/
static inline void hlist_del_init_rcu(struct hlist_node *n)
{
if (!hlist_unhashed(n)) {
__hlist_del(n);
n->pprev = NULL;
}
}
15.2.6 替换链表中的元素
下列函数用于替换双向循环链表中的某元素,其定义于include/linux/rculist.h:
/**
* hlist_replace_rcu - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* The @old entry will be replaced with the @new entry atomically.
*/
static inline void hlist_replace_rcu(struct hlist_node *old, struct hlist_node *new)
{
struct hlist_node *next = old->next;
new->next = next;
new->pprev = old->pprev;
rcu_assign_pointer(*(struct hlist_node __rcu **)new->pprev, new);
if (next)
new->next->pprev = &new->next;
old->pprev = LIST_POISON2;
}
15.2.7 移动链表中的元素
下列函数用于移动哈希链表中的元素,其定义于include/linux/list.h:
/*
* Move a list from one list head to another. Fixup the pprev
* reference of the first entry if it exists.
*/
static inline void hlist_move_list(struct hlist_head *old, struct hlist_head *new)
{
new->first = old->first;
if (new->first)
new->first->pprev = &new->first;
old->first = NULL;
}
15.2.8 获取包含链表元素的对象的地址
下列宏用于获取包含链表元素的对象的地址,其定义于include/linux/list.h:
#define hlist_entry(ptr, type, member) container_of(ptr,type,member)
其中,宏container_of()定义于include/linux/kernel.h:
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) ); })
函数retPtr = hlist_entry(ptr, type, member)的执行结果如下:
15.2.9 遍历链表元素
下列宏用于遍历链表元素:
15.2.9.1 hlist_for_each()/hlist_for_each_safe()
下列宏用于向后遍历哈希链表,其中pos指向struct hlist_node类型的对象,其定义于include/linux/list.h:
/*
* struct hlist_node *pos;
*/
#define hlist_for_each(pos, head) \
for (pos = (head)->first; pos; pos = pos->next)
#define hlist_for_each_safe(pos, n, head) \
for (pos = (head)->first; \
pos && ({ n = pos->next; 1; }); \
pos = n)
下列宏用于向后遍历哈希链表,其中pos指向struct hlist_node类型的对象,其定义于include/linux/rculist.h:
#define __hlist_for_each_rcu(pos, head) \
for (pos = rcu_dereference(hlist_first_rcu(head)); \
pos; \
pos = rcu_dereference(hlist_next_rcu(pos)))
15.2.9.2 hlist_for_each_entry()/hlist_for_each_entry_safe()/hlist_for_each_entry_rcu()/hlist_for_each_entry_rcu_bh()
下列宏用于向后遍历哈希链表,其中pos指向包含struct hlist_node类型元素的对象,其定义于include/linux/list.h:
/**
* hlist_for_each_entry - iterate over list of given type
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry(tpos, pos, head, member) \
for (pos = (head)->first; \
pos && ({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
/**
* hlist_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @n: another &struct hlist_node to use as temporary storage
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_safe(tpos, pos, n, head, member) \
for (pos = (head)->first; \
pos && ({ n = pos->next; 1; }) && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = n)
下列宏用于向后遍历哈希链表,其中pos指向包含struct hlist_node类型元素的对象,其定义于include/linux/rculist.h:
/**
* hlist_for_each_entry_rcu - iterate over rcu list of given type
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*
* This list-traversal primitive may safely run concurrently with
* the _rcu list-mutation primitives such as hlist_add_head_rcu()
* as long as the traversal is guarded by rcu_read_lock().
*/
#define hlist_for_each_entry_rcu(tpos, pos, head, member) \
for (pos = rcu_dereference_raw(hlist_first_rcu(head)); \
pos && ({ tpos = hlist_entry(pos, typeof(*tpos), member); 1; }); \
pos = rcu_dereference_raw(hlist_next_rcu(pos)))
/**
* hlist_for_each_entry_rcu_bh - iterate over rcu list of given type
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*
* This list-traversal primitive may safely run concurrently with
* the _rcu list-mutation primitives such as hlist_add_head_rcu()
* as long as the traversal is guarded by rcu_read_lock().
*/
#define hlist_for_each_entry_rcu_bh(tpos, pos, head, member) \
for (pos = rcu_dereference_bh((head)->first); \
pos && ({ tpos = hlist_entry(pos, typeof(*tpos), member); 1; }); \
pos = rcu_dereference_bh(pos->next))
15.2.9.3 hlist_for_each_entry_continue()/hlist_for_each_entry_from()/hlist_for_each_entry_continue_rcu()/hlist_for_each_entry_continue_rcu_bh()
如下宏定义于include/linux/list.h:
/**
* hlist_for_each_entry_continue - iterate over a hlist continuing after current point
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_continue(tpos, pos, member) \
for (pos = (pos)->next; \
pos && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
/**
* hlist_for_each_entry_from - iterate over a hlist continuing from current point
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_from(tpos, pos, member) \
for (; pos && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
如下宏定义于include/linux/rculist.h:
/**
* hlist_for_each_entry_continue_rcu - iterate over a hlist continuing after current point
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_continue_rcu(tpos, pos, member) \
for (pos = rcu_dereference((pos)->next); \
pos && ({ tpos = hlist_entry(pos, typeof(*tpos), member); 1; }); \
pos = rcu_dereference(pos->next))
/**
* hlist_for_each_entry_continue_rcu_bh - iterate over a hlist continuing after current point
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_continue_rcu_bh(tpos, pos, member) \
for (pos = rcu_dereference_bh((pos)->next); \
pos && ({ tpos = hlist_entry(pos, typeof(*tpos), member); 1; }); \
pos = rcu_dereference_bh(pos->next))
15.3 加锁哈希链表/struct hlist_bl_head/struct hlist_bl_node
该结构定义于include/linux/list_bl.h:
struct hlist_bl_head {
struct hlist_bl_node *first;
};
struct hlist_bl_node {
struct hlist_bl_node *next, **pprev;
};
Special version of lists, where head of the list has a lock in the lowest bit. This is useful for scalable hash tables without increasing memory footprint overhead.
For modification operations, the 0 bit of hlist_bl_head->first pointer must be set. With some small modifications, this can easily be adapted to store several arbitrary bits (not just a single lock bit), if the need arises to store some fast and compact auxiliary data.
NOTE 1: The “bl” in “struct hlist_bl_head” and “struct hlist_bl_node” stands for bit lock.
NOTE 2: hlist_bl_head->first是struct hlist_bl_node类型的指针,由于地址存在对齐的问题,因而其地址中的低几位为0,因而可将该若干比特位用于其他用途,此处用于加锁!
15.3.1 哈希链表的定义与初始化
空哈希链表的结构如下:
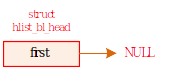
下列函数或宏可用于初始化哈希链表,其定义于include/linux/list_bl.h:
#define INIT_HLIST_BL_HEAD(ptr) \
((ptr)->first = NULL)
static inline void INIT_HLIST_BL_NODE(struct hlist_bl_node *h)
{
h->next = NULL;
h->pprev = NULL;
}
15.3.2 为链表加锁/解锁
下列函数用于为哈希链表加锁/解锁,其定义于include/linux/list_bl.h:
static inline void hlist_bl_lock(struct hlist_bl_head *b)
{
// 将b地址中的bit #0置位
bit_spin_lock(0, (unsigned long *)b);
}
static inline void hlist_bl_unlock(struct hlist_bl_head *b)
{
// 将b地址中的bit #0复位
__bit_spin_unlock(0, (unsigned long *)b);
}
哈希链表修改前要先调用hlist_bl_lock()为链表加锁,修改后调用hlist_bl_unlock()解锁,例如:
hlist_bl_lock(b);
__hlist_bl_del(&dentry->d_hash);
dentry->d_hash.pprev = NULL;
hlist_bl_unlock(b);
...
hlist_bl_lock(&tmp->d_sb->s_anon);
hlist_bl_add_head(&tmp->d_hash, &tmp->d_sb->s_anon);
hlist_bl_unlock(&tmp->d_sb->s_anon);
15.3.3 向链表中添加元素
包含有效元素的哈希链表的结构如下:
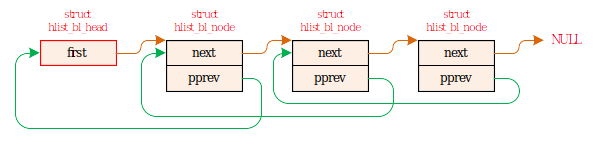
下列函数用于向哈希链表中添加元素,其定义于include/linux/list_bl.h:
#if defined(CONFIG_SMP) || defined(CONFIG_DEBUG_SPINLOCK)
#define LIST_BL_LOCKMASK 1UL
#else
#define LIST_BL_LOCKMASK 0UL
#endif
// 将元素n链接到链表头h之后、第一个元素之前
static inline void hlist_bl_add_head(struct hlist_bl_node *n, struct hlist_bl_head *h)
{
struct hlist_bl_node *first = hlist_bl_first(h);
n->next = first;
if (first)
first->pprev = &n->next;
n->pprev = &h->first;
hlist_bl_set_first(h, n);
}
static inline struct hlist_bl_node *hlist_bl_first(struct hlist_bl_head *h)
{
// 取消h->first最低位的锁标志,即此时h->first只表示地址
return (struct hlist_bl_node *)((unsigned long)h->first & ~LIST_BL_LOCKMASK);
}
static inline void hlist_bl_set_first(struct hlist_bl_head *h, struct hlist_bl_node *n)
{
// 若此判断为真,则说明地址未对齐,因为无法将地址中的最低位用于锁标志
LIST_BL_BUG_ON((unsigned long)n & LIST_BL_LOCKMASK);
/*
* 若此判断为真,则说明调用本函数之前未对h->first地址中的bit #0加锁;
* 在对链表进行修改操作前,调用函数hlist_bl_lock()加锁;之后,
* 调用函数hlist_bl_unlock()解锁
*/
LIST_BL_BUG_ON(((unsigned long)h->first & LIST_BL_LOCKMASK) != LIST_BL_LOCKMASK);
// 此处对链表进行了修改,因而需要对h->first地址中的bit #0加锁
h->first = (struct hlist_bl_node *)((unsigned long)n | LIST_BL_LOCKMASK);
}
下列函数用于向哈希链表中添加元素,其定义于include/linux/rculist_bl.h:
/**
* hlist_bl_add_head_rcu
* @n: the element to add to the hash list.
* @h: the list to add to.
*
* Description:
* Adds the specified element to the specified hlist_bl,
* while permitting racing traversals.
*
* The caller must take whatever precautions are necessary
* (such as holding appropriate locks) to avoid racing
* with another list-mutation primitive, such as hlist_bl_add_head_rcu()
* or hlist_bl_del_rcu(), running on this same list.
* However, it is perfectly legal to run concurrently with
* the _rcu list-traversal primitives, such as
* hlist_bl_for_each_entry_rcu(), used to prevent memory-consistency
* problems on Alpha CPUs. Regardless of the type of CPU, the
* list-traversal primitive must be guarded by rcu_read_lock().
*/
static inline void hlist_bl_add_head_rcu(struct hlist_bl_node *n, struct hlist_bl_head *h)
{
struct hlist_bl_node *first;
/* don't need hlist_bl_first_rcu because we're under lock */
first = hlist_bl_first(h);
n->next = first;
if (first)
first->pprev = &n->next;
n->pprev = &h->first;
/* need _rcu because we can have concurrent lock free readers */
hlist_bl_set_first_rcu(h, n);
}
static inline struct hlist_bl_node *hlist_bl_first_rcu(struct hlist_bl_head *h)
{
return (struct hlist_bl_node *)
((unsigned long)rcu_dereference(h->first) & ~LIST_BL_LOCKMASK);
}
static inline void hlist_bl_set_first_rcu(struct hlist_bl_head *h, struct hlist_bl_node *n)
{
LIST_BL_BUG_ON((unsigned long)n & LIST_BL_LOCKMASK);
LIST_BL_BUG_ON(((unsigned long)h->first & LIST_BL_LOCKMASK) != LIST_BL_LOCKMASK);
rcu_assign_pointer(h->first, (struct hlist_bl_node *)((unsigned long)n | LIST_BL_LOCKMASK));
}
15.3.4 判断链表是否为空
static inline int hlist_bl_empty(const struct hlist_bl_head *h)
{
return !((unsigned long)h->first & ~LIST_BL_LOCKMASK);
}
15.3.5 判断元素是否被链接到哈希表
static inline int hlist_bl_unhashed(const struct hlist_bl_node *h)
{
return !h->pprev;
}
15.3.6 从链表中删除元素
下列函数用于从哈希链表删除元素,其定义于include/linux/list_bl.h:
static inline void __hlist_bl_del(struct hlist_bl_node *n)
{
struct hlist_bl_node *next = n->next;
struct hlist_bl_node **pprev = n->pprev;
// 若此判断为真,则说明地址未对齐,因为无法将地址中的最低位用于锁标志
LIST_BL_BUG_ON((unsigned long)n & LIST_BL_LOCKMASK);
/* pprev may be `first`, so be careful not to lose the lock bit */
*pprev = (struct hlist_bl_node *) ((unsigned long)next | ((unsigned long)*pprev & LIST_BL_LOCKMASK));
if (next)
next->pprev = pprev;
}
static inline void hlist_bl_del(struct hlist_bl_node *n)
{
__hlist_bl_del(n);
n->next = LIST_POISON1;
n->pprev = LIST_POISON2;
}
static inline void hlist_bl_del_init(struct hlist_bl_node *n)
{
if (!hlist_bl_unhashed(n)) {
__hlist_bl_del(n);
INIT_HLIST_BL_NODE(n);
}
}
下列函数用于从哈希链表删除元素,其定义于include/linux/rculist_bl.h:
/**
* hlist_bl_del_rcu - deletes entry from hash list without re-initialization
* @n: the element to delete from the hash list.
*
* Note: hlist_bl_unhashed() on entry does not return true after this,
* the entry is in an undefined state. It is useful for RCU based
* lockfree traversal.
*
* In particular, it means that we can not poison the forward
* pointers that may still be used for walking the hash list.
*
* The caller must take whatever precautions are necessary
* (such as holding appropriate locks) to avoid racing
* with another list-mutation primitive, such as hlist_bl_add_head_rcu()
* or hlist_bl_del_rcu(), running on this same list.
* However, it is perfectly legal to run concurrently with
* the _rcu list-traversal primitives, such as
* hlist_bl_for_each_entry().
*/
static inline void hlist_bl_del_rcu(struct hlist_bl_node *n)
{
__hlist_bl_del(n);
n->pprev = LIST_POISON2;
}
/**
* hlist_bl_del_init_rcu - deletes entry from hash list with re-initialization
* @n: the element to delete from the hash list.
*
* Note: hlist_bl_unhashed() on the node returns true after this. It is
* useful for RCU based read lockfree traversal if the writer side
* must know if the list entry is still hashed or already unhashed.
*
* In particular, it means that we can not poison the forward pointers
* that may still be used for walking the hash list and we can only
* zero the pprev pointer so list_unhashed() will return true after
* this.
*
* The caller must take whatever precautions are necessary (such as
* holding appropriate locks) to avoid racing with another
* list-mutation primitive, such as hlist_bl_add_head_rcu() or
* hlist_bl_del_rcu(), running on this same list. However, it is
* perfectly legal to run concurrently with the _rcu list-traversal
* primitives, such as hlist_bl_for_each_entry_rcu().
*/
static inline void hlist_bl_del_init_rcu(struct hlist_bl_node *n)
{
if (!hlist_bl_unhashed(n)) {
__hlist_bl_del(n);
n->pprev = NULL;
}
}
15.3.7 获取包含链表元素的对象的地址
下列宏可用于获取包含链表元素的对象的地址,其定义于include/linux/list_bl.h:
#define hlist_bl_entry(ptr, type, member) container_of(ptr,type,member)
其中,宏container_of()定义于include/linux/kernel.h:
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) ); })
函数retPtr = hlist_bl_entry(ptr, type, member)的执行结果如下:
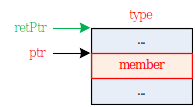
15.3.8 遍历链表元素
如下宏可用于遍历链表元素:
15.3.8.1 hlist_bl_for_each_entry()/hlist_bl_for_each_entry_safe()
下列宏用于向后遍历哈希链表,其中pos指向struct hlist_bl_node类型的对象,其定义于include/linux/list_bl.h:
/**
* hlist_bl_for_each_entry - iterate over list of given type
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_bl_node to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the hlist_bl_node within the struct.
*
*/
#define hlist_bl_for_each_entry(tpos, pos, head, member) \
for (pos = hlist_bl_first(head); \
pos && ({ tpos = hlist_bl_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
/**
* hlist_bl_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_bl_node to use as a loop cursor.
* @n: another &struct hlist_node to use as temporary storage
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_bl_for_each_entry_safe(tpos, pos, n, head, member) \
for (pos = hlist_bl_first(head); \
pos && ({ n = pos->next; 1; }) && ({ tpos = hlist_bl_entry(pos, typeof(*tpos), member);1;}); \
pos = n)
15.3.8.2 hlist_bl_for_each_entry_rcu()
下列宏用于向后遍历哈希链表,其中pos指向struct hlist_bl_node类型的对象,其定义于include/linux/rculist_bl.h:
/**
* hlist_bl_for_each_entry_rcu - iterate over rcu list of given type
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_bl_node to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the hlist_bl_node within the struct.
*
*/
#define hlist_bl_for_each_entry_rcu(tpos, pos, head, member) \
for (pos = hlist_bl_first_rcu(head); \
pos && ({ tpos = hlist_bl_entry(pos, typeof(*tpos), member); 1; }); \
pos = rcu_dereference_raw(pos->next))
15.4 Queues
15.4.1 队列结构/struct kfifo
该结构定义于include/linux/kfifo.h:
/*
* define compatibility "struct kfifo" for dynamic allocated fifos
*/
struct kfifo __STRUCT_KFIFO_PTR(unsigned char, 0, void);
#define __STRUCT_KFIFO_PTR(type, recsize, ptrtype) \
{ \
__STRUCT_KFIFO_COMMON(type, recsize, ptrtype); \
type buf[0]; \
}
#define __STRUCT_KFIFO_COMMON(datatype, recsize, ptrtype) \
union { \
struct __kfifo kfifo; \
datatype *type; \
char (*rectype)[recsize]; \
ptrtype *ptr; \
const ptrtype *ptr_const; \
}
则扩展后的struct kfifo为:
struct kfifo
{
union {
struct __kfifo kfifo; // 参见[15.4.1.1 struct __kfifo]节
unsigned char *type;
char (*rectype)[0];
void *ptr;
const void *ptr_const;
};
unsigned char buf[0];
};
其结构参见:
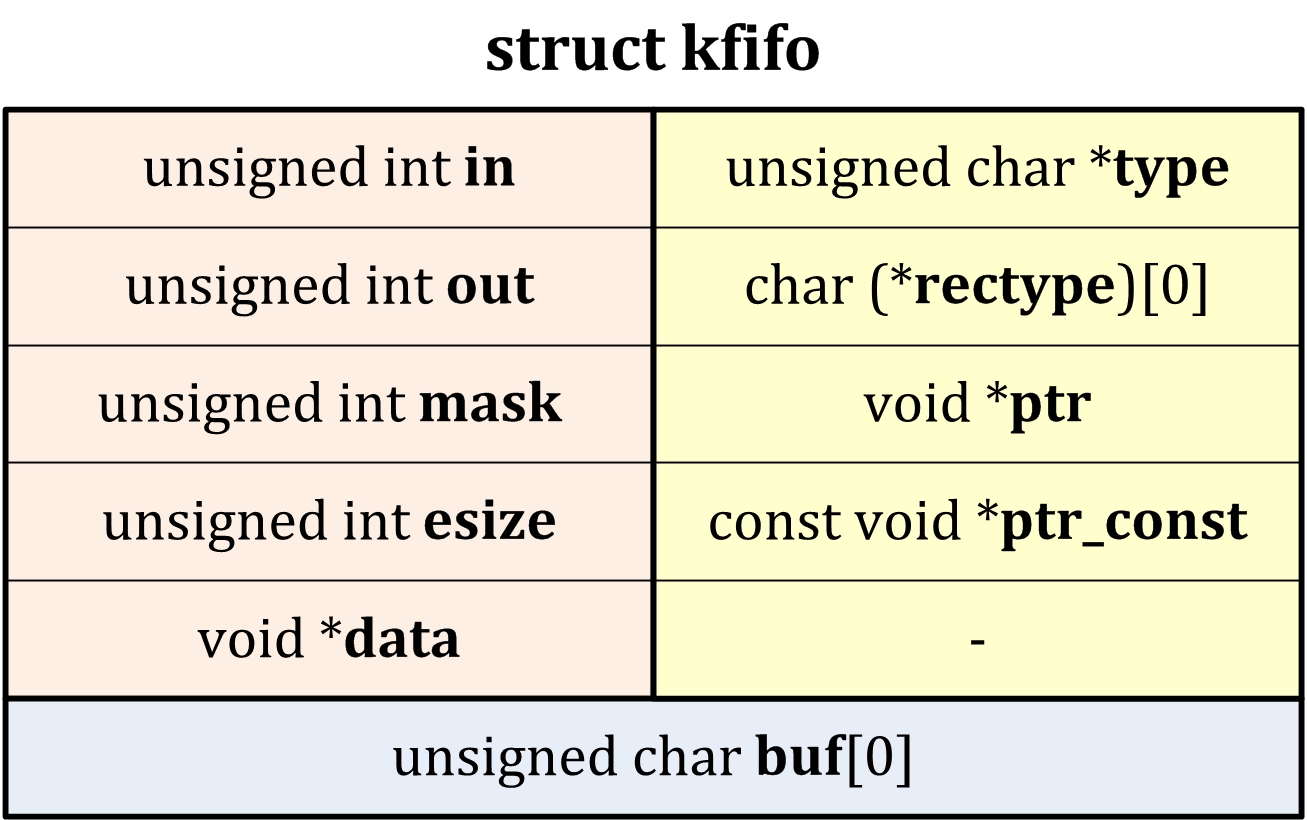
若执行如下程序段:
struct kfifo fifo;
int ret = __is_kfifo_ptr(&fifo);
int size = sizeof(*fifo.type);
int recsize = sizeof(*fifo. rectype);
则各变量的取值如下:
ret = 1 // 由于buf[0]不占用空间
size = 1 // 由于unsigned char类型占1个字节空间
recsize = 0 // 由于char (*rectype)[0]不占用空间
其中宏__is_kfifo_ptr()定义于include/linux/kfifo.h:
/*
* helper macro to distinguish between real in place fifo where the fifo
* array is a part of the structure and the fifo type where the array is
* outside of the fifo structure.
*/
#define __is_kfifo_ptr(fifo) (sizeof(*fifo) == sizeof(struct __kfifo))
15.4.1.1 struct __kfifo
该结构体定义于include/linux/kfifo.h:
struct __kfifo {
unsigned int in; // 缓冲区待写入元素下标
unsigned int out; // 缓冲区待读出元素下标
/*
* 缓冲区元素的个数减一。因为缓冲区元素个数为2的整数次幂,
* 故mask的二进制取值为1的序列
*/
unsigned int mask;
unsigned int esize; // 缓冲区中每个元素所占的字节数
void *data; // 指向缓冲区的首地址
};
各元素的含义:
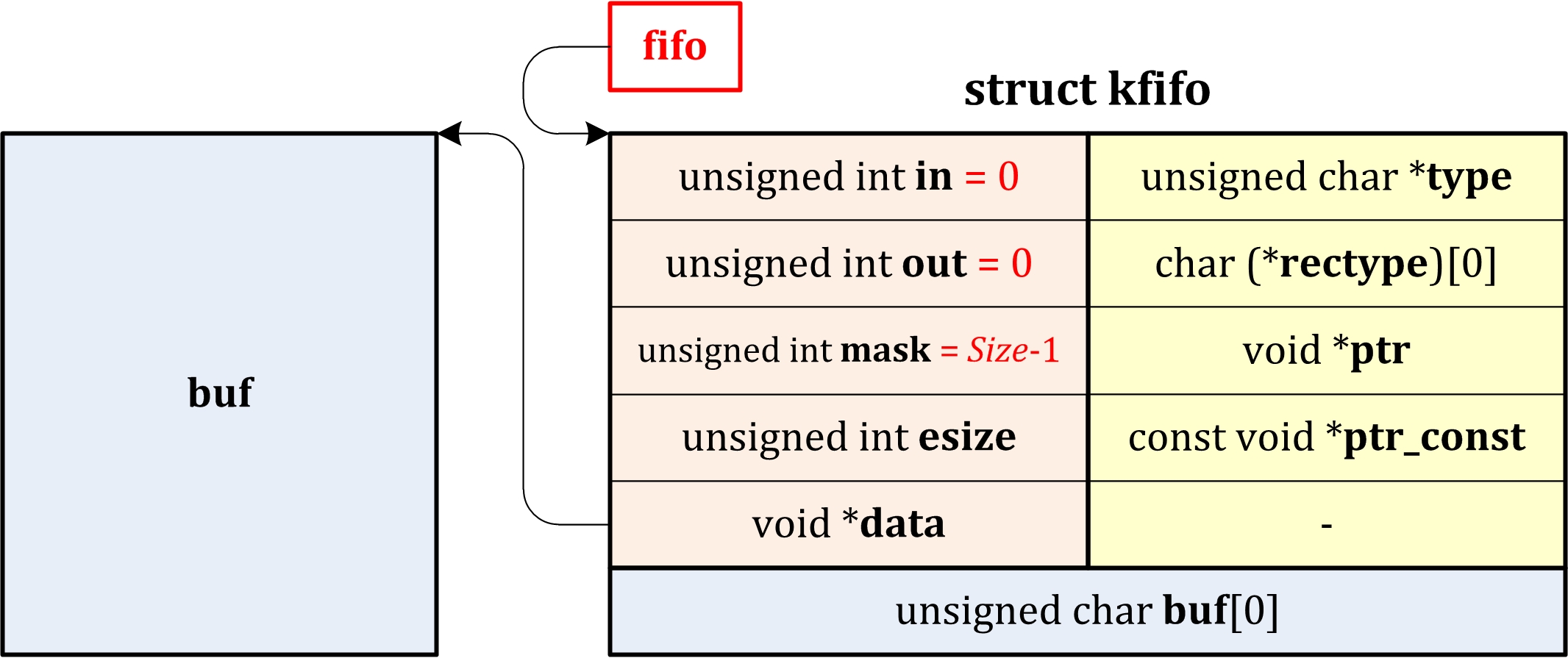
15.4.2 队列的定义与初始化
可以采用15.4.2.1 静态创建队列/DECLARE_KFIFO()/INIT_KFIFO()/DEFINE_KFIFO()节的方法静态创建队列,也可以采用15.4.2.2 动态创建队列/kfifo_alloc()/kfifo_init()节的方法动态创建队列。
若存在队列fifo,则可以通过宏__is_kfifo_ptr(fifo)来判断该对象是如何创建的:
- 返回true,则说明fifo是动态创建的,参见15.4.2.2 动态创建队列/kfifo_alloc()/kfifo_init()节的图;
- 返回false,则说明fifo是静态创建的,参见15.4.2.1 静态创建队列/DECLARE_KFIFO()/INIT_KFIFO()/DEFINE_KFIFO()节的图。
15.4.2.1 静态创建队列/DECLARE_KFIFO()/INIT_KFIFO()/DEFINE_KFIFO()
宏DECLARE_KFIFO()用于声明一个struct kfifo类型的对象fifo。该宏定义于include/linux/kfifo.h:
/**
* DECLARE_KFIFO - macro to declare a fifo object
* @fifo: name of the declared fifo
* @type: type of the fifo elements
* @size: the number of elements in the fifo, this must be a power of 2
*/
#define DECLARE_KFIFO(fifo, type, size) STRUCT_KFIFO(type, size) fifo
#define STRUCT_KFIFO(type, size) \
struct __STRUCT_KFIFO(type, size, 0, type)
#define __STRUCT_KFIFO(type, size, recsize, ptrtype) \
{ \
__STRUCT_KFIFO_COMMON(type, recsize, ptrtype); \
type buf[((size < 2) || (size & (size - 1))) ? -1 : size]; \
}
#define __STRUCT_KFIFO_COMMON(datatype, recsize, ptrtype) \
union { \
struct __kfifo kfifo; \
datatype *type; \
char (*rectype)[recsize]; \
ptrtype *ptr; \
const ptrtype *ptr_const; \
}
则语句DECLARE_KFIFO(fifo, type, size);声明的对象:
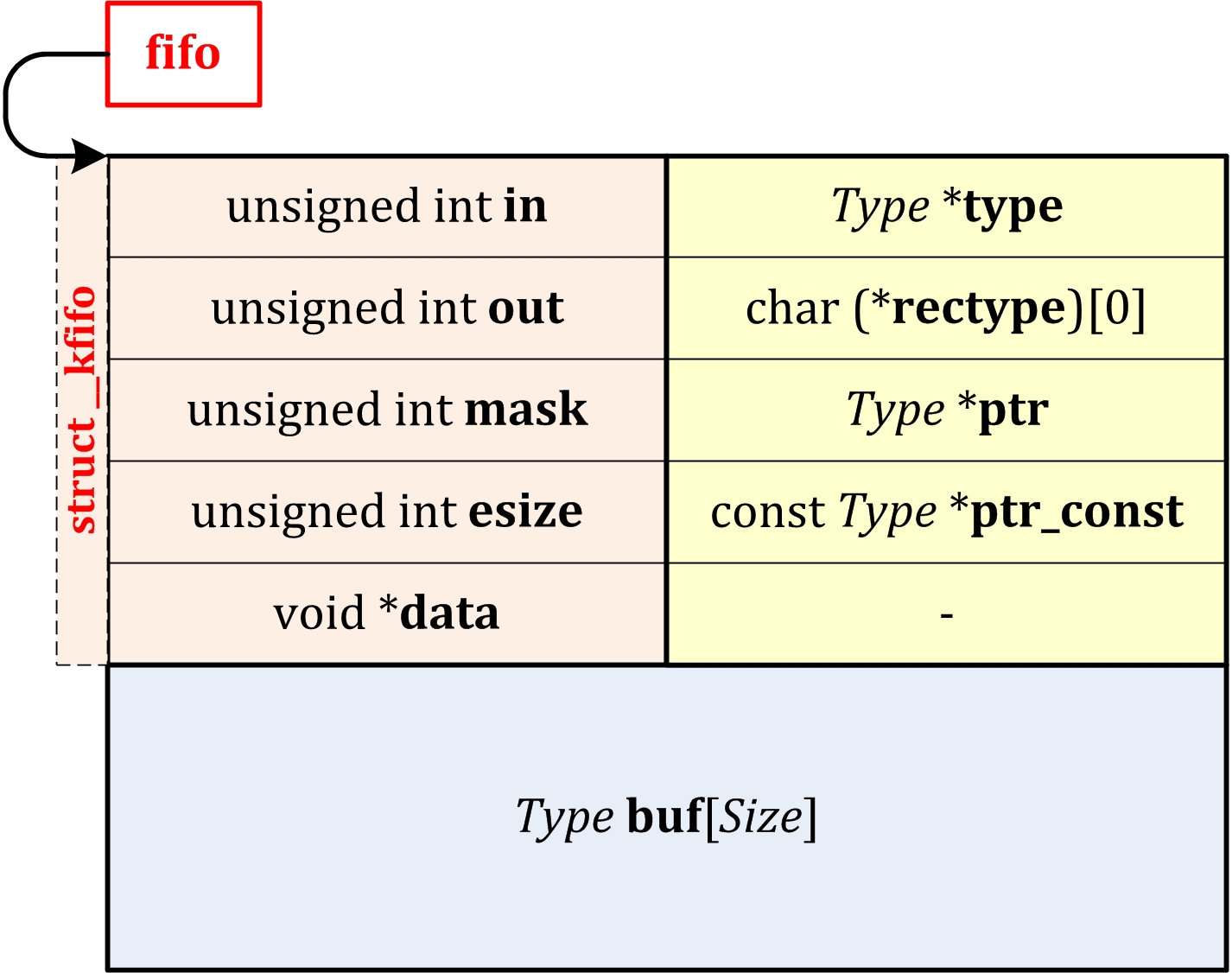
宏INIT_KFIFO()用于初始化一个用DECLARE_KFIFO()声明的对象,其定义于include/linux/kfifo.h:
/**
* INIT_KFIFO - Initialize a fifo declared by DECLARE_KFIFO
* @fifo: name of the declared fifo datatype
*/
#define INIT_KFIFO(fifo) \
(void)({ \
typeof(&(fifo)) __tmp = &(fifo); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
__kfifo->in = 0; \
__kfifo->out = 0; \
__kfifo->mask = __is_kfifo_ptr(__tmp) ? 0 : ARRAY_SIZE(__tmp->buf) - 1; \
__kfifo->esize = sizeof(*__tmp->buf); \
__kfifo->data = __is_kfifo_ptr(__tmp) ? NULL : __tmp->buf; \
})
则语句INIT_KFIFO(fifo);初始化后的对象:
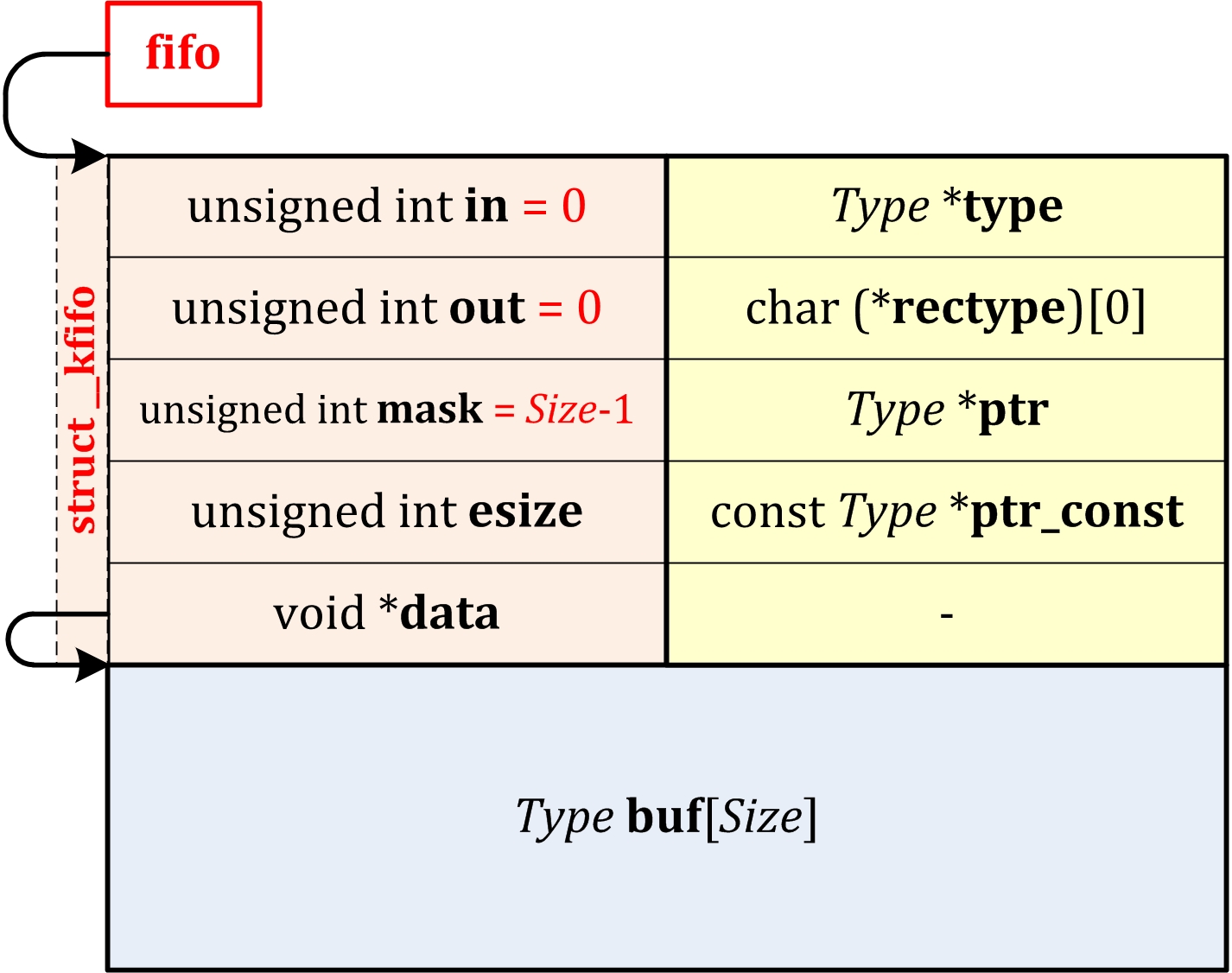
此外,宏DEFINE_KFIFO()相当于宏DECLARE_KFIFO()和INIT_KFIFO()的结合体,其定义于include/linux/kfifo.h:
/**
* DEFINE_KFIFO - macro to define and initialize a fifo
* @fifo: name of the declared fifo datatype
* @type: type of the fifo elements
* @size: the number of elements in the fifo, this must be a power of 2
*
* Note: the macro can be used for global and local fifo data type variables.
*/
#define DEFINE_KFIFO(fifo, type, size) \
DECLARE_KFIFO(fifo, type, size) = \
(typeof(fifo)) { \
{ \
{ \
.in = 0, \
.out = 0, \
.mask = __is_kfifo_ptr(&(fifo)) ? \
0 : ARRAY_SIZE((fifo).buf) - 1, \
.esize = sizeof(*(fifo).buf), \
.data = __is_kfifo_ptr(&(fifo)) ? \
NULL : (fifo).buf, \
} \
} \
}
15.4.2.2 动态创建队列/kfifo_alloc()/kfifo_init()
如果已定义对象struct kfifo fifo,则可以使用宏kfifo_alloc()为fifo分配缓冲区buf,并将fifo.data指向刚分配的buf。该宏定义于include/linux/kfifo.h:
static inline int __must_check __kfifo_int_must_check_helper(int val)
{
return val;
}
/**
* kfifo_alloc - dynamically allocates a new fifo buffer
* @fifo: pointer to the fifo
* @size: the number of elements in the fifo, this must be a power of 2
* @gfp_mask: get_free_pages mask, passed to kmalloc()
*
* This macro dynamically allocates a new fifo buffer.
*
* The numer of elements will be rounded-up to a power of 2.
* The fifo will be release with kfifo_free().
* Return 0 if no error, otherwise an error code.
*/
#define kfifo_alloc(fifo, size, gfp_mask) \
__kfifo_int_must_check_helper( \
({ \
typeof((fifo) + 1) __tmp = (fifo); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
// 若struct kfifo fifo,则__is_kfifo_ptr(&fifo)=1,参见[15.4.1 队列结构/struct kfifo]节
__is_kfifo_ptr(__tmp) ? \
// sizeof(*__tmp->type)=1,参见[15.4.1 队列结构/struct kfifo]节
__kfifo_alloc(__kfifo, size, sizeof(*__tmp->type), gfp_mask) : \
-EINVAL; \
}) \
)
其中,函数__kfifo_alloc()定义于kernel/kfifo.c:
int __kfifo_alloc(struct __kfifo *fifo, unsigned int size, size_t esize, gfp_t gfp_mask)
{
/*
* round down to the next power of 2, since our 'let the indices
* wrap' technique works only in this case.
*/
if (!is_power_of_2(size))
size = rounddown_pow_of_two(size);
fifo->in = 0;
fifo->out = 0;
fifo->esize = esize;
if (size < 2) {
fifo->data = NULL;
fifo->mask = 0;
return -EINVAL;
}
// 动态分配指定的缓冲区,该缓冲区不与fifo的地址相连
fifo->data = kmalloc(size * esize, gfp_mask);
if (!fifo->data) {
fifo->mask = 0;
return -ENOMEM;
}
fifo->mask = size - 1;
return 0;
}
则如下语句:
struct kfifo fifo;
int ret;
ret = kfifo_alloc(&kifo, PAGE_SIZE, GFP_KERNEL);
if (ret)
return ret;
创建的队列为:
如果已定义对象struct kfifo fifo,且已存在缓冲区buf,则可以使用宏kfifo_init将fifo.data指向buf。该宏定义于include/linux/kfifo.h:
/**
* kfifo_init - initialize a fifo using a preallocated buffer
* @fifo: the fifo to assign the buffer
* @buffer: the preallocated buffer to be used
* @size: the size of the internal buffer, this have to be a power of 2
*
* This macro initialize a fifo using a preallocated buffer.
*
* The numer of elements will be rounded-up to a power of 2.
* Return 0 if no error, otherwise an error code.
*/
#define kfifo_init(fifo, buffer, size) \
({ \
typeof((fifo) + 1) __tmp = (fifo); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
// 若struct kfifo fifo,则__is_kfifo_ptr(&fifo)=1,参见[15.4.1 队列结构/struct kfifo]节
__is_kfifo_ptr(__tmp) ? \
// sizeof(*__tmp->type)=1,参见[15.4.1 队列结构/struct kfifo]节
__kfifo_init(__kfifo, buffer, size, sizeof(*__tmp->type)) : \
-EINVAL; \
})
其中,函数__kfifo_init()定义于kernel/kfifo.c:
int __kfifo_init(struct __kfifo *fifo, void *buffer, unsigned int size, size_t esize)
{
size /= esize;
if (!is_power_of_2(size))
size = rounddown_pow_of_two(size);
fifo->in = 0;
fifo->out = 0;
fifo->esize = esize;
fifo->data = buffer;
if (size < 2) {
fifo->mask = 0;
return -EINVAL;
}
fifo->mask = size - 1;
return 0;
}
15.4.3 向队列中插入元素/kfifo_in()
该宏定义于include/linux/kfifo.h:
/**
* kfifo_in - put data into the fifo
* @fifo: address of the fifo to be used
* @buf: the data to be added
* @n: number of elements to be added
*
* This macro copies the given buffer into the fifo and returns the
* number of copied elements.
*
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these macro.
*/
#define kfifo_in(fifo, buf, n) \
({ \
typeof((fifo) + 1) __tmp = (fifo); \
typeof((buf) + 1) __buf = (buf); \
unsigned long __n = (n); \
// __recsize = 0,参见[15.4.1 队列结构/struct kfifo]节
const size_t __recsize = sizeof(*__tmp→rectype); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
if (0) { \
typeof(__tmp->ptr_const) __dummy __attribute__ ((unused)); \
__dummy = (typeof(__buf))NULL; \
} \
(__recsize) ? \
__kfifo_in_r(__kfifo, __buf, __n, __recsize) : \
__kfifo_in(__kfifo, __buf, __n); \
})
函数__kfifo_in()定义于kernel/kfifo.c:
unsigned int __kfifo_in(struct __kfifo *fifo, const void *buf, unsigned int len)
{
unsigned int l;
// l表示缓冲区中未使用的元素个数
l = kfifo_unused(fifo);
if (len > l)
len = l;
kfifo_copy_in(fifo, buf, len, fifo->in);
fifo->in += len;
return len; // 返回入队的元素个数
}
/*
* internal helper to calculate the unused elements in a fifo
*/
static inline unsigned int kfifo_unused(struct __kfifo *fifo)
{
/*
* fifo->mask + 1表示缓冲区中元素的总数,
* fifo->in - fifo->out表示已使用的元素个数;
* 其差值表示缓冲区中未使用的元素个数
*/
return (fifo->mask + 1) - (fifo->in - fifo->out);
}
static void kfifo_copy_in(struct __kfifo *fifo, const void *src,
unsigned int len, unsigned int off)
{
unsigned int size = fifo->mask + 1; // 缓冲区中元素的总数
unsigned int esize = fifo->esize; // 缓冲区中每个元素所占的字节数
unsigned int l;
// 入参off = fifo->in,因而此处限定off的取值范围,避免缓冲区出界
off &= fifo->mask;
if (esize != 1) {
off *= esize;
size *= esize;
len *= esize;
}
l = min(len, size - off);
// 将l字节拷贝到从fifo->in至缓冲区结尾的区间
memcpy(fifo->data + off, src, l);
// 将剩余部分拷贝到从缓冲区开始的len-l字节
memcpy(fifo->data, src + l, len - l);
/*
* make sure that the data in the fifo is up to date before
* incrementing the fifo->in index counter
*/
smp_wmb();
}
15.4.4 从队列中取出元素
15.4.4.1 kfifo_out()
该宏定义于include/linux/kfifo.h:
/**
* kfifo_out - get data from the fifo
* @fifo: address of the fifo to be used
* @buf: pointer to the storage buffer
* @n: max. number of elements to get
*
* This macro get some data from the fifo and return the numbers of elements
* copied.
*
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these macro.
*/
#define kfifo_out(fifo, buf, n) \
__kfifo_uint_must_check_helper( \
({ \
typeof((fifo) + 1) __tmp = (fifo); \
typeof((buf) + 1) __buf = (buf); \
unsigned long __n = (n); \
// __recsize = 0,参见[15.4.1 队列结构/struct kfifo]节
const size_t __recsize = sizeof(*__tmp->rectype); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
if (0) { \
typeof(__tmp->ptr) __dummy = NULL; \
__buf = __dummy; \
} \
(__recsize) ? \
__kfifo_out_r(__kfifo, __buf, __n, __recsize) : \
__kfifo_out(__kfifo, __buf, __n); \
}) \
)
函数__kfifo_out()定义于kernel/kfifo.c:
unsigned int __kfifo_out(struct __kfifo *fifo, void *buf, unsigned int len)
{
len = __kfifo_out_peek(fifo, buf, len);
fifo->out += len;
return len;
}
unsigned int __kfifo_out_peek(struct __kfifo *fifo, void *buf, unsigned int len)
{
unsigned int l;
// 当前缓冲区中已存在的元素个数为fifo->in – fifo->out
l = fifo->in - fifo->out;
if (len > l)
len = l;
kfifo_copy_out(fifo, buf, len, fifo->out);
// 返回取出的元素个数
return len;
}
static void kfifo_copy_out(struct __kfifo *fifo, void *dst,
unsigned int len, unsigned int off)
{
unsigned int size = fifo->mask + 1;
unsigned int esize = fifo->esize;
unsigned int l;
// 入参off = fifo->out,因而此处限定off的取值范围,避免缓冲区出界
off &= fifo->mask;
if (esize != 1) {
off *= esize;
size *= esize;
len *= esize;
}
l = min(len, size - off);
// 从fifo->out至缓冲区结尾的区间读出l字节
memcpy(dst, fifo->data + off, l);
// 拷贝从缓冲区开始的len-l字节
memcpy(dst + l, fifo->data, len - l);
/*
* make sure that the data is copied before
* incrementing the fifo->out index counter
*/
smp_wmb();
}
15.4.4.2 kfifo_out_peek()
该宏定义于include/linux/kfifo.h:
/**
* kfifo_out_peek - gets some data from the fifo
* @fifo: address of the fifo to be used
* @buf: pointer to the storage buffer
* @n: max. number of elements to get
*
* This macro get the data from the fifo and return the numbers of elements
* copied. The data is not removed from the fifo.
*
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these macro.
*/
#define kfifo_out_peek(fifo, buf, n) \
__kfifo_uint_must_check_helper( \
({ \
typeof((fifo) + 1) __tmp = (fifo); \
typeof((buf) + 1) __buf = (buf); \
unsigned long __n = (n); \
const size_t __recsize = sizeof(*__tmp->rectype); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
if (0) { \
typeof(__tmp->ptr) __dummy __attribute__ ((unused)) = NULL; \
__buf = __dummy; \
} \
(__recsize) ? \
__kfifo_out_peek_r(__kfifo, __buf, __n, __recsize) : \
// 此处直接调用__kfifo_out_peek(),而不是__kfifo_out(),因而不调整fifo->out的取值
__kfifo_out_peek(__kfifo, __buf, __n); \
}) \
)
函数kfifo_out_peek()与kfifo_out()的唯一区别在于,kfifo_out_peek()拷贝完成后,不调整fifo->out的取值,而kfifo_out()需要调整fifo->out的取值。
15.4.5 操纵队列
在include/linux/kfifo.h中,包含如下操纵队列的宏:
- kfifo_reset() / kfifo_reset_out(): 重置队列
- kfifo_free(): 销毁队列(NOTE: 缓冲区不会销毁)
- kfifo_size(): 缓冲区元素的总数
- kfifo_esize(): 缓冲区每个元素所占的字节数
- kfifo_len(): 缓冲区中已使用的元素个数
- kfifo_avail(): 缓冲区中未使用的元素个数
- kfifo_is_empty() / kfifo_is_full(): 缓冲区是否为空/已满
- kfifo_skip(): 调整fifo->out++,即跳过缓冲区中的一个元素
15.5 Maps
Linux Kernel中定义的Maps确定了整数UID至指针void *ptr的映射关系,参见15.5.1.1 struct idr / struct idr_layer节中的图。
15.5.1 与Maps有关的数据结构
15.5.1.1 struct idr / struct idr_layer
该结构用于UID到指针Ptr的映射,其定义于include/linux/idr.h:
struct idr {
struct idr_layer __rcu *top;
struct idr_layer *id_free;
int layers; /* only valid without concurrent changes */
int id_free_cnt;
spinlock_t lock;
};
struct idr_layer {
unsigned long bitmap; /* A zero bit means "space here" */
struct idr_layer __rcu *ary[1<<IDR_BITS];
int count; /* When zero, we can release it */
int layer; /* distance from leaf */
struct rcu_head rcu_head;
};
15.5.1.1.1 当BITS_PER_LONG==32时
最大层数为MAX_LEVEL=7层,顶层最多使用ary[]数组中的前2位,即top->ary[0],top->ary[1]。各结构之间的关系:
15.5.1.1.2 当BITS_PER_LONG==64时
最大层数为MAX_LEVEL=6层,顶层最多使用ary[]数组中的前2位,即top->ary[0],top->ary[1]。各结构之间的关系:
15.5.1.2 struct ida
该结构定义于include/linux/idr.h:
#define IDA_CHUNK_SIZE 128 /* 128 bytes per chunk */
#define IDA_BITMAP_LONGS (IDA_CHUNK_SIZE / sizeof(long) - 1) // 取值为31
#define IDA_BITMAP_BITS (IDA_BITMAP_LONGS * sizeof(long) * 8) // 取值为992
struct ida {
// 参见[15.5.1.1 struct idr / struct idr_layer]节
struct idr idr;
struct ida_bitmap *free_bitmap;
};
// 该结构体所占用的空间大小,与struct idr_layer中的ary[]所占用的空间大小完全相同
struct ida_bitmap {
long nr_busy;
// 该数组包含IDA_BITMAP_BITS个比特位
unsigned long bitmap[IDA_BITMAP_LONGS];
};
该结构用于指示哪些UID已分配,不存在与该UID相对应的指针Ptr,其结构参见:
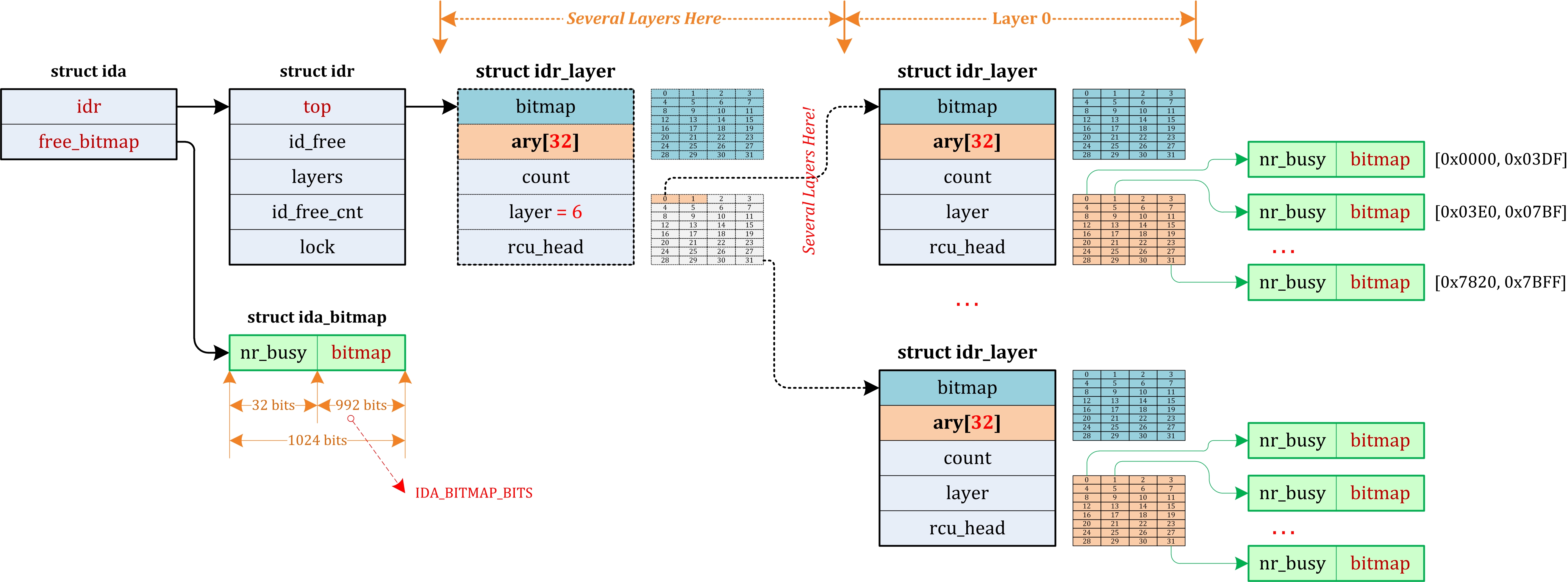
15.5.2 idr的定义及初始化
15.5.2.1 静态创建idr/DEFINE_IDR()
可以直接定义struct hdr类型的对象name,然后调用IDR_INIT(name)为之初始化。或者直接调用宏DEFINE_IDR(name)定义并初始化struct hdr类型的对象。该宏定义于include/linux/hdr.h:
#define IDR_INIT(name) \
{ \
.top = NULL, \
.id_free = NULL, \
.layers = 0, \
.id_free_cnt = 0, \
.lock = __SPIN_LOCK_UNLOCKED(name.lock), \
}
#define DEFINE_IDR(name) struct idr name = IDR_INIT(name)
15.5.2.2 动态创建idr/hdr_init()
可以动态分配struct hdr类型的对象name,然后调用函数idr_init()为之初始化。该函数定义于lib/idr.c:
/**
* idr_init - initialize idr handle
* @idp: idr handle
*
* This function is use to set up the handle (@idp) that you will pass
* to the rest of the functions.
*/
void idr_init(struct idr *idp)
{
memset(idp, 0, sizeof(struct idr));
spin_lock_init(&idp->lock);
}
15.5.3 分配新的UID
UID: Unique Identification Number
15.5.3.1 分配节点空间/idr_pre_get()
该函数用于分配节点空间,其定义于lib/idr.c:
/**
* idr_pre_get - reserve resources for idr allocation
* @idp: idr handle
* @gfp_mask: memory allocation flags
*
* This function should be called prior to calling the idr_get_new* functions.
* It preallocates enough memory to satisfy the worst possible allocation. The
* caller should pass in GFP_KERNEL if possible. This of course requires that
* no spinning locks be held.
*
* If the system is REALLY out of memory this function returns %0,
* otherwise %1.
*/
int idr_pre_get(struct idr *idp, gfp_t gfp_mask)
{
/*
* 当BITS_PER_LONG == 32时,IDR_FREE_MAX = 14
* 当BITS_PER_LONG == 64时,IDR_FREE_MAX = 12
*/
while (idp->id_free_cnt < IDR_FREE_MAX) {
struct idr_layer *new;
// 从idr_layer_cache缓存中分配空间,参见[15.5.6 idr_init_cache()]节
new = kmem_cache_zalloc(idr_layer_cache, gfp_mask);
if (new == NULL)
return (0);
/*
* 将新分配的new节点链接到idp->id_free,
* 并更新idp->id_free_cnt计数
*/
move_to_free_list(idp, new);
}
return 1;
}
执行后的结果:

15.5.3.2 分配从0开始的最小可用的UID并关联ptr/idr_get_new()
该函数定义于lib/idr.c:
/**
* idr_get_new - allocate new idr entry
* @idp: idr handle
* @ptr: pointer you want associated with the id
* @id: pointer to the allocated handle
*
* If allocation from IDR's private freelist fails, idr_get_new_above() will
* return %-EAGAIN. The caller should retry the idr_pre_get() call to refill
* IDR's preallocation and then retry the idr_get_new_above() call.
*
* If the idr is full idr_get_new_above() will return %-ENOSPC.
*
* @id returns a value in the range %0 ... %0x7fffffff
*/
int idr_get_new(struct idr *idp, void *ptr, int *id)
{
int rv;
// 从0开始查找最小可用的UID
rv = idr_get_new_above_int(idp, ptr, 0);
/*
* This is a cheap hack until the IDR code can be fixed to
* return proper error values.
*/
if (rv < 0)
return _idr_rc_to_errno(rv);
// 传回新分配的UID
*id = rv;
return 0;
}
static int idr_get_new_above_int(struct idr *idp, void *ptr, int starting_id)
{
struct idr_layer *pa[MAX_LEVEL];
int id;
// 从starting_id开始查找最小可用的UID
id = idr_get_empty_slot(idp, starting_id, pa);
if (id >= 0) {
/*
* Successfully found an empty slot. Install the user
* pointer and mark the slot full.
*/
// id对应的ptr都是挂到叶子节点的ary[]数组中,因此必然是pa[0]->ary[*]
rcu_assign_pointer(pa[0]->ary[id & IDR_MASK], (struct idr_layer *)ptr);
pa[0]->count++;
idr_mark_full(pa, id);
}
return id;
}
15.5.3.3 分配从starting_id开始的最小可用的UID并关联ptr/idr_get_new_above()
该函数定义于lib/idr.c:
/**
* idr_get_new_above - allocate new idr entry above or equal to a start id
* @idp: idr handle
* @ptr: pointer you want associated with the id
* @starting_id: id to start search at
* @id: pointer to the allocated handle
*
* This is the allocate id function. It should be called with any
* required locks.
*
* If allocation from IDR's private freelist fails, idr_get_new_above() will
* return %-EAGAIN. The caller should retry the idr_pre_get() call to refill
* IDR's preallocation and then retry the idr_get_new_above() call.
*
* If the idr is full idr_get_new_above() will return %-ENOSPC.
*
* @id returns a value in the range @starting_id ... %0x7fffffff
*/
int idr_get_new_above(struct idr *idp, void *ptr, int starting_id, int *id)
{
int rv;
/*
* 本函数与[15.5.3.2 分配从0开始的最小可用的UID并关联ptr/idr_get_new()]节
* 的idr_get_new()类似,区别仅在于查找id的起始点变为了starting_id而不是0
rv = idr_get_new_above_int(idp, ptr, starting_id);
/*
* This is a cheap hack until the IDR code can be fixed to
* return proper error values.
*/
if (rv < 0)
return _idr_rc_to_errno(rv);
*id = rv;
return 0;
}
15.5.4 查找id对应的ptr/idr_find()
该函数定义于lib/idr.c:
/**
* idr_find - return pointer for given id
* @idp: idr handle
* @id: lookup key
*
* Return the pointer given the id it has been registered with. A %NULL
* return indicates that @id is not valid or you passed %NULL in
* idr_get_new().
*
* This function can be called under rcu_read_lock(), given that the leaf
* pointers lifetimes are correctly managed.
*/
void *idr_find(struct idr *idp, int id)
{
int n;
struct idr_layer *p;
p = rcu_dereference_raw(idp->top);
if (!p)
return NULL;
n = (p->layer+1) * IDR_BITS;
/* Mask off upper bits we don't use for the search. */
id &= MAX_ID_MASK;
if (id >= (1 << n))
return NULL;
BUG_ON(n == 0);
while (n > 0 && p) {
n -= IDR_BITS;
BUG_ON(n != p->layer*IDR_BITS);
p = rcu_dereference_raw(p->ary[(id >> n) & IDR_MASK]);
}
return((void *)p);
}
15.5.5 操纵idr
此外,还有如下函数可以操纵idr:
int idr_for_each(struct idr *idp, int (*fn)(int id, void *p, void *data), void *data);
void *idr_get_next(struct idr *idp, int *nextid);
void *idr_replace(struct idr *idp, void *ptr, int id);
15.5.6 idr_init_cache()
该函数定义于lib/idr.c:
static struct kmem_cache *idr_layer_cache;
void __init idr_init_cache(void)
{
/*
* 为idr分配缓存空间,用于idr_pre_get(),参见[15.5.3.1 分配节点空间/idr_pre_get()]节
* kmem_cache_create()参见[6.5.1.1.2 Create a Specific Cache/kmem_cache_create()]节
*/
idr_layer_cache = kmem_cache_create("idr_layer_cache",
sizeof(struct idr_layer), 0, SLAB_PANIC, NULL);
}
在系统启动过程中,该函数被start_kernel()调用,参见4.3.4.1.4.3 start_kernel()节。
15.6 Red-Black Tree (rbtree)
Reading Materials on Red-Black Tree:
- Documentation/rbtree.txt
- http://lwn.net/Articles/184495/
- http://en.wikipedia.org/wiki/Red-black_tree
15.6.1 rbtree属性
参见http://en.wikipedia.org/wiki/Red-black_tree:
In addition to the requirements imposed on a binary search tree the following must be satisfied by a red–black tree:
1) A node is either red or black.
2) The root is black. (This rule is sometimes omitted. Since the root can always be changed from red to black, but not necessarily vice-versa, this rule has little effect on analysis.) 参见15.6.5.2 rb_insert_color()节的函数调用rb_insert_color()->rb_set_black(root->rb_node);
3) All leaves (NIL) are black. (All leaves are same color as the root.)
4) Every red node must have two black child nodes.
5) Every path from a given node to any of its descendant leaves contains the same number of black nodes.
These constraints enforce a critical property of red–black trees: that the path from the root to the furthest leaf is no more than twice as long as the path from the root to the nearest leaf. The result is that the tree is roughly height-balanced. Since operations such as inserting, deleting, and finding values require worst-case time proportional to the height of the tree, this theoretical upper bound on the height allows red–black trees to be efficient in the worst case, unlike ordinary binary search trees.
To see why this is guaranteed, it suffices to consider the effect of properties 4) and 5) together. For a red–black tree T, let B be the number of black nodes in property 5). Let the shortest possible path from the root of T to any leaf consist of B black nodes. Longer possible paths may be constructed by inserting red nodes. However, property 4) makes it impossible to insert more than one consecutive red node. Therefore the longest possible path consists of 2B nodes, alternating black and red.
The shortest possible path has all black nodes, and the longest possible path alternates between red and black nodes. Since all maximal paths have the same number of black nodes, by property 5), this shows that no path is more than twice as long as any other path.
rbtree示例:
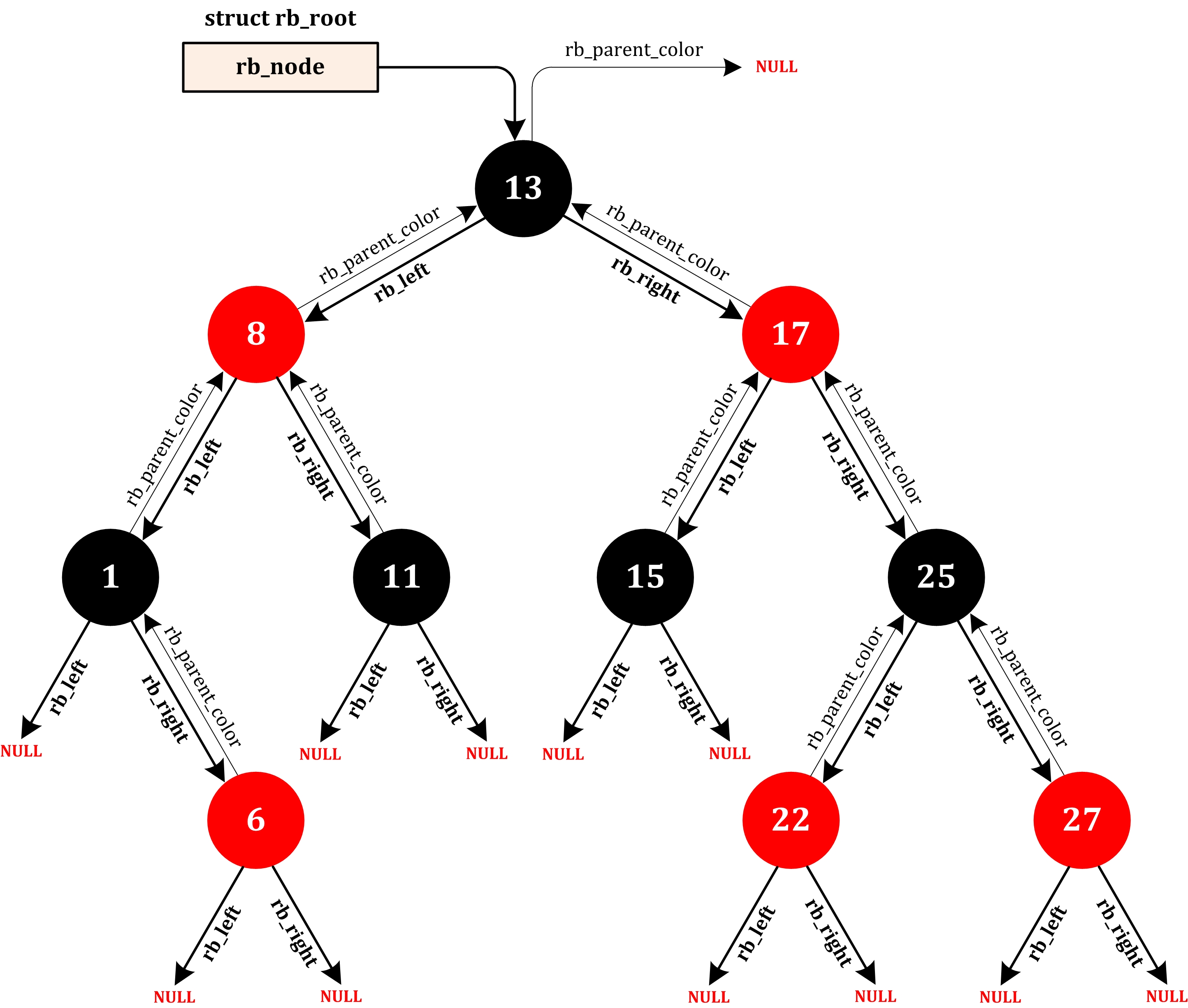
15.6.2 与rbtree有关的数据结构 / struct rb_root / struct rb_node
该结构定义于include/linux/rbtree.h:
struct rb_root
{
struct rb_node *rb_node;
};
struct rb_node
{
unsigned long rb_parent_color;
#define RB_RED 0
#define RB_BLACK 1
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
/* The alignment might seem pointless, but allegedly CRIS needs it */
struct rb_node使用了编译器属性__attribute__((aligned(sizeof(long)))),因而该类型的对象是4字节对齐的。举例:
struct rb_node rb;
则rb变量地址的最低2 bit取值为00,故可以使用成员rb_parent_color同时保存两种数据:父节点地址和本节点的颜色,参见:
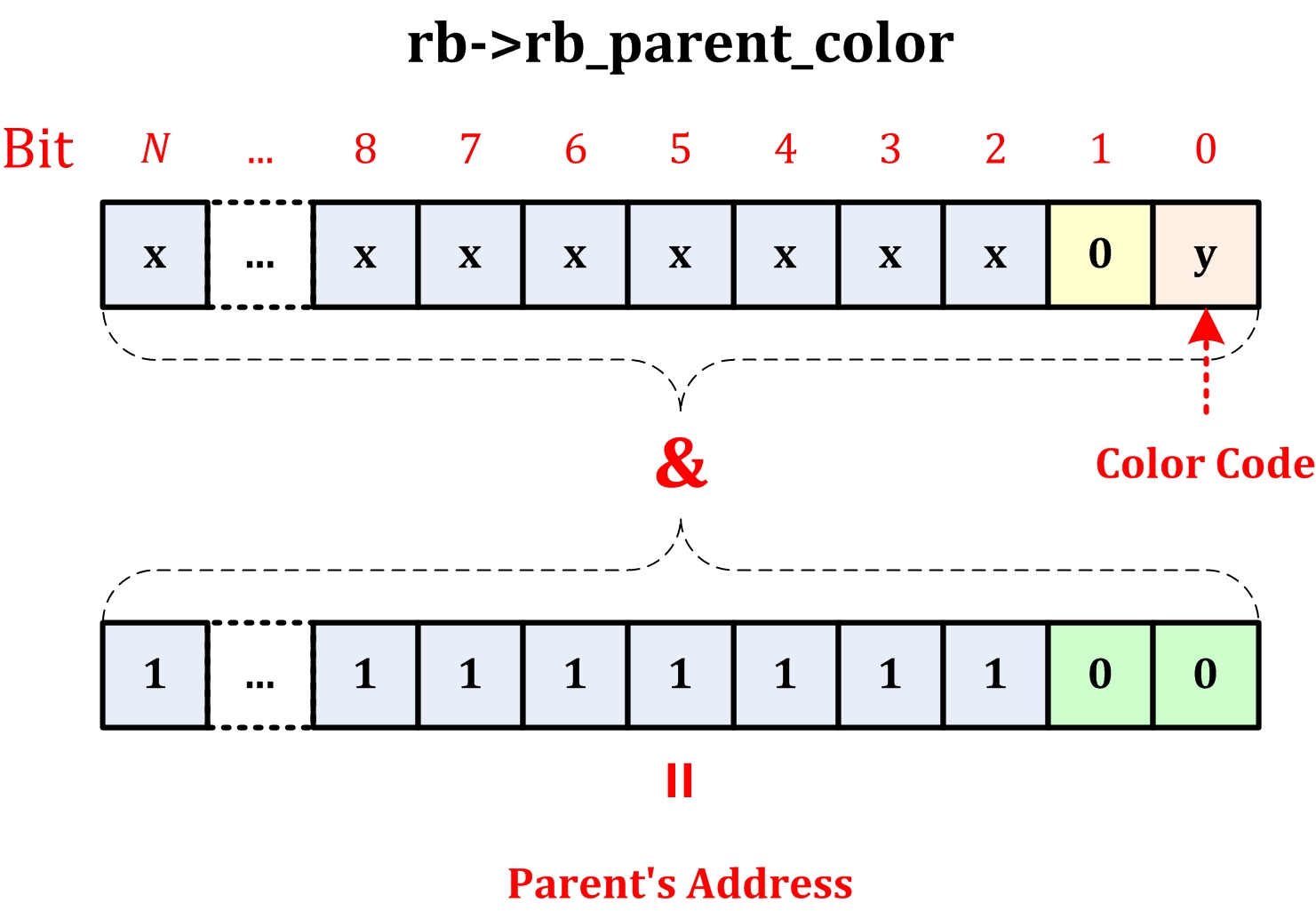
15.6.3 定义及初始化rbtree
15.6.3.1 定义并初始化struct rb_root类型的变量
宏RB_ROOT用于初始化struct rb_root类型的变量,例如:
struct rb_root root = RB_ROOT;
该宏定义于include/linux/rbtree.h:
#define RB_ROOT (struct rb_root) { NULL, }
宏RB_EMPTY_ROOT()用于判断root是否为空根节点,其定义于include/linux/rbtree.h:
#define RB_EMPTY_ROOT(root) ((root)->rb_node == NULL)
15.6.3.2 定义并初始化struct rb_node类型的变量
与struct list_head的使用方法类似(参见15.1 双向循环链表/struct list_head节),首先要定义包含struct rb_node成员的数据类型,例如:
struct mytype {
struct rb_node node;
char *keystring;
};
然后定义struct mytype类型的对象mydata,例如:
struct mytype mydata;
调用函数rb_init_node()初始化struct rb_node类型的变量,例如:
rb_init_node(&mydata.node);
``
该函数定义于include/linux/rbtree.h:
static inline void rb_init_node(struct rb_node *rb) { rb->rb_parent_color = 0; rb->rb_right = NULL; rb->rb_left = NULL; RB_CLEAR_NODE(rb); // 参见下文 }
初始化后的节点结构:
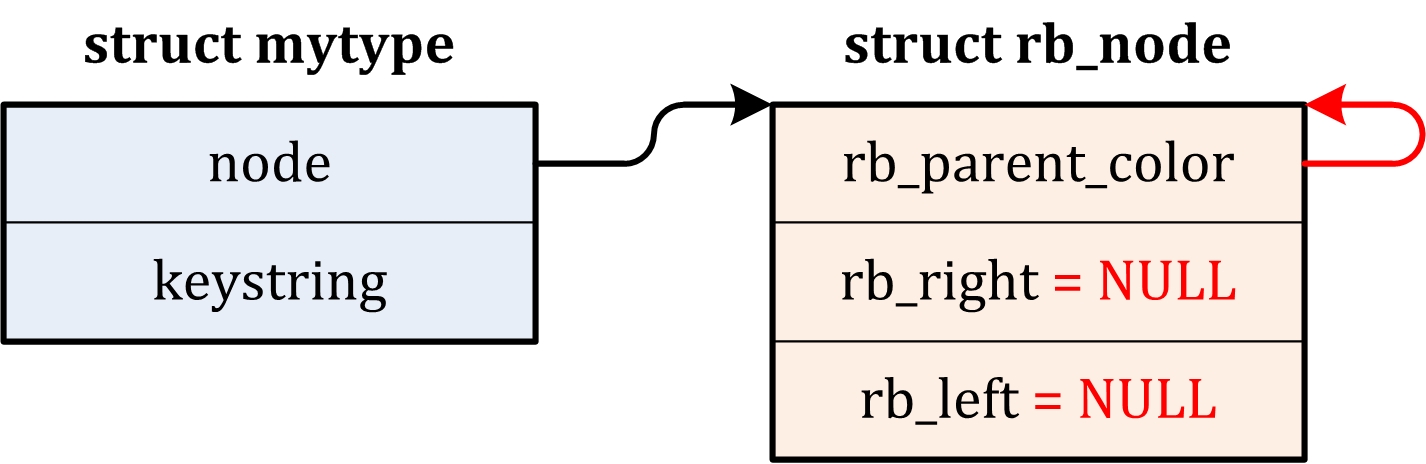
宏```rb_entry()```用于获取包含struct rb_node类型成员的变量,例如:
struct mytype *data = rb_entry(&mydata.node, struct mytype, node);
该宏定义于include/linux/rbtree.h:
#define rb_entry(ptr, type, member) container_of(ptr, type, member)
此外,include/linux/rbtree.h中的如下宏可以用来操纵struct rb_node类型的变量:
#define rb_parent(r) ((struct rb_node *)((r)->rb_parent_color & ~3)) #define rb_color(r) ((r)->rb_parent_color & 1)
#define rb_is_red(r) (!rb_color(r)) #define rb_is_black(r) rb_color(r)
#define rb_set_red(r) do { (r)->rb_parent_color &= ~1; } while (0) #define rb_set_black(r) do { (r)->rb_parent_color |= 1; } while (0)
static inline void rb_set_parent(struct rb_node rb, struct rb_node *p) { / * rb_parent_color包含父节点的地址和本节点的颜色, * 参见[15.6.2 与rbtree有关的数据结构 / struct rb_root / struct rb_node]节 */ rb->rb_parent_color = (rb->rb_parent_color & 3) | (unsigned long)p; } static inline void rb_set_color(struct rb_node *rb, int color) { rb->rb_parent_color = (rb->rb_parent_color & ~1) | color; }
#define RB_EMPTY_NODE(node) (rb_parent(node) == node) #define RB_CLEAR_NODE(node) (rb_set_parent(node, node))
### 15.6.4 搜索指定节点
由于struct rb_node不包含用户数据,因而rbtree无法直接提供用于搜索指定节点的函数。不过,在rbtree中搜索指定节点的算法很简单,例如:
struct mytype *my_search(struct rb_root *root, char *string) { struct rb_node *node = root->rb_node;
while (node) {
struct mytype *data = rb_entry(node, struct mytype, node);
int result;
result = strcmp(string, data->keystring);
if (result < 0)
node = node->rb_left;
else if (result > 0)
node = node->rb_right;
else
return data;
}
return NULL; } ```
15.6.5 插入新节点
插入新节点到rbtree中需要两个步骤:
- 1) 使用类似搜索指定节点节的算法查找新节点的插入位置,并调用函数rb_link_node()将新节点插入到rbtree中,参见15.6.5.1 rb_link_node()节;
- 2) 然后调用函数rb_insert_color()再平衡rbtree,参见15.6.5.2 rb_insert_color()节。
例如:
int my_insert(struct rb_root *root, struct mytype *data)
{
struct rb_node **new = &(root->rb_node), *parent = NULL;
/* Figure out where to put new node */
while (*new) {
struct mytype *this = rb_entry(*new, struct mytype, node);
int result = strcmp(data->keystring, this->keystring);
parent = *new;
if (result < 0)
new = &((*new)->rb_left);
else if (result > 0)
new = &((*new)->rb_right);
else
return FALSE;
}
/* Add new node and rebalance tree. */
rb_link_node(&data->node, parent, new); // 参见[15.6.5.1 rb_link_node()]节
rb_insert_color(&data->node, root); // 参见[15.6.5.2 rb_insert_color()]节
return TRUE;
}
15.6.5.1 rb_link_node()
该函数定义于include/linux/rbtree.h:
static inline void rb_link_node(struct rb_node * node, struct rb_node * parent,
struct rb_node ** rb_link)
{
// 设置rb_parent_color中的父节点地址,此时本节点的颜色为红色
node->rb_parent_color = (unsigned long )parent;
node->rb_left = node->rb_right = NULL;
// 根据入参的不同,此处将新节点连接到父节点的rb_left或rb_right中
*rb_link = node;
}
15.6.5.2 rb_insert_color()
该函数定义于lib/rbtree.c:
// 入参node为新增的节点
void rb_insert_color(struct rb_node *node, struct rb_root *root)
{
struct rb_node *parent, *gparent;
/*
* rbtree根节点的父节点指向NULL,参见[15.6.1 rbtree属性]节的图;
* 根据node获得其父节点parent,且颜色为红色,则分情况处理:
*/
while ((parent = rb_parent(node)) && rb_is_red(parent))
{
gparent = rb_parent(parent);
if (parent == gparent->rb_left)
{
{
register struct rb_node *uncle = gparent->rb_right;
if (uncle && rb_is_red(uncle))
{
rb_set_black(uncle);
rb_set_black(parent);
rb_set_red(gparent);
node = gparent;
continue;
}
}
if (parent->rb_right == node)
{
register struct rb_node *tmp;
// 左旋,参见[15.6.5.2.1 左旋/__rb_rotate_left()]节
__rb_rotate_left(parent, root);
/*
* 左旋后,父子关系颠倒,参见[15.6.5.2.1 左旋/__rb_rotate_left()]节的图;
* 此处更新parent和node,使其符合左旋后的实际情况
*/
tmp = parent;
parent = node;
node = tmp;
}
rb_set_black(parent);
rb_set_red(gparent);
// 右旋,参见[15.6.5.2.2 右旋/__rb_rotate_right()]节
__rb_rotate_right(gparent, root);
} else {
{
register struct rb_node *uncle = gparent->rb_left;
if (uncle && rb_is_red(uncle))
{
rb_set_black(uncle);
rb_set_black(parent);
rb_set_red(gparent);
node = gparent;
continue;
}
}
if (parent->rb_left == node)
{
register struct rb_node *tmp;
// 右旋,参见[15.6.5.2.2 右旋/__rb_rotate_right()]节
__rb_rotate_right(parent, root);
tmp = parent;
parent = node;
node = tmp;
}
rb_set_black(parent);
rb_set_red(gparent);
// 左旋,参见[15.6.5.2.1 左旋/__rb_rotate_left()]节
__rb_rotate_left(gparent, root);
}
} // end of while ((parent = ...
// 根据[15.6.1 rbtree属性]节的属性2),将根节点设置为黑色
rb_set_black(root->rb_node);
}
15.6.5.2.1 左旋/__rb_rotate_left()
该函数定义于lib/rbtree.c:
static void __rb_rotate_left(struct rb_node *node, struct rb_root *root)
{
struct rb_node *right = node->rb_right;
struct rb_node *parent = rb_parent(node);
if ((node->rb_right = right->rb_left))
rb_set_parent(right->rb_left, node);
right->rb_left = node;
rb_set_parent(right, parent);
if (parent)
{
if (node == parent->rb_left)
parent->rb_left = right;
else
parent->rb_right = right;
}
else
root->rb_node = right;
rb_set_parent(node, right);
}
15.6.5.2.2 右旋/__rb_rotate_right()
该函数定义于lib/rbtree.c:
static void __rb_rotate_right(struct rb_node *node, struct rb_root *root)
{
struct rb_node *left = node->rb_left;
struct rb_node *parent = rb_parent(node);
if ((node->rb_left = left->rb_right))
rb_set_parent(left->rb_right, node);
left->rb_right = node;
rb_set_parent(left, parent);
if (parent)
{
if (node == parent->rb_right)
parent->rb_right = left;
else
parent->rb_left = left;
}
else
root->rb_node = left;
rb_set_parent(node, left);
}
15.6.5.2.3 左旋/右旋的关系
由下列图可知,执行如下语句前后的rbtree没有变化:
15.6.5.2.1 左旋/__rb_rotate_left()节左旋前的图 => 15.6.5.2.1 左旋/__rb_rotate_left()节左旋后的图 => 15.6.5.2.2 右旋/__rb_rotate_right()节右旋前的图 => 15.6.5.2.2 右旋/__rb_rotate_right()节右旋后的图
__rb_rotate_left(node, root);
__rb_rotate_right(rb_parent(node), root);
由下列图可知,执行如下语句前后的rbtree没有变化:
15.6.5.2.2 右旋/__rb_rotate_right()节右旋前的图 => 15.6.5.2.2 右旋/__rb_rotate_right()节右旋后的图 => 15.6.5.2.1 左旋/__rb_rotate_left()节左旋前的图 => 15.6.5.2.1 左旋/__rb_rotate_left()节左旋后的图
__rb_rotate_right(node, root);
__rb_rotate_left(rb_parent(node), root);
15.6.6 遍历rbtree
在lib/rbtree.c中,定义了如下函数用于遍历rbtree:
/*
* This function returns the first node (in sort order) of the tree.
*/
// 该函数返回rbtree中最左子树的左节点
struct rb_node *rb_first(const struct rb_root *root)
{
struct rb_node *n;
n = root->rb_node;
if (!n)
return NULL;
while (n->rb_left)
n = n->rb_left;
return n;
}
// 该函数返回rbtree中最右子树的右节点
struct rb_node *rb_last(const struct rb_root *root)
{
struct rb_node *n;
n = root->rb_node;
if (!n)
return NULL;
while (n->rb_right)
n = n->rb_right;
return n;
}
// 该函数返回rbtree中最靠近节点node的右侧节点
struct rb_node *rb_next(const struct rb_node *node)
{
struct rb_node *parent;
/*
* 如果node节点刚被初始化(参见[15.6.3.2 定义并初始化struct rb_node类型的变量]节),
* 且还未被加入rbtree,则返回NULL
*/
if (rb_parent(node) == node)
return NULL;
/* If we have a right-hand child, go down and then left as far
as we can. */
if (node->rb_right) {
node = node->rb_right;
while (node->rb_left)
node = node->rb_left;
return (struct rb_node *)node;
}
/* No right-hand children. Everything down and left is
smaller than us, so any 'next' node must be in the general
direction of our parent. Go up the tree; any time the
ancestor is a right-hand child of its parent, keep going
up. First time it's a left-hand child of its parent, said
parent is our 'next' node. */
while ((parent = rb_parent(node)) && node == parent->rb_right)
node = parent;
return parent;
}
// 该函数返回rbtree中最靠近节点node的左侧节点
struct rb_node *rb_prev(const struct rb_node *node)
{
struct rb_node *parent;
/*
* 如果node节点刚被初始化(参见[15.6.3.2 定义并初始化struct rb_node类型的变量]节),
* 且还未被加入rbtree,则返回NULL
*/
if (rb_parent(node) == node)
return NULL;
/* If we have a left-hand child, go down and then right as far
as we can. */
if (node->rb_left) {
node = node->rb_left;
while (node->rb_right)
node = node->rb_right;
return (struct rb_node *)node;
}
/* No left-hand children. Go up till we find an ancestor which
is a right-hand child of its parent */
while ((parent = rb_parent(node)) && node == parent->rb_left)
node = parent;
return parent;
}
这些函数返回指向类型为struct rb_node的对象的指针,通过宏rb_entry()访问包含该对象的用户数据,例如:
struct rb_node *node;
// 从前向后遍历rbtree,并打印字符串取值
for (node = rb_first(&mytree); node; node = rb_next(node))
printk("key=%s\n", rb_entry(node, struct mytype, node)->keystring);
// 从后向前遍历rbtree,并打印字符串取值
for (node = rb_last(&mytree); node; node = rb_prev(node))
printk("key=%s\n", rb_entry(node, struct mytype, node)->keystring);
15.6.7 移除节点/rb_erase()
函数rb_erase()用于从rbtree中移除指定的节点。NOTE: 移除的节点并未被销毁,需要用户自己销毁该节点。
该定义于lib/rbtree.c:
void rb_erase(struct rb_node *node, struct rb_root *root)
{
struct rb_node *child, *parent;
int color;
if (!node->rb_left)
child = node->rb_right;
else if (!node->rb_right)
child = node->rb_left;
else // 当node的左右两个子节点都存在时,...
{
struct rb_node *old = node, *left;
/*
* 查找最靠近节点node的左侧节点(设为new_node),
* 并将其链接到node的父节点
*/
node = node->rb_right;
while ((left = node->rb_left) != NULL)
node = left;
if (rb_parent(old)) {
if (rb_parent(old)->rb_left == old)
rb_parent(old)->rb_left = node;
else
rb_parent(old)->rb_right = node;
} else
root->rb_node = node;
child = node->rb_right;
parent = rb_parent(node);
color = rb_color(node);
// 将new_node的右子节点链接到rb_parent(new_node)的左子节点
if (parent == old) {
parent = node;
} else {
if (child)
rb_set_parent(child, parent);
parent->rb_left = child;
node->rb_right = old->rb_right;
rb_set_parent(old->rb_right, node);
}
// 将原node的左子节点链接到new_node的左子节点
node->rb_parent_color = old->rb_parent_color;
node->rb_left = old->rb_left;
rb_set_parent(old->rb_left, node);
goto color;
}
// 当node最多存在一个有效的子节点时,...
parent = rb_parent(node);
color = rb_color(node);
if (child)
rb_set_parent(child, parent);
if (parent)
{
if (parent->rb_left == node)
parent->rb_left = child;
else
parent->rb_right = child;
}
else
root->rb_node = child;
color:
if (color == RB_BLACK)
__rb_erase_color(child, parent, root);
}
15.6.8 替换节点/rb_replace_node()
函数rb_replace_node()用于替换已有节点,其定义于lib/rbtree.c:
void rb_replace_node(struct rb_node *victim, struct rb_node *new, struct rb_root *root)
{
struct rb_node *parent = rb_parent(victim);
/* Set the surrounding nodes to point to the replacement */
if (parent) {
if (victim == parent->rb_left)
parent->rb_left = new;
else
parent->rb_right = new;
} else {
root->rb_node = new;
}
if (victim->rb_left)
rb_set_parent(victim->rb_left, new);
if (victim->rb_right)
rb_set_parent(victim->rb_right, new);
/* Copy the pointers/colour from the victim to the replacement */
*new = *victim;
}
Replacing a node this way does not re-sort the tree: If the new node doesn’t have the same key as the old node, the rbtree will probably become corrupted.
15.6.9 Augmented rbtree
如果使用augmented rbtree,需要先定义如下类型的回调函数,参见include/linux/rbtree.h:
typedef void (*rb_augment_f)(struct rb_node *node, void *data);
该回调函数作为rb_augment_insert(), rb_augment_erase_begin(), rb_augment_erase_end()的入参,参见下文。
15.6.9.1 rb_augment_insert()
该函数定义于lib/rbtree.c:
/*
* after inserting @node into the tree, update the tree to account for
* both the new entry and any damage done by rebalance
*/
void rb_augment_insert(struct rb_node *node, rb_augment_f func, void *data)
{
if (node->rb_left)
node = node->rb_left;
else if (node->rb_right)
node = node->rb_right;
/*
* 从node的左右子节点开始,直到根节点,
* 对其间的每个节点执行函数func()
*/
rb_augment_path(node, func, data);
}
其中,函数rb_augment_path()定义于lib/rbtree.c:
static void rb_augment_path(struct rb_node *node, rb_augment_f func, void *data)
{
struct rb_node *parent;
up:
func(node, data);
parent = rb_parent(node);
if (!parent) // 直到根节点才退出循环
return;
if (node == parent->rb_left && parent->rb_right)
func(parent->rb_right, data);
else if (parent->rb_left)
func(parent->rb_left, data);
node = parent;
goto up;
}
15.6.9.2 rb_augment_erase_begin()/rb_augment_erase_end()
该函数定义于lib/rbtree.c:
/*
* before removing the node, find the deepest node on the rebalance path
* that will still be there after @node gets removed
*/
struct rb_node *rb_augment_erase_begin(struct rb_node *node)
{
struct rb_node *deepest;
if (!node->rb_right && !node->rb_left) // node的左右子节点均为NULL
deepest = rb_parent(node);
else if (!node->rb_right) // node的左子节点不为NULL,右子节点为NULL
deepest = node->rb_left;
else if (!node->rb_left) // node的左子节点为NULL,右子节点不为NULL
deepest = node->rb_right;
else { // node的左右子节点不为NULL
deepest = rb_next(node);
if (deepest->rb_right)
deepest = deepest->rb_right;
else if (rb_parent(deepest) != node)
deepest = rb_parent(deepest);
}
return deepest;
}
/*
* after removal, update the tree to account for the removed entry
* and any rebalance damage.
*/
void rb_augment_erase_end(struct rb_node *node, rb_augment_f func, void *data)
{
if (node)
rb_augment_path(node, func, data); // 参见[15.6.9.1 rb_augment_insert()]节
}
15.7 kobject
The core concept of kobject is relatively simple: kobjects can be used to
- (1) maintain a reference count for an object and clean up when the object is no longer used, and
- (2) create a hierarchical data structure through kset membership.
kobject是组成设备模型的基本结构,一个kset是嵌入相同类型结构的kobject集合,一系列的kset就组成了subsystem。
该结构定义于include/linux/kobject.h:
struct kobject {
// 指向设备名称的指针
const char *name;
// 链接到以struct kset->list为链表头的链表中
struct list_head entry;
// 父节点
struct kobject *parent;
/*
* A kset is a group of kobjects all of which are embedded
* in structures of the same type. It's the basic container
* type for collections of kobjects. Ksets contain their own
* kobjects, for what it's worth. Among other things, that
* means that a kobject's parent is usually the kset that
* contains it, though things don't normally have to be that way.
*/
struct kset *kset;
/*
* ktype controls what happens when a kobject is no longer
* referenced and the kobject's default representation in sysfs.
*/
struct kobj_type *ktype;
// 本kobject在sysfs文件系统中的节点
struct sysfs_dirent *sd;
/*
* 标识本kobject的引用计数。通过kobject_get()和kobject_put()来
* 增加和减少该引用计数。当引用计数为0时,所有该对象使用的资源将被释放
*/
struct kref kref;
// 标志位
unsigned int state_initialized:1;
unsigned int state_in_sysfs:1;
unsigned int state_add_uevent_sent:1;
unsigned int state_remove_uevent_sent:1;
unsigned int uevent_suppress:1;
};
struct kobj_type {
// 用于释放本kobject占用的资源
void (*release)(struct kobject *kobj);
/*
* control how objects of this type are represented
* in sysfs file system and its default attributes
*/
const struct sysfs_ops *sysfs_ops;
struct attribute **default_attrs;
const struct kobj_ns_type_operations *(*child_ns_type)(struct kobject *kobj);
const void *(*namespace)(struct kobject *kobj);
};
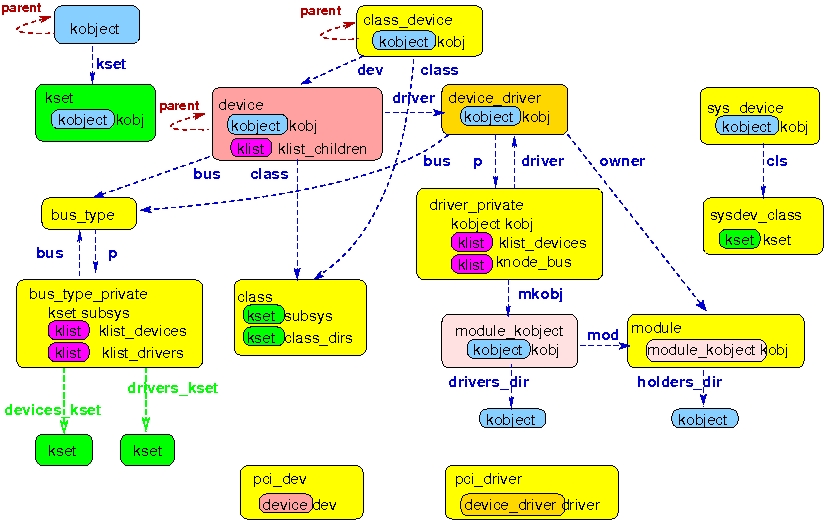
15.7.1 创建并初始化kobject对象
15.7.1.1 kobject_init_and_add()
该函数定义于lib/kobject.c:
/**
* kobject_init_and_add - initialize a kobject structure and add it to the kobject hierarchy
* @kobj: pointer to the kobject to initialize
* @ktype: pointer to the ktype for this kobject.
* @parent: pointer to the parent of this kobject.
* @fmt: the name of the kobject.
*
* This function combines the call to kobject_init() and
* kobject_add(). The same type of error handling after a call to
* kobject_add() and kobject lifetime rules are the same here.
*/
int kobject_init_and_add(struct kobject *kobj, struct kobj_type *ktype,
struct kobject *parent, const char *fmt, ...)
{
va_list args;
int retval;
// 参见[15.7.1.2.1.1 kobject_init()/kobject_init_internal()]节
kobject_init(kobj, ktype);
va_start(args, fmt);
// 参见[15.7.1.2.2.1 kobject_add_varg()]节
retval = kobject_add_varg(kobj, parent, fmt, args);
va_end(args);
return retval;
}
15.7.1.2 kobject_create_and_add()
该函数定义于lib/kobject.c:
/**
* kobject_create_and_add - create a struct kobject dynamically and register it with sysfs
*
* @name: the name for the kset
* @parent: the parent kobject of this kobject, if any.
*
* This function creates a kobject structure dynamically and registers it
* with sysfs. When you are finished with this structure, call
* kobject_put() and the structure will be dynamically freed when
* it is no longer being used.
*
* If the kobject was not able to be created, NULL will be returned.
*/
// 示例:kobject_create_and_add("fs", NULL)
struct kobject *kobject_create_and_add(const char *name, struct kobject *parent)
{
struct kobject *kobj;
int retval;
/*
* 分配并初始化一个struct kobject类型的对象kobj,
* 参见[15.7.1.2.1 kobject_create()]节
*/
kobj = kobject_create();
if (!kobj)
return NULL;
/*
* 示例:kobject_add(kobj, NULL, "%s", "fs");
* 即在sysfs文件系统的根目录下创建fs目录,而通常sysfs
* 文件系统被安装在/sys目录下,因而此处为/sys/fs目录
* 参见[15.7.1.2.2 kobject_add()]节
*/
retval = kobject_add(kobj, parent, "%s", name);
if (retval) {
printk(KERN_WARNING "%s: kobject_add error: %d\n", __func__, retval);
kobject_put(kobj); // 参见[15.7.2.2 kobject_put()]节
kobj = NULL;
}
return kobj;
}
15.7.1.2.1 kobject_create()
该函数定义于lib/kobject.c:
const struct sysfs_ops kobj_sysfs_ops = {
.show = kobj_attr_show,
.store = kobj_attr_store,
};
static struct kobj_type dynamic_kobj_ktype = {
.release = dynamic_kobj_release,
.sysfs_ops = &kobj_sysfs_ops,
};
/**
* kobject_create - create a struct kobject dynamically
*
* This function creates a kobject structure dynamically and sets it up
* to be a "dynamic" kobject with a default release function set up.
*
* If the kobject was not able to be created, NULL will be returned.
* The kobject structure returned from here must be cleaned up with a
* call to kobject_put() and not kfree(), as kobject_init() has
* already been called on this structure.
*/
struct kobject *kobject_create(void)
{
struct kobject *kobj;
kobj = kzalloc(sizeof(*kobj), GFP_KERNEL);
if (!kobj)
return NULL;
/*
* 参见[15.7.1.2.1.1 kobject_init()/kobject_init_internal()]节
* 默认的kobj->ktype = &dynamic_kobj_ktype
*/
kobject_init(kobj, &dynamic_kobj_ktype);
return kobj;
}
15.7.1.2.1.1 kobject_init()/kobject_init_internal()
该函数定义于lib/kobject.c:
/**
* kobject_init - initialize a kobject structure
* @kobj: pointer to the kobject to initialize
* @ktype: pointer to the ktype for this kobject.
*
* This function will properly initialize a kobject such that it can then
* be passed to the kobject_add() call.
*
* After this function is called, the kobject MUST be cleaned up by a call
* to kobject_put(), not by a call to kfree directly to ensure that all of
* the memory is cleaned up properly.
*/
void kobject_init(struct kobject *kobj, struct kobj_type *ktype)
{
char *err_str;
if (!kobj) {
err_str = "invalid kobject pointer!";
goto error;
}
if (!ktype) {
err_str = "must have a ktype to be initialized properly!\n";
goto error;
}
if (kobj->state_initialized) {
/* do not error out as sometimes we can recover */
printk(KERN_ERR "kobject (%p): tried to init an initialized "
"object, something is seriously wrong.\n", kobj);
dump_stack();
}
kobject_init_internal(kobj); // 参见下文
kobj->ktype = ktype; // kobj->ktype = &dynamic_kobj_ktype
return;
error:
printk(KERN_ERR "kobject (%p): %s\n", kobj, err_str);
dump_stack();
}
static void kobject_init_internal(struct kobject *kobj)
{
if (!kobj)
return;
// 设置引用计数为1
kref_init(&kobj->kref);
INIT_LIST_HEAD(&kobj->entry);
kobj->state_in_sysfs = 0;
kobj->state_add_uevent_sent = 0;
kobj->state_remove_uevent_sent = 0;
kobj->state_initialized = 1;
}
15.7.1.2.2 kobject_add()
该函数定义于lib/kobject.c:
/*
* NOTE: An initialized kobject will perform reference counting without trouble,
* but it will not appear in sysfs. To create sysfs entries, kernel code must
* pass the object to kobject_add(). The function kobject_del() will remove the
* kobject from sysfs. 参见[15.7.2.2.1.1 kobject_del()]节
*/
int kobject_add(struct kobject *kobj, struct kobject *parent, const char *fmt, ...)
{
va_list args;
int retval;
if (!kobj)
return -EINVAL;
if (!kobj->state_initialized) {
printk(KERN_ERR "kobject '%s' (%p): tried to add an "
"uninitialized object, something is seriously wrong.\n",
kobject_name(kobj), kobj);
dump_stack();
return -EINVAL;
}
va_start(args, fmt);
/*
* 示例:kobject_add_varg(kobj, NULL, "%s", "fs");
* 参见[15.7.1.2.2.1 kobject_add_varg()]节
*/
retval = kobject_add_varg(kobj, parent, fmt, args);
va_end(args);
return retval;
}
15.7.1.2.2.1 kobject_add_varg()
该函数定义于lib/kobject.c:
static int kobject_add_varg(struct kobject *kobj, struct kobject *parent,
const char *fmt, va_list vargs)
{
int retval;
/*
* 参见[15.7.3.2.1 kobject_set_name_vargs]节
* 设置kobj->name,示例:kobj->name = "fs"
*/
retval = kobject_set_name_vargs(kobj, fmt, vargs);
if (retval) {
printk(KERN_ERR "kobject: can not set name properly!\n");
return retval;
}
kobj->parent = parent;
// 参见[15.7.1.2.2.2 kobject_add_internal()]节
return kobject_add_internal(kobj);
}
15.7.1.2.2.2 kobject_add_internal()
函数定义于lib/kobject.c:
static int kobject_add_internal(struct kobject *kobj)
{
int error = 0;
struct kobject *parent;
if (!kobj)
return -ENOENT;
if (!kobj->name || !kobj->name[0]) {
WARN(1, "kobject: (%p): attempted to be registered with empty name!\n", kobj);
return -EINVAL;
}
// 增加父节点引用计数,并返回父节点的kobject引用
parent = kobject_get(kobj->parent);
/* join kset if set, use it as parent if we do not already have one */
if (kobj->kset) {
/*
* If parent is NULL when kobject_add() is called, kobj->parent
* will be set to the kobject of the containing kset.
*/
if (!parent)
parent = kobject_get(&kobj->kset->kobj);
kobj_kset_join(kobj);
kobj->parent = parent;
}
pr_debug("kobject: '%s' (%p): %s: parent: '%s', set: '%s'\n",
kobject_name(kobj), kobj, __func__,
parent ? kobject_name(parent) : "<NULL>",
kobj->kset ? kobject_name(&kobj->kset->kobj) : "<NULL>");
/*
* 创建kobj对应的目录,参见[15.7.1.2.2.2.1 create_dir()/populate_dir()]节
* 1) 若目录创建失败,则打印错误信息;
* 2) 若目录创建成功,则标记已经注册到sysfs中
*/
error = create_dir(kobj);
if (error) {
kobj_kset_leave(kobj);
kobject_put(parent); // 参见[15.7.2.2 kobject_put()]节
kobj->parent = NULL;
/* be noisy on error issues */
if (error == -EEXIST)
printk(KERN_ERR "%s failed for %s with "
"-EEXIST, don't try to register things with "
"the same name in the same directory.\n",
__func__, kobject_name(kobj));
else
printk(KERN_ERR "%s failed for %s (%d)\n",
__func__, kobject_name(kobj), error);
dump_stack();
} else
kobj->state_in_sysfs = 1;
return error;
}
15.7.1.2.2.2.1 create_dir()/populate_dir()
该函数定义于lib/kobject.c:
static int create_dir(struct kobject *kobj)
{
int error = 0;
/*
* 若kobj->name不为空,则在sysfs文件系统中创建kojbect对应的目录;
* 1) The name of the directory will be the same as the name
* given to the kobject itself.
* 2) The location within sysfs will reflect the kobject's
* position in the hierarchy you've created. In short:
* the kobject's directory will be found in its parent's
* directory, as determined by the kobject's parent field.
* If you have not explicitly set the parent field, but you
* have set its kset pointer, then the kset will become the
* kobject's parent. If there is no parent and no kset, the
* kobject's directory will become a top-level directory
* within sysfs, which is rarely what you really want.
*/
if (kobject_name(kobj)) {
error = sysfs_create_dir(kobj); // 参见[11.3.5.5.1 sysfs_create_dir()]节
if (!error) {
error = populate_dir(kobj); // 参见下文
if (error)
sysfs_remove_dir(kobj);
}
}
return error;
}
/*
* populate_dir - populate directory with attributes.
* @kobj: object we're working on.
*
* Most subsystems have a set of default attributes that are associated
* with an object that registers with them. This is a helper called during
* object registration that loops through the default attributes of the
* subsystem and creates attributes files for them in sysfs.
*/
static int populate_dir(struct kobject *kobj)
{
struct kobj_type *t = get_ktype(kobj);
struct attribute *attr;
int error = 0;
int i;
/*
* The default_attrs describes the attributes that
* all kobjects of this type should have.
*/
if (t && t->default_attrs) {
for (i = 0; (attr = t->default_attrs[i]) != NULL; i++) {
// 参见[11.3.5.6.2 sysfs_create_file()]节
error = sysfs_create_file(kobj, attr);
if (error)
break;
}
}
return error;
}
15.7.2 kobject的引用计数
15.7.2.1 kobject_get()
该函数定义于lib/kobject.c:
/**
* kobject_get - increment refcount for object.
* @kobj: object.
*/
struct kobject *kobject_get(struct kobject *kobj)
{
if (kobj)
kref_get(&kobj->kref);
return kobj;
}
/**
* kref_get - increment refcount for object.
* @kref: object.
*/
void kref_get(struct kref *kref)
{
WARN_ON(!atomic_read(&kref->refcount));
atomic_inc(&kref->refcount);
smp_mb__after_atomic_inc();
}
15.7.2.2 kobject_put()
该函数定义于lib/kobject.c:
/**
* kobject_put - decrement refcount for object.
* @kobj: object.
*
* Decrement the refcount, and if 0, call kobject_cleanup().
*/
void kobject_put(struct kobject *kobj)
{
if (kobj) {
if (!kobj->state_initialized)
WARN(1, KERN_WARNING "kobject: '%s' (%p): is not "
"initialized, yet kobject_put() is being "
"called.\n", kobject_name(kobj), kobj);
/*
* 函数kobject_release(),
* 参见[15.7.2.2.1 kobject_release()]节
*/
kref_put(&kobj->kref, kobject_release);
}
}
/**
* kref_put - decrement refcount for object.
* @kref: object.
* @release: pointer to the function that will clean up the object when the
* last reference to the object is released.
* This pointer is required, and it is not acceptable to pass kfree
* in as this function.
*
* Decrement the refcount, and if 0, call release().
* Return 1 if the object was removed, otherwise return 0. Beware, if this
* function returns 0, you still can not count on the kref from remaining in
* memory. Only use the return value if you want to see if the kref is now
* gone, not present.
*/
/*
* Note that kobject_init() sets the reference count to one, so the code
* which sets up the kobject will need to do a kobject_put() eventually
* to release that reference.
*/
int kref_put(struct kref *kref, void (*release)(struct kref *kref))
{
WARN_ON(release == NULL);
WARN_ON(release == (void (*)(struct kref *))kfree);
if (atomic_dec_and_test(&kref->refcount)) {
release(kref);
return 1;
}
return 0;
}
15.7.2.2.1 kobject_release()
该函数定义于lib/kobject.c:
static void kobject_release(struct kref *kref)
{
kobject_cleanup(container_of(kref, struct kobject, kref));
}
/*
* kobject_cleanup - free kobject resources.
* @kobj: object to cleanup
*/
static void kobject_cleanup(struct kobject *kobj)
{
struct kobj_type *t = get_ktype(kobj);
const char *name = kobj->name;
pr_debug("kobject: '%s' (%p): %s\n", kobject_name(kobj), kobj, __func__);
if (t && !t->release)
pr_debug("kobject: '%s' (%p): does not have a release() "
"function, it is broken and must be fixed.\n",
kobject_name(kobj), kobj);
/* send "remove" if the caller did not do it but sent "add" */
if (kobj->state_add_uevent_sent && !kobj->state_remove_uevent_sent) {
pr_debug("kobject: '%s' (%p): auto cleanup 'remove' event\n",
kobject_name(kobj), kobj);
kobject_uevent(kobj, KOBJ_REMOVE);
}
/* remove from sysfs if the caller did not do it */
if (kobj->state_in_sysfs) {
pr_debug("kobject: '%s' (%p): auto cleanup kobject_del\n",
kobject_name(kobj), kobj);
// 参见[15.7.2.2.1.1 kobject_del()]节
kobject_del(kobj);
}
if (t && t->release) {
pr_debug("kobject: '%s' (%p): calling ktype release\n",
kobject_name(kobj), kobj);
t->release(kobj);
}
/* free name if we allocated it */
if (name) {
pr_debug("kobject: '%s': free name\n", name);
kfree(name);
}
}
15.7.2.2.1.1 kobject_del()
该函数定义于lib/kobject.c:
/**
* kobject_del - unlink kobject from hierarchy.
* @kobj: object.
*/
/*
* NOTE: An initialized kobject will perform reference counting
* without trouble, but it will not appear in sysfs. To create
* sysfs entries, kernel code must pass the object to kobject_add().
* 参见[15.7.1.2.2 kobject_add()]节.
* The function kobject_del() will remove the kobject from sysfs.
*/
void kobject_del(struct kobject *kobj)
{
if (!kobj)
return;
sysfs_remove_dir(kobj); // 参见[11.3.5.5.2 sysfs_remove_dir()]节
kobj->state_in_sysfs = 0;
kobj_kset_leave(kobj); // remove the kobject from its kset's list
kobject_put(kobj->parent); // 参见[15.7.2.2 kobject_put()]节
kobj->parent = NULL;
}
15.7.3 kobject name
15.7.3.1 kobject_name()
该宏定义于include/linux/kobject.h:
static inline const char *kobject_name(const struct kobject *kobj)
{
return kobj->name;
}
15.7.3.2 kobject_set_name()
该函数定义于lib/kobject.c:
/**
* kobject_set_name - Set the name of a kobject
* @kobj: struct kobject to set the name of
* @fmt: format string used to build the name
*
* This sets the name of the kobject. If you have already added the
* kobject to the system, you must call kobject_rename() in order to
* change the name of the kobject.
*/
int kobject_set_name(struct kobject *kobj, const char *fmt, ...)
{
va_list vargs;
int retval;
va_start(vargs, fmt);
// 参见[15.7.3.2.1 kobject_set_name_vargs]节
retval = kobject_set_name_vargs(kobj, fmt, vargs);
va_end(vargs);
return retval;
}
15.7.3.2.1 kobject_set_name_vargs
该函数定义于lib/kobject.c:
/**
* kobject_set_name_vargs - Set the name of an kobject
* @kobj: struct kobject to set the name of
* @fmt: format string used to build the name
* @vargs: vargs to format the string.
*/
int kobject_set_name_vargs(struct kobject *kobj, const char *fmt, va_list vargs)
{
const char *old_name = kobj->name;
char *s;
if (kobj->name && !fmt)
return 0;
kobj->name = kvasprintf(GFP_KERNEL, fmt, vargs);
if (!kobj->name)
return -ENOMEM;
/* ewww... some of these buggers have '/' in the name ... */
while ((s = strchr(kobj->name, '/')))
s[0] = '!';
kfree(old_name);
return 0;
}
15.7.3.3 kobject_rename()
该函数定义于lib/kobject.c:
/**
* kobject_rename - change the name of an object
* @kobj: object in question.
* @new_name: object's new name
*
* It is the responsibility of the caller to provide mutual
* exclusion between two different calls of kobject_rename
* on the same kobject and to ensure that new_name is valid and
* won't conflict with other kobjects.
*/
int kobject_rename(struct kobject *kobj, const char *new_name)
{
int error = 0;
const char *devpath = NULL;
const char *dup_name = NULL, *name;
char *devpath_string = NULL;
char *envp[2];
kobj = kobject_get(kobj);
if (!kobj)
return -EINVAL;
if (!kobj->parent)
return -EINVAL;
devpath = kobject_get_path(kobj, GFP_KERNEL);
if (!devpath) {
error = -ENOMEM;
goto out;
}
devpath_string = kmalloc(strlen(devpath) + 15, GFP_KERNEL);
if (!devpath_string) {
error = -ENOMEM;
goto out;
}
sprintf(devpath_string, "DEVPATH_OLD=%s", devpath);
envp[0] = devpath_string;
envp[1] = NULL;
name = dup_name = kstrdup(new_name, GFP_KERNEL);
if (!name) {
error = -ENOMEM;
goto out;
}
error = sysfs_rename_dir(kobj, new_name);
if (error)
goto out;
/* Install the new kobject name */
dup_name = kobj->name;
kobj->name = name;
/* This function is mostly/only used for network interface.
* Some hotplug package track interfaces by their name and
* therefore want to know when the name is changed by the user. */
// 参见[15.7.5 kobject_uevent()]节
kobject_uevent_env(kobj, KOBJ_MOVE, envp);
out:
kfree(dup_name);
kfree(devpath_string);
kfree(devpath);
kobject_put(kobj); // 参见[15.7.2.2 kobject_put()]节
return error;
}
15.7.4 kset
In many ways, a kset looks like an extension of the kobj_type structure; a kset is a collection of identical kobjects. But, while struct kobj_type concerns itself with the type of an object, struct kset is concerned with aggregation and collection. The two concepts have been separated so that objects of identical type can appear in distinct sets.
A kset serves these functions:
- It serves as a bag containing a group of identical objects. A kset can be used by the kernel to track “all block devices” or “all PCI device drivers.”
- A kset is the directory-level glue that holds the device model (and sysfs) together. Every kset contains a kobject which can be set up to be the parent of other kobjects; in this way the device model hierarchy is constructed.
- Ksets can support the “hotplugging” of kobjects and influence how hotplug events are reported to user space.
In object-oriented terms, “kset” is the top-level container class; ksets inherit their own kobject, and can be treated as a kobject as well.
该结构定义于include/linux/kobject.h:
/**
* struct kset - a set of kobjects of a specific type, belonging to a specific subsystem.
*
* A kset defines a group of kobjects. They can be individually
* different "types" but overall these kobjects all want to be grouped
* together and operated on in the same manner. ksets are used to
* define the attribute callbacks and other common events that happen to
* a kobject.
*
* @list: the list of all kobjects for this kset
* @list_lock: a lock for iterating over the kobjects
* @kobj: the embedded kobject for this kset (recursion, isn't it fun...)
* @uevent_ops: the set of uevent operations for this kset. These are
* called whenever a kobject has something happen to it so that the kset
* can add new environment variables, or filter out the uevents if so
* desired.
*/
struct kset {
// 用于连接该kset中所有kobject的双向循环链表
struct list_head list;
// 用于保护list双向循环链表的自旋锁
spinlock_t list_lock;
/*
* 内嵌本kset的kobject对象。属于本kset的所有
* kobject对象的parent域均指向这个内嵌的对象
*/
struct kobject kobj;
const struct kset_uevent_ops *uevent_ops;
};
For initialization and setup, ksets have an interface very similar to that of kobjects. The following functions exist:
void kset_init(struct kset *kset);
int kset_add(struct kset *kset);
int kset_register(struct kset *kset);
void kset_unregister(struct kset *kset);
For the most part, these functions just call the analogous kobject_xxx function on the kset’s embedded kobject.
For managing the reference counts of ksets, the situation is about the same:
struct kset *kset_get(struct kset *kset);
void kset_put(struct kset *kset);
A kset, too, has a name, which is stored in the embedded kobject. So, if you have a kset called my_set, you would set its name with:
kobject_set_name(my_set->kobj, "The name");
15.7.4.1 kset_create_and_add()
/**
* kset_create_and_add - create a struct kset dynamically and add it to sysfs
*
* @name: the name for the kset
* @uevent_ops: a struct kset_uevent_ops for the kset
* @parent_kobj: the parent kobject of this kset, if any.
*
* This function creates a kset structure dynamically and registers it
* with sysfs. When you are finished with this structure, call
* kset_unregister() and the structure will be dynamically freed when it
* is no longer being used.
*
* If the kset was not able to be created, NULL will be returned.
*/
kset_create_and_add(const char *name,
const struct kset_uevent_ops *uevent_ops,
struct kobject *parent_kobj)
-> kset = kset_create(name, uevent_ops, parent_kobj)
-> kset_register(kset)
-> kset_init()
-> kobject_add_internal()
-> kobject_uevent() // 参见[15.7.5 kobject_uevent()]节
15.7.5 kobject_uevent()
该函数定义于lib/kobject_uevent.c:
/**
* kobject_uevent - notify userspace by sending an uevent
*
* @action: action that is happening
* @kobj: struct kobject that the action is happening to
*
* Returns 0 if kobject_uevent() is completed with success or the
* corresponding error when it fails.
*/
int kobject_uevent(struct kobject *kobj, enum kobject_action action)
{
return kobject_uevent_env(kobj, action, NULL);
}
/**
* kobject_uevent_env - send an uevent with environmental data
*
* @action: action that is happening
* @kobj: struct kobject that the action is happening to
* @envp_ext: pointer to environmental data
*
* Returns 0 if kobject_uevent_env() is completed with success or the
* corresponding error when it fails.
*/
int kobject_uevent_env(struct kobject *kobj, enum kobject_action action,
char *envp_ext[])
{
struct kobj_uevent_env *env;
const char *action_string = kobject_actions[action];
const char *devpath = NULL;
const char *subsystem;
struct kobject *top_kobj;
struct kset *kset;
const struct kset_uevent_ops *uevent_ops;
u64 seq;
int i = 0;
int retval = 0;
#ifdef CONFIG_NET
struct uevent_sock *ue_sk;
#endif
pr_debug("kobject: '%s' (%p): %s\n",
kobject_name(kobj), kobj, __func__);
/* search the kset we belong to */
top_kobj = kobj;
while (!top_kobj->kset && top_kobj->parent)
top_kobj = top_kobj->parent;
if (!top_kobj->kset) {
pr_debug("kobject: '%s' (%p): %s: attempted to send uevent "
"without kset!\n", kobject_name(kobj), kobj, __func__);
return -EINVAL;
}
/*
* 变量uevent_ops存在下列取值:
* bus_uevent_ops
* device_uevent_ops, 参见[15.7.5.1 device_uevent_ops]节
* module_uevent_ops
*/
kset = top_kobj->kset;
uevent_ops = kset->uevent_ops;
/* skip the event, if uevent_suppress is set*/
if (kobj->uevent_suppress) {
pr_debug("kobject: '%s' (%p): %s: uevent_suppress "
"caused the event to drop!\n",
kobject_name(kobj), kobj, __func__);
return 0;
}
/* skip the event, if the filter returns zero. */
/*
* 对于device_uevent_ops, 调用dev_uevent_filter(),
* 参见[15.7.5.1.1 dev_uevent_filter()]节
*/
if (uevent_ops && uevent_ops->filter)
if (!uevent_ops->filter(kset, kobj)) {
pr_debug("kobject: '%s' (%p): %s: filter function "
"caused the event to drop!\n",
kobject_name(kobj), kobj, __func__);
return 0;
}
/* originating subsystem */
/*
* 对于device_uevent_ops, 调用dev_uevent_name(),
* 参见[15.7.5.1.2 dev_uevent_name()]节
*/
if (uevent_ops && uevent_ops->name)
subsystem = uevent_ops->name(kset, kobj);
else
subsystem = kobject_name(&kset->kobj);
if (!subsystem) {
pr_debug("kobject: '%s' (%p): %s: unset subsystem caused the "
"event to drop!\n", kobject_name(kobj), kobj, __func__);
return 0;
}
/* environment buffer */
env = kzalloc(sizeof(struct kobj_uevent_env), GFP_KERNEL);
if (!env)
return -ENOMEM;
/* complete object path */
devpath = kobject_get_path(kobj, GFP_KERNEL);
if (!devpath) {
retval = -ENOENT;
goto exit;
}
/* default keys */
retval = add_uevent_var(env, "ACTION=%s", action_string);
if (retval)
goto exit;
retval = add_uevent_var(env, "DEVPATH=%s", devpath);
if (retval)
goto exit;
retval = add_uevent_var(env, "SUBSYSTEM=%s", subsystem);
if (retval)
goto exit;
/* keys passed in from the caller */
if (envp_ext) {
for (i = 0; envp_ext[i]; i++) {
retval = add_uevent_var(env, "%s", envp_ext[i]);
if (retval)
goto exit;
}
}
/* let the kset specific function add its stuff */
/*
* 对于device_uevent_ops, 调用dev_uevent(),
* 参见[15.7.5.1.3 dev_uevent()]节
*/
if (uevent_ops && uevent_ops->uevent) {
retval = uevent_ops->uevent(kset, kobj, env);
if (retval) {
pr_debug("kobject: '%s' (%p): %s: uevent() returned "
"%d\n", kobject_name(kobj), kobj, __func__, retval);
goto exit;
}
}
/*
* Mark "add" and "remove" events in the object to ensure proper
* events to userspace during automatic cleanup. If the object did
* send an "add" event, "remove" will automatically generated by
* the core, if not already done by the caller.
*/
if (action == KOBJ_ADD)
kobj->state_add_uevent_sent = 1;
else if (action == KOBJ_REMOVE)
kobj->state_remove_uevent_sent = 1;
/* we will send an event, so request a new sequence number */
/*
* 递增uevent序列号uevent_seqnum,
* 可通过命令"cat /sys/kernel/uevent_seqnum"查看
*/
spin_lock(&sequence_lock);
seq = ++uevent_seqnum;
spin_unlock(&sequence_lock);
retval = add_uevent_var(env, "SEQNUM=%llu", (unsigned long long)seq);
if (retval)
goto exit;
#if defined(CONFIG_NET)
/* send netlink message */
mutex_lock(&uevent_sock_mutex);
list_for_each_entry(ue_sk, &uevent_sock_list, list) {
struct sock *uevent_sock = ue_sk->sk;
struct sk_buff *skb;
size_t len;
/* allocate message with the maximum possible size */
len = strlen(action_string) + strlen(devpath) + 2;
skb = alloc_skb(len + env->buflen, GFP_KERNEL);
if (skb) {
char *scratch;
/* add header */
scratch = skb_put(skb, len);
sprintf(scratch, "%s@%s", action_string, devpath);
/* copy keys to our continuous event payload buffer */
for (i = 0; i < env->envp_idx; i++) {
len = strlen(env->envp[i]) + 1;
scratch = skb_put(skb, len);
strcpy(scratch, env->envp[i]);
}
NETLINK_CB(skb).dst_group = 1;
/*
* 通过netlink将该uevent广播到用户空间,用户空间通过udev监控该热插拔事件:
* (通过创建一个socket描述符,将描述符绑定到接收地址,即可实现监听热拔插事件);
* 参见[10.2B.3.4 守护进程udevd接收uevent并加载对应的驱动程序]节
*/
retval = netlink_broadcast_filtered(uevent_sock, skb,
0, 1, GFP_KERNEL,
kobj_bcast_filter,
kobj);
/* ENOBUFS should be handled in userspace */
if (retval == -ENOBUFS || retval == -ESRCH)
retval = 0;
} else
retval = -ENOMEM;
}
mutex_unlock(&uevent_sock_mutex);
#endif
/* call uevent_helper, usually only enabled during early boot */
if (uevent_helper[0] && !kobj_usermode_filter(kobj)) {
char *argv [3];
argv [0] = uevent_helper;
argv [1] = (char *)subsystem;
argv [2] = NULL;
retval = add_uevent_var(env, "HOME=/");
if (retval)
goto exit;
retval = add_uevent_var(env, "PATH=/sbin:/bin:/usr/sbin:/usr/bin");
if (retval)
goto exit;
/*
* 函数call_usermodehelper()调用函数call_usermodehelper_fns(),
* 参见[13.3.2.2.2 __call_usermodehelper()]节
*/
retval = call_usermodehelper(argv[0], argv, env->envp, UMH_WAIT_EXEC);
}
exit:
kfree(devpath);
kfree(env);
return retval;
}
15.7.5.1 device_uevent_ops
该变量定义于driver/base/core.c:
// 函数devices_init()引用该变量,参见[10.2.1.1 devices_init()]节
static const struct kset_uevent_ops device_uevent_ops = {
.filter = dev_uevent_filter,
.name = dev_uevent_name,
.uevent = dev_uevent,
};
15.7.5.1.1 dev_uevent_filter()
该函数定义于driver/base/core.c:
static int dev_uevent_filter(struct kset *kset, struct kobject *kobj)
{
struct kobj_type *ktype = get_ktype(kobj);
if (ktype == &device_ktype) {
struct device *dev = kobj_to_dev(kobj);
if (dev->bus)
return 1;
if (dev->class)
return 1;
}
return 0;
}
15.7.5.1.2 dev_uevent_name()
该函数定义于driver/base/core.c:
static const char *dev_uevent_name(struct kset *kset, struct kobject *kobj)
{
struct device *dev = kobj_to_dev(kobj);
if (dev->bus)
return dev->bus->name;
if (dev->class)
return dev->class->name;
return NULL;
}
15.7.5.1.3 dev_uevent()
该函数定义于driver/base/core.c:
static int dev_uevent(struct kset *kset, struct kobject *kobj,
struct kobj_uevent_env *env)
{
struct device *dev = kobj_to_dev(kobj);
int retval = 0;
/* add device node properties if present */
if (MAJOR(dev->devt)) {
const char *tmp;
const char *name;
umode_t mode = 0;
kuid_t uid = GLOBAL_ROOT_UID;
kgid_t gid = GLOBAL_ROOT_GID;
add_uevent_var(env, "MAJOR=%u", MAJOR(dev->devt));
add_uevent_var(env, "MINOR=%u", MINOR(dev->devt));
name = device_get_devnode(dev, &mode, &uid, &gid, &tmp);
if (name) {
add_uevent_var(env, "DEVNAME=%s", name);
if (mode)
add_uevent_var(env, "DEVMODE=%#o", mode & 0777);
if (!uid_eq(uid, GLOBAL_ROOT_UID))
add_uevent_var(env, "DEVUID=%u", from_kuid(&init_user_ns, uid));
if (!gid_eq(gid, GLOBAL_ROOT_GID))
add_uevent_var(env, "DEVGID=%u", from_kgid(&init_user_ns, gid));
kfree(tmp);
}
}
if (dev->type && dev->type->name)
add_uevent_var(env, "DEVTYPE=%s", dev->type->name);
if (dev->driver)
add_uevent_var(env, "DRIVER=%s", dev->driver->name);
/* Add common DT information about the device */
of_device_uevent(dev, env);
/* have the bus specific function add its stuff */
/*
* For PCI devices, call pci_uevent(), which add following key-values:
* PCI_CLASS=%04X, PCI_ID=%04X:%04X, PCI_SUBSYS_ID=%04X:%04X, PCI_SLOT_NAME=%s
* and most important one:
* MODALIAS=pci:v%08Xd%08Xsv%08Xsd%08Xbc%02Xsc%02Xi%02X
*/
if (dev->bus && dev->bus->uevent) {
retval = dev->bus->uevent(dev, env);
if (retval)
pr_debug("device: '%s': %s: bus uevent() returned %d\n",
dev_name(dev), __func__, retval);
}
/* have the class specific function add its stuff */
if (dev->class && dev->class->dev_uevent) {
retval = dev->class->dev_uevent(dev, env);
if (retval)
pr_debug("device: '%s': %s: class uevent() "
"returned %d\n", dev_name(dev), __func__, retval);
}
/* have the device type specific function add its stuff */
if (dev->type && dev->type->uevent) {
retval = dev->type->uevent(dev, env);
if (retval)
pr_debug("device: '%s': %s: dev_type uevent() "
"returned %d\n", dev_name(dev), __func__, retval);
}
return retval;
}
16 Kernel Synchronization Methods
参见«Understanding the Linux Kernel, 3rd Edition»第5. Kernel Synchronization章第Synchronization Primitives节:
Various types of synchronization techniques used by the kernel
| Technique | Description | Scope | Reference |
|---|---|---|---|
| Per-CPU variables | Duplicate a data structure among the CPUs | All CPUs | Section 16.1 Per-CPU Variables |
| Atomic operation | Atomic read-modify-write instruction to a counter | All CPUs | Section Atomic Operations |
| Spin lock | Lock with busy wait | All CPUs | Section Spin Locks/自旋锁, Reader-Writer Spin Locks |
| Seqlocks | Lock based on an access counter | All CPUs | Section Sequential Locks |
| Semaphore | Lock with blocking wait (sleep) | All CPUs | Section Semaphores/信号量, Reader-Writer Semaphore, Mutex/互斥 |
| Local interrupt disabling | Forbid interrupt handling on a single CPU | Local CPU | Section Disable/Enable Interrupts |
| Local softirq disabling | Forbid deferrable function handling on a single CPU | Local CPU | Section Preemption Disabling |
| Memory barrier | Avoid instruction reordering | Local CPU or All CPUs | Section Ordering and Barriers |
| Read-copy-update (RCU) | Lock-free access to shared data structures through pointers | All CPUs |
16.1 Per-CPU Variables
Basically, a per-CPU variable is an array of data structures, one element per each CPU in the system.
A CPU should not access the elements of the array corresponding to the other CPUs; on the other hand, it can freely read and modify its own element without fear of race conditions, because it is the only CPU entitled to do so.
While per-CPU variables provide protection against concurrent accesses from several CPUs, they do not provide protection against accesses from asynchronous functions (interrupt handlers and deferrable functions). In these cases, additional synchronization primitives are required.
Furthermore, per-CPU variables are prone to race conditions caused by kernel preemption, both in uniprocessor and multiprocessor systems. As a general rule, a kernel control path should access a per-CPU variable with kernel preemption disabled.
Functions and macros for the per-CPU variables
| Macro / Function Name | Description | Reference |
|---|---|---|
DECLARE_PER_CPU(type, name) |
Declare a per-CPU array called name of type data structures | include/linux/percpu-defs.h |
DEFINE_PER_CPU(type, name) |
Statically allocates a per-CPU array called name of type data structures | include/linux/percpu-defs.h |
per_cpu(name, cpu) |
Selects the element for CPU cpu of the per-CPU array name | include/asm-generic/percpu.h |
__get_cpu_var(name) |
Selects the local CPU’s element of the per-CPU array name | include/asm-generic/percpu.h |
get_cpu_var(name) |
Disables kernel preemption, then selects the local CPU’s element of the per-CPU array name | include/linux/percpu.h |
put_cpu_var(name) |
Enables kernel preemption (name is not used) | include/linux/percpu.h |
alloc_percpu(type) |
Dynamically allocates a per-CPU array of type data structures and returns its address | include/linux/percpu.h |
free_percpu(pointer) |
Releases a dynamically allocated per-CPU array at address pointer | include/linux/percpu.h mm/percpu.c |
per_cpu_ptr(pointer, cpu) |
Returns the address of the element for CPU cpu of the per-CPU array at address pointer | include/linux/percpu.h |
16.1.1 Per-CPU Variables宏的扩展
16.1.1.1 DECLARE_PER_CPU(type, name)/DEFINE_PER_CPU(type, name)
由include/linux/percpu-defs.h可知:
代码:
DECLARE_PER_CPU(int, x);
被扩展为:
extern __percpu __attribute__(section(".data..percpu")) __typeof__(int) x;
代码:
DEFINE_PER_CPU(int, x);
被扩展为:
__percpu __attribute__(section(".data..percpu")) __typeof__(int) x;
16.1.1.2 per_cpu(name, cpu)
该宏定义于include/asm-generic/percpu.h:
#ifdef CONFIG_SMP
/*
* per_cpu_offset() is the offset that has to be added to a
* percpu variable to get to the instance for a certain processor.
*
* Most arches use the __per_cpu_offset array for those offsets but
* some arches have their own ways of determining the offset (x86_64, s390).
*/
#ifndef __per_cpu_offset
extern unsigned long __per_cpu_offset[NR_CPUS];
#define per_cpu_offset(x) (__per_cpu_offset[x])
#endif
/*
* Add a offset to a pointer but keep the pointer as is.
* Only S390 provides its own means of moving the pointer.
*/
#ifndef SHIFT_PERCPU_PTR
/* Weird cast keeps both GCC and sparse happy. */
#define SHIFT_PERCPU_PTR(__p, __offset) ({ \
__verify_pcpu_ptr((__p)); \
RELOC_HIDE((typeof(*(__p)) __kernel __force *)(__p), (__offset)); \
})
#endif
/*
* A percpu variable may point to a discarded regions. The following are
* established ways to produce a usable pointer from the percpu variable
* offset.
*/
#define per_cpu(var, cpu) \
(*SHIFT_PERCPU_PTR(&(var), per_cpu_offset(cpu)))
#else /* ! SMP */
#define VERIFY_PERCPU_PTR(__p) ({ \
__verify_pcpu_ptr((__p)); \
(typeof(*(__p)) __kernel __force *)(__p); \
})
#define per_cpu(var, cpu) (*((void)(cpu), VERIFY_PERCPU_PTR(&(var))))
#endif /* SMP */
由此可知,代码:
per_cpu(x, 0);
被扩展为:
(*{
__verify_pcpu_ptr(&x);
unsigned long __ptr;
__asm__ ("" : "=r"(__ptr) : "0"((typeof(x) *)&x));
(typeof((typeof(x) *)&x)) (__ptr + __per_cpu_offset[0]);
});
16.1.1.3 get_cpu_var(name)/put_cpu_var(name)/__get_cpu_var(name)
该宏定义于include/linux/percpu.h:
/*
* Must be an lvalue. Since @var must be a simple identifier,
* we force a syntax error here if it isn't.
*/
#define get_cpu_var(var) (*({ \
preempt_disable(); \ // 参见[16.10.2 preempt_disable()]节
&__get_cpu_var(var); }))
/*
* The weird & is necessary because sparse considers (void)(var) to be
* a direct dereference of percpu variable (var).
*/
#define put_cpu_var(var) do { \
(void)&(var); \
preempt_enable(); \ // 参见[16.10.3 preempt_enable()/preempt_enable_no_resched()]节
} while (0)
其中,__get_cpu_var(var)定义于include/asm-generic/percpu.h:
#ifdef CONFIG_SMP
/*
* per_cpu_offset() is the offset that has to be added to a
* percpu variable to get to the instance for a certain processor.
*
* Most arches use the __per_cpu_offset array for those offsets but
* some arches have their own ways of determining the offset (x86_64, s390).
*/
#ifndef __per_cpu_offset
extern unsigned long __per_cpu_offset[NR_CPUS];
#define per_cpu_offset(x) (__per_cpu_offset[x])
#endif
/*
* Determine the offset for the currently active processor.
* An arch may define __my_cpu_offset to provide a more effective
* means of obtaining the offset to the per cpu variables of the
* current processor.
*/
#ifndef __my_cpu_offset
#define __my_cpu_offset per_cpu_offset(raw_smp_processor_id())
#endif
#ifdef CONFIG_DEBUG_PREEMPT
#define my_cpu_offset per_cpu_offset(smp_processor_id())
#else
#define my_cpu_offset __my_cpu_offset
#endif
#ifndef SHIFT_PERCPU_PTR
/* Weird cast keeps both GCC and sparse happy. */
#define SHIFT_PERCPU_PTR(__p, __offset) ({ \
__verify_pcpu_ptr((__p)); \
RELOC_HIDE((typeof(*(__p)) __kernel __force *)(__p), (__offset)); \
})
#endif
#ifndef __this_cpu_ptr
#define __this_cpu_ptr(ptr) SHIFT_PERCPU_PTR(ptr, __my_cpu_offset)
#endif
#ifdef CONFIG_DEBUG_PREEMPT
#define this_cpu_ptr(ptr) SHIFT_PERCPU_PTR(ptr, my_cpu_offset)
#else
#define this_cpu_ptr(ptr) __this_cpu_ptr(ptr)
#endif
#define __get_cpu_var(var) (*this_cpu_ptr(&(var)))
#else /* ! SMP */
#define VERIFY_PERCPU_PTR(__p) ({ \
__verify_pcpu_ptr((__p)); \
(typeof(*(__p)) __kernel __force *)(__p); \
})
#define __get_cpu_var(var) (*VERIFY_PERCPU_PTR(&(var)))
#endif
16.1.2 Per-CPU Variables的初始化
由16.1.1 Per-CPU Variables宏的扩展节可知,Per-CPU Variables中的关键变量为__per_cpu_offset[NR_CPUS],该变量在初始化过程中赋值。
系统启动时,对Per-CPU Variables的初始化过程如下:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> setup_per_cpu_areas() // arch/x86/kernel/setup_percpu.c
-> pcpu_embed_first_chunk() // mm/percpu.c
-> pcpu_setup_first_chunk() // Init pcpu_base_addr and pcpu_unit_offsets
-> delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
-> for_each_possible_cpu(cpu) {
// 初始化per_cpu_offset(cpu),即__per_cpu_offset[cpu]
per_cpu_offset(cpu) = delta + pcpu_unit_offsets[cpu];
...
}
函数setup_per_cpu_areas()定义于arch/x86/kernel/setup_percpu.c:
void __init setup_per_cpu_areas(void)
{
unsigned int cpu;
unsigned long delta;
int rc;
pr_info("NR_CPUS:%d nr_cpumask_bits:%d nr_cpu_ids:%d nr_node_ids:%d\n",
NR_CPUS, nr_cpumask_bits, nr_cpu_ids, nr_node_ids);
/*
* Allocate percpu area. Embedding allocator is our favorite;
* however, on NUMA configurations, it can result in very
* sparse unit mapping and vmalloc area isn't spacious enough
* on 32bit. Use page in that case.
*/
#ifdef CONFIG_X86_32
/*
* pcpu_chosen_fc定义于mm/percpu.c:
* enum pcpu_fc pcpu_chosen_fc __initdata = PCPU_FC_AUTO;
*/
if (pcpu_chosen_fc == PCPU_FC_AUTO && pcpu_need_numa())
pcpu_chosen_fc = PCPU_FC_PAGE;
#endif
rc = -EINVAL;
if (pcpu_chosen_fc != PCPU_FC_PAGE) {
const size_t atom_size = cpu_has_pse ? PMD_SIZE : PAGE_SIZE;
const size_t dyn_size = PERCPU_MODULE_RESERVE + PERCPU_DYNAMIC_RESERVE - PERCPU_FIRST_CHUNK_RESERVE;
// 示例:pcpu_embed_first_chunk(0, 20480, 4096, pcpu_cpu_distance, pcpu_fc_alloc, pcpu_fc_free);
rc = pcpu_embed_first_chunk(PERCPU_FIRST_CHUNK_RESERVE, dyn_size, atom_size,
pcpu_cpu_distance, pcpu_fc_alloc, pcpu_fc_free);
if (rc < 0)
pr_warning("%s allocator failed (%d), falling back to page size\n",
pcpu_fc_names[pcpu_chosen_fc], rc);
}
if (rc < 0)
rc = pcpu_page_first_chunk(PERCPU_FIRST_CHUNK_RESERVE,
pcpu_fc_alloc, pcpu_fc_free, pcpup_populate_pte);
if (rc < 0)
panic("cannot initialize percpu area (err=%d)", rc);
/* alrighty, percpu areas up and running */
/*
* __per_cpu_start定义于生成的vmlinux.lds,
* 参见Error: Reference source not found
*/
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu) {
/*
* per_cpu_offset(x)定义于include/asm-generic/percpu.h:
* #define per_cpu_offset(x) (__per_cpu_offset[x])
*/
per_cpu_offset(cpu) = delta + pcpu_unit_offsets[cpu];
per_cpu(this_cpu_off, cpu) = per_cpu_offset(cpu);
per_cpu(cpu_number, cpu) = cpu;
setup_percpu_segment(cpu);
setup_stack_canary_segment(cpu);
/*
* Copy data used in early init routines from the
* initial arrays to the per cpu data areas. These
* arrays then become expendable and the *_early_ptr's
* are zeroed indicating that the static arrays are
* gone.
*/
#ifdef CONFIG_X86_LOCAL_APIC
per_cpu(x86_cpu_to_apicid, cpu) = early_per_cpu_map(x86_cpu_to_apicid, cpu);
per_cpu(x86_bios_cpu_apicid, cpu) = early_per_cpu_map(x86_bios_cpu_apicid, cpu);
#endif
#ifdef CONFIG_X86_32
per_cpu(x86_cpu_to_logical_apicid, cpu) = early_per_cpu_map(x86_cpu_to_logical_apicid, cpu);
#endif
#ifdef CONFIG_X86_64
per_cpu(irq_stack_ptr, cpu) = per_cpu(irq_stack_union.irq_stack, cpu) + IRQ_STACK_SIZE - 64;
#endif
#ifdef CONFIG_NUMA
per_cpu(x86_cpu_to_node_map, cpu) = early_per_cpu_map(x86_cpu_to_node_map, cpu);
/*
* Ensure that the boot cpu numa_node is correct when the boot
* cpu is on a node that doesn't have memory installed.
* Also cpu_up() will call cpu_to_node() for APs when
* MEMORY_HOTPLUG is defined, before per_cpu(numa_node) is set
* up later with c_init aka intel_init/amd_init.
* So set them all (boot cpu and all APs).
*/
set_cpu_numa_node(cpu, early_cpu_to_node(cpu));
#endif
/*
* Up to this point, the boot CPU has been using .init.data
* area. Reload any changed state for the boot CPU.
*/
if (!cpu)
switch_to_new_gdt(cpu);
}
/* indicate the early static arrays will soon be gone */
#ifdef CONFIG_X86_LOCAL_APIC
early_per_cpu_ptr(x86_cpu_to_apicid) = NULL;
early_per_cpu_ptr(x86_bios_cpu_apicid) = NULL;
#endif
#ifdef CONFIG_X86_32
early_per_cpu_ptr(x86_cpu_to_logical_apicid) = NULL;
#endif
#ifdef CONFIG_NUMA
early_per_cpu_ptr(x86_cpu_to_node_map) = NULL;
#endif
/* Setup node to cpumask map */
setup_node_to_cpumask_map();
/* Setup cpu initialized, callin, callout masks */
setup_cpu_local_masks();
}
16.1.2.1 pcpu_embed_first_chunk()
该函数定义于mm/percpu.c:
#if defined(BUILD_EMBED_FIRST_CHUNK)
/**
* pcpu_embed_first_chunk - embed the first percpu chunk into bootmem
* @reserved_size: the size of reserved percpu area in bytes
* @dyn_size: minimum free size for dynamic allocation in bytes
* @atom_size: allocation atom size
* @cpu_distance_fn: callback to determine distance between cpus, optional
* @alloc_fn: function to allocate percpu page
* @free_fn: function to free percpu page
*
* This is a helper to ease setting up embedded first percpu chunk and
* can be called where pcpu_setup_first_chunk() is expected.
*
* If this function is used to setup the first chunk, it is allocated
* by calling @alloc_fn and used as-is without being mapped into
* vmalloc area. Allocations are always whole multiples of @atom_size
* aligned to @atom_size.
*
* This enables the first chunk to piggy back on the linear physical
* mapping which often uses larger page size. Please note that this
* can result in very sparse cpu->unit mapping on NUMA machines thus
* requiring large vmalloc address space. Don't use this allocator if
* vmalloc space is not orders of magnitude larger than distances
* between node memory addresses (ie. 32bit NUMA machines).
*
* @dyn_size specifies the minimum dynamic area size.
*
* If the needed size is smaller than the minimum or specified unit
* size, the leftover is returned using @free_fn.
*
* RETURNS:
* 0 on success, -errno on failure.
*/
int __init pcpu_embed_first_chunk(size_t reserved_size, size_t dyn_size, size_t atom_size,
pcpu_fc_cpu_distance_fn_t cpu_distance_fn,
pcpu_fc_alloc_fn_t alloc_fn,
pcpu_fc_free_fn_t free_fn)
{
void *base = (void *)ULONG_MAX;
void **areas = NULL;
struct pcpu_alloc_info *ai;
size_t size_sum, areas_size, max_distance;
int group, i, rc;
ai = pcpu_build_alloc_info(reserved_size, dyn_size, atom_size, cpu_distance_fn);
if (IS_ERR(ai))
return PTR_ERR(ai);
size_sum = ai->static_size + ai->reserved_size + ai->dyn_size;
areas_size = PFN_ALIGN(ai->nr_groups * sizeof(void *));
areas = alloc_bootmem_nopanic(areas_size);
if (!areas) {
rc = -ENOMEM;
goto out_free;
}
/* allocate, copy and determine base address */
for (group = 0; group < ai->nr_groups; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
unsigned int cpu = NR_CPUS;
void *ptr;
for (i = 0; i < gi->nr_units && cpu == NR_CPUS; i++)
cpu = gi->cpu_map[i];
BUG_ON(cpu == NR_CPUS);
/* allocate space for the whole group */
ptr = alloc_fn(cpu, gi->nr_units * ai->unit_size, atom_size);
if (!ptr) {
rc = -ENOMEM;
goto out_free_areas;
}
areas[group] = ptr;
base = min(ptr, base);
for (i = 0; i < gi->nr_units; i++, ptr += ai->unit_size) {
if (gi->cpu_map[i] == NR_CPUS) {
/* unused unit, free whole */
free_fn(ptr, ai->unit_size);
continue;
}
/* copy and return the unused part */
memcpy(ptr, __per_cpu_load, ai->static_size);
free_fn(ptr + size_sum, ai->unit_size - size_sum);
}
}
/* base address is now known, determine group base offsets */
max_distance = 0;
for (group = 0; group < ai->nr_groups; group++) {
ai->groups[group].base_offset = areas[group] - base;
max_distance = max_t(size_t, max_distance, ai->groups[group].base_offset);
}
max_distance += ai->unit_size;
/* warn if maximum distance is further than 75% of vmalloc space */
if (max_distance > (VMALLOC_END - VMALLOC_START) * 3 / 4) {
pr_warning("PERCPU: max_distance=0x%zx too large for vmalloc space 0x%lx\n",
max_distance, (unsigned long)(VMALLOC_END - VMALLOC_START));
#ifdef CONFIG_NEED_PER_CPU_PAGE_FIRST_CHUNK
/* and fail if we have fallback */
rc = -EINVAL;
goto out_free;
#endif
}
pr_info("PERCPU: Embedded %zu pages/cpu @%p s%zu r%zu d%zu u%zu\n",
PFN_DOWN(size_sum), base, ai->static_size, ai->reserved_size,
ai->dyn_size, ai->unit_size);
rc = pcpu_setup_first_chunk(ai, base);
goto out_free;
out_free_areas:
for (group = 0; group < ai->nr_groups; group++)
free_fn(areas[group], ai->groups[group].nr_units * ai->unit_size);
out_free:
pcpu_free_alloc_info(ai);
if (areas)
free_bootmem(__pa(areas), areas_size);
return rc;
}
#endif /* BUILD_EMBED_FIRST_CHUNK */
16.2 Atomic Operations
原子操作包括两部分:对整数的原子操作和对比特位的原子操作。
16.2.1 Atomic Integer Operations
An atomic_t holds an int value on all supported architectures. Because of the way this type works on some processors, however, the full integer range may not be available; thus, you should not count on an atomic_t holding more than 24 bits.
在include/linux/types.h中,包含类型atomic_t用于对整数的原子操作:
typedef struct {
int counter;
} atomic_t;
#ifdef CONFIG_64BIT
typedef struct {
long counter;
} atomic64_t;
#endif
原子操作的具体实现与体系架构有关,x86架构下的原子操作接口,参见arch/x86/include/asm/atomic.h:
// At declaration, initialize to i.
#define ATOMIC_INIT(i) { (i) }
// Atomically read the integer value of v.
static inline int atomic_read(const atomic_t *v);
// Atomically set v equal to i.
static inline void atomic_set(atomic_t *v, int i);
// Atomically add i to v.
static inline void atomic_add(int i, atomic_t *v);
// Atomically substract i from v.
static inline void atomic_sub(int i, atomic_t *v);
// Atomically add one to v.
static inline void atomic_inc(atomic_t *v);
// Atomically subtract one from v.
static inline void atomic_dec(atomic_t *v);
// Atomically add i to v and return the result.
static inline int atomic_add_return(int i, atomic_t *v);
// Atomically subtract i from v and return the result.
static inline int atomic_sub_return(int i, atomic_t *v);
// Atomically increment v by one and return the result.
#define atomic_inc_return(v) (atomic_add_return(1, v))
// Atomically decrement v by one and return the result.
#define atomic_dec_return(v) (atomic_sub_return(1, v))
// Atomically add i to v and return true if the result is negative; otherwise false.
static inline int atomic_add_negative(int i, atomic_t *v);
// Atomically subtract i from v and return true if the result is zero; otherwise false.
static inline int atomic_sub_and_test(int i, atomic_t *v);
// Atomically increment v by one and return true if the result is zero; false otherwise.
static inline int atomic_inc_and_test(atomic_t *v);
// Atomically decrement v by one and return true if zero; false otherwise.
static inline int atomic_dec_and_test(atomic_t *v);
...
#ifdef CONFIG_X86_32
# include "atomic64_32.h"
#else
# include "atomic64_64.h"
#endif
在arch/x86/include/asm/atomic64_64.h中,包含如下接口(与atomic.h类似,接口名字由atomic_xxx()改为atomic64_xxx()):
#define ATOMIC64_INIT(i) { (i) }
static inline long atomic64_read(const atomic64_t *v);
static inline void atomic64_set(atomic64_t *v, long i);
static inline void atomic64_add(long i, atomic64_t *v);
static inline void atomic64_sub(long i, atomic64_t *v);
static inline void atomic64_inc(atomic64_t *v);
static inline void atomic64_dec(atomic64_t *v);
static inline int atomic64_add_negative(long i, atomic64_t *v);
static inline int atomic64_sub_and_test(long i, atomic64_t *v);
static inline int atomic64_inc_and_test(atomic64_t *v);
static inline int atomic64_dec_and_test(atomic64_t *v);
static inline long atomic64_add_return(long i, atomic64_t *v)
static inline long atomic64_sub_return(long i, atomic64_t *v)
#define atomic64_inc_return(v) (atomic64_add_return(1, (v)))
#define atomic64_dec_return(v) (atomic64_sub_return(1, (v)))
arch/x86/include/asm/atomic64_32.h中的接口与atomic64_64.h中的类似,只是类型atomic64_t的定义有变化,因而接口的入参或返回值有相应改变:
typedef struct {
u64 __aligned(8) counter;
} atomic64_t;
16.2.2 Atomic Bitwise Operations
在arch/x86/include/asm/bitops.h中,包含如下有关比特位的原子操作接口:
// Atomically set the nr-th bit starting from addr.
static void set_bit(unsigned int nr, volatile unsigned long *addr);
static inline void __set_bit(int nr, volatile unsigned long *addr);
// Atomically clear the nr-th bit starting from addr.
static void clear_bit(int nr, volatile unsigned long *addr);
static inline void __clear_bit(int nr, volatile unsigned long *addr);
// Atomically flip the value of the nr-th bit starting from addr.
static inline void change_bit(int nr, volatile unsigned long *addr);
static inline void __change_bit(int nr, volatile unsigned long *addr);
// Atomically set the nr-th bit starting from addr and return the previous value.
static inline int test_and_set_bit(int nr, volatile unsigned long *addr);
static inline int __test_and_set_bit(int nr, volatile unsigned long *addr);
// Atomically clear the nr-th bit starting from addr and return the previous value.
static inline int test_and_clear_bit(int nr, volatile unsigned long *addr);
static inline int __test_and_clear_bit(int nr, volatile unsigned long *addr);
// Atomically flip the nr-th bit starting from addr and return the previous value.
static inline int test_and_change_bit(int nr, volatile unsigned long *addr);
static inline int __test_and_change_bit(int nr, volatile unsigned long *addr);
// Atomically return the value of the nr-th bit starting from addr.
#define test_bit(nr, addr) \
(__builtin_constant_p((nr)) \
? constant_test_bit((nr), (addr)) \
: variable_test_bit((nr), (addr)))
// find first set bit in word x
static inline int ffs(int x);
static inline unsigned long __ffs(unsigned long word);
// find last set bit in word x
static inline int fls(int x);
static inline unsigned long __fls(unsigned long word);
// find first zero bit in word word
static inline unsigned long ffz(unsigned long word);
Conveniently, nonatomic versions of all the bitwise functions are also provided. They behave identically to their atomic siblings, except they do not guarantee atomicity, and their names are prefixed with double underscores.
16.3 Spin Locks/自旋锁
16.3.1 Spin Lock的基本原理
参见《Linux Device Drivers, 3rd edition》第Spinlocks章第Spinlocks节:
Unlike semaphores, spinlocks may be used in code that cannot sleep, such as interrupt handlers. When properly used, spinlocks offer higher performance than semaphores in general.
Spinlocks are simple in concept. A spinlock is a mutual exclusion device that can have only two values: “locked” and “unlocked”. It is usually implemented as a single bit in an integer value. Code wishing to take out a particular lock tests the relevant bit. If the lock is available, the “locked” bit is set and the code continues into the critical section. If, instead, the lock has been taken by somebody else, the code goes intoa tight loop where it repeatedly checks the lock until it becomes available. This loop is the “spin” part of a spinlock.
Of course, the real implementation of a spinlock is a bit more complex than the description above. The “test and set” operation must be done in an atomic manner so that only one thread can obtain the lock, even if several are spinning at any given time. Care must also be taken to avoid deadlocks on hyperthreaded processors - chips that implement multiple, virtual CPUs sharing a single processor core and cache. So the actual spinlock implementation is different for every architecture that Linux supports. The core concept is the same on all systems, however, when there is contention for a spinlock, the processors that are waiting execute a tight loop and accomplish no useful work.
参见《Linux Kernel Development.[3rd Edition].[Robert Love]》第10. Kernel Synchronization Methods章第Spin Locks节:
The most common lock in the Linux kernel is the spin lock. A spin lock is a lock that can be held by at most one thread of execution. If a thread of execution attempts to acquire a spin lock while it is already held, which is called contended (竞争), the thread busy loops - spins - waiting for the lock to become available. If the lock is not contended, the thread can immediately acquire the lock and continue. The spinning prevents more than one thread of execution from entering the critical region at any one time.
The fact that a contended spin lock causes threads to spin (essentially wasting processor time) while waiting for the lock to become available is salient. This behavior is the point of the spin lock. It is not wise to hold a spin lock for a long time. This is the nature of the spin lock: a lightweight single-holder lock that should be held for short durations. An alternative behavior when the lock is contended is to put the current thread to sleep and wake it up when it becomes available. Then the processor can go off and execute other code. This incurs a bit of overhead - most notably the two context switches required to switch out of and back into the blocking thread, which is certainly a lot more code than the handful of lines used to implement a spin lock. Therefore, it is wise to hold spin locks for less than the duration of two context switches.
参见«Understanding the Linux Kernel, 3rd Edition» 第1. Introduction章第Spin locks节:
Spin locks are useless in a uniprocessor environment. When a kernel control path tries to access a locked data structure, it starts an endless loop. Therefore, the kernel control path that is updating the protected data structure would not have a chance to continue the execution and release the spin lock. The final result would be that the system hangs.
16.3.2 Spin Lock的数据结构
spinlock_t定义于include/linux/spinlock.h,其结构参见:
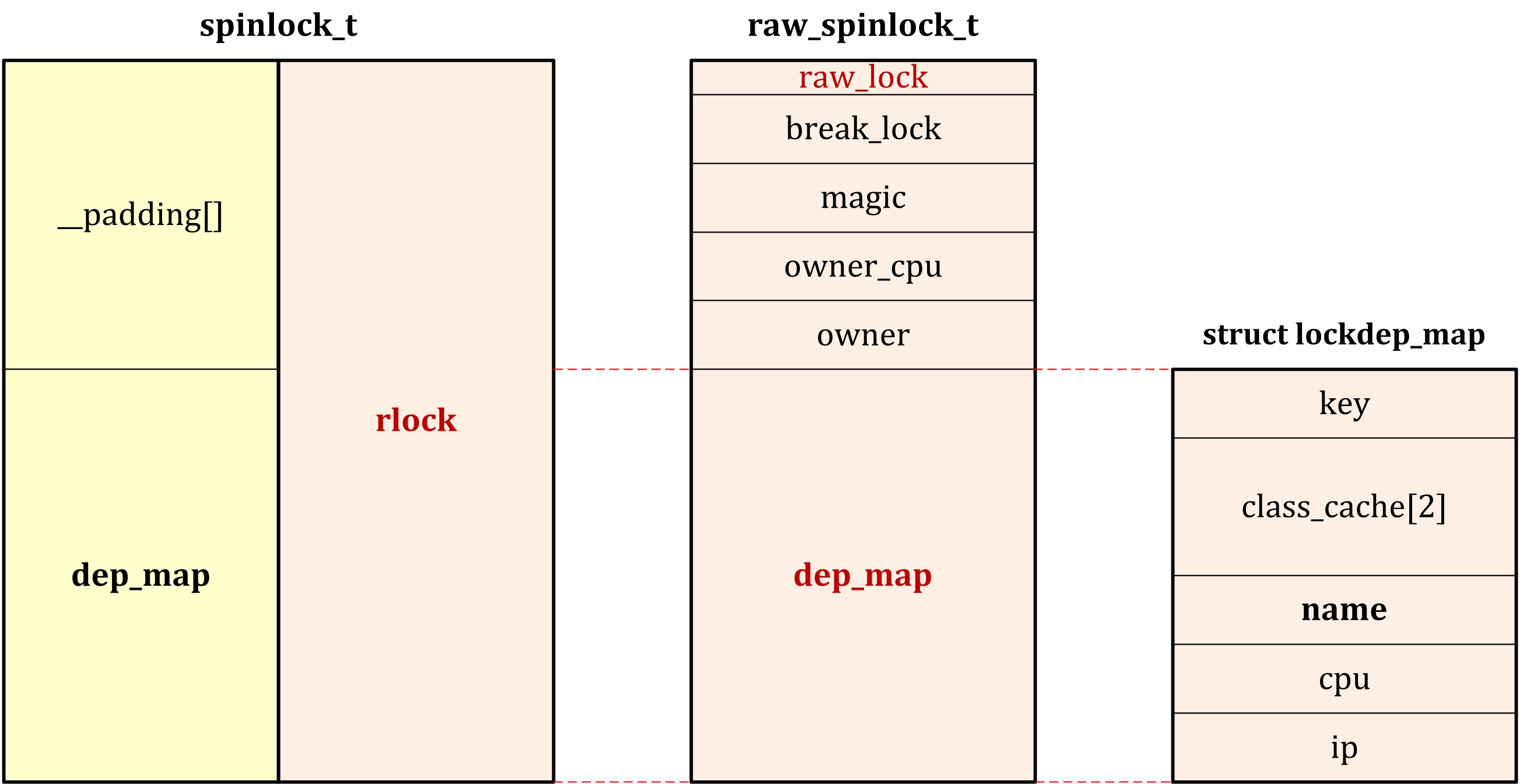
16.3.3 Spin Lock的初始化
The initialization may be done at compile time as follows, refer to include/linux/spinlock.h:
spinlock_t my_lock = SPIN_LOCK_UNLOCKED;
or at runtime with:
// Dynamically initializes given spinlock_t
#define spin_lock_init(_lock) \
do { \
spinlock_check(_lock); \
raw_spin_lock_init(&(_lock)->rlock); \
} while (0)
16.3.4 Spin Lock的用法
在include/linux/spinlock.h中,包含如下函数定义:
DEFINE_SPINLOCK(mr_lock);
spin_lock(&mr_lock);
/* critical region ... */
spin_unlock(&mr_lock);
The semaphores provide a lock that makes the waiting thread sleep, rather than spin, when contended.
Spin locks can be used in interrupt handlers, whereas semaphores cannot be used because they sleep. If a lock is used in an interrupt handler, you must also disable local interrupts (interrupt requests on the current processor) before obtaining the lock. Otherwise, it is possible for an interrupt handler to interrupt kernel code while the lock is held and attempt to reacquire the lock. The interrupt handler spins, waiting for the lock to become available. The lock holder, however, does not run until the interrupt handler completes. This is an example of the double-acquire deadlock. Note that you need to disable interrupts only on the current processor. If an interrupt occurs on a different processor, and it spins on the same lock, it does not prevent the lock holder (which is on a different processor) from eventually releasing the lock.
在include/linux/spinlock.h中,包含如下函数定义:
DEFINE_SPINLOCK(mr_lock);
unsigned long flags;
/*
* saves the current state of interrupts, disables
* them locally before taking the spinlock, and then
* obtains the given lock; the previous interrupt
* state is stored in flags.
*/
spin_lock_irqsave(&mr_lock, flags);
/* critical region ... */
/*
* unlocks the given lock and returns interrupts
* to their previous state
*/
spin_unlock_irqrestore(&mr_lock, flags);
Or, if you always know before the fact that interrupts are initially enabled, there is no need to restore their previous state:
DEFINE_SPINLOCK(mr_lock);
spin_lock_irq(&mr_lock);
/* critical region ... */
spin_unlock_irq(&mr_lock);
NOTE: As the kernel grows in size and complexity, it is increasingly hard to ensure that interrupts are always enabled in any given code path in the kernel. Use of spin_lock_irq(), spin_unlock_irq() therefore is not recommended.
Or, if you need to disable software interrupts before taking the lock, but leaves hardware interrupts enabled:
DEFINE_SPINLOCK(mr_lock);
/*
* disable software interrupts before taking the lock,
* but leaves hardware interrupts enabled
*/
spin_lock_bh(&mr_lock);
/* critical region ... */
spin_unlock_bh(&mr_lock);
There is also a set of nonblocking spinlock operations in include/linux/spinlock.h:
/*
* try to acquire given lock; if unavailable, returns nonzero
*/
static inline int spin_trylock(spinlock_t *lock);
static inline int spin_trylock_bh(spinlock_t *lock);
/*
* Return nonzero if the given lock is currently acquired,
* otherwise it returns zero
*/
static inline int spin_is_locked(spinlock_t *lock);
16.4 Reader-Writer Spin Locks
Reader-writer spin locks provide separate reader and writer variants of the lock. One or more readers can concurrently hold the reader lock. The writer lock, conversely, can be held by at most one writer with no concurrent readers.
16.4.1 Reader-Writer spin lock的初始化
They can be declared and initialized in two ways:
rwlock_t my_rwlock = RW_LOCK_UNLOCKED; /* Static way */
rwlock_t my_rwlock;
rwlock_init(&my_rwlock); /* Dynamic way */
16.4.2 Reader-Writer spin lock的用法
Usage is similar to spin locks, see include/linux/rwlock.h. In the reader code path:
DEFINE_RWLOCK(mr_rwlock);
read_lock(&mr_rwlock);
/* critical section (read only) ... */
read_unlock(&mr_rwlock);
In the writer code path:
DEFINE_RWLOCK(mr_rwlock);
write_lock(&mr_rwlock);
/* critical section (read and write) ... */
write_unlock(&mr_lock);
It is safe for multiple readers to obtain the same lock. In fact, it is safe for the same thread to recursively obtain the same read lock.
There are some other reader-writer spin lock methods in include/linux/rwlock.h:
// Disables local interrupts and acquires given lock for reading
read_lock_irq()
// Releases given lock and enables local interrupts
read_unlock_irq()
/*
* Saves the current state of local interrupts, disables
* local interrupts, and acquires the given lock for reading
*/
read_lock_irqsave()
/*
* Releases given lock and restores local interrupts to
* the given previous state
*/
read_unlock_irqrestore()
read_lock_bh(rwlock_t *lock)
read_unlock_bh(rwlock_t *lock)
// Disables local interrupts and acquires the given lock for writing
write_lock_irq()
// Releases given lock and enables local interrupts
write_unlock_irq()
/*
* Saves current state of local interrupts, disables local interrupts,
* and acquires the given lock for writing
*/
write_lock_irqsave()
// Releases given lock and restores local interrupts to given previous state
write_unlock_irqrestore()
write_lock_bh(rwlock_t *lock)
write_unlock_bh(rwlock_t *lock)
// Tries to acquire given lock for writing; if unavailable, returns nonzero
write_trylock()
A final important consideration in using the Linux reader-writer spin locks is that they favor readers over writers. If the read lock is held and a writer is waiting for exclusive access, readers that attempt to acquire the lock continue to succeed. The spinning writer does not acquire the lock until all readers release the lock. Therefore, a sufficient number of readers can starve pending writers.
16.5 Sequential Locks
The sequential lock, generally shortened to seq lock, is a newer type of lock introduced in the 2.6 kernel. It provides a simple mechanism for reading and writing shared data.
Seq locks are useful to provide a lightweight and scalable lock for use with many readers and a few writers. Seq locks, however, favor writers over readers. An acquisition of the write lock always succeeds as long as there are no other writers. Readers do not affect the write lock, as is the case with reader-writer spin locks and semaphores. Furthermore, pending writers continually cause the read loop to repeat, until there are no longer any writers holding the lock.
Seq locks are ideal when your locking needs meet most or all these requirements:
- Your data has a lot of readers.
- Your data has few writers.
- Although few in number, you want to favor writers over readers and never allow readers to starve writers.
- Your data is simple, such as a simple structure or even a single integer that, for whatever reason, cannot be made atomic.
A prominent user of the seq lock is jiffies, the variable that stores a Linux machine’s uptime.
Notice that when a reader enters a critical region, it does not need to disable kernel preemption; on the other hand, the writer automatically disables kernel preemption when entering the critical region, because it acquires the spin lock.
16.5.1 Seq Lock的数据结构
seqlock_t定义于include/linux/seqlock.h:
typedef struct {
/*
* Field sequence plays the role of a sequence counter.
* Each reader must read this sequence counter twice,
* before and after reading the data, and check whether
* the two values coincide. In the opposite case, a new
* writer has become active and has increased the sequence
* counter, thus implicitly telling the reader that the
* data just read is not valid.
*/
unsigned sequence;
spinlock_t lock; // 参见[16.3.2 Spin Lock的数据结构]节
} seqlock_t;
16.5.2 Seq Lock的定义及初始化
宏DEFINE_SEQLOCK()用于定义及初始化seq lock,其定义于include/linux/seqlock.h:
#define DEFINE_SEQLOCK(x) \
seqlock_t x = __SEQLOCK_UNLOCKED(x)
#define __SEQLOCK_UNLOCKED(lockname) \
{ 0, __SPIN_LOCK_UNLOCKED(lockname) }
宏seqlock_init()用于初始化seq lock,其定义于include/linux/seqlock.h:
#define seqlock_init(x) \
do { \
(x)->sequence = 0; \
spin_lock_init(&(x)->lock); \
} while (0)
定义seq lock举例:
seqlock_t lock1 = SEQLOCK_UNLOCKED;
seqlock_t lock2;
seqlock_init(&lock2);
16.5.3 Read path of Seq Lock
The reader code has a form like the following:
seqlock_t mr_seq_lock = DEFINE_SEQLOCK(mr_seq_lock);
unsigned long seq;
do {
seq = read_seqbegin(&mr_seq_lock); // 参见[16.5.3.1 read_seqbegin()]节
/* read data here ... */
} while (read_seqretry(&mr_seq_lock, seq)); // 参见[16.5.3.2 read_seqretry()]节
If your seqlock might be accessed from an interrupt handler, you should use the IRQ-safe versions instead:
seqlock_t mr_seq_lock = DEFINE_SEQLOCK(mr_seq_lock);
unsigned long seq;
unsigned long flags;
do {
seq = read_seqbegin_irqsave(&mr_seq_lock, flags);
/* read data here ... */
} while (read_seqretry_irqrestore(&mr_seq_lock, seq, flags));
16.5.3.1 read_seqbegin()
该函数定义于include/linux/seqlock.h:
/* Start of read calculation -- fetch last complete writer token */
static __always_inline unsigned read_seqbegin(const seqlock_t *sl)
{
unsigned ret;
repeat:
ret = ACCESS_ONCE(sl->sequence);
// 若sl->sequence取值为奇数,则说明当前正在写被锁对象
if (unlikely(ret & 1)) {
cpu_relax();
goto repeat;
}
smp_rmb();
return ret;
}
16.5.3.2 read_seqretry()
该函数定义于include/linux/seqlock.h:
/*
* Test if reader processed invalid data.
*
* If sequence value changed then writer changed data while in section.
*/
static __always_inline int read_seqretry(const seqlock_t *sl, unsigned start)
{
smp_rmb();
return unlikely(sl->sequence != start);
}
16.5.4 Write path of Seq Lock
Writers must obtain an exclusive lock to enter the critical section protected by a seqlock. To do so, call:
seqlock_t mr_seq_lock = DEFINE_SEQLOCK(mr_seq_lock);
write_seqlock(&mr_seq_lock); // 参见[16.5.4.1 write_seqlock()]节
/* write lock is obtained... */
write_sequnlock(&mr_seq_lock); // 参见[16.5.4.2 write_sequnlock()]节
Since spinlocks are used to control write access, all of the usual variants are available:
void write_seqlock_irqsave(seqlock_t *lock, unsigned long flags);
void write_sequnlock_irqrestore(seqlock_t *lock, unsigned long flags);
void write_seqlock_irq(seqlock_t *lock);
void write_sequnlock_irq(seqlock_t *lock);
void write_seqlock_bh(seqlock_t *lock);
void write_sequnlock_bh(seqlock_t *lock);
16.5.4.1 write_seqlock()
该函数定义于include/linux/seqlock.h:
static inline void write_seqlock(seqlock_t *sl)
{
spin_lock(&sl->lock);
// ->sequence初值为0,加锁时该值由偶数变为奇数
++sl->sequence;
smp_wmb();
}
16.5.4.2 write_sequnlock()
该函数定义于include/linux/seqlock.h:
static inline void write_sequnlock(seqlock_t *sl)
{
smp_wmb();
// ->sequence初值为0,解锁时该值由奇数变为偶数
sl->sequence++;
spin_unlock(&sl->lock);
}
16.6 Semaphores/信号量
参见《Linux Kernel Development.[3rd Edition].[Robert Love]》第10. Kernel Synchronization Methods章第Semaphores节:
Semaphores in Linux are sleeping locks. When a task attempts to acquire a semaphore that is unavailable, the semaphore places the task onto a wait queue and puts the task to sleep. The processor is then free to execute other code. When the semaphore becomes available, one of the tasks on the wait queue is awakened so that it can then acquire the semaphore.
This provides better processor utilization than spin locks because there is no time spent busy looping, but semaphores have much greater overhead than spin locks.
You can draw some interesting conclusions from the sleeping behavior of semaphores:
-
Because the contending tasks sleep while waiting for the lock to become available, semaphores are well suited to locks that are held for a long time.
-
Conversely, semaphores are not optimal for locks that are held for short periods because the overhead of sleeping, maintaining the wait queue, and waking back up can easily outweigh the total lock hold time.
-
Because a thread of execution sleeps on lock contention, semaphores must be obtained only in process context because interrupt context is not schedulable.
-
You can (although you might not want to) sleep while holding a semaphore because you will not deadlock when another process acquires the same semaphore. (It will just go to sleep and eventually let you continue.)
-
You cannot hold a spin lock while you acquire a semaphore, because you might have to sleep while waiting for the semaphore, and you cannot sleep while holding a spin lock.
In most uses of semaphores, there is little choice as to what lock to use. If your code needs to sleep, which is often the case when synchronizing with user-space, semaphores are the sole solution.
When you do have a choice, the decision between semaphore and spin lock should be based on lock hold time. Ideally, all your locks should be held as briefly as possible. With semaphores, however, longer lock hold times are more acceptable.
Additionally, unlike spin locks, semaphores do not disable kernel preemption and, consequently, code holding a semaphore can be preempted. This means semaphores do not adversely affect scheduling latency.
A final useful feature of semaphores is that they can allow for an arbitrary number of simultaneous lock holders. Whereas spin locks permit at most one task to hold the lock at a time, the number of permissible simultaneous holders of semaphores can be set at declaration time.
参见«Understanding the Linux Kernel, 3rd Edition»第5. Kernel Synchronization章第Semaphores节:
Actually, Linux offers two kinds of semaphores:
- Kernel semaphores, which are used by kernel control paths
- System V IPC semaphores, which are used by User Mode processes
16.6.1 Semaphore的数据结构
struct semaphore定义于include/linux/semaphore.h:
/* Please don't access any members of this structure directly */
struct semaphore {
/*
* 用于本结构中count和wait_list的自旋锁,
* 故对这两个元素的操作是原子的,参见[16.3.2 Spin Lock的数据结构]节
*/
raw_spinlock_t lock;
/*
* If count > 0, the resource is free — that’s,
* it is currently available.
* If count == 0, the semaphore is busy but no
* other process is waiting for the protected
* resource.
* If count < 0, the resource is unavailable and
* at least one process is waiting for it.
*/
unsigned int count;
/*
* Stores the address of a wait queue list that
* includes all sleeping processes that are currently
* waiting for the resource. If count is greater
* than or equal to 0, the wait queue is empty.
* 指向struct semaphore_waiter结构中的list变量
*/
struct list_head wait_list;
};
struct semaphore_waiter定义于kernel/semaphore.c:
struct semaphore_waiter {
struct list_head list;
struct task_struct *task;
int up;
};
其结构参见:
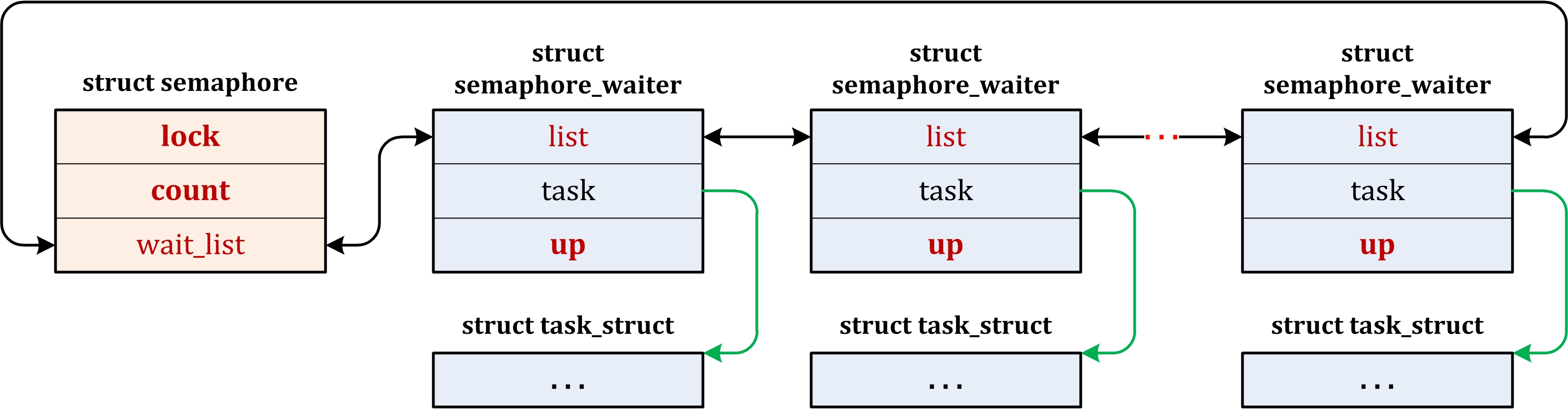
16.6.2 Semaphore的定义及初始化
宏DEFINE_SEMAPHORE()用于定义并初始化一个信号量,其count取值为1,参见include/linux/semaphore.h:
#define DEFINE_SEMAPHORE(name) \
struct semaphore name = __SEMAPHORE_INITIALIZER(name, 1)
#define __SEMAPHORE_INITIALIZER(name, n) \
{ \
.lock = __RAW_SPIN_LOCK_UNLOCKED((name).lock), \
.count = n, \
.wait_list = LIST_HEAD_INIT((name).wait_list), \
}
函数sema_init()用于初始化一个信号量,并可指定其count取值,参见include/linux/semaphore.h:
static inline void sema_init(struct semaphore *sem, int val)
{
static struct lock_class_key __key;
*sem = (struct semaphore) __SEMAPHORE_INITIALIZER(*sem, val);
lockdep_init_map(&sem->lock.dep_map, "semaphore->lock", &__key, 0);
}
举例如下:
struct semaphore name;
sema_init(&name, 5);
16.6.3 获取信号量/down_interruptible()
down_interruptible()
down_killable()
down()
down_xxx()
down_interruptible()
The function attempts to acquire the given semaphore. If the semaphore is unavailable, it places the calling process to sleep in the TASK_INTERRUPTIBLE state. This process state implies that a task can be awakened with a signal.
该函数定义于kernel/semaphore.c:
int down_interruptible(struct semaphore *sem)
{
unsigned long flags;
int result = 0;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
result = __down_interruptible(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
return result;
}
static noinline int __sched __down_interruptible(struct semaphore *sem)
{
// 参见[16.6.3.1 __down_common()]节
return __down_common(sem, TASK_INTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
16.6.3.1 __down_common()
该函数定义于kernel/semaphore.c:
static inline int __sched __down_common(struct semaphore *sem, long state, long timeout)
{
struct task_struct *task = current;
struct semaphore_waiter waiter;
// 将当前进程添加到等待队列末尾
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = task;
waiter.up = 0;
// 一直等待,直到 (1)当前进程接收到某信号;(2)超时;(3)信号量可用
for (;;) {
if (signal_pending_state(state, task))
goto interrupted;
if (timeout <= 0)
goto timed_out;
__set_task_state(task, state);
raw_spin_unlock_irq(&sem->lock);
// 调度其他进程运行(参见[7.4.7 schedule_timeout()]节),当前进程进入休眠状态
timeout = schedule_timeout(timeout);
raw_spin_lock_irq(&sem->lock);
// 若信号量可用,函数up()会唤醒本进程,参见[16.6.4 释放信号量/up()]节
if (waiter.up)
return 0;
}
timed_out:
list_del(&waiter.list);
return -ETIME;
interrupted:
list_del(&waiter.list);
return -EINTR;
}
16.6.3.2 down_killable()
该函数定义于kernel/semaphore.c:
/**
* down_killable - acquire the semaphore unless killed
* @sem: the semaphore to be acquired
*
* Attempts to acquire the semaphore. If no more tasks are allowed to
* acquire the semaphore, calling this function will put the task to sleep.
* If the sleep is interrupted by a fatal signal, this function will return
* -EINTR. If the semaphore is successfully acquired, this function returns
* 0.
*/
int down_killable(struct semaphore *sem)
{
unsigned long flags;
int result = 0;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
result = __down_killable(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
return result;
}
static noinline int __sched __down_killable(struct semaphore *sem)
{
// 参见[16.6.3.1 __down_common()]节
return __down_common(sem, TASK_KILLABLE, MAX_SCHEDULE_TIMEOUT);
}
16.6.3.3 down()
The function places the task in the TASK_UNINTERRUPTIBLE state when it sleeps. You most likely do not want this because the process waiting for the semaphore does not respond to signals.
该函数定义于kernel/semaphore.c:
/**
* down - acquire the semaphore
* @sem: the semaphore to be acquired
*
* Acquires the semaphore. If no more tasks are allowed to acquire the
* semaphore, calling this function will put the task to sleep until the
* semaphore is released.
*
* Use of this function is deprecated, please use down_interruptible() or
* down_killable() instead.
*/
void down(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
__down(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
static noinline void __sched __down(struct semaphore *sem)
{
// 参见[16.6.3.1 __down_common()]节
__down_common(sem, TASK_UNINTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
16.6.3.4 down_timeout()
该函数与down()类似,区别仅在于它可以指定超时时间。其定义于kernel/semaphore.c:
/**
* down_timeout - acquire the semaphore within a specified time
* @sem: the semaphore to be acquired
* @jiffies: how long to wait before failing
*
* Attempts to acquire the semaphore. If no more tasks are allowed to
* acquire the semaphore, calling this function will put the task to sleep.
* If the semaphore is not released within the specified number of jiffies,
* this function returns -ETIME. It returns 0 if the semaphore was acquired.
*/
int down_timeout(struct semaphore *sem, long jiffies)
{
unsigned long flags;
int result = 0;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
result = __down_timeout(sem, jiffies);
raw_spin_unlock_irqrestore(&sem->lock, flags);
return result;
}
static noinline int __sched __down_timeout(struct semaphore *sem, long jiffies)
{
return __down_common(sem, TASK_UNINTERRUPTIBLE, jiffies);
}
16.6.3.5 down_trylock()
The function tries to acquire the given semaphore without blocking. If the semaphore is already held, the function immediately returns nonzero. Otherwise, it returns zero and you successfully hold the lock.
该函数定义于kernel/semaphore.c:
/**
* down_trylock - try to acquire the semaphore, without waiting
* @sem: the semaphore to be acquired
*
* Try to acquire the semaphore atomically. Returns 0 if the mutex has
* been acquired successfully or 1 if it it cannot be acquired.
*
* NOTE: This return value is inverted from both spin_trylock and
* mutex_trylock! Be careful about this when converting code.
*
* Unlike mutex_trylock, this function can be used from interrupt context,
* and the semaphore can be released by any task or interrupt.
*/
int down_trylock(struct semaphore *sem)
{
unsigned long flags;
int count;
raw_spin_lock_irqsave(&sem->lock, flags);
count = sem->count - 1;
if (likely(count >= 0))
sem->count = count;
raw_spin_unlock_irqrestore(&sem->lock, flags);
return (count < 0);
}
16.6.4 释放信号量/up()
该函数定义于kernel/semaphore.c:
/**
* up - release the semaphore
* @sem: the semaphore to release
*
* Release the semaphore. Unlike mutexes, up() may be called from any
* context and even by tasks which have never called down().
*/
void up(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;
else
__up(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
static noinline void __sched __up(struct semaphore *sem)
{
// 获取等待队列中的第一个等待进程
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
struct semaphore_waiter, list);
list_del(&waiter->list);
waiter->up = 1;
/*
* 唤醒第一个等待进程,参见[7.4.10.2.3 wake_up_process()]节;
* 唤醒后,该进程会跳出函数__down_common()中的for(;;)
* 循环,参见[16.6.3.1 __down_common()]节
*/
wake_up_process(waiter->task);
}
16.7 Reader-Writer Semaphore
All reader-writer semaphores are mutexes - that is, their usage count is one - although they enforce mutual exclusion only for writers, not readers.
An rwsem allows either one writer or an unlimited number of readers to hold the semaphore. Writers get priority; as soon as a writer tries to enter the critical section, no readers will be allowed in until all writers have completed their work. This implementation can lead to reader starvation - where readers are denied access for a long time - if you have a large number of writers contending for the semaphore. For this reason, rwsems are best used when write access is required only rarely, and writer access is held for short periods of time.
16.7.1 Reader-Writer Semaphore的数据结构
struct rw_semaphore定义于include/linux/rwsem.h:
#ifdef CONFIG_RWSEM_GENERIC_SPINLOCK
#include <linux/rwsem-spinlock.h> /* use a generic implementation */
#else
/* All arch specific implementations share the same struct */
struct rw_semaphore {
long count;
/*
* A spin lock used to protect the wait queue
* list and the rw_semaphore structure itself.
*/
raw_spinlock_t wait_lock;
/*
* Points to a list of waiting processes. Each
* element in this list is a struct rwsem_waiter.
*/
struct list_head wait_list;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
#endif
在include/linux/rwsem-spinlock.h中,包含如下定义:
/*
* the rw-semaphore definition
* - if activity is 0 then there are no active readers or writers
* - if activity is +ve then that is the number of active readers
* - if activity is -1 then there is one active writer
* - if wait_list is not empty, then there are processes waiting for the semaphore
*/
struct rw_semaphore {
__s32 activity;
raw_spinlock_t wait_lock;
struct list_head wait_list;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
在kernel/rwsem.c和lib/rwsem-spinlock.c中,均包括struct rwsem_waiter的定义:
struct rwsem_waiter {
struct list_head list;
struct task_struct *task;
/*
* Reader or writer flags, use macros RWSEM_WAITING_FOR_READ
* or RWSEM_WAITING_FOR_WRITE respectively.
*/
unsigned int flags;
#define RWSEM_WAITING_FOR_READ 0x00000001
#define RWSEM_WAITING_FOR_WRITE 0x00000002
};
其结构参见:
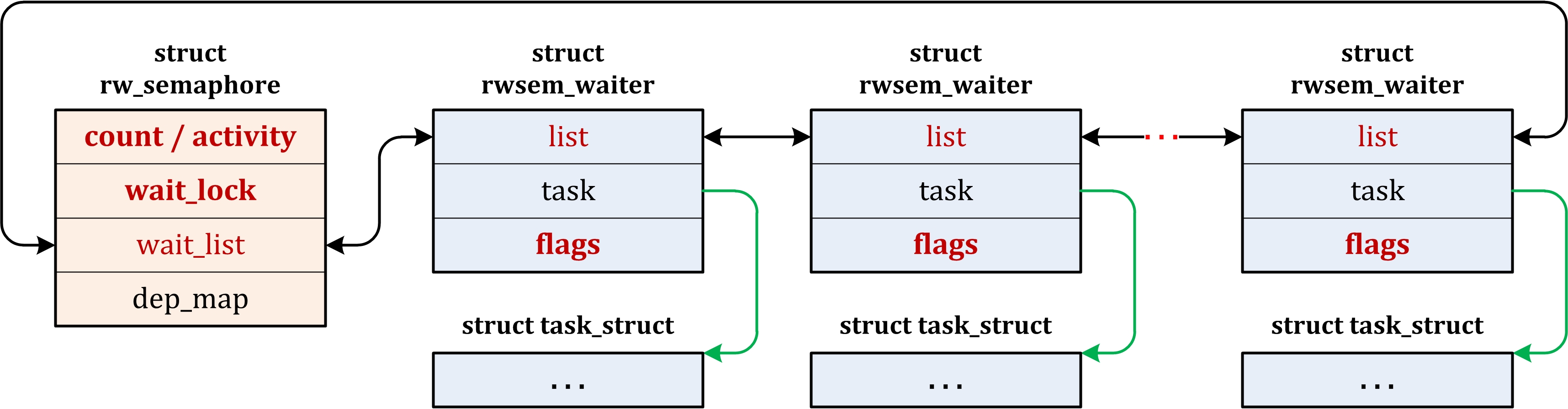
16.7.2 Reader-Writer Semaphore的定义及初始化
宏DECLARE_RWSEM()用于定义并初始化一个信号量,参见include/linux/rwsem.h:
#define DECLARE_RWSEM(name) \
struct rw_semaphore name = __RWSEM_INITIALIZER(name)
#define __RWSEM_INITIALIZER(name) \
{ RWSEM_UNLOCKED_VALUE, \ // 该宏取值为0
__RAW_SPIN_LOCK_UNLOCKED(name.wait_lock), \
LIST_HEAD_INIT((name).wait_list) \
__RWSEM_DEP_MAP_INIT(name) }
宏init_rwsem()用于初始化一个信号量,参见include/linux/rwsem.h:
#define init_rwsem(sem) \
do { \
static struct lock_class_key __key; \
\
__init_rwsem((sem), #sem, &__key); \ // 该函数定义于lib/rwsem.c或lib/rwsem-spinlock.c
} while (0)
16.7.3 获取Reader-Writer信号量
在include/linux/rwsem.h中声明的如下函数用于获取信号量:
/*
* Acquire the read/write semaphore for reading.
* NOTE: down_read() may put the calling process
* into an uninterruptible sleep.
*/
extern void down_read(struct rw_semaphore *sem);
/*
* Don’t block the process if the semaphore is busy
*/
extern int down_read_trylock(struct rw_semaphore *sem);
/*
* Acquire the read/write semaphore for writing
*/
extern void down_write(struct rw_semaphore *sem);
/*
* Don’t block the process if the semaphore is busy
*/
extern int down_write_trylock(struct rw_semaphore *sem);
/*
* Downgrade write lock to read lock
*/
extern void downgrade_write(struct rw_semaphore *sem);
16.7.4 释放Reader-Writer信号量
include/linux/rwsem.h中声明的如下函数用于释放信号量:
/*
* Release a read/write semaphore previously acquired
* for reading. A rwsem obtained with down_read() must
* eventually be freed with up_read().
*/
extern void up_read(struct rw_semaphore *sem);
/*
* Release a read/write semaphore previously acquired
* for writing.
*/
extern void up_write(struct rw_semaphore *sem);
16.8 Mutex/互斥
The mutex is represented by struct mutex. It behaves similar to a semaphore with a count of one, but it has a simpler interface, more efficient performance, and additional constraints on its use.
-
Only one task can hold the mutex at a time. That is, the usage count on a mutex is always one.
-
Whoever locked a mutex must unlock it. That is, you cannot lock a mutex in one context and then unlock it in another. This means that the mutex isn’t suitable for more complicated synchronizations between kernel and user-space. Most use cases, however, cleanly lock and unlock from the same context.
-
Recursive locks and unlocks are not allowed. That is, you cannot recursively acquire the same mutex, and you cannot unlock an unlocked mutex.
-
A process cannot exit while holding a mutex.
-
A mutex cannot be acquired by an interrupt handler or bottom half, even with
mutex_trylock(). -
A mutex can be managed only via the official API: It must be initialized via the methods
DEFINE_MUTEX(),mutex_init()and cannot be copied, hand initialized, or reinitialized.
Mutexes and semaphores are similar. Having both in the kernel is confusing. Thankfully, the formula dictating which to use is quite simple: Unless one of mutex’s additional constraints prevent you from using them, prefer the new mutex type to semaphores.
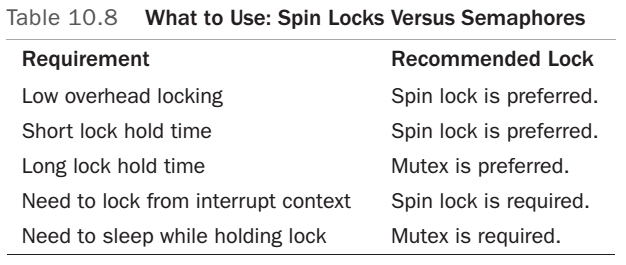
16.8.1 Mutex的数据结构
struct mutex定义于include/linux/mutex.h:
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;
spinlock_t wait_lock;
// 进程的等待队列,指向struct mutex_waiter结构中的list变量
struct list_head wait_list;
#if defined(CONFIG_DEBUG_MUTEXES) || defined(CONFIG_SMP)
struct task_struct *owner;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
const char *name;
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
struct mutex_waiter定义于include/linux/mutex.h:
struct mutex_waiter {
struct list_head list;
struct task_struct *task;
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
};
其结构参见:
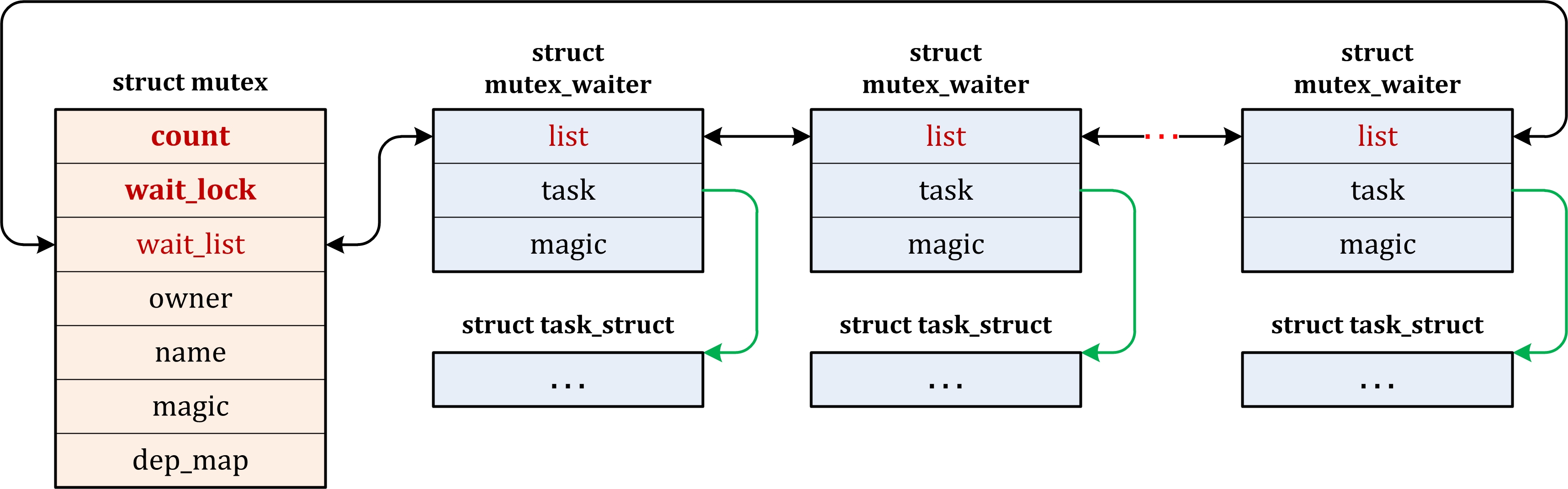
16.8.2 Mutex的定义及初始化
宏DECLARE_MUTEX()用于定义并初始化一个Mutex,参见include/linux/mutex.h:
#define DEFINE_MUTEX(mutexname) \
struct mutex mutexname = __MUTEX_INITIALIZER(mutexname)
#define __MUTEX_INITIALIZER(lockname) \
{ .count = ATOMIC_INIT(1) \
, .wait_lock = __SPIN_LOCK_UNLOCKED(lockname.wait_lock) \
, .wait_list = LIST_HEAD_INIT(lockname.wait_list) \
__DEBUG_MUTEX_INITIALIZER(lockname) \
__DEP_MAP_MUTEX_INITIALIZER(lockname) }
宏mutex_init()用于初始化一个Mutex,参见include/linux/mutex.h:
#define mutex_init(mutex) \
do { \
static struct lock_class_key __key; \
__mutex_init((mutex), #mutex, &__key); \
} while (0)
其中,__mutex_init()定义于kernel/mutex.c:
void __mutex_init(struct mutex *lock, const char *name, struct lock_class_key *key)
{
atomic_set(&lock->count, 1);
spin_lock_init(&lock->wait_lock);
INIT_LIST_HEAD(&lock->wait_list);
mutex_clear_owner(lock);
debug_mutex_init(lock, name, key);
}
16.8.3 获取和释放Mutex
Locking and unlocking the mutex is easy, see definination in include/linux/mutex.h:
mutex_lock(&mutex);
/* critical region ... */
mutex_unlock(&mutex);
此外,该文件还包含如下函数:
int mutex_trylock(struct mutex *lock);
static inline int mutex_is_locked(struct mutex *lock);
16.9 Completion Varibles/完成变量
Using completion variables is an easy way to synchronize between two tasks in the kernel when one task needs to signal to the other that an event has occurred. One task waits on the completion variable while another task performs some work. When the other task has completed the work, it uses the completion variable to wake up any waiting tasks.
参见«Understanding the Linux Kernel, 3rd Edition»第5. Kernel Synchronization章第Completions节:
The real difference between completions and semaphores is how the spin lock included in the wait queue is used.
-
In completions, the spin lock is used to ensure that
complete()andwait_for_completion()cannot execute concurrently. -
In semaphores, the spin lock is used to avoid letting concurrent
down()’s functions mess up the semaphore data structure.
16.9.1 Completion的数据结构
struct completion定义于include/linux/completion.h:
struct completion {
unsigned int done;
// 参见[7.4.2.4 等待队列/wait_queue_head_t/wait_queue_t]节
wait_queue_head_t wait;
};
其结构参见:
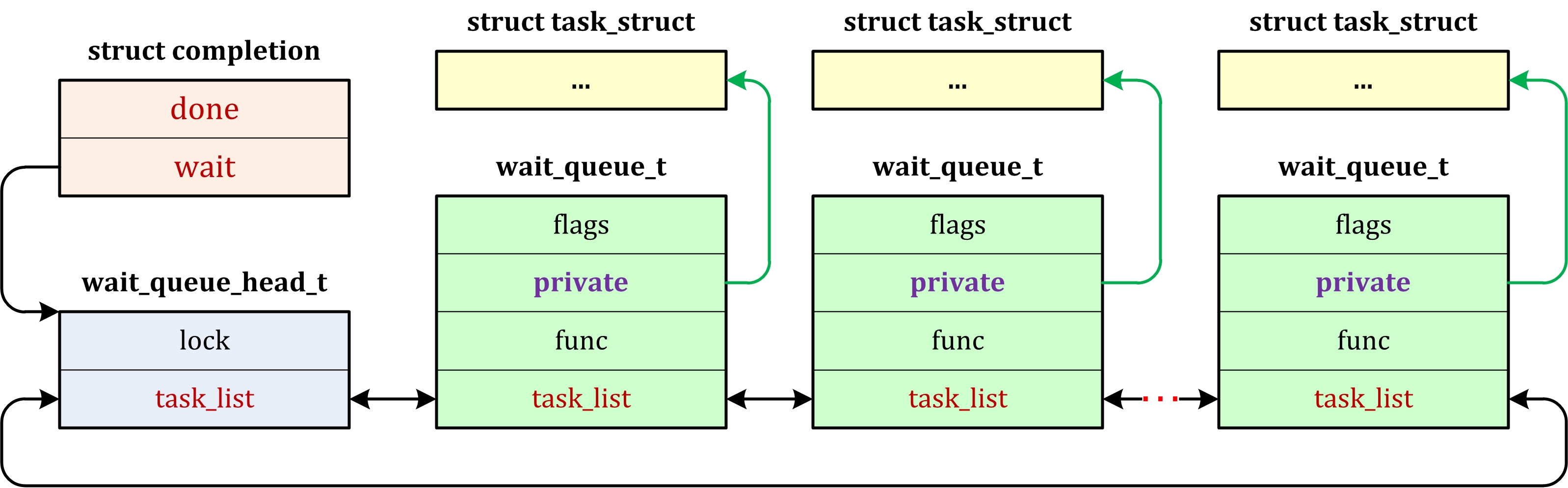
16.9.2 Completion的定义及初始化
宏DECLARE_COMPLETION()用于定义并初始化一个完成量,其定义于include/linux/completion.h:
#define DECLARE_COMPLETION(work) \
struct completion work = COMPLETION_INITIALIZER(work)
// 参见[7.4.2.4.1 定义/初始化等待队列头/wait_queue_head_t]节
#define COMPLETION_INITIALIZER(work) \
{ 0, __WAIT_QUEUE_HEAD_INITIALIZER((work).wait) }
函数init_completion()用于初始化一个完成量,其定义于include/linux/completion.h:
static inline void init_completion(struct completion *x)
{
x->done = 0;
// 参见[7.4.2.4.1 定义/初始化等待队列头/wait_queue_head_t]节
init_waitqueue_head(&x->wait);
}
此外,宏INIT_COMPLETION()用于重新初始化完成量中的done,其定义于include/linux/completion.h:
#define INIT_COMPLETION(x) ((x).done = 0)
16.9.3 wait_for_completion()/wait_for_completion_xxx()
16.9.3.1 wait_for_completion()
该函数定义于kernel/sched.c:
/**
* wait_for_completion: - waits for completion of a task
* @x: holds the state of this particular completion
*
* This waits to be signaled for completion of a specific task. It is NOT
* interruptible and there is no timeout.
*
* See also similar routines (i.e. wait_for_completion_timeout()) with timeout
* and interrupt capability. Also see complete().
*/
void __sched wait_for_completion(struct completion *x)
{
wait_for_common(x, MAX_SCHEDULE_TIMEOUT, TASK_UNINTERRUPTIBLE);
}
16.9.3.1.1 wait_for_common()
该函数定义于kernel/sched.c:
static long __sched wait_for_common(struct completion *x, long timeout, int state)
{
might_sleep();
spin_lock_irq(&x->wait.lock);
timeout = do_wait_for_common(x, timeout, state);
spin_unlock_irq(&x->wait.lock);
return timeout;
}
16.9.3.1.1.1 do_wait_for_common()
该函数定义于kernel/sched.c:
static inline long __sched do_wait_for_common(struct completion *x, long timeout, int state)
{
if (!x->done) {
/*
* 定义等待队列元素,并设置wait->func = default_wake_function,
* 参见[7.4.2.4.2 定义/初始化等待队列/wait_queue_t]节;
* 该函数在complete_xxx()->__wake_up_common()中被调用,
* 参见[7.4.10.1.1 __wake_up_common()]节
*/
DECLARE_WAITQUEUE(wait, current);
/*
* 设置wait->flags |= WQ_FLAG_EXCLUSIVE,
* 并将wait加入到链表x->wait的末尾
*/
__add_wait_queue_tail_exclusive(&x->wait, &wait);
do {
/*
* 若state = TASK_INTERRUPTIBLE或TASK_WAKEKILL,
* 则signal_pending_state()返回:
* True – 表示存在待处理的信号;
* False – 表示不存在待处理的信号。
* 若state取其他值,则signal_pending_state()返回0;
*/
if (signal_pending_state(state, current)) {
timeout = -ERESTARTSYS;
break;
}
__set_current_state(state);
spin_unlock_irq(&x->wait.lock);
// 调度其他进程运行,参见[7.4.7 schedule_timeout()]节
timeout = schedule_timeout(timeout);
spin_lock_irq(&x→wait.lock);
/*
* 满足如下条件之一就结束循环:
* (1) 信号量已完成; (2) 指定的等待时间已到达
*/
} while (!x->done && timeout);
// 将当前进程移除等待队列
__remove_wait_queue(&x->wait, &wait);
/*
* 若因为 "条件(2) 指定的等待时间已到达"
* 而退出循环,则返回剩余的等待时间
*/
if (!x->done)
return timeout;
}
x->done--;
return timeout ?: 1;
}
16.9.3.2 wait_for_completion_interruptible()
该函数定义于kernel/sched.c:
/**
* wait_for_completion_interruptible: - waits for completion of a task (w/intr)
* @x: holds the state of this particular completion
*
* This waits for completion of a specific task to be signaled. It is
* interruptible.
*
* The return value is -ERESTARTSYS if interrupted, 0 if completed.
*/
int __sched wait_for_completion_interruptible(struct completion *x)
{
/*
* 参见[16.9.3.1 wait_for_completion()]节。由于进程被设置为
* TASK_INTERRUPTIBLE状态,因而中途可能会被信号打断
*/
long t = wait_for_common(x, MAX_SCHEDULE_TIMEOUT, TASK_INTERRUPTIBLE);
if (t == -ERESTARTSYS)
return t;
return 0;
}
16.9.3.3 wait_for_completion_killable()
该函数定义于kernel/sched.c:
/**
* wait_for_completion_killable: - waits for completion of a task (killable)
* @x: holds the state of this particular completion
*
* This waits to be signaled for completion of a specific task. It can be
* interrupted by a kill signal.
*
* The return value is -ERESTARTSYS if interrupted, 0 if completed.
*/
int __sched wait_for_completion_killable(struct completion *x)
{
/*
* 参见[16.9.3.1 wait_for_completion()]节。
* TASK_KILLABLE = TASK_WAKEKILL | TASK_UNINTERRUPTIBLE
*/
long t = wait_for_common(x, MAX_SCHEDULE_TIMEOUT, TASK_KILLABLE);
if (t == -ERESTARTSYS)
return t;
return 0;
}
16.9.3.4 wait_for_completion_timeout()
该函数定义于kernel/sched.c:
/**
* wait_for_completion_timeout: - waits for completion of a task (w/timeout)
* @x: holds the state of this particular completion
* @timeout: timeout value in jiffies
*
* This waits for either a completion of a specific task to be signaled
* or for a specified timeout to expire. The timeout is in jiffies.
* It is not interruptible.
*
* The return value is 0 if timed out, and positive (at least 1, or number of
* jiffies left till timeout) if completed.
*/
unsigned long __sched wait_for_completion_timeout(struct completion *x, unsigned long timeout)
{
return wait_for_common(x, timeout, TASK_UNINTERRUPTIBLE);
}
16.9.3.5 wait_for_completion_interruptible_timeout()
该函数定义于kernel/sched.c:
/**
* wait_for_completion_interruptible_timeout: - waits for completion (w/(to,intr))
* @x: holds the state of this particular completion
* @timeout: timeout value in jiffies
*
* This waits for either a completion of a specific task to be signaled or for a
* specified timeout to expire. It is interruptible. The timeout is in jiffies.
*
* The return value is -ERESTARTSYS if interrupted, 0 if timed out,
* positive (at least 1, or number of jiffies left till timeout) if completed.
*/
long __sched wait_for_completion_interruptible_timeout(struct completion *x, unsigned long timeout)
{
return wait_for_common(x, timeout, TASK_INTERRUPTIBLE);
}
16.9.3.6 wait_for_completion_killable_timeout()
该函数定义于kernel/sched.c:
/**
* wait_for_completion_killable_timeout: - waits for completion of a task (w/(to,killable))
* @x: holds the state of this particular completion
* @timeout: timeout value in jiffies
*
* This waits for either a completion of a specific task to be
* signaled or for a specified timeout to expire. It can be
* interrupted by a kill signal. The timeout is in jiffies.
*
* The return value is -ERESTARTSYS if interrupted, 0 if timed out,
* positive (at least 1, or number of jiffies left till timeout) if completed.
*/
long __sched wait_for_completion_killable_timeout(struct completion *x, unsigned long timeout)
{
return wait_for_common(x, timeout, TASK_KILLABLE);
}
16.9.4 complete()/complete_xxx()
16.9.4.1 complete()
该函数定义与kernel/sched.c:
/**
* complete: - signals a single thread waiting on this completion
* @x: holds the state of this particular completion
*
* This will wake up a single thread waiting on this completion. Threads will be
* awakened in the same order in which they were queued.
*
* See also complete_all(), wait_for_completion() and related routines.
*
* It may be assumed that this function implies a write memory barrier before
* changing the task state if and only if any tasks are woken up.
*/
void complete(struct completion *x)
{
unsigned long flags;
spin_lock_irqsave(&x->wait.lock, flags);
x->done++;
// 唤醒等待队列中的第1个等待进程,参见[16.9.4.1.1 __wake_up_common()]节
__wake_up_common(&x->wait, TASK_NORMAL, 1, 0, NULL);
spin_unlock_irqrestore(&x->wait.lock, flags);
}
16.9.4.1.1 __wake_up_common()
该函数定义与kernel/sched.c:
/*
* The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just
* wake everything up. If it's an exclusive wakeup (nr_exclusive == small +ve
* number) then we wake all the non-exclusive tasks and one exclusive task.
*
* There are circumstances in which we can try to wake a task which has already
* started to run but is not in state TASK_RUNNING. try_to_wake_up() returns
* zero in this (rare) case, and we handle it by continuing to scan the queue.
*/
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode, int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
/*
* ->func()在如下函数(参见[16.9.3.1.1.1 do_wait_for_common()]节)中被设置
* 为default_wake_function(). 参见[7.4.10.2.2 default_wake_function()]节:
* wait_for_complete_xxx()->wait_for_common()->
* do_wait_for_complete()→DECLARE_WAITQUEUE()
*/
if (curr->func(curr, mode, wake_flags, key) && (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
16.9.4.2 complete_all()
NOTE: The two functions complete() and complete_all() behave differently if more than one thread is waiting for the same completion event. complete() wakes up only one of the waiting threads while complete_all() allows all of them to proceed. In most cases, there is only one waiter, and the two functions will produce an identical result.
该函数定义与kernel/sched.c:
/**
* complete_all: - signals all threads waiting on this completion
* @x: holds the state of this particular completion
*
* This will wake up all threads waiting on this particular completion event.
*
* It may be assumed that this function implies a write memory barrier before
* changing the task state if and only if any tasks are woken up.
*/
void complete_all(struct completion *x)
{
unsigned long flags;
spin_lock_irqsave(&x->wait.lock, flags);
x->done += UINT_MAX/2;
// 唤醒等待队列中的所有等待进程,参见[16.9.4.1.1 __wake_up_common()]节
__wake_up_common(&x->wait, TASK_NORMAL, 0, 0, NULL);
spin_unlock_irqrestore(&x->wait.lock, flags);
}
16.9.4.3 complete_done()
该函数定义与kernel/sched.c:
/**
* completion_done - Test to see if a completion has any waiters
* @x: completion structure
*
* Returns: 0 if there are waiters (wait_for_completion() in progress)
* 1 if there are no waiters.
*
*/
bool completion_done(struct completion *x)
{
unsigned long flags;
int ret = 1;
spin_lock_irqsave(&x->wait.lock, flags);
if (!x->done)
ret = 0;
spin_unlock_irqrestore(&x->wait.lock, flags);
return ret;
}
16.10 Preemption Disabling
Because the kernel is preemptive, a process in the kernel can stop running at any instant to enable a process of higher priority to run. This means a task can begin running in the same critical region as a task that was preempted. To prevent this, the kernel preemption code uses spin locks as markers of nonpreemptive regions. If a spin lock is held, the kernel is not preemptive.
To solve this, kernel preemption can be disabled via preempt_disable(). The call is nestable; you can call it any number of times. For each call, a corresponding call to preempt_enable() is required. The final corresponding call to preempt_enable() reenables preemption. For example:
preempt_disable();
/* preemption is disabled ... */
preempt_enable();
16.10.1 preempt_count()
The preemption count stores the number of held locks and preempt_disable() calls. If the number is zero, the kernel is preemptive. If the value is one or greater, the kernel is not preemptive.
该宏定义于include/linux/preempt.h:
#define preempt_count() (current_thread_info()->preempt_count)
其中,preempt_count中各比特位的含义参见7.1.1.3.1.1 struct thread_info->preempt_count节。
函数current_thread_info()定义于arch/x86/include/asm/thread_info.h:
DECLARE_PER_CPU(unsigned long, kernel_stack);
static inline struct thread_info *current_thread_info(void)
{
struct thread_info *ti;
// 返回当前进程的栈信息,参见Error: Reference source not found
ti = (void *)(percpu_read_stable(kernel_stack) + KERNEL_STACK_OFFSET - THREAD_SIZE);
return ti;
}
16.10.2 preempt_disable()
该函数定义于include/linux/preempt.h:
#if defined(CONFIG_DEBUG_PREEMPT) || defined(CONFIG_PREEMPT_TRACER)
extern void add_preempt_count(int val); // 定义于kernel/sched.c
#else
# define add_preempt_count(val) do { preempt_count() += (val); } while (0)
#endif
// 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
#define inc_preempt_count() add_preempt_count(1)
#ifdef CONFIG_PREEMPT_COUNT
#define preempt_disable() \
do { \
inc_preempt_count(); \
barrier(); \ // 参见[16.11.1 barrier()]节
} while (0)
#else /* !CONFIG_PREEMPT_COUNT */
#define preempt_disable() do { } while (0)
#endif /* CONFIG_PREEMPT_COUNT */
16.10.3 preempt_enable()/preempt_enable_no_resched()
该函数定义于include/linux/preempt.h:
#if defined(CONFIG_DEBUG_PREEMPT) || defined(CONFIG_PREEMPT_TRACER)
extern void sub_preempt_count(int val);
#else
# define sub_preempt_count(val) do { preempt_count() -= (val); } while (0)
#endif
// 参见[7.1.1.3.1.1 struct thread_info->preempt_count]节
#define dec_preempt_count() sub_preempt_count(1)
#ifdef CONFIG_PREEMPT
#define preempt_check_resched() \
do { \
if (unlikely(test_thread_flag(TIF_NEED_RESCHED))) \
preempt_schedule(); \ // 参见[16.10.3.1 preempt_schedule()]节
} while (0)
#else /* !CONFIG_PREEMPT */
#define preempt_check_resched() do { } while (0)
#endif /* CONFIG_PREEMPT */
#ifdef CONFIG_PREEMPT_COUNT
#define preempt_enable() \
do { \
preempt_enable_no_resched(); \
barrier(); \
preempt_check_resched(); \
} while (0)
#define preempt_enable_no_resched() \
do { \
barrier(); \ // 参见[16.11.1 barrier()]节
dec_preempt_count(); \
} while (0)
#else /* !CONFIG_PREEMPT_COUNT */
#define preempt_enable() do { } while (0)
#endif /* CONFIG_PREEMPT_COUNT */
16.10.3.1 preempt_schedule()
该函数定义于kernel/sched.c:
#ifdef CONFIG_PREEMPT
/*
* this is the entry point to schedule() from in-kernel preemption
* off of preempt_enable. Kernel preemptions off return from interrupt
* occur there and call schedule directly.
*/
asmlinkage void __sched notrace preempt_schedule(void)
{
struct thread_info *ti = current_thread_info();
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
if (likely(ti->preempt_count || irqs_disabled()))
return;
do {
add_preempt_count_notrace(PREEMPT_ACTIVE);
__schedule(); // 参见[7.4.5.2 __schedule()]节
sub_preempt_count_notrace(PREEMPT_ACTIVE);
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
barrier();
} while (need_resched());
}
#endif
16.11 Ordering and Barriers
When dealing with synchronization between multiple processors or with hardware devices, it is sometimes a requirement that memory-reads (loads) and memory-writes (stores) issue in the order specified in your program code.
The rmb() method provides a read memory barrier. It ensures that no loads are reordered across the rmb() call. That is, no loads prior to the call will be reordered to after the call, and no loads after the call will be reordered to before the call.
The wmb() method provides a write barrier. It functions in the same manner as rmb(), but with respect to stores instead of loads — it ensures no stores are reordered across the barrier.
The mb() call provides both a read barrier and a write barrier. No loads or stores will be reordered across a call to mb(). It is provided because a single instruction (often the same instruction used by rmb()) can provide both the load and store barrier.
A variant of rmb(), read_barrier_depends(), provides a read barrier but only for loads on which subsequent loads depend. All reads prior to the barrier are guaranteed to complete before any reads after the barrier that depend on the reads prior to the barrier.
This sort of reordering occurs because modern processors dispatch and commit instructions out of order, to optimize use of their pipelines.
The macros smp_rmb(), smp_wmb(), smp_mb(), and smp_read_barrier_depends() provide a useful optimization. On SMP kernels they are defined as the usual memory barriers, whereas on UP kernels they are defined only as a compiler barrier. You can use these SMP variants when the ordering constraints are specific to SMP systems.
The barrier() method prevents the compiler from optimizing loads or stores across the call.
Note that the actual effects of the barriers vary for each architecture.
16.11.1 barrier()
该宏定义于include/linux/compiler.h:
#ifdef __GNUC__
#include <linux/compiler-gcc.h>
#endif
/* Intel compiler defines __GNUC__. So we will overwrite implementations
* coming from above header files here.
*/
#ifdef __INTEL_COMPILER
# include <linux/compiler-intel.h>
#endif
/* Optimization barrier */
#ifndef barrier
# define barrier() __memory_barrier()
#endif
使用GCC编译内核时,宏__GNUC__会被定义,因而包含include/linux/compiler-gcc.h。其中包含barrier()的定义:
/* Optimization barrier */
/* The "volatile" is due to gcc bugs */
#define barrier() __asm__ __volatile__("": : :"memory")
where:
-
The asm instruction tells the compiler to insert an assembly language fragment (empty, in this case).
-
The volatile keyword forbids the compiler to reshuffle the asm instruction with the other instructions of the program.
-
The memory keyword forces the compiler to assume that all memory locations in RAM have been changed by the assembly language instruction; therefore, the compiler cannot optimize the code by using the values of memory locations stored in CPU registers before the asm instruction.
Notice that the optimization barrier does not ensure that the executions of the assembly language instructions are not mixed by the CPU — this is a job for a memory barrier. A memory barrier primitive ensures that the operations placed before the primitive are finished before starting the operations placed after the primitive. See section mb()/rmb()/wmb()/read_barrier_depends() and smp_mb()/smp_rmb()/smp_wmb()/smp_read_barrier_depends().
16.11.2 mb()/rmb()/wmb()/read_barrier_depends()
In the 80×86 processors, the following kinds of assembly language instructions are said to be “serializing” because they act as memory barriers:
-
All instructions that operate on I/O ports
-
All instructions prefixed by the lock byte
-
All instructions that write into control registers, system registers, or debug registers (for instance, cli and sti, which change the status of the IF flag in the eflags register)
-
The lfence, sfence, and mfence assembly language instructions, which have been introduced in the Pentium 4 microprocessor to efficiently implement read memory barriers, write memory barriers, and read-write memory barriers, respectively.
-
A few special assembly language instructions; among them, the iret instruction that terminates an interrupt or exception handler
以x86体系架构为例,其定义于arch/x86/include/asm/system.h:
#ifdef CONFIG_X86_32
#define mb() alternative("lock; addl $0,0(%%esp)", "mfence", X86_FEATURE_XMM2)
#define rmb() alternative("lock; addl $0,0(%%esp)", "lfence", X86_FEATURE_XMM2)
#define wmb() alternative("lock; addl $0,0(%%esp)", "sfence", X86_FEATURE_XMM)
#else
#define mb() asm volatile("mfence":::"memory")
#define rmb() asm volatile("lfence":::"memory")
#define wmb() asm volatile("sfence":::"memory")
#endif
#define read_barrier_depends() do { } while (0)
| Macro | Description |
|---|---|
mb() |
Memory barrier for multiprocessor and uniprocessor systems |
rmb() |
Read memory barrier for multiprocessor and uniprocessor systems |
wmb() |
Write memory barrier for multiprocessor and uniprocessor systems |
16.11.3 smp_mb()/smp_rmb()/smp_wmb()/smp_read_barrier_depends()
以x86体系架构为例,其定义于arch/x86/include/asm/system.h:
#ifdef CONFIG_SMP
#define smp_mb() mb()
#ifdef CONFIG_X86_PPRO_FENCE
# define smp_rmb() rmb()
#else
# define smp_rmb() barrier()
#endif
#ifdef CONFIG_X86_OOSTORE
# define smp_wmb() wmb()
#else
# define smp_wmb() barrier()
#endif
#define smp_read_barrier_depends() read_barrier_depends()
#else
#define smp_mb() barrier()
#define smp_rmb() barrier()
#define smp_wmb() barrier()
#define smp_read_barrier_depends() do { } while (0)
#endif
| Macro | Description |
|---|---|
smp_mb() |
Memory barrier for multiprocessor system only |
smp_rmb() |
Read memory barrier for multiprocessor system only |
smp_wmb() |
Write memory barrier for multiprocessor system only |
16.12 Read-Copy-Update (RCU)
Read-copy-update (RCU) is another synchronization technique designed to protect data structures that are mostly accessed for reading by several CPUs. RCU allows many readers and many writers to proceed concurrently (an improvement over seqlocks, which allow only one writer to proceed). Moreover, RCU is lock-free, that is, it uses no lock or counter shared by all CPUs; this is a great advantage over read/write spin locks and seqlocks, which have a high overhead due to cache line-snooping and invalidation.
How does RCU obtain the surprising result of synchronizing several CPUs without shared data structures? The key idea consists of limiting the scope of RCU as follows:
1) Only data structures that are dynamically allocated and referenced by means of pointers can be protected by RCU.
2) No kernel control path can sleep inside a critical region protected by RCU.
RCU is a new addition in Linux 2.6; it is used in the networking layer and in the Virtual Filesystem.
16.12.1 Read an RCU-protected data structure
Use below code to read an RCU-protected data structure:
rcu_read_lock(); // equivalent to preempt_disable()
...
/*
* The reader dereferences the pointer to the data structure and starts reading it.
* And the reader cannot sleep until it finishes reading the data structure.
*/
rcu_dereference()
...
rcu_read_unlock(); // equivalent to preempt_enable()
16.12.1.1 rcu_dereference()
该宏定义于include/linux/rcupdate.h:
/**
* rcu_dereference() - fetch RCU-protected pointer for dereferencing
* @p: The pointer to read, prior to dereferencing
*
* This is a simple wrapper around rcu_dereference_check().
*/
#define rcu_dereference(p) rcu_dereference_check(p, 0)
/**
* rcu_dereference_check() - rcu_dereference with debug checking
* @p: The pointer to read, prior to dereferencing
* @c: The conditions under which the dereference will take place
*
* Do an rcu_dereference(), but check that the conditions under which the
* dereference will take place are correct. Typically the conditions
* indicate the various locking conditions that should be held at that
* point. The check should return true if the conditions are satisfied.
* An implicit check for being in an RCU read-side critical section
* (rcu_read_lock()) is included.
*
* For example:
*
* bar = rcu_dereference_check(foo->bar, lockdep_is_held(&foo->lock));
*
* could be used to indicate to lockdep that foo->bar may only be dereferenced
* if either rcu_read_lock() is held, or that the lock required to replace
* the bar struct at foo->bar is held.
*
* Note that the list of conditions may also include indications of when a lock
* need not be held, for example during initialisation or destruction of the
* target struct:
*
* bar = rcu_dereference_check(foo->bar, lockdep_is_held(&foo->lock) ||
* atomic_read(&foo->usage) == 0);
*
* Inserts memory barriers on architectures that require them
* (currently only the Alpha), prevents the compiler from refetching
* (and from merging fetches), and, more importantly, documents exactly
* which pointers are protected by RCU and checks that the pointer is
* annotated as __rcu.
*/
#define rcu_dereference_check(p, c) \
__rcu_dereference_check((p), rcu_read_lock_held() || (c), __rcu)
16.12.2 Write an RCU-proctected data structure
When a writer wants to update the data structure, it dereferences the pointer and makes a copy of the whole data structure. Next, the writer modifies the copy. Once finished, the writer changes the pointer to the data structure so as to make it point to the updated copy. Because changing the value of the pointer is an atomic operation, each reader or writer sees either the old copy or the new one: no corruption in the data structure may occur. However, a memory barrier is required to ensure that the updated pointer is seen by the other CPUs only after the data structure has been modified. Such a memory barrier is implicitly introduced if a spin lock is coupled with RCU to forbid the concurrent execution of writers.
The real problem with the RCU technique, however, is that the old copy of the data structure cannot be freed right away when the writer updates the pointer. In fact, the readers that were accessing the data structure when the writer started its update could still be reading the old copy. The old copy can be freed only after all (potential) readers on the CPUs have executed the rcu_read_unlock() macro. The kernel requires every potential reader to execute that macro before:
- The CPU performs a process switch (see restriction 2 earlier).
- The CPU starts executing in User Mode.
- The CPU executes the idle loop.
In each of these cases, we say that the CPU has gone through aquiescent state.
The call_rcu() function is invoked by the writer to get rid of the old copy of the data structure.
16.12.2.1 rcu_assign_pointer()
该宏定义于include/linux/rcupdate.h:
/**
* rcu_assign_pointer() - assign to RCU-protected pointer
* @p: pointer to assign to
* @v: value to assign (publish)
*
* Assigns the specified value to the specified RCU-protected
* pointer, ensuring that any concurrent RCU readers will see
* any prior initialization. Returns the value assigned.
*
* Inserts memory barriers on architectures that require them
* (which is most of them), and also prevents the compiler from
* reordering the code that initializes the structure after the pointer
* assignment. More importantly, this call documents which pointers
* will be dereferenced by RCU read-side code.
*
* In some special cases, you may use RCU_INIT_POINTER() instead
* of rcu_assign_pointer(). RCU_INIT_POINTER() is a bit faster due
* to the fact that it does not constrain either the CPU or the compiler.
* That said, using RCU_INIT_POINTER() when you should have used
* rcu_assign_pointer() is a very bad thing that results in
* impossible-to-diagnose memory corruption. So please be careful.
* See the RCU_INIT_POINTER() comment header for details.
*/
#define rcu_assign_pointer(p, v) __rcu_assign_pointer((p), (v), __rcu)
16.12.3 RCU的初始化
命令make alldefconfig生成的配置文件包含如下选项:
#
# RCU Subsystem
#
CONFIG_TINY_RCU=y
# CONFIG_PREEMPT_RCU is not set
# CONFIG_RCU_STALL_COMMON is not set
# CONFIG_TREE_RCU_TRACE is not set
# CONFIG_IKCONFIG is not set
在系统启动时,调用RCU初始化函数rcu_init(),其定义于rcutiny_plugin.h:
#ifdef CONFIG_RCU_BOOST
...
#else /* CONFIG_RCU_BOOST */
void rcu_init(void)
{
/*
* 设置软中断RCU_SOFTIRQ的服务程序为rcu_process_callbacks(),
* 参见[9.2.2 struct softirq_action / softirq_vec[]]节;
* 该服务程序被__do_softirq()调用,参见[9.3.1.3.1.1.1 __do_softirq()]节
*/
open_softirq(RCU_SOFTIRQ, rcu_process_callbacks);
}
#endif /* CONFIG_RCU_BOOST */
函数rcu_init()的调用关系如下:
start_kernel()
-> rcu_init()
16.12.3.1 rcu_process_callbacks()
该函数定义于kernel/rcutiny.c:
static void rcu_process_callbacks(struct softirq_action *unused)
{
__rcu_process_callbacks(&rcu_sched_ctrlblk);
__rcu_process_callbacks(&rcu_bh_ctrlblk);
rcu_preempt_process_callbacks();
}
其中,变量rcu_sched_ctrlblk和rcu_bh_ctrlblk定义于kernel/rcutiny_plugin.h:
static struct rcu_ctrlblk rcu_sched_ctrlblk = {
.donetail = &rcu_sched_ctrlblk.rcucblist,
.curtail = &rcu_sched_ctrlblk.rcucblist,
RCU_TRACE(.name = "rcu_sched")
};
static struct rcu_ctrlblk rcu_bh_ctrlblk = {
.donetail = &rcu_bh_ctrlblk.rcucblist,
.curtail = &rcu_bh_ctrlblk.rcucblist,
RCU_TRACE(.name = "rcu_bh")
};
函数rcu_preempt_process_callbacks()定义于kernel/rcutiny_plugin.h:
static struct rcu_preempt_ctrlblk rcu_preempt_ctrlblk = {
.rcb.donetail = &rcu_preempt_ctrlblk.rcb.rcucblist,
.rcb.curtail = &rcu_preempt_ctrlblk.rcb.rcucblist,
.nexttail = &rcu_preempt_ctrlblk.rcb.rcucblist,
.blkd_tasks = LIST_HEAD_INIT(rcu_preempt_ctrlblk.blkd_tasks),
RCU_TRACE(.rcb.name = "rcu_preempt")
};
static void rcu_preempt_process_callbacks(void)
{
// 参见[16.12.3.1.1 __rcu_process_callbacks()]节
__rcu_process_callbacks(&rcu_preempt_ctrlblk.rcb);
}
变量rcu_sched_ctrlblk的结构,参见:
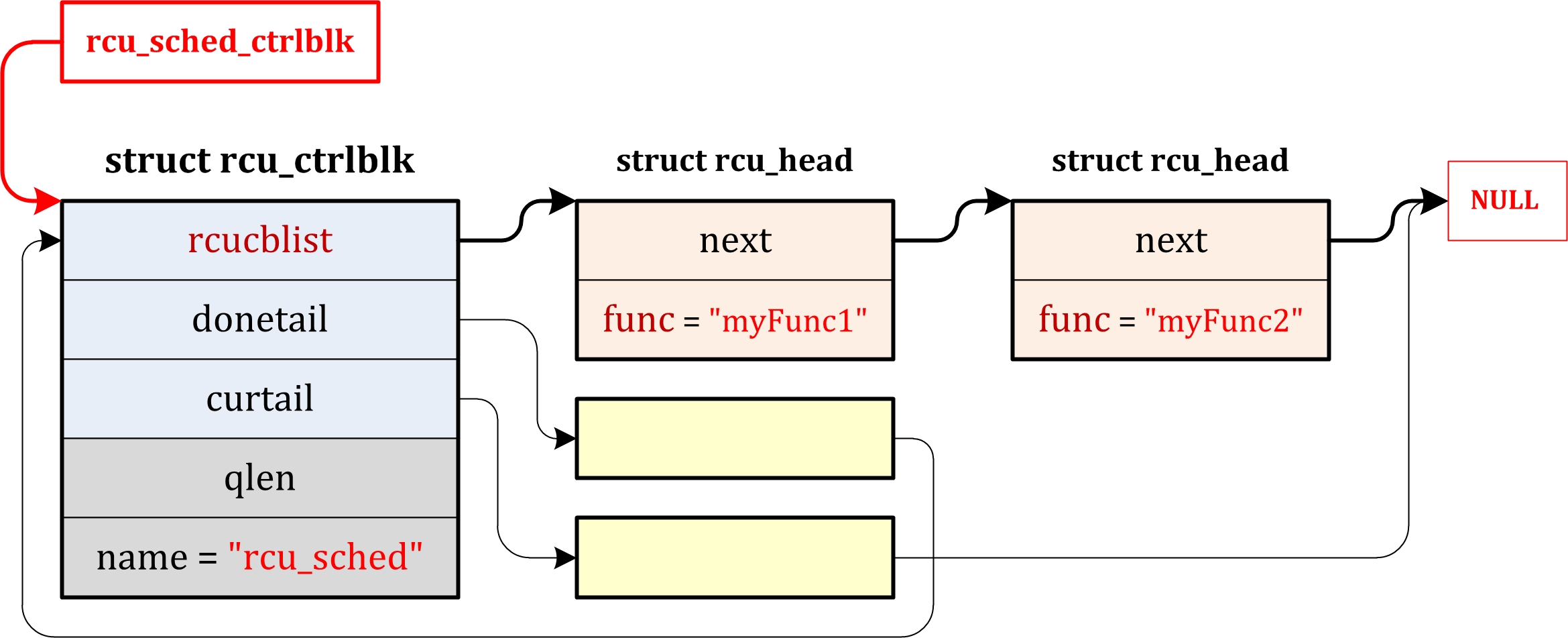
函数__rcu_process_callbacks(),参见[16.12.3.1.1 __rcu_process_callbacks()]节。
16.12.3.1.1 __rcu_process_callbacks()
该函数定义于kernel/rcutiny.c:
/*
* Invoke the RCU callbacks on the specified rcu_ctrlkblk structure
* whose grace period has elapsed.
*/
static void __rcu_process_callbacks(struct rcu_ctrlblk *rcp)
{
char *rn = NULL;
struct rcu_head *next, *list;
unsigned long flags;
RCU_TRACE(int cb_count = 0);
/* If no RCU callbacks ready to invoke, just return. */
if (&rcp->rcucblist == rcp->donetail) {
RCU_TRACE(trace_rcu_batch_start(rcp->name, 0, -1));
RCU_TRACE(trace_rcu_batch_end(rcp->name, 0));
return;
}
/* Move the ready-to-invoke callbacks to a local list. */
local_irq_save(flags);
RCU_TRACE(trace_rcu_batch_start(rcp->name, 0, -1));
list = rcp->rcucblist;
rcp->rcucblist = *rcp->donetail;
*rcp->donetail = NULL;
if (rcp->curtail == rcp->donetail)
rcp->curtail = &rcp->rcucblist;
rcu_preempt_remove_callbacks(rcp);
rcp->donetail = &rcp->rcucblist;
local_irq_restore(flags);
/* Invoke the callbacks on the local list. */
RCU_TRACE(rn = rcp->name);
while (list) {
next = list->next;
prefetch(next);
debug_rcu_head_unqueue(list);
local_bh_disable();
/*
* 执行RCU的处理函数,即list->func(list);
* Once executed, the callback function usually
* frees the old copy of the data structure.
*/
__rcu_reclaim(rn, list);
local_bh_enable();
list = next;
RCU_TRACE(cb_count++);
}
RCU_TRACE(rcu_trace_sub_qlen(rcp, cb_count));
RCU_TRACE(trace_rcu_batch_end(rcp->name, cb_count));
}
执行该函数前,参见:
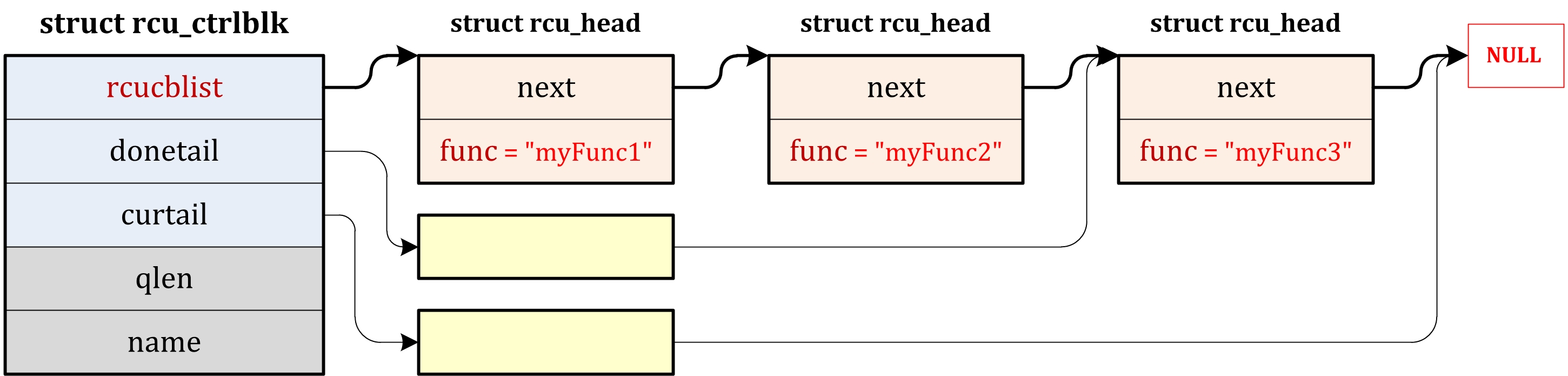
执行该函数后,参见:
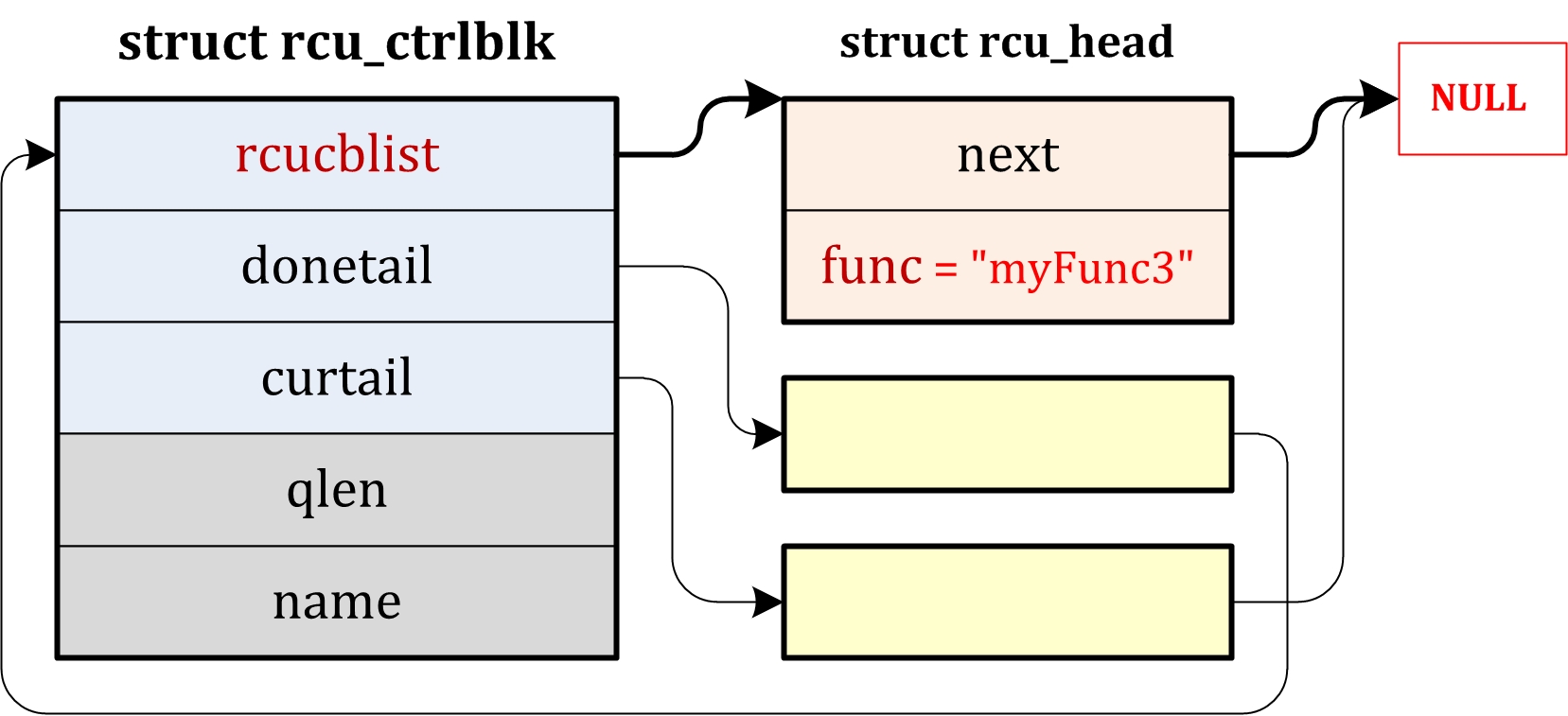

Q: 如何向后移动donetail指针的指向?
16.12.3.2 call_rcu()
该函数定义于include/linux/rcupdate.h:
#ifdef CONFIG_PREEMPT_RCU
/**
* call_rcu() - Queue an RCU callback for invocation after a grace period.
* @head: structure to be used for queueing the RCU updates.
* @func: actual callback function to be invoked after the grace period
*
* The callback function will be invoked some time after a full grace
* period elapses, in other words after all pre-existing RCU read-side
* critical sections have completed. However, the callback function
* might well execute concurrently with RCU read-side critical sections
* that started after call_rcu() was invoked. RCU read-side critical
* sections are delimited by rcu_read_lock() and rcu_read_unlock(),
* and may be nested.
*/
extern void call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *head));
#else /* CONFIG_PREEMPT_RCU */
/* In classic RCU, call_rcu() is just call_rcu_sched(). */
#define call_rcu call_rcu_sched
#endif /* CONFIG_PREEMPT_RCU */
其中,call_rcu_shed()定义于kernel/rcutiny.c:
/*
* Post an RCU callback to be invoked after the end of an RCU-sched grace
* period. But since we have but one CPU, that would be after any
* quiescent state.
*/
void call_rcu_sched(struct rcu_head *head, void (*func)(struct rcu_head *rcu))
{
__call_rcu(head, func, &rcu_sched_ctrlblk);
}
static void __call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *rcu),
struct rcu_ctrlblk *rcp)
{
unsigned long flags;
debug_rcu_head_queue(head);
head->func = func;
head->next = NULL;
local_irq_save(flags);
*rcp->curtail = head;
rcp->curtail = &head->next;
RCU_TRACE(rcp->qlen++);
local_irq_restore(flags);
}
执行函数call_rcu(myHead1, myFunc1)和call_rcu(myHead2, myFunc2)后,其结构参见:
17 SMP
SMP: Symmetric Multi-Processor,对称多处理器
17.1 SMP简介
The SMP need support from hardware, BIOS and operating system; refer to «Intel MultiProcessor Specification v1.4» chapter 2 System Overview:
While all processors in a compliant system are functionally identical, this specification classifies them into two types: the bootstrap processor (BSP) and the application processors (AP). Which processor is the BSP is determined by the hardware or by the hardware in conjunction with the BIOS. This differentiation is for convenience and is in effectively during the initialization and shutdown processes. The BSP is responsible for initializing the system and for booting the operating system; APs are activated only after the operating system is up and running.
Multiprocessor System Architecture – APIC Configuration
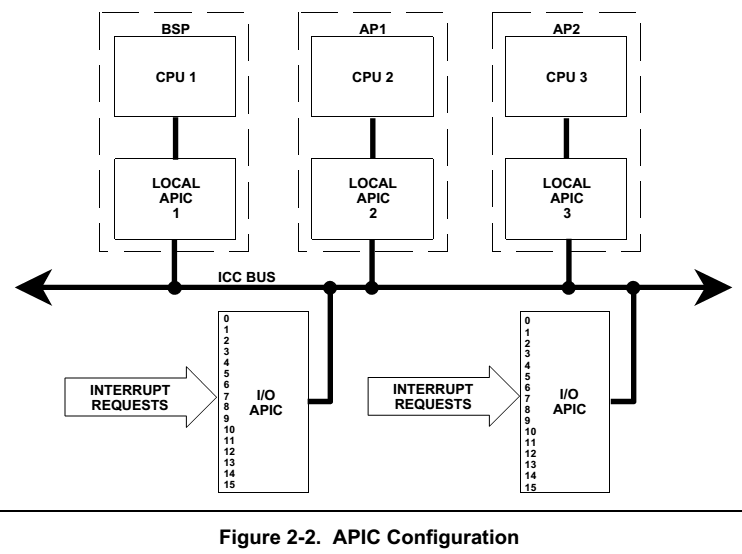
Also refer to «Intel 64 and IA-32 Architectures Software Developer’s Manual» Part 3, Chapter 8: Multi-Processor Management.
可通过下列命令查看CPU数目及类型:
[tcsh] cweixiax@dgsxvnc02:~> grep -c ^processor /proc/cpuinfo
24
[tcsh] cweixiax@dgsxvnc02:~> cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5670 @ 2.93GHz
stepping : 2
cpu MHz : 2933.527
cache size : 12288 KB
physical id : 0
siblings : 12
core id : 0
cpu cores : 6
apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm syscall nx pdpe1gb rdtscp lm constant_tsc ida nonstop_tsc arat pni monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr sse4_1 sse4_2 popcnt lahf_lm
bogomips : 5867.05
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management : [8]
...
17.2 SMP实现中的关键技术
SMP系统的实现需要硬件和软件协同完成。作为硬件来说,组成SMP系统的CPU需要支持处理器间的通信,需要硬件提供机制来维护CPU之间Cache内容的一致性等;作为软件的操作系统来说,需要配合硬件来实现进程在各个CPU间的调度,处理各种外部中断等工作。
17.2.1 处理器间的同步与互斥
进程间的同步实际上可以归结为对临界资源的互斥操作。在单处理器结构中,只要能保证在对临界资源的操作中不会发生进程调度,并且不会发生中断,或者即使发生了中断也与操作的对象无关,就保证了操作的互斥性。即使在极端的情况下(例如不允许关中断),只要对临界资源的操作能在单条指令中完成,也保证了操作的互斥性,因为中断只能发生于指令之间,而不会发生在执行一条指令的中途。
一般而言,只要能保证对临界资源操作的“原子性”,互斥性就得以保证,单处理器系统正是基于这样的机理:在单处理器系统中,能够在单条指令中完成的操作被认为是“原子操作”。但在SMP结构中,由于系统中有多个处理器在独立运行,即使能在单条指令中完成的操作也可能受到干扰。与单处理器结构相比,SMP结构对互斥操作的“分辨率”更高,有些在单处理器结构中的“原子操作”在SMP结构中不再是原子的了。
解决方案:单纯的读或写本来就是原子的,问题在于一些既要读又要写,需要两个或以上的微操作才能完成的指令,i386 CPU提供了在指令执行期间对总线加锁的手段。CPU芯片上有一条引线LOCK,如果汇编程序中在一条指令前加上前缀“LOCK”,汇编后的机器代码就会使CPU在执行这条指令时把引线LOCK的电位拉低,从而把总线锁住,同一总线上别的CPU就暂时不能通过总线访问内存了。特例:在执行指令xchg时CPU会自动将总线锁住,而不需要在程序中使用前缀“LOCK”。xchg指令将一个内存单元中的内容与一个寄存器的内容对换,常常用于对内核信号量(semaphore)的操作。
17.2.2 Cache与内存间的一致性问题
在SMP结构中,Cache的情况相对于单处理器系统更为复杂,因为一个CPU并不知道别的CPU会在何时改变内存的内容。Cache写操作有两种模式:
-
穿透模式(Write-Through):Cache对写操作好像不存在一样,每次写时都直接写到内存中,实际上只是对读操作使用Cache,因而效率相对较低;
-
回写模式(Write-Back):写的时候先写入Cache,然后由Cache硬件在周转时使用缓冲线自动写入内存,或由软件主动地“冲刷”有关的缓冲线。因此在改变了缓冲页面的内容,并启动DMA写操作将其写入磁盘前要先“冲刷”Cache中有关的缓冲线,因为改变了的内容可能还没有回写到内存缓冲区中。
在Intel Pentium CPU中有个寄存器,称为“存储类型及范围寄存器”(Memory Type Range Register,MTRR),通过这个寄存器可以将内存中的不同区间设置成使用或不使用Cache,以及对于写操作采用穿透模式或回写模式。
Cache的运用有可能改变对内存操作的次序。假定有两个观察者,一个观察CPU内部Cache受到访问的次序,另一个观察内存受到访问的次序,则二者可能会有相当大的差异。前者就是程序中编排好的次序,称作“指令序”(program ordering),后者则是实际出现在处理器外部,即系统总线上的次序,称作“处理器序”(process ordering)。不使用Cache时二者相同,如果使用Cache要看具体的情况和操作。如果保证“处理器序”与“指令序”相同,称作“强序”(strong ordering);反之,如果“处理器序”有时候可能不同于“指令序”,称作“弱序”(weak ordering)。对于单处理器结构的系统,这二者的不同并不成什么问题,然而对SMP结构的系统却可能成为问题。
单处理器系统中的DMA操作都是由设备驱动程序主动地启动的,所以设备驱动程序知道什么时候应该丢弃哪些缓冲线的内容,什么时候应该冲刷哪些缓冲线的内容。可在SMP结构中,每个CPU都可能改变内存中的内容,且异步改变,每个CPU都只知道自己何时会改变内存的内容,但不知道别的CPU什么时候改变内存的内容,也不知道本地Cache中的内容是否已经与内存中不一致,每个CPU也可能因为改变了内存的内容而使其他CPU的Cache变得不一致。
解决方案:对于Cache中的内容,一般只有数据才有一致性的问题,因为对指令一般都是只读,不在运行的过程中动态地加以改变。Intel在Pentium CPU中为已经装入Cache的数据提供了一种自动与内存保持一致的机制,称为“窥探”(Snooping)。每个CPU内部有一部分专门的硬件,一旦启用了Cache后就时刻监视系统总线上对内存的操作。由于对内存的操作定要经过系统总线,没有一次实际访问内存的操作能够逃过监视。如果发现有来自其他CPU的写操作,而本CPU的Cache中又缓冲存储着该次写操作的目标,就会自动把相应的缓冲线废弃,使得在需要用到这些数据时重新将其装入Cache,达到二者一致。这样,SMP结构中Cache与内存的数据一致性问题对软件而言就透明了。
17.2.3 中断处理
在单处理器结构中,整个系统只有一个CPU,所有的中断请求都由这个CPU响应和处理,而SMP结构不能固定让其中的某一个CPU处理所有的中断请求,否则其他CPU连时钟中断不能处理,这样如果在那些CPU上运行的进程陷入了死循环,就永远没有机会进行系统调用,这些CPU将永远不会有进程调度。另外,如果是让所有的CPU轮流处理中断,或谁空闲谁处理,中断请求的分配将如何处理,这些都需要软件和硬件协同来完成。
传统的i386处理器采用8259A中断控制器。一般而言,8259A的作用是提供多个外部中断源与单一CPU间的连接。如果在SMP结构中还是采用8259A中断控制器,就只能静态地把所有的外部中断源划分成若干组,分别把每一组都连接到一个8259A,而825A9则与CPU一对一连接,这样就达不到动态分配中断请求的目的。Intel为Pentium设计了一种更为通用的中断控制器,称为“高级可编程中断控制器”(Advanced Programmable Interrupt Controller,APIC)。考虑到“处理器间中断请求”的需要,每个CPU还要有Local APIC,因为CPU常常要有目标地向系统中的其他CPU发出中断请求。从Pentium开始,Intel在CPU芯片内部集成了Local APIC,但在SMP结构中还需要一个外部的、全局的APIC,即I/O APIC。
Besides distributing interrupts among processors, the multi-APIC system allows CPUs to generate interprocessor interrupts.
17.3 SMP的启动过程
在同一时间,一个“上下文”只能由一个CPU处理。在系统引导和初始化阶段,只有一个“上下文”,只能由一个处理器来处理。BSP完成系统的引导和初始化,并创建起多进程,从而可以由多个处理器同时参与处理时,才启动所有的AP,让它们在完成自身的初始化后投入运行。
在Linux中,SMP系统的引导是一个分阶段的过程,这中间需要主CPU和次CPU在几个地方进行同步,已取得相同的同步和协调,最终基本在同一时间进入SMP的进程调度。Linux中SMP系统在Intel的Pentium上的引导过程如下:
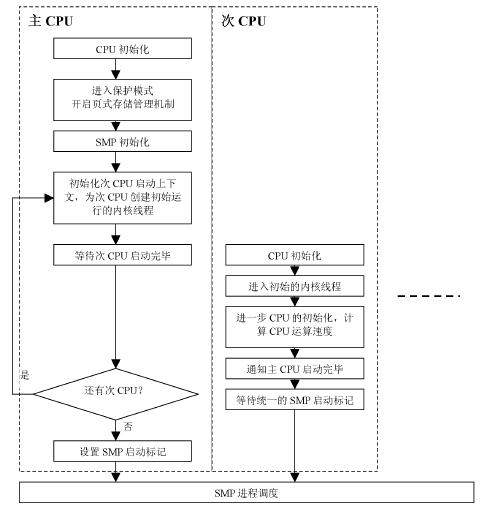
SMP的启动过程:
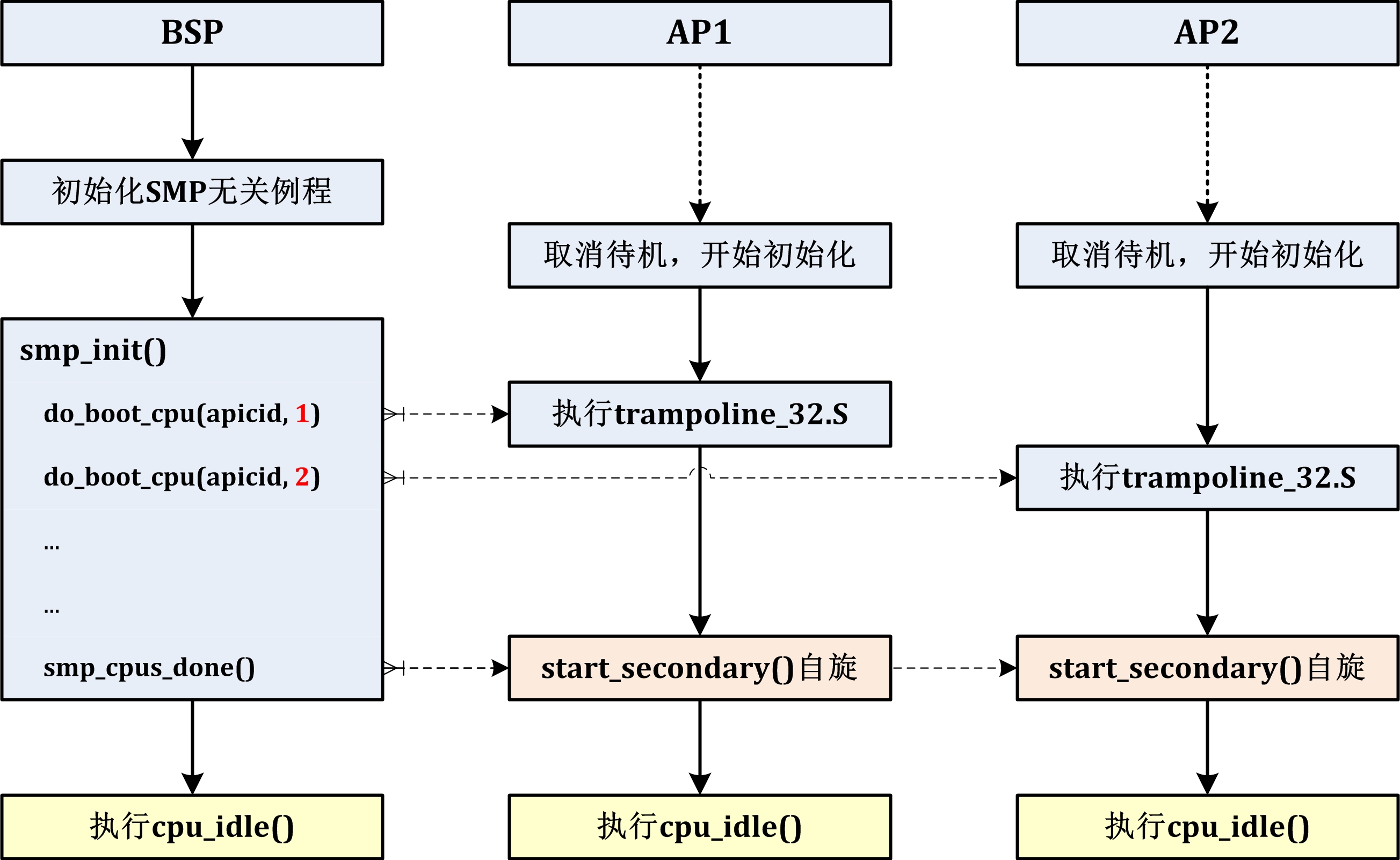
配置了SMP的Linux的启动过程如下:
start_kernel()
-> smp_setup_processor_id() // 空函数
-> boot_cpu_init() // 初始化主CPU
-> set_cpu_online(cpu, true); // cpu_online_bits, see NOTE 1
-> set_cpu_active(cpu, true); // cpu_active_bits, see NOTE 1
-> set_cpu_present(cpu, true); // cpu_present_bits, see NOTE 1
-> set_cpu_possible(cpu, true); // cpu_possible_bits, see NOTE 1
-> setup_arch()
-> find_smp_config() // 查找MP Configuration Table
// Refer to <<Intel MultiProcessor Specification v1.4>> Chapter 4: MP Configuration Table.
-> x86_init.mpparse.find_smp_config() // 即调用default_find_smp_config()
-> default_find_smp_config()
-> get_bios_ebda()
-> smp_scan_config(address, 0x400)
-> early_acpi_boot_init()
-> early_acpi_process_madt()
-> smp_found_config = 1;
-> if (smp_found_config) {
-> get_smp_config() // 根据MP Configuration Table获取具体的硬件信息
// Refer to <<Intel MultiProcessor Specification v1.4>> Chapter 4: MP Configuration Table.
-> x86_init.mpparse.get_smp_config(0); // 即调用default_get_smp_config()
-> default_get_smp_config(0)
-> mpf = mpf_found;
-> if (mpf->feature1 != 0) {
/*
* If mpf->feature1 != 0, the system configuration conforms to one of the
* default configurations. The default configurations may only be used to
* describe systems that always have two processors installed.
*/
-> construct_default_ISA_mptable(mpf->feature1)
-> for (i = 0; i < 2; i++) {
-> MP_processor_info(&processor)
-> construct_ioapic_table()
}
} else if (mpf->physptr) {
/* Check MP Configuration Table if not use default configuration */
-> check_physptr(mpf, 0)
-> mpc = early_ioremap(mpf->physptr, size);
-> smp_read_mpc(mpc, 0) // Read MP Configuration Table
// Check every item in MP Configuration Table
-> while (count < mpc->length) {
-> case MP_PROCESSOR:
-> MP_processor_info((struct mpc_cpu *)mpt);
-> apicid = x86_init.mpparse.mpc_apic_id(m); // 调用default_mpc_apic_id()
-> if (m->cpuflag & CPU_BOOTPROCESSOR) {
-> bootup_cpu = " (Bootup-CPU)";
-> boot_cpu_physical_apicid = m->apicid;
}
-> printk(KERN_INFO "Processor #%d%s\n", m->apicid, bootup_cpu);
-> generic_processor_info(apicid, m->apicver);
-> num_processors++;
-> set_cpu_possible(cpu, true); // cpu_possible_bits
-> set_cpu_present(cpu, true); // cpu_present_bits
}
}
}
-> prefill_possible_map()
// 设置cpu_possible_bits和nr_cpu_ids,此后可使用for_each_possible_cpu(cpu)
-> for (i = 0; i < possible; i++)
set_cpu_possible(i, true);
-> for (; i < NR_CPUS; i++)
set_cpu_possible(i, false);
-> nr_cpu_ids = possible;
-> init_apic_mappings() // Initialize APIC mappings
-> setup_nr_cpu_ids() // 通过检测cpu_possible_bits来设置nr_cpu_ids
-> nr_cpu_ids = find_last_bit(cpumask_bits(cpu_possible_mask),NR_CPUS) + 1;
-> setup_per_cpu_areas()
-> smp_prepare_boot_cpu() // arch-specific boot-cpu hooks
-> smp_ops.smp_prepare_boot_cpu() // 即调用native_smp_prepare_boot_cpu()
-> native_smp_prepare_boot_cpu()
-> per_cpu(cpu_state, me) = CPU_ONLINE;
-> rest_init()
-> kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
-> kernel_init()
-> smp_prepare_cpus(setup_max_cpus)
-> smp_ops.smp_prepare_cpus() // 即调用native_smp_prepare_cpus()
-> native_smp_prepare_cpus()
-> smp_sanity_check() // 若未配置CONFIG_X86_BIGSMP,最多支持8个CPU
-> do_pre_smp_initcalls()
// 调用.initcallearly.init段的初始化函数,由宏early_initcall()设置,参见[13.5.1.1.1.1.1 .initcall*.init]节
-> smp_init()
-> for_each_present_cpu(cpu) { // 轮询cpu_present_bits,调度每个CPU
-> cpu_up(cpu) // loop every cpu
-> _cpu_up(cpu, 0)
-> __cpu_up(cpu) // Arch-specific enabling code
-> smp_ops.cpu_up(cpu) // 即调用native_cpu_up(cpu)
-> per_cpu(cpu_state, cpu) = CPU_UP_PREPARE;
-> do_boot_cpu(apicid, cpu)
-> INIT_WORK_ONSTACK(&c_idle.work, do_fork_idle)
-> c_idle.idle = get_idle_for_cpu(cpu)
-> if (c_idle.idle) {
-> init_idle(c_idle.idle, cpu)
}
-> schedule_work(&c_idle.work) // 最终调用do_fork_idle()
-> do_fork_idle(work)
-> fork_idle(cpu) // create idle progress for cpu
-> complete(&c_idle->done)
-> wait_for_completion(&c_idle.done)
-> set_idle_for_cpu(cpu, c_idle.idle)
-> early_gdt_descr.address = (unsigned long)get_cpu_gdt_table(cpu);
-> initial_code = (unsigned long)start_secondary;
// AP初始化完成后,开始执行函数start_secondary()
-> stack_start = c_idle.idle->thread.sp;
-> start_ip = trampoline_address();
/*
* 该函数复制trampoline_data与trampoline_end之间的代码到
* 地址x86_trampoline_base处,其中:
* - x86_trampoline_base是之前在setup_arch()处申请的内存;
* - trampoline_data开始的代码
* 参见arch/x86/kernel/trampoline_32.S
* 参见[17.3.1 trampoline_data与trampoline_end之间的代码]节
*
* 该函数的返回值是x86_trampoline_base所对应的物理地址!
*/
-> printk(KERN_DEBUG "smpboot cpu %d: start_ip = %lx\n", cpu, start_ip);
// 设置启动地址为start_ip
-> smpboot_setup_warm_reset_vector(start_ip)
-> wakeup_secondary_cpu_via_init(apicid, start_ip)
/*
* 通过操纵APIC_ICR寄存器,BSP向目标AP发送IPI消息,
* 触发目标AP以实模式从地址start_ip处开始运行,
* 参见[17.3.1 trampoline_data与trampoline_end之间的代码]节
*/
}
-> printk(KERN_INFO "Brought up %ld CPUs\n", (long)num_online_cpus());
-> smp_cpus_done(setup_max_cpus)
-> smp_ops.smp_cpus_done(setup_max_cpus) // 即调用native_smp_cpus_done()
-> native_smp_cpus_done()
-> pr_debug("Boot done.\n");
-> impress_friends()
-> setup_ioapic_dest()
-> mtrr_aps_init() // Delayed MTRR initialization for all AP's
-> set_mtrr(~0U, 0, 0, 0) // 参见[17.3.2 set_mtrr()]节
// Update mtrrs (Memory Type Range Register) on all processors
-> stop_machine(mtrr_rendezvous_handler, &data, cpu_online_mask)
-> __stop_machine(mtrr_rendezvous_handler, &data, cpu_online_mask)
NOTE: Refer to Documentation/cputopology.txt:
-
kernel_max: the maximum CPU index allowed by the kernel configuration. [NR_CPUS-1]
-
offline: CPUs that are not online because they have been HOTPLUGGED off or exceed the limit of CPUs allowed by the kernel configuration (kernel_max above). [~cpu_online_mask + cpus >= NR_CPUS]
-
present: CPUs that have been identified as being present in the system. [cpu_present_mask] possible: CPUs that have been allocated resources and can be brought online if they are present. [cpu_possible_mask]
-
online: CPUs that are online and being scheduled. [cpu_online_mask]
17.3.1 trampoline_data与trampoline_end之间的代码
该代码段定义于arch/x86/kernel/trampoline_32.S:
#ifdef CONFIG_SMP
.section ".x86_trampoline","a"
.balign PAGE_SIZE
.code16
ENTRY(trampoline_data)
r_base = .
wbinvd # Needed for NUMA-Q should be harmless for others
mov %cs, %ax # Code and data in the same place
mov %ax, %ds
cli # We should be safe anyway
# 设置标识0xA5A5A5A5,以便BSP知道该AP已经运行到这段代码
# write marker for master knows we're running
movl $0xA5A5A5A5, trampoline_status - r_base
/* GDT tables in non default location kernel can be beyond 16MB and
* lgdt will not be able to load the address as in real mode default
* operand size is 16bit. Use lgdtl instead to force operand size
* to 32 bit.
*/
lidtl boot_idt_descr - r_base # load idt with 0, 0
lgdtl boot_gdt_descr - r_base # load gdt with whatever is appropriate
xor %ax, %ax
inc %ax # protected mode (PE) bit
lmsw %ax # into protected mode
# 程序段startup_32_smp定义于arch/x86/kernel/head_32.S,参见[17.3.1.1 startup_32_smp]节
# flush prefetch and jump to startup_32_smp in arch/i386/kernel/head.S
ljmpl $__BOOT_CS, $(startup_32_smp-__PAGE_OFFSET)
# These need to be in the same 64K segment as the above;
# hence we don't use the boot_gdt_descr defined in head.S
boot_gdt_descr:
.word __BOOT_DS + 7 # gdt limit
.long boot_gdt - __PAGE_OFFSET # gdt base
boot_idt_descr:
.word 0 # idt limit = 0
.long 0 # idt base = 0L
ENTRY(trampoline_status)
.long 0
.globl trampoline_end
trampoline_end:
#endif /* CONFIG_SMP */
17.3.1.1 startup_32_smp
该程序段定义于arch/x86/kernel/head_32.S:
#ifdef CONFIG_SMP
ENTRY(startup_32_smp)
cld
movl $(__BOOT_DS),%eax
movl %eax,%ds
movl %eax,%es
movl %eax,%fs
movl %eax,%gs
# 变量stack_start定义于do_boot_cpu(),参见[17.3 SMP的启动过程]节
movl pa(stack_start),%ecx
movl %eax,%ss
leal -__PAGE_OFFSET(%ecx),%esp
#endif /* CONFIG_SMP */
default_entry:
/*
* New page tables may be in 4Mbyte page mode and may
* be using the global pages.
*
* NOTE! If we are on a 486 we may have no cr4 at all!
* So we do not try to touch it unless we really have
* some bits in it to set. This won't work if the BSP
* implements cr4 but this AP does not -- very unlikely
* but be warned! The same applies to the pse feature
* if not equally supported. --macro
*
* NOTE! We have to correct for the fact that we're
* not yet offset PAGE_OFFSET..
*/
#define cr4_bits pa(mmu_cr4_features)
movl cr4_bits,%edx
andl %edx,%edx
jz 6f
movl %cr4,%eax # Turn on paging options (PSE,PAE,..)
orl %edx,%eax
movl %eax,%cr4
testb $X86_CR4_PAE, %al # check if PAE is enabled
jz 6f
/* Check if extended functions are implemented */
movl $0x80000000, %eax
cpuid
/* Value must be in the range 0x80000001 to 0x8000ffff */
subl $0x80000001, %eax
cmpl $(0x8000ffff-0x80000001), %eax
ja 6f
/* Clear bogus XD_DISABLE bits */
call verify_cpu
mov $0x80000001, %eax
cpuid
/* Execute Disable bit supported? */
btl $(X86_FEATURE_NX & 31), %edx
jnc 6f
/* Setup EFER (Extended Feature Enable Register) */
movl $MSR_EFER, %ecx
rdmsr
btsl $_EFER_NX, %eax
/* Make changes effective */
wrmsr
6:
/*
* Enable paging
*/
movl $pa(initial_page_table), %eax
movl %eax,%cr3 /* set the page table pointer.. */
movl %cr0,%eax
orl $X86_CR0_PG,%eax
movl %eax,%cr0 /* ..and set paging (PG) bit */
ljmp $__BOOT_CS,$1f /* Clear prefetch and normalize %eip */
1:
/* Shift the stack pointer to a virtual address */
addl $__PAGE_OFFSET, %esp
/*
* Initialize eflags. Some BIOS's leave bits like NT set. This would
* confuse the debugger if this code is traced.
* XXX - best to initialize before switching to protected mode.
*/
pushl $0
popfl
#ifdef CONFIG_SMP
cmpb $0, ready
jnz checkCPUtype
#endif /* CONFIG_SMP */
/*
* start system 32-bit setup. We need to re-do some of the things done
* in 16-bit mode for the "real" operations.
*/
call setup_idt
checkCPUtype:
movl $-1,X86_CPUID # -1 for no CPUID initially
/* check if it is 486 or 386. */
/*
* XXX - this does a lot of unnecessary setup. Alignment checks don't
* apply at our cpl of 0 and the stack ought to be aligned already, and
* we don't need to preserve eflags.
*/
movb $3,X86 # at least 386
pushfl # push EFLAGS
popl %eax # get EFLAGS
movl %eax,%ecx # save original EFLAGS
xorl $0x240000,%eax # flip AC and ID bits in EFLAGS
pushl %eax # copy to EFLAGS
popfl # set EFLAGS
pushfl # get new EFLAGS
popl %eax # put it in eax
xorl %ecx,%eax # change in flags
pushl %ecx # restore original EFLAGS
popfl
testl $0x40000,%eax # check if AC bit changed
je is386
movb $4,X86 # at least 486
testl $0x200000,%eax # check if ID bit changed
je is486
/* get vendor info */
xorl %eax,%eax # call CPUID with 0 -> return vendor ID
cpuid
movl %eax,X86_CPUID # save CPUID level
movl %ebx,X86_VENDOR_ID # lo 4 chars
movl %edx,X86_VENDOR_ID+4 # next 4 chars
movl %ecx,X86_VENDOR_ID+8 # last 4 chars
orl %eax,%eax # do we have processor info as well?
je is486
movl $1,%eax # Use the CPUID instruction to get CPU type
cpuid
movb %al,%cl # save reg for future use
andb $0x0f,%ah # mask processor family
movb %ah,X86
andb $0xf0,%al # mask model
shrb $4,%al
movb %al,X86_MODEL
andb $0x0f,%cl # mask mask revision
movb %cl,X86_MASK
movl %edx,X86_CAPABILITY
is486: movl $0x50022,%ecx # set AM, WP, NE and MP
jmp 2f
is386: movl $2,%ecx # set MP
2: movl %cr0,%eax
andl $0x80000011,%eax # Save PG,PE,ET
orl %ecx,%eax
movl %eax,%cr0
call check_x87
lgdt early_gdt_descr
lidt idt_descr
ljmp $(__KERNEL_CS),$1f
1: movl $(__KERNEL_DS),%eax # reload all the segment registers
movl %eax,%ss # after changing gdt.
movl $(__USER_DS),%eax # DS/ES contains default USER segment
movl %eax,%ds
movl %eax,%es
movl $(__KERNEL_PERCPU), %eax
movl %eax,%fs # set this cpu's percpu
#ifdef CONFIG_CC_STACKPROTECTOR
/*
* The linker can't handle this by relocation. Manually set
* base address in stack canary segment descriptor.
*/
cmpb $0,ready
jne 1f
movl $gdt_page,%eax
movl $stack_canary,%ecx
movw %cx, 8 * GDT_ENTRY_STACK_CANARY + 2(%eax)
shrl $16, %ecx
movb %cl, 8 * GDT_ENTRY_STACK_CANARY + 4(%eax)
movb %ch, 8 * GDT_ENTRY_STACK_CANARY + 7(%eax)
1:
#endif
movl $(__KERNEL_STACK_CANARY),%eax
movl %eax,%gs
xorl %eax,%eax # Clear LDT
lldt %ax
cld # gcc2 wants the direction flag cleared at all times
pushl $0 # fake return address for unwinder
movb $1, ready
# 变量initial_code = start_secondary,其定义于do_boot_cpu(),
# 参见[17.3 SMP的启动过程]节和[17.3.1.1.1 start_secondary()]节
jmp *(initial_code)
17.3.1.1.1 start_secondary()
该函数定义于arch/x86/kernel/smpboot.c:
/*
* Activate a secondary processor.
*/
notrace static void __cpuinit start_secondary(void *unused)
{
/*
* Don't put *anything* before cpu_init(), SMP booting is too
* fragile that we want to limit the things done here to the
* most necessary things.
*/
cpu_init();
preempt_disable();
smp_callin();
#ifdef CONFIG_X86_32
/* switch away from the initial page table */
load_cr3(swapper_pg_dir);
__flush_tlb_all();
#endif
/* otherwise gcc will move up smp_processor_id before the cpu_init */
barrier();
/*
* Check TSC synchronization with the BP:
*/
check_tsc_sync_target();
/*
* We need to hold call_lock, so there is no inconsistency
* between the time smp_call_function() determines number of
* IPI recipients, and the time when the determination is made
* for which cpus receive the IPI. Holding this
* lock helps us to not include this cpu in a currently in progress
* smp_call_function().
*
* We need to hold vector_lock so there the set of online cpus
* does not change while we are assigning vectors to cpus. Holding
* this lock ensures we don't half assign or remove an irq from a cpu.
*/
ipi_call_lock();
lock_vector_lock();
set_cpu_online(smp_processor_id(), true);
unlock_vector_lock();
ipi_call_unlock();
per_cpu(cpu_state, smp_processor_id()) = CPU_ONLINE;
x86_platform.nmi_init();
/*
* Wait until the cpu which brought this one up marked it
* online before enabling interrupts. If we don't do that then
* we can end up waking up the softirq thread before this cpu
* reached the active state, which makes the scheduler unhappy
* and schedule the softirq thread on the wrong cpu. This is
* only observable with forced threaded interrupts, but in
* theory it could also happen w/o them. It's just way harder
* to achieve.
*/
while (!cpumask_test_cpu(smp_processor_id(), cpu_active_mask))
cpu_relax();
/* enable local interrupts */
local_irq_enable();
/* to prevent fake stack check failure in clock setup */
boot_init_stack_canary();
x86_cpuinit.setup_percpu_clockev();
wmb();
// 若该CPU启动了,则调用cpu_idle()进行任务调度,参见[4.3.4.1.4.3.13.3 cpu_idle()]节
cpu_idle();
}
17.3.2 set_mtrr()
该函数定义于arch/x86/kernel/cpu/mtrr/main.c:
/**
* set_mtrr - update mtrrs on all processors
* @reg: mtrr in question
* @base: mtrr base
* @size: mtrr size
* @type: mtrr type
*
* This is kinda tricky, but fortunately, Intel spelled it out for us cleanly:
*
* 1. Queue work to do the following on all processors:
* 2. Disable Interrupts
* 3. Wait for all procs to do so
* 4. Enter no-fill cache mode
* 5. Flush caches
* 6. Clear PGE bit
* 7. Flush all TLBs
* 8. Disable all range registers
* 9. Update the MTRRs
* 10. Enable all range registers
* 11. Flush all TLBs and caches again
* 12. Enter normal cache mode and reenable caching
* 13. Set PGE
* 14. Wait for buddies to catch up
* 15. Enable interrupts.
*
* What does that mean for us? Well, stop_machine() will ensure that
* the rendezvous handler is started on each CPU. And in lockstep they
* do the state transition of disabling interrupts, updating MTRR's
* (the CPU vendors may each do it differently, so we call mtrr_if->set()
* callback and let them take care of it.) and enabling interrupts.
*
* Note that the mechanism is the same for UP systems, too; all the SMP stuff
* becomes nops.
*/
static void set_mtrr(unsigned int reg, unsigned long base, unsigned long size, mtrr_type type)
{
struct set_mtrr_data data = {
.smp_reg = reg,
.smp_base = base,
.smp_size = size,
.smp_type = type
};
stop_machine(mtrr_rendezvous_handler, &data, cpu_online_mask);
}
17.4 与SMP有关的数据结构
setup_max_cpus
Setup configured maximum number of CPUs to activate. 可通过内核参数maxcpus设置,可通过内核参数nosmp复位,参见kernel/smp.c.
nr_cpu_ids
The number of CPUs. 可通过内核参数nr_cpus设置,参见kernel/smp.c.
cpu_all_bits / cpu_bit_bitmap
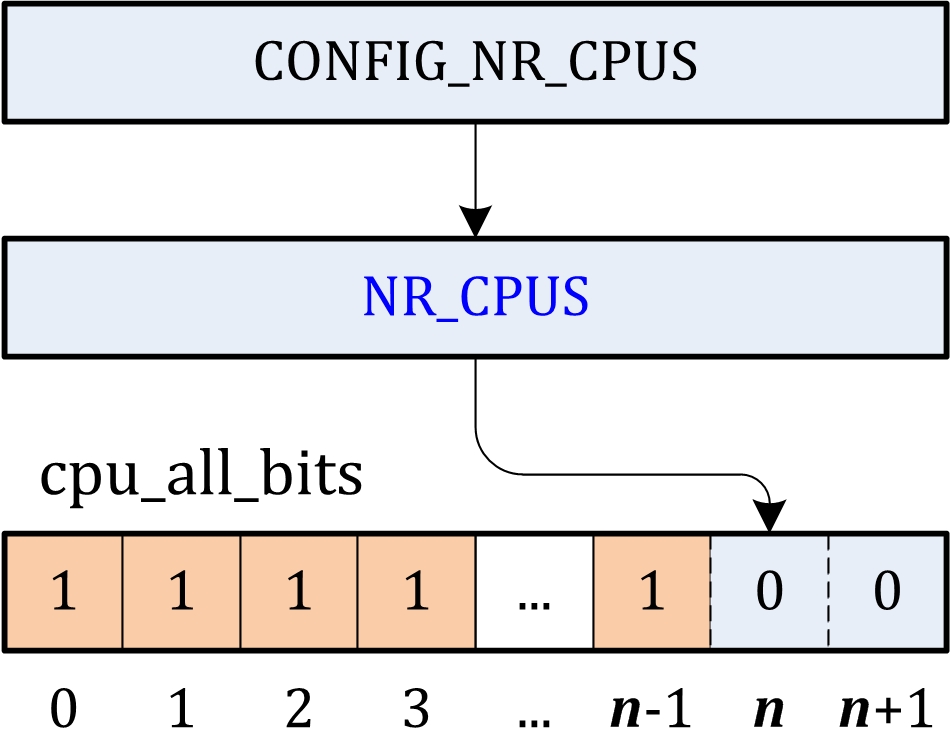
cpu_present_mask / cpu_present_mask
Refer to Documentation/cputopology.txt, CPUs that have been identified as being present in the system.
cpu_possible_bits / cpu_possible_mask
Refer to Documentation/cputopology.txt, CPUs that have been allocated resources and can be brought online if they are present.
cpu_online_bits / cpu_online_mask
Refer to Documentation/cputopology.txt, CPUs that are online and being scheduled.
cpu_active_bits / cpu_active_mask
表示目前处于可工作状态的处理器个数。
per-CPU Variables
17.5 与SMP有关的函数
smp_processor_id()
get the current CPU ID.
18 64-Bit Kernel
18.1 配置选项/编译选项
要启用64-bit Kernel,编译内核前需要配置选项(以x86架构为例):
CONFIG_64BIT=y
CONFIG_X86_64=y
在arch/x86/Makefile中,定义了如下编译选项:
# Unified Makefile for i386 and x86_64
# select defconfig based on actual architecture
ifeq ($(ARCH),x86)
KBUILD_DEFCONFIG := i386_defconfig
else
KBUILD_DEFCONFIG := $(ARCH)_defconfig
endif
# BITS is used as extension for files which are available in a 32 bit
# and a 64 bit version to simplify shared Makefiles.
# e.g.: obj-y += foo_$(BITS).o
export BITS
ifeq ($(CONFIG_X86_32),y)
BITS := 32
UTS_MACHINE := i386
CHECKFLAGS += -D__i386__
biarch := $(call cc-option,-m32)
KBUILD_AFLAGS += $(biarch)
KBUILD_CFLAGS += $(biarch)
ifdef CONFIG_RELOCATABLE
LDFLAGS_vmlinux := --emit-relocs
endif
KBUILD_CFLAGS += -msoft-float -mregparm=3 -freg-struct-return
# prevent gcc from keeping the stack 16 byte aligned
KBUILD_CFLAGS += $(call cc-option,-mpreferred-stack-boundary=2)
# Disable unit-at-a-time mode on pre-gcc-4.0 compilers, it makes gcc use
# a lot more stack due to the lack of sharing of stacklots:
KBUILD_CFLAGS += $(call cc-ifversion, -lt, 0400, $(call cc-option,-fno-unit-at-a-time))
# CPU-specific tuning. Anything which can be shared with UML should go here.
include $(srctree)/arch/x86/Makefile_32.cpu
KBUILD_CFLAGS += $(cflags-y)
# temporary until string.h is fixed
KBUILD_CFLAGS += -ffreestanding
else
BITS := 64
UTS_MACHINE := x86_64
CHECKFLAGS += -D__x86_64__ -m64
KBUILD_AFLAGS += -m64
KBUILD_CFLAGS += -m64
# FIXME - should be integrated in Makefile.cpu (Makefile_32.cpu)
cflags-$(CONFIG_MK8) += $(call cc-option,-march=k8)
cflags-$(CONFIG_MPSC) += $(call cc-option,-march=nocona)
cflags-$(CONFIG_MCORE2) += $(call cc-option,-march=core2,$(call cc-option,-mtune=generic))
cflags-$(CONFIG_MATOM) += $(call cc-option,-march=atom) \
$(call cc-option,-mtune=atom,$(call cc-option,-mtune=generic))
cflags-$(CONFIG_GENERIC_CPU) += $(call cc-option,-mtune=generic)
KBUILD_CFLAGS += $(cflags-y)
KBUILD_CFLAGS += -mno-red-zone
KBUILD_CFLAGS += -mcmodel=kernel
# -funit-at-a-time shrinks the kernel .text considerably
# unfortunately it makes reading oopses harder.
KBUILD_CFLAGS += $(call cc-option,-funit-at-a-time)
# this works around some issues with generating unwind tables in older gccs
# newer gccs do it by default
KBUILD_CFLAGS += -maccumulate-outgoing-args
endif
...
# Stackpointer is addressed different for 32 bit and 64 bit x86
sp-$(CONFIG_X86_32) := esp
sp-$(CONFIG_X86_64) := rsp
...
###
# Kernel objects
head-y := arch/x86/kernel/head_$(BITS).o
head-y += arch/x86/kernel/head$(BITS).o
可运行下列命令查看当前系统的配置:
chenwx@chenwx ~ $ uname -m
x86_64
18.2 64-Bit Kernel中数据类型的大小
宏BITS_PER_LONG定义于include/asm-generic/bitsperlong.h:
#ifdef CONFIG_64BIT
#define BITS_PER_LONG 64
#else
#define BITS_PER_LONG 32
#endif /* CONFIG_64BIT */
| C Type | 32-bit System / bits | 64-bit System / bits |
|---|---|---|
| char | 8 | 8 |
| short | 16 | 16 |
| float | 32 | 32 |
| double | 64 | 64 |
| int | 32 | 32 |
| long | 32 | 64 |
| long long | 64 | 64 |
| pointer | 32 | 64 |
18.3 Memory Management on 64-Bit Kernel
参见6.1.2.4 Paging for 64-bit Architectures节。
19 内核调试/Debug Kernel
Make sense of kernel data:
| System.map | kernel function addresses |
| /proc/kcore | image of system memory |
| vmlinux | the uncompressed kernel, can be disassembled using objdump |
19.1 内核调试选项
与内核调试有关的配置选项:
Kernel hacking --->
[*] Show timing information on printks // CONFIG_PRINTK_TIME
(4) Default message log level (1-7) // CONFIG_DEFAULT_MESSAGE_LOGLEVEL
[ ] Enable __deprecated logic // CONFIG_ENABLE_WARN_DEPRECATED
[ ] Enable __must_check logic // CONFIG_ENABLE_MUST_CHECK
(1024) Warn for stack frames larger than (needs gcc 4.4) // CONFIG_FRAME_WARN
-*- Magic SysRq key // CONFIG_MAGIC_SYSRQ
[ ] Strip assembler-generated symbols during link // CONFIG_STRIP_ASM_SYMS
[*] Enable unused/obsolete exported symbols // CONFIG_UNUSED_SYMBOLS
-*- Debug Filesystem // CONFIG_DEBUG_FS
[ ] Run 'make headers_check' when building vmlinux // CONFIG_HEADERS_CHECK
[ ] Enable full Section mismatch analysis // CONFIG_DEBUG_SECTION_MISMATCH
-*- Kernel debugging // CONFIG_DEBUG_KERNEL
[ ] Debug shared IRQ handlers // CONFIG_DEBUG_SHIRQ
[*] Detect Hard and Soft Lockups // CONFIG_LOCKUP_DETECTOR
[ ] Panic (Reboot) On Hard Lockups // CONFIG_BOOTPARAM_HARDLOCKUP_PANIC
[ ] Panic (Reboot) On Soft Lockups // CONFIG_BOOTPARAM_SOFTLOCKUP_PANIC
[*] Detect Hung Tasks // CONFIG_DETECT_HUNG_TASK
(120) Default timeout for hung task detection (in seconds) // CONFIG_DEFAULT_HUNG_TASK_TIMEOUT
[ ] Panic (Reboot) On Hung Tasks // CONFIG_BOOTPARAM_HUNG_TASK_PANIC
-*- Collect scheduler debugging info // CONFIG_SCHED_DEBUG
-*- Collect scheduler statistics // CONFIG_SCHEDSTATS
[*] Collect kernel timers statistics // CONFIG_TIMER_STATS
[ ] Debug object operations // CONFIG_DEBUG_OBJECTS
[ ] SLUB debugging on by default // CONFIG_SLUB_DEBUG_ON
[ ] Enable SLUB performance statistics // CONFIG_SLUB_STATS
[ ] Kernel memory leak detector // CONFIG_DEBUG_KMEMLEAK
[ ] RT Mutex debugging, deadlock detection // CONFIG_DEBUG_RT_MUTEXES
[ ] Built-in scriptable tester for rt-mutexes // CONFIG_RT_MUTEX_TESTER
[ ] Spinlock and rw-lock debugging: basic checks // CONFIG_DEBUG_SPINLOCK
[ ] Mutex debugging: basic checks // CONFIG_DEBUG_MUTEXES
[ ] Lock debugging: detect incorrect freeing of live locks // CONFIG_DEBUG_LOCK_ALLOC
[ ] Lock debugging: prove locking correctness // CONFIG_PROVE_LOCKING
[ ] Lock usage statistics // CONFIG_LOCK_STAT
[ ] Sleep inside atomic section checking // CONFIG_DEBUG_ATOMIC_SLEEP
[ ] Locking API boot-time self-tests // CONFIG_DEBUG_LOCKING_API_SELFTESTS
[ ] Stack utilization instrumentation // CONFIG_DEBUG_STACK_USAGE
[ ] kobject debugging // CONFIG_DEBUG_KOBJECT
[*] Verbose BUG() reporting (adds 70K) // CONFIG_DEBUG_BUGVERBOSE
[*] Compile the kernel with debug info // CONFIG_DEBUG_INFO
[ ] Reduce debugging information // CONFIG_DEBUG_INFO_REDUCED
[ ] Debug VM // CONFIG_DEBUG_VM
[ ] Debug VM translations // CONFIG_DEBUG_VIRTUAL
[ ] Debug filesystem writers count // CONFIG_DEBUG_WRITECOUNT
[*] Debug memory initialisation // CONFIG_DEBUG_MEMORY_INIT
[ ] Debug linked list manipulation // CONFIG_DEBUG_LIST
[ ] Linked list sorting test // CONFIG_TEST_LIST_SORT
[ ] Debug SG table operations // CONFIG_DEBUG_SG
[ ] Debug notifier call chains // CONFIG_DEBUG_NOTIFIERS
[ ] Debug credential management // CONFIG_DEBUG_CREDENTIALS
-*- Compile the kernel with frame pointers // CONFIG_FRAME_POINTER
[*] Delay each boot printk message by N milliseconds // CONFIG_BOOT_PRINTK_DELAY
RCU Debugging --->
< > torture tests for RCU // CONFIG_SPARSE_RCU_POINTER
(60) RCU CPU stall timeout in seconds // CONFIG_RCU_CPU_STALL_TIMEOUT
[ ] Kprobes sanity tests // CONFIG_KPROBES_SANITY_TEST
< > Self test for the backtrace code // CONFIG_BACKTRACE_SELF_TEST
[ ] Force extended block device numbers and spread them // CONFIG_DEBUG_BLOCK_EXT_DEVT
[ ] Force weak per-cpu definitions // CONFIG_DEBUG_FORCE_WEAK_PER_CPU
[ ] Debug access to per_cpu maps // CONFIG_DEBUG_PER_CPU_MAPS
< > Linux Kernel Dump Test Tool Module // CONFIG_LKDTM
<*> Notifier error injection
<M> CPU notifier error injection module // CONFIG_CPU_NOTIFIER_ERROR_INJECT
[ ] Fault-injection framework // CONFIG_FAULT_INJECTION
[*] Latency measuring infrastructure // CONFIG_LATENCYTOP
[*] Tracers --->
-*- Kernel Function Tracer // CONFIG_FUNCTION_TRACER
[*] Kernel Function Graph Tracer // CONFIG_FUNCTION_GRAPH_TRACER
[ ] Interrupts-off Latency Tracer // CONFIG_IRQSOFF_TRACER
[*] Scheduling Latency Tracer // CONFIG_SCHED_TRACER
[*] Trace syscalls // CONFIG_FTRACE_SYSCALLS
Branch Profiling (No branch profiling) --->
(X) No branch profiling // CONFIG_BRANCH_PROFILE_NONE
( ) Trace likely/unlikely profiler // CONFIG_PROFILE_ANNOTATED_BRANCHES
( ) Profile all if conditionals // CONFIG_PROFILE_ALL_BRANCHES
[*] Trace max stack // CONFIG_STACK_TRACER
[*] Support for tracing block IO actions // CONFIG_BLK_DEV_IO_TRACE
[*] Enable kprobes-based dynamic events // CONFIG_KPROBE_EVENT
[*] enable/disable ftrace tracepoints dynamically // CONFIG_DYNAMIC_FTRACE
[*] Kernel function profiler // CONFIG_FUNCTION_PROFILER
[ ] Perform a startup test on ftrace // CONFIG_FTRACE_STARTUP_TEST
[*] Memory mapped IO tracing // CONFIG_MMIOTRACE
< > Test module for mmiotrace // CONFIG_MMIOTRACE_TEST
< > Ring buffer benchmark stress tester // CONFIG_RING_BUFFER_BENCHMARK
[ ] Remote debugging over FireWire early on boot // CONFIG_PROVIDE_OHCI1394_DMA_INIT
[ ] Remote debugging over FireWire with firewire-ohci // CONFIG_FIREWIRE_OHCI_REMOTE_DMA
[ ] Enable dynamic printk() support // CONFIG_DYNAMIC_DEBUG
[ ] Enable debugging of DMA-API usage // CONFIG_DMA_API_DEBUG
[ ] Perform an atomic64_t self-test at boot // CONFIG_ATOMIC64_SELFTEST
<M> Self test for hardware accelerated raid6 recovery // CONFIG_ASYNC_RAID6_TEST
[ ] Sample kernel code --->
[*] KGDB: kernel debugger --->
<*> KGDB: use kgdb over the serial console // CONFIG_KGDB_SERIAL_CONSOLE
[ ] KGDB: internal test suite // CONFIG_KGDB_TESTS
[*] KGDB: Allow debugging with traps in notifiers // CONFIG_KGDB_LOW_LEVEL_TRAP
[*] KGDB_KDB: include kdb frontend for kgdb // CONFIG_KGDB_KDB
[*] KGDB_KDB: keyboard as input device // CONFIG_KDB_KEYBOARD
[*] Filter access to /dev/mem // CONFIG_STRICT_DEVMEM
[ ] Enable verbose x86 bootup info messages // CONFIG_X86_VERBOSE_BOOTUP
[*] Early printk // CONFIG_EARLY_PRINTK
[*] Early printk via EHCI debug port // CONFIG_EARLY_PRINTK_DBGP
[ ] Check for stack overflows // CONFIG_DEBUG_STACKOVERFLOW
[ ] Export kernel pagetable layout to userspace via debugfs // CONFIG_X86_PTDUMP
[*] Write protect kernel read-only data structures // CONFIG_DEBUG_RODATA
[ ] Testcase for the DEBUG_RODATA feature // CONFIG_DEBUG_RODATA_TEST
[*] Set loadable kernel module data as NX and text as RO // CONFIG_DEBUG_SET_MODULE_RONX
< > Testcase for the NX non-executable stack feature // CONFIG_DEBUG_NX_TEST
[ ] Enable IOMMU stress-test mode // CONFIG_IOMMU_STRESS
[ ] x86 instruction decoder selftest // CONFIG_X86_DECODER_SELFTEST
[ ] Debug boot parameters // CONFIG_DEBUG_BOOT_PARAMS
[ ] CPA self-test code // CONFIG_CPA_DEBUG
[*] Allow gcc to uninline functions marked 'inline' // CONFIG_OPTIMIZE_INLINING
[ ] Strict copy size checks // CONFIG_DEBUG_STRICT_USER_COPY_CHECKS
19.2 打印调试信息
19.2.1 内核日志系统
19.2.1.0 内核日志系统架构
内核日志系统层次结构,参见:
19.2.1.1 Ring log buffer - log_buf
环形缓冲区log_buf用于保存系统日志,通过如下变量访问该缓冲区,参见kernel/printk.c:
#ifdef CONFIG_PRINTK
/*
* logbuf_lock protects log_buf, log_start, log_end, con_start and logged_chars.
* It is also used in interesting ways to provide interlocking in
* console_unlock();.
*/
static DEFINE_RAW_SPINLOCK(logbuf_lock);
#define LOG_BUF_MASK (log_buf_len-1)
#define LOG_BUF(idx) (log_buf[(idx) & LOG_BUF_MASK])
/*
* The indices into log_buf are not constrained to log_buf_len - they
* must be masked before subscripting
*/
static unsigned log_start; /* Index into log_buf: next char to be read by syslog() */
static unsigned con_start; /* Index into log_buf: next char to be sent to consoles */
static unsigned log_end; /* Index into log_buf: most-recently-written-char + 1 */
#endif
19.2.1.1.1 默认分配的log_buf
The printk function writes messages into a circular buffer that is __LOG_BUF_LEN bytes long: a value from 4 KB to 1 MB chosen while configuring the kernel by CONFIG_LOG_BUF_SHIFT.
The printk function then wakes any process that is waiting for messages, that is, any process that is sleeping in the syslog system call or that is reading /proc/kmsg. These two interfaces to the logging engine are almost equivalent, but note that reading from /proc/kmsg consumes the data from the log buffer, whereas the syslog system call can optionally return log data while leaving it for other processes as well. In general, reading the /proc/kmsg file is easier and is the default behavior for klogd. The dmesg command can be used to look at the content of the buffer without flushing it; actually, the command returns to stdout the whole content of the buffer, whether or not it has already been read.
默认情况下,环形缓冲区log_buf为数组__log_buf[__LOG_BUF_LEN],其定义于kernel/printk.c:
#ifdef CONFIG_PRINTK
/*
* 环形缓冲区log_buf的长度为__LOG_BUF_LEN,
* 其由配置项CONFIG_LOG_BUF_SHIFT配置,
* 默认取值为17,即环形缓冲区长度为128KB
*/
#define __LOG_BUF_LEN (1 << CONFIG_LOG_BUF_SHIFT)
static char __log_buf[__LOG_BUF_LEN];
static char *log_buf = __log_buf;
/*
* 环形缓冲区为log_buf,长度为log_buf_len,
* 通过宏LOG_BUF(idx)访问该缓冲区
*/
static int log_buf_len = __LOG_BUF_LEN;
#define LOG_BUF_MASK (log_buf_len-1)
#define LOG_BUF(idx) (log_buf[(idx) & LOG_BUF_MASK])
#endif
19.2.1.1.2 通过内核参数log_buf_len分配的log_buf
若指定了内核参数log_buf_len,且其值大于当前缓冲区的长度log_buf_len,则重新分配缓冲区log_buf。内核参数log_buf_len定义于kernel/printk.c:
/* requested log_buf_len from kernel cmdline */
static unsigned long __initdata new_log_buf_len;
/* save requested log_buf_len since it's too early to process it */
static int __init log_buf_len_setup(char *str)
{
unsigned size = memparse(str, &str);
if (size)
size = roundup_pow_of_two(size);
/*
* 若请求的缓冲区长度大于默认缓冲区的长度,即__log_buf[__LOG_BUF_LEN],
* 则重新分配缓冲区;否则,无需分配新的缓冲区。参见函数setup_log_buf()
*/
if (size > log_buf_len)
new_log_buf_len = size;
return 0;
}
early_param("log_buf_len", log_buf_len_setup);
而函数setup_log_buf()用于重新分配长度为new_log_buf_len的缓冲区log_buf,其调用关系如下:
start_kernel() // 参见[4.3.4.1.4.3 start_kernel()]节
-> setup_arch()
-> setup_log_buf(1) // 由具体的体系架构决定是否调用setup_log_buf();X86体系架构会调用该函数
-> setup_log_buf(0) // 若某体系架构不调用setup_log_buf(),则在此处调用该函数;否则,该函数直接返回
其定义于kernel/printk.c:
void __init setup_log_buf(int early)
{
unsigned long flags;
unsigned start, dest_idx, offset;
char *new_log_buf;
int free;
if (!new_log_buf_len) // (1) 本函数只被调用一次
return;
if (early) {
unsigned long mem;
mem = memblock_alloc(new_log_buf_len, PAGE_SIZE);
if (mem == MEMBLOCK_ERROR)
return;
new_log_buf = __va(mem);
} else {
new_log_buf = alloc_bootmem_nopanic(new_log_buf_len);
}
if (unlikely(!new_log_buf)) {
pr_err("log_buf_len: %ld bytes not available\n", new_log_buf_len);
return;
}
raw_spin_lock_irqsave(&logbuf_lock, flags);
log_buf_len = new_log_buf_len;
log_buf = new_log_buf;
new_log_buf_len = 0; // (2) 本函数只被调用一次
free = __LOG_BUF_LEN - log_end;
offset = start = min(con_start, log_start);
dest_idx = 0;
while (start != log_end) {
unsigned log_idx_mask = start & (__LOG_BUF_LEN - 1);
log_buf[dest_idx] = __log_buf[log_idx_mask];
start++;
dest_idx++;
}
log_start -= offset;
con_start -= offset;
log_end -= offset;
raw_spin_unlock_irqrestore(&logbuf_lock, flags);
pr_info("log_buf_len: %d\n", log_buf_len);
pr_info("early log buf free: %d(%d%%)\n", free, (free * 100) / __LOG_BUF_LEN);
}
19.2.1.2 Log levels
One of the differences between printf() and printk() is that printk lets you classify messages according to their severity by associating different loglevels, or priorities, with the messages. The loglevel macro expands to a string, which is concatenated to the message text at compile time; that’s why there is no comma between the priority and the format string in the following example:
printk(KERN_CRIT "Hello, world!\n");
There are eight possible loglevel strings, defined in the header include/linux/kernel.h:
/*
* dmesg -t: Print all messages, but don't print kernel's timestampts
* dmesg -t -k: Print kernel messages
* dmesg -t -l <level>: 打印不同级别的信息,如下表所示,<level>参见dmesg --help
*/
#define KERN_EMERG "<0>" /* system is unusable */ // dmesg -t -l emerg
#define KERN_ALERT "<1>" /* action must be taken immediately */ // dmesg -t -l alert
#define KERN_CRIT "<2>" /* critical conditions */ // dmesg -t -l crit
#define KERN_ERR "<3>" /* error conditions */ // dmesg -t -l err
#define KERN_WARNING "<4>" /* warning conditions */ // dmesg -t -l warn
#define KERN_NOTICE "<5>" /* normal but significant condition */ // dmesg -t -l notice
#define KERN_INFO "<6>" /* informational */ // dmesg -t -l info
#define KERN_DEBUG "<7>" /* debug-level messages */ // dmesg -t -l debug
/* Use the default kernel loglevel */
#define KERN_DEFAULT "<d>"
/*
* Annotation for a "continued" line of log printout (only done after a
* line that had no enclosing \n). Only to be used by core/arch code
* during early bootup (a continued line is not SMP-safe otherwise).
* 日志行继续,以避免增加新的时间截
*/
#define KERN_CONT "<c>"
每种日志级别都有对应的宏来简化日志函数的使用,参见19.2.1.4.3 pr_debug()/pr_xxx()节。
NOTE 1: A printk statement with no specified priority defaults to DEFAULT_MESSAGE_LOGLEVEL, specified in kernel/printk.c as an integer. In the 2.6.10 kernel, DEFAULT_MESSAGE_LOGLEVEL is KERN_WARNING, but that has been known to change in the past.
NOTE 2: 使用下列命令可以显示日志中的级别信息:
chenwx@chenwx ~/linux $ dmesg -r
<7>[ 7.817513] ieee80211 phy0: Selected rate control algorithm 'minstrel_ht'
<6>[ 7.817975] ath5k: phy0: Atheros AR2425 chip found (MAC: 0xe2, PHY: 0x70)
<6>[ 8.408874] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
<12>[ 8.626111] init: plymouth-upstart-bridge main process ended, respawning
<6>[ 9.572093] floppy0: no floppy controllers found
<6>[ 9.681009] e1000e: eth0 NIC Link is Up 100 Mbps Full Duplex, Flow Control: Rx/Tx
<6>[ 9.681128] e1000e 0000:00:19.0 eth0: 10/100 speed: disabling TSO
<6>[ 9.681177] IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
<12>[ 11.492704] init: plymouth-stop pre-start process (1771) terminated with status 1
...
19.2.1.3 console_loglevel
Based on the loglevel, the kernel may print the message to the current console, be it a text-mode terminal, a serial port, or a parallel printer. If the priority is less than the integer variable console_loglevel, the message is delivered to the console one line at a time (nothing is sent unless a trailing newline is provided). That’s, if variable console_loglevel is set to 1, only messages of level 0 (KERN_EMERG) reach the console; if it’s set to 8, all messages, including debugging ones, are displayed.
变量console_loglevel定义于include/linux/printk.h:
extern int console_printk[];
#define console_loglevel (console_printk[0])
#define default_message_loglevel (console_printk[1])
#define minimum_console_loglevel (console_printk[2])
#define default_console_loglevel (console_printk[3])
其中,数组console_printk[]定义于kernel/printk.c:
/*
* CONFIG_DEFAULT_MESSAGE_LOGLEVEL是由如下配置选项设置的,其默认值为4
* Kernel hacking --->
* (4) Default message log level (1-7)
* /
/* printk's without a loglevel use this.. */
#define DEFAULT_MESSAGE_LOGLEVEL CONFIG_DEFAULT_MESSAGE_LOGLEVEL
/* We show everything that is MORE important than this.. */
#define MINIMUM_CONSOLE_LOGLEVEL 1 /* Minimum loglevel we let people use */
#define DEFAULT_CONSOLE_LOGLEVEL 7 /* anything MORE serious than KERN_DEBUG */
int console_printk[4] = {
DEFAULT_CONSOLE_LOGLEVEL, /* console_loglevel */
DEFAULT_MESSAGE_LOGLEVEL, /* default_message_loglevel */
MINIMUM_CONSOLE_LOGLEVEL, /* minimum_console_loglevel */
DEFAULT_CONSOLE_LOGLEVEL, /* default_console_loglevel */
};
The variable console_loglevel is initialized to DEFAULT_CONSOLE_LOGLEVEL and can be modified via following methods:
19.2.1.3.1 通过内核参数更改console_loglevel的取值
可以通过内核参数debug,quiet和loglevel来更改console_loglevel的取值,参见init/main.c:
static int __init debug_kernel(char *str)
{
// 即将所有级别的日志信息都打印到console上
console_loglevel = 10;
return 0;
}
static int __init quiet_kernel(char *str)
{
// 即将级别高于KERN_WARNING的日志信息打印到console上
console_loglevel = 4;
return 0;
}
// 函数early_param(),参见[4.3.4.1.4.3.3.2.1 early_param()/__setup()]节
early_param("debug", debug_kernel);
early_param("quiet", quiet_kernel);
static int __init loglevel(char *str)
{
int newlevel;
/*
* Only update loglevel value when a correct setting was passed,
* to prevent blind crashes (when loglevel being set to 0) that
* are quite hard to debug
*/
if (get_option(&str, &newlevel)) {
console_loglevel = newlevel;
return 0;
}
return -EINVAL;
}
early_param("loglevel", loglevel);
19.2.1.3.2 通过系统调用sys_syslog()更改console_loglevel的取值
19.2.1.3.2.1 dmesg -c
可通过下列命令更改console_loglevel的取值:
# dmesg -c <new_loglevel>
Man page of dmesg:
SYNOPSIS
dmesg [-c] [-r] [-n level] [-s bufsize]
DESCRIPTION
dmesg is used to examine or control the kernel ring buffer.
The program helps users to print out their bootup messages. Instead of copying the messages
by hand, the user need only:
dmesg > boot.messages
and mail the boot.messages file to whoever can debug their problem.
OPTIONS
-c Clear the ring buffer contents after printing.
-r Print the raw message buffer, i.e., don't strip the log level prefixes.
-s bufsize
Use a buffer of size bufsize to query the kernel ring buffer. This is 16392 by
default. (The default kernel syslog buffer size was 4096 at first, 8192 since
1.3.54, 16384 since 2.1.113.) If you have set the kernel buffer to be larger than
the default then this option can be used to view the entire buffer.
-n level
Set the level at which logging of messages is done to the console. For example,
-n 1 prevents all messages, except panic messages, from appearing on the console.
All levels of messages are still written to /proc/kmsg, so syslogd(8) can still
be used to control exactly where kernel messages appear. When the -n option is
used, dmesg will not print or clear the kernel ring buffer.
When both options are used, only the last option on the command line will have an
effect.
SEE ALSO
syslogd(8)
AVAILABILITY
The dmesg command is part of the util-linux-ng package and is available from
ftp://ftp.kernel.org/pub/linux/utils/util-linux-ng/.
NOTE: 不管console loglevel的取值为多少,dmesg始终都是可以打印出所有级别的日志信息!
dmesg通过调用系统调用sys_syslog()(参见19.2.1.5 系统调用sys_syslog()节)来更改console_loglevel的取值:
chenwx@chenwx-VirtualBox ~ $ strace dmesg
execve("/bin/dmesg", ["dmesg"], [/* 34 vars */]) = 0
brk(0) = 0x91a1000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb77b0000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=60459, ...}) = 0
mmap2(NULL, 60459, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb77a1000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/libc.so.6", O_RDONLY) = 3
read(3, "\177ELF\1\1\1\0\0\0\0\0\0\0\0\0\3\0\3\0\1\0\0\0@n\1\0004\0\0\0"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0755, st_size=1421892, ...}) = 0
mmap2(NULL, 1431976, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x28d000
mprotect(0x3e4000, 4096, PROT_NONE) = 0
mmap2(0x3e5000, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x157) = 0x3e5000
mmap2(0x3e8000, 10664, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x3e8000
close(3) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb77a0000
set_thread_area({entry_number:-1 -> 6, base_addr:0xb77a06c0, limit:1048575, seg_32bit:1, contents:0, read_exec_only:0, limit_in_pages:1, seg_not_present:0, useable:1}) = 0
mprotect(0x3e5000, 8192, PROT_READ) = 0
mprotect(0x8049000, 4096, PROT_READ) = 0
mprotect(0xb72000, 4096, PROT_READ) = 0
munmap(0xb77a1000, 60459) = 0
brk(0) = 0x91a1000
brk(0x91c2000) = 0x91c2000
open("/usr/lib/locale/locale-archive", O_RDONLY|O_LARGEFILE) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=8576432, ...}) = 0
mmap2(NULL, 2097152, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb75a0000
mmap2(NULL, 4096, PROT_READ, MAP_PRIVATE, 3, 0x2a1) = 0xb77af000
close(3) = 0
syslog(0xa, 0, 0) = 131072
syslog(0x3, 0x91a1880, 0x20008) = 0
exit_group(0) = ?
示例如下:
chenwx@chenwx ~ $ sudo dmesg -n 7
[sudo] password for chenwx:
chenwx@chenwx ~ $ cat /proc/sys/kernel/printk
7 4 1 7
chenwx@chenwx ~ $ sudo dmesg -n 3
chenwx@chenwx ~ $ cat /proc/sys/kernel/printk
3 4 1 7
19.2.1.3.2.2 klogd -c
The variable console_loglevel can be modified by sys_syslog system call, for instance:
- 1) kill klogd
- 2) run command “klogd -c
" to restart klogd
klogd参见19.2.1.7.1 klogd+syslogd节。
19.2.1.3.3 通过文件/proc/sys/kernel/printk更改console_loglevel的取值
It is also possible to read and modify the console loglevel using the text file /proc/sys/kernel/printk, see 19.2.1.6.2 /proc/sys/kernel/printk.
19.2.1.4 printk()/early_printk()
Another feature of the Linux approach to messaging is that printk can be invoked from anywhere, even from an interrupt handler, with no limit on how much data can be printed. The only disadvantage is the possibility of losing some data.
函数printk()用于将日志消息写入内核日志缓冲区log_buf中,其定义于kernel/printk.c:
#ifdef CONFIG_PRINTK
/**
* printk - print a kernel message
* @fmt: format string
*
* This is printk(). It can be called from any context. We want it to work.
*
* We try to grab the console_lock. If we succeed, it's easy - we log the output and
* call the console drivers. If we fail to get the semaphore we place the output
* into the log buffer and return. The current holder of the console_sem will
* notice the new output in console_unlock(); and will send it to the
* consoles before releasing the lock.
*
* One effect of this deferred printing is that code which calls printk() and
* then changes console_loglevel may break. This is because console_loglevel
* is inspected when the actual printing occurs.
*
* See also:
* printf(3)
*
* See the vsnprintf() documentation for format string extensions over C99.
*/
asmlinkage int printk(const char *fmt, ...)
{
va_list args;
int r;
#ifdef CONFIG_KGDB_KDB
if (unlikely(kdb_trap_printk)) {
va_start(args, fmt);
r = vkdb_printf(fmt, args);
va_end(args);
return r;
}
#endif
va_start(args, fmt);
r = vprintk(fmt, args);
va_end(args);
return r;
}
#endif
asmlinkage int vprintk(const char *fmt, va_list args)
{
int printed_len = 0;
int current_log_level = default_message_loglevel;
unsigned long flags;
int this_cpu;
char *p;
size_t plen;
char special;
boot_delay_msec();
printk_delay();
preempt_disable();
/* This stops the holder of console_sem just where we want him */
raw_local_irq_save(flags);
this_cpu = smp_processor_id();
/*
* Ouch, printk recursed into itself!
*/
if (unlikely(printk_cpu == this_cpu)) {
/*
* If a crash is occurring during printk() on this CPU,
* then try to get the crash message out but make sure
* we can't deadlock. Otherwise just return to avoid the
* recursion and return - but flag the recursion so that
* it can be printed at the next appropriate moment:
*/
if (!oops_in_progress) {
recursion_bug = 1;
goto out_restore_irqs;
}
zap_locks();
}
lockdep_off();
raw_spin_lock(&logbuf_lock);
printk_cpu = this_cpu;
if (recursion_bug) {
recursion_bug = 0;
strcpy(printk_buf, recursion_bug_msg);
printed_len = strlen(recursion_bug_msg);
}
/* Emit the output into the temporary buffer */
printed_len += vscnprintf(printk_buf + printed_len,
sizeof(printk_buf) - printed_len, fmt, args);
p = printk_buf;
/* Read log level and handle special printk prefix */
plen = log_prefix(p, ¤t_log_level, &special);
if (plen) {
p += plen;
switch (special) {
case 'c': /* Strip <c> KERN_CONT, continue line */
plen = 0;
break;
case 'd': /* Strip <d> KERN_DEFAULT, start new line */
plen = 0;
default:
if (!new_text_line) {
emit_log_char('\n');
new_text_line = 1;
}
}
}
/*
* Copy the output into log_buf. If the caller didn't provide
* the appropriate log prefix, we insert them here
*/
for (; *p; p++) {
if (new_text_line) {
new_text_line = 0;
if (plen) {
/* Copy original log prefix */
int i;
for (i = 0; i < plen; i++)
emit_log_char(printk_buf[i]);
printed_len += plen;
} else {
/* Add log prefix */
emit_log_char('<');
emit_log_char(current_log_level + '0');
emit_log_char('>');
printed_len += 3;
}
if (printk_time) {
/* Add the current time stamp */
char tbuf[50], *tp;
unsigned tlen;
unsigned long long t;
unsigned long nanosec_rem;
t = cpu_clock(printk_cpu);
nanosec_rem = do_div(t, 1000000000);
tlen = sprintf(tbuf, "[%5lu.%06lu] ",
(unsigned long) t,
nanosec_rem / 1000);
for (tp = tbuf; tp < tbuf + tlen; tp++)
emit_log_char(*tp);
printed_len += tlen;
}
if (!*p)
break;
}
emit_log_char(*p);
if (*p == '\n')
new_text_line = 1;
}
/*
* Try to acquire and then immediately release the
* console semaphore. The release will do all the
* actual magic (print out buffers, wake up klogd,
* etc).
*
* The console_trylock_for_printk() function
* will release 'logbuf_lock' regardless of whether it
* actually gets the semaphore or not.
*/
if (console_trylock_for_printk(this_cpu))
console_unlock();
lockdep_on();
out_restore_irqs:
raw_local_irq_restore(flags);
preempt_enable();
return printed_len;
}
#endif
NOTE: 在系统启动过程中,终端初始化之前的某些地方无法调用函数printk()。若需要调试系统启动过程最开始的地方,可用如下方法:
- 1) 使用串口调试,将调试信息输出到其他终端设备。
- 2) 使用early_printk(),该函数在系统启动初期就有打印能力,但仅支持部分硬件体系。
函数early_printk()定义于arch/x86/kernel/early_printk.c:
static struct console early_vga_console = {
.name = "earlyvga",
.write = early_vga_write,
.flags = CON_PRINTBUFFER,
.index = -1,
};
static struct console *early_console = &early_vga_console;
asmlinkage void early_printk(const char *fmt, ...)
{
char buf[512];
int n;
va_list ap;
va_start(ap, fmt);
n = vscnprintf(buf, sizeof(buf), fmt, ap);
early_console->write(early_console, buf, n);
va_end(ap);
}
19.2.1.4.0 DEBUG macro
可在Makefile中定义宏DEBUG,例如:
obj-m := helloworld.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
ccflags-y += -DDEBUG
all:
make -C $(KDIR) M=$(PWD) modules
clean:
make -C $(KDIR) M=$(PWD) clean
或者,在源文件中定义DEBUG宏,例如:
#define DEBUG 1
#include <device.h>
...
dev_dbg("%s %s\n", info1, info2);
19.2.1.4.1 CONFIG_DYNAMIC_DEBUG macro
See Documentation/dynamic-debug-howto.txt
Dynamic debug is designed to allow you to dynamically enable/disable kernel code to obtain additional kernel information. Currently, if CONFIG_DYNAMIC_DEBUG is set, then all pr_debug()/dev_dbg() calls can be dynamically enabled per-callsite.
Dynamic debug has even more useful features:
- Simple query language allows turning on and off debugging statements by matching any combination of:
- source filename
- function name
- line number (including ranges of line numbers)
- module name
- format string
- Provides a debugfs control file:
<debugfs>/dynamic_debug/controlwhich can be read to display the complete list of known debug statements, to help guide you. See section Debugfs.
19.2.1.4.1.1 在内核模块加载过程中打开动态调试功能
使用modprobe命令加载模块时,加上选项dyndbg='plmft'。
19.2.1.4.1.2 让内核模块的动态调试功能在重启后依然有效
编辑/etc/modprobe.d/modname.conf文件(若没有该文件就创建一个),添加选项dyndbg='plmft'。然而,对于那些通过initramfs加载的驱动来说,该配置基本无效。对于这类驱动,需要修改grub配置文件,在kernel那行添加参数module.dyndbg='plmft',这样你的驱动就可以开机启动动态调试功能了。要打印更详细的调试信息,使用选项dynamic_debug.verbose=1。
NOTE: 系统启动时,需要先让initramfs挂载一个虚拟的文件系统,然后再挂载启动盘上的真实文件系统。这个虚拟文件系统里面的文件是initramfs自己提供的,即在真实文件系统下面配置了文件/etc/modprobe.d/modname.conf,而initramfs是不去理会的。在内核驱动的角度看,如果内核驱动在initramfs过程中被加载到内核,这个驱动读取到的/etc/modprobe.d/modname.conf是initramfs提供的,而不是你编辑的那个,所以会有上述”写了配置文件后重启依然无效”的结论。
19.2.1.4.2 Different print styles
Each kernel subsystem usually has its own printk format. So when you are using network subsystem, you have to use netdev_dbg; when you are using V4L you have to use v4l_dbg. It standardizes the output format within the subsystem. Depending on what you are coding you should use a different print style:
printk() |
never |
pr_debug() |
always good |
dev_dbg() |
prefered when you have a struct device object |
netdev_dbg() |
prefered when you have a struct netdevice object |
[something]_dbg() |
prefered when you have a that something object |
19.2.1.4.3 pr_debug()/pr_xxx()
19.2.1.2 Log levels节中的每种日志级别都有对应的宏来简化日志函数的使用,其定义于include/linux/printk.h:
#ifndef pr_fmt
#define pr_fmt(fmt) fmt
#endif
/*
* If you are writing a driver, please use dev_dbg instead.
* 参见[19.2.1.4.4 dev_dbg()/dev_xxx()]节
*/
#if defined(DEBUG)
#define pr_debug(fmt, ...) printk(KERN_DEBUG pr_fmt(fmt), ##__VA_ARGS__)
#elif defined(CONFIG_DYNAMIC_DEBUG)
/* dynamic_pr_debug() uses pr_fmt() internally so we don't need it here */
#define pr_debug(fmt, ...) dynamic_pr_debug(fmt, ##__VA_ARGS__)
#else
#define pr_debug(fmt, ...) no_printk(KERN_DEBUG pr_fmt(fmt), ##__VA_ARGS__)
#endif
/*
* 下列为每种日志级别对应的宏
*/
#define pr_emerg(fmt, ...) printk(KERN_EMERG pr_fmt(fmt), ##__VA_ARGS__)
#define pr_alert(fmt, ...) printk(KERN_ALERT pr_fmt(fmt), ##__VA_ARGS__)
#define pr_crit(fmt, ...) printk(KERN_CRIT pr_fmt(fmt), ##__VA_ARGS__)
#define pr_err(fmt, ...) printk(KERN_ERR pr_fmt(fmt), ##__VA_ARGS__)
#define pr_warning(fmt, ...) printk(KERN_WARNING pr_fmt(fmt), ##__VA_ARGS__)
#define pr_warn pr_warning
#define pr_notice(fmt, ...) printk(KERN_NOTICE pr_fmt(fmt), ##__VA_ARGS__)
#define pr_info(fmt, ...) printk(KERN_INFO pr_fmt(fmt), ##__VA_ARGS__)
#define pr_cont(fmt, ...) printk(KERN_CONT fmt, ##__VA_ARGS__)
/* pr_devel() should produce zero code unless DEBUG is defined */
#ifdef DEBUG
#define pr_devel(fmt, ...) printk(KERN_DEBUG pr_fmt(fmt), ##__VA_ARGS__)
#else
#define pr_devel(fmt, ...) no_printk(KERN_DEBUG pr_fmt(fmt), ##__VA_ARGS__)
#endif
19.2.1.4.4 dev_dbg()/dev_xxx()
宏dev_dbg()定义于include/linux/device.h:
#if defined(DEBUG)
#define dev_dbg(dev, format, arg...) \
dev_printk(KERN_DEBUG, dev, format, ##arg)
#elif defined(CONFIG_DYNAMIC_DEBUG)
#define dev_dbg(dev, format, ...) \
do { \
dynamic_dev_dbg(dev, format, ##__VA_ARGS__); \
} while (0)
#else
#define dev_dbg(dev, format, arg...) \
({ \
if (0) \
dev_printk(KERN_DEBUG, dev, format, ##arg); \
0; \
})
#endif
宏dev_xxx()用于打印设备有关的调试信息,其定义于include/linux/device.h:
#ifdef CONFIG_PRINTK
extern __printf(3, 0)
int dev_vprintk_emit(int level, const struct device *dev, const char *fmt, va_list args);
extern __printf(3, 4)
int dev_printk_emit(int level, const struct device *dev, const char *fmt, ...);
extern __printf(3, 4)
int dev_printk(const char *level, const struct device *dev, const char *fmt, ...);
extern __printf(2, 3)
int dev_emerg(const struct device *dev, const char *fmt, ...);
extern __printf(2, 3)
int dev_alert(const struct device *dev, const char *fmt, ...);
extern __printf(2, 3)
int dev_crit(const struct device *dev, const char *fmt, ...);
extern __printf(2, 3)
int dev_err(const struct device *dev, const char *fmt, ...);
extern __printf(2, 3)
int dev_warn(const struct device *dev, const char *fmt, ...);
extern __printf(2, 3)
int dev_notice(const struct device *dev, const char *fmt, ...);
extern __printf(2, 3)
int _dev_info(const struct device *dev, const char *fmt, ...);
#else
...
#endif
#define dev_info(dev, fmt, arg...) _dev_info(dev, fmt, ##arg)
19.2.1.4.5 print_hex_dump()/print_hex_dump_bytes()
宏print_hex_dump()和print_hex_dump_bytes()声明于include/linux/printk.h:
#ifdef CONFIG_PRINTK
extern void print_hex_dump(const char *level, const char *prefix_str,
int prefix_type, int rowsize, int groupsize,
const void *buf, size_t len, bool ascii);
extern void print_hex_dump_bytes(const char *prefix_str, int prefix_type,
const void *buf, size_t len);
#else
static inline void print_hex_dump(const char *level, const char *prefix_str,
int prefix_type, int rowsize, int groupsize,
const void *buf, size_t len, bool ascii)
{
}
static inline void print_hex_dump_bytes(const char *prefix_str, int prefix_type,
const void *buf, size_t len)
{
}
#endif
定义于lib/hexdump.c:
#ifdef CONFIG_PRINTK
/**
* print_hex_dump - print a text hex dump to syslog for a binary blob of data
* @level: kernel log level (e.g. KERN_DEBUG)
* @prefix_str: string to prefix each line with;
* caller supplies trailing spaces for alignment if desired
* @prefix_type: controls whether prefix of an offset, address, or none
* is printed (%DUMP_PREFIX_OFFSET, %DUMP_PREFIX_ADDRESS, %DUMP_PREFIX_NONE)
* @rowsize: number of bytes to print per line; must be 16 or 32
* @groupsize: number of bytes to print at a time (1, 2, 4, 8; default = 1)
* @buf: data blob to dump
* @len: number of bytes in the @buf
* @ascii: include ASCII after the hex output
*
* Given a buffer of u8 data, print_hex_dump() prints a hex + ASCII dump
* to the kernel log at the specified kernel log level, with an optional
* leading prefix.
*
* print_hex_dump() works on one "line" of output at a time, i.e.,
* 16 or 32 bytes of input data converted to hex + ASCII output.
* print_hex_dump() iterates over the entire input @buf, breaking it into
* "line size" chunks to format and print.
*
* E.g.:
* print_hex_dump(KERN_DEBUG, "raw data: ", DUMP_PREFIX_ADDRESS,
* 16, 1, frame->data, frame->len, true);
*
* Example output using %DUMP_PREFIX_OFFSET and 1-byte mode:
* 0009ab42: 40 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f @ABCDEFGHIJKLMNO
* Example output using %DUMP_PREFIX_ADDRESS and 4-byte mode:
* ffffffff88089af0: 73727170 77767574 7b7a7978 7f7e7d7c pqrstuvwxyz{|}~.
*/
void print_hex_dump(const char *level, const char *prefix_str, int prefix_type,
int rowsize, int groupsize,
const void *buf, size_t len, bool ascii)
{
const u8 *ptr = buf;
int i, linelen, remaining = len;
unsigned char linebuf[32 * 3 + 2 + 32 + 1];
if (rowsize != 16 && rowsize != 32)
rowsize = 16;
for (i = 0; i < len; i += rowsize) {
linelen = min(remaining, rowsize);
remaining -= rowsize;
hex_dump_to_buffer(ptr + i, linelen, rowsize, groupsize,
linebuf, sizeof(linebuf), ascii);
switch (prefix_type) {
case DUMP_PREFIX_ADDRESS:
printk("%s%s%p: %s\n", level, prefix_str, ptr + i, linebuf);
break;
case DUMP_PREFIX_OFFSET:
printk("%s%s%.8x: %s\n", level, prefix_str, i, linebuf);
break;
default:
printk("%s%s%s\n", level, prefix_str, linebuf);
break;
}
}
}
EXPORT_SYMBOL(print_hex_dump);
/**
* print_hex_dump_bytes - shorthand form of print_hex_dump() with default params
* @prefix_str: string to prefix each line with;
* caller supplies trailing spaces for alignment if desired
* @prefix_type: controls whether prefix of an offset, address, or none
* is printed (%DUMP_PREFIX_OFFSET, %DUMP_PREFIX_ADDRESS, %DUMP_PREFIX_NONE)
* @buf: data blob to dump
* @len: number of bytes in the @buf
*
* Calls print_hex_dump(), with log level of KERN_DEBUG,
* rowsize of 16, groupsize of 1, and ASCII output included.
*/
void print_hex_dump_bytes(const char *prefix_str, int prefix_type,
const void *buf, size_t len)
{
print_hex_dump(KERN_DEBUG, prefix_str, prefix_type, 16, 1, buf, len, true);
}
EXPORT_SYMBOL(print_hex_dump_bytes);
#endif
19.2.1.5 系统调用sys_syslog()
系统调用sys_syslog()用于操纵日志缓冲区log_buf,其定义于kernel/printk.c:
SYSCALL_DEFINE3(syslog, int, type, char __user *, buf, int, len)
{
return do_syslog(type, buf, len, SYSLOG_FROM_CALL);
}
19.2.1.5.1 do_syslog()
该函数定义于kernel/printk.c:
static unsigned log_start; /* Index into log_buf: next char to be read by syslog() */
static unsigned con_start; /* Index into log_buf: next char to be sent to consoles */
static unsigned log_end; /* Index into log_buf: most-recently-written-char + 1 */
DECLARE_WAIT_QUEUE_HEAD(log_wait);
/*
* 文件/proc/kmsg所对应的文件操作函数均调用do_syslog(),
* 参见[11.3.4.4.1 /proc/kmsg]节
*/
int do_syslog(int type, char __user *buf, int len, bool from_file)
{
unsigned i, j, limit, count;
int do_clear = 0;
char c;
int error;
error = check_syslog_permissions(type, from_file);
if (error)
goto out;
error = security_syslog(type);
if (error)
return error;
switch (type) {
case SYSLOG_ACTION_CLOSE: /* Close log */
break;
case SYSLOG_ACTION_OPEN: /* Open log */
break;
case SYSLOG_ACTION_READ: /* Read from log */
error = -EINVAL;
if (!buf || len < 0)
goto out;
error = 0;
if (!len)
goto out;
if (!access_ok(VERIFY_WRITE, buf, len)) {
error = -EFAULT;
goto out;
}
error = wait_event_interruptible(log_wait, (log_start - log_end));
if (error)
goto out;
i = 0;
raw_spin_lock_irq(&logbuf_lock);
while (!error && (log_start != log_end) && i < len) {
c = LOG_BUF(log_start);
log_start++;
raw_spin_unlock_irq(&logbuf_lock);
error = __put_user(c,buf);
buf++;
i++;
cond_resched();
raw_spin_lock_irq(&logbuf_lock);
}
raw_spin_unlock_irq(&logbuf_lock);
if (!error)
error = i;
break;
/* Read/clear last kernel messages */
case SYSLOG_ACTION_READ_CLEAR:
do_clear = 1;
/* FALL THRU */
/* Read last kernel messages */
case SYSLOG_ACTION_READ_ALL:
error = -EINVAL;
if (!buf || len < 0)
goto out;
error = 0;
if (!len)
goto out;
if (!access_ok(VERIFY_WRITE, buf, len)) {
error = -EFAULT;
goto out;
}
count = len;
if (count > log_buf_len)
count = log_buf_len;
raw_spin_lock_irq(&logbuf_lock);
if (count > logged_chars)
count = logged_chars;
if (do_clear)
logged_chars = 0;
limit = log_end;
/*
* __put_user() could sleep, and while we sleep
* printk() could overwrite the messages
* we try to copy to user space. Therefore
* the messages are copied in reverse. <manfreds>
*/
for (i = 0; i < count && !error; i++) {
j = limit-1-i;
if (j + log_buf_len < log_end)
break;
c = LOG_BUF(j); // log_buf[j & LOG_BUF_MASK]
raw_spin_unlock_irq(&logbuf_lock);
error = __put_user(c,&buf[count-1-i]);
cond_resched();
raw_spin_lock_irq(&logbuf_lock);
}
raw_spin_unlock_irq(&logbuf_lock);
if (error)
break;
error = i;
if (i != count) {
int offset = count-error;
/* buffer overflow during copy, correct user buffer. */
for (i = 0; i < error; i++) {
if (__get_user(c,&buf[i+offset]) || __put_user(c,&buf[i])) {
error = -EFAULT;
break;
}
cond_resched();
}
}
break;
/* Clear ring buffer */
case SYSLOG_ACTION_CLEAR:
logged_chars = 0;
break;
/* Disable logging to console */
case SYSLOG_ACTION_CONSOLE_OFF:
if (saved_console_loglevel == -1)
saved_console_loglevel = console_loglevel;
console_loglevel = minimum_console_loglevel;
break;
/* Enable logging to console */
case SYSLOG_ACTION_CONSOLE_ON:
if (saved_console_loglevel != -1) {
console_loglevel = saved_console_loglevel;
saved_console_loglevel = -1;
}
break;
/* Set level of messages printed to console */
case SYSLOG_ACTION_CONSOLE_LEVEL:
error = -EINVAL;
if (len < 1 || len > 8)
goto out;
if (len < minimum_console_loglevel)
len = minimum_console_loglevel;
console_loglevel = len;
/* Implicitly re-enable logging to console */
saved_console_loglevel = -1;
error = 0;
break;
/* Number of chars in the log buffer */
case SYSLOG_ACTION_SIZE_UNREAD:
error = log_end - log_start;
break;
/* Size of the log buffer */
case SYSLOG_ACTION_SIZE_BUFFER:
error = log_buf_len;
break;
default:
error = -EINVAL;
break;
}
out:
return error;
}
其中,type定义于include/linux/syslog.h:
/* Close the log. Currently a NOP. */
#define SYSLOG_ACTION_CLOSE 0
/* Open the log. Currently a NOP. */
#define SYSLOG_ACTION_OPEN 1
/* Read from the log. */
#define SYSLOG_ACTION_READ 2
/* Read all messages remaining in the ring buffer. */
#define SYSLOG_ACTION_READ_ALL 3
/* Read and clear all messages remaining in the ring buffer */
#define SYSLOG_ACTION_READ_CLEAR 4
/* Clear ring buffer. */
#define SYSLOG_ACTION_CLEAR 5
/* Disable printk's to console */
#define SYSLOG_ACTION_CONSOLE_OFF 6
/* Enable printk's to console */
#define SYSLOG_ACTION_CONSOLE_ON 7
/* Set level of messages printed to console */
#define SYSLOG_ACTION_CONSOLE_LEVEL 8
/* Return number of unread characters in the log buffer */
#define SYSLOG_ACTION_SIZE_UNREAD 9
/* Return size of the log buffer */
#define SYSLOG_ACTION_SIZE_BUFFER 10
19.2.1.6 /proc文件系统中有关内核日志系统的配置
19.2.1.6.1 /proc/kmsg
文件/proc/kmsg成为一个I/O通道,它提供了从内核日志缓冲区读取日志消息的二进制接口。这个读取操作通常是由一个守护程序(klogd或rsyslogd)实现的,它会处理这些消息,然后将它们传递给rsyslog,以便(基于它的配置)转发到正确的日志文件中。参见11.3.4.4.1 /proc/kmsg节。
NOTE 1: 用户是不会用到/proc/kmsg文件的,因为守护进程用它来获取日志消息,并将其转发到/var目录内的日志文件中。
NOTE 2: 在GUI mode下的linux,因为开发module的需要, 需要使用printk来debug,又不想用強大但复杂的GDB来开发,只好用printk慢慢看。可是printk却不显示在console, 很不即时,只会存在/var/log/messages里面,每次加载完module, 就要执行dmesg或者cat /var/log/messages来看结果,要不就是要修改proc /sys/kernel/printk的级别, 并且按下ctrl+F1切换到纯粹console mode才可以即时显示在console。
解决办法:只要新开启一个终端并执行more /proc/kmsg,终端看起来当掉不会动,这是不管用它;在开启一个终端,安裝module并调试,这是printk信息就会出现在more /proc/kmsg的终端上了。
19.2.1.6.2 /proc/sys/kernel/printk
The variable console_loglevel can also be modified by changing file /proc/sys/kernel/printk.
chenwx@chenwx ~ $ cat /proc/sys/kernel/printk
4 4 1 7
The file hosts four integer values:
- the current console loglevel,
- the default console loglevel for messages that lack an explicit loglevel,
- the minimum allowed console loglevel,
- the boot-time default console loglevel
Writing a single value to this file changes the current loglevel to that value; thus, for example, you can cause all kernel messages to appear at the console by simply entering:
chenwx@chenwx ~ $ su
Password:
chenwx ~ # cat /proc/sys/kernel/printk
4 4 1 7
chenwx ~ # echo 8 > /proc/sys/kernel/printk
chenwx ~ # cat /proc/sys/kernel/printk
8 4 1 7
19.2.1.6.3 /proc/sys/kernel/printk_delay
文件/proc/sys/kernel/printk_delay表示函数printk()打印消息之间的延迟毫秒数,用于提高某些场景的可读性。
chenwx@chenwx ~ $ ll /proc/sys/kernel/printk_delay
-rw-r--r-- 1 root root 0 Jul 31 06:20 /proc/sys/kernel/printk_delay
chenwx@chenwx ~ $ cat /proc/sys/kernel/printk_delay
0
19.2.1.6.4 /proc/sys/kernel/printk_ratelimit, printk_ratelimit_burst
If you are not careful, you can find yourself generating thousands of messages with printk, overwhelming the console and, possibly, overflowing the system log file. When using a slow console device (e.g., a serial port), an excessive message rate can also slow down the system or just make it unresponsive. It can be very hard to get a handle on what is wrong with a system when the console is spewing out data non-stop. Therefore, you should be very careful about what you print, especially in production versions of drivers and especially once initialization is complete. In general, production code should never print anything during normal operation; printed output should be an indication of an exceptional situation requiring attention.
The function printk_ratelimit() should be called before you consider printing a message that could be repeated often. If the function returns a nonzero value, go ahead and print your message, otherwise skip it. Thus, typical calls look like this:
if (printk_ratelimit())
printk(KERN_NOTICE "The printer is still on fire\n");
The printk_ratelimit() works by tracking how many messages are sent to the console. When the level of output exceeds a threshold, printk_ratelimit starts returning 0 and causing messages to be dropped.
The behavior of printk_ratelimit can be customized by modifying /proc/sys/kernel/ printk_ratelimit (the number of seconds to wait before re-enabling messages) and are /proc/sys/kernel/printk_ratelimit_burst (the number of messages accepted before ratelimiting):
chenwx@chenwx ~ $ ll /proc/sys/kernel/printk_ratelimit*
-rw-r--r-- 1 root root 0 Jul 31 06:20 /proc/sys/kernel/printk_ratelimit
-rw-r--r-- 1 root root 0 Jul 31 06:20 /proc/sys/kernel/printk_ratelimit_burst
chenwx@chenwx ~ $ cat /proc/sys/kernel/printk_ratelimit
5
chenwx@chenwx ~ $ cat /proc/sys/kernel/printk_ratelimit_burst
10
NOTE:速度限制是由调用者控制的,而不是在printk()中实现。若printk()调用者要求进行速度限制,那么它需要调用函数printk_ratelimit()。
19.2.1.7 日志守护进程
所有日志应用程序都是基于一个标准化日志框架syslog,主流操作系统(包括Linux和Berkeley Software Distribution [BSD])都实现了这个框架。syslog使用自身的协议实现在不同传输协议的事件通知消息传输(将组件分成发起者、中继者和收集者)。在许多情况中,所有这三种组件都在一个主机上实现。除了syslog的许多有意思的特性,它还规定了日志信息是如何收集、过滤和存储的。syslog已经经过了许多的变化和发展,包括syslog, klog, sysklogd。最新版本的Ubuntu使用名为rsyslog (基于原先的 syslog)的新版本syslog,它指的是可靠的和扩展的syslogd。
19.2.1.7.1 klogd+syslogd
The package syslogd implements two system log daemons: syslogd and klogd.
The syslogd daemon is an enhanced version of the standard Berkeley utility program. This daemon is responsible for providing logging of messages received from programs and facilities on the local host as well as from remote hosts.
The klogd daemon listens to kernel message sources and is responsible for prioritizing and processing operating system messages. The klogd daemon can run as a client of syslogd or optionally as a standalone program. Klogd can now be used to decode EIP addresses if it can determine a System.map file.
用户空间的守护进程klogd从日志缓冲区中读取内核日志消息,再通过守护进程syslogd把这些消息保存到系统日志文件中:
chenwx@chenwx ~ $ ps -ef | grep logd
root 1241 1 0 Jul23 ? 00:00:00 /sbin/syslogd -C128
root 1269 1 0 Jul23 ? 00:00:00 /sbin/klogd
守护进程klogd既可以从/proc/kmsg文件读取消息(参见11.3.4.4.1 /proc/kmsg节和19.2.1.6 /proc文件系统中有关内核日志系统的配置节),也可以通过系统调用sys_syslog()读取消息(参见19.2.1.5 系统调用sys_syslog()节)。
默认情况下,守护进程klogd通过读取/proc/kmsg方式实现。在消息缓冲区有新的消息之前,守护进程klogd一直处于阻塞状态,一旦有新内核消息,守护进程klogd被唤醒,读出内核消息并进行处理。守护进程klogd把读取的内核消息传给守护进程syslogd。守护进程syslogd把收到的内核消息写入/var/log/messages文件中,输出文件可通过配置文件来更改,参见syslogd的帮助信息:
chenwx@chenwx ~/linux $ syslogd --help
BusyBox v1.21.1 (Ubuntu 1:1.21.0-1ubuntu1) multi-call binary.
Usage: syslogd [OPTIONS]
System logging utility
(this version of syslogd ignores /etc/syslog.conf)
-n Run in foreground
-O FILE Log to FILE (default:/var/log/messages)
-l N Log only messages more urgent than prio N (1-8)
-S Smaller output
-R HOST[:PORT] Log to IP or hostname on PORT (default PORT=514/UDP)
-L Log locally and via network (default is network only if -R)
-C[size_kb] Log to shared mem buffer (use logread to read it)
19.2.1.7.2 rsyslogd
Rsyslog is a rocket-fast system for log processing.
It offers high-performance, great security features and a modular design. While it started as a regular syslogd, rsyslog has evolved into a kind of swiss army knife of logging, being able to accept inputs from a wide variety of sources, transform them, and output to the results to diverse destinations.
Rsyslog can deliver over one million messages per second to local destinations when limited processing is applied (based on v7, December 2013). Even with remote destinations and more elaborate processing the performance is usually considered “stunning”.
Rsyslog’s configure files:
- /etc/init/rsyslog.conf
- /etc/rsyslog.conf
rsyslogd守护程序通过它的配置文件/etc/rsyslog.conf来理解/proc/kmsg接口,并使用这些接口获取内核日志消息。NOTE: 在内部,所有日志级别都是通过/proc/kmsg写入的,这样所传输的日志级别就不是由内核决定的,而是由rsyslog本身决定的。然后这些内核日志消息会存储在/var/log/kern.log (及其他配置的文件)。在/var/log中有许多的日志文件,包括一般消息和系统相调用(/var/log/messages)、系统启动日志(/var/log/boot.log)、认证日志(/var/log/auth.log)等。
// 查看rsyslogd的启动脚本
chenwx@chenwx ~ $ less /etc/init/rsyslog.conf
// 查看rsyslogd是否已经启动
chenwx@chenwx ~ $ initctl list | grep rsyslog
rsyslog start/running
// 查看rsyslogd的配置文件
chenwx@chenwx ~ $ less /etc/rsyslog.conf
chenwx@chenwx ~ $ ll /etc/rsyslog.d/
-rw-r--r-- 1 root root 311 Mar 17 2012 20-ufw.conf
-rw-r--r-- 1 root root 1.7K Jul 29 21:02 50-default.conf
19.2.1.7.3 syslogd-ng
19.2.1.8 Log files
Log files from the system and various programs/services, especially login (/var/log/wtmp, which logs all logins and logouts into the system) and syslog (/var/log/messages, where all kernel and system program message are usually stored). Files in /var/log can often grow indefinitely, and may require cleaning at regular intervals. Something that is now normally managed via log rotation utilities such as ‘logrotate’. This utility also allows for the automatic rotation compression, removal and mailing of log files. Logrotate can be set to handle a log file daily, weekly, monthly or when the log file gets to a certain size. Normally, logrotate runs as a daily cron job. This is a good place to start troubleshooting general technical problems.
/var/log/messages
Contains global system messages, including the messages that are logged during system startup. There are several things that are logged in /var/log/messages including mail, cron, daemon, kern, auth, etc.
/var/log/dmesg
Contains kernel ring buffer information. When the system boots up, it prints number of messages on the screen that displays information about the hardware devices that the kernel detects during boot process. These messages are available in kernel ring buffer and whenever the new message comes the old message gets overwritten. You can also view the content of this file using the dmesg command.
/var/log/auth.log
Contains system authorization information, including user logins and authentication machinsm that were used.
/var/log/boot.log
Contains information that are logged when the system boots.
/var/log/daemon.log
Contains information logged by the various background daemons that runs on the system.
/var/log/dpkg.log
Contains information that are logged when a package is installed or removed using dpkg command.
/var/log/kern.log
Contains information logged by the kernel. Helpful for you to troubleshoot a custom-built kernel.
/var/log/lastlog
Displays the recent login information for all the users. This is not an ascii file. You should use lastlog command to view the content of this file.
/var/log/maillog, /var/log/mail.log
Contains the log information from the mail server that is running on the system. For example, sendmail logs information about all the sent items to this file.
/var/log/user.log
Contains information about all user level logs.
/var/log/Xorg.x.log
Log messages from the X.
/var/log/alternatives.log
Information by the update-alternatives are logged into this log file. On Ubuntu, update-alternatives maintains symbolic links determining default commands.
/var/log/btmp
This file contains information about failed login attemps. Use the last command to view the btmp file. For example, last -f /var/log/btmp | more.
/var/log/cups
All printer and printing related log messages.
/var/log/anaconda.log
When you install Linux, all installation related messages are stored in this log file.
/var/log/yum.log
Contains information that are logged when a package is installed using yum.
/var/log/cron
Whenever cron daemon (or anacron) starts a cron job, it logs the information about the cron job in this file.
/var/log/secure
Contains information related to authentication and authorization privileges. For example, sshd logs all the messages here, including unsuccessful login.
/var/log/wtmp or /var/log/utmp
Contains login records. Using wtmp you can find out who is logged into the system. who command uses this file to display the information.
/var/log/faillog
Contains user failed login attemps. Use faillog command to display the content of this file. Apart from the above log files, /var/log directory may also contain the following sub-directories depending on the application that is running on your system.
/var/log/httpd/, or /var/log/apache2
Contains the apache web server access_log and error_log.
/var/log/lighttpd/
Contains light HTTPD access_log and error_log.
/var/log/conman/
Log files for ConMan client. conman connects remote consoles that are managed by conmand daemon.
/var/log/mail/
This subdirectory contains additional logs from your mail server. For example, sendmail stores the collected mail statistics in /var/log/mail/statistics file.
/var/log/prelink/
prelink program modifies shared libraries and linked binaries to speed up the startup process. /var/log/prelink/prelink.log contains the information about the .so file that was modified by the prelink.
/var/log/audit/
Contains logs information stored by the Linux audit daemon (auditd).
/var/log/setroubleshoot/
SELinux uses setroubleshootd (SE Trouble Shoot Daemon) to notify about issues in the security context of files, and logs those information in this log file.
/var/log/samba/
Contains log information stored by samba, which is used to connect Windows to Linux.
/var/log/sa/
Contains the daily sar files that are collected by the sysstat package.
/var/log/sssd/
Use by system security services daemon that manage access to remote.
19.2.2 BUG()/BUG_ON()
当调用宏BUG()和BUG_ON()时,引发OOPS(参见19.6 OOPS节),导致栈的回溯和错误消息的打印,因而可以把这两个宏当作断言使用。
该宏定义于include/asm-generic/bug.h:
#ifdef CONFIG_BUG
/*
* Don't use BUG() or BUG_ON() unless there's really no way out; one
* example might be detecting data structure corruption in the middle
* of an operation that can't be backed out of. If the (sub)system
* can somehow continue operating, perhaps with reduced functionality,
* it's probably not BUG-worthy.
*
* If you're tempted to BUG(), think again: is completely giving up
* really the *only* solution? There are usually better options, where
* users don't need to reboot ASAP and can mostly shut down cleanly.
*/
#ifndef HAVE_ARCH_BUG
#define BUG() do { \
// 打印文件名、行数、函数名,参见[19.2.1.4 printk()/early_printk()]节
printk("BUG: failure at %s:%d/%s()!\n", __FILE__, __LINE__, __func__); \
// Halt the system. This function never returns. 参见[19.2.2.1 panic()]节
panic("BUG!"); \
} while (0)
#endif
#ifndef HAVE_ARCH_BUG_ON
#define BUG_ON(condition) do { if (unlikely(condition)) BUG(); } while(0)
#endif
#else /* !CONFIG_BUG */
#ifndef HAVE_ARCH_BUG
#define BUG() do {} while(0)
#endif
#ifndef HAVE_ARCH_BUG_ON
#define BUG_ON(condition) do { if (condition) ; } while(0)
#endif
#endif
19.2.2.1 panic()
该函数定义于kernel/panic.c:
/**
* panic - halt the system
* @fmt: The text string to print
*
* Display a message, then perform cleanups.
*
* This function never returns.
*/
NORET_TYPE void panic(const char * fmt, ...)
{
static char buf[1024];
va_list args;
long i, i_next = 0;
int state = 0;
/*
* It's possible to come here directly from a panic-assertion and
* not have preempt disabled. Some functions called from here want
* preempt to be disabled. No point enabling it later though...
*/
preempt_disable();
console_verbose();
bust_spinlocks(1);
va_start(args, fmt);
vsnprintf(buf, sizeof(buf), fmt, args);
va_end(args);
printk(KERN_EMERG "Kernel panic - not syncing: %s\n",buf);
#ifdef CONFIG_DEBUG_BUGVERBOSE
dump_stack(); // 参见[19.2.2.1.1 dump_stack()]节
#endif
/*
* If we have crashed and we have a crash kernel loaded let it handle
* everything else.
* Do we want to call this before we try to display a message?
*/
crash_kexec(NULL); // 参见[19.6.3.3 触发kdump以完成内核转储/crash_kexec()]节
// dump kernel log to kernel message dumpers (dump_list).
kmsg_dump(KMSG_DUMP_PANIC);
/*
* Note smp_send_stop is the usual smp shutdown function, which
* unfortunately means it may not be hardened to work in a panic
* situation.
*/
smp_send_stop();
atomic_notifier_call_chain(&panic_notifier_list, 0, buf);
bust_spinlocks(0);
if (!panic_blink)
panic_blink = no_blink; // 函数no_blink()直接返回0
/*
* 若panic_timeout != 0,则等待指定时间后重启系统
*/
if (panic_timeout > 0) {
/*
* Delay timeout seconds before rebooting the machine.
* We can't use the "normal" timers since we just panicked.
*/
printk(KERN_EMERG "Rebooting in %d seconds..", panic_timeout);
// 变量panic_timeout的单位是秒,PANIC_TIMER_STEP = 100,即每次循环100ms
for (i = 0; i < panic_timeout * 1000; i += PANIC_TIMER_STEP) {
touch_nmi_watchdog();
if (i >= i_next) {
i += panic_blink(state ^= 1);
i_next = i + 3600 / PANIC_BLINK_SPD;
}
mdelay(PANIC_TIMER_STEP);
}
}
if (panic_timeout != 0) {
/*
* This will not be a clean reboot, with everything
* shutting down. But if there is a chance of
* rebooting the system it will be rebooted.
*/
emergency_restart();
}
#ifdef __sparc__
{
extern int stop_a_enabled;
/* Make sure the user can actually press Stop-A (L1-A) */
stop_a_enabled = 1;
printk(KERN_EMERG "Press Stop-A (L1-A) to return to the boot prom\n");
}
#endif
#if defined(CONFIG_S390)
{
unsigned long caller;
caller = (unsigned long)__builtin_return_address(0);
disabled_wait(caller);
}
#endif
local_irq_enable();
/*
* 否则,若panic_timeout == 0,则系统挂起,不再返回
*/
for (i = 0; ; i += PANIC_TIMER_STEP) {
touch_softlockup_watchdog();
if (i >= i_next) {
i += panic_blink(state ^= 1);
i_next = i + 3600 / PANIC_BLINK_SPD;
}
mdelay(PANIC_TIMER_STEP);
}
}
19.2.2.1.1 dump_stack()
该函数只在终端上打印栈的回溯信息。其定义于arch/x86/kernel/dumpstack.c:
/*
* The architecture-independent dump_stack generator
*/
void dump_stack(void)
{
unsigned long bp;
unsigned long stack;
bp = stack_frame(current, NULL);
printk("Pid: %d, comm: %.20s %s %s %.*s\n",
current->pid, current->comm, print_tainted(),
init_utsname()->release,
(int)strcspn(init_utsname()->version, " "),
init_utsname()->version);
show_trace(NULL, NULL, &stack, bp);
}
其中,函数print_tainted()输入如下信息:
/**
* print_tainted - return a string to represent the kernel taint state.
*
* 'P' - Proprietary module has been loaded.
* 'F' - Module has been forcibly loaded.
* 'S' - SMP with CPUs not designed for SMP.
* 'R' - User forced a module unload.
* 'M' - System experienced a machine check exception.
* 'B' - System has hit bad_page.
* 'U' - Userspace-defined naughtiness.
* 'D' - Kernel has oopsed before
* 'A' - ACPI table overridden.
* 'W' - Taint on warning.
* 'C' - modules from drivers/staging are loaded.
* 'I' - Working around severe firmware bug.
* 'O' - Out-of-tree module has been loaded.
*
* The string is overwritten by the next call to print_tainted().
*/
19.2.3 Printing Device Numbers
Occasionally, when printing a message from a driver, you will want to print the device number associated with the hardware of interest. It is not particularly hard to print the major and minor numbers, but, in the interest of consistency, the kernel provides a couple of utility macros (defined in <linux/kdev_t.h>) for this purpose:
int print_dev_t(char *buffer, dev_t dev);
char *format_dev_t(char *buffer, dev_t dev);
Both macros encode the device number into the given buffer; the only difference is that print_dev_t returns the number of characters printed, while format_dev_t returns buffer; therefore, it can be used as a parameter to a printk call directly, although one must remember that printk doesn’t flush until a trailing newline is provided. The buffer should be large enough to hold a device number; given that 64-bit device numbers are a distinct possibility in future kernel releases, the buffer should probably be at least 20 bytes long.
19.3 代码静态分析工具
19.3.0 CHECK & C in Makefile
在顶层Makefile中,包含如下代码:
# Call a source code checker (by default, "sparse") as part of the
# C compilation.
#
# Use 'make C=1' to enable checking of only re-compiled files.
# Use 'make C=2' to enable checking of *all* source files, regardless
# of whether they are re-compiled or not.
#
# See the file "Documentation/sparse.txt" for more details, including
# where to get the "sparse" utility.
ifeq ("$(origin C)", "command line")
KBUILD_CHECKSRC = $(C)
endif
ifndef KBUILD_CHECKSRC
KBUILD_CHECKSRC = 0
endif
export KBUILD_CHECKSRC
...
CHECK = sparse
CHECKFLAGS := -D__linux__ -Dlinux -D__STDC__ -Dunix -D__unix__ \
-Wbitwise -Wno-return-void $(CF)
export CHECK CHECKFLAGS
在scripts/Makefile.build中,包含如下代码:
# Linus' kernel sanity checking tool
ifneq ($(KBUILD_CHECKSRC),0) # KBUILD_CHECKSRC != 0
ifeq ($(KBUILD_CHECKSRC),2) # KBUILD_CHECKSRC = 2
quiet_cmd_force_checksrc = CHECK $<
cmd_force_checksrc = $(CHECK) $(CHECKFLAGS) $(c_flags) $< ;
else # KBUILD_CHECKSRC = 1
quiet_cmd_checksrc = CHECK $<
cmd_checksrc = $(CHECK) $(CHECKFLAGS) $(c_flags) $< ;
endif
endif
...
define rule_cc_o_c
$(call echo-cmd,checksrc) $(cmd_checksrc) \
$(call echo-cmd,cc_o_c) $(cmd_cc_o_c); \
$(cmd_modversions) \
$(call echo-cmd,record_mcount) \
$(cmd_record_mcount) \
scripts/basic/fixdep $(depfile) $@ '$(call make-cmd,cc_o_c)' > \
$(dot-target).tmp; \
rm -f $(depfile); \
mv -f $(dot-target).tmp $(dot-target).cmd
endef
# Built-in and composite module parts
$(obj)/%.o: $(src)/%.c $(recordmcount_source) FORCE
$(call cmd,force_checksrc)
$(call if_changed_rule,cc_o_c)
# Single-part modules are special since we need to mark them in $(MODVERDIR)
$(single-used-m): $(obj)/%.o: $(src)/%.c $(recordmcount_source) FORCE
$(call cmd,force_checksrc)
$(call if_changed_rule,cc_o_c)
@{ echo $(@:.o=.ko); echo $@; } > $(MODVERDIR)/$(@F:.o=.mod)
19.3.1 Sparse
Refer to:
- Documentation/sparse.txt
- http://codemonkey.org.uk/projects/git-snapshots/sparse/
Download sparse source code from git repository to ~/sparse:
chenwx@chenwx ~ $ git clone git://git.kernel.org/pub/scm/devel/sparse/sparse.git
Build and install sparse:
chenwx@chenwx ~ $ cd sparse/
chenwx@chenwx ~/sparse $ make
chenwx@chenwx ~/sparse $ ll sparse
-rwxr-xr-x 1 chenwx chenwx 1479179 Sep 19 16:13 sparse
chenwx@chenwx ~/sparse $ sudo make install PREFIX=/usr
[sudo] password for chenwx:
INSTALL ‘sparse’ -> ‘/usr/bin/sparse’
INSTALL ‘cgcc’ -> ‘/usr/bin/cgcc’
INSTALL ‘c2xml’ -> ‘/usr/bin/c2xml’
INSTALL ‘test-inspect’ -> ‘/usr/bin/test-inspect’
INSTALL ‘sparse-llvm’ -> ‘/usr/bin/sparse-llvm’
INSTALL ‘sparsec’ -> ‘/usr/bin/sparsec’
INSTALL ‘sparse.1’ -> ‘/usr/share/man/man1/sparse.1’
INSTALL ‘cgcc.1’ -> ‘/usr/share/man/man1/cgcc.1’
INSTALL ‘libsparse.a’ -> ‘/usr/lib/libsparse.a’
INSTALL ‘token.h’ -> ‘/usr/include/sparse/token.h’
INSTALL ‘parse.h’ -> ‘/usr/include/sparse/parse.h’
INSTALL ‘lib.h’ -> ‘/usr/include/sparse/lib.h’
INSTALL ‘symbol.h’ -> ‘/usr/include/sparse/symbol.h’
INSTALL ‘scope.h’ -> ‘/usr/include/sparse/scope.h’
INSTALL ‘expression.h’ -> ‘/usr/include/sparse/expression.h’
INSTALL ‘target.h’ -> ‘/usr/include/sparse/target.h’
INSTALL ‘linearize.h’ -> ‘/usr/include/sparse/linearize.h’
INSTALL ‘bitmap.h’ -> ‘/usr/include/sparse/bitmap.h’
INSTALL ‘ident-list.h’ -> ‘/usr/include/sparse/ident-list.h’
INSTALL ‘compat.h’ -> ‘/usr/include/sparse/compat.h’
INSTALL ‘flow.h’ -> ‘/usr/include/sparse/flow.h’
INSTALL ‘allocate.h’ -> ‘/usr/include/sparse/allocate.h’
INSTALL ‘storage.h’ -> ‘/usr/include/sparse/storage.h’
INSTALL ‘ptrlist.h’ -> ‘/usr/include/sparse/ptrlist.h’
INSTALL ‘dissect.h’ -> ‘/usr/include/sparse/dissect.h’
INSTALL ‘sparse.pc’ -> ‘/usr/lib/pkgconfig/sparse.pc’
chenwx@chenwx ~/sparse $ which sparse
/usr/bin/sparse
Build kernel with sparse:
chenwx@chenwx ~ $ cd linux/
chenwx@chenwx ~/linux $ make help
...
make C=1 [targets] Check all c source with $CHECK (sparse by default)
make C=2 [targets] Force check of all c source with $CHECK
...
# 为内核所有需要重新编译的C文件执行sparse语义检查
chenwx@chenwx ~/linux $ make allmodconfig
chenwx@chenwx ~/linux $ make C=1
# 为内核所有C文件(即使不需要重新编译)执行sparse语义检查
chenwx@chenwx ~/linux $ make allmodconfig
chenwx@chenwx ~/linux $ make C=2
# 为内核中某些模块的C文件执行sparse语义检查
chenwx@chenwx ~/linux $ make C=1 M=drivers/staging/
chenwx@chenwx ~/linux $ make C=2 M=drivers/staging/
19.3.2 Smatch
Refer to http://smatch.sourceforge.net
Download smatch source code from git repository to ~/smatch:
chenwx@chenwx ~ $ git clone git://repo.or.cz/smatch.git
Compile smatch:
# Checkout latest version of smatch
chenwx@chenwx ~ $ cd smatch/
chenwx@chenwx ~/smatch $ git tag -l
...
1.59
1.60
chenwx@chenwx ~/smatch $ git checkout 1.60
chenwx@chenwx ~/smatch $ make clean
# Build smatch failed because some packages are not installed
chenwx@chenwx ~/smatch $ make
/bin/sh: 1: llvm-config: not found
Makefile:89: Your system does not have libxml, disabling c2xml
Makefile:101: Your system does not have libgtk2, disabling test-inspect
Makefile:105: Your system does not have llvm, disabling sparse-llvm
CC test-lexing.o
...
AR libsparse.a
LINK test-lexing
/usr/bin/ld: cannot find -lsqlite3
collect2: error: ld returned 1 exit status
make: *** [test-lexing] Error 1
# Install needed packages
chenwx@chenwx ~/smatch $ sudo apt-get install llvm llvm-dev
chenwx@chenwx ~/smatch $ sudo apt-get install libxml2-dev libgtk2.0-dev
chenwx@chenwx ~/smatch $ sudo apt-get install sqlite3 libsqlite3-dev
# Build smatch successfully
chenwx@chenwx ~/smatch $ make
chenwx@chenwx ~/smatch $ ll ./smatch
-rwxr-xr-x 1 chenwx chenwx 3985744 Sep 18 19:28 ./smatch
# Help information of smatch
chenwx@chenwx ~/smatch $ ./smatch --help
Usage: smatch [smatch arguments][sparse arguments] file.c
--project=<name> or -p=<name>: project specific tests
--spammy: print superfluous crap.
--info: print info used to fill smatch_data/.
--debug: print lots of debug output.
--param-mapper: enable param_mapper output.
--no-data: do not use the /smatch_data/ directory.
--data=<dir>: overwrite path to default smatch data directory.
--full-path: print the full pathname.
--debug-implied: print debug output about implications.
--no-implied: ignore implications.
--assume-loops: assume loops always go through at least once.
--known-conditions: don't branch for known conditions.
--two-passes: use a two pass system for each function.
--file-output: instead of printing stdout, print to "file.c.smatch_out".
--help: print this helpful message.
Use smatch against the kernel:
# Goes to directory of linux kernel source code
chenwx@chenwx ~/smatch $ cd ~/linux/
# Build bzImage and modules with C=1:
# make C=1 [targets] Check all c source with $CHECK (sparse by default)
chenwx@chenwx ~/linux $ make CHECK="~/smatch/smatch -p=kernel" C=1 bzImage modules | tee warns.txt
# Build kernel with C=2:
# make C=2 [targets] Force check of all c source with $CHECK
chenwx@chenwx ~/linux $ make CHECK="~/smatch/smatch -p=kernel" C=2 | tee warns.txt
NOTE: Linux kernel v2.3.37 and after: Please set CONFIG_DYNAMIC_DEBUG=n. That feature uses declared label things that mess up Smatch’s flow analysis.
If you are using smatch on a different project then the most important thing is to build the list of functions which don’t return. Do the first build using the –info parameter and use smatch_scripts/gen_no_return_funcs.sh to create this list. Save the resulting file under smatch_data/(your project).no_return_funcs and use -p=(your project) for the next smatch run.
If you are using smatch to test wine then use -p=wine to turn on the wine specific checks.
19.3.3 Coccinelle
Refer to http://coccinelle.lip6.fr
19.4 内存调试工具
19.4.1 Kmemleak
参见Documentation/kmemleak.txt
kmemleak通过类似于垃圾收集器的功能来检测内核是否有内存泄漏问题。而kmemleak与垃圾收集器的不同之处在于前者不会释放孤儿目标(LCTT:不会再被使用的、应该被释放而没被释放的内存区域),而是将它们打印到/sys/kernel/debug/kmemleak文件中。用户态的Valgrind也有一个类似的功能,使用–leak-check选项可以检测并报错内存泄漏问题,但并不释放这个孤儿内存。
编译内核时开启CONFIG_DEBUG_KMEMLEAK选项打开kmemcleak调试功能:
Kernel hacking --->
[ ] Kernel memory leak detector
19.4.2 Kmemcheck
参见Documentation/kmemcheck.txt
kmemcheck是动态检查工具,可以检测出一些未被初始化的内存(内核态使用这些内存可能会造成系统崩溃)并发出警告。它的功能与Valgrind类似,只是Valgrind运行在用户态,而kmemchecke运行在内核态。
编译内核时开启CONFIG_KMEMCHECK选项打开kmemcheck调试功能:
Kernel hacking --->
Memory Debugging --->
19.4.3 Memwatch
Memwatch is a free programming tool for memory leak detection in C, released under the GNU General Public License.
It is designed to compile and run on any system which has an ANSI C compiler. While it is primarily intended to detect and diagnose memory leaks, it can also be used to analyze a program’s memory usage from its provided logging facilities. Memwatch differs from most debugging software because it is compiled directly into the program which will be debugged, instead of being compiled separately and loaded into the program at runtime.
19.4.4 YAMD
YAMD is Yet Another Malloc Debugger. It’s a package for finding dynamic allocation related bugs in C and C++. It currently runs on Linux/x86 and DJGPP.
19.4.5 Electric Fence
Electric Fence (efence) stops your program on the exact instruction that overruns (or underruns) a malloc() memory buffer. GDB will then display the source-code line that causes the bug. It works by using the virtual-memory hardware to create a red-zone at the border of each buffer - touch that, and your program stops. Catch all of those formerly impossible-to-catch overrun bugs that have been bothering you for years.
19.5 strace/ltrace/ktrace
strace is a debugging utility for Linux and some other Unix-like systems to monitor the system calls used by a program and all the signals it receives, similar to “truss” utility in other Unix systems. This is made possible by a kernel feature known as ptrace.
ltrace is a debugging utility in Linux, used to display the calls a userland application makes to shared libraries. It does this by hooking into the dynamic loading system, allowing it to insert shims which display the parameters which the applications uses when making the call, and the return value which the library call reports. ltrace can also trace Linux system calls. Because it uses the dynamic library hooking mechanism, ltrace cannot trace calls to libraries which are statically linked directly to the target binary.
NOTE: ktrace is a utility included with certain versions of BSD Unix and Mac OS X that traces kernel interaction with a program and dumps it to disk for debugging and analysis. It is somewhat similar to Linux’s strace, except much faster - with strace, every system call executed by the program being traced requires context switch to the tracing program and back, while with ktrace, tracing is actually performed by the kernel, so no additional context switches are required.
19.6 OOPS
参见Documentation/oops-tracing.txt
OOPS(也称Panic,参见19.2.2.1 panic()节)消息包含系统错误的细节,如CPU寄存器的内容等,是内核告知用户有异常发生的最常用的方式。内核只能发布OOPS,这个过程包括向终端输出错误消息,输出寄存器保存的信息,并输出可供跟踪的回溯线索。通常,发送完OOPS之后,内核会处于一种不稳定的状态。 OOPS的产生有很多可能原因,其中包括内存访问越界或非法的指令等。
- 作为内核的开发者,必定将会经常处理OOPS。
- OOPS中包含的重要信息,对所有体系结构都是完全相同的:寄存器上下文和回溯线索(回溯线索显示了导致错误发生的函数调用链)。
19.6.1 ksymoops
在Linux中,调试系统崩溃的传统方法是分析在发生崩溃时发送到系统控制台的Oops消息。一旦您掌握了细节,就可以将消息发送到ksymoops实用程序,它将试图将代码转换为指令并将堆栈值映射到内核符号。
ksymoops需要几项内容:Oops消息输出、来自正在运行的内核的System.map文件,还有/proc/ksyms、vmlinux和/proc/modules。
19.6.2 kallsyms
Linux Kernel v2.5引入了kallsyms特性,需启用配置选项CONFIG_KALLSYMS。该选项可以载入内核镜像所对应的内存地址的符号名称(即函数名),所以内核可以打印解码之后的跟踪线索。相应地,解码OOPS也不再需要System.map和ksymoops工具(参见19.6.1 ksymoops节)了。不过,这会导致内核变大,因为地址所对应的符号名称必须始终驻留在内核所在的内存上。
参见13.4.2 Kernel Symbol Table节。
19.6.3 kdump
- 参见Documentation/kdump/kdump.txt
- kexec-tools
- 深入探索 Kdump 1
- 深入探索 Kdump 2
19.6.3.1 kdump的初始化
系统启动过程中,如下函数调用初始化kdump:
start_kernel()
-> setup_arch()
-> reserve_crashkernel()
函数reserve_crashkernel()定义于arch/x86/kernel/setup.c:
#ifdef CONFIG_KEXEC
static inline unsigned long long get_total_mem(void)
{
unsigned long long total;
total = max_pfn - min_low_pfn;
return total << PAGE_SHIFT;
}
/*
* Keep the crash kernel below this limit. On 32 bits earlier kernels
* would limit the kernel to the low 512 MiB due to mapping restrictions.
* On 64 bits, kexec-tools currently limits us to 896 MiB; increase this
* limit once kexec-tools are fixed.
*/
#ifdef CONFIG_X86_32
# define CRASH_KERNEL_ADDR_MAX (512 << 20)
#else
# define CRASH_KERNEL_ADDR_MAX (896 << 20)
#endif
static void __init reserve_crashkernel(void)
{
unsigned long long total_mem;
unsigned long long crash_size, crash_base;
int ret;
total_mem = get_total_mem();
// 检查命令行参数"crashkernel=",并为捕获内核保留一段内存空间
ret = parse_crashkernel(boot_command_line, total_mem, &crash_size, &crash_base);
if (ret != 0 || crash_size <= 0)
return;
/* 0 means: find the address automatically */
if (crash_base <= 0) {
const unsigned long long alignment = 16<<20; /* 16M */
/*
* kexec want bzImage is below CRASH_KERNEL_ADDR_MAX
*/
crash_base = memblock_find_in_range(alignment,
CRASH_KERNEL_ADDR_MAX, crash_size, alignment);
if (crash_base == MEMBLOCK_ERROR) {
pr_info("crashkernel reservation failed - No suitable area found.\n");
return;
}
} else {
unsigned long long start;
start = memblock_find_in_range(crash_base,
crash_base + crash_size, crash_size, 1<<20);
if (start != crash_base) {
pr_info("crashkernel reservation failed - memory is in use.\n");
return;
}
}
memblock_x86_reserve_range(crash_base, crash_base + crash_size, "CRASH KERNEL");
printk(KERN_INFO "Reserving %ldMB of memory at %ldMB "
"for crashkernel (System RAM: %ldMB)\n",
(unsigned long)(crash_size >> 20),
(unsigned long)(crash_base >> 20),
(unsigned long)(total_mem >> 20));
crashk_res.start = crash_base;
crashk_res.end = crash_base + crash_size - 1;
insert_resource(&iomem_resource, &crashk_res);
}
#else
static void __init reserve_crashkernel(void)
{
}
#endif
19.6.3.2 设置捕获内核/sys_kexec_load()
系统调用sys_kexec_load()用于加载捕获内核和传递一些相关信息。工具kexec-tools中的实用程序kexec会调用系统调用sys_kexec_load()加载捕获内核。
可通过查看/sys/kernel/kexec_crash_loaded的取值来判断捕获内核是否已加载:
- 1 – 捕获内核已加载;
- 0 – 捕获内核未加载。
该系统调用定义于kernel/kexec.c:
/*
* Exec Kernel system call: for obvious reasons only root may call it.
*
* This call breaks up into three pieces.
* - A generic part which loads the new kernel from the current
* address space, and very carefully places the data in the
* allocated pages.
*
* - A generic part that interacts with the kernel and tells all of
* the devices to shut down. Preventing on-going dmas, and placing
* the devices in a consistent state so a later kernel can
* reinitialize them.
*
* - A machine specific part that includes the syscall number
* and the copies the image to it's final destination. And
* jumps into the image at entry.
*
* kexec does not sync, or unmount filesystems so if you need
* that to happen you need to do that yourself.
*/
struct kimage *kexec_image;
struct kimage *kexec_crash_image;
static DEFINE_MUTEX(kexec_mutex);
SYSCALL_DEFINE4(kexec_load, unsigned long, entry, unsigned long, nr_segments,
struct kexec_segment __user *, segments, unsigned long, flags)
{
struct kimage **dest_image, *image;
int result;
/* We only trust the superuser with rebooting the system. */
if (!capable(CAP_SYS_BOOT))
return -EPERM;
/*
* Verify we have a legal set of flags
* This leaves us room for future extensions.
*/
if ((flags & KEXEC_FLAGS) != (flags & ~KEXEC_ARCH_MASK))
return -EINVAL;
/* Verify we are on the appropriate architecture */
if (((flags & KEXEC_ARCH_MASK) != KEXEC_ARCH) &&
((flags & KEXEC_ARCH_MASK) != KEXEC_ARCH_DEFAULT))
return -EINVAL;
/*
* Put an artificial cap on the number of segments passed to kexec_load.
*/
if (nr_segments > KEXEC_SEGMENT_MAX)
return -EINVAL;
image = NULL;
result = 0;
/* Because we write directly to the reserved memory
* region when loading crash kernels we need a mutex here to
* prevent multiple crash kernels from attempting to load
* simultaneously, and to prevent a crash kernel from loading
* over the top of a in use crash kernel.
*
* KISS: always take the mutex.
*/
if (!mutex_trylock(&kexec_mutex))
return -EBUSY;
dest_image = &kexec_image;
if (flags & KEXEC_ON_CRASH)
dest_image = &kexec_crash_image;
if (nr_segments > 0) {
unsigned long i;
/* Loading another kernel to reboot into */
if ((flags & KEXEC_ON_CRASH) == 0)
result = kimage_normal_alloc(&image, entry, nr_segments, segments);
/* Loading another kernel to switch to if this one crashes */
else if (flags & KEXEC_ON_CRASH) {
/*
* Free any current crash dump kernel before we corrupt it.
*/
kimage_free(xchg(&kexec_crash_image, NULL));
result = kimage_crash_alloc(&image, entry, nr_segments, segments);
crash_map_reserved_pages(); // 空函数
}
if (result)
goto out;
if (flags & KEXEC_PRESERVE_CONTEXT)
image->preserve_context = 1;
result = machine_kexec_prepare(image);
if (result)
goto out;
for (i = 0; i < nr_segments; i++) {
result = kimage_load_segment(image, &image->segment[i]);
if (result)
goto out;
}
kimage_terminate(image);
if (flags & KEXEC_ON_CRASH)
crash_unmap_reserved_pages(); // 空函数
}
/* Install the new kernel, and Uninstall the old */
image = xchg(dest_image, image);
out:
mutex_unlock(&kexec_mutex);
kimage_free(image);
return result;
}
19.6.3.3 触发kdump以完成内核转储/crash_kexec()
如下函数调用触发kdump以完成内核转储:
panic()
-> crash_kexec()
函数crash_kexec()定义于kernel/kexec.c:
struct machine_ops machine_ops = {
.power_off = native_machine_power_off,
.shutdown = native_machine_shutdown,
.emergency_restart = native_machine_emergency_restart,
.restart = native_machine_restart,
.halt = native_machine_halt,
#ifdef CONFIG_KEXEC
.crash_shutdown = native_machine_crash_shutdown,
#endif
};
void crash_kexec(struct pt_regs *regs)
{
/* Take the kexec_mutex here to prevent sys_kexec_load
* running on one cpu from replacing the crash kernel
* we are using after a panic on a different cpu.
*
* If the crash kernel was not located in a fixed area
* of memory the xchg(&kexec_crash_image) would be
* sufficient. But since I reuse the memory...
*/
if (mutex_trylock(&kexec_mutex)) {
if (kexec_crash_image) {
struct pt_regs fixed_regs;
/*
* Dump kernel log to kernel message dumpers.
* Iterate through each of the dump devices
* and call the oops/panic callbacks with the
* log buffer.
*/
kmsg_dump(KMSG_DUMP_KEXEC);
// capture register states to fixed_regs
crash_setup_regs(&fixed_regs, regs);
crash_save_vmcoreinfo();
/*
* 调用machine_ops.crash_shutdown(),
* 即调用native_machine_crash_shutdown()
*/
machine_crash_shutdown(&fixed_regs);
/*
* 引导捕获内核启动,以完成内核转储。其定义于:
* arch/x86/kernel/machine_kexec_32.c, or
* arch/x86/kernel/machine_kexec_64.c
*/
machine_kexec(kexec_crash_image);
}
mutex_unlock(&kexec_mutex);
}
}
RHEL6.2中kdump的执行流程:
19.6.4 LKCD
LKCD (Linux Kernel Crash Dump)
19.7 Magic SysRq
SysRq is a magical key combo you can hit which the kernel will respond to regardless of whatever else it is doing, unless it is completely locked up. The SysRq key is also known as the “Print Screen” key on the top-right corner of keyboard.
参见Documentation/sysrq.txt
19.7.1 配置SysRq
19.7.1.1 内核配置项CONFIG_MAGIC_SYSRQ
要使用SysRq键,需要启用内核配置项:
Kernel hacking --->
[*] Magic SysRq key // CONFIG_MAGIC_SYSRQ
chenwx@chenwx ~/linux $ grep CONFIG_MAGIC_SYSRQ /boot/config-4.4.0-15-generic
CONFIG_MAGIC_SYSRQ=y
CONFIG_MAGIC_SYSRQ_DEFAULT_ENABLE=0x1
19.7.1.2 内核启动参数sysrq_always_enabled
若内核启动参数中包含参数sysrq_always_enabled(该参数在Linux kernel 2.6.20以后的版本中可用),则无论/proc/sys/kernel/sysrq的设置为何,SysRq键都会被启用。
可通过下列命令检查内核启动参数:
chenwx@chenwx ~/linux $ cat /proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-4.4.0-15-generic root=UUID=51ce0b57-1d7f-4da3-b46f-d6a0ea64c81d ro quiet splash vt.handoff=7
chenwx@chenwx ~/linux $ cat /proc/cmdline | grep sysrq_always_enabled
chenwx@chenwx ~/linux $
19.7.1.3 /proc/sys/kernel/sysrq
When running a kernel with SysRq compiled in and the parameter sysrq_always_enabled is not set, the /proc/sys/kernel/sysrq controls the functions allowed to be invoked via the SysRq key. By default the file contains 1 which means that every possible SysRq request is allowed (in older versions SysRq was disabled by default, and you were required to specifically enable it at run-time but this is not the case any more). Here is the list of possible values in /proc/sys/kernel/sysrq:
0 - disable sysrq completely
1 - enable all functions of sysrq
>1 - bitmask of allowed sysrq functions as below description (括号内为命令键):
2 - enable control of console logging level (0-9)
4 - enable control of keyboard (kr)
8 - enable debugging dumps of processes etc. (lptwmcz)
16 - enable sync command (s)
32 - enable remount read-only (u)
64 - enable signalling of processes, such as term, kill and oom-kill (ei)
128 - allow reboot/poweroff (b)
256 - allow nicing of all RT tasks (q)
You can set the value in the file by the following command:
echo "number" >/proc/sys/kernel/sysrq
In the following example, the enabled commands are 176 (= 16 + 32 + 128):
chenwx@chenwx ~/linux $ cat /proc/sys/kernel/sysrq
176
Note that the value of /proc/sys/kernel/sysrq influences only the invocation via a keyboard. Invocation of any operation via /proc/sysrq-trigger is always allowed (by a user with admin privileges). See 19.7.2 SysRq键的使用方法.
19.7.2 SysRq键的使用方法
19.7.2.1 从键盘输入SysRq键
从键盘输入SysRq键时,需要同时输入Alt + SysRq + <command>。其中,<command>参见19.7.2.2 /proc/sysrq-trigger节。
19.7.2.2 /proc/sysrq-trigger
On all platform, write a character to /proc/sysrq-trigger to invocate of specific operation by a user with admin privileges:
# echo <command> > /proc/sysrq-trigger
| mean | |
|---|---|
| 0 ~ 9 | Sets the console log level, controlling which kernel messages will be printed to your console. (‘0’, for example would make it so that only emergency messages like PANICs or OOPSes would make it to your console.) |
| b | Will immediately reboot the system without syncing or unmounting your disks. |
| c | Will perform a system crash by a NULL pointer dereference. A crashdump will be taken if configured. |
| d | Shows all locks that are held. |
| e | Send a SIGTERM to all processes, except for init. |
| f | Will call oom_kill to kill a memory hog process. |
| g | Used by kgdb (kernel debugger) |
| h | Will display help (actually any other key than those listed here will display help. but ‘h’ is easy to remember |
| i | Send a SIGKILL to all processes, except for init. |
| j | Forcibly “Just thaw it” - filesystems frozen by the FIFREEZE ioctl. |
| k | Secure Access Key (SAK) Kills all programs on the current virtual console. NOTE: See important comments below in SAK section. |
| l | Shows a stack backtrace for all active CPUs. |
| m | Will dump current memory info to your console. |
| n | Used to make RT tasks nice-able |
| o | Will shut your system off (if configured and supported). |
| p | Will dump the current registers and flags to your console. |
| q | Will dump per CPU lists of all armed hrtimers (but NOT regular timer_list timers) and detailed information about all clockevent devices. |
| r | Turns off keyboard raw mode and sets it to XLATE. |
| s | Will attempt to sync all mounted filesystems. |
| t | Will dump a list of current tasks and their information to your console. |
| u | Will attempt to remount all mounted filesystems read-only. |
| v | Forcefully restores framebuffer console. |
| w | Dumps tasks that are in uninterruptable (blocked) state. |
| x | Used by xmon interface on ppc/powerpc platforms. Show global PMU Registers on sparc64. |
| y | Show global CPU Registers [SPARC-64 specific] |
| z | Dump the ftrace buffer |
For instance:
chenwx@chenwx ~/linux $ su
Password:
chenwx linux # echo m > /proc/sysrq-trigger
chenwx linux # dmesg
...
[ 7681.400436] sysrq: SysRq : Show Memory
[ 7681.400448] Mem-Info:
[ 7681.400463] active_anon:334211 inactive_anon:31758 isolated_anon:0
active_file:278253 inactive_file:251496 isolated_file:0
unevictable:8 dirty:876 writeback:0 unstable:0
slab_reclaimable:42548 slab_unreclaimable:7331
mapped:90263 shmem:32110 pagetables:7278 bounce:0
free:29945 free_pcp:550 free_cma:0
[ 7681.400475] Node 0 DMA free:14536kB min:28kB low:32kB high:40kB active_anon:0kB inactive_anon:1044kB active_file:232kB inactive_file:12kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:15984kB managed:15900kB mlocked:0kB dirty:0kB writeback:0kB mapped:136kB shmem:1044kB slab_reclaimable:4kB slab_unreclaimable:64kB kernel_stack:0kB pagetables:8kB unstable:0kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
[ 7681.400493] lowmem_reserve[]: 0 2966 3861 3861 3861
[ 7681.400506] Node 0 DMA32 free:52072kB min:6016kB low:7520kB high:9024kB active_anon:972000kB inactive_anon:120228kB active_file:886604kB inactive_file:796180kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:3119808kB managed:3039540kB mlocked:0kB dirty:2908kB writeback:0kB mapped:278044kB shmem:121276kB slab_reclaimable:147928kB slab_unreclaimable:20056kB kernel_stack:5840kB pagetables:21276kB unstable:0kB bounce:0kB free_pcp:876kB local_pcp:204kB free_cma:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
[ 7681.400524] lowmem_reserve[]: 0 0 894 894 894
[ 7681.400536] Node 0 Normal free:53172kB min:1812kB low:2264kB high:2716kB active_anon:364844kB inactive_anon:5760kB active_file:226176kB inactive_file:209792kB unevictable:32kB isolated(anon):0kB isolated(file):0kB present:983040kB managed:916472kB mlocked:32kB dirty:596kB writeback:0kB mapped:82872kB shmem:6120kB slab_reclaimable:22260kB slab_unreclaimable:9204kB kernel_stack:2848kB pagetables:7828kB unstable:0kB bounce:0kB free_pcp:1324kB local_pcp:652kB free_cma:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
[ 7681.400552] lowmem_reserve[]: 0 0 0 0 0
[ 7681.400562] Node 0 DMA: 10*4kB (UME) 8*8kB (UME) 6*16kB (UME) 8*32kB (UME) 8*64kB (UME) 2*128kB (ME) 2*256kB (E) 1*512kB (M) 2*1024kB (UM) 1*2048kB (E) 2*4096kB (M) = 14536kB
[ 7681.400607] Node 0 DMA32: 493*4kB (UME) 348*8kB (UME) 418*16kB (UME) 171*32kB (UME) 74*64kB (ME) 70*128kB (UME) 28*256kB (UME) 16*512kB (UM) 6*1024kB (UM) 0*2048kB 0*4096kB = 52116kB
[ 7681.400646] Node 0 Normal: 717*4kB (UME) 648*8kB (UME) 454*16kB (UME) 272*32kB (UME) 120*64kB (UME) 42*128kB (UME) 19*256kB (UME) 12*512kB (UME) 5*1024kB (M) 0*2048kB 0*4096kB = 53204kB
[ 7681.400686] Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB
[ 7681.400691] 561858 total pagecache pages
[ 7681.400698] 0 pages in swap cache
[ 7681.400703] Swap cache stats: add 0, delete 0, find 0/0
[ 7681.400707] Free swap = 0kB
[ 7681.400710] Total swap = 0kB
[ 7681.400714] 1029708 pages RAM
[ 7681.400717] 0 pages HighMem/MovableOnly
[ 7681.400720] 36730 pages reserved
[ 7681.400724] 0 pages cma reserved
[ 7681.400727] 0 pages hwpoisoned
19.7.3 SysRq在内核中的实现
SysRq实现于drivers/tty/sysrq.c:
static int __init sysrq_init(void)
{
/*
* 创建文件/proc/sysrq-trigger,
* 参见[19.7.3.1 sysrq_init_procfs()]节
* 其用法参见[19.7.2 SysRq键的使用方法]节
*/
sysrq_init_procfs();
if (sysrq_on())
sysrq_register_handler();
return 0;
}
module_init(sysrq_init);
19.7.3.1 sysrq_init_procfs()
该函数用于创建文件/proc/sysrq-trigger,并定义其处理函数,其定义于drivers/tty/sysrq.c:
static const struct file_operations proc_sysrq_trigger_operations = {
.write = write_sysrq_trigger,
.llseek = noop_llseek,
};
static void sysrq_init_procfs(void)
{
if (!proc_create("sysrq-trigger", S_IWUSR, NULL, &proc_sysrq_trigger_operations))
pr_err("Failed to register proc interface\n");
}
其中,函数write_sysrq_trigger()用于处理写入文件/proc/sysrq-trigger中的命令,参见19.7.2 SysRq键的使用方法节,其定义于drivers/tty/sysrq.c:
/*
* writing 'C' to /proc/sysrq-trigger is like sysrq-C
*/
static ssize_t write_sysrq_trigger(struct file *file, const char __user *buf,
size_t count, loff_t *ppos)
{
if (count) {
char c;
if (get_user(c, buf))
return -EFAULT;
__handle_sysrq(c, false);
}
return count;
}
void __handle_sysrq(int key, bool check_mask)
{
struct sysrq_key_op *op_p;
int orig_log_level;
int i;
unsigned long flags;
spin_lock_irqsave(&sysrq_key_table_lock, flags);
/*
* Raise the apparent loglevel to maximum so that the sysrq header
* is shown to provide the user with positive feedback. We do not
* simply emit this at KERN_EMERG as that would change message
* routing in the consumers of /proc/kmsg.
*/
orig_log_level = console_loglevel;
console_loglevel = 7;
printk(KERN_INFO "SysRq : ");
op_p = __sysrq_get_key_op(key);
if (op_p) {
/*
* Should we check for enabled operations (/proc/sysrq-trigger
* should not) and is the invoked operation enabled?
*/
if (!check_mask || sysrq_on_mask(op_p->enable_mask)) {
printk("%s\n", op_p->action_msg);
console_loglevel = orig_log_level;
op_p->handler(key);
} else {
printk("This sysrq operation is disabled.\n");
}
} else {
printk("HELP : ");
/* Only print the help msg once per handler */
for (i = 0; i < ARRAY_SIZE(sysrq_key_table); i++) {
if (sysrq_key_table[i]) {
int j;
for (j = 0; sysrq_key_table[i] != sysrq_key_table[j]; j++)
;
if (j != i)
continue;
printk("%s ", sysrq_key_table[i]->help_msg);
}
}
printk("\n");
console_loglevel = orig_log_level;
}
spin_unlock_irqrestore(&sysrq_key_table_lock, flags);
}
19.8 KGDB & KDB
The kernel has two different debugger front ends (kdb and kgdb) which interface to the debug core. It is possible to use either of the debugger front ends and dynamically transition between them if you configure the kernel properly at compile and runtime.
Kdb is simplistic shell-style interface which you can use on a system console with a keyboard or serial console. You can use it to inspect memory, registers, process lists, dmesg, and even set breakpoints to stop in a certain location. Kdb is not a source level debugger, although you can set breakpoints and execute some basic kernel run control. Kdb is mainly aimed at doing some analysis to aid in development or diagnosing kernel problems. You can access some symbols by name in kernel built-ins or in kernel modules if the code was built with CONFIG_KALLSYMS.
Kgdb is intended to be used as a source level debugger for the Linux kernel. It is used along with gdb to debug a Linux kernel. The expectation is that gdb can be used to “break in” to the kernel to inspect memory, variables and look through call stack information similar to the way an application developer would use gdb to debug an application. It is possible to place breakpoints in kernel code and perform some limited execution stepping.
Two machines are required for using kgdb. One of these machines is a development machine and the other is the target machine. The kernel to be debugged runs on the target machine. The development machine runs an instance of gdb against the vmlinux file which contains the symbols (not boot image such as bzImage, zImage, uImage…). In gdb the developer specifies the connection parameters and connects to kgdb. The type of connection a developer makes with gdb depends on the availability of kgdb I/O modules compiled as built-ins or loadable kernel modules in the test machine’s kernel.
与KGDB和KDB有关的内核配置选项(added in kernel v3.8):
Kernel hacking --->
[*] Compile the kernel with debug info
[*] KGDB: kernel debugger ---> // CONFIG_KGDB
<*> KGDB: use kgdb over the serial console // CONFIG_KGDB_SERIAL_CONSOLE
[ ] KGDB: internal test suite // CONFIG_KGDB_TESTS
[*] KGDB: Allow debugging with traps in notifiers // CONFIG_KGDB_LOW_LEVEL_TRAP
[*] KGDB_KDB: include kdb frontend for kgdb // CONFIG_KGDB_KDB
[*] KGDB_KDB: keyboard as input device // CONFIG_KDB_KEYBOARD
(0) KDB: continue after catastrophic errors // CONFIG_KDB_CONTINUE_CATASTROPHIC
- KGDB git repository
- KGDB Documentation
- Using kgdb, kdb and the kernel debugger internals
- Linux系统内核的调试
- Linux内核调试器内幕
- KDB website
- KDB Patch FTP site
19.9 Kprobes
- 参见Documentation/kprobes.txt
- 使用Kprobes调试内核
与kprobes有关的配置选项:
General setup --->
[*] Kprobes // CONFIG_KPROBES
Kernel hacking --->
[*] Magic SysRq key // CONFIG_MAGIC_SYSRQ,参见[19.7 Magic SysRq]节
20 内核测试/Test Kernel
20.1 内核测试工具
内核源代码目录tools/testing/中包含如下测试工具:
20.1.1 ktest
20.1.2 selftests
内核源码的多个子系统都有自己的自测工具,到目前为止,断点、cpu热插拔、efivarfs、IPC、KCMP、内存热插拔、mqueue、网络、powerpc、ptrace、rcutorture、定时器和虚拟机子系统都有自测工具。另外,用户态内存的自测工具可以利用 testusercopy 模块来测试用户态内存到内核态的拷贝过程。
1) 编译并运行tools/testing/selftests/目录下所有测试工具:
chenwx@chenwx ~/linux $ sudo make -C tools/testing/selftests
chenwx@chenwx ~/linux $ sudo make -C tools/testing/selftests run_tests
2) 编译并运行tools/testing/selftests/目录下某个测试工具:
chenwx@chenwx ~/linux $ ll tools/testing/selftests/
-rw-r--r-- 1 chenwx chenwx 866 Sep 1 08:50 Makefile
-rw-r--r-- 1 chenwx chenwx 1765 Sep 1 08:50 README.txt
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 19:29 breakpoints
drwxr-xr-x 2 chenwx chenwx 4096 Sep 1 08:50 cpu-hotplug
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 19:26 efivarfs
drwxr-xr-x 2 chenwx chenwx 4096 Sep 1 08:50 firmware
drwxr-xr-x 2 chenwx chenwx 4096 Sep 3 21:55 ipc
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 08:59 kcmp
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 09:01 memfd
drwxr-xr-x 2 chenwx chenwx 4096 Sep 1 08:50 memory-hotplug
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 19:26 mount
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 08:59 mqueue
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 07:56 net
drwxr-xr-x 6 chenwx chenwx 4096 Sep 1 08:50 powerpc
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 19:26 ptrace
drwxr-xr-x 5 chenwx chenwx 4096 Sep 1 08:50 rcutorture
drwxr-xr-x 2 chenwx chenwx 4096 Sep 1 08:50 sysctl
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 19:26 timers
drwxr-xr-x 2 chenwx chenwx 4096 Sep 1 08:50 user
drwxr-xr-x 2 chenwx chenwx 4096 Sep 16 19:28 vm
chenwx@chenwx ~/linux $ sudo make -C tools/testing/selftests TARGETS=breakpoints run_tests
20.1.2.1 ptrace
参见tools/testing/selftests/ptrace/
20.1.2.2 timers
20.1.3 fault-injection
参见Documentation/fault-injection/fault-injection.txt
20.2 自动测试工具
20.2.1 AutoTest
Autotest is a framework for fully automated testing. It is designed primarily to test the Linux kernel, though it is useful for many other functions such as qualifying new hardware. It’s an open-source project under the GPL and is used and developed by a number of organizations, including Google, IBM, Red Hat, and many others.
20.2.2 Linux Test Project
Linux Test Project (LTP) is a joint project started by SGI, OSDL and Bull developed and maintained by IBM, Cisco, Fujitsu, SUSE, Red Hat, Oracle and others. The project goal is to deliver tests to the open source community that validate the reliability, robustness, and stability of Linux.
The LTP testsuite contains a collection of tools for testing the Linux kernel and related features. Our goal is to improve the Linux kernel and system libraries by bringing test automation to the testing effort.
20.2.3 LTP-DDT
20.2.4 Linaro Automated Validation Architecture
LAVA: Linaro Automated Validation Architecture
20.3 Linux Driver Verification
20.4 MMTests
20.5 Trinity
20.6 CrackerJack - Kernel Regression Tests
Appendixes
Appendix A: Makefile Tree
The top Makefile includes the following Makefiles:
linux-3.2/Makefile
+- include scripts/Kbuild.include
| +- build := -f $(srctree)/scripts/Makefile.build obj // 参见下文
+- include arch/$(SRCARCH)/Makefile // 以x86为例,即include linux-3.2/arch/x86/Makefile
| +- include $(srctree)/arch/x86/Makefile_32.cpu
and where, the scripts/Makefile.build includes the following scripts:
linux-3.2/scripts/Makefile.build
+- -include include/config/auto.conf
+- include scripts/Kbuild.include
+- include $(kbuild-file) // 包含指定目录下的Kbuild,或者Makefile(若不存在Kbuild的话)
+- include scripts/Makefile.lib
+- include scripts/Makefile.host
+- include $(cmd_files)
Run the following commands to check the relationships between Makefile and Kbuild:
chenwx@chenwx ~/linux $ make -d O=../linux-build/ -n bzImage > ../linux-build/build.log
chenwx@chenwx ~/linux $ grep "Reading makefile" ../linux-build/build.log
Reading makefiles...
Reading makefile 'Makefile'...
Reading makefiles...
Reading makefile '/home/chenwx/linux/Makefile'...
Reading makefile 'scripts/Kbuild.include' (search path) (no ~ expansion)...
Reading makefile 'include/config/auto.conf' (search path) (don't care) (no ~ expansion)...
Reading makefile 'include/config/auto.conf.cmd' (search path) (don't care) (no ~ expansion)...
Reading makefile 'arch/x86/Makefile' (search path) (no ~ expansion)...
Reading makefile 'arch/x86/Makefile_32.cpu' (search path) (no ~ expansion)...
Reading makefile 'scripts/Makefile.gcc-plugins' (search path) (no ~ expansion)...
Reading makefile 'scripts/Makefile.kasan' (search path) (no ~ expansion)...
Reading makefile 'scripts/Makefile.extrawarn' (search path) (no ~ expansion)...
Reading makefile 'scripts/Makefile.ubsan' (search path) (no ~ expansion)...
Reading makefile '.vmlinux.cmd' (search path) (no ~ expansion)...
Reading makefiles...
Reading makefile '/home/chenwx/linux/scripts/Makefile.build'...
Reading makefile 'include/config/auto.conf' (search path) (don't care) (no ~ expansion)...
Reading makefile 'scripts/Kbuild.include' (search path) (no ~ expansion)...
Reading makefile '/home/chenwx/linux/arch/x86/entry/syscalls/Makefile' (search path) (no ~ expansion)...
Reading makefile 'scripts/Makefile.lib' (search path) (no ~ expansion)...
...
Appendix B: make -f scripts/Makefile.build obj=列表
// Refer to target scripts_basic in top Makefile
make -f scripts/Makefile.build obj=scripts/basic
// Refer to target prepare0 in top Makefile
make -f scripts/Makefile.build obj=.
// Refer to target scripts in top Makefile
make -f scripts/Makefile.build obj=scripts
make -f scripts/Makefile.build obj=scripts/mod
// Refer to $(init-y) in top Makefile
make -f scripts/Makefile.build obj=init
// Refer to $(core-y) in top Makefile
make -f scripts/Makefile.build obj=usr
make -f scripts/Makefile.build obj=arch/x86
make -f scripts/Makefile.build obj=arch/x86/crypto
make -f scripts/Makefile.build obj=arch/x86/kernel
make -f scripts/Makefile.build obj=arch/x86/kernel/acpi
make -f scripts/Makefile.build obj=arch/x86/kernel/apic
make -f scripts/Makefile.build obj=arch/x86/kernel/cpu
make -f scripts/Makefile.build obj=arch/x86/kernel/cpu/mtrr
make -f scripts/Makefile.build obj=arch/x86/mm
make -f scripts/Makefile.build obj=arch/x86/net
make -f scripts/Makefile.build obj=arch/x86/platform
make -f scripts/Makefile.build obj=arch/x86/platform/ce4100
make -f scripts/Makefile.build obj=arch/x86/platform/efi
make -f scripts/Makefile.build obj=arch/x86/platform/geode
make -f scripts/Makefile.build obj=arch/x86/platform/iris
make -f scripts/Makefile.build obj=arch/x86/platform/mrst
make -f scripts/Makefile.build obj=arch/x86/platform/olpc
make -f scripts/Makefile.build obj=arch/x86/platform/scx200
make -f scripts/Makefile.build obj=arch/x86/platform/sfi
make -f scripts/Makefile.build obj=arch/x86/platform/uv
make -f scripts/Makefile.build obj=arch/x86/platform/visws
make -f scripts/Makefile.build obj=arch/x86/vdso
make -f scripts/Makefile.build obj=kernel
make -f scripts/Makefile.build obj=kernel/events
make -f scripts/Makefile.build obj=kernel/irq
make -f scripts/Makefile.build obj=kernel/time
make -f scripts/Makefile.build obj=mm
make -f scripts/Makefile.build obj=fs
make -f scripts/Makefile.build obj=fs/devpts
make -f scripts/Makefile.build obj=fs/exofs
make -f scripts/Makefile.build obj=fs/nls
make -f scripts/Makefile.build obj=fs/notify
make -f scripts/Makefile.build obj=fs/notify/dnotify
make -f scripts/Makefile.build obj=fs/notify/fanotify
make -f scripts/Makefile.build obj=fs/notify/inotify
make -f scripts/Makefile.build obj=fs/partitions
make -f scripts/Makefile.build obj=fs/proc
make -f scripts/Makefile.build obj=fs/quota
make -f scripts/Makefile.build obj=fs/ramfs
make -f scripts/Makefile.build obj=fs/sysfs
make -f scripts/Makefile.build obj=ipc
make -f scripts/Makefile.build obj=security
make -f scripts/Makefile.build obj=crypto
make -f scripts/Makefile.build obj=block
// Refer to $(drivers-y) in top Makefile
make -f scripts/Makefile.build obj=drivers
make -f scripts/Makefile.build obj=drivers/auxdisplay
make -f scripts/Makefile.build obj=drivers/base
make -f scripts/Makefile.build obj=drivers/base/power
make -f scripts/Makefile.build obj=drivers/block
make -f scripts/Makefile.build obj=drivers/cdrom
make -f scripts/Makefile.build obj=drivers/char
make -f scripts/Makefile.build obj=drivers/clk
make -f scripts/Makefile.build obj=drivers/clocksource
make -f scripts/Makefile.build obj=drivers/firewire
make -f scripts/Makefile.build obj=drivers/firmware
make -f scripts/Makefile.build obj=drivers/gpio
make -f scripts/Makefile.build obj=drivers/gpu
make -f scripts/Makefile.build obj=drivers/gpu/drm
make -f scripts/Makefile.build obj=drivers/gpu/drm/i2c
make -f scripts/Makefile.build obj=drivers/gpu/stub
make -f scripts/Makefile.build obj=drivers/gpu/vga
make -f scripts/Makefile.build obj=drivers/i2c
make -f scripts/Makefile.build obj=drivers/i2c/algos
make -f scripts/Makefile.build obj=drivers/i2c/busses
make -f scripts/Makefile.build obj=drivers/i2c/muxes
make -f scripts/Makefile.build obj=drivers/idle
make -f scripts/Makefile.build obj=drivers/ieee802154
make -f scripts/Makefile.build obj=drivers/input
make -f scripts/Makefile.build obj=drivers/input/keyboard
make -f scripts/Makefile.build obj=drivers/input/serio
make -f scripts/Makefile.build obj=drivers/leds
make -f scripts/Makefile.build obj=drivers/lguest
make -f scripts/Makefile.build obj=drivers/macintosh
make -f scripts/Makefile.build obj=drivers/media
make -f scripts/Makefile.build obj=drivers/media/common
make -f scripts/Makefile.build obj=drivers/media/common/tuners
make -f scripts/Makefile.build obj=drivers/media/rc
make -f scripts/Makefile.build obj=drivers/media/rc/keymaps
make -f scripts/Makefile.build obj=drivers/media/video
make -f scripts/Makefile.build obj=drivers/media/video/davinci
make -f scripts/Makefile.build obj=drivers/mfd
make -f scripts/Makefile.build obj=drivers/misc
make -f scripts/Makefile.build obj=drivers/misc/carma
make -f scripts/Makefile.build obj=drivers/misc/cb710
make -f scripts/Makefile.build obj=drivers/misc/eeprom
make -f scripts/Makefile.build obj=drivers/misc/lis3lv02d
make -f scripts/Makefile.build obj=drivers/misc/ti-st
make -f scripts/Makefile.build obj=drivers/net
make -f scripts/Makefile.build obj=drivers/nfc
make -f scripts/Makefile.build obj=drivers/pinctrl
make -f scripts/Makefile.build obj=drivers/platform
make -f scripts/Makefile.build obj=drivers/platform/x86
make -f scripts/Makefile.build obj=drivers/tty
make -f scripts/Makefile.build obj=drivers/tty/ipwireless
make -f scripts/Makefile.build obj=drivers/tty/serial
make -f scripts/Makefile.build obj=drivers/tty/vt
make -f scripts/Makefile.build obj=drivers/video
make -f scripts/Makefile.build obj=drivers/video/backlight
make -f scripts/Makefile.build obj=drivers/video/console
make -f scripts/Makefile.build obj=drivers/video/display
make -f scripts/Makefile.build obj=drivers/video/omap2
make -f scripts/Makefile.build obj=drivers/video/omap2/displays
make -f scripts/Makefile.build obj=sound
make -f scripts/Makefile.build obj=firmware
// Refer to $(net-y) in top Makefile
make -f scripts/Makefile.build obj=net
// Refer to $(libs-y) in top Makefile
make -f scripts/Makefile.build obj=lib
make -f scripts/Makefile.build obj=arch/x86/lib
Appendix C: Kconfig tree
linux-3.2/Kconfig
+- source "arch/$(SRCARCH)/Kconfig" // 此处以x86体系为例,即source "arch/x86/Kconfig"
| +- source "init/Kconfig"
| | +- source "kernel/irq/Kconfig"
| | +- source "usr/Kconfig"
| | +- source "arch/Kconfig"
| | | +- source "kernel/gcov/Kconfig"
| | +- source "block/Kconfig"
| | | +- source block/Kconfig.iosched
| | +- source "kernel/Kconfig.locks"
| +- source "kernel/Kconfig.freezer"
| +- source "kernel/time/Kconfig"
| +- source "arch/x86/xen/Kconfig"
| +- source "arch/x86/lguest/Kconfig"
| +- source "arch/x86/Kconfig.cpu"
| +- source "kernel/Kconfig.preempt"
| +- source "mm/Kconfig"
| +- source kernel/Kconfig.hz
| +- source "kernel/power/Kconfig"
| +- source "drivers/acpi/Kconfig"
| +- source "drivers/sfi/Kconfig"
| +- source "drivers/cpufreq/Kconfig"
| +- source "drivers/cpuidle/Kconfig"
| +- source "drivers/idle/Kconfig"
| +- source "drivers/pci/pcie/Kconfig"
| +- source "drivers/pci/Kconfig"
| +- source "drivers/eisa/Kconfig"
| +- source "drivers/mca/Kconfig"
| +- source "drivers/pcmcia/Kconfig"
| +- source "drivers/pci/hotplug/Kconfig"
| +- source "drivers/rapidio/Kconfig"
| +- source "fs/Kconfig.binfmt"
| +- source "net/Kconfig"
| | +- source "net/packet/Kconfig"
| | +- source "net/unix/Kconfig"
| | +- source "net/xfrm/Kconfig"
| | +- source "net/iucv/Kconfig"
| | +- source "net/ipv4/Kconfig"
| | +- source "net/ipv6/Kconfig"
| | +- source "net/netlabel/Kconfig"
| | +- source "net/netfilter/Kconfig"
| | +- source "net/ipv4/netfilter/Kconfig"
| | +- source "net/ipv6/netfilter/Kconfig"
| | +- source "net/decnet/netfilter/Kconfig"
| | +- source "net/bridge/netfilter/Kconfig"
| | +- source "net/dccp/Kconfig"
| | +- source "net/sctp/Kconfig"
| | +- source "net/rds/Kconfig"
| | +- source "net/tipc/Kconfig"
| | +- source "net/atm/Kconfig"
| | +- source "net/l2tp/Kconfig"
| | +- source "net/802/Kconfig"
| | +- source "net/bridge/Kconfig"
| | +- source "net/dsa/Kconfig"
| | +- source "net/8021q/Kconfig"
| | +- source "net/decnet/Kconfig"
| | +- source "net/llc/Kconfig"
| | +- source "net/ipx/Kconfig"
| | +- source "drivers/net/appletalk/Kconfig"
| | +- source "net/x25/Kconfig"
| | +- source "net/lapb/Kconfig"
| | +- source "net/econet/Kconfig"
| | +- source "net/wanrouter/Kconfig"
| | +- source "net/phonet/Kconfig"
| | +- source "net/ieee802154/Kconfig"
| | +- source "net/sched/Kconfig"
| | +- source "net/dcb/Kconfig"
| | +- source "net/dns_resolver/Kconfig"
| | +- source "net/batman-adv/Kconfig"
| | +- source "net/ax25/Kconfig"
| | +- source "net/can/Kconfig"
| | +- source "net/irda/Kconfig"
| | +- source "net/bluetooth/Kconfig"
| | +- source "net/rxrpc/Kconfig"
| | +- source "net/wireless/Kconfig"
| | +- source "net/mac80211/Kconfig"
| | +- source "net/wimax/Kconfig"
| | +- source "net/rfkill/Kconfig"
| | +- source "net/9p/Kconfig"
| | +- source "net/caif/Kconfig"
| | +- source "net/ceph/Kconfig"
| | +- source "net/nfc/Kconfig"
| +- source "drivers/Kconfig"
| | +- source "drivers/base/Kconfig"
| | +- source "drivers/connector/Kconfig"
| | +- source "drivers/mtd/Kconfig"
| | +- source "drivers/of/Kconfig"
| | +- source "drivers/parport/Kconfig"
| | +- source "drivers/pnp/Kconfig"
| | +- source "drivers/block/Kconfig"
| | +- source "drivers/misc/Kconfig"
| | +- source "drivers/ide/Kconfig"
| | +- source "drivers/scsi/Kconfig"
| | +- source "drivers/ata/Kconfig"
| | +- source "drivers/md/Kconfig"
| | +- source "drivers/target/Kconfig"
| | +- source "drivers/message/fusion/Kconfig"
| | +- source "drivers/firewire/Kconfig"
| | +- source "drivers/message/i2o/Kconfig"
| | +- source "drivers/macintosh/Kconfig"
| | +- source "drivers/net/Kconfig"
| | +- source "drivers/isdn/Kconfig"
| | +- source "drivers/telephony/Kconfig"
| | +- source "drivers/input/Kconfig"
| | +- source "drivers/char/Kconfig"
| | +- source "drivers/i2c/Kconfig"
| | +- source "drivers/spi/Kconfig"
| | +- source "drivers/pps/Kconfig"
| | +- source "drivers/ptp/Kconfig"
| | +- source "drivers/pinctrl/Kconfig"
| | +- source "drivers/gpio/Kconfig"
| | +- source "drivers/w1/Kconfig"
| | +- source "drivers/power/Kconfig"
| | +- source "drivers/hwmon/Kconfig"
| | +- source "drivers/thermal/Kconfig"
| | +- source "drivers/watchdog/Kconfig"
| | +- source "drivers/ssb/Kconfig"
| | +- source "drivers/bcma/Kconfig"
| | +- source "drivers/mfd/Kconfig"
| | +- source "drivers/regulator/Kconfig"
| | +- source "drivers/media/Kconfig"
| | +- source "drivers/video/Kconfig"
| | +- source "sound/Kconfig"
| | +- source "drivers/hid/Kconfig"
| | +- source "drivers/usb/Kconfig"
| | +- source "drivers/uwb/Kconfig"
| | +- source "drivers/mmc/Kconfig"
| | +- source "drivers/memstick/Kconfig"
| | +- source "drivers/leds/Kconfig"
| | +- source "drivers/accessibility/Kconfig"
| | +- source "drivers/infiniband/Kconfig"
| | +- source "drivers/edac/Kconfig"
| | +- source "drivers/rtc/Kconfig"
| | +- source "drivers/dma/Kconfig"
| | +- source "drivers/dca/Kconfig"
| | +- source "drivers/auxdisplay/Kconfig"
| | +- source "drivers/uio/Kconfig"
| | +- source "drivers/vlynq/Kconfig"
| | +- source "drivers/virtio/Kconfig"
| | +- source "drivers/xen/Kconfig"
| | +- source "drivers/staging/Kconfig"
| | +- source "drivers/platform/Kconfig"
| | +- source "drivers/clk/Kconfig"
| | +- source "drivers/hwspinlock/Kconfig"
| | +- source "drivers/clocksource/Kconfig"
| | +- source "drivers/iommu/Kconfig"
| | +- source "drivers/virt/Kconfig"
| | +- source "drivers/hv/Kconfig"
| | +- source "drivers/devfreq/Kconfig"
| +- source "drivers/firmware/Kconfig"
| +- source "fs/Kconfig"
| | +- source "fs/ext2/Kconfig"
| | +- source "fs/ext3/Kconfig"
| | +- source "fs/ext4/Kconfig"
| | +- source "fs/jbd/Kconfig"
| | +- source "fs/jbd2/Kconfig"
| | +- source "fs/reiserfs/Kconfig"
| | +- source "fs/jfs/Kconfig"
| | +- source "fs/xfs/Kconfig"
| | +- source "fs/gfs2/Kconfig"
| | +- source "fs/ocfs2/Kconfig"
| | +- source "fs/btrfs/Kconfig"
| | +- source "fs/nilfs2/Kconfig"
| | +- source "fs/notify/Kconfig"
| | +- source "fs/quota/Kconfig"
| | +- source "fs/autofs4/Kconfig"
| | +- source "fs/fuse/Kconfig"
| | +- source "fs/fscache/Kconfig"
| | +- source "fs/cachefiles/Kconfig"
| | +- source "fs/isofs/Kconfig"
| | +- source "fs/udf/Kconfig"
| | +- source "fs/fat/Kconfig"
| | +- source "fs/ntfs/Kconfig"
| | +- source "fs/proc/Kconfig"
| | +- source "fs/sysfs/Kconfig"
| | +- source "fs/configfs/Kconfig"
| | +- source "fs/adfs/Kconfig"
| | +- source "fs/affs/Kconfig"
| | +- source "fs/ecryptfs/Kconfig"
| | +- source "fs/hfs/Kconfig"
| | +- source "fs/hfsplus/Kconfig"
| | +- source "fs/befs/Kconfig"
| | +- source "fs/bfs/Kconfig"
| | +- source "fs/efs/Kconfig"
| | +- source "fs/jffs2/Kconfig"
| | +- source "fs/ubifs/Kconfig"
| | +- source "fs/logfs/Kconfig"
| | +- source "fs/cramfs/Kconfig"
| | +- source "fs/squashfs/Kconfig"
| | +- source "fs/freevxfs/Kconfig"
| | +- source "fs/minix/Kconfig"
| | +- source "fs/omfs/Kconfig"
| | +- source "fs/hpfs/Kconfig"
| | +- source "fs/qnx4/Kconfig"
| | +- source "fs/romfs/Kconfig"
| | +- source "fs/pstore/Kconfig"
| | +- source "fs/sysv/Kconfig"
| | +- source "fs/ufs/Kconfig"
| | +- source "fs/exofs/Kconfig"
| | +- source "fs/nfs/Kconfig"
| | +- source "fs/nfsd/Kconfig"
| | +- source "net/sunrpc/Kconfig"
| | +- source "fs/ceph/Kconfig"
| | +- source "fs/cifs/Kconfig"
| | +- source "fs/ncpfs/Kconfig"
| | +- source "fs/coda/Kconfig"
| | +- source "fs/afs/Kconfig"
| | +- source "fs/9p/Kconfig"
| | +- source "fs/partitions/Kconfig"
| | +- source "fs/nls/Kconfig"
| | +- source "fs/dlm/Kconfig"
| +- source "arch/x86/Kconfig.debug"
| | +- source "lib/Kconfig.debug"
| +- source "security/Kconfig"
| | +- source security/selinux/Kconfig
| | +- source security/smack/Kconfig
| | +- source security/tomoyo/Kconfig
| | +- source security/apparmor/Kconfig
| | +- source security/integrity/Kconfig
| +- source "crypto/Kconfig"
| | +- source "crypto/async_tx/Kconfig"
| | +- source "drivers/crypto/Kconfig"
| +- source "arch/x86/kvm/Kconfig"
| | +- source "virt/kvm/Kconfig"
| | +- source drivers/vhost/Kconfig
| | +- source drivers/lguest/Kconfig
| +- source "lib/Kconfig"
| | +- source "lib/xz/Kconfig"
Appendix D: make -f scripts/Makefile.modbuiltin obj=列表
make -f scripts/Makefile.modbuiltin obj=init
make -f scripts/Makefile.modbuiltin obj=usr
make -f scripts/Makefile.modbuiltin obj=arch/x86
make -f scripts/Makefile.modbuiltin obj=arch/x86/crypto
make -f scripts/Makefile.modbuiltin obj=arch/x86/kernel
make -f scripts/Makefile.modbuiltin obj=arch/x86/kernel/acpi
make -f scripts/Makefile.modbuiltin obj=arch/x86/kernel/apic
make -f scripts/Makefile.modbuiltin obj=arch/x86/kernel/cpu
make -f scripts/Makefile.modbuiltin obj=arch/x86/kernel/cpu/mcheck
make -f scripts/Makefile.modbuiltin obj=arch/x86/kernel/cpu/mtrr
make -f scripts/Makefile.modbuiltin obj=arch/x86/mm
make -f scripts/Makefile.modbuiltin obj=arch/x86/net
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/ce4100
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/efi
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/geode
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/iris
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/mrst
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/olpc
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/scx200
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/sfi
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/uv
make -f scripts/Makefile.modbuiltin obj=arch/x86/platform/visws
make -f scripts/Makefile.modbuiltin obj=arch/x86/vdso
make -f scripts/Makefile.modbuiltin obj=kernel
make -f scripts/Makefile.modbuiltin obj=kernel/events
make -f scripts/Makefile.modbuiltin obj=kernel/gcov
make -f scripts/Makefile.modbuiltin obj=kernel/irq
make -f scripts/Makefile.modbuiltin obj=kernel/power
make -f scripts/Makefile.modbuiltin obj=kernel/time
make -f scripts/Makefile.modbuiltin obj=kernel/trace
make -f scripts/Makefile.modbuiltin obj=mm
make -f scripts/Makefile.modbuiltin obj=fs
make -f scripts/Makefile.modbuiltin obj=fs/debugfs
make -f scripts/Makefile.modbuiltin obj=fs/devpts
make -f scripts/Makefile.modbuiltin obj=fs/exofs
make -f scripts/Makefile.modbuiltin obj=fs/exportfs
make -f scripts/Makefile.modbuiltin obj=fs/nls
make -f scripts/Makefile.modbuiltin obj=fs/notify
make -f scripts/Makefile.modbuiltin obj=fs/notify/dnotify
make -f scripts/Makefile.modbuiltin obj=fs/notify/fanotify
make -f scripts/Makefile.modbuiltin obj=fs/notify/inotify
make -f scripts/Makefile.modbuiltin obj=fs/partitions
make -f scripts/Makefile.modbuiltin obj=fs/proc
make -f scripts/Makefile.modbuiltin obj=fs/quota
make -f scripts/Makefile.modbuiltin obj=fs/ramfs
make -f scripts/Makefile.modbuiltin obj=fs/sysfs
make -f scripts/Makefile.modbuiltin obj=ipc
make -f scripts/Makefile.modbuiltin obj=security
make -f scripts/Makefile.modbuiltin obj=crypto
make -f scripts/Makefile.modbuiltin obj=block
make -f scripts/Makefile.modbuiltin obj=drivers
make -f scripts/Makefile.modbuiltin obj=drivers/accessibility
make -f scripts/Makefile.modbuiltin obj=drivers/accessibility/braille
make -f scripts/Makefile.modbuiltin obj=drivers/acpi
make -f scripts/Makefile.modbuiltin obj=drivers/acpi/acpica
make -f scripts/Makefile.modbuiltin obj=drivers/auxdisplay
make -f scripts/Makefile.modbuiltin obj=drivers/base
make -f scripts/Makefile.modbuiltin obj=drivers/base/power
make -f scripts/Makefile.modbuiltin obj=drivers/base/regmap
make -f scripts/Makefile.modbuiltin obj=drivers/block
make -f scripts/Makefile.modbuiltin obj=drivers/cdrom
make -f scripts/Makefile.modbuiltin obj=drivers/char
make -f scripts/Makefile.modbuiltin obj=drivers/clk
make -f scripts/Makefile.modbuiltin obj=drivers/clocksource
make -f scripts/Makefile.modbuiltin obj=drivers/cpufreq
make -f scripts/Makefile.modbuiltin obj=drivers/cpuidle
make -f scripts/Makefile.modbuiltin obj=drivers/cpuidle/governors
make -f scripts/Makefile.modbuiltin obj=drivers/crypto
make -f scripts/Makefile.modbuiltin obj=drivers/dma
make -f scripts/Makefile.modbuiltin obj=drivers/edac
make -f scripts/Makefile.modbuiltin obj=drivers/firewire
make -f scripts/Makefile.modbuiltin obj=drivers/firmware
make -f scripts/Makefile.modbuiltin obj=drivers/firmware/google
make -f scripts/Makefile.modbuiltin obj=drivers/gpio
make -f scripts/Makefile.modbuiltin obj=drivers/gpu
make -f scripts/Makefile.modbuiltin obj=drivers/gpu/drm
make -f scripts/Makefile.modbuiltin obj=drivers/gpu/drm/i2c
make -f scripts/Makefile.modbuiltin obj=drivers/gpu/stub
make -f scripts/Makefile.modbuiltin obj=drivers/gpu/vga
make -f scripts/Makefile.modbuiltin obj=drivers/i2c
make -f scripts/Makefile.modbuiltin obj=drivers/i2c/algos
make -f scripts/Makefile.modbuiltin obj=drivers/i2c/busses
make -f scripts/Makefile.modbuiltin obj=drivers/i2c/muxes
make -f scripts/Makefile.modbuiltin obj=drivers/idle
make -f scripts/Makefile.modbuiltin obj=drivers/ieee802154
make -f scripts/Makefile.modbuiltin obj=drivers/input
make -f scripts/Makefile.modbuiltin obj=drivers/input/joystick
make -f scripts/Makefile.modbuiltin obj=drivers/input/keyboard
make -f scripts/Makefile.modbuiltin obj=drivers/input/misc
make -f scripts/Makefile.modbuiltin obj=drivers/input/serio
make -f scripts/Makefile.modbuiltin obj=drivers/iommu
make -f scripts/Makefile.modbuiltin obj=drivers/isdn
make -f scripts/Makefile.modbuiltin obj=drivers/isdn/hardware
make -f scripts/Makefile.modbuiltin obj=drivers/isdn/hardware/avm
make -f scripts/Makefile.modbuiltin obj=drivers/isdn/hardware/eicon
make -f scripts/Makefile.modbuiltin obj=drivers/leds
make -f scripts/Makefile.modbuiltin obj=drivers/lguest
make -f scripts/Makefile.modbuiltin obj=drivers/macintosh
make -f scripts/Makefile.modbuiltin obj=drivers/md
make -f scripts/Makefile.modbuiltin obj=drivers/media
make -f scripts/Makefile.modbuiltin obj=drivers/media/common
make -f scripts/Makefile.modbuiltin obj=drivers/media/common/tuners
make -f scripts/Makefile.modbuiltin obj=drivers/media/rc
make -f scripts/Makefile.modbuiltin obj=drivers/media/rc/keymaps
make -f scripts/Makefile.modbuiltin obj=drivers/media/video
make -f scripts/Makefile.modbuiltin obj=drivers/media/video/davinci
make -f scripts/Makefile.modbuiltin obj=drivers/mfd
make -f scripts/Makefile.modbuiltin obj=drivers/misc
make -f scripts/Makefile.modbuiltin obj=drivers/misc/carma
make -f scripts/Makefile.modbuiltin obj=drivers/misc/cb710
make -f scripts/Makefile.modbuiltin obj=drivers/misc/eeprom
make -f scripts/Makefile.modbuiltin obj=drivers/misc/lis3lv02d
make -f scripts/Makefile.modbuiltin obj=drivers/misc/ti-st
make -f scripts/Makefile.modbuiltin obj=drivers/net
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/3com
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/8390
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/amd
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/atheros
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/broadcom
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/fujitsu
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/intel
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/marvell
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/mellanox
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/natsemi
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/oki-semi
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/packetengines
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/qlogic
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/racal
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/rdc
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/sis
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/smsc
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/stmicro
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/sun
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/ti
make -f scripts/Makefile.modbuiltin obj=drivers/net/ethernet/via
make -f scripts/Makefile.modbuiltin obj=drivers/net/wan
make -f scripts/Makefile.modbuiltin obj=drivers/net/wireless
make -f scripts/Makefile.modbuiltin obj=drivers/nfc
make -f scripts/Makefile.modbuiltin obj=drivers/pci
make -f scripts/Makefile.modbuiltin obj=drivers/pci/pcie
make -f scripts/Makefile.modbuiltin obj=drivers/pci/pcie/aer
make -f scripts/Makefile.modbuiltin obj=drivers/pinctrl
make -f scripts/Makefile.modbuiltin obj=drivers/platform
make -f scripts/Makefile.modbuiltin obj=drivers/platform/x86
make -f scripts/Makefile.modbuiltin obj=drivers/pnp
make -f scripts/Makefile.modbuiltin obj=drivers/pnp/isapnp
make -f scripts/Makefile.modbuiltin obj=drivers/pnp/pnpacpi
make -f scripts/Makefile.modbuiltin obj=drivers/tty
make -f scripts/Makefile.modbuiltin obj=drivers/tty/ipwireless
make -f scripts/Makefile.modbuiltin obj=drivers/tty/serial
make -f scripts/Makefile.modbuiltin obj=drivers/tty/vt
make -f scripts/Makefile.modbuiltin obj=drivers/usb
make -f scripts/Makefile.modbuiltin obj=drivers/usb/early
make -f scripts/Makefile.modbuiltin obj=drivers/usb/host
make -f scripts/Makefile.modbuiltin obj=drivers/video
make -f scripts/Makefile.modbuiltin obj=drivers/video/backlight
make -f scripts/Makefile.modbuiltin obj=drivers/video/console
make -f scripts/Makefile.modbuiltin obj=drivers/video/display
make -f scripts/Makefile.modbuiltin obj=drivers/video/omap2
make -f scripts/Makefile.modbuiltin obj=drivers/video/omap2/displays
make -f scripts/Makefile.modbuiltin obj=drivers/watchdog
make -f scripts/Makefile.modbuiltin obj=sound
make -f scripts/Makefile.modbuiltin obj=firmware
make -f scripts/Makefile.modbuiltin obj=arch/x86/pci
make -f scripts/Makefile.modbuiltin obj=arch/x86/power
make -f scripts/Makefile.modbuiltin obj=arch/x86/video
make -f scripts/Makefile.modbuiltin obj=net
make -f scripts/Makefile.modbuiltin obj=net/802
make -f scripts/Makefile.modbuiltin obj=net/8021q
make -f scripts/Makefile.modbuiltin obj=net/core
make -f scripts/Makefile.modbuiltin obj=net/ethernet
make -f scripts/Makefile.modbuiltin obj=net/ipv6
make -f scripts/Makefile.modbuiltin obj=net/ipv6/netfilter
make -f scripts/Makefile.modbuiltin obj=net/netfilter
make -f scripts/Makefile.modbuiltin obj=net/netlink
make -f scripts/Makefile.modbuiltin obj=net/sched
make -f scripts/Makefile.modbuiltin obj=net/wireless
make -f scripts/Makefile.modbuiltin obj=net/xfrm
make -f scripts/Makefile.modbuiltin obj=lib
make -f scripts/Makefile.modbuiltin obj=lib/lzo
make -f scripts/Makefile.modbuiltin obj=arch/x86/lib
Appendix E: arch目录下处理器体系架构介绍
alpha处理器
Alpha处理器最早由美国DEC公司设计制造,在Compaq(康柏)公司收购DEC之后,Alpha处理器继续得到发展,并且应用于许多高档的Compaq服务器上,HP(惠普)收购Compaq后,Alpha便为HP(惠普)所有,不过HP(惠普)已经放弃发展alpha 处理器。
arm处理器
Arm系列处理器是英国Arm公司设计的主流嵌入式32位RISC处理器,Arm公司不直接生产Arm处理器,而是采用IP授权的方式由第三方开发生产,著名的公司如Ti、Samsung等都有出品Arm处理器。目前在手机领域广泛应用。
avr32处理器
Avr32处理器是美国Atmel公司设计开发的32位RISC处理器,设计目的是在每一个时钟周期内完成更多处理工作,从而在较低的时钟频率下实现相同的吞吐量。适合在工业控制、汽车电子等嵌入式设备领域中使用。Avr32属于MCU(Micro Control Unit)型处理器。
blackfin处理器
Blackfin处理器是美国ADI公司开发的具有DSP能力的32位RISC处理器,Blackfin处理器基于由ADI和Intel公司联合开发的微信号架构(MSA),适用于嵌入式音频、视频和通信应用等领域。
cris处理器
Cris处理器是瑞典Axis通信公司开发的32位RISC处理器,主要用于网络设备,属于比较专业的应用领域。因为Axis通信公司主要开发网络监控设备,所以Cris处理器在其网络监控设备中应用广泛。
frv处理器
Frv处理器是日本富士通开发的32位高性能RISC处理器,采用VLIW(Very Long Instruction Word)构架,具备良好的多媒体处理能力,在机顶盒(STB)、数码刻录机(DVR)、数码相机(DSC)等嵌入式领域应用广泛。
h8300处理器
H8300处理器是日本瑞萨科技开发的32位高性能RISC处理器,具有强大的位操作指令,最适于实时控制应用如汽车电子、家用电器、医疗器械等领域。H8300属于MCU型的处理器。
hexagon处理器
Hexagon is a DSP based CPU architecture developed by Qualcomm. It uses VLIW and is capable of dispatching up to 4 instructions to 4 Execution Units every clock. The Hexagon architecture is designed to deliver performance with low power over a variety of applications. It has features such as multithreading, privilege levels, VLIW, SIMD, and instructions geared toward efficient signal processing. The port of Linux for Hexagon runs under a hypervisor layer and was merged with the 3.2 release of the kernel. Support for Hexagon was added in 3.1 release of LLVM by Tony Linthicum. There is also a non-FSF maintained branch of GCC. Hexagon DSPs are included in Snapdragon SoC since 2006. In Snapdragon S4 (MSM8960 and newer) there are three Hexagon cores, two in the Modem subsystem and one in the Multimedia subsystem. There are four generations of DSP architecture: H1 (2006), H2 (2007-2008), H3 (2009), H4 (2010-2011). H4 has 20 DMIPS per milliwatt, works with frequency 500 MHz. Clock speed of Hexagon varies in 400-600 MHz for QDSP6 and in 256-350 MHz for QDSP5.
ia64处理器
Ia64处理器是美国英特尔开发的面向服务器应用的64位处理器,由于具有64位寻址能力,它能够使用100万TB的地址空间,足以运算企业级或超大规模的数据库任务;64位宽的寄存器可以使CPU浮点运算达到非常高的精度。
m32r处理器
M32r处理器是日本瑞萨科技开发的32位高性能RISC处理器,内置大容量存储器,适用于车载系统、数字AV设备、数字成像设备等产品领域。属于MCU型的处理器。
m68k处理器
M68k处理器是美国Motorola公司开发的高性能处理器,具有高性价比、高集成度等特点,在工业自动化设备、控制设备、医疗仪器系统、安全系统等领域多有应用。现在为Freescale公司所有,风头已不敌PowerPC处理器。
microblaze处理器
Microblaze处理器是美国Xilinx公司提供的嵌入在其FPGA芯片上的32位RISC软核。 它具有运算能力强、外围接口配置灵活等特点,集成在FPGA中,可以和FPGA实现协同设计,具备软硬件可配置的灵活性。
mips处理器
Mips处理器是由美国斯坦福大学Hennessy教授领导的研究小组研制出来,现为Mips公司拥有,和Arm处理器一样采用IP授权的方式由第三方开发生产。著名的公司如Broadcom、Nxp等都有出品Mips处理器。我国的龙芯CPU也是采用Mips体系结构。
mn10300处理器
Mn10300处理器是日本松下开发的32位多媒体处理器。
openrisc处理器
OpenRisc是OpenCores组织提供的基于GPL协议的开放源代码的RISC(精简指令集计算机)处理器。有人认为其性能介于ARM7和ARM9之间,适合一般的嵌入式系统使用。最重要的一点是OpenCores组织提供了大量的开放源代码IP核供研究人员使用,因此对于一般的开发单位具有很大的吸引力。
parisc处理器
Parisc处理器是由HP(惠普)开发设计的处理器,主要用于HP(惠普)公司的服务器中,目前HP(惠普)已经放弃Parisc处理器的开发,不过一些Parisc处理器技术已经融合到ia64处理器之中。
powerpc处理器
Powerpc处理器是由美国IBM、Apple、Motorola联合开发的处理器,Powepc处理器在IBM的服务器、Apple的MAC电脑中都有应用。不过现在多应用在网络设备、视频系统、工业系统等领域。Sony PS3游戏机的Cell处理器也是Powerpc体系结构。
s390处理器
S390处理器是由美国IBM开发的面向大型机应用的处理器。
score处理器
Score处理器是由台湾凌阳开发的32位RISC处理器。Score属于MCU型处理器。
sh处理器
Sh处理器又称SuperH处理器,最先由日本Hitachi公司开发,后由Hitachi及ST Microelectronics两家公司共同开发,2003年瑞萨科技从Hitachi公司继承到拥有权。Sh属于MCU型处理器。
sparc处理器
Sparc处理器是由美国SUN和TI公司共同开发的RISC微处理器,最突出的特点是它的可扩展性。SUN公司将它做为高端处理器应用到服务器产品。
tile处理器
-
um处理器
-
unicore32处理器
-
x86处理器
X86处理器是由美国Intel推出的复杂指令集(cisc)处理器,广泛应用在PC电脑领域和服务器领域,在工业控制领域也有应用。目前主要是Intel、AMD、VIA在开发x86体系结构的处理器。
xtensa处理器
Xtensa处理器是由美国Tensilica(泰思立达)公司开发的可配置及可扩展的微处理器。
Appendix F: vmlinux.lds.S
/*
* ld script for the x86 kernel
*
* Historic 32-bit version written by Martin Mares <mj@atrey.karlin.mff.cuni.cz>
*
* Modernisation, unification and other changes and fixes:
* Copyright (C) 2007-2009 Sam Ravnborg <sam@ravnborg.org>
*
*
* Don't define absolute symbols until and unless you know that symbol
* value is should remain constant even if kernel image is relocated
* at run time. Absolute symbols are not relocated. If symbol value should
* change if kernel is relocated, make the symbol section relative and
* put it inside the section definition.
*/
#ifdef CONFIG_X86_32
/*
* See arch/x86/include/asm/page_32_types.h for __PAGE_OFFSET,
* 由.config中的配置CONFIG_PAGE_OFFSET有关
*/
#define LOAD_OFFSET __PAGE_OFFSET
#else
/*
* See arch/x86/include/asm/page_64_types.h
* for __START_KERNEL_map
*/
#define LOAD_OFFSET __START_KERNEL_map
#endif
#include <asm-generic/vmlinux.lds.h>
#include <asm/asm-offsets.h>
#include <asm/thread_info.h>
#include <asm/page_types.h>
#include <asm/cache.h>
#include <asm/boot.h>
#undef i386 /* in case the preprocessor is a 32bit one */
// Alex Note: See .config for CONFIG_OUTPUT_FORMAT
OUTPUT_FORMAT(CONFIG_OUTPUT_FORMAT, CONFIG_OUTPUT_FORMAT, CONFIG_OUTPUT_FORMAT)
#ifdef CONFIG_X86_32
OUTPUT_ARCH(i386) // Refer to output of linux command 'objdump -i'
ENTRY(phys_startup_32) // See System.map
jiffies = jiffies_64;
#else
OUTPUT_ARCH(i386:x86-64)
ENTRY(phys_startup_64)
jiffies_64 = jiffies;
#endif
#if defined(CONFIG_X86_64) && defined(CONFIG_DEBUG_RODATA)
/*
* On 64-bit, align RODATA to 2MB so that even with CONFIG_DEBUG_RODATA
* we retain large page mappings for boundaries spanning kernel text, rodata
* and data sections.
*
* However, kernel identity mappings will have different RWX permissions
* to the pages mapping to text and to the pages padding (which are freed) the
* text section. Hence kernel identity mappings will be broken to smaller
* pages. For 64-bit, kernel text and kernel identity mappings are different,
* so we can enable protection checks that come with CONFIG_DEBUG_RODATA,
* as well as retain 2MB large page mappings for kernel text.
*/
#define X64_ALIGN_DEBUG_RODATA_BEGIN . = ALIGN(HPAGE_SIZE);
#define X64_ALIGN_DEBUG_RODATA_END \
. = ALIGN(HPAGE_SIZE); \
__end_rodata_hpage_align = .;
#else
#define X64_ALIGN_DEBUG_RODATA_BEGIN
#define X64_ALIGN_DEBUG_RODATA_END
#endif
PHDRS {
text PT_LOAD FLAGS(5); /* R_E */ // 代码段配置,可加载,可读可执行
data PT_LOAD FLAGS(6); /* RW_ */ // 数据段配置,可加载,可读可写
#ifdef CONFIG_X86_64
#ifdef CONFIG_SMP
percpu PT_LOAD FLAGS(6); /* RW_ */
#endif
init PT_LOAD FLAGS(7); /* RWE */
#endif
note PT_NOTE FLAGS(0); /* ___ */ // 注释段配置
}
SECTIONS
{
#ifdef CONFIG_X86_32
/*
* LOAD_PHYSICAL_ADDR定义于arch\x86\include\asm\boot.h
* 由CONFIG_PHYSICAL_START、CONFIG_PHYSICAL_ALIGN计算而来
*/
. = LOAD_OFFSET + LOAD_PHYSICAL_ADDR;
phys_startup_32 = startup_32 - LOAD_OFFSET;
#else
. = __START_KERNEL;
phys_startup_64 = startup_64 - LOAD_OFFSET;
#endif
/* Text and read-only data */
.text : AT(ADDR(.text) - LOAD_OFFSET) {
_text = .;
/* bootstrapping code */
HEAD_TEXT // See include/asm-generic/vmlinux.lds.h
#ifdef CONFIG_X86_32
. = ALIGN(PAGE_SIZE); // See arch/x86/include/asm/page_types.h
*(.text..page_aligned)
#endif
. = ALIGN(8);
_stext = .;
TEXT_TEXT // See include/asm-generic/vmlinux.lds.h
SCHED_TEXT // See include/asm-generic/vmlinux.lds.h
LOCK_TEXT // See include/asm-generic/vmlinux.lds.h
KPROBES_TEXT // See include/asm-generic/vmlinux.lds.h
ENTRY_TEXT // See include/asm-generic/vmlinux.lds.h
IRQENTRY_TEXT // See include/asm-generic/vmlinux.lds.h
*(.fixup)
*(.gnu.warning)
/* End of text section */
_etext = .;
} :text = 0x9090
NOTES :text :note
EXCEPTION_TABLE(16) :text = 0x9090
#if defined(CONFIG_DEBUG_RODATA)
/* .text should occupy whole number of pages */
. = ALIGN(PAGE_SIZE);
#endif
X64_ALIGN_DEBUG_RODATA_BEGIN
RO_DATA(PAGE_SIZE)
X64_ALIGN_DEBUG_RODATA_END
/* Data */
.data : AT(ADDR(.data) - LOAD_OFFSET) {
/* Start of data section */
_sdata = .;
/* init_task */
INIT_TASK_DATA(THREAD_SIZE)
#ifdef CONFIG_X86_32
/* 32 bit has nosave before _edata */
NOSAVE_DATA
#endif
PAGE_ALIGNED_DATA(PAGE_SIZE)
CACHELINE_ALIGNED_DATA(L1_CACHE_BYTES)
DATA_DATA
CONSTRUCTORS
/* rarely changed data like cpu maps */
READ_MOSTLY_DATA(INTERNODE_CACHE_BYTES)
/* End of data section */
_edata = .;
} :data
#ifdef CONFIG_X86_64
. = ALIGN(PAGE_SIZE);
__vvar_page = .;
.vvar : AT(ADDR(.vvar) - LOAD_OFFSET) {
/* work around gold bug 13023 */
__vvar_beginning_hack = .;
/* Place all vvars at the offsets in asm/vvar.h. */
#define EMIT_VVAR(name, offset) \
. = __vvar_beginning_hack + offset; \
*(.vvar_ ## name)
#define __VVAR_KERNEL_LDS
#include <asm/vvar.h>
#undef __VVAR_KERNEL_LDS
#undef EMIT_VVAR
} :data
. = ALIGN(__vvar_page + PAGE_SIZE, PAGE_SIZE);
#endif /* CONFIG_X86_64 */
/* Init code and data - will be freed after init */
. = ALIGN(PAGE_SIZE);
.init.begin : AT(ADDR(.init.begin) - LOAD_OFFSET) {
__init_begin = .; /* paired with __init_end */
}
#if defined(CONFIG_X86_64) && defined(CONFIG_SMP)
/*
* percpu offsets are zero-based on SMP. PERCPU_VADDR() changes the
* output PHDR, so the next output section - .init.text - should
* start another segment - init.
*/
PERCPU_VADDR(INTERNODE_CACHE_BYTES, 0, :percpu)
#endif
INIT_TEXT_SECTION(PAGE_SIZE)
#ifdef CONFIG_X86_64
:init
#endif
INIT_DATA_SECTION(16)
.x86_cpu_dev.init : AT(ADDR(.x86_cpu_dev.init) - LOAD_OFFSET) {
__x86_cpu_dev_start = .;
*(.x86_cpu_dev.init)
__x86_cpu_dev_end = .;
}
/*
* start address and size of operations which during runtime
* can be patched with virtualization friendly instructions or
* baremetal native ones. Think page table operations.
* Details in paravirt_types.h
*/
. = ALIGN(8);
.parainstructions : AT(ADDR(.parainstructions) - LOAD_OFFSET) {
__parainstructions = .;
*(.parainstructions)
__parainstructions_end = .;
}
/*
* struct alt_inst entries. From the header (alternative.h):
* "Alternative instructions for different CPU types or capabilities"
* Think locking instructions on spinlocks.
*/
. = ALIGN(8);
.altinstructions : AT(ADDR(.altinstructions) - LOAD_OFFSET) {
__alt_instructions = .;
*(.altinstructions)
__alt_instructions_end = .;
}
/*
* And here are the replacement instructions. The linker sticks
* them as binary blobs. The .altinstructions has enough data to
* get the address and the length of them to patch the kernel safely.
*/
.altinstr_replacement : AT(ADDR(.altinstr_replacement) - LOAD_OFFSET) {
*(.altinstr_replacement)
}
/*
* struct iommu_table_entry entries are injected in this section.
* It is an array of IOMMUs which during run time gets sorted depending
* on its dependency order. After rootfs_initcall is complete
* this section can be safely removed.
*/
.iommu_table : AT(ADDR(.iommu_table) - LOAD_OFFSET) {
__iommu_table = .;
*(.iommu_table)
__iommu_table_end = .;
}
. = ALIGN(8);
.apicdrivers : AT(ADDR(.apicdrivers) - LOAD_OFFSET) {
__apicdrivers = .;
*(.apicdrivers);
__apicdrivers_end = .;
}
. = ALIGN(8);
/*
* .exit.text is discard at runtime, not link time, to deal with
* references from .altinstructions and .eh_frame
*/
.exit.text : AT(ADDR(.exit.text) - LOAD_OFFSET) {
EXIT_TEXT
}
.exit.data : AT(ADDR(.exit.data) - LOAD_OFFSET) {
EXIT_DATA
}
#if !defined(CONFIG_X86_64) || !defined(CONFIG_SMP)
PERCPU_SECTION(INTERNODE_CACHE_BYTES)
#endif
. = ALIGN(PAGE_SIZE);
/* freed after init ends here */
.init.end : AT(ADDR(.init.end) - LOAD_OFFSET) {
__init_end = .;
}
/*
* smp_locks might be freed after init
* start/end must be page aligned
*/
. = ALIGN(PAGE_SIZE);
.smp_locks : AT(ADDR(.smp_locks) - LOAD_OFFSET) {
__smp_locks = .;
*(.smp_locks)
. = ALIGN(PAGE_SIZE);
__smp_locks_end = .;
}
#ifdef CONFIG_X86_64
.data_nosave : AT(ADDR(.data_nosave) - LOAD_OFFSET) {
NOSAVE_DATA
}
#endif
/* BSS */
. = ALIGN(PAGE_SIZE);
.bss : AT(ADDR(.bss) - LOAD_OFFSET) {
__bss_start = .;
*(.bss..page_aligned)
*(.bss)
. = ALIGN(PAGE_SIZE);
__bss_stop = .;
}
. = ALIGN(PAGE_SIZE);
.brk : AT(ADDR(.brk) - LOAD_OFFSET) {
__brk_base = .;
. += 64 * 1024; /* 64k alignment slop space */
*(.brk_reservation) /* areas brk users have reserved */
__brk_limit = .;
}
_end = .;
STABS_DEBUG
DWARF_DEBUG
/* Sections to be discarded */
DISCARDS
/DISCARD/ : { *(.eh_frame) }
}
#ifdef CONFIG_X86_32
/*
* The ASSERT() sink to . is intentional, for binutils 2.14 compatibility:
*/
. = ASSERT((_end - LOAD_OFFSET <= KERNEL_IMAGE_SIZE),
"kernel image bigger than KERNEL_IMAGE_SIZE");
#else
/*
* Per-cpu symbols which need to be offset from __per_cpu_load
* for the boot processor.
*/
#define INIT_PER_CPU(x) init_per_cpu__##x = x + __per_cpu_load
INIT_PER_CPU(gdt_page);
INIT_PER_CPU(irq_stack_union);
/*
* Build-time check on the image size:
*/
. = ASSERT((_end - _text <= KERNEL_IMAGE_SIZE),
"kernel image bigger than KERNEL_IMAGE_SIZE");
#ifdef CONFIG_SMP
. = ASSERT((irq_stack_union == 0),
"irq_stack_union is not at start of per-cpu area");
#endif
#endif /* CONFIG_X86_32 */
#ifdef CONFIG_KEXEC
#include <asm/kexec.h>
. = ASSERT(kexec_control_code_size <= KEXEC_CONTROL_CODE_MAX_SIZE,
"kexec control code size is too big");
#endif
Appendix G: vmlinux.lds
vmlinux.lds是由vmlinux.lds.S经过预处理而生成的文件,用于链接器ld连接.o文件时的link script。该文件的生成过程参见3.4.2.2 $(vmlinux-lds)节,其具体内容如下:
OUTPUT_FORMAT("elf32-i386", "elf32-i386", "elf32-i386")
OUTPUT_ARCH(i386)
ENTRY(phys_startup_32)
jiffies = jiffies_64;
PHDRS {
text PT_LOAD FLAGS(5); /* R_E */
data PT_LOAD FLAGS(6); /* RW_ */
note PT_NOTE FLAGS(0); /* ___ */
}
SECTIONS
{
. = 0xC0000000 + ((0x1000000 + (0x1000000 - 1)) & ~(0x1000000 - 1));
phys_startup_32 = startup_32 - 0xC0000000;
/* Text and read-only data */
.text : AT(ADDR(.text) - 0xC0000000) {
_text = .;
/* bootstrapping code */
*(.head.text)
. = ALIGN((1 << 12));
*(.text..page_aligned)
. = ALIGN(8);
_stext = .;
. = ALIGN(8); *(.text.hot) *(.text) *(.ref.text) *(.devinit.text) *(.devexit.text) *(.text.unlikely)
. = ALIGN(8); __sched_text_start = .; *(.sched.text) __sched_text_end = .;
. = ALIGN(8); __lock_text_start = .; *(.spinlock.text) __lock_text_end = .;
. = ALIGN(8); __kprobes_text_start = .; *(.kprobes.text) __kprobes_text_end = .;
. = ALIGN(8); __entry_text_start = .; *(.entry.text) __entry_text_end = .;
*(.fixup)
*(.gnu.warning)
/* End of text section */
_etext = .;
} :text = 0x9090
.notes : AT(ADDR(.notes) - 0xC0000000) { __start_notes = .; *(.note.*) __stop_notes = .; } :text :note
. = ALIGN(16); __ex_table : AT(ADDR(__ex_table) - 0xC0000000) { __start___ex_table = .; *(__ex_table) __stop___ex_table = .; } :text = 0x9090
. = ALIGN(((1 << 12))); .rodata : AT(ADDR(.rodata) - 0xC0000000) { __start_rodata = .; *(.rodata) *(.rodata.*) *(__vermagic) . = ALIGN(8); __start___tracepoints_ptrs = .; *(__tracepoints_ptrs) __stop___tracepoints_ptrs = .; *(__tracepoints_strings) } .rodata1 : AT(ADDR(.rodata1) - 0xC0000000) { *(.rodata1) } . = ALIGN(8); __bug_table : AT(ADDR(__bug_table) - 0xC0000000) { __start___bug_table = .; *(__bug_table) __stop___bug_table = .; } .pci_fixup : AT(ADDR(.pci_fixup) - 0xC0000000) { __start_pci_fixups_early = .; *(.pci_fixup_early) __end_pci_fixups_early = .; __start_pci_fixups_header = .; *(.pci_fixup_header) __end_pci_fixups_header = .; __start_pci_fixups_final = .; *(.pci_fixup_final) __end_pci_fixups_final = .; __start_pci_fixups_enable = .; *(.pci_fixup_enable) __end_pci_fixups_enable = .; __start_pci_fixups_resume = .; *(.pci_fixup_resume) __end_pci_fixups_resume = .; __start_pci_fixups_resume_early = .; *(.pci_fixup_resume_early) __end_pci_fixups_resume_early = .; __start_pci_fixups_suspend = .; *(.pci_fixup_suspend) __end_pci_fixups_suspend = .; } .builtin_fw : AT(ADDR(.builtin_fw) - 0xC0000000) { __start_builtin_fw = .; *(.builtin_fw) __end_builtin_fw = .; } .rio_ops : AT(ADDR(.rio_ops) - 0xC0000000) { __start_rio_switch_ops = .; *(.rio_switch_ops) __end_rio_switch_ops = .; } . = ALIGN(4); .tracedata : AT(ADDR(.tracedata) - 0xC0000000) { __tracedata_start = .; *(.tracedata) __tracedata_end = .; } __ksymtab : AT(ADDR(__ksymtab) - 0xC0000000) { __start___ksymtab = .; *(SORT(___ksymtab+*)) __stop___ksymtab = .; } __ksymtab_gpl : AT(ADDR(__ksymtab_gpl) - 0xC0000000) { __start___ksymtab_gpl = .; *(SORT(___ksymtab_gpl+*)) __stop___ksymtab_gpl = .; } __ksymtab_unused : AT(ADDR(__ksymtab_unused) - 0xC0000000) { __start___ksymtab_unused = .; *(SORT(___ksymtab_unused+*)) __stop___ksymtab_unused = .; } __ksymtab_unused_gpl : AT(ADDR(__ksymtab_unused_gpl) - 0xC0000000) { __start___ksymtab_unused_gpl = .; *(SORT(___ksymtab_unused_gpl+*)) __stop___ksymtab_unused_gpl = .; } __ksymtab_gpl_future : AT(ADDR(__ksymtab_gpl_future) - 0xC0000000) { __start___ksymtab_gpl_future = .; *(SORT(___ksymtab_gpl_future+*)) __stop___ksymtab_gpl_future = .; } __kcrctab : AT(ADDR(__kcrctab) - 0xC0000000) { __start___kcrctab = .; *(SORT(___kcrctab+*)) __stop___kcrctab = .; } __kcrctab_gpl : AT(ADDR(__kcrctab_gpl) - 0xC0000000) { __start___kcrctab_gpl = .; *(SORT(___kcrctab_gpl+*)) __stop___kcrctab_gpl = .; } __kcrctab_unused : AT(ADDR(__kcrctab_unused) - 0xC0000000) { __start___kcrctab_unused = .; *(SORT(___kcrctab_unused+*)) __stop___kcrctab_unused = .; } __kcrctab_unused_gpl : AT(ADDR(__kcrctab_unused_gpl) - 0xC0000000) { __start___kcrctab_unused_gpl = .; *(SORT(___kcrctab_unused_gpl+*)) __stop___kcrctab_unused_gpl = .; } __kcrctab_gpl_future : AT(ADDR(__kcrctab_gpl_future) - 0xC0000000) { __start___kcrctab_gpl_future = .; *(SORT(___kcrctab_gpl_future+*)) __stop___kcrctab_gpl_future = .; } __ksymtab_strings : AT(ADDR(__ksymtab_strings) - 0xC0000000) { *(__ksymtab_strings) } __init_rodata : AT(ADDR(__init_rodata) - 0xC0000000) { *(.ref.rodata) *(.devinit.rodata) *(.devexit.rodata) } __param : AT(ADDR(__param) - 0xC0000000) { __start___param = .; *(__param) __stop___param = .; } __modver : AT(ADDR(__modver) - 0xC0000000) { __start___modver = .; *(__modver) __stop___modver = .; . = ALIGN(((1 << 12))); __end_rodata = .; } . = ALIGN(((1 << 12)));
/* Data */
.data : AT(ADDR(.data) - 0xC0000000) {
/* Start of data section */
_sdata = .;
/* init_task */
. = ALIGN(((1 << 12) << 1)); *(.data..init_task)
/* 32 bit has nosave before _edata */
. = ALIGN((1 << 12)); __nosave_begin = .; *(.data..nosave) . = ALIGN((1 << 12)); __nosave_end = .;
. = ALIGN((1 << 12)); *(.data..page_aligned)
. = ALIGN((1 << (5))); *(.data..cacheline_aligned)
*(.data) *(.ref.data) *(.data..shared_aligned) *(.devinit.data) *(.devexit.data) . = ALIGN(32); *(__tracepoints) . = ALIGN(8); __start___jump_table = .; *(__jump_table) __stop___jump_table = .; . = ALIGN(8); __start___verbose = .; *(__verbose) __stop___verbose = .; __start_annotated_branch_profile = .; *(_ftrace_annotated_branch) __stop_annotated_branch_profile = .; __start___trace_bprintk_fmt = .; *(__trace_printk_fmt) __stop___trace_bprintk_fmt = .;
CONSTRUCTORS
/* rarely changed data like cpu maps */
. = ALIGN((1 << 5)); *(.data..read_mostly) . = ALIGN((1 << 5));
/* End of data section */
_edata = .;
} :data
/* Init code and data - will be freed after init */
. = ALIGN((1 << 12));
.init.begin : AT(ADDR(.init.begin) - 0xC0000000) {
__init_begin = .; /* paired with __init_end */
}
. = ALIGN((1 << 12)); .init.text : AT(ADDR(.init.text) - 0xC0000000) { _sinittext = .; *(.init.text) *(.cpuinit.text) *(.meminit.text) _einittext = .; }
.init.data : AT(ADDR(.init.data) - 0xC0000000) { *(.init.data) *(.cpuinit.data) *(.meminit.data) . = ALIGN(8); __ctors_start = .; *(.ctors) __ctors_end = .; *(.init.rodata) . = ALIGN(8); __start_ftrace_events = .; *(_ftrace_events) __stop_ftrace_events = .; *(.cpuinit.rodata) *(.meminit.rodata) . = ALIGN(32); __dtb_start = .; *(.dtb.init.rodata) __dtb_end = .; . = ALIGN(16); __setup_start = .; *(.init.setup) __setup_end = .; __initcall_start = .; *(.initcallearly.init) __early_initcall_end = .; *(.initcall0.init) *(.initcall0s.init) *(.initcall1.init) *(.initcall1s.init) *(.initcall2.init) *(.initcall2s.init) *(.initcall3.init) *(.initcall3s.init) *(.initcall4.init) *(.initcall4s.init) *(.initcall5.init) *(.initcall5s.init) *(.initcallrootfs.init) *(.initcall6.init) *(.initcall6s.init) *(.initcall7.init) *(.initcall7s.init) __initcall_end = .; __con_initcall_start = .; *(.con_initcall.init) __con_initcall_end = .; __security_initcall_start = .; *(.security_initcall.init) __security_initcall_end = .; }
/*
* Code and data for a variety of lowlevel trampolines, to be
* copied into base memory (< 1 MiB) during initialization.
* Since it is copied early, the main copy can be discarded
* afterwards.
*/
.x86_trampoline : AT(ADDR(.x86_trampoline) - 0xC0000000) {
x86_trampoline_start = .;
*(.x86_trampoline)
x86_trampoline_end = .;
}
.x86_cpu_dev.init : AT(ADDR(.x86_cpu_dev.init) - 0xC0000000) {
__x86_cpu_dev_start = .;
*(.x86_cpu_dev.init)
__x86_cpu_dev_end = .;
}
/*
* start address and size of operations which during runtime
* can be patched with virtualization friendly instructions or
* baremetal native ones. Think page table operations.
* Details in paravirt_types.h
*/
. = ALIGN(8);
.parainstructions : AT(ADDR(.parainstructions) - 0xC0000000) {
__parainstructions = .;
*(.parainstructions)
__parainstructions_end = .;
}
/*
* struct alt_inst entries. From the header (alternative.h):
* "Alternative instructions for different CPU types or capabilities"
* Think locking instructions on spinlocks.
*/
. = ALIGN(8);
.altinstructions : AT(ADDR(.altinstructions) - 0xC0000000) {
__alt_instructions = .;
*(.altinstructions)
__alt_instructions_end = .;
}
/*
* And here are the replacement instructions. The linker sticks
* them as binary blobs. The .altinstructions has enough data to
* get the address and the length of them to patch the kernel safely.
*/
.altinstr_replacement : AT(ADDR(.altinstr_replacement) - 0xC0000000) {
*(.altinstr_replacement)
}
/*
* struct iommu_table_entry entries are injected in this section.
* It is an array of IOMMUs which during run time gets sorted depending
* on its dependency order. After rootfs_initcall is complete
* this section can be safely removed.
*/
.iommu_table : AT(ADDR(.iommu_table) - 0xC0000000) {
__iommu_table = .;
*(.iommu_table)
__iommu_table_end = .;
}
. = ALIGN(8);
.apicdrivers : AT(ADDR(.apicdrivers) - 0xC0000000) {
__apicdrivers = .;
*(.apicdrivers);
__apicdrivers_end = .;
}
. = ALIGN(8);
/*
* .exit.text is discard at runtime, not link time, to deal with
* references from .altinstructions and .eh_frame
*/
.exit.text : AT(ADDR(.exit.text) - 0xC0000000) {
*(.exit.text) *(.cpuexit.text) *(.memexit.text)
}
.exit.data : AT(ADDR(.exit.data) - 0xC0000000) {
*(.exit.data) *(.cpuexit.data) *(.cpuexit.rodata) *(.memexit.data) *(.memexit.rodata)
}
. = ALIGN((1 << 12)); .data..percpu : AT(ADDR(.data..percpu) - 0xC0000000) { __per_cpu_load = .; __per_cpu_start = .; *(.data..percpu..first) . = ALIGN((1 << 12)); *(.data..percpu..page_aligned) . = ALIGN((1 << 5)); *(.data..percpu..readmostly) . = ALIGN((1 << 5)); *(.data..percpu) *(.data..percpu..shared_aligned) __per_cpu_end = .; }
. = ALIGN((1 << 12));
/* freed after init ends here */
.init.end : AT(ADDR(.init.end) - 0xC0000000) {
__init_end = .;
}
/*
* smp_locks might be freed after init
* start/end must be page aligned
*/
. = ALIGN((1 << 12));
.smp_locks : AT(ADDR(.smp_locks) - 0xC0000000) {
__smp_locks = .;
*(.smp_locks)
. = ALIGN((1 << 12));
__smp_locks_end = .;
}
/* BSS */
. = ALIGN((1 << 12));
.bss : AT(ADDR(.bss) - 0xC0000000) {
__bss_start = .;
*(.bss..page_aligned)
*(.bss)
. = ALIGN((1 << 12));
__bss_stop = .;
}
. = ALIGN((1 << 12));
.brk : AT(ADDR(.brk) - 0xC0000000) {
__brk_base = .;
. += 64 * 1024; /* 64k alignment slop space */
*(.brk_reservation) /* areas brk users have reserved */
__brk_limit = .;
}
_end = .;
.stab 0 : { *(.stab) } .stabstr 0 : { *(.stabstr) } .stab.excl 0 : { *(.stab.excl) } .stab.exclstr 0 : { *(.stab.exclstr) } .stab.index 0 : { *(.stab.index) } .stab.indexstr 0 : { *(.stab.indexstr) } .comment 0 : { *(.comment) }
.debug 0 : { *(.debug) } .line 0 : { *(.line) } .debug_srcinfo 0 : { *(.debug_srcinfo) } .debug_sfnames 0 : { *(.debug_sfnames) } .debug_aranges 0 : { *(.debug_aranges) } .debug_pubnames 0 : { *(.debug_pubnames) } .debug_info 0 : { *(.debug_info .gnu.linkonce.wi.*) } .debug_abbrev 0 : { *(.debug_abbrev) } .debug_line 0 : { *(.debug_line) } .debug_frame 0 : { *(.debug_frame) } .debug_str 0 : { *(.debug_str) } .debug_loc 0 : { *(.debug_loc) } .debug_macinfo 0 : { *(.debug_macinfo) } .debug_weaknames 0 : { *(.debug_weaknames) } .debug_funcnames 0 : { *(.debug_funcnames) } .debug_typenames 0 : { *(.debug_typenames) } .debug_varnames 0 : { *(.debug_varnames) }
/* Sections to be discarded */
/DISCARD/ : { *(.exit.text) *(.cpuexit.text) *(.memexit.text) *(.exit.data) *(.cpuexit.data) *(.cpuexit.rodata) *(.memexit.data) *(.memexit.rodata) *(.exitcall.exit) *(.discard) *(.discard.*) }
/DISCARD/ : { *(.eh_frame) }
}
/*
* The ASSERT() sink to . is intentional, for binutils 2.14 compatibility:
*/
. = ASSERT((_end - 0xC0000000 <= (512 * 1024 * 1024)), "kernel image bigger than KERNEL_IMAGE_SIZE");
命令readelf -a vmlinux的输出参见文档vmlinux.lds/vmlinux.readelf -a.txt.zip
Appendix H: scripts/module-common.lds
script/module-common.lds是生成*.ko文件的链接脚本文件,其包含如下内容,引用参见3.4.3.4.2.3 $(modules)节:
/*
* Common module linker script, always used when linking a module.
* Archs are free to supply their own linker scripts. ld will
* combine them automatically.
*/
SECTIONS {
/DISCARD/ : { *(.discard) }
__ksymtab : { *(SORT(___ksymtab+*)) }
__ksymtab_gpl : { *(SORT(___ksymtab_gpl+*)) }
__ksymtab_unused : { *(SORT(___ksymtab_unused+*)) }
__ksymtab_unused_gpl : { *(SORT(___ksymtab_unused_gpl+*)) }
__ksymtab_gpl_future : { *(SORT(___ksymtab_gpl_future+*)) }
__kcrctab : { *(SORT(___kcrctab+*)) }
__kcrctab_gpl : { *(SORT(___kcrctab_gpl+*)) }
__kcrctab_unused : { *(SORT(___kcrctab_unused+*)) }
__kcrctab_unused_gpl : { *(SORT(___kcrctab_unused_gpl+*)) }
__kcrctab_gpl_future : { *(SORT(___kcrctab_gpl_future+*)) }
}
Appendix I: Targets Tree
References
- The Linux Kernel Documentation
- The Linux Kernel Archives
- Linux Kernel Master Branch Repository
- Linux Kernel Stable Branch Repository
- Linux Kernel Next Branch Repository
- LWN.net
- Linux Kernel Newbies
- Hugepage in Linux
- An Implementation Of Multiprocessor Linux
- Linux Device Drivers
- Linux Security Modules
- Operating System Specification
- Uniting Mobile Linux Application Platforms